- 投稿日:2020-03-10T23:38:32+09:00
aws ecr get-loginでポリシー不足でエラーが出力
記録としてメモしとく。
やりたかったこと
AWS-CLI使って Amazon ECRにログインしたい。
前提
私の環境
- Windows10 Pro
- AWS CLIインストール済> aws --version aws-cli/1.16.313 Python/3.7.2 Windows/10 botocore/1.13.49事象
PS C:\Users\taketakekaho> aws ecr get-login --region ap-northeast-1 --profile <profile> --no-include-email An error occurred (AccessDeniedException) when calling the GetAuthorizationToken operation: User: arn:aws:iam::XXXXXXXXXXXX:user/<profile> is not authorized to perform: ecr:GetAuthorizationToken on resource: *なんかアクセス権的なものがないようでエラーが出る。
対処
このAmazonEC2ContainerRegistryPowerUserというポリシーが足りなかったらしい。以下のようにアタッチした所解消しました。
というか…
情報探す中でたまたま読んだクラスメソッドさんの技術ブログ([アップデート]AWS CLI v2 で $ aws ecr get-login を使うときの注意点)で $ aws ecr get-login はv1でも非推奨 ということを初めて知った…気を付けよう。
参考


- 投稿日:2020-03-10T23:03:44+09:00
GuardDutyの結果をEvent Bridge→SNSで通知する
はじめに
前回、AWS LambdaからEvent Bridgeに通知してみました。
今回は、GuardDuty→EventBridge→SNS(Email)と連携させてみます。最近業務でセキュリティ!セキュリティ!と叫ばれておりますが、そこまでまともにセキュリティ系のサービスを使っていなかったので、GuardDutyを触り始めたのが理由です。。
構築手順
GuardDutyの有効化
AWSコンソールから
GuardDutyを有効化しておきます。(初回の場合、30日間は無料です。)SNSの作成
Emailで通知が受け取れるように設定しておきます。
EventBridgeの設定
イベントバスの作成
defaultのイベントバスを利用するので不要です。
最初カスタムイベントバスにルールを作ってしまい、全然アラートが飛ばす悩みました、、、
ここでは前回作成した、custom-application-event-busをそのまま使います。(無い方は任意の名前で作って下さい)イベントルールの作成
ルール名は任意でOK
カスタムパターンを選択し、イベントパターンに以下を入力します。
今回はSeverityがHighのものだけ通知するようにしています。Severityの定義はこちらを参照。{ "source": [ "aws.guardduty" ], "detail-type": [ "GuardDuty Finding" ], "detail": { "severity": [ { "numeric": [ ">=", 7 ] } ] } }ターゲットには先ほど作成したSNS Topicを指定します。
GuardDutyにサンプルを作成し通知
サンプル結果の作成
GuardDutyの検出を意図的に発生させるのは難しいため、サンプルで試します。
AWSコンソールのGuardDutyの画面で、「設定」→「結果サンプルの作成」を選択します。
(10数件ほどメールが来るのでご承知おきを。)メールの確認
SNS作成時に設定したEmailに以下のようなメールが届いていれば完了です!
{ "version": "0", "id": "0eef64b4-0f67-244d-400b-7677324fe2af", "detail-type": "GuardDuty Finding", "source": "aws.guardduty", "account": "xxxxxxxxxx", "time": "2020-03-10T13:50:01Z", "region": "us-west-2", "resources": [], "detail": { ・・・ "severity": 8, "createdAt": "2020-03-07T13:34:05.589Z", "updatedAt": "2020-03-10T13:49:52.052Z", "title": "DGA domain name queried by EC2 instance i-99999999.", "description": "EC2 instance i-99999999 is querying algorithmically generated domains. Such domains are commonly used by malware and could be an indication of a compromised EC2 instance." } }さいごに
セキュリティの検知をどの範囲で、どのような方法ですれば良いのか?はとても難しいと思います。
まずは、GuardDutyのような自動で検出してくれるサービスを有効にし、EventBridgeである程度必要なものに絞り込み、自分達に有用なアラートを取捨選択していければと思っています。



- 投稿日:2020-03-10T21:48:07+09:00
RDSスナップショットをS3に自動エクスポート
概要
RDSの自動スナップショットをバックアップのために、S3に自動でエクスポートするServerless functionを作ってみました。
とりあえず最新のスナップショットのみをバックアップするようにしています。処理のイメージはcloud watch eventでn時にlambda functionを実行するというシンプルなものです。
IAM ロール
AWSRDSSnapshotExportRoleのような適当なロールを作成し、そのロールにAmazonS3FullAccessとAWSKeyManagementServicePowerUserをアタッチします。そして、 そのロールの
信頼関係を編集します。{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "export.rds.amazonaws.com" }, "Action": "sts:AssumeRole" } ] }
Serviceの部分をexport.rds.amazonaws.comとすればOKです。KMSでキーを作成
KMSコンソールにアクセスをして、
カスタマー管理型のキーでキーを作成します。
その時に管理者にするのは上で作成したロールにしましょう。
作成したキーのIDはあとで使います。Serverless Frameworkでプロジェクト作成
$ sls create -t aws-nodejs -p hoge $ cd hoge $ npm init $ npm i --save aws-sdkserverless.yml
service: hoge provider: name: aws runtime: nodejs12.x region: ap-northeast-1 role: Lambda用のロールを設定(lambdaとrdsのfullaccessが必要) timeout: 100 package: individually: true exclude: - package.json - package-lock.json - .serverless/** - serverless.yml functions: main: handler: handler.main name: hoge environment: IamRoleArn: 先ほど作成したロールのARNを設定 KmsKeyId: 先ほど作成したキーのID S3BucketName: エクスポートしたS3バケット名 events: - schedule: rate: cron(0 12 * * ? *)毎日12時にエクスポートを実行する
handler.js
handler.jsを編集します。'use strict'; const AWS = require('aws-sdk') const RDS = new AWS.RDS({apiVersion: '2014-10-31'}) module.exports.main= async event => { try { const lastSnapshot = await getLastSnapshot('RDSのデータベース名') await startExportTask(lastSnapshot) } catch (e) { console.log(e) } } function getLastSnapshot(db){ return new Promise(function(resolve, reject){ let params = { DBInstanceIdentifier: db, SnapshotType: 'automated' // 自動で作成されたsnapshotを取得する } RDS.describeDBSnapshots(params, function(err,data){ if(err){ console.error(err,err.stack) reject(err) } else { console.log(data.DBSnapshots.pop()) resolve(data.DBSnapshots.pop()) } }) }) } function startExportTask(obj){ return new Promise(function(resolve, reject){ const params = { ExportTaskIdentifier: obj.DBSnapshotIdentifier, /* required */ IamRoleArn: process.env.IamRoleArn, /* required */ KmsKeyId: process.env.KmsKeyId, /* required */ S3BucketName: process.env.S3BucketName, /* required */ SourceArn: obj.DBSnapshotArn, /* required */ S3Prefix: `${obj.DBInstanceIdentifier}/` } RDS.startExportTask(params, function(err,data){ if(err){ console.error(err, err.stack) reject(err) } else { console.log(data) resolve(data) } }) }) }lambdaのバグについて
プロジェクトの作成の際にわざわざaws-sdkをローカルでインストールしているのですが、実はこれにはわけがあって、lambdaにデフォルトで内包されているaws-sdkがなぜか
startExportTaskメソッドが入っておらず(おそらくバグだと思う)、なのでローカルでインストールし、node_modulsごとデプロイして、node_modulsの中のsdkを参照するようにして回避しています。
- 投稿日:2020-03-10T18:18:44+09:00
Athenaでクエリを発行しようとすると「no viable alternative at input」となる
事象
Amazon Athenaのクエリエディタでクエリ(
SHOW PARTITION <table_name>)を実行すると以下のようなエラーとなる。
