- 投稿日:2019-06-07T15:18:35+09:00
画像のノイズ除去
はじめに
こんにちは!
今回は画像に入ったノイズの除去など画像処理について書いてみようと思います。
セグメンテーションのために前処理をしたら無駄なノイズが入って困った!なんて時に使えるので参考にしてみてください。今回使用する画像
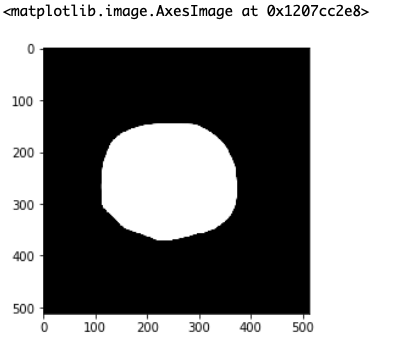
今回使用するのはこの画像です。
ノイズだらけの2値画像を作ってみたので、今からこれらのノイズをちょっとずつ消していこうと思います。
OpenCVを使うので、まだインストールしていない方はインストールの方宜しくお願いします。中央値フィルタ
一つ目は「中央値フィルタ」です。
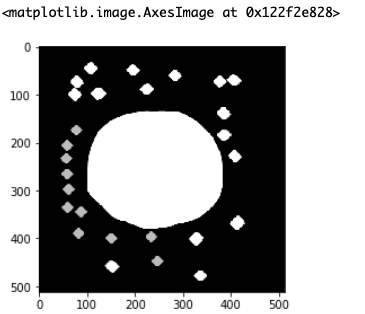
これは今回のような細かいノイズ(通称 ごま塩ノイズ)と呼ばれるノイズを消したい時に最適です。import cv2 import matplotlib.pyplot as plt img = cv2.imread("./test.png") # アパーチャーサイズ 3, 5, or 7 など 1 より大きい奇数。数値が大きいほどぼかしが出る。 ksize=3 #中央値フィルタ img_mask = cv2.medianBlur(img,ksize) plt.imshow(img_mask)するとこのような画像になります。
まだノイズが残っていますね。
なので、カーネルサイズをどんどん大きくしてみましょう。ここで注意なのですが、カーネルサイズは1より大きい奇数でないといけません。
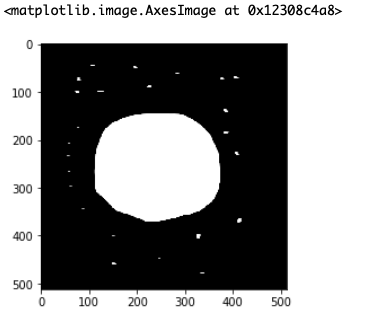
ksize = 15にしてみます。
これで完全にごま塩ノイズが消えました。
みなさんが自前の画像を使うときもちょっとずつksizeを変えて、その都度確認するようにしてみてください。膨張・収縮
2つ目は「膨張・収縮」です。
これらもOpenCVの機能であり、膨張処理は白色(255)の領域を膨張させ、収縮処理は白色(255)の部分を収縮させる処理です。
わかりにくいと思いうので実際にやってみましょう。ここで、収縮処理をした後に同じ回数だけ膨張処理をすることを「オープニング処理」、膨張処理をした後に同じ回数だけ収縮処理をする頃を「クロージング処理」と言います。
前者は白色のノイズ除去、後者は黒色のノイズ除去に役立ちます。
オープニング処理
まずはオープニング処理をしていきます。
import numpy as np import cv2 import matplotlib.pyplot as plt # 膨張・収縮処理 img = cv2.imread("./test.png") # 近傍の定義 neiborhood = np.array([[0, 1, 0],[1, 1, 1],[0, 1, 0]], np.uint8) # 収縮 img_erode = cv2.erode(img,neiborhood,iterations=10) # 膨張 img_dilate = cv2.dilate(img_erode,neiborhood,iterations=10) plt.imshow(img_erode)収縮処理をした後の画像がこれです。
確かに白いごま塩は消えていますが、白い部分が収縮したため、黒い部分が相対的に大きくなっています。
なので、次は膨張処理を加えます。
その後の画像がこちら
さっきよりは黒い部分が小さくなりましたね!
