- 投稿日:2020-07-01T22:20:21+09:00
PHPでMySQLのデータ操作その2
PHPでMySQLのデータ操作その2
PHPでMySQLを操作する方法を備忘録も兼ねてまとめました。
今回は検索編。
前回から引き続きまずこのようなデータがあるとします。
id name age position 選手id 選手名 選手の年齢 選手のポジション -- futsal_teamというデータベース(がなければ)作成。IF NOT EXISTSで判断。 CREATE DATABASE IF NOT EXISTS futsal_team DEFAULT CHARACTER SET utf8 COLLATE utf8_general_ci; -- GRANT文で権限をユーザーに付与、ユーザーはfutsal_team内の全てのテーブルを操作できる。 GRANT ALL PRIVILEGES ON *.* TO 'bs_user'@'localhost' IDENTIFIED BY 'futsal_team'; FLUSH PRIVILEGES; -- データベースfutsal_team使用。 USE futsal_team;-- テーブル作成後、カラム設定。 CREATE TABLE futsal_a ( id integer AUTO_INCREMENT NOT NULL, name varchar(255) NOT NULL, age integer NOT NULL, position varchar(255) NOT NULL, PRIMARY KEY (id) );-- カラムにそれぞれ値を入れてレコードを作成。idはシーケンス番号がauto_incrementオプションの効果で自動で追加される。 INSERT INTO futsal_a VALUES (null, '加藤A太郎', 25, 'ピヴォ'); INSERT INTO futsal_a VALUES (null, '佐藤B次郎', 27, 'アラ'); INSERT INTO futsal_a VALUES (null, '田中C三郎', 32, 'アラ'); INSERT INTO futsal_a VALUES (null, '山本D五郎', 38, 'フィクソ'); INSERT INTO futsal_a VALUES (null, '中島E十郎', 30, 'ゴレイロ);データの検索
<?php require './header.php'?> <form action="container_db_manipulate_search.php" method="post"> <input type="text" name="search_word"> <input type="submit" value="メンバー検索"> </form> <?php //今回は外部で$user, $passwordを設定してrequireで呼び出している。 require './ft_person.php'; //例外処理のためにtry carch文使用。 try { echo '<h1>','Aチームメンバー','</h1>'; echo '<table>'; echo '<tbody>'; //データベースにアクセスするためにPDOクラスのインスタンスをnew演算子で作成する。 $ft_team=new PDO('mysql:host=localhost;dbname=futsal_team;charset=utf8', $user, $password); //もしも名前を検索して、つまり検索ボックスに入力があって条件が一致したら if(isset($_REQUEST['search_word'])){ //prepareメソッドを使って、条件を設定。 $search=$ft_team->prepare('SELECT * FROM futsal_a WHERE name LIKE ?'); /* executeメソッドで、設定条件の?部分に値を当てはめて実行する。 この場合は当てはめるものが検索ボックスに入力した名前、結果↓ 「SELECT * FROM futsal_a WHERE name LIKE 入力キーワード」 ということになる。 */ $search->execute(array('%'.$_REQUEST['search_word'].'%')); } /* foreachとeachで「SELECT * FROM futsal_a WHERE name LIKE 入力キーワード」に当てはまるデータ一覧出力。 検索ボタンだけ押すとデータが一覧表示される。 */ foreach ($search as $person) { echo '<tr>'; echo '<td>','番号:',$person['id'],'、','</td>'; echo '<td>','名前:',$person['name'],'、','</td>'; echo '<td>','年齢:',$person['age'],'歳','、','</td>'; echo '<td>','ポジション:',$person['position'],'</td>'; echo '</tr>'; } echo '<tbody>'; echo '</table>'; } catch(PDOException $e){ echo $e->getMessage(); exit; } ?> <?php require './footer.php'?>PDOというクラスをインスタンス化することで、PHPでデータベースに接続しSQL文で操作ができるようになります。
今回はPDOクラスのメソッドのprepareとexecuteを使用して検索機能を実現しています。
おそらくセットで覚えたほうがいいと思います。
prepareで条件を指定し、その条件の中で?に指定した値を、executeで当てはめて実行します。
- 投稿日:2020-07-01T22:15:44+09:00
RDSのデフォルトパラメータグループの罠
はじめに
RDS の DB インスタンスを新規に作成する際、何も指定しないとデフォルトのパラメータグループを使う設定となります。
デフォルトのパラメータグループなので、それなりに標準的な設定になっており、とりあえずはこれを使っておくのが無難かなと思っていましたが、大きな間違いでした、、、というお話です。
かなり初歩的なお話ですね。。。ちなみに、MySQL 前提での話ですが、PostgreSQL など他のエンジンでも基本的には同じ話だと思います。
デフォルトのパラメータグループを使うと起きる問題
DB を使っていると、設定を変更したくなることが多々あります。
例えば、私の場合は DB インスタンスのリソースがまだガッツリ残っているのに Too many connections が出るようになったので、max_connections を引き上げたくなりました。
それ以外でも、例えば、slow_query_log を出したい/出したくないとか、その閾値 long_query_time を変えたいなどといったことはよくあると思います。
しかしながら、、、デフォルトのパラメータグループではパラメータの設定変更が一切できません!
