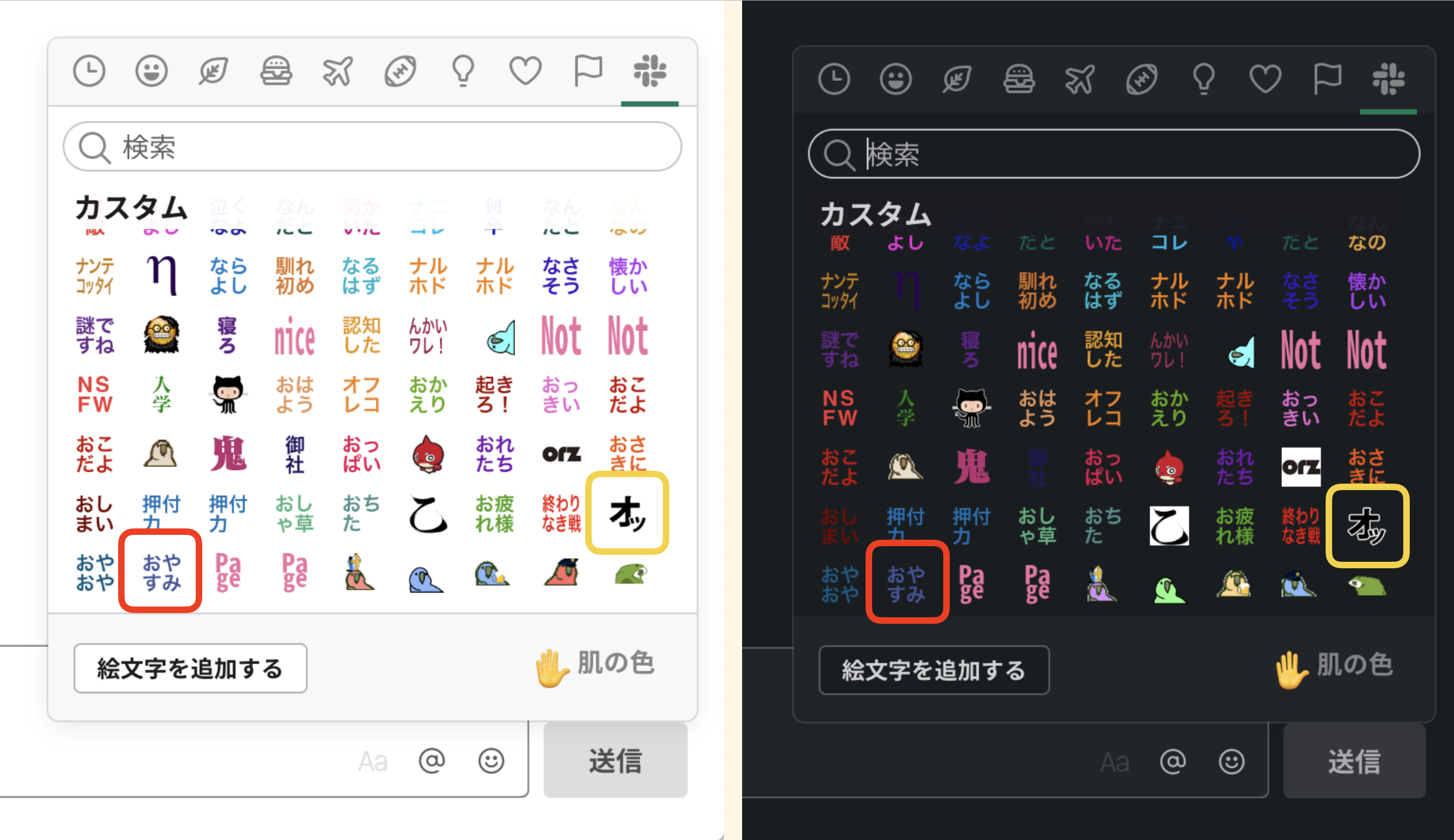
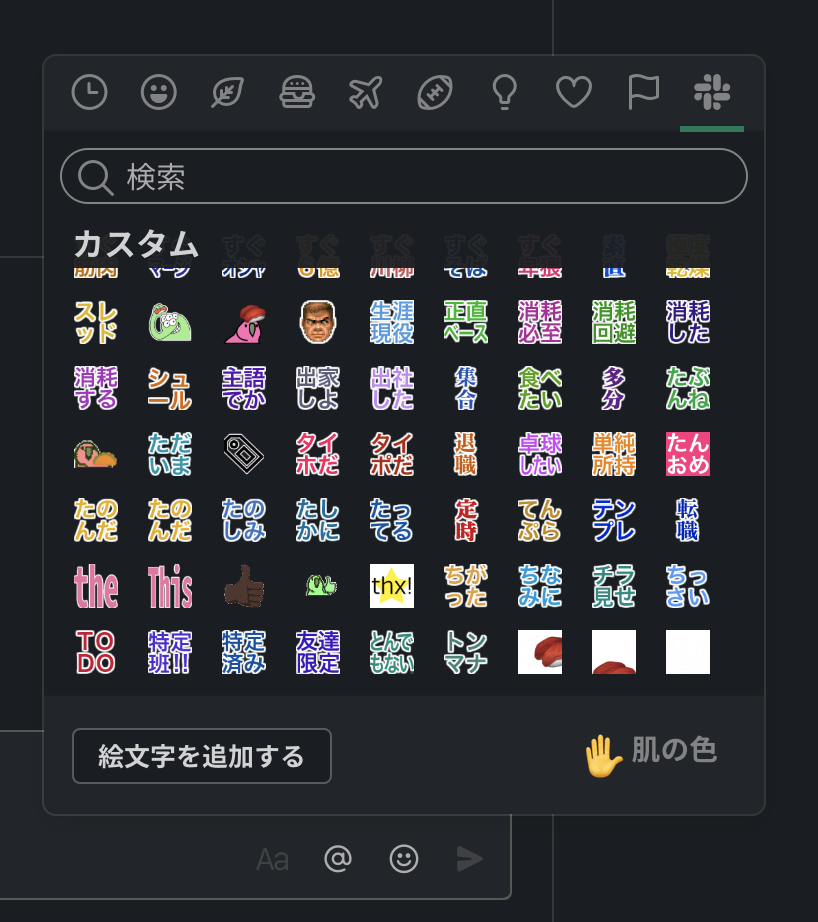
- 投稿日:2020-03-10T23:41:16+09:00
2.平均と標準偏差をニューラルネットワークで!
はじめに
シリーズ第2回です。
与えられたいくつかの数値データについて、その平均を出力するように、ニューラルネットワーク(NN)に学習させることはできるでしょうか?また、標準偏差はどうでしょうか?やってみましょう。NNが学習できる問題は、大きく分けて「分類問題」か「回帰問題」であるとされています。今回は「回帰問題」にあたります。
方針
- ニューラルネットワークに10個(固定)のランダムな数字を与える。
- 10個の数字の平均と、標準偏差を、計算する。
- 10個の数字と、これらの平均と標準偏差を、学習データとして、kerasで作成したNNに与える。
- NNの出口の数は2(「平均」と「標準偏差」の2つ)。
- NNをトレーニングした後、学習に用いたのではないデータセットを使って学習させたNNの性能評価を行う。
ではやってみましょう。一般的にNNのトレーニングは学習データの準備が大変とされていますが、その点今回は準備が楽です。
学習データの準備
とりあえず、50000個のトレーニング用データセットを準備することにしました。1セットは10個の数値よりなります。10個の数値は、numpyのrandom.normal(a,b,10)を使用して平均a、標準偏差bの分布データに従う10個のランダムな数値としますが、ここで、aとb自体もnumpyのrandom.rand()で発生させています。
「10個の数値」、および「これらの平均と標準偏差」を計算して、まずはそれぞれリストに格納します。
001.pyimport numpy as np trainDataSize = 50000 #作成するデータセットの数 dataLength = 10 #1セットあたりのデータ数 d = []#空のリスト 10個ずつ数値を入れる。 average_std = []#空のリスト 2つ目。2つずつ数値を入れる。 for num in range(trainDataSize): xx = np.random.normal(np.random.rand(),np.random.rand(),dataLength) average_std.append(np.mean(xx)) average_std.append(np.std(xx)) d.append(xx)50000セット全部入れたリストができたら、あらためてndarrayに変換します。
002.pyd = np.array(d) # ndarrayにする。 average_std = np.array(average_std)# ndarrayにする。なぜ最初からndarrayにしないかといえば、遅いからです。
002.py#良くないコード。遅いから。 d = np.array([])#空のnumpy array for num in range(trainDataSize): xx = np.random.normal(np.random.rand(),np.random.rand(),dataLength) d = np.append(d,xx) #この処理が遅い!作成したndarrayは、順番に数値データを放り込んだものです。ここで行列のshapeを変えます。
003.pyd = d.reshape(50000,10) average_std = average_std.reshape(50000,2)50000のデータセットを、トレーニング用の40000セットと評価用の10000セットの2つに分割。今回ハイパーパラメーターの検討はしないので、2分割で良いことにする。
004.py#前半40000でトレーニング。後半10000で評価。 d_training_x = d[:40000,:] d_training_y = average_std[:40000,:] d_test_x = d[40000:,:] d_test_y = average_std[40000:,:]NNのデザイン
ポイントは、
1. 入力のshapeを10にする(必須)
2. 最後のレイヤーの出力数を2にする(必須)。
3. 最後の活性化関数をlinearにする。今回のケースではsoftmaxとかsigmoidとかReLuはそぐわない。平均が0を下回るケースがあるため。
4. 損失関数をmean_squared_errorにする。クロスエントロピーはこの場合そぐわない(分類問題ではないから)。
5. その他レイヤーの数、各レイヤーの出力数と活性化関数は、適当に決定した。005.pyimport keras from keras.models import Sequential from keras.layers import Dense from keras.optimizers import Adam model = Sequential() model.add(Dense(100, activation='tanh', input_shape=(10,)))#入力スロットは10個。 model.add(Dense(100, activation='tanh')) model.add(Dense(40, activation='sigmoid')) model.add(Dense(20, activation='sigmoid')) model.add(Dense(2, activation='linear')) #出力スロットは2つ。 # 確率的勾配降下法 Adam optimizer = Adam(lr=0.001, beta_1=0.9, beta_2=0.999) # 損失関数 二乗平均誤差 model.compile(loss='mean_squared_error',optimizer=optimizer) model.summary() # NNの概要の出力NNのトレーニング
いよいよ訓練データを放り込みます。
006.pyhistory = model.fit(d_training_x, d_training_y, batch_size=256,# 訓練データを、256セットデータ分をまとめて放り込む。 epochs=20,# 訓練データを、何周繰り返すか。 verbose=1,# verboseは冗長、転じて「おしゃべり」の意。1にしておくとトレーニング過程を逐一出力してくれる。 validation_data=(d_test_x, d_test_y))学習の進み具合の確認
ここではfit()の返り値を、変数historyにしまっています。返り値historyをtype()で調べると、オブジェクトのようです。vars()で調べてみます。
007.pytype(history) # <class 'keras.callbacks.callbacks.History'> vars(history) # 情報がたくさん出力される。 # 出力される情報をかいつまむと、historyオブジェクトが持っているフィールドは、以下の通り。 # validation_data (リスト)、 # model (NNモデルへの参照)、 # params (辞書。keyは'batch_size'、'epochs'、'steps'、'samples'、'verbose'、'do_validation'、'metrics') # epoch (リスト)、 # history (辞書。keyは'val_loss'、'loss') # # historyのkeyは、'val_loss'と'loss'である。 # lossは学習データに対する損失。val_lossは評価用のデータに対する損失。ここでは変数名がhistoryなので、history.history['val_loss']で、学習がどう進んだかの経過データにアクセスできる。学習が進行する様子をプロットしてみる。
008.pyimport matplotlib.pyplot as plt plt.plot(history.history['val_loss'], label = "val_loss") plt.plot(history.history['loss'], label = "loss") plt.legend() # 凡例を表示 plt.title("Can NN learn to calculate average and standard deviation?") plt.xlabel("epoch") plt.ylabel(" Loss") plt.show()これで書いたグラフ:
NNの評価
学習が進行したことはわかりますが、どれほど精度良く「計算」できるようになったでしょうか?評価用データの先頭200セットをNNに放り込んで、その出力(縦軸)を数学的な計算結果(横軸)に対してプロットしてみる。
009.py#トレニーングしたNNにデータを与えてみる inp = d_test_x[:200,:] out = d_test_y[:200,:] pred = model.predict(inp, batch_size=1) #グラフにする: 平均 plt.scatter(out[:,0], pred[:,0]) plt.legend() # 凡例を表示 plt.title("average") plt.xlabel("mathematical calculation") plt.ylabel("NN output") # 線を引く。この線に乗れば、うまく予測できたことになる。 x = np.arange(-0.5, 2, 0.01) y = x plt.plot(x, y) plt.show()
おおよそ精度良く「計算」できていることがわかります。続いて、標準偏差はどうでしょうか?009.py#グラフにする: 標準偏差 plt.scatter(out[:,1], pred[:,1]) plt.legend() # 凡例を表示 plt.title("standard deviation") plt.xlabel("mathematical calculation") plt.ylabel("NN output") x = np.arange(0, 1.5, 0.01) y = x plt.plot(x, y) plt.show()
まずまずといったところでしょうか?平均の方は良いとして、標準偏差は今ひとつ物足りません。
ニューラルネットワークで行われる計算は、ざっくりといえば入力値xに対して各ウエイトパラメーターwを掛け合わせた積を得ること、この積の和を活性化関数の入力として出力値を得ること、です。
平均については、入力値それぞれに0.1 (今回の場合入力する数値が10個なので1/10 = 0.1)をかけて足し合わせれば平均になりますので、NNが10個の数値の平均を精度良く計算できるようになることは、容易に想像ができます。
一方で標準偏差はどうでしょうか?平均値を計算し、ついで入力値それぞれに、平均値に-1をかけたものを足して(つまり、平均との差をとって)、これを2乗して足し合わせて、9で割れば、標準偏差になるはずです。このプロセスで、難しそうなのは、2乗するところです。
NNでは内部的に、固定のウエイトパラメータと入力値の掛け算をおこない、これを足し合わせて活性化関数に渡しています。入力値に対して、これを2乗した値をほとんど誤差がないように返すことは果たして可能なのか?ちょっと私にはわかりません。
もしかすると、活性化関数に、入力値を2乗(拡張してn乗)してくれるやつがあったりすれば良いのかもしれませんね。これについてはどこかで考えてみたいと思いますが、とりあえず平均と標準偏差に近い値を出力できるNNができたということで、第2回は終了したいと思います。
シリーズ第3回はこちら



- 投稿日:2020-03-10T23:24:03+09:00
【Udemy Python3入門+応用】 56. クロージャー
※この記事はUdemyの
「現役シリコンバレーエンジニアが教えるPython3入門+応用+アメリカのシリコンバレー流コードスタイル」
の講座を受講した上での、自分用の授業ノートです。
講師の酒井潤さんから許可をいただいた上で公開しています。■クロージャー
難しい内容になるので、今の段階では「こんなものがあるんだな」とわかればOK。
closuredef circle_area_func(pi): # radiusを渡すと円の面積が返ってくる def circle_area(radius): return pi * radius * radius # circle_areaを返すだけで実行はしない return circle_area # piを3としてcircle_area_funcに渡し、返ってきたcircle_areaをcal1に代入 cal1 = circle_area_func(3) # piを3.14としてcircle_area_funcに渡し、返ってきたcircle_areaをcal2に代入 cal2 = circle_area_func(3.14) # radiusを10としてcal1に渡し、結果をprint print(cal1(10)) # radiusを10としてcal2に渡し、結果をprint print(cal2(10))result300 314.0クロージャーは、今回のように
初めに設定した引数(pi)を後々用途応じて使い分けたい(3とするのか3.14にするのか)とき
などに有効な手段なので、頭の片隅に置いておこう。
- 投稿日:2020-03-10T23:23:46+09:00
Heroku、Flask、Python、にゃん子掲示板をデータベースで作る(その①)
(1)まずはcsvを使って掲示板を作成する
<ディレクトリ構成>
test ├app.py ├articles.csv ├Procfile ├requirements.txt └templates ├index.html ├layout.html └index_result.html①コンテンツの作成
仮想環境をディレクトリtestの直下に設定、起動。
python3 -m venv . source bin/activate必要なフレームワークとwebサーバーをインストール。
pip install flask pip install gunicornarticles.csvに、掲示板のデータをはじめに入れておく。
articles.csvたま,眠いにゃー しろ,腹減ったにゃー クロ,なんだか暖かいにゃー たま,ぽえーぽえーぽえー ぽんたん,トイレットペーパーがない なおちん,チーンapp.pyを作成。
app.py# -*- coding: utf-8 -*- from flask import Flask,request,render_template app = Flask(__name__) @app.route('/') def bbs(): lines = [] #with openしてcsvファイルを読み込む with open('articles.csv',encoding='utf-8') as f: lines = f.readlines() #readlinesはリスト形式でcsvの内容を返す #index.htmlに返す return render_template('index.html',lines=lines) #postメソッドを受け取る @app.route('/result',methods=['POST']) def result(): #requestでarticleとnameの値を取得する article = request.form['article'] name = request.form['name'] #csvファイルに上書きモードで書き込む with open('articles.csv','a',encoding='utf-8') as f: f.write(name + ',' + article + '\n') #index_result.htmlに返す return render_template('index_result.html',article=article,name=name) if __name__ == '__main__': app.run(debug=False)index.htmlを作成。
index.html{% extends 'layout.html' %} {% block content %} <h1> にゃん子掲示板</h1> <form action='/result' method='post'> <label for='name'>にゃん子の名前</label> <input type='text' name='name'> <p></p> <label for='article'>投稿</label> <input type='text' name='article'> <button type='subimit'>書き込む</button> </form> <p></p> <p></p> <table border=1> <tr><th>にゃん子の名前</th><th>投稿内容</th></tr> {% for line in lines: %} <!--columnという変数をセット(変数セットにはsetが必要) --> <!--splitを利用して,で分類する。splitはリストを返す --> {% set column = line.rstrip().split(',') %} <tr><td>{{column[0]}}</td><td>{{column[1]}}</td></tr> {% endfor %} </table> {% endblock %}htmlのテンプレートを作成。
layout.html<!DOCTYPE html> <html lang='ja'> <head> <meta charset='utf-8'> <title>Nyanko BBS</title> <style>body{padding:10px;}</style> </head> <body> {% block content %} {% endblock %} </body> </html>index.htmlで入力したフォームの内容をindex_result.htmlであらわす。
layout.html{% extends 'layout.html' %} {% block content %} <h1> にゃ-んと掲示板に書き込みました</h1> <p>{{name}}{{article}}</p> <!--formで/に戻る --> <form action='/' method='get'> <button type='submit'>戻る</button> </form> {% endblock %}②Herokuへデプロイ
Herokuへのデプロイ詳細は以下の記事に書いた通りなので、詳細説明を省く。
Heroku、Flask、Python、Gitでアップロードする方法(その②)
Procfile、requirements.txtを作成、gitで操作して無事にデプロイできた。
”いわし”、”魚が大好き”と投稿すると、
書き込み成功!
戻ると、
ちゃんと掲示板に書き込みされてます。次回はデータベースを組み込む
csvの書き込みはしばらくすると(30分)データが消えてしまうので、データベースを使ってみたい。



- 投稿日:2020-03-10T23:06:35+09:00
機械学習でInput contains NaN, infinity or a value too large for dtype('float64').というエラーが出たときの対処法
機械学習で「Input contains NaN, infinity or a value too large for dtype('float64').」というエラーが出たときの対処法
エラーの原因
上のエラーに書いてある通りデータにNaNかinfかfloat64でないタイプのものが混じっている。文字列を含む列をpandasで以下のように書き、Naも埋めたのにエラーが出た。
df=df.drop(columns=df.select_dtypes(include='object').columns)これでは列の中に一部含まれるfloat以外の値を変換することができないみたいだ。
そこでnumpyで使えるようにndarrayに変換した後、float以外の値になるやつをfloat型に変換させ、float型に変更不可能なものをNaとし、その後欠損値を変換した。X = df.iloc[:, 1:].values y = df.iloc[:, 0].values for i in range(X.shape[1]): X[:,i]= pd.to_numeric(X[:,i], errors='coerce') X1=np.nan_to_num(X)これが正しい処理なのかはよくわからないが、とりあえずモデルを学習させるときのエラーはなくなった。
なにかいいやり方があったらコメントお願いします。
- 投稿日:2020-03-10T22:56:37+09:00
【Udemy Python3入門+応用】 55. 関数内関数
※この記事はUdemyの
「現役シリコンバレーエンジニアが教えるPython3入門+応用+アメリカのシリコンバレー流コードスタイル」
の講座を受講した上での、自分用の授業ノートです。
講師の酒井潤さんから許可をいただいた上で公開しています。■関数内関数
◆使い方
inner_functiondef outer(a, b): def plus(c, d): return c + d r = plus(a, b) print(r) outer(1, 2)result3関数の中で、さらに新しい関数を定義することも可能である。
内側の関数(plus)を、外側の関数(outer)以外の場所で使わない場合、
関数内関数として記述してやるとよい。
- 投稿日:2020-03-10T22:50:09+09:00
【Udemy Python3入門+応用】 54. Docstringsとは
※この記事はUdemyの
「現役シリコンバレーエンジニアが教えるPython3入門+応用+アメリカのシリコンバレー流コードスタイル」
の講座を受講した上での、自分用の授業ノートです。
講師の酒井潤さんから許可をいただいた上で公開しています。■関数の説明の記述
◆関数内に記述する
docstringsdef example_func(param1, param2): """Example function with types documented in the docstring. Args: param1 (int): The first parameter. param2 (str): The second parameter. Returns: bool: The return value. True for success, False otherwise. """ print(param1) print(param2) return True一旦サンプルの関数を用意した。
このサンプルの説明書きとして、通常であれば説明する行の上にコメントアウトするが、
関数の場合は内側の先頭に書くのがお約束。◆docstringsを呼び出す
docstringsdef example_func(param1, param2): """Example function with types documented in the docstring. Args: param1 (int): The first parameter. param2 (str): The second parameter. Returns: bool: The return value. True for success, False otherwise. """ print(param1) print(param2) return True print(example_func.__doc__)resultExample function with types documented in the docstring. Args: param1 (int): The first parameter. param2 (str): The second parameter. Returns: bool: The return value. True for success, False otherwise.
.__doc__のメソッドで、その関数のdocstrinsを呼び出せる。◆docstringsを呼び出す2
docstringsdef example_func(param1, param2): """Example function with types documented in the docstring. Args: param1 (int): The first parameter. param2 (str): The second parameter. Returns: bool: The return value. True for success, False otherwise. """ print(param1) print(param2) return True help(example_func)resultHelp on function example_func in module __main__: example_func(param1, param2) Example function with types documented in the docstring. Args: param1 (int): The first parameter. param2 (str): The second parameter. Returns: bool: The return value. True for success, False otherwise.
