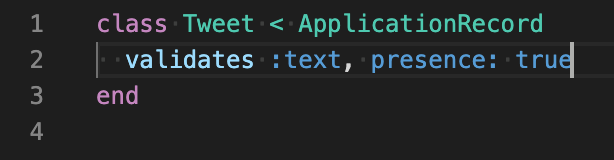
ExecJS::RuntimeUnavailable: Could not find a JavaScript runtime. See https://github.com/rails/execjs for a list of available runtimes.
/var/www/chat-space/config/application.rb:7:in `<top (required)>'
/var/www/chat-space/Rakefile:4:in `require_relative'
/var/www/chat-space/Rakefile:4:in `<top (required)>'
(See full trace by running task with --trace)
C:\Users\foobar>gem install sqlite3 --platform ruby
Temporarily enhancing PATH for MSYS/MINGW...
Installing required msys2 packages: mingw-w64-x86_64-sqlite3
警告: mingw-w64-x86_64-sqlite3-x.xx.x-x は最新です -- スキップ
Building native extensions. This could take a while...
ERROR: Error installing sqlite3:
ERROR: Failed to build gem native extension.
current directory: C:/Ruby26-x64/lib/ruby/gems/2.6.0/gems/sqlite3-1.4.0/ext/sqlite3
C:/Ruby26-x64/bin/ruby.exe -r ./siteconfyyyymmdd-foooo-baaaaar.rb extconf.rb
*** extconf.rb failed ***
Could not create Makefile due to some reason, probably lack of necessary
libraries and/or headers. Check the mkmf.log file for more details. You may
need configuration options.
Provided configuration options:
--with-opt-dir
--without-opt-dir
--with-opt-include
--without-opt-include=${opt-dir}/include
--with-opt-lib
--without-opt-lib=${opt-dir}/lib
--with-make-prog
--without-make-prog
--srcdir=.
--curdir
--ruby=C:/Ruby25-x64/bin/$(RUBY_BASE_NAME)
--with-sqlcipher
--without-sqlcipher
--with-sqlite3-config
--without-sqlite3-config
--with-pkg-config
--without-pkg-config
C:/Ruby26-x64/lib/ruby/2.6.0/mkmf.rb:467:in `try_do': The compiler failed to generate an executable file. (RuntimeError)
You have to install development tools first.
from C:/Ruby26-x64/lib/ruby/2.6.0/mkmf.rb:552:in `try_link0'
from C:/Ruby26-x64/lib/ruby/2.6.0/mkmf.rb:570:in `try_link'
from C:/Ruby26-x64/lib/ruby/2.6.0/mkmf.rb:672:in `try_ldflags'
from C:/Ruby26-x64/lib/ruby/2.6.0/mkmf.rb:1832:in `pkg_config'
from extconf.rb:35:in `<main>'
To see why this extension failed to compile, please check the mkmf.log which can be found here:
C:/Ruby26-x64/lib/ruby/gems/2.6.0/extensions/x64-mingw32/2.6.0/sqlite3-x.x.x/mkmf.log
extconf failed, exit code 1
Gem files will remain installed in C:/Ruby25-x64/lib/ruby/gems/2.5.0/gems/sqlite3-x.x.x for inspection.
Results logged to C:/Ruby26-x64/lib/ruby/gems/2.6.0/extensions/x64-mingw32/2.5.0/sqlite3-x.x.x/gem_make.out
$(function(){letbuildPrompt=`<option value>---</option>`letbuildHtmlOption=function(parent){letoption=`<option value ="${parent.id}">${parent.name}</option>`returnoption}$('#parent').change(function(){letparent_id=$(this).val();$.ajax({type:'GET',url:'products/new/children_category',data:{parent_category_id:parent_id},dataType:'json'}).done(function(parent){$('.child').css('display','block');$('#child').empty();$('.grand_child').css('display','none');$('#child').append(buildPrompt);parent.forEach(function(child){varhtml_option=buildHtmlOption(child);$('#child').append(html_option);});}).fail(function(){alert('エラー')});});$(this).on("change","#child",function(){letparent_id=$("#parent").val();letchild_id=$("#child").val();$.ajax({type:'GET',url:'products/new/grandchildren_category',data:{parent_category_id:parent_id,children_category_id:child_id},dataType:'json'}).done(function(parent){$('.grand_child').css('display','block');$('#grand_child').empty();$('#grand_child').append(buildPrompt);parent.forEach(function(child){varhtml_option=buildHtmlOption(child);console.log(buildHtmlOption(html_option));$('#grand_child').append(html_option);});})});})
