- 投稿日:2019-02-11T22:03:02+09:00
カメの甲羅をobject detection apiで認識してみる on win10
えー、リクガメ関連のエントリで染まって来ておりますが、更に浸かっていきます。
これまでの経緯としては・・
AppSyncとDynamodbとkinesisVideoStreamとリクガメモニタリング
が最後の方ですかね。くす玉システムもあるけど。
で、Nextとしては
・カメの位置を画像から捕捉し、カメラを向ける
・カメの移動距離を測る
・hlsのm3u8にWeb Video Text Track (WebVTT)を混ぜ込むとか妄想しています。
カメの位置の捕捉についてはなんとなくイメージできてるけどとりあえずやってみておきましょうか、というそういうエントリになります。
実際の動作環境はLinux上になると思うのですがまずはwindowsでお試し。環境
- win10 64bit
- python 3.6.6
- pip 18.1
- tensorflow 11.1
だったけどpipとtennsorflowはupgradeしときます
python -m pip install --upgrade pip pip install --upgrade https://storage.googleapis.com/tensorflow/windows/cpu/tensorflow-1.12.0-cp36-cp36m-win_amd64.whl
- pip 19.0.2
- tensorflow 1.12.0
になりました。
ラベリング
今回はカメの甲羅を学習させて覚えさせたいと思います。
床材と色が似てるし、識別どうなのかなー、とか思ったけど甲羅って特徴的だし案外イケるんでは?と思ってたりしております。
なお、TensorflowのObject Detection APIを使うのですが、いつものようにQiitaにお世話になります。Tensorflow Object Detection APIで寿司検出モデルを学習するまで
windowsにも対応しているlabelImgというツールをセットアップします。
windows_v1.8.1.zipというファイルをDL -> 解凍 -> labelImg.exeを実行操作は直感的。ディレクトリを開いて、画像の上で右クリックして
Create\nRectBox、甲羅を囲んでkamekusaとラベリングしました。
これを20枚分。いろんな角度から撮ってるけどだいたい同じ画像です。
画像一枚毎にxmlファイルが出来上がりました。1枚にまとまってくれると楽なんだけど、そういう風にできないもんかな。(出来そうな気はするけど今はいいや。)
TFRecordの作成
次はTFRecordというTensorflowに対応した形に画像とラベリングデータを変換する必要があります。
との事です。このままでは使えないのか。
こちらを使わせていただきます。git clone https://github.com/Jwata/sushi_detector_dataset.gitdata/sushi_label_map.pbtxt はkame_label_map.pbtxtに変えます。
imagesとannotationsというディレクトリを作り、画像は前者、xmlは後者に。
ちなみに画像はjpgで、拡張子以外は画像もxmlファイルも共通です。pip intall lxml pip install object_detection python create_tf_record.py --annotations_dir=.\annotations --images_dir=.\images --output_dir=.\data\ --label_map_path=.\data\kame_label_map.pbtxtなんか一回、これにひっかかる
Traceback (most recent call last): File "create_tf_record.py", line 14, in <module> from object_detection.utils import dataset_util, label_map_util File "C:\Users\user\AppData\Local\Programs\Python\Python36\lib\site-packages\object_detection\utils\label_map_util.py", line 21, in <module> from object_detection.protos import string_int_label_map_pb2 ImportError: cannot import name 'string_int_label_map_pb2'tensorflow/modelsというのがいるらしい。準備不足でした。
git clone https://github.com/tensorflow/models.gitまずはこちらを参考に。
cloneしてきたデータをsushi_detector_datasetのディレクトリ内にmodelsという名前でおきます。
お次はprotocというのを実行するらしい。
ここにありました。 https://github.com/protocolbuffers/protobuf/releases
最初3.7をDLしたのですが、うまくいかなかったので手順と同じ3.4にしたらうまくいきました。(どうやら3.5以上ではfor /r %v in (object_detection/protos/*.proto) do protoc "object_detection/protos/%~nxv" –python_out=.ってやると成功するもよう)cd models\research .\protoc.exe object_detection\protos\*.proto --python_out=.で、できたやつを
