- 投稿日:2019-12-11T20:54:18+09:00
[初歩的ミス]データベース作成でつまづいた時の話ー原因から解決まで
個人アプリを作成にあたり、DBを作成していたときにつまづいた話を以下に記載します。
カリキュラムなど指示通りにしかやっていなかったりすると、中々気づけないポイントだったと思います。何につまづいたのか+試してみたこと。
そもそも何につまづいたのか、以下に記載します。
個人アプリでDBを準備しようといつも通り下記コマンドを実行して、DB作成をしました。terminal$ rails db:create $ rails db:migrateその後、DBが作成できているか「Sequel Pro」を確認したところ、できていないことが判明。。。
念のため、ターミナルでもmysqlを確認しましたが、見つかりませんでした。そこで、何かコマンドミスがあったことを疑い、改めてDB作成コマンドを実行しました。
terminal$ rails db:create Database 'db/development.sqlite3' already exists Database 'db/test.sqlite3' already exists既にDBがあるよ!とのこと。でもやっぱり見つかりません。。。
ここで気づかないのが、初学者な私。まだまだでした。
その後、いろいろ調べた結果、原因が判明します。原因
まずは結論から、今回の問題の原因は、Database.ymlの記述とSequel proの設定が違うことでした!
以下、細かく記載していきます。
そもそもですが、$rails db:createは[Database.yml]の記述をベースにDBを作成します。
そこで、今まで私が作成していた記述と今回の記述を確認しました。database.yml#今までのファイル default: &default adapter: mysql2 #今回のファイル default: &default adapter: sqlite3上記は一部抜粋ですが、adapterが違ってます!
Sequel proはmysqlのデータを引っ張ってきているので、いくらDBを作成しても出てくるわけないですね。。。
これで原因はわかりました!早速修正していきます。解決方法
まずはdatabase.ymlを今までのものをベースに書き換えます。
database.ymldefault: &default adapter: mysql2まだこのままでは終わりません!
adapterを変更するにはgemも変更する必要があります。Gemfilegem 'sqlite3' #以下に変更 gem 'mysql2', '>= ver記載bundle installも忘れずに行いましょう。
terminal$bundle install以上で変更は完了です!
改めてDB作成コマンド実行し確認したところ、Sequel proでも確認できました!やはり自分で作成してみると、新たな気づきがありますね!
引き続き色々試しながらアプリ作成をがんばっていきたいと思います!以上となります。最後までご覧いただき、ありがとうございました!
今後も学習した事項に関してQiitaに投稿していきますので、よろしくお願いします!
記述に何か誤りなどございましたら、お手数ですが、ご連絡いただけますと幸いです。参照
[初学者]既存アプリのDBをMySQLに変更する方法
https://qiita.com/shi-ma-da/items/caac6a0b40bbaddd9a6f
- 投稿日:2019-12-11T20:05:01+09:00
Aurora MySQL を使っていたら異様にパフォーマンスが落ちた話
はじめに
KLab Engineer Advent Calendar 2019 の 12日目の記事です。
特に結論が出ているものではなく、Auroraをいろいろ検証していた際に遭遇した事例紹介となります環境
エンジンバージョン:5.6.10a
インスタンスクラス:db.r5.largeきっかけ
Auroraのストレージ設計としては履歴の塊なので、書き換えをし続けるとストレージ消費がどんどん増えていくのではないか?と考えて以下のようなワークロードを回してみました。
やってみた
1 . ガチャを引いては殆どを売却(削除)するようなプレイを想定し、以下のようなテーブルを作成して実験を行いました。
CREATE TABLE aurora_disk_test.heavy_write_test_table ( id BIGINT PRIMARY KEY AUTO_INCREMENT, message VARCHAR(511) -- データ量が多いテーブルの簡略化イメージで多めの文字列型 );2 . このテーブルにまず800万レコードを登録し、その後1000レコードの DELETE & INSERT を繰り返してみました。
MYSQL_CMD="mysql -h${DBHOST} -u${DBUSER} -p${DBPASS}" TABLE_NAME="aurora_disk_test.heavy_write_test_table" # INIT 約800万レコード登録 INIT_QUERY="BEGIN; DELETE FROM ${TABLE_NAME};" INIT_QUERY="${INIT_QUERY} INSERT INTO ${TABLE_NAME} (message) VALUES (SUBSTRING(MD5(RAND()), 1, 511));" for _ in $(seq 1 23); do INIT_QUERY="${INIT_QUERY} INSERT INTO ${TABLE_NAME} (message) SELECT SUBSTRING(MD5(RAND()), 1, 511) FROM ${TABLE_NAME};" done INIT_QUERY="${INIT_QUERY} COMMIT;" ${MYSQL_CMD} -e "${INIT_QUERY}" # DELETE & INSERT for i in $(seq 1 100000); do echo "${i}: $(date)" # 古いレコードから1000件まとめてDELETE DELETE_TARGETS=$(${MYSQL_CMD} -e "SELECT id FROM ${TABLE_NAME} ORDER BY id LIMIT 1000" -N | tr "\n" "," | sed -e "s/,\$//") LOOP_QUERY="DELETE FROM ${TABLE_NAME} WHERE id IN (${DELETE_TARGETS});" # 1件ずつ1000レコードINSERT for _ in $(seq 1 1000); do LOOP_QUERY="${LOOP_QUERY} INSERT INTO ${TABLE_NAME} (message) VALUES (SUBSTRING(MD5(RAND()), 1, 511));" done ${MYSQL_CMD} -e "${LOOP_QUERY}" doneこれは、グラフのように最初増え続けましたが途中で増加が止まりました。
※:再検証時のCloudWatchでのグラフ
3 . さらに極端な例として800万レコード全てで DELETE & INSERT を繰り返してみました。
MYSQL_CMD="mysql -h${DBHOST} -u${DBUSER} -p${DBPASS}" TABLE_NAME="aurora_disk_test.heavy_write_test_table" QUERY="DELETE FROM ${TABLE_NAME};" QUERY="${QUERY} INSERT INTO ${TABLE_NAME} (message) VALUES (SUBSTRING(MD5(RAND()), 1, 511));" # DELETE&INSERTするクエリの作成 # auto commit を利用して、それぞれのクエリを別々のトランザクションとして実行する for _ in $(seq 1 23); do QUERY="${QUERY} INSERT INTO ${TABLE_NAME} (message) SELECT SUBSTRING(MD5(RAND()), 1, 511) FROM ${TABLE_NAME};" done # クエリのループ実行 for i in $(seq 1 100); do echo "${i}: $(date)" ${MYSQL_CMD} -e "${QUERY}" doneおきたこと
だんだんと1セットの実行にかかる時間が伸びていきました。
9: Tue Nov 26 13:59:44 UTC 2019 mysql: [Warning] Using a password on the command line interface can be insecure. 10: Tue Nov 26 18:22:28 UTC 2019 mysql: [Warning] Using a password on the command line interface can be insecure. 11: Tue Nov 26 22:56:14 UTC 2019 mysql: [Warning] Using a password on the command line interface can be insecure. 12: Wed Nov 27 03:42:15 UTC 2019 mysql: [Warning] Using a password on the command line interface can be insecure. 13: Wed Nov 27 08:43:18 UTC 2019 mysql: [Warning] Using a password on the command line interface can be insecure. 14: Wed Nov 27 13:56:24 UTC 2019 mysql: [Warning] Using a password on the command line interface can be insecure. 15: Wed Nov 27 19:21:04 UTC 2019 mysql: [Warning] Using a password on the command line interface can be insecure. 16: Thu Nov 28 00:51:18 UTC 2019 mysql: [Warning] Using a password on the command line interface can be insecure.時間がかかっていたので途中でループを停止させてテーブルのカウントを取得してみました。
mysql> SELECT count(id) FROM aurora_disk_test.heavy_write_test_table; +-----------+ | count(id) | +-----------+ | 512 | +-----------+ 1 row in set (12 min 16.16 sec)カウント件数は少ないのにクエリ実行にかなりの時間がかかる事態に遭遇しました。
まとめ
負荷試験などで毎度大量のDELETE&INSERTしていると同じ事態に遭遇することがあるかもしれません。
後日再度カウントのクエリを実行した際には0秒でクエリの結果が出たため、バイナリログのような段階に大量に残っている段階だと処理スピードに影響しているのでしょうか。
あらためて時間を作って TRUNCATE での場合など実験していってみたいと思います。同様の事例や原因をご存知の方がいらっしゃいましたら、教えていただければありがたいです。

- 投稿日:2019-12-11T18:16:28+09:00
HeidiSQLのすゝめ
なんで書いたの
DBを見るときphpMyAdminからHeidiSQLに変えたら作業が爆速になったので
こんなソフトもあるよとの思いで書きました。
簡単に使えるので試してみてください。HeidiSQLって何?
DB管理ソフト
いいところ・わるいところ
長所
- 簡単に始めれる!
- 直感的な操作ができる!
- データを簡単にいじれる!
短所
- うっかり操作が危ないので本番環境では注意
- 重いと表示に時間がかかるorフリーズする
- フィルターを失敗したとき対処するのが面倒
さくっと使ってみよう
インストール
HeidiSql起動
起動すると下記画面でます
今回はローカルにつなぎます
画面
①でDBとテーブルの選択
②で入ってるデータの確認
データの編集・追加はマウスで選択するだけでガシガシできちゃいます
基本的な使い方は以上!
おわりに
・sshトンネルでつなぐ
・SQL直接叩く
・DBのCREATE文をコピー
・フィルター機能
・選択したデータをcsv/REPLACE/INSERTで吐き出す
等々色々な便利機能が簡単に使えるので、一度使ってみると作業速度があがるかも?


- 投稿日:2019-12-11T17:48:38+09:00
エラーメッセージ:SQLSTATE[21S01]
まれにPHPでコードを書く時がありますが、MYSQLでINSERTしたいとき、書いたコードがエラーで動かない。
時間がどんどん過ぎていく。
苛々してさらに進まない。。なんてことはありませんか?
