- 投稿日:2020-07-01T23:31:43+09:00
見様見真似でDiscordのチャット読み上げbotを作った
はじめに
Discordで使ってるチャット読み上げbotが一時的に使えなくなってしまったので臨時で自作しました。
Discordのチャットを読み上げるbotの作成を参考に一部コード書き換えて作ってます。事前準備
bot作成と環境構築は下記を見ながらやりました。
ffmpegは解凍したファイルをC:\open_jtalk\binに配置してます。
Pathの設定をわすれずに…botのソースコード
一番下の行の
bot作成時の時にコピーしたトークンの箇所は各々botのトークンを書き換えてください。read_bot.pyimport discord from discord.ext import commands import asyncio import os import subprocess import ffmpeg from voice_generator import creat_WAV client = commands.Bot(command_prefix='.') voice_client = None @client.event async def on_ready(): print('Logged in as') print(client.user.name) print(client.user.id) print('------') @client.command() async def join(ctx): print('#voicechannelを取得') vc = ctx.author.voice.channel print('#voicechannelに接続') await vc.connect() @client.command() async def bye(ctx): print('#切断') await ctx.voice_client.disconnect() @client.event async def on_message(message): msgclient = message.guild.voice_client if message.content.startswith('.'): pass else: if message.guild.voice_client: print(message.content) creat_WAV(message.content) source = discord.FFmpegPCMAudio("output.wav") message.guild.voice_client.play(source) else: pass await client.process_commands(message) client.run("bot作成時の時にコピーしたトークン")音声ファイルのソースコード
ボイスファイルのパスのところにいろいろコメントアウトして書いてあるんですけど、MMDAgentにある
Sample ScriptのSource codeをダウンロードしてもらうと女性声に変更できます。
(解凍したファイルのVoice/meiディレクトリのhtsvoiceファイルがあるのでmeiディレクトリをソースコードと同じ階層に配置してください)voice_generator.pyimport subprocess import re # remove_custom_emoji # 絵文字IDは読み上げない def remove_custom_emoji(text): pattern = r'<:[a-zA-Z0-9_]+:[0-9]+>' # カスタム絵文字のパターン return re.sub(pattern,'',text) # 置換処理 # urlAbb # URLなら省略 def urlAbb(text): pattern = "https?://[\w/:%#\$&\?\(\)~\.=\+\-]+" return re.sub(pattern,'URLは省略するのデス!',text) # 置換処理 # creat_WAV # message.contentをテキストファイルに書き込み def creat_WAV(inputText): # message.contentをテキストファイルに書き込み inputText = remove_custom_emoji(inputText) # 絵文字IDは読み上げない inputText = urlAbb(inputText) # URLなら省略 input_file = 'input.txt' with open(input_file,'w',encoding='shift_jis') as file: file.write(inputText) command = 'C:/open_jtalk/bin/open_jtalk -x {x} -m {m} -r {r} -ow {ow} {input_file}' #辞書のPath x = 'C:/open_jtalk/bin/dic' #ボイスファイルのPath m = 'C:/open_jtalk/bin/nitech_jp_atr503_m001.htsvoice' #m = 'C:/open_jtalk/bin/mei/mei_sad.htsvoice' #m = 'C:/open_jtalk/bin/mei/mei_angry.htsvoice' #m = 'C:/open_jtalk/bin/mei/mei_bashful.htsvoice' #m = 'C:/open_jtalk/bin/mei/mei_happy.htsvoice' #m = 'C:/open_jtalk/bin/mei/mei_normal.htsvoice' #発声のスピード r = '1.0' #出力ファイル名 and Path ow = 'output.wav' args= {'x':x, 'm':m, 'r':r, 'ow':ow, 'input_file':input_file} cmd= command.format(**args) print(cmd) subprocess.run(cmd) return True if __name__ == '__main__': creat_WAV('テスト')ディレクトリ構成
構成としてはこんなかんじです。
使い方
botを招待するところまでは記載があったのですが使い方については書かれていなかったので適当に書いておきます。
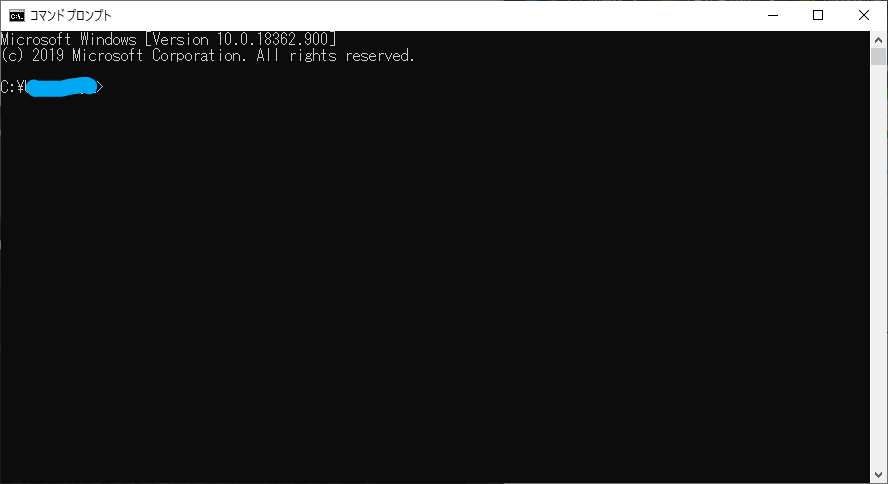
コマンドプロンプト起動
C:\open_jtalk\binの「read_bot.py」をコマンドプロンプトにドラッグアンドドロップしてEnter
するとbotがログインしてくれます
ボイスチャンネルに呼ぶ
まず自分がボイチャに入ります。
(このbotは基本的にボイチャに呼んだ人のところに入ってきます。)
呼ぶコマンドは.joinです
しゃべらせる
適当にチャットすれば読んでくれます。
絵文字とかカスタム絵文字は読んでくれません…
あと、URLは省略するようにしてます。退出させる
ボイスチャンネルからbotを退出させるコマンドは
.byeです
後片付け
コマンドプロンプトは
Ctrl + Cかウィンドウを閉じましょう。おわり
簡単な英語も割とアルファベットで読まれちゃう感じがあるので、辞書登録機能とか追加できたらいいなーって思いますね。
まあそれはそのうちやります。たぶん





- 投稿日:2020-07-01T23:27:27+09:00
Windows 10環境 pipでbox2d-pyをインストールしよう
box2d-pyとは?
Pythonの強化学習でよく使用するOpenAI Gymパッケージで利用されているライブラリです。
https://pypi.org/project/box2d-py/
box2d-py Windwosのインストールの問題
このパッケージ、Windows環境でインストールするのは、なかなか骨が折れます。私も次のようなエラーで苦しみました。
swig.exe -python -c++ -IBox2D -small -O -includeall -ignoremissing -w201 -globals b2Globals -outdir library\Box2D -keyword -w511 -D_SWIG_KWARGS -o Box2D\Box2D_wrap.cpp Box2D\Box2D.i Box2D\Box2D.i(44) : Error: Unknown directive '%exception'.Windows上で問題を避けるのはcondaでのインストールが最も手早いようですが、condaを使っていない私にはちょっとハードルが高いです。Wheelファイルを作って、pipで簡単にインストールできるようにしました。gym[all]などをインストールする前に、こちらのwheelファイルをご活用ください。
wheelファイルでインストール
Python環境にあわせたwheelファイルをダウンロードし、wheelファイルでbox2d-pyをインストールしましょう。
https://github.com/kitfactory/box2d-py-wheel
> pip install box2d_py-2.3.8-cp38-cp38m-win_amd64.whl > pip install box2d_py-2.3.8-cp37-cp37m-win_amd64.whl > pip install box2d_py-2.3.8-cp36-cp36m-win_amd64.whl
- 投稿日:2020-07-01T23:24:49+09:00
Biopython Tutorial and Cookbook和訳(4.4)
4.4 Comparison
The SeqRecord objects can be very complex, but here’s a simple example:
SeqRecordはとても複雑ですが、簡単な例があります:>>> from Bio.Seq import Seq >>> from Bio.SeqRecord import SeqRecord >>> record1 = SeqRecord(Seq("ACGT"), id="test") >>> record2 = SeqRecord(Seq("ACGT"), id="test")What happens when you try to compare these “identical” records?
同じrecordで比較したらどうなりますか?>>> record1 == record2 ...Perhaps surprisingly older versions of Biopython would use Python’s default object comparison for the SeqRecord, meaning record1 == record2 would only return True if these variables pointed at the same object in memory.
In this example, record1 == record2 would have returned False here!
古いッバージョンのBiopythonはpythonデフォルトのオブジェクト比較を使うため、メモリ上同じポイントを指すrecord1とrecord2の比較はTrueを返します。
この例ではFalseを返します。>>> record1 == record2 # on old versions of Biopython! FalseAs of Biopython 1.67, SeqRecord comparison like record1 == record2 will instead raise an explicit error to avoid people being caught out by this:
Biopython 1.67ではSeqRecordの比較は明示的な例外を起こします。*>>> record1 == record2 Traceback (most recent call last): ... NotImplementedError: SeqRecord comparison is deliberately not implemented. Explicitly compare the attributes of interest.Instead you should check the attributes you are interested in, for example the identifier and the sequence:
他はご自身で試して見てください。例えば配列の識別子の比較なら:>>> record1.id == record2.id True >>> record1.seq == record2.seq TrueBeware that comparing complex objects quickly gets complicated (see also Section 3.11).
複雑なオブジェクトを比較するとややこしくなることに用心しましょう。
- 投稿日:2020-07-01T21:50:24+09:00
スクレイピングって何?【初心者用まとめ】
はじめに
これは初心者向けに(と言うか、過去の自分に向けて)書いた「スクレイピングとは何か?」という記事です。
これからスクレイピングをやってみようという人のための概要説明ですので、ここが貴方の初めの一歩としてお役に立てますように。スクレイピングとは
「ウェブスクレイピング(英: Web scraping)とは、ウェブサイトから情報を抽出するコンピュータソフトウェア技術のこと(Wikipedia出典)」
つまり、ウェブページから自分が欲しいと思った情報を取ってくる技術のことを「スクレイピング」と言うわけです。
混同されやすいものとして「クローリング」というのもあります。
こちらは「プログラムがインターネット上のリンクを辿ってWebサイトを巡回し、Webページ上の情報を複製・保存すること(weblio辞書出典)」違いはなんだ…?一緒では…?と思ったかもしれませんが、その感覚はほぼ正解です。
どちらの技術も情報収集が目的ですから。しかし、重きを置いている部分が少し違います。
スクレイピングは「webサイトの情報から必要な情報だけ取り出す(=抽出)」ことに重きを置いており、クローリングは「webサイトを複数巡回して情報を集める(=収集)」ことに重きを置いているようです。
なので、webページを複数辿りながら必要な情報だけを取りたい場合「クローリングしてスクレイピングする」ということになります。
人によって少し捉え方が違うようですが、「互いを補完し合う技術(=収集と抽出)」という解釈で大丈夫でしょう。注意点
クローリングは自動でwebサイトの情報を取得するので、場合によっては著作権に関する法律やサイトポリシーに違反する行為となる恐れがあります。何か調査をする際には、十分に気を付けましょう。
逆に、自分のサイトをクローリングされたくない場合も考えてみましょう。
いくつか方法がありますが、まずはサイトポリシーにハッキリ書くことが重要です。しかし、それだけでは自動でクローリングしている相手(いわゆるボットなど)に気付かれない可能性があるので、robots.txtを作成しましょう。
このファイルに、クローリングを許可するかどうかなどの設定を書いておくと、悪意のある相手でない限りはクローリングを避けられます。
参考サイトとして「ぼくらのハウツーノート」さんをご紹介しておきます。Scrapy(スクレイピー)
さて、先ほど、スクレイピングとクローリングの違いについて説明しましたが、勘の良い人はこう思ったかもしれません。
「クローリングとスクレイピングって別々にやらないといけないの?」
クローリングやスクレイピングを行うためのフレームワークはたくさんありますが、実は、クローリングしながらスクレイピングもできるフレームワークがあります。
それがScrapyです。Scrapyの使い方に関して、参考サイト「note.nkmk.me」をご紹介します。
こちらのサイトではScrapyのチュートリアル解説や、分かりやすい実例を書いてくれていますので、もしも「やってみたい!」と思った方はぜひ参考にして下さい。(私も参考にさせて頂きました。)おわりに
Qiitaへの投稿はこれが初めてですので、今回は書き方の練習も兼ねた記事としてシンプルな内容にしました。
追加・訂正はご指摘があった場合、または私の知識が更新された場合に行います。
- 投稿日:2020-07-01T21:44:44+09:00
ゼロから始めるLeetCode Day73 「1491. Average Salary Excluding the Minimum and Maximum Salary」
概要
海外ではエンジニアの面接においてコーディングテストというものが行われるらしく、多くの場合、特定の関数やクラスをお題に沿って実装するという物がメインである。
どうやら多くのエンジニアはその対策としてLeetCodeなるサイトで対策を行うようだ。
早い話が本場でも行われているようなコーディングテストに耐えうるようなアルゴリズム力を鍛えるサイトであり、海外のテックカンパニーでのキャリアを積みたい方にとっては避けては通れない道である。
と、仰々しく書いてみましたが、私は今のところそういった面接を受ける予定はありません。
ただ、ITエンジニアとして人並みのアルゴリズム力くらいは持っておいた方がいいだろうということで不定期に問題を解いてその時に考えたやり方をメモ的に書いていこうかと思います。
Python3で解いています。
前回
ゼロから始めるLeetCode Day72 「1498. Number of Subsequences That Satisfy the Given Sum Condition」今はTop 100 Liked QuestionsのMediumを優先的に解いています。
Easyは全て解いたので気になる方は目次の方へどうぞ。Twitterやってます。
技術ブログ始めました!!
技術はLeetCode、Django、Nuxt、あたりについて書くと思います。こちらの方が更新は早いので、よければブクマよろしくお願いいたします!問題
1491. Average Salary Excluding the Minimum and Maximum Salary
難易度はEasy。今日はかなり軽めの問題です。
問題としては、
salary[i]が従業員iの給与である一意の整数salaryの配列が与えられます。最小給料と最大給料を除いた従業員の平均給料を返します。
Example 1:
Input: salary = [4000,3000,1000,2000]
Output: 2500.00000
Explanation: Minimum salary and maximum salary are 1000 and 4000 respectively.
Average salary excluding minimum and maximum salary is (2000+3000)/2= 2500Example 2:
Input: salary = [1000,2000,3000]
Output: 2000.00000
Explanation: Minimum salary and maximum salary are 1000 and 3000 respectively.
Average salary excluding minimum and maximum salary is (2000)/1= 2000Example 3:
Input: salary = [6000,5000,4000,3000,2000,1000]
Output: 3500.00000Example 4:
Input: salary = [8000,9000,2000,3000,6000,1000]
Output: 4750.00000解法
class Solution: def average(self, salary: List[int]) -> float: temp,low,high = 0,float('inf'),float('-inf') for s in salary: temp += s low,high = min(low,s),max(high,s) return (temp - low - high)/(len(salary)-2) # Runtime: 36 ms, faster than 59.24% of Python3 online submissions for Average Salary Excluding the Minimum and Maximum Salary. # Memory Usage: 13.8 MB, less than 100.00% of Python3 online submissions for Average Salary Excluding the Minimum and Maximum Salary.比較的簡単な問題でしたね。
一行で書いたりするのはあまり好きではありませんが、これは一行で書いた方が分かりやすいかもしれません。
以下のように、全体の和からmin,maxを使って最大値と最小値を除外、そして割るための長さから除外した分の数,2を引いた値で割ってあげると解けます。class Solution: def average(self, salary: List[int]) -> float: return (sum(salary)-min(salary)-max(salary))/(len(salary)-2) # Runtime: 20 ms, faster than 99.36% of Python3 online submissions for Average Salary Excluding the Minimum and Maximum Salary. # Memory Usage: 13.9 MB, less than 25.00% of Python3 online submissions for Average Salary Excluding the Minimum and Maximum Salary.疲れていたのでこういった簡単な問題にしました。
では今回はここまで。お疲れ様でした。
- 投稿日:2020-07-01T21:23:42+09:00
Python3.8でuWSGIをインストールする時の「Python.h: No such file or directory」に対処した
Ubuntu上で、Poetryを使って仮想環境上にuWSGIをインストールしようとすると、次のようなエラーが出ました。
poetry installエラーメッセージの中で原因となっている箇所はこちらです。
fatal error: Python.h: No such file or directory compilation terminated.「Python3かつvenv使用時にuWSGIをインストールする時の注意点」という記事もあり、こちらでは
sudo apt-get install python3-devで解決すると書いていたのですが、実はpython3-devは既にインストールしていたにも関わらずこのエラーが出てしまっていました。更に調べると、「fatal error: Python.h: No such file or directory」に解決方法が載っていました。どうやら
python3.x-devをバージョン指定してインストールする必要があったようです。こちらのコマンドで解決しました。sudo apt-get install python3.8-dev最初はPoetry自体のエラーだと考えていて、少し原因の特定に時間がかかってしまいました。同様の問題にハマってしまった人のお役に立てると嬉しいです。
- 投稿日:2020-07-01T21:12:56+09:00
from scipy.misc import imread, imresize で "ImportError: cannot import name imread" が起こったら
表題通りです。scipyが画像を読むために使うモジュールが不足しているのが原因です。
エラー内容
Traceback (most recent call last): File "vg_to_imdb.py", line 9, in <module> from scipy.misc import imread, imresize ImportError: cannot import name imreadscipyで画像処理なんかをするとき、こういうエラーが出ることがあると思います。
解決法
pip install PillowPillowをインストールで解決できました。
参考: Stackoverflow: Importing image to python :cannot import name 'imread'
- 投稿日:2020-07-01T20:39:18+09:00
連載:cx_Oracle入門 目次
- 投稿日:2020-07-01T20:02:27+09:00
MoneyForwardクラウド勤怠の打刻を自動化【面倒なことはPythonにやらせよう】
免責事項
当記事に掲載された内容によって生じた損害等の一切の責任を負いません。この記事は個人の趣味として執筆したもので、私の所属している企業とは関係ありません。また、企業の規則等を破ることを推奨するものではありません。
MoneyForwardクラウド勤怠の利用規約について
利用規約を確認しましたが、コンピューターからの自動操作を禁止している記載は発見できませんでした。(お前見落としてるぞというところに気づいた方がいらっしゃれば、教えてください。すぐにやめます)
(6) 本サービス並びに本サービスを通じてアクセスするコンテンツサイト及び情報提供元のネットワーク又はシステム等に過度な負荷をかける行為
(13) 当社による本サービスの運営を妨害するおそれのある行為
過度なアクセスをする処理は含まれていないので問題ないと判断しました。
(16) その他、当社が不適切と判断する行為
お願いMoneyForwardさん、不適切と判断しないで
自動化しようと思った経緯
毎朝同じ時刻に出勤打刻を行い、同じ時刻に退勤打刻を行う。これはもう、完全にwhile文なわけですよ。人がやる作業じゃないでしょ。ということで自動化します。(打刻の意味ねーじゃんというツッコミをお待ちしております)
使ったコード
Githubでコードを公開しています。
記事内では全てのコードを載せているわけではないので、もっと知りたい方は直接コードをご覧ください。もっとエレガントな方法があると思うので、気軽にIssueやPR投げてください。お願いします。
https://github.com/Haruka0522/AutoMFKintai全体の構成
Seleniumを使ってPythonから打刻のウェブページにアクセス
↓
datetimeとjpholidayを使って休日/平日の判断
↓
事前に設定した出勤/退勤時刻になったらボタンをクリックシンプルですね!
ログイン画面の突破
ソースコード(抜粋)
id_box = self.driver.find_element_by_name("employee_session_form[office_account_name]") id_box.send_keys(self.company_id) mail_box = self.driver.find_element_by_name("employee_session_form[account_name_or_email]") mail_box.send_keys(self.mail) password_box = self.driver.find_element_by_name("employee_session_form[password]") password_box.send_keys(self.password) login_button = self.driver.find_element_by_name("commit") login_button.click()ログイン画面にアクセス後、要素の名前で入力ボックスを特定し、そこにログイン情報を入力する処理を行います。この要素の名前というのはchromeでアクセスしてF12キーを押すことで開発者モードを使って確認することができます。
困難が予想されたログイン画面の突破ですが、簡単に突破することが可能でした。注意
ソースコード上にパスワード等をハードコーディングして間違ってGithubにアップしてしまうと大変なので、pass.txtというテキストファイルにパスワード等を書き込んでこれを読み込むような方法を取りましょう。.gitignoreでpass.txtをgitの管理から除いておけば間違ってpushしてしまう心配がありません。
打刻ボタンのクリック
ソースコード(抜粋)
actions = ActionChains(self.driver) actions.move_by_offset(480, 250) actions.click() actions.perform()地味に苦戦したのがここです。打刻ボタンの要素を指定してクリックを試みるもうまくいかず、onclick()が書かれていたので直接Javascriptを実行することを試みるも何故かうまくいきませんでした。そこであまりいい方法ではないですが、画面の座標を指定してクリックするという手法を取りました。最初の設定でChromeのウィンドウサイズを固定しているので、おそらく環境が変わっても動くとは思いますが正直エレガントではないので今後改善したいところです。
土日祝、平日の判断
土日に間違って打刻してしまうことは避けたいです。私の場合は基本的に平日は働いているので、平日だけ打刻するように設定しました。
ソースコード
def is_holiday(date): return date.weekday() >= 5 or jpholiday.is_holiday(date)datetimeライブラリとjpholidayライブラリを使用し、平日を判断させました。
datetimeの方は単純な土曜日曜を判断させるために、jpholidayは祝日を判断させるために使用しました。参考記事
https://qiita.com/hid_tanabe/items/3c5e6e85c6c65f7b38be
メインループ
while True: dt_now = datetime.datetime.now() if is_holiday(datetime.date.today()): # 平日判断 continue if dt_now.hour == start_time.hour and dt_now.minute == start_time.minute: operator.syukkin() elif dt_now.hour == end_time.hour and dt_now.minute == end_time.minute: operator.taikin() else: time.sleep(wait_time)最後に
これを24時間動いてるコンピューター(ラズパイが省電力で良さそう)で走らせることで自動で打刻してくれるようになります。Googleカレンダーなどと連携して独自の休日などにも対応できればいいなー、そもそもこんなスクリプトを書かなくてもいいような制度になればいいなーなどと思っております。各方面から怒られそうな予感がしてますが、大丈夫かな…?
- 投稿日:2020-07-01T19:58:30+09:00
Anvil をローカル実行する
概要
Anvil は Python でコーディングする、Web ベースの統合開発環境です。
Python さえ知っていればなんとかなる、というのがウリだそうで、以下の特徴があります。
- Web ベースなのでインストール不要
- HTML を書かずにビジュアルエディタで UI 作成
- 作ったらそのまま Web で公開できる
そんな Anvil ですが、作ったアプリをローカルで実行することも可能ということで、試してみました。
準備
Hello World
Hello World をやった前提で説明しますので、まだの方は Hello World をやっておくと良いです。
- Anvil のサイト へ行って "Start building for free" をクリックして、サインアップします。
- ログインしたら "Things to do" の "2. Build a Hello World app" の "Start the interactive tutorial" をクリックすれば、チュートリアルが始まります。
ローカル実行
では、作った Hello World をローカル実行できるようにしてみます。
情報ソース
ローカル実行の手順は
anvil-runtimeのリポジトリ で説明されています。
anvil-runtimeはオープンソースの、Anvil のランタイムエンジンです。Java のインストール
説明を読むと OpenJDK の 8 以上をインストールするようにと書かれています。
私の場合、jdk1.8.0 が入っていたのでそれでやってみたら動きました。ローカル仮想環境を作る
ここからアプリごとの手順になります。
ローカルにフォルダを用意して仮想環境を作ります (以下はpipenvで作った場合)。helloworld ├─ .venv ├─ Pipfile └─ Pipfile.lockanvil-app-server
仮想環境内に
anvil-app-serverをインストールします。
PyPI からインストールできます。pipenvで入れる場合は以下のようにします。> pipenv install anvil-app-serverアプリのクローン
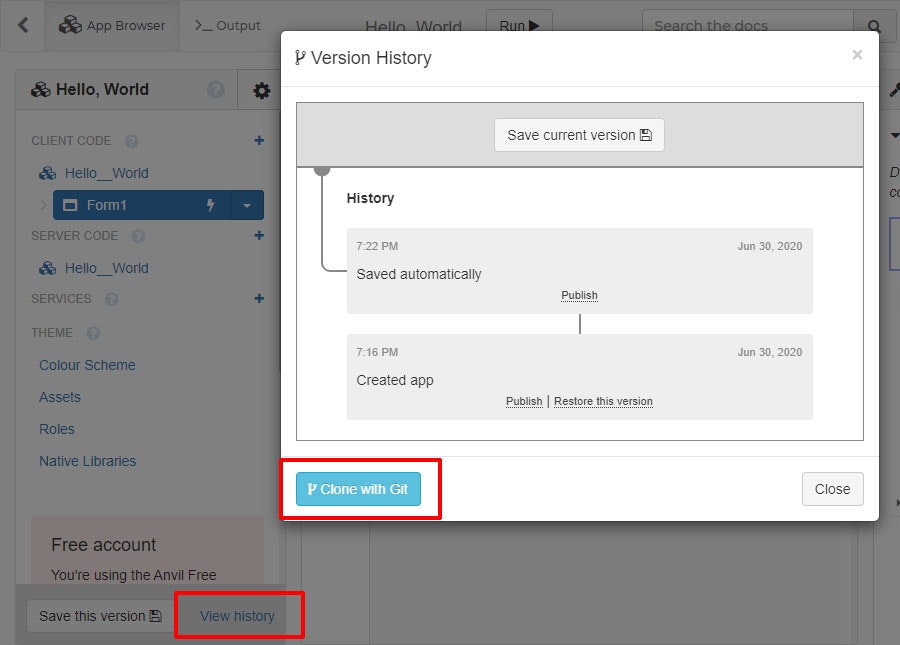
Anvil の Web IDE で作ったアプリは最初から Git 管理されているので、それをクローンすればローカルに持ってこれます。
クローンするには Web IDE でアプリの "Version History" を開いて、"Clone with Git" を押します。
するとクローンするためのコマンドが表示されるので、クリップボードにコピーして、先ほどの仮想環境のフォルダ (helloworld フォルダ) で実行します。
実行するとサブフォルダ (=ローカルリポジトリ) が出来て、アプリのソースが格納されます。helloworld ├─ .venv ├─ Hello__World │ ├─ .git │ ├─ client_code │ ├─ theme │ ├─ .gitignore │ ├─ __init__.py │ └─ anvil.yaml ├─ Pipfile └─ Pipfile.lock実行…?
