- 投稿日:2019-05-27T23:37:37+09:00
Lightsailを使ってWordpress環境を用意する
wordpressの使い勝手を試すため、検証用にwordpressを立ち上げる。
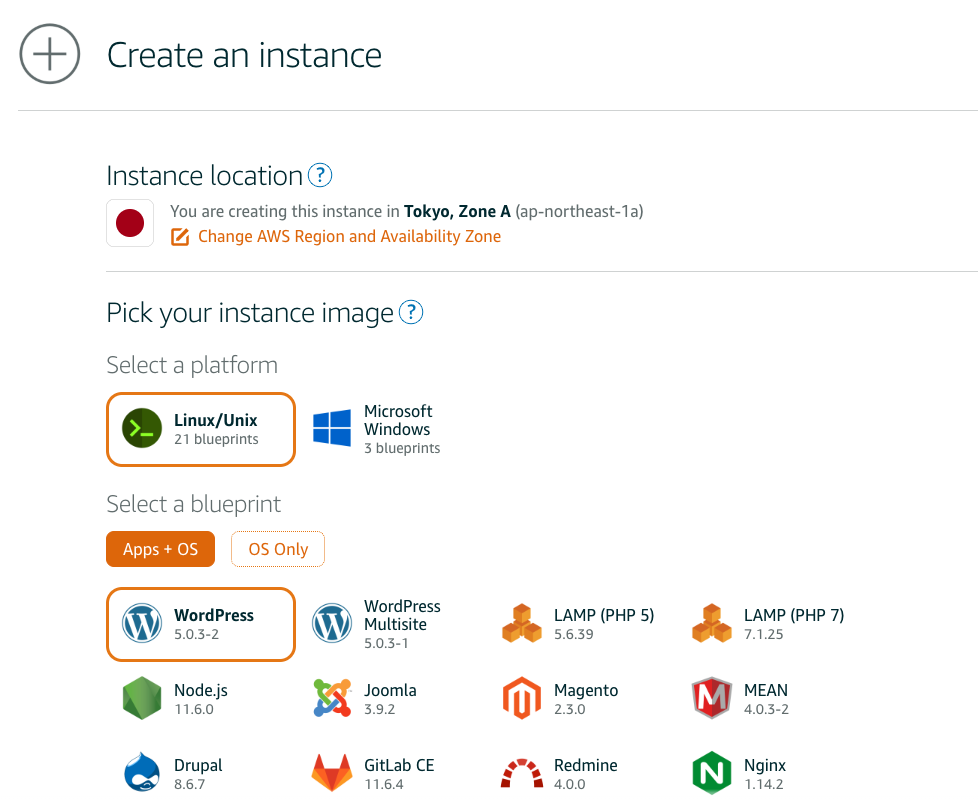
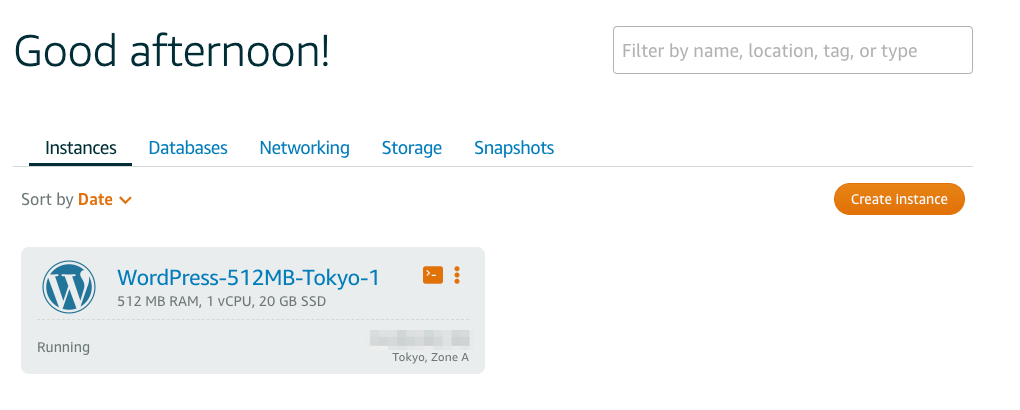
Lightsailを起動
画面に沿ってサーバーを起動する。
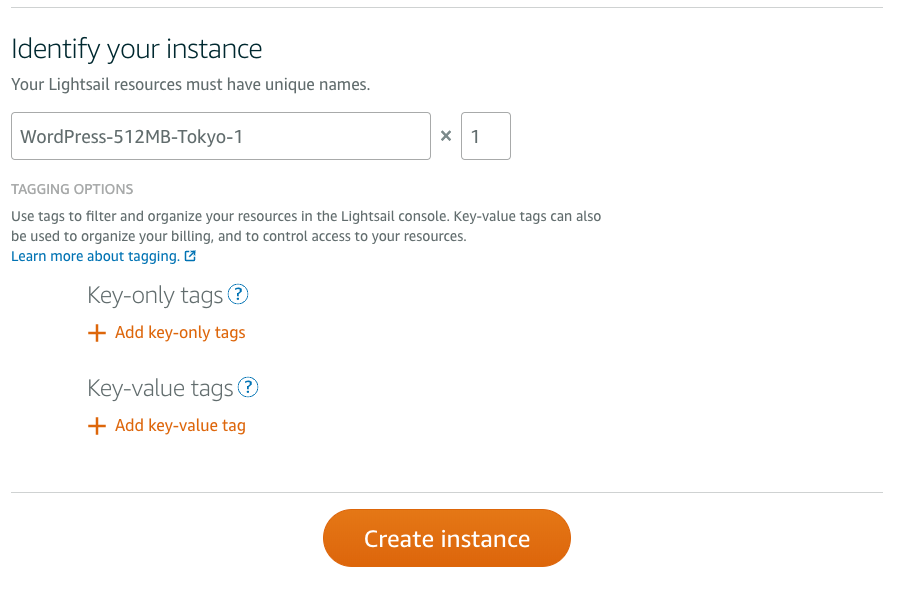
ミニマムの構成で良いので、デフォルトの設定のまま、Create instanceを選択する。
しばらくするとサーバーが起動する。
Wordpressにログイン
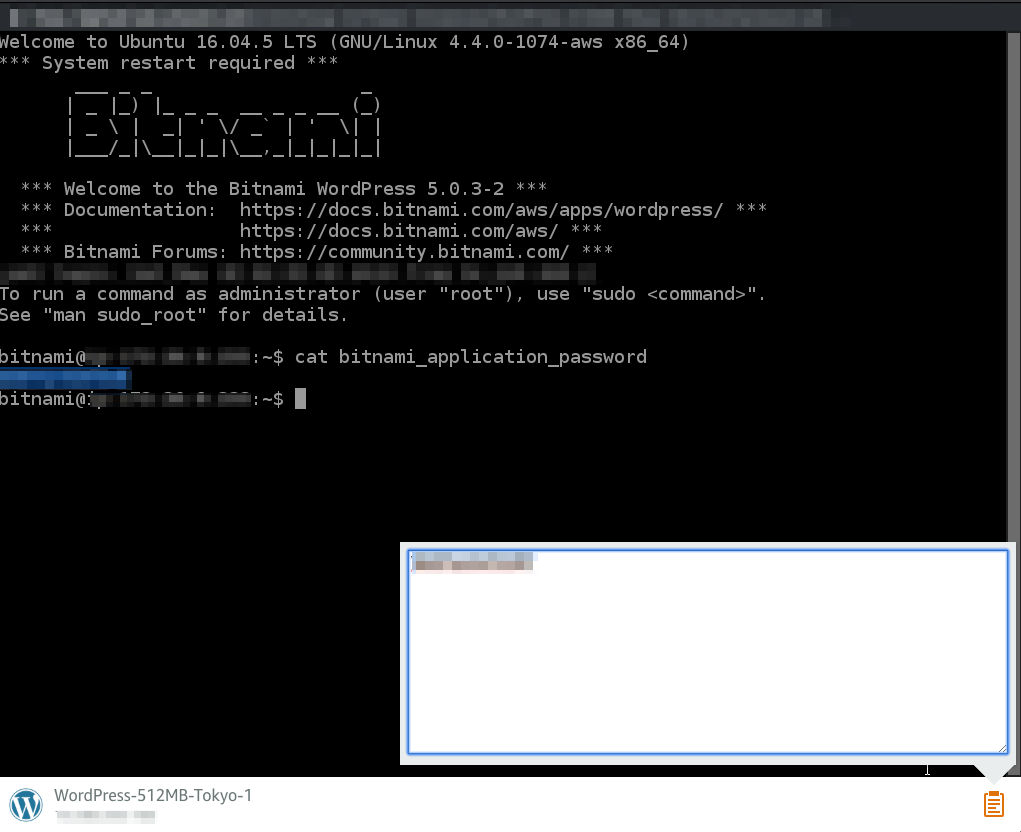
まずはコンソールを起動しインスタンスにログインする。
初期パスワードはサーバーを起動時にホームディレクトリに作成させるファイルに記述されている。
cat $HOME/bitnami_application_passwordパスワードをハイライトすると右下のクリップアイコンのテキストエリア内に文字列が表示されるので、それをコピーする
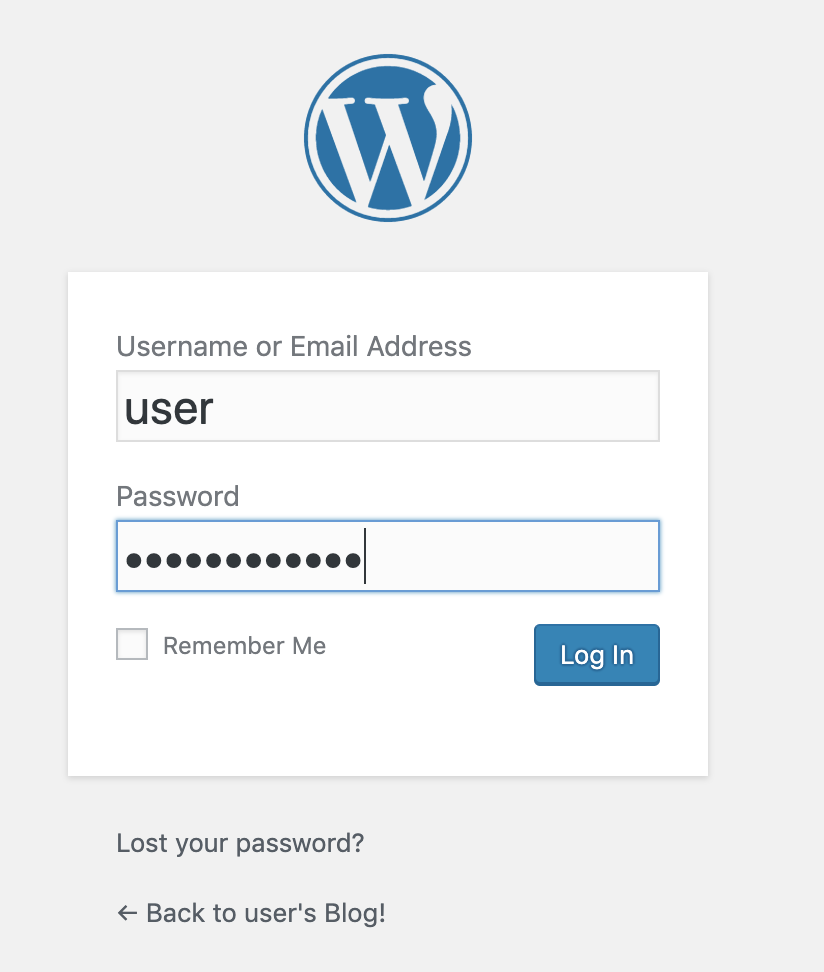
Wordpressのログイン画面にアクセスし、
Username: user
password: 先程コピーしてきたものを入力してログインする。
参考
https://aws.amazon.com/jp/lightsail/
Amazon Lightsail - ほんの数分で WordPress のサイトを開設
Getting started using WordPress from your Amazon Lightsail instance | Lightsail Documentation

- 投稿日:2019-05-27T23:29:12+09:00
AWS上のWindowsServerに対して、ローカルmacからansibleを実行 #2 pingテスト実行用のplaybook
pingテスト実行用のplaybook。
マニュアルは、https://docs.ansible.com/ansible/latest/modules/win_ping_module.htmlpingTest.yml--- - hosts: - windows # インベントリファイルで指定した名前 tasks: - name: Test Ping win_ping: data: test # dataを指定しなければpongになる。crashを指定すると、例外が発生する # data: crash以下コマンドで実行。
ansible-playbook -i ./ansible/hosts ./ansible/pingTest.ymlコマンド実行結果PLAY [windows] ************************************************************************************************************************ TASK [Gathering Facts] **************************************************************************************************************** ok: [ホスト名] TASK [Test Ping] ********************************************************************************************************************** ok: [ホスト名] PLAY RECAP **************************************************************************************************************************** ホスト名 : ok=2 changed=0 unreachable=0 failed=0 なお、data: crashにすると、以下の例外が発生する。 fatal: [ホスト名]: FAILED! => {"changed": false, "module_stderr": "boomAt line:14 char:5+ throw \"boom\"+ ~~~~~~~~~~~~ + CategoryInfo : OperationStopped: (boom:String) [], RuntimeException + FullyQualifiedErrorId : boom ", "module_stdout": "", "msg": "MODULE FAILURE\nSee stdout/stderr for the exact error", "rc": 1} to retry, use: --limit @/Users/kuritayu/git/ansible/pingTest.retry
- 投稿日:2019-05-27T21:41:33+09:00
AWS上のWindowsServerに対して、ローカルmacからansibleを実行 #1
AWS上のWindowsServerに対して、ローカルmacからansibleを実行したい、と思った。
環境
ローカル(mac)
- python -> 3.6.4
- ansible -> 2.7.10
リモート(Windows Server 2019)
ローカルの準備
とりあえず、pipでansibleとpywinrmをインストール。
pip install ansible pip install pywinrmあと、接続するためのhostsファイルを用意する。私は、ansibleディレクトリを作り、
その下にhostsファイルを作りました。hosts[windows] AWSのパブリックDNS名 [windows:vars] ansible_user=管理者ユーザ ansible_password=管理者ユーザのパスワード ansible_port=5986 ansible_connection=winrm ansible_winrm_server_cert_validation=ignoreリモートの準備
ansibleで、Windowsの環境を設定するスクリプトが提供されているので、ダウンロード。
Invoke-WebRequest -Uri https://raw.githubusercontent.com/ansible/ansible/devel/examples/scripts/ConfigureRemotingForAnsible.ps1 -OutFile ConfigureRemotingForAnsible.ps1で、ダウンロードしたスクリプトを実行する。私のネットワークはパブリックだったので、以下を実行した。
powershell -ExecutionPolicy RemoteSigned .\ConfigureRemotingForAnsible.ps1 -SkipNetworkProfileCheckAWSの準備
セキュリティグループで、インバウンドルールとして、ポート5986を許可しよう。
動作確認
ansible windows -i ansible/hosts -m win_ping -vvvv
ANSのパブリックDNS名 | SUCCESS => {
"changed": false,
"ping": "pong"
}的な感じでリターンがあるとOK。
- 投稿日:2019-05-27T18:27:40+09:00
aws × Goサーバー環境構築:ゼロからのhelloworld
まずはAWSサーバーをゲットする
AWSには一年間の無料体験があるので、安心に登録できます。
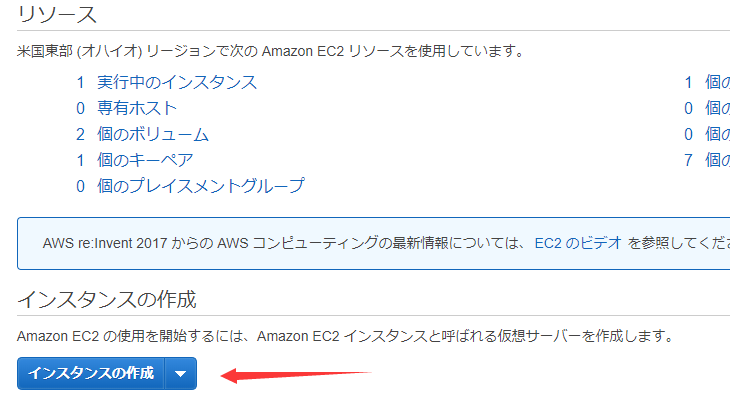
インスタンスを作成する
ここではAmazon Linuxを使いました。必要なパッケージが揃っているので使いやすいです。
僕も無料体験中なので、設定はディフォルトで作成しました。
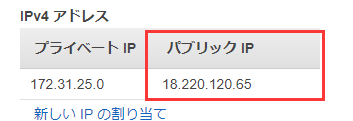
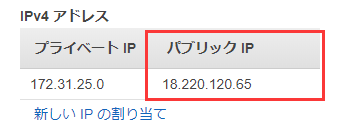
起動バタンを押すとキーの作成画面が出て、キーペア名を入力したら、.pemのファイルをダウンロードします。サーバーにアクセスにはキーが必要なの、これを大事に保存しましょう。IPをもらいます
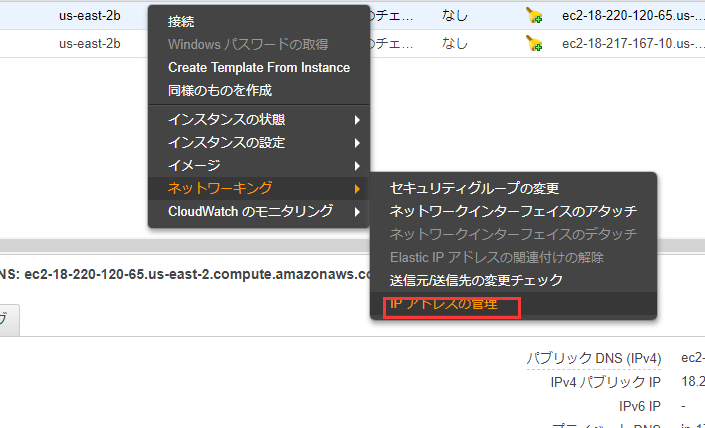
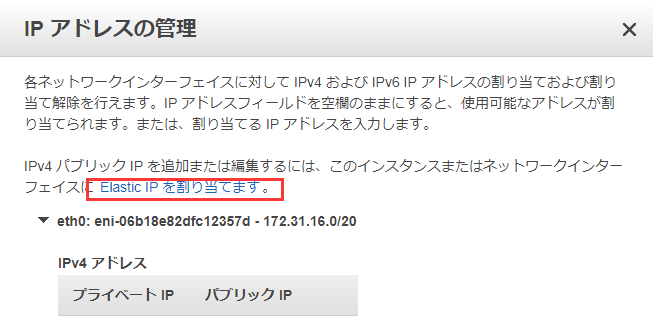
右ボタンを押せばこういうパネルが出ます。IPアドレス管理を選択。
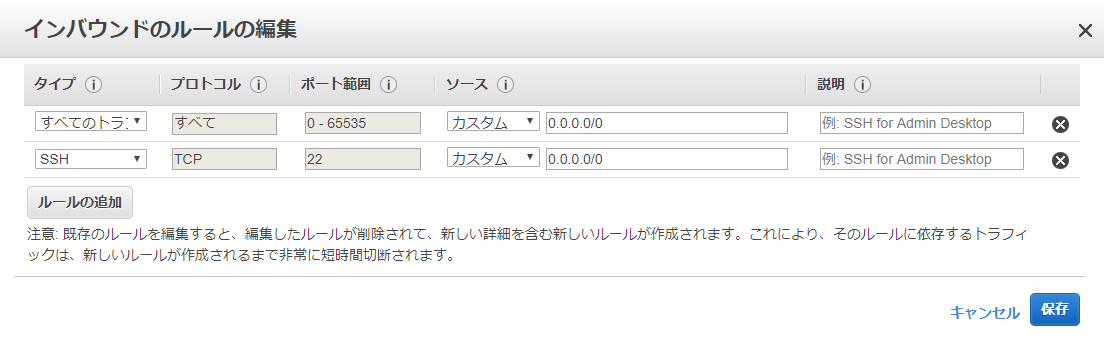
こうすることでIPの割り当てが完了しました。それからセキュリティグループを設定する、テストとしてこのように設定します。