C:\Users\user\AppData\Local\Programs\Python\Python36\lib\site-packages\object_detection\protosにコピってみた。
models/research/object_detectionで作業すればpathは問題ないのかも。もしくは環境変数のPYTHONPATHあたりを設定するか。
とりあえず自分の環境で動かせるようにした感じです。(※結論からいうと落としてきたレポジトリのmodels/research/object_detectionを作業ディレクトリにしちゃえばよかったです)なんかtrainval.txtにファイルを羅列しなくちゃいけないっぽく、gitのbash(windowsのgit入れる時に入るやつ)でやりました。単にテキストファイルに学習したいファイルの拡張子抜きのファイル名が羅列されてればいいみたい。
$ cd [projectdir]/annotations $ for f in *.xml ; do echo ${f:0:-4} >> trainval.txt; donetrainval.txtIMG_0001 IMG_0002みたいなファイルがあって、imagesにはIMG_0001.jpgやIMG_0002.jpgが、annotationsにはIMG_0001.xmlやIMG_0002.xmlが入ってる感じです。
で、cmdにてpython create_tf_record.py --annotations_dir=.\annotations\ --images_dir=.\images\ --output_dir=.\data\ --label_map_path=.\data\kame_label_map.pbtxtkame_train.recordとか、dataディレクトリの中身が更新されてたし、これでええんやろか。
トレーニングConfigファイルの作成
なんだろうか、これ。
学習させるときのパラメーターとかが書かれてるっぽいけど、
とりあえず、git cloneしてきたファイルにssd_mobilenet_v1_sushi.docker.configというのがあるので複製してみる。ssd_mobilenet_v1_kame.configとした。
なお、pathがすべてスラッシュ(/)区切りで書かれてたけどwindows風のセパレータに変えております。
学習に使うファイルとかのpathや、反復回数とかを設定できるっぽいです。トレーニング
そして学習済モデルのDLが必要らしい。今回はカメだけ認識できればいいから細かいことはなんか適当に。
coco(common objects in context)ってモデルをひとまずベースにするのがいいらしいです。mobilenetのv1ってのか1番ライトなやつっぽい。rnnってついてるのが遅いけど正確。curl -O http://download.tensorflow.org/models/object_detection/ssd_mobilenet_v1_coco_2018_01_28.tar.gz tar zxvf ssd_mobilenet_v1_coco_2018_01_28.tar.gz(何でDLしてもいいです。tar.gzはwindowsではなじみがないですが7-Zipとかで解凍できるみたいです)
落としたものは解凍して、data/ssdとして保存しました。そして、ひとまず
Python -m object_detection.trainしてみるんだけど、train.pyなんてものがない。はて。https://stackoverflow.com/questions/51404957/tensorflow-object-detection-api-no-train-py-file
ほー。なんかlegacyってとこに移動したって。
あとDLしたmodelのslimってのがPYTHONPATHにないといけないみたいなので設定する。
そして実行。set PYTHONPATH=%PYTHONPATH%;c:\a\kame\sushi_detector_dataset\models\research\slim python -m object_detection.legacy.train --logtostderr --pipeline_config_path=.\data\ssd_mobilenet_v1_kame.config --train_dir=.\data\trainで、実行してみたら負荷かかりすぎてPCがフリーズした。。configいじった方が良さそうだ。
TensorFlow Object Detectionチュートリアルのデータセットを変えて学習させたい
こちらがすごくわかりやすい。
わけもわからないままやってた事がこれ見てわかってきた。
ふむ。configはmodel.num_classesとtrain_config.batch_sizeは変えないといけなそう。batch_sizeは2くらいにしとこう。
あとnum_stepsとnum_examplesを減らす。
いいや、せっかくDLしたけど使用済モデルも無しにしてみよう。
fine_tune_checkpointをコメントアウトし、from_detection_checkpointはfalseに。
PCはGPUはおろか、core i5のしょぼいノートPCですので。