仮想環境内で以下のコマンドを実行するとアプリが起動するらしいのですが…。
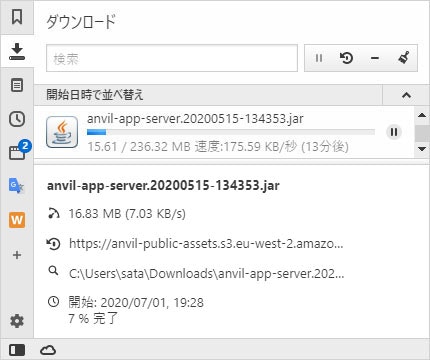
> anvil-app-server --app Hello__World236MB の jar ファイルをダウンロードしようとして失敗したようです。
Downloading Anvil App Server JAR to package directory 5% of 236.3 MiB |### | Elapsed Time: 0:01:29 ETA: 0:18:25 Failed to download App Server to package directory. Retrying in ~/.anvil Traceback (most recent call last): File "xxx\.venv\lib\site-packages\anvil_app_server\__init__.py", line 167, in find_or_download_app_server _urlretrieve(url, package_dir_path, show_progress)もう一度同じコマンドを実行してみたところ、今度は「ファイルが存在する。壊れている」と言われました。
壊れていても再度ダウンロードしようとはしないようです。Found Anvil App Server JAR in package directory Error: Invalid or corrupt jarfile xxx\.venv\lib\site-packages\anvil_app_server\anvil-app-server.20200515-134353.jarjar ファイルを手動で取ってくる
上記のエラーメッセージに書かれたパスに、問題の jar ファイルがあれば良いのでしょうから、別途ダウンロードしてやりましょう。
取得元はanvil_app_serverの__init__.pyを見ると分かります。164行目:
url = "https://anvil-public-assets.s3.eu-west-2.amazonaws.com/app-server/" + server_jar_nameこれにファイル名をくっつけて、Web ブラウザでアクセスするとダウンロードできました。
これを anvil_app_server フォルダに入れ (て上書きす) れば OK です。実行
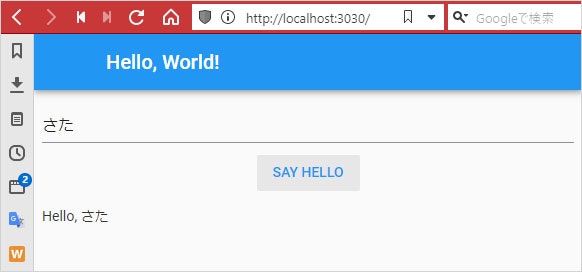
> anvil-app-server --app Hello__World Found Anvil App Server JAR in package directory Found 0 migration(s) for (base runtime) DB. Executing Anvil migrations... Database currently at "2019-09-23-B-denormalise-app-sessions" 0 migration(s) to perform. Migration complete. [INFO anvil.core.server] HTTP Server running on port 3030 [INFO anvil.app-server.run] App URL: http://localhost:3030 [INFO anvil.app-server.dispatch] Launching built-in downlink... [INFO anvil.app-server.run] SMTP Server running on port 25 Warning: PDF Rendering not supported on Windows. Renderer not initialised Connecting to ws://localhost:3030/_/downlink Anvil websocket open [INFO anvil.executors.downlink] Downlink client connected with spec {:runtime "python3-full", :session_id "LIEwah7xDUSHG6S4uazw"} Downlink authenticated OKローカルで実行しても Web アプリであることに変わりはないので、ブラウザで開きます。
ログに出ている App URL をブラウザに入力します。
動きました!所感
取り急ぎ、ローカルで実行できることを確認しました。
ランタイムエンジンはフリーだし、ローカルなら外部ライブラリも入れ放題です。
ただやはり、これで作ったアプリを人に配布して使ってもらうのは、結構ハードルが高そうです。
どういうものを開発するのに合っているか、見極めが必要かと思います。
- 投稿日:2020-07-01T19:35:24+09:00
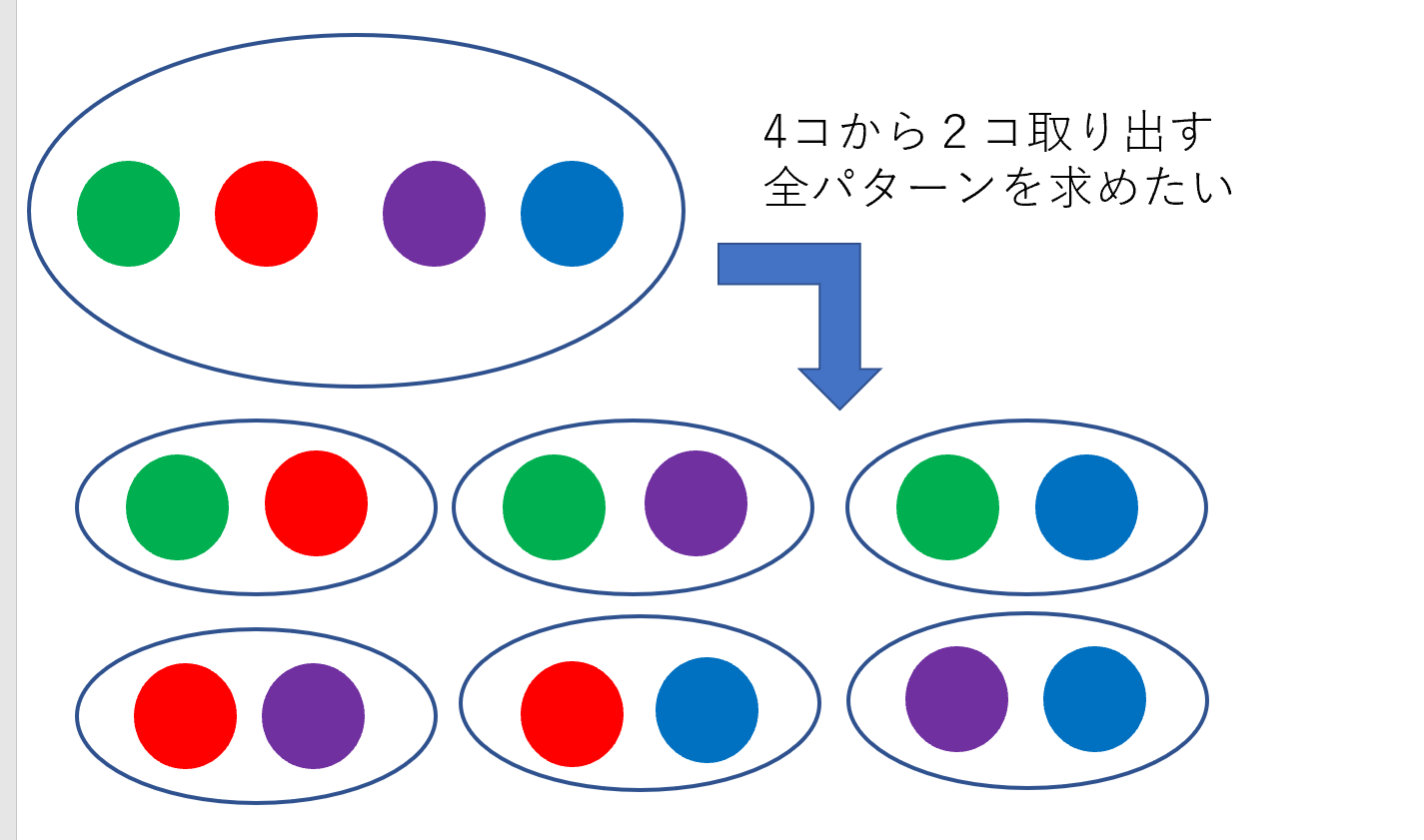
集合から特定個数取り出す全パターンを求める
概要
5コの集合から3コ取り出した小集合全パターンを書き出すアルゴリズムを求めます
こちらを参考にしました。(追記)
便利なライブラリがあるので、そちらを使いましょう。教えてくださった方ありがとうございます。from itertools import combinations list(combinations([1,2,4,3],3)) >>[(1, 2, 4), (1, 2, 3), (1, 4, 3), (2, 4, 3)]使用言語はpythonです。
アルゴリズム
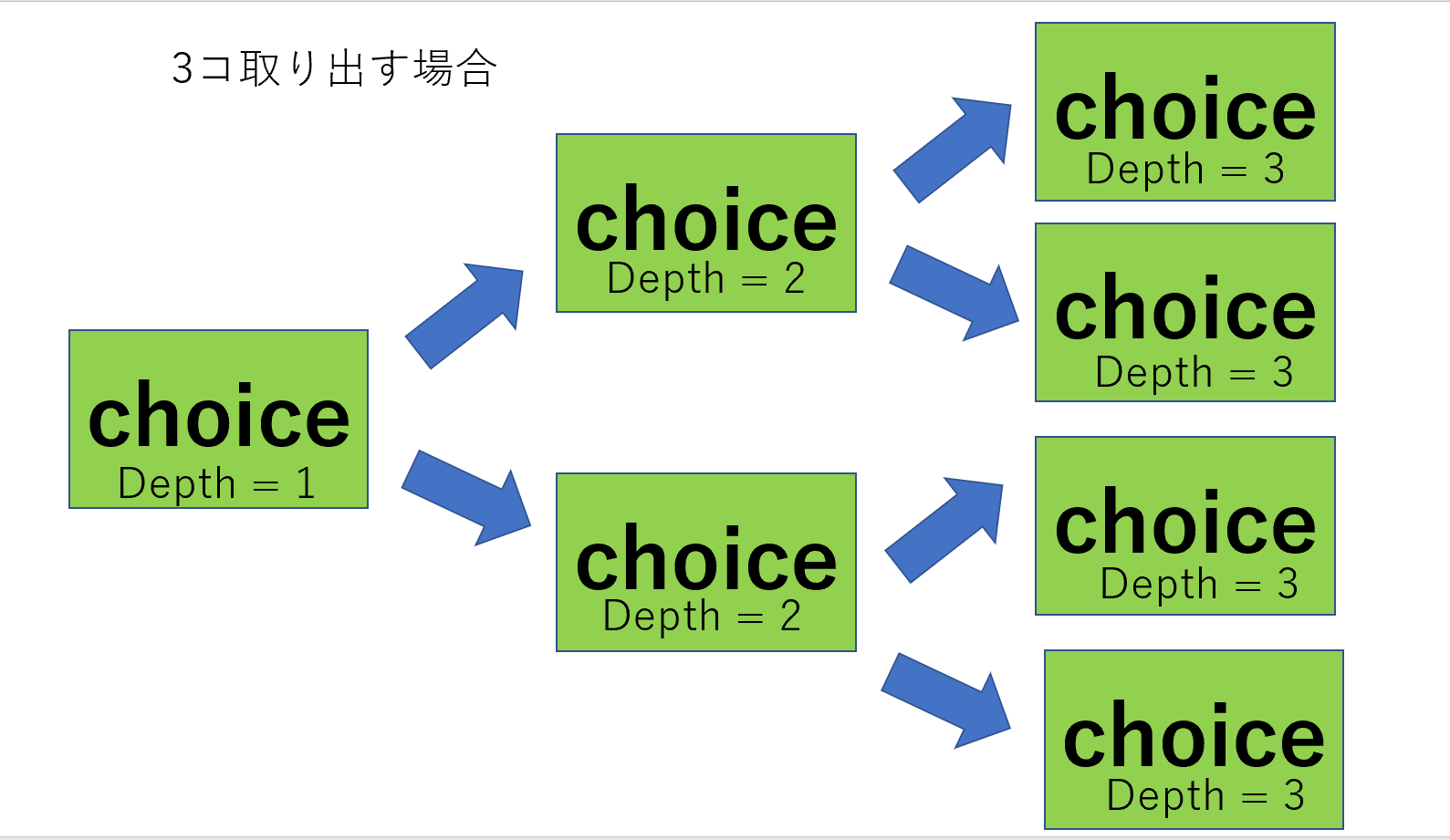
2コから3コ取り出す全パターン(取り出しても消えない場合)
"choice”という全体集合から1つ取り出す関数を作ります。
"choice"で1つ取り出したら、depthを1つ増やして、"choice”をまた呼びます。depthが取り出す個数に達したら、帰ってきます。
これで、全パターンが生成できます。取り出して消える場合は、"choice"を実行したら、次の"choice"には選んだヤツを除いた全体集合を渡せばよいでしょう。
一つ問題なのは、これだと
[赤、緑] 、[緑 、赤] という同じパターンが混ざってしまう問題があります。
ここは仕方ないので、同じ要素がないか確認し、有った場合片方を削除します。
もっと良い方法があれば教えてください。プログラム
import copy class Allpattern(): def __init__(self,n,r): self.n = n #n このうち rこ 取り出す全パターン self.r = r self.pattern = [] used = [0] * self.n hoge =[] for i in range(r): hoge.append(used) def make(self): """ list1 = [1 , ・・・・ , n] という全体集合を作る """ list1=[] for i in range(self.n): list1.append(i+1) """ choice_list : choiceしたものを入れるリスト depth : choiceっした回数 """ choice_list = [] depth = 0 self.choice(list1,depth,choice_list) def choice(self,list1,depth,choice_list): for i in list1: list2 = copy.deepcopy(list1) list2.remove(i) #一回選んだものは二度と選ばない choice_list2 = copy.deepcopy(choice_list) choice_list2.append(i) if depth+1 >= self.r: self.work(choice_list2) else: self.choice(list2,depth+1,choice_list2) def work(self,choice_list): """ rコの選択が終わったとき呼び出される。 """ choice_list.sort() if self.pattern.count(choice_list) == 0: self.pattern.append(choice_list) def disp(self): for i in self.pattern: print(i) if __name__ == '__main__' : hoge = Allpattern(5,3) hoge.make() hoge.disp()実行結果
[1, 2, 3] [1, 2, 4] [1, 2, 5] [1, 3, 4] [1, 3, 5] [1, 4, 5] [2, 3, 4] [2, 3, 5] [2, 4, 5] [3, 4, 5]
- 投稿日:2020-07-01T19:35:14+09:00
pythonでtwitterのツイート検索をする
- 投稿日:2020-07-01T19:16:45+09:00
見間違えのある囚人のジレンマゲームをPythonで実装してみた
概要
見間違えのある囚人のジレンマゲームをPythonで実装してみました.そのプログラムを使って,繰り返し囚人のジレンマゲームのある戦略をシミュレーション実験してみました.
囚人のジレンマゲームは,主に経済分野で企業間の談合といった協調行動を分析するために使われたりします.その他にも様々な応用事例があります.
従来の囚人のジレンマゲームモデルでは,事後的に,相手の行動を直接観測できる(完全観測)という仮定がされていて,それを基にプレイヤーたちは,次の行動を決めることができました.しかし,現実社会では相手の行動が完全に観測できないことは多くあります.この場合,従来のモデルでは,それら状況をうまく捉えることができません.
そこで,近年,不完全観測の囚人のジレンマゲームが盛んに研究されています.不完全観測では,相手の行動を直接観測できない代わりに,相手の行動に依存したシグナル(信号)を観測できるとします.
今回はこの不完全観測の繰り返し囚人のジレンマゲームをシミュレーションしていきます.
囚人のジレンマゲームとは?
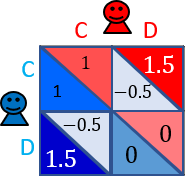
囚人のジレンマゲームとは、ゲーム理論における最も代表的なゲームの1つです.このゲームは,よく以下の得点表で与えられます.
このゲームのルールは,2人のプレイヤー$X$と$Y$がそれぞれ,協力($C$:Cooperate)または,裏切り($D$:Defect)かを選びます.各プレイヤーが選んだ行動によって,得点が決まります.
プレイヤー$X$と$Y$がお互い$C$を選べば,両者はそこそこ良い得点である$1$点を得ることができます.$X$と$Y$のどちらかが$C$を選び,もう一方が$D$を選べば,$C$を選んだプレイヤーは最も低い得点である$-0.5$点を得ることになり,$D$を選んだプレイヤーは最も高い得点である$1.5$点を得ることができます.$X$と$Y$がお互い$D$を選べば,両者は,少ない得点である$0$点を得ることになります.お互い$C$を選べば,両者の得点を合わせると$2\ (=1+1)$となり,全体にとっては最も良い得点になり,相手に一方的に裏切られると,裏切られたプレイヤーは大損をするといった構造になっています.
このように,各プレイヤーは本当は協力し合いたいと思っているのに,裏切りに誘惑されてしまうというジレンマがあります.
1回のゲームの施行において,利己的なプレイヤー間では協力が実現しません(ナッシュ均衡).一方で,このゲームを無期限に渡って繰り返す繰り返し囚人のジレンマゲームにおいては,利己的なプレイヤー間においても,協力が実現されるということが理論的に証明されています(フォークの定理).
そこで,この繰り返し囚人のジレンマゲームにおいて,どんな戦略が強いかが研究されてきました(アクセルロッドの実験).
不完全私的観測付き繰り返しゲーム
プレーヤーが過去に採った行動をすべて正確に観測できる完全観測(Perfect Monitoring)を仮定する従来の囚人のジレンマゲームとは異なります.不完全観測(Imperfect Private Monitoring)では,過去のプレイヤーたちの行動を直接観測することができません.その代わり,前回のプレイヤーの行動に依存したシグナルを観測すると仮定します.今回のゲームでは,個別のシグナルを受けとる私的観測(Private Monitoring)を仮定します.この各プレイヤーが受け取るシグナルは,相手は観測することができません.
具体例
不完全私的観測の囚人のジレンマゲームは,以下の小売店の価格競争を想定しています.
小売店の価格競争では,同じ商品を売っているとして,その商品の価格を維持するか,価格を下げるかによって,売り上げを確保しようとします.
実際の小売店の利益は,来客数(シグナル)と商品の価格(自分の行動)によって決まります.例えば,お互いに価格を維持(協力)をしていれば,お客さんは一方の店に偏ることなく,高い値段で商品を売ることができ,両店舗とも,そこそこ高い利益を確保することができます.
※お客さんは,各店舗の商品の値段によって,増減するので,囚人のジレンマと同じ構造を持ちます.
そのような状況では,以下の場合が想定されます.本来であれば,各店舗が価格維持していれば,両店舗とも高い利益を得ることができますが,来客数はさまざまな要因によって変動します.例えば,予測できない需要ショックや近隣に知らずのうちに新しく同様な店舗ができることによって,店舗の客が減るかもしれません(下図).店舗の利益は,各店舗が決めた商品の値段(行動)が直接利益に結び付くわけではないということがポイントです.
一方で,店舗は相手に知られないように,商品を値下げし,お客さんを獲得することもできます(カタログ価格より低い値段をお客さんの前のみで提示など).そのような状況を従来の囚人のジレンマゲームでとらえることはできません.
そのような状況を不完全私的観測付き繰り返しゲームは想定しています.
ゲームの内容
- ゲームを定義します.
以下の得点表で与えられるゲームを繰り返し行います.
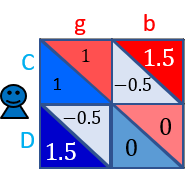
このゲームのルールは,$2$人のプレイヤー$X$と$Y$がそれぞれ,協力($C$:Cooperate)または,裏切り($D$:Defect)かを選びます.各プレイヤーが選んだ行動によって,得点が決まります.
基本的に相手プレイヤーが$C$を選んだとき,自分はgoodを意味する$g$というシグナルを観測します.そのとき,自分が$C$の行動を選択していれば$1$点を得ます.また,$D$の行動を選択していれば$1.5$点を得ます.同様に,相手プレイヤーが$D$を選んだとき,自分はbadを意味する$b$というシグナルを観測します.そのとき,自分が$C$の行動を選択していれば$-0.5$点を得ます.また,$D$の行動を選択していれば$0$点を得ます.
ここまでの仮定は従来の囚人のジレンマゲームとほぼ同じです.
- 観測エラーを定義します.
今回のモデルでは,行動に関するシグナル$g$と$b$が環境などの要因でエラーが起き反転することとします.
相手プレイヤーが$C$を選んだとしても,自分は,相手が$D$を選んだことを意味する$b$というシグナルを得ることがあります.反対に,相手が$D$を選んだとしても,自分は,相手が$C$を選んだことを意味する$g$というシグナルを得ることがあります.このように,実際の行動を意味するシグナルと逆のシグナルを観測することを観測エラーと言います.
今回は,プレイヤーの一方のみがエラーする確率を$\epsilon$,両方エラーする確率を$\xi$と定義します.このエラー率$\epsilon$,$\xi$はあまり大きくないとします.
- プレイヤーの戦略を定義します.
プレイヤー$X$の戦略を,${\bf p}=(p_{Cg},p_{Cb},p_{Dg},p_{Db}; p_0)$と定義します.この戦略,記憶1(Memory-One)戦略と呼ばれます.この戦略を使うプレイヤーは,前回のゲームの結果のみを考慮して,今回の行動($C$ or$ D$)を確率的に決定します.
例えば,$p_{Cg}$は,前回のゲームで,プレイヤー$X$が$C$を選び,$g$を観測したとき,今回のゲームで協力する確率となります.$p_{Cb}$は,前回のゲームで,プレイヤー$X$が$C$を選び,$b$を観測したとき,今回のゲームで協力する確率となります.その他も同様に考えます.$p_0$は,初回のゲームで協力する確率です.
プレイヤー$Y$の戦略は,同様に,${\bf q}=(q_{Cg},q_{Cb},q_{Dg},q_{Db}; q_0)$とします.
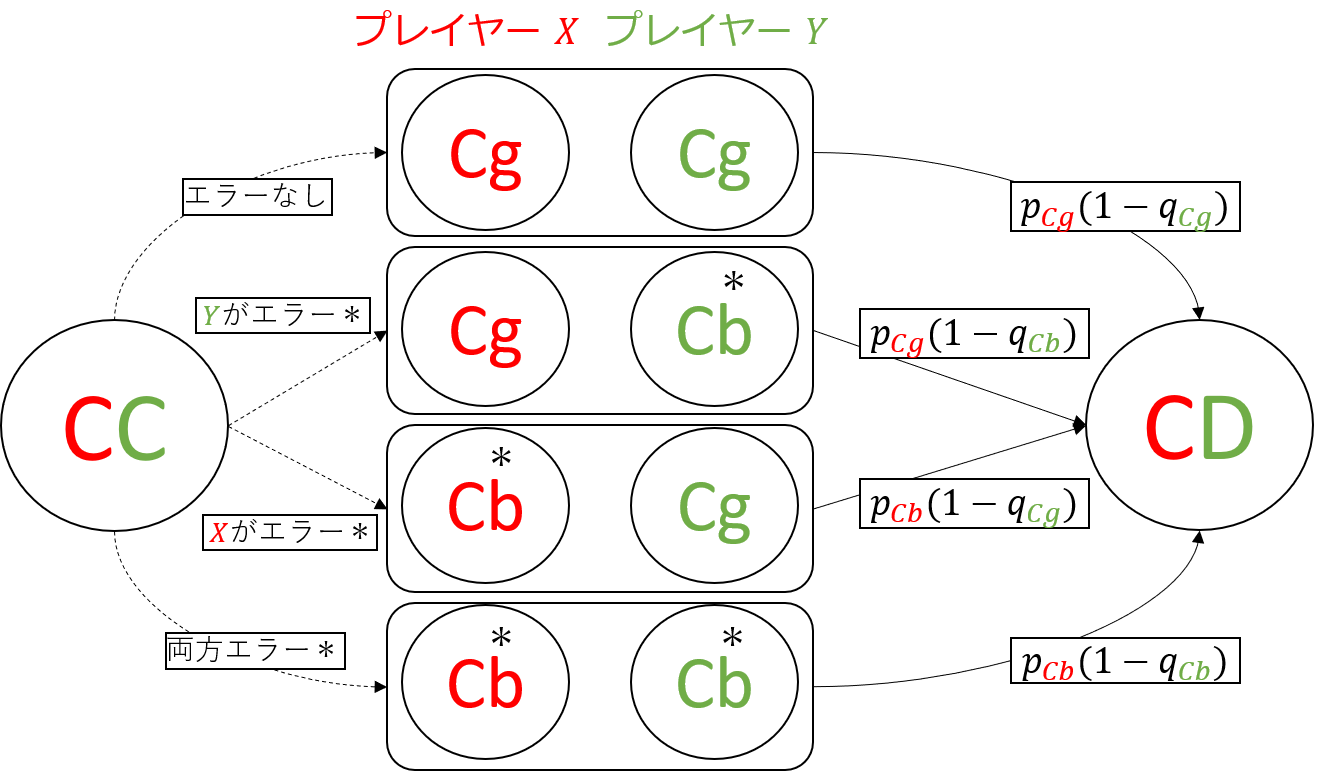
以下の図は,ゲームの状態が$CC$(相互協力)から$CD$($X$が協力,$Y$が裏切り)へと遷移する例です.この図は,各プレイヤーが決めた行動によって,どのように各プレイヤーがシグナルを観測し,上記で定義した戦略を基に,次の状態に遷移するかを理解することができます.今回のシミュレーションでは関係ありませんが,これをマルコフ過程と捉えることができて,以下のような遷移図から,このゲームの遷移行列を定義することができます.