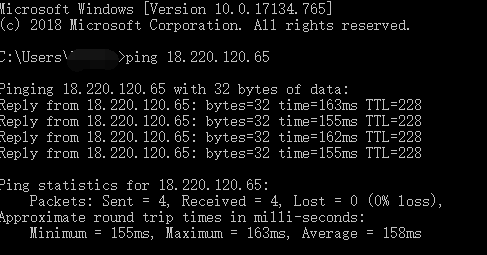
早速テストしましょう!
cmdを開いて、pingでテストします。
アクセス出来ました!Puttyで接続
まずはPuttyをダウンロード↓
https://www.chiark.greenend.org.uk/~sgtatham/putty/latest.html
続いてPuttyの環境配置を行います。↓
https://docs.aws.amazon.com/ja_jp/AWSEC2/latest/UserGuide/putty.html
↑公式ドキュメンテーションに詳しく記述してあります。GO環境の構築
では始めます~
公式サイトでlinkを取得します。
https://golang.org/dl/
https://dl.google.com/go/go1.12.5.linux-amd64.tar.gz
↑私が選択したバージョン
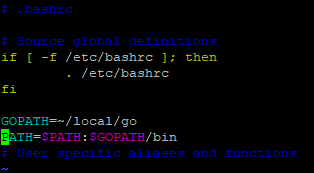
Linuxの下で//ダウンロード wget https://dl.google.com/go/go1.12.5.linux-amd64.tar.gz //フォルダーを作ります。 mkdir ~/local //内容を抽出 sudo tar -C ~/local -xzf go1.12.5.linux-amd64.tar.gz //PATHを設定 cd ~/ vim .bashrc //開いたテクストエディターにPATHを入れる GOPATH=~/local/go PATH=$PATH:$GOPATH/bin //shift+zz(二回押し)保存 //テスト go version//
vim .bashrc でこんな感じです。↓
Helloworld
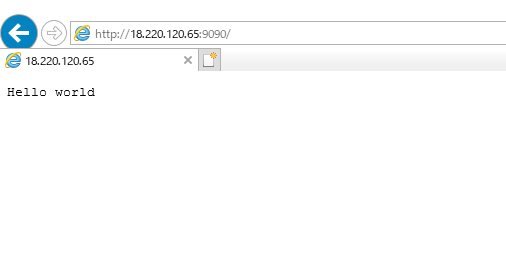
//goファイルを作る vi HelloWorld.go//以下のコードを中にコピーする package main import ( "fmt" "log" "net/http" ) func main() { http.HandleFunc("/", func(w http.ResponseWriter, r *http.Request) { fmt.Fprintf(w, "Hello world\n") }) err := http.ListenAndServe(":9090", nil) if err != nil { log.Fatal("ListenAndServe: ", err) } }//保存 shift+zz //実行 go run HelloWorld.goテスト
go run の後、puttyをそのまま放置
ブラウザに [自分のIP]:9090を入力 例:http://18.220.120.65:9090/
自分のIPはさっき取得した:
テスト成功!!!
もう一歩-------SupervisorでHelloWorldを管理する
//まずはSupervisorをインストール sudo easy_install supervisor //バージョン確認 supervisord -vSupervisorの設定ファイルを作る↓
sudo mkdir /etc/supervisor //権限を取得する sudo chmod -R 777 /etc/supervisor //ディフォルト配置ファイルを作る echo_supervisord_conf > /etc/supervisor/supervisord.confこのように編集する
//後ろにこれを挿入 [include] files = /etc/supervisor/config/*.conf //ほかのpackageを導入、プロセスが多くなってもコントロールしやすい。 mkdir /etc/supervisor/config/ //HelloWorld.confをこう編集する vim /etc/supervisor/config/HelloWorld.conf[program:HelloWorld] command=go run /home/ec2-user/GoCode/hello/HelloWorld.go ;実行するコマンド autostart=true ;Supervisorと共に起動 autorestart=true ;自動再起動 startsecs=10 stdout_logfile=/var/log/HelloWorld.log ;ログファイルのディレクトリを設定 stdout_logfile_maxbytes=1MB stdout_logfile_backups=10 stdout_capture_maxbytes=1MB stderr_logfile=/var/log/HelloWorld.log ;うえと同じくディレクトリを設定 stderr_logfile_maxbytes=1MB stderr_logfile_backups=10 stderr_capture_maxbytes=1MBmkdir /var/log/ //ディレクトリの権限を取得する sudo chmod -R 777 /var/log/ //起動 supervisord -c /etc/supervisor/supervisord.conf //作動状態をチェック supervisorctl起動しプロセスはこんな感じ
よく使うsupervisord/supervisorctl コマンド
supervisord -c supervisor.conf 配置ファイルでsupervisorを起動 supervisorctl -c supervisor.conf status 状態チェック supervisorctl -c supervisor.conf reload 配置ファイルの再読み込み supervisorctl -c supervisor.conf start [all]|[x] すべて/指定のプロセスを起動 supervisorctl -c supervisor.conf stop [all]|[x] すべて/指定のプロセスを中止




- 投稿日:2019-05-27T16:46:56+09:00
MFA認証が有効なユーザがAWS CLIを利用する際にきっと役立つシェルスクリプト
概要
- AWSの他要素認証(MFA)を利用している場合、AWS CLI利用時に一時的なセッショントークンを作成する必要がある
セッショントークンの作成のコマンド実行の際には、MFAデバイスのARN名と認証コードの2つの情報が必要となる
- 前者は固定だが後者は認証の度に変化する
→ readコマンドを用いて、認証コードを実行時に受け付けるようにする
スクリプト内容
auth_mfa.sh#!/bin/sh AWS_MFA_DEVICE_ARN="arn:aws:iam::1234567890:mfa/username" # MFAデバイスのARN名を指定 unset AWS_ACCESS_KEY_ID unset AWS_SECRET_ACCESS_KEY unset AWS_SESSION_TOKEN read -p '認証コードを入力してください: ' AWS_MFA_CODE eval `aws sts get-session-token \ --serial-number $AWS_MFA_DEVICE_ARN \ --token-code $AWS_MFA_CODE | \ awk ' $1 == "\"AccessKeyId\":" { gsub(/\"/,""); gsub(/,/,""); print "export AWS_ACCESS_KEY_ID="$2 } $1 == "\"SecretAccessKey\":" { gsub(/\"/,""); gsub(/,/,""); print "export AWS_SECRET_ACCESS_KEY="$2 } $1 == "\"SessionToken\":" { gsub(/\"/,""); gsub(/,/,""); print "export AWS_SESSION_TOKEN="$2 } '`なお、zshを利用している場合は
readコマンドのオプションが異なるため、以下を利用する。auth_mfa_zsh.sh#!/bin/zsh AWS_MFA_DEVICE_ARN="arn:aws:iam::1234567890:mfa/username" # MFAデバイスのARN名を指定 unset AWS_ACCESS_KEY_ID unset AWS_SECRET_ACCESS_KEY unset AWS_SESSION_TOKEN read 'AWS_MFA_CODE?認証コードを入力してください: ' eval `aws sts get-session-token \ --serial-number $AWS_MFA_DEVICE_ARN \ --token-code $AWS_MFA_CODE | \ awk ' $1 == "\"AccessKeyId\":" { gsub(/\"/,""); gsub(/,/,""); print "export AWS_ACCESS_KEY_ID="$2 } $1 == "\"SecretAccessKey\":" { gsub(/\"/,""); gsub(/,/,""); print "export AWS_SECRET_ACCESS_KEY="$2 } $1 == "\"SessionToken\":" { gsub(/\"/,""); gsub(/,/,""); print "export AWS_SESSION_TOKEN="$2 } '`実行方法
