- 投稿日:2019-02-11T23:10:11+09:00
SQLだけでランダム抽出
SQLだけでrandomに値を抽出する方法です。
SQLServerを題材に実際に抽出するクエリのサンプルを用いて説明します。やりたいこと
ユーザごとにお気に入り登録している商品があり、商品は複数存在するカテゴリーのどれかに属しているとします。全てのユーザーに対しカテゴリ毎にランダムで1件抽出して、カテゴリーの種類数分の商品をユーザに紐づけることを目指します。
データ
CREATE TABLE Member ( id int, name text ); CREATE TABLE MemberFavoriteItem ( member_id int, item_id int ); CREATE TABLE Item ( id int, category_id int, name text ); -- 最終的に作りたいデータ CREATE TABLE UserRandomCategoryItem ( member_name text, category_id int, item_name text )抽出方法
STEP 1
全ての対象データを結合し、ウィンドウ関数で分割したデータの中にランダムな連続する値を持たせます。ポイントはウィンドウ関数でランダム化したい単位に分割して、カテゴリーの中に含まれるitem_idの中でランダムな値を割り振っているところです。
注意点
* SQLServerではテーブル名の先頭に#をつけるとtempテーブル
* NEWID()によってレコード毎にユニークな文字列を付与し、それを基準にORDER BYした結果にROW_NUMBERを付与することでランダムな順序を実現している。NEWID()ではなくRAND()を使いたかったが、シードをユニークにしないと値が同じになってしまうので使っていないSTEP2
ランダムに割り振った数値を見て必要な個数分where句で絞ります。
※ウィンドウ関数の結果は直接whereで指定できないので、一度tempテーブルを経由するか、サブクエリとして用いる必要があります。実際のクエリ
-- STEP1 SELECT Member.name AS member_name, Item.category_id AS category_id, Item.name as item_name, ROW_NUMBER() OVER(PARTITION BY member_id, category_id ORDER BY NEWID()) AS random_num INTO #AggregateResult FROM Member INNER JOIN MemberFavoriteItem ON Member.id = MemberFavoriteItem.member_id INNER JOIN Item ON MemberFavoriteItem.item_id = Item.id ; -- STEP2 INSERT INTO MemberRandomCategoryItem SELECT member_name, category_id, item_name FROM #AggregateResult WHERE -- カテゴリ毎に複数種類欲しいなら数を変える random_num <= 1SQLServerでやってみる
検証用データを用意する
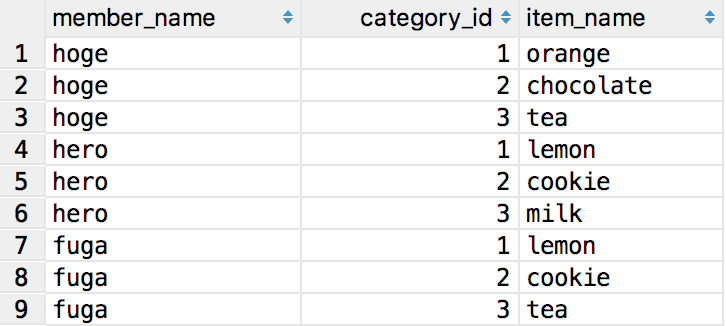
INSERT INTO Member VALUES (1, 'hoge'), (2, 'hero'), (3, 'fuga') ; INSERT INTO MemberFavoriteItem VALUES (1, 1), (1, 2), (1, 3), (1, 4), (1, 5), (1, 6), (1, 7), (1, 8), (1, 9), (2, 1), (2, 2), (2, 3), (2, 4), (2, 5), (2, 6), (2, 7), (2, 8), (2, 9), (3, 1), (3, 2), (3, 3), (3, 4), (3, 5), (3, 6), (3, 7), (3, 8), (3, 9) ; INSERT INTO Item VALUES (1, 1, 'apple'), (2, 1, 'orange'), (3, 1, 'lemon'), (4, 2, 'chocolate'), (5, 2, 'cookie'), (6, 2, 'candy'), (7, 3, 'tea'), (8, 3, 'milk'), (9, 3, 'coffee')結果
全てのメンバーに対してカテゴリ毎に1件ランダムで結果が返ってきました。
実行するたびに結果は変わります。
- 投稿日:2019-02-11T20:30:59+09:00
【R】RODBC経由でSQL Serverからデータ取得。
環境
Windows
R 3.2.5
Microsoft R Open 3.2.5Windows認証を使ってRODBCでSQL Serverに接続
RからRODBCパッケージを使ってSQL Serverに接続する。
library(RODBC) #データベース接続 setDB<-function(){ driver<-'{SQL Server}' server <- 'localhost\\SQLEXPRESS' database <- 'NicoNico' trusted_connection <- 'yes' conn<-paste('DRIVER=',driver,';SERVER=',server,';DATABASE=',database,';Trusted_Connection=',trusted_connection,';',sep="") cnxn <- odbcDriverConnect(conn) return(cnxn) }SQL構文でデータ取得
返り値はdateframe。適宜date.table等に変換すると使いやすいかと。
conn <- setDB() sqlText <- "select * from [dbo].[Hoge];" videoData<-sqlQuery(conn, sqlText)結果
RからSQL Serverに接続、データを取得できた。
あとはR側で統計分析すればOK。
- 投稿日:2019-02-11T18:49:16+09:00
SQLをオンラインで試せるサービス
- 投稿日:2019-02-11T17:44:53+09:00
pandas の DataFrame と SQL の記述方法の比較
動機
仕事で AI や機械学習、データ分析といった技術を身に付ける必要性ができ、
まずは Python を使ったデータ分析を修得するために pandas を
利用したデータ分析にチャレンジしています。自分にはシステム開発経験があり SQL には使い慣れているのですが、
pandas のデータ分析の記述方法があまり理解できない状況でした。巷では「pandas は SQL と似ている」といった表現をよく聞くので、
それならば SQL での書き方を pandas の書き方と比較したら
理解が深まるのではないかと思い、今回まとめてみました。なお本記事は、ある程度のターミナル操作や
MySQL、Python、pandas についての知識がある方を対象としています。なお、ここからの説明は長いためコードの比較結果のみを見たい場合は、
比較結果まとめを参照ください。環境
項目 内容 OS CentOS Linux release 7.5.1804 DB 5.7.23-23 Percona Server (GPL), Release 23, Revision 500fcf5 Python anaconda3-5.3.1 / Python 3.7.0 Editor jupyterlab Version 0.34.9 ブラウザ Google Chrome 71.0.3578.98 DB は、MySQL 互換の「Percona Server」です。
