- 投稿日:2019-02-11T22:47:27+09:00
AWS Lambda で C のバイナリを動かす
ありふれたネタですが、 Lambda のカスタムランタイムで C を動かしてみました。
ディレクトリ構成
. ├── bin │ ├── bootstrap │ └── lambda_function ├── docker-compose.yml ├── Dockerfile └── src ├── lambda_function.c └── Makefile一連のコードは https://github.com/tsubasaogawa/lambda-with-c にあげています。
手順
概要
- C のソースを書く
- Lambda と同じ実行環境でソースをコンパイルする
- bootstrap を修正する
- Lambda にアップロードする
詳細
C のソースを書く
普段どおりソースを書きます。今回は「標準入力された内容を出力する」だけの簡単なものを作ってみました。
lambda_function.c#include <stdio.h> int main(void) { char buf[512]; while(1) { /* Obtain from Stdin https://qiita.com/mpyw/items/aff12a6ff2c7726ed1d8 */ if(scanf("%511[^\n]%*[^\n]", buf) != 1) { break; } /* Ignore linefeed */ scanf("%*c"); printf("%s\n", buf); } return 0; }MakefilePROGRAM = lambda_function CC = gcc CFLAGS = -Wall OBJS = $(PROGRAM).o $(PROGRAM): $(OBJS) $(CC) $(CFLAGS) -o $(PROGRAM) $(OBJS) $(OBJS): $(PROGRAM).c $(CC) -c $(PROGRAM).c .PHONY: clean clean: rm -f $(PROGRAM) $(OBJS) .PHONY: clean_obj clean_obj: rm -f $(OBJS)Lambda と同じ実行環境でソースをコンパイルする
Lambda で動かすので、Lambda と同じ環境でコンパイルする必要があります。
Lambda 実行環境と利用できるライブラリ によると Amazon Linux を使っている (2019/02 時点) ことがわかるため、Amazon Linux のコンテナ上でコンパイルすることにします。DockerfileFROM amazonlinux:2 MAINTAINER tsubasaogawa WORKDIR /usr/local/src/lambda-with-c RUN set -x && yum install -y gcc make # ADD ./bootstrap . COPY ./src/lambda_function.c . COPY ./src/Makefile . RUN make && make clean_objなんとなく Amazon Linux 2 にしてしまいました。docker-compose は以下です。
docker-compose.ymlversion: '3' services: lambda-with-c-compiler: build: . volumes: - ./bin:/var/tmp command: /bin/bash -c 'cp -r /usr/local/src/lambda-with-c/lambda_function /var/tmp'コンテナビルド時に
makeで作られたバイナリを、マウントしたディレクトリにコピーしています。また、コンテナを実行するとホストのbin/配下にバイナリが作られます。$ docker-compose build $ docker-compose up -d $ ls -l bin/lambda_function -rwxr-xr-x 1 root root 8232 Feb 11 12:49 bin/lambda_functionbootstrap を修正する
カスタムランタイムを使用すると、
bootstrapというファイルが実行されます。bootstrap 経由でバイナリを実行するような形になります。
チュートリアル では、シェルスクリプトで bootstrap が書かれています。これを一部 (というかほとんど) 流用します。bootstrap#!/bin/sh set -euo pipefail # Processing while true do HEADERS="$(mktemp)" # Get an event EVENT_DATA=$(curl -sS -LD "$HEADERS" -X GET "http://${AWS_LAMBDA_RUNTIME_API}/2018-06-01/runtime/invocation/next") REQUEST_ID=$(grep -Fi Lambda-Runtime-Aws-Request-Id "$HEADERS" | tr -d '[:space:]' | cut -d: -f2) # Execute the handler function from the script EXEC="$LAMBDA_TASK_ROOT/$(echo "$_HANDLER" | cut -d. -f1)" RESPONSE=$(echo "$EVENT_DATA" | $EXEC) # Send the response curl -X POST "http://${AWS_LAMBDA_RUNTIME_API}/2018-06-01/runtime/invocation/$REQUEST_ID/response" -d "$RESPONSE" doneLambda にアップロードする
成果物を zip にして Lambda へアップロードします。Role は予め適当なものを用意してください。
Lambdaへアップロード$ cd bin $ zip ../lambda_function.zip ./* $ cd .. $ ls -l lambda_function.zip -rw-rw-r-- 1 vagrant vagrant 3032 Feb 11 12:55 lambda_function.zip $ aws lambda create-function --function-name lambda-with-c \ --zip-file fileb://lambda_function.zip --handler lambda_function.handler \ --runtime provided --role arn:aws:iam::***:role/role_name試しに実行してみます。
実行$ aws lambda invoke --function-name lambda-with-c \ --invocation-type RequestResponse \ --payload '{ "test1": "value1" }' \ /tmp/lambda-with-c.log { "StatusCode": 200, "ExecutedVersion": "$LATEST" }実行結果$ cat /tmp/lambda-with-c.log { "test1": "value1" }よさそうです。引数が得られたので、あとは自由にパースして使えそうです。
おわりに
- Lambda のカスタムランタイムを使って、 C で作られたバイナリを動かしてみた
- Amazon Linux 上でコンパイルを行うと安心
- カスタムランタイム使用時は bootstrap というファイルがまず実行される
- bootstrap 経由でバイナリを実行する
- なお、C++ では便利なライブラリが公開されているのでこれを使うと幸せになれそう
- 参考記事
- 投稿日:2019-02-11T22:32:08+09:00
[AWS SDK for Go] 異なる AWS アカウントの IAM ロールを使用する方法
はじめに
本格的に AWS の運用を行いたい場合、開発用 / 本番用 AWS アカウントなど、異なる用途の複数 AWS アカウントを使い分ける事が多いかと思います。
開発者が操作したい AWS アカウントを切り替えるとき、マネジメントコンソールでは一般的に IAM ロールの切り替えを行います。AWS CLI や AWS SDK を利用したプログラムでは、AWS STS で一時的なセキュリティ認証情報のリクエストを行う必要があります。
今回は AWS SDK for Go を使用して、一時的な認証情報を取得する方法を紹介します。
環境
- macOS Mojave 10.14.3
- go version go1.9.4 darwin/amd64
- aws-sdk-go: Release v1.16.29
事前準備
- 開発用/本番用などの AWS アカウントを 2 つ以上用意する。
- 開発用アカウントの IAM ユーザーのクレデンシャルを
aws configureコマンドから設定する。(~/.aws/credentialsが存在すること。)
- 開発用アカウントの IAM ユーザーには
sts:AssumeRoleのポリシーが許可されている状態にする。- 本番用アカウントの IAM ロールを任意の権限で作成し、
Principal句で開発用アカウントおよび IAM ユーザーからアクセスできる状態にする。サンプルコード
以下は AWS STS の AssumeRole を使用して、異なる AWS アカウントの EC2 インスタンス情報を取得するサンプルコードです。
コード中の
profile,region,roleArn変数はご利用の環境に合わせて変更してください。main.gopackage main import ( "fmt" "github.com/aws/aws-sdk-go/aws" "github.com/aws/aws-sdk-go/aws/credentials" "github.com/aws/aws-sdk-go/aws/credentials/stscreds" "github.com/aws/aws-sdk-go/aws/session" "github.com/aws/aws-sdk-go/service/ec2" ) var ( profile = "default" region = "ap-northeast-1" // FIXME: Rewrite your AWS Account ID and IAM Role Name. roleArn = "arn:aws:iam::<123456789012>:role/<Your-Role-Name>" ) // AssumeRoleWithSession returns switched role session from argument session and IAM role's arn in same region. func AssumeRoleWithSession(sess *session.Session, rolearn string) *session.Session { sCreds := stscreds.NewCredentials(sess, rolearn) sConfig := aws.Config{Region: sess.Config.Region, Credentials: sCreds} sSess := session.New(&sConfig) return sSess } func main() { // Get credentials from default(~/.aws/credentials) path. // 開発環境などで使用している認証情報を取得する。 creds := credentials.NewSharedCredentials("", profile) config := aws.Config{Region: aws.String(region), Credentials: creds} dSess := session.New(&config) // Get the Switched Role Session. // 本番環境など、開発環境で使用している認証情報を取得する。 sSess := AssumeRoleWithSession(dSess, roleArn) // Example: Get EC2 info using the switched session. // 開発環境の認証情報から、本番環境の EC2 情報などが(IAM ロールの権限で許可された範囲内で)取得できる。 result, _ := ec2.New(sSess).DescribeInstances(nil) fmt.Println(result) }おわりに
筆者が検証した際に、AWS SDK for Go での AssumeRole の日本語記事がさっと見つからなかったので記事にしました。
どなたかのお役に立てば幸いです。
参考 AWS 公式ドキュメント
- 投稿日:2019-02-11T21:10:17+09:00
VPC FlowLogsをLogstashで正規化してみた
はじめに
AWS VPCFlowLogsの通信ログをEC2で構築したElasticStackに取り込む方法をまとめてみました。
利用環境
実施内容
- IAM Role作成
- CloudWatchLogs LogGroup作成
- VPCFlowLogs作成
- ElasticStackマシン作成
- 正規化フィルタ作成
- Kibana画面
1. IAM Role作成
以下、2つのIAM Roleを事前に作成します。
- VPCFlowLogsがCloudWatchLogsにログを出力するために必要なIAM Role
flowlogs_role{ "Statement": [ { "Action": [ "logs:CreateLogGroup", "logs:CreateLogStream", "logs:DescribeLogGroups", "logs:DescribeLogStreams", "logs:PutLogEvents" ], "Effect": "Allow", "Resource": "*" } ] }
- ElasticStackがCloudWatchLogsからログを取得するために必要なIAM Role
cloudwatchlogs_readonly_role{ "Version": "2012-10-17", "Statement": [ { "Action": [ "logs:Describe*", "logs:Get*", "logs:List*", "logs:StartQuery", "logs:StopQuery", "logs:TestMetricFilter", "logs:FilterLogEvents" ], "Effect": "Allow", "Resource": "*" } ] }2. CloudWatchLogs LogGroup作成
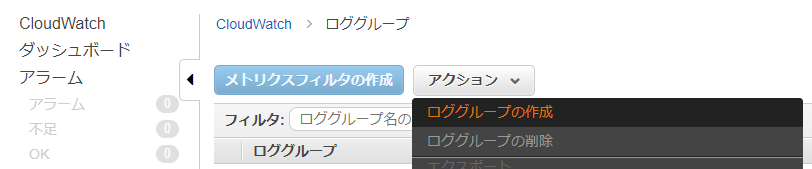
AWS Management Consoleから[CloudWatch] > [ログ] > [アクション]で[ロググループの作成]を選択します。
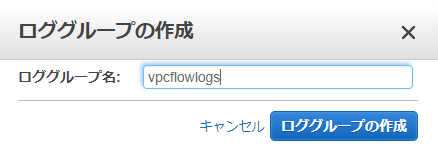
[ロググループ名]に任意の名前を付けて、[ロググループの作成]を選択します。(今回は、vpcflowlogs)
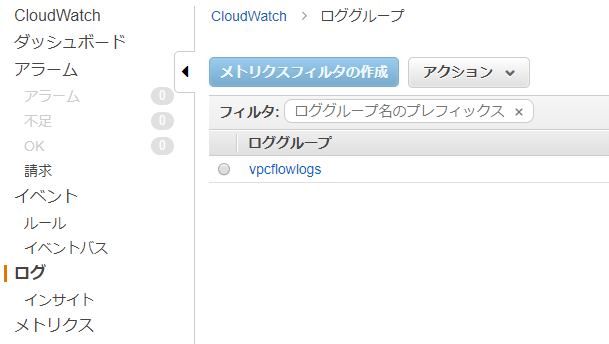
以下のように作成されていればOKです。
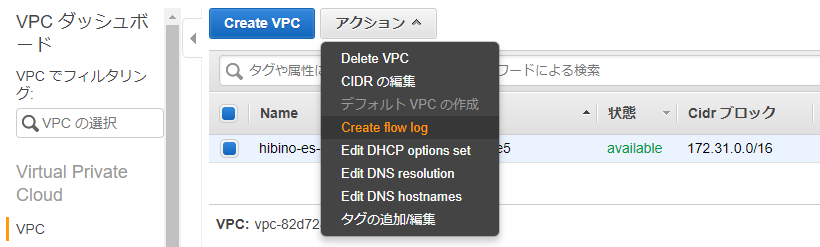
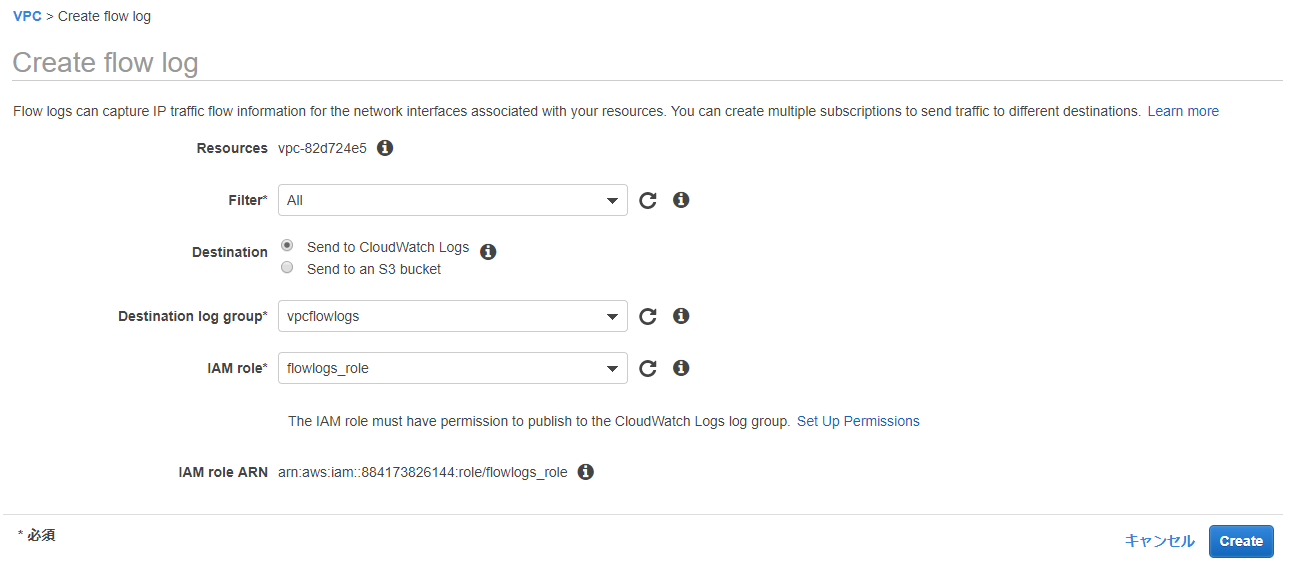
3. VPCFlowLogs作成
次に、[VPC] > [VPC] > [アクション]で[Create fow log]を選択します。
全ての通信ログを対象(FilterをAll)に作成した
ロググループとIAM Roleを指定して、[Create]を選択します。
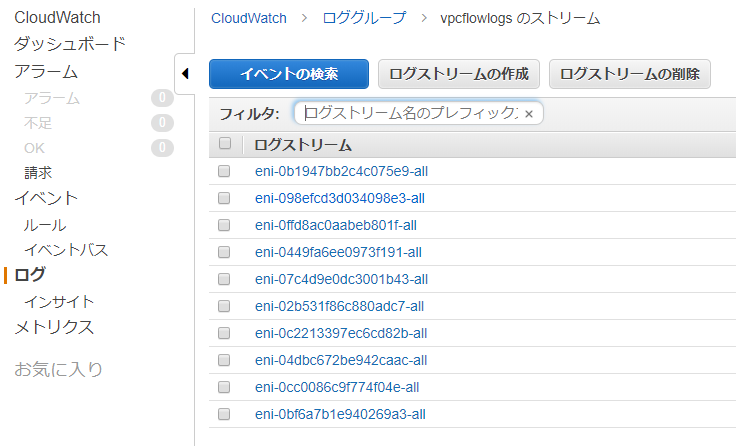
CloudWatchLogsの作成したvpcflowlogsのロググループにENIごとの通信ログが出力されていればOKです。
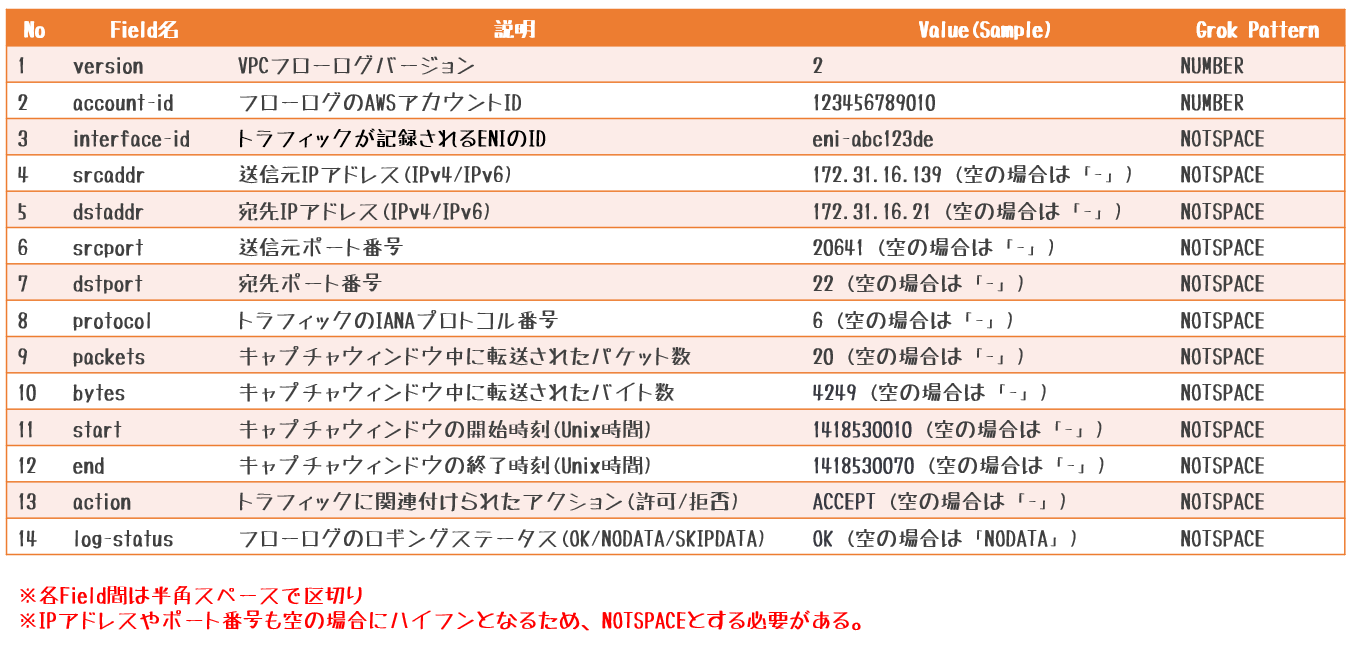
【参考】vpcflowlogsのログフォーマット
・ VPC フローログレコード
4. ElasticStackマシン作成
- EC2インスタンスにJava1.8.0、logstash、Kibana、Elasticsearchを導入します。
- JVMヒープサイズの設定は省略しています。
[root@ip-172-31-34-49]# vi /etc/yum.repos.d/elastic.repo ------ [elasticsearch-6.x] name=Elasticsearch repository for 6.x packages baseurl=https://artifacts.elastic.co/packages/6.x/yum gpgcheck=1 gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch enabled=1 autorefresh=1 type=rpm-md ------ [root@ip-172-31-34-49]# yum install -y java-1.8.0-openjdk [root@ip-172-31-34-49]# yum install -y logstash kibana elasticsearch [root@ip-172-31-34-49]# systemctl start elasticsearch
logstash-input-cloudwatch_logspluginを導入します。[root@ip-172-31-34-49]# /usr/share/logstash/bin/logstash-plugin install logstash-input-cloudwatch_logs Validating logstash-input-cloudwatch_logs Installing logstash-input-cloudwatch_logs Installation successful5. 正規化フィルタ作成
- logstashの
grok filterで正規化するためのパターン(grok patterns)を作成します。[root@ip-172-31-34-49]# cd /etc/logstash [root@ip-172-31-34-49 logstash]# mkdir patterns [root@ip-172-31-34-49 patterns]# vi vpcflowlogs_patterns # VPC_Flow_Logs VPCFLOWLOG %{NUMBER:version} %{NUMBER:account-id} %{NOTSPACE:interface-id} %{NOTSPACE:srcaddr} %{NOTSPACE:dstaddr} %{NOTSPACE:srcport} %{NOTSPACE:dstport} %{NOTSPACE:protocol} %{NOTSPACE:packets} %{NOTSPACE:bytes} %{NOTSPACE:start} %{NOTSPACE:end} %{NOTSPACE:action} %{NOTSPACE:log-status}【参考】Grok Patternの標準セット
- 次に
logstash.confを作成します。- cloudwatchlogsから取得した通信ログを加工し、Elasticsreachに保存します。
/etc/logstash/conf.d/logstash.confinput { cloudwatch_logs { region => "ap-southeast-1" log_group => [ "vpcflowlogs" ] sincedb_path => "/var/lib/logstash/sincedb" } } filter { grok { patterns_dir => [ "/etc/logstash/patterns/vpcflowlogs_patterns" ] match => { "message" => "%{VPCFLOWLOG}"} } date { match => [ "start_time","UNIX" ] target => "@timestamp" } } output { elasticsearch { hosts => [ "localhost:9200" ] index => "vpcflowlogs-%{+YYYY.MM.dd}" } }
- Logstashのサービスを起動します。
[root@ip-172-31-34-49]# systemctl start logstash6. Kibana画面
- Kibanaにアクセスするために
kibana.ymlを修正し、サービス起動します。[root@ip-172-31-34-49]# vi /etc/kibana/kibana.yml server.host: "0.0.0.0" [root@ip-172-31-34-49]# systemctl start kibana
- http://:5601にWebアクセスします。
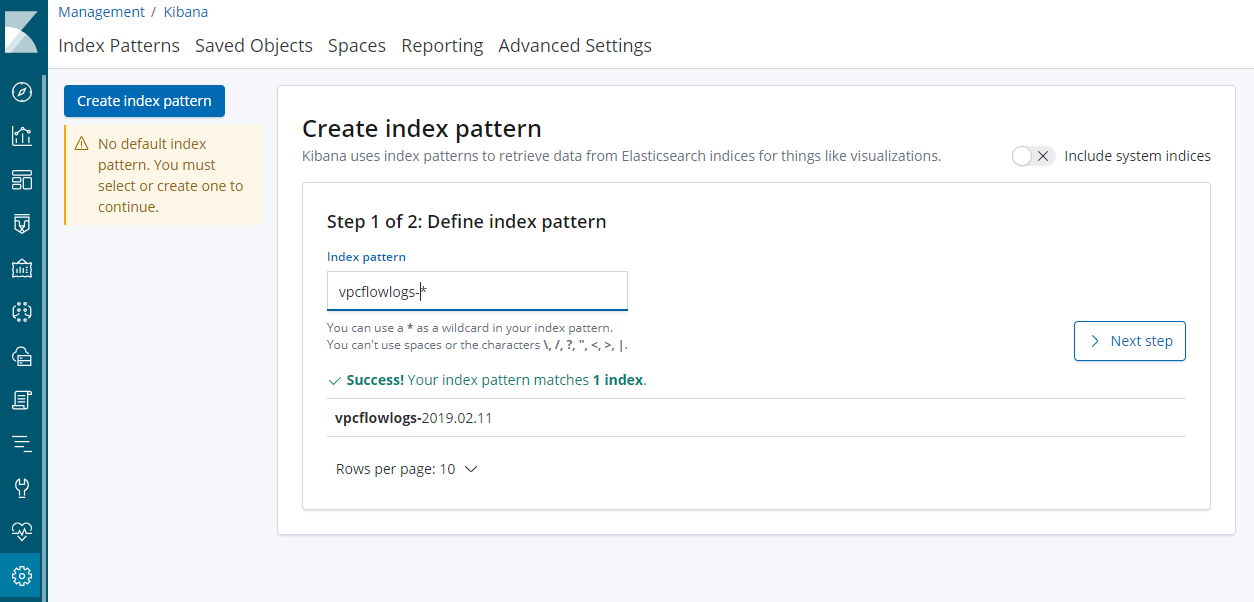
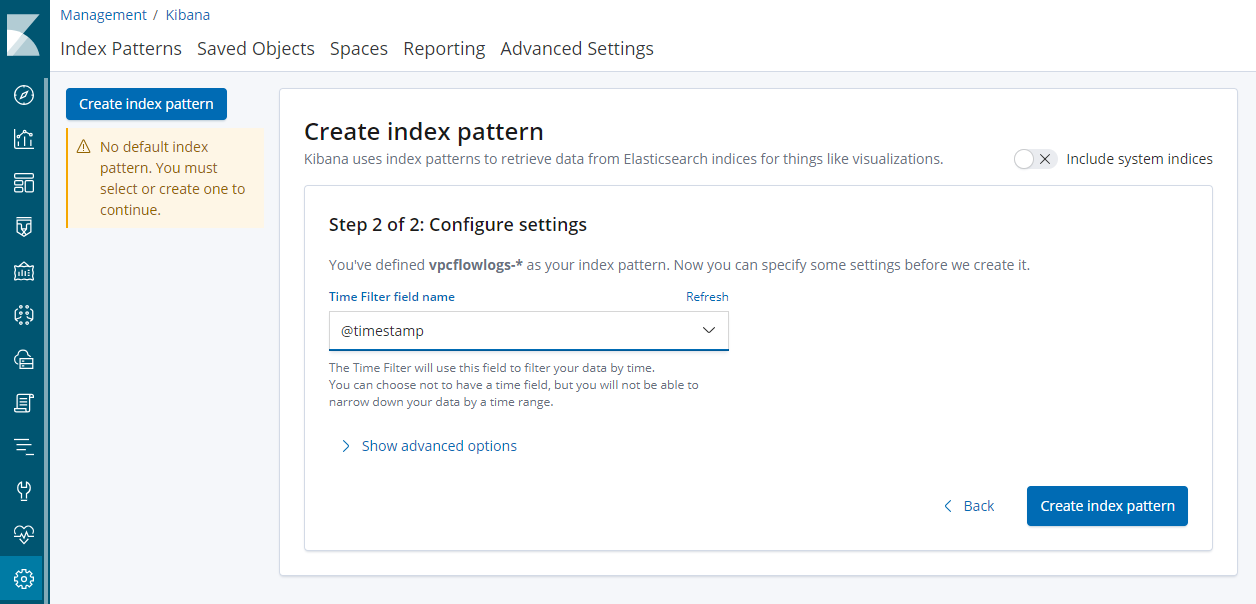
- Kibanaの[Management] > [Index Patterns]で[Create Index pattern]を選択します。
- [Index pattern]に
vpcflowlogs-*とIndex名を指定し、[Next step]を選択します。
- [Time Filter field name]に
@timestampを選択し、[Create index pattern]を選択します。
- [Discover]画面でログが検索出来るようになっていると思います。
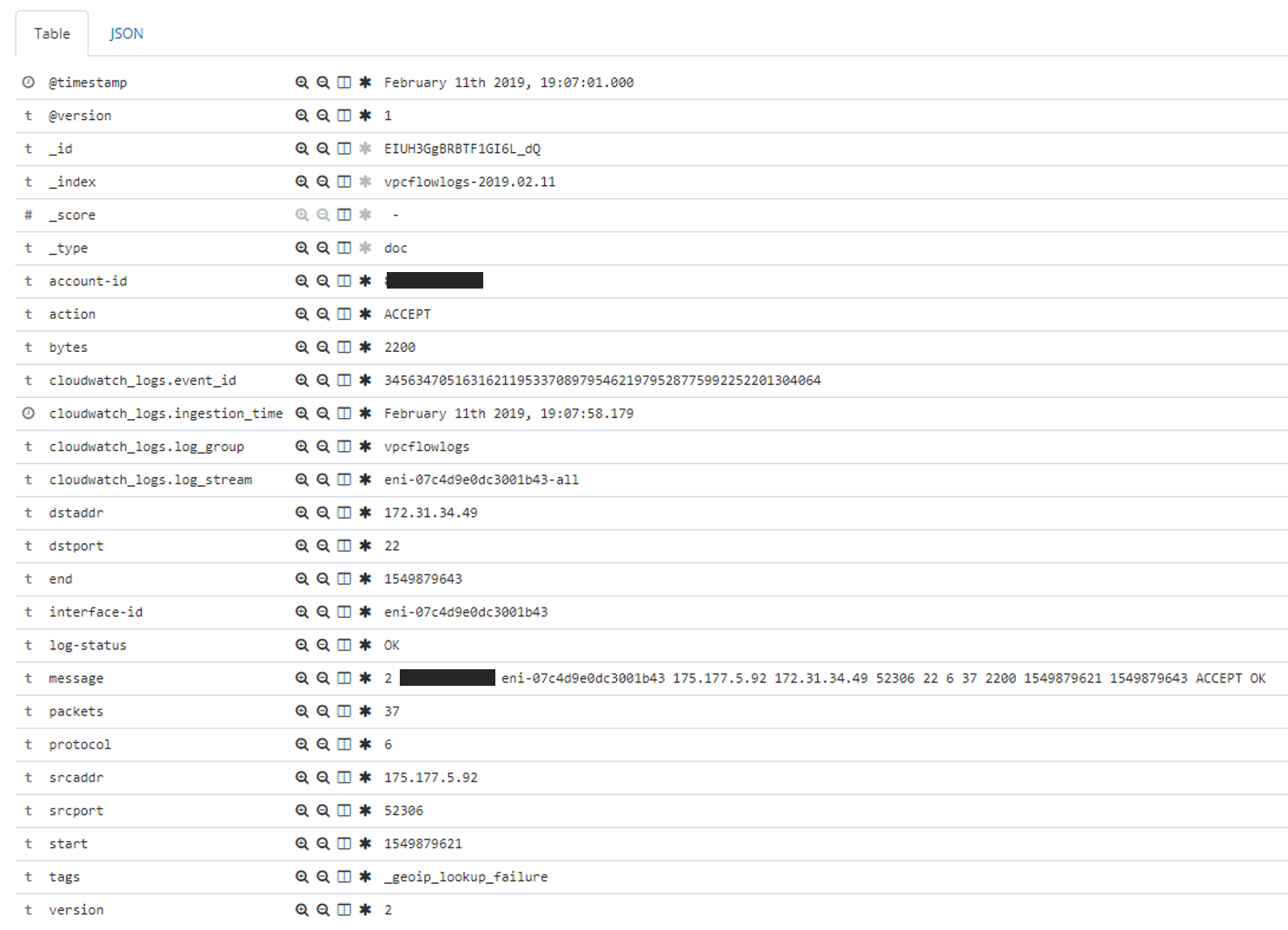
- ログの中身は以下のような感じです。
まとめ
本来はsrcaddrやdstaddrをIP型にしたり、bytesをFloat型にしたりdata.typeを変換したいところではありますが、ログの内容によって、[-(ハイフン)]になる可能性があるため、今回は断念しました。もし良い方法があれば、教えてください!!

- 投稿日:2019-02-11T19:57:38+09:00
見ながらやろう! AWSを使った「簡単!! 独自ドメインの送受信システム構築」#後編
前編はこちら!!
https://qiita.com/nago3/items/bdcbc7fac604aea9b2c1
続きとして
こちらは「見ながらやろう! AWSを使った「簡単!! 独自ドメインの送受信システム構築」」の後編です。
前編を終えた後というのが前提です。注意!!!
今回の記事は初学者向け、もしくは自分のようなアドバイスがなくて解決方法を模索している方が対象です。周りに正しい知識や経験を聞ける方や、経験の長い皆様は「ほーん、こんな奴もいるんだ」程度で認識していただけると幸いです。
今回やったこと
メールの送受信を(従業員全体が)使い慣れているGmailでできるようにする
前提条件:
#前編が終わっていること
ローカルディレクトリに[ temporary ]というディレクトリが 存在しない こと作業内容:
#前編
- AWSでSESの設定をする
- 送信の設定に使うメールアドレスの登録
- 送受信の設定に使うドメインの登録
- IAMユーザ作成
- メールの受信用S3バケットの作成、設定
- Gmailでの送信設定
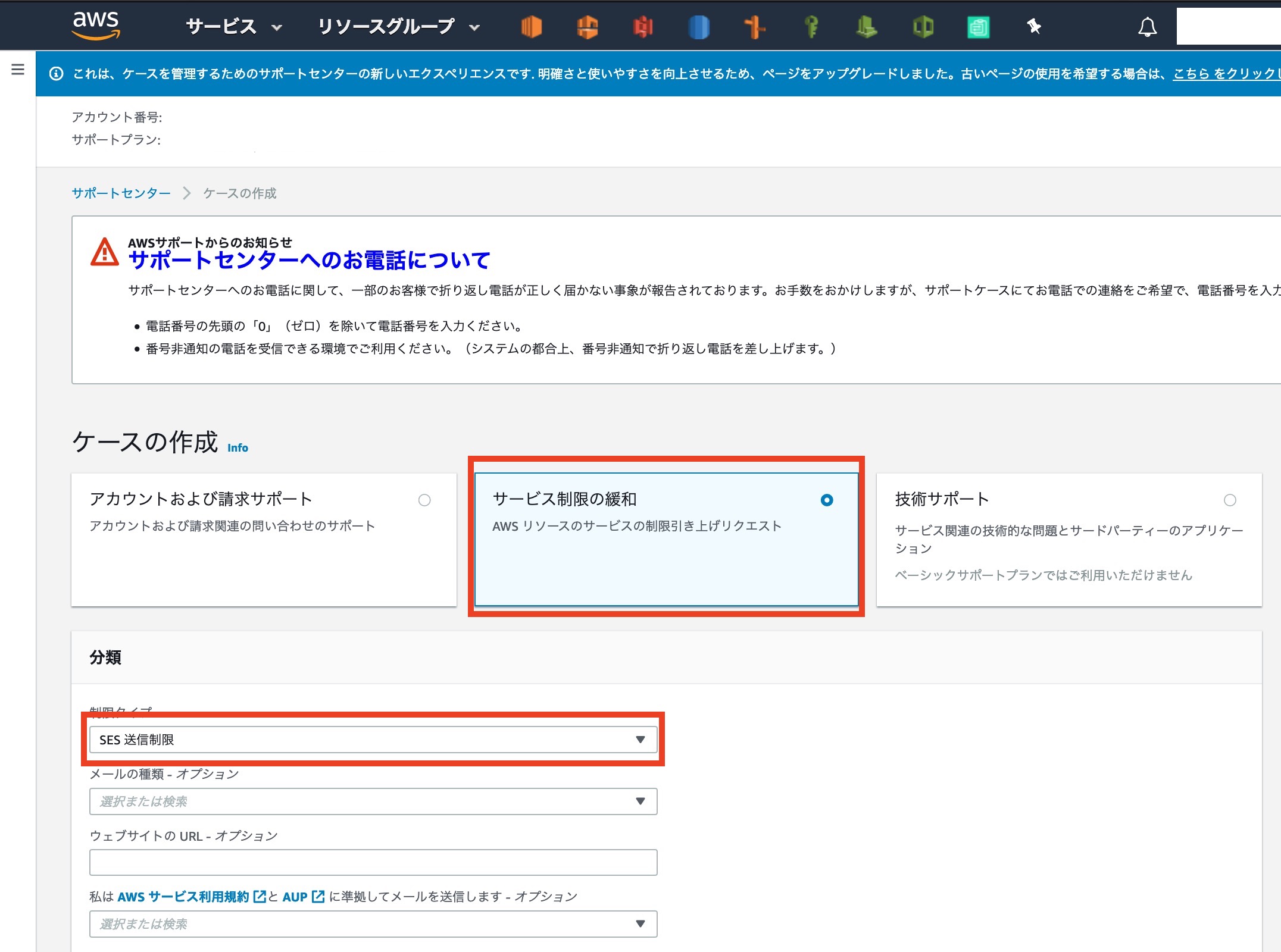
#後編 <- (今回はこれ) 2. SESの送信制限の解除 1. サポート宛に送信制限解除の連絡をする 3. SESで受信した内容をGmailに転送する 1. ライブラリのデータを自分用に設定し直す 2. Lambda用の作業用[ IAM Role ]を作成する 3. Lambdaの関数作成 4. SESでLambdaの呼び出すルールを追加する 5. 受信用S3バケットにライフサイクルポリシーを設定する 4. 最終確認2. SESの送信制限の解除
SESの送信制限...
