- 投稿日:2019-12-11T23:31:22+09:00
Kerasでの中間層出力の取得について
はじめに
Tensorflow2.0のKerasを用いてDeep Learningを試みており,中間層の出力が必要になりました.Kerasのドキュメントにしたがって中間層の出力を得ようとしたのですが,エラーが出てうまく行きませんでした.
調べてもいいやり方が出てこなかった(私の調べ方がまずかっただけ?)ので,尤もらしいやり方でやったところうまくいったのでまとめることにしました.
- 環境
- tensorflow-gpu==2.0.0-rc1
Kerasでのモデル構築について
tf.keras.Modelを用いたモデル構築のやり方はドキュメントによるとfunction APIを用いる方法とclassを用いる方法の2通りあります.
function APIを用いる方法
import tensorflow as tf inputs = tf.keras.Input(shape=(3,)) x = tf.keras.layers.Dense(4, activation=tf.nn.relu)(inputs) outputs = tf.keras.layers.Dense(5, activation=tf.nn.softmax)(x) model = tf.keras.Model(inputs=inputs, outputs=outputs)classを用いる方法
import tensorflow as tf class MyModel(tf.keras.Model): def __init__(self): super(MyModel, self).__init__() self.dense1 = tf.keras.layers.Dense(4, activation=tf.nn.relu) self.dense2 = tf.keras.layers.Dense(5, activation=tf.nn.softmax) def call(self, inputs): x = self.dense1(inputs) return self.dense2(x) model = MyModel()中間層出力の取得
今回はclassを用いて記述していたのですが,ドキュメントのFAQにはfunction APIの使用を前提とした説明のみがなされており,classを用いている場合には同じ方法ではうまくいきません.
function APIを用いる場合
from keras.models import Model model = ... # create the original model layer_name = 'my_layer' intermediate_layer_model = Model(inputs=model.input, outputs=model.get_layer(layer_name).output) intermediate_output = intermediate_layer_model.predict(data)function APIを用いてる場合には,このように中間層の値を出力するモデルを構築することで中間層出力を得ることができます.
classを用いる場合
function APIを用いる場合は上記のやりかたでできるのですが,classを用いている場合にこのコードを実行すると
AttributeError: Layer my_model is not connected, no input to return.と怒られてしまいます.
classの方ではfunction APIと違ってinputやoutputを明示的に定めていないのが原因のようです.そこで(考えてみれば当たり前なのですが)modelを定義したclassに中間層出力を出力するメソッドを追加します.
import tensorflow as tf class MyModel(tf.keras.Model): def __init__(self): super(MyModel, self).__init__() self.dense1 = tf.keras.layers.Dense(4, activation=tf.nn.relu) self.dense2 = tf.keras.layers.Dense(5, activation=tf.nn.softmax) def call(self, inputs): x = self.dense1(inputs) return self.dense2(x) def hidden_layer(self, input): return self.dense1(input) model = MyModel()このようにすることで
model.hidden_layer(input)などとすることで中間層の出力を得ることができます.
最後に
中身自体は全然大したことは書いてないのですが単純に自分が困ってしまったので記事としてまとめさせていただきました.