実は一回、num_stepsを20000で始めてしまって、ぜんぜん終わらないのでCtrl+Cした経緯があります。結果、configはこんな感じになりました。
ssd_mobilenet_v1_kame.configmodel { ssd { num_classes: 1 box_coder { faster_rcnn_box_coder { y_scale: 10.0 x_scale: 10.0 height_scale: 5.0 width_scale: 5.0 } } matcher { argmax_matcher { matched_threshold: 0.5 unmatched_threshold: 0.5 ignore_thresholds: false negatives_lower_than_unmatched: true force_match_for_each_row: true } } similarity_calculator { iou_similarity { } } anchor_generator { ssd_anchor_generator { num_layers: 6 min_scale: 0.2 max_scale: 0.95 aspect_ratios: 1.0 aspect_ratios: 2.0 aspect_ratios: 0.5 aspect_ratios: 3.0 aspect_ratios: 0.3333 } } image_resizer { fixed_shape_resizer { height: 300 width: 300 } } box_predictor { convolutional_box_predictor { min_depth: 0 max_depth: 0 num_layers_before_predictor: 0 use_dropout: false dropout_keep_probability: 0.8 kernel_size: 1 box_code_size: 4 apply_sigmoid_to_scores: false conv_hyperparams { activation: RELU_6, regularizer { l2_regularizer { weight: 0.00004 } } initializer { truncated_normal_initializer { stddev: 0.03 mean: 0.0 } } batch_norm { train: true, scale: true, center: true, decay: 0.9997, epsilon: 0.001, } } } } feature_extractor { type: 'ssd_mobilenet_v1' min_depth: 16 depth_multiplier: 1.0 conv_hyperparams { activation: RELU_6, regularizer { l2_regularizer { weight: 0.00004 } } initializer { truncated_normal_initializer { stddev: 0.03 mean: 0.0 } } batch_norm { train: true, scale: true, center: true, decay: 0.9997, epsilon: 0.001, } } } loss { classification_loss { weighted_sigmoid { anchorwise_output: true } } localization_loss { weighted_smooth_l1 { anchorwise_output: true } } hard_example_miner { num_hard_examples: 3000 iou_threshold: 0.99 loss_type: CLASSIFICATION max_negatives_per_positive: 3 min_negatives_per_image: 0 } classification_weight: 1.0 localization_weight: 1.0 } normalize_loss_by_num_matches: true post_processing { batch_non_max_suppression { score_threshold: 1e-8 iou_threshold: 0.6 max_detections_per_class: 100 max_total_detections: 100 } score_converter: SIGMOID } } } train_config: { batch_size: 2 optimizer { rms_prop_optimizer: { learning_rate: { exponential_decay_learning_rate { initial_learning_rate: 0.004 decay_steps: 800720 decay_factor: 0.95 } } momentum_optimizer_value: 0.9 decay: 0.9 epsilon: 1.0 } } #fine_tune_checkpoint: ".