- 投稿日:2019-05-27T23:11:17+09:00
ArxivのDeep Learning関連論文を被引用数順に1000本並べてみる
Deep Learning関連の最新の論文をピックアップする方法ではなく、抄読会で取り上げるような目的で「のちの研究に大きな影響を与えた論文」を網羅的に探す方法が欲しかったため、論文を被引用数順に並べたリストの作成を試みた。
下記のコードで15000本の論文情報をArxivから取得してSemantic ScholarのAPIで被引用数を取得 (取得日は2019年5月27日)。import arxiv import pandas as pd import requests result = arxiv.query(search_query="all:deep learning") data = pd.DataFrame(columns = ["title","id",'arxiv_url','published']) for i in range(len(result)): id = result[i]['id'].split("/")[-1].split("v")[0] title = result[i]['title'] arxiv_url = result[i]['arxiv_url'] published = result[i]['published'] data_tmp = pd.DataFrame({"title":title,"id":id, "arxiv_url":arxiv_url, "published":published},index=[0]) data = pd.concat([data,data_tmp]).reset_index(drop=True) citation_num_list = [] for i in data["id"]: try: sem = requests.get("https://api.semanticscholar.org/v1/paper/arXiv:"+i).json() citation_num = len(sem["citations"]) except: citation_num = 0 citation_num_list.append(citation_num) data["citation"] = citation_num_list data = data.sort_values(by='citation', ascending=False) data.to_csv("data.csv",index=False)被引用数999以上は999+となって具体的な数値が得られなかったため結局手入力(30ちょいほどあった)。APIが不安定な挙動をするため、被引用数が取得できなかったレコードには0を割り当てており、そのために上位に出てこない論文があるので完璧なリストではない。
実際のところArxivのwebページでDeep Learningで検索すると16000ほど論文が引っかかってくるが、APIで得られたのは15000本であったため、ここでも抜けがあると思われる。そもそも検索単語が"Deep Learning"だけでいいのかという問題もある。
15000本の論文を得たにも関わらず、トップのResNetが被引用数16101なので、これも拾いきれていない論文があることを示唆する結果となった (Arxiv外の論文にも多々引用されているのかもしれないが)。
*34位の論文は、APIで被引用数999+の結果が得られたが、Arxivページに被引用数が表示されず、具体的な数字が不明。**2019年5月29日修正:上位1000本の論文の結果をこちら(Googleスプレッドシート)に公開しました。1000件全てをこのページに貼り付けておりましたが、ページが重すぎるとのご意見を頂いてGoogleスプレッドシートのリンクに置き換えました。このページ内ではTop100のテーブルのみ表示しています。
Rank Title Arxiv url Citation Publish date 1 Deep Residual Learning for Image Recognition http://arxiv.org/abs/1512.03385v1 16101 2015/12/10 2 Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift http://arxiv.org/abs/1502.03167v3 7490 2015/2/11 3 Caffe: Convolutional Architecture for Fast Feature Embedding http://arxiv.org/abs/1408.5093v1 7352 2014/6/20 4 Sequence to Sequence Learning with Neural Networks http://arxiv.org/abs/1409.3215v3 5048 2014/9/10 5 TensorFlow: Large-Scale Machine Learning on Heterogeneous Distributed Systems http://arxiv.org/abs/1603.04467v2 4343 2016/3/14 6 Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification http://arxiv.org/abs/1502.01852v1 3284 2015/2/6 7 Representation Learning: A Review and New Perspectives http://arxiv.org/abs/1206.5538v3 2915 2012/6/24 8 Deep Learning in Neural Networks: An Overview http://arxiv.org/abs/1404.7828v4 2854 2014/4/30 9 Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks http://arxiv.org/abs/1511.06434v2 2728 2015/11/19 10 TensorFlow: A system for large-scale machine learning http://arxiv.org/abs/1605.08695v2 2355 2016/5/27 11 FaceNet: A Unified Embedding for Face Recognition and Clustering http://arxiv.org/abs/1503.03832v3 2054 2015/3/12 12 OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks http://arxiv.org/abs/1312.6229v4 2037 2013/12/21 13 DeCAF: A Deep Convolutional Activation Feature for Generic Visual Recognition http://arxiv.org/abs/1310.1531v1 2028 2013/10/6 14 Two-Stream Convolutional Networks for Action Recognition in Videos http://arxiv.org/abs/1406.2199v2 1866 2014/6/9 15 Intriguing properties of neural networks http://arxiv.org/abs/1312.6199v4 1710 2013/12/21 16 Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling http://arxiv.org/abs/1412.3555v1 1692 2014/12/11 17 DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs http://arxiv.org/abs/1606.00915v2 1679 2016/6/2 18 How transferable are features in deep neural networks? http://arxiv.org/abs/1411.1792v1 1670 2014/11/6 19 Playing Atari with Deep Reinforcement Learning http://arxiv.org/abs/1312.5602v1 1581 2013/12/19 20 Identity Mappings in Deep Residual Networks http://arxiv.org/abs/1603.05027v3 1494 2016/3/16 21 Multi-column Deep Neural Networks for Image Classification http://arxiv.org/abs/1202.2745v1 1485 2012/2/13 22 Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding http://arxiv.org/abs/1510.00149v5 1484 2015/10/1 23 Learning Spatiotemporal Features with 3D Convolutional Networks http://arxiv.org/abs/1412.0767v4 1412 2014/12/2 24 SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation http://arxiv.org/abs/1511.00561v3 1343 2015/11/2 25 Asynchronous Methods for Deep Reinforcement Learning http://arxiv.org/abs/1602.01783v2 1283 2016/2/4 26 Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs http://arxiv.org/abs/1412.7062v4 1281 2014/12/22 27 DeepWalk: Online Learning of Social Representations http://arxiv.org/abs/1403.6652v2 1249 2014/3/26 28 Network In Network http://arxiv.org/abs/1312.4400v3 1216 2013/12/16 29 The Cityscapes Dataset for Semantic Urban Scene Understanding http://arxiv.org/abs/1604.01685v2 1121 2016/4/6 30 Deep Learning Face Attributes in the Wild http://arxiv.org/abs/1411.7766v3 1112 2014/11/28 31 WaveNet: A Generative Model for Raw Audio http://arxiv.org/abs/1609.03499v2 1061 2016/9/12 32 Image Super-Resolution Using Deep Convolutional Networks http://arxiv.org/abs/1501.00092v3 1054 2014/12/31 33 Conditional Random Fields as Recurrent Neural Networks http://arxiv.org/abs/1502.03240v3 1028 2015/2/11 34 Distilling the Knowledge in a Neural Network http://arxiv.org/abs/1503.02531v1 *999 2015/3/9 35 Theano: new features and speed improvements http://arxiv.org/abs/1211.5590v1 973 2012/11/23 36 Feature Pyramid Networks for Object Detection http://arxiv.org/abs/1612.03144v2 872 2016/12/9 37 Fast and Accurate Deep Network Learning by Exponential Linear Units (ELUs) http://arxiv.org/abs/1511.07289v5 844 2015/11/23 38 Character-level Convolutional Networks for Text Classification http://arxiv.org/abs/1509.01626v3 840 2015/9/4 39 Accurate Image Super-Resolution Using Very Deep Convolutional Networks http://arxiv.org/abs/1511.04587v2 825 2015/11/14 40 End-to-End Training of Deep Visuomotor Policies http://arxiv.org/abs/1504.00702v5 809 2015/4/2 41 Wide Residual Networks http://arxiv.org/abs/1605.07146v4 804 2016/5/23 42 Learning Deep Features for Discriminative Localization http://arxiv.org/abs/1512.04150v1 800 2015/12/14 43 Teaching Machines to Read and Comprehend http://arxiv.org/abs/1506.03340v3 789 2015/6/10 44 Deep Learning Face Representation by Joint Identification-Verification http://arxiv.org/abs/1406.4773v1 772 2014/6/18 45 DeepPose: Human Pose Estimation via Deep Neural Networks http://arxiv.org/abs/1312.4659v3 768 2013/12/17 46 DRAW: A Recurrent Neural Network For Image Generation http://arxiv.org/abs/1502.04623v2 758 2015/2/16 47 Dropout as a Bayesian Approximation: Representing Model Uncertainty in Deep Learning http://arxiv.org/abs/1506.02142v6 716 2015/6/6 48 Semi-Supervised Learning with Deep Generative Models http://arxiv.org/abs/1406.5298v2 704 2014/6/20 49 Understanding deep learning requires rethinking generalization http://arxiv.org/abs/1611.03530v2 700 2016/11/10 50 Generative Adversarial Text to Image Synthesis http://arxiv.org/abs/1605.05396v2 697 2016/5/17 51 3D ShapeNets: A Deep Representation for Volumetric Shapes http://arxiv.org/abs/1406.5670v3 693 2014/6/22 52 Xception: Deep Learning with Depthwise Separable Convolutions http://arxiv.org/abs/1610.02357v3 688 2016/10/7 53 PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation http://arxiv.org/abs/1612.00593v2 676 2016/12/2 54 Deep Reinforcement Learning with Double Q-learning http://arxiv.org/abs/1509.06461v3 674 2015/9/22 55 Deep Speech 2: End-to-End Speech Recognition in English and Mandarin http://arxiv.org/abs/1512.02595v1 659 2015/12/8 56 Domain-Adversarial Training of Neural Networks http://arxiv.org/abs/1505.07818v4 654 2015/5/28 57 BinaryConnect: Training Deep Neural Networks with binary weights during propagations http://arxiv.org/abs/1511.00363v3 651 2015/11/2 58 Learning Transferable Features with Deep Adaptation Networks http://arxiv.org/abs/1502.02791v2 607 2015/2/10 59 Unsupervised Domain Adaptation by Backpropagation http://arxiv.org/abs/1409.7495v2 602 2014/9/26 60 MXNet: A Flexible and Efficient Machine Learning Library for Heterogeneous Distributed Systems http://arxiv.org/abs/1512.01274v1 601 2015/12/3 61 DeepFool: a simple and accurate method to fool deep neural networks http://arxiv.org/abs/1511.04599v3 591 2015/11/14 62 Wasserstein GAN http://arxiv.org/abs/1701.07875v3 588 2017/1/26 63 Pixel Recurrent Neural Networks http://arxiv.org/abs/1601.06759v3 588 2016/1/25 64 Deep contextualized word representations http://arxiv.org/abs/1802.05365v2 587 2018/2/15 65 Convolutional Neural