- 投稿日:2020-03-10T23:49:19+09:00
【4日目】JavaScript2日目
目的
毎週末の予定でしたが、継続的にアウトプットしていく方針にします。
なぜなら・・・昨日学習した事を忘れているから!
毎日のアウトプットにより、知識の定着を図ります。
progate Javascript 学習コース1
昨日の内容です。
qiita.rb//表示 console.log("name"); //変数(変更は追記すればよい) let name ="masa"; //定数 const name ="masa"; //テンプレートリテラル(記号注意) console.log(`私は${name}`) //if else if(条件1){ console.log( ); }else if(条件2){ console.log( ); }else { console.log( ); } //swich(フローチャートみたいなイメージ) swich(条件){ case " ": console.log(" "); default: 処理 break; }progate Javascript 学習コース2
qiita.rb//while let number =1; while(number<= 50){ console.log(number); number+=1; //for(変数の定義;条件式;変数の更新) for(let number=1 ; number<=100 ;number++) //length for(let i=0; i<=number,length;i++) //配列(0から数える) console name=["値","値","値"] //オブジェクト const name = [ {プロパティ:値,・・・}, ];所感
記号が複雑でなかなかノーミスでは書けないです。
最初のうちは見ながら間違えないように書いていこうと思います。昨日の学習内容を全然覚えていなかったのは、残念な点。
アウトプットで定着させていきます。
アウトプットのコツ等あれば教えてください。これからの未来を変えるために時間を使おう
今日の学習
— masa (@axxm0615) March 10, 2020
☑️ProgateのJavaScript 学習コース 2
記号のパターンが多くて難しい印象
苦手意識を作らないように注意!
今日はできなかったけど、
明日は出勤前も少しでもやりたいな#駆け出しエンジニアと繋がりたい#100DaysOfCode
- 投稿日:2020-03-10T23:27:44+09:00
JavaScriptでサイトの言語切り替え
昔作った物の書き換えた物です
class Lang { lang; el; data; ctx; content; afterContent; address; constructor(obj) { this.el = obj.el || "body"; this.data = obj.data || {}; this.lang = obj.data.def || "en"; this.address = obj.data.address || false; this.ctx = document.querySelector(this.el); this.content = this.ctx.textContent; this.afterContent = this.ctx.textContent; this.loads(); return this; } run() { for (const key in this.data) { let val = this.data[key]; const reg = new RegExp(`\%\{${key}\}`, "g"); this.afterContent = this.afterContent.replace(reg, val[this.lang]); } this.ctx.textContent = this.afterContent; } loads() { if(location.hash) { this.lang = location.hash.split("#")[1]; } else { this.lang = ((window.navigator.languages && window.navigator.languages[0]) || window.navigator.language || window.navigator.userLanguage || window.navigator.browserLanguage).split("-")[0]; } this.run(); if(this.adress) history.replaceState("", "", `#${this.lang}`); } }使用方法
```html
%{title} %{message}
%{title}
%{box}element はcssセレクター指定 (未指定document) def は初期表示の言語 (未指定時en or 先に宣言したlangに合わせる) adress は URLの後ろにセクターを付けるか (未指定時false 指定時true) trueのとき ○○.com/home#ja #ja の部分を変えるとその言語になる
- 投稿日:2020-03-10T23:27:44+09:00
JavaScriptでサイトの言語切り替え2
昔作った物の書き換えた物です
class Lang { lang; el; data; ctx; content; afterContent; address; constructor(obj) { this.el = obj.el || "body"; this.data = obj.data || {}; this.lang = obj.data.def || "en"; this.address = obj.data.address || false; this.ctx = document.querySelector(this.el); this.content = this.ctx.textContent; this.afterContent = this.ctx.textContent; this.loads(); return this; } run() { for (const key in this.data) { let val = this.data[key]; const reg = new RegExp(`\%\{${key}\}`, "g"); this.afterContent = this.afterContent.replace(reg, val[this.lang]); } this.ctx.textContent = this.afterContent; } loads() { if(location.hash) { this.lang = location.hash.split("#")[1]; } else { this.lang = ((window.navigator.languages && window.navigator.languages[0]) || window.navigator.language || window.navigator.userLanguage || window.navigator.browserLanguage).split("-")[0]; } this.run(); if(this.adress) history.replaceState("", "", `#${this.lang}`); } }使用方法
element はcssセレクター指定
(未指定body)def は初期表示の言語
(未指定時en or 先に宣言したlangに合わせる)adress は URLの後ろにセクターを付けるか
(未指定時false 指定時true)
trueのとき ○○.com/home#ja
#ja の部分を変えるとその言語になる<div id="title"> %{title} %{message} <div id="test"> %{title} </div> </div> <div id="box"> %{box} </div> <!-- 上記のコードを読み込む --> <script> new Lang({ el: "#title", // element def: "ja", // default address: false, // adressbar data: { "title": { "ja": "タイトル", "en": "title" }, "message": { "ja": "メッセージ", "en": "message" } } }); new Lang({ data: { "box": { "ja": "ボックス", "en": "box" } } }); </script>
- 投稿日:2020-03-10T22:43:34+09:00
初めてのGraphQL ~特徴・導入・簡単なクエリまで
最近Reactを学びはじめたこともあって同じFacebookが作ったGraphQLにも手を出してみました。
GraphQLの輪郭もわからない時は「NoSQLのクエリの弱さを独自の検索エンジンで全て解決してくれる魔法のクエリ言語」なんて思ってました。(浅はかなり)GraphQLを勉強しはじめて2日目で書いた記事なのであやふやなところや間違ってる点など多々あると思います...
GraphQLとは
実際のところはクエリとレスポンスの構造に対応関係を持たせることができたり、スキーマ設定によりエディタにおける補完や型チェックなどが行えたり、REST APIと違い処理によってGETエンドポイントを分ける必要がなく冗長化を防ぐことができたりと、いわばAPIのフレームワークのような印象を受けました。
イメージ図を作ってみました↓
インストール(導入)
今回はNodeベースのexpress + apollo + GraphQLでAPIサーバーをたてていきます。
// プロジェクトフォルダを作成 $ mkdir first_graphql $ cd first_graphql // プロジェクトのセットアップ $ npm init // 必要なモジュールをインストール $ npm i --save express apollo-server-express graphql // index.jsを作成 $ touch index.jsコードを書いていく
index.js
const express = require('express') const { ApolloServer, gql } = require('apollo-server-express') const app = express() // GraphQL言語のschemaを使ったconstruct定義 // レスポンスするデータの型を設定しておく const typeDefs = gql` type Query { firstQuery: String } ` // schemaごとに取得ロジックを設定していく const resolvers = { Query: { firstQuery: () => "Hello,world!", }, } const server = new ApolloServer({ typeDefs, resolvers }) server.applyMiddleware({ app }) app.listen({ port: 4000 }, () => console.log(`Server ready at http://localhost:4000${server.graphqlPath}`)動かしてみる
$ nodemon index.js //$ node index.jsでも可動かしたら
http://localhost:4000/graphql にアクセス!
こんな画面が出たらうまく立ち上がっています。
これはapolloサーバーが提供しているものでGraphQLへのクエリをGUIでテストすることができます。クエリを実行してみる
index.jsの↓の部分で設定したQueryを実行してみます。
// GrapohQL言語のschemaを使ったconstruct定義 // レスポンスするデータの型を設定しておく const typeDefs = gql` type Query { firstQuery: String } ` // schemaごとに取得ロジックを設定していく const resolvers = { Query: { firstQuery: () => "Hello,world!", }, }GUIの左側のエディタに以下の通り書いて実行してみましょう。
{ firstQuery }右側の実行結果画面にこのように表示されればデータの引き出し成功です。
{ "data": { "firstQuery": "Hello,world!" } }最後に
少し勉強してみるとGraphQLは決して魔法の言語などではなく、型の定義やデータ取得ロジックを自分でしっかり書いていかなければならないということがわかりました。
しかしながらGETエンドポイントを1つに集約できること、フロント側からの直感的なクエリを実装できること、TypeScriptのようにコード管理を容易にしてくれることなどなど...便利なことに違いはありません!
まだまだ勉強しはじめたばかりなのでこれからどんどん知識を蓄えていきたいと思います!
それでは!



- 投稿日:2020-03-10T22:36:48+09:00
TSfCM1日目_プログラミング学習初日の初日
はじめに
2020年3月7日からプログラミングを習い始めました。
Tech Scool for Change Makers
https://gs4good.tokyo/
というところに半年間通って勉強します。html,JavaScript,Pythonなど学ぶ予定です。
プログラミングは全くの初心者です。
Pythonがprintと書くことだけは知っていました。ここでは自分の復習のため、あとQiita投稿に慣れるため
TSfCMの授業メモと学びを書いていきたいと思います。OSはWindows10
登場人物など
ツール
スクリプトを書く → GAS(グーグル・アップス・スクリプト)
プログラミングを書く場所(エディター) → Visual Studio Codeスクリプトの連携先 → LINE Nortify
マークアップ式メモ帳 → Stack Edit
言語
JavaScript
htmlNode.js = サーバサイドJavaScript
デプロイ方法
GAS
nowそもそも
そもそもデプロイとは
"ソフトウェア開発の工程のうち、開発した機能やサービスを利用できる状態にする作業を指す語として用いられています。"
https://www.weblio.jp/content/%E3%83%87%E3%83%97%E3%83%AD%E3%82%A4
weblio辞書よりJSONとは
ZEIT now
https://dev.classmethod.jp/server-side/serverless/zero-configuration-zeit-now/
"一言でいうと、シンプルで簡単にそして高速なデプロイを実現するPaaSです。
極端な話をすると、nowと打つだけでデプロイが完了するくらいに簡単です。
他のPaaSと同様に、Node.js、Python、Goといった様々な言語が使用できフロントエンド、バックエンドのデプロイが可能です。
またデプロイ時に固有のURLが発行され、HTTPSのアクセスが可能です。"やったこと①
GASを使ってLINEと連携させる!
体験学習のときの復習。天気APIを取得してLINEで通知
応用編:Slackと連携させる
やったこと②
nowのインストール
nowとは
https://dev.classmethod.jp/server-side/serverless/zero-configuration-zeit-now
一言でいうと、シンプルで簡単にそして高速なデプロイを実現するPaaSです。
極端な話をすると、nowと打つだけでデプロイが完了するくらいに簡単です。他のPaaSと同様に、Node.js、Python、Goといった様々な言語が使用できフロントエンド、バックエンドのデプロイが可能です。
またデプロイ時に固有のURLが発行され、HTTPSのアクセスが可能です。インストール方法
1 .Visual Studio Code?のTerminaiにて下記実行
$ npm install -g now
$ yarn global add now
$ now login
$ nowし・か・し、npmが使えなかったため下記参考に
2.Node.jsのインストール
https://qiita.com/taiponrock/items/9001ae194571feb63a5e
3.yarnもインストール
4.ZEITサインアップ
"Production: https://**********.now.sh
と出ていれば成功です。URLをブラウザで開けるか確認してみてください。そして、開けていたら、Twitterで、「初めてのデプロイ #駆け出しエンジニア #TSfCM #初日」などと呟いてみましょう!"
↑ここまではできてつぶやいてもみたけど次のGithubでコード更新できなかった
やったこと③
Githubへコードを上げる
gitのインストール
https://gitforwindows.org/ここでも上げれたように見えて、実態ファイルがなかった
先生にがんばっていただいてVSコードのterminalでいろいろ
そのhistory
1 git init
2 git add .
3 git commit -m "first commit"
4 git remote add origin https://github.com/honasa21/tsfcm_01.git
5 git push -u origin master
6 git init
7 git commit -m "second commit"
8 git add.
9 git add .
10 git push -u origin master
11 git init
12 git add .
13 git commit -m "first"
14 git push -u origin master
15 git remote add origin https://github.com/honasa21/firstGit.git
16 git push -u origin master
17 history
18 nownowはVSコードからだとエラーになるのでcmdから実行
C:\Users\”※姓名”\Desktop\DAY1_20200307の階層知ったこと
HTML書き方
CSS
JavaScript
デプロイの仕方
プログレッシブ・エンハンスメント
重要度
html > css > JavaScriptなぜ??
https://ja.wikipedia.org/wiki/%E3%83%97%E3%83%AD%E3%82%B0%E3%83%AC%E3%83%83%E3%82%B7%E3%83%96%E3%82%A8%E3%83%B3%E3%83%8F%E3%83%B3%E3%82%B9%E3%83%A1%E3%83%B3%E3%83%88
"プログレッシブエンハンスメントは、核となるコンテンツを最重要視するウェブデザイン戦略である。
この戦略では、エンドユーザーのブラウザーやインターネット接続に合わせて、プレゼンテーション面や機能面で微妙に異なる内容や技術的に困難な内容をコンテンツに漸次追加していく。
この戦略の利点として挙げられるのは、すべてのユーザーが任意のブラウザーまたはインターネット接続を用いてウェブページの基本的なコンテンツと機能性にアクセスできることと、
より高度なブラウザーソフトウェアまたはより広帯域の接続を有するユーザーには
同じページの拡張バージョンを提供できることである。"
- 投稿日:2020-03-10T21:38:37+09:00
GROWI に draw.io 連携機能を PR (Pull Request)して v3.7.0-RC としてリリースされた話
はじめに
GROWI に draw.io 連携機能を実装して Pull Request し、無事マージされて、バージョン 3.7.0 RC(Release Candidate) としてリリースされました!
(今は docker image のみ提供されてます)
weseek/growi Add draw.io Integration #1685
使い方のドキュメントはこちらです。
draw.io で様々な図を作成する | GROWI Docs
この記事では簡単な機能紹介と実装のモチベーション、どうやって実装したかなどをお話しようと思います。
GROWI って何?
株式会社 WESEEK が OSS として開発している Markdown で書ける Wiki です。
- 公式 HP
- ドキュメント
- クラウド(SaaS)版
技術スタックは下記の通り、わりと鉄板な構成です
- React
- webpack
- Express
- MongoDB
- etc ...
どういうことができるようになったの?
