- 投稿日:2020-03-10T23:50:58+09:00
正規表現
正規表現とは
特徴的なのは
電話番号のハイフンを取り除く(文字列の一部分を置換する)
パスワードに英数字8文字以上という制約を設定する(文字列が制約を満たしているか調べる)
メールアドレスからドメインの部分のみ抽出する(文字列の一部分を抽出する)
などがあります。
正規表現にはsubメソッドとmatchメソッドがあります。subメソッド
文字列の指定した部分を別の文字列に置き換えるためのメソッドです。
【例】ターミナル$ irbirb(main):001:0> str = "水を飲む" => "水を飲む" irb(main):002:0> str.sub(/水/,"お茶") => "お茶を飲む"操作したい文字列は/で囲みます。
matchメソッド
引数に指定した文字列がレシーバの文字列にあるかを確認するためのメソッドです。ある場合は、指定した文字列がMatchDataオブジェクトの返り値になります。ない場合は、返り値としてnilになります。
【例】ターミナルrb(main):001:0> str = "おはよう, おやすみ" => "おはよう, おやすみ" irb(main):002:0> str.match(/おはよう/) => #<MatchData "おはよう"> irb(main):003:0> str.match(/こんにちわ/) => nilMatchDataオブジェクト
マッチした文字列等はMatchDataオブジェクトで返されます。MatchDataオブジェクトから文字列等を取り出してみます。
【例】ターミナルirb(main):001:0> str = "おはよう, おやすみ" => "おはよう, おやすみ" irb(main):002:0> md = str.match(/おはよう/) => #<MatchData "おはよう"> irb(main):003:0> md[0] => "おはよう"ハイフンの取り除きかた
subメソッドでは最初のハイフンしか置換されないのでgsubメソッドを使います。
【例】irb(main):001:0> tel = '090-1234-5678' => "090-1234-5678" irb(main):002:0> tel.sub(/-/,'') => "0901234-5678" irb(main):003:0> tel.gsub(/-/,'') => "09012345678"このgがは、指定した文字が複数ある場合、その全てを置換します。
パスワードに英数字の制約
【例】matchメソッドを使用します。
rb(main):001:0> pass = 'Hoge1234' => "Hoge1234" irb(main):002:0> pass.match(/[a-z\d]{8,}/i) => #<MatchData "Hoge1234">ここでは今までとかなり違う部分が出てきました。意味合いは
・[a-z]: 角括弧で囲まれた文字のいずれか1個にマッチ
・\d: 数字にマッチ
・{n, m}: 直前の文字が少なくともn回、多くてもm回出現するものにマッチ
・i: 大文字・小文字を区別しない検索
・.: どの1文字にもマッチ
・+: 直前の文字の 1 回以上の繰り返しにマッチ[a-z]
角括弧で囲まれた文字の1つがマッチするかをチェックしています。また、-で範囲を設定することができます。指定なので[a-z]だけではなく[a-c]みたいにもできます。
【例】irb(main):001:0> 'dog'.match(/[a-c]/) => nil irb(main):002:0> 'dog'.match(/[a-d]/) => #<MatchData "d">となります。
\d
\dは数字にマッチするので、[a-z\d]は「英数字のいずれか1つにマッチ」という意味になります。
【例】数字のみ抽出しますirb(main):001:0> 'abc 3 xyz'.match(/\d/) => #<MatchData "3">{n, m}
直前の文字が少なくともn回、多くてもm回出現するものにマッチします。例えば{4,8}は、直前の文字が少なくとも4回出現、直後の文字が最大8回出現にマッチという意味になります。
【例】irb(main):001:0> '12345678'.match(/\d{4,6}/) => #<MatchData "123456"> irb(main):002:0> '123'.match(/\d{4,6}/) => nili
大文字・小文字を区別しない検索します。iを付けない場合だと、[a-z]と小文字で記述しているので大文字にマッチしません。
【例】irb(main):001:0> 'Dog'.match(/dog/) => nil irb(main):002:0> 'Dog'.match(/dog/i) => #<MatchData "Dog">.
ハイフンやピリオドなど含めたどの1文字にもマッチします。
【例】irb(main):001:0> 'abc'.match(/./) => #<MatchData "a">+
直前の文字が1回以上の繰り返しにマッチします。
【例】irb(main):001:0> 'aaabbc'.match(/a+/) => #<MatchData "aaa">.と+は何かしらの文字が1回以上繰り返すものにマッチします。例えばメールアドレスみたいに先頭に@を付けることで@から始まり、何かしらの文字が1回以上繰り返すものにマッチします。
【例】irb(main):001:0> mail = 'hoge@takashi.com' => "hoge@takashi.com" irb(main):002:0> mail.match(/@.+/) => #<MatchData "@takashi.com">
- 投稿日:2020-03-10T23:31:52+09:00
Ruby on rails で星を散らす
はじめに
railsで、リロードする度に見え方が変わる星空を再現してみます
作成したWebアプリにも採用しています。
実行
最初に次のファイルを用意します。
index.html.haml.sky .starsstar_sky.css.sky{ background-color: #014; //黒っぽければなんでもいい }次に、星を表すオブジェクトを用意します。
index.html.haml.sky .stars .starstar_sky.css.sky{ background-color: #014; //黒っぽければなんでもいい } .star{ border-radius: 50%; position: fixed; z-index: 0; -ms-filter: blur(6px); filter: blur(6px); }星が一つだけなのもおかしいので、複数表示させます。
また、リロードする度に、数が変わるようにもしてみます。
使用するのはrandメソッドとtimesメソッドです。index.html.haml.sky .stars - number = rand(100..200) - number.times do .starこれだけだと、同じ場所にひたすら100個以上の
.starが作られるだけです。
そのため、timesで.starが一つ生成される度に、位置がランダムで指定されるようにします。
それにはCSSを適用すれば良いですが、CSSはHamlのコードにも直接指定できるので、これと変数展開を利用します。index.html.haml.sky .stars - number = rand(100..200) //100から200までの間の数字をランダムで - number.times do - top = rand(100) - left = rand(100) .star{style: "top: #{top}%; left: #{left}%; height: #{size}px;}次に星の色と大きさを指定します。
折角なので、全て違う色と大きさにしてみます。index.html.haml.sky .stars - number = rand(100..200) - color = ["red","blue","green","yellow","purple","white","pink","orange"] - number.times do - top = rand(100) - left = rand(100) - size = rand(10..20) - cnum = rand(0..7) .star{style: "top: #{top}%; left: #{left}%; height: #{size}px; width: #{size}px; background-color: #{color[cnum]}"}これで完了です。
試しに画面をリロードしてみると、星の配置が変わると思います。
今回はほぼ
randメソッドを利用しましたが、
頑張って数式を適用すれば、もっと幾何学的で美しい背景を作ることができそうです。


- 投稿日:2020-03-10T22:26:33+09:00
アプリケーションを作ってみます
自分用メモ
new コマンド実行
rails 5.0.7.2 new Put.Memo -d mysql
データベースを作成
rails db:create作るのは単語帳アプリ
最初にデータベース設計をしてみて自分のしてみたいことを整理してみた
機能として
---アカウント機能
---投稿機能
---いいね機能
---検索機能
---意味の部分にurl,画像を描けるようにする
---ランキング機能
次にフロント実装
topページには
:スクロール機能
:ランキング機能↑とりあえずこれだけ実装したい
できればタグごとのランキング,ページネーション機能をつけたいビューはこんな感じ
単語、意味とurlと画像
で一つの投稿としてこれをランキングで複数並べる形にしたい
Put.Memoのところをクリックするとでtopページに戻るようにした
ヘッダーだけだけどまぁ機能としては上だけで十分だと思う
https://gyazo.com/429eb62d3c07605ff058e91be4f43712後で
タイトルのところに作った人のアカウント名を付けようと思うとりあえず今日はここまで

- 投稿日:2020-03-10T22:17:32+09:00
中間テーブルとは 〜DB設計〜
概要
アソシエーションの中で多対多の関係性で使われる中間テーブル。
今回、中間テーブルとは何か? 自分の復習用に記事を執筆しようと思います。
そもそもアソシエーションとは?
Railsで使われているテーブルとテーブルを関連づける機能。
例えば、TwitterではUserとtweetがあるとして、
二つはUserがtweetすることでtweetが生じる関連付いた関係性である。
アソシエーションを組まないとどうなるのか?
AさんがtweetしたtweetがAさんと関連づけされなくなる。
AさんのtweetもBさんのtweetも一緒くたに扱われるため、外部キーのIDを取得する必要が出てきます。
一対多、一対一の関係性
アソシエーションの中には一対多、一対一
最後に中間テーブルが使われる多対多の関係性が存在する。
一対多
最初に一対多とは親モデルが子モデルに対して多数の要素を持つこと。
Twitterの場合、一つのUser(親モデル)は沢山のtweet(子モデル)をします。
Userモデル(親モデル)
ID Username 1 tarou 2 jirou 3 saburou 4 sirou 5 gorou Tweetモデル(子モデル)
ID User_id text 1 1 あいうえお 1 1 たろうです 2 2 かきくけこ 3 3 さしすせそ 4 4 たちつてと 5 5 なにぬねの railsでUserモデル(親モデル)に
User.rbhas_many :tweethas_manyの記述を加えます。
Tweetモデル(子モデル)に
Tweet.rbbelongs_to :userbelongs_toの記述を加えます。
一対一
一対一は関連するモデルの立場が対等です。
Userモデル
ID Username 1 tarou 2 jirou 3 saburou 4 sirou 5 gorou Profileモデル
ID User_id text 1 1 よろしく 2 2 じろうです 3 3 さぶろうです 4 4 しろうです 5 5 ごろうです Userモデルに対するProfileといった具合に同等の関係を示す場合に使われます。
railsでUserモデル(親モデル)に
User.rbhas_one :profilehas_oneの記述を加えます。
Profileモデル(子モデル)に
Tweet.rbbelongs_to :userbelongs_toの記述を加えます。
中間テーブルとは?
二つのモデルが多対多の関係性の時に使われるモデル。
ChatアプリのDB設計をする際、UserモデルとGroupモデルがあるとします。
Userは複数のチャットGroupに属し、チャットGroupも複数のUserが所属している。
この場合、中間テーブルが必要になってきます。
なんで中間テーブルを使う必要があるの?