$ source ./auth_mfa.sh 認証コードを入力してください: 123456 # 入力例 # Enterを押して何もエラーが表示されなければ成功備忘
シェルスクリプト実行後に
exportという名前の空文字("")の環境変数が設定されてしまう。。参考
- 投稿日:2019-05-27T16:46:56+09:00
MFA認証が有効なユーザがAWS CLI利用時に使うと便利なシェルスクリプト
概要
- AWSの他要素認証(MFA)を利用している場合、AWS CLI利用時に一時的なセッショントークンを作成する必要がある
セッショントークンの作成のコマンド実行の際には、MFAデバイスのARN名と認証コードの2つの情報が必要となる
- 前者は固定だが後者は認証の度に変化する
→ readコマンドを用いて、認証コードを実行時に受け付けるようにする
スクリプト内容
auth_mfa.sh#!/bin/sh AWS_MFA_DEVICE_ARN="arn:aws:iam::1234567890:mfa/username" # MFAデバイスのARN名を指定 unset AWS_ACCESS_KEY_ID unset AWS_SECRET_ACCESS_KEY unset AWS_SESSION_TOKEN read -p '認証コードを入力してください: ' AWS_MFA_CODE eval `aws sts get-session-token \ --serial-number $AWS_MFA_DEVICE_ARN \ --token-code $AWS_MFA_CODE | \ awk ' $1 == "\"AccessKeyId\":" { gsub(/\"/,""); gsub(/,/,""); print "export AWS_ACCESS_KEY_ID="$2 } $1 == "\"SecretAccessKey\":" { gsub(/\"/,""); gsub(/,/,""); print "export AWS_SECRET_ACCESS_KEY="$2 } $1 == "\"SessionToken\":" { gsub(/\"/,""); gsub(/,/,""); print "export AWS_SESSION_TOKEN="$2 } '`なお、zshを利用している場合は
readコマンドのオプションが異なるため、以下を利用する。auth_mfa_zsh.sh#!/bin/zsh AWS_MFA_DEVICE_ARN="arn:aws:iam::1234567890:mfa/username" # MFAデバイスのARN名を指定 unset AWS_ACCESS_KEY_ID unset AWS_SECRET_ACCESS_KEY unset AWS_SESSION_TOKEN read 'AWS_MFA_CODE?認証コードを入力してください: ' eval `aws sts get-session-token \ --serial-number $AWS_MFA_DEVICE_ARN \ --token-code $AWS_MFA_CODE | \ awk ' $1 == "\"AccessKeyId\":" { gsub(/\"/,""); gsub(/,/,""); print "export AWS_ACCESS_KEY_ID="$2 } $1 == "\"SecretAccessKey\":" { gsub(/\"/,""); gsub(/,/,""); print "export AWS_SECRET_ACCESS_KEY="$2 } $1 == "\"SessionToken\":" { gsub(/\"/,""); gsub(/,/,""); print "export AWS_SESSION_TOKEN="$2 } '`実行方法
$ source ./auth_mfa.sh 認証コードを入力してください: 123456 # 入力例 # Enterを押して何もエラーが表示されなければ成功備忘
シェルスクリプト実行後に
exportという名前の空文字("")の環境変数が設定されてしまう。。参考
- 投稿日:2019-05-27T16:46:56+09:00
AWS CLIユーザがスムーズにMFA認証を行うためのシェルスクリプト
概要
- AWSの他要素認証(MFA)を利用している場合、AWS CLI利用時に一時的なセッショントークンを作成する必要がある
セッショントークンの作成のコマンド実行の際には、MFAデバイスのARN名と認証コードの2つの情報が必要となる
- 前者は固定だが後者は認証の度に変化する
→ readコマンドを用いて、認証コードを実行時に受け付けるようにする
スクリプト内容
auth_mfa.sh#!/bin/sh AWS_MFA_DEVICE_ARN="arn:aws:iam::1234567890:mfa/username" # MFAデバイスのARN名を指定 unset AWS_ACCESS_KEY_ID unset AWS_SECRET_ACCESS_KEY unset AWS_SESSION_TOKEN read -p '認証コードを入力してください: ' AWS_MFA_CODE eval `aws sts get-session-token \ --serial-number $AWS_MFA_DEVICE_ARN \ --token-code $AWS_MFA_CODE | \ awk ' $1 == "\"AccessKeyId\":" { gsub(/\"/,""); gsub(/,/,""); print "export AWS_ACCESS_KEY_ID="$2 } $1 == "\"SecretAccessKey\":" { gsub(/\"/,""); gsub(/,/,""); print "export AWS_SECRET_ACCESS_KEY="$2 } $1 == "\"SessionToken\":" { gsub(/\"/,""); gsub(/,/,""); print "export AWS_SESSION_TOKEN="$2 } '`なお、zshを利用している場合は
readコマンドのオプションが異なるため、以下を利用する。auth_mfa_zsh.sh#!/bin/zsh AWS_MFA_DEVICE_ARN="arn:aws:iam::1234567890:mfa/username" # MFAデバイスのARN名を指定 unset AWS_ACCESS_KEY_ID unset AWS_SECRET_ACCESS_KEY unset AWS_SESSION_TOKEN read 'AWS_MFA_CODE?認証コードを入力してください: ' eval `aws sts get-session-token \ --serial-number $AWS_MFA_DEVICE_ARN \ --token-code $AWS_MFA_CODE | \ awk ' $1 == "\"AccessKeyId\":" { gsub(/\"/,""); gsub(/,/,""); print "export AWS_ACCESS_KEY_ID="$2 } $1 == "\"SecretAccessKey\":" { gsub(/\"/,""); gsub(/,/,""); print "export AWS_SECRET_ACCESS_KEY="$2 } $1 == "\"SessionToken\":" { gsub(/\"/,""); gsub(/,/,""); print "export AWS_SESSION_TOKEN="$2 } '`実行方法
$ source ./auth_mfa.sh 認証コードを入力してください: 123456 # 入力例 # Enterを押して何もエラーが表示されなければ成功備忘
シェルスクリプト実行後に
exportという名前の空文字("")の環境変数が設定されてしまう。。参考
- 投稿日:2019-05-27T16:37:12+09:00
EMR「You cannot specify a ServiceAccessSecurityGroup for a cluster launched in public subnet.」
問題
AWS Lambda(以下Lambda)からAmazon EMR(以下EMR)を起動する構成で、Lambdaのコードは通るのにEMRが立ち上がらない(リストには表示されるけどエラーになる)というあるあるな問題に遭遇。
そのエラーのクラスターをコンソールから手動でクローンして同じ設定で立ち上げるとエラーなく起動する、という謎な状態。エラーの内容