https://docs.aws.amazon.com/ja_jp/ses/latest/DeveloperGuide/Welcome.html
SESには送信制限が存在しています。同時に制限解除するまでは
サンドボックス内での操作となり、外部との接続は限定的になっています。
まずは送信制限の解除から始めましょう。2-1: サポート宛に送信制限解除の連絡をする
前編の続きからスタートします
再び[ SES ]のコンソールにログインしましょう
次にサイドバー[ Sending Statistics ]を見てみましょう
現時点ではサンドボックスのため、制限がかかっています
画面上部の[ Request a Sending Limit Increase ]をクリックしましょう
今度は[ サポート ]の画面に移動します。
自動で[ SES送信制限 ]までの入力が終わっているはずです
各種項目を記入していきましょう
まずは分類からです・規約やAUPはしっかり読みましょう
・メールの種類は今回は取引にしています。システムなど、場合にあった項目を選択しましょう
・メールは許可のない不特定多数に送ることは認められません。
・バウンス等の処理は[ Lambda ] などのサービスを用いて対応する記事を別途作成予定です
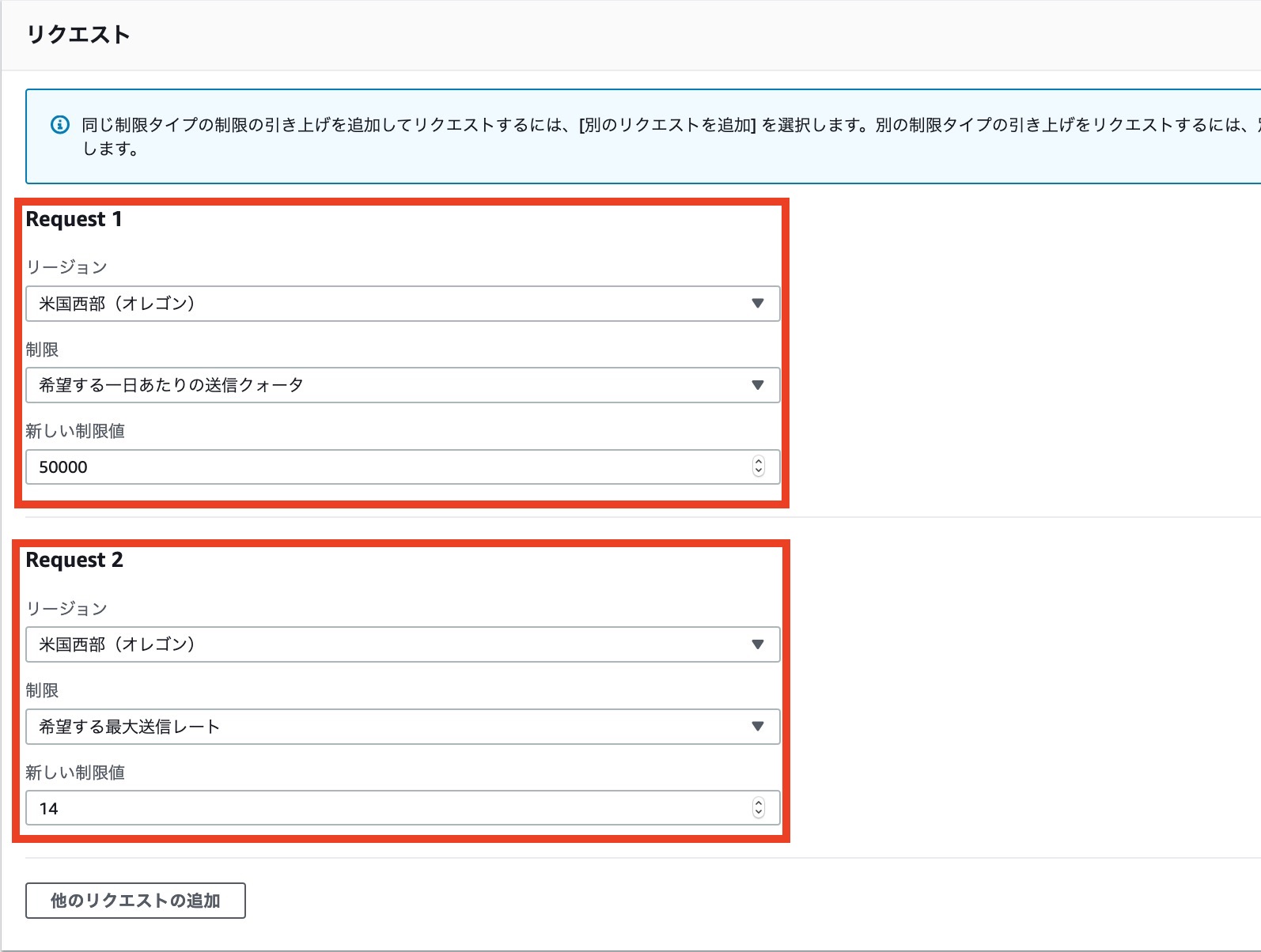
リクエスト内容です
・送信クォータ[ 50000 ]
・最大送信レート[ 14 ]
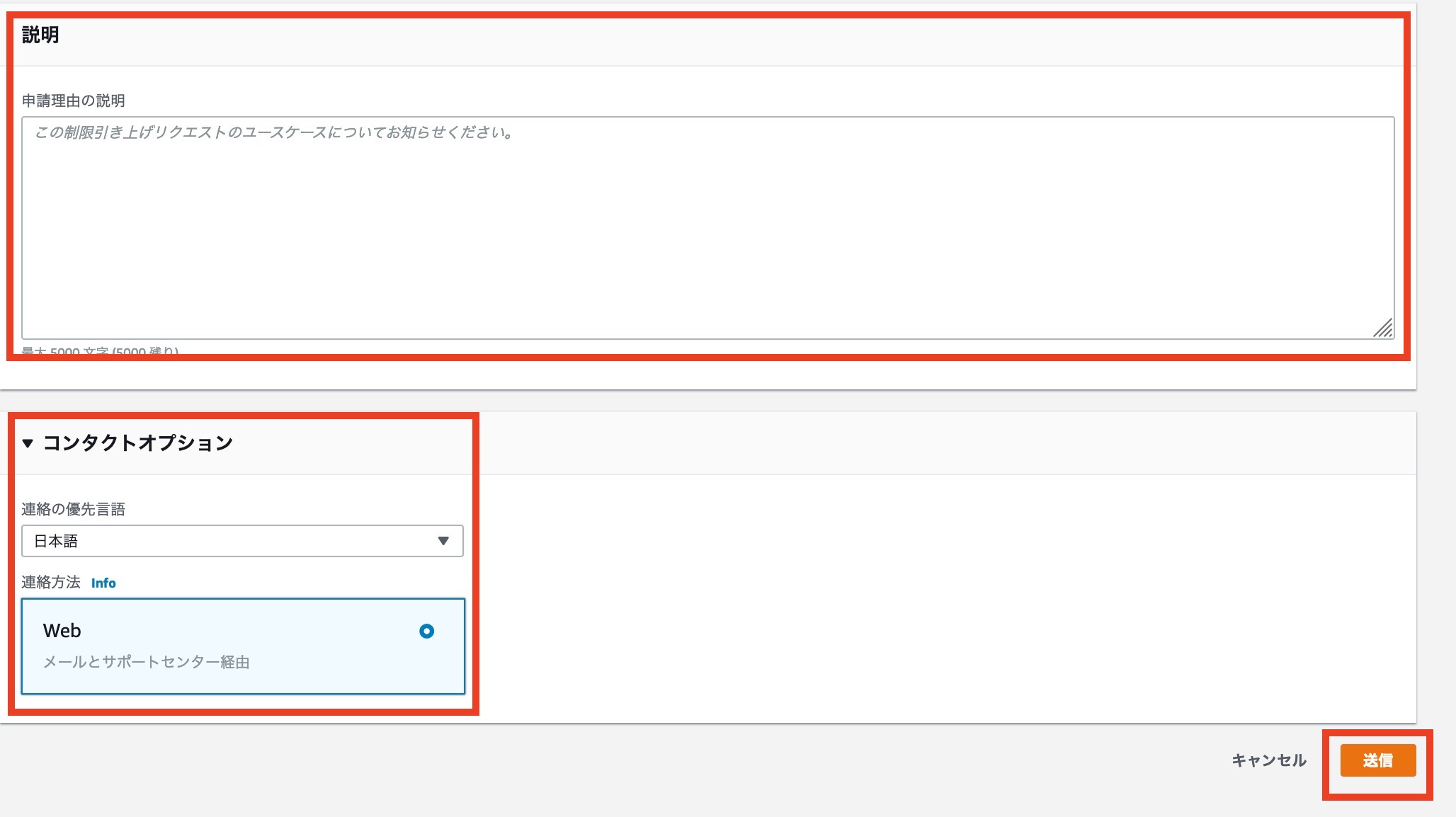
最後に制限解除の理由を説明しましょう
皆さんの申請理由をここに述べましょう
終わりましたら[ 送信 ]を押して完了です
制限解除はAWS側に行ってもらうので、多少時間がかかります
3. SESで受信した内容をGmailに転送する
参考にさせていただいた記事:
https://tech.taiko19xx.net/entry/2018/05/01/195119
今度は現在[ S3 ]で受信しているメールをGmailに転送する設定を行います。
SESでは[ POP3 ]などの受信に対応していません(別途複数のアクションがあるのですが今回は省略)
そのため[ Lambda ]を用いて転送処理を行います。今回はこちらのライブラリを使わせていただきます
https://github.com/arithmetric/aws-lambda-ses-forwarder
3-1: ライブラリのデータを自分用に設定し直す
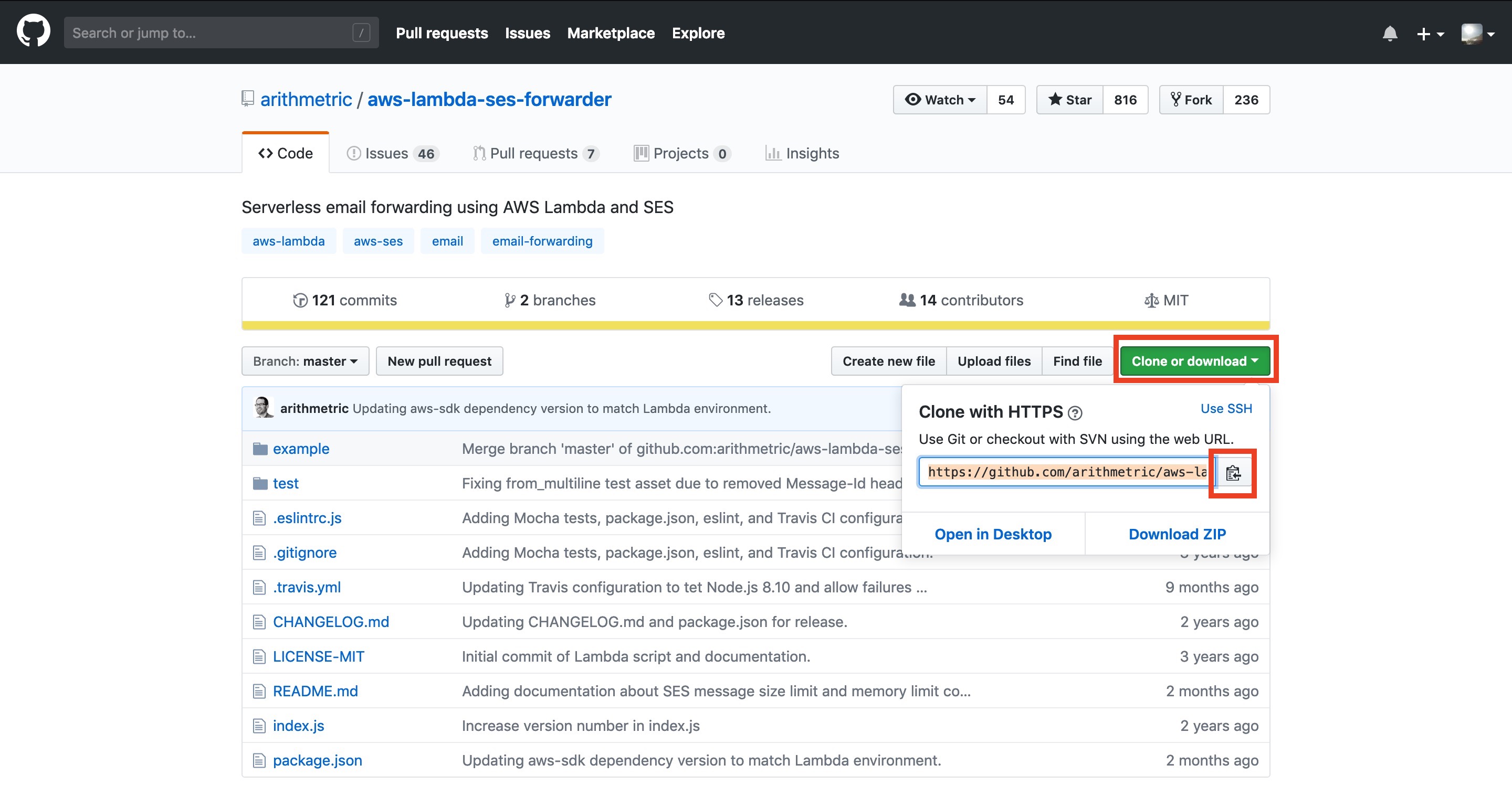
まずはライブラリのコードをクローンさせてもらいましょう
ライブラリにアクセスし、URLをコピーします
今度は自分のローカルに一時的な作業ディレクトリを作って作業をします
以下はコピペである程度作業ができるようにしています。以下は[ Terminal ]での作業です
[ npm ]のインストール方法はこちらの記事を参照してください
https://qiita.com/Alex_mht_code/items/422f5ce10d9c9d5729b7
cd ~ mkdir temporary && cd temporary/ git clone https://github.com/arithmetric/aws-lambda-ses-forwarder.git mkdir my-lambda-ses cp -r aws-lambda-ses-forwarder/example/ my-lambda-ses/ cd my-lambda-ses/ファイルの中身を書き換えていきます
下のコードをコピペして書き換えてください書き換える際は好きなテキストエディタをご利用ください
cat << ETX > index.js var LambdaForwarder = require("aws-lambda-ses-forwarder"); exports.handler = function(event, context, callback) { // See aws-lambda-ses-forwarder/index.js for all options. var overrides = { config: { fromEmail: "noreply@example.com", // 転送元に使うアドレス emailBucket: "s3-bucket-name", // 前回作成したS3バケット名 emailKeyPrefix: "mails/", // S3のプレフィックス名 forwardMapping: { "info@example.com": [ // 受信用に設定したメールアドレス "example.john@example.com" // 受信メールの転送先Gmailアドレス ] } } }; LambdaForwarder.handler(event, context, callback, overrides); }; ETX終わったら[ npm install ]をしてZIP化します
cd temporary/my-lambda-ses/ npm install zip -r my-lambda-ses ./*以上で[ Terminal ]画面での作業は終了です
3-2: Lambda用の作業用[ IAM Role ]を作成する
作業はAWSに戻ります
外面左上[ サービス ]から[ IAM ]を選択します
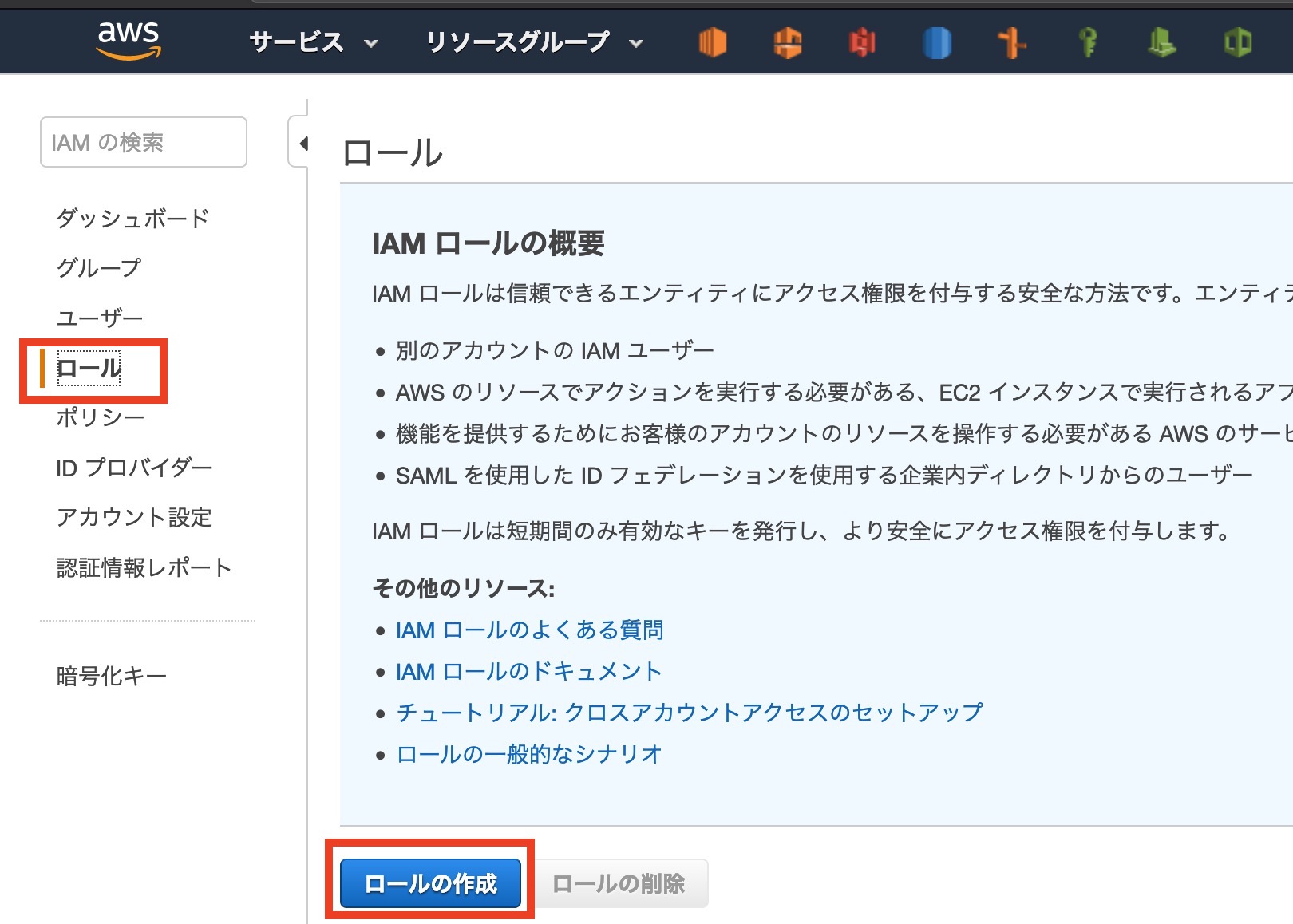
サイドバー[ ロール ]から[ ロールの作成 ]をクリックします
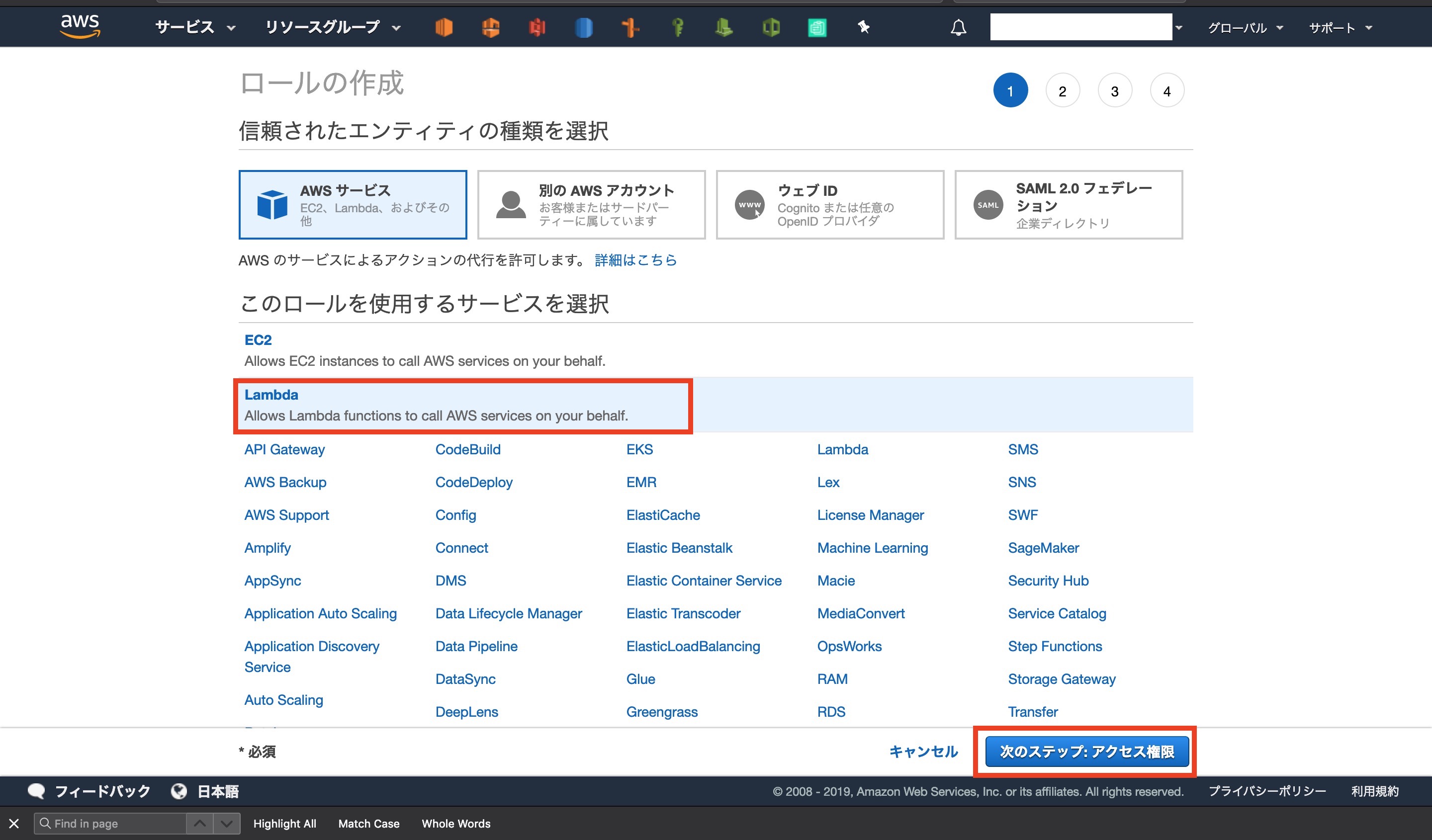
エンティティに[ Lambda ]を選択して次のステップに進みます
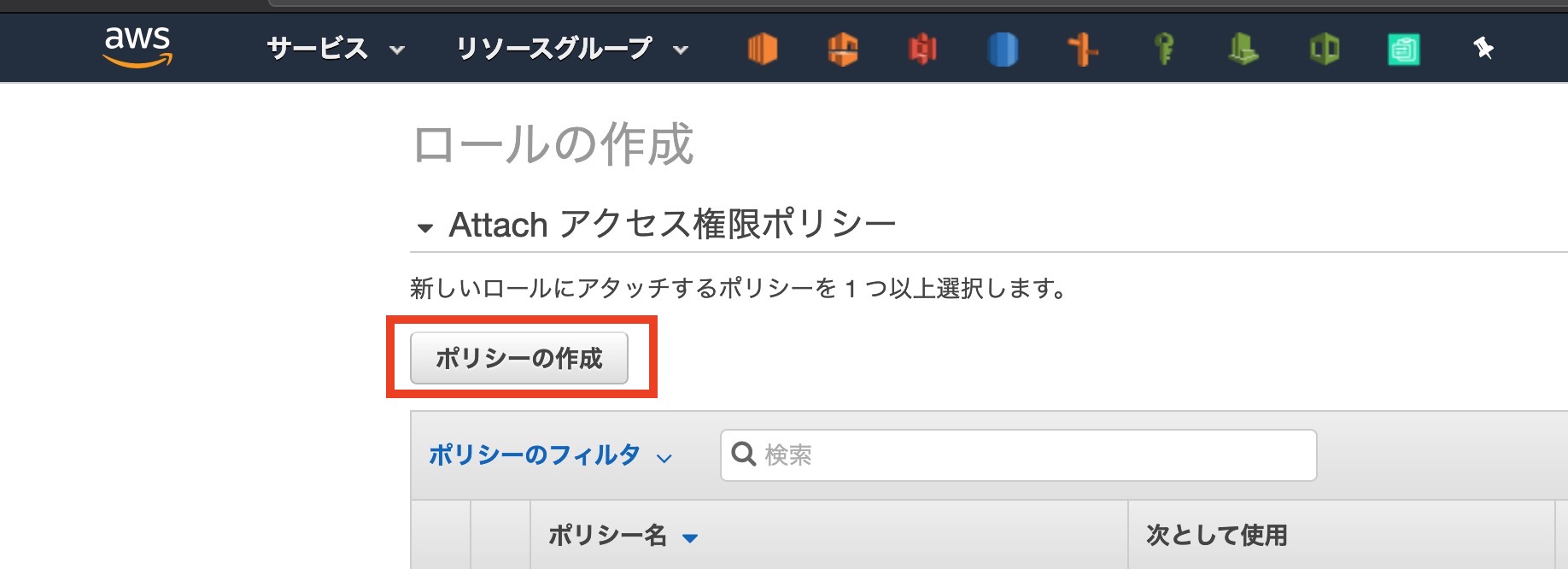
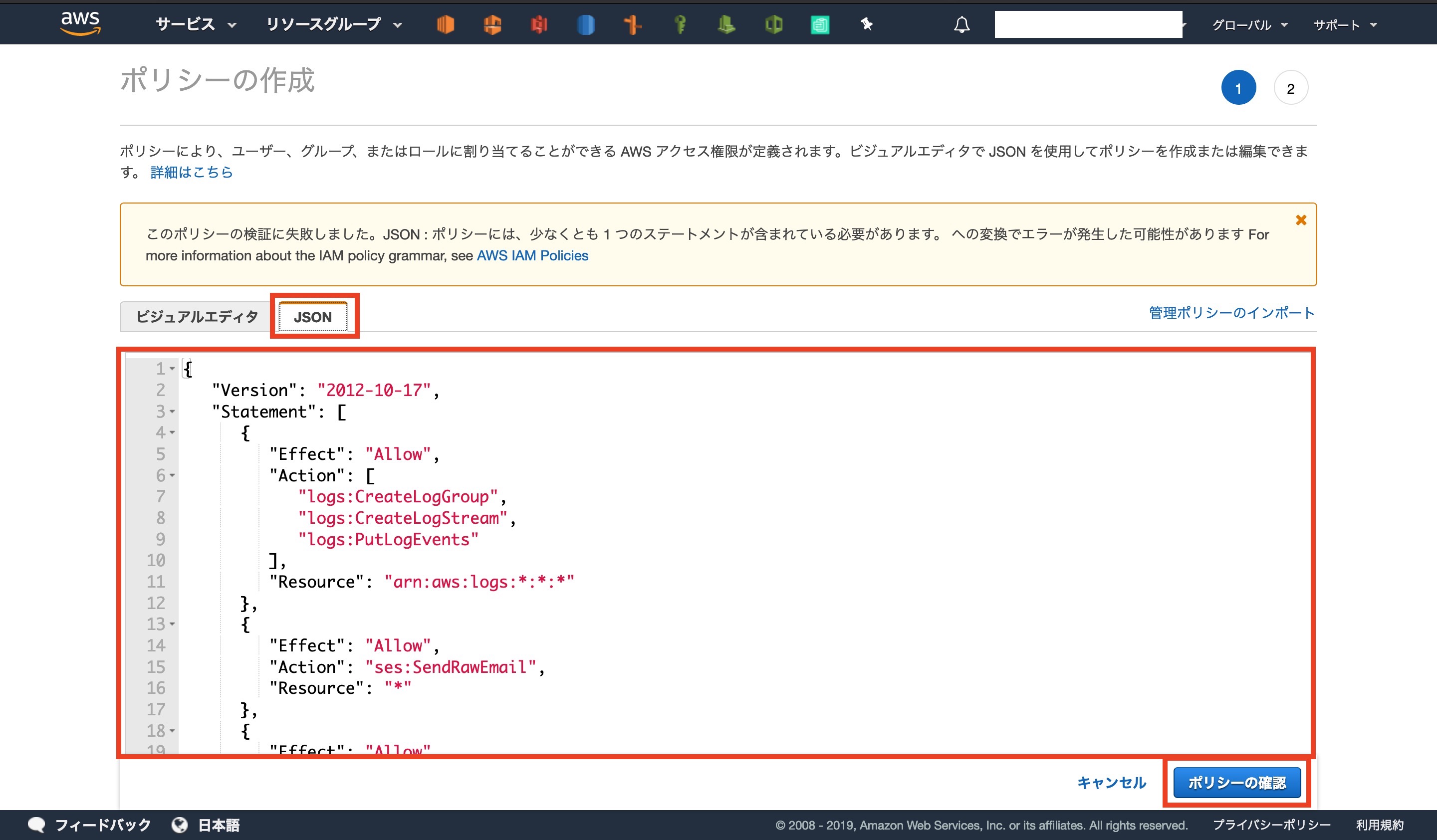
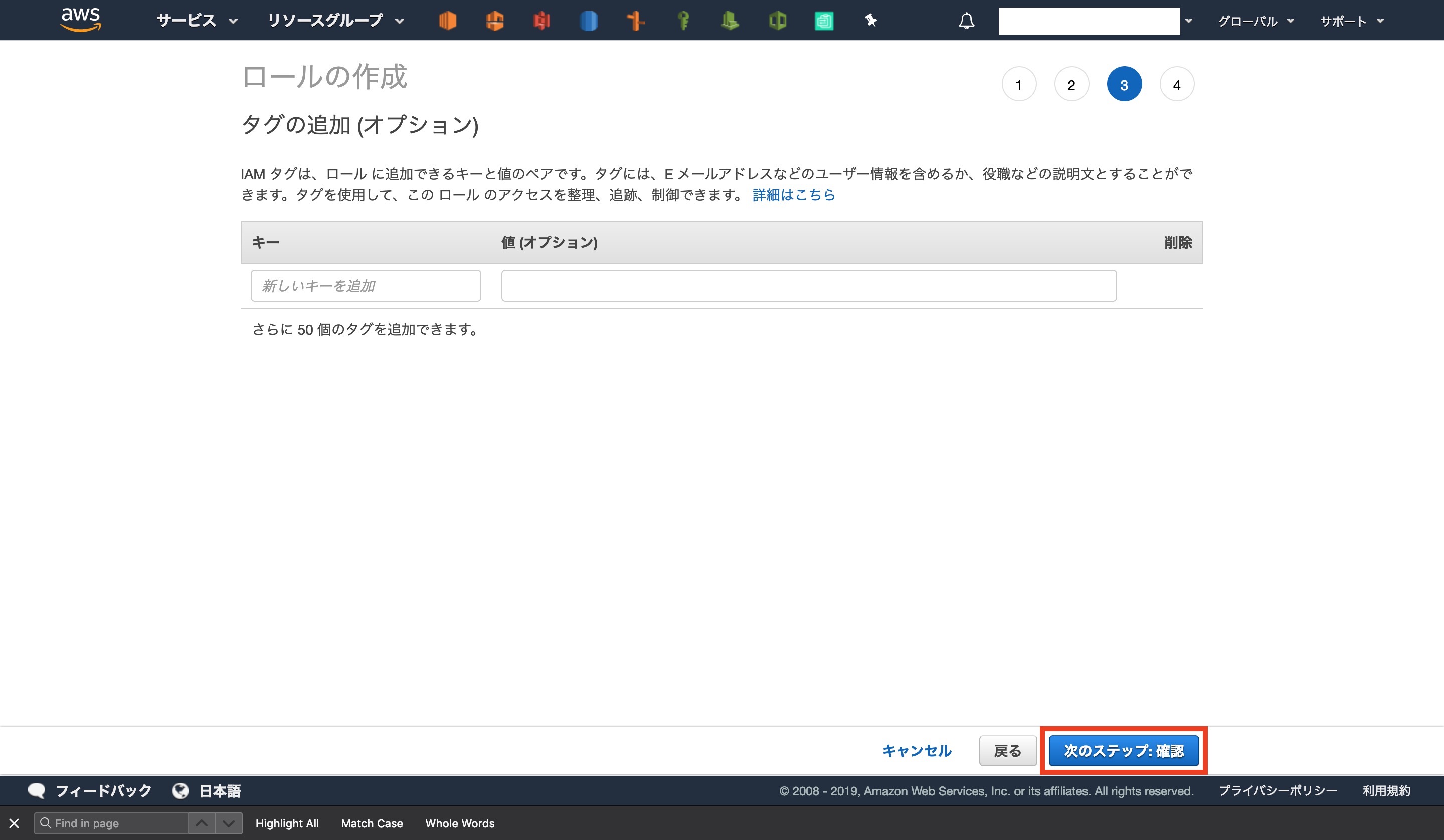
[ ポリシーの作成 ]をクリックします
コード下部の[ S3-BUCKET-NAME ]の部分は。自分のメール用S3バケットの名前に変更してください
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "logs:CreateLogGroup", "logs:CreateLogStream", "logs:PutLogEvents" ], "Resource": "arn:aws:logs:*:*:*" }, { "Effect": "Allow", "Action": "ses:SendRawEmail", "Resource": "*" }, { "Effect": "Allow", "Action": [ "s3:GetObject", "s3:PutObject" ], "Resource": "arn:aws:s3:::S3-BUCKET-NAME/*" } ] }ポリシーの作成画面に移動するので、[ JSON ]を選択し、上のコードを編集したものを貼り付けます
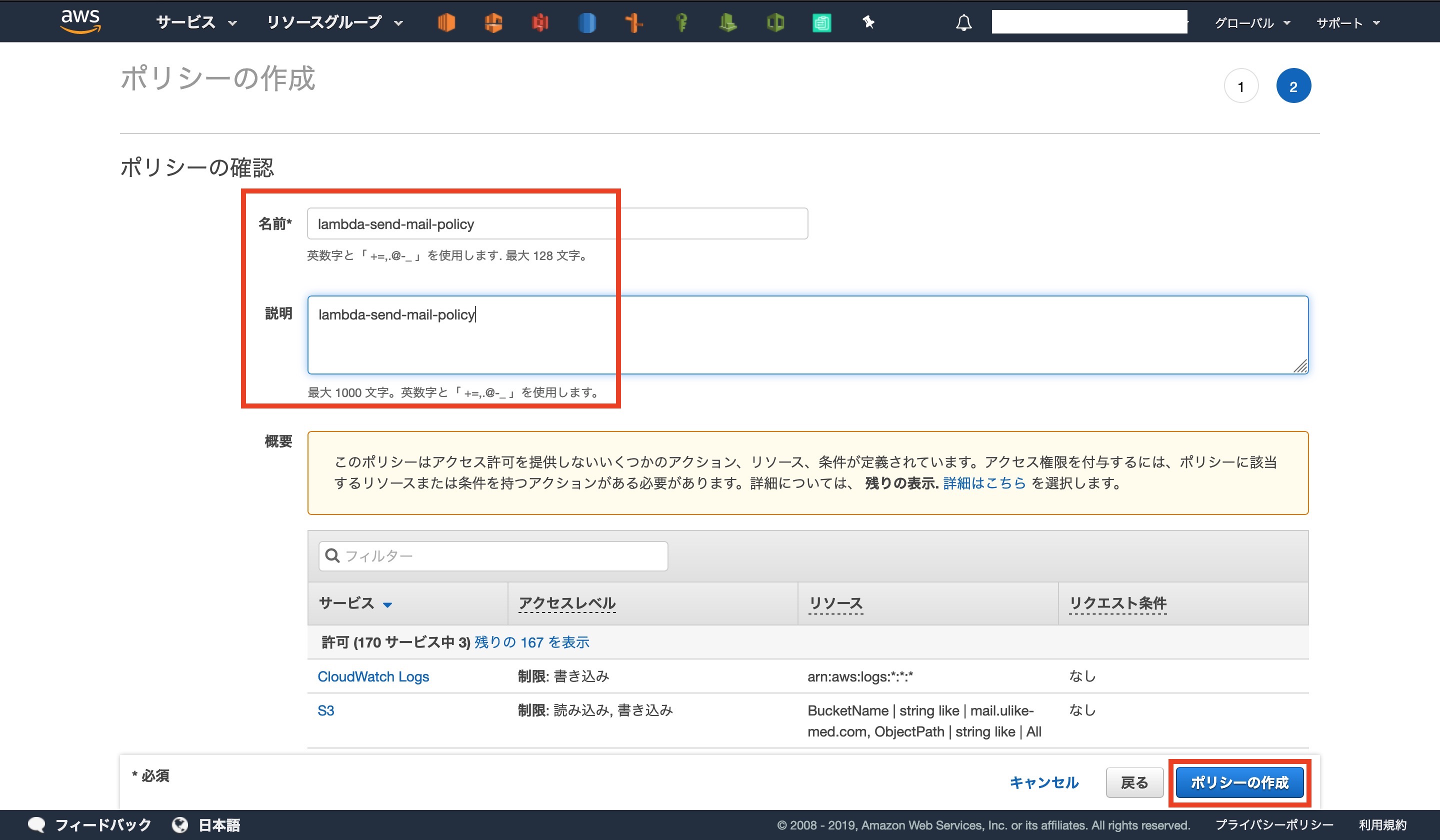
ポリシーに名前と説明を入力します
今回は[ lambda-send-mail-policy ]にしました。
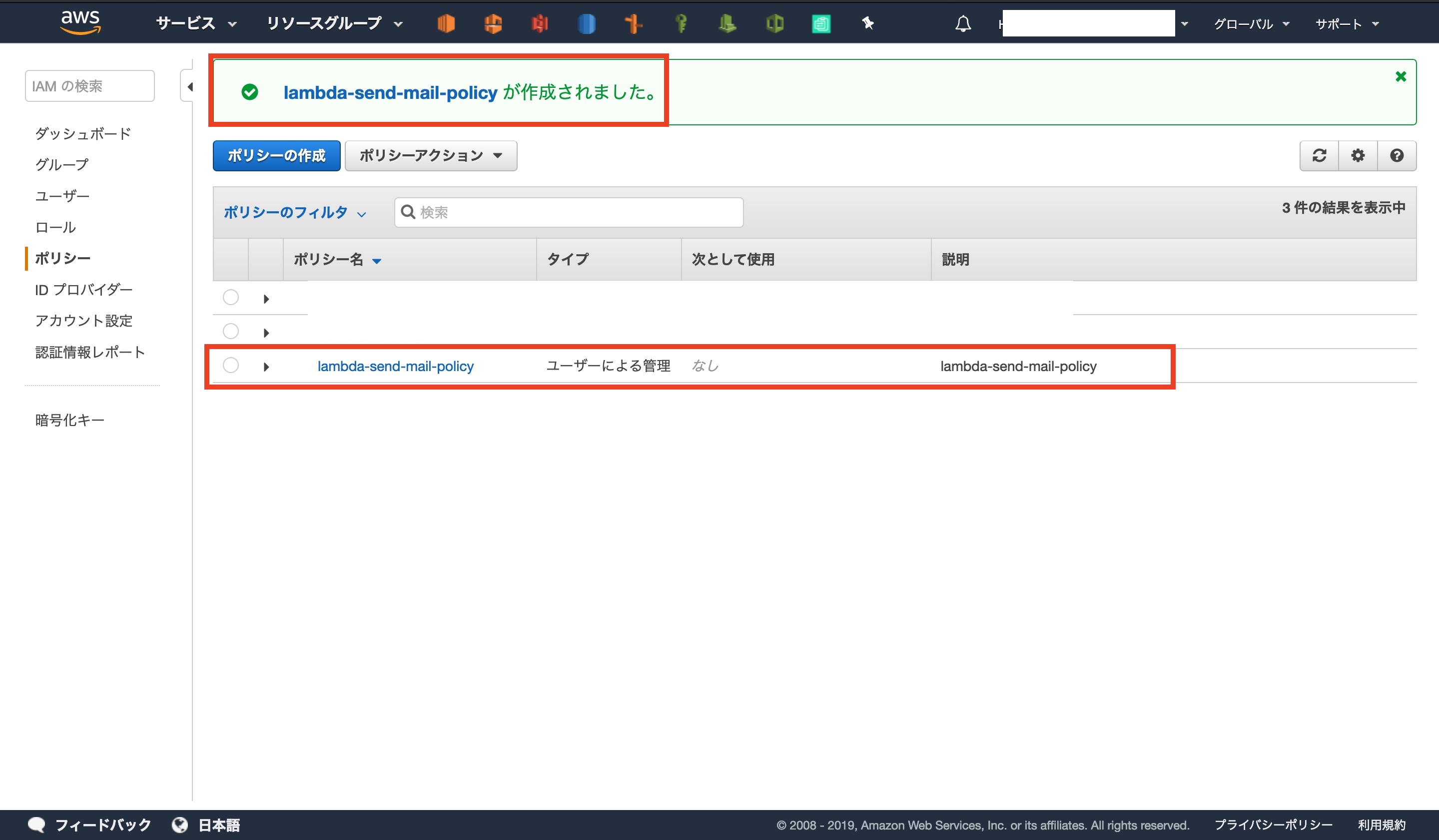
確認のボタンを押すと、コンソール画面で作成されていることが確認できます
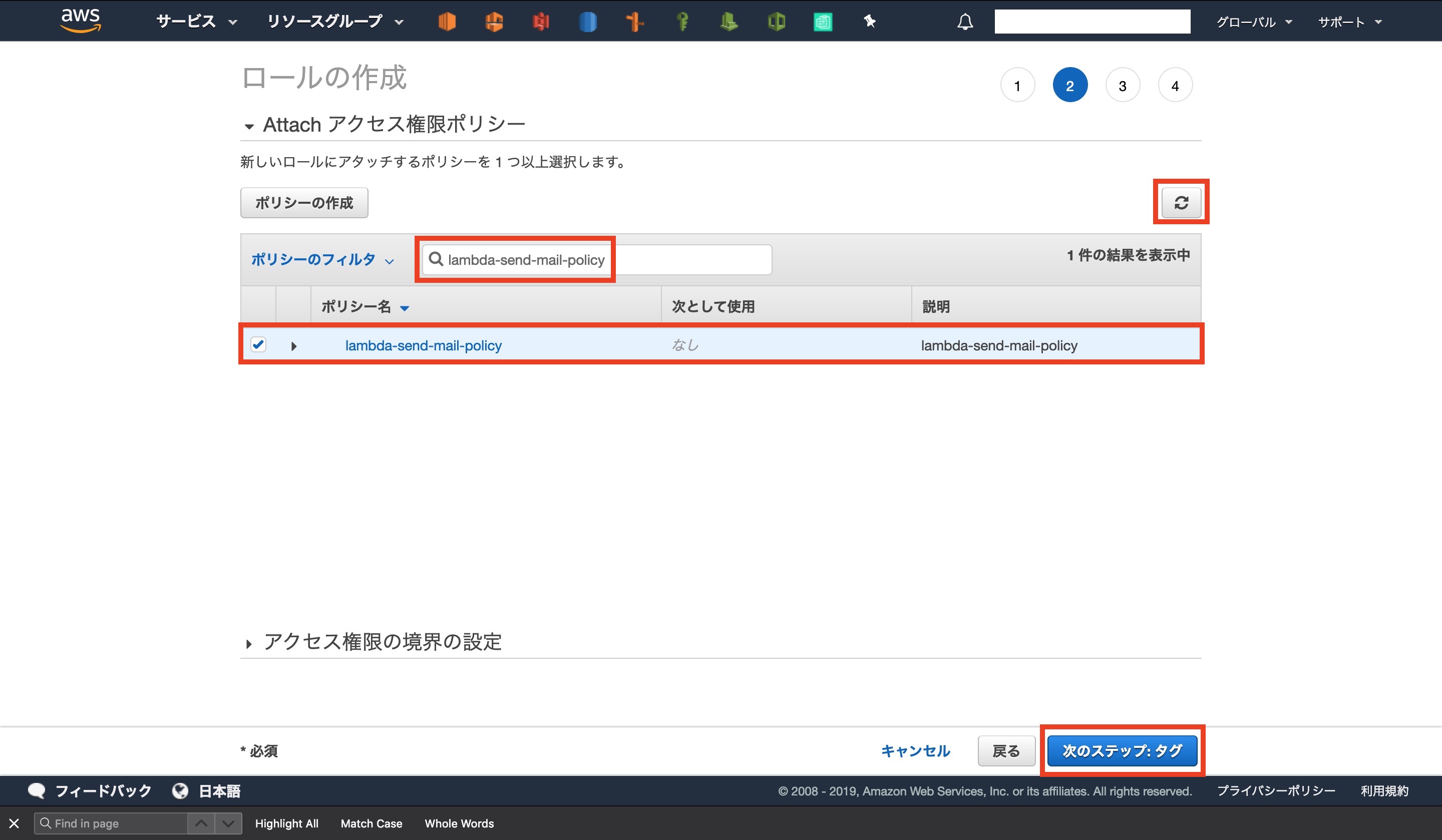
元の画面に戻りロールの設定の続きを行います
更新ボタンを押し、作成したポリシーを検索窓に入力します
ポリシーが見つかったらチェックして先に進みます
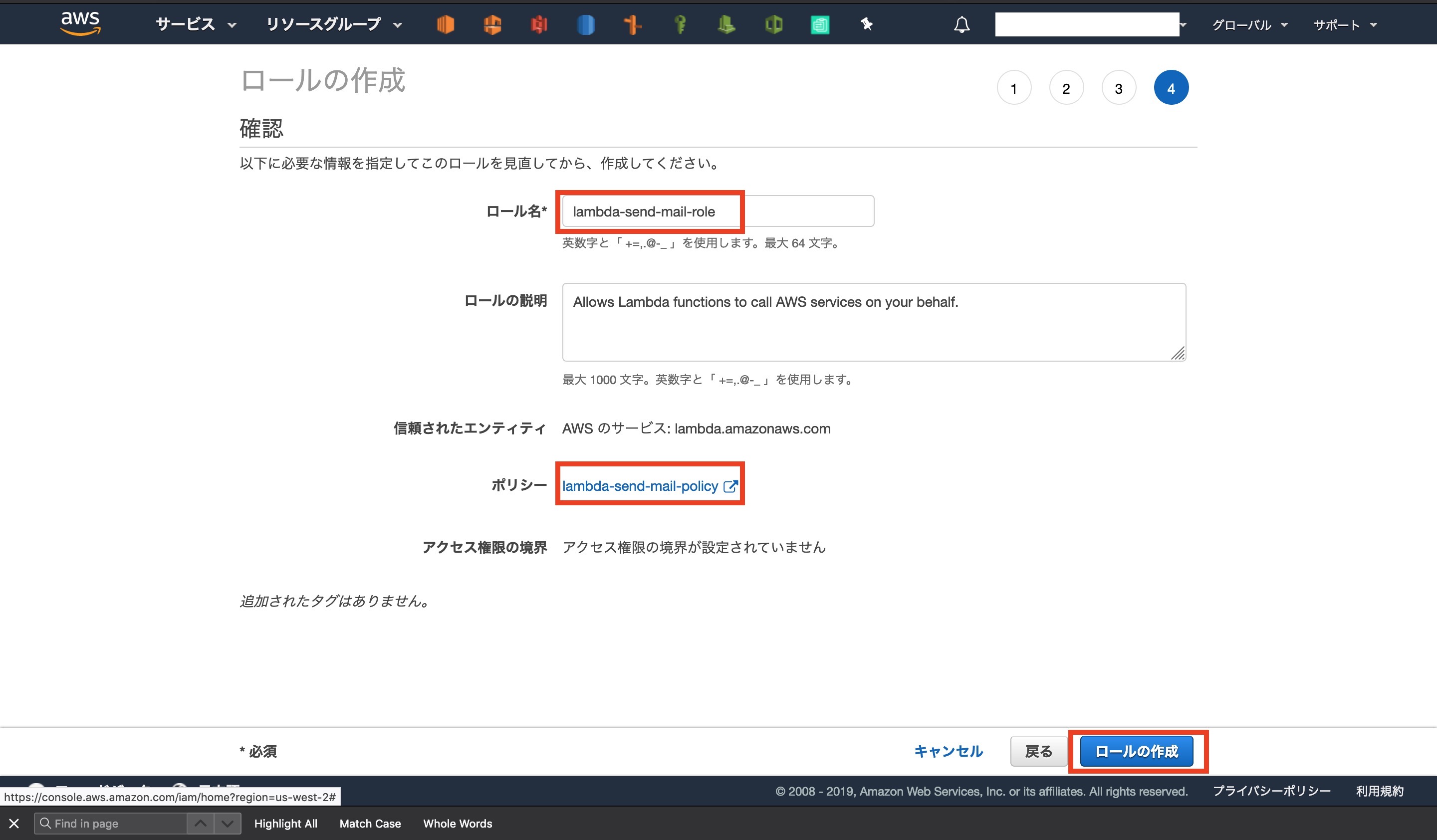
ロール名に[ lambda-send-mail-role ]と入力すれば完了です
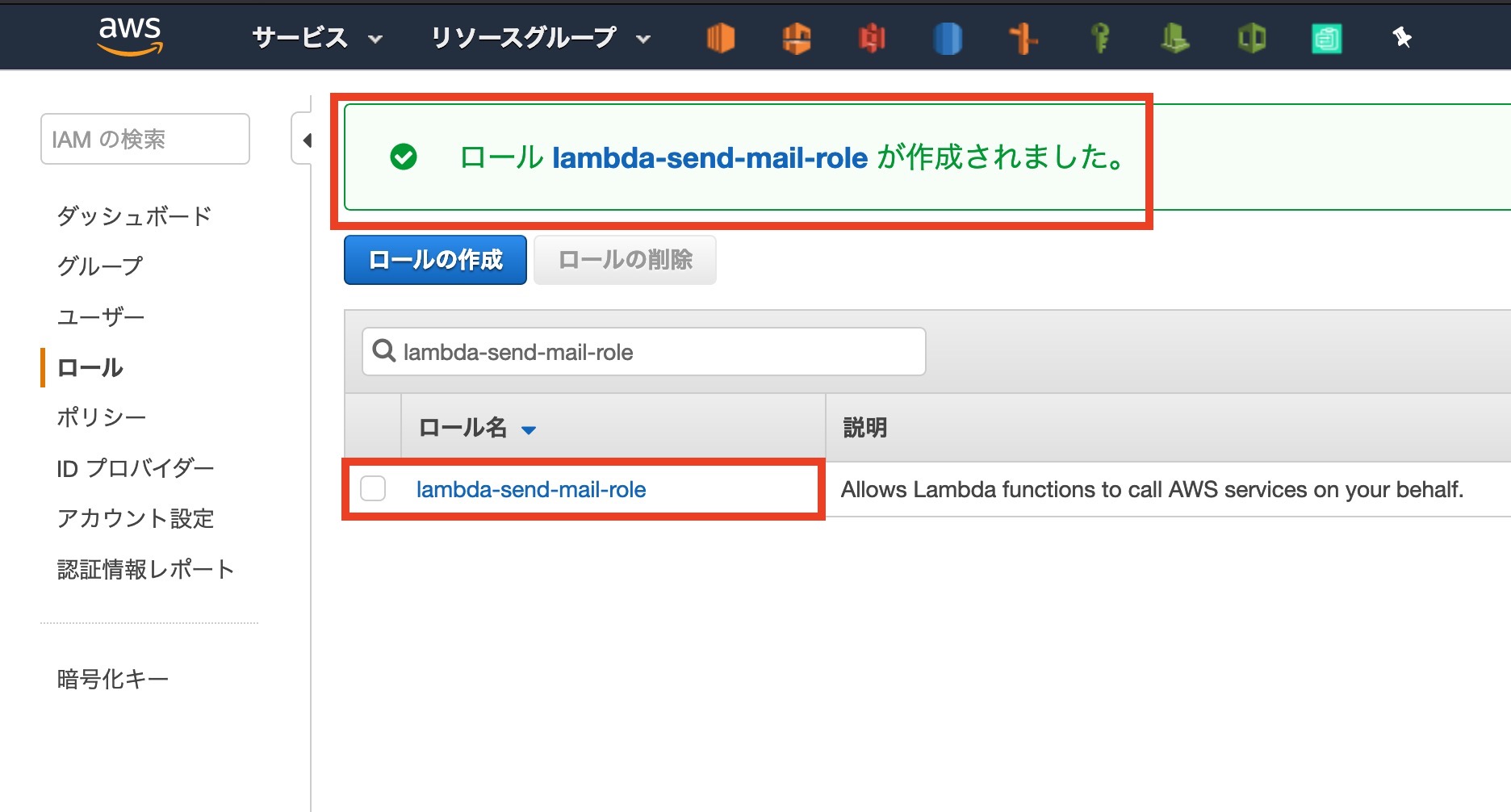
コンソール画面で作成されていることが確認できます
3-3: Lambdaの関数作成
受信設定の中心になるLambdaの関数を設定していきます
外面左上[ サービス ]から[ Lambda ]を選択します
画面内の[ 関数の作成 ]をクリックします
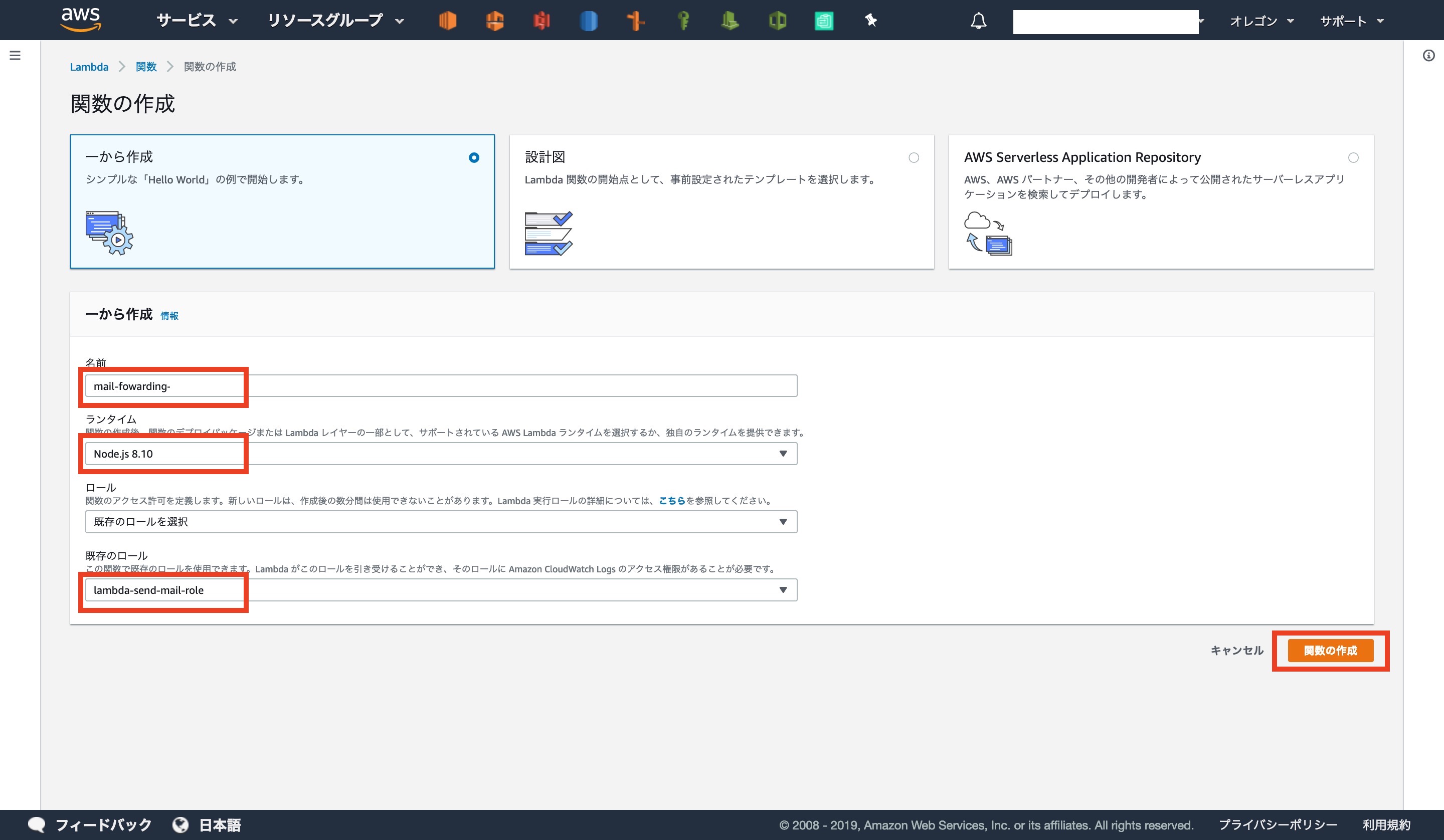
関数の作成画面になります
名前: mail-fowarding-[Gmailのアドレス]