\data\ssd\model.ckpt" from_detection_checkpoint: false # Note: The below line limits the training process to 200K steps, which we # empirically found to be sufficient enough to train the pets dataset. This # effectively bypasses the learning rate schedule (the learning rate will # never decay). Remove the below line to train indefinitely. #num_steps: 200000 num_steps: 100 data_augmentation_options { random_horizontal_flip { } } data_augmentation_options { ssd_random_crop { } } } train_input_reader: { tf_record_input_reader { input_path: ".\data\kame_train.record" } label_map_path: ".\data\kame_label_map.pbtxt" } eval_config: { num_examples: 20 # Note: The below line limits the evaluation process to 10 evaluations. # Remove the below line to evaluate indefinitely. max_evals: 10 } eval_input_reader: { tf_record_input_reader { input_path: ".\data\kame_val.record" } label_map_path: ".\data\kame_label_map.pbtxt" shuffle: false num_readers: 1 num_epochs: 1 }num_stepsを100にしたせいか、15分くらいで終わりました。
精度がどの程度出てるかはわからないけど、ひとまず先に進みましょう。Jupyter notebook
出来上がったモデルを試してみます。
手っ取り早く、Jupyter notebookで。
とかいいつつ使うのはじめてだし、setupからですけど。
(ただ、Kaggleでそれっぽいのは使ったことある)
で、DLしてきたmodelsの中にnotebookのソースがあったのでそれを動かしてみる。
というかmodels\research\object_detectionをプロジェクトディレクトリとしちゃった方が良さそうな気がしてきました。
出来上がったdataフォルダをコピーします。
あとtest_imagesに、テストしたい画像を置きました。cd models\research\object_detection pip install Jupyter pip install Matplotlib Jupyter notebookmatplotlibも使いそうなのでinstallしました。
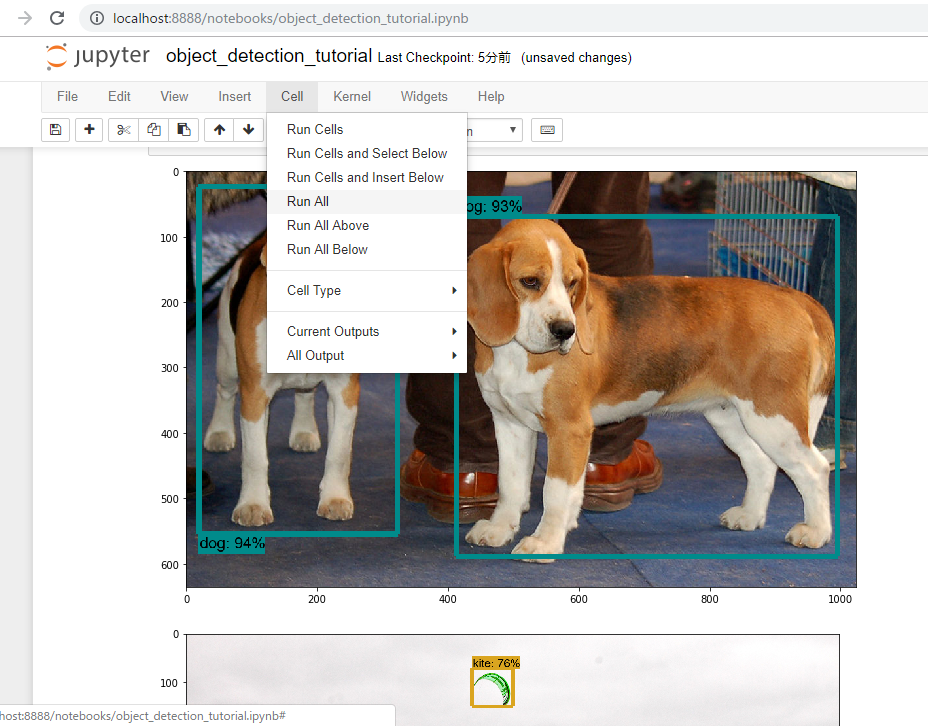
で、一回runAllしてみます。
dogだとかkiteだとかpersonだとか、ちゃんと認識してます。
次は自作の方を・・
Any model exported using the export_inference_graph.py tool can be loaded here simply by changing PATH_TO_FROZEN_GRAPH to point to a new .pb file.とあるのでexport_inference_graph.pyを実行しますpython export_inference_graph.py --input_type image_tensor --pipeline_config_path .\data\ssd_mobilenet_v1_kame.config --trained_checkpoint_prefix .\data\train\model.ckpt-100 --output_directory inference_graphそしたらinference_graph/frozen_inference_graph.pbというのができたのでnotebookを書き換えます。
# What model to download. #MODEL_NAME = 'ssd_mobilenet_v1_coco_2017_11_17' #MODEL_FILE = MODEL_NAME + '.tar.gz' #DOWNLOAD_BASE = 'http://download.tensorflow.org/models/object_detection/' # Path to frozen detection graph. This is the actual model that is used for the object detection. PATH_TO_FROZEN_GRAPH = 'inference_graph/frozen_inference_graph.pb' # List of the strings that is used to add correct label for each box. PATH_TO_LABELS = os.path.join('data', 'kame_label_map.pbtxt')Download Modelのとこは全てコメント化
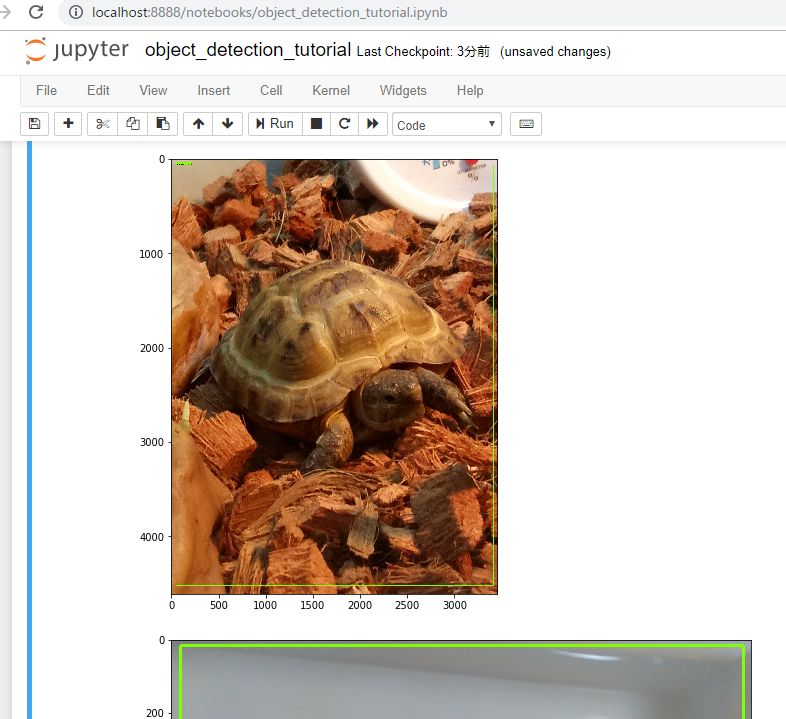