EMRのコンソール上部にでているメッセージは「You cannot specify a ServiceAccessSecurityGroup for a cluster launched in public subnet.」。
S3にクラスターのログはあがっていない。環境
Lambda python3.6
EMR emr-5.15.0解決方法
boto3のrun_job_flow()で指定するパラメータ「ServiceAccessSecurityGroup」の指定を外したら解決した。
原因
「ServiceAccessSecurityGroup」は
プライベートサブネットでクラスターにアクセスするためにサービスが使用する (Amazon EMR によって管理される) EC2 セキュリティグループの ID です。
とのこと。
エラーメッセージの「You cannot specify a ServiceAccessSecurityGroup for a cluster launched in public subnet.」を翻訳すると「パブリックサブネットで起動されたクラスタにServiceAccessSecurityGroupを指定することはできません。」となるので、そのまま。。。クローンして正常に立ち上がってしまうところが厄介だった、、、(良しなに判断していらないならそのまま使用せずに立ててくれればいいのに)
本番環境とテスト環境をわけていて、本番環境ではプライベートサブネットに、テスト環境ではパブリックサブネットにそれぞれ構築している状態だったので、当たり前だけどなるべく環境合わせないと思わぬところで余計な時間食ってしまうといういい(?)例に。おまけ
LambdaからEMRを立てる場合、インスタンスサイズを指定するが、EMRが対応していないインスタンスサイズがあるので注意が必要。その他にも注意点はたくさんあるが、追々。
参考
- 投稿日:2019-05-27T15:09:10+09:00
(仕事用)用語&リンク集
一般的な用語だけど忘れっぽいので備忘録として
CodeCommit (AWS CodeCommit)
- AWSがフルマネージドで提供するGitリポジトリ1サービス
- GitHub2のAWS版。というのが近いのだろうか?
- コードを格納し、バージョン管理する場所
- AWS CodeCommit UserGuide
- DevelopersIO CodeCommit入門 – Code三兄弟を知る
CodeBuild(AWS CodeBuild)
ソースコードをコンパイル3し、テストを実行し、デプロイ可能なソフトウェアパッケージを作成できる完全マネージド型のビルドサービス
CodeDeploy(AWS CodeDeploy)
Amazon EC2 インスタンスやオンプレミスインスタンス、サーバーレス Lambda 関数、または Amazon ECS サービスに対するアプリケーションのデプロイを自動化するデプロイメントサービス
CodePipeline(AWS CodePipeline)
完全マネージド型の継続的デリバリーサービスで、素早く確実性のあるアプリケーションとインフラストラクチャのアップデートのための、パイプライン4のリリースを自動化
Amazon ECS(Amazon ECS)
Docker コンテナをサポートする拡張性とパフォーマンスに優れたコンテナオーケストレーション5サービスです
Docker
コンテナ6
BIgQuery
BigQuery は、高スケーラビリティでコスト効率に優れたサーバーレス クラウド データウェアハウスで、インメモリ BI エンジン6と機械学習ビルトインを備えています
Embluk
並列データ転送ツール
リポジトリ(repository)情報工学において、仕様・デザイン・ソースコード・テスト情報・インシデント情報など、システムの開発プロジェクトに関連するデータの一元的な貯蔵庫を意味する ↩
コンパイルはソースコードをコンピュータが実行可能な形式に変換すること。ビルド(build)はコンパイル(compile)に加えてライブラリのリンクなどをおこない、実行可能な状態にすること ↩
パイプラインに関する[Wikipediaの解説](https://ja.wikipedia.org/wiki/%E3%83%91%E3%82%A4%E3%83%97_(%E3%82%B3%E3%83%B3%E3%83%94%E3%83%A5%E3%83%BC%E3%82%BF) ↩
Wikipedia: インメモリデータベースとは、複数システムから、必要なデータを収集し、目的別に再構成して時系列に蓄積した統合データベースのこと最近ではBI(Business Intelligence)の一つ ↩
- 投稿日:2019-05-27T14:26:34+09:00
Rancher で AWS EC2上に Kubernetes クラスタを構築
Rancher(v2.2.3)で AWS EC2上に Kubernetes クラスタ構築のメモ。
[1] そもそもRancherとは
・Kubernetesクラスタをはじめとした各種OSSの構築・運用を一元的に行える管理ツール
・(米)Rancher Labs社が開発するOSS
・無料のOSS版は全機能利用可能らしく、別途有料のエンタープライズサポートサービスがある。
・2014年に初版リリースされ、当初複数のコンテナオーケストレーションツールをサポートしていたが、2017年のRancer2.0で、k8sベースのマルチクラウド対応特化に生まれ変わった。
・国内でもNTT Com社、LINE社、CyberAgent社、リクルートテクノロジーズ社など多くの企業で導入されてるようですk8sクラスタ構築のサービスやツールは他にも各種出てます。
例えば本家GCPならGKE、AWSならEKS、PaaS系ならPKS、ツール系ならKubeadmやKOPSなど様々。
そんな中Rancherは、個人的な所感としては「カタログ」機能で、PrometheusやGrafana、Helmのような実運用する上で必要となる周辺のツール群もセットでかつ容易にセットアップして管理できる点が大きな魅力かと感じます。
k8sは様々なツール群のエコシステムでなりなっているので、全部個別にセットアップして管理するのはかなりタフです。
さらに、etcdやk8s masterの冗長化も簡単に組み込める点(HA構成の考慮)も大きな魅力かと思います。Rancher公式
https://rancher.com/GitHub
https://github.com/rancher/rancher参考
https://thinkit.co.jp/article/15816
[2] とりあえずRancherでk8sクラスタを立てる
①はじめに
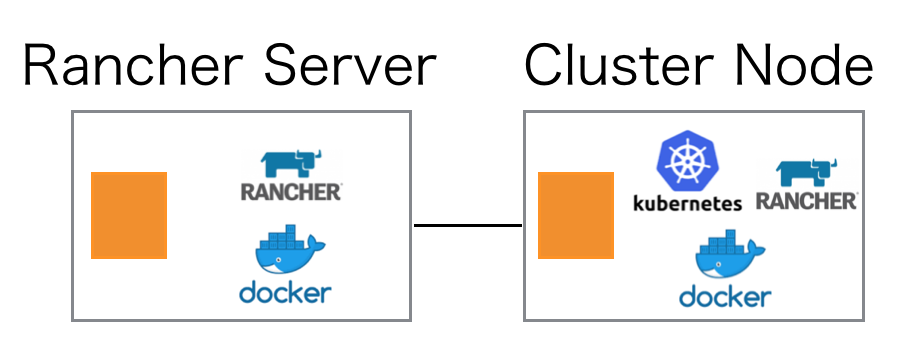
RancherはGUIを有するRancherサーバと、k8sクラスタサーバがあり、今回はRancherサーバ用のEC2と、k8sクラスタ(master/worker兼用の1node構成)用のEC2の計2台で構築。
基本的にすべてのコンポーネントはdockerコンテナで構築されるので、EC2は基本dockerさえ入っていればOK。
ClusterノードのRancherは、Rancherサーバとやりとりするエージェンドが稼働する。またk8sもhyperkubeでコンテナベースで起動される。環境情報
EC2: Amazon Linux2 m5.large
Rancher: version 2.2.3
docker: version 18.06.1-ce②Rancherセットアップ
※dockerセットアップ方法は省略
dockerインストール済みインスタンスで下記実行するのみ
sudo docker run -d --restart=unless-stopped -p 80:80 -p 443:443 rancher/rancherブラウザアクセスすると、Rancher GUI画面にアクセスできる。
初回はadminアカウントが生成されており、パスワードを設定すればログインできる。
③k8sクラスタ作成
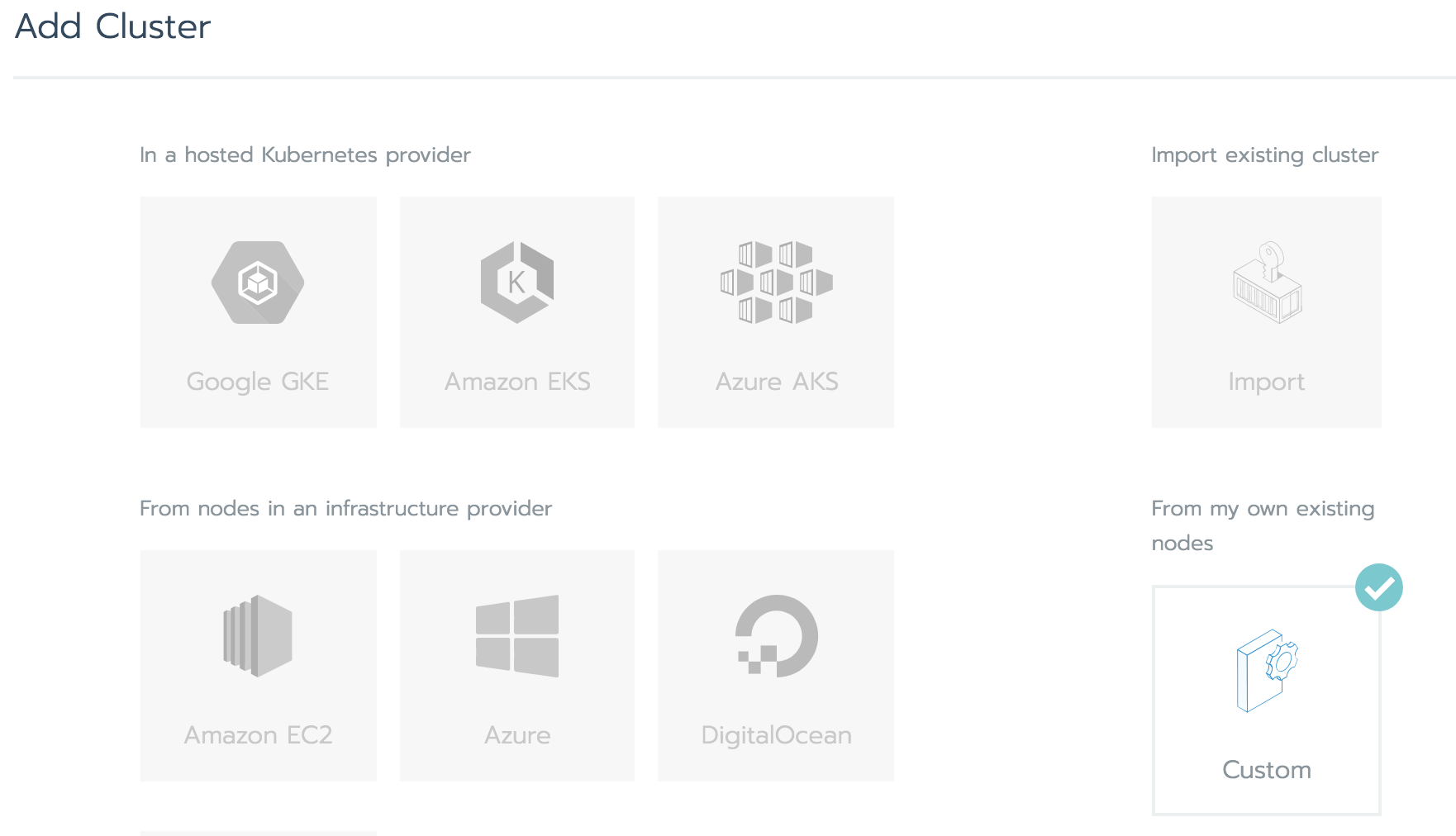
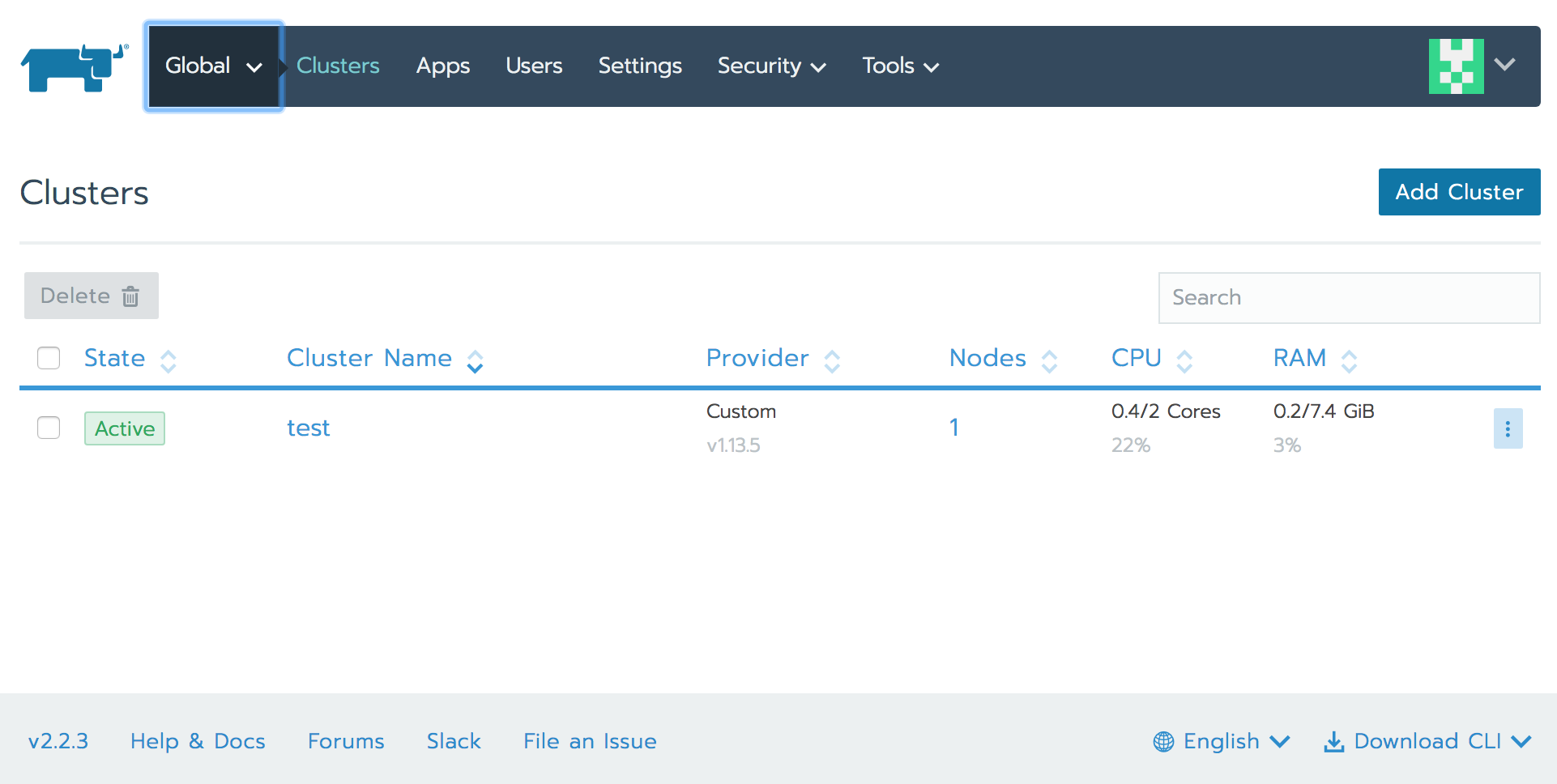
ログイン後の画面の「Add Cluster」メニュー
Add Clusterで「Custom」を選択
クラウドサービスの選択肢もあるので、ゼロの状態からマネージドサービスを活用したクラスタの作成や、新規ノード作成も含めた構築もできるが、
今回のようにホスト(EC2)を立てた状態からのスタートの場合は「Custom」。
オンプレサーバでの構築の場合もおそらく同じ。
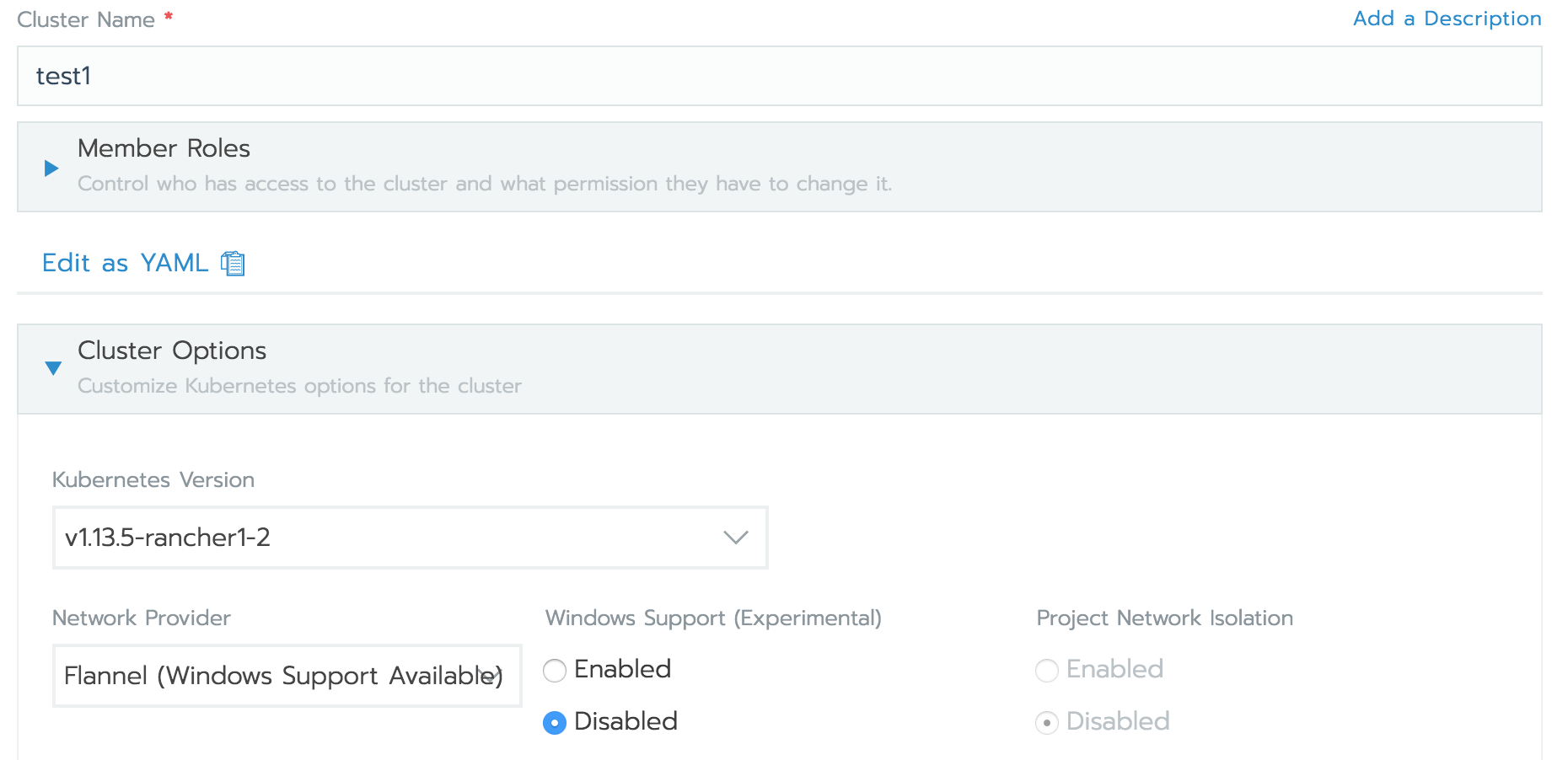
次にクラスタ名を入れて、k8sバージョンを選択。
さらにオーバーレイネットワークのツールを選択。ざっくり言うと、k8sノード間のコンテナ間通信で仮想ネットワークを構成する機能。
いろいろあるが、Flannelを選択。
最後のCustom ProviderはNoneを選択。
最後に、クラスタを構築するホストサーバ上で実行するためのコマンドを生成する。