ランタイム: Node.js 8.10
既存のロール: 先ほど作成したIAMロール
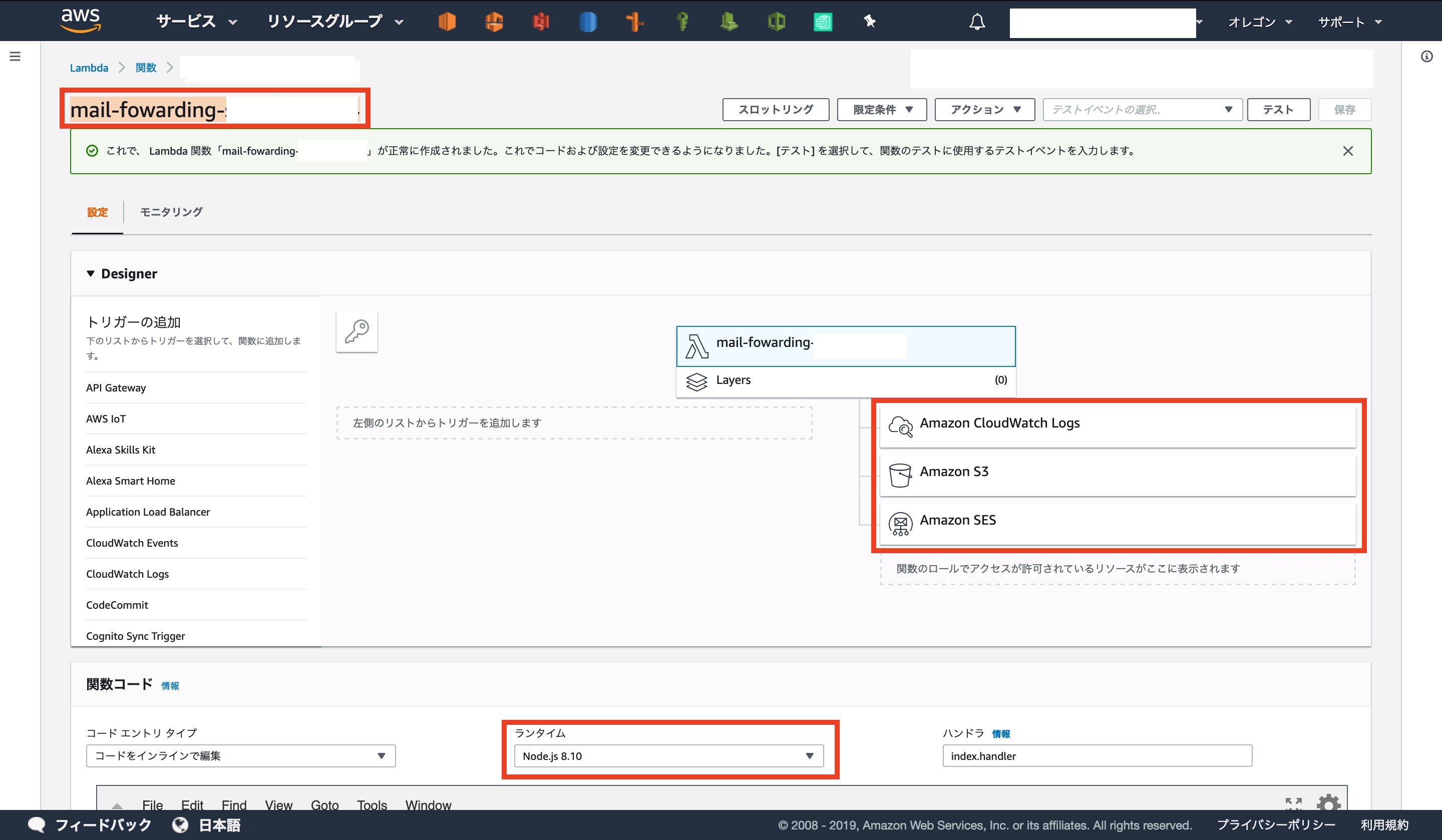
Lambdaのコンソール画面になります
ロールが間違っていなければ、アクセス許可されているサービスやランタイムが
下の画像のようになっているはずです
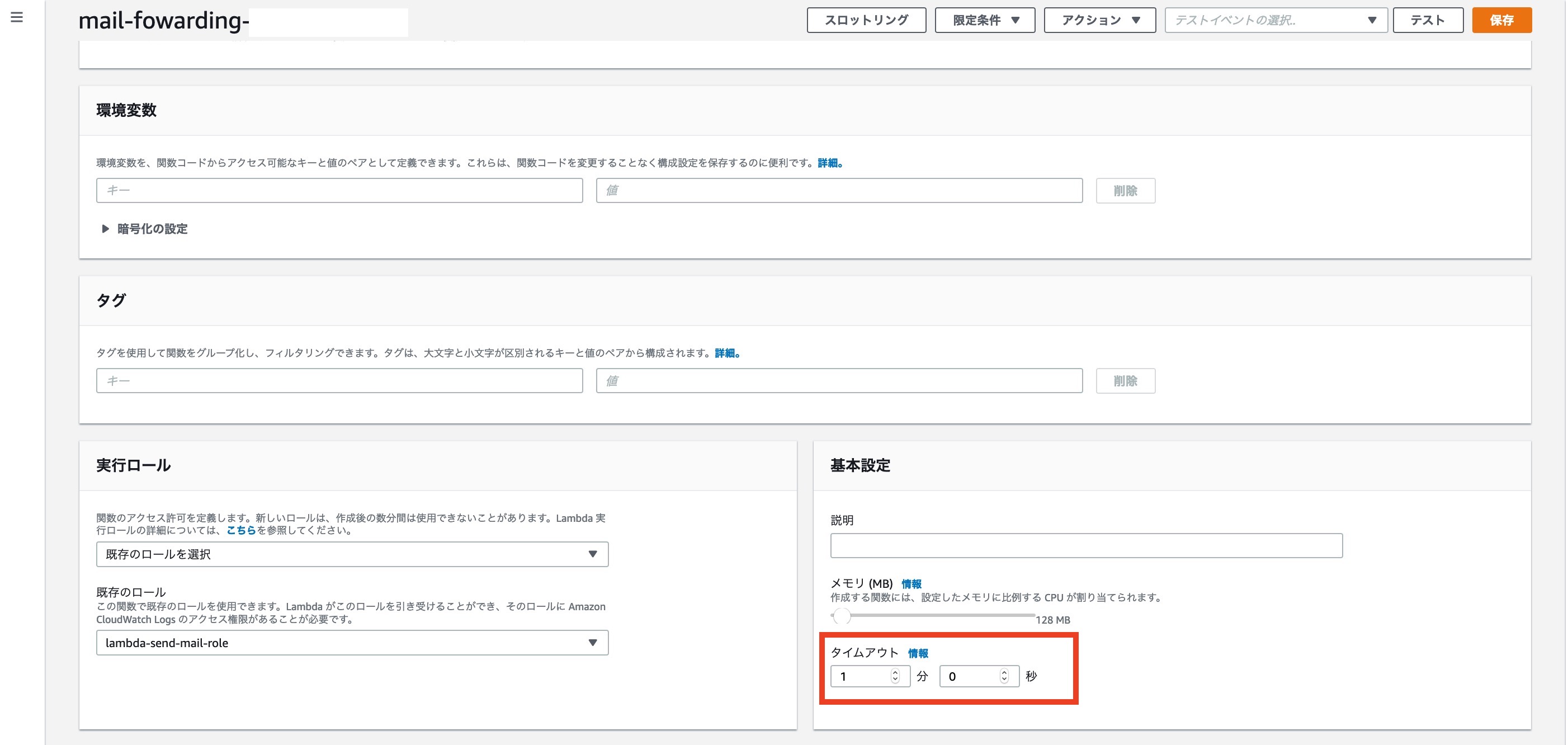
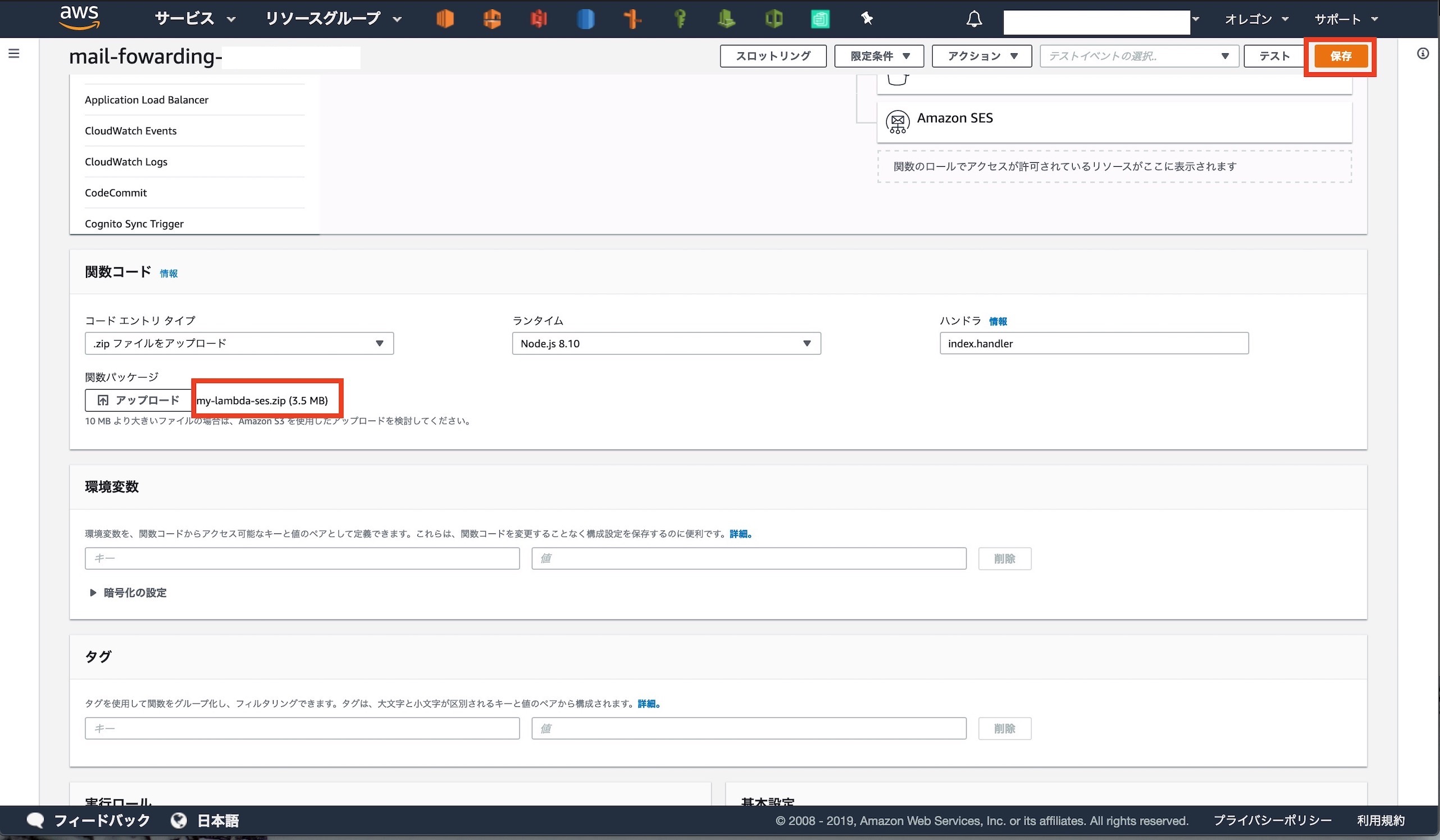
基本設定のタイムアウトを[ 1分 ]に設定します
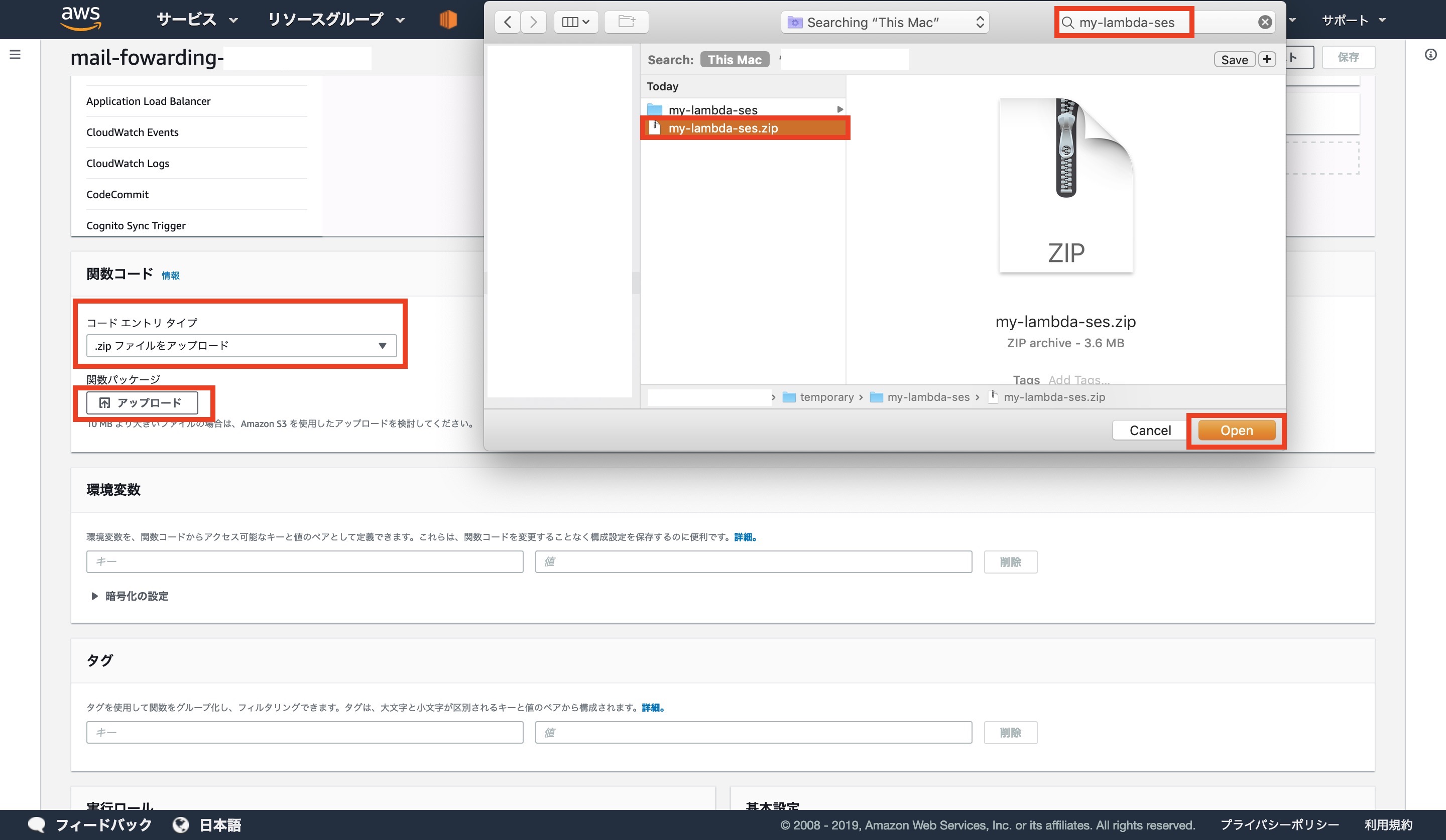
コードエントリタイプを[ .zpiファイルをアップロード ]に変更します
Macの画面ですが、先ほど作成したZIPファイルを選択します
アップロードが完了したら画面右上の[ 保存 ]をクリックします
以上で[ Lambda ]での作業は完了です
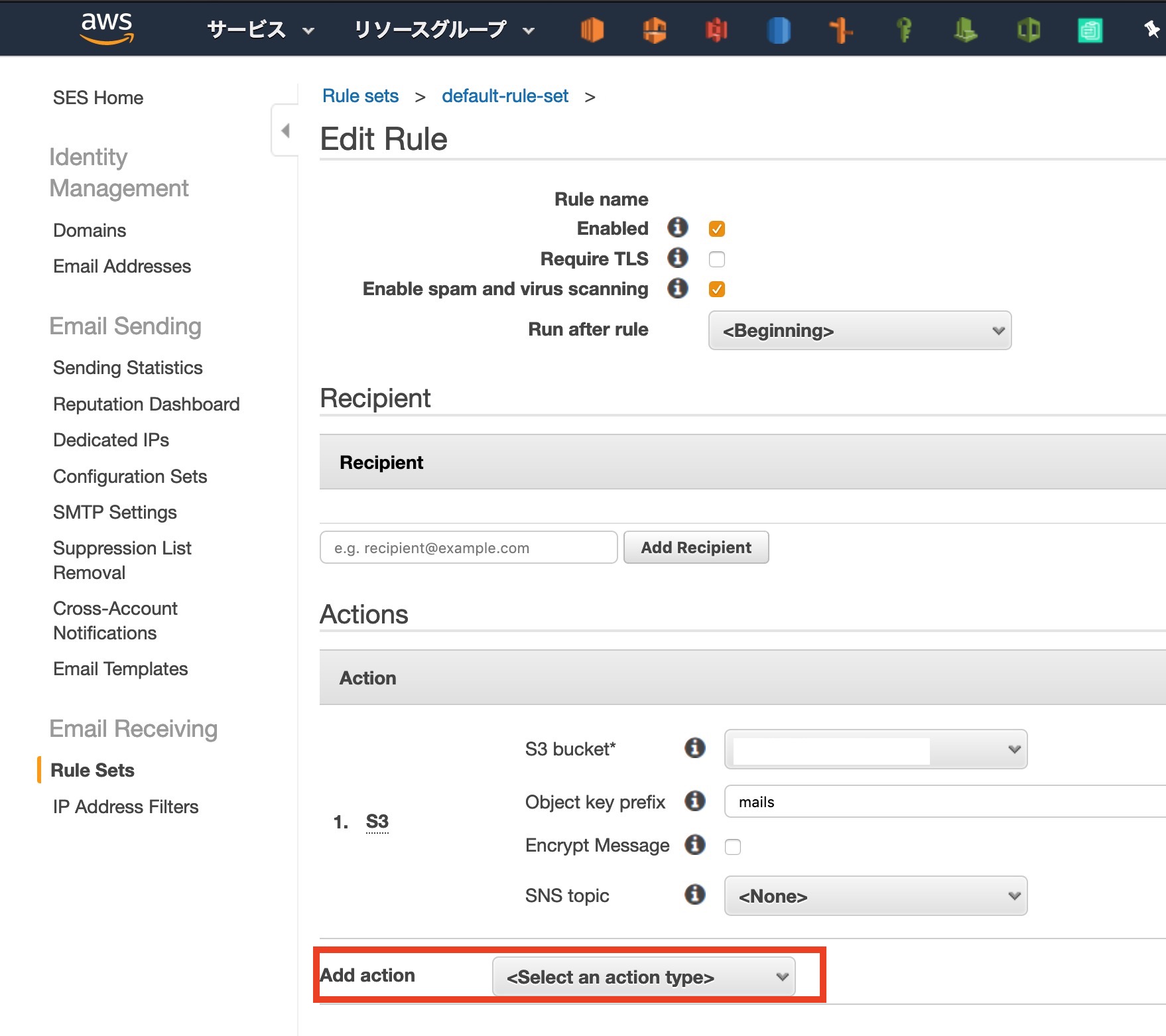
3-4: SESでLambdaの呼び出すルールを追加する
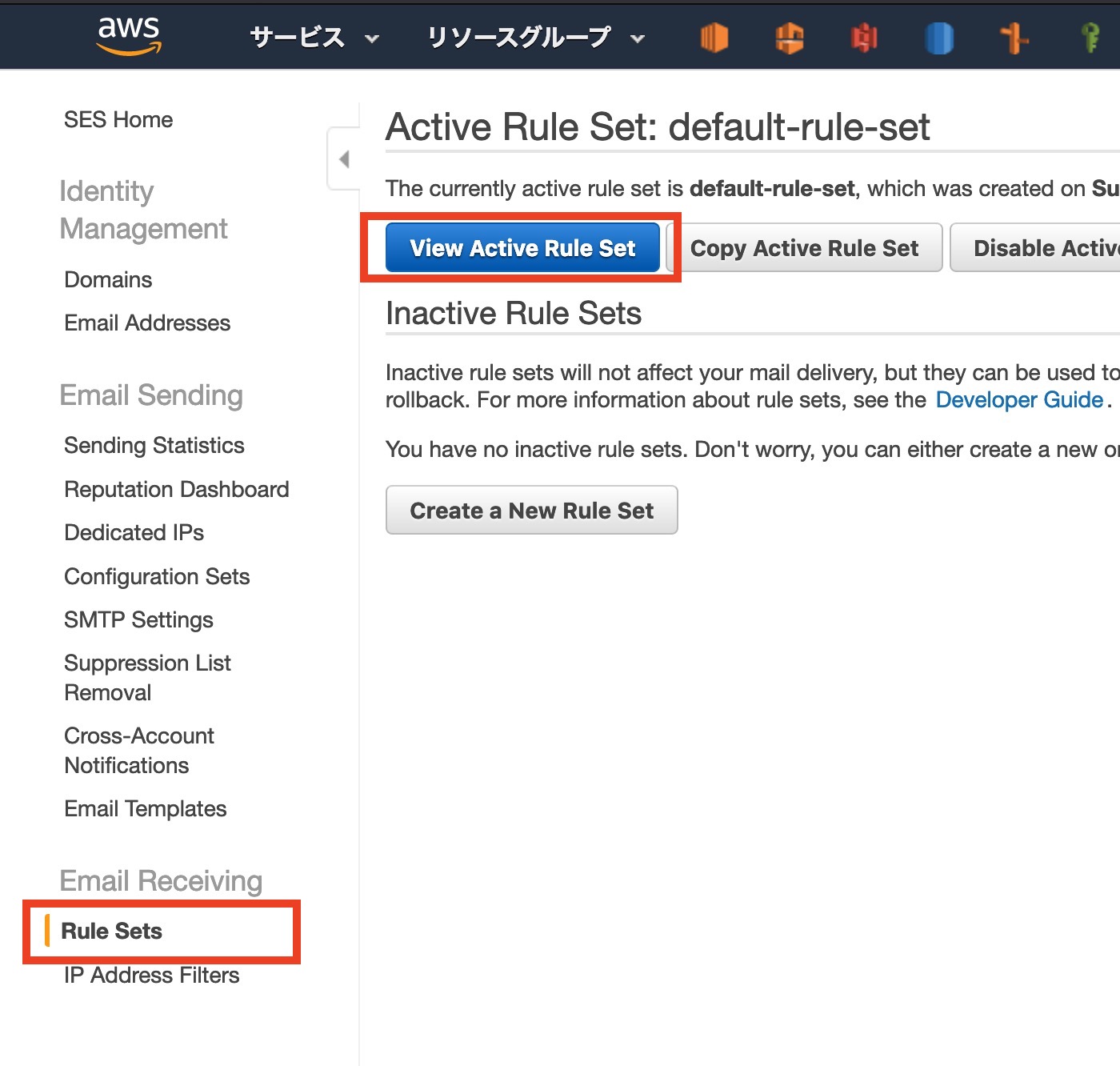
SESのコンソールに移動します
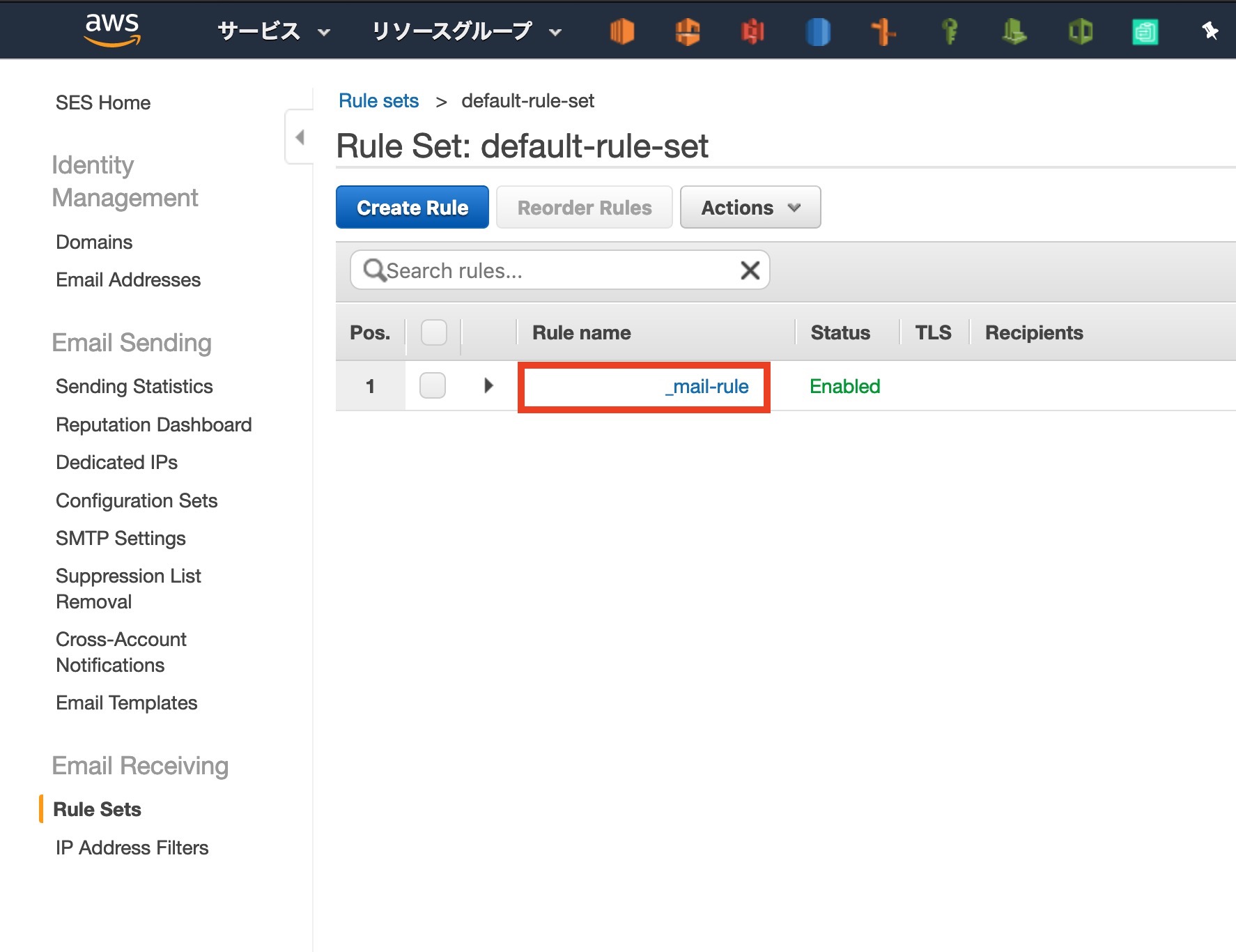
サイドバ[ Rule Sets ]から[ View Active Rule Set ]をクリック
前回製作したルールをクリック
[ Actions ]で新しくルールを追加します
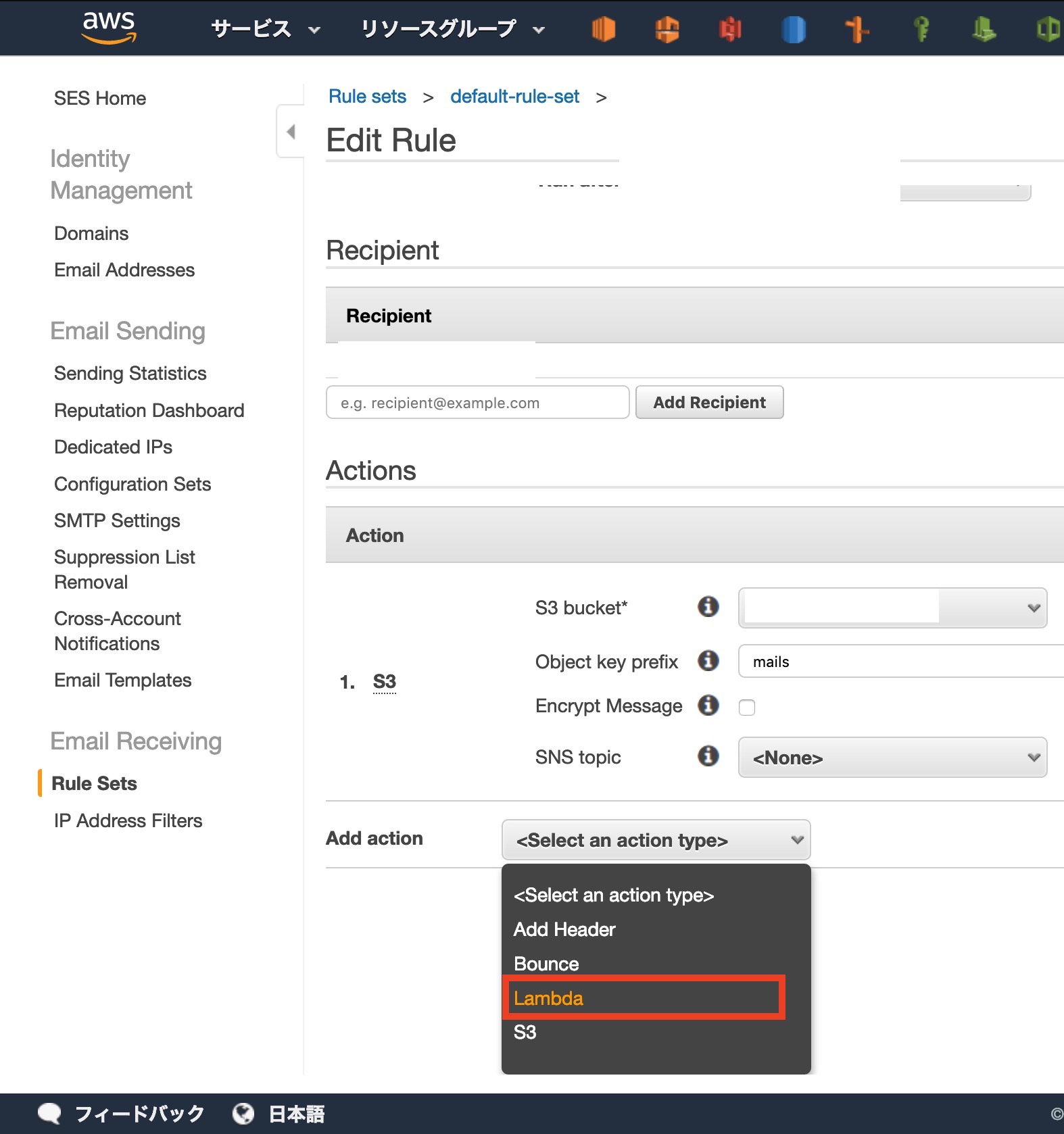
[ Add action ]から[ Lambda ]を選択します
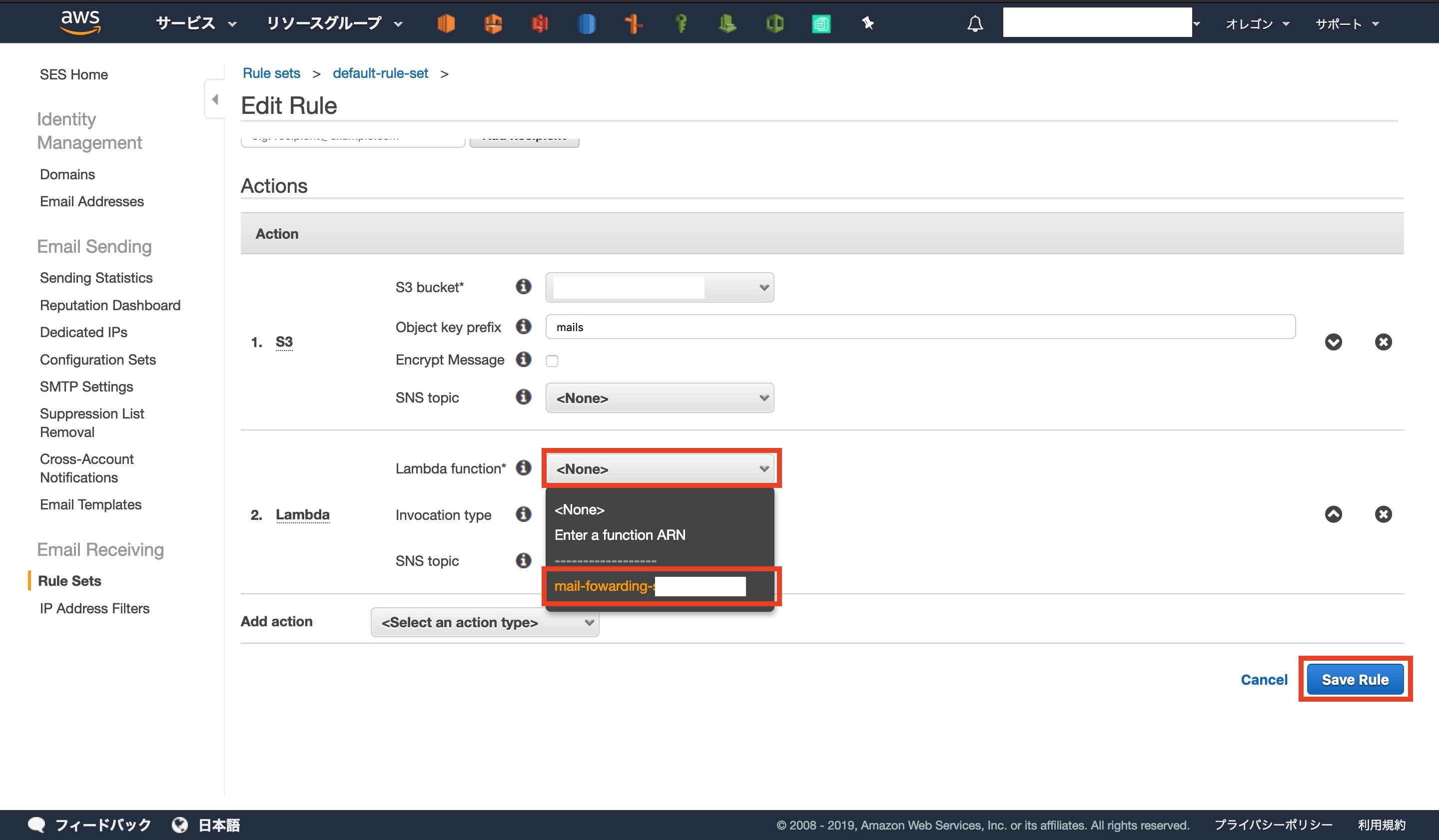
[ Lambda function ]から先ほど作成した関数を選択します
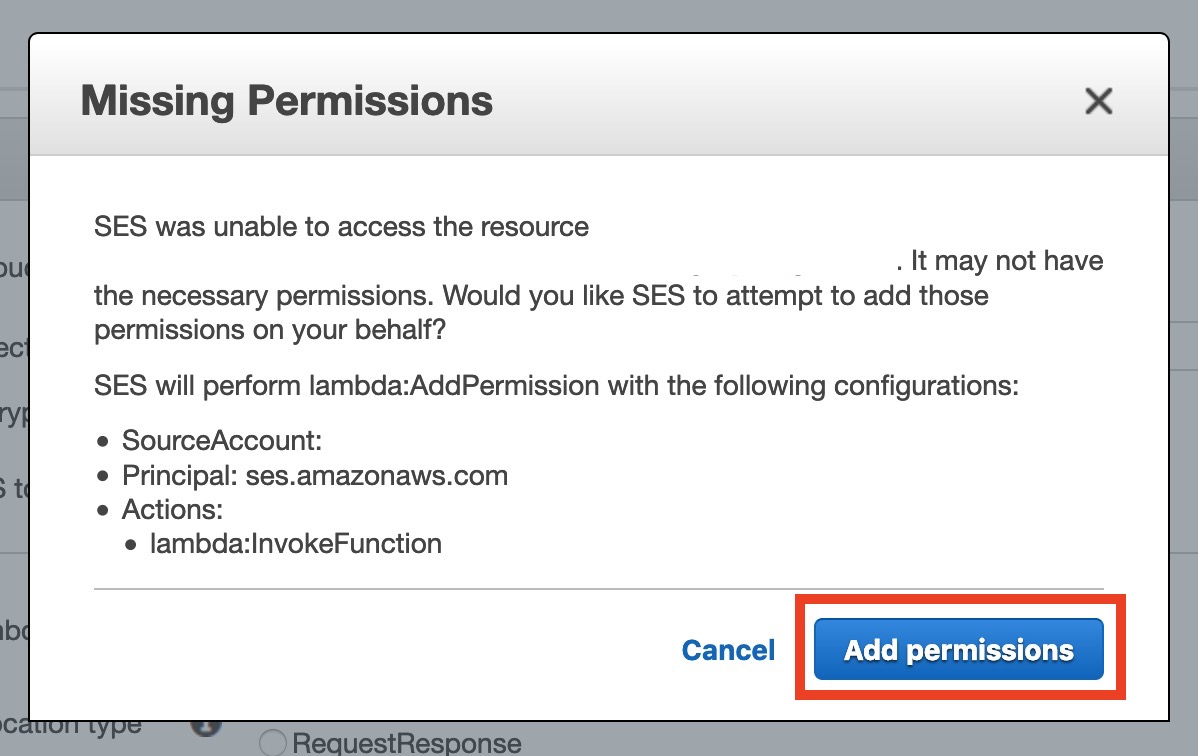
作っただけではアクセスの許可がないので、許可します
以上でSESの設定終了です
3-5: 受信用S3バケットにライフサイクルポリシーを設定する
まずはS3の作成したバケットに移動します
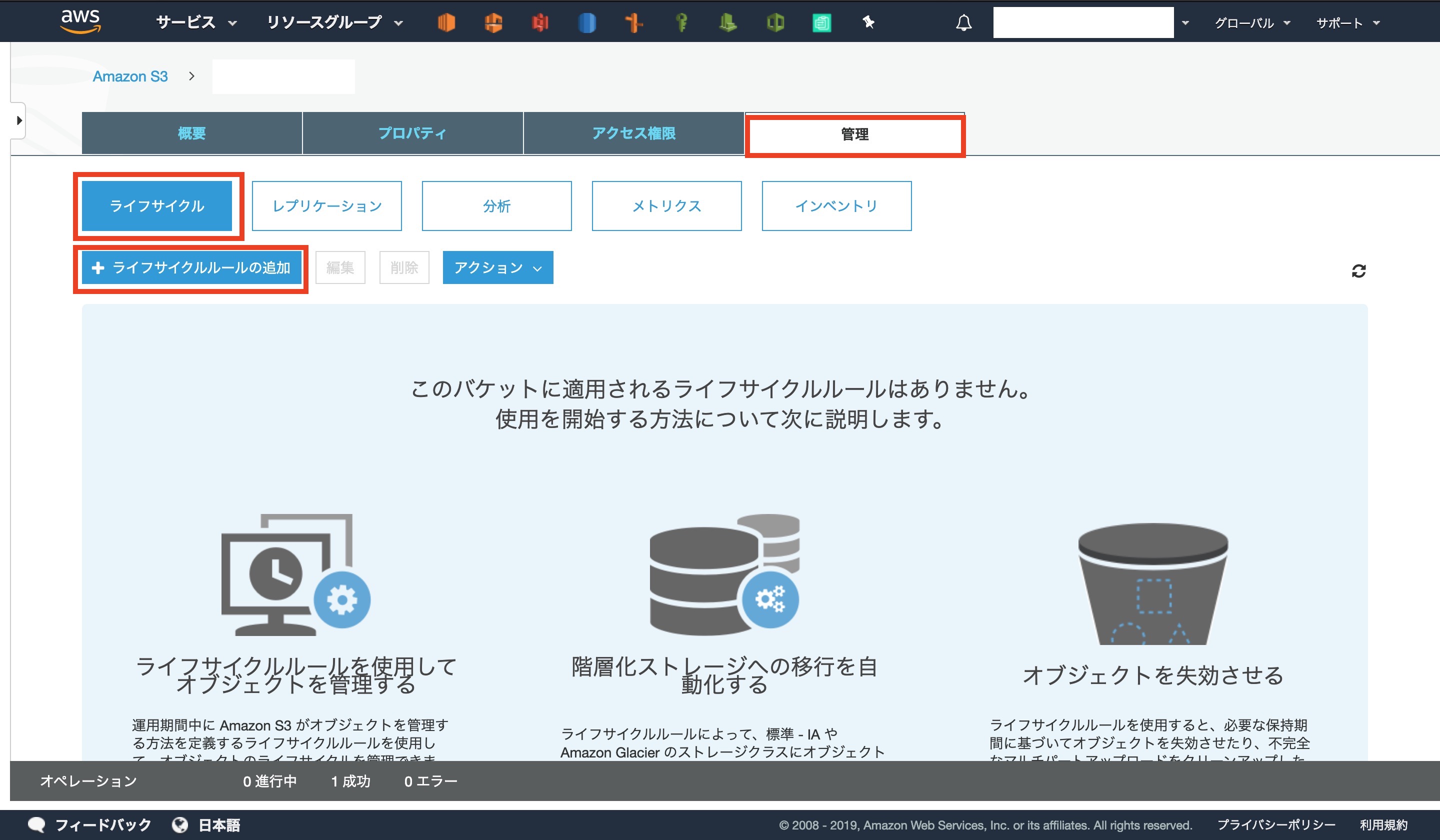
タグの[ 管理 ]から[ ライフサイクル ]、[ライフサイクルルールの追加]を選択します
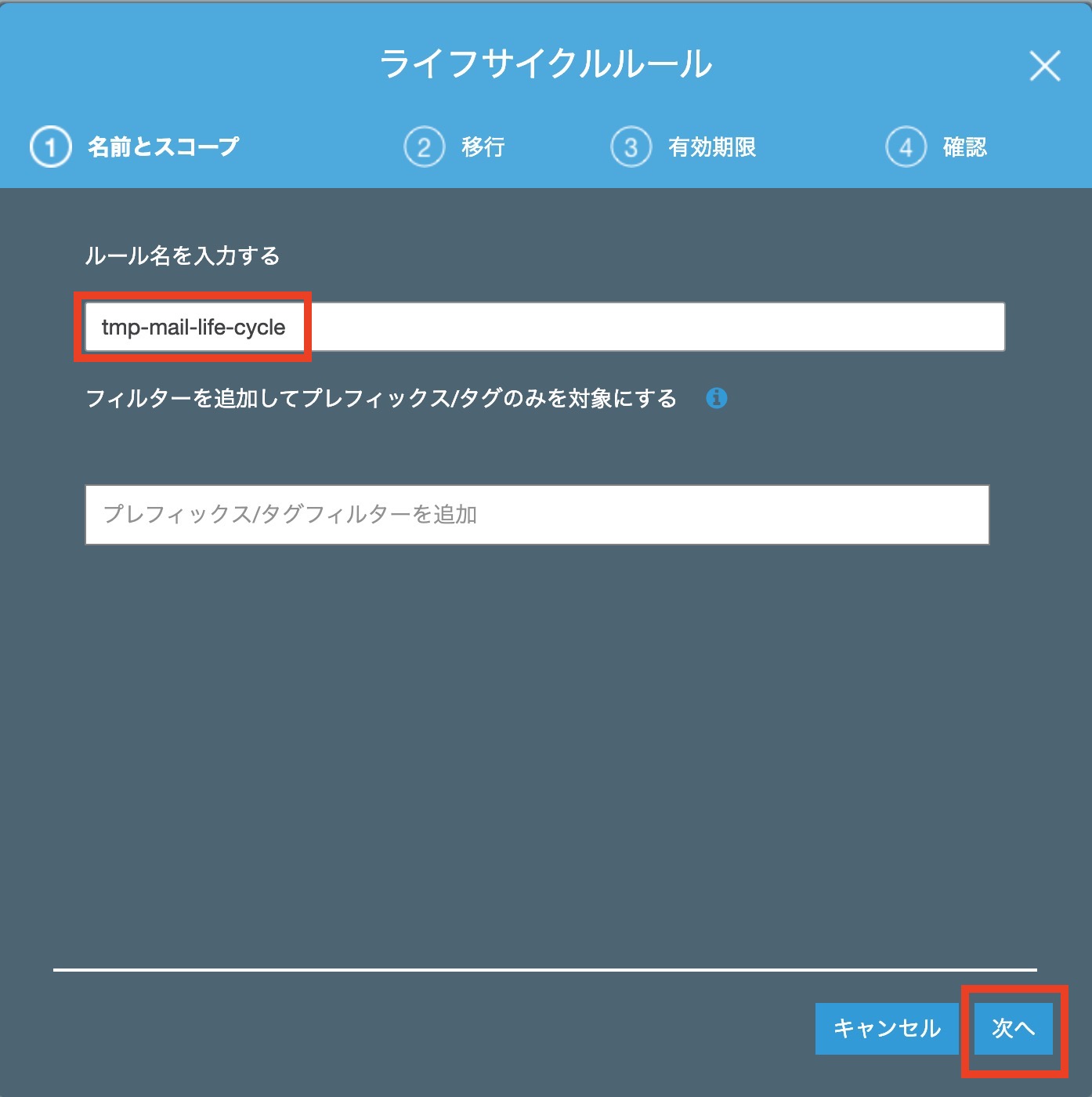
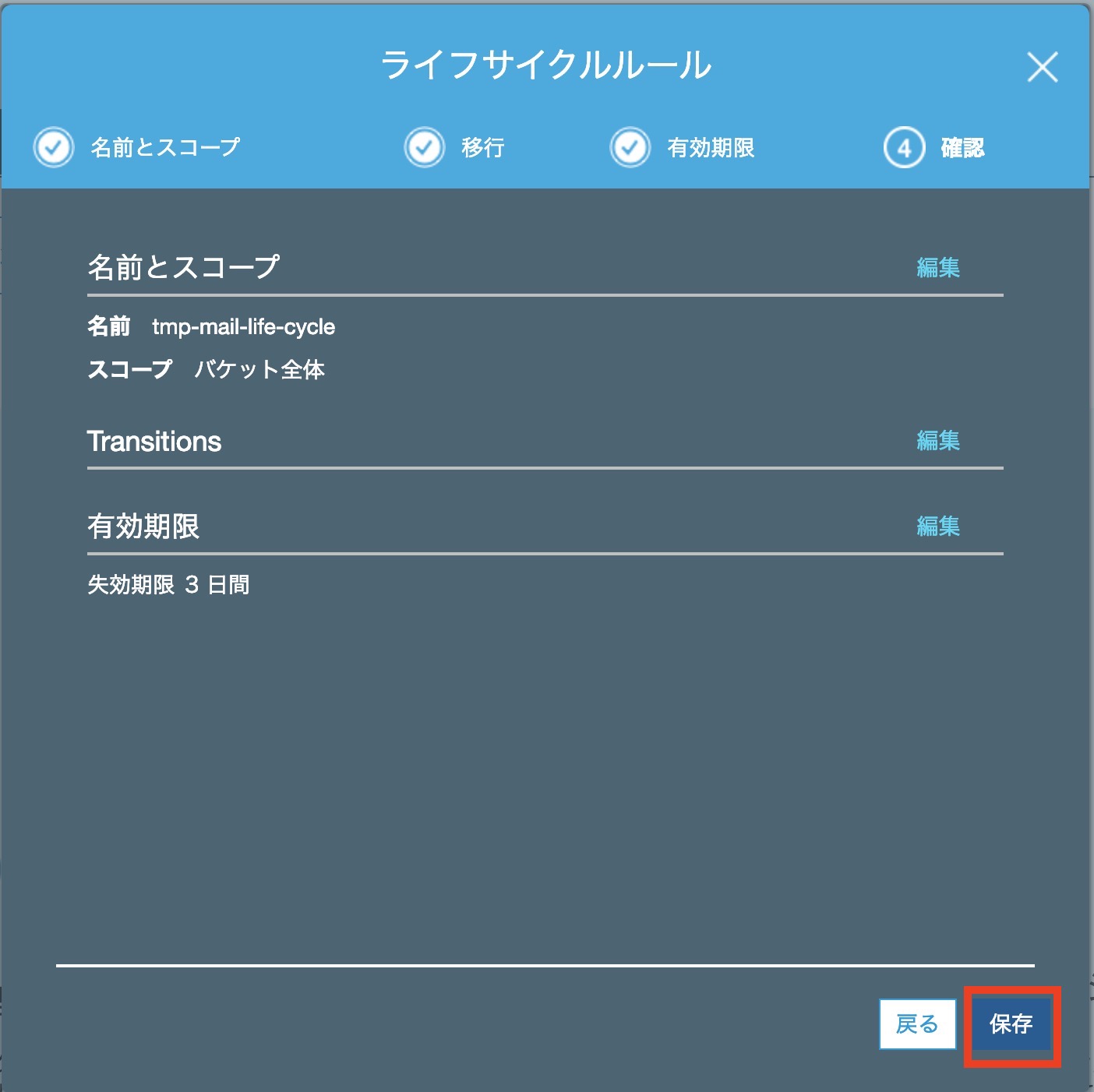
ルール名に[ tmp-mail-life-cycle ]と入力します
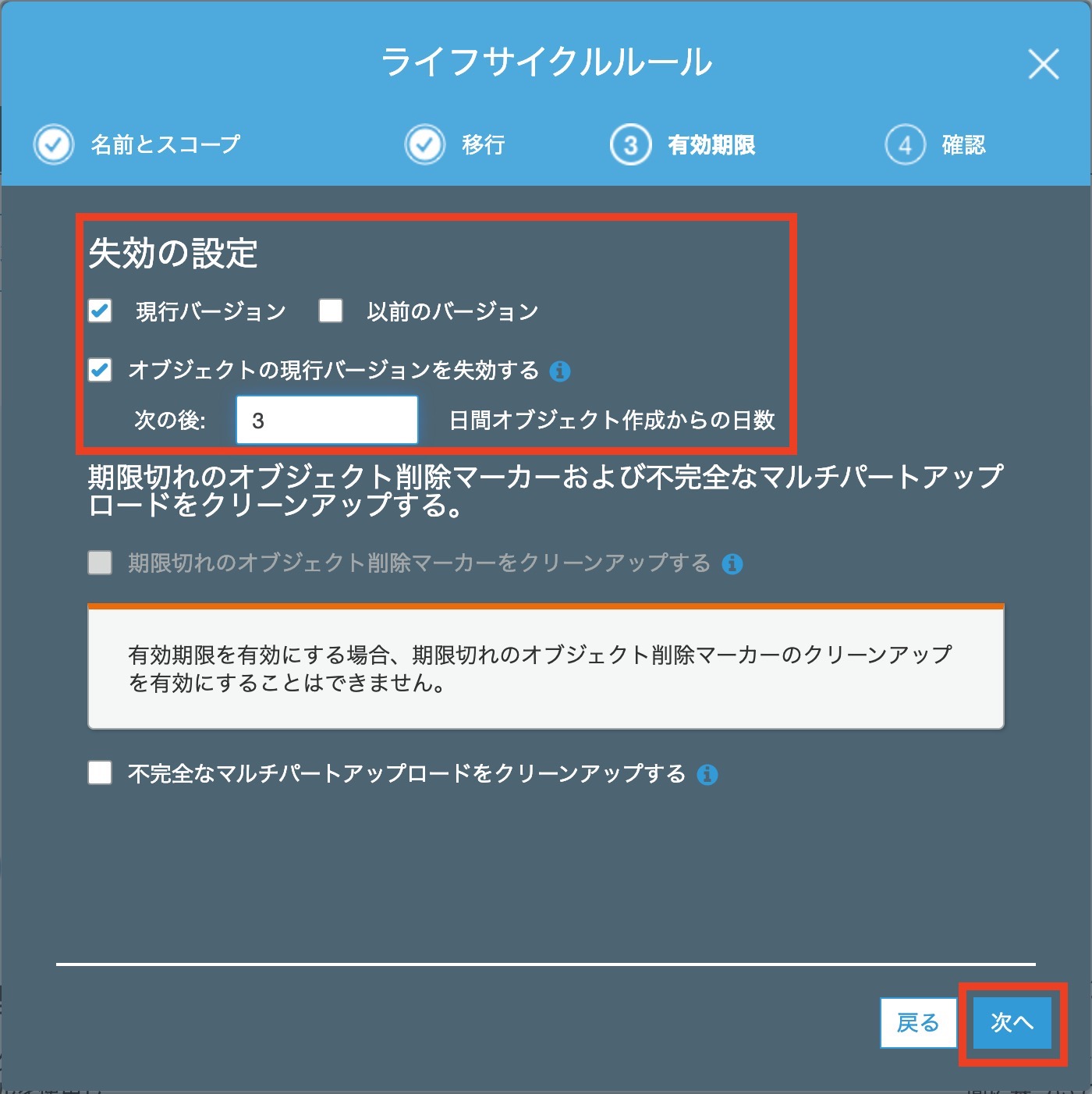
失効の設定を[ 現行バージョン ]で[ 3 ]日後と記入します
これはお好みの数字でどうぞ
最後に確認をして[ 保存 ]します
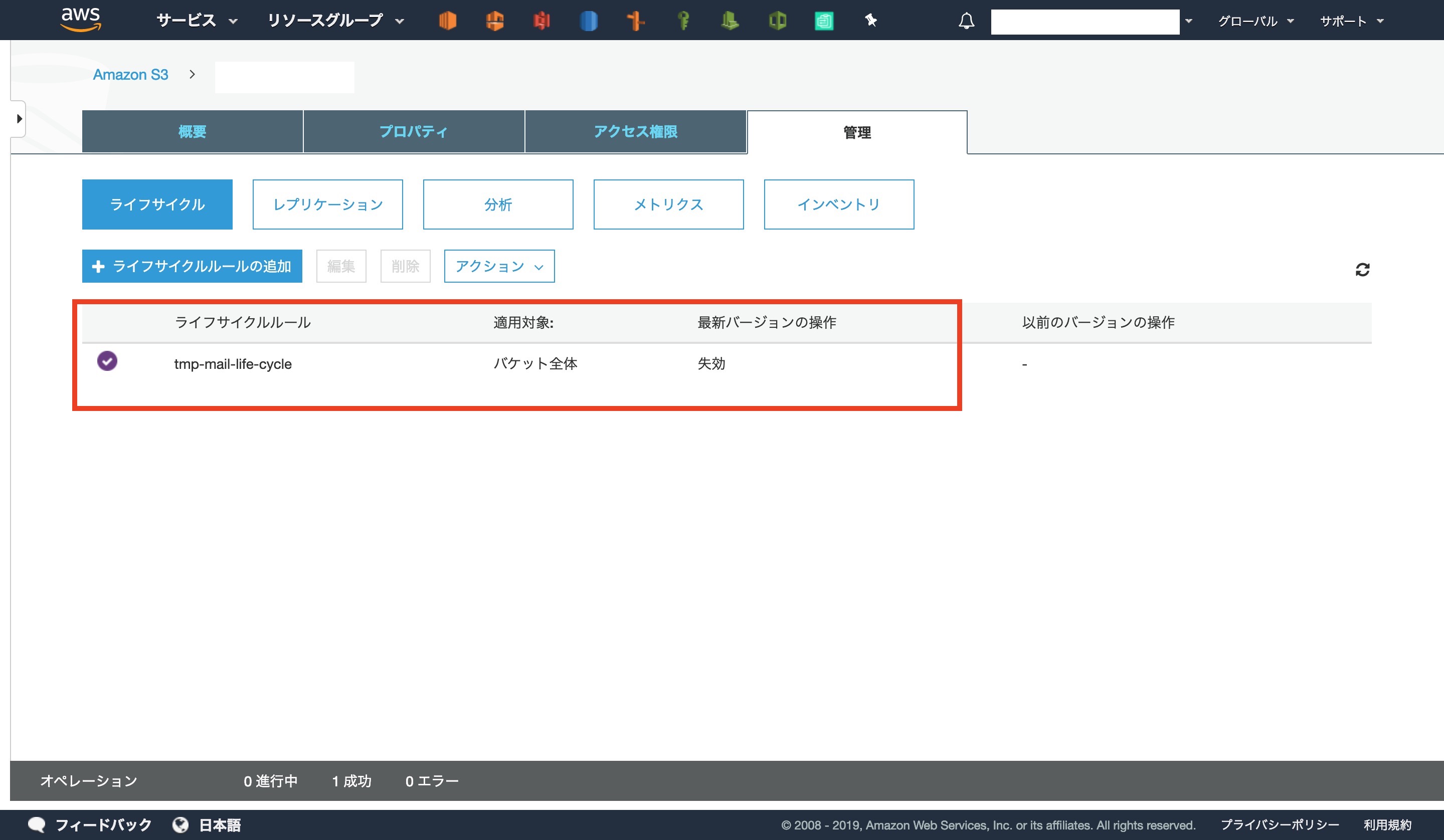
コンソール画面で反映が確認できました
4: 最終確認
最後にメールが確かに転送されているか確認します
自分が持っている適当なメールアドレスから、受信したい独自ドメインのメールアドレスに送信します
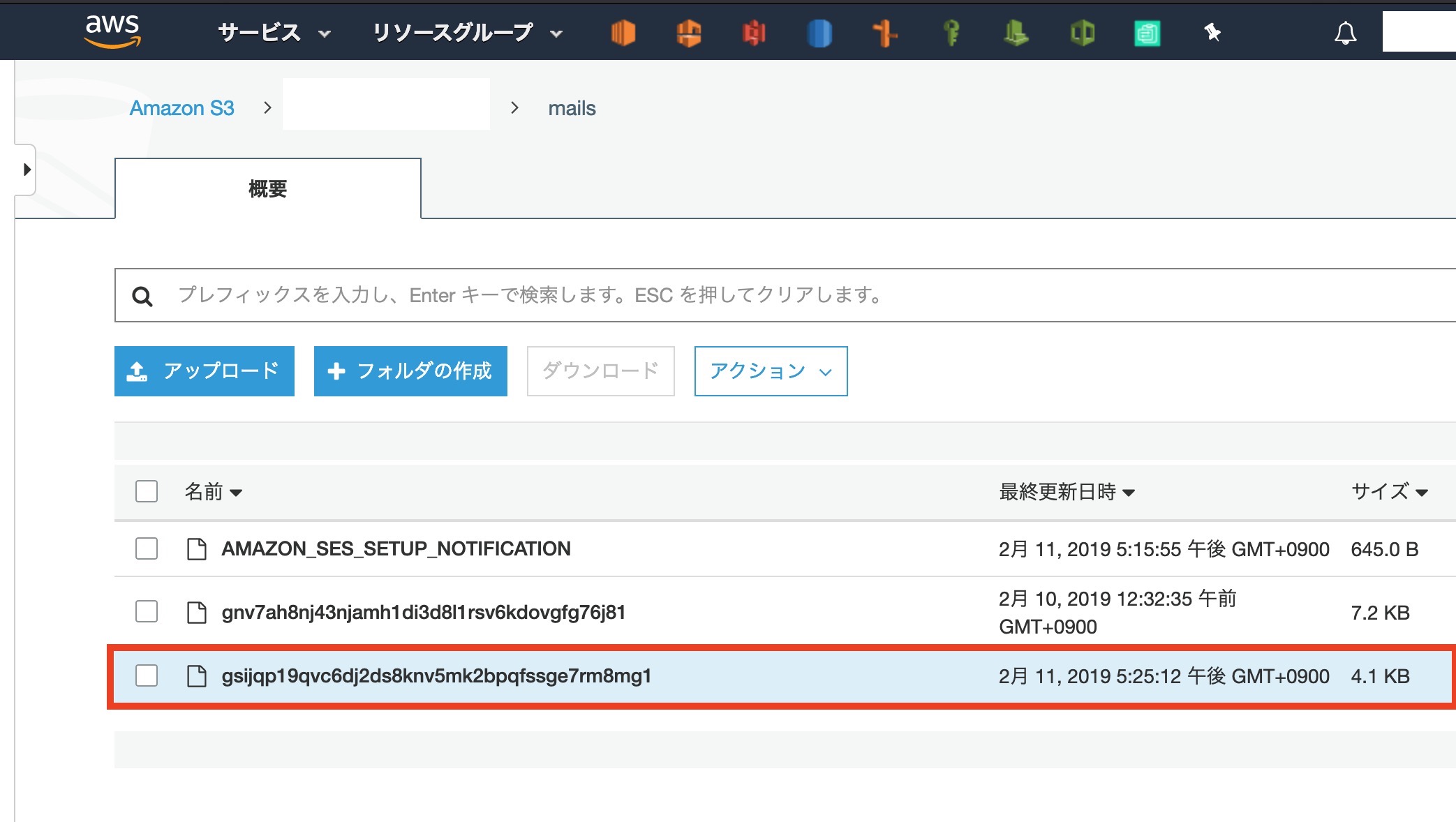
S3にメールが入っていますね
メールが先ほど設定した[ index.js ]で設定した形で受信できているはずです
以上で作業終了です、お疲れ様でした!!
後片付け
最後にローカルディレクトリを片付けましょう
temporaryディレクトリに大事なファイルが存在しないことを確認してください
また、このディレクトリ以外で作成した場合は、各人で判断して削除をお願いします
cd ~/ rm -rf temporary/終わりに
ここまでお付き合いいただき、ありがとうございました。
以上でSESを使ったGmailでの送受信についての作業を完了します。前半でも述べたことですが、SESのサービスは日本のキャリアメールには向きません。
そちらを念頭に置いた上でご利用いただくようにお願いします。アドバイスや意見、感想などございましたら連絡をお待ちしております。
参考、引用
SES-Gmail受信:
https://tech.taiko19xx.net/entry/2018/05/01/195119Lambdaライブラリ:
https://github.com/arithmetric/aws-lambda-ses-forwardernpm:
https://qiita.com/Alex_mht_code/items/422f5ce10d9c9d5729b7

- 投稿日:2019-02-11T19:00:23+09:00
AWS 認定ソリューションアーキテクト – アソシエイト合格体験記
0.はじめに
どうも。大変ご無沙汰しています。zd6ir7です。前回の投稿「本(書籍)について考えさせられた、2018年夏」からだいぶ時間がたってしまいましたが、この度2019年1月末にAWS 認定ソリューションアーキテクト – アソシエイトに合格することができましたので、ここに合格体験を記載します。今後受験される方の参考になればと思います。
1.筆者(受験者)の基礎情報
業務略歴
キャリアの大半はプロジェクトマネジメントに従事。ここ数年はインフラ構築プロジェクトに携わってきた。AWS経験
業務経験なし。プライベートでアプリをデプロイして少々遊んだ程度。勉強着手時はAWSの基礎知識はあまりない状態。勉強着手から合格までの所要期間
2018年11月中旬から2019年1月末までの約2か月半。受験履歴
2018年12月下旬の受験するも不合格。2回目、2019年1月末に再受験して合格。2.使った教材
以下に、筆者が使った教材を紹介します。
合格対策 AWS認定ソリューションアーキテクト - アソシエイト
本の詳細はこちら。
後述しますが、通算して5回くらい繰り返し読みました。AWSに関する基礎的なことが書かれているのでとっかかりの教材としては適していると思います。一方で、この本は2016年に出版されておりサービスの中には古い情報も含まれています。後述の教材で最新情報を把握するようにしたほうがよいです。AWS クラウドサービス活用資料集
詳細はこちら。
このページにはAWSの各サービスについて、詳細な解説を記載したスライドが掲載されています。EC2やS3等主要なサービスについては2、3回目を通しました。ただ1つのサービスで60~80スライドとボリュームがすごくあるため、全部読むというよりは(サービスの概要、主要機能が記載された)最初の20ページ程度目を通し、あとは問題集と併せて活用しました。udemyオンライン学習「手を動かしながら2週間で学ぶ AWS 基本から応用まで」
udemyが提供する、AWSのオンライン学習講座です。講座の詳細はこちら。
定価15,000円超しますが、よくキャンペーンをやっていて筆者は割安で購入できました。動画を視聴しながら自分でAWS上でサービスを立てて動かすものです。動画なので、途中で止めることもできますし、理解できなかったり聞き取れなかったりした部分は立ち戻ることができます。記載のとおり実際に手を動かすのでAWSの各サービスへの理解が非常に深まりました。14日分全部は受けませんでしたが、お勧めしたいです。徹底攻略 AWS認定 ソリューションアーキテクト – アソシエイト教科書
本の詳細はこちら。
2019年1月に出た試験対策本です。AWS各種サービスに関する最新情報も記載されています。また、後述しますが、演習問題や「模擬試験」もついているので試験対策として有効です。3.勉強方法
もう一度改めて、筆者が使った教材を以下に記します。
1. 合格対策 AWS認定ソリューションアーキテクト - アソシエイト
2. AWS クラウドサービス活用資料集
3. udemyオンライン学習「手を動かしながら2週間で学ぶ AWS 基本から応用まで」
4. 徹底攻略 AWS認定 ソリューションアーキテクト – アソシエイト教科書そのうえで、筆者がとった勉強方法を以下に記します。
2018年11月中旬~第1回目受験(2018年12月下旬)までの勉強法
教材1.を2回全部読む。EC2やS3、EBS等の主要サービスについては、2.のスライドに目を通すことで知識を補強。
⇒その状態で第1回試験に臨むも不合格。受験時点で全く未知のサービスから多く出題されていたことに加え、知っているサービスであってもまだまだ理解が不十分であったことを痛感。勉強法を見直すことを決意。2018年12月下旬~第2回受験(2019年1月末)までの勉強法
