- 投稿日:2019-12-11T22:43:32+09:00
CircleCI で複数のディレクトリ(Dockerfile)に対して、別々にビルドやデプロイを行う
CircleCI で 複数フォルダのDockerビルドを行おうとして少し詰まったので備忘録としておいておきます。
実現したかったこと
- 複数のディレクトリに対して、別々にビルドやデプロイを行いたかった
- 対象ディレクトリは Dockerfile を持っている
- rootディレクトリ から docker-compose で操作する
主に使った機能(?)
executors
同一リポジトリ内に、 CI/CD 対象が複数存在している場合は、
executorsで切り分けることができる。ref: https://circleci.com/docs/2.0/configuration-reference/#executors-requires-version-21
executors: first: # executor に付けた任意の名前 machine: image: circleci/classic:edge docker_layer_caching: true second: # executor に付けた任意の名前 machine: image: circleci/classic:edge docker_layer_caching: trueenvironment
executors ごとに設定したい変数がある場合、
environmentで設定できる。ref: https://circleci.com/docs/2.0/configuration-reference/#executors-requires-version-21
executors: first: # executor に付けた任意の名前 machine: image: circleci/classic:edge docker_layer_caching: true environment: CONTAINER_REPOSITORY_NAME: iemarco-crawler-ecr # 任意の変数名 TARGET_DIR: . # 任意の変数名 SERVICE_NAME: app # 任意の変数名parameters
parametersを使うことで変数の宣言を行うことができる。
<< parameters.変数名 >>とすることで、該当スコープ内で変数を使用することができる。入っている値がそのまま評価される みたいなので、 quote 等を使う場合は
"<< parameters.変数名 >>"こういった形で使ってあげる。ref: https://circleci.com/docs/2.0/configuration-reference/#parameters-requires-version-21
jobs: exec_test: # job に付けた任意の名前 parameters: executor: # 変数名 type: string # 変数の型 default: first # 初期値の設定も可能 executor: << parameters.executor >> # 変数の呼び出しサンプル
version: 2.1 executors: first: machine: image: circleci/classic:edge docker_layer_caching: true environment: CONTAINER_REPOSITORY_NAME: iemarco-crawler-ecr TARGET_DIR: ./app SERVICE_NAME: ./app second: machine: image: circleci/classic:edge docker_layer_caching: true environment: CONTAINER_REPOSITORY_NAME: iemarco-crawl-batch-manager-ecr TARGET_DIR: ./db SERVICE_NAME: db commands: push_docker_image: steps: - run: | eval $(aws ecr get-login --region $AWS_DEFAULT_REGION --no-include-email) docker build -t $DOCKER_REGISTORY_HOST/$CONTAINER_REPOSITORY_NAME:$STAGE $TARGET_DIR docker push $DOCKER_REGISTORY_HOST/$CONTAINER_REPOSITORY_NAME:$STAGE jobs: exec_test: parameters: executor: type: string executor: << parameters.executor >> steps: - checkout - run: touch $TARGET_DIR/.env - run: mkdir $TARGET_DIR/lib && chmod 777 $TARGET_DIR/lib - run: docker-compose run $SERVICE_NAME shards - run: | # environment を使って条件分岐 if [[ `cat $SERVICE_NAME` == "app" ]]; then docker-compose run $SERVICE_NAME /bin/bash -c "./bin/micrate up"; fi - run: docker-compose run $SERVICE_NAME crystal spec image_push: parameters: executor: type: string executor: << parameters.executor >> environment: STAGE: production steps: - checkout - push_docker_image workflows: build_and_test: jobs: - exec_test: executor: first - image_push: executor: first filters: branches: only: - master requires: - exec_test build_and_test_for_second: jobs: - exec_test: executor: second - image_push: executor: second filters: branches: only: - master requires: - exec_testもっと良い感じの書き方があれば教えていただきたいですm(_ _)m
主に jobs でexecutor を毎回渡してるところとかをすっきりさせたい…
- 投稿日:2019-12-11T22:23:37+09:00
マルチOS対応Docker開発環境の作り方【Mac対応編】
この投稿は Magento Advent Calendar 2019 の11日目です。
皆さんDocker使ってますか?
以前はVirtualbox+Vagrantを使って開発環境を整えていたのですが、動きが遅い重い!
当時個人的に気になっていたDockerに(趣味半分で)乗り換えてみたところ、早い軽いで素晴らしいものでした。私はもっぱらLinux(Ubuntu)をメインで使っているのですが、社内にはMacやWindowsを使っている開発者もいます。
せっかく作ったし他のOSでも使えるようにしよう、まずはMacで試してみよう!と思っていたところ、ある問題に阻まれてしまったのでした。
Docker for Macの欠点
Linuxで使っていたイメージや設定ファイルを移動させ、起動させるところまでは順調でした。
ですが…明らかに動きが遅い……!!!
実はこの問題、Docker for Macでは有名で、以前私もこの問題を解決しようと悪戦苦闘していました。
Docker Meetup Kansai で発表したスライドがあるので、もし興味があればそちらもご覧ください。このときは1/4程度しか改善されないという、早くはなったが実用的ではないという悲しい結果でした。
今回はその続きの話となります。
その後調べたところ、2つ効果があるかも知れない解決策を見つけることが出来ました。
NFS Sharing Volume
実は、dockerにはVolumeにNFSをマウントする機能があります。
ですが、Docker for Macの遅さはmacOSとLinuxコンテナのファイルシステムの違いが原因なので、NFS越しにマウントしたところで早くなるはず無いだろう…と思っていました。ところが、
こちらの記事によるとNFS Volumeを使うことでかなり改善されることが判明しました。
なぜ早くなるのかは謎ですが、効果があるかも知れないなら試すしかありません!Macでnfsdを動かすには、
/etc/nfs.confと/etc/exportsを設定しておく必要があります。/etc/nfs.conf# # nfs.conf: the NFS configuration file # nfs.server.mount.require_resv_port = 0/etc/exports/System/Volumes/Data/Users/{USERNAME}/{PASS_TO_PROJECTROOT} localhost -alldirs -mapall={uid}:{gid}
-mapallオプションで指定したUIDとGIDは、NFSでアクセスした際に指定したユーザーのものとして扱われます。macOS Catalinaをお使いの方には注意点が二点あって、一つは
/Users/{USERNAME}で始まるパスを指定してもエラーになってしまいます。
詳しくは以下の記事が参考になるかと思います。もう一点は、DocumentsやDownloads、Desktop下を使う場合は明示的に権限を付与(?)しなくてはいけないようです。
以上が設定できれば
sudo nfsd startで起動するとホスト側の設定は終了です。docker-compose.ymlの方にもNFSを使う設定をします。
docker-compose.ymlversion: "3" services: nfs: image: ubuntu:18.04 volumes: - src:/src:nocopy volumes: src: driver: local driver_opts: type: nfs device: ":/System/Volumes/Data/Users/{USERNAME}/{PASS_TO_PROJECTROOT}" o: addr=host.docker.internal,rw,nolock,hard,nointr,nfsvers=3services下のvolumesに
:nocopyを忘れず、driver_optsのdeviceにexportsで指定したパスを書くことを忘れずに!
これでNFS Volumeを使ったコンテナが起動できます✌️欠点を挙げるとするならば、プロジェクトごとにdocker-compose.ymlにパスを書く必要があって手間という点です。
Gitで管理していたりすると、誤Pushとかがありそうで怖いですよね…。Docker-sync
もう一つは高速にホストとコンテナ間を同期するためのツール、docker-syncです。
このツールは、ホストとコンテナ間でrsyncやunisonなどを使って高速な同期を実現しているようです。
rsyncの方が高速(?)のようですが同期が双方向ではなく一方通行(ホスト→コンテナ)なのがネックなので、今回はunisonを使ってみます。brew install unison brew install eugenmayer/dockersync/unox gem install docker-sync以上のコマンドでインストールが完了します。
詳しいインストール手順は公式ドキュメントをご覧ください。docker-syncには
docker-sync.ymlが必要になります。docker-sync.ymlversion: "2" syncs: src: src: '/{PASS_TO_PROJECTROOT}' sync_strategy: 'unison' sync_userid: '{UID}'docker-compose.ymlversion: "3" services: nfs: image: ubuntu:18.04 volumes: - src:/src volumes: src: external: truedocker-sync.ymlとdocker-compose.yml間でVolume名を統一しないと正しく起動しないので注意が必要です。
設定ファイルが準備できたら、docker-sync startこのコマンドで起動してあげると、Volumeを作成して同期が開始されるという仕組みになっています。
Docker-syncを起動した状態でdockerコンテナにVolumeをマウントすると、ホスト-コンテナ間が同期されている状態になる、といった具合です。Docker-syncの欠点は別途インストールが必要な点と、このコマンドを打つ手間があるところでしょうか。
起動しっぱなしでも良いのかも知れませんが、使い終わったら終わらせておきたい気もしますよね…?測定
time dd if=/dev/zero of=/benchmark bs=1k count=100000このコマンドで100MBのファイルを作成する時間を計測するベンチマークを取ってみました。
結果は…
- 通常のVolumeが約25秒
- NFS Volumeが約2.5秒
- Docker-syncが約0.4秒
と、Docker-syncの圧倒的勝利となりました!
NFS Volumeもかなりはやいのですが、Docker-syncはほぼネイティブと変わらない速度ですね。まとめ
いかがだったでしょうか?(殴)
NFSでもかなり早くで感動したのですが、Docker-syncはさらに早くてこんなにも違うのかと驚きました。
ここまでMagento Adventcalendarっぽく無い内容でしたが、Magento2はプロジェクトのファイル数がどうしても多くなってしまうので、読み書きのスピードはとても大事になってきます。
今回のこの結果を踏まえて次回、どうマルチOSに対応したdocker-compose.ymlを書くといいのかを書いていこうかと思います。

- 投稿日:2019-12-11T22:10:10+09:00
TerraformでAWS ECRの作成してpushする
はじめに
SREエンジニアやってます。@hayaosatoです。
今回はAWS ECR(以下、ECR)でのリポジトリ作成をTerraformで作成した際に、その勢いでコンテナイメージのpushまでやっちゃおうという小ネタです。Terraform
ECRのリポジトリ作成のTerraformは簡単で、Terraformのリソースの中でもArgumentは非常に少ないです。
リポジトリは以下のように作成できます。resource "aws_ecr_repository" "default" { name = var.container_name image_tag_mutability = "MUTABLE" image_scanning_configuration { scan_on_push = true } }
image_scanning_configurationでコンテナイメージのセキュリティ診断も行ってくれるようなので有効にしておくと良いと思います。コンテナイメージのpush
ここからが本題です。
上記のように作成したECRリポジトリにterraform applyの際に同時にコンテナイメージをpushしてしまいましょう。
ECRへのpushコマンドは以下のようになっています。$(aws ecr get-login --no-include-email --region ${リージョン}) docker build -t ${コンテナイメージ名} ${Dockerfileのディレクトリ} docker tag ${コンテナイメージ名}:latest ${リポジトリURL} docker push ${リポジトリURL}terraformでは、このようなコマンド実行はprovisioningで実行すると良いのですが、ECRリソースにはprovisionerが提供されていません。
そこで、そのような場合にはnull_resourceというリソースを使うことで任意のコマンドをterraform apply時に実行することができます。
コンテナイメージのpushコマンドをterraformで実現すると以下のようになります。resource "null_resource" "default" { provisioner "local-exec" { command = "$(aws ecr get-login --no-include-email --region ${var.region})" } provisioner "local-exec" { command = "docker build -t ${var.container_name} ${var.docker_dir}" } provisioner "local-exec" { command = "docker tag ${var.container_name}:latest ${aws_ecr_repository.default.repository_url}" } provisioner "local-exec" { command = "docker push ${aws_ecr_repository.default.repository_url}" } }最後に
このように、ECRのリポジトリを作成してその流れでコンテナイメージのビルド&プッシュも実現しました。
現実的に使うかは別として、Fargateとか作成するときにちょっとだけ使えるんじゃないかな。。。と思っています。参考
- 投稿日:2019-12-11T22:10:10+09:00
TerraformでAWS ECRのリポジトリを作成してpushする
はじめに
SREエンジニアやってます。@hayaosatoです。
今回はAWS ECR(以下、ECR)でのリポジトリ作成をTerraformで作成した際に、その勢いでコンテナイメージのpushまでやっちゃおうという小ネタです。terraform及びプロバイダのバージョンは以下の通りです。
Terraform v0.12.12 + provider.aws v2.40.0 + provider.null v2.1.2ECR
ECRのリポジトリ作成のTerraformは簡単で、Terraformのリソースの中でもArgumentは非常に少ないです。
リポジトリは以下のように作成できます。resource "aws_ecr_repository" "default" { name = var.image_name image_tag_mutability = "MUTABLE" image_scanning_configuration { scan_on_push = true } }
image_scanning_configurationでコンテナイメージのセキュリティ診断も行ってくれるようなので有効にしておくと良いと思います。コンテナイメージのpush
ここからが本題です。
上記のように作成したECRリポジトリにterraform applyの際に同時にコンテナイメージをpushしてしまいましょう。
ECRへのpushコマンドは以下のようになっています。$(aws ecr get-login --no-include-email --region ${リージョン}) docker build -t ${コンテナイメージ名} ${Dockerfileのディレクトリ} docker tag ${コンテナイメージ名}:latest ${リポジトリURL} docker push ${リポジトリURL}terraformでは、このようなコマンド実行はprovisioningで実行すると良いのですが、ECRリソースにはprovisionerが提供されていません。
そこで、そのような場合にはnull_resourceというリソースを使うことで任意のコマンドをterraform apply時に実行することができます。
コンテナイメージのpushコマンドをterraformで実現すると以下のようになります。resource "null_resource" "default" { provisioner "local-exec" { command = "$(aws ecr get-login --no-include-email --region ${var.region})" } provisioner "local-exec" { command = "docker build -t ${var.image_name} ${var.docker_dir}" } provisioner "local-exec" { command = "docker tag ${var.image_name}:latest ${aws_ecr_repository.default.repository_url}" } provisioner "local-exec" { command = "docker push ${aws_ecr_repository.default.repository_url}" } }最後に
このように、ECRのリポジトリを作成してその流れでコンテナイメージのビルド&プッシュも実現しました。
現実的に使うかは別として、Fargateとか作成するときにちょっとだけ使えるんじゃないかな。。。と思っています。参考
- 投稿日:2019-12-11T20:45:41+09:00
コンテナ型仮想化技術 Study08 / Statefulset, Ingress
はじめに
今回は、ステートフルセット、イングレス辺りをやってみます。
関連記事
コンテナ型仮想化技術 Study01 / Docker基礎
コンテナ型仮想化技術 Study02 / Docker レジストリ
コンテナ型仮想化技術 Study03 / Docker Compose
コンテナ型仮想化技術 Study04 / Minikube & kubectl簡易操作
コンテナ型仮想化技術 Study05 / Pod操作
コンテナ型仮想化技術 Study06 / ReplicaSet, Deployment, Service
コンテナ型仮想化技術 Study06' / Kubernetesネットワーク問題判別
コンテナ型仮想化技術 Study07 / ストレージ
コンテナ型仮想化技術 Study08 / Statefulset, Ingress
コンテナ型仮想化技術 Study09 / Helm参考情報
レプリカを持つステートフルアプリケーションを実行する
Exposing TCP and UDP Services via ingress on Minikube
Accessing Kubernetes Pods from Outside of the Cluster
NGINX Ingress Controller - Exposing TCP and UDP servicesステートフルセットの操作
ステートフルセットはデプロイメントと似たリソースで複数Podの管理を行うことができますが、ステートフルという名前の通り、各Podの"ステート"を維持するための仕組みが組み込まれたリソースです。デプロイメントと違い、個々のPodはIDにより識別され、それぞれ専用の永続ボリュームがアサインされることになります。
Minikube環境で、以下のチュートリアルをやってみます。
レプリカを持つステートフルアプリケーションを実行するただ、このチュートリアルで提供されているマニフェストファイルのパラメータ値は、mysqlというネーミングがいたるところに出てきて、実際のところどの値とどの値を合わせないといけないかが分かりにくい。
ネーミング変更や余分と思われる箇所を削除するなど、若干カスタマイズを行って試してみます。ConfigMap作成
mysql-configmap.yml適用 (これはそのまま)
vagrant@minikube:~/statefulset$ kubectl apply -f mysql-configmap.yaml configmap/mysql created確認
vagrant@minikube:~/statefulset$ kubectl get configmap NAME DATA AGE mysql 2 2m47s vagrant@minikube:~/statefulset$ kubectl get configmap mysql -o yaml apiVersion: v1 data: master.cnf: | # Apply this config only on the master. [mysqld] log-bin slave.cnf: | # Apply this config only on slaves. [mysqld] super-read-only kind: ConfigMap metadata: annotations: kubectl.kubernetes.io/last-applied-configuration: | {"apiVersion":"v1","data":{"master.cnf":"# Apply this config only on the master.\n[mysqld]\nlog-bin\n","slave.cnf":"# Apply this config only on slaves.\n[mysqld]\nsuper-read-only\n"},"kind":"ConfigMap","metadata":{"annotations":{},"labels":{"app":"mysql"},"name":"mysql","namespace":"default"}} creationTimestamp: "2019-12-11T02:04:42Z" labels: app: mysql name: mysql namespace: default resourceVersion: "263977" selfLink: /api/v1/namespaces/default/configmaps/mysql uid: 6ced75a7-61af-4cbc-a468-149fc606ab08Service作成
mysql-services.yamlをカスタマイズ
mysql-services.yaml# Headless service for stable DNS entries of StatefulSet members. apiVersion: v1 kind: Service metadata: name: mysql-service spec: ports: - name: mysql-port port: 3306 type: ClusterIP clusterIP: None selector: app: mysql-sts --- # Client service for connecting to any MySQL instance for reads. # For writes, you must instead connect to the master: mysql-0.mysql. apiVersion: v1 kind: Service metadata: name: mysql-read spec: ports: - name: mysql-port port: 3306 selector: app: mysql-sts※2つ目のClusterIPのサービスもここでは使わないので削除しておけばよかった....