line 1:6: no viable alternative at input 'show partition' (service: amazonathena; status code: 400; error code: invalidrequestexception; request id: b8ec4813-f216-4767-88e4-da44da2b223e)
解決
文法の正しくないクエリを実行しようとしていたからだった。
- 誤:
SHOW PARTITION <table_name>- 正:
SHOW PARTITIONS <table_name>正しいクエリであればエラーなく実行できた。
以上


- 投稿日:2020-03-10T18:17:13+09:00
sopsでのクレデンシャル管理【Tips】
TL; DR
Terraformなどで秘匿情報を扱う際に、
lifecycle { ignore_changes = ["hogehoge"] }などで管理から外していたりすることがあります。基本的には問題ないと思うのですが、DBのパスワードなど秘伝のタレ化しがちです。折角のコード化なのでこれらも一緒に管理できるとちょっとだけ幸せになれると思います。
そこでsopsというmozilla社の開発している暗号化/復号化ツールがあります。これを用いてクレデンシャル管理も一緒にやり、少しだけ幸せになろうというTipsです。Install
Macユーザーならおなじみ
brewでインストール可能です。
goがインストール済みであればgo getでもインストール可能です。
わたしはbrewでインストールしました。install sops$ brew install sops ==> Downloading https://homebrew.bintray.com/bottles/sops-3.5.0_1.catalina.bottle.tar.gz Already downloaded: /Users/Library/Caches/Homebrew/downloads/fa1e1ceaec6d966efe2c08d9d4eae6b27d01f616d9d7043f2545f8075268c7ac--sops-3.5.0_1.catalina.bottle.tar.gz ==> Pouring sops-3.5.0_1.catalina.bottle.tar.gz ? /usr/local/Cellar/sops/3.5.0_1: 7 files, 27.9MB $ sops --version sops 3.5.0 (latest)go install$ go get -u go.mozilla.org/sops/v3/cmd/sops $ cd $GOPATH/src/go.mozilla.org/sops/ $ git checkout develop $ make install # Makefileのinstall $ cat Makefile | grep "install:" -A 3 install: $(GO) install go.mozilla.org/sops/v3/cmd/sops tag: all暗号鍵
sopsを利用するに当たって暗号化に利用する鍵が必要になります。
PGPを利用するか、以下のクラウドサービスの鍵を利用することが可能です。
対象の鍵はオプションもしくは変数として呼び出すことができるため適宜利用してください。
対象 サービス名 オプション 変数名 PGP - --pgpSOPS_PGP_FPGCP Cloud Key Management Service --gcp-kmsSOPS_GCP_KMS_IDSAzure Key Vault --azure-kvSOPS_AZURE_KEYVAULT_URLSAWS Key Management Service --kmsSOPS_KMS_ARN必要な環境に応じて用意してください。
使い方
ざっとした使い方ですので参考までに見てもらえるといいかと思います。
筆者はAWS KMSを用いて実施しました。
※ あらかじめexport SOPS_KMS_ARN="arn:aws:kms:ap-northeast-1:123456789012:key/hogehoge"を入力して環境変数に入れています。新規作成
ファイルが無い状態で
sops ファイル名と入力するとエディタが開かれ下記のようなサンプルが表示されます。sops new file$ sops sample_secret.yml hello: Welcome to SOPS! Edit this file as you please! example_key: example_value # Example comment example_array: - example_value1 - example_value2 example_number: 1234.5679 example_booleans: - true - false試しに下記のように編集してみました。
edited fileexample_key: example_value example_number: 1234.5679これを保存して抜けるともう暗号化されています。
sample_secret.ymlexample_key: ENC[AES256_GCM,data:D9pPc7dRd6PuoLUPPw==,iv:zWZxW42YhJsETnWCfgDnIQL55iTSxNrthVmB5gC4bJI=,tag:E/6EBAQ/MnLbCpGCOSnFHg==,type:str] example_number: ENC[AES256_GCM,data:93sOpzQJvu4N,iv:aigNbYXg+2uSB7cB+JEOnCguBea49DjU2eSGyaBJM5I=,tag:Kf//or7XpUmPChrdhx4Idg==,type:float] sops: kms: - arn: arn:aws:kms:ap-northeast-1:123456789012:key/890hoge1-67ho-34ga-01fu-1234hoge567 created_at: '2020-03-10T08:12:15Z' enc: AQICAHjzJdn8BrQ9cSoqu5NVOLqeyLNJxw4Gm2+8UkJCyqr6ngHoCN1jRMUoKeYuz1ybQhRDAAAAfjB8BgkqhkiG9w0BBwagbzBtAgEAMGgGCSqGSIb3DQEHATAeBglghkgBZQMEAS4wEQQM10R9JpvAo2TpWegYAgEQgDte4OJEdbpEmI0pyuZ6Wmz3qvNtw4TJv7TfEujHIpkf6g9Kapq3wEoETiqjy2z+CYt2VptB9+fQZ3h0hQ== aws_profile: "" gcp_kms: [] azure_kv: [] lastmodified: '2020-03-10T08:33:14Z' mac: ENC[AES256_GCM,data:JDiJlMegTqzPRbG2hlcAziRToXhwoz9q8g5d2e0X/8B/sP8T8a+/Z9EhOprsBO8T/S7LaC2pAgOevYXonn906VouY+Kn/8kDGyYFU9qAr50gUJ1DZApCUneM58uKUYIhdo0+erKO7594+hSbbf0Ny9Br1ldPmlHf/TkJ1UtN87o=,iv:qpZQ3fxYXijrKd5u9uXDg+2eOx6hxZv909VZCislKbk=,tag:T+77DkwadQp0YhYf69PXbQ==,type:str] pgp: [] unencrypted_suffix: _unencrypted version: 3.5.0復号化
上記で作成したファイルを復号化してみます。
-dオプションをつけるだけなので非常に簡単です。decryption$ sops -d sample_secret.yml example_key: example_value example_number: 1234.5679シークレットの追加
新規同様
sops ファイル名で開いて追加するだけです。add secret$ sops sample_secret.yml example_key: example_value example_number: 1234.5679 additional: value_addこれで保存して確認すると、
sample_secret.ymlexample_key: ENC[AES256_GCM,data:D9pPc7dRd6PuoLUPPw==,iv:zWZxW42YhJsETnWCfgDnIQL55iTSxNrthVmB5gC4bJI=,tag:E/6EBAQ/MnLbCpGCOSnFHg==,type:str] example_number: ENC[AES256_GCM,data:93sOpzQJvu4N,iv:aigNbYXg+2uSB7cB+JEOnCguBea49DjU2eSGyaBJM5I=,tag:Kf//or7XpUmPChrdhx4Idg==,type:float] additional: ENC[AES256_GCM,data:KCkWJ7gd9GHV,iv:RaAhQzuRckK6jaXBTl9lgk0YEs3RHS7xxozOgfTtXPo=,tag:sfi7QStVN5BMy/SGX5RO6Q==,type:str] sops: kms: - arn: arn:aws:kms:ap-northeast-1:123456789012:key/890hoge1-67ho-34ga-01fu-1234hoge567 created_at: '2020-03-10T08:12:15Z' enc: AQICAHjzJdn8BrQ9cSoqu5NVOLqeyLNJxw4Gm2+8UkJCyqr6ngHoCN1jRMUoKeYuz1ybQhRDAAAAfjB8BgkqhkiG9w0BBwagbzBtAgEAMGgGCSqGSIb3DQEHATAeBglghkgBZQMEAS4wEQQM10R9JpvAo2TpWegYAgEQgDte4OJEdbpEmI0pyuZ6Wmz3qvNtw4TJv7TfEujHIpkf6g9Kapq3wEoETiqjy2z+CYt2VptB9+fQZ3h0hQ== aws_profile: "" gcp_kms: [] azure_kv: [] lastmodified: '2020-03-10T08:42:48Z' # 更新されていることがわかる mac: ENC[AES256_GCM,data:JDiJlMegTqzPRbG2hlcAziRToXhwoz9q8g5d2e0X/8B/sP8T8a+/Z9EhOprsBO8T/S7LaC2pAgOevYXonn906VouY+Kn/8kDGyYFU9qAr50gUJ1DZApCUneM58uKUYIhdo0+erKO7594+hSbbf0Ny9Br1ldPmlHf/TkJ1UtN87o=,iv:qpZQ3fxYXijrKd5u9uXDg+2eOx6hxZv909VZCislKbk=,tag:T+77DkwadQp0YhYf69PXbQ==,type:str] pgp: [] unencrypted_suffix: _unencrypted version: 3.5.0これで簡単にクレデンシャルを追加できます。
ファイルからリダイレクト
複数あってめんどくさい場合はリダイレクトする形で吐き出してあげましょう。
$ cat new_file.yml simple: yaml_file add: fromfile test: encryption $ $ sops -e new_file.yml > enc_new_file.yml $ $ ll enc_new_file.yml -rw-r--r-- 1 staff staff 1252 3 10 17:49 enc_new_file.yml確認すると、
