- 投稿日:2019-12-11T22:56:45+09:00
コスモを感じた初めてのRSpec
自己紹介
さっそくだが、君は、小宇宙(コスモ)を感じたことがあるか!?
はじめまして。営業からRuby on RailsのWebエンジニアになったたっきー(半年)と言います。
僕は文系出身で開発は全くの未経験ですが、一念発起してJOBチェンジした者です。
とても優しく指導して下さっている先輩たちのもと、コツコツと勉強を進めているのですが、やはり分からない事も多く、先輩たちの時間を頂くことが多い恐縮な日々を過ごしています。。とりあえずRubyを触って半年経ちました。
formの動きとか基礎的なものはようやく動かせるようになりましたが、まだまだ半人前。
そんなちょっとやそっと触っただけで、できる甘い世界ではないですね。家はシェアハウスに住んでいて住人達から黒魔術ってタイトルのQiita記事をネタにされてブラックマジシャンって呼ばれてます。
今回は、会社で自分の書いたコードのテストを書いてねって言われた10月を振り返ります。スキル
HTMLとCSSは最低限作りたいイメージのものは作れるようになった。
JSはまだまだテンプレートとか調べながらじゃないと、全然できません。
rubyは分岐やら正規表現やら初歩中の初歩は理解したけど、綺麗には書いていない(らしい)
railsはチュートリアル二周半回って、イメージはつくけどまだお手本ないと辛い感じ。テスト元のコントローラー
細かくは書けないですが、ユーザーに設定してもらうユーザーに設定してもらうparamsを削除・作成・編集(RENAME)するものを作りました。
アクティブレコードで対象のモデルからデータを引っ張ってきて、idで合わせている書き方をしています。文法
作法は難しい。
これまで書いていたRails的なdef...endみたいな単純な書き方ではないからだ。
それでも任されたからに書き始めないといけない・・・STEP1 RSpecのファイルを作る。該当のcontrollerの名前に合致するようにspecファイルを作成してください。
$ touchでコマンドで書いてもよし、該当フォルダで右クリックしてファイルを作ってもよし、まあ良しなにやってくれ。STEP2 ファイルの中身をまずはdescribeを書いてく
例えば、GET関連のテストを書きたい時には一番最初にこのように書くんだ。
categories_controller_spec.rbdescribe'⚪︎◯#show'do コメント it "●●" do expect(××).to eq □□ end end※実際にどのように書いていくかは伊藤さんの記事がとても丁寧に紹介されているよ。
https://qiita.com/jnchito/items/42193d066bd61c740612RSpecという小宇宙
テストを書く意義はテストにアサインされる身になるとよくわかる。
何十何百ってパターンを回さないといけないようなテストを人力なんかでやっちゃいけない。
勿論、必要なケースもあるだろうが、あまり生産性を感じない。その点自動テストは、勝手にやってくれる。ロジックに誤りがないならヒューマンエラーも起きない。
ヒューマンエラーってのは最悪だ。時間を使って、無駄なことをしている。
だから、効率化効率化なんていろんなところで言われているんだ。自分は自動テストというものに途轍もない「小宇宙(コスモ)」を感じてしまった。
勉強法
書籍
https://leanpub.com/everydayrailsrspec-jp
おすすめ記事
https://qiita.com/jnchito/items/42193d066bd61c740612
実践
http://tech-drill.in/questions/12最後に
割愛しすぎた部分もあるので、今後はもう少しhogeとか使って、イメージしやすい記事にします!
- 投稿日:2019-12-11T21:27:31+09:00
Ruby on Rails、ハマったところ
Ruby on Railsを使っている中でハマったポイントを適宜追加して行きます。
・gem
paranoiaを利用中、application_record.rbにacts_as_paranoidと記述してしまい、論理削除を必要としないテーブルで
UnknownAttributeError: unknown attribute 'deleted_at' for Bill.と怒られまくってしまった。
- 投稿日:2019-12-11T21:12:33+09:00
Ruby 価値が大きくなる組み合わせ問題 解いてみた
はじめに
毎月先輩から出していただいた課題に取り組んでいます、 mi0です。
11月は価値が大きくなる組み合わせ問題、いわゆる最適化問題を解きました。
この記事は解く〜レビューをいただくまでの過程を纏めた備忘録です。
こうやったらもっとよくなる、などのご指摘があればコメント頂けると嬉しいです!過去の記事はこちら!↓
登場人物
- 私
- 社会人2年目PG。
3年目が最近の恐怖ワード。最近異様に#selectを乱用している気がして不安になってきた。- 出汁巻先輩
- オムレツちゃんの先輩。大根おろしはほどほどにしてほしいと思っている。コーディングが得意。
- オムレツちゃん
- 私の心の中に住んでいる妖精。ケチャップはしっかりかけて欲しいらしい。
出題された問題
価値が大きくなる組み合わせ問題
問題
- 価格と重量のある、いくつかの品物を重量制限のある入れ物で運ぶ際、価格の合計が大きくなる組み合わせを出力する
メニューの元データ
db/data.csvから取得要求仕様
- 詰め込む入れ物の重量制限は指定できる
- 品物は 1 つずつ詰め込むことができる
- 同じ商品を複数詰め込むことができない
- 提案する組み合わせ数は指定できる
- 組み合わせは価格が大きくなる順に並び替える
- 価格が同じ場合は、重量の重い順に並び替える
- 組み合わせる品物は
idの昇順- 引数値の検証は不要
0 <= 入れ物の制限 <= 130 <= 提案する組み合わせ数 <= 10- 使用するデータの価格と重量の組み合わせはユニーク
- 例) 価格: 2、重量: 3 の商品は 1 つのみで複数あることは考慮しないものとする
- 1 つも品物を詰め込まない組み合わせは除外すること
- 処理が複雑になる場合は、コメントや gem を追加しても良い
メソッドの返す値の形式
例)下記の形式(答えでは無い)
Array
- Hash
- key: Symbol
- value:
- total_price: 合計価格
- total_weight: 合計重量
- records: Array
- Hash: CSV の1レコード(一部型変換)
- key: Symbol
- value:
- id: Integer
- price: Integer
- weight: Integer
[ { records: [{ id: 1, price: 1, weight: 1 }, { id: 2, price: 2, weight: 2 }, { id: 3, price: 3, weight: 3 }], total_price: 10, total_weight: 10 }, { records: [{ id: 1, price: 1, weight: 1 }, { id: 2, price: 2, weight: 2 }], total_price: 9, total_weight: 9 }, { records: [{ id: 1, price: 1, weight: 1 }], total_price: 8, total_weight: 8 } ]※CSVの中身は以下。
data.csvid,price,weight 1,2,3 2,3,4 3,2,1 4,3,2 5,6,3フェーズ1 自分で考える
私「CSVかぁ…………(バッチバチの
RubyでCSVいじったこと無くないか?って顔)」オムレツちゃん「大丈夫、それくらいならチョチョイよ!それにしても出汁巻先輩、なかなかの問題を出してきたわね……!」
私「そーなの?何となく出来そうな気がしているんだけども……組み合わせを作っていくんでしょ?その組み合わせを作るのも、パターンだからメソッド使ったらうまいこと出来るんじゃないかなあ(無知)」
オムレツちゃん「(大丈夫かしらこいつ……)」
私「とりあえず全然イメージ湧かないから
具体的に組み合わせを作ってみよう!」私「とりあえず
価値が大きいものからぶち込んでいけばその入れ物の中の価値は最大になるんじゃないかな?同じ価値の場合は重量が軽いものを優先的に入れる。と、いい感じに組み合わせが作れるんじゃないでしょうか!」私「実際のデータを使って纏めてみよう!」
私「ふんふん、具体的な組み合わせがあると考えやすいな〜。これでテストデータも出来たようなものだし、ガシガシ書いて行こう」
私「やることとしてはこんな感じかな〜」
- ソートされたデータを作る
- 袋の容量よりも大きいものは除いておく
- 大きいものから入れられるだけ袋に詰める
- 詰めたものの中で可能な組み合わせを作る
- 組み合わせを元に重量と価値を計算する
実際に解いていく
私「よし!かくぞ!」
私「出汁巻先輩から事前にいただいたコードは……と。」
require 'csv' class Suggest def initialize(limit, combinations) @limit = limit @combinations = combinations @data = CSV.read('db/data.csv', headers: true) end def result [] end end私「なるほどなるほど……CSVの取り込みのところだけ少しいじろうかな。ヘッダーの情報とかいらないもんな」
require 'csv' class Suggest def initialize(limit, combinations) @limit = limit @combinations = combinations @data = CSV.read('db/data.csv', headers: true) end def result sorted_data.map { |data| create_suggest(data) }[0..(@combinations - 1)] end end私「ついでに
resultメソッドの理想形も書いておいたぞ!ソートしたデータを使ってなんかメソッド呼んだらいい感じの配列ができて、そこから指定範囲分取り出す!いい感じじゃない!?」私「もう少し具体的に
create_suggestを書いておこう………」require 'csv' class Suggest def initialize(limit, combinations) @limit = limit @combinations = combinations @data = CSV.read('db/data.csv', headers: true) end def result sorted_data.map { |data| create_suggest(data) }[0..(@combinations - 1)] end private def create_suggest create_records.map do |result| { result: result, total_price: result.sum { |item| item['price'].to_i } total_weight: result.sum { |item| item['weight'].to_i } } end end私「組み合わせを作ってくれる
create_resultメソッドを呼んだ後に欲しい形にデータを整形してくれるメソッド!うんうん、大まかn私「よしよし……次はデータをソートしよう!」
require 'csv' class Suggest def initialize(limit, combinations) @limit = limit @combinations = combinations @data = CSV.read('db/data.csv', headers: true) end # 中略 private # 中略 def sorted_data @data.sort_by { |data| data['price'].to_i }.reverse.map do |data| { id: data['id'].to_i, price: data['price'].to_i, weight: data['weight'].to_i } end end end私「まず
sort_byで価値順に並び替える。sort_byだと価値が低い順に並んじゃうからreverseメソッドで価値が高い順に並び替える。その上でそれぞれの値を文字列から数値に置換しておくよ。以降の処理では値のことを気にしなくてよくなるもんね!」※
sort_byのブロック内のdata['price'].to_iを負の数にしてあげるとreverseが不要になることに後日気付きましたが、直感的じゃないような気も……。メソッド呼び出しが少なくなるから-(data['price'].to_i )みたいに書いてあげるのがいいんでしょうか……私「次はそれぞれの組み合わせを作ってくれるメソッドを作ろう!」
require 'csv' class Suggest def initialize(limit, combinations) @limit = limit @combinations = combinations @data = CSV.read('db/data.csv', headers: true) end # 中略 private def sorted_data @data.sort_by { |data| data['price'].to_i }.reverse.map do |data| { id: data['id'].to_i, price: data['price'].to_i, weight: data['weight'].to_i } end end def create_records sorted_data.each_with_object([]) do |record, array| next if @limit < record[:weight] end end end私「とりあえず
ソートしたデータを使って配列を作るからeach_with_objectを使うよ〜!そんでもって袋の重量を超過している品物は最初から省いてしまう処理を書いておく。」私「次は袋に入るだけ詰め込んでいくよ〜!」
私「サンタクロースみたいで楽しいね!(??????)」
require 'csv' class Suggest def initialize(limit, combinations) @limit = limit @combinations = combinations @data = CSV.read('db/data.csv', headers: true) end # 中略 private def sorted_data @data.sort_by { |data| data['price'].to_i }.reverse.map do |data| { id: data['id'].to_i, price: data['price'].to_i, weight: data['weight'].to_i } end end def create_records sorted_data.each_with_object([]) do |record, array| next if @limit < record[:weight] array << create_records_pattarn_array end end def create_records_pattarn_array sorted_data.each_with_object([]) do |target_item, result| result << target_item if result.sum { |r| r[:weight] } + target_item[:weight] <= @limit end end end私「今ある品物の中で一番価値の高い組み合わせを作る。それを最終的な組み合わせを格納するarrayに入れるよ。」
私「で、この最大の組み合わせから作ることのできる全パターンを作ればいいんだけど……。」
私「ど………………………………………………………………。」
私「これ組み合わせの個数バラバラじゃんね……………………?」
私「
combination使えないじゃんね……………………?」オム「気付くのおそ………………」
require 'csv' class Suggest # 中略 private # 中略 def create_records sorted_data.each_with_object([]) do |record, array| next if @limit < record[:weight] pattarns = create_records_pattarn_array array << pattarns [pattarns.first].product(pattarns - [pattarns.first]).each { |p| array << p } if pattarns.size > 2 end end # 略 end私「3つ入っている時は、6つの組み合わせが作れるように、
3つ以上品物が入っている時はそれぞれの組み合わせを作れるはず。」私「1回のループでその組み合わせは作りきれないから、ひとまず
今できている組み合わせの、一番最初に入っているものベースで作れる組み合わせを全部作る。」私「
create_recordsを全部回し切ったら全パターン作れてるはず!」オム「それだと被りが出ちゃうんじゃない?」
私「う、うーん……」
私「
uniqで……。」オム「ダメじゃん……………。」
私「これだと処理がめちゃ遅なのは分かるんだけど……今の私ではもう……これくらいしか思い浮かばない……。」
〜〜その後、
create_recordsをベースにデータを整え返すような実装に整えた結果が以下〜〜require 'csv' class Suggest def initialize(limit, combinations) @limit = limit @combinations = combinations @data = CSV.read('db/data.csv', headers: true) end def result create_suggests.sort_by { |suggest| suggest.values_at(:total_price, :total_weight) }.reverse[0..(@combinations - 1)] end private def sorted_data @data.sort_by { |data| data['price'].to_i }.reverse.map do |data| { id: data['id'].to_i, price: data['price'].to_i, weight: data['weight'].to_i } end end def create_suggests records_array = create_records return [{ records: [], total_price: 0, total_weight: 0 }] if records_array.empty? records_array.map do |records| { records: records.sort_by { |record| record[:id] }, total_price: records.sum { |record| record[:price] }, total_weight: records.sum { |record| record[:weight] } } end.uniq end def create_records sorted_data.each_with_object([]) do |record, array| next if @limit < record[:weight] pattarns = create_records_pattarn_array array << pattarns [pattarns.first].product(pattarns - [pattarns.first]).each { |p| array << p } if pattarns.size > 2 end end def create_records_pattarn_array sorted_data.each_with_object([]) do |target_item, result| result << target_item if result.sum { |r| r[:weight] } + target_item[:weight] <= @limit end end endフェーズ2 レビューをいただく
出汁巻「じゃあレビューしていこう」私「お願いします!」
出汁巻「まず私さんのコードなんだけど」
私「はい」
出汁巻「
combinationsに0を渡すと組み合わせが全パターン取得できちゃうんだよね」私「そんな…………」
出汁巻「これをよく見て」
reverse[0..(@combinations - 1)]私「…………」
私「アッ!!!!!!!!!」
私「うそ……無理…ダメすぎる……これはダメ……
[0..(0-1)]は[0..-1]で全部じゃん……ちょっとこれは恥ずかしすぎました……[0...@combinations]ですね…………」出汁巻「そうだね。
[0, @combinations]とも書ける。」私「はい………」
出汁巻「次!
#sorted_dataの中でデータをto_iしてたけど、せっかくなら#initializeの中でやった方がより良かったかな。sorted_dataの時点で同じキーの値にto_iを二回当ててたけど、そういうのがなくなる。」私「あ……確かに。」
出汁巻「それから、以下みたいなコードは早期
nextした方が可読性が上がるよ」[pattarns.first].product(pattarns - [pattarns.first]).each { |p| array << p } if pattarns.size > 2 ↓ next if pattarns.size <= 2 [pattarns.first].product(pattarns - [pattarns.first]).each { |p| array << p }出汁巻「最後になんだけど……私ちゃんの処理、
sorted_dataの個数分同じパターンを作ってたよ」私「えっ」
出汁巻「以下のメソッド見て。」
def create_records sorted_data.each_with_object([]) do |record, array| next if @limit < record[:weight] pattarns = create_records_pattarn_array array << pattarns [pattarns.first].product(pattarns - [pattarns.first]).each { |p| array << p } if pattarns.size > 2 end end def create_records_pattarn_array sorted_data.each_with_object([]) do |target_item, result| result << target_item if result.sum { |r| r[:weight] } + target_item[:weight] <= @limit end end出汁巻「
sorted_data起点でやってるから、何回繰り返しても処理が走っちゃって、同じ組み合わせが出来ちゃうよね。これ、本当ならcreate_records_pattarn_arrayにrecordを渡すんだったんじゃない?」私「…………………………………………(死)」
出汁巻「それから、重複する組み合わせが発生してるってことは
その分余計なループが回ってるってことだから、その分処理も遅くなるよね」私「はひ…………。」
出汁巻「この記事とかを参考にしたら、基本の考え方は分かり易かったと思う。私ちゃんは力技でやって一番いいパターンは正解するんだからすげーよ。」
私「あは……(頑張って具体例を出して考えたことが唯一活かされた瞬間)」
※以下、先輩の解答例コード
require 'csv' # # 組み合わせを提案するクラス # class Suggest # # 提案クラスインスタンス作成 # # @param [Integer] limit 重量の上限 # @param [Integer] combinations 組み合わせの要求提案数 # # @return [Object] インスタンス # def initialize(limit, combinations) @limit = limit @combinations = combinations @data = CSV.read('db/data.csv', headers: true).map do |row| { id: row['id'].to_i, price: row['price'].to_i, weight: row['weight'].to_i } end end # # 結果を取得 # # @return [Array<Hash>] 価値、重量の高い順の組み合わせ # @example # Example return output: # # [{:records=> # [{:id=>2, :price=>3, :weight=>4}, # {:id=>3, :price=>2, :weight=>1}, # {:id=>4, :price=>3, :weight=>2}, # {:id=>5, :price=>6, :weight=>3}], # :total_price=>14, # :total_weight=>10}, # {:records=> # [{:id=>1, :price=>2, :weight=>3}, # {:id=>3, :price=>2, :weight=>1}, # {:id=>4, :price=>3, :weight=>2}, # {:id=>5, :price=>6, :weight=>3}], # :total_price=>13, # :total_weight=>9}, # {:records=> # [{:id=>1, :price=>2, :weight=>3}, # {:id=>4, :price=>3, :weight=>2}, # {:id=>5, :price=>6, :weight=>3}], # :total_price=>11, # :total_weight=>8}] # def result r = calculation.sort do |a, b| (b[:total_price] <=> a[:total_price]).nonzero? || b[:total_weight] <=> a[:total_weight] end r[0, @combinations] end # # 組み合わせの算出 # # @return [Array<Hash>] 価値、重量、データ毎にまとめた組み合わせ # @example # Example return output: # # [{:total_price=>2, # :total_weight=>1, # :records=>[{:id=>3, :price=>2, :weight=>1}]}, # {:total_price=>3, # :total_weight=>2, # :records=>[{:id=>4, :price=>3, :weight=>2}]}, # {:total_price=>6, # :total_weight=>3, # :records=>[{:id=>5, :price=>6, :weight=>3}]}] # def calculation aggregate.inject([]) do |array, data| next array if data[:records].size.zero? array << { total_price: data[:value], total_weight: data[:records].map { |record| record[:weight] }.sum, records: data[:records].sort_by { |record| record[:id] } } end end # # 価値毎に集計した組み合わせ # # @return [Array<Hash>] 価値、重量、データ毎にまとめた組み合わせ # @example # Example return output: # # [{:value=>0, :records=>[]}, # {:value=>2, :records=>[{:id=>3, :price=>2, :weight=>1}]}, # {:value=>3, :records=>[{:id=>4, :price=>3, :weight=>2}]}, # {:value=>6, :records=>[{:id=>5, :price=>6, :weight=>3}]}] # def aggregate array = work_array @data.each do |data| (0..@limit).to_a.reverse.each do |i| next if array[i][:value].nil? || (i + data[:weight]) > @limit array[i + data[:weight]] = format_value(array[i], data) end end array end # # 集計時に使用する作業領域 # # @return [Array<Hash>] 初期化された作業領域(重量の上限数 + 1) # @example # Example return output: # # [{:value=>0, :records=>[]}, # {:value=>nil, :records=>[]}, # {:value=>nil, :records=>[]}] # def work_array array = Array.new(@limit + 1) { { value: nil, records: [] } } array[0][:value] = 0 array end # # 集計時に # # @param [Hash] value 加算先のHashオブジェクト # @example # Example value output: # # {:value=>0, :records=>[]} # @param [Hash] data 加算元のHashオブジェクト # @example # Example data output: # # {:id=>1, :price=>2, :weight=>3} # # @return [Hash] 初期化された作業領域(重量の上限数 + 1) # @example # Example return output: # # {:value=>2, :records=>[{:id=>1, :price=>2, :weight=>3}]} # def format_value(value, data) { value: value[:value] + data[:price], records: value[:records] + [data] } end end最後に
今回は初歩的なミスが目立ったのが良くなかったです。自力でやったが故に、迷走に迷走を重ねてしまったのも良くなかったです。もう少し
既に存在する知識を調べて活用しなければ……と痛感しました。最適化問題、難しいですね……。考え方を理解した上で、有事の時に活かせるようにしたいです。



- 投稿日:2019-12-11T20:11:37+09:00
ユーザのプロフィール画像を追加する方法(devise使ってる前提)
ImageMagick(画像変換ツール)の導入
$sudo yum install ImageMagickmini_magicのインストール
ImageMagicをrailsアプリから使えるようにする。
Gemfilegem 'mini_magick' bundle installdeviseのクラス(今回はUser)のモデルの一番最初に以下を追加
User.rbclass User < ApplicationRecord has_one_attached :image ~ endviewファイルでform_forでプロフィール画像を追加
<%= f.file_field :image, class: "form-control floating-label", placeholder: "画像" %>viewファイルで画像の表示
<div class="image" style="background-image: url(<%= rails_blob_path(@user.image) %>) "></div>
- 投稿日:2019-12-11T20:08:24+09:00
HTTP formでDELETEリクエストを送信する【sinatra】
背景
HTMLで使えるHTTPメソッドは
GETとPOSTのみWEBアプリでapiを作成
フレームワークはsinatraを使用
目的
- HTTP formで
DELETE、PUTリクエストを送信したい結論
sinatraの設定
method_overrideを使用することでHTTPでDELETE、PUTリクエストを送信できる
- アプリケーションクラス:
enable :method_overrideを追記する- view側のform指定:
input type="hidden" name="_method" value="delete"を追記する対応内容を詳しく
【対応前】
main.rbDELETE "http://example.com/hoge/" do #処理内容 end▼
DELETEリクエストを指定views.erb<form method="delete" action="http://example.com/hoge/"> #処理内容 </form>▼ log上のリクエストは
POSTになっている実行logyyyy-MM-ddTHH:mm:ss +0900 [DEBUG] "POST http://example.com/hoge/"【対応内容】
▼
enable :method_overrideを追記main.rbenable :method_override DELETE "http://example.com/hoge/" do #処理内容 end▼
input type="hidden" name="_method" value="delete"を追記views.erb<form method="post" action="http://example.com/hoge/"> <input type="hidden" name="_method" value="delete"> #処理内容 </form>▼ log上のリクエストが
DELETEに変化している実行logyyyy-MM-ddTHH:mm:ss +0900 [DEBUG] "DELETE http://example.com/hoge/"参考にしたサイト
http://sinatrarb.com/intro-ja.html
http://jxck.hatenablog.com/entry/why-form-dosent-support-put-delete
http://portaltan.hatenablog.com/entry/2015/07/22/122031
- 投稿日:2019-12-11T19:38:51+09:00
(備忘録・思い出)railsでページネーションを手作りする
まず、ページネーションとはこんなやつです↓
ほとんどの人が見たことあると思います。記事系のサイトだと必ずいるやつ。今回はこれを手作りします!