#opener = urllib.request.URLopener() #opener.retrieve(DOWNLOAD_BASE + MODEL_FILE, MODEL_FILE) #tar_file = tarfile.open(MODEL_FILE) #for file in tar_file.getmembers(): # file_name = os.path.basename(file.name) # if 'frozen_inference_graph.pb' in file_name: # tar_file.extract(file, os.getcwd())あとは3つめの画像を判別したいので
TEST_IMAGE_PATHS = [ os.path.join(PATH_TO_TEST_IMAGES_DIR, 'image{}.jpg'.format(i)) for i in range(3, 4) ]とするそしたらRun ALLいきます。
ん~・・微妙。。
学習が全然たりないのかなぁ。。
再学習
fine_tune_checkpoint、from_detection_checkpoint、num_stepsを変更します。
ssd_mobilenet_v1_kame.configfine_tune_checkpoint: ".\data\ssd\model.ckpt" from_detection_checkpoint: true num_steps: 2000これで5時間くらいか?
そんなわけでも一度。トレーニングデータの場所はちょっと変える。python -m object_detection.legacy.train --logtostderr --pipeline_config_path=.\data\ssd_mobilenet_v1_kame.config --train_dir=.\data\train.1でもまた失敗。。
labelImgの時の範囲指定が大きすぎたかなあ。
欲張らず甲羅だけ指定するようにしてみる。
そしてcreate_tf_record.py をまたやってTFRecord作成し、またトレーニング実行。
2000stepだと4時間くらいかかったし、まずはお試しで200stepから。
あとmatched_thresholdとunmatched_thresholdを0.5から0.7に変えました。python -m object_detection.legacy.train --logtostderr --pipeline_config_path=.\data\ssd_mobilenet_v1_kame.config --train_dir=.\data\train.2 ... INFO:tensorflow:Recording summary at step 191. INFO:tensorflow:Recording summary at step 191. INFO:tensorflow:global step 192: loss = 7.9095 (7.091 sec/step) INFO:tensorflow:global step 192: loss = 7.9095 (7.091 sec/step) INFO:tensorflow:global step 193: loss = 14.9527 (5.446 sec/step) INFO:tensorflow:global step 193: loss = 14.9527 (5.446 sec/step) INFO:tensorflow:global step 194: loss = 7.4112 (7.121 sec/step) INFO:tensorflow:global step 194: loss = 7.4112 (7.121 sec/step) INFO:tensorflow:global step 195: loss = 8.6017 (6.059 sec/step) INFO:tensorflow:global step 195: loss = 8.6017 (6.059 sec/step) INFO:tensorflow:global step 196: loss = 7.5035 (6.000 sec/step) INFO:tensorflow:global step 196: loss = 7.5035 (6.000 sec/step) INFO:tensorflow:global step 197: loss = 7.5494 (10.491 sec/step) INFO:tensorflow:global step 197: loss = 7.5494 (10.491 sec/step) INFO:tensorflow:global step 198: loss = 6.6824 (5.668 sec/step) INFO:tensorflow:global step 198: loss = 6.6824 (5.668 sec/step) INFO:tensorflow:global step 199: loss = 7.5866 (6.179 sec/step) INFO:tensorflow:global step 199: loss = 7.5866 (6.179 sec/step) INFO:tensorflow:global step 200: loss = 23.8177 (5.964 sec/step) INFO:tensorflow:global step 200: loss = 23.8177 (5.964 sec/step) INFO:tensorflow:Stopping Training. INFO:tensorflow:Stopping Training. INFO:tensorflow:Finished training! Saving model to disk. INFO:tensorflow:Finished training! Saving model to disk.んー。lossの値が大きい。2000回やった時は3ぐらいまで下がってたけど。