enc_new_file.ymlsimple: ENC[AES256_GCM,data:jdgFlc05BALm,iv:n4jexuOttomE2Rr/rfUfgdtO79b/AkMg1+id/P6q5Oc=,tag:0t4rwKW/emWymw8TYQjTeg==,type:str] add: ENC[AES256_GCM,data:qjYDDU4x4yU=,iv:KBlpm+WFZcHIlHtdMLJljRWxoTIdjR8aEuQ/PQzTLBs=,tag:LaE8tXuQskvknUUdftH/MA==,type:str] test: ENC[AES256_GCM,data:eA5R4hRAYK/erQ==,iv:qkrpdBxWUNI6lJEuQcxfDsIL3mCWEIHlVUhZ6P4Fdsg=,tag:KJI97tTgntFSupfhgVLTBg==,type:str] sops: kms: - arn: arn:aws:kms:ap-northeast-1:123456789012:key/890hoge1-67ho-34ga-01fu-1234hoge567 created_at: '2020-03-10T08:49:23Z' enc: AQICAHjzJdn8BrQ9cSoqu5NVOLqeyLNJxw4Gm2+8UkJCyqr6ngHhoC2HA0cFLSpkhEEpdOdEAAAAfjB8BgkqhkiG9w0BBwagbzBtAgEAMGgGCSqGSIb3DQEHATAeBglghkgBZQMEAS4wEQQMkqxdUJrTZdJglnV2AgEQgDs8jfVf1giaaMUGp0czzmgUZlAI49D3ekFiEEr9RNcWwoj55KWgNr/q+Umg3Fu+RpPd6wc32eXmw3i2Iw== aws_profile: "" gcp_kms: [] azure_kv: [] lastmodified: '2020-03-10T08:49:24Z' mac: ENC[AES256_GCM,data:Af2KHbsAqo35DyS2m4XufoqFc7x4XfNetGC1BIYcVZhy8strbhFEAn0EYn7dHXgpZJI/ZwPzmA2adhioA1+qhJIL8U/mrHJTufPJWEw/8VTkl3JoCBMWO9gB6+Ip525AwNFi6sJEj6GLbwMaI4alZsSSFGs82HiBLe0Q2OpJNQ4=,iv:VlCaQipPx9p96QB4VWl1X7UxTcDQLO1d2SVP6LMz1+g=,tag:Hkt/zqjoN60HMKR6tro60A==,type:str] pgp: [] unencrypted_suffix: _unencrypted version: 3.5.0decryption$ sops -d enc_new_file.yml simple: yaml_file add: fromfile test: encryption使い方はざっとこんな感じです。
Terraformで使ってみる
Terraformで使う場合は公式のproviderではないので自分でpluginを持ってくる必要があります。
https://github.com/carlpett/terraform-provider-sopsREADME.mdにも記載あるとおりreleaseから自分の環境に合わせて持ってきます。
下記に配置してね、と記載ありますがこれだとダメな場合があるのでその場合は.terraform/plugins/配下に置きましょう。・Windows %APPDATA%\terraform.d\plugins
・All other systems ~/.terraform.d/plugins書き方
非常にシンプルです。
sops.tfprovider "sops" {} data "credentials" "new_file" { filename = "enc_new_file.yml" } resource "aws_ssm_parameter" "test" { name = "sops-test" type = "String" key_id = "alias/aws/ssm" value = data.credentials.new_file.data["simple"] }プロバイダのバージョン指定は不要です。 ※ コミュニティ提供のため指定できない。
data構文にてクレデンシャルのファイルを指定します。あとはdataリソースとして呼び出してあげるだけです。
これでインフラコードとクレデンシャルが一緒に管理できて幸せですね!所感
KMSやKey Vault側で権限を管理しているため、権限管理も簡単ですしなにより一緒に管理できるのが非常に楽でいいです!たとえYAMLファイルをお漏らししても復号できないので安心ですね。(そもそもお漏らししないのが一番ですが。。)
ぜひこれで少しでも幸せになる方が増えればと思います。参考
- 投稿日:2020-03-10T17:10:59+09:00
AWSでの権限設定がわかりません!→IAMについてわかりやすくまとめてみました。
IAMとは
IAM = Identify and Access Managementの略です。これもAWSで提供されているサービスの一つになります。AWSで提供されている各種リソースへの認証および認可について管理するサービスです。
まずリソースへアクセスする際に該当ユーザーについて認証をして、アクセスできるか確認します。さらにアクセスできる度合いも制御します。例えばフルアクセス、読み込みのみ等です。
"誰"が"何に"対して"どのように"アクセスできるかを決め、実現するサービスです。
IAMの概要
- ユーザーはAWS CLI, AWS SDK, AWSマネージメントコンソールを利用してAWSにログインする。
- AWSにログインする際には、IAMユーザーあるいはIAMグループを用いて、パスワードなどを利用して認証する
- 認証されたIAMユーザーおよびIAMグループはIAMポリシーに従って各AWSリソースに対するアクセス権限が許可される(フルアクセス、読み込み・書き込み、読み込みのみ等)
IAMはなぜ重要か
AWS権限設定はIAMに統合
AWSは利用できるサービスが多岐にわたります。それに対して権限設定はIAMに統合されています。例えば開発・QA・本番環境の構築を考えます。
- 開発メンバーは開発環境のすべてのサービス、リソースにアクセスできる。
- プロビジョニングアカウントはそれぞれQAと本番環境にアクセスできるがLambdaの変更はできない。
- データベース運用メンバーは本番環境のS3へのすべての権限を持っている
これらの権限設定はすべてのIAMのユーザー、グループ、ポリシー、ロールにより設定します。
IAMで設定すべき必要なリソースがわかりにくい
またIAMを正しく理解すべきもう一つの理由は、対象となるサービスおよびリソースの関連性が複雑ためです。
例えばLambdaを考えてみます。Lambda関数を利用するには該当の関数に対する許可があればよいのは明らかです。Lambdaを作成した際に自動的にIAM実行ロールが作成されます。
しかし例えばLambdaでDyanamoDBを利用していると、DynamoDBの該当のテーブルに対しても許可が必要となります。コードを書いているだけでは許可が必要かどうかわかりません。実際に動かしてみてから、実は必要だったことが明らかになり、適宜ポリシーで許可を与えることになります。このような場合Lambda作成者とIAMの管理者が同じであればトライアルアンドエラーで済ませることができますが、Lambda作成者が日本、IAM管理者が海外にいる場合時間ばかりかかります。
IAMに関係する用語
サービス
AWSで提供されるサービス。例えばEC2, S3, Lambdaなどです。
AWSリソース
AWSで提供されているサービスの中で、ユーザーが実際に操作できる対象です。
- 例えばAmazon EC2サービスならEC2インスタンス、Amazon S3ならばS3バゲットがあります。
ルートユーザー
ルートユーザーはAWSアカウントを作成した際に作るユーザーになります。
- アカウントに紐づいているすべてのAWSサービスとリソースについてアクセス権を持ちます。
- IAMアクセスポリシーによるアクセス許可はできない→常にすべてのサービス・リソースにアクセスできます。
- 基本ルートユーザーは使いません。
- 管理者用に別のIAMユーザーを作成して、管理者権限を割り振りましょう。
- アカウント乗っ取りを防ぐためにMFAを設定するのがよいでしょう。
IAMユーザー
IAMユーザーはAWSを操作する人に個別に割り当てるユーザーになります。
- ユーザーはログインする際に認証ができます。
- ユーザーに紐づけられたIAMポリシーにより各種リソースに対する認可を設定できます。
- ただし基本はIAMグループに所属させて、グループごとにポリシーを設定するのが望ましいでしょう。
- 一つのIAMユーザーは複数のグループに所属することができます。
IAMグループ
ユーザーをアサインするグループです。
- グループに紐づけられたIAMポリシーにより各種リソースに対する認可を設定できます。
- グループに設定された認可はグループに所属しているIAMユーザーに引き継がれます。
IAMポリシー
AWSリソースに対して許可されるあるいは許可されない操作、つまり権限を設定します。
- IAMポリシーはJSONで記述します。一見取り付きにくいですが、フォーマットは決まっています。慣れればそれほど難しくはありません。
- ポリシー作成時にはAWS Policy GeneratorもしくはIAM Policy Simulatorが利用できます。
IAMロール
IAMを構成する要素の中でもっとも理解が難しいのがIAMロールになります。
IAMロールを用いるメリットは2つあります。
- IAMポリシーを個別にオブジェクトに割り振る必要がなくなります。
- IAMポリシーの割り当てについて柔軟な条件を付けることができる
IAMロールはAWSサービスもしくは、個別のアプリケーションに割り当てられます。
- IAMロールはIAMユーザーもしくはグループには付与されません。
- IAMロールにはIAMポリシーを紐づけます。
詳細および使用例については後程説明します。ここでは権限をユーザーだけではなく、サービスおよびAWSリソースにも割り振ることができる、ということだけ理解してください。
IAMユーザーの認証方法
ユーザーがログインする際に認証する方法は複数あります。アカウントの重要度あるいは環境に合わせて認証方法は変えるべきです。主な認証を方法を記載しておきます。
パスワード認証
- 主にマネージメントコンソールへログインする際に利用されます。
- ユーザー名とパスワードの組み合わせ。
アクセスキー認証
- API経由でAWSリソースへアクセスする際に利用される認証方法です
- 長期的な認証を提供するために用いられます。
- アクセスキーIDとシークレットアクセスキーの組み合わせになります。認証の際には両方が必要です。
- IAMユーザーもしくはルートユーザーに紐づけることができます。最大2つまで作成できます。
- ただしルートユーザーに紐づくアクセスキーは避けるべきでしょう。
MFA
- 認証を強化したい場合に用います。
- 第一要素はパスワード認証もしくはアクセスキー認証になります。
- 第二要素は認証されたデバイスもしくはSMSに送信される認証コードにより認証します。
IAMロールの使い方
IAMロールは説明だけ読んでいてもなかなか理解できません。しかしユースケースでIAMロールを利用しないときーつまりパスワード認証もしくはアクセスキー認証の時ーと、IAMロールを利用するときを比べてみるとすぐ理解できます。
ここではもっともよくつかわれるパターンであるEC2からのS3バゲット利用シーンを使って比べてみます。
まず下記はEC2インスタンスのアプリケーションからS3バゲットを利用する際に、アクセスキーを利用して認証をする方法です。
この例ではアクセスキーがEC2インスタンス内のアプリに埋め込まれています。
- ACCESSキーはアプリケーションとポリシーの組み合わせによりユニークになります。
- アクセスキーを変更するためにはアプリを修正する必要があります。
- EC2インスタンスに不正アクセスがあった場合には、アクセスキーが漏洩する可能性があります。