Pythonプログラム
以下のPythonプログラムは上記を実装しました.シミュレーションによって,どんな戦略が強いかを調べることができます.以下では,各プレイヤーの戦略を${\bf p}=(1/2,1/2,1/2,1/2; 1/2)$と${\bf q}=(1/2,1/2,1/2,1/2; 1/2)$としています.ゲームの繰り返し回数を$100000$回としています.エラー率は,$\epsilon=0.05$と$\xi=0.05$と設定しています.
import random max_t = 100000 # ゲームの繰り返し回数 point = {'x' : 0, 'y' : 0} # プレイヤーの合計点数 action = {'x' : None, 'y' : None} # プレイヤーの行動 C or D signal = {'x' : None, 'y' : None} # プレイヤーの観測したシグナル state = {'x' : '0', 'y' : '0'} # ゲームの状態を設定 payoff = {'Dg':1.5, 'Cg':1.0, 'Db':0, 'Cb':-0.5} # ゲームの得点 epsilon = 0.05; xi = 0.05 # 一方のみがエラー,両方エラーする確率 p = {'Cg':1/2, 'Cb':1/2, 'Dg':1/2, 'Db':1/2, '0' :1/2} # プレイヤーXの戦略 q = {'Cg':1/2, 'Cb':1/2, 'Dg':1/2, 'Db':1/2, '0' :1/2} # プレイヤーYの戦略 # 繰り返しゲーム for t in range(max_t): # 前回のゲームの結果を基に,C or Dを選択する action['x'] = 'C' if random.random() < p[state['x']] else 'D' action['y'] = 'C' if random.random() < q[state['y']] else 'D' # シグナル signal['x'] = 'g' if action['y'] == 'C' else 'b' signal['y'] = 'g' if action['x'] == 'C' else 'b' # 観測エラー if random.random() < 2 * epsilon: player = 'x' if random.random() < 0.5 else 'y' if signal[player] == 'g': signal[player] = 'b' else: signal[player] = 'g' elif 2 * epsilon < random.random() < 2 * epsilon + xi: for player in ['x', 'y']: if signal[player] == 'g': signal[player] = 'b' else: signal[player] = 'g' # 行動とシグナルを基に利得を配分 for player in ['x', 'y']: if action[player] == 'C' and signal[player] == 'g': point[player] += payoff['Cg'] elif action[player] == 'C' and signal[player] == 'b': point[player] += payoff['Cb'] elif action[player] == 'D' and signal[player] == 'g': point[player] += payoff['Dg'] elif action[player] == 'D' and signal[player] == 'b': point[player] += payoff['Db'] # ゲームの結果を代入 state[player] = action[player] + signal[player] # 各プレイヤーの平均点数を出力 print('Player X: {} Points'.format(point['x'] / max_t)) print('Player Y: {} Points'.format(point['y'] / max_t))このプログラムを実行すると,以下の実行結果が得られます..
Player X: 0.49855 Points Player Y: 0.49827 Pointsつまり,${\bf p}=(1/2,1/2,1/2,1/2; 1/2)$と${\bf q}=(1/2,1/2,1/2,1/2; 1/2)$の戦略を対戦させたとき,
ほぼ同点の結果となることがわかります.これは当然の結果です.次に,いろいろな戦略を試してみたいと思います.
Zero-determinant戦略を実験する
Zero-determinant戦略(ゼロ行列式戦略:ZD戦略)は,囚人のジレンマゲームのある1つの戦略です.以前,囚人のジレンマゲームの相手を搾取する戦略(Qiita)で紹介しました.このZD戦略は,シンプルな戦略で,記憶1戦略$\bf p$や$\bf q$で定義することができます(ZD戦略の導出自体は少々難しい).今回は,この見間違えがある囚人のジレンマゲームにおいて,この戦略を実験していきます.
ZD戦略は,有名な部分戦略として,Equalizer戦略やExtortion戦略があります.Equalizer戦略は,相手の平均得点を固定ことができ,Extortion戦略のExtortionは恐喝という意味で,この戦略は相手の得点を搾取することができます.
細かい説明はここまでとして,この戦略を実験していきます.
Equalizer戦略
相手がどんな戦略であっても,相手の得点を固定することができます.相手の平均得点を$0.5$点にさせるEqualizer戦略${\bf p} = (0.8, 0.365217,0.634783, 0.2;1/2)$と${\bf q}=(1/2,1/2,1/2,1/2; 1/2)$と設定し,シミュレーションを実行すると,以下の結果が得られます.
Player X: 0.496385 Points Player Y: 0.50177 Points確かに,
Player Y: 0.50177 Pointsとなっていて,相手の得点が$0.5$点に近いことがわかります.たまたまかもしれないので,相手の戦略を囚人のジレンマゲームでは最強な常に裏切り戦略($ALLD$戦略)${\bf q}=(0,0,0,0;0)$でも試してみると,以下の結果が得られます.Player X: -0.004545 Points Player Y: 0.50022 Pointsやはり,
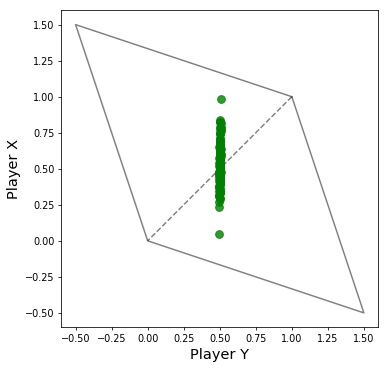
Player Y: 0.50022 Pointsとなっていて,相手の得点が$0.5$点に近いことがわかります.以下の図は,上の戦略のほかに相手の戦略$\bf q$を乱数で,いろいろを与えてみて,シミュレーションを行ったものです.$\bf q$は100戦略分生成して,それぞれでプログラムを実行しました.この図からどんな相手の戦略$\bf q$であっても,相手は$0.5$点に固定されてしまっていることがわかります.
※灰色の線で囲まれた領域は,実現可能な利得関係の領域です.二人のプレイヤーの利得関係は必ずこの領域のどこかになります.縦軸がEqualizer戦略を採るプレイヤーの得点,横軸が相手の得点としています.
したがって,Equalizer戦略は,エラーがあるときも,相手の戦略に関わらず,相手の得点を固定することができます.
Extortion戦略
Extortion戦略は,エラーなしの普通の囚人のジレンマゲームでは,相手の得点を搾取する戦略であることが知られています.最も強い常に裏切り戦略($ALLD$戦略)やExtortion戦略に対しては,引き分けで返すことができます.
エラーありの場合ではそれが可能なのか?
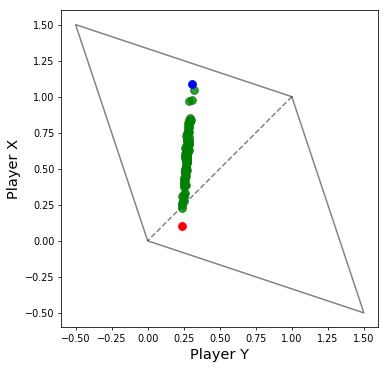
Equalizer戦略のときに作成した図と同じように,乱数で相手の戦略$\bf q$をいろいろ変えて,Extortion戦略とゲームを行わせると,以下の図が得られます.
※赤点は相手が$ALLD$戦略,青点は相手が$ALLC$戦略(常に協力戦略)のときのものです.縦軸がExtortion戦略を採るプレイヤーの得点,横軸が相手の得点としています.
この図から,もはやExtortion戦略は$ALLD$戦略(赤点)に勝てなくなってしまっていることがわかります.一方で,$ALLD$戦略以外の大部分の戦略に対しては,まだまだ勝つことができています.
エラーがない場合は,Extortion戦略は$ALLD$戦略に対して,引き分けという結果にさせることができ,$ALLD$からの搾取を防ぐことができていました.しかし,エラーが入ると,$ALLD$戦略からの搾取を許す結果となってしまいました.一方で,$ALLD$戦略以外の戦略に対しては,搾取できるということがわかりました.
まとめ
見間違えのある囚人のジレンマゲームのシミュレーションをPythonで実装してみました.今回のプレイヤーの戦略は,単純な記憶1戦略としていますが,もしかすると,記憶を増やした戦略や学習を入れた戦略にするともっと強い戦略が見つかるかもしれません.
今回は,Zero-determinant戦略を実験してみました.エラーある場合でもなお,Equalizer戦略は相手の得点を固定することができ,Extortion戦略は$ALLD$戦略に対しては,搾取を許してしまうが,その他の大部分の戦略に対しては,搾取することができるということがわかりました.したがって,エラーがある場合でも,ある程度有効な戦略であるとはいえるのではないかと思います.
強い戦略やおもしろい戦略などを見つけることができたら,ぜひ教えてください(>_<)
関連文献
- 囚人のジレンマゲームの相手を搾取する戦略(Qiita)
A. Mamiya and G. Ichinose, Strategies that enforce linear payoff relationships under observation errors in Repeated Prisoner’s Dilemma game J. Theor. Biol. 477, 63-76, 2019.


- 投稿日:2020-07-01T18:33:13+09:00
StyleGAN2の潜在空間に、新垣結衣は住んでいるのか?
1.はじめに
前回、「GAN の潜在空間に、新垣結衣は住んでいるのか?」というテーマについて ProgressiveGAN で調べてみた結果、残念ながら住んでいないことが分かりました。
今回は、最新の StyleGAN2 を使って同じテーマに取り組んでみたいと思います。なお、コードは Google Colab で作成し Githubに上げてありますので、自分でやってみたい方は試してみて下さい。
2.StyleGAN2とは?
まず、StyleGANについて説明します。
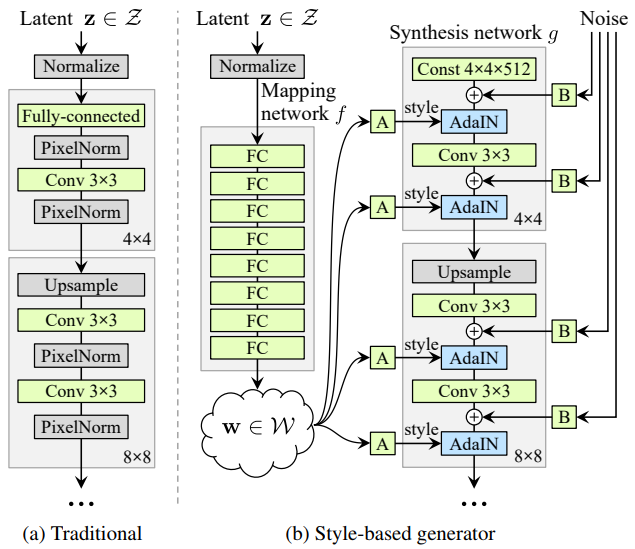
これは、(a)今までのGAN(ProgressiveGAN) と(b) StyleGANのネットワーク構造を比較した図です。StyleGANは今までとは構造をがらりと変えて、Mapping network とSynthesis network の2つで構成されています。
Mapping network は8層の全結合層から成り、入力の潜在変数z (1,512)を中間出力である潜在変数w (18,512)にマッピングします。
Synthesis networkは9層から成り、入力は4×4×512の定数で、そこへ潜在変数w(A)とノイズ(B)が各層に入力されます。潜在変数wは各層の入力が2つのため、9層×2=18個あります。
潜在変数wはスタイルと呼ばれ主な画像生成(顔の形、肌の色、髪の毛の色、性別など)をコントロールし、ノイズは細部の特徴(髪質や髪の流れ、ヒゲ、そばかす、肌質など)をコントロールします。Synthesis networkの解像度は4×4から順次アップサンプリングし、最終的には1024×1024になります。
このStyleGANは2018年にNVIDIAから発表されました。そして、StyleGAN2はStyleGANの改良版(AdaINの代わりにCNNのWeightを正規化など)として2020年にNVIDIAから発表されたました。
3.新垣結衣の潜在変数をどう見つけるか
潜在変数z(1×512)より、潜在変数w(18×512)の方が明らかに表現力が豊なので、潜在変数wの探索を行います。
アルゴリズムは、Synthesis networkの9個ある各層において、潜在変数wを適当に初期化して inital image を出力し、target image (新垣結衣の画像)との差をロスとして、ロスが出来るだけ小さくなるように潜在変数wを最適化するものです。
そのために、target image は9種類の解像度の画像(4×4〜1024×1024)で用意しておく必要があります。また、顔画像の切り取り位置が適切でないと今まで学習した内容が生かしきれず、上手く画像生成が出来ないことに注意が必要です。
それでは、実際にやってみましょう。
4.手順
1)顔画像の切り取り
普通はOpenCVでやるわけですが、StyleGAN2が学習したFFHQデータセットは、dlibを使いalign(顔が直立するように回転させる)して独自の設定の範囲を切り取って作成されているので、自分でオリジナル画像を使う場合も同様な処理を行います。
そして、切り出した顔画像(target image)は、1024×1024の大きさにリサイズします。2)マルチ解像度データの作成
切り取った顔画像を9種類の解像度の画像に変換します。dataset_tool.pyを使って、Tensorflowの仕様であるマルチ解像度の画像TFRecordを作成します。3)潜在変数wの探索
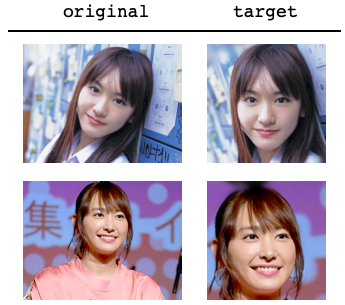
マルチ解像度の画像を元に、各層でロスを最小化して、潜在変数wを探索します。結果をターゲット画像は「target」、探索した潜在変数wを元に生成した画像は「generate」としてまとめてみると、こんな感じ。
割と出来が良かったものを選んでいますが、まずまずの出来ではないでしょうか。後一味足らないのが残念で70点くらいかな。