posts_controller.rbdef index @current_page = params[:page].nil? ? 1 : params[:page].to_i @max_page = (Post.all.size.to_f / 3).ceil @posts = Post.all.order(created_at: :desc).limit(3).offset(3 * (@current_page -1)) @pagenation = {} if @max_page == 0 @current_page = 1 elsif @current_page > @max_page && @max_page != 0 @current_page = @max_page end @pagenation['<<'] = 1 if @max_page >= 5 && @current_page >= 4 if @max_page >= 4 && @current_page >= 3 if @current_page == @max_page @pagenation['<'] = @current_page - 3 else @pagenation['<'] = @current_page - 2 end end if @max_page >= 0 && @max_page == @current_page @pagenation.merge!({@current_page - 2 => @current_page - 2, @current_page - 1 => @current_page - 1, @current_page => @current_page}) else @pagenation.merge!({@current_page - 1 => @current_page - 1, @current_page => @current_page }) end delete_list = [0, -1] @pagenation.delete_if do |key, value| delete_list.include?(value) end if @current_page == 1 && @max_page >= 3 @pagenation.merge!({@current_page + 1 => @current_page + 1, @current_page + 2 => @current_page + 2 }) elsif (@current_page == 1 && @max_page == 2) || (@current_page != 1 && @max_page != @current_page) @pagenation.merge!({@current_page + 1 => @current_page + 1 }) end if @max_page >= 4 && @current_page == 1 @pagenation['>'] = @current_page + 3 elsif (@max_page >= 4 && @current_page != 1 && @max_page - @current_page >= 2) @pagenation['>'] = @current_page + 2 end @pagenation['>>'] = @max_page if @max_page >= 5 && @max_page - @current_page >= 3 endこの記事を読んでわかること/感じるかもしれないこと
・kaminariというgemを使わずページネーションをどうやって作るのか理解できる(ほとんどタイトル通り・・・。)
・手作り感が味わえる(きっと楽しいはず!!)気をつけるポイント
・ところどころ寄り道します。無駄な話はしませんので許してください? 寄り道の際には「寄り道します!」と一声かけます
・文才がないので読みにくいかも
・コードが汚いかもしれません(確実に汚い)
・分量が長すぎるくらい長いこの記事を書くに至った経緯
おそらく皆さんも自分の書いたコードに思い出があると思います。僕の場合は、ページネーションを作成しようとしていたある日、どこの記事を読んでも、「gemを使ってページネーションを実現してみた」といったものが多く、「gem!gem!gem!ってうるさい!えええいgemを使わず手作りしてやる!」とカップラーメンを食べながら心に決めた瞬間でした(「gemを使ってページネーションを実現してみた」系の記事をあげている方すみません。)
そんな思い出があるコードをもう一度見てみると、???となる部分があり、自分の為にも、皆さんのためにも記事を書くことにしました。どんなページネーションを作成するのか
今回はこんなやつを作成します↓
ポイント
①「<<」をクリックすると一番最初の記事、つまり1ページ目に飛ぶ。「>>」をクリックすると一番最後の記事に飛ぶ。
②「<」をクリックすると、表示されていないページ数の1つ前のページに飛ぶ。「>」をクリックすると、表示されていないページ数の1つ後のページに飛ぶ。例えば、現在のページ数が4ページ目であった場合、
<< < 3 4 5 > >>
「<」をクリックすると、2ページ目に飛ぶということです。(3ページ目ではないのであしからず、、、。)、反対に、「>」をクリックすると6ページ目に飛びます。
③最大のページ数が5ページだった場合、6ページ目は存在しないので、「>>」「>」は共に表示しない。反対に、現在のページ数が1ページ目であった場合は、0ページ目は存在しないので「<<」「<」は表示しない。
④「<<」と「<」のどちらをクリックしても、同じページに飛ぶ場合は、「<<」は表示しない。反対に、「>>」と「>」のどちらをクリックしても、同じページに飛ぶ場合は、「>>」は表示しない。
例えば、現在のページ数が3ページ目であった場合、「<<」「<」は共に1ページ目を表すので
<< < 2 3 4 > >>
こうではなく、
< 2 3 4 > >>
このように表示します。
⑤現在のページ数を表示されているページ数の真ん中に置きます。qiitaのページネーションがわかりやすいはずです。
※注意点として、最大のページ数が6ページだった場合、6ページ目を真ん中には置きません(次ページがないため)。同様に1ページ目も真ん中に置きません(0ページ目は存在しないため)。文字ばかりで辛い、、、。と思われた方もいると思うので、gifを作成しました。
最大ページ数が3ページの時の挙動
最大ページ数が4ページの時の挙動
最大ページ数が5ページの時の挙動
最大ページ数が6ページの時の挙動
この動きと、5つのポイントと照らし合わせて、全体の理解をしていただけれたらと思います?
それでは作成!
ここからがワクワクする部分。まずルーティングを定めます。routes.rbに以下を記述しました。
routes.rbget 'posts/:page/index' => 'posts#index', as: :posts_page_index表示をするだけなので、「get」を指定し、postsコントローラーのindexアクションを呼んでいます。また重要な部分は、「posts/:page/index」のところです。この部分の「:page」で現在のページ数を取得します。
例えば、URL上で「posts/1/index」なら1ページ目、「posts/4/index」なら4ページ目といった具合です。
ここまできたら次はpostsコントローラーのindexアクションの記述に移ります。
必要な変数などを定義します。
①現在のページ数を表す「@current_page」@current_page = params[:page].nil? ? 1 : params[:page].to_i記述方法に少し、??が浮かぶかもしれませんが、「三項演算子」というのを使っています。(響きがまたカッコいい)
三項演算子は、if文を短く記述できる優れものです。文法はこんな感じです。条件文 ? trueの場合 : falseの場合
params[:page].nil?が条件文で、trueの場合は@current_pageは、1になり、falseの場合は、posts/:page/indexの「:page」にある値になります。params[:page]でposts/:page/indexの「:page」を取得しているわけです。
params[:page].nil? と条件を置いている理由は、:pageがnilの場合を避ける為です。nilであったらきちんと1ページ目に飛ばしてあげようという算段です。さらに、重要な点は、paramsで受け取った値は文字列ですので、きちんと数値にしてあげる必要があります。なので、params[:page].to_i とし、数値に直しています。(iはintegerの略)
②最大ページ数を表す「@max_page」
@max_page = (Post.all.size.to_f / 3).ceilここでは、最大ページ数を取得します。取得の仕方が面白い!
全体の投稿数が10であるとして、1ページにつき3つ投稿を表示するとしましょう。そうすると、最大ページ数は、4ページになるはずです。3/3/3/1 といった具合ですね。そのように考えると、10/3 となり、3.33333・・・なので、小数点以下は値を切り上げてあげれば良いはずです。つまり
⑴全体の投稿数を、表示したい値で割る
⑵小数点以下を切り上げる
これらが必要になります。⑴ですが、Postモデルがあるとしてそこから、Post.all.sizeで全体の投稿数を取得しています。次にto_fをつけて少数の値にしてあげます(fはfloatの略)。なんでこんなことをするかというと、割った際にきちんと小数点以下を出してあげるためです。モデルから全体の数を取り出す時、その値は必ず整数になるはずです。3人のユーザーが一人1記事投稿して、全体の総数が2.8などになるはずはありません。3のはずです。しかしそうなると、割った際に小数点以下は無視されてしまいます。整数型は小数点以下を無視するからです。
そこでto_fをつけると、3は3.0となるんです。?
次は⑵ですが、この部分に当たるのはceilです。ceilは小数点以下を切り上げます。
1.2でも切り上がって2になります。-----ここで寄り道します!-----
小数点を扱うメソッドとしてceilの他に、round、floorなどが存在します。
ceil → 小数点以下を切り上げ
floor → 小数点以下を切り捨て(1.8は1になります)
round → 小数点以下を四捨五入今回は、小数点以下は必ず切り上げて欲しいので、ceilを利用します。
-----寄り道終わり-----よって@max_pageは最大ページ数が入ることになります!
③viewで用いる「@posts」
@posts = Post.all.order(created_at: :desc).limit(3).offset(3 * (@current_page -1))この部分ですが、viewのところで説明します。
④空ハッシュな「@pagenation」
空ハッシュを用意します。簡単に説明すると、この空ハッシュに、ketとvalueの1セットをたくさん入れていき、あとはviewの方で取り出していきます。
-----ここで寄り道します!-----
ハッシュについて聞きなれない方もいると思うので、説明します。「keyとvalueを1セットにして管理する」ハッシュという仕組みには、言語によって様々な呼び方があります。(あーあのことかと思う人もいるはず。。。)ruby ・・・ハッシュ
php ・・・連想配列
swift ・・・ディクショナリー
などなど響きがかっこいいのは、連想配列です。でも僕はディクショナリーの方がしっくりします。というのもkeyとそれに紐づけられたvalueという形はまさに辞書(ディクショナリー)らしいからです。
keyとvalueの関係とは、
fruits = {"apple": "100円", "orange": "80円", "melon": "500"}このような感じです。"apple"がkeyであり、それに"100円"というvalueが結びついています。配列よりも優れている点は、「順番を気にしなくてもいい」というところです。配列だと先頭が0になるので、順番によって取り出す値が変わってしまいます。しかしハッシュはkeyにvalueが結びついているので、それがどの順番であろうとも、keyを指定すれば取り出すことができます。(今回はview内で@pagenationを先頭から取り出していく為、その利点は失われていますが)
また、rubyには「シンボル」というものが存在します。:pageみたいに先頭に「:」がついたやつです。ここの部分を少しまとめます。シンボルの利点は以下になります。
①表面上は文字列なので、プログラマが理解しやすい
②内部的には、整数で管理されるので、コンピュターは高速に値を比較できる
③同じシンボルは同じオブジェクト(IDが一緒)であるので、メモリの使用効率がいい
④イミュータブルなので、勝手に値を書き換えられない(破壊的なオブジェクトメソッドが効かない)またシンボルには様々な形があります。
①基本構文
“日本” => “japan”②keyをシンボル化
:日本 => “japan”③=>を:で代用する。この時の:はシンボルではない。また、keyの:は省略される
日本 : “japan”④valueをシンンボル化
日本 : :japan特にrailsでは、「:key」の形が多く見受けられる。
-----寄り道終わり-----
こうしてコントローラー内で重要な要素、
①現在のページ数を表す「@current_page」
②最大ページ数を表す「@max_page」
④空ハッシュな「@pagenation」
が出揃いました!なので、コードを上から順番に説明したいと思います。if文が多いので、それを1つのワンブロックと考えて説明します。
※@current_pageも@max_pageも「ページ数」であることを念頭に置いてくださいね?if @max_page == 0 @current_page = 1 elsif @current_page > @max_page && @max_page != 0 @current_page = @max_page endまず、@max_pageが0である場合は、@current_pageを1にします。次に、@max_pageが0でなく、かつ@current_pageが@max_pageよりも大きい場合@current_pageは@max_pageの値にします。
例えば、@max_pageが6である時、ユーザーがいたずらでURLをposts/100/index
とした場合、100ページ目はありません。この時@current_pageは@max_pageを超えてしまうので、@current_page = 6になるようにして調整しています。
@pagenation['<<'] = 1 if @max_page >= 5 && @current_page >= 4空ハッシュに値を入れていきます!後ろにif文がついていますが、条件とtrueの場合のすることが逆転してるだけなので、抵抗感はありますが、形自体は理解できるはずです?
@pagenation['key'] = value の関係です。<< は1になるので、そこの部分はokなはずです。次に条件文の@max_page >= 5 && @current_page >= 4 ですが、ここは理解しにくいはずなので図で説明します!(@current_pageは赤色です)
これを見ると、@max_page >= 5でかつ@current_page >= 4の時に「<<」が出現することが分かりますね!。なのでこのような条件文にしました。
次に「<」の出現条件です。
if @max_page >= 4 && @current_page >= 3 if @current_page == @max_page @pagenation['<'] = @current_page - 3 else @pagenation['<'] = @current_page - 2 end endここはif文の中にif文を入れています(if文の入れ子)。また先ほどの図を見れば分かりやすいと思いますが、
「<」が出現する条件として、@max_page >= 4 かつ @current_page >= 3でなければなりません。その場合、@current_page == @max_pageであるならば、「<」は@current_page - 3 を意味します。
それ以外は、@current_page - 2 になります。
if @max_page >= 0 && @max_page == @current_page @pagenation.merge!({@current_page - 2 => @current_page - 2, @current_page - 1 => @current_page - 1, @current_page => @current_page}) else @pagenation.merge!({@current_page - 1 => @current_page - 1, @current_page => @current_page }) endさあここで、mergeというメソッドを使っていきます。mergeをすることで、ハッシュ同士を結合することができます。
例えば、
hash1 = {"経済学" => 80, "財政学" => 70, "会計学" => 60} hash2 = {"経営学" => 75, "会社法" => 65} hash3 = hash1.merge(hash2) p hash3 #=> {"経済学"=>80, "財政学"=>70, "会計学"=>60, "経営学"=>75, "会社法"=>65}このように、元のハッシュのお尻にハッシュが結合されていくわけです。
元のハッシュである@pagenationには、上記の条件を満たした場合、「<<」「<」というkeyがあり、それに結びついたvalueがあるはずです。ここに新たにmergeを使うことで足していきます。まず条件として、@max_page >= 0 && @max_page == @current_page を満たした場合、
@pagenation.merge!({@current_page - 2 => @current_page - 2, @current_page - 1 => @current_page - 1, @current_page => @current_page})が行われます。先ほどの図を見てもいいのですが分かりにくいかもしれないので、具体的な例を出しますね!
@max_page = 6 で @current_page = 6の場合、その条件を満たすはずです。その時、ページネーションはこのような形になります。
<< < 4 5 6
この時、4は@current_page - 2であり、5は@current_page - 1、6は@current_pageになります。
よって @pagenation = {'<<' => 1, '<' => 3, 4 => 4, 5 => 5, 6 => 6}
の形になります。@max_page = 4 で @current_page = 4の場合、<<は出現しませんから、
@pagenation = {'<' => 1, 2 => 2, 3 => 3, 4 => 4}
の形になります。@max_page >= 0 && @max_page == @current_pageを満たさない場合、例えば
@max_page = 4 で @current_page = 3の場合< 2 3 4
この時は、
@pagenation.merge!({@current_page - 1 => @current_page - 1, @current_page => @current_page })を実行します。
よって @pagenation = {'<' => 1, 2 => 2, 3 => 3} となります。(4はこの時@pagenationにありません。後ほど付け足す感じです。)
しかしこのようにしていくと問題が発生します。
@max_page >= 0 && @max_page == @current_pageを満たさない場合、@max_page = 4 で @current_page = 1の時は一体どうなるでしょう。@pagenation.merge!({@current_page - 1 => @current_page - 1, @current_page => @current_page })を実行しますから、
@pagenation = {0 => 0, 1 => 1}
になるはずです。(<< < は、それぞれの条件を満たさないのでありません。)
ですが、ページ数に0ページ目なんてものはありません。そこで重要になるのが、
delete_list = [0, -1] @pagenation.delete_if do |key, value| delete_list.include?(value) endです!目を通しただけで何をしているかわかると思いますが、delete_list = [0, -1] から、@pagenationにその値が、valueにあれば(含めば)、消去しています。
delete_ifについては、この記事が参考になったので、見ていただければ良いと思います。
https://qiita.com/zom/items/4461d786c35ae9eced0bこれで、
@pagenation = {0 => 0, 1 => 1} ↓ @pagenation = {1 => 1} になるのです!ここまでで前半部分は終了です。どうでしょうか。次は後半部分ですが、少しややこしいかもです!
@current_pageまでを@pagenationに入れてきました。後半部分では、それ以降を@pagenationに入れていきます。
次に、「>」「>>」を除く、@current_page以降、表示される数字の部分です。以下の1ブロックは、@current_page以降、数字を2つつけるべきなのか、1つつけるべきなのか条件づけています。
if @current_page == 1 && @max_page >= 3 @pagenation.merge!({@current_page + 1 => @current_page + 1, @current_page + 2 => @current_page + 2 }) elsif (@current_page == 1 && @max_page == 2) || (@current_page != 1 && @max_page != @current_page) @pagenation.merge!({@current_page + 1 => @current_page + 1 }) endここも、if文の入れ子になっていますが、まず最初の条件として
@current_page == 1 であり、かつ @max_page >= 3 の時です。この場合は、@current_page以降、数字を2つつけなけらばなりません。
図を再掲しますが、@current_pageが1であり、@max_pageが3以上の時は、2つ以上数字が並ぶことがわかると思います!
この場合、
@pagenation.merge!({@current_page + 1 => @current_page + 1, @current_page + 2 => @current_page + 2 })を行います。おなじみのmergeですね!先頭に2つつけるので、
@current_pageに+1し、さらに+2したものを結合しています。さて次に、@current_page以降に数字を1つつける場合はどうでしょう。
(@current_page == 1 && @max_page == 2) || (@current_page != 1 && @max_page != @current_page①@current_pageが1であり、かつ@max_pageが2である時、
「または」
②@current_pageが1ではなく、かつ@max_pageが@current_pageと値が異なる時です。②から見ていきましょう。というのも、①は条件が具体的でピンポイントですので、②を押さえてから、①を見た方が、理解しやすいと思うからです。
②の時は、@current_pageと@max_pageが同じであったら、次に表示される数字はありません。ですので@max_page != @current_page をつかって避けないといけません。
しかし、
@current_page != 1 && @max_page != @current_page 時の条件と、初めの
@current_page == 1 && @max_page >= 3の条件のうち、外れる条件がでてきます。それが
①@current_pageが1であり、かつ@max_pageが2である時です。この時、@current_page以降に表示される数字は、1つなので、きちんと条件づけています。
これらの条件を満たした場合、
@pagenation.merge!({@current_page + 1 => @current_page + 1 })
を行い、@current_pageに+1したものを追加してあげます。
次のブロックで、「>」をつけていきます。
if @max_page >= 4 && @current_page == 1 @pagenation['>'] = @current_page + 3 elsif (@max_page >= 4 && @current_page != 1 && @max_page - @current_page >= 2) @pagenation['>'] = @current_page + 2 end「>」が現れる時の条件と、それを満たした場合、「>」がどんな値を持つかが重要になります。
まず、
@max_page >= 4 && @current_page == 1ですが、
この時に初めて、「>」は出現します。その際当然、「>」は@current_page+3の値を持つことになりますので、
@pagenation['>'] = @current_page + 3になります。
しかし、それ以外では、「>」は@current_page+2の値を持たせねばなりません。この時の条件が
@max_page >= 4 && @current_page != 1 && @max_page - @current_page >= 2になります。&&で区切って見ていきますが、まず@max_pageが4以上である必要があります。そして、@current_pageは1であってはなりません。次に、@max_page - @current_page した場合、2以上であれば「>」は@current_page+2の値になります。
そして最後に、「>>」を見ていきます!
@pagenation['>>'] = @max_page if @max_page >= 5 && @max_page - @current_page >= 3この文法は、「<<」で見た時と同じ形ですので、大丈夫でしょう。それでは、この時、「>>」はどのような条件で出現し、どのような値をもつべきなのでしょうか。
まず、
@max_page >= 5 && @max_page - @current_page >= 3が、条件文になりますが、@max_pageが5以上である時にしか「>>」は出現しません。また、@max_page - @current_page >= 3でない限り、「>>」は出現してはいけません。というのも
「<<」と「<」のどちらをクリックしても、同じページに飛ぶ場合は、「<<」は表示しない。反対に、「>>」と「>」のどちらをクリックしても、同じページに飛ぶ場合は、「>>」は表示しない。
と決めているからです、、、。こちらは僕の勝手な都合です?
その条件を満たした場合、「>>」は最後のページに飛ぶことになりますから、最後のページ = 最大ページ数になり、それはすなわち
@pagenation['>>'] = @max_pageで表すことができます!
これで@pagenationには、その時々の値を持つことができています!
@max_page = 3 で@current_page = 2の時は、 @pagenation = {1 => 1, 2 => 2, 3 => 3} @max_page = 6 で@current_page = 3の時は、 @pagenation = {'<' => 1, 2 => 2, 3 => 3, 4 => 4, '>' => 5, '>>' => 6}といった具合です!
さて次に@pagenationと、先述した@postsを携えて、viewの方で使っていきましょう!!
index.htmk.erb<div> <% unless @max_page <= 0 %> <ul> <% @pagenation.each do |key, value| %> <li class="<%= ' active' if value == @current_page %>"> <%= link_to key, posts_page_index_path(value) %> </li> <% end %> </ul> <% end %> </div>まず、@max_page <= 0 でない時に、ページネーションを表示させてあげています。
unlessはifと反対の意味を持ち、if文が「〜である時」なのに対して、unlessは「〜でない時」を表します。
そして、@pagenationをeach文で回し、それぞれkeyとvalueを取り出していきます!