MySQL のコマンドはすべてターミナルより直接入力します。詳細は割愛しますが、Windows をホストマシンとし、
vagrant でゲスト OS に Linux を使っています。また Linux では pyenv を利用して、一部パスのみ
上記 Python のバージョンとして動作するように設定しています。利用データ
MySQL のサンプルデータを使います。
https://dev.mysql.com/doc/index-other.html
Example Databases → world database
このような素晴らしいサンプルデータがあることに感謝します。
今回は次のデータを利用します。
- データベース:world
- テーブル:
- city
- country
環境準備
ダウンロードした MySQL のサンプルデータを解凍し、次のようなコマンドでデータベースに取り込みます。
「world」という名前のデータベース(スキーマ)を作成するため、事前に利用するデータベースに重複する名前がないか確認することをお勧めします。
mysql -u [MySQLのユーザー] -p < world.sqlMySQL にログイン後、データベースが作成されていることを確認したら、 次のようなコマンドで、今度はタブ区切りの csv ファイルを作成します。
mysql -u [MySQLのユーザー] -p world -e "SELECT * FROM city;" > city.csv mysql -u [MySQLのユーザー] -p world -e "SELECT * FROM country;" > country.csv今回は「data」というディレクトリを作って保存したため、
csvファイルのパスは次の通りになります。
- data/city.csv
- data/country.csv
Python コード
Python では、jupyterlab で次のようなコードを記述して
csv ファイルのデータを pandas の DataFrame に取り込みます。import pandas as pd city = pd.read_csv("data/city.csv", sep="\t") country = pd.read_csv("data/country.csv", sep="\t")抽出方法の比較
1. 列指定
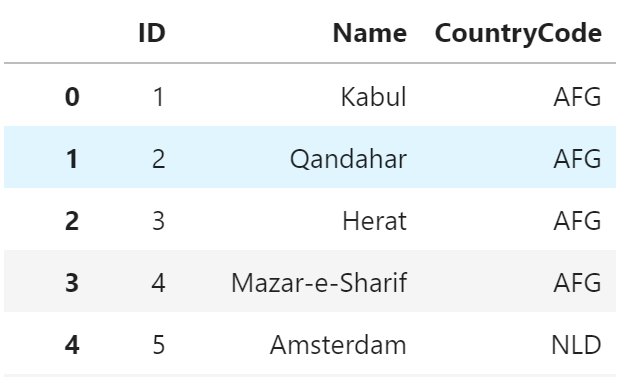
SQL
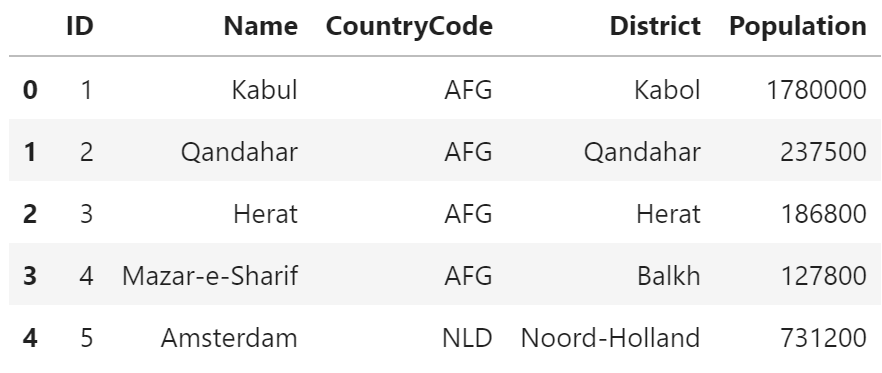
SELECT ID, Name, CountryCode FROM city;+----+----------------+-------------+ | ID | Name | CountryCode | +----+----------------+-------------+ | 1 | Kabul | AFG | | 2 | Qandahar | AFG | | 3 | Herat | AFG | | 4 | Mazar-e-Sharif | AFG | | 5 | Amsterdam | NLD | (5件まで)pandas
city[["ID", "Name", "CountryCode"]]
説明
SQL では列名を SELECT句 に指定するのに対して、
pandas では DataFrame のインデックスに列名のリストを指定します。SQLはテーブル定義されているため、列名をダブルクォートで囲む必要がありません。
対して pandas では文字列として指定するためダブルクォートで囲む必要があります。2. 条件指定
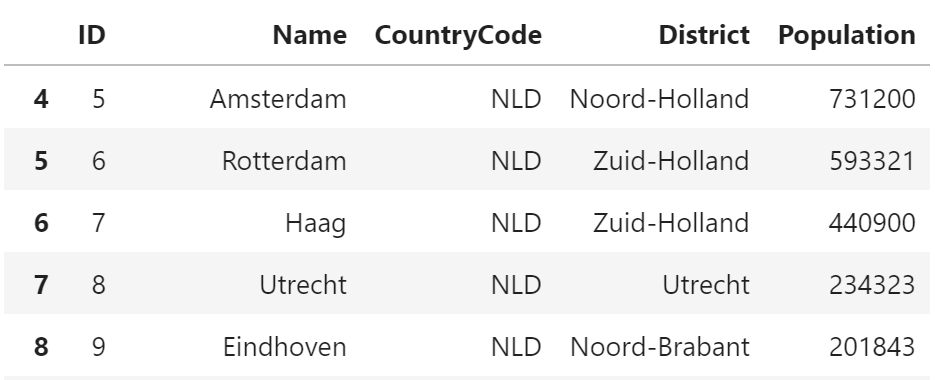
SQL
SELECT * FROM city WHERE CountryCode = 'NLD';+----+-------------------+-------------+---------------+------------+ | ID | Name | CountryCode | District | Population | +----+-------------------+-------------+---------------+------------+ | 5 | Amsterdam | NLD | Noord-Holland | 731200 | | 6 | Rotterdam | NLD | Zuid-Holland | 593321 | | 7 | Haag | NLD | Zuid-Holland | 440900 | | 8 | Utrecht | NLD | Utrecht | 234323 | | 9 | Eindhoven | NLD | Noord-Brabant | 201843 | (5件まで)pandas
city[city.CountryCode == "NLD"]
説明
SQL では WHERE句 に条件を指定するのに対して、
pandas では、「ブールインデックス」を使って、
DataFrame のインデックスに条件を指定します。DataFrame のインデックスに
[True, False・・・]のようなリストを、DataFrame のレコード数分指定すると、Trueが指定されたレコードのみを抽出することができます。
city.CountryCode == "NLD"インデックスに指定しているこの式は、
すべてのcityのレコードに対して True または False を返す式です。3. 複数条件指定
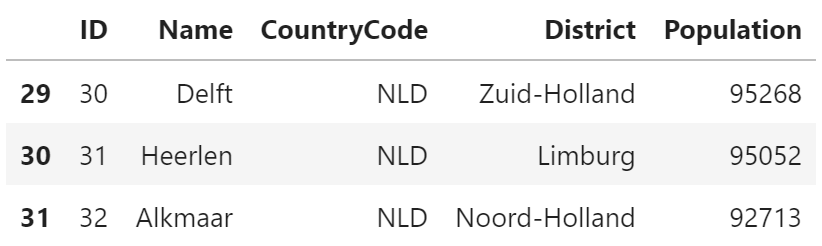
SQL
SELECT * FROM city WHERE CountryCode = 'NLD' AND Population < 100000;+----+---------+-------------+---------------+------------+ | ID | Name | CountryCode | District | Population | +----+---------+-------------+---------------+------------+ | 30 | Delft | NLD | Zuid-Holland | 95268 | | 31 | Heerlen | NLD | Limburg | 95052 | | 32 | Alkmaar | NLD | Noord-Holland | 92713 | +----+---------+-------------+---------------+------------+pandas
city[(city.CountryCode == "NLD") & (city.Population < 100000)]
説明
SQL では AND で条件をつなぎますが、
pandas では「&」で条件をつなぎます。各条件式は()で囲む必要があります。
ブールインデックス同士で両方とも True になるレコードが抽出されます。4. 複数条件指定(同項目内)
SQL
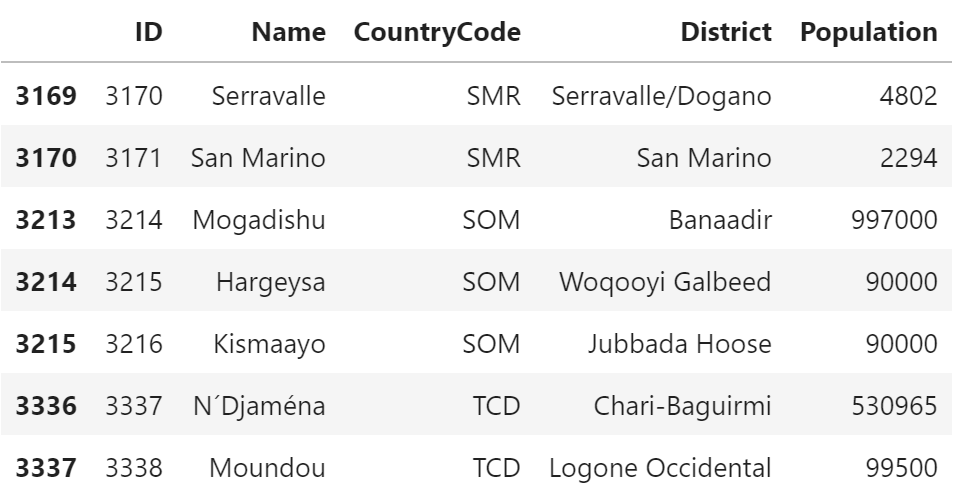