エラーメッセージ:SQLSTATE[21S01]: Insert value list does not match column list: 1136 Column count doesn't match value count at row 1
カラムの数が間違っている。ってエラーですが、
どこをミスタイプしてエラーを発生しているか調べるの難しいです。そんな時は、エクセルなどのソフトに各項目を1行ずつ貼り付けて、項目数や入力の間違いないかを確認すると、
以外とあっさり見つけられます。初心者でもそうでなくても、見つけられない時は、少しいつもと発想を変えて、チェックしてみるとよいです。
- 投稿日:2019-12-11T17:30:48+09:00
Rails+MySQL+Docker+AWS(EC2, RDS, ALB, Route53, S3)で作成したポートフォリオについて
記事の概要
私が作成したポートフォリオ、「GoodCoffeeByGoodBarista」を解説します。
なぜ作ったか、どう作ったか、今後どうしていくかをまとめました。実際に作成したサイトやソースコードは下記のリンクからご覧いただけます。
GoodCoffeeByGoodBarista
GitHubこちらの記事の書き方は下記の記事を参考にさせていただきました。
PHP+MySQLでポートフォリオ作成なぜ作ったか
私は、愛知県名古屋市にある個人経営のカフェで、2年半ほどバリスタとして勤務しておりました。
ある時、バリスタの大会に出場したのですが、結果は惨敗でした。
バリスタは、生豆の仕入れからロースト、抽出までを全て個人で行い、それをプレゼンするのですが、超小規模店舗で勤務していた私は、生豆の仕入れルートもなければ高価な焙煎機もない、大会で使われる最新のエスプレッソマシンもない、練習に使うミルクも何百本と自腹で用意するしかない環境下で戦うしかありませんでした。
対して、大きな企業が経営するカフェに勤めているバリスタは、会社が持っているルートから最高品質の生豆を仕入れ、会社が用意する材料を使って、最新のエスプレッソマシンで毎日練習ができるのです。私は、環境の差による大きな挫折を味わいました。
バリスタを辞め、エンジニアになるべく勉強をしていた私は、「エンジニアリングの力で、バリスタ業界を良くできないか」と考えるようになりました。
エンジニアのように気軽に転職をする事ができる文化があれば、スキルを身に付けたいバリスタはより大きな企業に転職できるし、大企業にいてスキルはあるけれどもっと個人の店舗で接客を身に付けたいバリスタの願いも叶えられる。
バリスタが、自分の所属する環境でスキルを身に付けられなかったり、夢を諦めたりしなくて良くなるのではないか。
そんな思いから、バリスタ版Wantedlyのようなサービスを作成し、私のポートフォリオとすることにしました。スペック
言語
Ruby 2.5.3
フレームワーク
Ruby on Rails 5.2.2
CSSフレームワーク
Bootstrap4
データベース
MySQL 5.7
WEBサーバ
Nginx 1.15.8
開発環境
Docker 19.03.5
docker-compose 1.21.1バージョン管理
Git 2.24.0
本番環境
AWS (EC2, RDS, ALB, Route53, S3)
主な機能
・バリスタ(カフェ)一覧表示
バリスタの一覧、またはカフェの一覧を表示します。
ログインしていなくてもアクセスできる仕様です。
・バリスタ(カフェ)を検索
バリスタの場合、性別で検索できます。
カフェの場合、店舗名、雇用形態、所在地で検索できます。
・バリスタ登録
バリスタはトップページから新規作成のリンクを踏むことでユーザー登録ができます。
入力内容は最低限必要な内容のみです。
入力に誤りがあれば、登録はされずエラ〜メッセージが表示されます。
・オーナー登録
オーナーはナビゲーションにある「採用担当者の方」というところからオーナー用のトップページに移動し、そこから新規作成画面に移動できます。
入力内容は最低限必要な内容のみです。
入力に誤りがあれば、登録はされずエラ〜メッセージが表示されます。
・バリスタプロフィール編集
登録では基本情報のみの入力なので、プロフィール編集で詳細な情婦を入力していきます。
上記のリンクから自分のプロフィールを確認しながら編集できます。
・オーナーカフェ情報編集
登録では基本情報のみの入力なので、プロフィール編集で詳細な情婦を入力していきます。
上記のリンクから自分のプロフィールを確認しながら編集できます。
・ログイン
ログインできます。
バリスタとオーナーではフォームが分けてあります。
・面談したい(面談に誘いたい)バリスタ(カフェ)に対してメールを送信
ログインしている状態で、気になるバリスタ(カフェ)の詳細ページから面談を申し込む(誘う)内容のメールを送る事ができます。
・退会
プロフィール編集の画面から退会できます。
開発手順
1.要件定義
今回作成するアプリに必要な機能は、
・バリスタユーザー登録機能
・オーナーユーザー登録機能
・ユーザー一覧表示機能
・ユーザー検索機能
・応募プロフィールや、求人情報作成機能
・面談応募(勧誘)機能のため、ユーザー情報を保存しておくデータベースが必要であり、尚且つデータベースに保存した情報を動的に表示できるビューが必要です。
また、面談の応募(勧誘)にはメイラー機能を使いたいので、メール用のサーバーも用意する必要があります。
バリスタユーザーとオーナーユーザーで動線を分けたいので、わかりやすい動線づくりを心がけます。
2.環境選定
言語は、自分にとって技術的資産の多いRubyを選択しました。
よってフレームワークもRuby on Railsとしました。データベースは、もっともメジャーに、広く使用されているMySQLを選択しました。
今回はバックエンド開発がメインだったため、フロントエンド開発の工数を減らす目的でCSSフレームワークを使用しました。
CSSフレームワークにはネット上に公開されている情報のリソースが多いことから、Bootstrapを使用しました。WEBサーバーには、pumaとの連携が簡単で、かつネット上に情報のリソースが多かったNginxを使用します。
なお、これらの環境はDocker,docker-composeを使用して構築しています。
Dockerを使用したのは、最終的にCircleCIやcapistoranoを用いた自動テスト&ビルド&デプロイを行いたいと考えているためです。そして、本番環境はAWSのEC2,RDS等を用いて構築します。
これは、個人的にAWSに興味があったため使ってみたかったのと、転職用のポートフォリオとして使用する際、クラウドにAWSを取り入れている企業様が多いと感じたことから、技術アピールができると考えたからです。3.データベース設計
今回は、2種類のユーザーを作成する必要があるため、ユーザーモデルを一つ作成し、オーナーフラグがtrueかfalseかでユーザーを識別するか、ユーザーモデルを二つ作成してそれぞれで管理するかで悩みましたが、
今回は後者の方法でデータベースを作成することにしました。
理由は、私が参考にしている著書「達人に学ぶDB設計徹底指南書」にて、一つのモデルはなるべくシンプルにし、分けられるところは分けて管理するのが良いとされていたので、その教えを守る形にしました。4.コーディング
コーディングの際に注意した点は以下の通りです。
・一つの機能を実装する度にRSpecでSystemスペックを記述する
・GitHubFlowを意識した開発(マスターブランチでの作業は基本的にはしない、擬似的にプルリクエストを作成して、マスターブランチにマージする -> リモートリポジトリの変更を、ローカルにpullする)また、ユーザーをバリスタユーザーとオーナーユーザーに分けて実装していましたが、自身の練習もかねて、バリスタユーザーの登録や認証周りをdeviseで実装し、オーナーユーザーの登録はscaffoldで作成、認証は簡易的なsessionで実装しました。
ただ、ログイン状態のバリスタユーザーをcurrent_userで取得し、ログイン状態のオーナーユーザーをcurrent_ownerで取得するように実装したのですが、これはベストプラクティスではないように感じました。
次回また似たようなアプリケーションを作成する際は、この辺りのDB設計に関してきちんと見直す必要がありそうです。この段階で、動作確認も兼ねてdevelopment環境でもAWSのS3に画像が保存されるように実装しました。
5.デプロイ
本番環境はAWSで構築しました。
docker-composeでアプリケーション用のコンテナ、Nginxのコンテナ、メイラーのコンテナを用意していたので、それらをまとめてEC2でビルド&実行するようにしました。
データベースはRDSを使用しています。
画像の保存には、S3を使用しており、こちらはproduction環境だけでなく、development環境でもS3に保存するようにしています。
また、今回はEC2は一つしか用意していませんが、後々HTTPS化するのに必要だったので、ALBを配置しました。
独自ドメインは、過去にブログを運営していたときにも利用していて使い慣れたお名前.comから取得し、Route53で設定しました。AWSを使ったデプロイのために何冊も書籍を読み、様々な記事を読んだので、ネットワーク周りの知識がかなりついたと実感しました。
今後の改善点や追加実装について
アプリケーション自体としては、SNSログインや画像アップロードの際のプレビュー表示などを実装したいと考えております。
加えて、特にフォーム関連のUIを向上させたいと考えています。
具体的には、入力するべき項目をplaceholderでわかりやすくしたりできるかと考えております。また、要件定義の段階から考えているCircleCIを使用した自動ビルド&テスト、capistoranoを使用した自動デプロイを実装していきたいです。
そのためにも、現在はCircleCIの公式ドキュメントを読みながら準備をしている段階です。それから、AWSに関しても、画像の配信をCloudFlontで行うことで、より高速化を測ってみたいと思います。
参考文献
・Ruby on Rails5.2 速習実践ガイド
・プロを目指す人のためのRuby入門
・Docker/Kubernetes 実践コンテナ開発入門
・Amazon Web Services 基礎からのネットワーク&サーバー構築 改訂版
・ゼロからわかる Amazon Web Services超入門 はじめてのクラウド かんたんIT基礎講座
・Webを支える技術 ―― HTTP,URI,HTML,そしてREST
・リーダブルコード
・達人に学ぶDB設計 徹底指南書











- 投稿日:2019-12-11T12:41:26+09:00
xampp/mamp/cyberdockサーバー各種 起動方法(mac)
【dotinstall cyberdock】
※cdコマンドでホームに戻り、開きたいフォルダに移動その後下記コマンド実行
