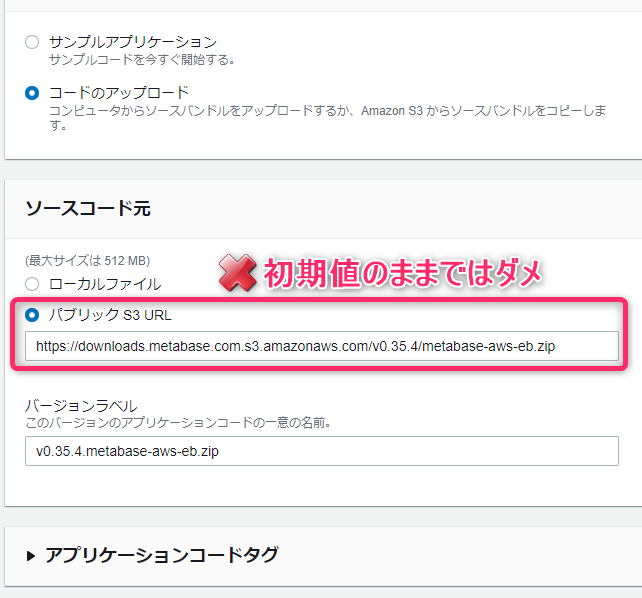
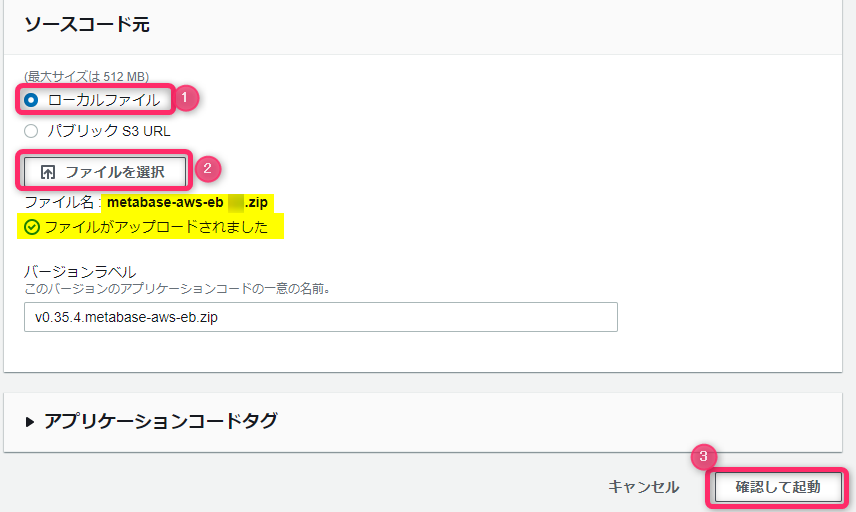
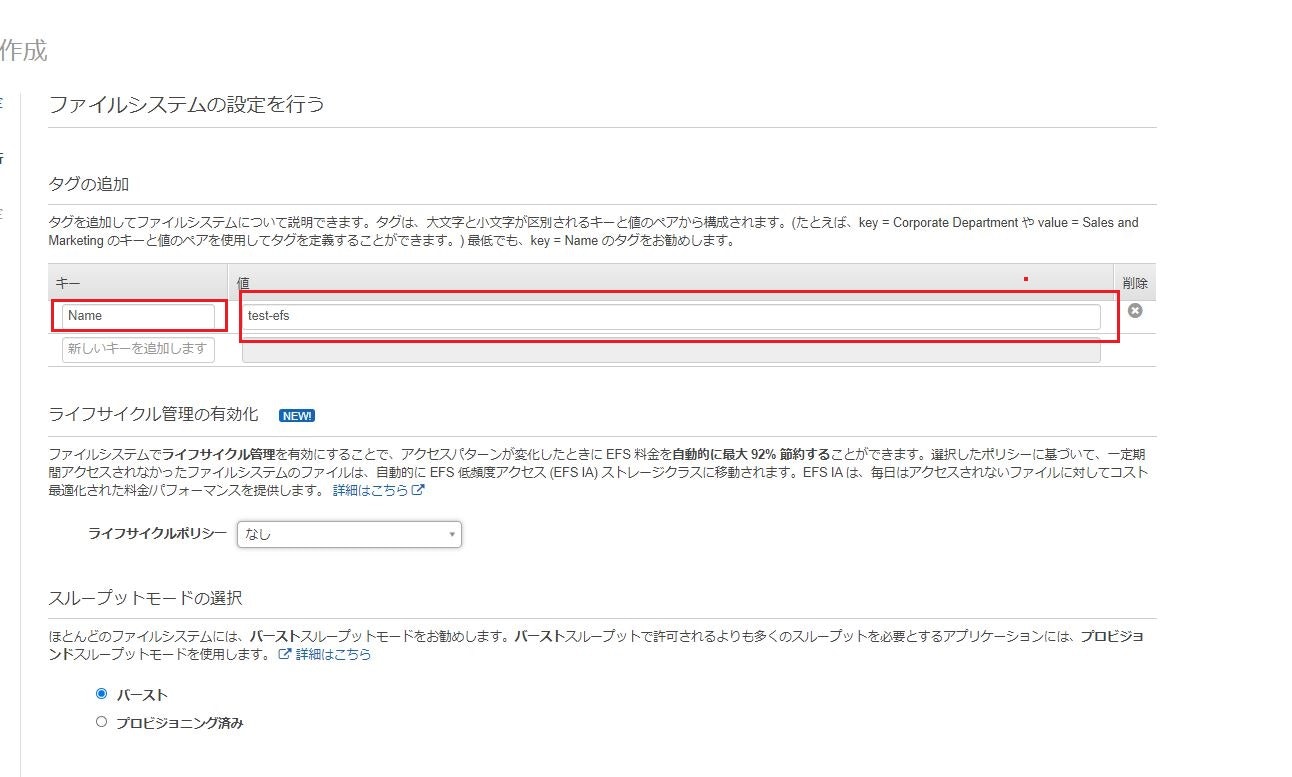
コスト削減の一環でステージング環境のEC2インスタンスを整理していたときのお話
ECS on EC2やら on Fargateを行き来していてとあるタイミングでEC2インスタンスが要らなくなったと勘違いしてコンソール上でボケーッとインスタンスを削除しました
が、なんと運悪くコスト節約のためにElasticsearchとECS on EC2の共有ホストを削除してしまっていました ステージング環境くらいからはちゃんとインフラもコード管理 & 気分でリソース削除しないこと
DB を使っていると、設定を変更したくなることが多々あります。
例えば、私の場合は DB インスタンスのリソースがまだガッツリ残っているのに Too many connections が出るようになったので、max_connections を引き上げたくなりました。
それ以外でも、例えば、slow_query_log を出したい/出したくないとか、その閾値 long_query_time を変えたいなどといったことはよくあると思います。
しかしながら、、、デフォルトのパラメータグループではパラメータの設定変更が一切できません!