でもまだ足りないので、iterationsの箇所を10より大きくすると、もっと綺麗に黒いノイズが消えるのでやってみてください。クロージング処理
さっきの逆ですね。
import numpy as np import cv2 import matplotlib.pyplot as plt # 膨張・収縮処理 img = cv2.imread("./test.png") # 近傍の定義 neiborhood = np.array([[0, 1, 0],[1, 1, 1],[0, 1, 0]], np.uint8) #膨張 img_dilate = cv2.dilate(img,neiborhood,iterations=10) #収縮 img_erode = cv2.erode(img_dilate,neiborhood,iterations=10) plt.imshow(img_dilate)するとこのような画像が表示されます。
白い部分が膨張して、黒い部分がかき消されていますが、白いノイズが大きくなってしまっています。
なので収縮処理を加えるとこのようになります。
このように白いノイズが小さくなりました!
先ほどと同様にiterationを大きくするともっと綺麗に消えますが、この方が効果がわかりやすいので今はご了承ください。終わりに
いかがでしたか?
今回のノイズ処理はセグメンテーションのために頑張って色ぬりをした人のためにあるようなものです。
色塗りしたのに、なんか変なノイズが入った。。。なんて時にご活用ください。最後に、医学生である僕が所属しているツカザキ病院眼科AIチームのページも見ていただけたら幸いです!ぜひご覧ください!
ツカザキ病院眼科AIチーム DeepOculus
では、また次の記事で!




- 投稿日:2019-06-07T15:09:50+09:00
文字コードにまつわる7つの迷信
現在はUTF-8が文字コードのデファクトスタンダードになっていますが、かつては文字コード周りがややこしい時代がありました。
そのせいか、経験年数の長いプログラマーでさえ(経験年数が長い故に?)文字コード周りの誤った「ベストプラクティス」が信じていることがあります。
私も新人の頃、先輩に色々な「ベストプラクティス」を教えられ、後で「これはアンチプラクティスだったんだ・・・」と気づくことがなんどもありました。この記事ではそういった文字コード周りの「誤り」「迷信」を列挙していきたいと思います。
なお、文字コードには「お前の言うのShift_JISは、Shift_JISじゃなくCP932」といった種類の迷信もありますがここで、この記事では文字コードの取り扱いについての迷信を扱います。
迷信
おことわり: ここで説明するのは原則論です。「誤りです」といった表現をしていますが、もちろん、現場ではバッドプラクティスをとらなければいけないこともあります。しかし、バッドプラクティスであることを簡潔に表現するために「誤りです」という表現にしています。
迷信1: 「うちのLinuxサーバーはLANG=ja_JP.EUCJPだから、ソースコードもEUC-JPにしないと文字化けする」
Unixには
LANGという環境変数があり、端末で使う文字コードを指定します。プログラムは
LANGを参照して出力の文字コードを決めます。プログラムが間違った文字コードで出力してくると、端末上で文字化けが起こります。それを誤解して:
「うちのLinuxサーバーはLANG=ja_JP.EUCJPだから、ソースコードもEUC-JPにする」と言われるかもしれませんが、誤りです。
プログラムが意識するべきは出力の文字コードであって、ソースコードの文字コードは関係ありません。また、最近のプログラミング言語では、出力の処理は言語処理系が自動でやってくれることもあります。
なお、シェルスクリプトの場合は、「ソースコードの文字コード = 出力の文字コード = LANG」にせざるを得ない(別の文字コードを使う方法もあるが面倒)ので、このような誤解が生じるのかもしれません。
迷信2: 「vi だとLANGと違う文字コードのファイルは文字化けする」
LANGとソースコードの文字コードを合わせる別の理由として、
「vi だとLANGと違う文字コードのファイルは文字化けする」といったものが挙がることがありますが、誤りです。