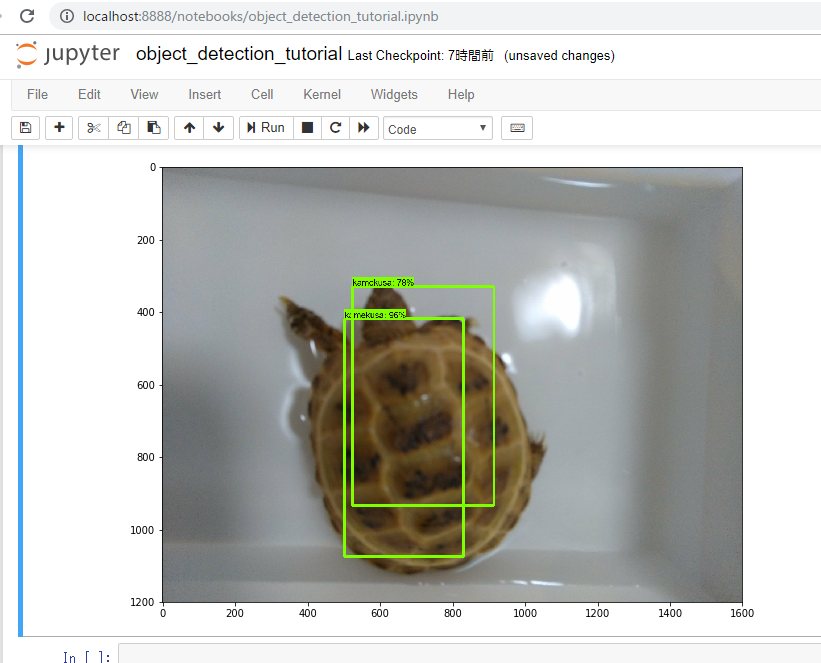
とりあえずJupyter notebook起動してみる。
・・が、何も認識できていない結果となりました。。
matched_threshold変えたから閾値にひっかかってるのかな。
ただ、checkpointがあるので続きからできるはず。num_stepsを800にしてもう少しトレーニングを進めます。そしてJupyter notebookを再度起動。
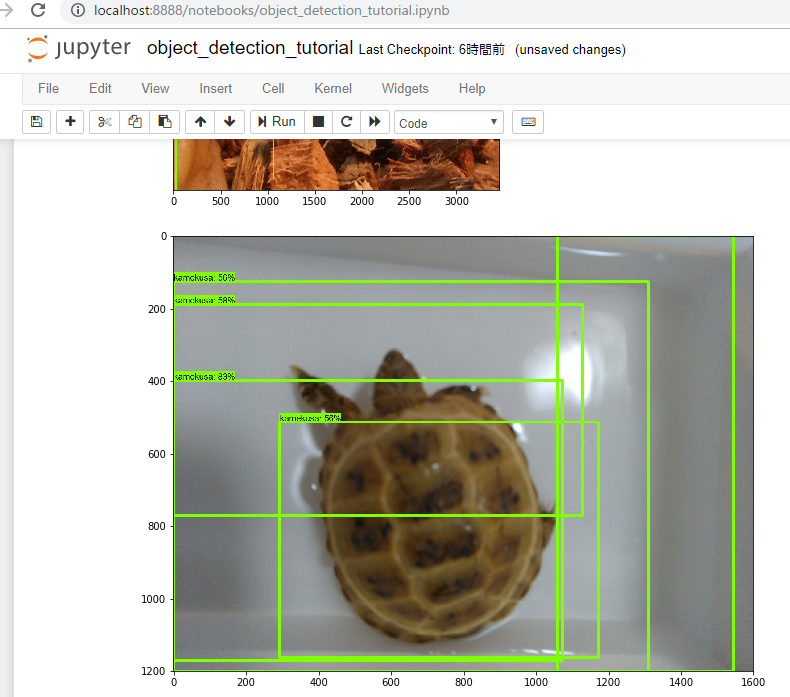
そして・・
またアカン。。なんかよくわからんところが認識されてる。
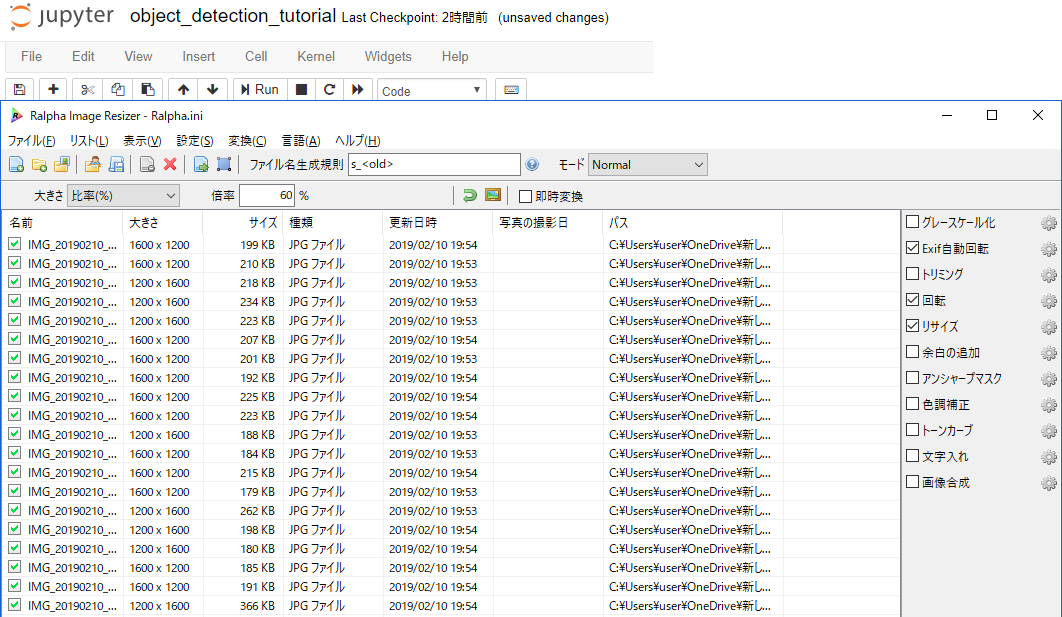
今度はちょっと画像を増やしてみるかー。同じ画像を加工して水増しする。これ使ってみます。
https://forest.watch.impress.co.jp/library/software/ralpha/
大きさと左右反転とアンシャープマスクかけた。アンシャープマスクは逆にシャープにする方にかけたけど。
画像が40枚になったのでまたTFRecord生成するとこから。
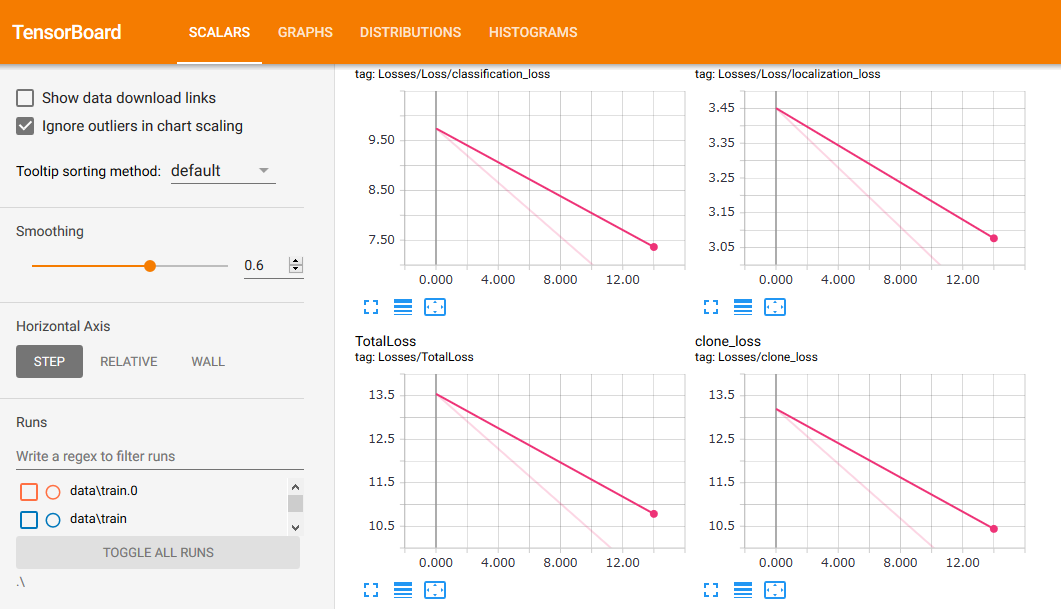
そしてstepや閾値を調整しつつ、何度かやり直す。python -m object_detection.legacy.train --logtostderr --pipeline_config_path=.\data\ssd_mobilenet_v1_kame.config --train_dir=.\data\train.3 ... INFO:tensorflow:Recording summary at step 0. INFO:tensorflow:Recording summary at step 0. INFO:tensorflow:global step 1: loss = 13.1957 (32.560 sec/step) INFO:tensorflow:global step 1: loss = 13.1957 (32.560 sec/step) INFO:tensorflow:global step 2: loss = 12.0376 (7.747 sec/step) INFO:tensorflow:global step 2: loss = 12.0376 (7.747 sec/step) INFO:tensorflow:global step 3: loss = 11.0935 (4.905 sec/step) INFO:tensorflow:global step 3: loss = 11.0935 (4.905 sec/step) INFO:tensorflow:global step 4: loss = 11.2538 (4.690 sec/step) INFO:tensorflow:global step 4: loss = 11.2538 (4.690 sec/step) INFO:tensorflow:global step 5: loss = 10.3707 (5.106 sec/step) INFO:tensorflow:global step 5: loss = 10.3707 (5.106 sec/step) INFO:tensorflow:global step 6: loss = 10.8260 (5.108 sec/step) INFO:tensorflow:global step 6: loss = 10.8260 (5.108 sec/step) INFO:tensorflow:global step 7: loss = 9.6286 (5.158 sec/step) INFO:tensorflow:global step 7: loss = 9.6286 (5.158 sec/step) INFO:tensorflow:global step 8: loss = 9.9401 (5.029 sec/step) INFO:tensorflow:global step 8: loss = 9.9401 (5.029 sec/step) INFO:tensorflow:global step 9: loss = 9.3262 (5.330 sec/step) INFO:tensorflow:global step 9: loss = 9.3262 (5.330 sec/step) INFO:tensorflow:global step 10: loss = 9.5075 (5.274 sec/step) INFO:tensorflow:global step 10: loss = 9.5075 (5.274 sec/step) INFO:tensorflow:global step 11: loss = 8.8719 (5.587 sec/step) INFO:tensorflow:global step 11: loss = 8.8719 (5.587 sec/step) INFO:tensorflow:global step 12: loss = 7.7746 (5.752 sec/step) INFO:tensorflow:global step 12: loss = 7.7746 (5.752 sec/step) ...なんかキレイに収束していって面白い。今度は期待できるか?