つまり、どうしても設定変更をしたいのであれば、まずは DB インスタンスが使用しているパラメータグループ自体を変えないといけないことになります。さらに、、、使用するパラメータグループを変更する際には、DB インスタンスの再起動 が必要となります。
つまり、サービスが止まります。この辺の話が、下記の AWS のページに記載されています。
https://aws.amazon.com/jp/premiumsupport/knowledge-center/rds-modify-parameter-group-values/DB インスタンスを作成する際に、安易にデフォルトのパラメータグループを使うことを選択しただけでサービス停止を余儀なくされるのは、サービスによってはとても痛いと思います。
独自のパラメータグループを作成することはまったく難しくないので、DB インスタンスの作成時には必ずパラメータグループも新規に作成するクセを付けるくらいで良いと思います。パラメータグループの設定パラメータの変更
稼働中の DB インスタンスで使われているパラメータグループの設定パラメータの変更は、DB インスタンスの再起動無しに動的に行えます。
ただし、動的パラメータと呼ばれるパラメータのみで、静的パラメータの変更後の有効化には再起動が必要となります。パラメータグループの共有
独自に作成したパラメータグループを複数の DB インスタンスで共有することも可能です。
これはこれで便利な仕組みなのですが、注意が必要です。
設定パラメータの変更は、あくまでもパラメータグループの内容の変更になります。
従って、設定パラメータを変更するとそのパラメータグループを参照しているすべての DB インスタンスの設定が変更されます。よって、明確に設定値を揃える必要がない限りは、基本的にはそれぞれの DB インスタンスには別々のパラメータグループを用意するのが無難だと思います。
※例えば、同じ種別の複数台のreadレプリカには同じパラメータグループを割り当てた方が都合が良いといったことが考えられます。結論
- サービスを簡単に停止できない DB インスタンスにはデフォルトのパラメータグループは使わない
- 特別な理由がない限りは、パラメータグループは DB インスタンスごとに作成して関連づける
あくまでもザックリとした個人的な感覚レベルなので、ベストプラクティス的な情報があれば教えていただけるとありがたいです。
- 投稿日:2020-07-01T22:11:17+09:00
PHPでMySQLのデータ操作その1
PHPでMySQLのデータ操作その1
PHPでMySQLを操作する方法を備忘録も兼ねてまとめました。
まずこのようなデータを作成、用意します。
架空のフットサルチームがあるとします。
id name age position 選手id 選手名 選手の年齢 選手のポジション -- futsal_teamというデータベース(がなければ)作成。IF NOT EXISTSで判断。 CREATE DATABASE IF NOT EXISTS futsal_team DEFAULT CHARACTER SET utf8 COLLATE utf8_general_ci; -- GRANT文で権限をユーザーに付与、ユーザーはfutsal_team内の全てのテーブルを操作できる。 GRANT ALL PRIVILEGES ON *.* TO 'bs_user'@'localhost' IDENTIFIED BY 'futsal_team'; FLUSH PRIVILEGES; -- データベースfutsal_team使用。 USE futsal_team;-- テーブル作成後、カラム設定。 CREATE TABLE futsal_a ( id integer AUTO_INCREMENT NOT NULL, name varchar(255) NOT NULL, age integer NOT NULL, position varchar(255) NOT NULL, PRIMARY KEY (id) );-- カラムにそれぞれ値を入れてレコードを作成。idはシーケンス番号がauto_incrementオプションの効果で自動で追加される。 INSERT INTO futsal_a VALUES (null, '加藤A太郎', 25, 'ピヴォ'); INSERT INTO futsal_a VALUES (null, '佐藤B次郎', 27, 'アラ'); INSERT INTO futsal_a VALUES (null, '田中C三郎', 32, 'アラ'); INSERT INTO futsal_a VALUES (null, '山本D五郎', 38, 'フィクソ'); INSERT INTO futsal_a VALUES (null, '中島E十郎', 30, 'ゴレイロ);データの一覧表示