vi(などのエディタ)はファイルの内容をそのまま画面に表示しているわけではなく、LANGにしたがって変換したものを表示しています。文字化けするのは、ファイルが間違った文字コードで開かれているからです。
正しい文字コードを指定すれば、文字化けは起きないはずです。
ファイルを文字コード指定して開くとき:
vi -c ':e ++enc=sjis' sjis.txtファイルを文字コード指定して再読み込みするとき:
:e ++enc=sjis迷信3: 「内部エンコーディングをOSに合わせるべき」
ご存知の通り、ソフトウェア内では文字列はバイト列として表現します。
プログラミング言語ごとに処理系内で文字列をバイト列として表現する際の文字コード(内部エンコーディング)が決まっており、言語によっては内部エンコーディングをオプションで切り替えられます。
先輩に
「内部エンコーディングは、OSのエンコーディングと合わせた方が良い」
「うちのサーバーは LANG=ja_JP.EUCJP だから、Rubyの内部エンコーディングも EUC-JP にしないといけない」なんて言われたかもしれませんが、これは誤りです。
最近のプログラミング言語では、文字列型には文字通り「文字の列」としてのインターフェースが備わっていたり、ファイル読み込み時にエンコーディングを変換したりと、バイト列であることを意識しなくてもよい設計になっています。内部エンコーディングをあえて変更する機会はないはずです。
# Ruby str = "⛄️雪だるま" # 文字列に含まれる「文字」にアクセスできる char = str.chars.first puts char # => ⛄ # 文字の「コードポイント」を取得できる。コードポイントはUnicodeの文字に割り当てあられた通し番号で、UTF-8エンコードした時の表現(=3バイトのバイト列)ではないことに注意 puts char.ord # => 9924 # もちろん、内部表現(UTF-8のバイト列)を取り出すこともできる puts str.encoding.to_s # => "UTF-8" puts str.bytes.inspect # => [226, 155, 132, 239, 184, 143, 233, 155, 170, 227, 129, 160, 227, 130, 139, 227, 129, 190]迷信4: 「文字コードを自動判定しよう」
fileやnkfといったツールにはテキストファイルの文字コードを判別する機能があります。これはシェル上で調査をするときには、便利です。しかし、テキストファイルを処理するバッチ処理やCLIツールなどについても
「このツールでは、ファイルの文字コードを自動判定して処理しよう」 「自動判別すれば、文字コードの指定が不要になる」 「文字コードを意識しなくても使えるようにするべきだ」といったことを言われるかもしれませんが、誤りです。
そもそも、文字コードを完璧に自動判定することは原理的に不可能です:
- ある文字コードのバイト列が、たまたま別の文字コードとしても解釈できることがある
- 特にASCII文字しか含まれていない場合は、どの文字コードなのか分からない
そのため、ツールを作るときは、
- ファイルを開くときにユーザーが文字コードを指定できるようにする
- 文字コードを自動判定するときは、判定結果を画面に表示した上で、ユーザーが判定結果を上書きできるようにする
とするべきです。
迷信5: 「Windowsだから文字コードはShift_JISのはずだ」
Unicode(特にUTF-8)が普及する前は、OSごとに標準的な文字コードが異なっていました。
Unix系ではEUC-JP、Windows系ではShift_JISなど。特にWindowsではメモ帳などの標準アプリで、ファイルがShift_JISで保存される(保存時に文字コードを選択できない)ため、Windowsで使える文字コードはShift_JISに決まっているという印象が強かった。
しかし、こういった「OSごとの標準的な文字コード」はあくまで、標準「的」なもので、他の文字コードのテキストファイルを扱うのは普通のことです1。
デフォルト設定としては「WindowsではShift_JIS、MacではUTF-8にする」とかでもいいかもしれませんが、決め打ちにするのは誤りです。
迷信6: 「DBの文字コードがShift_JISだから、接続時にShift_JISを指定しなければならない」