PR に掲載しているアニメーション GIF を置いておきます。
端的に言うと下記の項目が一通りできるようになりました。
- 編集画面から、ツールバーの draw.io アイコンをクリックすることで図を追加できる
- 追加した draw.io の図がページ表示画面で表示できる
- draw.io の図を2通りの方法で編集できる
- ページ表示画面で「編集」ボタンから図の編集ができる
- 編集画面で画面左側にあるエディタ上で Base64 エンコードされた箇所にカーソルを合わせて、ツールバーの draw.io アイコンをクリックすることで既存の図が編集できる
作ったモチベーション
GROWI には元々 PlantUML で UML 図を描画できる機能 や blockdiag で図を描画できる機能 が搭載されていました。
「これでめっちゃドキュメント書き放題やんけ!」と思っていたのですが、やはり記法を覚えないといけなかったり、自分で図のカスタムを行いたいときの不自由さが目につきました。
また、 Twitter や Qiita で GROWI の反応を見ると、作図機能を使おうと試行錯誤してくれている方は結構居るものの「使いづらいかもしれん ... (´・ω・`)」という気持ちが湧きました。といいつつ、blockdiag の図を生成する機能を追加したのも自分なんですが。 (PR はこちら)
アレコレ考えるうちに、「図はやっぱり見たまま編集できる (WYSIWYG) 方法が一番だろ!」という至極シンプルな理由で実装することを決めました。
また、実装中何度も心が折れかけましたが、 Qiita で draw.io の使い方の解説記事が公開されて「これは実装しきるしかない!」と後押しされた、というのも最後まで完成させる大きなモチベーションになりました。
また、 draw.io の図が GROWI で管理できるようになると、ページの「更新履歴」タブから過去の図を復元できるため、GROWI の仕組みを上手く活かせるのも嬉しいポイントですね
完成に至るまでの道のり
ここからはどのように実装していったかの経緯を書いておきます。
1. draw.io の図をテキスト形式で表現できないか調べる
GROWI の編集画面は WYSIWYG 形式ではなく、テキスト形式を想定していますので、Markdown 内にバイナリデータを埋め込もうとしても、その表現方法がありません。
そのため、テキストで埋め込む形式をまず調べる必要があります。Google さんにお尋ねしてもあまりいい答えは返ってこなかったため、 draw.io を提供している jgraph の github を調べることにしました。そこで、jgraph/drawio-integration という目的に合ったものが見つかったため、このソースコードを見つつ、テキスト形式で表現できることが分かりました。
コードでいうと ここらへん
大分ざっくり話しますが、バイナリ形式を Base64 化した形式で表現していることが分かります。
2. draw.io の仕組みについて調べる
draw.io の図のサンプルを見ながら、データ形式を探っていきます。
さらにデータ形式を解釈して図として変換してくれる JS が draw.io のコードのどこに該当するかを見つけるために、コードを読み進めていきます。 GraphViewer.js というものがデータを解釈して、図として変換してくれることが分かったため、この JS を使ってプレビューを行うことが分かりました。
実際にビルドされたソースは viewer.min.js という最適化された形の JS です。
ここまで分かれば「特定の HTML タグに Base64 化されたデータを埋め込んで、 viewer.min.js に食わせれば
表示ができる」というところまで到達できます。(実際もっと途方も無い時間がかかってますが)その後に小さなプロトタイプを HTML と JS で作り、自分の仮定が上手く行っていることを確認しました。
3. markdown-it が draw.io のデータを食って、特定のタグを吐けるような npm パッケージ を作る
プロトタイプ実装後、 GROWI にすべての担当をお任せすることはコード量が増えることを懸念し、 「draw.io のデータを食わせると、特定のタグを吐かせる markdown-it のプラグインを担当」する npm パッケージを作りました。かなり端折ってるので、詳しく知りたい方は質問していただけると。
- ソースコード: https://github.com/kaishuu0123/markdown-it-drawio-viewer
- 実行サンプル: https://runkit.com/embed/c8zmotx8yypi
入力
::: drawio (ここに draw.io のデータ(Base64 エンコードされたもの)が入る) :::出力
<div class="drawio-viewer-index-0 markdownItDrawioViewer" data-begin-line-number-of-markdown="2" data-end-line-number-of-markdown="6"> <div class="mxgraph" style="max-width: 100%; border: 1px solid transparent" data-mxgraph="{"editable":false,"highlight":"#0000ff","nav":false,"toolbar":null,"edit":null,"resize":true,"lightbox":"open","xml":"<?xml version=\"1.0\" encoding=\"UTF-8\"?>\n<mxfile userAgent=\"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36\" version=\"6.8.9\" editor=\"www.draw.io\" type=\"atlas\"><mxAtlasLibraries/><diagram name=\"Page-1\" id=\"bac0fdb4-bee4-c619-222c-02e826218fb6\">1VtNk5s4EP01vqYQAhsfY2eS3UMqqfJu7eaowQooAeQI4Y/99SsGgXELJw7GoPHBhRrRkl4/ulste4bX6fGDILv4I9/SZOY62+MMv5u5brBcqO9ScKoEfhBUgkiwbSVCZ8GG/Ue10NHSgm1pftFRcp5ItrsUhjzLaCgvZEQIfrjs9pUnl6PuSKRHdM6CTUgSanT7h21lrJflt3r/QVkU1yMjR995JuH3SPAi0+PNXPz15VPdTkmtS/fPY7Llh5YIP83wWnAuq6v0uKZJCW0NW/Xc+yt3m3kLmslbHnCrB/YkKfTS3zESCZLq6clTDckhZpJudiQs2wdl9Rle5VLw7w1CWElimSbqEqlLcyp6dnsqJD22RHpqHyhPqRQn1UXf9eYaJk0jTzcPZ5ugGsm4ZY/6MaJpEDWaz1CoC41GNzLYQGYjRRHKQtCZO1d2VVzFK5vQat4ejRYaEy7PgGtFY7JnvBCWwhVMCZdvwLVOSJ4rkU0QLS8Rcv0REZqbCPF0x3OFQotQtr+TgGM4GBHBhYHgZxWdyshnJ1YYTwhWYAZCukv4KS3XYydeaDEhXsvu1zOzF67Ge03hzWo/0MLr0/O3MnW1EywPTQkWMsB6G0q2Z/JkKVx+MCVcZhL/ZyapIAoznlmK2AJPiZiZ3P+dq7DorElua3QMJqWYmd5vJCkzMecjCWOW2YoaciblmZnmb+iPgmahrXhBRzZqToE6c/60yFhIXpErGxczM8vvdv6f1IL2jB4sBRG6t3FBNLP/v1jKsshSsAyvNi5aZu5voEK3Ed3oJk2e+eHpLFi9CNSNcsHq1VbjrF5KprQcwLkRrZwXItSj6XAuiYio7qWnVM7jp4i2AXM6AGuEgibKCe0vC8RdMOoxPnNWboWulFKavVutoVqOfuhsC0MPAoqgngoDQ8+LTZtl32Tmmj72mNmz38w+LJm5Pe08h4SBigY0tLndmtjQvmlobJmhYVqJ+77PQBGCiq7Y+a0Q5NTqtis75Nfni2D14/JgSF1UGnuTyNyE3k0iemTy35JCb3zd+qIJpcgjTq1bZfOLZth91Fu+Ouo15xb3Ug/qGYh5xinC0MwzN/MTu6+6dmYzifyh8hG/Vz7yuyTCiweTyCxwTEyiuf0cgo5oOZAjgnqGCoGPdkRmtedVhsDAfuYBS/q9mQcUeQ+innH2NDT1zMrZ/dT7CcGu0/I+6i3spx50erCi0tfpQT1DBU7vwcwz648TB8769LBNIs8yEvngh21u0JNFc6AIQUUD0WgBJzw0jcwK7NQ06qg22UYjD54J9o2D8NjHSOUGotESTnhoGj2gND1FHKyP9G0mn3/tZPW3fRgMqVDRQOQL4IQHJl+t/tWTr+M4xTryOQN5vrkzkueDP6gamnzWFfFRRxW/9mvW8MiDO8m+Tgwe/Hg3OrE+pnatM3VHsco6U89B7uH33bktgCLvxq1bH1PbV9vu2KLbZ2o0lKnReKa2rgKNOgqB1pka+l2/904aOvAbd9K/NrVqnv/QV3U//2kSP/0P</diagram></mxfile>"}"></div> </div>4. GROWI に実装