例えば、Userが1と3のChatグループに属していたとします。
中間テーブルを挟まない場合、Groupに所属することを示すカラムが2つ必要になります。
Userが1と2と3のChatグループに属していたら、3つのカラムが必要になります。
際限なくカラムが多くなってくるので、それを防ぐために中間テーブルが必要になります。
Memberモデル(中間テーブル)
ID User_id group_id 1 1 1 2 1 2 3 2 1 4 2 3 5 3 2 この様に中間テーブルを挟むことでカラムを増やす必要がなくなります。
User.rbhas_many :group, through: :membergroup.rbhas_many :user, through: :memberモデルファイルに以上の記述を行えば、多対多のアソシエーションが設定されます。
- 投稿日:2020-03-10T22:14:45+09:00
【RSpec】System Specが動作するRails+Docker開発環境を構築する
はじめに
Rspec3.7以降で実装された"System Spec"を動作できるRails+Docker環境の作り方をまとめました。
基本コピペで進められるように書きましたので、初学者の方であっても「まず動く」状態まで持っていけると思います。
この記事では、Docker、docker-composeがすでにインストールされた状態からスタートします。私は、自PC(Mac)のホストOSに「Docker for Mac」をインストールしています。
著者動作環境における、Docker、docker-composeのバージョンは以下の通りです。
$ docker --version Docker version 19.03.5, build 633a0ea$ docker-compose -v docker-compose version 1.25.4, build 8d51620aDockerでのRails環境の構築
まずは、Docker公式が用意してくれているRals用のクイックスタート「Quickstart: Compose and Rails」をベースに、Railsが動作するDocker環境を作成していきます。
一部、公式のファイル内容に変更を加えていますので、ご注意ください。
早速始めていきましょう。作業ディレクトリ用意し、cdで移動します。
$ mkdir sample_app $ cd sample_appQuickstartに則り、sample_app内に下記5ファイルを作成します。
/sample_app$ touch Dockerfile docker-compose.yml Gemfile Gemfile.lock entrypoint.shディレクトリ構造/sample_app ├── Dockerfile ├── Gemfile ├── Gemfile.lock ├── entrypoint.sh └── docker-compose.yml各ファイルを下記の通り編集します。5ファイルのうち、docker-compose.yml以外は、Quickstart公式のコピペです。vim等、お好きなテキストエディタをお使いください。
DockerfileFROM ruby:2.5 RUN apt-get update -qq && apt-get install -y nodejs postgresql-client RUN mkdir /myapp WORKDIR /myapp COPY Gemfile /myapp/Gemfile COPY Gemfile.lock /myapp/Gemfile.lock RUN bundle install COPY . /myapp # Add a script to be executed every time the container starts. COPY entrypoint.sh /usr/bin/ RUN chmod +x /usr/bin/entrypoint.sh ENTRYPOINT ["entrypoint.sh"] EXPOSE 3000 # Start the main process. CMD ["rails", "server", "-b", "0.0.0.0"]Gemfilesource 'https://rubygems.org' gem 'rails', '~>5'Gemfile.lock(空のまま)entrypoint.sh#!/bin/bash set -e # Remove a potentially pre-existing server.pid for Rails. rm -f /myapp/tmp/pids/server.pid # Then exec the container's main process (what's set as CMD in the Dockerfile). exec "$@"docker-compose.ymlversion: '3' services: db: image: postgres volumes: - ./tmp/db:/var/lib/postgresql/data environment: - "POSTGRES_USER=xxxx" # 追記 - "POSTGRES_PASSWORD=xxxx" # 追記 web: build: . command: bash -c "rm -f tmp/pids/server.pid && bundle exec rails s -p 3000 -b '0.0.0.0'" volumes: - .:/myapp ports: - "3000:3000" depends_on: - db environment: - "SELENIUM_DRIVER_URL=http://selenium_chrome:4444/wd/hub" # 追記 selenium_chrome: image: selenium/standalone-chrome-debug # 追記上記5ファイルのうち、docker-compose.ymlのみ、編集で手を加えています。具体的には、
・postgresにユーザー名、パスワードを指定
・System Specを動作させるためのコンテナイメージ「selenium/standalone-chrome-debug」を追加ファイルを作成したら、Railsアプリを新規作成します。
$ docker-compose run web rails new . --force --no-deps --database=postgresql/sample_app$ ls Dockerfile README.md bin db lib public tmp Gemfile Rakefile config docker-compose.yml log storage vendor Gemfile.lock app config.ru entrypoint.sh package.json testrails newに伴い、Gemfileにデフォルトのgemがインストールされました。
Gemfileに編集を加えます。具体的には、
・"rspec-rails"を追加
・"chromedriver-helper"を削除Gemfile# 省略 group :development, :test do # Call 'byebug' anywhere in the code to stop execution and get a debugger console gem 'byebug', platforms: [:mri, :mingw, :x64_mingw] gem 'rspec-rails' # 追記 end group :test do # Adds support for Capybara system testing and selenium driver gem 'capybara', '>= 2.15' gem 'selenium-webdriver' # Easy installation and use of chromedriver to run system tests with Chrome # gem 'chromedriver-helper' # 削除 end #省略Gemfileを更新したため、再ビルドします。
$ docker-compose buildこれで、新しいGemfileでbundle installが実行されました。
続いて、configディレクトリ内のdatabase.ymlを編集します。
config/database.ymldefault: &default adapter: postgresql encoding: unicode host: db username: xxxx password: xxxx pool: 5 development: <<: *default database: myapp_development test: <<: *default database: myapp_testDBを作成します。
$ docker-compose run web rails db:create Starting sample_app_db_1 ... done Created database 'myapp_development' Created database 'myapp_test'コンテナを起動します。このタイミングで、selenium/standalone-chrome-debugのプルが実行されます。
$ docker-compose up -d Pulling selenium_chrome (selenium/standalone-chrome-debug:)... latest: Pulling from selenium/standalone-chrome-debug . . .イメージプルが終了しましたら、docker-composeが正常に立ち上がっているか、確認してみましょう。
$ docker-compose ps Name Command State Ports ----------------------------------------------------------------------------------------------- sample_app_db_1 docker-entrypoint.sh postgres Up 5432/tcp sample_app_selenium_chrome_1 /opt/bin/entry_point.sh Up 4444/tcp, 5900/tcp sample_app_web_1 entrypoint.sh bash -c rm - ... Up 0.0.0.0:3000->3000/tcpweb,db,selenium_chromeの3つが立ち上がっていれば、OKです。ついでに、http://localhost:3000 にアクセスし、いつもの「Yay! You’re on Rails!」が表示されているか、確認しましょう。
また、RSpecが正確にインストールされているかも確認してみましょう。
$ docker-compose run web rspec -v Starting sampleApp_db_1 ... done RSpec 3.9 - rspec-core 3.9.1 - rspec-expectations 3.9.0 - rspec-mocks 3.9.1 - rspec-rails 3.9.0 - rspec-support 3.9.2各バージョンは状況により異なるかと思いますが、RSpec 3.7以上のバージョンであれば、System Specを動作させることができます。
RSpecの初期設定
無事、必要なgemが揃った状態のDockerコンテナを用意できたので、ここからは中身の諸々の設定をいじっていきます。
まず、Railsにデフォルトで配置されているtestディレクトリは使用しないため、削除してしまいましょう。
$ rm -rf testRSpecをインストールします。
$ docker-compose run web rails generate rspec:installこれにより、以下のディレクトリ構造に対して、計3ファイルが生成・配置されます。
ディレクトリ構造/sample_app ├── .rspec └── spec ├── rails_helper.rb └── spec_helper.rb.rpsecファイルを編集します。2行目のコードを追記してください。これにより、テスト結果の表示形式が変更されます。
.rspec--require spec_helper --format documentationデフォルトでは、”失敗したテスト”のみがターミナル上に出力されるのですが、この変更を行うことにより、”成功・失敗両方のテスト”の結果を出力してくれるようになります。必須ではありませんが、設定しておくことをオススメします。
続いて、spec/rails_helper.rbについて、25行目あたりに書かれている下記コードのコメントアウトを外してください。
spec/rails_helper.rb# 省略 Dir[Rails.root.join('spec', 'support', '**', '*.rb')].each { |f| require f } # 省略これにより、後ほど定義するCapybara用の設定ファイルを読み込めるようになります。
specファイルの自動生成機能OFF
デフォルトでは、controllerやviewを作成したタイミングで、対応するspecファイル(=テストコードを書くためのファイル)が自動生成されます。
今回は初学者にとっての混乱を防ぐため、自動生成はOFFにしておきます。config/application.rbに下記コードを追加します。
config/application.rbequire_relative 'boot' require 'rails/all' # Require the gems listed in Gemfile, including any gems # you've limited to :test, :development, or :production. Bundler.require(*Rails.groups) module Myapp class Application < Rails::Application # Initialize configuration defaults for originally generated Rails version. config.load_defaults 5.2 # Settings in config/environments/* take precedence over those specified here. # Application configuration can go into files in config/initializers # -- all .rb files in that directory are automatically loaded after loading # the framework and any gems in your application. ### 追記 ###################################### config.generators do |g| g.test_framework :rspec, view_specs: false, helper_specs: false, controller_specs: false, routing_specs: false, request_specs: false end ############################################## end endCapybaraの初期設定
Capybaraに設定を加えるため、capybara.rbファイルを作ります。
$ mkdir spec/support $ touch spec/support/capybara.rbspec/support/capybara.rbrequire 'capybara/rspec' RSpec.configure do |config| config.before(:each, type: :system) do driven_by :selenium, using: :headless_chrome, options: { browser: :remote, url: ENV.fetch("SELENIUM_DRIVER_URL"), desired_capabilities: :chrome } Capybara.server_host = 'web' Capybara.app_host='http://web' end endこれで、SystemSpecが動作する環境が整いました。
System Spec実践
それでは実際に、静的ページを用いてSystemSpecを使用してみましょう。
今回は、
・rootページにアクセスし、"Hello World!"が表示されていることを検証
・rootページに、"Helpページ"へのリンクが置かれていることを検証
・リンク先のHelpページに、"This is the help page."が表示されていることを検証という流れのテストを書いてみたいと思います。
下準備として、home,helpを持ったStaticPagesコントローラーを作成します。
$ docker-compose run web rails generate controller StaticPages home helpルートとビューをいじります。
config/routes.rbRails.application.routes.draw do root 'static_pages#home' get '/help', to: 'static_pages#help' endapp/views/static_pages/home.html.erb<h1>StaticPages#home</h1> <p><%= link_to "Help", help_path %></p>app/views/static_pages/help.html.erb<h1>This is the help page.</h1>下準備が終わったため、specファイルを書いていきます。specディレクトリ下にsystemディレクトリを作成し、その中に"homes_spec.rb"を配置します。
$ mkdir spec/system $ touch spec/system/homes_spec.rbspec/system/homes_spec.rbを編集します。
spec/system/homes_spec.rbrequire 'rails_helper' RSpec.describe 'Home', type: :system do it 'shows greeting' do # root_pathへアクセス visit root_path # ページ内に'Hello World!'が含まれているかを検証 expect(page).to have_content 'Hello World!' # 'Help'文字列をクリック click_on 'Help' # ページ内に'This is the help page.'が含まれているかを検証 expect(page).to have_content 'This is the help page.' end endいよいよ動かします!今回用意した環境でSystem Specを動かすためには、webコンテナ内に入る必要があります。
$ docker-compose exec web bashrspecは、"rails spec"コマンドで実行できます。
webコンテナ内$ rails spec /usr/local/bin/ruby -I/usr/local/bundle/gems/rspec-core-3.9.1/lib:/usr/local/bundle/gems/rspec-support-3.9.2/lib /usr/local/bundle/gems/rspec-core-3.9.1/exe/rspec --pattern spec/\*\*\{,/\*/\*\*\}/\*_spec.rb Home Capybara starting Puma... * Version 3.12.4 , codename: Llamas in Pajamas * Min threads: 0, max threads: 4 * Listening on tcp://web:45873 shows greeting Finished in 2.33 seconds (files took 8.35 seconds to load) 1 example, 0 failures無事、テストが通ればOKです!!
スクリーンショット保存機能
ちなみにですが、System Specには、「失敗時の画面をスクリーンショットで自動保存する」という便利機能があります。
ビューをいじって、わざとテストを失敗させてみましょう。
app/views/static_pages/home.html.erb<h1>StaticPages#home</h1> <p><%= link_to "Hel", help_path %></p> # "Help"をタイポしてしまったケースwebコンテナ内$ rails spec . . . Home Capybara starting Puma... * Version 3.12.4 , codename: Llamas in Pajamas * Min threads: 0, max threads: 4 * Listening on tcp://web:44173 shows greeting (FAILED - 1) Failures: 1) Home shows greeting Failure/Error: click_on 'Help' Capybara::ElementNotFound: Unable to find link or button "Help" [Screenshot]: tmp/screenshots/failures_r_spec_example_groups_home_shows_greeting_612.png . . .「'Help'が見つかりません!」とメッセージが出され、tmp/screenshotsにエラーが発生したタイミングでのブラウザ画面が保存されています。
"Help"と書いたつもりのところが"Hel"になってしまっているのが、確認できます。
最後に
以上です!不明な点、間違っている点などがありましたら、私のTwitter(@ddpmntcpbr)のDMまで連絡頂けると幸いです。

- 投稿日:2020-03-10T22:11:22+09:00
prefixを正確に調べた
prefixの認識レベル
ミニブログを作っている最中、ふとprefixについて考えた時に
「パスを代入する変数」というレベルでしか認識していなかったので
詳しく理解するために調べてみた。【詳しく調べたかったポイント】
①prefixを使用するメリット(必要性。パス記入の方が分かりやすくない?)
②普通にパスを記入する事との使い分け調べてわかった事
まず第一に、prefixはRailsが推奨している記述方法らしい。
tweet_pathでパスの指定完成。
①prefixを使用するメリット(必要性。パス記入の方が分かりやすくない?)について
→結論あまりないらしい。
1,Railsが推奨している
2,シンプルで直感的に分かりやすくなる(?)というのが使用している理由らしい。
②普通にパスを記入する事との使い分け
→開発現場による。「こんな時はprefix!!」みたいなのはないっぽい。
結論
僕は普通にパスを書く方が好き。
「私はprefix派!」「prefixにはこんなメリットがあるぞ!」
というご意見があれば教えて下さい...!!
- 投稿日:2020-03-10T22:00:53+09:00
Sass::SyntaxError in Devise::Registrations#new 解決方法
前提条件
・gemfileに使いたいパッケージを記述している
Gemfilegem 'devise'・ターミナルで
bundle installが済んでいるエラー内容
どうやら
@import "modules/user"でうまく'_user.scss'が読み込めてないみたいです_user.scssを動かしてみます
ここから
modulesディレクトリの中へ入れてみました
無事に動くようになりました
ここで考えたこと
@import "modules/user"と書いてあったけど、
これをよく読むと、
modulesディレクトリの中にある、_user.scssを読み込んでね(@import)
ってことだから、試しに
@import "user"に変えて
_user.scssのファイルの位置を元に戻したら、
ちゃんと動きましたとさめでたしめでたし




- 投稿日:2020-03-10T21:45:12+09:00
Railsからデータベースを参照(集計)するときの書き方
前置き?
ビューを作成する前に、railsコントローラにおいて、データーベースの値を取ってくる場合にどのように記述するのか。今回はgroup by してからのカウントした値を取得する場合のRailsの書き方を調べるのに随分苦労したので、残しておく。
前提条件
JavaScriptで作成したタイピングゲームをRuby on Railsにのせようとしている。
集計が必要か?ってなったのは、タイピングした結果をランキング表示させようと思い立った時に、問題別のランキング表示をする前に、問題別にどれだけチャレンジャーがいたのか、っていうのを先に一覧表示した後で、ランキング表示をしようか、と思ったから。テーブル
Qfiles id title category results_count その他
Results id user_id qfile_id その他 出そうとした値
- 「Qfile辺りのResultを残したuser_id数」
- 「Qfile辺りのResultを残した数」
まぁ、単純だしすぐに終わると思いつつ、先にクエリを作成。
Select results.`qfile_id`, qfiles.`title`, count(distinct results.`user_id`), count(*) from results inner join qfiles on results.`qfile_id` = qfiles.`id` group by results.`qfile_id`, qfiles.`title` ;パンケーキ(Sequel Pro)で実行させて望み通りの値が表示されてることを確認。さあRailsに直すぞ、と意気込む。
調べる
ポイントは3点。
1. テーブルの結合はどう書くんだ?
2. group by はどう書くんだ?
3. countはどう書くんだ?(ついでにdistinctも)とにかくググって調べたコードをrails cで片っ端から実行。うまく実行できず、よく分からない時は「こう書けば動くんじゃね?」という勘に頼ったテストもした!笑
とりあえずページ保存
Rails controllerに書く記述をRails cでテスト
- テーブル結合はjoinsで行う。この時selectはいらないが、書かなかった場合、主にしたモデルのカラム(Qfiles.*)しか参照できない。
Qfile.joins(:results).select("results.*, qfiles.*").first.idここでもう一つ、先頭に記述するモデルは、親子関係の親の方のモデルでないといけない。これは先頭に記述するモデルを実際に変えてみて、サーバーログに表示されるクエリを見てたらわかる。
- 単純カウントは、最後に.count入れるだけ
- distinctカウントは、selectした後に.countを入れて、さらにcountオプション内でdistinctを記述する
Qfile.joins(:results).group("results.qfile_id").select("results.qfile_id").count("distinct results.user_id")どうやって一文で実行するのか?
色々調べてテストして分かったのは、Countを2ついっぺんには無理じゃね!?ってこと。ひょっとしたら何か方法があるのかもしれないが、もうギブアップした。
カウントの片一方だけなら合わせることができた。
Qfile.joins(:results).group("results.qfile_id").group("qfiles.category").select("results.qfile_id").order("qfiles.id ASC").count("distinct results.user_id")もう一個のカウントも一緒にやりたいんだよ・・・。
もう面倒い。生クエリ実行できるんじゃね?
find_by_sql で Rails から生 SQL クエリを直接実行する
ここの通りに実行できた。でもあれ?rails cで実行したらカウント要素が入ってなくね?どうゆうこと???
Railsのfind_by_sqlで取得できるモデルからは、select句で指定した名前で値が取れる
取得してるのに表示されないんか〜〜〜い!
これが分かればなんとか値を参照できるから、あとはビューに渡すだけ!!!