DBの内部エンコーディングには文字種が多いUTF-8を使うのが無難ですが、古いDBではShift_JISなどを使っていることがあります。
ここで、
「うちのDBはShift_JISだから、プログラム側の文字コードもShift_JISにしなければならない」 「NLS_LANG=JAPANESE_JAPAN.JA16SJISTILDE を指定しなければならない」と言われるかもしれませんが、誤りかもしれません。「プログラム側の文字コード」が何を指すのか見極めるべきです。
例えばOracle DBでは、クライアントライブラリに環境変数
NLS_LANGで文字コードを指定できますが、NLS_LANGはサーバーとクライアントライブラリの間の通信でどの文字コードを使うかを指定するものです。クライアントライブラリがプログラムに返すのはバイト型ではなく、文字列型なので、プログラム側の処理はNLS_LANGが何であるかは関係ありません。Oracleサーバー(Shift_JIS) ↓ (クライアント/DBサーバー間の通信)(UTF-8) ↓ クライアントライブラリ ↓ (StringやStringのリスト) ↓ プログラム(UTF-16)もちろん、Shift_JISのDBに「⛄️」を扱うことはできません。そういった意味ではプログラム側も文字コードを意識しなければいけないこともあります。
迷信7: 「デフォルトの外部エンコーディングをUTF-8にしよう」
各種プログラミング言語では、
open()などでファイルを開くとき、encodingを指定しなければ何らかのデフォルト値が使用されます。例:
- RubyではEncoding.default_external
- Pythonではlocale.getpreferredencoding()「このプロジェクトのテキストファイルは全てShift_JISだから、Encoding.default_external = 'Shift_JIS' に変更しよう」 「デフォルトエンコーディングで読み書きすれば、OSが変わっても動作する」と言われるかもしれませんが、考えものです。
他の項でも述べたように、OSの標準とは別の文字コードを扱うことは普通にあることで、文字コードを決め打ちにするのは後々苦労の元です。また、デフォルトの文字コードを決めるとしても、それはアプリケーションの仕様なので、プログラミング言語の仕組みに乗っかるべきではないと思います(例えば
Encoding.default_externalは環境変数で変更できてしまう)。個人的には、
- 「外部エンコーディング」という概念は混乱の元
open()関数はencoding引数を必須にするべき- デフォルトのエンコーディングを決めたければ、
DefaultEncodingといったグローバル変数を自前で定義したりすればよい。と思っています。
文字コードをどう考えるか?
文字コード周りは個別の条件を細かくつつき出せばキリがありません。結局、文字コードの扱いはどのように理解すればよいのでしょうか?
色々な意見・色々な言い方があると思います。「内部の文字コードは統一せよ」「文字コードはIO境界で変換せよ」なんて、よく言われます。
私が重要だと思うのはプログラムの「内部」は文字コードが登場しない世界。文字コードはプログラムの外側の問題だということです。
「文字列型」で文字コードが隠蔽されていたりするので、プログラムの「内部」の処理には文字コードを意識する必要がありません。「内部」で文字コードの問題が起きたとしたら、何かがおかしい。
一方、「ファイル」「WEB API」「別のプログラム」などは、プログラムの「外側」にあるので文字コードを『必ず』意識しなければなりません。ここで「OS標準のエンコーディングを使う」などと横着すると後で痛い目を見るかもしれません。
また、「プログラム」同士が連携するとき:
- ターミナルと vi
- パイプで通信する2つのプログラム
- DBサーバーとクライアント
文字コードは、2つのプログラムの「外側」の「間の部分」の問題なので、それぞれが内部でどんな文字コードを使っていても問題は起きません。「間の部分」で、エンコーディングを適切に指定したり、変換層を咬ませたりすれば、良いのです。
OS標準ツールが文字コードを決め打ちしていて、ムキー! ヽ(`Д´#)ノ となることはあります。 ↩
- 投稿日:2019-06-07T12:30:33+09:00
こんな時代だからこそ要件定義の重要性を思い出せ!