SELECT * FROM city WHERE CountryCode IN ('SMR', 'TCD', 'SOM');+------+-------------+-------------+-------------------+------------+ | ID | Name | CountryCode | District | Population | +------+-------------+-------------+-------------------+------------+ | 3170 | Serravalle | SMR | Serravalle/Dogano | 4802 | | 3171 | San Marino | SMR | San Marino | 2294 | | 3214 | Mogadishu | SOM | Banaadir | 997000 | | 3215 | Hargeysa | SOM | Woqooyi Galbeed | 90000 | | 3216 | Kismaayo | SOM | Jubbada Hoose | 90000 | | 3337 | N´Djaména | TCD | Chari-Baguirmi | 530965 | | 3338 | Moundou | TCD | Logone Occidental | 99500 | +------+-------------+-------------+-------------------+------------+pandas
city[city.CountryCode.isin(["SMR", "TCD", "SOM"])]
説明
SQL では、IN句 でカンマ区切りに条件を指定します。
pandas では、DataFrame の isin関数 を利用します。isin関数 の引数に条件をリストで指定します。
5. 件数指定
SQL
SELECT * FROM city LIMIT 5;+----+----------------+-------------+---------------+------------+ | ID | Name | CountryCode | District | Population | +----+----------------+-------------+---------------+------------+ | 1 | Kabul | AFG | Kabol | 1780000 | | 2 | Qandahar | AFG | Qandahar | 237500 | | 3 | Herat | AFG | Herat | 186800 | | 4 | Mazar-e-Sharif | AFG | Balkh | 127800 | | 5 | Amsterdam | NLD | Noord-Holland | 731200 | +----+----------------+-------------+---------------+------------+pandas
city.head(5)
説明
SQL では、LIMIT句 を利用して取得します。
pandas では head関数 を利用します。
また、最後のレコードを取得する tail関数 も存在します。6. 並び替え
SQL
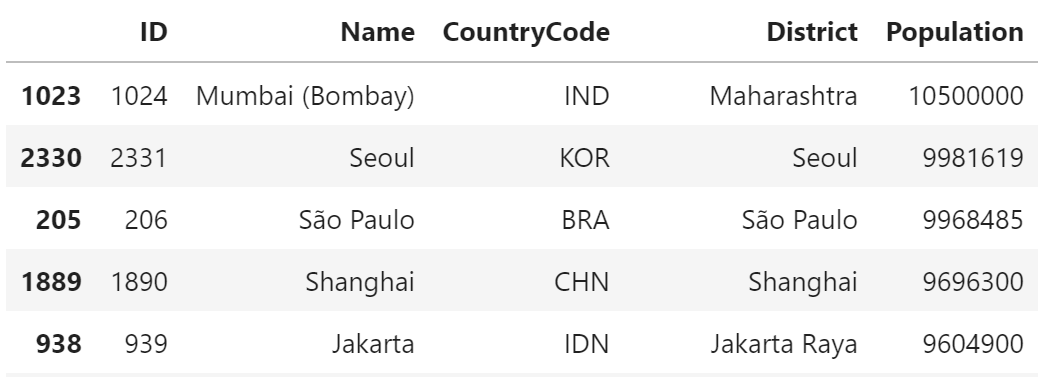
SELECT * FROM city ORDER BY Population DESC;+------+-----------------+-------------+--------------+------------+ | ID | Name | CountryCode | District | Population | +------+-----------------+-------------+--------------+------------+ | 1024 | Mumbai (Bombay) | IND | Maharashtra | 10500000 | | 2331 | Seoul | KOR | Seoul | 9981619 | | 206 | São Paulo | BRA | São Paulo | 9968485 | | 1890 | Shanghai | CHN | Shanghai | 9696300 | | 939 | Jakarta | IDN | Jakarta Raya | 9604900 | (5件まで)pandas
city.sort_values(by="Population", ascending=False)
説明
SQL では、ORDER BY句 を利用して並び順を指定します。
pandas では、DataFrame の sort_values関数 を利用します。引数の by に文字列で列を指定して、降順にする場合は、
引数の ascending に False を設定します。7. 件数
SQL
SELECT COUNT(*) FROM city;+----------+ | COUNT(*) | +----------+ | 4079 | +----------+pandas
len(city)
説明
SQL では COUNT関数 を使います。
pandas では複数方法はありますが、len関数 の引数に
DataFrame を指定する方法が SQL とも似ていて分かりやすいと思います。8. 合計
SQL
SELECT SUM(Population) FROM city;+-----------------+ | SUM(Population) | +-----------------+ | 1429559884 | +-----------------+pandas
city.Population.sum()
説明
SQL では、SUM関数 を利用します。
pandas では、DataFrame の列に対して合計をとることをオブジェクト指向の方法で sum関数 を使って行います。9. 平均
SQL
SELECT AVG(Population) FROM city;+-----------------+ | AVG(Population) | +-----------------+ | 350468.2236 | +-----------------+pandas
city.Population.mean()
説明
SQL では、AVG関数 を使います。
pandas では、DataFrame の列に対して合計をとることをオブジェクト指向の方法で mean関数 を使って行います。MySQL ではデフォルトの計算では、
Python に比べて精度の低いものになっています。
MySQL で小数精度を高める方法の一つとして、あらかじめ大きな数をかけて整数とし、
平均をとった後に同じ数で割る方法があります。MySQL では次のような SQL になります。
SELECT FORMAT(AVG(Population * 100000000000) / 100000000000, 20) FROM city;+-----------------------------------------------------------+ | FORMAT(AVG(Population * 100000000000) / 100000000000, 20) | +-----------------------------------------------------------+ | 350,468.22358421181662172100 | +-----------------------------------------------------------+Python で同様の方法で計算しても結果は変わりませんでした。
あまり取るべき手法ではないと考えられます。((city.Population * 100000000000).mean())/100000000000
掛けて割る値を大きくしすぎると、
問題が起きるので気を付ける必要があります。
MySQL ではエラーに、pandas では、不正値が出力されます。SQL(エラー)
ERROR 1690 (22003): BIGINT value is out of range in '(`world`.`city`.`Population` * 1000000000000)'pandas(エラー)※不正計算
((city.Population * 1000000000000).mean())/1000000000000