この実装を行う際には GROWI のメンテナである @yuki-takei さんに GROWI でのレンダリングの仕組みなどを教えていただきつつ、実装を行いました。ありがとうございます
- draw.io エディタの起動方法を調べて、iframe 内で draw.io エディタを表示して
position: fixedで既存画面に被るように表示し、 iframe と GROWI 間でデータが受け渡せるように実装したり- 不用意に再レンダリングが走らないように GROWI の lsx プラグインなどと同様に draw.io の図を React コンポーネント化したり
- Table 編集機能と同じようにページ表示部分から「編集」ボタンを押すことで、図の更新ができるようにしたり
- 既存の仕組みに乗っかるようなコード構成に大修正したり
と GROWI に組み込む際にもそこそこのコード量になりました。( PR の内容 )
アドバイスもあり、とてもシンプルな形で機能を追加できたんじゃないかなと思っています。
今後の課題
- やっぱり図が大きくなればなるほど、レンダリングが遅くなるんじゃないか、という不安
- これは実際に使ってみてもらってから様子を見ればいいかな、と思っています
- 最悪、図を他のページに分割して保存するという方法で回避していただく方向で ...
- エディタ画面に Base64 エンコードした文字列がそのまま書かれるのは分かりづらい
- これはエディタの折りたたみ機能を使って、なるべく Base64 エンコードされた文字列が意識されないようにできるといいかなぁと思っています。
- 本当は添付ファイルを CRUD できる機能が GROWI にあれば、 draw.io の図は画像みたいな取り扱いができるっちゃできるんですが、それはそれで実装コストが高すぎる気がするので
最後に
draw.io の仕組みを理解するまでに結構な時間がかかりましたが、 Markdown に draw.io の図を埋め込める機能が作れた経験は貴重でした
また、 draw.io に関する様々なノウハウを得ることができました。(データ構造や viewer.min.js の仕組みなどは今回の記事ではめちゃくちゃ端折っています)Visual Studio Code の拡張機能に応用できたりするかもしれません。
皆さんも是非今回実装した機能を使ってみてください
- 投稿日:2020-03-10T21:20:56+09:00
Firefoxを改造してみようハンズオン
Firefoxの改造を通してコントリビューター(特にN高生)を増やそうという記事です。
今回の改造ではFirefoxに隠しコマンドを追加します。HTMLとJavaScriptを使うので、N予備校のプログラミング入門コースを終えている人が対象です。
何か分からない事があれば、僕にSlack(圧倒的初心者の極み)かTwitter(u7693)で聞いてください。
とりあえずビルドしてみる
改造する前にFirefoxをビルドできるか確認します。
OSによって変わってきますが、大まかな流れは以下の通りです。詳細はBuilding Firefox - Mozilla | MDNを見てください。# ソースコードをとってくる $ hg clone https://hg.mozilla.org/mozilla-central/ $ cd mozilla-central # 依存関係のインストール $ ./mach bootstrap # ビルド $ ./mach build # 動かす $ ./mach run今回はC、C++、Rustのコードを変更しないので、Artifact buildsを設定することでビルド時間が短縮されます。
目標の確認
今回作るのはAboutダイアログでコナミコマンドを実行するとアラートが表示されるという機能です。
下の画像をクリックするとYouTubeで完成品の動画を視聴できます。
改造する
Aboutダイアログのソースコードを探す
まずはAboutダイアログのソースコードを見つけましょう。
見つける方法は色々あると思いますが、今回はダイアログ内の文字列を使って見つけます。Firefoxで使われている文字列の中でAboutダイアログでしか使われていないものを検索し、該当のソースコードを見つけます。
例えば上の画像にもある「参加しませんか?」という文字列で検索してみましょう。先ほど取得したリポジトリやソースコード閲覧ツール『Mozilla DXR』を使って検索してみてください。おそらく見つからないでしょう。
文字列を使って検索するにはコツが必要です。
「参加しませんか?」という文字列は日本語です。Firefoxは多言語対応なので他にも様々な言語がありますが、それらは全て別のリポジトリで管理されています。皆さんが先ほど取得したリポジトリはFirefox自体のリポジトリ『mozilla-central』で、これには英語版だけが管理されています。
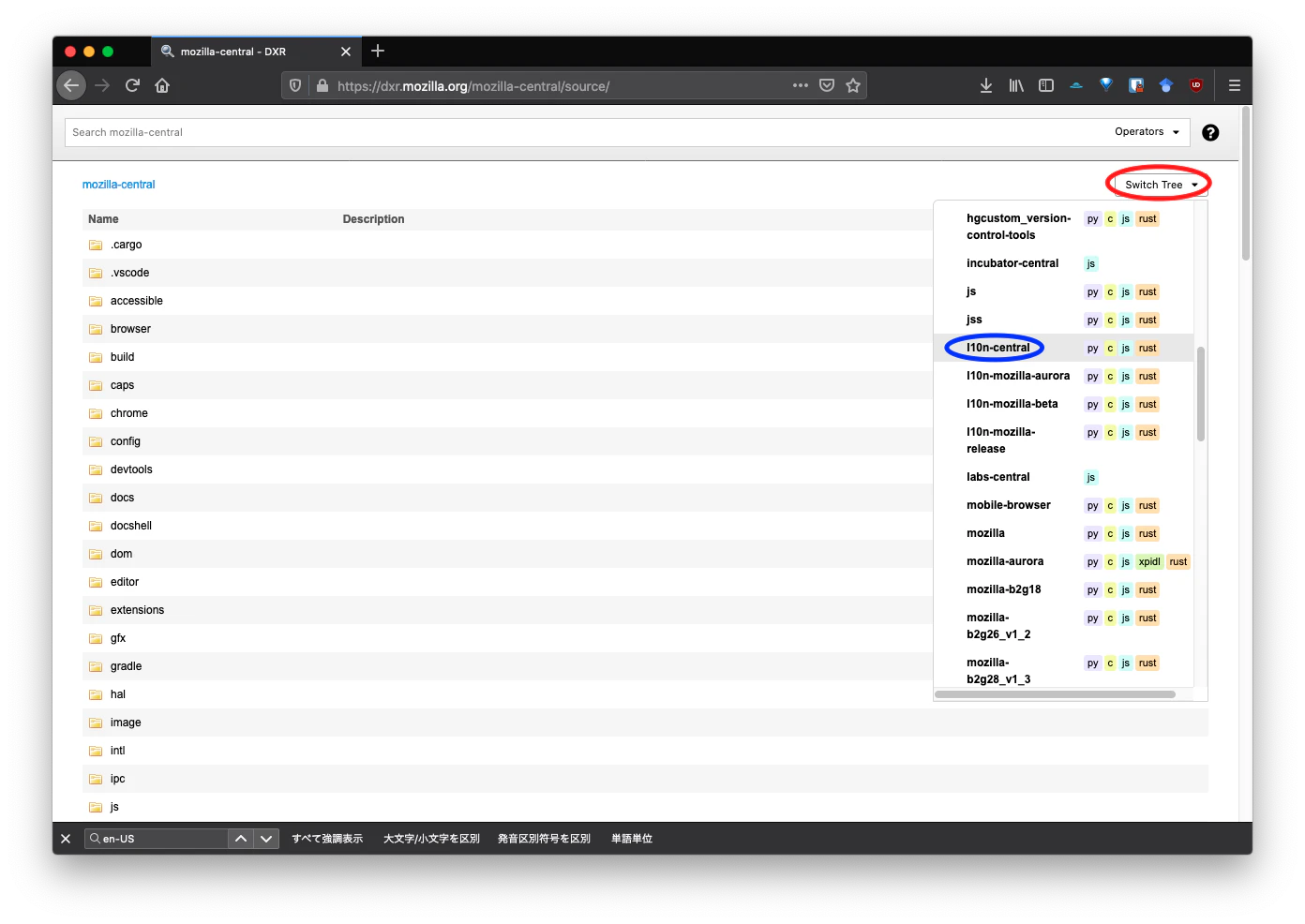
よって文字列を使って検索する場合は、英語で検索するか翻訳したテキストを管理するリポジトリ『l10n-central』を検索する必要があります。先ほど紹介したMozilla DXRというツールはMozillaの様々なリポジトリを閲覧でき、もちろんl10nのリポジトリも閲覧できます。
Switch Treeからl10n-centralを選択してリポジトリを切り替えてください。
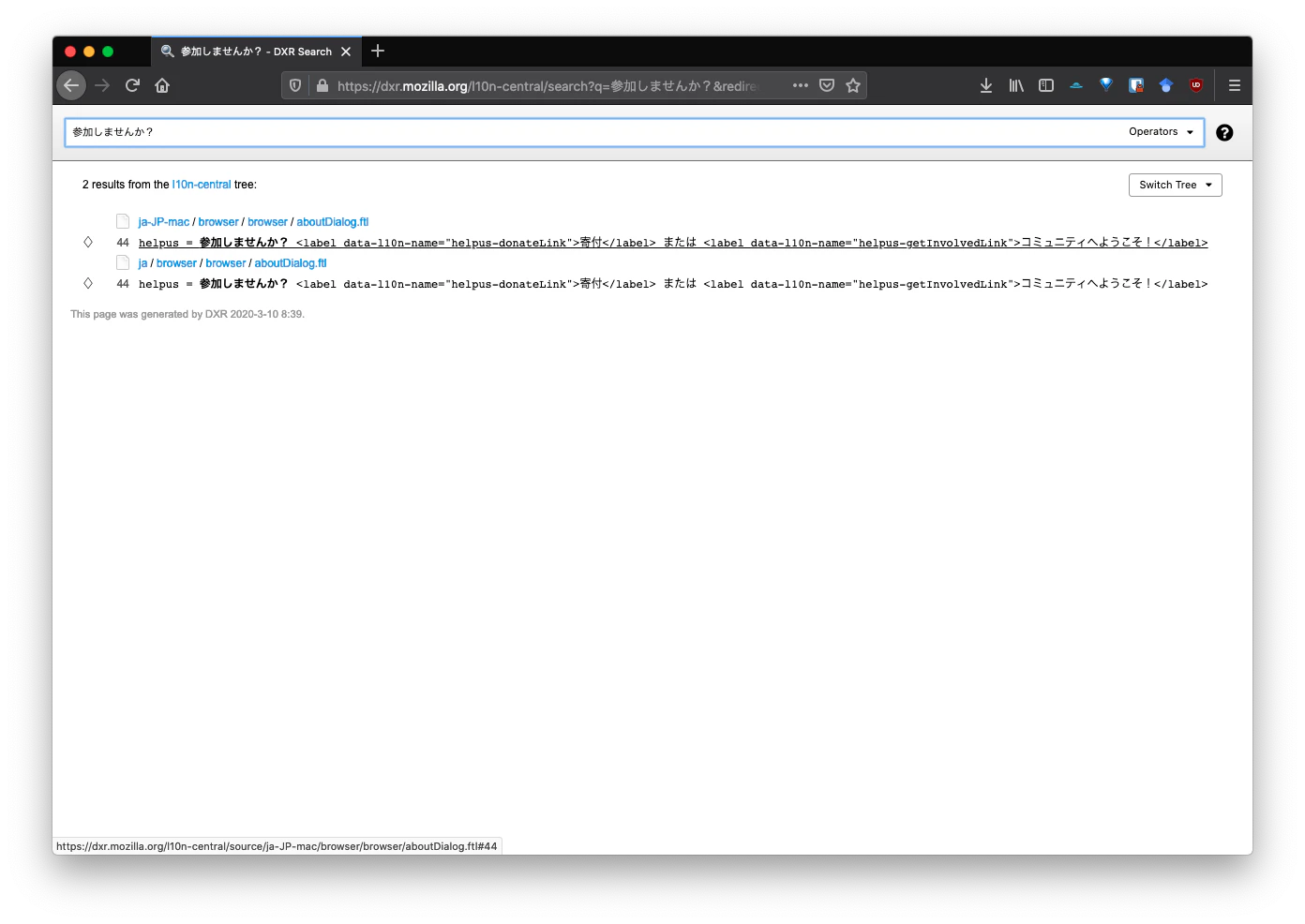
ここで「参加しませんか?」という文字列を検索してみましょう。
出てきましたね。どうやら「参加しませんか?」という文字列は
helpusという文字列の一部だったようです。この
helpusというのはl10nデータを指定するためのIDです。
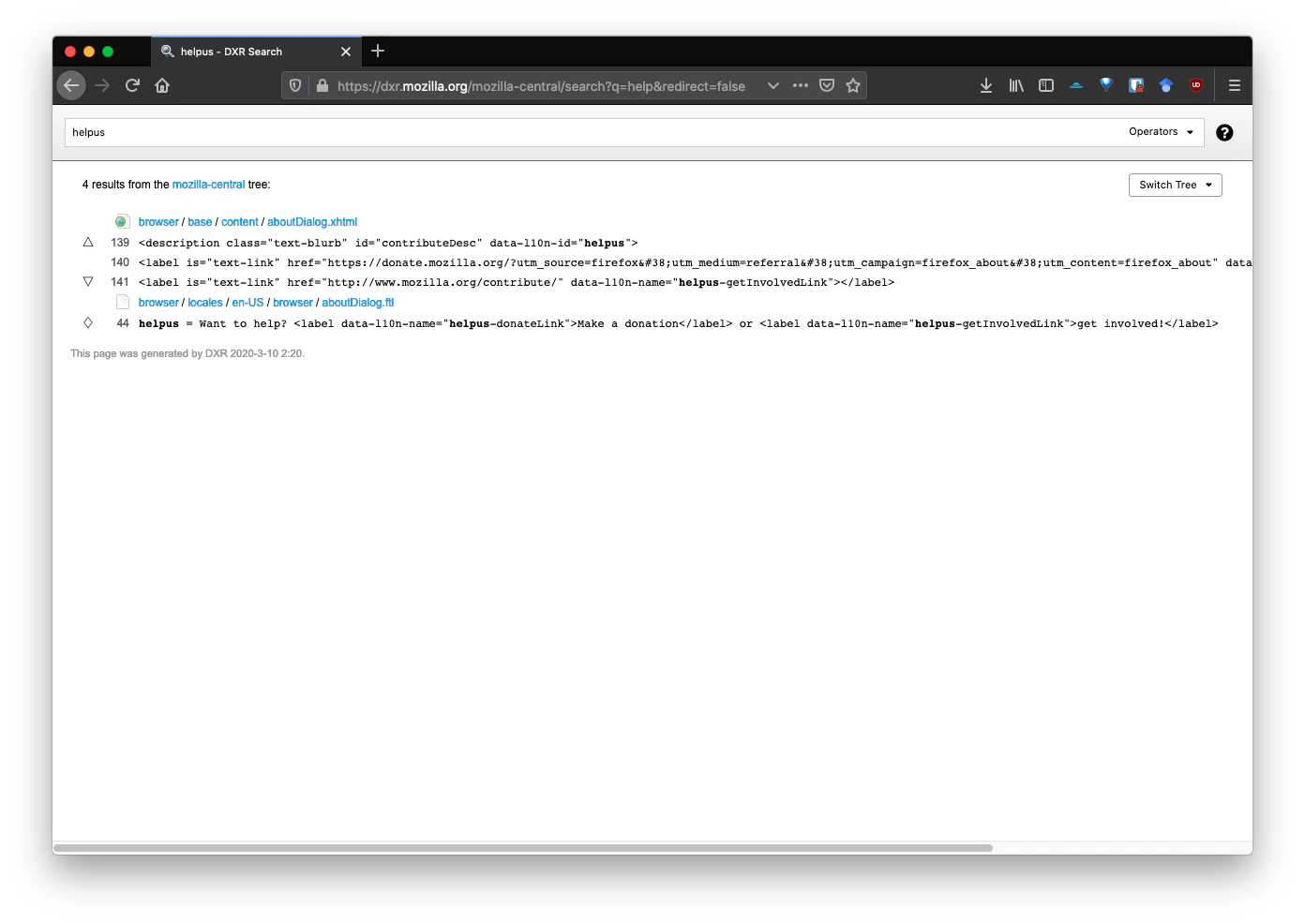
今度はmozilla-centralでhelpusを検索してみましょう。
Aboutダイアログのソースコードとl10nの英語データが出てきました。
これでAboutダイアログのソースコードはaboutDialog.xhtmlだと分かりました。念のために
aboutDialog.xhtmlを変更して確認してみましょう。
helpusを含むdescriptionタグを削除してビルドした後、Aboutダイアログから消えるか確かめてみてください。
ちゃんと消えていますね!!
コナミコマンドを実装してみる
Aboutダイアログにコナミコマンドを実装してみましょう。
aboutDialog.xhtmlを読んでいくとJavaScriptやCSSのファイルを読み込んでいるのが分かりますが、パスがよく分かりません。例えばchrome://browser/content/aboutDialog.jsというURLはソースコードではどのファイルなのでしょうか。このURLを定義しているファイルは場合によりますが、
aboutDialog.jsの場合はbrowser/base/jar.mnに定義されています。
jar.mnはJAR Manifestsのことでchrome://で始まるファイルを登録するのに使います。詳しくはJAR Manifests - Mozilla Source Tree Docsを見てください。
これでaboutDialog.jsはbrowser/base/content/aboutDialog.jsにある事がわかりました。では
aboutDialog.jsにコナミコマンドを実装していきましょう。コナミコマンドの実装については詳しく書きませんが、patchファイルを貼っておきます。Gist: u7693/Firefox_KonamiCode.patch
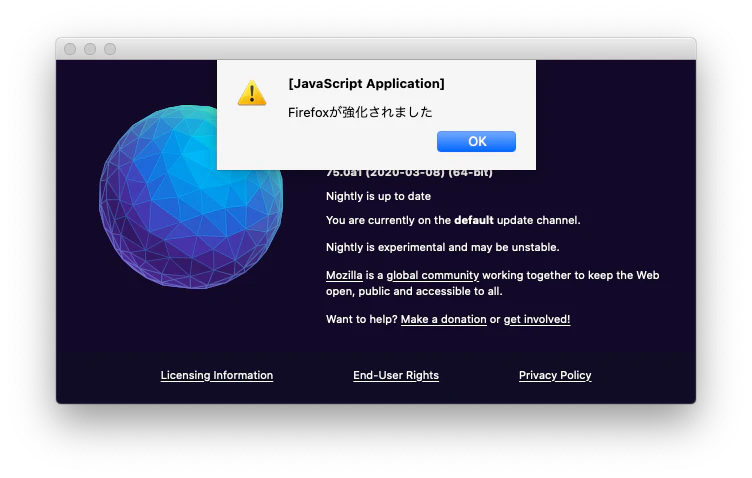
diff --git a/browser/base/content/aboutDialog.js b/browser/base/content/aboutDialog.js --- a/browser/base/content/aboutDialog.js +++ b/browser/base/content/aboutDialog.js @@ -12,6 +12,21 @@ var { AppConstants } = ChromeUtils.impor "resource://gre/modules/AppConstants.jsm" ); +const konamiCode = [38, 38, 40, 40, 37, 39, 37, 39, 66, 65]; +let konamiCodePos = 0; + +document.addEventListener("keydown", function(event) { + if (event.keyCode == konamiCode[konamiCodePos]) { + konamiCodePos++; + if (konamiCodePos == konamiCode.length) { + alert("Firefoxが強化されました"); + konamiCodePos = 0; + } + } else { + konamiCodePos = 0; + } +}); + async function init(aEvent) { if (aEvent.target != document) { return;ビルドして実行してみましょう。
無事コナミコマンドが実装できました!!


