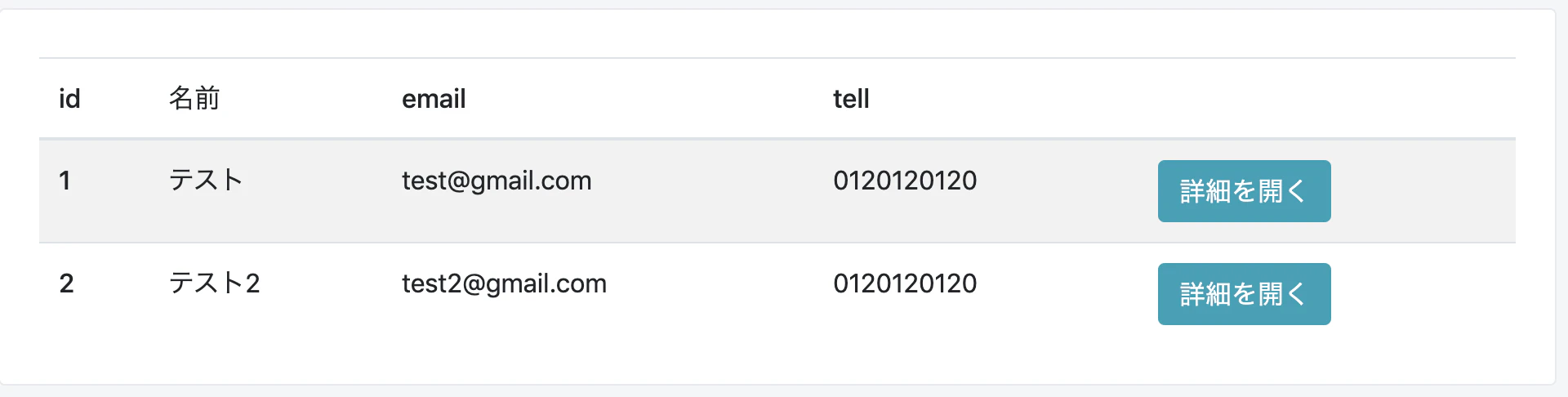
ビューを作成する前に、railsコントローラにおいて、データーベースの値を取ってくる場合にどのように記述するのか。今回はgroup by してからのカウントした値を取得する場合のRailsの書き方を調べるのに随分苦労したので、残しておく。
前提条件
JavaScriptで作成したタイピングゲームをRuby on Railsにのせようとしている。
集計が必要か?ってなったのは、タイピングした結果をランキング表示させようと思い立った時に、問題別のランキング表示をする前に、問題別にどれだけチャレンジャーがいたのか、っていうのを先に一覧表示した後で、ランキング表示をしようか、と思ったから。
$ rbenv -v
rbenv 1.1.2-26-gc6324ff
$ rbenv versions
system
* 2.5.1 (set by /Users/y-agatsuma/.rbenv/version)$ bundler -v
Bundler version 1.16.2
$ ruby -v
ruby 2.5.1p57 (2018-03-29 revision 63029)[x86_64-darwin18]
$ bundle exec gem list | grep slack
slack-incoming-webhooks (0.3.0)
2. 事象
SSL_connect returned=1 errno=0 state=error: tlsv1 alert protocol version
Traceback (most recent call last):
23: from app/controllers/scout_actions/execute_bot_periodically.rb:84:in `<main>'
22: from app/controllers/scout_actions/execute_bot_periodically.rb:41:in `start'
21: from /Users/y-agatsuma/.rbenv/versions/2.5.1/lib/ruby/gems/2.5.0/gems/parallel-1.12.1/lib/parallel.rb:264:in `y-agatsuma'
20: from /Users/y-agatsuma/.rbenv/versions/2.5.1/lib/ruby/gems/2.5.0/gems/parallel-1.12.1/lib/parallel.rb:358:in `work_in_processes'
19: from /Users/y-agatsuma/.rbenv/versions/2.5.1/lib/ruby/gems/2.5.0/gems/parallel-1.12.1/lib/parallel.rb:418:in `create_workers'
18: from /Users/y-agatsuma/.rbenv/versions/2.5.1/lib/ruby/gems/2.5.0/gems/parallel-1.12.1/lib/parallel.rb:418:in `each_with_index'
17: from /Users/y-agatsuma/.rbenv/versions/2.5.1/lib/ruby/gems/2.5.0/gems/parallel-1.12.1/lib/parallel.rb:418:in `each'
16: from /Users/y-agatsuma/.rbenv/versions/2.5.1/lib/ruby/gems/2.5.0/gems/parallel-1.12.1/lib/parallel.rb:419:in `block in create_workers'
15: from /Users/y-agatsuma/.rbenv/versions/2.5.1/lib/ruby/gems/2.5.0/gems/parallel-1.12.1/lib/parallel.rb:428:in `worker'
14: from /Users/y-agatsuma/.rbenv/versions/2.5.1/lib/ruby/gems/2.5.0/gems/parallel-1.12.1/lib/parallel.rb:428:in `fork'
13: from /Users/y-agatsuma/.rbenv/versions/2.5.1/lib/ruby/gems/2.5.0/gems/parallel-1.12.1/lib/parallel.rb:437:in `block in worker'
12: from /Users/y-agatsuma/.rbenv/versions/2.5.1/lib/ruby/gems/2.5.0/gems/parallel-1.12.1/lib/parallel.rb:455:in `process_incoming_jobs'
11: from /Users/y-agatsuma/.rbenv/versions/2.5.1/lib/ruby/gems/2.5.0/gems/parallel-1.12.1/lib/parallel.rb:484:in `call_with_index'
# <----- 何かしら処理 ----->
6: from /Users/y-agatsuma/.rbenv/versions/2.5.1/lib/ruby/gems/2.5.0/gems/slack-incoming-webhooks-0.2.0/lib/slack/incoming/webhooks/request.rb:11:in `post'
5: from /Users/y-agatsuma/.rbenv/versions/2.5.1/lib/ruby/2.5.0/net/http.rb:1455:in `request'
4: from /Users/y-agatsuma/.rbenv/versions/2.5.1/lib/ruby/2.5.0/net/http.rb:909:in `start'
3: from /Users/y-agatsuma/.rbenv/versions/2.5.1/lib/ruby/2.5.0/net/http.rb:920:in `do_start'
2: from /Users/y-agatsuma/.rbenv/versions/2.5.1/lib/ruby/2.5.0/net/http.rb:981:in `connect'
1: from /Users/y-agatsuma/.rbenv/versions/2.5.1/lib/ruby/2.5.0/net/protocol.rb:44:in `ssl_socket_connect'
/Users/y-agatsuma/.rbenv/versions/2.5.1/lib/ruby/2.5.0/net/protocol.rb:44:in `connect_nonblock': SSL_connect returned=1 errno=0 state=error: tlsv1 alert protocol version (OpenSSL::SSL::SSLError)