でもやっぱり生クエリは邪道な気がする
一生懸命探しました。ふとしたきっかけで新しいキーワードを用いてググったところ、ありました。
ふむ。「Qfile辺りのResultを残した数」はこれで保存しときゃいいじゃん。
gem 'counter_culture'を採用。これで作成したカラムが、Qfiles.results_countここまでで作成した実行文
Qfile.joins(:results).group("results.qfile_id").group("qfiles.category").group("results_count").select("results.qfile_id").order("qfiles.id ASC").count("distinct results.user_id")まぁ、なんとか値が出たから使えるんだけども。なんか参照しづらいハッシュ値で取得してしまう。group by の副作用っぽい。
=> {[1, "英語-単語", 4]=>1, [2, "英語-単語", 1]=>1, [4, "英語-単語", 1]=>1, [7, "英語-文章", 4]=>1}group by 使わなかった時みたいに、@モデル.カラムで参照させて欲しい!!
Rails ActiveRecordでgroup_by countによる集計結果をrelationとして取得する
なるほど、selectにまとめて入力できるのか!!!最終的に以下になった。
Qfile.joins(:results).select("qfiles.id, qfiles.title, qfiles.results_count, COUNT(distinct results.user_id) AS count_distinct_results_user_id").group("results.qfile_id, qfiles.category, results_count").order("qfiles.id ASC")=> [#<Qfile:0x00007f88586419b8 id: 1, title: "abide - certification 200語", results_count: 4>, #<Qfile:0x00007f8858641878 id: 2, title: "certify - drill 200語", results_count: 1>, #<Qfile:0x00007f8858641738 id: 4, title: "induction - painter 200語", results_count: 1>, #<Qfile:0x00007f88586415d0 id: 7, title: "英語例文 200件 1", results_count: 4>]上記にdistinct countが含まれてないが、select文中に指定した名前で参照できる。
Qfile.joins・・・・.count_distinct_results_user_idselectの記述が長くなってしまうのでなんかイヤな書き方ではあるけども、参照時にインデックス番号で指定しなければなくなるよりはマシか?と思った。
- 投稿日:2020-03-10T21:10:26+09:00
【初心者】長めのモデル名(スネークケース)からfindとかをする
コンソールでモデルから値を取得しようとしたとき
知らずにスネークケースでモデルを指定してエラーになっていたので調べました。
おそらく初心者や始めたばかりの頃はUserモデルとかPostモデルなどしか扱わないので悩まないと思います。。
そもそもスネークケース、キャメルケースとは?という方へ。UserとかPostとかの短いモデル名のとき
User.find(1)簡単に取得できますね。
長めのモデル名のとき
キャメルケースとスネークケースとは
CustomerOrderキャメルケース(大文字部分がラクダの背中っぽい)
CとOが大文字customer_orderスネークケース(ヘビっぽい)
単語と単語のつなぎ目に_が使われているモデルから値を取得
CustomerOrder.find(1)で取れます。(キャメルケース)
Customer_order.find(1)スネークケースでは不可。
- 投稿日:2020-03-10T19:04:58+09:00
環境変数設定メモ
完全に個人的めも
基本的にrails アプリケーションにおいて環境変数を設定する際はターミナル上で.bash_profileを作成して管理をして行くのが一般的である。
vim ~/.bash_profile コマンドで展開i でinsertモード
ESCキー
:wq 保存
:q! 保存せずに閉じる環境変数の記述は
export KEY = '*******************' export SECRET_KEY ='***********************'の形で定義
ここに記載した、環境変数を
ENV['KEY']
ENV['SECRET_KEY']
の形で使用する。source ~/.bash_profile コマンドにて.bash_fileを読み込み
もう一つの環境編すの構成方法
Dotenvという.envファイルに記述する方法。rails ではGEMをインストール
gem 'dotenv-rails'gemfileなどが存在するrootディレクトリに.envファイルを作成
作成した.envファイルがgithubにアップされないように.gitgnoreを編集する。/.env
を追加これで環境変数をgithubにアップすることなく使用できる。
環境変数の使用方法は同じ
- 投稿日:2020-03-10T16:55:11+09:00
【Rails】Sorceryでログイン機能を実装する
Sourceryでログイン機能を実装してみました。
Deviseよりカスタマイズしやすそうで、自分で実装するより手軽なので結構好印象です。
フレンドリーフォワーディングが簡単に実装できるのが良いですね。セットアップ
Gemfilegem 'sorcery'terminal$ bundle install $ rails g sorcery:installUserモデルとマイグレーションファイル、設定ファイルなどもろもろ生成されます。
terminal$ rails db:migrateモデルにバリデーションを設定
model/user.rbclass User < ApplicationRecord authenticates_with_sorcery! validates :email, uniqueness: true, presence: true validates :password, presence: true end
application_controller.rbにbefore_actionとメソッドを定義application_controller.rbclass ApplicationController < ActionController::Base before_action :require_login #sorceryが作成するメソッド。ログインしてない時not_authenticatedメソッドを発火する protected def not_authenticated redirect_to login_url end end新規ユーザー登録
users_controller.rbclass UsersController < ApplicationController skip_before_action :require_login, only: [:new, :create] def new @user = User.new end def create @user = User.new(user_params) if @user.save redirect_to root_url else render :new end end private def user_params params.require(:user).permit(:email, :password) end endnew.html.erb<%= form_with model: @user, local: true do |f| %> <%= f.label :email, 'メールアドレス' %> <%= f.text_field :email %> <%= f.label :password, 'パスワード' %> <%= f.password_field :password %> <%= f.label :password_confirmation, 'パスワード確認' %> <%= f.password_field :password_confirmation %> <%= f.submit '登録' %> <% end %>route.rbresources :users, only: %i[index create]ログイン
login:見つかったユーザーでログインする
logout:ログアウトする
redirect_back_or_to:保存されたURLがある場合そのURLに、ない場合は指定されたURLにリダイレクトする。(フレンドリーフォワーディング)sessions_controller.rbclass UsersController < ApplicationController skip_before_action :require_login, only: [:new, :create] def index @user = User.new end def create if @user = login(params[:email], params[:password]) redirect_back_or_to(hoge_url, notice: 'ログインしました') else flash[:alert] = 'ログイン失敗' render :new end end def destory logout redirect_to(root_url, notice: 'ログアウトしました') end endnew.html.erb<%= form_with url: sessions_path, local: true do |f| %> <%= f.label :email, 'メールアドレス' %> <%= f.text_field :email %> <%= f.label :password, 'パスワード' %> <%= f.password_field :password %> <%= f.submit "ログイン" %> <% end %>routes.rbresources :contacts, only: %i[index create destroy]参考
- 投稿日:2020-03-10T16:32:12+09:00
[Rails, jQ]インクリメンタルサーチ
インクリメンタルサーチ
本記事では前回作成したユーザーの名前検索機能を使用して実装していきます。
以下を使用しています。
- ruby 2.5.1
- rails 5.2.4.1
- gem 'jquery-rails'
- gem 'devise'
なお、使用するビューは以下を使用します。
index.html.erb<%= form_with(url: users_searches_path, local: true, method: :get, class: "search_form") do |f| %> <%= f.text_field :keyword, placeholder: "Name", class: "search_input" %> <%= f.submit "Search", class: "search_btn" %> <div class="contents"> <% @users.each do |user| %> <div class="user_content"> <p class="user_name"> user.name </p> </div> <% end %> </div>準備
以下が記入されていなければ記入します。
app/assets/javascripts/application.js
//= require jquery
フォーマット毎に処理を分ける
フォーマット毎に処理を分けるためコントローラーのindexアクションを編集します。
controllers/users/searches_controller.rbdef index @users = User.search(params[:keyword]) respond_to do |format| format.html format.json end endrespond_to
アクションの中でHTMLとJSONなどのフォーマット毎にhtmlかjsonかを条件分岐することができます。
jbuilderファイルの作成、編集
index.json.jbuilderを新規作成し内容を編集します。
app/views/tweets/searches/index.json.jbuilderjson.array! @users do |user| json.id user.id json.name name.name endjbuilderという拡張子を持つテンプレートでは、JSONという名前のJbuilderオブジェクトが自動的に利用できるようになります。
arrayメソッドはその内の一つでJavaScript側に配列で値を送ることができます。search.jsの作成、編集
検索フォームの値を取得
app/assets/javascripts/search.js$(function() { $(".search_input").on("keyup", function() { var input = $(".search_input").val(); }); });keyupイベントを使用して文字が入力される度に発火するようにします。
JSON形式で値を返す
app/assets/javascripts/search.js$(function() { $(".search_input").on("keyup", function() { var input = $(".search_input").val(); //---以下を追記--- $.ajax({ type: 'GET', url: '/users/searches', data: { keyword: input }, dataType: 'json' }) //---以上を追記--- }); });Ajax通信を実現するためには、上記のように$.ajaxメソッドを使用します。
また。上記のコードは
HTTPメソッドはGETで、/users/searchのURLに{ keyword: input }を送信。サーバーから値を返す際は、JSON。
という意味を持ちます。JSON形式の場合は、app/views/users/searches/index.json.jbuilderが読まれ,該当する投稿情報はjbuilderによってJSONに変換されてJavaScriptのファイルに返されます。レスポンス結果によって処理を分ける
app/assets/javascripts/search.js$(function() { $(".search_input").on("keyup", function() { var input = $(".search_input").val(); $.ajax({ type: 'GET', url: '/users/searches', data: { keyword: input }, dataType: 'json' }) //---以下を追記--- .done(function(users) { $(".contents").empty(); if (users.length !== 0) { users.forEach(function(user){ appendUser(user); }); } else { appendErrMsgToHTML("一致するユーザーはいません"); } }) .fail(function() { alert('error'); }); //---以上を追記--- }); });レスポンスが成功した場合は、ユーザーが表示される親要素の中身を都度空っぽにします。そしてusersが空ではない場合usersの中身の数だけappendUser関数を呼び出します。
該当ユーザーがいない場合は”一致するツイートがありません”という引数を与え、appendErrMsgToHTML関数を呼び出します。
また、レスポンスに失敗した場合はアラートを表示させます。empty()メソッド
指定したDOM要素の子要素のみを削除するメソッドです。
指定したDOM要素自体を削除するremoveメソッドとは異なります。forEachメソッド
forEachは、与えられた関数を配列に含まれる各要素に対して一度ずつ呼び出します。
検索に該当ユーザーいた場合、いない場合の関数を定義
app/assets/javascripts/search.js$(function() { //---以下を追記--- var search_list = $(".contents"); function appendUser(user) { var html = ` <div class="user_content"> <p class="user_name"> #{user.name} </p> </div> ` search_list.append(html); } function appendErrMsgToHTML(msg) { var html = ` <div class="user_content"> <p class="user_name"> ${ msg } </p> </div> ` search_list.append(html); } //---以上を追記--- $(".search_input").on("keyup", function() { var input = $(".search_input").val(); $.ajax({ type: 'GET', url: '/users/search', data: { keyword: input }, dataType: 'json' }) .done(function(users) { search_list.empty(); if (users.length !== 0) { users.forEach(function(user){ appendUser(user); }); } else { appendErrMsgToHTML("一致するユーザーはいません"); } }) .fail(function() { alert('error'); }); }); });検索に該当ユーザーがいた場合
変数htmlにユーザー情報を表示する要素を代入し、appendメソッドで親要素の一番下に追加します。
検索に該当ユーザがいない場合
変数htmlに"一致するユーザーはいません"を表示する要素を代入し、appendメソッドで親要素の一番下に追加します。おわり
これでインクルメンタルサーチが実装できました。
- 投稿日:2020-03-10T16:13:04+09:00
gonを使ってJavaScriptへの直書き環境変数を防ぐ
まず環境変数を設定する
Dotenvを用いて環境変数を設定していきます。
1 gemのインストール
Gemfilegem 'dotenv-rails'bundle install2 envファイルの作成
appファイルやcofigファイル、Gemfileがあるルートディレクトリに「.env」というファイルを作成して下さい。
私は一瞬迷ったので画像載せておきます。
歯車マークが目印です。3 環境変数の設定
|.env|ACCESS_KEY='*******'4 .gitignoreの編集
環境変数をGitのトラッキングの対象外にする為記述します。|.gitignore|.envこれでgonを使うための下準備は完了です。
gonのインストール
Gemfileに追記して下さい。
Gemfilegem 'gon'bundle installJSファイルでRails環境変数を扱う
1 コントローラーの編集
JavaScriptを呼び出しているViewに対応させてコントローラーのメソッド内に以下を記述します。
例えば、new.html.hamlでjsを呼び出しているのであればnewメソッド内に追記します。gons_controller.rbdef new gon.xxx_access_key = ENV['ACCESS_KEY'] end2 renderメソッド
application.html.haml内のheadタグに以下を記述して下さい。application.html.haml= Gon::Base.render_data3 JSファイルに記述
jsファイル内にコントローラーで設定した変数を記述します。gon.jsgon.xxx_access_keyこれでjavascriptとrailsの連携が出来ました。
- 投稿日:2020-03-10T15:44:53+09:00
【Rails】ransackで検索機能を実装
ransackというgemを使って、検索、ソートの機能を実装したのでまとめます。
手軽にできて良い感じでした。基本的な使い方
Gemfilegem 'ransack'terminal$ bundle installusers_controller.rbdef index @q = User.ransack(params[:q]) @users = @q.result(distinct: true) endindex.html.erb<!-- 検索フォーム --> <%= search_form_for @q do |f| %> <%= f.label :name, "名前" %> <%= f.search_field :name_cont %> <%= f.label :email, "メールアドレス" %> <%= f.search_field :email_cont %> <%= f.submit "検索" %> <% end %> <!-- ユーザー一覧 --> <table> <tr> <th>名前</th> <th>メールアドレス</th> </tr> <% users.each do |user| %> <tr> <td><%= user.name %></td> <td><%= user.email %></td> </tr> <% end %> </table>ソート機能
index.html.erb<!-- ユーザー一覧 --> <table> <tr> <th><%= sort_link(@q, :name, "名前") %></th> <th><%= sort_link(@q, :email, "メールアドレス") %></th> </tr> . .検索条件を組み合わせる
ステータスがアクティブなユーザーの中から検索して、ページネーションをつける
users_controller.rbdef index @q = User.ransack(params[:q]) #後ろに自由に条件を追加できる @users = @q.result(distinct: true).where(status: 1).page(params[:page]) end様々な検索方法
検索フォームの中で
:name_contなどと記載していた部分は、他にもいろんな指定ができます。
検索方法 意味(英語) 意味 *_eq equal 等しい *_not_eq not equal 等しくない *_lt less than より小さい *_lteq less than or equal より小さい(等しいものも含む) *_gt grater than より大きい *_gteq grater than or equal より大きい(等しいものも含む) *_cont contains value 部分一致(内容を含む) その他:activerecord-hackery/ransack: Object-based searching.