Networks on Graphs with Fast Localized Spectral Filtering http://arxiv.org/abs/1606.09375v3 579 2016/6/30 66 Deep Convolutional Neural Networks for Computer-Aided Detection: CNN Architectures, Dataset Characteristics and Transfer Learning http://arxiv.org/abs/1602.03409v1 567 2016/2/10 67 Distillation as a Defense to Adversarial Perturbations against Deep Neural Networks http://arxiv.org/abs/1511.04508v2 564 2015/11/14 68 Practical recommendations for gradient-based training of deep architectures http://arxiv.org/abs/1206.5533v2 560 2012/6/24 69 Temporal Segment Networks: Towards Good Practices for Deep Action Recognition http://arxiv.org/abs/1608.00859v1 556 2016/8/2 70 Deep multi-scale video prediction beyond mean square error http://arxiv.org/abs/1511.05440v6 554 2015/11/17 71 Convolutional Sequence to Sequence Learning http://arxiv.org/abs/1705.03122v3 552 2017/5/8 72 Deep Speech: Scaling up end-to-end speech recognition http://arxiv.org/abs/1412.5567v2 538 2014/12/17 73 Towards Deep Learning Models Resistant to Adversarial Attacks http://arxiv.org/abs/1706.06083v3 534 2017/6/19 74 Bag of Tricks for Efficient Text Classification http://arxiv.org/abs/1607.01759v3 532 2016/7/6 75 Beyond a Gaussian Denoiser: Residual Learning of Deep CNN for Image Denoising http://arxiv.org/abs/1608.03981v1 530 2016/8/13 76 The Limitations of Deep Learning in Adversarial Settings http://arxiv.org/abs/1511.07528v1 530 2015/11/24 77 Matching Networks for One Shot Learning http://arxiv.org/abs/1606.04080v2 529 2016/6/13 78 Learning Face Representation from Scratch http://arxiv.org/abs/1411.7923v1 527 2014/11/28 79 A Survey on Deep Learning in Medical Image Analysis http://arxiv.org/abs/1702.05747v2 520 2017/2/19 80 Understanding Neural Networks Through Deep Visualization http://arxiv.org/abs/1506.06579v1 520 2015/6/22 81 Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network http://arxiv.org/abs/1609.05158v2 516 2016/9/16 82 Deep Learning with Limited Numerical Precision http://arxiv.org/abs/1502.02551v1 513 2015/2/9 83 cuDNN: Efficient Primitives for Deep Learning http://arxiv.org/abs/1410.0759v3 509 2014/10/3 84 Deeply-Supervised Nets http://arxiv.org/abs/1409.5185v2 509 2014/9/18 85 Joint Face Detection and Alignment using Multi-task Cascaded Convolutional Networks http://arxiv.org/abs/1604.02878v1 503 2016/4/11 86 From Captions to Visual Concepts and Back http://arxiv.org/abs/1411.4952v3 501 2014/11/18 87 Do Deep Nets Really Need to be Deep? http://arxiv.org/abs/1312.6184v7 496 2013/12/21 88 Action Recognition with Trajectory-Pooled Deep-Convolutional Descriptors http://arxiv.org/abs/1505.04868v1 494 2015/5/19 89 A Theoretically Grounded Application of Dropout in Recurrent Neural Networks http://arxiv.org/abs/1512.05287v5 487 2015/12/16 90 FitNets: Hints for Thin Deep Nets http://arxiv.org/abs/1412.6550v4 483 2014/12/19 91 Spectral Networks and Locally Connected Networks on Graphs http://arxiv.org/abs/1312.6203v3 477 2013/12/21 92 Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks http://arxiv.org/abs/1703.03400v3 467 2017/3/9 93 Identifying and attacking the saddle point problem in high-dimensional non-convex optimization http://arxiv.org/abs/1406.2572v1 459 2014/6/10 94 Exact solutions to the nonlinear dynamics of learning in deep linear neural networks http://arxiv.org/abs/1312.6120v3 455 2013/12/20 95 Prioritized Experience Replay http://arxiv.org/abs/1511.05952v4 452 2015/11/18 96 Deep Captioning with Multimodal Recurrent Neural Networks (m-RNN) http://arxiv.org/abs/1412.6632v5 446 2014/12/20 97 Training Very Deep Networks http://arxiv.org/abs/1507.06228v2 441 2015/7/22 98 Dueling Network Architectures for Deep Reinforcement Learning http://arxiv.org/abs/1511.06581v3 441 2015/11/20 99 Unifying Visual-Semantic Embeddings with Multimodal Neural Language Models http://arxiv.org/abs/1411.2539v1 431 2014/11/10 100 Learning Fine-grained Image Similarity with Deep Ranking http://arxiv.org/abs/1404.4661v1 426 2014/4/17 Top1000の結果はこちら(Googleスプレッドシート)にあります。
Markdownのテーブルの幅調整むずかしい・・・
- 投稿日:2019-05-27T16:55:06+09:00
kerasでvgg16とGrad-CAMの実装による異常検出および異常箇所の可視化
概要
画像認識による異常検出は最近工場現場の品質検査工程などで実用化が進められていますが、ディープラーニングの仕組みがブラックボックスとなっているため、AIが提示してくれた結果に不信感が生じやすいです。そのような課題を解消するために、Grad-CAMなどの判断根拠可視化手法が近年提案されました。
本稿では、kerasでvgg16モデルをファインチューニングし、DAGMデータセットの異常検知を試してみました。それから、Grad-CAMによる異常箇所の可視化も実装してみました。わりと良い結果が得られましたので、その手順と注意点をまとめて公開します。
特にGrad-CAMの実装にあたって、かなりエラーで苦しんでいたので、その注意点とコードをもしご参考になれれば嬉しいです。開発環境
Google Colaboratoryを使って、その便利さにめっちゃ感動されました。jupyter, python, kerasなどのライブラリーを一から導入する必要が無いため、ライブラリー間のバージョンによる互換性を全く意識せずにコードを書けて、機械学習の初心者にはとても優しい開発環境です。また、高速なGPUを無料で使えることが何より幸せです!具体的にどのGPUを使っているかは調べていませんが、筆者の経験だとNvidia Tesla K80よりも速いです。
使い方や詳しい説明はすでにいっぱい記事が書かれたので、本稿では割愛します。
以下のリンクよりご参照ください⬇️⬇️
【秒速で無料GPUを使う】深層学習実践Tips on Colaboratoryデータセット
DAGM 2007というドイツで開催されたコンペで使われたデータセット
素材の模様に人為的につけられた欠陥の検出を目的とし、異常検出によく使われるデータセットです。
正常画像1000枚と異常画像150枚を1セットで、合計5セットあります。
データは以下のサイトより入手できます。
https://resources.mpi-inf.mpg.de/conference/dagm/2007/prizes.html実装
さてさて、ここからは実装のコードと注意点のご紹介です。
Import
vgg16_grad-cam.ipynbfrom __future__ import print_function import keras from keras.applications import VGG16 from keras.models import Sequential, load_model, model_from_json from keras import models, optimizers, layers from keras.optimizers import SGD from keras.layers import Dense, Dropout, Activation, Flatten from sklearn.model_selection import train_test_split from PIL import Image from keras.preprocessing import image as images from keras.preprocessing.image import array_to_img, img_to_array, load_img from keras import backend as K import os import numpy as np import glob import pandas as pd import cv2Google Driverにマウント
vgg16_grad-cam.ipynbfrom google.colab import drive drive.mount('/content/gdrive') %cd ./gdrive/'My Drive'/"Colab Notebooks"データの前処理
DAGMのClass1データセットを使います。正常異常データを150枚ずつ取得し、事前にGoogle Driverの'/Colab Notebooks/DAGM/'にあるClass1とClass1_defの中にアップロードしておきます。
vgg16_grad-cam.ipynbnum_classes = 2 folder = ["Class1","Class1_def"] image_size = 224 x = [] y = [] for index, name in enumerate(folder): dir = "./DAGM/" + name files = glob.glob(dir + "/*.png") for i, file in enumerate(files): image = Image.open(file) image = image.convert("RGB") image = image.resize((image_size, image_size)) data = np.asarray(image) x.append(data) y.append(index) x = np.array(x) y = np.array(y) x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=111) x_train = x_train.astype('float32') x_test = x_test.astype('float32') x_train /= 255 x_test /= 255 # y ラベルをワンホット表現に y_train = keras.utils.to_categorical(y_train, num_classes) y_test = keras.utils.to_categorical(y_test, num_classes) print(x_train.shape[0], 'train samples') print(x_test.shape[0], 'test samples')保存した重みの読み込み
事前に保存した学習済みモデルのパラーメーターの重みを読みこみます。初回は実行しないでください。
vgg16_grad-cam.ipynbmodel.load_weights('grad1_vgg16_weight_DAGM_C1.h5')vgg16モデル構築
vgg16モデルの紹介およびファインチューニングに関する記事が多く書かれているため、説明は省略します。
Keras VGG16学習済みモデルでファインチューニングをやってみる
ディープラーニング実践入門 〜 Kerasライブラリで画像認識をはじめよう!ただし、Grad-CAMを実装するために、ここで1つ注意点があります!
モデルの構築にはSequentialモデルを使うと、Grad-CAMを実装するときはエラーが出まくってしまいます。本当の理由は未だにわかっていないのですが、筆者が考えている原因は以下の通りです。
・Grad-CAMの実装には、K.gradients()で各レイヤーのパラメーターの勾配を取得する必要があります。sequentialモデルを使うと、vgg16自体がモデルの1つのレイヤーになってしまうため(model.summary()でレイヤーの形を確認できる)、vgg16の畳み込み層のパラメーターの勾配を取得しようとすると、戻り値がnoneとなってしまいます。
(もし間違っていれば、ぜひご指摘いただけるとありがたいです)vgg16_grad-cam.ipynbvgg_conv = VGG16(weights='imagenet', include_top=False, input_shape=(image_size, image_size, 3)) last = vgg_conv.output mod = Flatten()(last) mod = Dense(1024, activation='relu')(mod) mod = Dropout(0.5)(mod) preds = Dense(2, activation='sigmoid')(mod) model = models.Model(vgg_conv.input, preds) model.summary() epochs = 100 batch_size = 48 model.compile(loss='binary_crossentropy', optimizer=optimizers.SGD(lr=1e-4, momentum=0.9), metrics=['accuracy'])モデルのサマリー_________________________________________________________________ Layer (type) Output Shape Param # ================================================================= input_2 (InputLayer) (None, 224, 224, 3) 0 _________________________________________________________________ block1_conv1 (Conv2D) (None, 224, 224, 64) 1792 _________________________________________________________________ block1_conv2 (Conv2D) (None, 224, 224, 64) 36928 _________________________________________________________________ block1_pool (MaxPooling2D) (None, 112, 112, 64) 0 _________________________________________________________________ block2_conv1 (Conv2D) (None, 112, 112, 128) 73856 _________________________________________________________________ block2_conv2 (Conv2D) (None, 112, 112, 128) 147584 _________________________________________________________________ block2_pool (MaxPooling2D) (None, 56, 56, 128) 0 _________________________________________________________________ block3_conv1 (Conv2D) (None, 56, 56, 256) 295168 _________________________________________________________________ block3_conv2 (Conv2D) (None, 56, 56, 256) 590080 _________________________________________________________________ block3_conv3 (Conv2D) (None, 56, 56, 256) 590080 _________________________________________________________________ block3_pool (MaxPooling2D) (None, 28, 28, 256) 0 _________________________________________________________________ block4_conv1 (Conv2D) (None, 28, 28, 512) 1180160 _________________________________________________________________ block4_conv2 (Conv2D) (None, 28, 28, 512) 2359808 _________________________________________________________________ block4_conv3 (Conv2D) (None, 28, 28, 512) 2359808 _________________________________________________________________ block4_pool (MaxPooling2D) (None, 14, 14, 512) 0 _________________________________________________________________ block5_conv1 (Conv2D) (None, 14, 14, 512) 2359808 _________________________________________________________________ block5_conv2 (Conv2D) (None, 14, 14, 512) 2359808 _________________________________________________________________ block5_conv3 (Conv2D) (None, 14, 14, 512) 2359808 _________________________________________________________________ block5_pool (MaxPooling2D) (None, 7, 7, 512) 0 _________________________________________________________________ flatten_2 (Flatten) (None, 25088) 0 _________________________________________________________________ dense_3 (Dense) (None, 1024) 25691136 _________________________________________________________________ dropout_2 (Dropout) (None, 1024) 0 _________________________________________________________________ dense_4 (Dense) (None, 2) 2050 ================================================================= Total params: 40,407,874 Trainable params: 40,407,874 Non-trainable params: 0 _________________________________________________________________最後のプーリング層の1つ前のレイヤーが「block5_conv3」であることにご注目を、後ほどのGrad-CAMの実装で使われます。
学習
vgg16_grad-cam.ipynbhistory = model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs, validation_data=(x_test, y_test), shuffle=True)学習済みモデルの評価とaccuracy&lossの推移
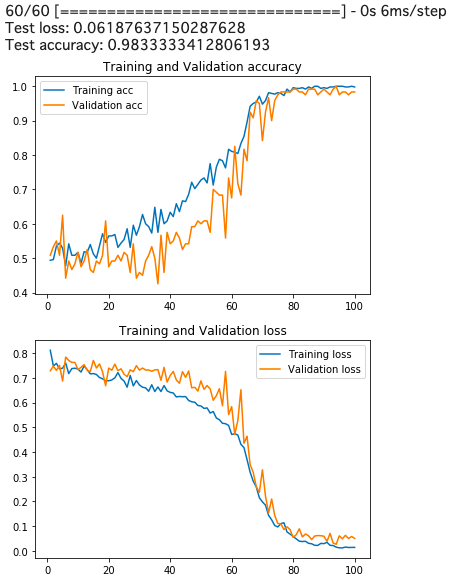
vgg16_grad-cam.ipynbscores = model.evaluate(x_test, y_test, verbose=1) print('Test loss:', scores[0]) print('Test accuracy:', scores[1]) ### Plot accuracy & loss import matplotlib.pyplot as plt acc = history.history["acc"] val_acc = history.history["val_acc"] loss = history.history["loss"] val_loss = history.history["val_loss"] epochs = range(1, len(acc) + 1) #plot accuracy plt.plot(epochs, acc, label = "Training acc" ) plt.plot(epochs, val_acc, label = "Validation acc") plt.title("Training and Validation accuracy") plt.legend() plt.show() #plot loss plt.plot(epochs, loss, label = "Training loss" ) plt.plot(epochs, val_loss, label = "Validation loss") plt.title("Training and Validation loss") plt.legend() plt.show()
100epoch回したら精度が98.3%となり、良い感じの結果が得られましたので、こちらの学習済みモデルで、Grad-CAMを実装します。学習済みモデルの重みの保存
vgg16_grad-cam.ipynbmodel.save_weights('grad_vgg16_weight_DAGM_C1.h5')Grad-CAMの実装
コード自体は下のリンクを参照していますので、詳細の説明は譲りますが、ここで何をやっているかを簡単に説明します。
出力層に最も近いレイヤーを抽出し(vgg16の場合は「block5_conv3」)、このレイヤーのパラメーターの勾配を元に、画像の各領域が最終の出力に与える影響を計算し、その影響度の高さをヒートマップで表現します。
kerasでGrad-CAM 自分で作ったモデルで
ディープラーニングの注視領域の可視化
vgg16_grad-cam.ipynbK.set_learning_phase(1) #set learning phase def Grad_Cam(input_model, pic_array, layer_name): # 前処理 pic = np.expand_dims(pic_array, axis=0) pic = pic.astype('float32') preprocessed_input = pic / 255.0 # 予測クラスの算出 predictions = model.predict(preprocessed_input) class_idx = np.argmax(predictions[0]) class_output = model.output[:, class_idx] # 勾配を取得 conv_output = model.get_layer(layer_name).output # layer_nameのレイヤーのアウトプット grads = K.gradients(class_output, conv_output)[0] # gradients(loss, variables) で、variablesのlossに関しての勾配を返す gradient_function = K.function([model.input], [conv_output, grads]) # model.inputを入力すると、conv_outputとgradsを出力する関数 output, grads_val = gradient_function([preprocessed_input]) output, grads_val = output[0], grads_val[0] # 重みを平均化して、レイヤーのアウトプットに乗じる weights = np.mean(grads_val, axis=(0, 1)) cam = np.dot(output, weights) # 画像化してヒートマップにして合成 cam = cv2.resize(cam, (224, 224), cv2.INTER_LINEAR) cam = np.maximum(cam, 0) cam = cam / cam.max() jetcam = cv2.applyColorMap(np.uint8(255 * cam), cv2.COLORMAP_JET) # モノクロ画像に疑似的に色をつける jetcam = cv2.cvtColor(jetcam, cv2.COLOR_BGR2RGB) # 色をRGBに変換 jetcam = (np.float32(jetcam) + x / 2) # もとの画像に合成 return jetcamテスト画像を指定
vgg16_grad-cam.ipynbpic_array = img_to_array(load_img('DAGM/Class1_def/12.png', target_size=(224, 224))) pic = pic_array.reshape((1,) + pic_array.shape) array_to_img(pic_array)
まずは異常系画像を試してみます。
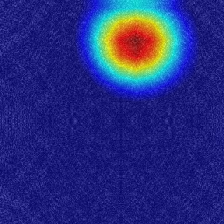
若干見辛いのですが、画像の上部にシミがついていることがわかります。異常箇所の可視化
vgg16_grad-cam.ipynbpicture = Grad_Cam(model, pic_array, 'block5_conv3') picture = picture[0,:,:,] array_to_img(picture)
完璧に異常箇所を示していることを確認できます。
ヒートマップの赤のところは、今回訓練したモデルがこの画像を異常画像に分類している根拠であると示しています。正常画像の判別
元画像 判別根拠 上記の出力結果からわかるように、正常画像を判定する場合は、画像全体を見渡して、異常箇所や欠陥があるかを確認していることが明らかになっています。
終わりに
以上でvgg16とGrad-CAMの実装手順をまとめました。
ディープラーニング入門してからまだ1ヶ月程度なので、もし間違いがあればぜひご指摘ください!また、ご意見やご質問などありましたら、ぜひコメントで気軽に教えてくれると嬉しいです!参考
【秒速で無料GPUを使う】深層学習実践Tips on Colaboratory
Keras VGG16学習済みモデルでファインチューニングをやってみる
ディープラーニング実践入門 〜 Kerasライブラリで画像認識をはじめよう!
kerasでGrad-CAM 自分で作ったモデルで
ディープラーニングの注視領域の可視化




- 投稿日:2019-05-27T16:54:10+09:00
ディープラーニング入門 Chainer チュートリアル(補足メモ1)
ディープラーニング入門 Chainer チュートリアルの学習メモ
概要
既にディープラーニングやChainerを勉強されている方向けの情報ではありませんので、ご注意下さい。
私も勉強中ですので、聞かれても困るのですが。
ディープラーニングの勉強を何からやれば良いかとのご相談には、Preferred Networks, Inc.が公開されているディープラーニング入門 Chainer チュートリアルが非常に良いと思っていますので、ご紹介させて頂いています。本記事は、Chainer チュートリアルに取り組む際に、参考になりそうな用語などの事前情報や、補足情報をメモしたものです。
Chainer チュートリアル自体の解説ではありませんので、ご注意下さい。
少しづつ追記していきます。Chainer (チェイナー) とは
ディープラーニングに関する計算および学習を行うためのソフトウェア開発に利用可能なライブラリの名前。
オープンソースソフトウェア(プログラムが公開されており、開発に誰でも参加できるもの)ですが、日本の企業であるPreferred Networksの主導で開発が進められています。お勧めする理由
- 日本語!
- 入門者が基礎的な内容を理解するための教材であり、解説が丁寧
- 実際にプログラムを動かして理解できる
以降は各パート毎の情報です。
厳密には間違いですが はじめての方にイメージして頂くならこの位かな?と思いながら記載している内容も多々あります、ご容赦下さい。
準備編
1. はじめに
必要となる知識は数学とプログラミング
ディープラーニングはコンピュータで複雑で膨大な量の計算をすることで結果を得ます。
何を計算すれば結果が出るかの理論が数学です。
コンピュータに計算させるための手段がプログラミングです。Google Colaboratory
Googleが無償提供するディープラーニングの学習環境。
Jupyter Notebookというソフトウェアが元になっています。
学校/会社/個人でGSuiteを使われている方は、利用しているアカウントを間違えないようにするため、学習用のGoogleアカウントを新規に作成し、Chromeのシークレットタブでチュートリアルを進めることをお勧めします。
クラウド上で動作するサービス(外部のネットワークで処理される)ですので、企業や個人の情報は決して漏洩させないようにご注意下さい。2. Python 入門
Python
ディープラーニングのために勉強するなら、Pythonのバージョン3系(バージョン3.?)が良いです。
Python2系のサポート期限は2020年ですので、2系しか動かない環境以外では使う機会はありません。なぜPythonかという点ですが、ディープラーニングの開発者が多く使っている・Chainerはじめ便利なライブラリが沢山ある・ディープラーニングの説明書や記事が多いため。
他の言語が得意な方も、Pythonを勉強する方が早いと思います。3. 機械学習に使われる数学
用語が色々と出てきますが、今後の内容を理解するために重要なものばかりですので、覚えておいて下さい。
「微分」「線形代数」「確率・統計」をこれから学習される方は、ディープラーニングに関係する数学の分野として、この3つが特に重要な道具である事がイメージできれば良いと思います。4. 微分の基礎
課題を数学で分析しようとしたとき、「変化する割合が最も大きい瞬間」や「最大値や最小値(変化の割合がプラスからマイナス、またはその逆)になる瞬間」がわかると大きな手がかりになります。
微分はそのような場合に、強力な道具になります。身近な例では、「速度は位置の時間微分」(ある瞬間に位置が変化する量)、「加速度は速度の時間微分」(ある瞬間に速度が変化する量)になっています。
5. 線形代数の基礎
線形代数に出てくる行列は、そもそも連立方程式(数式)を簡単に書くために生み出された経緯があります。
ディープラーニングでコンピュータに計算をさせるときも、効率的に計算する事がとても重要です。
線形代数はそのような場合に、強力な道具になります。身近な例では、画像を回転したり拡大する処理で使われています。
6. 確率・統計の基礎
イメージとしては。
確率はある出来事が起きる割合を、数字で示したり計算することです。
統計はある出来事が起きたデータから、現象の分析を行うことです。
統計で出来事の分析を行う場合、その出来事が起きる確率を考慮する事が重要になります。
確率と統計は関連が強い(同時に使う事が非常に多い)ため、まとめて説明されます。ディープラーニングで確率・統計はとても重要です。
コンピュータで実際に計算する過程では、得られたデータがどのようなものか考えるため、実際に計算できる処理(数式)を検討するため、確率・統計を使います。
また、そもそも確率・統計で解決する問題をディープラーニングで検討してしまうとコストがかかります。アプローチが正しいかの判断もできるようになります。入門の今は理解する必要はありませんが、最尤推定を詳しく掘り下げるだけでも、ディープラーニングで非常に多くのサンプルが必要な理由や、最尤推定のアプローチが適していない問題(テーマ)かの判断ができるようになると思います。
機械学習とデータ分析入門
7. 単回帰分析と重回帰分析
8. NumPy 入門
9. scikit-learn 入門
10. CuPy 入門
11. Pandas 入門
12. Matplotlib 入門
ディープラーニング入門
13. ニューラルネットワークの基礎
14. Chainer の基礎
15. Chainer の応用
16. トレーナとエクステンション
以上
- 投稿日:2019-05-27T16:54:10+09:00
ディープラーニング入門 Chainer チュートリアルの学習メモ
ディープラーニング入門 Chainer チュートリアルの学習メモ
概要
既にディープラーニングやChainerを勉強されている方向けの情報ではありませんので、ご注意下さい。
私も勉強中ですので、聞かれても困るのですが。
ディープラーニングの勉強を何からやれば良いかとのご相談には、Preferred Networks, Inc.が公開されているディープラーニング入門 Chainer チュートリアルが非常に良いと思っていますので、ご紹介させて頂いています。本記事は、Chainer チュートリアルに取り組む際、各章に取組む前に、読んで頂くことを想定して書いています。
その章で扱われている内容のディープラーニングでの役割などを記載しており、Chainer チュートリアル自体の解説ではありませんので、ご注意下さい。
少しづつ追記していきます。Chainer (チェイナー) とは
ディープラーニングに関する計算および学習を行うためのソフトウェア開発に利用可能なライブラリの名前。
オープンソースソフトウェア(プログラムが公開されており、開発に誰でも参加できるもの)ですが、日本の企業であるPreferred Networksの主導で開発が進められています。お勧めする理由
- 日本語!