適用
vagrant@minikube:~/statefulset$ kubectl apply -f mysql-services.yaml service/mysql-service created service/mysql-read created確認
vagrant@minikube:~/statefulset$ kubectl get service -o wide NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 41d <none> mysql-read ClusterIP 10.98.33.98 <none> 3306/TCP 6m51s app=mysql-sts mysql-service ClusterIP None <none> 3306/TCP 6m51s app=mysql-stsStatefulset作成
mysql-statefulset.yamlをカスタマイズ
mysql-statefulset.yamlapiVersion: apps/v1 kind: StatefulSet metadata: name: mysql spec: selector: matchLabels: app: mysql-sts serviceName: mysql-service replicas: 3 template: metadata: labels: app: mysql-sts spec: initContainers: - name: init-mysql image: mysql:5.7 command: - bash - "-c" - | set -ex # Generate mysql server-id from pod ordinal index. [[ `hostname` =~ -([0-9]+)$ ]] || exit 1 ordinal=${BASH_REMATCH[1]} echo [mysqld] > /mnt/conf.d/server-id.cnf # Add an offset to avoid reserved server-id=0 value. echo server-id=$((100 + $ordinal)) >> /mnt/conf.d/server-id.cnf # Copy appropriate conf.d files from config-map to emptyDir. if [[ $ordinal -eq 0 ]]; then cp /mnt/config-map/master.cnf /mnt/conf.d/ else cp /mnt/config-map/slave.cnf /mnt/conf.d/ fi volumeMounts: - name: conf mountPath: /mnt/conf.d - name: config-map mountPath: /mnt/config-map - name: clone-mysql image: gcr.io/google-samples/xtrabackup:1.0 command: - bash - "-c" - | set -ex # Skip the clone if data already exists. [[ -d /var/lib/mysql/mysql ]] && exit 0 # Skip the clone on master (ordinal index 0). [[ `hostname` =~ -([0-9]+)$ ]] || exit 1 ordinal=${BASH_REMATCH[1]} [[ $ordinal -eq 0 ]] && exit 0 # Clone data from previous peer. ncat --recv-only mysql-$(($ordinal-1)).mysql 3307 | xbstream -x -C /var/lib/mysql # Prepare the backup. xtrabackup --prepare --target-dir=/var/lib/mysql volumeMounts: - name: data mountPath: /var/lib/mysql subPath: mysql - name: conf mountPath: /etc/mysql/conf.d containers: - name: mysql-container image: mysql:5.7 env: - name: MYSQL_ALLOW_EMPTY_PASSWORD value: "1" ports: - name: mysql-port containerPort: 3306 volumeMounts: - name: data mountPath: /var/lib/mysql subPath: mysql - name: conf mountPath: /etc/mysql/conf.d resources: requests: cpu: 500m memory: 1Gi livenessProbe: exec: command: ["mysqladmin", "ping"] initialDelaySeconds: 30 periodSeconds: 10 timeoutSeconds: 5 readinessProbe: exec: # Check we can execute queries over TCP (skip-networking is off). command: ["mysql", "-h", "127.0.0.1", "-e", "SELECT 1"] initialDelaySeconds: 5 periodSeconds: 2 timeoutSeconds: 1 - name: xtrabackup image: gcr.io/google-samples/xtrabackup:1.0 ports: - name: xtrabackup containerPort: 3307 command: - bash - "-c" - | set -ex cd /var/lib/mysql # Determine binlog position of cloned data, if any. if [[ -f xtrabackup_slave_info && "x$(<xtrabackup_slave_info)" != "x" ]]; then # XtraBackup already generated a partial "CHANGE MASTER TO" query # because we're cloning from an existing slave. (Need to remove the tailing semicolon!) cat xtrabackup_slave_info | sed -E 's/;$//g' > change_master_to.sql.in # Ignore xtrabackup_binlog_info in this case (it's useless). rm -f xtrabackup_slave_info xtrabackup_binlog_info elif [[ -f xtrabackup_binlog_info ]]; then # We're cloning directly from master. Parse binlog position. [[ `cat xtrabackup_binlog_info` =~ ^(.*?)[[:space:]]+(.*?)$ ]] || exit 1 rm -f xtrabackup_binlog_info xtrabackup_slave_info echo "CHANGE MASTER TO MASTER_LOG_FILE='${BASH_REMATCH[1]}',\ MASTER_LOG_POS=${BASH_REMATCH[2]}" > change_master_to.sql.in fi # Check if we need to complete a clone by starting replication. if [[ -f change_master_to.sql.in ]]; then echo "Waiting for mysqld to be ready (accepting connections)" until mysql -h 127.0.0.1 -e "SELECT 1"; do sleep 1; done echo "Initializing replication from clone position" mysql -h 127.0.0.1 \ -e "$(<change_master_to.sql.in), \ MASTER_HOST='mysql-0.mysql', \ MASTER_USER='root', \ MASTER_PASSWORD='', \ MASTER_CONNECT_RETRY=10; \ START SLAVE;" || exit 1 # In case of container restart, attempt this at-most-once. mv change_master_to.sql.in change_master_to.sql.orig fi # Start a server to send backups when requested by peers. exec ncat --listen --keep-open --send-only --max-conns=1 3307 -c \ "xtrabackup --backup --slave-info --stream=xbstream --host=127.0.0.1 --user=root" volumeMounts: - name: data mountPath: /var/lib/mysql subPath: mysql - name: conf mountPath: /etc/mysql/conf.d resources: requests: cpu: 100m memory: 100Mi volumes: - name: conf emptyDir: {} - name: config-map configMap: name: mysql volumeClaimTemplates: - metadata: name: data spec: accessModes: ["ReadWriteOnce"] resources: requests: storage: 10Gi※Statefulset自体のLabel指定をはずす、Pod TemplateのLabel名、コンテナーの名前、ポートの名前辺りを変更しています。
適用
vagrant@minikube:~/statefulset$ kubectl apply -f mysql-statefulset.yaml statefulset.apps/mysql created確認
vagrant@minikube:~/statefulset$ kubectl get service,pod,storageclass,pvc,pv -o wide NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR service/kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 41d <none> service/mysql-read ClusterIP 10.98.33.98 <none> 3306/TCP 10m app=mysql-sts service/mysql-service ClusterIP None <none> 3306/TCP 10m app=mysql-sts NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES pod/mysql-0 2/2 Running 0 9m44s 172.17.0.10 minikube <none> <none> pod/mysql-1 2/2 Running 0 9m36s 172.17.0.11 minikube <none> <none> pod/mysql-2 2/2 Running 0 9m28s 172.17.0.12 minikube <none> <none> NAME PROVISIONER AGE storageclass.storage.k8s.io/standard (default) k8s.io/minikube-hostpath 41d NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE VOLUMEMODE persistentvolumeclaim/data-mysql-0 Bound pvc-4570a5b6-6e12-48da-bb16-b9524e0a9dfd 10Gi RWO standard 3h35m Filesystem persistentvolumeclaim/data-mysql-1 Bound pvc-b2fdc30d-ea7a-4b2b-9f07-016db25f03aa 10Gi RWO standard 3h35m Filesystem persistentvolumeclaim/data-mysql-2 Bound pvc-c991093e-96b5-4844-9ed9-897824b3c029 10Gi RWO standard 3h35m Filesystem NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE VOLUMEMODE persistentvolume/pvc-4570a5b6-6e12-48da-bb16-b9524e0a9dfd 10Gi RWO Delete Bound default/data-mysql-0 standard 3h35m Filesystem persistentvolume/pvc-b2fdc30d-ea7a-4b2b-9f07-016db25f03aa 10Gi RWO Delete Bound default/data-mysql-1 standard 3h35m Filesystem persistentvolume/pvc-c991093e-96b5-4844-9ed9-897824b3c029 10Gi RWO Delete Bound default/data-mysql-2 standard 3h35m Filesystemmysql-0,1,2というPodが3つ起動しました!それぞれ、172.17.0.10, 172.17.0.11, 172.17.0.12 というIPアドレスが割り当てられています。
さて、busyboxのpod作成して、名前解決を試してみます。
vagrant@minikube:~$ kubectl run -it busybox --restart=Never --rm --image=busybox sh If you don't see a command prompt, try pressing enter. / # ping -c 3 mysql-service PING mysql-service (172.17.0.11): 56 data bytes 64 bytes from 172.17.0.11: seq=0 ttl=64 time=0.366 ms 64 bytes from 172.17.0.11: seq=1 ttl=64 time=0.122 ms 64 bytes from 172.17.0.11: seq=2 ttl=64 time=0.049 ms --- mysql-service ping statistics --- 3 packets transmitted, 3 packets received, 0% packet loss round-trip min/avg/max = 0.049/0.179/0.366 ms / # ping -c 3 mysql-service PING mysql-service (172.17.0.10): 56 data bytes 64 bytes from 172.17.0.10: seq=0 ttl=64 time=0.049 ms 64 bytes from 172.17.0.10: seq=1 ttl=64 time=0.051 ms 64 bytes from 172.17.0.10: seq=2 ttl=64 time=0.054 ms --- mysql-service ping statistics --- 3 packets transmitted, 3 packets received, 0% packet loss round-trip min/avg/max = 0.049/0.051/0.054 ms / # ping -c 3 mysql-service PING mysql-service (172.17.0.12): 56 data bytes 64 bytes from 172.17.0.12: seq=0 ttl=64 time=0.040 ms 64 bytes from 172.17.0.12: seq=1 ttl=64 time=0.042 ms 64 bytes from 172.17.0.12: seq=2 ttl=64 time=0.080 ms --- mysql-service ping statistics --- 3 packets transmitted, 3 packets received, 0% packet loss round-trip min/avg/max = 0.040/0.054/0.080 msmysql-serviceにpingを打ってみると、その都度ランダムにmysql-xのアドレスにアクセスしているのが分かります。
補足
各リソースの関連図
上で出来上がった各リソースの関連を図示してみると、こんなイメージでしょうか。
ステートフルセットでは、PodやVolumeが動的に作成されますが、各Podには固有の名前が付けられてVolumeもそれぞれのPod専用に割り当てられます。また、ステートフルセットを作成する際はHeadlessのサービス(clusterIP: Noneを指定したサービス)と関連付ける必要があります。
この例では、Headlessサービス以外に、もう一つClusterIPのサービスを定義しています。
また、上で使用したmysql-statefulset.yamlではvolumeClaimTemplates.spec.storageClassNameを明示指定していませんが、その場合、デフォルトのStorageClassが使われます。minikube環境の場合standardというStorageClassがデフォルトとして定義されており、ここから動的にVolumeがプロビジョニングされることになります。vagrant@minikube:~/statefulset$ kubectl get storageclass NAME PROVISIONER AGE standard (default) k8s.io/minikube-hostpath 41d vagrant@minikube:~/statefulset$ kubectl describe storageclass standard Name: standard IsDefaultClass: Yes Annotations: storageclass.kubernetes.io/is-default-class=true Provisioner: k8s.io/minikube-hostpath Parameters: <none> AllowVolumeExpansion: <unset> MountOptions: <none> ReclaimPolicy: Delete VolumeBindingMode: Immediate Events: <none>Serviceについての整理
DeploymentやStatefulsetなど、複数Podへのアクセスを考えた場合、手前にServiceを配置してそれを利用してアクセスすることになると思われますが、ClusterIP, NodePort, Headless辺り混乱してきたので理解を一旦整理します。
参考: コンセプト - Service
ClusterIP
ClusterIPのServiceを定義すると、代表IPアドレスが動的にアサインされて、サービスの名前でIPアドレスが解決できるよう内部DNSに登録される。
サービスの定義では、ターゲットのPodがListenしているポート番号と、公開用のポート番号の組を指定する(複数ポート指定可)。上の例だと、クライアントとなるPodからは、my-service:80にアクセスすると、ターゲットのPodの9376ポートにリクエストが割り振られることになる。
ClusterIPはk8s Cluster内で利用できるものなので、クラスター内のPodから利用することが前提(外部からのアクセスは不可)。
type指定を省略した場合デフォルトでClusterIPと認識される。NodePort
NodePortのServiceを定義すると、各ノードのIPアドレス上の特定のポートを外部に公開することができる。
「nodePort: 30000」というように公開用のポートを明示指定しなければ、30000-32767の範囲で使用されていないポートが動的に割り当てられる。
k8s Cluster外のクライアントから、<各ノードのIP>:<公開用ポート番号>でアクセス可能。
各ノードで受け付けられたリクエストはkube-proxyによりMyAppのPodに負荷分散される(受け付けたノード以外のノードのPodにも分散される)。
※Podへのルーティングを行うために前述のClusterIPが内部的に作成される。Statefulset と Headless Service
Serviceの定義で"type: ClusterIP"、および、"clusterIP: None"を指定するとHeadless Serviceとして認識される。代表IPアドレスの付与や負荷分散は行われない。
サービス名で名前解決すると、各ターゲットのPodのアドレスがランダムに返される。
k8s Cluster内のクライアントとなるPodからは、my-service:3306で、ターゲットのいずれかのPodにアクセスすることになる。
Statefulsetを作成する場合、Headless Serviceの定義は必須。StatefulSets currently require a Headless Service to be responsible for the network identity of the Pods. You are responsible for creating this Service.
MySQLクライアントからの操作
MySQLクライアントのコンテナが稼働するPodを一時的に立ち上げて、上で作成したSQLサーバーにアクセスしてみます。
vagrant@minikube:~$ kubectl run mysql-client --image=mysql:5.7 -it --rm --restart=Never bash If you don't see a command prompt, try pressing enter. root@mysql-client:/# mysql -h mysql-service -e 'SELECT @@server_id,NOW()' +-------------+---------------------+ | @@server_id | NOW() | +-------------+---------------------+ | 100 | 2019-12-11 08:17:07 | +-------------+---------------------+ root@mysql-client:/# mysql -h mysql-service -e 'SELECT @@server_id,NOW()' +-------------+---------------------+ | @@server_id | NOW() | +-------------+---------------------+ | 102 | 2019-12-11 08:17:18 | +-------------+---------------------+ root@mysql-client:/# mysql -h mysql-service -e 'SELECT @@server_id,NOW()' +-------------+---------------------+ | @@server_id | NOW() | +-------------+---------------------+ | 101 | 2019-12-11 08:17:19 | +-------------+---------------------+MySQLのクライアントからmysqlコマンドで"mysql-service"というホスト名のMySQLサーバーにアクセスしてサーバーの情報を取得していますが、同じホスト名を指定してもサーバーIDが異なるものが返される、つまり、その都度別のPodのMySQLサーバーにアクセスしている様子が確認できます。
イングレスの操作(non-HTTP/HTTPS)
Ingressは、Kubernetesクラスタにデプロイされたサービスを、クラスタの外部へ公開するためのリソースです。
TCP/IPベースの通信であれば、Ingressを用いて外部にサービスを公開できると思われますが、ほとんどのドキュメントが、HTTP/HTTPSの通信を前提に記述されているようです。恐らく、Kubernetesで管理するアプリケーションとしては、主としてWebアプリケーションやRESTfulなサービスを想定しているからだと思われます。
公式ドキュメントでも以下のような記述となっています。What is Ingress?
Ingress exposes HTTP and HTTPS routes from outside the cluster to services within the cluster. Traffic routing is controlled by rules defined on the Ingress resource.また、Ingressの実体としてIngress Controllerという実装が必要になりますが、nginxを利用したNGINX Ingress ControllerというものがOSSとして無料で提供されており、HTTP/HTTPSの公開はこれを利用することで実現できるようです。
ただ、訳あってHTTP/HTTPS以外の通信を扱いたいので(ゆくゆくは独自プロトコルを使用したミドルウェアをKubernetes環境で動かしたいので)、TCP/UDPの通信の公開方法を探ります。
ここでは、上でステートフルセットとして作成したMySQLのサービスを外部公開してKubernetesクラスター外のMySQLクライアントからKubernetes上のMySQLサーバーにアクセスする、というのを目指します。ということで色々調べていると、ドンピシャで以下のような記事がありました!
Exposing TCP and UDP Services via ingress on Minikube
先達あらまほしき事なり。
これをベースに進めます。その他、参考
Accessing Kubernetes Pods from Outside of the Cluster
NGINX Ingress Controller - Exposing TCP and UDP services全体像
やろうとしてることのイメージを図示します。
※今回は、minikube環境で1ノード構成上で簡易的に試すために、NGINX Ingress Controller実装のPodの設定でhostNetwork:trueにすることで、このノードのアドレス上にポートを公開するようにしていますが、実際のKubernetesクラスター環境では、当然このPodがどのノードで動くか分からないし、シングルポイントにならないように構成しないといけません。
NGINX Ingress Controller - Exposing TCP and UDP servicesにあるように、LoadBlancerタイプのService作って公開する、といったようなことを考える必要があると思われます。K8s Cluster側
NGINX Ingress Controller準備
Ingress Controller実装のマニフェストファイルを入手 (Deploymentとして実装されているっぽい)。
https://raw.githubusercontent.com/kubernetes/ingress-nginx/master/deploy/static/mandatory.yamlvagrant@minikube:~/ingress$ wget https://raw.githubusercontent.com/kubernetes/ingress-nginx/master/deploy/static/mandatory.yaml --2019-12-11 10:07:24-- https://raw.githubusercontent.com/kubernetes/ingress-nginx/master/deploy/static/mandatory.yaml Resolving raw.githubusercontent.com (raw.githubusercontent.com)... 151.101.196.133 Connecting to raw.githubusercontent.com (raw.githubusercontent.com)|151.101.196.133|:443... connected. HTTP request sent, awaiting response... 200 OK Length: 6364 (6.2K) [text/plain] Saving to: ‘mandatory.yaml’ mandatory.yaml 100%[===========================================================================================================================================>] 6.21K --.-KB/s in 0s 2019-12-11 10:07:25 (104 MB/s) - ‘mandatory.yaml’ saved [6364/6364]
hostNetwork: trueを追記します。mandatory.yaml抜粋... template: metadata: labels: app.kubernetes.io/name: ingress-nginx app.kubernetes.io/part-of: ingress-nginx annotations: prometheus.io/port: "10254" prometheus.io/scrape: "true" spec: # wait up to five minutes for the drain of connections terminationGracePeriodSeconds: 300 serviceAccountName: nginx-ingress-serviceaccount nodeSelector: kubernetes.io/os: linux hostNetwork: true containers: - name: nginx-ingress-controller image: quay.io/kubernetes-ingress-controller/nginx-ingress-controller:0.26.1 args: - /nginx-ingress-controller - --configmap=$(POD_NAMESPACE)/nginx-configuration - --tcp-services-configmap=$(POD_NAMESPACE)/tcp-services - --udp-services-configmap=$(POD_NAMESPACE)/udp-services - --publish-service=$(POD_NAMESPACE)/ingress-nginx - --annotations-prefix=nginx.ingress.kubernetes.io ...適用します。
vagrant@minikube:~/ingress$ kubectl apply -f mandatory.yaml namespace/ingress-nginx created configmap/nginx-configuration created configmap/tcp-services created configmap/udp-services created serviceaccount/nginx-ingress-serviceaccount created clusterrole.rbac.authorization.k8s.io/nginx-ingress-clusterrole created role.rbac.authorization.k8s.io/nginx-ingress-role created rolebinding.rbac.authorization.k8s.io/nginx-ingress-role-nisa-binding created clusterrolebinding.rbac.authorization.k8s.io/nginx-ingress-clusterrole-nisa-binding created deployment.apps/nginx-ingress-controller created確認
vagrant@minikube:~/ingress$ kubectl get all -n ingress-nginx -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES pod/nginx-ingress-controller-5bbd46cd86-pk4ft 1/1 Running 0 79s 10.0.2.15 minikube <none> <none> NAME READY UP-TO-DATE AVAILABLE AGE CONTAINERS IMAGES SELECTOR deployment.apps/nginx-ingress-controller 1/1 1 1 79s nginx-ingress-controller quay.io/kubernetes-ingress-controller/nginx-ingress-controller:0.26.1 app.kubernetes.io/name=ingress-nginx,app.kubernetes.io/part-of=ingress-nginx NAME DESIRED CURRENT READY AGE CONTAINERS IMAGES SELECTOR replicaset.apps/nginx-ingress-controller-5bbd46cd86 1 1 1 79s nginx-ingress-controller quay.io/kubernetes-ingress-controller/nginx-ingress-controller:0.26.1 app.kubernetes.io/name=ingress-nginx,app.kubernetes.io/part-of=ingress-nginx,pod-template-hash=5bbd46cd86MySQL用ポート公開用ConfigMap
マニフェストファイル作成
configmap-tcp-services.yamlapiVersion: v1 kind: ConfigMap metadata: name: tcp-services namespace: ingress-nginx data: 3306: "default/mysql-service:3306"適用
vagrant@minikube:~/ingress$ kubectl apply -f configmap-tcp-services.yaml configmap/tcp-services configured確認
vagrant@minikube:~/ingress$ netstat -an | grep 3306 tcp 0 0 0.0.0.0:3306 0.0.0.0:* LISTEN tcp6 0 0 :::3306 :::* LISTENminikubeのノード上でnetstat見ると、3306ポートがListenされました!!!