参考
- 投稿日:2020-03-10T14:59:29+09:00
【Rails】新規投稿機能、編集機能、削除機能の実装
新規投稿機能、編集機能、削除機能の実装
本記事でのモデルケース:
・Photoモデル
・photosコントローラー
・カラム名:image,title,memo
なので、記事をご覧の皆さんのモデル名やコラム名などに応じて書き換えていってもらえれば実装できると思います!新規投稿機能の実装
ルーティングの設定
ここではnewアクションとcreateアクションを定義する
routes.rbRails.application.routes.draw do # ここから resources :photos, only: %i(new create) # ここを追加 endこの記述によって
以上のルーティングが生成されるコントローラーの設定
photos_controller.rbclass PhotosController < ApplicationController # ここから def new @photo = Photo.new end def create @photo = Photo.new(photo_params) if @photo.save redirect_to action: :index else redirect_to action: :new end end private def photo_params params.require(:photo).permit(:image,:title,:memo) end # ここまでを追加 end投稿ページの設計
まず、viewsファイルの中でedit.html.erbを作成してください!
new.html.erb<%= form_for(@photo, :url => { controller:'photos', action:'create'})do |f| %> <div class="field"> <%= f.label :image %> <br> <%= f.file_field :image %> <br> <%= f.label :title %> <br> <%= f.text_field :title %> <br> <%= f.label :memo %> <br> <%= f.text_field :memo %> </div> <div class="action"> <%= f.submit %> </div> <% end %>投稿一覧ページの実装
まず、viewの中でindex.html.erbファイルを作成ください!
photos_controller.rbclass PhotosController < ApplicationController #ここから def index @photos = Photo.all end #ここまでを追加 def new @photo = Photo.new end def create @photo = Photo.new(photo_params) if @photo.save redirect_to action: :index else redirect_to action: :new end end private def photo_params params.require(:photo).permit(:image,:title,:memo) end endindex.html.erb<% @photos.each do |photo| %> <div> <%= image_tag photo.image_url %> <p><%= photo.title %></p> <p><%= photo.memo %></p> </div> <% end %>投稿編集機能の実装
ルーティングの実装
routes.rbRails.application.routes.draw do # edit,updateをroutes.rbに追加 resources :photos, only: %i(new create edit update) endコントローラーの設定
photos_controller.rbclass PhotosController < ApplicationController def new @photo = Photo.new end def create @photo = Photo.new(photo_params) if @photo.save redirect_to action: :index else redirect_to action: :new end end def edit @photo = Photo.find_by(id: params[:id]) end def update @photo = Photo.find_by(id: params[:id]) if @photo.update_attributes(photo_params) redirect_to "/" else render action: :edit end end private def photo_params params.require(:photo).permit(:image,:title,:memo) end end編集ページの設計
edit.html.erb<%= form_with model: @photo, url: { action: :update }, html: { class: 'listForm' }, local: true do |f| %> <%= f.label :title %> <%= f.text_field :title, class: "form-control listName", placeholder: "タイトル" %> <%= f.label :memo %> <%= f.text_field :memo, class: "form-control listName", placeholder: "詳細" %> <div class="text-center"><%= f.submit "編集する", class: "submitBtn" %></div> <% end %>一覧ページから投稿ページへの遷移のリンク実装
index.html.erb<% @photos.each do |photo| %> <div> <%= image_tag photo.image_url %> <p><%= photo.title %></p> <p><%= photo.memo %></p> <%= link_to "編集", edit_photo_path(photo) %> # この1行を追加 </div> <% end %>投稿削除機能の実装
ルーティングの設定
routes.rbRails.application.routes.draw do # destroyを追加 resources :photos, only: %i(new create edit update destroy) endコントローラーの設定
photos_controller.rbclass PhotosController < ApplicationController def new @photo = Photo.new end def create @photo = Photo.new(photo_params) if @photo.save redirect_to action: :index else redirect_to action: :new end end def edit @photo = Photo.find_by(id: params[:id]) end def update @photo = Photo.find_by(id: params[:id]) if @photo.update_attributes(photo_params) redirect_to "/" else render action: :edit end end # ここから def destroy @photo = Photo.find_by(id: params[:id]) @photo.destroy redirect_to :root end # ここまで追加する private def photo_params params.require(:photo).permit(:image,:title,:memo) end endindex.html.erb<% @photos.each do |photo| %> <div> <%= image_tag photo.image_url %> <p><%= photo.title %></p> <p><%= photo.memo %></p> <%= link_to "編集", edit_photo_path(photo) %> <%= link_to ”削除”, photo, method: :delete, data: { confirm: "#{photo.title}を削除して大丈夫ですか?" } %> # 上の1行を追加 </div> <% end %>

- 投稿日:2020-03-10T14:49:07+09:00
【Rails】外部キー制約とreference型について
外部キー制約とreference型
Railsで外部キーのカラムを追加するときにreference型を使用することがあります。
その際のreference型を使用した書き方について記録します。※外部キー制約:他のテーブルのデータに参照(依存)するようにカラムにつける制約
reference型を使用しない場合
reference型なしで外部キー制約のついたカラムを作成します。
制約がないカラムの作成
2020_create_tweets.rbclass CreateTweets < ActiveRecord::Migration[5.0] def change create_table :tweets do |t| t.string :text t.integer :user_id end end end上記はインデックスが貼られない、外部キー制約もつかないカラムを作成しているコードになります。
インデックスを貼るカラムの作成
2020_create_tweets.rbclass CreateTweets < ActiveRecord::Migration[5.0] def change create_table :tweets do |t| t.string :text t.integer :user_id, index: true #indexオプション end end end2020_create_tweets.rbclass CreateTweets < ActiveRecord::Migration[5.0] def change create_table :tweets do |t| t.string :text t.integer :user_id end add_index :tweets, :user_id # add_index :対象のテーブル名, インデックス対象のカラム名 end endインデックスを張る場合は上記の2つの記載方法がある。
外部キー制約がついているカラムの作成
2020_create_tweets.rbclass CreateTweets < ActiveRecord::Migration[5.0] def change create_table :tweets do |t| t.string :text t.integer :user_id end add_foreign_key :tweets, :users # add_foreign_key :対象のテーブル名, :指定先のテーブル end endreference型を使用しない場合は
foreign_key: trueでは外部キー制約にならないので注意が必要です。
また、外部キー制約をつける場合は、インデックスは自動で付与されるので、先ほどのindex: trueは不要になります。reference型を使用する場合
■reference型を使用するメリット
・userではなくuser_idというカラム名で作成してくれる。
・インデックスを自動で張ってくれる。2020_create_tweets.rbclass CreateTweets < ActiveRecord::Migration[5.0] def change create_table :tweets do |t| t.string :text t.references :user end end endしかし、
t.reference :userだけでは外部キー制約はつきません。
下記のようにreference型は外部キー制約をつけるときは、foreign_key: trueを記載して使えるようにします。2020_create_tweets.rbclass CreateTweets < ActiveRecord::Migration[5.0] def change create_table :tweets do |t| t.string :text t.references :user, foreign_key: true end end end下記のように
add_foreign_keyでも可能。2020_create_tweets.rbclass CreateTweets < ActiveRecord::Migration[5.0] def change create_table :tweets do |t| t.string :text t.references :user end add_foreign_key :tweets, :users end end参照URL
- 投稿日:2020-03-10T12:08:16+09:00
Cancancanを使っているときのtest
Cancancanとは?
この記事を見て下さっているということは既にご存知だと思いますが、 権限管理のgem です。
Cancancanを使っているときのテストはどうしたらいいのか?
権限があるときは、権限を持つテストユーザーでログインして
test "test#indexにmanager権限を持つユーザーがアクセスして、正常レスポンスが返されること" do # manager権限を持つユーザーでログイン login(:yama_p) get tests_path assert_response :success end正常に処理ができることを確認すればまぁいいかも知れませんが、 アクセスできない(権限がない)ことを確認する にはどうしたらよいでしょうか?
というのも、上記でassert_response :errorsなどとしてもcancancanで弾かれたときにエラーが返ってくるわけではなくそもそもアクセスできないのでCanCan::AccessDenied: You are not authorized to access this page.とテストが落ちてしまいます。
権限を持つかどうかをテストする
Cancancanのwikiにテストについての記述があります。
test "test#indexにmember権限を持つユーザーはアクセス権限を持たないこと" do # member権限を持つユーザー user = users('fan_bingbing') ability = Ability.new(user) assert ability.cannot?(:manage, Test.new) end上記のような感じで、ユーザーが権限を持たないことをテストすればOK!
- 投稿日:2020-03-10T11:41:56+09:00
deviseとActive Storage を使ってavatar(アイコン)登録する
Active Storageの場合 (Rails 5.2以降の場合)
アクティブストレージは保存場所を信頼性の高いamazon, google, microsoftが提供するクラウドに保存できる。またバックアップもできるので、データが消えた場合などに非常に重宝されます。
設定方法も非常に簡単です。
概要
Active StorageによるRails ファイルアップロード
Active Strageを使用してユーザーのアバターを登録、表示する
参考になるページ
【Rails 5.2】 Active Storageの使い方ターミナル$ rails active_storage:install $ bundle exec rake db:migraterails active_storage:installコマンドを実行すると、active_storage_blobs と active_storage_attachmentsテーブルが生成されるのでこちらをモデルに反映させるためrails db:migrateする
作成されたテーブルは下記の役割となります。
テーブル 機能 active_storage_blobs アバター画像の保存先 active_storage_attachments userとavatorの中間テーブル ローカル環境、テスト環境、本番環境で保存先を変更する。
storage.ymlで設定を変えていくconfig/storage.ymltest: service: Disk root: <%= Rails.root.join("tmp/storage") %> local: service: Disk root: <%= Rails.root.join("storage") %> # Use rails credentials:edit to set the AWS secrets (as aws:access_key_id|secret_access_key) # amazon: # service: S3 # access_key_id: <%= Rails.application.credentials.dig(:aws, :access_key_id) %> # secret_access_key: <%= Rails.application.credentials.dig(:aws, :secret_access_key) %> # region: us-east-1 # bucket: your_own_bucket # Remember not to checkin your GCS keyfile to a repository # google: # service: GCS # project: your_project # credentials: <%= Rails.root.join("path/to/gcs.keyfile") %> # bucket: your_own_bucket # Use rails credentials:edit to set the Azure Storage secret (as azure_storage:storage_access_key) # microsoft: # service: AzureStorage # storage_account_name: your_account_name # storage_access_key: <%= Rails.application.credentials.dig(:azure_storage, :storage_access_key) %> # container: your_container_name # mirror: # service: Mirror # primary: local # mirrors: [ amazon, google, microsoft ]すでにamazonの記述はあります。なので,amazonのs3で保存する場合はコメントアウトを解除して下記のようにします。