- もう一度基礎からやり直そうということで、教材3.のオンライン学習を開始。平日の夜と休日を利用し、学習を通じて実際にAWS上でインスタンスを立てたり各種サービスを利用してみたりする。その合間に教材1.を読んだり、教材2.に目を通したりする。
- AWS認定のサイトから模擬試験を購入。その場でダウンロードしPC上で問題を解くことができる。問題を解くことで、実際に出題される問題の特徴・傾向をつかむことに加え、自分の理解が不十分だった分野については教材2.を使って知識を強化。
- 教材4.を購入した1月中旬からは、それを最初から読むというよりは、演習問題を解いて、間違った問題やタマタマ正解だった問題について、教材に記載の解説を読んで理解を深めるとともに、更に教材2.に目を通すことで関連知識を補強。更に教材4.には「模擬試験」がついている。こちらも同様に、問題を解いて、間違った問題やタマタマ正解だった問題を中心に復習。
- 試験直前は、まだ不安に残っている分野を中心に教材2.と4.に目を通す。
4.おわりに~幾つか注意点~
いかがだったでしょうか?筆者が使った教材、勉強法が、これから受験される方への手助けになれば幸いです。こう申し上げるのも何ですが、1度不合格になって良かったと思います。手を動かすことでAWS各種サービスへの理解が深まりスキルが定着できたためです。最後に、幾つか注意点を述べて本稿の締めにしたいと思います。
- この試験は2018年にリニューアルされています。書籍等の学習教材はできる限り最新のものを利用するようにしてください。上記の教材1.は初めに読むものとしては適していますが最新情報に触れる点では適していないため他の教材とも併用するようにしてください。
- 試験名が「アソシエイト」と言うことで、簡単そうなイメージを浮かべますが、この試験に関して言うと絶対にそういうことはありません。かなり難しいです。舐めてかからないようにしてください。
- 試験はコンピュータ上で行われます。画面上に問題文が表示されるのですが、日本語の意味があまりよく分からない箇所も出てきます。そうした場合、英語表示に切り替えられますので英語で文意を理解して問題を解くようにしてください。
5.余談
過去に小生が投稿した以下3つのトピックが投稿から1~2年経過しても多くの方々に読まれたり、「いいね」を送っていただいているようで大変感謝しています。初めて本稿を読まれた方は是非こちらもご参照ください。
- 投稿日:2019-02-11T17:42:34+09:00
AWS SSOでマルチアカウント環境へのログインを楽にする (ビルトインAWS SSO Directoryを使う場合)
昨今のベストプラクティスとして、1企業につき1AWSアカウントではなく、セキュリティ/リソース/コスト管理の分離のためにマルチアカウント戦略を取ることが推奨されるようになってきました。一般的な例としては、情シス管理の共有システム用アカウント + SOCのためのログ集約&監査アカウント + 各事業部/サービス用アカウントであったり、マイクロサービスを採用している場合はマイクロサービスごとのアカウント分離などが考えられます。そうすると、1人の利用者が複数のIAMユーザを持つことになりユーザを払い出す側も利用する側も運用が煩雑になってしまいますし、キーの流出などのリスクも大きくなります。こういった場合はActive Directory + ADFSを使ったフェデレーションによってユーザ管理の一元化とシングルサインオンを実現していましたが、ADFSの運用や難しいクレームルールの記述が必要でした。そこで大変便利に使えるのが、2017/12にデビューしたAWS SSOサービスです。ADFSを立てたりクレームルールを書くことなく、簡単にマルチアカウントでのユーザ管理とシングルサインオンの設定ができるようになります。ユーザーにとってもマルチアカウントへのログインが簡単になりますし、ポータル画面からAWS CLI/API実行のためのテンポラリクレデンシャル(Access Key/Secret Access Key/Token)が取得できるのもポイントが高いです。またSAML2.0を利用できるAWS以外のアプリケーションへのシングルサインオン(Salesforce、BOX、Office 365など)にも利用可能です。
ユーザのディレクトリとしては、ビルトインのAWS SSO DirectoryまたはActive Directoryを利用できます。今回はビルトインのディレクトリを使用してSSOを構成しています。
前提条件
- AWS SSOはAWS Organizationsと連携しているため、ログイン対象のAWSアカウントはAWS Organizationsの同じマスターアカウント配下に属している必要があります。もしOrganizationsの外で作成されたアカウントを含める場合は、自身のOrganizationに招待しておく必要があります。(その場合は旧Consolidated Billingと同じ考え方で請求もマスターアカウントに一本化されるため注意してください)
SSOの対象となるアカウントの確認
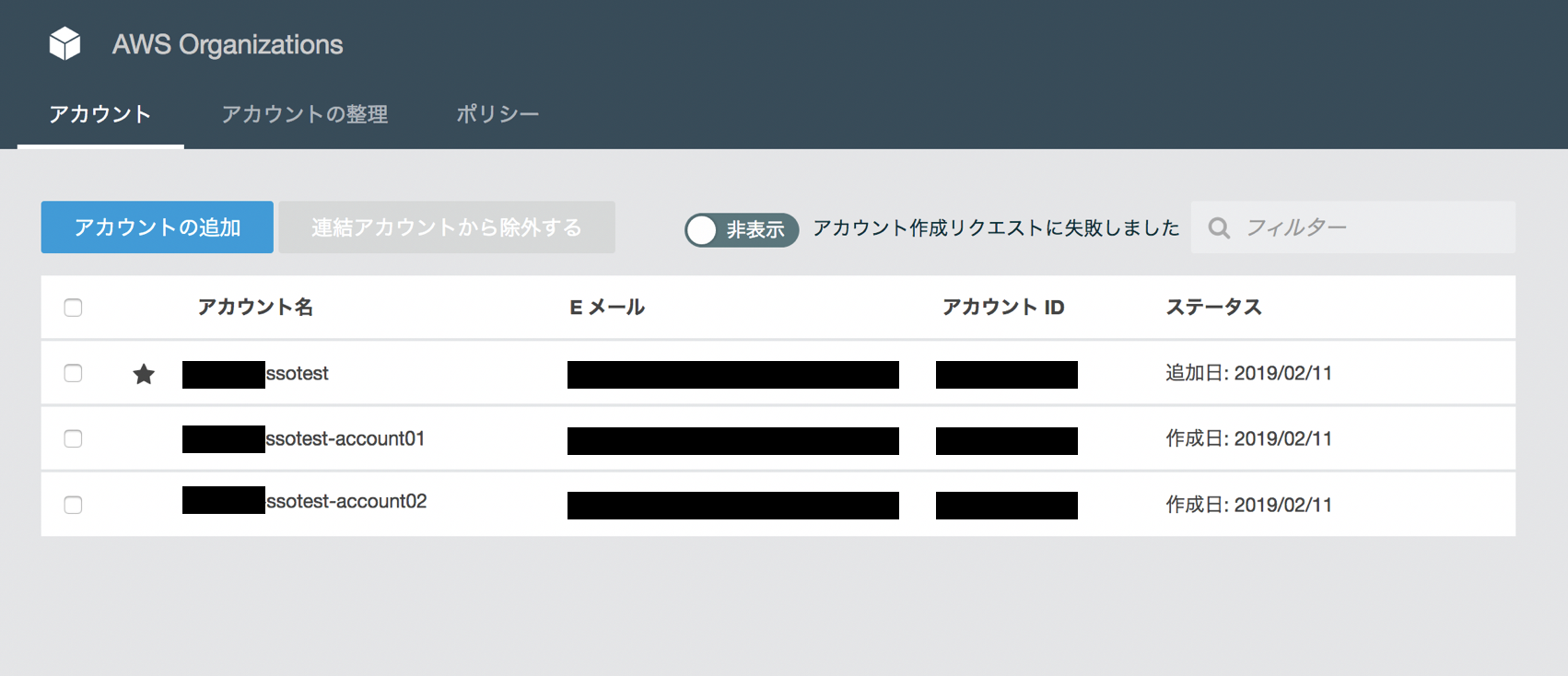
ここからの設定は全てAWS Organizationsのマスターアカウントで実施します。
今回はテスト用に、AWS Organizationsから2つの子アカウントを作成済みです。
AWS Organizationsの有効化と子アカウントの作成は以下の参考リンクなどを参考に実施しておきます。(めちゃ簡単です。)
AWS Organizationsの新規設定と確認AWS SSOの設定
AWS SSOの有効化
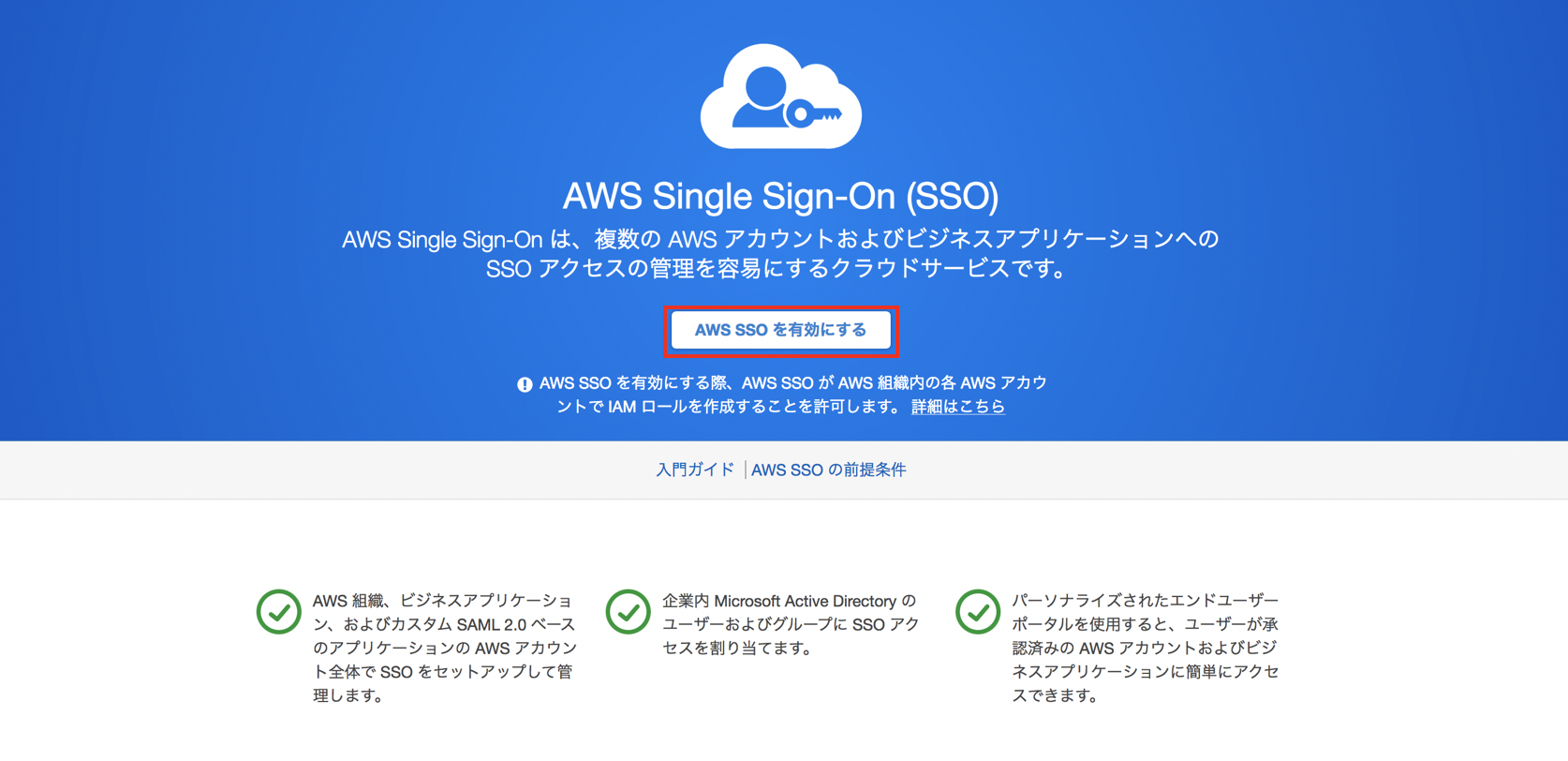
マネジメントコンソールから、AWS Single Sign Onのコンソールへ移動します。
(AWS SSOは2019/2/11時点でバージニア北部リージョンにのみエンドポイントがあるため設定はバージニア北部リージョンで実施します。)"AWS SSOを有効にする"をクリックします。
ユーザの追加
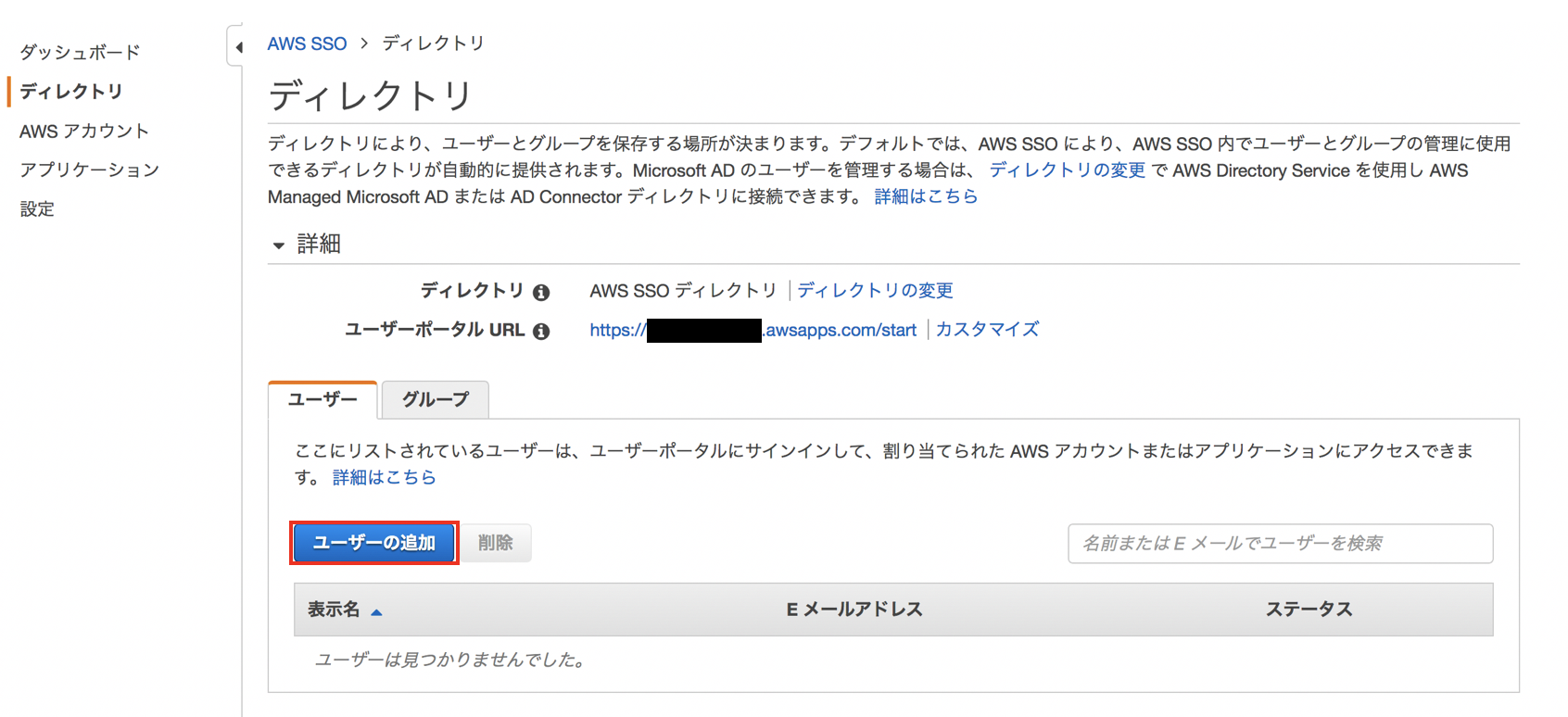
ダッシュボードが表示されるので、"ディレクトリの管理"をクリックします。
"ユーザの追加"をクリックします。
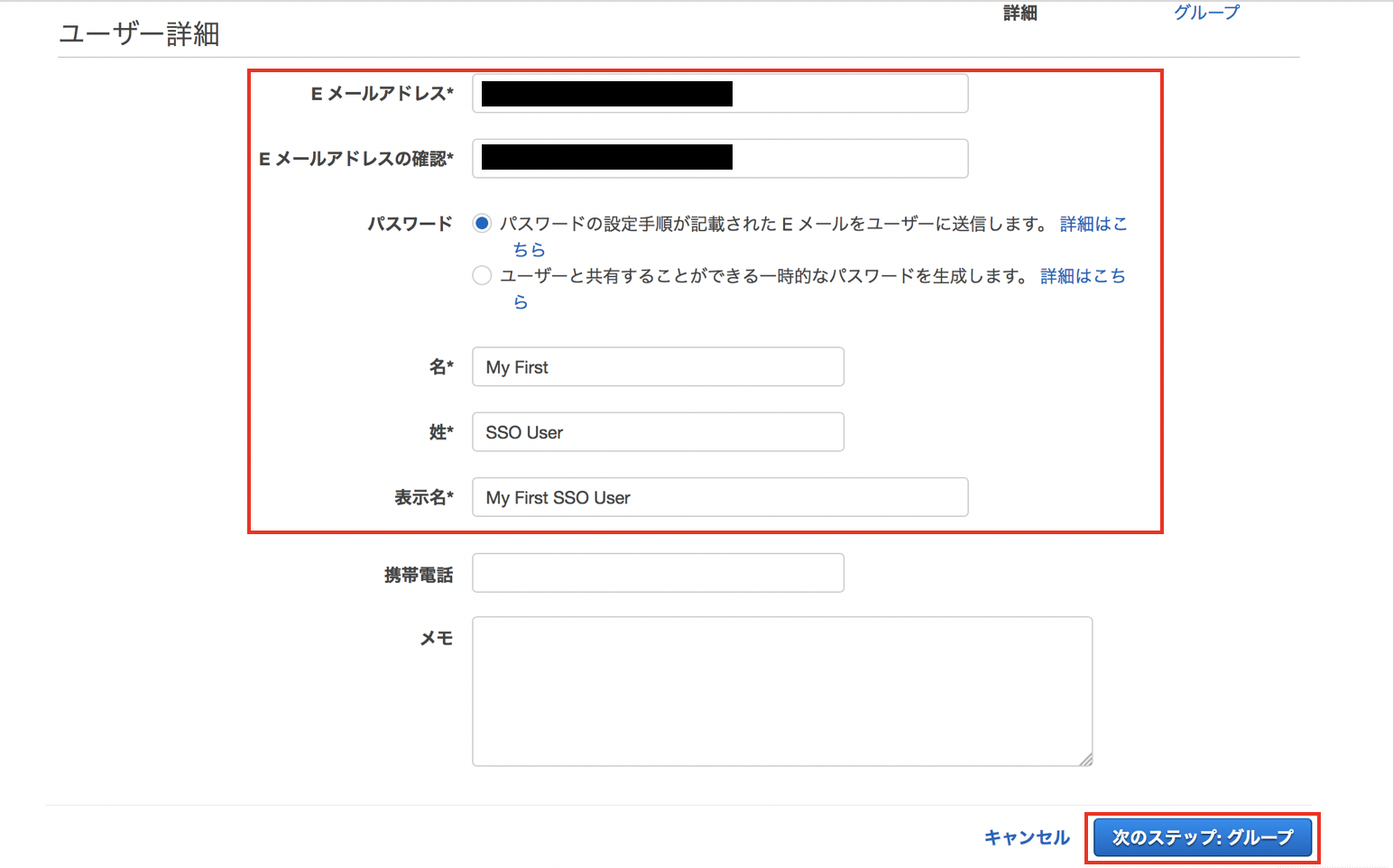
Eメールアドレスと名、性、表示名を入力して"次のステップ:グループ"をクリックします。
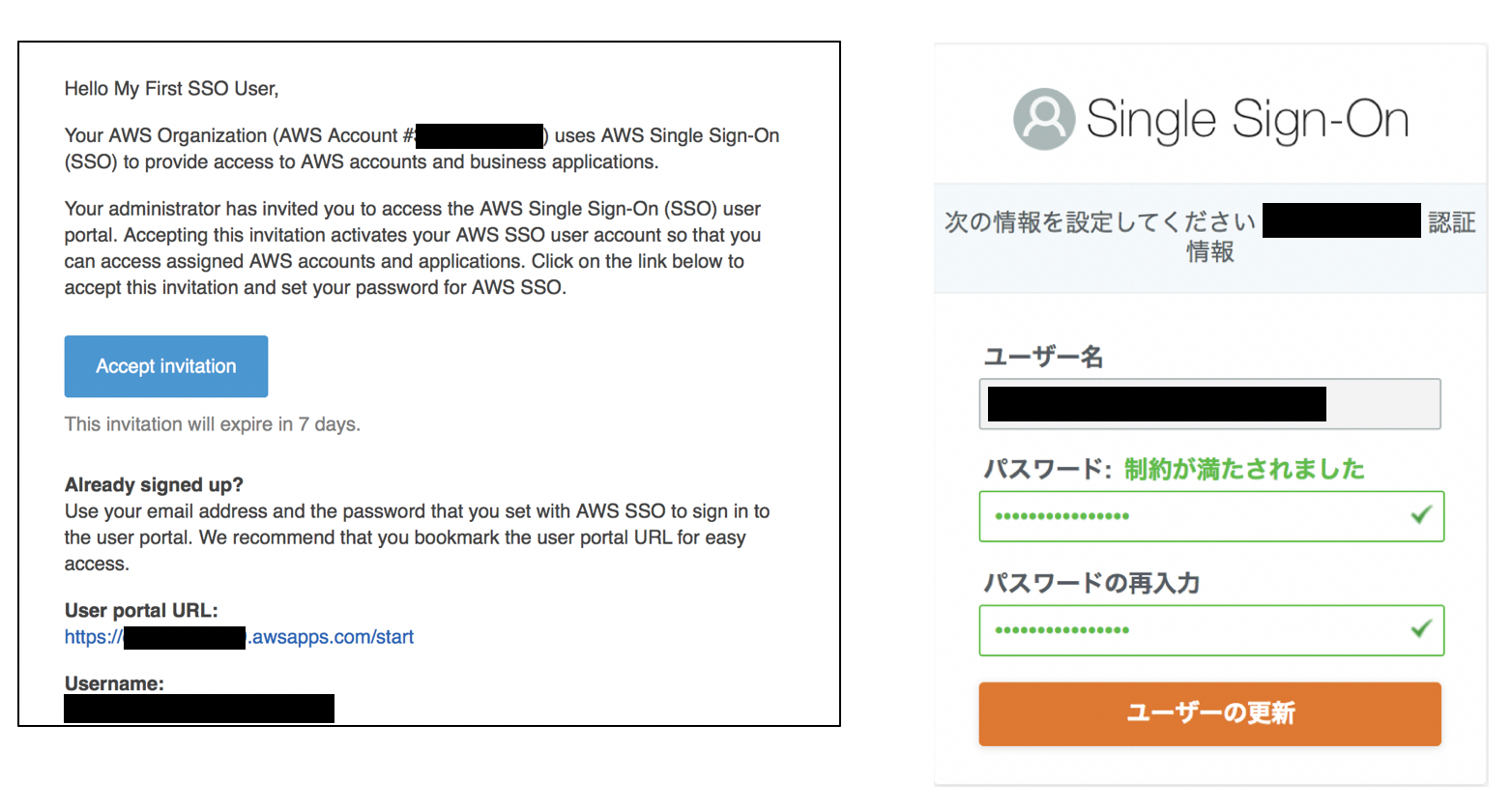
"パスワード"の設定において"パスワードの設定手順が記載されたEメールをユーザに送信します"を選択するとユーザ作成完了と同時にユーザにInvitationメール(パスワード設定用リンク)が送られます。
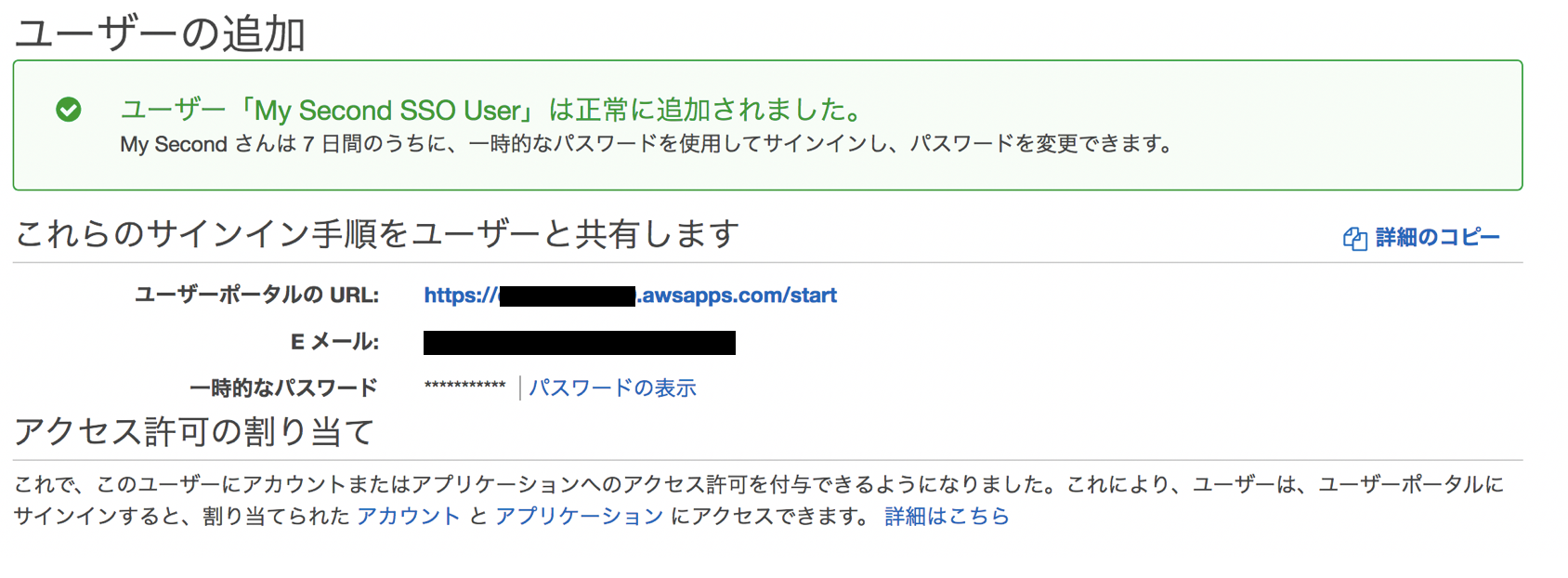
"ユーザーと共有することのできる一時的なパスワードを生成します"を選択した場合にはメールは自動送信されずにポータルURLと仮パスワードが設定コンソールに表示されるため、権限設定の完了後などに手動でユーザに連絡できます。
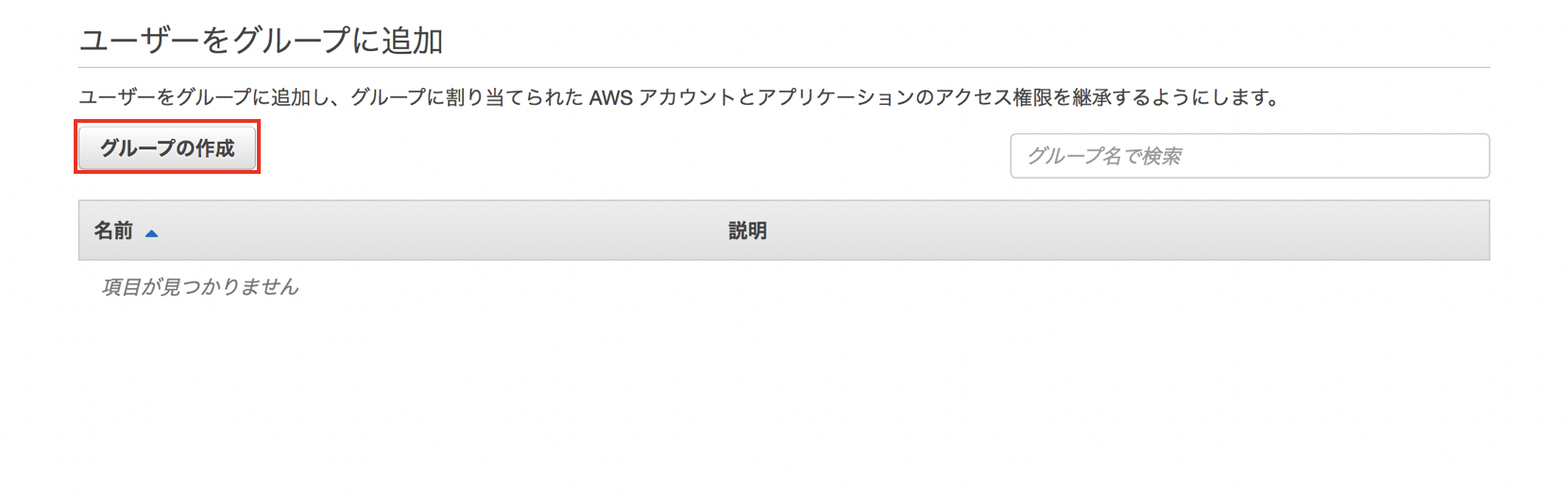
グループの作成とユーザの追加
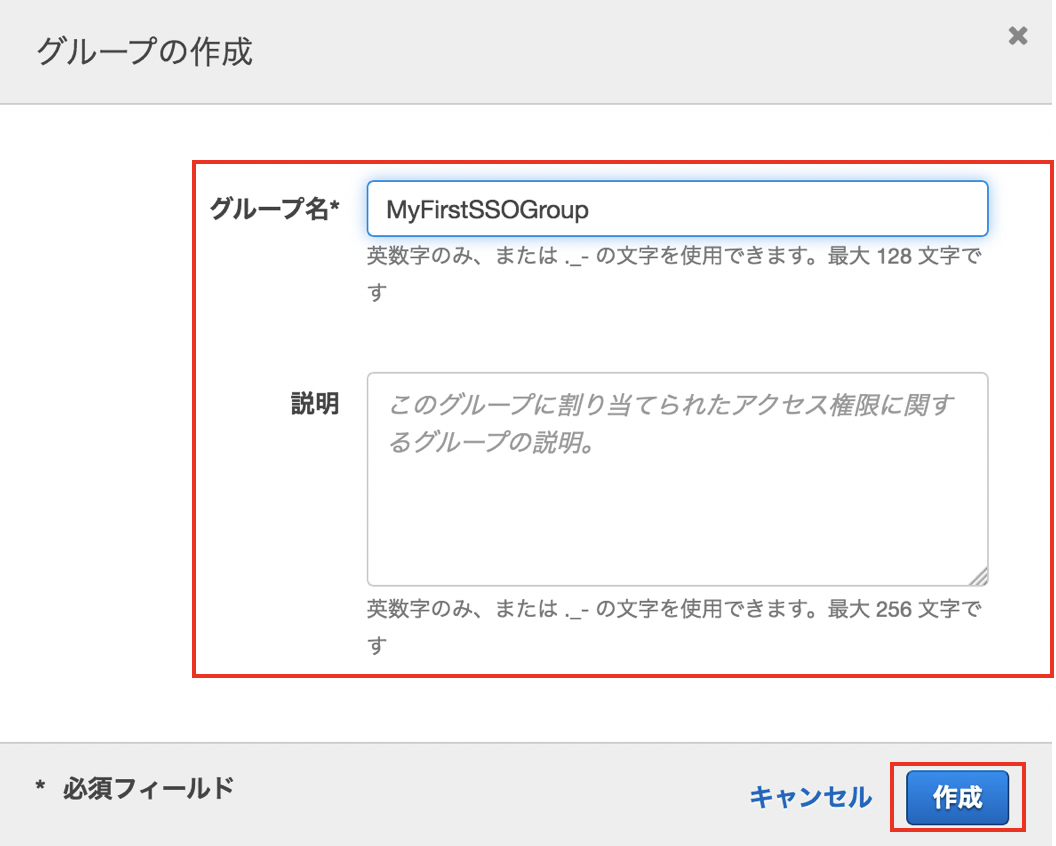
"グループの作成"をクリックします。
グループ名と説明(オプション)を入力して"作成"をクリックします。
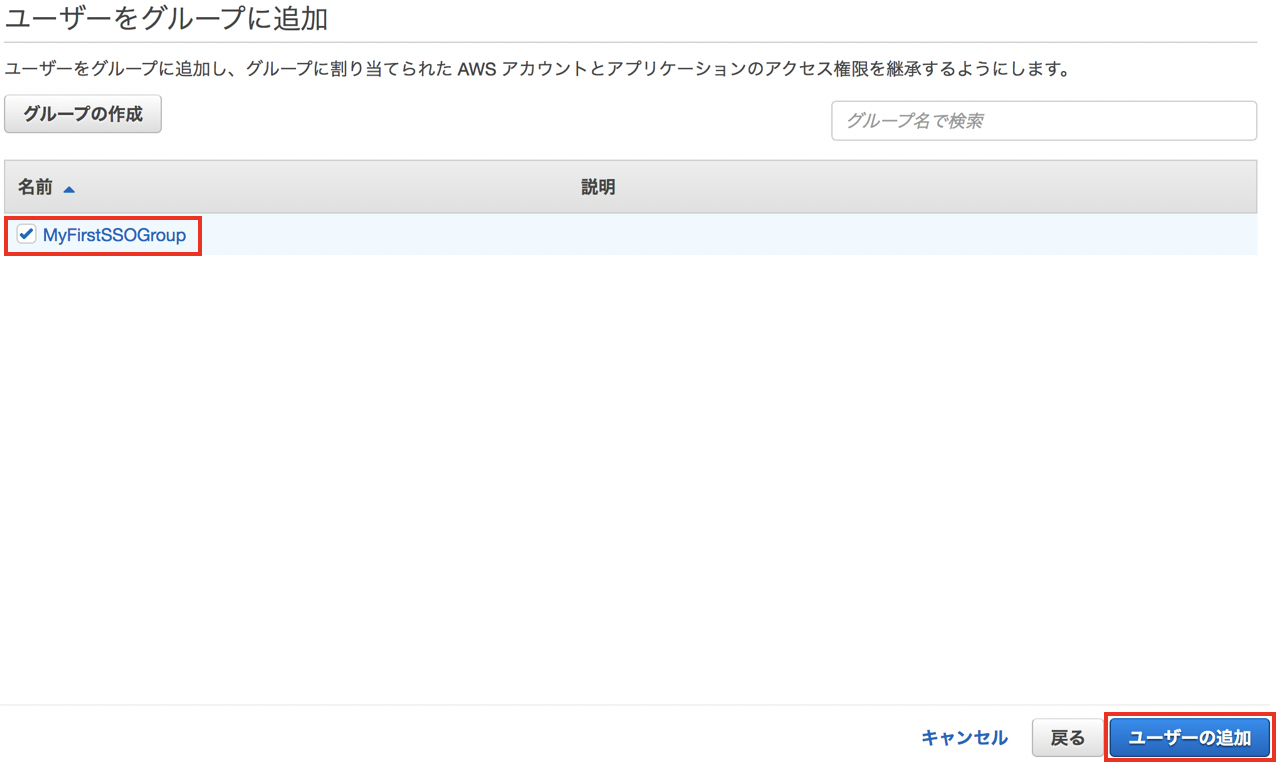
作成されたグループにチェックを入れ、 "ユーザの追加"をクリックします。
ユーザのパスワード変更
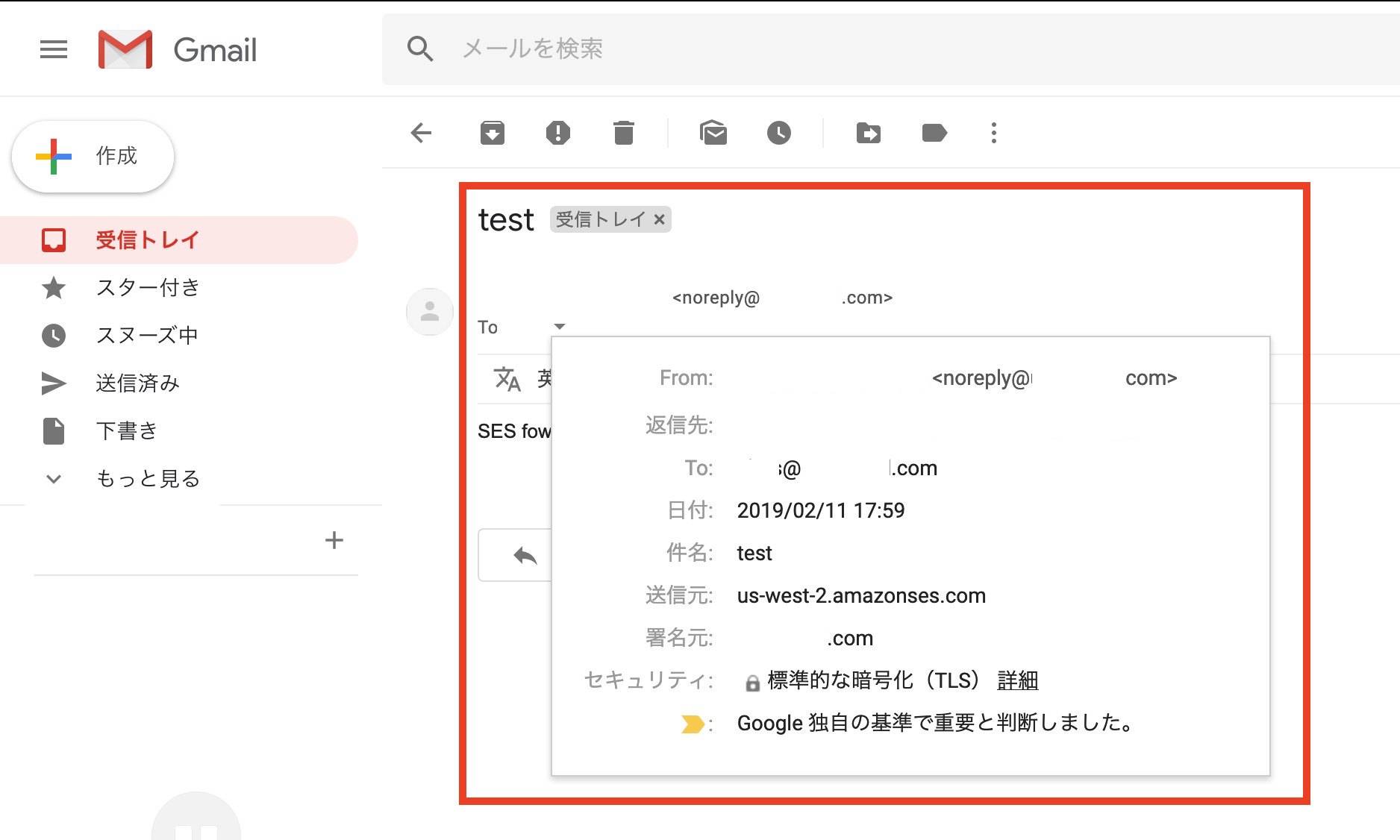
ユーザの追加において、"パスワードの設定手順が記載されたEメールをユーザに送信します"を選択した場合、ユーザのメールアドレス宛に画像左のようなメールが届きます。(送信元:"no-reply@login.awsapps.com"、タイトル:"Invitation to join AWS Single Sign-On")。Accept Invitation"をクリックすると画像右のようにブラウザでパスワード設定画面が表示されるためパスワードを設定するとユーザの作成は完了し、ユーザーポータルに自動的にログインします。(この時点ではログインできるAWSアカウントはありません。)