- 投稿日:2020-03-10T21:19:15+09:00
Vuetifyのv-data-tableで階層構造のデータを検索できるようにする
最近はAngularからVue.jsに浮気中の8amjpです。Vue.jsめっちゃ楽しいです。
v-data-tableコンポーネントを使う
さて、下記のようなデータがあるとします。
(ちなみにこのデータ、Zabbix APIで取得できるホスト一覧データから抜粋したものです)[ { "hostid": "1", "host": "Server 1", "description": "サーバ1号機", "parentTemplates": [ { "name": "Windows Servers", "templateid": "1" }, { "name": "Web Servers", "templateid": "2" } ], "interfaces": [ { "interfaceid": "1", "ip": "192.168.1.1", "port": "80", } ] }, { ....よくあるタイプのJSONデータですね。
parentTemplatesやinterfacesといった項目が配列になっており、その中に複数の子オブジェクトが格納されている……という階層構造になっています。さて、このデータを、Vuetifyのv-data-tableコンポーネントを使って表示すると、こんな感じになると思います。
<template> <v-data-table :headers="headers" :items="items" :search="search"> <template v-slot:top> <v-text-field v-model="search" append-icon="mdi-magnify" label="Search" single-line/> </template> <template v-slot:item.parentTemplates="{ item }"> <div v-for="i in item.parentTemplates" :key="i.templateid">{{ i.name }}</div> </template> <template v-slot:item.interfaces="{ item }"> <div v-for="i in item.interfaces" :key="i.interfaceid">{{ i.ip }}:{{ i.port }}</div> </template> </v-data-table> </template> <script> export default { props: ['items'], data () { return { search: '', headers: [ { text: 'ホスト名', value: 'host', }, { text: '説明', value: 'description', }, { text: 'テンプレート', value: 'parentTemplates', }, { text: 'インターフェース', value: 'interfaces', }, ] } }, } </script>階層構造のデータは、そのままだと表示できないので、
item.<name>スロットを使ってv-forですべてのデータを表示したりします。便利ですねー。カスタムフィルタを使う
さて、ここから本題。
v-data-tableは、データを簡単にフィルタリングするためにsearchプロパティが用意されています。
バインドされたテキストフィールドに文字を入力すると、その文字列が含まれる行のみをフィルタリングできます。よくある機能ではありますが、最初から用意されていると実装もとても簡単。ところが、です。前述のデータで言うと、
hostやdescriptionなどの項目はフィルタリングできるのですが、parentTemplatesやinterfacesの項目に含まれるデータはフィルタリングができません。例えば、「Windows」というキーワードを入力してもヒットしません。
理由はもちろん、文字列じゃないから。さすがに配列の中身までは検索してくれません。
こういう時こそカスタムフィルタの出番です。標準のフィルタを確認する
まずは、標準のフィルタがどういう動きをしているのか確認します。
function defaultFilter(value, search, item) { return value != null && search != null && typeof value !== 'boolean' && value.toString().toLocaleLowerCase().indexOf(search.toLocaleLowerCase()) !== -1; }この中の
valueという変数に、JSONデータの「値」の部分が入るんですけど。
値が配列の場合でも、うまい具合に文字列に変換して渡すことで、なんとかなりそうな感じがします。では実際にやってみましょう。
v-data-tableのcustom-filterプロパティに独自のメソッドを追加することで、動作を上書きすることができるんです。
まずはcustom-filterプロパティを追加して、独自のメソッドを指定します。<v-data-table :headers="headers" :items="items" :search="search" :custom-filter="customFilter">で、追加したメソッドで、フィルタリングの動作を上書きします。こんな感じで。
methods: { customFilter (value, search) { return value != null && search != null && typeof value !== 'boolean' && // value.toString().toLocaleLowerCase().indexOf(search.toLocaleLowerCase()) !== -1; (typeof value === 'object' ? value.map(v => v.name).join('\t') : value) .toString().toLocaleLowerCase().indexOf(search.toLocaleLowerCase()) !== -1; }, },まず、変数
value(=JSONデータの「値」)の型をtypeof演算子で判定します。
で、objectだった場合は配列とみなし、.mapメソッドで配列内のnameプロパティのみを抽出して、タブ文字で連結して単一の文字列にしています。
このように、単一の文字列にしてしまうことで、検索ができるようになります。
(当然ながら、typeofでobjectが返ってきても、配列じゃない場合もあるんですけど。その辺は使用するデータに応じて各自いい感じに処理を分岐してくださいね(丸投げ))ついでに、
interfaces配列内のipプロパティも検索対象に含めたい場合は、こんな感じでどうでしょうか。(typeof value === 'object' ? value.map(v => v.name || v.ip).join('\t') : value) .toString().toLocaleLowerCase().indexOf(search.toLocaleLowerCase()) !== -1;完成
完成品はこちらです。わーい。
<template> <v-data-table :headers="headers" :items="items" :search="search" :custom-filter="customFilter"> <template v-slot:top> <v-text-field v-model="search" append-icon="mdi-magnify" label="Search" single-line/> </template> <template v-slot:item.parentTemplates="{ item }"> <div v-for="i in item.parentTemplates" :key="i.templateid">{{ i.name }}</div> </template> <template v-slot:item.interfaces="{ item }"> <div v-for="i in item.interfaces" :key="i.interfaceid">{{ i.ip }}:{{ i.port }}</div> </template> </v-data-table> </template> <script> export default { props: ['items'], data () { return { search: '', headers: [ { text: 'ホスト名', value: 'host', }, { text: '説明', value: 'description', }, { text: 'テンプレート', value: 'parentTemplates', }, { text: 'インターフェース', value: 'interfaces', }, ] } }, methods: { customFilter (value, search) { return value != null && search != null && typeof value !== 'boolean' && (typeof value === 'object' ? value.map(v => v.name || v.ip).join('\t') : value) .toString().toLocaleLowerCase().indexOf(search.toLocaleLowerCase()) !== -1; }, }, } </script>
- 投稿日:2020-03-10T20:52:55+09:00
ES2019で追加されたflatMap()の使いどころ
はじめに
ES2019のアップデートで配列のメソッドflatMap()が追加されました。
はじめてflatMap()を見たときは「これはどんなときに使うのだろう」と思いました。
私のようにflatMap()をいつ使うのかピンと来ていない方も多いと思います。しかし調べていくうちに色々使える事がわかったので、flatMap()の使いどころをご紹介します。
flat()とは
まず事前知識として同じくES2019で追加されたflat()について説明します。
flat()は配列のメソッドで、自身の配列の次元を1つ下げたものを返します。2次元配列を1次元配列に変換const example1 = [ [1, 2, 3], [4, 5, 6], [7, 8, 9], ]; example1.flat(); // 実行結果:[1, 2, 3, 4, 5, 6, 7, 8, 9] const example2 = [ 1, 2, 3, [4, 5, 6], [[7], [8], [9]], ]; example2.flat(); // 実行結果:[1, 2, 3, 4, 5, 6, [7], [8], [9]] const example3 = [ 1, 2, 3, 4, 5, 6, 7, 8, 9, ]; example3.flat(); // 実行結果:[1, 2, 3, 4, 5, 6, 7, 8, 9] // 1次元配列の場合はそのままflatMap()メソッドとは
flatMap()はmap()とflat()を合成したメソッドです。
array.flatMap(callback)はarray.map(callback).flat()と同じ意味になります。const array = [1, 2, 3]; const callback = element => [element]; array.flatMap(callback); // 実行結果:[1, 2, 3] // 1. 関数callbackで配列の要素を配列にラップする // [1, 2, 3] => [[1], [2], [3]] // 2. 次元を1つ下げる // [[1], [2], [3]] => [1, 2, 3]また、以下のようにmap(), flat(), flatMap()を呼び出すと同じ意味になります。
const array = [1, 2, 3]; // すべて同じ結果になる array.map(element => element); array.map(element => [element]).flat(); array.flatMap(element => [element])flatMap()でできること
map()を利用すると配列の要素の値を変更することができました。
一方で配列の要素を増やしたり、減らしたりするような配列の構造を変える操作はできませんでした。この配列の構造を変える操作をしたいときにflatMap()が役立ちます。
callback関数の戻り値を工夫することで要素を増やしたり減らしたりすることができます。
具体的にどうやったら実現できるか見ていきます。配列の要素を増やす
callback関数の戻り値に大きさが2以上の配列を返すと、呼び出し元の配列よりも長さが大きい配列を作ることができます。
下のコード例では配列の要素を2つに複製しています。
配列の要素を2つに複製するconst array = [1, 2, 3] const callback = element => [element, element] array.flatMap(callback); // 実行結果:[1, 1, 2, 2, 3, 3] // 1. 関数callbackの処理 // [1, 2, 3] => [[1, 1], [2, 2], [3, 3]] // 2. 次元を1つ下げる // [[1, 1], [2, 2], [3, 3]] => [1, 1, 2, 2, 3, 3]要素を削除する
要素を削除したい場合はcallback関数が空配列[]を返すようにします。
下のコード例では引数が奇数ならば空配列を返す関数をcallback関数にすることで、奇数の要素を配列から削除することを実現しています。
奇数の要素を削除するconst array = [1, 2, 3] const callback = element => element % 2 == 0 ? [] : [element] array.flatMap(callback); // [2] // 1. 関数callbackの処理 // [1, 2, 3] => [[], [2], []] // 2. 次元を1つ下げる // [[], [2], []] => [2]要素の次元を下げる
要素の次元を下げたい場合はcallback関数が引数をそのまま返すことで実現できます。
要素の次元を1つ下げるconst array = [1, [2], [[3]]]; const callback = element => element; array.flatMap(callback); // [1, 2, [3]] // 1. 関数callbackの処理 // [1, [2], [[3]]] => [1, [2], [[3]]] // 2. 次元を1つ下げる // [1, [2], [[3]]] => [1, 2, [3]]flatMap()で複雑な処理
flatMap()を使うことで配列に複雑な処理行いたいときでも、callback関数の中だけで完結できるようになります。
下の例はMDNのサイトから引用したflatMap()のコード例です。
const a = [5, 4, -3, 20, 17, -33, -4, 18] // |\ \ x | | \ x x | // [4,1, 4, 20, 16, 1, 18] a.flatMap((n) => (n < 0) ? [] : (n % 2 == 0) ? [n] : [n-1, 1] )上の例をflatMap()を使わないで書く場合は、filter()とreducer()を駆使して以下のように書くことができます。
ですがflatMap()を使ったほうがロジックがわかりやすく、可読性の高いコードになっています。a.filter(n => !(n < 0)).reduce((pre, n) => { if(n % 2 == 0) { return [...pre, n] } return [...pre, n - 1, 1] }, [])まとめ
- flatMap()はmap()とflat()の合成メソッド
- flatMap()を使うと配列の要素を増やしたり減らしたりできる
- 配列に複雑の処理を行いたいときはflatMap()を使ってシンプルに書ける
- flatMap()はmap()の上位互換
- 投稿日:2020-03-10T19:33:17+09:00
【Django】axiosを使って自作Like機能を作ってみた
はじめに
今回はDjangoで作ったWebサイトにaxiosを使っていいね機能が作れないかと調べてみました。
案の定、Ajaxを使うか画面リロード付きいいね機能の作り方しかなかったので、参考サイトを見ながらaxiosでいいね機能を作ってみました。参考サイト
いいね機能を実装したサイトのチュートリアルサイト
https://tutorial.djangogirls.org/ja/
いいね機能参考
https://jyouj.hatenablog.com/entry/2018/07/22/232911
本題
記事の順序に従って実装していきます。
この機能が欲しい人はそこそこコードを読めると信じているので簡単な説明は省きました。Model.py
PostクラスなどはDjango Girls Tutorialのモデルを参照しています。
from django.db import models from django.conf import settings from django.utils import timezone from django.contrib.auth.models import User #追加 class Post(models.Model): author = models.ForeignKey(settings.AUTH_USER_MODEL, on_delete=models.CASCADE) title = models.CharField(max_length=200) text = models.TextField() created_at = models.DateTimeField(default=timezone.now) published_date = models.DateTimeField(blank=True, null=True) like_num = models.IntegerField(default=0) #追加 def publish(self): self.published_date = timezone.now() self.save() def __str__(self): return self.title 以下コードがいいね機能モデル ↓追加 class Like(models.Model): user = models.ForeignKey(User, on_delete=models.CASCADE, related_name='like_user') post = models.ForeignKey(Post, on_delete=models.CASCADE)View.py
今回はクラスベースで書いていますので、関数ベースで作りたい方は工夫してください
#like#unlikeのJsonResponseの引数に関しては渡したいJsonデータを設定してくださいclass Like_Detail(View): def get(self, request, pk, *args, **kwargs): post = Post.objects.get(id=pk) is_like = Like.objects.filter(user=self.request.user).filter(post=post).count() # unlike if is_like > 0: liking = Like.objects.get(post__id=pk, user=self.request.user) liking.delete() post.like_num -= 1 post.save() post = get_object_or_404(Post, pk=pk) json = {'like_value': post.like_num} #ここのJsonデータに関してはご自由に return JsonResponse(json) # like post.like_num += 1 post.save() like = Like() like.user = self.request.user like.post = post like.save() post = get_object_or_404(Post, pk=pk) json = {'like_value': post.like_num} #ここのJsonデータに関してはご自由に return JsonResponse(json)URL.py
from django.urls import path from . import views from .views import Like_Detail # View.pyで設定したクラス名をインポートさせてください app_name = 'application' #アプリケーション名で合わせてください urlpatterns = [ path('', views.post_list, name='post_list'), path('post/<int:pk>/', views.post_detail, name='post_detail'), path('post/new/', views.post_new, name='post_new'), path('post/<int:pk>/edit/', views.post_edit, name='post_edit'), path('post/<int:pk>/like/',Like_Detail.as_view(), name='get'), #追加 ]POST_Detail.html
最後に一番重要なHTML内のJavaScript処理について説明します。
< 記事サイトに飛んだ時の処理の流れです >
1.記事詳細ページに飛んだClientユーザーの情報をView.pyに渡す様に命令をします。
2.Javascript側にView.py側から渡されたClientユーザーがいいねしているか、していないかと記事の総合いいね数の情報を受け取ります。
3.もし、記事に対してユーザーがいいねをしていない場合は<input>タグのclassにunlikeタグを追加します。(いいねしている場合はlikeを追加させる処理が書かれています。)< いいねボタンが押された際の処理の流れです >
1.いいねボタンを押すとaxiosを利用して画面リロードなしてリクエストを送ります。
2.View.py側でユーザーの記事のいいね処理を行います。
3.HTML側ではJavascriptが押されたら数値を変更するので毎回View.py側からデータを受け取る必要がなくなることになります{% extends 'application/base.html' %} {% block content %} <div class="post"> {% if post.published_date %} <div class="date"> {{ post.published_date }} </div> {% endif %} {% if user.is_authenticated %} <a class="btn btn-default" href="{% url 'application:post_edit' pk=post.pk %}"><span class="glyphicon glyphicon-pencil"></span></a> <script src="https://cdn.jsdelivr.net/npm/axios/dist/axios.min.js"></script> <input type="button" value="Check" onclick="like()" id="like-data"> いいね<span id="like-count">{{ post.like_num }}</span> <script> var likeinfo = {{ is_like }}; var likecount = {{ post.like_num }}; window.onload = function () { if (likeinfo > 0){ document.getElementById("like-data").classList.add("unlike"); }else{ document.getElementById("like-data").classList.add("like"); } }; var like = function () { const response = axios.get('/post/{{ post.pk }}/like/'); console.log(response); console.log( document.getElementById('like-count').innerText); if (likeinfo > 0){ likeinfo = likeinfo - 1; likecount = likecount - 1; document.getElementById('like-count').innerText=likecount; }else{ likeinfo = likeinfo + 1; likecount = likecount + 1; document.getElementById('like-count').innerText=likecount; } document.getElementById("like-data").classList.toggle("unlike"); document.getElementById("like-data").classList.toggle("like"); } </script> {% endif %} <h2>{{ post.title }}</h2> <p>{{ post.text|linebreaksbr }}</p> </div> {% endblock %}補足 CSS