config/storage.ymltest: service: Disk root: <%= Rails.root.join("tmp/storage") %> local: service: Disk root: <%= Rails.root.join("storage") %> amazon: service: S3 access_key_id: <%= Rails.application.credentials.dig(:aws, "YOUR ACCESS_KEY_ID") %> secret_access_key: <%= Rails.application.credentials.dig(:aws, "YOUR SECRET_ACCESS_KEY") %> region: ap-northeast-1 # 東京の場合(海外の場合異なります) bucket: バケット名config/environments/production.rb# :localから:amazonに変更することで、先ほど定義したamazon:を読み込みさせる。 config.active_storage.service = :amazonAWS用のGemを追加します
Gemfilegem 'aws-sdk-s3', require: falseuserモデルとavatorを紐づける
user.rbclass User < ApplicationRecord #Include default devise modules. Others available are: #:confirmable, :lockable, :timeoutable, :trackable and :omniauthable devise :database_authenticatable, :registerable, :recoverable, :rememberable, :validatable has_one_attached :avatar # 追加 endこのアクセサに、Active Strageがファイルをアタッチしてくれます。
なお、レコードとファイルが1対1の場合は has_one_attached ですが、1対多の場合は has_many_attached になります。form= f.file_field :avatarこれで登録可能です。
編集の場合
今回はgem "devise"を利用してアイコンを登録する場合です。
deviseのparamsを指定するために、application_controllerでaccount_updateの記述を追加します
application_controller.rbdef configure_permitted_parameters devise_parameter_sanitizer.permit(:sign_up, keys: [ :avatar] ) devise_parameter_sanitizer.permit(:account_update, keys: [ :avatar]) endこれでparamsにavatarが読み取れます。
つづいて、active_strageで保存する場合、親要素.イメージ名.attach(params[:key]とする必要があります。
例えば,既存のuserにavatarを付与するにはUser.avatar.attach(params[:avatar])とします。
.attachメソッドで追加/更新しなければいけないのがポイントです。
ですから、通常通りupdateするだけでは更新されません。
update処理に.attachを追加します。今回はdeviseということなので、deviseのregistration_controller.rbに処理を追加します。コメントアウトを解除して、下記の処理にします。registration_controller.rbdef update super if account_update_params[:avatar].present? resource.avatar.attach(account_update_params[:avatar]) end endこれでavatarが付与/更新されます。
参考資料
- 投稿日:2020-03-10T11:35:31+09:00
シンボルとは
シンボルとは
Symbol とは、Ruby が内部でメソッド名などの識別に使っている数値で、任意の文字列に対して異なった値が割り当てらる。
なるほど、よく分かりませんね。
つまり、文字列だけど数値。みたいなものです。ハッシュのキーや文字列自体がデータでは無い物に使うことが吉です。
前コロンと後コロンの違い
シンボルとは主に文字列にコロン記号「:」を前置して定義したものです。
それにより、文字列を””で囲む必要がなくなります。
コロン記号「:」が、文字列記号「””」の代わりに、「これはシンボルだよ」とRubyに知らせています。
上記のように、コロン記号「:」を文字列に前置するとシンボルになります。
たとえば、ハッシュのキーとしてシンボルを使う際や、キーワード引数を使う際に、コロン記号「:」を後置します。
シンボルはオブジェクトの一つ
メソッドなどの名前を識別するためのラベルをオブジェクト化
samurai /*文字列 :samurai /*シンボルハッシュのキーとして利用する
よく使われるのが、ハッシュのキーだと思います。
hash_symbol = { tsuma: "sazae", otto: "masuo", kodomo: "tarao" }取り出しは
puts hash_string[:tsuma] # "sazae" と表示 puts hash_string[:otto] # "masuo" と表示 puts hash_string[:kodomo] # "tarao" と表示なり、キーをシンボルで定義しています。
ハッシュはデータを持たない
最初に記述した通り、ハッシュは「文字列だけど数値。」なのでデータを持ちません。
そのため、文字列そのもののデータを必要としない場合にシンボルが使われています。シンボルのメリット
シンボルを使うことでコードが短くなり可読性が上がったり、処理が早くなったり、メモリ消費が少なくなったりと、いいことばかりらしいので、一緒に勉強しましょう。
- 投稿日:2020-03-10T11:05:58+09:00
Railsで作ったアプリをAWSでデプロイ① 〜アカウント作成編〜
こんにちは
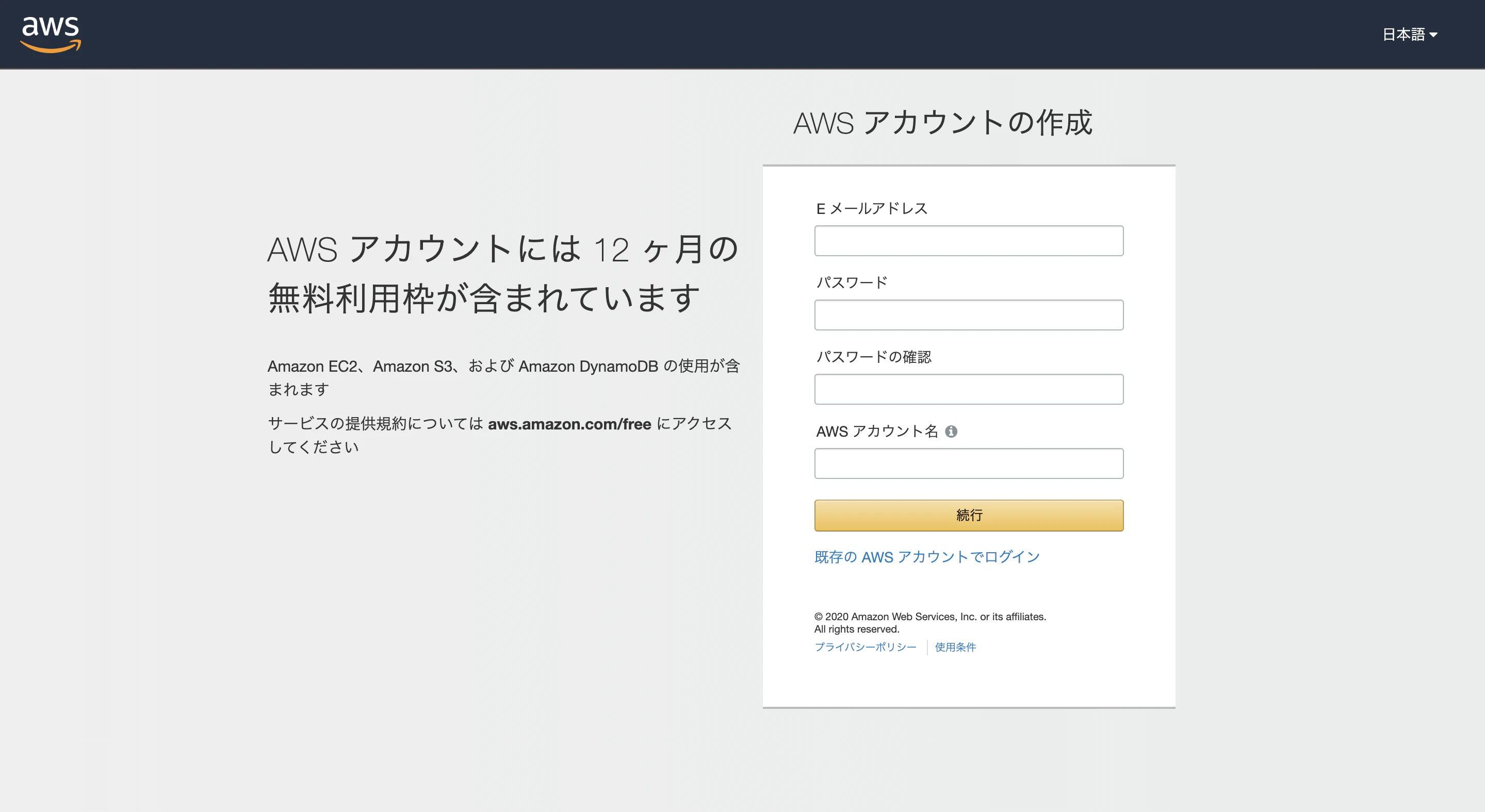
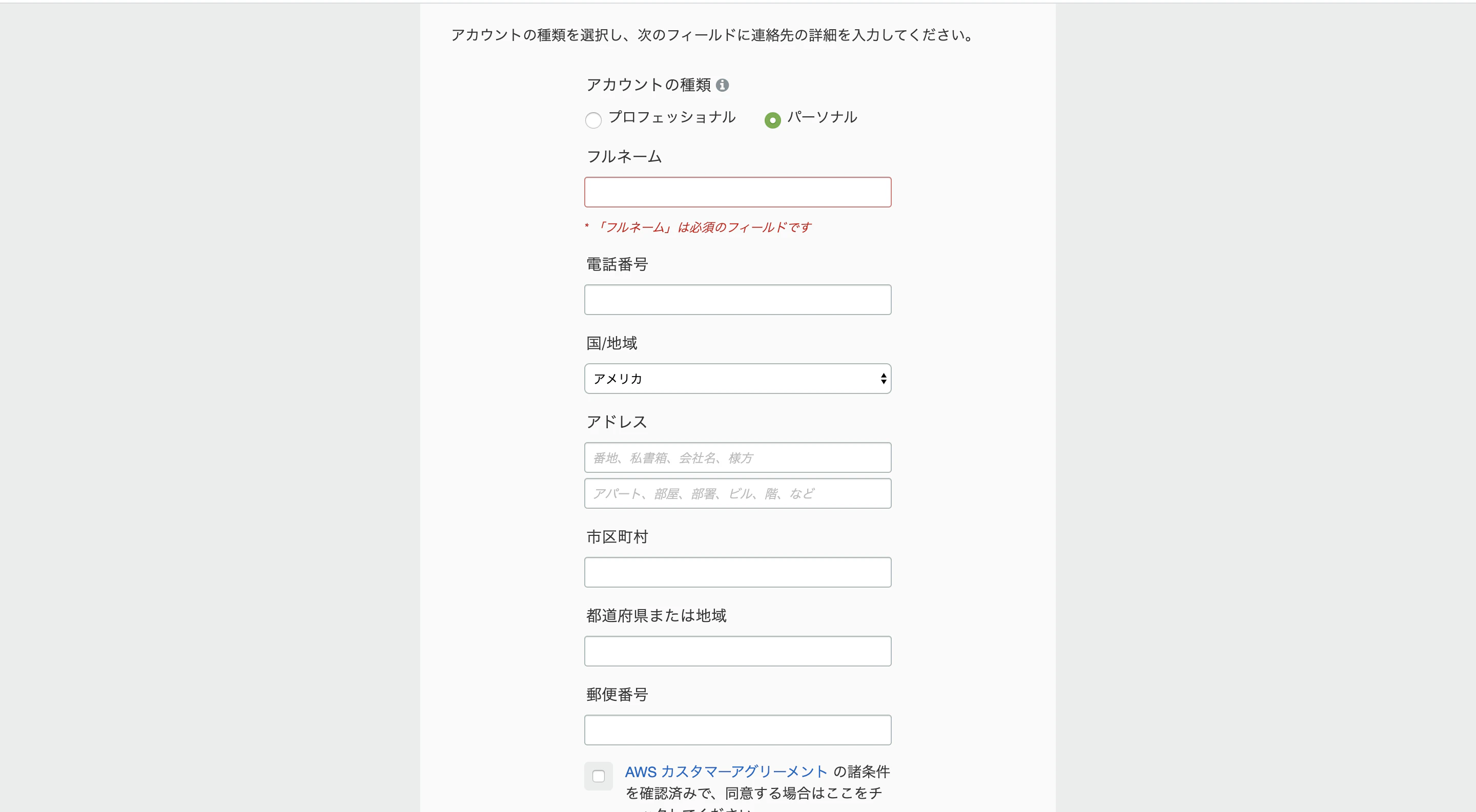
AWSをつかってRailsアプリをデプロイしたいと思いますまず、AWSアカウントを作成します
注意点として一度使ったメールアドレスは、削除すると二度と使えなくなるそうです。
次の画面、僕はパーソナルです。
この後、クレジットカード→本人認証画面なので割愛します
プランはベーシックです。晴れてAWSアカウント作成完了!
早速EC2インスタンスを作りたかったのですが、どうやらアカウント作成直後はできないみたいです。
少し待ちます。
- 投稿日:2020-03-10T10:54:29+09:00
DB接続がない状態でassets:precompileを行う
本番とは違う環境だったり、Dockerfile内でassets:precompileを行ったりするときにDB接続でエラーになるときがある。これを回避する方法ってあるのかなと思ったので調べてみた
activerecord-nulldb-adapterを使う
github
https://github.com/nulldb/nulldbgem 'activerecord-nulldb-adapter'config/database.ymldefault: &default adapter: <%= ENV['DB_ADAPTER'] ||= "mysql2" %>database.ymlに環境変数で
DB_ADAPTERを指定する。$ DB_ADAPTER=nulldb bundle exec rake assets:precompile上記を実行すればDB接続なしでprecompileできる
参考
Rails × ECS でオートスケーリング&検証環境の自動構築
https://tech.medpeer.co.jp/entry/2018/06/20/080000
- 投稿日:2020-03-10T10:20:31+09:00
AWS ECSのビルド〜デプロイをCodePipelineで自動化した
Docker + ECS + RailsのプロジェクトでCodePipelineを使用してデプロイまでを自動化したので、その知見をまとめたい。(ブルーグリーンデプロイではなく、通常のデプロイ時の方法)
RailsのプロジェクトだけれどCodePipeline基本的な使い方は、他の言語でもそれほど変わらないと思う
デプロイの流れ
githubにpushすれば自動でデプロイが開始される。デプロイは以下の流れで行うように作った。
- GitHubの特定のブランチ(masterなど)にpushする
- pushされたことがCodepipelineに通知されビルドが開始
- docker-composeを利用して、Dockerをbuildする
- Dockerイメージタグにコミット番号を付与して一意にする
- ビルドが完了したらECRにpushする
- ビルド完了後にECSにデプロイ通知がいく
CodePipelineの設定
CodePipelineはソース管理、ビルド、デプロイをパーツのようにつなげてCD/CIを管理することができるAWSのサービス。以下のサービスをつなぎ合わせて連携することができる
- CodeCommit
- CodeBuild
- CodeDeploy
CodeCommit
まずはGithubで特定のリポジトリにpushされたときに検知できるようにする。ここではmasterがpushsされたときにビルドされる設定した。
ちなみにCodeCommitはGithub以外にも、ECRやS3などと連携することもできる。CodeCommit自体にコードを管理させることも可能。
CodeBuild
CodeBuildではビルドプロジェクトというものを作成する。このビルドプロジェクトはOS環境や、ビルドコマンドを記載するbuildspec.ymlのパスを設定していく。ようはビルドの設定を管理している感じだ。
Ubuntuでイメージが最新バージョンのものを使っておけば特に問題はないかと思う。buildspec.ymlはGithubにあげたプロジェクトに入れておく。そのパスをビルドプロジェクトで設定すればOK
buildspec.yml
ビルドするコマンドをyamlに書いていく。ビルドは以下のような流れで行う。
- ECRからDockerのイメージを取得
- コミットハッシュを取得する(コミットハッシュはDockerイメージタグとして使用する)
- .envに環境変数を追加していく
- docker-composeを利用してビルドする
- dbのmigrateを行う
- デプロイを通知する
version: 0.2 phases: install: runtime-versions: docker: 18 pre_build: commands: - echo -------- Logging in to Amazon ECR... -------- - aws --version - $(aws ecr get-login --region $AWS_DEFAULT_REGION --no-include-email) - REPOSITORY_URI=$AWS_ACCOUNT_ID.dkr.ecr.$AWS_DEFAULT_REGION.amazonaws.com/hogehoge - COMMIT_HASH=$(echo $CODEBUILD_RESOLVED_SOURCE_VERSION | cut -c 1-7) - IMAGE_TAG=${COMMIT_HASH:=latest} build: commands: - echo -------- Build started on `date` -------- - echo -------- Building the Docker image... -------- - echo AWS_ACCESS_KEY=$AWS_ACCESS_KEY >> .env - echo AWS_SECRET_KEY=$AWS_SECRET_KEY >> .env - echo ECS_ENV_NAME=$ECS_ENV_NAME >> .env - docker-compose -f docker-compose-$ECS_ENV_NAME.yml build - docker-compose -f docker-compose-$ECS_ENV_NAME.yml run --name hogehoge-image web sh -c "bundle exec rake db:create && bundle exec rake db:migrate" - docker commit hogehoge-image $REPOSITORY_URI:latest - docker tag $REPOSITORY_URI:latest $REPOSITORY_URI:$IMAGE_TAG post_build: commands: - echo -------- Build completed on `date` -------- - echo -------- Pushing the Docker images... -------- - docker push $REPOSITORY_URI:latest - docker push $REPOSITORY_URI:$IMAGE_TAG - echo [\{\"name\":\"hogehoge\",\"imageUri\":\"$REPOSITORY_URI:$IMAGE_TAG\"\}] > imagedefinitions.json artifacts: files: imagedefinitions.jsonbuildspec.ymlはpre_build、build、post_buildという3段階で処理を行う。一個ずつ分解して説明していく。
pre_build
ビルドする前の下準備。 GithubのURLとか、コミットハッシュとかをあとで使うので変数に入れている。ちなみにコミットハッシュはDockerイメージタグとして後で使う。
build
- echo AWS_ACCESS_KEY=$AWS_ACCESS_KEY >> .env - echo AWS_SECRET_KEY=$AWS_SECRET_KEY >> .env - echo S3_BUCKET=$S3_BUCKET >> .env環境変数を.envに書き込むようにしている。僕のRailsプロジェクトでは.envで環境変数を管理しており、CodeBuildでもdocker-composeが使用したいという理由でこの形にしている。このやり方がベストプラクティスではないような気がするので、もっと良い方法を見つけたい。
ちなみに環境変数はSystem Managerで管理している。環境変数についてはのちほどもう少し詳しく記載する。
- docker-compose -f docker-compose-$ECS_ENV_NAME.yml build - docker-compose -f docker-compose-$ECS_ENV_NAME.yml run --name hogehoge-image web sh -c "bundle exec rake db:create && bundle exec rake db:migrate" - docker commit hogehoge-image $REPOSITORY_URI:latest - docker tag $REPOSITORY_URI:latest $REPOSITORY_URI:あとはdocker-composeでビルドして、migrateして、Dockerイメージをcommitしているだけ。
ちなみに僕はDockerfile内に
assets:precompileを行っているため、buildspec.ymlにはコマンドが書いていない。post_build
ECSにデプロイするためには最終的にimagedefinitions.jsonというファイルを作成する必要がある。
- docker push $REPOSITORY_URI:latest - docker push $REPOSITORY_URI:$IMAGE_TAG - echo [\{\"name\":\"hogehoge\",\"imageUri\":\"$REPOSITORY_URI:$IMAGE_TAG\"\}] > imagedefinitions.json artifacts: files: imagedefinitions.jsonimagedefinitions.jsonはnameとimageUirを関連付けたjsonを書いていく。複数環境あるときは当たり前だけど複数書いていく。
- name
- ECSのコンテナ名
- imageUri
- ECRのURL
ECSのタスク定義との関連は以下のようになる。
補足
環境変数について
環境変数は秘匿化する必要があるためSystem Managerでパラメータを管理するようにした。
安全な文字列を選択してパラメータを設定する。「名前」欄で設定した値をCodeBuildで使用する。
System Managerで設定した値をbuildspec.ymlで使用するために、CodeBuildに環境変数として設定する必要がある。これを設定しておくとbuildspec.ymlの中で
$HOGEHOGEという値で使用できるようになる。
- 名前
- buildspec.ymlで使用する環境変数名
- 値
- System Managerで設定した名前
- 入力
- 『パラメータ』を選択する
- echo AWS_ACCOUNT_ID=$AWS_ACCOUNT_ID >> .env - echo AWS_ACCESS_KEY=$AWS_ACCESS_KEY >> .env - echo AWS_SECRET_KEY=$AWS_SECRET_KEY >> .envこれでbuildspec.ymlにファイルの中でCodeBuildで設定した環境変数が利用できるようになる
デプロイしたときにタスク定義のバージョンは更新されていく
デプロイされるとimagedefinitions.jsonで設定したコンテナ名とイメージのURLでタスク定義のイメージが変更され、リビジョンが新しく更新されていく。タスクをリビジョンで管理するメリットとして「切り戻しが簡単になる」という点がある。
もしも本番で障害が発生したとき場合にもリビジョンを戻すだけで動作する。ただしDBのカラム変更などしているときは、DBをロールバックする必要もあるので注意が必要。
CodePipelineからデプロイを実行する
なんらかの理由でソースコードをpushせずにデプロイしたい場合は、Codepipelineの画面から直接行うことができる
終わり
ECSは少人数の開発にこそ向いていると思う。ECSでスケールアップから障害復旧までまかせ、CodePipelineでデプロイを自動化しておけばインフラの運用をそれほど考慮しなくて済むようになる。アプリケーション層に集中して開発ができるようになる。