<li class="<%= ' active' if value == @current_page %>">ここのclassについてですが、@current_pageであれば、そのページネーションの表示の色を、他のページ数で表示されている色と変えてあげたいはずです。ですので、このように
if value == @current_page とすることで、valueと@current_pageの値が等しければ、activeクラスが付与されて、そこをcssで変えることができるという流れになっています。
また、keyの部分に関しては、aタグをつけたいので、link_toを用いて、そのvalueそれぞれにリンクを貼ります。
posts_page_index_path(value)
となっているのは、ルーティング設定の時に、
routes.rbget 'posts/:page/index' => 'posts#index', as: :posts_page_indexと、asで名前を変更しているからです。当然、posts_page_indexだけでは、どのページ数か判別できないので、posts_page_index_path(value)と(value)をつけています。(pathもつけることもお忘れなく、、、。)
そして最後に、コントローラー内で登場した、
@posts = Post.all.order(created_at: :desc).limit(3).offset(3 * (@current_page -1))を説明します。
@max_page = (Post.all.size.to_f / 3).ceilで、「最大ページ数」を取得することはできました。しかし実際に、「取り出す順番」であったり、「取り出す投稿」は取得していません。
少し疑問に思われる方もいると思うので、踏み込んで説明します。
@max_pageでは、「1ページにつき、最大3投稿表示できるとしたら、最大ページ数はいくつか」を取得したものであり、1ページごとに、どの順番で、どの投稿を表示させるのかは取得できておらず、あくまでその全体の枠組みだけです。ですので、@postsでそれらを取得しています。もちろん、@max_pageと対応させなければ、なりません。もし、全体の投稿数が10で、1ページにつき、投稿を3つまで表示できるとしたら、@max_page = 4になるはずですが、@postsの方で、1ページあたり4つ投稿を取得するとしたら、@max_pageとずれてしまうからです。今回は1ページにつき最大3つ投稿を表示できるようにしていますから、それに合わせます。
@posts = Post.all.order(created_at: :desc).limit(3).offset(3 * (@current_page -1))まず、Post.allでモデルからデータを引っ張ってきます。その時、
①取り出す順番
②取り出す投稿を指定しています。①については、order(created_at: :desc) とすることで、作成された日付順に投稿を取得します。日付が新しい投稿を先に取得していくわけです。
そして②です。
limit(3).offset(3 * (@current_page -1))limitで取り出す投稿の最大数を取得します。当然3つまで投稿を取得して欲しいので、limit(3)です。そして次に@current_pageで取得した、ページ数に合わせて、取得する3つの投稿数を変更させます。それが
offset(3 * (@current_page -1))
にあたる部分です。offsetメソッドは、指定した位置からデータを取得します。例を出すと
12/10
12/9
12/8
12/7
12/4
12/3
11/20
11/18
11/16というようなデータ(降順で表示)があった場合、limit(3).offset(0)なら、
12/10
12/9
12/8が取得され、limit(3).offset(3)なら、
12/7
12/4
12/3が取得されます。なんとなく雰囲気はつかめるはず?
なので、@current_pageとoffsetを組み合わせて、@current_pageが1なら(つまり1ページ目)
offset(3 * (@current_page -1))
↓
offset(3 * (1 -1))
↓
offset(3 * 0)
↓
offset(0)になるといった具合です。
これで、@postsには、その@current_pageに合わせて、投稿を@max_pageに対応させながら取得することに成功しました!
あとは、viewで表示する際に、
index.html.erb<% @posts.each do |post|%> 省略 <% end %>とすればいいでしょう!
終わりに
短く書くつもりが、あれもこれもとなってしまい、非常に読みにくくなってしまったかもしれません。?
重複するコードや説明の間違いなどあるかもしれません。ですが、少しでも手作り感を味わっていただければ幸いです。
「あれ、これってどうだったっけ?」というのが、取り除かれてスッキリしました!それでは!参考
「プロを目指す人のためのRuby入門」伊藤淳一、技術評論社、2019年
配列の複数要素の削除はdelete_ifかreject、-なんかを使おう
Rubyのmergeメソッドでハッシュを結合する方法【初心者向け】
kaminariではないバニラなページネーションをやっていく








- 投稿日:2019-12-11T19:03:47+09:00
【Ruby】Discogs::Wrapper でアーティスト情報とかもろもろを取得する
discogsでアーティスト名、ジャンル、リリースされたトラックの情報を取得したい。
discogs APIのwrapperを利用して適宜ロジック等を記載していく。ドキュメント等
discogsについて
https://ja.wikipedia.org/wiki/Discogs公式
https://www.discogs.com/ja/gem
https://github.com/buntine/discogsアクセストークンの取得
wrapperを使う前にアクセストークンを取得する。
googleアカウントでdiscogsにサインアップ後、User Tokenを取得する。個人的に利用する分には当面はUserTokenで良さそう。
手順
Developer Settingsをクリックしてサインアップ
トークンを生成
使ってみる


- 投稿日:2019-12-11T19:03:07+09:00
Webサービス(CtoC)集客・マネタイズ成功させたければこれを実装しろ
はじめまして。加藤です。
本業はインフラエンジニアですが、技術書典で技術系同人誌を頒布したりWebサービスを個人開発したりしています。さて、突然ですが、あなたはWebサービスを個人開発して公開していますか。
そして「せっかく開発したのに誰も利用してくれない」「マネタイズ(収益化)したいが上手くいかない」といった悩みを抱えていないでしょうか。
PythonやRuby、PHPなどの言語やそれらのフレームワークを使ってWebサービスを個人開発し、Firebaseなどで公開する人たちは年々増えており、彼らと話す機会も多いので、そういった声をよく聞きます。
私はそれを聞くたびに心の中で「そりゃ当たり前だ!あんなクソサービス誰も使わないわ。」と叫んでいます。
脳内妄想をこじらせた技術オタクがゴミを生む
私を含めて、Webサービスを個人開発している人たちの大多数がしている会話は「○○の言語と△△のフレームワークを使って開発しました~~」とか「Firebaseを使って~~」「フロントエンドは□□で~~」みたいにどんな技術を用いて開発したかを語るものばかりです。
「お前ら、マネタイズがしたいんだよね?マーケティングの話とかしないの?」
「素晴らしいサービス(自称)だから黙っていれば利用者が増えてスケールすると思ってない?」
「口ではマネタイズに困っているとか言いながら、そのための行動も勉強もしてないじゃん。」と感じるようになって、私は自然と彼らと距離を置くようになりました。
自戒を込めて言うと、世の中には業務改善に役立った素晴らしいサービス(この伝票開発アプリとか)やマシュマロ(質問箱)のように多く人が利用したサービスもありますが、大多数は技術者が「面白いサービスを思いついた。こりゃ流行るぞ!」とか「この人たちはきっとこれに悩んでいるから、こういったサービスなら課題解決できるに違いない」と自分の脳内妄想を実現させた結果生みだしたゴミなので過疎って終了するわけです。
「金稼ぎ」や「欲求充足」ができる仕組みを実装しろ
では、どうしたら利用者が増えるサービス開発ができて、その結果マネタイズが成功するのか。
これを研究してきた私がたどり着いたのが、利用者が「金稼ぎ」と「欲求充足」ができる機能を実装したサービスを作れでした。
その証拠にYoutuberが雨後の筍のように増えていますし、ニコ生主等が続々とVTuberに転生してYouTubeやMirrativ等で配信していますし、小説家になろうでは書籍化を目指して多くの作家が小説公開していて、絵師や同人漫画家がTwitterやPixivでイラスト・マンガを投稿して、いまだ多くのブロガーが無料ブログやWordPressで記事を投稿しています。
みんな本音を言えば「(広告収入・投げ銭・書籍化・マンガ化等で)大金を稼ぎたい」し「承認欲求を満たしたい」から、それらのサービスを使ってせっせと活動しているんです。
※好きでやっている勢もいるでしょうが、なぜ1円にもならないのにPVや再生数が伸びなくてもクソリプやアンチコメが来ても作品・動画の投稿が続けられるかといったら、ここに集約されます。そして、それらの実装のために参考になるWebサービスが無料小説投稿サイトです。
詳細は後述しますが、収益還元の仕組みや作家・ユーザー相互の交流機能により「金稼ぎ」と「欲求充足」がどちらもできるからですね。
あなたが手っ取り早く集客やマネタイズに成功するWebサービスが作りたいのなら「大金がほしい」「注目されたい、ちやほやされたい、モテたい」といった人間が普遍的に持つ欲を(法律に抵触しない範囲で)利用者が満たせるものを開発してはいかがでしょうか。
※あなた自身が欲望に忠実になり闇落ちすると、悪質アフィリエイターやSEOを悪用したWELQ中の人のような存在になるので、健全な精神状態と倫理観は維持しましょう。
金稼ぎとは
ここでは投稿した作品に対する収益還元や作家への投げ銭が得られるサービスを紹介します。
これ以外にも、自分の小説やイラストを販売できるBOOTHのようなサービス、Youtubeのスーパーチャット・メンバーシップやFANBOXのようなクリエイター支援や投げ銭のサービスでもお金が稼げますので、サービス設計の参考にしてはいかがでしょうか。
Webサービス運営者は単発の課金であれ月額課金であれ自分の金もうけ(いかに無課金勢に課金させるか)第一で会議でも金や数字(KPIなど)の話しかしない人種なくせに、やれ「カスタマーエクスペリエンス」だとか「カスタマーサクセス」だとかぬかしおるのであほかと思います。
「利用者に収益を還元する」とか「生み出した作品の対価が得られる仕組みを提供する」とか、利用者にメリットがある仕組みの構築(+その結果としてのマネタイズ)ができてはじめてカスタマーについて語る資格があるのではないでしょうか。
広告収益の分配
作品のPVや閲覧人数などに応じて広告収益が分配される仕組みです。
Peing(質問箱)開発者のSeseriさんが作った小説投稿サイト「scraiv」がこの仕組みを導入しています。
他にもアルファポリス、カクヨム、ノベルバなどが同じ仕組みを導入していますね。広告収入の分配といっても、作家の作品内にある広告リンクがGoogleアドセンスのようにクリックされたり、アフィリエイトのように商品が購入されたりすることで分配されるわけではありません。
それぞれのサービスで広告収益分配の基準は異なりますが、純粋に作品が読まれるほど収益が増える仕組みとなっています。
予約投稿を課金で先読み
読者が課金することで、作家が予約投稿した最新話を公開日前に読める仕組みを導入し、課金額の40%を作家に還元しています。
※最新話を無料で読みたいときは公開日まで待てばOK。
これを導入しているのは待ラノだけですね。
利用者による投げ銭
Youtubeのスーパーチャットのように、作者に対して読者が投げ銭を行える仕組みです。
投げ銭機能はノベルアッププラスやマグネットマクロリンク、カクヨムなどが実装しています。
コンテストの開催
優秀な作品は賞金がもらえたり書籍化したりといった特典があるWebコンテストをサイト内で開催し、作家がそれに応募できるようにする仕組みです。
カクヨムやアルファポリス、エブリスタなどがWebコンテストを定期的に開催しています。
欲求充足とは
ここからはマズローの欲求5段階説を用いて説明します。
詳しく知りたい方はfelletさんの下記記事をご覧ください。
マズローの欲求5段階説を図付きで解説!各段階に合わせたサービスも紹介そして「金稼ぎ」で説明した仕組みは小説投稿サイトでいう作家向けのものですが、欲求充足に関しては作家と読者双方の欲求(承認欲求とか作家・読者と繋がりたい欲求とかコミュニティに所属したい欲求など)を満たす仕組みとなっています。
そうしないと、金と欲を満たしたい作家しかおらず読者がいないという地獄のようなサービス(どれだけ作品投稿しようがPVもブックマークも感想も増えない)と化してしまうからです。
社会的欲求を満たす
集団への帰属や愛情を求める欲求です。
コミュニティへの所属や人とのつながりなどが得られることで満たされます。これを満たす機能として、ノベルデイズのコラボノベル(他のユーザーと共同で作品を作る)機能やエブリスタのコミュニティ機能などが挙げられます。
また、ハーメルンには「捜索掲示板」という機能があり、自分が探している作品について質問すると他の利用者が返信で教えてくれるので、そこで作品について盛り上がることができます。
承認欲求を満たす
他人から尊敬されたい、認められたい、賞賛されたいという欲求です。
具体的には作品を読まれたい、読者に応援されたいなどです。マグネットマクロリンクでは読者が作品を読んだり、作家が創作活動をすることによって自動的に「磁界」というポイントが貯まります。
作家は自分が獲得した磁界(ポイント)と読者からプレゼントされた磁界(ポイント)を消費することで、サイト内で自分の作品を宣伝することができます。ノベルアッププラスでは、ログインするともらえるポイントを作家にプレゼントしたり、感想コメントや感想スタンプを送るなどで作家・作品を応援する仕組みがあります。
また、豊富なランキングやピックアップがあり、自分の作品が露出する機会が多いことも重要です。
例えばノベルアッププラスには新着作品・注目作品・読者のオススメ作品などのピックアップがありますし、ハーメルンには総合・短編・オリジナル(作品)・二次創作・R18など複数のランキングがあります。カクヨムでは特集(カクヨム公式レビュアーが選んだ作品を紹介する記事)や各ジャンルの作品のピックアップが公開されており、多くの作品に日があたりやすくなっています。
自己実現欲求を満たす
自分の可能性を追求し、技術や能力の向上に努めて作家としての自分の理想像を実現したいという欲求です。
ツギクルには「人工知能を用いた文章解析システム」があり、AIが客観的に作品の分析をしてくれます。
また、ノベルアッププラスでは小説を投稿する、小説を読む、感想を書き込むなどにより自分のアカウントのレベルや称号がアップしていきます。
一番の悪手は「運営が多数の利用者を置き去りにして全力で金儲けしだすこと」
今回ご紹介した方法が正解ではありません。
多くの利用者を獲得する方法が他にもありますし、そこを研究していただけたらと思います。
ただし、「絶対にWebサービス運営者がやってはならない悪手」が存在します。
それは一部の利用者のみ優遇するや運営の商品・広告を推しすぎることです。
一部の利用者のみ優遇するとは、小説投稿サイトで例えると「PVが稼げる作家の作品バナーをトップページの目立つ場所に掲載したり、書籍化のバックアップや(公式ブログ等で)販促支援を行う」「運営を通じてお仕事がもらえる」「PVが稼げる作家との打ち合わせと称して高級なご飯を奢る」などの運営が不自然なまでに特定利用者を推していたり癒着している状況を指します。
※実際に小説投稿サイト運営がこれらを行っていると言うわけではありません。運営の商品・広告を推しすぎるとは、小説投稿サイトで例えると「トップページなどが書籍の広告などで溢れかえっていて利用者が使いづらい」状況です。
※アルファポリスがこの傾向にあります。利用者が報われる仕組み、飽きさせない仕組みを作れ
報われる仕組みとは
また、悪手というよりは過疎らないためにやっておいた方がベターなのが「利用者が注目される機会をなるべく平等に与える」「利用者の努力が報われる」サービス設計をする事です。
小説投稿サイトで例えると、既存のランキング(PVやブックマークに基づくもの)だけでなく、活動歴が浅い作家のみのランキングや細かくジャンルわけしたランキングを用意したり、活動歴が長い作家の作品やニッチなジャンルでPVは高くないものの濃いファンがついている作品等を運営がピックアップして紹介するなどです。
ぶっちゃけると、小説投稿サイトもYoutubeもはてなブログも、何らかのコンテンツを投稿するプラットフォームのランキングっていうのは
ランキング上位勢がランキングにのることによってさらにPVやブクマを稼いでランキングにのり続けているのが現状です
そしてそんな状況で並み居る古参上位勢を押しのけてランキング上位に食い込めるのは「強力な個性や才能の持ち主」か「元々大多数のファンを抱えている人間(芸能人や他の小説サイトで固定ファンを抱えた作家など)」か「箱推しされている事務所に所属したり動画再生数や配信の同時接続人数が稼げる人とコラボする(VTuberのにじさんじやホロライブなど)」くらいです。
※お金や互助会の力で何とかしようとする人もいますが、それは多くのサービスで利用規約違反になるので割愛。
きっと、商業出版を果たしたつよつよ作家や自称有識者の読者は「ランキング出来ない人間の努力が足りないからだ。才能がないからだ。」と言うでしょう。
登録者10万人越えのYoutuber・VTuberもオンラインサロンを開いちゃうようなはてなブロガーも「そうだそうだ」と賛同するでしょう。※その格差があるからこそアフィリエイトの情報商材やサロン、コンサル、事務所(○○ネットワークとか)に金を払う人が出てくるわけです。
それは利用者目線で言えば正しい事なのかもしれませんが、Webサービスの運営側としては、努力(作品のコンセプトを工夫する、毎日投稿する、コメント返しするなど)を続けてもランキング入りできず離脱する作家が増えて過疎化するリスクのケアを考えなければいけません。
あなたのWebサービスが世界でオンリーワンのものでないのなら、作家たちは競合他社の類似サービスに移っていくからです。
飽きさせない仕組みとは
そして、代わり映えしない作品(所謂なろう系の異世界転生ものとか)や作家で埋め尽くされたランキングに飽きて離脱する読者もケアしないと、作家と同様に競合他社の類似サービスに移っていかれます。
これへのケアも報われる仕組みと同じく、既存のものとは違うランキングの創設やピックアップで作品を掘り起こす仕組みが必要となります。
- 投稿日:2019-12-11T18:41:06+09:00
ゲームエンジンを自作しながら思ったこと
本稿では、私が長く続けている個人でのゲームエンジン開発で得られた知識や経験を紹介します。
嘘ですポエムです。アルコールとか入ってます。
本当はかっこいいこと言ってみんなの役に立つこと書きたかったです。書きたかったけど無理だったよ…。
ひとつのゲームエンジンを作り続けてもう何年も経ちます。その間コンセプトも定められず満足なメジャーリリースもできないままだらだら作り続けてしまったので、あんまり役に立つことは書けなさそう。
とりあえず昨今のゲームエンジンの開発に必要な技術要素と、私が開発している Lumino というゲームエンジンでの代表的な実装例を紹介する、みたいな体で書いてみようと思います。なにか間違ってそうでしたらコメントお願いします。
多分、ちょっとでも役に立つかもしれないのは、「ゲーム作ってたけど気が付いたらゲームエンジン作ってて、ゲームが出来てないけどゲームエンジン公開してみたくなっちゃった」みたいな方です。
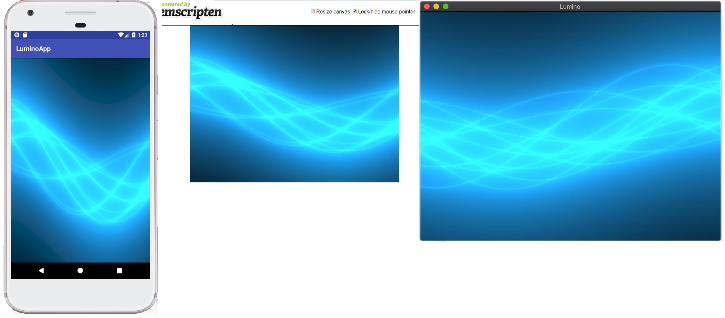
どんなのを作ってるの?
ゲームっぽい絵が出せたり、
いろんなプラットフォームで動いたり、
エディタがあったり、
いろんな言語で書けたり、
example.cpp#include <Lumino.hpp> using namespace ln; void Main() { auto texture = Texture2D::create(u"logo.png"); auto sprite = Sprite::create(texture , 5, 5); while (Engine::update()) { # Executed per frame } }example.rb# gem install lumino --pre require 'lumino' include Lumino texture = Texture2D.new("logo.png") sprite = Sprite.new(texture , 5, 5) while Engine.update do # Executed per frame end↓
したいです。
序論
ゲームエンジンというチャームスペル
なぜゲームプログラマはゲームエンジン自作に魅せられるのだろう。
皆がそうというわけではないけど「ゲームを完成させたいなら、ゲームエンジン(or ライブラリ) を自作するな!」というのをよく見かけます。
それはその通りだと思うし、実際にやってみるとものすごい勢いで時間が溶けていくので Unity や UE4、ツクールとか使うのが現実的な方針です。それで仕事もできるようになるし。
それでもここ数年、新しいゲームエンジンが現れては消えていくのをたくさん見てきました。
ほとんどはランディングページもなくリポジトリだけあったり、テスト版をZIPで固めたものだけだったりしたけれど。それでも作っちゃうのは、学習とかプロダクト開発とか、そういう建前じゃなくて、根源的にはやっぱりそれが自分の本当にやりたいこと、楽しみたいことなのだと思う。
それは絵を描いたり、音楽を作ったり、物語を書いたり、そういうアーティスト的な、なんていうのかな、なんかゲームのキャラクターのセリフだったと思うんだけど「何故自分の内から湧き出るイメージを具象化しこの世に残さずにいられるのか」っていうのがしっくり来てる。
趣味でゲーム作ってる人が新たな楽しみを知ってやりたいことが変わるなら、それはきっと正しい。趣味は人生を豊かにするもののひとつである。対外的にはどうかわからないけど。
またちょっと落とし穴臭いのが、ゲームのホントに基本的なフレームワークって小規模~大規模までほぼ同じでありシンプルなので、「あれ、これ俺ちょっと頑張れば作れちゃうんじゃない?」って思えてしまうのだ。
まぁそんな風にモチベの源泉が変なところにあったり、イイ感じに知的好奇心を満たしてくれるテーマであったり、いろんなものが混ざってゲームエンジンというものを書きたくなっちゃうのだ。
あと「このゲームはゲームエンジンも自作して作りました!」とか言えるとちょーかっちょいい。ただしモテはしない。
ゲームエンジンは救われづらい
自身の周り、例えばサークルでのゲーム開発で自作エンジンが使われていれば、そこで役に立てただけでも個人開発のゲームエンジンとしては成功だと思います。
公開を考え出してはじめて、あまりにも周りが強すぎることに気付いたりします。実際自分と同じように個人開発で公開しているようなものですら、名状しがたい規模で作ってたりするのがたくさんあったりします。
救いがあるとしたら、各種ジャンルに特化した専用のゲームエディタかな。RPG専用や、シューティング専用、みたいなやつ。
これも今やレッドオーシャンって感じですが、特化していくほどある程度のユーザーはついてくると思います。
例えば、
- PIXI.js に乗っている RPGツクールMV
- DXライブラリ に乗っているウディタ
- Unity に乗っている 宴あ、一応捕捉しておくと、この記事で「ゲームエンジン」と呼んでいるのは、この DXライブラリ とか Unity とかのベースの部分です。
でこのベースになっている部分。この領域に挑むのは救いが無いです。ライバルが名実ともにめっちゃつよい。
もし救いがあるとすれば、それはゲームエンジン自体ではなく、そのようなベースシステムを構築できる技術力。それを持っているあなた自身の存在、って思います。
こんなエントリ読んでないでそのシステムを持ち込んで就活した方がいいと思います。
書いてて思ったけど、有名どころがユーザーをかっさらっていく構図はどんなソフトウェアでも同じだよなって思いだした。
うるせーおれはゲームエンジンつくるのがすきなんだよ
一緒に沈もう!