<input>タグのclassにlikeやunlikeをタグで付け替える意味はいいねしているか、してないかでCSSのデザインを変更する設定をしているからです。.unlike { color:red; } .like { color: black; }最後に
自分用に書いてはいますが、
参考になりましたらいいね?よろしくお願いします。
色んな人に見ていただければ次回allauthに関しても書こうかなと思います。
- 投稿日:2020-03-10T19:32:39+09:00
Amazon Kinesis Video Streams WebRTC で無理やり複数人のビデオチャットを作る
はじめに
以前、Amazon Kinesis Video Streams WebRTC(以後 KVS WebRTC)を調べてみましたが、1対1か、1対nを前提にしていて、複数人の双方向ビデオチャットのような仕組みは対象にしていないことが分かりました。
できないと言われるとやりたくなるのが人のサガなので、あえて多人数のビデオチャットを作ってみました。KVS WebRTCの通信形態
以前の記事でも書いたように、KVS WebRTCではマスター(Master)1つと、複数のビューワー(Viewer)が通信することができます。図にすると次のような形です。
このままではViewer同士は通信できません。そこでMasterが仲立ちをして、すべてのViewerの映像を合成して返す形にすれば、Viewer同士で全員の映像を見ることができます。
MCUをブラウザで
先ほどの合成する形態はMCU(Multi-point Control Unit)と呼ばれる方式で、ビデオ会議システムでは以前から利用されてきた仕組みです。サーバーとしてMCUを用意することになりますが、のが一般的ですが、CPU負荷が重くサーバー費用が高くつくことが難点です。
このMCUをWebブラウザで手軽に作れるライブラリを作ったことを思い出して、今回KVS WebRTCと組み合わせてみました。
- Browser MCU Core ... GitHub
- ブラウザの映像/音声処理を活用した、MCUライブラリです
- WebRTC でやり取りする MediaStream を扱うために作成されています
- シグナリングや PeerConnection の処理は、Browser MCU Core には含まれていません
- Browser MCU with KVS WebRTC example ... GitHub
- Browser MCU Coreを使ったサンプル
- シグナリング処理はKVS WebRTCのWeb用 SDKを利用
- RTCPeerConnectionはSDKのサンプルを参考に自分で実装
サンプルを動かす
GitHub Pagesで公開しているので、すぐに試すことができます。サンプルはChrome 80で動作確認しています。
事前準備として、KVS WebRTCのシグナリングチャネルを作成しておく必要があります。
- ブラウザでラウンチャーページ を開く
- パラメータを指定する
- Region ... シグナリングチャネルを作成したリージョン
- ARN ... 作成したシグナリングチャネルのARN
- AccessKeyId ... 割り当てたIAMのアクセスキーID
- AccessSecretKey ... 割り当てたIAMのシークレットアクセスキー
- Masterを起動
- [open MCU master]ボタンをクリック
- 開いたウィンドウ/タブが開き、ボタンの横に" setup KVS done."と表示されれば初期化完了
- 開いたウィンドウ/タブで、[Connect]ボタンをクリック
- "-- signaling client open --" と表示されれば、KVS シグナリングチャネルに接続成功
- ※Masterのウィンドウ/タブは、完全に隠れてしまわないよう、別ウィンドウにしてどこかに表示しておく必要あり
- 完全に隠れてしまうと、画面更新(動画の描画)がポーズしてしまうため
- 最初のViewerを起動
- [open MCU member(viewer)]ボタンをクリック
- ※その時のURLを別マシンで開いてもOK
- 開いたウィンドウ/タブで、[start MCU member(offer)]ボタンをクリック
- カメラ/マイクへのアクセス許可を求められたら、許可
- 自分の映像と、MCU masterが合成した映像(最初は1人)が映ったら接続成功
- 2つ目以降のViewerを起動
- 1つ目と同様、合成した映像の人数が増えていく
- Viewerの切断
- [stop MCU member]ボタンをクリック
- Masterの切断
- [Disconnet]ボタンをクリック
これで無事、多人数でのビデオ会議ができます。
サンプルを編集する
サンプルをクローンして編集すれば、ARNやシークレットキーを利用者が入力しないで使えるようになります。
- レポジトリをクローン
- git clone --recursive https://github.com/mganeko/kvs_webrtc_example.git
- kvs_keys.js を編集
- AWS_CHANNEL_ARN ... シグナリングチャネルのARNを指定
- AWS_ACCESS_KEY_ID ... ユーザーのアクセスキーIDを指定
- AWS_SECRET_ACCESS_KEY ... シークレットアクセスキーを指定
- Webサーバーにhtml, jsファイルを配置
- ※ローカルホストでない場合は、https通信が必要です
内部の仕組み
Master(MCU)での映像合成
こちらのスライド(WebRTC Build MCU on browserにあるように、Canvasを使って映像を合成しています。
スライドの図より:
- Videoタグから、Canvasタグに描画
- これをrequestAnimationFrame()を使って連続的に実行
- Canvasタグでは、captureStream()を使ってMediaStream(映像)を取得
Master(MCU)での音声合成
先ほどのスライド(WebRTC Build MCU on browserにあるように、WebAudioを使って映像を合成しています。
実は映像よりも音声のほうが厄介です。音声は自分の声を除外した他の全員の声を合成して返します。したがって3人の参加者がいたら3通り(n人の場合はn通り)の合成を行う必要があります。
スライドの図より:
- MediaStreamから、MediaStreamAudioSourceNodeに変換
- 複数のAudioSourceNodeをMediaStreamDestinationNodeに接続
- ここで音声合成が行われる
- MediaStreamDestinationNodeから、MediaStreamを取得
ChromeではWebAudioの処理の前にユーザージェスチャーが必要になったので、過去のMCU Browserのサンプルとは初期化のタイミングを変えて、ユーザーがボタンをクリックしてから音声合成のための処理を行っています。
Masterでの複数PeerConnection管理
RTCPeerConnectionを、ViewerのClinetIDをキーにしたハッシュ(連想配列)に格納して管理しています。雑なコードですが、こちらのファイルにまとめています。
またPeerConnectionで発生したイベントを処理するためのコールバック関数をあらかじめセットしておくことで、KVSのシグナリングチャネル経由でSDPやICE candidateを送信するようにしています。
Viewer側
Viewer側はMasterとだけ双方向通信しているので、1対1の通信の場合と同様です。
- 参考:Viewerの処理(Qiita)
おわりに
一番身近な映像/音声処理装置としてブラウザを利用することで、KVS WebRTCでも多人数でのビデオ会議ができるようになりました。実用性は??ですが、工夫次第で制約は乗り越えらえる、ということですね。
あらためて利用上の注意
映像合成を行っているMasterのウィンドウ/タブが完全に隠れてしまうと、requestAnimationFrame()のイベントが発火せず合成動画が止まってしまいます。絵が出ない/動かない、というケースでは念のためご確認ください。






- 投稿日:2020-03-10T18:34:12+09:00
javascriptで一定時間処理を停止する
はじめに
初学者による初学者向けの記事となります。
筆者が初学者のため、正しくない記述も含まれているかもしれません。 また、1つ1つの説明を省略しています。 本記事を読んで、その場を乗り切った後、 しっかりと Promise, async / await について勉強することを推奨します。 末尾の参考記事を参照してください。javascript の Promise, async / await を勉強し始めました。
await の記述方法が直感的でとても気に入ったので、
いつも await で記述したかったのですが、
記述できるときと記述できないときがあります。本記事では、「一定時間処理を停止する」という具体例をもとに、
知見を共有したいと思います。※javascriptで処理の停止はできないため、
正しくは、 一定時間後にコールバックする という表現になります。まとめ
await を使って一定時間処理を停止したい場合は、
一定時間処理を停止したい場所がasyncの関数内かどうか
を確認する。
- asyncの関数内なら、awaitを使って記述する。
- asyncの関数内でないなら、awaitを使わず記述する。
- asyncの即時関数内を定義して、即時関数内でawaitを使って記述する。(別解)
- もしくは、一定時間処理を停止したい処理をasyncの関数内に移動する。
await は async の関数内でしか使用することができません。
一定時間処理停止(疑似)
サンプル
CodePenにサンプルを作成しました。
https://codepen.io/sonoshou/pen/RwPxyVBasyncの関数内かどうか
本記事では、以下のように定義しています。
asyncの関数内
async function () { /* asyncの関数内 */ }asyncの関数内ではない
function () { /* asyncの関数内ではない */ }asyncの関数内のsleep処理
function mySleep(time) { return new Promise( (resolve) => { setTimeout(resolve, time) }) } async function asyncMyFunc() { console.log("asyncMyFunc:1") /* ここで一定時間処理を停止することを考える。 */ /* asyncの関数内なので、awaitを使う。 */ await mySleep(2000) // 2000ミリ秒停止 /* 停止した以降の処理を記述する。 */ console.log("asyncMyFunc:2") }
asyncMyFunc()を実行すると、以下の通り出力される。asyncMyFunc:1 asyncMyFunc:2asyncの関数内ではないsleep処理
function mySleep(time) { return new Promise( (resolve) => { setTimeout(resolve, time) }) } function myFunc() { console.log("myFunc:1") /* ここで一定時間処理を停止することを考える。 */ /* asyncの関数内ではないので、awaitを使わず記述する。 */ mySleep(2000).then( () => { /* 停止した以降の処理を記述する。 */ console.log("myFunc:2") }) console.log("continue...") }
myFunc()を実行すると、以下の通り出力される。myFunc:1 continue... myFunc:2一定時間処理を停止したい方にとっては、
continue...は処理されてほしくないですね。したがって、
mySleep(2000).then( () => { /* 停止した以降の処理を記述する。 */ console.log("myFunc:2") })こちらに記述する必要があります。
asyncの関数内ではないsleep処理の別解
asyncの即時関数を使えば、awaitは使えます。
こちらの使用も検討しましょう。
しかし、結局、ネストは増えてしまいます。function mySleep(time) { return new Promise( (resolve) => { setTimeout(resolve, time) }) } function myFuncAsync() { console.log("myFuncAsync:1"); /* ここで一定時間処理を停止することを考える。 */ (async () => { await mySleep(2000) /* 停止した以降の処理を記述する。 */ console.log("myFuncAsync:2") })(); console.log("continue...") }
myFuncAsync()を実行すると、以下の通り出力される。myFunc:1 continue... myFunc:2参考記事
- 投稿日:2020-03-10T18:26:59+09:00
for...of文がずれる!?NodeListやHTMLCollectionなどの動的オブジェクトを使うときに知っておかなければならないこと
TL;DR
HTMLCollectionなどの動的なイテラブルオブジェクトを回すときにはArrayに変換するべし- Arrayに変換するにはスプレッド構文と使うか
Array.from()を使うべし
for...of文を動かしてみる単純なループ
たとえば、次のような構造の
div要素を作って、その子要素または子ノードの数だけループさせて処理がしたいような状況で次のコードをを実行します。<div> <dummy-a></dummy-a> <dummy-b></dummy-b> <dummy-c></dummy-c> <dummy-d></dummy-d> <dummy-e></dummy-e> </div>const div = (() => { const node = document.createElement('div'); node.innerHTML = ` <dummy-a></dummy-a> <dummy-b></dummy-b> <dummy-c></dummy-c> <dummy-d></dummy-d> <dummy-e></dummy-e> `; return node; })(); const iterable = div.children; // HTMLCollection for (const elm of iterable) { console.log(0); }「0」は5回出力されます。
const div = (() => { const node = document.createElement('div'); node.innerHTML = ` <dummy-a></dummy-a> <dummy-b></dummy-b> <dummy-c></dummy-c> <dummy-d></dummy-d> <dummy-e></dummy-e> `; return node; })(); const iterable = div.childNodes; // NodeList for (const node of iterable) { console.log(0); }「0」はテキストノード(改行)を含めて11回出力されます。
子要素や子ノードをすべて削除しようとしてみる
const div = (() => { const node = document.createElement('div'); node.innerHTML = ` <dummy-a></dummy-a> <dummy-b></dummy-b> <dummy-c></dummy-c> <dummy-d></dummy-d> <dummy-e></dummy-e> `; return node; })(); const iterable = div.children; // HTMLCollection for (const elm of iterable) { elm.remove(); // 要素を削除 console.log(0); }「0」は3回しか出力されず、
dummy-b要素とdummy-d要素が子に残った状態になります。const div = (() => { const node = document.createElement('div'); node.innerHTML = ` <dummy-a></dummy-a> <dummy-b></dummy-b> <dummy-c></dummy-c> <dummy-d></dummy-d> <dummy-e></dummy-e> `; return node; })(); const iterable = div.childNodes; // NodeList for (const node of iterable) { node.remove(); // ノードを削除 console.log(0); }テキストノードを含めて本来は11回ループするはずが、「0」は6回しか出力されずテキストノードだけが削除されて
dummy-*要素が5つとも残った状態になります。いずれも
div要素の中身が空になることを期待していましたが、そうはなりませんでした。これは、オブジェクトの中身が1ループごとに更新されているために起こる現象です。これは
iterableの中に入っている子を他の要素やドキュメントにappend()などで移動させても同様の現象が起こります。属性を削除しようとしてみる
const div = document.createElement('div'); div.setAttribute('data-a', ''); div.setAttribute('data-b', ''); div.setAttribute('data-c', ''); div.setAttribute('data-d', ''); div.setAttribute('data-e', ''); const iterable = div.attributes; // NamedNodeMap for (const attr of iterable) { div.removeAttribute(attr.name); // 属性を削除 console.log(0); }
attributesで参照できる属性情報が詰まったNamedNodeMapも同様に、途中で中身を削除してしまうと「0」は3回しか出力されず、data-bとdata-dが残りました。クラス名を削除しようとしてみる
const div = document.createElement('div'); div.className = 'a b c d e'; const iterable = div.classList; // DOMTokenList for (const name of iterable) { div.classList.remove(name); // クラス名を削除 console.log(0); }
classListで参照できるクラス名の情報が詰まったDOMTokenListも同様に、途中でクラス名を削除してしまうとループ回数がずれ、「0」は3回出力で最終的なクラス名はclass="b d"となります。なぜすべてに対してループ処理が走らないのか?
NodeListやHTMLCollection、DOMTokenListやNamedNodeMapも、すべて動的なオブジェクトです。動的なオブジェクトは、構成する元になった情報が変更された時点で、オブジェクト自体の中身も更新されます。
構成する元になった情報とは、「どの要素の子だったか」「どの要素の属性だったか」「どの条件で探索された要素だったか」などです。
たとえば、ページ内に存在する
hogeというクラス名を持つ要素をgetElementsByClassName()ですべて取得した後に、DOMからその中の要素を1つ削除すると、あらかじめ取得しておいたにもかかわらずHTMLCollectionの長さは変化します。<div class="hoge a"></div> <div class="hoge b"></div> <div class="hoge c"></div> <div class="hoge d"></div> <div class="hoge e"></div> <script> const iterable = document.getElementsByClassName('hoge'); console.log(iterable.length); // > 5 document.querySelector('.hoge.b').remove(); // 外から2つめを削除 console.log(iterable.length); // > 4 </script>ここまで登場してきた変数
iterableはいずれも「特定の誰かの何か」というルールで構成されているオブジェクトですから、ループ内で「誰か」から削除されると「特手の誰かの何か」ではなくなってしまい、動的オブジェクトから削除されます。1ループ目でDOM上で先頭の要素が削除されたとき、オブジェクトからも先頭の要素が削除されます。この時、オブジェクトの子たちは抜けた穴を埋めるように詰まります。しかしループ時には常に1週目には0番目、2週目には1番目という風に n 週目には n - 1 番目の子を参照するという振る舞いをするため、ループの最中でオブジェクトが更新されると、参照するべき子の位置がずれてしまいます。
ちなみにこの特性は
NodeList.prototype.forEach()を用いていても同様です。1週目 [a, b, c, d, e] // 1週目、0番目である a を削除。次は1番目を見る。 2週目 [b, c, d, e] // 2週目、1番目である c を削除。次は2番目を見る。 3週目 [b, d, e] // 3週目、2番目である e を削除。次は3番目を見る。 4週目 [b, d] // 4週目、3番目は存在しないのでループを終了。それでも
for...ofですべての子をどうにかしてしまいたいそういう時には、動的オブジェクトを静的オブジェクトに変換してしまえばOKです。
スプレッド構文やArray.form()メソッドなどを用いて、単純な配列にしてしまうのが簡単でしょう。[...document.getElementsByClassName('hoge')] // HTMLCollection -> Array [...div.children] // HTMLCollection -> Array [...div.childNodes] // NodeList -> Array [...div.attributes] // NamedNodeMap -> Array [...div.classList] // DOMTokenList -> Arrayこれだけでオブジェクトはただの
Arrayになりますから、構成する元になる情報がどうなろうとも配列の中身が更新されることはありません。しっかりすべての子を削除したり移動したりできます。
const div = (() => { const node = document.createElement('div'); node.innerHTML = ` <dummy-a></dummy-a> <dummy-b></dummy-b> <dummy-c></dummy-c> <dummy-d></dummy-d> <dummy-e></dummy-e> `; return node; })(); const iterable = [...div.children]; // Array for (const elm of iterable) { elm.remove(); // 要素を削除 console.log(0); }ただし
querySelectorAll()は特別