helpを使うことでも、docstringsを呼び出すことができる。
- 投稿日:2020-03-10T22:31:07+09:00
Pythonで毎日AtCoder #1
はじめに
今回から、python3で競プロの問題(AtCoder)を解く毎日という企画をしようと思います。問題の選択は、AtCoder ProblemsのRecommendationsからです。
目的
- レートを上げる。
- 初見問題への対応力をつける
#1
考えたこと
2WAしました。場合分けを考える問題が苦手なことが分かりました。
この問題は、n mod(10)の大きさで場合分けしました。問題を読むと、N個以上買うのにいくらかかるかを答えるので、Nを越えた数を買ってもよいことが分かります。個別に買った方が安いのか、まとめて買った方が安いのかをn mod(10)で比較すると次のようになります。n mod(10), 個別, 個別とまとめて買ったときの差 1 , 15 , 85 2 , 30 , 70 3 , 45 , 55 4 , 60 , 40 5 , 75 , 25 6 , 90 , 10 7 , 105 , -5 8 , 120 , -20 9 , 135 , -35 10 , 150 , -50となります。
このことからn mod(10)>6のときにまとめて買った方が安いことが分かります。
よって、if n % 10 > 6: b = 100 * (n // 10 + 1) else: p = n % 10 b = 100 * (n // 10) + p * 15にすれば、うまく条件を満すことができます。
あとは上のコードに標準入力と出力をつけるだけです。出力には、min()を使います。n = int(input()) a = 15 * n if n % 10 > 6: b = 100 * (n // 10 + 1) else: p = n % 10 b = 100 * (n // 10) + p * 15 print(min(a,b))まとめ
A問題なのに2WAも出してしまったのが悔しい。タグに不穏なワードが入っていますが、そうならないようにがんばります。
- 投稿日:2020-03-10T22:31:04+09:00
【Udemy Python3入門+応用】 53. キーワード引数の辞書化
※この記事はUdemyの
「現役シリコンバレーエンジニアが教えるPython3入門+応用+アメリカのシリコンバレー流コードスタイル」
の講座を受講した上での、自分用の授業ノートです。
講師の酒井潤さんから許可をいただいた上で公開しています。■キーワード引数の辞書化
◆例
keyword_augment_dictdef menu(food='beef', drink='wine'): print(food, drink) menu(food='beef', drink='coffee')resultbeef coffeeまずこういったサンプルを用意する。
ここに、食べ物や飲み物だけでなく、他にも付け足したいときを考える。◆キーワード引数を辞書化する
keyword_augment_dictdef menu(**kwargs): print(kwargs) menu(food='beef', drink='coffee')result{'food': 'beef', 'drink': 'coffee'}
menuにわたす引数の頭に**をつけることで、
わたした引数が辞書化される。keyword_augment_dictdef menu(**kwargs): for k , v in kwargs.items(): print(k, v) menu(food='beef', drink='coffee')resultfood beef drink coffee作成された辞書のkeyとvalueを引っ張ってきてprintするように組んだ。
keyword_augment_dictdef menu(**kwargs): for k , v in kwargs.items(): print(k, v) d = { 'food': 'beef', 'drink': 'ice coffee', 'dessert': 'ice cream' } menu(**d)resultfood beef drink ice coffee dessert ice cream
dで作った辞書は、menu(**d)により、それぞれのkeyとvalueのセットに展開されて渡される。■普通の引数、位置引数のタプル化、キーワード引数の辞書化の同時使用
◆同時使用も可能
argsdef menu(fruit, *args, **kwargs): print(fruit) print(args) print(kwargs) menu('banana', 'apple', 'orange', food='beef', drink='wine')resultbanana ('apple', 'orange') {'food': 'beef', 'drink': 'wine'}最初の
bananaは普通の引数としてfruitに渡され、
appleとorangeは*argsに渡されることでタプル化され、
beefとwineは**kwargsにより辞書化された。◆注意点
argsdef menu(fruit, **kwargs, *args): print(fruit) print(kwargs) print(args) menu('banana', food='beef', drink='wine', 'apple', 'orange')resultdef menu(fruit, **kwargs, *args): ^ SyntaxError: invalid syntax
**kwargsを先に、*argsを後にするとエラーとなる。
これらを同時に使う場合は、*→**の順で使うようにしよう。
- 投稿日:2020-03-10T22:10:15+09:00
【Udemy Python3入門+応用】 52. 位置引数のタプル化
※この記事はUdemyの
「現役シリコンバレーエンジニアが教えるPython3入門+応用+アメリカのシリコンバレー流コードスタイル」
の講座を受講した上での、自分用の授業ノートです。
講師の酒井潤さんから許可をいただいた上で公開しています。■位置引数のタプル化
◆例
positional_augment_tupledef say_something(word1, word2, word3): print(word1) print(word2) print(word3) say_something('Hi!', 'Mike', 'Nancy')resultHi! Mike Nancyもちろんこのように、いちいち
word1,word2,word3のように設定してもよいが、
位置引数をタプル化することでうまくやる方法がある。◆位置引数をタプル化する
positional_augment_tupledef say_something(*args): print(args) say_something('Hi!', 'Mike', 'Nancy')result('Hi!', 'Mike', 'Nancy')
say_something()の()の中に入れる引数の頭に*をつけることで、
そこに入ってくる引数をタプル化することができる。これで生成したタプルをさらにforループを回してprintすることで、先程のものを再現できる。
positional_augment_tupledef say_something(*args): for arg in args: print(arg) say_something('Hi!', 'Mike', 'Nancy')resultHi! Mike Nancy◆普通の引数と組み合わせる
positional_augment_tupledef say_something(word, *args): print('word =', word) for arg in args: print('arg =', arg) say_something('Hi!', 'Mike', 'Nancy')resultword = Hi! arg = Mike arg = Nancysay_something'に渡す引数として、
wordを追加してみた。
すると、最初の引数であるHi!のみがまずwordに入り、
それ以降の引数であるMikeとNancyは*argsに入ることがわかる。◆注意点
positional_augment_tupledef say_something(*args, word): print('word =', word) for arg in args: print('arg =', arg) say_something('Hi!', 'Mike', 'Nancy')resultsay_something('Hi!', 'Mike', 'Nancy') TypeError: say_something() missing 1 required keyword-only argument: 'word'
*argsを先に、wordを後にすると、エラーとなってしまう。
必ず、普通の引数 →*の順で使うようにしよう。
- 投稿日:2020-03-10T22:09:37+09:00
AtCoder ABC43(ARC59) C,D問題
今回はABC43のC,D問題を解いてみた。
まずC問題から。
abc43_c.pyn = int(input()) a = list(map(int,input().split())) avg = 0 for i in a: avg = avg + i avg1 = avg//n avg2 = avg//n + 1 ans1 = 0 ans2 = 0 for i in a: ans1 = ans1 + pow((i-avg1),2) ans2 = ans2 + pow((i-avg2),2) print(min(ans1,ans2))続いてD問題。
abc43_d.pys = input() # print(s) flag=0 for i in range(len(s)-1): if s[i]==s[i+1]: print(i+1,i+2) flag = 1 break if i<len(s)-2: if s[i]==s[i+2]: print(i+1,i+3) flag = 1 break if flag ==0: print(-1,-1)

- 投稿日:2020-03-10T21:56:11+09:00
AWS lambda (python) でツイート分析して楽曲推薦するTwitter botを作った
最初に
https://twitter.com/shikumie に @付きでメンションするとオススメボカロ曲を教えてくれます。
こちらを試してからの方が下記記事は理解しやすいかもしれません。こんな感じになる筈です
なお、 返信までに最大5分程度かかります。
気長にお待ちください。5分待っても返信が来なかったらとりこぼしていたり、なんらかの理由で落ちている可能性があります。
次の日などに試していただけるともしかしたらうまくいくかもしれませんやったこと(ざっくり)
下記を5分に1回実行するlambdaを作成した
1. メンションがきているかを確認し、リプライ先となるstatus_idを取得
2. 1.で得られた返信先ユーザの直近のツイート(最大5つ)を取得
3. ツイートに含まれる特徴量を抽出し、事前に作っておいた楽曲の特徴量と比較、最も近い物を選択
4. 3で得た楽曲情報を1.で得たstatus_idにリプライやったこと(詳細)
0. 事前準備
0.1 Twitter APIの準備
botにツイートしてもらったり、オススメを聞いてきた人のツイートを取得したりするのにAPIを利用します。
自分が開発を行った際は、下記記事を読んで、とりあえずツイートできるところまで進めました。
https://qiita.com/channel-techtok/items/dc5028f667a9dde170920.2 lambdaの準備
5分に1回、lambdaが起動するように準備しておきます。
今回はsam-cliを使用しました。この辺りの準備に関しては、以前記事を書いているので参考にしていただければと思います。
https://qiita.com/miyatsuki/items/c221b48830db2b0a9eba#2-1%E3%81%A7%E4%BD%9C%E3%81%A3%E3%81%9F%E3%82%B9%E3%82%AF%E3%83%AA%E3%83%97%E3%83%88%E3%82%92lambda%E7%B5%8C%E7%94%B1%E3%81%A7%E5%AE%9A%E6%9C%9F%E5%AE%9F%E8%A1%8C%E3%81%95%E3%81%9B%E3%82%8B1. メンションがきているかを確認し、リプライ先となるstatus_idを取得
メンションは下記のAPIで取得できます。
https://developer.twitter.com/en/docs/tweets/timelines/api-reference/get-statuses-mentions_timelineメンションの投稿時刻, screen_name, ツイート文, メンションのstatus_id(リプライ先) を取得します。
get_mentions.pydef get_mentions(twitter): # ツイート処理 res = twitter.get("https://api.twitter.com/1.1/statuses/mentions_timeline.json", params={"count": 200}) # エラー処理 if res.status_code != HTTPStatus.OK: print(f"Failed: {res.status_code}") return [] mentions = [] for mention in res.json(): # 会話中の@mentionは無視する if mention["in_reply_to_status_id_str"]: continue unixtime = int(datetime.strptime(mention["created_at"], '%a %b %d %H:%M:%S %z %Y').timestamp()) mentions.append((unixtime, mention["user"]["screen_name"], mention["text"], mention["id"])) return mentions CONSUMER_KEY = 'XXX' CONSUMER_SECRET = 'XXX' ACCESS_TOKEN_KEY = 'XXX' ACCESS_TOKEN_SECRET = 'XXX' # twitter操作用クラス twitter = OAuth1Session( CONSUMER_KEY, CONSUMER_SECRET, ACCESS_TOKEN_KEY, ACCESS_TOKEN_SECRET ) #[[unixtime, screen_name, tweet, status_id], ...] mentions = get_mentions(twitter)2. 1.で得られた返信先ユーザの直近のツイート(最大5つ)を取得
各ユーザのツイートは下記APIで取得できます。
https://developer.twitter.com/en/docs/tweets/timelines/api-reference/get-statuses-user_timelineget_new_tweets.pydef get_new_tweets(twitter, screen_name): # RTなども取得件数に含まれてしまうので、countは多めに取っておく res = twitter.get("https://api.twitter.com/1.1/statuses/user_timeline.json", params={"screen_name": screen_name, "count": 20}) # エラー処理 tweets = [] if not res.status_code == HTTPStatus.OK: print(f"Failed: {res.status_code}") return [] for res_i in res.json(): print(res_i["text"]) tweet = res_i["text"] # メンションは無視する (botへの呼びかけも含んでしまうので) if "@" in tweet: continue tweets.append(tweet) # いったん5ツイート集まったら終わりにする if len(tweets) >= 5: break return tweets CONSUMER_KEY = 'XXX' CONSUMER_SECRET = 'XXX' ACCESS_TOKEN_KEY = 'XXX' ACCESS_TOKEN_SECRET = 'XXX' # twitter操作用クラス twitter = OAuth1Session( CONSUMER_KEY, CONSUMER_SECRET, ACCESS_TOKEN_KEY, ACCESS_TOKEN_SECRET ) user_tweets_map = {} # screen_namesはツイートを取得したいscreen_nameを格納したiteratable for screen_name in screen_names: tweets = get_new_tweets(twitter, screen_name) if tweets: user_tweets_map[screen_name] = tweets3. ツイートに含まれる特徴量を抽出し、事前に作っておいた楽曲の特徴量と比較、最も近い物を選択
3.1. 楽曲から特徴量を取得
3.1.0 歌詞データの収集
今回は推薦対象の楽曲の歌詞データから特徴量を取得します。
その前提として、推薦する楽曲の歌詞データを事前に取得しておく必要がありますが、ここはすでにあるものとして話を進めます。
実際にはスクレイピングしてデータを集めていますが、その部分の詳細についてはここでは触れません。3.1.1 特徴量の計算(学習)
今回は「ドキュメント内の文字を漢字のみに絞った」上で各漢字をwordとみなしてword2vecを計算することで漢字ごとにベクトルを算出、ドキュメント内に含まれる漢字ベクトルの平均値をドキュメントの特徴量としました。
普通に考えると「既存のword2vec」のモデルを流用した方が良さそうな気もするのですが、それができない、異なるレイヤーの問題が存在します
- 歌詞という文脈における単語の使われ方と既存のニュース記事やwikipediaにおける単語の使われ方が一致していないような気がする
- 例えば「太陽」という単語はニュース記事では天文分野の他の単語(惑星)などが近い気がするが、歌詞の文脈だと比喩表現としてもっと近い単語があるように思える(情熱とか)
- そもそも推論フェーズで形態素解析が動かない可能性があるので、形態素ベースの既存モデルが使えない
- lambdaの場合、使用できるライブラリの上限が250MBという制約がある
- 厳密にはlambdaにアップロードできるファイルサイズの上限
- 例えばpure pythonの形態素解析ライブラリであるjanomeはこれだけで100MB程度を占有する
- さらに、実行時もメモリ量ごとに従量課金額が変動するので可能な限り使用するライブラリを節約しメモリ量を削減したい
ということで、推論時の負荷を可能な限り下げ、かつ、歌詞の文脈における情報も可能な限り持たせる方法ということで漢字のみのword2vecを使用することにしました。
学習時のコードは下記の通りです。
この部分のコードは事前に計算しておく前提なので、numpyやgensimを使っています。なお、漢字だけを抜き出す部分については下記を参考にしました
https://qiita.com/mocha_xx/items/00c5a968f7069d8e092ctrain.py### 歌詞から漢字の部分だけを抜き出して、学習用データ作成 import re re_kanji = re.compile(r'^[\u4E00-\u9FD0]$') corpus = [] title_list = [] ### lyrics_mapは lyrics_map["title"] = "lyrics" であるdict for title, lyric in lyrics_map.items(): token_list = [] for line in lyric.split("\n"): for token in line: if re_kanji.fullmatch(token): token_list.append(token) if len(token_list) > 20: title_list.append(title) corpus.append(token_list) ### gensimのword2vecで漢字ごとのベクトルを計算 from gensim.models import word2vec model = word2vec.Word2Vec(corpus, size=200, min_count=20, window=10) ### 推論時はgensimのモデルを使えないので、普通のdictにしておく word_wv_map = {} print(len(model.wv.index2word)) for word in model.wv.index2word: wv = [0.0] * len(model.wv[word]) for i, val in enumerate(model.wv[word]): wv[i] = float(val) word_wv_map[word] = wv ### 歌詞全体のベクトルは、歌詞に含まれる漢字ベクトルの平均とする import numpy as np import json import math title_wv_map = {} for title in title_list: token_count = 0 wv = np.array([0.0] * len(model.wv[word])) wv_list = [0] * len(wv) lyric = lyrics_map[title] for line in lyric.split("\n"): for token in line: if token in model.wv: wv += model.wv[token] token_count += 1 # 平均した後L2正規化する if token_count > 20: wv /= token_count wv /= math.sqrt(sum(wv*wv)) for i, val in enumerate(wv): wv_list[i] = float(val) title_wv_map[title] = wv_list ### 推論用に保存 with open("features_wv.json", "w") as f: json.dump(word_wv_map, f) with open("title_wv.json", "w") as f: json.dump(title_wv_map, f)3.1.2 特徴量の計算(推論)
3.1.1で作ったモデルを使って推論=最もその人のツイートに近い楽曲の推薦を行います。
この部分はlambda上で動かすので、numpyやgensimは使わずにpure pythonで書いています。predict.pydef get_wv_from_tweets(feature_wv_map, tweets): wv_length = 200 wv = [0.0] * wv_length token_count = 0 for tweet in tweets: for token in tweet: if token in feature_wv_map: for i, val in enumerate(feature_wv_map[token]): wv[i] += val token_count += 1 if token_count == 0: return # 平均を計算する for i in range(len(wv)): wv[i] /= token_count # L2正規化 l2_acc = 0 for val in wv: l2_acc += val * val for i in range(len(wv)): wv[i] /= math.sqrt(l2_acc) return wv def get_nearest_title(title_vector_map, wv): max_sim = 0 max_title = None for title, vec in title_vector_map.items(): sim = 0 for val_wv, val_test in zip(vec, wv): sim += val_wv * val_test if sim > max_sim: print(title, sim) max_sim = sim max_title = title if sim == 0: return else: return max_title with open("features_wv.json") as f: feature_wv_map = json.load(f) with open("title_wv.json") as f: title_wv_map = json.load(f) ### tweets = ["tweet1", "tweet2", ... ] というiteratable wv = get_wv_from_tweets(feature_wv_map, tweets) nearest_title = get_nearest_title(title_wv_map, wv)4. 3で得た楽曲情報を1.で得たstatus_idにリプライ
tweet.pydef post_tweet(twitter, body, reply_id): res = twitter.post( "https://api.twitter.com/1.1/statuses/update.json", params={"status": body, "in_reply_to_status_id": reply_id}, ) print(res) # エラー処理 if res.status_code == HTTPStatus.OK: print("Successfuly posted: ", body) else: print(f"Failed: {res.status_code}") print(body) CONSUMER_KEY = 'XXX' CONSUMER_SECRET = 'XXX' ACCESS_TOKEN_KEY = 'XXX' ACCESS_TOKEN_SECRET = 'XXX' # twitter操作用クラス twitter = OAuth1Session( CONSUMER_KEY, CONSUMER_SECRET, ACCESS_TOKEN_KEY, ACCESS_TOKEN_SECRET ) ### 「本文」には3.で求めた楽曲のタイトルとかをよしなに入れてください ### reply_idは1.で求めてたstatus_idです post_tweet(twitter, "本文", reply_id)所感
- lambdaで機械学習系のプロダクトを作るのはかなり厳しいなあと思いました
- 実行時のメモリはお金を積めば無理やり解決できるが、アップロード制限を回避する方法がないため
- 今回はいったん形にすることを最優先にして「漢字だけのword2vec」という謎のアプローチを採用しましたが、ちゃんとEC2立てて普通にword2vec使った方がいいんだろうなあという気がしています
- ただ、(自分がTwitterでそこまで感情を吐く方ではないので、)楽曲の推薦結果が妥当かどうかの判断が主観的にすら難しいなあと思いました
- ので、誰かが使ってくれるとうれしいです。
再掲
https://twitter.com/shikumie に @付きでメンションするとオススメボカロ曲を教えてくれます。
ここまで書いた仕組みで動いていますので、興味がある方はお試しください。

- 投稿日:2020-03-10T21:50:48+09:00
【Udemy Python3入門+応用】 51. デフォルト引数で気をつけること
※この記事はUdemyの
「現役シリコンバレーエンジニアが教えるPython3入門+応用+アメリカのシリコンバレー流コードスタイル」
の講座を受講した上での、自分用の授業ノートです。
講師の酒井潤さんから許可をいただいた上で公開しています。■デフォルト引数で気をつけること
◆空のリストや辞書はデフォルト引数に使わない
list_augmentdef test_func(x, l = []): l.append(x) return l r = test_func(100) print(r) r = test_func(100) print(r)result[100] [100, 100]毎回新しいリストを使う場面が多いが、
そんなときにデフォルト引数に空のリストを設定してしまうと、
1つのリストをずっと使い続けることになる。◆毎回初期化するように組み込む
list_augmentdef test_func(x, l = None): # lを空のリストに初期化する if l is None: l = [] l.append(x) return l r = test_func(100) print(r) r = test_func(100) print(r)result[100] [100]
def内で、最初にlを初期化するように記述してやる。
そうすると、test_funcを呼び出すごとに毎回lの初期化が行われるため、
毎回空のリストを使えるようになる。
- 投稿日:2020-03-10T21:16:30+09:00
BERTを使った汎用的な日本語QAモデルの作成
はじめに
自然言語処理の様々なタスクでSOTAを更新したBERTですが、2019年12月に日本語のpretrainedモデルがpytorch版BERTに追加されました。これにより日本語のBERTが以前より簡単に試せるようになりました。しかし、依然としてBERTの日本語QAモデルに関する記事が存在しなかったため、この記事では日本語pretrainedモデルをfinetuningすることで日本語QAモデルを作成する方法について説明します。モデル作成の大まかな流れは以下のようになっているので、この流れを頭に入れて記事を読むと理解しやすいと思います。
モデル作成の流れ
1.モデルの学習データを用意する(これができれば、ほぼ完了です)
2.すでに用意された、run_squad.pyと言うスクリプトを実行する
3.モデル完成この記事で扱う内容
- 事前知識
・BERTとは
・squadの形式- 学習データの用意
・学習データの構造の説明
・squadを25025問翻訳する
・Squad2形式に変更
・オリジナルデータを使う場合
- finetuningの仕方
・使用する事前学習モデルの選択
・変更する必要のあるスクリプトについて
・finetuningに必要なデータ量の目安、学習時間
- モデルの使用方法
- 結果
・モデルの精度
・モデルの出力事前知識
この記事で紹介する方法でfinetuningをする場合、BERTへの理解よりもSQuADの形式の理解の方が大切になってくるため、SQuADの説明を重点的にします。
BERTとは
BERTに関する説明はすでに多くの方が説明しているのでここでは詳細は省きますが、BERTは2018年にgoogleが発表した自然言語処理モデルで現在googleの検索エンジンなどに使われています。BERTの大きな特徴はfinetuningすることでQA、感情分析など様々なタスクに適用することができることです。
詳しいことが気になる方は下記のリンクをご覧ください。
https://qiita.com/Kosuke-Szk/items/4b74b5cce84f423b7125squadの形式
Stanford Question Answering Dataset(SQuAD)は質疑応答に関するタスクで、問題文とそれに関する質問・回答で構成されるデータセットです。すべての質問に対する回答は、対応する問題文の一部になっています(国語の抜き出し問題に似ています)。SQuADにはバージョンが二つあり(v1.1、v2.0)、v1.1は全ての質問が回答可能でv2.0では答えられない質問が含まれています。今回は答えられない質問などにも対応したいため、SQuAD 2.0形式のデータを使ってBERTをfinetuningします。
SQuAD 1.1
SQuAD 2.0
実際のSQuAD 2.0のデータ形式は以下のようになります。
{ "version": "v2.0", "data": [ { "title": "りんご", "paragraphs": [ { "qas": [ { "question": "りんごは何色?", "id": "56be85543aeaaa14008c9063", "answers": [ { "text": "赤", "answer_start": 4 } ], "is_impossible": false }, { "plausible_answers": [ { "text": "美味しい", "answer_start": 7 } ], "question": "バナナは美味しい?", "id": "5a8d7bf7df8bba001a0f9ab1", "answers": [], "is_impossible": true } ], "context": "りんごは赤くて美味しい。" } ] } ] }それぞれの項目の説明
キー 値 version バージョンを示している(今回は SQuAD 2.0を使うため v2.0) data 問題文ごとにデータをリスト形式で保持 title 問題文のタイトル paragraphs 問題文の段落一つとそれに関連する複数の質問、回答を保持 qas 質問と回答をリスト形式で保持 question 質問 answers 問題文から抜き出した答えとその位置のデータをリスト形式で保持。
train-v2.0では答えは0個または1個、dev-v2.0では答えは4つ存在する。text 問題文から抜き出した答えのテキスト answer_start 問題文中の答えの位置情報、pythonの 問題文.find(答え) の値と一致する。(問題文内に答えが一回しか登場しない場合) id 質問固有のid is_impossible 答えられない質問の時にtrue、それ以外の時はfalse plausible_answers 質問が答えられないの時のみ存在する項目、問題文から答えになりうる部分を抜き出している context 答えが存在すると考えられる文章(問題文に当たる) 学習データの用意
すでにQAのデータを持っている場合、データをSQuAD2.0の形式に成形するだけで学習データができるのですが、おそらく多くの方はこれらのデータを用意できないと思うので、今回はデータがない状態からSQuAD 2.0形式のデータを2万問分用意した方法も説明します。
データ作成
SQuAD 2.0形式のデータを作成するためには以下の情報が必要です。
1.context(問題文)
2.question(質問)
3.answer(回答)日本語のQAデータにはNIILC Question Answering Dataset、NTCIR-6 QAC4、Yahoo! 知恵袋データ(第3版)などがありますが、上記の情報が含まれデータ数が多いデータセットが存在しません。(もし知っていれば教えてください)
そのため今回はSQuAD 2.0自体ををgoogle翻訳で翻訳してデータを作成します。finetuningの仕方
はじめにでも言ったようにfinetuningはrun_squad.pyを少し変更して実行するだけでできます。
事前学習モデルの選択
この記事で使用しているTransformersのバージョン(2.8.0)では4つのモデルが使用できます。
- bert-base-japanese
- bert-base-japanese-whole-word-masking
- bert-base-japanese-char
- bert-base-japanese-char-whole-word-masking
詳細はcl-tohoku repositoryを見てください。
今回試したところbert-base-japanese-whole-word-maskingが一番性能がよかったのでこれを使用しますが、もし他のモデルも試してみたい場合はこのノートブックで簡単に試せるので試してみてください。run_squad.pyの変更点
run_squad.pyの変更点は以下の3つだけです。すでに必要なところを変更したスクリプトをgithubに公開しているのでこちらを見るとわかりやすいと思います。
https://github.com/kuma807/bert_qa/blob/master/run_squad.py1.mecabをimportする
import MeCabmecabは形態素解析器で、BERTに与える日本語を分割するために使用します。
2.transformersレポジトリから新たに
- BertForQuestionAnswering
- AutoTokenizer
- AutoConfig
をimportする。これらは事前学習モデル、tokenizer、設定になっています。
from transformers import ( WEIGHTS_NAME, AdamW, AlbertConfig, AlbertForQuestionAnswering, AlbertTokenizer, ...省略... XLNetTokenizer, get_linear_schedule_with_warmup, squad_convert_examples_to_features, BertForQuestionAnswering, AutoTokenizer, AutoConfig, )3.MODEL_CLASSESに
- bert-base-japanese-whole-word-masking
を追加する。このクラス名はのちにfinetuningするときに使います。
MODEL_CLASSES = { "bert": (BertConfig, BertForQuestionAnswering, BertTokenizer), "camembert": (CamembertConfig, CamembertForQuestionAnswering, CamembertTokenizer), "roberta": (RobertaConfig, RobertaForQuestionAnswering, RobertaTokenizer), "xlnet": (XLNetConfig, XLNetForQuestionAnswering, XLNetTokenizer), "xlm": (XLMConfig, XLMForQuestionAnswering, XLMTokenizer), "distilbert": (DistilBertConfig, DistilBertForQuestionAnswering, DistilBertTokenizer), "albert": (AlbertConfig, AlbertForQuestionAnswering, AlbertTokenizer), "bert-base-japanese-whole-word-masking": (AutoConfig.from_pretrained("cl-tohoku/bert-base-japanese-whole-word-masking"), BertForQuestionAnswering.from_pretrained("cl-tohoku/bert-base-japanese-whole-word-masking"), AutoTokenizer.from_pretrained("cl-tohoku/bert-base-japanese-whole-word-masking")), }MODEL_CLASSESに追加する形式は
"モデルのクラス名": モデルの設定, 事前学習モデル, tokinizerの設定
となっています。run_squad.pyの実行
run_squad.pyの実行は以下のコマンドでできます。以下のコマンドはノートブック形式で実行されることを想定しているため、ターミナルから実行する場合は一番最初の!を取り除いてください。
!python bert_qa/run_squad.py\ --model_type モデルのクラス名 \ --model_name_or_path モデルの名前 \ --predict_file テストデータへのパス \ --train_file 学習データへのパス \ --do_train \ --per_gpu_train_batch_size 12 \ --learning_rate 3e-5 \ --num_train_epochs 2.0 \ --max_seq_length 384 \ --doc_stride 128 \ --fp16 \ --do_eval \ --save_steps 3000 \ --version_2_with_negative \ --output_dir 学習したモデルの保存場所/今回の例でいくとモデルのクラス名がbert-base-japanese-whole-word-masking、モデルの名前がcl-tohoku/bert-base-japanese-whole-word-maskingになっています。
オプション 意味 fp16 浮動小数点の精度を落とすことで学習を高速化する、これがないとcolaboratoryで実行できない version_2_with_negative squad 2.0で学習する場合必要 モデルの使用方法
こちらもノートブックの ”モデルの使用方法” にモデルを使用するためのスクリプトが乗っているので確認してください。qiitaではモデルを使用するためのスクリプトについて説明します。さらに詳しいことがきになる方はこちらへ。
モデルの読み込み
1.設定をmodel_directoryから読み込む
config = AutoConfig.from_pretrained(model_directory + "/config.json") tokenizer_config = AutoConfig.from_pretrained(model_directory + "/tokenizer_config.json")名前から分かるようにconfigはモデルの設定、tokenizer_configはtokenizerの設定になっています。
2. 1.の設定でモデル読み込む
model = BertForQuestionAnswering.from_pretrained(pretrained_model, config=config) model.load_state_dict(torch.load(model_directory + "/pytorch_model.bin", map_location=torch.device('cpu'))) tokenizer = AutoTokenizer.from_pretrained(pretrained_model, config=tokenizer_config)2行目のmap_location=torch.device('cpu')となっているところをmap_location=torch.device('cuda')と変更することでgpuでの実行ができるようになります。
モデルへの入力
モデルへの入力は
- input_ids
- token_type_ids
の二つになります。question = "りんごは何色?" context = "りんごは赤くて美味しい。" input_ids = tokenizer.encode(question, context) token_type_ids = [0 if i <= input_ids.index(3) else 1 for i in range(len(input_ids))]input_ids
tokenizer.encode(question, context)で行われてる処理を説明します。
まずquestionとcontextをmecabで分割します。この時一つの単語が分割された場合、 ##を前につけることでもとは一つの単語であったことを表しています。分割したものを特別なトークン(CLSとSEP)を使って、[CLS] + question + [SEP] + context + [SEP] のように連結します。この特別なトークンについてはそのようなものがある程度の認識でいいと思います。実際の値
['[CLS]', 'りん', '##ご', 'は', '何', '色', '?', '[SEP]', 'りん', '##ご', 'は', '赤く', 'て', '美味', '##しい', '。', '[SEP]'][CLS]は文章の始まり、[SEP]は文章の終わりに追加される特別なトークンです。
これを単語ごとにidに変換したものがinput_idsになります。実際の値
[2, 9768, 29066, 9, 1037, 1232, 2935, 3, 9768, 29066, 9, 22628, 16, 18178, 485, 8, 3]
対応関係
{'[CLS]': 2, 'りん':9768, '##ご':29066, 'は':9, '何':1037, '色':1232, '?':2935, '[SEP]':3, '赤く':22628, 'て':16, '美味':18178, '##しい':485, '。':8, '[SEP]'}ここで注意する点としては日本語のBERTでは[CLS]が2、[SEP]が3に対応していることです。(英語版では[CLS]:101, [SEP]:102に対応しています)
token_type_ids
token_type_idsは一つ目の文章には0, 二つ目の文章には1を割り当てたリストです。
実際の値
[0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1]また一つ目の[SEP]は一つ目の文章として扱われます。
モデルの出力
モデルの出力のされ方は、「start_scores」「end_scores」のスコアで表現され、それぞれ「答えが始まる位置のスコア」「答えが終わる位置のスコア」にあたります。
start_scores, end_scores = model(torch.tensor([input_ids]), token_type_ids=torch.tensor([token_type_ids]))start_scores,end_scores共にtensorflowのtensor型(softmax前)です。
実際の値
start_scores
tensor([[-5.4366, -3.2602, -8.1666, -8.0910, -3.1464, -5.3078, -6.6031, -5.4042,
-1.6283, -6.9755, -7.4763, 2.0868, -6.4028, -3.1525, -6.1728, -6.0557,
-5.2687]], grad_fn=)
end_scores
tensor([[-4.9398, -9.0989, -7.0649, -8.9144, -3.7368, -2.6993, -4.5407, -0.1127,
-7.2395, -5.5424, -7.2156, 1.9255, -1.7737, -4.3648, -0.3700, -1.0993,
0.0879]], grad_fn=)この時のstart_scoresの最大値のindexから、end_scoresの最大値のindexまでがモデルの予想する答えになります。(例は "モデルの出力を日本語に変換" に記載)
モデルの出力を日本語に変換
input_idsは全て日本語に対応する数値だ表されているため、これを日本語に直しall_tokensと言う変数に格納します。
all_tokens = tokenizer.convert_ids_to_tokens(input_ids)実際の値
all_tokens
['[CLS]', 'りん', '##ご', 'は', '何', '色', '?', '[SEP]', 'りん', '##ご', 'は', '赤く', 'て', '美味', '##しい', '。', '[SEP]']このall_tokoensとstart_scores、end_scoresを使うことでモデルの出力を見ることができます。
prediction = ''.join(all_tokens[torch.argmax(start_scores) : torch.argmax(end_scores)+1]) prediction = prediction.replace("#", "") prediction = prediction.replace(" ","")上のstart_scoresとend_scoresの例で言うとstart_scoresの最大値のindexが11、end_scoresの最大値のindexが11となっているため、モデルの予想はall_tokens[11:11 + 1]の"赤く"になります。またpredictionには無駄なスペースや"#"が含まれるためこれを取り除きます。
結果
作成したモデルの精度
20,216問学習させたところ答えが存在しない問題に対して精度は約97.09%の確率で答えがないと、答えが存在する問題に対して完全一致する答えを約57.46%の確率で文章中から抜き取ることができました。
テストデータの詳細 答えがある問題 2329問 答えがない問題 2295問 全体 4624問
モデルの予想精度 答えと出力が完全一致したパーセント 答えがある問題 57.46% 答えがない問題 97.09% 全体 77.11% また学習に使った質問数とモデルの精度の関係は以下のグラフのようになりました。このグラフから分かるようにモデルの性能が14,000問を超えたあたりから全体の精度・答えのある問題の精度が共に収束してきているので、おそらく14,000問ほどデータを用意できれば十分だと思います。答えのない問題だけに関しては学習に使った問題数が2,000問の時点で97%を超える精度で予想できてるので、人間の作成したデータのみでの学習も比較的容易だと思います。
モデルの出力
実際にモデルを動かせるノートブックを作成したのでよかったら動かしてみてください。ノートブックを使うには学習済みモデルを事前にダウンロードしておいてください。
テストデータの一部に対するモデルの予想は以下のようになっており、答えられない問題のanswerは[CLS]となっています。
モデルの精度評価に利用した4624問に対する全ての予想をみたい方はこちらを。questionが質問、answerは正しい答え、predictionはモデルの予想結果になっています。問題文
他のほとんどの大学と同様、ノートルダムの学生は多くのニュースメディアを運営しています。学生が運営する9か所のアウトレットには、3つの新聞、ラジオ局とテレビ局、いくつかの雑誌と雑誌があります。 1876年9月に1ページの雑誌として始まり、Scholastic誌は月に2回発行され、米国で最も古い継続的な大学出版物であると主張しています。もう1つの雑誌The Jugglerは年に2回発行され、学生の文学とアートワークに焦点を当てています。ドーム年鑑は毎年発行されます。新聞にはさまざまな出版物の関心があり、オブザーバーは毎日発行され、主に大学やその他のニュースを報告し、ノートルダムとセントメアリー大学の両方の学生がスタッフを務めています。 ScholasticやThe Domeとは異なり、The Observerは独立した出版物であり、教授陣や大学からの編集上の監督はありません。 1987年、一部の学生がThe Observerが保守的な偏見を示し始めたと信じたとき、リベラルな新聞、Common Senseが出版されました。同様に、2003年に、他の学生がこの論文がリベラルな偏見を示していると信じたとき、保守的な論文Irish Roverが生産に移行しました。どちらの論文もThe Observerほど頻繁には出版されていません。ただし、3つはすべての生徒に配布されます。最後に、2008年春、政治学研究のための学部ジャーナルBeyond Politicsがデビューしました。
question answer prediction 学生論文Common Senseがノートルダムで出版を開始したのは何年ですか? 1987 1876 聖十字会の本部はどこですか? ローマ ローマ ポーランド文学におけるショパンの最も早い目撃は何ですか? [CLS] [CLS] ノートルダム寺院で最も古い建物は何ですか? オールドカレッジ オールドカレッジ 建設技術者は誰として知られていましたか? [CLS] [CLS] 世界の文化の中心地と呼ばれているのはどの都市ですか? [CLS] [CLS] ビヨンセは誰と結婚していますか? [CLS] [CLS] ノートルダム大学工学部は何年に設立されましたか? 1920 1920

- 投稿日:2020-03-10T20:50:46+09:00
小売業に必要なデータサイエンティストの役割について考える②
はじめに
最近データサイエンティストやデジタル人材の役割・スキルの記事が多いので、小売業に必要となるデータサイエンティストの役割について考察していきたいと考えています。
データサイエンティストを内部に置くべきか
私の立場から言うのはおかしいかもしれませんが、本当に社内にデータサイエンティストが必要でしょうか。
小売の本質はものを仕入れて(バイヤー)・ものを売る(店舗)こと。それを補助する業務は、適切に外部に依頼してしまうのも手だと思います。ただ、一方で「データを扱う」という理由だけで、IT部門がデータサイエンスの業務を兼任するというパターンがあります。(というか、他社に聞く限り、それが多い)
しかし、IT部門(またはCIO)は、システムのプロフェッショナルであって、データのプロフェッショナルではありません。ですので、それだけは絶対に避けなければいけません。そうではなく、顧客接点やビジネスを”仕切っている”部署がリードすべき事項です。その部署が中心になって、データサイエンティストを外部に依頼するのか、内部に創り出すのかを検討していくべきでしょう。
どのような役割が必要か
外部・内部のどちらにせよ、小売業のデータサイエンティストにはどの様な役割が必要でしょうか。
ビジネスオーナー(経営層)
自社でも、他社の例を聞いていても思いますが、やはり経営層のコミットメントは必須です。
他の業界では、現場のリーダーから小さく育ててということもあるようですが、こと小売業については、それは難しいですね。店舗の意見が強い企業・商品部門の意見が強い企業、それぞれあると思いますが、どちらも大体データを使って何かと言っても、聞いてくれないので、経営層から推進してもらうことが重要です。
データが分かるビジネスリーダー(内部)
「データサイエンスや機械学習が分かるリーダー」となると、あまりにも探すのが難しいので、「データが分かるリーダー」としました。(もちろん、データサイエンスや機械学習が分かれば、それに越したことはないです)
やはり、小売業は現場叩き上げのリーダーが多い(様に思う)ので、KKD(経験・勘・度胸)でなんとかしようとしてしまいがち&部下にもそれを求めがちです。
もちろん、それも良いんだけど、「ちょっと待って、1度データがどうなっているか見てみよう」と言える人が必ずいるはず。そんな人が、ビジネスオーナーとセットで動いていくと、データサイエンスの声が全体に広まっていきやすいと思います。
データアナリスト(内部 + 外部)
チームのメインとなるプレイヤーですが、いわゆる、データサイエンティストほどのスキルは必要ないかなと。
※必要なスキルセットも今後整理したいですがよくあるのが、データ出すのは外部のベンダーとかに集計してもらって、その結果を読んでますという役割の人。
最初はそれでいいと思いますが、結局外部のベンダー頼みになると、自分が指示しているはずが、上手くコントロールされてしまっていることにもなりかねない。本当は自分が操作(SQLでもBIシステムでも)して数字を出している。その上で、外部に指示を出すというのが望ましいですね。データエンジニア(内部 or 外部)
ここはIT部門の役割だと思います。
ただ、IT部門に依存しすぎてしまうと、「必要なデータを出すこと」という最も基本となる仕事が、分析部署のコントロール外になりがちなので、そのパイプが重要ですね。企業によっては、ITのほぼ全てを外部に任せてしまっている企業もあるので、それは仕方がないですね。
でも、データ活用を進めるのであれば、多少なりともITの機能を内部に戻す or 自分の手足のように使える外部を持たせるデータストーリーテラー(内部)
これが良いワードか分かりませんが、「すべてのデータサイエンスチームが雇うべき3つの見落とされがちな役割」で、おお!となったのがこの役割。
結果、このアウトプットに基づくと、こうすべきなんだよを言える人です。
なぜ、我々はデータを分析するのか?