<?php require './header.php'?> <?php //今回は外部で$user, $passwordを設定してrequireで呼び出している。 require './ft_person.php'; //例外処理のためにtry carch文使用。 try { echo '<h1>','Aチームメンバー','</h1>'; echo '<table>'; echo '<tbody>'; //データベースにアクセスするためにPDOクラスのインスタンスをnew演算子で作成する。 $ft_team=new PDO('mysql:host=localhost;dbname=futsal_team;charset=utf8', $user, $password); /* PDOクラスのインスタンスからqueryセレクタを使用し、SQL文でfutsal_aの全データ取得。 その後、foreach文とecho文を用いてデータを全て表示。 */ foreach ($ft_team->query('SELECT * FROM futsal_a') as $person) { echo '<tr>'; echo '<td>','番号:',$person['id'],'、','</td>'; echo '<td>','名前:',$person['name'],'、','</td>'; echo '<td>','年齢:',$person['age'],'歳','、','</td>'; echo '<td>','ポジション:',$person['position'],'</td>'; echo '</tr>'; } echo '</tbody>'; echo '</table>'; } catch(PDOException $e){ echo $e->getMessage(); exit; } //結果 /* 番号:1、 名前:加藤A太郎、 年齢:25歳、 ポジション:ピヴォ 番号:2、 名前:佐藤B次郎、 年齢:27歳、 ポジション:アラ 番号:3、 名前:田中C三郎、 年齢:32歳、 ポジション:アラ 番号:4、 名前:山本D五郎、 年齢:38歳、 ポジション:フィクソ 番号:5、 名前:中島E十郎、 年齢:30歳、 ポジション:ゴレイロ */ ?> <?php require './footer.php'?>PDOというクラスをインスタンス化することで、PHPでデータベースに接続しSQL文で操作ができるようになります。
さらには専用のメソッドを使用することで、検索機能など使えるようになります。
その2に続く
- 投稿日:2020-07-01T16:41:17+09:00
FOREAIGN KEY(外部キー制約)
FOREIGN KEYとは、一つのデータベース内に、親テーブル、子テーブルが存在し、共通部分があった場合、FOREIGN KEYが設定されたカラムには、親テーブルのカラムに格納されている値しか格納することができなくなる。そして、やテーブルに存在しないデータを入力すると、エラーになる。
- 投稿日:2020-07-01T15:38:13+09:00
[Docker+Windows]mysqlのdockerイメージがmy.cnfのマウントのエラーで起動しない時の対処法
問題
mysqld: [Warning] World-writable config file '/etc/mysql/my.cnf' is ignored.というエラーがvolumeのmy.cnfファイルのマウントで起こっていて人用の備忘録です。
mysql8はmy.cnfの権限設定が適切でない(誰でも書き込みができてしまう)と起動しなません。
なので、my.cnfをイメージ内で適切に設定する必要があるが、
windows環境下ではlinuxのような権限設定はできないので、
一工夫する必要があります。対策 マウントするmy.cnfファイルにwindowsでread-onlyをつける
文字どりです。
read-onlyを設定した状態でvolumeにマウントするとマウント先で書き込み権限が消えます。
なので、この状態でコンテナを起動すればmy.cnfの権限設定が適切になり、エラーが解消されます。久しぶりの投稿の割にひたすら短いですが、
かなり簡単な解決で感動したので残します。参考:https://stackoverflow.com/questions/37001272/fixing-world-writable-mysql-error-in-docker
- 投稿日:2020-07-01T14:23:17+09:00
MySQL コマンド一覧
MySQLを使用する機会があったので、メモとして記載したいと思います。
サーバー
起動
mysql.server start停止
mysql.server stop再起動
mysql.server restartユーザー
ログイン
