- 投稿日:2019-12-11T23:39:44+09:00
AWS Amplifyで高負荷に耐えられるWebサイトを早急に立てて、Webフロントコーダーが運用を回した話。
はじめに
こんにちは、AWS Amplify Advent Calendar 2019の12日目担当、Oceans株式会社 竹本と申します。
クリスマスまであと2週間、アドベンドカレンダーと共にクリスマスを一緒に過ごせる素敵な方と出逢わなければならない私のカウントダウンも進行しており大変焦っております。さて、今回は「高負荷に耐えられるWebサイトを早急に立てて、Webフロントコーダーが運用回せるようにしたい!」と言う焦っている方向けに、弊社の事例をお伝えします。
それぞれの詳細な手順は他の方がたくさん上げて下さっていますので割愛しつつ、組み合わせて商用環境で使ってますよと言う事例を参考にして頂ければと思います。
(静的Webサイトのホスティングのお話ですので、動的ゴリゴリを期待されてしまった方は読み飛ばして頂けますと幸いです。)背景
2019年のある日、私は入社したてのO社でとんでもない光景を目にしてしまいました。
弊社で提供しているKIZUNAのブランドWebサイトが共用レンタルサーバーで動いていたのです。
- うちのサービス海外にも出してるしレイテンシまずくね
- バックアップやバージョン管理してないし、間違えてアップしたり消したり事故るじゃん
- サーバのスペック的にもスパイクのようなアクセスに耐えられ無いよね
- 共有サーバーで高負荷にさせると、相乗りしている他社さんも影響受けるよね
と恐ろしい事に気付いてしまいました。
しかし、
- CMSや静的サイトジェネレーターへ移行している余裕はない。
- これまで通りWebフロントコーダーがHTMLをアップロードするだけの簡単な方法を使えないといけない
- AWS S3で簡単ホスティングもできるけど、いちいちファイルのアップロードは手間がかかりすぎる
うーん、どうしよう。
そうだ「AWS Amplify」を使おう。概要
商用で使うには不安がいっぱいな、FTPでアップロードする昔ながらのレンタル共用サーバー
から
商用で使う上で安心がいっぱいな、今風のCIによる静的サイトホスティング
への移行をAmplifyで実現しました。AWS Amplifyのメリット
全ての不安が解消されます。そう、AWS Amplifyならね。
うちのサービス海外にも出してるレイテンシまずくね
=> CDNで世界中からのアクセスでもレイテンシ問題解決
バックアップやバージョン管理してないし、間違えてアップしたり消したり事故るじゃん
=> AWS CodeCommitと連携したCI環境で、バージョン管理ができ、デプロイも自動
サーバのスペック的にもスパイクのようなアクセスに耐えられ無いよね
共有サーバーで高負荷にさせると、相乗りしている他社さんも影響受けるよね=> フルマネージドされた環境でAWSに全部お任せで大丈夫
アカウント管理
ここからは実際にどのような使い方をしたかです。
AWSコンソールユーザーアカウント
今回はWebフロントコーダーが運用します。
そこで、コンソールユーザーアカウントはこのようにしました。
- MFAやスイッチロールは使わず、特定のAWSアカウント上に運用者用ユーザを作成しパスワード認証のみ
- その運用者ユーザが使えるサービスをAmplify、CodeCommit、自身のIAMのみに限定
扱う情報はブランドWebサイトのみで、個人情報など影響の大きい情報は含みませんでした。
いくつかのリスクは比較的小さいと判断し、運用者がログインに関して学習するコストを省く事を優先としました。
もちろん管理者アカウントはMFAとスイッチロールを使っています。AWS CodeCommitアカウント
AWS CodeCommitアカウントは、IAMのアカウントそのものとは異なります。
IAMより発行します。こちらもAWSコンソールユーザーアカウントと同様の考えで、SSHキー使わずパスワード認証としました。
構築
構築は知見のあるエンジニアが行いました。
AWS CodeCommitでソースコードを管理。
Githubをご存知であれば違和感なく触れるかと思います。
Webのツールよりリポジトリを作成します。リージョン
構築当時AWS Amplifyは東京リージョンには無かった事もあり、バージニア北部リージョンを使いました。
フロントはCloud Frontが入っている事もあり、レイテンシに懸念はありませんでした。AWS AmplifyとAWS CodeCommitを接続
ウィザードに従ってポチポチ選択するだけです。
正直簡単過ぎて驚きました。
ドメインの設定
AWS Amplifyより一般的なCNAMEレコードで判定する方法でドメインを設定できます。
ステージング環境の設定
事前に作ったWebページを確認できる環境を構築しました。
運用上異なるブランチでのコーディングは3つまでと限定し、「stg」「stg2」「stg3」を構築しました。
その枠に合わせて、AWS CodeCommitのブランチを切っています。
2019年10月にはAWS Amplifyに新しくPreviewsと言う機能が加わりました。
こちらを使えばもっと簡単にできるかもしれません。(すみません、まだ試せてません。)運用
運用はWebフロントコーダーが行います。
Gitクライアント
PC側のGitクライアントには、GUIで扱えるSourcetreeを使いました。
運用者には、サルでもわかるGit入門を読んでもらい概念を理解してもらった上で、Sourcereeの操作方法を教え込みました。ステージング環境への範囲
運用者にこれまで通りHTMLを編集してもらい、それをコミットの後、各リモートブランチにプッシュしてもらいます。
すると、プッシュをトリガーにAWS Amplifyが動き出し、デプロイが行われます。例えば、弊社のサービスKIZUNAではイニエスタ選手がアンバサダー就任となる一大イベントがありました。
それに向けて製作した特設ランディングページをリモートstgブランチへプッシュし、https://stg.kizuna-athletes.jpから確認を行っていました。商用環境への反映
ステージング環境への反映と同様に、ブランチだけ
masterとしてプッシュすると反映されます。例えば、
stgブランチで作業していた場合は、masterブランチへマージし、リモートのmasterブランチへプッシュし、商用環境へ反映を行っていました。まとめ
さて、今回はすごく初歩的なお話だったかと思います。
しかし、エンジニアを抱えられない現場では、こう言った状況も意外にあるのではないでしょうか。
この1年でAWS Amplifyの機能もますます拡充し、より痒いところに手が届くようになりました。
今後のAWS Amplifyの更なる拡充も期待しつつ、Webホスティングを実現する上での1つの候補として参考にして頂ければと思います。



- 投稿日:2019-12-11T22:44:31+09:00
ALBのIPを固定したい? GlobalAccelaratorを紹介するよ!
この記事は CBcloud Advent Calendar 2019 10日目の記事です。
CBcloud 徳盛です。最近オフィスで飲みながら仕事をすることが増えました。
今回は、AWSのGlobalAccelaratorについて書いていきたいと思います。このサービスにいきついた背景としては、ALBで運用している最中、「IP固定して」という依頼を早急に対応する必要があったことが始まりです。忙しい人向け要約
- リージョンを跨いだロードバランシングが可能なので、耐障害性を向上させることができる!
- GlobalAccelaratorにALBをぶら下げることができるので、これまでの環境を変えずにIPを固定できる
- ALBを複数ぶら下げることができるため、Blue-Green Deployができる
- weightの変更での1分以内にはほぼ全てのリクエストが切り替わるため、Blue-Green DeployするならEBのswap機能より使いやすい
- 2019年9月より、接続元IPアドレスを保持できるようになり、さらに便利になった
GlobalAccelarator(GA)とは
かなり端折って説明するとリージョン間のロードバランサーです。
が、実はそれ以外での使い道もあります。それと名前がかっこいい。ALB運用そのままにIPが固定できる
GAの特徴として、作成時に固定IPが二つ割り振られます。
また、ALB・NLB・EC2インスタンス・EIPをぶら下げることが可能なので、これまでALB運用していたサービスでも簡単にIPを固定することが可能になります。
Blue-Green Deployに利用できる
複数のALBをぶら下げた際に、Weightの設定でリクエストを振り分けることが可能です。
この機能を利用し、デプロイの際に新しく立ち上げる環境を始めはWeight0で紐づけておき、環境が整ったらWeight設定を元の環境と逆転させることで実現させます。EBとGAのBlue Green デプロイした際の比較
Blue-Green Deployを簡単に行う手段として、他にElasticBeanstalk(EB)のswap機能を利用した方法があります。ただ、DNSレコードの有効期限が切れるまで旧環境へのリクエストが発生する可能性があるため、切り替えてすぐ旧環境を止めることはできません。
公式でもEBのスワップは以下のように注意事項があります。Elastic Beanstalk がスワップ操作を完了した後、古い環境の URL に接続するときに新しい環境が応答することを確認します。DNS の変更が一括適用され、古い DNS レコードの有効期限が切れるまで、古い環境を終了しないでください。DNS サーバーは、ユーザーが DNS レコードで設定したライブ期間 (TTL) に基づいてキャッシュから古いレコードを消去するわけではありません。
その点、GAは1分以内にほとんどのリクエストが切り替わるため、扱いやすいです。
利用コスト
固定料金+データ転送量で課金されます。
固定料金は0.025USD/hです。
また転送量はGB単位の課金になっており、クロスリージョンだとさらに価格が上がります。アジア→アジア 0.01USD/GB 米国→アジア 0.035USD/GB弊社ではGAを本番で運用した際の転送量が90GB程度だったため、だいたい$20/月ぐらいの利用料に収まりました。
まとめ
今回はGlobalAcceralatorについて書かせていただきました。
もともとALBのIPを固定するために利用を始めたGAですが、その他にも恩恵があり、意外と便利です。また、今回は速度面をそこまでシビアに考えていないため書きませんでしたが、エニーキャストを介してトラフィックを最も近いエッジロケーションにルーティングし、さらに最も近いリージョナルエンドポイントにルーティングすることによってアプリケーションのパフォーマンスを向上させてくれるようです。



- 投稿日:2019-12-11T22:32:08+09:00
AWS Amplify フレームワークの使い方Part2〜Auth実践編〜
はじめに
AmplifyのAuth関係で提供されているAPIについて解説していきます。まだ未検証のAPIも多く存在していますが、下記の内容がわかれば、ログインフォームくらいは実装ができると思います。
Auth API一覧
APIの一覧をまとめています。基本的には、
import { Auth } from 'aws-amplify'をインポートしておいて、Auth.〇〇という形で使います。基本的に非同期処理で行いたいので、asyncをつけた関数の中で、awaitをすべてつけて実行しています。ログイン周り系API
signUp
const userData = await Auth.signUp( userId, // 一意なID、すでに使われている場合はエラーになります passward, // cognitoで定めたパスワードポリシーに則ったパスワード email // メールアドレス )サインアップについても基本的には1行実装です。たったこれだけです。メールアドレスの検証を設定していると認証コードが登録したメールアドレスに送信されます。
confirmSignUp
await Auth.confirmSignUp( userId, // singUp時に入力したuserId verificationCode // 認証コード )signUp時に届いた認証コードを入力し、メールアドレスの検証を行います。
resendSignUp
await Auth.resendSignUp( userId // singUp時に入力したuserId )認証コードの再送信をしてくれます。
singIn
const userData = await Auth.signIn(userId, passward)返り値(userData)に、ログイン情報が入っています。この返り値には、usernameや二段階認証の設定有無の情報が含まれています。二段階認証(SMS認証)を設定している場合は、認証コードが送信されます。
confirmSignIn
const userData = await Auth.confirmSignIn( user, // signInの返り値のuserData verificationCode, // 認証コード user.challengeName // 自身が設定している認証設定 'SMS' or 'TOTP' )SMS認証やTOTP認証を設定している場合は、このAPIを叩いて初めて、サインインが完了します。
federatedSignIn
Auth.federatedSignIn({ provider: 'Google' })各種設定は必要ですが、たったこれだけでソーシャルログインが可能になります。
forgotPassword
await Auth.forgotPassword(userId)これだけで、登録しているメールアドレスにパスワードの再設定の認証コードを送信してくれます。
forgotPasswordSubmit
await Auth.forgotPasswordSubmit( userId, verificationCode, // 認証コード newPassword // 新しいパスワード )届いた認証コードと新しいパスワードを渡せば、これだけでパスワードの更新は完了です。
signOut
await Auth.signOut()ログアウトは至ってシンプルです。
Cognito情報変更系API
changePassword
const user = await Auth.currentAuthenticatedUser() // ログイン中のユーザー情報 await Auth.changePassword( user, nowPassword, // 現在のパスワード newPassword // 新しいパスワード )これだけでパスワードの更新が行えます。
updateUserAttributes
const user = await Auth.currentAuthenticatedUser() await Auth.updateUserAttributes( user, { // 更新したい情報を渡す email: newEmail, // 新しいメールアドレス phone_number: newPhoneNumber // 新しい電話番号 } )Cognitoに保存している情報(emailやphone_numberなど)を更新ができます。
verifyCurrentUserAttributeSubmit
await Auth.verifyCurrentUserAttributeSubmit( 'email', verificationCode // 認証コード )メールアドレスを変更した際に、認証コードが届くので、入力してそのメールアドレスを有効にします。
ログイン情報取得系API
currentAuthenticatedUser
const user = await Auth.currentAuthenticatedUser()ログイン中のユーザー情報が取得できます。
currentSession
const user = await Auth.currentSession()ログイン中のユーザーのセッション情報が取得できます。
currentCredentials
const user = await Auth.currentCredentials()identityIdを習得したい時に利用しました。
user.identityIdで取得ができます。currentUserCredentials, currentUserInfo
const user = await Auth.currentUserCredentials() const user = await Auth.currentUserInfo()明確に違いがあるAPIなんだと思いますが、現状特に活躍はしていません。同じようにログイン車の情報が取得?できます。このあたりも明確にわかるとより細かい設定ができるのではないかと思います。
currentUserPoolUser
const user = await Auth.currentUserPoolUser(user)こちらも細かい違いはわかりませんが、ログイン中のユーザー情報にプラスでUserPoolのIDなどのプラスアルファの情報が取得できます。使い所は不明です。
2段階認証系API
getPreferredMFA
const user = await Auth.currentAuthenticatedUser() const state = await Auth.getPreferredMFA( user, { bypassCache: false } // おまじない ) // state = // 'SMS_MFA' => SMS認証 // 'SOFTWARE_TOKEN_MFA' => TOTP認証 // 'NOMFA' => 2段階認証未設定現在の2段階認証の設定情報を取得します。
setPreferredMFA
const user = await Auth.currentAuthenticatedUser() await Auth.setPreferredMFA( user, authType // 'SMS' or 'TOTP' or 'NOMFA' )二段階認証の設定を変更できます。
NOMFAにすると二段階認証がOFFになります。setupTOTP
const data = await Auth.setupTOTP( userData // signIn時の返り値のuserData ) token = 'otpauth://totp/AWSCognito:' + userId + '?secret=' + data + '&issuer=サイト名'このtokenをQRコードの生成コンポーネントに渡すことで、TOTP認証のQRコードを生成することができます。あとはこのQRコードを読み込んで、アプリに表示されている認証コードをconfirmSignUpで入力すればログインができます。
issuer=〇〇の部分が認証コードアプリに表示される名前になります。トラップとして、二段階認証をTOTPで設定している際に、
setupTOTPを実行しverifyTotpTokenで有効にする前に設定をやめてしまうと、無効なTOTPという扱いになり、TOTP認証ができなくなります。(二段階認証が有効というUI表示なのに、実際はTOTP認証ができないという事象が生まれる)
回避策として、setPreferredMFA(user, 'NOMFA')で二段階認証をOFFにしてから、setupTOTP実行するようにしています。
まだ、公式からもこのバグに対する回答は得られていない状態のようです。以下のissuesが解決されることを祈ります。
https://github.com/aws-amplify/amplify-js/issues/1226verifyTotpToken
// ログインユーザーの認証情報取得 const user = await Auth.currentAuthenticatedUser() // QRコードを読み込んだあとに表示される認証コードをstring化 const _verificationCode = this.verificationCode.toString() // tokenの検証 => 正しければ有効 await Auth.verifyTotpToken(user, _verificationCode) // tokenが有効な状態で初めてTOTP await Auth.setPreferredMFA(user, 'TOTP')二段階認証をTOTPに変更する場合は、
setPreferredMFAを行う前にこのverifyTotpTokenでのtokenの検証が必要です。そして、verifyTotpTokenに渡す認証コードはstring型でなければならないという罠があるため、認証コードをstring型に変換しています。disableSMS, enableSMS
const user = await Auth.currentAuthenticatedUser() await Auth.disableSMS(user) // SMSを無効 await Auth.enableSMS(user) // SMSを有効SMS認証の切り替えができるみたいなのですが、いまいちまだ動作が明確にわかっていないため、SMS認証を実装するためには要調査となっています。
未解明/未調査のAPI
- completeNewPassword
- configure
- essentialCredentials
- getModuleName
- getMFAOptions
- sendCustomChallengeAnswer
- userAttributes
- userSession
- verifiedContact
- verifyCurrentUserAttribute
- verifyUserAttribute
- verifyUserAttributeSubmit
おわりに
未解明・未調査のAPIも使いこなせるようになるともっとAuthの可能性が広がると思います。ぜひ、ご存知なAPIがありましたら、コメントをお願いいたします。
参考記事
- 投稿日:2019-12-11T22:10:10+09:00
TerraformでAWS ECRの作成してpushする
はじめに
SREエンジニアやってます。@hayaosatoです。
今回はAWS ECR(以下、ECR)でのリポジトリ作成をTerraformで作成した際に、その勢いでコンテナイメージのpushまでやっちゃおうという小ネタです。Terraform
ECRのリポジトリ作成のTerraformは簡単で、Terraformのリソースの中でもArgumentは非常に少ないです。
リポジトリは以下のように作成できます。resource "aws_ecr_repository" "default" { name = var.container_name image_tag_mutability = "MUTABLE" image_scanning_configuration { scan_on_push = true } }
image_scanning_configurationでコンテナイメージのセキュリティ診断も行ってくれるようなので有効にしておくと良いと思います。コンテナイメージのpush
ここからが本題です。
上記のように作成したECRリポジトリにterraform applyの際に同時にコンテナイメージをpushしてしまいましょう。
ECRへのpushコマンドは以下のようになっています。$(aws ecr get-login --no-include-email --region ${リージョン}) docker build -t ${コンテナイメージ名} ${Dockerfileのディレクトリ} docker tag ${コンテナイメージ名}:latest ${リポジトリURL} docker push ${リポジトリURL}terraformでは、このようなコマンド実行はprovisioningで実行すると良いのですが、ECRリソースにはprovisionerが提供されていません。
そこで、そのような場合にはnull_resourceというリソースを使うことで任意のコマンドをterraform apply時に実行することができます。
コンテナイメージのpushコマンドをterraformで実現すると以下のようになります。resource "null_resource" "default" { provisioner "local-exec" { command = "$(aws ecr get-login --no-include-email --region ${var.region})" } provisioner "local-exec" { command = "docker build -t ${var.container_name} ${var.docker_dir}" } provisioner "local-exec" { command = "docker tag ${var.container_name}:latest ${aws_ecr_repository.default.repository_url}" } provisioner "local-exec" { command = "docker push ${aws_ecr_repository.default.repository_url}" } }最後に
このように、ECRのリポジトリを作成してその流れでコンテナイメージのビルド&プッシュも実現しました。
現実的に使うかは別として、Fargateとか作成するときにちょっとだけ使えるんじゃないかな。。。と思っています。参考
- 投稿日:2019-12-11T22:10:10+09:00
TerraformでAWS ECRのリポジトリを作成してpushする
はじめに
SREエンジニアやってます。@hayaosatoです。
今回はAWS ECR(以下、ECR)でのリポジトリ作成をTerraformで作成した際に、その勢いでコンテナイメージのpushまでやっちゃおうという小ネタです。terraform及びプロバイダのバージョンは以下の通りです。
Terraform v0.12.12 + provider.aws v2.40.0 + provider.null v2.1.2ECR
ECRのリポジトリ作成のTerraformは簡単で、Terraformのリソースの中でもArgumentは非常に少ないです。
リポジトリは以下のように作成できます。resource "aws_ecr_repository" "default" { name = var.image_name image_tag_mutability = "MUTABLE" image_scanning_configuration { scan_on_push = true } }
image_scanning_configurationでコンテナイメージのセキュリティ診断も行ってくれるようなので有効にしておくと良いと思います。コンテナイメージのpush
ここからが本題です。
上記のように作成したECRリポジトリにterraform applyの際に同時にコンテナイメージをpushしてしまいましょう。
ECRへのpushコマンドは以下のようになっています。$(aws ecr get-login --no-include-email --region ${リージョン}) docker build -t ${コンテナイメージ名} ${Dockerfileのディレクトリ} docker tag ${コンテナイメージ名}:latest ${リポジトリURL} docker push ${リポジトリURL}terraformでは、このようなコマンド実行はprovisioningで実行すると良いのですが、ECRリソースにはprovisionerが提供されていません。
そこで、そのような場合にはnull_resourceというリソースを使うことで任意のコマンドをterraform apply時に実行することができます。
コンテナイメージのpushコマンドをterraformで実現すると以下のようになります。resource "null_resource" "default" { provisioner "local-exec" { command = "$(aws ecr get-login --no-include-email --region ${var.region})" } provisioner "local-exec" { command = "docker build -t ${var.image_name} ${var.docker_dir}" } provisioner "local-exec" { command = "docker tag ${var.image_name}:latest ${aws_ecr_repository.default.repository_url}" } provisioner "local-exec" { command = "docker push ${aws_ecr_repository.default.repository_url}" } }最後に
このように、ECRのリポジトリを作成してその流れでコンテナイメージのビルド&プッシュも実現しました。
現実的に使うかは別として、Fargateとか作成するときにちょっとだけ使えるんじゃないかな。。。と思っています。参考
- 投稿日:2019-12-11T21:59:33+09:00
AWS Deckbuilding Game 日本語(意)訳
この記事は
AWS Deckbuilding Gameのルールブックを日本語に訳した記事です。
ただし原書のルールブックはそのまま読んでもルールが把握できなかったので、ルールブックの構成を組み替えたり、一部のルールを想像で補ったりしています。
その結果、ゲームとして一応遊べるようになっているはずです・・・なっているといいなあ。ゲームの目的
数々の素晴らしいAWSサービスを購入して、Well Architectを実現しよう!