複雑なプログラムが欲しいからでも、綺麗な数表が欲しいからでもありませんよね。
それの基づいて行動し、結果を生み出すためです。ただ、行動するまで全てを1人ではできないため、ストーリーテラー的な役割で店舗や、商品部に広めていき、行動を生み出していく。
その役割をこれまでは、ビジネスリーダーが兼務していました(まあ、兼務できる力量があれば問題ないかもいしれません)が、これをメインでやる役割の人が、小売にも今後は必要になってくるように思います。おわりに
今回は、小売業のデータサイエンス組織において、必要と思われる役割を整理してみました。
もちろん、企業の規模によって、もっと様々に役割を分担したり、兼務したりというのはあると思います。ただ、今の世の中の様に、派手に宣伝をすれば売れる・いい商品を出せば売れるといった単純にはいかない状況になっている中で、「データ」という武器をつかいこなしていくためには、それを自社の中でどの様な位置づけとするのか考えることが重要です。
そんな役割は、内部で持たせていくべきだと思います。
- 投稿日:2020-03-10T20:38:09+09:00
テーブルのクリップボードをマークダウンにするコマンドを作った
概要
Webやスプレッドシートなどのテーブルをクリップボードにコピーして、それを何かしらのマークダウンに記録したい時、地味に面倒だったのでコマンドを作った話です。
PyPIにも上げています。
下記のようなものです。
インストール方法
pip install clipableツールの概要
こちら何も難しいことはしておらず、下記の2つのライブラリがあれば誰でも瞬殺で作れるやつです。
- pandas(クリップボードからテーブルを作成し、マークダウン出力するため)
- pyperclip(クリップボードにコピーするため)
poetryが凄かった
今回依存関係の管理にpoetryを使いました。
poetry new パッケージ名で新しいプロジェクトを作成し
poetry add パッケージ名で依存するパッケージを追加します。
新規作成したパッケージ名と同名のフォルダの下にcli.pyというファイルを作ります。
そこにmain関数を作成します。そしてその後にtomlでコマンドを実行できるようにscriptの設定を追加します。pyproject.toml[tool.poetry.scripts] clipable = "clipable.cli:main"基本的に重要なのはこれぐらいでした。
あとは
poetry buildでビルドして
poetry publishとするとPyPIに登録できます。
感想
Poetryで公開までがあまりの簡単さに感動した。
参考

- 投稿日:2020-03-10T20:32:49+09:00
「コロナ」に関するツイートをpythonで収集して、「コロナ」の影響で話題になった単語を自動検出する
Twitterデータのpythonでの収集方法と、時系列のテキストデータに対するバースト検出方法の説明です。
技術的には、以下の過去記事と同様です。
過去記事:
「クッパ姫」に関するツイートをpythonで収集して、バースト検出してみた
https://qiita.com/pocket_kyoto/items/de4b512b8212e53bbba3この時に採用した方法の汎用性を確認するために、2020年3月10日時点で話題の「コロナ」をキーワードとして、Twitterデータの収集と、「コロナ」と共起する語のバースト検出を実践してみました。
「コロナ」に関するツイートを収集する
収集方法は、基本的に過去記事とほぼ同じです。
まずは、ライブラリの読み込みなど、ツイート収集の準備を行います。
# Twitterデータ収集用のログインキーの情報 KEYS = { # 自分のアカウントで入手したキーを記載 'consumer_key':'*********************', 'consumer_secret':'*********************', 'access_token':'*********************', 'access_secret':'*********************', } # Twitterデータの収集(収集準備) import json from requests_oauthlib import OAuth1Session twitter = OAuth1Session(KEYS['consumer_key'],KEYS['consumer_secret'],KEYS['access_token'],KEYS['access_secret'])Twitterデータ収集用のログインキーの取得方法に関する情報は、参考[1]のサイトが分かりやすいです。
ツイート収集用の関数は、以下のように定義しています。
ツイート場所は今回使わないため、デフォルトの引数(None)を設定できるようにしました。
また、1回あたり最大100ツイートしか検索できないので、for文で繰り返しリクエストする必要があるのですが、Twitterデータ取得関数の外で管理した方がスマートだったので、そのように実装しています。
このあたりは、参考[2]の書き方を踏襲しました。# Twitterデータ取得関数 def getTwitterData(key_word, latitude=None, longitude=None, radius=None, mid=-1): url = "https://api.twitter.com/1.1/search/tweets.json" params ={'q': key_word, 'count':'100', 'result_type':'recent'} #取得パラメータ if latitude is not None: # latitudeのみで判定 params = {'geocode':'%s,%s,%skm' % (latitude, longitude, radius)} params['max_id'] = mid # midよりも古いIDのツイートのみを取得する req = twitter.get(url, params = params) if req.status_code == 200: #正常通信出来た場合 tweets = json.loads(req.text)['statuses'] #レスポンスからツイート情報を取得 # 最も古いツイートを取るための工夫(※もっと良い書き方ありそう) user_ids = [] for tweet in tweets: user_ids.append(int(tweet['id'])) if len(user_ids) > 0: min_user_id = min(user_ids) else: min_user_id = -1 # メタ情報 limit = req.headers['x-rate-limit-remaining'] if 'x-rate-limit-remaining' in req.headers else 0 reset = req.headers['x-rate-limit-reset'] if 'x-rate-limit-reset' in req.headers else 0 return {'tweets':tweets, 'min_user_id':min_user_id, 'limit':limit, 'reset':reset} else: #正常通信出来なかった場合 print("Failed: %d" % req.status_code) return {}上記の関数を連続で実行するための制御関数(getTwitterDataRepeat)を作成しました。
リクエスト制限に引っかからないように、制限に引っかかりそうになったら自動で待機します。# Twitterデータ連続取得 import datetime, time def getTwitterDataRepeat(key_word, latitude=None, longitude=None, radius=None, mid=-1, repeat=10): tweets = [] for i in range(repeat): res = getTwitterData(key_word, latitude, longitude, radius, mid) if 'tweets' not in res: #エラーとなった場合は離脱 break else: sub_tweets = res['tweets'] for tweet in sub_tweets: tweets.append(tweet) if int(res['limit']) == 0: # 回数制限に達した場合は休憩 # 待ち時間の計算. リミット+5秒後に再開する now_unix_time = time.mktime(datetime.datetime.now().timetuple()) #現在時刻の取得 diff_sec = int(res['reset']) - now_unix_time print ("sleep %d sec." % (diff_sec+5)) if diff_sec > 0: time.sleep(diff_sec + 5) mid = res['min_user_id'] - 1 print("ツイート取得数:%s" % len(tweets)) return tweetsこのように実装することで、リクエストの上限を気にせず、ツイートの収集が自動で可能となります。
あとは、時間帯別でツイートを分けて収集したかったので、以下のようなスクリプトを回しました。# 参考[3]で作成されていた関数を拝借しました import time, calendar def YmdHMS(created_at): time_utc = time.strptime(created_at, '%a %b %d %H:%M:%S +0000 %Y') unix_time = calendar.timegm(time_utc) time_local = time.localtime(unix_time) # 2018/9/24に修正しました return time.strftime("%Y/%m/%d %H:%M:%S", time_local) # コロナに関するツイートを6時間おきに1週間分取得する tweet_corona = {} mid = -1 for t in range(4*7): tweets = getTwitterDataRepeat("コロナ", mid=mid, repeat=10) old_tweet = tweets[-1] # 収集した中で最も古いツイート key = YmdHMS(old_tweet["created_at"]) # YmdHMS関数 tweet_corona[key] = tweets # 最も古いツイートの時刻をキーとして保存する mid = old_tweet["id"] - 15099494400000*6 # 約6時間遡って収集するツイートを6時間ずつ遡りながら収集したかったので、最も古いツイートのmidから15,099,494,400,000 * 6を引いています。
この15,099,494,400,000という値は、Tweeterのtweet IDの仕様より決めています。
Twitter の tweet ID はミリ秒タイムスタンプ+ ID を発行するマシンの番号+シーケンス番号を 64 bit に押し込めた構造になっています。(参考[4])「コロナ」に関するツイートを時系列で比較してみる
ここまでで、「コロナ」を含むツイートを時系列で収集することができました。
まずはデータを理解するために、単語の出現頻度を時系列で可視化したいと思います。以下のような関数を定義して、janomeで形態素解析して、単語の出現頻度をカウントしました。
# 文章を形態素解析して、Bag of Wordsに変換する from janome.tokenizer import Tokenizer import collections import re def CountWord(tweets): tweet_list = [tweet["text"] for tweet in tweets] all_tweet = "\n".join(tweet_list) t = Tokenizer() # 原形に変形、名詞のみ、1文字を除去、漢字・平仮名・カタカナの連続飲みに限定 c = collections.Counter(token.base_form for token in t.tokenize(all_tweet) if token.part_of_speech.startswith('名詞') and len(token.base_form) > 1 and token.base_form.isalpha() and not re.match('^[a-zA-Z]+$', token.base_form)) freq_dict = {} mc = c.most_common() for elem in mc: freq_dict[elem[0]] = elem[1] return freq_dict可視化方法はWordCloudを用いました。以下のように実装しました。
# Word Cloudで可視化、WordCloud可視化関数 def color_func(word, font_size, position, orientation, random_state, font_path): return 'white' from wordcloud import WordCloud import matplotlib.pyplot as plt get_ipython().run_line_magic('matplotlib', 'inline') from matplotlib.font_manager import FontProperties fp = FontProperties(fname=r'C:\WINDOWS\Fonts\meiryo.ttc', size=50) #日本語対応 def DrawWordCloud(word_freq_dict, fig_title): # デフォルト設定を変更して、colormapを"rainbow"に変更 wordcloud = WordCloud(background_color='white', min_font_size=15, font_path='C:\WINDOWS\Fonts\meiryo.ttc', max_font_size=200, width=1000, height=500, prefer_horizontal=1.0, relative_scaling=0.0, colormap="rainbow") wordcloud.generate_from_frequencies(word_freq_dict) plt.figure(figsize=[20,20]) plt.title(fig_title, fontproperties=fp) plt.imshow(wordcloud,interpolation='bilinear') plt.axis("off")これらを用いて、
単語の出現頻度を時系列で可視化します。出力:
(中略)
:
:
(中略)
:
:
(中略)
:
:
(中略)
:
:
(中略)
:
「新型」「ウイルス」「感染」など、「コロナ」という単語と共起しやすい語群の影響が強く出ました。
この可視化結果からは、「コロナ」の影響で話題になった単語が分かりにくいため、自動検出してみることにします。コロナの影響で、話題になった単語を自動検出してみる
今回収集したデータセットと、バースト検出と呼ばれる手法を用いて、「コロナ」の影響で、話題になった単語を自動検出してみたいと思います。
バースト検出という手法に関しては、書籍では、「ウェブデータの機械学習 (機械学習プロフェッショナルシリーズ)」に詳しくまとめられているようですが、ネットには解説記事が少ないです。
今回は、自然言語処理に関する研究室として著名な、東北大学 乾・鈴木研究室の解説記事を参考として、バースト検出手法の実装・適用に挑戦してみたいと思います。今回は、Moving Average Convergence Divergence (MACD) という指標を用いて、バースト検出に取り組んでみました。
バースト検出手法としては、Kleinbergが2002年に発表した手法がベースラインとして、よく用いられるようですが、He and Parker が2010年に発表したMACDのほうがシンプル、かつ計算量が少ないようです。↓MACDの解説については、乾・鈴木研究室のものが分かりやすいので、そのまま引用したいと思います。
【MACDの解説】
ある時刻におけるMACDは,
MACD = (時系列値の過去f期間の移動指数平均) - (時系列値の過去s期間の移動指数平均)
Signal = (MACD値の過去t期間の移動指数平均)
Histgram = MACD - Signalここで,f, s, tはパラメータ(f < s)で,これらをまとめてMACD(f, s, t)と書きます. 今回の実験では,He and Parker (2010) の実験でも用いられていた MACD(4, 8, 5) を採用しました. MACDをテクニカル指標として用いる時は,「Signal < MACD」の状態を上げトレンド,「MACD < Signal」の状態を下げトレンドとし,Histgramがトレンドの強さを表すと言われています. 今回は,15分間の期間をひとまとまりとして(15分足),その期間内にツイッター上に出現した単語の出現頻度を15で割った値,つまり出現速度[回/分]を観測値として,MACDによるトレンド分析を行いました. MACDの計算に必要な移動指数平均の値は逐次計算が可能で,今回のトレンド分析はストリーミング・アルゴリズムとして実装できるため,ビッグデータからのトレンド分析に適していると考えています.
上記の解説内容から、MACDを以下のように実装しました。
# Moving Average Convergence Divergence (MACD) の計算 class MACDData(): def __init__(self,f,s,t): self.f = f self.s = s self.t = t def calc_macd(self, freq_list): n = len(freq_list) self.macd_list = [] self.signal_list = [] self.histgram_list = [] for i in range(n): if i < self.f: self.macd_list.append(0) self.signal_list.append(0) self.histgram_list.append(0) else : macd = sum(freq_list[i-self.f+1:i+1])/len(freq_list[i-self.f+1:i+1]) - sum(freq_list[max(0,i-self.s):i+1])/len(freq_list[max(0,i-self.s):i+1]) self.macd_list.append(macd) signal = sum(self.macd_list[max(0,i-self.t+1):i+1])/len(self.macd_list[max(0,i-self.t+1):i+1]) self.signal_list.append(signal) histgram = macd - signal self.histgram_list.append(histgram)このプログラムを用いて、2020年3月4日(水)~2020年3月10日(火)にかけて、
コロナの影響で、話題になった単語を自動検出してみたいと思います。
上記の関数へデータを代入するプログラム(折り込み)
# 各時間帯のツイートで、上位100語にランクインする用語をバースト検出する top_100_words = [] i = 0 for freq_dict in datetime_freq_dicts: for k,v in freq_dict.items(): top_100_words.append(k) i += 1 if i >= 100: i = 0 break top_100_words = list(set(top_100_words)) # ユニークな単語に限定 print(len(top_100_words)) # MACD計算結果の取得 word_list_dict = {} for freq_dict in datetime_freq_dicts: for word in top_100_words: if word not in word_list_dict: word_list_dict[word] = [] if word in freq_dict: word_list_dict[word].append(freq_dict[word]) else: word_list_dict[word].append(0) # 正規化 word_av_list_dict = {} for k, v in word_list_dict.items(): word_av_list = [elem/sum(v) for elem in v] word_av_list_dict[k] = word_av_list # 計算(He and Parker(2010)と同じパラメータ) f = 4 s = 8 t = 5 word_macd_dict = {} for k, v in word_av_list_dict.items(): word_macd_data = MACDData(f,s,t) word_macd_data.calc_macd(v) word_macd_dict[k] = word_macd_data # バースト検出 word_burst_dict = {} for k,v in word_macd_dict.items(): burst = max(v.histgram_list) # Histgramがトレンドの強さを表すことから、期間内での最大値を取る word_burst_dict[k] = burstデータを投入した結果は以下の通りです。
i = 1 for k, v in sorted(word_burst_dict.items(), key=lambda x: -x[1]): print(str(i) + "位:" + str(k)) i += 1出力:
1位:九郎
2位:ロッテマリーンズ
3位:グラウンド
4位:区役所
5位:尊厳
6位:つば
7位:自習
8位:配達員
9位:メタノール
10位:港北
11位:血清
12位:イープラス
13位:ハラスメント
14位:装置
15位:スナック
16位:佐川急便
17位:リベロ
18位:みゆき
19位:美神
20位:サイケ
21位:ライヴ
22位:横浜市立大学
23位:恐慌
24位:全巻
25位:コロハラ
26位:獣疫
27位:払戻し
28位:登場
29位:義務
30位:表示
:
(中略)
:
「つば」「九郎」「ロッテマリーンズ」などが、「コロナ」の影響で話題になった単語として検出されました。
他の単語についても、概ね納得感のある結果でした。
次いで、話題になった時期の推定も行ってみました。
可視化プログラム(折り込み)
# 結果の可視化 import numpy as np import matplotlib.pyplot as plt get_ipython().run_line_magic('matplotlib', 'inline') from matplotlib.font_manager import FontProperties fp = FontProperties(fname=r'C:\WINDOWS\Fonts\meiryo.ttc', size=10) #日本語対応 x = np.array(sorted(tweet_corona.keys())) y1 = np.array(word_macd_dict["ロッテマリーンズ"].histgram_list) y2 = np.array(word_macd_dict["自習"].histgram_list) y3 = np.array(word_macd_dict["配達員"].histgram_list) y4 = np.array(word_macd_dict["メタノール"].histgram_list) y5 = np.array(word_macd_dict["スナック"].histgram_list) y6 = np.array(word_macd_dict["ハラスメント"].histgram_list) plt.plot(x, y1, marker="o") plt.plot(x, y2, marker="+", markersize=10, markeredgewidth=2) plt.plot(x, y3, marker="s", linewidth=1) plt.plot(x, y4, marker="o") plt.plot(x, y5, marker="+", markersize=10, markeredgewidth=2) plt.plot(x, y6, marker="s", linewidth=1) plt.xticks(rotation=90) plt.title("バースト検出結果", fontproperties=fp) plt.xlabel("日時", fontproperties=fp) plt.ylabel("バースト検出結果", fontproperties=fp) plt.ylim([0,0.2]) plt.legend(["「ロッテマリーンズ」","「自習」", "「配達員」","「メタノール」", "「スナック」","「ハラスメント」"], loc="best", prop=fp)可視化結果は、以下の通りです。
ヤクルトスワローズ 対 ロッテマリーンズの無観客試合が行われたのが、
3月7日(土)なので、正しく推定できていそうです。
3月10日(火)現在では、「メタノール」が話題の単語の一つとなっているようです。まとめと今後
今回は、「コロナ」をテーマにバースト検出に取り組んでみました。
技術的には、過去記事の内容の焼き直しですが、妥当な分析結果が得られたのではないかと考えています。
過去記事では、「クッパ姫」をテーマとしていましたが、手法自体は汎用性が高いことを確認できました。引き続き、Twitterデータ分析にチャレンジしていきたいと思います。
参考
[1]
【2019年】TwitterのAPIに登録し、アクセスキー・トークンを取得する具体的な方法
https://miyastyle.net/twitter-api
[2]
スタバのTwitterデータをpythonで大量に取得し、データ分析を試みる その1
https://qiita.com/kenmatsu4/items/23768cbe32fe381d54a2
[3]
Streaming APIで取得したつぶやきの処理方法
http://blog.unfindable.net/archives/4302
[4]
スケーラブルな採番とsnowflake
https://kyrt.in/2014/06/08/snowflake_c.html
[5]
東北大学 乾・鈴木研究室 Project 311 / Trend Analysis
http://www.cl.ecei.tohoku.ac.jp/index.php?Project%20311%2FTrend%20Analysis
[6]
Dan He and D. Stott Parker(2010)
「Topic Dynamics: An Alternative Model of 'Bursts' in Streams of Topics」
https://dollar.biz.uiowa.edu/~street/HeParker10.pdf






- 投稿日:2020-03-10T20:07:42+09:00
discord.py入門(一日目)~discord.pyの準備編~
ご挨拶
初めまして。あめみんと申します。discord.py始めたばかりですが、
これから自分が教わったこと・共有できることどんどん共有するので、
上級者の皆様温かい目で見守ってください...
一緒に頑張りましょう!~動作環境~
python V3.8.1
pip V19.3.1
discord.py V1.2.5
Windows10discordのbotを作るうえで必要なもの...
①discordbot用のアカウント
discord developer portalで以下の画像を参照に初期設定を行います!
1.portalのapplicationから、"New Application"を選択する
2.botの名前を決める。※名前はあとから変更できます。
3."Create"をクリックしsettingsのBotカテゴリをクリックする。
4.画面の右のほうにある"Add bot"をクリックして、確認画面が出てくるのでyesを選択する
5.botカテゴリの下の方に移動し、botの権限を設定する。
6(サーバーに招待するとき).OAuth2カテゴリへ移動し、botを選択する
7.下の方に移動し、そのサーバーにbotが入る際に必要とする権限を設定する。
※botカテゴリのTOKENは他人に絶対教えないこと!botのプログラムにアクセスするのに必要なキーだと思ってください。
botアカウントの作成については以上です。
②discord.pyのインストール
以下をターミナルで実行する。
discord.py インストール$ python3 -m pip install -U discord.py[voice]今回はここまでとしとく。。。
明日何書こう...









- 投稿日:2020-03-10T20:03:19+09:00
ディープラーニングで肉体変化のタイムラプスを劇的に見やすくした
はじめに
トレーニー(筋トレを愛している人)の多くが習慣化している「自撮り(肉体)」。トレーニング後にパンプした肉体を撮りためて、後で見返すのが至福のときですよね。さらに、撮りためた画像をタイムラプスのようにアニメーションで表示させたら、より筋肉の成長が手に取るようにわかりますよね!
この記事はディープラーニングを使って、肉体のタイムラプスを劇的に見やすくした話を書いています。まずは結果から
2017/12~2020/3の体の変化※データサイズの都合上、画像をクロップ&圧縮しています。
概要
撮りためた画像からタイムラプスの作成を行いました。しかし、画像間のズレが気になるため、手作業で補正を行い、なめらかなタイムラプスを作成しました。さらに、手作業の手間を省くために、ディープラーニングを用いて自動で補正を行いました。
1.手作業での補正
1-1. そのまま表示
とりあえず、そのままの画像を連続で切り替えるだけのタイムラプスを作ってみます。
タイムラプス作成コード(一部)# opencvでもで動画は作れますが、 # google colabの環境で、discord上で再生できるmp4ファイルを作るためには、 # skvideoを使うやり方が楽ちんでした。 import skvideo.io def create_video(imgs, out_video_path, size_wh): video = [] vid_out = skvideo.io.FFmpegWriter(out_video_path, inputdict={ '-r': '10' }, outputdict={ '-r': '10' }) for img in imgs: img = cv2.resize(img, size_wh) vid_out.writeFrame(cv2.cvtColor(img, cv2.COLOR_BGR2RGB)) vid_out.close() imgs = load_images("images_dir") create_video(imgs, "video.mp4", (w,h))結果は、下記の通りです。
ズレが気になって我が子(肉体)に集中できません。
1-2. 位置の固定
なんとかして楽にこのズレを解消したい。身体のどこかに基準点を設けてそれを固定すれば、、、と考えて0.1秒くらいで「乳首」と「おへそ」という解にたどり着きました。
乳首とおへそをどのように固定するかを以下に説明します。1-2-1. 乳首おへそ座標付与ツール
まず、乳首とへそのUV座標を付与するツールを作ります。cvatなどを使っても実現できるかもしれませんが、使いこなすまでの時間とツールを自作する時間を見積もると、今回は自作した方が早いという結論になったので作りました。
ツールの仕様は、フォルダを指定すると、画像が連続して表示されるので各画像に対して、乳首とおへその3点をクリックしていき、クリックした座標をcsvファイルに出力する、というものになります。GUIはtkinterを利用しました。
※後述で利用するディープラーニング用のアノテーションデータの場合は、画像とアノテーションデータが1:1になったほうが取り回しが良いと思います。が今回はさくっと済ませるために作り込みませんでした。
1-2-2.動画作成
乳首とおへその場所は、1枚目の画像に合わせてアフィン変換することにより固定します。
補正版タイムラプス作成コード(一部)def p3affine_img(img, src_p, dst_p): h, w, ch = img.shape pts1 = np.float32([src_p[0],src_p[1],src_p[2]]) pts2 = np.float32([dst_p[0],dst_p[1],dst_p[2]]) M = cv2.getAffineTransform(pts1,pts2) dst = cv2.warpAffine(img,M,(h, w)) return dst df = read_annotationd() # 省略 imgs = [] src_p = None for index, row in df.iterrows(): img = cv2.imread(row.file) dst_p = [ [row.p1x, row.p1y], # 左乳首 [row.p2x, row.p2y], # 右乳首 [row.p3x, row.p3y]] # おへそ if src_p is None: src_p = dst_p else: img = p3affine_img(img, dst_p, src_p) imgs.append(img) write_video(imgs) # 省略結果は以下の通りです。
期待通りのタイムラプスを作ることができました、めでたしめでたし。ではありません!
