- 投稿日:2019-06-07T23:02:14+09:00
Jetson NanoにPipenvでTensorFlowをインストール
はじめに
本記事はJetson NanoにPipenvによりTensorFlowをセットアップするための方法を示したものである。Pythonの環境構築をPipenvで統一しつつある中で、TensorFlowをpip3でインストールしていたことが気になっていたのでPipenvでインストールし直した。
準備
基本的なセットアップは「Jetson Nanoの実験環境のまとめ」に従っている。
追加で下記のパッケージをインストールする。ターミナルsudo apt install libhdf5-serial-dev hdf5-tools libhdf5-dev zlib1g-dev zip libjpeg8-devインストール
$HOME/Documents/TensorFlowにインストールする。
ターミナルyamamo-to@jetson-nano:~$ mkdir ~/Documents/TensorFlow yamamo-to@jetson-nano:~$ cd ~/Documents/TensorFlow yamamo-to@jetson-nano:~/Documents/TensorFlow$このディレクトリに下記の内容でPipfileを置く1。
Pipfile[[source]] name = "pypi" url = "https://pypi.org/simple" verify_ssl = true [[source]] name = "nvidia" url = "https://developer.download.nvidia.com/compute/redist/jp/v42" verify_ssl = true [dev-packages] [packages] numpy = {version="*", index="pypi"} grpcio = {version="*", index="pypi"} absl-py = {version="*", index="pypi"} py-cpuinfo = {version="*", index="pypi"} psutil = {version="*", index="pypi"} portpicker = {version="*", index="pypi"} six = {version="*", index="pypi"} mock = {version="*", index="pypi"} requests = {version="*", index="pypi"} gast = {version="*", index="pypi"} h5py = {version="*", index="pypi"} astor = {version="*", index="pypi"} termcolor = {version="*", index="pypi"} tensorflow_gpu = {version="==1.13.1+nv19.5", index="nvidia"} [requires] python_version = "3.6" [pipenv] allow_prereleases = trueあとは次のコマンドでインストールされる。
ターミナルyamamo-to@jetson-nano:~/Documents/TensorFlow$ pipenv install確認
ターミナルyamamo-to@jetson-nano:~/Documents/TensorFlow$$ pipenv run python3 -c 'import tensorflow; print(tensorflow.__version__)' 1.13.1