ゲームのセットアップ
初期手札
プレイヤーごとに異なる色のついたオンプレミスカードが、1プレイヤーあたり10枚で4人分あります。
各プレイヤーは色を1つ選び、その色のオンプレミスカード10枚を取ってください。(プレイヤーが3人以下の時に)誰も選ばなかった色は使用しないので脇によけておきます。マーケットプレイスの構築
(オンプレミスカード以外の)全てのバトルカードを裏向きにしてシャッフルし、山札を作ります。山の上からカードを5枚引き、山のそばに表向きに並べてください。
次に、バトルカードのそばにWell Architectカードの山を作ります。Well Architectカードは表向きにして、3ポイントのWell Architectカードをすべて山にします。その上に、1ポイントのWell Architectカードを乗せてください。上に乗せる1ポイントのWell Architectカードの枚数は、プレイヤー数で決まります。
2人:4枚、3人:5枚、4人:7枚ここで配置した、裏向きのバトルカードの山、表向きに並べたバトルカード、表向きにしたWell Architectカードの山を、マーケットプレイスと呼びます。
ようこそクラウドへ(ゲームセットアップ続き)
じゃんけんなどで最初のプレイヤーを決めてください。
最初になったプレイヤーは、マーケットプレイスで表になっているカードを1枚取ってください。ただし、取れるカードはコスト(カード左上)が黒丸の数字で書かれたカードだけです(オレンジ色の丸が書かれたカードは取れません)。カードを取ったらバトルカードの山から1枚カードを引いて補充し表向きに並んだバトルカードが5枚になるようにしてください。
次に左隣(時計回り)のプレイヤーが同じことをして、最後のプレイヤーまで同様にします。
最後のプレイヤーまで終わったら、今度は最後のプレイヤーから逆順(反時計回り)で最初のプレイヤーまで同じことをします。
この結果、各プレイヤーは2枚ずつマーケットプレイスからカードを取った状態になるはずです。プレイヤーはそれぞれ、自分の12枚(オンプレミスカード10枚+マーケットプレイスから取ったカード2枚)のカードを裏向きにしてシャッフルし、自分のそばに置きます。そしてこの自分の山札から5枚を引いて自分の手札にします。
これでゲームのセットアップは終了です。
カード説明
バトルカード
ルールブック2/4の図を参照しながら読んでください。
cost: このカードを購入するのに必要なクレジット。黒丸に数字は、購入にTCOクレジットが必要であることを示します。オレンジの丸に数字は、購入にAWSomeクレジットが必要であることを示します。
name & description: 名称と簡単な説明です。
service category: このカードのサービスのカテゴリーです。バトルカードの主効果/副効果で参照されることがあります。
TCO credits / AWSome credits: 黒丸に数字が、使用可能なTCOクレジットです。オレンジ色に数字が、使用可能なAWSomeクレジットです。
primary and/or secondary effect: 主効果/副効果。条件を満たすと(カードによっては無条件のものもあります)主効果、副効果に書かれた効果を得ることができます。主効果/副効果と二つに分類されていますが、主効果と副効果で特にルール上の差異はありません。効果アイコン
主効果/副効果欄に表示されたアイコンの意味は以下の通りです。
金色の丸囲みにドルマーク:(記載された条件を満たしている場合)購入を追加で1回行うことができます。
黒い四角の中に?マーク:(記載された条件を満たしている場合)自分の山札からカードを1枚引くことができます。
オレンジ色の丸に数字:(記載された条件を満たしている場合)書かれた数字の分だけAWSomeクレジットを追加で使用することができます。ゲームプレイ開始
ターン進行
最初のプレイヤーからプレイを始めます。
最初のプレイヤーは自分の手札から、使用したいカードを何枚でも選び、公開してください。
公開したカードを使ってできることは以下の通りです。
(1) 公開したカードに書かれた主効果(Primary effect)・副効果(Secondary effect)の効果を適用する
公開した各カードに書かれた主効果・副効果を読み、条件を満たしているものを適用してください。
山札からカードを引く効果の場合、引いてきたカードに書かれた主効果・副効果も同様に処理をします。
(2) マーケットプレイスで表向きになっているカードを1枚購入する
表向きになっているバトルカード、または、山の一番上にあるWell Architectカードを購入します。
公開したカードのTCOクレジット、AWSomeクレジットをそれぞれ合計し、それ以下のコスト(カード左上に書かれた数字)のカードを購入することができます。コストが黒丸の場合はTCOクレジットで購入、オレンジ色の丸の場合はAWSomeクレジットで購入する必要がある点に注意してください。
購入したカードがバトルカードの場合
購入したバトルカードは(手札にせず)表向きにして捨て札にしてください。捨て札の山はプレイヤーごとに分けて管理するので、自分の近くに置くようにします。また、バトルカードを購入したら、バトルカードの山札からカードを引いて補充してください。
購入したカードがWell Architectカードの場合
Well Architectカードは捨て札にしません。点数計算のために、捨て札の山とは別にして表向きで自分のそばに置いてください。購入したのがバトルカードであれWell Architectカードであれ、カードを1枚購入したら、主効果・副効果で購入枚数が増えていない限り、そのプレイヤーのターンは終了となります。ターンの終了へ進んでください。購入枚数が増えている場合は、購入可能な枚数分を購入した時点でターン終了となります。
ターンの終了
購入可能な枚数分カードを購入するか、購入可能枚数に満たなくても自発的に手番の終了を望んだ場合、そのプレイヤーのターンは終了します。
手札(公開したカードも公開しなかったカードも)にあるAWSカードの枚数が、オンプレミスカードの枚数以上の場合、オンプレミスカードを1枚除去することができます。除去されたオンプレミスカードは捨て札にはならず、ゲームから完全に除外されます。
すべての手札(公開したカードも公開しなかったカードも)を捨て札にしてください。その後、自分の山札からカードを5枚補充し、手札にします。
カードの補充が終わったら、次のプレイヤーに手番が移り、同様にターンを進行してください。自分の山札の再構築
カードを引く必要があるときに自分の山札にカードがない場合、自分の捨て札をすべて裏向きにしてシャッフルし、自分の山札にします。
ポイント!:捨て札を山札にするタイミングは、山札がなくなった瞬間ではなく、カードを引く必要がある場合に、山札にカードがなかった時です。以降、翻訳中
- 投稿日:2019-12-11T21:52:03+09:00
NtripCaster~ネットワーク式RTK-GNSSの補正情報配信サーバー~について
はじめに
インターネット回線を利用したRTK-GNSSのNtrip方式には
1. Ntrip Server(基準局)
2. Ntrip Client (移動局)
3. Ntrip Caster (配信サーバー)
が必要です。
画像引用元:https://toragi.cqpub.co.jp/tabid/865/Default.aspx基準局・移動局についてはQiitaなどネット上に情報がありWindowsPC、ラズベリ-パイ、ESP32などでの方法が詳しく紹介されています。
参考
Raspberry Piでcm精度のRTK-GPSガイダンスの制作(その1)
F9Pで基地局
ESP32でRTCM3受信機ここではNtrip Casterについて私の知っている限りでまとめてみました。
rtk2go.com
http://www.rtk2go.com/
○ 無料で使える
(注意)2019/9 以降仕様が変更となメールアドレスの登録が必須となりました
http://www.rtk2go.com/new-reservation/
以前のパスワード「BETATEST」は使えません● 基準局は公開
自宅に基準局を立てている場合、分かる人には住所をcm精度で特定されます。● 安定性に難あり
個人的経験ですが繋がらないときが半日ぐらい続いたり、送られてくるデータも不連続だったりしたことがありました。そもそも半径10kmしか使えないのにわざわざ海外のサーバーまで往復させるのはトラフィックの無駄じゃないかととりあえず試しに使ってみたい人にはおすすめ
自前のWindowsサーバーでSNIPを利用
https://www.use-snip.com/
rtk2goを開設しているところが作っているソフトウェアです
多機能の有料版もありますが無料の評価版もあります。
詳しくは最近発売されたこの本を参考にしてください。『SNIPによるRTK基準局開設・運用入門』コロナ社
https://www.coronasha.co.jp/np/isbn/9784339009293/○無料(評価版)で使える
○自宅/会社のWindowsPCで使える(Ubuntu版もあり)
英語ですがGUI画面で設定可能○基準局は非公開も可能
●外部からアクセスするにはポートマッピングが必要
プロバイダー等によっては出来ない場合も、またセキュリティーも自己責任で電気代だけでランニングコストがかからない。
AgriBus-Caster を利用
https://agri-info-design.com/agribus-caster/
農業技術情報社の農業用トラクタガイダンスアプリ「AgriBus-NAVI」の有料サービスです○日本語サポートあり
○基準局は非公開
●年額6000円(2019.12現在)のスタンダードプラン購読が必要AgriBus-NAVIを使用してる方にはおすすめ
有料VPSを利用
さくらVPS https://vps.sakura.ad.jp/ (585円/月~)
Amazon Lightsail https://aws.amazon.com/jp/lightsail/ (3.5ドル/月~)
などに立てたサーバーにフリーのNtrip Casterソフトを動かす方法です。
rtcmの場合、数kbpsのデータストリームを1~数台の移動局に配信するだけなので最低クラスのプランで十分ですAmazon Lightsailについては丁度いい記事があったのでこちらをご覧ください
[動画あり] たった5分でAWSに月額3.5ドルの格安VPNサーバーを構築する方法
AWS Lightsailでインスタンスを作成する
記事ではDebianとUbuntuですが今回はCentOSでの方法を紹介します。
yum と apt-get の違いだけで多分いけると思います。
$ su
$ yum update -y
$ yum install git gcc nano
$ git clone git@github.com:mnltake/ntripcaster.git
https://github.com/roice/ntripcaster
からForkしました。作者はBKGとありますがGNUライセンスと書いてあるので自由に使っていいのでしょう(多分)。インストールの方法はREADME.txtに書いてあります
$ cd ntripcaster/ntripcaster0.1.5/
$ ./configue
$ make
$ make install
$ cd usr/local/ntrincaster/conf
$ nano ntripcaster.conf.dist
サーバー名、最大接続数、Ntrip Server接続用パスワード、サーバーIP/ポート、Ntrip Caster用パスワードを設定して「ntripcaster.conf」に名前を変えて保存
$ nano sourcetable.dat.dist
こちらを参考に sourcetable を書き換えて「sourcetable.dat」に名前を変えて保存
(公開しないなら適当でも)
https://software.rtcm-ntrip.org/wiki/STR
$ cd usr/local/ntrincaster/bin
$ ./ntripcaster設定したポート(例:2101)をAmazon LightsailのFirewall設定で開けて必要ないポートは閉じておきます。
○基準局は非公開も可能
○自宅のルーターでポート開放ができない場合でも可能
○安定
Amazonのサーバーがダウンすることなんかそうそうないよね
●有料
ただし月400円弱で電気代やセキュリティーの心配はない安定重視で仕事で使いたい方におすすめ

- 投稿日:2019-12-11T20:58:17+09:00
AWS WAF v2 が出たので触ってみた
こんにちは、馬場です。
2019年11月末にAWS WAF v2が出たので軽く触ってみました。
丁寧な説明は他の方々におまかせして、個人的に気になった点を書きます。WAF Capacity Unit (WCU)
旧WAFでは、ルールの設定数で制限があったのですが、v2では考え方が変わりました。
個々のルールに対してポイント(Capacity)が設定され、1つのWeb ACLにつき、標準で 1500 WCU までのルールが設定できるというルールになりました。
WCU上限値は緩和申請可能です。こんな↓感じでルール毎にCapacityが設定されている
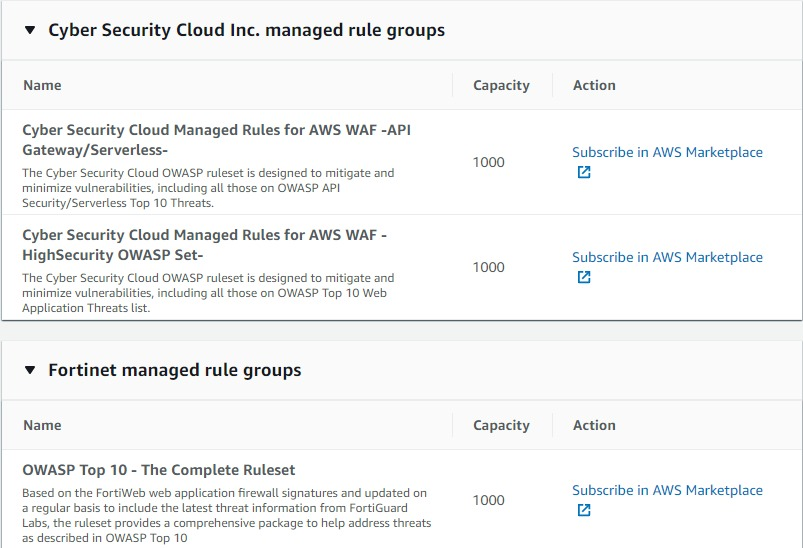
3rd party製のマネージドルールの提供が少ない
旧WAFでは多くの会社がマネージドルールを提供しており、Marketplaceから購入できました。
v2では、2019年12月時点では、サイバーセキュリティクラウド(CSC)さんの2ルールと、Fortinetさん1ルールのみの提供です。
これからですかね。
AWS公式のマネージドルール
AWS公式のマネージドルールが出ました。
こちらはMarketplace経由ではないので、ルール個別で費用はかかりません。
割と一般的に設定されるものが揃っているイメージです。
手動でのルール設定も可能、設定の柔軟性が上がった
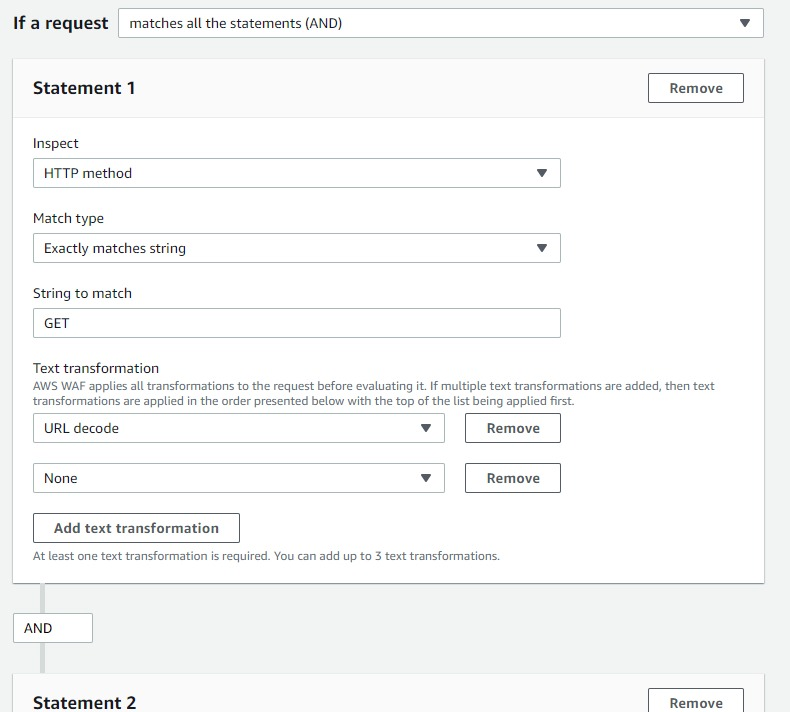
引き続き手動によるルール設定も可能です。
設定方法は旧WAFを踏襲しているようですが、コンディション複数のand/or条件記載が書きやすくなったり、ルール評価時の変換処理(URLデコードとか小文字化とか)が一度に指定出来るようになったので、設定の柔軟性が上がっています。
クエリパラメータ名指定の文字制限
ちょいと前のアップデートで、リクエストに含まれるクエリパラメータのチェック機能が実装されています。
とある案件で、これを利用した条件設定を試みたのですが、チェックするパラメータ名の指定で、指定可能な文字列は30文字が上限でした。
案件では、たまたまチェックすべきパラメータ名が30文字を超えており、、、しかも、パラメータ名部分は部分一致や正規表現も使えず(valueは使えるのに・・)、実装を断念した苦い思い出が。。。v2でここの仕様がどうなったのか確認しました。
旧WAFでは、パラメータ名入力時点で30文字を超えるとエラー表示が出てたのですが、v2では出ない・・・っ!