- 入門者が基礎的な内容を理解するための教材であり、解説が丁寧
- 実際にプログラムを動かして理解できる
以降は各パート毎の情報です。
厳密には間違いですが はじめての方にイメージして頂くならこの位かな?と思いながら記載している内容も多々あります、ご容赦下さい。
準備編
1. はじめに
必要となる知識は数学とプログラミング
ディープラーニングはコンピュータで複雑で膨大な量の計算をすることで結果を得ます。
何を計算すれば結果が出るかの理論が数学です。
コンピュータに計算させるための手段がプログラミングです。Google Colaboratory
Googleが無償提供するディープラーニングの学習環境。
Jupyter Notebookというソフトウェアが元になっています。
学校/会社/個人でGSuiteを使われている方は、利用しているアカウントを間違えないようにするため、学習用のGoogleアカウントを新規に作成し、Chromeのシークレットタブでチュートリアルを進めることをお勧めします。
クラウド上で動作するサービス(外部のネットワークで処理される)ですので、企業や個人の情報は決して漏洩させないようにご注意下さい。2. Python 入門
Python
ディープラーニングのために勉強するなら、Pythonのバージョン3系(バージョン3.?)です。
Python2系のサポート期限は2020年ですので、2系しか動かない環境以外では使う機会はありません。なぜPythonかという点ですが、ディープラーニングの開発者が多く使っている・Chainerはじめ便利なライブラリが沢山ある・ディープラーニングの参考書や記事が多いため。
他の言語が得意な方も、Pythonを勉強する方が早いと思います。3. 機械学習に使われる数学
用語が色々と出てきますが、今後の内容を理解するために重要なものばかりですので、覚えておいて下さい。
「微分」「線形代数」「確率・統計」をこれから学習される方は、ディープラーニングに関係する数学の分野として、この3つが特に重要な道具である事がイメージできれば良いと思います。4. 微分の基礎
課題を数学で分析しようとしたとき、「変化する割合が最も大きい瞬間」や「最大値や最小値(変化の割合がプラスからマイナス、またはその逆)になる瞬間」がわかると大きな手がかりになります。
微分はそのような場合に、強力な道具になります。身近な例では、「速度は位置の時間微分」(ある瞬間に位置が変化する量)、「加速度は速度の時間微分」(ある瞬間に速度が変化する量)になっています。
5. 線形代数の基礎
線形代数に出てくる行列は、そもそも連立方程式(数式)を簡単に書くために生み出された経緯があります。
ディープラーニングでコンピュータに計算をさせるときも、効率的に計算する事がとても重要です。
線形代数はそのような場合に、強力な道具になります。身近な例では、画像を回転したり拡大する処理で使われています。
6. 確率・統計の基礎
イメージとしては。
確率はある出来事が起きる割合を、数字で示したり計算することです。
統計はある出来事が起きたデータから、現象の分析を行うことです。
統計で出来事の分析を行う場合、その出来事が起きる確率を考慮する事が重要になります。
確率と統計は関連が強い(同時に使う事が非常に多い)ため、まとめて説明されます。ディープラーニングで確率・統計はとても重要です。
コンピュータで実際に計算する過程では、得られたデータがどのようなものか考えるため、実際に計算できる処理(数式)を検討するため、確率・統計を使います。
また、そもそも確率・統計で解決する問題を、認識できず、ディープラーニングで分析してしまうと無駄なコストを発生させてしまいます。入門の今は理解する必要はありませんが、最尤推定を詳しく掘り下げるだけでも、ディープラーニングで非常に多くのサンプルが必要な理由や、最尤推定のアプローチが適していない問題(テーマ)かの判断ができるようになると思います。
機械学習とデータ分析入門
7. 単回帰分析と重回帰分析
蓄積したデータを分析する理由は、それで未来を予測できた結果、価値を生むと期待するからです。
たとえば、過去の顧客データを分析し、顧客の未来の購買行動を予測できれば、売上のUPという価値を生みます。
当然、増加する価値・売上に対して、データ分析にかかるコストが安ければ安いほど良いため、シンプルで効果的な分析手法はとても使い勝手が良いです。
その代表的なものが単回帰分析で、その応用(現実世界の出来事に適応し易くしたもの)が重回帰分析です。8. NumPy 入門
どうしてPythonでディープラーニングをプログラミングするか?の理由は、プログラミングが楽だからです。
その1つはPythonがインタプリタ型言語(ざっくりいうと、書いたプログラムが1行づつ、順番に実行される)であり、データサイエンティストにとってもわかりやすい点です。
ただ、インタプリタ型言語は計算が遅くなる仕組みであり、膨大な計算が必要なディープラーニングでは計算が遅いことは致命的です。NumPyは線形代数の計算を行うPython用のライブラリ(Pythonプログラムが簡単に記載できるようになるもの)で、内部での計算をPythonに比べ非常に高速なC言語というプログラム言語で行ってくれます。
Pythonの処理が遅いという弱点は、ディープラーニングで多用する線形代数の計算を高速に行えるNumPyを使えば解決できます。
別の言い方をすると、NumPyがわからないとPythonでディープラーニングの計算をプログラミングすることはできません。(それくらい大事)9. scikit-learn 入門
SciPyは高度な科学/工学の分析処理を作成するためのPythonプログラム作成用のライブラリで、NumPyをベースに開発されました。
SciPyのToolkit(scikit)のMachine Learning用がscikit-learnです。このチュートリアルではscikit-learnのライブラリを使えば簡単にプログラミングができることを紹介しながら、機械学習における分析作業の流れを解説されています。
10. CuPy 入門
NumPyでPythonの計算が早くなったとしても、もっと大量のデータを高速に計算する必要があることが多いです。
たとえば。
- 顧客の購買活動が悪くなることを予測できても、実際に売れなくなってから計算結果が出たら対策が間に合わず、マーケティングの役には立ちません
- 機械の故障を予測できても、計算が間に合わなければ、既に壊れてしまっています
- 自動運転で人が飛び出してくることが予測できても、計算が間に合わなければブレーキをかけるのは交通事故が起きた後です分析(プログラム)が無駄なく十分考えられたにも関わらず、計算が間に合わないときは、処理が早いコンピュータ(演算装置)を使うしかありません。
11. Pandas 入門
PandasはExcelのような表や時系列のデータを行うのが得意なPython用のライブラリ(Pythonプログラムが簡単に記載できるようになるもの)です。
解析対象となる蓄積データはExcelのファイルだったりすることも多いのですが、Pandasを使うとExcelファイルやCSV形式のファイルを簡単にPythonプログラムに読込みし、表として表示、処理することができ大変便利です。12. Matplotlib 入門
解析対象になるデータを入手したとき、分析してみたとき、グラフで表示してどのようなデータ/結果なのかを知ることが、大きな手がかかりになることがあります。
Pandasはデータをグラフなどで可視化することが得意なPython用のライブラリ(Pythonプログラムが簡単に記載できるようになるもの)です。ColabでPythonプログラムを使って分析する際、ノートブックに処理の解説や結果(グラフなどで可視化)を追加しておくと後でわかりやすいものになります。
ただ、綺麗な思い通りのグラフを描くことに、こだわり過ぎない方が良いかも。
高度な可視化は、商用のシステムでは、BIツールという種類の製品で構築し、Matplotlibでは行いません。ディープラーニング入門
13. ニューラルネットワークの基礎
どのようなものかを理解することは大事なのですが、こう考えると上手くいくものだと思って、まずは試してみるのが良いと思います。
私が勉強をはじめたとき、解説本があまりなく、論文を読んで理論をまず理解しようとしたのですが、なかなか理解は進みませんでした。
その後に、実際にプログラムサンプルを写して実行してみたことで、少し理解できた気がします。14. Chainer の基礎
Chainerは複雑なニューラルネットワークの構築が必要となるディープラーング※用のライブラリ(Pythonプログラムが簡単に記載できるようになるもの)です。
※例
音声認識、被写体の認識(画像に何が写っているか)、画像検索、線画自動着色(塗り絵をする)、自然言語処理(言葉を認識し処理する)わからない用語は調べながら読み進めてみてください。
以下、難しそうなものだけ解説。
Iris
- Irisは花の名前(アヤメ、菖蒲、文目、綾目)ですが、ここでのIrisは の練習に利用できる、公開されているアヤメの花に関するデータIris plants datasetのこと。
- アヤメの花を1輪づつ計測したデータですが、実際は同じアヤメ科ではあるものの、品種が異なる花のデータとなっています。似ていて品種を見分けるのが難しい花のデータですので、ディープラーニングの題材として最適なことから、色々な説明に出てきます。
- 英語の意味
- Attribute:説明
- sepal length:ガクの長さ
- sepal width:ガクの幅
- petal length:花弁の長さ
- petal width:花弁の幅
モジュール
- この説明の中では、プログラム・ライブラリの一部、関数が集まったもの(ライブラリにあるプログラムが多いと、機能が似ていたり、特定の用途に使うものをまとめて整理しておくと使いやすくなるのでモジュールという単位にプログラムをまとめる。モジュールXXに属する(プログラムの)関数YY のように使う。)
15. Chainer の応用
結果は信頼して使える精度(高い確率で正しい答えを出す)になるまで改善する必要があります。
14. Chainer の基礎で行ったディープラーニングの精度を上げる方法について代表的なものが解説されています。
これも理論的に理解することは大事ですが、こうすると上手くいく(結果が変わり場合によっては上手くいかない)ことがわかれば良いかと思います。最適化手法を理解し、使えるようになると、解析する手法を何通りかで試せるようになります。
1つの最適化手法しか知らない/使えないより、精度の高い分析ができる可能性が高くなります。16. トレーナとエクステンション
Chainerではニューラルネットワークのトレーニングを行うためのPythonプログラムを簡単に書くために、Trainerというクラス(作成するプログラムの定義)を提供しています。
端的に言ってしまえば、Trainerというクラスを利用できるようになると、プログラミングが簡潔(わかりやすい/間違えたりバグが起きにくい)なのに高性能なPythonプログラミングが作れるようになります。プログラミングが簡潔(わかりやすい/間違えたり不具合が起きにくい)ことは高度でデータが大量にある分析ではとても重要です。
GPUを搭載した高性能なコンピュータを多数導入したり、同じ規模をレンタルして解析する場合、計算に必要なコスト(お金、時間)も凄い規模になります。
プログラミングが簡潔でなければ、不具合でとんでもないコストを使うことになりかねません。
また、実施している最中や、実施した後にトレーニングがうまくいっているのかを評価できれば、コストを抑えつつ効率的に分析を進めることができます。以上
- 投稿日:2019-05-27T16:31:43+09:00
Optuna と Chainer で深層学習のハイパーパラメータ自動最適化
はじめに
Optuna は、オープンソースのハイパーパラメータ自動最適化ツールです。この記事では、Optuna と Chainer を用いて、実際に深層学習(ディープラーニング)のハイパーパラメータ最適化を行う方法を説明します。Optuna の examples にはさまざまなフレームワークでの例が載っていますが、ドキュメントとして説明はされていないようなので、私なりにアレンジを加えたものを紹介します。
内容としては:
- ハイパーパラメータとは何か?
- Optuna でシンプルな最適化
- Optuna + Chainer で深層学習のハイパーパラメータ最適化
のようになっています。
対象とする読者は以下です:
- Chainer などの深層学習フレームワークに慣れ親しんでいる方
- Optuna のチュートリアルは触ったものの、そこから深層学習のハイパーパラメータ自動最適化に活用する方法がわからない方
反対に、対象と しない 読者は以下です:
- Optuna のチュートリアル をまだやっていない方 → まずはそちらやることをオススメします。
- Optuna の examples を読んで理解できる方 → それらを超える内容はほぼありません。
- 機械学習の基礎的な概念・Python の基本的な文法を知らない方 → この記事では説明しないので、ほかで習得してから読んでください。
また、この記事で解説するコードの完全なものは GitHub のリポジトリ にあります。
ハイパーパラメータとは何か?