tensorflow2.0が登場してドキュメントのバージョンとかがちゃんと更新されていなかったりするのがわかりにくかった原因なのかな...
- 投稿日:2019-12-11T22:23:25+09:00
Cifar10用DCGANモデルを晒すwith keras
概要
- 時間がないので,GANの仕組みなどはとりあえず割愛
- generatorとdiscriminatorの設定を書く
- 味噌はgenerator,discriminatorともに活性化関数にLeakyReLuを使う
- 学習プロセス全体のソースコードはgithubにアップロード予定です(準備中です申し訳ありません)
モデルパラメータ達
Generator
generatordef _build_generator(self) -> Model: start_pix_x = 4 start_pix_y = 4 kernel_ini = RandomNormal(mean=0.0, stddev=0.02) inputs = Input(shape=self.noise_shape) x = Dense( units=256*start_pix_x*start_pix_y, kernel_initializer=kernel_ini, bias_initializer='zeros')(inputs) x = LeakyReLU(alpha=0.2)(x) x = Reshape((start_pix_x, start_pix_y, 256))(x) x = Conv2DTranspose( filters=128, kernel_size=4, strides=2, padding='same', kernel_initializer=kernel_ini, bias_initializer='zeros')(x) x = LeakyReLU(alpha=0.2)(x) # x = BatchNormalization(axis=3)(x) x = Conv2DTranspose( filters=128, kernel_size=4, strides=2, padding='same', kernel_initializer=kernel_ini, bias_initializer='zeros')(x) x = LeakyReLU(alpha=0.2)(x) # x = BatchNormalization(axis=3)(x) x = Conv2DTranspose( filters=128, kernel_size=4, strides=2, padding='same', kernel_initializer=kernel_ini, bias_initializer='zeros')(x) x = LeakyReLU(alpha=0.2)(x) x = Conv2D( filters=3, kernel_size=3, padding='same', kernel_initializer=kernel_ini, bias_initializer='zeros')(x) y = Activation('tanh')(x) model = Model(inputs, y) if self.verbose: model.summary() return modelDiscriminator
discriminatordef _build_discriminator(self) -> Model: kernel_ini = RandomNormal(mean=0.0, stddev=0.02) inputs = Input(shape=self.shape) x = GaussianNoise(stddev=0.05)(inputs) # prevent d from overfitting. x = Conv2D( filters=64, kernel_size=3, padding='SAME', kernel_initializer=kernel_ini, bias_initializer='zeros')(x) x = LeakyReLU(alpha=0.2)(x) # x = Dropout(0.5)(x) x = Conv2D( filters=128, kernel_size=3, strides=2, padding='SAME', kernel_initializer=kernel_ini, bias_initializer='zeros')(x) x = LeakyReLU(alpha=0.2)(x) # x = Dropout(0.5)(x) # x = BatchNormalization(axis=3)(x) x = Conv2D( filters=128, kernel_size=3, strides=2, padding='SAME', kernel_initializer=kernel_ini, bias_initializer='zeros')(x) x = LeakyReLU(alpha=0.2)(x) # x = Dropout(0.5)(x) # x = BatchNormalization(axis=3)(x) x = Conv2D( filters=256, kernel_size=3, strides=2, padding='SAME', kernel_initializer=kernel_ini, bias_initializer='zeros')(x) x = LeakyReLU(alpha=0.2)(x) x = Flatten()(x) features = Dropout(0.4)(x) validity = Dense(1, activation='sigmoid')(features) model4d = Model(inputs, validity) model4g = Model(inputs, validity) if self.verbose: model4d.summary() return model4d, model4g出力結果
出力結果の行はクラスに対応しています.
DCGANはただ画像を生成するだけですが,元の画像で構築した学習モデルに生成画像を入力して予測されたラベルによってラベリングして,予測クラスごとに画像を出力させています.
generatorにLeakyReLUをいれることで,物体の対象がよりしっかりと生成できてる感がある感じがします.
結論
突貫でやったので,詳しく後日ちゃんと書きたいと思います.

- 投稿日:2019-12-11T11:38:49+09:00
tensorflow.jsでクリスマス度を数値化してみる
こんにちは。NIJIBOXのエンジニアのつんあーです。
こちらの記事はNIJIBOX Advent Calendar 2019の12日目の記事です。
https://github.com/ats05/christmas_scouter
デモはこちら※画面を開いてからモデルのロードが完了するまで
--.-%と表示されます。しばらくお待ちください。
※カメラの映像が滑らかに表示できません。なんとかしたい。TensorFlow.jsの情報を調べてみると、意外にまだまだ「コレ!」といった情報が少ない印象でした。
情報を探している方の助け&web技術の発展の助けになれば幸甚です。
導入
さて、厚手のコートを着ていても吹く風の冷たさを感じる今日この頃。
街はクリスマスムード真っ只中です。そこかしこにイルミネーションが輝き、少し浮かれ気味なムードが漂っています。
実は、私はこの華やかな時期の街中が結構好きなのです。
イルミネーションが綺麗な街で、「ああクリスマスっぽいなぁ」ってぼんやりするのは結構楽しいものです。はたと思いました。
クリスマスっぽいとは一体なんなのでしょう。
なぜだかワクワクするような気持ちを感じさせる街の雰囲気とは、
一体どんなところから溢れてくるのでしょう。とりあえず検索してみましょう。
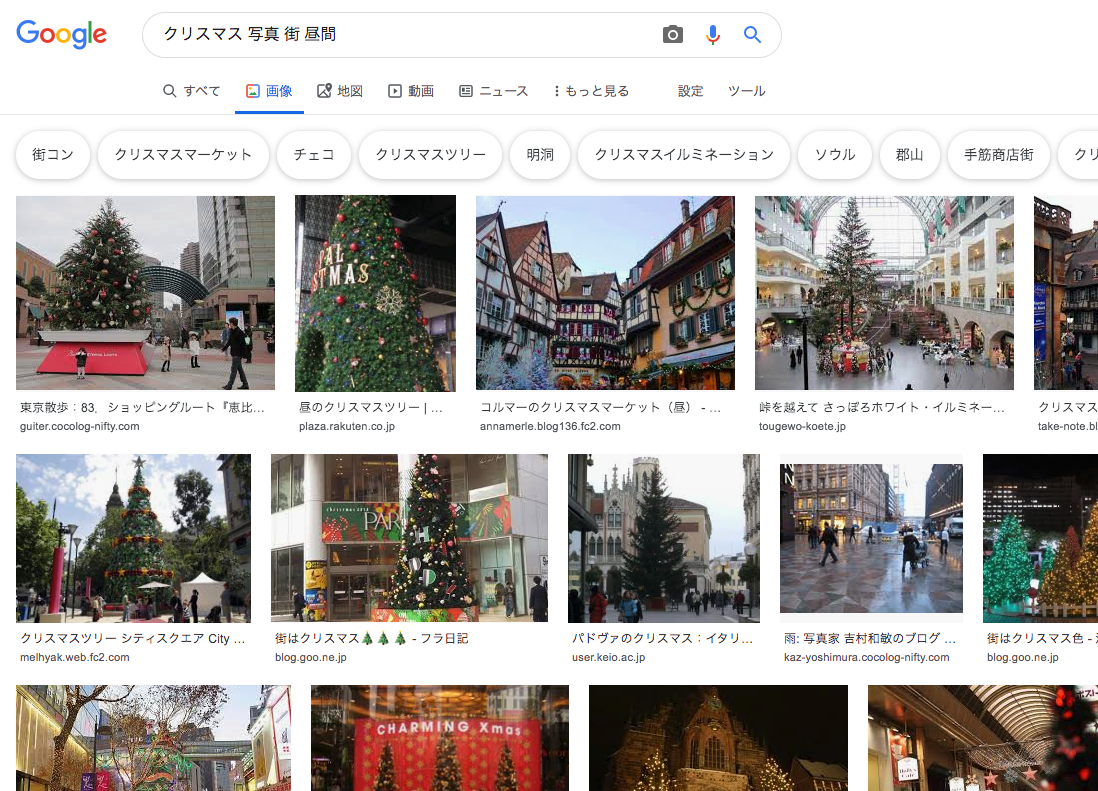
いいですね。
こういう雰囲気ですよ。こういう雰囲気。
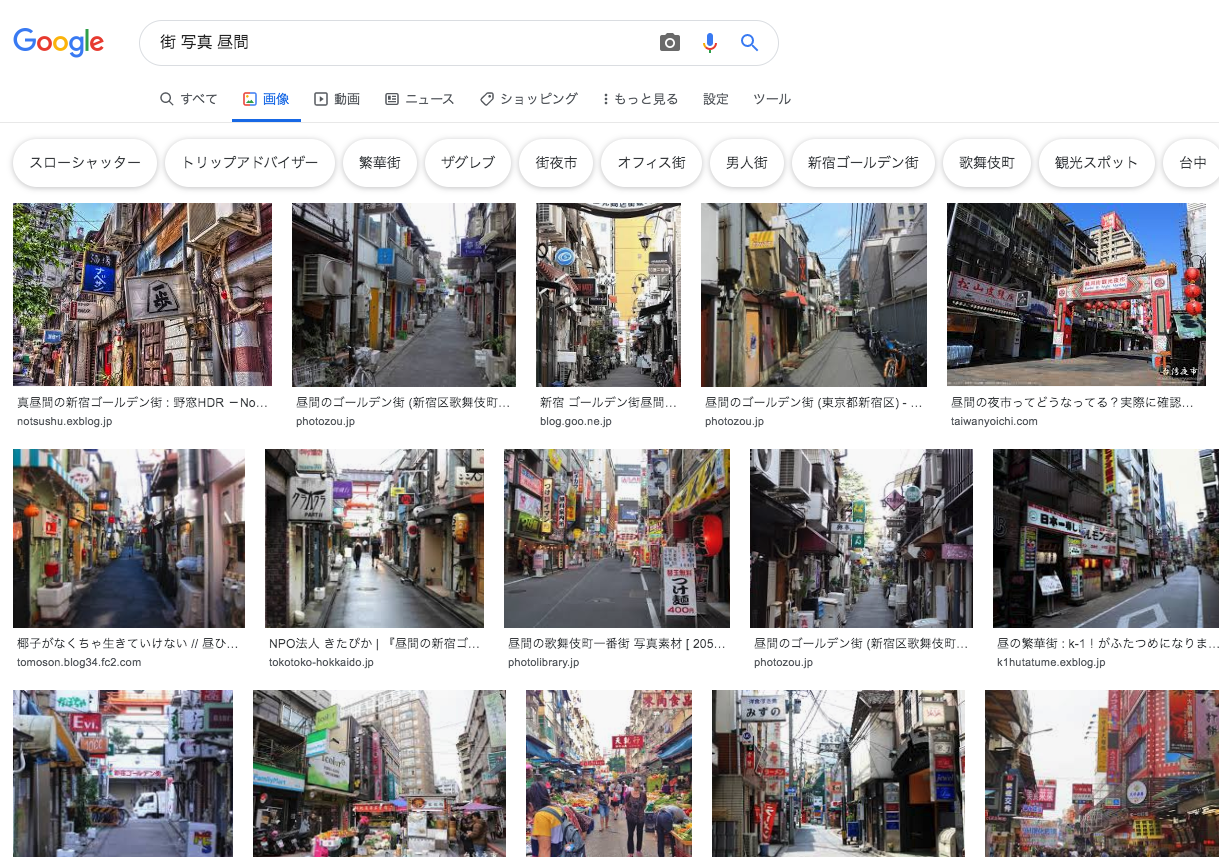
今度はクリスマスを感じない街を検索してみます。
普通ですね。(そりゃそうだ)
画像検索してるのにキーワードに「写真」と入れているあたりに茶目っ気を感じます。
ところで、私達はこれらの画像検索の結果から「クリスマスっぽさ」
をなんとなく感じ取ることができていますでは、これらの画像をひたすら学習させれば、コンピュータでも
「ああクリスマスっぽいなぁ」と感じさせることができるのではないでしょうか。モノは試し、やってみましょう。
というわけで、今回はTensorflowを使い、画像のクリスマスっぽさをコンピュータに判断させてみます。
ついでに、NIJIBOXはWebに強い会社ということで、
これをWebに移植しスマホからでも簡単に実行できるようにしてみましょう。今回はコチラの記事を参考に、画像の分類を行ってみました。
Tensorflowでクリスマスっぽさを判断させる
画像を集める
まず、こちらのツールを使ってGoogle画像検索から画像を集めます。
https://github.com/hardikvasa/google-images-download1度に100件以上の画像をダウンロードする際はChromeDriverを入れないといけないようなので、導入します。
$ brew tap homebrew/cask $ brew cask install chromedriver$ which chromedriver => /usr/local/bin/chromedriver # 入った!先ほどと同じキーワードで、クリスマスっぽさを感じる画像を集めてみます。
とりあえず上限は10000件にしてみました。欲張りですね!$ googleimagesdownload --keywords "クリスマス 写真 昼間 街" --limit 10000 --chromedriver /usr/local/bin/chromedriverと思ったら残念、376件までしかダウンロードしてくれませんでした。ガックシガックシ。