ではそれに対してIAMロールを利用してみます。
- アクセスキーはアプリケーション内部には埋め込まれていません。
- 権限のつけ外しは、アプリケーションをいじることなく可能です。
IAMの使い方
IAMポリシー全体のデザイン
テスト開発ならともかくとして本番環境ならば、かならずIAMの全体像をデザインする。はじめてであればなかなかうまくいかない。しかし最初にデザインをしておき、問題が起きたらデザインの手直し→実装とすればセキュリティについて漏れがなくなりやすい。デザインは以下のポイントで整理する。
- 管理するオブジェクトもしくはサービスの一覧を作成する
- 上記で明らかになった対象について必要なポリシーを明らかにする
- ポリシーにアタッチするグループを作成する
- 各グループに所属するユーザーの一覧を作成する
IAMオブジェクトの作成
デザインが仕上がったら順番にIAMオブジェクトを作成していきます。
- IAMユーザーを作成します。
- IAMグループを作成します。
- IAMポリシーを作成します。
- IAMポリシーをIAMグループに割り当てます。
- IAMユーザーをIAMグループに割り当てます。
IAMポリシーの内容
IAMポリシーでは、どのAWSサービスの、どのリソースに対して、どのようなアクションを許可するかをJSON形式で記述する。ただし、AWSコンソールではGUIが提供されているために、一般的なポリシーを作成するならばJSONを気にする必要はない。
** GUI形式でポリシーを作成 **
** 同じポリシーをJSON形式で作成 **
参考
Introduction to AWS Identity and Access Management
英語ですが10分ちょっとでIAMの概念とIAMロールのユースケースを理解できます。IAM初めての人はまずここから!【図解/AWS】IAM入門~ロールとグループとポリシーの違い,設計・設定手順について~
概要を理解したら、次にIAMユーザー、グループ、ポリシー、ロールについて勉強する必要があります。このページはそれぞれの概念がわかりやすく説明されています。AWS IAM入門
IAMロールについての基本およびユースケースがわかりやすく記載されています。上記の資料と合わせて読めば、ほぼIAMロールについて理解できます。【[AWS Black Belt Online Seminar] AWS Identity and Access Management (AWS IAM) Part1 資料公開
IAMロールについてさらに理解を深めたければAWSブラックベルトです。スライド68枚、動画50分近くとかなり内容が濃くなっていますが、これを理解すれば間違いなくIAMブラックベルトでしょう。その反面IAM初心者にはおお勧めできませんので、まずは上記3つをこなし、自分でもいくつかIAMサービスをいじってからチャレンジしましょう。






- 投稿日:2020-03-10T16:54:21+09:00
[作ってみた]fondeskからSlackへの受電通知にメンションをつけるbot
はじめに
皆さんリモートワークしていますか?弊社では2月中旬から全社的なリモートワークが始まり、この記事を書いている現在(2020/03/10)も引き続きリモートワークをしています。
本記事はリモートワーク時の電話対応をスムーズにストレスなくするべく、AWS Lambda・API Gatewayを使用してbotを開発しましたよというお話です。(先人としてGASを使ったbotを開発された方がいらっしゃいました。)関連ツール&技術
今回紹介するbotの関連項目です。
- Slack
- AWS
- API Gateway
- Lambda
- S3
- Serverless Framework
- Python3.7
リモート時の電話対応について
リモートワークを実施する場合に、電話対応をどうしよう…オフィスに誰もいない?ということで弊社ではfondeskを導入しました。
fondeskとはオフィスへの電話対応を代行して、各種ツール(メールとかSlackとかとか)へ通知してくれるサービスです。
(導入方法・設定等は割愛します)Slackへの通知
弊社では社内コミュニケーションツールとしてSlackを使用しているので、通知先としてSlackを選択しました。このように入電があると指定したチャンネルに通知が飛んできます。
Slack通知の問題点
便利なfondeskですが、チャンネルへの投稿はしてくれますが残念ながら個人宛のメンションは飛びません。公式を見に行くとこんな質問が…電話の宛先によって通知先を変えたり、メンションを付けたりすることはできますか?
宛先に応じた通知機能は多くのご要望をいただいていますが、期待される精度での通知が難しいだけでなく、ユーザーのみなさまにも多くのご負担がかかってしまうため、慎重に検討を進めています。
現時点ではメンションはつかないということで、メンション機能は自前で作ることとします。
先達としてGASを使ったbotを開発された方がいらっしゃいました。今回は自分が慣れている、Slack bot + API Gateway + Lambdaの構成で作成してみようと思います。
botの要件
- fondeskアプリの投稿に反応する
- 投稿内容から宛先を割り出しメンション付きで投稿する
- 宛先を特定できなかった場合
@hereで投稿するフロー
- fondeskからSlackに通知(メンションなし)が飛ぶ
- チャンネルに招待されたSlackAppがAPI Gatewayにリクエストを飛ばす
- API GatewayがLambdaを起動し、宛先を特定する
- LambdaからSlackに投稿(メンション付き)をする
設定&実装
設定
Slack側
まずは、fondeskの投稿を検知し、APIGatewayにリクエストを飛ばすためのbotを作成します。
お好きな名前でAppsを作成し、以下のような権限を与えておきます。(commandsは別件でslash commandを使用するために付与しています。本記事の内容のみであれば不要です。)
後述するLambda+APIGatewayをserverlessでデプロイした後に、APIGatewayのエンドポイントを貼り付けておきます。
Subscribeするeventsはmessage.channelsです。
設定が終わった後、fondeskが通知するチャンネルにbotユーザーを招待しておきます。
AWS側
基本的にはServerlessでズドンとやります。
LambdaにはS3とファイルのやり取りをしてもらうので、Get/Put Object権限を与えておきます。またLambda起動のトリガーとしてAPI Gatewayを定義しておきます。(x-www-form-urlencodedをjsonにマッピングするテンプレートを置いていますが、本当に必要かは謎です。slash commandと混同している?)service: fondesk-bot provider: name: aws runtime: python3.7 stage: ${opt:stage, self:custom.defaultStage} region: ap-northeast-1 memorySize: 512 logRetentionInDays: 30 iamRoleStatements: - Effect: Allow Action: - "s3:GetObject" - "s3:PutObject" Resource: - ${self:custom.S3Bucket.arn} - ${self:custom.S3Bucket.arn_obj} functions: receiver: handler: receiver.handler name: fondesker-receiver-${self:provider.stage} timeout: 10 events: - http: path: fondesker/receiver method: post integration: lambda request: passThrough: WHEN_NO_TEMPLATES template: application/x-www-form-urlencoded: '{"body": $input.json(''$'')}' environment: FONDESK_BOT_ID: ${env:FONDESK_BOT_ID} SLACK_TOKEN: ${self:custom.token.${self:provider.stage}} S3BUCKET: ${self:custom.S3Bucket.name}実装
API GatewayがLambdaを起動する。
起動したLambdaに受け渡されるeventの中身はこんな感じになっています。着目するポイントは次の4点です。
- event.type
- event.subtype
- event.bot_id
- event.attachments.fields
1.~3.でfondeskアプリからの投稿であることを特定し、4.の中身で宛先を特定するという流れです。
event.attachements.fields内に宛先項目があれば、良かったのですがありません…どうやら「内容」に入っているようです。{ "body": { "token": "<token>", "team_id": "<team_id>", "api_app_id": "<app_id>", "event": { "type": "message", "subtype": "bot_message", "text": "", "ts": "1583124518.035200", "bot_id": "<bot_id>", "attachments": [{ "fallback": "test", "id": 1, "ts": 1583124518, "color": "36a64f", "fields": [ { "title": "発信者", "value": "test", "short": false }, { "title": "折り返し先の電話番号", "value": "xx-xxxx-xxxx", "short": true }, { "title": "折り返しの連絡", "value": "必要", "short": true }, { "title": "内容", "value": "◯◯様宛に入電。先程連絡頂きました件についてです。", "short": false } ] }], "channel": "<channel_id>", "event_ts": "1583124518.035200", "channel_type": "channel" }, "type": "event_callback", "event_id": "<event_id>", "event_time": 1583124518, "authed_users": ["<user_id>"] }, ... }宛先を特定する
「内容」欄から宛先らしい所を抽出することを試みます。正規表現沼や自然言語処理沼には入って行きたくないので、今回は単純に辞書をS3に持つことにして、Lambdaはその辞書を参照し宛先を特定します。
辞書の構造
{ "<SLACKUSER_ID>": ["テスト", "てすと", "test"] }内容欄の中から"宛"を検索し、存在した場合"宛"以前を、存在しない場合は内容欄全体を宛先検索に使用します。
