- 投稿日:2019-02-11T23:40:16+09:00
只今勉強中!機械学習 スカラー回帰の例:住宅価格の予想
スカラー回帰
前回は 只今勉強中!機械学習 多クラス分類の例:ニュース配信の分類 の演習をしました。多クラス単一ラベル分類では複数のラベルのうちの1つを予測する問題でした。
回帰問題はラベルを予想するのではなく連続値を予測します。たとえば過去の株価から明日の株価を予測したり、過去の気温から明日の気温を予測したりします。
※回帰とロジスティック回帰は異なることに注意。ロジスティック回帰は分類アルゴリズムに属する。住宅価格の予想
今回は1970年代中ごろのボストン近郊の住宅価格の中央値を予測する問題の演習をします。
予測データには部屋数や大きさ、犯罪発生率や税率などのデータ点が含まれています。
また、今回使用するデータ点は506個(404の訓練データと102個のテストデータ)しかなく、分類問題の時と比較して非常に少ないのが特徴的です。
入力データの特徴量はそれぞれ異なる尺度を使用(犯罪発生率、税率、部屋数など)している点も前回までの分類問題とは大きく異なる。サンプルデータを読み込む
tutorial.py# データ読み込み from keras.datasets import boston_housing (train_data, train_targets), (test_data, test_targets) = boston_housing.load_data() # データの確認 print(train_data.shape) >>> (404, 13) print(test_data.shape) >>> (102, 13) print(train_data[0]) >>> [ 1.23247 0. 8.14 0. 0.538 6.142 91.7 3.9769 4. 307. 21. 396.9 18.72 ]データの準備
特徴量のデータは価格や部屋の大きさ、部屋のタイプなど、値がバラバラなので正規化する必要がある
※正規化:価格も部屋の大きさも部屋のタイプも同じ基準の数値に揃えてあげる処理のこと
一般的に正規化で用いられる方法が「入力データを特徴量ごとに特徴量の平均値を引き、標準偏差で割る」である。tutorial.py# データを特徴量ごとに正規化する関数 def make_train_data(dataset, axis = 0): """ 特徴量ごとにデータを正規化する [手順] 入力データを特徴量ごとに特徴量の平均値を引き、標準偏差で割る -------- dataset:正規化するデータ axis :軸を指定(データが2次元配列なら0 #列が対象) """ mean = dataset.mean(axis) # 1軸目の平均値(2次配列なので各列の平均値) dataset -= mean # 平均値で引く std = dataset.std(axis) # 標準偏差 dataset /= std # 標準偏差で割る return dataset # 訓練でータを正規化 train_data = make_train_data(train_data, 0) # テストデータも正規化 test_data = make_train_data(test_data, 0)ニューラルネットワークの構築とモデルの定義
モデルを設計します。
レイヤー層のタイプ、出入力数、活性化関数のタイプ、そして層の数を設計します。
今回はモデルインスタンスを複数呼び出すk分割交差検証と呼ばれる方法を用いる為、model生成用の関数として定義し実装時に関数を呼び出すようにします。tutorial.py# モデルの定義 from keras import models from keras import layers """ MEA 平均絶対誤差(mean absolute error):予測値と目的地の誤差の絶対値の平均 """ def build_model(train_data): # モデルインスタンスを生成するメソッド model = models.Sequential() model.add(layers.Dense(64, activation='relu', input_shape=(train_data.shape[1],))) model.add(layers.Dense(64, activation='relu')) model.add(layers.Dense(1)) model.compile(optimizer='rmsprop', loss='mse', metrics=['mae']) return modelモデルの実装
k分割交差検証
- k分割交差検証とはデータセットをk個のサンプルセット(フォールド)に分割して、同じモデルのインスタンスもk個作成する。 k個のモデルをk-1個のサンプルセットでの訓練と1回の検証を行い、最後に検証スコアの平均を求める方法。 k値は4または5で行われることが多い。
tutorial.pyimport numpy as np # k分割交差検証データの生成 """ エポック数を500に増やし、エポックごとに検証ログを保存するようにして再訓練と検証を行う """ num_epochs = 500 k = 4 num_val_samples = len(train_data) // 4 # 小数点以下切り捨て all_mae_histories = [] for i in range(k): print('processing fold #', i) # 検証データの準備:フォールドiのデータ key = i * num_val_samples value = (i + 1) * num_val_samples val_data = train_data[key:value] val_targets = train_targets[key:value] # 訓練データの準備:残りのフォールドのデータ partial_train_data = np.concatenate( [ train_data[:key], train_data[value:] ], axis = 0 ) partial_train_targets = np.concatenate( [ train_targets[:key], train_targets[value:] ], axis = 0 ) # モデルインスタンスを取得 model = build_model(train_data) # モデルをサイレントモードで訓練と検証を実施 history = model.fit( partial_train_data, partial_train_targets, validation_data = (val_data, val_targets), epochs = num_epochs, batch_size = 1, verbose = 0 ) # i回目の平均絶対誤差を取得して格納 mea_history = history.history['val_mean_absolute_error'] all_mae_histories.append(mea_history) # k分割交差検証の平均スコアの履歴を作成 average_mae_history = [np.mean([x[i] for x in all_mae_histories]) for i in range(num_epochs)]i回目の(訓練、検証)出力ログ
processing fold # 0 processing fold # 1 processing fold # 2 processing fold # 3訓練(検証)データをプロット
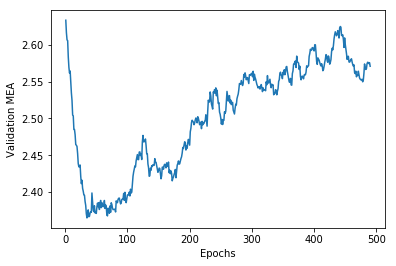
tutorial.py# 結果をプロット import matplotlib.pyplot as plt # このままだとグラフがみずらいので見やすくなるように修正 def smooth_curve(points, factor = 0.9): smoothed_points = [] for point in points: if smoothed_points: previous = smoothed_points[-1] smoothed_points.append(previous * factor + point * (1 - factor)) else: smoothed_points.append(point) return smoothed_points smoothed_mea_history = smooth_curve(average_mae_history[10:]) plt.plot(range(1, len(smoothed_mea_history) + 1), smoothed_mea_history) plt.xlabel('Epochs') plt.ylabel('Validation MEA') plt.show()
データの検証
上記プロットから検証スコア(MEA=平均絶対誤差)が30エポック付近で大きく改善され、その後過学習に陥っていることが伺える。
ということでモデルをチューニングしてもう一度訓練を実施する。tutorial.pyimport numpy as np model = build_model(train_data) # モデルをサイレントモードでfit model.fit( train_data, train_targets, epochs = 30, batch_size = 8, verbose = 0 # サイレントモード ) # 検証スコアを取得 test_mse_score, test_mea_score = model.evaluate(test_data, test_targets) # 訓練結果出力 print(test_mea_score) >>> 2.7296556491477815振り返り
改めて30エポックでバッチサイズを8にして実行してみたが誤差は2700ほどと芳しくなかった。
この後、エポック数を調整していろいろ変えてみるも思わしい結果はでない。
本演習の目的は回帰問題のモデルの実装方法、そしてモデルのチューニング方法である。
モデルをチューニングするにあたって検証スコア(MEA=平均絶対誤差)をプロットし最小点を見つけ出すということがわかったので良しとする(肝心のテスト結果は芳しくないのだが、演習の教科書でも結果は思わしくないようである)。まとめ
- 回帰ではデータを正規化(一般的に正規化で用いられる方法が「入力データを特徴量ごとに特徴量の平均値を引き、標準偏差で割る」)する。
- 損失関数は、MSE(平均二乗誤差)を用いることが多い。
- 評価関数は、MEA(平均絶対誤差)を用いることが多い。
- 利用可能なデータが少ない場合はk分割交差検証を用いることが有効。
- 利用可能な訓練データが少ない場合は隠れ層の数を少ない(1か2)小さなネットワークを使用する。
- 投稿日:2019-02-11T22:52:20+09:00
ConoHaでDjango+Wagtail+PuputのCMSでブログを作る件 備忘録
PythonでCMS
最近pythonを使うことが多いのでpythonでCMS環境を構築してみようと思い立ち、やってみました。
紆余曲折の末に次の手順でやるとブログサイトを作り始めるまでに比較的早く辿りつけることがわかってきましたので備忘録としてまとめておきます。
選択としてもっとベターなものがあるかもしれませんが参考まで。サマリー
1.ConoHaでUbuntuサーバを借りる
2.Anacondaをインストール/python環境を作る
3.Djangoをインストール
4.Wagtailをインストール
5.Puputをインストール
6.Wagtailでサイトを作成
7.テストサーバの起動
8.ブラウザからアクセス1.ConoHaでUbuntuサーバを借りる
- 今回はConoHaのUbuntuイメージを選択しました。
- ConohaのVPS Ubuntu 64 / 512 を使う
- クリーンな状態のlinuxサーバを手早く手に入れることが今回の目的です。
調べたところでは。。。
- ConohaのDjangoアプリケーションイメージを最初は使おうとしていたが、入っているpythonも2系で、今後AIをやりたいということもあるのでこのVPSイメージを一旦諦めることにする。
- Linux単体のイメージを使用しpython環境から構築してみることに。
- CentOSよりもUbubntuの方がPython/Djangoに対するフォローが早いようなので Ubuntuにする。
作業用にユーザを一つ作りました。
2.Anacondaをインストール/python環境を作る
ConohaのVPSを使うことにしたのでCUI環境でインストールしなければなりませんが、linuxの場合Anacondaのインストールはシェルスクリプトで行えるのでやってみました。
こちらのサイトを参考にさせていただきました。とてもわかりやすいと思います。
⇨ Ubuntu で Anaconda のインストールAnacondaインストール後
- python3.6の環境を作る$ conda create --name py36 python=3.6.2 $ conda activate py363.Djangoをインストール
$ conda install djangoDjangoはインストールだけしてここでは素通りです。
4.Wagtailをインストール
⇨ "Welcome to Wagtail’s documentation"
$ pip install wagtailここまでで、CMS開発環境ができました。
WagtailがDjango上で使える状態になっているはずですが、先にWagtailで扱えるblogライブラリであるPuputをインストールしてしまいます。5.Puputをインストール
pip install --upgrade pip pip install wheel pip install wagtail django-colorful django-el-pagination django-social-share pip install --no-deps puput6.Wagtailでサイトを作成/Puputの有効化
$ mkdir myProjects $ cd myProjects $ wagtail start mysite $ cd mysite $ pip install -r requirements.txtdjango-adminを使っていませんが、
wagtail start mysiteだけで
django-admin startproject mysiteとpython manage.py startapp homeが行われているように思えます。mysite/settings/base.pyのINSTALLED_APPSに以下を追加
'wagtail.contrib.sitemaps', 'wagtail.contrib.routable_page', 'django_social_share', 'puput', 'colorful',同じく mysite/settings/base.py のどこかに以下を記述
PUPUT_AS_PLUGIN = Trueurls.pyに以下を追加
from puput import urls as puput_urls ...snip url(r'',include(puput_urls)), #この1行を追加 url(r'', include(wagtail_urls)), #この記述が元からあるのでその上にmigrate
$ python manage.py migrate $ python manage.py createsuperuser
python manage.py createsuperuserでCMSの管理者のユーザを設定します。
ブラウザからアクセスした時にこのユーザ名でログインすることでサイトやブログの管理を行います。7.テストサーバの起動
Djangoがローカルのマシンで動いているわけではないので、リモートでアクセス可能なように起動時にオプションをつけます。
$ python manage.py runserver xxx.xxx.xxx.xxx:ppppxxx.xxx.xxx.xxx:pppp は今まさに使っているConoHaのVPSのアドレスと任意のポート番号です。
Djangoを直接使用する場合にはsettings.pyにALLOWED_HOSTS = ['xxx.xxx.xxx.xxx']を記述しておく必要がありますが、wagtailでは必要ありませんでした。
開発用なので本運用には不適当です。8.ブラウザからアクセス
ログイン
上で、123.456.789.123:8080でサーバを起動したとしたら、
http://123.456.789.123:8080/admin/ で作成したサイトの管理画面に入れます。
ログインを促されるので、設定したユーザ名/パスワードでログインします。サイトの設定
Defaultの状態では、サイトのアドレスがlocalhostの8000になっているので開発環境に合わせておきます。
左のパネルから Settings > Sites を選択しSITEとport番号をサーバを起動した時のxxx.xxx.xxx.xxx:ppppに合わせます。
Blogページの作成
本来Wagtailを導入しただけだと、CMSの環境にはなりますが空っぽの状態なので、実装して作り込んで行かなくてはなりません。
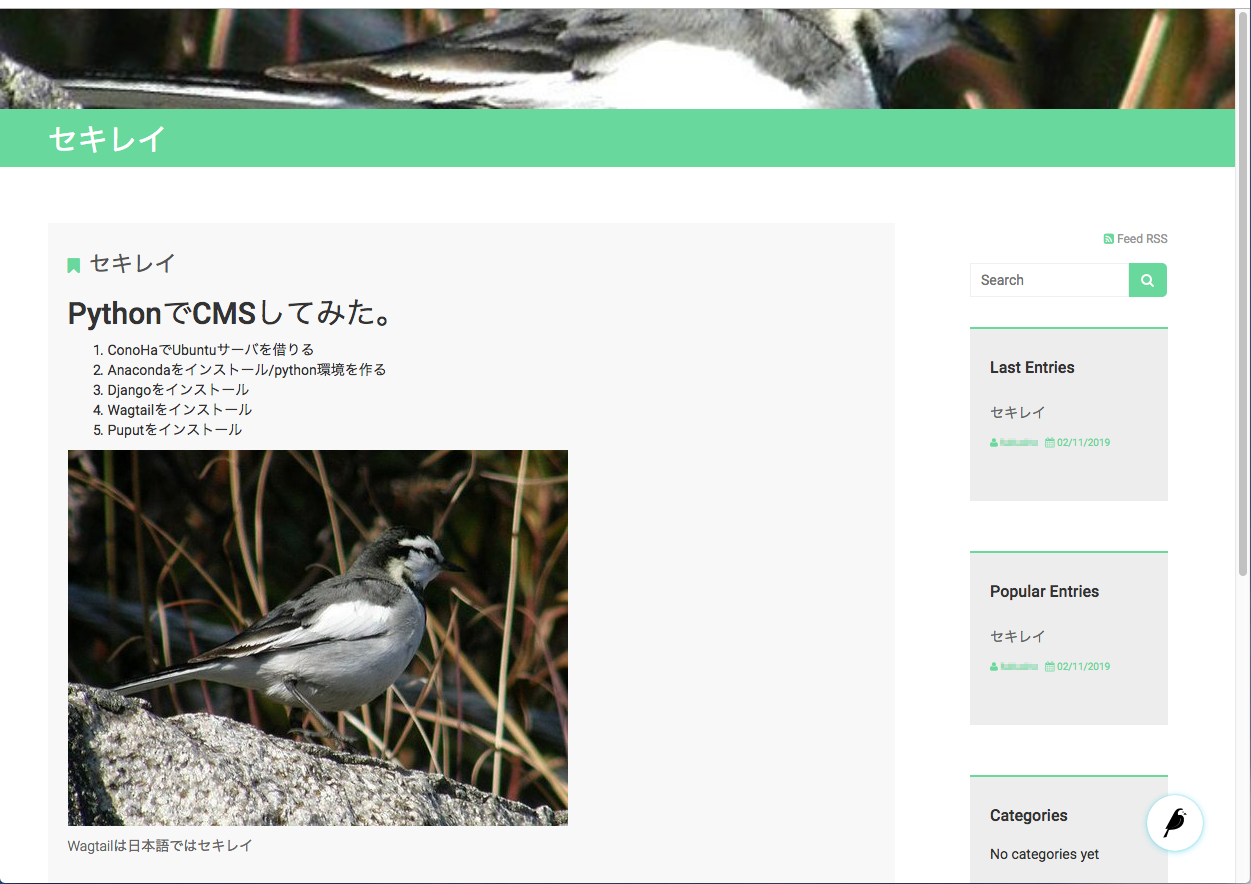
実装にはDjangoやWagtailの知識が必要になりますが、今回はPuputを入れて有効にしているので、最初からブログのページを作成することができました。
試しに作ってみたブログページ
以上備忘録でした。
ちなみにDjangoには詳しくないので。。。これを機会に勉強してみます。
参考にさせてもらったサイト/記事
PythonでCMS、どれ使えばいいの? 〜Mezzanine vs django CMS vs Wagtail〜
Djangoを最速でマスターする part1
Ubuntu で Anaconda のインストール
wagtail Your first Wagtail site を参考に、Blog を作る
- 投稿日:2019-02-11T22:48:53+09:00
if __name__ == '__main__' とはなにか
コードの例などでよく見る
if __name__ == '__main__'について、ずっとモヤらせていたものを調べたので記録。if name == 'main' とはなにか
簡単に言えば、「外部からimportして読み込んだときに実行されないようにするため」のもの。
pythonは同じディレクトリであれば
import ファイル名でモジュールとして読み込みができる。この読み込みのときにはコード全体が実行されるため、平文で書いていたらimportしたときに値が返ってきてしまう。たとえば、
python:hello.py
print('hello world')
上のコードを別のファイルからimport helloとすると読み込めるが、読み込みと同時にhello worldと返ってきてしまう。これはいけてない。し、場合によっては不具合がでうる。それを防ぐためには、
python:hello.py
if __name__ == '__main__':
print('hello world')
とするだけでOK。なぜか
どうやらimportする際には内部で
__name__という変数にモジュール名が与えられているらしい。hello.pyをモジュールとして実行すると
__name__はhelloになる。
なのでif文は実行されなかったという仕組みっぽい。
- 投稿日:2019-02-11T22:34:22+09:00
Macで使うmatplotlibのbackendエラー
はじめに
pythonを使ったデータ解析環境として、まず用意したいライブラリの一つが、matplotlibだと思います。少なくとも僕はそう思っています。
なので、macのpython環境でもまずmatplotlibを入れることを考えました。matplotlibのインストールと実行
とりあえずpipenv環境をactivateして、いつも通り下記を実行すると問題なくするっと入ります。
$ pip install matplotlibじゃあいけるだろうと思い、下記を実行。
main.pyimport matplotlib.pyplot as plt a = [1, 2, 5, 4, 3] plt.plot(a)ImportError: Python is not installed as a framework. The Mac OS X backend will not be able to function correctly if Python is not installed as a framework. See the Python documentation for more information on installing Python as a framework on Mac OS X. Please either reinstall Python as a framework, or try one of the other backends. If you are using (Ana)Conda please install python.app and replace the use of 'python' with 'pythonw'. See 'Working with Matplotlib on OSX' in the Matplotlib FAQ for more information.なんかエラー出た。。
macでのmatplotlibインストール エラー対策
どうやらmacあるあるらしく、たくさん解決法が書いてありました。
matplotlibのmatplotlibrcファイルのbackendをmacosxから、TkAggに変えろ、というもの。
早速、matplotlibrcの場所を下記コマンドで調べて書き換える。import matplotlib matplotlib.matplotlib_fname() .venv/lib/python3.5/site-packages/matplotlib/mpl-data/matplotlibrc'matplotlibrc# backend: macosx backend: TkAggそして、また実行してみると、
いやいや、グラフ出ないじゃん。ということで、別情報を得て、backendをQtAggに変更するとできると知る。GUIとしてPyQtを使う手のようです。下記の方法でうまくいきました。
$ pip install PyQt5matplotlibrc# backend: macosx # backend: TkAgg backend: Qt5Aggこれで、matplotlibのコードを動かすと・・
動きました。まとめ
とりあえず2019/2の段階では、PyQt5をインストールして、backendをQt5Aggにすれば動きそうです。Qt4Aggにすれば動くという話も出回っていますが、私の環境ではうまくいきませんでした。
皆さんのご参考になれば。

- 投稿日:2019-02-11T22:03:36+09:00
Raspberry Pi(Raspbian)でモーションセンサー式の防犯カメラ的なものを作ってみる
はじめに
Raspberry Pi(Raspbian)でモーションセンサー式の防犯カメラ的なものを作る方法です。
必要なもの
- RaspbianがインストールされているRaspberry Pi
- Raspberry Pi用のカメラモジュール
- 赤外線モーションセンサー(HC-SR501)
- ジャンパー線(メス/メス)x3
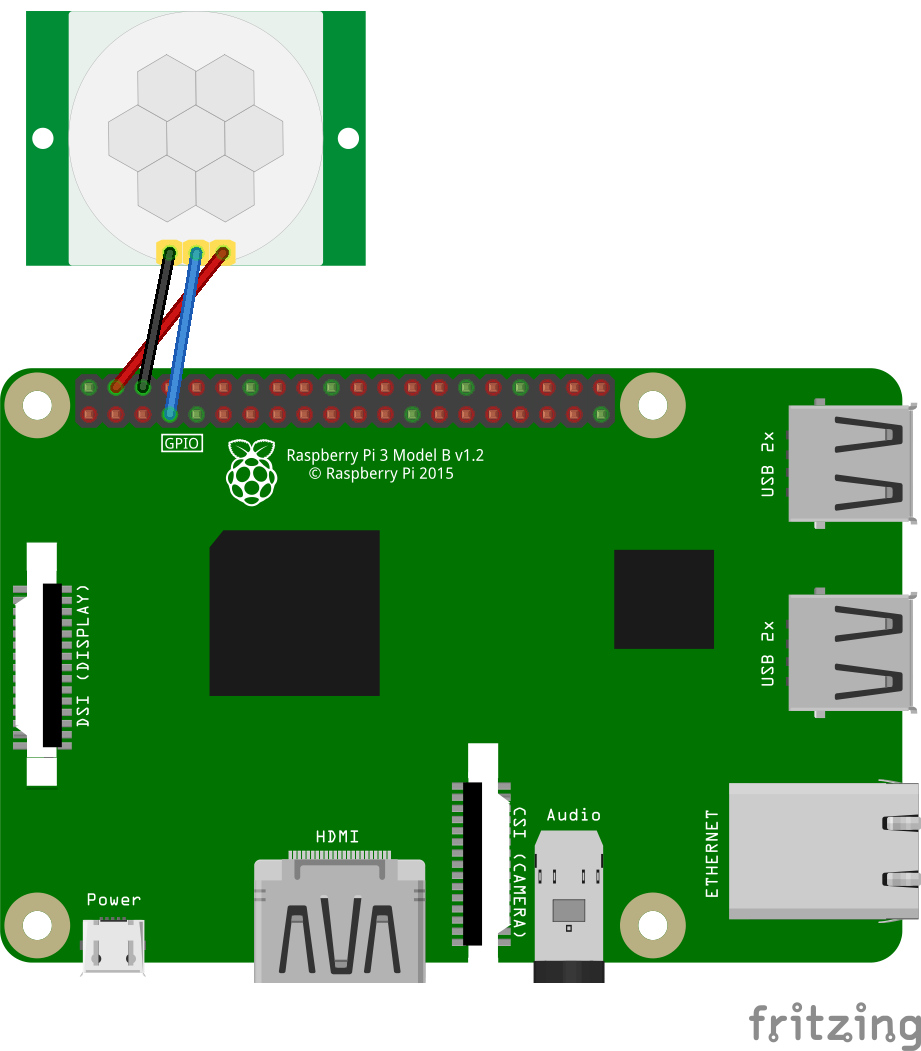
配線
GPIO, 5V, GNDならどこでも可ですが、今後の拡張性などを考えるとGPIOのみのピン(3, 5, 8, 10, 19, 21, 23, 24, 25以外)を使う方が無難だと思います。
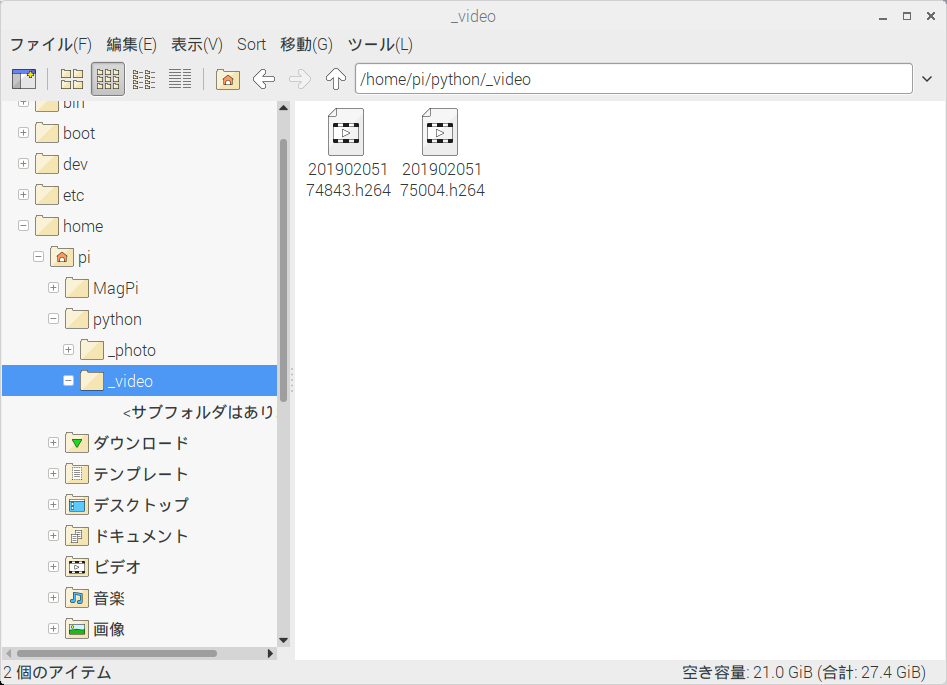
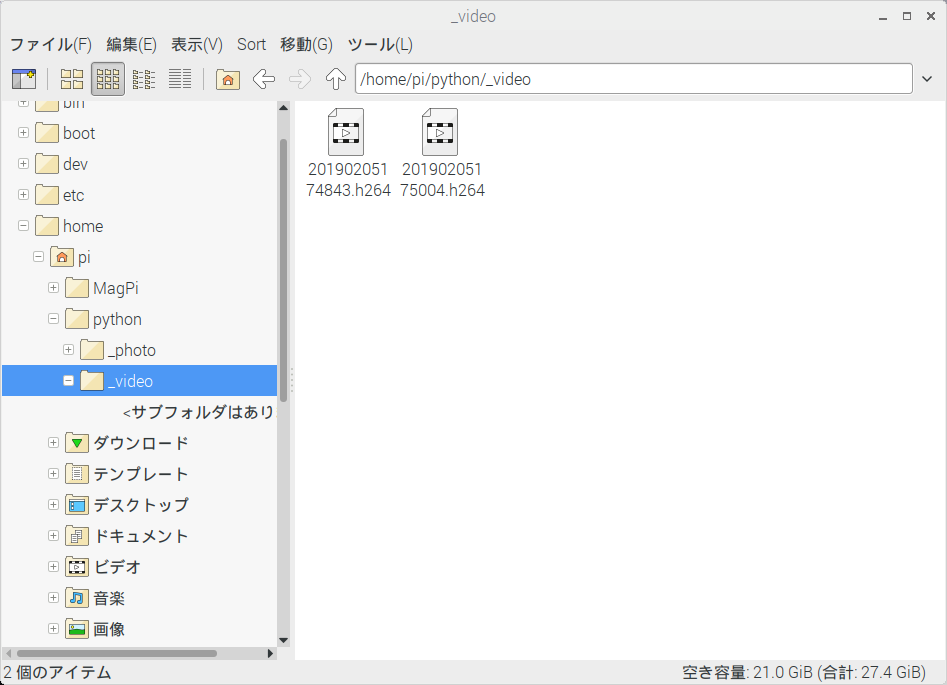
この投稿では4(5V), 6(GND), 7(GPIO4)ピンを使用しています。
↓HC-SR501の配線は左から順にGND, OUT, VCC。
↓右側のダイヤルで距離、左側のダイヤルで時間を調整することができるので、使用用途と環境に合わせて調整する。(調整するのが面倒なら↓と同じにしておけばOK)
プログラム
security_camera.py#Import Files import RPi.GPIO as GPIO import picamera import time #GPIO Settings GPIO.setmode(GPIO.BCM) GPIO.setup(4, GPIO.IN, pull_up_down=GPIO.PUD_DOWN) #Camera Settings CAM_DIR = "/home/pi/python/_video/" camera = picamera.PiCamera() #Main try: while True: if GPIO.input(4) == 1: filename = time.strftime("%Y%m%d%H%M%S") + ".h264" save_dir_filename = CAM_DIR + filename camera.start_recording(save_dir_filename) camera.wait_recording(300) camera.stop_recording() else: pass except KeyboardInterrupt: GPIO.cleanup()解説
- スイッチの制御に使用する
RPi.GPIOライブラリをインポートする- Raspberry Piのカメラモジュールの制御に使用する
picameraライブラリをインポートする- 時間を取得するために使用する
timeライブラリをインポートする- GPIOのモードをBCMに設定する(物理的なピン番号ではなく、GPIO**を使用する)
- GPIO4を入力端子に設定し、状態をプルダウン(Low)にする(Hi=ON, Low=OFF)
CAM_DIRに保存先のディレクトリを設定する- PiCameraクラスのインスタンスを生成する
while True:で解説9〜16の処理を無限ループさせる- センサーが動きを検知したら(GPIO4がHiになったら)動画を撮る処理を行う
time.strftimeでセンサーが動きを検知した時の日時を取得するtime.strftimeで取得した日時+拡張子(.h264)をファイル名にするCAM_DIRで指定したディレクトリとファイル名を連結させるcamera.start_recordingで動画を撮るcamera.wait_recordingで指定した時間が経過したら動画を撮る処理を終了する(括弧には秒数を入れる)CAM_DIRで指定したディレクトリに動画を保存する- 解説9に遷移 or プログラムが終了するのを待つ
- Control+Cが押されたらGPIOを解放してプログラムを終了する
プログラムを実行してみる
- プログラムを実行する
- センサーが動きを検知すると動画ファイルに記録される
- 人や動物など、動くものが映っていれば完成(Raspberry Piだと正常に再生できないので手持ちのPCにコピーして再生する)

参考
- 「Raspberry Pi(Raspbian)で写真を撮るプログラムを作る」と組み合わせることで
センサーが動きを検知したら写真を撮るプログラムを作ることができる- センサーの状態(Hi/Low)は目視で確認できないので、GPIOの入力値を
- 動画の保存先には使い捨ての外部ストレージ(USBメモリ)などを指定した方が安全に運用できる
- 屋外に設置すると雨などの影響で壊れる可能性が高いので、屋内での運用が望ましい




- 投稿日:2019-02-11T22:03:02+09:00
カメの甲羅をobject detection apiで認識してみる on win10
えー、リクガメ関連のエントリで染まって来ておりますが、更に浸かっていきます。
これまでの経緯としては・・
AppSyncとDynamodbとkinesisVideoStreamとリクガメモニタリング
が最後の方ですかね。くす玉システムもあるけど。
で、Nextとしては
・カメの位置を画像から捕捉し、カメラを向ける
・カメの移動距離を測る
・hlsのm3u8にWeb Video Text Track (WebVTT)を混ぜ込むとか妄想しています。
カメの位置の捕捉についてはなんとなくイメージできてるけどとりあえずやってみておきましょうか、というそういうエントリになります。
実際の動作環境はLinux上になると思うのですがまずはwindowsでお試し。環境
- win10 64bit
- python 3.6.6
- pip 18.1
- tensorflow 11.1
だったけどpipとtennsorflowはupgradeしときます
python -m pip install --upgrade pip pip install --upgrade https://storage.googleapis.com/tensorflow/windows/cpu/tensorflow-1.12.0-cp36-cp36m-win_amd64.whl
- pip 19.0.2
- tensorflow 1.12.0
になりました。
ラベリング
今回はカメの甲羅を学習させて覚えさせたいと思います。
床材と色が似てるし、識別どうなのかなー、とか思ったけど甲羅って特徴的だし案外イケるんでは?と思ってたりしております。
なお、TensorflowのObject Detection APIを使うのですが、いつものようにQiitaにお世話になります。Tensorflow Object Detection APIで寿司検出モデルを学習するまで
windowsにも対応しているlabelImgというツールをセットアップします。
windows_v1.8.1.zipというファイルをDL -> 解凍 -> labelImg.exeを実行操作は直感的。ディレクトリを開いて、画像の上で右クリックして
Create\nRectBox、甲羅を囲んでkamekusaとラベリングしました。
これを20枚分。いろんな角度から撮ってるけどだいたい同じ画像です。
画像一枚毎にxmlファイルが出来上がりました。1枚にまとまってくれると楽なんだけど、そういう風にできないもんかな。(出来そうな気はするけど今はいいや。)
TFRecordの作成
次はTFRecordというTensorflowに対応した形に画像とラベリングデータを変換する必要があります。
との事です。このままでは使えないのか。
こちらを使わせていただきます。git clone https://github.com/Jwata/sushi_detector_dataset.gitdata/sushi_label_map.pbtxt はkame_label_map.pbtxtに変えます。
imagesとannotationsというディレクトリを作り、画像は前者、xmlは後者に。
ちなみに画像はjpgで、拡張子以外は画像もxmlファイルも共通です。pip intall lxml pip install object_detection python create_tf_record.py --annotations_dir=.\annotations --images_dir=.\images --output_dir=.\data\ --label_map_path=.\data\kame_label_map.pbtxtなんか一回、これにひっかかる
Traceback (most recent call last): File "create_tf_record.py", line 14, in <module> from object_detection.utils import dataset_util, label_map_util File "C:\Users\user\AppData\Local\Programs\Python\Python36\lib\site-packages\object_detection\utils\label_map_util.py", line 21, in <module> from object_detection.protos import string_int_label_map_pb2 ImportError: cannot import name 'string_int_label_map_pb2'tensorflow/modelsというのがいるらしい。準備不足でした。
git clone https://github.com/tensorflow/models.gitまずはこちらを参考に。
cloneしてきたデータをsushi_detector_datasetのディレクトリ内にmodelsという名前でおきます。
お次はprotocというのを実行するらしい。
ここにありました。 https://github.com/protocolbuffers/protobuf/releases
最初3.7をDLしたのですが、うまくいかなかったので手順と同じ3.4にしたらうまくいきました。(どうやら3.5以上ではfor /r %v in (object_detection/protos/*.proto) do protoc "object_detection/protos/%~nxv" –python_out=.ってやると成功するもよう)cd models\research .\protoc.exe object_detection\protos\*.proto --python_out=.で、できたやつを
C:\Users\user\AppData\Local\Programs\Python\Python36\lib\site-packages\object_detection\protosにコピってみた。
models/research/object_detectionで作業すればpathは問題ないのかも。もしくは環境変数のPYTHONPATHあたりを設定するか。
とりあえず自分の環境で動かせるようにした感じです。(※結論からいうと落としてきたレポジトリのmodels/research/object_detectionを作業ディレクトリにしちゃえばよかったです)なんかtrainval.txtにファイルを羅列しなくちゃいけないっぽく、gitのbash(windowsのgit入れる時に入るやつ)でやりました。単にテキストファイルに学習したいファイルの拡張子抜きのファイル名が羅列されてればいいみたい。
$ cd [projectdir]/annotations $ for f in *.xml ; do echo ${f:0:-4} >> trainval.txt; donetrainval.txtIMG_0001 IMG_0002みたいなファイルがあって、imagesにはIMG_0001.jpgやIMG_0002.jpgが、annotationsにはIMG_0001.xmlやIMG_0002.xmlが入ってる感じです。
で、cmdにてpython create_tf_record.py --annotations_dir=.\annotations\ --images_dir=.\images\ --output_dir=.\data\ --label_map_path=.\data\kame_label_map.pbtxtkame_train.recordとか、dataディレクトリの中身が更新されてたし、これでええんやろか。
トレーニングConfigファイルの作成
なんだろうか、これ。
学習させるときのパラメーターとかが書かれてるっぽいけど、
とりあえず、git cloneしてきたファイルにssd_mobilenet_v1_sushi.docker.configというのがあるので複製してみる。ssd_mobilenet_v1_kame.configとした。
なお、pathがすべてスラッシュ(/)区切りで書かれてたけどwindows風のセパレータに変えております。
学習に使うファイルとかのpathや、反復回数とかを設定できるっぽいです。トレーニング
そして学習済モデルのDLが必要らしい。今回はカメだけ認識できればいいから細かいことはなんか適当に。
coco(common objects in context)ってモデルをひとまずベースにするのがいいらしいです。mobilenetのv1ってのか1番ライトなやつっぽい。rnnってついてるのが遅いけど正確。curl -O http://download.tensorflow.org/models/object_detection/ssd_mobilenet_v1_coco_2018_01_28.tar.gz tar zxvf ssd_mobilenet_v1_coco_2018_01_28.tar.gz(何でDLしてもいいです。tar.gzはwindowsではなじみがないですが7-Zipとかで解凍できるみたいです)
落としたものは解凍して、data/ssdとして保存しました。そして、ひとまず
Python -m object_detection.trainしてみるんだけど、train.pyなんてものがない。はて。https://stackoverflow.com/questions/51404957/tensorflow-object-detection-api-no-train-py-file
ほー。なんかlegacyってとこに移動したって。
あとDLしたmodelのslimってのがPYTHONPATHにないといけないみたいなので設定する。
そして実行。set PYTHONPATH=%PYTHONPATH%;c:\a\kame\sushi_detector_dataset\models\research\slim python -m object_detection.legacy.train --logtostderr --pipeline_config_path=.\data\ssd_mobilenet_v1_kame.config --train_dir=.\data\trainで、実行してみたら負荷かかりすぎてPCがフリーズした。。configいじった方が良さそうだ。
TensorFlow Object Detectionチュートリアルのデータセットを変えて学習させたい
こちらがすごくわかりやすい。
わけもわからないままやってた事がこれ見てわかってきた。
ふむ。configはmodel.num_classesとtrain_config.batch_sizeは変えないといけなそう。batch_sizeは2くらいにしとこう。
あとnum_stepsとnum_examplesを減らす。
いいや、せっかくDLしたけど使用済モデルも無しにしてみよう。
fine_tune_checkpointをコメントアウトし、from_detection_checkpointはfalseに。
PCはGPUはおろか、core i5のしょぼいノートPCですので。
実は一回、num_stepsを20000で始めてしまって、ぜんぜん終わらないのでCtrl+Cした経緯があります。結果、configはこんな感じになりました。
ssd_mobilenet_v1_kame.configmodel { ssd { num_classes: 1 box_coder { faster_rcnn_box_coder { y_scale: 10.0 x_scale: 10.0 height_scale: 5.0 width_scale: 5.0 } } matcher { argmax_matcher { matched_threshold: 0.5 unmatched_threshold: 0.5 ignore_thresholds: false negatives_lower_than_unmatched: true force_match_for_each_row: true } } similarity_calculator { iou_similarity { } } anchor_generator { ssd_anchor_generator { num_layers: 6 min_scale: 0.2 max_scale: 0.95 aspect_ratios: 1.0 aspect_ratios: 2.0 aspect_ratios: 0.5 aspect_ratios: 3.0 aspect_ratios: 0.3333 } } image_resizer { fixed_shape_resizer { height: 300 width: 300 } } box_predictor { convolutional_box_predictor { min_depth: 0 max_depth: 0 num_layers_before_predictor: 0 use_dropout: false dropout_keep_probability: 0.8 kernel_size: 1 box_code_size: 4 apply_sigmoid_to_scores: false conv_hyperparams { activation: RELU_6, regularizer { l2_regularizer { weight: 0.00004 } } initializer { truncated_normal_initializer { stddev: 0.03 mean: 0.0 } } batch_norm { train: true, scale: true, center: true, decay: 0.9997, epsilon: 0.001, } } } } feature_extractor { type: 'ssd_mobilenet_v1' min_depth: 16 depth_multiplier: 1.0 conv_hyperparams { activation: RELU_6, regularizer { l2_regularizer { weight: 0.00004 } } initializer { truncated_normal_initializer { stddev: 0.03 mean: 0.0 } } batch_norm { train: true, scale: true, center: true, decay: 0.9997, epsilon: 0.001, } } } loss { classification_loss { weighted_sigmoid { anchorwise_output: true } } localization_loss { weighted_smooth_l1 { anchorwise_output: true } } hard_example_miner { num_hard_examples: 3000 iou_threshold: 0.99 loss_type: CLASSIFICATION max_negatives_per_positive: 3 min_negatives_per_image: 0 } classification_weight: 1.0 localization_weight: 1.0 } normalize_loss_by_num_matches: true post_processing { batch_non_max_suppression { score_threshold: 1e-8 iou_threshold: 0.6 max_detections_per_class: 100 max_total_detections: 100 } score_converter: SIGMOID } } } train_config: { batch_size: 2 optimizer { rms_prop_optimizer: { learning_rate: { exponential_decay_learning_rate { initial_learning_rate: 0.004 decay_steps: 800720 decay_factor: 0.95 } } momentum_optimizer_value: 0.9 decay: 0.9 epsilon: 1.0 } } #fine_tune_checkpoint: ".\data\ssd\model.ckpt" from_detection_checkpoint: false # Note: The below line limits the training process to 200K steps, which we # empirically found to be sufficient enough to train the pets dataset. This # effectively bypasses the learning rate schedule (the learning rate will # never decay). Remove the below line to train indefinitely. #num_steps: 200000 num_steps: 100 data_augmentation_options { random_horizontal_flip { } } data_augmentation_options { ssd_random_crop { } } } train_input_reader: { tf_record_input_reader { input_path: ".\data\kame_train.record" } label_map_path: ".\data\kame_label_map.pbtxt" } eval_config: { num_examples: 20 # Note: The below line limits the evaluation process to 10 evaluations. # Remove the below line to evaluate indefinitely. max_evals: 10 } eval_input_reader: { tf_record_input_reader { input_path: ".\data\kame_val.record" } label_map_path: ".\data\kame_label_map.pbtxt" shuffle: false num_readers: 1 num_epochs: 1 }num_stepsを100にしたせいか、15分くらいで終わりました。
精度がどの程度出てるかはわからないけど、ひとまず先に進みましょう。Jupyter notebook
出来上がったモデルを試してみます。
手っ取り早く、Jupyter notebookで。
とかいいつつ使うのはじめてだし、setupからですけど。
(ただ、Kaggleでそれっぽいのは使ったことある)
で、DLしてきたmodelsの中にnotebookのソースがあったのでそれを動かしてみる。
というかmodels\research\object_detectionをプロジェクトディレクトリとしちゃった方が良さそうな気がしてきました。
出来上がったdataフォルダをコピーします。
あとtest_imagesに、テストしたい画像を置きました。cd models\research\object_detection pip install Jupyter pip install Matplotlib Jupyter notebookmatplotlibも使いそうなのでinstallしました。
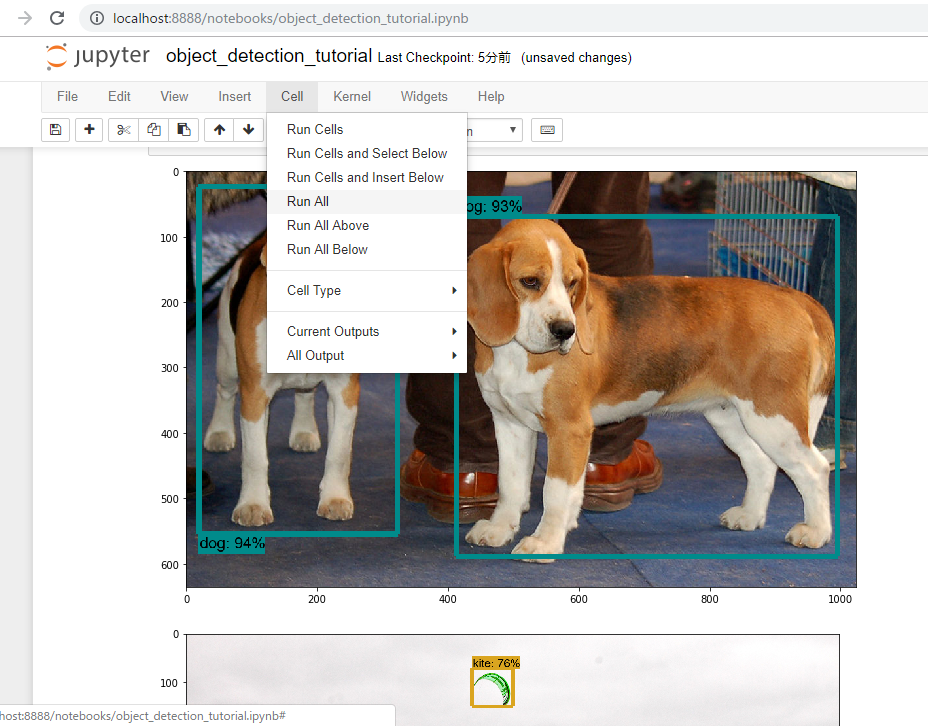
で、一回runAllしてみます。
dogだとかkiteだとかpersonだとか、ちゃんと認識してます。
次は自作の方を・・
Any model exported using the export_inference_graph.py tool can be loaded here simply by changing PATH_TO_FROZEN_GRAPH to point to a new .pb file.とあるのでexport_inference_graph.pyを実行しますpython export_inference_graph.py --input_type image_tensor --pipeline_config_path .\data\ssd_mobilenet_v1_kame.config --trained_checkpoint_prefix .\data\train\model.ckpt-100 --output_directory inference_graphそしたらinference_graph/frozen_inference_graph.pbというのができたのでnotebookを書き換えます。
# What model to download. #MODEL_NAME = 'ssd_mobilenet_v1_coco_2017_11_17' #MODEL_FILE = MODEL_NAME + '.tar.gz' #DOWNLOAD_BASE = 'http://download.tensorflow.org/models/object_detection/' # Path to frozen detection graph. This is the actual model that is used for the object detection. PATH_TO_FROZEN_GRAPH = 'inference_graph/frozen_inference_graph.pb' # List of the strings that is used to add correct label for each box. PATH_TO_LABELS = os.path.join('data', 'kame_label_map.pbtxt')Download Modelのとこは全てコメント化
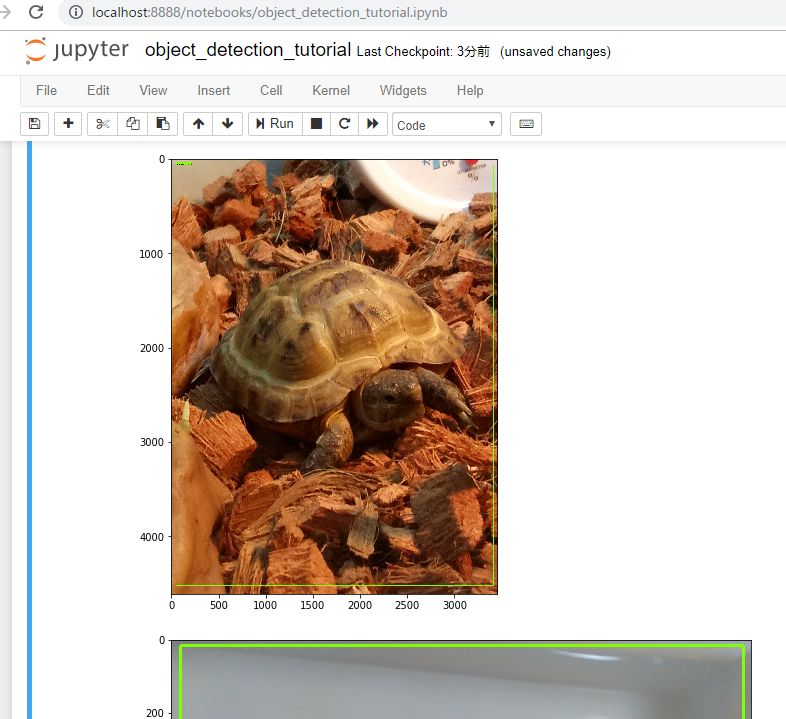
#opener = urllib.request.URLopener() #opener.retrieve(DOWNLOAD_BASE + MODEL_FILE, MODEL_FILE) #tar_file = tarfile.open(MODEL_FILE) #for file in tar_file.getmembers(): # file_name = os.path.basename(file.name) # if 'frozen_inference_graph.pb' in file_name: # tar_file.extract(file, os.getcwd())あとは3つめの画像を判別したいので
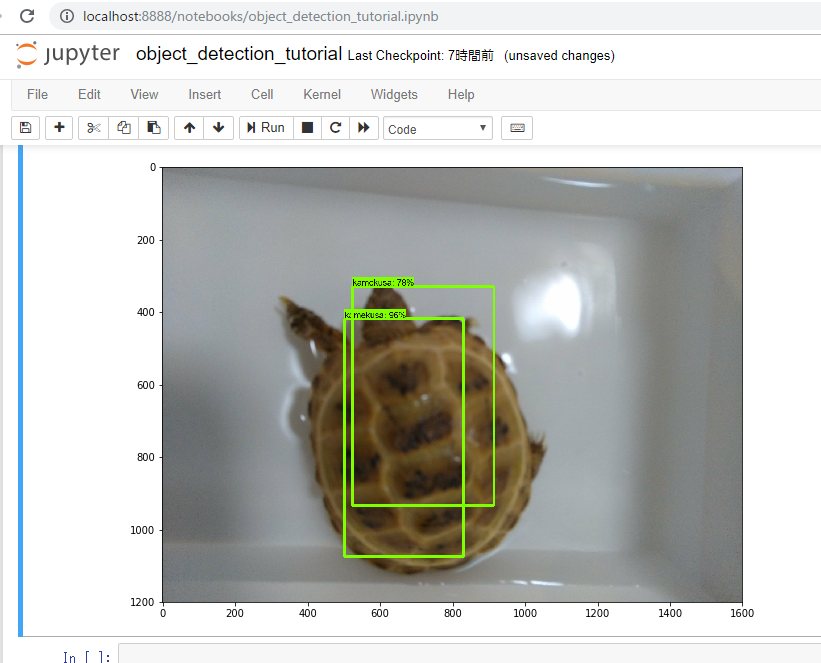
TEST_IMAGE_PATHS = [ os.path.join(PATH_TO_TEST_IMAGES_DIR, 'image{}.jpg'.format(i)) for i in range(3, 4) ]とするそしたらRun ALLいきます。
ん~・・微妙。。
学習が全然たりないのかなぁ。。
再学習
fine_tune_checkpoint、from_detection_checkpoint、num_stepsを変更します。
ssd_mobilenet_v1_kame.configfine_tune_checkpoint: ".\data\ssd\model.ckpt" from_detection_checkpoint: true num_steps: 2000これで5時間くらいか?