深層学習の場合、ハイパーパラメータとは例えば層の数や活性化関数の種類など、学習の過程で変化しないパラメータを指します。実際に学習を行うときはそれらを決めた上で、それぞれの層が持っている重みやバイアスなどのパラメータを最適化することで学習を行うわけですが、層の数や活性化関数の種類は学習の過程で最適化されるわけではなく、あらかじめ人間が手で与える必要がありました。したがって、学習の過程で最適化されるパラメータ(層が持っている重みやバイアス)と区別するために、層の数や活性化関数の種類のことを ハイパーパラメータ と呼びます。以下に、深層学習におけるパラメータの例とハイパーパラメータの例を示します。
深層学習におけるパラメータの例:
- 層の重み
- 層のバイアス
深層学習におけるハイパーパラメータの例:
- 層の数
- 活性化関数の種類(ReLU や Sigmoid など)
- 最適化方法の種類(Adam や SGD など)
- 最適化方法のパラメータ(学習率など)
深層学習では誤差逆伝播を用いて勾配(loss のパラメータによる微分)を計算しパラメータのアップデートを行います。対してハイパーパラメータでは層の数や活性化関数の種類など、それを変えるとモデルの性質がドラスティックに変わるため微分が簡単に行えなそうなものが多いです。そういった意味でも、これらのハイパーパラメータは学習時に最適化することが難しく、学習を始める前に決めうちにならざるを得ないという背景もあります。
ハイパーパラメータ最適化のプロセス
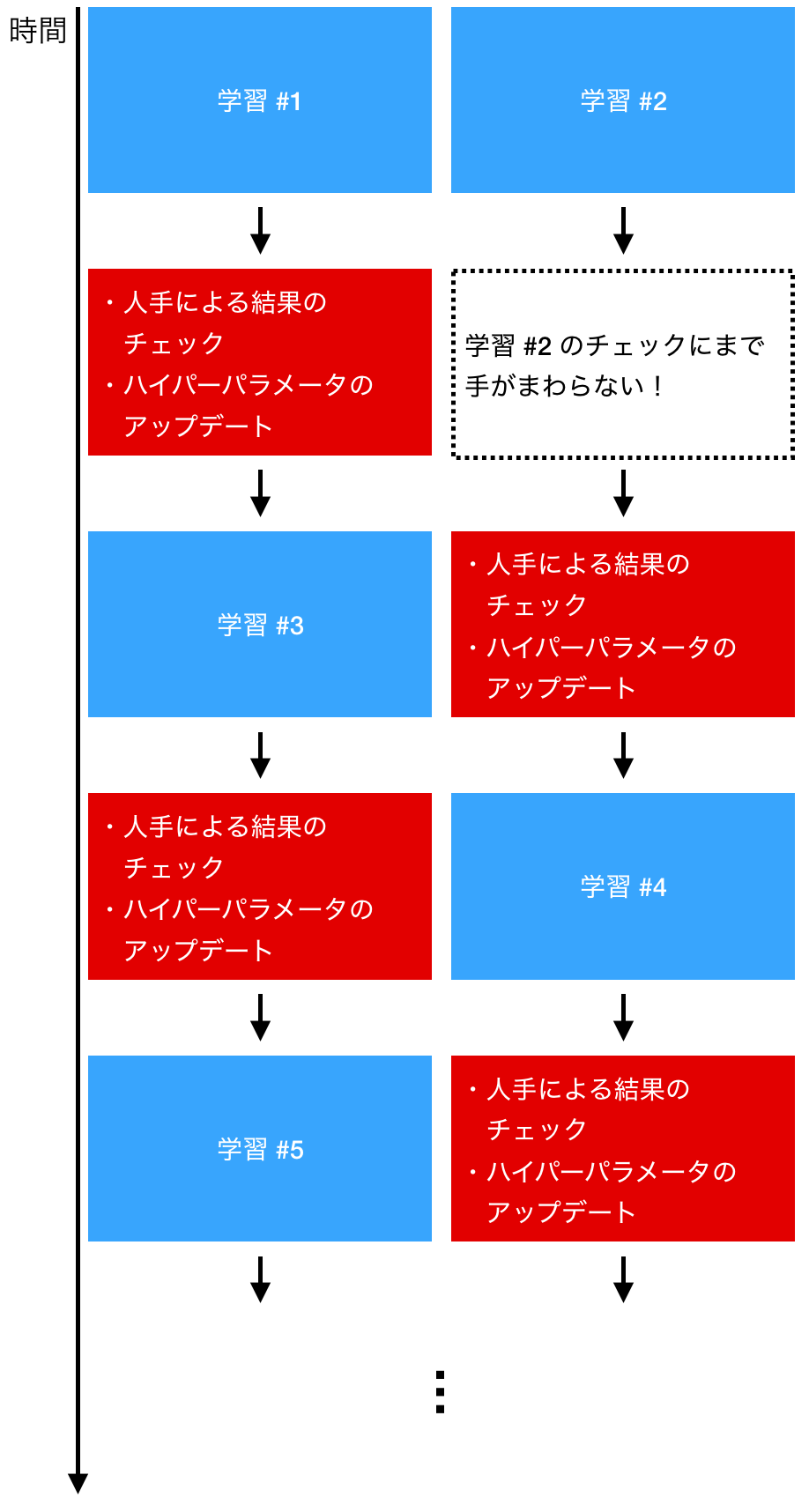
人手によるハイパーパラメータ更新の例を以下に示します。例ではふたつの学習を同時に走らせていますが、学習が終わるごとに人手によるチェックが入るため、ハイパーパラメータを試せる数に限りがあり、またスケールもしません。例えば 100 個 GPU を用意して 100 セットのハイパーパラメータで同時に学習させることを考えてください。それらの学習が終わった際に、次にみるべきハイパーパラメータを即座に判断できるでしょうか?
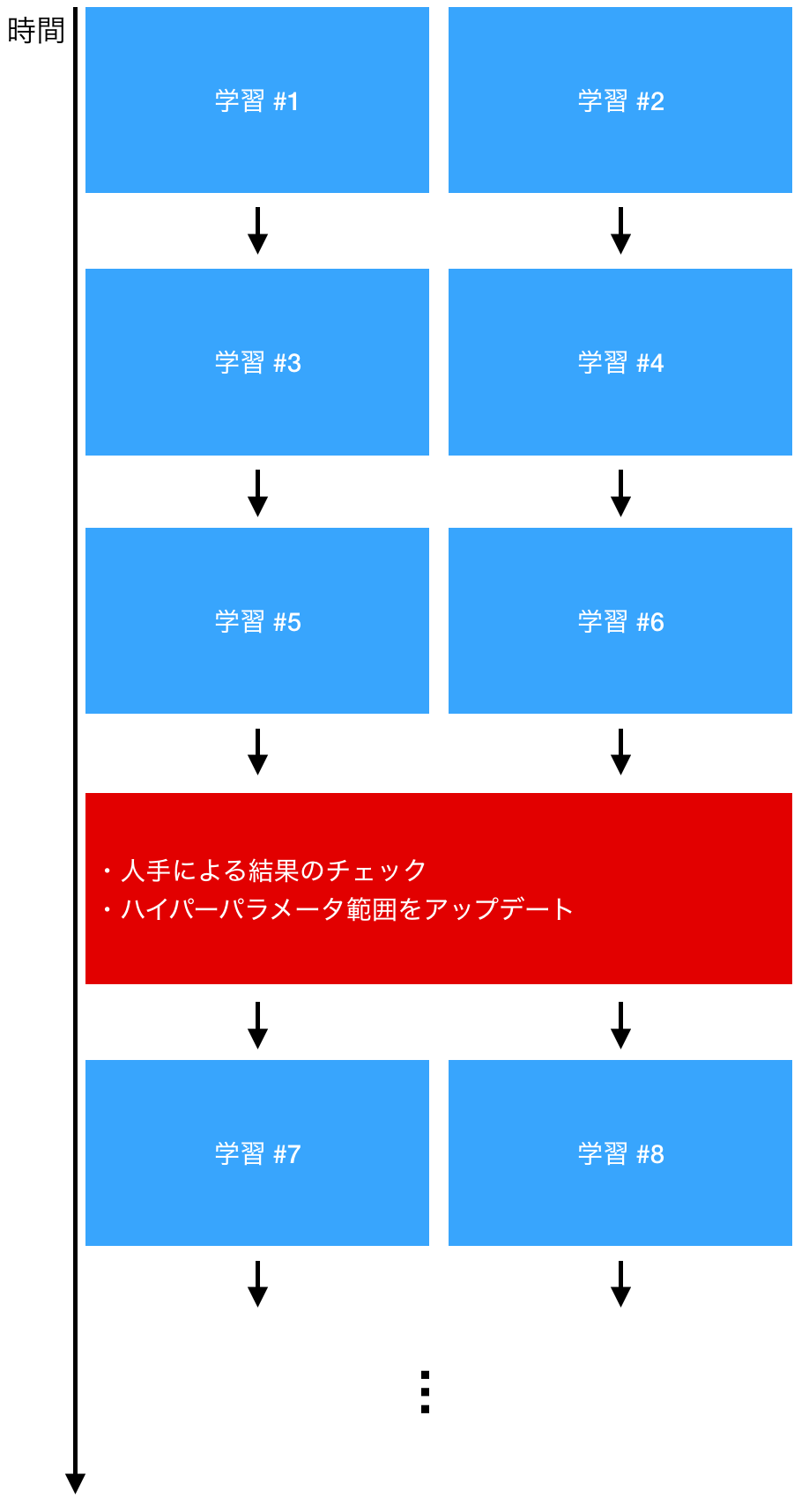
一方で、Optuna などのハイパーパラメータ自動最適化ツールを使った場合の例をいかに示します。人手が入る時間は限られているため、学習が効率的に回せていることが見て取れます。また、この方法であれば、 100 セットのハイパーパラメータで同時に学習させたとしても、学習回数はそれに応じてスケールしていきます。詳しくは後で述べますが、結果を評価する際も、スジのよいハイパーパラメータだけを見ればよいため、評価を行うコストも実はそこまで高くありません。
以上より、ハイパーパラメータ自動最適化ツールを使ったほうがより効率的に機械学習プロセスを回せそうであることがわかりました。当然、実際にはすべての点で自動最適化が勝っているわけではありません。ハイパーパラメータ自動最適化ツールとはいえ、どのハイパーパラメータを最適化するかをあらかじめ指定する必要があります(ハイパーパラメータ自動最適化ツールのハイパーパラメータ!)が、そういった制約から完全に自由である、人手による最適化が勝る可能性もゼロではないからです。
とはいえ、人手では試せる回数も限られたものになりますので、ハイパーパラメータ自動最適化ツールより性能がよいハイパーパラメータを見つけられたとしてもそれは「たまたま」かもしれません。実務上ではこういった「たまたま」に頼るよりは、試行回数をできるだけ増やしてなるべくうまくいく確率を統計的に増やしていくことが求められると思います。また、近年ではハイパーパラメータ自動最適化を含む領域として AutoML という対象が盛んに研究されており、こういった方向性は今後より一層強まっていくと予想できます。
Optuna でシンプルな最適化
ではいよいよ Optuna で最適化を行っていきましょう。いきなり深層学習の最適化を行ってもわかりにくいので、まずはシンプルな例からいきましょう。
問題として、サインウェーブのフィッティングを考えます。範囲 $[0, 2 \pi]$ をとる $x$ に対して、
y = \sin xである $y$ を予測するモデルを、まずは多項式で立てます。
この際のハイパーパラメータとしては、多項式の次数を選びます。次数が 2 だったら 2 次関数で $\sin$ をフィッティングするということですね。
全体像
まずはコードの
main関数を示します。それぞれの関数やメソッドの中身はまだ説明していませんので、ここでは大まかなながれをつかんでいただければ十分です。流れとしては:
- データを作る
- ハイパーパラメータ最適化(
study)のための設定をする- 実際に最適化計算を行う
- もっともよかった結果を可視化する
といった流れとなっています。
from pathlib import Path import optuna STUDY_NAME = 'poly' N_TRIALS = 10 MODEL_DIRECTORY = Path('models/poly') def main(): # Generate dataset prepare_dataset() # Prepare study if not MODEL_DIRECTORY.exists(): MODEL_DIRECTORY.mkdir(parents=True) study = optuna.create_study( study_name=STUDY_NAME, storage=f"sqlite:///{STUDY_NAME}.db", load_if_exists=True) # Optimize study.optimize(objective, n_trials=N_TRIALS) # Visualize the best result print('=== Best Trial ===') print(study.best_trial) evaluate_results(study.best_trial) if __name__ == '__main__': main()
studyというのが今考えているタスクに対するハイパーパラメータ自動最適化の計算ワンセットを指していて、ハイパーパラメータをひとつセットして学習を 1 回行うことはtrialと呼ばれています。trialがたくさんあつまってひとつのstudyをつくっているイメージですね。データの作成
ではデータを作りましょう。 $x$ として $[0, 2 \pi]$ の範囲をとる一様乱数を作り、それに $\sin$ を作用させます。また、機械学習で使うデータでは
(サンプルサイズ, 特徴量次元)の 2 次元配列になっていることが多いので、今回は特徴量次元を 1 として、(DATA_SIZE, 1)次元の配列としてxとyを作ります。import numpy as np DATA_SIZE = 1000 DATASET_DIRECTORY = Path(f"./data/dataset_{DATA_SIZE}") def generate_data(size=1000): """Generate training data. Args: length: int The sample size of the data. Returns: x_train: numpy.ndarray The input data for training. y_train: numpy.ndarray The output data for training. x_valid: numpy.ndarray The input data for validation. y_valid: numpy.ndarray The output data for validation. """ x = np.random.rand(size, 1).astype(np.float32) * 2 * np.pi y = np.sin(x) n_train = int(size * 0.8) return x[:n_train], y[:n_train], x[n_train:], y[n_train:]最後のところでは、データを train dataset と validation dataset に 8:2 の割合で分割しています。最適化計算のたびにデータを作るとデータが計算に時間がかかるばかりかデータも変わってしまうので、データがまだ作られていなかったらデータを作って保存する関数も別途作っておきます。
def prepare_dataset(): """Prepare dataset for optimization.""" if not DATASET_DIRECTORY.exists(): DATASET_DIRECTORY.mkdir(parents=True) x_train, y_train, x_valid, y_valid = generate_data(DATA_SIZE) np.save(DATASET_DIRECTORY / 'x_train.npy', x_train) np.save(DATASET_DIRECTORY / 'y_train.npy', y_train) np.save(DATASET_DIRECTORY / 'x_valid.npy', x_valid) np.save(DATASET_DIRECTORY / 'y_valid.npy', y_valid)目的関数
次はいよいよ Optuna に直接関係する部分の実装です。Optuna では最小化したい目的関数(Objective function)を定義し、ハイパーパラメータを変化させながら目的関数の値を評価することで、ハイパーパラメータ自動最適化を行います。
import pickle from sklearn.linear_model import Ridge from sklearn.preprocessing import PolynomialFeatures from sklearn.pipeline import make_pipeline def objective(trial): """Objective function to make optimization for Optuna. Args: trial: optuna.trial.Trial Returns: loss: float Loss value for the trial """ # Suggest hyperparameters polynomial_degree = trial.suggest_int('polynomial_degree', 1, 10) print('--') print(f"Trial: {trial.number}") print('Current hyperparameters:') print(f" Polynomial degree: {polynomial_degree}") print('--') # Generate the model model = make_pipeline(PolynomialFeatures(polynomial_degree), Ridge()) # Load dataset x_train = np.load(DATASET_DIRECTORY / 'x_train.npy') y_train = np.load(DATASET_DIRECTORY / 'y_train.npy') x_valid = np.load(DATASET_DIRECTORY / 'x_valid.npy') y_valid = np.load(DATASET_DIRECTORY / 'y_valid.npy') # Train model.fit(x_train, y_train) # Save model with open(MODEL_DIRECTORY / f"model_{trial.number}.pickle", 'wb') as f: pickle.dump(model, f) # Evaluate loss loss = np.mean((model.predict(x_valid) - y_valid)**2) return lossちょっと関数としては長いですが、やっていることはそんなに多くありません。順番に説明していきましょう。
まずは引数ですが、これは
optuna.trial.Trialクラスのオブジェクトです。Optuna の最適化プロセスでは、このTrialオブジェクトを作ってはobjective関数に渡して評価して……というのを繰り返します。つまりこの引数は Optuna によって自動で与えられるため、ユーザ自らこのオブジェクトを作ってobjective関数を呼ぶことはあまりないと思います。この中で特に重要なのが
# Suggest hyperparameters polynomial_degree = trial.suggest_int('polynomial_degree', 1, 10)の部分でしょう。ここでひとつの
trialを行うためのハイパーパラメータを 1 セット(ここではpolynomial_degreeのみ)を生成しています。polynomial_degree(多項式の次数)は整数値をとるため、suggest_intメソッドを使ってハイパーパラメータを生成しています。引数の'polynomial_degree'はパラメータの名前(結果の表示などで必要です)、そのあとの1と10はハイパーパラメータのとりうる最小値と最大値です。つまり、1 次関数 〜 10 次関数の間でフィッティングを試みようとしているということです。他の部分はデータを読み込んだり、
sklearnのmodelを作成してデータにフィッティングし保存したりしている部分です。最後に# Evaluate loss loss = np.mean((model.predict(x_valid) - y_valid)**2) return lossの部分ですが、validation dataset に対してモデルによる推定を行い、正解との平均二乗誤差(
loss)を計算してそれをreturnしています。Optuna での最適化に使う目的関数の返り値は、必ず最小化したい値でなければいけません。結果の可視化
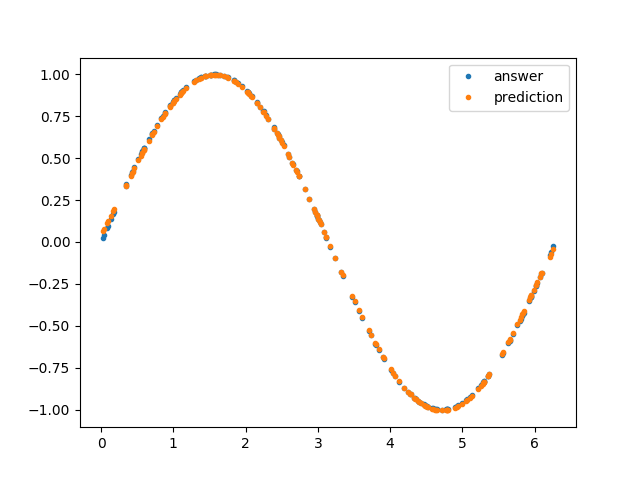
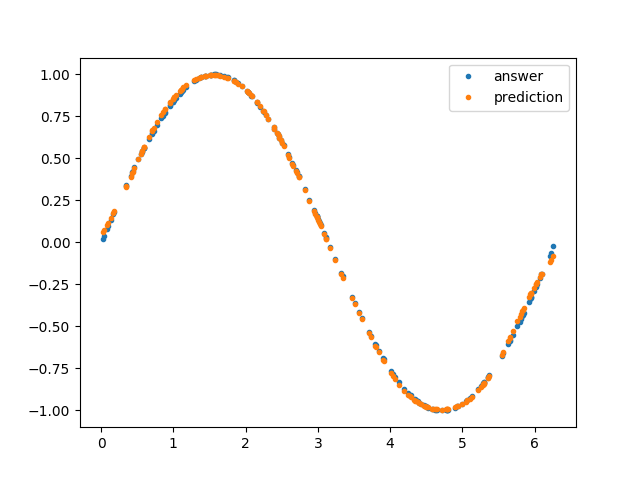
結果の可視化の部分も軽く触れておきます。この関数は、引数として与えられた
trialに対応するモデルのデータを読み込んで、validation dataset に対する結果をプロットするものです。import matplotlib.pyplot as plt def evaluate_results(trial): """Evaluate the optimization results. Args: study: optuna.trial.Trial Returns: None """ # Load model trial_number = trial.number with open( MODEL_DIRECTORY / f"model_{trial_number}.pickle", 'rb') as f: model = pickle.load(f) # Load data x_valid = np.load(DATASET_DIRECTORY / 'x_valid.npy') y_valid = np.load(DATASET_DIRECTORY / 'y_valid.npy') # Plot plt.plot(x_valid, y_valid, '.', label='answer') plt.plot(x_valid, model.predict(x_valid), '.', label='prediction') plt.legend() plt.show()main 関数ふたたび
ここでふたたび