if subtype == "bot_message" and slack_event["bot_id"] == FONDESK_BOT_ID: value = [field["value"] for field in attachments[0]["fields"] if field["title"] == "内容"][0] if "宛" in value: value = value.split("宛")[0] user_ids = lookup_user_id(value) def lookup_user_id(value: str) -> List[Optional[str]]: """ (前提)"SlackユーザーID": [名前表記候補のリスト]という構成のJSONファイルを準備しておく。 params: value: 宛名が入っている(と期待する)文字列 return: user_ids: SlackユーザーIDのリスト。該当者がいない場合は空のリスト。 """ BUCKET_NAME = os.environ["S3BUCKET"] s3_bucket = S3Bucket("ap-northeast-1", BUCKET_NAME) name_list = json.load(s3_bucket.get_object_body("synonyms.json")) user_ids = [] for user_id, candidates in name_list.items(): if any([candidate in value for candidate in candidates]): user_ids.append(user_id) return user_idsLambdaからSlackに投稿(メンション付き)をする
Slackではhere, channelなどは<!here>, <!channel>でメンションできますが、個人にメンションしたいときは<@user_id>としなければいけません。
以前までは<@username>でもメンションできたようですが、変更されたようです。message = "" if user_ids: for user_id in user_ids: message += f"<@{user_id}> " message += "さん、" else: message += "<!here> " message += "入電ですよ!" post_slack(channel, message) def post_slack(channel: str, message: str) -> None: """ Slackにメッセージを投げます """ params = {"token": SLACK_TOKEN, "channel": channel, "text": message} requests.post(SLACK_MESSAGE_URL, headers={"Content-Type": "application/json"}, params=params)↓のようにメンションが飛べばOKです。
メンション有り版
メンション無し版
運用してみて気付いたポイント
- 辞書の更新が結構手間
- Slackタイムアウト結構厳しい
辞書の更新に関しては、最初は手作業でやっていたのですが、結構手間なので最終的には辞書の更新機能を別途slash command化して、ユーザーに委ねる形にしました。slash commandに関しては、この記事内に書くと長くなるので別記事にまとめようと思います。
S3にあるJSONファイルをダウンロードするようにした所、botからの投稿が3連打されるという事象が有りました。Slackはレスポンスを3000ms以内に受け取らないとタイムアウトし、3度ほどリトライされるようです。これについては、Lambdaへの割当メモリを増やすという対策でなんとかなっています。どうにもならなくなった場合は、LambdaからLambdaを非同期実行で呼び出すという対策が必要になりそうです。
まとめ
今回はfondeskからの投稿にメンションをつけるbotの紹介をしました。fondeskによってリモートワークしていても電話対応できるし、メンションがつくことで見落としへの対策が取れました。
あとは、普段一緒に仕事をしない別部署の同僚とマージリクエストのやり取りができて、全社的な取り組みっぽくなった点も個人的には良かったです。






- 投稿日:2020-03-10T15:54:15+09:00
AWS NAT Gatewayの費用を抑えようと思ったら高くなった話
概要
NAT Gatewayの費用を抑えようと思ってVPCエンドポイントを使ったら、逆に高くなった話です
結論
- 前提条件
- 外部APIへのリクエストなどすでにNAT Gatewayを使っている
- セキュリティ(インターネットに出てはいけない)のことは考慮不要
- インターネットに出てアクセスするレイテンシは考慮不要
NAT Gatewayを普段使っているのであれば、VPCエンドポイントはS3とDynamoDB(ゲートウェイエンドポイント)だけでいい
と思ってます(個人的見解です)考察
現状
- NAT Gatewayの費用が高くなっていった
- NAT Gatewayを利用しているリクエストは以下
- S3とかECRとかDynamoDBとかCloudWatchLogsとかAWSのサービスにアクセスしているもの
- 外部APIにアクセスしているもの
AWSのサービスにはVPCエンドポイントを利用することでNAT Gatewayを通さずにアクセスできる
VPCエンドポイント
- 概要:https://docs.aws.amazon.com/ja_jp/vpc/latest/userguide/vpc-endpoints.html
- インターフェイスエンドポイント
- ゲートウェイエンドポイント
インターフェイスエンドポイントは各AZごとにENIが作成され、そこ経由でアクセスする
ゲートウェイエンドポイントはルートテーブルのみインターフェイスエンドポイントはENIを作成する関係で使っていなくても時間課金される(AZ単位で)
インターフェイスエンドポイントを作れば作るほど、起動時間で課金されてしまう
https://aws.amazon.com/jp/privatelink/pricing/損益分岐点
- 東京リージョン、3AZ利用
- VPCエンドポイント費用:($0.014/h*24h*31day*3AZ){VPCエンドポイント数}+$0.01/GB通信量
- NAT Gateway費用:$0.062/GB*通信量
- 現状NAT Gatewayを使っているという前提なので起動時間課金については考慮しない
通信量\VPCエンドポイント数 1 2 3 4 5 NATGW増加費用 100GB 32.248 63.496 94.744 125.992 157.24 6.2 200GB 33.248 64.496 95.744 126.992 158.24 12.4 300GB 34.248 65.496 96.744 127.992 159.24 18.6 400GB 35.248 66.496 97.744 128.992 160.24 24.8 500GB 36.248 67.496 98.744 129.992 161.24 31 600GB 37.248 68.496 99.744 130.992 162.24 37.2 1000GB 41.248 72.496 103.744 134.992 166.24 62 結果、VPCエンドポイント1つでかつ600GB以上の通信をその1つのVPCエンドポイントでする場合に限り、NAT Gatewayを通すよりも安くなる
600GBの通信、CloudWatchLogsとかKinesisとかであれば可能性ありそうでしょうか・・・?
VPCエンドポイントの起動時間課金が安くなるorなくなること、複数AWSサービスに対して1つのVPCエンドポイントでまかなえるようになることを期待しています。ちなみに、VPCエンドポイントを9個作ったので、費用跳ね上がりました・・・とさ。
- 投稿日:2020-03-10T14:11:30+09:00
プライベートサブネットのEC2からCloudwatchへログを飛ばす
やりたいこと
プライベートサブネットにおいたEC2から、Cloudwatchへログを飛ばしたい
※Cloudwatch agentをEC2にインストールしている前提で。普通にできそうじゃない…?
Cloudwatch agentからCloudwatchに飛ばすとなると、1回外へ出ていこうとする。
プライベートサブネットは外へ出る足がないので、サブネットの中で糞詰まってしまう。やりかた
前提:Cloudwatchに、飛ばしたいログを受けとるためのロググループを作成済みであること
セキュリティグループを作成する
EC2をsourceとした443のinbound通信を受けられるルールを作成する
VPCエンドポイントを作成する
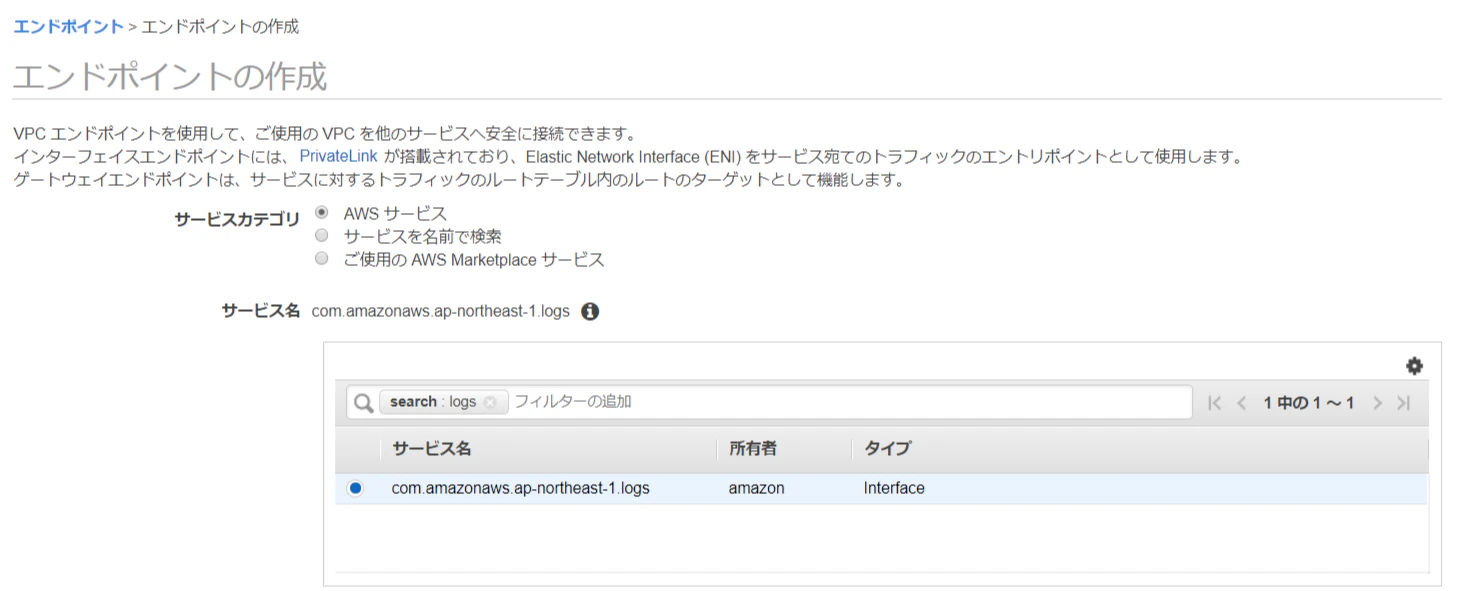
VPC → エンドポイントを選択
エンドポイントの作成を選択
どのサービス用のエンドポイントであるかを指定する
Cloudwach Logs用なので、com.amazonaws.リージョン名.logsを選択する
logsで検索すれば出てくる
検索して出てきたエンドポイントを選択する
すると、VPC、サブネット、セキュリティグループ等々が選択できるようになる
VPCとサブネットの選択
ログを飛ばしたいEC2が存在するVPCを選択する。サブネットも同様。
セキュリティグループの選択
1番で作成したセキュリティグループを選択する
file_config.jsonに"endpoint_override"を追記する
AWSのリファレンスによるとこんな設定が必要とのこと。
CloudWatch エージェント設定ファイルを手動で作成または編集する

ちょっと何言ってるがよくわからないが、この赤枠の値をfile_config.jsonに書けばOK
file_config.jsonはコチラ↓
/etc/amazon/amazon-cloudwatch-agent/amazon-cloudwatch-agent.d最後に、Cloudwatchで飛ばしたかったログが飛んできてるか確認する。
普通にCloudwatch見るだけなので省略。以上






- 投稿日:2020-03-10T12:49:32+09:00
Cloudformation/CDKで最新のSolution Stackを指定する方法
https://forums.aws.amazon.com/thread.jspa?threadID=252614
This API returns platform's with their ARN's. One ARN might look like this: "arn:aws:elasticbeanstalk:us-west-2::platform/Node.js running on 64bit Amazon Linux/4.0.0". This ARN can be passed in via the "SolutionStackName" parameter. Additionally, you can truncate the version and just specify "arn:aws:elasticbeanstalk:us-west-2::platform/Node.js running on 64bit Amazon Linux", and this should resolve to the latest 64bit Node JS platform available to you when creating or updating an environment.SolutionStackNameパラメタとして
arn:aws:elasticbeanstalk:us-west-2::platform/Node.js running on 64bit Amazon Linux/4.0.0
のようにバージョンを明示せずに、
arn:aws:elasticbeanstalk:us-west-2::platform/Node.js running on 64bit Amazon Linux
と書けば、最新版が使われるとのことです。知らなかった。。。。
- 投稿日:2020-03-10T12:25:36+09:00
ありの~ままの~DBスキーマを、go言語ソースコードに自動変換【xorm/reverse】
はい
今回ご紹介するのは、こちらのxorm/reverseです。
https://gitea.com/xorm/reverseなんと!