$ cd /Users/ユーザー名/ (cd移動省略) $pwd /Users/ユーザー名/MyVagrant/MyCentos $vagrant up $vagrant ssh [vagrant@localhost ~]$ [vagrant@localhost ~]$ ls //開きたいフォルダの確認 centos6 php_lessons todo_app_php [vagrant@localhost ~]$ cd todo_app_php //開きたいファイルのフォルダへ移動 [vagrant@localhost todo_app_php]$ ip a (省略) pfifo_fast state UP qlen 1000 link/ether 08:00:27:91:bf:ad brd ff:ff:ff:ff:ff:ff inet 192.168.33.10/24 brd 192.168.33.255 scope global eth1 inet6 fe80::a00:27ff:fe91:bfad/64 scope link (省略) [vagrant@localhost php_lessons]$ php -S 192.168.33.10:8000 URLで下記入力で上記ファイルのindex.phpが開かれる。 http://192.168.33.10:8000
【mamp】
1.MANPを起動2.mac内のアプリケーション内からhtdocsを開きアクセスしたいフォルダまで移動してアドレス入力
http://localhost:8888/todo_app_php/index.phpmampファイルのhtdocsの中のプロジェクトファイル指定でアクセス可能となる。
【xampp】
1.maneger-osxを起動2.アプリケーション→xampp→htdocs→アクセスしたいフォルダまで移動してアドレス入力
例:http://localhost/todo_app_php/index.php
- 投稿日:2019-12-11T12:04:31+09:00
AWS Glue で 億超えレコードなテーブルからETLする
この記事はfreee データに関わる人たち Advent Calendar 2019の11日目です。
シンプルにAWS Glueで RDB(MySQLとか)から巨大なテーブルデータを取り出すときの話です。
tl;dr
Glueを使ってMySQLなどRDSから億単位のデータを引っこ抜くときは、Glueの並列取り込み機能を使わず、sparkの機能を使おう
やりたいこと & 問題
- RDB(MySQL)の一つのテーブルが 1億件以上データを持っている
- そのままGlueで取り込むと遅い -> なんかGlueで並列読み込みする機能があるらしい
- Glueの並列読み込み機能試したけど、クソ遅い
- Spark自身の機能を使った -> めちゃ早くできた
Glue と Sparkの関係
用語・語弊を生みそうなので、最初に整理
Glue は Managed Sparkと言い換えられます。Sparkを使いやすくしたもの。よってベースは普通のSpark
そこにGlue独自の実装をかぶせてある。このエントリでは
- Glue = (DynamicFrame dyf)
- Spark = (DataFrame df)
とかき分けます。Glueは dyfもdfも両方つかえます。 dyf は dfの拡張版です。Glueの並列取り込み機能
Glue(dyf)は並列取り込みの機能を持っています。具体的には
https://docs.aws.amazon.com/ja_jp/glue/latest/dg/run-jdbc-parallel-read-job.html
hashfieldに int/bigintなど数値型の主キーとなるカラムを指定
hashpartitionsに N分割するという数値を指定しますこの機能のいいところは、glue の jobとして上記パラメータを与えることはもちろん、glue データカタログのテーブルパラメータで指定することもできます。データが太ってきたら、分割数をブラウザポチポチで増やせばいい。
最高!と思ってましたが、実際試してみるとダメダメだった。
Glueの並列取り込みが遅い原因
どうやって分割しているかは、実際にRDBに打ち込むSQLを捕まえればすぐわかります。mysqlサーバ側で
show processlistとかで一旦どんなSQLを叩いているのかを見ると、、、(glueの人のエントリ)上記例では、
hashfieldに 数値型以外のカラムを指定しているのでMD5とかゴニョって数値型にしていますが、数値型のカラムを指定してればこの処理はなくなります。が、問題は数値 % 7 = 0の演算です。7分割する場合だと 7で割って余りを出してます。たしかに分割はできますがselect * from hoge where id % 7 = 0; select * from hoge where id % 7 = 1; select * from hoge where id % 7 = 2; ... select * from hoge where id % 7 = 6;というSQLが走ることになります。つまり対象テーブルのレコード数が 1億件あれば、
1億レコードのidの値を7で割るという演算が7回も走ることになります。どう考えても遅い=RDB側がしんどいよね。解決方法 = Sparkの機能
Spark自身が持っている並列取り込み機能
Glueではどうにかならんのか。。
と思ってたら、Sparkで普通にできるで!なネタを見つけた。
https://medium.com/@radek.strnad/tips-for-using-jdbc-in-apache-spark-sql-396ea7b2e3d3見た感じ アホな割り算もやらないし、これでええんとちゃう?と思ったら、普通に行けた。
import sys from awsglue.transforms import * from awsglue.utils import getResolvedOptions from pyspark.context import SparkContext from awsglue.context import GlueContext from awsglue.job import Job from pyspark.sql import SQLContext args = getResolvedOptions(sys.argv, ['JOB_NAME']) sc = SparkContext() sqlContext = SQLContext(sc) glueContext = GlueContext(sc) spark = glueContext.spark_session job = Job(glueContext) job.init(args['JOB_NAME'], args) DB_HOSTNAME="mysql.example.com" DB_DATABASE="hogedb" DB_USERNAME="user" DB_PASSWORD="hogefuga" df = sqlContext.read.format("jdbc") \ .option("url", "jdbc:mysql://{0}:3306/{1}".format(DB_HOSTNAME, DB_DATABASE])) \ .option("driver", "com.mysql.jdbc.Driver") \ .option("user", DB_USERNAME) \ .option("password", DB_PASSWORD) \ .option("dbtable", "huge_table") \ .option("numPartitions", 100) \ .option("partitionColumn", "id") \ #数値型のカラム、 whereがかかる & ユニークである必要があるので、実質主キー .option("lowerBound", 1) \ .option("upperBound", 100000000) \ # select max(id) とかで最大値を調べておく必要ある .load()1億レコードを100に分割するので 100万レコードに分割して走るとなります。
SELECT * FROM huge_table WHERE owner_id >= 1 and owner_id < 1000000 SELECT * FROM huge_table WHERE owner_id >= 1000000 and owner_id < 2000000 SELECT * FROM huge_table WHERE owner_id >= 2000000 and owner_id < 3000000 ... SELECT * FROM huge_table WHERE owner_id >= 99000000 and owner_id < 100000001分割数の考え方
Sparkに本来備わっている機能を使えば、巨大なテーブルでも十分なパフォーマンスを得られることはわかりましたが、うまく使うにはもう少し工夫が必要です。
まず、GlueはWorkerTypeと Workerの数を調整することができます。
- WorkerType は EC2のインスタンスタイプのように1WorkerあたりのCPU/メモリに影響します
- Worker数 は文字通りです、どれだけWorkerが動くかです
分割数は、Workerの数を上回っても問題ないです。キューイングされます。では Worker数も分割数もものすごい高い値にすればいいのか?というとそれは間違いです。データソースをRDBとしているので、Glue(Sparkで)全力で殴るとすぐにRDB側のリソースがサチります。よって
Worker数をそこそこに押さえて、RDB側の負荷をコントロールし、かつWorkerTypeに合致する分割数を決める
という工夫が必要です。ここらへんはインフラ屋の腕のみせどころです。まとめ・雑感
データソースRDB(RDS含む)の場合は Glueのウィザードがソレっぽいコードをdyfで自動生成してくれるが、それで対応できるのはせいぜい1000万件レコード以下です。それ以上の場合はdfでsparkの機能でやるとよい。
dyfのメリットとしては、Glueのウィザードで一応コード一切書けなくてもできるが、コード少しは書ける人だったら、データソースがRDBの場合dyfを使うメリット全く無いのでdfだけで書いてよい。

- 投稿日:2019-12-11T10:13:32+09:00
カバレッジエラーの対策[404編]
まえがき
株式会AncarのWebエンジニアをしている、keiと申します。
「株式会Ancar ~Advent Calendar 2019~」 11日目を担当させていただきます。弊社は安心・安全な移動体験を届けるをモットーに
中古車の個人間売買をオンラインで行うサービス
全国の中古車からお買い得な車を検索・比較できるサービス を展開しております。当記事では、GoogleSearchConsoleにサイトマップを登録後、発生したカバレッジエラーに対しての対応について共有させていただきます。
おしながき
- カバレッジエラーの現状把握
- 404の調査結果
- カバレッジエラー対策
- その1
- その2
- 最終結果
カバレッジエラーの現状把握
上記サービスは、50万以上の車両詳細ページがあります。しかし、どんなにユーザーに役立つページを持っていたとしても、クローラーがページを見つけられなかったら、検索結果に表示されません。
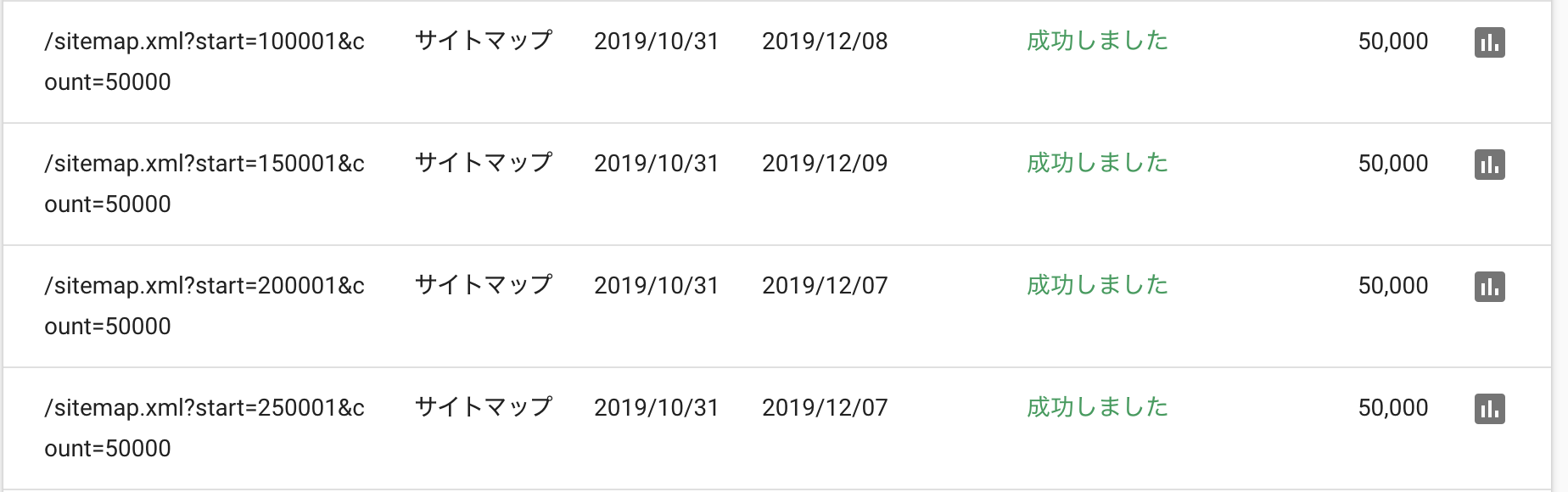
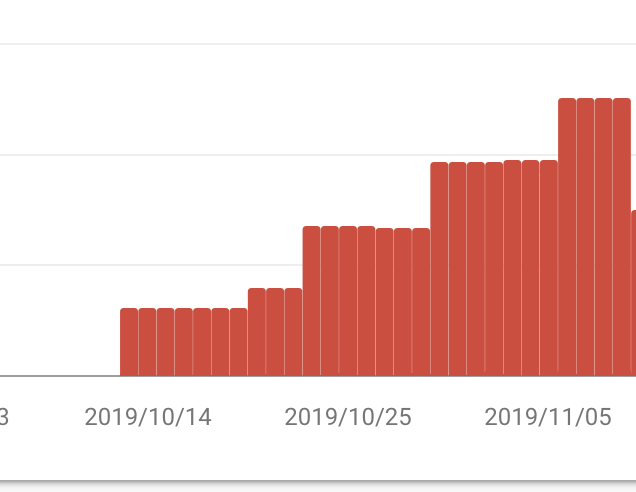
ということで、より多くのページを検索結果に表示させたいと思い、サイトマップをGoogleSearchConsoleで登録しました。送信したサイトマップの一部
ステータスが成功になり送信できました
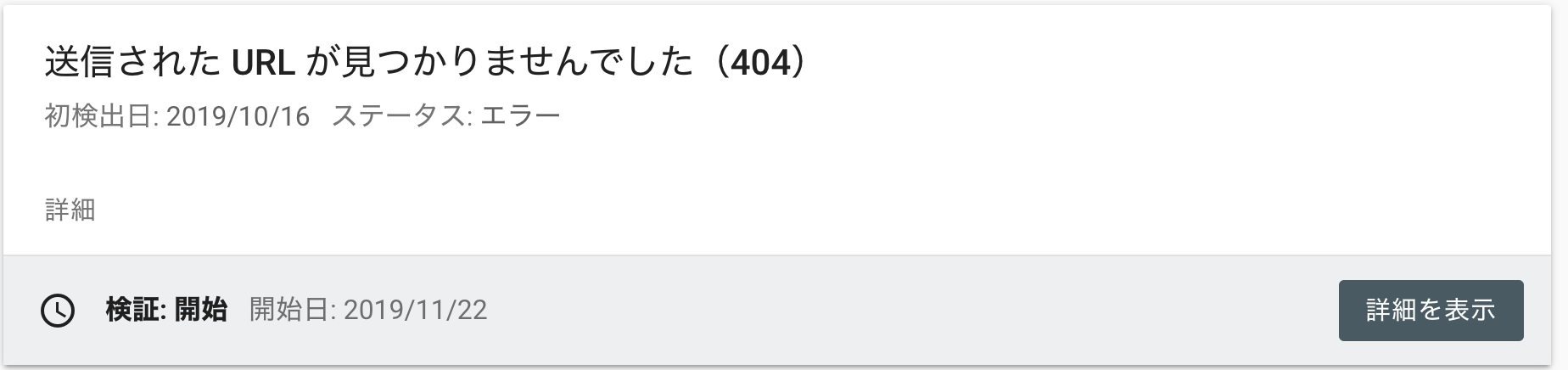