10. データ定義
SQL
desc city;+-------------+----------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +-------------+----------+------+-----+---------+----------------+ | ID | int(11) | NO | PRI | NULL | auto_increment | | Name | char(35) | NO | | | | | CountryCode | char(3) | NO | MUL | | | | District | char(20) | NO | | | | | Population | int(11) | NO | | 0 | | +-------------+----------+------+-----+---------+----------------+pandas
city.dtypes
説明
MySQL では、desc コマンドを利用します。
SHOW CREATE TABLE city\Gにすると、
テーブル作成クエリを確認できます。pandas では、dtypesプロパティ で確認できます。
11. あいまい条件指定
SQL
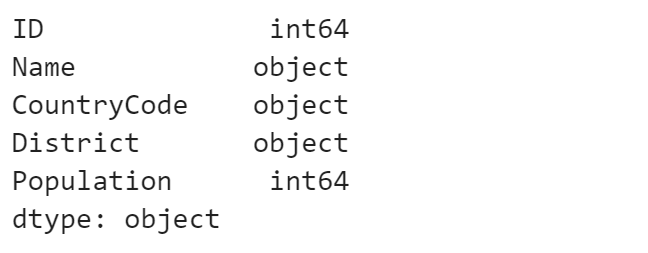
SELECT * FROM city WHERE LOWER(Name) LIKE '%nab%';+------+---------------------+-------------+-------------------+------------+ | ID | Name | CountryCode | District | Population | +------+---------------------+-------------+-------------------+------------+ | 38 | Annaba | DZA | Annaba | 222518 | | 835 | Panabo | PHL | Southern Mindanao | 133950 | | 1551 | Funabashi | JPN | Chiba | 545299 | | 1831 | Burnaby | CAN | British Colombia | 179209 | | 2925 | Guaynabo | PRI | Guaynabo | 100053 | | 3114 | Osnabrück | DEU | Niedersachsen | 164539 | | 3610 | Nabereznyje Tšelny | RUS | Tatarstan | 514700 | | 4078 | Nablus | PSE | Nablus | 100231 | +------+---------------------+-------------+-------------------+------------+pandas
city[city.Name.str.lower().str.contains("nab")]
説明
SQL では、LIKEステートメントを利用して、
正規表現の記号として「%」を利用します。
文字列を条件にする場合、大文字・小文字の区別がされない設定に
されていることが多いです。今回はわかりやすくするため LOWER関数 を利用しましたが、
この関数を利用しなくても結果は同じです。pandas では、少し工夫が必要で、文字列の列にある strアクセサを使います。
大文字・小文字を区別させない場合は、lower関数 を利用して小文字状態で確認します。また、今回は「nab」を含むことを条件としているため、
同じく strアクセサ の containsメソッド を利用しています。12. グループ化
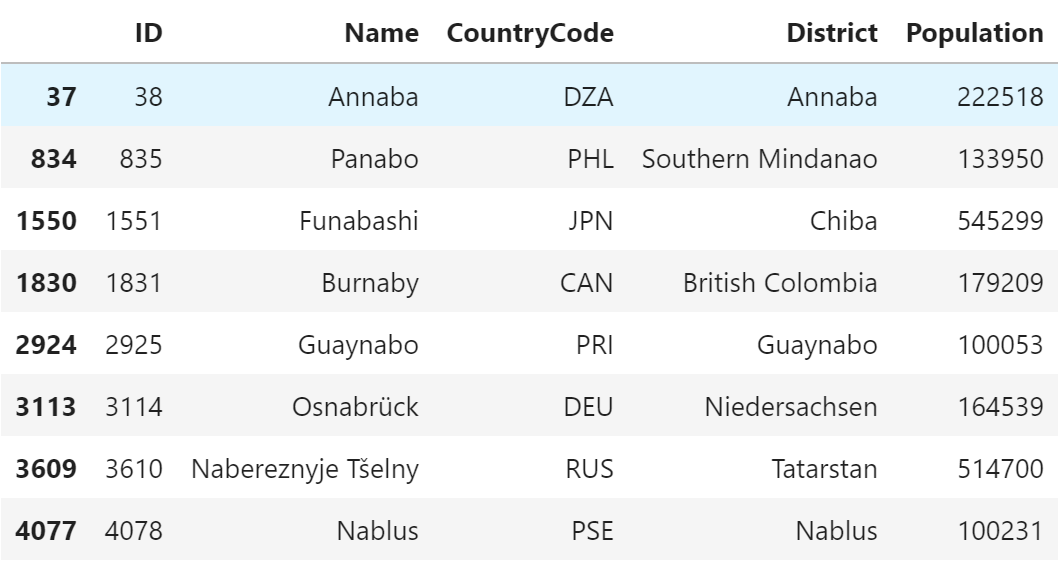
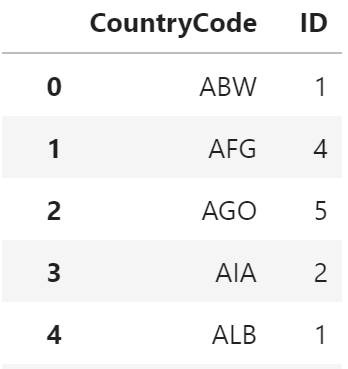
SQL
SELECT CountryCode, COUNT(*) FROM city GROUP BY CountryCode;+-------------+----------+ | CountryCode | COUNT(*) | +-------------+----------+ | ABW | 1 | | AFG | 4 | | AGO | 5 | | AIA | 2 | | ALB | 1 | (5件まで)pandas
city.groupby("CountryCode", as_index=False).count()[["CountryCode","ID"]]
説明
SQL では以下を指定するのがポイントです。
- 抽出列
- グループ集計関数
- GROUP BY句
「抽出列」と「GROUP BY句」に指定する列名を同じにし、
必要なグループ集計関数を指定すれば、グループ化されたデータを
抽出することができます。pandas では、「軸」の考え方が重要で、SQL で抽出列に該当するものです。
この軸を groupby関数 の引数に文字列で指定して、
どこのの列を集計処理するのか、どのように集計するのかを関数にすることでグループ化したデータを抽出することができます。今回は次の通りです。
- 軸 ⇒ CountryCode
- どこの列を集計処理 ⇒ ID
- どのように集計 ⇒ 件数を集計(count)
as_index に False を指定しているのは、
指定しないと、軸をインデックスに設定してしまうので
他と違い扱いづらくなるためです。13. テーブル結合
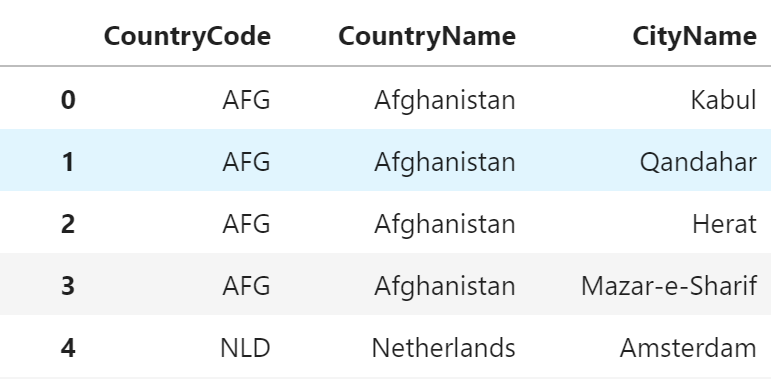
SQL
SELECT city.CountryCode, country.Name AS CountryName, city.Name AS CityName FROM city LEFT JOIN country ON city.CountryCode = country.Code;+-------------+-------------+----------------+ | CountryCode | CountryName | CityName | +-------------+-------------+----------------+ | AFG | Afghanistan | Kabul | | AFG | Afghanistan | Qandahar | | AFG | Afghanistan | Herat | | AFG | Afghanistan | Mazar-e-Sharif | | NLD | Netherlands | Amsterdam | (5件まで)pandas
country_city = pd.merge(city, country, how="left", left_on="CountryCode", right_on="Code" )[["CountryCode", "Name_y", "Name_x"]] country_city.columns = ["CountryCode", "CountryName", "CityName"] country_city
説明
SQL では、LEFT JOIN句 を使って結合するテーブルと、
結合条件を指定します。
また列名は AS句 を使ってエイリアス指定により変更します。pandas では処理が2段階に分かれます。
まずは、pandas の merge関数 を使って
結合するデータを2つ指定し、結合方法、結合条件となる列名を指定します。「Name_y」「Name_x」としているのは、
city、country ともに「Name」という列を保持しているため、
pandas がデフォルトで重複する場合にサフィックスとして「_x」「_y」を