MySQLクライアント側
別のノードにMySQLクライアント環境を作ってアクセスしてみます。NFSサーバー用に用意したVirtualBox上のノード使うことにします。
Ubuntu上にDockerCEインストール
以下のガイドに従ってDockerCEインストール
https://docs.docker.com/install/linux/docker-ce/ubuntu/以下のコマンド順番に実行
vagrant@nfsserver:~$ sudo apt-get update vagrant@nfsserver:~$ sudo apt-get install apt-transport-https ca-certificates curl gnupg-agent software-properties-common vagrant@nfsserver:~$ curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add - vagrant@nfsserver:~$ sudo add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable" vagrant@nfsserver:~$ sudo apt-get update vagrant@nfsserver:~$ sudo apt-get install docker-ce docker-ce-cli containerd.ioバージョン確認
vagrant@nfsserver:~$ docker version Client: Docker Engine - Community Version: 19.03.5 API version: 1.40 Go version: go1.12.12 Git commit: 633a0ea838 Built: Wed Nov 13 07:50:12 2019 OS/Arch: linux/amd64 Experimental: false Got permission denied while trying to connect to the Docker daemon socket at unix:///var/run/docker.sock: Get http://%2Fvar%2Frun%2Fdocker.sock/v1.40/version: dial unix /var/run/docker.sock: connect: permission deniedMySQLクライアント用コンテナ実行
実行!(クライアントと言いつつサーバー上げちゃってますが、これのクライアントコマンドを使います。)
vagrant@nfsserver:~$ sudo docker container run -it --rm -e MYSQL_ROOT_PASSWORD=password mysql:5.7確認
vagrant@nfsserver:~$ sudo docker container ls CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 0523e710e118 mysql:5.7 "docker-entrypoint.s…" About a minute ago Up About a minute 3306/tcp, 33060/tcp zealous_galileoコンテナに接続してbashからMySQLサーバーにアクセスしてみます。
が、pingコマンド入ってなかったのでまずインストールvagrant@nfsserver:~$ sudo docker exec -it 0523e710e118 bash root@0523e710e118:/# apt-get update ... root@0523e710e118:/# apt-get install iputils-ping net-tools ...一応minikubeのノードのIPアドレスにpingが通るのを確認。
root@0523e710e118:/# ping -c 3 172.16.10.10 PING 172.16.10.10 (172.16.10.10) 56(84) bytes of data. 64 bytes from 172.16.10.10: icmp_seq=1 ttl=62 time=0.705 ms 64 bytes from 172.16.10.10: icmp_seq=2 ttl=62 time=0.785 ms 64 bytes from 172.16.10.10: icmp_seq=3 ttl=62 time=0.836 ms --- 172.16.10.10 ping statistics --- 3 packets transmitted, 3 received, 0% packet loss, time 2000ms rtt min/avg/max/mdev = 0.705/0.775/0.836/0.058 msでは、いよいよMySQLサーバーにアクセス。
root@0523e710e118:/# mysql -h 172.16.10.10 -e 'SELECT @@server_id,NOW()' +-------------+---------------------+ | @@server_id | NOW() | +-------------+---------------------+ | 102 | 2019-12-11 11:39:33 | +-------------+---------------------+ root@0523e710e118:/# mysql -h 172.16.10.10 -e 'SELECT @@server_id,NOW()' +-------------+---------------------+ | @@server_id | NOW() | +-------------+---------------------+ | 101 | 2019-12-11 11:39:36 | +-------------+---------------------+ root@0523e710e118:/# mysql -h 172.16.10.10 -e 'SELECT @@server_id,NOW()' +-------------+---------------------+ | @@server_id | NOW() | +-------------+---------------------+ | 100 | 2019-12-11 11:39:39 | +-------------+---------------------+来ました!きちんと、リクエスト毎に違うサーバー(Pod)にアクセスしているのが確認できました!





- 投稿日:2019-12-11T19:12:08+09:00
Docker "Cannot connect to the Docker daemon. Is the docker daemon running on this host?"
docker ps
docker info
何を打ってもこれがかえってくる・・・ぐぐろう
結構あるあるなエラー文なのでしょうか、たくさん解決方法が出てきますよね
ちなみに
systemctl status docker
でDockerが起動していることは確認済み代表的な解決策は以下でした
- rootで実行 or dockergroupを作成しユーザーを追加
- OS再起動
- Docker入れ直しそもそもrootで実行しているし、OS再起動も効果なし
諸事情によりDockerの入れ直しはできないはて・・・
この前、どんな操作したっけ・・・
そう、記憶を辿ると、
/etc/sysconfig/dockerを編集していました
それを反映させるためにsystemctl restart dockerを行ったら先ほどの状態になったのです
ということは変更内容が何か悪さをしているんだなそういえば、APIを受け付けるDockerソケットを設定したのでした
/etc/sysconfig/dockerOPTIONS='--selinux-enabled -H tcp://0.0.0.0:4242 --log-driver=journald'ソケットを設定した後は、オプションでdaemonと接続するソケットを指定してdockerコマンドを実行しないと思うように動作してくれないようです
http://docs.docker.jp/v1.11/engine/reference/commandline/cli.htmlちゃんと指定してあげると・・・
[root@docker ~]# docker -H=tcp://127.0.0.1:4242 ps -a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES解決〜〜!
- 投稿日:2019-12-11T18:01:21+09:00
SVNを廃止してGitを導入した話(開発フロー/環境の改善)
※ 1年ほど前に対応した内容を思い出しながら書いています
背景
サービス開始から6年ほど稼働し続けている保守プロジェクトで、プログラムソースの管理を「Subversion」(以下SVN)で行っている案件がありました
3年目くらいから保守対応に携わっているが、複数人の開発メンバーに対して「開発環境が1つ」しかなく、SVNによる一極集中型のソース管理だったため、複数メンバーによる並行開発に不都合があることが度々ありました
そこで、VCSをSVNからGitに移行+Dockerを利用して個別のローカル開発環境を構築することにしました
狙い/目的
- 「検証環境/本番環境(VPS上)」のプログラムソースの差分を解消する
→ どちらかの環境にしかソースがアップされていない or 差分の発生による、デグレやバグの予防- 複数人で並行開発しやすい環境を作る
→ 同じソースを同タイミングで複数人が改修しづらい問題の解消(SVNだとロックの取り合いになる)- リリース対象の手動アップロードを止める
→ 人の手と労力に頼らずに、システム+ツールに頼って可能な限り自動化することでミスや事故を減らす- コードレビューしやすい環境+文化を作る
→ プログラム修正差分をRedmineのチケットに添付する運用が常習化していたため、コードレビューしづらい状況を改善するやったこと
1. SVN → Gitリポジトリの移行
- SVNから「過去のcommitログ」を引き継いだ状態でGitに移行するために、git-svnを利用してSVNリポジトリをGitリポジトリに変換する
git svn clone -s --prefix=svn/ svn+ssh://svnserve@hogehoge.com/hoge2. Gitリポジトリ/ブランチの設定
※ 自社で管理しているGitLab(CE)のリポジトリで管理する前提
- ローカル上から以下のコマンドを実行
git remote add origin {GitLab上に作成したリポジトリ} git add . git commit -m "first commit" git push origin/master
- Gitlab管理画面で以下の設定を行う
masterからdevelopブランチを作成developブランチを「defaultブランチ」に設定masterとdevelopブランチを「protected」に設定(直push禁止にする)3. ローカル開発環境の用意
- 既存の本番環境と同じ構成になるようにDockerファイルを用意(CentOS6.8/PHP5.4/その他ライブラリ等)
- 作成したDockerファイルは、新規作成したGitリポジトリで管理できるようにaddする
- Docker環境のセットアップに関する手順書、Gitブランチの運用方針、検証/本番環境へのデプロイ方法をプロジェクトのメンバーに共有
4. 検証環境/本番環境(VPS)のデプロイ設定
- 各環境のWebサーバのドキュメントルートで、Gitリポジトリの設定
cd {Webサーバのドキュメントルート} git init git remote add origin https://{デプロイ用GitLabのユーザ名}:{GitLabユーザのPW}@{リポジトリのURL} git pull git checkout master # デプロイに利用するブランチ
- GitLabの指定ブランチを監視し、変更を検知して自動でcommit内容をpullしてくるシェルを作成
(複数台のサーバにrsyncする設定)※ 本当はCIを使ってデプロイさせたかったが、当時は知見がなかった+大人の事情(?)があって難しかったので、シェルをデーモン化して常時起動+自動デプロイを実現した
→ 何らかのCIが使える状況であれば、普通にCIでデプロイしましょうdeploy_maser.sh#!/bin/sh function sync_src { SVRLIST="{rsyncで同期先となるサーバを指定} {rsyncで同期先となるサーバを指定} {rsyncで同期先となるサーバを指定}"; for syncsvr in $SVRLIST ; do echo "---------------- ${syncsvr} ---------------" >> /tmp/git_src_update.log rsync -vaW -e ssh --delete-after \ --exclude "data/*" \ {git initコマンドを実行したディレクトリを指定} {ssh認証ユーザ名}@${syncsvr}:{rsyncで同期する先のディレクトリを指定} >> /tmp/git_src_update.log done } function run { # how we want to extract the variables from the commit message. format_name="--format=%cn" format_when="--format=%cr" format_summary="--format=%s" format_body="--format=%b" # what repository do we want to watch (default to origin/master) if [ -z "$1" ]; then repository="origin/master" # ここは環境によって書き換えるべし else repository="$1" fi latest_revision="none" # loop forever, need to kill the process. while [ 1 ]; do # get the latest revision SHA. git remote update > /dev/null 2>&1 current_revision=`git rev-parse $repository` # if we haven't seen that one yet, then we know there's new stuff. if [ $latest_revision != $current_revision ]; then # mark the newest revision as seen. latest_revision=$current_revision # extract the details from the log. commit_name=`git log -1 $format_name $latest_revision` commit_when=`git log -1 $format_when $latest_revision` commit_summary=`git log -1 $format_summary $latest_revision` commit_body=`git log -1 $format_body $latest_revision` # notify the user of the commit. summary="$commit_name committed to $repository $commit_when!" body="$commit_summary\n\n$commit_body" echo "#-------------------------------------#" >> /tmp/git_commit_log date >> /tmp/git_commit_log echo -e "Summary:$summary" >> /tmp/git_commit_log echo -e "Body:$body" >> /tmp/git_commit_log git pull >> /tmp/git_commit_log sync_src fi sleep 5 done } cd {git initコマンドを実行したディレクトリを指定} if git rev-parse --git-dir > /dev/null 2>&1; then (run $1) else echo "Error: not a git repository" fi
- nohupコマンドでデーモン化
nohup sh deploy_master &これで
masterブランチにpushが走ると本番環境へ自動デプロイされる感想
複数人かつ同タイミングで同じソースを修正する際、SVNだと「ロックの取り合い」による管理の煩わしさや生産性の低下が気になっていたが、Gitに移行したことでその束縛+ストレスから解き放たれた開発が可能となりました
今回は比較的小規模なプロジェクト(開発メンバー3~4人ほど)だったので、並行する保守開発の作業にあまり影響が出ないような計らいが出来ました
Gitの操作やDocker環境に慣れていないメンバーへの教育が課題だが、手順書やRedmineの社内Wikiを充実させたり、質問や相談の窓口を用意して、適切にアドバイスするか一緒に悩むことでカバーします
- 投稿日:2019-12-11T17:30:48+09:00
Rails+MySQL+Docker+AWS(EC2, RDS, ALB, Route53, S3)で作成したポートフォリオについて
記事の概要
私が作成したポートフォリオ、「GoodCoffeeByGoodBarista」を解説します。
なぜ作ったか、どう作ったか、今後どうしていくかをまとめました。実際に作成したサイトやソースコードは下記のリンクからご覧いただけます。
GoodCoffeeByGoodBarista
GitHubこちらの記事の書き方は下記の記事を参考にさせていただきました。
PHP+MySQLでポートフォリオ作成なぜ作ったか
私は、愛知県名古屋市にある個人経営のカフェで、2年半ほどバリスタとして勤務しておりました。
ある時、バリスタの大会に出場したのですが、結果は惨敗でした。
バリスタは、生豆の仕入れからロースト、抽出までを全て個人で行い、それをプレゼンするのですが、超小規模店舗で勤務していた私は、生豆の仕入れルートもなければ高価な焙煎機もない、大会で使われる最新のエスプレッソマシンもない、練習に使うミルクも何百本と自腹で用意するしかない環境下で戦うしかありませんでした。
対して、大きな企業が経営するカフェに勤めているバリスタは、会社が持っているルートから最高品質の生豆を仕入れ、会社が用意する材料を使って、最新のエスプレッソマシンで毎日練習ができるのです。私は、環境の差による大きな挫折を味わいました。
バリスタを辞め、エンジニアになるべく勉強をしていた私は、「エンジニアリングの力で、バリスタ業界を良くできないか」と考えるようになりました。
エンジニアのように気軽に転職をする事ができる文化があれば、スキルを身に付けたいバリスタはより大きな企業に転職できるし、大企業にいてスキルはあるけれどもっと個人の店舗で接客を身に付けたいバリスタの願いも叶えられる。
バリスタが、自分の所属する環境でスキルを身に付けられなかったり、夢を諦めたりしなくて良くなるのではないか。
そんな思いから、バリスタ版Wantedlyのようなサービスを作成し、私のポートフォリオとすることにしました。スペック
言語
Ruby 2.5.3
フレームワーク
Ruby on Rails 5.2.2
CSSフレームワーク
Bootstrap4
データベース
MySQL 5.7
WEBサーバ
Nginx 1.15.8
開発環境
Docker 19.03.5
docker-compose 1.21.1バージョン管理
Git 2.24.0
本番環境
AWS (EC2, RDS, ALB, Route53, S3)
主な機能
・バリスタ(カフェ)一覧表示
バリスタの一覧、またはカフェの一覧を表示します。
ログインしていなくてもアクセスできる仕様です。
・バリスタ(カフェ)を検索
バリスタの場合、性別で検索できます。
カフェの場合、店舗名、雇用形態、所在地で検索できます。
・バリスタ登録
バリスタはトップページから新規作成のリンクを踏むことでユーザー登録ができます。
入力内容は最低限必要な内容のみです。
入力に誤りがあれば、登録はされずエラ〜メッセージが表示されます。
・オーナー登録
オーナーはナビゲーションにある「採用担当者の方」というところからオーナー用のトップページに移動し、そこから新規作成画面に移動できます。
入力内容は最低限必要な内容のみです。
入力に誤りがあれば、登録はされずエラ〜メッセージが表示されます。
・バリスタプロフィール編集
登録では基本情報のみの入力なので、プロフィール編集で詳細な情婦を入力していきます。
上記のリンクから自分のプロフィールを確認しながら編集できます。
・オーナーカフェ情報編集
登録では基本情報のみの入力なので、プロフィール編集で詳細な情婦を入力していきます。
上記のリンクから自分のプロフィールを確認しながら編集できます。
・ログイン
ログインできます。
バリスタとオーナーではフォームが分けてあります。
・面談したい(面談に誘いたい)バリスタ(カフェ)に対してメールを送信
ログインしている状態で、気になるバリスタ(カフェ)の詳細ページから面談を申し込む(誘う)内容のメールを送る事ができます。
・退会
プロフィール編集の画面から退会できます。
開発手順
1.要件定義
今回作成するアプリに必要な機能は、
・バリスタユーザー登録機能
・オーナーユーザー登録機能
・ユーザー一覧表示機能
・ユーザー検索機能
・応募プロフィールや、求人情報作成機能
・面談応募(勧誘)機能のため、ユーザー情報を保存しておくデータベースが必要であり、尚且つデータベースに保存した情報を動的に表示できるビューが必要です。
また、面談の応募(勧誘)にはメイラー機能を使いたいので、メール用のサーバーも用意する必要があります。
バリスタユーザーとオーナーユーザーで動線を分けたいので、わかりやすい動線づくりを心がけます。
2.環境選定
言語は、自分にとって技術的資産の多いRubyを選択しました。
よってフレームワークもRuby on Railsとしました。データベースは、もっともメジャーに、広く使用されているMySQLを選択しました。
今回はバックエンド開発がメインだったため、フロントエンド開発の工数を減らす目的でCSSフレームワークを使用しました。
CSSフレームワークにはネット上に公開されている情報のリソースが多いことから、Bootstrapを使用しました。WEBサーバーには、pumaとの連携が簡単で、かつネット上に情報のリソースが多かったNginxを使用します。
なお、これらの環境はDocker,docker-composeを使用して構築しています。
Dockerを使用したのは、最終的にCircleCIやcapistoranoを用いた自動テスト&ビルド&デプロイを行いたいと考えているためです。そして、本番環境はAWSのEC2,RDS等を用いて構築します。
これは、個人的にAWSに興味があったため使ってみたかったのと、転職用のポートフォリオとして使用する際、クラウドにAWSを取り入れている企業様が多いと感じたことから、技術アピールができると考えたからです。3.データベース設計
今回は、2種類のユーザーを作成する必要があるため、ユーザーモデルを一つ作成し、オーナーフラグがtrueかfalseかでユーザーを識別するか、ユーザーモデルを二つ作成してそれぞれで管理するかで悩みましたが、
今回は後者の方法でデータベースを作成することにしました。