Unfortunately all 10000 could not be downloaded because some images were not downloadable. 376 is all we got for this search filter!集まった画像はこんな感じ。良さそうですね。
画像は実行したディレクトリ/download/キーワードという場所に保存されます。同様の手順で、クリスマスっぽくない画像も集めます。
$ googleimagesdownload --keywords "街 写真" --limit 10000 --chromedriver /usr/local/bin/chromedriver ... Unfortunately all 10000 could not be downloaded because some images were not downloadable. 379 is all we got for this search filter!やはり途中で終わってしまいました。こちらは379件。
先ほどのスクリーンショットを見ていただくとわかるのですが、
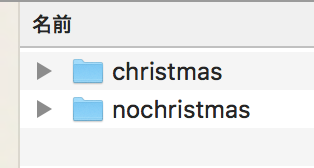
データが壊れていて開けない画像や、重複した画像、そもそもクリスマスとあまり関係のない画像が混ざっています。これらを手作業で除外していきます。
その結果、
クリスマスっぽい画像:300枚くらい
クリスマスっぽくない画像:350枚くらいまで減りました。
画像は、「chrsitmas」ディレクトリと「nochristmas」ディレクトリに分けておきます。
downloads/ ├── christmas └── nochristmas
ちなみに、クリスマス画像にはやたらと合コン募集の画像が入っていました。
どうしろと言うのでしょう。
画像を学習させる
画像が集まったので、これらをTensorflowで読み込ませ学習させていきます。
既に基本的な訓練をされたモデルがあるので、それを利用します。
下記のスクリプトをダウンロード。
https://github.com/tensorflow/hub/raw/r0.1/examples/image_retraining/retrain.pyとりあえず、実行してみます。
--追記--
ここでは--saved_model_dirオプションをつける必要がありました。
私はこれに気付かずかなりの時間を使ってしまいました。$ python retrain.py --image_dir ./google-images-download/downloads/ --saved_model_dir ./SavedModel ... AttributeError: module 'tensorflow' has no attribute 'app'まあ、一発でうまく行くわけがないですよね。
エラーが出ました。上記エラーの内容を調べてみると、TensorFlow2.x以降だと
tf.appが使えないからエラーになっているようです。
手元のTensorflowのバージョンを確認してみます。$ pip show tensorflow => Name: tensorflow Version: 2.0.0残念、2.0.0が入っていました。。。。
仕方ないので、1.x系にダウングレードします。
今入っているものを削除し、1.x系の最新をインストール。$ pip uninstall tensorflow $ pip install tensorflow==1.15 $ pip uninstall tensorflow-hub $ pip install tensorflow-hub $ pip show tensorflow => Name: tensorflow Version: 1.15.0もう一度、学習のスクリプトを実行してみます。
$ python retrain.py --image_dir ./google-images-download/downloads/お、何か始まりましたね。
... OSError: [Errno 63] File name too long: '/tmp/bottleneck/christmas/363.%E3%83%8B%E3%83%A5%E3%83%BC%E3%83%A8%E3%83%BC%E3%82%AF-%E3%82%AF%E3%83%AA%E3%82%B9%E3%83%9E%E3%82%B9%E3%82%B7%E3%83%BC%E3%82%B9%E3%82%99%E3%83%B3-%E3%82%AB%E3%83%AB%E3%83%86%E3%82%A3%E3%82%A8.jpg_https~tfhub.dev~google~imagenet~inception_v3~feature_vector~1.txt'。。。と思ったらまたエラーが出ました。
読み込んだ画像のファイル名が長すぎるそうです。(そんなことあるのか。。)ダウンロードした画像のファイル名を修正し、再々チャレンジ。