main関数の部分を示します。def main(): # Generate dataset prepare_dataset() # Prepare study if not MODEL_DIRECTORY.exists(): MODEL_DIRECTORY.mkdir(parents=True) study = optuna.create_study( study_name=STUDY_NAME, storage=f"sqlite:///{STUDY_NAME}.db", load_if_exists=True) # Optimize study.optimize(objective, n_trials=N_TRIALS) # Visualize the best result print('=== Best Trial ===') print(study.best_trial) evaluate_results(study.best_trial)Optuna を直接使っている部分は
study = optuna.create_study以下なので、そこを説明します。まず
studyの作成部分ですが、study = optuna.create_study( study_name=STUDY_NAME, storage=f"sqlite:///{STUDY_NAME}.db", load_if_exists=True)このようになっています。
storage=f"sqlite:///{STUDY_NAME}.cb"となっていますが、これは変数が展開されてstorage=f"sqlite:///poly.cb"となります。この部分でstudyのデータをどこに保存するかを指定しています。ここでは SQLite を使っているため、インストールしてデータベースサーバを立ち上げた上で実行する必要があります。また、load_if_exists=Trueとしているので、すでに DB が存在していた場合はそのデータを読み込んで、最適化を再開します。もし SQLite 関連でうまくいかない場合は、該当する場所を
study = optuna.create_study( study_name=STUDY_NAME)のように書き換えてください。データが保存されませんが、SQLite のインストールなどは不要になります。
実際にハイパーパラメータの自動最適化を実行している部分は
study.optimize(objective, n_trials=N_TRIALS)です。目的関数として上で定義した
objectiveを与えており、それに基づいてN_TRIALSに指定した回数だけtrialを行い、studyを終了します。実行
全体のコードは こちら にありますので、
git cloneなどでダウンロードした上で、ターミナル上で$ python3 poly.pyとすれば、
data/dataset_1000にデータセットが作成され、モデルのパラメータがmodels/polyに保存されながら以下のような結果がターミナルに表示されるはずです。[I 2019-05-27 04:41:29,531] A new study created with name: poly -- Trial: 0 Current hyperparameters: Polynomial degree: 8 -- [I 2019-05-27 04:41:29,654] Finished trial#0 resulted in value: 0.0005262039485387504. Current best value is 0.0005262039485387504 with parameters: {'polynomial_degree': 8}. -- Trial: 1 Current hyperparameters: Polynomial degree: 2 -- [I 2019-05-27 04:41:29,754] Finished trial#1 resulted in value: 0.19891643524169922. Current best value is 0.0005262039485387504 with parameters: {'polynomial_degree': 8}. ... [I 2019-05-27 04:41:30,626] Finished trial#9 resulted in value: 0.004659125581383705. Current best value is 5.815048280055635e-05 with parameters: {'polynomial_degree': 5}. === Best Trial === FrozenTrial(number=2, state=<TrialState.COMPLETE: 1>, value=5.815048280055635e-05, datetime_start=datetime.datetime(2019, 5, 27, 4, 41, 29, 755017), datetime_complete=datetime.datetime(2019, 5, 27, 4, 41, 29, 843021), params={'polynomial_degree': 5}, distributions={'polynomial_degree': IntUniformDistribution(low=1, high=10)}, user_attrs={}, system_attrs={'_number': 2}, intermediate_values={}, params_in_internal_repr={'polynomial_degree': 5.0}, trial_id=3)最適化が終わったら、試した中でもっともスコアがよかった(
best_trial)ときのハイパーパラメータが表示されます。試されたハイパーパラメータとその結果はすべてデータベースに保存されているため、スコアの高い順に n 個データをとってくるなども簡単にでき、結果として人手によるチェックのコストを下げてくれています。私が実行したところによると、'polynomial_degree': 5のときに validation dataset に対するlossが5.815048280055635e-05で最小になったようです。また、それを用いた結果の可視化として下のようなグラフも表示されるはずです。
Optuna + Chainer で深層学習のハイパーパラメータ最適化
では Chainer で多層パーセプトロン(MLP)を作って、そのハイパーパラメータを Optuna で自動最適化してみましょう。タスクは先ほどと同様、$\sin$ のフィッティングとします。また、ハイパーパラメータとしては:
- 層の数
- 層を構成するユニットの個数
- 活性化関数
を選びました。
全体像
全体像自体もあまり変わりませんが、
main関数まわりをまず示します。import optuna STUDY_NAME = 'mlp' N_TRIALS = 100 PRUNER_INTERVAL = 100 def main(): # Generate dataset prepare_dataset() # Prepare study study = optuna.create_study( study_name=STUDY_NAME, storage=f"sqlite:///{STUDY_NAME}.db", load_if_exists=True, pruner=optuna.pruners.MedianPruner()) # Optimize study.optimize(objective, n_trials=N_TRIALS) # Visualize the best result print('=== Best Trial ===') print(study.best_trial) evaluate_results(study.best_trial) if __name__ == '__main__': main()ここで重要な変更はひとつだけで、
study = optuna.create_study( study_name=STUDY_NAME, storage=f"sqlite:///{STUDY_NAME}.db", load_if_exists=True, pruner=optuna.pruners.MedianPruner())のところです。新しい引数として
pruner=optuna.pruners.MedianPruner()を与えていますが、これは pruning (枝刈り)と呼ばれる、途中で明らかにダメそうな学習を早めに打ち切る機能です。人手でハイパーパラメータチューニングをするときも、10 epoch くらい走らせてみてダメそうだったら学習を止めて別のハイパーパラメータを試しますよね。それを機械がやってくれるということです。ただし、 pruning を行うには学習器自体にも設定が必要で、それは後述します。目的関数
データ生成の部分はまったく同じなので、目的関数から見ていきましょう。
from pathlib import Path import chainer as ch import optuna PRUNER_INTERVAL = 100 EPOCH = 1000 DATA_SIZE = 5000 BATCH_SIZE = 100 GPU_ID = -1 # Set value >= 0 to use GPU (-1: CPU mode) DATASET_DIRECTORY = Path(f"./data/dataset_{DATA_SIZE}") MODEL_DIRECTORY = Path('models/mlp') def objective(trial): """Objective function to make optimization for Optuna. Args: trial: optuna.trial.Trial Returns: loss: float Loss value for the trial """ # Generate model classifier = generate_model(trial) # Create dataset x_train = np.load(DATASET_DIRECTORY / 'x_train.npy') y_train = np.load(DATASET_DIRECTORY / 'y_train.npy') x_valid = np.load(DATASET_DIRECTORY / 'x_valid.npy') y_valid = np.load(DATASET_DIRECTORY / 'y_valid.npy') # Prepare training train_iter = ch.iterators.SerialIterator( ch.datasets.TupleDataset(x_train, y_train), batch_size=BATCH_SIZE, shuffle=True) valid_iter = ch.iterators.SerialIterator( ch.datasets.TupleDataset(x_valid, y_valid), batch_size=BATCH_SIZE, shuffle=False, repeat=False) optimizer = ch.optimizers.Adam() optimizer.setup(classifier) updater = ch.training.StandardUpdater(train_iter, optimizer, device=GPU_ID) stop_trigger = ch.training.triggers.EarlyStoppingTrigger( monitor='validation/main/loss', check_trigger=(100, 'epoch'), max_trigger=(EPOCH, 'epoch')) trainer = ch.training.Trainer( updater, stop_trigger, out=MODEL_DIRECTORY/f"model_{trial.number}") log_report_extension = ch.training.extensions.LogReport( trigger=(100, 'epoch'), log_name=None) trainer.extend(log_report_extension) trainer.extend(ch.training.extensions.PrintReport( ['epoch', 'main/loss', 'validation/main/loss'])) trainer.extend(ch.training.extensions.snapshot( filename='snapshot_epoch_{.updater.epoch}')) trainer.extend(ch.training.extensions.Evaluator(valid_iter, classifier)) trainer.extend(ch.training.extensions.ProgressBar()) trainer.extend( optuna.integration.ChainerPruningExtension( trial, 'validation/main/loss', (PRUNER_INTERVAL, 'epoch'))) # Train trainer.run() loss = log_report_extension.log[-1]['validation/main/loss'] return loss処理は長くなっていますが、やっていることは多項式のときとそう変わりません。Chainer に慣れ親しんでいる方なら見慣れた処理が多いと思います(Updater や Trainer を使わずに Chainer をやっている方は、もったいないのでこのタイミングでそれらの使い方をおさえておきましょう)。ただ唯一
trainer.extend( optuna.integration.ChainerPruningExtension( trial, 'validation/main/loss', (PRUNER_INTERVAL, 'epoch')))のところは Optuna に由来する部分で、これが例の pruning のための設定その 2 です。いま
PRUNER_INTERVAL = 100としているので、 100 epoch おきに学習をとめるかどうか判断するという設定になっています。別途stop_triggerとして early stopping の設定もしていますので、
- 望みのなさそうなハイパーパラメータでの学習は早めに止める(pruning)
- 望みがありそうなハイパーパラメータでの学習でも、学習が停滞したら止める(early stopping)
の 2 重の構えになっています。したがって、最大のエポック数
EPOCH = 5000としていますが、私がためした限りでは 5000 epoch フルに学習が走った trial はありませんでした。適切なタイミングで学習を(自動的に)止めるのも、より多くのハイパーパラメータを試すための重要なファクターになっています。モデルの生成
上の目的関数のところで、モデルの生成部分は
# Generate model classifier = generate_model(trial)と、別の関数に置き換えてあっさり終わってしまっていました。実はこの部分こそが Optuna で深層学習をやるための重要な部分です。ハイパーパラメータ自動最適化ツールで深層学習を行いたい場合、もっとも重要なことは
- モデル生成をできるだけ柔軟にできるようにする
ことです。ハイパーパラメータ自動最適化ツールではハイパーパラメータを何か選んできてそれをもとにモデルを作るわけですが、裏を返せばモデル生成をパラメトリックに行える必要があります。ではそれを気にしながらモデル生成部分のコードを見ていきましょう。