NodeListは基本的に動的オブジェクトですが、querySelectorAll()が返すNodeListは静的オブジェクトなため、Arrayに変換する必要はありません。const div = (() => { const node = document.createElement('div'); node.innerHTML = ` <dummy-a></dummy-a> <dummy-b></dummy-b> <dummy-c></dummy-c> <dummy-d></dummy-d> <dummy-e></dummy-e> `; return node; })(); const iterable = div.querySelectorAll('*'); // 静的なNodeList for (const elm of iterable) { elm.remove(); // 要素を削除 console.log(0); }参考文献
- 投稿日:2020-03-10T16:32:12+09:00
[Rails, jQ]インクリメンタルサーチ
インクリメンタルサーチ
本記事では前回作成したユーザーの名前検索機能を使用して実装していきます。
以下を使用しています。
- ruby 2.5.1
- rails 5.2.4.1
- gem 'jquery-rails'
- gem 'devise'
なお、使用するビューは以下を使用します。
index.html.erb<%= form_with(url: users_searches_path, local: true, method: :get, class: "search_form") do |f| %> <%= f.text_field :keyword, placeholder: "Name", class: "search_input" %> <%= f.submit "Search", class: "search_btn" %> <div class="contents"> <% @users.each do |user| %> <div class="user_content"> <p class="user_name"> user.name </p> </div> <% end %> </div>準備
以下が記入されていなければ記入します。
app/assets/javascripts/application.js
//= require jquery
フォーマット毎に処理を分ける
フォーマット毎に処理を分けるためコントローラーのindexアクションを編集します。
controllers/users/searches_controller.rbdef index @users = User.search(params[:keyword]) respond_to do |format| format.html format.json end endrespond_to
アクションの中でHTMLとJSONなどのフォーマット毎にhtmlかjsonかを条件分岐することができます。
jbuilderファイルの作成、編集
index.json.jbuilderを新規作成し内容を編集します。
app/views/tweets/searches/index.json.jbuilderjson.array! @users do |user| json.id user.id json.name name.name endjbuilderという拡張子を持つテンプレートでは、JSONという名前のJbuilderオブジェクトが自動的に利用できるようになります。
arrayメソッドはその内の一つでJavaScript側に配列で値を送ることができます。search.jsの作成、編集
検索フォームの値を取得
app/assets/javascripts/search.js$(function() { $(".search_input").on("keyup", function() { var input = $(".search_input").val(); }); });keyupイベントを使用して文字が入力される度に発火するようにします。
JSON形式で値を返す
app/assets/javascripts/search.js$(function() { $(".search_input").on("keyup", function() { var input = $(".search_input").val(); //---以下を追記--- $.ajax({ type: 'GET', url: '/users/searches', data: { keyword: input }, dataType: 'json' }) //---以上を追記--- }); });Ajax通信を実現するためには、上記のように$.ajaxメソッドを使用します。
また。上記のコードは
HTTPメソッドはGETで、/users/searchのURLに{ keyword: input }を送信。サーバーから値を返す際は、JSON。
という意味を持ちます。JSON形式の場合は、app/views/users/searches/index.json.jbuilderが読まれ,該当する投稿情報はjbuilderによってJSONに変換されてJavaScriptのファイルに返されます。レスポンス結果によって処理を分ける
app/assets/javascripts/search.js$(function() { $(".search_input").on("keyup", function() { var input = $(".search_input").val(); $.ajax({ type: 'GET', url: '/users/searches', data: { keyword: input }, dataType: 'json' }) //---以下を追記--- .done(function(users) { $(".contents").empty(); if (users.length !== 0) { users.forEach(function(user){ appendUser(user); }); } else { appendErrMsgToHTML("一致するユーザーはいません"); } }) .fail(function() { alert('error'); }); //---以上を追記--- }); });レスポンスが成功した場合は、ユーザーが表示される親要素の中身を都度空っぽにします。そしてusersが空ではない場合usersの中身の数だけappendUser関数を呼び出します。
該当ユーザーがいない場合は”一致するツイートがありません”という引数を与え、appendErrMsgToHTML関数を呼び出します。
また、レスポンスに失敗した場合はアラートを表示させます。empty()メソッド
指定したDOM要素の子要素のみを削除するメソッドです。
指定したDOM要素自体を削除するremoveメソッドとは異なります。forEachメソッド
forEachは、与えられた関数を配列に含まれる各要素に対して一度ずつ呼び出します。
検索に該当ユーザーいた場合、いない場合の関数を定義
app/assets/javascripts/search.js$(function() { //---以下を追記--- var search_list = $(".contents"); function appendUser(user) { var html = ` <div class="user_content"> <p class="user_name"> #{user.name} </p> </div> ` search_list.append(html); } function appendErrMsgToHTML(msg) { var html = ` <div class="user_content"> <p class="user_name"> ${ msg } </p> </div> ` search_list.append(html); } //---以上を追記--- $(".search_input").on("keyup", function() { var input = $(".search_input").val(); $.ajax({ type: 'GET', url: '/users/search', data: { keyword: input }, dataType: 'json' }) .done(function(users) { search_list.empty(); if (users.length !== 0) { users.forEach(function(user){ appendUser(user); }); } else { appendErrMsgToHTML("一致するユーザーはいません"); } }) .fail(function() { alert('error'); }); }); });検索に該当ユーザーがいた場合
変数htmlにユーザー情報を表示する要素を代入し、appendメソッドで親要素の一番下に追加します。
検索に該当ユーザがいない場合
変数htmlに"一致するユーザーはいません"を表示する要素を代入し、appendメソッドで親要素の一番下に追加します。おわり
これでインクルメンタルサーチが実装できました。
- 投稿日:2020-03-10T16:13:04+09:00
gonを使ってJavaScriptへの直書き環境変数を防ぐ
まず環境変数を設定する
Dotenvを用いて環境変数を設定していきます。
1 gemのインストール
Gemfilegem 'dotenv-rails'bundle install2 envファイルの作成
appファイルやcofigファイル、Gemfileがあるルートディレクトリに「.env」というファイルを作成して下さい。
私は一瞬迷ったので画像載せておきます。
歯車マークが目印です。3 環境変数の設定
|.env|ACCESS_KEY='*******'4 .gitignoreの編集
環境変数をGitのトラッキングの対象外にする為記述します。|.gitignore|.envこれでgonを使うための下準備は完了です。
gonのインストール
Gemfileに追記して下さい。
Gemfilegem 'gon'bundle installJSファイルでRails環境変数を扱う
1 コントローラーの編集
JavaScriptを呼び出しているViewに対応させてコントローラーのメソッド内に以下を記述します。
例えば、new.html.hamlでjsを呼び出しているのであればnewメソッド内に追記します。gons_controller.rbdef new gon.xxx_access_key = ENV['ACCESS_KEY'] end2 renderメソッド
application.html.haml内のheadタグに以下を記述して下さい。application.html.haml= Gon::Base.render_data3 JSファイルに記述
jsファイル内にコントローラーで設定した変数を記述します。gon.jsgon.xxx_access_keyこれでjavascriptとrailsの連携が出来ました。
- 投稿日:2020-03-10T14:20:19+09:00
Tecpitの教材「【Go】技術ブログサイトを自作してみよう!」を試してみました / TechCommit企画
テックコミットさんのお年玉企画でTecpitさんの「【Go】技術ブログサイトを自作してみよう!」を試してみましたので、情報をまとめて見ました!
自分の知識
GoはTour of Goを一度なぞった程度
完成物
https://damp-journey-45035.herokuapp.com/
教材の概要
マークダウンに対応した、記事投稿システムです
この教材で学べる知識
- echoでサーバーたてる
- Modulesでモジュール管理
- pongo2
- sqlx
- goose(マイグレーションツール)
- freshでホットリロード
- basic認証のかけ方
- 多対多のリレーション
- herokuデプロイ
※Goの文法自体の説明はありません!
教材の注意書きにもありますが、Goの文法自体の説明はありません!
そこらは抑えている前提で話が進みます感想
Goの文法はわかったけど、実際どうやって組み立てていくの?って人にはかなりいい感じの教材だと思いました。
またコードの随所に何をやっているのかという説明が記載されているのもとても分かりやすかったです。
難点をあげるとすれば、HTML、CSS、JavaScriptのパートが多かった気がします。。。プロダクトの性質上仕方ないのですが。
とはいえ、Go楽しかった!教材をありがとうございます
TechCommitさん
Tecpitさん
- 投稿日:2020-03-10T14:06:36+09:00
GASのカスタムメニュー
こうしておくと間違いないかな、という備忘
メニューを作成する手段は2通り。
サブメニューを作りたい場合は1−1の方法、
途中で更新する場合は1−2の方法という微妙な仕様。1.メニュー、2つの追加方法
メニュークラス
メニュークラスには追加系のメソッドしかないlet menu = SpreadsheetApp.getUI().createMenu('My Menu'); menu.addItem('Menu Item','myFunc'); menu.addSeparator(); let subMenu = SpreadsheetApp.getUI().createMenu('My Sub Menu'); menu.addSubMenu(subMenu); menu.addToUi();addItemでメニューアイテムの追加、
addSeparatorでセパレータ、
addSubMenuでメニューオブジェクトをサブメニューとして追加できる。
最後にaddToUiでUIに追加。この一連をOnOpenなどでよんであげる1-1.UIクラスから作成
上記のサンプルソースのように追加する。作る以外は考慮されてないっぽい。
1-2.スプレットシートクラスから作成
Spreadsheetクラスには、
addMenu
removeMenu
updateMenu
があり、なにかのイベントの際に作成、削除、更新が可能。function createMyMenu() { let menuItem = []; menuItem.push({name:'Menu Item',functionName:'MyFunc'}); menuItem.push(null); menuItem.push({name:'Menu Item-2',functionName:'MyFunc2'}); SpreadsheetApp.getActiveSpreadsheet().addMenu('My Menu',menuItem); } function updateMyMenu() { let menuItem = []; menuItem.push({name:'Menu Item',functionName:'MyFunc-New'}); SpreadsheetApp.getActiveSpreadsheet().updateMenu('My Menu',menuItem); } function removeMyMenu() { SpreadsheetApp.getActiveSpreadsheet().removeMenu('My Menu'); }逆にサブメニューはつくれそうにない。
2.呼び出しの関数について
只の関数は可能
クラスのスタティックメソッドは可能
グローバル変数にいれたクラスオブジェクトのメソッドは可能というわけで、私の使い方としては以下とした。
function onOpen(e) { let menuItem = []; menuItem.push({name:'my doSome',functionName :'MyFunc'}); SpreadsheetApp.getActiveSpreadsheet().addMenu('My Menu',menuItem); } function MyFunc() { let myClassObj = new MyClass(); myClassObj.doSomething(); }3.現状の対応
私自身はサブメニューより、状況に応じたメニューにしたかったので1−2の実装をすることにした。
スプレットシート以外のクラスには上記メソッドないんだけど、作らないor作れない、のかな?
それぞれ今後調べる機会があれば。
- 投稿日:2020-03-10T12:03:09+09:00
HTMLでPixi.js
Pixi.js とは、ブラウザ上で動作するWebGLを用いた2Dグラフィックスライブラリです。
Pixi.js は、JavaScript から使用するライブラリで、以下のようなプログラムを書くことで使用できます。
const app = new PIXI.Application() document.body.appendChild(app.view) // スプライトを追加 const sprite = PIXI.Sprite.from("hoge.png") app.stage.addChild(sprite)上記の例では、Pixi.js の初期化と、スプライト(画像)の表示を行っています。
PIXI.Sprite.fromで新たなスプライトのオブジェクトを生成し、それをapp.stageに対してaddChildで追加することで、画像の表示が行われる、という例です。Pixi.js は、表示物の情報を階層構造で保持し、その情報に従って画面の表示を行います。これは、HTMLの構造とよく似ています。
そこで、Custom Element の機能を用いれば、HTML で Pixi.js の表示物を宣言的に定義して Pixi.js による画面表示が行えるのではないかと考えて、試してみました。
Custom Element を使った要素の定義
まずは、
PIXI.Applicationを指す<pixi-app>という要素を定義してみます。とりあえず動作させられることだけを確認したいため、内部の実装は雑です。customElements.define("pixi-app", class PixiApplication extends HTMLElement { constructor() { super() this.pixiObj = new PIXI.Application() const shadow = this.attachShadow({mode: "open"}) shadow.appendChild(this.pixiObj.view) const style = document.createElement("style") style.textContent = ` :host { display: inline-block; } ` shadow.appendChild(style) } })Shadow DOM で、内部に Pixi.js の
<canvas>要素を追加しています。次に、画像リソースを表す
PIXI.Textureの要素として<pixi-texture>を定義します。customElements.define("pixi-texture", class PixiTexture extends HTMLElement { constructor() { super() const pixiApp = getPixiApp(this) if (pixiApp === null) { return } const src = this.getAttribute("src") this.pixiObj = new PIXI.Texture.from(src) } })次に、画像の表示を行う要素である
PIXI.Spriteの要素として<pixi-sprite>を定義します。親要素から<pixi-app>要素を探す関数としてgetPixiApp()関数も定義して使用しています。const getPixiApp = (elem) => { let node = elem.parentElement while (node !== null) { if (node.tagName === "PIXI-APP") { return node } node = node.parentElement } return null } customElements.define("pixi-sprite", class PixiSprite extends HTMLElement { constructor() { super() const pixiApp = getPixiApp(this) const pixiTexture = pixiApp.querySelector(`#${this.getAttribute("texture")}`) this.pixiObj = new PIXI.Sprite(pixiTexture.pixiObj) const parentPixiObj = this.parentElement.pixiObj if (parentPixiObj instanceof PIXI.Application) { parentPixiObj.stage.addChild(this.pixiObj) } else if (parentPixiObj instanceof PIXI.Container) { parentPixiObj.addChild(this.pixiObj) } } })
<pixi-sprite>のtexture属性の値は、表示の対象としたい<pixi-texture>要素のid属性の値が設定される想定です。これで、とりあえず何らかの表示を行うための最小限の要素の定義ができました。
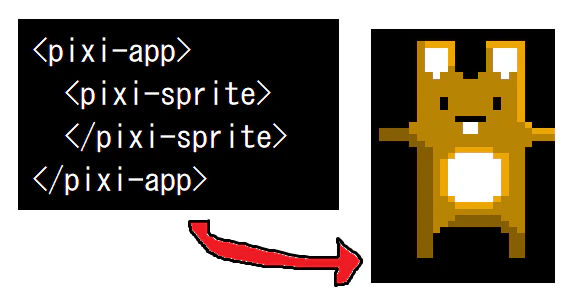
実際に使用した例は以下のようになります。
<pixi-app> <pixi-texture id="bunny" src="bunny.png"></pixi-texture> <pixi-sprite texture="bunny"></pixi-sprite> </pixi-app>
<pixi-app>の子要素として<pixi-texture>、<pixi-sprite>を追加する形を想定しています。とりあえず表示だけはされるのかの実験をするために、
PIXI.Spriteの各プロパティを操作するための仕組みの実装は省略しました。定義した要素を使用する
動作を試しますと、以下のように黒い
<canvas>の左上に小さな画像が表示されます。
うまくできました。
この Pixi.js の要素を HTML の要素として記述できる仕組みが本格的に実装できれば(されれば)、React、Preact、Superfine などの仮想DOMの仕組みを持ったフレームワークを用いて Pixi.js プログラミングができそうです。
すでに React のコンポーネントで Pixi.js の要素を扱えるようにするライブラリとして React PIXI というものがありますが、こちらは React 限定になります。
- 投稿日:2020-03-10T10:49:50+09:00
Node.js: CPU負荷で3秒かかっていた処理を「Worker Threads」で1秒に時短する
本稿では、Node.jsのWorker Threadsとその基本的な使い方について説明します。
本稿で知れること
- Worker Threadsの概要
- Worker Threadsとは何か?
- それが解決してくれる問題は何か?
- worker_threadsモジュールの基本的な使い方
- スレッド起動時にデータを渡すにはどうしたらいいか?
- 3秒かかる処理を、並列処理で1秒に短縮する方法。
Worker Threadsとは?
- CPUがボトルネックになる処理を、別スレッドに負荷分散し、効率的に処理する仕組み。
Worker Threadsが解決する問題
- Node.jsはシングルプロセス、シングルスレッド。
- シングルプロセス、シングルスレッドは、シンプルさという利点がある。
- 一方で、CPUに高い負荷がかかる処理は、他の処理を止めてしまう欠点があった。
- Worker Threadsは、複数のスレッドを使えるようにすることで、この欠点を解決する。
Worker Threadsが解決しない問題
- I/Oがボトルネックになる処理。
- これは、Node.jsの非同期I/OのほうがWorkerより効率的に処理できる。
worker_threadsモジュールとは?
- JavaScriptを並列(parallel)で実行するスレッドが利用できるモジュール。
- libuvを用いた本物のスレッド(イベントループやマルチプロセスはない)。
- Web WorkerそっくりのAPI。つまりフロントエンドの知識が活きる。
- Node.js 10.5.0から使える。
- Node.js 11.7.0未満は、
--experimental-workerフラグをつけてNodeを起動する必要があった。child_processモジュール、clusterモジュールとの違い
- worker_threadsはメモリを共有できる。
- child_processとclusterはメモリが共有できない。
worker_threadsモジュール入門
worker_threadsモジュールの基本的な使い方を見ていきましょう。
Workerを起動するには?