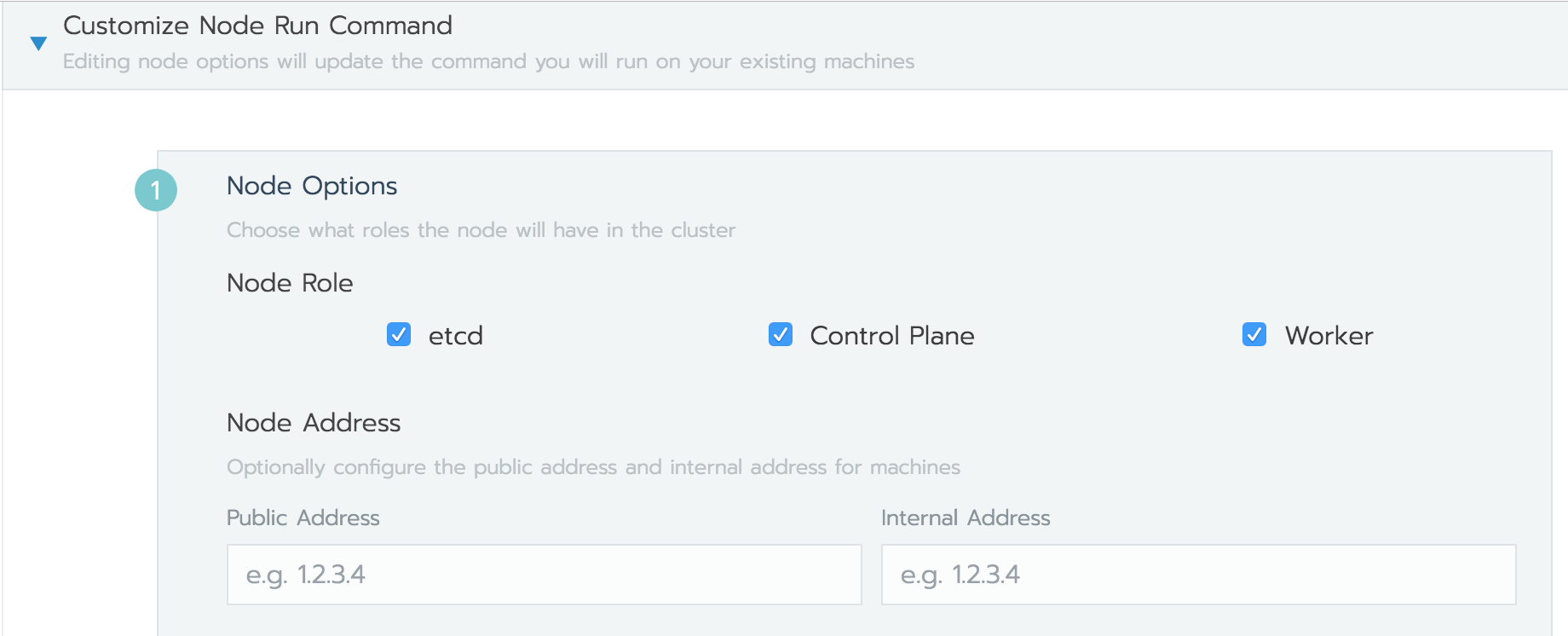
Rancherは、Rancherサーバで生成するコマンドを、k8sクラスタに組み込みたいホストサーバで実行するだけで、Rancherエージェントが起動しノードをRancherサーバに登録することで、一元管理可能なk8sクラスタを構築できる便利物。「Node Option」の「show advanced option」で詳細表示にして、k8sクラスタ用EC2のプライベートIP(Internal Address)を設定する。
Node Roleでは、「etcd」「controll plane」「Worker」すべてにチェックをつける。
各Roleを分離したい場合は、分けてコマンドを生成して実行するだけで、ホスト分散ができるイメージ。以下のようなコマンドが生成される。
この時、--serverはデフォルトではrancherサーバのグローバルIPが指定されているが、Private IPに手動で変更することも可能。sudo docker run -d --privileged --restart=unless-stopped --net=host -v /etc/kubernetes:/etc/kubernetes -v /var/run:/var/run rancher/rancher-agent:v2.2.3 --server https://172.16.0.10 --token xxxxxxxx --ca-checksum xxxxxxxx --internal-address 172.16.0.20 --etcd --controlplane --workerこの画面を表示したまま、このコマンドをk8sクラスタ用EC2で実行し、Rancherサーバが認識すると、
「1 new node has registered」
と表示されるので「Done」を押して完了
クラスタ用のホストサーバ上でdocker psで確認すると以下のようなコンテナが立ち上がっている。
a1896a96de66 rancher/hyperkube:v1.13.5-rancher1 "/opt/rke-tools/entr…" About an hour ago Up About an hour kube-proxy df7f65730a93 rancher/hyperkube:v1.13.5-rancher1 "/opt/rke-tools/entr…" About an hour ago Up About an hour kubelet 356dc597c277 rancher/hyperkube:v1.13.5-rancher1 "/opt/rke-tools/entr…" About an hour ago Up About an hour kube-scheduler 478128e7a70a rancher/hyperkube:v1.13.5-rancher1 "/opt/rke-tools/entr…" About an hour ago Up About an hour kube-controller-manager 04577fca9103 rancher/hyperkube:v1.13.5-rancher1 "/opt/rke-tools/entr…" About an hour ago Up About an hour kube-apiserver 2f0087e09a03 rancher/coreos-etcd:v3.2.24-rancher1 "/usr/local/bin/etcd…" About an hour ago Up About an hour etcd 747414e88256 rancher/rancher-agent:v2.2.3 "run.sh --server htt…" About an hour ago Up About a minute jovial_brahmagupta 5770e05cc24b rancher/rancher-agent:v2.2.3 "run.sh --server htt…" About an hour ago Up About an hour boring_clarke
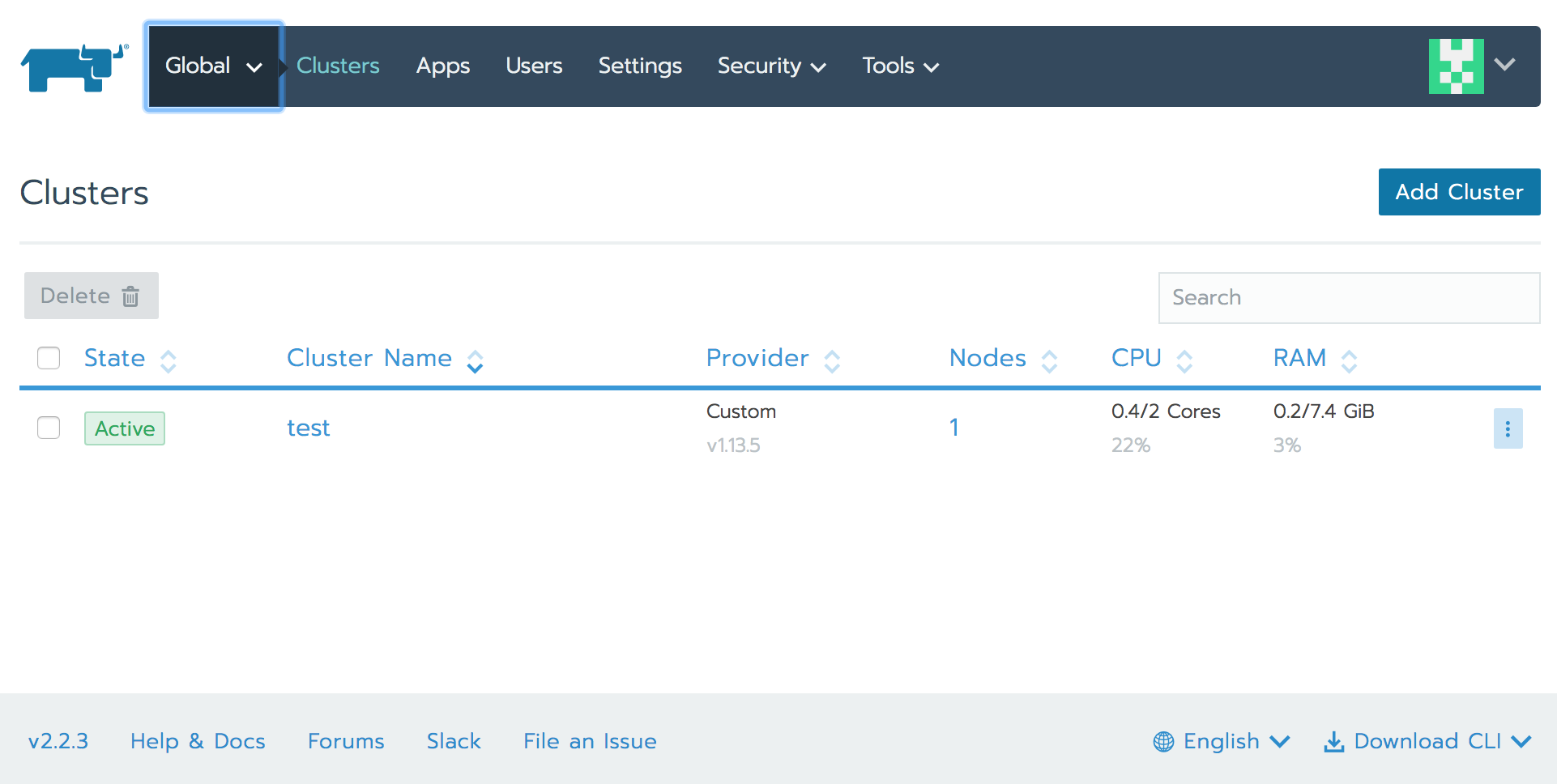
StateがActiveになればOK
④k8s動作確認
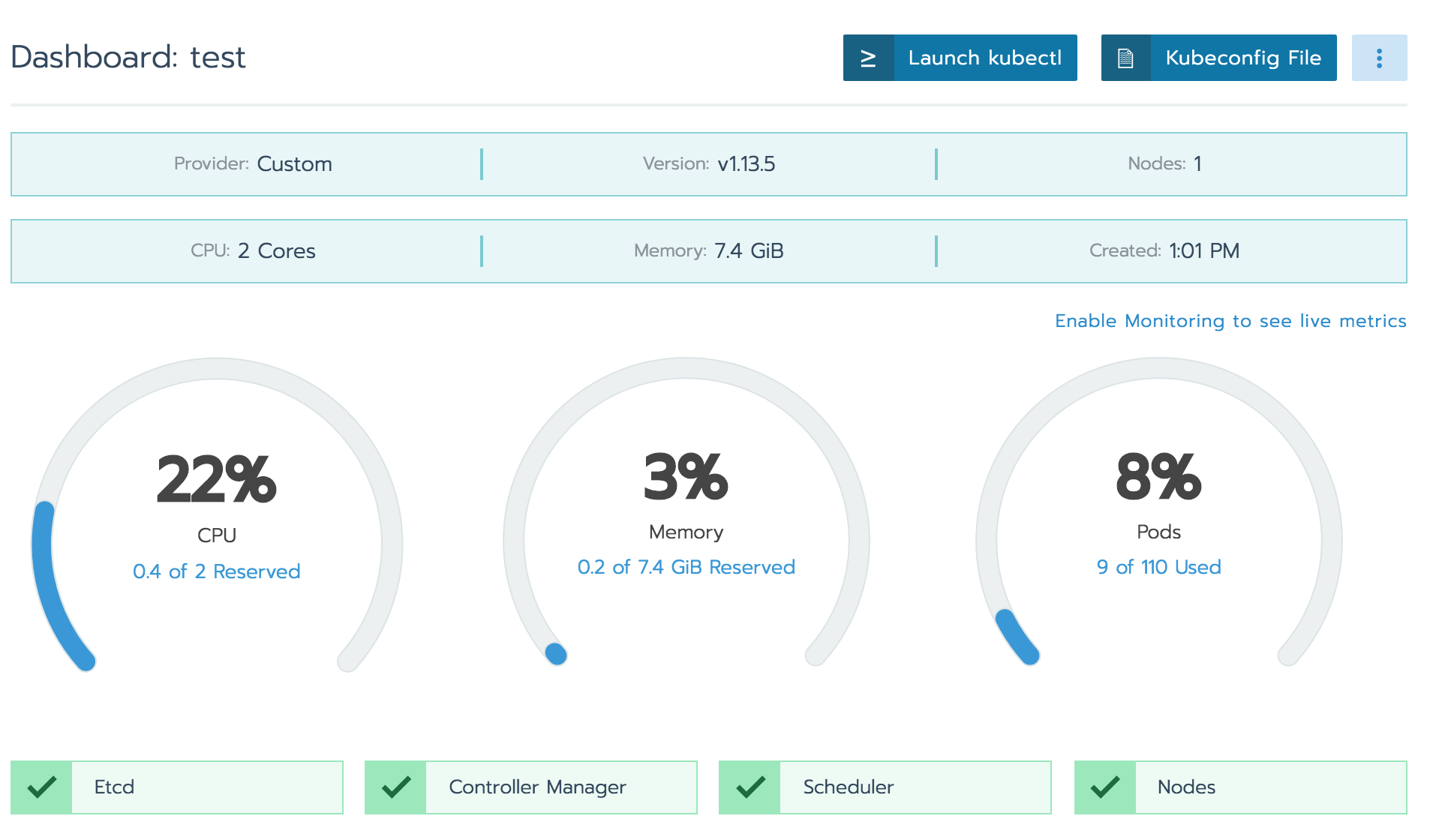
クラスタのリソースモニターも標準で確認可能。
ダッシュボードの「Launch kubectl」もしくは「Kubeconfig File」からdownloadしたconfigを設定したクライアントから、kubectlコマンドを実行できる。
$ kubectl get nodes NAME STATUS ROLES AGE VERSION ip-172-16-0-20 Ready controlplane,etcd,worker 96m v1.13.5試しにnginx podを立てる
$ kubectl create deployment --image nginx my-nginx deployment.apps/my-nginx created $ kubectl get pod NAME READY STATUS RESTARTS AGE my-nginx-6cc48cd8db-f4nd6 1/1 Running 0 9s[3] 機能拡張とカタログ
モニタリング
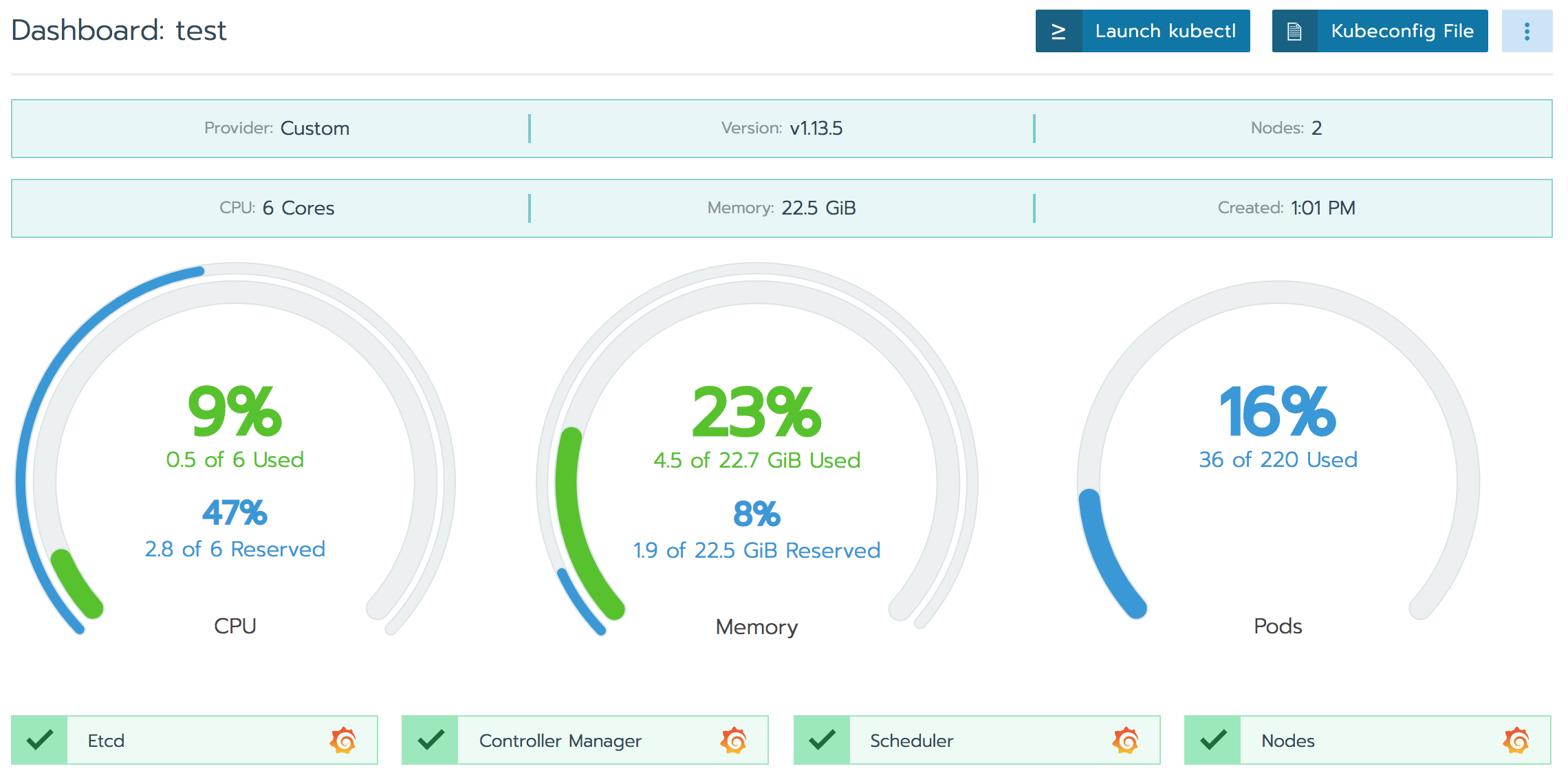
煩雑な設定なしに、「Tools」 - 「Monitoring」の設定をenableにするだけで、k8sモニタリングのデファクト「grafana」が利用できる。
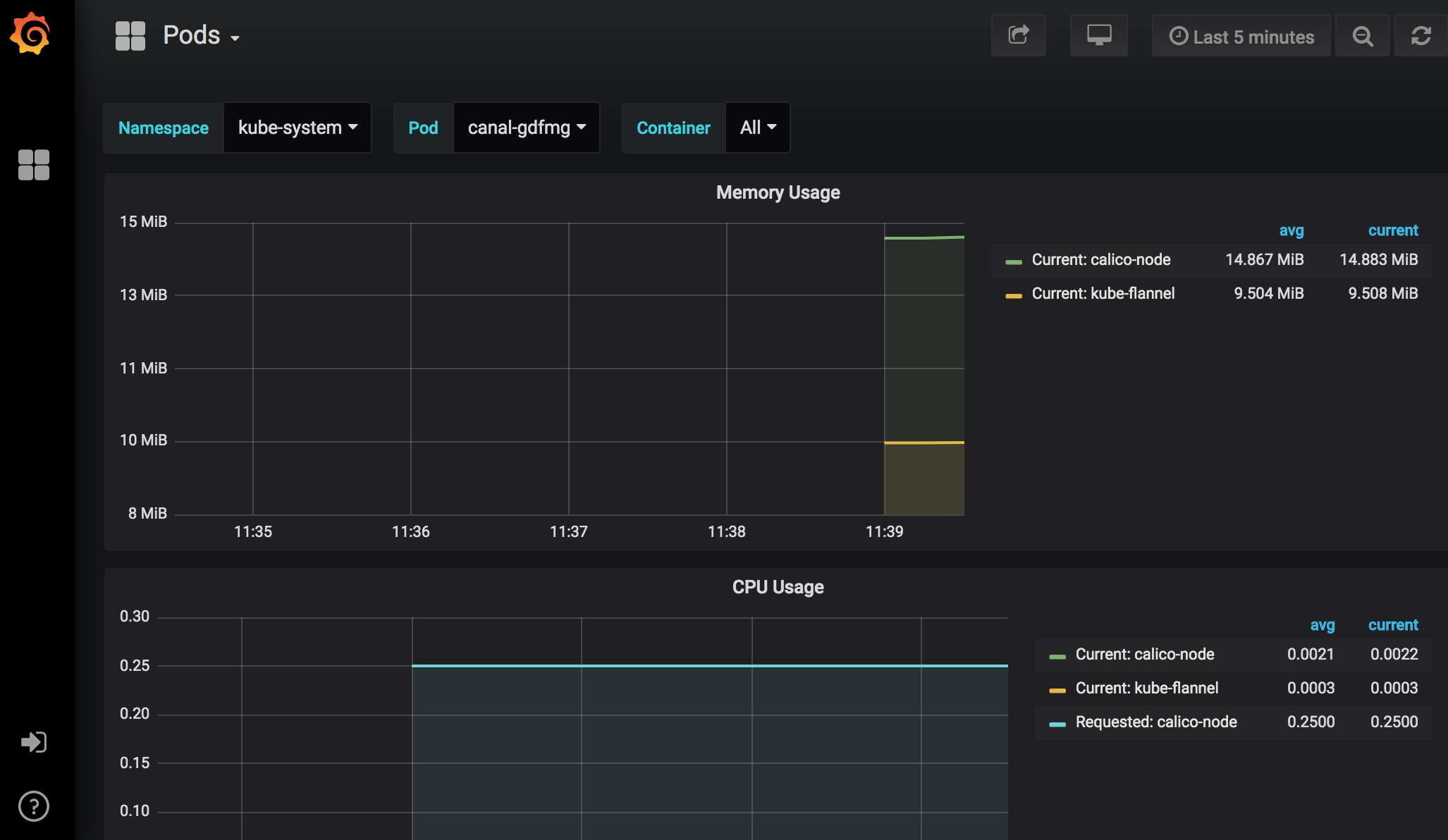
Rancherダッシュボードでもサマリー出力されるが、grafanaアイコンで別途grafanaが起動し、詳細モニターを閲覧可能。
GrafanaでPod単位のリソース消費量も確認できるので便利。
ロギング
Rancherが対応しているロギングツール一式。
k8sクラスタの各ノードのログを収集する仕組みを設定できる。
[4] workerノードの追加
先ほどの1node k8sクラスタにworkerノードを追加する方法。
dockerインストールしたEC2を、同じセグメントに設置して、
先ほど同様にホスト上でコマンドを実行するのみ。
差分は、
--internal-addressオプションが、該当ホストのIPであることと
node roleは、--workerオプションをつける点。sudo docker run -d --privileged --restart=unless-stopped --net=host -v /etc/kubernetes:/etc/kubernetes -v /var/run:/var/run rancher/rancher-agent:v2.2.3 --server https://172.16.0.10 --token xxxxxxxx --ca-checksum xxxxxxxx --internal-address [追加するノードのIP] --worker[5] はまりどころ
Case1 : Etcd Cluster is not healthy
クラスタ構築を何度か試したところ、以下のエラーが発生
[etcd] Failed to bring up Etcd Plane: [etcd] Etcd Cluster is not healthyどうやらゴミをちゃんと掃除しないといけないらしい。
下記サイトの「Cleaning a Node Manually」の手順を実行し、再度クラスタ作成をしたところエラーは解消。https://rancher.com/docs/rancher/v2.x/en/cluster-admin/cleaning-cluster-nodes/
Case2 cattle-cluster-agent CrashLoopBackOff
cattle-cluster-agentとcattle-node-agentというPodが再起動を繰り返す。
NAMESPACE NAME READY STATUS RESTARTS AGE cattle-system cattle-cluster-agent-xxxxx 0/1 CrashLoopBackOff 40 4h31m cattle-system cattle-node-agent-xxxxx 1/1 Running 17 98m cattle-system cattle-node-agent-xxxxx 0/1 CrashLoopBackOff 40 4h31mlogを見てみたところ、k8sのノードから、RancherサーバのグローバルIPへの通信でタイムアウトしていた模様。