4)潜在変数wによるアニメーション
2つ画像の潜在変数wの差を等分して少しづつ変化させて画像を生成すると、いわゆるアニメーションが作成できます。
オリジナルは1024×1024サイズですが、それではQiitaにアップロード出来ないので、その1/16である256×256サイズで表示しています。さすがに高品質です。
5.結論
結論は、「StyleGAN2の潜在空間には、かなり新垣結衣似の人が住んでいました」(笑)です。


- 投稿日:2020-07-01T18:32:28+09:00
kivyを使ってGUIプログラミング ~その6 レイアウトいろいろ~
はじめに
その4でボタンの説明をしましたが、レイアウトに関しても複数存在するためいろいろ紹介してみたいと思います。
前回と同様に簡単な説明と、例を示して行きます、詳しい説明はリファレンスを見ていただけたらと思います。レイアウト
リファレンスのレイアウト一覧にある順番で紹介していきます。
AnchorLayout
kivy.uix.anchorlayout
配置するオブジェクトを画面の上、真ん中等簡単に配置が行えるレイアウトです。
配置場所の指定は、anchor_x、anchor_yという変数に対して
anchor_xならleft,center,right
anchor_yならtop,center,bottomの組み合わせ計9箇所から指定できます。
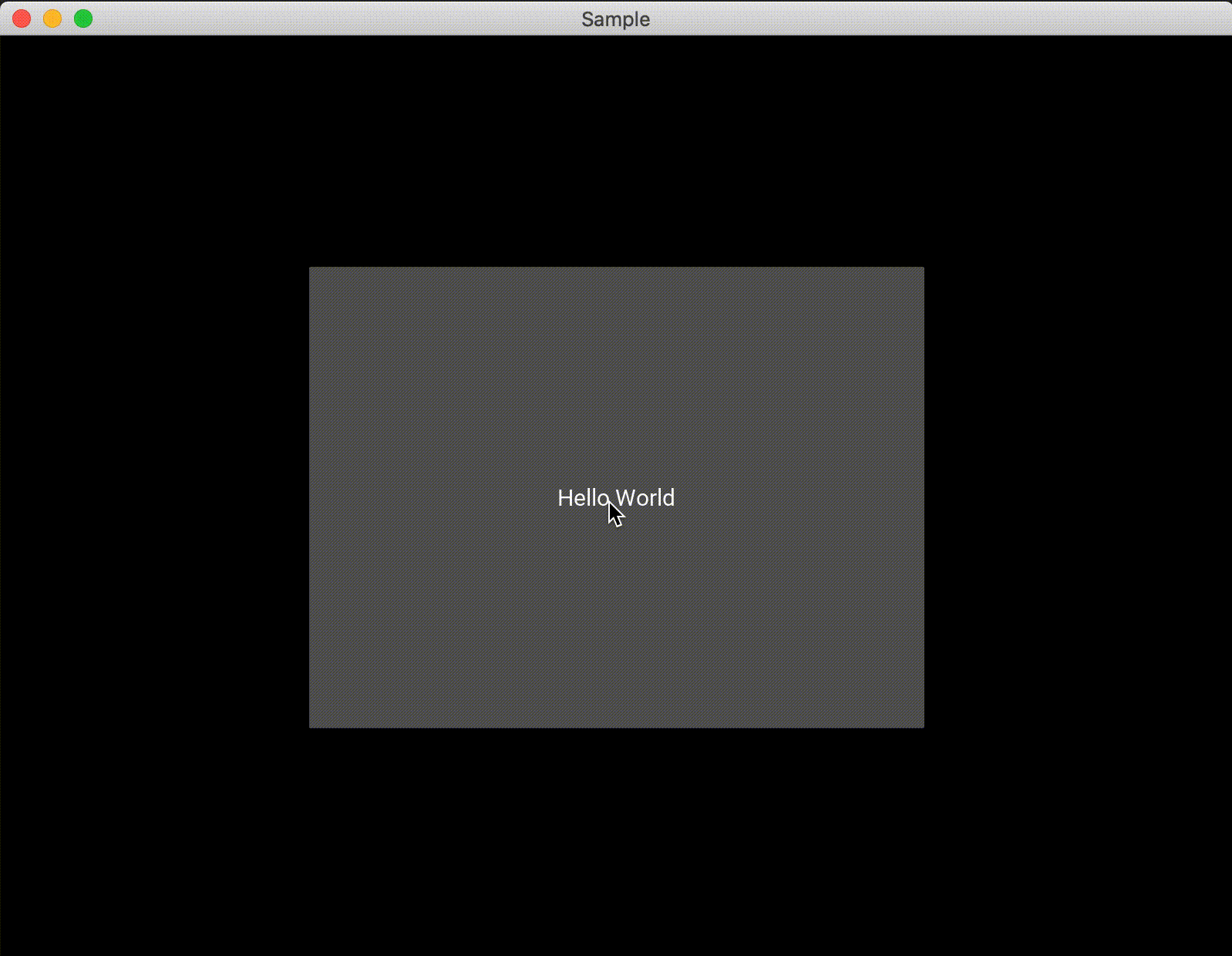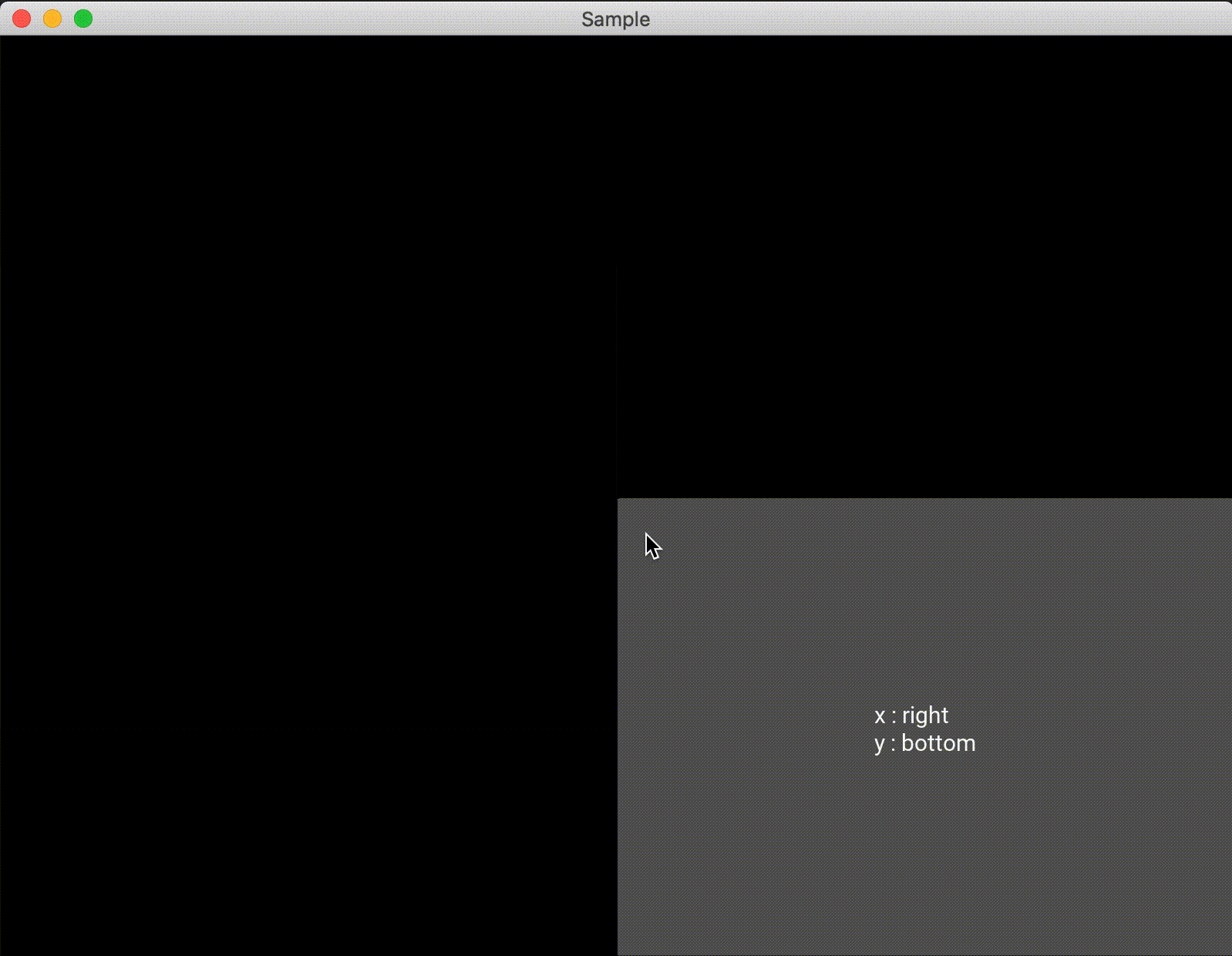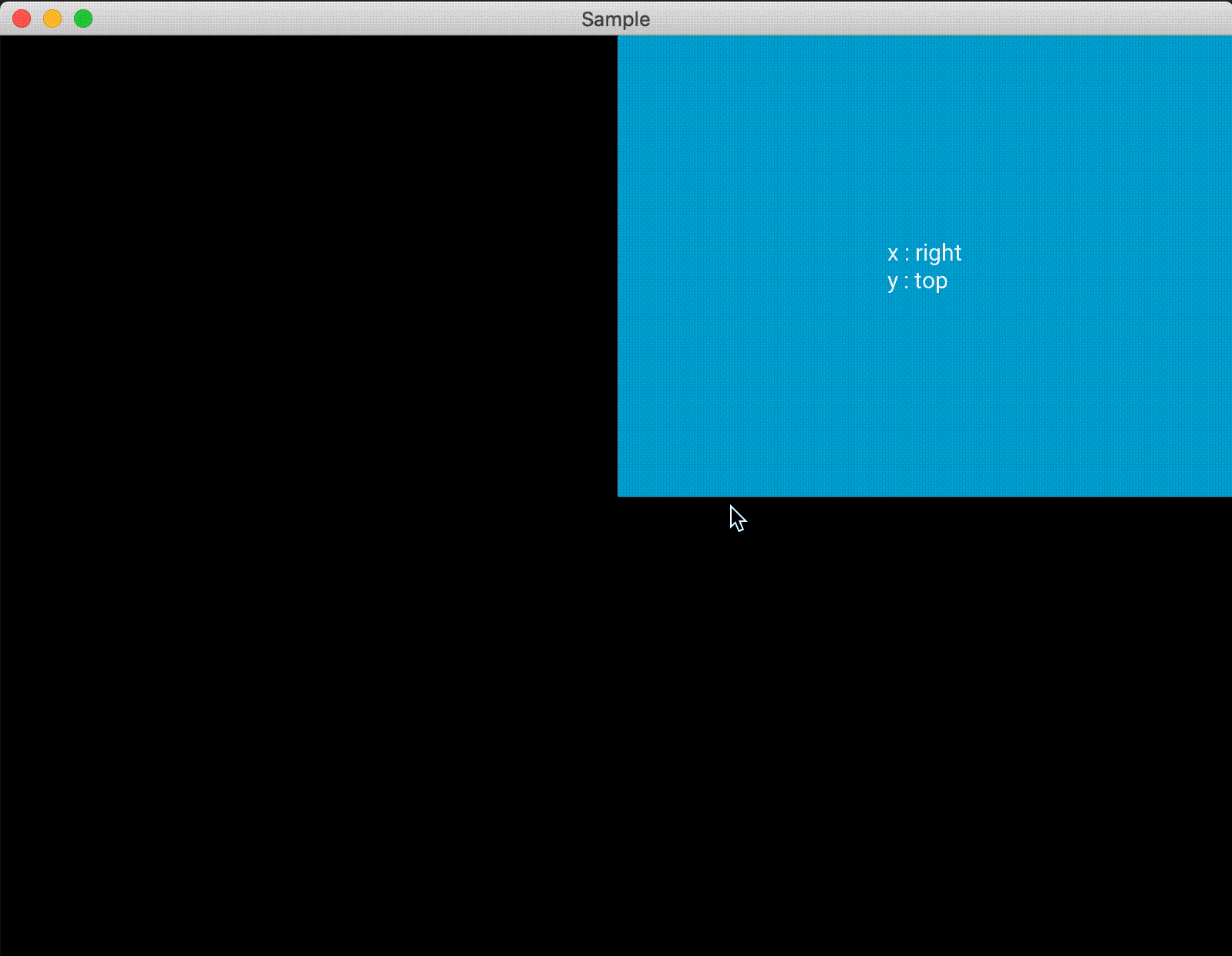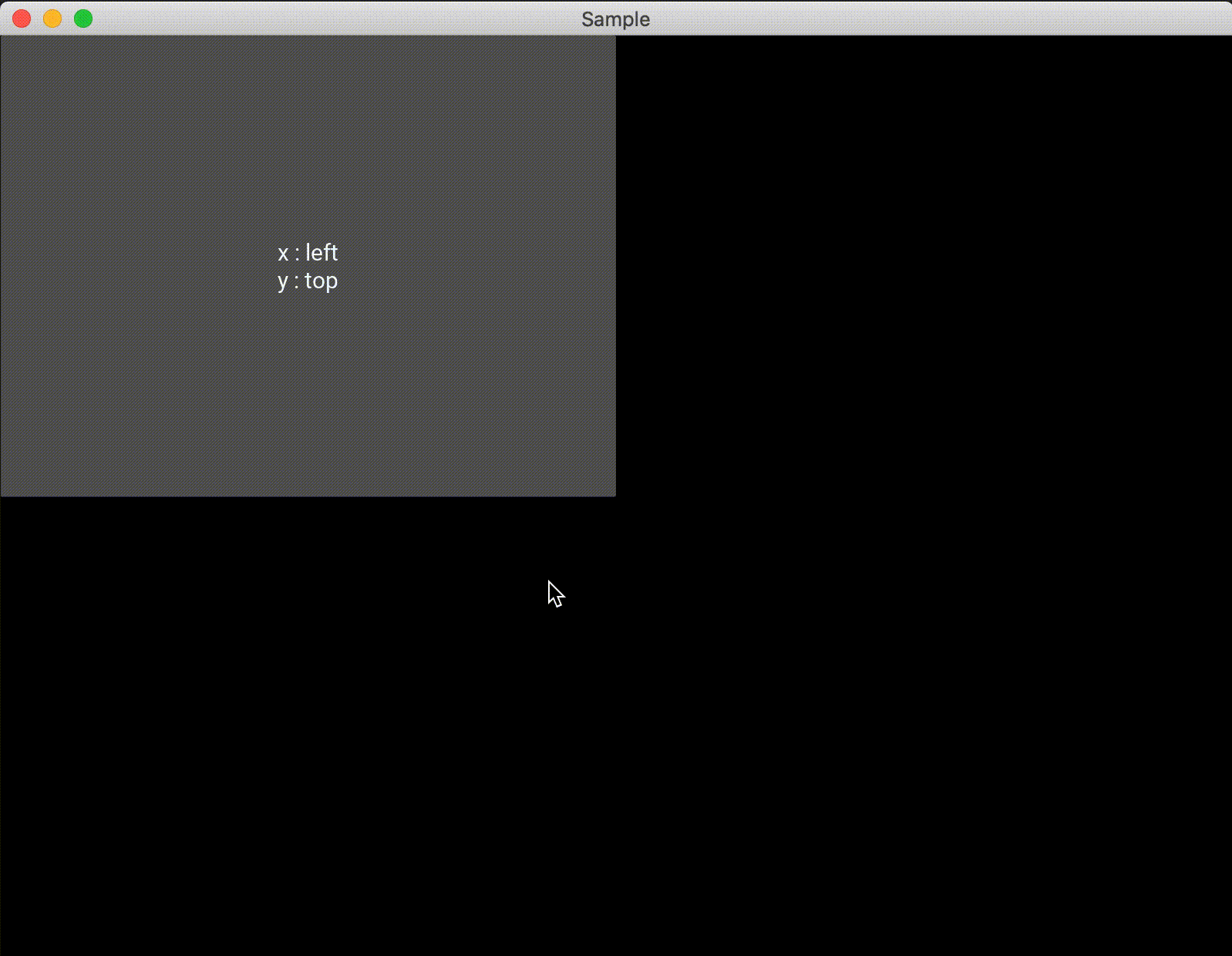
また、1つのAnchorLayoutに対して1つしかwidgetを追加できないので注意する必要があります。複数配置したい場合は、AnchorLayoutに別のレイアウトを追加すれば良いと思います。import random from kivy.app import App from kivy.uix.anchorlayout import AnchorLayout from kivy.uix.button import Button class Test(AnchorLayout): def __init__(self, **kwargs): super(Test, self).__init__(**kwargs) self.x_positon = ["left", "center", "right"] self.y_positon = ["top", "center", "bottom"] self.anchor_x = "center" self.anchor_y = "center" btn = Button(text='Hello World', size_hint=(0.5,0.5), on_press=self.click) self.add_widget(btn) def click(self,btn): x = random.choice(self.x_positon) y = random.choice(self.y_positon) self.anchor_x = x self.anchor_y = y btn.text = "x : {}\ny : {}".format(x, y) class Sample(App): def build(self): return Test() if __name__ == '__main__': Sample().run()
BoxLayout
kivy.uix.boxlayout
ウィジェットを水平方向か垂直方向に並べるように配置するレイアウトです。
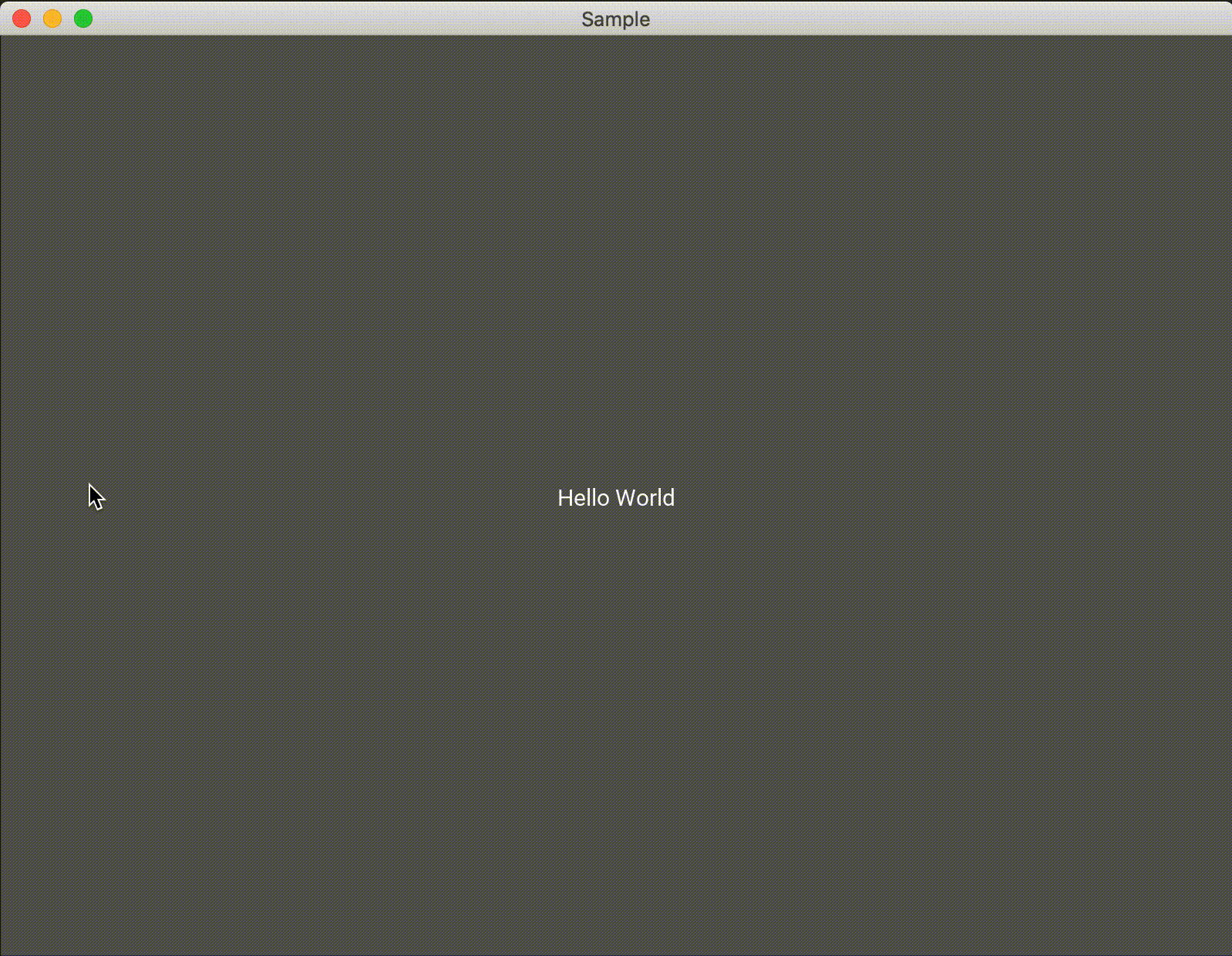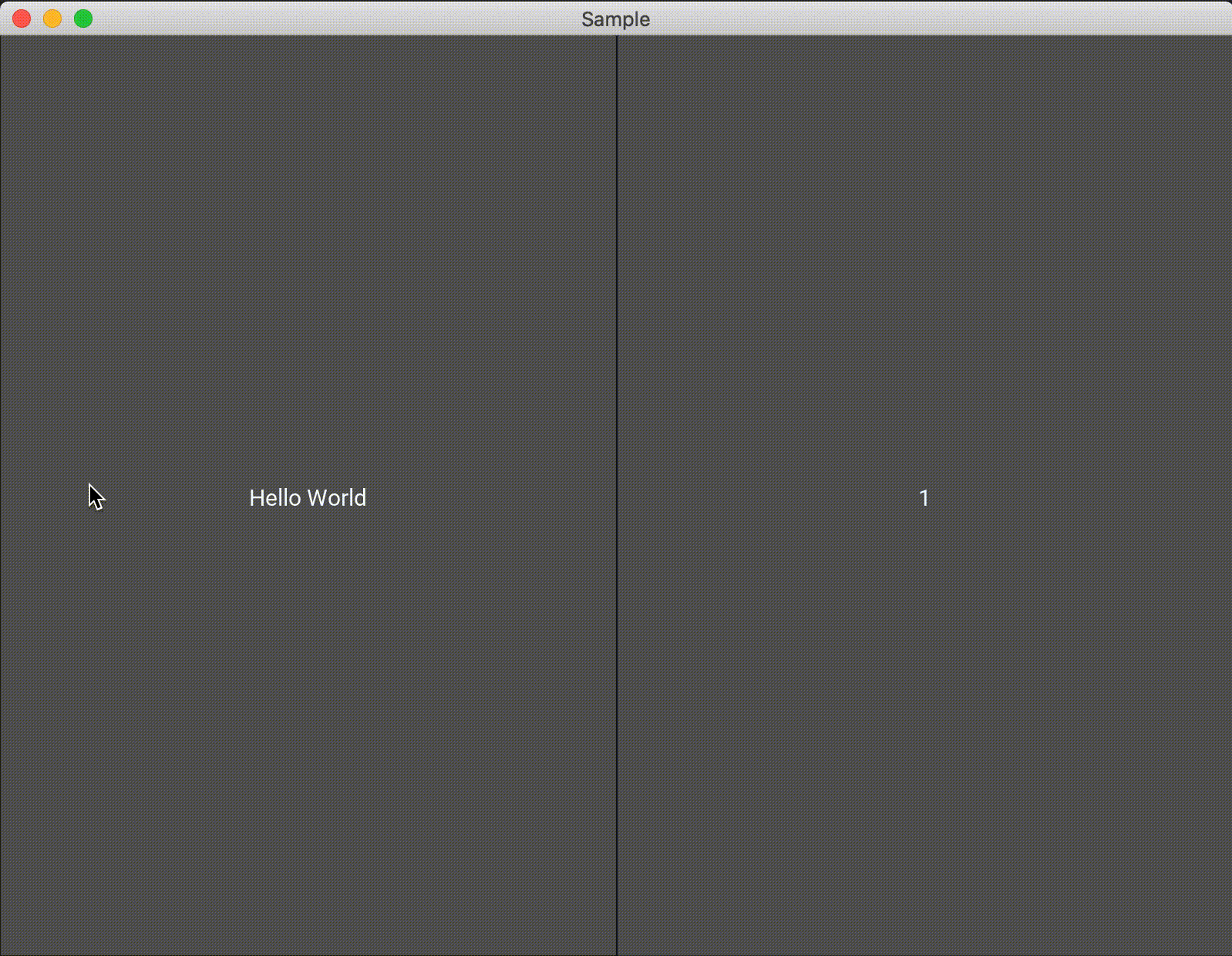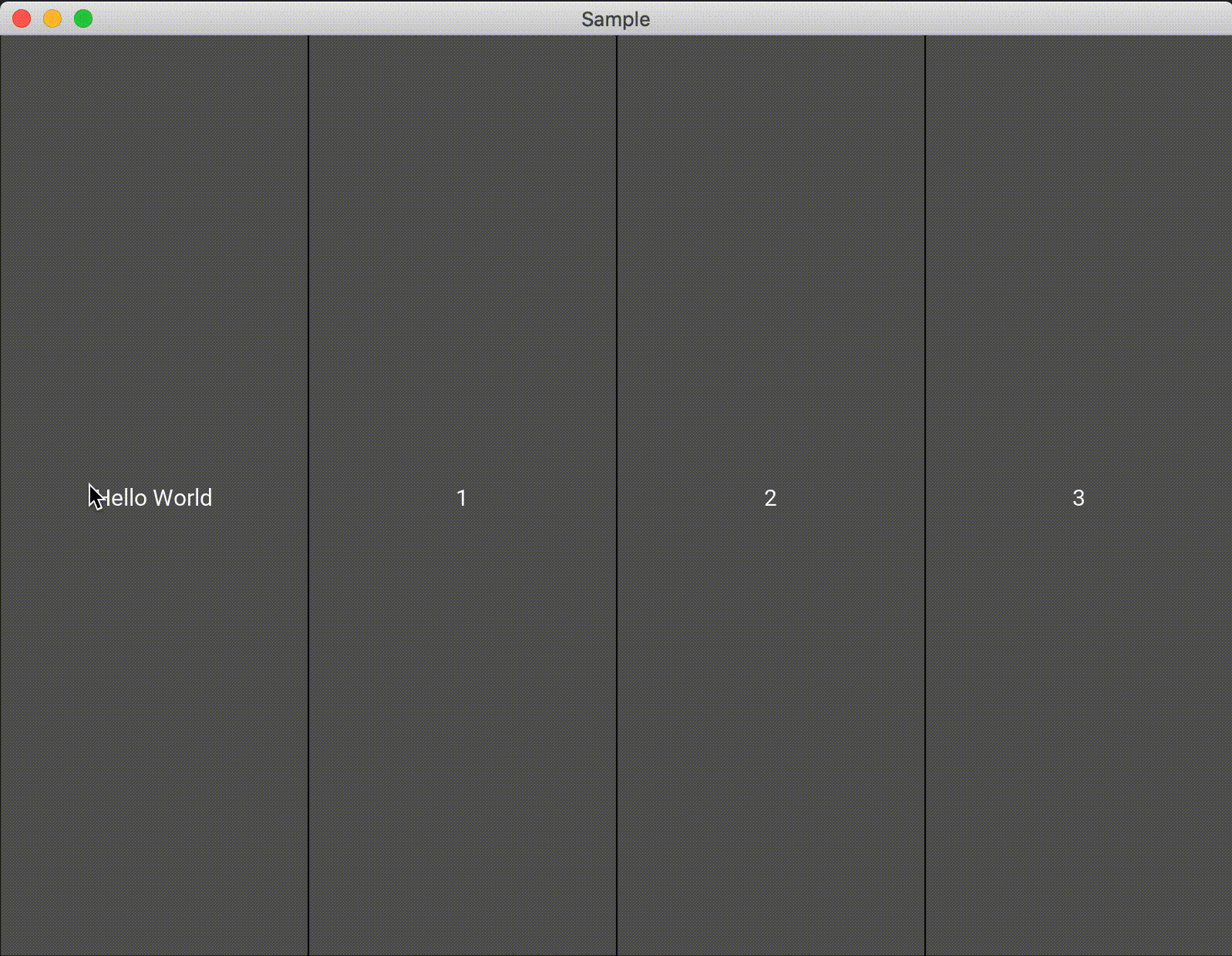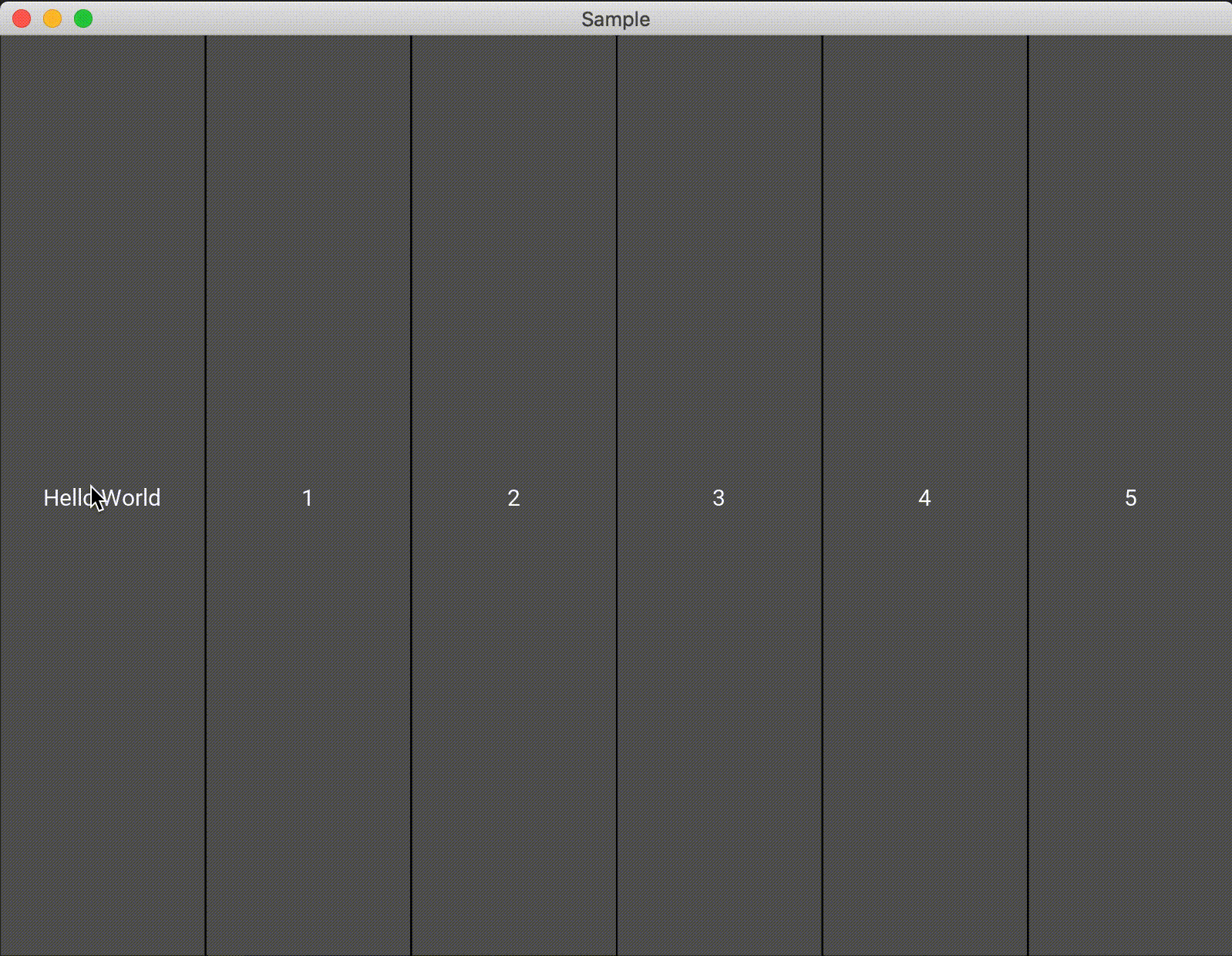
デフォルトでは、水平方向にウィジェットが追加されていきます。方向を変更するには、orientationという変数に垂直方向にしたいならvertical、水平方向に配置したいならhorizontalを代入することで向きを変えることができます。途中でウィジェットの追加向きを変えるということはできないと思うので、新しいBoxLayoutをadd_wigetして配置を変える感じになるかと思います。from kivy.app import App from kivy.uix.boxlayout import BoxLayout from kivy.uix.button import Button class Test(BoxLayout): def __init__(self, **kwargs): super(Test, self).__init__(**kwargs) self.count = 0 #デフォルトは"horizontal"水平方向に配置されます。 self.orientation = "horizontal" #self.orientation = "vertical" btn = Button(text='Hello World', on_press=self.click) self.add_widget(btn) def click(self,btn): self.count += 1 self.add_widget(Button(text="{}".format(self.count),on_press=self.dismiss)) def dismiss(self, a): self.remove_widget(a) class Sample(App): def build(self): return Test() if __name__ == '__main__': Sample().run()
FloatLayout
kivy.uix.floatlayout
FloatLayoutは上で紹介したようなレイアウトとは異なり、絶対位置を指定して配置することができます。
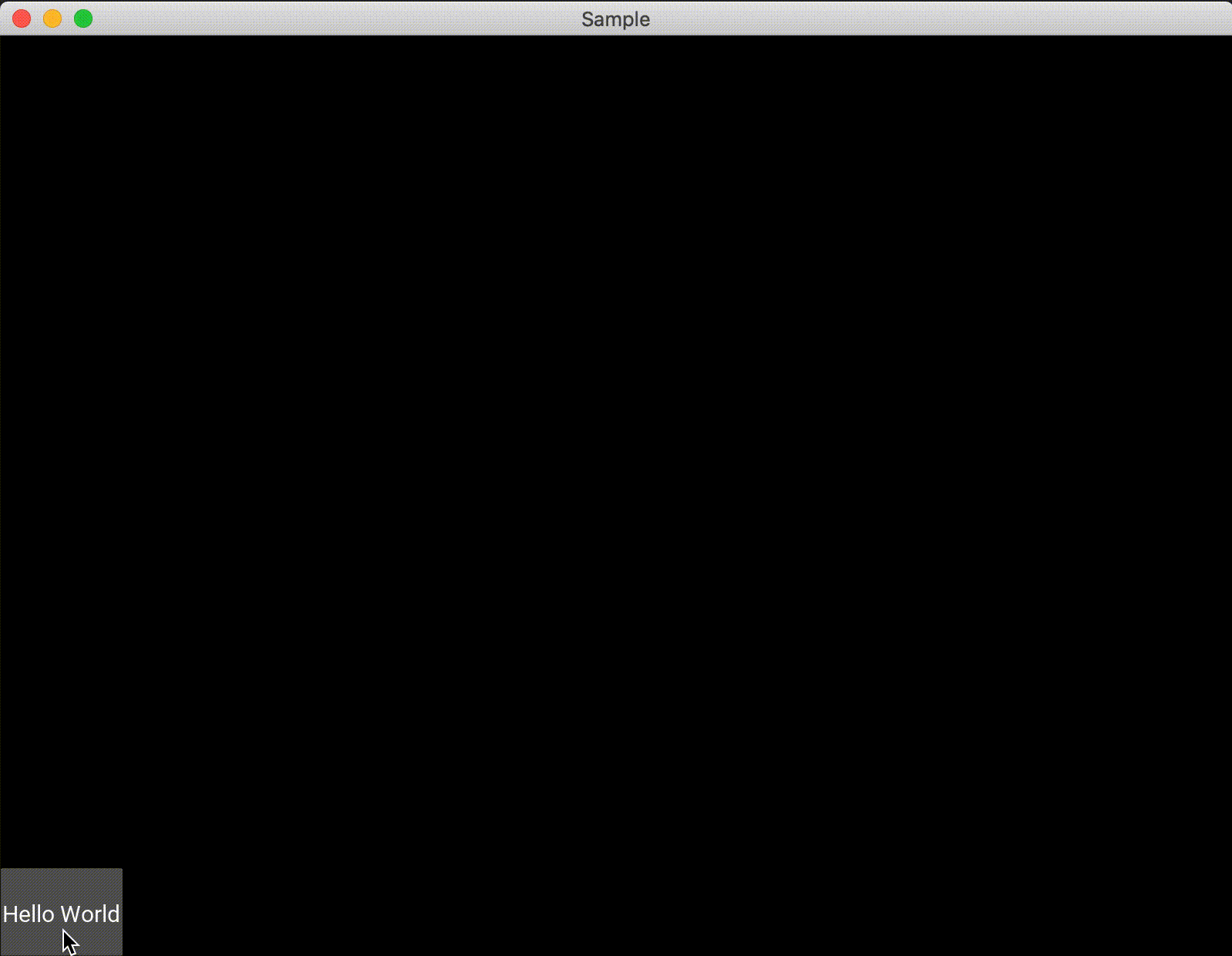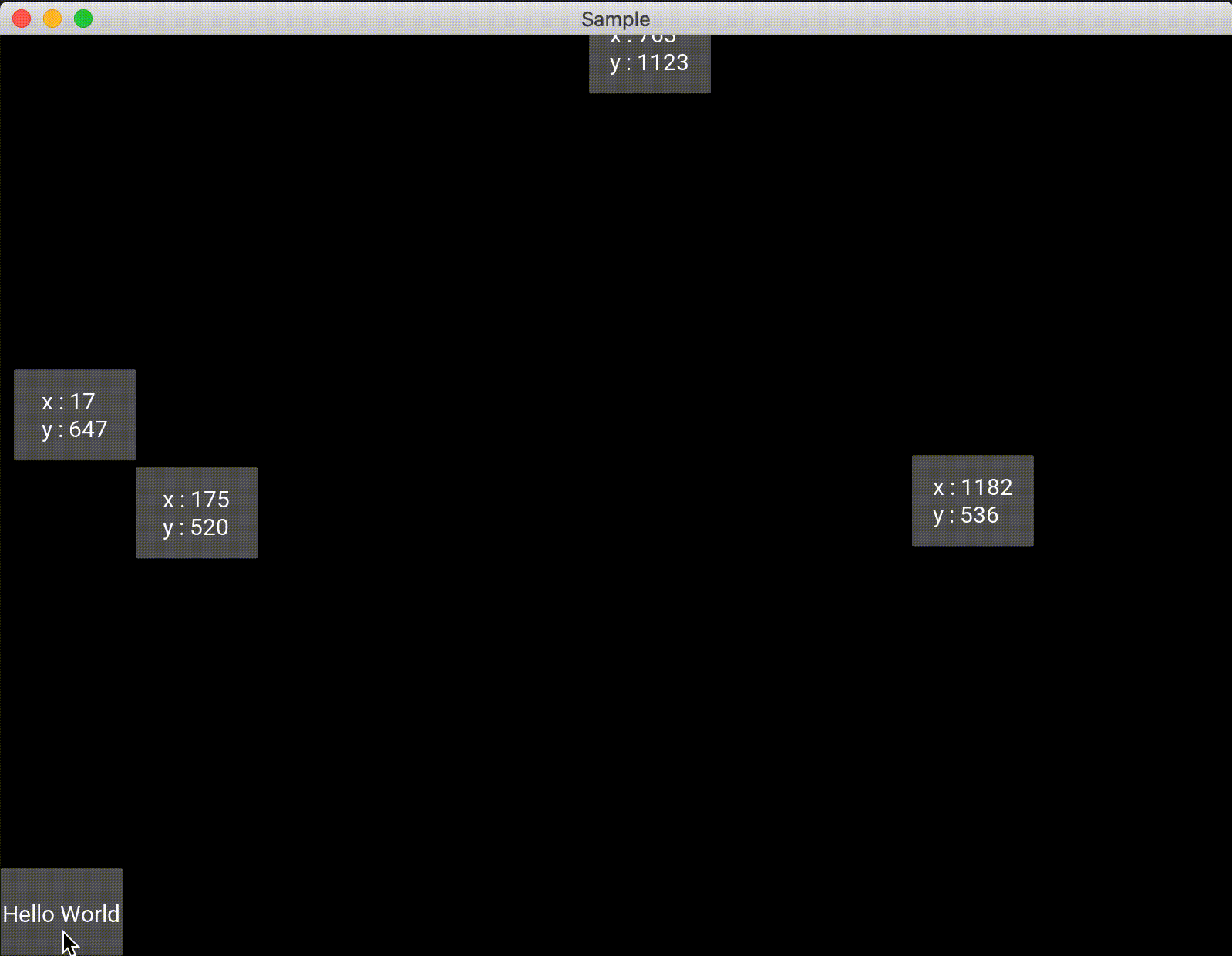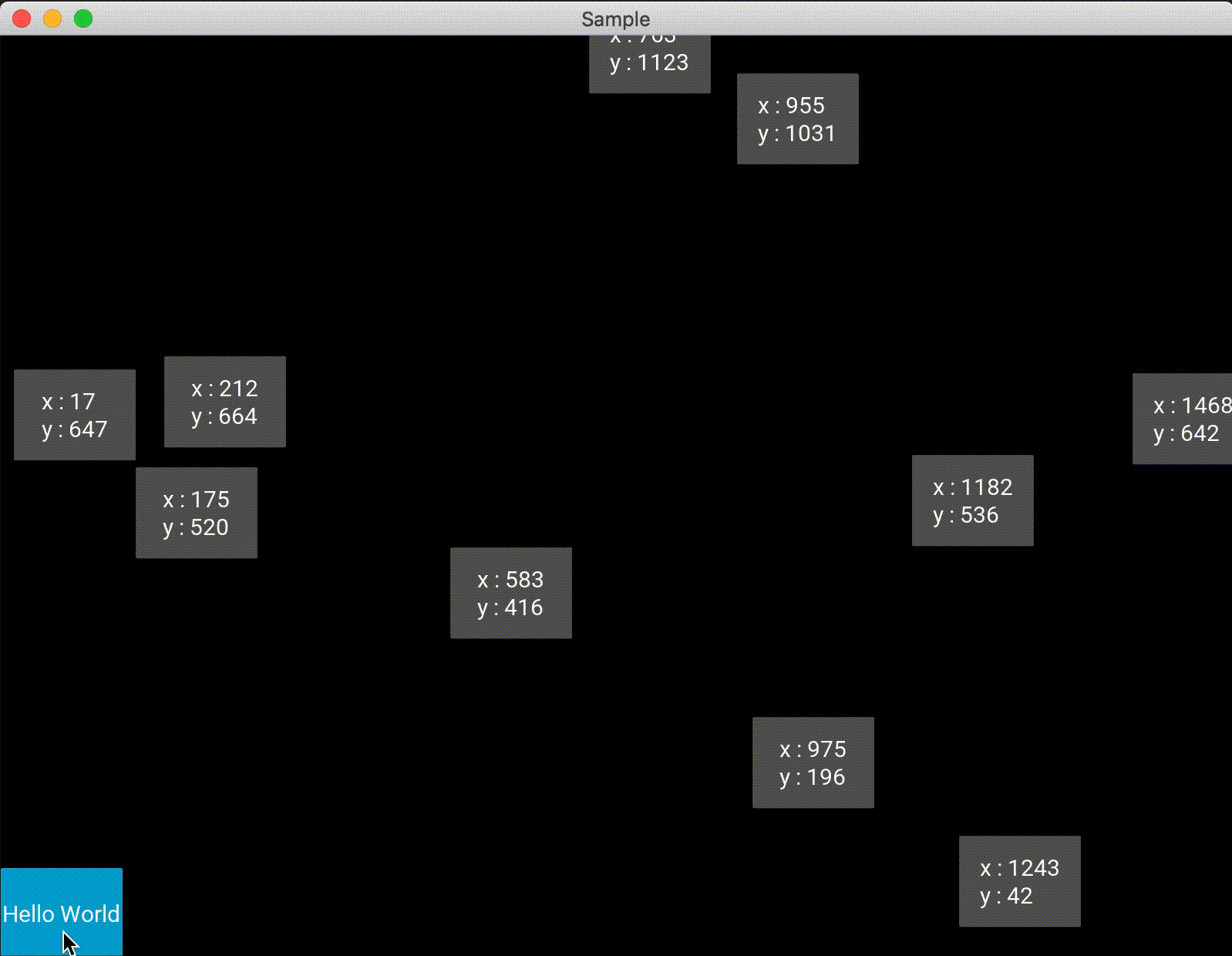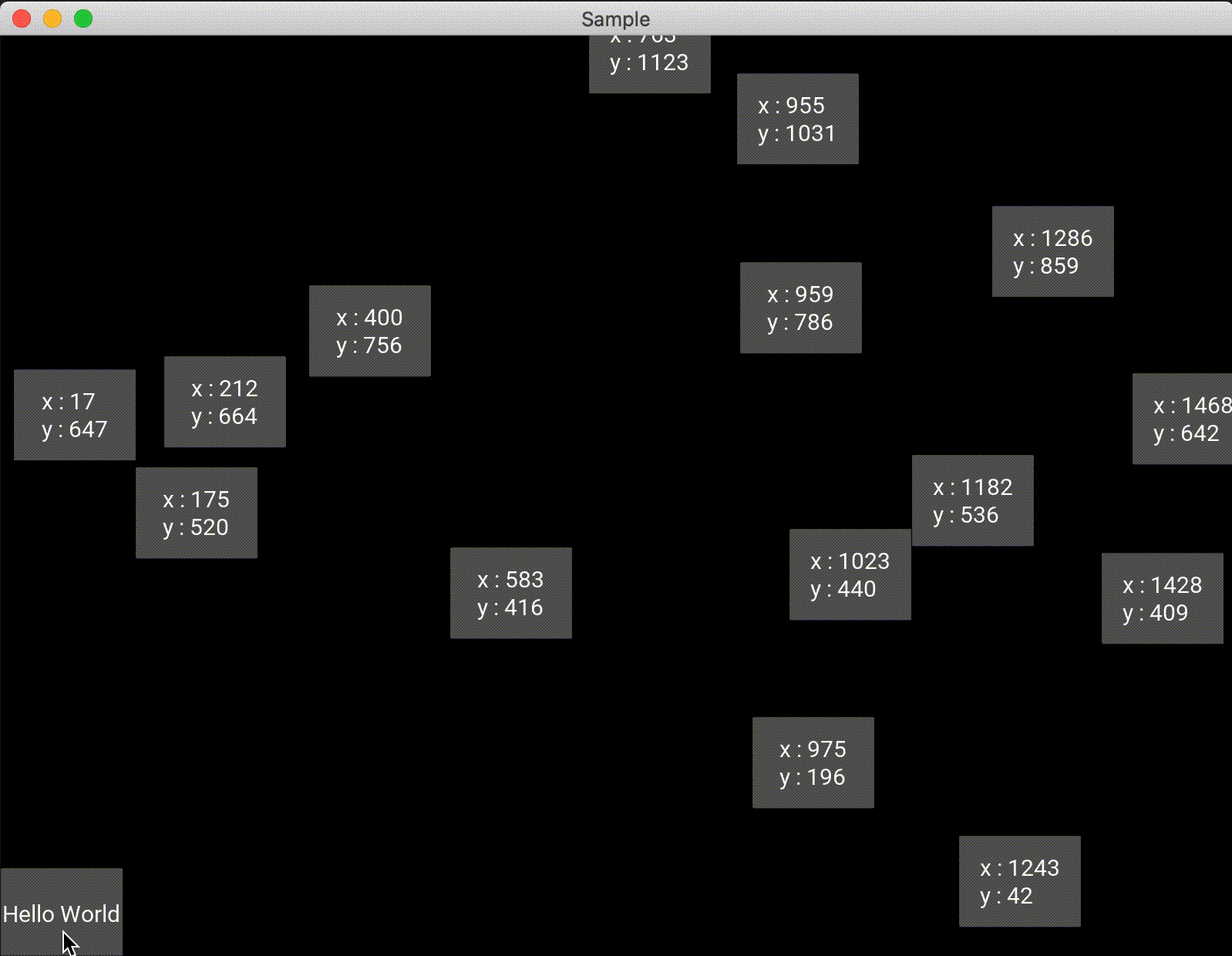
絶対位置であるため、widget配置後にウィンドウの大きさを変えたりしてもオブジェクトはウィンドウに合わせて位置が変化することはないため注意する必要があります。import random from kivy.app import App from kivy.uix.floatlayout import FloatLayout from kivy.uix.button import Button class Test(FloatLayout): def __init__(self, **kwargs): super(Test, self).__init__(**kwargs) btn = Button(text='Hello World', size_hint=(0.1,0.1), on_press=self.click) self.add_widget(btn) def click(self,btn): x = int(random.uniform(0,self.width)) y = int(random.uniform(0,self.height)) self.add_widget(Button(text="x : {}\ny : {}".format(x, y), pos=(x,y), size_hint=(0.1,0.1))) class Sample(App): def build(self): return Test() if __name__ == '__main__': Sample().run()
RelativeLayout
kivy.uix.relativelayout
使い方がイマイチわかりませんでした。
わかり次第記事を更新したいと思います。GridLayout
kivy.uix.gridlayout
GridLayoutはグリッドとあるように表計算みたいな形でウィジェットを追加していく配置になります。
配置はcolsとrowsから指定することができます。colsに数値を代入すると、その数値分だけ横に配置が終わるとその下に新しい段を作りさらに追加していきます。rowsは縦方向の最大値を指定して、横方向にウィジェットを追加していきますが、イマイチ挙動がよくわかりませんでした。同時にcolsとrowsを用いると、cols×rowsのグリッドを作成することができます。from kivy.app import App from kivy.uix.gridlayout import GridLayout from kivy.uix.button import Button class Test(GridLayout): def __init__(self, **kwargs): super(Test, self).__init__(**kwargs) self.count = 0 btn = Button(text='Hello World', on_press=self.click) self.cols = 5 #self.rows = 5 self.add_widget(btn) def click(self,btn): self.count += 1 self.add_widget(Button(text="{}".format(self.count))) class Sample(App): def build(self): return Test() if __name__ == '__main__': Sample().run()
PageLayout
kivy.uix.pagelayout
PageLayoutは、画面に別の画面を配置できるようなレイアウトになっており、簡単な画面遷移のようなことができると思います。画面端の線(見辛いですが,,)をクリックしながら横にドラッグすると別の画面が出てきます(ちょっと操作しづらいですw)。例ではボタンをそのまま貼り付けていますが、本来はPageLayoutに別のレイアウトをadd_widgetをするような使い方になると思います。
from kivy.app import App from kivy.uix.pagelayout import PageLayout from kivy.uix.button import Button class Test(PageLayout): def __init__(self, **kwargs): super(Test, self).__init__(**kwargs) btn1 = Button(text='Hello World1', size_hint=(0.5, 0.5)) self.add_widget(btn1) btn2 = Button(text='Hello World2', size_hint=(0.5, 0.5)) self.add_widget(btn2) btn3 = Button(text='Hello World3', size_hint=(0.5, 0.5)) self.add_widget(btn3) class Sample(App): def build(self): return Test() if __name__ == '__main__': Sample().run()
ScatterLayout
kivy.uix.scatterlayout
ScatterLayoutは、マウスで位置を変えたり、大きさを変えることができたりするレイアウトです。例では、ラベルを2つ貼ったBoxLayoutをScatterLayout上で動かしてみています(ラベルだけだと見辛かったので破線を追加しています)。本来なら画像アプリなどで画面を拡大したりとかそういった使い方をすると思います。パソコンよりスマホアプリような気がします。
from kivy.app import App from kivy.uix.scatterlayout import ScatterLayout from kivy.uix.boxlayout import BoxLayout from kivy.uix.label import Label from kivy.config import Config #破線を表示する Config.set('modules', 'ShowBorder', '') class Test(ScatterLayout): def __init__(self, **kwargs): super(Test, self).__init__(**kwargs) layout = BoxLayout() label = Label(text="Hello World!") layout.add_widget(label) label2 = Label(text="Hello World!") layout.add_widget(label2) self.add_widget(layout) class Sample(App): def build(self): return Test() if __name__ == '__main__': Sample().run()
StackLayout
kivy.uix.stacklayout
StackLayoutは、BoxLayoutと同じように配置する方向を指定するようなレイアウトになっています。
BoxLayoutと違いは、並べる向きを8つのパラメータから指定できることと、画面外に出そうになると、