def generate_model(trial): """Generate MLP model. Args: trial: optuna.trial.Trial Returns: classifier: chainer.links.Classifier """ # Suggest hyperparameters layer_number = trial.suggest_int('layer_number', 2, 5) activation_name = trial.suggest_categorical( 'activation_name', ['relu', 'sigmoid']) unit_numbers = [ trial.suggest_int(f"unit_number_layer{i}", 10, 100) for i in range(layer_number - 1)] + [1] dropout_ratio = trial.suggest_uniform('dropout_ratio', 0.0, 0.2) print('--') print(f"Trial: {trial.number}") print('Current hyperparameters:') print(f" The number of layers: {layer_number}") print(f" Activation function: {activation_name}") print(f" The number of units for each layer: {unit_numbers}") print(f" The ratio for dropout: {dropout_ratio}") print('--') # Generate the model model = MLP( unit_numbers, activation_name=activation_name, dropout_ratio=dropout_ratio) classifier = ch.links.Classifier( model, lossfun=ch.functions.mean_squared_error) classifier.compute_accuracy = False return classifierモデル生成部分はこのようになっており、前半部分は
trial.suggest_***でそれぞれに合った型のハイパーパラメータを生成しています。unit_numbers(各層を構成するユニットの個数)はintの配列ですが、layer_number(層の数)によって配列の長さ(=ハイパーパラメータの個数)が動的に変わります。こういった、ハイパーパラメータの数が動的に変化するような問題に対しても最適化を行える柔軟性が Optuna の長所のひとつだと思います1。また、今回は MLP の出力(y)の特徴量次元は 1 なので、unit_numbersの末尾に 1 を付け足しています。このようにして作成されたハイパーパラメータは、たとえばCurrent hyperparameters: The number of layers: 4 Activation function: sigmoid The number of units for each layer: [36, 99, 87, 1] The ratio for dropout: 0.6906857740018953のようになっています。
ハイパーパラメータが無事生成できたところで、モデルの具体的な生成の実装に移っていきます。モデルの実装は以下のようになっています。
class MLP(ch.ChainList): """Multi Layer Perceptron.""" def __init__( self, unit_numbers, activation_name, dropout_ratio): """Initialize MLP object. Args: unit_numbers: list of int List of the number of units for each layer. activation_name: str The name of the activation function applied to layers except for the last one (The activation of the last layer is always identity). dropout_ratio: float The ratio of dropout. Dropout is applied to all layers. Returns: None """ super().__init__(*[ ch.links.Linear(unit_number) for unit_number in unit_numbers]) self.activations = [ self._create_activation_function(activation_name) for _ in self[:-1]] \ + [ch.functions.identity] # The last one is identity self.dropout_ratio = dropout_ratio def _create_activation_function(self, activation_name): """Create activation function. Args: activation_name: str The name of the activation function. Returns: activation_function: chainer.FunctionNode Chainer FunctionNode object corresponding to the input name. """ if activation_name == 'relu': return ch.functions.relu elif activation_name == 'sigmoid': return ch.functions.sigmoid elif activation_name == 'identity': return ch.functions.identity else: raise ValueError(f"Unknown function name {activation_name}") def __call__(self, x): """Execute the NN's forward computation. Args: x: numpy.ndarray or cupy.ndarray Input of the NN. Returns: y: numpy.ndarray or cupy.ndarray Output of the NN. """ h = x for i, link in enumerate(self): h = link(h) if i + 1 != len(self): h = ch.functions.dropout(h, ratio=self.dropout_ratio) h = self.activations[i](h) return h
ChainListクラスを継承してMLPクラスを定義しました。ChainListは層の数がわかっていなくても定義が書けるので、このような場合には重宝します。重要なメソッドをひとつひとつ見ていきます。まずはオブジェクトの初期化部分ですが、def __init__( self, unit_numbers, activation_name, dropout_ratio): """Initialize MLP object. Args: unit_numbers: list of int List of the number of units for each layer. activation_name: str The name of the activation function applied to layers except for the last one (The activation of the last layer is always identity). dropout_ratio: float The ratio of dropout. Dropout is applied to all layers. Returns: None """ super().__init__(*[ ch.links.Linear(unit_number) for unit_number in unit_numbers]) self.activations = [ self._create_activation_function(activation_name) for _ in self[:-1]] \ + [ch.functions.identity] # The last one is identity self.dropout_ratio = dropout_ratioのようになっています。
unit_numbersの長さの分だけchainer.links.Linearオブジェクト(重みとバイアス)が生成されていることがわかると思います。また、self.activationsでは各層の活性化関数を定義しているのですが、出力層のみchainer.functions.identity(恒等写像=何もしない関数)、ほかはハイパーパラメータとして与えられたactivation_nameをとるようにしています。ネットワークの foward 部分は、以下のようになっています。こちらでは層の数だけループを回して、線形変換とドロップアウト、活性化関数の適用を行っています。ただし、出力層にはドロップアウトを適用しないようにしています。
def __call__(self, x): """Execute the NN's forward computation. Args: x: numpy.ndarray or cupy.ndarray Input of the NN. Returns: y: numpy.ndarray or cupy.ndarray Output of the NN. """ h = x for i, link in enumerate(self): h = link(h) if i + 1 != len(self): h = ch.functions.dropout(h, ratio=self.dropout_ratio) h = self.activations[i](h) return h結果の可視化
残るは結果の可視化の部分です。こちらも多項式のときと同様、指定された
trialに対応するモデルをロードして推測させ、答えと比較しています。def evaluate_results(trial): """Evaluate the optimization results. Args: study: optuna.trial.Trial Returns: None """ # Load model trial_number = trial.number unit_numbers = [] for i in range(100): param_key = f"unit_number_layer{i}" if param_key not in trial.params: break unit_numbers.append(trial.params[param_key]) model = MLP( unit_numbers + [1], trial.params['activation_name'], trial.params['dropout_ratio']) snapshots = glob.glob(str(MODEL_DIRECTORY / f"model_{trial_number}" / '*')) latest_snapshot = max( snapshots, key=os.path.getctime) # The latest snapshot of the trial print(f"Loading: {latest_snapshot}") ch.serializers.load_npz( latest_snapshot, model, path='updater/model:main/predictor/') # Load data x_valid = np.load(DATASET_DIRECTORY / 'x_valid.npy') y_valid = np.load(DATASET_DIRECTORY / 'y_valid.npy') # Plot plt.plot(x_valid, y_valid, '.', label='answer') with ch.using_config('train', False): predict = model(x_valid).data plt.plot(x_valid, predict, '.', label='prediction') plt.legend() plt.show()まず予備知識として、
trial.paramsは例えば{'activation_name': 'sigmoid', 'dropout_ratio': 0.1948279849856978, 'layer_number': 5, 'unit_number_layer0': 77, 'unit_number_layer1': 56, 'unit_number_layer2': 51, 'unit_number_layer3': 80}のような辞書型のオブジェクトとしてその trial のハイパーパラメータを保持しています。したがって、これらのハイパーパラメータを使ってモデルを再構成し、(ハイパーでない)パラメータを読み込めばいいわけです。パラメータの読み込みでは、その trial のもっとも新しい snapshot を見つけてきてそれを読み込んでいます。ちょっとややこしいのが
unit_numbersを読み込んでいるところで、unit_numbersの長さが不定のため、ひとつひとつ読みながら配列に要素を追加していっています。このあたりが Optuna にがんばってほしいところで、配列などもハイパーパラメータとして扱えるようになればかなり取り回しがしやすくなると思います。実行
全体のコードは こちら にありますので、
git cloneなどでダウンロードした上で、ターミナル上で$ python3 mlp.pyとすれば、モデルのパラメータが