デフォルトではRancherサーバのグローバルIPが、各種制御のエンドポイントになっている様で、各nodeから443(HTTPS)のアクセス制御を許可する必要がある。$ kubectl -n cattle-system logs cattle-cluster-agent-6fbc6f6b68-68l8l INFO: Environment: CATTLE_ADDRESS=X.X.X.X CATTLE_CA_CHECKSUM=xxxxx CATTLE_CLUSTER=true CATTLE_INTERNAL_ADDRESS= CATTLE_K8S_MANAGED=true CATTLE_NODE_NAME=cattle-cluster-agent-xxxxx CATTLE_SERVER=https://[RancherサーバのグローバルIP] INFO: Using resolv.conf: nameserver X.X.X.X search cattle-system.svc.cluster.local svc.cluster.local cluster.local ap-northeast-1.compute.internal options ndots:5 ERROR: https://[RancherサーバのグローバルIP]/ping is not accessible (Failed to connect to [RancherサーバのグローバルIP] port 443: Connection timed out)k8sの各workerから、RancherサーバのグローバルIP(エンドポイント)への443(HTTPS)を許可することで問題解消。
Case3 : Monitoring API is not ready
Toolsの「Cluster Monitoring Configuration」をenableにしたのに、dashboardで「Monitoring API is not ready」とアラート表示。
Case2同様の原因。同じ対処で問題解消。
Case4 : kubectl Closed Code: 1006
「Launch kubectl」でRancherのダッシュボード上からkubectlコマンドを実行しようとすると、何の反応もなく、「Closed Code: 1006」などのエラーに。
k8sノードとのコネクションに問題がある。
Case2同様の原因。同じ対処で問題解消。
Case5 adminユーザのパスワード忘れ
adminユーザパスワードは下記でリセット可能
docker exec [RancherサーバのコンテナID] reset-passwordランダム文字列のパスワードが出力される
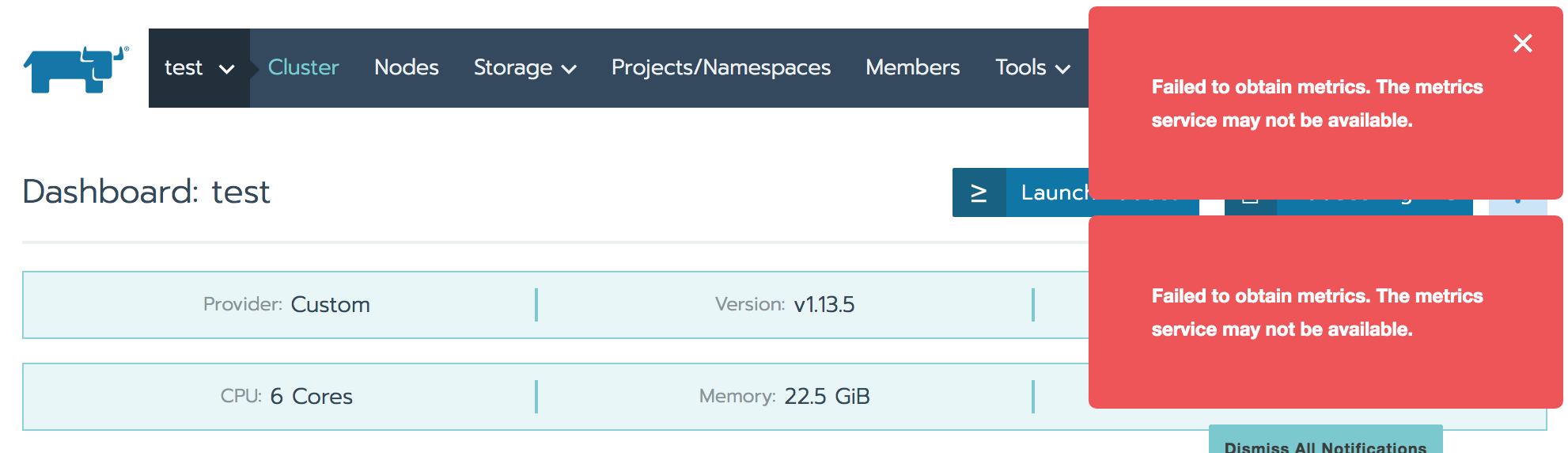
Case6 Failed to obtain metrics.
prometheusからのメトリクス収集でエラーとなっている模様。
workerで稼働している「k8s_prometheus_prometheus-cluster-monitoring-0_XXX」という名前のコンテナの各logを確認すると、
context deadline exceededとか、
only allow maximum 512 connections with 5m0s read timeoutとか、
http: proxy error: context canceledとか
いろいろ出ていた。クラスタ再起動や作り直しをした過程のゴミの可能性もあったので
下記手順でホストを掃除し、作り直したところ、とりあえず問題解消。https://rancher.com/docs/rancher/v2.x/en/cluster-admin/cleaning-cluster-nodes/



- 投稿日:2019-05-27T13:07:24+09:00
AWSのPolicyに関する備忘録
APIのクロスアカウントアクセスについて調べていて、アクセス許可についてしっかり理解する必要を感じたので自分なりにまとめます。
アクセス許可
AWSのリソースも、OAuthのAPIと同じように「リクエストしたユーザー・ロール(=プリンシパルエンティティ)が認証されているか」「アクセス許可を持っているか」を確認します。
私がよく躓くのは、この「アクセス許可を持っているか」の部分のようです。ポリシー
アクセス許可は、IAMユーザー・ロールにアタッチされているポリシーと、リソースにアタッチされているポリシーの両方を重ねて評価して判断されます。
ちなみに...
* アイデンティティ・リソース以外にも4種類のポリシータイプがあるらしい。
参考:ポリシーとアクセス許可
* ポリシー以外のアクセス許可もあるらしい。例えば、ポリシーの条件にタグを含めるなど。
参考: ポリシーを利用したアクセス制御大体の場合はアイデンティティベースのポリシーを設定するだけで済んでいると思いますが、クロスアカウントアクセスの場合はリソースベースのポリシーを設定することも必要になることがあります。
アイデンティティベースとリソースベース
共通するポイント
どちらもJSONです。あ、CloudFormationで作成する場合はYAMLですね。でもAWS上ではJSONです。
文法もだいたい同じです。Resourceに対するActionのEffect(Allow/Deny)のリストをStatementとしてリストにする、ってとこですね。
アイデンティティベースの場合はPrincipal要素は指定してはいけないようです。
参考: IAM JSONポリシー言語の文法
参考: AWS JSON ポリシーの要素:Principal異なるポイント
アイデンティティベースのポリシーでは管理ポリシーを作ることができますが、リソースベースだとできません。つまり、リソースに対して似たようなポリシーを適用する場合は、リソースごとに同じポリシーをコピペする必要がある、ということです。
https://docs.aws.amazon.com/ja_jp/IAM/latest/UserGuide/access_policies_managed-vs-inline.html迷ったポイント
リソースとしてのIAM Roleにもリソースポリシーがあります。
例えばECSのサービスがIAM RoleとしてS3にオブジェクトをアップロードする場合、そのRoleに引受(Assume)可能かどうかをリソースポリシーとして設定するわけですね。クロスアカウントアクセス
要するに、IAM側でもリソース側でもアクセス許可をする必要があるようです。
参考資料
- 投稿日:2019-05-27T13:06:47+09:00
Windows On AWS
今更ながら、Windows Server 2019をAWS上に作ってみた。
アカウント作成〜インスタンスの作成まではここを参考にした。
https://qiita.com/HitomiHoshisaki/items/4e1eff6b32bcf91ec0d8気をつけなきゃいけないのは、日本語版のWindowsは、
クイックAMIにはでてこない。コミュニティAMIでJapaneseで検索すると、でてくる。
詳しくは、
https://qiita.com/nasuvitz/items/c479073a695f63b1b949
を見てみましょう。実際、RDPで接続し、日本語にはなっていたものの、
時刻はUTCのままだった。
- 設定 -> 日付と時刻で日付と時刻画面を起動
- 日付と時刻タブ -> タイムゾーンの変更をクリック
- UTC+9 を選択
これで時刻ももとに戻ったぞ。よかった。
- 投稿日:2019-05-27T12:43:14+09:00
S3をNextCloudのプライマリストレージ(データディレクトリ)に設定する方法
TL;DR
- NextCloudのユーザデータを,AWS S3に保存する方法を解説します
- NextCloudのデータがクラウドストレージに格納されるようになるので(費用が掛かるデメリットを除けば),容量を気にせずに使用することができます
- (NextCloudの機能通り)ユーザごとに個別のディレクトリが使え,かつ,共有設定もできます
NextCloudがS3を利用する2つの方法
- NextCloudがS3を利用する方法として,以下の2つの方法があります
- NextCloudアプリを使用して,ユーザが共有されるディレクトリをS3上に作る方法
- データディレクトリをS3にまるまる置く方法
- この記事では,後者の方法を扱います
- 前者の(アプリを使う)方法は,NextCloudに設定された全ユーザが共有するディレクトリを作る方法で,ユーザごとに振り分けることができないようです(未調査です)
- Qiita nextcloudによるプライベートオンラインストレージの構築などが参考になります
- 後者の方法は,データディレクトリがS3に置かれるので,ホストのストレージ負荷を軽減できます(その分費用も掛かります)
NextCloudのユーザデータをS3に置く方法
- NextCloudの主ストレージ設定のドキュメントを参考に取り組みます
設定
- 以下の3つの手順で進めます
- IAMでS3にアクセスできるユーザを作成する
- S3にNextCloud用のバケットを作成する
- NextCloudに作成したバケット情報を設定する
IAMでS3アクセスユーザを作成する
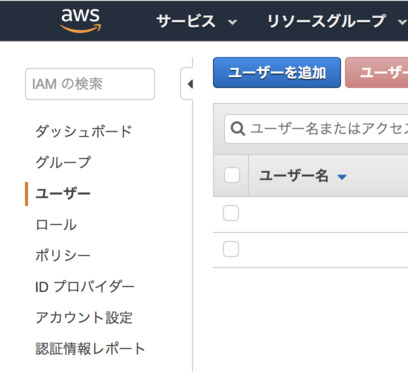
aws IAMにアクセスし,ユーザを作成します.