そんなわけでも一度。トレーニングデータの場所はちょっと変える。python -m object_detection.legacy.train --logtostderr --pipeline_config_path=.\data\ssd_mobilenet_v1_kame.config --train_dir=.\data\train.1でもまた失敗。。
labelImgの時の範囲指定が大きすぎたかなあ。
欲張らず甲羅だけ指定するようにしてみる。
そしてcreate_tf_record.py をまたやってTFRecord作成し、またトレーニング実行。
2000stepだと4時間くらいかかったし、まずはお試しで200stepから。
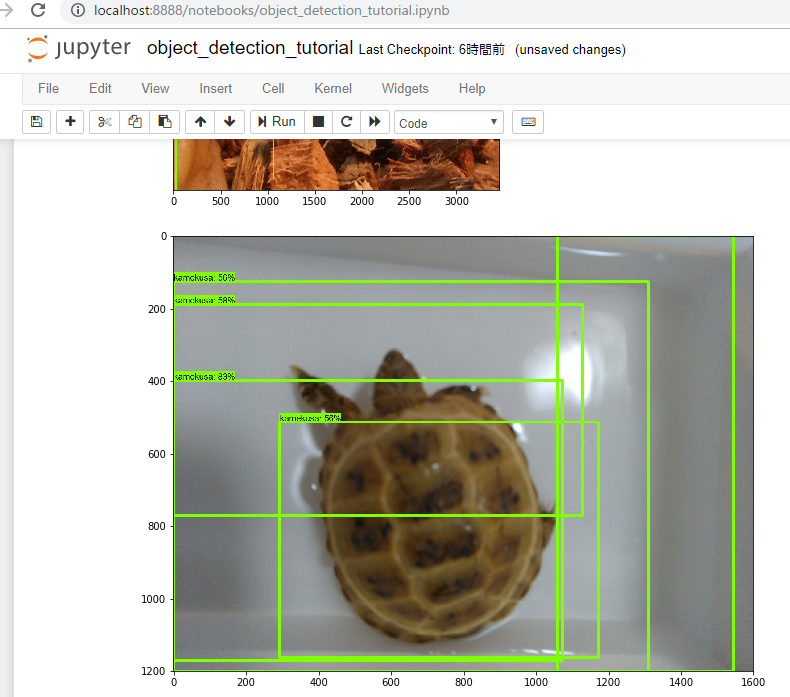
あとmatched_thresholdとunmatched_thresholdを0.5から0.7に変えました。python -m object_detection.legacy.train --logtostderr --pipeline_config_path=.\data\ssd_mobilenet_v1_kame.config --train_dir=.\data\train.2 ... INFO:tensorflow:Recording summary at step 191. INFO:tensorflow:Recording summary at step 191. INFO:tensorflow:global step 192: loss = 7.9095 (7.091 sec/step) INFO:tensorflow:global step 192: loss = 7.9095 (7.091 sec/step) INFO:tensorflow:global step 193: loss = 14.9527 (5.446 sec/step) INFO:tensorflow:global step 193: loss = 14.9527 (5.446 sec/step) INFO:tensorflow:global step 194: loss = 7.4112 (7.121 sec/step) INFO:tensorflow:global step 194: loss = 7.4112 (7.121 sec/step) INFO:tensorflow:global step 195: loss = 8.6017 (6.059 sec/step) INFO:tensorflow:global step 195: loss = 8.6017 (6.059 sec/step) INFO:tensorflow:global step 196: loss = 7.5035 (6.000 sec/step) INFO:tensorflow:global step 196: loss = 7.5035 (6.000 sec/step) INFO:tensorflow:global step 197: loss = 7.5494 (10.491 sec/step) INFO:tensorflow:global step 197: loss = 7.5494 (10.491 sec/step) INFO:tensorflow:global step 198: loss = 6.6824 (5.668 sec/step) INFO:tensorflow:global step 198: loss = 6.6824 (5.668 sec/step) INFO:tensorflow:global step 199: loss = 7.5866 (6.179 sec/step) INFO:tensorflow:global step 199: loss = 7.5866 (6.179 sec/step) INFO:tensorflow:global step 200: loss = 23.8177 (5.964 sec/step) INFO:tensorflow:global step 200: loss = 23.8177 (5.964 sec/step) INFO:tensorflow:Stopping Training. INFO:tensorflow:Stopping Training. INFO:tensorflow:Finished training! Saving model to disk. INFO:tensorflow:Finished training! Saving model to disk.んー。lossの値が大きい。2000回やった時は3ぐらいまで下がってたけど。
とりあえずJupyter notebook起動してみる。
・・が、何も認識できていない結果となりました。。
matched_threshold変えたから閾値にひっかかってるのかな。
ただ、checkpointがあるので続きからできるはず。num_stepsを800にしてもう少しトレーニングを進めます。そしてJupyter notebookを再度起動。
そして・・
またアカン。。なんかよくわからんところが認識されてる。
今度はちょっと画像を増やしてみるかー。同じ画像を加工して水増しする。これ使ってみます。
https://forest.watch.impress.co.jp/library/software/ralpha/
大きさと左右反転とアンシャープマスクかけた。アンシャープマスクは逆にシャープにする方にかけたけど。
画像が40枚になったのでまたTFRecord生成するとこから。
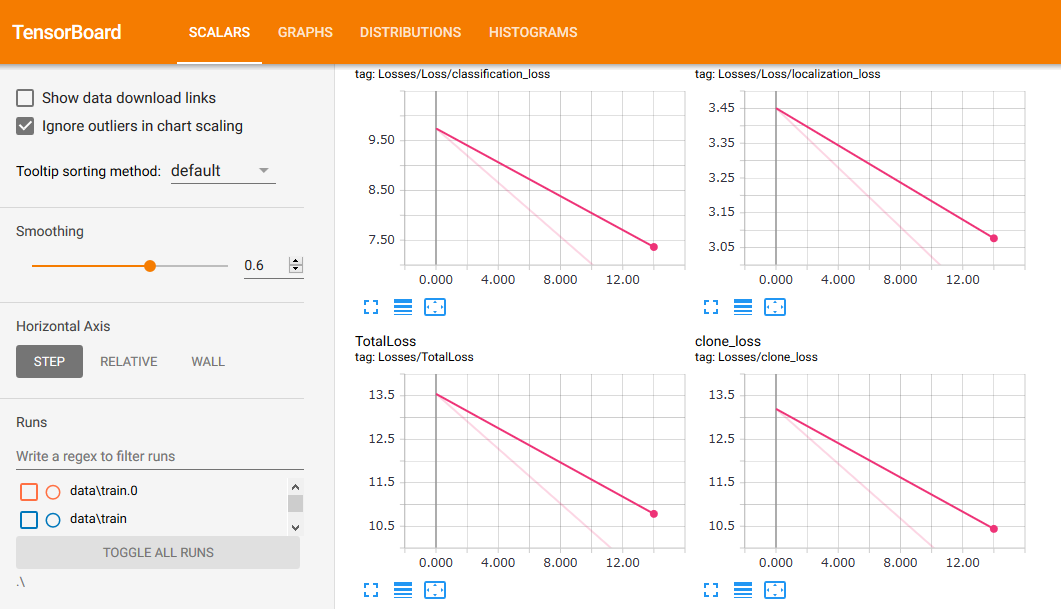
そしてstepや閾値を調整しつつ、何度かやり直す。python -m object_detection.legacy.train --logtostderr --pipeline_config_path=.\data\ssd_mobilenet_v1_kame.config --train_dir=.\data\train.3 ... INFO:tensorflow:Recording summary at step 0. INFO:tensorflow:Recording summary at step 0. INFO:tensorflow:global step 1: loss = 13.1957 (32.560 sec/step) INFO:tensorflow:global step 1: loss = 13.1957 (32.560 sec/step) INFO:tensorflow:global step 2: loss = 12.0376 (7.747 sec/step) INFO:tensorflow:global step 2: loss = 12.0376 (7.747 sec/step) INFO:tensorflow:global step 3: loss = 11.0935 (4.905 sec/step) INFO:tensorflow:global step 3: loss = 11.0935 (4.905 sec/step) INFO:tensorflow:global step 4: loss = 11.2538 (4.690 sec/step) INFO:tensorflow:global step 4: loss = 11.2538 (4.690 sec/step) INFO:tensorflow:global step 5: loss = 10.3707 (5.106 sec/step) INFO:tensorflow:global step 5: loss = 10.3707 (5.106 sec/step) INFO:tensorflow:global step 6: loss = 10.8260 (5.108 sec/step) INFO:tensorflow:global step 6: loss = 10.8260 (5.108 sec/step) INFO:tensorflow:global step 7: loss = 9.6286 (5.158 sec/step) INFO:tensorflow:global step 7: loss = 9.6286 (5.158 sec/step) INFO:tensorflow:global step 8: loss = 9.9401 (5.029 sec/step) INFO:tensorflow:global step 8: loss = 9.9401 (5.029 sec/step) INFO:tensorflow:global step 9: loss = 9.3262 (5.330 sec/step) INFO:tensorflow:global step 9: loss = 9.3262 (5.330 sec/step) INFO:tensorflow:global step 10: loss = 9.5075 (5.274 sec/step) INFO:tensorflow:global step 10: loss = 9.5075 (5.274 sec/step) INFO:tensorflow:global step 11: loss = 8.8719 (5.587 sec/step) INFO:tensorflow:global step 11: loss = 8.8719 (5.587 sec/step) INFO:tensorflow:global step 12: loss = 7.7746 (5.752 sec/step) INFO:tensorflow:global step 12: loss = 7.7746 (5.752 sec/step) ...なんかキレイに収束していって面白い。今度は期待できるか?
なおこの様子はtensorboardというのでモニターできるみたい。
tensorboard --logdir .\ --host 0.0.0.0ってresearch/object-detectionディレクトリで実行したらトレーニングの様子が可視化された。細かい設定何もいらないのか。楽だな。
学習中のPCが重いので別PCからモニタリングしてます。
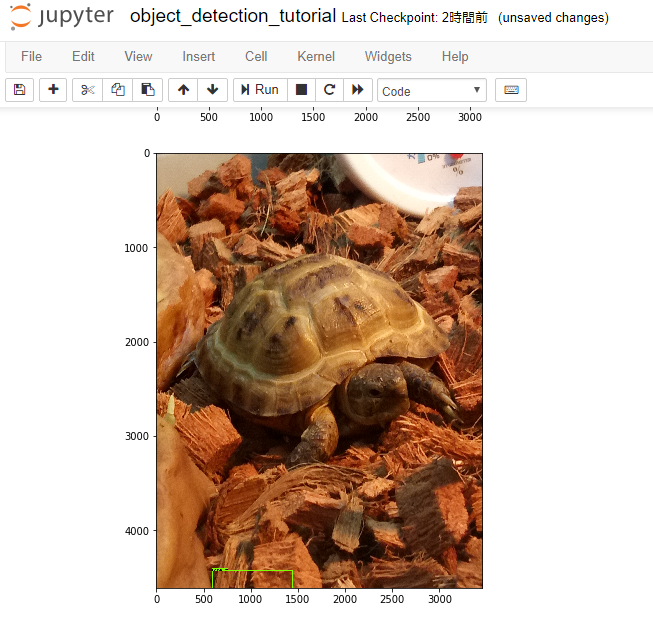
で、とりあえずの結果としては・・
とりあえずこんな所でしょうか。。
- 甲羅を中心に狭めの範囲タグ付けして
- num_stepsは200
- 画像は加工後の20枚だけ
しかし、もうちょっといろんなバリエーションで認識してくれないとツライなー。甲羅は特徴的だし、比較的捉えやすいかと思ったんだけど。
ひとまず記事としてはここまでとしますが、10000stepくらいまでトレーニング続けてどうなるかを試してみようと思います。基本、時系列で記事書いてるのでまとまりわるいですが、躓いた点とか試行錯誤してるあたりを参考にしていただければいいなと思っております。


- 投稿日:2019-02-11T21:58:57+09:00
Raspberry Pi 3 Mobel B+とカムプログラムを使ってロボット作成
はじめに
Raspberry Pi 3 Model B+をタミアのカムプログラムロボット(ガンメタ/オレンジ)に組み込んでロボットを作成しました。外観と動作はこんな感じです。
なるべく外観を崩さないようにしたかったのですが、いろいろと詰め込んでゴテゴテしてます(笑)
ComeRob動作の様子(Youtubeへ移動します)
機能一覧
現在は下記の機能があります。
- TA7291Pを使ったモータ制御を行い、前進、後退、左旋回、右旋回、ブレーキ、ストップを行う
- モータ動作モードや出力(%)と作動時間(秒)を記述したCSVファイルを読み込み、その内容で動作させる
- MPU9250による加速度、ジャイロ、地磁気の取得し、取得した加速度などに時間と動作モードと追加してCSVファイルへの保存
動作は指定された出力と秒数で、前進、後退、左旋回、右旋回を行うだけです。
Webカムはいまのところ、動作はしていません(2019/02現在)。今回はブレッドボードの配線や、GPIOの接続などの説明はしておらず、ソフトウェア関連の記述になっています。作ってソフト関連のところが一番苦労したので、こちらを先に公開しようと考えました。
これだけ見れば動作できるようには出来ないようにはならんだろうな。。と思います。
ハードウェア周りはまた別の機会に記述したいと思います。参考にした本やサイト
実装の際、下記の本やサイトを参考にしました。
■ カラー図解 最新 Raspberry Piで学ぶ電子工作(ブルーバックス刊)
こちらの本、すごく参考になりました。
はじめは記述されたとおりに、LEDをチカチカさせて遊ぶのから初めて、段々と複数のLEDを光らせたり、ランダム間隔で点滅させたりと、各記述を色々と改良して試しました。
モータドライバの制御やGPIO配線はほぼこちらの書籍の内容になっています。■Rasberry pi 3でストロベリー・リナックス社製の「MPU-9250 9軸センサモジュール (メーカー品番:MPU-9250)」を使う
Qiitaのboyaki_machineさんのページです。
加速度センサやジャイロはデータシートなどみて何とかできたのですが、地磁気センサーの制御はこのページのコードを利用しております。
はじめは地磁気センサー周りだけ移植しようかとも思ったのですが、加速度などもそのまま利用させて頂いています。RaspberryPiの設定について
RaspberryPiのOS設定などは、詳しく解説しているページが多々ありますので、そちらを参照してください。
特殊な設定はしていなく、
- piユーザのパスワード変更と自動ログインの停止
- CUIログインの設定
- sshの有効化
- GPIOの有効化
の設定を行っています。
利用OSはNOOBSです。Raspbianでも動作すると思います。
将来的にOpenCVをいれてWebカムによる画像認識と動作確認をしたいので、GUIも利用できるようフルパッケージ版にしました。今のところGUIの機能はいらないの、起動はCUIベースに変更しています。動作コード
プログラムは仕事でやったことがあるのですが、pythonはほとんど使ったことがなく、ここまでのステップ数のプログラムを書いたのは初めてなので、問題がある部分もあると思います。
その点はご了承ください。下記のコードに3つになります。
- motor_sensor.py(メインプログラム)
- mpu9250.py (MPU9250制御クラス)
- ta7291p.py (TA7291P制御クラス)
メインプログラムや各制御クラスはRaspberry Piの下記のディレクトリに配置して動作させています。
/home/pi/Documents/RaspberryPi_DIY/CamRobo/MPU9250やTA7291Pはクラスライブラリにしています。motor_sensor.pyと同じディレクトリに置いてください。
main code
motor_sensor.py#!/usr/bin/python3 # -*- coding: utf_8 -*- from time import sleep,time from datetime import datetime import sys import threading import ta7291p import mpu9250 # MPU9250 センサクラス class mpu9250_sesor(threading.Thread): def __init__(self, mode): threading.Thread.__init__(self) # mpu9250センサオブジェクト self.sensor = mpu9250.SL_MPU9250(0x68,1) # 動作モード self.mode = mode def run(self): try: # センサ初期化 self.sensor.resetRegister() self.sensor.powerWakeUp() self.sensor.setAccelRange(8,True) self.sensor.setGyroRange(1000,True) self.sensor.setMagRegister('100Hz','16bit') # 静止モード's'に設定 self.mode = 's' # センセデータ出力ファイル filename = '/home/pi/Documents/RaspberryPi_DIY/CamRobo/data/gryo_accel_{!s}.csv'.format(datetime.now().strftime("%Y%m%d%H%M%S")) with open(filename,'w') as f: f.write('tm,ax,ay,az,gx,gy,gz,mx,my,mz,md\n') while True: # 動作モードが終了以外の場合 if self.mode != 'd': now = time() acc = self.sensor.getAccel() gyr = self.sensor.getGyro() mag = self.sensor.getMag() f.write('{0:.7f},' '{1[0]:.7f},{1[1]:.7f},{1[2]:.7f},' '{2[0]:.7f},{2[1]:.7f},{2[2]:.7f},' '{3[0]:.7f},{3[1]:.7f},{3[2]:.7f},' '{4}\n' .format(now,acc,gyr,mag,self.mode)) sleep(0.1) # 動作モードが終了の場合は whileを抜ける else: break except KeyboardInterrupt: pass finally: self.sensor.finallySensor() # モータ制御オブジェクト PWMを 50Hzに指定 motor = ta7291p.TB_TA7291P(50) # 動作ファイルの指定がない場合は、move_list.csvを読み込む if len(sys.argv) < 2: file_path = './move_list.csv' else: file_path = sys.argv[1] try: # MPU9205センサスレッド生成、モードを初期化(i)で設定 acc_gyr_mag_senser = mpu9250_sesor('i') # MPU9250 センサスタート acc_gyr_mag_senser.start() # MPU9250センサの初期が終わるまでwait while acc_gyr_mag_senser.mode == 'i': sleep(0.1) # 静止モードに設定 acc_gyr_mag_senser.mode = 's' # モーター電源On motor.power_on() with open(file_path) as f: for line in f: move_data = line.rstrip('\n').split(',') # MPU9250にセンサモードを設定 acc_gyr_mag_senser.mode = move_data[0] # 動作モードごとに呼び出し先を変更 if move_data[0] == 'fw': # 前進 motor.mv_forward(float(move_data[1]), float(move_data[2])) elif move_data[0] == 'bw': # 後退 motor.mv_backword(float(move_data[1]), float(move_data[2])) elif move_data[0] == 'rt': # 右旋回 motor.mv_right_turn(float(move_data[1]), float(move_data[2])) elif move_data[0] == 'lt': # 左旋回 motor.mv_left_turn(float(move_data[1]), float(move_data[2])) elif move_data[0] == 'b': # ブレーキ motor.mv_brake(float(move_data[2])) elif move_data[0] == 's': # Stop motor.mv_stop(float(move_data[2])) # MPU9250センサを終了モートに設定 acc_gyr_mag_senser.mode = 'd' except KeyboardInterrupt: pass finally: # モーター電源off motor.power_down()mpu9250 センサ制御
MPU9250とTA7291Pの制御クラスは下記になります。
MPU9250のコードはboyaki_machineさんのコードについて次の部分を修正しています。
1. python3で動作するようにする
2. Ctrl+Cで停止させた場合なので終了処理の追加
3. 単体動作時にセンサから取得したデータを表示するprint文を変更しています。mpu9250.py#!/usr/bin/python3 -u # -*- coding: utf-8 -*- import smbus import time # Strawberry Linux社の「MPU-9250」からI2Cでデータを取得するクラス(python 2) # https://strawberry-linux.com/catalog/items?code=12250 # # 2016-05-03 Boyaki Machine # オリジナル # 2019-02-09 K-ponta # Python3 に対応。 # MPU9250 終了処理を追加。finallySensor() # class SL_MPU9250: # 定数宣言 REG_PWR_MGMT_1 = 0x6B REG_INT_PIN_CFG = 0x37 REG_GYRO_CONFIG = 0x1B REG_ACCEL_CONFIG1 = 0x1C REG_ACCEL_CONFIG2 = 0x1D MAG_MODE_POWERDOWN = 0 # 磁気センサpower down MAG_MODE_SERIAL_1 = 1 # 磁気センサ8Hz連続測定モード MAG_MODE_SERIAL_2 = 2 # 磁気センサ100Hz連続測定モード MAG_MODE_SINGLE = 3 # 磁気センサ単発測定モード MAG_MODE_EX_TRIGER = 4 # 磁気センサ外部トリガ測定モード MAG_MODE_SELF_TEST = 5 # 磁気センサセルフテストモード MAG_ACCESS = False # 磁気センサへのアクセス可否 MAG_MODE = 0 # 磁気センサモード MAG_BIT = 14 # 磁気センサが出力するbit数 offsetRoomTemp = 0 tempSensitivity = 333.87 gyroRange = 250 # 'dps' 00:250, 01:500, 10:1000, 11:2000 accelRange = 2 # 'g' 00:±2, 01:±4, 10:±8, 11:±16 magRange = 4912 # 'μT' offsetAccelX = 0.0 offsetAccelY = 0.0 offsetAccelZ = 0.0 offsetGyroX = 0.0 offsetGyroY = 0.0 offsetGyroZ = 0.0 # コンストラクタ def __init__(self, address, channel): self.address = address self.channel = channel self.bus = smbus.SMBus(self.channel) self.addrAK8963 = 0x0C # Sensor initialization self.resetRegister() self.powerWakeUp() self.gyroCoefficient = self.gyroRange / float(0x8000) # センシングされたDecimal値をdpsに変換する係数 self.accelCoefficient = self.accelRange / float(0x8000) # センシングされたDecimal値をgに変換する係数 self.magCoefficient16 = self.magRange / 32760.0 # センシングされたDecimal値をμTに変換する係数(16bit時) self.magCoefficient14 = self.magRange / 8190.0 # センシングされたDecimal値をμTに変換する係数(14bit時) # レジスタを初期設定に戻します。 def resetRegister(self): if self.MAG_ACCESS == True: self.bus.write_i2c_block_data(self.addrAK8963, 0x0B, [0x01]) self.bus.write_i2c_block_data(self.address, 0x6B, [0x80]) time.sleep(0.1) # DLPF設定 self.bus.write_i2c_block_data(self.address, 0x1A, [0x00]) self.MAG_ACCESS = False time.sleep(0.1) # レジスタをセンシング可能な状態にします。 def powerWakeUp(self): # PWR_MGMT_1をクリア self.bus.write_i2c_block_data(self.address, self.REG_PWR_MGMT_1, [0x00]) time.sleep(0.1) # I2Cで磁気センサ機能(AK8963)へアクセスできるようにする(BYPASS_EN=1) self.bus.write_i2c_block_data(self.address, self.REG_INT_PIN_CFG, [0x02]) self.MAG_ACCESS = True time.sleep(0.1) # センサの終了処理 def finallySensor(self): self.bus.write_i2c_block_data(self.address, self.REG_PWR_MGMT_1, [0x80]) time.sleep(0.1) self.bus.write_i2c_block_data(self.address, self.REG_PWR_MGMT_1, [0x40]) time.sleep(0.1) # 磁気センサのレジスタを設定する def setMagRegister(self, _mode, _bit): if self.MAG_ACCESS == False: # 磁気センサへのアクセスが有効になっていないので例外を上げる raise Exception('001 Access to a sensor is invalid.') _writeData = 0x00 # 測定モードの設定 if _mode=='8Hz': # 連続測定モード1 _writeData = 0x02 self.MAG_MODE = self.MAG_MODE_SERIAL_1 elif _mode=='100Hz': # 連続測定モード2 _writeData = 0x06 self.MAG_MODE = self.MAG_MODE_SERIAL_2 elif _mode=='POWER_DOWN': # パワーダウンモード _writeData = 0x00 self.MAG_MODE = self.MAG_MODE_POWERDOWN elif _mode=='EX_TRIGER': # 外部トリガ測定モード _writeData = 0x04 self.MAG_MODE = self.MAG_MODE_EX_TRIGER elif _mode=='SELF_TEST': # セルフテストモード _writeData = 0x08 self.MAG_MODE = self.MAG_MODE_SELF_TEST else: # _mode='SINGLE' # 単発測定モード _writeData = 0x01 self.MAG_MODE = self.MAG_MODE_SINGLE # 出力するbit数 if _bit=='14bit': # 14bit出力 _writeData = _writeData | 0x00 self.MAG_BIT = 14 else: # _bit='16bit' # 16bit 出力 _writeData = _writeData | 0x10 self.MAG_BIT = 16 self.bus.write_i2c_block_data(self.addrAK8963, 0x0A, [_writeData]) # 加速度の測定レンジを設定します。広レンジでは測定粒度が荒くなります。 # val = 16, 8, 4, 2(default) def setAccelRange(self, val, _calibration=False): # ±2g (00), ±4g (01), ±8g (10), ±16g (11) if val==16 : self.accelRange = 16 _data = 0x18 elif val==8 : self.accelRange = 8 _data = 0x10 elif val==4 : self.accelRange = 4 _data = 0x08 else: self.accelRange = 2 _data = 0x00 self.bus.write_i2c_block_data(self.address, self.REG_ACCEL_CONFIG1, [_data]) self.accelCoefficient = self.accelRange / float(0x8000) time.sleep(0.1) # オフセット値をリセット(過去のオフセット値が引き継がれないように) self.offsetAccelX = 0 self.offsetAccelY = 0 self.offsetAccelZ = 0 # 本当はCalibrationしたほうが良いと思うけれど、時間もかかるし。 if _calibration == True: self.calibAccel(1000) return # ジャイロの測定レンジを設定します。広レンジでは測定粒度が荒くなります。 # val= 2000, 1000, 500, 250(default) def setGyroRange(self, val, _calibration=False): if val==2000: self.gyroRange = 2000 _data = 0x18 elif val==1000: self.gyroRange = 1000 _data = 0x10 elif val==500: self.gyroRange = 500 _data = 0x08 else: self.gyroRange = 250 _data = 0x00 self.bus.write_i2c_block_data(self.address, self.REG_GYRO_CONFIG, [_data]) self.gyroCoefficient = self.gyroRange / float(0x8000) time.sleep(0.1) # オフセット値をリセット(過去のオフセット値が引き継がれないように) self.offsetGyroX = 0 self.offsetGyroY = 0 self.offsetGyroZ = 0 # 本当はCalibrationしたほうが良いのだが、時間もかかるし。 if _calibration == True: self.calibGyro(1000) return # 加速度センサのLowPassFilterを設定します。 # def setAccelLowPassFilter(self,val): #センサからのデータはそのまま使おうとするとunsignedとして扱われるため、signedに変換(16ビット限定) def u2s(self,unsigneddata): if unsigneddata & (0x01 << 15) : return -1 * ((unsigneddata ^ 0xffff) + 1) return unsigneddata # 加速度値を取得します def getAccel(self): data = self.bus.read_i2c_block_data(self.address, 0x3B ,6) rawX = self.accelCoefficient * self.u2s(data[0] << 8 | data[1]) + self.offsetAccelX rawY = self.accelCoefficient * self.u2s(data[2] << 8 | data[3]) + self.offsetAccelY rawZ = self.accelCoefficient * self.u2s(data[4] << 8 | data[5]) + self.offsetAccelZ return rawX, rawY, rawZ # ジャイロ値を取得します。 def getGyro(self): data = self.bus.read_i2c_block_data(self.address, 0x43 ,6) rawX = self.gyroCoefficient * self.u2s(data[0] << 8 | data[1]) + self.offsetGyroX rawY = self.gyroCoefficient * self.u2s(data[2] << 8 | data[3]) + self.offsetGyroY rawZ = self.gyroCoefficient * self.u2s(data[4] << 8 | data[5]) + self.offsetGyroZ return rawX, rawY, rawZ def getMag(self): if self.MAG_ACCESS == False: # 磁気センサが有効ではない。 raise Exception('002 Access to a sensor is invalid.') # 事前処理 if self.MAG_MODE==self.MAG_MODE_SINGLE: # 単発測定モードは測定終了と同時にPower Downになるので、もう一度モードを変更する if self.MAG_BIT==14: # 14bit出力 _writeData = 0x01 else: # 16bit 出力 _writeData = 0x11 self.bus.write_i2c_block_data(self.addrAK8963, 0x0A, [_writeData]) time.sleep(0.01) elif self.MAG_MODE==self.MAG_MODE_SERIAL_1 or self.MAG_MODE==self.MAG_MODE_SERIAL_2: status = self.bus.read_i2c_block_data(self.addrAK8963, 0x02 ,1) if (status[0] & 0x02) == 0x02: # データオーバーランがあるので再度センシング self.bus.read_i2c_block_data(self.addrAK8963, 0x09 ,1) elif self.MAG_MODE==self.MAG_MODE_EX_TRIGER: # 未実装 return elif self.MAG_MODE==self.MAG_MODE_POWERDOWN: raise Exception('003 Mag sensor power down') # ST1レジスタを確認してデータ読み出しが可能か確認する。 status = self.bus.read_i2c_block_data(self.addrAK8963, 0x02 ,1) while (status[0] & 0x01) != 0x01: # データレディ状態まで待つ time.sleep(0.01) status = self.bus.read_i2c_block_data(self.addrAK8963, 0x02 ,1) # データ読み出し data = self.bus.read_i2c_block_data(self.addrAK8963, 0x03 ,7) rawX = self.u2s(data[1] << 8 | data[0]) # 下位bitが先 rawY = self.u2s(data[3] << 8 | data[2]) # 下位bitが先 rawZ = self.u2s(data[5] << 8 | data[4]) # 下位bitが先 st2 = data[6] # オーバーフローチェック if (st2 & 0x08) == 0x08: # オーバーフローのため正しい値が得られていない raise Exception('004 Mag sensor over flow') # μTへの変換 if self.MAG_BIT==16: # 16bit出力の時 rawX = rawX * self.magCoefficient16 rawY = rawY * self.magCoefficient16 rawZ = rawZ * self.magCoefficient16 else: # 14bit出力の時 rawX = rawX * self.magCoefficient14 rawY = rawY * self.magCoefficient14 rawZ = rawZ * self.magCoefficient14 return rawX, rawY, rawZ def getTemp(self): data = self.bus.read_i2c_block_data(self.address, 0x65 ,2) raw = data[0] << 8 | data[1] return ((raw - self.offsetRoomTemp) / self.tempSensitivity) + 21 def selfTestMag(self): print ("start mag sensor self test") self.setMagRegister('SELF_TEST','16bit') self.bus.write_i2c_block_data(self.addrAK8963, 0x0C, [0x40]) time.sleep(1.0) data = self.getMag() print (data) self.bus.write_i2c_block_data(self.addrAK8963, 0x0C, [0x00]) self.setMagRegister('POWER_DOWN','16bit') time.sleep(1.0) print ("end mag sensor self test") return # 加速度センサを較正する # 本当は緯度、高度、地形なども考慮する必要があるとは思うが、簡略で。 # z軸方向に正しく重力がかかっており、重力以外の加速度が発生していない前提 def calibAccel(self, _count=1000): print ("Accel calibration start") _sum = [0,0,0] # 実データのサンプルを取る for _i in range(_count): _data = self.getAccel() _sum[0] += _data[0] _sum[1] += _data[1] _sum[2] += _data[2] # 平均値をオフセットにする self.offsetAccelX = -1.0 * _sum[0] / _count self.offsetAccelY = -1.0 * _sum[1] / _count self.offsetAccelZ = -1.0 * ((_sum[2] / _count ) - 1.0) # 重力分を差し引く # オフセット値をレジスタに登録したいけれど、動作がわからないので実装保留 print ("Accel calibration complete") return self.offsetAccelX, self.offsetAccelY, self.offsetAccelZ # ジャイロセンサを較正する # 各軸に回転が発生していない前提 def calibGyro(self, _count=1000): print ("Gyro calibration start") _sum = [0,0,0] # 実データのサンプルを取る for _i in range(_count): _data = self.getGyro() _sum[0] += _data[0] _sum[1] += _data[1] _sum[2] += _data[2] # 平均値をオフセットにする self.offsetGyroX = -1.0 * _sum[0] / _count self.offsetGyroY = -1.0 * _sum[1] / _count self.offsetGyroZ = -1.0 * _sum[2] / _count # オフセット値をレジスタに登録したいけれど、動作がわからないので実装保留 print ("Gyro calibration complete") return self.offsetGyroX, self.offsetGyroY, self.offsetGyroZ if __name__ == "__main__": sensor = SL_MPU9250(0x68,1) try: sensor.resetRegister() sensor.powerWakeUp() sensor.setAccelRange(8,True) #sensor.setAccelRange(8,False) sensor.setGyroRange(1000,True) sensor.setMagRegister('100Hz','16bit') # sensor.selfTestMag() while True: now = time.time() acc = sensor.getAccel() gyr = sensor.getGyro() mag = sensor.getMag() print ('{0[0]:.7f},{0[1]:.7f},{0[2]:.7f},' '{1[0]:.7f},{1[1]:.7f},{1[2]:.7f},' '{2[0]:.7f},{2[1]:.7f},{2[2]:.7f}'.format(acc,gyr,mag)) sleepTime = 0.1 - (time.time() - now) if sleepTime < 0.0: continue time.sleep(sleepTime) except KeyboardInterrupt: pass finally: sensor.finallySensor()TA7291P モータドライバ制御
TA7291Pの制御クラスは下記のコードになります。
Raspberry Piで学ぶ電子工作のコードを参考に、Python3化や各動作を関数化したりしています。ta7291p.py#!/usr/bin/python3 -u # -*- coding: utf_8 -*- import RPi.GPIO as GPIO from time import sleep class TB_TA7291P: # 定数宣言 GPIO_L1 = 24 # 左モーター Line1 GPIO_L2 = 25 # 左モーター Line2 GPIO_R1 = 22 # 右モーター Line1 GPIO_R2 = 23 # 右モーター Line2 MAX_POWER = 75 # PWM最大値 これ以上の値が入力されて場合はこの値に変更 # コンストラクタ def __init__(self, pwm_hz = 50): GPIO.setmode(GPIO.BCM) # Left Sied GPIO.setup(self.GPIO_L1, GPIO.OUT) GPIO.setup(self.GPIO_L2, GPIO.OUT) # Right Side GPIO.setup(self.GPIO_R1, GPIO.OUT) GPIO.setup(self.GPIO_R2, GPIO.OUT) # self.L_p0 = GPIO.PWM(self.GPIO_L1, pwm_hz) # GPIO=24、周波数50Hz self.L_p1 = GPIO.PWM(self.GPIO_L2, pwm_hz) # GPIO=25、周波数50Hz # self.R_p0 = GPIO.PWM(self.GPIO_R1, pwm_hz) # GPIO=24、周波数50Hz self.R_p1 = GPIO.PWM(self.GPIO_R2, pwm_hz) # GPIO=25、周波数50Hz # Power ON def power_on(self): self.L_p0.start(100) self.L_p1.start(100) self.R_p0.start(100) self.R_p1.start(100) # Power Down def power_down(self): ### 終了処理 self.L_p0.stop(0) self.L_p1.stop(0) self.R_p0.stop(0) self.R_p1.stop(0) GPIO.cleanup() # 前進 def mv_forward(self, power_gain, op_time): # 出力が100% を超えていた場合は 100% にする if ( power_gain > 100 ): power_gain = 100 # 左右前進 self.L_p0.ChangeDutyCycle(self.MAX_POWER * power_gain / 100) self.L_p1.ChangeDutyCycle(0) self.R_p0.ChangeDutyCycle(self.MAX_POWER * power_gain / 100) self.R_p1.ChangeDutyCycle(0) # op_time秒維持 sleep(op_time) return # 後退 def mv_backword(self, power_gain, op_time): # 出力が100% を超えていた場合は 100% にする if ( power_gain > 100 ): power_gain = 100 # 左右 back self.L_p0.ChangeDutyCycle(0) self.L_p1.ChangeDutyCycle(self.MAX_POWER * power_gain / 100) self.R_p0.ChangeDutyCycle(0) self.R_p1.ChangeDutyCycle(self.MAX_POWER * power_gain / 100) # op_time秒維持 sleep(op_time) return # 左旋回 def mv_left_turn(self, power_gain, op_time): # 出力が100% を超えていた場合は 100% にする if ( power_gain > 100 ): power_gain = 100 # 左後退、右前進 self.L_p0.ChangeDutyCycle(0) self.L_p1.ChangeDutyCycle(self.MAX_POWER * power_gain / 100) self.R_p0.ChangeDutyCycle(self.MAX_POWER * power_gain / 100) self.R_p1.ChangeDutyCycle(0) # op_time秒維持 sleep(op_time) return # 右旋回 def mv_right_turn(self, power_gain, op_time): # 出力が100% を超えていた場合は 100% にする if ( power_gain > 100 ): power_gain = 100 # 左前進、右後退 self.L_p0.ChangeDutyCycle(self.MAX_POWER * power_gain / 100) self.L_p1.ChangeDutyCycle(0) self.R_p0.ChangeDutyCycle(0) self.R_p1.ChangeDutyCycle(self.MAX_POWER * power_gain / 100) # op_time秒維持 sleep(op_time) return # Brake def mv_brake(self, op_time = 0.1): # Brake self.L_p0.ChangeDutyCycle(self.MAX_POWER) self.L_p1.ChangeDutyCycle(self.MAX_POWER) self.R_p0.ChangeDutyCycle(self.MAX_POWER) self.R_p1.ChangeDutyCycle(self.MAX_POWER) # op_time秒維持、標準は0.1秒 sleep(op_time) return # Stop def mv_stop(self, op_time = 0.1): # Stop self.L_p0.ChangeDutyCycle(0) self.L_p1.ChangeDutyCycle(0) self.R_p0.ChangeDutyCycle(0) self.R_p1.ChangeDutyCycle(0) # op_time秒維持、省略した場合は0.1秒 sleep(op_time) return if __name__ == "__main__": moter = TB_TA7291P(50) try: # 動作テスト # 電源On moter.power_on() # 前進 出力100%で2秒間 moter.mv_forward(100,2) # 停止 1秒間 moter.mv_stop(1) # 後退 出力100%で2秒間 moter.mv_backword(100,2) # 停止 1秒間 moter.mv_stop(1) # 左旋回 出力100%で3秒間 moter.mv_left_turn(100,3) # 停止 省略した場合は0.1秒間 moter.mv_stop() # 右旋回 出力100%で3秒間 moter.mv_right_turn(100,3) # 停止 省略した場合は0.1秒間 moter.mv_stop() # 前進 出力100%で2秒間 moter.mv_forward(100,2) # ブレーキ 1秒間 moter.mv_brake(1) # 後退 出力100%で2秒間 moter.mv_backword(100,2) # 停止 1秒間 moter.mv_stop(1) except KeyboardInterrupt: pass finally: # 電源Off moter.power_down()起動方法
motor_sensor.py に実行権限を与えておきます。
motor_sensor.py は、引数で動作指定CSVファイルを指定しないと、 motor_sensor.py と同じ場所の move_list.csv を読み込みに行くので、起動前に move_list.csv を次項目の「動作指定CSVファイル」の書式に作成してください。
MPU9250センサがファイルを出力するディレクトリも作成しておきます。$ chmod +x ./motor_sensor.py $ vi move_list.csv $ mkdir data $ ./motor_sensor.py任意の動作指定CSVを指定する場合は下記にように指定してください。
$ ./motor_sensor.py ./move_list_2.csv動作指定CSVファイル
motor_sensor.pyは、引数に動作ファイルを指定しないと、同じ場所に置かれた move_list.csv を読み込むようになっています。
move_list.csv の記述例は下記のとおりです。move_list.csvfw,100,3 s,,1 bw,100,3 s,,1 rt,100,5 s,,1 lt,100,5 s,,1 fw,100,3 s,,1 bw,100,3 s,,1 rt,100,5 s,,1 lt,100,5 s,,1 fw,100,3 s,,1 bw,100,3 s,,1 rt,100,5 s,,1 lt,100,5 s,,1動作指定CSVファイルは下記のような書式で記述します。
動作モード 書式 記述例 前進 fw,出力(%),動作時間(秒) fw,100,5 後退 bw,出力(%),動作時間(秒) bw,80,10 左旋回 lt,出力(%),動作時間(秒) lt,100,15 右旋回 rt,出力(%),動作時間(秒) rt,70,10 ブレーキ b,,動作時間(秒) b,,1 ストップ s,,動作時間(秒) s,,0.1 MPU9250センサの出力結果
実行が終了すると、dataディレクトリに gryo_accel_YYYYMMDDHHMISS.csv というファイル名で実行結果が出力されます。
MPU9250センサの出力結果例
gryo_accel_20190211171249.csvtm,ax,ay,az,gx,gy,gz,mx,my,mz,md 1549872769.3912337,-0.0016426,-0.0022119,0.9971360,0.1807556,-0.0335693,0.0632019,3.2986569,1.1995116,52.4786325,s 1549872769.5083649,-0.0275215,-0.0832666,0.9876145,2.8663025,2.0111084,0.6125183,4.1982906,2.3990232,50.3794872,fw 1549872769.6260414,0.0999199,-0.0019678,0.9761399,-1.5587463,5.7037354,1.0397644,3.2986569,2.9987790,50.9792430,fw 1549872769.7436359,0.0051934,-0.0881494,0.7981614,0.1807556,-3.3905029,2.3825378,2.6989011,1.4993895,51.8788767,fw ・ ・ 中略 ・ ・ 1549872781.9190757,-0.0411934,-0.0073389,0.7908372,-6.6246643,4.6661377,5.2511902,3.1487179,1.9492063,52.0288156,bw 1549872782.0366840,-0.1910957,0.0590674,1.0276536,3.8733826,-3.8177490,4.7934265,2.2490842,3.1487179,51.1291819,bw 1549872782.1542869,0.0618340,0.1633154,0.9378098,-3.2982483,3.1402588,-0.1504211,2.6989011,3.2986569,51.5789988,bw 1549872782.2611101,-0.1989082,0.0949561,0.8975266,-2.0165100,2.9571533,2.5046082,2.6989011,1.7992674,51.2791209,bw 1549872782.3787096,0.0545098,-0.1186670,1.0347336,-6.3194885,6.6802979,3.9084167,1.7992674,2.0991453,50.9792430,bw各値は下記のとおりです。
UNIX時間,X軸加速度,Y軸加速度,Z軸加速度,X角速度,Y角速度,Z角速度,X地磁気,Y地磁気,Z地磁気,動作モードこれのデータを元に機械学習して、自分がどのように動作しているのか認識できるよう出来ないかな〜、と漠然と考えています。
データにばらつきが多いので、果たしでできるかどうか分かりませんが。。おわりに
取り急ぎ、自己満足的な備忘録的な内容になっていると思います。
当初の目的が、動作中の挙動データがほしかったので、しばらくはこちらで色々と試して見たいと思います。

- 投稿日:2019-02-11T20:36:22+09:00
SentiWordNet を日本語化する
Sentiment Analysisに使えるデータセットとしてSentiWordNetというものがあります。これは、概念 (synset) ごとにポジティブ値とネガティブ値、そして例文がついています。具体的には以下のようになっています。
a 00001740 0.125 0 able#1 (usually followed by `to') having the necessary means or skill or know-how or authority to do something; "able to swim"; "she was able to program her computer"; "we were at last able to buy a car"; "able to get a grant for the project" a 00002098 0 0.75 unable#1 (usually followed by `to') not having the necessary means or skill or know-how; "unable to get to town without a car"; "unable to obtain funds"しかし日本語版が提供されていないので、今回はこれを無理やり日本語化しようと思います。
やり方は単純に日本語WordNetのDBを利用してSentiWordNetのsynsetから日本語の見出し語を取得して、例文はGoogle Apps Scriptを使って翻訳します。
コードはこちら
https://gist.github.com/ikegami-yukino/2a5ed3fd3ccde2938f020e47a8e4c9af
実行するには、SentiWordnet 3.0と日本語WordNetのDB (Japanese Wordnet and English WordNet in an sqlite3 databaseって書いてあるやつ) のダウンロードと、Google Apps ScriptのPlease_write_hereの部分を書き換えるのと、requestsのインストールが必要です。実行すると以下のような結果が得られます。
00001740-a 可能 0.125 0 泳げる,彼女は自分のコンピューターをプログラムできた,ついに車を買うことができました,プロジェクトの助成金を得ることができる 00002098-a できない 0 0.75 車なしでは町に行けない,資金を獲得できないただし例文の翻訳が下記のように微妙なことが多々あります。
古い世界をかき回した活発な議論によって触れられないそのささいな地方主義でシチュー 彼の頭は種を蒔くために行ってタンポポのようにあいまい 部屋は窒息していた - 暑くて空気のないまた、英語から日本語に訳す際にニュアンスが変わってしまう言葉があったりするので、このデータをそのままつかうのではなく、シードとして誤りを正すなり除外するなりしたほうがいいと思います。お金があれば翻訳処理の箇所を有償サービスのものに書き換えてみるのも手です。
- 投稿日:2019-02-11T20:35:31+09:00
ブーストラップ法:データに正しい意味づけをするための手法
はじめに
こんばんは。最近統計学をやってますが、如何せん時間に理解のかかる分野ですね(▽)
統計学はデータから導き出す論理なので、最近覚えたPythonと組み合わせて検証なんか面白いのではないかと思って定期的にやることにしました。ブーストラップ法についてです(^0^)ブーストラップ法について
ブートストラップ法とは簡単にいうと、標本から母集団の性質を推定するための方法です(なので母集団の統計量が未知の時によく使います)。標本集団から標本集団と同じ数だけランダムに値を再抽出し、新しいデータセットを取得し統計値を計算し、これを何回も繰り返し行います。
母集団に属する複雑なパラメータ(相関係数やオッズ比など)に対して標準誤差や信頼区間を求めたりすることが可能で、実用的な方法といえます。今回はデータから算出した相関係数について、どのくらい信頼できるのかを調べました。相関係数
相関係数はある2つのデータについて、どれだけ関連性が高いかを示す指標です。
数式はこのようになります。数式だけを見るとなかなか難しそうですが、各値の「平均との差」同士を掛け合わせて合計した共分散を各データの標準偏差で割ればも止まるので、比較的算出は楽です。ある2変数データがあるとしましょう。例えば10人の生徒が居るとします。英語・数学・理科それぞれのテストを測定した結果、それぞれの点数が出席番号一人目から数えて
英語:[60, 89, 65, 60, 73, 52, 70, 65, 65, 70]
数学:[80, 82, 60, 65, 85, 56, 57, 75, 42, 90]
理科:[90, 87, 60 ,61, 82, 53, 60, 74, 85, 35]
となったとしましょう。英語と数学、理科について、それぞれがどの程度関係性があるかをそう関係係数を用いてPythonで算出してみましょう。
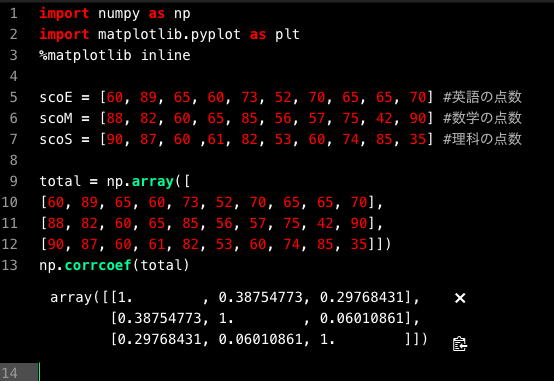
corref.pyimport numpy as np import matplotlib.pyplot as plt %matplotlib inline scoE = [60, 89, 65, 60, 73, 52, 70, 65, 65, 70] #英語の点数 scoM = [88, 82, 60, 65, 85, 56, 57, 75, 42, 90] #数学の点数 scoS = [90, 87, 60 ,61, 82, 53, 60, 74, 85, 35] #理科の点数 total = np.array([ [60, 89, 65, 60, 73, 52, 70, 65, 65, 70], [88, 82, 60, 65, 85, 56, 57, 75, 42, 90], [90, 87, 60, 61, 82, 53, 60, 74, 85, 35]]) np.corrcoef(total)Numpyのcorrcoef関数を用いると行列式で結果が帰ってきます。
簡単なコードで実装できましたb
相関係数は
英語-数学で0.3875
英語-理科で0.2977
数学-理科で0.0601
となり、英語と数学の相関が最も高いことがわかりました!(行列の対角成分は1となってますが、自分自身との相関なので自動的に1となります)本当に相関係数は正しい結論が出ているのか?