models/mlpに保存されながら以下のような結果がターミナルに表示されるはずです。[I 2019-05-27 15:26:18,496] Using an existing study with name 'mlp' instead of creating a new one. -- Trial: 0 Current hyperparameters: The number of layers: 3 Activation function: sigmoid The number of units for each layer: [83, 80, 1] The ratio for dropout: 0.043383365517199284 -- epoch main/loss validation/main/loss 100 0.131512 0.123286 200 0.0594965 0.0570084 300 0.0364821 0.0299548 400 0.0196009 0.00784213 500 0.014053 0.00332701 600 0.0111817 0.0023173 700 0.00912656 0.00166577 800 0.00797004 0.00153381 900 0.006777 0.0012653 1000 0.00608755 0.00110705 1100 0.00560331 0.00109022 1200 0.00517723 0.00108871 1300 0.00489841 0.00112543 1400 0.00468537 0.00100757 1500 0.00446898 0.000979245 1600 0.00428505 0.000921101 1700 0.00424085 0.000983566 1800 0.00405002 0.000959924 1900 0.00384459 0.000955113 [I 2019-05-27 15:28:03,244] Finished trial#0 resulted in value: 0.0009551127247686964. Current best value is 0.0009551127247686964 with parameters: {'activation_name': 'sigmoid', 'dropout_ratio': 0.043383365517199284, 'layer_number': 3, 'unit_number_layer0': 83, 'unit_number_layer1': 80}. -- Trial: 1 Current hyperparameters: The number of layers: 5 Activation function: relu The number of units for each layer: [53, 87, 75, 12, 1] The ratio for dropout: 0.10755231083048578 -- epoch main/loss validation/main/loss 100 0.249045 0.225993 200 0.0869799 0.0862519 ... === Best Trial === FrozenTrial(number=1, state=<TrialState.COMPLETE: 1>, value=0.00015463905489013997, datetime_start=datetime.datetime(2019, 5, 27, 7, 15, 22, 258062), datetime_complete=datetime.datetime(2019, 5, 27, 7, 16, 59, 707008), params={'activation_name': 'sigmoid', 'dropout_ratio': 0.0032366848483553535, 'layer_number': 3, 'unit_number_layer0': 41, 'unit_number_layer1': 18}, distributions={'activation_name': CategoricalDistribution(choices=('relu', 'sigmoid')), 'dropout_ratio': UniformDistribution(low=0.0, high=0.2), 'layer_number': IntUniformDistribution(low=2, high=5), 'unit_number_layer0': IntUniformDistribution(low=10, high=100), 'unit_number_layer1': IntUniformDistribution(low=10, high=100)}, user_attrs={}, system_attrs={'_number': 1}, intermediate_values={100: 0.0697100069373846, 200: 0.04887961223721504, 300: 0.036658125929534435, 400: 0.01331155956722796, 500: 0.001735480735078454, 600: 0.00048741648788563907, 700: 0.00028684467542916536, 800: 0.0001745481313264463, 900: 0.0001783440457074903, 1000: 0.00014417021156987175, 1100: 0.00017049246162059717, 1200: 0.00015490048099309206, 1300: 0.0001087129203369841, 1400: 0.00011426526543800719, 1500: 0.0001357111832476221, 1600: 0.00020704924827441573, 1700: 0.00016470269474666566}, params_in_internal_repr={'activation_name': 1.0, 'dropout_ratio': 0.0032366848483553535, 'layer_number': 3.0, 'unit_number_layer0': 41.0, 'unit_number_layer1': 18.0}, trial_id=2)途中で
-- Trial: 98 Current hyperparameters: The number of layers: 4 Activation function: sigmoid The number of units for each layer: [22, 49, 60, 1] The ratio for dropout: 0.8962421296002223 -- epoch main/loss validation/main/loss Exception in main training loop: Trial was pruned at epoch 50.] 5.00% Traceback (most recent call last):............................] 0.00% File "/usr/local/var/pyenv/versions/3.7.3/lib/python3.7/site-packages/chainer/training/trainer.py", line 319, in runers/sec. Estimated time to finish: 0:01:00.705030. entry.extension(self) File "/usr/local/var/pyenv/versions/3.7.3/lib/python3.7/site-packages/optuna/integration/chainer.py", line 109, in __call__ raise optuna.structs.TrialPruned(message) Will finalize trainer extensions and updater before reraising the exception. [I 2019-05-27 05:59:31,203] Setting status of trial#98 as TrialState.PRUNED. Trial was pruned at epoch 50.のような出力が出ていたら、その trial は Pruning されているということで、Pruning が動いていることも確認できると思います。最適化が終わったら(20 〜 30 分ほどかかるかもしれませんので、ログを眺めつつこの記事を読み返してみるのもいいかもしれません)、下のようなグラフも表示されるはずです(タスクが単純すぎたので、多項式よりよくなっているわけではないのが世知辛いですが)。
おわりに
この記事では、簡単なデータを作成して、その回帰問題に対して Optuna によるハイパーパラメータ最適化を行う方法を解説しました。Optuna は機械学習タスクのハイパーパラメータ最適化だけでなく、さまざまなブラックボックス最適化にもつかえるようなジェネラルなフレームワークだと思います。これを使いこなすことによって最適化タスクが格段に便利になることは確かだと思いますので、ぜひ使いこなして業務を効率化していきましょう!
ただし、実用上はユニットの数を層によってばらつかせることはあまりなく、中間層のユニット数は同じにすることが多いかもしれません。ここでは、Optuna のキャパシティを見るためにもあえて層ごとにユニット数を変えています。 ↩
- 投稿日:2019-05-27T15:29:07+09:00
ElixirでDeep Learning ー並列バックプロパゲーションー
はじめに
制作中のElixirによるDeep learningフレームワーク(Deep Pipeといいます)の基本的な機能がまとまりました。並列処理によるバックプロパゲーションについてどの程度、効率改善があるのか計測しました。
Deep Pipe
このページをご覧ください。
https://qiita.com/sym_num/items/a49cdb3cf50fc2226780並列機能
DPB module にあるのは逐次実行型のバックプロパゲーションです。行列積についてのみElixirのSpawnによる並列処理が施されています。
DPP moduleにあるのは並列処理型のバックプロパゲーションです。ミニバッチ学習をするデータをN個のグループに分割し、生成したプロセスに渡します。Nが省略された場合はデフォルトは5です。icore5マシンでの利用を想定しています。各プロセスから返ってきた勾配のデータを集計し、勾配の平均値としています。
計測に使ったデータ
MNISTを使いました。教師データの最初から3000個のうちから乱数で100個を取り出し、ミニバッチ学習をさせます。エポック数は50回です。
ネットワークは下記の通りです。
# for adagrad test defnetwork init_network4(_x) do _x |> f(5,5,0.02) |> flatten |> w(576,300,0.02) |> b(300,0.02) |> relu |> w(300,100,0.02) |> b(100,0.02) |> relu |> w(100,10,0.02) |> b(10,0.02) |> softmax end初段がCNN畳み込みであり、その後、重み行列による層を3層としています。中間層の活性化関数はreLuで、出力層はsoftmaxです。損失関数はcross-entropyです。
計測に使ったハード
Intel Core i5-6500
3.20 GHz
RAM 8.0GBWindows10 WSL Ubuntu
計測結果
行列積を並列とした場合
CPU使用率43%~50%
Time.time(Test.adagrad(100,50)) ... 0.7836927371701387 accuracy rate = 0.94 "time: 232843449 micro second" "-------------" :okミニバッチ学習を並列にした場合
CPU使用率79%~81%
Time.time(Test.adagrad(100,50)) ... 1.242132930743846 0.4962753332476217 accuracy rate = 0.94 "time: 184198758 micro second" "-------------" :okおよそ20%程度の速度改善があることがわかりました。
感想
期待したほどの大きな速度改善はありませんでした。ミニバッチ学習のところ以外でも勾配の更新などで手間がかかっているからだろうと予想しています。icore5でこの程度ならば今後のハードに期待できそうです。icore9など今後どんどんマルチCPUは進化、普及していくことでしょう。マルチCPUによってElixirでは線形な速度改善があると聞いています。そうすればいずれハードの後押しを受けて高速に学習することも期待できるだろうと思います。さらにGPUを利用するHastegaによる速度改善にも期待がかかります。
全コード
GitHubにて公開しています。
https://github.com/sasagawa888/DeepLearning
- 投稿日:2019-05-27T13:30:25+09:00
VSCodeのRemote ContainersでABEJA Platformの学習コードをデバッグする方法
はじめに
プログラムを作る際に、デバックを迅速に行えることは重要です。Visual Studio CodeがDockerコンテナ内のリモートデバッグ機能をサポートしたということで、早速ABEJA Platform上で学習コードをデバッグしてみました。本記事ではその方法について説明します。なお、本記事はプラットフォームの使い方を一通り学んだ方を対象とし、用語の説明などは省略します。
VSCodeのインストール
2019年5月現在、VSCodeのRemote Containers機能は、VSCodeではなく、VSCode Insidersという新機能をいち早く試せるバージョンでしか利用できませんので、そちらをダウンロードして利用しましょう。Macならば以下でも使えるらしいです。
$ brew cask install visual-studio-code-insidersRemoteContainerをインストール
以下をインストールするだけです。
Dockerfileの作成
以下のようなDockerfileを作成しましょう。
USER_ID、TOKEN、ORGANIZATION_IDはプラットフォームのコンソールに表示されているものを使いましょう。DATASETSは学習データセットのIDを入れます。1 FROM abeja/all-cpu:18.10 2 3 ENV ABEJA_PLATFORM_USER_ID user-XXXXXXXXXXXXXXXXXXXXX 4 ENV ABEJA_PLATFORM_PERSONAL_ACCESS_TOKEN XXXXXXXXXXXXXXXXXXXXXXXXXXX 5 ENV ABEJA_ORGANIZATION_ID XXXXXXXXXXXXXXXXX 6 ENV DATASETS '{"train":"XXXXXXXXXXXXXXX"}' 7 8 RUN pip install -U abeja-sdk abejacli 9 10 RUN mkdir /appDocker Containerを立ち上げ
ここではコードが
/home/user/workspaceに保存されていることとしましょう。対象のディレクトリをマウントしてコンテナを立ち上げておきます。$ docker build -t platform_container . $ docker run -it --rm -v /home/user/workspace:/app platform_container:latestコンテナ内にアクセス
VSCode Insidersを起動し、F1から
Remote-Containers: Attach to Running Containerを選択し、先ほど起動したコンテナを選択します。すると、新しくVSCodeの画面が立ち上がります。
プロジェクトの初期設定
先ほどコードを
/appにマウントしたので、FileのOpen...メニューから、そのディレクトリを開きましょう。以下のような画面になっているかと思います。
Pythonのデバッグをするために、PythonのExtensionをインストールしましょう。
続いて、ABEJA Platformの仕組みでデバッグするためにConfigurationを設定します。以下のメニューを選択し、Pythonを選択しましょう。
すると、
launch.jsonの編集画面に移るので以下のように修正します。{ "version": "0.2.0", "configurations": [ { "name": "Python: Current File", "type": "python", "request": "launch", "program": "/usr/local/bin/abeja-model", "args": ["train", "--handler", "main:handler"], "console": "integratedTerminal" } ] }デバッグの実行
準備はできたので、F5を押してデバッグできます!
まとめ
VSCodeを使ってABEJA Platformのコードをデバッグする手順について書きました。良きABEJA Platformライフを!







