- 投稿日:2019-06-07T22:37:29+09:00
PythonとFirebase (storage)まとめ
友人に頼まれ、先日初めてWebアプリを作ったので色々勉強したことをまとめておこうと思った。
前提知識(firebase)
Firebaseとは
Firebaseはgoogleの提供している「mobile Backend as a Service(mbass)」
モバイルアプリを作る際に必要となるデータベース、ユーザー認証、あとはメッセージの送信がすぐにできるサービスである。採用理由は二つ
一つはクレカの登録なしで無料プランを使えること。
一つは、画像を保存できるStorageと名簿で使う個人情報を保存できるCloud FirestoreStorageは画像をネット上に保存できる
CloudFirestoreは流行りのNoSQLである。python側の設定
必要なモジュール等をインストールする
pip install requests-toolbelt sseclientfirebase上の設定(Storageのための設定)
Firebaseのログインやプロジェクトの作成等は割愛
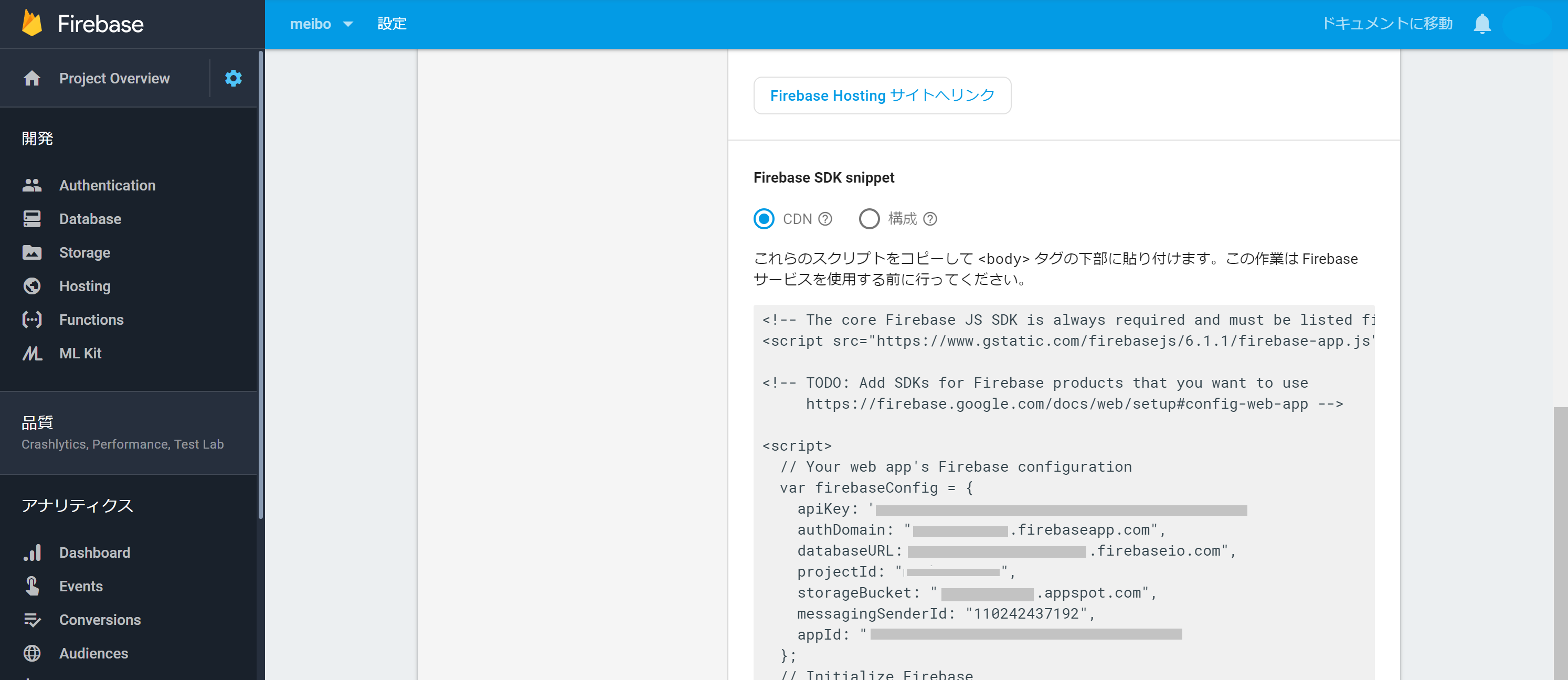
Project OverViewから</>マークのウェブを選択