ユーザの追加において、"ユーザーと共有することのできる一時的なパスワードを生成します"を選択している場合は以下の画面が表示され、権限設定などの完了後に手動でログインポータルURLと仮パスワードを連絡することができます。
ユーザ/グループのAWSアカウントへのアクセス設定
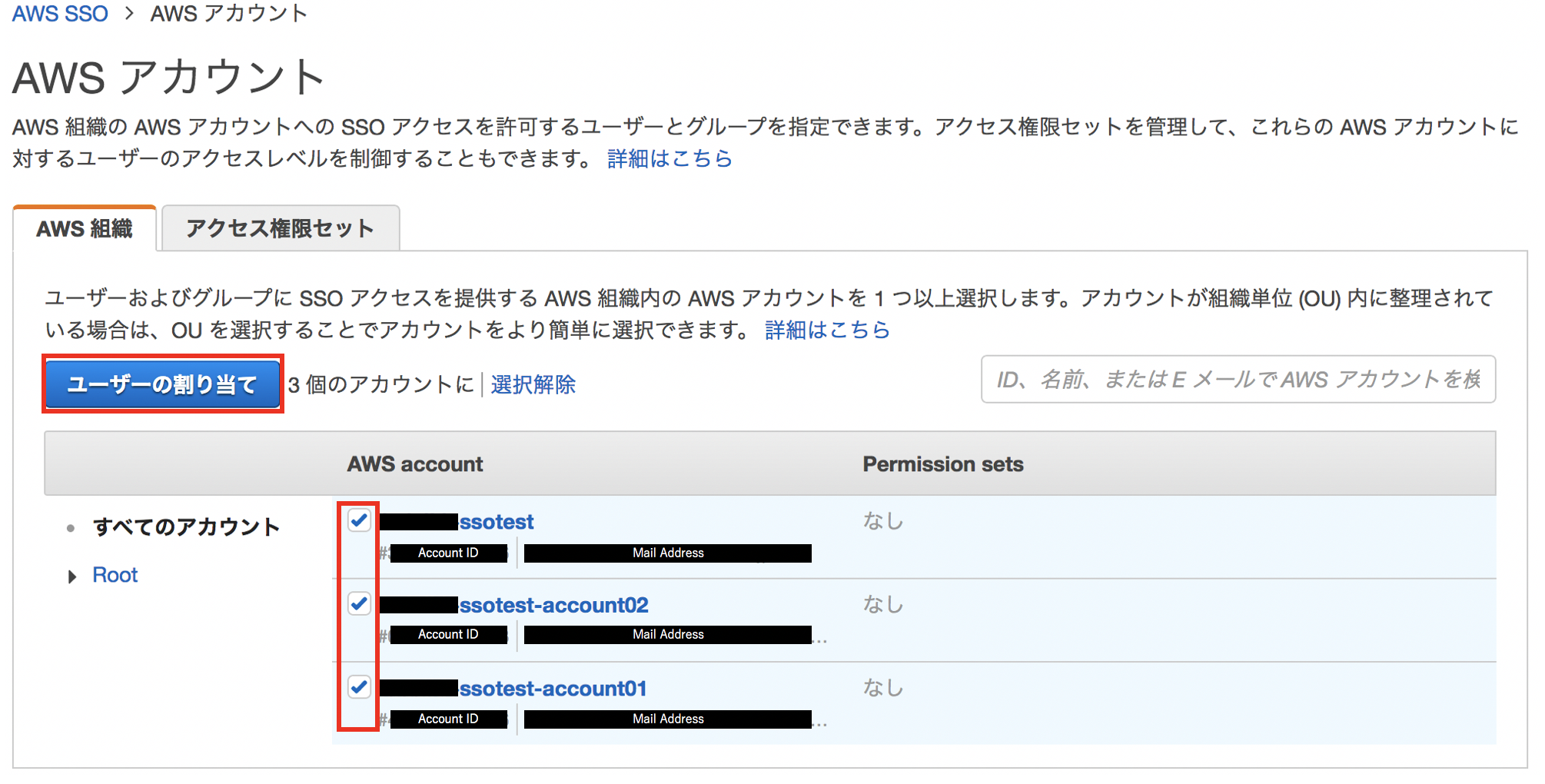
AWS SSOのダッシュボードから"AWS アカウントへのSSOアクセスの管理"をクリックします。
先ほど作成したユーザ/グループに対してログインを許可したいアカウントにチェックを入れ、"ユーザの割り当て"をクリックします。
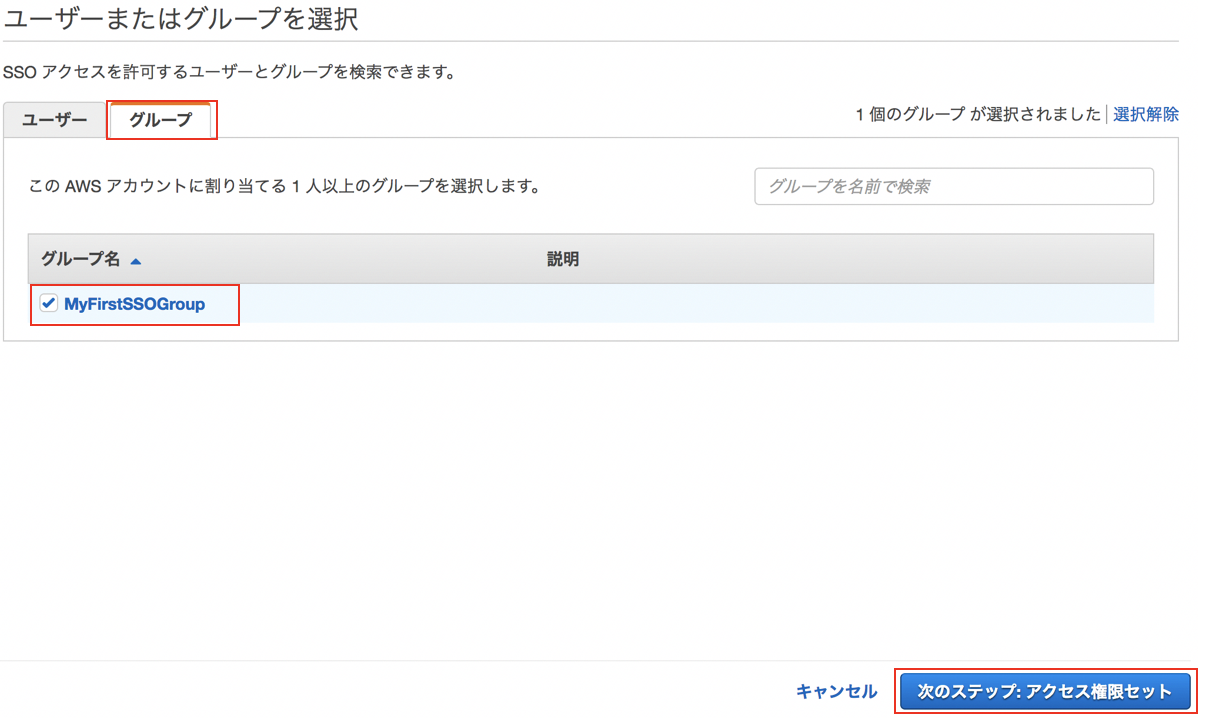
"グループ"タブに切り替え、作成したグループを選択して"次のステップ:アクセス権限セット"をクリックします。
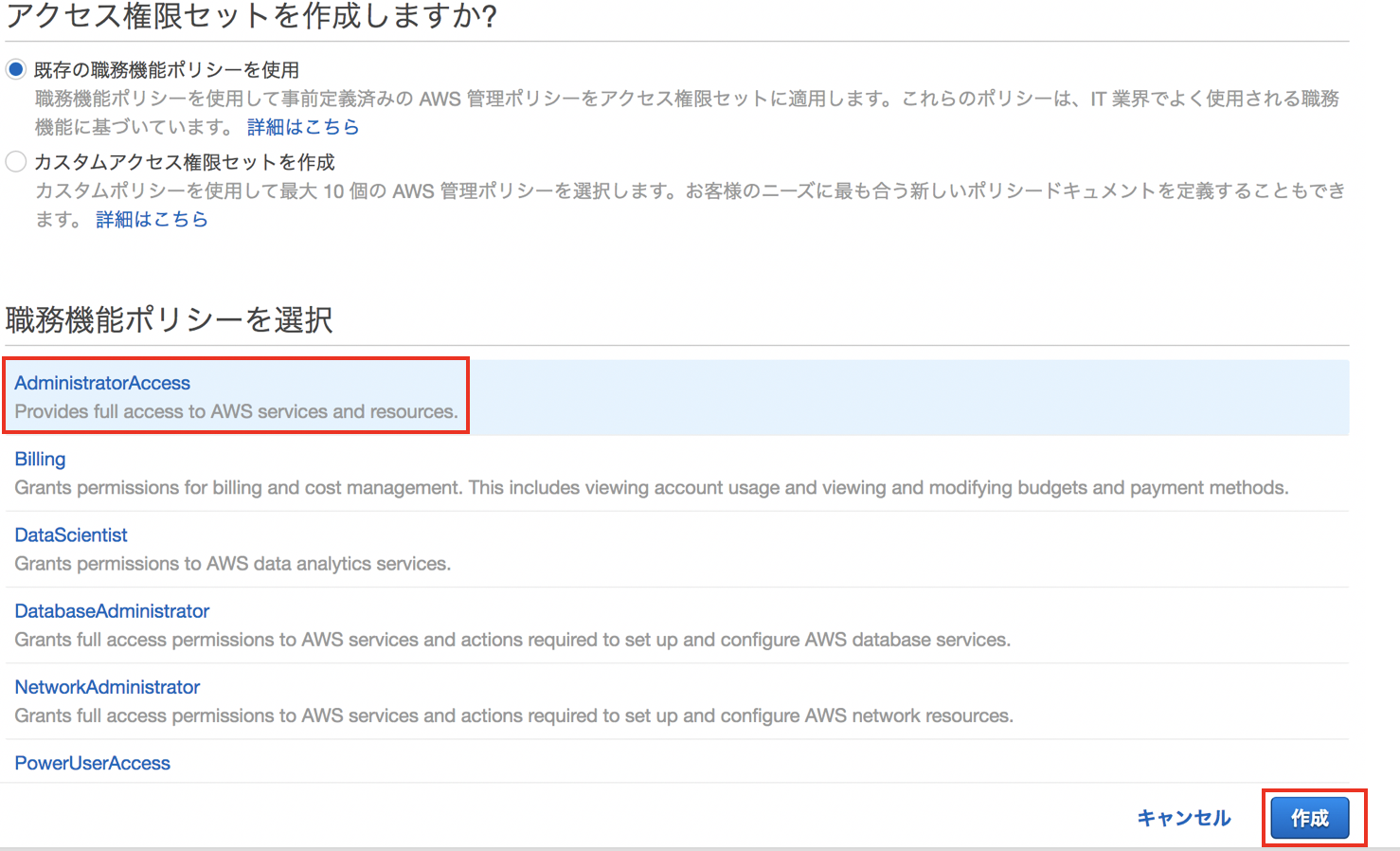
"アクセス権限セットを作成"をクリックします。"アクセス権限セット"はIAMポリシーのセットであり、アクセスを許可されたアカウントにおいてSSOユーザが行使できる権限のセットになります。実体としては、アクセス権限セットと同じ権限を持つIAM Roleがログインを許可したアカウントに自動的に作成され、SSOのユーザはマネコン利用時にこのRoleを自動的にAssumeRoleします。このRoleはService-Linked RoleというAWSサービスが作成するRoleで、ユーザによって編集することができません。つまり、ログイン先で勝手に自分のRoleを書き換えて権限を拡張することを防ぐことができます。
アクセス権限セットに含めるポリシーには既存のAWS管理ポリシーを使うことも、自分でカスタムのポリシーを作成することもできます。今回はテストのため"AdninistratorAccess"管理ポリシーを選択し、"作成"をクリックします。
作成されたアクセス権限セットを選択して"完了"をクリックします。
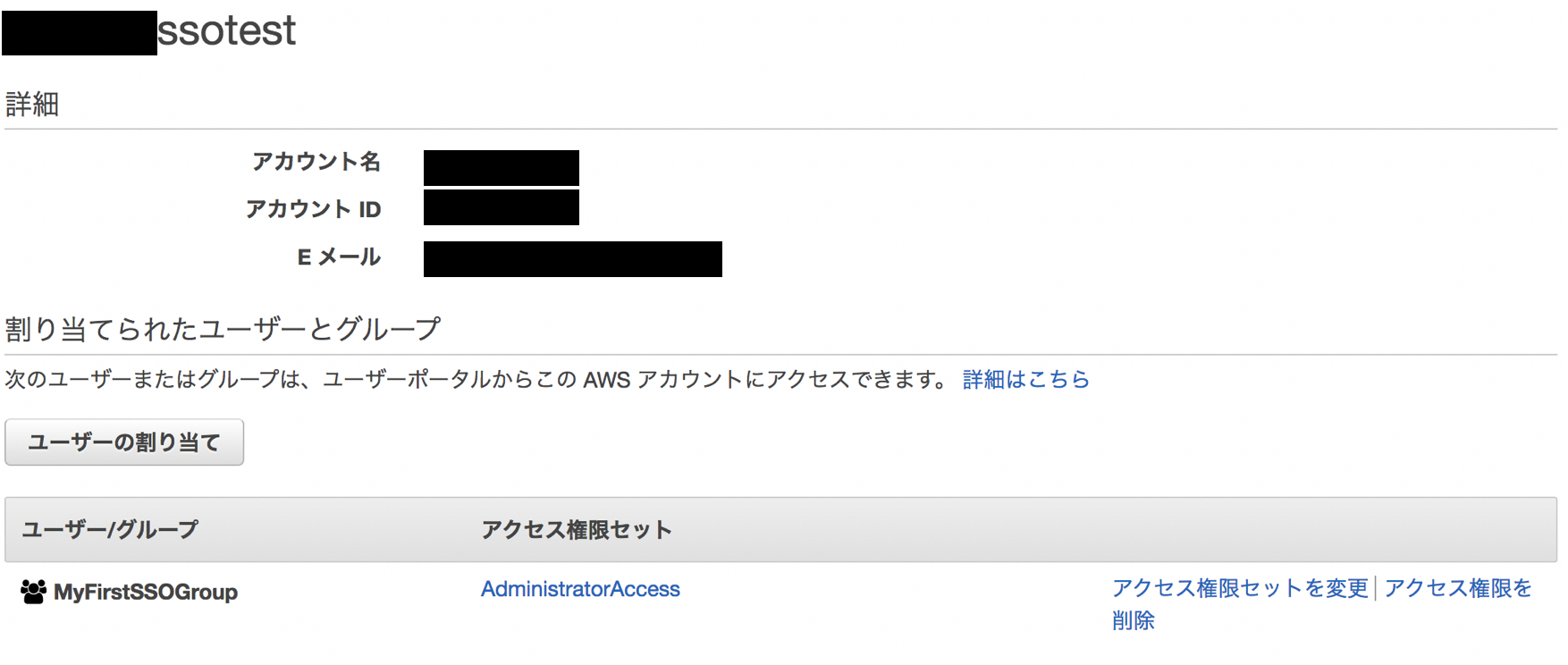
数十秒で設定が完了します。
各アカウントの詳細ページを表示すると、どのユーザ/グループに対してどのアクセス権限セットが割り当てられているかが確認できます。
AWS SSOユーザポータルヘログインとAWSコンソール/CLIの利用
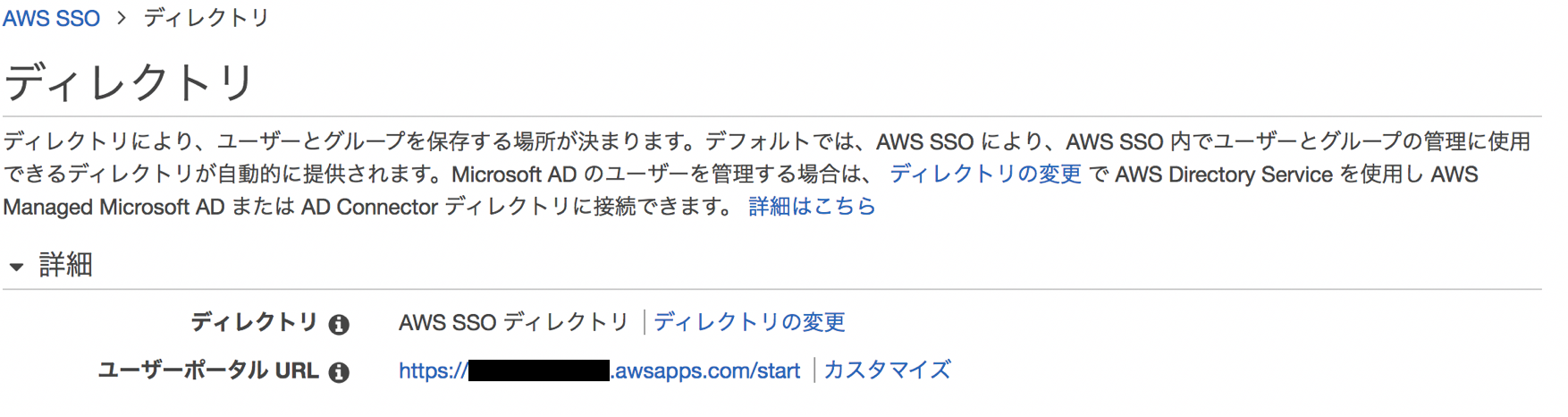
ユーザポータルへのログイン
"AWS SSOコンソール" > "ディレクトリ"にユーザーポータルURLが表示されていますのでこれをユーザーに案内します。https://[x-xxxxxxxxxx].awsapps.com/start というURLになっており[]の部分はカスタマイズできます。
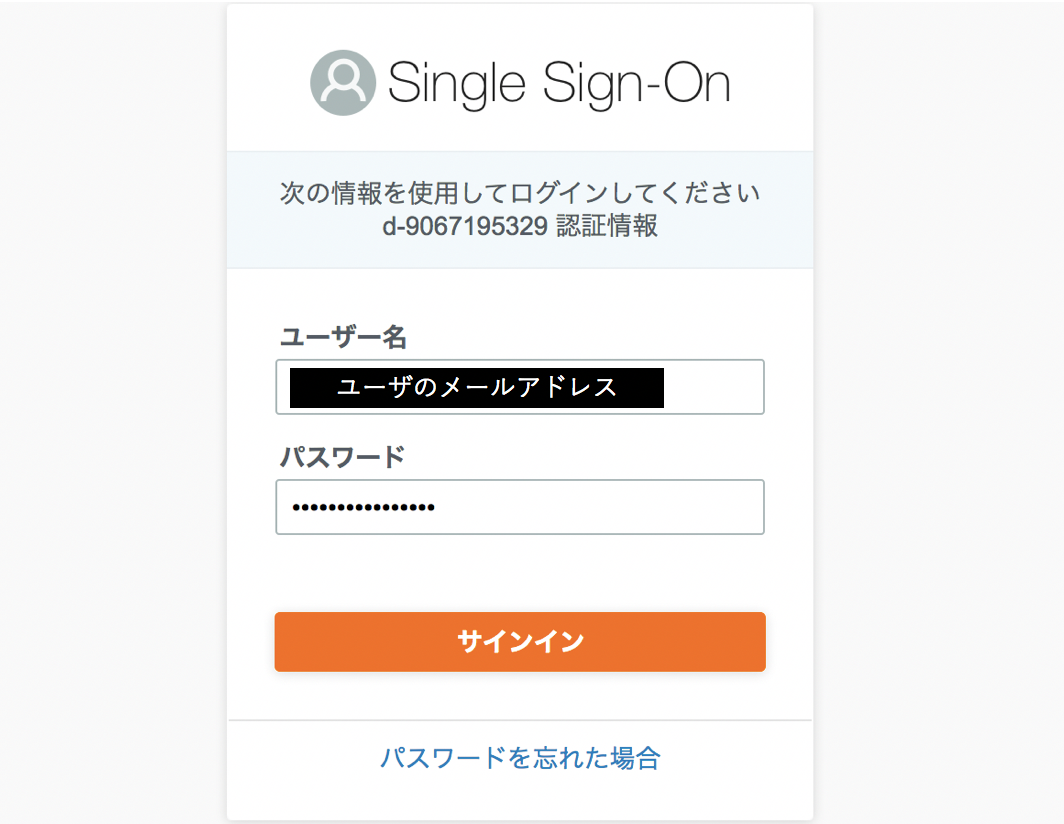
ユーザーポータルURLにアクセスするとユーザ名とパスワードが求められます。ユーザ名にはユーザのメールアドレスを入力します。
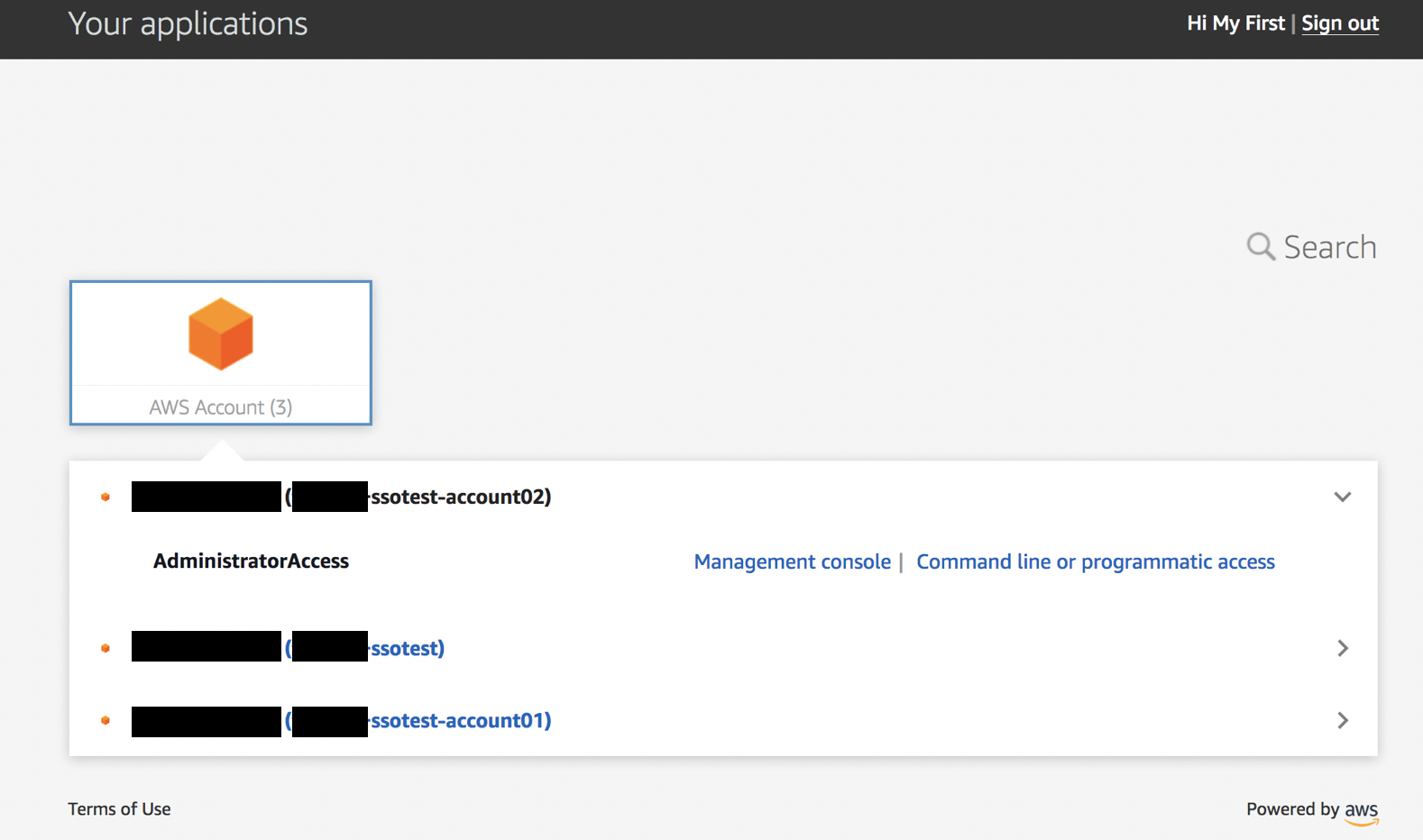
サインインすると、ユーザーポータルが表示されます。SSO対象のアプリケーションとしてAWSアカウントが表示されています。これをクリックして展開します。
ログイン可能なアカウント一覧が表示されます。下の画像では3つのアカウントがリストされており、さらに一番上のアカウントのみクリックして展開した状態です。
上記で"Management console"をクリックするとそのアカウントのマネジメントコンソールにログインすることができます。"AWSReservedSSO_AdministratorAccess_xxxxxxx..."というAWS SSOによって作成されたService-Linked Roleの権限でログインしています。
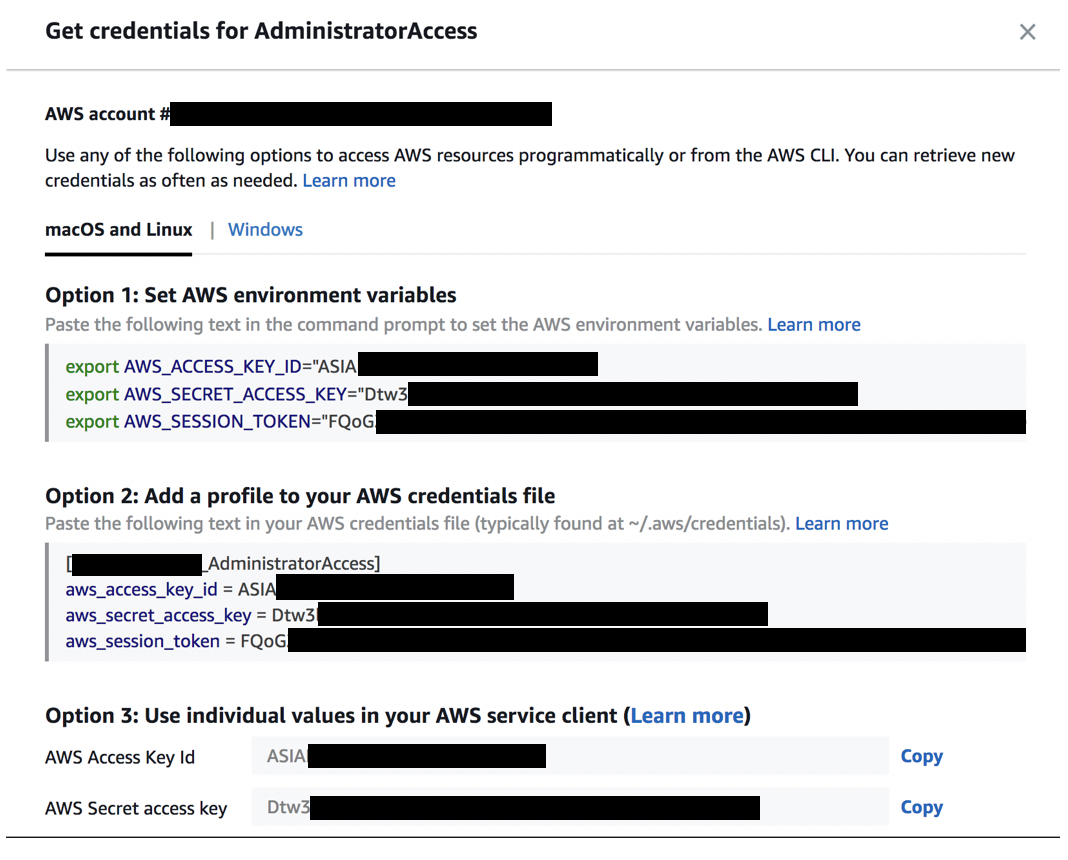
また、"Command line or programatic access"の方をクリックするとCLI/API利用に使えるテンポラリーのクレデンシャル(デフォルト期限1時間)が発行されます。例えば環境変数をターミナルに貼り付ければそのままAWS CLIを利用して環境を操作することができます。従来SAMLを使ったSSOの場合、CLIの利用が手間でしたがこれはとても便利です。一時的なクレデンシャルなので万が一漏洩しても期限が切れていれば使用できません。
まとめ
AWS SSOとビルトインのDirectoryを使用してマルチアカウント環境のSSOを構築しました。フルマネージドで構築もこれだけなので、マルチアカウントで運用している場合はIAMユーザ払い出しから切り替えれば運用者/利用者双方にメリットが大きいと思います。また以下のようなケースでは、ビルトインのDirectoryではなくActive Directoryに接続した方が良い場合もありそうです。その場合の設定方法は後日記載予定です。
- 既存のAWS上またはオンプレミスのActive Directoryユーザ、グループでログインしたい場合
- パスワードポリシーを自由に設定したい場合 (AWS SSOディレクトリのパスワードポリシーは以下に設定されており、現在は変更できない模様)
- 8 ~ 64 文字
- 次の 4 つのうち 4 つを含む
- 英小文字
- 英大文字
- 数字
- 特殊文字
- 大量のユーザをホストする場合(デフォルトリミットは500ユーザ、100グループ) AWS SSOの制限 :https://docs.aws.amazon.com/singlesignon/latest/userguide/limits.html
おまけ
セッション期間を変更する
ログインセッションの期限を変更するには、アクセス権限セットの詳細ページで"編集"をクリックします。
"セッション期間"設定を変更すればOKです。最小1時間、最大12時間まで設定可能です。
https://docs.aws.amazon.com/singlesignon/latest/userguide/howtosessionduration.html
多要素認証の設定
現在メールによる多要素認証を設定できます。設定方法はこちら。



- 投稿日:2019-02-11T16:16:15+09:00
AWS認定ソリューションアーキテクトプロフェッショナルを10日で取得する
はじめに
AWS認定ソリューションアーキテクトプロフェッショナルにだいたい10日で合格しました。
一通り書いてから気づきましたが、
どうやって勉強するかよりどうやって回答するかに重きをおいた記事になりました。3行で
- 普通の資格試験と思うな普通免許試験だと思え
- とにかく英語で一次資料読め
- 過去問はベースロードにはなるが過信はするな
Who am I
- AWSの実務経験は約1年
- ソリューションアーキテクトアソシエイト(新テスト)のスコアは865。
- 受験日は、2019.01(Retiring 2019=旧テスト)
- プロフェッショナルのスコアは83%(90%は遠い)
総合成績: 83% 分野別の成績 : 1.0 High Availability and Business Continuity: 90% 2.0 Costing: 100% 3.0 Deployment Management: 71% 4.0 Network Design: 71% 5.0 Data Storage: 72% 6.0 Security: 78% 7.0 Scalability & Elasticity: 100% 8.0 Cloud Migration & Hybrid Architecture: 85%普通の資格試験と思うな普通免許試験だと思え
その前に。
アソシエイトも同様ですが、とにかく日本語の翻訳精度が悪いです。(AWS Japanさんお願いします)
単純に直訳したと思われる翻訳(例:EC2フリート、EC2作業者)等もありますが、
ひどいものだと否定文が肯定文になっている時があり、選択肢に答えが無いときがあります。
80問を170分で回答する必要があるため、とにかくスピード勝負なのに、これはキツイ。
対応策は2つ。英語が得意な人
最初から英語で受験しましょう。切り替えの手間が省けます。
英語が苦手な人
日本語があることに感謝し日本語で受験しましょう。
なんとなく問題文に違和感があったときは、
画面上部の「日本語」と書かれたリストボックスを選択し「English」に切り替えましょう。
(模擬テスト受けていないので文言は記憶違いがあるやも。ご容赦を。)普通免許の話は?