今回座標を付与した枚数は、120日分(期間は2019/9〜2020/3)。しかし手元には2017/12から撮りためた、座標付与していない画像がまだ281枚もあるのです。更に今後数十年に渡って筋トレを行う、つまり数十年に渡って座標を付与し続ければいけないのです。想像しただけでもコルチゾールが分泌されカタボリックに陥ってしまいます。これを解決するために糖質補給して考えました。
そうだ、
ジム行こうディープラーニングだ。2.ディープラーニングを用いた自動補正
「乳首」と「おへそ」の位置推定をするモデルを作ります。これが実現すればあとは先ほどの通りアフィン変換をかけるだけです。乳首とおへその検出には、セグメンテーションタスクとしてアプローチします。姿勢推定のようなキーポイント検出のほうが筋が良さそうですが、個人的にセグメンテーションタスクの経験の方が多いのでそちらをチョイスしました。
2-1.アノテーションデータ作成
「右乳首」「左乳首」「おへそ」「背景」の4クラス分類で解くことも考えられますが、今回は「右乳首・左乳首・おへそ」「背景」の2クラス分類にしました。3点の検出さえできればルールベースでそれらをクラス分類することは簡単だと考えたからです。
では、早速マスク画像を作ります。先ほど作成した座標データを元に、座標点を少し大きくして1で埋めます。それ以外は背景なので0とします。for index, row in df.iterrows(): file = row.file mask = np.zeros((img_h, img_w), dtype=np.uint8) mask = cv2.circle(mask,(row.p1x, row.p1y,), 15, (1), -1) mask = cv2.circle(mask,(row.p2x, row.p2y,), 15, (1), -1) mask = cv2.circle(mask,(row.p3x, row.p3y,), 15, (1), -1) save_img(mask, row.file) # 省略視覚的にする(1を白、0を黒にする)と下記のようなデータになります。
これらを肉体画像とペアになるように作ります。
2-2.学習
学習は、DeepLab v3(torchvision)を使いました。120枚の画像を訓練と検証のために8:2になるように分けました。だいぶ枚数は少ないですが、下記の理由より、データ拡張はしませんでした。
- 肉体画像は同じカメラで撮影している
- カメラ姿勢や照明環境が画像間である程度揃っている
ただし、本来はデータ拡張はした方が良いと思います(めんどくさくてしてないだけです)。
データセットクラス・学習関連関数class MaskDataset(Dataset): def __init__(self, imgs_dir, masks_dir, scale=1, transforms=None): self.imgs_dir = imgs_dir self.masks_dir = masks_dir self.imgs = list(sorted(glob.glob(os.path.join(imgs_dir, "*.jpg")))) self.msks = list(sorted(glob.glob(os.path.join(masks_dir, "*.png")))) self.transforms = transforms self.scale = scale def __len__(self): return len(self.imgs_dir) @classmethod def preprocess(cls, pil_img, scale): # グレースケールにしても良さそうだけど、めんどうだからしない # pil_img = pil_img.convert("L") w, h = pil_img.size newW, newH = int(scale * w), int(scale * h) pil_img = pil_img.resize((newW, newH)) img_nd = np.array(pil_img) if len(img_nd.shape) == 2: img_nd = np.expand_dims(img_nd, axis=2) # HWC to CHW img_trans = img_nd.transpose((2, 0, 1)) if img_trans.max() > 1: img_trans = img_trans / 255 return img_trans def __getitem__(self, i): mask_file = self.msks[i] img_file = self.imgs[i] mask = Image.open(mask_file) img = Image.open(img_file) img = self.preprocess(img, self.scale) mask = self.preprocess(mask, self.scale) item = {'image': torch.from_numpy(img), 'mask': torch.from_numpy(mask)} if self.transforms: item = self.transforms(item) return item from torchvision.models.segmentation.deeplabv3 import DeepLabHead def create_deeplabv3(num_classes): model = models.segmentation.deeplabv3_resnet101(pretrained=True, progress=True) model.classifier = DeepLabHead(2048, num_classes) # グレースケールにしても良さそうだけど、めんどうだからしない #model.backbone.conv1 = nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3, bias=False) return model def train_model(model, criterion, optimizer, dataloaders, device, num_epochs=25, print_freq=1): since = time.time() best_model_wts = copy.deepcopy(model.state_dict()) best_loss = 1e15 for epoch in range(num_epochs): print('Epoch {}/{}'.format(epoch+1, num_epochs)) print('-' * 10) loss_history = {'train': [], 'val': []} for phase in ['train', 'val']: if phase == 'train': model.train() else: model.eval() for sample in tqdm(iter(dataloaders[phase])): imgs = sample['image'].to(device, dtype=torch.float) msks = sample['mask'].to(device, dtype=torch.float) optimizer.zero_grad() with torch.set_grad_enabled(phase == 'train'): outputs = model(imgs) loss = criterion(outputs['out'], msks) if phase == 'train': loss.backward() optimizer.step() epoch_loss = np.float(loss.data) if (epoch + 1) % print_freq == 0: print('Epoch: [%d/%d], Loss: %.4f' %(epoch+1, num_epochs, epoch_loss)) loss_history[phase].append(epoch_loss) # deep copy the model if phase == 'val' and epoch_loss < best_loss: best_loss = epoch_loss best_model_wts = copy.deepcopy(model.state_dict()) time_elapsed = time.time() - since print('Training complete in {:.0f}m {:.0f}s'.format(time_elapsed // 60, time_elapsed % 60)) print('Best val Acc: {:4f}'.format(best_loss)) model.load_state_dict(best_model_wts) return model, loss_history学習実行dataset = MaskDataset("images_dir", "masks_dir", 0.5, transforms=None) # 訓練用と検証用に分ける val_percent= 0.2 batch_size=4 n_val = int(len(dataset) * val_percent) n_train = len(dataset) - n_val train, val = random_split(dataset, [n_train, n_val]) train_loader = DataLoader(train, batch_size=batch_size, shuffle=True, num_workers=8, pin_memory=True, drop_last=True ) val_loader = DataLoader(val, batch_size=batch_size, shuffle=False, num_workers=8, pin_memory=True, drop_last=True ) dataloaders = {'train': train_loader, 'val': val_loader} device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") num_classes = 1 # BCEWithLogitsLossを使う際に2値分類だと1と指定 model = create_deeplabv3(num_classes) # pre trained用 #model.load_state_dict(torch.load("model.pth")) model.to(device) # 背景が圧倒的に多いのでpos_weightで調整する criterion = nn.BCEWithLogitsLoss(pos_weight=torch.tensor(10000.0).to(device)) params = [p for p in model.parameters() if p.requires_grad] #optimizer = torch.optim.SGD(params, lr=0.005,momentum=0.9, weight_decay=0.0005) optimizer = optim.Adam(params) total_epoch = 50 model, loss_dict = train_model(model, criterion, optimizer, dataloaders, device, total_epoch)今回は50エポックほど回すとある程度学習が収束しました。
2-3.未知画像への適用
2017/12~2019/8の、未知の(アノテーションしていない)画像に適用します。
結果としては、概ね良好で、3点がちゃんと反応していましたが、たまに下記のような結果もありました(ヒートマップ表現)。
当然、左乳首が2つあることはないので、一番右上の小さな点がFalse Positiveです。
ちなみに、False Negativeはありませんでした。2-4.後処理
先ほどの推論結果から、後処理では以下を行います。
- 各ピクセルの出力値が閾値以下のものは切り捨てる
- オブジェクト分割する
- クラスタが4つ以上の場合は、面積の大きい順に3つ選択し、残りを破棄する
- 各クラスタの重心を求める
- 各クラスタの重心のx座標が小さい順に並べ替える(右乳首→おへそ→左乳首)
2-4-1.各ピクセルの出力値が閾値以下のものは切り捨てる
次の処理のために、明確な確度をもったピクセル以外は切り捨てます。今回の閾値は経験的に、0.995にします。
2-4-2.オブジェクト分割する
オブジェクト分割には、cv2.connectedComponentsを使います。詳細は、OpenCV - connectedComponents で連結成分のラベリングを行う方法 - pynoteをご参考ください。
2-4-3.クラスタが4つ以上の場合は、面積の大きい順に3つ選択し、残りを破棄する
事例から、乳首とおへそ以外にでたFalse Positiveは面積が小さいことがわかりました。よって、面積の大きい3つを選択することにします。本当はこのような対処はあまり頑健性がない気がしますが、今回はうまくいったので採用します。
2-4-4.各クラスタの重心を求める
各クラスタの重心を求めるのは、cv2.momentsを使います。詳細は、Python+OpenCVで重心を求める - CV画像解析入門をご参考ください。
2-4-5.各クラスタの重心のx座標が小さい順に並べ替える(右乳首→おへそ→左乳首)
アフィン変換する際に点が対応する必要があるため、画像間で乳首とおへその座標順を統一する必要があります。今回の画像は、全て直立して撮ったものであり、横軸方向で乳首→おへそ→乳首が出現することは間違いないため、単純にx座標で並び替えます。
推論時#マスクから3点検出 def triangle_pt(heatmask, thresh=0.995): mask = heatmask.copy() # 2-4-1.各ピクセルの出力値が閾値以下のものは切り捨てる mask[mask>thresh] = 255 mask[mask<=thresh] = 0 mask = mask.astype(np.uint8) # 2-4-2.オブジェクト分割する nlabels, labels = cv2.connectedComponents(mask) pt = [] if nlabels != 4: # 少ない場合は、何もしない # 本当は閾値さげてやりたいけど、めんどいので if nlabels < 4: return None # 2-4-3.クラスタが4つ以上の場合は、面積の大きい順に3つ選択し、残りを破棄する elif nlabels > 4: sum_px = [] for i in range(1, nlabels): sum_px.append((labels==i).sum()) # 背景分+1する indices = [ x+1 for x in np.argsort(-np.array(sum_px))[:3]] else: indices = [x for x in range(1, nlabels)] # 2-4-4.各クラスタの重心を求める for i in indices: base = np.zeros_like(mask, dtype=np.uint8) base[labels==i] = 255 mu = cv2.moments(base, False) x,y= int(mu["m10"]/mu["m00"]) , int(mu["m01"]/mu["m00"]) pt.append([x,y]) # 2-4-5.各クラスタの重心のx座標が小さい順に並べ替える(右乳首→おへそ→左乳首) sort_key = lambda v: v[0] pt.sort(key=sort_key) return np.array(pt) def correct_img(model, device, in_dir, out_dir, draw_heatmap=True, draw_triangle=True, correct=True): imgs = [] base_3p = None model.eval() with torch.no_grad(): imglist = sorted(glob.glob(os.path.join(in_dir, "*.jpg"))) for idx, img_path in enumerate(imglist): # めんどいのでバッチサイズ1 full_img = Image.open(img_path) img = torch.from_numpy(BasicDataset.preprocess(full_img, 0.5)) img = img.unsqueeze(0) img = img.to(device=device, dtype=torch.float32) output = model(img)["out"] probs = torch.sigmoid(output) probs = probs.squeeze(0) tf = transforms.Compose( [ transforms.ToPILImage(), transforms.Resize(full_img.size[0]), transforms.ToTensor() ] ) probs = tf(probs.cpu()) full_mask = probs.squeeze().cpu().numpy() full_img = np.asarray(full_img).astype(np.uint8) full_img = cv2.cvtColor(full_img, cv2.COLOR_RGB2BGR) # 三角形 triangle = triangle_pt(full_mask) if draw_triangle and triangle is not None: cv2.drawContours(full_img, [triangle], 0, (0, 0, 255), 5) # ヒートマップ if draw_heatmap: full_mask = (full_mask*255).astype(np.uint8) jet = cv2.applyColorMap(full_mask, cv2.COLORMAP_JET) alpha = 0.7 full_img = cv2.addWeighted(full_img, alpha, jet, 1 - alpha, 0) # アフィン変換 if correct: if base_3p is None and triangle is not None: base_3p = triangle elif triangle is not None: full_img = p3affine_img(full_img, triangle, base_3p) if out_dir is not None: cv2.imwrite(os.path.join(out_dir, os.path.basename(img_path)), full_img) imgs.append(full_img) return imgs imgs = correct_img(model, device, "images_dir", None, draw_heatmap=False, draw_triangle=False, correct=True)2-5.結果
補正直前のタイムラプスは下記の通りです。
補正後のタイムラプスは下記の通りです。
まとめ
ディープラーニングを用いて乳首とおへその検出を行い、自動で画像補正することによって、タイムラプスを劇的に見やすくしました。これでさらにトレーニングに対するモチベーションが上がりました。開発は、座標付与ツールを除いて全部google colabで行いました、3150ぅう!
課題としては、他の人の肉体でうまくいくのかは不明(まあ学習させればいいのですが)。全体的に大きくなった場合は非対応(乳首・おへそ以外の基準点が必要)。などがありますが、コルチゾールが分泌されるのであまり硬いことは気にしないようにします!それでは、楽しい筋トレライフを!








- 投稿日:2020-03-10T19:55:35+09:00
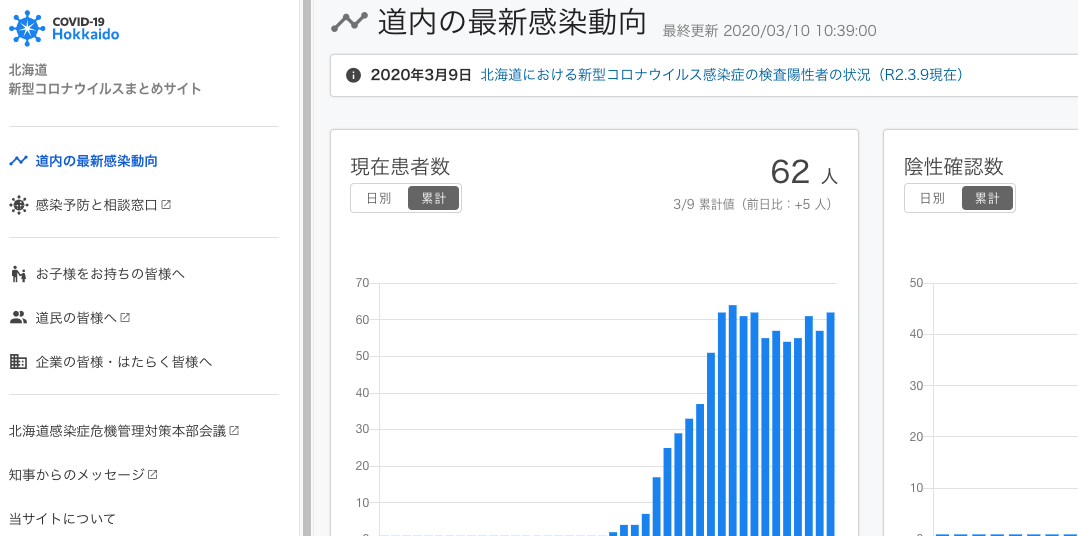
北海道版新型コロナウイルス情報サイトのデータ管理について
はじめに
東京都とCode for Japanにより東京都公式コロナウイルス対策サイトがリリースされ、そのソースコードがなんとGitHubでMITライセンスで公開されました。つまり他の道府県でも「同様のデータを用意できれば」同じように可視化するウェブアプリケーションを作成出来るという事です(実際はサーバーのリソースなども必要になってきますが)。画期的な取組です。
さてそんな訳で、全国各地の動きも活発化し、北海道ではCode for Sapporoや道内IT企業、自治体職員など多彩なバックグラウンドをもつ有志によるJUST道ITというグループが結成され、3月6日に東京都からフォークしたプロジェクトが3月9日の昼にリリースされました。
Covid19Hokkaido 北海道新型コロナウイルスまとめサイト
ほぼ同時に神奈川でも同様の形でサイトがリリースされたり、これらの動きが窓の杜さんやITmediaさんにもこの動きが紹介されるなど、東京発の画期的な取組が全国へ波及し始めています。
この記事について
前述のとおり、「同様のデータを用意できれば」同じように可視化するウェブアプリケーションを作成出来る訳ですが、自治体によってデータの公開状況・提供方法が異なるため、それらをうまいこと収集してデータをこさえるのが重要になってくる訳です。私も微力ながら本プロジェクトに参加させて頂き、データ周りの開発に携わった事から、データの取得・生成・管理のフローについて本記事にまとめる事とします。
東京都公式サイトのデータ
東京都公式サイト(以下都サイト)のソースコードでは、data/data.jsonというファイルに可視化されるべきデータが全て格納されており、key別に以下の構成になっていました(フォーク時点)。
key 東京都サイトでの名称 内容 contacts 新型コロナコールセンター相談件数 日別コールセンター相談件数 discharges 未実装 退院者別属性 discharges_summary 未実装 日別退院者数 inspections 未実装 日別検査データ inspections_summary 未実装(devでは検査実施日別状況) 検査により陽性が判明した日・人数のデータ(1/24〜、都内外別) patients 陽性患者の属性 感染者別属性 patients_summary 陽性患者数 日別感染者数 better_patients_summary 未実装 感染者数、退院者数、死亡者数、軽症、中等症、重症の日別データ querents 帰国者・接触者電話相談センター相談件数 日別電話相談センター相談件数 またkeyごとの各カラムの意味は以下のとおりです(必要なデータのみ)。
key colum 東京版の何に使われているか memo contacts 日付 新型コロナコールセンター相談件数 utils/formatGraph.tsに読まれます contacts 小計 新型コロナコールセンター相談件数 utils/formatGraph.tsに読まれます inspections_summary labels 検査実施日別状況 index.vueで読まれます inspections_summary 都内 検査実施日別状況 index.vueで読まれます inspections_summary その他 検査実施日別状況 index.vueで読まれます patients リリース日 陽性患者の属性 utils/formatTable.tsに読まれます patients 居住地 陽性患者の属性 utils/formatTable.tsに読まれます patients 年代 陽性患者の属性 utils/formatTable.tsに読まれます patients 性別 陽性患者の属性 utils/formatTable.tsに読まれます patients_summary 日付 陽性患者数 utils/formatGraph.tsに読まれます patients_summary 小計 陽性患者数 utils/formatGraph.tsに読まれます querents 日付 帰国者・接触者電話相談センター相談件数 utils/formatGraph.tsに読まれます querents 小計 帰国者・接触者電話相談センター相談件数 utils/formatGraph.tsに読まれます 以上を踏まえたdata.jsonの構造は以下です。
data.json{ "contacts": { "data": [ { "日付": "2020-02-14T08:00:00.000Z", "曜日": "金", "9-13時": "", "13-17時": "", "17-21時": "", "date": "2020-02-14", "w": "", "short_date": "02/14", "小計": 172 }, { "日付": "2020-02-15T08:00:00.000Z", "曜日": "土", "9-13時": "", "13-17時": "", "17-21時": "", "date": "2020-02-15", "w": "", "short_date": "02/15", "小計": 179 }, //以下略 ], "date": "2020-03-07T17:55:16.974293+09:00" }, "querents": {}, "patients": {}, "patients_summary": {}, "discharges": {}, "discharges_summary": {}, "inspections": {}, "inspections_summary": {}, "better_patients_summary": {}, "last_update": "2020-03-07T17:55:16.974293+09:00", //ISO-8601フォーマットのdatetime "main_summary": {} } //last_updateとmain_summary以外は、contactsと同様にdateとdataを持ちます //contacts以外は要素を割愛しています //main_summaryは特殊ですが、システム上は使用されていないので無視しても問題ありません北海道版V0のデータ
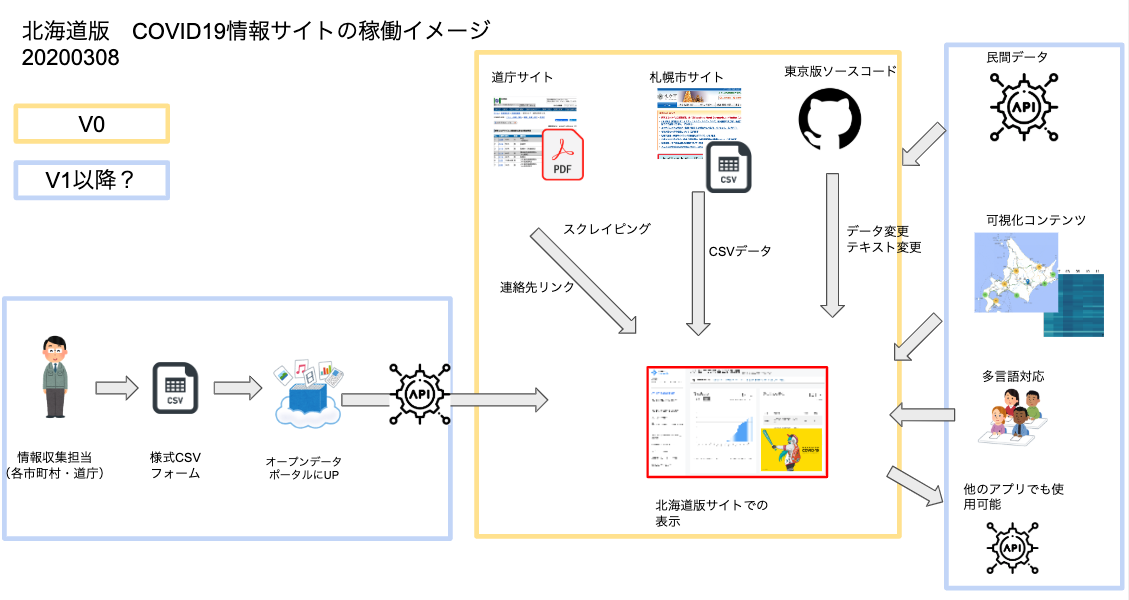
V0時点で外部から取得可能なデータは北海道のウェブサイトに掲載されているデータに限られており、その中で機械判読可能な情報は、HTMLのtableに表示される患者の属性のみでした。また、札幌市が相談件数のCSVファイルをオープンデータとして公開していた事から、北海道版V0時点ではこれらのデータを用いる事となります。使えるデータと形式は以下のとおりです。
key データの出所 形式 patients 道ウェブサイト HTMLのテーブル patients_summary 道ウェブサイト HTMLのテーブル contacts 札幌市 CSVファイル querents 札幌市 CSVファイル ※検査データはV0では用意出来ないと判断し、表示しない事としました
以上から、V0時点とV1以降の稼働イメージが以下のとおりになりました。
以下、データの取得・生成・管理のフローをまとめます。データの取得・生成
さすがに手作業でデータを更新する事はなく、データ取得・生成を自動で行うスクリプトを書きました。
Kanahiro/covid19hokkaido_scraping
※V0時点では上記リポジトリを利用していましたが、現在はcodeforsapporoにフォークされそちらが本流になっております本スクリプト(main.py)は実行されると以下の手順でdata.jsonを生成します。
- data.jsonに準拠した構造のdictを生成(各要素のデータは空)
- 道ウェブサイトをスクレイピングしてdictに変換
- importの中にあるcsvファイルをすべてdictに変換
- 2,3のdictを1の各要素に突っ込む
- 1をdata.jsonとして出力
道ウェブサイトのスクレイピング
道ウェブサイトは、PythonとBeautifulSoupによりスクレイピングしています。table内の全ての行(tr)を取得してdictに変換しています。
※コードは割愛、上記リポジトリのpatients.pyになりますCSVファイルの読み込み
V0時点で、contantsとquerentsはソースが生のCSVファイルであるため、importディレクトリ内に保存されたCSVファイルを全て読み込みdictに変換する仕組みとしました。
データの管理
V0から現在まで、本スクリプトで生成されたdata.jsonを「手動で」本体リポジトリにプッシュしています。
data.jsonの生成自体はGitHub Actionsでスケジューリングしており、15分間隔でmain.pyを実行する事で生成・別ブランチにプッシュするようになっています。
なので、リリース時点では適宜私がdata.jsonを本体にプッシュしていました(1日2,3回くらい)。自動化へ向けて
V0段階ではdata.jsonのプッシュが手動になっており、手間や即時性を考えると自動化したい訳です。
APIサーバーを別途立てるなど、様々な手法が考えられますが、以下であればGitHubのみで完結します。
(都公式も、他自治体での運用も考えてGitHubだけで完結するように作っていたのかなぁ)
- data.jsonの生成をGitHub Actionsで自動化
- その自動生成されたjsonファイルに直接アクセス・非同期通信し、UIに反映させる
※都公式サイトのUIは(フォーク時点では)非同期通信は想定されていなかったので、適宜フロントの修正が必要です
- 投稿日:2020-03-10T19:50:47+09:00
深層学習/LSTMのスクラッチコード
1.はじめに
今回は、LSTMの理解を深める為に、TensorFlowでLSTMをスクラッチで書いてみます。
2.LSTMのブロック図
Forget_gate付きLSTMのブロック図は以下の様で、4つの小さなネットワーク( output_gate, input_gate, forget_gate, z )から構成されていることが分かります。
3.LSTM中間層のスクラッチコード
4つあるネットワークの重み self.W とバイアス self.B の形は同じなので、まとめて宣言します。
self.W = tf.Variable(tf.zeros([input_size + hidden_size, hidden_size *4 ])) self.B = tf.Variable(tf.zeros([hidden_size * 4 ]))
順伝播のコードです。今回は、後処理の都合上、h, c をstackしているので、まず復元します。そして、4つのネットワークの重み付き線形和をまとめて計算し、結果を4分割します。def forward(self, prev_state, x): # h, c を復元 h, c = tf.unstack(prev_state) # 4つのネットワークの重み付き線形和をまとめて計算 inputs = tf.concat([x, h], axis=1) inputs = tf.matmul(inputs, self.W) + self.B z, i, f, o = tf.split(inputs, 4, axis=1)3つのゲートからの信号にsigmoidを通します。
# 各ゲートの信号にsigmoidを通す input_gate = tf.sigmoid(i) forget_gate = tf.sigmoid(f) output_gate = tf.sigmoid(o)ゲート及び中間層入力を元にメモリセルを更新して、中間層出力を計算します。なお、output_gate 前のtanhは無くても問題はないので、省いています。
# メモリセルの更新、中間出力の計算 next_c = c * forget_gate + tf.nn.tanh(z) * input_gate next_h = next_c * output_gate # 後処理の関係で stack する return tf.stack([next_h, next_c])4.コード全体
それでは、このLSTMを使って、実際に予測を実行するコードを作成します。データセットは、dagitsという数字の0〜9 (8*8ピクセルの小さなもの) の画像を使います。
1つのデータを1行づつ8回スキャンした結果を元に、LSTMにその数字は何かを予測させます。
import numpy as np import tensorflow as tf from sklearn import datasets from sklearn.model_selection import train_test_split from matplotlib import pyplot as plt class LSTM(object): def __init__(self, input_size, hidden_size, output_size): self.input_size = input_size self.hidden_size = hidden_size self.output_size = output_size # 入力層 self.inputs = tf.placeholder(tf.float32, shape=[None, None, self.input_size], name='inputs') self.W = tf.Variable(tf.zeros([input_size + hidden_size, hidden_size *4 ])) self.B = tf.Variable(tf.zeros([hidden_size * 4 ])) # 出力層 self.Wv = tf.Variable(tf.truncated_normal([hidden_size, output_size], mean=0, stddev=0.01)) self.bv = tf.Variable(tf.truncated_normal([output_size], mean=0, stddev=0.01)) self.init_hidden = tf.matmul(self.inputs[:,0,:], tf.zeros([input_size, hidden_size])) self.init_hidden = tf.stack([self.init_hidden, self.init_hidden]) self.input_fn = self._get_batch_input(self.inputs) def forward(self, prev_state, x): # h, c を復元 h, c = tf.unstack(prev_state) # 4つのネットワークの重み付き線形和をまとめて計算 inputs = tf.concat([x, h], axis=1) inputs = tf.matmul(inputs, self.W) + self.B z, i, f, o = tf.split(inputs, 4, axis=1) # 各ゲートの信号にsigmoidを通す input_gate = tf.sigmoid(i) forget_gate = tf.sigmoid(f) output_gate = tf.sigmoid(o) # メモリセルの更新、中間出力の計算 next_c = c * forget_gate + tf.nn.tanh(z) * input_gate next_h = next_c * output_gate # 後処理の関係で stack する return tf.stack([next_h, next_c]) def _get_batch_input(self, inputs): return tf.transpose(tf.transpose(inputs, perm=[2, 0, 1])) def calc_all_layers(self): all_hidden_states = tf.scan(self.forward, self.input_fn, initializer=self.init_hidden, name='states') return all_hidden_states[:, 0, :, :] def calc_output(self, state): return tf.nn.tanh(tf.matmul(state, self.Wv) + self.bv) def calc_outputs(self): all_states = self.calc_all_layers() all_outputs = tf.map_fn(self.calc_output, all_states) return all_outputs # データセットの読み込み ( 8*8 image of a digit) digits = datasets.load_digits() X = digits.images Y_= digits.target Y=tf.keras.utils.to_categorical(Y_, 10) X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=0.2, random_state=42) print(Y.shape) # 予測実行 hidden_size = 50 input_size = 8 output_size = 10 y = tf.placeholder(tf.float32, shape=[None, output_size], name='inputs') lstm = LSTM(input_size, hidden_size, output_size) outputs = lstm.calc_outputs() last_output = outputs[-1] output = tf.nn.softmax(last_output) loss = -tf.reduce_sum(y * tf.log(output)) train_step = tf.train.AdamOptimizer().minimize(loss) correct_predictions = tf.equal(tf.argmax(y, 1), tf.argmax(output, 1)) acc = (tf.reduce_mean(tf.cast(correct_predictions, tf.float32))) sess=tf.InteractiveSession() sess.run(tf.global_variables_initializer()) log_loss = [] log_acc = [] log_val_acc = [] for epoch in range(100): start=0 end=100 for i in range(14): X=X_train[start:end] Y=y_train[start:end] start=end end=start+100 sess.run(train_step,feed_dict={lstm.inputs:X, y:Y}) log_loss.append(sess.run(loss,feed_dict={lstm.inputs:X, y:Y})) log_acc.append(sess.run(acc,feed_dict={lstm.inputs:X_train[:500], y:y_train[:500]})) log_val_acc.append(sess.run(acc,feed_dict={lstm.inputs:X_test, y:y_test})) print("\r[%s] loss: %s acc: %s val acc: %s"%(epoch, log_loss[-1], log_acc[-1], log_val_acc[-1])), # acc グラフ作成 plt.ylim(0., 1.) plt.plot(log_acc, label='acc') plt.plot(log_val_acc, label = 'val_acc') plt.legend() plt.show()
割と良い精度ですね。


- 投稿日:2020-03-10T19:33:17+09:00
【Django】axiosを使って自作Like機能を作ってみた
はじめに
今回はDjangoで作ったWebサイトにaxiosを使っていいね機能が作れないかと調べてみました。
案の定、Ajaxを使うか画面リロード付きいいね機能の作り方しかなかったので、参考サイトを見ながらaxiosでいいね機能を作ってみました。参考サイト
いいね機能を実装したサイトのチュートリアルサイト
https://tutorial.djangogirls.org/ja/
いいね機能参考
https://jyouj.hatenablog.com/entry/2018/07/22/232911
本題
記事の順序に従って実装していきます。
この機能が欲しい人はそこそこコードを読めると信じているので簡単な説明は省きました。Model.py
PostクラスなどはDjango Girls Tutorialのモデルを参照しています。
from django.db import models from django.conf import settings from django.utils import timezone from django.contrib.auth.models import User #追加 class Post(models.Model): author = models.ForeignKey(settings.AUTH_USER_MODEL, on_delete=models.CASCADE) title = models.CharField(max_length=200) text = models.TextField() created_at = models.DateTimeField(default=timezone.now) published_date = models.DateTimeField(blank=True, null=True) like_num = models.IntegerField(default=0) #追加 def publish(self): self.published_date = timezone.now() self.save() def __str__(self): return self.title 以下コードがいいね機能モデル ↓追加 class Like(models.Model): user = models.ForeignKey(User, on_delete=models.CASCADE, related_name='like_user') post = models.ForeignKey(Post, on_delete=models.CASCADE)View.py
今回はクラスベースで書いていますので、関数ベースで作りたい方は工夫してください
#like#unlikeのJsonResponseの引数に関しては渡したいJsonデータを設定してくださいclass Like_Detail(View): def get(self, request, pk, *args, **kwargs): post = Post.objects.get(id=pk) is_like = Like.objects.filter(user=self.request.user).filter(post=post).count() # unlike if is_like > 0: liking = Like.objects.get(post__id=pk, user=self.request.user) liking.delete() post.like_num -= 1 post.save() post = get_object_or_404(Post, pk=pk) json = {'like_value': post.like_num} #ここのJsonデータに関してはご自由に return JsonResponse(json) # like post.like_num += 1 post.save() like = Like() like.user = self.request.user like.post = post like.save() post = get_object_or_404(Post, pk=pk) json = {'like_value': post.like_num} #ここのJsonデータに関してはご自由に return JsonResponse(json)URL.py
from django.urls import path from . import views from .views import Like_Detail # View.pyで設定したクラス名をインポートさせてください app_name = 'application' #アプリケーション名で合わせてください urlpatterns = [ path('', views.post_list, name='post_list'), path('post/<int:pk>/', views.post_detail, name='post_detail'), path('post/new/', views.post_new, name='post_new'), path('post/<int:pk>/edit/', views.post_edit, name='post_edit'), path('post/<int:pk>/like/',Like_Detail.as_view(), name='get'), #追加 ]POST_Detail.html
最後に一番重要なHTML内のJavaScript処理について説明します。
< 記事サイトに飛んだ時の処理の流れです >
1.記事詳細ページに飛んだClientユーザーの情報をView.pyに渡す様に命令をします。
2.Javascript側にView.py側から渡されたClientユーザーがいいねしているか、していないかと記事の総合いいね数の情報を受け取ります。
3.もし、記事に対してユーザーがいいねをしていない場合は<input>タグのclassにunlikeタグを追加します。(いいねしている場合はlikeを追加させる処理が書かれています。)< いいねボタンが押された際の処理の流れです >
1.いいねボタンを押すとaxiosを利用して画面リロードなしてリクエストを送ります。
2.View.py側でユーザーの記事のいいね処理を行います。
3.HTML側ではJavascriptが押されたら数値を変更するので毎回View.py側からデータを受け取る必要がなくなることになります{% extends 'application/base.html' %} {% block content %} <div class="post"> {% if post.published_date %} <div class="date"> {{ post.published_date }} </div> {% endif %} {% if user.is_authenticated %} <a class="btn btn-default" href="{% url 'application:post_edit' pk=post.pk %}"><span class="glyphicon glyphicon-pencil"></span></a> <script src="https://cdn.jsdelivr.net/npm/axios/dist/axios.min.js"></script> <input type="button" value="Check" onclick="like()" id="like-data"> いいね<span id="like-count">{{ post.like_num }}</span> <script> var likeinfo = {{ is_like }}; var likecount = {{ post.like_num }}; window.onload = function () { if (likeinfo > 0){ document.getElementById("like-data").classList.add("unlike"); }else{ document.getElementById("like-data").classList.add("like"); } }; var like = function () { const response = axios.get('/post/{{ post.pk }}/like/'); console.log(response); console.log( document.getElementById('like-count').innerText); if (likeinfo > 0){ likeinfo = likeinfo - 1; likecount = likecount - 1; document.getElementById('like-count').innerText=likecount; }else{ likeinfo = likeinfo + 1; likecount = likecount + 1; document.getElementById('like-count').innerText=likecount; } document.getElementById("like-data").classList.toggle("unlike"); document.getElementById("like-data").classList.toggle("like"); } </script> {% endif %} <h2>{{ post.title }}</h2> <p>{{ post.text|linebreaksbr }}</p> </div> {% endblock %}補足 CSS
<input>タグのclassにlikeやunlikeをタグで付け替える意味はいいねしているか、してないかでCSSのデザインを変更する設定をしているからです。.unlike { color:red; } .like { color: black; }最後に
自分用に書いてはいますが、
参考になりましたらいいね?よろしくお願いします。
色んな人に見ていただければ次回allauthに関しても書こうかなと思います。
- 投稿日:2020-03-10T19:27:36+09:00
物件、どうせ買うなら元を取りたい@都心部好立地
私は現在、株式会社Lightblue Technologyでインターンをしています。
そこで都心部の物件について調べたので、その結果をまとめたいと思います。概要
SUUMOに掲載されている物件の購入・賃貸のデータをWebスクレイピングを用いて取得して、地域(丁目以下はまとめました)、広さ(10m^2区切り)、築年数(5年区切り)で分類し、それぞれのグループについて物件の購入額の平均、賃貸額の平均を計算します。
そこから同じグループにおいて、物件を購入する場合、賃貸と比較して何年で元を取ることができるのかを求めました。対象物件
- 都心部 ( 港区、千代田区、中央区、文京区、新宿区、渋谷区 )
- 好立地 ( 駅徒歩5分以内 )
- 間取り2LDK
- 築年数25年以内
このページで都心部を全選択、借りるor買うの選択、間取り、駅徒歩、築年数を絞って検索すればOK.