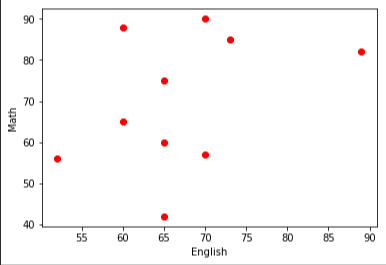
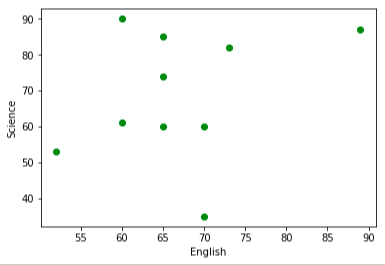
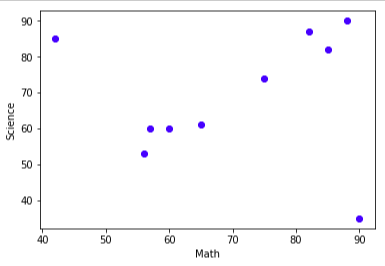
この相関の順番で本当に良いのか?ということすが、このデータに関しては実際にプロットした図をみると違和感を覚えませんかね。
bootstrup.pyimport numpy as np import matplotlib.pyplot as plt %matplotlib inline scoE = [60, 89, 65, 60, 73, 52, 70, 65, 65, 70] #英語の点数 scoM = [88, 82, 60, 65, 85, 56, 57, 75, 42, 90] #数学の点数 scoS = [90, 87, 60 ,61, 82, 53, 60, 74, 85, 35] #理科の点数 total = np.array([ [60, 89, 65, 60, 73, 52, 70, 65, 65, 70], [88, 82, 60, 65, 85, 56, 57, 75, 42, 90], [90, 87, 60, 61, 82, 53, 60, 74, 85, 35]]) np.corrcoef(total) plt.scatter(scoE, scoM,color = "red") plt.xlabel("English") plt.ylabel("Math") plt.show() plt.scatter(scoE, scoS, color = "green") plt.xlabel("English") plt.ylabel("Science") plt.show() plt.scatter(scoM, scoS, color = "blue") plt.xlabel("Math") plt.ylabel("Science") plt.show()結果:
英語ー数学
英語ー理科
数学ー理科
となります。実際プロットしてみるとなんか数学と理科が一番関係してそうじゃないですか!?ってことなんですね。。。
違和感を感じた方は、おそらく数学ー理科への直線の当てはまりがとても良さそうなことだと思います。左上、右下の問題児が値を狂わせるだけだと考えます。ブーストラップ法は特徴量の誤差を評価するためにある。
ブーストラップ法の意味は、非復元無作為抽出を何回も繰り返して標本をたくさん作ることで誤差や信頼区間を求めることができるので、
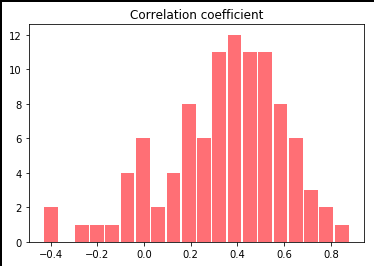
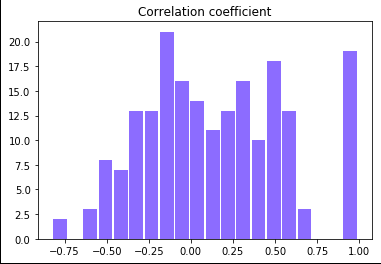
数学ー英語の相関係数rの算出を繰り返し、得られた相関係数のヒストグラムを描きます。bootstrup.pyimport numpy as np import matplotlib.pyplot as plt %matplotlib inline from numpy import random scoE = np.array([60, 89, 65, 60, 73, 52, 70, 65, 65, 70]) #英語の点数 scoM = np.array([88, 82, 60, 65, 85, 56, 57, 75, 42, 90]) #数学の点数 scoS = np.array([90, 87, 60 ,61, 82, 53, 60, 74, 85, 35]) #理科の点数 r_list = [] scoE_data = [] scoM_data = [] for i in range(0,100): for j in range(0,10): #データから10個のデータをランダムに取り出し標本を作成 var = np.random.randint(0,10) scoE_data.append(scoE[var]) scoM_data.append(scoM[var]) r = np.corrcoef(scoE_data, scoM_data) #作られた標本を元に相関係数を導出 r_list.append(r[0][1]) #相関係数を"相関係数のリスト"に代入 scoE_data.clear() #初期化 scoM_data.clear() #初期化 print(r_list) plt.hist(r_list, bins=20, rwidth = 0.9, color = "red", alpha = 0.5) plt.title("Correlation coefficient(English-Math)") plt.show()ランダムに作った標本の相関係数が100個されました。
[0.15585253823785258, 0.4305950697037106, -0.03605950604170644, 0.6895914209391649, 0.31730006314271886, 0.3571133940151882, 0.19235034767504772, 0.6604428333327486, 0.34624057748664877, 0.58739740964641, 0.3923342604650358, 0.34982802529568724, 0.37654394258141777, 0.6823344142547625, 0.26931232680365996, 0.3945405713525839, 0.5473013360492976, 0.3972558346301867, -0.014104654480949838, 0.5976257570137701, 0.5372925887633204, 0.28752828548647047, 0.5283345806099249, 0.5940113092694755, 0.7879208402738033, 0.6494747564288043, 0.13714668859593104, -0.07916220211899541, 0.4323235027266908, 0.2981580800528894, -0.036130190979291356, 0.38462886076620495, -0.08602450166292225, 0.1605332861541743, 0.26495611732346275, 0.007258756085075637, 0.4850878590607039, 0.5271967063712417, 0.0560651964634963, 0.5370778152226662, 0.6631130755480596, 0.5518047537543804, -0.4138715864761385, 0.17880183606547947, 0.44587872593154515, 0.8786518859359814, 0.44663361008233027, -0.09199113478155758, 0.44206830104754385, 0.17317850286085323, 0.3527569359486347, 0.02903453532831167, 0.30324100615147653, 0.4659062252828043, 0.36579811733823675, 0.6172409065635549, -0.4304239561846442, 0.4674885654245649, 0.0026228406936778105, -0.16976162750429294, 0.4964958991584344, -0.02845184525323593, 0.2192234013728081, 0.43728466018406714, 0.39454114048797484, 0.5467962835249239, 0.3236567706128534, 0.4905233568089641, 0.25853628119575633, 0.795733061984808, -0.2750759839004001, 0.23758912621891137, 0.5917957647188727, 0.4048812700603928, 0.29588321456141475, 0.5051473660742645, 0.4371408890294217, 0.5345353329276067, 0.31393863261724697, 0.1396781204218693, 0.28503328929367666, 0.16255482611670974, 0.5529714214125769, 0.5610424848640276, 0.2204529677799291, 0.3224797592194247, 0.6352813771554283, 0.3976137186707352, 0.578025141200671, 0.7141681567115036, 0.37172280357440474, 0.15806257086130274, 0.40112964046440924, 0.3112260142848983, 0.5069334332226477, 0.6549800690567563, -0.07955443225108468, -0.12012013025444407, 0.1825061363337386, 0.47319527315037974]これだけではわけわからないのでヒストグラムで表しました(^▽^)
平均が0.4の近くに寄っていますね。先ほど導出した相関係数が0.38だったので
理論値を中心とした正規分布に近い形になっていますね。次に先ほど違和感のあった数学ー理解の導出です。(サンプルコードはほぼ同じなので省略しました)
こちらは正規分布っぽい形ではありますが、裾が広がっていることがわかりますね。
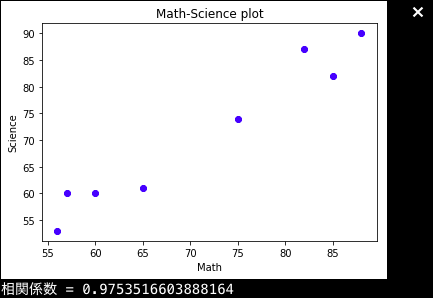
そして、分散も大きいので、信頼区間も狭いことがわかります。ちなみにですが、先ほどの数学ー理科の問題児を度外視したグラフはこのようになり、
plot2.pyimport numpy as np import matplotlib.pyplot as plt %matplotlib inline scoM = [88, 82, 60, 65, 85, 56, 57, 75] #数学の点数 scoS = [90, 87, 60 ,61, 82, 53, 60, 74] #理科の点数 plt.scatter(scoM, scoS, color = "blue") plt.xlabel("Math") plt.ylabel("Science") plt.title("Math-Science plot") plt.show()相関係数は非常に高く、
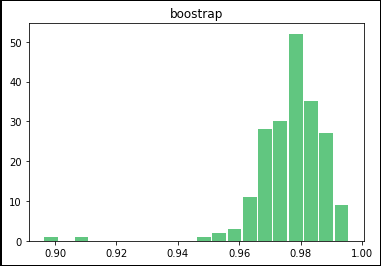
ブーストラップ法による測定値をヒストグラムに直すと、非常に分散の小さい正規分布になります。
まとめ
ブーストラップ法は、複雑なパラメーターの誤差や信頼区間を求めるためにあるそうです。そして、同じ相関係数を示場合でも、標本の分布によって標準誤差などは違ってくるようです。他にも実用的な測定法があれば載せていく予定なので見ていただければと思いますm(_ _)m
- 投稿日:2019-02-11T20:35:31+09:00
ブーストラップ法:統計量を導き出すための手法
はじめに
こんばんは。最近統計学をやってますが、如何せん理解に時間のかかる分野ですね。。
統計学はデータから導き出す論理なので、最近覚えたPythonと組み合わせて検証なんか面白いのではないかと思って定期的にやることにしました。ブーストラップ法についてです(^0^)ブーストラップ法について
ブートストラップ法とは簡単にいうと、標本から母集団の性質を推定するための方法です(なので母集団の統計量が未知の時によく使います)。標本集団から標本集団と同じ数だけランダムに値を再抽出し、新しいデータセットを取得し統計値を計算し、これを何回も繰り返し行います。
母集団に属する複雑なパラメータ(相関係数やオッズ比など)に対して標準誤差や信頼区間を求めたりすることが可能で、実用的な方法といえます。今回はデータから算出した相関係数について、どのくらい信頼できるのかを調べました。相関係数
相関係数はある2つのデータについて、どれだけ関連性が高いかを示す指標です。
数式だけを見るとなかなか難しそうですが、各値の「平均との差」同士を掛け合わせて合計した共分散を各データの標準偏差で割ればも止まるので、比較的算出は楽です。
ある2変数データがあるとしましょう。例えば10人の生徒が居るとします。英語・数学・理科それぞれのテストを測定した結果、それぞれの点数が出席番号一人目から数えて
英語:[60, 89, 65, 60, 73, 52, 70, 65, 65, 70]
数学:[80, 82, 60, 65, 85, 56, 57, 75, 42, 90]
理科:[90, 87, 60 ,61, 82, 53, 60, 74, 85, 35]
となったとしましょう。英語と数学、理科について、それぞれがどの程度関係性があるかをそう関係係数を用いてPythonで算出してみましょう。
corref.pyimport numpy as np import matplotlib.pyplot as plt %matplotlib inline scoE = [60, 89, 65, 60, 73, 52, 70, 65, 65, 70] #英語の点数 scoM = [88, 82, 60, 65, 85, 56, 57, 75, 42, 90] #数学の点数 scoS = [90, 87, 60 ,61, 82, 53, 60, 74, 85, 35] #理科の点数 total = np.array([ [60, 89, 65, 60, 73, 52, 70, 65, 65, 70], [88, 82, 60, 65, 85, 56, 57, 75, 42, 90], [90, 87, 60, 61, 82, 53, 60, 74, 85, 35]]) np.corrcoef(total)Numpyのcorrcoef関数を用いると行列式で結果が帰ってきます。
簡単なコードで実装できましたb
相関係数は
英語-数学で0.3875
英語-理科で0.2977
数学-理科で0.0601
となり、英語と数学の相関が最も高いことがわかりました!(行列の対角成分は1となってますが、自分自身との相関なので自動的に1となります)本当に相関係数は正しい結論が出ているのか?
この相関の順番で本当に良いのか?ということすが、このデータに関しては実際にプロットした図をみると違和感を覚えませんかね。
bootstrup.pyimport numpy as np import matplotlib.pyplot as plt %matplotlib inline scoE = [60, 89, 65, 60, 73, 52, 70, 65, 65, 70] #英語の点数 scoM = [88, 82, 60, 65, 85, 56, 57, 75, 42, 90] #数学の点数 scoS = [90, 87, 60 ,61, 82, 53, 60, 74, 85, 35] #理科の点数 total = np.array([ [60, 89, 65, 60, 73, 52, 70, 65, 65, 70], [88, 82, 60, 65, 85, 56, 57, 75, 42, 90], [90, 87, 60, 61, 82, 53, 60, 74, 85, 35]]) np.corrcoef(total) plt.scatter(scoE, scoM,color = "red") plt.xlabel("English") plt.ylabel("Math") plt.show() plt.scatter(scoE, scoS, color = "green") plt.xlabel("English") plt.ylabel("Science") plt.show() plt.scatter(scoM, scoS, color = "blue") plt.xlabel("Math") plt.ylabel("Science") plt.show()結果:
英語ー数学
英語ー理科
数学ー理科
となります。実際プロットしてみるとなんか数学と理科が一番関係してそうじゃないですか!?ってことなんですね。。。
違和感を感じた方は、おそらく数学ー理科への直線の当てはまりがとても良さそうなことだと思います。左上、右下の問題児が値を狂わせるだけだと考えます。ブーストラップ法は特徴量の誤差を評価するためにある。
ブーストラップ法の意味は、非復元無作為抽出を何回も繰り返して標本をたくさん作ることで誤差や信頼区間を求めることができたり、ヒストグラムに直すと信頼度が視覚的にわかるようになります。
```python:bootstrap.py
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
from numpy import randomscoE = np.array([60, 89, 65, 60, 73, 52, 70, 65, 65, 70]) #英語の点数
scoM = np.array([88, 82, 60, 65, 85, 56, 57, 75, 42, 90]) #数学の点数
scoS = np.array([90, 87, 60 ,61, 82, 53, 60, 74, 85, 35]) #理科の点数r_list = []
scoE_data = []
scoM_data = []for i in range(0,100):
for j in range(0,10): #データから10個のデータをランダムに取り出し標本を作成
var = np.random.randint(0,10)
scoE_data.append(scoE[var])
scoM_data.append(scoM[var])r = np.corrcoef(scoE_data, scoM_data) #作られた標本を元に相関係数を導出 r_list.append(r[0][1]) #相関係数を"相関係数のリスト"に代入 scoE_data.clear() #初期化 scoM_data.clear() #初期化print(r_list)
plt.hist(r_list, bins=20, rwidth = 0.9, color = "red", alpha = 0.5)
plt.title("Correlation coefficient(English-Math)")
plt.show()
```
ランダムに作った標本の相関係数が100個されました。
[0.15585253823785258, 0.4305950697037106, -0.03605950604170644, 0.6895914209391649, 0.31730006314271886, 0.3571133940151882, 0.19235034767504772, 0.6604428333327486, 0.34624057748664877, 0.58739740964641, 0.3923342604650358, 0.34982802529568724, 0.37654394258141777, 0.6823344142547625, 0.26931232680365996, 0.3945405713525839, 0.5473013360492976, 0.3972558346301867, -0.014104654480949838, 0.5976257570137701, 0.5372925887633204, 0.28752828548647047, 0.5283345806099249, 0.5940113092694755, 0.7879208402738033, 0.6494747564288043, 0.13714668859593104, -0.07916220211899541, 0.4323235027266908, 0.2981580800528894, -0.036130190979291356, 0.38462886076620495, -0.08602450166292225, 0.1605332861541743, 0.26495611732346275, 0.007258756085075637, 0.4850878590607039, 0.5271967063712417, 0.0560651964634963, 0.5370778152226662, 0.6631130755480596, 0.5518047537543804, -0.4138715864761385, 0.17880183606547947, 0.44587872593154515, 0.8786518859359814, 0.44663361008233027, -0.09199113478155758, 0.44206830104754385, 0.17317850286085323, 0.3527569359486347, 0.02903453532831167, 0.30324100615147653, 0.4659062252828043, 0.36579811733823675, 0.6172409065635549, -0.4304239561846442, 0.4674885654245649, 0.0026228406936778105, -0.16976162750429294, 0.4964958991584344, -0.02845184525323593, 0.2192234013728081, 0.43728466018406714, 0.39454114048797484, 0.5467962835249239, 0.3236567706128534, 0.4905233568089641, 0.25853628119575633, 0.795733061984808, -0.2750759839004001, 0.23758912621891137, 0.5917957647188727, 0.4048812700603928, 0.29588321456141475, 0.5051473660742645, 0.4371408890294217, 0.5345353329276067, 0.31393863261724697, 0.1396781204218693, 0.28503328929367666, 0.16255482611670974, 0.5529714214125769, 0.5610424848640276, 0.2204529677799291, 0.3224797592194247, 0.6352813771554283, 0.3976137186707352, 0.578025141200671, 0.7141681567115036, 0.37172280357440474, 0.15806257086130274, 0.40112964046440924, 0.3112260142848983, 0.5069334332226477, 0.6549800690567563, -0.07955443225108468, -0.12012013025444407, 0.1825061363337386, 0.47319527315037974]これだけではわけわからないのでヒストグラムで表しました(^▽^)
平均が0.4の近くに寄っていますね。先ほど導出した相関係数が0.38だったので
理論値を中心とした正規分布に近い形になっていますね。次に先ほど違和感のあった数学ー理解の導出です。(サンプルコードはほぼ同じなので省略しました)
こちらは正規分布っぽい形ではありますが、裾が広がっていることがわかりますね。
そして、分散も大きいので、信頼区間も狭いことがわかります。ちなみにですが、先ほどの数学ー理科の問題児を度外視したグラフはこのようになり、
plot2.pyimport numpy as np import matplotlib.pyplot as plt %matplotlib inline scoM = [88, 82, 60, 65, 85, 56, 57, 75] #数学の点数 scoS = [90, 87, 60 ,61, 82, 53, 60, 74] #理科の点数 plt.scatter(scoM, scoS, color = "blue") plt.xlabel("Math") plt.ylabel("Science") plt.title("Math-Science plot") plt.show()相関係数は非常に高く、
ブーストラップ法による測定値をヒストグラムに直すと、非常に分散の小さい正規分布になります。
まとめ
ブーストラップ法は、複雑なパラメーターの誤差や信頼区間を求めるためにあるそうです。そして、同じ相関係数を示場合でも、標本の分布によって標準誤差などは違ってくるようです。他にも実用的な測定法があれば載せていく予定なので見ていただければと思いますm(_ _)m

- 投稿日:2019-02-11T20:26:30+09:00
Python機械学習プログラミング レポート
「Python機械学習プログラミング」Sebastian Raschka/Vahid Mirjalili著 株式会社インプレス
を読んだので、備忘録としてまとめておく。・Python機械学習プログラミング パーセプトロンの学習アルゴリズム
・Python機械学習プログラミング ADALINE
・Python機械学習プログラミング ADALINE 改良版
・Python機械学習プログラミング SBS
・Python機械学習プログラミング カーネル主成分分析
・Python機械学習プログラミング 単純な多数決分類器
- 投稿日:2019-02-11T20:22:24+09:00
Pythonで学ぶアルゴリズム(二分探索とデータ構造)
はじめに
本記事は、Pythonによるアルゴリズム(二分探索とデータ構造)の検証結果のまとめです。
仮説
二分探索をPyhtonで記述する場合、合わせてデータ構造を考慮すると、Pythonでもリストより配列の方が早いと考えました。配列の場合、連続的にメモリのアドレスを確保し、ランダムアクセスやすべての要素を瞬時に調べることができるためです。対して、リストだと10番目の要素を読み取りたい場合は、9番目の要素を読み取って10番目の要素をたどる必要があるなど、総合的に配列の方が早いと思いました。
検証
1億個の要素から、目的の要素を見つけるのにかかる計算時間を計測します。
まずは、学習がてら単純探索より、二分探索が早いことを確認します。
次に、二分探索でリストと配列の場合での計算時間を計測します。環境:MacBook Air
プロセッサ名:Intel Core i5
プロセッサ速度:1.6 GHz
メモリ:4 GB単純探索
まずは、試しに以下のプログラムを実行し、単純探索でかかる計算時間を見てみます。
- simple_search.py
my_list = [] for i in range(100000000): my_list.append(i) def simple_search(list, item): for i in list: guess = i if guess == item: return guess print(simple_search(my_list, 77777777))timeコマンドでsimple_search.pyを実行したところ、約3分ほどかかりました。
$ time python3 simple_search.py 77777777 real 2m56.905s user 0m59.758s sys 0m53.585s二分探索
binary_search関数は、ソート済みの配列とアイテムを1つずつ受け取ります。そのアイテムが配列に含まれている場合、その位置(インデックス)の値を返します。
二分探索の検証では、binary_search.pyとbinary_search2.pyのプログラムを使用します。
binary_search関数の動きは同じですが、データを用意する方法をそれぞれ変えました。binary_search.pyは、forでデータを取り出し、リストに追加して用意します。
binary_search2.pyは、リスト内包表記でデータを取り出し、Numpyの一次元配列に格納して用意します。
- binary_search.py
my_list = [] for i in range(100000000): my_list.append(i) def binary_search(list, item): low = 0 high = len(list) - 1 while low <= high: mid = (low + high) //2 guess = list[mid] if guess == item: return mid if guess > item: high = mid -1 else: low = mid + 1 return None print (binary_search(my_list, 77777777))timeコマンドでsimple_search.pyを実行したところ、約1分半ほどかかりました。
想定通りですが、二分探索の方が単純探索より早いです。$ time python3 binary_search.py 77777777 real 1m34.540s user 0m43.687s sys 0m38.348s
- binary_search2.py
import numpy as np my_list = np.array([i for i in range(100000000)]) def binary_search(list, item): low = 0 high = len(list) - 1 while low <= high: mid = (low + high) //2 guess = list[mid] if guess == item: return mid if guess > item: high = mid -1 else: low = mid + 1 return None print (binary_search(my_list, 77777777))データをリスト内包表記にして、Numpyに置き換えて実行すれば、リストより早いと考えていましたが、1回目はリストの方に軍配が上がりました。
77777777 real 1m57.078s user 0m41.351s sys 0m43.036s検証結果
検証の精度を上げるため、それぞれ、3回ずつ実行した結果が以下になります。
二分探索(リスト) 二分探索(配列) 1回目:1m34.540s 1回目:1m57.078s 2回目:1m56.788s 2回目:1m24.709s 3回目:1m33.924s 3回目:1m28.110s 平均:1m41.751s 平均:1m36.632s 上記より、3回ずつ実行した結果の平均では、仮説の通りに二分探索(リスト)より、二分探索(配列)の早い(※)ことが確認できました。
(※)但し、1回目のタイムのように、キャッシュしていない状態だと、二分探索(リスト)の方が早い場合があります。
キャッシュメモリ
それぞれ、2回目以降のタイムが1回目より早くなっているのは、キャッシュするためです。
Intelプロセッサではキャッシュメモリが3段になっており、CPUがメモリアクセスを行うときに、まずはキャッシュメモリを見に行き、キャッシュメモリにない場合はメインメモリからデータをキャッシュメモリにコピーして使います。また、メインメモリにもキャッシュがあるので、同様の動きをします。
一般的には、キャッシュメモリへデータをコピーする場合は、ブロック呼ばれる単位で、まとめてコピーします。L1キャッシュの場合は64バイト単位でコピーされます。よって、配列のアクセスを行う場合は、連絡的にアクセスすると効率的です。
参考:今回のプログラムは単純ですが、コンテナや1GBのラズパイで試したところ、OOM Killerが発生しました。Numpyでメモリ消費を抑える場合は、dtype=np.float32を使用するといいかもしれません。
おわりに
プログラミングを学ぶことができるWebサービスはたくさんありますが、アルゴリズムについて教えてくれているサイトはあまりないような気がします。
プログラミング言語は、あくまでサービスを実現する手段なので、本質的なところを突き詰めるのもおもしろいです。次は、システムコールの呼びだしからメモリがどのように確保されるかなど、もっと掘り下げて検証したいと思います。
- 投稿日:2019-02-11T19:27:07+09:00
[Python]とにかくわかりやすく!Djangoでアプリ開発!ーその4ー
前回の記事
前回の記事→とにかくわかりやすく!Djangoでアプリ開発!ーその3ー
※前回までの記事、おかげさまでユーザーランキング7位までいきました。ありがとうございます。
本記事の目的
python初心者の方が、本記事を見たあとに、一人でアプリ開発できることを目的にしております。
※インストールや開発環境については記載しません環境
macOSX Sierra
python3.7
django 2.1.5前回まで
プロジェクトを立ち上げ(startproject)
→アプリの作成(startapp)
→view.pyを変更してレスポンスを書く
→urls.pyを修正する
→アプリの登録する
→index.html作る
→views.pyを直す
→htmlに変数入れる
→views.pyを直す
→複数ページ作るためにリンクつける
→views.pyを直す
→cssで装飾できるようにする
→htmlでフォームを作る
→views.pyを直す
→urls.pyを修正する
→やっぱりformクラスでフォームを作る
→views.pyを直す
→index.html直すとここまででした。
ここからはDBとの連携を記載していきます。
DBについて
Djangoで使えるSQLは以下になっています。
- MySQL:サーバータイプなのでwebサーバーとDBサーバーの間で通信を行います。
- PostgresQL:サーバータイプなのでwebサーバーとDBサーバーの間で通信を行います。
- SQLite:エンジンタイプなのでDBに直接アクセスを行います。
がDjangoにはすでにSQLiteが組み込まれています。そのファイルもすでにdb.sqliteとして用意されていますね。
DBの設定を見てみる
設定に関することなので、myapp/settings.pyを見てみます。
デフォルトで設定されている項目が2つあります。
DBへのアクセスに使われるENGINEとDBそのものの名前を表すNAMEです。
os.path.joinはディレクトリパスを繋げているだけなので難しくないですね。DATABASES = { 'default': { 'ENGINE': 'django.db.backends.sqlite3', 'NAME': os.path.join(BASE_DIR, 'db.sqlite3'), } }僕はPostgreSQLを使うことが多いので以下の設定にすることもあります。
settings.pyDATABASES = { 'default': { 'ENGINE': 'django.db.backends.postgresql', 'NAME': postgres, 'USER': ユーザー名, 'PASSWORD': パスワード, 'HOST': ホスト名, 'PORT': '5432', } }テーブルを作る
ユーザー情報を管理できるようにテーブルを作成してみたいと思います。
テーブル定義に関しては割愛しますが、以前投稿したこちらのDB構築の記事を参考にしてください。でここからが大事になってきます。
テーブル定義をした後にSQLでcreate文でテーブルを作る必要はなく、models.pyで定義をしておけば、自動で生成をしてくれます。便利ですね。
モデルでclassを作り、それのインスタンスをテーブルのレコードとして利用することができます。ということでmodels.pyを書き換えていきます。
今回はユーザー情報テーブルを作っていきます。冒頭にあるmodelsというクラスを継承して作成できるので簡単です。
__str__を用意して、内容をreturnで返せるようにしています。あとあとindex.htmlで{{}}で埋め込めます。models.pyfrom django.db import models class Touroku(models.Model): name = models.CharField(max_length=30) gender = models.BooleanField() age = models.IntegerField(default = 0) def __str__(self): return '<ID:'+str(self.id)+'> 名前:'+self.name+' ('+str(self.age)+'歳)'ここまでできたら、DBの立ち上げやアップデートに行うための「マイグレーション」を行います。
やることは2つだけ。「作成」と「適用」だけです。簡単です。
ターミナルで以下を打ち込みます。ディレクトリはmanage.pyがあるところです。$ python manage.py makemigrations #作成$ python manage.py migrate #適用 Operations to perform: Apply all migrations: admin, auth, contenttypes, sessions Running migrations: Applying contenttypes.0001_initial... OK Applying auth.0001_initial... OK Applying admin.0001_initial... OK Applying admin.0002_logentry_remove_auto_add... OK Applying admin.0003_logentry_add_action_flag_choices... OK Applying contenttypes.0002_remove_content_type_name... OK Applying auth.0002_alter_permission_name_max_length... OK Applying auth.0003_alter_user_email_max_length... OK Applying auth.0004_alter_user_username_opts... OK Applying auth.0005_alter_user_last_login_null... OK Applying auth.0006_require_contenttypes_0002... OK Applying auth.0007_alter_validators_add_error_messages... OK Applying auth.0008_alter_user_username_max_length... OK Applying auth.0009_alter_user_last_name_max_length Applying sessions.0001_initial... OKエラーがでなければOKです!一度管理ツールを使ってDBを確認しておきます。
ということで管理者を作成しておきます。
*パスワードが雑すぎて警告でてますが無視します。$ python manage.py createsuperuser ユーザー名 (leave blank to use 'hiropy'): hiroyuki メールアドレス: hogehoge@gmail.com Password: Password (again): このパスワードは メールアドレス と似すぎています。 このパスワードは短すぎます。最低 8 文字以上必要です。 Bypass password validation and create user anyway? [y/N]: y Superuser created successfully.次は管理ツールで先ほど作ったクラス(モデル)を使えるようにします。
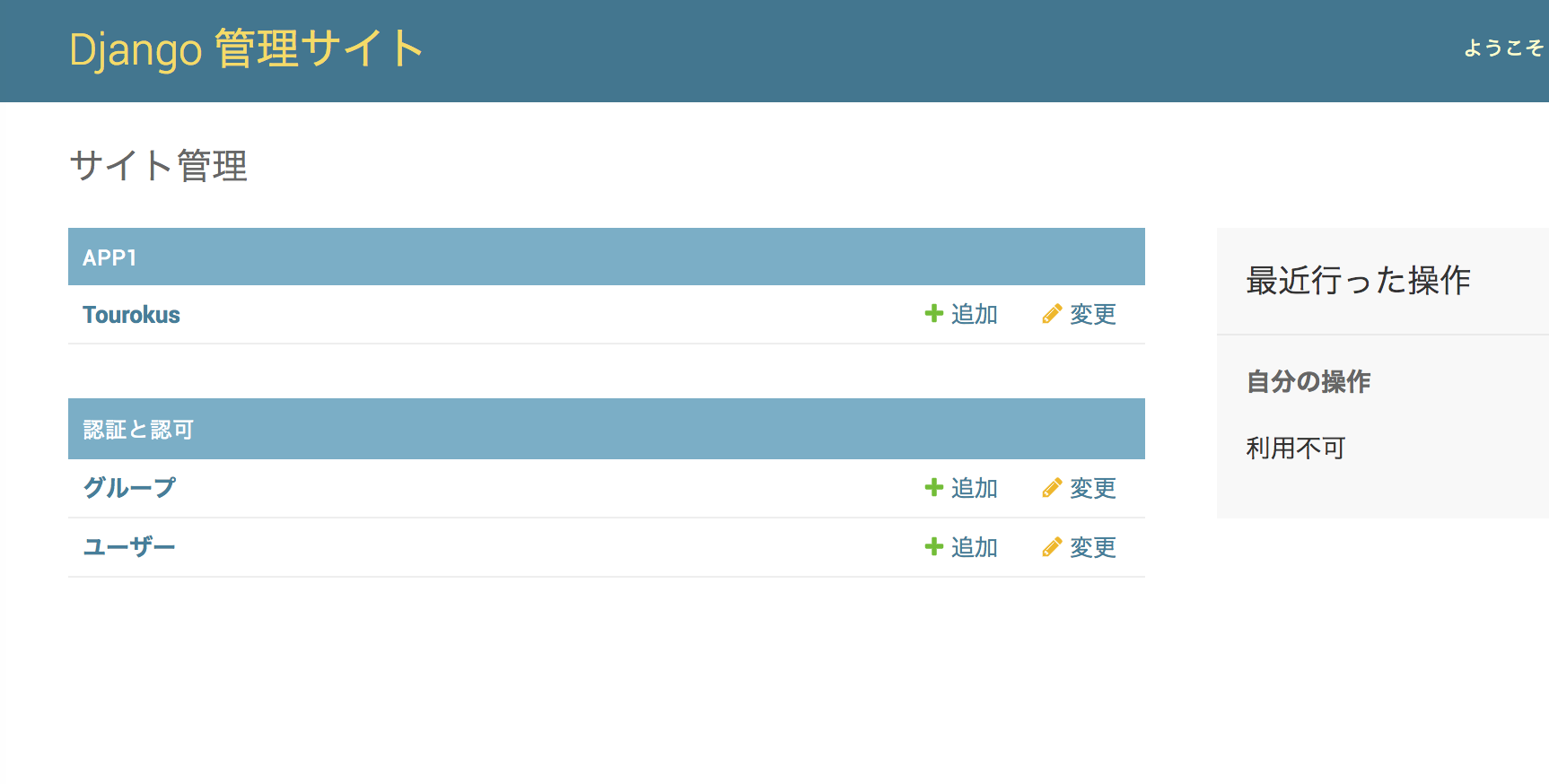
admin.pyの中身を書き換えます。クラスを呼び出して、さらにadminのregisterメソッドを使ってクラスを登録します。from django.contrib import admin from .models import Touroku admin.site.register(Touroku)ここまできたらブラウザで127.0.0.8000/adminにアクセスします。毎度ですがrunserverしておいてください。
以下のような認証画面がでてきます。
認証して、自身で定義したモデルが入っていればOKです!