DBのテーブル構造を直接見に行って、go言語の構造体ソースコードに自動変換してくれます。
対象DB種類も、MySQL以外に色々対応しています。ライセンスは、MITかな?
LICENSEファイルには明示的には書いてないですが、xorm公式ページではMITとなっているので。
https://xorm.io/こちら、実は2年以上前から開発されているようです。
以前はリポジトリはgithubだったんですが、親プロジェクトxormと共にgiteaに移籍したみたいですね。また当時のバージョンではC言語や他の言語ソースへもリバースできたんですが、リニューアル以降はまだ
language/golang.go以外の出力プラグインは作られてないみたいですね。パブリックリポジトリなので、gitea のアカウントを持ってなくてもマイPCからgit cloneできました。
ただ、EC2インスタンスからのgit cloneは失敗しました。AWSはブロックしてるのかしら?
ままエアロ。使い方
・・・をご紹介しようと思ったのですが、早速失敗しました。
READMEどおり
$ go get xorm.io/reverseしたら
# xorm.io/reverse/vendor/github.com/mattn/go-sqlite3 exec: "gcc": executable file not found in %PATH%
gccがインストールされてないと動かない、と。
gcc入れるのダルいなー。それとちょっと改造する用事もあったので、
git cloneしてソースをいじってxorm/reverseのmainコードを直接実行するようにしちゃいましょう。(下準備)リバース対象のお試しMySQLを用意
https://github.com/yagrush/simple-docker-mysql
↑こちらに、docker-composeですぐ起動できるお試しMySQLをご用意しました。
これをgit cloneして起動します。※
docker-compose自体の設定は割愛します。
あるいはAWS EC2用でよろしければ、こちら https://qiita.com/yagrush/items/e85d2da1b0ef9997fa07 をご参照ください。$ cd ~ $ git clone https://github.com/yagrush/simple-docker-mysql.git $ cd simple-docker-mysql $ docker-compose up --build -d
xorm/reverse実行を試みる
xorm/reverseをgit cloneしてくるhttps://gitea.com/xorm/reverse にgit用URLが(githubと同じように)載っているので、ありがたく
git cloneしましょう。$ cd ~ $ git clone https://gitea.com/xorm/reverse.git $ cd reversesqlite3 を対応DBから外す
sqlite3は今回使わないし、
gcc見つからないエラーをちゃっちゃと回避したいので、↓をコメントアウトしちゃいます。
go.mod
require宣言のgithub.com/mattn/go-sqlite3
main.go
import宣言の_ "github.com/mattn/go-sqlite3"
reverse設定ファイルを作る
reverse/examples/goxorm.ymlをmy-mysql.ymlに改名して、プロジェクトルートreverse/にコピーします。そして、中身を適宜編集します。
例えばこんな感じ。kind: reverse name: my-mysql source: database: mysql conn_str: 'root:hogerootpassword@tcp(127.0.0.1:3306)/hogedb' targets: - type: codes include_tables: - hogetable exclude_tables: - foo language: golang template_path: example/template/goxorm.tmpl output_dir: models実行
早速実行してみます。
$ cd reverse $ go run main.go -f my-mysql.yml $何も表示されないですが、エラーもないし、どうやら無事実行されましたかね。
出力を見てみましょう。
設定ファイルにoutput_dir: modelsと書いていたので、これかな?$ cat models/models.go package models type Hogetable struct { Hogename string `xorm:"not null VARCHAR(32)"` Id int `xorm:"not null pk autoincr INT"` }素晴らしい…
ちなみに「
package modelsはいったいどこから来てん?」というと、
↓設定ファイルから参照しているテンプレートファイルgoxorm.tmplにあります。template_path: example/template/goxorm.tmplこれをいじれば、さらにカスタマイズできます。
あと、構造体のフィールドに
xorm:タグがおまけで付いてますね。
これはxorm/reverseの親プロジェクトでもある、オープンソースORMxorm用みたいですね。ちなみにリバース対象にしたDBスキーマは↓こんな感じです。
(上の方でご紹介したお試しセットまんまです)CREATE DATABASE IF NOT EXISTS hogedb; use hogedb; CREATE TABLE hogetable ( id INT NOT NULL AUTO_INCREMENT, hogename VARCHAR(32) NOT NULL, PRIMARY KEY (id) );改造
と、ここまでは良かったのですが、実際使ってみるとつまづきが・・・
この続きは、また!
- 投稿日:2020-03-10T11:37:47+09:00
Cloud9環境作成時にInstalling Nakで止まってしまった時の対処法
状況
Cloud9の「Create environment」を選択すると、作成されるEC2のAMIは自動的にAmazon Linux AMIになってしまう。今回は最新のAmazon Linux 2を使ってみたいのでEC2を作成→Cloud9からSSH接続設定をしてみた。
その際、Cloud9の初回初回起動時にAWS Cloud9 Installerが途中で止まってしまうケースが何度かあった。
特にInstalling Nakという箇所で30分程度止まってしまうことがあった。対処法
Cancellボタンを押す。その後ページを再読み込みするとインストールされていないもののみが表示されているので、もう一度インストールを開始すると上手くいった。
原因はわからないのであくまで暫定の対処ですが、ハマっている人の助けになれば幸いです。
- 投稿日:2020-03-10T11:05:58+09:00
Railsで作ったアプリをAWSでデプロイ① 〜アカウント作成編〜
こんにちは
AWSをつかってRailsアプリをデプロイしたいと思いますまず、AWSアカウントを作成します
注意点として一度使ったメールアドレスは、削除すると二度と使えなくなるそうです。
次の画面、僕はパーソナルです。
この後、クレジットカード→本人認証画面なので割愛します
プランはベーシックです。晴れてAWSアカウント作成完了!
早速EC2インスタンスを作りたかったのですが、どうやらアカウント作成直後はできないみたいです。
少し待ちます。
- 投稿日:2020-03-10T10:53:09+09:00
AWSのRDSで接続エラーにハマった話
記事概要
- 趣味で使っているRedmineをコンテナ環境に移行したいなと思って、Redmine内のMySQLをマネージドサービスのRDSに移行しようとした
- セキュリティグループなど適切に設定した(つもりだった)
- バックアップファイルをEC2(redmineが稼働中)からRDSにエクスポートしようとしたところでエラー
- 最初は接続出来たような気がするのに、しばらく日にちが経った後に接続しようとしたらエラー…?