もしかしていけるんじゃね??
ってことで validateボタンをポチっとな。
おぉーー!これは期待出来ます。
続けて確定ボタンをポチっとな。・・・
・・・
・・・・・・あれ?
・・・反応がない・・・。どうやっても確定ボタンが反応しないので、画面上の色んなボタンをポチポチ。
デフォルトのvisual editorではなく、JSON editorに切り替えられたので validateボタンをポチっ。
・・・やっぱダメじゃん。さいごに
パラメータ名指定部分の仕様が変わっていないのは残念ですが、旧WAFと比べるとメリットが多いので、新規でAWS WAFを構築する場合はv2で良いのではと思います。
なお、引き続き旧WAFは継続されるようなので、慌てて移行する必要もなさそうです。
ただ、旧WAFの名称が「AWS WAF Classic」なので、いつか終わるんじゃね感が漂います。。。





- 投稿日:2019-12-11T20:53:22+09:00
AWS re:Inventふりかえり勉強会 re:Growth東京
どんなイベントか
AWSではめちゃくちゃブログ更新して良質な記事をアップデートしてくれるクラスメソッドさんが主宰したRe:Invent2019の振り返りイベント。
発表があった新機能、新サービスについての説明
re:Invent総括
アマゾン ウェブ サービス ジャパン株式会社
パートナー技術本部
パートナー ソリューション アーキテクト
金森政雄 氏
- 主役はクラスメソッドさんだよ
- Re:Inventは学習型カンファレンス。2012年から実施
- クラスメソッドで82名、日本人だけでも1700人以上が参加(総数で65000人以上
- 販売や商品説明よりも、技術者の集まるイベント
- 新製品の発表などキーノートがあるけど、勉強会のためのイベント
- 音楽イベント、ドッジボール、マラソン、バッファローウイングの大食い競争とか楽しめるイベントも盛りだくさん
- DeepRacer League 日本人が1,2フィニッシュ 3位も台湾人でアジア最強説
- AWS GameDay Event(参加者にうまいことDevOpsで改善していく構築イベント)
- ⇒Gamedayは来年日本でも実施予定
- 会期中のアップデートは74件(予選落ちが116件) ⇒200+のアップデート
AWS Bracket(毛布じゃないよ、量子だよ)
AWS Outpost(ハイブリッドクラウドじゃないよ、ミリ秒レスポンスAWSサービスだよ)
AWS DeepComposer(AWS流 ハッカーがハッピーになるキーボードHHKBじゃーー)
⇒直接業務に影響の改善にはつながらないかもしれないけど、わくわくするでしょ。AWS Wavelengthのこれから
株式会社ソラコム
プリンシパルソフトウェアエンジニア
片山暁雄 氏AWS wavelength・・・次世代通信規格”5G”に向けた取り組み
ネットワークの近くにEdgeコンピュータを置いて超低レイテンシーでのレスポンスを返すためのサービス
日本ではKDDIがパートナーとなって始めるサービス5Gの特徴
- 大容量
- 低遅延
- 多接続5Gになることで低遅延で処理ができるけど、あくまで端末と基地局の間のみ、それ以降は今までと変わらない
⇒通信キャリア内部にAWSのZoneを用意するのがこのサービス(wavelengthZoneとなる)
(所感)LAローカルリージョンみたいなサービスの具体的実装かな。OutPostっぽい感じもある。なぜソラコムが発表するかというと、Soracom Discoveryという遅延の少ないMEC上で処理を行えるということで考えていた結果、今回のサービスにつながった。
ユースケース
- ゲームサーバ
- VR/ARのレンダリング
- 自動運転時の諸良寛のリアルタイム通信
- レスポンスの良いシンクライアント
- 産業装置との連携など
いまのところ、あくまでこうなればという想定でしかない、これからどうなるかはこれから!!
(余談)
ローカル5G・・・自分たちで基地局を立ち上げる「DeepComposer」〜Deep Learning を学ぶ最高のツール
AWS事業本部 金泰雨
外国人だから日本語間違えもゆるしてね(2019年6月から日本で働いている)
Deepleaning知ってる?詳しく知ってる?コードレベルでわかる?
⇒これを理解するためのサービスがDeepComposer
GANn(敵対的生成ネットワーク) 教師なし機械学習の一種
⇒作ったモデルを本物かどうかチェックして精度を上げていく仕組み
GANのコードについてはある程度の知識があれば書ける(数学的知識があればもっとよくわかるけど)
GANのコードはGithubにいっぱいデモとか情報がある。
⇒DeepComposerを使うことでGANを学べ、GANがわかると機械学習の世界が広がるよ。Nitro Infrastructure 2019
AWS事業本部 渡辺聖剛
インフラ周り大好きAWS Nitro Systemについて話したい。
⇒AWSのインフラストラクチャ
- Nitro Hypervisor
- Nitro Card
- for EBS
- for VPC
- for Instance Storafe
- Nitro Security
- EC2
- Firecracker microVM
- Outpost
- いろいろ、、、
Nitro以前はXENベース、AWSがハードウェアレベルから作り直した。
Annapurna labs(ARMチップを作っている会社をAWSが買収し、そういったハードウェアを作っている)2017年にNitro使ったよ
2018年 今後のすべてのインスタンスはNitroだよ(AWSのためのハイパーバイザー)
OutpostもNitro(完全暗号化とかで顧客先でも安全に運用できる?)
2019年のキーノートでは3回も取り上げられた。
Nitro使ったスーパーコンピュータ作るよ、Graviton2で最強のインスタンス作るよ、すべてを暗号化するよ
⇒AWSのイノベーションの基盤
Nitroがあればネットワーク早くなる。NitroではEC2アップデートが再起動なしできるようになる?
セキュリティ系まとめとみんなで使おうDetective
CX事業本部 城岸直希
AWS WAFv2の発表
⇒古いのはClassic WAFになった。
- JSONでWebACL定義できるようになった(一括にできる)
- ルール10個制限廃止(代わりにキャパシティユニット)
- OR演算子が使える
- AWS Managed Rulesもリリース
- APIもwafv2になってregionalに統合
IMDSv2
- インスタンスメタサービス
- SSRF攻撃に使われるので、v2にすることでtokenを使うことでセキュリティ向上させることなる
- あくまで多層防御
Amazon Detictive
- インシデントの調査がめちゃくちゃはかどる
- いままではいろいろなセキュリティ対策を講じる必要があった。(検知 GuardDuty 、調査 Cloudtrail、 とか)
- それが1つの統合された
30日間は無料(プレビュー中)
利用料金も割安
取り込むログは自動的⇒SUMO Logicとか殺しに行くサービス??
EKS on Fargate
CX事業本部 城岸直希
kuberntesのおさらい
コンテナのオーケストレーションツールのデファクトスタンダード
masterノードとWorkerノードの2つから成り立つ
Masterでクラスタを管理する(エンドポイントとか)
Workerでコンテナ(=Pod)が動くEKS on EC2ではMasterをマネージドしてくれるサービス(一部Workerも見てくれているけど)
EC2ではAutoscallingがあるので負荷が高まったらEC2立ち上げてくれるFargate For EKSになると、EC2の管理が不要となる(勝手にスケーリングする)
⇒いままではEC2に対して詰め込める、マネジメントが必要であった。Fargateだと1対1なので気にしなくなる。
⇒つまり、ユーザが管理するレイヤーが減った(はず)ただし、制約がある(2019年現在の制約)
- 利用できるLBはALBのみ(今後NLBも使えるはず)
- DeamonSetはサポートされない
- GPUはなし
- パブリックIPアドレスが割り当てることができない
- コスト的には安くなるかは微妙ECS+Fargate EKS+Fargateどっちがいいか?
⇒悩むならECSのが絶対いいよ。(理由は弊社にお問い合わせください。。)ECSの次世代スケーリング戦略「Capacity Provider」
AWS事業本部 濱田孝治
ECSにおけるタスク実行のインフラをより柔軟に設定する新しい仕組み
Capacity Provider (CP)インフラを決定する
Capacity Provider Strategy(CPS) 比率とかを組み合わせる仕組みCapacity Providerの構造
CPの中にAutoscallingがあってCPを取りまとめるのにCPSがある従来はEC2インスタンスを立ち上げてからコンテナを配置、CPでは配置戦略を考えてからインスタンス
Fargate_SPOT
使っている間に落ちる可能性もあるが、お値段70%OFFというものCapacity Provider Strategyによるタスク配置戦略
複数のCPの組み合わせ比率を決定
BASE:最小タスク数(1つのみ指定)
Weight:タスク数比率
⇒例えばFargate:FargateSPOTを1:1に設定したら最高効率ではインスタンス2倍でコスト1.3倍に収まる
いまFargate_SPOTは46時間ずっと落ちていない。(使い放題やん、、、)
※まだ使っている人がいないから
とりあえず開発環境に入れればすぐに7割引きの世界にこれるよ!S3アクセスポイントでS3のアクセスを制御しよう
AWS事業本部 北野佑一
2019年のElastiCacheアップデートと運用について(仮)
AWS事業本部 深澤俊
What's New with Amazon ElastiCacheに参加した
- オンラインでのスケールアップ、スケールダウンが可能(いままでは水平スケールアップのみだったのが垂直ができる)
- リーダエンドポイント(クラスタモードを無効にしてすべてのノードをリーダエンドポイントに向ければよくなった)
- 名前変更コマンド(renameコマンドで紛らわしいコマンド名前を変更することが可能になった)
- メンテナンスアップデートをダウンタイムなしにできるようになった。
IAM/S3 access analyzer
AWS事業本部 吉井亮(AWS初心者の会社に説明する人)
外部プリンシパルと共有しているアカウント内のリソースを検出する。
- 自分のアカウント以外のアクセスとかないかチェック
- S3 IAMロール KMS Lambda SQS
- 実際にアクセスがあったかどうかを検出するのではなく、穴があるかどうかをチェックする仕組み(実際の攻撃は調べる必要がある)
- 追加料金はなし
- S3だとCSVでレポートみえるけどIAMはないのでAWSさん対応してほしいです。
IAMはグローバルサービスなのに、設定は各リージョンで必要。一発で全リージョンに設定したかったら私のブログみて!!Transit Gatewayのアップデートまとめ(仮)
AWS事業本部 島川寿希也(声がカワイイとの回りからのこえがある、、、)
ネットワークの管理って大変なのでシンプルにしたい
⇒ TransitGatewayでVPC間とかがものすごく簡単に設定できるようになった
2019年のre:invent2019では大きく4つのアップデートがあった
- マルチキャスト(ストリーミング、テレビ会議とか)
- インターリージョンピアリング(2つのリージョンを跨げるようになった)
- ネットワークマネージャー(一元管理できるGUIツール
- AWS Accelerated site to site VPN Connections
TransitGateway使ってネットワーク管理を簡単にしよう!!
- 投稿日:2019-12-11T20:52:31+09:00
CloudWatch-LogsからリアルタイムにLambdaを呼ぶ
アドカレ案内
- ← 10日目 @taniyam さん BigQueryで配列をヒストグラム用のデータに加工するUDFなど
- → 12日目 @saitotakashi さん GASでChatworkを自由自在に操る方法
ピカピカの新卒1年目のuetashです。
ちょっとAWSをさわる機会があり、ググっても日本語でヒットしなかったりしたので、この機会にナレッジを共有したいと思います。tl; dr
サブスクリプションフィルタを使いましょう。 以上!
あとこの記事最高です: https://dev.classmethod.jp/cloud/aws/notify-error-cloudwatch-logs-with-lambda/
背景・問題
あるとき、CloudWatch-Logsに特定のログが来た場合に、その内容をSlackに通知をしたいということがありました。
この際、CloudWatch-Logsにメトリクスフィルタを用意して、CloudWatch Alarm経由でそのイベントが起きたタイミングで、Lambdaを発火させる用にすることを考えていました。
このとき「Lambda上でログの内容を取得したい」ということを追加で行う必要があることがわかりました。
となると、Alarm経由では「特定のログが来たこと」は分かるのですが、「特定のログの内容」を知るためには、いい感じにさかのぼってあげる必要があるようでした。
(こちらの記事を参考にしていました https://qiita.com/onooooo/items/f59c69e30dc5b477f9fd )もっと簡単にできればなぁ、とぼんやり考えているところに天啓を受けました。
神(サブスクリプションフィルタ…サブスクリプションフィルタを使うのです…………)サブスクリプションフィルタとは
公式にサイトによると
サブスクリプションを使用して CloudWatch Logs からのログイベントのリアルタイムフィードにアクセスし、カスタム処理、分析、他のシステムへのロードを行うために、Amazon Kinesis ストリーム、Amazon Kinesis Data Firehose ストリーム、AWS Lambda などの他のサービスに配信することができます。ログイベントのサブスクリプションを開始するには、Kinesis ストリームなど、イベントを配信する宛先ソースを作成します。サブスクリプションフィルタは、AWS リソースに配信されるログイベントのフィルタリングに使用するフィルタパターンと、一致するログイベントの送信先に関する情報を定義します。
とのこと。なんとなくリアルタイム処理ができそうなことは伺えました。
実際にCloudWatch Logsを見に行くとすごーーーーく、わかりにくいところにサブスクリプションフィルタを設定できる場所がありました。引用ですが図を乗せておきます。ロググループのアクションのところを開くとCloudWatch Logsの上の方のところににありました。
引用元: https://dev.classmethod.jp/cloud/aws/notify-error-cloudwatch-logs-with-lambda/設定する
次のような世界を実現したいと思います。
注意ですが、サブスクリプションフィルタはロググループに対して1つのみしか設定できないため、複数設定したいという場合は、ロググループをそもそも分けるか、Lambda側で判定したり(これはあまりかっこよくないですね)が必要になると思います。
リソース デフォルトの制限 .. ... サブスクリプションフィルター 1 ロググループあたり 1。この制限は変更できません。 引用元: https://docs.aws.amazon.com/ja_jp/AmazonCloudWatch/latest/logs/cloudwatch_limits_cwl.html
Filter
今回は例としてErrorのログが流れてきた場合通知するみたいなものを考えようと思います。
そのためFilterは単に"ERRORと"します。
なんども同じ記事から引用するのは忍びないですが、分かりやすいには越したことがないので引用します。
引用元: https://dev.classmethod.jp/cloud/aws/notify-error-cloudwatch-logs-with-lambda/またフィルタパターンはメトリクスフィルタを設定するときと同じ文法が使えるようです。
Lambda
Lambda側ではフィルタに引っかかったログの内容をそのまま利用する事ができます。
当初の設計ではログを遡る必要がありましたが、その際の懸念などもなくなりますね。雰囲気だけ伝えるためにpython3でのLambdaのやつを書いておきます。
# -*- coding: utf-8 -*- import base64 import zlib import io import json import os import urllib.request def lambda_handler(event, context): ids = parse_log_text(extract_event(event)) send_to_slack(make_messages_blocks([ '次のidで書き込みエラーが発生しています!', 'ids: ' +','.join(messages), ])) # サブスクリプションフィルタから送られてくるeventはエンコードされているためいい感じにデコードしてあげる必要がある def extract_event(event): decoded_data = zlib.decompress( base64.b64decode(event['awslogs']['data']), 16+zlib.MAX_WBITS ) json_data = json.loads(decoded_data) # これでdecode終わり return json_data['logEvents'][0]['message'] # 今回はログの内容を指定して返す def parse_log_text(log_text): # 今回の例では次のようなエラーがきたことを考える # log_text = '[ERROR] 次のIDがなんらかのエラーでDBに書き込まれせんでした#1,123,234' ids = log_text.split('#')[1].split(',') return ids def make_messages_blocks(messages): return list(map(lambda m: { "type": "section", "text": { "type": "mrkdwn", "text": m } }, messages)) def send_to_slack(blocks): send_data = { "attachments": [ { "color": "#000000", "blocks": blocks } ] } slack_text = "payload=" + json.dumps(send_data) request = urllib.request.Request( os.environ['WebhookURL'], data = slack_text.encode("UTF-8"), method = "POST" ) with urllib.request.urlopen(request) as response: response_body = response.read().decode('utf-8')今回の例でいくとSlackに通知をおこなうやつですね。結構そのまんま使えるので有用だと思います!
まとめ
サブスクリプションフィルタすごい!