つけるためです。次に columnsプロパティ に新しい列名を設定しています。
14. グループ化 + 並び替え + 件数指定 + 件数
SQL
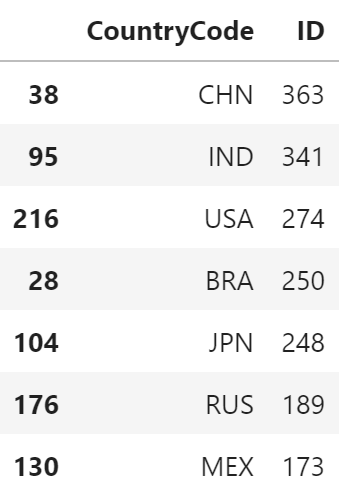
SELECT CountryCode, COUNT(*) AS cnt FROM city GROUP BY CountryCode ORDER BY cnt DESC LIMIT 7;+-------------+-----+ | CountryCode | cnt | +-------------+-----+ | CHN | 363 | | IND | 341 | | USA | 274 | | BRA | 250 | | JPN | 248 | | RUS | 189 | | MEX | 173 | +-------------+-----+pandas
city.groupby("CountryCode", as_index=False)[["ID"]].count().sort_values(by="ID", ascending=False).head(7)
説明
SQL では、グループ集計と並び替え、指定件数を組み合わせただけになります。
pandas では、少々複雑で次の順番でデータ抽出を考えてコードを作りました。
- グループ化
- 抽出列指定
- 集計関数指定
- 並び替え指定
- 抽出件数指定
どの処理も DataFrame を返すので処理順を考えて指定するのがポイントです。
比較結果まとめ
1. 列指定 SQL SELECT ID, Name, CountryCode FROM city; pandas city[["ID", "Name", "CountryCode"]]
2. 条件指定 SQL SELECT * FROM city WHERE CountryCode = 'NLD'; pandas city[city.CountryCode == "NLD"]
3. 複数条件指定 SQL SELECT * FROM city WHERE CountryCode = 'NLD' AND Population < 100000; pandas city[(city.CountryCode == "NLD") & (city.Population < 100000)]
4. 複数条件指定(同項目内) SQL SELECT * FROM city WHERE CountryCode IN ('SMR', 'TCD', 'SOM'); pandas city[city.CountryCode.isin(["SMR", "TCD", "SOM"])]
5. 件数指定 SQL SELECT * FROM city LIMIT 5; pandas city.head(5)
6. 並び替え SQL SELECT * FROM city ORDER BY Population DESC; pandas city.sort_values(by="Population", ascending=False)
7. 件数 SQL SELECT COUNT(*) FROM city; pandas len(city)
8. 合計 SQL SELECT SUM(Population) FROM city; pandas city.Population.sum()
9. 平均 SQL SELECT AVG(Population) FROM city; pandas city.Population.mean()
10. データ定義 SQL desc city; pandas city.dtypes
11. あいまい条件指定 SQL SELECT * FROM city WHERE LOWER(Name) LIKE '%nab%'; pandas city[city.Name.str.lower().str.contains("nab")]
12. グループ化 SQL SELECT CountryCode, COUNT(*) FROM city GROUP BY CountryCode; pandas city.groupby("CountryCode", as_index=False).count()[["CountryCode","ID"]]
13. テーブル結合 SQL SELECT city.CountryCode, country.Name AS CountryName, city.Name AS CityName
FROM city LEFT JOIN country ON city.CountryCode = country.Code;pandas country_city = pd.merge(city, country,
how="left", left_on="CountryCode", right_on="Code"
)[["CountryCode", "Name_y", "Name_x"]]
country_city.columns = ["CountryCode", "CountryName", "CityName"]
country_city
14. グループ化 + 並び替え + 件数指定 + 件数 SQL SELECT CountryCode, COUNT(*) AS cnt
FROM city GROUP BY CountryCode ORDER BY cnt DESC LIMIT 7;pandas city.groupby("CountryCode", as_index=False)[["ID"]].count().sort_values(by="ID", ascending=False).head(7) 所感
pandas での書き方だけで考えていたらあまり理解できませんでしたが、
SQL で書いたものを pandas で書く、と考えたところ理解しやすく感じました。抽出条件が複雑になると SQL の方が組み立てやすく、
pandas では特徴を理解して工夫をする必要があるように感じました。
この辺りは実践で反復して身に付ける必要があると思います。pandas では、戻り値が2次元データの DataFrame なのか、
1次元データの Series なのかを考えるのがコツに感じました。DataFrame であればその後ろに DataFrame 用の
関数や記述ができるので、少し複雑になっても組み合わせられると思います。Series であれば値がすべてブール型ならば、
DataFrame のインデックスに指定して条件とできると考えるのがよいと思います。以上です。
この記事が同じようなことを考えられている方にとって、
有用になれば幸いです。


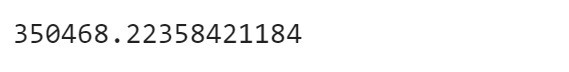


- 投稿日:2019-02-11T15:47:51+09:00
[SQL入門] 営業向けSQL勉強会やってみた vol.1
イントロ
営業戦略を立てる上で顧客データや行動を知るのは大事ですよね。僕の勤めている会社でも営業の方から〇〇のデータが欲しい、xxの現状を知りたいとお願いされることがあります。今回はそんな営業の方達が簡単なデータなら自分たちでいつでも調べられるように、社内で営業向けSQL勉強会を開いた際の手順を投稿させていただきます。
*僕が勤めている会社の社内勉強会は1回あたり1時間なので、複数回開催。この記事は第1回目の勉強会が終わった時点で投稿しています。
第1回目を終えた感想
ちょっと早いですが、最初に勉強会を開催してみての感想を書きます。
良かった点
- 内容を絞ったので営業の方たちにスムーズにすすめてもらえた。
- ハンズオン形式が好評で、自分でデータを取得できる快感に目覚めてもらえた。
- 後日、「こんなデータ取れませんかね?」と営業活動に活かせてもらえた。
3つ目のクエリは流石に僕が書きましたが、データに興味を持ってもらえたのは大きな進歩かなと思いました!