はじめに
SIerからマーケティング会社に転職したため、最近はあまり行っていませんが、
どの業種においても、業務をきちんと進める上で要件定義の進め方・考え方は参考になるため、
久しぶりに要件定義のポイントについて振り返ってみました。特に要件定義はシステム開発の上流工程に位置するので、難しい、、、というか、
如何にクライアントと、これから作るシステムの「認識を合わせられるか」、
お互いの「合意が取れるか」が肝になってくるので大事なフェーズと言えます。そもそも「要件」って
ようけん
【要件】
1.
大切な用事。
2.
必要な条件。
「資格―」Google先生に聞くと要件とは「必要な条件」と出てきます。
つまり、クライアントの要望や課題を洗い出して、
システムを作る上で「必要な条件」を定義するということになるのでしょうか。要件定義で定義する項目
とにかくたくさんあるので抜粋します。
- システム概要
- システム化の背景
- 目的・方針
- システム化する範囲
- ・・・
- 機能要件
- 業務フロー
- 機能一覧
- ・・・
- 非機能要件
- 性能
- 拡張性
- ・・・
- 移行要件
- 移行プロセス
- 移行タイミング
- ・・・
- 運用・保守
- 運用体制
- 保守
- ・・・
特に重要だと感じる項目
要件定義で定義する項目はたくさんありますが、
特に大事だと考えているのは「システム化の背景」「目的・方針」「範囲」「業務フロー」です。というのも、要件定義では
- なぜシステム化する必要があるのか
- システムが果たす役割はなんなのか
- システムに何を期待しているのか
- 依頼したい範囲はどこなのか
が重要で、これを誤るとこの先の工程が全て破綻してしまう恐れがあるからです。
最後の最後になって、「期待していたのと違うなあ」とならないためにも、
目的を明確化し、認識を合わせ、コミュニケーションを取ることが大事だと思います。余談ですが、これはマーケティング業界でも同じことが言えると思っており、
- 現状の課題は何なのか(課題の本質は何か)
- なぜ分析する必要があるのか
- 分析結果がもたらす役割は何か
- どんな施策につなげたいのか
など、初めの認識を合わせるということはとても大切になってきますね。
業務フローについては、当然といえば当然ですが、
現状の業務を洗い出し、どんなフローで業務を回しているのかを整理することで、
何処のフローを変え、効率化を図り、どんなシステムとするのか、を
全体を通して俯瞰して見ることが出来るためしっかり押さえておきたいポイントです。これもクライアントと認識を合わせるためには大事な要素になってきます。
要件定義には業界・業務の基礎知識は必要?
要件定義を進める上では、クライアントと会話をする必要があるので、
基礎知識はやはり必要です。何でもかんでも「それはどういう意味でしょうか?」「どういう事でしょうか?」と
聞いていては、クライアントに不安を与えることになってしまいます。とは言え、知らないものは知らないし、業界特有の言い回しもあるので、
聞くべきところはちゃんと質問して疑問を残さないようにしたいですね。クライアントからの要件を切り分ける
クライアントと会話を進める中で、当初のRFPに記載のない要望が出てくる
ことがあります。(夢がふくらんできます)すべてを実装してあげた方が喜んでもらえる場合もありますが、
逆に実装したため納期が遅延し、怒られるなんてこともあるかもしれません。そこで大事になってくるのが、
- 必要な機能
- あったらいいな機能
を切り分けることです。
これらの判断は、予算、スケジュール、リソースなどを総合的に判断して、
決めきる必要があります。特にウォーターフォールモデルで開発を進めている場合、
あとで実装するかも?的な機能要件を残しておくなんて出来ないですよね。要件定義では「あったらいいな機能」の落とし所(無理やりではなく双方が納得する)を見つけ、
要件を整理することも大事になってきますねー。すべての要件を決めきるなんて出来るの?