開発環境を整える
プログラミング言語
エンジン本体を書くための言語の話です。スクリプティングはのちほど。
ネイティブクロスプラットフォームで速度と品質を目指すなら、C++ か Rust かな。
小規模ゲームをターゲットにするならWeb周りの技術(Electronとか)を使いつつ Javascript でいいと思う。
最近は C# もブラウザ上でそのまま動くようになってきてるけど、ゲーム作れるかは調べきれてないです。
僕はC++への刷り込みがひどいのでオススメをがっつり語るのは止めておこうと思います。
ただ入門者がモダンC++を理解したうえで独自のシーングラフ作りつつOpenGLあたり使って画面に三角形出せるところまで行けたとして、だいたいその辺で大満足してフェードアウト → UE4 あたりへ GO するくらいにはモダンC++は難しいと思う。
Rust がっつり触ったことないけど、風のうわさでは並列処理なレンダリングエンジンを書くときに、Rust の並列処理セーフティがいろいろと指摘してくるので回避するのに苦労するらしい。
個人的には Javascript はなんか好きになれないんだけど、現実的な方法としてはすごくオススメします。
でも TypeScript はすごくいいぞ。で、申し訳ないですが以下は C++ かつネイティブクロスプラットフォームで3Dなゲームエンジンを開発する想定で書いていきます。ひどい目標だ…。
GitHub にリポジトリを用意する
プロダクトをどのように公開するかはともかく、プロジェクトの第一の資産であるソースコードを保存しておく場所は真っ先に作っておくべきです。
なんかヨサゲなゲームエンジン作ってたけど「PC壊れてソースコード無くしました」みたいに SNS で自虐ネタ流した日には、ソフトウェアエンジニアとしての信用に致命的なダメージを受けます。ついでに単純にモチベが崩壊します。そんな人を何人も見てきました。自虐はほどほどに。
GitHub も個人リポジトリならコードを公開しないプライベートリポジトリを作ることができます。
ついでに Dropbox あたりも使って、開発資料とか関係するものは全部クラウドに上げておいた方がいいよ。開発ツールを学ぶ
CMake
C++ のビルドツールとしては実質スタンダードだと思います。ビルドしたり、配布用パッケージ作ったり、サードパーティライブラリを取り込んだり、いろいろできます。CMakeLists.txt はちょっと書きづらいけど。
こういうのを使わずに、VisualStudio や Xcode のプロジェクトファイルを直接リポジトリで管理するのもありですが、ターゲットプラットフォームが増えるにつれてそのうち管理しきれなくなります。
どのみち Android-NDK の標準的なビルドツールが CMake なので、最初から使ってた方がいいと思う。
各 IDE やビルド方法
とはいえ CMake の生成物についての知識は入れておかないと、ゲームエンジンのランタイムはどうやって起動したらいいの?とかいう話になりかねないので、CMake だけ覚えれば万事解決ってわけじゃないのが悩みどころか。
- Visual Studio
- Xcode
- Android Studio
- (IDE じゃないけど Linux や Emscripten 向けに)Makefile
それぞれで、ビルド、実行、デバッグ、デプロイはできるようになっておきたい。
配布方法を考える
最初に配布を考えるの?って思うかもですが、イマドキの開発スタイルは、最初に小さなパッケージを作っておいていつでも動かせるようにしておき、それを壊さないように少しずつバージョンアップを重ねるのが良いぞ、っていう流れです。
というより、ゲームエンジンみたいな大きなものを個人で作っていくにはその考えがベースに無いと正直やってられんです。詳しくは CI/CD のところで。
ここではユーザーに届ける最終成果物は何?って話です。
一番簡単なのは ZIP とかに固めて配布かな。雑かもしれないけどこのスタイルをとっているものは結構多いと思う。DXLib とかウディタとか Cinder とか。
C++ 以外の言語だと、使いやすいパッケージ管理システムが付いているので、ユーザーはそれ経由でインストールしたいと思うかもしれない。(自分だったら思う
dotnet なら Nuget, Ruby なら Gem とか。
OSS を学ぶ
今日日開発されているシステムの多くは、既に出来上がっているモジュールを集めて繋げることで大部分が作られていたりします。
PNG 画像を読み込むために ZIP デコーダを自分で書くというのかい?という話。
まぁ技術的なところへの興味は絶えないけれど、自分で作るべきところと他に任せるべきところを考えておかないと、とてもじゃないけど手が足りないです。
というところでほとんどのケースでは OSS のライブラリを借りてくることになるですが、最低限ライセンスには気を配ろうよ、って話です。
ちゃんとやるなら最新バージョンや不具合情報を追跡とかしたいところだけど、これも時間との相談か。
テストを学ぶ
プログラムを組んだことがある人ならだれしも、ちょっとコードを変えただけで、全然関係ないと思っていた機能が動かなくなったような経験があると思います。いわゆるデグレード。略してデグレ。
新しく作った機能をテストするのはもちろん、デグレを防ぐためにリグレッションテストと呼ばれる類のテストを回し続ける必要があります。
プロダクトの規模が大きくなってくると、どれほど慎重にコードを書いていてもデグレのリスクは跳ね上がっていきます。サイクロマティック複雑度とか調べてみるとちょっと面白い。
コードレビューしてくれる協力者が一人でもいればだいぶマシになると思うけど、それでもゼロはなかなか難しい。
てことで繰り返し同じテストをする必要があるけどこれが本当に心をやられる。誰もやりたくないので仕事として成り立つくらいには心をやられる。個人開発でテスト会社に依頼するとかは難しいので、テストは真っ先に自動化するべき。
C++ だったら googletest 使うのがいいと思う。
CI/CD を学ぶ
↑ の配布やテストを自動的にやっちゃおうぜ、っていう取り組みです。
GitHub のリポジトリにコードを上げたとき、
- ゲームエンジン一式をクリーンビルドして、失敗したら教えてくれる(メールとかチャットで)
- ビルドしたものをリグレッションテストして、失敗したら教えてくれる
- テスト成功した一式を ZIP に固めて、いつでもダウンロードできるようにしてくれる
これを、各プラットフォーム (Windows, macOS, Linux...) で自動的にやらせるようにする。
これができたらいいよね、っていうより、大きなテーマで個人開発するにあたってはこの仕組みを作っておかないと、そのうち破綻します。(した
テストを一度書いたらそれを自動的に回すようにして、絶対にテストは失敗させない、失敗してたらすぐ直すくらいの心構えじゃないと、個人で大きなプロジェクトを長く続けていくのは不可能です。ていうか怖くてリファクタリングできなくなるので、すぐコードが腐る。
新しめのプログラミング言語は言語仕様レベルで不具合を防ぐような仕組みを設けてたりするから、実装難易度の高い C++ 特有の問題化もしれんです。
ドキュメントライティングを学ぶ
文書を書けるようになろう。小説とかじゃなくて、自分の作ったものを他の人に説明するためのものです。
こんなブログで紹介してる時点で説得力皆無だけど、口語とか使わずちゃんと技術文書として正しい言葉を使ったりしよう。
キレイに書けると google 翻訳さんがキレイに翻訳できるようになったりします。あと文書構造をちゃんと知る。見出し、文節、箇条書きなどのこと。
世の中にはいろいろなドキュメントを作るツールがありますが、文書構造が適切に使えている文書は大抵どんなツールを使ってもキレイな最終出力が得られます。それは最終的に多くの人が見易いドキュメントを作ることになります。
なんか気に入らないから全角スペースでインデントしたり、変なところで改行して行間つけたりすると結果がぐちゃぐちゃになったりで、変なところでストレス溜めることになります。Word 上手く使えない人はこの傾向がすごく多い気がする。
デザインやレイアウトはツールに任せろ。自分は気に入らなくても、ほとんどの人はそれでよい。自分はドキュメントの中身に集中せよ。
開発環境まとめ
公開を考えなければ、ここまでやる必要はないと思います。
ていうかこれ全部できたら仕事できるよ。
設計を学ぶ
最初は設計手法なんて全くモチベーション持てないです。
原理理論は後回しでまずは動くモノを作って動かして全能感に浸りながら、画面の中で動くキャラクターを小一時間ほど不敵な笑みで眺めるのは多分正しいです。また心の健康によいです。
ただそのうちどうしても破れない「壁」にぶち当たります。自分の最初の壁は2万行くらい(適当)だったかな。main 関数何行書いたかなー
そんな時に助けになるのはやはり先人の知恵で、ここで初めて設計やソフトウェア工学に対する関心が出てきます。
設計の勉強のついでに、「技術的負債」っていう言葉を知っておくといいかも。長期メンテにあたっては、これと、先に書いた CI/CD とリファクタリングがものすごく重要になってくる。
聖書 → C++のためのAPIデザイン
変更に耐えられるようにすること
ソフトウェア設計について調べ出すと信頼性とか拡張性とかのいわゆる「品質特性」や「デザインパターン」などたくさん情報が得られると思います。
ただそれらは本当にあらゆるソフトウェアプロダクトをターゲットとした指標であって「ゲーム」や「ゲームエンジン」という領域では必要な要素はかなり絞られます。
極端な話、自動車や医療など、一歩間違えば人が亡くなるようなクリティカルシステムと、娯楽であるゲームでは品質に対する要求が全然違うということ。なので、ちゃんと自分のシステムに必要な手法を取捨選択できるようになろう。
というところで、ゲームエンジンとして重視したい品質ってなんだろうと個人的に強く思うのが、表題のとおり「変更に耐えられるようにすること」ではないかと。(まぁ他にも重要なのはあるけど "より" 重視するものとして。
ゲームはソフトウェアシステムという中でも特殊なもので、仕様はあらかじめ決められるものではなく、動かして、面白さを確認して、ダメなら修正を入れるというサイクルで作られることがほとんどです。
フォーマルっぽい言い方だと「アジャイル開発」と言います。情報処理技術者試験にも新しく入ってきてたような気がする。一般的な実装やAPIを知ること
迷ったらスタンダードに合わせよ。
まぁそのスタンダードを知るところがまずひとつのハードルだったりするんだけど。
一番のよりどころは各言語の標準ライブラリかな。
特徴を出すべきところとそうではないところを、ちゃんとわきまえないと後々メンテが大変になる。(なってる
というか覚えることが増えるので、作る人も使う人も脳の負担が増えたりする。
新しいもの考えてるときは色々と想像が膨らむんだけど、一個人が頑張って考えたものなんてのは往々にして誰も幸せにならないことが多いので、そういう時に参考にするべきなのは一般常識、つまりスタンダード。
あと一般に合わせておくと、書くべきドキュメントが少なくても済んだりする。
世の流行りから学ぶ
複雑化するソフトウェアに何とか対応しようと、いろいろな手法が提案されています。
Web 界隈は特に顕著かな。React とか Vue とかはインパクト大きかった。
流行ってるものはそれなりに理由があるわけで、ただ煌びやかであるわけじゃないです。
関数型とか宣言的UI とかめっちゃ参考になる。参考にできるようになりたい。
ただ個人で大きいプロダクト作ってると、そういうの勉強して実装したぞ!ってなったあたりで次の流行りが来たりするからとてもつらい。特に Web 系はとてもつらい。
つらいので枯れた技術で作りこむのはアリだけど、サードパーティのライブラリとかはベンダーにサポート切られたりすることもあるので要注意。
プロジェクトの運営を学ぶ
ごめんなさい丸投げ → オープンソースソフトウェアの育て方
OSS にしなくても参考になると思う。
ゲームエンジンを学ぶ
前例を探そう。仕事の効率的な進め方の鉄板メソッドである。
守破離を踏襲せよ。真のオリジナリティは王道を知るところからだ。というところで、ゲームエンジンへの要求の整理です。
見出しは聖典 → ゲームエンジン・アーキテクチャ と似せてあるので、それを合わせて読んでもイイかも。
前例を学ぶのは、意図しない車輪の再開発や落とし穴を踏むのを防ぐためですが、最初は「なんでそんな機能が必要なの?」と腹に落ちないことも多いです。
これも設計同様、実際に作ってみて、壁にぶち当たって始めて、なるほどそういうことか、ってなるのを繰り返して行くしかないのかなと思ったりしてます。
エラーの捕捉と処理
診断は全ての機能のベースになるものなので、これは最初に考えておかないと後々苦労することになります。
コツはできるだけシンプルに考えることかな・・・。エラーコードや例外の種類をたくさん増やしても管理しきれなくなるだけだし。
ゲームエンジンだと次のような分類が多いと思います。
- ロジックエラー(プログラマエラー
- ゲームエンジンを開発するプログラマーが原因で発生したエラー
- エンジンユーザーエラー(開発者エラー
- ゲームエンジンを使うクリエイターが原因で発生したエラー
- エンドユーザーエラー(プレイヤーエラー
- エンドユーザー(ゲームプレイヤー)が原因で発生したエラー
※"ゲームエンジン" をターゲットとしていることに注意。ミッションクリティカルなシステムではまた違ってくるので、システムの要求を考慮しよう。
ロジックエラー
null チェック忘れたなどが典型的な原因であるエラー。
これが発生した場合はログを残し、潔くアプリを落とすのが懸命です。
バグか仕様かに関わらずアプリが、そもそもプログラマが想定していなかった状態になっているため、無理に復帰させてもセーブデータが壊れたり脆弱性がチートの温床になったりします。
UE4 の アサーション が現実的な解かな、と思う。
エンジンユーザーエラー
テクスチャファイルの名前を間違えていたり、スクリプト API に変な値を渡してしまったりした場合のエラーです。
ゲームエンジンを使う側のデザイナー、プランナーさんのミスで発生するもので、これが起こったときにアプリを落とすのはダメ。開発効率が致命的に落ちるので。
テクスチャが無いなら真っ黒でいいからメッシュを表示してあげたり、画面上部に赤文字で「テクスチャ無いっす」って表示したり、いわゆる「復帰可能エラー」として扱うべき。
何をこの類のエラーとして扱うかはゲームエンジンのポリシーに依ります。
初期設定ファイルが無かったら、パッケージ異常と考えてアプリを中断するのか、デフォルト設定を使って継続するのか、とか。エンドユーザーエラー
動作環境が問題だったり、ゲーム内のログインフォームで間違った文字入力した場合などのエラーです。
一般的に良いとされるエラーメッセージのお作法に則って、ユーザーに懇切丁寧に現象と復帰方法を知らせるメッセージボックスを出してあげるのがベターな対応でしょうか。
ゲームデザイン寄りの話なので、ゲームエンジンとしてどうにかできるのは動作環境エラーくらいかな・・・。
メモリアロケーション戦略
エンジン内部での毎フレーム new は大罪。オーダーは償却定数時間までなら許してやろう。とか、そういうポリシー。
リアルタイムグラフィックスは性質上、1フレームの中でだけたくさんメモリ使って、そのフレームが終わったら不要になるケースがたくさんあります。シェイプをCPUでテッセレーションして頂点バッファ作るときや、描画コマンドをキューに詰めるときとか。
ので、それ用のアロケータを作っておくと便利。というか必須。アライメントも馬鹿にならなかったりする。
DirectX Sample の LinearAllocator とかおすすめ。
たまにコマンドにラムダ式使ってるエンジン見かけるけど、STLの実装によってはサイズの大きい変数をキャプチャすると new が発生することがあるから注意。
算術
ベクトル、行列、クォータニオンといった3D線形代数はこの後のほぼすべてで利用します。
ので、簡単なものを自作するなりライブラリ使うなり、何かしら無いとお話にならんですので早めに用意しておきます。
ライブラリ使うなら Eigen がいいと思う。
あと乱数について。これは標準ライブラリの rand 関数は精度的に使い物にならんって注意しておけば大丈夫かな。C++11 以降はイイ乱数ジェネレータが標準ライブラリに入ったし。
エンジンの起動方法
エントリポイント(main 関数)をゲームエンジンの内部に隠蔽するか、しないか。
と言っても Web をサポートするなら実質隠蔽するしかない。
この場合ランタイムに、初期化時、フレーム更新時、などのコールバックを登録することになる。
ほとんどの場合は こんな感じ で
仮想関数を実装するスタイルになると思うけど。アセット管理
画像や音声などの素材をどう管理するか、という話。なかなか fopen とか fstream で読むだけじゃ済まないのが悩みどころ。
まさか素材をパッキングや暗号化せずにそのままゲームフォルダに突っ込んでリリースした日にはネタバレが危険で危なかったり、素材の二次配布問題になることもあります。
DXライブラリのアーカイブ はシンプルでいい感じ。
圧縮が絡むとロード速度にすごい響いてくるのでいっそやらないのも手かもしれない。でも Web ターゲットだと通信のオーバーヘッドの方が大きいことが多いので必要になるかも。
あと非同期ロード。"Now loading..." を実装するために必要。
キャッシュや寿命の管理も入れておきたいところ。これが無いとゲームプレイ中にファイルアクセスのためカクカクしたりすることが多くなる。
キャッシュは、既に同じ名前のアセットがロードされていたらそれの参照を返すことで、ファイルアクセス回数を減らして高速化したり、メモリ使用量を抑えたりする仕組み。
寿命管理は、参照カウントなどを使用して、アセットが本当に不要になったらアンロードする仕組み。
ユーザー入力
ゲームパッドやキーボード、マウスからの入力を受け取るための機能。
ハードウェアだけではなく、タッチベースのソフトウェアキーボードや独自の仮想パッドから入力することもあるので、これらをまとめて抽象化して使えるインターフェイスがほしい。
それとキーコンフィグとそのプリセット。
「ゲームパッド」または「キーボード & マウス」で遊べるっていうゲームもたくさんあります。マルチプレイヤーできるようにもしておきたいところ。
あと最近は VR や IoT ぽいセンサーとか従来の枠組みにとらわれない入力インターフェイスを持つデバイスがたくさん登場してるので、そういったものに対応しておくとキャッチーな機能としてアピールできるかもしれない。
レンダリングエンジン
ランタイムの中でも多分最も大きなテーマである絵を描く部分です。やりがいがある一方、いまなお進化を続けているテーマであり、すごい沼です。どっぷり浸かったら多分戻ってこれないです。なんかレイトレとか聞こえてくるし。
領域は大きく次の2つ。
- 低レベルグラフィックスAPIの部分
- それをぶん回してリアルタイム描画する部分
グラフィックスAPI
OpenGL は滅びる。りんごのてんてーがゆってた。
また DirectX11 以前では GPU の恩恵を 100% 得ることはできない。(主に並列処理)
ついでにこれら古い API は消費電力が大きい。モバイル全盛期にこれが痛い。
ということでネイティブは DirectX12, Metal, Vulkan へ、Web は多分 WebGPU への移行が求められています。
がんばれ。
リアルタイム描画
がんばれ。
正直つらい。
がんばれなさそうなときは既存の実装借りてくるのがいいと思う。個人的に filament 大好き。
この領域はいかに速く描くか、ではなく、「不要な部分を描かないことで時間を稼ぐ」がメインテーマになってくるので、そんな感じを目指すといいかも。
ただレイトレがどうなってくるかちょっとキャッチアップ追い付いてない・・・。
物理エンジン
正直なところ、"物理" の部分を積極的に使うことは少なく、"衝突検知" の部分の方がよく使われる気がします。まぁタイトル次第ではあるけれど。
物理エンジンはいろいろなライブラリがあるけど、それぞれ微妙にクセがあるので注意。例えば物理マテリアルが形状データにつくのか、剛体データにつくのか、とか。
無理にラップして抽象化しないのもアリかなと思う。Box2D とか Bullet とか、みんなクロスプラットフォームで動くし。
シーングラフ
このへんの設計手法はほぼ枯れつつあると思う。
ツリー構造でオブジェクトを作って、オブジェクトに意味を持たせるためのコンポーネントをたくさんアタッチしてゲームワールドを作り上げていく方式です。Unity とかで「コンポーネント指向」とか言われるアレ。
C++ だとシーンエディタを作る場合はこれらをセーブ・ロードできる仕組みを作るのに少し苦労するかも。
C# とか他の言語だとたいていリフレクションの機能を持ってるから楽なんだけど、C++ だと cereal とか使って頑張るのが現実解か。
あとマルチシーンのロードとか、オープンワールドのための先行ロードとかキャッシュとか考え出すとおなか痛くなるかも。(なってる
Audio
ただ再生するだけならすごく簡単。だけど SE 再生しようとすると一瞬カクッってなるの何とかしてほしいかなって思います。
これは音声ファイルを同期的に再生しようとしているため、ファイルオープンが終わるまでプログラムが止まってしまうのが原因なんだけど、個人でゲーム開発してて OpenAL とか直接叩いてますぜみたいなのでかなり多い。
要するに非同期実装が必須。
再生するだけなら素直に SDL_Mixer とか使った方が少しは救いがあると思います。
ただ最近はツクール仕様のループに対応している OGG ファイルを素材として配布されている方が多いので、ぜひ対応してみたいところなんだけど、そうすると非同期でストリーミング再生する必要があり SDL_Mixer の再開発っぽくなってきます。
でもやりたいんだよ。やったけど。
次の壁はエフェクト。Volume や Pan だけじゃなくて、エコーとかピッチとか、あるいはプログラマに波形を渡して独自のエフェクタ作れるようにしたりとか、ビジュアライザ作れるようにしたりとか。
WebAudio はホントによくできてると思います。汎用的を極めるならあんな感じにしたいところ。
アニメーション
毎フレーム座標を +1 とかすればそれでアニメーションです。でもそれだけじゃ「気持ちのいい」アニメーションの実現は難しい。
スキンメッシュアニメーション、パーティクルエフェクト、UI の遷移とかで使います。
やりたいことの根っこは2つの値の補間ですが、それをなんやかんや汎用的にまとめた、キーフレームアニメーションとかアニメーションカーブとか呼ばれる、いい感じでうにょうにょした値を作ってくれるモジュールです。
個人的には UI で EaseOutExpo とか使うのが好き。
スキンメッシュアニメーションの合成がひとつの壁か。
ビジュアルエフェクト
ビジュアルエフェクトはゲームの状況を効果的にプレイヤーに印象付けるための、非常に重要なファクターです。
ゲームのかっこよさの第一線を張る重要なものですが、これを作るのはホントに大変。
というわけで Effekseer とか専用のツールを組み込んだりします。
一方で火花散らすくらいの簡単なエフェクトならエンジンに組み込んで欲しいなーと思うところもあったり。単純なスプライトパーティクル。
それ以上の数百万粒子とかやべーやつはコンピュートシェーダ使えるようになったらぜひ。
でもコンピュートシェーダのパワーを100%発揮するにはさっきの DX12,Metal,Vulkan あたりが必要になるから道のりはかなり長そう。
スクリプティング
昔と比べて PC の性能が良くなったといっても、C++ だけでゲームを作るのはまだまだつらいです。主にコンパイル時間が。
エンジンを C++ で作るのは良いとしても、ゲームは変更と調整のオンパレードなのでちょっと変えてすぐに実行できるようじゃないとやってられんです。
実装方法としては、
- スクリプトのランタイムの中でゲームエンジンを動かす
- ゲームエンジンの中でスクリプトのランタイムを動かす
があるけど、それぞれコンセプトが全然違うので注意。後者の場合多分 Ruby を Web で動かせたりもするけど、パッケージ管理に制約が付いたりする。
ちなみに Lumino の Ruby 版は現在前者のみの対応となっています。
AI
AI の性質ってタイトルごとに違うからゲームエンジンとしてどこまでサポートできるかってのは難しいところです。
やっぱりビヘイビアツリーのサポートがベターか。
ちなみに私が今作ってる ARPG では これ に近い ビヘイビアツリーとルールベースAI が階層的になってるような行動決定システムが爆誕したりしたので、ゲームエンジンとしてサポートするならこんな変則的な使われ方も想定した方がいいのかもしれない。
ネットワーク
シーン内のキャラクターの同期あたりが大きなテーマになりそう。ユーザー入力との抽象化というか棲み分けが大変かも。
というかそれ以前にゲームのリアルタイム同期システムは、HTTP をベースとしたような一般的な Web 開発とは全然違ったりするので、「ネットワーク」のひとくくりで考えてると躓きポイント多い気がする。僕は P2P でキャラ同期したことある程度なので詳しいことわからんですが。
最近知ったけど IoT で使われてる MQTT とかイイ感じな気がしてる。
あと忘れがちだけどセキュリティ。でもこれはゲームエンジンの外側の話かな・・・。
これすごく重いテーマで、最近友人と匿名ランキングを HTTP で作るとき、チート対策はできるのか?みたいなこと話したりした。(いいアイデア無かったゲームエンジンを実装する
あーやっと作れる。
実装と言っても先に書いたように、OSS なライブラリをお借りしてつなぎ合わせていくのが多分現実的な落としどころなんじゃないかなと思う。
例えば自分も物理エンジンやフォントレンダリングを自作しかけたけど、結局 OSS のを利用することになりました。
ほんの少しの間は自作を使ってたけれど、メンテナンスに取られる時間が多すぎて他の開発がさっぱり進まなかったのであきらめました。車輪を作ったことでいろいろ勉強にはなったけど、やっぱり実運用となると上手くいかないことの方が多い。
さて、Lumino の実装を少し紹介しようと思います。
主なモジュールごとに色々説明していきますが、リポジトリのincludeフォルダ を見てみると大体どんな人がいるのかつかめると思います。
プログラミング言語
Lumino はネイティブクロスプラットフォームかつクロスランゲージを狙っていたりします。