あとは適当な名前で登録を行います。テストなのでなんでも。
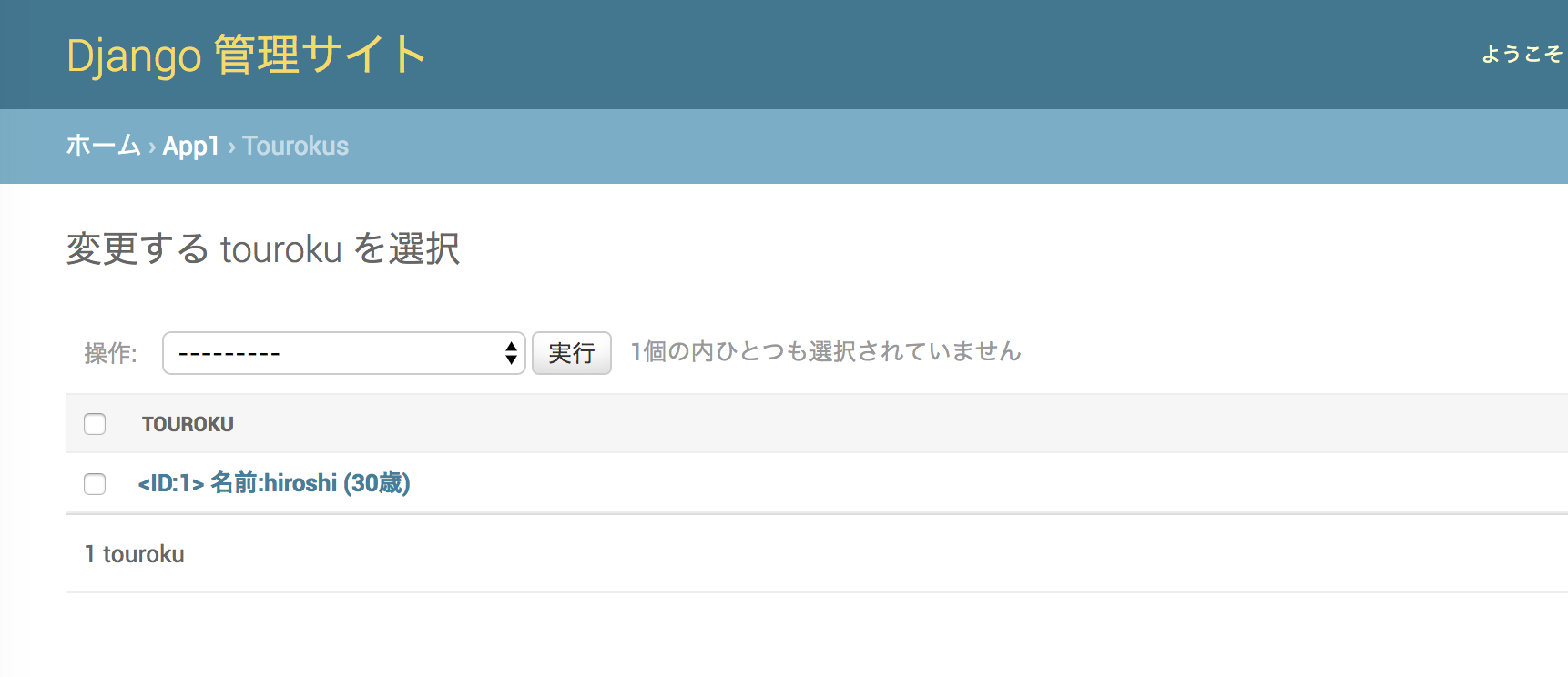
ここで疑問に思った人がいるかと思います。「ID」っていつ振ったんだろうと。定義しなかったものです。
ここでマイグレーションによって実は生成されてた、app1/migration配下の0001_initial.pyをみてみます。
Migrationというものが作られていて、operationsという変数の中に、テーブルを作るための定義が記述されています。この中のidの部分をみてみるとAutoField(auto_created=Trueと記載されていることから、自動で割り振られていることがわかります。from django.db import migrations, models class Migration(migrations.Migration): initial = True dependencies = [ ] operations = [ migrations.CreateModel( name='Touroku', fields=[ ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')), ('name', models.CharField(max_length=30)), ('gender', models.BooleanField()), ('age', models.IntegerField(default=0)), ], ), ]と少し話はそれましたが、ユーザーなどの追加に関してもこの管理ツールを使えば簡単に行うことができます。
この後のアプリ本体からDBにアクセスし、情報を表示させることに関しては少し長くなるので、次回の記事に記載していきます。
この記事はここまで
次回、続きを投稿していきます。

- 投稿日:2019-02-11T18:45:06+09:00
[2019年]raspberry pi初期設定(pipenv導入まで)
0.確認事項
ログインpassword, ネットワーク設定は初回起動時に設定済みとします。
使用機器は以下の通りです。・Windows10 Home
・Raspberry Pi 3 Model B+ (2018)$ llsb_release -a No LSB modules are available. Distributor ID: Raspbian Description: Raspbian GNU/Linux 9.6 (stretch) Release: 9.6 Codename: stretch1. SSH,VNC接続設定
ローカルPCからraspberry piを操作できるようにSSH,VNC接続環境を整えます。
Raspberry Pi へのリモート接続 を参考にします。
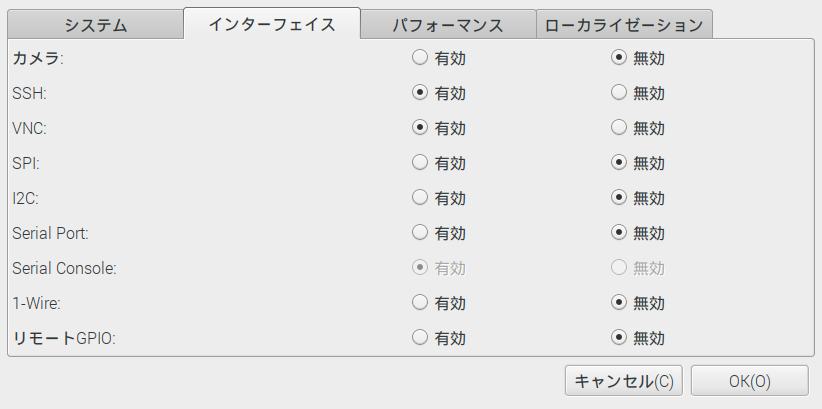
1.タスクバーから '設定>raspberry piの設定>インターフェイス タブを選択
以下のようにSSH,VNCを有効にチェックし、OKを押します。
2.ローカルからssh接続する
raspberry piでLxTerminalを開きifconfigコマンドでraspberry piのipアドレスをメモしておきます。$ ifconfig wlan0: inet 192.168.1.12 netmask 255.255.255.0 broadcast 192.168.1.255ローカルPCから、以下コマンドを実行することでraspberry piへ接続します。
$ ssh pi@192.168.1.123.ローカルからVNC接続する
VNC ViewerをローカルPCにインストールします。
VNC Viewerを起動しraspberry piのipアドレスで接続設定を行います。
認証画面でraspberry piのユーザID、ログインpasswordを入力して接続します。
以下の画面が出れば成功です。
2.ipアドレスを固定する
Raspberry PiのセットアップからPython実行環境構築とイメージファイルバックアップまで
の⑥IPアドレスを固定するを参考にします。1.dhcpcd.confを編集して固定する
$ sudo vi /etc/dhcpcd.conf #viエディタで設定ファイルを編集dhcpcd.confinterface wlan0 #有線なら「eth0」無線なら「wlan0」 static ip_address=192.168.1.12 #Raspberry PiのIP static routers=192.168.1.1 #ルーターのIP static domain_name_servers=192.168.1.1 #ルーターのIPCtrl+X → Y → Enter で保存して閉じる
$ sudo service dhcpcd reload #設定を反映する $ sudo reboot #再起動3.ソフトウェアを最新化する
以下コマンドでraspberry piの各ソフトウェアを最新化します。
$sudo apt update $sudo apt upgrade $sudo apt install rpi-update $sudo rpi-update $sudo reboot4.OSをバックアップする
USB Image Toolを使用してOSをバックアップします。
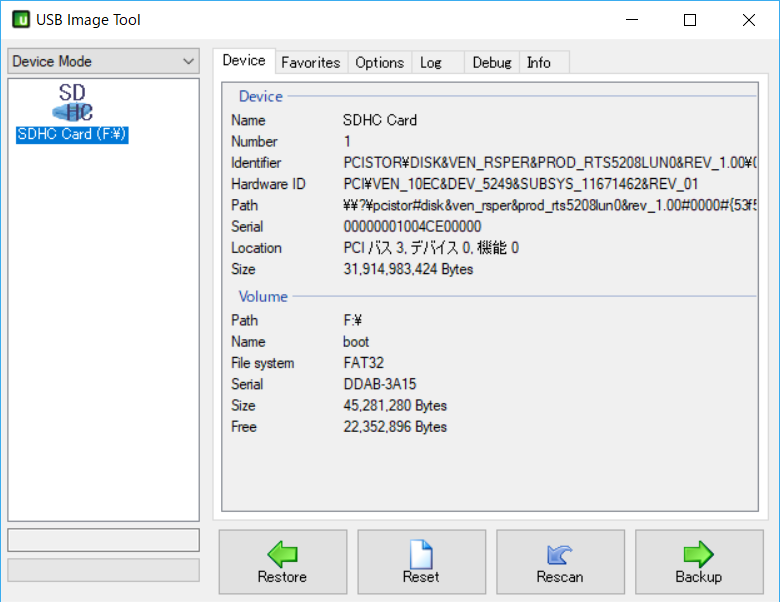
USB Image ToolはSDカードをまるごとイメージファイルとしてバックアップしてくれるソフトです。
使い方は簡単です。1.バックアップする
ローカルPCにraspberry piのOSが入ったSDカードを接続してUSB Image Toolを起動します。
Backupボタンを押して任意のフォルダにイメージを保存します。2.リストアする時
・Resetボタンを押して、SDカードを初期化します。
・Restoreボタンを押して保存したイメージファイルをリストアします。5.sambaのインストール
sambaを使いローカルPCとraspberry piでファイル共有できるようにします。
$sudo apt-get install samba $sudo vi /etc/samba/smb.conf #設定ファイルの編集先頭行に以下を追加
smb.conf[global] workgroup=WORKGROUP dos charset = CP932 unix charset = utf-8 hosts allow = 192.168. #192.168.xx.xxのipのみアクセス許可 max log size =50 log file = /var/log/samba/log.%m security=user passdb backend=tdbsam [share] comment =share directory browseable=yes writable=yes path=/home/piローカルPCのネットワークアドレスに
\\192.168.1.12\shareと打つことでraspberry piのホームディレクトリにアクセスが可能になります。6.pyenv,pipenvをインストールする
raspberry piのpython実行環境は以下の通りです。
raspberry piでpython3.6以上を使用する場合pyenvのインストールが必要になります。
pipenvはプロジェクトごとにpython仮想環境を構築するアプリケーションです。$python -V Python 2.7.13 $python3 -V Python 3.5.31.pyenvインストール
raspberry piで以下を実行します。$ sudo apt install git $ git clone https://github.com/yyuu/pyenv.git ~/.pyenv $ echo 'export PYENV_ROOT="$HOME/.pyenv"' >> ~/.bash_profile $ echo 'export PATH="$PYENV_ROOT/bin:$PATH"' >> ~/.bash_profile $ echo 'eval "$(pyenv init -)"' >> ~/.bash_profile $ exec $SHELL $ sudo reboot#依存関係のあるライブラリをインストール $sudo apt-get install -y make build-essential libssl-dev zlib1g-dev libbz2-dev libreadline-dev libsqlite3-dev wget curl llvm libncurses5-dev libncursesw5-dev xz-utils tk-dev $sudo apt-get install libffi-devpyenvでpython3.7.0をインストールします。
$source ~/home/pi/.bash_profile #pyenvが読み込めない場合に実行 $pyenv install 3.7.0 #python 3.7.0をインストール $pyenv global 3.7.0 #Python 3.7.0をデフォルトのインタプリタとして設定以下になっていれば成功
$python3 -V python 3.7.02.pipenvのインストール
$pip install --upgrade pip $pip install pipenvpipenv使い方
$mkdir ./project1 #プロジェクトごとにディレクトリを作成 $cd ./project1 $pipenv install --python 3.7.0 #3.7.0で仮想環境構築 ローカルにpipfile, pipfile.lockが生成 $pipenv install <package_name> #仮想環境にパッケージのインストール #または $pip shell #仮想環境を実行 (project1)$ pip install <package_name> #仮想環境にパッケージのインストールおわり
以上でraspberry piの初期設定は終了です。
あとはお好きなタイミングでOSのバックアップを取ればいいかと思います。
お疲れ様でした。
- 投稿日:2019-02-11T18:44:08+09:00
im2col関数の理解
書籍「ゼロから作るディープラーニング」をもとに
畳み込みニューラルネットワーク(CNN、Convolutional Neural Network)を勉強しているのですが、途中に出てくるim2col関数というものについて理解が難しかったため、
自分なりの噛み砕きの経緯を書いてみました。もしもどなたかの参考になれば幸いです。
im2col関数について
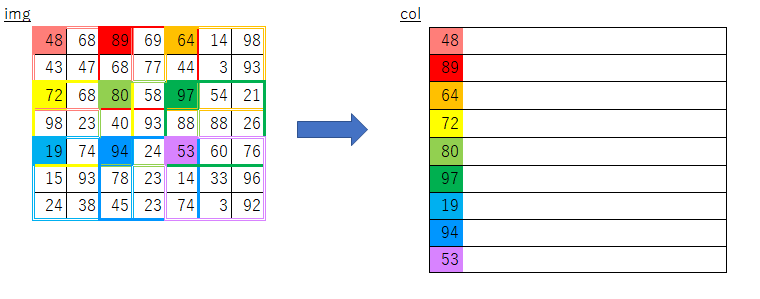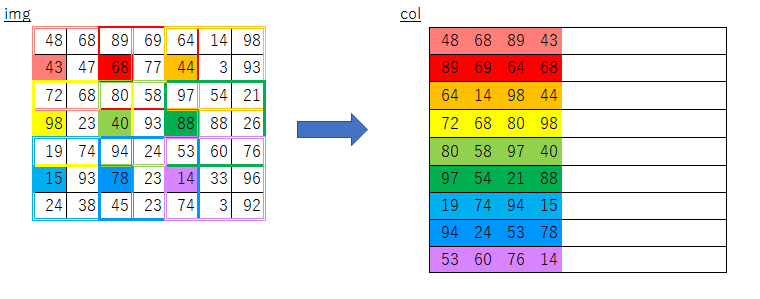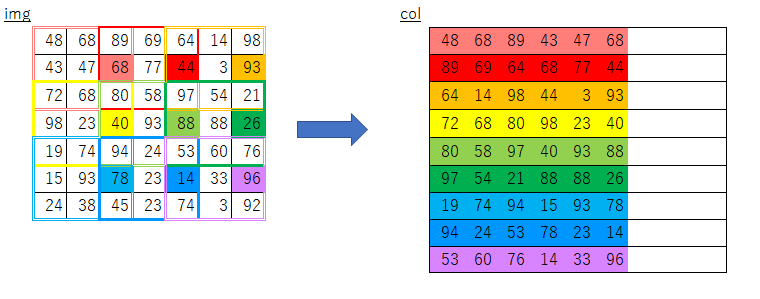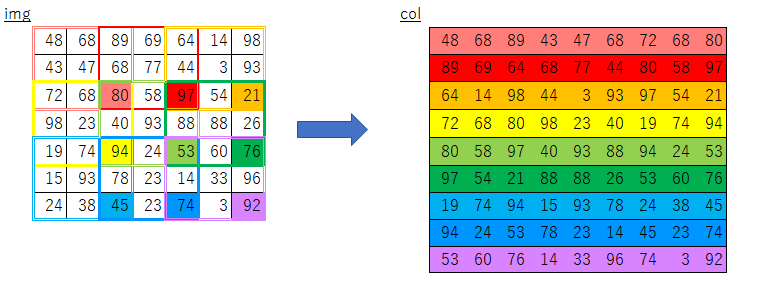
CNNの畳み込み演算において複雑なループ処理を避けるため、
フィルター適用領域ごとに一列のデータになるよう変換する関数です。入力データとフィルターにこの関数を適用することで、
行列のドット演算で一気に畳み込み演算が行えます。オリジナルの実装
「ゼロから作る〜」で紹介されている実装はこのようなものです。
def im2col(input_data, filter_h, filter_w, stride=1, pad=0): N, C, H, W = input_data.shape out_h = (H + 2*pad - filter_h)//stride + 1 out_w = (W + 2*pad - filter_w)//stride + 1 img = np.pad(input_data, [(0,0), (0,0), (pad, pad), (pad, pad)], 'constant') col = np.zeros((N, C, filter_h, filter_w, out_h, out_w)) for y in range(filter_h): y_max = y + stride*out_h for x in range(filter_w): x_max = x + stride*out_w col[:, :, y, x, :, :] = img[:, :, y:y_max:stride, x:x_max:stride] col = col.transpose(0, 4, 5, 1, 2, 3).reshape(N*out_h*out_w, -1) return col書籍の説明を見ると目指すところは理解できるのですが、
このループ処理部分で行っている事がどうにも理解できませんでした。引っかかった点
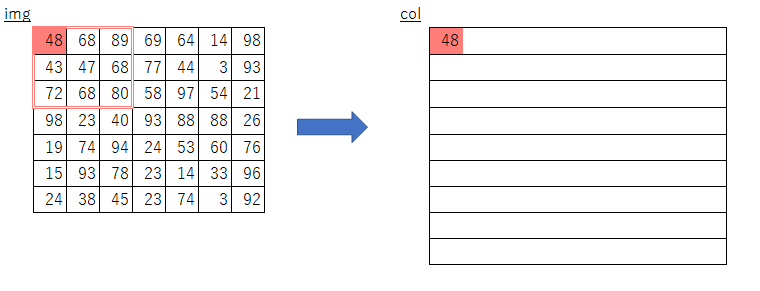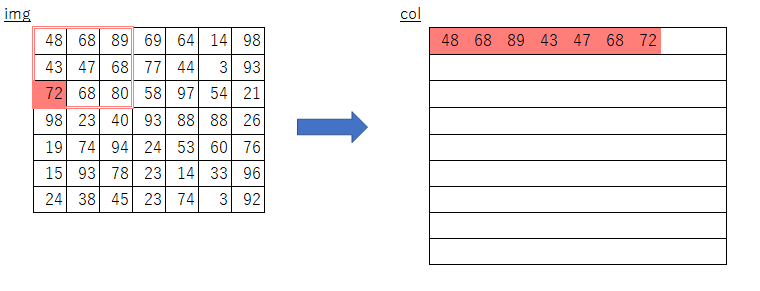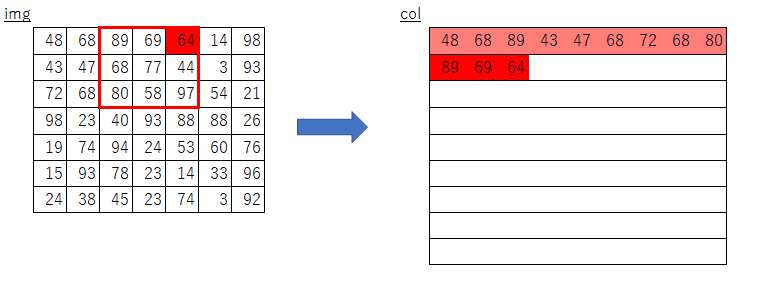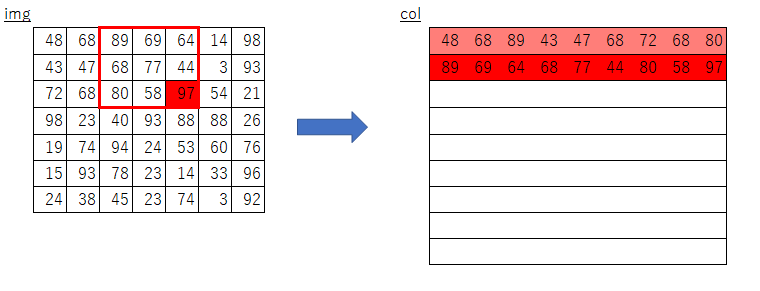
y_maxとx_maxが何を意味しているのかよくわからない- imgのスライスで何を取り出しているのかよくわからない
y:y_max:stride,、x:x_max:strideって何?- フィルターサイズについてのループだけで処理できる理由がよくわからない
そこで、まずは自分なりに素朴な発想で実装してみました。
素朴な実装
フィルターを移動させるループ
→フィルタ内の各画素をコピーするループ
の順でx方向・y方向、4重ループ処理すればいけるはず...
という発想でforループ部分のみ変更してみたのが以下のim2col_slowです。def im2col_slow(input_data, filter_h, filter_w, stride=1, pad=0): N, C, H, W = input_data.shape out_h = (H + 2*pad - filter_h)//stride + 1 out_w = (W + 2*pad - filter_w)//stride + 1 img = np.pad(input_data, [(0,0), (0,0), (pad, pad), (pad, pad)], 'constant') col = np.zeros((N, C, filter_h, filter_w, out_h, out_w)) for move_y in range(out_h): for move_x in range(out_w): for y in range(filter_h): for x in range(filter_w): col[:, :, y, x, move_y, move_x] = \ img[:, :, y + stride * move_y, x + stride * move_x] col = col.transpose(0, 4, 5, 1, 2, 3).reshape(N*out_h*out_w, -1) return col実行してみます。
(見やすくするためにデータ数1、チャンネル数1に絞ってます)data = np.random.rand(1, 1, 7, 7) * 100 // 1 print('========== input ==========\n', data) print('=====================') filter_h = 3 filter_w = 3 stride = 2 pad = 0 col = im2col(data, filter_h=filter_h, filter_w=filter_w, stride=stride, pad=pad) col2 = im2col_slow(data, filter_h=filter_h, filter_w=filter_w, stride=stride, pad=pad) print('========== col ==========\n', col) print('=====================') print('========== col2 ==========\n', col2) print('=====================')同様の結果を得られました。
========== input ========== [[[[30. 91. 11. 13. 52. 44. 98.] [99. 6. 35. 41. 97. 72. 79.] [ 5. 92. 15. 95. 72. 8. 10.] [68. 5. 86. 25. 69. 46. 70.] [95. 32. 98. 49. 51. 19. 46.] [32. 15. 39. 44. 76. 58. 49.] [43. 47. 95. 1. 1. 12. 21.]]]] ===================== ========== col ========== [[30. 91. 11. 99. 6. 35. 5. 92. 15.] [11. 13. 52. 35. 41. 97. 15. 95. 72.] [52. 44. 98. 97. 72. 79. 72. 8. 10.] [ 5. 92. 15. 68. 5. 86. 95. 32. 98.] [15. 95. 72. 86. 25. 69. 98. 49. 51.] [72. 8. 10. 69. 46. 70. 51. 19. 46.] [95. 32. 98. 32. 15. 39. 43. 47. 95.] [98. 49. 51. 39. 44. 76. 95. 1. 1.] [51. 19. 46. 76. 58. 49. 1. 12. 21.]] ===================== ========== col2 ========== [[30. 91. 11. 99. 6. 35. 5. 92. 15.] [11. 13. 52. 35. 41. 97. 15. 95. 72.] [52. 44. 98. 97. 72. 79. 72. 8. 10.] [ 5. 92. 15. 68. 5. 86. 95. 32. 98.] [15. 95. 72. 86. 25. 69. 98. 49. 51.] [72. 8. 10. 69. 46. 70. 51. 19. 46.] [95. 32. 98. 32. 15. 39. 43. 47. 95.] [98. 49. 51. 39. 44. 76. 95. 1. 1.] [51. 19. 46. 76. 58. 49. 1. 12. 21.]] =====================オリジナルとの比較
自分で実装してみたおかげで、オリジナルの実装は
上記の素朴版で行っているフィルター移動分の2重ループをしなくて済むよう効率化したものだと気づきました。
(ストライド幅刻みでスライスすることで、フィルタを移動させて取得する分を一気に取得・コピーしている)絵にしてみるとこんな感じになるかと思います。
素朴版の実装におけるimgからcolへのコピー
オリジナルim2colにおけるimgからcolへのコピー
ループ処理が効率化された結果、あのような実装になっているのだなぁ...
という感じで自分の理解は落ち着きました。
- 投稿日:2019-02-11T18:43:11+09:00
python 現在時刻を文字列として整形する。
すぐ忘れるやつ
現在時刻からタイムスタンプストリングを作成する。import datetime now = datetime.datetime.now() str_timestamp = now.strftime("%y/%m/%d_%H:%M:%S")ファイルの最終更新日を取得して文字列として成形する。import datetime myfile = r"test\test.txt" dt = datetime.datetime.fromtimestamp(os.stat(myfile).st_mtime) str_timestamp = dt.strftime('%Y/%m/%d_%H:%M:%S')こんな感じの文字列になる>>> '19/02/11-18:29:14'
- 投稿日:2019-02-11T18:12:23+09:00
Dockerを使って機械学習の環境を作ろうとした話
目次
- 目標
- どんな環境作るの?
- Dockerfileの準備
- イメージを作成してコンテナを起動して潜入してみる
- Volumeを指定して、ファイルを同期してみる
- docker-composeで更に楽に作ろう!
- まとめ
目標
- Dockerを実際に触って慣れる
- Dockerを使って環境構築してみる
どんな環境作るの??
まず、今回はDockerを使用して環境構築することが目標なので、そこまで厳密に環境にこだわっていません。
作成する環境は以下です。
python3.7.2をベースに機械学習に使うライブラリを用意していきます。
インストールするのは以下です。
- python 3.7.2
- numpy
- scikit-learn
- pandas
- matplotlib
- pytest
ディレクトリの構成は以下です。
bashsample001. ├── Dockerfile ├── docker-compose.yml ├── pip │ └── requirements.txt ├── src │ └── hello.py └── test以下のhello.pyを先に用意しておきます。
hello.pyprint("hello")requirements.txtの中身は以下です。
本当はverの指定とかをするべきなんでしょうが省略。requirements.txtnumpy pandas matplotlib scikit-learn pytestDockerfileの準備
実際に作って行きましょう。
簡単に言うとDockerfileって何????
Dockerのイメージを作る際に使用する設計書
そして、以下が作成したDockerfileです。
Dockerfile# pythonの3.7.2-slimをベースにする FROM python:3.7.2-slim # ARGで変数を定義 # buildする時に変更可能 # コンテナ内のディレクトを決めておく ARG root_directory=/sample001 # python3 pipのインストール RUN apt-get update && apt-get install -y \ python3 \ python3-pip \ # imageのサイズを小さくするためにキャッシュ削除 && apt-get clean \ && rm -rf /var/lib/apt/lists/* \ # pipのアップデート && pip install --upgrade pip # Dockerfileを実行したディレクトにあるファイルを全てイメージにコピー COPY . ${root_directory}/ # 機械学習に使用するライブラリのインストール WORKDIR ${root_directory}/pip/ RUN pip install -r requirements.txt # ディレレクトリの移動 WORKDIR ${root_directory}今回はimageのサイズの削減にも取り組んだので、以下のことをしています。
- -slimを使用
- Runコマンドは一つにまとめる
- キャッシュの削除
詳しくは、こちらに載っています。
http://docs.docker.jp/engine/userguide/eng-image/dockerfile_best-practice.html#build-cache
イメージを作成,コンテナを起動して潜入してみる
buildで用意したDockerfileからイメージを作成します。
作成したイメージが確認しやすいように、名前を付けてbuildしています。
lang:bash
docker build ./ -t python_image
イメージが作成されているか確認
bash$ docker images REPOSITORY TAG IMAGE ID CREATED SIZE python_image latest 8c9cc96fbb5a About a minute ago 580MB python 3.7.2-slim 12c44ed85032 5 days ago 143MBイメージが作成されていることが確認出来たので
これを基にしてコンテナを作成します。bash$ docker run -it --rm --name python_container python_image /bin/bash使用しているオプションの説明
- -i:ホストマシンとコンテナの双方向に接続できるようにするため
- --rm:コンテナから抜けるとコンテナを削除
- -t:コンテナ内に擬似的なターミナルを割り当て
- -name:コンテナに名前を付ける
最後の/bin/basはターミナルの起動のために追加
コンテナの内部に入ると以下のように表示されます。
bash$ docker run -it --rm --name python_container python_image /bin/bash root@0e86c2a3cfcb:/sample001#この状態で別のターミナルを開いてコンテナの確認をしましょう。
docker psで現在稼働中のコンテナのみを確認ができます。bash$ docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 0e86c2a3cfcb python_image "/bin/bash" 3 minutes ago Up 3 minutes python_containerコンテナ内部に潜入できたので、実際にpythonを動かしてみましょう!
bashroot@759f6d3f586a:/sample001# python src/hello.py hello root@759f6d3f586a:/sample001#これでpythonの実行環境は構築できました。
ただし、一つ開発していく上で不便なことがあります。
作成したhello.pyを編集して再度、コンテナ上で実行してみます。hello.pyprint("hello") print("world")bashroot@759f6d3f586a:/sample001# python src/hello.py hello root@759f6d3f586a:/sample001# python src/hello.py hello root@759f6d3f586a:/sample001#編集したはずの内容が反映されていません。
これを解決するのが次の項目です。Volumeを指定して、ファイルを同期してみる
話は一旦、Dockerfileに戻ります。
Dockerfileの中に、以下のコードがありました。Dockerfile# Dockerfileを実行したディレクトにあるファイルを全てイメージにコピー COPY . ${root_directory}/buildをする際にイメージの中にファイルを含めています。
つまり、このイメージをコンテナ化してもイメージに含まれているファイルしかコンテナには存在しないのです。
ホストマシンで編集した内容が、即時コンテナにも反映されるようにするには以下のコマンドでコンテナを立ち上げます。
bash$ docker run -it --rm -v $PWD/src:/sample001/src --name python_container python_image /bin/bash
$ docker run -v #{ホストマシンの任意のディレクトリ}:#{Dockerコンテナ内の任意のディレクトリ}これでホストマシンとコンテナの同期が完了しました。
実際に編集して試してみました。bash$ docker run -it --rm -v $PWD/src:/sample001/src --name python_container python_image /bin/bash root@a2a0a825ef79:/sample001# cd src root@a2a0a825ef79:/sample001/src# python hello.py hello root@a2a0a825ef79:/sample001/src# python hello.py hello world root@a2a0a825ef79:/sample001/src#これで環境ができましたね!!ようやく開発に移れる。
あとは、毎回コンテナを立ち上げる時に以下を打ち込んでと。。。bashdocker run -it --rm -v $PWD/src:/sample001/src --name python_container python_image /bin/bashこれ、もう少し楽に記述できないかな??
次の項目へdocker-composeで更に楽に作ろう!
開発環境を、もっと楽に立ち上げる為に以下のファイルを用意します。
docker-composeversion: "3" services: app: container_name: "python_app" build: context: . dockerfile: ./Dockerfile image: python_ml:3.7.2 volumes: - $PWD/src:/sample001/src - $PWD/test:/sample001/test ports: - 80:80 tty: true簡単に言うとdocker-composeって何?????