遭遇したエラー
普通につながるかどうか具体的にはこんなエラーが出る
ubuntu@ip-10-0-0-167:~$ mysql -h xxxxxx-database-1.xxxxxx.ap-northeast-1.rds.amazonaws.com -u <username> -p ERROR 2003 (HY000): Can't connect to MySQL server on 'xxxxxx-database-1.cluster-xxxxxx.ap-northeast-1.rds.amazonaws.com' (60)普通にググると「セキュリティグループの設定見直せ!」というアドバイスが出てくるが、そんなことはわかっている。
原因調査
RDSの基本がわかっていなかったが、
- 複数のAZをまたがったサブネットグループを登録する
- セキュリティグループも複数登録可能
という条件でサブネットを登録する必要がある。
ということでVPCを選択した時に全てのサブネットをグループに含めてしまった。
これがいけない。
本来ならプライベートサブネットA,Bでグループを作るつもりが、全然関係ないプライベートサブネットCが紛れ込んでいた。
プライベートサブネットCのネットワークACLはガチガチに制限されているため、アクセス元のコンテナがあるサブネットから通信は出来ない。
最初は接続出来たという謎についても何となく原因がわかった。
RDSではプライマリインスタンスとスタンバイインスタンスが複数のサブネットに配置される。
そうなるとプライマリインスタンスが…
①サブネットA/Bに配置された場合 → 接続可能
②サブネットCに配置された場合 → 接続不可という現象が起きる。
今回は最初①で接続出来たのに、RDSのインスタンスの設定をもう一回やり直した時に②になってしまったようだ。
対処方法
サブネットグループに登録するサブネットのネットワークACLを確認する。
- 投稿日:2020-03-10T10:20:31+09:00
AWS ECSのビルド〜デプロイをCodePipelineで自動化した
Docker + ECS + RailsのプロジェクトでCodePipelineを使用してデプロイまでを自動化したので、その知見をまとめたい。(ブルーグリーンデプロイではなく、通常のデプロイ時の方法)
RailsのプロジェクトだけれどCodePipeline基本的な使い方は、他の言語でもそれほど変わらないと思う
デプロイの流れ
githubにpushすれば自動でデプロイが開始される。デプロイは以下の流れで行うように作った。
- GitHubの特定のブランチ(masterなど)にpushする
- pushされたことがCodepipelineに通知されビルドが開始
- docker-composeを利用して、Dockerをbuildする
- Dockerイメージタグにコミット番号を付与して一意にする
- ビルドが完了したらECRにpushする
- ビルド完了後にECSにデプロイ通知がいく
CodePipelineの設定
CodePipelineはソース管理、ビルド、デプロイをパーツのようにつなげてCD/CIを管理することができるAWSのサービス。以下のサービスをつなぎ合わせて連携することができる
- CodeCommit
- CodeBuild
- CodeDeploy
CodeCommit
まずはGithubで特定のリポジトリにpushされたときに検知できるようにする。ここではmasterがpushsされたときにビルドされる設定した。
ちなみにCodeCommitはGithub以外にも、ECRやS3などと連携することもできる。CodeCommit自体にコードを管理させることも可能。
CodeBuild
CodeBuildではビルドプロジェクトというものを作成する。このビルドプロジェクトはOS環境や、ビルドコマンドを記載するbuildspec.ymlのパスを設定していく。ようはビルドの設定を管理している感じだ。
Ubuntuでイメージが最新バージョンのものを使っておけば特に問題はないかと思う。buildspec.ymlはGithubにあげたプロジェクトに入れておく。そのパスをビルドプロジェクトで設定すればOK
buildspec.yml
ビルドするコマンドをyamlに書いていく。ビルドは以下のような流れで行う。
- ECRからDockerのイメージを取得
- コミットハッシュを取得する(コミットハッシュはDockerイメージタグとして使用する)
- .envに環境変数を追加していく
- docker-composeを利用してビルドする
- dbのmigrateを行う
- デプロイを通知する
version: 0.2 phases: install: runtime-versions: docker: 18 pre_build: commands: - echo -------- Logging in to Amazon ECR... -------- - aws --version - $(aws ecr get-login --region $AWS_DEFAULT_REGION --no-include-email) - REPOSITORY_URI=$AWS_ACCOUNT_ID.dkr.ecr.$AWS_DEFAULT_REGION.amazonaws.com/hogehoge - COMMIT_HASH=$(echo $CODEBUILD_RESOLVED_SOURCE_VERSION | cut -c 1-7) - IMAGE_TAG=${COMMIT_HASH:=latest} build: commands: - echo -------- Build started on `date` -------- - echo -------- Building the Docker image... -------- - echo AWS_ACCESS_KEY=$AWS_ACCESS_KEY >> .env - echo AWS_SECRET_KEY=$AWS_SECRET_KEY >> .env - echo ECS_ENV_NAME=$ECS_ENV_NAME >> .env - docker-compose -f docker-compose-$ECS_ENV_NAME.yml build - docker-compose -f docker-compose-$ECS_ENV_NAME.yml run --name hogehoge-image web sh -c "bundle exec rake db:create && bundle exec rake db:migrate" - docker commit hogehoge-image $REPOSITORY_URI:latest - docker tag $REPOSITORY_URI:latest $REPOSITORY_URI:$IMAGE_TAG post_build: commands: - echo -------- Build completed on `date` -------- - echo -------- Pushing the Docker images... -------- - docker push $REPOSITORY_URI:latest - docker push $REPOSITORY_URI:$IMAGE_TAG - echo [\{\"name\":\"hogehoge\",\"imageUri\":\"$REPOSITORY_URI:$IMAGE_TAG\"\}] > imagedefinitions.json artifacts: files: imagedefinitions.jsonbuildspec.ymlはpre_build、build、post_buildという3段階で処理を行う。一個ずつ分解して説明していく。
pre_build
ビルドする前の下準備。 GithubのURLとか、コミットハッシュとかをあとで使うので変数に入れている。ちなみにコミットハッシュはDockerイメージタグとして後で使う。
build
- echo AWS_ACCESS_KEY=$AWS_ACCESS_KEY >> .env - echo AWS_SECRET_KEY=$AWS_SECRET_KEY >> .env - echo S3_BUCKET=$S3_BUCKET >> .env環境変数を.envに書き込むようにしている。僕のRailsプロジェクトでは.envで環境変数を管理しており、CodeBuildでもdocker-composeが使用したいという理由でこの形にしている。このやり方がベストプラクティスではないような気がするので、もっと良い方法を見つけたい。
ちなみに環境変数はSystem Managerで管理している。環境変数についてはのちほどもう少し詳しく記載する。
- docker-compose -f docker-compose-$ECS_ENV_NAME.yml build - docker-compose -f docker-compose-$ECS_ENV_NAME.yml run --name hogehoge-image web sh -c "bundle exec rake db:create && bundle exec rake db:migrate" - docker commit hogehoge-image $REPOSITORY_URI:latest - docker tag $REPOSITORY_URI:latest $REPOSITORY_URI:あとはdocker-composeでビルドして、migrateして、Dockerイメージをcommitしているだけ。
ちなみに僕はDockerfile内に
assets:precompileを行っているため、buildspec.ymlにはコマンドが書いていない。post_build
ECSにデプロイするためには最終的にimagedefinitions.jsonというファイルを作成する必要がある。
- docker push $REPOSITORY_URI:latest - docker push $REPOSITORY_URI:$IMAGE_TAG - echo [\{\"name\":\"hogehoge\",\"imageUri\":\"$REPOSITORY_URI:$IMAGE_TAG\"\}] > imagedefinitions.json artifacts: files: imagedefinitions.jsonimagedefinitions.jsonはnameとimageUirを関連付けたjsonを書いていく。複数環境あるときは当たり前だけど複数書いていく。
- name
- ECSのコンテナ名
- imageUri
- ECRのURL
ECSのタスク定義との関連は以下のようになる。
補足
環境変数について
環境変数は秘匿化する必要があるためSystem Managerでパラメータを管理するようにした。
安全な文字列を選択してパラメータを設定する。「名前」欄で設定した値をCodeBuildで使用する。
System Managerで設定した値をbuildspec.ymlで使用するために、CodeBuildに環境変数として設定する必要がある。これを設定しておくとbuildspec.ymlの中で
$HOGEHOGEという値で使用できるようになる。
- 名前
- buildspec.ymlで使用する環境変数名
- 値
- System Managerで設定した名前
- 入力
- 『パラメータ』を選択する
- echo AWS_ACCOUNT_ID=$AWS_ACCOUNT_ID >> .env - echo AWS_ACCESS_KEY=$AWS_ACCESS_KEY >> .env - echo AWS_SECRET_KEY=$AWS_SECRET_KEY >> .envこれでbuildspec.ymlにファイルの中でCodeBuildで設定した環境変数が利用できるようになる
デプロイしたときにタスク定義のバージョンは更新されていく
デプロイされるとimagedefinitions.jsonで設定したコンテナ名とイメージのURLでタスク定義のイメージが変更され、リビジョンが新しく更新されていく。タスクをリビジョンで管理するメリットとして「切り戻しが簡単になる」という点がある。
もしも本番で障害が発生したとき場合にもリビジョンを戻すだけで動作する。ただしDBのカラム変更などしているときは、DBをロールバックする必要もあるので注意が必要。
CodePipelineからデプロイを実行する
なんらかの理由でソースコードをpushせずにデプロイしたい場合は、Codepipelineの画面から直接行うことができる
終わり
ECSは少人数の開発にこそ向いていると思う。ECSでスケールアップから障害復旧までまかせ、CodePipelineでデプロイを自動化しておけばインフラの運用をそれほど考慮しなくて済むようになる。アプリケーション層に集中して開発ができるようになる。
まだまだECSやCodePipelineに対しての知見が足りないので、また気づきがあったら書いていきたい









- 投稿日:2020-03-10T10:20:31+09:00
Rails + Docker + ECSのビルド〜デプロイをCodePipelineで自動化した
Docker + ECS + RailsのプロジェクトでCodePipelineを使用してデプロイまでを自動化したので、その知見をまとめたい。(ブルーグリーンデプロイではなく、通常のデプロイ時の方法)
RailsのプロジェクトだけれどCodePipeline基本的な使い方は、他の言語でもそれほど変わらないと思う
デプロイの流れ
githubにpushすれば自動でデプロイが開始される。デプロイは以下の流れで行うように作った。
- GitHubの特定のブランチ(masterなど)にpushする
- pushされたことがCodepipelineに通知されビルドが開始
- docker-composeを利用して、Dockerをbuildする
- Dockerイメージタグにコミット番号を付与して一意にする
- ビルドが完了したらECRにpushする