//①=====HTMLで表示させるviewを定義===========================$(function(){letbuildPrompt=`<option value>---</option>`letbuildHtmlOption=function(parent){letoption=`<option value ="${parent.id}">${parent.name}</option>`returnoption}//=================================================//②=====親カテゴリーが選択され子カテゴリーを呼び出す処理============$('#parent').change(function(){letparent_id=$(this).val();//ajaxでコントローラーに送る$.ajax({type:'GET',url:'products/new/children_category',data:{parent_category_id:parent_id},dataType:'json'})//以下はコントローラーからのレスポンス後の処理.done(function(parent){$('.child').css('display','block');$('#child').empty();$('.grand_child').css('display','none');$('#child').append(buildPrompt);//コントローラーから取得した値をforEachで全て取得し、.appendでHTML要素に追加するparent.forEach(function(child){varhtml_option=buildHtmlOption(child);$('#child').append(html_option);});}).fail(function(){alert('エラー')});});//=============================================//②=====子カテゴリーが選択され孫カテゴリーを呼び出す処理============$(this).on("change","#child",function(){letparent_id=$("#parent").val();letchild_id=$("#child").val();//ajaxでコントローラーに送る$.ajax({type:'GET',url:'products/new/grandchildren_category',data:{parent_category_id:parent_id,children_category_id:child_id},dataType:'json'})//以下はコントローラーからのレスポンス後の処理.done(function(parent){$('.grand_child').css('display','block');$('#grand_child').empty();$('#grand_child').append(buildPrompt);//コントローラーから取得した値をforEachで全て取得し、.appendでHTML要素に追加するparent.forEach(function(child){varhtml_option=buildHtmlOption(child);console.log(buildHtmlOption(html_option));$('#grand_child').append(html_option);});})});//=============================================})
Processing by HomesController#new_guest as HTML
Parameters:{"authenticity_token"=>"c1Qc02T4i6+77OtxhGDwxJwEQUYO8d9cIncoNjZ/hXa5c3IzxHPjFAr2QleTBCuMpnxd5+1Sk+HRa9RNXLGSkg=="}
Completed 401 Unauthorized in 1ms (ActiveRecord: 0.0ms)
Processing by Users::SessionsController#new_guest as HTML
Parameters: {"authenticity_token"=>"2UEwYr4gIvtHF4GqHNPaXIiWgQSbEXPVjI9kneVS27oTZl6CHqtKQPYNKIwLtwEUsu6dpXiyP2h/k5jmj5zMXg=="}
User Load (4.0ms) SELECT `users`.* FROM `users` WHERE `users`.`email` = 'guest@example.com' LIMIT 1
↳ app/models/user.rb:31
Redirected to http://localhost:3000/
Completed 302 Found in 10ms (ActiveRecord: 4.0ms)
Processing by HomesController#new_guest as HTML
Parameters:{"authenticity_token"=>"c1Qc02T4i6+77OtxhGDwxJwEQUYO8d9cIncoNjZ/hXa5c3IzxHPjFAr2QleTBCuMpnxd5+1Sk+HRa9RNXLGSkg=="}
Completed 401 Unauthorized in 1ms (ActiveRecord: 0.0ms)
Processing by Users::SessionsController#new_guest as HTML
Parameters: {"authenticity_token"=>"2UEwYr4gIvtHF4GqHNPaXIiWgQSbEXPVjI9kneVS27oTZl6CHqtKQPYNKIwLtwEUsu6dpXiyP2h/k5jmj5zMXg=="}
User Load (4.0ms) SELECT `users`.* FROM `users` WHERE `users`.`email` = 'guest@example.com' LIMIT 1
↳ app/models/user.rb:31
Redirected to http://localhost:3000/
Completed 302 Found in 10ms (ActiveRecord: 4.0ms)
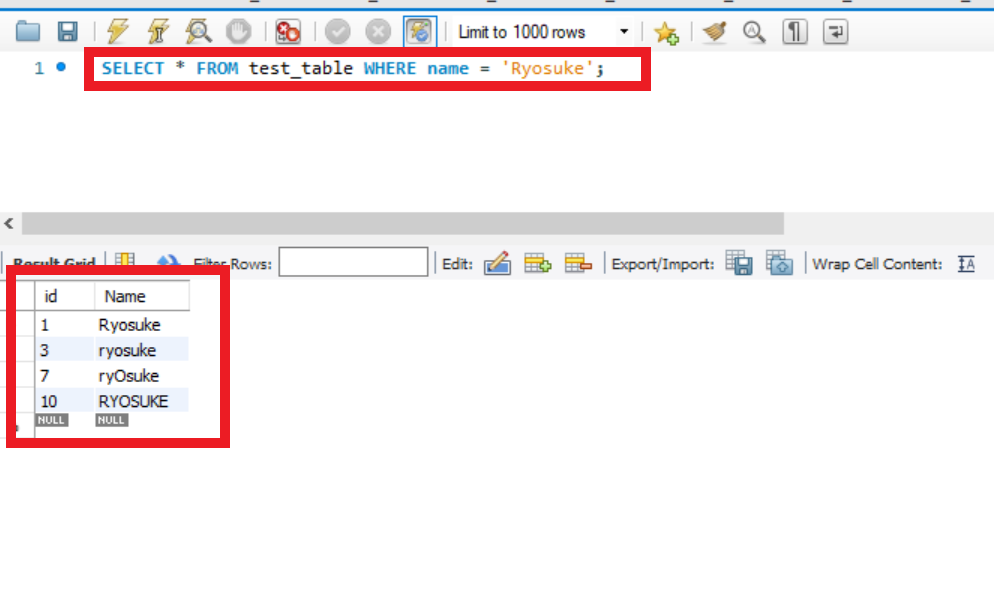
$ ruby rds_cache.rb "SELECT * FROM test_table WHERE name = 'Ryosuke';"
Cache MISS
[Query results from datasource]
--------------------id=> 1
Name => Ryosuke
--------------------id=> 3
Name => ryosuke
--------------------id=> 7
Name => ryOsuke
--------------------id=> 10
Name => RYOSUKE
[ec2-user@ip-172-31-34-150 ~]$ ruby rds_cache.rb "SELECT * FROM test_table WHERE name = 'Ryosuke';"
Cache HIT!
[Query results from cache]
--------------------id=> 1
Name => Ryosuke
--------------------id=> 3
Name => ryosuke
--------------------id=> 7
Name => ryOsuke
--------------------id=> 10
Name => RYOSUKE
③小文字化かつスペースをいじったクエリを再実行(キャッシュヒットパターン2)
[ec2-user@ip-172-31-34-150 ~]$ ruby rds_cache.rb "select * from test_table where name = 'Ryosuke';"
Cache HIT!
[Query results from cache]
--------------------id=> 1
Name => Ryosuke
--------------------id=> 3
Name => ryosuke
--------------------id=> 7
Name => ryOsuke
--------------------id=> 10
Name => RYOSUKE