複数のコンテナを同時に立ち上げてくれるもの。
オプションを記述することで各コンテナの起動時の設定などができる。
今回は複数のコンテナではないですが、起動時のオプションをこちらに持たせておくことにしましょう。
docker-composeのあるディレクトリに移動して
以下のコマンドでイメージの作成からコンテナの起動まで全て行ってくれます。bash$ docker-compose up -dあとはコンテナの内部に以下のコマンドで入ります。
docker exec -it python_app /bin/sh -c "[ -e /bin/bash ] && /bin/bash || /bin/sh"まとめ
Dockerを使って、機械学習用の環境が構築できました。
docker-composeの説明が、自分の中で纏まっていないので纏まり次第追記していく予定です。
説明不足な所や、間違った所は指摘していただけると助かります。
- 投稿日:2019-02-11T18:00:08+09:00
StyleGAN 写真が証拠になる時代は終わった
StyleGAN
スタイル変換の技術を基にGeneratorのアーキテクチャを設計し直したことで
画像合成の過程をコントロールすることができるようになった
Style-based generator
StyleGANのGenerator
図のAはアフィン変換、Bは足し合わせができるようにノイズのチャンネル変換を行うことを意味する構成
Style-based generatorではこれまでのような入力層をまるごとなくして全結合層を連ねたものにする
Mapping network fは8層で構成されSynthesis network gは18層で構成されている流れ(上図の矢印を追う)
Mapping network fで入力である潜在変数zを一度潜在空間Wにマッピングする。
潜在変数wはアフィン変換されることでスタイルyになる
スタイルyは各convolution層後でのAdaIn処理で使われ、Generatorをコントロールする。
ガウシアンノイズをAdaInと各convolution層の間に加える。
最終層の出力は1×1のconvolution層を使ってRGBに変換する
解像度は4×4で始まり、最終的に1024×1024
Style-based generatorの合計パラメーター数は26.2M
従来のGeneratorの合計パラメーター数は23.1M
これまでの改良の流れ
様々な改良をすることで画像のクオリティを上げてきた
評価指標はFID
FIDはGANの生成分布と真のデータ分布の距離を表す指標
数値は低いほど良いことを意味する(A)
ベースラインとして設定したのはProgressive GAN
ネットワークとハイパーパラメーターの変更はしておらず、提案されたままを使った(B)
ベースラインの改良として、bilinear up/downsamplingとハイパーパラメーターチューニングをした(C)
更にベースラインの改良として、マッピングネットワークとAdaIN処理を加えた
この時点で、従来通り最初のconvolution層に潜在変数を与えるネットワークでは改善の余地がないという見解に至った(D)
これまでの入力層を取り除き4×4×512のconstant tensorで画像生成を始めるというシンプルなアーキテクチャにしたsynthesis network(Generator)は
AdaINをコントロールするスタイルのみの入力で素晴らしい生成ができることがわかった(E)
ノイズを入れることで更に改善(F)
mixing regularizationを導入により
隣接したスタイルの相互関係をなくし、より洗練された画像を生成することができるStyle mixing
スタイルを細部にも適用できるようにmixing regularizationを導入する
訓練時、画像の指定範囲分(%)の生成を
1つのランダム潜在変数ではなく2つのランダム潜在変数を使ってすること
テスト時は下記結果表が示すように3つ以上でも実行されているSynthesis networkのランダムに選ばれたところで潜在変数を他のものに切り替える(これをstyle mixingと呼ぶ)
具体的には、Mapping networkではz1とz2という2つの潜在変数を実行する
Synthesis networkではw1を適用して、その後ランダムに選ばれたところからw2を適用するこの正則化手法により、隣り合ったスタイルは相互に関連しているということをネットワークが仮定せずに生成することができる
テスト結果
潜在変数の数(Number of latents during testing)と潜在変数を混ぜて生成する比率(Mixing regularization)を変えて結果を表にして示している
評価指標はFID
FIDはGANの生成分布と真のデータ分布の距離を表す指標
数値は低い方が良い結果表のE,Fは最初に見た表のE,Fと対応している
Mixing regularizationの比率を大きくすることで結果が良くなっているのがわかる
2つの潜在変数を混ぜて生成された画像
1つの潜在変数で生成されたスタイル(source)に、同じく1つの潜在変数から生成されたスタイル(destination)を合わせると画像はどのように変化していくのかを可視化している・解像度が粗い段階で合わせた場合(4×4 ~ 8×8)
顔の向き・髪型・顔の形・眼鏡のような大まかな特徴はsourceの要素が画像で表現されている一方で、目・髪・明暗のような色や顔の特徴はdestinationの要素が表現されている・解像度(16×16 ~ 32×32)の場合
顔の特徴・髪型・目の特徴がsourceの要素で
顔の向きや顔の形や眼鏡がdestinationの要素で構成されている・高解像度(64×64 ~ 1024×1024)の場合
配色や細部のデザインはsource由来になっているノイズの効果
・確率的特徴
正しい分布に従って生成されていれば、ランダムに生成しても画像の見た目に大きな影響を与えない特徴
例)髪質や髪の流れ、ヒゲ、そばかす、肌質従来のジェネレーターが確率的特徴を生成する場合、
入力層への入力のみになるため、ネットワークは必要となったら以前のアクティベーションから
空間的に変化する疑似乱数を生成しなくてはならないこれはネットワーク容量を消費し、周期性がなく本当にランダムな乱数を生成することは困難で成功する保証はない
本研究のアーキテクチャでは各convolution層の後に、ピクセルごとのノイズを加えることでこれらの問題を解決する
例1
上図はベースとなる生成画像は同じでノイズだけを変えた場合の結果である
ノイズは確率的特徴(毛の流れ)だけを変化させて、その他の高レベルな特徴(顔の特徴や向きなど)はそのままである
上図右の白黒の画像はどこがノイズの影響を受けているかを表している
白い部分がノイズの影響を受けている部分ほとんどが髪の毛、輪郭、背景だが、目の反射も白くなっているのは興味深い点
例2
この図もノイズがどのように生成画像を変化させるかについてである
男性の生成画像も同じように(a)(b)(c)(d)で分割して見てほしい(a)すべての層でノイズを加えた場合
(b)ノイズを全く加えない場合
(c)ノイズを解像度がきれいな層(64×64 ~ 1024×1024)でのみノイズを加える場合
(d)ノイズを解像度が粗い層(4×4 ~ 32×32)でのみノイズを加える場合(a)と(b)を比較するとわかるが、
ノイズを加えないことで特徴のない絵画っぽい(リアルではない)画像が生成される(d)ノイズを解像度が粗い層(4×4 ~ 32×32)でのみノイズを加える場合、
髪の毛のカールが大きくなっていたり、背景の特徴が大きく表現されている(c)ノイズを解像度がきれいな層(64×64 ~ 1024×1024)でのみノイズを加える場合、
髪の毛のカール、背景、肌質が細かくきれいに描かれていているスタイルとノイズのまとめ
スタイルを変化させることは全体的な影響(姿勢、向き、顔の特徴を変える)を与えるのに対して、
ノイズはそこまで重要ではない部分(髪の毛の流れやヒゲ)に影響を与えるスタイルが画像全体に影響を与えるのはすべての特徴マップが同じ値でスケール変換、バイアス変換されるからである(AdaIn処理)
そのため、画像全体への影響(姿勢、明暗、背景)は一貫してコントロールされる一方ノイズは独立的にピクセルごとに加えられ、確率的な変化をコントロールするには理想的である
もし生成画像の姿勢を変えたいときにノイズの使ってしまったら、
矛盾した選択でありDiscriminatorに見破られてしまうネットワークは明確な指示がなくても、適切にスタイルとノイズを使えるように学習する
潜在空間Wの必要性
上図は2つの変動要因(男性らしさと髪の長さ)だけを考えた例(a)訓練データの特徴分布
長い髪の男性など一部の組み合わせが存在しない訓練データ(b)Zから特徴表現へのマッピング(従来のやり方)
訓練データになかった組み合わせ(長い髪の男性)がサンプリングされないようにするため
Zから画像特徴へのマッピングは曲線になる(c)Wから特徴表現へのマッピング(本研究)
ZからWへのマッピングは学習されたマッピングであるため、このゆがみを元に戻すことができる仮定
特徴が絡み合っている表現に基づいてリアルな画像を生成するよりも、
それぞれの特徴がしっかり分解されている表現に基づいてリアルな画像を生成する方が容易であるはず例)人の顔を生成したいとき
・特徴が絡み合っている
→この軸を調整すると、目が大きくなって髪が長くなって輪郭が丸くなるみたいになると
各軸が複雑に影響し合って生成しづらい・特徴がしっかり分解されている
→この軸は目の大きさ、この軸は髪の長さ、この軸は輪郭みたいに特徴が独立していると
生成がしやすい目標
線形部分空間(それぞれの線形部分空間が1つの変動要因をコントロールする)を用意する
変動要因が事前にわかっていない状況の中で、学習によって可能な限り特徴が分解されたWができることが理想問題
ただし、従来のGANのようなアーキテクチャでは
Z内の各要因の組み合わせのサンプリング確率は、学習データ内の対応する密度と一致する必要がある
そのため、各要因がデータセットの分布と入力潜在分布から完全に分解することができない対策
本研究のGeneratorが優れている点は
中間潜在空間Wは任意の固定分布に従ってサンプリングする必要がないことWのサンプリング密度は学習された区分的連続写像f(z)(線形変換である全結合層を8つ重ねて計算する)によってできたものを使う
このマッピングによって、変動要因はより線形になりゆがみのない潜在空間Wができる
指標
「特徴が分解されている」ということを定量化するための指標が最近提案されたのだが、
残念なことにその指標を使うには入力画像を潜在変数にマッピングするエンコーダーがなくてはならない
本研究ではそういったエンコーダーは使っていないため適した指標とは言えない
そのためにエンコーダーをわざわざ追加することもできるが、根本的解決にはならないのでやらないその代りに新しい定量化手法を2つ提案する
その指標の場合はエンコーダーを必要とせず、変動要因を事前に知らなくていいため
どんな画像データセットやGeneratorでも問題ない新指標1:Perceptual path length
潜在空間のinterpolation(上図)をすると両端の画像(①や⑨)にはない特徴が中間の画像(④、⑤、⑥)に現れるという非線形な変化が起こることがある
これは潜在空間が絡み合っていて変動要因が適切に分離されていないことを示す潜在空間でinterpolationをしたときに、どれだけ急激に画像が変化するかを測ることでこの効果を定量化することができる
直感的には、曲りの大きい曲線の潜在空間よりも曲りの少ない曲線の潜在空間の方が画像がなめらかに変化していくと考えられる
方法
2枚の画像の距離を測定する
この計算はVGG16のembeddingで計算されるため、人間が2枚の画像を見たときに感じる画像の類似性と一致するようになっている定義上は潜在空間のinterpolation pathを線形セグメントに無限に細分化した状況で計測することになっているが、
実際にはepsilon(10のマイナス4乗)を用いて近似計算する潜在空間Zの取り得るすべての両端(①や⑨)の平均距離(perceptual path length)の定義は以下のようになる
G・・・Generator
D・・・画像間の距離を計測
slerp・・・標準化された入力潜在空間のinterpolationに最も適した球状interpolation
潜在空間Wの場合は以下のようになる
Wのベクトルは標準化されていないため線形interpolation(lerp)
結果1
・ノイズありのStyle-based generator(本研究のgenerator)が最もpath lengthが短くなった
これはWがZよりも知覚的に線形であることを意味している・Style mixingができるようなネットワークにすると中間潜在空間Wを多少ゆがませてしまうようだ
・Style mixingによって、Wが複数のスケールにわたる変動要因をエンコードすることを困難にしていると仮定できる結果2
Path lengthがマッピングネットワークからどのように影響を受けているかを示している従来のGeneratorでも本研究のstyle-based generatorでもマッピングネットワークを持つことは有益である
深さを増すこともほとんどのPath lengthとFIDで良い結果につながっている従来のGeneratorのlwは向上しているのに対し、lzは悪化している点を見ると
これまでの様々なGANモデルの入力潜在空間が無作為に絡み合っていることがわかる新指標2:Linear separability
潜在空間が十分に分解されていれば、個々の変動要因に対応した方向ベクトルを見つけることができるはず
この効果を定量化する指標がLinear separability
どれだけ上手に潜在空間の点を線形超平面で2つに分けられるかを計測する
分けられた2つはそれぞれ、画像のバイナリ属性に対応する(例:片方は男性、もう片方は女性)方法
①生成画像にラベルを付けるために、画像の二値分類(男性と女性の顔を見分ける)ができる補助ネットワーク(Discriminatorと同じアーキテクチャ)を訓練する
②訓練データはCelebA-Hデータセット(元のCelebAデータセットの中の40属性を保持するデータセット)
属性の分離度を測るために20万枚の画像を生成し補助ネットワークを使って分類する
分類器のスコアが高い10万枚だけをラベル付きの潜在空間ベクトルとする③各属性について、潜在空間点(従来の場合はz, style-basedではw)に基づいたラベルを予測するために線形SVMで学習する
④超平面がどれほど正確に点を分類できたかを条件付きエントロピーH(Y|X)で計算する
X・・・SVMで予測したクラス
Y・・・補助ネットワークが決めたクラス条件付きエントロピーは正しいクラス分類をするために、どれほど追加情報が必要かを示している
もし変動要因が矛盾した潜在空間の方向を持っていたら、サンプル点を超平面でわけるのは一層難しいため
条件付きエントロピーは高い数値になる低い数値になるということは簡単に分けられたということを示す
すなわち属性が対応する要因と潜在空間の方向が一致したことを意味する最終的な分離スコアは下記のように求める
iは40属性
潜在空間Wについてのまとめ
・結果1と結果2からWはZよりも分離しやすい(表現が絡み合っていない)ことがわかる
・マッピングネットワークの深さを増すことは画質とWの分離性を向上させる
これは合成ネットワーク(Synthesis network)がもつれを解消した入力表現を好むという仮説と一致している・従来のジェネレータの前にマッピングネットワークを追加するとZの分離性が大幅に失われるが、中間潜在空間Wの状況は改善されFIDの結果も良くなる
これは訓練データの分布に従わなくてよい中間潜在空間を導入すると、従来のジェネレータアーキテクチャでもパフォーマンスが向上することを示している全体まとめ
・従来のGANアーキテクチャは様々な点でStyleGANよりも劣っていることが明らかになった
・高レベルの属性(スタイル)と確率的効果(ノイズ)の分離、中間潜在空間の線形性に対する調査が
StyleGANの理解を深める上で有益であると確信している・Path length指標とLinear separability指標が訓練時の正則化として容易に使えることも示した
・訓練時に直接、中間潜在空間を形成する方法が今後の研究のキーになっていくと考えている
FFHQデータセット
FlickrFaces-HQ (FFHQ)という顔画像のデータセットを提供する
・70000枚
・解像度:1024×1024
・データセットは年齢・民族・視点・明暗・画像の背景に関して多様な種類がある
・眼鏡・サングラス・帽子などを身に着けた画像も十分に用意されている論文
画像引用
https://users.aalto.fi/~laines9/publications/laine2018iclr_paper.pdf





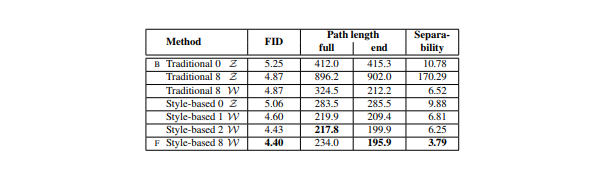
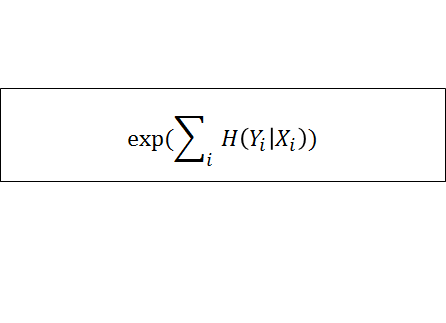

- 投稿日:2019-02-11T18:00:08+09:00
StyleGAN「写真が証拠になる時代は終わった」
StyleGAN
スタイル変換の技術を基にGeneratorのアーキテクチャを設計し直したことで
画像合成の過程をコントロールすることができるようになった
Style-based generator
StyleGANのGenerator
図のAはアフィン変換、Bは足し合わせができるようにノイズのチャンネル変換を行うことを意味する構成
Style-based generatorではこれまでのような入力層をまるごとなくして全結合層を連ねたものにする
Mapping network fは8層で構成されSynthesis network gは18層で構成されている流れ(上図の矢印を追う)
Mapping network fで入力である潜在変数zを一度潜在空間Wにマッピングする。
潜在変数wはアフィン変換されることでスタイルyになる
スタイルyは各convolution層後でのAdaIn処理で使われ、Generatorをコントロールする。
ガウシアンノイズをAdaInと各convolution層の間に加える。
最終層の出力は1×1のconvolution層を使ってRGBに変換する
解像度は4×4で始まり、最終的に1024×1024
Style-based generatorの合計パラメーター数は26.2M
従来のGeneratorの合計パラメーター数は23.1M
これまでの改良の流れ
様々な改良をすることで画像のクオリティを上げてきた
評価指標はFID
FIDはGANの生成分布と真のデータ分布の距離を表す指標
数値は低いほど良いことを意味する(A)
ベースラインとして設定したのはProgressive GAN
ネットワークとハイパーパラメーターの変更はしておらず、提案されたままを使った(B)
ベースラインの改良として、bilinear up/downsamplingとハイパーパラメーターチューニングをした(C)
更にベースラインの改良として、マッピングネットワークとAdaIN処理を加えた
この時点で、従来通り最初のconvolution層に潜在変数を与えるネットワークでは改善の余地がないという見解に至った(D)
これまでの入力層を取り除き4×4×512のconstant tensorで画像生成を始めるというシンプルなアーキテクチャにしたsynthesis network(Generator)は
AdaINをコントロールするスタイルのみの入力で素晴らしい生成ができることがわかった(E)
ノイズを入れることで更に改善(F)
mixing regularizationを導入により
隣接したスタイルの相互関係をなくし、より洗練された画像を生成することができるStyle mixing
スタイルを細部にも適用できるようにmixing regularizationを導入する
訓練時、画像の指定範囲分(%)の生成を
1つのランダム潜在変数ではなく2つのランダム潜在変数を使ってすること
テスト時は下記結果表が示すように3つ以上でも実行されているSynthesis networkのランダムに選ばれたところで潜在変数を他のものに切り替える(これをstyle mixingと呼ぶ)
具体的には、Mapping networkではz1とz2という2つの潜在変数を実行する
Synthesis networkではw1を適用して、その後ランダムに選ばれたところからw2を適用するこの正則化手法により、隣り合ったスタイルは相互に関連しているということをネットワークが仮定せずに生成することができる
テスト結果
潜在変数の数(Number of latents during testing)と潜在変数を混ぜて生成する比率(Mixing regularization)を変えて結果を表にして示している
評価指標はFID
FIDはGANの生成分布と真のデータ分布の距離を表す指標
数値は低い方が良い結果表のE,Fは最初に見た表のE,Fと対応している
Mixing regularizationの比率を大きくすることで結果が良くなっているのがわかる
2つの潜在変数を混ぜて生成された画像
1つの潜在変数で生成されたスタイル(source)に、同じく1つの潜在変数から生成されたスタイル(destination)を合わせると画像はどのように変化していくのかを可視化している・解像度が粗い段階で合わせた場合(4×4 ~ 8×8)
顔の向き・髪型・顔の形・眼鏡のような大まかな特徴はsourceの要素が画像で表現されている一方で、目・髪・明暗のような色や顔の特徴はdestinationの要素が表現されている・解像度(16×16 ~ 32×32)の場合
顔の特徴・髪型・目の特徴がsourceの要素で
顔の向きや顔の形や眼鏡がdestinationの要素で構成されている・高解像度(64×64 ~ 1024×1024)の場合
配色や細部のデザインはsource由来になっているノイズの効果
・確率的特徴
正しい分布に従って生成されていれば、ランダムに生成しても画像の見た目に大きな影響を与えない特徴
例)髪質や髪の流れ、ヒゲ、そばかす、肌質従来のジェネレーターが確率的特徴を生成する場合、
入力層への入力のみになるため、ネットワークは必要となったら以前のアクティベーションから
空間的に変化する疑似乱数を生成しなくてはならないこれはネットワーク容量を消費し、周期性がなく本当にランダムな乱数を生成することは困難で成功する保証はない
本研究のアーキテクチャでは各convolution層の後に、ピクセルごとのノイズを加えることでこれらの問題を解決する
例1
上図はベースとなる生成画像は同じでノイズだけを変えた場合の結果である
ノイズは確率的特徴(毛の流れ)だけを変化させて、その他の高レベルな特徴(顔の特徴や向きなど)はそのままである
上図右の白黒の画像はどこがノイズの影響を受けているかを表している
白い部分がノイズの影響を受けている部分ほとんどが髪の毛、輪郭、背景だが、目の反射も白くなっているのは興味深い点
例2
この図もノイズがどのように生成画像を変化させるかについてである
男性の生成画像も同じように(a)(b)(c)(d)で分割して見てほしい(a)すべての層でノイズを加えた場合
(b)ノイズを全く加えない場合
(c)ノイズを解像度がきれいな層(64×64 ~ 1024×1024)でのみノイズを加える場合
(d)ノイズを解像度が粗い層(4×4 ~ 32×32)でのみノイズを加える場合(a)と(b)を比較するとわかるが、
ノイズを加えないことで特徴のない絵画っぽい(リアルではない)画像が生成される(d)ノイズを解像度が粗い層(4×4 ~ 32×32)でのみノイズを加える場合、
髪の毛のカールが大きくなっていたり、背景の特徴が大きく表現されている(c)ノイズを解像度がきれいな層(64×64 ~ 1024×1024)でのみノイズを加える場合、
髪の毛のカール、背景、肌質が細かくきれいに描かれていているスタイルとノイズのまとめ
スタイルを変化させることは全体的な影響(姿勢、向き、顔の特徴を変える)を与えるのに対して、
ノイズはそこまで重要ではない部分(髪の毛の流れやヒゲ)に影響を与えるスタイルが画像全体に影響を与えるのはすべての特徴マップが同じ値でスケール変換、バイアス変換されるからである(AdaIn処理)
そのため、画像全体への影響(姿勢、明暗、背景)は一貫してコントロールされる一方ノイズは独立的にピクセルごとに加えられ、確率的な変化をコントロールするには理想的である
もし生成画像の姿勢を変えたいときにノイズの使ってしまったら、
矛盾した選択でありDiscriminatorに見破られてしまうネットワークは明確な指示がなくても、適切にスタイルとノイズを使えるように学習する
潜在空間Wの必要性
上図は2つの変動要因(男性らしさと髪の長さ)だけを考えた例(a)訓練データの特徴分布
長い髪の男性など一部の組み合わせが存在しない訓練データ(b)Zから特徴表現へのマッピング(従来のやり方)
訓練データになかった組み合わせ(長い髪の男性)がサンプリングされないようにするため
Zから画像特徴へのマッピングは曲線になる(c)Wから特徴表現へのマッピング(本研究)
ZからWへのマッピングは学習されたマッピングであるため、このゆがみを元に戻すことができる仮定
特徴が絡み合っている表現に基づいてリアルな画像を生成するよりも、
それぞれの特徴がしっかり分解されている表現に基づいてリアルな画像を生成する方が容易であるはず例)人の顔を生成したいとき
・特徴が絡み合っている
→この軸を調整すると、目が大きくなって髪が長くなって輪郭が丸くなるみたいになると
各軸が複雑に影響し合って生成しづらい・特徴がしっかり分解されている
→この軸は目の大きさ、この軸は髪の長さ、この軸は輪郭みたいに特徴が独立していると
生成がしやすい目標
線形部分空間(それぞれの線形部分空間が1つの変動要因をコントロールする)を用意する
変動要因が事前にわかっていない状況の中で、学習によって可能な限り特徴が分解されたWができることが理想問題
ただし、従来のGANのようなアーキテクチャでは
Z内の各要因の組み合わせのサンプリング確率は、学習データ内の対応する密度と一致する必要がある
そのため、各要因がデータセットの分布と入力潜在分布から完全に分解することができない対策
本研究のGeneratorが優れている点は
中間潜在空間Wは任意の固定分布に従ってサンプリングする必要がないことWのサンプリング密度は学習された区分的連続写像f(z)(線形変換である全結合層を8つ重ねて計算する)によってできたものを使う
このマッピングによって、変動要因はより線形になりゆがみのない潜在空間Wができる
指標
「特徴が分解されている」ということを定量化するための指標が最近提案されたのだが、
残念なことにその指標を使うには入力画像を潜在変数にマッピングするエンコーダーがなくてはならない
本研究ではそういったエンコーダーは使っていないため適した指標とは言えない
そのためにエンコーダーをわざわざ追加することもできるが、根本的解決にはならないのでやらないその代りに新しい定量化手法を2つ提案する
その指標の場合はエンコーダーを必要とせず、変動要因を事前に知らなくていいため
どんな画像データセットやGeneratorでも問題ない新指標1:Perceptual path length
潜在空間のinterpolation(上図)をすると両端の画像(①や⑨)にはない特徴が中間の画像(④、⑤、⑥)に現れるという非線形な変化が起こることがある
これは潜在空間が絡み合っていて変動要因が適切に分離されていないことを示す潜在空間でinterpolationをしたときに、どれだけ急激に画像が変化するかを測ることでこの効果を定量化することができる
直感的には、曲りの大きい曲線の潜在空間よりも曲りの少ない曲線の潜在空間の方が画像がなめらかに変化していくと考えられる
方法
2枚の画像の距離を測定する
この計算はVGG16のembeddingで計算されるため、人間が2枚の画像を見たときに感じる画像の類似性と一致するようになっている定義上は潜在空間のinterpolation pathを線形セグメントに無限に細分化した状況で計測することになっているが、
実際にはepsilon(10のマイナス4乗)を用いて近似計算する潜在空間Zの取り得るすべての両端(①や⑨)の平均距離(perceptual path length)の定義は以下のようになる
G・・・Generator
D・・・画像間の距離を計測
slerp・・・標準化された入力潜在空間のinterpolationに最も適した球状interpolation
潜在空間Wの場合は以下のようになる
Wのベクトルは標準化されていないため線形interpolation(lerp)
結果1
・ノイズありのStyle-based generator(本研究のgenerator)が最もpath lengthが短くなった
これはWがZよりも知覚的に線形であることを意味している・Style mixingができるようなネットワークにすると中間潜在空間Wを多少ゆがませてしまうようだ
・Style mixingによって、Wが複数のスケールにわたる変動要因をエンコードすることを困難にしていると仮定できる結果2
Path lengthがマッピングネットワークからどのように影響を受けているかを示している従来のGeneratorでも本研究のstyle-based generatorでもマッピングネットワークを持つことは有益である
深さを増すこともほとんどのPath lengthとFIDで良い結果につながっている従来のGeneratorのlwは向上しているのに対し、lzは悪化している点を見ると
これまでの様々なGANモデルの入力潜在空間が無作為に絡み合っていることがわかる新指標2:Linear separability
潜在空間が十分に分解されていれば、個々の変動要因に対応した方向ベクトルを見つけることができるはず
この効果を定量化する指標がLinear separability
どれだけ上手に潜在空間の点を線形超平面で2つに分けられるかを計測する
分けられた2つはそれぞれ、画像のバイナリ属性に対応する(例:片方は男性、もう片方は女性)方法
①生成画像にラベルを付けるために、画像の二値分類(男性と女性の顔を見分ける)ができる補助ネットワーク(Discriminatorと同じアーキテクチャ)を訓練する
②訓練データはCelebA-Hデータセット(元のCelebAデータセットの中の40属性を保持するデータセット)
属性の分離度を測るために20万枚の画像を生成し補助ネットワークを使って分類する
分類器のスコアが高い10万枚だけをラベル付きの潜在空間ベクトルとする③各属性について、潜在空間点(従来の場合はz, style-basedではw)に基づいたラベルを予測するために線形SVMで学習する
④超平面がどれほど正確に点を分類できたかを条件付きエントロピーH(Y|X)で計算する
X・・・SVMで予測したクラス
Y・・・補助ネットワークが決めたクラス条件付きエントロピーは正しいクラス分類をするために、どれほど追加情報が必要かを示している
もし変動要因が矛盾した潜在空間の方向を持っていたら、サンプル点を超平面でわけるのは一層難しいため
条件付きエントロピーは高い数値になる低い数値になるということは簡単に分けられたということを示す
すなわち属性が対応する要因と潜在空間の方向が一致したことを意味する最終的な分離スコアは下記のように求める
iは40属性
潜在空間Wのまとめ
・結果1と結果2からWはZよりも分離しやすい(表現が絡み合っていない)ことがわかる
・マッピングネットワークの深さを増すことは画質とWの分離性を向上させる
これは合成ネットワーク(Synthesis network)がもつれを解消した入力表現を好むという仮説と一致している・従来のジェネレータの前にマッピングネットワークを追加するとZの分離性が大幅に失われるが、中間潜在空間Wの状況は改善されFIDの結果も良くなる
これは訓練データの分布に従わなくてよい中間潜在空間を導入すると、従来のジェネレータアーキテクチャでもパフォーマンスが向上することを示している全体まとめ
・従来のGANアーキテクチャは様々な点でStyleGANよりも劣っていることが明らかになった
・高レベルの属性(スタイル)と確率的効果(ノイズ)の分離、中間潜在空間の線形性に対する調査が
StyleGANの理解を深める上で有益であると確信している・Path length指標とLinear separability指標が訓練時の正則化として容易に使えることも示した
・訓練時に直接、中間潜在空間を形成する方法が今後の研究のキーになっていくと考えている
FFHQデータセット
FlickrFaces-HQ (FFHQ)という顔画像のデータセットを提供する
・70000枚
・解像度:1024×1024
・データセットは年齢・民族・視点・明暗・画像の背景に関して多様な種類がある
・眼鏡・サングラス・帽子などを身に着けた画像も十分に用意されている論文
画像引用
https://users.aalto.fi/~laines9/publications/laine2018iclr_paper.pdf
- 投稿日:2019-02-11T18:00:08+09:00
StyleGAN「写真が証拠になる時代は終わった。」
StyleGAN
スタイル変換の技術を基にGeneratorのアーキテクチャを設計し直したことで
画像合成の過程をコントロールすることができるようになった
Style-based generator
StyleGANのGenerator
図のAはアフィン変換、Bは足し合わせができるようにノイズのチャンネル変換を行うことを意味する構成
Style-based generatorではこれまでのような入力層をまるごとなくして全結合層を連ねたものにする
Mapping network fは8層で構成されSynthesis network gは18層で構成されている流れ(上図の矢印を追う)
Mapping network fで入力である潜在変数zを一度潜在空間Wにマッピングする。
潜在変数wはアフィン変換されることでスタイルyになる
スタイルyは各convolution層後でのAdaIn処理で使われ、Generatorをコントロールする。
ガウシアンノイズをAdaInと各convolution層の間に加える。
最終層の出力は1×1のconvolution層を使ってRGBに変換する
解像度は4×4で始まり、最終的に1024×1024
Style-based generatorの合計パラメーター数は26.2M
従来のGeneratorの合計パラメーター数は23.1M
これまでの改良の流れ
様々な改良をすることで画像のクオリティを上げてきた
評価指標はFID
FIDはGANの生成分布と真のデータ分布の距離を表す指標
数値は低いほど良いことを意味する(A)
ベースラインとして設定したのはProgressive GAN
ネットワークとハイパーパラメーターの変更はしておらず、提案されたままを使った(B)
ベースラインの改良として、bilinear up/downsamplingとハイパーパラメーターチューニングをした(C)
更にベースラインの改良として、マッピングネットワークとAdaIN処理を加えた
この時点で、従来通り最初のconvolution層に潜在変数を与えるネットワークでは改善の余地がないという見解に至った(D)
これまでの入力層を取り除き4×4×512のconstant tensorで画像生成を始めるというシンプルなアーキテクチャにしたsynthesis network(Generator)は
AdaINをコントロールするスタイルのみの入力で素晴らしい生成ができることがわかった(E)
ノイズを入れることで更に改善(F)
mixing regularizationを導入により
隣接したスタイルの相互関係をなくし、より洗練された画像を生成することができるStyle mixing
スタイルを細部にも適用できるようにmixing regularizationを導入する
訓練時、画像の指定範囲分(%)の生成を
1つのランダム潜在変数ではなく2つのランダム潜在変数を使ってすること
テスト時は下記結果表が示すように3つ以上でも実行されているSynthesis networkのランダムに選ばれたところで潜在変数を他のものに切り替える(これをstyle mixingと呼ぶ)
具体的には、Mapping networkではz1とz2という2つの潜在変数を実行する
Synthesis networkではw1を適用して、その後ランダムに選ばれたところからw2を適用するこの正則化手法により、隣り合ったスタイルは相互に関連しているということをネットワークが仮定せずに生成することができる
テスト結果
潜在変数の数(Number of latents during testing)と潜在変数を混ぜて生成する比率(Mixing regularization)を変えて結果を表にして示している
評価指標はFID
FIDはGANの生成分布と真のデータ分布の距離を表す指標
数値は低い方が良い結果表のE,Fは最初に見た表のE,Fと対応している
Mixing regularizationの比率を大きくすることで結果が良くなっているのがわかる
2つの潜在変数を混ぜて生成された画像
1つの潜在変数で生成されたスタイル(source)に、同じく1つの潜在変数から生成されたスタイル(destination)を合わせると画像はどのように変化していくのかを可視化している・解像度が粗い段階で合わせた場合(4×4 ~ 8×8)
顔の向き・髪型・顔の形・眼鏡のような大まかな特徴はsourceの要素が画像で表現されている一方で、目・髪・明暗のような色や顔の特徴はdestinationの要素が表現されている・解像度(16×16 ~ 32×32)の場合
顔の特徴・髪型・目の特徴がsourceの要素で
顔の向きや顔の形や眼鏡がdestinationの要素で構成されている・高解像度(64×64 ~ 1024×1024)の場合
配色や細部のデザインはsource由来になっているノイズの効果
・確率的特徴
正しい分布に従って生成されていれば、ランダムに生成しても画像の見た目に大きな影響を与えない特徴
例)髪質や髪の流れ、ヒゲ、そばかす、肌質従来のジェネレーターが確率的特徴を生成する場合、
入力層への入力のみになるため、ネットワークは必要となったら以前のアクティベーションから
空間的に変化する疑似乱数を生成しなくてはならないこれはネットワーク容量を消費し、周期性がなく本当にランダムな乱数を生成することは困難で成功する保証はない
本研究のアーキテクチャでは各convolution層の後に、ピクセルごとのノイズを加えることでこれらの問題を解決する
例1
上図はベースとなる生成画像は同じでノイズだけを変えた場合の結果である
ノイズは確率的特徴(毛の流れ)だけを変化させて、その他の高レベルな特徴(顔の特徴や向きなど)はそのままである
上図右の白黒の画像はどこがノイズの影響を受けているかを表している
白い部分がノイズの影響を受けている部分ほとんどが髪の毛、輪郭、背景だが、目の反射も白くなっているのは興味深い点
例2
この図もノイズがどのように生成画像を変化させるかについてである
男性の生成画像も同じように(a)(b)(c)(d)で分割して見てほしい(a)すべての層でノイズを加えた場合
(b)ノイズを全く加えない場合
(c)ノイズを解像度がきれいな層(64×64 ~ 1024×1024)でのみノイズを加える場合
(d)ノイズを解像度が粗い層(4×4 ~ 32×32)でのみノイズを加える場合(a)と(b)を比較するとわかるが、
ノイズを加えないことで特徴のない絵画っぽい(リアルではない)画像が生成される(d)ノイズを解像度が粗い層(4×4 ~ 32×32)でのみノイズを加える場合、
髪の毛のカールが大きくなっていたり、背景の特徴が大きく表現されている(c)ノイズを解像度がきれいな層(64×64 ~ 1024×1024)でのみノイズを加える場合、
髪の毛のカール、背景、肌質が細かくきれいに描かれていているスタイルとノイズのまとめ
スタイルを変化させることは全体的な影響(姿勢、向き、顔の特徴を変える)を与えるのに対して、
ノイズはそこまで重要ではない部分(髪の毛の流れやヒゲ)に影響を与えるスタイルが画像全体に影響を与えるのはすべての特徴マップが同じ値でスケール変換、バイアス変換されるからである(AdaIn処理)
そのため、画像全体への影響(姿勢、明暗、背景)は一貫してコントロールされる一方ノイズは独立的にピクセルごとに加えられ、確率的な変化をコントロールするには理想的である
もし生成画像の姿勢を変えたいときにノイズの使ってしまったら、
矛盾した選択でありDiscriminatorに見破られてしまうネットワークは明確な指示がなくても、適切にスタイルとノイズを使えるように学習する
潜在空間Wの必要性
上図は2つの変動要因(男性らしさと髪の長さ)だけを考えた例(a)訓練データの特徴分布
長い髪の男性など一部の組み合わせが存在しない訓練データ(b)Zから特徴表現へのマッピング(従来のやり方)
訓練データになかった組み合わせ(長い髪の男性)がサンプリングされないようにするため
Zから画像特徴へのマッピングは曲線になる(c)Wから特徴表現へのマッピング(本研究)
ZからWへのマッピングは学習されたマッピングであるため、このゆがみを元に戻すことができる仮定
特徴が絡み合っている表現に基づいてリアルな画像を生成するよりも、
それぞれの特徴がしっかり分解されている表現に基づいてリアルな画像を生成する方が容易であるはず例)人の顔を生成したいとき
・特徴が絡み合っている
→この軸を調整すると、目が大きくなって髪が長くなって輪郭が丸くなるみたいになると
各軸が複雑に影響し合って生成しづらい・特徴がしっかり分解されている
→この軸は目の大きさ、この軸は髪の長さ、この軸は輪郭みたいに特徴が独立していると
生成がしやすい目標
線形部分空間(それぞれの線形部分空間が1つの変動要因をコントロールする)を用意する
変動要因が事前にわかっていない状況の中で、学習によって可能な限り特徴が分解されたWができることが理想問題
ただし、従来のGANのようなアーキテクチャでは
Z内の各要因の組み合わせのサンプリング確率は、学習データ内の対応する密度と一致する必要がある
そのため、各要因がデータセットの分布と入力潜在分布から完全に分解することができない対策
本研究のGeneratorが優れている点は
中間潜在空間Wは任意の固定分布に従ってサンプリングする必要がないことWのサンプリング密度は学習された区分的連続写像f(z)(線形変換である全結合層を8つ重ねて計算する)によってできたものを使う
このマッピングによって、変動要因はより線形になりゆがみのない潜在空間Wができる
指標
「特徴が分解されている」ということを定量化するための指標が最近提案されたのだが、
残念なことにその指標を使うには入力画像を潜在変数にマッピングするエンコーダーがなくてはならない
本研究ではそういったエンコーダーは使っていないため適した指標とは言えない
そのためにエンコーダーをわざわざ追加することもできるが、根本的解決にはならないのでやらないその代りに新しい定量化手法を2つ提案する
その指標の場合はエンコーダーを必要とせず、変動要因を事前に知らなくていいため
どんな画像データセットやGeneratorでも問題ない新指標1:Perceptual path length
潜在空間のinterpolation(上図)をすると両端の画像(①や⑨)にはない特徴が中間の画像(④、⑤、⑥)に現れるという非線形な変化が起こることがある
これは潜在空間が絡み合っていて変動要因が適切に分離されていないことを示す潜在空間でinterpolationをしたときに、どれだけ急激に画像が変化するかを測ることでこの効果を定量化することができる
直感的には、曲りの大きい曲線の潜在空間よりも曲りの少ない曲線の潜在空間の方が画像がなめらかに変化していくと考えられる
方法
2枚の画像の距離を測定する
この計算はVGG16のembeddingで計算されるため、人間が2枚の画像を見たときに感じる画像の類似性と一致するようになっている定義上は潜在空間のinterpolation pathを線形セグメントに無限に細分化した状況で計測することになっているが、
実際にはepsilon(10のマイナス4乗)を用いて近似計算する潜在空間Zの取り得るすべての両端(①や⑨)の平均距離(perceptual path length)の定義は以下のようになる
G・・・Generator
D・・・画像間の距離を計測
slerp・・・標準化された入力潜在空間のinterpolationに最も適した球状interpolation
潜在空間Wの場合は以下のようになる
Wのベクトルは標準化されていないため線形interpolation(lerp)
結果1
・ノイズありのStyle-based generator(本研究のgenerator)が最もpath lengthが短くなった
これはWがZよりも知覚的に線形であることを意味している・Style mixingができるようなネットワークにすると中間潜在空間Wを多少ゆがませてしまうようだ
・Style mixingによって、Wが複数のスケールにわたる変動要因をエンコードすることを困難にしていると仮定できる結果2
Path lengthがマッピングネットワークからどのように影響を受けているかを示している従来のGeneratorでも本研究のstyle-based generatorでもマッピングネットワークを持つことは有益である
深さを増すこともほとんどのPath lengthとFIDで良い結果につながっている従来のGeneratorのlwは向上しているのに対し、lzは悪化している点を見ると
これまでの様々なGANモデルの入力潜在空間が無作為に絡み合っていることがわかる新指標2:Linear separability
潜在空間が十分に分解されていれば、個々の変動要因に対応した方向ベクトルを見つけることができるはず
この効果を定量化する指標がLinear separability
どれだけ上手に潜在空間の点を線形超平面で2つに分けられるかを計測する
分けられた2つはそれぞれ、画像のバイナリ属性に対応する(例:片方は男性、もう片方は女性)方法
①生成画像にラベルを付けるために、画像の二値分類(男性と女性の顔を見分ける)ができる補助ネットワーク(Discriminatorと同じアーキテクチャ)を訓練する
②訓練データはCelebA-Hデータセット(元のCelebAデータセットの中の40属性を保持するデータセット)
属性の分離度を測るために20万枚の画像を生成し補助ネットワークを使って分類する
分類器のスコアが高い10万枚だけをラベル付きの潜在空間ベクトルとする③各属性について、潜在空間点(従来の場合はz, style-basedではw)に基づいたラベルを予測するために線形SVMで学習する
④超平面がどれほど正確に点を分類できたかを条件付きエントロピーH(Y|X)で計算する
X・・・SVMで予測したクラス
Y・・・補助ネットワークが決めたクラス条件付きエントロピーは正しいクラス分類をするために、どれほど追加情報が必要かを示している
もし変動要因が矛盾した潜在空間の方向を持っていたら、サンプル点を超平面でわけるのは一層難しいため
条件付きエントロピーは高い数値になる低い数値になるということは簡単に分けられたということを示す
すなわち属性が対応する要因と潜在空間の方向が一致したことを意味する最終的な分離スコアは下記のように求める
iは40属性
潜在空間Wのまとめ
・結果1と結果2からWはZよりも分離しやすい(表現が絡み合っていない)ことがわかる
・マッピングネットワークの深さを増すことは画質とWの分離性を向上させる
これは合成ネットワーク(Synthesis network)がもつれを解消した入力表現を好むという仮説と一致している・従来のジェネレータの前にマッピングネットワークを追加するとZの分離性が大幅に失われるが、中間潜在空間Wの状況は改善されFIDの結果も良くなる
これは訓練データの分布に従わなくてよい中間潜在空間を導入すると、従来のジェネレータアーキテクチャでもパフォーマンスが向上することを示している全体まとめ
・従来のGANアーキテクチャは様々な点でStyleGANよりも劣っていることが明らかになった
・高レベルの属性(スタイル)と確率的効果(ノイズ)の分離、中間潜在空間の線形性に対する調査が
StyleGANの理解を深める上で有益であると確信している・Path length指標とLinear separability指標が訓練時の正則化として容易に使えることも示した
・訓練時に直接、中間潜在空間を形成する方法が今後の研究のキーになっていくと考えている
FFHQデータセット
FlickrFaces-HQ (FFHQ)という顔画像のデータセットを提供する
・70000枚
・解像度:1024×1024
・データセットは年齢・民族・視点・明暗・画像の背景に関して多様な種類がある
・眼鏡・サングラス・帽子などを身に着けた画像も十分に用意されている論文
画像引用
https://users.aalto.fi/~laines9/publications/laine2018iclr_paper.pdf
- 投稿日:2019-02-11T17:44:53+09:00
pandas の DataFrame と SQL の記述方法の比較
動機
仕事で AI や機械学習、データ分析といった技術を身に付ける必要性ができ、
まずは Python を使ったデータ分析を修得するために pandas を
利用したデータ分析にチャレンジしています。自分にはシステム開発経験があり SQL には使い慣れているのですが、
pandas のデータ分析の記述方法があまり理解できない状況でした。巷では「pandas は SQL と似ている」といった表現をよく聞くので、
それならば SQL での書き方を pandas の書き方と比較したら
理解が深まるのではないかと思い、今回まとめてみました。なお本記事は、ある程度のターミナル操作や
MySQL、Python、pandas についての知識がある方を対象としています。なお、ここからの説明は長いためコードの比較結果のみを見たい場合は、
比較結果まとめを参照ください。環境
項目 内容 OS CentOS Linux release 7.5.1804 DB 5.7.23-23 Percona Server (GPL), Release 23, Revision 500fcf5 Python anaconda3-5.3.1 / Python 3.7.0 Editor jupyterlab Version 0.34.9 ブラウザ Google Chrome 71.0.3578.98 DB は、MySQL 互換の「Percona Server」です。
MySQL のコマンドはすべてターミナルより直接入力します。詳細は割愛しますが、Windows をホストマシンとし、
vagrant でゲスト OS に Linux を使っています。また Linux では pyenv を利用して、一部パスのみ
上記 Python のバージョンとして動作するように設定しています。利用データ
MySQL のサンプルデータを使います。
https://dev.mysql.com/doc/index-other.html
Example Databases → world database
このような素晴らしいサンプルデータがあることに感謝します。
今回は次のデータを利用します。
- データベース:world
- テーブル:
- city
- country
環境準備
ダウンロードした MySQL のサンプルデータを解凍し、次のようなコマンドでデータベースに取り込みます。
「world」という名前のデータベース(スキーマ)を作成するため、事前に利用するデータベースに重複する名前がないか確認することをお勧めします。
mysql -u [MySQLのユーザー] -p < world.sqlMySQL にログイン後、データベースが作成されていることを確認したら、 次のようなコマンドで、今度はタブ区切りの csv ファイルを作成します。
mysql -u [MySQLのユーザー] -p world -e "SELECT * FROM city;" > city.csv mysql -u [MySQLのユーザー] -p world -e "SELECT * FROM country;" > country.csv今回は「data」というディレクトリを作って保存したため、
csvファイルのパスは次の通りになります。
- data/city.csv
- data/country.csv
Python コード
Python では、jupyterlab で次のようなコードを記述して
csv ファイルのデータを pandas の DataFrame に取り込みます。import pandas as pd city = pd.read_csv("data/city.csv", sep="\t") country = pd.read_csv("data/country.csv", sep="\t")抽出方法の比較
1. 列指定
SQL
SELECT ID, Name, CountryCode FROM city;+----+----------------+-------------+ | ID | Name | CountryCode | +----+----------------+-------------+ | 1 | Kabul | AFG | | 2 | Qandahar | AFG | | 3 | Herat | AFG | | 4 | Mazar-e-Sharif | AFG | | 5 | Amsterdam | NLD | (5件まで)pandas
city[["ID", "Name", "CountryCode"]]
説明
SQL では列名を SELECT句 に指定するのに対して、
pandas では DataFrame のインデックスに列名のリストを指定します。SQLはテーブル定義されているため、列名をダブルクォートで囲む必要がありません。
対して pandas では文字列として指定するためダブルクォートで囲む必要があります。2. 条件指定
SQL
SELECT * FROM city WHERE CountryCode = 'NLD';+----+-------------------+-------------+---------------+------------+ | ID | Name | CountryCode | District | Population | +----+-------------------+-------------+---------------+------------+ | 5 | Amsterdam | NLD | Noord-Holland | 731200 | | 6 | Rotterdam | NLD | Zuid-Holland | 593321 | | 7 | Haag | NLD | Zuid-Holland | 440900 | | 8 | Utrecht | NLD | Utrecht | 234323 | | 9 | Eindhoven | NLD | Noord-Brabant | 201843 | (5件まで)pandas
city[city.CountryCode == "NLD"]
説明
SQL では WHERE句 に条件を指定するのに対して、
pandas では、「ブールインデックス」を使って、
DataFrame のインデックスに条件を指定します。DataFrame のインデックスに
[True, False・・・]のようなリストを、DataFrame のレコード数分指定すると、Trueが指定されたレコードのみを抽出することができます。
city.CountryCode == "NLD"インデックスに指定しているこの式は、
すべてのcityのレコードに対して True または False を返す式です。3. 複数条件指定
SQL
SELECT * FROM city WHERE CountryCode = 'NLD' AND Population < 100000;+----+---------+-------------+---------------+------------+ | ID | Name | CountryCode | District | Population | +----+---------+-------------+---------------+------------+ | 30 | Delft | NLD | Zuid-Holland | 95268 | | 31 | Heerlen | NLD | Limburg | 95052 | | 32 | Alkmaar | NLD | Noord-Holland | 92713 | +----+---------+-------------+---------------+------------+pandas
city[(city.CountryCode == "NLD") & (city.Population < 100000)]
説明
SQL では AND で条件をつなぎますが、
pandas では「&」で条件をつなぎます。各条件式は()で囲む必要があります。
ブールインデックス同士で両方とも True になるレコードが抽出されます。4. 複数条件指定(同項目内)
SQL
SELECT * FROM city WHERE CountryCode IN ('SMR', 'TCD', 'SOM');+------+-------------+-------------+-------------------+------------+ | ID | Name | CountryCode | District | Population | +------+-------------+-------------+-------------------+------------+ | 3170 | Serravalle | SMR | Serravalle/Dogano | 4802 | | 3171 | San Marino | SMR | San Marino | 2294 | | 3214 | Mogadishu | SOM | Banaadir | 997000 | | 3215 | Hargeysa | SOM | Woqooyi Galbeed | 90000 | | 3216 | Kismaayo | SOM | Jubbada Hoose | 90000 | | 3337 | N´Djaména | TCD | Chari-Baguirmi | 530965 | | 3338 | Moundou | TCD | Logone Occidental | 99500 | +------+-------------+-------------+-------------------+------------+pandas
city[city.CountryCode.isin(["SMR", "TCD", "SOM"])]
説明
SQL では、IN句 でカンマ区切りに条件を指定します。
pandas では、DataFrame の isin関数 を利用します。isin関数 の引数に条件をリストで指定します。
5. 件数指定
SQL
SELECT * FROM city LIMIT 5;+----+----------------+-------------+---------------+------------+ | ID | Name | CountryCode | District | Population | +----+----------------+-------------+---------------+------------+ | 1 | Kabul | AFG | Kabol | 1780000 | | 2 | Qandahar | AFG | Qandahar | 237500 | | 3 | Herat | AFG | Herat | 186800 | | 4 | Mazar-e-Sharif | AFG | Balkh | 127800 | | 5 | Amsterdam | NLD | Noord-Holland | 731200 | +----+----------------+-------------+---------------+------------+pandas
city.head(5)
説明
SQL では、LIMIT句 を利用して取得します。