悪かった点
- PC操作に慣れていない点を十分考慮できなかった。
- 英語に不慣れであった点を考慮できなかった。
普段の仕事ではPC & 英語に慣れている人が大半なので、もうちょっと考慮すべきでした。
主にぶつかった点は、
① コピペで練習問題をすすめてしまった人がちらほら。(写経して体で覚えてほしかった)
② 半角、全角の区別。(主にスペースでエラーになってしまう人がちらほら)第2回目の勉強会では以上の点を反省して進めていきたいと思いました。
みなさんも自社で勉強会を開催する際は十分配慮してあげてください。
勉強会の進め方
以下の手順で勉強会を進めました。
- 簡単な構成のDB、本番DBを用意
- SQLの概要説明
- 簡単な構成のDBでselect文の講義
- 簡単な構成のDBを用いて練習問題
- 問題の解答、解説
- トピック(select, where, order, etc...)を変えて 3~5の繰り返し
- 本番DBを用いて、各トピックの問題を出題
- 問題の解答、解説
- 本番DBへはRead権限でアクセスできるように設定。
環境
MySQL 5.7.24
事前準備
営業の方が各自のPCでセットアップする必要がないように、僕の会社ではRe:dashでDBへアクセスできる環境を整えました。
第1回目の講義に使うDBのSQLは以下。
データは各自適当なものをinsertしてください。-- データベースの作成 CREATE DATABASE sales_practice_database; -- データベースの選択 USE sales_practice_database; -- テーブルの作成 CREATE TABLE users ( id BIGINT NOT NULL, name VARCHAR(255) NOT NULL, created DATETIME NOT NULL, modified DATETIME, PRIMARY KEY (id) ); CREATE TABLE posts ( id BIGINT NOT NULL, comments VARCHAR(255), created DATETIME NOT NULL, modified DATETIME, PRIMARY KEY (id) ); -- データの登録 INSERT INTO users VALUES (1, "田中太郎", "2019-02-01", "2019-02-12"), (2, "安川小太郎", "2019-02-02", "2019-02-10"), (3, "緑安江", "2019-02-03", "2019-02-03"), (4, "竜崎かなえ", "2019-02-04", "2019-02-11"), (5, "田中聡", "2019-02-05", "2019-02-05"); INSERT INTO posts VALUES (1, "こんにちは", "2019-02-01", "2019-02-02"), (2, "おはよう", "2019-02-02", "2019-02-02"), (3, "こんばんわ", "2019-02-03", "2019-02-03"), (4, "お腹空いた", "2019-02-04", "2019-02-04"), (5, "バイバイ", "2019-02-05", "2019-02-05");usersテーブル
+----+-----------------+---------------------+---------------------+ | id | name | created | modified | +----+-----------------+---------------------+---------------------+ | 1 | 田中太郎 | 2019-02-01 00:00:00 | 2019-02-12 00:00:00 | | 2 | 安川小太郎 | 2019-02-02 00:00:00 | 2019-02-10 00:00:00 | | 3 | 緑安江 | 2019-02-03 00:00:00 | 2019-02-03 00:00:00 | | 4 | 竜崎かなえ | 2019-02-04 00:00:00 | 2019-02-11 00:00:00 | | 5 | 田中聡 | 2019-02-05 00:00:00 | 2019-02-05 00:00:00 | +----+-----------------+---------------------+---------------------+postsテーブル
+----+-----------------+---------------------+---------------------+ | id | comments | created | modified | +----+-----------------+---------------------+---------------------+ | 1 | こんにちは | 2019-02-01 00:00:00 | 2019-02-02 00:00:00 | | 2 | おはよう | 2019-02-02 00:00:00 | 2019-02-02 00:00:00 | | 3 | こんばんわ | 2019-02-03 00:00:00 | 2019-02-03 00:00:00 | | 4 | お腹空いた | 2019-02-04 00:00:00 | 2019-02-04 00:00:00 | | 5 | バイバイ | 2019-02-05 00:00:00 | 2019-02-05 00:00:00 | +----+-----------------+---------------------+---------------------+
以下のコンテンツを読む前に
ここからは実際の講義用いた内容を使用して進めていきます。
その際には以下の点について注意していただけたらなと思います。
- RDBMSを前提とした説明になっています。
- エンジニアを対象とした講義ではないので、正確な表現よりもわかりやすさを重視した表現を用いています。
- この記事は講義の資料としても使用しました。多少追記していますが解説で補っている箇所もあります。ご自身で読み進める方は不明瞭な箇所は適宜調べながらすすめてください。
- 初心者の方はわからなければすぐ解答を確認してみてください、この記事には考えるような問題は載っていません。
- 本番DBの練習問題は社外秘なので記事には載せていません。
SQLとは
保存されたデータを取り出すためのコンピュータ言語
以下の4つを覚えれば簡単なデータを取得できるようになります。
- テーブル
- レコード
- カラム
- データベース
テーブル
データの保存先です。1つのテーブルは意味のあるデータの集合体となっています。
多くのシステムは複数のテーブルで構成されています。エクセルやスプレッドシートでは
表みたいなものです。レコード
テーブルの横1行のデータです。例えばusersテーブルというユーザの情報を保存するテーブルがあるとすると、usersテーブルの1レコードはユーザ1人のデータを表します。
エクセルやスプレッドシートでは
行みたいなものです。カラム
テーブルの縦1列のデータです。例えばusersテーブルの名前を保存するnameカラムは、すべてのユーザの氏名のデータを表します。
エクセルやスプレッドシートでは
列みたいなものです。データベース(DB)
意味のあるテーブルの集合体です。
また、SQLは大文字小文字の区別がありません。載せている解説はわかりやすいようにSQL固有の単語(命令)を大文字として表示しています。
練習環境
練習するデータベースとして以下の環境を用意しました。今回は第1回の講義なので、簡易的なテーブル構成を用意しました。
イメージとしては、写真もいいねもフォローもできないインスタグラムを思い浮かべてください。
usersテーブル: ユーザのデータを保存するテーブル
- id: usersテーブル上で一意となる番号、システム的な値を保存するカラム
- name: ユーザの名前が保存されているカラム
- created: ユーザが作成された日時を保存するカラム
- modified: ユーザデータが変更された日時を保存するカラム
postsテーブル: ユーザの投稿を保存するテーブル
- id: postsテーブル上で一意となる番号、システム的な値を保存するカラム
- comments: 投稿内容を保存するカラム
- created: 投稿が作成された日時を保存するカラム
- modified: 投稿が変更された日時を保存するカラム
データの取得: SELECT, FROM
SELECTは取得したいカラムを指定します。
FROMは取得したいデータがあるテーブルを指定します。例
usersテーブルのidカラムの値を取得したい場合は以下のようなSQL文を書きます。
SELECT id FROM users;結果
+----+ | id | +----+ | 1 | | 2 | | 3 | | 4 | | 5 | +----+最後のセミコロンは絶対必要なので忘れないように注意しましょう
以下の例はusersテーブルにaddressというカラムは存在しないのでエラーになります。
// エラー SELECT address FROM users;また、すべてのカラムの値を知りたい場合は以下のようにアスタリスクを用いた表現を使用できます。
SELECT * FROM users;結果
+----+-----------------+---------------------+---------------------+ | id | name | created | modified | +----+-----------------+---------------------+---------------------+ | 1 | 田中太郎 | 2019-02-01 00:00:00 | 2019-02-12 00:00:00 | | 2 | 安川小太郎 | 2019-02-02 00:00:00 | 2019-02-10 00:00:00 | | 3 | 緑安江 | 2019-02-03 00:00:00 | 2019-02-03 00:00:00 | | 4 | 竜崎かなえ | 2019-02-04 00:00:00 | 2019-02-11 00:00:00 | | 5 | 田中聡 | 2019-02-05 00:00:00 | 2019-02-05 00:00:00 | +----+-----------------+---------------------+---------------------+練習問題
- postsテーブルのすべてのカラムの値を取得しましょう。
- postsテーブルのcommentsカラムの値を取得しましょう。
- postsテーブルのidカラムとcommentsカラムの値を取得しましょう。
解答
1. postsテーブルのすべてのカラムの値を取得しましょう。
SELECT * FROM posts;2. postsテーブルのcommentsカラムの値を取得しましょう。
SELECT comments FROM posts;3. postsテーブルのidカラムとcommentsカラムの値を取得しましょう。
SELECT id, comments FROM posts;
データの取得: ORDER
ORDERは
ORDER BY {並び替えたいカラム}と指定することで取得したいデータの並び替えを指定します。
降順(DESC)と昇順(ASC)を指定できます。例
usersテーブルのデータを更新日の降順(日時が新しい順)に並び替えたい場合、以下のようなSQL文になります。
SELECT * FROM users ORDER BY modified DESC;結果