関係ないパッケージもnvidiaに参照しに行っていたので修正(2019/06/09)。 ↩
- 投稿日:2019-06-07T18:41:16+09:00
協力するAI開発
協力するAI開発
記事の目的
こんにちは!今ちょうど深層学習(ディープラーニング)や強化学習の勉強をしていてAI同士を協力させると面白くないかな?と思ってこのプロジェクトを始めました。
このシリーズを通して学べる事
LSTM
強化学習
興味を用いた強化学習
アクタークリティック
簡単なゲームの作り方
Unity
Ml Agents動機
ちょうど「キングダム」という漫画
を読んで兵法や戦場における人というものの面白さに触れられてこのような思想戦を行えるゲームがしてみたかったからです。もちろん将棋やチェスみたいな簡略化したゲームはありますが戦場における以下の点を無視しているような気がしました(両方苦手ですがw)。1. 指揮系統がない
普通の戦場では命令系統があり、上からの命令と目の前の状況から次にする行動を決めると思います。しかし普通のゲームでは単純に命令を与えたらその場所に動き、駒に作戦などがありません。よって駒が自分で考えて上からの命令を参考するようにしました。
2. ランダムではない
ここで言っているのは一つの駒がもう一方の駒を攻撃したときに結果が決まっているということです。例えば飛車を歩の場所までもっていったら歩が取れるということが将棋では決まっています。しかし、正直それって正確には大してあっていないと思います。例えば四方向から誰かを囲めば確かに倒す確率は上げられるかもしれませんが逆にやられてしまう可能性が皆無というわけではないと思います。なので、そういったこと確率なども含んでみました。
3. 見える範囲
戦場において一番重要だと思うことは相手に自分の戦略が明らかにならないことです。ここで一番それができる確実な方法は相手に自分が見えないことです。よってそれを可能にするために各AIに個人個人見える範囲を設定しました。
4.動きが変
チェスや将棋にはマスがあり、双方順番に駒を進めます。しかし、実際には360度のどの方向にも動くことはできるはずでしかも両方毎秒毎秒動きます。順番などはありません。なのでそれも含めてみました。
手順
1.上の4条件を満たすゲームを考えてみる。
2. AIで学習できるようにする。
3. 結果報告
4+2n 改善したこと
5+2n 結果報告
でき次第リンクをつけておきますがここではとりあえず1を先に説明します。
とりあえず、最初の1だけここでとりあげます。1.ゲームのルール
前提に置いておきますが、このゲームは上の四つの条件を満たす最低限度のゲームを考えてみたのですが結構複雑になってしまったのでそのことはすみません。
すべてのプレイヤーは丸です。
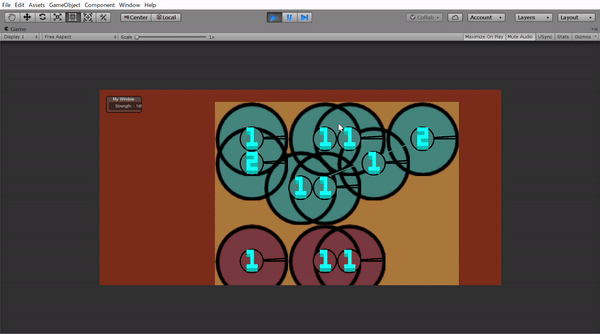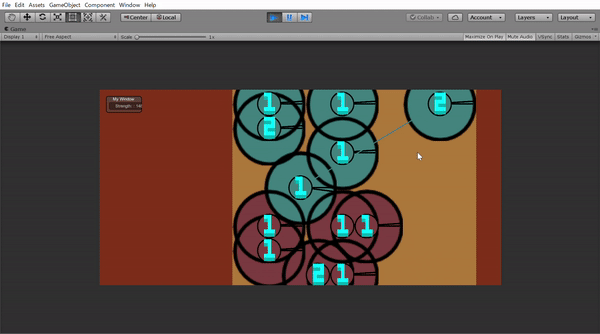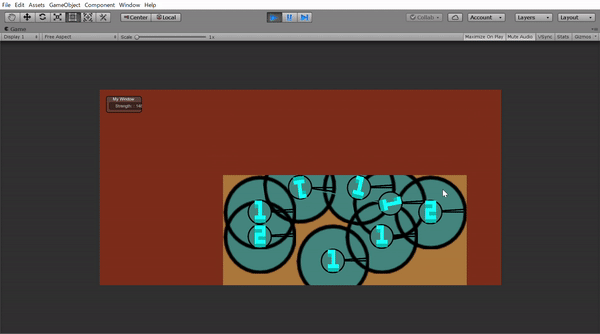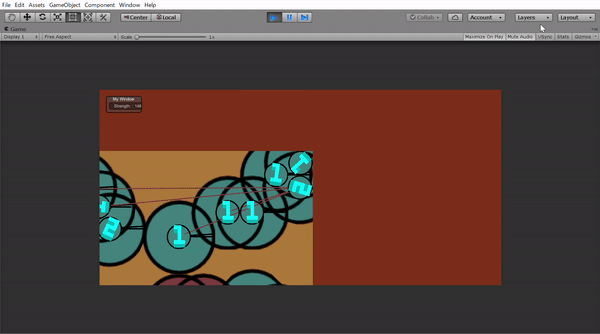
この丸は動くことができ、攻撃範囲と攻撃する角度を指定すれば敵の丸を攻撃できます。Unityで作ったら下のようになりました。(学習したモデルはのっけてないです)
このゲームにはHPとかはなく、生きていると死んでいるという二つの状態しかありません。だから攻撃範囲(二つの黒い棒の間)に入ったら死ぬか相手を殺すかの2パターンしかありません。ここで第二条件の「ランダム」をいれてみました。
具体的にはすべての兵に正規分布からてきとうに「力」というパラメターを付けます。物理にならって力を$f$となずけましょう!