pandas では head関数 を利用します。
また、最後のレコードを取得する tail関数 も存在します。6. 並び替え
SQL
SELECT * FROM city ORDER BY Population DESC;+------+-----------------+-------------+--------------+------------+ | ID | Name | CountryCode | District | Population | +------+-----------------+-------------+--------------+------------+ | 1024 | Mumbai (Bombay) | IND | Maharashtra | 10500000 | | 2331 | Seoul | KOR | Seoul | 9981619 | | 206 | São Paulo | BRA | São Paulo | 9968485 | | 1890 | Shanghai | CHN | Shanghai | 9696300 | | 939 | Jakarta | IDN | Jakarta Raya | 9604900 | (5件まで)pandas
city.sort_values(by="Population", ascending=False)
説明
SQL では、ORDER BY句 を利用して並び順を指定します。
pandas では、DataFrame の sort_values関数 を利用します。引数の by に文字列で列を指定して、降順にする場合は、
引数の ascending に False を設定します。7. 件数
SQL
SELECT COUNT(*) FROM city;+----------+ | COUNT(*) | +----------+ | 4079 | +----------+pandas
len(city)
説明
SQL では COUNT関数 を使います。
pandas では複数方法はありますが、len関数 の引数に
DataFrame を指定する方法が SQL とも似ていて分かりやすいと思います。8. 合計
SQL
SELECT SUM(Population) FROM city;+-----------------+ | SUM(Population) | +-----------------+ | 1429559884 | +-----------------+pandas
city.Population.sum()
説明
SQL では、SUM関数 を利用します。
pandas では、DataFrame の列に対して合計をとることをオブジェクト指向の方法で sum関数 を使って行います。9. 平均
SQL
SELECT AVG(Population) FROM city;+-----------------+ | AVG(Population) | +-----------------+ | 350468.2236 | +-----------------+pandas
city.Population.mean()
説明
SQL では、AVG関数 を使います。
pandas では、DataFrame の列に対して合計をとることをオブジェクト指向の方法で mean関数 を使って行います。MySQL ではデフォルトの計算では、
Python に比べて精度の低いものになっています。
MySQL で小数精度を高める方法の一つとして、あらかじめ大きな数をかけて整数とし、
平均をとった後に同じ数で割る方法があります。MySQL では次のような SQL になります。
SELECT FORMAT(AVG(Population * 100000000000) / 100000000000, 20) FROM city;+-----------------------------------------------------------+ | FORMAT(AVG(Population * 100000000000) / 100000000000, 20) | +-----------------------------------------------------------+ | 350,468.22358421181662172100 | +-----------------------------------------------------------+Python で同様の方法で計算しても結果は変わりませんでした。
あまり取るべき手法ではないと考えられます。((city.Population * 100000000000).mean())/100000000000
掛けて割る値を大きくしすぎると、
問題が起きるので気を付ける必要があります。
MySQL ではエラーに、pandas では、不正値が出力されます。SQL(エラー)
ERROR 1690 (22003): BIGINT value is out of range in '(`world`.`city`.`Population` * 1000000000000)'pandas(エラー)※不正計算
((city.Population * 1000000000000).mean())/1000000000000
10. データ定義
SQL
desc city;+-------------+----------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +-------------+----------+------+-----+---------+----------------+ | ID | int(11) | NO | PRI | NULL | auto_increment | | Name | char(35) | NO | | | | | CountryCode | char(3) | NO | MUL | | | | District | char(20) | NO | | | | | Population | int(11) | NO | | 0 | | +-------------+----------+------+-----+---------+----------------+pandas
city.dtypes
説明
MySQL では、desc コマンドを利用します。
SHOW CREATE TABLE city\Gにすると、
テーブル作成クエリを確認できます。pandas では、dtypesプロパティ で確認できます。
11. あいまい条件指定
SQL
SELECT * FROM city WHERE LOWER(Name) LIKE '%nab%';+------+---------------------+-------------+-------------------+------------+ | ID | Name | CountryCode | District | Population | +------+---------------------+-------------+-------------------+------------+ | 38 | Annaba | DZA | Annaba | 222518 | | 835 | Panabo | PHL | Southern Mindanao | 133950 | | 1551 | Funabashi | JPN | Chiba | 545299 | | 1831 | Burnaby | CAN | British Colombia | 179209 | | 2925 | Guaynabo | PRI | Guaynabo | 100053 | | 3114 | Osnabrück | DEU | Niedersachsen | 164539 | | 3610 | Nabereznyje Tšelny | RUS | Tatarstan | 514700 | | 4078 | Nablus | PSE | Nablus | 100231 | +------+---------------------+-------------+-------------------+------------+pandas
city[city.Name.str.lower().str.contains("nab")]
説明
SQL では、LIKEステートメントを利用して、
正規表現の記号として「%」を利用します。
文字列を条件にする場合、大文字・小文字の区別がされない設定に
されていることが多いです。今回はわかりやすくするため LOWER関数 を利用しましたが、
この関数を利用しなくても結果は同じです。pandas では、少し工夫が必要で、文字列の列にある strアクセサを使います。
大文字・小文字を区別させない場合は、lower関数 を利用して小文字状態で確認します。また、今回は「nab」を含むことを条件としているため、
同じく strアクセサ の containsメソッド を利用しています。12. グループ化
SQL
SELECT CountryCode, COUNT(*) FROM city GROUP BY CountryCode;+-------------+----------+ | CountryCode | COUNT(*) | +-------------+----------+ | ABW | 1 | | AFG | 4 | | AGO | 5 | | AIA | 2 | | ALB | 1 | (5件まで)pandas
city.groupby("CountryCode", as_index=False).count()[["CountryCode","ID"]]
説明
SQL では以下を指定するのがポイントです。
- 抽出列
- グループ集計関数
- GROUP BY句
「抽出列」と「GROUP BY句」に指定する列名を同じにし、
必要なグループ集計関数を指定すれば、グループ化されたデータを
抽出することができます。pandas では、「軸」の考え方が重要で、SQL で抽出列に該当するものです。
この軸を groupby関数 の引数に文字列で指定して、
どこのの列を集計処理するのか、どのように集計するのかを関数にすることでグループ化したデータを抽出することができます。今回は次の通りです。
- 軸 ⇒ CountryCode
- どこの列を集計処理 ⇒ ID
- どのように集計 ⇒ 件数を集計(count)
as_index に False を指定しているのは、
指定しないと、軸をインデックスに設定してしまうので
他と違い扱いづらくなるためです。13. テーブル結合
SQL
SELECT city.CountryCode, country.Name AS CountryName, city.Name AS CityName FROM city LEFT JOIN country ON city.CountryCode = country.Code;+-------------+-------------+----------------+ | CountryCode | CountryName | CityName | +-------------+-------------+----------------+ | AFG | Afghanistan | Kabul | | AFG | Afghanistan | Qandahar | | AFG | Afghanistan | Herat | | AFG | Afghanistan | Mazar-e-Sharif | | NLD | Netherlands | Amsterdam | (5件まで)pandas
country_city = pd.merge(city, country, how="left", left_on="CountryCode", right_on="Code" )[["CountryCode", "Name_y", "Name_x"]] country_city.columns = ["CountryCode", "CountryName", "CityName"] country_city
説明
SQL では、LEFT JOIN句 を使って結合するテーブルと、
結合条件を指定します。
また列名は AS句 を使ってエイリアス指定により変更します。pandas では処理が2段階に分かれます。
まずは、pandas の merge関数 を使って
結合するデータを2つ指定し、結合方法、結合条件となる列名を指定します。「Name_y」「Name_x」としているのは、
city、country ともに「Name」という列を保持しているため、
pandas がデフォルトで重複する場合にサフィックスとして「_x」「_y」を
つけるためです。次に columnsプロパティ に新しい列名を設定しています。
14. グループ化 + 並び替え + 件数指定 + 件数
SQL
SELECT CountryCode, COUNT(*) AS cnt FROM city GROUP BY CountryCode ORDER BY cnt DESC LIMIT 7;+-------------+-----+ | CountryCode | cnt | +-------------+-----+ | CHN | 363 | | IND | 341 | | USA | 274 | | BRA | 250 | | JPN | 248 | | RUS | 189 | | MEX | 173 | +-------------+-----+pandas
city.groupby("CountryCode", as_index=False)[["ID"]].count().sort_values(by="ID", ascending=False).head(7)
説明
SQL では、グループ集計と並び替え、指定件数を組み合わせただけになります。
pandas では、少々複雑で次の順番でデータ抽出を考えてコードを作りました。
- グループ化
- 抽出列指定
- 集計関数指定
- 並び替え指定
- 抽出件数指定
どの処理も DataFrame を返すので処理順を考えて指定するのがポイントです。
比較結果まとめ
1. 列指定 SQL SELECT ID, Name, CountryCode FROM city; pandas city[["ID", "Name", "CountryCode"]]
2. 条件指定 SQL SELECT * FROM city WHERE CountryCode = 'NLD'; pandas city[city.CountryCode == "NLD"]
3. 複数条件指定 SQL SELECT * FROM city WHERE CountryCode = 'NLD' AND Population < 100000; pandas city[(city.CountryCode == "NLD") & (city.Population < 100000)]
4. 複数条件指定(同項目内) SQL SELECT * FROM city WHERE CountryCode IN ('SMR', 'TCD', 'SOM'); pandas city[city.CountryCode.isin(["SMR", "TCD", "SOM"])]
5. 件数指定 SQL SELECT * FROM city LIMIT 5; pandas city.head(5)
6. 並び替え SQL SELECT * FROM city ORDER BY Population DESC; pandas city.sort_values(by="Population", ascending=False)
7. 件数 SQL SELECT COUNT(*) FROM city; pandas len(city)
8. 合計 SQL SELECT SUM(Population) FROM city; pandas city.Population.sum()
9. 平均 SQL SELECT AVG(Population) FROM city; pandas city.Population.mean()
10. データ定義 SQL desc city; pandas city.dtypes
11. あいまい条件指定 SQL SELECT * FROM city WHERE LOWER(Name) LIKE '%nab%'; pandas city[city.Name.str.lower().str.contains("nab")]
12. グループ化 SQL SELECT CountryCode, COUNT(*) FROM city GROUP BY CountryCode; pandas city.groupby("CountryCode", as_index=False).count()[["CountryCode","ID"]]
13. テーブル結合 SQL SELECT city.CountryCode, country.Name AS CountryName, city.Name AS CityName
FROM city LEFT JOIN country ON city.CountryCode = country.Code;pandas country_city = pd.merge(city, country,
how="left", left_on="CountryCode", right_on="Code"
)[["CountryCode", "Name_y", "Name_x"]]
country_city.columns = ["CountryCode", "CountryName", "CityName"]
country_city
14. グループ化 + 並び替え + 件数指定 + 件数 SQL SELECT CountryCode, COUNT(*) AS cnt
FROM city GROUP BY CountryCode ORDER BY cnt DESC LIMIT 7;pandas city.groupby("CountryCode", as_index=False)[["ID"]].count().sort_values(by="ID", ascending=False).head(7) 所感
pandas での書き方だけで考えていたらあまり理解できませんでしたが、
SQL で書いたものを pandas で書く、と考えたところ理解しやすく感じました。抽出条件が複雑になると SQL の方が組み立てやすく、
pandas では特徴を理解して工夫をする必要があるように感じました。
この辺りは実践で反復して身に付ける必要があると思います。pandas では、戻り値が2次元データの DataFrame なのか、
1次元データの Series なのかを考えるのがコツに感じました。DataFrame であればその後ろに DataFrame 用の
関数や記述ができるので、少し複雑になっても組み合わせられると思います。Series であれば値がすべてブール型ならば、
DataFrame のインデックスに指定して条件とできると考えるのがよいと思います。以上です。
この記事が同じようなことを考えられている方にとって、
有用になれば幸いです。


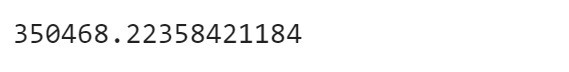


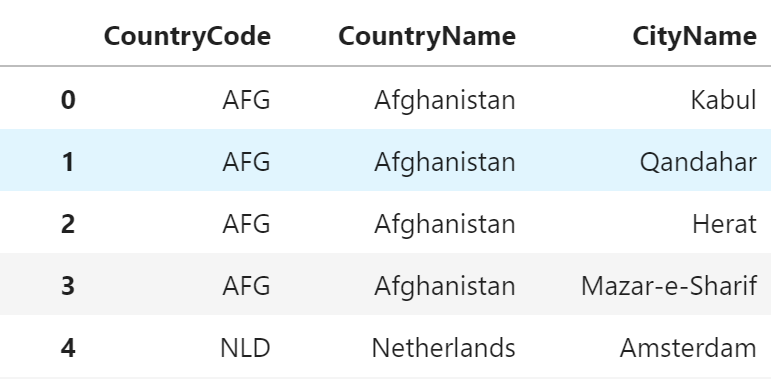
- 投稿日:2019-02-11T17:30:02+09:00
WSLでMeCabとJupyter Notebookを動かす
WSLでMeCabとJupyter Notebookを動かす
PythonはWindowsでも動きますが、いざ色々やろうとするとUbuntu対応だってことが多いですね。
(そんな時のために?)Windows10ではWindows Subsystem for Linux(WSL)があるのですが、今回MeCabを入れて、Jupyter Notebookで動かしてみるのにそこそこ苦労したので、ご紹介します。
たぶんもう一回やろうとしても難しいので、備忘録です。尚、MeCabについては、下記を参考にしています。
https://github.com/neologd/mecab-ipadic-neologd/blob/master/README.ja.mdWSLインストール
下記リンクの手順なのですが、UbuntuはUbuntu 18.04 LTSを入れました。
尚、一度入れていたUbuntuではMeCabのインストールが行かなかった(MeCabが見つからなかった)ので、アンインストールしてやり直しました。
リンクの手順ではPower ShellでWSLを有効にしていますが、コントロールパネルからでも(おそらく)同じだと思います。
https://docs.microsoft.com/ja-jp/windows/wsl/install-win10
Ubuntu起動
スタートメニューからUbuntu 18.04を最初に起動すると、下記のようにusernameとpasswordを設定します。
Installing, this may take a few minutes... Please create a default UNIX user account. The username does not need to match your Windows username. For more information visit: https://aka.ms/wslusers Enter new UNIX username: XXXXXXXX Enter new UNIX password: Retype new UNIX password: passwd: password updated successfully Installation successful! To run a command as administrator (user "root"), use "sudo <command>". See "man sudo_root" for details.aptitudeインストール
手順ではaptitudeを使うとありますが、
aptitude: command not foundと怒られるので、インストールします。
尚、sudoコマンドを最初に使うときには、passwordを求めらます。sudo apt-get install aptitude [sudo] password for XXXXXXXX:Do you want to continue? [Y/n] yinstallが終わったら、手順の通りupdateとupgradeします。
sudo aptitude updatesudo aptitude upgradeDo you want to continue? [Y/n] yMeCabインストール
手順の通りMeCabその他をインストールします。Ubuntuを再インストールする前はここでエラーが出てました。
sudo aptitude install make automake autoconf autotools-dev m4 mecab libmecab-dev mecab-ipadic-utf8 git make curl xz-utils fileDo you want to continue? [Y/n] ysudo sed -i -e 's%/lib/mecab/dic%/share/mecab/dic%' /usr/bin/mecab-configmecab-ipadic-NEologd をインストール
~$ git clone --depth 1 https://github.com/neologd/mecab-ipadic-neologd.git Cloning into 'mecab-ipadic-neologd'... remote: Enumerating objects: 75, done. remote: Counting objects: 100% (75/75), done. remote: Compressing objects: 100% (74/74), done. remote: Total 75 (delta 5), reused 55 (delta 0), pack-reused 0 Unpacking objects: 100% (75/75), done.~$ cd mecab-ipadic-neologd ~/mecab-ipadic-neologd$ ./bin/install-mecab-ipadic-neologd -n[install-mecab-ipadic-NEologd] : Do you want to install mecab-ipadic-NEologd? Type yes or no. yesインストール先はオプション未指定の場合 mecab-config に従って決まります。
以下のコマンドを実行すると確認できます。~/mecab-ipadic-neologd$ echo `mecab-config --dicdir`"/mecab-ipadic-neologd" /usr/lib/x86_64-linux-gnu/mecab/dic/mecab-ipadic-neologdテスト
~$ echo "8月3日に放送された「中居正広の金曜日のスマイルたちへ」(TBS系)で、1日たった5分でぽっこ りおなかを解消するというダイエット方法を紹介。キンタロー。にも密着。" | mecab 8 名詞,数,*,*,*,*,* 月 名詞,一般,*,*,*,*,月,ツキ,ツキ 3 名詞,数,*,*,*,*,* 日 名詞,接尾,助数詞,*,*,*,日,ニチ,ニチ に 助詞,格助詞,一般,*,*,*,に,ニ,ニ 放送 名詞,サ変接続,*,*,*,*,放送,ホウソウ,ホーソー さ 動詞,自立,*,*,サ変・スル,未然レル接続,する,サ,サ れ 動詞,接尾,*,*,一段,連用形,れる,レ,レ た 助動詞,*,*,*,特殊・タ,基本形,た,タ,タ 「 記号,括弧開,*,*,*,*,「,「,「 中居 名詞,固有名詞,人名,姓,*,*,中居,ナカイ,ナカイ 正広 名詞,固有名詞,人名,名,*,*,正広,マサヒロ,マサヒロ の 助詞,連体化,*,*,*,*,の,ノ,ノ 金曜日 名詞,副詞可能,*,*,*,*,金曜日,キンヨウビ,キンヨービ の 助詞,連体化,*,*,*,*,の,ノ,ノ スマイル 名詞,一般,*,*,*,*,スマイル,スマイル,スマイル たち 名詞,接尾,一般,*,*,*,たち,タチ,タチ へ 助詞,格助詞,一般,*,*,*,へ,ヘ,エ 」( 名詞,サ変接続,*,*,*,*,* TBS 名詞,一般,*,*,*,*,* 系 名詞,接尾,一般,*,*,*,系,ケイ,ケイ ) 名詞,サ変接続,*,*,*,*,* で 助詞,格助詞,一般,*,*,*,で,デ,デ 、 記号,読点,*,*,*,*,、,、,、 1 名詞,数,*,*,*,*,* 日 名詞,接尾,助数詞,*,*,*,日,ニチ,ニチ たっ 動詞,自立,*,*,五段・タ行,連用タ接続,たつ,タッ,タッ た 助動詞,*,*,*,特殊・タ,基本形,た,タ,タ 5 名詞,数,*,*,*,*,* 分 名詞,接尾,助数詞,*,*,*,分,フン,フン で 助動詞,*,*,*,特殊・ダ,連用形,だ,デ,デ ぽ 形容詞,接尾,*,*,形容詞・アウオ段,ガル接続,ぽい,ポ,ポ っ 動詞,非自立,*,*,五段・カ行促音便,連用タ接続,く,ッ,ッ こり 動詞,自立,*,*,一段,連用形,こりる,コリ,コリ おなか 名詞,一般,*,*,*,*,おなか,オナカ,オナカ を 助詞,格助詞,一般,*,*,*,を,ヲ,ヲ 解消 名詞,サ変接続,*,*,*,*,解消,カイショウ,カイショー する 動詞,自立,*,*,サ変・スル,基本形,する,スル,スル という 助詞,格助詞,連語,*,*,*,という,トイウ,トユウ ダイエット 名詞,サ変接続,*,*,*,*,ダイエット,ダイエット,ダイエット 方法 名詞,一般,*,*,*,*,方法,ホウホウ,ホーホー を 助詞,格助詞,一般,*,*,*,を,ヲ,ヲ 紹介 名詞,サ変接続,*,*,*,*,紹介,ショウカイ,ショーカイ 。 記号,句点,*,*,*,*,。,。,。 キンタロー 名詞,一般,*,*,*,*,* 。 記号,句点,*,*,*,*,。,。,。 に 助詞,格助詞,一般,*,*,*,に,ニ,ニ も 助詞,係助詞,*,*,*,*,も,モ,モ 密着 名詞,サ変接続,*,*,*,*,密着,ミッチャク,ミッチャク 。 記号,句点,*,*,*,*,。,。,。 EOSPIPインストール
sudo aptitude install python3-pipmecab-python3インストール
mecab-python3をインストールするのですが、
unable to execute 'swig': No such file or directoryと怒られるのでswigをインストールします。sudo aptitude install swigpip3 install mecab-python3pip3でnumpyなど、他に使うライブラリをインストールします。
(尚、pipをアップグレードしようとして何かやらかしたので、以後 --user を付けないとpip3が動かなくなりました…)Jupyter Notebookインストール
pip3 install ipython[all] --userpip3 install jupyter --userJupyter Notebook起動
jupyter notebookをタイプすると、下記メッセージが出るので、ブラウザのURLに
http://localhost:8888/?token=7517a29f9ebd226603577be161642b11961463aaf2674d05を張り付けるとjupyter notebookが起動します。やったー!~$ jupyter notebook [I 16:16:51.697 NotebookApp] Writing notebook server cookie secret to /home/XXXXXXXX/.local/share/jupyter/runtime/notebook_cookie_secret [I 16:16:52.689 NotebookApp] Serving notebooks from local directory: /home/XXXXXXXX [I 16:16:52.689 NotebookApp] The Jupyter Notebook is running at: [I 16:16:52.690 NotebookApp] http://localhost:8888/?token=7517a29f9ebd226603577be161642b11961463aaf2674d05 [I 16:16:52.691 NotebookApp] Use Control-C to stop this server and shut down all kernels (twice to skip confirmation).MeCabテスト
import MeCabtagger = MeCab.Tagger("-Ochasen") node = tagger.parse("坊主が屏風に上手に坊主の絵を描いた") print(node)坊主 ボウズ 坊主 名詞-一般 が ガ が 助詞-格助詞-一般 屏風 ビョウブ 屏風 名詞-一般 に ニ に 助詞-格助詞-一般 上手 ジョウズ 上手 名詞-形容動詞語幹 に ニ に 助詞-副詞化 坊主 ボウズ 坊主 名詞-一般 の ノ の 助詞-連体化 絵 エ 絵 名詞-一般 を ヲ を 助詞-格助詞-一般 描い エガイ 描く 動詞-自立 五段・カ行イ音便 連用タ接続 た タ た 助動詞 特殊・タ 基本形 EOSdef tokenize(sentence): """日本語の文を形態素の列に分割する関数 :param sentence: str, 日本語の文 :return tokenized_sentence: list of str, 形態素のリスト """ node = tagger.parse(sentence) node = node.split("\n") tokenized_sentence = [] for i in range(len(node)): feature = node[i].split("\t") if feature[0] == "EOS": # 文が終わったら終了 break # 分割された形態素を追加 tokenized_sentence.append(feature[0]) return tokenized_sentence tokenize("坊主が屏風に上手に坊主の絵を描いた")['坊主', 'が', '屏風', 'に', '上手', 'に', '坊主', 'の', '絵', 'を', '描い', 'た']今後の抱負
Windows環境でMeCabは無理かなと思っていたのですが、なんとかできてよかったです。
MeCabとPyTorchを組み合わせてNLPをやりたいのですが、PyTorchのインストールはできていますが、WSLでGPUを有効にできていません。そもそもできるのか不明ですが…import torch device = torch.device("cuda" if torch.cuda.is_available() else "cpu") devicedevice(type='cpu')Bash on Ubuntuの起動設定(追記)
作業フォルダを設定したショートカットを使えば、Ubuntuからデフォルトのフォルダを参照しやすい形で起動できます。
GPUは色々やったけど、だめでした。
ネットを見ても、対応していないようですね…
- 投稿日:2019-02-11T17:24:36+09:00
[python3] すぐに使える numpy の使い方まとめ
はじめに
numpyは、pythonで配列の計算をするためのライブラリです。配列同士の計算が、高速にできる特徴があります。1次元(ベクトル)、2次元(マトリックス)、3次元(テンソル)配列の直感的な演算処理ができます。
numpyと似たpythonライブラリで有名なpandasがあります。(pandasの中でもnumpyは使われています)
[python3] 非IT業務でも使える pandas の基本的な使い方
numpyとの違いは、ざっくり下記のような感じでしょうか。numpyは数字だけを扱うのに特化しているイメージですね。pandasは様々なデータ形式や欠損値への処理が可能なので、機械学習などにおいては、元データをpandasで呼び出して整形、numpyで数値処理 => 機械学習ライブラリへといった流れになるのでは無いでしょうか。
numpy pandas 扱うデータ 数値 様々(数値、文字列、時系列) 計算速度 高速 numpyよりは遅い 得意な処理 配列演算処理 データ整形、欠損値処理 インストール
$ pip3 install numpyインポート
npとしてインポートするのが慣例。
import numpy as npnumpy アレイの作成
pythonリストから作成
単純にpythonリストを渡して、numpyアレイを作成する。
1次元配列my_list = [1, 3, 4, 10] np.array(my_list) # => array([1, 3, 4, 10])2次元配列my_matrix = [[1, 3, 4], [9, 2, 3], [2, 5, 9]] np.array(my_matrix) # => array([[1, 3, 4], # [9, 2, 3], # [2, 5, 9]])numpy関数を使う
np.arange()
pythonのrange()と同じような働きをする、arange()。np.arange(start, end, (step))。
np.arange()np.arange(0, 11) # => array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10]) np.arange(0, 11, 2) # => array([0, 2, 4, 6, 8, 10])np.zeros() / np.ones()
0のみ、1のみの要素を持つ配列の作成
np.zeros()np.zeros(4) # => array([0., 0., 0., 0.,]) np.zeros((3, 2)) # => array([[0., 0.], # [0., 0.], # [0., 0.]])np.ones()np.ones(3) # => array([1., 1., 1.])np.linspace()
始まりと終わりの数字を指定して、均等に分割する。np.arange(start, end, 分割数)。
np.linspace(0,10,3) # => array([ 0., 5., 10.]) np.linspace(0, 10, 10) # => array([ 0. , 1.11111111, 2.22222222, 3.33333333, 4.44444444, # 5.55555556, 6.66666667, 7.77777778, 8.88888889, 10. ])np.eye()
np.eye(3) # => array([[1., 0., 0.], # [0., 1., 0.], # [0., 0., 1.]])random関数
numpyには、ランダムな数値配列を生成する方法が多数ある。
.rand()
与えられた形状配列を作成して、0~1の一様分布からランダムに数値をサンプリングする。
np.random.rand(3) # => array([0.07713379, 0.17275998, 0.57856427]) np.random.rand(4, 4) # => array([[0.1793304 , 0.46509954, 0.29201518, 0.44933199], # [0.72024083, 0.69927245, 0.5703159 , 0.15318234], # [0.25567981, 0.99377745, 0.39728105, 0.25397251], # [0.77973278, 0.79301535, 0.12647443, 0.9207554 ]]).randn()
"正規分布”からサンプリングする。一様分布からサンプリングするrand()とは異なる。
np.random.randn(2) # => array([-0.77946845, -0.61496784]) np.random.randn(3, 3) # => array([[ 0.6605953 , -1.59772636, 0.48223159], # [ 0.97797005, 1.52575177, 0.50617422], # [-1.00068423, -0.40814908, -2.22607208]]).randint()
ランダムに整数を取り出す。注意点として、指定するstart値は含まれるが、end値は含まれない。
例) np.random.randint(2, 8) => 2~7の中からサンプリング。np.random.randint(1, 100) # => 25 np.random.randint(1, 100, 5) # => array([73, 14, 66, 88, 2])numpyアトリビュート、メソッドを使う
下記のような2つの配列を定義する。
arr = np.arange(25) # => array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, # 17, 18, 19, 20, 21, 22, 23, 24]) ranarr = np.random.randint(0,50,10) # => array([ 9, 13, 45, 25, 27, 22, 2, 29, 21, 9])reshape()
同じデータを使用した、新しい形状の配列を返す。
arr.reshape(5, 5) # => array([[ 0, 1, 2, 3, 4], # [ 5, 6, 7, 8, 9], # [10, 11, 12, 13, 14], # [15, 16, 17, 18, 19], # [20, 21, 22, 23, 24]])shape
配列の形状を確認する。メソッドでは無いので、()はつけない。
arr.shape # => (25,) arr.reshape(5, 5).shape # => (5, 5)要素の取り出し
arr = np.arange(0, 11) arr # => array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10]) arr[5] # => 5 arr[1:5] # => array([1, 2, 3, 4])Broadcasting
arr[0:5] = 100 arr # => array([100, 100, 100, 100, 100, 5, 6, 7, 8, 9, 10])Selection
arr = np.arange(1,11) arr # => array([ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10]) arr > 4 # => array([False, False, False, False, True, True, True, True, True, True]) bool_arr = arr > 4 arr[bool_arr] # => array([ 5, 6, 7, 8, 9, 10])配列演算
pythonのlistとは異なり、配列同士の演算が容易に可能。
arr = np.arange(0,11) arr # => array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10]) arr + arr # => array([ 0, 2, 4, 6, 8, 10, 12, 14, 16, 18, 20]) arr * arr # => array([ 0, 1, 4, 9, 16, 25, 36, 49, 64, 81, 100]) arr**4 # => array([ 0, 1, 16, 81, 256, 625, 1296, 2401, 4096, 6561, 10000])Numpyには多くの配列関数が付属している。配列全体で操作を実行するために使用できる。
# 各要素のルートを取得 np.sqrt(arr) # => array([0. , 1. , 1.41421356, 1.73205081, 2. , # 2.23606798, 2.44948974, 2.64575131, 2.82842712, 3. , # 3.16227766]) # 指数関数 np.exp(arr) # => array([1.00000000e+00, 2.71828183e+00, 7.38905610e+00, 2.00855369e+01, # 5.45981500e+01, 1.48413159e+02, 4.03428793e+02, 1.09663316e+03, # 2.98095799e+03, 8.10308393e+03, 2.20264658e+04]) # sin np.sin(arr) # => array([ 0. , 0.84147098, 0.90929743, 0.14112001, -0.7568025 , # -0.95892427, -0.2794155 , 0.6569866 , 0.98935825, 0.41211849, # -0.54402111]) # log np.log(arr) # => array([ -inf, 0. , 0.69314718, 1.09861229, 1.38629436, # 1.60943791, 1.79175947, 1.94591015, 2.07944154, 2.19722458, # 2.30258509])
- 投稿日:2019-02-11T17:24:36+09:00
[python3] numpy の使い方まとめ
はじめに
numpyは、pythonで配列の計算をするためのライブラリです。配列同士の計算が、高速にできる特徴があります。1次元(ベクトル)、2次元(マトリックス)、3次元(テンソル)配列の直感的な演算処理ができます。
numpyと似たpythonライブラリで有名なpandasがあります。(pandasの中でもnumpyは使われています)
[python3] 非IT業務でも使える pandas の基本的な使い方
numpyとの違いは、ざっくり下記のような感じでしょうか。numpyは数字だけを扱うのに特化しているイメージですね。pandasは様々なデータ形式や欠損値への処理が可能なので、機械学習などにおいては、元データをpandasで呼び出して整形、numpyで数値処理 => 機械学習ライブラリへといった流れになるのでは無いでしょうか。
numpy pandas 扱うデータ 数値 様々(数値、文字列、時系列) 計算速度 高速 numpyよりは遅い 得意な処理 配列演算処理 データ整形、欠損値処理 インストール
$ pip3 install numpyインポート
npとしてインポートするのが慣例。
import numpy as npnumpy アレイの作成
pythonリストから作成
単純にpythonリストを渡して、numpyアレイを作成する。
1次元配列my_list = [1, 3, 4, 10] np.array(my_list) # => array([1, 3, 4, 10])2次元配列my_matrix = [[1, 3, 4], [9, 2, 3], [2, 5, 9]] np.array(my_matrix) # => array([[1, 3, 4], # [9, 2, 3], # [2, 5, 9]])numpy関数を使う
np.arange()
pythonのrange()と同じような働きをする、arange()。np.arange(start, end, (step))。
np.arange()np.arange(0, 11) # => array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10]) np.arange(0, 11, 2) # => array([0, 2, 4, 6, 8, 10])np.zeros() / np.ones()
0のみ、1のみの要素を持つ配列の作成
np.zeros()np.zeros(4) # => array([0., 0., 0., 0.,]) np.zeros((3, 2)) # => array([[0., 0.], # [0., 0.], # [0., 0.]])np.ones()np.ones(3) # => array([1., 1., 1.])np.linspace()
始まりと終わりの数字を指定して、均等に分割する。np.arange(start, end, 分割数)。
np.linspace(0,10,3) # => array([ 0., 5., 10.]) np.linspace(0, 10, 10) # => array([ 0. , 1.11111111, 2.22222222, 3.33333333, 4.44444444, # 5.55555556, 6.66666667, 7.77777778, 8.88888889, 10. ])np.eye()
np.eye(3) # => array([[1., 0., 0.], # [0., 1., 0.], # [0., 0., 1.]])random関数
numpyには、ランダムな数値配列を生成する方法が多数ある。
.rand()
与えられた形状配列を作成して、0~1の一様分布からランダムに数値をサンプリングする。
np.random.rand(3) # => array([0.07713379, 0.17275998, 0.57856427]) np.random.rand(4, 4) # => array([[0.1793304 , 0.46509954, 0.29201518, 0.44933199], # [0.72024083, 0.69927245, 0.5703159 , 0.15318234], # [0.25567981, 0.99377745, 0.39728105, 0.25397251], # [0.77973278, 0.79301535, 0.12647443, 0.9207554 ]]).randn()
"正規分布”からサンプリングする。一様分布からサンプリングするrand()とは異なる。
np.random.randn(2) # => array([-0.77946845, -0.61496784]) np.random.randn(3, 3) # => array([[ 0.6605953 , -1.59772636, 0.48223159], # [ 0.97797005, 1.52575177, 0.50617422], # [-1.00068423, -0.40814908, -2.22607208]]).randint()
ランダムに整数を取り出す。注意点として、指定するstart値は含まれるが、end値は含まれない。
例) np.random.randint(2, 8) => 2~7の中からサンプリング。np.random.randint(1, 100) # => 25 np.random.randint(1, 100, 5) # => array([73, 14, 66, 88, 2])numpyアトリビュート、メソッドを使う
下記のような2つの配列を定義する。
arr = np.arange(25) # => array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, # 17, 18, 19, 20, 21, 22, 23, 24]) ranarr = np.random.randint(0,50,10) # => array([ 9, 13, 45, 25, 27, 22, 2, 29, 21, 9])reshape()
同じデータを使用した、新しい形状の配列を返す。
arr.reshape(5, 5) # => array([[ 0, 1, 2, 3, 4], # [ 5, 6, 7, 8, 9], # [10, 11, 12, 13, 14], # [15, 16, 17, 18, 19], # [20, 21, 22, 23, 24]])shape
配列の形状を確認する。メソッドでは無いので、()はつけない。
arr.shape # => (25,) arr.reshape(5, 5).shape # => (5, 5)要素の取り出し
arr = np.arange(0, 11) arr # => array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10]) arr[5] # => 5 arr[1:5] # => array([1, 2, 3, 4])Broadcasting
arr[0:5] = 100 arr # => array([100, 100, 100, 100, 100, 5, 6, 7, 8, 9, 10])Selection
arr = np.arange(1,11) arr # => array([ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10]) arr > 4 # => array([False, False, False, False, True, True, True, True, True, True]) bool_arr = arr > 4 arr[bool_arr] # => array([ 5, 6, 7, 8, 9, 10])配列演算
pythonのlistとは異なり、配列同士の演算が容易に可能。
arr = np.arange(0,11) arr # => array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10]) arr + arr # => array([ 0, 2, 4, 6, 8, 10, 12, 14, 16, 18, 20]) arr * arr # => array([ 0, 1, 4, 9, 16, 25, 36, 49, 64, 81, 100]) arr**4 # => array([ 0, 1, 16, 81, 256, 625, 1296, 2401, 4096, 6561, 10000])Numpyには多くの配列関数が付属している。配列全体で操作を実行するために使用できる。
# 各要素のルートを取得 np.sqrt(arr) # => array([0. , 1. , 1.41421356, 1.73205081, 2. , # 2.23606798, 2.44948974, 2.64575131, 2.82842712, 3. , # 3.16227766]) # 指数関数 np.exp(arr) # => array([1.00000000e+00, 2.71828183e+00, 7.38905610e+00, 2.00855369e+01, # 5.45981500e+01, 1.48413159e+02, 4.03428793e+02, 1.09663316e+03, # 2.98095799e+03, 8.10308393e+03, 2.20264658e+04]) # sin np.sin(arr) # => array([ 0. , 0.84147098, 0.90929743, 0.14112001, -0.7568025 , # -0.95892427, -0.2794155 , 0.6569866 , 0.98935825, 0.41211849, # -0.54402111]) # log np.log(arr) # => array([ -inf, 0. , 0.69314718, 1.09861229, 1.38629436, # 1.60943791, 1.79175947, 1.94591015, 2.07944154, 2.19722458, # 2.30258509])
- 投稿日:2019-02-11T17:15:36+09:00
[Python]TwitterAPIとMeCabを使った形態素解析
はじめに
仕事上フリーコメント分析する機会が沢山あります。一件一件目を通して、アフターコーディングみたいなことをしてもいいのですが、せっかく世の中色んなツールがあるので、便利にできたらなと思っています。
本記事は、いつも使っている分析動作を簡単な形式で記載していきます。成果物としてはこんな感じ。
※mecabやwordcloudの準備の話はありません。環境
macOS
Python3.7情報収集
今回は、題材探すのも面倒なので、twtterAPIを利用して、情報収集を行なっていきます。
APIの利用方法は以下を参照にしてください。
Twitter API 登録 (アカウント申請方法) から承認されるまでの手順まとめ
Twitter APIでつぶやきを取得する
PythonでTwitter API を利用していろいろ遊んでみる適当にデスクトップに以下のファイルを作成します。
内容としてタイムライン取得用のURLにアクセスして、パラメタでtwitterアカウントの名前やリプライ、リツイート等を指定して、OAuthで認証を行ないます。一方でAPI制限についてはターミナル上で表示を行うようにしています。twpy.pyimport requests import json from requests_oauthlib import OAuth1Session access_token = 'hogehogehogehoge' access_token_secret = 'hogehogehogehoge' consumer_key = 'hogehogehogehoge' consumer_key_secret = 'hogehogehogehoge' url = "https://api.twitter.com/1.1/statuses/user_timeline.json" params = {'screen_name':'@AbeShinzo', 'exclude_replies':True, 'include_rts':False, 'count':200} twitter = OAuth1Session(consumer_key, consumer_key_secret, access_token, access_token_secret) res = twitter.get(url, params = params) f_out = open('/Users/hoge/Desktop/abe.txt','w') for j in range(100): res = twitter.get(url, params = params) if res.status_code == 200: limit = res.headers['x-rate-limit-remaining'] print ("API制限の残り: " + limit) if limit == 1: sleep(60*15) n = 0 timeline = json.loads(res.text) for i in range(len(timeline)): if i != len(timeline)-1: f_out.write(timeline[i]['text'] + '\n') else: f_out.write(timeline[i]['text'] + '\n') params['max_id'] = timeline[i]['id']-1 f_out.close()ファイルを保存したら、ターミナル上でファイルを実行。
デスクトップ上にファイルができています。$ python twitter1.py API制限の残り: 898 API制限の残り: 897 API制限の残り: 896 API制限の残り: 895 API制限の残り: 894 API制限の残り: 893 API制限の残り: 892 API制限の残り: 891 API制限の残り: 890 API制限の残り: 889 API制限の残り: 888 API制限の残り: 887 API制限の残り: 886 API制限の残り: 885 API制限の残り: 884 API制限の残り: 883 API制限の残り: 882 API制限の残り: 881 API制限の残り: 880 API制限の残り: 879 API制限の残り: 878 API制限の残り: 877 API制限の残り: 876 API制限の残り: 875 ・・・整形
ここからは対話型インタプリタで作業をします。jupyternotebook利用しました。
必要なパッケージをimportします。※本記事では全部使いません。import re import MeCab import numpy as np import matplotlib.pyplot as plt import pandas as pd import matplotlib import seaborn as sns import wordcloud from wordcloud import WordCloud,STOPWORDS import json import itertools from collections import Counter %matplotlib inline sns.set()ファイルを読み込みます。
ファイルパスを指定して、UTF-8の読み取りで、分割した形でsptextに代入します。
例えば、手元に分析したいファイルがあれば、ここで指定をしてください。エクセルだとS-JISでエンコーディングを指定するとできます。多分。filename = "/Users/hoge/Desktop/abe.txt" with open(filename, "r", encoding="utf-8") as afile: string = afile.read() sptext = whole_str.splitlines()中身の確認。何が行われているかわかるように都度中身確認します。