- ビルド完了後にECSにデプロイ通知がいく
CodePipelineの設定
CodePipelineはソース管理、ビルド、デプロイをパーツのようにつなげてCD/CIを管理することができるAWSのサービス。以下のサービスをつなぎ合わせて連携することができる
- CodeCommit
- CodeBuild
- CodeDeploy
CodeCommit
まずはGithubで特定のリポジトリにpushされたときに検知できるようにする。ここではmasterがpushsされたときにビルドされる設定した。
ちなみにCodeCommitはGithub以外にも、ECRやS3などと連携することもできる。CodeCommit自体にコードを管理させることも可能。
CodeBuild
CodeBuildではビルドプロジェクトというものを作成する。このビルドプロジェクトはOS環境や、ビルドコマンドを記載するbuildspec.ymlのパスを設定していく。ようはビルドの設定を管理している感じだ。
Ubuntuでイメージが最新バージョンのものを使っておけば特に問題はないかと思う。buildspec.ymlはGithubにあげたプロジェクトに入れておく。そのパスをビルドプロジェクトで設定すればOK
buildspec.yml
ビルドするコマンドをyamlに書いていく。ビルドは以下のような流れで行う。
- ECRからDockerのイメージを取得
- コミットハッシュを取得する(コミットハッシュはDockerイメージタグとして使用する)
- .envに環境変数を追加していく
- docker-composeを利用してビルドする
- dbのmigrateを行う
- デプロイを通知する
version: 0.2 phases: install: runtime-versions: docker: 18 pre_build: commands: - echo -------- Logging in to Amazon ECR... -------- - aws --version - $(aws ecr get-login --region $AWS_DEFAULT_REGION --no-include-email) - REPOSITORY_URI=$AWS_ACCOUNT_ID.dkr.ecr.$AWS_DEFAULT_REGION.amazonaws.com/hogehoge - COMMIT_HASH=$(echo $CODEBUILD_RESOLVED_SOURCE_VERSION | cut -c 1-7) - IMAGE_TAG=${COMMIT_HASH:=latest} build: commands: - echo -------- Build started on `date` -------- - echo -------- Building the Docker image... -------- - echo AWS_ACCESS_KEY=$AWS_ACCESS_KEY >> .env - echo AWS_SECRET_KEY=$AWS_SECRET_KEY >> .env - echo ECS_ENV_NAME=$ECS_ENV_NAME >> .env - docker-compose -f docker-compose-$ECS_ENV_NAME.yml build - docker-compose -f docker-compose-$ECS_ENV_NAME.yml run --name hogehoge-image web sh -c "bundle exec rake db:create && bundle exec rake db:migrate" - docker commit hogehoge-image $REPOSITORY_URI:latest - docker tag $REPOSITORY_URI:latest $REPOSITORY_URI:$IMAGE_TAG post_build: commands: - echo -------- Build completed on `date` -------- - echo -------- Pushing the Docker images... -------- - docker push $REPOSITORY_URI:latest - docker push $REPOSITORY_URI:$IMAGE_TAG - echo [\{\"name\":\"hogehoge\",\"imageUri\":\"$REPOSITORY_URI:$IMAGE_TAG\"\}] > imagedefinitions.json artifacts: files: imagedefinitions.jsonbuildspec.ymlはpre_build、build、post_buildという3段階で処理を行う。一個ずつ分解して説明していく。
pre_build
ビルドする前の下準備。 GithubのURLとか、コミットハッシュとかをあとで使うので変数に入れている。ちなみにコミットハッシュはDockerイメージタグとして後で使う。
build
- echo AWS_ACCESS_KEY=$AWS_ACCESS_KEY >> .env - echo AWS_SECRET_KEY=$AWS_SECRET_KEY >> .env - echo S3_BUCKET=$S3_BUCKET >> .env環境変数を.envに書き込むようにしている。僕のRailsプロジェクトでは.envで環境変数を管理しており、CodeBuildでもdocker-composeが使用したいという理由でこの形にしている。このやり方がベストプラクティスではないような気がするので、もっと良い方法を見つけたい。
ちなみに環境変数はSystem Managerで管理している。環境変数についてはのちほどもう少し詳しく記載する。
- docker-compose -f docker-compose-$ECS_ENV_NAME.yml build - docker-compose -f docker-compose-$ECS_ENV_NAME.yml run --name hogehoge-image web sh -c "bundle exec rake db:create && bundle exec rake db:migrate" - docker commit hogehoge-image $REPOSITORY_URI:latest - docker tag $REPOSITORY_URI:latest $REPOSITORY_URI:あとはdocker-composeでビルドして、migrateして、Dockerイメージをcommitしているだけ。
ちなみに僕はDockerfile内に
assets:precompileを行っているため、buildspec.ymlにはコマンドが書いていない。post_build
ECSにデプロイするためには最終的にimagedefinitions.jsonというファイルを作成する必要がある。
- docker push $REPOSITORY_URI:latest - docker push $REPOSITORY_URI:$IMAGE_TAG - echo [\{\"name\":\"hogehoge\",\"imageUri\":\"$REPOSITORY_URI:$IMAGE_TAG\"\}] > imagedefinitions.json artifacts: files: imagedefinitions.jsonimagedefinitions.jsonはnameとimageUirを関連付けたjsonを書いていく。複数環境あるときは当たり前だけど複数書いていく。
- name
- ECSのコンテナ名
- imageUri
- ECRのURL
ECSのタスク定義との関連は以下のようになる。
補足
環境変数について
環境変数は秘匿化する必要があるためSystem Managerでパラメータを管理するようにした。
安全な文字列を選択してパラメータを設定する。「名前」欄で設定した値をCodeBuildで使用する。
System Managerで設定した値をbuildspec.ymlで使用するために、CodeBuildに環境変数として設定する必要がある。これを設定しておくとbuildspec.ymlの中で
$HOGEHOGEという値で使用できるようになる。
- 名前
- buildspec.ymlで使用する環境変数名
- 値
- System Managerで設定した名前
- 入力
- 『パラメータ』を選択する
- echo AWS_ACCOUNT_ID=$AWS_ACCOUNT_ID >> .env - echo AWS_ACCESS_KEY=$AWS_ACCESS_KEY >> .env - echo AWS_SECRET_KEY=$AWS_SECRET_KEY >> .envこれでbuildspec.ymlにファイルの中でCodeBuildで設定した環境変数が利用できるようになる
デプロイしたときにタスク定義のバージョンは更新されていく
デプロイされるとimagedefinitions.jsonで設定したコンテナ名とイメージのURLでタスク定義のイメージが変更され、リビジョンが新しく更新されていく。タスクをリビジョンで管理するメリットとして「切り戻しが簡単になる」という点がある。
もしも本番で障害が発生したとき場合にもリビジョンを戻すだけで動作する。ただしDBのカラム変更などしているときは、DBをロールバックする必要もあるので注意が必要。
CodePipelineからデプロイを実行する
なんらかの理由でソースコードをpushせずにデプロイしたい場合は、Codepipelineの画面から直接行うことができる
終わり
ECSは少人数の開発にこそ向いていると思う。ECSでスケールアップから障害復旧までまかせ、CodePipelineでデプロイを自動化しておけばインフラの運用をそれほど考慮しなくて済むようになる。アプリケーション層に集中して開発ができるようになる。
まだまだECSやCodePipelineに対しての知見が足りないので、また気づきがあったら書いていきたい
- 投稿日:2020-03-10T04:29:15+09:00
Azure ADをIdPに設定してALBでユーザ認証してみた
Azure ADをIdPに設定してALBでユーザ認証してみました。
手順
- HTMLを出力するLambdaを作成し、ALBのターゲットに設定する
- Azure ADにアプリケーションを登録する
- ALBを設定する
- テストする
1. HTMLを出力するLambdaを作成し、ALBのターゲットに設定する
以下記事を参考に、Lambdaを作成してALBのターゲットに設定します。
https://docs.aws.amazon.com/ja_jp/elasticloadbalancing/latest/application/lambda-functions.html
ALBのリスナーはHTTPSに設定し、Route53にALBのエイリアスレコードを登録します。lambda_function.pydef lambda_handler(event, context): print(event) res = { "isBase64Encoded": False, "statusCode": 200, "statusDescription": "200 OK", "headers": { "Set-cookie": "cookies", "Content-Type": "text/html" } } res['body'] = """<html> <head> <title>hello world</title> </head> <body> <h1>Hello World</h1> </body> </html>""" return res2. Azure ADにアプリケーションを登録する
Azureにログインして、Azure Active DirectoryーApp registrationsからアプリケーションを登録します。
Redirect URIは以下を指定します。
https://Route53に登録したALBのエイリアスレコード/oauth2/idpresponse
次にアプリケーションのクライアントシークレットを作成します。
最後に各種エンドポイントを確認します。
下記コマンドでも確認できます。
curl https://login.microsoftonline.com/********-****-****-****-************/v2.0/.well-known/openid-configuration3. ALBを設定する
ALBのリスナーを編集して、Authenticateアクションを追加します。
ALBの設定値 対応するAzure側の値 Authenticate OIDC Issure Authorization endpointの"/oauth2/v2.0/authorize"の部分を"/v2.0"で置換したURL Authorization endpoint OAuth 2.0 authorization endpoint (v2) Token endpoint OAuth 2.0 token endpoint (v2) User info endpoint https://graph.microsoft.com/oidc/userinfo Client ID Application (client) ID Client secret 作成したシークレット 4. テストする
ALBのエイリアスレコードをURLに指定するとサインイン画面が表示されます。
サインイン後、Lambdaが出力するHTMLが表示されれば成功です。
CloudwatchLogsを確認すると、アクセストークン等が渡されているのが分かります。
雑感
- 慣れてしまえば設定はとても簡単です。(多分)
- OpenID Connectで認証するがブラウザ・ALB間はアクセストークンでなくセッションクッキーでセキュリティを担保する方式は、アクセストークン漏洩の問題がなくてなんかいい感じ。