理由は、私が参考にしている著書「達人に学ぶDB設計徹底指南書」にて、一つのモデルはなるべくシンプルにし、分けられるところは分けて管理するのが良いとされていたので、その教えを守る形にしました。4.コーディング
コーディングの際に注意した点は以下の通りです。
・一つの機能を実装する度にRSpecでSystemスペックを記述する
・GitHubFlowを意識した開発(マスターブランチでの作業は基本的にはしない、擬似的にプルリクエストを作成して、マスターブランチにマージする -> リモートリポジトリの変更を、ローカルにpullする)また、ユーザーをバリスタユーザーとオーナーユーザーに分けて実装していましたが、自身の練習もかねて、バリスタユーザーの登録や認証周りをdeviseで実装し、オーナーユーザーの登録はscaffoldで作成、認証は簡易的なsessionで実装しました。
ただ、ログイン状態のバリスタユーザーをcurrent_userで取得し、ログイン状態のオーナーユーザーをcurrent_ownerで取得するように実装したのですが、これはベストプラクティスではないように感じました。
次回また似たようなアプリケーションを作成する際は、この辺りのDB設計に関してきちんと見直す必要がありそうです。この段階で、動作確認も兼ねてdevelopment環境でもAWSのS3に画像が保存されるように実装しました。
5.デプロイ
本番環境はAWSで構築しました。
docker-composeでアプリケーション用のコンテナ、Nginxのコンテナ、メイラーのコンテナを用意していたので、それらをまとめてEC2でビルド&実行するようにしました。
データベースはRDSを使用しています。
画像の保存には、S3を使用しており、こちらはproduction環境だけでなく、development環境でもS3に保存するようにしています。
また、今回はEC2は一つしか用意していませんが、後々HTTPS化するのに必要だったので、ALBを配置しました。
独自ドメインは、過去にブログを運営していたときにも利用していて使い慣れたお名前.comから取得し、Route53で設定しました。AWSを使ったデプロイのために何冊も書籍を読み、様々な記事を読んだので、ネットワーク周りの知識がかなりついたと実感しました。
今後の改善点や追加実装について
アプリケーション自体としては、SNSログインや画像アップロードの際のプレビュー表示などを実装したいと考えております。
加えて、特にフォーム関連のUIを向上させたいと考えています。
具体的には、入力するべき項目をplaceholderでわかりやすくしたりできるかと考えております。また、要件定義の段階から考えているCircleCIを使用した自動ビルド&テスト、capistoranoを使用した自動デプロイを実装していきたいです。
そのためにも、現在はCircleCIの公式ドキュメントを読みながら準備をしている段階です。それから、AWSに関しても、画像の配信をCloudFlontで行うことで、より高速化を測ってみたいと思います。
参考文献
・Ruby on Rails5.2 速習実践ガイド
・プロを目指す人のためのRuby入門
・Docker/Kubernetes 実践コンテナ開発入門
・Amazon Web Services 基礎からのネットワーク&サーバー構築 改訂版
・ゼロからわかる Amazon Web Services超入門 はじめてのクラウド かんたんIT基礎講座
・Webを支える技術 ―― HTTP,URI,HTML,そしてREST
・リーダブルコード
・達人に学ぶDB設計 徹底指南書











- 投稿日:2019-12-11T16:37:57+09:00
プロキシのある環境でDockerを動かす方法
日立製作所の小出です。この記事ではDockerを使う際にプロキシを設定する方法と、それに関連するDockerの挙動について説明します。
はじめに
会社からインターネットに接続するためにはプロキシを経由する必要がある、というのはありがちなシチュエーションだと思いますが、Dockerは他のツールに比べて設定につまづくポイントが多いように思います。実際、Qiitaで検索してみると、以下の件数の記事がヒットします (2019/12/5時点)。
yum proxy: 1281件apt proxy: 1042件npm proxy: 832件docker proxy: 2055件という具合で、開発者の苦労が伺えます。
また、Docker本体にたびたび設定方法や細かい挙動の変更が入ることも混乱の一因かと思われます。そこで、この記事では2019年12月現在のDocker事情を反映した設定方法を紹介したいと思います。
動作環境
この記事は以下の環境での動作を基に執筆しました。
- Ubuntu 18.04.3 LTS (Bionic Beaver)
- Docker 19.03.5
なお、Dockerの実行や設定にはroot権限が必要です。
TL; DR
先に結論を書いておくと、以下の設定をしておけばイメージの取得からビルド、コンテナ内のコマンド実行まで、プロキシ経由で作業できます。
192.168.0.10:8080でプロキシサーバが動いていると仮定した場合の例を記載するので、環境に合わせてIPとポートを書き換えてください。また、認証プロキシの場合はhttp_proxy=http://USER:PASSWORD@example.com:8080のような書式でユーザ名とパスワードが指定できます。1. systemdに環境変数を設定する
systemctl edit dockerで設定ファイルを開き、以下を記載します。/etc/systemd/system/docker.service.d/override.conf[Service] Environment = 'http_proxy=http://192.168.0.10:8080' 'https_proxy=http://192.168.0.10:8080' # 必要なら 'no_proxy=...'2. Dockerクライアントを設定する
~/.docker/config.json{ "proxies": { "default": { "httpProxy": "http://192.168.0.10:8080", "httpsProxy": "http://192.168.0.10:8080" } } }Docker proxy deep dive
ここからはなぜ上記の設定で良いのかの解説です。
dockerdとdocker
Dockerはクライアントサーバモデルのソフトウェアです。MySQLを使うとき
mysqldに対してmysqlコマンドで話しかけるように、Dockerはdockerdに対してdockerコマンドで話しかけることができます。プロキシもこれら2つのプログラムに対して設定する必要があります。コンテナの中で動くプログラムに対してプロキシを設定する場合は
dockerを設定し、それ以外の場合 (pullとか) はdockerdを設定する、という風に分かれているようです。dockerdの設定
dockerdにプロキシを設定する方法は、環境変数ただ1つです。
systemctl stop dockerでサービスを止めて、dockerdをフォアグラウンドで動かしてみると検証しやすいと思います。
単にdockerdコマンドを実行すると、フォアグラウンドでdockerdが起動します。$ sudo dockerd INFO[2019-12-05T06:46:10.612966150Z] detected 127.0.0.53 nameserver, assuming systemd-resolved, so using resolv.conf: /run/systemd/resolve/resolv.conf <いろいろ出ますが省略> INFO[2019-12-05T06:46:10.892366184Z] Docker daemon commit=633a0ea838 graphdriver(s)=overlay2 version=19.03.5 INFO[2019-12-05T06:46:10.892416069Z] Daemon has completed initialization INFO[2019-12-05T06:46:10.909923228Z] API listen on /var/run/docker.sock端末をもう一つ開いて、イメージをpullしてみます。この時点では何も設定していないのでpullに失敗します。
$ sudo docker pull alpine Using default tag: latest Error response from daemon: Get https://registry-1.docker.io/v2/: dial tcp: lookup registry-1.docker.io: No address associated with hostnamedockerdの標準出力にも、名前解決ができずエラーになったという旨のメッセージが表示されます。
WARN[2019-12-05T07:34:29.915501297Z] Error getting v2 registry: Get https://registry-1.docker.io/v2/: dial tcp: lookup registry-1.docker.io: No address associated with hostname INFO[2019-12-05T07:34:29.915555514Z] Attempting next endpoint for pull after error: Get https://registry-1.docker.io/v2/: dial tcp: lookup registry-1.docker.io: No address associated with hostname ERRO[2019-12-05T07:34:29.915607313Z] Handler for POST /v1.40/images/create returned error: Get https://registry-1.docker.io/v2/: dial tcp: lookup registry-1.docker.io: No address associated with hostnamedockerdに
http_proxy,https_proxyを渡せば、pullできるようになります。$ export http_proxy=http://192.168.0.10:8080 $ export https_proxy=http://192.168.0.10:8080 $ sudo -E dockerd$ sudo docker pull alpine Using default tag: latest latest: Pulling from library/alpine Digest: sha256:c19173c5ada610a5989151111163d28a67368362762534d8a8121ce95cf2bd5a Status: Downloaded newer image for alpine:latest docker.io/library/alpine:latestまた、
docker infoでdockerdが認識しているプロキシを確認することもできます。$ sudo docker info Client: Debug Mode: false Server: Containers: 0 Running: 0 <略> Debug Mode: false HTTP Proxy: http://192.168.0.10:8080 HTTPS Proxy: http://192.168.0.10:8080 Registry: https://index.docker.io/v1/ <略>この時点で
docker pullがうまく動かない場合は、そもそもネットワーク設定が正しくできていない可能性が高いので、OSの流儀に従ってネットワーク設定を見直してください。systemdの設定
上記と同じ設定をdockerサービスに反映するために、systemdのserviceファイルを編集します。
systemdの設定ファイルは
/etc/systemd/systemディレクトリにあります (他にもたくさんありますが、詳細はman systemd.unitを参照してください)。このディレクトリにdocker.serviceというファイルを作って設定を記述すれば良いのですが、プロキシ設定のような「既存の設定にプラスアルファで付け加えたい」という類のものに適したドロップインファイルという機能があるので、それを使うのがおすすめです。以下のコマンドを実行すると、ドロップインファイルの編集画面が開きます。
$ sudo systemctl edit dockerこのファイル (
/etc/systemd/system/docker.service.d/override.conf) に対して、環境変数の設定を記載すれば、dockerサービスがプロキシ経由で動くようになります。/etc/systemd/system/docker.service.d/override.conf[Service] Environment = "http_proxy=http://192.168.0.10:8080" "https_proxy=http://192.168.0.10:8080"あとはサービスを起動すれば、dockerdの設定は完了です。
$ sudo systemctl start docker $ sudo docker pull alpine Using default tag: latest latest: Pulling from library/alpine Digest: sha256:c19173c5ada610a5989151111163d28a67368362762534d8a8121ce95cf2bd5a Status: Downloaded newer image for alpine:latest docker.io/library/alpine:latestかつて
/etc/sysconfig/dockerというファイルに環境変数を設定する、という方法もありましたが、今はdeprecatedになったようです。dockerクライアントの設定
冒頭に書いた通り、
~/.docker/config.jsonに設定を書けば良いのですが、この設定方法はDocker 17.07以降で有効な設定方法で、昔のバージョンでは使えませんでした (CentOS 7のextrasリポジトリで配布されているdockerは1.13.1のようなので、この方法は使えません)。この設定ファイルができる前は、以下のように
docker runの引数で環境変数を指定したり、$ sudo docker run -it -e http_proxy=http://192.168.0.10:8080 -e https_proxy=http://192.168.0.10:8080 alpine / # wget https://qiita.comコンテナの中で環境変数を設定していました。もちろん今でもこれらの方法は有効です。
$ sudo docker run -it alpine / # export http_proxy=http://192.168.0.10:8080 / # export https_proxy=http://192.168.0.10:8080 / # wget https://qiita.com
~/.docker/config.jsonにプロキシ設定を書いておくと、自動的に上記の環境変数を設定してくれます (大文字のHTTP_PROXY,HTTPS_PROXYも設定されます)。$ sudo docker run -it alpine # ~/.docker/config.json を記載した上で起動 / # env HTTPS_PROXY=http://192.168.0.10:8080 HOSTNAME=e60420de06d3 SHLVL=1 HOME=/root https_proxy=http://192.168.0.10:8080 http_proxy=http://192.168.0.10:8080 TERM=xterm PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin PWD=/ HTTP_PROXY=http://192.168.0.10:8080ただし、環境変数が設定されるのはコンテナの生成時なので、起動済みのコンテナに
execするときは設定されません。$ mv ~/.docker/config.json{,.bak} # ファイルをリネームして設定を無効化 $ sudo docker run -itd --name alpine alpine $ mv ~/.docker/config.json{.bak,} # 有効化 $ sudo docker exec -it alpine ash / # env <http_proxy は表示されない>
docker build先述した設定がしてあれば、ビルド時に特別何かする必要はありません。「あれ?
--build-argでプロキシ指定するんじゃないの?」と思った方もいるかもしれません。もちろん指定しても動きますが、~/.docker/config.jsonで指定してあれば不要です。ちなみに、17.05より前のバージョンでは
--build-argに指定した内容がdocker historyに漏れなく残っていたので、認証プロキシを使っているとどうしてもイメージにユーザ名やパスワードが残ってしまう問題がありました。17.06以降のバージョンであれば、--build-argを使う方法でも、~/.docker/config.jsonに指定する方法でも、イメージに情報が残ることはないので安心です (逆に残したい場合は、DockerfileにARGで明示的に指定するとhistoryに残せます)。付録
~/.docker/config.jsonに書いてある "default" の部分には、dockerdが動いているマシンが指定できます。もし複数のマシンでdockerdを動かしていて、それぞれのマシンで起動するコンテナに別々のプロキシを設定したい場合は以下のように設定できます。~/.docker/config.json{ "proxies": { "tcp://docker-host1:2375": { "httpProxy": "http://proxy1.example.com:8080", "httpsProxy": "http://proxy1.example.com:8080" }, "tcp://docker-host2:2375": { "httpProxy": "http://proxy2.example.com:8080", "httpsProxy": "http://proxy2.example.com:8080" }, "default": { // 上2つ以外のマシンに適用される "httpProxy": "http://proxy.example.com:8080", "httpsProxy": "http://proxy.example.com:8080" } } }参考資料
- 投稿日:2019-12-11T16:32:48+09:00
テスト環境におけるDockerコンテナ間のHTTPS通信
この記事はZOZOテクノロジーズ #1 Advent Calendar 2019 17日目の記事になります。
昨日の記事は @pakio さんによる「非ElasticsearchユーザーにもおススメなKibanaで地味に便利な機能を紹介したい」でした。本記事では、Dockerのコンテナ間でHTTPS通信をするテストを実装した際に困ったことの解決方法を紹介します。
概要
テスト環境に対してHTTPS通信を行うために自己証明書(いわゆるオレオレ証明書)を使う場合、基本的に警告が出るので明示的に通信を許可する必要があります。
SeleniumやPuppeteerなどを使っている場合は、証明書に関するエラーを無視するようなオプションを設定することで、この状況を回避できますが、内部でHTTPS通信を行うライブラリによっては、そのようなオプションが用意されていない場合もあります。
Dockerのコンテナ間でHTTPS通信する際にそういった状況に遭遇した場合の解決方法を紹介していきます。環境
- macOS High Sierra (v10.13.6)
- mkcert (v1.4.0)
- docker desktop (v2.1.0.4)
解決方法の概要
オレオレ証明書の代わりにオレオレ認証局を作り、その認証局をアクセス元のコンテナで信用するようにします。
- ホストマシン上に認証局を作成
- 認証局からコンテナB用のSSLサーバー証明書を発行
- 認証局のルート証明書をコンテナAが持つルート証明書一覧に追加
- 発行されたサーバー証明書をコンテナBで利用
- コンテナAからコンテナBにHTTPSアクセス
サンプルコード
本記事で紹介する例とは多少異なりますが、SSLサーバー証明書を利用したNginxにPuppeteerでアクセスする場合のサンプルコードを上げているので、こちらも必要に応じてご参照ください。
詳細手順
認証局の作成
mkcertを使うと簡単に認証局を作成できます。
mkcert -installSSLサーバー証明書の発行
続いて、mkcertを使って認証局からSSLサーバー証明書を発行します。
mkcert container-bこのコマンドでは、証明するホスト名を指定する必要があるので、コンテナAから見たコンテナBのホスト名を指定します。
ルート証明書のエクスポート
キーチェーンアクセスからmkcertによって作られた認証局のルート証明書を探し、メニューバーの「ファイル」→「書き出す」で保存します。
この記事ではlocal-root-ca.pemというファイル名で保存しています。ルート証明書の追加
Dockerfile... COPY local-root-ca.pem /usr/local/share/ca-certificates/local-root-ca.crt RUN update-ca-certificates ...エクスポートしたルート証明書をコンテナAのルート証明書一覧が管理されているディレクトリ下に配置し、一覧情報を更新します。
* 証明書一覧が管理されているディレクトリや、更新のコマンドはOSによって異なります。上のはDebianの場合です。
SSLサーバー証明書の利用
構成によって変わるので、割愛します。
コンテナAからコンテナBへのHTTPSアクセス
DockerfileCMD curl https://container-b/
-kや--insecureのオプションを付けなくてもエラーが出ないことを確認します。最後に
オレオレ認証局を作成して発行したSSLサーバー証明書を利用することで、コンテナ間のHTTPS通信を警告なしに行うことができるようになりました。開発環境やテスト環境でお困りの際にはぜひご活用ください。
明日の記事は、 @katsuyan さんによる「Googleスプレッドシートの縦横変換をSQLでおこなう」です。そちらもぜひご覧下さい。
余談
JRE (Java Runtime Environment)といった環境やライブラリによってはルート証明書一覧が同梱されており、OS側のルート証明書一覧を参照しないという場合もあります。
こういった場合には、ルート証明書追加の手順で行ったような操作では意味がないため、ライブラリ等に同梱されたルート証明書一覧に追加する方法や、OS側のルート証明書一覧を見るように処理を上書きする方法を考える必要があります。


- 投稿日:2019-12-11T16:26:45+09:00
Dockerコンテナ内で起きたcore dumpをデバッグ
前置き
自作したプログラムがコンテナの中でセグフォを起こした...そんな経験はありませんか?
コンテナ内部のcoredumpctlにはデバッグ情報が残りません.
またコンテナに特権を与えなかった場合,/proc以下のファイルはコンテナ側で操作することができず,coreファイルの出力設定も変更ができません.
そこで今回はそんな環境下でもコンテナ内部で発生したcore dumpをデバッグする手法を公開します.やり方
結論は非常に簡単で,ホスト側のcoredumpctlにデバッグ情報が保存されています.