実は今回サブスクリプションフィルタの存在を教えていただいたのは @ikeisuke さんだったりしました。社内からこういったことをフランクに教えてもらえて最高ですね。(その節はありがとうございます:) )この実装を通して、イベント駆動というかストリーム処理というか、そういった考え方みたいなことをこれを通して学ぶことができたような気がします。
次は @saitotakashi さん の「GASでChatworkを自由自在に操る方法」とのことで明日も楽しみですね(dance)




- 投稿日:2019-12-11T20:05:01+09:00
Aurora MySQL を使っていたら異様にパフォーマンスが落ちた話
はじめに
KLab Engineer Advent Calendar 2019 の 12日目の記事です。
特に結論が出ているものではなく、Auroraをいろいろ検証していた際に遭遇した事例紹介となります環境
エンジンバージョン:5.6.10a
インスタンスクラス:db.r5.largeきっかけ
Auroraのストレージ設計としては履歴の塊なので、書き換えをし続けるとストレージ消費がどんどん増えていくのではないか?と考えて以下のようなワークロードを回してみました。
やってみた
1 . ガチャを引いては殆どを売却(削除)するようなプレイを想定し、以下のようなテーブルを作成して実験を行いました。
CREATE TABLE aurora_disk_test.heavy_write_test_table ( id BIGINT PRIMARY KEY AUTO_INCREMENT, message VARCHAR(511) -- データ量が多いテーブルの簡略化イメージで多めの文字列型 );2 . このテーブルにまず800万レコードを登録し、その後1000レコードの DELETE & INSERT を繰り返してみました。
MYSQL_CMD="mysql -h${DBHOST} -u${DBUSER} -p${DBPASS}" TABLE_NAME="aurora_disk_test.heavy_write_test_table" # INIT 約800万レコード登録 INIT_QUERY="BEGIN; DELETE FROM ${TABLE_NAME};" INIT_QUERY="${INIT_QUERY} INSERT INTO ${TABLE_NAME} (message) VALUES (SUBSTRING(MD5(RAND()), 1, 511));" for _ in $(seq 1 23); do INIT_QUERY="${INIT_QUERY} INSERT INTO ${TABLE_NAME} (message) SELECT SUBSTRING(MD5(RAND()), 1, 511) FROM ${TABLE_NAME};" done INIT_QUERY="${INIT_QUERY} COMMIT;" ${MYSQL_CMD} -e "${INIT_QUERY}" # DELETE & INSERT for i in $(seq 1 100000); do echo "${i}: $(date)" # 古いレコードから1000件まとめてDELETE DELETE_TARGETS=$(${MYSQL_CMD} -e "SELECT id FROM ${TABLE_NAME} ORDER BY id LIMIT 1000" -N | tr "\n" "," | sed -e "s/,\$//") LOOP_QUERY="DELETE FROM ${TABLE_NAME} WHERE id IN (${DELETE_TARGETS});" # 1件ずつ1000レコードINSERT for _ in $(seq 1 1000); do LOOP_QUERY="${LOOP_QUERY} INSERT INTO ${TABLE_NAME} (message) VALUES (SUBSTRING(MD5(RAND()), 1, 511));" done ${MYSQL_CMD} -e "${LOOP_QUERY}" doneこれは、グラフのように最初増え続けましたが途中で増加が止まりました。
※:再検証時のCloudWatchでのグラフ
3 . さらに極端な例として800万レコード全てで DELETE & INSERT を繰り返してみました。
MYSQL_CMD="mysql -h${DBHOST} -u${DBUSER} -p${DBPASS}" TABLE_NAME="aurora_disk_test.heavy_write_test_table" QUERY="DELETE FROM ${TABLE_NAME};" QUERY="${QUERY} INSERT INTO ${TABLE_NAME} (message) VALUES (SUBSTRING(MD5(RAND()), 1, 511));" # DELETE&INSERTするクエリの作成 # auto commit を利用して、それぞれのクエリを別々のトランザクションとして実行する for _ in $(seq 1 23); do QUERY="${QUERY} INSERT INTO ${TABLE_NAME} (message) SELECT SUBSTRING(MD5(RAND()), 1, 511) FROM ${TABLE_NAME};" done # クエリのループ実行 for i in $(seq 1 100); do echo "${i}: $(date)" ${MYSQL_CMD} -e "${QUERY}" doneおきたこと
だんだんと1セットの実行にかかる時間が伸びていきました。
9: Tue Nov 26 13:59:44 UTC 2019 mysql: [Warning] Using a password on the command line interface can be insecure. 10: Tue Nov 26 18:22:28 UTC 2019 mysql: [Warning] Using a password on the command line interface can be insecure. 11: Tue Nov 26 22:56:14 UTC 2019 mysql: [Warning] Using a password on the command line interface can be insecure. 12: Wed Nov 27 03:42:15 UTC 2019 mysql: [Warning] Using a password on the command line interface can be insecure. 13: Wed Nov 27 08:43:18 UTC 2019 mysql: [Warning] Using a password on the command line interface can be insecure. 14: Wed Nov 27 13:56:24 UTC 2019 mysql: [Warning] Using a password on the command line interface can be insecure. 15: Wed Nov 27 19:21:04 UTC 2019 mysql: [Warning] Using a password on the command line interface can be insecure. 16: Thu Nov 28 00:51:18 UTC 2019 mysql: [Warning] Using a password on the command line interface can be insecure.時間がかかっていたので途中でループを停止させてテーブルのカウントを取得してみました。
mysql> SELECT count(id) FROM aurora_disk_test.heavy_write_test_table; +-----------+ | count(id) | +-----------+ | 512 | +-----------+ 1 row in set (12 min 16.16 sec)カウント件数は少ないのにクエリ実行にかなりの時間がかかる事態に遭遇しました。
まとめ
負荷試験などで毎度大量のDELETE&INSERTしていると同じ事態に遭遇することがあるかもしれません。
後日再度カウントのクエリを実行した際には0秒でクエリの結果が出たため、バイナリログのような段階に大量に残っている段階だと処理スピードに影響しているのでしょうか。
あらためて時間を作って TRUNCATE での場合など実験していってみたいと思います。同様の事例や原因をご存知の方がいらっしゃいましたら、教えていただければありがたいです。

- 投稿日:2019-12-11T20:03:55+09:00
【プログラミング歴1年】初心者が全力でアプリを作ってみる。
はじめに
自己紹介
未経験の23歳からIT教育関係に転職し、2019の年末でプログラミング歴が1年になります。
副業でスタートアップの企業にも参加して色々教えてもらってきました。しかし、仕事が忙しくポートフォリオを作ろうとしても途中で辞めてしまう事が多く・・・
そうだ人生初!ポートフォリオを作成してまとめようという事で1〜10までの足跡を記事にしていきたいと思います。ベテランエンジニアの方からは見苦しい内容かもしれませんが、
アドバイス頂けると幸いです!!!※半年後の完成を描いています
目次
目次は随時更新します!!
(最終更新日2019/12/11)
アプリケーションについて
名前
未定
目的
新しい物語の伝え方を開拓する。
概要
写真家/イラストレーターと小説家のマッチングアプリ供給できるもの
- 写真やイラスト付きの
イメージ膨らむ小説写真やイラストと小説の相乗効果を生んだ新しい作品- 新感覚の小説の楽しみ方
- クリエイターの活躍機会を増やす
ペルソナ
写真家/イラストレーター,小説家
- 写真/イラストが好き
- 小説が好き
- 他人に見てもらう機会がない
- いい作品ができても披露する機会がない
- 投稿日:2019-12-11T19:38:44+09:00
S3 + Route53 + CloudFront&ACMを使って独自ドメインの静的ページをhttpsで表示させる
公式Doc通りにやっていたら意外な落とし穴にあったので、最初の設定から問題の所まで上手くいったやり方を書いときます。
問題があった所:
CloudFrontからhttpsのURLリンクにアクセスしたら以下の様な結果が返ってきた。
This XML file does not appear to have any style information associated with it. The document tree is shown below.
結論から言うと原因は、CloudFrontのOrigin Dmain Nameをリストからバケットを選択せずに、S3バケットの静的ホスティング名を記入しなければ行けなかった。
問題の部分を見たい方は呼び飛ばして、手順の第6項にスキップして下さい
手順:
1. ドメインの取得
お名前.com等を使ってドメインを取得して下さい
https://www.onamae.com/2. Route53への登録
https://qiita.com/sadayuki-matsuno/items/4c371ba984d9b22b3737
こちらの記事を参考に、Route 53でHosted Zoneを作成するとNSレコードが作成されるので、お名前.comの場合ドメイン設定でNSレコードを購入したdomainに追加して下さい。3. S3のバケットを作成し、HTMLファイルをアップロード
S3コンソールを開いて用意したhtmlファイルをアップロード
https://s3.console.aws.amazon.com/こちらを参考に自分のドメイン名のbucketを作成しアップロード
https://qiita.com/TheONeru/items/e8aef19375befae6ee094. Website hostingでendpointを取得
作成したbucketのPropertiesでStatic Website hositingを選択
・Use this bucke to host a websiteを選択し
index documentにアップロードしたトップページのhtmlファイル名を書く。
自分の場合はindex.htmlEndpointのURLがあるのでメモする http://⬛️⬛️⬛️-website-us-east-1.amazonaws.com
試しにURLのリンクにアクセスすると、アップロードしたhtmlが閲覧できる5. ACMでSSL証明書を発行
https://console.aws.amazon.com/acm/
からProvision CertificatesのGet Startedを選択
Request a public certificateを選択しRequest a certificateボタンをクリック
取得済みのドメインを入力
Add another name to this certificationをクリックし
*.⬛️⬛️⬛️.com
(⬛️⬛️⬛️は取得したドメイン名)
を入力
認証方法を選択
どちらでも問題ないがここではDNS validationで認証する
その後の項目は全てNext
ValidationのページでExport DNS configuration to fileをクリックし、csvファイルをダウンロードする。
Route 53のコンソールを開き
・Create Record Setをクリックし、NameにダウンロードしたCSVのRecord Nameを記述する。
・TypeはCNAMEを選択
・AliasはNoを選択し、ValueにCSVのRecord Valueを記述する
Save Recort SetをクリックACMのコンソールに戻り
https://console.aws.amazon.com/acm/Validation statusがSuccessになっているのを確認
6. CloudFrontでACMで認可されたcustom SSL証明書を登録(要注意事項あり)
cloudfrontのコンソールを開く
https://console.aws.amazon.com/cloudfront/create distributionをクリック
WebでGet startedをクリック要注意事項発生!
Origin Domain Nameを選択するとプルダウンにAmazon S3 Bucketで作成したbucketがでてくるが、
選択してはいけない!
Origin Domain Nameには
Website hostingで書かれていたEndpointを記述する
Alternate Domain Namesに
取得した
domain と www⬛️⬛️⬛️
(⬛️⬛️⬛️はdomain名)
を追加し
Custom SSL Certificateを選択し
ACMで認証したSSLを選択
あとはCreate Distributionをクリック
StatusがIn progressからDeployedに変わるまで待つ!
(結構時間がかかる。15分くらい?)
DeployedになったらIDをクリックし以下のDomain nameの
〇〇.cloudfront.netをメモする
〇〇.cloudfront.netのURLでアクセスして、
httpsで表示されれば、ここまでは順調です!7. Route53のドメインにtype AでCloudFrontのDmain Nameを登録
Route53でCreate Record Setをクリック
Nameは空で問題ないAliasはYesで、Aliastargetに〇〇.cloudfront.netを記述
Save Record Setをクリック
8. httpsでの表示が可能になる
https://⬛️⬛️⬛️.comのURLをアクセス
表示されれば成功!















- 投稿日:2019-12-11T19:31:27+09:00
re:Invent2019で個人的に面白かったセッション その①
これはMedia Doアドベントカレンダーの記事です。
先日開催されたAWS re:Invent2019で個人的に面白かったセッションをまとめていきたいと思います。
動画や資料があるセッションについては、リンクもまとめていきます。(サムネをクリックするとYoutubeに飛びます)Keynote with Andy Jassy
https://www.youtube.com/watch?v=7-31KgImGgUやはりAWS CEOによる基調講演はしっかりチェックしておきたいところです。
ところどころでバンドの演奏が入ったり、AWSユーザー企業のトップによる事例紹介が入ったりと構成がしっかり練られていているなと感じました。
この講演では以下のようなサービスが発表され、発表のたびに会場から拍手と歓声が起こっていたのが印象的でした。
- コンピューティング
- EC2のインスタンスタイプ追加(M6g/R6g/C6g/Inf1)
- Amazon Fargate for Amazon EKS
- DB・ストレージ
- Amazon S3 Access Points
- Amazon Managed Cassandra Service
- Amazon UltraWarm
- ML
- Amazon SageMaker Studio
- Amazon SageMaker Notebook
- Amazon SageMaker Experiments
- Amazon SageMaker Debugger
- Amazon SageMaker Autopilot
- Amazon CodeGru
- Amazon Kendra
- Amazon Fraud Detector
- Contact Lens for Amazon Connect
- その他
- AWS Outposts
- AWS Local Zones
- AWS Wavelength
Innovation at Speed
https://www.youtube.com/watch?v=8ona5ZTu4_E
- 文化
- スキル
- 組織構造
- リスク
という4つの観点から、どうすれば組織がイノベーションを起こせるのか?についてのベストプラクティスとアンチパターンを紹介するセッションです。スピーカーは、元Netflixのアーキテクトで今はAWSのクラウド戦略部門VPをしている方でした。
印象的だったのは、「Project to Product(単発のプロジェクトではなく、長期的視点に立ち良いプロダクトを作っていく)」、「Time to value(機能を作ってそれがユーザーに価値をもたらすまでの時間の短さがイノベーションの指標である)」という2つの考え方です。
A Day In The Life Of A Netflix Engineer
https://www.youtube.com/watch?v=0QS1TWLooo0
Migrating the live Pokémon database to Aurora PostgreSQL
https://www.youtube.com/watch?v=2eEKuK5eOC4最後に
引き続き、明日はカオスエンジニアリング、機械学習、サーバーレス周りのセッションで面白かったものをまとめます。




- 投稿日:2019-12-11T17:47:27+09:00
就活用ポートフォリオとしてWebサービス「Asobi」を作りました。
はじめに
こんにちは、ササクラ(@n_sasakura870)と申します。
SIerで働いておりましたが会社が倒産しました。今はWeb業界に転職するべく就活中です。今回は僕のポートフォリオを紹介するとともに、
- どういった技術を使用して開発したか
- どういった反省点、課題点が生まれたか
を解説できればと思います。
作ったもの
Asobi
様々なローカルルールや自分で考えた遊びを記録・共有するサービスです。
URL : http://www.asobi-app.com/
GitHub : https://github.com/sasakura870/asobi作った背景
友達とたまーにローカルでアナログな遊び(トランプ使ったゲームとかレクリエーションとか)をやることがあるんですが、結構面白くて盛り上がるんですよね。ただ、ふとやりたいなーと思ってググるとローカルルールって探してもあんまり出てこないことが多いんです。
なのでそういったローカルな遊びを記録・共有できるサービスがあれば、投稿して後で思い出せると考え、作ってみました。制作日数
GitHubへの最初のコミットからデプロイまでちょうど100日でした。
選定した技術
ここでは使用した技術の紹介と、めぼしい技術の選定理由を説明します。
バックエンド
- Ruby 2.6.3
- Ruby on Rails 6.0.0
- Webpacker 4.39.3
- ActiveStorage
- ActionText
- slim 4.0.1
- kaminari 1.1.1
- ActiveRecord-Import 1.0.3
- counter_culture 2.2.4
- RSpec 3.9
選定理由
ActionText
サービスの要件上、遊びのルール説明にリッチテキストエディタを使用したかったため。
これがまあ簡単に実装できて素晴らしいものだったので、またQiitaに記事を書こうと思います。ActiveRecord-Import
Rails6からバルクインサート機能が実装されたのですが、直接SQLを発行するものでIDのオートインクリメントやvalidation, callbackが効かなかったため。
公式リファレンスはこちらRails6の新しいバルクインサートメソッドに関してはこちらをご覧ください。
Rails6 のちょい足しな新機能を試す85(insert_all upsert_all編)フロントエンド
- Vue.js 2.6.10
- Vue Croppa 1.3.8
- FontAwesome 5.10.2
- sweetalert2 8.18.3
- Tippy.js 5.1.1
- selectize.js 0.12.6
最初CSSフレームワークにBootstrapを採用していましたが気に入ったデザインにならず、最終的にFLOCSSに基づいて自作しました。
自分でCSSを書いてみると、思った100倍楽しかったです。選定理由
Vue.js
jQueryを使用したことはあったのですが、DOMの操作がより簡単そうだったため。
Vue Croppa
ユーザーアイコンのトリミング機能に使用。Cropper.jsと悩みましたが、UIがこちらの方が好みだったのでこちらを採用しました。
公式リファレンスはこちらsweetalert2
アラート機能、トースト機能に使用。ポップで可愛いデザインがAsobiにぴったりだと思い採用しました。
カスタマイズ性が高く、Ajaxを絡めた実装も簡単でした。
公式リファレンスはこちらselectize.js
投稿画面のタグ入力フォームに使用。こちらもカスタマイズ性が高く使いやすかったです。
公式リファレンスはこちらインフラ
- AWS
- VPC
- EC2
- Route 53
- RDS
- PostgreSQL 11.5
- S3
- Nginx 1.16.1
- Unicorn 5.5.1
選定理由
一度HerokuでデプロイしたことがあったのでAWSに挑戦しました。
SSL化したかったのですがまだできていません…。ここはもっと学習しないといけないです。データベース設計
- ユーザーに関する
usersテーブル- ユーザーが投稿する遊びに関する