今からします。
普通免許の試験はなかなか悪名高いクソ試験ですが、本試験もこれと同様の対策で乗り越えます。
つまり
- 正しい答えではなく誤っている答えを探す(消去法を使う)
- どちらも正しそうな2択が残った時は、より具体的な選択肢を選ぶ
- どちらも具体的でどちらも正しそうな2択が残った時は、より重視する要素を問題文から探す
正しい答えではなく誤っている答えを探す(消去法を使う)
普通免許試験だけでなく、選択式の試験では至極当たり前のテクニックですが、
それ故に、本試験においても最重要テクニックです。
問題の要件に対し相応しい選択肢がほぼ1つであったアソシエイトと異なり、
プロフェッショナルの試験では、複数の選択肢がそれらしいことがほとんどです。
また、もっと辛いのはどの選択肢も違いそうという状況です。
迷ったらとにかく誤りがある選択肢を探します。
(ex,○○というインスタンスタイプでは△△機能は使えない等)
最も大事なのは消去法だけで即答できる問題を確実に瞬殺することで、時間を節約し、悪文問題に使える時間を稼ぐことです。どちらも正しそうな2択が残った時は、より具体的な選択肢を選ぶ
例えば、消去法により以下の2つが残った時
- A:◇◇機能を使用する
- B:○○APIを使用して一時的な△△を取得する××機能を使用する
一見して、◇◇機能と××機能は同じ機能を指しているように見える場合でも、Bが正解のことが多いです。
逆に、実は△△を取得するのは○○APIではなく□□APIである=選択肢Aが正解というパターンもあります。どちらも具体的でどちらも正しそうな2択が残った時は、より重視する要素を問題文から探す
多くの場合は、よりW-Aに叶う選択肢(≒よりクールな選択肢)が正解ですが、
ときには問題文に可用性を重視するやコスト最適化のためにAWSに移行した等の、
その問題が重要視する要素が記載されている時があります。落ち着いて読み直しましょう。とにかく英語で一次資料読め
AWSはあらゆる機能が恐ろしい速度で更新されているため、あらゆる資料が恐ろしい速度で陳腐化する。
つまり試験対策本はクソ
その恐ろしさは、公式サイトの情報すら英語以外は追従できていないほど。
このため、私を含む英語苦手人種からすると地獄のようだが、AWSをやるにはもう仕方がない。やるしか無い。
次の資料を読む
- Blackbelt
- ユーザーガイド
- ホワイトペーパー
Blackbelt
名前に反してそのサービスの初学者向けになっている。
わからない問題があったら、まずその問題に関連するサービスのBlackbeltをざっと読む。(日本語でもいい)
Blackbeltの中に更にわからない単語やサービスがあれば、それも読む。
(とはいえ、こうなると無限に時間が過ぎるので焦る
矛盾するようだがあまり重要度が高くないと思うものはブログ記事等の二次資料でお茶を濁すことも考える)ユーザガイド
ある程度知っているサービスも含め一通り読む。
得手不得手は人によると思うが、VPC、EC2、ELB、IAMは必須だと思う。ホワイトペーパー
悲しいけどほぼ全部英語のPDF。Google翻訳にぶちこんで気合で読む。
W-Aの各柱、特にAWS Well-Architected フレームワーク – セキュリティの柱や
AWS への移行に関するホワイトペーパーやDDoS に対する回復性に関する AWS のベストプラクティスは読むほうがいい。過去問はベースロードにはなるが過信はするな
過去問は公式/非公式問わずいろいろあるが、最低でも公式は目を通しておく。
アソシエイトを取得した人がほとんどだろうから、問題文の雰囲気はある程度わかっているかもしれないが、
プロフェッショナルの試験はアソシエイト(や他のAWS資格)と比べて問題文がやたら長いので、慣れておく必要がある。
非公式の過去問(や類似問)はいろいろあるが、ほぼ英語必須である。Google翻訳にかけると本番さながらの精度になるのでおすすめ
私が見たものは以下。特にGoldstine研究所は、A CLOUD GURUのフォーラムの存在に気づかせてくれた。感謝してもしたりない。私は利用していないが、以下も有名なようだ。
過去問はある程度近い問題が出るが、問題文はほぼそのままでも条件や選択肢が変わっている場合があるので過信はできない。
それでも、自身が苦手とするサービスや問題を掴めるし、何より問題文の表現に慣れることが重要である。その他
とにかく急げ
上でも書いたが即答できる問題を増やすことが最重要。
80問を170分なので、単純計算だと1問あたり2分しかない。
問題文が5行以上あったり、選択肢が1つ2行ある問題もあるので、ダラダラ読んでると回答時間がない。
つまり、問題文を真面目に読んでいると時間がない。目的、要件だけ流し読みする必要がある。
一番痛いのは最後までやりきれない白紙回答なので、ちょっと微妙だと思ったらフラグをつけておいて、ひたすら次の問題をやる。
で、見直しの時にちゃんと読み直す。(見直しする時間を作る)
私は、問題1周時点で残り60分。2周目は全ての問題を読み直し残り15分。3周目はフラグした問題だけやり直し残り2分だった。最新なら良いのか?
上で書いたことと矛盾するが、こと試験のことだけを考えるとYESとは言い切れない。
一定間隔ごとに試験問題は更新されているが(SAPについて言えば直近だと2019.2.5から新問題となった)
AWSは変化し続けるので、改訂から日が経つほど現実と問題との乖離が広がる。
そういった意味では、試験の制定時にどうだったかまで含めて考える必要がある。
ここまで来るとかなり苦痛だが、私は、どの選択肢も微妙な時だけ、制定時期について考えるようにしていた。
今なら問題文のやり方でできるが、制定時点ではできなかったので誤りという問題があると引っかかるだろうが、それはもう捨てることにした。
今すぐ試験を受けるならこの点についてはあまり考えなくて良いだろう。
- 投稿日:2019-02-11T15:12:26+09:00
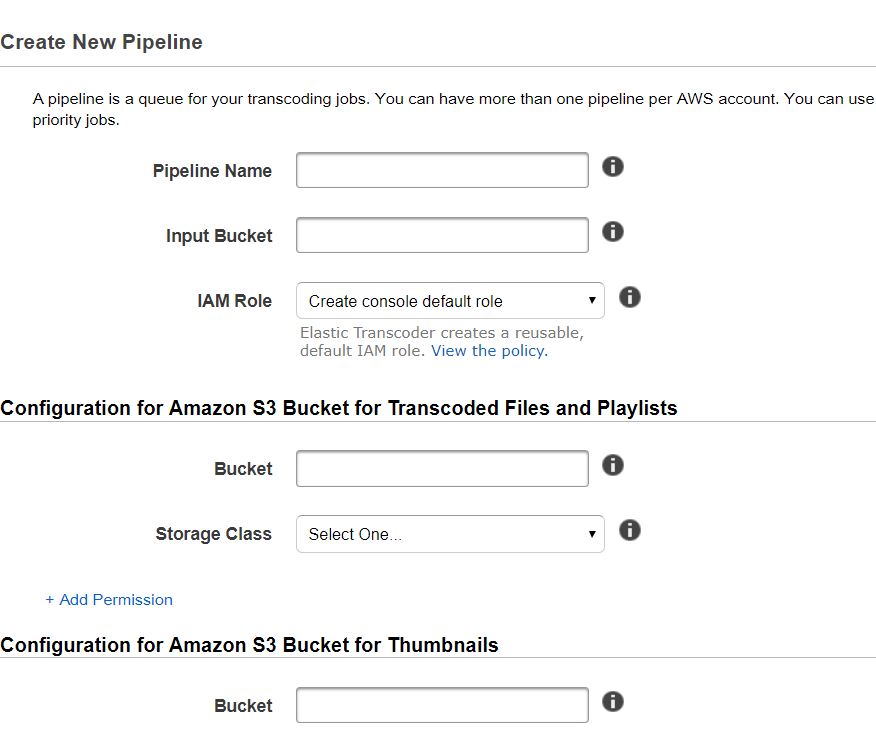
ElasticTranscoder VS MediaConvert
要件
1.ユーザーが動画をアップロードする
2.動画をHLSにエンコードする
3.HLSの動画を配信するどちらを使うか?
AWSを用いた動画のエンコードをする時はどっちかを使うことになります。
MediaConvertはElasticTranscoderより幅広い種類のエンコードを対応しており超高画質の動画に対応するとかじゃない限り料金も安いです。
動画の結合や音声の差し替えなど高度な編集も可能です。
エンコードの処理時間も短縮されていますので基本的にはMediaConvertを選ぶべき。
AWSも推奨しています。ただし、お互いできることできないことがあるので慎重選びましょう。
この記事が参考になると幸いです。料金(2019/02/12)
どれくらいの高画質にエンコードするかにもよりますが参考
ElasticTranscoder
0.034USD
MediaConvert
0.0212USD
詳細はこちら
https://aws.amazon.com/jp/elastictranscoder/pricing/
https://aws.amazon.com/jp/mediaconvert/pricing/できないこと
全てではないですが自分が気になったとこ
ElasticTranscoder
・高度な動画の結合などの高度な編集
・H.265に対応していない
※H.265とは従来のH.264とくらべて圧縮率が2倍になっているので動画ファイルのサイズも大幅に削減されます、8Kにも対応しており今後の応用が期待されている
・エンコード結果はSNSにしか通知できないMediaConvert
・動画ファイルの暗号化のキーにKMSを利用できない
・動画の自動回転
・WebM動画の作成
・アニメーションGIFの作成UI、管理しやすさ
ElasticTranscoder
シンプル
英語
MediaConvert
ぱっと見でわかると思うがElasticTranscoderより大分使いやすい
また、設定をテンプレートとして保存できるので管理もしやすい
MediaConvertの弱み
MediaConvertは動画の自動回転ができません
これがきつかったです。スマホで縦に撮影した動画はエンコード後に必ず横向きになります。
私のサービスとしてはこれは結構致命的でした。
参考
https://blog.shibayan.jp/entry/20140708/1404775800解決方法としては動画をエンコードする前にffmpegかなんかで動画を縦向きにすりゃいんですが、動画の変換処理をサーバサイドで行うとなると負荷がつらい。
クライアント側でもできなくはないですが動画ファイルが大きいとブラウザが停止します。よって私たちは途中で方針変換し、結局 ElasticTranscoderを使うことにしました。
AWSにも問い合わせたのですがMediaConvertへの自動変換実装予定はまだないそうです(2019/02/12)。余談
ElasticTranscoderを利用しつつ、自動回転がMediaConvertに機能実装されたら乗り換えりゃいいや
と思ってたのですが、動画の暗号化のやりかたが両者では大分異なるので、ElasticTranscoderで暗号化した動画はMediaConvertでは復号できなさそうです。
よって、、一度サービスでElasticTransocderを選んでしまうとそれは片道切符になります。(動画暗号化する場合に限り)MediaConvertの利点数多くみながらも、ElasticTranscoderを選ばざるを得ない状況はつらいもんがありました。
おわり。
参考サイト
https://aws.amazon.com/jp/elastictranscoder/pricing/
https://aws.amazon.com/jp/mediaconvert/pricing/
https://blog.shibayan.jp/entry/20140708/1404775800
- 投稿日:2019-02-11T14:47:59+09:00
プロキシのある社内から利用できるjupyter notebook(GPU、EC2、ubuntu16.04、TensorFlow)の構築
はじめに
主に下記を参考にさせていただきました
ubuntu 16.04が使いたかったので、その部分が違いますProxyが厳しい企業内からも利用できるJupyter NotebookをAWS上に用意する
https://qiita.com/shunyas/items/3fa1a0f9e3287b6fb5bfAWSのGPUインスタンスでJupyter Notebookを実行する(Windows 2018/07版)
https://qiita.com/nicco_mirai/items/1da092912adbce71b82b一通りやるのに1~2時間ぐらいかかると思われます
手順
前提
利用環境
- ブラウザの80と443しかポートがあいてない環境
- AWSのアカウントがある
- AWSにブラウザで接続できる
構築環境
- ブラウザのポート自由
- AWSのアカウントがある
- AWSにブラウザで接続できる
- AWSにSSHで接続できる
1 利用環境でEC2の準備をする
AWSに繋がる確認も含めて利用環境からサインインしてバージニア北部に移動します
EC2ダッシュボードから、インスタンスの作成をします
「Ubuntu」で検索すると下記が表示されるので、これを選択してくださいUbuntu Server 16.04 LTS (HVM), SSD Volume Type
インスタンスタイプは p2.2xlarge を選択してください
Volume Storage は20Gにしてください2 構築環境でjupyter notebookのインストール
- 2-1 SSHで作成したEC2インスタンスに接続する
puttyで接続する場合は、インスタンス作成時に保存したキーペアの.pemファイルを.ppkファイルに変換します
参考
pem ⇒ ppk 変換
https://qiita.com/naka46/items/3297242f3386b5f9e3dcAWSにログインして作成したEC2のインスタンスの「パブリック DNS (IPv4)」を調べputtyのHostに入力します
puttyのconnection -> SSH -> Auth にあるPrivate key file for authenticationに変換したppkファイルを指定します
puttyのconnection -> Data にあるAuto-login username に ubuntu と入力します
これでOpenを押して接続します下記を参考にしました
AWSのGPUインスタンスでJupyter Notebookを実行する(Windows 2018/07版)
https://qiita.com/nicco_mirai/items/1da092912adbce71b82b#%E4%BB%BB%E6%84%8F%E3%81%AEssh%E3%82%AF%E3%83%A9%E3%82%A4%E3%82%A2%E3%83%B3%E3%83%88%E3%81%A7%E3%82%A4%E3%83%B3%E3%82%B9%E3%82%BF%E3%83%B3%E3%82%B9%E3%81%AB%E5%85%A5%E3%82%8B
- 2-2 下記を参考にしてjupyter notebookをインストールします
英語ですが、コマンド部分を上から順にコピペすればできます
コマンド部分は$の行です
tensorFlowの動作確認の部分は飛ばしたほうがいいと思いますSetup TensorFlow GPU with AWS EC2 on Ubuntu 16.04 in 10 minutes.
https://medium.com/@dichen_5479/setup-tensorflow-gpu-with-aws-ec2-on-ubuntu-16-04-in-10-minutes-7ee64e47a66a10minitesとかいてますが、私は30分はかかりました
p2.xlargeですと、0.5ドルぐらいですね3 構築環境でjupyter notebookの確認
- 3-1 セキュリティグループの設定
作成したEC2インスタンスのセキュリティグループの「インバウンド」を開いて編集を押す
「カスタム TCP ルール」
「ポート範囲」を8888
ソースを「任意の場所」
にして保存するルールの追加で
「HTTPS」
ソースを「任意の場所」
を選択して保存する
- 3-2 画面の確認
「2 構築環境でjupyter notebookのインストール」を最後まで実行すると、下記のような文字列が表示されます
http://localhost:8888/?token=abcdefg12345jkfatecatetalocalhostを、「パブリック DNS (IPv4)」に変更してブラウザで開くと、jupyter notebookが表示されています
4 構築環境で自動起動の設定
ここからは下記を参考にします
Proxyが厳しい企業内からも利用できるJupyter NotebookをAWS上に用意する
https://qiita.com/shunyas/items/3fa1a0f9e3287b6fb5bf「Port 8888 を Proxyが通過できる443へフォワードする」以降を実施します
上記ではエディタをnano で編集していますが、操作がわからないのでviで実施しました
「起動スクリプト」はパスがかわります
source /home/ubuntu/src/anaconda3/bin/activate root ↓ source /home/ubuntu/miniconda3/bin/activate root「GPU用の環境変数の設定」に関しては
AWSのGPUインスタンスでJupyter Notebookを実行する(Windows 2018/07版)
https://qiita.com/nicco_mirai/items/1da092912adbce71b82b#ssl%E8%A8%BC%E6%98%8E%E6%9B%B8%E3%82%92%E4%BD%9C%E3%82%8B「SSL証明書を作る」
「パスワードのハッシュを作る」
「Jupyter Notebook(Lab)の構成ファイルを作る」
の3つを実施してからになりますc.NotebookApp.certfile と c.NotebookApp.keyfile のパスはsslかcertかどちらかにそろえてください
パスワードはsha1からの文字列になります
あと下記にしないとエラーになりましたc.NotebookApp.ip = '*' ↓ c.NotebookApp.ip = '0.0.0.0'minicondaをインストールしているので、
5 利用環境で確認
AWSにサインインして、EC2を再起動
https://パブリック DNS (IPv4)
に「この接続ではプライバシーが保護されません」、「このサイトの閲覧を続行する (推奨されません)。 」を突破してアクセスして
jupyter notebook のログイン画面が表示されたら完了です
ログインのパスワードは「パスワードのハッシュを作る」で入力した文字列ですおわりに
プロキシには負けたくない
- 投稿日:2019-02-11T13:45:27+09:00
AWSのLambdaとDynamoDBのローカル開発(SAM)
概要
AWSのコンソールで割と簡単にLambdaの処理とDynamoDBのテーブルを作成したり、編集したりすることができます。
ただ、チームでやるプロジェクトだと、バージョン管理とローカルのテストが重要になってきます。
SAMのCLIを使うと本物のコンソールを使わなくても、ローカルで動作確認もできますし、簡単にAWSにデプロイもできます。
環境の情報
- Windows 10
- Docker for Windows
- Visual Studio Code
- Python 3.7 (他のでも大丈夫だと思います)
プロジェクト作成
プロジェクトフォルダーを作成し、VSCodeで開きます。
Pythonの確認
VSCodeのターミナルは【Ctrl+@】で開けます。
sam-lambda-dynamodb> python -V Python 3.7.2pipの更新
sam-lambda-dynamodb> python -m pip install --upgrade pip仮想環境の作成
仮想環境を作ることで、別の環境で構築する時に、Pythonのインストールされているライブラリーのバージョンを簡単に合わせることができるので、ライブラリーのバージョンの違いで問題になることはなくなります。
sam-lambda-dynamodb> python -m venv venv sam-lambda-dynamodb> .\venv\Scripts\activate (venv) sam-lambda-dynamodb>仮想環境に入っていると、左側に(venv)が表示されます。
activateスクリプトを実行できない場合、管理者として以下のコマンドを実行します。
set-executionpolicy remotesigned仮想環境の中のpipの更新
(venv) sam-lambda-dynamodb> python -m pip install --upgrade pipVSCodeのWorkspaceの設定
仮想環境のための設定を入れます。
- VSCODEに「Python」というExtensionをインストールします。
- 「F1」を押し、>Preferences: Open Workspace Settingsを書きます。
- 「Python: Python Path」の設定を探し、仮想環境のpython.exeのパスを入力します。
- 例:C:\\Users\\path\\to\\sam-lambda-dynamodb\\venv\\Scripts\\python.exe
- 「Python: Venv Path」の設定を探し、仮想環境のベースパスを入力します。
- 例:C:\\Users\\path\\to\\sam-lambda-dynamodb\\venv
- 設定終わると、ワークスペースフォルダーに.vscode/settings.jsonが自動的に作成されます。
-settings.jsonの中身は以下のようになります。settings.json{ "python.pythonPath": "C:\\Users\\path\\to\\sam-lambda-dynamodb\\venv\\Scripts\\python.exe", "python.venvPath": "C:\\Users\\path\\to\\sam-lambda-dynamodb\\venv" }仮想環境に必要なライブラリーをインストール
(venv) sam-lambda-dynamodb> pip install aws-sam-cli (venv) sam-lambda-dynamodb> sam --version SAM CLI, version 0.11.0 (venv) sam-lambda-dynamodb> pip install awscli (venv) sam-lambda-dynamodb> aws --version aws-cli/1.16.101 Python/3.7.2 Windows/10 botocore/1.12.91他の環境でも同じライブラリーのバージョンになるため、
requirements.txtを作成します。(venv) sam-lambda-dynamodb> pip freeze | Out-File -Encoding UTF8 .\requirements.txt
requirements.txtからインストールしたい時、このコマンドでできます。
「pip install -r requirements.txt」SAMのinit処理を実行
(venv) sam-lambda-dynamodb> sam init --runtime python3.7こちらのコマンドを実行すると、
sam-appのフォルダーが作成されます。
hello_worldのデフォルトプロジェクトは設定されているので、試してみましょう。awsの設定
ローカル用のテスト環境なので、内容はあまり重要ではないです。
(venv) sam-lambda-dynamodb> aws configure AWS Access Key ID [None]: testid AWS Secret Access Key [None]: testsecret Default region name [None]: ap-northeast-1 Default output format [None]: jsonhello_worldのテンプレートのテスト
sam_appに入り、ビルドを実行(venv) sam-lambda-dynamodb> cd .\sam-app\ (venv) sam-lambda-dynamodb\sam-app> sam build
- dockerは実行中か確認し、APIを実行
(venv) sam-lambda-dynamodb\sam-app> sam local start-api
- hello_worldのapiを実行
ブラウザーで「localhost:3000/hello」にアクセスします。
画面に
{"message": "hello world"}が表示されたら成功です。ローカルのDynamoDBの設定
「Ctrl+C」でhello_worldのlambdaを止めます。
DynamoDBをプルします。
(venv) sam-lambda-dynamodb\sam-app> docker pull amazon/dynamodb-locallambdaとdynamodbは同じネットワークにあると楽なので、dockerのネットワークを作成します。
(venv) sam-lambda-dynamodb\sam-app> docker network create lambda-localcontainerを作成し、runします。
(venv) sam-lambda-dynamodb\sam-app> docker run --network lambda-local --name dynamodb -p 8000:8000 amazon/dynamodb-local -jar DynamoDBLocal.jar -sharedDbrunの後は「Ctrl+C」を押します。
PS: 上のコマンドを1回目の時にしか使わないです。次の実行の時「
docker start dynamodb」のコマンドを使います。DynamoDBのテーブルを作成
- プロジェクトフォルダのに「DynamoDB」のフォルダを作成し、AccessTable.jsonのファイルを作成します。
AccessTable.json{ "TableName": "Access", "KeySchema": [ { "AttributeName": "Path", "KeyType": "HASH" }, { "AttributeName": "Date", "KeyType": "RANGE" } ], "AttributeDefinitions": [ { "AttributeName": "Path", "AttributeType": "S" }, { "AttributeName": "Date", "AttributeType": "S" } ], "ProvisionedThroughput": { "ReadCapacityUnits": 2, "WriteCapacityUnits": 2 } }
- プロジェクトのルートフォルダーに戻り、テーブルの作成コマンドを実行します。
(venv) sam-lambda-dynamodb\sam-app> cd .. (venv) sam-lambda-dynamodb> aws dynamodb create-table --cli-input-json file://.\DynamoDB\AccessTable.json --endpoint-url http://localhost:8000 (venv) sam-lambda-dynamodb> aws dynamodb list-tables --endpoint-url http://localhost:8000 { "TableNames": [ "Access" ] }これでテーブルの作成ができました。
「hello_world」のapiを編集
まず、ローカルと本番の接続処理は違うので、ローカルだとわかるように
template.yamlに環境のパラメーターを追加します。実際にデプロイをする時パラメーターを上書きできます。
template.yaml... 略 +Parameters: + Env: + Type: String + Default: local Globals: Function: Timeout: 3 + Environment: + Variables: + ENV: !Ref Env ... 略「hello_world」のフォルダーの中にある
requirements.txtにboto3のライブラリーを追加します。requirements.txtrequests boto3「hello_world」のフォルダーの中にある
app.pyを編集します。returnの前に以下のコードを追加します。
app.pyimport json import boto3 import os import logging from datetime import datetime # ... 略 try: logger = logging.getLogger() logger.setLevel(logging.INFO) session = boto3.session.Session() awsRegion = session.region_name paramList = event['queryStringParameters'] client = boto3.client('dynamodb') # ローカルの場合 if os.environ['ENV'] == 'local': dynamodb = boto3.resource('dynamodb', region_name = awsRegion, endpoint_url = "http://dynamodb:8000") # ローカル以外の環境の場合 else: dynamodb = boto3.resource('dynamodb', region_name = awsRegion) # テーブルを取得 table = dynamodb.Table('Access') # 日時の文字列 date = datetime.utcnow().isoformat() # 登録するアイテムのベース item = {'Path': event['path'], 'Date': date} if paramList != None: for key,value in paramList.items(): item[key] = value table.put_item( Item=item ) except Exception as e: # Lambdaログにエクセプションの情報を入れる logger.exception(e) return { 'statusCode': 500, 'body': json.dumps({ 'error_message': str(e) }), } # ... 略APIを試す
もう一度「
sam-app」に入り、ビルドを実行します。(venv) sam-lambda-dynamodb> cd .\sam-app\ (venv) sam-lambda-dynamodb\sam-app> sam buildAPIを
lambda-localのネットワークで開始します。(venv) sam-lambda-dynamodb\sam-app> sam local start-api --docker-network lambda-localブラウザーでGatewayにアクセスします。(http://localhost:3000/hello?param=test)
成功できたら、以下のコマンドでテーブルのアイテムが見れます。
(venv) sam-lambda-dynamodb> aws dynamodb scan --table-name Access --endpoint-url http://localhost:8000 { "Items": [ { "Path": { "S": "/hello" }, "param": { "S": "test" }, "Date": { "S": "2019-02-11T03:48:44.017178" } } ], "Count": 1, "ScannedCount": 1, "ConsumedCapacity": null }これでDynamoDBとLambdaをローカルで使えるようになりました。
その他の情報
- CloudFormationのテンプレートに使える定義をSAMのテンプレートにも使えます。
- git管理をする場合、仮想環境のフォルダーをgitignoreに入れます。
- SAMのテンプレートのドキュメンテーション:
- boto3のDynamoDBのドキュメンテーション:
- このプロジェクトのgit:
- 投稿日:2019-02-11T12:50:40+09:00
AWS メディアサービスの概要と使いどころ
AWSメディアサービスとは
AWSが提供しているAWSElementalを主軸とした映像メディア系のサービス群
何を提供しているかは以下を見ればわかるのだが、自身の理解も含めてどんなことができるのか噛み砕いてみた
https://aws.amazon.com/jp/media-services/大きく3つが可能
1. OTT(オーバザ・トップ)ビデオ配信
2. ブロードキャスト配信
3. メディア変換サービスOTTビデオ配信は、ライブ映像やビデオファイルなどをインターネットを介して、顧客に映像配信するサービス。
ブロードキャスト配信サービスはOTTとの違いが難しいが、ライブ映像を多地点に同時に提供する
ライブビューイングなども可能(OTTでも可能と思うが)メディア変換サービスはわかりやすく、元のビデオファイルをMP4やHLSなどのビデオ形式および適切な解像度などに変換し、ビデオ提供をしやすくするサービス
FFMpegで実施していたことがサーバレスで可能上記から、AWSメディアサービスを使うと
・YoutubeやNetfilxなどのビデオ配信(ライブ含む)
・AmazonVideoなどのVOD(ビデオオンデマンド)サービス
・映画館などで実施しているライブビューイング(youtubeライブなども同等)
・ビデオ変換/ダウンローダサービス(FFMpeg相当のビデオ変換)
ができるようになる割と初期投資が必要そうな内容を手軽にサービスとして組み込んで始められる
またはすでに提供している業者もサーバレスとしての拡張性やクラウド特有の使った分だけの料金コストになることも魅力の1つと言える次からはAWSメディアサービスの概要とどこで使うかをざっと記載する
AWSメディアサービスの概要
MediaConvert
大規模なブロードキャストやマルチスクリーン配信向けのビデオオンデマンド (VOD) コンテンツを簡単に作成
⇨繰り返しになるがFFMpegによる変換と同等のことをサーバレスに実施できる。ビデオファイルをMP4やHLSなりに変換して提供。AWSメディアサービスの中で最もわかりやすく使われそう。
老舗サービスとなるElastic Transcoderとできることはだいたい同じでの比較は別途詳細に実施したいが、とりあえずはMediaConvertを使うべき。AWSが力を入れて機能拡張をしていくのはこちらなので。
これを書いた時点ではざっくり音声のみのHLS作るなどかゆいところでまだElastic Transcoderが優位なこともある模様。MediaConnect
高品質なライブ動画伝送サービス。
放送事業者が伝送のために利用している、衛星ネットワークやファイバー接続の代わりに安定した伝送を提供できる
⇨放送事業者のためのライブ伝送サービス。ライブビューイングなどを利用する事業者は利用してということか。放送事業者や映画館など品質を確実に担保する映像サービスを提供する事業者以外に利用するところが思いつかない、、MediaLive
ブロードキャストとマルチスクリーンビデオ配信のために入力をライブ出力に変換する
RTP/RTMP/MP4⇨HLS/Microsoft Smooth/RTMP/UDPなどのメディア出力に変換
⇨ライブストリーミングよる映像配信を手軽に実施する場合に利用。
AmabaTVみたいなインターネットTV局みたいなサービスが使いどころかMediaPackage
インターネット配信に向けた信頼性の高い動画の作成と保護を行う
ライブ映像をマルチデバイス向けに加工、DRM保護などを行える
今の所HLSのみインプット対応の模様。CloudFrontの配信用ディストリビューションも同時作成可能
⇨ライブ映像をサービスとして提供するための加工、配信に利用
MediaLiveやMediaConvertとなどとセットで使うことが前提に見えるMediaTailor
ビデオストリームにターゲット広告を個別に挿入
⇨ビデオに広告を手軽に挿入しマージできる。動画で広告サービスを実施するときはやりやすいMediaStore
メディア向けに最適化された AWS ストレージサービス
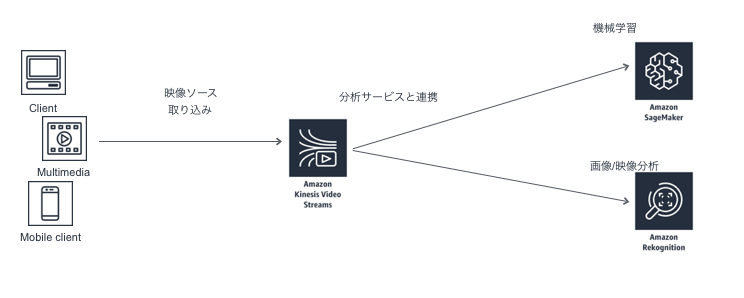
⇨メディア用S3と考えればよさそう。容量、アクセスにあわせてスケールする。大規模配信向けKinesis Video Streams
Elementalサービスではないけど、おまけ的に
分析、機械学習 (ML)、再生、およびその他の処理のために、接続されたデバイスから AWS へ動画を簡単かつ安全にストリーミングする
⇨映像分析のためのバイパス。配信のためにも使えはしそうだが、映像を渡してその先で分析や学習するための利用を推奨している
SageMakerでの映像分析やRekognition Videoでの機械学習などメディアサービスの使い所
いろんなサービスがあるのはわかったが、じゃあどういう風に連携して使うのかについて
サービス提供例をまとめてみた
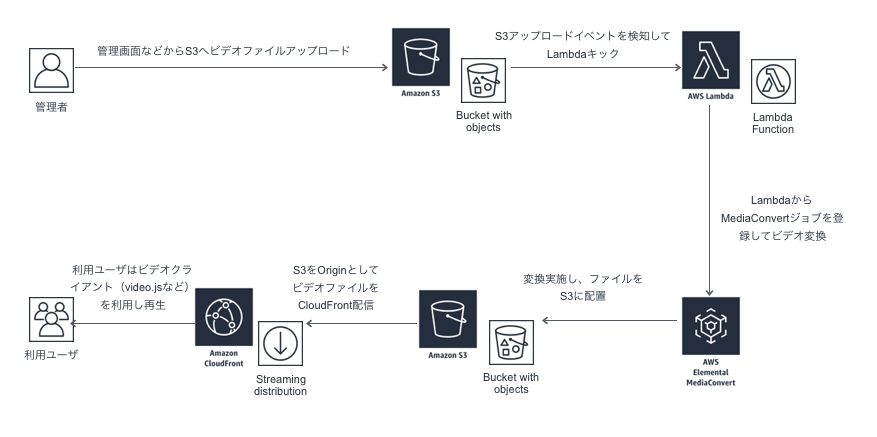
いままで物理機器やOSSソフトウェアに頼っていたところをAWSサービスに置き換えて、スケーリングを任せられる感じが良いVoD変換配信サービス
GUI⇨S3アップロード⇨Lambdaでキック⇨MediaConvert変換⇨CloudFrontで配信
みたいな構成で利用
video再生クライアントはなんでも良いけど、Video.JSなど
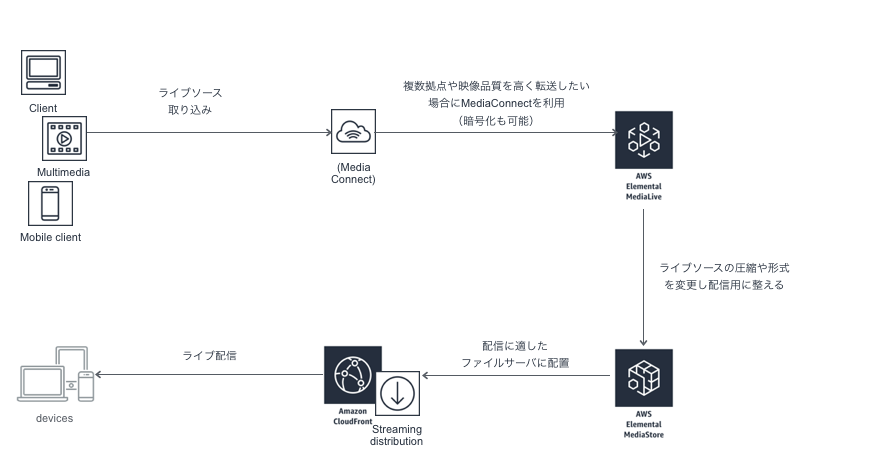
ライブビューイングサービス(インターネットTVサービス)
ライブソース取り込み⇨(MediaConnect)⇨MediaLive⇨MediaStore⇨CloudFrontで配信のような構成で利用
インターネットTVなどを実施したい場合
・複数形式に変換やDRMなどのコンテンツ保護を入れたい場合はMediaPackageを利用
・広告を入れたい場合はMediaTailorを利用
・ライブではなくビデオファイルを利用する場合、上記のVOD変換形式などでビデオを作成しつて利用防犯カメラ分析
映像ソースをKinesisVideoStreamsに取り込み⇨機械学習のSageMakerや映像分析RekognitionVideoのサービスに渡して分析
まとめ
メディアサービスはAWSの中でも、ニッチよりなサービスと思うが
映像関連はメディア系、教育系などにニーズは多々あると思われるため今後も使い方を学んでいきたい。
- 投稿日:2019-02-11T07:32:08+09:00
認証のあるサイトをAWSで構築する際にCognitoユーザープールに必要な最低限の操作
はじめに
「あのとき、こんなドキュメントを見つけられてれば良かったのに・・・」を形にしてみた。
たとえば、
- Apacheとかnginxとか/何かてきとーな言語/何かてきとーなデータベースの組み合わせで、認証の必要なサイトを構築したことがある。
- アカウント情報はデータベースにあって、何かてきとーな言語であれこれ処理するような形だ。
- ユーザー自身でアカウントを作成したりしない。管理者が操作する運用だ。
- そーゆーのをAWSで構築したいと考えたとする。
- Lambdaがあるから、何かてきとーな言語の代わりができると考えちゃったわけだ。
- そして、AWSにCognitoがあってユーザープールがあることを見つけちゃったとする。
- 別のやり方があるのはわかるが、従来通りに近い方法を踏襲したい。
という状況のときに、AWSのドキュメントを見て、いきなり理解できるだろうか?