なので、エンジンのソースコードを解析して他言語用のバインダを自動生成できるようにしたかったです。というところでまずはランタイムをいろんな言語から呼び出せるようにできる、ネイティブアーキテクチャで動かせるものであることが第一。
あとそれなりに安定しているパーサ(コンパイラのフロントエンド API)が提供されている言語がほしかった。
ので、安定(とは明言していないけど)して提供しているのはやっぱり昔からある clang、つまり C++。これの検討したのはもう2,3年前だから、今なら Rust もイイ感じのコンパイラ API 提供してるかもしれないです。
Core
文字列クラスとか動的配列とか文字コード変換とかJSONシリアライザとかが入っている、ゲームエンジンとは直接関係ないけどアプリを作るうえで必要な基本機能をまとめたモジュールです。
C#の標準ライブラリっぽいのを再実装したみたいな闇の深いブツです。
char16_t ベースのライブラリが欲しかったんじゃ、というのが建前で実際は、
本業で世話してるシステムのあまりのレガシーっぷりと反OSSの姿勢にキレて「じゃあ俺の責任でライブラリを作れば文句無いよなァ!?」って感じで作って弊社の主力製品の中核にぶち込んでリリースしちゃった感じのやつ
です。
なので Core は別なサードパーティライブラリには依存してなかったりします。
でももう何年も前の話で文化も変わってきてるので、さすがに RapidJSON とか利用するのに置き換えたい。
Engine
Lumino の一番てっぺんにいる人が EngineManager です。Lumino を起動することは即ち EngineManager のインスタンスを作ることです。
この人が以下の各種モジュールの管理を担当する ~Manager (GraphicsManager とか AudioManager) とかのインスタンスを
作りまくります。またメインループの制御も EngineManager が担当します。
Animation
AnimationCurve, AnimationTrack, AnimationClip あたりで、よくあるスキンメッシュやオブジェクト移動ルートを作るためのキーフレームアニメーションの定義を行います。モーションファイルを読み込むと作られるのがこの人たち。
これに対するアニメーションのインスタンスが、AnimationController, AnimationLayer, AnimationState です。
なんとかしてスキンメッシュアニメーションと UI のスタイルアニメーションを抽象化した API を作ってみたかったのですがびみょーに無理だったので、UI 用にはインスタンスとして AnimationClock とかが居たりします。
Asset
アセットファイルを暗号化アーカイブできるようにしてありますが、非同期ロードがまだ入ってないです。非同期は Promise っぽく作ってみたい。
ちなみにアセットの識別子は GUID を使う実装 (Unity とか) と、ファイルパスを使う実装 (ツクールとか) があるそうです。
Lumino も GUID にチャレンジしてみたけど、エディタサポートが無い状況では管理がつらすぎたので止めました。いや、その後エディタも作ってみてるけど今度はデバッグが辛すぎた。
ファイルパスを使う場合は Unix 形式(セパレータは /)一択なんだけど、システムの絶対パスと Asset フォルダをルートとした絶対パスと単純な相対パスを区別したかったり、やっぱりなんか細かいところが色々気になる・・・。
ってことで、最近は URL ぽい形式にしました。"asset://アーカイブ名/path/to/file" みたいな感じ。
どの方式も一長一短がすごいあるので、自分のエンジンがターゲットにする規模に合わせればいいと思う。
Audio
WebAudio ライクなノードベースでエフェクト自由に掛けられるスタイルで開発中。ただ再生するだけならできてます。
おそらくWeb 漁って OpenAL のサンプルとかでフツーに再生できるようにしたものは「プッシュ型」と呼ばれるオーディオストリームの実装になっているはず。1秒分を音声ファイルから取り出して OpenAL の API に突っ込むのを繰り返す方式です。
一方ノードベースでエフェクトを柔軟にカスタマイズできるフレームワークを作るには「プル型」と呼ばれる方式で実装することになるはずで、これは音声データが欲しいときに呼ばれるコールバックの中で、シーン内の音声を全部まぜまぜして返してあげる方式です。
C++ から使えるライブラリだと LabSound とかかなりよさそうに見えたけど iOS とか対応してなかった。あとコードほとんど Chromium のだった。
興味ある人は ここ から読みだすといいかも。
こういうの頑張って実装してお気に入りの音楽とか聴くと、体から色々な液体がたくさん流れると思う。必聴。
Effect
ビジュアルエフェクトの再生を行う人たちです。
最近 Effekseer を組み込みましたが、スタンドアロンでもパーティクルエフェクトや、スプライトのフリップアニメーションはできるようになっています。
エフェクトって効果音と同じように、ソースデータの管理するのすごくめんどくさいので、
Effect::emit("Laser01.efk", Vector3(位置));みたいに再生開始だけメソッド呼んであげればあとはエンジンがよしなにやってくれるようにしてみてます。
あとパーティクルはそろそろパラメータの数がやべーことになってるのでエディタが無いとつらい。
Graphics
低レイヤーの描画機能を扱う人たちで、多分 Lumino のユーザーは Texture 以外はほとんど使わないかも。
0.8.0 で一度 fix したつもりになってましたが、Vulkan バックエンドを実装したことで、Apple が OpenGL を非推奨にした理由みたいにフロント API とのミスマッチで処理負荷がウェイウェイな感じになってきました。
で、今のところ DirextX11 に RenderPass を足したみたいな API になっています。
また描画スレッドの実装もこのモジュールの役目にしていて、UE4 みたいに 描画コマンドを作るためのラムダ式相当のファンクタを生成するマクロ とか少し黒魔術っぽいこととかやってます。
前述しましたがラムダ式は変なところで new してくれるので、アロケータも含めて自分でコマンドリスト作ってます。
ただもともとは OpenGL とか古い API だと描画が完全に終わるまで Present や SwapBuffers といった関数が制御返さないのが嫌で作ったシステムですが、
DirectX12 とか Vulkan だとそのあたりの制御も自分でできるので、もういらないんじゃないかと思い始めてます。Scene
コンポーネントがアタッチされたオブジェクトをツリー構造で繋げて、シーングラフを表現する人たち。一応マルチシーンの Save・Load とかできるようにしてあります。
ぶっちゃけオブジェクトの姿勢を決めた後、次の Rendering モジュールを使って形状を描くだけなのであんまりいうこと無い。
World が一番てっぺんにいる人で、その下にたくさんの Scene がぶらさがる。その中にさらにたくさんの WorldObject (Unity でいうところの GameObject) がいる。そんなイメージ。
Rendering
多分スクラップアンドビルド回数が一番多いモジュールです。8 回くらいかな?
マルチシェーダパスとかレイヤーとかマルチビューとかデバッグ描画とか、なにか機能を増やしたくなるたびに「あー今のアーキテクチャじゃだめだ」ってなって色々なゲームエンジンのソースコード見に行って、必要な範囲だけ最小実装を続けたらいつの間にかいろんなことができるようになったけど屍の数がひどい、みたいな。
最初に立てたコンセプトと照らし合わせて、やるかやらないか、線引きするべきだったんだろうけどなぁ・・・。
さて、大体次のような流れで描画が行われます。
- SceneRenderer を準備する。次の Pass を持たせる。
- RenderingContext::drawXXXX() で描画コマンドを作ってコマンドリストに追加する
- コマンドリストを SceneRenderer に投げる。
- 最初に持たせたパスごとに描画コマンドを、
- フィルタリング(半透明を描くかとか)・ビューカリング
- Zソート
- バッチ化(ステートでコマンドをまとめたり)
- バッチの描画
- で最後にポストエフェクト。
書き出しちゃうと簡単だな。ここにたどり着くまで時間かかりすぎたけど。
ちなみに Lumino の標準は "Clustered Forward+ Shading" です。
あと最近はこの処理を描画スレッドに追い出した方がいいのではと思い始めています。あーまた変わる
Physics
物理エンジンは 2D 3D それぞれ領域を分けていて、Unity と同じく 2D 物理はクラス名に "2D" サフィックスがついてます。
バックエンドは Box2D と Bullet で、Physics モジュールの基本方針はそれらの API を統一するためのラッパーです。
ゲームエンジンとしての物理モジュールを作るよりも物理エンジン自体の使い方を理解する方が大変かもしれない。
Shader
Lumino はプログラマブルシェーダをサポートしています。
でも、シェーダは通常実行環境ごとに HLSL, GLSL, SPIR-V などたくさん用意しなければならず、それをユーザーにやらせるのは嫌だったので、glslang と SPIRV-cross を使って HLSL から他へのトランスパイラを作ったりしました。
UI
この人もスクラップアンドビルド回数がなかなかのもんです。
昔は Scene の中の一部としてボタンとかテキストを表示するためのものでしたが、今は UI の一部として Scene を描くような感じになってます。おかげで規模が大変なことになってます。
それもこれもマルチウィンドウで別窓にデバッグ情報を表示したいとか、この UI モジュールでエディタ作ってインプレースで 3D シーンを描画したいとか、複雑な要求に耐えられるようにしたい重いが積もり積もって取捨選択できなかったのがひとつの原因か・・・。
あと「UI なんて imgui でいいじゃん」ってよく聞くけど、個人的には imgui そのまま使ってエンドユーザー(プレイヤー)に見せる UI を作るのはちょっと疑問。キレイにアニメーションとかやるのに、結局 imgui をラップして Retained-mode な UI ライブラリ作ることになったりしがちだし・・・。(でも完全に自作するよりはマシかも)
でもデバッグ用やエディタ用の UI に使うなら imgui 以外の選択肢は無いと思います。
ちなみにこの UI モジュールの元ネタ(?)は、Windows アプリの皮をかぶった化け物であるところの WPF です。
一度は WPF の再実装みたいなことをやってましたが、C++ で柔軟なリフレクションするのはものすごく大変だったので当然の挫折。その後レイアウトの仕組みは残しつつ、HTML+CSS の真似事をしながら今の形になっています。
ぼくはいったい何を・・・
どうでもいいこと書きすぎた気がする。いったい何と戦っていたのだろう。
とりあえず色々な言語に、簡単に使えるちょっと背伸びしたゲームエンジンを提供したい。みたいなことが言いたい。
拙い文章ですが、読んでいただきありがとうございます。



- 投稿日:2019-12-11T18:20:18+09:00
VBScriptを作ってみる(構文解析編・代入文まで)
さて、前日に字句解析した結果を構文解析器に入力することで構文解析をしましょう。
言語実装をするときの大きな山の1つが構文解析器の実装です。
字句解析同様に、一から実装するということはせず、ライブラリを利用します。RubyにはraccというLALR(1)パーサージェネレーターが付属しているので、これを使います。
yaccに似た書式なので、yaccを使ったことがある方ならば、ある程度雰囲気で読めるかと思います。
yaccもraccも使ったことがない場合は、以下のオンラインマニュアルが一番詳しくまとまっているので、以下の記事を読む前に一読することをおすすめします。経験的に構文解析ルールを一気に書くと、conflictが大量に発生して辛い思いをすることが多いので、一旦小さなマイルストーンを決めることにします。
まずは、変数宣言と変数代入文が動くところまでを目指します。具体的には以下のスクリプトを実行できれば良しとします。
Dim a, b a = 10 b = (a + 1) * 3 ' この時点でaに10がbに33が代入されているVBScriptの文法とにらめっこすることで、以下の構文解析ルールを得ます。
# vim:filetype=ruby class TinyVbsParser start program rule program : nl_opt global_statement_list { result = val[1] } nl_opt : nl | nl : NEWLINE nl | NEWLINE global_statement_list : global_statement { result = AST::Program.new(val[0]) } | global_statement_list global_statement { result = result.add_child(val[1]) } global_statement : option_explicit | block_statement option_explicit : 'Option' 'Explicit' nl { result = AST::OptionExplicit.new } block_statement : var_declartion | inline_statement nl var_declartion : 'Dim' var_name other_vars_opt nl { result = AST::Dim.new([val[1]] + val[2]) } other_vars_opt : ',' var_name other_vars_opt { result = val[2] + [val[1]] } | { result = [] } var_name : extended_id inline_statement : assign_statement assign_statement : left_expr '=' expr { result = AST::AssignStatement.new(val[0], val[2]) } left_expr : qualified_id { result = AST::LeftExpr.new(val[0]) } qualified_id : ID { result = AST::Identifier.new(val[0]) } extended_id : safe_keyword_id | ID { result = AST::Identifier.new(val[0]) } safe_keyword_id : 'Option' { result = AST::Identifier.new(val[0]) } | 'Step' { result = AST::Identifier.new(val[0]) } expr : imp_expr imp_expr : imp_expr 'Imp' eqv_expr { result = AST::BinaryExpr.new('Imp', val[0], val[2]) } | eqv_expr eqv_expr : eqv_expr 'Eqv' xor_expr { result = AST::BinaryExpr.new('Eqv', val[0], val[2]) } | xor_expr xor_expr : xor_expr 'Xor' or_expr { result = AST::BinaryExpr.new('Xor', val[0], val[2]) } | or_expr or_expr : or_expr 'Or' and_expr { result = AST::BinaryExpr.new('Or', val[0], val[2]) } | and_expr and_expr : and_expr 'And' not_expr { result = AST::BinaryExpr.new('And', val[0], val[2]) } | not_expr not_expr : 'Not' compare_expr { result = AST::UnaryExpr.new('Not', val[1]) } | compare_expr compare_expr : compare_expr '>=' concat_expr { result = AST::BinaryExpr.new('>=', val[0], val[2]) } | compare_expr '<=' concat_expr { result = AST::BinaryExpr.new('<=', val[0], val[2]) } | compare_expr '>' concat_expr { result = AST::BinaryExpr.new('>', val[0], val[2]) } | compare_expr '<' concat_expr { result = AST::BinaryExpr.new('<', val[0], val[2]) } | compare_expr '<>' concat_expr { result = AST::BinaryExpr.new('<>', val[0], val[2]) } | compare_expr '=' concat_expr { result = AST::BinaryExpr.new('=', val[0], val[2]) } | concat_expr concat_expr : concat_expr '&' add_expr { result = AST::BinaryExpr.new('&', val[0], val[2]) } | add_expr add_expr : add_expr '+' mod_expr { result = AST::BinaryExpr.new('+', val[0], val[2]) } | add_expr '-' mod_expr { result = AST::BinaryExpr.new('-', val[0], val[2]) } | mod_expr mod_expr : mod_expr 'Mod' mult_expr { result = AST::BinaryExpr.new('Mod', val[0], val[2]) } | mult_expr mult_expr : mult_expr '*' unary_expr { result = AST::BinaryExpr.new('*', val[0], val[2]) } | mult_expr '/' unary_expr { result = AST::BinaryExpr.new('/', val[0], val[2]) } | unary_expr unary_expr : '+' exp_expr { result = AST::UnaryExpr.new('+', val[1]) } | '-' exp_expr { result = AST::UnaryExpr.new('-', val[1]) } | exp_expr exp_expr : value '^' exp_expr { result = AST::BinaryExpr.new('^', val[0], val[2]) } | value value : const_expr | left_expr | '(' expr ')' { result = val[1] } const_expr : int_literal { result = AST::NumberLiteral.new(val[0]) } | bool_literal { result = AST::BoolLiteral.new(val[0]) } | STRING_LITERAL { result = AST::StringLiteral.new(val[0]) } | nothing int_literal : INT_LITERAL | HEX_LITERAL | OCT_LITERAL bool_literal : 'True' | 'False' nothing : null | empty null : 'Null' { result = AST::NullLiteral.new } empty : 'Empty' { result = AST::EmptyLiteral.new } end ---- header require_relative 'ast' require_relative 'tiny_vbs.rex'VBScriptでは代入は式ではなく文であるということが理解できていれば、比較的シンプルな構文解析ルールです。
また、要素を還元したときのルール中に
AST::Hogeクラスが多く登場しますが、一旦は以下の以下の抽象クラスを継承している具象クラスであるという理解でも問題ないです。
デザインパターンでいうところのインタープリターパターンです。module AST class Node def eval(environment) raise 'not implemented' end end class Leaf < Node end class List < Node def initialize(children) @children = children end def children @children end def child(index) @children[index] end def add_child(child) @children.push(child) self end def add_child_head(child) @children.unshift(child) self end endさて、これで構文解析に必要なものは揃ったので、最後はVBScriptのプログラムを構文解析器に入力する部分を作ればOKです。
program = ARGF.read parser = TinyVbsParser.new ast = parser.scan(program) pp ast上記のプログラムを実行することで、以下の抽象構文木(AST)を得ることが出来ます。
#<AST::Program:0x00007f7f2a81f280 @children= [#<AST::Dim:0x00007f7f2a81f2f8 @var_names= [#<AST::Identifier:0x00007f7f2a81ff00 @identifier="a">, #<AST::Identifier:0x00007f7f2a81f6e0 @identifier="b">]>, #<AST::AssignStatement:0x00007f7f2a81ece0 @children= [#<AST::LeftExpr:0x00007f7f2a81f190 @children=[], @identifier=#<AST::Identifier:0x00007f7f2a81f1e0 @identifier="a">>, #<AST::NumberLiteral:0x00007f7f2a81edd0 @value=10>]>, #<AST::AssignStatement:0x00007f7f2a81da98 @children= [#<AST::LeftExpr:0x00007f7f2a81eb50 @children=[], @identifier=#<AST::Identifier:0x00007f7f2a81eba0 @identifier="b">>, #<AST::BinaryExpr:0x00007f7f2a81db10 @children= [#<AST::BinaryExpr:0x00007f7f2a81e038 @children= [#<AST::LeftExpr:0x00007f7f2a81e600 @children=[], @identifier= #<AST::Identifier:0x00007f7f2a81e650 @identifier="a">>, #<AST::NumberLiteral:0x00007f7f2a81e290 @value=1>], @operator="+">, #<AST::NumberLiteral:0x00007f7f2a81dc50 @value=3>], @operator="*">]>]>
@childrenで表現されているインスタンス毎の入れ子構造を見ると、正しく構文解析が出来ていることがわかります。次回はこのASTオブジェクトに対する
evalメソッドの実行を行います。
- 投稿日:2019-12-11T17:59:39+09:00
Ruby on Jetsでserverlessなサービスの運用環境を作ってみた
Ateam cyma Advent Calendar 2019、16日目です!
トップバッターに続いて本日は 株式会社エイチーム のエンジニア @u_minor3110 が務めさせていただきます。
今回はRuby on Jetsの紹介をします。
アプリの開発に時間を割いて、サーバ運用は楽したい!という人にオススメだと感じています。Ruby on Jetsとは
Ruby on JetsはAWSサービスと連携し、serverlessなサービスを作ることができるRubyのフレームワークです。もちろん開発マシンではAWSサービスを使わずとも開発を行うことができます。
https://rubyonjets.com/
https://github.com/tongueroo/jetsRuby on Jetsの個人的に感じた魅力
- severlessでサービスを運用することができるため、アプリの開発に集中ができる
- サーバのメンテナンスコストが発生しない!
- Ruby on Railsに似ているのでRailsを知っていれば学習コストがかからない
- 料金もEC2を使って運用するより安く済む可能性がある(料金計算自信なし)
- Lambdaは月100万リクエスト、128MBの のメモリを割り当てた場合約37日実行時間分までは無料
- API Gatewayは月100万リクエストまでは無料だが、超えてくると100万リクエスト毎に$1以上かかるので高いか?