次の段や横などに配置を変更する点です。並べる方向ですが、orientationという変数から指定することができ、lrやtbというパラメータを組み合わせたもので向きを指定します。例で書いてあるlr-tbですがlrは左(left)から右(right)、tbは上(Top)から下(Bottom)であり、左から右方向に配置し、画面端にいったら上から下にウィジェットを追加するとなります。from kivy.app import App from kivy.uix.stacklayout import StackLayout from kivy.uix.button import Button class Test(StackLayout): def __init__(self, **kwargs): super(Test, self).__init__(**kwargs) ori = ["lr-tb","tb-lr","rl-tb","tb-rl","lr-bt","bt-lr","rl-bt","bt-rl"] # デフォルトでは右方向、上から下方向に進みます。 self.orientation="lr-tb" for i in range(100): btn = Button(text=str(i), width=40 + i * 5, size_hint=(None, 0.15)) self.add_widget(btn) class Sample(App): def build(self): return Test() if __name__ == '__main__': Sample().run()
lr-tbを指定すると左の画像、bt-rlを指定すると右の画像のようになります。
まとめ
普段はboxlayoutを使うことが多いため、その他のレイアウトについてほぼ知識がない状態でしたので良い機会となりました。結局調べたもののrelativelayoutについてはイマイチ使い方がわからなかったのでもう一度調べてみたいと思いました。
参考サイト
https://pyky.github.io/kivy-doc-ja/gettingstarted/layouts.html


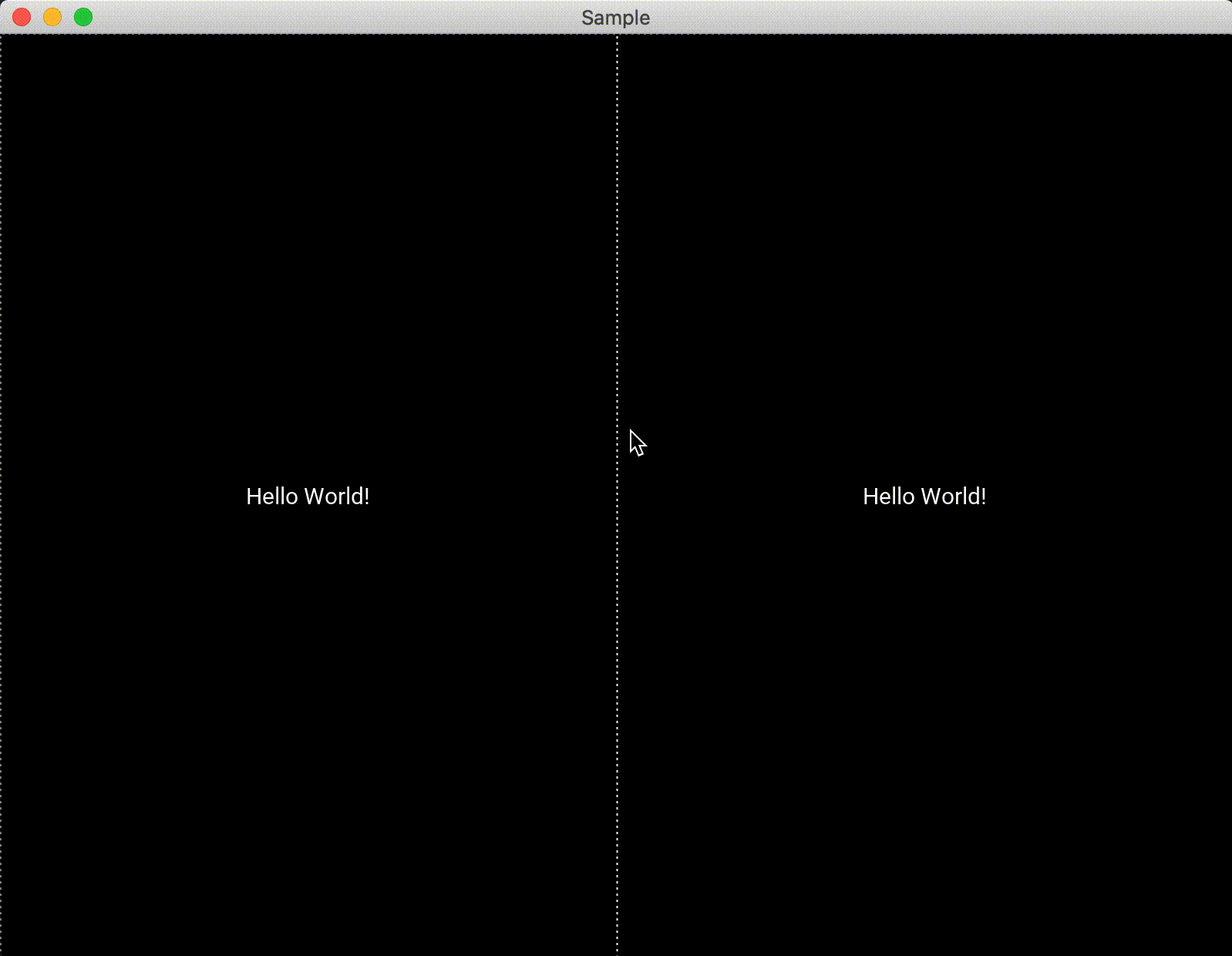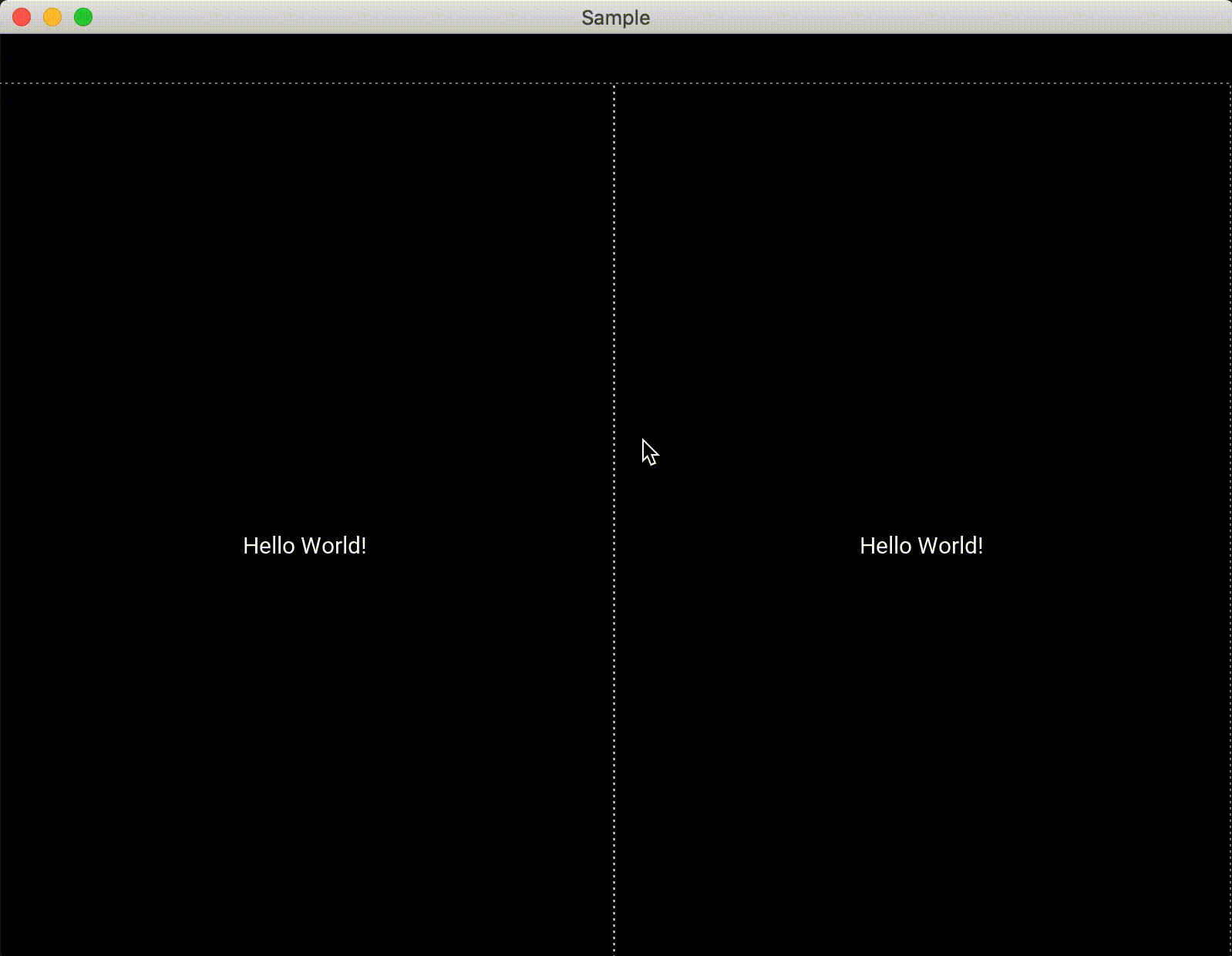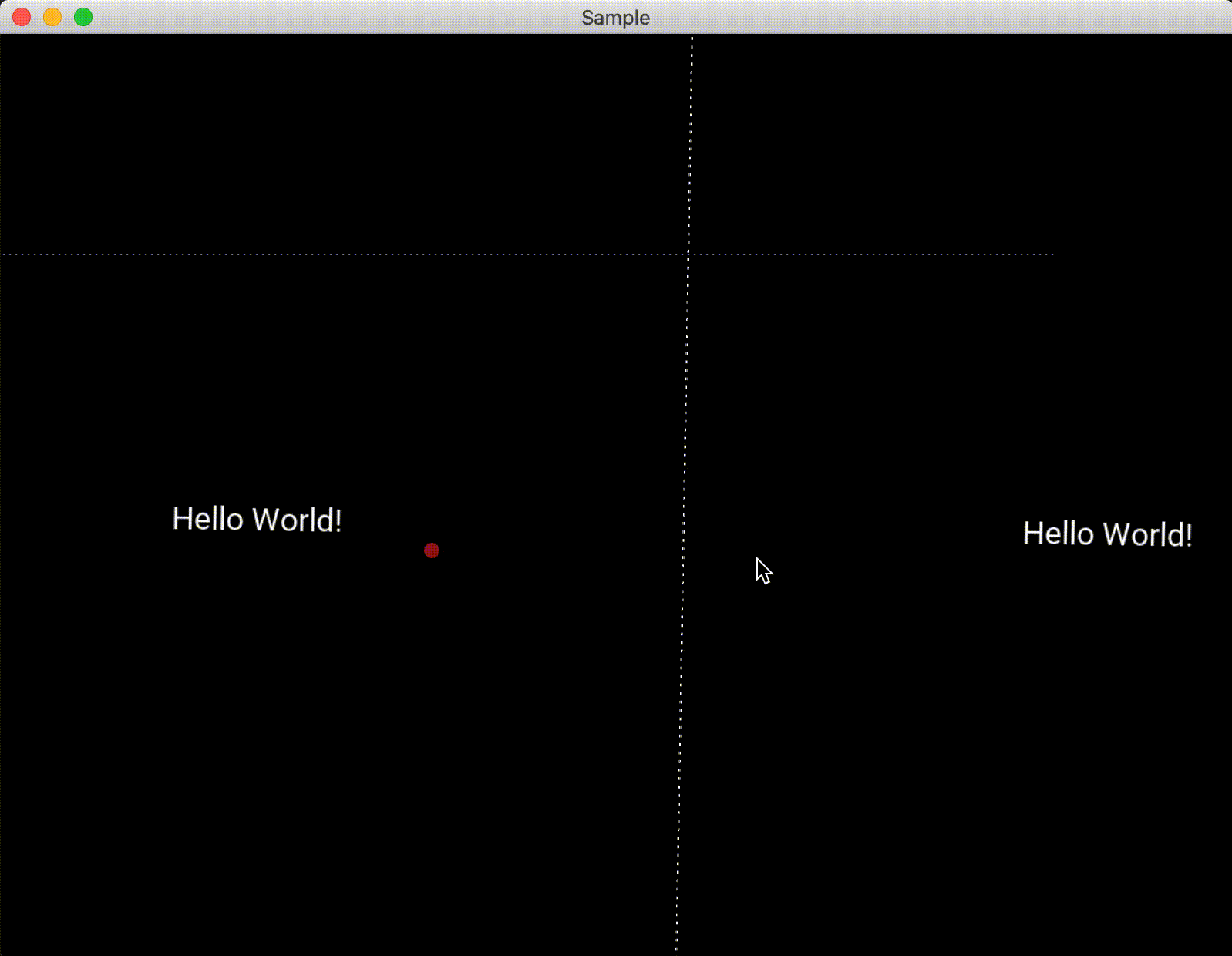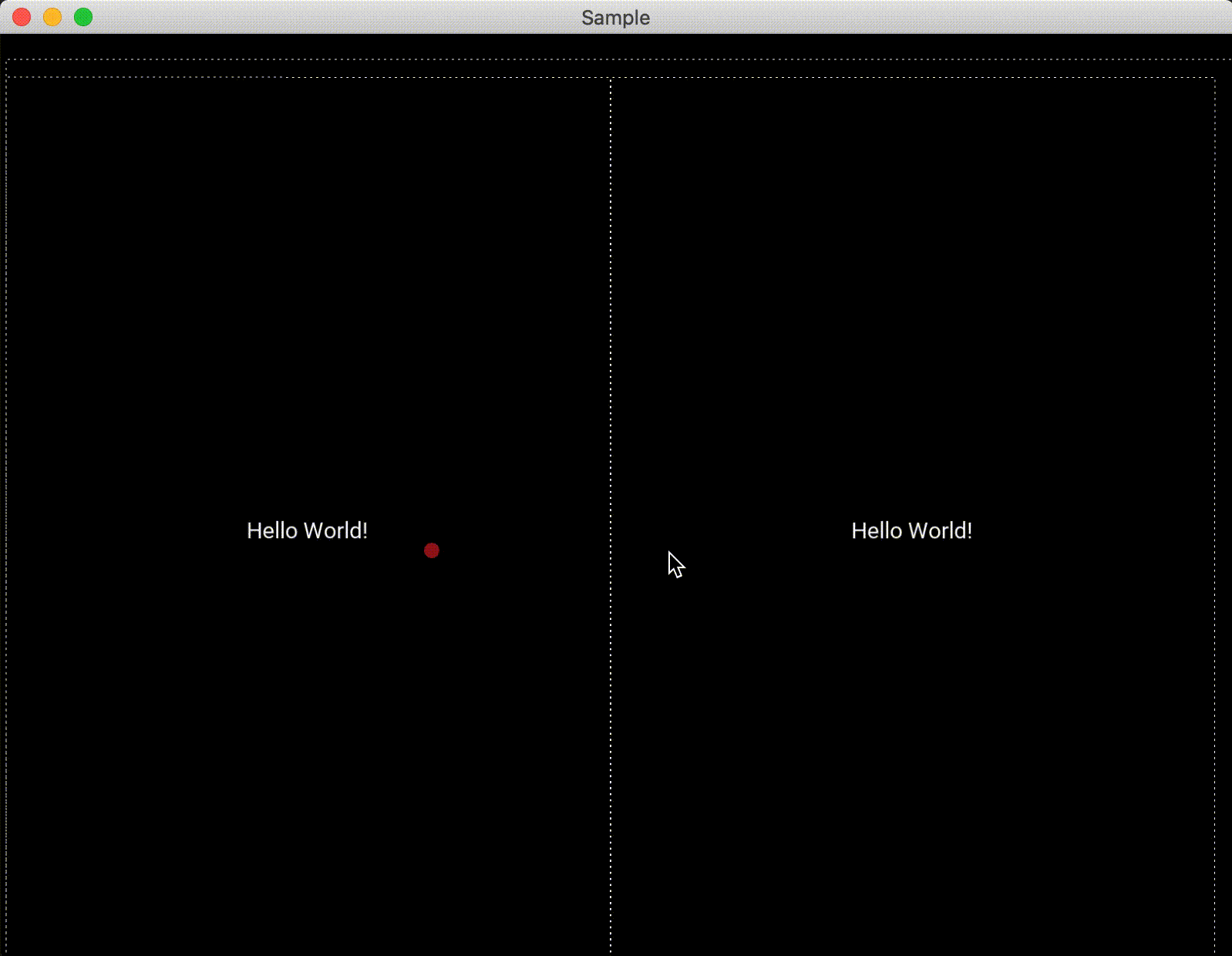

- 投稿日:2020-07-01T18:12:02+09:00
学会のプログラムからWord Cloudを作成
はじめに
先日参加した人工知能学会(JSAI2020)のトレンドを調べようと思い、プログラムの講演タイトルからWord Cloudを作成しました。
Word Cloudとは
文章中の単語の出現頻度を調べ、頻度に応じて文字の大きさを変えて図示するものです。ツイートからWord Cloudを作成して、多く呟いている単語を可視化したものなどを見たことがある方もいるのではないでしょうか。
テキストの用意
こちらからJSAI2020の大会論文集をダウンロードし、index.htmlというファイルを開いてセッション一覧をメモ帳にコピペしました。
プログラムがPDFで公開されている場合は次のようにしてテキストを抽出するといいと思います。
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter from pdfminer.converter import TextConverter from pdfminer.layout import LAParams from pdfminer.pdfpage import PDFPage input_path = './Program.pdf' output_path = 'Program.txt' manager = PDFResourceManager() with open(output_path, "wb") as output: with open(input_path, 'rb') as input: with TextConverter(manager, output, codec='utf-8', laparams=LAParams()) as conv: interpreter = PDFPageInterpreter(manager, conv) for page in PDFPage.get_pages(input): interpreter.process_page(page)必要ない情報を削除
日付や発表者など、講演タイトル以外の情報をテキストから削除します。発表者は()で囲まれていたので()の中の文字を削除しました。()の中の文字や時刻・日付の指定は正規表現を使っています。
import re with open('Program.txt', mode='rt', encoding='utf-8') as fo: Program = fo.read() #[]を()に変換 Program = Program.replace("[", "(") Program = ProgramP.replace("]", ")") #()で囲まれている文字を削除(この時[]だと削除できないため上記のコードが必要) Program = re.sub(r'\([^)]*\)', '', Program) #時刻・日付を削除 Program = re.sub(r'((0?|1)[0-9]|2[0-3])[:][0-5][0-9]?', '', Program) Program = re.sub(r'2020年([0-1]?[0-9])月([0-3]?[0-9])日?', '', Program) Program = re.sub('時間・会場', '', Program) Program = re.sub('セッション', '', Program) Program = re.sub('発表一覧', '', Program) Program = re.sub('会場', '', Program) with open('Program_new.txt', 'w') as f: print(Program, file=f)Word Cloudの作成
from matplotlib import pyplot as plt from wordcloud import WordCloud with open('Program_new.txt', mode='rt', encoding='utf-8') as fo: cloud_text = fo.read() #font_pathは自分の端末にある日本語フォントを指定 word_cloud = WordCloud(width=640, height=480, font_path="/System/Library/AssetsV2/com_apple_MobileAsset_Font6/c7c8e5cb889b80fff0175bf138a7b66c6f027f21.asset/AssetData/ToppanBunkyuMidashiGothicStdN-ExtraBold.otf").generate(cloud_text) word_cloud.to_file('wordcloud4.png') plt.imshow(word_cloud) plt.axis('off') plt.show()

- 投稿日:2020-07-01T17:42:15+09:00
画像処理 100 本ノック Q9 (ガウシアンフィルタ) の高速化
最近画像処理 100 本ノックというのを始めました。
https://qiita.com/yoyoyo_/items/2ef53f47f87dcf5d1e14最近画像処理にちょっと興味があって numpy を上手に使いたいなぁ〜と思っていたので非常にありがたい問題集なのですが, Q.9. ガウシアンフィルタ の解答例に不満があった(python で for 文を使いたくない!)のでなるべく numpy を使う処理を書いて速度を比較しました。
今回書いたコード:
def gaussian_filter(_img, filter_matrix): # assume that fY and fX is odd number (fY, fX) = filter_matrix.shape mY = (fY - 1) // 2 mX = (fX - 1) // 2 (Y, X, C) = _img.shape img = np.zeros((Y + mY*2, X + mX*2, C)) img[mY:Y+mY, mX:X+mX, :] = _img out_img = np.zeros_like(_img, np.float32) for dy in range (fY): for dx in range(fX): out_img += filter_matrix[dy][dx] * img[dy:Y+dy, dx:X+dx, :] return out_img.astype(np.uint8)画像の y, x ではなく
filter_matrixの y, x を for で回すことで画像における足し算は numpy の for を使えるようにしています。
速度比較
gaussian_filter を 100 回呼び出して何秒かかるかを比較しました。timeコマンドを使ってるので画像読み込み 1 回分の時間も含まれてますが大勢に影響はないと思います。
手法 時間 今回のコード 0.72 模範解答 50.60 圧倒的じゃないか我が軍は〜〜〜
メディアンフィルタについても, H * W * (filter_size) の画像(?)を作ってからその画像に対して np.median(axis=2) をやれば高速化できるんじゃないかと思います。ところで Pooling については for 文を使わない方法を思いついてないので誰か知ってたら教えて下さい。
- 投稿日:2020-07-01T17:42:15+09:00
画像処理 100 本ノック Q9, Q10 (フィルタ) の高速化
最近画像処理 100 本ノックというのを始めました。
https://qiita.com/yoyoyo_/items/2ef53f47f87dcf5d1e14最近画像処理にちょっと興味があって numpy を上手に使いたいなぁ〜と思っていたので非常にありがたい問題集なのですが, Q.9. ガウシアンフィルタ, Q.10. メディアンフィルタ の解答例に不満があった(python で for 文を使いたくない!)のでなるべく numpy を使う処理を書いて速度を比較しました。
今回書いたコード:
def gaussian_filter(_img, filter_matrix): # assume that fY and fX is odd number (fY, fX) = filter_matrix.shape mY = (fY - 1) // 2 mX = (fX - 1) // 2 (Y, X, C) = _img.shape img = np.zeros((Y + mY*2, X + mX*2, C)) img[mY:Y+mY, mX:X+mX, :] = _img out_img = np.zeros_like(_img, np.float32) for dy in range (fY): for dx in range(fX): out_img += filter_matrix[dy][dx] * img[dy:Y+dy, dx:X+dx, :] return out_img.astype(np.uint8)画像の y, x ではなく
filter_matrixの y, x を for で回すことで画像における足し算は numpy の for を使えるようにしています。
速度比較
gaussian_filter を 100 回呼び出して何秒かかるかを比較しました。timeコマンドを使ってるので画像読み込み 1 回分の時間も含まれてますが大勢に影響はないと思います。
手法 時間 今回のコード 0.72 模範解答 50.60 圧倒的じゃないか我が軍は〜〜〜
Q10. メディアンフィルタについても, H * W * (filter_size) の画像(?)を作ってからその画像に対して np.median(axis=2) をやれば高速化できるんじゃないかと思います。できました。def median_filter(_img, filter_size): # assume that filter_size is odd half_size = (filter_size - 1) // 2 (Y, X, C) = _img.shape img = np.zeros((Y + half_size*2, X + half_size*2, C)) img[half_size:Y+half_size, half_size:X+half_size, :] = _img out_img = np.zeros_like(_img) for c in range(C): big_ch_img = np.zeros((Y, X, filter_size**2)) for fy in range(filter_size): for fx in range(filter_size): ch = fy * filter_size + fx big_ch_img[:,:,ch] = img[fy:fy+Y, fx:fx+X,c] out_img[:,:,c] = np.median(big_ch_img, axis=2) return out_img計測時間は 1.71 秒 vs 302.98 秒でした。
ところで Pooling については for 文を使わない方法を思いついてないので誰か知ってたら教えて下さい。
- 投稿日:2020-07-01T17:23:56+09:00
だから僕はpandasをやめた【データサイエンス100本ノック(構造化データ加工編)篇 #3】
だから僕はpandasをやめた【データサイエンス100本ノック(構造化データ加工編)篇 #3】
データサイエンス100本ノック(構造化データ加工編)のPythonの問題を解いていきます。この問題群は、模範解答ではpandasを使ってデータ加工を行っていますが、私達は勉強がてらにNumPyの構造化配列を用いて処理していきます。
はじめに
NumPyの構造化配列の勉強として、データサイエンス100本ノック(構造化データ加工編)のPythonの問題を解いていきます。
Pythonでデータサイエンス的なことをする人の多くはpandas大好き人間かもしれませんが、実はpandasを使わなくても、NumPyで同じことができます。そしてNumPyの方がたいてい高速です。