mysql -u 'ユーザー名' -p Enter password: 'パスワード'確認
mysql > select user, host from mysql.user;作成
mysql > create user 'ユーザー名' identified by 'パスワード';権限付与
mysql > grant all on データベース名.テーブル名 to 'ユーザー名';権限確認
mysql > show grants for 'ユーザー名';権限剥奪
mysql > revoke all データベース名.テーブル名 from 'ユーザー名';データベース
作成
mysql > create database データベース名;中身確認
mysql > show databases;接続中のデータベース確認
mysql > select database();指定
mysql > use データベース名;テーブル一覧取得
mysql > show tables from データベース名;削除
mysql > drop database データベース名;テーブル
テーブル作成
mysql > create table テーブル名( -> カラム名 型 その他, -> カラム名 型 その他 );テーブルの中身確認
mysql > desc テーブル名;データ追加
mysql > insert into テーブル名 (カラム名, カラム名,...) values (データ1, データ2,...);データ確認
mysql > select * from テーブル名;削除
mysql > drop table テーブル名;その他
入力キャンセル
mysql > \c接続しているDBサーバーのホスト名確認
mysql > show variables like 'hostname';ステータス確認
mysql > status
- 投稿日:2020-07-01T13:32:21+09:00
curl でDBやキャッシュの疎通確認もできる
これは何
DBへのネットワーク的な疎通確認といえば、MySQLだったら mysql-client、Redisならredis-cliなど専用のコマンドが一般的ですが、単にネットワーク的に疎通を確認したいということであれば curl だけでもできます。
コマンドイメージ
$ curl -v telnet://hogehoge.com:3306疎通確認をする一般的なコマンドといえば
- ping コマンド
- メリット: だいたいどんなサーバにも入っている(気がする)
- デメリット:
- icmp を通していないサーバの確認には使えないし、pingだけの確認だと実際には到達できていてもサーバに到達していないと勘違いを起こしやすい
- トランスポート層のポートまで確認できない
- telnet コマンド
- メリット: ホスト名とポートを指定できる柔軟なコマンド
- デメリット: 接続を解除する方法がわかりにくかったりしてやや使いづらい
- curl コマンド
- 一般的に http や https での接続確認
- 使いやすい
よくある curl の使い方(httpやhttpsに対する疎通確認)
$ curl -v https://hogehoge.comのように http や https プロトコルを使って接続。
プロトコルをつけなかった時にはどうなるのか?
ubuntuで$ man curlをすると以下のような記述がありました。If you specify URL without protocol:// prefix, curl will attempt to guess what protocol you might want. It will then default to HTTP but try other protocols based on often-used host name prefixes. For example, for host names starting with "ftp." curl will assume you want to speak FTP.プロトコルをつけないと、よく使われるスキーマが適当に試されるようです。
例えばローカルに立っているサーバに対してプロトコルを指定せずにlocalhostに対して叩くと、httpだと解釈されて実行されます。
$ curl -I localhost HTTP/1.1 404 Not Found Server: nginx Content-Type: text/html; charset=UTF-8 Connection: keep-alive X-Powered-By: PHP/7.2.0RC6 Cache-Control: no-cache, private date: Tue, 30 Jun 2020 09:27:28 GMTDBやキャッシュへの接続確認