が、、、喜んでるのも束の間
最大で251ページも404が見つかってしまいました
エラーがたくさん見つかってしまったので、次になぜクローラーが251ページも404を返してしまったのかを調査していきました。404の調査結果
サーバーのアクセスログとDBを調査したところ、2019年の第41週において、中古車情報取得コマンドの実行中にデータの欠損が起きていたことが判明しました
そのため、第42週のデータがcreateされる前にクローラーが欠損した出品ページにアクセスしエラーを吐いた。
中古車情報取得コマンドにおいて、41週目のデータ欠損が起こった一例+---- +------+--------------+----------------------+---------------------+ | uid | week | car_make_id | created_at | updated_at | | +-----+------+--------------+ ---------------------+---------------------+ | 1 | 40 | 7 | 2019-09-30 16:44:03 | 2019-09-30 22:25:10 | +-----+------+--------------+----------------------+---------------------+ 1 row in set, 1 warning (0.00 sec)+---- +------+--------------+----------------------+---------------------+ | uid | week | car_make_id | created_at | updated_at | | +-----+------+--------------+ ---------------------+---------------------+ | 1 | 42 | 7 | 2019-10-08 17:30:03 | 2019-10-08 21:55:10 | +-----+------+--------------+----------------------+---------------------+ 1 row in set, 1 warning (0.00 sec)しかし、たとえ中古車取得コマンドで欠損が起こらなくても、
前の週にあった出品が今週なくなったという場合に同様のエラーが起こる可能性がある。
したがって、前週にあって今週には存在しない出品について、今週のサイトマップをSearch Consoleが読み込むまでの間はクローラーが存在しない出品ページにアクセスするという状況を作り出してはならない。カバレッジエラー対策その1
対応策として行ったことは、前の週にあった出品が今週なくなった場合、掲載終了ページを作成することで404のレスポンスコードを返さないようにする方法である。
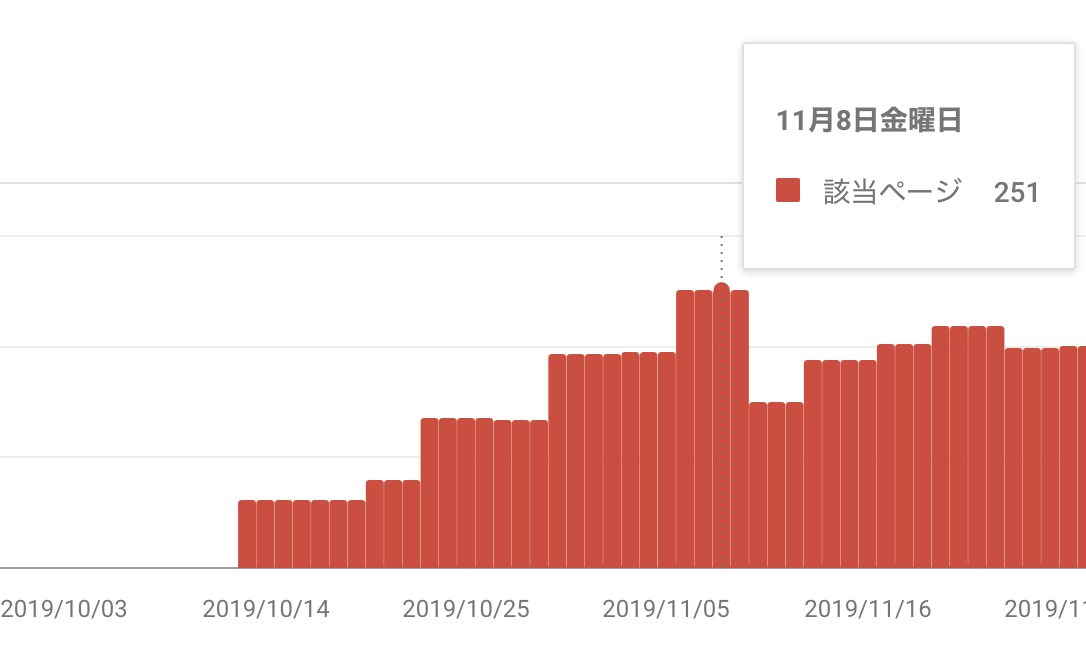
カバレッジエラー修正リクエスト後
GoogleSearchConsoleを見てみると、あれ?増えているではありませんか。。
カバレッジエラー対策その2
ということで、第2弾修正を行っていくことにしました。
エラー再調査
クローラーがサイトを訪れたタイミングとデータが作られた時間の比較
+---- +------+--------------+----------------------+---------------------+ | uid | week | car_make_id | created_at | updated_at | | +-----+------+--------------+ ---------------------+---------------------+ | 4 | 41 | 5 | 2019-10-07 05:53:03 | 2019-10-07 12:43:15 | +-----+------+--------------+----------------------+---------------------+ 1 row in set, 1 warning (0.00 sec)+---- +------+--------------+----------------------+---------------------+ | uid | week | car_make_id | created_at | updated_at | | +-----+------+--------------+ ---------------------+---------------------+ | 4 | 45 | 5 | 2019-11-05 06:55:03 | 2019-11-06 07:25:10 | +-----+------+--------------+----------------------+---------------------+ 1 row in set, 1 warning (0.00 sec)上記時刻を見てみると、クローラーが2019/11/04に対して、DBのcreateした時刻は2019/11/05である。
今回の場合は、41週目の次にデータが出来たのは45週目でした。そのため、前週のデータが有り、かつ今週のデータが無い場合は掲載終了ページを表示するようにしていたが、先週だけのステータスだけだと今回みたいに過去にデータがあった場合、クローラーがきた時に404を返してしまうということが新たに判明した。
対策として、先週だけのステータスだけではなく、データが過去1週でも有り、かつ今週のデータが無い場合は掲載終了ページを表示するようにしました。
最終結果
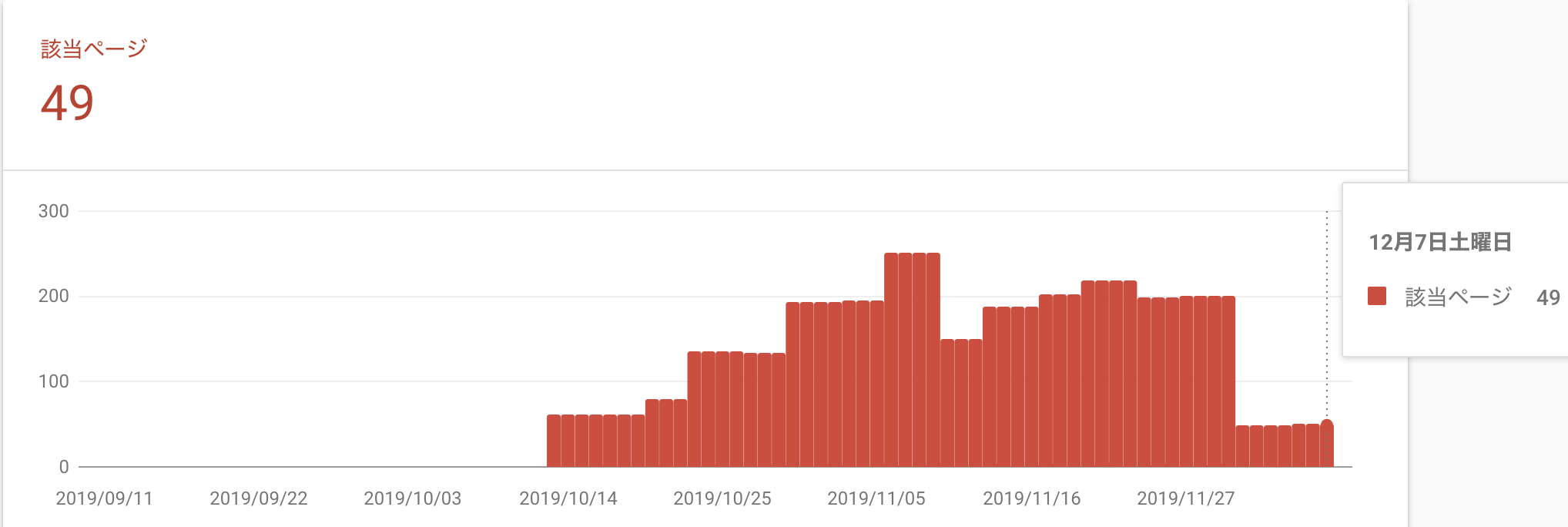
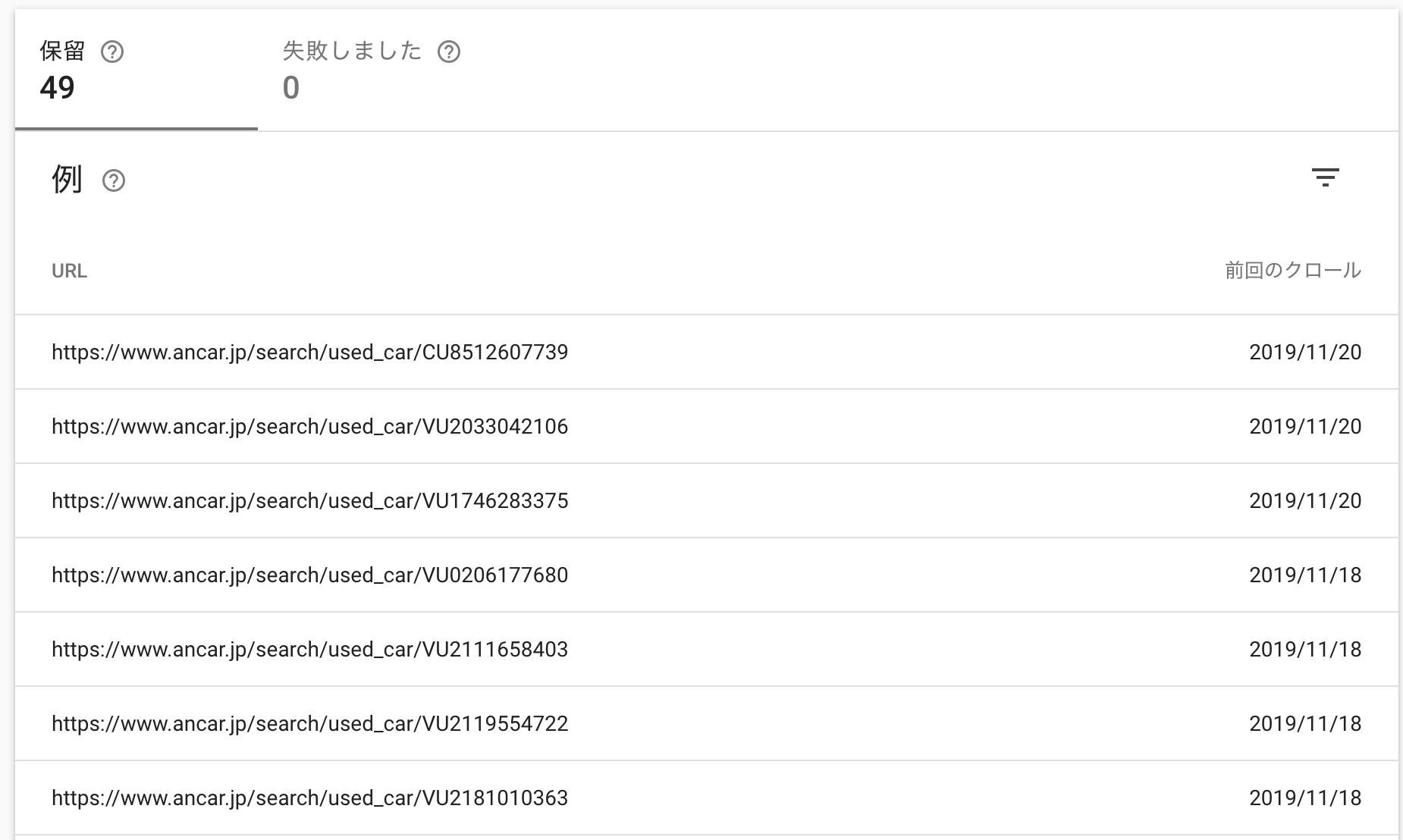
カバレッジエラー対策その2後、再度Googleにクロールをリクエストすると、251ページもあったエラーが49ページまで減りました
残りの49ページはクロールが来るのを待っているという状況なので、404のカバレッジエラー が0件になる日もそう遠くはありません!!

- 投稿日:2019-12-11T08:28:13+09:00
C++とPHPとMySQLの連携を試してみた
タイトルの通り、C++とPHPとMySQLを用いてデータのやり取りをやってみたのでメモ。
使用したもの
ツール
・VisualStudio2017
・Xampp
ライブラリ
・Boost (通信するために使用)
・Json11 (JSONを解析するために使用)やりたいこと
流れとしては、
①C++ → ②PHP → ③MySQL → ④PHP → ⑤C++ の順でデータをやり取りしたい。
取りあえず、今回は2つの値を足し算した結果を取得することを目標とする。① 足し算したい2つの値を入力し、GET方式で送る。
② 足し算を行い、MySQLに計算結果を送る。
③ 結果を保存する。
④ 今までの計算結果を受け取り、JSON形式で送る。
④ JSON形式で計算結果を受け取り、それらを表示する。コード
main.cpp#include <iostream> #include <iomanip> #include <boost/asio.hpp> #include <boost/algorithm/string.hpp> #include <vector> #include "json11.hpp" using namespace std; namespace asio = boost::asio; namespace ip = asio::ip; using namespace json11; int main() { //足し算する値の入力 int value1, value2; cout << "value1を入力 : "; cin >> value1; cout << "value2を入力 : "; cin >> value2; cout << '\n'; //リクエストに対するレスポンス string allRes = ""; //通信を開始 try { asio::io_service io_service; //TCPソケットを作成する ip::tcp::socket sock(io_service); //名前解決(ホスト名からIPアドレスに変換)する ip::tcp::resolver resolver(io_service); ip::tcp::resolver::query query("127.0.0.1", "http"); //ホスト情報を設定する ip::tcp::endpoint endpoint(*resolver.resolve(query)); //ソケットへ接続 sock.connect(endpoint); //メッセージを送信 asio::streambuf request; ostream request_ostream(&request); string getRequest = "GET add.php?value1=" + to_string(value1) + "&value2=" + to_string(value2) + " HTTP/1.0\r\n\r\n"; request_ostream << getRequest; asio::write(sock, request); //メッセージを受信 asio::streambuf response; boost::system::error_code error; while (asio::read(sock, response, asio::transfer_at_least(1), error)) { //streambufからstringに変換 string tmp = asio::buffer_cast<const char *>(response.data()); allRes += tmp.substr(0, response.size()); } } catch (exception& e) { cout << e.what() << '\n'; return 1; } //二重改行で区切る(レスポンスボディを取得するため) vector<string> res; res = boost::split(res, allRes, boost::is_any_of("\r\n\r\n")); //stringからJsonに変換 string err; const Json jsonData = Json::parse(res[res.size() - 1], err); cout << jsonData.dump() << "\n\n"; //各値を取得 auto jsonArray = jsonData.array_items(); cout << " id value1 value2 ans" << endl; for (auto &item : jsonArray) { cout << setw(6) << right << item["id"].string_value() << " "; cout << setw(6) << right << item["value1"].string_value() << " "; cout << setw(6) << right << item["value2"].string_value() << " "; cout << setw(6) << right << item["ans"].string_value() << '\n'; } return 0; }MySQLに「calc_db」というデータベースを作り、テーブル名を「result」とした。