INFO:tensorflow:Froze 378 variables. I1206 19:20:09.427611 140737240245184 graph_util_impl.py:334] Froze 378 variables. INFO:tensorflow:Converted 378 variables to const ops. I1206 19:20:09.723118 140737240245184 graph_util_impl.py:394] Converted 378 variables to const ops.今度は成功しました。
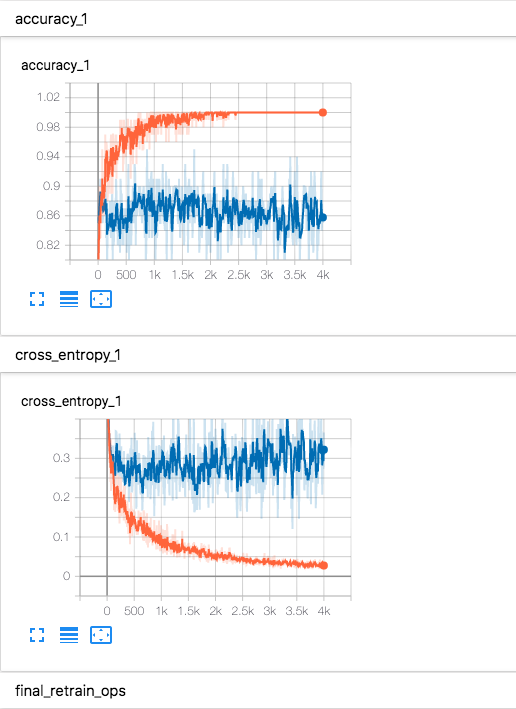
所要時間は私の環境で30分ほど。あれ?思ったより少ない。学習の状況が知りたいですね。
とりあえずどの説明でもTensorBoardを使って確認しているようなので、同じようにやってみました。$ pip install tensorboard $ tensorboard --logdir /tmp/retrain_logs => TensorBoard 1.15.0 at http://localhost:6006/ (Press CTRL+C to quit)
ほうほう、それっぽいそれっぽい。
私は読み方がわからないので何も活用ができないのですが、それっぽいのでヨシとしましょう。
ちなみに、TensorBoardで表示するのに必要なログの出力先は
retrain.pyの中に書いてありました。
実行してみる
適当に用意した画像を使って、実行してみましょう。
実行用には、こちらのスクリプトを使います。
https://github.com/tensorflow/tensorflow/raw/master/tensorflow/examples/label_image/label_image.py
retrain.pyは、--saved_model_dirオプションをつけない場合/tmp配下にモデルファイルが生成されるようですので、
--graphと--labelsオプションでそれらを指定します。--追記--
--saved_model_dirオプションが付いているとここはうまくいかないようです。
pythonで実行してみたい方は、上記オプションを外してみてください。$ python label_image.py \ --graph=/tmp/output_graph.pb --labels=/tmp/output_labels.txt \ --input_layer=Placeholder \ --output_layer=final_result \ --image=画像ファイルでは、早速いってみましょう。
こちらは、表参道のイルミネーションの写真です。
christmas 0.9571908 nochristmas 0.042809136約96%でクリスマスと判定されました。
なかなかの精度です。
こちらは、お肉のフリー素材サイトoniku images様から頂いたサーロインの画像です。
とても美味しそうです。
christmas 0.7308841 nochristmas 0.26911587若干クリスマス度が高めです。
やはりクリスマスといえばご馳走ということなのでしょう。
こちらは、いつのまにかクリスマス仕様になっていた弊社エントランスです。
christmas 0.994396 nochristmas 0.0056040385これもクリスマスと判定されました。
かなりいいですね。
こちらは、お肉のフリー素材サイトoniku images様から頂いた動きのあるお肉の画像です。
躍動感に溢れています。
christmas 0.5222237 nochristmas 0.47777635お肉に躍動感はいらないかもしれません。
Webに乗せる
さて、クリスマス度を判定してくれるモデルができたところで、
これをTensorFlow.jsで扱えるように変換していきます。TensorFlowには、公式で変換ツールが用意されています。
https://github.com/tensorflow/tfjs/tree/master/tfjs-converter
tfjs-converterはpythonのTensorFlow.jsに付属しています。
ので、インストール。$ pip install tensorflowjs
ここからの試行錯誤が色々ありました。興味のある方は開いてみてください。
https://github.com/tensorflow/tfjs/tree/master/tfjs-converter
こちらのReadmeを参照しながら、試してみます。こんなことが書いてあります。
The converter expects a TensorFlow SavedModel, TensorFlow Hub module, TensorFlow.js JSON format, Keras HDF5 model, or tf.keras SavedModel for input.