- S3は月100万リクエストで平均ファイルサイズも5KB程度あれば、$1未満程度
- CloudFormationは8リソースを使用しており、リリースに2分かかるとして、一日4回、20日リリースを行ったとしても、
- (8 * 4 * 20 - 1000) + 2 * 20 * 4 * 0.00008 ≒ $1未満
- 結論、小規模のサービスなら安くすみそうだが、デイリー100万リクエストを超えるようなサービスだと、高くなりそう(´・ω・`)
- AWS料金シミュレーター
セットアップからAWSへのデプロイはとても簡単
# gemのインストール $ gem install jets # プロジェクトの作成(オプションもrails newと似ている) $ jets new app --mode=api --no-database # ディレクトリの移動 $ cd app # コントローラの作成 $ jets g controller Hellos index # rackサーバの起動(開発マシンで検証する場合) $ jets serve # awsへの本番deploy(IAMのアクセスキーを環境変数として指定する必要があり) $ jets deploy productionサービスの運用にあたり
本番用カスタムドメインの指定
AWS Certificate Managerで証明書を作成し、API Gatewayでカスタムドメインの設定を行う。
デプロイ権限の管理について
検証環境は誰でも、本番環境にリリースできる人は制限したい。Lambda, S3等への権限がFullAccessでは検証も本番にもデプロイがされてしまう。
例えばS3に対してなら、以下のようにpolicyを指定し、本番用と開発用の権限を別々に作るのが良さそう。{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "s3:*" ], "Resource": [ "arn:aws:s3:::*-dev-*" ] } ] }まとめ
時間が無くてきちんとした運用に乗せられていないですが、リリースまでが本当に簡単だったので、小規模なサービスには使ってみたいと考えています。
終わりに
Ateam cyma Advent Calendar 2019の16日目、いかがでしたか。
17日目は@ouka___さんがseo関連の話をしてくれますのでお楽しみに!株式会社エイチームでは、一緒に働けるチャレンジ精神旺盛な仲間を募集しています。
エンジニアで興味を持った方はcymaのQiita Jobsをご覧ください。
そのほかの職種は、エイチームグループ採用サイトをご覧ください。
- 投稿日:2019-12-11T17:47:27+09:00
就活用ポートフォリオとしてWebサービス「Asobi」を作りました。
はじめに
こんにちは、ササクラ(@n_sasakura870)と申します。
SIerで働いておりましたが会社が倒産しました。今はWeb業界に転職するべく就活中です。今回は僕のポートフォリオを紹介するとともに、
- どういった技術を使用して開発したか
- どういった反省点、課題点が生まれたか
を解説できればと思います。
作ったもの
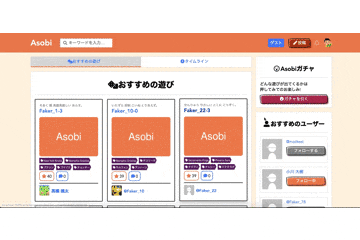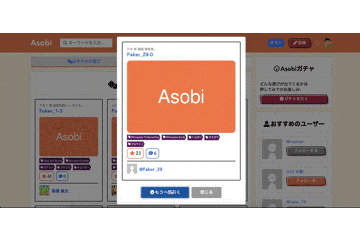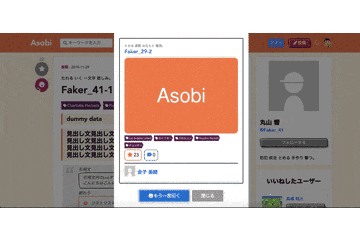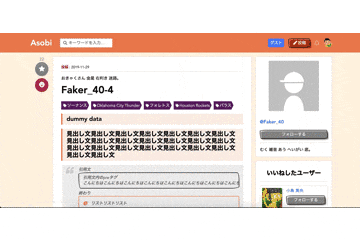
Asobi
様々なローカルルールや自分で考えた遊びを記録・共有するサービスです。
URL : http://www.asobi-app.com/
GitHub : https://github.com/sasakura870/asobi作った背景
友達とたまーにローカルでアナログな遊び(トランプ使ったゲームとかレクリエーションとか)をやることがあるんですが、結構面白くて盛り上がるんですよね。ただ、ふとやりたいなーと思ってググるとローカルルールって探してもあんまり出てこないことが多いんです。
なのでそういったローカルな遊びを記録・共有できるサービスがあれば、投稿して後で思い出せると考え、作ってみました。制作日数
GitHubへの最初のコミットからデプロイまでちょうど100日でした。
選定した技術
ここでは使用した技術の紹介と、めぼしい技術の選定理由を説明します。
バックエンド
- Ruby 2.6.3
- Ruby on Rails 6.0.0
- Webpacker 4.39.3
- ActiveStorage
- ActionText
- slim 4.0.1
- kaminari 1.1.1
- ActiveRecord-Import 1.0.3
- counter_culture 2.2.4
- RSpec 3.9
選定理由
ActionText
サービスの要件上、遊びのルール説明にリッチテキストエディタを使用したかったため。
これがまあ簡単に実装できて素晴らしいものだったので、またQiitaに記事を書こうと思います。ActiveRecord-Import
Rails6からバルクインサート機能が実装されたのですが、直接SQLを発行するものでIDのオートインクリメントやvalidation, callbackが効かなかったため。
公式リファレンスはこちらRails6の新しいバルクインサートメソッドに関してはこちらをご覧ください。
Rails6 のちょい足しな新機能を試す85(insert_all upsert_all編)フロントエンド
- Vue.js 2.6.10
- Vue Croppa 1.3.8
- FontAwesome 5.10.2
- sweetalert2 8.18.3
- Tippy.js 5.1.1
- selectize.js 0.12.6
最初CSSフレームワークにBootstrapを採用していましたが気に入ったデザインにならず、最終的にFLOCSSに基づいて自作しました。
自分でCSSを書いてみると、思った100倍楽しかったです。選定理由
Vue.js
jQueryを使用したことはあったのですが、DOMの操作がより簡単そうだったため。
Vue Croppa
ユーザーアイコンのトリミング機能に使用。Cropper.jsと悩みましたが、UIがこちらの方が好みだったのでこちらを採用しました。
公式リファレンスはこちらsweetalert2
アラート機能、トースト機能に使用。ポップで可愛いデザインがAsobiにぴったりだと思い採用しました。
カスタマイズ性が高く、Ajaxを絡めた実装も簡単でした。
公式リファレンスはこちらselectize.js
投稿画面のタグ入力フォームに使用。こちらもカスタマイズ性が高く使いやすかったです。
公式リファレンスはこちらインフラ
- AWS
- VPC
- EC2
- Route 53
- RDS
- PostgreSQL 11.5
- S3
- Nginx 1.16.1
- Unicorn 5.5.1
選定理由
一度HerokuでデプロイしたことがあったのでAWSに挑戦しました。
SSL化したかったのですがまだできていません…。ここはもっと学習しないといけないです。データベース設計
- ユーザーに関する
usersテーブル- ユーザーが投稿する遊びに関する
articlesテーブル- タグに関する
tagsテーブル- いいねに関する
favoritesテーブル- コメントに関する
commentsテーブル- ユーザー同士のフォローを実装する
relationshipsテーブル- usersテーブル、articlesテーブルとtagsテーブルの中間テーブルである
tag_mapテーブルQiitaのようなユーザーがタグをフォローできる機能を実装するために、
tag_mapテーブルにポリモーフィック関連を実装しました。主な機能
機能やUIはQiitaを参考に設計しました。
機能の概要はGitHubのREADMEにも記載しているので、こちらではより技術的な部分に踏み込んだ説明をしていきます。ユーザー
登録
Railsチュートリアル第11章を参考に、登録後送られてくるメールのリンクから本登録が完了するシステムを採用しました。
仮登録状態では、一部のページへアクセスした場合に仮登録完了ページへリダイレクトすることで機能を制限しています。
また、仮登録完了ページにメール再送リンクを作成し、Ajaxで登録されたアドレスにメールを再送する処理を実装しています。ゲストログイン
登録せずとも一通りの機能を試してもらえるようにゲストログイン機能を実装しました。
ゲストログイン後は本登録ユーザーと同じように操作することができます。(退会とメールアドレス変更のみ禁止しています。)ユーザーアイコン
Vue.jsとVue Croppaを使って画像をトリミングしてユーザーアイコンに設定する機能を実装しました。
画像作成後、適応するボタンを押すことでVue Croppaで作成された画像のBase64形式のデータを送信し、Rails側がそのデータをエンコードしてActiveStorageに保存する処理が走ります。永続ログイン
ログイン時、またはユーザー設定のアカウント画面から「ブラウザを閉じた後もログイン状態を保持するか」を設定できます。
こちらはRailsチュートリアル第9章を参考に実装しました。投稿
タグ入力にselectize.jsを使用しています。編集時には遊びに関連付いているタグを取得し、フォームに初期値として入れるように実装しています。
本文入力フォームにはActionTextを使用しています。自動生成されるactiontext.scssのCSSが入力フォームと本文の両方に適応されるのがいいですね。いいねとフォロー
いいねボタンとフォローボタンはVue.jsでコンポーネント化し、Ajaxで処理をするように実装しました。Asobiガチャ
他のWebサービスにはない機能として、「Asobiガチャ」機能を実装しました。
ボタンを押すとAjaxでRails側でランダムに遊びを1つ取得し、そのデータをjson形式でフロントに渡してJavascriptで表示しています。
使いやすさを向上させるため、引いた後に「もう一度引く」ボタンで再度ガチャが引けるようになっています。反省点
頑張らないと投稿出来ないような雰囲気のサービスにしてしまった
遊びのルールを記録・共有するサービスのため、しっかりとした記事が書けるようにリッチテキストエディタを採用しました。
そのためぱっと見で投稿するハードルの高いWebサービスになってしまいました。
もう少し投稿する心理的なハードルが下がるように工夫をしたいと考えています。ドメイン駆動設計に憧れてService層とか作っちゃった
作成途中に
ドメイン駆動開発(DDD)を知り、「なにこれすげー!」と手を出したのが失敗でした。
Service層を作りながら「どこまでがこのServiceクラスの責務なんだ…?」と悩むタネを増やしてしまい、完成に余計な時間がかかりました。
最終的にHandlerクラスというものまで作成し、こういった処理の流れになりました。
Controllerは自分のクラス、アクションに合ったHandlerクラスを呼び出し、HandlerクラスはServiceクラスを呼び出しています。
Serviceクラスは「ログインする」「タグ入力フォームに記載されたタグを取得または作成する」「いいねする」といった最小単位の処理のみ実行することで、様々なHandlerクラスから再利用できる仕組みです。
…が、振り返れば単純なCRUDしかしないアプリにこんな大層なアーキテクチャを採用する必要はなかったと感じています。テストをほぼ書いていない
先ほどの
ドメイン駆動開発(DDD)で各処理を切り分けておきながら、テストを書いていません。何のためのDDDなんだ…
GitHubには制作初期に書いたRSpecのテスト(ほぼ通らない)が置いてあります。DockerとかCircleCIとか触ってみたかった
これは制作中に存在を知ったので手を出しませんでした。次のポートフォリオで採用してみようと思います。
今後の課題点
HTTPS化
AWSの
ELBやCloudFrontを使ってサイトのHTTPS化を行いたいです(挫折済み)。レスポンシブ対応
サービスの要件上、モバイルからのアクセスの方が多そうなので(実際アクセスされるかは別として)レスポンシブ対応したいです。
入力フォームのエラーメッセージの表示
現状だと新規登録や投稿画面の入力フォームのエラーメッセージが画面上部に表示される仕様です。
これもsubmitの前に、validationチェックし、エラーがあれば入力フォームの近くにそれぞれのエラーメッセージを表示するようにしたいです。ソーシャルログイン機能
Twitterログインを実装してもっと利用しやすい仕組みにしたいと考えています。
作ってみた感想
自分で考えたWebサービスを形にするということは予想以上に大変でした。
Railsチュートリアルと違って道筋がない(当たり前ですが)ので、「この機能で本当にいいのか?」「このUIでいいのか?」「この処理はどこに書けばいいんだ?」と常に迷子になりながらコーディングしていました。その分デプロイできた時は脳汁出まくりで気持ちよかったです。振り返れば大変だった以上に楽しかったです。エラー出しまくりながらやりたいことが実装できた時の感動は他では味わえないです。
このWebサービスを最後まで作りきることが出来たのも、ひとえにQiitaやSlackやもくもく会でアドバイスを下さった皆様のおかげです。本当にありがとうございます。今後もこのWebサービスを改修しながら別のWebサービスも作りつつ、就活に励む所存です。
あとがき
名古屋でもくもく会を開催するのでよかったら参加してください。
https://connpass.com/event/158832/









- 投稿日:2019-12-11T17:30:48+09:00
Rails+MySQL+Docker+AWS(EC2, RDS, ALB, Route53, S3)で作成したポートフォリオについて
記事の概要
私が作成したポートフォリオ、「GoodCoffeeByGoodBarista」を解説します。
なぜ作ったか、どう作ったか、今後どうしていくかをまとめました。実際に作成したサイトやソースコードは下記のリンクからご覧いただけます。
GoodCoffeeByGoodBarista
GitHubこちらの記事の書き方は下記の記事を参考にさせていただきました。
PHP+MySQLでポートフォリオ作成なぜ作ったか
私は、愛知県名古屋市にある個人経営のカフェで、2年半ほどバリスタとして勤務しておりました。
ある時、バリスタの大会に出場したのですが、結果は惨敗でした。
バリスタは、生豆の仕入れからロースト、抽出までを全て個人で行い、それをプレゼンするのですが、超小規模店舗で勤務していた私は、生豆の仕入れルートもなければ高価な焙煎機もない、大会で使われる最新のエスプレッソマシンもない、練習に使うミルクも何百本と自腹で用意するしかない環境下で戦うしかありませんでした。
対して、大きな企業が経営するカフェに勤めているバリスタは、会社が持っているルートから最高品質の生豆を仕入れ、会社が用意する材料を使って、最新のエスプレッソマシンで毎日練習ができるのです。私は、環境の差による大きな挫折を味わいました。
バリスタを辞め、エンジニアになるべく勉強をしていた私は、「エンジニアリングの力で、バリスタ業界を良くできないか」と考えるようになりました。
エンジニアのように気軽に転職をする事ができる文化があれば、スキルを身に付けたいバリスタはより大きな企業に転職できるし、大企業にいてスキルはあるけれどもっと個人の店舗で接客を身に付けたいバリスタの願いも叶えられる。
バリスタが、自分の所属する環境でスキルを身に付けられなかったり、夢を諦めたりしなくて良くなるのではないか。
そんな思いから、バリスタ版Wantedlyのようなサービスを作成し、私のポートフォリオとすることにしました。スペック
言語
Ruby 2.5.3
フレームワーク
Ruby on Rails 5.2.2
CSSフレームワーク
Bootstrap4
データベース
MySQL 5.7
WEBサーバ
Nginx 1.15.8
開発環境
Docker 19.03.5
docker-compose 1.21.1バージョン管理
Git 2.24.0
本番環境
AWS (EC2, RDS, ALB, Route53, S3)
主な機能
・バリスタ(カフェ)一覧表示
バリスタの一覧、またはカフェの一覧を表示します。
ログインしていなくてもアクセスできる仕様です。
・バリスタ(カフェ)を検索
バリスタの場合、性別で検索できます。
カフェの場合、店舗名、雇用形態、所在地で検索できます。
・バリスタ登録
バリスタはトップページから新規作成のリンクを踏むことでユーザー登録ができます。
入力内容は最低限必要な内容のみです。
入力に誤りがあれば、登録はされずエラ〜メッセージが表示されます。
・オーナー登録
オーナーはナビゲーションにある「採用担当者の方」というところからオーナー用のトップページに移動し、そこから新規作成画面に移動できます。
入力内容は最低限必要な内容のみです。
入力に誤りがあれば、登録はされずエラ〜メッセージが表示されます。
・バリスタプロフィール編集
登録では基本情報のみの入力なので、プロフィール編集で詳細な情婦を入力していきます。
上記のリンクから自分のプロフィールを確認しながら編集できます。
・オーナーカフェ情報編集
登録では基本情報のみの入力なので、プロフィール編集で詳細な情婦を入力していきます。
上記のリンクから自分のプロフィールを確認しながら編集できます。
・ログイン
ログインできます。
バリスタとオーナーではフォームが分けてあります。
・面談したい(面談に誘いたい)バリスタ(カフェ)に対してメールを送信
ログインしている状態で、気になるバリスタ(カフェ)の詳細ページから面談を申し込む(誘う)内容のメールを送る事ができます。
・退会
プロフィール編集の画面から退会できます。
開発手順
1.要件定義
今回作成するアプリに必要な機能は、
・バリスタユーザー登録機能
・オーナーユーザー登録機能
・ユーザー一覧表示機能
・ユーザー検索機能
・応募プロフィールや、求人情報作成機能
・面談応募(勧誘)機能のため、ユーザー情報を保存しておくデータベースが必要であり、尚且つデータベースに保存した情報を動的に表示できるビューが必要です。
また、面談の応募(勧誘)にはメイラー機能を使いたいので、メール用のサーバーも用意する必要があります。
バリスタユーザーとオーナーユーザーで動線を分けたいので、わかりやすい動線づくりを心がけます。
2.環境選定
言語は、自分にとって技術的資産の多いRubyを選択しました。
よってフレームワークもRuby on Railsとしました。データベースは、もっともメジャーに、広く使用されているMySQLを選択しました。
今回はバックエンド開発がメインだったため、フロントエンド開発の工数を減らす目的でCSSフレームワークを使用しました。
CSSフレームワークにはネット上に公開されている情報のリソースが多いことから、Bootstrapを使用しました。WEBサーバーには、pumaとの連携が簡単で、かつネット上に情報のリソースが多かったNginxを使用します。
なお、これらの環境はDocker,docker-composeを使用して構築しています。
Dockerを使用したのは、最終的にCircleCIやcapistoranoを用いた自動テスト&ビルド&デプロイを行いたいと考えているためです。そして、本番環境はAWSのEC2,RDS等を用いて構築します。
これは、個人的にAWSに興味があったため使ってみたかったのと、転職用のポートフォリオとして使用する際、クラウドにAWSを取り入れている企業様が多いと感じたことから、技術アピールができると考えたからです。3.データベース設計
今回は、2種類のユーザーを作成する必要があるため、ユーザーモデルを一つ作成し、オーナーフラグがtrueかfalseかでユーザーを識別するか、ユーザーモデルを二つ作成してそれぞれで管理するかで悩みましたが、
今回は後者の方法でデータベースを作成することにしました。
理由は、私が参考にしている著書「達人に学ぶDB設計徹底指南書」にて、一つのモデルはなるべくシンプルにし、分けられるところは分けて管理するのが良いとされていたので、その教えを守る形にしました。4.コーディング
コーディングの際に注意した点は以下の通りです。
・一つの機能を実装する度にRSpecでSystemスペックを記述する
・GitHubFlowを意識した開発(マスターブランチでの作業は基本的にはしない、擬似的にプルリクエストを作成して、マスターブランチにマージする -> リモートリポジトリの変更を、ローカルにpullする)また、ユーザーをバリスタユーザーとオーナーユーザーに分けて実装していましたが、自身の練習もかねて、バリスタユーザーの登録や認証周りをdeviseで実装し、オーナーユーザーの登録はscaffoldで作成、認証は簡易的なsessionで実装しました。
ただ、ログイン状態のバリスタユーザーをcurrent_userで取得し、ログイン状態のオーナーユーザーをcurrent_ownerで取得するように実装したのですが、これはベストプラクティスではないように感じました。
次回また似たようなアプリケーションを作成する際は、この辺りのDB設計に関してきちんと見直す必要がありそうです。この段階で、動作確認も兼ねてdevelopment環境でもAWSのS3に画像が保存されるように実装しました。
5.デプロイ
本番環境はAWSで構築しました。
docker-composeでアプリケーション用のコンテナ、Nginxのコンテナ、メイラーのコンテナを用意していたので、それらをまとめてEC2でビルド&実行するようにしました。
データベースはRDSを使用しています。
画像の保存には、S3を使用しており、こちらはproduction環境だけでなく、development環境でもS3に保存するようにしています。
また、今回はEC2は一つしか用意していませんが、後々HTTPS化するのに必要だったので、ALBを配置しました。
独自ドメインは、過去にブログを運営していたときにも利用していて使い慣れたお名前.comから取得し、Route53で設定しました。AWSを使ったデプロイのために何冊も書籍を読み、様々な記事を読んだので、ネットワーク周りの知識がかなりついたと実感しました。
今後の改善点や追加実装について
アプリケーション自体としては、SNSログインや画像アップロードの際のプレビュー表示などを実装したいと考えております。
加えて、特にフォーム関連のUIを向上させたいと考えています。
具体的には、入力するべき項目をplaceholderでわかりやすくしたりできるかと考えております。また、要件定義の段階から考えているCircleCIを使用した自動ビルド&テスト、capistoranoを使用した自動デプロイを実装していきたいです。
そのためにも、現在はCircleCIの公式ドキュメントを読みながら準備をしている段階です。それから、AWSに関しても、画像の配信をCloudFlontで行うことで、より高速化を測ってみたいと思います。
参考文献
・Ruby on Rails5.2 速習実践ガイド
・プロを目指す人のためのRuby入門
・Docker/Kubernetes 実践コンテナ開発入門
・Amazon Web Services 基礎からのネットワーク&サーバー構築 改訂版
・ゼロからわかる Amazon Web Services超入門 はじめてのクラウド かんたんIT基礎講座
・Webを支える技術 ―― HTTP,URI,HTML,そしてREST
・リーダブルコード
・達人に学ぶDB設計 徹底指南書











- 投稿日:2019-12-11T16:46:02+09:00
画像アップロード時に「Missing required arguments: aws_access_key_id, aws_secret_access_key」エラーが発生する
プログラミングスクールのカリキュラムでメルカリのクローンサイトを開発中、商品の画像をデータベースに保存しようとしたところ、タイトルのエラーが発生。
検索しても、該当する記事が見当たらなかったので記事にしました。
エラー画面がこちらです。
ローカルで画像を保存しようとしてるだけだし、AWSとか関係ないだろーと思って解決方法を模索していましたが、辿り着いた答えは単純でした。
画像をアップロードするためにCarrierWaveを使用していたのですが、「image_uploader.rb」の記述に問題がありました。エラーの原因
image_uploader.rb# Choose what kind of storage to use for this uploader: # storage :file storage :fogstorage :fogが適用されているせいでCarrierWaveの保存先がS3になっていました。
解決方法
storage :fogをコメントアウトしてあげて、storage :fileのコメントアウトを解除してあげればエラーが無事解決します。
image_uploader.rb# Choose what kind of storage to use for this uploader: storage :file # storage :fog補足
ローカルでの作業後、CarrierWaveの保存先をS3に戻す場合は逆の修正を行えば簡単に戻せます。
- 投稿日:2019-12-11T16:22:50+09:00
デザインパターンを通して変更に強いソフトウェア設計を考える
はじめに
Webエンジニア2年目の @nagata03 です。最近「変更に強いプログラミングができるようになりたい!」と思いデザインパターンについて個人的に勉強してみました。
普段業務ではRuby/Railsを使っているので、「Rubyによるデザインパターン」という本を読んでみました。
勉強してわかったことは、大事なのはパターンそのものよりもその根底にある原則を意識して設計・実装することでした。
なのでこの記事では、デザインパターンを通してその根底にある原則について理解を深めていきたいと思います。デザインパターンって何?