カラムは、「id」「value1」「value2」「ans」の4つである。
これにより、挿入された順番、入力した値、二つの値の足し算の結果がDBに保存される。add.php<?php //計算する値を入力 $isInput = TRUE; if(isset($_GET['value1'])){ $value1 = intval($_GET['value1']); } else { $isInput = FALSE; } if(isset($_GET['value2'])){ $value2 = intval($_GET['value2']); } else { $isInput = FALSE; } //DBの設定 $mysql = mysqli_connect('localhost', 'root', '') or die(mysqli_error($mysql)); mysqli_select_db($mysql, 'calc_db'); mysqli_query($mysql, 'SET NAMES UTF8'); //入力があるならデータをDBに追加 if($isInput){ //結果を計算 $ans = $value1 + $value2; //DBにデータを挿入 $insert = sprintf('INSERT INTO result SET value1=%d,value2=%d,ans=%d', mysqli_real_escape_string($mysql, $value1), mysqli_real_escape_string($mysql, $value2), mysqli_real_escape_string($mysql, $ans) ); mysqli_query($mysql, $insert) or die(mysqli_error($mysql)); } //DBからデータを取得 $request = sprintf('SELECT * FROM result'); $result = mysqli_query($mysql, $request) or die(mysqli_error($mysql)); $ansList = array(); while($row = mysqli_fetch_assoc($result)){ $ansList[] = array( 'id'=>$row['id'], 'value1'=>$row['value1'], 'value2'=>$row['value2'], 'ans'=>$row['ans'] ); } //jsonで出力 $jsonData = json_encode($ansList); header("Content-Type: application/json; charset=utf-8"); echo $jsonData; ?>出力結果
value1に「1」、value2に「2」を入力した。
足し算をした結果、ansが「3」となっていることが分かる。value1を入力 : 1 value2を入力 : 2 [{"ans": "3", "id": "1", "value1": "1", "value2": "2"}] id value1 value2 ans 1 1 2 3次に、value1に「2」、value2に「3」を入力した。
ansは「5」となり、表にはこれまでの計算結果が表示されている。value1を入力 : 2 value2を入力 : 3 [{"ans": "3", "id": "1", "value1": "1", "value2": "2"}, {"ans": "5", "id": "2", "value1": "2", "value2": "3"}] id value1 value2 ans 1 1 2 3 2 2 3 5データベースの中身は以下ようになっている。
まとめ
C++からPHP、PHPからMySQLへの連携は簡単ながら行うことができた。
GET形式をPOST形式にしたり、同期通信を非同期通信にするなどまだやることはある。
また、コードに関してももっと良い書き方があると思う。
今度はこれを応用して何か作りたい。参考にしたサイト
・ネットワーク - TCP
・Boost.AsioでHTTP通信
・C++11でjsonを扱う方法。json11
・C++11でjson扱うならdropbox/json11がよさそうなど。

- 投稿日:2019-12-11T08:22:39+09:00
docker-compose+MySQL8(8.0.18)で初期データをCSVロードしようとするとエラー(The used command is not allowed with this MySQL version)に
docker-compose+MySQL8(8.0.18)で初期データをCSVロードしようとするとエラー(The used command is not allowed with this MySQL version)に
環境情報
- MacOS X 10.15.1(19B88)
- Docker 19.03.5
- MySQL 8.0.18
docker-composeのディレクトリ構成
. ├── docker-compose.yml └── mysql ├── init │ ├── 10_ddl.sql │ └── data.csv各ファイルの中身
docker-compose.ymlファイルの中身
version: '3' services: mysql: image: mysql:latest environment: #イメージの起動時に作成するデータベースの名前 MYSQL_DATABASE: yudb #このユーザはMYSQL_DATABASE変数で指定されたデータベースに対してスーパーユーザとしての権限(GRANT ALL)を保持する MYSQL_USER: mysqluser #MYSQL_USERのパスワード MYSQL_PASSWORD: MySQLPass00 # MySQLにおけるスーパーユーザであるrootアカウントに設定するためのパスワード MYSQL_ROOT_PASSWORD: MySQLRootPass00 ports: - "3306:3306" volumes: #- ./mysql/var_lib_mysql:/var/lib/mysql ← 起動するたびにMySQLのデータベースを初期化したいのでコメントアウトしておく # /docker-entrypoint-initdb.d/配下は、Dockerコンテナが初回起動(初期化)される際に1度だけ実行されるスクリプトなどを配置 # *.sh / *.sql / *.sql.gzの拡張子のファイルはファイル名の昇順に実行される。 - ./mysql/init:/docker-entrypoint-initdb.d10_ddl.sqlファイルの中身
create table if not exists m_sample( `code` char(3) not null, `name` varchar(80) not null, primary key(`code`) ) engine=innodb default charset=utf8; LOAD DATA LOCAL INFILE '/docker-entrypoint-initdb.d/data.csv' INTO TABLE yudb.m_sample FIELDS TERMINATED BY ',' ENCLOSED BY '"';data.csvファイルの中身
"001","test001" "002","test002" "003","test003" "004","test004"docker-composeでmysqlのコンテナを起動するとエラーが発生
docker-compose upコマンドを実行してコンテナを起動$ docker-compose up -d Creating network "docker-mysql8-err_default" with the default driver Creating docker-mysql8-err_mysql_1 ... done
docker-compose psコマンドを実行して状態を確認$ docker-compose ps Name Command State Ports ------------------------------------------------------------------------ docker-mysql8-err_mysql_1 docker-entrypoint.sh mysqld Exit 1
docker-compose logsコマンドを実行してログを確認$ docker-compose logs Attaching to docker-mysql8-err_mysql_1 mysql_1 | 2019-12-10 22:45:36+00:00 [Note] [Entrypoint]: Entrypoint script for MySQL Server 8.0.18-1debian9 started. mysql_1 | 2019-12-10 22:45:36+00:00 [Note] [Entrypoint]: Switching to dedicated user 'mysql' mysql_1 | 2019-12-10 22:45:36+00:00 [Note] [Entrypoint]: Entrypoint script for MySQL Server 8.0.18-1debian9 started. mysql_1 | 2019-12-10 22:45:36+00:00 [Note] [Entrypoint]: Initializing database files mysql_1 | 2019-12-10T22:45:36.889727Z 0 [Warning] [MY-011070] [Server] 'Disabling symbolic links using --skip-symbolic-links (or equivalent) is the default. Consider not using this option as it' is deprecated and will be removed in a future release. mysql_1 | 2019-12-10T22:45:36.889859Z 0 [System] [MY-013169] [Server] /usr/sbin/mysqld (mysqld 8.0.18) initializing of server in progress as process 44 mysql_1 | 2019-12-10T22:45:38.650792Z 5 [Warning] [MY-010453] [Server] root@localhost is created with an empty password ! Please consider switching off the --initialize-insecure option. mysql_1 | 2019-12-10 22:45:42+00:00 [Note] [Entrypoint]: Database files initialized mysql_1 | 2019-12-10 22:45:42+00:00 [Note] [Entrypoint]: Starting temporary server mysql_1 | 2019-12-10T22:45:42.613856Z 0 [Warning] [MY-011070] [Server] 'Disabling symbolic links using --skip-symbolic-links (or equivalent) is the default. Consider not using this option as it' is deprecated and will be removed in a future release. mysql_1 | 2019-12-10T22:45:42.614006Z 0 [System] [MY-010116] [Server] /usr/sbin/mysqld (mysqld 8.0.18) starting as process 93 mysql_1 | 2019-12-10T22:45:43.302666Z 0 [Warning] [MY-010068] [Server] CA certificate ca.pem is self signed. mysql_1 | 2019-12-10T22:45:43.307378Z 0 [Warning] [MY-011810] [Server] Insecure configuration for --pid-file: Location '/var/run/mysqld' in the path is accessible to all OS users. Consider choosing a different directory. mysql_1 | 2019-12-10T22:45:43.342347Z 0 [System] [MY-010931] [Server] /usr/sbin/mysqld: ready for connections. Version: '8.0.18' socket: '/var/run/mysqld/mysqld.sock' port: 0 MySQL Community Server - GPL. mysql_1 | 2019-12-10 22:45:43+00:00 [Note] [Entrypoint]: Temporary server started. mysql_1 | 2019-12-10T22:45:43.361902Z 0 [System] [MY-011323] [Server] X Plugin ready for connections. Socket: '/var/run/mysqld/mysqlx.sock' mysql_1 | Warning: Unable to load '/usr/share/zoneinfo/iso3166.tab' as time zone. Skipping it. mysql_1 | Warning: Unable to load '/usr/share/zoneinfo/leap-seconds.list' as time zone. Skipping it. mysql_1 | Warning: Unable to load '/usr/share/zoneinfo/zone.tab' as time zone. Skipping it. mysql_1 | Warning: Unable to load '/usr/share/zoneinfo/zone1970.tab' as time zone. Skipping it. mysql_1 | 2019-12-10 22:45:47+00:00 [Note] [Entrypoint]: Creating database yudb mysql_1 | 2019-12-10 22:45:47+00:00 [Note] [Entrypoint]: Creating user mysqluser mysql_1 | 2019-12-10 22:45:47+00:00 [Note] [Entrypoint]: Giving user mysqluser access to schema yudb mysql_1 | mysql_1 | 2019-12-10 22:45:47+00:00 [Note] [Entrypoint]: /usr/local/bin/docker-entrypoint.sh: running /docker-entrypoint-initdb.d/10_ddl.sql mysql_1 | ERROR 1148 (42000) at line 7: The used command is not allowed with this MySQL versionログを確認すると、ログの最終行に
mysql_1 | ERROR 1148 (42000) at line 7: The used command is not allowed with this MySQL versionというログが出力されていました。
調べてみると、MySQL8以降では、デフォルトのMySQLサーバーのままだとLOAD DATA LOCAL INFILEによるCSVファイルのロードが出来ないようです。https://dev.mysql.com/doc/refman/8.0/en/load-data-local.html
解決方法
解決するには2つの対応が必要になります。
- 1つはサーバーサイドの設定としてlocal_infileシステム変数をONにする
- もう1つがクライアントから接続する際に--local-infile[=1]オプションを指定するサーバーサイドの設定で
local_infileシステム変数をON
10_ddl.sqlファイルに1行追加して以下のように定義する。
LOAD DATA LOCAL INFILEの行はコメントアウトして使えなくしておく。set global local_infile = 1; create table if not exists m_sample( `code` char(3) not null, `name` varchar(80) not null, primary key(`code`) ) engine=innodb default charset=utf8; -- LOAD DATA LOCAL INFILE '/docker-entrypoint-initdb.d/data.csv' INTO TABLE yudb.m_sample FIELDS TERMINATED BY ',' ENCLOSED BY '"';クライアントから接続する際に
--local-infile[=1]オプションを指定するこれを実現するために、sqlファイルでのロードではなく、shellによるロードへ切り替えることで解消できました。
ディレクトリ構成は以下の通り。. ├── docker-compose.yml └── mysql └── init ├── 10_ddl.sql ├── 20_data_load.sh ← このファイルを追加 └── data.csv
20_data_load.shファイルを追加します。mysql -uroot -pMySQLRootPass00 --local-infile=1 yudb -e "LOAD DATA LOCAL INFILE '/docker-entrypoint-initdb.d/data.csv' INTO TABLE m_sample FIELDS TERMINATED BY ',' ENCLOSED BY '\"' LINES TERMINATED BY '\n'"解消したか確認する
docker-compose up -dを実行後、しばらくしてからdocker-compose psを実行すると、今度は正常にMySQLのコンテナが起動していることがわかる。$ docker-compose up -d Creating network "docker-mysql8-err_default" with the default driver Creating docker-mysql8-err_mysql_1 ... done $ docker-compose ps Name Command State Ports --------------------------------------------------------------------------------------------------- docker-mysql8-err_mysql_1 docker-entrypoint.sh mysqld Up 0.0.0.0:3306->3306/tcp, 33060/tcp念のためロードしたデータがちゃんと入っているかも確認してみる。
$ docker-compose exec mysql bash root@46a05fff4d72:/# root@46a05fff4d72:/# mysql -umysqluser -pMySQLPass00 mysql: [Warning] Using a password on the command line interface can be insecure. Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 8 Server version: 8.0.18 MySQL Community Server - GPL Copyright (c) 2000, 2019, Oracle and/or its affiliates. All rights reserved. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql> connect yudb Reading table information for completion of table and column names You can turn off this feature to get a quicker startup with -A Connection id: 9 Current database: yudb mysql> show tables; +----------------+ | Tables_in_yudb | +----------------+ | m_sample | +----------------+ 1 row in set (0.00 sec) mysql> select * from m_sample; +------+---------+ | code | name | +------+---------+ | 001 | test001 | | 002 | test002 | | 003 | test003 | | 004 | test004 | +------+---------+ 4 rows in set (0.00 sec)とりあえずデータも無事にロードされているので、これでエラーの問題は解消できることがわかりました。
- 投稿日:2019-12-11T02:51:36+09:00
ちゃんとフォームに名前入れたのに、Mysql2::Error: Field 'nickname' doesn't have a default value: INSERT INTO ?