まだまだECSやCodePipelineに対しての知見が足りないので、また気づきがあったら書いていきたい









- 投稿日:2020-03-10T10:20:31+09:00
Rails + Docker + ECSのビルド〜デプロイをCodePipelineで自動化した
Docker + ECS + RailsのプロジェクトでCodePipelineを使用してデプロイまでを自動化したので、その知見をまとめたい。(ブルーグリーンデプロイではなく、通常のデプロイ時の方法)
RailsのプロジェクトだけれどCodePipeline基本的な使い方は、他の言語でもそれほど変わらないと思う
デプロイの流れ
githubにpushすれば自動でデプロイが開始される。デプロイは以下の流れで行うように作った。
- GitHubの特定のブランチ(masterなど)にpushする
- pushされたことがCodepipelineに通知されビルドが開始
- docker-composeを利用して、Dockerをbuildする
- Dockerイメージタグにコミット番号を付与して一意にする
- ビルドが完了したらECRにpushする
- ビルド完了後にECSにデプロイ通知がいく
CodePipelineの設定
CodePipelineはソース管理、ビルド、デプロイをパーツのようにつなげてCD/CIを管理することができるAWSのサービス。以下のサービスをつなぎ合わせて連携することができる
- CodeCommit
- CodeBuild
- CodeDeploy
CodeCommit
まずはGithubで特定のリポジトリにpushされたときに検知できるようにする。ここではmasterがpushsされたときにビルドされる設定した。
ちなみにCodeCommitはGithub以外にも、ECRやS3などと連携することもできる。CodeCommit自体にコードを管理させることも可能。
CodeBuild
CodeBuildではビルドプロジェクトというものを作成する。このビルドプロジェクトはOS環境や、ビルドコマンドを記載するbuildspec.ymlのパスを設定していく。ようはビルドの設定を管理している感じだ。
Ubuntuでイメージが最新バージョンのものを使っておけば特に問題はないかと思う。buildspec.ymlはGithubにあげたプロジェクトに入れておく。そのパスをビルドプロジェクトで設定すればOK
buildspec.yml
ビルドするコマンドをyamlに書いていく。ビルドは以下のような流れで行う。
- ECRからDockerのイメージを取得
- コミットハッシュを取得する(コミットハッシュはDockerイメージタグとして使用する)
- .envに環境変数を追加していく
- docker-composeを利用してビルドする
- dbのmigrateを行う
- デプロイを通知する
version: 0.2 phases: install: runtime-versions: docker: 18 pre_build: commands: - echo -------- Logging in to Amazon ECR... -------- - aws --version - $(aws ecr get-login --region $AWS_DEFAULT_REGION --no-include-email) - REPOSITORY_URI=$AWS_ACCOUNT_ID.dkr.ecr.$AWS_DEFAULT_REGION.amazonaws.com/hogehoge - COMMIT_HASH=$(echo $CODEBUILD_RESOLVED_SOURCE_VERSION | cut -c 1-7) - IMAGE_TAG=${COMMIT_HASH:=latest} build: commands: - echo -------- Build started on `date` -------- - echo -------- Building the Docker image... -------- - echo AWS_ACCESS_KEY=$AWS_ACCESS_KEY >> .env - echo AWS_SECRET_KEY=$AWS_SECRET_KEY >> .env - echo ECS_ENV_NAME=$ECS_ENV_NAME >> .env - docker-compose -f docker-compose-$ECS_ENV_NAME.yml build - docker-compose -f docker-compose-$ECS_ENV_NAME.yml run --name hogehoge-image web sh -c "bundle exec rake db:create && bundle exec rake db:migrate" - docker commit hogehoge-image $REPOSITORY_URI:latest - docker tag $REPOSITORY_URI:latest $REPOSITORY_URI:$IMAGE_TAG post_build: commands: - echo -------- Build completed on `date` -------- - echo -------- Pushing the Docker images... -------- - docker push $REPOSITORY_URI:latest - docker push $REPOSITORY_URI:$IMAGE_TAG - echo [\{\"name\":\"hogehoge\",\"imageUri\":\"$REPOSITORY_URI:$IMAGE_TAG\"\}] > imagedefinitions.json artifacts: files: imagedefinitions.jsonbuildspec.ymlはpre_build、build、post_buildという3段階で処理を行う。一個ずつ分解して説明していく。
pre_build
ビルドする前の下準備。 GithubのURLとか、コミットハッシュとかをあとで使うので変数に入れている。ちなみにコミットハッシュはDockerイメージタグとして後で使う。
build
- echo AWS_ACCESS_KEY=$AWS_ACCESS_KEY >> .env - echo AWS_SECRET_KEY=$AWS_SECRET_KEY >> .env - echo S3_BUCKET=$S3_BUCKET >> .env環境変数を.envに書き込むようにしている。僕のRailsプロジェクトでは.envで環境変数を管理しており、CodeBuildでもdocker-composeが使用したいという理由でこの形にしている。このやり方がベストプラクティスではないような気がするので、もっと良い方法を見つけたい。
ちなみに環境変数はSystem Managerで管理している。環境変数についてはのちほどもう少し詳しく記載する。
- docker-compose -f docker-compose-$ECS_ENV_NAME.yml build - docker-compose -f docker-compose-$ECS_ENV_NAME.yml run --name hogehoge-image web sh -c "bundle exec rake db:create && bundle exec rake db:migrate" - docker commit hogehoge-image $REPOSITORY_URI:latest - docker tag $REPOSITORY_URI:latest $REPOSITORY_URI:あとはdocker-composeでビルドして、migrateして、Dockerイメージをcommitしているだけ。
ちなみに僕はDockerfile内に
assets:precompileを行っているため、buildspec.ymlにはコマンドが書いていない。post_build
ECSにデプロイするためには最終的にimagedefinitions.jsonというファイルを作成する必要がある。
- docker push $REPOSITORY_URI:latest - docker push $REPOSITORY_URI:$IMAGE_TAG - echo [\{\"name\":\"hogehoge\",\"imageUri\":\"$REPOSITORY_URI:$IMAGE_TAG\"\}] > imagedefinitions.json artifacts: files: imagedefinitions.jsonimagedefinitions.jsonはnameとimageUirを関連付けたjsonを書いていく。複数環境あるときは当たり前だけど複数書いていく。
- name
- ECSのコンテナ名
- imageUri
- ECRのURL
ECSのタスク定義との関連は以下のようになる。
補足
環境変数について
環境変数は秘匿化する必要があるためSystem Managerでパラメータを管理するようにした。
安全な文字列を選択してパラメータを設定する。「名前」欄で設定した値をCodeBuildで使用する。
System Managerで設定した値をbuildspec.ymlで使用するために、CodeBuildに環境変数として設定する必要がある。これを設定しておくとbuildspec.ymlの中で
$HOGEHOGEという値で使用できるようになる。
- 名前
- buildspec.ymlで使用する環境変数名
- 値
- System Managerで設定した名前
- 入力
- 『パラメータ』を選択する
- echo AWS_ACCOUNT_ID=$AWS_ACCOUNT_ID >> .env - echo AWS_ACCESS_KEY=$AWS_ACCESS_KEY >> .env - echo AWS_SECRET_KEY=$AWS_SECRET_KEY >> .envこれでbuildspec.ymlにファイルの中でCodeBuildで設定した環境変数が利用できるようになる
デプロイしたときにタスク定義のバージョンは更新されていく
デプロイされるとimagedefinitions.jsonで設定したコンテナ名とイメージのURLでタスク定義のイメージが変更され、リビジョンが新しく更新されていく。タスクをリビジョンで管理するメリットとして「切り戻しが簡単になる」という点がある。
もしも本番で障害が発生したとき場合にもリビジョンを戻すだけで動作する。ただしDBのカラム変更などしているときは、DBをロールバックする必要もあるので注意が必要。
CodePipelineからデプロイを実行する
なんらかの理由でソースコードをpushせずにデプロイしたい場合は、Codepipelineの画面から直接行うことができる
終わり
ECSは少人数の開発にこそ向いていると思う。ECSでスケールアップから障害復旧までまかせ、CodePipelineでデプロイを自動化しておけばインフラの運用をそれほど考慮しなくて済むようになる。アプリケーション層に集中して開発ができるようになる。
まだまだECSやCodePipelineに対しての知見が足りないので、また気づきがあったら書いていきたい
- 投稿日:2020-03-10T00:46:17+09:00
【Ruby on Rails】Google Books APIを叩く際の5つのTips
想定読者
- Railsで読書系ポートフォリオを作っている方
$ ruby -v ruby 2.6.5 $ rails -v Rails 5.2.4.1その1.APIを叩くロジックはcontrollerから切り分ける
まず以下記事(私の前記事です)のようにAPIを叩くわけですが、これをcontrollerに書いたらあっという間にFat controllerになりました。
Ruby on RailsでGoogle Books APIを叩くAPIを叩くロジックは、以下を参考にmodlueとしてapp/libに置きました。
Rails 5 で自作のモジュールを読み込む方法APIを叩く自作module
app/lib/google_books_api.rbmodule GoogleBooksApi def get_json_from_url(url) JSON.parse(Net::HTTP.get(URI.parse(Addressable::URI.encode(url)))) end # ①検索するAPIを叩く def url_from_keyword(keyword) "https://www.googleapis.com/books/v1/volumes?q=#{keyword}&country=JP&maxResults=20" end # ②IDから本の情報を取得するAPIを叩く def url_from_id(googlebooksapi_id) "https://www.googleapis.com/books/v1/volumes/#{googlebooksapi_id}" end endcontrollerにincludeする
app/controllers/books_controller.rbclass BooksController < ApplicationController include GoogleBooksApi (略) endbooks_controller内で、GoogleBooksAPIというmoduleをincludeしたので、そのmoduleの関数が使えます。
app/libというディレクトリが自作なので、
「そもそもgoogle_books_api.rbを読み込んでくれるの?」
と不安に思うかもしれません。しかし、実はRailsでは自動的に
app/〇〇(ディレクトリ)/〇〇.rbを読み込んでくれるという仕様があるようです。
※ さらに階層が深くなるとNGみたいです。その2.APIの構造のうち、itemを理解する
Google Books APIからは下記のように色々な情報が入ってるので、APIに慣れていないと混乱するかもしれません。
https://www.googleapis.com/books/v1/volumes?q=Rails先に結論を書きます。
①https://www.googleapis.com/books/v1/volumes?q=#{keyword}では以下が取り出せます。
{ (他のハッシュ),
"items" => [{ item1 }, { item2 }, { item3 }, ....] }②
https://www.googleapis.com/books/v1/volumes/#{googlebooksapi_id}
では以下が取り出せます。
{ item }①本を検索するAPIも、②IDから本情報を取得するAPIも、結局itemを取り出せるわけです。
(このitemの中に、本1つの情報が入っています)
このitemに対してのロジックを書くだけで、①本を検索するAPIに対しても、②IDから本情報を取得するAPIに対しても、共通のロジックを使うことができます。
よって①本を検索するAPIに対しては、以下のように処理するのが良いと思われます。(検索するAPIから得たjson文字列)["items"].each do |item| (itemに対するロジック) endその3.検索時にはActiveRecordのオブジェクトを作らないようにする
これは私がやってしまったアンチパターンです。
最終的には検索した本をActionViewで使う際に、
render @books
あるいは
@books.each do |book|
のような繰り返し処理を書きたいかと思います。その際に、以下のようにActiveRecordのオブジェクトを大量生成するロジックを作ってしまいました。
ActiveRecordから@booksを作る(アンチパターン)
books_controllerdef search @books = [] (items).each do |item| (中略) @books << Book.new( author: (itemから引っ張ってきた著者) title: (itemから引っ張ってきたタイトル) (その他 略) ) end endFat controllerになる以外にも、これの問題点は2つあります。
- ActiveRecordのインスタンス生成(
Book.new)はコストが高いのに、それを繰り返し処理させている- モデルと同じattirbuteを使わなくてはいけない
1の解説
実際にやってみるとわかります。
検索し始めてから結果が表示されるまで5〜10秒くらいかかってて、UXが悪かったです。参考(理解はできてません笑):
ActiveRecordのパフォーマンス・チューニング2の解説
例えば検索結果としては詳細な情報が表示できるようにしたいが、アプリのDBに保存させるつもりは無い、というような場合があります。
パッと思いつくのは、
averageRating: 4.0
amount: 3960.0
みたいな情報でしょうか。レーティングや値段はその時々で変わるので、DBに保存しようとは思わないでしょう。こういう場合は検索結果表示のときだけ
book.averageRatingでレーティングを返せるようにし、DBには保存はしない、という設計が思いつきます。
しかし、ActiveRecordを使うとDBにも同一カラムが存在する必要がある、というわけです。2つの問題点の原因
実は1,2とも原因は共通していて、要はActiveRecordはO/Rマッパーであるからです。
- 検索結果はDBに保存するわけではありません(=DBを使いません)
- ActiveRecordはView <-> DBの仲介役(O/Rマッパー)です。
- よってActiveRecordを使う必要はありません。(少なくともそういう設計になってません)
ということになります。
その4.APIの情報は、オレオレクラス内に格納する
その3に対して、では具体的にどうするかをお伝えします。
結論から言うと、以下のようなオレオレクラスを作成しました。オレオレクラス
app/lib/google_book.rbclass GoogleBook attr_reader :googlebooksapi_id, :author, :buy_link, :description, :image, :published_at, :title class << self include GoogleBooksApi def new_from_id(googlebooksapi_id) url = url_of_creating_from_id(googlebooksapi_id) item = get_json_from_url(url) new(item) end def search(keyword) url = url_of_searching_from_keyword(keyword) json = get_json_from_url(url) books = [] if items = json['items'] items.each do |item| books << GoogleBook.new(item) end end books end end def initialize(item) @item = item @volume_info = @item['volumeInfo'] retrieve_attribute end def retrieve_attribute @googlebooksapi_id = @item['id'] @author = @volume_info['authors'].first @buy_link = @item['saleInfo']['buyLink'] @description = @volume_info['description'] @image = @volume_info['imageLinks']['smallThumbnail'] @published_at = @volume_info['publishedDate'] @title = @volume_info['title'] end end重要なポイントはitemを引数にinitializeができるようにすることです。