とあるサーバ(ubuntu)からあるDBサーバに接続確認したいケースは以下のようになります。
telnetプロトコルを使用してポートを指定します。telnetはコマンド名だと思っていましたが、実際にはtelnetプロトコルというのがあるようでした。
参考: https://ja.wikipedia.org/wiki/Telnet$ curl -v telnet://hogehoge.com:3306 * Rebuilt URL to: telnet://hogehoge.com:3306/ * Trying xx.xx.xx.xx... * TCP_NODELAY set * Connected to hogehoge.com (xx.xx.xx.xx) port 3306 (#0) Warning: Binary output can mess up your terminal. Use "--output -" to tell Warning: curl to output it to your terminal anyway, or consider "--output Warning: <FILE>" to save to a file. * Failed writing body (0 != 29) * Closing connection 0上記出力はちょっとわかりづらいですが、接続自体は成功(Connected to hogehoge.comのところ)していて、出力を書き込むのに失敗しているような形。
ちょっと見ずらかったので使わなかったですが、出力の通りoutputオプションを使って--output /dev/nullなど指定するのもいいかもしれません。
- 投稿日:2020-07-01T12:42:49+09:00
【AWS ElastiCache】AWS ElastiCache(Memcached)を利用してRDSへのクエリをキャッシング
目標
・AWS ElastiCache(Memcached)(※)を利用してRDSへのクエリをキャッシングするシステムを構築すること。
・キャッシングの方式はキャッシュ戦略(説明後述)に沿って構築を行う。※ElastiCacheに関する基本・詳細情報は以下記事を参照
AWS キャッシュ活用 ElastiCacheはじめに
これまでの記事でEC2⇔RDS、及びEC2⇔ElastiCacheの接続を構築したので、
今度はElastiCacheを利用してRDSへのクエリをキャッシングさせるプログラムをほぼポートフォリオ的なノリで書いてみました。
言語はRubyを利用しました。
実務で経験したことのない実装ですので、何か変なとこあったらコメントください笑キャッシュ戦略(※)とは
ElastiCacheをキャッシュ利用する際のAWSが推奨するベストプラクティスのこと。
以下2つの方式に分かれ、システムのユースケースに沿った戦略を選択する必要がある。
今回は遅延読み込みを利用した実装を行う。・遅延読み込み
データ読み込み時にキャッシュを参照し、ヒットしなかった場合にのみデータソースへアクセスし必要なデータを取得してキャッシュに書き込む方式
⇒キャッシュのメモリ使用量を抑えることが可能だが、キャッシュデータが古い可能がある(キャッシュミス時にしかキャッシュを書き換えないため)・書き込みスルー
データ書き込み時に毎回キャッシュにも書き込みを行う方式
⇒キャッシュのメモリ使用量は多くなってしまうが、常に最新のキャッシュデータを取得可能※より詳しくはAWSドキュメント参照
キャッシュ戦略
https://docs.aws.amazon.com/ja_jp/AmazonElastiCache/latest/mem-ug/Strategies.html前提
・EC2とRDS(MySQL)間の接続が確立されていること(※1)。
・EC2とElactiCache(Memcached)間の接続が確立されていること(※2)。※1 以下記事で構築済み
【RDS】EC2とRDS(MySQL)間の接続を確立する※2 以下記事で構築済み
【AWS ElastiCache】AWS ElastiCache(Memcached)を構築し、EC2から接続システム環境
・EC2
OS(AMI) : Amazon Linux 2 AMI (HVM), SSD Volume Type
ソフトウェア: Rubyを利用した自作プログラム・RDS
エンジン: MySQL・ElastiChache
エンジン: Memcached完成フロー
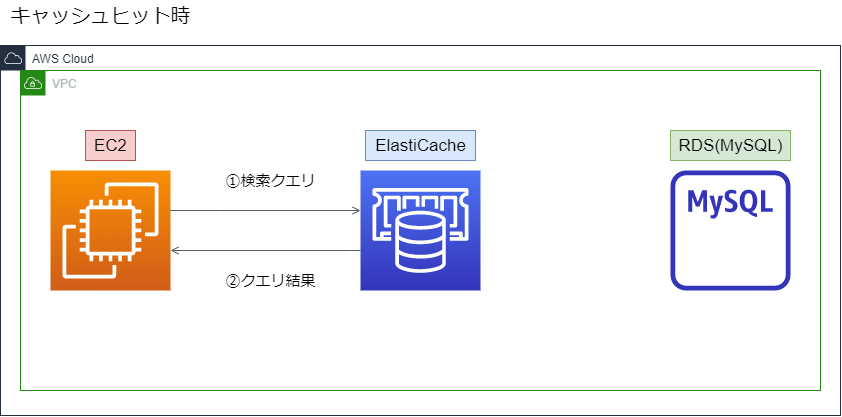
キャッシュヒット時は以下のフロー
①EC2から検索クエリを投げる
②ElaElastiCacheがクエリ結果を返し、通信終了
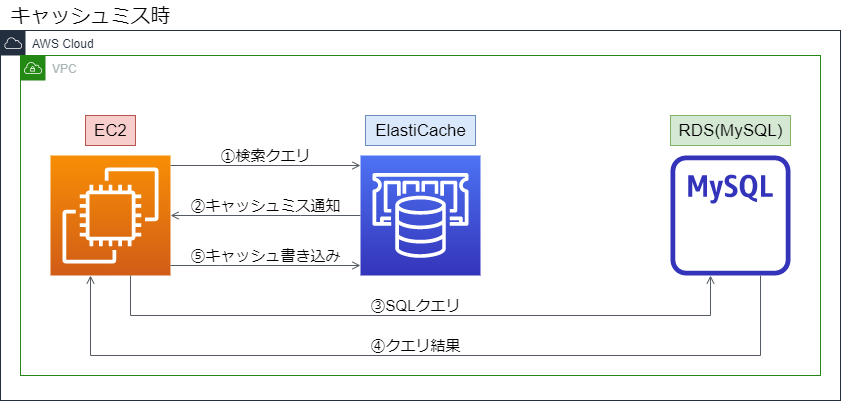
キャッシュミス時は以下のフロー
①EC2から検索クエリを投げる