なおこの様子はtensorboardというのでモニターできるみたい。
tensorboard --logdir .\ --host 0.0.0.0ってresearch/object-detectionディレクトリで実行したらトレーニングの様子が可視化された。細かい設定何もいらないのか。楽だな。
学習中のPCが重いので別PCからモニタリングしてます。
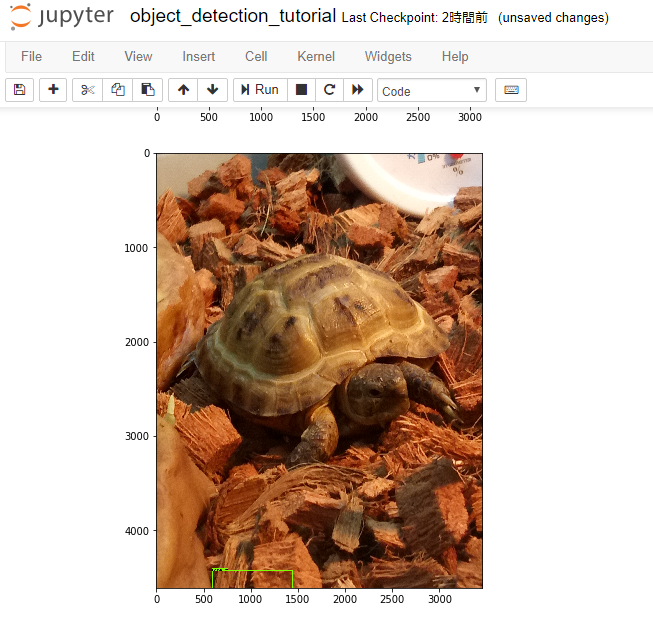
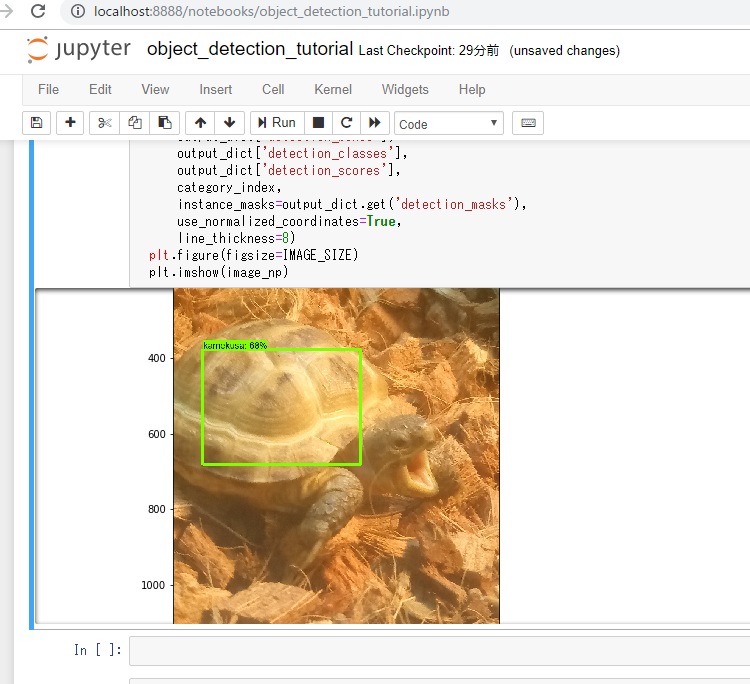
で、とりあえずの結果としては・・
とりあえずこんな所でしょうか。。
- 甲羅を中心に狭めの範囲タグ付けして
- num_stepsは200
- 画像は加工後の20枚だけ
しかし、もうちょっといろんなバリエーションで認識してくれないとツライなー。甲羅は特徴的だし、比較的捉えやすいかと思ったんだけど。
ひとまず記事としてはここまでとしますが、10000stepくらいまでトレーニング続けてどうなるかを試してみようと思います。基本、時系列で記事書いてるのでまとまりわるいですが、躓いた点とか試行錯誤してるあたりを参考にしていただければいいなと思っております。
その後
22000stepくらいまでやってはみたものの、いわゆる正解画像の精度が上がるだけで、それ以外のは認識せず、lossの値もたいして下がらずでした。
で、今度はfaster_rnn_うんちゃらのモデルで試してみることにしました。
あと、画像は10枚ほど追加し、今度はトレーニング用のデータとテスト用のデータをちゃんと分けたりしてみた。
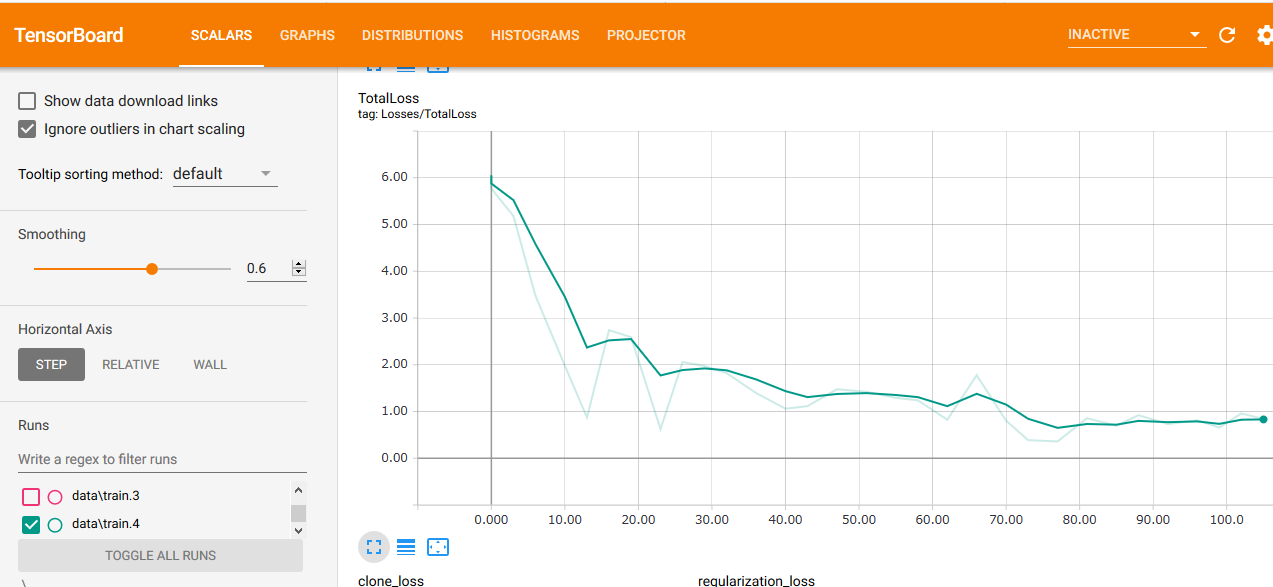
まだ100stepくらいだけど、前のやつとか基準がぜんぜん違うのかって感じのスコアです。
とりあえず200stepで中間結果をみる。
教師データとしてはなかった画像だけどなんとか認識してる。
学習続けたら精度上がるかな。
気長に5555stepくらいまで回してみます。


- 投稿日:2019-02-11T02:21:29+09:00
Google Colabでの TPU 使い方メモ
各ライブラリで実装する前に, Google Colab のランタイムで TPU を選択する必要があります. 事前に Google Colab メニューバーの Runtime > Change runtime type から Notebook settings を開き, Hardware accelerator を TPU に変更してください.
以下のサンプルコードでは,簡単な掛け算を TPU を使って実行します.
Tensorflow
import os import tensorflow as tf X = tf.placeholder(tf.int32, [5, ]) Y = tf.placeholder(tf.int32, [5, ]) tpu_ops = tf.contrib.tpu.rewrite(tf.multiply, [X, Y]) tpu_address = "grpc://" + os.environ['COLAB_TPU_ADDR'] with tf.Session(tpu_address) as session: try: session.run(tf.contrib.tpu.initialize_system()) result = session.run(tpu_ops, { X: [1, 2, 3, 4, 5], Y: [2, 3, 4, 5, 6] }) # 結果を出力 print(result) finally: session.run(tf.contrib.tpu.shutdown_system())Keras