ここで一対一の勝負の場合もし兵1と兵2が戦う場合、兵1が勝つ確率,$p_1$を
$$p_1 = \dfrac{f_1}{f_1+f_2}$$
と定義しました。しかし、1対4とかの場合ではどうでしょう?こういう試合を4回するだけでしたら1対1の戦いを4回繰り広げるだけとなり、兵法においてとても大切な「戦術の分断」と「多数で少数を攻撃する」ことじたいを否定してしまいます。なので、先ほど言った攻撃範囲というものも作ってみました。
攻撃範囲とは攻撃を始める角度と攻撃を終了する角度の二つによって定義しました。敵の中心が攻撃範囲に入ったら攻撃したことになります。攻撃範囲が小さければ小さいほど力$f$が大きくなり、攻撃範囲が大きいほど$f$が小さくなります。よって攻撃範囲を広くすればするほど勝ちにくくなります。
では、学習したら兵たちは全員小さい攻撃範囲になるはずというかもしれませんが攻撃範囲以外の場所からの攻撃を考えてみました。その場合は力を$\dfrac{1}{4}$くらいにするように設定しました。これがUnityの上のGifで一人で全員倒せた理由です。攻撃範囲の外から攻撃してたからです。
これによって、大勢いる際は必ず攻撃範囲を広げないといけなく、多勢の方は攻撃範囲を狭くできて勝ちやすくなるようにしました。
Gifに出ていた数も気になると思います。これは階級です。1は一番下っ端で2がその一個上3はそれのさらに上っという感じで無限に付けられます。つけ方も結構簡単で5人同じ階級の兵がいたら一番優秀な一人(一番力があるもの)は必ず一個上の階級になる。というのを繰り返すと全員に階級がつけられました。
では、階級が上の人の存在意義というのは何でしょう?これは少し将棋とか少ししたりキングダムを読んで感じたものですが「次の状態を予測する」ことでついでに言うと「より広い視野」を持つことだと個人的に思いました。なので学習の際では指令として、上からの指令と今見える盤上をもとに次に起こると予想した兵の位置や状態などを送ることにしました。結構屁理屈かもしれませんが個人的には結構な理屈です。ここでどれくらいもっと見えるかは
$$r_{base}2^{rank-1}$$
ということにしました。つまり部下の2倍の景色が見れるようにしました。Unityで見せるとしたらこんな感じです。
人間で遊ぶ場合はどうやって次の状態っというのを送るかは思いつきませんでしたので、上のように自由に階級を行き来できるようにするつもりです!



- 投稿日:2019-06-07T18:41:16+09:00
兵法ができるAI開発
兵法ができるAI開発
記事の目的
こんにちは!今ちょうど深層学習(ディープラーニング)や強化学習の勉強をしていてAI同士を協力させると面白くないかな?と思ってこのプロジェクトを始めました。
このシリーズを通して学べる事
LSTM
強化学習
興味を用いた強化学習
アクタークリティック
簡単なゲームの作り方
Unity
Ml Agents動機
ちょうど「キングダム」という漫画
を読んで兵法や戦場における人というものの面白さに触れられてこのような思想戦を行えるゲームがしてみたかったからです。もちろん将棋やチェスみたいな簡略化したゲームはありますが戦場における以下の点を無視しているような気がしました(両方苦手ですがw)。1. 指揮系統がない
普通の戦場では命令系統があり、上からの命令と目の前の状況から次にする行動を決めると思います。しかし普通のゲームでは単純に命令を与えたらその場所に動き、駒に作戦などがありません。よって駒が自分で考えて上からの命令を参考するようにしました。
2. ランダムではない
ここで言っているのは一つの駒がもう一方の駒を攻撃したときに結果が決まっているということです。例えば飛車を歩の場所までもっていったら歩が取れるということが将棋では決まっています。しかし、正直それって正確には大してあっていないと思います。例えば四方向から誰かを囲めば確かに倒す確率は上げられるかもしれませんが逆にやられてしまう可能性が皆無というわけではないと思います。なので、そういったこと確率なども含んでみました。