②ElastiCacheからキャッシュミスが返る
③RDSへSQLクエリを発行
④RDSからSQLクエリ結果が返ってくる
⑤取得したクエリ結果をElastiCacheに書き込む
作業の流れ
項番 タイトル 1 デプロイ 2 動作検証 手順
1.デプロイ
①EC2にOSログイン
②Ruby実行環境をインストール
$ sudo yum install ruby③Ruby用Memocacheクライアントのgem(Rubyのライブラリ)をインストール(※)
※参考にしたサイト
16.6.3.7 Ruby での MySQL と memcached の使用$ gem install Ruby-MemCache③Mysqlクライアントのgemをインストール(※)
Mysqlクライアントgemを利用する際に必要となるライブラリをインストール
(以下はEC2のAmazon Linux 2を利用した際の手順です。他のディストリビューションでは必要なライブラリが異なる可能性があります。)※一部参考にした記事
AWS Cloud9のEC2上にmysql2のgemを導入する$ sudo yum -y install ruby-develsudo yum groupinstall "Development Tools"sudo yum install mysql-develMysqlクライアントgemインストール
gem install mysql2④自作Rubyスクリプト(※)をEC2に配備
<Elasticache_endpoint>、<rds_endpoint>、<db_login_user>、<db_login_password>、<db_name>は適宜書き換えファイル名: rds_cache.rb# ********************************************************************************** # 機能概要: AWS ElastiCache(Memcached)を利用して、RDSへのクエリ結果をキャッシングする # 機能詳細: ElastiCacheにクエリを発行し、キャッシュが存在する場合にはそのバリューを返す。 # キャッシュが存在しない場合、データソースであるRDS(MySQL)にアクセスし結果表示後、ElastiCacheにキャッシュ保存する。 # スクリプト用法: ruby <スクリプトパス> "<検索SQLクエリ>" # ********************************************************************************** unless ARGV.size() == 1 puts "The number of arguments is incorrect." exit end # パッケージ require 'base64' require 'memcache' require 'mysql2' # 変数 sql_query = ARGV[0] # 実行SQLクエリ cache_host = "<Elasticache_endpoint>" # Elasticacheエンドポイント cache_port = 11211 # Elasticacheポート番号 db_host = "<rds_endpoint>" # RDSエンドポイント db_user = "<db_login_user>" # DBログインユーザ db_password = "<db_login_password>" # DBパスワード db_name = "<db_name>" # データベース名 # SQLクエリ(空白除去、小文字変換)をBase64でエンコード(キャッシュのキーとして利用する) encoded_query = Base64.encode64(sql_query.gsub(" ", "").downcase) # MemCache、Mysql接続用インスタンス作成 memc_connect = MemCache::new "#{cache_host}:#{cache_port}" db_connect = Mysql2::Client.new(host: db_host, username: db_user, password: db_password, database: db_name) # Elacacheからキャッシュを取得 cache_outcome = memc_connect[encoded_query] if !cache_outcome[0].nil? puts "Cache HIT!" puts "[Query results from cache]" puts cache_outcome[0] else puts "Cache MISS" puts "[Query results from datasource]" # キャッシュミスした場合、データベースへSQLクエリ発行 