print(sptext) ['本日、#ドイツ の#メルケル首相が来日し、安倍総理と首脳会談を行いました。その様子を動画にまとめましたので、是非ご覧ください。 https://t.co/DutVH8XjRl', '1月は行く。2月は逃げる。と祖母はよく言っていたものでしたが、もう2月。いよいよ予算委員会も始まります。', 'そこで一句。', '', '「鏡餅食べ終わる間に月が明け」 https://t.co/K3d479jttd', '今、海外では、キャッシュレス決済が急速に普及しています。外国人観光客4000万人時代に向けて、大胆な5%ポイント還元で、日本でもキャッシュレスを一気に拡大したいと思いま・・・今はツイートごとの文字列のリストになっているので、全部くっつけます。
string = '\n'.join(sptext) print(string) '本日、#ドイツ の#メルケル首相が来日し、安倍総理と首脳会談を行いました。その様子を動画にまとめましたので、是非ご覧ください。 https://t.co/DutVH8XjRl\n1月は行く。2月は逃げる。と祖母はよく言っていたものでしたが、もう2月。いよいよ予算委員会も始まります。\nそこで一句。\n\n「鏡餅食べ終わる間に月が明け」 https://t.co/K3d479jttd\n今、海外では、キャッシュレス決済が急速に普及しています。外国人観・・・さらに半角スペースを消しちゃいます。正規表現の置換です。
今回はtwitterのハッシュタグがあるので「#」も削除します。string = re.sub(' ', '', string) string = re.sub('#', '', string) print(string) '本日、ドイツ のメルケル首相が来日し、安倍総理と首脳会談を行いました。その様子を動画にまとめましたので、是非ご覧ください。 https://t.co/DutVH8XjRl\n1月は行く。2月は逃げる。と祖母はよく言っていたものでしたが、もう2月。いよいよ予算委員会も始まります。\nそこで一句。\n\n「鏡餅食べ終わる間に月が明け」 https://t.co/K3d479jttd\n今、海外では、キャッシュレス決済が急速に普及しています。外国人観光客4000万人時代に向・・・文章の区切りで分割します。句読点や括弧、改行が出てきたら分割します。正規表現です。
いい感じになってきました。string = re.split('。(?!」)|\n', string) print(string) ['本日、ドイツ のメルケル首相が来日し、安倍総理と首脳会談を行いました', 'その様子を動画にまとめましたので、是非ご覧ください', ' https://t.co/DutVH8XjRl', '1月は行く', '2月は逃げる', 'と祖母はよく言っていたものでしたが、もう2月', 'いよいよ予算委員会も始まります', ・・・Twitter情報のためのURLが混ざっているので、URL要素は削除します。
正規表現で削除しました。他にも特定のワードを削除したければ、こちらやこちらを参照に。newstring = [] for st in string: words = re.sub(r'.*http.*', '', st) newstring.append(words) print(newstring) ['本日、ドイツ のメルケル首相が来日し、安倍総理と首脳会談を行いました', 'その様子を動画にまとめましたので、是非ご覧ください', '', '1月は行く', '2月は逃げる', 'と祖母はよく言っていたものでしたが、もう2月', 'いよいよ予算委員会も始まります', '', 'そこで一句', '', '', '', ・・・上記の通りですが、中身を見てみると、'',←このような空の行が出てきているので、まとめて削除します。
while '' in newstring: newstring.remove('') print(newstring) ['本日、ドイツ のメルケル首相が来日し、安倍総理と首脳会談を行いました', 'その様子を動画にまとめましたので、是非ご覧ください', '1月は行く', '2月は逃げる', 'と祖母はよく言っていたものでしたが、もう2月', 'いよいよ予算委員会も始まります', 'そこで一句', '今、海外では、キャッシュレス決済が急速に普及しています', '外国人観光客4000万人時代に向けて、大胆な5%ポイント還元で、日本でもキャッシュレスを一気に拡大したいと思います', '花屋さんでは、QR決済に挑戦しました', '初めてだったのでかなり緊張しましたが、本当に簡単でほっとしました', '海外のお客さんも来て使ったそうですが、QRコードの紙を一枚だけでいいので、花屋さんの方も簡単に導入できたとおっしゃってました', ・・・形態素分解
ここまできたらお馴染みのMeCabを使います。
wakatiでもいいですが、このあと名詞のみを抽出するので、品詞がセットになっているchasenを使います。m = MeCab.Tagger("-Ochasen")ここから肝です。
内包表記で複雑になっていますが、chasenで形態素にしたものの中に名詞が含まれているものだけをさらにリストにしています。
ここまでくれば、数えることも簡単になります。wordlists = [ \ [v.split()[2] for v in m.parse(sentense).splitlines() \ if (len(v.split())>=3 and v.split()[3][:2]=='名詞')] \ for sentense in newstring] print(wordlists) [['本日', 'ドイツ', 'メルケル', '首相', '来日', '安倍', '総理', '首脳', '会談'], ['様子', '動画', '是非', 'ご覧'], ['1月'], ['2月'], ['祖母', 'もの', '2月'], ['予算', '委員', '会'], ['一句'], ['今', '海外', 'キャッシュ', 'レス', '決済', '急速', '普及'], ['外国',今はリストの入れ子になっているので、これを結合して一つのリストにします。
wordlist = list(itertools.chain.from_iterable(wordlists)) print(wordlist) ['本日', 'ドイツ', 'メルケル', '首相', '来日', '安倍', '総理', '首脳', '会談', '様子', '動画', '是非', 'ご覧', '1月', '2月', '祖母', 'もの', '2月', '予算', '委員', '会', '一句', '今', '海外', 'キャッシュ', 'レス', '決済', '急速', '普及', '外国', '人', '観光', '客', '4000', '万', '人', '時代', '大胆', '5', '%',解析(とりあえず数える)
せっかくなのでカウントしておきます。上位100個。
話題がわかるかなと思ったら、そうでもない。。。共起関係とか見ないとダメそう。別で記事投稿します。cnt = Counter(wordlist) sorted(cnt.items(), key=lambda x: x[1],reverse=True)[:100] [('安倍', 281), ('日本', 257), ('日', 245), ('三', 233), ('晋', 213), (':', 202), ('演説', 182), ('こと', 167), ('総裁', 164), ('会', 159), ('県', 151), ・・・可視化の準備
続いて文字の可視化の準備をします。半角スペースで一つの文字列にします。
※このやり方は合ってるか知りませんが、昔可視化を試みた時に、英語は分割されて綺麗に表示されたのに、日本語だとできなかったことから、とりあえず半角スペースで区切ってみてます。mojiretu = ' '.join(wordlist) print(mojiretu) '本日 ドイツ メルケル 首相 来日 安倍 総理 首脳 会談 様子 動画 是非 ご覧 1月 2月 祖母 もの 2月 予算 委員 会 一句 今 海外 キャッシュ レス 決済 急速 普及 外国 人 観光 客 4000 万 人 時代 大胆 5 % ポイント 還元 日本 キャッシュ レス 拡大 花屋 さん QR 決済 挑戦 緊張 簡単 海外 お客 さん そう QR コード 紙 一 枚 花屋 さん 方 簡単 導入 東京 戸越 銀座 商店 街 キャッシュ レス 決済 体験 最初 コンビニ プリペイドカード ん 店頭可視化(wordcloud)
最後に可視化ですが、全然分析するには不便だけど、なんとなくかっこよく見えるwordcloudを利用します。これのためだけに全部を繋げた文字列にしました。
font指定/可視化させない言葉の指定/色や大きさの指定等をした上で、matplotlibでwordcloudを呼び出します。
fpath = "/Library/Fonts/ヒラギノ丸ゴ ProN W4.ttc" stop_words = [ u'もの',u'こと',u'安倍',u'今日',u'日本',u'昨日',u'私',u'総理',u'本日',u'さん'] wordcloud = WordCloud(background_color="white", width=900, height=500,max_font_size=40,stopwords=set(stop_words),font_path=fpath).generate(mojiretu) plt.figure(figsize=(15,12)) plt.imshow(wordcloud) plt.axis("off") plt.show()
ちなみに形容詞はこんな感じでした。
最大フォントサイズを少し調整しました。
僕が愛読している日経ヴェリタス小栗さんの可視化
終わり



- 投稿日:2019-02-11T17:15:36+09:00
[Python]TwitterAPIとMeCabを使った形態素解析と可視化
はじめに
仕事上フリーコメント分析する機会が沢山あります。一件一件目を通して、アフターコーディングみたいなことをしてもいいのですが、せっかく世の中色んなツールがあるので、便利にできたらなと思っています。
本記事は、いつも使っている分析動作を簡単な形式で記載していきます。成果物としてはこんな感じ。
※mecabやwordcloudの準備の話はありません。環境
macOS
Python3.7情報収集
今回は、題材探すのも面倒なので、twtterAPIを利用して、情報収集を行なっていきます。
APIの利用方法は以下を参照にしてください。
Twitter API 登録 (アカウント申請方法) から承認されるまでの手順まとめ
Twitter APIでつぶやきを取得する
PythonでTwitter API を利用していろいろ遊んでみる適当にデスクトップに以下のファイルを作成します。
内容としてタイムライン取得用のURLにアクセスして、パラメタでtwitterアカウントの名前やリプライ、リツイート等を指定して、OAuthで認証を行ないます。一方でAPI制限についてはターミナル上で表示を行うようにしています。twpy.pyimport requests import json from requests_oauthlib import OAuth1Session access_token = 'hogehogehogehoge' access_token_secret = 'hogehogehogehoge' consumer_key = 'hogehogehogehoge' consumer_key_secret = 'hogehogehogehoge' url = "https://api.twitter.com/1.1/statuses/user_timeline.json" params = {'screen_name':'@AbeShinzo', 'exclude_replies':True, 'include_rts':False, 'count':200} twitter = OAuth1Session(consumer_key, consumer_key_secret, access_token, access_token_secret) res = twitter.get(url, params = params) f_out = open('/Users/hoge/Desktop/abe.txt','w') for j in range(100): res = twitter.get(url, params = params) if res.status_code == 200: limit = res.headers['x-rate-limit-remaining'] print ("API制限の残り: " + limit) if limit == 1: sleep(60*15) n = 0 timeline = json.loads(res.text) for i in range(len(timeline)): if i != len(timeline)-1: f_out.write(timeline[i]['text'] + '\n') else: f_out.write(timeline[i]['text'] + '\n') params['max_id'] = timeline[i]['id']-1 f_out.close()ファイルを保存したら、ターミナル上でファイルを実行。
デスクトップ上にファイルができています。$ python twitter1.py API制限の残り: 898 API制限の残り: 897 API制限の残り: 896 API制限の残り: 895 API制限の残り: 894 API制限の残り: 893 API制限の残り: 892 API制限の残り: 891 API制限の残り: 890 API制限の残り: 889 API制限の残り: 888 API制限の残り: 887 API制限の残り: 886 API制限の残り: 885 API制限の残り: 884 API制限の残り: 883 API制限の残り: 882 API制限の残り: 881 API制限の残り: 880 API制限の残り: 879 API制限の残り: 878 API制限の残り: 877 API制限の残り: 876 API制限の残り: 875 ・・・整形
ここからは対話型インタプリタで作業をします。jupyternotebook利用しました。
必要なパッケージをimportします。※本記事では全部使いません。import re import MeCab import numpy as np import matplotlib.pyplot as plt import pandas as pd import matplotlib import seaborn as sns import wordcloud from wordcloud import WordCloud,STOPWORDS import json import itertools from collections import Counter %matplotlib inline sns.set()ファイルを読み込みます。
ファイルパスを指定して、UTF-8の読み取りで、分割した形でsptextに代入します。
例えば、手元に分析したいファイルがあれば、ここで指定をしてください。エクセルだとS-JISでエンコーディングを指定するとできます。多分。filename = "/Users/hoge/Desktop/abe.txt" with open(filename, "r", encoding="utf-8") as afile: string = afile.read() sptext = whole_str.splitlines()中身の確認。何が行われているかわかるように都度中身確認します。
print(sptext) ['本日、#ドイツ の#メルケル首相が来日し、安倍総理と首脳会談を行いました。その様子を動画にまとめましたので、是非ご覧ください。 https://t.co/DutVH8XjRl', '1月は行く。2月は逃げる。と祖母はよく言っていたものでしたが、もう2月。いよいよ予算委員会も始まります。', 'そこで一句。', '', '「鏡餅食べ終わる間に月が明け」 https://t.co/K3d479jttd', '今、海外では、キャッシュレス決済が急速に普及しています。外国人観光客4000万人時代に向けて、大胆な5%ポイント還元で、日本でもキャッシュレスを一気に拡大したいと思いま・・・今はツイートごとの文字列のリストになっているので、全部くっつけます。
string = '\n'.join(sptext) print(string) '本日、#ドイツ の#メルケル首相が来日し、安倍総理と首脳会談を行いました。その様子を動画にまとめましたので、是非ご覧ください。 https://t.co/DutVH8XjRl\n1月は行く。2月は逃げる。と祖母はよく言っていたものでしたが、もう2月。いよいよ予算委員会も始まります。\nそこで一句。\n\n「鏡餅食べ終わる間に月が明け」 https://t.co/K3d479jttd\n今、海外では、キャッシュレス決済が急速に普及しています。外国人観・・・さらに半角スペースを消しちゃいます。正規表現の置換です。
今回はtwitterのハッシュタグがあるので「#」も削除します。string = re.sub(' ', '', string) string = re.sub('#', '', string) print(string) '本日、ドイツ のメルケル首相が来日し、安倍総理と首脳会談を行いました。その様子を動画にまとめましたので、是非ご覧ください。 https://t.co/DutVH8XjRl\n1月は行く。2月は逃げる。と祖母はよく言っていたものでしたが、もう2月。いよいよ予算委員会も始まります。\nそこで一句。\n\n「鏡餅食べ終わる間に月が明け」 https://t.co/K3d479jttd\n今、海外では、キャッシュレス決済が急速に普及しています。外国人観光客4000万人時代に向・・・文章の区切りで分割します。句読点や括弧、改行が出てきたら分割します。正規表現です。
いい感じになってきました。string = re.split('。(?!」)|\n', string) print(string) ['本日、ドイツ のメルケル首相が来日し、安倍総理と首脳会談を行いました', 'その様子を動画にまとめましたので、是非ご覧ください', ' https://t.co/DutVH8XjRl', '1月は行く', '2月は逃げる', 'と祖母はよく言っていたものでしたが、もう2月', 'いよいよ予算委員会も始まります', ・・・Twitter情報のためのURLが混ざっているので、URL要素は削除します。
正規表現で削除しました。他にも特定のワードを削除したければ、こちらやこちらを参照に。newstring = [] for st in string: words = re.sub(r'.*http.*', '', st) newstring.append(words) print(newstring) ['本日、ドイツ のメルケル首相が来日し、安倍総理と首脳会談を行いました', 'その様子を動画にまとめましたので、是非ご覧ください', '', '1月は行く', '2月は逃げる', 'と祖母はよく言っていたものでしたが、もう2月', 'いよいよ予算委員会も始まります', '', 'そこで一句', '', '', '', ・・・上記の通りですが、中身を見てみると、'',←このような空の行が出てきているので、まとめて削除します。
while '' in newstring: newstring.remove('') print(newstring) ['本日、ドイツ のメルケル首相が来日し、安倍総理と首脳会談を行いました', 'その様子を動画にまとめましたので、是非ご覧ください', '1月は行く', '2月は逃げる', 'と祖母はよく言っていたものでしたが、もう2月', 'いよいよ予算委員会も始まります', 'そこで一句', '今、海外では、キャッシュレス決済が急速に普及しています', '外国人観光客4000万人時代に向けて、大胆な5%ポイント還元で、日本でもキャッシュレスを一気に拡大したいと思います', '花屋さんでは、QR決済に挑戦しました', '初めてだったのでかなり緊張しましたが、本当に簡単でほっとしました', '海外のお客さんも来て使ったそうですが、QRコードの紙を一枚だけでいいので、花屋さんの方も簡単に導入できたとおっしゃってました', ・・・形態素分解
ここまできたらお馴染みのMeCabを使います。
wakatiでもいいですが、このあと名詞のみを抽出するので、品詞がセットになっているchasenを使います。m = MeCab.Tagger("-Ochasen")ここから肝です。
内包表記で複雑になっていますが、chasenで形態素にしたものの中に名詞が含まれているものだけをさらにリストにしています。
ここまでくれば、数えることも簡単になります。wordlists = [ \ [v.split()[2] for v in m.parse(sentense).splitlines() \ if (len(v.split())>=3 and v.split()[3][:2]=='名詞')] \ for sentense in newstring] print(wordlists) [['本日', 'ドイツ', 'メルケル', '首相', '来日', '安倍', '総理', '首脳', '会談'], ['様子', '動画', '是非', 'ご覧'], ['1月'], ['2月'], ['祖母', 'もの', '2月'], ['予算', '委員', '会'], ['一句'], ['今', '海外', 'キャッシュ', 'レス', '決済', '急速', '普及'], ['外国',今はリストの入れ子になっているので、これを結合して一つのリストにします。
wordlist = list(itertools.chain.from_iterable(wordlists)) print(wordlist) ['本日', 'ドイツ', 'メルケル', '首相', '来日', '安倍', '総理', '首脳', '会談', '様子', '動画', '是非', 'ご覧', '1月', '2月', '祖母', 'もの', '2月', '予算', '委員', '会', '一句', '今', '海外', 'キャッシュ', 'レス', '決済', '急速', '普及', '外国', '人', '観光', '客', '4000', '万', '人', '時代', '大胆', '5', '%',解析(とりあえず数える)
せっかくなのでカウントしておきます。上位100個。
話題がわかるかなと思ったら、そうでもない。。。共起関係とか見ないとダメそう。別で記事投稿します。cnt = Counter(wordlist) sorted(cnt.items(), key=lambda x: x[1],reverse=True)[:100] [('安倍', 281), ('日本', 257), ('日', 245), ('三', 233), ('晋', 213), (':', 202), ('演説', 182), ('こと', 167), ('総裁', 164), ('会', 159), ('県', 151), ・・・可視化の準備
続いて文字の可視化の準備をします。半角スペースで一つの文字列にします。
※このやり方は合ってるか知りませんが、昔可視化を試みた時に、英語は分割されて綺麗に表示されたのに、日本語だとできなかったことから、とりあえず半角スペースで区切ってみてます。mojiretu = ' '.join(wordlist) print(mojiretu) '本日 ドイツ メルケル 首相 来日 安倍 総理 首脳 会談 様子 動画 是非 ご覧 1月 2月 祖母 もの 2月 予算 委員 会 一句 今 海外 キャッシュ レス 決済 急速 普及 外国 人 観光 客 4000 万 人 時代 大胆 5 % ポイント 還元 日本 キャッシュ レス 拡大 花屋 さん QR 決済 挑戦 緊張 簡単 海外 お客 さん そう QR コード 紙 一 枚 花屋 さん 方 簡単 導入 東京 戸越 銀座 商店 街 キャッシュ レス 決済 体験 最初 コンビニ プリペイドカード ん 店頭可視化(wordcloud)
最後に可視化ですが、全然分析するには不便だけど、なんとなくかっこよく見えるwordcloudを利用します。これのためだけに全部を繋げた文字列にしました。
font指定/可視化させない言葉の指定/色や大きさの指定等をした上で、matplotlibでwordcloudを呼び出します。
fpath = "/Library/Fonts/ヒラギノ丸ゴ ProN W4.ttc" stop_words = [ u'もの',u'こと',u'安倍',u'今日',u'日本',u'昨日',u'私',u'総理',u'本日',u'さん'] wordcloud = WordCloud(background_color="white", width=900, height=500,max_font_size=40,stopwords=set(stop_words),font_path=fpath).generate(mojiretu) plt.figure(figsize=(15,12)) plt.imshow(wordcloud) plt.axis("off") plt.show()
ちなみに形容詞はこんな感じでした。
最大フォントサイズを少し調整しました。
僕が愛読している日経ヴェリタス小栗さんのツイート可視化
無駄に黒背景にしました。
終わり

- 投稿日:2019-02-11T17:08:40+09:00
日本の古文書で機械学習を試す(9) 筆跡鑑定?どの作品の文字画像かを当てる
前回、日本の古文書で機械学習を試す(8) で、人文学オープンデータ共同利用センターの日本古典籍くずし字データセットから複数作品のデータをダウンロードしたので、文字認識以外にも使ってみよう、ということで、どの作品から切り出した文字かを当てるモデルを作成してみる。
学習、テスト用データを作る
まずは、前回までにダウンロードした「好色一代男」「雨月物語」「おらが春」「養蚕秘録」「物類称呼」の5作品のデータから、学習、テスト用データを作る。前回使った作品のうち「当世料理」はデータ数が少ないので今回は除外する。
学習データとテストデータは、前半後半で分けると文字種が片寄ってしまうので、画像を順番に読み込みながら画像数をカウントし、画像数が10で割り切れるときにテストデータとした。(つまり、10個に1個の割合でテストデータとした。)
学習、テストデータ生成# 画像を読み込んで、行列に変換する関数を定義 from keras.preprocessing.image import load_img, img_to_array def img_to_traindata(file, img_rows, img_cols): img = load_img(file, color_mode = "grayscale", target_size=(img_rows,img_cols)) # <- Warningが出たので grayscale=True から修正 # x = img.convert('L') # PIL/Pillow グレイスケールに変換 x = img_to_array(img) x = x.astype('float32') x /= 255 return x # 1つの作品のデータから学習用データとテストデータを生成する関数を定義 import glob, os from keras.utils import np_utils import numpy as np def get_train_test_data(root, y_value, nb_classes, img_rows, img_cols): X_train = [] Y_train = [] X_test = [] Y_test = [] count = 0 chars = glob.glob(root) # 画像のルートディレクトリ内のファイル/ディレクトリ一覧 for char in chars: if os.path.isdir(char): # ディレクトリなら img_files = glob.glob(char+"/*.jpg") for img_file in img_files: # ディレクトリ(文字種)ごとのファイル一覧取得 x = img_to_traindata(img_file, img_rows, img_cols) # 各画像ファイルを読み込んで行列に変換 if count % 10 == 0: # 10個おきにテストデータにする X_test.append(x) # 画像データ Y_test.append(y_value) # 正解データ=作品ごとに振った番号 else: # のこりは学習用データにする X_train.append(x) # 画像データ Y_train.append(y_value) # 正解データ=作品ごとに振った番号 count = count + 1 # listからnumpy.ndarrayに変換 X_train = np.array(X_train, dtype=float) Y_train = np.array(Y_train, dtype=float) Y_train = np_utils.to_categorical(Y_train, nb_classes) X_test = np.array(X_test, dtype=float) Y_test = np.array(Y_test, dtype=float) Y_test = np_utils.to_categorical(Y_test, nb_classes) return [X_train, Y_train, X_test, Y_test] # 作品ごとにデータを読み込んで学習、テストデータ生成 nb_classes = 5 img_rows = 28 img_cols =28 # 好色一代男 正解=0 kosyoku_data = get_train_test_data("../200003076/characters/*", 0, nb_classes, img_rows, img_cols) # 雨月物語 正解=1 ugetsu_data = get_train_test_data("../200014740/characters/*", 1, nb_classes, img_rows, img_cols) # おらが春 正解=2 oraga_data = get_train_test_data("../200003967/characters/*", 2, nb_classes, img_rows, img_cols) # 養蚕秘録 正解=3 yosan_data = get_train_test_data("../200021660/characters/*", 3, nb_classes, img_rows, img_cols) # 物類称呼 正解=4 butsu_data = get_train_test_data("../brsk00000/characters/*", 4, nb_classes, img_rows, img_cols) # 複数作品の学習データ、テストデータを連結(軸0でデータを連結) X_train = np.concatenate([kosyoku_data[0],ugetsu_data[0],oraga_data[0],yosan_data[0],butsu_data[0]], 0) Y_train = np.concatenate([kosyoku_data[1],ugetsu_data[1],oraga_data[1],yosan_data[1],butsu_data[1]], 0) X_test = np.concatenate([kosyoku_data[2],ugetsu_data[2],oraga_data[2],yosan_data[2],butsu_data[2]], 0) Y_test = np.concatenate([kosyoku_data[3],ugetsu_data[3],oraga_data[3],yosan_data[3],butsu_data[3]], 0) # 学習データ、テストデータの型を表示 print(X_train.shape) print(Y_train.shape) print(X_test.shape) print(Y_test.shape)学習データは205175個、テストデータは22800個生成された。今までの文字認識に比べたら、かなり多いデータ数だ。
モデルを作って学習
次にモデルを定義して学習させてみる。前回までで一番良かった畳み込み3層、プーリング2層のモデルを使い、パラメータと最適化関数も前回までにチューニングしたものを使う。やろうとしていることが違うので、前回までと同じ条件が最適かどうかは分からないが。
モデル生成、学習# 再現性を得るための設定をする関数を定義 # https://keras.io/ja/getting-started/faq/#how-can-i-obtain-reproducible-results-using-keras-during-development import tensorflow as tf import random import os from keras import backend as K def set_reproducible(): os.environ['PYTHONHASHSEED'] = '0' np.random.seed(1337) random.seed(1337) session_conf = tf.ConfigProto(intra_op_parallelism_threads=1, inter_op_parallelism_threads=1) tf.set_random_seed(1337) sess = tf.Session(graph=tf.get_default_graph(), config=session_conf) K.set_session(sess) # 畳み込み3層のモデルを使って学習 from keras.models import Sequential from keras.layers import Dense, Dropout, Activation, Flatten from keras.layers import Conv2D, MaxPooling2D # 【パラメータ設定】 batch_size = 32 epochs = 40 input_shape = (img_rows, img_cols, 1) nb_filters = 32 # size of pooling area for max pooling pool_size = (2, 2) # convolution kernel size kernel_size = (3, 3) # 【モデル定義】 model = Sequential() model.add(Conv2D(nb_filters, kernel_size, # 畳み込み層 padding='valid', activation='relu', input_shape=input_shape)) model.add(Conv2D(nb_filters, kernel_size, activation='relu')) # 畳み込み層 model.add(MaxPooling2D(pool_size=pool_size)) # プーリング層 model.add(Conv2D(nb_filters, kernel_size, activation='relu')) # 畳み込み層 model.add(MaxPooling2D(pool_size=pool_size)) # プーリング層 model.add(Dropout(0.25)) # ドロップアウト(過学習防止のため、入力と出力の間をランダムに切断) model.add(Flatten()) # 多次元配列を1次元配列に変換 model.add(Dense(128, activation='relu')) # 全結合層 model.add(Dropout(0.2)) # ドロップアウト model.add(Dense(nb_classes, activation='softmax')) # 全結合層 model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy']) # 【各エポックごとの学習結果を生成するためのコールバックを定義(前回より精度が良い時だけ保存)】 from keras.callbacks import ModelCheckpoint import os model_checkpoint = ModelCheckpoint( filepath=os.path.join('add_models','model_kantei_{epoch:02d}_{val_acc:.3f}.h5'), monitor='val_acc', mode='max', save_best_only=True, verbose=1) # 【学習】 set_reproducible() result = model.fit(X_train, Y_train, batch_size=batch_size, epochs=epochs, verbose=1, validation_data=(X_test, Y_test), callbacks=[model_checkpoint])結果
データ量が多いため、1エポック当たり950~1000秒 × 40エポックで、前回までより学習にかなり時間がかかった。
いつものように結果をプロットしてみる。日本の古文書で機械学習を試す(6)の最後に、学習データのプロットはあまり意味がないかも?ということが判明したのだが、とりあえず、確認のためプロットしてみる。
結果をプロット# 【学習データとテストデータに対する正解率をプロット】 import matplotlib.pyplot as plt %matplotlib inline plt.plot(range(1, epochs+1), result.history['acc'], label="Training") plt.plot(range(1, epochs+1), result.history['val_acc'], label="Validation") plt.xlabel('Epochs') plt.ylabel('Accuracy') plt.ylim([0.8,1])# y軸の最小値、最大値 plt.grid(True) # グリッドを表示 plt.xticks(np.arange(0, epochs+1, 10)) plt.legend(bbox_to_anchor=(1.8, 0), loc='lower right', borderaxespad=1, fontsize=15) plt.show()
途中で一度ガクッと精度が下がっているのが謎だが、だいたい0.975あたりで安定してきている。テストデータに対する精度の最大値は0.97794 (30エポック目)だった。
学習データが約20万で、5クラス分類(0~4のどれかをあてる)問題なので、前回までの文字認識と比べるとかなり精度は高めだ。パラメータをいじったり、RNNと組み合わせたりするともっと良くなるのだろうか?
データの一部を表示してみる
確認のため、データの一部を表示してみた。各作品のテストデータから、ひらがなの「あ」を表示させた。
テストデータの一部を表示import matplotlib.pyplot as plt %matplotlib inline fig = plt.figure(figsize=(10,5)) # 全体の表示領域のサイズ(横, 縦) fig.subplots_adjust(left=0, right=1, bottom=0, top=1, hspace=0.5, wspace=0.05) # ↑サブ画像余白(左と下は0、右と上は1で余白なし) サブ画像間隔 縦,横 # 好色一代男 for i in range(10): ax = fig.add_subplot(5, 10, i+1, xticks=[], yticks=[]) # 縦分割数、横分割数、何番目か、メモリ表示なし ax.title.set_text("[0]") # グラフタイトルとして正解番号を表示 ax.imshow(kosyoku_data[2][i+50].reshape((img_rows, img_cols)), cmap='gray') # 雨月物語 for i in range(10): ax = fig.add_subplot(5, 10, i+11, xticks=[], yticks=[]) # 縦分割数、横分割数、何番目か、メモリ表示なし ax.title.set_text("[1]") # グラフタイトルとして正解番号を表示 ax.imshow(ugetsu_data[2][i+40].reshape((img_rows, img_cols)), cmap='gray') # おらが春 for i in range(10): ax = fig.add_subplot(5, 10, i+21, xticks=[], yticks=[]) # 縦分割数、横分割数、何番目か、メモリ表示なし ax.title.set_text("[2]") # グラフタイトルとして正解番号を表示 ax.imshow(oraga_data[2][i+12].reshape((img_rows, img_cols)), cmap='gray') # 養蚕秘録 for i in range(10): ax = fig.add_subplot(5, 10, i+31, xticks=[], yticks=[]) # 縦分割数、横分割数、何番目か、メモリ表示なし ax.title.set_text("[3]") # グラフタイトルとして正解番号を表示 ax.imshow(yosan_data[2][i+30].reshape((img_rows, img_cols)), cmap='gray') # 物類称呼 for i in range(10): ax = fig.add_subplot(5, 10, i+41, xticks=[], yticks=[]) # 縦分割数、横分割数、何番目か、メモリ表示なし ax.title.set_text("[4]") # グラフタイトルとして正解番号を表示 ax.imshow(butsu_data[2][i+100].reshape((img_rows, img_cols)), cmap='gray')
ひらがなの「あ」を選ぶのは、原始的だが、データの何番目を表示するかの数字(ソースコード中のax.imshowの最初の引数内の[i+]のの数字部分)を、表示データを見ながら手動で調整した。3列目の「おらが春」(作品番号[2])だけ、「あ」の数が9個しかなく、最後の文字は「い」になっている。
今回は全部の文字種を混ぜて学習させたので、字形の違いはあまり関係ないはずだが、人間の目で見ると、作品ごとの特徴としては、筆遣いよりも、背景(紙の特徴とか、画像化のしかたとか?)の影響の方が大きいように見える。
畳み込みフィルタをかけた結果を表示してみる
学習時にどんな特徴を抽出したのかを知るため、モデルの中間層の出力を見てみる。
まず、学習させたモデルの層構造を表示させてみる。
モデルの層構造を表示print(model.layers)結果はこうなった。出力が見づらかったので、カンマで改行したら少し見やすくなった。<>で囲まれた要素が、モデル定義の際に model.add で追加した要素に対応しているっぽい。
[<keras.layers.convolutional.Conv2D object at 0x00000219D5ACAA20>, <keras.layers.convolutional.Conv2D object at 0x00000219D5ACAA58>, <keras.layers.pooling.MaxPooling2D object at 0x00000219D5ACAE80>, <keras.layers.convolutional.Conv2D object at 0x00000219D5967F28>, <keras.layers.pooling.MaxPooling2D object at 0x00000219D5ACAC50>, <keras.layers.core.Dropout object at 0x00000219D5982208>, <keras.layers.core.Flatten object at 0x0000021939311320>, <keras.layers.core.Dense object at 0x0000021939311A58>, <keras.layers.core.Dropout object at 0x000002193932FFD0>, <keras.layers.core.Dense object at 0x0000021914DD3C50>]1層目の畳み込みフィルタ model.layers[0] を「好色一代男」の50番目のテストデータ(上の画像の左上端の画像、kosyoku_data[2][50])に適用した結果を表示してみる。途中の層のフィルタを取り出すには、新しく中間層のみのモデルを作れば良いらしい。
1層目の畳み込みフィルタをかけた結果を出力from keras.models import Model #中間層のmodelを作成 intermediate_layer_model = Model(inputs=model.input, outputs=model.layers[0].output) #1つのテストデータの画像に対して、フィルタをかけた結果を出力 intermediate_output = intermediate_layer_model.predict([[kosyoku_data[2][50]]]) # 好色一代男 print(intermediate_output.shape)出力されたデータ型を表示してみると、(26, 26, 32)となっている。最初の26x26が画素数、最後の32がフィルタの数だろう。このままだと扱いにくいので、(32, 26, 26)に変換してから表示させてみる。
1層目の畳み込みフィルタをかけた結果を表示# (26, 26, 32) -> (32, 26, 26) data = intermediate_output[0].transpose(2, 0, 1) import matplotlib.pyplot as plt %matplotlib inline fig = plt.figure(figsize=(8,4)) # 全体の表示領域のサイズ(横, 縦) fig.subplots_adjust(left=0, right=1, bottom=0, top=1, hspace=0.5, wspace=0.05) for i in range(32): ax = fig.add_subplot(4,8, i+1, xticks=[], yticks=[]) # 縦分割数、横分割数、何番目か、メモリ表示なし ax.imshow(data[i], cmap='gray')
これが、「好色一代男」の50番目のテストデータに32種類の畳み込みフィルタをかけた結果です。結局どんな特徴を抽出したのかは、私の目にはサッパリ分からない。
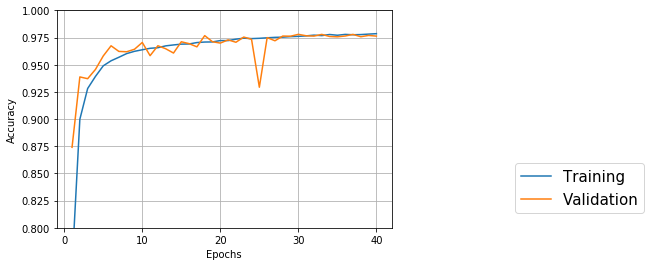

- 投稿日:2019-02-11T17:07:12+09:00
Macで始めるPython環境づくり2019 初心者編
はじめに
この記事は最近MacBookProの2018年版TouchBar付きをPayPayで購入した筆者が、
家でPython開発を始めようとしている記事です。
正直初心者なので、深い部分は理解していないものも多いですが、
初心者の方の参考になれば幸いです。仮想環境選び Pyenv+Pipenv
Pyenvは特に要らないとか、venvが公式だからいいとか色々と記事が書かれていますが、まぁ個人的に困らないものを使えばいいと思っているので、今回はPyenv + Pipenvで環境構築を行ってみます。これがベストかは知りませんが、特に問題なく導入できたので僕は良いと思います。
XCodeのインストール
本体は普通にXCodeをAppStoreからインストールします。
そのあとターミナルで下記を実行して、Command Line Toolsをインストールする。$ xcode-select --installHomebrewのインストール
HomebrewはMacでのパッケージ管理ツールみたいなものと理解しています。
pyenvをインストールするためにもまずはインストール。
インストール先にあるコマンドをそのままコピペすればOK。$ /usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"pyenvのインストール
Homebrewさえ入れば、あとはpython系を入れていくだけです。
まずはpyenvを入れます。$ brew install pyenvその後、PATHを通すので、home/.bash_profileに下記を書き込みます。viでの編集に慣れている人は、下記を実行して、.bash_profileに書き込みます。
$ vi ~/.bash_profile.bash_profileexport PYENV_ROOT="$HOME/.pyenv" export PATH="$PYENV_ROOT/bin:$PATH" eval "$(pyenv init -)"慣れていない人は、ファインダーからホームディレクトリの隠しファイルを表示してテキストエディタで.bash_profileの中身を編集しましょう。ちなみに隠しファイルはMacでは下記のショートカットで表示できます。
[command] + [shift] + [.(ドット)]その後設定したファイルを反映させます。
$ source ~/.bash_profile一応、動いているかを確認するため、叩いてみましょう。
下記のようなヘルプ表示が出ればOKです。$ pyenvpyenv 1.2.9 Usage: pyenv <command> [<args>] Some useful pyenv commands are: commands List all available pyenv commands local Set or show the local application-specific Python version global Set or show the global Python version shell Set or show the shell-specific Python version install Install a Python version using python-build uninstall Uninstall a specific Python version rehash Rehash pyenv shims (run this after installing executables) version Show the current Python version and its origin versions List all Python versions available to pyenv which Display the full path to an executable whence List all Python versions that contain the given executable See `pyenv help <command>' for information on a specific command. For full documentation, see: https://github.com/pyenv/pyenv#readmePipenvのインストール
次にPipenvをインストールします。
brewで一発です。$ brew install pipenvこちらも設定を
.bash_profileに追記します。
仮想環境をフォルダに作成するフラグを立てておくことがメインです。
ついでにインストールがうまくいっているか叩いてみましょう。.bash_profileexport PIPENV_VENV_IN_PROJECT=true eval "$(pipenv --completion)"$ source ~/.bash_profile $ pipenvUsage: pipenv [OPTIONS] COMMAND [ARGS]... Options: --where Output project home information. --venv Output virtualenv information. --py Output Python interpreter information. --envs Output Environment Variable options. --rm Remove the virtualenv. --bare Minimal output. --completion Output completion (to be eval'd). --man Display manpage. --support Output diagnostic information for use in GitHub issues. --site-packages Enable site-packages for the virtualenv. [env var: PIPENV_SITE_PACKAGES] --python TEXT Specify which version of Python virtualenv should use. --three / --two Use Python 3/2 when creating virtualenv. --clear Clears caches (pipenv, pip, and pip-tools). [env var: PIPENV_CLEAR] -v, --verbose Verbose mode. --pypi-mirror TEXT Specify a PyPI mirror. --version Show the version and exit. -h, --help Show this message and exit. Usage Examples: Create a new project using Python 3.7, specifically: $ pipenv --python 3.7 Remove project virtualenv (inferred from current directory): $ pipenv --rm Install all dependencies for a project (including dev): $ pipenv install --dev Create a lockfile containing pre-releases: $ pipenv lock --pre Show a graph of your installed dependencies: $ pipenv graph Check your installed dependencies for security vulnerabilities: $ pipenv check Install a local setup.py into your virtual environment/Pipfile: $ pipenv install -e . Use a lower-level pip command: $ pipenv run pip freeze Commands: check Checks for security vulnerabilities and against PEP 508 markers provided in Pipfile. clean Uninstalls all packages not specified in Pipfile.lock. graph Displays currently-installed dependency graph information. install Installs provided packages and adds them to Pipfile, or (if no packages are given), installs all packages from Pipfile. lock Generates Pipfile.lock. open View a given module in your editor. run Spawns a command installed into the virtualenv. shell Spawns a shell within the virtualenv. sync Installs all packages specified in Pipfile.lock. uninstall Un-installs a provided package and removes it from Pipfile. update Runs lock, then sync.pyenvとpipenvを利用したpython環境構築
ここまででインストレーションは終わりました。
ここから実際にPythonの環境を作っていきます。
今回は例として、python3.5.6の環境を作ってきます。
pipenvはpyenvの仮想環境をラップするようなイメージで動きますので、まずpython3.5系列をpyenvでインストールしてあげてから、pipenvでディレクトリの環境を整えます。$ pyenv install 3.5.6これでpipenvを使う準備が整いました。プロジェクトディレクトリを作りましょう。
$ mkdir sample_project $ cd sample_project $ pipenv --python 3.5.6これでsample_project内でpython3.5を使って開発をすることができます。
あとは動くかを試してみましょう。pipenvで作った環境をactivateするには、shellというコマンドを実行します。
ぬける際にはexitです。
下記例を見るとわかる通り、pipenvの仮想環境をactivateしている状態では、pythonのバージョンが3.5.6になっており、deactivateした状態では2.7.10となっています。ちなみに作った仮想環境は、sample_project/.venvに作られていますので、pycharmなどのinterpreterの設定も簡単に行えます。$ pipenv shell $ python --version Python 3.5.6 $ exit $ python --version Python 2.7.10これでpyenvとpipenvを使った簡単なpython環境構築は完了です。
凝ったことはできないので、今後も初心者向けの投稿をしていくつもりです。
- 投稿日:2019-02-11T16:30:00+09:00
各言語で定義できる関数のパラメータの最大個数
ちょっと気になって、関数で定義できるパラメータの最大個数について実験してみました。
255を閾値として、それ以上のパラメータを持つ関数を定義・実行できるのか、各言語のREPLを使って調べました。 (JavaScript はブラウザのコンソールです。)
256以上のパラメータを持つ関数を定義・実行できた場合は "(unlimited)" と記述しています。
Language Version the maximum number note Python 3.6.5 255 256個以上のパラメータを持つ関数は定義不可。 PHP 7.2.9 (unlimited) Ruby 2.5.1 (unlimited) Kotlin 1.3.0 255 256個以上のパラメータを持つ関数は定義可能だが実行時に java.lang.NullPointerExceptionが発生します。Java 11.0.2 255 256個以上のパラメータを持つ関数は定義不可。 JavaScript Chrome 72.0.3626.96 (unlimited) 特に Kotlin は 1.3 で 255個のパラメータを持つ関数を定義できるようになりました。 Java も、 ルールとして 255までしかパラメータ持てないことになっています。 たぶん Scala も?