どうやら一口に「TensorFlowのモデル」といっても色々な形式があるようです。
変換時にはそれを指定する必要があります。さて、今使っているモデルの形式は何なんでしょう?
https://github.com/tensorflow/hub/raw/r0.1/examples/image_retraining/retrain.py
こちらは先ほどの学習済みモデルのスクリプトなのですが、urlには
tensorflow/hubという記載があります。ということは、
TensorFlow Hub module
が正しそう?
$ tensorflowjs_converter \ --input_format=tf_hub \ /tmp/output_graph.pb \ ./output/web_model => OSError: SavedModel file does not exist at: /tmp/output_graph.pb/{saved_model.pbtxt|saved_model.pb}指定するパスが変なことになっていますね。
output_graph.pbを使って欲しいのですが、
指定するのはディレクトリだけみたいですね。$ tensorflowjs_converter \ --input_format=tf_hub \ /tmp \ ./output/web_model => OSError: SavedModel file does not exist at: /tmp/{saved_model.pbtxt|saved_model.pb}おおん?
エラーをよくみると、
/tmp/{saved_model.pbtxt|saved_model.pb}
とあります。
つまり、saved_model.pbtxtかsaved_model.pbというファイル名でないといけないようです。リネームしてもう一度。
$ mv /tmp/output_graph.pb /tmp/saved_model.pb $ tensorflowjs_converter \ --input_format=tf_hub \ /tmp \ ./output/web_model => RuntimeError: MetaGraphDef associated with tags 'serve' could not be found in SavedModel. To inspect available tag-sets in the SavedModel, please use the SavedModel CLI: `saved_model_cli`
serveというtagが見つからないそうです。何だそれは。
saved_model_cliを使ってくれよな!という記述があります。
やってみます。
$ saved_model_cli show --dir /tmp => The given SavedModel contains the following tag-sets:tagの中身は何も無いようです。。。
というか、さっきからSavedModelというのが何度も出てきています。先ほどのtfjs_converterの説明によると、
The converter expects a TensorFlow SavedModel, TensorFlow Hub module, TensorFlow.js JSON format, Keras HDF5 model, or tf.keras SavedModel for input.
どうやら
SavedModelというのもモデルの形式の一つのようです。このモデルは
tf_hubでなくSavedModelなのでしょうか?やってみましょう。
--signature_name=serving_defaultと--saved_model_tags=serveというオプションが追加されているようです。$ tensorflowjs_converter \ --input_format=tf_saved_model \ --output_format=tfjs_graph_model \ --signature_name=serving_default \ --saved_model_tags=serve \ /tmp \ ./output/web_model => RuntimeError: MetaGraphDef associated with tags 'serve' could not be found in SavedModel. To inspect available tag-sets in the SavedModel, please use the SavedModel CLI: `saved_model_cli`同じエラーが。。。
グラフの中に
serveというタグが無いとのことです。
調べたところ、これを解消するには、tf.saved_model.builderを使うときに[tf.saved_model.tag_constants.SERVING]というキーワードを入れてあげれば良いようです。
retrain.pyでモデルを保存している箇所に、その記述を追加すれば良さそうですね。
retrain.pyの中を見てみます。
私はpythonリテラシーが極低なので、saveとかそれっぽいキーワードでgrepして怪しいところを探してみました。retrain.py... # Save out the SavedModel. builder = tf.saved_model.builder.SavedModelBuilder(saved_model_dir) builder.add_meta_graph_and_variables( sess, [tf.saved_model.tag_constants.SERVING], signature_def_map={ tf.saved_model.signature_constants. DEFAULT_SERVING_SIGNATURE_DEF_KEY: signature }, legacy_init_op=legacy_init_op) builder.save() # <- ここ?お、
[tf.saved_model.tag_constants.SERVING]に関する記述が初めからありますね。この部分は
export_model()という関数の中にあります。
そもそもこの関数が呼ばれているのかどうかを確認調べてみたところ、下記の記述が。retrain.py... if FLAGS.saved_model_dir: export_model(module_spec, class_count, FLAGS.saved_model_dir) ...