システム開発を進める上で、プロジェクト初期の段階で要件定義のスケジュールを
引いていると思いますが、その要件定義の期間中にすべての要件を完全に「詰める」「決めきる」ことは、
小さなプロジェクトならともかく、大規模プロジェクトでは難しくなってきます。そのため、「優先度」をつけ、重要な要件、次の工程に影響の出る要件などは優先的に進め、
後からでもスケジュールに影響の出ない要件(簡易な定義等)は優先度を下げるなど、
全体スケジュールを意識し進めることも大切になってきますね。要件の詰め方
要件詰めを口頭確認だけで済ますと、
お互いの認識がフワッとしたまま進んでしまう恐れがありますので、
「時系列のデータの流れ」や「ステータスの遷移」など、認識が曖昧になりそうな定義は、
サンプルデータなどの補足資料を準備し会議を進めた方が、時間も短縮され、
認識も合わせ易くなると思います。誰と会話するの?
基本的にはクライアントの「プロジェクト担当者」と進めると思いますが、
役職が上の方であったり、情シスの方であったりと、
現場から意見を吸い上げて持ってきている場合があります。もちろん最終判断はプロジェクト担当者に決めてもらえば良いと思いますが、
要件を詰める中では、現場のユーザーにヒアリングさせてもらったり、
会議の場に呼んでもらったりした方が生の意見を聞けるため、認識が合わせやすく、
リスクも減るかと思います。議事録の重要性
要件定義を進める上でもう一つ大事になってくるのが「議事録」です。
議事録は下記の利用が考えられます。
- 会議の振り返り/メンバーへの共有
- 議題・課題の「可決・否決・保留」の承認記録
- 課題管理への起票(対応期限は明確に(※))
(※)会議の中で新たに出てくる課題については、誰がいつまでに対応するのか、を
明確にする必要があります。また、議事録の重要な用途としては、後から「言った、言わない」の水掛け論を防ぐことに
あると思います。水掛け論になってしまった場合、調整がややこしくなる(押し切られるなんてことも...orz)ので、
そうならないためにも、
- 必要要件は議題にのせる
- 議事録を取る
- 議事録をクライアントと共有する
- 議事録自体の承認を得る(必要に応じ、読み合わせや捺印返却)
しっかり記録を残しておきましょー。
その他
要件定義書、議事録、スケジュール表、課題管理表、設計書などなど
事前に使いまわしのきく資料は「テンプレート化」しておくと良いと思います。
出来れば社内全体で。メリットとして、
- 時間短縮(フォーマットを考えなくて良い)
- 品質向上(抜け漏れが減る)
- 社内共通のため人の入れ替わりに強い(急遽プロジェクトに組み込まれたとき 汗)
但し、これらをちゃんと運用していくには、整備担当を決め、改善点のブラッシュアップを行い、
社内教育を行ってメンバーに利用を促していく必要があるのでハードルは上がります。もしテンプレート化されていないようであれば、まずは個人利用から始めても良いかもですね。
まとめ
- 要件定義では「システム化の背景」や「方針・目的」を明確にし、「お互いの合意」を取る
- 必要機能とあったらいいな機能を「切り分ける」
- 後で「言った言わない」が発生しないよう必要事項は議題にのせ記録を取る
- わからないことは素直に聞く、疑問を残さない
- 必要要件を可能な限り詰め切る(課題が残っていると後工程の影響がデカい)
- プロジェクト担当だけでなく、ユーザーの意見も聞く
- 資料のテンプレート化は行った方が良い
おわりに
少しだけ進め方のポイントを振り返るつもりが長々と書いてしました。。。が、
これらをスムーズに進めるためにはクライアントとコミュニケーションをちゃんと取って
お互いの目指すべき方向性や意識を合わせることが大事ですね。要件定義の難しさは、それぞれの仕様・定義をもれなく決めるというところにありますが、
クライアントから見れば、出来ればこれもやってほしいなあと思うのが人情です。
でも、対応が難しい場合はちゃんと会話し、お互いが納得する落とし所を見つけてあげる
のも要件定義の醍醐味かなあと思います。私自身、打ち合わせの場でクライアントの要件を汲みつつ、
こちらのペースに持っていくことが出来たときは気持ちよく帰れたものです 笑要件定義の進め方は、各社、各人各様あると思いますので、少しでも内容がお役に立てれば幸いです。