以下はSUUMOのページのスクショです。
「借りる」を賃貸、「買う」を購入としました。
購入については、「中古マンション」、「中古一戸建て」のみを対象としました。
(新築だと価格が未定であったり、まだ建設されていなかったりしたので。)Webスクレイピング
urllibやBeautifulSoupを使いました。
SUUMOのページはきれいに情報がまとまっているので、スクレイピングは比較的しやすいと思います。家賃や駅徒歩、築年数を抽出する際は正規表現を用いました。
実際のコード
モジュールたち
import urllib import urllib.request as req from bs4 import BeautifulSoup import re import pandas as pd賃貸
賃貸のデータ取得に使った関数
chintai.pydef chintai_td0(td): """ <div/ class_="infodatabox-boxgroup" /div>のtd_ls[0]を受け取る 住所を返す """ d0 = re.sub(r"[\t\n\u3000\r\d]+", "", td.text) d0 = d0.replace("東京都", "") #d0 = re.sub("東京都", "", d0) return d0 def chintai_td2(td, i): """ 第二引数はデバッグ用 <div/ class_="infodatabox-boxgroup" /div>のtd_ls[2]を受け取る 駅徒歩の時間を0-1, 2-3, 4-5のグループで返す(実際には煩雑になるため駅徒歩ではグループ分けしなかった) """ d2 = re.sub(r'[\t\n\u3000\r]+', '', td.text) m2 = re.search(r"徒歩\d+分", d2) if m2: m2 = m2.group(0) else: print(i) # m2 = re.search(r"\d", m2).group(0) _ = int(m2) if 0 <= _ <= 1: res = "0-1" elif 2<= _ <= 3: res = "2-3" else: res = "4-5" return res def chintai_td3(td): """ <div/ class_="infodatabox-boxgroup" /div>のtd_ls[3]を受け取る 家賃を返す """ d3 = re.sub(r'[\t\n\u3000\r]+', '', td.text) m3 = re.search(r"\d+(\.\d+)?万円", d3).group(0) m3 = re.search(r"\d+(\.\d+)?", m3).group(0) return float(m3) def chintai_td4_1(td): """ <div/ class_="infodatabox-boxgroup" /div>のtd_ls[4]を受け取る 間取りが2LDKかどうかを返す(SUUMOの検索条件で絞っても2LDKのみにはならない。) """ d4 = re.sub(r"[\t\n\u3000\r]+", "", td.text) #m4 = re.search(r"\d+(\.\d+)?m2", d4) #return d4[m4.span()[1] : ] == "間取り:2LDK" return "2LDK" in d4 def chintai_td4_2(td, i): """ <div/ class_="infodatabox-boxgroup" /div>のtd_ls[4]を受け取る 面積を10m2区切りでグループにして返す """ d4 = re.sub(r'[\t\n\u3000\r]+', '', td.text) m4 = re.search(r"\d+(\.\d+)?m2", d4) if m4: m4 = m4.group(0) else: print(i) m4 = re.search(r"\d+(\.\d+)?", m4).group(0) _ = int(float(m4)) res1 = (_ // 10) * 10 res2 = res1 + 10 return "{}-{}".format(res1, res2) def chintai_td5(td): """ <div/ class_="infodatabox-boxgroup" /div>のtd_ls[5]を受け取る 築年数を5年区切りでグループにして返す """ d5 = re.sub(r'[\t\n\u3000\r]+', '', td.text) if d5 == "新築": res1 = 0 else: m5 = re.search(r"\d+", d5).group(0) _ = int(m5) res1 = (_ // 5) * 5 res2 = res1 + 5 return "{}-{}".format(res1, res2) def chintai_key(td_ls, i): """ 辞書のキー(グループ分け)を返す """ td0 = chintai_td0(td_ls[0]) # 住所 #td2 = chintai_td2(td_ls[2], i) # 駅徒歩 td2 = "0-5" #td3 = chintai_td3(td) td4_1 = "2LDK" # 間取り td4_2 = chintai_td4_2(td_ls[4], i) # 広さ td5 = chintai_td5(td_ls[5]) # 築年数 return td0 + "_"+ td2 + "_"+ td4_1 + "_"+ td4_2 + "_"+ td5 def chintai(): dic = {} dic_cnt = {} # 全体(2020/03/10現在) pre_url = "https://suumo.jp/jj/common/ichiran/JJ901FC004/?initFlg=1&seniFlg=1&ar=030&ta=13&scTmp=13101&scTmp=13102&scTmp=13103&scTmp=13104&scTmp=13105&scTmp=13113&ct=9999999&cb=0.0&kt=9999999&kb=0&xt=9999999&xb=0&md=4,5,6&et=5&cn=25&newflg=0&km=1&sc=13101&sc=13102&sc=13103&sc=13104&sc=13105&sc=13113&bs=040&pc=100&pn=" cnt = 0 #ループによりページ番号を変える #ループの範囲は適宜変更 for i in range(1, 92): url = pre_url + str(i) request = req.Request(url=url, headers=headers) res = req.urlopen(request) soup = BeautifulSoup(res, "html.parser") ls = soup.find_all("div", class_="infodatabox-boxgroup") for box in ls: td_ls = box.find_all("td") if chintai_td4_1(td_ls[4]): cnt += 1 key = chintai_key(td_ls, i) # 辞書のキー rent = chintai_td3(td_ls[3]) # 家賃 if key in dic: dic[key] += rent dic_cnt[key] += 1 else: dic[key] = rent dic_cnt[key] = 1 else: continue print(cnt) return dic, dic_cnt次のように実行する。
dic, dic_cnt = chintai()
dicは各キーに対する家賃の合計金額を値に持つ辞書、dic_cntは各キーに対するデータ数を持つ辞書。
この2つからdic_mean = {} for k in dic: dic_mean[k] = int(dic[k]/dic_cnt[k])とすれば
dic_meanは各キーに対する家賃の平均値を持った辞書となる。購入
購入のデータ取得に使った関数。賃貸と購入とでページの仕様上一部関数を変更しましたが、ほとんど同様です。(
purchase_td3とchintai_td3`に分けるのは蛇足だったかも。。)purchase.pydef purchase_td3(td): """ <div/ class_="infodatabox-boxgroup" /div>のtd_ls[3]を受け取る 家賃を返す """ d3 = re.sub(r'[\t\n\u3000\r]+', '', td.text) m3b = re.search(r"(\d+億)", d3) m3m = re.search(r"\d+(\.\d+)?万", d3) if m3b: m3b = m3b.group(0) m3b = re.search(r"\d+", m3b).group(0) m3b = int(m3b) * 10000 else: m3b = 0 if m3m: m3m = m3m.group(0) m3m = re.search(r"\d+", m3m).group(0) m3m = int(m3m) else: m3m = 0 return m3b + m3m def purchase_td5(td): """ <div/ class_="infodatabox-boxgroup" /div>のtd_ls[5]を受け取る 築年数を5年区切りでグループにして返す """ d5 = re.sub(r'[\t\n\u3000\r]+', '', td.text) if d5 == "新築": res1 = 0 else: m5 = re.search(r"\d+年", d5).group(0) m5 = re.search(r"\d+", d5).group(0) _ = int(m5) _ = 2020 - _ res1 = (_ // 5) * 5 res2 = res1 + 5 return "{}-{}".format(res1, res2) def purchase_key(td_ls, i): td0 = chintai_td0(td_ls[0]) # 住所 #td2 = chintai_td2(td_ls[2], i) # 駅徒歩 td2 = "0-5" #td3 = chintai_td3(td) td4_1 = "2LDK" # 間取り td4_2 = chintai_td4_2(td_ls[4], i) # 広さ td5 = purchase_td5(td_ls[5]) # 築年数 return td0 + "_"+ td2 + "_"+ td4_1 + "_"+ td4_2 + "_"+ td5 def purchase(): dic = {} dic_cnt = {} # 全体(2020/03/10現在) pre_url = "https://suumo.jp/jj/common/ichiran/JJ901FC004/?initFlg=1&seniFlg=1&ar=030&ta=13&scTmp=13101&scTmp=13102&scTmp=13103&scTmp=13104&scTmp=13105&scTmp=13113&ct=9999999&cb=0.0&kt=9999999&kb=0&xt=9999999&xb=0&md=4,5,6&et=5&cn=25&newflg=0&km=1&sc=13101&sc=13102&sc=13103&sc=13104&sc=13105&sc=13113&bs=011&bs=021&pc=100&pn=" cnt = 0 for i in range(1, 9): url = pre_url + str(i) request = req.Request(url=url, headers=headers) res = req.urlopen(request) soup = BeautifulSoup(res, "html.parser") ls = soup.find_all("div", class_="infodatabox-boxgroup") for box in ls: td_ls = box.find_all("td") if chintai_td4_1(td_ls[4]): cnt += 1 key = purchase_key(td_ls, i) # 辞書のキー rent = purchase_td3(td_ls[3]) # 家賃 if key in dic: dic[key] += rent dic_cnt[key] += 1 else: dic[key] = rent dic_cnt[key] = 1 else: continue print(cnt) return dic, dic_cnt
賃貸の出力結果
家賃平均でソートしました。単位は万円です。{'新宿区中落合_0-5_2LDK_40-50_25-30': 13, '渋谷区本町_0-5_2LDK_40-50_15-20': 13, '文京区音羽_0-5_2LDK_50-60_20-25': 15, '千代田区神田三崎町_0-5_2LDK_50-60_20-25': 16, '中央区東日本橋_0-5_2LDK_40-50_15-20': 16, '中央区日本橋久松町_0-5_2LDK_40-50_15-20': 16, '新宿区上落合_0-5_2LDK_50-60_25-30': 16, '渋谷区東_0-5_2LDK_40-50_25-30': 16, '中央区東日本橋_0-5_2LDK_40-50_10-15': 16, '中央区新川_0-5_2LDK_40-50_10-15': 16, '港区芝浦_0-5_2LDK_40-50_15-20': 16, '新宿区西早稲田_0-5_2LDK_50-60_20-25': 16, '渋谷区笹塚_0-5_2LDK_50-60_25-30': 16, '中央区新川_0-5_2LDK_40-50_15-20': 17, '中央区新川_0-5_2LDK_50-60_15-20': 17, '新宿区西落合_0-5_2LDK_60-70_20-25': 17, '文京区水道_0-5_2LDK_40-50_10-15': 17, '文京区本駒込_0-5_2LDK_50-60_15-20': 17, '中央区勝どき_0-5_2LDK_50-60_20-25': 17, '中央区日本橋富沢町_0-5_2LDK_40-50_15-20': 17, '中央区日本橋本町_0-5_2LDK_50-60_15-20': 17, '中央区月島_0-5_2LDK_60-70_15-20': 17, '新宿区西早稲田_0-5_2LDK_50-60_15-20': 17, '新宿区上落合_0-5_2LDK_40-50_0-5': 17, '新宿区西落合_0-5_2LDK_50-60_20-25': 17, '新宿区上落合_0-5_2LDK_50-60_20-25': 17, '新宿区弁天町_0-5_2LDK_50-60_20-25': 17, '文京区白山_0-5_2LDK_80-90_20-25': 17, '千代田区岩本町_0-5_2LDK_40-50_0-5': 18, '中央区東日本橋_0-5_2LDK_50-60_10-15': 18, '新宿区西新宿_0-5_2LDK_50-60_20-25': 18, '新宿区西落合_0-5_2LDK_60-70_5-10': 18, '文京区西片_0-5_2LDK_50-60_20-25': 18, '中央区日本橋小伝馬町_0-5_2LDK_50-60_20-25': 18, '中央区佃_0-5_2LDK_60-70_15-20': 18, '新宿区西早稲田_0-5_2LDK_60-70_20-25': 18, '新宿区百人町_0-5_2LDK_50-60_5-10': 18, '新宿区大久保_0-5_2LDK_60-70_20-25': 18, '文京区千石_0-5_2LDK_40-50_0-5': 18, '文京区大塚_0-5_2LDK_50-60_5-10': 18, '文京区千駄木_0-5_2LDK_50-60_10-15': 18, '千代田区東神田_0-5_2LDK_60-70_20-25': 18, '港区芝_0-5_2LDK_40-50_5-10': 18, '新宿区早稲田鶴巻町_0-5_2LDK_40-50_0-5': 18, '新宿区早稲田南町_0-5_2LDK_60-70_0-5': 18, '新宿区新宿_0-5_2LDK_50-60_15-20': 18, '新宿区高田馬場_0-5_2LDK_50-60_10-15': 18, '文京区本駒込_0-5_2LDK_60-70_20-25': 18, '文京区根津_0-5_2LDK_50-60_20-25': 18, '新宿区市谷薬王寺町_0-5_2LDK_50-60_5-10': 19, '千代田区岩本町_0-5_2LDK_50-60_0-5': 19, '中央区勝どき_0-5_2LDK_50-60_15-20': 19, '中央区日本橋堀留町_0-5_2LDK_50-60_15-20': 19, '中央区勝どき_0-5_2LDK_50-60_5-10': 19, '中央区湊_0-5_2LDK_40-50_10-15': 19, '中央区新川_0-5_2LDK_50-60_25-30': 19, '中央区月島_0-5_2LDK_60-70_20-25': 19, '新宿区信濃町_0-5_2LDK_50-60_0-5': 19, '新宿区南町_0-5_2LDK_40-50_10-15': 19, '文京区向丘_0-5_2LDK_50-60_20-25': 19, '文京区大塚_0-5_2LDK_50-60_15-20': 19, '渋谷区本町_0-5_2LDK_50-60_15-20': 19, '中央区晴海_0-5_2LDK_60-70_10-15': 20, '中央区日本橋馬喰町_0-5_2LDK_50-60_10-15': 20, '中央区八丁堀_0-5_2LDK_50-60_15-20': 20, '千代田区外神田_0-5_2LDK_40-50_5-10': 20, '中央区佃_0-5_2LDK_40-50_15-20': 20, '中央区佃_0-5_2LDK_50-60_15-20': 20, '中央区日本橋浜町_0-5_2LDK_60-70_20-25': 20, '港区台場_0-5_2LDK_70-80_20-25': 20, '新宿区新宿_0-5_2LDK_60-70_20-25': 20, '文京区本駒込_0-5_2LDK_60-70_5-10': 20, '渋谷区富ヶ谷_0-5_2LDK_40-50_20-25': 20, '千代田区神田神保町_0-5_2LDK_40-50_5-10': 20, '中央区日本橋浜町_0-5_2LDK_50-60_0-5': 20, '中央区勝どき_0-5_2LDK_60-70_15-20': 20, '中央区日本橋中洲_0-5_2LDK_50-60_15-20': 20, '中央区月島_0-5_2LDK_40-50_5-10': 20, '港区台場_0-5_2LDK_70-80_25-30': 20, '新宿区愛住町_0-5_2LDK_50-60_5-10': 20, '新宿区四谷坂町_0-5_2LDK_50-60_10-15': 20, '新宿区中井_0-5_2LDK_60-70_20-25': 20, '文京区本郷_0-5_2LDK_40-50_15-20': 20, '文京区本駒込_0-5_2LDK_60-70_10-15': 20, '文京区音羽_0-5_2LDK_60-70_15-20': 20, '文京区湯島_0-5_2LDK_60-70_25-30': 20, '渋谷区笹塚_0-5_2LDK_50-60_20-25': 20, '千代田区神田須田町_0-5_2LDK_50-60_15-20': 21, '千代田区岩本町_0-5_2LDK_50-60_10-15': 21, '中央区日本橋蛎殻町_0-5_2LDK_40-50_0-5': 21, '新宿区余丁町_0-5_2LDK_50-60_10-15': 21, '新宿区南町_0-5_2LDK_50-60_5-10': 21, '千代田区神田三崎町_0-5_2LDK_60-70_20-25': 21, '中央区東日本橋_0-5_2LDK_50-60_5-10': 21, '中央区新川_0-5_2LDK_60-70_25-30': 21, '中央区日本橋横山町_0-5_2LDK_50-60_15-20': 21, '新宿区余丁町_0-5_2LDK_50-60_15-20': 21, '文京区本郷_0-5_2LDK_50-60_20-25': 21, '中央区日本橋蛎殻町_0-5_2LDK_50-60_10-15': 21, '中央区日本橋蛎殻町_0-5_2LDK_50-60_20-25': 21, '中央区日本橋蛎殻町_0-5_2LDK_50-60_0-5': 21, '中央区日本橋馬喰町_0-5_2LDK_50-60_5-10': 21, '中央区日本橋馬喰町_0-5_2LDK_40-50_5-10': 21, '港区海岸_0-5_2LDK_50-60_10-15': 21, '新宿区西早稲田_0-5_2LDK_60-70_25-30': 21, '新宿区高田馬場_0-5_2LDK_50-60_20-25': 21, '新宿区若松町_0-5_2LDK_60-70_20-25': 21, '新宿区北町_0-5_2LDK_50-60_20-25': 21, '文京区湯島_0-5_2LDK_60-70_15-20': 21, '文京区湯島_0-5_2LDK_50-60_5-10': 21, '文京区本郷_0-5_2LDK_50-60_5-10': 21, '中央区佃_0-5_2LDK_50-60_20-25': 22, '中央区日本橋蛎殻町_0-5_2LDK_50-60_15-20': 22, '港区海岸_0-5_2LDK_50-60_0-5': 22, '中央区日本橋富沢町_0-5_2LDK_40-50_0-5': 22, '中央区日本橋馬喰町_0-5_2LDK_50-60_0-5': 22, '中央区日本橋箱崎町_0-5_2LDK_40-50_0-5': 22, '中央区日本橋久松町_0-5_2LDK_40-50_0-5': 22, '中央区佃_0-5_2LDK_60-70_10-15': 22, '新宿区若松町_0-5_2LDK_50-60_15-20': 22, '新宿区中落合_0-5_2LDK_70-80_20-25': 22, '新宿区市谷本村町_0-5_2LDK_50-60_15-20': 22, '新宿区西新宿_0-5_2LDK_70-80_20-25': 22, '文京区本郷_0-5_2LDK_40-50_0-5': 22, '文京区本駒込_0-5_2LDK_60-70_15-20': 22, '文京区本郷_0-5_2LDK_50-60_0-5': 22, '文京区音羽_0-5_2LDK_40-50_0-5': 22, '渋谷区上原_0-5_2LDK_60-70_5-10': 22, '渋谷区千駄ヶ谷_0-5_2LDK_50-60_0-5': 22, '千代田区飯田橋_0-5_2LDK_50-60_15-20': 23, '港区白金台_0-5_2LDK_60-70_20-25': 23, '文京区本郷_0-5_2LDK_50-60_10-15': 23, '文京区千石_0-5_2LDK_50-60_15-20': 23, '渋谷区神山町_0-5_2LDK_50-60_15-20': 23, '中央区入船_0-5_2LDK_50-60_0-5': 23, '中央区日本橋浜町_0-5_2LDK_40-50_0-5': 23, '中央区新川_0-5_2LDK_60-70_20-25': 23, '中央区日本橋箱崎町_0-5_2LDK_50-60_15-20': 23, '中央区日本橋浜町_0-5_2LDK_50-60_10-15': 23, '港区高輪_0-5_2LDK_50-60_0-5': 23, '新宿区山吹町_0-5_2LDK_50-60_0-5': 23, '新宿区早稲田町_0-5_2LDK_50-60_0-5': 23, '渋谷区神泉町_0-5_2LDK_50-60_15-20': 23, '渋谷区神宮前_0-5_2LDK_60-70_20-25': 23, '中央区新川_0-5_2LDK_60-70_15-20': 23, '中央区湊_0-5_2LDK_40-50_0-5': 23, '中央区八丁堀_0-5_2LDK_50-60_20-25': 23, '中央区日本橋人形町_0-5_2LDK_50-60_10-15': 23, '新宿区新宿_0-5_2LDK_50-60_5-10': 23, '新宿区市谷田町_0-5_2LDK_60-70_5-10': 23, '文京区大塚_0-5_2LDK_60-70_15-20': 23, '渋谷区初台_0-5_2LDK_60-70_20-25': 23, '渋谷区神泉町_0-5_2LDK_50-60_20-25': 23, '中央区日本橋蛎殻町_0-5_2LDK_60-70_15-20': 24, '中央区日本橋箱崎町_0-5_2LDK_60-70_15-20': 24, '新宿区左門町_0-5_2LDK_50-60_0-5': 24, '渋谷区恵比寿_0-5_2LDK_50-60_20-25': 24, '中央区新川_0-5_2LDK_60-70_5-10': 24, '中央区日本橋浜町_0-5_2LDK_60-70_15-20': 24, '中央区日本橋富沢町_0-5_2LDK_50-60_0-5': 24, '港区海岸_0-5_2LDK_60-70_15-20': 24, '港区海岸_0-5_2LDK_50-60_15-20': 24, '新宿区改代町_0-5_2LDK_50-60_0-5': 24, '文京区本郷_0-5_2LDK_50-60_15-20': 24, '千代田区外神田_0-5_2LDK_50-60_0-5': 24, '千代田区神田須田町_0-5_2LDK_50-60_0-5': 24, '千代田区九段北_0-5_2LDK_50-60_5-10': 24, '千代田区神田小川町_0-5_2LDK_50-60_10-15': 24, '千代田区麹町_0-5_2LDK_70-80_20-25': 24, '中央区日本橋馬喰町_0-5_2LDK_60-70_10-15': 24, '港区芝_0-5_2LDK_50-60_5-10': 24, '港区芝公園_0-5_2LDK_50-60_5-10': 24, '港区高輪_0-5_2LDK_60-70_20-25': 24, '港区白金台_0-5_2LDK_50-60_0-5': 24, '新宿区南元町_0-5_2LDK_50-60_5-10': 24, '新宿区原町_0-5_2LDK_50-60_10-15': 24, '新宿区原町_0-5_2LDK_60-70_10-15': 24, '文京区向丘_0-5_2LDK_50-60_0-5': 24, '文京区白山_0-5_2LDK_60-70_20-25': 24, '渋谷区元代々木町_0-5_2LDK_70-80_15-20': 24, '渋谷区円山町_0-5_2LDK_50-60_0-5': 24, '渋谷区代々木_0-5_2LDK_50-60_20-25': 24, '渋谷区千駄ヶ谷_0-5_2LDK_50-60_20-25': 24, '千代田区神田多町_0-5_2LDK_50-60_0-5': 25, '千代田区平河町_0-5_2LDK_60-70_10-15': 25, '新宿区左門町_0-5_2LDK_50-60_5-10': 25, '新宿区西五軒町_0-5_2LDK_50-60_0-5': 25, '渋谷区本町_0-5_2LDK_50-60_0-5': 25, '渋谷区松濤_0-5_2LDK_70-80_25-30': 25, '千代田区神田小川町_0-5_2LDK_50-60_15-20': 25, '千代田区神田三崎町_0-5_2LDK_50-60_15-20': 25, '中央区勝どき_0-5_2LDK_50-60_0-5': 25, '港区白金台_0-5_2LDK_50-60_20-25': 25, '港区赤坂_0-5_2LDK_60-70_20-25': 25, '港区三田_0-5_2LDK_50-60_5-10': 25, '港区港南_0-5_2LDK_50-60_10-15': 25, '新宿区市谷砂土原町_0-5_2LDK_40-50_25-30': 25, '新宿区左門町_0-5_2LDK_50-60_15-20': 25, '新宿区市谷薬王寺町_0-5_2LDK_50-60_10-15': 25, '新宿区市谷山伏町_0-5_2LDK_60-70_5-10': 25, '文京区小石川_0-5_2LDK_60-70_15-20': 25, '千代田区東神田_0-5_2LDK_50-60_5-10': 25, '中央区築地_0-5_2LDK_60-70_15-20': 25, '中央区新富_0-5_2LDK_50-60_5-10': 25, '中央区湊_0-5_2LDK_50-60_15-20': 25, '中央区湊_0-5_2LDK_50-60_5-10': 25, '中央区勝どき_0-5_2LDK_70-80_15-20': 25, '中央区月島_0-5_2LDK_50-60_5-10': 25, '港区芝_0-5_2LDK_60-70_20-25': 25, '新宿区河田町_0-5_2LDK_60-70_15-20': 25, '新宿区白銀町_0-5_2LDK_70-80_15-20': 25, '新宿区西新宿_0-5_2LDK_60-70_15-20': 25, '新宿区左門町_0-5_2LDK_60-70_15-20': 25, '文京区千石_0-5_2LDK_70-80_10-15': 25, '文京区湯島_0-5_2LDK_50-60_0-5': 25, '文京区千石_0-5_2LDK_770-780_10-15': 25, '文京区関口_0-5_2LDK_60-70_10-15': 25, '文京区本駒込_0-5_2LDK_70-80_15-20': 25, '渋谷区本町_0-5_2LDK_70-80_0-5': 25, '渋谷区広尾_0-5_2LDK_40-50_10-15': 25, '中央区日本橋室町_0-5_2LDK_50-60_15-20': 26, '中央区日本橋茅場町_0-5_2LDK_50-60_5-10': 26, '新宿区新小川町_0-5_2LDK_50-60_0-5': 26, '新宿区西新宿_0-5_2LDK_50-60_0-5': 26, '文京区本郷_0-5_2LDK_60-70_15-20': 26, '渋谷区代々木_0-5_2LDK_60-70_0-5': 26, '中央区勝どき_0-5_2LDK_60-70_10-15': 26, '中央区八丁堀_0-5_2LDK_50-60_0-5': 26, '中央区新富_0-5_2LDK_50-60_0-5': 26, '中央区勝どき_0-5_2LDK_70-80_10-15': 26, '港区六本木_0-5_2LDK_50-60_15-20': 26, '新宿区信濃町_0-5_2LDK_70-80_10-15': 26, '文京区小石川_0-5_2LDK_60-70_0-5': 26, '渋谷区東_0-5_2LDK_50-60_0-5': 26, '千代田区飯田橋_0-5_2LDK_50-60_5-10': 26, '中央区日本橋堀留町_0-5_2LDK_50-60_10-15': 26, '港区南麻布_0-5_2LDK_50-60_10-15': 26, '港区東麻布_0-5_2LDK_40-50_5-10': 26, '新宿区新宿_0-5_2LDK_50-60_0-5': 26, '渋谷区恵比寿_0-5_2LDK_60-70_20-25': 26, '渋谷区幡ヶ谷_0-5_2LDK_50-60_15-20': 26, '千代田区四番町_0-5_2LDK_60-70_20-25': 27, '港区海岸_0-5_2LDK_60-70_5-10': 27, '新宿区荒木町_0-5_2LDK_50-60_0-5': 27, '渋谷区上原_0-5_2LDK_60-70_0-5': 27, '渋谷区代々木_0-5_2LDK_50-60_5-10': 27, '中央区勝どき_0-5_2LDK_80-90_15-20': 27, '港区麻布十番_0-5_2LDK_50-60_10-15': 27, '新宿区四谷_0-5_2LDK_60-70_15-20': 27, '文京区白山_0-5_2LDK_50-60_0-5': 27, '中央区銀座_0-5_2LDK_50-60_15-20': 27, '中央区日本橋箱崎町_0-5_2LDK_50-60_0-5': 27, '中央区佃_0-5_2LDK_70-80_20-25': 27, '港区新橋_0-5_2LDK_50-60_0-5': 27, '新宿区下落合_0-5_2LDK_70-80_15-20': 27, '新宿区大久保_0-5_2LDK_60-70_0-5': 27, '渋谷区千駄ヶ谷_0-5_2LDK_60-70_5-10': 27, '中央区新川_0-5_2LDK_50-60_0-5': 28, '港区東麻布_0-5_2LDK_40-50_0-5': 28, '港区高輪_0-5_2LDK_60-70_5-10': 28, '港区東麻布_0-5_2LDK_50-60_0-5': 28, '渋谷区代々木_0-5_2LDK_50-60_0-5': 28, '渋谷区千駄ヶ谷_0-5_2LDK_50-60_15-20': 28, '千代田区神田錦町_0-5_2LDK_50-60_0-5': 28, '千代田区九段北_0-5_2LDK_60-70_0-5': 28, '千代田区外神田_0-5_2LDK_50-60_15-20': 28, '中央区日本橋茅場町_0-5_2LDK_60-70_10-15': 28, '新宿区住吉町_0-5_2LDK_60-70_5-10': 28, '千代田区三番町_0-5_2LDK_50-60_0-5': 28, '中央区日本橋大伝馬町_0-5_2LDK_70-80_5-10': 28, '港区港南_0-5_2LDK_80-90_10-15': 28, '港区東麻布_0-5_2LDK_20-30_0-5': 28, '港区新橋_0-5_2LDK_60-70_10-15': 28, '新宿区天神町_0-5_2LDK_50-60_5-10': 28, '渋谷区代々木_0-5_2LDK_70-80_15-20': 28, '千代田区神田錦町_0-5_2LDK_60-70_0-5': 29, '中央区八丁堀_0-5_2LDK_70-80_15-20': 29, '文京区小石川_0-5_2LDK_70-80_20-25': 29, '渋谷区代々木_0-5_2LDK_60-70_20-25': 29, '渋谷区千駄ヶ谷_0-5_2LDK_60-70_15-20': 29, '千代田区四番町_0-5_2LDK_50-60_0-5': 29, '中央区湊_0-5_2LDK_70-80_10-15': 29, '港区高輪_0-5_2LDK_50-60_10-15': 29, '渋谷区桜丘町_0-5_2LDK_50-60_5-10': 29, '千代田区神田小川町_0-5_2LDK_50-60_5-10': 29, '中央区月島_0-5_2LDK_60-70_5-10': 29, '中央区築地_0-5_2LDK_50-60_5-10': 29, '港区赤坂_0-5_2LDK_50-60_5-10': 29, '新宿区四谷坂町_0-5_2LDK_60-70_5-10': 29, '新宿区市谷甲良町_0-5_2LDK_50-60_0-5': 29, '渋谷区富ヶ谷_0-5_2LDK_60-70_20-25': 29, '千代田区神田須田町_0-5_2LDK_60-70_0-5': 30, '千代田区内神田_0-5_2LDK_50-60_5-10': 30, '港区浜松町_0-5_2LDK_60-70_10-15': 30, '港区赤坂_0-5_2LDK_50-60_20-25': 30, '港区虎ノ門_0-5_2LDK_50-60_5-10': 30, '港区高輪_0-5_2LDK_50-60_15-20': 30, '新宿区市谷本村町_0-5_2LDK_70-80_10-15': 30, '新宿区横寺町_0-5_2LDK_50-60_0-5': 30, '新宿区富久町_0-5_2LDK_50-60_5-10': 30, '千代田区四番町_0-5_2LDK_80-90_15-20': 30, '千代田区四番町_0-5_2LDK_60-70_5-10': 30, '千代田区内神田_0-5_2LDK_50-60_15-20': 30, '千代田区三番町_0-5_2LDK_60-70_0-5': 30, '中央区日本橋堀留町_0-5_2LDK_70-80_5-10': 30, '中央区日本橋浜町_0-5_2LDK_80-90_5-10': 30, '中央区新川_0-5_2LDK_60-70_0-5': 30, '港区海岸_0-5_2LDK_60-70_0-5': 30, '港区北青山_0-5_2LDK_50-60_5-10': 30, '新宿区山吹町_0-5_2LDK_60-70_0-5': 30, '新宿区荒木町_0-5_2LDK_60-70_0-5': 