できないような気がする。
ある程度AWSを理解してるならいいんだろうけど、何というか独特の表現を把握できてないとイマイチ頭に入ってこない構造をしてると思う。
たぶん、「最低限何をしたらいいの?」を判断できない。ここでは、想定した状況のときに最低限何をしたらよいか、AWS CLIの操作で説明する。
ここで実行してるAWS CLIのコマンドはAPIに1対1で対応してる。
それをLamndaで実装したら、最低限のレベルでユーザー認証の必要なサイトのユーザー管理部分を実装できるようになる。何度も最低限と書いてるように、ここで説明した方法は実装するには不足がある。
また、唯一の方法ではない。他の方法が適切な場合もあるだろう。前提条件
それぞれの作成方法は後述するが、既に次の2つが作成済みであることが必要となる。
- Cognitoユーザープール
- Cognitoユーザープールのアプリクライアント
ここではAWS CLIをプロファイルを指定して実行してるが、プロファイルは必須ではない。
普段はプロファイルの指定なしで操作してる場合は、そのように読み替えればよい。Cognitoユーザープールの操作
実際にはLambdaで実装するのだが、ここではAWS CLIで操作してみる。
この操作を、お好きな言語を使ってLambdaで実装すれば良い。
ユーザーの作成と削除は、実際の運用でもAWS CLIで操作したほうが簡単かもしれない。ユーザーの作成
admin-create-user,admin-initiate-auth,admin-respond-to-auth-challenge,global-sign-outを使う。# 仮パスワードを指定してユーザーを作成する。 # この時点ではユーザーに連絡しない。 aws --profile 'プロファイル名' cognito-idp admin-create-user \ --user-pool-id 'ユーザープールID' \ --username 'ユーザー名に使うメールアドレス' \ --message-action SUPPRESS \ --temporary-password '仮パスワード' # 初回ログインの反応を見る。 aws --profile 'プロファイル名' cognito-idp admin-initiate-auth \ --user-pool-id 'ユーザープールID' \ --client-id 'アプリクライアントID' \ --auth-flow ADMIN_NO_SRP_AUTH \ --auth-parameters 'USERNAME=ユーザー名に使うメールアドレス,PASSWORD=仮パスワード' # 次のような結果が表示される # { # "ChallengeName": "NEW_PASSWORD_REQUIRED", # "Session": "この部分をセッション情報としてメモする", # (略) # } # ユーザーに連絡する初期パスワードを設定する。 aws --profile 'プロファイル名' cognito-idp admin-respond-to-auth-challenge \ --user-pool-id 'ユーザープールID' \ --client-id 'アプリクライアントID' \ --session 'セッション情報' \ --challenge-name NEW_PASSWORD_REQUIRED \ --challenge-responses 'USERNAME=ユーザー名に使うメールアドレス,NEW_PASSWORD=初期パスワード' # 次のような結果が表示される # { # "ChallengeParameters": {}, # "AuthenticationResult": { # "AccessToken": "この部分をアクセストークンとしてメモする", # (略) # } # } # ログアウトしておく。 aws --profile 'プロファイル名' cognito-idp global-sign-out \ --access-token 'アクセストークン' # 以上の流れにするのは「"ChallengeName": "NEW_PASSWORD_REQUIRED"」に対する実装を省略するため。ユーザーの削除
admin-delete-userを使う。aws --profile 'プロファイル名' cognito-idp admin-delete-user \ --user-pool-id 'ユーザープールID' \ --username 'ユーザー名に使うメールアドレス'ログイン
admin-initiate-authを使う。aws --profile 'プロファイル名' cognito-idp admin-initiate-auth \ --user-pool-id 'ユーザープールID' \ --client-id 'アプリクライアントID' \ --auth-flow ADMIN_NO_SRP_AUTH \ --auth-parameters 'USERNAME=ユーザー名に使うメールアドレス,PASSWORD=パスワード' # 次のような結果が表示される # { # "ChallengeParameters": {}, # "AuthenticationResult": { # "AccessToken": "この部分をアクセストークンとしてメモしておく", # (略) # } # } # ここでは「クライアント側にアクセストークンを通知して以降はアクセストークンを送ってもらう」という形を想定する。 # とりあえず的なレベルではこの程度だが、実際にはもっと複雑になる。ログイン後の認証
get-userを使う。aws --profile 'プロファイル名' cognito-idp get-user \ --access-token 'アクセストークン' # ユーザーを取得できれば「アクセストークンは正しい/ログインしてる」と判断する。 # そうでなければ「アクセストークンは正しくない/ログインしてない」と判断する。 # とりあえず的なレベルではこの程度だが、実際にはもっと複雑になる。ログアウト
global-sign-outを使う。aws --profile 'プロファイル名' cognito-idp global-sign-out \ --access-token 'アクセストークン'パスワードの変更
change-passwordを使う。aws --profile 'プロファイル名' cognito-idp change-password \ --previous-password '以前のパスワード' \ --proposed-password '新しいパスワード' \ --access-token 'アクセストークン'このドキュメントの不足
たぶん、実際に実装してみると、いろいろと追加したくなる。
次のような点を検討することになると思う。
- ふつー考えるに、パスワード忘れ対策は必要だ。
- アクセストークンの期限は1時間なので、期限が切れたらリフレッシュトークンを使って更新する必要がある。
- リフレッシュトークンにも期限がある。期限が切れたら再ログインを促すことになる。
- 一定期間が経過したらパスワード変更を要求する機能も欲しくなる。それの是非はともかく、欲しがる人はいるので。
前提条件を整える
テスト用のIAMユーザーを準備する
- てきとーなユーザー名を考えて、AWSマネジメントコンソールのIAMで作成する。
- アクセスの種類は「プログラムによるアクセス」で、グループに追加する必要はない。タグもいらない。
- 「このユーザーにはアクセス権限がありません」とか言われるが、気にしない。あとで権限を設定する。
- 作成したら、アクセスキーIDとシークレットアクセスキーをメモっておく。
- 作成したユーザーを選ぶと「アクセス権限」を確認できる。
- 「アクセス権限の開始方法」の囲みの中の「インラインポリシーの追加」をクリックする。
次の内容のポリシーを、てきとーな名前をつけて設定する。
{ "Version": "2012-10-17", "Statement": [ { "Sid": "AlowCognitoUserPool", "Effect": "Allow", "Action": "cognito-idp:*", "Resource": "*" } ] }AWS CLIを準備する
- AWSのドキュメントを参考に、AWS CLIを使えるように準備する。
プロファイルを設定しておく。例えばこんな感じ。
aws --profile 'プロファイル名' configure # AWS Access Key ID [None]: アクセスキーID # AWS Secret Access Key [None]: シークレットアクセスキー # Default region name [None]: ap-northeast-1 # Default output format [None]: jsonユーザープールの作成
aws --profile 'プロファイル名' cognito-idp create-user-pool \ --admin-create-user-config 'AllowAdminCreateUserOnly=true,UnusedAccountValidityDays=7' \ --auto-verified-attributes email \ --mfa-configuration OFF \ --policies 'PasswordPolicy={MinimumLength=8,RequireUppercase=true,RequireLowercase=true,RequireNumbers=true,RequireSymbols=true}' \ --pool-name 'ユーザープール名' \ --username-attributes email # 次のような結果が表示される # { # "UserPool": { # "Id": "この部分をユーザープールIDとしてメモしておく", # (略) # } # }ユーザープールと関連するアプリクライアントの作成
aws --profile 'プロファイル名' cognito-idp create-user-pool-client \ --user-pool-id 'ユーザープールID' \ --client-name 'アプリクライアント名' \ --explicit-auth-flows ADMIN_NO_SRP_AUTH \ --no-generate-secret \ --read-attributes email \ --refresh-token-validity 30 \ --write-attributes email # 次のような結果が表示される # { # "UserPoolClient": { # (略) # "ClientId": "この部分をアプリクライアントIDとしてメモしておく", # (略) # } # }
- 投稿日:2019-02-11T05:57:55+09:00
AWS S3で静的サイトを構築
はじめに
私は今回の記事が初投稿であり、また文章を書くことなども慣れていないので、読みにくい部分などが多数存在すると思いますがご了承ください。
概要
静的サイトをAWSのS3を用いて構築する。
静的サイトとは
AWS S3ではHTMLやCSS、JavaScriptなどのサーバー側の処理を行われないサイトを静的webサイトと呼びます。反対にPHPなどの言語を使用してサーバー側で処理を行うことでページを変化させるようなサイトを動的サイトと呼びます。
静的サイトの利点はサーバーとの通信回数を減らすことが出来るので、表示を速く出来たり、サーバーの負担を減らすなどが有ります。またサーバーの負担を減らせるので使用料金を安く出来ます。
静的サイトを作ってみる
正確な情報は以下の公式ドキュメントをご覧ください。私の書いていることは殆ど乗っています。
公式ドキュメントBucketsを作成する
・AWSアカウントにログインする
・S3のページまで移動する
・バケットを作成するを押す(Create bucketsを押す)
・バケットの名前を入力する。(バケットの名前は被らないように命名する必要がある。サイトのFQDN(URL)として使用することがあるので被らないように設定されている)
・オプションの設定は特に変えず、次へ
・アクセス許可の設定の「このバケットのパブリックバケットポリシーを管理する」の項目2つのチェックを外す。
・バケットの作成を押して完了
サイトを外部に公開する
今の状態だと、ただのストレージの状態なのでこれを外部に公開する必要がある。
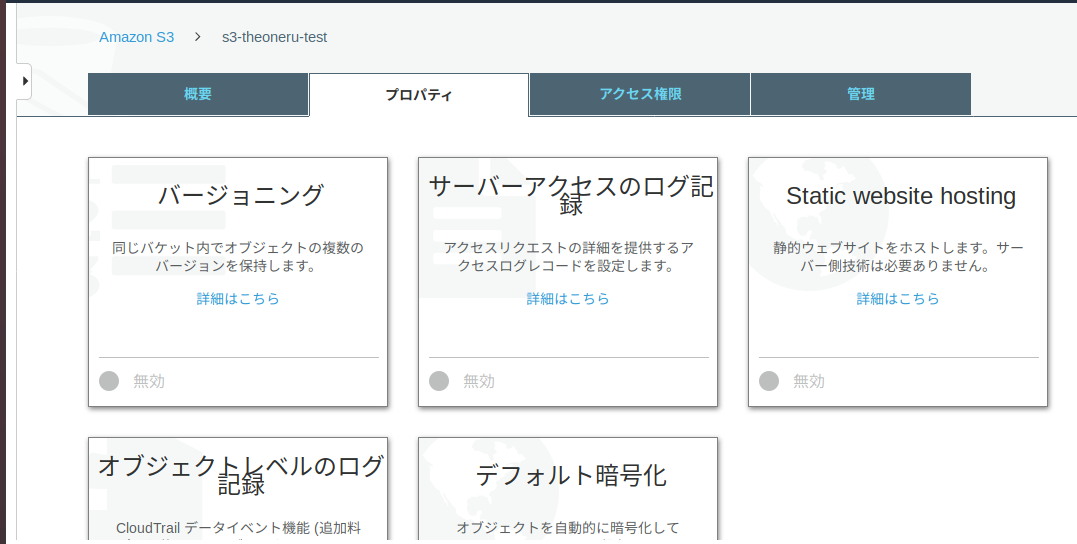
・作成したバケットを開き、プロパティに移動する。
・プロパティページのStatic website hostingを選択。
・「このバケットを使用してウェブサイトをホストする」を選択
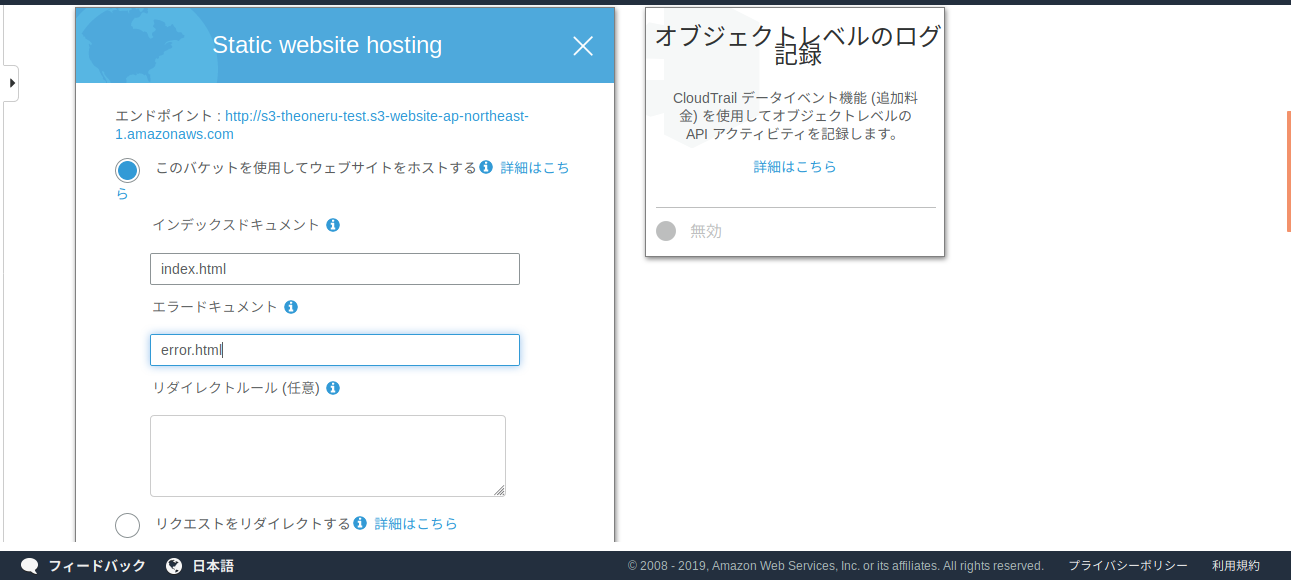
・インデックスドキュメント、エラードキュメント名を入力。(インデックスドキュメントはURLに接続したときに最初に出てくるページ、エラードキュメントは何かしらのエラーが合った時に出てくるページ)
・保存をクリック
上の画像のエンドポイントがサイトのURLになります。またサイトのURL変更の記事は別で書きます。
アクセス権限の変更
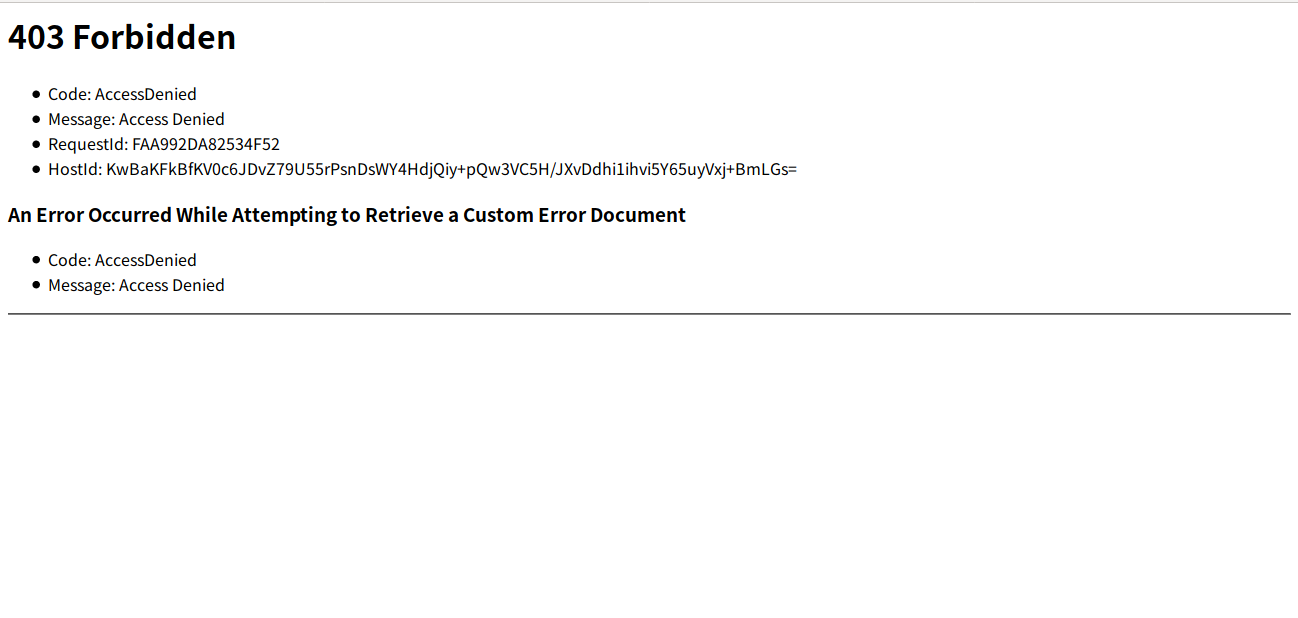
・先程のウェブサイトのホストページで出てきたエンドポイントにアクセスしてみる。
アクセスできないはずです。バケットのアクセス権限はデフォルトで外部からのアクセスを禁止しています。そのためアクセス権限の変更を行わないといけません。
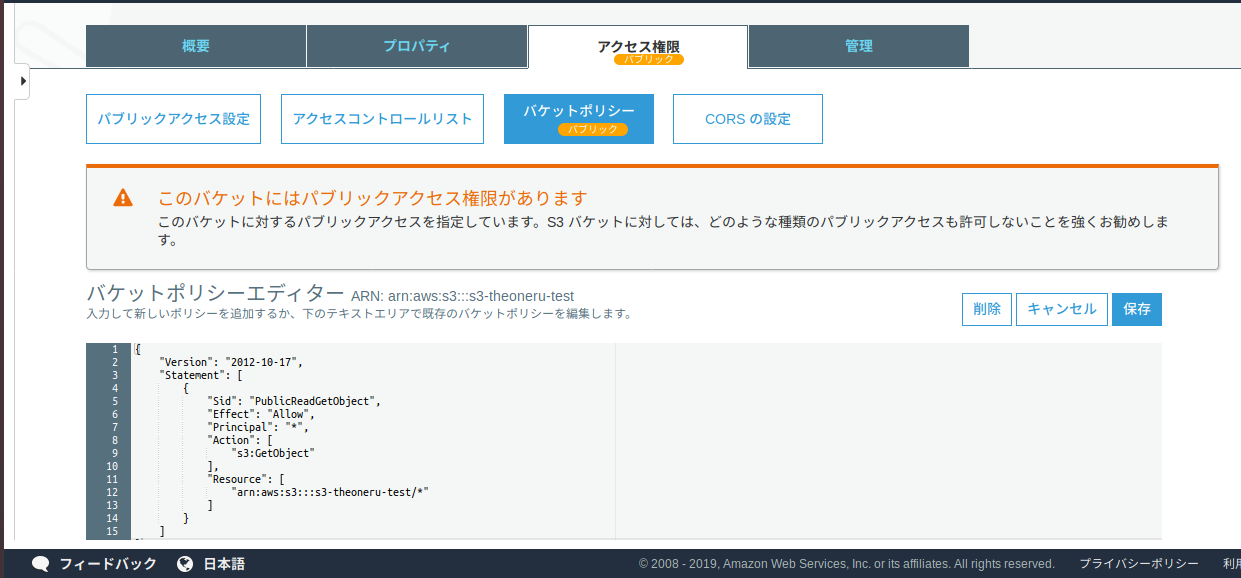
・バケットのアクセス権限のページに移動
・バケットポリシーを選択
・バケットポリシーの編集画面に以下のコード記入(Resourceには各自のARNを記入)
(ARNとはAWSでの名前の識別子みたいなもので、今回使用するS3ならば、バケットの名前がhogeなら、"arn:aws:s3:::hoge/*"と打ち込めばいい。){ "Version":"2012-10-17", "Statement":[{ "Sid":"PublicReadGetObject", "Effect":"Allow", "Principal": "*", "Action":["s3:GetObject"], "Resource":["arn:aws:s3:::example-bucket/*" ] } ] }・保存を押して、以下の画像のようになれば成功。
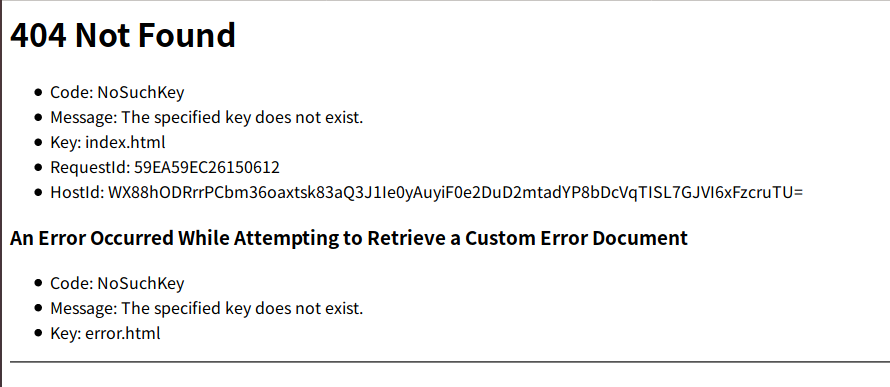
・アクセスしてみる。
・エラーコードは404なので、先程設定したindex.htmlがアップロードされていないため、ページが見れない。
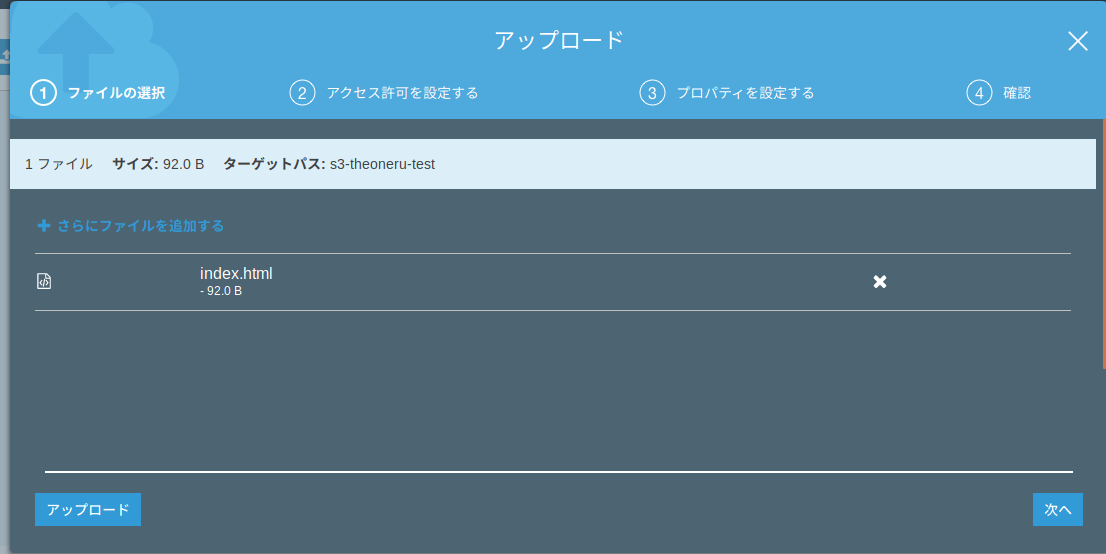
・以下のコードをメモ帳などのテキストエディターで編集し、バケットにアップロードする。(ファイル名はindex.html)index.html<html> <head> <title>S3 test</title> </head> <body> Hello World </body> </html>
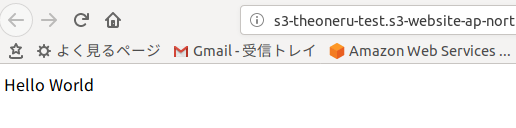
・もう一度エンドポイントにアクセスしてみる。
成功しました!
まとめ
S3を使用して、静的サイトを構築することできました!
これでページの作成は大変ですが安く自分のwebページを持つことが出来ます。他にも色々追加オプションなどもあるので時間が有ったら記事にしていきたいです。次回はRoute53をつかってドメイン(URL)を独自ドメインにします。
またご意見や、記事の中での間違いなどがございましたらコメント下さい。
- 投稿日:2019-02-11T03:05:42+09:00
Elasticsreachのデータ暗号化
はじめに
Elasticsearchのデータ暗号化について、検討する機会があったので、記事にまとめてみました^^:
利用した環境
product version cryptsetup 1.7.4 Elasticsearch 6.6.0 OS Amazon Linux2 (4.14.88) Instance Type m5.2xlarge EBS ルート(8GB)、追加(30GB) AMI ami-04677bdaa3c2b6e24 【ディスクの状態】
nvme0n1が8GBのルートボリューム、nvme1n1が追加の30GBボリュームです。
※m5はNitro世代のEC2インスタンスでEBS NVMeボリュームのため、/dev/nvmeXnXという名称[root@ip-172-31-34-49 ~]# lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT nvme1n1 259:0 0 30G 0 disk nvme0n1 259:1 0 8G 0 disk ├─nvme0n1p1 259:2 0 8G 0 part / └─nvme0n1p128 259:3 0 1M 0 part [root@ip-172-31-34-49 ~]# df -h Filesystem Size Used Avail Use% Mounted on devtmpfs 16G 0 16G 0% /dev tmpfs 16G 0 16G 0% /dev/shm tmpfs 16G 388K 16G 1% /run tmpfs 16G 0 16G 0% /sys/fs/cgroup /dev/nvme0n1p1 8.0G 1.2G 6.9G 15% / tmpfs 3.1G 0 3.1G 0% /run/user/1000基本的な考え方
Elasticsearchのデータ(=Index)暗号化では、日立ソリューションズ社のCredeon Secure Full-text Searchがありますが、あくまで全文検索のためのIndex暗号化であって、Kibanaが利用する
aggregation機能には対応していません。ElasticStackでは5.3.0から保存データの暗号化に対応しています。
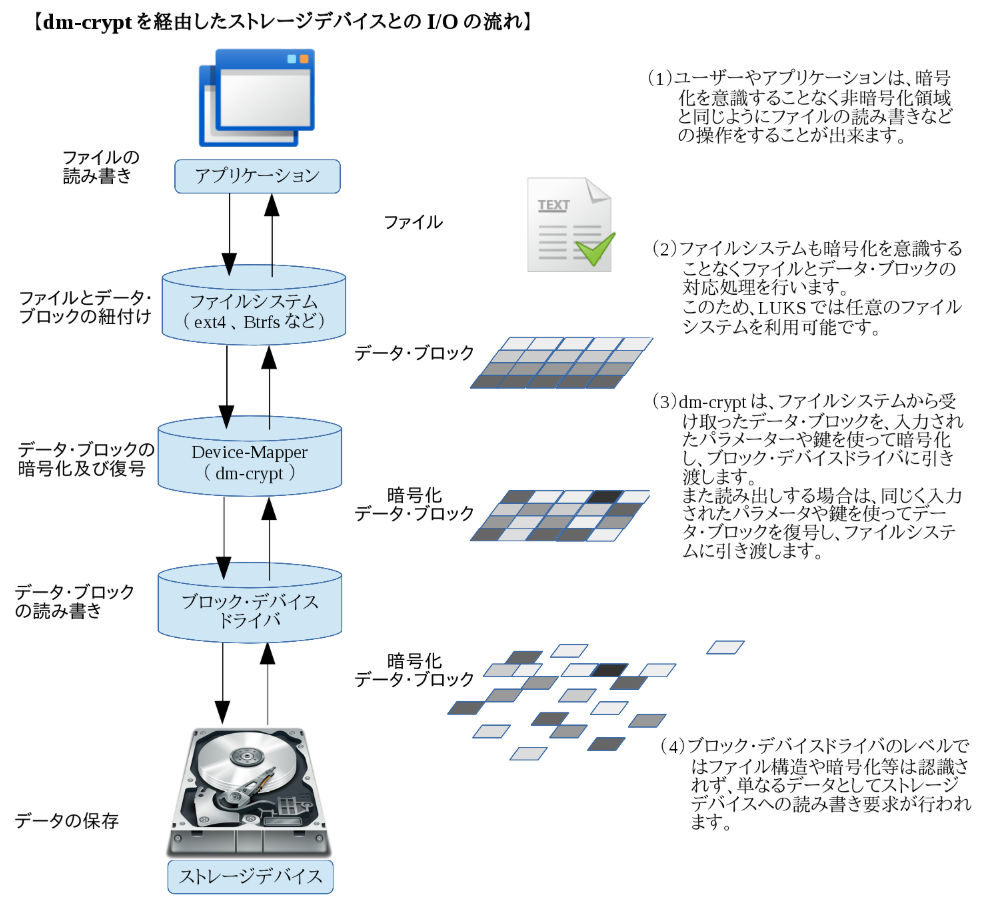
サブスクリプションのPlatinum Editionで対応していますが、あくまでdm-cryptを用いたボリュームの暗号化を利用した場合でもElasticsreachとしてサポートするというものです。暗号化機能が付いている訳ではありません。dm-cryptとは
Device-Mapperの機能の1つでLinuxにおけるブロックデバイス暗号の仕組みです。
Kernel 2.6以降のdevice-mapperモジュールに標準で組み込まれていて、cyptsetupという暗号化管理ツールを使ってストレージデバイスの暗号化を行います。
【参考】
・LUKSとは?設定手順
- Java 1.8.0 インストール
- Elasticsearch 6.6.0 インストール
- JVMヒープサイズ設定
- Elasticsreach設定
- 暗号化ボリュームの設定
- Index保存領域の作成
- 設定確認
1. Java 1.8.0 インストール
Javaがインストールされていないことを確認した上でJava 1.8.0をインストールします。
[root@ip-172-31-34-49 ~]# java -version -bash: java: command not found [root@ip-172-31-34-49 ~]# yum install -y java-1.8.0-openjdk <インストールの経過は省略> [root@ip-172-31-34-49 ~]# java -version openjdk version "1.8.0_191" OpenJDK Runtime Environment (build 1.8.0_191-b12) OpenJDK 64-Bit Server VM (build 25.191-b12, mixed mode)2. Elasticsearch 6.6.0 インストール
Elastic社公式のリポジトリを登録し、Elasticsearch 6.6.0をインストールします。
[root@ip-172-31-34-49 ~]# vi /etc/yum.repos.d/elastic.repo [root@ip-172-31-34-49 ~]# cat /etc/yum.repos.d/elastic.repo [elasticsearch-6.x] name=Elasticsearch repository for 6.x packages baseurl=https://artifacts.elastic.co/packages/6.x/yum gpgcheck=1 gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch enabled=1 autorefresh=1 type=rpm-md [root@ip-172-31-34-49 ~]# yum install -y elasticsearch <インストールの経過は省略> [root@ip-172-31-34-49 ~]# systemctl status elasticsearch ● elasticsearch.service - Elasticsearch Loaded: loaded (/usr/lib/systemd/system/elasticsearch.service; disabled; vendor preset: disabled) Active: inactive (dead) Docs: http://www.elastic.co3. JVMヒープサイズ設定
Elasticsreachには物理メモリの半分を上限にJVMヒープを割り当てます。
m5.2xlargeのメモリは32GBなので、今回は15GBのメモリを割り当てます。[root@ip-172-31-34-49 ~]# vi /etc/elasticsearch/jvm.options -Xms15g -Xmx15g # 以下、設定の確認です。 [root@ip-172-31-34-49 ~]# cat /etc/elasticsearch/jvm.options | grep 154. Elasticsreach設定
ElasticsearchのIndex保存領域を
path.dataで指定します。今回は/mnt/es/elasticsearchとします。[root@ip-172-31-34-49 ~]# vi /etc/elasticsearch/elasticsearch.yml path.data: /mnt/es/elasticsearch # 以下、設定の確認です。 [root@ip-172-31-34-49 ~]# cat /etc/elasticsearch/elasticsearch.yml | grep path.data5. 暗号化ボリュームの設定
cryptsetupコマンドで
/dev/nvme1n1にAES256/SHA1暗号化ボリューム(esvol)を作成し、/mnt/esにマウントします。[root@ip-172-31-34-49 ~]# cryptsetup --key-size 512 --hash sha512 luksFormat /dev/nvme1n1 WARNING! ======== This will overwrite data on /dev/nvme1n1 irrevocably. Are you sure? (Type uppercase yes): YES Enter passphrase: #パスワードを設定 Verify passphrase: #パスワードの確認 [root@ip-172-31-34-49 ~]# cryptsetup luksOpen /dev/nvme1n1 esvol Enter passphrase for /dev/nvme1n1: #上記で設定したパスワードを入力 [root@ip-172-31-34-49 ~]# ls /dev/mapper control esvol [root@ip-172-31-34-49 ~]# mkfs.ext4 /dev/mapper/esvol mke2fs 1.42.9 (28-Dec-2013) Filesystem label= OS type: Linux Block size=4096 (log=2) Fragment size=4096 (log=2) Stride=0 blocks, Stripe width=0 blocks 1966080 inodes, 7863808 blocks 393190 blocks (5.00%) reserved for the super user First data block=0 Maximum filesystem blocks=2155872256 240 block groups 32768 blocks per group, 32768 fragments per group 8192 inodes per group Superblock backups stored on blocks: 32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632, 2654208, 4096000 Allocating group tables: done Writing inode tables: done Creating journal (32768 blocks): done Writing superblocks and filesystem accounting information: done [root@ip-172-31-34-49 ~]# mount /dev/mapper/esvol /mnt/es [root@ip-172-31-34-49 ~]# ll /mnt total 4 drwxr-xr-x 3 root root 4096 Feb 10 18:29 es暗号化ボリュームが作成されていることを確認します。
[root@ip-172-31-34-49 ~]# lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT nvme1n1 259:0 0 30G 0 disk └─esvol 253:0 0 30G 0 crypt /mnt/es nvme0n1 259:1 0 8G 0 disk ├─nvme0n1p1 259:2 0 8G 0 part / └─nvme0n1p128 259:3 0 1M 0 part [root@ip-172-31-34-49 ~]# df -h Filesystem Size Used Avail Use% Mounted on devtmpfs 16G 0 16G 0% /dev tmpfs 16G 0 16G 0% /dev/shm tmpfs 16G 392K 16G 1% /run tmpfs 16G 0 16G 0% /sys/fs/cgroup /dev/nvme0n1p1 8.0G 1.5G 6.6G 19% / /dev/mapper/esvol 30G 45M 28G 1% /mnt/es tmpfs 3.1G 0 3.1G 0% /run/user/10006. Index保存領域の作成
/mnt/es配下に
elasticsearchディレクトリを作成し、適切な権限を付与します。[root@ip-172-31-34-49 elasticsearch]# cd /mnt/es [root@ip-172-31-34-49 es]# mkdir elasticsearch [root@ip-172-31-34-49 es]# chown elasticsearch:elasticsearch elasticsearch/ [root@ip-172-31-34-49 es]# chmod 750 elasticsearch/ [root@ip-172-31-34-49 es]# ll total 20 drwxr-x--- 2 elasticsearch elasticsearch 4096 Feb 10 21:47 elasticsearch drwx------ 2 root root 16384 Feb 10 18:29 lost+foundElasticsearchをサービス起動し、
path.data配下にNodeIDファイル(node-0.st)が生成されていることを確認します。[root@ip-172-31-34-49 es]# systemctl start elasticsearch [root@ip-172-31-34-49 es]# cat elasticsearch/nodes/0/_state/node-0.st ?lstate:) node_idUWTgg6zqmS2Cq72YdCOdCpA(7. 設定確認
- 暗号化した30GBの追加EBSボリュームのSnapshotを作成します。
- 作成したSnapshotから別途EBSボリュームを作成し、別EC2にアタッチします。
EBSをアタッチしたEC2にログインし、追加EBSとして
nvme1n1が存在していることを確認します。[root@ip-172-31-6-22 ~]# lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT nvme0n1 259:0 0 100G 0 disk ├─nvme0n1p1 259:1 0 100G 0 part / └─nvme0n1p128 259:2 0 1M 0 part nvme1n1 259:3 0 30G 0 disk [root@ip-172-31-6-22 ~]# df -h Filesystem Size Used Avail Use% Mounted on devtmpfs 3.8G 0 3.8G 0% /dev tmpfs 3.8G 0 3.8G 0% /dev/shm tmpfs 3.8G 380K 3.8G 1% /run tmpfs 3.8G 0 3.8G 0% /sys/fs/cgroup /dev/nvme0n1p1 100G 2.2G 98G 3% / tmpfs 763M 0 763M 0% /run/user/1000/mnt/esにマウントし、内容を確認してみます。
[root@ip-172-31-6-22 ~]# mkdir /mnt/es [root@ip-172-31-6-22 ~]# mount -o discard /dev/nvme1n1 /mnt/es mount: /mnt/es: unknown filesystem type 'crypto_LUKS'.まとめ
LUKSで暗号化したボリュームを他マシンにマウントしても認識しませんでした。
これでElasticsreachノードにログインされない限り、OSレベルでのIndexデータの機密性は確保できました。ElasticsreachのData Nodeをi3系インスタンスで構築し、NVMe SSDにIndexを配置することで暗号化することも可能です。
NVMe インスタンスストレージのデータは、インスタンスのハードウェアモジュールに実装されている XTS-AES-256 ブロック暗号を使用して暗号化されます。暗号化キーは、ハードウェアモジュールで作成され、NVMe インスタンスストレージデバイスごとに固有です。すべての暗号化キーは、インスタンスが停止または終了して復元できないときに破棄されます。この暗号化を無効にしたり、独自の暗号キーを指定したりすることはできません。
以上、いかがでしたでしょうか。
不明な点、誤植などありましたら、コメントをお願いします!!