articlesテーブル- タグに関する
tagsテーブル- いいねに関する
favoritesテーブル- コメントに関する
commentsテーブル- ユーザー同士のフォローを実装する
relationshipsテーブル- usersテーブル、articlesテーブルとtagsテーブルの中間テーブルである
tag_mapテーブルQiitaのようなユーザーがタグをフォローできる機能を実装するために、
tag_mapテーブルにポリモーフィック関連を実装しました。主な機能
機能やUIはQiitaを参考に設計しました。
機能の概要はGitHubのREADMEにも記載しているので、こちらではより技術的な部分に踏み込んだ説明をしていきます。ユーザー
登録
Railsチュートリアル第11章を参考に、登録後送られてくるメールのリンクから本登録が完了するシステムを採用しました。
仮登録状態では、一部のページへアクセスした場合に仮登録完了ページへリダイレクトすることで機能を制限しています。
また、仮登録完了ページにメール再送リンクを作成し、Ajaxで登録されたアドレスにメールを再送する処理を実装しています。ゲストログイン
登録せずとも一通りの機能を試してもらえるようにゲストログイン機能を実装しました。
ゲストログイン後は本登録ユーザーと同じように操作することができます。(退会とメールアドレス変更のみ禁止しています。)ユーザーアイコン
Vue.jsとVue Croppaを使って画像をトリミングしてユーザーアイコンに設定する機能を実装しました。
画像作成後、適応するボタンを押すことでVue Croppaで作成された画像のBase64形式のデータを送信し、Rails側がそのデータをエンコードしてActiveStorageに保存する処理が走ります。永続ログイン
ログイン時、またはユーザー設定のアカウント画面から「ブラウザを閉じた後もログイン状態を保持するか」を設定できます。
こちらはRailsチュートリアル第9章を参考に実装しました。投稿
タグ入力にselectize.jsを使用しています。編集時には遊びに関連付いているタグを取得し、フォームに初期値として入れるように実装しています。
本文入力フォームにはActionTextを使用しています。自動生成されるactiontext.scssのCSSが入力フォームと本文の両方に適応されるのがいいですね。いいねとフォロー
いいねボタンとフォローボタンはVue.jsでコンポーネント化し、Ajaxで処理をするように実装しました。Asobiガチャ
他のWebサービスにはない機能として、「Asobiガチャ」機能を実装しました。
ボタンを押すとAjaxでRails側でランダムに遊びを1つ取得し、そのデータをjson形式でフロントに渡してJavascriptで表示しています。
使いやすさを向上させるため、引いた後に「もう一度引く」ボタンで再度ガチャが引けるようになっています。反省点
頑張らないと投稿出来ないような雰囲気のサービスにしてしまった
遊びのルールを記録・共有するサービスのため、しっかりとした記事が書けるようにリッチテキストエディタを採用しました。
そのためぱっと見で投稿するハードルの高いWebサービスになってしまいました。
もう少し投稿する心理的なハードルが下がるように工夫をしたいと考えています。ドメイン駆動設計に憧れてService層とか作っちゃった
作成途中に
ドメイン駆動開発(DDD)を知り、「なにこれすげー!」と手を出したのが失敗でした。
Service層を作りながら「どこまでがこのServiceクラスの責務なんだ…?」と悩むタネを増やしてしまい、完成に余計な時間がかかりました。
最終的にHandlerクラスというものまで作成し、こういった処理の流れになりました。
Controllerは自分のクラス、アクションに合ったHandlerクラスを呼び出し、HandlerクラスはServiceクラスを呼び出しています。
Serviceクラスは「ログインする」「タグ入力フォームに記載されたタグを取得または作成する」「いいねする」といった最小単位の処理のみ実行することで、様々なHandlerクラスから再利用できる仕組みです。
…が、振り返れば単純なCRUDしかしないアプリにこんな大層なアーキテクチャを採用する必要はなかったと感じています。テストをほぼ書いていない
先ほどの
ドメイン駆動開発(DDD)で各処理を切り分けておきながら、テストを書いていません。何のためのDDDなんだ…
GitHubには制作初期に書いたRSpecのテスト(ほぼ通らない)が置いてあります。DockerとかCircleCIとか触ってみたかった
これは制作中に存在を知ったので手を出しませんでした。次のポートフォリオで採用してみようと思います。
今後の課題点
HTTPS化
AWSの
ELBやCloudFrontを使ってサイトのHTTPS化を行いたいです(挫折済み)。レスポンシブ対応
サービスの要件上、モバイルからのアクセスの方が多そうなので(実際アクセスされるかは別として)レスポンシブ対応したいです。
入力フォームのエラーメッセージの表示
現状だと新規登録や投稿画面の入力フォームのエラーメッセージが画面上部に表示される仕様です。
これもsubmitの前に、validationチェックし、エラーがあれば入力フォームの近くにそれぞれのエラーメッセージを表示するようにしたいです。ソーシャルログイン機能
Twitterログインを実装してもっと利用しやすい仕組みにしたいと考えています。
作ってみた感想
自分で考えたWebサービスを形にするということは予想以上に大変でした。
Railsチュートリアルと違って道筋がない(当たり前ですが)ので、「この機能で本当にいいのか?」「このUIでいいのか?」「この処理はどこに書けばいいんだ?」と常に迷子になりながらコーディングしていました。その分デプロイできた時は脳汁出まくりで気持ちよかったです。振り返れば大変だった以上に楽しかったです。エラー出しまくりながらやりたいことが実装できた時の感動は他では味わえないです。
このWebサービスを最後まで作りきることが出来たのも、ひとえにQiitaやSlackやもくもく会でアドバイスを下さった皆様のおかげです。本当にありがとうございます。今後もこのWebサービスを改修しながら別のWebサービスも作りつつ、就活に励む所存です。
あとがき
名古屋でもくもく会を開催するのでよかったら参加してください。
https://connpass.com/event/158832/









- 投稿日:2019-12-11T17:30:48+09:00
Rails+MySQL+Docker+AWS(EC2, RDS, ALB, Route53, S3)で作成したポートフォリオについて
記事の概要
私が作成したポートフォリオ、「GoodCoffeeByGoodBarista」を解説します。
なぜ作ったか、どう作ったか、今後どうしていくかをまとめました。実際に作成したサイトやソースコードは下記のリンクからご覧いただけます。
GoodCoffeeByGoodBarista
GitHubこちらの記事の書き方は下記の記事を参考にさせていただきました。
PHP+MySQLでポートフォリオ作成なぜ作ったか
私は、愛知県名古屋市にある個人経営のカフェで、2年半ほどバリスタとして勤務しておりました。
ある時、バリスタの大会に出場したのですが、結果は惨敗でした。
バリスタは、生豆の仕入れからロースト、抽出までを全て個人で行い、それをプレゼンするのですが、超小規模店舗で勤務していた私は、生豆の仕入れルートもなければ高価な焙煎機もない、大会で使われる最新のエスプレッソマシンもない、練習に使うミルクも何百本と自腹で用意するしかない環境下で戦うしかありませんでした。
対して、大きな企業が経営するカフェに勤めているバリスタは、会社が持っているルートから最高品質の生豆を仕入れ、会社が用意する材料を使って、最新のエスプレッソマシンで毎日練習ができるのです。私は、環境の差による大きな挫折を味わいました。
バリスタを辞め、エンジニアになるべく勉強をしていた私は、「エンジニアリングの力で、バリスタ業界を良くできないか」と考えるようになりました。
エンジニアのように気軽に転職をする事ができる文化があれば、スキルを身に付けたいバリスタはより大きな企業に転職できるし、大企業にいてスキルはあるけれどもっと個人の店舗で接客を身に付けたいバリスタの願いも叶えられる。
バリスタが、自分の所属する環境でスキルを身に付けられなかったり、夢を諦めたりしなくて良くなるのではないか。
そんな思いから、バリスタ版Wantedlyのようなサービスを作成し、私のポートフォリオとすることにしました。スペック
言語
Ruby 2.5.3
フレームワーク
Ruby on Rails 5.2.2
CSSフレームワーク
Bootstrap4
データベース
MySQL 5.7
WEBサーバ
Nginx 1.15.8
開発環境
Docker 19.03.5
docker-compose 1.21.1バージョン管理
Git 2.24.0
本番環境
AWS (EC2, RDS, ALB, Route53, S3)
主な機能
・バリスタ(カフェ)一覧表示
バリスタの一覧、またはカフェの一覧を表示します。
ログインしていなくてもアクセスできる仕様です。
・バリスタ(カフェ)を検索
バリスタの場合、性別で検索できます。
カフェの場合、店舗名、雇用形態、所在地で検索できます。
・バリスタ登録
バリスタはトップページから新規作成のリンクを踏むことでユーザー登録ができます。
入力内容は最低限必要な内容のみです。
入力に誤りがあれば、登録はされずエラ〜メッセージが表示されます。
・オーナー登録
オーナーはナビゲーションにある「採用担当者の方」というところからオーナー用のトップページに移動し、そこから新規作成画面に移動できます。
入力内容は最低限必要な内容のみです。
入力に誤りがあれば、登録はされずエラ〜メッセージが表示されます。
・バリスタプロフィール編集
登録では基本情報のみの入力なので、プロフィール編集で詳細な情婦を入力していきます。
上記のリンクから自分のプロフィールを確認しながら編集できます。
・オーナーカフェ情報編集
登録では基本情報のみの入力なので、プロフィール編集で詳細な情婦を入力していきます。
上記のリンクから自分のプロフィールを確認しながら編集できます。
・ログイン
ログインできます。
バリスタとオーナーではフォームが分けてあります。
・面談したい(面談に誘いたい)バリスタ(カフェ)に対してメールを送信
ログインしている状態で、気になるバリスタ(カフェ)の詳細ページから面談を申し込む(誘う)内容のメールを送る事ができます。
・退会
プロフィール編集の画面から退会できます。
開発手順
1.要件定義
今回作成するアプリに必要な機能は、
・バリスタユーザー登録機能
・オーナーユーザー登録機能
・ユーザー一覧表示機能
・ユーザー検索機能
・応募プロフィールや、求人情報作成機能
・面談応募(勧誘)機能のため、ユーザー情報を保存しておくデータベースが必要であり、尚且つデータベースに保存した情報を動的に表示できるビューが必要です。
また、面談の応募(勧誘)にはメイラー機能を使いたいので、メール用のサーバーも用意する必要があります。
バリスタユーザーとオーナーユーザーで動線を分けたいので、わかりやすい動線づくりを心がけます。
2.環境選定
言語は、自分にとって技術的資産の多いRubyを選択しました。
よってフレームワークもRuby on Railsとしました。データベースは、もっともメジャーに、広く使用されているMySQLを選択しました。
今回はバックエンド開発がメインだったため、フロントエンド開発の工数を減らす目的でCSSフレームワークを使用しました。
CSSフレームワークにはネット上に公開されている情報のリソースが多いことから、Bootstrapを使用しました。WEBサーバーには、pumaとの連携が簡単で、かつネット上に情報のリソースが多かったNginxを使用します。
なお、これらの環境はDocker,docker-composeを使用して構築しています。
Dockerを使用したのは、最終的にCircleCIやcapistoranoを用いた自動テスト&ビルド&デプロイを行いたいと考えているためです。そして、本番環境はAWSのEC2,RDS等を用いて構築します。
これは、個人的にAWSに興味があったため使ってみたかったのと、転職用のポートフォリオとして使用する際、クラウドにAWSを取り入れている企業様が多いと感じたことから、技術アピールができると考えたからです。3.データベース設計
今回は、2種類のユーザーを作成する必要があるため、ユーザーモデルを一つ作成し、オーナーフラグがtrueかfalseかでユーザーを識別するか、ユーザーモデルを二つ作成してそれぞれで管理するかで悩みましたが、
今回は後者の方法でデータベースを作成することにしました。
理由は、私が参考にしている著書「達人に学ぶDB設計徹底指南書」にて、一つのモデルはなるべくシンプルにし、分けられるところは分けて管理するのが良いとされていたので、その教えを守る形にしました。4.コーディング
コーディングの際に注意した点は以下の通りです。
・一つの機能を実装する度にRSpecでSystemスペックを記述する
・GitHubFlowを意識した開発(マスターブランチでの作業は基本的にはしない、擬似的にプルリクエストを作成して、マスターブランチにマージする -> リモートリポジトリの変更を、ローカルにpullする)また、ユーザーをバリスタユーザーとオーナーユーザーに分けて実装していましたが、自身の練習もかねて、バリスタユーザーの登録や認証周りをdeviseで実装し、オーナーユーザーの登録はscaffoldで作成、認証は簡易的なsessionで実装しました。
ただ、ログイン状態のバリスタユーザーをcurrent_userで取得し、ログイン状態のオーナーユーザーをcurrent_ownerで取得するように実装したのですが、これはベストプラクティスではないように感じました。
次回また似たようなアプリケーションを作成する際は、この辺りのDB設計に関してきちんと見直す必要がありそうです。この段階で、動作確認も兼ねてdevelopment環境でもAWSのS3に画像が保存されるように実装しました。
5.デプロイ
本番環境はAWSで構築しました。
docker-composeでアプリケーション用のコンテナ、Nginxのコンテナ、メイラーのコンテナを用意していたので、それらをまとめてEC2でビルド&実行するようにしました。
データベースはRDSを使用しています。
画像の保存には、S3を使用しており、こちらはproduction環境だけでなく、development環境でもS3に保存するようにしています。
また、今回はEC2は一つしか用意していませんが、後々HTTPS化するのに必要だったので、ALBを配置しました。
独自ドメインは、過去にブログを運営していたときにも利用していて使い慣れたお名前.comから取得し、Route53で設定しました。AWSを使ったデプロイのために何冊も書籍を読み、様々な記事を読んだので、ネットワーク周りの知識がかなりついたと実感しました。
今後の改善点や追加実装について
アプリケーション自体としては、SNSログインや画像アップロードの際のプレビュー表示などを実装したいと考えております。
加えて、特にフォーム関連のUIを向上させたいと考えています。
具体的には、入力するべき項目をplaceholderでわかりやすくしたりできるかと考えております。また、要件定義の段階から考えているCircleCIを使用した自動ビルド&テスト、capistoranoを使用した自動デプロイを実装していきたいです。
そのためにも、現在はCircleCIの公式ドキュメントを読みながら準備をしている段階です。それから、AWSに関しても、画像の配信をCloudFlontで行うことで、より高速化を測ってみたいと思います。
参考文献
・Ruby on Rails5.2 速習実践ガイド
・プロを目指す人のためのRuby入門
・Docker/Kubernetes 実践コンテナ開発入門
・Amazon Web Services 基礎からのネットワーク&サーバー構築 改訂版
・ゼロからわかる Amazon Web Services超入門 はじめてのクラウド かんたんIT基礎講座
・Webを支える技術 ―― HTTP,URI,HTML,そしてREST
・リーダブルコード
・達人に学ぶDB設計 徹底指南書











- 投稿日:2019-12-11T16:46:02+09:00
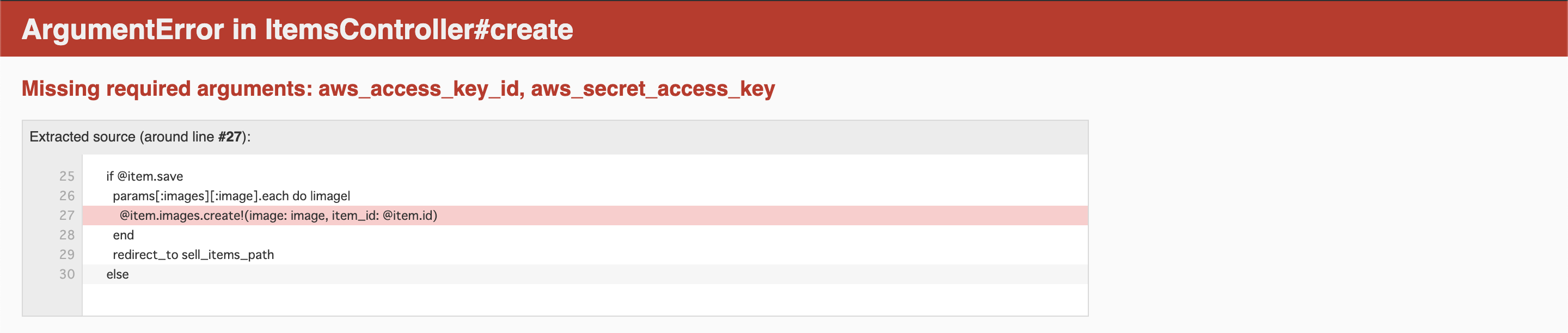
画像アップロード時に「Missing required arguments: aws_access_key_id, aws_secret_access_key」エラーが発生する
プログラミングスクールのカリキュラムでメルカリのクローンサイトを開発中、商品の画像をデータベースに保存しようとしたところ、タイトルのエラーが発生。
検索しても、該当する記事が見当たらなかったので記事にしました。
エラー画面がこちらです。
ローカルで画像を保存しようとしてるだけだし、AWSとか関係ないだろーと思って解決方法を模索していましたが、辿り着いた答えは単純でした。
画像をアップロードするためにCarrierWaveを使用していたのですが、「image_uploader.rb」の記述に問題がありました。エラーの原因
image_uploader.rb# Choose what kind of storage to use for this uploader: # storage :file storage :fogstorage :fogが適用されているせいでCarrierWaveの保存先がS3になっていました。
解決方法
storage :fogをコメントアウトしてあげて、storage :fileのコメントアウトを解除してあげればエラーが無事解決します。
image_uploader.rb# Choose what kind of storage to use for this uploader: storage :file # storage :fog補足
ローカルでの作業後、CarrierWaveの保存先をS3に戻す場合は逆の修正を行えば簡単に戻せます。
- 投稿日:2019-12-11T16:14:21+09:00
ElasticTranscoderでサムネイルサイズを調整する方法
Lambda関数からElasticTranscoderを呼び出し、動画変換処理を行う際、サムネイルも自動で出力することができます。しかし、デフォルトで作成されるサムネイルはサイズが小さく、viewで表示するととても荒くなってしまうので、サイズを調整したくなったのでやり方をまとめてみました。
サムネイルのサイズを調整する方法は以下の通りです。
- AWSから「
Elastic Transcoder」を選択- 左側サイドバーの「
Presets」を選択- 任意のプリセットをチェックし、画面上部の「Copy」をクリック
- 画面下部の「Thumbnail」の項目から「Height」「Width」を入力
- Lambda関数で呼び出す際には、ここで作成したPresetIDを指定する
- 投稿日:2019-12-11T15:10:59+09:00
AWS の EC2 が ping に応答するように設定
AWS の EC2 はディフォールトでは、ping に応答しません。
セキュリティグループ の設定をすることで、応答するようになります。IPCM プロトコルを付け加えます。
次のようになります。

- 投稿日:2019-12-11T14:18:14+09:00
SSH接続時、初回確認メッセージを出さないようにするAnsibleロール
このエントリは Ansible 3 Advent Calendar 2019の11日目の投稿です。
ちょうど空いていたので、書いてみました。この記事の内容
- SSH初回接続時の確認メッセージを、出さないようにAnsibleで設定する
前提
- 特定のホストへのSSH接続時のみ、確認メッセージを出さないようにしたい
- ホストA、ホストBがあると仮定し、A -> BへSSH接続する
- Ansibleを実行するクライアントは、A、BどちらへもSSH接続できる前提
- StrictHostKeyCheckingの設定はいじらない
実装方法
- Aのknown_hostsにBの公開鍵情報を直接記載する
- Ansibleのknown_hostsモジュールを使う
コード
main.yml# vars: # - ssh_host_and_user: # - from: # user: vagrant # host: A # to: # user: root # host: B # ホストBのrootユーザの公開鍵を、変数に格納する - name: Copy public key to variable slurp: src: "{{ ROOT_PUBLIC_KEY_HOST_B }}" with_items: "{{ ssh_host_and_user }}" register: to_host_public_key when: item.to.host == inventory_hostname # ホストAの,任意ユーザのホームディレクトリを取得する - name: Get home direcotry of from.user shell: | set -o pipefail egrep "^{{ item.from.user }}:" /etc/passwd | awk -F: '{ print $6 }' register: from_user_home_directory with_items: "{{ ssh_host_and_user }}" changed_when: false failed_when: from_user_home_directory.rc != 0 when: item.from.host == inventory_hostname # ホストBのrootユーザの公開鍵を、ホストAのknown_hostsへ書き込む - name: Add Host B infomation to known_hosts in Host A become: item.from.user known_hosts: key: "{{ item.to.host }} {{ hostvars[item.to.host].to_host_public_key.results[0].content | b64decode }}" name: "{{ item.to.host }}" path: "{{ hostvars[item.from.host].from_user_home_directory.results[my_idx].stdout }}/.ssh/known_hosts" state: present with_items: "{{ ssh_host_and_user }}" loop_control: index_var: my_idx when: item.from.host == inventory_hostname終わりに
known_hostsモジュールを使って、SSH初回確認メッセージを出さないように処理を書いてみました。
- 特定のホストへSSH接続するときのみ、確認メッセージを出さないようにできた
- 場合によっては、StrictHostKeyCheckingの設定をいじったほうが便利かもしれない
- 投稿日:2019-12-11T14:13:12+09:00
ジェイソンはLambdaを実行できるのか
はじめに
この記事はAWS初心者 Advent Calendar 2019に参加しています。
AWS初学者のため間違い等ありましたらコメントで指摘していただけると大変助かりますジェイソンって?