よく知られているデザインパターンは、1995年にGoFが書籍「オブジェクト指向における再利用のためのデザインパターン」で発表したデザインパターンです。その本では23種類のデザインパターンが示されています。
出版されてからもう25年近く経つのですね。デザインパターンは、ソフトウェア開発で出会う問題に対して頻出する解決策をパターンとして整理したものです。
なので、適切な問題に適切なパターンを適用すれば問題をスマートに解決することができます。また、各パターンには名前がつけられているので「そこは●●パターンでいこう」というように開発者間で設計方針を明確に伝えることができます。前提にある原則
GoFは書籍の中で、ソフトウェア設計をするうえで大事にすべき原則を示しています。
変わるものを変わらないものから分離する
ほぼ言葉の通りなので説明は割愛します。インターフェイスに対してプログラムし、実装に対して行わない
疎結合なコードを書くこと。可能な限り一般的な型に対してプログラミングすること。継承より集約
オブジェクトが何かの一種である(is-a-kind-of)関係は避けて、何かを持っている(has-a)関係にすること。委譲、委譲、委譲
仕事を他のオブジェクトに押し付ける「責任転嫁」。何となーくわかった気になる。けど、インターフェイスに対してプログラムするというのはどういうこと?委譲って具体的にはどういうこと?などの疑問が残ります。
Strategyパターンを通して原則を理解する
サンタクロースがプレゼントを届ける機能を実装してみましょう。
サンタクラスを作り、その中にプレゼントを届けるメソッドを生やします。santa_sample.rbclass Santa def initialize(present) @present = present end def deliver(transporter) if transporter == :sled puts "#{@present} をソリでお届け。トナカイ頑張れ。" elsif transporter == :car puts "#{@present} を車でお届け。スピードの出し過ぎに注意。" elsif transporter == :airplane puts "#{@present} を飛行機でお届け。航空券は早めに予約しよう。" else raise "Unknown Transporter: #{transporter}" end end end santa = Santa.new("絵本") santa.deliver(:sled) santa.deliver(:car)実行結果は以下です。
$ ruby santa_sample.rb 絵本 をソリでお届け。トナカイ頑張れ。 絵本 を車でお届け。スピードの出し過ぎに注意。
Santaクラスは「何を使って(if文の判定条件)、どのように(各条件での処理内容)プレゼントを届けるか」に関心を持っています。
サンタはプレゼントを届けることだけに集中し、それよりも詳細なことは気にしないでおきたいです。まずは変わるものを変わらないものから分離しましょう。そして分離したものに仕事を委譲しましょう。
santa_sample.rbclass Santa def initialize(present, transporter) @present = present @transporter = transporter end def deliver if @transporter.is_a?(SledTransporter) @transporter.ride(@present) elsif @transporter.is_a?(CarTransporter) @transporter.drive(@present) elsif @transporter.is_a?(AirplaneTransporter) @transporter.fly(@present) else raise "Unknown Transporter: #{@transporter}" end end end class SledTransporter def ride(present) puts "#{present} をソリでお届け。トナカイ頑張れ。" end end class CarTransporter def drive(present) puts "#{present} を車でお届け。スピードの出し過ぎに注意。" end end class AirplaneTransporter def fly(present) puts "#{present} を飛行機でお届け。航空券は早めに予約しよう。" end end santa = Santa.new("絵本", SledTransporter.new) santa.deliver #=> 絵本 をソリでお届け。トナカイ頑張れ。 santa = Santa.new("ぬいぐるみ", CarTransporter.new) santa.deliver #=> ぬいぐるみ を車でお届け。スピードの出し過ぎに注意。
SledTransporter、CarTransporter、AirplaneTransporterクラスを新たに作り、その中に輸送処理を書きました。
これでどのように届けるかをSantaクラスから分離しました。次に何を使って届けるかを切り離しましょう。
今のつくりでは、SledTransporter、CarTransporter、AirplaneTransporterクラス毎にメソッドのインターフェイスが異なっているため、Santaクラスはtransporterが何クラスであるかを意識し、その種類毎にメソッドを使い分けなければなりません。
インターフェイスを共通化することで、Santaクラスから何を使って届けるかの関心を分離しましょう。santa_sample.rbclass Santa def initialize(present, transporter) @present = present @transporter = transporter end def deliver @transporter.run(@present) # 各Transporterで共通のrunメソッドを使う。@transporterが何クラスであるかを意識する必要はない end end class SledTransporter def run(present) puts "#{present} をソリでお届け。トナカイ頑張れ。" end end class CarTransporter def run(present) puts "#{present} を車でお届け。スピードの出し過ぎに注意。" end end class AirplaneTransporter def run(present) puts "#{present} を飛行機でお届け。航空券は早めに予約しよう。" end end各Transporterには
runという共通のインターフェイスを設けました。これによりSantaクラスは何を使って届けるかを意識しなくて済むようになりました。
輸送手段が増えたり輸送処理の内容が変わったりしても、Santaクラスは何も気にせず届けることだけに集中できます。
最初の例と比べるとぐんと変更に強いつくりにすることができました。このように「別々のオブジェクトにアルゴリズムを引き出す」テクニックをGoFではStrategyパターンと呼んでいます。
コンテキストとストラテジ間のデータの受け渡し
Strategyパターンでは、
SledTransporter、CarTransporter、AirplaneTransporterクラスのように同じ目的(今回の例ではプレゼントを輸送すること)を持った一群のオブジェクトをストラテジ、ストラテジを利用する側(今回でいうSantaクラス)をコンテキストと呼んでいます。
コンテキストとストラテジはクラスが異なるので、データの分離にも一役買っています。その代わりコンテキストが持っている情報をストラテジが取得する方法を用意しておく必要があります。
これには基本的に2つの選択肢があります。引数を使う
1つめは、これまで示してきたサンプルコードのようにコンテキストがストラテジオブジェクトのメソッドを呼び出すときにストラテジが必要とする情報をすべて引数で渡す方法です。
santa_sample.rbの抜粋class Santa def initialize(present, transporter) @present = present @transporter = transporter end def deliver @transporter.run(@present) # プレゼントの情報を引数で渡している end endこの方法はコンテキストとストラテジオブジェクトが明確に分離できているのが良いところです。ただ、渡すべき情報が多くなってくると少し厳しくなります。
コンテキスト自身の参照を使う
2つめの方法は、コンテキスト自身の参照を使ってストラテジがコンテキストの情報を引き出す方法です。
ストラテジオブジェクトはデータが必要になったときにコンテキストのメソッドを呼び出すことができます。新たなsanta_sample.rbの一部class Santa attr_reader :present def initialize(present, transporter) @present = present @transporter = transporter end def deliver @transporter.run(self) # コンテキスト自身の参照を渡す end end class SledTransporter def run(context) puts "#{context.present} をソリでお届け。トナカイ頑張れ。" # コンテキストの参照を使って情報を取得している end endこの方法はデータを渡すのが楽になる反面、コンテキストとストラテジ間の結合度を上げてしまうことになります。
状況によってうまく使い分けましょう。Rubyだとこう書ける
ダックタイピング
Strategyパターンのクラス図は以下になります。(「Rubyによるデザインパターン」より引用)
このパターンに忠実に従うと、今回示した実装例はストラテジの共通のインターフェイス(
runメソッド)を規定するTransporter基底クラスを用意し、各ストラテジはそのTransporterクラスを継承する形になります。class Transporter def run(present) raise 'Abstract method called!' end end class SledTransporter < Transporter def run(present) # 省略 end endしかしRubyではダックタイピング哲学より、
SledTransporter、CarTransporter、AirplaneTransporterクラスはいずれもrunメソッドを実装しているので、すでにどれも同じインターフェイスを共有しているとみなすことができます。
なのでわざわざTransporterクラスを作ることはしないでしょう。Procとブロック
Procオブジェクトを使ってこんな書き方をすることもできます。
class Santa def initialize(present, &transporter) # 引数transporterに&をつけてコードブロックを受け取れるようにする @present = present @transporter = transporter end def deliver @transporter.call(@present) # Procオブジェクトのcallメソッドでコードブロックを実行 end end SLED_TRANSPORTER = lambda { |present| puts "#{present} をソリでお届け。トナカイ頑張れ。" } CAR_TRANSPORTER = lambda { |present| puts "#{present} を車でお届け。スピードの出し過ぎに注意。" } santa = Santa.new("絵本", &SLED_TRANSPORTER) santa.deliver #=> 絵本 をソリでお届け。トナカイ頑張れ。こうすれば、ストラテジのためにあえてクラスを作る必要がなくなります。ここで出てきたクラスはコンテキストである
Santaクラスだけになりました。このようなコードブロックベースのストラテジは、そのインターフェイスが単純で、処理が1つのメソッドで事足りるようなときに有効です。
ストラテジにもっとやることがあるのなら、クラスベースのやり方で作ることになるでしょう。おわりに
今回の勉強を通してまず思ったのはシンプルに「オブジェクト指向おもしろい!」でした。GoFが示した原則にしたがって実装することでオブジェクト指向の真価やおもしろさを垣間見たと思います。
オブジェクト指向を使いこなして変更に強いソフトウェアを作っていきたいですね!それでは、ちょっと趣向を変えてフロントエンドの世界を覗いてみましょう。
明日は @nakia さんの「Vue.jsはじめました(ビギナー向けまとめ)」です。お楽しみに!参考文献

- 投稿日:2019-12-11T16:18:22+09:00
ActiveStorageをcarrierwaveに置換する方法
やりたいこと
- 既にActiveStorageでのファイルアップロード機構がある
- ActiveStorageによってアップロードされているファイル群をCarrierwaveに置換したい
知識
- ActiveStorageでアップロードされているファイルは、以下でURLを特定することができます。
'https://your_domain.com' + Rails.application.routes.url_helpers.rails_blob_path(task.image, options = {only_path: true})
- carrierwaveにはURLからファイルをアップロードできる機能があります。
# 例 Galaxy.create!(name: 'Andromeda', remote_photo_url: 'http://apod.nasa.gov/apod/image/1407/m31_bers_960.jpg', address: 'next to the Milky Way')実装
上記の2つの知識を組み合わせて、ActiveStorageでアップロード済みの動画をCarrierwaveで置換していきます。
task has_one_attached imageとします。- carrierwave用として
image_fileというカラムを追加したとします09_task.rb# seedファイルで作成 Task.all.each do |task| image_url = 'https://domain.com' + Rails.application.routes.url_helpers.rails_blob_path(task.image, options = {only_path: true}) task.update!(remote_image_file_url: image_url) p '###################################' p task.title + 'の画像アップロードが完了しました' p '###################################' end上記をseed_fuファイルで作成し、Herokuで反映させたい時には以下のコマンドから実行できます。
$ heroku run rails db:see_fu FILTER=09 --app your_app_name
- 投稿日:2019-12-11T16:06:58+09:00
facebook-ruby-business-sdkで広告結果データを取得しchartkickでグラフ化
実装したいこと
- facebookページでかけた広告結果データを取得して画面描画したい
- 広告結果データ取得にはfacebook-ruby-business-sdkを使う
- グラフ描画にはchartkickを使用する
トークン取得
developer for facebookにアクセスしてアクセストークンを取得します、下記キャプチャから取得できます
画面左側メニューの「設定 > ベーシック」から「app secret」も取得できるので、これも控えておきます。
ここで取得したトークンとシークレットをcredentialsに入れておきます。
Railsアプリから呼び出す
トークンを設定できたら呼び出す準備は完了しているので、必要な記述を追加していきます。
taskテーブル
カラム名 型 name string ad_id string dataテーブル
カラム名 型 impressions integer country_name string task_id bigint
task has_many datasタスクを登録した時に、広告結果を取得してみます。
app/models/task.rbrequire 'facebookbusiness' class Video < ApplicationRecord # facebook marketing API FacebookAds.configure do |config| config.access_token = Rails.application.credentials.dig(:facebook_ads, :access_token) config.app_secret = Rails.application.credentials.dig(:facebook_ads, :app_secret) end # callback after_save :fetch_facebook_insights def fetch_facebook_insights ad = FacebookAds::Ad.get(ad_id) insightss = ad.insights( fields: 'impressions', breakdowns: 'country', date_preset: 'this_quarter' ) insightss.all.each do |insight| data.create( country_name: insight.country, impressions: insight.impressions.to_i ) end end end地味に気を付けたい点としては、
- impressionsが
Stringで返ってくるので型変換が必要- countryは
AUなどの略称で返ってくるので、UIで日本語表示したい場合は対応が必要2点目については、facebookの国コード一覧などが役に立つかと思います。
chartkickでグラフ化
READMEに沿って進めれば簡単にグラフ化できます。
https://github.com/ankane/chartkick
show.html.erb<%= bar_chart @task.datas.group(:country_name).sum(:impressions) %>

- 投稿日:2019-12-11T15:55:33+09:00
Rubyの変数の定義(インスタンス変数)
Rubyの変数の定義について、今回はインスタンス変数
前回はローカル変数について書きました
続いてインスタンス変数です。
命名規則
変数の先頭は@
変数の構成は英数字と_@student = "Taro" @_student_2 = "Jiro" @STUDENT_3 = "Sabu" @4_STUDENT_4 = 'Fourth' #@の隣に数字は定義できない SyntaxError:`@@1' is not allowed as a class variable name #ちなみに初期値を設定しないで呼び出すと「nil」になる @student_5 puts @student_5 => nilスコープ
そのインスタンス内で参照できる
@student = "Taro" #インスタンス変数を定義 ことのき"Taro"というStringクラスのインスタンスが生成 puts @student Taro => nil 3.times do |n| puts @student end Taro Taro Taro => 3 def students @student end students #Stringクラスを継承しているインスタンス内なので参照が可能 Taro => nil class Students puts @student end #クラスの外部の@studentをクラス内部で読み込むことはできない => nilではなぜStudentsクラスから@studentが呼び出せないか。
理由はインスタンス変数はインスタンス内で参照ができるからです。
どういうことか?そもそもインスタンスとはなにか??インスタンスとは
クラスは設計図でクラスで作られたものがインスタンスです。
たとえば@student = "Taro" @student.class => Stringのように@studentはStringクラスのインスタンスです。
たとえばこうすると@student = 123 @student.class => Fixnumとなり@studentはFixnumクラスのインスタンスとなるのです。
つまりStudentsクラスで作ったインスタンスであれば、インスタンスごとにStudentsクラス内で呼び出すことができます。
class Students def name=(name) @student = name end def greet puts "Hi,#{@student}!!" end end a = Students.new a.name = "Hanako" a.greet "Hi,Hanako!!" b = Students.new b.name = "Yoshiko" b.greet "Hi,Yoshiko!!"インスタンスを作成するごとに、インスタンス変数に値を代入して呼び出すことができる。
ただしこれだといちいちインスタンスを呼び出して値を代入しないといけないので、インスタンスを作成するタイミングで値を引数に入れて代入するinitializeメソッドを使うのが一般的かなと思います。
class MedicalStudents attr_accessor :name def initialize(name) @student = name end def greet "Hi,#{@student}!!" end end a = MedicalStudents.new("Hanako") a.greet "Hi,Hanako!!" a.name = "Yoshiko" a.geet "Hi,Yoshiko!!"以上がインスタンス変数でした。
またインタンスの生成などはオブジェクトとはの段階から理解したほうが良いということが分かりました。
ここでは詳しく説明してないので次回以降に書けたらいいなと思います!!
- 投稿日:2019-12-11T15:47:26+09:00
私が欲しいのはruby2.3.1。ruby2.3.1がなぜかinstallできない件。middlemanをローカルで動かそうと思ったら、突然動かなくなった件について
今まで普通に動いていたmiddlemanのローカルサーバー。
突然次の日middlemanのローカルサーバーを動かそうと思ったら、動かなくなりました・・・なんで?
ボスに教えてもらいながら、解決方法を片っ端から実践して見たことをここに書こうと思います。
slackだと消えてしまうのと、
私のような人がいた時のヘルプになれるように。まずやったこと
ruby 2.3.1を使っていて難なく動いていたが、突然動かなくなってしまったので、仕方なくruby2.3.1のアンインストールを実行する。
次にやったこと
ruby2.3.1のインストールを実行するがなぜか入らない・・・。とっても困りました。
エラーが出現↓
ruby-build: using readline from homebrew
BUILD FAILED (OS X 10.13.6 using ruby-build 20190828)
Inspect or clean up the working tree at /var/folders/ry/yfy244t51blb55lmrdq02wcc0000gn/T/ruby-build.20191206153836.44874
Results logged to /var/folders/ry/yfy244t51blb55lmrdq02wcc0000gn/T/ruby-build.20191206153836.44874.log
Last 10 log lines:
ERROR: Ruby install aborted due to missing extensions
Configure options used:
--prefix=/Users/Himekichi/.rbenv/versions/2.3.1
--with-reaine-dir=/usr/local/opt/readline
--with-openssl-dir=/usr/local/opt/openssl@1.1
--with-readline-dir=/usr/local/opt/readline
CC=clang
CFLAGS= -O3 -Wno-error=shorten-64-to-32
LDFLAGS=-L/Users/Himekichi/.rbenv/versions/2.3.1/lib
CPPFLAGS=-I/Users/Himekichi/.rbenv/versions/2.3.1/includeほんでまた次にやったこと
似たような事例がネットにあったので、試して見ました。
https://qiita.com/Axl178TakLoose/items/861e953e998f232a1bd8
これも効果なく撃沈。次にやったこと
brew update
brew install openssl
これでもだめ・・・。次へ進む
ruby versionをなるべく新しいものへ変更。
middlemanで動く一番新しいバージョンはruby2.4.1
最新ruby versionは入るのか?古いruby versionは入るのか片っ端から実験スタート
結果
ruby2.3.1 入らない
ruby2.3.2入らない
ruby2.4.1入らない
ruby2.4.3入る
ruby2.4.4入る
ruby2.5.1入る
ruby2.5.2入らない
ruby2.5.6入る
ruby2.6.1入る
ruby2.6.4入る(少し数が飛んでいるのは、私のパソコンにすでにそのバージョンが入っているからです。)
そこで上記に書いてあることを一通りした後にruby2.3.1が入るか再度試してみることにした。
かなりダメ元、プラスやけくそでw。
$ rbenv install 2.3.1
結果入りました!!!いええええええい。でもなんでなぜruby2.3.1が急に入ったのかは定かではありません。(今の所)
次へ進む
とりあえず
ruby2.6.4が入ったならば、
gemのバージョンをあげて動作すれば問題なしということで実行。あとはxcodeが入っていないとmiddleman動かないとか書いてあった記事がどこかにあったような気がする。
xcodeはすでにもうインストール済みなので、これは問題ではない。じゃあ結局原因はなんなんだということで今日も原因究明は続きます・・・・・・・・
- 投稿日:2019-12-11T15:38:14+09:00
ユーザー属性によってdeviseの新規登録フォームを変える方法
実装したいこと
- ユーザー属性によって異なるフォームパーツを出力する
- 会社ユーザーであれば、会社名・email・password
- 通常ユーザーであれば、email・password
- 認証周りはdeviseで一括管理したいけれど、むやみにcontrollerやviewを増やしたくない
結論: パラメータで条件分岐
deviseのcontrollerは
users下のものを使用するroutes.rbdevise_for :users, controllers: { sessions: 'users/sessions', registrations: 'users/registrations', passwords: 'users/passwords', confirmations: 'users/confirmations' }app/controller/users/registrations_controller.rb# GET /resource/sign_up def new super do |resource| if params[:as] == 'company' build_resource({}) self.resource.company = Company.new end end endapp/views/users/registrations/new.html.erb<% if params[:as] == 'company' %> <h2 class="has-text-weight-bold">会社アカウント作成</h2> <%= f.fields_for :company do |company_form| %> <div class="field"> <%= company_form.label :name, class: 'label has-margin-top is-inline-block' %> <span class="has-text-danger">*</span> <%= company_form.text_field :name, autofocus: true, class: 'input' %> </div> <% end %> <% end %>こんな感じで書いておけば、パラメータで
companyが渡ってきた時だけ、フォームパーツを出力することができます。app/controller/application_controller.rbbefore_action :configure_permitted_parameters, if: :devise_controller? private def configure_permitted_parameters devise_parameter_sanitizer.permit(:sign_up, keys: [company_attributes: [:name]]) endサインアップの時にパラメータを送信できるよう許可しておく必要があります。
参考: https://github.com/plataformatec/devise#strong-parameters
- 投稿日:2019-12-11T15:09:51+09:00
railsでのデータ取得方法 find,where,group by など
はじめに
railsの基本的なデータ取得方法をまとめます。
allメソッド
全ての要素を取り出すメソッドです。モデルのすべての要素を配列で取得します。
#モデル名.all #以下が例となります。 User.allfindメソッド
モデルのidをキーとして検索するメソッドです。
idに当たるレコードがない場合はエラー(ActiveRecord::RecordNotFound)を起こします。#モデル名.find(取得したいレコードのid) #以下が例となります。 User.find(1)find_byメソッド
条件にマッチしたレコードを1件だけ返すメソッドです。
条件に一致するものがない場合はnilを返します。#モデル名.find_by(検索するテーブルのカラム名: 検索したいデータ) #以下が例となります。 User.find_by(name: "たかし")whereメソッド
条件に対しての結果をすべて返すメソッドです。
条件に一致するものがない場合はActiveRecord_Relationクラスを返します。# モデル.where(検索条件) #nameがたかしのものを検索 User.where(name: "たかし") #nameがたかしかつseiがすずきのものを検索 User.find_by("name = ? and sei = ?", "たかし", "すずき")終わりに
railsで基本的なデータの取得方法について紹介しました。
条件に一致するものがないときはそれぞれ違う結果を返すことは頭に入れておきたいです!