まず、Workerを起動する方法を見ておきましょう。Workerの起動はシンプルに言って、
Workerクラスをnewするだけです。第一引数は、ワーカーの処理を書いたファイル名です。main.jsconst {Worker} = require('worker_threads') const worker = new Worker('./worker.js')worker.jsconsole.log('Hello from worker')このmain.jsをnodeで起動すれば、worke.jsがスレッドで実行されます。
console$ node main.js Hello from workerWorker起動時にデータを渡すには?
次に、Worker起動時にmain.jsからデータを渡す方法を見てみましょう。データを渡すには、
Workerクラスをnewするときに、第2引数にworkerDataに渡したいデータを入れます。main.jsconst {Worker} = require('worker_threads') const worker = new Worker('./worker.js', { workerData: 'message from main.js!', })ワーカー側のコードでは、
workerDataをworker_threadsモジュールからインポートすることで、渡されたデータを参照できます。worker.jsconst {workerData} = require('worker_threads') console.log('Hello from worker') console.log(workerData)この例では、
'message from main.js!'がワーカーに伝わっているのがわかります。console$ node main.js Hello from worker message from main.js!workerDataは複製される
Workerにデータを渡せることは渡せるのですが、共有はされないので注意してください。次の例では、配列をワーカーに渡し、ワーカーがその配列を変更するコードですが、main.jsにはワーカーが加えた変更が伝わってきません。つまり、
workerDataで渡されるデータは、複製されるのです。main.jsconst {Worker} = require('worker_threads') const workerData = [1, 2, 3] const worker = new Worker('./worker.js', { workerData }) // オブジェクトを渡す setTimeout(() => console.log('main.js: %O', workerData), 1000) // どうなる?worker.jsconst {workerData} = require('worker_threads') console.log('worker.js %O', workerData) workerData.push(4, 5, 6) // Worker側で変更を加える console.log('worker.js %O', workerData)実行結果worker.js [ 1, 2, 3 ] worker.js [ 1, 2, 3, 4, 5, 6 ] main.js: [ 1, 2, 3 ]複数のWorkerを起動するには?
Workerにデータを渡す方法が分かったので、今度は複数のWorkerを起動してみましょう。
複数のWorkerを起動するには、単純に
Workerインスタンスを複数作るだけです:const {Worker} = require('worker_threads') const worker1 = new Worker('./worker.js', { workerData: 'worker1', }) const worker2 = new Worker('./worker.js', { workerData: 'worker2', })const {workerData} = require('worker_threads') console.log(`I'm a ${workerData}`)実行結果$ node main.js I'm a worker1 I'm a worker2CPU高負荷な処理を分散してみよう
worker_threadsモジュールの基本的な使い方が分かったと思うので、CPU高負荷な処理をマルチスレッドで分散することを試してみましょう。
高負荷な関数を準備する
処理分散を試すために、CPUに高負荷がかかり、処理に時間がかかる関数を用意します。
この
highLoadTask関数は、単純に20億回ループするだけですが、実行するとCPU使用率が100%になるくらいの負荷が発生します。(CPUの性能によって実行時間が左右されるので、手元の環境で実行してみる際は、20億回の部分を調整して数秒で終わる程度の回数に直してください)highLoadTask.jsfunction highLoadTask() { for (let i = 0; i < 2_000_000_000; i++) { } } module.exports = {highLoadTask}どのくらい負荷と時間がかかるか確認してみよう
highLoadTask関数をシングルスレッドで3回実行するようにしたコードが次です:main.jsconst {highLoadTask} = require('./highLoadTask') console.time('total') console.time('task#1') highLoadTask() console.timeEnd('task#1') console.time('task#2') highLoadTask() console.timeEnd('task#2') console.time('task#3') highLoadTask() console.timeEnd('task#3') console.timeEnd('total')このスクリプトを実行すると、(僕のPCでは)合計で約3秒かかります:
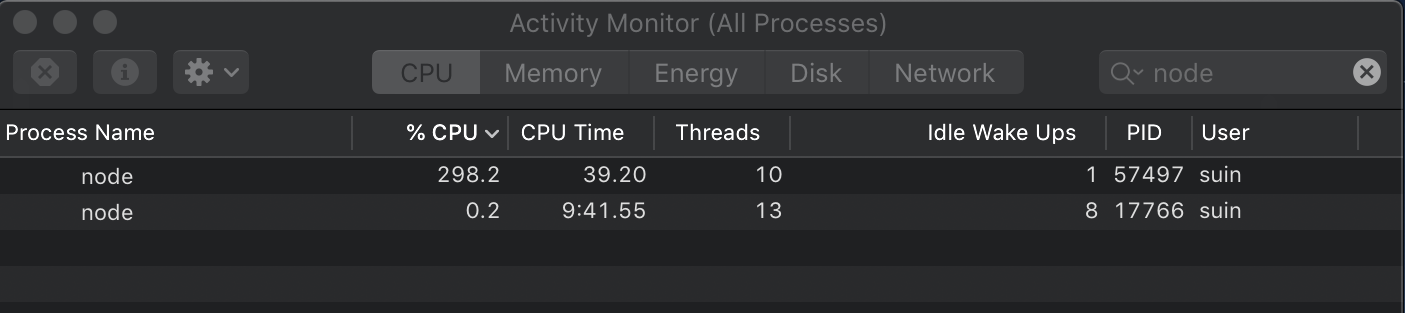
実行結果node main.js task#1: 1.455s task#2: 1.460s task#3: 478.089ms total: 3.399sCPU負荷のほうは、Activity Monitorで「node」に検索を絞って、モニタリングすると、99%が使われていることがわかります。使用率が100%を超えていないので、当てられているCPUコア数は1個ということもわかります。(CPU使用率が上がりきらない場合は、
highLoadTask関数のループ数を増やしてください)
CPU高負荷処理は非同期処理でも解決しない
ちなみに、次のように
Promiseを使って各タスクを非同期処理にしても、かかる時間は変わりませんので、この関数はシングルスレッドでは限界があるということが確認できます:main.jsconst {highLoadTask} = require('./highLoadTask') function asyncHighLoadTask(taskName) { return new Promise(resolve => { console.time(taskName) highLoadTask() console.timeEnd(taskName) resolve() }) } (async function () { console.time('total') await Promise.all([ asyncHighLoadTask('task#1'), asyncHighLoadTask('task#2'), asyncHighLoadTask('task#3'), ]) console.timeEnd('total') })()Workerを使って3秒かかる処理を1秒にする
では実際にWorkerを使って、処理を分散するコードを書いてみます。
まず、Worker側の実装です:
worker.jsconst {workerData} = require('worker_threads') const {highLoadTask} = require('./highLoadTask') console.time(workerData) highLoadTask() console.timeEnd(workerData)次に、メイン側の実装です。
main.jsconst {Worker} = require('worker_threads') console.time('total') const worker1 = new Worker('./worker.js', { workerData: 'worker1', }) const worker2 = new Worker('./worker.js', { workerData: 'worker2', }) const worker3 = new Worker('./worker.js', { workerData: 'worker3', }) Promise.all([ new Promise(r => worker1.on('exit', r)), new Promise(r => worker2.on('exit', r)), new Promise(r => worker3.on('exit', r)), ]).then(() => console.timeEnd('total'))main.jsでは、ワーカーを3つ起動して、3並列で処理させるようにしました。
最後の
Promise.allの部分は、ワーカーの終了を待って合計所要時間を計測するためのコードですので、ここでは気にしないでください。実行してみましょう:
実行結果$ node main.js worker1: 1.526s worker3: 1.529s worker2: 1.529s total: 1.579s実行結果を見てのとおり、各タスクの処理は1.5秒程度で変化はありませんが、並列実行したため3秒かかっていた合計所要時間が1.5秒に短縮されました。
気になるCPU使用率は、298%になっているので、コアが3つがきびきび働いているのがわかります。
おわり
本稿では、Node.jsのWorker Threadsの概要と、worker_threadsモジュールの基本的な使い方を解説しました。
CPUがボトルネックとなる処理をマルチスレッドで分散すると、マルチコア環境で眠っているCPUを効率的に働かせられたり、その結果処理時間を短縮できることが分かったかと思います。
今後投稿するかもしれないこと
本稿では基本的なことがらにしか触れませんでしたが、下記のような疑問も気になるところなので、追って投稿できたらと思います。
- スレッドで例外が発生したらどうなる?
- 素のNode, child_process, worker_threadsのアーキテクチャ上どういう違いが出てくるか?
- メインスレッドとの通信方法は?
- メモリ共有は具体的にどうやるのか?
- Workerを扱いやすくするライブラリはある?
- Workerを停止するには?
- 通信のオーバーヘッドは?
- Worker生成のオーバヘッドはどのくらい?

- 投稿日:2020-03-10T09:28:58+09:00
JavaScriptの勉強用にBookmarkletの作成を勧めてみた話
はじめに
こんにちは。友人(IT業界勤めではない)から「JavaScript の勉強をしているが、せっかくなので何かつくってみたい」という話を聞きました。そこで僕は Bookmarklet をつくってみてはどうか という提案をしてみました。
今日はそんな実際にあった話をもとに記事を書いてみたいとおもいます。
Bookmarklet ってなに?
そもそもブックマークとはWEBサイトのURLをブラウザに登録しておき、好きなタイミングで登録したURLを呼び出せるようにする機能のことですよね。このあたりは普段インターネットを使っている方はよくご存じかとおもいます。(この記事を見ている時点でインターネットをつかっていますので聞くまでもなかったと書いてからおもったw)
これに対し、ブックマークレットですが同じくブックマークの機能を使うことには変わりありません。違うのはURLの代わりに JavaScript で作ったプログラムを登録しておくことです。ブックマークの場合は登録しておいたURLを呼び出すとそこにジャンプしますが、ブックマークレットの場合は登録しておいたプログラムが実行されます。
ちなみにwikipedia先生によるとこうです。僕の説明もだいたいあってるはずw
ブックマークレット (Bookmarklet) とは、ユーザーがウェブブラウザのブックマークなどから起動し、なんらかの処理を行う簡易的なプログラムのことである[注釈 1]。携帯電話のウェブブラウザで足りない機能を補ったり、ウェブアプリケーションの処理を起動する為に使われることが多い。
実際に簡単なブックマークレットをつくってみます
ブックマークレットひな型
こんなかんじです。ここにプログラムにやらせたいことを書いていきます。
ひな型javascript : (function() { //実行する処理内容 })();例えば
Qiitaへのログインを楽に行うブックマークレット をつくってみたいとおもいます。さっそくスクリプトを書いてみますが下記のようなかんじです。※パスワードはダミーです
ユーザー名とパスワードを入力するプログラムjavascript : (function() { document.getElementById("identity").value = "tommy_aka_jps"; document.getElementById("password").value = "yourpassword"; })();これを実行すると、ここに書いておいたユーザー名とパスワードが Qiita のログインフォームにパッと入力されます。
改行とインデントを削って1行になおします
あくまでもブックマークとして登録する文字列なので改行等が入っているとうまく登録できません。そのためいろいろ削って1行にします。
改行とスペースを削ったよjavascript:(function(){document.getElementById("identity").value="tommy_aka_jps";document.getElementById("password").value="yourpassword";})();プログラム本文自体は何も変えていません。
さっそくブックマークに登録してみます
画面は Google Chrome のものです。手順はふつうのブックマーク追加と一緒です。このとき、URLの欄にはURLのかわりにさきほど作成したスクリプトを入力している点だけが異なります。
登録したブックマークレットを実行してみます
するとこのようになります。
必要な情報がすべて入力されましたね。あとはログインボタンを押すだけです。うむ、便利じゃ。
IDとパスならブラウザに記憶させておけば済む話じゃないかとか言ってはいけませんログインボタンを押すのもスクリプトにやらせることも可能ですが、何が起きているかわかりづらくなりそうなので今回は説明用サンプルということであえてユーザー名とパスワードの入力までにしています。
使用したメソッドについて
JavaScript の入門書にも載っている JavaScript で HTML 操作を行うためのポピュラーなメソッドです。入門中の友人も「あ、それこの間やったやつだ」と言ってました。
所感
なぜ JavaScript の勉強にブックマークレットを勧めたかといいますと、完成まであまり所要時間をかけずに、かつそこそこプログラムで手作業を楽にした成功体験を実感できる と考えたからです。
ログインフォームへスクリプトで値を入力するのは僕がかつて初めて作ったブックマークレットということもあり、経験上DOM操作を覚え始めた初級者には勉強したものを手軽に試すことができる良い教材になるんじゃないかと思いました。
ここで僕が紹介したプログラムは本当に初歩ですが、ブックマークレットについては先人のみなさまが残した良記事・スクリプトが世の中にはたくさんあります。興味を持たれた方は勉強の合間やネットサーフィンのついでに少し検索してみるとちょっと楽しい気持ちになれるかもしれません。
参考
- Bookmarkletを作ろう(準備編) - Qiita
- GoogleChromeでのブックマークレットの登録方法 - 書籍横断検索システム
- Create Bookmarklets - The Right Way
- Bookmarklet - Wikipedia
どれも僕の記事よりもめちゃくちゃ手厚くて質の高い記事ですねwというか Wikipedia にも作り方が載っていたのには笑いましたw


- 投稿日:2020-03-10T07:55:59+09:00
JavaScriptの`Object.assign()`を背景・原理から解説する
はじめに
最近JavaScriptの学習をはじめました。
Object.assign()メソッドの説明を読み疑問に感じた点を調べたためまとめました。疑問点1: MDN Web Docsの
Object.assign()の説明にあるThis may make it unsuitable for merging new properties into a prototype if the merge sources contain getters.とはどういう意味かassign元がgetterを保つ場合、そのstatmentではなく値をコピーするということ。以下のコードで検証した。
let target = {} const source = { log: ['a', 'b', 'c'], get latest() { if (this.log.length == 0) { return undefined; } return this.log[this.log.length - 1]; } } Object.assign(target, source) console.log(source) console.log(target)
疑問点2: なぜ
Object.merge()ではなくObject.assign()と名付けたのか疑問点1に書いたように元のオブジェクトを完全にコピーして結合するのではなく、値をコピーするだけであるため。assignは数えられるものを与えるというニュアンスを持つ。
If you assign a characteristic or value to something, you say that it has it:

- 投稿日:2020-03-10T07:55:59+09:00
JavaScriptのObject.assign()に関する疑問点の解決
はじめに
最近JavaScriptの学習をはじめました。MDN Web Docsの
Object.assign()の説明 を読み疑問に感じた点を調べたためまとめました。疑問点1:
This may make it unsuitable for merging new properties into a prototype if the merge sources contain getters.とはどういう意味かassign元がgetterを保つ場合、そのstatmentではなく値をコピーするということ。以下のコードで検証した。
let target = {} const source = { log: ['a', 'b', 'c'], get latest() { if (this.log.length == 0) { return undefined; } return this.log[this.log.length - 1]; } } Object.assign(target, source) console.log(source) console.log(target)
因みに内部的な処理はプロパティの値をgetしてsetしているだけらしい。
It uses
[[Get]]on the source and[[Set]]on the target, so it will invoke getters and setters.Object.assign() - JavaScript | MDN
疑問点2: なぜ
Object.merge()ではなくObject.assign()と名付けたのか疑問点1に書いたように元のオブジェクトをコピーして結合するのではなく、値をコピーするだけであるため。assignは数えられるものを与えるというニュアンスを持つ。
If you assign a characteristic or value to something, you say that it has it:
ASSIGN | 意味, Cambridge 英語辞書での定義
参考
- ECMAScript® 2019 Language Specification https://www.ecma-international.org/ecma-262/10.0/index.html#sec-object.assign
- 投稿日:2020-03-10T04:56:57+09:00
Next.js 9.3: 新世代の静的サイト生成、Built-in Sassのサポート
本日、Next.js 9.3 がリリースされました。本リリースの特徴は次のものです。
- Static Site Genration のサポート
- プレビューモードのサポート
- ビルトインの Sass サポート
- 404 ページの静的化
- ランタイムの縮小
各トピックごとに簡単に説明します。詳しく知りたい場合は公式のリリースノートが公開されているのでご確認ください。
Static Site Generation のサポート
Next.js では 9.0 から Automatic Static Optimization というコンセプトを打ち出し、
getInitialPropsでデータを取得しない場合はビルド時に HTML ファイルを生成していました。(また、getInitialPropsでのデータ取得はnext exportで生成した場合であっても、クライアントのルーティング変更時に実行されるため、完璧な静的サイトとは言い難いものでした。)
しかし、データを取得しつつ、HTML をビルド時に生成したいケースが増えてきています。Headless CMS を使ったマーケティングブログがよい例です。そこでコミュニティ内で討論したできたのが本機能です。Next.js 9.3 では
getStaticPropsとgetServerSidePropsという 2 つのデータ取得方法が用意されています。また、動的なルーティングを実現する際に、パラメータを付与するgetStaticPathsも追加されています。
getStaticPropsビルド時にデータを取得するgetStaticPathsデータに基づいて動的ルーティングを指定するgetServerSidePropsリクエストごとにデータを取得する後方互換性も担保されており、今までの
getInitialPropsも使うこともできますが、新しい方法が推奨されます。公式ブログのリリースノートには各メソッドの要点がまとまっています。
またドキュメントも大きく書き直されているので一読をおすすめします。
プレビューモードのサポート
Static Generation は Headless CMS から取得するのに役立ちますが、下書き段階には理想的ではありませんでした。
Static Generation で生成されるのは静的なプレビューなため、変更を反映するには再生性する必要があるからです。そこで用意されたのがプレビューモードです。静的に生成されたページを通して、下書き状態のページを SSR することができます。
Preview Mode のドキュメントも用意されているのでそちらをご覧ください。
ビルトインの Sass サポート
Next.js 9.2 では Built-in CSS がサポートされましたが、Next.js 9.3 では Sass のサポートも追加されました。
Built-in CSS と同様に、Global Stylesheet と CSS Modules がサポートされています。簡単なコード例をお見せします。// Global Styles import "global.scss" // CSS Modules // 注意: 拡張子はmodule.scssにすること import styles from "./Button.module.scss" const Button = () => { return <button className={styles.success}>Save</button> }CSS Modules ではコード分割も行われるので、global ではなくなるべく CSS Modules の方に寄せるといいでしょう。1
今まで
@zeit/next-sassを使っていた方は、この機能は自動的に無効化されます。Built-in の Sass に乗り換えたい方は@zeit/next-sassを外しましょう。404 ページの静的化
上記で紹介した Automatic Static Optimization というコンセプトはありましたが、404 ページは静的にレンダリングされたページではありませんでした。
今までは
pages/_error.jsにおいたファイルがエラーページとなっていましたが、Next.js 9.3 からはpages/404.jsというファイルを置くと 404 ページとして扱われます。
この 404 ページを静的に保つことでエラーページを表示する度にレンダリングされなくなり、サーバーへの負荷が減ります。こちらもドキュメントがあるので読みましょう!