そこでホスト側のcoredumpctlを使い,コンテナから(ヴォリュームマウントなどで)取り出した実行ファイルと合わせてデバッグすればOKです.
※ coredumpctlを使わずにcoreファイルが直接吐き出される場合は,落ちたコンテナをcommitして作ったイメージをrunして中でデバッグすればOKです.何故ホスト側のcoredumpctlにデバッグ情報が?
同じようにコンテナ側でcoredumpctlがお仕事をしてくれない件がissueとして出ていました.
その中でcatrixs氏が「Because coredump is captured by kernel」と指摘しています.実験
実験環境
環境 名前 OS Manjaro 18.1.3 Juhraya Dockerクライアント 19.03.4-ce Cコンパイラ gcc 9.2.0 デバッガ gdb 8.3.1 手順
以下のように
segfo_sample.cを作成します.#include<stdio.h> int main() { char* null_po = NULL; printf("%d", *null_po); }コンパイルした実行ファイルをコンテナにマウントして実行しましょう.
$ gcc -g segfo_sample.c -o segfo_sample $ docker run --rm -it -v ${PWD}/segfo_sample:/root/segfo_sample -w /root debian bash root@f36b0603fce1:~# ./segfo_sample Segmentation fault (core dumped) root@f36b0603fce1:~# exitコンテナを抜け,ホスト側でコアダンプ情報を確認しましょう.
$ coredumpctl info segfo_sample PID: 31371 (segfo_sample) UID: 0 (root) GID: 0 (root) Signal: 11 (SEGV) Timestamp: Wed 2019-12-11 15:10:30 JST (25s ago) Command Line: ./segfo_sample Executable: /root/segfo_sample Control Group: /system.slice/docker.service Unit: docker.service Slice: system.slice Boot ID: 6890bb7e1fbf4346af58a455e5087c1c Machine ID: 4ea99d5d328042c1985355191e83ab72 Hostname: cabon Storage: /var/lib/systemd/coredump/core.segfo_sample.0.6890bb7e1fbf4346af58a455e5087c1c.31371.1576044630000000.lz4 (inaccessible) Message: Process 31371 (segfo_sample) of user 0 dumped core. Stack trace of thread 7: #0 0x000055feb6c0f14d n/a (/root/segfo_sample) #1 0x00007f05571f12e1 n/a (/lib/x86_64-linux-gnu/libc-2.24.so)ちゃんとホスト側に情報が来ているので,PIDを指定してデバッグしちゃいましょう.
$ sudo coredumpctl debug 31371 [sudo] password for takahiro: PID: 31371 (segfo_sample) UID: 0 (root) GID: 0 (root) Signal: 11 (SEGV) Timestamp: Wed 2019-12-11 15:10:30 JST (2min 12s ago) ... /root/segfo_sample: No such file or directory. [New LWP 7] Core was generated by `./segfo_sample'. Program terminated with signal SIGSEGV, Segmentation fault. #0 0x000055feb6c0f14d in ?? () (gdb)あらら...
/root/segfo_sampleなんて実行ファイルが無いから覗けないよ?って言われてしまいましたね...コンテナとはパスが違うので当然といえば当然ですが...
fileコマンドを使って,ホスト側に残された実行ファイルを指定しましょう.(gdb) file segfo_sample Reading symbols from segfo_sample... (gdb) run Starting program: /home/takahiro/hoge/segfo_sample Program received signal SIGSEGV, Segmentation fault. 0x000055555555514d in main () at sample.c:5 5 printf("%d", *null_po); (gdb) backtrace #0 0x000055555555514d in main () at sample.c:5いい感じです.
- 投稿日:2019-12-11T15:38:33+09:00
Dockerコマンドに触れてみる
はじめに
先日めでたくDocker入門したので、早速操作方法を習得していきます。
座学で覚えてもほとんど身にならないタイプなので、実践あるのみです。
Docker環境がまだ無い方は以下の記事を参照してみてください。参考:今話題のDocker + Rails + Circle CI + Terraform構成を試したいんじゃ!
コマンド
確認系
docker ps
コンテナの状態確認
-a をつけることで停止中のコンテナも表示できるdocker ps -aCONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES e8f5056d7bf4 hello-world "/hello" 3 hours ago Exited (0) 3 hours ago ecstatic_snyderdocker images
ローカルにあるイメージファイルの一覧
docker imagesREPOSITORY TAG IMAGE ID CREATED SIZE hello-world latest fce289e99eb9 11 months ago 1.84kBdocker info
Dockerの状態を確認
ダッシュボード的存在[root@localhost docker]# docker info Client: Debug Mode: false Server: Containers: 1 Running: 0 Paused: 0 Stopped: 1 Images: 2 Server Version: 19.03.5 Storage Driver: overlay2 Backing Filesystem: xfs Supports d_type: true Native Overlay Diff: true Logging Driver: json-file Cgroup Driver: cgroupfs <略>操作系
docker start/stop
コンテナの起動/停止
###コンテナの起動 # docker start <コンテナ名> ###コンテナの停止 # docker stop <コンテナ名>docker pull
Dockerイメージのダウンロード
(例)CentOS7のイメージダウンロード# docker pull centos:7docker run
コンテナ起動
# docker run -it -d -p <ホスト側ポート>:<コンテナ側ポート> -v <ホスト側ディレクトリ>:<コンテナ側ディレクトリ> --name <コンテナ名> <Dockerイメージ名>run オプション
オプション 説明 例 --name コンテナ名を指定 docker run --name "test" centos -d バッググラウンド実行 docker run -d centos -it コンソールに結果を出力 docker run -it --name "test" centos /bin/cal -p host:cont ポートフォワーディング docker run -d -p 8080:80 httpd --add-host ホスト名とIPを指定 docker run -it --add-host=test.com:192.168.1.1 centos --dns DNSサーバを指定 docker run --dns=192.168.1.1 httpd --mac-address MACアドレスを指定 docker run -it --mac-address="92:d0..." centos --cpu-shares CPU配分 (全体で1024) docker run --cpu-shares=512 centos --memory メモリの上限 docker run --memory=512m centos -v ディレクトリの共有 docker run -v /c/Users/src:/var/www/html httpd -e 環境変数を設定 docker run -it -e foo=bar centos /bin/bash --env-file 環境変数リストから設定 docker run -it --env-file=env_list centos /bin/bash -w 作業ディレクトリを指定 docker run -it -w=/tmp/work centos /bin/bash docker cp
コンテナ-ホスト間のファイルコピー
###コンテナ→ホストへのファイルコピー # docker cp <コンテナ名>:<コンテナ内のコピー元ファイル> <ホスト側のコピー先ディレクトリ> ###ホスト→コンテナへのファイルコピー # docker cp <ホスト側のファイル> <コンテナ名>:<コンテナ内のコピー先ディレクトリ>docker exec
コンテナへのログイン
(例)『tomcat』コンテナへログイン[root@localhost docker]# docker exec -it tomcat bash [root@e01ba3d18e31 /]#docker commit
コンテナからdockerイメージの作成
# docker commit <コンテナ名> <作成するDockerイメージ名>docker rm(i)
コンテナ(dockerイメージ)の削除
###コンテナの削除 # docker rm (-f) <コンテナ名> ###dockerイメージの削除 # docker rmi (-f) <dockeriイメージファイル名>今日はここまで
新しく覚えたコマンドは追記していきます。
- 投稿日:2019-12-11T13:53:45+09:00
NuxtをCloudRunにデプロイする。
この記事は Nuxt.js Advent Calendar 2019 7日目の記事です。
今回のコード:https://github.com/yujiteshima/cloudrun-test
NuxtをGoogleCloudRunにデプロイする。
NuxtをCloudRunにデプロイする方法について嵌った部分を中心に説明します。
今回やる事
Nuxt.jsの
create-nuxt-appしてだけの状態のアプリををGCPのCloudRunにデプロイしてみるというものです。Cloud Runとは
私のざっくりとした理解です。理解がまだまだ不足している分はどんどん色んなサービスを使いながら理解していきたいと思います。
Cloud Runは自分で作ったコンテナを、GCPのサーバ環境上で動かせるサービスです。
誰もアクセスしていない時は課金されず、誰かがアクセスしてきた時に立ち上がり、立ち上がっている時間だけが課金対象となるサービスです。多くのアクセスがこれば自動でスケールアップして、少なくなれば自動でスケールダウンしてくれるというスケーリングも面倒をみてくれます。
CloudFunctionとの一番の違いはコンテナ上で動かすので、ランタイムが制限されていない事のように思います。
GKEとの違いは、kubernetesのアップデートの管理をCloudRunでは追わなく
良いということ。GKEの方が面倒をみなくてならない事が多い分自由度が高いという感じがします。このFunctionsとGKEの間の性格を持っている為、コンテナで動かしたいけどGKEを使うほどではない、もっと簡単に面倒をみる事が少ないように使いたいという時にCloudRunの存在価値があるのかなと思いました。
Cloud Runを使う準備
GCPのサインアップをされてない方はサインアップして下さい。
請求先(クレジットカードの情報)が必要です。
初めて利用される方は$300の無料クレジットがつくはずです。Cloud SDK
- Cloud SDKをインストールしていない方はインストールして下さい。 https://cloud.google.com/sdk/install?hl=JA
CloudSDKをアップデートしておきます。
Beta版コンポーネントのインストールもしておきます。$ gcloud components update $ gcloud components install betaGCPのコンソールでプロジェクトを作リます。
作成はプロジェクトの作成から作成します。
好きな名前をつけて下さい。よくある重複している名前は勝手に番号を末尾につけてくれます、このプロジェクトの名前は後で何回か使います。
プロジェクトの請求を有効にしておく必要があります。
メニューのお支払いから設定して下さい。
CloudBuildを有効化しておく
クラウドビルドを使うので有効化しておきます。
CloudRunを有効化しておく
Nuxtのプロジェクト作成
はじめからExpress入れて作成します。
Functions等でExpressのミドルウエアとしてNuxtを動かして、SSRのデプロイをした事がある方は馴染みある形だと思いますが、Chose custom server frameworkでExpress選んでおけば、よしなにやってくれます。$ npx create-nuxt-app sample-appcreate-nuxt-app v2.11.1 ✨ Generating Nuxt.js project in sample-app ? Project name sample-app ? Project description My exquisite Nuxt.js project ? Author name Yuji Teshima ? Choose the package manager Yarn ? Choose UI framework Bulma ? Choose custom server framework Express ? Choose Nuxt.js modules Axios, Progressive Web App (PWA) Support ? Choose linting tools ESLint, Prettier, Lint staged files ? Choose test framework Jest ? Choose rendering mode Universal (SSR) ? Choose development tools (Press <space> to select, <a> to toggle all, <i> to invert selection) yarn run v1.19.0portの変更
動作確認をしてみます。
$ yarn run devするとターミナルにリッスンしているアプリケーションポートが表示されます。
$ READY Server listening on http://localhost:3000クラウドの実行には、
process.env.PORTを設定しておく必要があります。
またlocalhostや127.0.0.1では無くて0.0.0.0をホストにしておかなくてはならないので、その設定を書き加えていきます。nuxt.config.jsにserverの設定を書き加えます。
nuxt.config.jsserver: { port: process.env.PORT || 3000, host: '0.0.0.0', timing: false }Dockerfileを作成する
From node:latest WORKDIR /src COPY . . Run yarn install \ --prefer-offline \ --frozen-lockfile\ --non-interractive \ --production=false Run yarn build CMD [ "yarn", "start" ]クラウドビルドの設定をyamlで書く
cloud-build.ymlsteps: - name: gcr.io/cloud-builders/docker args: [ "build", "-f", "Dockerfile", "-t", "gcr.io/gcpコンソールで先程作ったプロジェクトName/コンテナの名前(好きな名前)", ".", ] images: - gcr.io/gcpコンソールで先程作ったプロジェクトName/コンテナの名前(好きな名前)Google Cloud Buildでビルドする
gcloud builds submit --project "gcpコンソールで先程作ったプロジェクトName" --config=./cloud-build.yamlデプロイする
gcloud beta run deploy cloud-run-name --region us-central1 --project "gcpコンソールで先程作ったプロジェクトName" --image gcr.io/gcpコンソールで先程作ったプロジェクトName/コンテナの名前(好きな名前)リージョンはBeta版の時はus-central1に制限されていましたが、2019 年 11 月 14 日にGAになった際に、
asia-northeast1(東京)も追加されました。デプロイ時にオプションで渡していた値は事前に登録しておく事も出来ます。
例$ gcloud config set project "gcpコンソールで先程作ったプロジェクトName" $ gcloud config set run/region asia-northeast1成功すると、ページのアドレスがターミナルに表示されます。
Service [sample-app] revision [sample-app-00001-puw] has been deployed and is serving 100 percent of traffic at https://sample-app-<生成された値>-uc.a.run.app現時点で表示されたアドレスにリクエストしても、エラーが表示されます。
公開設定の変更
このままだとデプロイしたものを誰でも見れるようにはなっていません。
見れるようにするには、公開設定を変えなくてはなりません。
自身が利用するAPIであればそれに応じた公開設定をする必要があります。
今回は誰でも見れるようにAllUserに変更してデプロイ出来ているか確認しておきます。コンソールでCloudRunのページから権限を変更します。
これで、表示されるはずです。
今回は初期画面が表示されるだけですが、きちんと表示できれば成功です。
まとめ
Docker使い初めの、私のような初級者には、自分が作ったコンテナが実際GCPのサーバ上で動いているというだけで、少し感動しました。
どんどん使っていきたいです。あらためて、使ってみて初めて理解できるという事あると思いました。









- 投稿日:2019-12-11T12:36:02+09:00
VSCodeで複数ある名前の異なるDockerfileに対してLanguageModeを利かせる
VSCodeでは
Dockerfileという名前のファイルでしか、認識されずDockerfileのSyntax Highlightが適用されない。
.vscode/settings.jsonに以下のような内容を追記すれば、Dockerfile.devやDockerfile.prodにも適用される。{ "files.associations": { "Dockerfile.*": "dockerfile" } }上記はワークスペースに対する設定だが、ユーザ設定で変えても大丈夫。
- 投稿日:2019-12-11T09:41:41+09:00
HashiCorp Nomad で作るコンテナ実行基盤
2019年3月から、さくらインターネットで働いている、自称「構成管理おじさん」です。
チームでの役割としては下記のようなことをやっています。
- コンテナ実行基盤の構築
- メトリクス管理、監視基盤の構築
- ログ管理、監視基盤の構築
今回は、コンテナ実行基盤の構築について少しだけお話しさせていただきます。
内容
- 世の流れは Kubernetes だけど、 Docker + Nomad + Consul + Traefik を組み合わせるとこんなことができ、この構成に至るまでにどのように思考していったのかについて書いています。
Nomad + Consul を利用したコンテナオーケストレーションを行っている国内の企業がここにもいますよということをアピールしておきます。(いつか対面でお話できる日がくるとよいなと思っています。)
- LINEの金融系サービスを支えるサーバーエンジニアの仕事
Consul・Nomad・Envoyを利用したコンテナオーケストレーションシステム開発- https://logmi.jp/tech/articles/322097
入社前のコンテナ経験
- LXC
- 自宅や自身の業務 PC にてミドルウェアの検証などに利用していました。
- Docker
- 2013年12月の出始めのときに少し触った程度です。
前職の仮想サーバーでアプリケーションを実行するという構成から、現職では、アプリケーションを Docker コンテナで実行するという構成になり、技術要素が、仮想サーバーからコンテナになったなと感じています。
モチベーション
何故コンテナ技術に触れるに至ったのかというところをお話ししていきたいと思います。
入社時に上長からは「 Prometheus を使った監視基盤を作ってもらいたい」と言われました。
これからやっていきたいところとして手を付けられていない部分である監視基盤を主導していってもらいたいということを言われました。