+----+-----------------+---------------------+---------------------+ | id | name | created | modified | +----+-----------------+---------------------+---------------------+ | 1 | 田中太郎 | 2019-02-01 00:00:00 | 2019-02-12 00:00:00 | | 4 | 竜崎かなえ | 2019-02-04 00:00:00 | 2019-02-11 00:00:00 | | 2 | 安川小太郎 | 2019-02-02 00:00:00 | 2019-02-10 00:00:00 | | 5 | 田中聡 | 2019-02-05 00:00:00 | 2019-02-05 00:00:00 | | 3 | 緑安江 | 2019-02-03 00:00:00 | 2019-02-03 00:00:00 | +----+-----------------+---------------------+---------------------+練習問題
- postsテーブルのデータを更新日の新しい順で取得しましょう。
- usersテーブルのデータを更新日の古い順で取得しましょう。
- postsテーブルのデータを次の並び替え優先順位で取得しましょう。①更新日の新しい順、②idの大きい順。
解答
1. postsテーブルのデータを更新日の新しい順で取得しましょう。
SELECT * FROM posts ORDER BY modified DESC;2. usersテーブルのデータを更新日の古い順で取得しましょう。
SELECT * FROM users ORDER BY modified ASC;3. usersテーブルのデータを次の並び替え優先順位で取得しましょう。①更新日の新しい順、②idの大きい順。
// ②の並び替え条件は,(カンマ)で区切りましょう。 SELECT * FROM posts ORDER BY modified DESC, id DESC;
データの取得: WHERE
WHEREは取得したいデータの条件を指定します。
例
postsテーブルのidが5のデータを取得したい場合、以下のようなSQL文になります。
SELECT * FROM posts WHERE id = 5;結果
+----+--------------+---------------------+---------------------+ | id | comments | created | modified | +----+--------------+---------------------+---------------------+ | 5 | バイバイ | 2019-02-05 00:00:00 | 2019-02-05 00:00:00 | +----+--------------+---------------------+---------------------+また、LIKEは文字列の検索をする際に使用できます。
さらに%をつけると、そこに任意の0文字以上の文字列があることを表現します。
usersテーブルのidが1の田中さんのみを取得したい場合は、以下のようなSQLになります。SELECT * FROM users WHERE id = 1 AND name LIKE '田中%';結果
+----+--------------+---------------------+---------------------+ | id | name | created | modified | +----+--------------+---------------------+---------------------+ | 1 | 田中太郎 | 2019-02-01 00:00:00 | 2019-02-12 00:00:00 | +----+--------------+---------------------+---------------------+田中デイヴィッド義徳 という名前の人がusersテーブルに登録されている場合、以下のSQLで検索可能です。
SELECT * FROM users WHERE name LIKE '%デイヴィッド%';練習問題
- usersテーブルのidが2のユーザを取得しましょう。
- usersテーブルのnameが 安川小太郎 のユーザを取得しましょう。
- postsテーブルのcommentsに は が含まれるデータを取得しましょう。
解答
1. usersテーブルのidが2のユーザを取得しましょう。
SELECT * FROM users WHERE id = 2;2. usersテーブルのnameが 安川小太郎 のユーザを取得しましょう。
SELECT * FROM users WHERE name LIKE '安川小太郎';3. postsテーブルのcommentsに は が含まれるデータを取得しましょう。
SELECT * FROM posts WHERE comments LIKE '%は%';
会社の勉強会はここで講義が終え、本番DBをいじる問題を出題しました。
最後に
僕の社内では好評でした!
記事はこれで終わりではないですが皆さんの会社でもチャレンジしてみてくださいね!vol.2へ続く

- 投稿日:2019-02-11T15:02:30+09:00
私は分析官。MySQLが嫌い。
三連休最終日。
休日出勤をして、ちょっとした集計をしようと思っただけなのに。
MySQLを通じて嫌な思いをしたので、書きなぐる、、、何をしたかったか
Userの[年齢]情報の統計を確認したかった。
※ 実際には年齢の集計ではないが、安全のために正規分布しておらず、むしろロングテールなのが今回のデータの特徴で、
代表値として平均を使うのは危険で、中央値を集計したかった。準備
とりあえずこんな感じで一時テーブルを作った。
年齢が例だと冗長だけど、実際には重い処理だったので、必要だった。drop temporary table if exists user_age ; create temporary table user_age select user_id , age from user ;平均、合計、カウント
かんたんである
select avg(age) average , count(distinct user_id) count , sum(age) sum from user_age ;中央値の集計でイラッとした
本件データは100万レコードをゆうに超えており、Excelにうつしてmedian()するわけにもいかない。
そもそも、SQLの世界から飛び出てしまうのは、分析の再現性や、ポータビリティの観点から好ましくない。
というわけで、今回はいやいやMySQL内での完結を試みたのである。イラッと①:MySQLには
median()がない。medianを出すには、わざわざこんな書き方をしないといけない
select avg(distinct age) median from( select t1.age from user_age t1 , user_age t2 group by t1.age having sum(case when t2.age>= t1.age then 1 else 0 end) >= count(*) / 2 and sum(case when t2.age <= t1.age then 1 else 0 end) >= count(*) / 2 )tmp ;可読性が終わっている。
どんな操作をしているか、全く読者に伝わらない。
どういうふうにコメントすればいいのだろうか。解説サイトのURLでも貼るか。イラッと②:一時テーブルを複数回参照できない
上記コードは動かない。
mysql can't reopen tableって怒られた。
いやいやいや、なんでダメなの、、、
したがって、先のコードに、drop temporary table if exists ua_copy ; create temporary table ua_copy select * from user_age ;というおまけがつき最終的な出来上がりは、
drop temporary table if exists ua_copy ; create temporary table ua_copy select * from user_age ; select avg(distinct age) median from( select t1.age from user_age t1 , ua_copy t2 group by t1.age having sum(case when t2.age>= t1.age then 1 else 0 end) >= count(*) / 2 and sum(case when t2.age <= t1.age then 1 else 0 end) >= count(*) / 2 )tmp ;イラッと③:遅い
なお、この記事書いてずいぶん時間がたつが、まだ実行が終わっていない。
もちろん、数百万行のcross joinをしているのが悪いわけだが、それにしてもしかしひどい。
100万行以下だったら、SQLでmedian求めずに、Excelでmedian()できたのに…
言い換えると、実質MySQLでmedianは求めるのは常に筋悪である、というのが所感である。最後に
MySQL以外の環境に詳しくはない。
もしかしたらPostgreSQLでも同じこと起きるのかもしれない。
MySQLの名指しで叩くのはアンフェアかもしれない。分析専業でもないので、何か知識不足で拙いことをしているのかもしれない。
しかし、数百人規模のIT企業の非エンジニアで1,2のSQLスキルを持っている。私はデータ分析文化を育むには、一定数、ビジネス職がSQLを叩く必要があると思っている。
データ分析に興味を持ってくれた人が、こんなmedian一つで、躓いてほしくない。技術選定にあたっては、そういった、データ分析環境のことも考えてもらえると嬉しい。
もしくは、積極的にBigQueryなどモダンな環境にレプリしてくれると嬉しい。
SASなどを入れるとUIの力で解決するのかもしれないが、どうなのだろうか。
- 投稿日:2019-02-11T13:10:49+09:00
【Laravel】実行されたSQLを取得する
実行されたSQLを出力します。
SQLだけでなく、プリペアドステートメントや実行時間も出力されるので便利です。ログの出力
// ログを有効化 DB::enableQueryLog(); City::where('Name', '=', 'Kabul')->get(); // ログ出力 dd(DB::getQueryLog()); // ログを無効化 DB::disableQueryLog();出力結果
array:1 [▼ 0 => array:3 [▼ "query" => "select * from `city` where `Name` = ?" "bindings" => array:1 [▼ 0 => "Kabul" ] "time" => 6.46 ] ]
- 投稿日:2019-02-11T11:48:46+09:00
【Python】pyodbc経由でSQL Serverにデータを追加する。
環境 Windows Python3.7
これからやること
Pythonからpyodbc経由でSQL Serverに接続、SQLでデータを追加する。
前回( https://qiita.com/gaborotta/items/328d01355cd3e12bd070 )取得したデータをSQL Serverに入れておきます。追加するデータ