Python
シンタックスエラーが関数定義の時に255までしか受け付けませんとメッセージを返します。
>>> def f(a0, a1, a2, a3, a4, a5, a6, a7, a8, a9, a10, a11, a12, a13, a14, a15, a16, a17, a18, a19, a20, a21, a22, a23, a24, a25, a26, a27, a28, a29, a30, a31, a32, a33, a34, a35, a36, a37, a38, a39, a40, a41, a42, a43, a44, a45, a46, a47, a48, a49, a50, a51, a52, a53, a54, a55, a56, a57, a58, a59, a60, a61, a62, a63, a64, a65, a66, a67, a68, a69, a70, a71, a72, a73, a74, a75, a76, a77, a78, a79, a80, a81, a82, a83, a84, a85, a86, a87, a88, a89, a90, a91, a92, a93, a94, a95, a96, a97, a98, a99, a100, a101, a102, a103, a104, a105, a106, a107, a108, a109, a110, a111, a112, a113, a114, a115, a116, a117, a118, a119, a120, a121, a122, a123, a124, a125, a126, a127, a128, a129, a130, a131, a132, a133, a134, a135, a136, a137, a138, a139, a140, a141, a142, a143, a144, a145, a146, a147, a148, a149, a150, a151, a152, a153, a154, a155, a156, a157, a158, a159, a160, a161, a162, a163, a164, a165, a166, a167, a168, a169, a170, a171, a172, a173, a174, a175, a176, a177, a178, a179, a180, a181, a182, a183, a184, a185, a186, a187, a188, a189, a190, a191, a192, a193, a194, a195, a196, a197, a198, a199, a200, a201, a202, a203, a204, a205, a206, a207, a208, a209, a210, a211, a212, a213, a214, a215, a216, a217, a218, a219, a220, a221, a222, a223, a224, a225, a226, a227, a228, a229, a230, a231, a232, a233, a234, a235, a236, a237, a238, a239, a240, a241, a242, a243, a244, a245, a246, a247, a248, a249, a250, a251, a252, a253, a254, a255, a256, a257): ... print(1) ... File "<stdin>", line 1 SyntaxError: more than 255 argumentsPHP
256以上のパラメータでも定義・実行できます。
php > function f($a0, $a1, $a2, $a3, $a4, $a5, $a6, $a7, $a8, $a9, $a10, $a11, $a12, $a13, $a14, $a15, $a16, $a17, $a18, $a19, $a20, $a21, $a22, $a23, $a24, $a25, $a26, $a27, $a28, $a29, $a30, $a31, $a32, $a33, $a34, $a35, $a36, $a37, $a38, $a39, $a40, $a41, $a42, $a43, $a44, $a45, $a46, $a47, $a48, $a49, $a50, $a51, $a52, $a53, $a54, $a55, $a56, $a57, $a58, $a59, $a60, $a61, $a62, $a63, $a64, $a65, $a66, $a67, $a68, $a69, $a70, $a71, $a72, $a73, $a74, $a75, $a76, $a77, $a78, $a79, $a80, $a81, $a82, $a83, $a84, $a85, $a86, $a87, $a88, $a89, $a90, $a91, $a92, $a93, $a94, $a95, $a96, $a97, $a98, $a99, $a100, $a101, $a102, $a103, $a104, $a105, $a106, $a107, $a108, $a109, $a110, $a111, $a112, $a113, $a114, $a115, $a116, $a117, $a118, $a119, $a120, $a121, $a122, $a123, $a124, $a125, $a126, $a127, $a128, $a129, $a130, $a131, $a132, $a133, $a134, $a135, $a136, $a137, $a138, $a139, $a140, $a141, $a142, $a143, $a144, $a145, $a146, $a147, $a148, $a149, $a150, $a151, $a152, $a153, $a154, $a155, $a156, $a157, $a158, $a159, $a160, $a161, $a162, $a163, $a164, $a165, $a166, $a167, $a168, $a169, $a170, $a171, $a172, $a173, $a174, $a175, $a176, $a177, $a178, $a179, $a180, $a181, $a182, $a183, $a184, $a185, $a186, $a187, $a188, $a189, $a190, $a191, $a192, $a193, $a194, $a195, $a196, $a197, $a198, $a199, $a200, $a201, $a202, $a203, $a204, $a205, $a206, $a207, $a208, $a209, $a210, $a211, $a212, $a213, $a214, $a215, $a216, $a217, $a218, $a219, $a220, $a221, $a222, $a223, $a224, $a225, $a226, $a227, $a228, $a229, $a230, $a231, $a232, $a233, $a234, $a235, $a236, $a237, $a238, $a239, $a240, $a241, $a242, $a243, $a244, $a245, $a246, $a247, $a248, $a249, $a250, $a251, $a252, $a253, $a254, $a255, $a256, $a257) { echo 1; } php > php > function f($a0 = 1, $a1 = 1, $a2 = 1, $a3 = 1, $a4 = 1, $a5 = 1, $a6 = 1, $a7 = 1, $a8 = 1, $a9 = 1, $a10 = 1, $a11 = 1, $a12 = 1, $a13 = 1, $a14 = 1, $a15 = 1, $a16 = 1, $a17 = 1, $a18 = 1, $a19 = 1, $a20 = 1, $a21 = 1, $a22 = 1, $a23 = 1, $a24 = 1, $a25 = 1, $a26 = 1, $a27 = 1, $a28 = 1, $a29 = 1, $a30 = 1, $a31 = 1, $a32 = 1, $a33 = 1, $a34 = 1, $a35 = 1, $a36 = 1, $a37 = 1, $a38 = 1, $a39 = 1, $a40 = 1, $a41 = 1, $a42 = 1, $a43 = 1, $a44 = 1, $a45 = 1, $a46 = 1, $a47 = 1, $a48 = 1, $a49 = 1, $a50 = 1, $a51 = 1, $a52 = 1, $a53 = 1, $a54 = 1, $a55 = 1, $a56 = 1, $a57 = 1, $a58 = 1, $a59 = 1, $a60 = 1, $a61 = 1, $a62 = 1, $a63 = 1, $a64 = 1, $a65 = 1, $a66 = 1, $a67 = 1, $a68 = 1, $a69 = 1, $a70 = 1, $a71 = 1, $a72 = 1, $a73 = 1, $a74 = 1, $a75 = 1, $a76 = 1, $a77 = 1, $a78 = 1, $a79 = 1, $a80 = 1, $a81 = 1, $a82 = 1, $a83 = 1, $a84 = 1, $a85 = 1, $a86 = 1, $a87 = 1, $a88 = 1, $a89 = 1, $a90 = 1, $a91 = 1, $a92 = 1, $a93 = 1, $a94 = 1, $a95 = 1, $a96 = 1, $a97 = 1, $a98 = 1, $a99 = 1, $a100 = 1, $a101 = 1, $a102 = 1, $a103 = 1, $a104 = 1, $a105 = 1, $a106 = 1, $a107 = 1, $a108 = 1, $a109 = 1, $a110 = 1, $a111 = 1, $a112 = 1, $a113 = 1, $a114 = 1, $a115 = 1, $a116 = 1, $a117 = 1, $a118 = 1, $a119 = 1, $a120 = 1, $a121 = 1, $a122 = 1, $a123 = 1, $a124 = 1, $a125 = 1, $a126 = 1, $a127 = 1, $a128 = 1, $a129 = 1, $a130 = 1, $a131 = 1, $a132 = 1, $a133 = 1, $a134 = 1, $a135 = 1, $a136 = 1, $a137 = 1, $a138 = 1, $a139 = 1, $a140 = 1, $a141 = 1, $a142 = 1, $a143 = 1, $a144 = 1, $a145 = 1, $a146 = 1, $a147 = 1, $a148 = 1, $a149 = 1, $a150 = 1, $a151 = 1, $a152 = 1, $a153 = 1, $a154 = 1, $a155 = 1, $a156 = 1, $a157 = 1, $a158 = 1, $a159 = 1, $a160 = 1, $a161 = 1, $a162 = 1, $a163 = 1, $a164 = 1, $a165 = 1, $a166 = 1, $a167 = 1, $a168 = 1, $a169 = 1, $a170 = 1, $a171 = 1, $a172 = 1, $a173 = 1, $a174 = 1, $a175 = 1, $a176 = 1, $a177 = 1, $a178 = 1, $a179 = 1, $a180 = 1, $a181 = 1, $a182 = 1, $a183 = 1, $a184 = 1, $a185 = 1, $a186 = 1, $a187 = 1, $a188 = 1, $a189 = 1, $a190 = 1, $a191 = 1, $a192 = 1, $a193 = 1, $a194 = 1, $a195 = 1, $a196 = 1, $a197 = 1, $a198 = 1, $a199 = 1, $a200 = 1, $a201 = 1, $a202 = 1, $a203 = 1, $a204 = 1, $a205 = 1, $a206 = 1, $a207 = 1, $a208 = 1, $a209 = 1, $a210 = 1, $a211 = 1, $a212 = 1, $a213 = 1, $a214 = 1, $a215 = 1, $a216 = 1, $a217 = 1, $a218 = 1, $a219 = 1, $a220 = 1, $a221 = 1, $a222 = 1, $a223 = 1, $a224 = 1, $a225 = 1, $a226 = 1, $a227 = 1, $a228 = 1, $a229 = 1, $a230 = 1, $a231 = 1, $a232 = 1, $a233 = 1, $a234 = 1, $a235 = 1, $a236 = 1, $a237 = 1, $a238 = 1, $a239 = 1, $a240 = 1, $a241 = 1, $a242 = 1, $a243 = 1, $a244 = 1, $a245 = 1, $a246 = 1, $a247 = 1, $a248 = 1, $a249 = 1, $a250 = 1, $a251 = 1, $a252 = 1, $a253 = 1, $a254 = 1, $a255 = 1, $a256 = 1) { echo 1; } php > f() php > ; 1Ruby
256以上のパラメータでも実行できます。
2.5.1 :004 > def f(a0, a1, a2, a3, a4, a5, a6, a7, a8, a9, a10, a11, a12, a13, a14, a15, a16, a17, a18, a19, a20, a21, a22, a23, a24, a25, a26, a27, a28, a29, a30, a31, a32, a33, a34, a35, a36, a37, a38, a39, a40, a41, a42, a43, a44, a45, a46, a47, a48, a49, a50, a51, a52, a53, a54, a55, a56, a57, a58, a59, a60, a61, a62, a63, a64, a65, a66, a67, a68, a69, a70, a71, a72, a73, a74, a75, a76, a77, a78, a79, a80, a81, a82, a83, a84, a85, a86, a87, a88, a89, a90, a91, a92, a93, a94, a95, a96, a97, a98, a99, a100, a101, a102, a103, a104, a105, a106, a107, a108, a109, a110, a111, a112, a113, a114, a115, a116, a117, a118, a119, a120, a121, a122, a123, a124, a125, a126, a127, a128, a129, a130, a131, a132, a133, a134, a135, a136, a137, a138, a139, a140, a141, a142, a143, a144, a145, a146, a147, a148, a149, a150, a151, a152, a153, a154, a155, a156, a157, a158, a159, a160, a161, a162, a163, a164, a165, a166, a167, a168, a169, a170, a171, a172, a173, a174, a175, a176, a177, a178, a179, a180, a181, a182, a183, a184, a185, a186, a187, a188, a189, a190, a191, a192, a193, a194, a195, a196, a197, a198, a199, a200, a201, a202, a203, a204, a205, a206, a207, a208, a209, a210, a211, a212, a213, a214, a215, a216, a217, a218, a219, a220, a221, a222, a223, a224, a225, a226, a227, a228, a229, a230, a231, a232, a233, a234, a235, a236, a237, a238, a239, a240, a241, a242, a243, a244, a245, a246, a247, a248, a249, a250, a251, a252, a253, a254, a255, a256, a257) 2.5.1 :005?> puts 1 2.5.1 :006?> end => :f 2.5.1 :001 > def f(a0 = 1, a1 = 1, a2 = 1, a3 = 1, a4 = 1, a5 = 1, a6 = 1, a7 = 1, a8 = 1, a9 = 1, a10 = 1, a11 = 1, a12 = 1, a13 = 1, a14 = 1, a15 = 1, a16 = 1, a17 = 1, a18 = 1, a19 = 1, a20 = 1, a21 = 1, a22 = 1, a23 = 1, a24 = 1, a25 = 1, a26 = 1, a27 = 1, a28 = 1, a29 = 1, a30 = 1, a31 = 1, a32 = 1, a33 = 1, a34 = 1, a35 = 1, a36 = 1, a37 = 1, a38 = 1, a39 = 1, a40 = 1, a41 = 1, a42 = 1, a43 = 1, a44 = 1, a45 = 1, a46 = 1, a47 = 1, a48 = 1, a49 = 1, a50 = 1, a51 = 1, a52 = 1, a53 = 1, a54 = 1, a55 = 1, a56 = 1, a57 = 1, a58 = 1, a59 = 1, a60 = 1, a61 = 1, a62 = 1, a63 = 1, a64 = 1, a65 = 1, a66 = 1, a67 = 1, a68 = 1, a69 = 1, a70 = 1, a71 = 1, a72 = 1, a73 = 1, a74 = 1, a75 = 1, a76 = 1, a77 = 1, a78 = 1, a79 = 1, a80 = 1, a81 = 1, a82 = 1, a83 = 1, a84 = 1, a85 = 1, a86 = 1, a87 = 1, a88 = 1, a89 = 1, a90 = 1, a91 = 1, a92 = 1, a93 = 1, a94 = 1, a95 = 1, a96 = 1, a97 = 1, a98 = 1, a99 = 1, a100 = 1, a101 = 1, a102 = 1, a103 = 1, a104 = 1, a105 = 1, a106 = 1, a107 = 1, a108 = 1, a109 = 1, a110 = 1, a111 = 1, a112 = 1, a113 = 1, a114 = 1, a115 = 1, a116 = 1, a117 = 1, a118 = 1, a119 = 1, a120 = 1, a121 = 1, a122 = 1, a123 = 1, a124 = 1, a125 = 1, a126 = 1, a127 = 1, a128 = 1, a129 = 1, a130 = 1, a131 = 1, a132 = 1, a133 = 1, a134 = 1, a135 = 1, a136 = 1, a137 = 1, a138 = 1, a139 = 1, a140 = 1, a141 = 1, a142 = 1, a143 = 1, a144 = 1, a145 = 1, a146 = 1, a147 = 1, a148 = 1, a149 = 1, a150 = 1, a151 = 1, a152 = 1, a153 = 1, a154 = 1, a155 = 1, a156 = 1, a157 = 1, a158 = 1, a159 = 1, a160 = 1, a161 = 1, a162 = 1, a163 = 1, a164 = 1, a165 = 1, a166 = 1, a167 = 1, a168 = 1, a169 = 1, a170 = 1, a171 = 1, a172 = 1, a173 = 1, a174 = 1, a175 = 1, a176 = 1, a177 = 1, a178 = 1, a179 = 1, a180 = 1, a181 = 1, a182 = 1, a183 = 1, a184 = 1, a185 = 1, a186 = 1, a187 = 1, a188 = 1, a189 = 1, a190 = 1, a191 = 1, a192 = 1, a193 = 1, a194 = 1, a195 = 1, a196 = 1, a197 = 1, a198 = 1, a199 = 1, a200 = 1, a201 = 1, a202 = 1, a203 = 1, a204 = 1, a205 = 1, a206 = 1, a207 = 1, a208 = 1, a209 = 1, a210 = 1, a211 = 1, a212 = 1, a213 = 1, a214 = 1, a215 = 1, a216 = 1, a217 = 1, a218 = 1, a219 = 1, a220 = 1, a221 = 1, a222 = 1, a223 = 1, a224 = 1, a225 = 1, a226 = 1, a227 = 1, a228 = 1, a229 = 1, a230 = 1, a231 = 1, a232 = 1, a233 = 1, a234 = 1, a235 = 1, a236 = 1, a237 = 1, a238 = 1, a239 = 1, a240 = 1, a241 = 1, a242 = 1, a243 = 1, a244 = 1, a245 = 1, a246 = 1, a247 = 1, a248 = 1, a249 = 1, a250 = 1, a251 = 1, a252 = 1, a253 = 1, a254 = 1, a255 = 1, a256 = 1) 2.5.1 :002?> puts 1 2.5.1 :003?> end => :f 2.5.1 :004 > f() 1 => nilKotlin
定義はできているように見えます。しかし実行時にエラーが出ました。
>>> fun f(a0: Int, a1: Int, a2: Int, a3: Int, a4: Int, a5: Int, a6: Int, a7: Int, a8: Int, a9: Int, a10: Int, a11: Int, a12: Int, a13: Int, a14: Int, a15: Int, a16: Int, a17: Int, a18: Int, a19: Int, a20: Int, a21: Int, a22: Int, a23: Int, a24: Int, a25: Int, a26: Int, a27: Int, a28: Int, a29: Int, a30: Int, a31: Int, a32: Int, a33: Int, a34: Int, a35: Int, a36: Int, a37: Int, a38: Int, a39: Int, a40: Int, a41: Int, a42: Int, a43: Int, a44: Int, a45: Int, a46: Int, a47: Int, a48: Int, a49: Int, a50: Int, a51: Int, a52: Int, a53: Int, a54: Int, a55: Int, a56: Int, a57: Int, a58: Int, a59: Int, a60: Int, a61: Int, a62: Int, a63: Int, a64: Int, a65: Int, a66: Int, a67: Int, a68: Int, a69: Int, a70: Int, a71: Int, a72: Int, a73: Int, a74: Int, a75: Int, a76: Int, a77: Int, a78: Int, a79: Int, a80: Int, a81: Int, a82: Int, a83: Int, a84: Int, a85: Int, a86: Int, a87: Int, a88: Int, a89: Int, a90: Int, a91: Int, a92: Int, a93: Int, a94: Int, a95: Int, a96: Int, a97: Int, a98: Int, a99: Int, a100: Int, a101: Int, a102: Int, a103: Int, a104: Int, a105: Int, a106: Int, a107: Int, a108: Int, a109: Int, a110: Int, a111: Int, a112: Int, a113: Int, a114: Int, a115: Int, a116: Int, a117: Int, a118: Int, a119: Int, a120: Int, a121: Int, a122: Int, a123: Int, a124: Int, a125: Int, a126: Int, a127: Int, a128: Int, a129: Int, a130: Int, a131: Int, a132: Int, a133: Int, a134: Int, a135: Int, a136: Int, a137: Int, a138: Int, a139: Int, a140: Int, a141: Int, a142: Int, a143: Int, a144: Int, a145: Int, a146: Int, a147: Int, a148: Int, a149: Int, a150: Int, a151: Int, a152: Int, a153: Int, a154: Int, a155: Int, a156: Int, a157: Int, a158: Int, a159: Int, a160: Int, a161: Int, a162: Int, a163: Int, a164: Int, a165: Int, a166: Int, a167: Int, a168: Int, a169: Int, a170: Int, a171: Int, a172: Int, a173: Int, a174: Int, a175: Int, a176: Int, a177: Int, a178: Int, a179: Int, a180: Int, a181: Int, a182: Int, a183: Int, a184: Int, a185: Int, a186: Int, a187: Int, a188: Int, a189: Int, a190: Int, a191: Int, a192: Int, a193: Int, a194: Int, a195: Int, a196: Int, a197: Int, a198: Int, a199: Int, a200: Int, a201: Int, a202: Int, a203: Int, a204: Int, a205: Int, a206: Int, a207: Int, a208: Int, a209: Int, a210: Int, a211: Int, a212: Int, a213: Int, a214: Int, a215: Int, a216: Int, a217: Int, a218: Int, a219: Int, a220: Int, a221: Int, a222: Int, a223: Int, a224: Int, a225: Int, a226: Int, a227: Int, a228: Int, a229: Int, a230: Int, a231: Int, a232: Int, a233: Int, a234: Int, a235: Int, a236: Int, a237: Int, a238: Int, a239: Int, a240: Int, a241: Int, a242: Int, a243: Int, a244: Int, a245: Int, a246: Int, a247: Int, a248: Int, a249: Int, a250: Int, a251: Int, a252: Int, a253: Int, a254: Int, a255: Int, a256: Int, a257: Int) { println(1) } >>> fun f(a0: Int = 1, a1: Int = 1, a2: Int = 1, a3: Int = 1, a4: Int = 1, a5: Int = 1, a6: Int = 1, a7: Int = 1, a8: Int = 1, a9: Int = 1, a10: Int = 1, a11: Int = 1, a12: Int = 1, a13: Int = 1, a14: Int = 1, a15: Int = 1, a16: Int = 1, a17: Int = 1, a18: Int = 1, a19: Int = 1, a20: Int = 1, a21: Int = 1, a22: Int = 1, a23: Int = 1, a24: Int = 1, a25: Int = 1, a26: Int = 1, a27: Int = 1, a28: Int = 1, a29: Int = 1, a30: Int = 1, a31: Int = 1, a32: Int = 1, a33: Int = 1, a34: Int = 1, a35: Int = 1, a36: Int = 1, a37: Int = 1, a38: Int = 1, a39: Int = 1, a40: Int = 1, a41: Int = 1, a42: Int = 1, a43: Int = 1, a44: Int = 1, a45: Int = 1, a46: Int = 1, a47: Int = 1, a48: Int = 1, a49: Int = 1, a50: Int = 1, a51: Int = 1, a52: Int = 1, a53: Int = 1, a54: Int = 1, a55: Int = 1, a56: Int = 1, a57: Int = 1, a58: Int = 1, a59: Int = 1, a60: Int = 1, a61: Int = 1, a62: Int = 1, a63: Int = 1, a64: Int = 1, a65: Int = 1, a66: Int = 1, a67: Int = 1, a68: Int = 1, a69: Int = 1, a70: Int = 1, a71: Int = 1, a72: Int = 1, a73: Int = 1, a74: Int = 1, a75: Int = 1, a76: Int = 1, a77: Int = 1, a78: Int = 1, a79: Int = 1, a80: Int = 1, a81: Int = 1, a82: Int = 1, a83: Int = 1, a84: Int = 1, a85: Int = 1, a86: Int = 1, a87: Int = 1, a88: Int = 1, a89: Int = 1, a90: Int = 1, a91: Int = 1, a92: Int = 1, a93: Int = 1, a94: Int = 1, a95: Int = 1, a96: Int = 1, a97: Int = 1, a98: Int = 1, a99: Int = 1, a100: Int = 1, a101: Int = 1, a102: Int = 1, a103: Int = 1, a104: Int = 1, a105: Int = 1, a106: Int = 1, a107: Int = 1, a108: Int = 1, a109: Int = 1, a110: Int = 1, a111: Int = 1, a112: Int = 1, a113: Int = 1, a114: Int = 1, a115: Int = 1, a116: Int = 1, a117: Int = 1, a118: Int = 1, a119: Int = 1, a120: Int = 1, a121: Int = 1, a122: Int = 1, a123: Int = 1, a124: Int = 1, a125: Int = 1, a126: Int = 1, a127: Int = 1, a128: Int = 1, a129: Int = 1, a130: Int = 1, a131: Int = 1, a132: Int = 1, a133: Int = 1, a134: Int = 1, a135: Int = 1, a136: Int = 1, a137: Int = 1, a138: Int = 1, a139: Int = 1, a140: Int = 1, a141: Int = 1, a142: Int = 1, a143: Int = 1, a144: Int = 1, a145: Int = 1, a146: Int = 1, a147: Int = 1, a148: Int = 1, a149: Int = 1, a150: Int = 1, a151: Int = 1, a152: Int = 1, a153: Int = 1, a154: Int = 1, a155: Int = 1, a156: Int = 1, a157: Int = 1, a158: Int = 1, a159: Int = 1, a160: Int = 1, a161: Int = 1, a162: Int = 1, a163: Int = 1, a164: Int = 1, a165: Int = 1, a166: Int = 1, a167: Int = 1, a168: Int = 1, a169: Int = 1, a170: Int = 1, a171: Int = 1, a172: Int = 1, a173: Int = 1, a174: Int = 1, a175: Int = 1, a176: Int = 1, a177: Int = 1, a178: Int = 1, a179: Int = 1, a180: Int = 1, a181: Int = 1, a182: Int = 1, a183: Int = 1, a184: Int = 1, a185: Int = 1, a186: Int = 1, a187: Int = 1, a188: Int = 1, a189: Int = 1, a190: Int = 1, a191: Int = 1, a192: Int = 1, a193: Int = 1, a194: Int = 1, a195: Int = 1, a196: Int = 1, a197: Int = 1, a198: Int = 1, a199: Int = 1, a200: Int = 1, a201: Int = 1, a202: Int = 1, a203: Int = 1, a204: Int = 1, a205: Int = 1, a206: Int = 1, a207: Int = 1, a208: Int = 1, a209: Int = 1, a210: Int = 1, a211: Int = 1, a212: Int = 1, a213: Int = 1, a214: Int = 1, a215: Int = 1, a216: Int = 1, a217: Int = 1, a218: Int = 1, a219: Int = 1, a220: Int = 1, a221: Int = 1, a222: Int = 1, a223: Int = 1, a224: Int = 1, a225: Int = 1, a226: Int = 1, a227: Int = 1, a228: Int = 1, a229: Int = 1, a230: Int = 1, a231: Int = 1, a232: Int = 1, a233: Int = 1, a234: Int = 1, a235: Int = 1, a236: Int = 1, a237: Int = 1, a238: Int = 1, a239: Int = 1, a240: Int = 1, a241: Int = 1, a242: Int = 1, a243: Int = 1, a244: Int = 1, a245: Int = 1, a246: Int = 1, a247: Int = 1, a248: Int = 1, a249: Int = 1, a250: Int = 1, a251: Int = 1, a252: Int = 1, a253: Int = 1, a254: Int = 1, a255: Int = 1) { println(1) } >>> f() java.lang.NullPointerException at Line_1.f$default(Line_1.kts:1) >>> f(1) java.lang.NullPointerException at Line_1.f$default(Line_1.kts:1) >>> fun f(a0: Int = 1, a1: Int = 1, a2: Int = 1, a3: Int = 1, a4: Int = 1, a5: Int = 1, a6: Int = 1, a7: Int = 1, a8: Int = 1, a9: Int = 1, a10: Int = 1, a11: Int = 1, a12: Int = 1, a13: Int = 1, a14: Int = 1, a15: Int = 1, a16: Int = 1, a17: Int = 1, a18: Int = 1, a19: Int = 1, a20: Int = 1, a21: Int = 1, a22: Int = 1, a23: Int = 1, a24: Int = 1, a25: Int = 1, a26: Int = 1, a27: Int = 1, a28: Int = 1, a29: Int = 1, a30: Int = 1, a31: Int = 1, a32: Int = 1, a33: Int = 1, a34: Int = 1, a35: Int = 1, a36: Int = 1, a37: Int = 1, a38: Int = 1, a39: Int = 1, a40: Int = 1, a41: Int = 1, a42: Int = 1, a43: Int = 1, a44: Int = 1, a45: Int = 1, a46: Int = 1, a47: Int = 1, a48: Int = 1, a49: Int = 1, a50: Int = 1, a51: Int = 1, a52: Int = 1, a53: Int = 1, a54: Int = 1, a55: Int = 1, a56: Int = 1, a57: Int = 1, a58: Int = 1, a59: Int = 1, a60: Int = 1, a61: Int = 1, a62: Int = 1, a63: Int = 1, a64: Int = 1, a65: Int = 1, a66: Int = 1, a67: Int = 1, a68: Int = 1, a69: Int = 1, a70: Int = 1, a71: Int = 1, a72: Int = 1, a73: Int = 1, a74: Int = 1, a75: Int = 1, a76: Int = 1, a77: Int = 1, a78: Int = 1, a79: Int = 1, a80: Int = 1, a81: Int = 1, a82: Int = 1, a83: Int = 1, a84: Int = 1, a85: Int = 1, a86: Int = 1, a87: Int = 1, a88: Int = 1, a89: Int = 1, a90: Int = 1, a91: Int = 1, a92: Int = 1, a93: Int = 1, a94: Int = 1, a95: Int = 1, a96: Int = 1, a97: Int = 1, a98: Int = 1, a99: Int = 1, a100: Int = 1, a101: Int = 1, a102: Int = 1, a103: Int = 1, a104: Int = 1, a105: Int = 1, a106: Int = 1, a107: Int = 1, a108: Int = 1, a109: Int = 1, a110: Int = 1, a111: Int = 1, a112: Int = 1, a113: Int = 1, a114: Int = 1, a115: Int = 1, a116: Int = 1, a117: Int = 1, a118: Int = 1, a119: Int = 1, a120: Int = 1, a121: Int = 1, a122: Int = 1, a123: Int = 1, a124: Int = 1, a125: Int = 1, a126: Int = 1, a127: Int = 1, a128: Int = 1, a129: Int = 1, a130: Int = 1, a131: Int = 1, a132: Int = 1, a133: Int = 1, a134: Int = 1, a135: Int = 1, a136: Int = 1, a137: Int = 1, a138: Int = 1, a139: Int = 1, a140: Int = 1, a141: Int = 1, a142: Int = 1, a143: Int = 1, a144: Int = 1, a145: Int = 1, a146: Int = 1, a147: Int = 1, a148: Int = 1, a149: Int = 1, a150: Int = 1, a151: Int = 1, a152: Int = 1, a153: Int = 1, a154: Int = 1, a155: Int = 1, a156: Int = 1, a157: Int = 1, a158: Int = 1, a159: Int = 1, a160: Int = 1, a161: Int = 1, a162: Int = 1, a163: Int = 1, a164: Int = 1, a165: Int = 1, a166: Int = 1, a167: Int = 1, a168: Int = 1, a169: Int = 1, a170: Int = 1, a171: Int = 1, a172: Int = 1, a173: Int = 1, a174: Int = 1, a175: Int = 1, a176: Int = 1, a177: Int = 1, a178: Int = 1, a179: Int = 1, a180: Int = 1, a181: Int = 1, a182: Int = 1, a183: Int = 1, a184: Int = 1, a185: Int = 1, a186: Int = 1, a187: Int = 1, a188: Int = 1, a189: Int = 1, a190: Int = 1, a191: Int = 1, a192: Int = 1, a193: Int = 1, a194: Int = 1, a195: Int = 1, a196: Int = 1, a197: Int = 1, a198: Int = 1, a199: Int = 1, a200: Int = 1, a201: Int = 1, a202: Int = 1, a203: Int = 1, a204: Int = 1, a205: Int = 1, a206: Int = 1, a207: Int = 1, a208: Int = 1, a209: Int = 1, a210: Int = 1, a211: Int = 1, a212: Int = 1, a213: Int = 1, a214: Int = 1, a215: Int = 1, a216: Int = 1, a217: Int = 1, a218: Int = 1, a219: Int = 1, a220: Int = 1, a221: Int = 1, a222: Int = 1, a223: Int = 1, a224: Int = 1, a225: Int = 1, a226: Int = 1, a227: Int = 1, a228: Int = 1, a229: Int = 1, a230: Int = 1, a231: Int = 1, a232: Int = 1, a233: Int = 1, a234: Int = 1, a235: Int = 1, a236: Int = 1, a237: Int = 1, a238: Int = 1, a239: Int = 1, a240: Int = 1, a241: Int = 1, a242: Int = 1, a243: Int = 1, a244: Int = 1, a245: Int = 1, a246: Int = 1, a247: Int = 1, a248: Int = 1, a249: Int = 1, a250: Int = 1, a251: Int = 1, a252: Int = 1, a253: Int = 1, a254: Int = 1) { println(1) } >>> f() 1 >>>Java
256個以上のパラメータがあると、定義することもできません。
jshell> void f(int a0, int a1, int a2, int a3, int a4, int a5, int a6, int a7, int a8, int a9, int a10, int a11, int a12, int a13, int a14, int a15, int a16, int a17, int a18, int a19, int a20, int a21, int a22, int a23, int a24, int a25, int a26, int a27, int a28, int a29, int a30, int a31, int a32, int a33, int a34, int a35, int a36, int a37, int a38, int a39, int a40, int a41, int a42, int a43, int a44, int a45, int a46, int a47, int a48, int a49, int a50, int a51, int a52, int a53, int a54, int a55, int a56, int a57, int a58, int a59, int a60, int a61, int a62, int a63, int a64, int a65, int a66, int a67, int a68, int a69, int a70, int a71, int a72, int a73, int a74, int a75, int a76, int a77, int a78, int a79, int a80, int a81, int a82, int a83, int a84, int a85, int a86, int a87, int a88, int a89, int a90, int a91, int a92, int a93, int a94, int a95, int a96, int a97, int a98, int a99, int a100, int a101, int a102, int a103, int a104, int a105, int a106, int a107, int a108, int a109, int a110, int a111, int a112, int a113, int a114, int a115, int a116, int a117, int a118, int a119, int a120, int a121, int a122, int a123, int a124, int a125, int a126, int a127, int a128, int a129, int a130, int a131, int a132, int a133, int a134, int a135, int a136, int a137, int a138, int a139, int a140, int a141, int a142, int a143, int a144, int a145, int a146, int a147, int a148, int a149, int a150, int a151, int a152, int a153, int a154, int a155, int a156, int a157, int a158, int a159, int a160, int a161, int a162, int a163, int a164, int a165, int a166, int a167, int a168, int a169, int a170, int a171, int a172, int a173, int a174, int a175, int a176, int a177, int a178, int a179, int a180, int a181, int a182, int a183, int a184, int a185, int a186, int a187, int a188, int a189, int a190, int a191, int a192, int a193, int a194, int a195, int a196, int a197, int a198, int a199, int a200, int a201, int a202, int a203, int a204, int a205, int a206, int a207, int a208, int a209, int a210, int a211, int a212, int a213, int a214, int a215, int a216, int a217, int a218, int a219, int a220, int a221, int a222, int a223, int a224, int a225, int a226, int a227, int a228, int a229, int a230, int a231, int a232, int a233, int a234, int a235, int a236, int a237, int a238, int a239, int a240, int a241, int a242, int a243, int a244, int a245, int a246, int a247, int a248, int a249, int a250, int a251, int a252, int a253, int a254, int a255) { System.out.println(1); } | Error: | too many parameters | void f(int a0, int a1, int a2, int a3, int a4, int a5, int a6, int a7, int a8, int a9, int a10, int a11, int a12, int a13, int a14, int a15, int a16, int a17, int a18, int a19, int a20, int a21, int a22, int a23, int a24, int a25, int a26, int a27, int a28, int a29, int a30, int a31, int a32, int a33, int a34, int a35, int a36, int a37, int a38, int a39, int a40, int a41, int a42, int a43, int a44, int a45, int a46, int a47, int a48, int a49, int a50, int a51, int a52, int a53, int a54, int a55, int a56, int a57, int a58, int a59, int a60, int a61, int a62, int a63, int a64, int a65, int a66, int a67, int a68, int a69, int a70, int a71, int a72, int a73, int a74, int a75, int a76, int a77, int a78, int a79, int a80, int a81, int a82, int a83, int a84, int a85, int a86, int a87, int a88, int a89, int a90, int a91, int a92, int a93, int a94, int a95, int a96, int a97, int a98, int a99, int a100, int a101, int a102, int a103, int a104, int a105, int a106, int a107, int a108, int a109, int a110, int a111, int a112, int a113, int a114, int a115, int a116, int a117, int a118, int a119, int a120, int a121, int a122, int a123, int a124, int a125, int a126, int a127, int a128, int a129, int a130, int a131, int a132, int a133, int a134, int a135, int a136, int a137, int a138, int a139, int a140, int a141, int a142, int a143, int a144, int a145, int a146, int a147, int a148, int a149, int a150, int a151, int a152, int a153, int a154, int a155, int a156, int a157, int a158, int a159, int a160, int a161, int a162, int a163, int a164, int a165, int a166, int a167, int a168, int a169, int a170, int a171, int a172, int a173, int a174, int a175, int a176, int a177, int a178, int a179, int a180, int a181, int a182, int a183, int a184, int a185, int a186, int a187, int a188, int a189, int a190, int a191, int a192, int a193, int a194, int a195, int a196, int a197, int a198, int a199, int a200, int a201, int a202, int a203, int a204, int a205, int a206, int a207, int a208, int a209, int a210, int a211, int a212, int a213, int a214, int a215, int a216, int a217, int a218, int a219, int a220, int a221, int a222, int a223, int a224, int a225, int a226, int a227, int a228, int a229, int a230, int a231, int a232, int a233, int a234, int a235, int a236, int a237, int a238, int a239, int a240, int a241, int a242, int a243, int a244, int a245, int a246, int a247, int a248, int a249, int a250, int a251, int a252, int a253, int a254, int a255) { System.out.println(1); } | ^----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------^ | modified method f(int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int), however, it cannot be referenced until this error is corrected: | too many parameters | void f(int a0, int a1, int a2, int a3, int a4, int a5, int a6, int a7, int a8, int a9, int a10, int a11, int a12, int a13, int a14, int a15, int a16, int a17, int a18, int a19, int a20, int a21, int a22, int a23, int a24, int a25, int a26, int a27, int a28, int a29, int a30, int a31, int a32, int a33, int a34, int a35, int a36, int a37, int a38, int a39, int a40, int a41, int a42, int a43, int a44, int a45, int a46, int a47, int a48, int a49, int a50, int a51, int a52, int a53, int a54, int a55, int a56, int a57, int a58, int a59, int a60, int a61, int a62, int a63, int a64, int a65, int a66, int a67, int a68, int a69, int a70, int a71, int a72, int a73, int a74, int a75, int a76, int a77, int a78, int a79, int a80, int a81, int a82, int a83, int a84, int a85, int a86, int a87, int a88, int a89, int a90, int a91, int a92, int a93, int a94, int a95, int a96, int a97, int a98, int a99, int a100, int a101, int a102, int a103, int a104, int a105, int a106, int a107, int a108, int a109, int a110, int a111, int a112, int a113, int a114, int a115, int a116, int a117, int a118, int a119, int a120, int a121, int a122, int a123, int a124, int a125, int a126, int a127, int a128, int a129, int a130, int a131, int a132, int a133, int a134, int a135, int a136, int a137, int a138, int a139, int a140, int a141, int a142, int a143, int a144, int a145, int a146, int a147, int a148, int a149, int a150, int a151, int a152, int a153, int a154, int a155, int a156, int a157, int a158, int a159, int a160, int a161, int a162, int a163, int a164, int a165, int a166, int a167, int a168, int a169, int a170, int a171, int a172, int a173, int a174, int a175, int a176, int a177, int a178, int a179, int a180, int a181, int a182, int a183, int a184, int a185, int a186, int a187, int a188, int a189, int a190, int a191, int a192, int a193, int a194, int a195, int a196, int a197, int a198, int a199, int a200, int a201, int a202, int a203, int a204, int a205, int a206, int a207, int a208, int a209, int a210, int a211, int a212, int a213, int a214, int a215, int a216, int a217, int a218, int a219, int a220, int a221, int a222, int a223, int a224, int a225, int a226, int a227, int a228, int a229, int a230, int a231, int a232, int a233, int a234, int a235, int a236, int a237, int a238, int a239, int a240, int a241, int a242, int a243, int a244, int a245, int a246, int a247, int a248, int a249, int a250, int a251, int a252, int a253, int a254, int a255) { System.out.println(1); } | ^----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------^ jshell> void f(int a0, int a1, int a2, int a3, int a4, int a5, int a6, int a7, int a8, int a9, int a10, int a11, int a12, int a13, int a14, int a15, int a16, int a17, int a18, int a19, int a20, int a21, int a22, int a23, int a24, int a25, int a26, int a27, int a28, int a29, int a30, int a31, int a32, int a33, int a34, int a35, int a36, int a37, int a38, int a39, int a40, int a41, int a42, int a43, int a44, int a45, int a46, int a47, int a48, int a49, int a50, int a51, int a52, int a53, int a54, int a55, int a56, int a57, int a58, int a59, int a60, int a61, int a62, int a63, int a64, int a65, int a66, int a67, int a68, int a69, int a70, int a71, int a72, int a73, int a74, int a75, int a76, int a77, int a78, int a79, int a80, int a81, int a82, int a83, int a84, int a85, int a86, int a87, int a88, int a89, int a90, int a91, int a92, int a93, int a94, int a95, int a96, int a97, int a98, int a99, int a100, int a101, int a102, int a103, int a104, int a105, int a106, int a107, int a108, int a109, int a110, int a111, int a112, int a113, int a114, int a115, int a116, int a117, int a118, int a119, int a120, int a121, int a122, int a123, int a124, int a125, int a126, int a127, int a128, int a129, int a130, int a131, int a132, int a133, int a134, int a135, int a136, int a137, int a138, int a139, int a140, int a141, int a142, int a143, int a144, int a145, int a146, int a147, int a148, int a149, int a150, int a151, int a152, int a153, int a154, int a155, int a156, int a157, int a158, int a159, int a160, int a161, int a162, int a163, int a164, int a165, int a166, int a167, int a168, int a169, int a170, int a171, int a172, int a173, int a174, int a175, int a176, int a177, int a178, int a179, int a180, int a181, int a182, int a183, int a184, int a185, int a186, int a187, int a188, int a189, int a190, int a191, int a192, int a193, int a194, int a195, int a196, int a197, int a198, int a199, int a200, int a201, int a202, int a203, int a204, int a205, int a206, int a207, int a208, int a209, int a210, int a211, int a212, int a213, int a214, int a215, int a216, int a217, int a218, int a219, int a220, int a221, int a222, int a223, int a224, int a225, int a226, int a227, int a228, int a229, int a230, int a231, int a232, int a233, int a234, int a235, int a236, int a237, int a238, int a239, int a240, int a241, int a242, int a243, int a244, int a245, int a246, int a247, int a248, int a249, int a250, int a251, int a252, int a253, int a254) { System.out.println(1); } | created method f(int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int,int) jshell> f(1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1); 1 jshell>JavaScript
パラメータが256個以上でも関数定義できます・
function f(a0, a1, a2, a3, a4, a5, a6, a7, a8, a9, a10, a11, a12, a13, a14, a15, a16, a17, a18, a19, a20, a21, a22, a23, a24, a25, a26, a27, a28, a29, a30, a31, a32, a33, a34, a35, a36, a37, a38, a39, a40, a41, a42, a43, a44, a45, a46, a47, a48, a49, a50, a51, a52, a53, a54, a55, a56, a57, a58, a59, a60, a61, a62, a63, a64, a65, a66, a67, a68, a69, a70, a71, a72, a73, a74, a75, a76, a77, a78, a79, a80, a81, a82, a83, a84, a85, a86, a87, a88, a89, a90, a91, a92, a93, a94, a95, a96, a97, a98, a99, a100, a101, a102, a103, a104, a105, a106, a107, a108, a109, a110, a111, a112, a113, a114, a115, a116, a117, a118, a119, a120, a121, a122, a123, a124, a125, a126, a127, a128, a129, a130, a131, a132, a133, a134, a135, a136, a137, a138, a139, a140, a141, a142, a143, a144, a145, a146, a147, a148, a149, a150, a151, a152, a153, a154, a155, a156, a157, a158, a159, a160, a161, a162, a163, a164, a165, a166, a167, a168, a169, a170, a171, a172, a173, a174, a175, a176, a177, a178, a179, a180, a181, a182, a183, a184, a185, a186, a187, a188, a189, a190, a191, a192, a193, a194, a195, a196, a197, a198, a199, a200, a201, a202, a203, a204, a205, a206, a207, a208, a209, a210, a211, a212, a213, a214, a215, a216, a217, a218, a219, a220, a221, a222, a223, a224, a225, a226, a227, a228, a229, a230, a231, a232, a233, a234, a235, a236, a237, a238, a239, a240, a241, a242, a243, a244, a245, a246, a247, a248, a249, a250, a251, a252, a253, a254, a255) { console.log(1); } f(1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1); 1
- 投稿日:2019-02-11T16:23:00+09:00
[macOS] PyenvでPython使う (VSCode)
mac に乗り換えてデフォルトで python 入ってんだ、へぇと思い、
VSCode 使ってコード書いてみたら、こんな感じで軽く注意された
You have selected the macOS system install of Python, Which is not recommended for use with the Python extension. Some functionality will be limited, please select a different interpreter.デフォルの python は VSCode 非推奨と言っとる。。
色々ゴニョゴニョやって怒られなくなったのですが、もう一度同じ事ができる気がしなかったのでメモ環境
macOS Mojave 10.14.2
Visual Studio Code 1.30.2
Python 2.7.10の環境に以下を追加する
pyenv 1.2.9 → pythonの複数バージョンを切り替えるため
anaconda3-5.3.1 → 色々入ってて便利なためVSCodeの拡張機能
そもそもこれ入れないと注意すらされない
VSCode の拡張機能から、
pythonと入力して入れるpyenv インストール
$ brew install pyenvbrewは 公式を参考に1ライナーでインストール可能
pyenv のインストールが無事終わると、最後の方に忠告がある
==> Caveats To use Homebrew's directories rather than ~/.pyenv add to your profile: export PYENV_ROOT=/usr/local/var/pyenv To enable shims and autocompletion add to your profile: if which pyenv > /dev/null; then eval "$(pyenv init -)"; fi・ デフォルトだと
~/.pyenvなので、/usr/local/var/pyenvを指定してね。的な
・ 自動補完機能使うには、eval "$(pyenv init -)"やってね。的な忠告に従い以下の様に追記
$ vi ~/.bash_profile export PYENV_ROOT=/usr/local/var/pyenv if which pyenv > /dev/null; then eval "$(pyenv init -)"; fi $ . ~/.bash_profile因みにどうでもいいですが、以下を
evalで評価して実行してた$ pyenv init - export PATH="/usr/local/var/pyenv/shims:${PATH}" export PYENV_SHELL=bash source '/usr/local/Cellar/pyenv/1.2.9/libexec/../completions/pyenv.bash' command pyenv rehash 2>/dev/null pyenv() { local command command="${1:-}" if [ "$#" -gt 0 ]; then shift fi case "$command" in rehash|shell) eval "$(pyenv "sh-$command" "$@")";; *) command pyenv "$command" "$@";; esac }pyenv のインストールが完了
$ type pyenv pyenv is /usr/local/bin/pyenv $ pyenv --version pyenv 1.2.9python3のインストール
インストール可能なリストを表示
$ pyenv install -l | grep anaconda3 anaconda3-2.0.0 anaconda3-2.0.1 anaconda3-2.1.0 anaconda3-2.2.0 anaconda3-2.3.0 anaconda3-2.4.0 anaconda3-2.4.1 anaconda3-2.5.0 anaconda3-4.0.0 anaconda3-4.1.0 anaconda3-4.1.1 anaconda3-4.2.0 anaconda3-4.3.0 anaconda3-4.3.1 anaconda3-4.4.0 anaconda3-5.0.0 anaconda3-5.0.1 anaconda3-5.1.0 anaconda3-5.2.0 anaconda3-5.3.0 anaconda3-5.3.1 anaconda3-2018.12最新を入れる(5分ぐらいかかった気がします)
今回はanaconda入れてますが、普通に2系とか3系とか入れれます$ pyenv install anaconda3-5.3.1 Downloading Anaconda3-5.3.1-MacOSX-x86_64.sh.sh... -> https://repo.continuum.io/archive/Anaconda3-5.3.1-MacOSX-x86_64.sh Installing Anaconda3-5.3.1-MacOSX-x86_64.sh... Installed Anaconda3-5.3.1-MacOSX-x86_64.sh to /usr/local/var/pyenv/versions/anaconda3-5.3.1インストールが終わったら、
pyenv versionsで切り替え可能な python を参照~$ pyenv versions * system (set by /usr/local/var/pyenv/version) anaconda3-5.3.1
pyenv global 'Interpreter'で切り替える$ pyenv global anaconda3-5.3.1もう一度
pyenv versionsで確認してみると、「*」の場所が変わってる$ pyenv versions system * anaconda3-5.3.1 (set by /Users/ando/.pyenv/version)インタプリタちゃんと変わってた
$ python -V Python 3.7.0 $ type python python is /usr/local/var/pyenv/shims/python因みに、
pyenv local Interpreterとすると、そのディレクトリのみ切り替わる~$ mkdir py2 ~$ cd py2 ~/py2$ pyenv versions system * anaconda3-5.3.1 (set by /usr/local/var/pyenv/version) ~/py2$ pyenv local system ~/py2$ python -V Python 2.7.10 ~/py2$ cd .. ~$ python -V Python 3.7.0VSCode の Python Interpreter の指定
ようやく本題
Code → 基本設定 → 設定
適当にスクロールしてどこかしらで、settings.json を見つけて編集をポチ
で以下の様にインストールした python のインタプリタを指定settings.json{ "python.pythonPath": "/usr/local/var/pyenv/versions/anaconda3-5.3.1/bin/python" }
ワークスペースの設定にも同様に指定
※ここポイント(これやんなくて、あれって30分ぐらいなってた)"settings": { "python.pythonPath": "/usr/local/var/pyenv/versions/anaconda3-5.3.1/bin/python" }これで VSCode で pythonファイル開いても、警告がでなくなりました
因みに VScode でF1押して、検索窓出して、
Python: Select Interpreterと入力すると、
インタプリタの指定が出来ます。そして、macデフォルトを指定すると当たり前ですがまた警告が出ます。
python2系使う場合、 pyenv で別途インストールが必要です。