つまり、どうしても設定変更をしたいのであれば、まずは DB インスタンスが使用しているパラメータグループ自体を変えないといけないことになります。
DB インスタンスを作成する際に、安易にデフォルトのパラメータグループを使うことを選択しただけでサービス停止を余儀なくされるのは、サービスによってはとても痛いと思います。
独自のパラメータグループを作成することはまったく難しくないので、DB インスタンスの作成時には必ずパラメータグループも新規に作成するクセを付けるくらいで良いと思います。
パラメータグループの設定パラメータの変更
稼働中の DB インスタンスで使われているパラメータグループの設定パラメータの変更は、DB インスタンスの再起動無しに動的に行えます。
ただし、動的パラメータと呼ばれるパラメータのみで、静的パラメータの変更後の有効化には再起動が必要となります。
パラメータグループの共有
独自に作成したパラメータグループを複数の DB インスタンスで共有することも可能です。
これはこれで便利な仕組みなのですが、注意が必要です。
設定パラメータの変更は、あくまでもパラメータグループの内容の変更になります。
従って、設定パラメータを変更するとそのパラメータグループを参照しているすべての DB インスタンスの設定が変更されます。
よって、明確に設定値を揃える必要がない限りは、基本的にはそれぞれの DB インスタンスには別々のパラメータグループを用意するのが無難だと思います。
※例えば、同じ種別の複数台のreadレプリカには同じパラメータグループを割り当てた方が都合が良いといったことが考えられます。
satton@sattonMBP AWS_SSH % sudo ssh -i testkey.pem ec2-user@3.112.4.99
The authenticity of host '3.112.4.99 (3.112.4.99)' can't be established.
ECDSA key fingerprint is SHA256:dTS2Al40C6Ewa/hi//jd50WDbbAUVJsGnrC6Y0z/6x8.
Are you sure you want to continue connecting (yes/no/[fingerprint])? yes
Warning: Permanently added '3.112.4.99' (ECDSA) to the list of known hosts.
__| __|_ )
_| ( / Amazon Linux 2 AMI
___|\___|___|
https://aws.amazon.com/amazon-linux-2/
13 package(s) needed for security, out of 22 available
Run "sudo yum update" to apply all updates.
[ec2-user@ip-10-0-0-124 ~]$
※キーペアの絶対パス指定でも可能
satton@sattonMBP ~ % sudo ssh -i /Users/satton/Desktop/AWS_SSH/testkey.pem ec2-user@3.112.4.99
Last login: Wed Jul 1 12:44:28 2020 from om126204165127.6.openmobile.ne.jp
__| __|_ )
_| ( / Amazon Linux 2 AMI
___|\___|___|
https://aws.amazon.com/amazon-linux-2/
13 package(s) needed for security, out of 22 available
Run "sudo yum update" to apply all updates.
[ec2-user@ip-10-0-0-124 ~]$
sudoを付けない場合
ファイルの権限の関係でSSHログインができません。
satton@sattonMBP ~ % ssh -i /Users/satton/Desktop/AWS_SSH/testkey.pem ec2-user@3.112.4.99
The authenticity of host '3.112.4.99 (3.112.4.99)' can't be established.
ECDSA key fingerprint is SHA256:dTS2Al40C6Ewa/hi//jd50WDbbAUVJsGnrC6Y0z/6x8.
Are you sure you want to continue connecting (yes/no/[fingerprint])? yes
Failed to add the host to the list of known hosts (/Users/satton/.ssh/known_hosts).
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
@ WARNING: UNPROTECTED PRIVATE KEY FILE! @
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
Permissions 0644 for '/Users/satton/Desktop/AWS_SSH/testkey.pem' are too open.
It is required that your private key files are NOT accessible by others.
This private key will be ignored.
Load key "/Users/satton/Desktop/AWS_SSH/testkey.pem": bad permissions
ec2-user@3.112.4.99: Permission denied (publickey,gssapi-keyex,gssapi-with-mic).
satton@sattonMBP ~ %
上記リンクとは別の対処になるのですが、弊社では文字列型で一旦テーブルを作り、キャストしてcreate table as selectを利用しています。
キャストはcast(time_column as timestamp)でできるので、キャストしてテーブルを作り直す、またはキャストでタイムスタンプ型を都度作るようにしています。