テーブルはSQL Serverの方で作成しておく。Pythonからはデータの追加のみ。
- 動画情報テーブル(動画IDを基にした重複なしテーブルとする)
- 動画ID
- 投稿日時
- 再生時間
- 過去最高ランク
- 投稿者情報テーブル(投稿者IDを基にした重複なしテーブルとする)
- 投稿者ID
- ユーザー登録時のニコニコ動画のバージョン
- フォロワー数
- 投稿動画数
- 動画-投稿者関連テーブル(動画IDを基にした重複なしテーブルとする)
- 動画ID
- 投稿者ID
- 動画タグテーブル(動画ID and タグ名を基にした重複なしテーブルとする)
- 動画ID
- タグ名
pyodbcについて
pythonからODBCを通してデータベースを操作するライブラリ。
SQL構文を介してデータベース側とやりとりが出来る。
詳しくはこちら。
https://docs.microsoft.com/ja-jp/sql/connect/python/pyodbc/python-sql-driver-pyodbc?view=sql-server-2017
https://mkleehammer.github.io/pyodbc/Windows認証でSQL Serverへ接続
ユーザーIDとパスワードを使って接続もできるけど、こちらの方が楽な気がするので。
driver='{SQL Server}' server = 'localhost\SQLEXPRESS' database = 'データベース名' trusted_connection='yes' cnxn = pyodbc.connect('DRIVER='+driver+';SERVER='+server+';DATABASE='+database+';Trusted_Connection='+trusted_connection+';') cursor = cnxn.cursor()接続の切り方
忘れずにcloseしましょう。
cursor.close() cnxn.close()重複チェックをしてデータの追加
SQLを書いてexecuteで投げる。
commitを忘れずに行わないとデータベースに追加されない。sql = "INSERT INTO [dbo].[Hoge]\ ([ID],[DATE],[DATA])\ SELECT 1,'20190202','hogehoge'\ WHERE NOT EXISTS(SELECT [ID] FROM [dbo].[Hoge] WHERE [ID] = '{id}' )" cursor.execute(sql) cnxn.commit()実際にやってみた
というわけで、前回取得したデータを全てSQLに突っ込んでみた。
#%% import pyodbc import datetime import json import sys ###SQL Serverへの接続 def connectSQL(): driver='{SQL Server}' server = 'localhost\SQLEXPRESS' database = 'NicoNico' trusted_connection='yes' cnxn = pyodbc.connect('DRIVER='+driver+';SERVER='+server+';DATABASE='+database+';Trusted_Connection='+trusted_connection+';') cursor = cnxn.cursor() print("ok") return cnxn,cursor def closeSQL(_cursor,_cnxn): _cursor.close() _cnxn.close() print("close") return ###Videoデータの追加 def insetVideo(_cn,_cur,_dateStr): ##Jsonファイル読み込み fr = open("VideoData/"+ _dateStr +".json", 'r',encoding='utf-8') videoData = json.load(fr) fr.close() ##SQLへの書き込み #クエリ構文の作成 SQL_TEMPLATE = "INSERT INTO [dbo].[Video]\ ([ID],[DATE],[LENGTH],[MAX_RANK],[URL])\ SELECT '{id}','{date}','{length}','{maxRank}','{videoUrl}'\ WHERE NOT EXISTS(SELECT [ID] FROM [dbo].[Video] WHERE [ID] = '{id}' )" #SQLへの書き込みクエリの実行 for videoId in videoData: editSql = SQL_TEMPLATE editSql = editSql.replace('{id}', videoId) video=videoData[videoId] tags=video.pop('tags',None) if video["date"] : video["date"]=video["date"].replace('年','-').replace('月','-').replace('日','T') if video["maxRank"]==sys.maxsize: video["maxRank"]=None for key,data in video.items(): editSql = editSql.replace('{' + key + '}', str(data)) editSql=editSql.replace("None","") #print(editSql) _cur.execute(editSql) #コミット _cn.commit() return ###Usersデータの追加 def insetUsers(_cn,_cur,_dateStr): ##Jsonファイル読み込み fr = open("UserData/"+ _dateStr +".json", 'r',encoding='utf-8') userData = json.load(fr) fr.close() ##SQLへの書き込み #クエリ構文の作成 SQL_TEMPLATE = "INSERT INTO [dbo].[Users]\ ([ID],[NAME],[FOLLOWER_NUM],[VIDEO_NUM],[NICO_VER],[URL])\ SELECT '{id}','{userName}','{followerNum}','{videoNum}','{nicoVer}','{userUrl}'\ WHERE NOT EXISTS(SELECT [ID] FROM [dbo].[Users] WHERE [ID] = '{id}' )" #SQLへの書き込みクエリの実行 for userId in userData: editSql = SQL_TEMPLATE editSql = editSql.replace('{id}', userId) user=userData[userId] for key,data in user.items(): editSql = editSql.replace('{' + key + '}', str(data)) editSql=editSql.replace("None","") #print(editSql) _cur.execute(editSql) #コミット _cn.commit() return ###UsersVideoデータの追加 def insetUsers_Video(_cn,_cur,_dateStr): ##Jsonファイル読み込み fr = open("User_VideoData/"+ _dateStr +".json", 'r',encoding='utf-8') user_videoData = json.load(fr) fr.close() ##SQLへの書き込み #クエリ構文の作成 SQL_TEMPLATE = "INSERT INTO [dbo].[UsersVideo]\ ([VIDEO_ID],[USER_ID])\ SELECT '{id}','{userId}'\ WHERE NOT EXISTS(SELECT [VIDEO_ID] FROM [dbo].[UsersVideo] WHERE [VIDEO_ID] = '{id}' )" #SQLへの書き込みクエリの実行 for videoId in user_videoData: editSql = SQL_TEMPLATE editSql = editSql.replace('{id}', videoId) editSql = editSql.replace('{userId}', user_videoData[videoId]["userId"]) editSql=editSql.replace("None","") #print(editSql) _cur.execute(editSql) #コミット _cn.commit() return ###動画タグデータの追加 def insetVideoTags(_cn,_cur,_dateStr): ##Jsonファイル読み込み fr = open("VideoData/"+ _dateStr +".json", 'r',encoding='utf-8') videoData = json.load(fr) fr.close() ##SQLへの書き込み #クエリ構文の作成 SQL_TEMPLATE = "INSERT INTO [dbo].[VideoTag]\ ([VIDEO_ID],[TAG_NAME])\ SELECT '{id}','{tagName}'\ WHERE NOT EXISTS(SELECT [VIDEO_ID] FROM [dbo].[VideoTag] WHERE ([VIDEO_ID] = '{id}') AND ([TAG_NAME] LIKE '{tagName}') )" #SQLへの書き込みクエリの実行 for videoId in videoData: video=videoData[videoId] if not video["tags"]: continue for tag in video["tags"]: name=str(tag).replace("'","''") editSql = SQL_TEMPLATE editSql = editSql.replace('{id}', videoId) #print(name) editSql = editSql.replace('{tagName}', str(name)) #print(editSql) _cur.execute(editSql) #コミット _cn.commit() return print("ok") #%% ##SQL接続 cn,cur=connectSQL() ###データを挿入 date = datetime.date(2019,2,2) count=365 for num in range(count): date -=datetime.timedelta(days=1) dateStr=date.strftime("%Y%m%d") print(dateStr) insetVideo(cn,cur,dateStr) insetUsers(cn,cur,dateStr) insetUsers_Video(cn,cur,dateStr) insetVideoTags(cn,cur,dateStr) #%% closeSQL(cn,cur)結果
前回収集したJsonファイルからデータをSQL Serverに追加できた。
次回はこのデータをRから取り出して統計処理。