ジェイソンとは映画13日の金曜日に登場する殺人鬼の名前です。
JSONではない。
1作目での殺人鬼はジェイソンの母親なので少しタイトルは的外れな感じがありますが気にしないでください。何がしたいのか
13日の金曜日の時だけLambda関数を実行するルールを作りたい。
ジェイソンはLambdaを実行できる?
結論から言うとできません。
この記事ではその理由とCloudWatchEvents(長いので以後CWE)でのCron式の使い方について解説していこうと思います。Cron式って?
スケジューリングを行うための式です。
CWEでは6つの項目を設定するCron式を利用します。cron(分 時間 日 月 曜日 年)このように記述します。
実際の例
実際の例をもとにその時使うべきCron式を記述して行きます
その1
例えば毎日正午にお昼ご飯を食べるように通知してくれる関数を作りたいとします。
Lambda側に通知をしてくれるプログラムを記述し、CWEで毎日12時に関数を実行してくれるように設定するとします。
その際のCron式はCron(0 3 * * ? *)のように書きます。
12時なのに3を指定しているのはUTC(協定世界時)で管理されてるからです。UTC = JST - 9時間 です。
*や?はワイルドカードで特に指定しない場所に記述します。
ここでなぜ*と?を併用しているのかは後ほど説明します。その2
目覚ましのスヌーズ機能のようにある時間から一定間隔の時間ごとに関数を実行したい場合を考えます。
Cron式では分を指定するところを(開始/間隔)とすることで開始分から間隔分ごとに関数を実行することができます。24時間5分おきに何かを確認しなければいけない仕事についている人がいるとします。
AIに仕事を奪われそうな人No.1ですね。
その人に対して5分間隔で通知を送ってくれるCron式を書くとするとCron(0/5 * * * ? *)と記述します。
すると毎時0分から5分おきにLambda関数を叩いてくれるようになります。なぜジェイソンはLambdaを実行できないのか
やっと本題に入っていきます。
例の1と2でどちらも曜日の欄にワイルドカード「?」を利用しています。
その理由は日付か曜日のどちらかに「?」を利用しなければならないからです。公式ドキュメントには次のように書かれています。
You can't specify the Day-of-month and Day-of-week fields in the same cron expression. If you specify a value (or a *) in one of the fields, you must use a ? (question mark) in the other.
片方に値か*を使ったならもう片方には?を使えよ的なことが書いてあります。
つまりこれがジェイソンをLambdaを実行することができないかわいそうな子にしている原因なのです。
Cron(0 0 13 * 6 *) //13日の金曜日になった瞬間に実行されそうな見た目 保存↓ ルール ~ の保存中にエラーが発生しました 詳細: Parameter ScheduleExpression is not valid.。と出てしまいます。(曜日は日曜日始まりの1-7の数字で指定)
まとめ
もう1つ、Cron式には制限があります。
それは秒までの時間を調整することができないという点です。
なので秒調整の機能はLambda関数側に実装する必要があります。CWEではこのようにCron式に制限がかかっています。
なかなか日時+曜日で指定することもないとは思いますが、通常設定時にも片方のワイルドカードを?にする必要があるので覚えておくとスムーズに設定を終えることができます。おわりに
今回は運よく13日の金曜日の欄が開いていたためAdvent Calendar
童貞を卒業に参加させていただきました、一人でもこの記事が役に立つと感じてくれる方がいてくだされば幸いです
- 投稿日:2019-12-11T13:32:51+09:00
(備忘録) 2日で合格 AWS 認定ソリューションアーキテクト - アソシエイト / AWS Certified Solution Architect – Associate
実務でも使えるし出題対象で覚えておいた方が良い次のまとめ記事(マトリクス形式、リスト形式で比較してある便利記事)
(https://awsjp.com/AWS/hikaku/list0.html 比較表より、
このまとめサイト https://awsjp.com/
かなり網羅的で学習や試験対策ではかなり便利と気づく(特に比較表)・・・
アーキテクト系のアソシエイト試験やプロフェッショナル試験はお勧め、
受験後の感想ではこれだけでも合格できそうな感じ。出題の多くは次のうち
どのソリューションが最適ですかみたいな問題が多いので、
サービスの種類と比較表が頭の中に入っていれば即答できるものがほとんどだと思う)リージョン, AZ, エッジロケーション, グローバルサービス・クロスリージョンスナップショット の違い:
https://awsjp.com/AWS/hikaku/Region-AZ-Edge.html
https://awsjp.com/AWS/hikaku/AZ-Region-Global-service-difference.htmlストレージサービスの違い:
https://awsjp.com/AWS/hikaku/EBS-Storage-Type-chigi.html
https://awsjp.com/AWS/hikaku/AWS-StorageServer-hikaku.html
https://awsjp.com/AWS/hikaku/EBS-InstanceStore-hikaku.html
https://awsjp.com/AWS/hikaku/ElasticBlockStorage-chigai.html
https://awsjp.com/AWS/hikaku/Snapshot-AMI-hikaku.html
※2020年3月改定の試験では一つのAZのS3(障害対応を諦める劣化版、安価版)や
Glacierのプラン細分化など最近時変わっている問題が出てくる可能性がある。
追加の勉強でAWSの価格表でS3, Glacierの細分化は把握しておいた方が良い。
※EBSは名の通り、ブロック型のストレージ、その他(EFS/S3/Glacier)はオブジェクトストレージ
※EBS, S3シングルAZ版を除きHA(high availability)対応=自動で複数AZにコピーされるRedshift / DynamoDB / RDS / ElasticCache:
https://awsjp.com/AWS/hikaku/Redshift-DynamoDB-RDS-ElasticCache-chigai.html
※Auroraは自動でマルチAZ(3拠点、最近AWSとして推している製品)なので覚えておいた方が良い
※大半のRDSはRead Replica作成で読み取り負荷を軽減、より高速化を検討することが可能だが、現時点ではRDS SQL Serverは未対応の様子
※DynamoDBやRedshiftはread replicaという概念は無い
※RedshiftはHA, マルチAZという機能はない(単体で複数作らないといけない、必要ならば)
※RDSやDynamoDB, RedshiftにAuto scalingという機能はない(ただし、最近RDSの一部においてサイズの自動拡張を行う目的のauto scalingは搭載された、負荷を軽減するものではないことに留意)VPCエンドポイント(インターフェースとゲートウェイがあり、
Lambda, EC2, RDS, Redshiftなどは直接対応できないことを留意):
https://docs.aws.amazon.com/ja_jp/vpc/latest/userguide/vpc-endpoints.html
VPC vs.サブネット:https://awsjp.com/AWS/hikaku/VPC-subnet-chigai.html
セキュリティグループとNACLの違い:https://awsjp.com/AWS/hikaku/Securitygroup-acl-compare.html
NAT関係:
https://docs.aws.amazon.com/ja_jp/vpc/latest/userguide/vpc-nat-comparison.html
※NATはパブリックサブネットにアタッチし、プライベートサブネットからインターネットにアクセスする場合は / 必要な場合はプライベートサブネットのルートテーブルからNATに到達できるようルート情報を追加しますDedicatedほにゃらら、課金関係:
https://awsjp.com/AWS/hikaku/DedicatedInstance-DedicatedHost-chigai.html
https://awsjp.com/AWS/hikaku/OndemandInstance-ReservedInstance-SpotInstance-hikaku.htmlロードバランサーの違い:
https://awsjp.com/AWS/hikaku/ApplicationLoadBalancer-NetworkLoadBalancer-ClassicLoadBalabcer-chigai.htmlアクセスキーとロールの違い、キーやロール関係:
https://awsjp.com/AWS/hikaku/SSE-S3_SSE-KMS_SSE-C-compare.html
https://awsjp.com/AWS/hikaku/access_key_ID-secret_access_key-hikauk.html
https://awsjp.com/AWS/hikaku/access_key-role-difference.html
https://awsjp.com/AWS/hikaku/KMC_Encrypt_Key_difference.html
https://awsjp.com/AWS/hikaku/AWSAccount-IAUser-IAMGroup-hikaku.html
https://qiita.com/leomaro7/items/46dafff79206087c2524Route53:
https://awsjp.com/AWS/hikaku/Route53-furiwake-hikaku.htmlStop vs. Terminate:
https://awsjp.com/AWS/hikaku/stop-instances-terminate-instances-chigai.htmlLambda, API Gatewayの違い(通常はセットで利用される):
https://awsjp.com/AWS/hikaku/API_Gateway-Lambda-chigai.html思い立ったら動くが吉!ネットの情報のみで対策・・・
何も買わずに合格できました。やはり英語だとネットに情報がたくさん転がっていて過去問やその問いに対するディスカッションフォーラムを結構見かけます(問題自体が現時点では古いなどの言及もある)ので、ググった後からありふれている情報や広告を排除していかにして価値ある情報を見つけ出すのかもスキルの一つかなあと思うことがあります。
上記の比較表にありますが、NAT instance, NAT Gateway, security groups, network access control list (NACL), private subnet, public subnet, VPC, 各種ストレージ(EFS, EBSディスクタイプ、S3, Glacier), KMS/S3/Clientキー暗号化, DynamoDB vs. 他のデータベース, インスタンスタイプの課金、Read only replica, cross region snapshot などなど基本的な事項を把握していれば1日〜2日で合格できる試験であると思います。追記
概略でCloudFrontとS3連携OAI含む話、
Cognitoの外部認証連携は把握しておきましょう
- 投稿日:2019-12-11T11:26:57+09:00
[2019年12月]AWS素人でもSAAを試験対策の基本に従って力づくで取得する方法
SAA取りました。852点だったのでそこそこ安全に取得できたと思います。私の勉強方法を晒します。
私のスペック
- 老害アプリケーションエンジニア
- インフラはググりながらなんとかするレベル
- AWS経験は無料枠で単発のEC2立ててサービス投入できる程度
上記のようなスペックの人間でも取得できた方法を説明します。
準備
- 時間100時間程度
- 1万円弱ぐらいのお金(受験費用含まず)
私の場合は80時間ぐらい勉強したと思います。
教材費など5000円+25$弱ぐらいかかったのではないかな。
実際にAWSを触る部分の費用がかかるので「ぐらい」という表現になります。教材
AWSの資料を読み込むとかしませんでした。わからないところを「AWS <サービス名>」とかでググってつまみ読みはしました。
本
この1冊で合格! AWS認定ソリューションアーキテクト - アソシエイト テキスト&問題集
教科書買いました。発刊日が新しいのでこれにしました。内容が少し薄い印象。2500円ぐらい。巻末に用語集とか付いてるので折に触れて見直しましょう。とりあえず買っとくという感じ。オンライン講座
- これだけでOK! AWS 認定ソリューションアーキテクト – アソシエイト試験突破講座(初心者向け21時間完全コース)
- AWS 認定ソリューションアーキテクト アソシエイト模擬試験問題集(5回分325問)
1200円で安売りしているときに買いましょう。上の講座が21時間のハンズオンがついているので実際にAWSにふれることができるのでオススメ。こちらを中心にしました。知識だけじゃなく割と生きた知識(AWS実務したことないから実際のところはしらんけど)が身につく気がします。費用2400円。この講座を勉強のメインに据えました。
勉強方法
試験対策は
- 問題が最低限理解できるレベルまでの知識を素早くインプットする
- ひたすら問題を解いて解答を読み込む
と思っているので愚直に遂行しました。Phase.1 udemyの動画で知識とハンズオン
21時間の動画なので時間かかります。私はVideo Speed ControllerというChrome拡張を入れて2.5倍速程度で再生し、ハンズオンで実際に手を動かすところを含めて20時間で終わるようにしました。めっちゃ疲れる。
2回ビデオを見ました。1回目は2.5倍速でハンズオンしながら、2回目は4倍速程度で流すだけ。
反省するとすれば、実際にAWSを触るときに画面にどんなオプションがあるのかをハンズオンから離れてじっくり確認すると良かったと思います。あとでちょっと苦労しました。
勉強時間ここまで25時間程度Phase.2 本をよむ
6時間ぐらいかけて読んだと思います。この時点では模擬試験をしてません。本は内容がうすいです。udemyのビデオは検索性が低いので仕方がなく目を通す感じです。ビデオも良いですが本も必要ですね。
勉強時間ここまでで31時間Phase.3 udemy模擬試験を回す
一周目の模擬試験の結果が
こんな感じでした。模擬試験①は1回目で70%ちょうどだったと思います。
問題を解いてみて、「こいつはやべぇ試験だ」と思ったのを思い出します。単純な知識問題ではないです。このあたり、認定としては正しいのかもしれません(後から考えると)。このときはビビりました。
ひとつの模擬試験を1時間で解いて1.5時間かけて問題と解答を読み込みました。解説を読み込むのが大事です。違う切り口で問題出されたときに対応できるかどうかは解答の読み込みにかかってます。ホント。udemyの解説で気になったところをクラウドのメモにベターっとコピペして移動時間とかに読んだりしました。
udemyの模擬試験が7回分あります。2週回しました。1時間で解いて1.5時間かけて問題と解答を読み込んでわからないところは調べて、実際にサービス触ってみて確認したりしました。
模擬試験を2週まわしてに35時間。勉強時間ここまでで66時間Phase.4 本の模擬試験を解いてみる
72%の正答率でした。やべぇと思いました。切り口が違う。この時点で試験の申し込みは完了していたのですが「これは2回目あるな。。」と覚悟しました。勉強時間ここまでで68時間
Phase.5 模擬試験をもう一度回す
模擬試験をもう一度回しました。結構問題覚えてしまっているので問題を解くのと解答をよむのに一回1時間ぐらいでできるようになってます。正答率は90%以上になってます。ここまでで勉強時間76時間
勉強は以上です
すでに脳内にAWSの地図ができているのであせらず、試験を受けられました。というかもうできることがなくなっていました。
試験と模擬試験について
模擬試験のほうが難しいので安心してください。コンスタントに模擬試験で72%取れるようになってたら問題なかったんじゃないかな。。udemyの模擬試験は内容が本番より難しいです。日本語が壊れてると感じるところとかもあって+αでより難しいです。頑張りましょう。実際の試験は日本語もおかしくなく、良問揃いなので安心してください。
費用について
AWSのサービスをゴリゴリためして使って試すので利用料金が25$ぐらいかかりました。しかたなしです。
以上です。
教科書を読んで最低限の知識をいれたらあとはひたすら問題を解く、という試験対策の基本に従えば合格できました。もっと効率良く、時短で合格できるのかもしれませんが、udemyのUIの良さが最高で負けた感じもあります。試験そのものとは関係なかったかもしれませんがudemyでハンズオンできたことが収穫でした。すぐ対応できるようになった感じあります。わりと示唆に富むコメントがあったりして良い内容と思います。udemyの模擬試験はもうちょっと日本語ブラッシュアップしてほしい。
AWSはサービスがドンドン増えています。この記事で紹介した教科書、講座は早晩陳腐化するとおもいます。私の方法を参考にするのならば、udemyの安売りを発見し次第すぐに取り掛かることをオススメします。RDS Proxyとかおばけ機能が来てたりしますので(超使いたい)。では〜。

- 投稿日:2019-12-11T09:55:19+09:00
eksctl を使用して Fargate for EKS を試してみた。
前提条件
eksctl のバージョンは次のとおりです。
% eksctl version [ℹ] version.Info{BuiltAt:"", GitCommit:"", GitTag:"0.11.0"}eksctl の認証
--profileオプションを使用して ~/.aws/config のプロファイルを選択できます。% eksctl get clusters --profile dummy No clusters foundEKS クラスタの構築
公式サイトの案内の通り、
--fargateオプションをeksctl create clusterへ付加するだけです。% eksctl create cluster --fargate --profile dummy [ℹ] eksctl version 0.11.0 [ℹ] using region ap-northeast-1 ...長いので省略しばらく待つと EKS クラスタが構築されます。
[✔] EKS cluster "ferocious-painting-xxxxxxxxxx" in "ap-northeast-1" region is readykubectl コマンドからノードを確認します。
% kubectl get node NAME STATUS ROLES AGE VERSION fargate-ip-192-168-130-xxx.ap-northeast-1.compute.internal Ready <none> 2m54s v1.14.8-eks fargate-ip-192-168-143-xxx.ap-northeast-1.compute.internal Ready <none> 3m3s v1.14.8-eksKubernetes のノードが Fargate で構成されていることがわかります。
Pod のデプロイ
nginx の Pod をデプロイします。
% kubectl apply -f https://k8s.io/examples/application/deployment.yaml deployment.apps/nginx-deployment created当然ですが、問題なくデプロイできました。
% kubectl describe deployment nginx-deployment Name: nginx-deployment Namespace: default CreationTimestamp: Thu, 05 Dec 2019 22:26:45 +0900 Labels: <none> Annotations: deployment.kubernetes.io/revision: 1 kubectl.kubernetes.io/last-applied-configuration: {"apiVersion":"apps/v1","kind":"Deployment","metadata":{"annotations":{},"name":"nginx-deployment","namespace":"default"},"spec":{"replica ... Selector: app=nginx Replicas: 2 desired | 2 updated | 2 total | 0 available | 2 unavailable StrategyType: RollingUpdate MinReadySeconds: 0 RollingUpdateStrategy: 25% max unavailable, 25% max surge Pod Template: Labels: app=nginx Containers: nginx: Image: nginx:1.7.9 Port: 80/TCP Host Port: 0/TCP Environment: <none> Mounts: <none> Volumes: <none> Conditions: Type Status Reason ---- ------ ------ Available False MinimumReplicasUnavailable Progressing True ReplicaSetUpdated OldReplicaSets: <none> NewReplicaSet: nginx-deployment-6dd86d77d (2/2 replicas created) Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal ScalingReplicaSet 7s deployment-controller Scaled up replica set nginx-deployment-6dd86d77d to 2後始末
次のコマンドから今回作成した EKS クラスタを削除できます。
eksctl delete cluster type_your_cluster_name --profile dummy今回は試していませんが、
--waitフラグをコマンドへ付加すると CloudFormation の stack が完全に削除されるまで待機してくれるようです。詳しくは次のページに記載されています。
https://eksctl.io/usage/creating-and-managing-clusters/
- 投稿日:2019-12-11T09:50:01+09:00
AWS 認定セキュリティ – 専門知識 受験対策
先日合格したAWS認定スペシャリティ-セキュリティ試験について、自分が行った対策を紹介します。
試験範囲
試験ガイドに記載の通りです。
「インシデント対応」「ログと監視」「インフラストラクチャのセキュリティ」「ID及びアクセス管理」「データ保護」の5分野について
他のプロフェッショナル試験や専門知識同様、170分の試験になります。(受験料:30,000円)受験対策
受験にあたり自分が行った対策は以下になります。
AWSのセキュリティ関係のサービスのBlackbeltを読む
https://aws.amazon.com/jp/aws-jp-introduction/aws-jp-webinar-service-cut/
「AWS クラウドサービス活用資料集」の「Security, Identity & Compliance」に分類されているサービスのBlackbeltに全て目を通しました。
IAMやKMSについてはYouTube動画もあり、理解しやすいです。Security, Identity & Complianceに分類されていたのは以下の通りです。
・AWS Identity and Access Management (IAM)
・Amazon Cognito
・Amazon GuardDuty
・Amazon Inspector
・Amazon Macie
・AWS Certificate Manager
・AWS CloudHSM
・AWS Directory Service
・AWS Key Management Service
・AWS Organizations
・AWS Shield
・AWS WAFベストプラクティスを読む
日本語のベストプラクティスは少々古いですが、基本的な考え方等の確認に使いました。
https://d1.awsstatic.com/International/ja_JP/Whitepapers/AWS_Security_Best_Practices.pdfサンプル問題を解く
公式にサンプル問題が10問掲載されています。サンプル問題も更新されているようで複数パターンありました。
旧バージョン?(10問)
公式ページからのリンクされているバージョン(10問)
その他の認定資格状況
・SAA,SAP,DOPを旧試験で取得しています。
個人の印象ではありますが、他のプロフェッショナル試験よりは簡単に感じました。
SAAの取得後、ステップアップとしてセキュリティ試験も受験してみてはどうかと思います。
- 投稿日:2019-12-11T09:24:36+09:00
Transcribeの英語ミーティング文字起こしをmarkdownにする
fushimiです。
この記事は Wanoグループ Advent Calendar 2019 Advent Calendar 2019 の11日目の記事になります。(英語)会議 is ...