3. 見える範囲
戦場において一番重要だと思うことは相手に自分の戦略が明らかにならないことです。ここで一番それができる確実な方法は相手に自分が見えないことです。よってそれを可能にするために各AIに個人個人見える範囲を設定しました。
4.動きが変
チェスや将棋にはマスがあり、双方順番に駒を進めます。しかし、実際には360度のどの方向にも動くことはできるはずでしかも両方毎秒毎秒動きます。順番などはありません。なのでそれも含めてみました。
手順
1.上の4条件を満たすゲームを考えてみる。
2. AIで学習できるようにする。
3. 結果報告
4+2n 改善したこと
5+2n 結果報告
でき次第リンクをつけておきますがここではとりあえず1を先に説明します。
とりあえず、最初の1だけここでとりあげます。1.ゲームのルール
前提に置いておきますが、このゲームは上の四つの条件を満たす最低限度のゲームを考えてみたのですが結構複雑になってしまったのでそのことはすみません。
すべてのプレイヤーは丸です。
この丸は動くことができ、攻撃範囲と攻撃する角度を指定すれば敵の丸を攻撃できます。Unityで作ったら下のようになりました。(学習したモデルはのっけてないです)
このゲームにはHPとかはなく、生きていると死んでいるという二つの状態しかありません。だから攻撃範囲(二つの黒い棒の間)に入ったら死ぬか相手を殺すかの2パターンしかありません。ここで第二条件の「ランダム」をいれてみました。
具体的にはすべての兵に正規分布からてきとうに「力」というパラメターを付けます。物理にならって力を$f$となずけましょう!
ここで一対一の勝負の場合もし兵1と兵2が戦う場合、兵1が勝つ確率,$p_1$を
$$p_1 = \dfrac{f_1}{f_1+f_2}$$
と定義しました。しかし、1対4とかの場合ではどうでしょう?こういう試合を4回するだけでしたら1対1の戦いを4回繰り広げるだけとなり、兵法においてとても大切な「戦術の分断」と「多数で少数を攻撃する」ことじたいを否定してしまいます。なので、先ほど言った攻撃範囲というものも作ってみました。
攻撃範囲とは攻撃を始める角度と攻撃を終了する角度の二つによって定義しました。敵の中心が攻撃範囲に入ったら攻撃したことになります。攻撃範囲が小さければ小さいほど力$f$が大きくなり、攻撃範囲が大きいほど$f$が小さくなります。よって攻撃範囲を広くすればするほど勝ちにくくなります。
では、学習したら兵たちは全員小さい攻撃範囲になるはずというかもしれませんが攻撃範囲以外の場所からの攻撃を考えてみました。その場合は力を$\dfrac{1}{4}$くらいにするように設定しました。これがUnityの上のGifで一人で全員倒せた理由です。攻撃範囲の外から攻撃してたからです。
これによって、大勢いる際は必ず攻撃範囲を広げないといけなく、多勢の方は攻撃範囲を狭くできて勝ちやすくなるようにしました。
Gifに出ていた数も気になると思います。これは階級です。1は一番下っ端で2がその一個上3はそれのさらに上っという感じで無限に付けられます。つけ方も結構簡単で5人同じ階級の兵がいたら一番優秀な一人(一番力があるもの)は必ず一個上の階級になる。というのを繰り返すと全員に階級がつけられました。
では、階級が上の人の存在意義というのは何でしょう?これは少し将棋とか少ししたりキングダムを読んで感じたものですが「次の状態を予測する」ことでついでに言うと「より広い視野」を持つことだと個人的に思いました。なので学習の際では指令として、上からの指令と今見える盤上をもとに次に起こると予想した兵の位置や状態などを送ることにしました。結構屁理屈かもしれませんが個人的には結構な理屈です。ここでどれくらいもっと見えるかは
$$r_{base}2^{rank-1}$$
ということにしました。つまり部下の2倍の景色が見れるようにしました。Unityで見せるとしたらこんな感じです。
人間で遊ぶ場合はどうやって次の状態っというのを送るかは思いつきませんでしたので、上のように自由に階級を行き来できるようにするつもりです!