- 投稿日:2019-02-11T00:48:31+09:00
S3をEC2インスタンスにマウントして使うときのStorageGateway, s3fs, goofysそれぞれのパフォーマンス
背景
オンプレミスで運用している自社システムをAWSに移行する場合に、CSVファイルとしてディスクにためているデータをどうするか。現状は複数あるサーバー間でrsyncを定期的に実行して同期を取っているが、AWS移行後は共通のファイルシステムをマウントして使うことで、同期自体が必要ない運用にしたい。
共通のEFSストレージを複数インスタンスでマウントして共有するという手もあるが、EFSはEBSのようにスナップショットを取ることができない。ということはファイルのバックアップは自前で仕組みを用意する必要がある。しかしできるだけAWSマネージドな仕組みを使うことで運用の手間を減らしたい。
選択肢
選択肢としては
- AWS Storage Gatewayのファイルゲートウェイをセットアップし、NFSを通してEC2にマウントして使用する。
- s3fsでファイルシステムにS3バケットを直接マウント。
- goofysでファイルシステムにS3バケットを直接マウント。
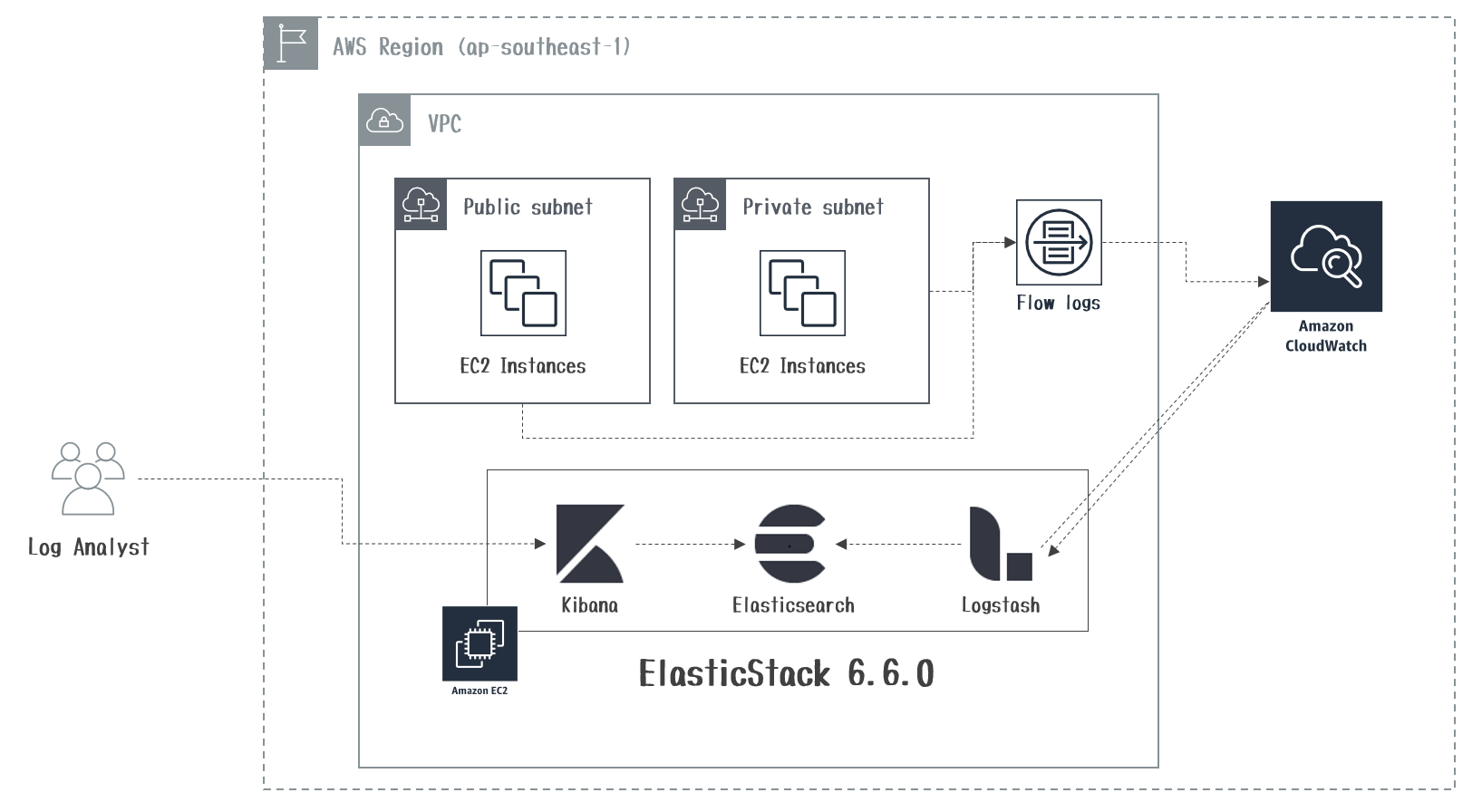
がある。図にするとこんな感じ
いずれの方法も、S3をファイルシステムとしてマウントするため、プログラム側の変更が必要ない。
Storage GatewayがファイルゲートウェイとなるインスタンスをセットアップしてNFS等で他のインスタンスでマウントするなどの方法を取る必要があるのに対して、s3fsやgoofysは各サーバーが直接S3をマウントできる。
Storage Gatewayは構築がめんどくさそうなので、とりあえず簡単そうなs3fsとgoofysでやってみて、最後にStorage Gatewayもやってみる。
IAMロールの作成
EC2からS3にアクセスするために、S3FullAccess権限を付与した
S3FsRoleというロールを作成して、テスト用のEC2インスタンスを作る際に作成したロールを指定する。s3fsのセットアップ
$ sudo apt-get install make automake autoconf git libfuse-dev libfuse2 $ sudo apt-get install libcurl4 libcurl4-openssl-dev $ sudo apt-get install libxml2 libxml2-dev libssl-dev libssl1.1 $ git clone https://github.com/s3fs-fuse/s3fs-fuse.git $ cd s3fs-fuse $ ./autogen.sh $ ./configure $ make $ sudo make installマウントポイントを作る。
$ sudo mkdir /usr/local/var/s3fs $ sudo chown ubuntu:ubuntu /usr/local/var/s3fs
/etc/s3fs.confを編集してマウントしたs3バケットをだれでも使えるようにする。/etc/s3fs.conf# Allow non-root users to specify the allow_other or allow_root mount options. user_allow_otherマウントを実行(
uid=1000,gid=1000はubuntuユーザーのuid,gid)$ sudo /usr/local/bin/s3fs <buckdet名> /usr/local/var/s3fs -o use_path_request_style,rw,allow_other,use_cache=/tmp,uid=1000,gid=1000,iam_role=S3FsRolegoofysのセットアップ
$ sudo apt-get install golang git $ export GOPATH=/usr/local/go $ chown ubuntu:ubuntu $GOPATH $ go get github.com/kahing/goofys $ go install github.com/kahing/goofysマウントする
$ sudo mkdir /usr/local/var/s3 $ sudo chown ubuntu:ubuntu /usr/local/var/s3 $ /usr/local/go/bin/goofys --use-content-type <buket名> /usr/local/var/s3ちなみに起動時にマウントするには
/etc/fstabに/usr/local/go/bin/goofys#<bucket名> /usr/local/var/s3 fuse _netdev,allow_other,--use-content-type,--file-mode=0666,--uid=1000,--gid=1000 0 0パフォーマンス測定
インスタンスに Ruby 2.5.1をインストールして以下のようなコードで測定する。
file_s3_test.rbtime = Time.now 1000.times do |v| File.open("#{v}", "w") {|f| f.write "hello world #{v}" } end 1000.times do |v| File.unlink("#{v}") end puts passed = Time.now - time puts "#{passed} sec passed."EBSでの計測
比較対象として、EBS上で実行してみよう。
$ mkdir ~/tmp $ cd ~/tmp $ ruby ~/file_s3_test.rb 0.055169964 sec passed.はやい
s3fsでマウントしたS3に対して実行
$ mkdir -f /usr/local/var/s3/ruby_test $ cd /usr/local/var/s3/ruby_test $ ruby ~/file_s3_test.rb 167.091888939 sec passed.当たり前だけどEBSよりはるかに遅い。
goofysでマウントしたS3に対して実行
$ mkdir -f /usr/local/var/s3/ruby_test $ cd /usr/local/var/s3/ruby_test $ ruby ~/file_s3_test.rb 67.559308286 sec passed.EBSよりはるかに遅いのは同じだけど、s3fsより2.5倍ぐらい速い。
Storage Gatewayのセットアップ
ここに書いてある通りに作業してStorage Gatewayを準備する。
http://blog.serverworks.co.jp/tech/2017/03/01/filegateway/S3バケットを別途作ってNFSとしてマウント
$ sudo apt-get install nfs-common $ mkdir gatewayfs $ sudo mount -t nfs -o nolock,hard 172.31.53.xxx:/<bucket名> gatewayfsStorage Gateway + NFSでマウントしたS3に対して実行
では先ほどのスクリプトを使って試してみる。
$ cd gatewayfs $ ruby ~/file_s3_test.rb 53.024792688 sec passed.おお、これが一番速いようです。ただ、goofysとの差はそこまで大きくはないみたい。
まとめ
まず最初に、どの方法を使っても速度面でEBSには遠く及びません。したがって多数のファイルを横断的に処理するようなことには全く向いていないと思います。
ただ、性能面でこれで問題ないのであれば、既存のアプリのファイルアクセスをコード変更なしにS3に移行できるという点で魅力的です。S3をマウントしてファイルシステムとして保存、読み取りする方法であればプログラム変更が必要ない上にS3の機能である、AZ3箇所への冗長化や、別リージョンへのレプリケーションなどS3の機能を活用してデータの耐障害性を高めることができる上にコスト面でもEBSに保存するより有利です。
その上で性能面で比較すると一番よさそうなのはStoraga Gatewayみたいです。ただ、これ多分ゲートウェイの機能を提供するインスタンスがSPOFになる気がします。
あと、コスト面でもあまりいいとは言えないと思います。s3fsやgoofysを使う場合はEC2上に直接マウントできるのに対して、ゲートウェイ用にxlarge以上のインスタンスを常時起動しておく必要があるので、その分コストがかかります。s3fsはこれらの問題がありませんが、StorageGatewayやgoofysに比べるとかなり遅いです。あと、正しくマウントしないと、マウントしても書き込めないなどのちょっとハマりました。
個人的に一番よい印象を受けたのはgoofysです。まずセットアップが一番簡単でした。このあたりはgolangの恩恵かもしれません。依存関係とか気にせず、
go getとgo installでインストールできました。あとマウントも特にハマるところもなく、すぐにファイルの書き込みや読み込みが行えましたし速度もStorageGatewayには及ばないまでも近い性能が出ています。ネットで色々見ていると不安定だという情報もありましたが、いずれも古い情報だったので現状どうなのかはもう少し試してみないとわからないです。そんなわけで、今後はgoofysに的を絞って、もうちょっと詳しく調べてみようと思います。



- 投稿日:2019-02-11T00:05:25+09:00
SwaggerでLambdaのデバッグ環境を作る(5):Clovaをデバッグする
第1回投稿で、SwaggerでLambdaのデバッグ環境を作りました。
GoogleHome、Alexaと続いて、とうとうClovaのスキルをデバッグします。
Clovaスキルを作る
早速、Clovaスキルを作成しましょう。
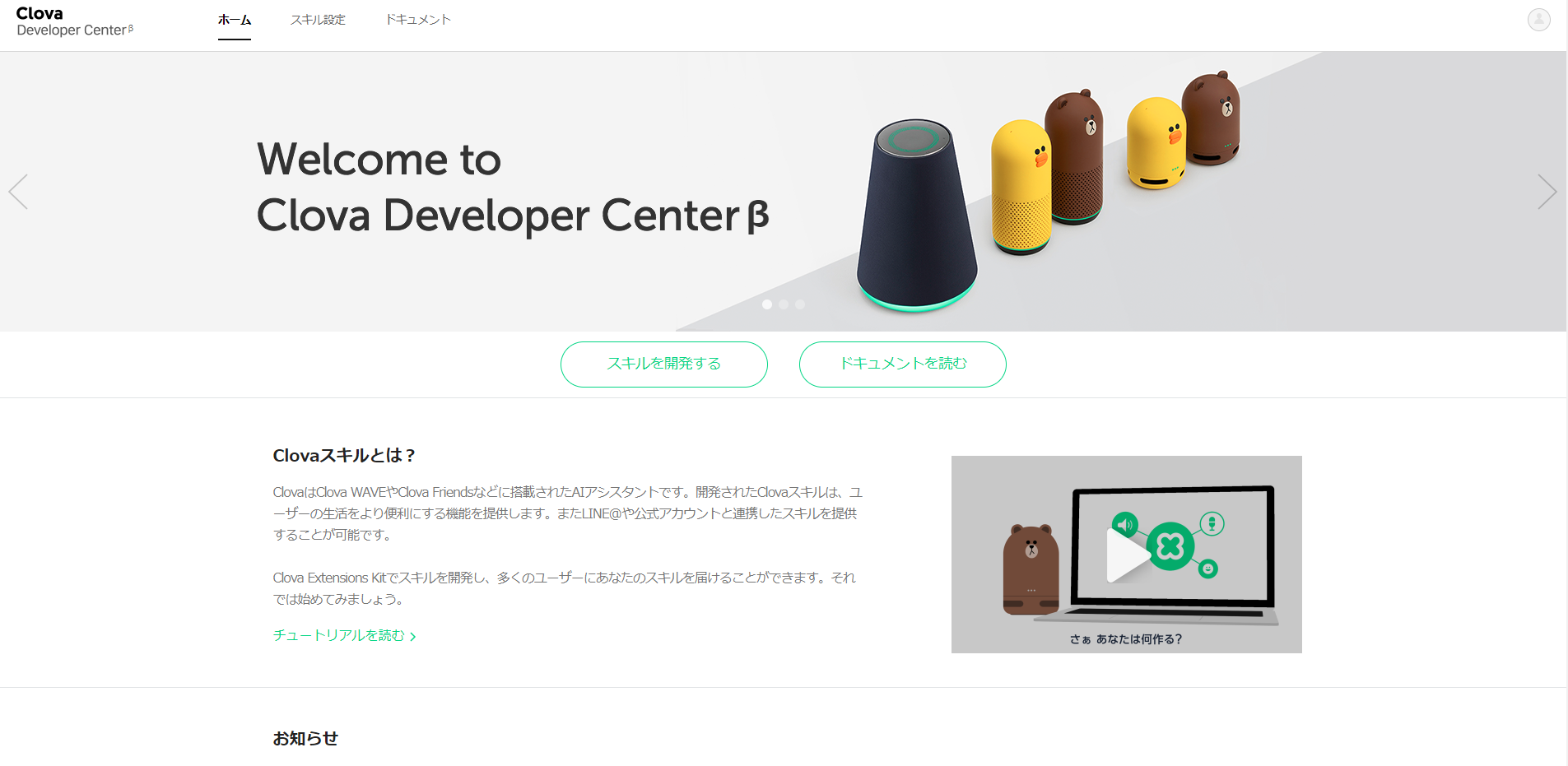
Clova Developer Center β
https://clova-developers.line.biz/
スキル設定、または、スキルを開発する ボタンを押下します。
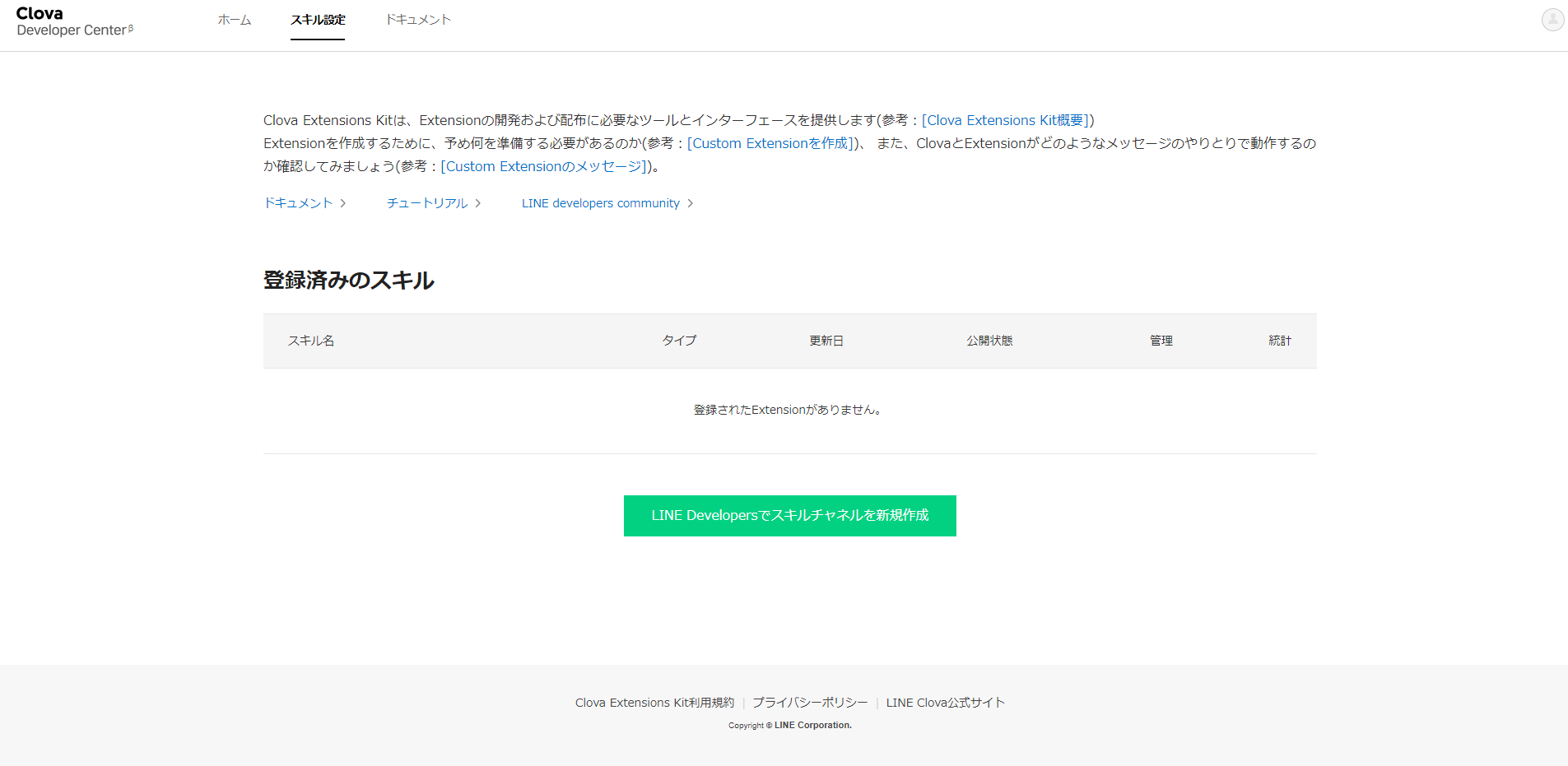
それでは、「LINE Developersでスキルチャネルを新規作成」を押下しましょう。
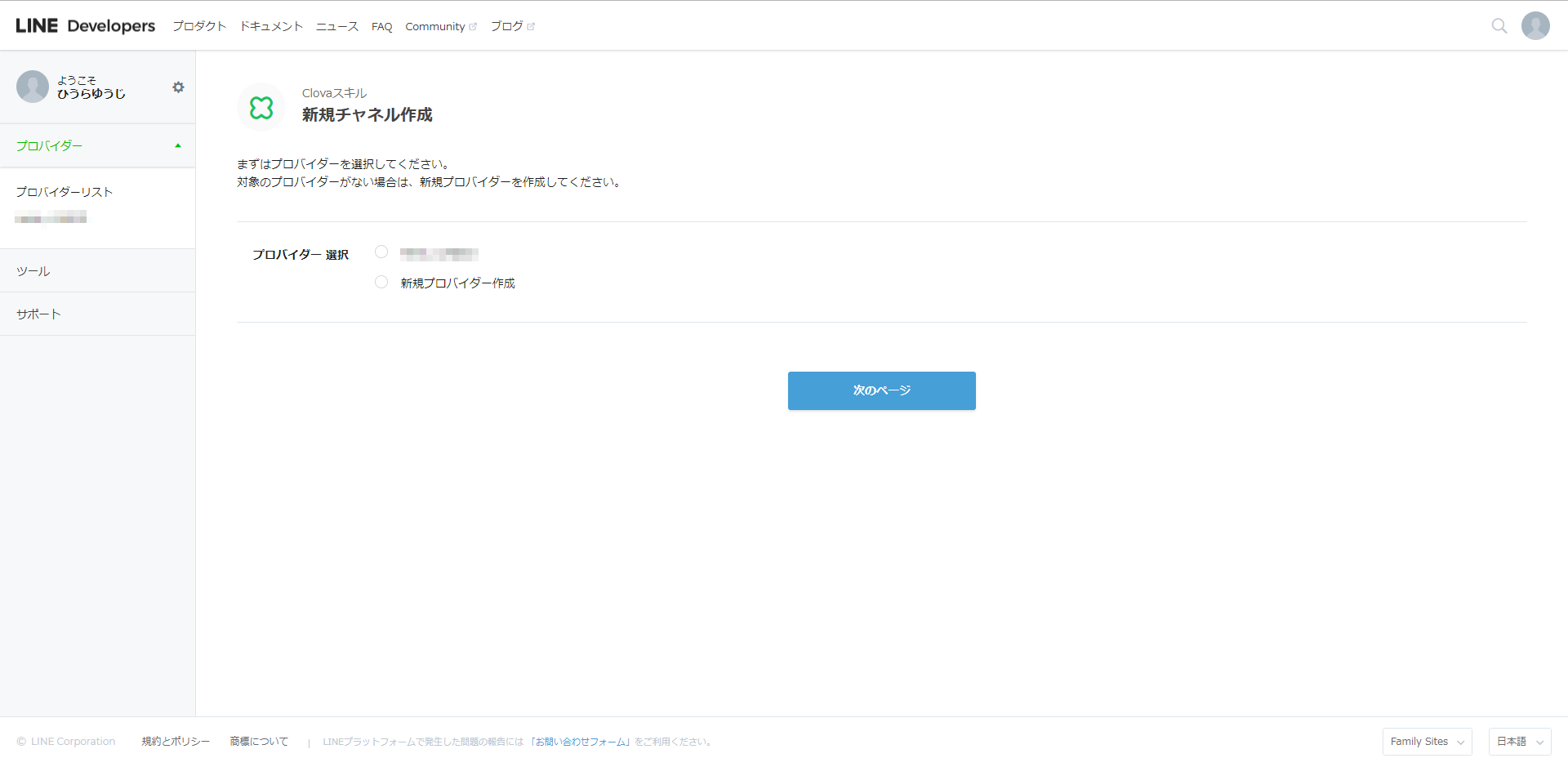
まずは、プロバイダを選択します。まだ作っていなければ、これを機に作りましょう。
チャネル名は適当に「テストスキル」にしました。
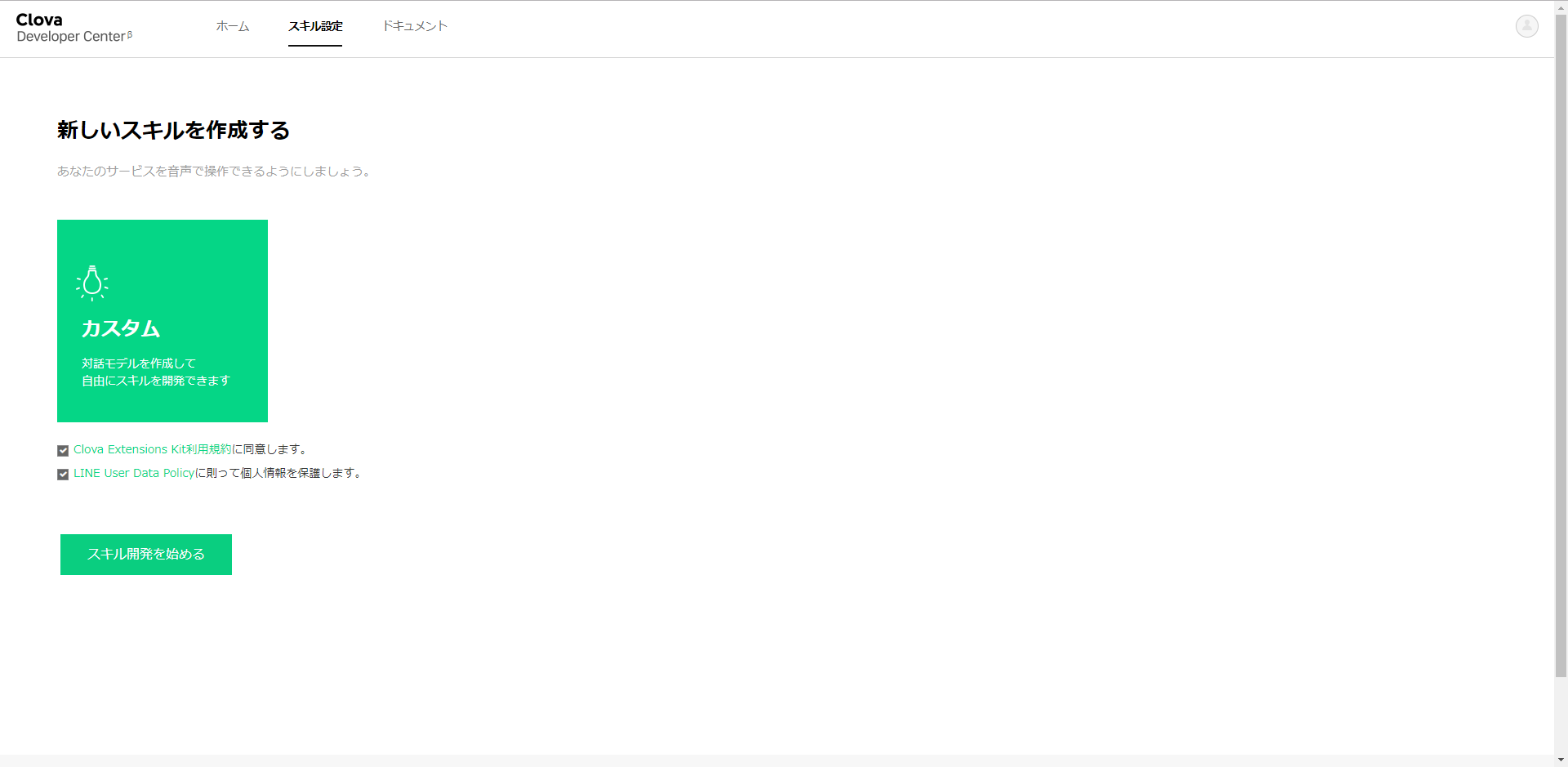
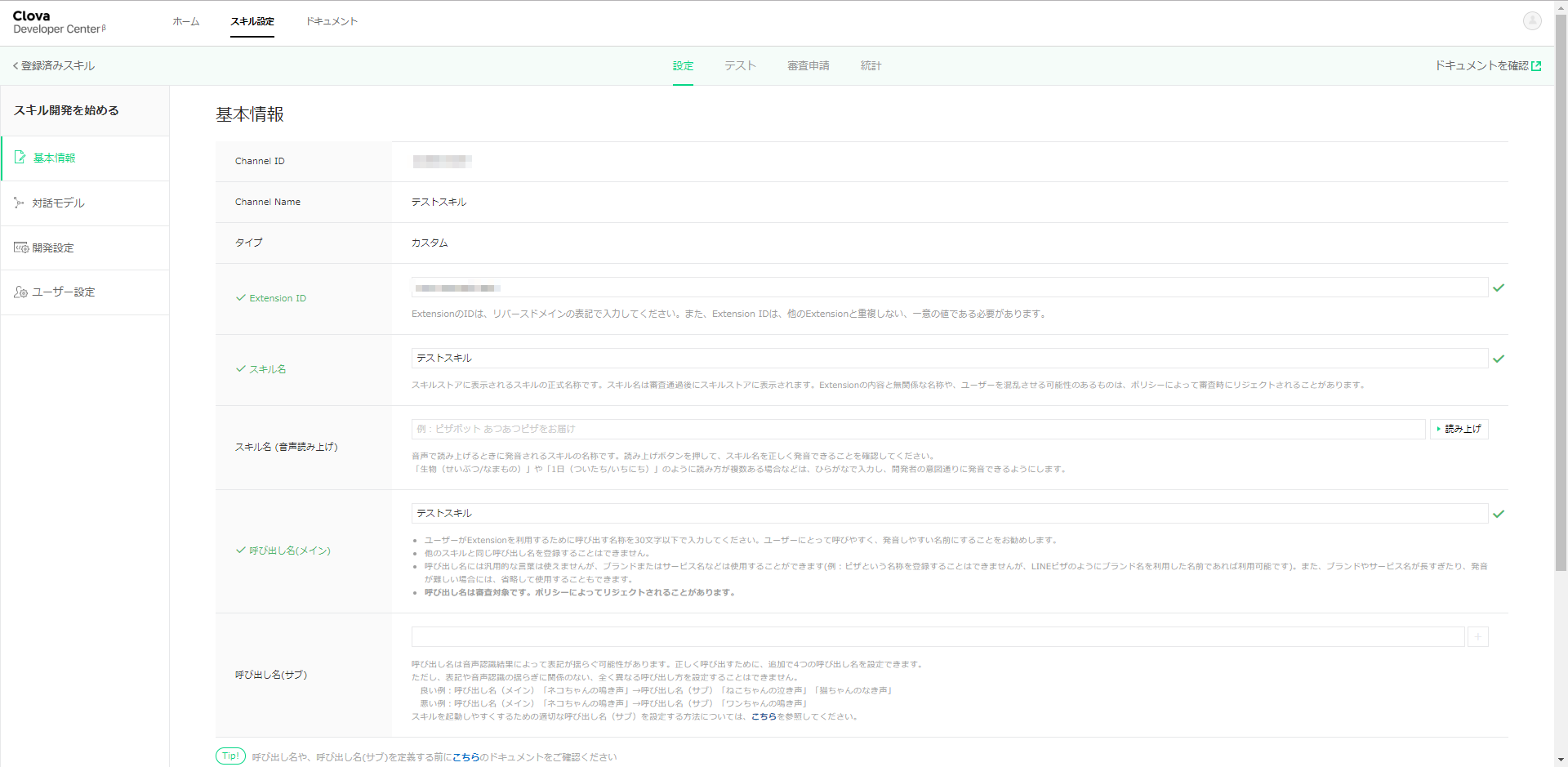
さあ、スキル開発を始めましょう。
手始めに、いくつか入力しなければいけないのですが、適当で大丈夫です。スキル名や呼び出し名は「テストスキル」にしました。
それでは、発話を設定していきます。
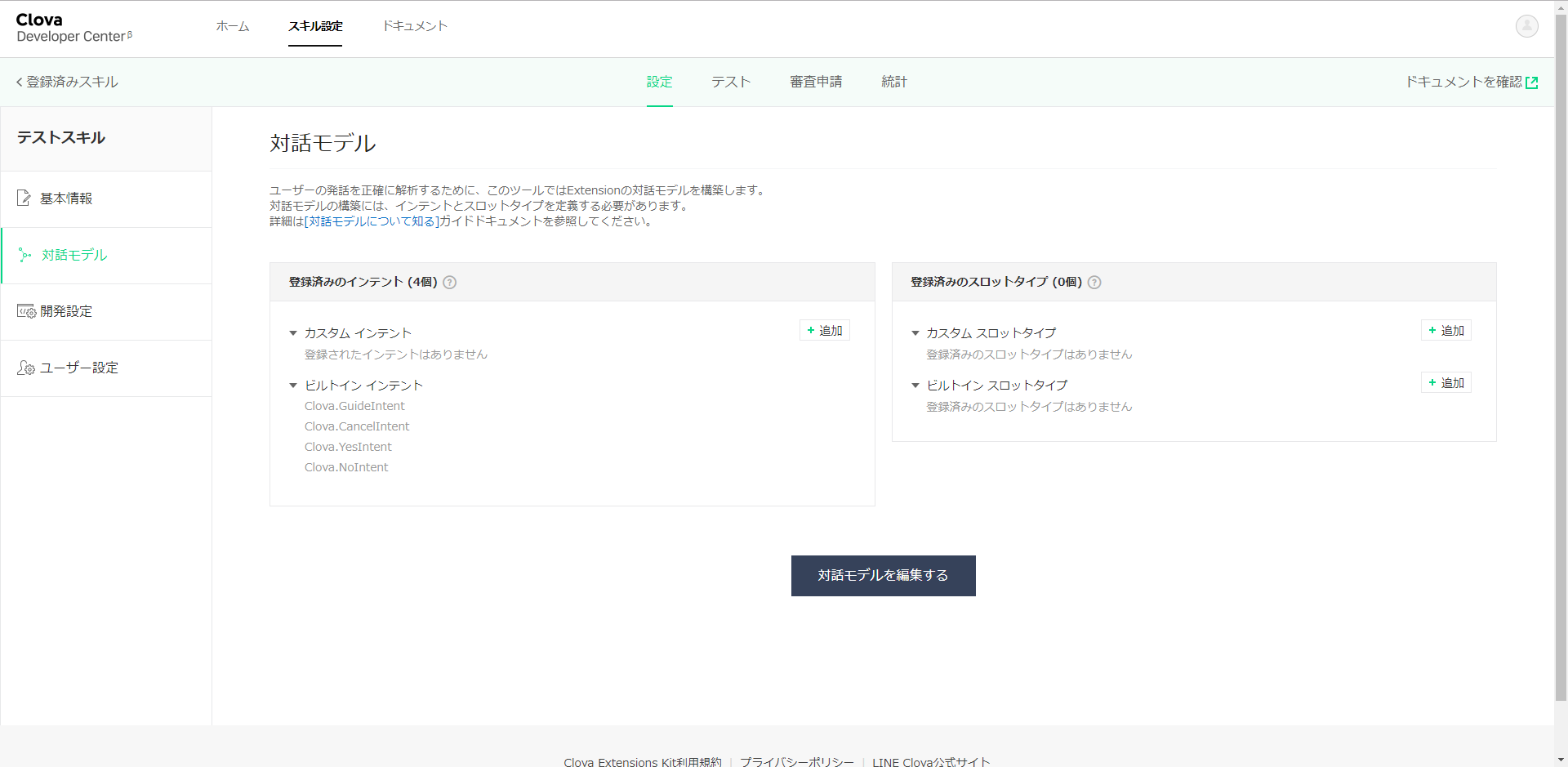
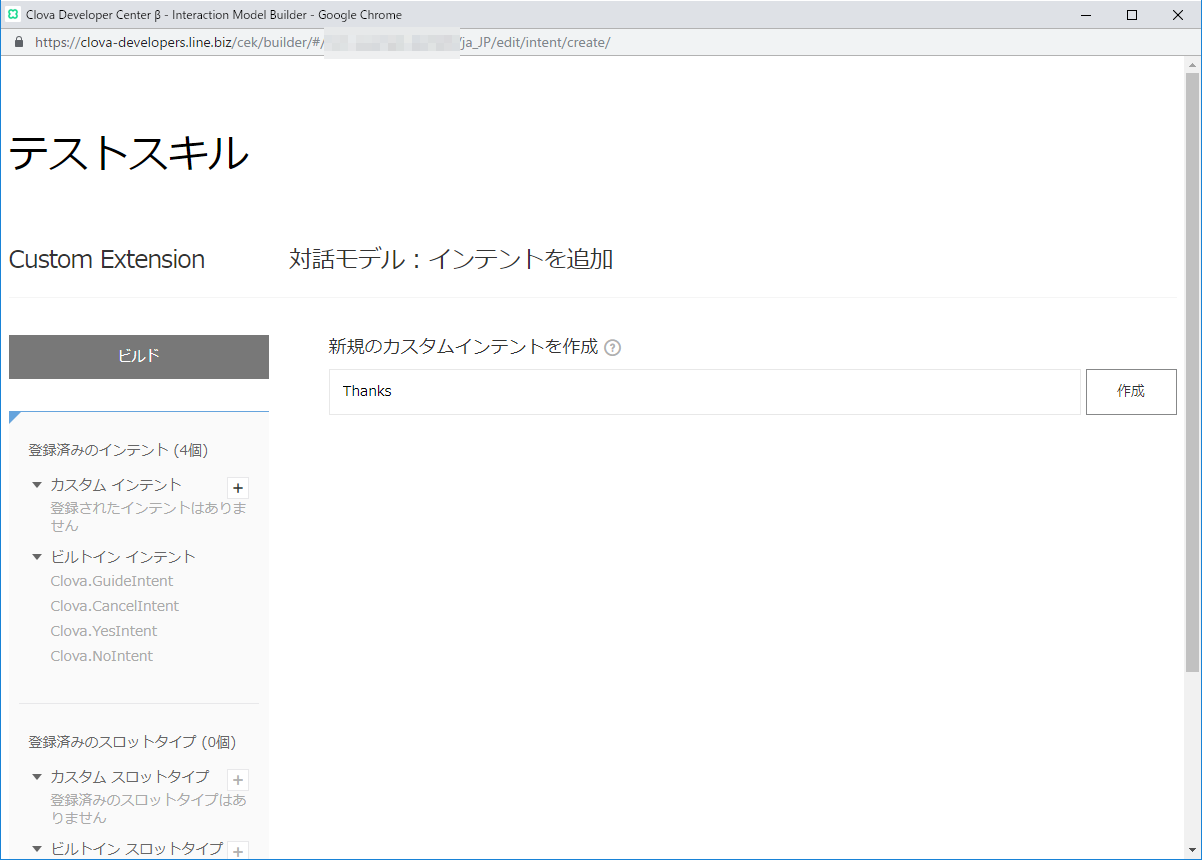
まずは、カスタムインテントを作りましょう。毎度の通り、インテント名を「Thanks」とします。
「ありがとう」というと「どういたしまして」、と返すためです。
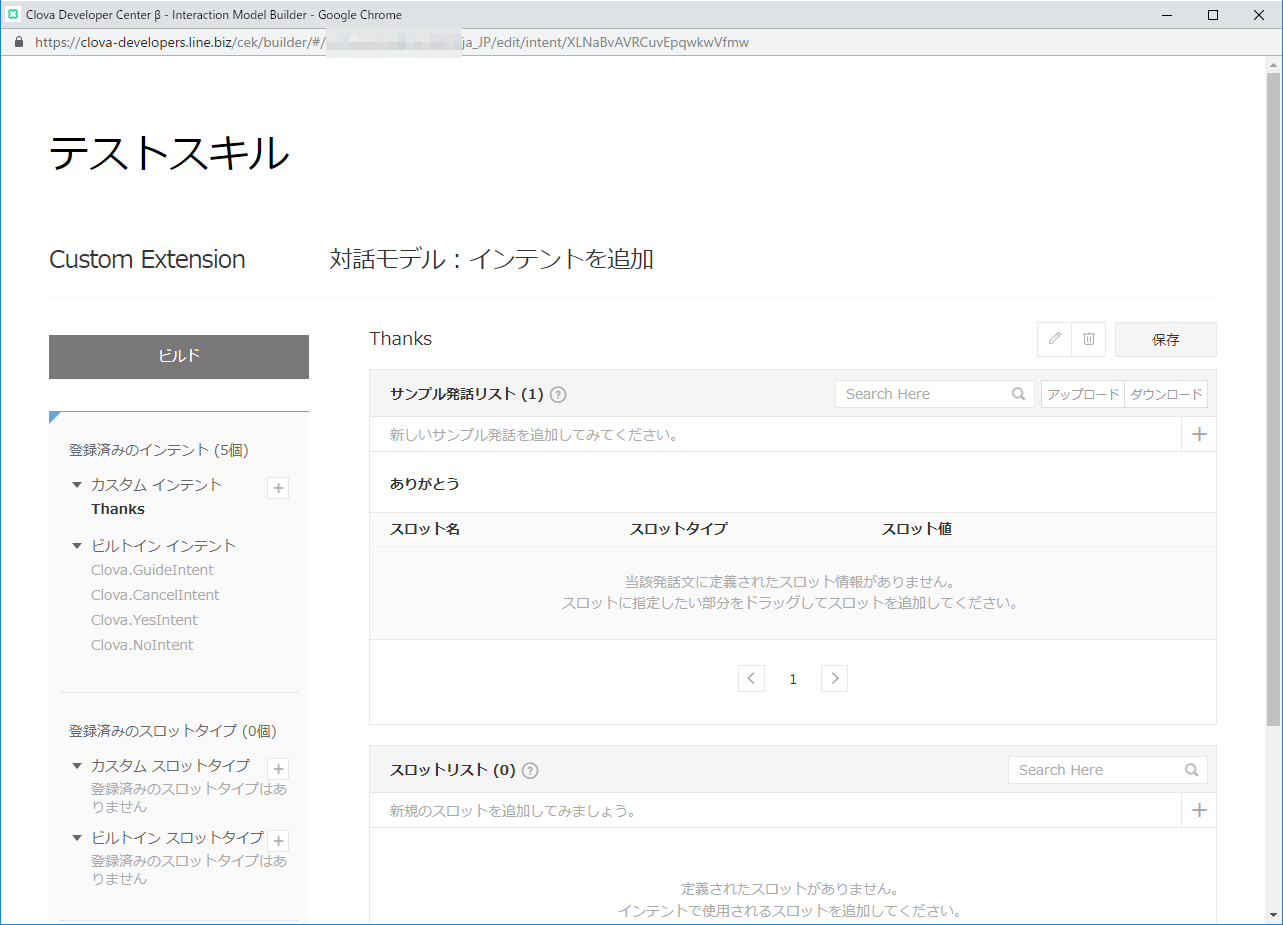
サンプル発話に「ありがとう」と入力します。
そして、ビルドボタンでビルドを開始しておきます。
完了まで数分かかります。ローカルのデバッグ環境に転送する。
それでは、受け付けた発話をローカルのデバッグ環境に転送する設定をします。
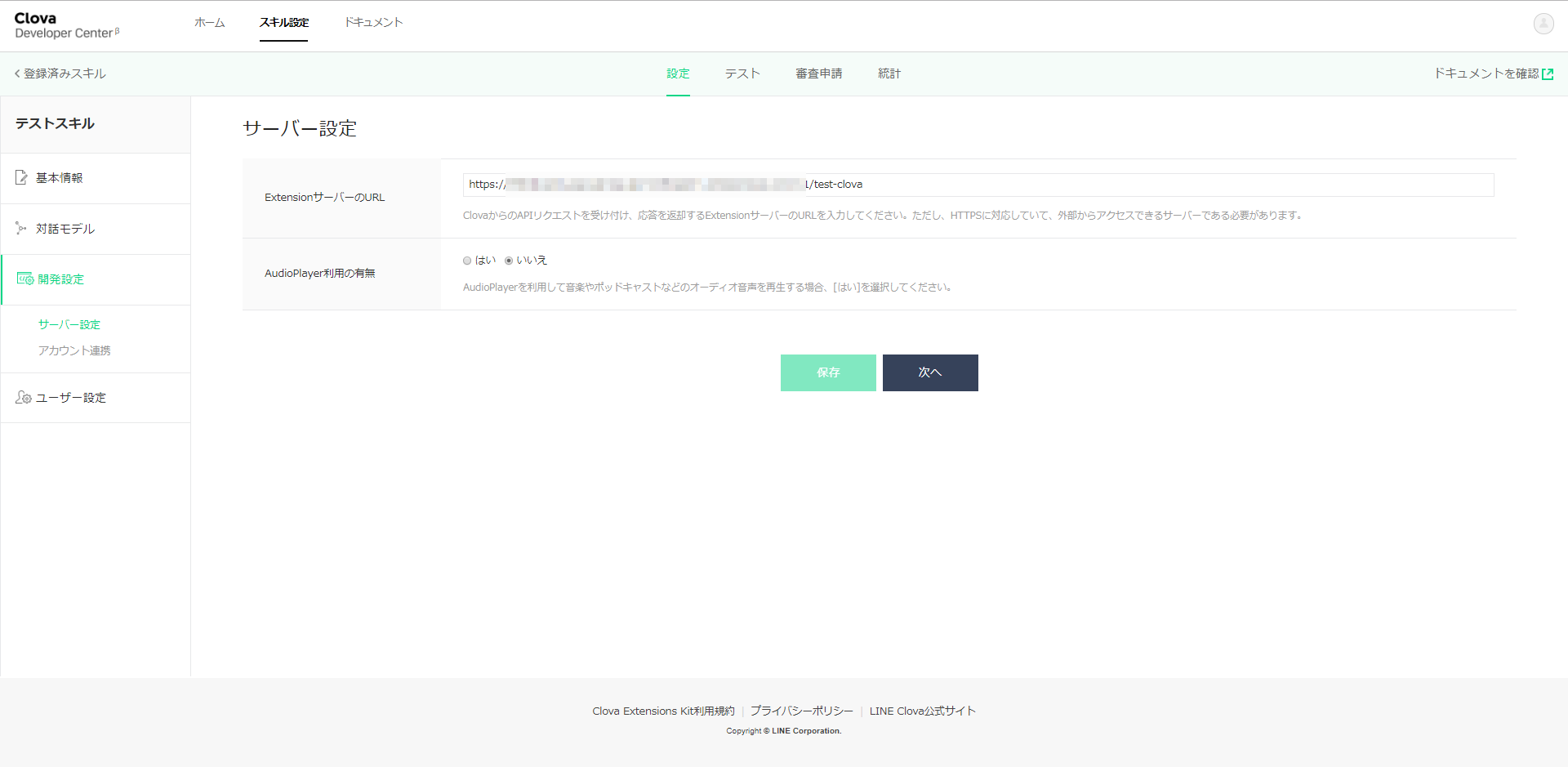
左側のナビゲータから開発設定を選択します。
ここで表示される「ExtensionサーバーのURL」に、これから立ち上げるRESTfulサーバのURLを指定します。
そして、保存ボタンを押下しておきます。ローカルのデバッグ環境を立ち上げる。
それでは、転送を引き受けるデバッグ環境を設定していきます。
Swagger定義ファイルは以下の感じです。
swagger.yaml/test-clova: post: x-swagger-router-controller: routing operationId: test-clova parameters: - in: body name: body schema: $ref: "#/definitions/CommonRequest" responses: 200: description: Success schema: $ref: "#/definitions/CommonResponse"実装の場所をrouting.jsに指定するのですが、これまたちょっと違う場所に指定します。Alexaの時と同じところです。
routing.jsconst alexa_table = { // "test-alexa" : require('./test_alexa').handler, // "test-clova": require('./test-clova').handler, "test-clova": require('./test-clova').handler, };実装には、以下のnpmモジュールを利用しますので、ローカル環境にインストールしておきます。
npm install --save @line/clova-cek-sdk-nodejs
実装は
api/controllers/test-clova/index.jsに置きます。index.jsconst clova = require('@line/clova-cek-sdk-nodejs'); const HELPER_BASE = process.env.HELPER_BASE || '../../helpers/'; const ClovaUtils = require( HELPER_BASE + 'clova-utils'); const app = new ClovaUtils(clova); app.intent('LaunchRequest', async (responseHelper) =>{ responseHelper.setSimpleSpeech({ lang: 'ja', type: 'PlainText', value: 'こんにちは', }); }); app.intent('Thanks', async (responseHelper) =>{ responseHelper.setSimpleSpeech({ lang: 'ja', type: 'PlainText', value: 'どういたしまして。', }); }); exports.handler = app.lambda();Dialogflowと同じような書き方ができるように、ヘルパを使っています。
api/helpers/clova-utils.jsに置きます。clova-utils.js'use strict'; class ClovaUtils{ constructor(clova){ this.clova = clova; this.clovaSkillHandler = clova.Client.configureSkill(); this.launchHandle = null; this.eventHandle = null; this.sessionEndedHandle = null; this.intentHandles = new Map(); this.clovaSkillHandler .onLaunchRequest(async responseHelper => { if( this.launchHandle ){ console.log('handle: LaunchRequest called'); return await this.launchHandle(responseHelper); } }) .onIntentRequest(async responseHelper => { const intent = responseHelper.getIntentName(); var handle = this.intentHandles.get(intent); if( handle ){ console.log('handle: ' + intent + ' called'); return await handle(responseHelper); } }) .onSessionEndedRequest(async responseHelper => { if( this.sessionEndedHandle ){ console.log('handle: SessionEndedRequest called'); return await this.sessionEndedHandle(responseHelper); } }) .onEventRequest(async responseHelper => { if( this.eventHandle ){ console.log('handle: EventRequest called'); return await this.eventdHandle(responseHelper); } }); } intent( matcher, handle ){ if( matcher == 'LaunchRequest') this.launchHandle = handle; else if( matcher == 'SessionEndedRequest') this.sessionEndedHandle = handle; else if( matcher == 'EventRequest') this.eventHandle = handle; else this.intentHandles.set(matcher, handle); } getAttributes( responseHelper ){ return responseHelper.getSessionAttributes(); } setAttributes( responseHelper, attributes){ responseHelper.setSessionAttributes(attributes); } getSlots( responseHelper ){ return responseHelper.getSlots(); } handle(){ return this.clovaSkillHandler.handle(); } lambda(){ return this.clovaSkillHandler.lambda(); } }; module.exports = ClovaUtils;こんな感じで、インテント名を指定すれば、それに該当する発話を受けて関数が呼ばれます。
app.intent(【インテント名】, async (responseHelper) =>{
関数の中身は、Clovaが提供してくれているSDKの作法に従います。
Clova CEK SDK Nodejs
https://github.com/line/clova-cek-sdk-nodejsインテント名「LaunchRequest」は、特別なインテントで、***を開いて と言ってスキルを起動させたときに呼ばれるものです。
さあ、起動させましょう。
Clova Developer Centerで接続確認ができます。
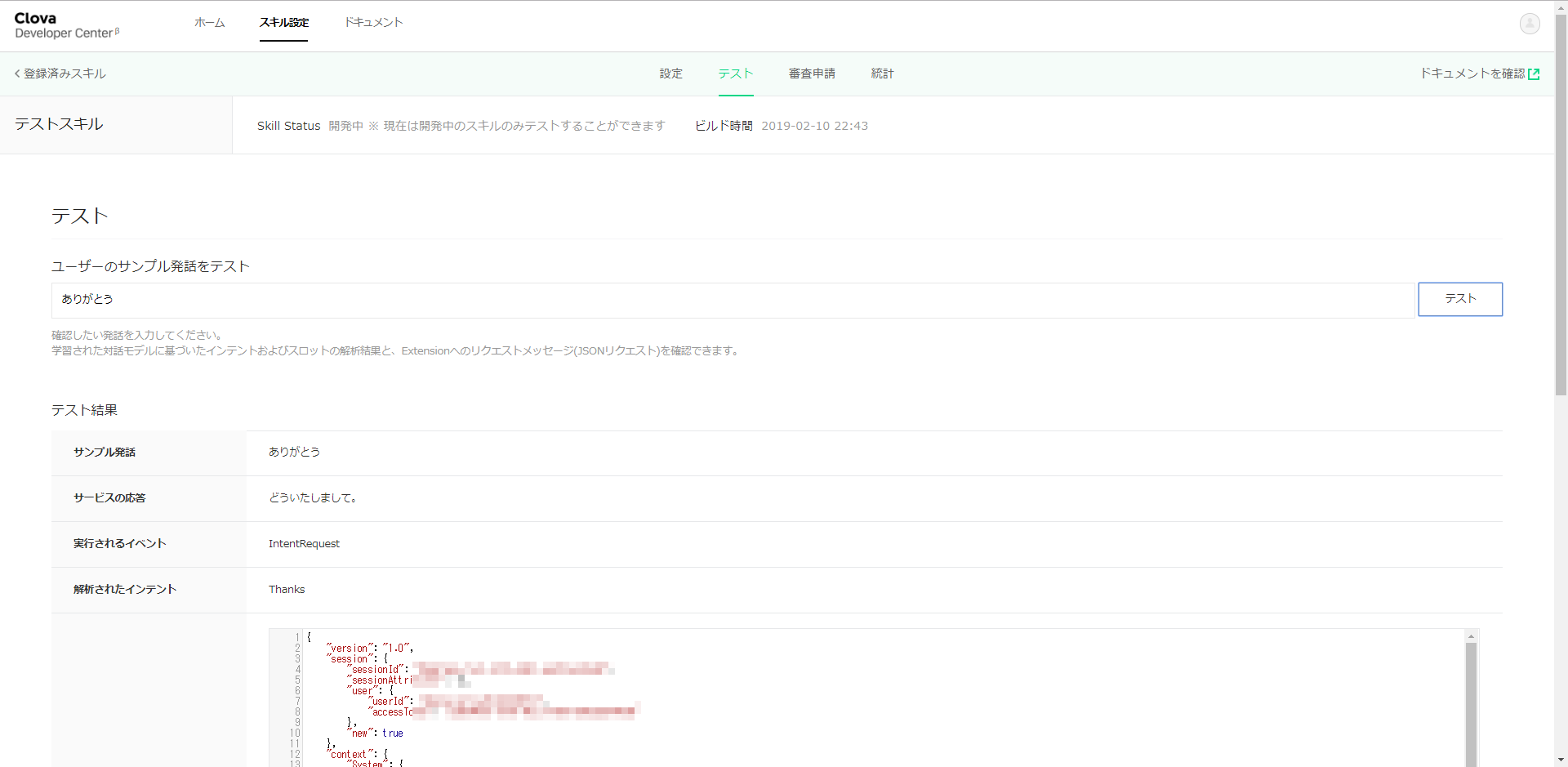
テストタブを選択します。「ユーザのサンプル発話をテスト」のところに、「ありがとう」と入力して、「テスト」ボタンを押してみましょう。
「どういたしまして」が返ってきましたでしょうか?
Clova Friendsでも試してみます。
Clovaに対して、以下を話してみましょう。→「Clova、テストスキルを開いて」
← 「こんにちは」
→「ありがとう」
← 「どういたしまして」この通りになりましたでしょうか?
Lambdaに配置する
以下を参考に、アップロードします。
SwaggerでLambdaのデバッグ環境を作る(1)
SwaggerでLambdaのデバッグ環境を作る(3):DialogflowをデバッグするSwaggerでLambdaのデバッグ環境を作る(1)の「AWS LambdaにヘルパライブラリのLayerを追加」のあたりからです。
注意点として、clova-utils.jsというヘルパーライブラリを追加していますので、レイヤは更新が必要です。
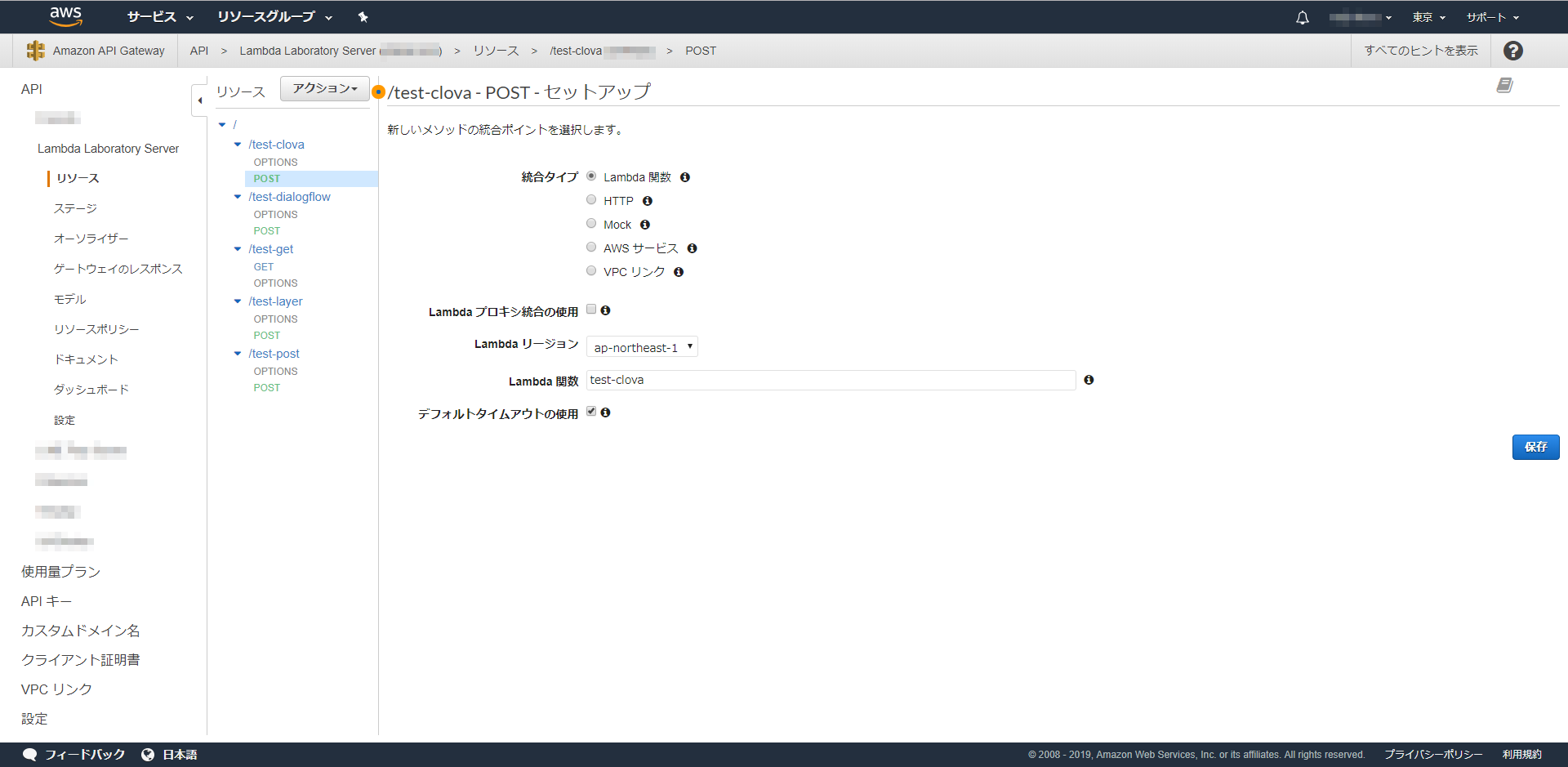
また、Clova用にnpmモジュールを追加していますので、Lambdaに上げるときに一緒にアップしてください。それについては、SwaggerでLambdaのデバッグ環境を作る(3)の「Lambdaにアップロードする」 のあたりを参考にしてください。API Gatewayのエンドポイントを作る際に、注意点があります。
「Lambda プロキシ統合の使用」のチェックボックスはOnにしないでください。
以上です。