口頭での情報だけでは少ないなと思ったので、現状チームにて取り組んでいることキャッチアップするため、社内にあるドキュメントやコードを読み漁ることにしました。
すると下記のような思いを読み取れました。
- アプリケーションは Docker コンテナとして動かしていきたい
- スケールアウトが容易なシステム基盤にしていきたい
- メトリクス管理、監視の基盤が欲しい
- ログ管理、監視の基盤が欲しい
やっていきたいという思いは確認できましたが、この時点で動いているものは一つもありませんでした。
これらを動くものとして形にしていくことが自身の役割であると考え、まずはコンテナを実行する基盤を構築することにしました。Docker
Docker
https://www.docker.com/まずはコンテナとして Docker を採用することにしました。
「アプリケーションを Docker コンテナとして動かしていきたい」思いを読み取ったという部分もありますが、 Docker を採用したのはそれだけではなく、下記のようなことも考えました。デファクトスタンダード
Docker がコンテナのデファクトスタンダートとなっており周辺のツールが充実していることも採用の理由の一つです。
アプリケーションの依存関係を切り離せる
前職ではバッチサーバーなるものの管理を任され、ホストサーバーにはバッチを動かすためのランタイムと現地ビルドのためのビルド用のパッケージがモリモリと追加され肥大化した結果、いま動いているバッチが動く環境ではあるが、それぞれのバッチの依存関係がわからないという辛みを味わいました。
それぞれのアプリケーションの依存関係は、それぞれの Docker コンテナに閉じ込めることで、ホストサーバーからアプリケーションの依存関係を切り離せるというのはメリットであると考えました。ポータビリティを確保できる
先ほどのバッチサーバーの話が続きますが、アプリケーションを実行するための依存関係がわからなくなり移行が捗らないとう現場も目の当たりにしてきました。
ホストサーバーからアプリケーションの依存関係を切り離せるとホストサーバーに必要になってくるのは、 Docker コンテナを動かす実行環境だけになるため、アプリケーション自体のポータビリティを確保できるという点もメリットであると考えました。使っていくにあたって
アプリケーションは Docker コンテナにするとして、どうデプロイするのかという問題に当たりました。
Ansible にて Docker コンテナをデプロイすることはできましたが、 Ansible をインフラ担当がサーバーのセットアップに、アプリケーション開発者が Docker コンテナのデプロイにと Ansible に 2 つの役割りを持たせることをしたくありませんでした。
両者が同じツールを利用するのではなく、アプリケーション開発者からは Ansible の存在を隠蔽し、別の手段をもって Docker コンテナをデプロイする世界を作りたいなと考えました。
Ansible は Docker の実行環境をセットアップをするところまでと決め、 Docker コンテナをデプロイするための手段を探すことにしました。Nomad
Nomad
https://www.nomadproject.io/入社前に時間があったので Kubernetes を触ってみましたが、セットアップして Nginx をデプロイしたところで、運用していくイメージが持てず力尽きました。現在のチームにて一緒にやっている方も同じようなところで力尽きていました。
やりたかったことは、コンテナ実行基盤の運用に疲弊することではなく、 Docker コンテナをデプロイしたいということでした。
ではどうするのかというところで、下記の記事が出て来たので Nomad を試してみることにしました。
- 多分あなたにKubernetesは必要ない
Nomad は環境を構築して、 Docker コンテナをデプロイするまでに1日掛からず、なんだかやっていけそうな気がしました。
Nomad は Nomad Server, Nomad Client の構成で動作し、 Nomad は Job と呼ばれるものを記述し実行することで、 Nomad Client に Docker コンテナが起動します。
Architecture
https://www.nomadproject.io/docs/internals/architecture.htmlJob Specification
https://www.nomadproject.io/docs/job-specification/index.htmlConsul
Consul
https://www.consul.io/Nomad により Docker コンテナのアプリケーション(以下、コンテナアプリケーション)のデプロイを Ansible でやらない環境を構築することができました。
しかし Nomad Client 間を動きまわるコンテナアプリケーションに対してどのように名前解決し、接続するのかという問題に当たりました。
従来のホストサーバーとアプリケーションが一対一になっているサーバーであれば、サーバーの IP アドレスに対して DNS にて名前を付けておけば、その名前を使いアプリケーションに接続できていました。
Nomad では、コンテナアプリケーションがどの Nomad Client に配置するかは人間が決めるのではなく、 Nomad Server が決めます。
Consul と Nomad を組み合わせることで、 Nomad Client にデプロイされたコンテナアプリケーションの名前解決が可能になるということがわかりました。
Nomad Reference Architecture
https://www.nomadproject.io/guides/install/production/reference-architecture.htmlConsul Architecture
https://www.consul.io/docs/internals/architecture.htmlここで Service Discovery という概念を知ることになりました。
従来のサーバー構成から、サービスというレイヤーにてコンテナアプリケーションに接続するための名前解決の仕組みが提供されるようになったのだなと感じました。どの Nomad Client にコンテナアプリケーションが配置されたかという情報は Consul に登録され、 Consul の提供している DNS Interface や HTTP API にて名前解決できるようになります。
DNS Interface
https://www.consul.io/docs/agent/dns.htmlService - Agent HTTP API
https://www.consul.io/api/agent/service.htmlCatalog HTTP API
https://www.consul.io/api/catalog.htmlTraefik
Traefik
https://traefik.io/Nomad Client にデプロイされたコンテナアプリケーションは、 Consul により名前解決できるようになりました。
しかし、これは Nomad + Consul の動作しているサーバーだけの話で、これらが動作していないサーバーは、 Nomad Client のコンテナアプリケーションと通信できないため、橋渡しを担うエンドポイントが必要です。
Consul は、どの Nomad Client に何のコンテナアプリケーションが配置されているかというカタログ情報を持っており、 Traefik は Consul のカタログ情報をもとに HTTP のエンドポイントを生成できるようになっています。
Consul Catalog Provider
https://docs.traefik.io/v1.7/configuration/backends/consulcatalog/Nomad に下記を設定すると Consul に登録され Traefik は HTTP エンドポイントを生成します。
Load Balancing with Traefik
https://learn.hashicorp.com/nomad/load-balancing/traefiktags = [ "traefik.tags=service", "traefik.frontend.rule=PathPrefixStrip:/myapp", ]開発者がアプリケーションをデプロイし、 インフラ担当がロードバランサにエンドポイントを登録するという、よくあるオペレーションが、ここでは登場しないのだということを思いました。
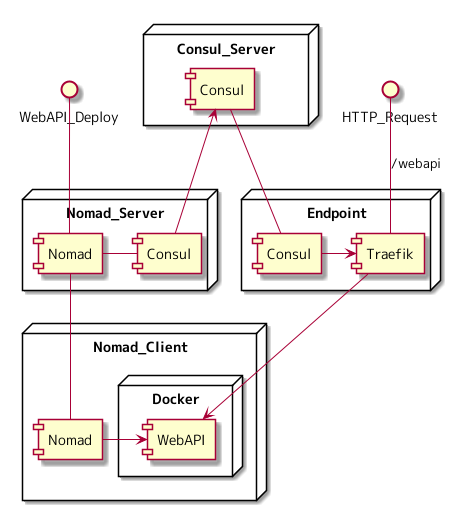
構成図
テキストばかりだったので、最終的にどのような構成サーバー構成になっているのかということを図にしました。 Nomad Client に WebAPI のコンテナアプリケーションが起動し、エンドポイントから参照できるようになるまでが図に起こされています。
Nomad の Job ファイルには下記を設定していると仮定します。
tags = [ "traefik.tags=service", "traefik.frontend.rule=PathPrefixStrip:/webapi", ]
- WebAPI_Deploy
- Nomad Server に対して WebAPI のデプロイを指示
- Nomad Server は Nomad Client に対して WebAPI の起動を指示
- Nomad Client は WebAPI の Docker コンテナを起動
- Nomad Server は Consul Server に WebAPI の情報を登録
- HTTP_Request
- Traefik は Consul のカタログ情報から /webapi のエンドポイントを生成
- /webapi にリクエストが来ると Nomad Client の WebAPI にルーティングされる
この構成において、人間がやることは 1-1 の Nomad Job を実行するというところだけになります。
1-2 以降は、各ソフトウェアがよしなに連携していきます。まとめ
- 影も形も無く、ほぼ全てがはじめての取り組みという状態から、動くものが形になりました。
- コンテナ実行基盤の構築を進める中で、当たった問題というのは解決する技術が揃っているということがわかりました。
- アプリケーションを Docker コンテナとして動かせる環境が構築できました。
- Nomad Client を追加していけばスケールアウトが可能です。
また構成管理の範囲を明確に分けることができたと考えています。
- サーバのデプロイは Terraform
- コンテナ実行基盤のセットアップは Ansible
- アプリケーションのデプロイは Nomad
如何でしたでしょうか。
Kubernetes でなくても、ここまで出来るということを感じていただけたらと思います。
最後まで読んでいただき、ありがとうございました。




- 投稿日:2019-12-11T08:22:39+09:00
docker-compose+MySQL8(8.0.18)で初期データをCSVロードしようとするとエラー(The used command is not allowed with this MySQL version)に
docker-compose+MySQL8(8.0.18)で初期データをCSVロードしようとするとエラー(The used command is not allowed with this MySQL version)に
環境情報
- MacOS X 10.15.1(19B88)
- Docker 19.03.5
- MySQL 8.0.18
docker-composeのディレクトリ構成
. ├── docker-compose.yml └── mysql ├── init │ ├── 10_ddl.sql │ └── data.csv各ファイルの中身
docker-compose.ymlファイルの中身
version: '3' services: mysql: image: mysql:latest environment: #イメージの起動時に作成するデータベースの名前 MYSQL_DATABASE: yudb #このユーザはMYSQL_DATABASE変数で指定されたデータベースに対してスーパーユーザとしての権限(GRANT ALL)を保持する MYSQL_USER: mysqluser #MYSQL_USERのパスワード MYSQL_PASSWORD: MySQLPass00 # MySQLにおけるスーパーユーザであるrootアカウントに設定するためのパスワード MYSQL_ROOT_PASSWORD: MySQLRootPass00 ports: - "3306:3306" volumes: #- ./mysql/var_lib_mysql:/var/lib/mysql ← 起動するたびにMySQLのデータベースを初期化したいのでコメントアウトしておく # /docker-entrypoint-initdb.d/配下は、Dockerコンテナが初回起動(初期化)される際に1度だけ実行されるスクリプトなどを配置 # *.sh / *.sql / *.sql.gzの拡張子のファイルはファイル名の昇順に実行される。 - ./mysql/init:/docker-entrypoint-initdb.d10_ddl.sqlファイルの中身
create table if not exists yudb.m_sample( `code` char(3) not null, `name` varchar(80) not null, primary key(`code`) ) engine=innodb default charset=utf8; LOAD DATA LOCAL INFILE '/docker-entrypoint-initdb.d/data.csv' INTO TABLE yudb.m_sample FIELDS TERMINATED BY ',' ENCLOSED BY '"';data.csvファイルの中身
"001","test001" "002","test002" "003","test003" "004","test004"docker-composeでmysqlのコンテナを起動するとエラーが発生
docker-compose upコマンドを実行してコンテナを起動$ docker-compose up -d Creating network "docker-mysql8-err_default" with the default driver Creating docker-mysql8-err_mysql_1 ... done
docker-compose psコマンドを実行して状態を確認$ docker-compose ps Name Command State Ports ------------------------------------------------------------------------ docker-mysql8-err_mysql_1 docker-entrypoint.sh mysqld Exit 1
docker-compose logsコマンドを実行してログを確認$ docker-compose logs Attaching to docker-mysql8-err_mysql_1 mysql_1 | 2019-12-10 22:45:36+00:00 [Note] [Entrypoint]: Entrypoint script for MySQL Server 8.0.18-1debian9 started. mysql_1 | 2019-12-10 22:45:36+00:00 [Note] [Entrypoint]: Switching to dedicated user 'mysql' mysql_1 | 2019-12-10 22:45:36+00:00 [Note] [Entrypoint]: Entrypoint script for MySQL Server 8.0.18-1debian9 started. mysql_1 | 2019-12-10 22:45:36+00:00 [Note] [Entrypoint]: Initializing database files mysql_1 | 2019-12-10T22:45:36.889727Z 0 [Warning] [MY-011070] [Server] 'Disabling symbolic links using --skip-symbolic-links (or equivalent) is the default. Consider not using this option as it' is deprecated and will be removed in a future release. mysql_1 | 2019-12-10T22:45:36.889859Z 0 [System] [MY-013169] [Server] /usr/sbin/mysqld (mysqld 8.0.18) initializing of server in progress as process 44 mysql_1 | 2019-12-10T22:45:38.650792Z 5 [Warning] [MY-010453] [Server] root@localhost is created with an empty password ! Please consider switching off the --initialize-insecure option. mysql_1 | 2019-12-10 22:45:42+00:00 [Note] [Entrypoint]: Database files initialized mysql_1 | 2019-12-10 22:45:42+00:00 [Note] [Entrypoint]: Starting temporary server mysql_1 | 2019-12-10T22:45:42.613856Z 0 [Warning] [MY-011070] [Server] 'Disabling symbolic links using --skip-symbolic-links (or equivalent) is the default. Consider not using this option as it' is deprecated and will be removed in a future release. mysql_1 | 2019-12-10T22:45:42.614006Z 0 [System] [MY-010116] [Server] /usr/sbin/mysqld (mysqld 8.0.18) starting as process 93 mysql_1 | 2019-12-10T22:45:43.302666Z 0 [Warning] [MY-010068] [Server] CA certificate ca.pem is self signed. mysql_1 | 2019-12-10T22:45:43.307378Z 0 [Warning] [MY-011810] [Server] Insecure configuration for --pid-file: Location '/var/run/mysqld' in the path is accessible to all OS users. Consider choosing a different directory. mysql_1 | 2019-12-10T22:45:43.342347Z 0 [System] [MY-010931] [Server] /usr/sbin/mysqld: ready for connections. Version: '8.0.18' socket: '/var/run/mysqld/mysqld.sock' port: 0 MySQL Community Server - GPL. mysql_1 | 2019-12-10 22:45:43+00:00 [Note] [Entrypoint]: Temporary server started. mysql_1 | 2019-12-10T22:45:43.361902Z 0 [System] [MY-011323] [Server] X Plugin ready for connections. Socket: '/var/run/mysqld/mysqlx.sock' mysql_1 | Warning: Unable to load '/usr/share/zoneinfo/iso3166.tab' as time zone. Skipping it. mysql_1 | Warning: Unable to load '/usr/share/zoneinfo/leap-seconds.list' as time zone. Skipping it. mysql_1 | Warning: Unable to load '/usr/share/zoneinfo/zone.tab' as time zone. Skipping it. mysql_1 | Warning: Unable to load '/usr/share/zoneinfo/zone1970.tab' as time zone. Skipping it. mysql_1 | 2019-12-10 22:45:47+00:00 [Note] [Entrypoint]: Creating database yudb mysql_1 | 2019-12-10 22:45:47+00:00 [Note] [Entrypoint]: Creating user mysqluser mysql_1 | 2019-12-10 22:45:47+00:00 [Note] [Entrypoint]: Giving user mysqluser access to schema yudb mysql_1 | mysql_1 | 2019-12-10 22:45:47+00:00 [Note] [Entrypoint]: /usr/local/bin/docker-entrypoint.sh: running /docker-entrypoint-initdb.d/10_ddl.sql mysql_1 | ERROR 1148 (42000) at line 7: The used command is not allowed with this MySQL versionログを確認すると、ログの最終行に
mysql_1 | ERROR 1148 (42000) at line 7: The used command is not allowed with this MySQL versionというログが出力されていました。