import os import numpy as np import tensorflow as tf X = tf.keras.Input([5, ]) Y = tf.keras.Input([5, ]) outputs = tf.keras.layers.Multiply()([X, Y]) model = tf.keras.Model([X, Y], outputs) tpu_address = "grpc://" + os.environ['COLAB_TPU_ADDR'] storategy = tf.contrib.tpu.TPUDistributionStrategy( tf.contrib.cluster_resolver.TPUClusterResolver(tpu_address)) tpu_model = tf.contrib.tpu.keras_to_tpu_model(model, storategy) result = tpu_model.call([ np.array([1, 2, 3, 4, 5]), np.array([2, 3, 4, 5, 6]) ]) # 結果を出力 print(result) tf.contrib.tpu.shutdown_system()
- 投稿日:2019-02-11T02:21:29+09:00
Google ColabでのTPU使い方メモ
各ライブラリで実装する前に, Google Colab のランタイムで TPU を選択する必要があります. 事前に Google Colab メニューバーの Runtime > Change runtime type から Notebook settings を開き, Hardware accelerator を TPU に変更してください.
以下のサンプルコードでは,簡単な掛け算を TPU を使って実行します.
Tensorflow
import os import tensorflow as tf X = tf.placeholder(tf.int32, [5, ]) Y = tf.placeholder(tf.int32, [5, ]) tpu_ops = tf.contrib.tpu.rewrite(tf.multiply, [X, Y]) tpu_address = "grpc://" + os.environ['COLAB_TPU_ADDR'] with tf.Session(tpu_address) as session: try: session.run(tf.contrib.tpu.initialize_system()) result = session.run(tpu_ops, { X: [1, 2, 3, 4, 5], Y: [2, 3, 4, 5, 6] }) # 結果を出力 print(result) finally: session.run(tf.contrib.tpu.shutdown_system())Keras
import os import numpy as np import tensorflow as tf X = tf.keras.Input([5, ]) Y = tf.keras.Input([5, ]) outputs = tf.keras.layers.Multiply()([X, Y]) model = tf.keras.Model([X, Y], outputs) tpu_address = "grpc://" + os.environ['COLAB_TPU_ADDR'] storategy = tf.contrib.tpu.TPUDistributionStrategy( tf.contrib.cluster_resolver.TPUClusterResolver(tpu_address)) tpu_model = tf.contrib.tpu.keras_to_tpu_model(model, storategy) result = tpu_model.call([ np.array([1, 2, 3, 4, 5]), np.array([2, 3, 4, 5, 6]) ]) # 結果を出力 print(result) tf.contrib.tpu.shutdown_system()