pandas大好き人間だった僕もNumPyの操作には依然として慣れていないので、今回この『データサイエンス100本ノック』をNumPyで操作することでpandasからの卒業を試みて行きたいと思います。今回は17~22問目をやっていきます。このあたりはソート・ランク付けというテーマのようです。
初期データは以下のようにして読み込みました。
なおnp.vectorize()やnp.frompyfunc()等による関数のベクトル化は行わない方針です。import numpy as np import pandas as pd from numpy.lib import recfunctions as rfn # 模範解答用 df_customer = pd.read_csv('data/customer.csv') df_receipt = pd.read_csv('data/receipt.csv') # 僕たちが扱うデータ arr_customer = np.genfromtxt( 'data/customer.csv', delimiter=',', encoding='utf-8', names=True, dtype=None) arr_receipt = np.genfromtxt( 'data/receipt.csv', delimiter=',', encoding='utf-8', names=True, dtype=None)P_017
P-17: 顧客データフレーム(df_customer)を生年月日(birth_day)で高齢順にソートし、先頭10件を全項目表示せよ。
配列をソートする場合は
np.sort()を用いますが、これはソートした配列が帰ってきます。今回欲しいのはソートの順番なので、np.argsort()ないしnp.ndarray.argsort()を使います。np.sort()のorder引数に列名を渡す方法もありますが挙動がいまいちだったので推奨しません。In[017]arr_customer[arr_customer['birth_day'].argsort()][:10]Out[017]array([('CS003813000014', '村山 菜々美', 1, '女性', '1928-11-26', 90, '182-0007', '東京都調布市菊野台**********', 'S13003', 20160214, '0-00000000-0'), ('CS026813000004', '吉村 朝陽', 1, '女性', '1928-12-14', 90, '251-0043', '神奈川県藤沢市辻堂元町**********', 'S14026', 20150723, '0-00000000-0'), ('CS018811000003', '熊沢 美里', 1, '女性', '1929-01-07', 90, '204-0004', '東京都清瀬市野塩**********', 'S13018', 20150403, '0-00000000-0'), ('CS027803000004', '内村 拓郎', 0, '男性', '1929-01-12', 90, '251-0031', '神奈川県藤沢市鵠沼藤が谷**********', 'S14027', 20151227, '0-00000000-0'), ('CS013801000003', '天野 拓郎', 0, '男性', '1929-01-15', 90, '274-0824', '千葉県船橋市前原東**********', 'S12013', 20160120, '0-00000000-0'), ('CS001814000022', '鶴田 里穂', 1, '女性', '1929-01-28', 90, '144-0045', '東京都大田区南六郷**********', 'S13001', 20161012, 'A-20090415-7'), ('CS016815000002', '山元 美紀', 1, '女性', '1929-02-22', 90, '184-0005', '東京都小金井市桜町**********', 'S13016', 20150629, 'C-20090923-C'), ('CS009815000003', '中田 里穂', 1, '女性', '1929-04-08', 89, '154-0014', '東京都世田谷区新町**********', 'S13009', 20150421, 'D-20091021-E'), ('CS005813000015', '金谷 恵梨香', 1, '女性', '1929-04-09', 89, '165-0032', '東京都中野区鷺宮**********', 'S13005', 20150506, '0-00000000-0'), ('CS012813000013', '宇野 南朋', 1, '女性', '1929-04-09', 89, '231-0806', '神奈川県横浜市中区本牧町**********', 'S14012', 20150712, '0-00000000-0')], dtype=[('customer_id', '<U14'), ('customer_name', '<U10'), ('gender_cd', '<i4'), ('gender', '<U2'), ('birth_day', '<U10'), ('age', '<i4'), ('postal_cd', '<U8'), ('address', '<U26'), ('application_store_cd', '<U6'), ('application_date', '<i4'), ('status_cd', '<U12')])Time[017]%timeit df_customer.sort_values('birth_day', ascending=True).head(10) # 21.8 ms ± 346 µs per loop (mean ± std. dev. of 7 runs, 10 loops each) %timeit arr_customer[arr_customer['birth_day'].argsort()][:10] # 17.1 ms ± 473 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)P_018
P-18: 顧客データフレーム(df_customer)を生年月日(birth_day)で若い順にソートし、先頭10件を全項目表示せよ。
順番を逆にするだけです。
In[018]arr_customer[arr_customer['birth_day'].argsort()][::-1][:10]Out[018]array([('CS035114000004', '大村 美里', 1, '女性', '2007-11-25', 11, '156-0053', '東京都世田谷区桜**********', 'S13035', 20150619, '6-20091205-6'), ('CS022103000002', '福山 はじめ', 9, '不明', '2007-10-02', 11, '249-0006', '神奈川県逗子市逗子**********', 'S14022', 20160909, '0-00000000-0'), ('CS002113000009', '柴田 真悠子', 1, '女性', '2007-09-17', 11, '184-0014', '東京都小金井市貫井南町**********', 'S13002', 20160304, '0-00000000-0'), ('CS004115000014', '松井 京子', 1, '女性', '2007-08-09', 11, '165-0031', '東京都中野区上鷺宮**********', 'S13004', 20161120, '1-20081231-1'), ('CS002114000010', '山内 遥', 1, '女性', '2007-06-03', 11, '184-0015', '東京都小金井市貫井北町**********', 'S13002', 20160920, '6-20100510-1'), ('CS025115000002', '小柳 夏希', 1, '女性', '2007-04-18', 11, '245-0018', '神奈川県横浜市泉区上飯田町**********', 'S14025', 20160116, 'D-20100913-D'), ('CS002113000025', '広末 まなみ', 1, '女性', '2007-03-30', 12, '184-0015', '東京都小金井市貫井北町**********', 'S13002', 20171030, '0-00000000-0'), ('CS033112000003', '長野 美紀', 1, '女性', '2007-03-22', 12, '245-0051', '神奈川県横浜市戸塚区名瀬町**********', 'S14033', 20150606, '0-00000000-0'), ('CS007115000006', '福岡 瞬', 1, '女性', '2007-03-10', 12, '285-0845', '千葉県佐倉市西志津**********', 'S12007', 20151118, 'F-20101016-F'), ('CS014113000008', '矢口 莉緒', 1, '女性', '2007-03-05', 12, '260-0041', '千葉県千葉市中央区東千葉**********', 'S12014', 20150622, '3-20091108-6')], dtype=[('customer_id', '<U14'), ('customer_name', '<U10'), ('gender_cd', '<i4'), ('gender', '<U2'), ('birth_day', '<U10'), ('age', '<i4'), ('postal_cd', '<U8'), ('address', '<U26'), ('application_store_cd', '<U6'), ('application_date', '<i4'), ('status_cd', '<U12')])P_019
P-19: レシート明細データフレーム(df_receipt)に対し、1件あたりの売上金額(amount)が高い順にランクを付与し、先頭10件を抽出せよ。項目は顧客ID(customer_id)、売上金額(amount)、付与したランクを表示させること。なお、売上金額(amount)が等しい場合は同一順位を付与するものとする。
売上金額が高い順に並び替えるのは簡単です。
sorted_array = arr_receipt[['customer_id', 'amount']][ arr_receipt['amount'].argsort()[::-1]] sorted_array[:10] # array([('CS011415000006', 10925), ('ZZ000000000000', 6800), # ('CS028605000002', 5780), ('ZZ000000000000', 5480), # ('ZZ000000000000', 5480), ('CS015515000034', 5480), # ('CS021515000089', 5440), ('ZZ000000000000', 5440), # ('ZZ000000000000', 5280), ('ZZ000000000000', 5280)], # dtype={'names':['customer_id','amount'], 'formats':['<U14','<i4'], 'offsets':[40,140], 'itemsize':144})この売上金額にランク付けします。もっとも簡単な方法は
scipy.stats.rankdata()を使う方法。今回求めるのは多い順ですが、この関数は少ない順のランキングが返されるので、最大値から引いてひっくり返します。import scipy.stats rank_asc = scipy.stats.rankdata(sorted_array['amount'], 'max') rank = rank_asc.max() - rank_asc + 1 rank[:10] # array([1, 2, 3, 4, 4, 4, 7, 7, 9, 9], dtype=int64)
scipy.stats.rankdata()関数を使わない場合は、同順位の存在をチェックし、「各行が何番目に大きい値か」という配列と「n番目に大きい値が第何位か」という配列を作成して、ランク配列を作成します。# 一つ上の行と同じ順位ならFalse,そうでない場合はTrueの配列 rank_cutidx = np.concatenate( ([True], sorted_array['amount'][1:] != sorted_array['amount'][:-1])) # rank_cutidx.cumsum()-1 :各行が何番目に大きい値か、を示す配列 # rank_cutidx.nonzero() :「n番目に大きい値」がそれぞれ第何位か、を示す配列 rank = rank_cutidx.nonzero()[0][rank_cutidx.cumsum()-1] + 1 rank[:10] # array([1, 2, 3, 4, 4, 4, 7, 7, 9, 9], dtype=int64)列追加は
numpy.lib.recfunctions.append_fields()を使いますが、この関数が激遅でした(1から新しく配列を作り直すようです)。In[019]sorted_array = arr_receipt[['customer_id', 'amount']][ arr_receipt['amount'].argsort()[::-1]] rank_cutidx = np.concatenate( ([True], sorted_array['amount'][1:] != sorted_array['amount'][:-1])) rank = rank_cutidx.nonzero()[0][rank_cutidx.cumsum()-1]+1 rfn.append_fields(sorted_array, 'ranking', rank, dtypes=rank.dtype, usemask=False)[:10]となると自前で空白のテーブルを準備するべき……?