まとめ
ここ最近の Next.js は今までとひと味違う動きを見せているので要注目です。
繰り返しにはなりますが、本記事では概要のみを扱っています。詳しく知りたいと思った方は公式のリリースノートをご覧ください。
私はお仕事のプロジェクトでも移行しましたが、module.scss では IE 対応のセレクタが壊れて大変でした。 ↩
- 投稿日:2020-03-10T01:11:06+09:00
WebStormでAirbnbのJavascript style guideベースのESLintを使う
概要
以下に関するメモです
- WebStormのESLint連携機能を使う方法(WebStormのJSCS連携機能は使わない)
- ESLintはAirbnbのJavaScript Style Guideをベースにします
- WebStormのコードフォーマッターもこれにあわせ変更します
環境
- WebStorm 2019.3
- ES6
- Webpack4
- Babel7
WebStormでESLint対応する
WebStormのESLintサポートを有効にする
File > Settingsで設定画面を開き
Languages&Frameworks > JavaScript > Code Quality Tools > ESLint と進みAutomatic ESLint configurationを選択する
これで、プロジェクトにある.eslintrcや.eslintignoreをよみにいってESLintが使えるようになる。
以下のようにエディタ上で違反箇所が赤になって確認できるようになる。カーソルをあてれば、詳細や自動修正の候補が出るので便利。
WebStormのコードフォーマッターをESLint用にしつける
WebStormのコードフォーマッターで自動フォーマットするときに、Airbnbスタイルガイドにそったフォーマットをするようにする。
しつけ、その1 改行コードはLFにすべし「linebreak-style」
●AirbnbスタイルになるようにWebStormを設定する
File > Settingsで設定画面を開き
Editor > Code Styleで General タブを選択する
- Line separatorの値を"Unix and macOS(\n)"にする
※新規ファイルの場合は↑でOK。既存ファイルの改行コードを変更するときは、エディタ右下にCRLFなどと書いてあるのでそれをクリックして、LFに変更すればOK
しつけ、その2 インデント「indent」
●WebStormのデフォルトフォーマットだとこんなエラーになる
Expected indentation of 2 spaces but found 4
●AirbnbスタイルになるようにWebStormを設定する
File > Settingsで設定画面を開き
Editor > Code Style > JavaScript ** でTabs and Indents**タブを選択
- Use tab characterのチェックを外す
- Tab sizeを2にする
- Indentを2にする
- Continuation indentを2にする
しつけ、その3 関数の括弧()の前あけろ「space-before-function-paren」
●Airbnbスタイルに嫌がられる書き方
function test ()→Unexpected space before function parentheses
●Airbnbスタイルに好まれる書き方
function test()●AirbnbスタイルになるようにWebStormを設定する
File > Settingsで設定画面を開き
Editor > Code Style > JavaScriptでSpacesタブを選択する
- Before Parentheses/In function expressionのチェックを外す
しつけ、その4 中括弧{}の内側にスペースいれろ「object-curly-spacing」
●Airbnbスタイルに嫌がられる書き方
export {default} from './my-lib';→A space is required after '{'
→A space is required after '}'
●Airbnbスタイルに好まれる書き方
export { default } from './my-lib';●AirbnbスタイルになるようにWebStormを設定する
File > Settingsで設定画面を開き
Editor > Code Style > JavaScriptでSpacesタブを選択する
- Object literal bracesにチェックを入れる
- ES6 import/export bracesにチェックを入れる
参考
ESLintに必要なパッケージをインストールする
WebStormの設定にいくまえに、npmプロジェクトでESLint(Airbnbスタイル)を使えるようにする
- ESLintをインストールする
npm install --save-dev eslint eslint-loader
- Babelで使えるコード(ES6,ES7で書いたコードなど)でESLintがつかえるよう、babel-eslintをインストールする。
npm install --save-dev babel-eslintここまでで、ESLintが使えるようになるが、
Airbnbのスタイルガイドに対応させるため、もう一手間以下を実行する。npx install-peerdeps --dev eslint-config-airbnb-base.eslintrc を作る
{ "parser": "babel-eslint", "extends": ["airbnb-base"], "root": true, "env": { "browser": true, "node": true }, "rules": { "class-methods-use-this":"off" } }まとめ&いつもありがとう静的解析さん
- ES6,Babel7,Webpack4という環境でAirbnbスタイルのESLintをWebStormと連携する方法について説明しました
- 新しい設定があれば、適宜追加していきます
- lint,QAC,Coverity,Fortifyそして、なんとかLint。静的解析レポートは新しい知識を得るきっかけになります。何年たっても。







- 投稿日:2020-03-10T00:01:23+09:00
javascriptで連長圧縮された文字列を解凍してみた。
今回は、前回の記事で圧縮したデータを解凍するアルゴリズムについて解説して行きます。
前回の記事:javascriptで連長圧縮してみた。
“連長圧縮”という圧縮処理を経た文字列を、解答していくわけですが、前回同様に、
はじめに例をお見せします。まずは例から。。。
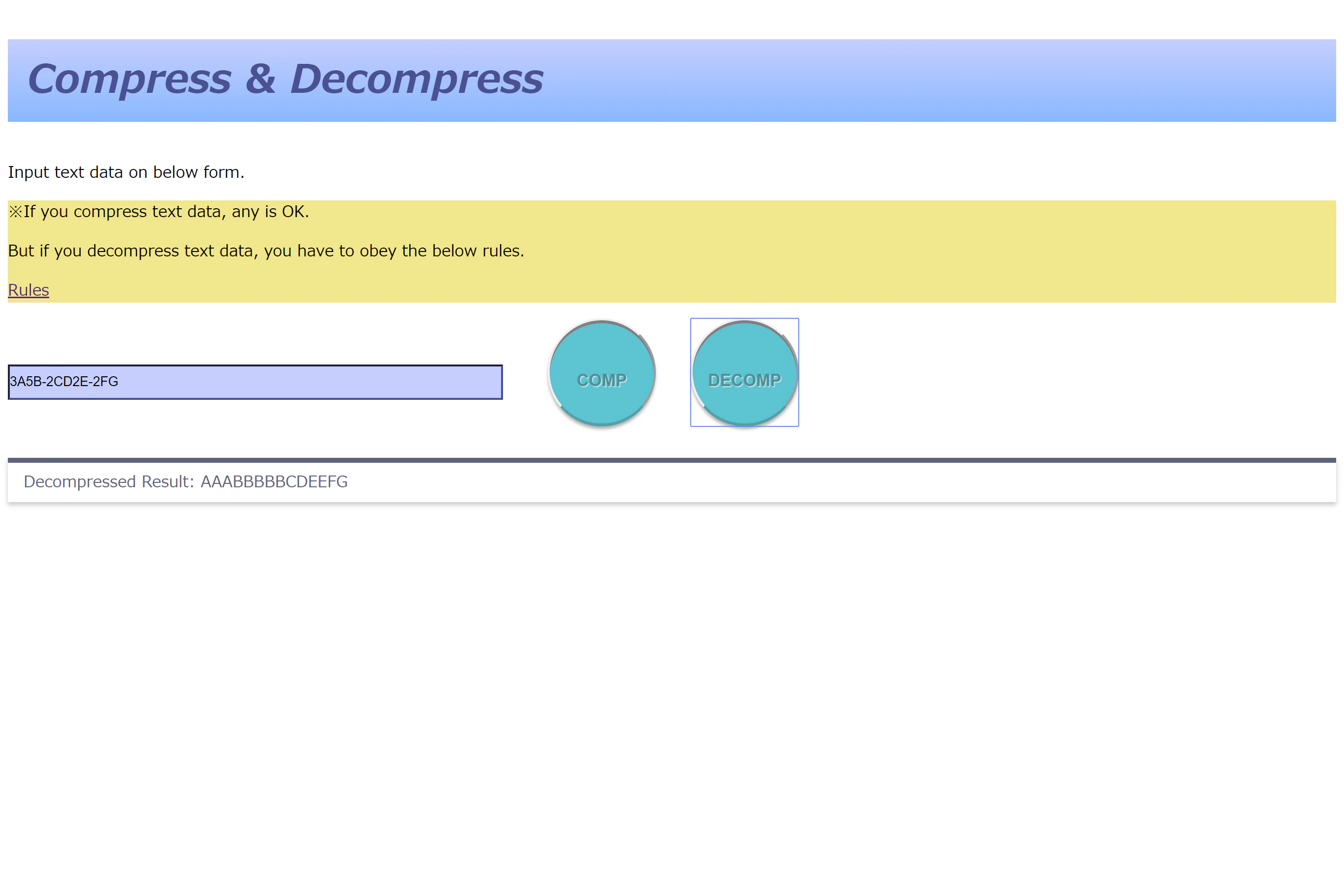
自作のローカルページに「3A5B-2CD2E-2FG」と入力すると、前回の記事で圧縮処理をかけた「AAABBBBBCDEEFG」というオリジナルの文字列が表示されます。
正の数字は連続の文字の回数を表しているので、その回数分、文字を連続して出力します。
(ex. 3A → AAA(解凍)となるわけです!)負の数字は不連続文字の数を表しており、その回数分、不連続の文字を続けて出力します。
(ex. -5CDEFG → CDEFG(解凍)となり、解凍後の方が情報量が少ないですね...笑)やはり、「連続する文字が多い」という特性を持った情報でないと、効果を発揮する場面が無さそうですね。
解凍のアルゴリズム(JavaScript)
Rentyo.jsfunction doDecompress(charData){ //連長圧縮に対する復号処理 var decompressedText = []; //解凍結果を格納する場所 var minusFlag = false; //連続か不連続かの状態を決定する var countStock = 0; //文字の数を数えるようの変数 var preNumStock = []; //前回までの文字のストック(2桁以上に対応) for(i=0;i<charData.length;i++){ if(charData[i]=="-"){ //マイナスの符号を検知 minusFlag = true; } else if(charData[i].match(/[a-z]/gi)){ //アルファベットを検知 if(minusFlag==true){ //不連続だったら countStock = parseInt(preNumStock.join("")); for(j=0;j<countStock;j++){ decompressedText.push(charData[i+j]); //不連続の文字の回数出力 } i = i + countStock - 1; //ループを次の状態まで飛ばす minusFlag = false; //諸々初期化しとく preNumStock = []; countStock = 0; }else{ //連続だったら countStock = parseInt(preNumStock.join("")); for(j=0;j<countStock;j++){ decompressedText.push(charData[i]); //連続の回数分、同じ文字を出力 } preNumStock = []; //諸々初期化しとく countStock = 0; } }else{ //数字だったら countStock = parseInt(charData[i]); //int型に変換 preNumStock.push(countStock); //2桁以上の場合に備えて保持しておく } } var resultText = decompressedText.join(""); //配列を文字列に変換 document.getElementById("show_result").textContent = "Decompressed Result: " + resultText; }注意すること
デコーダーにおいて一番私が躓いたのは、1文字ずつ調べるが故に、普通にやってたら2桁以上の数字に対応できない!という点でした。笑
そのためpreNumStockという配列を用意し、数字をどんどん貯め、アルファベットが始まった段階で初期化して2桁以上に対応しました。真価を発揮するとき。。。
連長圧縮は、2進数のように情報の種類がAとBの2種類しかない場合では、かなり圧縮率を高く出来ます!
「ABBBBABABAAAAAA」という文字列があるとしましょう。最初にAが来ることを前提とすると、
「-1,4,-4,6」というふうに数字だけで表せます。
この数字からなる情報だけで、オリジナルの文字列を解読出来ちゃいますね!
最初の文字がAかBかを決定するだけで、あとは数字のみで表せてしまうのです。