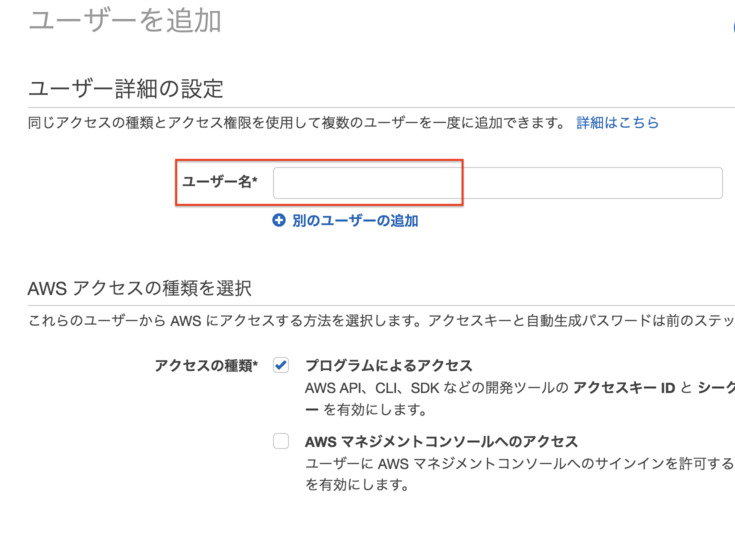
- メニューから[ユーザ]を選び,[ユーザを追加]をクリックする
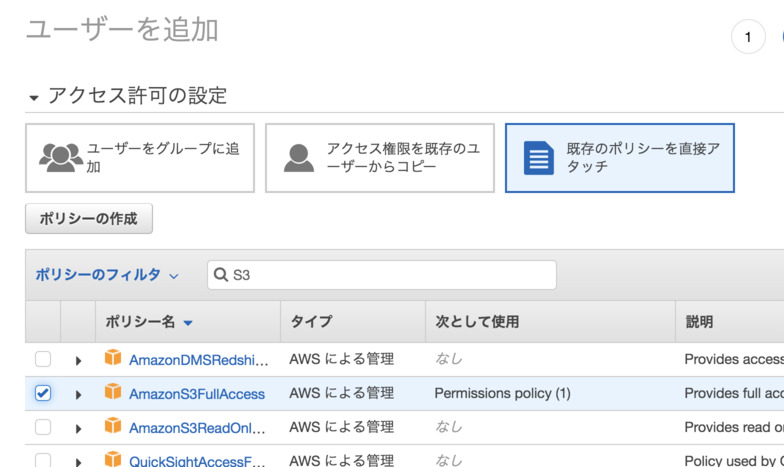
- 適当なユーザ名を入力し[プログラムによるアクセス]にチェックします
- アクセス許可の設定で[既存のポリシーを直接アタッチ]を選択し,[AmazonS3FullAccess]をチェックする
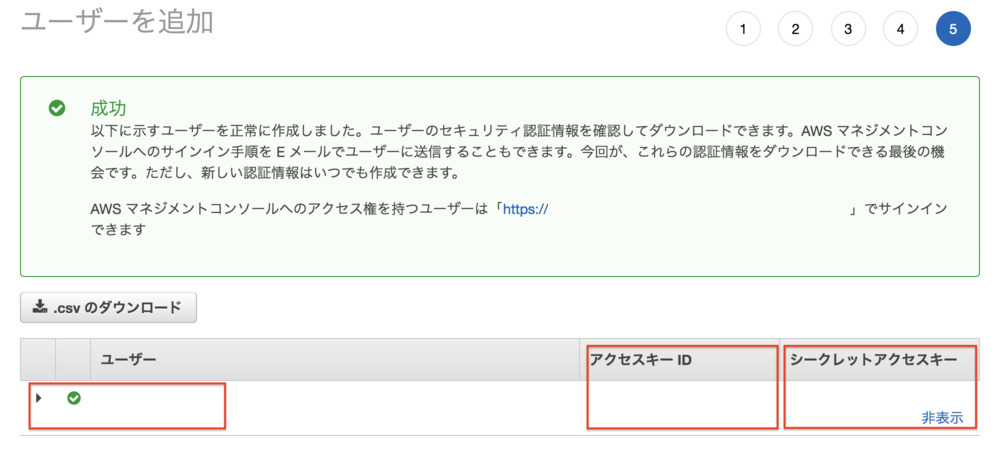
- 「成功」と言われたら,[アクセスキーID]および[シークレットアクセスキー]を記録しておく
- 注意: [表示]リンクをクリックするとシークレットアクセスキーが表示されますが,このときだけしか表示されないので注意してください!紛失したら別のユーザを作る必要があります.
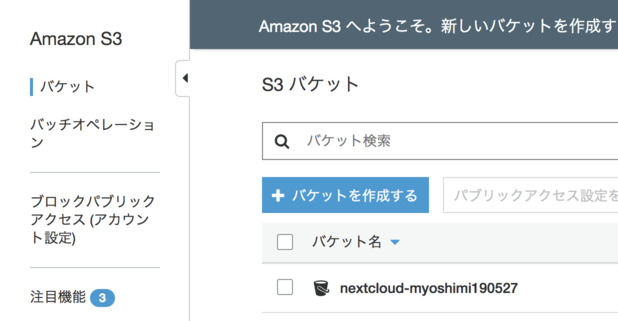
S3のバケットを作成する
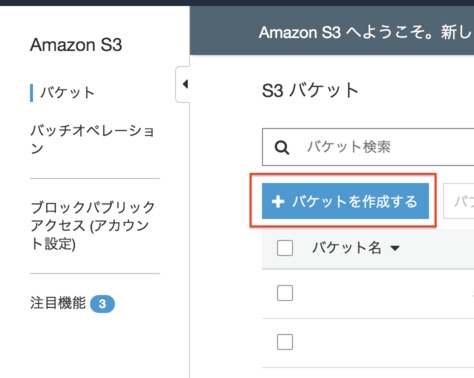
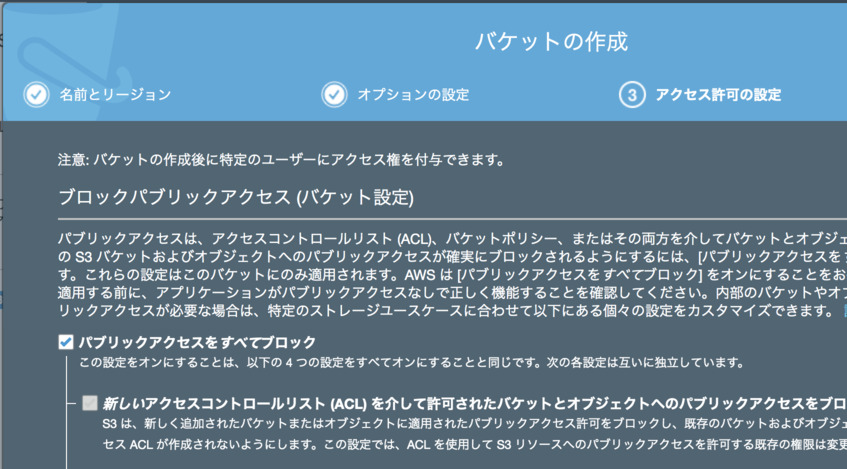
aws S3で,前項のユーザでアクセスできるNextCloud用のバケットを作成します.
- [バケットを作成する]をクリックします
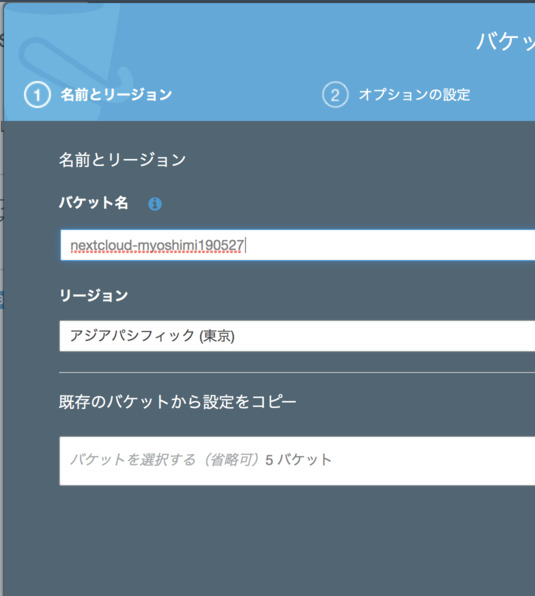
- 適当なバケット名を入力します
- (別のユーザも含めて)awsサービス全体一意な名前である必要があります
- 適当な名前や日付などを入れて一意な名前にしてください
- アクセス許可などはそのまま(「パブリックアクセスをすべてブロック」)でOKです
- 「バケットの作成」をクリックし,バケットを作成します
- バケットが作成されました.次節では,このバケットにデータを格納するようにNextCloudの設定を行います
NextCloudの設定
- NextCloudが稼働しているホストの,
config/config.phpのCONFIGアレイの中に,S3の設定を記載します.
- NextCloudをDockerで稼働させている場合は,コンテナの
/var/www/htmlにconfigディレクトリがあります- 以下のように,
objectstoreキーで,前項までで作ったawsユーザおよびS3の情報を記載します
'bucket': バケット名'region': S3のリージョン('ap-northeast-1'など)'key': 20文字の大文字英数字のアクセスキー'secret': 40文字の英数字記号のシークレットキー<?php // config/config.php $CONFIG = array ( //.....<snip>..... 'objectstore' => array( 'class' => 'OC\\Files\\ObjectStore\\S3', 'arguments' => array( 'bucket' => '<バケット名>', 'autocreate' => true, 'region' => '<S3のリージョン>', 'key' => '<20文字の大文字英数字のアクセスキー>', 'secret' => '<40文字の英数字記号のシークレットキー>', 'use_ssl' => false, 'use_path_style'=> false, ), ), //.....<snip>..... );動作確認
- ブラウザでNextCloudにアクセス(ログイン)すると,ユーザディレクトリがS3になります
- もともとデータが(ローカルに)存在していた場合は,設定が上書きされて見えなくなっています
- 上述のconfig.phpの設定を消すと,元に戻すことができます
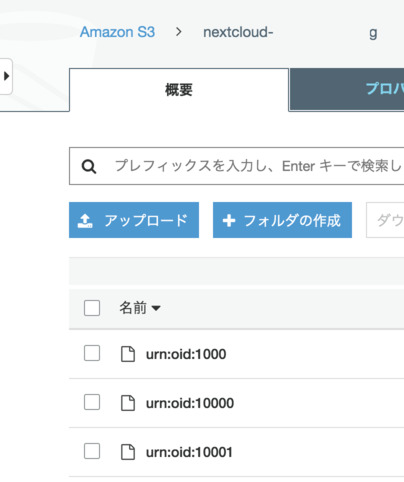
- S3のバケットには,
urn:oid:数字のようなファイル名で,データが格納されます
参考
- 投稿日:2019-05-27T01:23:27+09:00
闇の深い AMI を Packer で Infra as Code する
闇が深いとは
このくらいを指すものとします。
- AMIの出所がわからない
- EC2インスタンスのAMI IDが、自前AMIになってる
- Linuxディストリはわかるが、起点にしたバージョンはわからない
- AMIがどうやってできたのかわからない
- sudo vi /etc/hoge.conf してるっぽい
- sudo yum install -y hoge してるっぽい
- wget https://~~~~/hoge.tar.gz から make install してるっぽい
- AMI更新手順がわからない
- 変更したい人々と、変更できる人々が違っている
- 実施できるのは、本番環境にSSHできる極少人数
- 簡単なはずのconfの変更も尻込みして進まない
- Dockerize & k8s移行とか盛り上がるけど、遠すぎて動きが鈍い
AWS使っててもこれよりヤバい現場や、オンプレでさらにヤバい現場はいくらでもあるでしょうけど、一旦このくらいで。
闇に光を当てる情報収集
現状の変更の作業手順を各方面に聞き出したり、諸々の参照権限をもらったりして、文書化します。「してくださいお願いしますね」ではなく、私が文書化します。「してください」で文書化されるなら、もうされてます。みんな忙しい。
AWS 利用状況、インフラ構成調査
AWS以外にもSaaSは使ってそうでしたが、聞いた範囲ではAWSにほぼ収まっているので、AWSに絞って調査します。AWSで使っているものは、AWSの月次の請求書を見ればわかります。AWSの請求書はたいへん親切で、
- 何を、何ドル、どのリージョンで、どれだけ使ったか
をひとつの文書にまとめてくれています。しかも、無料枠で収まっていても、利用料金ゼロドルで、無料枠の範囲でこれだけ利用しましたを記載してくれるのが大変良い。
これをもとに、推定と聞き込みとを織り交ぜ、実際の姿を明らかにしていきます。
AMI 内部構成調査
ここまで明らかになると、どのEC2 AMIをInfra as Codeでカバーしたら効果高いかわかります(わかるよな?)。
アプリケーションコードのデプロイが頻繁で、バグや障害などの問題が、ユーザーから見たダウンタイムに結びつきやすいところからです。つまりはウェブサーバーですね。優先順位を決めて、EC2の内部構成調査のためSSHしてガサガサします。手法は以下のような。
AMI 更新手順
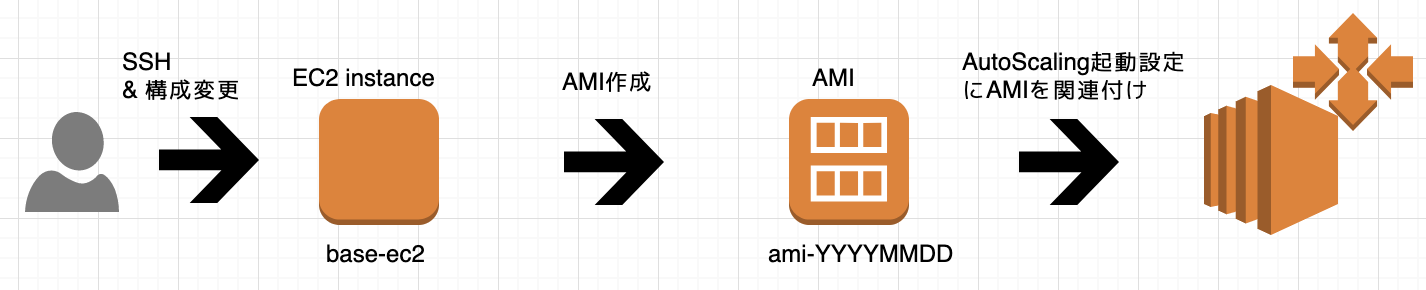
EC2に、SSHしてオラオラして、AMIを作成して、AutoScaling Groupに入れていました。
方向性を考える
ここからDocker & k8sに行くには、ジャンプが大きすぎるなあという所感でした。簡単なはずのconfの設置とかも、モジモジして入れられてない。とはいえ、いまさら滅茶苦茶に工数ぶちこんで解決を目指すのももったいない。遠からず捨てる前提で、重厚長大にせず、安全にAMIを変更できることに専念したワークフローを構築したい。
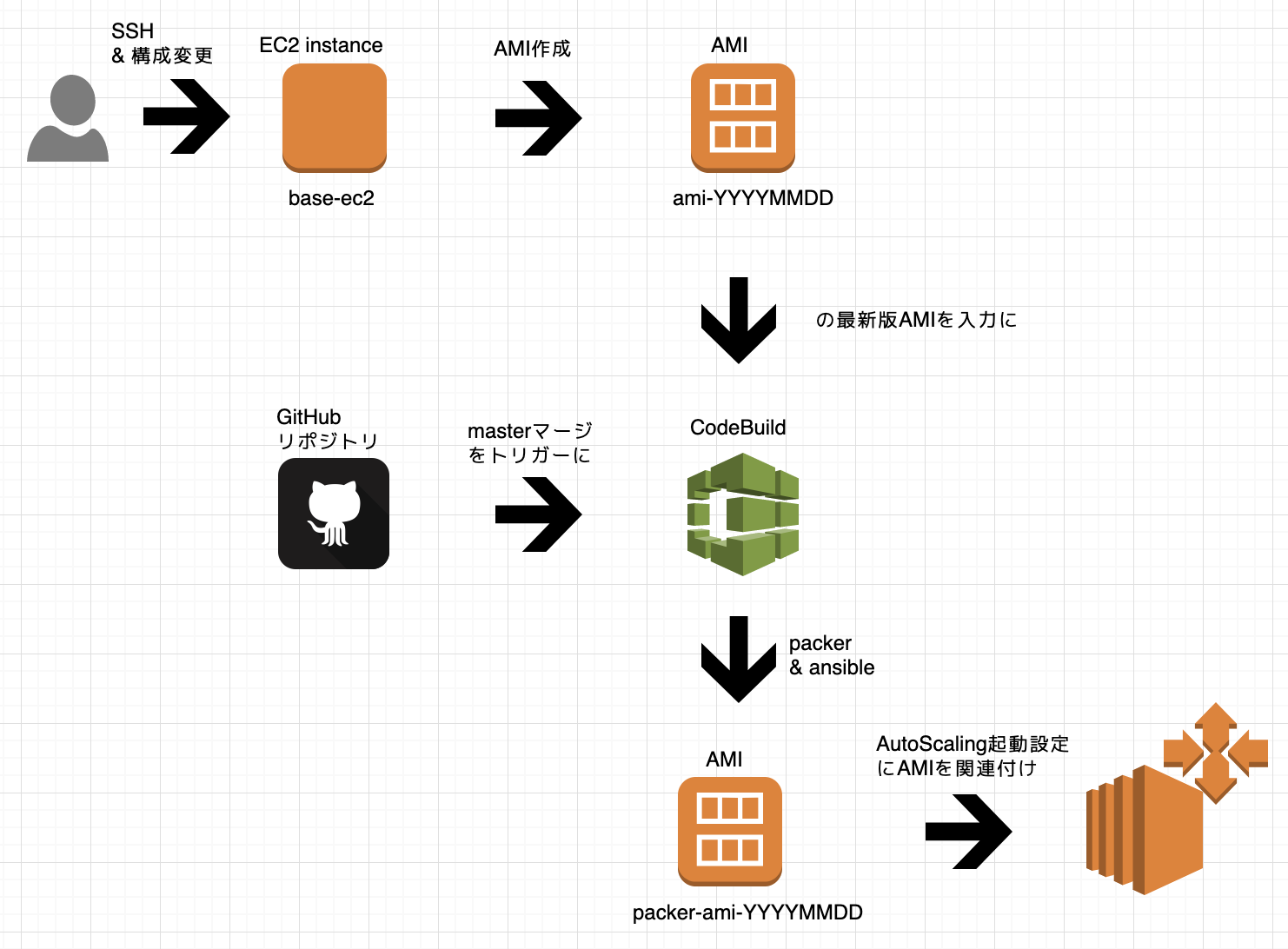
そこで、現状に接ぎ木して、乗っ取って、乗り換えられるような、AMIビルドのパイプラインを考えてみることにしました。
AMIビルドのパイプラインを妄想する
ちょっと前にCodeBuildの使い方を調べてたので、CodeBuildを使って、仕事の流れを組み立てます。CircleCIもありましたが、AMIにSSHさせるのに難儀しそうだなという直感があり、VPCで動かせるCodeBuildを選びました。
CodeBuild + Packer + Ansible を組み入れることで、このような仕事の流れにできそうだよねというのを、まずは妄想します。Ansibleでカバーの追いついてないconfの類は、SSHしてオラつけるよう仕事の流れにも遊びを残しておきます。
AMIビルドのパイプラインを作り始める
ようやく作り始めます。CodeBuildでジョブを組むのは慣れたものです。Docker Hubを漁ると hashicorp/packer があるのでこれを使います。Ansibleもチョットデキルので心配してない。
ぶっちゃけると Packer イジるの初めてなので、まず目標地点を
闇のAMIを入力に、Packerを通して、EC2内に
sudo echo hello-packer >> /tmp/hogehoge.txtしたAMIを作るくらいにしました。しかしここから3営業日くらい、PackerからEC2にSSHできないという症状を解決できず、憂鬱な日々でした。
その過程で、闇のAMIを Packer で Infra as Code する掟を見いだせたので、以下列挙します。
掟1. デフォルト VPC は使わない
本件に着手する少し前に AWS環境のセキュリティ監査サービス insightwatch(インサイトウォッチ)by クラスメソッド の指摘を受けてデフォルトVPCを削除しまくっていました。しかもEC2-ClassicなAWSアカウントなので、サポート問い合わせしないとデフォルトVPCを作れない。めんどくせええ。。。
マニュアルを読むと、嬉しいことに、VPC IDなどを明示して動かすことができるとわかるので、 packer.json に盛り込んでいきます。
振り返ると、デフォルトVPCで動かしてたらより一層進まなくなってたので、まあ、結果オーライでした。
掟2. CodeBuild は、本番環境SSH踏台サーバーと同一のサブネット、セキュリティグループで起動させる
今回どうにかしたいAMIは、SSH踏み台サーバーのセキュリティグループがついたところからのみ、SSHを受付けるよう設定されていました。
スパゲッティなセキュリティグループを無理にほぐそうとすると、何が起きるか見極めきれていなかったので、表題のように起動するよう、CodeBuildジョブを設定しました。
掟3. AMIは、本番環境のVPC,サブネット,などなど利用時と同一の諸々で起動させる
Packerは、元のAMIから、作業用EC2インスタンスを起動し、AMIを作成します。この作業用EC2インスタンスを、どのような設定で起動させるか。チュートリアルではPackerが、デフォルトVPCで何もかも良しなに仕上げてAMIを作ってくれます。