30, '新宿区市谷本村町_0-5_2LDK_70-80_15-20': 30, '渋谷区上原_0-5_2LDK_70-80_0-5': 30, '渋谷区桜丘町_0-5_2LDK_50-60_10-15': 30, '千代田区一番町_0-5_2LDK_70-80_15-20': 31, '港区六本木_0-5_2LDK_70-80_10-15': 31, '港区六本木_0-5_2LDK_50-60_5-10': 31, '新宿区富久町_0-5_2LDK_60-70_5-10': 31, '中央区勝どき_0-5_2LDK_80-90_10-15': 31, '中央区湊_0-5_2LDK_50-60_0-5': 31, '千代田区一番町_0-5_2LDK_70-80_10-15': 31, '中央区湊_0-5_2LDK_70-80_0-5': 31, '中央区日本橋蛎殻町_0-5_2LDK_90-100_15-20': 31, '中央区日本橋蛎殻町_0-5_2LDK_70-80_5-10': 31, '中央区銀座_0-5_2LDK_60-70_5-10': 31, '港区東麻布_0-5_2LDK_50-60_5-10': 31, '港区南青山_0-5_2LDK_50-60_0-5': 31, '港区芝浦_0-5_2LDK_70-80_20-25': 31, '新宿区西新宿_0-5_2LDK_50-60_5-10': 31, '渋谷区代々木_0-5_2LDK_60-70_10-15': 31, '渋谷区広尾_0-5_2LDK_50-60_0-5': 31, '渋谷区笹塚_0-5_2LDK_60-70_5-10': 31, '中央区東日本橋_0-5_2LDK_70-80_0-5': 32, '渋谷区代官山町_0-5_2LDK_50-60_5-10': 32, '渋谷区富ヶ谷_0-5_2LDK_50-60_0-5': 32, '千代田区神田駿河台_0-5_2LDK_60-70_0-5': 32, '千代田区神田須田町_0-5_2LDK_60-70_10-15': 32, '新宿区西新宿_0-5_2LDK_70-80_15-20': 32, '港区西新橋_0-5_2LDK_60-70_10-15': 32, '港区海岸_0-5_2LDK_80-90_15-20': 32, '文京区本駒込_0-5_2LDK_60-70_0-5': 32, '渋谷区渋谷_0-5_2LDK_50-60_5-10': 32, '千代田区平河町_0-5_2LDK_60-70_0-5': 33, '千代田区四番町_0-5_2LDK_60-70_15-20': 33, '港区芝_0-5_2LDK_60-70_15-20': 33, '港区赤坂_0-5_2LDK_60-70_15-20': 33, '港区高輪_0-5_2LDK_70-80_0-5': 33, '文京区本郷_0-5_2LDK_80-90_20-25': 33, '渋谷区代官山町_0-5_2LDK_60-70_20-25': 33, '中央区日本橋浜町_0-5_2LDK_70-80_15-20': 33, '中央区日本橋大伝馬町_0-5_2LDK_60-70_0-5': 33, '港区白金台_0-5_2LDK_70-80_0-5': 33, '文京区関口_0-5_2LDK_70-80_10-15': 33, '港区高輪_0-5_2LDK_60-70_10-15': 34, '渋谷区桜丘町_0-5_2LDK_70-80_15-20': 34, '千代田区富士見_0-5_2LDK_70-80_10-15': 34, '港区白金台_0-5_2LDK_60-70_0-5': 34, '港区東麻布_0-5_2LDK_60-70_5-10': 34, '渋谷区恵比寿南_0-5_2LDK_50-60_5-10': 34, '渋谷区東_0-5_2LDK_70-80_15-20': 34, '港区高輪_0-5_2LDK_60-70_0-5': 35, '渋谷区富ヶ谷_0-5_2LDK_60-70_0-5': 35, '千代田区麹町_0-5_2LDK_70-80_15-20': 35, '港区赤坂_0-5_2LDK_60-70_5-10': 35, '港区東新橋_0-5_2LDK_70-80_15-20': 35, '港区白金台_0-5_2LDK_70-80_15-20': 35, '中央区銀座_0-5_2LDK_60-70_0-5': 35, '中央区日本橋浜町_0-5_2LDK_70-80_0-5': 35, '中央区新川_0-5_2LDK_70-80_0-5': 35, '中央区勝どき_0-5_2LDK_90-100_10-15': 35, '港区高輪_0-5_2LDK_80-90_5-10': 35, '港区南青山_0-5_2LDK_50-60_5-10': 35, '渋谷区恵比寿南_0-5_2LDK_60-70_0-5': 35, '渋谷区広尾_0-5_2LDK_60-70_0-5': 36, '千代田区平河町_0-5_2LDK_60-70_5-10': 36, '中央区新川_0-5_2LDK_90-100_10-15': 36, '港区南麻布_0-5_2LDK_60-70_0-5': 36, '中央区日本橋人形町_0-5_2LDK_70-80_10-15': 36, '港区芝_0-5_2LDK_70-80_15-20': 36, '港区浜松町_0-5_2LDK_70-80_10-15': 36, '新宿区新宿_0-5_2LDK_70-80_15-20': 36, '新宿区河田町_0-5_2LDK_70-80_15-20': 36, '渋谷区大山町_0-5_2LDK_60-70_5-10': 36, '新宿区西新宿_0-5_2LDK_70-80_10-15': 37, '千代田区一番町_0-5_2LDK_60-70_10-15': 37, '港区高輪_0-5_2LDK_70-80_25-30': 37, '港区芝_0-5_2LDK_70-80_20-25': 38, '港区港南_0-5_2LDK_60-70_0-5': 38, '新宿区原町_0-5_2LDK_80-90_10-15': 38, '港区六本木_0-5_2LDK_70-80_15-20': 38, '新宿区河田町_0-5_2LDK_80-90_15-20': 38, '新宿区四谷_0-5_2LDK_60-70_0-5': 38, '港区三田_0-5_2LDK_60-70_10-15': 38, '港区東麻布_0-5_2LDK_60-70_0-5': 38, '港区港南_0-5_2LDK_90-100_15-20': 38, '港区西麻布_0-5_2LDK_80-90_15-20': 38, '港区虎ノ門_0-5_2LDK_70-80_10-15': 38, '新宿区原町_0-5_2LDK_90-100_10-15': 38, '渋谷区代々木_0-5_2LDK_100-110_20-25': 38, '新宿区西新宿_0-5_2LDK_70-80_0-5': 39, '新宿区四谷_0-5_2LDK_50-60_10-15': 39, '渋谷区恵比寿_0-5_2LDK_50-60_0-5': 39, '千代田区飯田橋_0-5_2LDK_70-80_10-15': 39, '港区海岸_0-5_2LDK_70-80_0-5': 39, '新宿区荒木町_0-5_2LDK_90-100_15-20': 39, '千代田区麹町_0-5_2LDK_70-80_0-5': 39, '新宿区富久町_0-5_2LDK_70-80_5-10': 39, '新宿区西新宿_0-5_2LDK_80-90_15-20': 39, '新宿区西新宿_0-5_2LDK_60-70_5-10': 39, '新宿区赤城下町_0-5_2LDK_140-150_20-25': 39, '渋谷区渋谷_0-5_2LDK_70-80_15-20': 40, '新宿区河田町_0-5_2LDK_90-100_15-20': 40, '千代田区麹町_0-5_2LDK_80-90_0-5': 40, '中央区日本橋小舟町_0-5_2LDK_70-80_0-5': 40, '新宿区新宿_0-5_2LDK_70-80_5-10': 41, '港区六本木_0-5_2LDK_60-70_5-10': 41, '渋谷区恵比寿西_0-5_2LDK_70-80_10-15': 42, '渋谷区恵比寿南_0-5_2LDK_70-80_10-15': 42, '港区高輪_0-5_2LDK_80-90_10-15': 42, '港区白金_0-5_2LDK_60-70_15-20': 42, '渋谷区元代々木町_0-5_2LDK_70-80_0-5': 42, '港区赤坂_0-5_2LDK_50-60_0-5': 43, '新宿区大久保_0-5_2LDK_70-80_5-10': 43, '渋谷区恵比寿_0-5_2LDK_60-70_0-5': 43, '港区南麻布_0-5_2LDK_80-90_15-20': 43, '新宿区西新宿_0-5_2LDK_70-80_5-10': 43, '港区浜松町_0-5_2LDK_50-60_0-5': 43, '港区白金台_0-5_2LDK_90-100_10-15': 43, '港区三田_0-5_2LDK_90-100_15-20': 44, '渋谷区神宮前_0-5_2LDK_60-70_0-5': 44, '渋谷区恵比寿西_0-5_2LDK_60-70_0-5': 45, '港区南青山_0-5_2LDK_70-80_10-15': 45, '渋谷区恵比寿_0-5_2LDK_80-90_0-5': 45, '新宿区新宿_0-5_2LDK_80-90_5-10': 46, '千代田区一番町_0-5_2LDK_70-80_0-5': 46, '渋谷区恵比寿_0-5_2LDK_70-80_0-5': 47, '中央区月島_0-5_2LDK_80-90_5-10': 47, '港区虎ノ門_0-5_2LDK_70-80_0-5': 47, '渋谷区東_0-5_2LDK_70-80_5-10': 48, '港区赤坂_0-5_2LDK_80-90_10-15': 48, '新宿区河田町_0-5_2LDK_100-110_15-20': 48, '港区台場_0-5_2LDK_110-120_10-15': 48, '新宿区西新宿_0-5_2LDK_80-90_0-5': 48, '新宿区四谷_0-5_2LDK_70-80_0-5': 48, '渋谷区千駄ヶ谷_0-5_2LDK_80-90_5-10': 48, '新宿区荒木町_0-5_2LDK_120-130_15-20': 49, '千代田区富士見_0-5_2LDK_90-100_10-15': 49, '新宿区西新宿_0-5_2LDK_90-100_10-15': 49, '新宿区西新宿_0-5_2LDK_80-90_10-15': 50, '港区赤坂_0-5_2LDK_60-70_0-5': 50, '港区南青山_0-5_2LDK_60-70_0-5': 50, '港区東新橋_0-5_2LDK_80-90_15-20': 50, '渋谷区神宮前_0-5_2LDK_70-80_0-5': 50, '渋谷区渋谷_0-5_2LDK_80-90_15-20': 50, '渋谷区猿楽町_0-5_2LDK_80-90_10-15': 51, '港区東麻布_0-5_2LDK_90-100_10-15': 52, '千代田区一番町_0-5_2LDK_100-110_15-20': 53, '渋谷区富ヶ谷_0-5_2LDK_80-90_0-5': 53, '千代田区四番町_0-5_2LDK_70-80_0-5': 53, '千代田区六番町_0-5_2LDK_70-80_0-5': 53, '新宿区原町_0-5_2LDK_110-120_10-15': 53, '渋谷区恵比寿西_0-5_2LDK_70-80_0-5': 54, '港区虎ノ門_0-5_2LDK_60-70_0-5': 54, '渋谷区猿楽町_0-5_2LDK_100-110_10-15': 54, '新宿区新宿_0-5_2LDK_100-110_5-10': 55, '中央区銀座_0-5_2LDK_90-100_10-15': 55, '港区海岸_0-5_2LDK_90-100_0-5': 55, '港区麻布狸穴町_0-5_2LDK_80-90_10-15': 55, '新宿区西新宿_0-5_2LDK_90-100_5-10': 56, '港区浜松町_0-5_2LDK_80-90_0-5': 56, '港区海岸_0-5_2LDK_100-110_0-5': 58, '港区六本木_0-5_2LDK_80-90_5-10': 58, '港区南青山_0-5_2LDK_90-100_15-20': 59, '渋谷区代々木_0-5_2LDK_100-110_0-5': 59, '新宿区西新宿_0-5_2LDK_110-120_10-15': 59, '千代田区西神田_0-5_2LDK_90-100_15-20': 59, '千代田区二番町_0-5_2LDK_100-110_10-15': 59, '千代田区西神田_0-5_2LDK_80-90_15-20': 60, '港区南青山_0-5_2LDK_110-120_20-25': 60, '渋谷区渋谷_0-5_2LDK_90-100_15-20': 61, '新宿区西新宿_0-5_2LDK_100-110_10-15': 61, '港区六本木_0-5_2LDK_80-90_0-5': 61, '新宿区大久保_0-5_2LDK_100-110_5-10': 61, '渋谷区渋谷_0-5_2LDK_100-110_15-20': 63, '港区東麻布_0-5_2LDK_110-120_10-15': 64, '港区赤坂_0-5_2LDK_90-100_10-15': 65, '港区白金台_0-5_2LDK_90-100_5-10': 65, '港区六本木_0-5_2LDK_70-80_5-10': 65, '港区白金_0-5_2LDK_100-110_0-5': 65, '港区麻布永坂町_0-5_2LDK_90-100_15-20': 65, '渋谷区神宮前_0-5_2LDK_80-90_0-5': 65, '渋谷区恵比寿西_0-5_2LDK_90-100_0-5': 66, '港区三田_0-5_2LDK_100-110_10-15': 66, '渋谷区千駄ヶ谷_0-5_2LDK_100-110_15-20': 66, '渋谷区千駄ヶ谷_0-5_2LDK_70-80_15-20': 66, '港区六本木_0-5_2LDK_80-90_15-20': 67, '港区海岸_0-5_2LDK_120-130_0-5': 68, '千代田区一番町_0-5_2LDK_100-110_20-25': 68, '港区虎ノ門_0-5_2LDK_90-100_0-5': 68, '港区芝公園_0-5_2LDK_100-110_15-20': 69, '港区赤坂_0-5_2LDK_110-120_10-15': 70, '渋谷区恵比寿_0-5_2LDK_120-130_15-20': 70, '港区南青山_0-5_2LDK_80-90_0-5': 74, '港区赤坂_0-5_2LDK_70-80_0-5': 74, '港区赤坂_0-5_2LDK_80-90_0-5': 76, '港区愛宕_0-5_2LDK_90-100_15-20': 76, '新宿区西新宿_0-5_2LDK_130-140_10-15': 76, '港区赤坂_0-5_2LDK_100-110_10-15': 77, '港区芝_0-5_2LDK_110-120_20-25': 78, '渋谷区渋谷_0-5_2LDK_110-120_15-20': 78, '港区虎ノ門_0-5_2LDK_100-110_10-15': 80, '千代田区二番町_0-5_2LDK_130-140_10-15': 80, '港区南青山_0-5_2LDK_100-110_10-15': 80, '渋谷区恵比寿西_0-5_2LDK_110-120_0-5': 81, '港区六本木_0-5_2LDK_100-110_15-20': 82, '港区愛宕_0-5_2LDK_100-110_15-20': 84, '港区虎ノ門_0-5_2LDK_110-120_10-15': 85, '港区赤坂_0-5_2LDK_140-150_20-25': 86, '港区赤坂_0-5_2LDK_130-140_20-25': 86, '渋谷区代々木_0-5_2LDK_160-170_10-15': 89, '港区六本木_0-5_2LDK_90-100_15-20': 90, '港区赤坂_0-5_2LDK_120-130_10-15': 90, '港区赤坂_0-5_2LDK_100-110_15-20': 90, '港区六本木_0-5_2LDK_120-130_5-10': 91, '渋谷区神宮前_0-5_2LDK_100-110_10-15': 93, '渋谷区恵比寿西_0-5_2LDK_120-130_10-15': 94, '港区虎ノ門_0-5_2LDK_80-90_5-10': 95, '港区六本木_0-5_2LDK_100-110_0-5': 97, '新宿区舟町_0-5_2LDK_170-180_15-20': 98, '港区六本木_0-5_2LDK_100-110_5-10': 98, '港区海岸_0-5_2LDK_130-140_15-20': 99, '渋谷区神宮前_0-5_2LDK_100-110_0-5': 100, '港区六本木_0-5_2LDK_110-120_15-20': 103, '港区六本木_0-5_2LDK_90-100_5-10': 103, '港区六本木_0-5_2LDK_110-120_10-15': 110, '渋谷区神宮前_0-5_2LDK_120-130_0-5': 110, '港区六本木_0-5_2LDK_110-120_0-5': 115, '千代田区平河町_0-5_2LDK_130-140_10-15': 120, '千代田区五番町_0-5_2LDK_110-120_5-10': 120, '港区六本木_0-5_2LDK_130-140_5-10': 120, '港区三田_0-5_2LDK_110-120_10-15': 120, '千代田区永田町_0-5_2LDK_170-180_0-5': 150, '港区南青山_0-5_2LDK_140-150_0-5': 160, '新宿区西新宿_0-5_2LDK_300-310_10-15': 198, '港区南青山_0-5_2LDK_170-180_0-5': 250}
購入の出力結果
ソートしました。単位は万円です。{'新宿区西落合_0-5_2LDK_60-70_15-20': 3880, '新宿区高田馬場_0-5_2LDK_40-50_5-10': 4080, '新宿区上落合_0-5_2LDK_50-60_20-25': 4090, '新宿区下落合--_0-5_2LDK_50-60_20-25': 4480, '新宿区下落合_0-5_2LDK_50-60_20-25': 4480, '文京区千駄木_0-5_2LDK_50-60_20-25': 4600, '文京区千石_0-5_2LDK_50-60_20-25': 4680, '中央区築地_0-5_2LDK_50-60_10-15': 4680, '新宿区百人町--_0-5_2LDK_50-60_20-25': 4880, '文京区音羽_0-5_2LDK_50-60_15-20': 4880, '中央区日本橋堀留町_0-5_2LDK_50-60_20-25': 4980, '中央区新富_0-5_2LDK_40-50_5-10': 4980, '中央区湊_0-5_2LDK_60-70_20-25': 4980, '新宿区北新宿_0-5_2LDK_50-60_15-20': 4980, '新宿区余丁町-_0-5_2LDK_50-60_10-15': 4980, '文京区大塚_0-5_2LDK_40-50_10-15': 4999, '中央区新富--_0-5_2LDK_40-50_5-10': 5122, '中央区月島_0-5_2LDK_50-60_20-25': 5126, '文京区白山_0-5_2LDK_50-60_15-20': 5150, '中央区東日本橋--_0-5_2LDK_50-60_5-10': 5180, '文京区関口_0-5_2LDK_50-60_20-25': 5180, '渋谷区代々木--_0-5_2LDK_50-60_20-25': 5280, '新宿区中落合_0-5_2LDK_50-60_5-10': 5450, '文京区根津_0-5_2LDK_50-60_20-25': 5480, '中央区日本橋人形町_0-5_2LDK_50-60_20-25': 5480, '中央区新川--_0-5_2LDK_60-70_15-20': 5480, '新宿区山吹町_0-5_2LDK_50-60_25-30': 5480, '新宿区富久町-_0-5_2LDK_50-60_15-20': 5480, '新宿区四谷_0-5_2LDK_50-60_15-20': 5630, '文京区音羽--_0-5_2LDK_50-60_5-10': 5680, '中央区日本橋堀留町_0-5_2LDK_50-60_10-15': 5680, '文京区西片_0-5_2LDK_50-60_20-25': 5680, '文京区音羽--_0-5_2LDK_50-60_5-10': 5680, '中央区月島_0-5_2LDK_50-60_10-15': 5690, '中央区湊_0-5_2LDK_50-60_15-20': 5730, '文京区本駒込_0-5_2LDK_50-60_20-25': 5755, '新宿区山吹町-_0-5_2LDK_50-60_10-15': 5778, '中央区日本橋中洲_0-5_2LDK_50-60_20-25': 5780, '文京区音羽_0-5_2LDK_50-60_5-10': 5780, '中央区勝どき_0-5_2LDK_60-70_5-10': 5840, '渋谷区本町_0-5_2LDK_70-80_20-25': 5940, '新宿区西早稲田_0-5_2LDK_60-70_20-25': 5980, '渋谷区渋谷_0-5_2LDK_30-40_10-15': 5980, '千代田区東神田_0-5_2LDK_50-60_5-10': 5980, '中央区日本橋蛎殻町_0-5_2LDK_50-60_15-20': 5980, '中央区日本橋蛎殻町_0-5_2LDK_50-60_5-10': 5980, '中央区入船_0-5_2LDK_60-70_15-20': 5980, '中央区新川_0-5_2LDK_70-80_15-20': 5980, '新宿区西早稲田--_0-5_2LDK_60-70_20-25': 5980, '新宿区西早稲田_0-5_2LDK_60-70_10-15': 5980, '渋谷区本町_0-5_2LDK_50-60_10-15': 5980, '文京区向丘_0-5_2LDK_70-80_25-30': 5990, '文京区向丘--_0-5_2LDK_70-80_25-30': 5990, '港区海岸_0-5_2LDK_60-70_15-20': 6030, '中央区湊_0-5_2LDK_50-60_20-25': 6080, '渋谷区代々木_0-5_2LDK_50-60_20-25': 6080, '新宿区新宿_0-5_2LDK_50-60_15-20': 6100, '中央区佃_0-5_2LDK_50-60_5-10': 6165, '渋谷区本町_0-5_2LDK_50-60_0-5': 6180, '中央区新川_0-5_2LDK_50-60_15-20': 6180, '中央区新川--_0-5_2LDK_50-60_15-20': 6180, '新宿区北新宿_0-5_2LDK_60-70_5-10': 6190, '新宿区北新宿--_0-5_2LDK_60-70_5-10': 6190, '中央区日本橋蛎殻町--_0-5_2LDK_60-70_20-25': 6280, '中央区日本橋兜町_0-5_2LDK_50-60_15-20': 6280, '中央区日本橋堀留町_0-5_2LDK_50-60_5-10': 6280, '港区港南_0-5_2LDK_60-70_10-15': 6280, '港区海岸_0-5_2LDK_70-80_15-20': 6300, '中央区佃_0-5_2LDK_50-60_10-15': 6350, '新宿区市谷薬王寺町_0-5_2LDK_60-70_5-10': 6380, '新宿区西早稲田_0-5_2LDK_60-70_5-10': 6380, '文京区本郷--_0-5_2LDK_50-60_10-15': 6380, '新宿区原町_0-5_2LDK_40-50_10-15': 6380, '中央区月島_0-5_2LDK_50-60_5-10': 6420, '文京区小石川_0-5_2LDK_50-60_15-20': 6430, '中央区東日本橋_0-5_2LDK_40-50_10-15': 6450, '中央区日本橋浜町_0-5_2LDK_50-60_15-20': 6480, '文京区湯島--_0-5_2LDK_70-80_20-25': 6480, '中央区日本橋蛎殻町_0-5_2LDK_60-70_5-10': 6490, '文京区関口_0-5_2LDK_50-60_10-15': 6490, '文京区湯島_0-5_2LDK_70-80_20-25': 6530, '港区三田_0-5_2LDK_50-60_20-25': 6580, '新宿区歌舞伎町--_0-5_2LDK_60-70_15-20': 6580, '新宿区新宿--_0-5_2LDK_60-70_15-20': 6580, '新宿区払方町_0-5_2LDK_40-50_0-5': 6580, '新宿区中里町_0-5_2LDK_40-50_0-5': 6580, '新宿区歌舞伎町_0-5_2LDK_60-70_15-20': 6600, '中央区日本橋馬喰町--_0-5_2LDK_60-70_0-5': 6646, '新宿区二十騎町_0-5_2LDK_50-60_20-25': 6680, '新宿区築地町-_0-5_2LDK_50-60_15-20': 6680, '文京区本郷--_0-5_2LDK_60-70_20-25': 6680, '新宿区西早稲田--_0-5_2LDK_60-70_5-10': 6730, '中央区勝どき_0-5_2LDK_50-60_5-10': 6760, '中央区月島--_0-5_2LDK_70-80_10-15': 6780, '中央区日本橋馬喰町_0-5_2LDK_50-60_0-5': 6780, '新宿区上落合_0-5_2LDK_70-80_15-20': 6780, '中央区月島_0-5_2LDK_60-70_5-10': 6800, '中央区湊_0-5_2LDK_50-60_5-10': 6800, '中央区月島--_0-5_2LDK_60-70_5-10': 6800, '新宿区新宿_0-5_2LDK_60-70_15-20': 6846, '中央区新川--_0-5_2LDK_50-60_5-10': 6850, '新宿区市谷甲良町_0-5_2LDK_50-60_0-5': 6865, '中央区日本橋中洲_0-5_2LDK_60-70_0-5': 6880, '新宿区北新宿--_0-5_2LDK_60-70_15-20': 6888, '中央区勝どき_0-5_2LDK_50-60_10-15': 6896, '港区麻布十番_0-5_2LDK_50-60_20-25': 6900, '中央区日本橋馬喰町_0-5_2LDK_60-70_0-5': 6925, '新宿区新宿--_0-5_2LDK_60-70_15-20': 6930, '新宿区原町_0-5_2LDK_40-50_0-5': 6980, '中央区日本橋浜町--_0-5_2LDK_60-70_5-10': 6980, '中央区新川--_0-5_2LDK_60-70_5-10': 6980, '港区芝_0-5_2LDK_50-60_15-20': 6980, '文京区千石_0-5_2LDK_50-60_0-5': 6980, '文京区湯島_0-5_2LDK_70-80_15-20': 6980, '渋谷区代々木_0-5_2LDK_70-80_20-25': 6980, '渋谷区代々木_0-5_2LDK_70-80_15-20': 6980, '新宿区北新宿_0-5_2LDK_60-70_15-20': 7037, '中央区勝どき--_0-5_2LDK_50-60_10-15': 7080, '渋谷区広尾_0-5_2LDK_50-60_20-25': 7150, '中央区勝どき_0-5_2LDK_60-70_10-15': 7166, '渋谷区笹塚_0-5_2LDK_70-80_15-20': 7180, '中央区月島_0-5_2LDK_70-80_10-15': 7200, '新宿区西新宿_0-5_2LDK_50-60_5-10': 7216, '港区台場--_0-5_2LDK_70-80_10-15': 7280, '中央区日本橋大伝馬町-_0-5_2LDK_50-60_0-5': 7280, '中央区佃_0-5_2LDK_60-70_15-20': 7286, '新宿区左門町-_0-5_2LDK_60-70_15-20': 7300, '新宿区左門町_0-5_2LDK_60-70_15-20': 7300, '新宿区南元町_0-5_2LDK_50-60_5-10': 7330, '中央区月島_0-5_2LDK_70-80_15-20': 7343, '千代田区外神田--_0-5_2LDK_50-60_0-5': 7380, '渋谷区代々木_0-5_2LDK_50-60_10-15': 7430, '中央区月島_0-5_2LDK_60-70_15-20': 7480, '港区三田_0-5_2LDK_60-70_20-25': 7480, '新宿区舟町_0-5_2LDK_70-80_20-25': 7480, '渋谷区初台_0-5_2LDK_50-60_5-10': 7480, '新宿区市谷甲良町_0-5_2LDK_60-70_0-5': 7490, '新宿区西早稲田--_0-5_2LDK_60-70_0-5': 7490, '中央区日本橋蛎殻町_0-5_2LDK_70-80_15-20': 7680, '港区海岸_0-5_2LDK_60-70_0-5': 7680, '新宿区大京町-_0-5_2LDK_50-60_10-15': 7680, '新宿区大京町_0-5_2LDK_50-60_10-15': 7694, '中央区銀座--_0-5_2LDK_50-60_15-20': 7760, '文京区湯島_0-5_2LDK_50-60_0-5': 7776, '中央区日本橋人形町_0-5_2LDK_50-60_5-10': 7780, '中央区新川_0-5_2LDK_50-60_0-5': 7785, '新宿区四谷-_0-5_2LDK_70-80_10-15': 7850, '新宿区若松町_0-5_2LDK_50-60_0-5': 7870, '中央区日本橋蛎殻町_0-5_2LDK_80-90_15-20': 7880, '新宿区市谷甲良町_0-5_2LDK_60-70_15-20': 7880, '新宿区中里町_0-5_2LDK_70-80_20-25': 7880, '文京区湯島_0-5_2LDK_60-70_0-5': 7880, '新宿区四谷坂町_0-5_2LDK_60-70_5-10': 7900, '新宿区四谷坂町-_0-5_2LDK_60-70_5-10': 7900, '中央区勝どき_0-5_2LDK_80-90_20-25': 7980, '港区南麻布_0-5_2LDK_50-60_20-25': 7980, '新宿区市谷田町_0-5_2LDK_60-70_5-10': 7980, '港区浜松町_0-5_2LDK_60-70_20-25': 8100, '新宿区若松町_0-5_2LDK_60-70_0-5': 8180, '新宿区四谷_0-5_2LDK_80-90_10-15': 8250, '新宿区山吹町_0-5_2LDK_60-70_0-5': 8260, '渋谷区広尾--_0-5_2LDK_50-60_10-15': 8280, '中央区日本橋浜町_0-5_2LDK_70-80_5-10': 8380, '中央区銀座_0-5_2LDK_50-60_15-20': 8380, '渋谷区広尾--_0-5_2LDK_50-60_0-5': 8380, '新宿区白銀町_0-5_2LDK_60-70_15-20': 8480, '中央区銀座_0-5_2LDK_60-70_5-10': 8480, '中央区東日本橋--_0-5_2LDK_80-90_20-25': 8480, '中央区銀座--_0-5_2LDK_60-70_5-10': 8480, '港区赤坂_0-5_2LDK_60-70_20-25': 8480, '文京区千駄木_0-5_2LDK_60-70_0-5': 8480, '渋谷区代々木--_0-5_2LDK_50-60_0-5': 8480, '港区東麻布_0-5_2LDK_50-60_0-5': 8490, '新宿区西新宿_0-5_2LDK_50-60_15-20': 8490, '千代田区神田須田町_0-5_2LDK_50-60_0-5': 8499, '千代田区神田東松下町_0-5_2LDK_60-70_0-5': 8500, '文京区白山_0-5_2LDK_90-100_15-20': 8500, '新宿区四谷_0-5_2LDK_70-80_10-15': 8515, '港区赤坂_0-5_2LDK_50-60_5-10': 8700, '渋谷区広尾_0-5_2LDK_50-60_0-5': 8703, '港区港南_0-5_2LDK_80-90_10-15': 8735, '新宿区岩戸町_0-5_2LDK_70-80_5-10': 8780, '新宿区荒木町_0-5_2LDK_50-60_0-5': 8790, '新宿区北町_0-5_2LDK_60-70_15-20': 8800, '新宿区富久町_0-5_2LDK_50-60_5-10': 8830, '港区台場_0-5_2LDK_80-90_10-15': 8880, '中央区勝どき_0-5_2LDK_80-90_10-15': 8908, '港区虎ノ門_0-5_2LDK_50-60_5-10': 8925, '港区海岸--_0-5_2LDK_60-70_0-5': 8930, '中央区日本橋人形町_0-5_2LDK_60-70_0-5': 8980, '中央区湊_0-5_2LDK_50-60_0-5': 8980, '港区南麻布_0-5_2LDK_50-60_10-15': 8980, '新宿区北山伏町_0-5_2LDK_70-80_0-5': 8980, '新宿区住吉町_0-5_2LDK_50-60_0-5': 8980, '新宿区西新宿_0-5_2LDK_70-80_15-20': 8980, '新宿区富久町-_0-5_2LDK_60-70_5-10': 8980, '港区港南--_0-5_2LDK_80-90_10-15': 8990, '渋谷区神泉町_0-5_2LDK_60-70_15-20': 8990, '新宿区新宿_0-5_2LDK_70-80_15-20': 8990, '新宿区市谷本村町_0-5_2LDK_70-80_10-15': 8990, '港区麻布十番_0-5_2LDK_70-80_5-10': 9000, '港区虎ノ門--_0-5_2LDK_50-60_5-10': 9000, '文京区千駄木_0-5_2LDK_50-60_5-10': 9000, '渋谷区本町_0-5_2LDK_60-70_10-15': 9100, '中央区日本橋人形町_0-5_2LDK_70-80_15-20': 9180, '渋谷区初台_0-5_2LDK_60-70_0-5': 9190, '千代田区神田東松下町_0-5_2LDK_50-60_0-5': 9280, '港区芝_0-5_2LDK_60-70_10-15': 9280, '港区港南_0-5_2LDK_80-90_15-20': 9380, '文京区向丘_0-5_2LDK_60-70_0-5': 9380, '港区東麻布_0-5_2LDK_50-60_5-10': 9455, '港区白金台_0-5_2LDK_70-80_20-25': 9480, '渋谷区恵比寿_0-5_2LDK_60-70_20-25': 9480, '文京区本郷_0-5_2LDK_60-70_5-10': 9480, '渋谷区代々木_0-5_2LDK_50-60_0-5': 9480, '渋谷区恵比寿西_0-5_2LDK_60-70_5-10': 9480, '中央区日本橋蛎殻町_0-5_2LDK_70-80_5-10': 9490, '新宿区愛住町_0-5_2LDK_70-80_5-10': 9500, '港区麻布十番_0-5_2LDK_60-70_20-25': 9680, '港区六本木_0-5_2LDK_80-90_20-25': 9684, '渋谷区千駄ヶ谷--_0-5_2LDK_60-70_0-5': 9700, '渋谷区代々木--_0-5_2LDK_70-80_15-20': 9900, '港区芝_0-5_2LDK_60-70_15-20': 9956, '中央区勝どき_0-5_2LDK_90-100_10-15': 9980, '港区新橋--_0-5_2LDK_50-60_5-10': 9980, '新宿区市谷本村町_0-5_2LDK_50-60_0-5': 9980, '渋谷区恵比寿_0-5_2LDK_60-70_10-15': 