- 投稿日:2019-12-11T14:43:55+09:00
Ruby2.3.1でgemがインストールできない(cannot load such file -- openssl)
cannot load such file -- openssl
rvmで2.3.1をインストールし、gem install xxx を実行すると以下のエラー。
ERROR: Loading command: install (LoadError) cannot load such file -- openssl ERROR: While executing gem ... (NoMethodError) undefined method `invoke_with_build_args' for nil:NilClass何らかの原因でOpenSSLが読み込めないのが原因らしい。
解決法
自分の場合は、rvmのパッケージでopensslをインストールして、それを参照するようにしたら動いた。
rvm pkg install openssl rvm reinstall ruby-2.3.1 --with-openssl-dir=$rvm_path/usr
- 投稿日:2019-12-11T14:09:35+09:00
Rubyで文字コードや区切りを指定して、CSVを読み込む
TL;DR
一括読み取る
CSV.table('path/to/tsv', encoding: 'utf-16', col_sep: "\t")注意:
1. BOM付きUTF-8など扱う時、encoding: 'bom|utf-8'を使うと便利です。
2.col_sep: "\t"のダブルクォーテーションをシングルにするとエラーになります。行ごと読み取る
CSV.foreach('path/to/tsv', encoding: 'utf-16', col_sep: "\t", headers: true) do |data| p data endNKFを使って、文字コードを推定
require 'nkf' enc = NKF.guess(File.read('path/to/tsv', 10)) p enc.name # => "UTF-16" CSV.foreach('path/to/tsv', encoding: enc, col_sep: "\t", headers: true) do |data| p data endおまけ
fileコマンドで文字コードの検知$ file -b utf16.tsv Little-endian UTF-16 Unicode text, with very long lines, with CRLF, LF line terminators $ file -b utf8bom.tsv UTF-8 Unicode (with BOM) text, with very long lines, with CRLF, LF line terminators $ file -b shift_jis.tsv Non-ISO extended-ASCII text, with very long lines, with CRLF, LF, NEL line terminators
iconvで文字コード変換# 変換結果を見る $ iconv -f utf-16 -t utf-8 utf16.tsv | less # utf8.tsvに書き込む $ iconv -f utf-16 -t utf-8 utf16.tsv -o utf8.tsv注意:
Rubyで使う場合、ruby/iconvというライブラリがありますが、どうやらv1.9から非推奨になりました。参考
- 投稿日:2019-12-11T13:05:15+09:00
メタプログラミングRuby 2章のメモ書き
Overview of p29-p45
途中から途中まで読んだので、メモしておきます。
全部メモしたら追記しておきます。メソッド探索
Ruby がレシーバのクラスに入り、メソッドを見つけるまで継承チェーンを上ることをメソッド探索と呼ぶ。
例えば下記のように、レシーバである MySubClass のスーパークラスを辿っていくことで、
my_methodを探し出すことが出来る。class MyClass def my_method; 'my_method()'; end end class MySubClass < MyClass end obj = MySubClass.new obj.my_method() # => "my_method()"継承チェーンとは BasicObject までのクラスの継承関係の軌跡のことで、Module#ancestors で参照することができる。
MySubClass.ancestors # => => [MySubClass, MyClass, Object, Kernel, BasicObject]モジュールとメソッド探索
Ruby はモジュールを継承チェーンに挿入する。モジュールは2通りの挿入方法があり、1つはインクルード、2つめはプリペンドだ。
インクルードはクラスの真上にモジュールを挿入し、プリペンドはクラスの真下にモジュールを挿入する。
module M1 def my_method 'M1#my_method()' end end class C include M1 end class D < C; end D.ancestors # => [D, C, M1, Object, Kernel, BasicObject] class C2 prepend M1 end class D2 < C2; end D2.ancestors # => [D2, M1, C2, Object, Kernel, BasicObject]多重インクルード
あるモジュールが既に継承チェーンに含まれているとき、2回目以降の挿入は無視される。
下記の例では、M1 は既に M3 の継承チェーンに含まれているため、 M2 でインクルードされている M1 は無視される。
module M1; end module M2 include M1 end module M3 prepend M1 include M2 end M3.ancestors # => [M1, M3, M2]Kernel
Object クラスが Kernel モジュールをインクルードしているため、Kernel モジュールのメソッドはどこからでも呼び出すことが出来る。
下記から分かるように、print は Kernelの private インスタンスメソッドであるため、どこからでも呼び出せる。
Kernel.private_instance_methods.grep(/^pr/) # => [:proc, :printf, :print]メソッドの実行
self キーワード
メソッドを呼び出すとき、メソッドのレシーバが self になる。
全てのインスタンス変数は self のインスタンス変数になり、レシーバを明示しないメソッド呼び出しは全て self に対する呼び出しとなる。
class MyClass def testing_self @var = 10 my_method self end def my_method @var = @var + 1 end end obj = MyClass.new obj.testing_self # => #<MyClass:0x00007feae89f4dd8 @var=11>self の特殊ケース
- トップレベル
- メソッドを呼び出さないとき、self は Ruby のインプリンタが作った main 内部にいる。
- このオブジェクトはトップレベルコンテキストと呼ばれる。
- クラス定義と self
- クラスやモジュールの定義の内側では、self の役割はクラスやモジュールそのものになる。
private の本当の意味
- Ruby では「private ルール」が定義されている。
- ルール1: 自分以外のオブジェクトのメソッドを呼び出すには、レシーバを明示的に指定する必要がある
- ルール2: private のついたメソッドを呼び出すときはレシーバを指定できない
以下の例では、ルール2 を破っているためエラーとなる。
class C def public_method self.private_method end private def private_method; end end C.new.public_method # => NoMethodError (private method `private_method' called for #<C:0x00007feae8a3c7a0>)Refinements
クラスを再定義して拡張する機能として Refinements がある。
Refinements はモンキーパッチと似ているが、影響範囲が特定のスコープに限定される点で異なる。以下の例では、refine ブロック内で拡張された reverse メソッドを、using メソッドを使うことで有効にしている。
module StringExtensions refine String do def reverse "esrever" end end end module StringStuff using StringExtensions "my_string".reverse # => "esrever" end "my_string".reverse # => "gnirts_ym"Refinements は現在も進化を続けている機能であるため、ベストプラクティスは確立されていないようです。
まとめ
- クラスはそれぞれ BasicObject まで続く継承チェーンを持っている。
- クラスにモジュールをインクルード(プリペンド)すると、そのクラスの継承チェーンの真上(真下)にモジュールが挿入される。
- メソッドを呼び出すと、レシーバが self になる。
- モジュール(あるいはクラス)を定義すると、そのモジュールが self になる。
- インスタンス変数は常に self のインスタンス変数と見なされる。
- レシーバを明示的に指定せずにメソッドを呼び出すと、self のメソッドだと見なされる。
- Refinements は using を呼び出したところから、ファイルやモジュールの定義が終わるところまでの限られた部分でのみ有効になる。
所感
- メタプロ、面白い。
- なんで面白いかというと、曖昧だったオブジェクトとクラスの違いが整理されている気がしている。
- 今までは「鯛焼きの型がクラスで、出来あがった鯛焼きがオブジェクトだよ」みたいな抽象的な理解に落ち着いてた。
- でも、実際はインスタンス変数やメソッドがどちらに帰属するのかなど、言語レベルで明確な違いがある。
- メタプロを読んだ後にプロRuby のクラス・モジュール以降を読むともっと理解深まるかもしれない。
- 投稿日:2019-12-11T13:05:15+09:00
メタプログラミングRuby 2章 完全理解した
Overview of p29-p45
途中 → 途中まで読んだので、メモしておきます。
全部メモしたら追記しておきます。メソッド探索
Ruby がレシーバのクラスに入り、メソッドを見つけるまで継承チェーンを上ることをメソッド探索と呼ぶ。
例えば下記のように、レシーバである MySubClass のスーパークラスを辿っていくことで、
my_methodを探し出すことが出来る。class MyClass def my_method; 'my_method()'; end end class MySubClass < MyClass end obj = MySubClass.new obj.my_method() # => "my_method()"継承チェーンとは BasicObject までのクラスの継承関係の軌跡のことで、Module#ancestors で参照することができる。
MySubClass.ancestors # => => [MySubClass, MyClass, Object, Kernel, BasicObject]モジュールとメソッド探索
Ruby はモジュールを継承チェーンに挿入する。モジュールは2通りの挿入方法があり、1つはインクルード、2つめはプリペンドだ。
インクルードはクラスの真上にモジュールを挿入し、プリペンドはクラスの真下にモジュールを挿入する。
module M1 def my_method 'M1#my_method()' end end class C include M1 end class D < C; end D.ancestors # => [D, C, M1, Object, Kernel, BasicObject] class C2 prepend M1 end class D2 < C2; end D2.ancestors # => [D2, M1, C2, Object, Kernel, BasicObject]多重インクルード
あるモジュールが既に継承チェーンに含まれているとき、2回目以降の挿入は無視される。
下記の例では、M1 は既に M3 の継承チェーンに含まれているため、 M2 でインクルードされている M1 は無視される。
module M1; end module M2 include M1 end module M3 prepend M1 include M2 end M3.ancestors # => [M1, M3, M2]Kernel
Object クラスが Kernel モジュールをインクルードしているため、Kernel モジュールのメソッドはどこからでも呼び出すことが出来る。
下記から分かるように、print は Kernelの private インスタンスメソッドであるため、どこからでも呼び出せる。
Kernel.private_instance_methods.grep(/^pr/) # => [:proc, :printf, :print]メソッドの実行
self キーワード
メソッドを呼び出すとき、メソッドのレシーバが self になる。
全てのインスタンス変数は self のインスタンス変数になり、レシーバを明示しないメソッド呼び出しは全て self に対する呼び出しとなる。
class MyClass def testing_self @var = 10 my_method self end def my_method @var = @var + 1 end end obj = MyClass.new obj.testing_self # => #<MyClass:0x00007feae89f4dd8 @var=11>self の特殊ケース
- トップレベル
- メソッドを呼び出さないとき、self は Ruby のインプリンタが作った main 内部にいる。
- このオブジェクトはトップレベルコンテキストと呼ばれる。
- クラス定義と self
- クラスやモジュールの定義の内側では、self の役割はクラスやモジュールそのものになる。
private の本当の意味
- Ruby では「private ルール」が定義されている。
- ルール1: 自分以外のオブジェクトのメソッドを呼び出すには、レシーバを明示的に指定する必要がある
- ルール2: private のついたメソッドを呼び出すときはレシーバを指定できない
以下の例では、ルール2 を破っているためエラーとなる。
class C def public_method self.private_method end private def private_method; end end C.new.public_method # => NoMethodError (private method `private_method' called for #<C:0x00007feae8a3c7a0>)Refinements
クラスを再定義して拡張する機能として Refinements がある。
Refinements はモンキーパッチと似ているが、影響範囲が特定のスコープに限定される点で異なる。以下の例では、refine ブロック内で拡張された reverse メソッドを、using メソッドを使うことで有効にしている。
module StringExtensions refine String do def reverse "esrever" end end end module StringStuff using StringExtensions "my_string".reverse # => "esrever" end "my_string".reverse # => "gnirts_ym"Refinements は現在も進化を続けている機能であるため、ベストプラクティスは確立されていないようです。
まとめ
- クラスはそれぞれ BasicObject まで続く継承チェーンを持っている。
- クラスにモジュールをインクルード(プリペンド)すると、そのクラスの継承チェーンの真上(真下)にモジュールが挿入される。
- メソッドを呼び出すと、レシーバが self になる。
- モジュール(あるいはクラス)を定義すると、そのモジュールが self になる。
- インスタンス変数は常に self のインスタンス変数と見なされる。
- レシーバを明示的に指定せずにメソッドを呼び出すと、self のメソッドだと見なされる。
- Refinements は using を呼び出したところから、ファイルやモジュールの定義が終わるところまでの限られた部分でのみ有効になる。
所感
- メタプロ、面白い。
- なんで面白いかというと、曖昧だったオブジェクトとクラスの違いが整理されている気がしている。
- 今までは「鯛焼きの型がクラスで、出来あがった鯛焼きがオブジェクトだよ」みたいな抽象的な理解に落ち着いてた。
- でも、実際はインスタンス変数やメソッドがどちらに帰属するのかなど、言語レベルで明確な違いがある。
- メタプロを読んだ後にプロRuby のクラス・モジュール以降を読むともっと理解深まるかもしれない。
- 投稿日:2019-12-11T11:24:25+09:00
警察官二人の取り調べ定義
あなたは警官です。aとb二人の容疑者の取り調べをしています。
どちらも証言がTrue、またはFalseであればその証言はTrueです。
しかしどちらかがFalseでTrueであればその証言はFalse、と出力するメソッドを作りましょう。呼び出し方:
police_trouble(a, b)出力例:
police_trouble(true, false) → False
police_trouble(false, false) → True
police_trouble(true, true) → Truedef police_trouble(a, b) if a && b || !a && !b puts "True" else puts "False" end endアルゴリズムの組み立て方
まず、aとbの両者の証言がTrueの条件を考える。
【a && b】 # a かつ b がtrueの時の条件式次に、aとbの両者の証言がFalseの条件を考える。
【!a && !b】 # a かつ b がFalseの時の条件式最後に、上記2つの論理を「または」でつなげる。
【a && b || !a && !b】以上で、「両者の証言がTrue、またはFalseであれば、その証言はTrueとする。」の条件式が出来上がる。あとは、これをif文で書くだけ。
<参考記事>
・https://docs.ruby-lang.org/ja/latest/doc/symref.html
・http://www.tohoho-web.com/ruby/operators.html
・https://docs.ruby-lang.org/ja/latest/doc/spec=2foperator.html
- 投稿日:2019-12-11T11:24:25+09:00
警察官二人の取り調べ定義(自分メモ)
あなたは警官です。aとb二人の容疑者の取り調べをしています。
どちらも証言がTrue、またはFalseであればその証言はTrueです。
しかしどちらかがFalseでTrueであればその証言はFalse、と出力するメソッドを作りましょう。呼び出し方:
police_trouble(a, b)出力例:
police_trouble(true, false) → False
police_trouble(false, false) → True
police_trouble(true, true) → Truedef police_trouble(a, b) if a && b || !a && !b puts "True" else puts "False" end endアルゴリズムの組み立て方
まず、aとbの両者の証言がTrueの条件を考える。
【a && b】 # a かつ b がtrueの時の条件式次に、aとbの両者の証言がFalseの条件を考える。
【!a && !b】 # a かつ b がFalseの時の条件式最後に、上記2つの論理を「または」でつなげる。
【a && b || !a && !b】以上で、「両者の証言がTrue、またはFalseであれば、その証言はTrueとする。」の条件式が出来上がる。あとは、これをif文で書くだけ。
<参考記事>
・https://docs.ruby-lang.org/ja/latest/doc/symref.html
・http://www.tohoho-web.com/ruby/operators.html
・https://docs.ruby-lang.org/ja/latest/doc/spec=2foperator.html
- 投稿日:2019-12-11T10:38:05+09:00
エラーを乗り越えろ!! くじけないRuby初心者のRuby On Rails + Vue.js 環境構築(Ruby 2.6.4, Rails 6.0.1)
Ruby On Rails + Vue.js で何かを作りたいと思って環境構築し始めたところ、次々とエラーが出てきました。環境を構築したいだけなのにエラーで前に進めないのはとても辛いです。構築手順についてはわかりやすい先輩型のQiitaがあったので、今回はそれに沿って構築した際に、詰まった箇所とその対応策を備忘録としてまとめます。
参考文献に沿って構築 + 詰まった箇所
1. まずはこの記事に沿って実行
Ruby初学者のRuby On Rails 環境構築【Mac】
❶Homebrewはインストール済みだったので、アップデート
❷rbenvもインストール済みだったので、Homebrewでアップデート
❸一応cat ~/.bash_profileでrbenvのパスが通っているか確認
❹せっかくなので今回は本家サイトで安定版と書かれていたRuby2.6.5をインストール...しようと思ったら、listになかったので、2.6.4をインストールした
❺Bundlerはインストール済みだったので、アップデート
❻MySQLはHomebrewでインストール&起動
❼作業フォルダを作成して、作成したフォルダの中へ移動し、Rubyのバージョンを2.6.4に指定
❽bundle initでGemfileを作成、vimでGemfileを開き、# gem "rails"のコメント解除して保存
❾Railsをインストールしてバージョン確認
➓Railsアプリを作成(blogという名前で今回はプロジェクトを作成)
①Railsアプリ起動
② http://localhost:3000/ にアクセスして、下記画面が出たら、Ruby On Railsの環境構築はOK!(いったんCtrl+Cでサーバの起動は止めておく)
1.の詰まった箇所
・1-❸で、Qiitaだと、
export PATH="~/.rbenv/shims:/usr/local/bin:$PATH"だったけど、
私の環境はexport PATH="$HOME/.rbenv/bin:$PATH"となっていた: は区切りの意味。$PATHはPATHの設定に追加しますよって意味(つけないと、PATHの上書きになってしまうので、それまでの設定がなくなっちゃう)。
なのでQiitaの方は下記2つのパスが通っていることになる。~/.rbenv/shims /usr/local/binでも私の方は
$HOME/.rbenv/binしかパスが通ってないことなのかな、と思って、
echo $PATHして見たら、~/.rbenv/shims、/usr/local/bin共にパス通っていたので、良しとする。(cf. Pathを通すとは、環境変数とは)
・1-➓で、bootsnapのLoadErrorが出てしまった
cannot load such file -- bootsnap/setup (LoadError)→ Gemfileに
gem 'bootsnap', require: falseを追記し、bundle installし、もう一回プロジェクト作成コマンドを叩く(上書き聞かれたら全部Y)。ここで上書きするので、プロジェクト配下のconfig/boot.rbにrequire 'bootsnap/setup'の追記は自分でしなくて大丈夫(cf. bootsnapのせいでRails5.2とかが動かない人へ)
・1-➓で、webpackerがないためエラーになった
rails aborted! Don't know how to build task 'webpacker:install' (See the list of available tasks with `rails --tasks`)→ Gemfileに
gem 'webpacker', github: "rails/webpacker"を追記し、bundle installし、もう一回プロジェクト作成コマンドを叩く(上書き聞かれたら全部Y)
(cf. Rails6 開発時につまづきそうな webpacker, yarn 関係のエラーと解決方法)・1-➓で、yarnがないため警告がでる
Yarn not installed. Please download and install Yarn from https://yarnpkg.com/lang/en/docs/install/→
brew install yarnを実行してyarnをインストールし、もう一回プロジェクト作成コマンドを叩く(上書き聞かれたら全部Y)・1-➓で、listenのエラーが出る
rails aborted! LoadError: Could not load the 'listen' gem. Add `gem 'listen'` to the development group of your Gemfile→ ここはだいぶ詰まった。けど、プロジェクト配下のGemfileのdevelopmentの箇所に書かれているlistenの記述をコメントアウトし、それをまるっと、一個上の階層のGemfileに追記(
gem 'listen', '>= 3.0.5', '< 3.2')して、bundle install --with development testを実行して、もう一回プロジェクト作成コマンドを叩く(上書き聞かれたら全部Y)(cf. LoadError: Could not load the 'listen' gem (Rails 5))
・1-➓で、yarnをアップデートせよと出た
error Found 1 errors. ======================================== Your Yarn packages are out of date! Please run `yarn install --check-files` to update. ======================================== To disable this check, please change `check_yarn_integrity` to `false` in your webpacker config file (config/webpacker.yml). yarn check v1.19.2 info Visit https://yarnpkg.com/en/docs/cli/check for documentation about this command.→ アップデートしても治らなかったので、プロジェクト配下のconfig/webpacker.ymlに記述されていた、check_yarn_integrityをfalseにした(2箇所あって、片方はfalseにすでになっていたのでそれはそのままにしてもう一個のtrueの方をfalseにした)ら、エラーが消えた
(cf. yarnが原因でdocker-compose runが実行できないときの対処法)
・1-①で、railsコマンド使えないけど、といった感じのエラーがでる
Rails is not currently installed on this system. To get the latest version, simply type: $ sudo gem install rails You can then rerun your "rails" command.→ バージョン確認
bundle exec rails -vの時のように、bundle exec railsを使って、プロジェクトblogに入ってbundle exec rails serverを実行したら無事起動した!HOGEGE-no-Air-2:pra_ruby HOGE$ cd blog/ HOGEGE-no-Air-2:blog HOGE$ bundle exec rails server => Booting Puma => Rails 6.0.1 application starting in development => Run `rails server --help` for more startup options Puma starting in single mode... * Version 4.3.1 (ruby 2.6.4-p104), codename: Mysterious Traveller * Min threads: 5, max threads: 5 * Environment: development * Listening on tcp://127.0.0.1:3000 * Listening on tcp://[::1]:3000 Use Ctrl-C to stop(cf. bundle exec rails serverで起動時にエラーとなってしまう。。。)
2. 次にVue.jsを下記記事に沿って追加
【Rails6】10分でRails + Vue + Vuetifyの環境を構築する
❶--webpack=vueを指定してrails newでプロジェクトを作成する部分は、1.で作成したプロジェクト
blogを使いたかったので、プロジェクト配下で、bundle exec rails webpacker:install:vueを実行し、既存のプロジェクトにVue.jsをインストール
(cf. webpackerを使ってRuby on Rails 6.0とVue.jsを連携する方法(フロントエンド編))
❷プロジェクト配下でbundle exec rails sを実行し、サーバーを起動(bundle exec rails serverでもok)、確認終わったらCtrl+Cで止めておく
❸プロジェクト配下でbundle exec rails db:createを実行し、DBを作成
❹プロジェクト配下でbundle exec rails g controller home indexを実行し、コントローラーを作成
❹プロジェクト配下のconfig/routes.rbを編集してルーティングを設定
❺プロジェクト配下にできていたapp/views/home/index.html.erbを編集して、再びプロジェクト配下でbundle exec rails sを実行し、サーバーを起動
❻ http://localhost:3000 に接続して以下の画面が表示されればVueの環境構築は完了。確認終わったらCtrl+Cでサーバを止めておく
2.の詰まった箇所
(※特にどこもひっからなかった。強いてあげれば、1.同様、
railsコマンドは全て、bundle exec railsに置き換えてプロジェクトは以下で実行した部分)3. 次に2.と同じ記事を参考におまけでVuetifyを追加
❶
yarn add vuetifyをそのままプロジェクト配下で投げ、yarnを使ってvuetifyをインストール
❷プロジェクト配下のapp/javascript/packs/hello_vue.jsを編集し、vuetifyを読み込ませる
❷プロジェクト配下のapp/javascript/app.vueを編集し、Vuetifyで表示させるファイルを作成
❹プロジェクト配下でbundle exec rails sを実行し、サーバーを起動
❻ http://localhost:3000 に接続して以下の画面が表示されればVuetifyの環境構築も完了
3.の詰まった箇所
(※特にどこもひっからなかった。強いてあげれば、1.2.同様、
railsコマンドは全て、bundle exec railsに置き換えてプロジェクトは以下で実行した部分)4. せっかく環境が整ったので、少しいじってみる
※後ほど追記します!



- 投稿日:2019-12-11T08:54:30+09:00
Windows10 Ruby2.6でRubyOnRailsインストールメモ
Windows10だと良く失敗するので。
なんかWebpacker必須になったため面倒くさくなった。(1)Rubyをインストール
安定版の2.6あたりをWindows用のInstallerでいれる。
https://rubyinstaller.org/
なんか途中で立ち上がる黒い画面のRubyInstaller2と書いてあるやつに対しては、「1」と入力後Enter終わるともう一回出るのでEnterで終える。
(2)NodeJSをインストール
https://nodejs.org/ja/
LTS版を入れておけばよい(3)Yarnをインストール
https://yarnpkg.com/lang/ja/docs/install/#windows-stable
入れる。(4)Railsをインストール
コマンドプロンプトを立ち上げて
gem install rails多分うまくいく。
(5)Railsのプロジェクトを作る
プロジェクトを作りたいフォルダに移動します。そしてコマンドプロンプトで
rails new プロジェクト名実行します。
SQLite関連のエラーが出たら、(6)へ、
Webpacker関連のエラーが出たら(7)へ
失敗しなかったら(8)へ飛ぶもし、よくわからないなら(6)へ。
(6)SQLiteをいれる
コマンドプロンプトで
gem install sqlite3 -v '1.4.1'と実行する。
※もし失敗したら、
https://www.sqlite.org/download.html から、SQLiteをダウンロードして、Rubyのインストールしたフォルダの中のbinフォルダに「sqlite3.dll」をコピーしてコマンドを再実行する。(7)Webpackerをいれる
先ほどのプロジェクトフォルダの中で実行する!
※フォルダを移動するには、コマンドプロンプトでcd プロジェクト名フォルダの移動ができたら、再びコマンドプロンプトで
bundle installすんなりwebpackerがインストールされるはず。
(8) サーバーを立てる
先ほどのプロジェクトフォルダの中で実行する!
rails sサーバーが立つ。
その後、ブラウザを開いて、アドレスバーに「localhost:3000」と打って、トップページが出たら終わり。もしうまくいかなかったら、
bundle installを再実行する。それでもエラーが出たら、エラーが出た項目を手動インストールする。
動くといいね
- 投稿日:2019-12-11T08:48:47+09:00
Rubyで九九表を作ってみた(2)
以前、九九表を作ってみましたが、任意で縦横を指定できるようにしてみました。
仕様要件
・テーブルになるようにする。横幅はどこのセルも同じ大きさにする。
・縦横の見出しはなし。そのまま値が表になっているものをつくる。
・出来るだけコンパクトな構文にする。
・9×9個定ではなく、入力して任意の数値にする実際に書いてみた
table_of_tables_multi.rb# Settiing Request def req_num loop { input_judge = gets.chomp.to_i if input_judge != 0 return input_judge end } end puts "Set the X line." x_line = req_num puts "" puts "Set the Y line." y_line = req_num puts "" puts "X: #{x_line}" puts "Y: #{y_line}" puts "" # Cell setting size = (x_line * y_line).to_s.size puts ("+" + "-" * size) * x_line + "+" # Y line is output (1..y_line).each do |y| # X line is output (1..x_line).each do |x| print "|%#{size}d" % (x * y) end puts "|\n" + ("+" + "-" * size) * x_line + "+" end exitソースコードで使ったもの
後々まとめる。
・文字入力