sql_outcome = db_connect.query(sql_query) cache_val = "" for row in sql_outcome do puts "--------------------" cache_val = cache_val + "--------------------\n" for key, value in row do puts "#{key} => #{value}" cache_val = cache_val + "#{key} => #{value}\n" end end # Elasticacheにバリューをセット memc_connect[encoded_query] = cache_val end※実装方針は以下
・SQLクエリを引数としてスクリプト実行
・引数として指定したSQLクエリを空白除去・小文字変換後、Base64によってエンコードし、Elasticacheのキーとしてキャッシュ検索・保存に利用する。
・キャッシュヒットした場合は、結果を出力しスクリプト終了
・キャッシュミスした場合は、RDS(データソース)にアクセスしSQLクエリを実行し結果を出力。最後にその結果をElasticacheに保存。2.動作検証
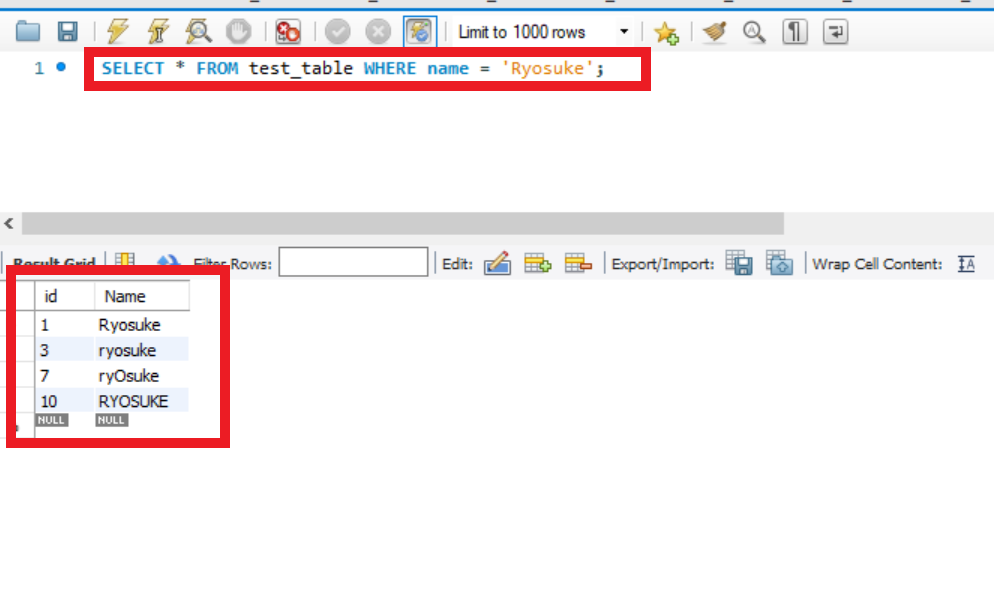
検証用DBデータ
+----+-----------+ | id | Name | +----+-----------+ | 1 | Ryosuke | | 2 | Tomoharu | | 3 | ryosuke | | 4 | shunsuke | | 5 | sato | | 6 | sato | | 7 | ryOsuke | | 8 | Kawashima | | 9 | tomoharu | | 10 | RYOSUKE | +----+-----------+実行SQLクエリ及びその結果期待値
①クエリ初回実行(キャッシュミスパターン)
Cache MISSメッセージが出力され、データソース(RDS)からクエリ結果が適切に表示されているためOK$ ruby rds_cache.rb "SELECT * FROM test_table WHERE name = 'Ryosuke';" Cache MISS [Query results from datasource] -------------------- id => 1 Name => Ryosuke -------------------- id => 3 Name => ryosuke -------------------- id => 7 Name => ryOsuke -------------------- id => 10 Name => RYOSUKE②クエリ再実行(キャッシュヒットパターン1)
Cache HIT!が出力され、Elasticacheから適切なクエリ結果が返ってきているためOK[ec2-user@ip-172-31-34-150 ~]$ ruby rds_cache.rb "SELECT * FROM test_table WHERE name = 'Ryosuke';" Cache HIT! [Query results from cache] -------------------- id => 1 Name => Ryosuke -------------------- id => 3 Name => ryosuke -------------------- id => 7 Name => ryOsuke -------------------- id => 10 Name => RYOSUKE③小文字化かつスペースをいじったクエリを再実行(キャッシュヒットパターン2)
[ec2-user@ip-172-31-34-150 ~]$ ruby rds_cache.rb "select * from test_table where name = 'Ryosuke';" Cache HIT! [Query results from cache] -------------------- id => 1 Name => Ryosuke -------------------- id => 3 Name => ryosuke -------------------- id => 7 Name => ryOsuke -------------------- id => 10 Name => RYOSUKE所感
本来はキャッシュを利用してクエリのレスポンスを高速化させたり、データベース負荷を下げることがこのシステムの目的なのですが、
データ数が少なすぎて性能面でのメリットは確認できていないのがなんとも言えない感じです…笑
いずれ時間あったらそこらへんも軽く確認出来たらとは思ってはいます。