調べてみると、MySQL8以降では、デフォルトのMySQLサーバーのままだとLOAD DATA LOCAL INFILEによるCSVファイルのロードが出来ないようです。https://dev.mysql.com/doc/refman/8.0/en/load-data-local.html
解決方法
LOAD DATA LOCAL INFILEによるCSVファイルのロードを実行するには、mysqlへログインする際に--local-infile=1のオプションを意図的に付けてログインしないといけないということなので、shellを作って意図的にそのオプションを付けてログインし、LOAD DATA LOCAL INFILEを実行することでこの問題は解消できます。ディレクトリ構成は以下の通り。
. ├── docker-compose.yml └── mysql └── init ├── 10_ddl.sql ├── 20_data_load.sh ← このファイルを追加 └── data.csv
20_data_load.shファイルを追加します。mysql -uroot -pMySQLRootPass00 --local-infile=1 -e "LOAD DATA LOCAL INFILE '/docker-entrypoint-initdb.d/data.csv' INTO TABLE yudb.m_sample FIELDS TERMINATED BY ',' ENCLOSED BY '\"' LINES TERMINATED BY '\n'"
10_ddl.sqlファイルのLOADコマンドをコメントアウトしておきます。set global local_infile = 1; create table if not exists yudb.m_sample( `code` char(3) not null, `name` varchar(80) not null, primary key(`code`) ) engine=innodb default charset=utf8; -- LOAD DATA LOCAL INFILE '/docker-entrypoint-initdb.d/data.csv' INTO TABLE yudb.m_sample FIELDS TERMINATED BY ',' ENCLOSED BY '"';
docker-compose up -dを実行後、しばらくしてからdocker-compose psを実行すると、今度は正常にMySQLのコンテナが起動していることがわかる。$ docker-compose up -d Creating network "docker-mysql8-err_default" with the default driver Creating docker-mysql8-err_mysql_1 ... done $ docker-compose ps Name Command State Ports --------------------------------------------------------------------------------------------------- docker-mysql8-err_mysql_1 docker-entrypoint.sh mysqld Up 0.0.0.0:3306->3306/tcp, 33060/tcp念のためロードしたデータがちゃんと入っているかも確認してみる。
$ docker-compose exec mysql bash root@46a05fff4d72:/# root@46a05fff4d72:/# mysql -umysqluser -pMySQLPass00 mysql: [Warning] Using a password on the command line interface can be insecure. Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 8 Server version: 8.0.18 MySQL Community Server - GPL Copyright (c) 2000, 2019, Oracle and/or its affiliates. All rights reserved. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql> connect yudb Reading table information for completion of table and column names You can turn off this feature to get a quicker startup with -A Connection id: 9 Current database: yudb mysql> show tables; +----------------+ | Tables_in_yudb | +----------------+ | m_sample | +----------------+ 1 row in set (0.00 sec) mysql> select * from m_sample; +------+---------+ | code | name | +------+---------+ | 001 | test001 | | 002 | test002 | | 003 | test003 | | 004 | test004 | +------+---------+ 4 rows in set (0.00 sec)とりあえずデータも無事にロードされているので、これでエラーの問題は解消できることがわかりました。
- 投稿日:2019-12-11T07:46:37+09:00
コンテナ超初心者向け勉強会で利用している資料を公開します
はじめに
現在、ディップさんに週1回程度お邪魔して、(個人の趣味で)定期的にコンテナに関する勉強会を開催しています。
本記事では、コンテナ導入のメリットを説明する際に利用している資料を公開します。
注) この記事でことわりがない場合、「コンテナ」は「Dockerコンテナ」を指します。本記事はディップ Advent Calendar 2019の記事です。
コンテナ技術とコンテナイメージ
コンテナ技術とは、プロセスを隔離して実行するための技術です。
コンテナイメージとは「アプリケーションコードと依存関係を一つにまとめたファイル」です。
コンテナイメージを動かして、隔離されたプロセスになったものをコンテナと呼ばれます。
https://www.docker.com/resources/what-containerVMとの違い
VMは一つ一つにゲストOSが必要です。
コンテナは、プロセスを隔離してHostOS上で動作させることができます。
そのためオーバーヘッドや利用するリソースも少なく、高速に起動します。
https://www.docker.com/resources/what-containerコンテナを導入するメリット
新人向け
- アプリケーションコードと依存関係を一つのイメージにまとめられる
- 依存パッケージによるエラーがなくなる
- 最初の環境構築がめっちゃ楽になる
- 複雑なインストール手順を踏まなくていい
- 公式のコンテナイメージを利用すると、だいたいの設定は完了する
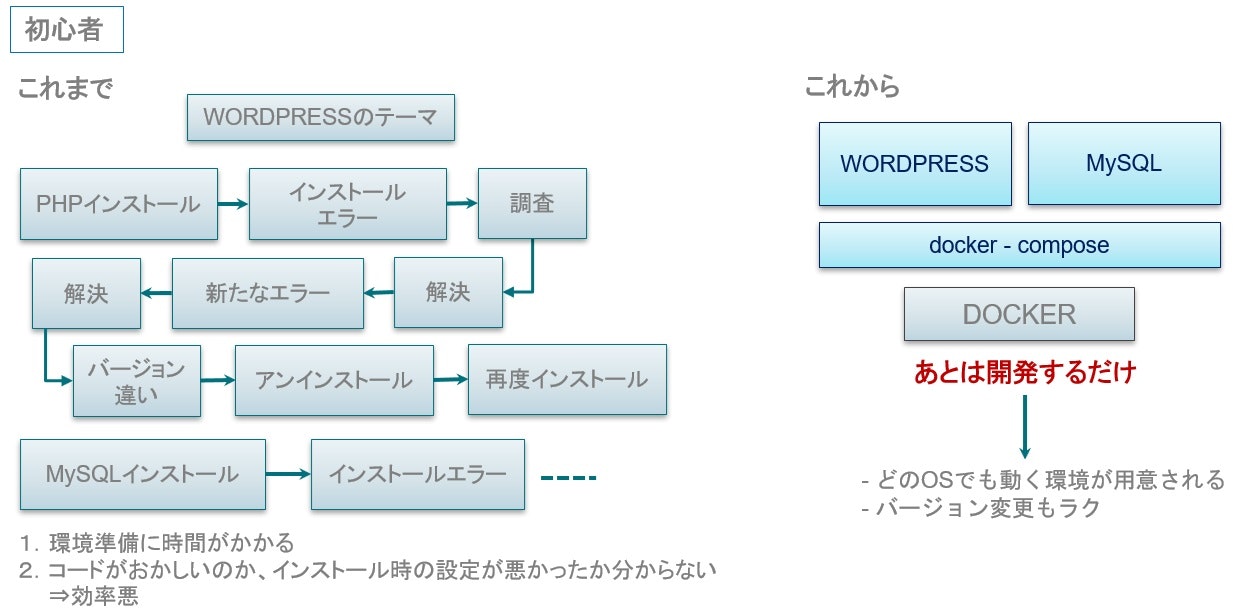
サービス開発者向け
- 開発環境の構築がコードベースで行える
- 開発開始までの時間が短い
- VMに比べてコンピュータリソースを有効活用できる
- 既存の環境に影響を与えず、新しい環境を利用できる
- 実際にプログラムをインストールしなくてよい
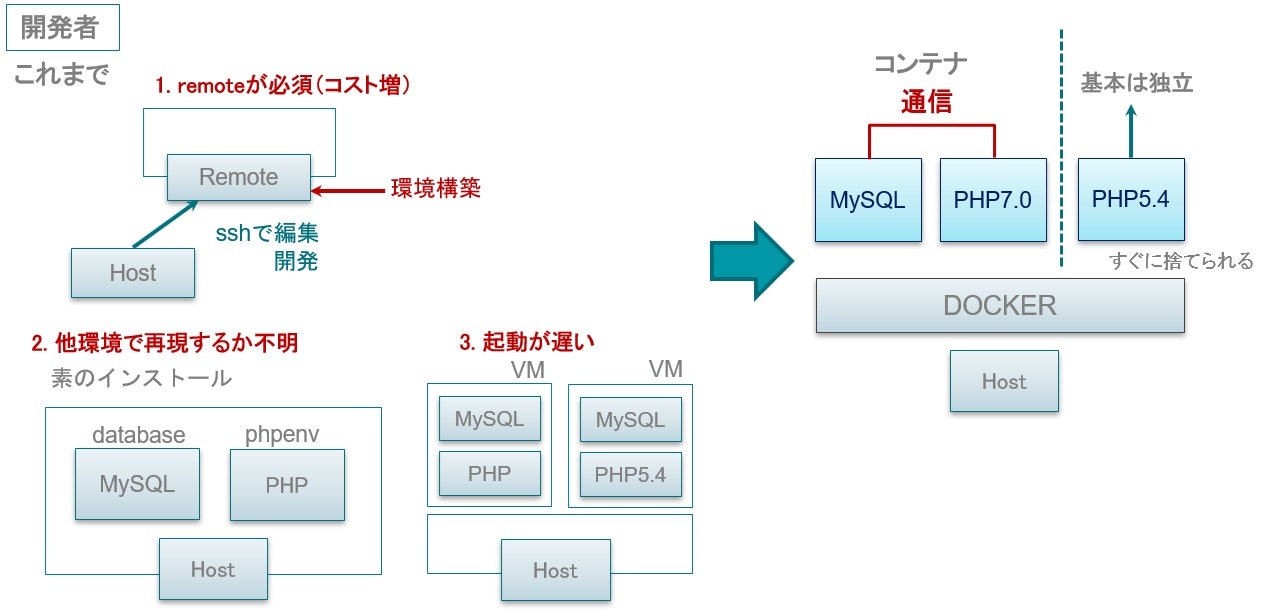
PHP5.6と7.3のどちらもインストールせずに、各バージョンのコードを試すことができます。
https://github.com/tomoyamachi/docker-tutorial/blob/master/00-introduction-ja.md# ver5.6環境で実行 $ docker run -it -v $(pwd)/00-php-sample:/app \ --rm php:5.6-cli-alpine \ php /app/main.php NULL # ver7.3環境で実行 $ docker run -it -v $(pwd)/00-php-sample:/app \ --rm php:7.3-cli-alpine \ php /app/main.php Fatal error: Redefinition of parameter $void in /app/main.php on line 3インフラ担当向け
- The Twelve-Factor Apps の文脈に沿っている
- コードベースでインフラを管理できる
- OSへの依存度を減らし、移植しやすくする
- 開発環境と本番環境の差異を最小限 → CI/CDの促進
- スケールアップしやすい
コンテナベースのオーケストレーションサービスが複数存在する
宣言的アプローチ
- クラスターの状態をフィードバックして、宣言された状態に自己回復する
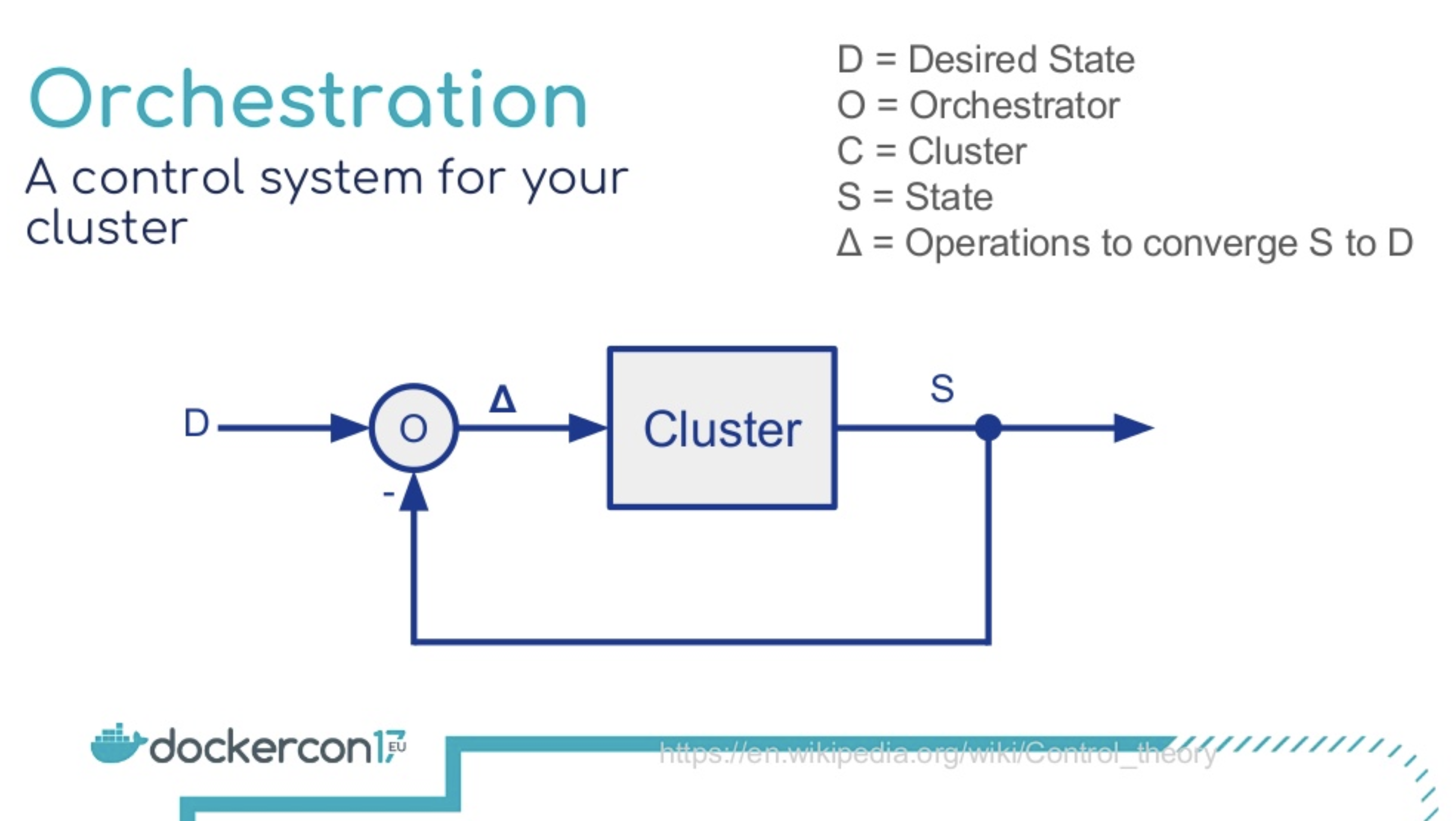
- https://www.slideshare.net/Docker/container-orchestration-from-theory-to-practice/
Kubernetes
Docker-Swarm
セキュリティ担当向け
- CI/CDを実行すると、自動でパッケージが最新のものになる
- アプリケーションに関するパッケージのアップデート非常に楽
- コンテナプロセスは非root権限で実行されるので、侵入されたときのリスクが下げられる
- アプリケーションコードと依存関係を一つのイメージにまとめた「イメージ」ごとに責任を分割できる → どこで利用されているかわからないパッケージ/ライブラリを減らせる
- ただし、Dockerやオーケストレーションツール(Kubernetesなど)に脆弱性が発見されることもある
FAQ
どういう原理で動くの?
Linuxカーネルの機能を組み合わせて動きます。
Mac / Windowsだと、Linuxカーネルの機能を小さくまとめたLinuxKitを動かしています。これまで覚えた知識は無駄になるの?
無駄になりません。
たとえば、コンテナ間のネットワーク通信では、veth(バーチャルイーサネットデバイス)を用いて通信を実現しています。また、iptablesなどを駆使してコンテナ間の名前解決を行っています。
トラブルシュートの際、結局Linuxカーネルの知識は必要になってきます。向いてないことはある?
たとえば以下の場合は向いてません。
複雑なモノリスアプリケーション
Dockerは1プロセスごとにコンテナを分けることが推奨されます。そのため、複雑すぎてプロセスの分離が難しいものは向いていません。その場合は、LXCなど1コンテナで複数プロセス起動が許されているコンテナ技術をつかえます。特殊なデバイス/リソースを利用する
たとえば、現在NVIDIA以外のGPUを利用できません。特殊なリソースを利用したい場合、対応できないことがあります。次のステップ
Docker Playgroundで実際にさわってみる
- DockerHubのアカウントを作成
- Docker Playground にDockerHubアカウントでログインする
- 「ADD NEW INSTANCE」でインスタンスをつくって、dockerコマンドを実行する
- https://events.docker.com/learndocker-workshop/ の手順に沿ってコマンドを打つ
宣伝
PHPer向けのDockerチュートリアルを作成しました。
日本語で、さっとDockerを動かしたい人はこちらもどうぞ。まとめ
実際の勉強会だと、最初の10分くらいで概要を説明して、2時間くらいハンズオン形式で実際にdockerを触っていきます。
うちの会社でもやってほしい、みたいなのがあればご相談ください。


- 投稿日:2019-12-11T07:46:37+09:00
コンテナ超初心者向けの社内勉強会で利用している資料を公開します
はじめに
現在、ディップさんに週1回程度お邪魔して、(個人の趣味で)定期的にコンテナに関する勉強会を開催しています。
本記事では、コンテナに触ったことがない人に対して、導入のメリットを説明するための資料を公開します。
注) この記事でことわりがない場合、「コンテナ」は「Dockerコンテナ」を指します。本記事はディップ Advent Calendar 2019の記事です。
コンテナ技術とコンテナイメージ
コンテナ技術とは、プロセスを隔離して実行するための技術です。
コンテナイメージ(イメージ)とは、「アプリケーションコードと依存関係を一つにまとめたファイル」です。
コンテナイメージを元に実行された、隔離されたプロセスになったものをコンテナと呼ばれます。
https://www.docker.com/resources/what-containerVMとの違い
VMは一つ一つにゲストOSが必要です。
コンテナは、プロセスを隔離してHostOS上で動作させることができます。
そのためオーバーヘッドや利用するリソースも少なく、高速に起動します。
https://www.docker.com/resources/what-containerコンテナを導入するメリット
新人向け
- アプリケーションコードと依存関係を一つのイメージにまとめられる
- 依存パッケージによるエラーがなくなる
- 最初の環境構築がめっちゃ楽になる
- 複雑なインストール手順を踏まなくていい
- 公式のコンテナイメージを利用すると、だいたいの設定は完了する
サービス開発者向け
- 開発環境の構築がコードベースで行える
- 開発開始までの時間が短い
- VMに比べてコンピュータリソースを有効活用できる
- 既存の環境に影響を与えず、新しい環境を利用できる
- 実際にプログラムをインストールしなくてよい
PHP5.6と7.3のどちらもインストールせずに、各バージョンのコードを試すことができます。
https://github.com/tomoyamachi/docker-tutorial/blob/master/00-introduction-ja.md# ver5.6環境で実行 $ docker run -it -v $(pwd)/00-php-sample:/app \ --rm php:5.6-cli-alpine \ php /app/main.php NULL # ver7.3環境で実行 $ docker run -it -v $(pwd)/00-php-sample:/app \ --rm php:7.3-cli-alpine \ php /app/main.php Fatal error: Redefinition of parameter $void in /app/main.php on line 3インフラ担当向け
- The Twelve-Factor Apps の文脈に沿っている
- コードベースでインフラを管理できる
- OSへの依存度を減らし、移植しやすくする
- 開発環境と本番環境の差異を最小限 → CI/CDの促進
- スケールアップしやすい
コンテナベースのオーケストレーションサービスが複数存在する
宣言的アプローチ
- クラスターの状態をフィードバックして、宣言された状態に自己回復する
- https://www.slideshare.net/Docker/container-orchestration-from-theory-to-practice/
Kubernetes
Docker-Swarm
セキュリティ担当向け
- CI/CDを実行すると、自動でパッケージが最新のものになる
- アプリケーションに関するパッケージのアップデート非常に楽
- コンテナプロセスは非root権限で実行されるので、侵入されたときのリスクが下げられる
- アプリケーションコードと依存関係を一つのイメージにまとめた「イメージ」ごとに責任を分割できる → どこで利用されているかわからないパッケージ/ライブラリを減らせる
- ただし、Dockerやオーケストレーションツール(Kubernetesなど)に脆弱性が発見されることもある
FAQ
どういう原理で動くの?
Linuxカーネルの機能を組み合わせて動きます。
Mac / Windowsだと、Linuxカーネルの機能を小さくまとめたLinuxKitを動かしています。これまで覚えた知識は無駄になるの?
無駄になりません。
たとえば、コンテナ間のネットワーク通信では、veth(バーチャルイーサネットデバイス)を用いて通信を実現しています。また、iptablesなどを駆使してコンテナ間の名前解決を行っています。
伝統的な手法を仮想的に行っていることが多いので、トラブルシュートの際は、これまでの知識が必要になってきます。向いてないことはある?
たとえば以下の場合は向いてません。
複雑なモノリスアプリケーション
Dockerは1プロセスごとにコンテナを分けることが推奨されます。そのため、複雑すぎてプロセスの分離が難しいものは向いていません。その場合は、LXCなど1コンテナで複数プロセス起動が許されているコンテナ技術をつかえます。特殊なデバイス/リソースを利用する
たとえば、現在NVIDIA以外のGPUを利用できません。特殊なリソースを利用したい場合、対応できないことがあります。次のステップ
Docker Playgroundで実際にさわってみる
- DockerHubのアカウントを作成
- Docker Playground にDockerHubアカウントでログインする
- 「ADD NEW INSTANCE」でインスタンスをつくって、dockerコマンドを実行する
- https://events.docker.com/learndocker-workshop/ の手順に沿ってコマンドを打つ
宣伝
PHPer向けのDockerチュートリアルを作成しました。
日本語で、さっとDockerを動かしたい人はこちらもどうぞ。まとめ
実際の勉強会だと、最初の10分くらいで概要を説明して、2時間くらいハンズオン形式で実際にdockerを触っていきます。
うちの会社でもやってほしい、みたいなのがあればご相談ください。
- 投稿日:2019-12-11T07:46:37+09:00
なぜコンテナを導入するのか ~ 各職種への説得材料をまとめる
はじめに
本記事はディップ Advent Calendar 2019の記事です。
現在、ディップさんに週1回程度お邪魔して、(個人の趣味で)定期的にコンテナに関する勉強会を開催しています。
本記事では、コンテナに触ったことがない人に対して、コンテナ利用時のメリットを説明するための資料を公開します。
なお、ディップ社内ではPHPが利用している部署が多いので、PHPに関する記述が多いです。
注) この記事でことわりがない場合、「コンテナ」は「Dockerコンテナ」を指します。コンテナ技術とコンテナイメージ
コンテナ技術とは、プロセスを隔離して実行するための技術です。
コンテナイメージ(イメージ)とは、「アプリケーションコードと依存関係を一つにまとめたファイル」です。
コンテナイメージを元に実行された、隔離されたプロセスになったものをコンテナと呼ばれます。
https://www.docker.com/resources/what-containerVMとの違い
VMは一つ一つにゲストOSが必要です。
コンテナは、プロセスを隔離してHostOS上で動作させることができます。
そのためオーバーヘッドや利用するリソースも少なく、高速に起動します。
https://www.docker.com/resources/what-containerコンテナを導入するメリット
新人教育関連
- アプリケーションコードと依存関係を一つのイメージにまとめられる
- 依存パッケージによるエラーがなくなる
- 最初の環境構築がめっちゃ楽になる
- 複雑なインストール手順を踏まなくていい
- 公式のコンテナイメージを利用すると、だいたいの設定は完了する
サービス開発者
- 開発環境の構築がコードベースで行える
- 開発開始までの時間が短い
- VMに比べてコンピュータリソースを有効活用できる
- 既存の環境に影響を与えず、新しい環境を利用できる
- 実際にプログラムをインストールしなくてよい
以下の例では、PHPをインストールせず、PHP5.6とPHP7.3の各バージョンでPHPのコードを動かしています。
https://github.com/tomoyamachi/docker-tutorial/blob/master/00-introduction-ja.md# ver5.6環境で実行 $ docker run --rm -it -v $(pwd)/00-php-sample:/app \ --rm php:5.6-cli-alpine \ php /app/main.php NULL # ver7.3環境で実行 $ docker run --rm -it -v $(pwd)/00-php-sample:/app \ --rm php:7.3-cli-alpine \ php /app/main.php Fatal error: Redefinition of parameter $void in /app/main.php on line 3インフラ担当向け
- The Twelve-Factor Apps の文脈に沿っている
- コードベースでインフラを管理できる
- OSへの依存度を減らし、移植しやすくする
- 開発環境と本番環境の差異を最小限 → CI/CDの促進
- スケールアップしやすい
コンテナベースのオーケストレーションサービスが複数存在する
宣言的アプローチ
- クラスターの状態をフィードバックして、宣言された状態に自己回復する
- https://www.slideshare.net/Docker/container-orchestration-from-theory-to-practice/
Kubernetes
Docker-Swarm
セキュリティ担当向け
- CI/CDを実行すると、自動でパッケージが最新のものになる
- アプリケーションに関するパッケージのアップデート非常に楽
- コンテナプロセスは非root権限で実行されるので、侵入されたときのリスクが下げられる
- アプリケーションコードと依存関係を一つのイメージにまとめた「イメージ」ごとに責任を分割できる → どこで利用されているかわからないパッケージ/ライブラリを減らせる
- ただし、Dockerやオーケストレーションツール(Kubernetesなど)に脆弱性が発見されることもある
FAQ
どういう原理で動くの?