最近プロジェクトではニューヨークのチームと英語での会議をする機会が多いです。基本リスニングも不得手なので、会議同席中も熱が入って速度が速い時はなかなか聞き取れないことがあります。
そこで会議の後など、勉強/議事録がてらAmazon Transcribeでの音声文字起こしを見てわからなかったところの文脈を追ってみたりしています。
今回はTranscribeの出力をmarkdown化するやつをwebアプリに起こしてみました。制作物
リポジトリ:
wano/aws-transcribe-renderアプリケーションのページ:
https://wano.github.io/aws-transcribe-render/Amazon Transcribe
いわゆる文字起こしサービスです。S3上の音声ファイルを解析してくれます。
最近日本語対応したり東京リージョンで使えるようになったりしました。
ただ文字起こしをする、ってだけではなく、話者解析(誰がそのフレーズを喋っているか)が取得できるのがなかなか面白いところかな、と思います。
Termは割と適当なんだけど、話者解析もあって文脈が追えるので復習にはいいかな...というステータスのサービスです。ちょっとした文ならコンソール上で結果がプレビューできるのですが、ある程度の長さになると出力結果であるオリジナルのjsonを使うしかありません。
... Can you see the seats? No option. Hello. It's not"}],"speaker_labels":{"speakers":8,"segments":[{"start_time":"1.44","speaker_label":"spk_4","end_time":"2.35","items":[{"start_time":"1.44","speaker_label":"spk_4","end_time":"1.81"},{"start_time":"1.94","speaker_label":"spk_4","end_time":"2.35"}]},{"start_time":"11.94","speaker_label":"spk_4","end_time":"12.45","items":[{"start_time":"11.94","speaker_label":"spk_4","end_time":"12.45"}]},{"start_time":"13.71","speaker_label":"spk_4","end_time":"14.16","items":[{"start_time":"13.71","speaker_label":"spk_4","end_time":"14.16"}]},{"start_time":"14.71","speaker_label":"spk_4","end_time":"15.38","items":[{"start_time":"14.71","speaker_label":"spk_4","end_time":"15.38"}]},{"start_time":"16.24","speaker_label":"spk_4","end_time":"16.91","items":[{"start_time":"16.24","speaker_label":"spk_4","end_time":"16.91"}]},{"start_time":"25.86","speaker_label":"spk_1","end_time":"26.97", ...こういう感じ。なかなか辛い
初めはPHP製のパーサーaws-transcribe-transcriptを改変してコマンド叩いていたのですが、jsonパース/整形/改変くらいwebのクライアントサイドでサクッとやれるべきだよな...という感想があったので、今回のアドベントカレンダーを機にjsで書いてみました。
aws-transcribe-render
markdown化する、と書きましたが、mustache記法でテンプレを書いているだけなのでなんでもありといえばありです。
テンプレートの塊は、ある話者が話し始めてから終わるまでとなっています。使い方
事前: まずは文字起こし
まず、会話/会議の音声データをs3に上げ、transcribeのコンソールからjson化しておきます。
jsonをアプリに入力/テンプレート編集
そのjsonをこちらのアプリに入力します。
- speaker
- text
- time
がテンプレート変数として渡ってくるので、markdownでもhtmlでもお好みのフォーマットで出力できます。
話者名の上書き機能
Transcribeのデフォルトの話者名を上書きすることもできます。
spk_0 という身も蓋もないラベリングになってたりするので、多少記憶を掘り起こし話者の名前を書きましょう。結果
ここまでの結果が以下のような感じです。
あとはコピーして議事録に貼り付けるなど。
まとめ
これで、出力結果をinputするだけでさっくりと編集する機能ができました。
英語で行われるミーティングでまた試す予定ですが、そういえば日本語会話でTranscribeを試したことがないので、そちらの精度も気になりますね。課題
- 外に出しても差し支えないような会話でアプリにサンプルを載っけたかったんだけど、著作権フリーな「会話音声データ」ってなかなか見つからないですね....
- GUIと関係ないコア部分のロジックは切り離されていますが、肝心のnpmモジュール化とかはまだしていません。 1年以上ぶりくらいにReactを触ったら「useStateすげー!」「useEffectすげー!」ってなってたりしたのでそっちで時間が溶けました。
- XSS対策真面目にやっていません。mustacheのテンプレをそのまま出しています。どこか永続化するサイトに使うわけでもないのでどうということはないのですが。
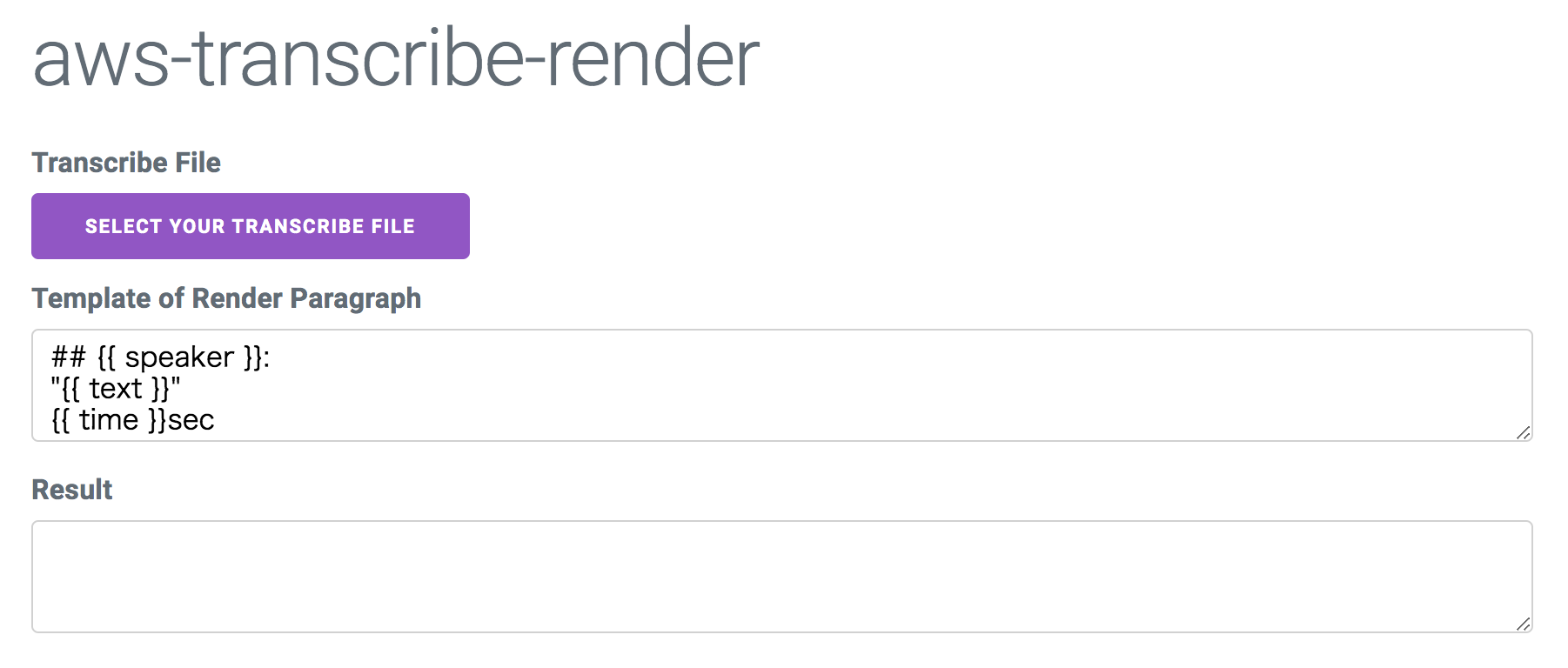
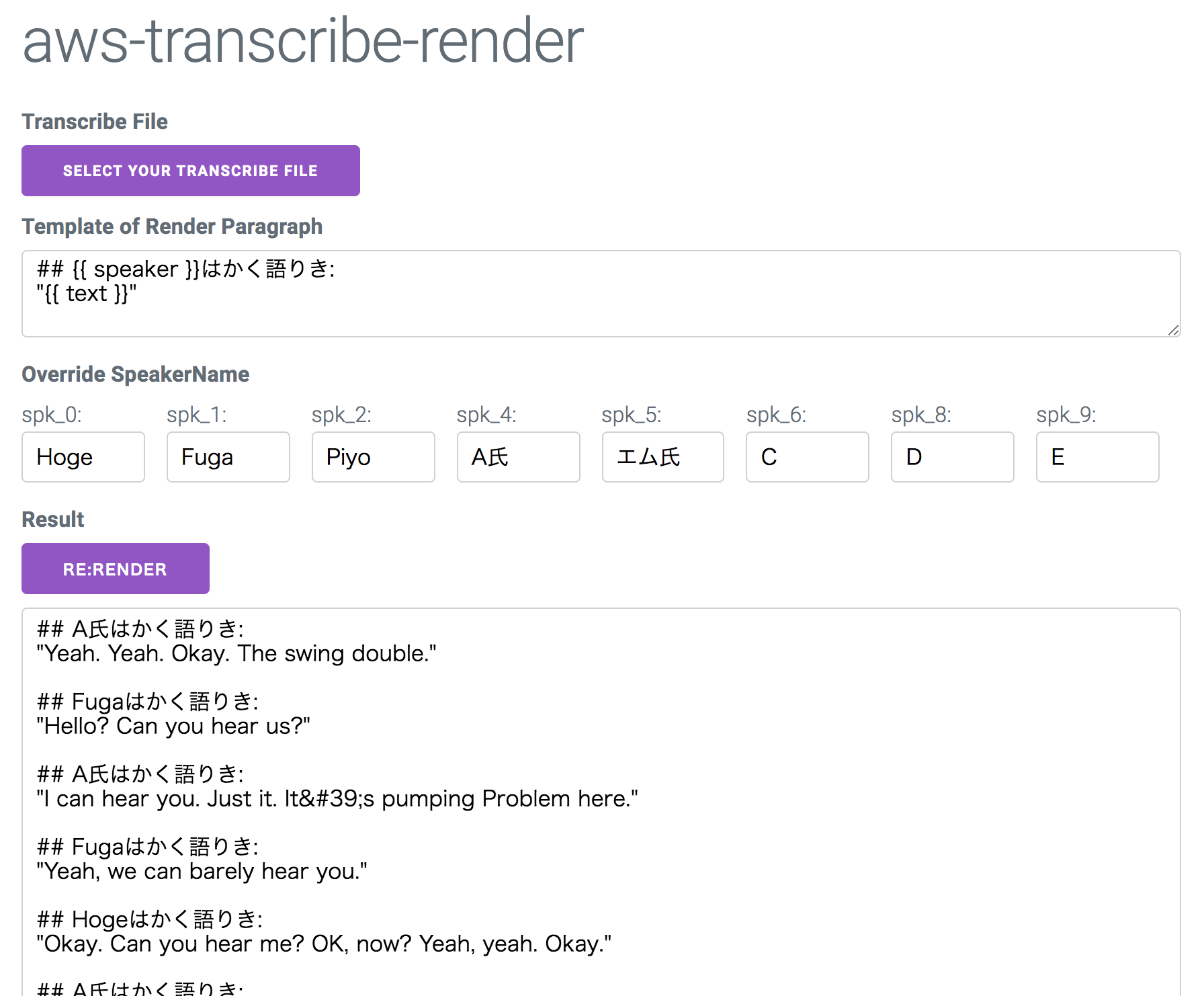
- 投稿日:2019-12-11T09:00:15+09:00
Amazon ECSのコンテナからGCP Cloud Storageへアクセスしてみた
Amazon Elastic Container Service(Amazon ECS)のコンテナからGCP Cloud Storage(GCS)へアクセスするのにどうしたらよいものか調べて試してみたのでメモ。
ポイント
- GCPサービスアカウントのキーファイルで認証する
- Amazon ECSでGCPが提供しているgsutilのイメージが使えた
- AWS Systems Manager パラメータストアでキーファイルを管理する
GCPサービスアカウントのキーファイルで認証する
こちらが参考になりました。
GCPサービスアカウントでgsutilを利用したりAPIアクセスする方法 - kikumotoのメモ帳
http://kikumoto.hatenablog.com/entry/2015/10/05/203545サーバーサイドのアプリケーションなどからGCPのリソースへアクセスするにはサービスアカウントを利用するのが良いそうなので、サービスアカウントを作成、権限(役割)を付与します。サービスアカウントに権限を付与するにはIAM管理権限が必要になります。
GCSのバケットの参照とオブジェクトの参照・作成するには以下の権限(役割)を付与します。
- ストレージのオブジェクト作成者
- ストレージ オブジェクト閲覧者
Cloud Storage の認証 | Cloud Storage | Google Cloud
https://cloud.google.com/storage/docs/authentication?hl=jaサービスアカウントのキーファイルはJSONかP12形式が選択できますが、JSONファイルで取得します。
JSONファイルは下記のようになっていて、プライベートキーなどが含まれています。取り扱いにご注意ください。{ "type": "service_account", "project_id": "<GCPプロジェクトID>", "private_key_id": "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx", "private_key": "-----BEGIN PRIVATE KEY-----\nxxxxxx=\n-----END PRIVATE KEY-----\n", "client_email": "<サービスアカウント>@<GCPプロジェクトID>.iam.gserviceaccount.com", "client_id": "xxxxxxxxxxxxxxxxxxxxx", "auth_uri": "https://accounts.google.com/o/oauth2/auth", "token_uri": "https://oauth2.googleapis.com/token", "auth_provider_x509_cert_url": "https://www.googleapis.com/oauth2/v1/certs", "client_x509_cert_url": "https://www.googleapis.com/robot/v1/metadata/x509/<サービスアカウント名>%40<GCPプロジェクト>.iam.gserviceaccount.com" }Amazon ECSでGCPが提供しているgsutilのイメージが使えた
Amazon ECSで稼働させるコンテナ内からGCSのバケットへアクセスするのに
gsutilコマンドが利用できれば事足りたので、利用できるイメージを探したところ、GCPが提供するDockerイメージが使えました。cloud-builders/gsutil at master · GoogleCloudPlatform/cloud-builders
https://github.com/GoogleCloudPlatform/cloud-builders/tree/master/gsutil本来はGCPのCloud Build用のイメージなのですが、公開されているイメージなので利用しても多分大丈夫?