その2でも述べたように、itemに対して同じ処理をするように心がければ、共通のロジックを用いることができます。使用例
これにより、以下のようにオブジェクト志向っぽく扱えるようになります。
book = GoogleBook.new_from_id("axicQgAACAAJ") book.title => "影響力の武器" book.author => "ロバート・B. チャルディーニ" books = GoogleBook.search("影響力の武器") => [ book1, book2, book3, .... ](例) book = books.first book.id => "axicQgAACAAJ" book.title => "影響力の武器"このクラスはインスタンス生成にかかるコストは大したことはありません。
よってその3のような、ActiveRecordのインスタンスを複数生成時に発生していたコストも解消できています。注意点
books = GoogleBook.search
のbooksのクラスは、ただのArrayです。そのままではgem kaminariによるpaginateとか、render @booksとかが出来ません。
以下のように続けて書くことで、kaminariのpaginateを利用できます。@books = Kaminari.paginate_array(books).page(params[:page])その5.リソース登録時にはモデルにロジックを書く
上記で作ったGoogleBookクラスを使って、いざDBに本を保存するロジックを書こうとすると、これまたFat controllerになりがちです。
app/controllers/books_controller.rbdef create google_book = GoogleBook.new_from_id(取ってきたid) @book = Book.new( author: google_book.author title: google_book.title (その他 略) ) if @book.save (以下略) endcontrollerというのは、DBの情報を知りすぎない、というのが良い設計らしいです。上のような書き方は「DBにこれとこれが入るんでしょ」って言ってしまっています。
実装
app/controllers/books_controller.rbdef create google_book = GoogleBook.new_from_id(取ってきたid) @book = current_user.books.build @book = @book.substitute_for_googlebook(google_book) if @book.save (以下略) endapp/models/book.rbdef substitute_for_googlebook(google_book) self.author = google_book.author self.description = google_book.description self.googlebooksapi_id = google_book.googlebooksapi_id self.published_at = google_book.published_at self.title = google_book.title self.buy_link = google_book.buy_link self.image = google_book.image self end割とcontrollerはスッキリできたのでは無いでしょうか。
といいながら実はその5はあんまり自信無いです笑
もうちょっと上手くできる気がします。
- 投稿日:2020-03-10T00:20:42+09:00
コーディング未経験のPO/PdMのためのRails on Dockerハンズオン vol.10 - TDD & Test Automation -
はじめに
記念すべき第10回目(ドドーン)。
前回まででサインアップ、サインインの機能を作っていきました。
ただどんどんアプリケーションを作っていくうちに、テスト、面倒になってきましたね。デグレも気になるし...ということで今回は少しアプリ開発を離れまして、TDD(Test Driven Development)、そしてテスト自動化を体得していきましょう!
前回のソースコード
前回のソースコードはこちらに格納してます。今回のハンズオンからやりたい場合はこちらからダウンロードしてください。
TDD
まずはTDDをご紹介。
特にアジャイル開発をやったりすると耳にする単語ですよね。
Test Driven Development、日本語だとテスト駆動開発です。
なんちゃら駆動開発って色々あるんですが、まぁ『なんちゃら』部分を第1に考えた開発って感じで、TDDの場合はテストファーストで開発をしていくって意味ですね。TDDでは『レッド』『グリーン』『リファクタリング』の3つのフェーズを辿ります。
レッド
『レッド』はテストが通らないフェーズです。
TDDではまず機能をコーディングする前に期待動作のテストコードを書きます。
当然、機能をコーディングしていないのですからテストは通りません。この状態が『レッド』です。
TDDでは、この『レッド』のフェーズから機能をコーディングしていって『グリーン』のフェーズをめざします。グリーン
『グリーン』はテストがとりあえず通ったフェーズです。
『レッド』フェーズからアプリをコーディングしていってテストコードが全て通った状態が『グリーン』フェーズです。リファクタリング
『リファクタリング』はテストが通っていてコードとしても良い状態になったフェーズです。
『グリーン』フェーズは、『とりあえず動く』という状態です。
この『グリーン』な状態を保ちつつ、コードをより可読性高く、効率的に変更していくフェーズが『リファクタリング』です。
TDDではテスト自動化を行いますが、これがあるからこそ『動く』状態をキープしながらよりよいコードをめざせます。TDDでは、機能やユーザーストーリー単位にこれらの3つのフェーズで開発を進めていくことで、デグレなくよいコードを作り上げることができます。
BDD
TDDの派生として、BDD(Behavior Driven Development)があります。
日本語では『振る舞い駆動開発』と言われています。これは、TDDよりもより要望に近いテストを記述するフォーマットのようなものと覚えてもらえればよいかと思います。
開発の進め方はTDDと同じで、テストコードを記述して『レッド』『グリーン』『リファクタリング』をしていきます。BDDでは、
Given、When、Thenの3つをテストケースとして定義します。
Given: 前提条件です。「サインイン済みのユーザーが」って感じです。When: 操作や入力です。「プロフィールページでサインアウトリンクをクリックしたとき」って感じです。Then: 期待結果です。「未サインイン状態になりトップページに遷移すること」って感じです。はい、例を出してますが、BDDにのっとると例えば
サインイン済みのユーザーが、プロフィールページでサインアウトリンクをクリックしたとき、未サインイン状態になりトップページに遷移すること
というようなテスト項目を作れます。このようにBDDはよりユーザー目線の振る舞いをテスト項目として定義する考え方です。
このハンズオンでは、このBDDを使ってテストを定義し、テストコードを書いていきます。
テスト自動化
さて、アジャイル開発やTDD/BDDを採用する場合、テスト自動化が必須です。
というよりも一回作ったらもう絶対に追加で開発をしないシステム(どんなシステム?)以外は必須だと思っています。
リファクタリングをしていったり新しい機能を作っていくときに、全てのテストケースをいちいち人間の手でやっていくのは、時間的にも人員的にも不可能だとわかりますよね。そこで、このハンズオンでもテスト自動化を導入していきます。
Rails(Ruby)には使いやすいテストフレームワークRSpecがあります。
またプログラムでWeb画面を操作するSeleniumとこれらをよりコーディングしやすくラッピングしてくれるCapybaraというフレームワークがあります。
このハンズオンでは、この3つのツールを使って実際にユーザーが操作しているのと同じ状態をテストするE2E(End to End)テストを自動化してみます。必要なライブラリ類をインストールする
まずはテスト自動化を実行するために必要なライブラリ類をDockerイメージやRailsアプリにインストールしていきます。
最初に、Dockerコンテナ内でブラウザを立ち上げられないとE2Eテストが行えないので、Dockerfileを編集してDockerイメージにブラウザをインストールします。
今回はChromeを立ち上げてテストできるようにします。DockerfileFROM ruby:2.6.5-alpine3.11 ENV HOME="/app" ENV LANG=C.UTF-8 ENV TZ=Asia/Tokyo WORKDIR $HOME RUN apk update && \ apk upgrade && \ apk add --no-cache \ gcc \ g++ \ less \ libc-dev \ libxml2-dev \ linux-headers \ make \ nodejs \ postgresql \ postgresql-dev \ tzdata \ yarn && \ + apk add --no-cache \ + chromium \ + chromium-chromedriver \ + dbus \ + mesa-dri-swrast \ + ttf-freefont \ + udev \ + wait4ports \ + xorg-server \ + xvfb \ + zlib-dev && \ apk add --virtual build-packs --no-cache \ build-base \ curl-dev COPY Gemfile $HOME COPY Gemfile.lock $HOME RUN bundle install && \ apk del build-packs COPY . $HOME EXPOSE 3000 CMD ["rails", "server", "-b", "0.0.0.0"]これらのパッケージを追加することでDockerコンテナ内でChromeブラウザを起動させてテストすることができるようになります。
次にRailsアプリに必要なライブラリを追加していきます。
Gemfile... group :development, :test do gem 'byebug', platforms: [:mri, :mingw, :x64_mingw] gem 'pry-rails' + + # For test automation + gem 'rspec-rails', '~>3.9' + gem 'capybara' + gem 'selenium-webdriver' end ...ここまでで一度Dockerイメージを再ビルドしましょう。
$ docker-compose build必要なライブラリ類がDockerイメージにインストールされた状態になります。
RSpecの初期設定をする
次にRailsアプリにRSpecの初期インストールをしていきます。
まず、ビルドしたDockerイメージからDockerコンテナを立ち上げて、rails g rspec:installコマンドを実行します。$ docker-compose up -d $ docker-compose exec web ash# rails g rspec:install Running via Spring preloader in process 131 create .rspec create spec create spec/spec_helper.rb create spec/rails_helper.rb色々とファイルが出来上がりました。それぞれの役割は以下の通りです。
.rspec: RSpecを実行するにあたりimportする設定ファイルを定義しているspec/spec_helper.rb: RSpecの設定ファイルspec/rails_helper.rb: RSpecのRails要素をプラスした設定ファイル
rails_helper.rbはspec_helper.rbをオーバーライドしている間柄ですね。ここで
.rspecを少し編集します。.rspec- --require spec_helper + --require rails_helperこれでデフォルトで
rails_helper.rbが設定ファイルとして読み込まれるようになりました。
rails_helper.rbにRSpecで利用するWebドライバーの設定をしていきます。spec/rails_helper.rbrequire 'spec_helper' ENV['RAILS_ENV'] ||= 'test' require File.expand_path('../config/environment', __dir__) abort("The Rails environment is running in production mode!") if Rails.env.production? require 'rspec/rails' # Dir[Rails.root.join('spec', 'support', '**', '*.rb')].each { |f| require f } begin ActiveRecord::Migration.maintain_test_schema! rescue ActiveRecord::PendingMigrationError => e puts e.to_s.strip exit 1 end + + Capybara.register_driver :selenium_chrome_headless do |app| + options = ::Selenium::WebDriver::Chrome::Options.new + options.add_argument('--no-sandbox') + options.add_argument('--headless') + options.add_argument('--disable-gpu') + options.add_argument('--disable-dev-shm-usage') + options.add_argument('--window-size=1680,1050') + Capybara::Selenium::Driver.new(app, browser: :chrome, options: options) + end RSpec.configure do |config| + # Driver setting for system tests. + config.before(:each, type: :system) do + driven_by :selenium_chrome_headless + end + + config.before(:each, type: :system, js: false) do + driven_by :rack_test + end config.fixture_path = "#{::Rails.root}/spec/fixtures" config.use_transactional_fixtures = true config.infer_spec_type_from_file_location! config.filter_rails_from_backtrace! end
Capybara.register_driverでWebドライバーの設定を新しく作ります。
ちょっと書き方が独特な気がすると思いますが、こういうものなのだと思ってください。笑
途中に--headlessという設定がありますが、headlessは目に見える形でブラウザを立ち上げることなくブラウザテストを行うことができるものです。(ヘッドレス Chrome ことはじめ | Web | Google Developers)
これによってテストの実行速度が速くなったりするので是非使いましょう。
RSpec.configureで2つのパターンのWebドライバー設定をしています。
config.before(:each, type: :system)はシステムテストが実行される都度設定されるものことを意味しています。(システムテストはRSpecの用語でE2Eテストと同義と思っていただいていいかと)
driven_byでドライバーを指定するのですが、デフォルトでは先ほど上で定義したselenium_chrome_headlessが、js: falseの場合にはrack_testが設定されることがわかりますね。
rack_testは高速にテストができるのですがjavascriptの機能などを見ることはできないドライバーです。
javascriptの確認をする必要がなく高速にテストを終えたいケースや、javascriptを動かしたくないテストケースに使えます。また、このままでは
rails gコマンドを実行したときに意図しないテストファイルが自動生成されてしまいます。
面倒なのでテスト関連のファイルが生成できないようにします。config/application.rb... module App class Application < Rails::Application config.load_defaults 6.0 # Don't generate system test files. config.generators.system_tests = nil # Timezone config.time_zone = 'Tokyo' config.active_record.default_timezone = :local # Language config.i18n.default_locale = :ja + + # Don't create test files atomatically. + config.generators do |g| + g.test_framework :rspec, + fixtures: false, + view_specs: false, + helper_specs: false, + routing_specs: false, + controller_specs: false, + request_specs: false + end end endここまででRSpecでE2Eテストを実行する初期設定ができました!