Linuxカーネルの機能を組み合わせて動きます。
Mac / Windowsだと、Linuxカーネルの機能を小さくまとめたLinuxKitを動かしています。これまで覚えた知識は無駄になるの?
無駄になりません。
たとえば、コンテナ間のネットワーク通信では、veth(バーチャルイーサネットデバイス)を用いて通信を実現しています。また、iptablesなどを駆使してコンテナ間の名前解決を行っています。
伝統的な手法を仮想的に行っていることが多いので、トラブルシュートの際は、これまでの知識が必要になってきます。向いてないことはある?
たとえば以下の場合は向いてません。
複雑なモノリスアプリケーション
Dockerは1プロセスごとにコンテナを分けることが推奨されます。そのため、複雑すぎてプロセスの分離が難しいものは向いていません。その場合は、LXCなど1コンテナで複数プロセス起動が許されているコンテナ技術をつかえます。特殊なデバイス/リソースを利用する
たとえば、現在NVIDIA以外のGPUを利用できません。特殊なリソースを利用したい場合、対応できないことがあります。次のステップ
Docker Playgroundで実際にさわってみる
- DockerHubのアカウントを作成
- Docker Playground にDockerHubアカウントでログインする
- 「ADD NEW INSTANCE」でインスタンスをつくって、dockerコマンドを実行する
- https://events.docker.com/learndocker-workshop/ の手順に沿ってコマンドを打つ
宣伝
PHPer向けのDockerチュートリアルを作成しました。
日本語で、さっとDockerを動かしたい人はこちらもどうぞ。まとめ
実際の勉強会だと、最初の10分くらいで概要を説明して、2時間くらいハンズオン形式で実際にdockerを触っていきます。
うちの会社でもやってほしい、みたいなのがあればご相談ください。
- 投稿日:2019-12-11T05:55:35+09:00
【モダン技術習得への道】DockerでのNuxt.js / Vuetify開発環境構築による、迅速かつ効率的なプロジェクト作成
概要
- 今回はDockerを利用して、Nuxt.js / Vuetify開発環境を迅速に構築する。
- 下記の2つのフレームワークを利用することで、迅速に効率的におしゃれな画面を作成することができる。
結論
- 下記の2つのコマンドで、Nuxt.js / VuetifyのDocker開発環境が作成・起動され、迅速に開発を始められる。
docker-compose builddocker-compose up -d- 最終的なフォルダ構成は下記。
. ├── README.md ├── node_modules ├── nuxt.config.js ├── package.json ├── src └── yarn.lock └── .dockerignore └── Dockerfile └── docker-compose.yml
- Nuxt.js / Vuetifyを利用することにより、下記のような画面を素早く効率的に作成することができる。
環境
- Mac OS X 10.14.5
- Node.js v11.11.0
- yarn 1.17.3
- yarnを未導入の場合、こちらでインストールするかnpmでの置き換えを行う。
- Docker 19.03.1
- docker-compose 1.24.1
- Docker・docker-compose未導入の場合、こちらを参考にインストールしておく。
手順
雛形プロジェクトの作成 & ソースフォルダの整理
- 下記のコマンドを入力して、以下の作業を行う。
- Nuxt.js / Vuetifyの雛形プロジェクトの作成
- ソースフォルダの作成・整理
- ソースパスの明記
# フォルダ作成 & 移動 mkdir -p ~/work; cd $_ # 雛形プロジェクト作成 yarn create nuxt-app t_o_d_project # 作成段階で確認される質問には、下記で対応。 # UI frameworkの部分で「Vuetify」を選択 ? Project name t_o_d_project ? Project description My first-rate Nuxt.js project ? Author name xxxxxxx ? Choose the package manager Yarn ? Choose UI framework Vuetify.js ? Choose custom server framework None (Recommended) ? Choose Nuxt.js modules axios ? Choose linting tools eslint ? Choose test framework None ? Choose rendering mode Universal (SSR) # 作成後、プロジェクトフォルダへ移動 cd ~/work/t_o_d_project # ソースフォルダ(src/)作成 & ディレクトリ移動・整理 mkdir -p src; mv pages/ store/ static/ plugins/ components/ assets/ layouts/ middleware/ $_
- 上記の作業によって、下記のディレクトリ構成になっていることを確認する。
. ├── README.md ├── node_modules ├── nuxt.config.js ├── package.json ├── src │ ├── assets │ ├── components │ ├── layouts │ ├── middleware │ ├── pages │ ├── plugins │ ├── static │ └── store └── yarn.lock
- 確認後、プロジェクト直下の
nuxt.config.jsの中身を下記のように修正する。nuxt.config.jsexport default { mode: 'universal', srcDir: 'src', // こちらの1行を追加して、ソースディレクトリパスを明記。Docker関連ファイルの作成
- 作成した雛形プロジェクトをDocker環境で立ち上げるため、以下の3つのファイルをプロジェクト直下に作成する。
- Dockerfile
- docker-compose.yml
- .dockerignore
# Dockerfileとdocker-compose.ymlと.dockerignoreの作成 touch Dockerfile docker-compose.yml .dockerignore
- 上記の作業によって、下記の最終ディレクトリ構成になっていることを確認する。
. ├── README.md ├── node_modules ├── nuxt.config.js ├── package.json ├── src └── yarn.lock └── .dockerignore └── Dockerfile └── docker-compose.yml
- 作成した3つのファイルの中身を下記のようにする。
Dockerfile# 開発環境用 FROM node:10.17.0-alpine as dev-env # コンテナソースパス定義 ENV APP_HOME /app # 必要物インストール・不要物削除 RUN apk update --no-cache && \ apk add --no-cache vim && \ rm -rf /var/cache/apk/* # コンテナソースパス作成・移動 WORKDIR ${APP_HOME} # Nuxt Host定義 ENV NUXT_HOST 0.0.0.0 # パッケージインストール COPY package*.json ./ COPY yarn.lock ./ RUN yarn # コンテナ内へのソースディレクトリのコピー COPY . . # Port公開 EXPOSE 3000 # 開発サーバー立ち上げ CMD [ "yarn", "dev"]docker-compose.ymlversion: '3.7' services: web: # コンテナ指定 build: context: . target: dev-env ports: - 3000:3000 restart: always # ローカルプロジェクトと同期 volumes: - .:/app - /app/node_modules.dockerignorenode_modules .nuxt .DS_Storeイメージの作成・起動・確認
- 上記の関連ファイルの記述後、下記のコマンドをうち、Nuxt環境のDockerイメージの作成・起動を行う。
# Dockerfileがあるパスへ移動 cd ~/work/t_o_d_project # イメージの作成 docker-compose build # イメージの起動 docker-compose up -d
- イメージの起動後、ブラウザ上で
localhost:3000にアクセスして下記の画面になることを確認する。
参考
- 投稿日:2019-12-11T03:08:04+09:00
skaffold を用いた Windows での Kubernetes 開発環境構築
Skaffold とは
Google が開発した Kubernetes 向け開発支援ツールです。(公式HP)
ソースコードの変更をトリガーにイメージのビルド及びプッシュ、デプロイを行うので、
開発環境にていちいちイメージのビルドやらデプロイやらを手動でやらなくて済みます。更に開発言語が Go なので環境依存度が低く、Windows でも利用が可能です。
環境
- Windows 10 Pro
- Docker for Windows を導入するためには Pro エディション以上が必要となります。
必須条件
下記のアプリケーションが必要となります。
導入方法は先人たちの知恵がたくさんありますのでここでは割愛します。
- Git
- Go
- Docker for Windows
- Kubernetes を有効化する必要があります。
Skaffold の導入
Skaffold は Go で書かれたプログラムなのでビルドしてPATHを通すだけです。簡単ですね。
以降のコマンドは powershell を「管理者」で起動させ発行してください。# 作業用ディレクトリの作成 mkdir C:\work # Skaffold のビルド cd C:\work git clone https://github.com/GoogleCloudPlatform/skaffold go build .\cmd\skaffold\skaffold.goビルドが終われば、カレントディレクトリに「skaffold.exe」が作成されます。
これにPATHを通します。# Skaffold コマンドを移動 mkdir C:\Skaffold mv .\skaffold.exe C:\skaffold\ # 環境変数の設定 $SystemPath = [System.Environment]::GetEnvironmentVariable("Path", "Machine") $SystemPath += ";C:\Skaffold" [System.Environment]::SetEnvironmentVariable("Path", $SystemPath, "Machine")以上でSkaffold の導入は完了です。
Let's Try
導入したなら実際に触ってみましょう!
ありがたいことにサンプルが用意されているのでそれを利用します。
サンプルはさきほどクローンしたレポジトリの中にあります。cd C:\work\skaffold\examples\getting-startedサンプルファイルの説明
- skaffold.yaml
- Skaffold の設定ファイル
ここに記載された情報を基にビルド、プッシュ、デプロイを行います。skaffold.yamlapiVersion: skaffold/v1 kind: Config build: artifacts: - image: gcr.io/k8s-skaffold/skaffold-example deploy: kubectl: manifests: - k8s-*
- apiVersion
- おまじない(怒られそう
- kind
- おまじない(怒られそう
- build - artifacts
- プッシュする際のイメージ名称
- deploy - kubectl - manifests
- デプロイする Kubernetes のマニフェスト
ビルド終了後、ここで指定したマニフェストが apply されます。
この例では「k8s-」で始まるマニフェストファイルが全て対象となります。実際に動かしてみよう
実際にサンプルを利用して skaffold の動作を確認してみましょう。
# サンプル用ディレクトリへ移動 cd C:\work\skaffold\examples\getting-started # 開発モードで起動 skaffold.exe dev開発モードで起動すると下記のような表示になり、podが起動し変更を待ち受けた状態になります。
- pod/getting-started created [33mWatching for changes...[0m [91m[getting-started] [0mHello world!この状態で main.go を書き換えてみましょう。
試しに「Hello world!」を「Hello Skaffold world!」に変更してみました![91m[getting-started] [0mHello world! [91m[getting-started] [0mHello world! [91m[getting-started] [0mHello world! [34mGenerating tags...[0m [34m - gcr.io/k8s-skaffold/skaffold-example -> [0mgcr.io/k8s-skaffold/skaffold-example:v1.0.0-143-g3f2a7ae2-dirty [34mChecking cache...[0m [34m - gcr.io/k8s-skaffold/skaffold-example: [0m[33mNot found. Building[0m [34mFound [docker-desktop] context, using local docker daemon. [0m[34mBuilding [gcr.io/k8s-skaffold/skaffold-example]... [0mSending build context to Docker daemon 3.072kB Step 1/6 : FROM golang:1.12.9-alpine3.10 as builder ---> e0d646523991 Step 2/6 : COPY main.go . ---> 8aaae19f0631 Step 3/6 : RUN go build -o /app main.go ---> Running in 021cefa024cb ---> 144dbc0b32f7 Step 4/6 : FROM alpine:3.10 ---> 965ea09ff2eb Step 5/6 : CMD ["./app"] ---> Using cache ---> d4a076e9ef1b Step 6/6 : COPY --from=builder /app . ---> df3ff8885e21 Successfully built df3ff8885e21 Successfully tagged gcr.io/k8s-skaffold/skaffold-example:v1.0.0-143-g3f2a7ae2-dirty [34mTags used in deployment:[0m [34m - gcr.io/k8s-skaffold/skaffold-example -> [0mgcr.io/k8s-skaffold/skaffold-example:df3ff8885e21c3152744f85d88c1f19e1cc80746d552949c14afaada225e63e1 [32m local images can't be referenced by digest. They are tagged and referenced by a unique ID instead[0m [34mStarting deploy...[0m - pod/getting-started configured [33mWatching for changes...[0m [91m[getting-started] [0mHello Skaffold world! [91m[getting-started] [0mHello Skaffold world! [91m[getting-started] [0mHello Skaffold world!おぉ、すげぇ。
変更をトリガーにビルド、プッシュ、デプロイが走り、
見事に出力内容が変更されました。
こんな感じでファイルを変更するだけで kubernetes の環境に反映されるので作業が非常に楽になりますね!お掃除
お掃除がさらに楽!
Ctrl + C を押す!それだけ!
- 投稿日:2019-12-11T00:53:47+09:00
code-server ローカル環境篇 (10) おまけ
これは、2019年 code-server に Advent Calender の 第9日目の記事です。今回も、code-server って何だろう?と言う事を解説していきます。
(1) code-server って何?
(2) Dockerで独自のcode-server 環境を作って見る
(3) VSCode の Plugin を 利用してみる
(4) DBなども含めたMVC環境を用意してみよう (1)
(5) DBなども含めたMVC環境を用意してみよう (2)
(6) DBなども含めたMVC環境を用意してみよう (3)
(7) DBなども含めたMVC環境を用意してみよう (4)
(8) DBなども含めたMVC環境を用意してみよう (5)
(9) DBなども含めたMVC環境を用意してみよう (6)
(10) おまけ(..) ローカルで、DBなどの環境も含めて構築するには
(..) オンライン上に置くには?
(..) K8Sなどの最近の流行りの環境と連携するには?
(..) Code-Serverを改造して、より良くしたいローカル環境篇 を通して、DB と アプリ と VSCode を含む開発環境を、Docker-Composeで固めて提供できるようになりました。
WebFrameWork を用いた開発環境などは、組めるようになったのではないでしょうか。
オンライン篇と魔改造篇に進むわけですが、Docker について、補足していきたいと思います。今回の何?
Image として 固めて再利用できる
開発環境を固めたい!!
Dockerfile を書いたとはいえ、次に必ず Docker Image の Build が成功するとは限りません。
一度、ビルドに成功したイメージは、使いまわしましょう。
Python の開発環境があるとします。
FROM python:3.8.0-buster RUN apt-get update # code-server を取得するのに wget を install しておく RUN apt-get install -y wget # 作業ディレクトリを /works にする。どこでも良いです WORKDIR /works # code-server のバイナリーを取得 RUN wget https://github.com/cdr/code-server/releases/download/2.1692-vsc1.39.2/code-server2.1692-vsc1.39.2-linux-x86_64.tar.gz # code-server を /works 配下に解凍する RUN tar -xzf code-server2.1692-vsc1.39.2-linux-x86_64.tar.gz -C ./ --strip-components 1 WORKDIR /works/app ENV PYTHONPATH=/works/app # python の plugin をインストール RUN /works/code-server --install-extension ms-python.python RUN /usr/local/bin/python -m pip install -U pylint --user # デフォルトは、/works/app で起動するようにする。 CMD [ "/works/code-server", "--allow-http", "--auth", "none", "--port", "8443", "/works/app"]
$ docker build -t for_python .としてビルドしてあげれば、以降は、$ docker run -it for_python bashといった感じで使えます。この、Image を、他の人と共有するには、Docker Hub が便利です。
https://hub.docker.com/会員登録後、作成したImage を公開することができます。公開してみましょう。
リポジトリーに配置しよう
まずは、Loginします。
$ docker login -u kyorohiro Password: Login Succeededビルドして、Pushしてみましょう
# rename $ docker tag for_python kyorohiro/for_python:latest # push $ docker push kyorohiro/for_python:latest $ docker push kyorohiro/for_python:latest The push refers to repository [docker.io/kyorohiro/for_python] 64a79ea89615: Pushing [============> ] 9.104MB/11.06MB 72d671b5ce06: Pushing [=> ] 6.086MB/195MB 36788bc3e719: Pushed 1ca79cb1c3f8: Pushing [==> ] 8.901MB/182.6MB 9a5303639ce9: Pushing [==> ] 2.46MB/47.3MB 14f67da8f102: Pushing 1.536kB 4f67a1129031: Waiting a4371f75e248: Waiting 00947a3aa859: Waiting 7290ddeeb6e8: Waiting d3bfe2faf397: Waiting cecea5b3282e: Waiting以降は、
docker pull kyorohiro/for_pythonとして Build 済みの Image を取得できるようになります。Dockerfileに書かれていない内容も、Image化できる。
独自の Docker Image を Dockerfile を Build するだけではありません。
実際に手作業で行った作業の結果も Docker Image 化 できます。試してみましょう
$ docker run -it ubuntu bash # 以降は Docker の中 $ curl www.google.com bash: curl: command not found $ apt-get update $ apt-get install -y curl $ curl www.google.com <!doctype html><html itemscope="" ... lang="ja"><head>... $ exitでは、この終了したContainerを再起動してみましょう
# container 一覧を取得 $ docker ps -a | grep ubuntu 8269ec081004 ubuntu "bash" 4 minutes ago Exited (0) 46 seconds ago agitated_goldberg # 再開 $ docker start 8269ec081004 # Bashを起動 $ docker exec -it 8269ec081004 bash # Curl も動きます $ curl www.google.com次は、Image化してみましょう
# 起動しているか確認 $ docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 8269ec081004 ubuntu "bash" 7 minutes ago Up 3 seconds agitated_goldberg # 起動しているなら停止 $ docker stop 8269ec081004 # Image化する $ docker commit 8269ec081004 manual_test sha256:ec4c80afae824f4b3bf5c6b4997e30cdebb7264d80f0144dff9af07e38bbe73b # 確認 $ docker image ls manual_test REPOSITORY TAG IMAGE ID CREATED SIZE manual_test latest ec4c80afae82 49 seconds ago 106MBおっ、Image 化できましたね!! これで、再度ビルドする事なくアレコレできますね..
次回
オンライン篇に入ります。
PS