In[019]sorter_index = arr_receipt['amount'].argsort()[::-1] sorted_id = arr_receipt['customer_id'][sorter_index] sorted_amount = arr_receipt['amount'][sorter_index] rank_cutidx = np.concatenate( ([True], sorted_amount[1:] != sorted_amount[:-1])) rank = rank_cutidx.nonzero()[0][rank_cutidx.cumsum()-1]+1 # 配列作成 new_arr = np.empty(arr_receipt.size, dtype=[('customer_id', sorted_id.dtype), ('amount', sorted_amount.dtype), ('ranking', rank.dtype)]) new_arr['customer_id'] = sorted_id new_arr['amount'] = sorted_amount new_arr['ranking'] = rank new_arr[:10]Out[019]array([('CS011415000006', 10925, 1), ('ZZ000000000000', 6800, 2), ('CS028605000002', 5780, 3), ('ZZ000000000000', 5480, 4), ('ZZ000000000000', 5480, 4), ('CS015515000034', 5480, 4), ('CS021515000089', 5440, 7), ('ZZ000000000000', 5440, 7), ('ZZ000000000000', 5280, 9), ('ZZ000000000000', 5280, 9)], dtype=[('customer_id', '<U14'), ('amount', '<i4'), ('ranking', '<i8')])Time[019]# 模範解答 %%timeit df_tmp = pd.concat([df_receipt[['customer_id', 'amount']], df_receipt['amount'].rank(method='min', ascending=False)], axis=1) df_tmp.columns = ['customer_id', 'amount', 'ranking'] df_tmp.sort_values('ranking', ascending=True).head(10) # 35 ms ± 643 µs per loop (mean ± std. dev. of 7 runs, 10 loops each) # 少し改良して1行で %%timeit df_receipt[['customer_id', 'amount']] \ .assign(ranking=df_receipt['amount'].rank(method='min', ascending=False)) \ .sort_values('ranking', ascending=True).head(10) # 34.1 ms ± 943 µs per loop (mean ± std. dev. of 7 runs, 10 loops each) # Numpy %%timeit tmp_amount = np.ascontiguousarray(arr_receipt['amount']) sorter_index = tmp_amount.argsort()[::-1] sorted_id = arr_receipt['customer_id'][sorter_index] sorted_amount = tmp_amount[sorter_index] rank_cutidx = np.concatenate(([True], sorted_amount[1:] != sorted_amount[:-1])) rank = rank_cutidx.nonzero()[0][rank_cutidx.cumsum()-1]+1 new_arr = np.empty(arr_receipt.size, dtype=[('customer_id', sorted_id.dtype), ('amount', sorted_amount.dtype), ('ranking', rank.dtype)]) new_arr['customer_id'] = sorted_id new_arr['amount'] = sorted_amount new_arr['ranking'] = rank new_arr[:10] # 22.6 ms ± 464 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)なんとかpandasより速く処理できました。
P_020
P-020: レシート明細データフレーム(df_receipt)に対し、1件あたりの売上金額(amount)が高い順にランクを付与し、先頭10件を抽出せよ。項目は顧客ID(customer_id)、売上金額(amount)、付与したランクを表示させること。なお、売上金額(amount)が等しい場合でも別順位を付与すること。
これは順位というか、
np.arange()で連番をつければいいだけですね。In[020]rfn.append_fields(arr_receipt[['customer_id', 'amount']] [arr_receipt['amount'].argsort()[::-1]], 'ranking', np.arange(1, arr_receipt.size+1), dtypes='<i4', usemask=False)[:10]In[020]sorter_index = arr_receipt['amount'].argsort()[::-1] sorted_id = arr_receipt['customer_id'][sorter_index] sorted_amount = arr_receipt['amount'][sorter_index] rank = np.arange(1, sorted_id.size+1) # 配列作成 new_arr = np.empty(arr_receipt.size, dtype=[('customer_id', sorted_id.dtype), ('amount', sorted_amount.dtype), ('ranking', rank.dtype)]) new_arr['customer_id'] = sorted_id new_arr['amount'] = sorted_amount new_arr['ranking'] = rank new_arr[:10]Out[020]array([('CS011415000006', 10925, 1), ('ZZ000000000000', 6800, 2), ('CS028605000002', 5780, 3), ('ZZ000000000000', 5480, 4), ('ZZ000000000000', 5480, 5), ('CS015515000034', 5480, 6), ('CS021515000089', 5440, 7), ('ZZ000000000000', 5440, 8), ('ZZ000000000000', 5280, 9), ('ZZ000000000000', 5280, 10)], dtype=[('customer_id', '<U14'), ('amount', '<i4'), ('ranking', '<i4')])P_021
P-021: レシート明細データフレーム(df_receipt)に対し、件数をカウントせよ。
In[021]arr_receipt.size len(arr_receipt) arr_receipt.shape[0]Out[021]104681 104681 104681P_022
P-022: レシート明細データフレーム(df_receipt)の顧客ID(customer_id)に対し、ユニーク件数をカウントせよ。
文字列データのユニークカウントはNumPyが苦手なやつです。
In[022]np.unique(arr_receipt['customer_id']).sizeOut[022]8307これはpandasが公式ドキュメントで自慢している通り、NumPyよりもpandasのほうがはるかに速いということが知られており、NumPy操縦士の僕たちにはおそらくどうしようもありません。
Time[022]%timeit len(df_receipt['customer_id'].unique()) # 8.19 ms ± 204 µs per loop (mean ± std. dev. of 7 runs, 100 loops each) %timeit np.unique(arr_receipt['customer_id']).size # 30.9 ms ± 635 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)
- 投稿日:2020-07-01T15:26:24+09:00
GoogleのVisionAPIをPythonからとりあえず触ってみる
この記事について
この記事ではGCPのVisionAPIを難しいことをすっ飛ばして使ってみる方法について書いています。
初めてでも、画像の通りにすれば使えます。参考ページ
Google Vision API
https://cloud.google.com/vision/docs/ocr/?hl=ja
(Google Cloud SDKをインストールせずに行けました。pipでgoogle-cloud-visionを入れたおかげ?)作業準備
Windows10
Python 3.7のインストール
GCPアカウントの作成
読み取りたい画像の準備作業開始
ライブラリのインストール
最初にGoogle Vision APIのライブラリを取得します。
以下のコマンドを入力します。pip install --upgrade google-cloud-vision
インストールが出来たらテストを行います。
Pythonを開いてfrom google.cloud import vision
を実行します。
これでエラーが出なければ大丈夫です。
もしできていなければPython 3.7.7 (default, May 6 2020, 11:45:54) [MSC v.1916 64 bit (AMD64)] :: Anaconda, Inc. on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> from google.cloud import vision
Traceback (most recent call last):
File "", line 1, in
ImportError: cannot import name 'vision' from 'google.cloud' (unknown location)と表示されます。
GCPプロジェクトの作成
今回は新規でGCPプロジェクトを立てます。
新しいプロジェクトを押します。
プロジェクト名などはわかりやすい名前で適当に作成してください。
APIの有効化
プロジェクトを作成したら次にVision APIを有効にします。
画像の番号の順番でクリックしてください。
検索窓に「google vision api」と入力します。
表示された項目をクリックします。
有効にするボタンをクリックします。
サービスアカウントの作成
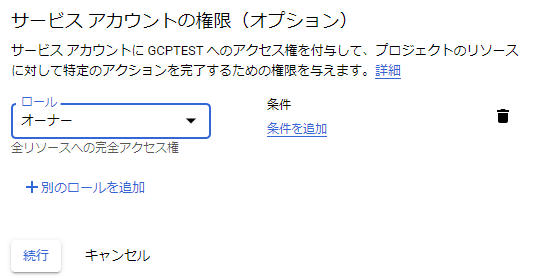
画像の番号の通りに選択します。
適当なサービスアカウント名を入力します。
IDは自動的に入力されますので、そのままで大丈夫です。
適当なロールを選択してください。
次の画面はそのまま完了します。
サービスアカウントが追加されました。
操作のをクリックして、「鍵を作成」を選択します。
JSONを選択して完了ボタンを押します。
ダウンロードしたファイルを任意の場所に移動します。環境変数の設定
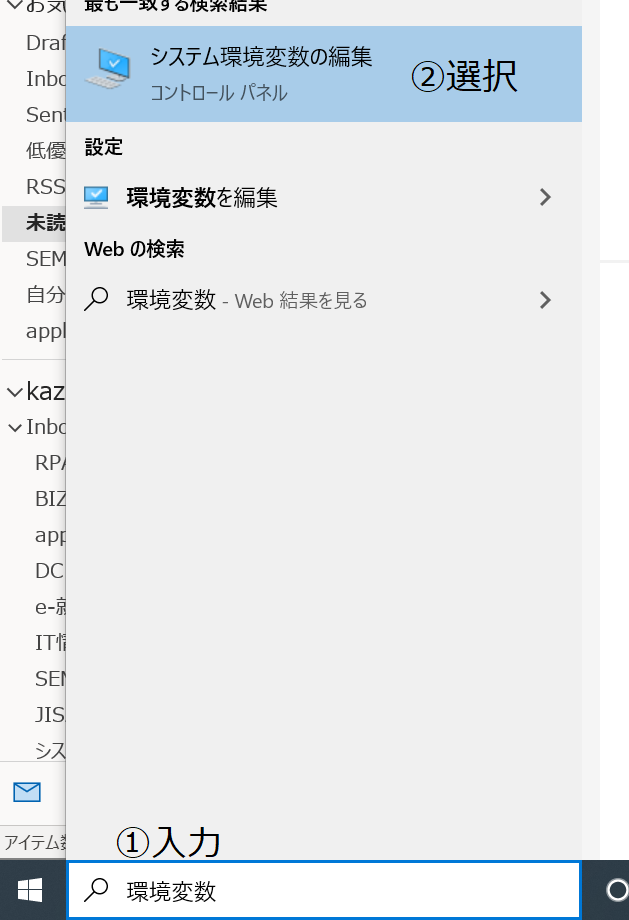
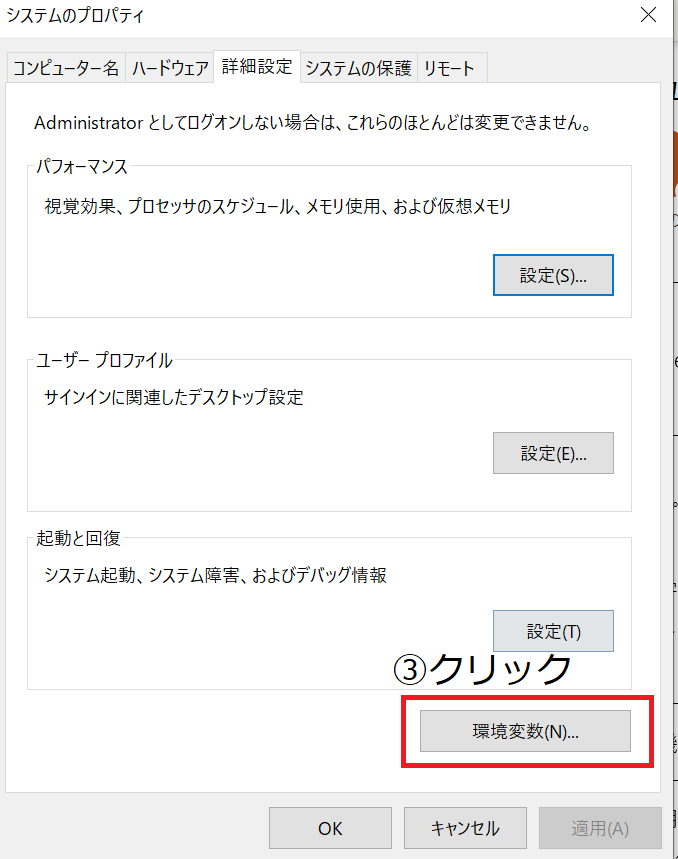
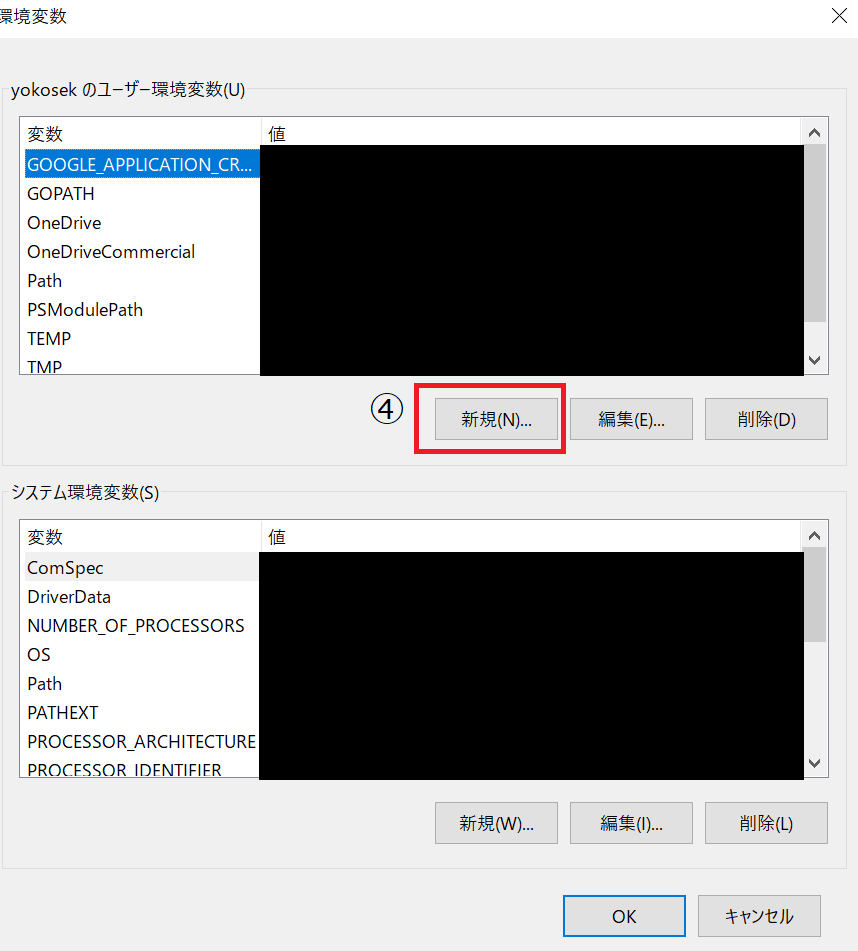
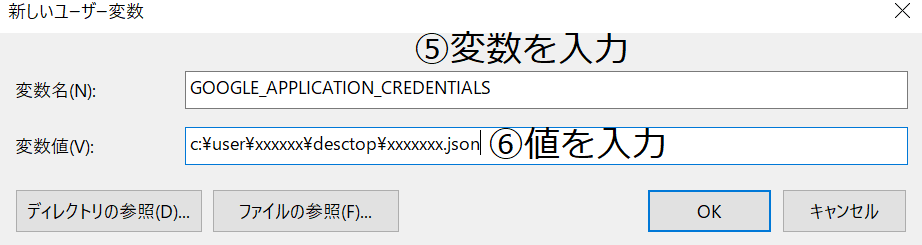
環境変数の設定を行います。
変数:GOOGLE_APPLICATION_CREDENTIALS
値 :ダウンロードしたjsonファイルの場所と名前(例:c:\user\xxxxxx\desctop\xxxxxxx.json)以下設定手順です。
画像内の番号通りに進めます。
ソースコード
Githubから持ってきたソースコードを変更します。
detext.py"""Detects text in the file.""" from google.cloud import vision import io client = vision.ImageAnnotatorClient() # [START vision_python_migration_text_detection] path = "C:\\Users\\xxxx\\Desktop\\gcptest\\xxxxx.png" with io.open(path, 'rb') as image_file: content = image_file.read() image = vision.types.Image(content=content) response = client.text_detection(image=image) texts = response.text_annotations print('Texts:') for text in texts: print('\n"{}"'.format(text.description)) vertices = (['({},{})'.format(vertex.x, vertex.y) for vertex in text.bounding_poly.vertices]) print('bounds: {}'.format(','.join(vertices))) if response.error.message: raise Exception( '{}\nFor more info on error messages, check: ' 'https://cloud.google.com/apis/design/errors'.format( response.error.message))ソースコード内の7行目の「path = "C:\Users\xxxx\Desktop\gcptest\xxxxx.png"」の部分を変更することで画像を変更できます。
例として以下の画像を使用します。
出力結果
"かんばれニッポン
明治チョコスナック
きのこの山
薫るいちご味
ほんの
TOKTO 0
20
ES
子)
©Tokyo 2020
"
bounds: (1,66),(745,66),(745,954),(1,954)
"かんばれ"
bounds: (72,80),(351,73),(353,152),(74,159)
"ニッポン"
bounds: (353,73),(619,66),(621,145),(355,152)
"明治"
bounds: (208,151),(305,150),(305,190),(208,191)
"チョコ"
bounds: (307,151),(405,150),(405,189),(307,190)
"スナック"
bounds: (394,156),(535,155),(535,184),(394,185)
"きのこ"
bounds: (33,167),(471,157),(475,354),(37,364)
"の"
bounds: (473,157),(569,155),(573,352),(477,354)
"山"
bounds: (571,155),(735,151),(739,348),(575,352)
"薫る"
bounds: (131,403),(314,390),(322,502),(139,516)
"いちご"
bounds: (315,390),(596,370),(604,482),(323,503)
"味"
bounds: (598,370),(671,365),(679,476),(606,482)
"ほんの"
bounds: (637,551),(736,527),(745,564),(646,588)
"TOKTO"
bounds: (236,697),(260,690),(263,701),(239,708)
"0"
bounds: (262,691),(277,687),(280,696),(265,701)
"20"
bounds: (1,804),(34,804),(34,829),(1,829)
"ES"
bounds: (1,828),(16,828),(16,844),(1,844)
"子"
bounds: (1,910),(18,910),(18,932),(1,932)
")"
bounds: (19,912),(24,912),(24,927),(19,927)
"©Tokyo"
bounds: (72,924),(150,921),(151,951),(73,954)
"2020"
bounds: (157,921),(210,919),(211,949),(158,951)さすがきのこの山









- 投稿日:2020-07-01T14:36:31+09:00
Pythonのバージョンを変更する方法
これからPythonを始める人で、デフォルトのバージョンを変えたい!という時に役立つかと思います。
自分もPythonを3系に変更しようとした際に、手間取りました。ここではpyenvというツールを使用していきます。
2系に再度切り替えも簡単にできますので非常に便利かと思います。まずはバージョンを確認
$ python -V Python 2.7.10Homebrewを使ってpyenvのインストールを実行
$ brew update # Homebrewを最新にする$ brew install pyenv # pyenvのインストール必要なPythonのバージョンを選択してインストール
$ pyenv install --list # インストールできるバージョンの一覧を表示するコマンド$ pyenv install 3.5.6 # Pythonのインストールを実行インストール済みのバージョンが表示される
$ pyenv versions * system 3.5.6 (set by $HOME/.pyenv/version)グローバルのバージョンを設定する
$ pyenv global 3.5.6 # グローバルのバージョンを指定する
- しかしpython -Vで、最初のバージョンが変わらず表示される
$ python -V Python 2.7.10
- eval "$(pyenv init -)"の実行し、変更を反映させる
$ eval "$(pyenv init -)" # pyenv initを実行することで、($HOME/.pyenv/version)のPathを環境変数のPathに追加することで適用される最後に確認
% python -V Python 3.5.6[pyenv global バージョン]のコマンドを使ってバージョンを選択してあげればいつでも変更ができます。
eval "$(pyenv init -)"は仕組みがわかっていないので、もっと学ばないといけないですね。。
非常に便利ですが、自分の理解もまだ浅いので、もう少し深掘りしたいと思います。
- 投稿日:2020-07-01T13:53:17+09:00
IT界技術界のレジェンドを知りたい
本記事に技術情報は一切ありませんし、誰か教えて!っていう大変他人任せで低レベルな記事です。タイトルからわかるかと思いますが、適当にタグをつけております。すみませんがご了承ください。
不快な方はスルー推奨です。レジェンド(憧れの存在)
どんな業界でもレジェンドの存在は憧れ、希望を生み、業界全体のレベルアップに繋がると思います。
私が好きなバスケ界では、マイケルジョーダン、マジックジョンソン、ラリーバードなどなど多くのレジェンドたちの存在がありました。
私の学生時代はアイバーソン、コービー、ナッシュ、シャックなどなどのスーパースターがNBAを引っ張っていました。ジェイソンウィリアムズの肘パスは誰もが一度練習したでしょう。(笑)
そうです。普段のモチベーションに「憧れ」は必要だと思うんです!!!
私は知らない!(ドン!!!)
私は大卒後、社会人からエンジニアになり今年で5年目になります。(早いなー)
学生時代は全くITに興味がありませんでした。そのためスゴイ技術者・経営者を全く知りません。orz
Appleのスティーブジョブズ&ウォズニアックコンビ、Microsoftのビル・ゲイツ、facebookのザッカーバーグ、Googleのラリー・ペイジ、Amazonのジェフ・ベゾス、Oracleのラリーエリソンくらいなら(名前だけ)もちろん知っています。↓ウォズ
そしてそして、日本人技術者の名前を本当に知りません!!
これは実際悲しいことですが、若手技術者の多くはそんなもんじゃないでしょうか。
私が知っているのは堀江貴文さん、西村ひろゆきさん、つくばの落合さん等メディアに出ている人たちくらいです。(本当はもう少し知っています。)おすすめのレジェンド教えてください
私はIT業界は少数の天才たちによって支えられているんじゃないかと思っています。知らんけど。
そこで!日本のIT系技術者・経営者で(もちろん外国の方でも嬉しいです。)おススメのレジェンドの方を教えて頂けないでしょうか。(インフラ技術開発者・ソフトウェア開発者・OSS開発者・言語開発者・伝説的な経営者などなど。)
この人はこんな方だ!というコメントもあればぜひ調べ、書籍もあったら読んでみます。
私のこれからのエンジニア人生のため、皆さんのモチベーションを高めるために!紹介いただけないでしょうか。orz
※ある程度調べれば出てくる人でないと情報ゲットできないので調べれば出てくる方でお願い致します。「IT業界」と、本当にざっくりしていて恐縮ですが よろしくお願い致します。


- 投稿日:2020-07-01T13:53:17+09:00
IT技術界のレジェンドを知りたい
本記事に技術情報は一切ありませんし、誰か教えて!っていう大変他人任せで低レベルな記事です。タイトルからわかるかと思いますが、適当にタグをつけております。すみませんがご了承ください。
不快な方はスルー推奨です。レジェンド(憧れの存在)
どんな業界でもレジェンドの存在は憧れ、希望を生み、業界全体のレベルアップに繋がると思います。
私が好きなバスケ界では、マイケルジョーダン、マジックジョンソン、ラリーバードなどなど多くのレジェンドたちの存在がありました。
私の学生時代はアイバーソン、コービー、ナッシュ、シャックなどなどのスーパースターがNBAを引っ張っていました。ジェイソンウィリアムズの肘パスは誰もが一度練習したでしょう。(笑)
そうです。普段のモチベーションに「憧れ」は必要だと思うんです!!!
私は知らない!(ドン!!!)