Cloud Build - 継続的インテグレーションのためのビルドの自動化 | Cloud Build | Google Cloud
https://cloud.google.com/cloud-build/?hl=jaイメージは
gcr.io/cloud-builders/gsutilで取得することができます。> docker run -it --rm \ gcr.io/cloud-builders/gsutil \ --version Updates are available for some Cloud SDK components. To install them, please run: $ gcloud components update gsutil version: 4.46このイメージと作成したサービスアカウントのキーファイル(JSON)でGCSのバケットへアクセスしてみます。
キーファイルを利用するにはgcloud auth activate-service-accountコマンドが利用できます。> cd キーファイルがあるディレクトリ > docker run -it --rm \ --mount type=bind,source="($pwd)"/,target=/work \ --entrypoint="bash" \ gcr.io/cloud-builders/gsutil # ここからコンテナ内 $ gcloud auth activate-service-account \ --key-file /work/<JSONファイル名> Activated service account credentials for: [<サービスアカウント名>@<GCPプロジェクト>.iam.gserviceaccount.com] # 権限がないとバケット一覧は取得できない $ gsutil ls You are attempting to perform an operation that requires a project id, with none configured. Please re-run gsutil config and make sure to follow the instructions for finding and entering your default project id. # プロジェクトIDを指定しても権限がないとダメ $ gsutil ls -p <GCPプロジェクトID> AccessDeniedException: 403 <サービスアカウント名>@<GCPプロジェクト>.iam.gserviceaccount.com does not have storage.buckets.list access to project xxxxxxxxxxxx. # ファイルをアップロードする $ echo "hoge" > hoge.txt $ gsutil cp hoge.txt gs://<バケット名>/ Copying file://hoge.txt... / [1 files][ 5.0 B/ 5.0 B] Operation completed over 1 objects/5.0 B. $ gsutil ls gs://<バケット名> gs://<バケット名>/hoge.txt # ファイルをダウンロードする $ gsutil cp gs://<バケット名>/hoge.txt hoge2.txt Copying gs://<バケット名>/hoge.txt... - [1 files][ 5.0 B/ 5.0 B] Operation completed over 1 objects/5.0 B. $ cat hoge2.txt hogeAWS Systems Manager パラメータストアでキーファイルを管理する
Amazon ECSのコンテナで認証情報を取り扱うのにはAWS Systems Manager(AWS SSM) パラメータストアを利用するのが良いみたいです。
機密データの指定 - Amazon Elastic Container Service
https://docs.aws.amazon.com/ja_jp/AmazonECS/latest/developerguide/specifying-sensitive-data.htmlAWS Systems Manager パラメータストア - AWS Systems Manager
https://docs.aws.amazon.com/ja_jp/systems-manager/latest/userguide/systems-manager-parameter-store.htmlファイルをアップロードすることはできませんが、ファイル内容を文字列として登録することで利用できます。
AWS Systems Manager(SSM) パラメータストアに改行コードを含むデータを保存するときの方法 - Qiita
https://qiita.com/pdsyun/items/ca31834e864a09cd828f> aws ssm put-parameter \ --name "<パラメータ名>" \ --value fileb://<キーファイルのパス> \ --description "GCPサービスアカウントのキーファイル" \ --type StringAmazon ECSでAWS SSM パラメータストアのキーを参照するにはAmazon ECSのタスク実行ロールにポリシーを追加する必要があります。設定方法は下記が参考になりました。
ECSでごっつ簡単に機密情報を環境変数に展開できるようになりました! | Developers.IO
https://dev.classmethod.jp/cloud/aws/ecs-secrets/ECS(Fargate)で動かすコンテナにSSMからクレデンシャル情報を渡す - Software engineering from east direction
https://khigashigashi.hatenablog.com/entry/2018/08/28/214417Amazon ECSのタスク定義で以下のようなコンテナを追加します。
環境変数に設定された復号化済みのファイル内容をファイルに出力してgcloud auth activate-service-accountコマンドで指定して認証します。
- イメージ:
gcr.io/cloud-builders/gsutil- 環境変数
- Key:
GCLOUD_KEY- ValueForm:
<AWS SSM パラメータストアに登録したパラメータ名>- エンドポイント:
bash,-c- コマンド:
echo $GCLOUD_KEY > gcloud_key.json gcloud auth activate-service-account --key-file gcloud_key.json gsutil --version gsutil ls gs://<バケット名>/ gsutil cp gs://<バケット名>/hoge.txt . echo hoge > hoge3.txt gsutil cp hoge3.txt gs://<バケット名>/Amazon ECSでAWS SSM パラメータストアを利用すると、パラメータの復号化を自動で行ってくれるのでコンテナで行う処理を減らすことができて素敵でした。
参考
GCPサービスアカウントでgsutilを利用したりAPIアクセスする方法 - kikumotoのメモ帳
http://kikumoto.hatenablog.com/entry/2015/10/05/203545Cloud Storage の認証 | Cloud Storage | Google Cloud
https://cloud.google.com/storage/docs/authentication?hl=jacloud-builders/gsutil at master · GoogleCloudPlatform/cloud-builders
https://github.com/GoogleCloudPlatform/cloud-builders/tree/master/gsutilCloud Build - 継続的インテグレーションのためのビルドの自動化 | Cloud Build | Google Cloud
https://cloud.google.com/cloud-build/?hl=ja機密データの指定 - Amazon Elastic Container Service
https://docs.aws.amazon.com/ja_jp/AmazonECS/latest/developerguide/specifying-sensitive-data.htmlAWS Systems Manager パラメータストア - AWS Systems Manager
https://docs.aws.amazon.com/ja_jp/systems-manager/latest/userguide/systems-manager-parameter-store.htmlECSでごっつ簡単に機密情報を環境変数に展開できるようになりました! | Developers.IO
https://dev.classmethod.jp/cloud/aws/ecs-secrets/ECS(Fargate)で動かすコンテナにSSMからクレデンシャル情報を渡す - Software engineering from east direction
https://khigashigashi.hatenablog.com/entry/2018/08/28/214417
- 投稿日:2019-12-11T08:47:53+09:00
Amazon EBSの種類でNextcloud の occ files:scan の速度を比較してみた
はじめに
先般、Nextcloud におけるファイルスキャン速度を比較してみた の記事を書きながら、「そういえば、ストレージの種類でもパフォーマンス変わるんじゃないか?」と思いたち、ざっくり検証してみることにしました。
今回は、Amazon EBS の種類で Nextcloud のファイルスキャンコマンドocc files:scanのパフォーマンスがどれほど変化するのかを確認してみました。検証の条件
Nextcloud サーバー環境
- Nextcloud アプリケーションのバージョン
- Nextcloud: 17.0.1
- ミドルウェアのバージョン
- PHP: 7.3
- MariaDB: 10.4
- サーバー構成: Nextcloud 本体、データベース等を含めた1台のオールインワン。
- サーバー環境: AWS EC2(CentOS7、M5.large)+EBS(500GB)
比較対象の EBS の種類
- EBS 汎用 SSD (gp2) ※IOPS:最大1,500
- EBS マグネティック ※IOPS:最大500
- EBS プロビジョンド IOPS SSD (io1) ※IOPS:最大3,000
※「スループット最適化 HDD (st1)」と「Cold HDD (sc1)」はルートボリュームに設定できないため今回は対象から除外しました。時間があったら環境をそろえるなどして改めて検証してみます。
検証ファイル/フォルダ数
- フォルダ数: 41,732
- ファイル数: 313,860
- 合計ファイルサイズ: 3,075 MB
検証方法
- テストファイル/フォルダ群を Nextcloud サーバの規定ディレクトリに配備し、
occ files:scan [アカウント名]コマンドでファイル/フォルダの同期を行う。- テストは3回行って、実行平均時間で比較する。
検証結果
実行時間 (汎用 SSD) 実行時間 (マグネティック) 実行時間 (プロビジョンド IOPS SSD) 1 11分44秒 11分34秒 11分20秒 2 11分54秒 12分21秒 11分32秒 3 11分49秒 11分56秒 11分47秒 平均 11分49秒 11分57秒 11分33秒 ※平均値としては、プロビジョンド IOPS SSD ⇒ 汎用 SSD ⇒ マグネティック の順という、まぁ期待通りの結果とはなりましたが、IOPS 性能を考えるとそれほど大きな違いとはなりませんでした。
考察、あとがき
今回は、
occ files:scanをシングルタスクで実行していることから、処理内容に対して IOPS 性能に余裕があり、大きな差が見えづらかったと考えます。
EBS のメトリック情報を見る限りでは、処理開始から前半は 高い IOPS 値でしたが、後半はそれほど IOPS 値が上がっておらず、ディスクI/Oが少ない小さな処理が続いていたと思われます。ここではおそらくデータベースにフォルダ/ディレクトリ情報をこまごま INSERT し続けているんだと思われます。次の機会では、
occ files:scanを多重実行してみて比較をしてみようと思います。EBS の種類もいろいろあるため選択に迷うこともあるかと思います。とりあえず迷ったらいったん汎用 SSD を選択するのが無難だと思います。
で、性能試験してみて、IOPS が頭打ちになるような傾向となったら、
- SSD の容量を増やして IOPS 性能を上げる
- プロビジョンド IOPS SSD に変更してみる
といった対策になるでしょうか。
マグネティックは、容量単価はルートボリュームにできる種別の中では最安ですが、容量単価のほかに I/O 100万回単位の単価もプラスされますので、開発環境やちょっとした動作検証での用途で使う程度がおすすめですね。
- 投稿日:2019-12-11T06:58:58+09:00
AWS Lambdaでスクリーンショットを撮ってS3に保存
はじめに
この記事は、mohikanz Advent Calendar 2019の11日目の記事です。
去年は、マイコンネタでした。
今年は、AWSで日頃便利に使わせてもらっている技術ネタについて書きます。あるプロジェクトで、Webサイトを定期的にキャプチャして、S3に保存しておきたいなぁと言う事があり、それならばサーバレスで挑戦してみようと言うことになり、それをやってみたときの記事になります。
Lambdaは便利ですよね。何よりお安いですし。必要な知識
- Python
- AWS Lambda
- Selenium
事前準備
headless chromeを使いますので、いくつか事前準備が必要です。
Lambda Layers
Lambdaのファイルサイズ上限に引っかかるので、Lambda Layersにheadless chromeを用意します。
GitHubに置いておきましたので、ご自由にお使いください。
Lambda Layersは、マネジメントコンソールからアップロードが出来ます。https://github.com/akikinyan/headless_chrome_python360
日本語フォント
IPAexフォントがあると文字化けしませんので、あらかじめダウンロードしておいてください。
./fontsディレクトリに保存しておきます。
Lambda Layersに含めると50MBを超えてしまうので、Lambdaの方に追加します。https://ipafont.ipa.go.jp/old/ipaexfont/download.html
- 2書体パック(IPAex明朝(Ver.002.01)、IPAexゴシック(Ver.002.01))
Lambdaの作成
Serverless Frameworkを使って構築します。
$ sls create --template aws-python3 --path headless-chromeserverless.ymlservice: headless-chrome provider: name: aws runtime: python3.6 memorySize: 1600 timeout: 120 stage: ${opt:stage, 'dev'} region: ap-northeast-1 # 権限設定 iamRoleStatements: - Effect: "Allow" Action: - "s3:GetObject" - "s3:PutObject" Resource: "arn:aws:s3:::headless-chrome-${self:provider.stage}/*" functions: chrome: handler: chrome.lambda_handler description: Headless Chrome environment: TZ: Asia/Tokyo STAGE: ${self:provider.stage} S3BUCKET: headless-chrome-${self:provider.stage} package: # フォントを追加する include: - '.fonts/**' layers: - arn:aws:lambda:ap-northeast-1:xxxxxxxxxxxx:layer:headless_chrome_python360:1Lambdaのソースコード
chrome.pyfrom selenium import webdriver import boto3 import json import os import time os.environ['HOME'] = '/var/task' def lambda_handler(event, context): options = webdriver.ChromeOptions() options.add_argument("--headless") options.add_argument("--disable-gpu") # options.add_argument("--window-size=3408x2156") options.add_argument("--window-size=1704x1078") options.add_argument("--disable-application-cache") options.add_argument("--disable-infobars") options.add_argument("--no-sandbox") options.add_argument("--hide-scrollbars") options.add_argument("--enable-logging") options.add_argument("--log-level=0") options.add_argument("--v=99") options.add_argument("--single-process") options.add_argument("--ignore-certificate-errors") options.add_argument("--homedir=/tmp") options.binary_location = "/opt/bin/headless-chromium" bucket = os.environ.get("S3BUCKET", "") s3 = boto3.client('s3') driver = webdriver.Chrome( "/opt/bin/chromedriver", chrome_options=options) driver.get("https://www.google.co.jp") time.sleep(5) driver.save_screenshot("/tmp/shot.png") driver.close() s3.upload_file(Filename="/tmp/shot.png", Bucket=bucket, Key="hoge.png") return "ok"実行してみた
$ sls deploy -v $ sls invoke -f chromeこんな感じになりました。
さいごに
Seleniumを使いこなせる人は、CI/CDに組み込んだりしてみると、リリースの動作確認まで出来ちゃうので、夢が広がりますね。
chromeはfileプロトコルも使えるので、ローカルに置いたファイル(Lambdaが動いてる実行環境)を使うこともできます。

- 投稿日:2019-12-11T06:37:25+09:00
AWSでJupyterHub (JupyterHubへのログイン)
概要
全体概要は,AWSでJupyterHub (概要) にあるので,参照してください.
今回は,前回セットアップしたJupyterHubへのログイン周りを固めていきます.
JupyterHubの認証はいくつかあるのですが,今回はPAM認証を利用しています.前回のままでは,ログインできないので,正しくログインできるように整えてます.
おしながき
- JupyterHubへのログイン
- 権限の修正
- リトライ
- notebookのディレクトリ変更
JupterHubへのログイン
実は
ec2-userでログインしようとすると,ログインできないのです.
どんなに丁寧に入力してもログインできません.ここで動作確認もかねて,テスト用のアカウント
admin_userとtest_userの2つを作っておきます.
以下のコマンドで,ユーザ追加,パスワード設定,JupyterHub用ディレクトリの作成を行います.
ユーザ追加時にjupyterhubグループを指定しておきます.
パスワードは自分が分かるものにしておきます.(後で使うので)
ディレクトリは各ユーザのホームディレクトリ配下にnotebookという名前で作ります.アカウント追加useradd admin_user -g jupyterhub passwd admin_user sudo -u admin_user mkdir /home/admin_user/notebook同様に
test_userも同じコマンドで作成していきます.
次に,jupyterhub_config.pyにユーザ追加します.
追加の仕方は次のようにします./etc/jupyterhub/jupyterhub_config.pyc.Authenticator.admin_users = { 'ec2-user', 'admin_user' } c.Authenticator.whitelist = { 'ec2-user', 'admin_user', 'test_user' }追加したら,
jupyterhubを起動させます.ログイン画面で,作ったばかりのユーザでログインしてみます.
いずれのユーザもログインに失敗してしまいます.
ログにも同じような情報が出ていると思います./var/log/secureというログにもその時の記録がされています.(sudoを使おうとしているため記録されます)
これは,PAM認証がうまく機能していないためです.PAM認証とは
Linuxには,各アプリケーションが共通して認証できる機構が備わっています.
それが,PAM(Pluggable Authentication Modules)のようです.
詳しい説明はここではやりません.(あまり知らないので出来ません...)実行権限の修正
ユーザ名・パスワードがあってても,Linuxユーザの
jupyterhubがログインユーザへのsudo権限がないためです.
jupyterhubがどのユーザにもsudoが使えるように設定していきます.
sudo権限を管理できる/etc/sudoers.d/というディレクトリがあります.実はec2-userの設定がここにあり,root同等の権限を持てる設定になってます.
jupyterhubというユーザがjupyterhubグループに対して,sudo -u {username} /opt/anaconda3/bin/sudospawnerというコマンドをパスワードなしで実行できるようにします.この手の権限付与はピンポイントでやっておくべきなので,コマンドに対して付与していきます./etc/sudoers.d/jupyterhub## Jupyterhub Cmnd_Alias JUPYTER_CMD = /opt/anaconda3/bin/sudospawner %jupyterhub ALL=(jupyterhub) /usr/bin/sudo jupyterhub ALL=(%jupyterhub) NOPASSWD:JUPYTER_CMD次に,Anacondaに
sudospawnerパッケージを追加します.sudo /opt/anaconda3/bin/conda install -y -c conda-forge sudospawnerこれとは他に,
jupyterhubユーザにPAM認証の権限を付与するためにshadowグループに追加させる必要があります.
/etc/shadowというファイルを操作するため状態を確認しておきます.[root@xxx ~] ls -l /etc/shadow ---------- 1 root root 708 Dec 4 07:41 /etc/shadow権限はrootになっていますが,
000と読み書きできないファイルになっています.以下のコマンドを実行して,変更していきます.# shadowグループの追加 sudo groupadd shadow # /etc/shadowファイルをshadowグループに変更 sudo chgrp shadow /etc/shadow # /etc/shadowファイルのshadowグループにread権限追加 sudo chmod g+r /etc/shadow # jupyterhubユーザをshadowグループに追加 sudo usermod -a -G shadow jupyterhub/etc/shadowファイルについて
このファイルは,ユーザのパスワード情報が記録されています.
入力したパスワードを指定されたハッシュ化によって得られた値とファイル内のハッシュ値を突き合わせて認証をするようです.
ファイル内のec2-userが,!!となっているので,「このユーザにログインできない」というロック状態を意味しているようです.
そのため,JupyterHubでいくらログインしても失敗するようでした.(詳細まで理解できてないです)再度,ログイン
jupyterhubの権限が設定出来たら,jupyterhubを起動させます.
起動コマンドは以下のようにします.JupyterHub.spawner_classのオプションを付けただけです.cd /etc/jupyterhub sudo -u jupyterhub /opt/anaconda3/bin/jupyterhub --JupyterHub.spawner_class=sudospawner.SudoSpawner起動後,ブラウザでアクセスして,最初に作った
test_userでログインしてみると,以下のような画面に遷移します.
ここまで表示できれば,JupyterHubの設定は完了です.
JupyterHubのホームディレクトリの変更
この時(AWSでJupyterHub (EC2))に追加したEBSに向けさせようと思います.
/etc/jupyterhub/jupyterhub_config.pyを以下のように修正します./etc/jupyterhub/jupyterhub_config.py# c.Spawner.notebook_dir = '~/notebook' c.Spawner.notebook_dir = '/mnt/jupyterhub/{username}'修正したら,
/mnt/jupyterhub/配下に各ユーザのディレクトリを作ります.今回はtest_userを対象にします.
ディレクトリが出来たら,JupyterHubを再起動させて設定ファイルを反映させます.ディレクトリ作成sudo -u test_user mkdir /mnt/jupyterhub/test_userログイン後,ブラウザで試しにnotebookを作成します.
/mnt/jupyterhub/test_user/Untitled.ipynbというファイルが作成されていれば,Spawner.notebook_dirの設定が反映できたことになります.まとめ
今回は,JupyterHubのユーザ管理をPAM認証によって制御するための設定を行いました.
jupyterhubユーザへのsudo権限の追加,shadowファイルのread権限修正を経て,Linuxユーザでのログインができるようになりました.
また,notebookのディレクトリを追加したEBSに向けさせるようにしました.ストレージを分けることで管理しやすくなると同時に,JupyterHubが稼働するストレージに問題が起きても,notebookのあるストレージに影響が出ないため安全になります.認証機能は,デフォルトで
PAMAuthenticatorというクラスが機能するのですが,他にもLDAPやGitHubなどのアカウントでログインできるような仕組みがあります.