前置き
deviseを導入して、rails g devise:installで設定ファイルをrailsアプリケーションに作成。
ターミナルrails g devise:installその後rails g devise userでdeviseのuserモデルを作成。
ターミナルrails g devise userこれでuser.rbやマイグレーションファイルなどができるので、nicknameカラムをnull: falseで追加。そしてrake db:migrate。
XXXXXXXXXXXXX_devise_create_users.rbt.string :nickname, null: falseターミナルrake db:migrate元々emailカラムとencrypted_passwordカラムが入ったdeviseのuserテーブルにnicknameカラムの入ったものが出来上がったので次に移る。
rails g devise:viewsでdeviseのviewを作成した後に、下記のようにnicknameのフォームを追加して、名前、email、パスワードをテーブルに新規登録するするフォームが出来上がった。
ターミナルrails g devise:viewsnew.html.erb<div class="field"> <%= f.label :nickname %><br /> <%= f.text_field :nickname, autofocus: true %> </div>ここから本題
前置きが長くなってしまったけれど、詰まったところはここから。
全てのフォームに情報を入力し、signupを押すと、、
Field 'nickname' doesn't have a default valueというエラーに。※エラー画像はうまく画像が表示されないので割愛。
原因
調べたら、nicknameが空ですよーと言っていると判明。
ちゃんとデータとんでいるのになんで?
と思って調べたら、deviseのコントローラはデフォルトで入っているemailとパスワードのみを受け取るストロングパラメータが設定されているらしい。。ので、application_controllerclass ApplicationController < ActionController::Base protect_from_forgery with: :exception before_action :configre_permitted_parameters, if: :devise_controller? def configre_permitted_parameters devise_parameter_sanitizer.permit(:sign_up, keys: [:nickname]) end endこれでなんとかエラーは解消。usersテーブルにもデータ入ってるのを確認。
まとめ
前半、書くこと忘れてdeviseの導入手順みたいになってしまったけど、必要なところは本題だけかなと。エラー画像Gyazo使って載せようとしたけれどなぜか載せれず。それを調べる気力がなくなってしまったので寝
- 投稿日:2019-12-11T02:51:36+09:00
ちゃんとフォームに名前入れたのに、Mysql2::Error: Field 'nickname' doesn't have a default value: INSERT INTO 言われた
前置き
deviseを導入して、rails g devise:installで設定ファイルをrailsアプリケーションに作成。
ターミナルrails g devise:installその後rails g devise userでdeviseのuserモデルを作成。
ターミナルrails g devise userこれでuser.rbやマイグレーションファイルなどができるので、nicknameカラムをnull: falseで追加。そしてrake db:migrate。
XXXXXXXXXXXXX_devise_create_users.rbt.string :nickname, null: falseターミナルrake db:migrate元々emailカラムとencrypted_passwordカラムが入ったdeviseのuserテーブルにnicknameカラムの入ったものが出来上がったので次に移る。
rails g devise:viewsでdeviseのviewを作成した後に、下記のようにnicknameのフォームを追加して、名前、email、パスワードをテーブルに新規登録するするフォームが出来上がった。
ターミナルrails g devise:viewsnew.html.erb<div class="field"> <%= f.label :nickname %><br /> <%= f.text_field :nickname, autofocus: true %> </div>ここから本題
前置きが長くなってしまったけれど、詰まったところはここから。
全てのフォームに情報を入力し、signupを押すと、、
Field 'nickname' doesn't have a default valueというエラーに。※エラー画像はうまく画像が表示されないので割愛。
原因
調べたら、nicknameが空だと言っていると判明。
ちゃんとデータとんでいるのになんで?
と思って調べたら、deviseのコントローラはデフォルトで入っているemailとパスワードのみを受け取るストロングパラメータが設定されているらしい。。ので、application_controllerclass ApplicationController < ActionController::Base protect_from_forgery with: :exception before_action :configre_permitted_parameters, if: :devise_controller? def configre_permitted_parameters devise_parameter_sanitizer.permit(:sign_up, keys: [:nickname]) end endこれでなんとかエラーは解消。usersテーブルにもデータ入ってるのを確認。
まとめ
前半、書くこと忘れてdeviseの導入手順みたいになってしまったけど、必要なところは本題だけかなと。エラー画像Gyazo使って載せようとしたけれどなぜか載せれず。それを調べる気力がなくなってしまったので寝
- 投稿日:2019-12-11T00:46:08+09:00
Rails6のwebアプリをherokuでデプロイしてdb:migrateしたときのエラーを解決した話
目的
- コマンド
heroku run rake db:migrateを実行したときに出たエラーの解決したときの話をまとめるエラー概要
herokuにpush後にコマンド
heroku run rake db:migrateを実行した際に下記のエラーが出た。$ heroku run rake db:migrate Running rake db:migrate on ⬢ study-record... up, run.3764 (Free) rake aborted! Mysql2::Error::ConnectionError: Can't connect to local MySQL server through socket '/tmp/mysql.sock' (2) /app/vendor/bundle/ruby/2.5.0/gems/mysql2-0.5.2/lib/mysql2/client.rb:90:in `connect' /app/vendor/bundle/ruby/2.5.0/gems/mysql2-0.5.2/lib/mysql2/client.rb:90:in `initialize' /app/vendor/bundle/ruby/2.5.0/gems/activerecord-6.0.0/lib/active_record/connection_adapters/mysql2_adapter.rb:24:in `new' /app/vendor/bundle/ruby/2.5.0/gems/activerecord-6.0.0/lib/active_record/connection_adapters/mysql2_adapter.rb:24:in `mysql2_connection' /app/vendor/bundle/ruby/2.5.0/gems/activerecord-6.0.0/lib/active_record/connection_adapters/abstract/connection_pool.rb:879:in `new_connection' /app/vendor/bundle/ruby/2.5.0/gems/activerecord-6.0.0/lib/active_record/connection_adapters/abstract/connection_pool.rb:923:in `checkout_new_connection' /app/vendor/bundle/ruby/2.5.0/gems/activerecord-6.0.0/lib/active_record/connection_adapters/abstract/connection_pool.rb:902:in `try_to_checkout_new_connection' /app/vendor/bundle/ruby/2.5.0/gems/activerecord-6.0.0/lib/active_record/connection_adapters/abstract/connection_pool.rb:863:in `acquire_connection' /app/vendor/bundle/ruby/2.5.0/gems/activerecord-6.0.0/lib/active_record/connection_adapters/abstract/connection_pool.rb:587:in `checkout' /app/vendor/bundle/ruby/2.5.0/gems/activerecord-6.0.0/lib/active_record/connection_adapters/abstract/connection_pool.rb:431:in `connection' /app/vendor/bundle/ruby/2.5.0/gems/activerecord-6.0.0/lib/active_record/connection_adapters/abstract/connection_pool.rb:1111:in `retrieve_connection' /app/vendor/bundle/ruby/2.5.0/gems/activerecord-6.0.0/lib/active_record/connection_handling.rb:231:in `retrieve_connection' /app/vendor/bundle/ruby/2.5.0/gems/activerecord-6.0.0/lib/active_record/connection_handling.rb:199:in `connection' /app/vendor/bundle/ruby/2.5.0/gems/activerecord-6.0.0/lib/active_record/tasks/database_tasks.rb:238:in `migrate' /app/vendor/bundle/ruby/2.5.0/gems/activerecord-6.0.0/lib/active_record/railties/databases.rake:85:in `block (3 levels) in <top (required)>' /app/vendor/bundle/ruby/2.5.0/gems/activerecord-6.0.0/lib/active_record/railties/databases.rake:83:in `each' /app/vendor/bundle/ruby/2.5.0/gems/activerecord-6.0.0/lib/active_record/railties/databases.rake:83:in `block (2 levels) in <top (required)>' /app/vendor/bundle/ruby/2.5.0/gems/rake-13.0.0/exe/rake:27:in `<top (required)>' /app/vendor/bundle/ruby/2.5.0/gems/bundler-2.0.2/lib/bundler/cli/exec.rb:74:in `load' /app/vendor/bundle/ruby/2.5.0/gems/bundler-2.0.2/lib/bundler/cli/exec.rb:74:in `kernel_load' /app/vendor/bundle/ruby/2.5.0/gems/bundler-2.0.2/lib/bundler/cli/exec.rb:28:in `run' /app/vendor/bundle/ruby/2.5.0/gems/bundler-2.0.2/lib/bundler/cli/exec.rb:28:in `run' /app/vendor/bundle/ruby/2.5.0/gems/bundler-2.0.2/lib/bundler/cli/exec.rb:28:in `run' /app/vendor/bundle/ruby/2.5.0/gems/bundler-2.0.2/lib/bundler/cli.rb:465:in `exec' /app/vendor/bundle/ruby/2.5.0/gems/bundler-2.0.2/lib/bundler/vendor/thor/lib/thor/command.rb:27:in `run' /app/vendor/bundle/ruby/2.5.0/gems/bundler-2.0.2/lib/bundler/vendor/thor/lib/thor/invocation.rb:126:in `invoke_command' /app/vendor/bundle/ruby/2.5.0/gems/bundler-2.0.2/lib/bundler/vendor/thor/lib/thor.rb:387:in `dispatch' /app/vendor/bundle/ruby/2.5.0/gems/bundler-2.0.2/lib/bundler/cli.rb:27:in `dispatch' /app/vendor/bundle/ruby/2.5.0/gems/bundler-2.0.2/lib/bundler/vendor/thor/lib/thor/base.rb:466:in `start' /app/vendor/bundle/ruby/2.5.0/gems/bundler-2.0.2/lib/bundler/cli.rb:18:in `start' /app/vendor/bundle/ruby/2.5.0/gems/bundler-2.0.2/exe/bundle:30:in `block in <top (required)>' /app/vendor/bundle/ruby/2.5.0/gems/bundler-2.0.2/lib/bundler/friendly_errors.rb:124:in `with_friendly_errors' /app/vendor/bundle/ruby/2.5.0/gems/bundler-2.0.2/exe/bundle:22:in `<top (required)>' /app/bin/bundle:104:in `load' /app/bin/bundle:104:in `<main>' Tasks: TOP => db:migrate (See full trace by running task with --trace)エラーの予想