9980, '渋谷区神宮前_0-5_2LDK_90-100_10-15': 10033, '新宿区西新宿_0-5_2LDK_80-90_10-15': 10033, '文京区本郷_0-5_2LDK_70-80_10-15': 10093, '渋谷区広尾_0-5_2LDK_60-70_0-5': 10130, '千代田区平河町_0-5_2LDK_60-70_0-5': 10350, '文京区後楽_0-5_2LDK_80-90_15-20': 10480, '港区赤坂_0-5_2LDK_70-80_15-20': 10500, '千代田区一番町_0-5_2LDK_60-70_10-15': 10590, '千代田区一番町-_0-5_2LDK_60-70_10-15': 10590, '港区赤坂_0-5_2LDK_60-70_5-10': 10600, '港区六本木_0-5_2LDK_60-70_5-10': 10600, '千代田区岩本町_0-5_2LDK_70-80_5-10': 10645, '中央区築地_0-5_2LDK_70-80_5-10': 10700, '港区港南_0-5_2LDK_90-100_15-20': 10800, '港区六本木_0-5_2LDK_60-70_10-15': 10890, '新宿区原町_0-5_2LDK_80-90_10-15': 10980, '港区六本木--_0-5_2LDK_70-80_5-10': 11000, '港区六本木_0-5_2LDK_70-80_5-10': 11000, '文京区根津--_0-5_2LDK_80-90_10-15': 11000, '渋谷区西原_0-5_2LDK_70-80_15-20': 11000, '渋谷区広尾--_0-5_2LDK_60-70_0-5': 11180, '文京区本郷_0-5_2LDK_70-80_5-10': 11380, '中央区新川_0-5_2LDK_70-80_0-5': 11411, '中央区明石町_0-5_2LDK_80-90_0-5': 11490, '新宿区矢来町_0-5_2LDK_70-80_5-10': 11500, '新宿区矢来町_0-5_2LDK_80-90_0-5': 11500, '千代田区平河町_0-5_2LDK_60-70_5-10': 11800, '港区芝_0-5_2LDK_60-70_0-5': 11800, '港区高輪--_0-5_2LDK_70-80_15-20': 11800, '新宿区富久町_0-5_2LDK_60-70_5-10': 11940, '渋谷区恵比寿西_0-5_2LDK_50-60_0-5': 11950, '千代田区麹町_0-5_2LDK_60-70_0-5': 11980, '港区海岸_0-5_2LDK_80-90_15-20': 11980, '港区虎ノ門_0-5_2LDK_50-60_10-15': 11980, '渋谷区広尾_0-5_2LDK_80-90_5-10': 11980, '渋谷区東_0-5_2LDK_70-80_5-10': 11986, '渋谷区恵比寿南_0-5_2LDK_60-70_0-5': 12000, '千代田区麹町_0-5_2LDK_80-90_15-20': 12100, '中央区月島--_0-5_2LDK_90-100_15-20': 12180, '新宿区横寺町-_0-5_2LDK_80-90_0-5': 12200, '中央区月島_0-5_2LDK_90-100_15-20': 12240, '中央区銀座_0-5_2LDK_80-90_15-20': 12380, '渋谷区千駄ヶ谷_0-5_2LDK_60-70_0-5': 12400, '港区高輪_0-5_2LDK_100-110_20-25': 12500, '新宿区大京町_0-5_2LDK_90-100_10-15': 12500, '中央区湊_0-5_2LDK_40-50_10-15': 12500, '渋谷区富ヶ谷_0-5_2LDK_60-70_0-5': 12550, '港区赤坂--_0-5_2LDK_60-70_10-15': 12690, '港区東新橋--_0-5_2LDK_80-90_15-20': 12800, '港区芝_0-5_2LDK_90-100_20-25': 12800, '渋谷区富ヶ谷--_0-5_2LDK_60-70_0-5': 12800, '渋谷区恵比寿西_0-5_2LDK_70-80_20-25': 12800, '新宿区西新宿_0-5_2LDK_60-70_10-15': 12900, '港区浜松町_0-5_2LDK_60-70_0-5': 12930, '中央区銀座_0-5_2LDK_50-60_5-10': 12980, '渋谷区恵比寿西_0-5_2LDK_60-70_0-5': 13000, '新宿区荒木町_0-5_2LDK_120-130_15-20': 13300, '新宿区富久町_0-5_2LDK_70-80_5-10': 13450, '渋谷区代々木_0-5_2LDK_100-110_10-15': 13480, '千代田区六番町_0-5_2LDK_70-80_20-25': 13480, '千代田区六番町-_0-5_2LDK_70-80_20-25': 13480, '渋谷区東_0-5_2LDK_60-70_5-10': 13500, '中央区月島_0-5_2LDK_70-80_5-10': 13680, '港区白金_0-5_2LDK_70-80_15-20': 13800, '新宿区愛住町_0-5_2LDK_110-120_10-15': 13800, '渋谷区代官山町_0-5_2LDK_70-80_5-10': 13900, '渋谷区神宮前_0-5_2LDK_60-70_0-5': 13900, '港区三田--_0-5_2LDK_70-80_15-20': 13980, '新宿区新宿_0-5_2LDK_120-130_15-20': 13980, '港区虎ノ門_0-5_2LDK_70-80_5-10': 14450, '中央区勝どき_0-5_2LDK_100-110_10-15': 14500, '港区白金_0-5_2LDK_70-80_0-5': 14500, '文京区小石川_0-5_2LDK_100-110_10-15': 14500, '文京区西片_0-5_2LDK_100-110_0-5': 14537, '港区白金台_0-5_2LDK_80-90_5-10': 14800, '新宿区北新宿_0-5_2LDK_120-130_10-15': 14800, '新宿区市谷本村町_0-5_2LDK_100-110_10-15': 14800, '新宿区四谷_0-5_2LDK_100-110_10-15': 14900, '千代田区麹町_0-5_2LDK_80-90_0-5': 14946, '千代田区富士見_0-5_2LDK_80-90_5-10': 14950, '中央区勝どき_0-5_2LDK_120-130_10-15': 14980, '千代田区一番町_0-5_2LDK_80-90_15-20': 14980, '千代田区一番町-_0-5_2LDK_80-90_15-20': 14980, '千代田区三番町_0-5_2LDK_70-80_0-5': 14980, '港区赤坂_0-5_2LDK_80-90_10-15': 14980, '港区高輪--_0-5_2LDK_100-110_15-20': 14990, '港区高輪_0-5_2LDK_100-110_15-20': 14990, '港区白金_0-5_2LDK_70-80_20-25': 15000, '港区南青山_0-5_2LDK_60-70_0-5': 15053, '渋谷区富ヶ谷--_0-5_2LDK_80-90_0-5': 15400, '渋谷区恵比寿南_0-5_2LDK_70-80_0-5': 15730, '千代田区外神田_0-5_2LDK_90-100_15-20': 15800, '渋谷区渋谷_0-5_2LDK_70-80_15-20': 15800, '千代田区五番町_0-5_2LDK_80-90_15-20': 15900, '港区赤坂--_0-5_2LDK_90-100_10-15': 15980, '港区赤坂_0-5_2LDK_90-100_10-15': 15980, '渋谷区恵比寿南--_0-5_2LDK_70-80_0-5': 15980, '港区赤坂--_0-5_2LDK_70-80_10-15': 16220, '港区赤坂_0-5_2LDK_70-80_10-15': 16340, '港区三田_0-5_2LDK_60-70_10-15': 16590, '中央区月島_0-5_2LDK_80-90_5-10': 16800, '港区浜松町_0-5_2LDK_70-80_0-5': 16826, '港区台場_0-5_2LDK_150-160_10-15': 16900, '港区南青山_0-5_2LDK_100-110_15-20': 17500, '港区白金_0-5_2LDK_80-90_15-20': 17500, '渋谷区代官山町_0-5_2LDK_90-100_20-25': 17760, '港区三田_0-5_2LDK_80-90_10-15': 17985, '港区白金_0-5_2LDK_90-100_0-5': 18000, '港区東新橋_0-5_2LDK_90-100_15-20': 18800, '港区浜松町_0-5_2LDK_80-90_0-5': 18900, '渋谷区神宮前_0-5_2LDK_80-90_10-15': 18900, '渋谷区東_0-5_2LDK_90-100_5-10': 18900, '港区赤坂_0-5_2LDK_110-120_10-15': 19000, '港区三田_0-5_2LDK_70-80_10-15': 19300, '渋谷区松濤_0-5_2LDK_100-110_15-20': 19300, '港区南麻布_0-5_2LDK_80-90_5-10': 19500, '港区南麻布--_0-5_2LDK_80-90_5-10': 19500, '港区南青山_0-5_2LDK_70-80_0-5': 19600, '新宿区南榎町_0-5_2LDK_160-170_10-15': 19700, '千代田区四番町-_0-5_2LDK_110-120_15-20': 19800, '千代田区四番町_0-5_2LDK_110-120_15-20': 19800, '千代田区神田東松下町_0-5_2LDK_100-110_0-5': 19980, '港区虎ノ門_0-5_2LDK_100-110_10-15': 20500, '港区三田_0-5_2LDK_90-100_10-15': 20900, '港区南青山_0-5_2LDK_110-120_15-20': 21000, '港区東新橋_0-5_2LDK_100-110_15-20': 21000, '港区南青山--_0-5_2LDK_80-90_0-5': 21450, '港区六本木_0-5_2LDK_90-100_5-10': 21786, '港区虎ノ門_0-5_2LDK_90-100_10-15': 21800, '渋谷区恵比寿西_0-5_2LDK_110-120_10-15': 22000, '港区六本木_0-5_2LDK_80-90_5-10': 22250, '港区南青山_0-5_2LDK_80-90_0-5': 22321, '港区六本木--_0-5_2LDK_90-100_5-10': 22500, '港区南青山--_0-5_2LDK_90-100_15-20': 22800, '港区南青山_0-5_2LDK_90-100_15-20': 22800, '渋谷区恵比寿西_0-5_2LDK_90-100_0-5': 22800, '千代田区三番町_0-5_2LDK_100-110_10-15': 23000, '渋谷区渋谷_0-5_2LDK_100-110_15-20': 24800, '港区六本木_0-5_2LDK_30-40_0-5': 24800, '港区六本木--_0-5_2LDK_30-40_10-15': 24800, '港区六本木_0-5_2LDK_30-40_10-15': 24800, '港区赤坂_0-5_2LDK_100-110_10-15': 24866, '渋谷区神宮前--_0-5_2LDK_100-110_10-15': 24900, '渋谷区神宮前_0-5_2LDK_100-110_10-15': 24900, '港区港南_0-5_2LDK_110-120_10-15': 25000, '港区虎ノ門_0-5_2LDK_110-120_10-15': 25300, '港区六本木_0-5_2LDK_150-160_10-15': 25500, '港区六本木--_0-5_2LDK_150-160_10-15': 25500, '千代田区三番町_0-5_2LDK_110-120_15-20': 25980, '渋谷区猿楽町_0-5_2LDK_100-110_5-10': 26750, '港区東新橋_0-5_2LDK_140-150_15-20': 27800, '港区赤坂_0-5_2LDK_70-80_0-5': 29300, '千代田区永田町_0-5_2LDK_130-140_10-15': 29800, '港区南青山_0-5_2LDK_100-110_0-5': 31500, '渋谷区神宮前_0-5_2LDK_130-140_10-15': 31500, '港区六本木_0-5_2LDK_100-110_0-5': 33800, '港区虎ノ門_0-5_2LDK_80-90_5-10': 34800, '千代田区永田町_0-5_2LDK_100-110_5-10': 35000, '港区南青山_0-5_2LDK_110-120_0-5': 36300, '港区六本木_0-5_2LDK_130-140_5-10': 36700, '渋谷区渋谷_0-5_2LDK_60-70_5-10': 36888, '港区三田_0-5_2LDK_130-140_10-15': 37800, '千代田区四番町_0-5_2LDK_190-200_10-15': 39800, '千代田区四番町-_0-5_2LDK_190-200_10-15': 39800, '渋谷区神宮前_0-5_2LDK_130-140_0-5': 40135, '港区南青山_0-5_2LDK_140-150_0-5': 47800, '港区南青山--_0-5_2LDK_140-150_0-5': 47800, '港区南青山_0-5_2LDK_120-130_0-5': 48800, '千代田区六番町_0-5_2LDK_140-150_0-5': 49446}
参考 : https://www.sejuku.net/blog/51241
参考 : https://qiita.com/Azunyan1111/items/9b3d16428d2bcc7c9406結果
賃貸のキーと購入のキーの共通部分のみを抜き出して、何年で元を取ることができるのかを求めました。
結果のデータ
1列目は地域、2列目は広さ、3列目は築年数、4列目は何年で元を取ることができるか、5列目は購入額の平均、6列目は家賃(1ヶ月分)の平均です。
4列目についてソートしてあります。all_ls = [['港区六本木', '70-80', '5-10', 14.102564102564102, 11000, 65], ['新宿区西新宿', '80-90', '10-15', 16.721666666666668, 10033, 50], ['港区六本木', '90-100', '5-10', 17.62621359223301, 21786, 103], ['中央区日本橋堀留町', '50-60', '10-15', 18.205128205128204, 5680, 26], ['中央区湊', '50-60', '15-20', 19.099999999999998, 5730, 25], ['新宿区西新宿', '50-60', '5-10', 19.397849462365592, 7216, 31], ['中央区月島', '60-70', '5-10', 19.54022988505747, 6800, 29], ['新宿区市谷甲良町', '50-60', '0-5', 19.727011494252874, 6865, 29], ['千代田区東神田', '50-60', '5-10', 19.933333333333334, 5980, 25], ['新宿区上落合', '50-60', '20-25', 20.04901960784314, 4090, 17], ['港区赤坂', '90-100', '10-15', 20.487179487179485, 15980, 65], ['渋谷区本町', '50-60', '0-5', 20.599999999999998, 6180, 25], ['渋谷区代々木', '70-80', '15-20', 20.773809523809522, 6980, 28], ['渋谷区東', '70-80', '5-10', 20.80902777777778, 11986, 48], ['新宿区新宿', '70-80', '15-20', 20.810185185185187, 8990, 36], ['港区海岸', '60-70', '15-20', 20.9375, 6030, 24], ['渋谷区代々木', '50-60', '20-25', 21.11111111111111, 6080, 24], ['港区海岸', '60-70', '0-5', 21.333333333333332, 7680, 30], ['港区虎ノ門', '100-110', '10-15', 21.354166666666668, 20500, 80], ['中央区月島', '50-60', '5-10', 21.400000000000002, 6420, 25], ['港区六本木', '60-70', '5-10', 21.544715447154474, 10600, 41], ['渋谷区神宮前', '100-110', '10-15', 22.311827956989248, 24900, 93], ['港区赤坂', '110-120', '10-15', 22.61904761904762, 19000, 70], ['新宿区荒木町', '120-130', '15-20', 22.61904761904762, 13300, 49], ['中央区日本橋蛎殻町', '50-60', '15-20', 22.651515151515152, 5980, 22], ['中央区湊', '50-60', '5-10', 22.666666666666668, 6800, 25], ['新宿区四谷坂町', '60-70', '5-10', 22.701149425287355, 7900, 29], ['中央区銀座', '60-70', '5-10', 22.795698924731184, 8480, 31], ['新宿区山吹町', '60-70', '0-5', 22.944444444444443, 8260, 30], ['中央区勝どき', '60-70', '10-15', 22.96794871794872, 7166, 26], ['中央区新川', '50-60', '0-5', 23.169642857142858, 7785, 28], ['新宿区西新宿', '70-80', '15-20', 23.385416666666668, 8980, 32], ['渋谷区広尾', '50-60', '0-5', 23.39516129032258, 8703, 31], ['渋谷区広尾', '60-70', '0-5', 23.449074074074076, 10130, 36], ['港区港南', '90-100', '15-20', 23.68421052631579, 10800, 38], ['中央区勝どき', '90-100', '10-15', 23.761904761904763, 9980, 35], ['千代田区一番町', '60-70', '10-15', 23.85135135135135, 10590, 37], ['中央区勝どき', '80-90', '10-15', 23.946236559139788, 8908, 31], ['渋谷区恵比寿西', '60-70', '0-5', 24.074074074074076, 13000, 45], ['新宿区原町', '80-90', '10-15', 24.078947368421055, 10980, 38], ['中央区湊', '50-60', '0-5', 24.13978494623656, 8980, 31], ['新宿区左門町', '60-70', '15-20', 24.333333333333332, 7300, 25], ['新宿区富久町', '50-60', '5-10', 24.527777777777775, 8830, 30], ['港区虎ノ門', '50-60', '5-10', 24.791666666666668, 8925, 30], ['港区虎ノ門', '110-120', '10-15', 24.803921568627448, 25300, 85], ['港区南青山', '140-150', '0-5', 24.895833333333332, 47800, 160], ['新宿区市谷本村町', '70-80', '10-15', 24.972222222222225, 8990, 30], ['港区赤坂', '50-60', '5-10', 25.0, 8700, 29], ['港区南青山', '60-70', '0-5', 25.088333333333335, 15053, 50], ['港区南青山', '80-90', '0-5', 25.136261261261264, 22321, 74], ['港区芝', '60-70', '15-20', 25.141414141414142, 9956, 33], ['港区赤坂', '60-70', '5-10', 25.238095238095237, 10600, 35], ['港区東麻布', '50-60', '0-5', 25.267857142857142, 8490, 28], ['文京区根津', '50-60', '20-25', 25.37037037037037, 5480, 18], ['港区東麻布', '50-60', '5-10', 25.416666666666668, 9455, 31], ['新宿区南元町', '50-60', '5-10', 25.45138888888889, 7330, 24], ['港区六本木', '130-140', '5-10', 25.48611111111111, 36700, 120], ['中央区日本橋蛎殻町', '70-80', '5-10', 25.510752688172044, 9490, 31], ['中央区日本橋馬喰町', '50-60', '0-5', 25.681818181818183, 6780, 22], ['中央区銀座', '50-60', '15-20', 25.8641975308642, 8380, 27], ['文京区湯島', '50-60', '0-5', 25.92, 7776, 25], ['港区港南', '80-90', '10-15', 25.99702380952381, 8735, 28], ['港区赤坂', '80-90', '10-15', 26.006944444444443, 14980, 48], ['千代田区平河町', '60-70', '0-5', 26.136363636363637, 10350, 33], ['文京区西片', '50-60', '20-25', 26.296296296296294, 5680, 18], ['渋谷区神宮前', '60-70', '0-5', 26.325757575757578, 13900, 44], ['港区赤坂', '100-110', '10-15', 26.91125541125541, 24866, 77], ['新宿区荒木町', '50-60', '0-5', 27.12962962962963, 8790, 27], ['中央区新川', '70-80', '0-5', 27.169047619047618, 11411, 35], ['千代田区平河町', '60-70', '5-10', 27.314814814814813, 11800, 36], ['新宿区西早稲田', '60-70', '20-25', 27.685185185185187, 5980, 18], ['港区浜松町', '80-90', '0-5', 28.125, 18900, 56], ['渋谷区代々木', '50-60', '0-5', 28.21428571428571, 9480, 28], ['新宿区新宿', '50-60', '15-20', 28.240740740740744, 6100, 18], ['港区赤坂', '60-70', '20-25', 28.266666666666666, 8480, 25], ['渋谷区恵比寿南', '60-70', '0-5', 28.57142857142857, 12000, 35], ['新宿区富久町', '70-80', '5-10', 28.73931623931624, 13450, 39], ['港区南麻布', '50-60', '10-15', 28.78205128205128, 8980, 26], ['渋谷区恵比寿西', '90-100', '0-5', 28.787878787878785, 22800, 66], ['新宿区市谷田町', '60-70', '5-10', 28.91304347826087, 7980, 23], ['港区六本木', '100-110', '0-5', 29.037800687285223, 33800, 97], ['千代田区神田須田町', '50-60', '0-5', 29.510416666666668, 8499, 24], ['中央区勝どき', '50-60', '5-10', 29.649122807017545, 6760, 19], ['中央区月島', '80-90', '5-10', 29.78723404255319, 16800, 47], ['渋谷区富ヶ谷', '60-70', '0-5', 29.88095238095238, 12550, 35], ['中央区新川', '50-60', '15-20', 30.294117647058822, 6180, 17], ['渋谷区恵比寿', '60-70', '20-25', 30.384615384615387, 9480, 26], ['港区虎ノ門', '80-90', '5-10', 30.526315789473685, 34800, 95], ['千代田区麹町', '80-90', '0-5', 31.1375, 14946, 40], ['港区海岸', '80-90', '15-20', 31.197916666666668, 11980, 32], ['港区六本木', '80-90', '5-10', 31.968390804597703, 22250, 58], ['新宿区富久町', '60-70', '5-10', 32.09677419354839, 11940, 31], ['港区南青山', '90-100', '15-20', 32.20338983050848, 22800, 59], ['渋谷区渋谷', '100-110', '15-20', 32.804232804232804, 24800, 63], ['渋谷区渋谷', '70-80', '15-20', 32.916666666666664, 15800, 40], ['港区赤坂', '70-80', '0-5', 32.9954954954955, 29300, 74], ['中央区東日本橋', '40-50', '10-15', 33.59375, 6450, 16], ['中央区佃', '60-70', '15-20', 33.73148148148148, 7286, 18], ['港区三田', '60-70', '10-15', 36.38157894736842, 16590, 38], ['中央区月島', '60-70', '15-20', 36.666666666666664, 7480, 17], ['中央区湊', '40-50', '10-15', 54.824561403508774, 12500, 19]]
結果のデータを表にすると次のようになりました。(一部抜粋)
まとめ
今回の結果では、港区六本木にあり、広さが70〜80[m^2]、築年数5〜10年の物件が一番元を取りやすいことがわかりました。
さらにどの物件も大体40年ほど住めば元を取ることはできると言えそうです。また13番目の、渋谷区代々木、広さ70〜80[m^2]、築年数15年〜20年の物件も、広さを確保しつつ価格を抑えられるでお子さんがいる家族には適した物件ではないかと思われます。



- 投稿日:2020-03-10T19:01:34+09:00
SQLファイルを読みBigQueryを実行しcsvを保存してくれるPythonスクリプト
python 3.6.1 にて動作。
bq_runnner.pyimport argparse import pandas as pd def run_query(sql_file): with open(sql_file, 'r') as f: query = f.read() project_id = 'YOUR_PROJECT_ID' df = pd.read_gbq(query, project_id=project_id, dialect='standard') return df if __name__ == '__main__': parser = argparse.ArgumentParser() parser.add_argument('sql_file') parser.add_argument('--output_csv', default='output.csv') args = parser.parse_args() df = run_query(args.sql_file) df.to_csv(args.output_csv, index=False)使い方
$ python bq_runnner.py YOUR_QUERY.sqlcsvファイル名はお好みで。
必要ライブラリ
requirements.txtpandas==0.25.3 pandas-gbq==0.13.0
- 投稿日:2020-03-10T18:00:03+09:00
【Udemy Python3入門+応用】 50. 位置引数とキーワード引数とデフォルト引数
※この記事はUdemyの
「現役シリコンバレーエンジニアが教えるPython3入門+応用+アメリカのシリコンバレー流コードスタイル」
の講座を受講した上での、自分用の授業ノートです。
講師の酒井潤さんから許可をいただいた上で公開しています。■位置引数
positional_argumentdef menu(food, drink, dessert): print('food =', food) print('drink =', drink) print('dessert = ', dessert) menu('beef', 'wine', 'ice cream')resultfood = beef drink = wine dessert = ice cream今回はきちんと入力されているが、
drinkにice cream、
dessertにwineとあえて間違えみる。argumentdef menu(food, drink, dessert): print('food =', food) print('drink =', drink) print('dessert =', dessert) menu('beef', 'ice cream', 'wine')resultfood = beef drink = ice cream dessert = wineこのような間違いを防ぎたい。
■キーワード引数
keyword_argumentdef menu(food, drink, dessert): print('food =', food) print('drink =', drink) print('dessert =', dessert) menu(food='beef', dessert='ice cream', drink='wine')resultfood = beef drink = wine dessert = ice creamキーワード引数を設定したことで、順番どおりに書かなくてもきちんとprintされた。
■デフォルト引数
default_argumentdef menu(food='beef', drink='wine', dessert='ice cream'): print('food =', food) print('drink =', drink) print('dessert =', dessert) menu()resultfood = beef drink = wine dessert = ice creamデフォルト引数を設定した上で、引数を何も渡さないと
設定したデフォルト引数が返ってくる。default_argumentdef menu(food='beef', drink='wine', dessert='ice cream'): print('food =', food) print('drink =', drink) print('dessert =', dessert) menu(food='chicken', drink='orange juice')resultfood = chicken drink = orange juice dessert = ice creamデフォルト引数を設定した上で、
デフォルト引数から変更したいものだけキーワード引数を渡してやると、
その部分だけ変更されて返ってくる。
- 投稿日:2020-03-10T17:57:21+09:00
pythonコードをコミットする時にflake8で自動リントチェックする仕組み
背景
git commit時にリントチェックし、チェックが通らなかったらcommitできないようにしたい。今回は自動フォーマットはしたくなかったので、リントチェックだけするようにした。ちなみに、リントチェック + 自動フォーマットしたい場合はこの辺り → pre-commit時にformatterを実行する
やり方
pre-commit + flake8をインストール
cd $GIT_PROJECT pipenv install pre-commit pipenv install flake8pre-commit用のconfigファイルを作成
.pre-commit-config.yamlrepos: - repo: https://gitlab.com/PyCQA/flake8 rev: master hooks: - id: flake8.flake8用のconfigファイルを作成
.flake8[flake8] ignore = E501 # 1行の文字数チェックをignoreにする ; exclude = tests/* max-complexity = 10
.git/hook/pre-commitのスクリプトを生成pre-commit installこれでpre-commitの設定完了。ここまでくれば各開発者がそれぞれフォーマットできる仕組みを入れればいい。
例えば、VSCodeの場合は以下の記事が参考になる↓
VSCodeのPython開発環境でpylintの代わりにflake8を導入し自動整形を設定する
- 投稿日:2020-03-10T17:50:41+09:00
【Python】初めての データ分析・機械学習(Kaggle)
はじめに
就職間近(大学4年の春休み)になって、急遽データサイエンティストになりたいと思い、とりあえずKaggleに取り組み始めました。
今回取り組んだのは、Kaggleのチュートリアルである「Titanic」の問題です。
研究で統計解析の経験はあるが、機械学習は全くわからない状態からなので、めちゃくちゃ優秀な方のコードを参考にして勉強することにしました!
ちなみに、参考にしたのがこちら
✔︎Introduction to Ensembling/Stacking in Python
Notebookで「Most voted」と評されていたコードです。(2020.3.10時点)あと、上記のコードを参考にしたこちらの記事も参考にしました笑
Pythonでアンサンブル(スタッキング)学習 & 機械学習チュートリアル in KaggleIntroduction
今回取り組むタイタニック号のコンペの内容は、年齢、性別、同室者数、部屋のクラス、生死などの乗客に関するデータが与えれます。
そのデータを元に、
データの前処理
→データの可視化
→スタッキングモデル構築
→テストデータ
→評価といった流れで、最後にはテストデータから構築したモデルを使って乗客の生死の予測をします。この予測がどれくらいあっているかもスコアの基準になります。
かなりボリュームがあるので本記事では「前処理」・「データの可視化」に絞ります!
モデル構築以降は次回の記事に乗っけます!
では、早速データの前処理に取り掛かります!!