テストが実行できるか試してみる
まずは試しにここまでの設定でちゃんとテスト自動化ができるのか試してみましょう。
まず、RSpecのシステムテストを実行するファイルを格納する
spec/systemディレクトリを作成し、その中にsample_spec.rbの名前のサンプルファイルを用意してみましょう。# mkdir spec/system # touch spec/system/sample_spec.rbRSpecは
_spec.rbをテストコードと判断して実行するようになっているのでお忘れなきよう。では
sample_spec.rbに「トップページにアクセスできること」を確認するテストコードを記述していきます。spec/system/sample_spec.rbfeature "サンプルテスト", type: :system do scenario "トップページにアクセスできること" do visit root_path expect(current_path).to eq root_path end endテストコード自体は
scenarioブロックに囲まれた部分です。featureは複数のscenarioを束ねるものでtype: :systemオプションをつけることでシステムテストとして実行することを宣言しています。「トップページにアクセスできること」シナリオのテストコードの中身もちょっと紹介します。
visit root_pathでroot_path、つまり/にアクセスしています。
expect([検査対象]).to [期待結果]で[検査対象]が[期待結果]であるかどうかを検査します。
今回の検査対象はcurrent_pathです。これは今表示されているページのパスのことです。期待結果がroot_pathなので、現在表示されているページが/であればOK、そうでなければNGになります。実はここで使っている
visitやcurrent_pathはCapybaraのおかげでわかりやすい言葉で使えるようになっています。Capybaraの使い方は「使えるRSpec入門・その4「どんなブラウザ操作も自由自在!逆引きCapybara大辞典」 - Qiita」などがわかりやすいと思います。あとは全力で公式ドキュメントよむ。このように操作と検査が一つのシナリオの中に記述され、検査が通るかどうかでOK/NGが判断されます。
もちろん、操作も検査も1つのシナリオの中で複数記述することができます。では、このテストを実行してみましょう。
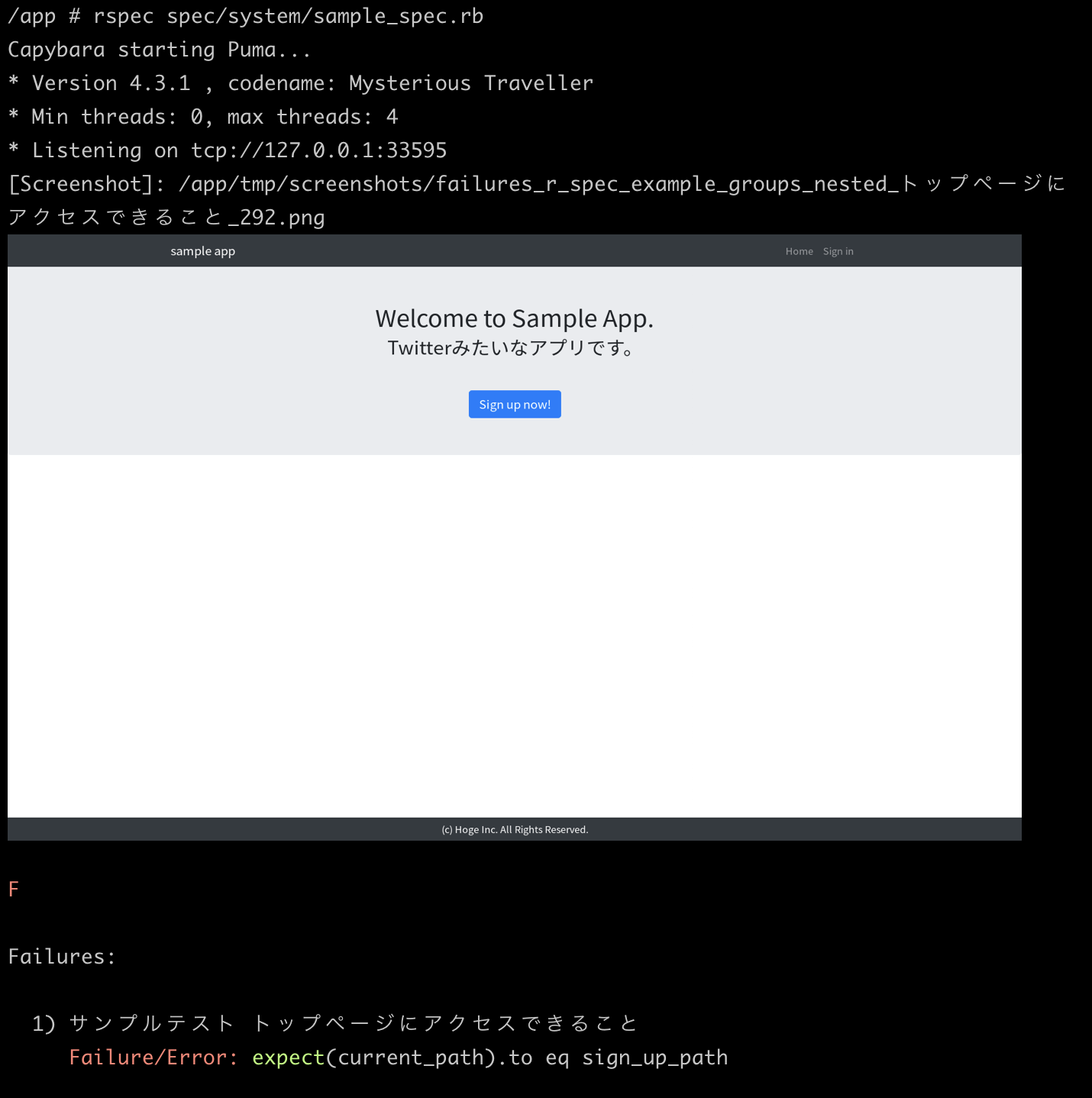
# rspec spec/system/sample_spec.rb Capybara starting Puma... * Version 4.3.1 , codename: Mysterious Traveller * Min threads: 0, max threads: 4 * Listening on tcp://127.0.0.1:40933 . Finished in 16.97 seconds (files took 16.66 seconds to load) 1 example, 0 failuresRSpecのテストを実行するときは
rspecコマンドを使います。今回の例のようにファイル名を指定することで、そのテストファイルのみが実行されます。
ディレクトリを指定した場合は、そのディレクトリの全てのテストコードが、rspecだけの場合はspecディレクトリの全てのテストファイルが実行されるます。最後に
1 example, 0 failuresと表示されています。exampleはシナリオ数、failuresはそのうちNGだった数を表すので、今回は1つのテストシナリオが実行され全てOKであったことがわかります。試しに、エラーになったときにどうなるか試してみましょう。
spec/system/sample_spec.rbfeature "サンプルテスト", type: :system do scenario "トップページにアクセスできること" do visit root_path - expect(current_path).to eq root_path + expect(current_path).to eq sign_up_path end endCapybara starting Puma... * Version 4.3.1 , codename: Mysterious Traveller * Min threads: 0, max threads: 4 * Listening on tcp://127.0.0.1:37237 F Failures: 1) サンプルテスト トップページにアクセスできること Failure/Error: expect(current_path).to eq sign_up_path expected: "/sign_up" got: "/" (compared using ==) # ./spec/system/sample_spec.rb:4:in `block (2 levels) in <main>' Finished in 4.23 seconds (files took 6.85 seconds to load) 1 example, 1 failure Failed examples: rspec ./spec/system/sample_spec.rb:2 # サンプルテスト トップページにアクセスできること
1 example, 1 failureなのでNGになっていることがわかりますね。
途中の内容をみてみると、expected: "/sign_up"に対してgot: "/"であるためにNGになっていることが分かります。想定通りテストがNGになりました。RSpecのシステムテストではテストがNGになった場合、自動的にスクリーンショットを保存して置いてくれます。そのファイルは
tmp/screenshots/に保存されます。
ただ、ファイルをみると真っ白。本当はroot_pathにアクセスしているのでトップページが表示されていてほしいですよね。
実はこれRSpecのバグっぽいんですよね...(Rails アプリケーションの不安定なテストを撲滅したい 〜system spec のデバッグ方法とテストを不安定にさせる要因〜 - あらびき日記)ということでスクリーンショットがちゃんと表示されるようにヘルパーを作ってみましょう!
スクリーンショットを正しく表示させる
まずはテストを実行するときにヘルパーファイルを読み取るようにします。
これはrails_helper.rbでコメントアウトを外すだけでOKです。spec/rails_helper.rb... - # Dir[Rails.root.join('spec', 'support', '**', '*.rb')].each { |f| require f } + Dir[Rails.root.join('spec', 'support', '**', '*.rb')].each { |f| require f } ...これで、
spec/support/**/*.rbのファイルがテスト実行時に読み込まれるようになります。
ヘルパーファイルを格納しておくディレクトリを作って、スクリーンショットを表示させるためのヘルパーとしてvisible_screenshot_helper.rbを作りましょう!# mkdir -p spec/support/helpers # touch spec/support/helpers/visible_screenshot_helper.rbvisible_screenshot_helper.rbmodule VisibleScreenshotHelper extend ActiveSupport::Concern included do |example_group| example_group.after do take_failed_screenshot end end def take_failed_screenshot return if @is_failed_screenshot_taken super @is_failed_screenshot_taken = true end end RSpec.configure do |config| config.include VisibleScreenshotHelper, type: :system end「Rails アプリケーションの不安定なテストを撲滅したい 〜system spec のデバッグ方法とテストを不安定にさせる要因〜 - あらびき日記」の記事を参考にしました。
これでもう一度テストを実行してみましょう。スクリーンショットがちゃんと表示されるようになるはずです。テスト開始前にスクリーンショットを削除する
こうやってテストしているとスクリーンショットが溜まっていっちゃいますよね...
ということでテスト実行の直前にスクリーンショットを一度全て削除するようにrails_helper.rbに設定を追加します。spec/rails_helper.rb... RSpec.configure do |config| # Driver setting for system tests. config.before(:each, type: :system) do driven_by :selenium_chrome_headless end config.before(:each, type: :system, js: false) do driven_by :rack_test end + + # Delete screenshots before starting new tests + config.before(:all) do + FileUtils.rm_rf(Rails.root.join('tmp', 'screenshots'), secure: true) + end config.fixture_path = "#{::Rails.root}/spec/fixtures" config.use_transactional_fixtures = true config.infer_spec_type_from_file_location! config.filter_rails_from_backtrace! endこれを追加するだけです。
config.before(:all)はテスト実行前に1度だけ実行されることを意味しています。
FileUtils.rm_rfはRubyプログラムとしてrm -rfをやるためのモジュールです。
「【Rails】RSpecのSystem Test実行前に前回テスト時のScreenshotを削除しておく - Qiita」これでスクリーンショットが溢れかえる心配がなくなりました♪
(オプション)iTerm2でスクリーンショットを表示する
ちょっと裏技みたいな感じですが、iTerm2の場合、webコンテナにとある環境変数を与えるとテストNGのタイミングでiTerm2上にスクリーンショットを表示してくれるようになります。
docker-compose.ymlversion: '3' services: db: image: postgres:12.1-alpine environment: - TZ=Asia/Tokyo volumes: - ./tmp/db:/var/lib/postgresql/data web: build: . volumes: - .:/app ports: - 3000:3000 depends_on: - db + environment: + - RAILS_SYSTEM_TESTING_SCREENSHOT=inlineたったこれだけ。この環境変数を適用するために一度コンテナを再起動してRSpecを実行してみましょう。
# exit$ docker-compose down $ docker-compose up -d $ docker-compose exec web ash# rspec spec/system/sample_spec.rb
ちゃんとスクリーンショットが表示されていますね。
RSpecのスクリーンショットはどのファイルなのか探すのが面倒だったりするので、テストシナリオと紐づいてiTerm2で表示してくれるのは非常に助かります。本日はここまでにしましょう!
後片付け
では後片付けしていきますー。
今回は特にDBにデータも保存していないのでDBを初期化する必要もありませんね。
そういえば、RSpecはテスト実行時に保存されたデータはテストシナリオごとに削除されるようになっているので、テストコード内でデータを保存したとしてもDBの初期化は必要ないんです。(しかもRSpecでテストをする場合、勝手にRAILS_ENVがtestで実行されるので、developmentのDBを汚染することもないんです。)と、いうことで今回はコンテナだけ落として終了です!
# exit$ docker-compose downあ、あと、
sample_spec.rbは今回のサンプル用だったので消しておきましょー。
あ、ついでにスクリーンショットも。$ rm spec/system/sample_spec.rb $ rm tmp/screenshots/*まとめ
今回はTDD/BDDを説明させていただきました。
Red → Green → リファクタリング の流れと、
Given、When、Then で受入条件を考えていく方法を紹介しましたね。さらにテスト自動化を実現するために、
RSpecを導入しました。(SeleniumとCapybaraも)
そして初めてのテストコードを書いて実行することができましたね!次回は、実際にここまでつくってきたアプリのテストコードをコーディングします。
その中でテストコードの書き方を覚えていきましょう!では、次回も乞うご期待!ここまでお読みいただきありがとうございました!
本日のソースコード
Reference
- TDDがうまくいかないときは、BDD形式でバックログを書いてみる | Raksul ENGINEERING
- 【Rails】こわくない!TDD/BDD・テスト自動化はじめの一歩ハンズオン! - Qiita
- 使えるRSpec入門・その4「どんなブラウザ操作も自由自在!逆引きCapybara大辞典」 - Qiita
- Rails アプリケーションの不安定なテストを撲滅したい 〜system spec のデバッグ方法とテストを不安定にさせる要因〜 - あらびき日記
Other Hands-on Links