- pushまでは問題なかったため、直前に実施したDB系の設定がおかしいのでは??と予想した。
- ソケット系のエラーが出ているので、その辺の情報も怪しいと思った。
調査
直前に設定していたDB系の設定を確認
下記コマンドを実行して設定を確認した。
$ heroku config- 上記コマンドの出力↓ ``` === study-record Config Vars CLEARDB_DATABASE_URL: mysql://b60b5336b9085d:754f140c@us-cdbr-iron-east-05.cleardb.net/heroku_f69d4fc63e3b43f?reconnect=true DB_HOSTNAME: us-cdbr-iron-east-05.cleardb.net DB_NAME: heroku_f69d4fc63e3b43f DB_PASSWORD: 754f140c DB_PORT: 3306 DB_USERNAME: b60b5336b9085d LANG: en_US.UTF-8 RACK_ENV: production RAILS_ENV: production RAILS_LOG_TO_STDOUT: enabled RAILS_SERVE_STATIC_FILES: enabled SECRET_KEY_BASE: 0d58d7c950379d4bfe741b3ae465b46aaa159ae398c2aaaea5010ae2d817b308a90a7d4702e6281ad609c94de1acf03cb50c1e39d21d9e66af636d812f2e823f ```おかしいところ発見
- 設定の
CLEARDB_DATABASE_URLのURLがmysqlから始まっていることに気が付いた。- 自分が使用しているの
mysql2なのにmysqlで良いのかと違和感があった。下記コマンドを実行して
mysql2に修正した。$ heroku config:set DATABASE_URL='mysql2://b60b5336b9085d:754f140c@us-cdbr-iron-east-05.cleardb.net/heroku_f69d4fc63e3b43f?reconnect=true'再度下記コマンドを実行してheroku側でdb:migrateを行なったところ正常に実行できた。
$ heroku run rake db:migrate Running rake db:migrate on ⬢ study-record... up, run.5104 (Free) D, [2019-12-10T15:16:34.677916 #4] DEBUG -- : (2.4ms) SET NAMES utf8mb4, @@SESSION.sql_mode = CONCAT(CONCAT(@@sql_mode, ',STRICT_ALL_TABLES'), ',NO_AUTO_VALUE_ON_ZERO'), @@SESSION.sql_auto_is_null = 0, @@SESSION.wait_timeout = 2147483 D, [2019-12-10T15:16:34.715120 #4] DEBUG -- : (2.2ms) SELECT @@innodb_file_per_table = 1 AND @@innodb_file_format = 'Barracuda' D, [2019-12-10T15:16:34.732371 #4] DEBUG -- : (16.9ms) CREATE TABLE `schema_migrations` (`version` varchar(255) NOT NULL PRIMARY KEY) ROW_FORMAT=DYNAMIC D, [2019-12-10T15:16:34.752768 #4] DEBUG -- : (13.9ms) CREATE TABLE `ar_internal_metadata` (`key` varchar(255) NOT NULL PRIMARY KEY, `value` varchar(255), `created_at` datetime(6) NOT NULL, `updated_at` datetime(6) NOT NULL) ROW_FORMAT=DYNAMIC D, [2019-12-10T15:16:34.757508 #4] DEBUG -- : (2.4ms) SELECT GET_LOCK('3434563884671206245', 0) D, [2019-12-10T15:16:34.774649 #4] DEBUG -- : (3.1ms) SELECT `schema_migrations`.`version` FROM `schema_migrations` ORDER BY `schema_migrations`.`version` ASC I, [2019-12-10T15:16:34.775957 #4] INFO -- : Migrating to CreateUsers (20191106122609) == 20191106122609 CreateUsers: migrating ====================================== -- create_table(:users) D, [2019-12-10T15:16:34.795305 #4] DEBUG -- : (15.9ms) CREATE TABLE `users` (`id` bigint NOT NULL AUTO_INCREMENT PRIMARY KEY, `name` varchar(255), `email` varchar(255), `created_at` datetime(6) NOT NULL, `updated_at` datetime(6) NOT NULL) ROW_FORMAT=DYNAMIC -> 0.0168s == 20191106122609 CreateUsers: migrated (0.0169s) ============================= D, [2019-12-10T15:16:34.811775 #4] DEBUG -- : (4.0ms) BEGIN D, [2019-12-10T15:16:34.814482 #4] DEBUG -- : primary::SchemaMigration Create (2.6ms) INSERT INTO `schema_migrations` (`version`) VALUES ('20191106122609') D, [2019-12-10T15:16:34.816842 #4] DEBUG -- : (2.2ms) COMMIT I, [2019-12-10T15:16:34.816964 #4] INFO -- : Migrating to CreatePosts (20191110100157) == 20191110100157 CreatePosts: migrating ====================================== -- create_table(:posts) D, [2019-12-10T15:16:34.832775 #4] DEBUG -- : (15.0ms) CREATE TABLE `posts` (`id` bigint NOT NULL AUTO_INCREMENT PRIMARY KEY, `content` text, `created_at` datetime(6) NOT NULL, `updated_at` datetime(6) NOT NULL) ROW_FORMAT=DYNAMIC -> 0.0154s == 20191110100157 CreatePosts: migrated (0.0155s) ============================= D, [2019-12-10T15:16:34.835642 #4] DEBUG -- : (2.3ms) BEGIN D, [2019-12-10T15:16:34.838096 #4] DEBUG -- : primary::SchemaMigration Create (2.3ms) INSERT INTO `schema_migrations` (`version`) VALUES ('20191110100157') D, [2019-12-10T15:16:34.840385 #4] DEBUG -- : (2.1ms) COMMIT I, [2019-12-10T15:16:34.840476 #4] INFO -- : Migrating to AddStudyTimeHashTagToPosts (20191112145912) == 20191112145912 AddStudyTimeHashTagToPosts: migrating ======================= -- add_column(:posts, :study_time, "decimal") D, [2019-12-10T15:16:34.861032 #4] DEBUG -- : (19.9ms) ALTER TABLE `posts` ADD `study_time` decimal -> 0.0202s -- add_column(:posts, :hash_tag, "text") D, [2019-12-10T15:16:34.877828 #4] DEBUG -- : (16.4ms) ALTER TABLE `posts` ADD `hash_tag` text -> 0.0168s == 20191112145912 AddStudyTimeHashTagToPosts: migrated (0.0371s) ============== D, [2019-12-10T15:16:34.880640 #4] DEBUG -- : (2.2ms) BEGIN D, [2019-12-10T15:16:34.882939 #4] DEBUG -- : primary::SchemaMigration Create (2.1ms) INSERT INTO `schema_migrations` (`version`) VALUES ('20191112145912') D, [2019-12-10T15:16:34.885466 #4] DEBUG -- : (2.3ms) COMMIT D, [2019-12-10T15:16:34.898276 #4] DEBUG -- : ActiveRecord::InternalMetadata Load (2.7ms) SELECT `ar_internal_metadata`.* FROM `ar_internal_metadata` WHERE `ar_internal_metadata`.`key` = 'environment' LIMIT 1 D, [2019-12-10T15:16:34.909203 #4] DEBUG -- : (2.3ms) BEGIN D, [2019-12-10T15:16:34.911642 #4] DEBUG -- : ActiveRecord::InternalMetadata Create (2.3ms) INSERT INTO `ar_internal_metadata` (`key`, `value`, `created_at`, `updated_at`) VALUES ('environment', 'production', '2019-12-10 15:16:34.906194', '2019-12-10 15:16:34.906194') D, [2019-12-10T15:16:34.914188 #4] DEBUG -- : (2.3ms) COMMIT D, [2019-12-10T15:16:34.916800 #4] DEBUG -- : (2.4ms) SELECT RELEASE_LOCK('3434563884671206245')自分用メモ
- db:migrate系のエラーはだいたい設定のミスなのでよく見直すこと。
付録
- 誤っていたBDの設定ファイルと正常なDBの設定ファイルを下記に記載する。
誤っていたDBの設定ファイル↓
CLEARDB_DATABASE_URL: mysql://b60b5336b9085d:754f140c@us-cdbr-iron-east-05.cleardb.net/heroku_f69d4fc63e3b43f?reconnect=true DB_HOSTNAME: us-cdbr-iron-east-05.cleardb.net DB_NAME: heroku_f69d4fc63e3b43f DB_PASSWORD: 754f140c DB_PORT: 3306 DB_USERNAME: b60b5336b9085d LANG: en_US.UTF-8 RACK_ENV: production RAILS_ENV: production RAILS_LOG_TO_STDOUT: enabled RAILS_SERVE_STATIC_FILES: enabled SECRET_KEY_BASE: 0d58d7c950379d4bfe741b3ae465b46aaa159ae398c2aaaea5010ae2d817b308a90a7d4702e6281ad609c94de1acf03cb50c1e39d21d9e66af636d812f2e823f正常なDBの設定ファイル↓
CLEARDB_DATABASE_URL: mysql2://b60b5336b9085d:754f140c@us-cdbr-iron-east-05.cleardb.net/heroku_f69d4fc63e3b43f?reconnect=true DB_HOSTNAME: us-cdbr-iron-east-05.cleardb.net DB_NAME: heroku_f69d4fc63e3b43f DB_PASSWORD: 754f140c DB_PORT: 3306 DB_USERNAME: b60b5336b9085d LANG: en_US.UTF-8 RACK_ENV: production RAILS_ENV: production RAILS_LOG_TO_STDOUT: enabled RAILS_SERVE_STATIC_FILES: enabled SECRET_KEY_BASE: 0d58d7c950379d4bfe741b3ae465b46aaa159ae398c2aaaea5010ae2d817b308a90a7d4702e6281ad609c94de1acf03cb50c1e39d21d9e66af636d812f2e823f