FLAGS.saved_model_dirが真でないと、そもそも呼ばれなさそうですね。
FLAGS.saved_model_dirがどこで代入されるかを調べると、こんな感じ。retrain.pyparser.add_argument( '--saved_model_dir', type=str, default='', help='Where to save the exported graph.') FLAGS, unparsed = parser.parse_known_args()どうやら、実行時のオプションにて
--saved_model_dirを指定しないと正しい形で保存してくれないようです。
/tmp配下に保存されるものは一体。。。?結論から言いますと、
学習時に--saved_model_dirパラメータをつけるのが正しそうです。$ python retrain.py --image_dir ./google-images-download/downloads/ --saved_model_dir ./SavedModelこれで、SavedModel配下にモデルが保存されます。
このモデルをsaved_model_cliで確認してみると、saved_model_cli show --dir ./SavedModel/ (2019ac) The given SavedModel contains the following tag-sets: serve
serveというタグが設定されています!良さそうですね。
もう一度、tfjs_converterで変換してみます。--追記--
この変換の際に、--quantization_bytesオプションをつけることで、量子化バイト数を指定し、出来上がるモデルの精度とサイズを調整することができました。
デフォルトでは--quantization_bytes=4になっているそうです。$ tensorflowjs_converter \ --input_format=tf_saved_model \ --output_format=tfjs_graph_model \ --signature_name=serving_default \ --saved_model_tags=serve \ ./SavedModel/ \ ./WebModel/web_model ... 2019-12-10 15:48:40.072180: I tensorflow/core/grappler/optimizers/meta_optimizer.cc:788] arithmetic_optimizer: Graph size after: 332 nodes (0), 376 edges (0), time = 168.506ms. 2019-12-10 15:48:40.072183: I tensorflow/core/grappler/optimizers/meta_optimizer.cc:788] dependency_optimizer: Graph size after: 332 nodes (0), 376 edges (0), time = 58.479ms. 2019-12-10 15:48:40.072186: I tensorflow/core/grappler/optimizers/meta_optimizer.cc:788] remapper: Graph size after: 332 nodes (0), 376 edges (0), time = 111.758ms. 2019-12-10 15:48:40.072273: I tensorflow/core/grappler/optimizers/meta_optimizer.cc:788] constant_folding: Graph size after: 332 nodes (0), 376 edges (0), time = 263.073ms. 2019-12-10 15:48:40.072296: I tensorflow/core/grappler/optimizers/meta_optimizer.cc:788] arithmetic_optimizer: Graph size after: 332 nodes (0), 376 edges (0), time = 165.07ms. 2019-12-10 15:48:40.072308: I tensorflow/core/grappler/optimizers/meta_optimizer.cc:788] dependency_optimizer: Graph size after: 332 nodes (0), 376 edges (0), time = 55.012ms. Writing weight file ./WebModel/web_model/model.json...おお!終わった!