しかし私がどうにかしたいのは、デフォルトとはおよそ程遠い構成となっているAMIです。
Pakcerから出来上がったAMIを起動させるときのEC2インスタンスと、同一になるように、Packerに起動させます。具体的には、同一のIAMロール、VPC、サブネット、セキュリティグループ、同一のグレードのEC2、SSHキーペア、などとなるよう、packer.json に事細かに明記していきます。
今回は、チュートリアルの packer.json をベースに、つながらないな、これか?これか?これも必要か?などと試していきましたが、闇のAMIをどうにかするというシナリオでは、
ここで列挙されているオプションをまずは全て明記して、これ削っても動くかな?大丈夫かな?ってやったほうが、早く進んだのではないかと思います。
Ansibleで何かイジる
PackerからSSHさえできれば、ひたすら楽です。
ふとCodeBuildを眺めると、hashicorp/packer を使い続けるのか問題がありました。
- hashicorp/packer はalpineベースのコンテナイメージなので、pythonにpipに依存ライブラリに、、、ansibleをインストールするのは割と難儀しそうです。
- また、闇のAMIからEC2インスタンスを作って試してみたところ、 Ansible Local - Provisioners でansibleをインストールして使うのも、pythonを始めとした依存関係の解決にかなり難儀しましたので、これも避けたい。
- ansible/ansible-runner に Install Packer し、 Ansible - Provisioners するのが、最も簡単に走れると見極め、実際に最も簡単でした。
Ansibleのロール、プレイブックなどは、 packer.json を置いたのと同一ディレクトリに、 Best Practices — Ansible Documentation の体系で置きます。
クレデンシャルは、SSMパラメータストアにKMS暗号化保管したものを、CodeBuildの環境変数に持ってきて、Ansibleではlookupで引き込みます。
- このように。
- 手法はいくつかありそうでしたが、この記事で理解を整理してlookupだなと。
- SSMパラメータストアのクレデンシャルを、CodeBuildまで持ってくるには
闇の深い AMI に光を当てる packer.json
そんなこんなで以下できあがりの packer.json です。variablesのenvは、CodeBuildジョブの環境変数として定義してあります。今回はこの程度で済みましたが、闇の深さによっては、他にも記載すべき項目が増えるのではないかと思います。
- SECURITY_GROUP_ID_BASE には、出来上がりのEC2インスタンスに付けるべきセキュリティグループIDを指定します。今回はひとつだけでしたが、もし複数指定が必要なら、よしなに書き換えてください。
- SECURITY_GROUP_ID_PACKER には、Packer用にSSHポートを開放したセキュリティグループを作成しておき、そのセキュリティグループIDを指定します。
- SSH_XXXX には、ec2-userで22から変更していれば、そのように指定してください。
- Ansibleのsftp_commandは、Amazon Linux前提なのでこう書いてますが、sftp-serverコマンドのパスを指定してください。
- Ansibleを使うことにしてますが、私が超慣れてるからなだけで、ItamaeでもChefでも好きにしてください。
{ "variables" : { "instance_type": "{{env `INSTANCE_TYPE`}}", "source_ami_name": "{{env `SOURCE_AMI_NAME`}}", "source_ami_owner": "{{env `SOURCE_AMI_OWNER`}}", "dest_ami_name": "{{env `DEST_AMI_NAME`}}", "region": "{{env `REGION`}}", "vpc_id": "{{env `VPC_ID`}}", "subnet_id": "{{env `SUBNET_ID`}}", "ssh_interface": "{{env `SSH_INTERFACE`}}", "security_group_id_base": "{{env `SECURITY_GROUP_ID_BASE`}}", "security_group_id_packer": "{{env `SECURITY_GROUP_ID_PACKER`}}", "ssh_username": "{{env `SSH_USERNAME`}}", "ssh_port": "{{env `SSH_PORT`}}", "ssh_timeout": "{{env `SSH_TIMEOUT`}}" }, "builders" : [ { "type": "amazon-ebs", "region": "{{user `region`}}", "source_ami_filter": { "filters": { "name": "{{user `source_ami_name`}}" }, "owners": ["{{user `source_ami_owner`}}"], "most_recent": true }, "instance_type": "{{user `instance_type`}}", "ssh_username": "{{user `ssh_username`}}", "ssh_port": "{{user `ssh_port`}}", "ssh_pty": true, "ssh_timeout": "{{user `ssh_timeout`}}", "vpc_id": "{{user `vpc_id`}}", "subnet_id": "{{user `subnet_id`}}", "ssh_interface": "{{user `ssh_interface`}}", "user_data_file": "./ec2-user-data", "security_group_ids" : [ "{{user `security_group_id_base`}}", "{{user `security_group_id_packer`}}" ], "ami_name": "{{user `dest_ami_name`}}-{{isotime \"20060102-150405\"}}", "tags": { "Name": "{{user `dest_ami_name`}}-{{isotime \"20060102-150405\"}}", "Base_AMI_ID": "{{ .SourceAMI }}", "Base_AMI_name": "{{ .SourceAMIName }}" } } ], "provisioners": [{ "type": "shell", "inline": [ "sudo echo hello world > /tmp/helloworld.txt", "ls -alF /tmp/helloworld.txt", "cat /tmp/helloworld.txt" ] }, { "type" : "ansible", "user" : "ec2-user", "sftp_command" : "/usr/libexec/openssh/sftp-server -e", "playbook_file" : "site.yml" }, { "type": "shell", "inline": [ "sudo echo hello world" ] } ] }user dataも入れて起動できるので、こんな感じに使ってます。
#!/bin/bash # ここで入れたEC2ユーザーデータは、packerビルド時のみ投入される。 # AutoScaling起動設定のもので上書きされる。 # SourceAMIの起動時にねじ込んで実行させるシェルスクリプト # このファイルが存在してるとPacker生成のSSHキーの設置に失敗する rm -f /home/ec2-user/.ssh/authorized_keys # packerしてる最中に動かれると、果てしなく面倒なものは止めておく chkconfig app-server off || trueCodeBuildの buildspec.yml はこのくらいで。DockerイメージはAnsible全部入りの ansible/ansible-runner です。
version: 0.2 phases: install: commands: - yum install -y -q wget which unzip - (cd /usr/local/bin && wget -q https://releases.hashicorp.com/packer/${PACKER_VERSION}/packer_${PACKER_VERSION}_linux_amd64.zip && unzip ./packer_${PACKER_VERSION}_linux_amd64.zip) - pip install --upgrade pip - pip install awscli - ansible --version - packer version pre_build: commands: - ansible-galaxy install -p ./roles -r ./requirements.yml - packer validate packer.json build: commands: - packer build -machine-readable packer.json未来展望
CodeBuild + Packer + Ansibleで、誰でも安全に変更を反映できる環境を整備できました。この先は、
- 変更したそうな /etc/hoge.conf をAnsible管理下に置くようにする
- 実際に変更していく
- サーバーロール間の結合を疎にするような変更を随時入れていく
- サーバーロール単位でのDockerizeと足回りのk8s移行
みたいな流れを組んでいきたいなあと妄想しています。