私は大卒後、社会人からエンジニアになり今年で5年目になります。(早いなー)
学生時代は全くITに興味がありませんでした。そのためスゴイ技術者・経営者を全く知りません。orz
Appleのスティーブジョブズ&ウォズニアックコンビ、Microsoftのビル・ゲイツ、facebookのザッカーバーグ、Googleのラリー・ペイジ、Amazonのジェフ・ベゾス、Oracleのラリーエリソンくらいなら(名前だけ)もちろん知っています。↓ウォズ
そしてそして、日本人技術者の名前を本当に知りません!!
これは実際悲しいことですが、若手技術者の多くはそんなもんじゃないでしょうか。
私が知っているのは堀江貴文さん、西村ひろゆきさん、つくばの落合さん等メディアに出ている人たちくらいです。(本当はもう少し知っています。)おすすめのレジェンド教えてください
私はIT業界は少数の天才たちによって支えられているんじゃないかと思っています。知らんけど。
そこで!日本のIT系技術者・経営者で(もちろん外国の方でも嬉しいです。)おススメのレジェンドの方を教えて頂けないでしょうか。またはこんなすごいことが現在進行形で行われている。などなど
(インフラ技術開発者・ソフトウェア開発者・OSS開発者・言語開発者・伝説的な経営者)この人はこんな方だ!というコメントもあればぜひ調べ、書籍もあったら読んでみます。
私のこれからのエンジニア人生のため、皆さんのモチベーションを高めるために!orz
※ある程度調べれば出てくる人でないと情報ゲットできないので調べれば出てくる方でお願い致します。
好奇心を満たしたいだけなので何卒お気軽に。。「IT業界」と、本当にざっくりしていて恐縮ですが よろしくお願い致します。
- 投稿日:2020-07-01T13:46:55+09:00
OpenCVで『スケッチ風』に画像加工してみた
はじめに
インスタグラムをはじめ、SNSで写真をシェアする方も多いのではないでしょうか。
その際、アプリを使用して画像を加工することもあるかと思います。
明るさや色味の調整、肌をキレイに見せるためのレタッチ、写真をスケッチ風に加工するなど、様々な機能があります。今回は、OpenCVを用いて簡単なスケッチ風の画像加工に挑戦してみました。
OpenCVで『スケッチ風』に画像加工
環境
環境はGoogle Colaboratoryを使用します。
Pythonのバージョンは以下です。import platform print("python " + platform.python_version()) # python 3.6.9画像の表示
では、早速コードを書いていきましょう。
まずは、画像の表示に必要なライブラリのインポートと設定を行います。import cv2 import matplotlib.pyplot as plt import matplotlib %matplotlib inline matplotlib.rcParams['image.cmap'] = 'gray'サンプルの画像も用意しておきましょう。
今回は、Pixabayのフリー画像を使用します。それでは、用意したサンプル画像を表示してみましょう。
image = cv2.imread(input_file) # input_fileは画像のパス plt.figure(figsize=[10,10]) plt.axis('off') plt.imshow(image[:,:,::-1])
結論
それではOpenCVを使用して、この画像をスケッチ風に加工してみましょう。
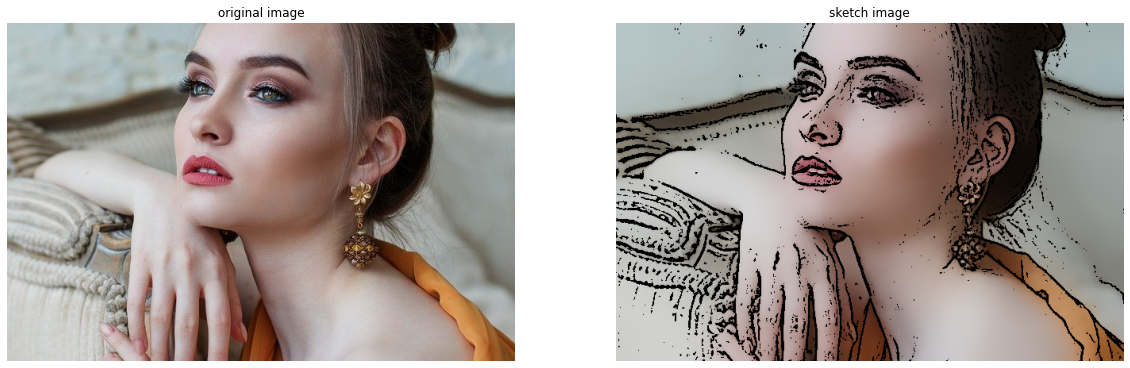
コードは以下です。def sketch(image): pencilSketch_img = pencilSketch(image) bilateral_img = cv2.bilateralFilter(image, 75, 100, 100) sketch_img = cv2.bitwise_and(bilateral_img, pencilSketch_img) return sketch_img def pencilSketch(image): gray_img = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) median_img = cv2.medianBlur(gray_img, 5) laplacian_img = cv2.Laplacian(median_img, cv2.CV_8U, ksize=5) _, thresh_img = cv2.threshold(laplacian_img, 100, 255, cv2.THRESH_BINARY_INV) pencilSketch_img = cv2.cvtColor(thresh_img, cv2.COLOR_GRAY2BGR) return pencilSketch_img sketch = sketch(image) plt.figure(figsize=[20,10]) plt.subplot(121);plt.imshow(image[:,:,::-1]);plt.axis('off') plt.title("original image") plt.subplot(122);plt.imshow(sketch[:,:,::-1]);plt.axis('off') plt.title("sketch image")
スケッチ風に加工する処理は、sketch関数として定義しています。
sketch関数の処理の流れは以下になります。
- 鉛筆画風の画像作成(pencilSketch関数)
- 平滑化(cv2.bilateralFilter)
- マスク処理(cv2.bitwise_and)
鉛筆で線を描き、そこに色を塗っていくという順番になります。
各処理の説明
以下、各処理について説明していきます。
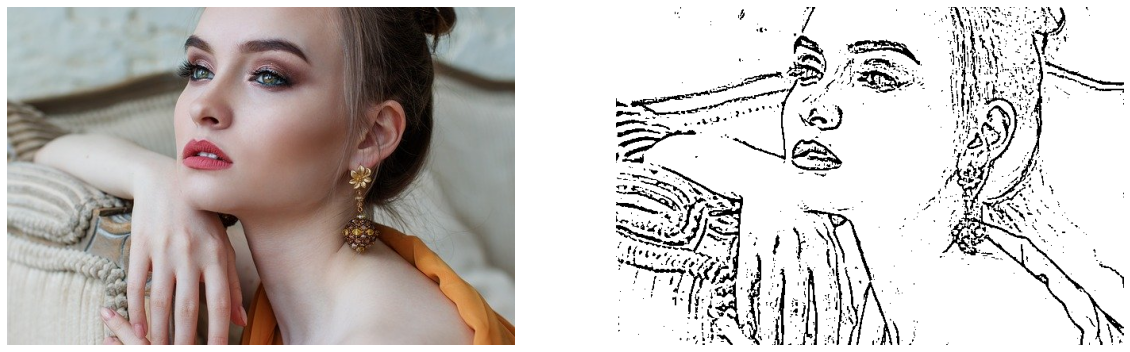
鉛筆画風の画像作成(pencilSketch関数)
鉛筆画風に加工する処理は、pencilSketch関数として定義しています。
pencilSketch関数の処理の流れは以下になります。
- グレースケール
- 平滑化(medianBlur)
- 画像の微分(Laplacian)
- 二値化
画像を表示してみます。
image = cv2.imread(input_file) # 元画像の読み込み pencilSketch_img = pencilSketch(image) # 鉛筆画風の画像 plt.figure(figsize=[20,10]) plt.subplot(121);plt.axis('off');plt.imshow(image[:,:,::-1]) plt.subplot(122);plt.axis('off');plt.imshow(pencilSketch_img[:,:,::-1])[
pencilSketch関数について、詳細はこちらを参照下さい。
平滑化(cv2.bilateralFilter)
平滑化(へいかつか)、あるいはスムージング処理とは、簡単に言うと画像をぼかすことです。
画像をぼかすということは、画素値の変化を滑らかにすることとも言えます。
ノイズやエッジは、画素値の急激な変化です。
平滑化により、ノイズやエッジを消したり、目立たなくすることができます。平滑化にはいくつかの方法が存在し、bilateralFilterはそのうちの一つです。
bilateralとは「両方の」という意味ですが、このフィルタはエッジをうまく残すことができます。
平滑化フィルタは、エッジなどのピークも含めて画像をぼかしてしまいます。
bilateralフィルタを使用すれば、エッジを残しつつ画像をぼかすことが可能です。平滑化についての詳細は、こちらを参照下さい。
bilateralFilterのコードは以下です。
bilateral_img = cv2.bilateralFilter(image, 75, 100, 100) plt.figure(figsize=[20,10]) plt.subplot(121);plt.axis('off');plt.imshow(image[:,:,::-1]) plt.subplot(122);plt.axis('off');plt.imshow(bilateral_img[:,:,::-1])
画像がぼやけているのが確認できます。
cv2.bilateralFilterを使用して、画像を平滑化しました。
cv2.bilateralFilterの用法は以下です。
- dst = cv2.bilateralFilter(src, d, sigmaColor, sigmaSpace[, dst[, borderType]] )
- src:インプット画像
- dst:アウトプット画像
- d:着目する領域の直径。
- sigmaColor:色空間に関するパラメーター。値が大きいほど、色空間的に離れた色同士が影響し合う。
- sigmaSpace:座標空間に関するパラメーター。値が大きいほど、座標空間的に離れたピクセル同士が影響し合う。
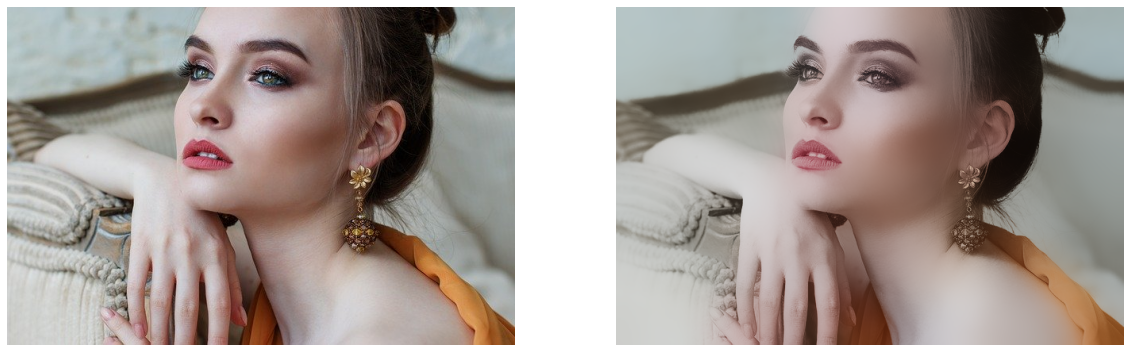
マスク処理(cv2.bitwise_and)
それでは最後に、マスク処理を用いてカラー画像と鉛筆画風スケッチ画像を合成します。
マスク処理にはcv2.bitwise_andを使用します。
cv2.bitwise_andは、2つの画像のビット単位のAND処理を行う関数です。マスク処理のコードは以下です。
merged_img = cv2.bitwise_and(bilateral_img, pencilSketch_img) plt.figure(figsize=[20,10]) plt.subplot(121);plt.axis('off');plt.imshow(bilateral_img[:,:,::-1]) plt.subplot(122);plt.axis('off');plt.imshow(merged_img[:,:,::-1])
うまく鉛筆画風スケッチをカラー画像にのせることができました。
まとめ
いかがだったでしょうか。
今回は、OpenCVを使用してスケッチ風の画像加工に挑戦してみました。
処理のフローをおさらいしておきます。
- 鉛筆画風の画像作成(pencilSketch関数)
- 平滑化(cv2.bilateralFilter)
- マスク処理(cv2.bitwise_and)
パラメーターを色々と変えて、画像を出力してみると面白いと思います。


- 投稿日:2020-07-01T13:21:35+09:00
Pythonで実装する「RとStanではじめるベイズ統計モデリングによるデータ分析入門」
Pythonで実装するベイズ統計モデリング
「RとStanではじめるベイズ統計モデリングによるデータ分析入門」はアヒル本よりも手軽にベイズ推定の実装に入門できる書籍です。
アヒル本は統計モデルの座学的章がありますが、こちらはほとんどありません。
まずはやってみよう、というところから入る本です。
また、階層ベイズについての考え方は、アヒル本と合わせて読むことでより理解が深まるかもしれません。何故Pythonで実装するのか
オフィシャルではこちらもRで実装があります。
最近はPythonを使う方が多いので、アヒル本だけでなくこちらもPythonで実装してみました。コード
PythoとPyStanで実装しています。
Github
https://github.com/MasazI/python-r-stan-bayesian-model
何かありましたらプルリクエストをいただけると助かります。
点推定だけでなく、ベイズ推定も一般的に広まっていくといいのかな、と個人的に思っています。

- 投稿日:2020-07-01T13:17:22+09:00
webiopiの質問です
webiopiを使って、ブラウザに複数のボタンを表示させ、ラズベリーパイの複数のGPIOをon,offしたいのですが、うまくいきません。
具体的にはGPIO12,13をそれぞれブラウザのボタンでON,OFFしたいのですが。
下記のようにプログラムを作成すると、ブラウザが「このサイトにアクセスできません」と表示されます。script.pyの7行目「LIGHT2 = 13」と14行目「GPIO.setFunction(LIGHT2, GPIO.OUT)」と最終行「GPIO.digitalWrite(LIGHT2, GPIO.LOW)」を消すと、ブラウザはアクセスできて、GPIO12だけ操作できます。
GPIO13も操作できるようにするにはどうしたらいいでしょうか?
宜しくお願い致します。index.html<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd"> <html> <head> <meta http-equiv="Content-Type" content="text/html; charset=UTF-8"> <title>WebIOPi | Light Control</title> <script type="text/javascript" src="/webiopi.js"></script> <script type="text/javascript"> webiopi().ready(function() { var content,button; content=$("#content"); // Create a "Light" labeled button for GPIO 12 button = webiopi().createGPIOButton(12, "ranp1"); // Append button to HTML element with ID="controls" using jQuery $("#controls").append(button); button = webiopi().createGPIOButton(13, "Light2"); $("#controls").append(button); // Refresh GPIO buttons // pass true to refresh repeatedly of false to refresh once webiopi().refreshGPIO(true); }); </script> <style type="text/css"> button { display: block; margin: 5px 5px 5px 5px; width: 160px; height: 45px; font-size: 24pt; font-weight: bold; color: white; } #gpio12.LOW { background-color: Black; } #gpio12.HIGH { background-color: Blue; } #gpio13.LOW { background-color: Black; } #gpio13.HIGH { background-color: Blue; } </style> </head> <body> <div id="controls" align="center"></div> </body> </html>script.py#! /usr/bin/env /usr/bin/python3 #_*_ cording:utf-8 _*_ import webiopi import datetime GPIO = webiopi.GPIO LIGHT = 12 # GPIO pin using BCM numbering LIGHT2 = 13 HOUR_ON = 8 # Turn Light ON at 08:00 HOUR_OFF = 18 # Turn Light OFF at 18:00 # setup function is automatically called at WebIOPi startup def setup(): # set the GPIO used by the light to output GPIO.setFunction(LIGHT, GPIO.OUT) GPIO.setFunction(LIGHT2, GPIO.OUT) # retrieve current datetime now = datetime.datetime.now() # test if we are between ON time and tun the light ON if ((now.hour >= HOUR_ON) and (now.hour < HOUR_OFF)): GPIO.digitalWrite(LIGHT, GPIO.HIGH) # loop function is repeatedly called by WebIOPi def loop(): # retrieve current datetime now = datetime.datetime.now() # toggle light ON all days at the correct time if ((now.hour == HOUR_ON) and (now.minute == 0) and (now.second == 0)): if (GPIO.digitalRead(LIGHT) == GPIO.LOW): GPIO.digitalWrite(LIGHT, GPIO.HIGH) # toggle light OFF if ((now.hour == HOUR_OFF) and (now.minute == 0) and (now.second == 0)): if (GPIO.digitalRead(LIGHT) == GPIO.HIGH): GPIO.digitalWrite(LIGHT, GPIO.LOW) # gives CPU some time before looping again webiopi.sleep(1) # destroy function is called at WebIOPi shutdown def destroy(): GPIO.digitalWrite(LIGHT, GPIO.LOW) GPIO.digitalWrite(LIGHT2, GPIO.LOW)
- 投稿日:2020-07-01T10:50:27+09:00
meta-learningのベンチマークデータセットを簡単にloadできるtorchmetaについて
はじめに
MNISTやCIFAR10といった画像分類タスクのベンチマークデータセットはtorchvisionで簡単に読み込むことができました。
meta-learningのベンチマークとして用いられるOmniglotやMiniImageNetなどのデータセットに対してもこのようなものはないのかと思い調べていたところtorchmetaというライブラリに出会ったのでご紹介することにしました。
meta-learningにおいては通常の学習に比べdataloaderの設計が少し面倒なのですが、それもtorchmetaではうまいことやってくれるので非常に便利です。
meta-learningについて
ここではN-way K-shotのfew-shot learningにmeta-learningを用いるケースを考え簡単にmeta-learningについてご紹介します。
N-way K-shotのfew-shot learningとは、まず大規模な学習データセットでモデルを学習して、学習後に学習データに含まれていなかった新たなN-classの画像について各classについてK枚ずつの画像のみから再学習しN-class分類器を学習する問題です。通常はK=1やK=5とする場合が多く、少ない画像で学習することになります。ここからはこれに対してmeta-learningを応用する手順について話します。
データセットはtrain setとtest setに分割します。
学習時にはデータはtaskと呼ばれる塊で管理し、taskにはN*K枚のmeta-train dataとQ枚のmeta-test dataが含まれています。meta-trainとmeta-testは共にtrain setからサンプリングされます。各taskではN*K枚のmeta-trainで学習しQ枚のmeta-testで評価し、meta-test時の勾配を用いてmodelのパラメータを更新します(ここら辺は手法によって若干異なる場合があるのであくまでイメージだと思っていただければと思います)。
これを複数のtaskに対し繰り返すことで、N*K枚の画像から学習する方法を学習するという感じになります。例えばOmniglotという手書き文字データセットは50の言語の計1623文字のデータセットになっており、各文字がclassに対応しています。これは日本語の「あ」「い」「う」などがそれぞれ1つのclassになっているということです。各classには20枚ずつ画像が含まれています。
この画像で学習する際には1623文字から例えば1100文字をtrain setに振り分け、各taskにおいて1100文字の中からN文字をランダムに選び、N*K枚の画像で学習するという流れになります。torchmeta
ここから本題のtorchmetaの話に移りたいと思います。
torchmetaはOmniglotやMiniImageNetといったデータセットの読み込みだけでなく、上記のようなtaskをサンプリングするdataloaderを提供しています。インストールは簡単で
pip install torchmetaとやればできます。
例えば5-way 5-shotでMiniImageNetを読み込みたい場合は
from torchmeta.datasets.helpers import miniimagenet from torchmeta.utils.data import BatchMetaDataLoader dataset = miniimagenet("data", ways=5, shots=5, test_shots=15, meta_train=True, download=True) dataloader = BatchMetaDataLoader(dataset, batch_size=1, num_workers=4, shuffle=Flase)とするとdataloaderができます。実際に学習する際にはミニバッチで学習するのでBatchMetaDataLoaderによってバッチを作成しています(ここではバッチサイズを1としています)。
また実際の学習時にはshuffle=Trueとすべきですが、ここでは後ほど5-way 5-shotでデータが読み込まれていることを確かめるためにFalseとしています。データの取り出しは
dataiter = iter(dataloader) data = dataiter.next() train_images, train_labels = data['train']とすることででき、ここで取り出されたtrain_imagesの形状は[1, 25, 3, 84, 84]となっています(第一次元がbatch数、第二次元がtaskに含まれる画像の枚数N*K、第三次元が画像のチャンネル数、第四次元、第五次元が画像の縦横のピクセル数)。
import numpy as np import matplotlib.pyplot as plt import torchvision def imshow(img): npimg = img.numpy() plt.imshow(np.transpose(npimg, (1,2,0))) plt.show() imshow(torchvision.utils.make_grid(train_images[0]))とすると先ほど取り出した画像が次のように表示されます。
左上から順番に5枚ずつ同じclassに含まれる画像が取り出されていることがわかるかと思います(一部よくわからない画像もありますが)。終わりに
公式の紹介記事とGitHubを参考に動かしてみてとりあえず最低限学習に使えそうな状態にはこれたので紹介記事を書かせていただきました。
GitHubの中にドキュメントも用意されているみたいなので、そちらも併せて参照されると良いと思います。
またmeta-learningについてはかなり緩く書いてしまったので、何かあればご指摘いただけたらと思います。

- 投稿日:2020-07-01T10:49:20+09:00
図鑑 データ構造 アルゴリズム Python
https://www.amazon.co.jp/dp/B08BZFX31V
データ構造とアルゴリズムPythonの実践、トピック自体は複雑ですが、読みやすく理解しやすいように設計されています。アルゴリズムは、ソフトウェアプログラムがデータ構造を操作するために使用する手順です。明確で単純なサンプルプログラムに加えて、プログラムは、データ構造がどのように見え、どのように動作するかをグラフィック形式で示します。基本的なつのデータ構造をすべてイラストで解説,誌面がフルカラーなので、図の「動き」がわかりやすい,あなたはそれを簡単に、速く、うまく学びます。

- 投稿日:2020-07-01T08:20:56+09:00
【統計学】ふつうのエンジニアが統計学の勉強を始めてみた
はじめに
数学がちょっとデキル
ふつうのバックエンドエンジニアが
統計学を勉強してみたという話
学びのキッカケ
Python3のデータ分析試験で
統計系の問題がイマイチ解けなかったこと
統計学とは
データのよりよい使い方を探る学問
またはそういう分野
データとは
なんかしらの情報。ここでは
デジタルデータについて扱う
データの種類
主に2種類存在する。
既に手に入れているデータ
まだ手に入れていないデータ
確率(Probability)
あるデータが登場する頻度、割合のこと
例)サイコロを10回振ったら6の目が何回出るか
確率変数
ある確率によって登場した値
確率(P)に影響して算出される値
例)サイコロの6の目
母集団
まだ手に入れていないデータを含む
すべてのデータをいう
例)この世すべてのサイコロの目
標本
手持ちのデータのこと
サンプリング(標本抽出)
母集団から標本を得ること
また、標本の大きさをサンプルサイズと呼ぶ
統計の種類
記述統計:既にある手持ちのデータを要約すること
推測統計:まだ手に入れていないデータを推測すること
統計学のすごいとこ
将来的に得られるデータを
予想したり、傾向を分析できる。
まとめ
用語が多くて大変だけど
ちゃんと紙を用意して数学の勉強をしようと
思いました。
おわり
- 投稿日:2020-07-01T01:49:48+09:00
Django~settings.py~ 備忘録
はじめに
この記事はDjangoでのsettings.pyの設定を忘れないようにメモするために書きました。
時間帯を合わせる
まずは時間帯を合わせましょう。
「settings.py」を開いて、ガーとしたの方までスクロールするとLANGUAGE_CODE = 'en-us' TIME_ZONE = 'UTC'この部分が見つかるので、少し変更していきます。
LANGUAGE_CODE = 'ja' TIME_ZONE = 'Asia/Tokyo'このように変更することで、日本時間に合わせることができます。
アプリの登録
「settings.py」の一番上から少しスクロールし他ところに「INSTALLED_APPS」というところがあります。
ここにアプリケーションの構成情報を登録するために追加していきます。
ここではアプリ名を「app」としておきます。INSTALLED_APPS = [ 'app.apps.AppConfig', ]カッコ内の一番最初か一番最後にこのように追加します。
最後のカンマを忘れないように気をつけてください。テンプレートの登録
「INSTALLED_APPS」からさらに少し下にいくと、「TEMPLATES」というものが見つかります。
HTMLファイルを入れておく「templates」をここに登録します。TEMPLATES = [ { 'BACKEND': 'django.template.backends.django.DjangoTemplates', 'DIRS': [], 'APP_DIRS': True, 'OPTIONS': { 'context_processors': [ 'django.template.context_processors.debug', 'django.template.context_processors.request', 'django.contrib.auth.context_processors.auth', 'django.contrib.messages.context_processors.messages', ], }, }, ]こんな感じになっているはずです。
ここの「DIRS」に登録していきます。'DIRS': [os.path.join(BASE_DIR, 'templates')],このように入れることができれば完了です。
staticディレクトリの登録
CSSやJavaScript、画像などを入れておく「static」ディレクトリの登録をしていきます。
デフォルトでは抱えrていないので、一番最後に追記していきます。STATICFILES_DIRS = ( [os.path.join(BASE_DIR, 'static')] )このように追記すれば完璧です。
最後に
今回は「settings.py」に書くものをまとめました。
今後さらにあっっぷデートしていく予定です。
一つ前の記事
PycharmでDjangoでアプリケーションを作成する手順~準備編~