上記コマンドで指定した
/WebModel/web_model配下に、何やらファイルが作成されました。WebModel/ └── web_model ├── group1-shard10of21.bin ├── group1-shard11of21.bin ├── group1-shard12of21.bin ├── group1-shard13of21.bin ├── group1-shard14of21.bin ├── group1-shard15of21.bin ├── group1-shard16of21.bin ├── group1-shard17of21.bin ├── group1-shard18of21.bin ├── group1-shard19of21.bin ├── group1-shard1of21.bin ├── group1-shard20of21.bin ├── group1-shard21of21.bin ├── group1-shard2of21.bin ├── group1-shard3of21.bin ├── group1-shard4of21.bin ├── group1-shard5of21.bin ├── group1-shard6of21.bin ├── group1-shard7of21.bin ├── group1-shard8of21.bin ├── group1-shard9of21.bin └── model.json多っ。
全部で87MBもあります。--追記--
このあと、--quantization_bytes=1のオプションをつけて実行したところ、22MBまで削減できました。
正確に1/4になっていますね。
この程度の用途であれば精度への影響はほとんど感じませんでした。
デモもこの軽量化したモデルを使用しています。JSから呼び出してみる
ここからはJSを使っていきます。
とりあえず、npmのモジュールとしては下記が必要になります。
npm i -S @tensorflow/tfjs @tensorflow/tfjs-converter作成したモデルはやたら重たいですが、とりあえずjsから呼び出してみます。
呼び出すのはmodel.jsonだけでいいとのことですが、同じディレクトリにgroup1-xxxxx.binが全て揃っているような状態にします。import * as tf from '@tensorflow/tfjs'; import {loadGraphModel} from '@tensorflow/tfjs-converter'; ... tf.loadGraphModel('...../model.json').then((model) => { console.log(model) })何か出ました!今のところエラーは出ていないので順調のようです。
canvas要素に適当な画像を突っ込んで、getElementByIdとかで取得して、モデルに渡してみます。
let model = null; tf.loadGraphModel('...../model.json').then((model) => { model = model; }) const channels = 3; let inputImage = tf.browser.fromPixels(canvasElement, 3); // <- canvas要素からテンソルを作ってくれるらしい console.log(inputImage); let result = model.predict(inputImage);下記のようなエラーが出ました。
入力に使うテンソルのシェイプは [-1, 299, 299, 3] でないといけないが、入力されたのは[720, 406, 3]である
てなところでしょうか。
渡したcanvas要素のシェイプを確認してみます。
let inputImage = tf.browser.fromPixels(canvasElement, 3); console.log(inputImage.shape); // => [720, 406, 3]720, 406というのは渡したcanvas要素の縦横サイズです。
これを[-1, 299, 299, 3]に直さないといけないようです。
label_image.pyで画像を分類させるときに、pythonスクリプト内で行なっている画像の下処理と同様のことを、JSで行わないといけないようです。
label_image.pyはこんな感じlabel_image.pyfloat_caster = tf.cast(image_reader, tf.float32) dims_expander = tf.expand_dims(float_caster, 0) resized = tf.image.resize_bilinear(dims_expander, [input_height, input_width]) normalized = tf.divide(tf.subtract(resized, [input_mean]), [input_std]) sess = tf.compat.v1.Session() # <-ここはセッションの起動だから、JSでは無視 result = sess.run(normalized) # <-ここで計算tensorflow.jsのリファレンスをみながら、頑張ってみます。
https://js.tensorflow.org/api/1.0.0/こんな感じ。
// Pyrhonだと : float_caster = tf.cast(image_reader, tf.float32) let float_caster = tf.cast(inputImage, 'float32'); console.log(float_caster.shape); // => [720, 406, 3] // Pythonだと : dims_expander = tf.expand_dims(float_caster, 0) let dims_expander = float_caster.expandDims(0); console.log(dims_expander); // => [1, 720, 406, 3] // Pythonだと : resized = tf.image.resize_bilinear(dims_expander, [input_height, input_width]) // ※ input_height, input_widthは共に299 let resized = tf.image.resizeBilinear(dims_expander, [299, 299]); console.log(resized); // => [1, 299, 299, 3] // Pythonだと : normalized = tf.divide(tf.subtract(resized, [input_mean]), [input_std]) // ※ input_meanは0, input_stdは255 let normalized = tf.div(tf.sub(resized, [0]), [255]); console.log(normalized); // => [1, 299, 299, 3] this.state.model.predict(normalized).print();※シェイプの一つ目が
-1ではなく1になっていますが、なぜかうまくいきました。理由はよくわかりません。それっぽい結果がコンソールに出力されました。
これがどうやら、pythonで画像分類を行なったときに出た
christmas xxx nochristmas xxxという結果と対応しているようです。
ラベルがないとわかりにくいですね。コードを整理する
生成したテンソルがメモリを食いつぶさないようにtidyで囲み、推定結果をpromiseで非同期に受け取るようにしました。
結果もテンソルではなく、配列で受け取るようにしています。その他Reactで実装したりアレコレやっていますが、必要なnpmモジュールはGithubを参照してもらえたらと思います。
let tensor = tf.tidy(() => { const channels = 3; let inputImage = tf.browser.fromPixels(this.videoElement, 3); let float_caster = tf.cast(inputImage, 'float32'); let dims_expander = float_caster.expandDims(0); let resized = tf.image.resizeBilinear(dims_expander, [299, 299]); let normalized = tf.div(tf.sub(resized, [0]), [255]); return normalized; }) new Promise((resolve, reject) => { let result = this.state.model.predict(tensor).array(); // 値はarray()で取り出せる resolve(result); }).then(result => { console.log(result); })
これらを元に、ブラウザとwebカメラで推定を行えるようにしたデモを作成しました。
https://github.com/ats05/christmas_scouterアクセスしてしばらくは
--.-%と表示されるかと思います。
TensorFlow.jsはどうも読み込む際に時間がかかるみたいです。これを持って少し街に繰り出してみました。
やはりイルミネーションは高スコアになりますね。
おしまい。
※特にオチはありません。