データの前処理
ライブラリのインポート
今回使用するライブラリをざっくり
- 数学的、統計的処理: numpy, pundas
- 正規表現操作(指定した形の言葉や数値の検索だったり置き換えだったり): re
- いろんなモデルを持ってるよ~: sklearn
- 勾配ブースティング決定木のアルゴリズム: XGboost
- グラフや図: matplotlib, seaborn, plotly
- 警告の表示/非表示: warnings
- 5つの基礎モデル
- これらの5つのモデルライブラリを同時に適応するのがKfold
import_library.pyimport pandas as pd import numpy as np import re import sklearn import xgboost as xgb import seaborn as sns import matplotlib.pyplot as plt %matplotlib inline import plotly.offline as py py.init_notebook_mode(connected=True) import plotly.graph_objs as go import plotly.tools as tls import warnings warnings.filterwarnings('ignore') # 5つのモデル from sklearn.ensemble import (RandomForestClassifier, AdaBoostClassifier, GradientBoostingClassifier, ExtraTreesClassifier) from sklearn.svm import SVC #複数の機械学習ライブラリを同時に適応する from sklearn.cross_validation import KFoldデータの取得
import_data.pytrain = pd.read_csv('../input/train.csv') test = pd.read_csv('../input/test.csv') #乗客のIDをPassengerIDに保持させる PassengerId = test['PassengerId'] train.head(3)出力
データの説明
- PassengerId:乗客のID
- Survived:生死フラグ(生き残った場合:1, 亡くなった場合:0)
- Pclass:チケットクラス
- Name:乗客の名前
- Sex:性別
- Age:年齢
- SibSp:同乗している兄弟/配偶者
- Parch:同乗している両親/子供
- fare:料金
- cabin:客室番号
- Embarked:乗船した港
特徴量エンジニアリング
取得したデータを分析しやすいように加工していきます。
機械学習において、この前処理はかなり重要らしいので、長いけど頑張ります!!基本的には、欠損値(値がない)や文字データを全て数値データに変換します。
FeatureEngineering.pyfull_data = [train, test] #乗客の名前の長さ train['name_length'] = train['name'].apply(len) test['name_length'] = test['name'].apply(len) #客室番号データがあるなら1を、欠損値なら0を train['Has_Cabin'] = train['Cabin'].apply(lambda x: 0 if type(x) == float else 1) test['Has_Cabin'] = test['Cabin'].apply(lambda x: 0 if type(x) == float else 1) #家族の大きさをタイタニックに同乗している"兄弟/配偶者の数"と"親/子供の数"から定義する for dataset in full_data: dataset ['FamilySize'] = dataset['Sibsp'] + dataset['Parch'] +1 #家族がいないなら"IsAlone"が1 for dataset in full_data: dataset['IsAlone'] = 0 dataset.loc[dataset['FamilySize'] == 1, 'IsAlone'] = 1 #出港地の欠損値を一番多い'S'としておく for dataset in full_data: dataset['Embarked'] = dataset['Embarked'].fillna('S') #料金の欠損値を中央値としておく #料金を大きく4つのグループに分ける for dataset in full_data: dataset['Fare'] = dataset['Fare'].fillna(train['Fare'].median()) train['CategoricalFare'] = pd.qcut(train['Fare'], 4) #年齢を5つのグループに分ける for dataset in full_data: age_avg = dataset['Age'].mean() age_std = dataset['Age'].std() age_null_count = dataset['Age'].isnull().sum() #欠損値に入れるランダム値のリスト #平均値から偏差分だけ大きいor小さい値を用いる age_null_random_list = np.random.randint(age_avg - age_std, age_avg + age_std, size = age_null_count) dataset['Age'][np.isnan(dataset['Age'])] = age_null_random_list #データをint型に変換 dataset['Age'] = dataset['Age'].astype(int) train['CategoricalAge'] = pd.qcut(train['Age'],5) #名前を取り出す関数get_titleの定義 def get_title(name): title_search = re.search('([A-Za-z]+)\.',name) #名前があれば取り出して返す if title_search: return title_search.group(1) return "" #関数get_titleを使う for dataset in ftll_data: dataset['Title'] = dataset['Name'].apply(get_title) #名前の記入ミス部分の修正 dataset['Title'] = dataset['Title'].replace(['Lady', 'Countess','Capt', 'Col','Don', 'Dr', 'Major', 'Rev', 'Sir', 'Jonkheer', 'Dona'], 'Rare') dataset['Title'] = dataset['Title'].replace('Mlle', 'Miss') dataset['Title'] = dataset['Title'].replace('Ms', 'Miss') dataset['Title'] = dataset['Title'].replace('Mme', 'Mrs') for dataset in full_data: # 女なら0、男なら1 dataset['Sex'] = dataset['Sex'].map( {'female': 0, 'male': 1} ).astype(int) # 名前の5種類にラベル付 title_mapping = {"Mr": 1, "Miss": 2, "Mrs": 3, "Master": 4, "Rare": 5} dataset['Title'] = dataset['Title'].map(title_mapping) dataset['Title'] = dataset['Title'].fillna(0) # 出港地の3種類にラベル付 dataset['Embarked'] = dataset['Embarked'].map( {'S': 0, 'C': 1, 'Q': 2} ).astype(int) # 料金を4つのグループに分ける dataset.loc[ dataset['Fare'] <= 7.91, 'Fare'] = 0 dataset.loc[(dataset['Fare'] > 7.91) & (dataset['Fare'] <= 14.454), 'Fare'] = 1 dataset.loc[(dataset['Fare'] > 14.454) & (dataset['Fare'] <= 31), 'Fare'] = 2 dataset.loc[ dataset['Fare'] > 31, 'Fare'] = 3 dataset['Fare'] = dataset['Fare'].astype(int) # 年齢を5つのグループに分ける dataset.loc[ dataset['Age'] <= 16, 'Age'] = 0 dataset.loc[(dataset['Age'] > 16) & (dataset['Age'] <= 32), 'Age'] = 1 dataset.loc[(dataset['Age'] > 32) & (dataset['Age'] <= 48), 'Age'] = 2 dataset.loc[(dataset['Age'] > 48) & (dataset['Age'] <= 64), 'Age'] = 3 dataset.loc[ dataset['Age'] > 64, 'Age'] = 4 ; # 必要ない特徴を削除 drop_elements = ['PassengerId', 'Name', 'Ticket', 'Cabin', 'SibSp'] train = train.drop(drop_elements, axis = 1) train = train.drop(['CategoricalAge', 'CategoricalFare'], axis = 1) test = test.drop(drop_elements, axis = 1)勉強になったコーディング
- lambda関数の使い方
- fillna()
- pandasのqcut
- map関数
- if文を使わず、loc[]の[]内でTrueの場合のみ値を入力
- axis = 1
データの可視化
やっと前処理が終わりました!!
ちゃんと全てのデータが数値データになっているか確認してみましょう!visualize.pytrain.head(3)
ピアソン相関ヒートマップ(Peason Correlation Heatmap)
特徴量同士の相関をヒートマップにて確認します。
heatmap.pycolormap = plt.cm.RdBu plt.figure(figsize = (14,12)) plt.title('Peason Correlation of Features', y = 1.05, size = 15) sns.heatmap(train.astype(float).corr(), linewidths=0.1, vmax=1.0, square = True, cmap=colormap, linecolor='white', annot=True)
このプロットから、そこまで特徴量が互いに強く相関していないことがわかります。
特徴量が互いに独立
→無駄な特徴がない
→学習モデルを構築する上で重要
(ParchとFamilySizeは比較的相関が強いですが、そのまま残しておきます。)ペアプロット(PairPlot)
ある特徴から別の特徴へのデータの分布
PairPlot.pyg = sns.pairplot(train[[u'Survived', u'Pclass', u'Sex', u'Age', u'Parch', u'Fare', u'Embarked', u'FamilySize', u'Title']], hue='Survived', palette = 'seismic',size=1.2,diag_kind = 'kde',diag_kws=dict(shade=True),plot_kws=dict(s=10) ) g.set(xticklabels=[])
まとめ
本記事では、Kaggleのチュートリアルの「Titanic」に取り組みました。
流れれとしては、
- ライブラリのインポート
- データの取得
- データの前処理
- 欠損値をなくす(平均値に近い値をランダムに挿入等)
- データの等分
- カテゴリーデータを数値に変換
- データの可視化
- ピアソン相関ヒートマップ
- ペアプロット
ここまででも結構大変でしたが、ここからがモデル構築の本番なので引き続き頑張ります!!




- 投稿日:2020-03-10T17:35:02+09:00
クローラーの作り方 - Basic 編
LAPRAS アウトプットリレー1日目の記事です!
こんにちは!LAPRAS クローラーエンジニアの @Chanmoro です!
この度LAPRAS アウトプットリレーと題しまして、今日から3月末まで LAPRAS のメンバーが日替わりで記事をアウトプットしていきます!
昨今のコロナショックの影響で勉強会やカンファレンスが中止になってしまっていますが、今回の LAPRAS アウトプットリレーを通して少しでもエンジニアの皆さんのインプットやアウトプットするモチベーションのお役に立てればと思っています。この記事の内容
さて、僕は普段クローラー開発者として仕事をしているのですが、新規にクローラーを開発する時にどういう流れで開発を進めているのかというのを今回記事にしてみようと思います。
ここではサンプルとして、 LAPRAS が運営している自社メディアである LAPRAS NOTE に公開されている記事の情報を取得して JSON 形式のファイルに出力するクローラーの実装例を紹介していきたいと思います。
※LAPRAS NOTE はエンジニアの方向けに、LAPRAS に関連したニュースやインタビュー記事を発信しているサイトです。クローラー開発の手順
クローラーを実装する時にはざっくりと以下のような手順で調査と設計・実装を進めていきます。
- サイトのリンク構造と各ページの導線を調査する
- クロールするページの HTML 構造を調査する
- クローラーを実装する
それぞれ詳細を説明していきます。
1. サイトのリンク構造と各ページの導線を調査する
LAPRAS NOTE のページをざっと見てみると、トップページには記事の一覧が表示されていて、一覧にある記事へのリンクから各記事のページに移動するという導線になっています。
ざっくりと 2 種類のページで構成されていることがわかります。
- 記事一覧ページ
- 記事詳細ページ
これらのページの作りについてもう少し詳しく見ていきましょう。
記事一覧ページを調べる
記事一覧ページではこのように記事タイトル、カテゴリー、公開日、本文のダイジェストの情報と、各記事の詳細ページへのリンクが掲載されていることがわかります。
またページの下の方には次ページへのページングのリンクが表示されているとわかります。
現時点での最終ページである 2 ページ目へ移動すると、ここでは次ページへのリンクが表示されていないことがわかります。
なので、次ページへのリンクがある場合は次のページへ移動し、リンクがなくなったらそこが最終ページだと判断すればよさそうです。
記事詳細ページを調べる
次に記事詳細ページの内容を見てみます。
このページからは記事のタイトル、公開日、カテゴリー、記事本文が取得できることがわかります。
全ての記事を取得する目的に対しては、記事詳細ページから他のページへの移動は特に考えなくてよさそうです。
抽出するデータの構造をまとめる
先ほどのサイトの調査から、これらのデータが抽出できそうだということが分かりました。
- 記事
- タイトル
- 公開日
- カテゴリー
- 記事本文
また、 LAPRAS NOTE の全ての記事に対して上記のデータを抽出するためには以下のフローでサイトを辿ればいいことが分かりました。
- 公開されている記事の一覧ページへアクセスして記事詳細への URL を取得 1. 次ページへのリンクがあれば次ページへ移動して (1) と同様に記事詳細への URL を取得
- 記事詳細ページへアクセスして記事の情報を取得
2. クロールするページの HTML 構造を調査する
次に、クロール対象のページの HTML 構造を見ることで、対象のデータをどうやって抽出するかを調査していきます。
ここでは Web ブラウザの開発者ツールを利用します。公開されている記事の一覧ページ
記事の一覧ページからは以下を抽出したいです。
- 記事詳細ページのリンク URL
- 次ページへのリンク URL
記事詳細ページのリンク URL を取得する
まずは記事詳細ページへのリンクを探すために、1つの記事と対応している要素を見つけます。
ページの HTML 構造を見ると、
post-itemの class がセットされたdiv要素が1つの記事の範囲と対応していることが分かりました。
また、該当のdiv.post-itemの中の要素をみていくと、h2タグの直下にあるaタグに記事詳細ページの URL がセットされていることが分かります。
この取得したい a タグを指定するための CSS パスは
div.post-item h2 > aということになります。今の予想では記事一覧の 1 ページ目ではこの CSS パスにマッチする要素は 10 件取得できるはず ですが、他に関係ない URL が取得されないかを確認したいです。
例えば以下のような JavaScript のコードをブラウザのコンソールから実行してみて、 CSS セレクタにマッチする件数を確かめることができます。document.querySelectorAll("#main div.post-item h2 > a").length実際に、記事一覧ページの 1 ページ目を表示した状態でブラウザのコンソールから以下を実行すると
10という結果が得られるので、先ほどの CSS パスで問題なさそうということが確認できました。
次ページへのリンク URL を取得する
次に、記事一覧ページの次ページへのリンク URL を探します。
nav.navagation.paginationの要素を見ると、ここが各ページへのリンクや次ページへのリンクを表示している領域だということが分かります。
この要素の中にあるnextとpage-numbersの class を持ったaタグに次ページへのリンク URL がセットされていることが分かります。
こちらを取得するための CSS パスは
nav.navigation.pagination a.next.page-numbersということになります。
こちらもブラウザのコンソールから実際に取得できる件数を調べてみます。document.querySelectorAll("nav.navigation.pagination a.next.page-numbers").length実行すると
1と結果が得られたので目的のリンク URL が取得できているということで大丈夫そうです。
また、最終ページである 2 ページ目では次ページへのリンクの要素が表示されていないことが確認できます。
念のためコンソールから次ページへのリンクの要素を検索しても
0の結果が得られました。
記事詳細ページ
記事詳細ページからは以下を抽出したいです。
- タイトル
- 公開日
- カテゴリー
- 記事本文
先ほどと同様に HTML 構造を調べて目的の要素への CSS パスを調べます。
以下の要素からデータを抽出すればよいことが分かりました。
- タイトル
h1- 公開日
article header div.entry-meta- カテゴリー
article header div.entry-meta a- 記事本文
article div.entry-content3. クローラーを実装する
ここまで調査した内容でクロールのためのロジックはほぼ明らかになっているのでそれをコードで実装していきます。
実装する言語は何を使ってもほとんどの場合で問題ありませんが、ここでは Python での実装例を書いていきたいと思います。やることを整理
まずはベタにやることを列挙してみます。
# TODO: https://note.lapras.com/ へアクセスする # TODO: レスポンス HTML から記事詳細の URL を取得する # TODO: 次ページのリンクがあれば取得する # TODO: 記事詳細ページへアクセスする # TODO: レスポンス HTML から記事の情報を取得する # TODO: URL # TODO: タイトル # TODO: 公開日 # TODO: カテゴリー # TODO: 記事本文 # 取得されたデータを JSON 形式でファイルに保存するクローラー実装時の注意点
実装時の注意点としては、クロール先サービスへ過度な負荷をかけないように適宜 sleep を入れてアクセスする間隔を調整します。
たいていの場合は目安として多くても1秒あたり1リクエスト程度に収まるようにしておくのがよいと思いますが、クロールにより対応先サービスをダウンさせてしまったりすると問題になるので、クロール先からのレスポンスがエラーになっていないかは常に確認するようにしましょう。Python でベタに実装する
Python の場合は requests と Beautiful Soup を組み合わせてクローラーを書くことが多いです。
ライブラリの使い方は 10分で理解する Beautiful Soup も参考にしてみてください。Scrapy などのクローラーを実装するフレームワークも存在していますが、クローラーの全体像を理解するためにはまずフレームワークを使わずに実装してみるのがオススメです。
一旦設計を深く考えずに、書きたい処理をベタにコードで表すとこんな感じになります。
import json import time import requests from bs4 import BeautifulSoup def parse_article_list_page(html): """ 記事一覧ページをパースしてデータを抜き出す :param html: :return: """ soup = BeautifulSoup(html, 'html.parser') next_page_link = soup.select_one("nav.navigation.pagination a.next.page-numbers") return { "article_url_list": [a["href"] for a in soup.select("#main div.post-item h2 > a")], "next_page_link": next_page_link["href"] if next_page_link else None } def crawl_article_list_page(start_url): """ 記事一覧ページをクロールして記事詳細の URL を全て取得する :return: """ print(f"Accessing to {start_url}...") # https://note.lapras.com/ へアクセスする response = requests.get(start_url) response.raise_for_status() time.sleep(10) # レスポンス HTML から記事詳細の URL を取得する page_data = parse_article_list_page(response.text) article_url_list = page_data["article_url_list"] # 次ページのリンクがあれば取得する while page_data["next_page_link"]: print(f'Accessing to {page_data["next_page_link"]}...') response = requests.get(page_data["next_page_link"]) time.sleep(10) page_data = parse_article_list_page(response.text) article_url_list += page_data["article_url_list"] return article_url_list def parse_article_detail(html): """ 記事詳細ページをパースしてデータを抜き出す :param html: :return: """ soup = BeautifulSoup(html, 'html.parser') return { "title": soup.select_one("h1").get_text(), "publish_date": soup.select_one("article header div.entry-meta").find(text=True, recursive=False).replace("|", ""), "category": soup.select_one("article header div.entry-meta a").get_text(), "content": soup.select_one("article div.entry-content").get_text(strip=True) } def crawl_article_detail_page(url): """ 記事詳細ページをクロールして記事のデータを取得する :param url: :return: """ # 記事詳細へアクセスする print(f"Accessing to {url}...") response = requests.get(url) response.raise_for_status() time.sleep(10) # レスポンス HTML から記事の情報を取得する return parse_article_detail(response.text) def crawl_lapras_note_articles(start_url): """ LAPRAS NOTE をクロールして記事のデータを全て取得する :return: """ article_url_list = crawl_article_list_page(start_url) article_list = [] for article_url in article_url_list: article_data = crawl_article_detail_page(article_url) article_list.append(article_data) return article_list def collect_lapras_note_articles(): """ LAPRAS NOTE の記事のデータを全て取得してファイルに保存する :return: """ print("Start crawl LAPRAS NOTE.") article_list = crawl_lapras_note_articles("https://note.lapras.com/") output_json_path = "./articles.json" with open(output_json_path, mode="w") as f: print(f"Start output to file. path: {output_json_path}") json.dump(article_list, f) print("Done output.") print("Done crawl LAPRAS NOTE.") if __name__ == '__main__': collect_lapras_note_articles()実装したコードはこちらのリポジトリで公開しています。
https://github.com/Chanmoro/lapras-note-crawler使い捨てコードっぽい雰囲気が漂っていますが、 Basic 編としては一旦ここまでで解説を終わりたいとおもいます。
まとめ
さて、今回は 「クローラーの作り方 - Basic 編」 ということで、 LAPRAS NOTE のクローラー実装をテーマにして、クローラーを開発する時の一連の流れの基本を紹介しました。
僕がクローラーを開発する時は今回紹介したような手順で開発を進めることがほとんどです。
実装例にあげているコードは長期間メンテナンスし続けるクローラーとしてみるとまだまだ不足していることは多いので、実際の仕事ではデータモデリングやクロールフローの設計にもっと時間をかけることがほとんどですが、
例えばなんらかの調査のためにクロールをしたり、簡易的な利用であればこれくらいのコードでも十分だと思います。個人的には1回のみの調査であれば Python を使わなくてもシェルスクリプトだけで簡単に実装してしまう場合もよくあります。
LAPRAS アウトプットリレーの期間中にいくつか記事を書かせていただく予定ですが、次回の僕の記事では 「クローラーの作り方 - Advanced 編」 ということで今回の記事の内容を踏まえて、長期的にメンテナンスし続けるクローラーを開発するにはここからどういうところを気をつけて設計していけばいいか?というのをご紹介したいと思っていますので、お楽しみに!
明日の LAPRAS アウトプットリレー2日目は @nasum さんが書いてくれる予定なので、こちらもお楽しみに!









- 投稿日:2020-03-10T17:28:37+09:00
【Udemy Python3入門+応用】 49. 関数の引用と返り値の宣言
※この記事はUdemyの
「現役シリコンバレーエンジニアが教えるPython3入門+応用+アメリカのシリコンバレー流コードスタイル」
の講座を受講した上での、自分用の授業ノートです。
講師の酒井潤さんから許可をいただいた上で公開しています。■関数の引用と返り値の宣言
function# a,b,返り値をint型とし、a+bを返す def add_num(a: int, b: int) -> int: return a + b r = add_num(10, 20) print(r)result30Python3.6以降では、
num: int = 10
とすると、
「num = 10で、かつnumはint型にする」、
というように記述できた。
-> intとしているのは、
「返り値もint型にする」
という意味。こういう風にする場合は多くはないが、
このような記述をする場合もあるため、頭の片隅に入れておこう。
- 投稿日:2020-03-10T17:20:55+09:00
TSC(Tableau Server Client)を使ってTableauサーバーからpdf, pngを取得する。
導入
python3.8.0を使用します。
TSCはインストールが必要になります。
github( https://github.com/tableau/server-client-python )
PyPI( https://pypi.org/project/tableauserverclient/ )pip install tableauserverclientimport tableauserverclient as TSCusername, password, siteid, serverurlには使用されるアカウントとサーバーの情報を入力してください。
また、最新版を使用したいのでuser_server_versionオプションをTrueにしています。tableau_auth = TSC.TableauAuth('username', 'password', 'siteid') server = TSC.Server('serverurl', use_server_version=True)以下のコードを実行して、ビューがサイト上に存在するか確認しましょう。
また、all_viewsは後で使用するので必ず実行してください。all_views, pagination_item = server.views.get() print([view.name for view in all_views])PDFで保存する
ビューをファイル形式:pdf、サイズ:A4、向き:横で取得する場合は以下のコードになります。
pdf_req_option = TSC.PDFRequestOptions(page_type=TSC.PDFRequestOptions.PageType.A4, orientation=TSC.PDFRequestOptions.Orientation.Landscape) with server.auth.sign_in(tableau_auth): for view_item in all_views: # pdfイメージを生成 server.views.populate_pdf(view_item, req_options=pdf_req_option) with open(f'{view_item.name}.pdf', 'wb') as f: f.write(view_item.pdf)PDFRequestOptions
Use this class to specify the format of the PDF that is returned for the view. See views.populate_pdf.
PDFRequestOptions(page_type=None, orientation=None)page_type
pdfのサイズを指定できます。デフォルトは
Legal。-
PageType.A3
-PageType.A4
-PageType.A5
-PageType.B5
-PageType.Executive
-PageType.Folio
-PageType.Ledger
-PageType.Legal
-PageType.Letter
-PageType.Note
-PageType.Quarto
-PageType.Tabloidorientation
ページの向きを指定できます。デフォルトは
Portrait(縦)。
-Orientation.Portrait:縦
-Orientation.Landscape:横vf(フィルター)
また、このクラスに
vfメソッドを使用するとビューに対してフィルターをかけることができます。
たとえば、# (optional) set a view filter pdf_req_option.vf('Region', 'West')とすると、
RegionがWestにフィルターされたビューがpdf化されます。PNGで保存する
ビューをファイル形式:png、向き:横で取得する場合は以下のコードになります。
image_req_option = TSC.ImageRequestOptions(imageresolution=TSC.ImageRequestOptions.Resolution.High) with server.auth.sign_in(tableau_auth): for view_item in all_views: # pngイメージを生成 server.views.populate_image(view_item, req_options=image_req_option) with open(f'{view_item.name}.png', 'wb') as f: f.write(view_item.image)ImageRequestOptions
Use this class to specify the resolution of the view returned as an image. You can also use this class to specify view filters to be applied when the image is generated. See views.populate_image.
imageresolutionで解像度の指定ができるようです。
ImageRequestOptions(imageresolution=None)imageresolution
指定しない場合は横幅784ピクセルで出力され、上記のように
Rresolution.High(最高値)を指定すると1568ピクセルになります(画像は縦横比を維持するため、横幅に合わせて縦幅が変動します)。vf(フィルター)
また、画像形式でもビューに対しフィルターをかけることができます。
# (optional) set a view filter image_req_option.vf('Category', 'Furniture')まとめ
# -*- coding: utf-8 -*- # Python 3.8.0 (tags/v3.8.0:fa919fd, Oct 14 2019, 19:21:23) [MSC v.1916 32 bit (Intel)] on win32 import tableauserverclient as TSC # 認証情報入力 username= '入力' password= '入力' siteid = '入力' serverurl = '入力' tableau_auth = TSC.TableauAuth(username, password, siteid) server = TSC.Server(serverurl, use_server_version=True) with server.auth.sign_in(tableau_auth): all_views, pagination_item = server.views.get() pdf_req_option = TSC.PDFRequestOptions(page_type=TSC.PDFRequestOptions.PageType.A4, orientation=TSC.PDFRequestOptions.Orientation.Landscape) with server.auth.sign_in(tableau_auth): for view_item in all_views: # pdfイメージを生成 server.views.populate_pdf(view_item, req_options=pdf_req_option) with open(f'{view_item.name}.pdf', 'wb') as f: f.write(view_item.pdf) image_req_option = TSC.ImageRequestOptions(imageresolution=TSC.ImageRequestOptions.Resolution.High) with server.auth.sign_in(tableau_auth): for view_item in all_views: # pngイメージを生成 server.views.populate_image(view_item, req_options=image_req_option) with open(f'{view_item.name}.png', 'wb') as f: f.write(view_item.image)上記スクリプトと同階層に、サーバー上のすべてのビューの画像、pdfが出力されるのでご注意を。
お好みで出力ファイルをご指定ください。
Tableau Server Client (Python) API reference
Tableau REST API - API Reference—All Methods
- 投稿日:2020-03-10T17:15:34+09:00
ダークモードでもSlack絵文字をちゃんと見たい!
Slackのカスタム絵文字、楽しいですよね。
さて、ダークモードで使ってる方ならあるあるかもしれませんが、ダークモードにしてしまうとこんな問題が発生します。
_人人人人人人人人人人_
> 絵文字が見えない <
 ̄Y^Y^Y^Y^Y^Y^Y^Y^Y ̄絵文字の背景を透明ではなく白にすることで解決してらっしゃった記事もありましたが、今回は上の画像で黄色く囲んだ「オッ」のように、縁取りをする方法で解決したいと思います。
今回作成したソースコードは、以下のリポジトリに置いてあります。是非使ってみてください!
1. 絵文字を取り込む
まずは、Slackから絵文字画像を取ってきます。これは比較的簡単で、
emoji.listAPIを使うと取得することができます。
emoji:readのスコープを設定したアプリケーションを作成してトークンを取得したら、以下のアドレスを叩くとJSONが得られます。https://slack.com/api/emoji.list?token=xoxb-...{ "ok": true, "emoji": { "bowtie": "https:\/\/emoji.slack-edge.com\/xxxxxx\/bowtie\/yyyyyy.png", "squirrel": "https:\/\/emoji.slack-edge.com\/xxxxxx\/squirrel\/zzzzzz.png", } }これをもとにPythonでシュシュっと取ってくるプログラムを書きます。
import os from time import sleep import requests def download_image(url): response = requests.get(url) if response.status_code != 200: print(f"HTTP Error: {response}") return None content_type = response.headers["content-type"] if 'image' not in content_type: print(f"Error: {content_type} is not image") return None return response.content def make_filename(base_dir, alias, url): ext = os.path.splitext(url)[1] filename = alias + ext fullpath = os.path.join(base_dir, filename) return fullpath def save_image(path, image): with open(path, "wb") as fout: fout.write(image) def main(): TOKEN = os.getenv('SLACK_TOKEN') BASE_DIR = './original/' os.makedirs(BASE_DIR, exist_ok=True) res = requests.get('https://slack.com/api/emoji.list', headers={'Authorization': f'Bearer {TOKEN}'}) emojis = res.json()['emoji'] for alias, emoji_url in emojis.items(): if (emoji_url.startswith('alias:')): continue img = download_image(emoji_url) if img is None: continue img_path = make_filename(BASE_DIR, alias, emoji_url) save_image(img_path, img) sleep(1) if __name__ == "__main__": main()注意すべき点は、エイリアスを設定しているとそれも含まれてしまうので除外する処理が必要です。
2. フチを抽出する
フチの抽出にはラプラシアンフィルタを使います。
今回は画像処理全般をPillowで行いました。当初、OpenCVも試しましたが、一部絵文字のアルファチャンネルが正常に読み込めなかったので諦めました。f = Image.open('hoge.png') gf = f.convert('LA') edge = gf.filter(ImageFilter.FIND_EDGES)
いい感じですね〜3. 白でフチ取りする
抽出した輪郭をもとに、白で縁取りをします。
フィルタをかけた後のアルファチャンネルのみ活用し、色は全部白で塗ったものを用意しました。l, a = edge.split() _l, _a = np.full_like(a, 255), np.array(a) img_array = np.stack([_l, _a], 2) border = Image.fromarray(np.uint8(img_array), "LA")ただ、残念ながらこのまま重ねても元画像と重なってしまいほとんど縁が見えません。
border_color = border.convert('RGBA') res = Image.alpha_composite(border_color, f)
そのため、輪郭を太らせて重ねます。一般的にはモルフォロジー変換で行うことができるようです。
PillowではこのOpenCVにあるようなメソッドはありませんが、MaxFilterを使うことで同等のことができます。理由については、こちらの記事が詳しいです。ただ、やっていることはあまり変わりませんが、今回はずらして重ねるという力技の方が見た目が良かったので、そちらを採用しました。
border_color = border.convert('RGBA') diff = [-border_size, border_size] res = f for xd in range(-border_size, border_size + 1): for yd in range(-border_size, border_size + 1): b = border_color.rotate(0, translate=(xd, yd)) res = Image.alpha_composite(b, res)
4. 微調整
平滑化
輪郭検出後の画像に平滑化フィルタ(
ImageFilter.SMOOTH)をかけてあげると、少し綺麗になります。
(左が平滑化しない場合、右がした場合)
アニメーションGIFの対応
このままだと、アニメGIFを読み込んだ際にエラーで落ちてしまうのでついでに対応してみます。
アニメGIFの場合、各フレームをImageSequence.IteratorやImageSequence.all_framesで取得することができます。f = Image.open(file) duration, loop = f.info.get('duration', 0), f.info.get('loop', 0) frames = [] for frame in ImageSequence.Iterator(f): bf = make_border(frame.convert('RGBA'), BORDER_SIZE) frames.append(bf) if len(frames) > 1: frames[0].save(OUTPUT_DIR / file.name, save_all=True, append_images=frames[1:], optimize=False, duration=duration, loop=loop, transparency=255, disposal=2) else: frames[0].save(OUTPUT_DIR / file.name)これでおおよそのイメージはうまくいきますが、どうやらアニメGIFの読み書き周りはハマりどころが多く、透明色がパレットの255番じゃなかったりして正常に処理できない画像も一部ありました。
5. 置き換えるには?
Slackの絵文字は同じ名前で後から差し替えることができないので、削除->追加の手順を取る必要があります。
APIはEnterprise Gridのみ
カスタム絵文字の登録・削除に関するAPIは、実は提供自体はされています。しかし、これらはEnterprise Gridプランでのみ使うことができるので、おそらく使えない人が多いのではないかと思います。
非公開API or 管理画面からなんとかする
公式APIが使えない場合、管理画面から頑張って登録するか、管理画面で呼んでいるAPIを叩いてあげるしかなさそうです。
非公開APIのため、Qiitaでは触れませんが、一括処理できるスクリプトをリポジトリ内に置いたので、そちらをご覧ください。ちなみに、一括登録のツールとしてはNeutral Face Emoji Toolsが有名ですが、大量の絵文字を登録しようとするとすぐレートリミットに引っかかるのでご注意ください。
まとめ
今回行った画像処理はごくごく簡単なものですが、意外とアニメGIFの処理やSlack側との出し入れに戸惑いました。
このツールで皆さんも快適にダークモードライフをお過ごしください?