この画面に行き着いたら、
- apiKey
- authDomain
- DatabaseURL
- StorageBucket をコピペしておく

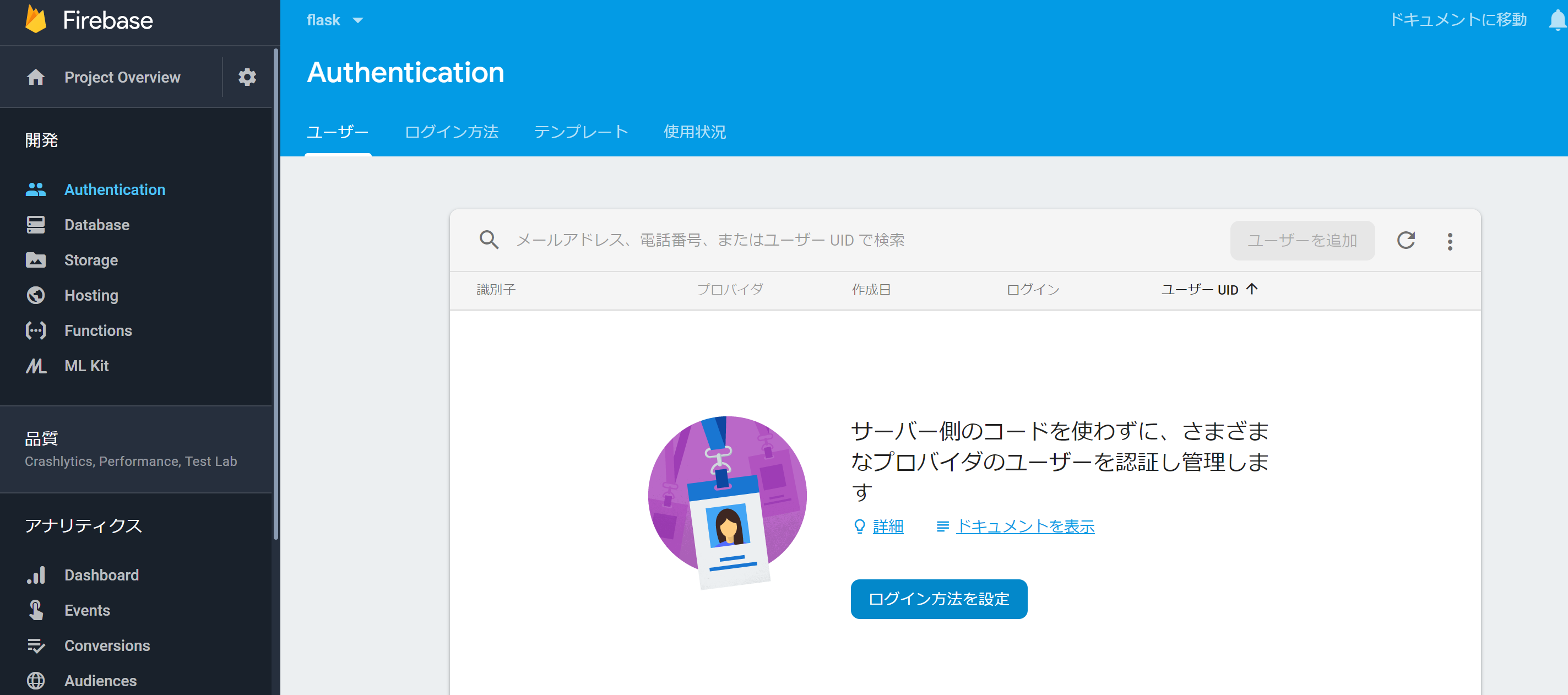
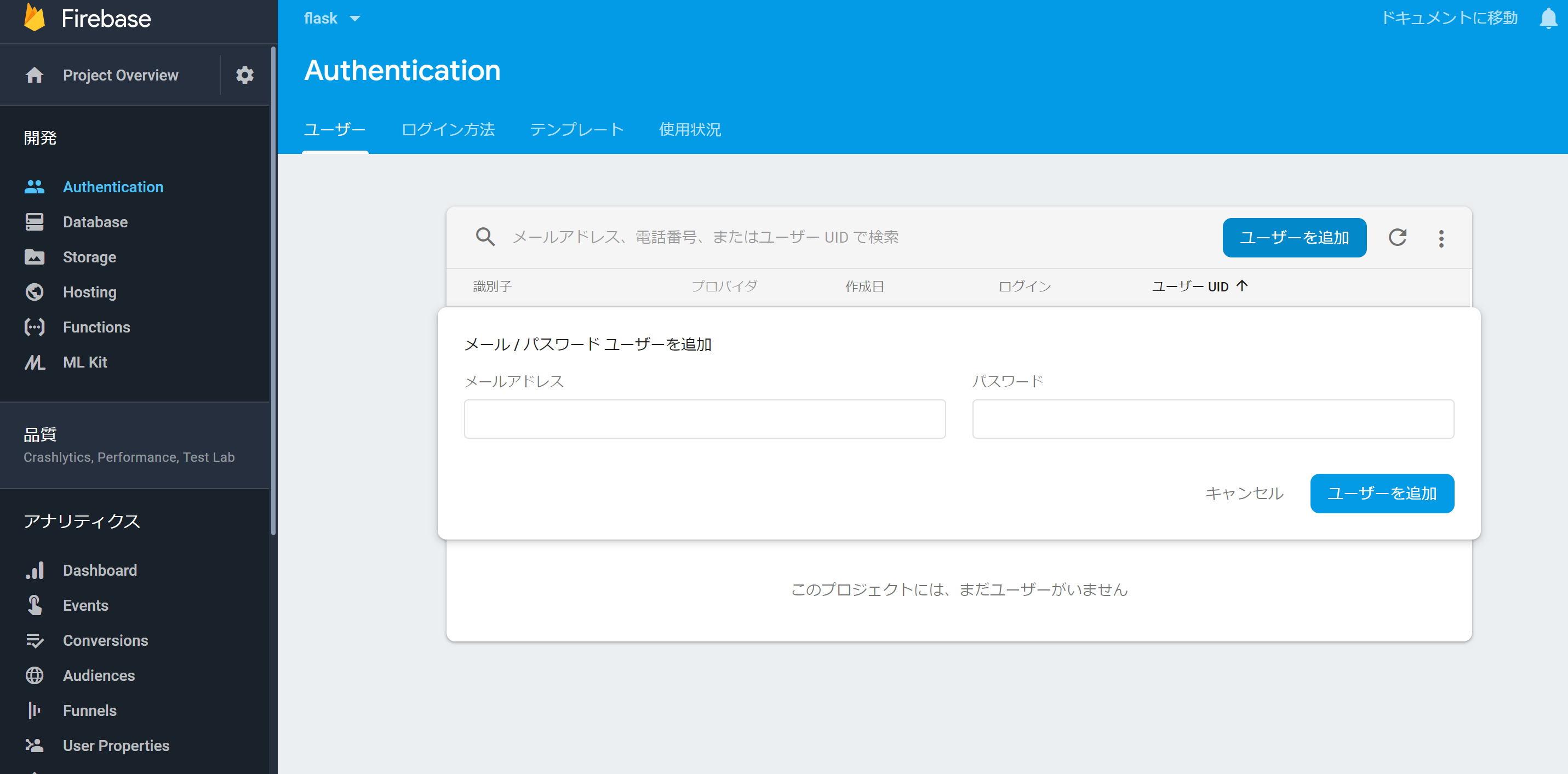
メールアドレスとパスワードを登録するために、Authentificationからログイン方法を設定
メールアドレスとパスワードを追加
pyrebaseを使って画像をアップロード
画像をアップロードすることができるライブラリは他にもあるが、その画像のURLが分かるライブラリが他に見当たらないので、Pyrebaseを使う。おそらく普通にpipを使っても入らない。入る人はpipでいいし、ダメならこれを参照してほしい。
https://github.com/thisbejim/Pyrebase/issues/288#issuecomment-445496948Storageのテスト
今回は適当にGoogleから検索したQiitaの画像をStorageに入れてみる。空欄になっている部分は先ほどコピペしたものとEmailアドレスとパスワードを入れる。upload_image.pyimport requests import pyrebase # from Pyrebase import pyrebaseの場合も #コピペしたものの貼り付け config = { 'apiKey': "", 'authDomain': "", 'databaseURL': "", 'storageBucket': "" } firebase = pyrebase.initialize_app(config) auth = firebase.auth() #アドレスとパスワード user = auth.sign_in_with_email_and_password("", "") storage = firebase.storage() photo_path = requests.get('https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcRqLfdDUW1cdWkKH63aink0HPtR8wFlCQ5aaNO0vUTY_X2Z612p').content #.childの中は保存するStorage内のディレクトリ storage.child('google.jpg').put(photo_path,user['idToken'])firebase上の設定(CloudFirestoreのための設定)
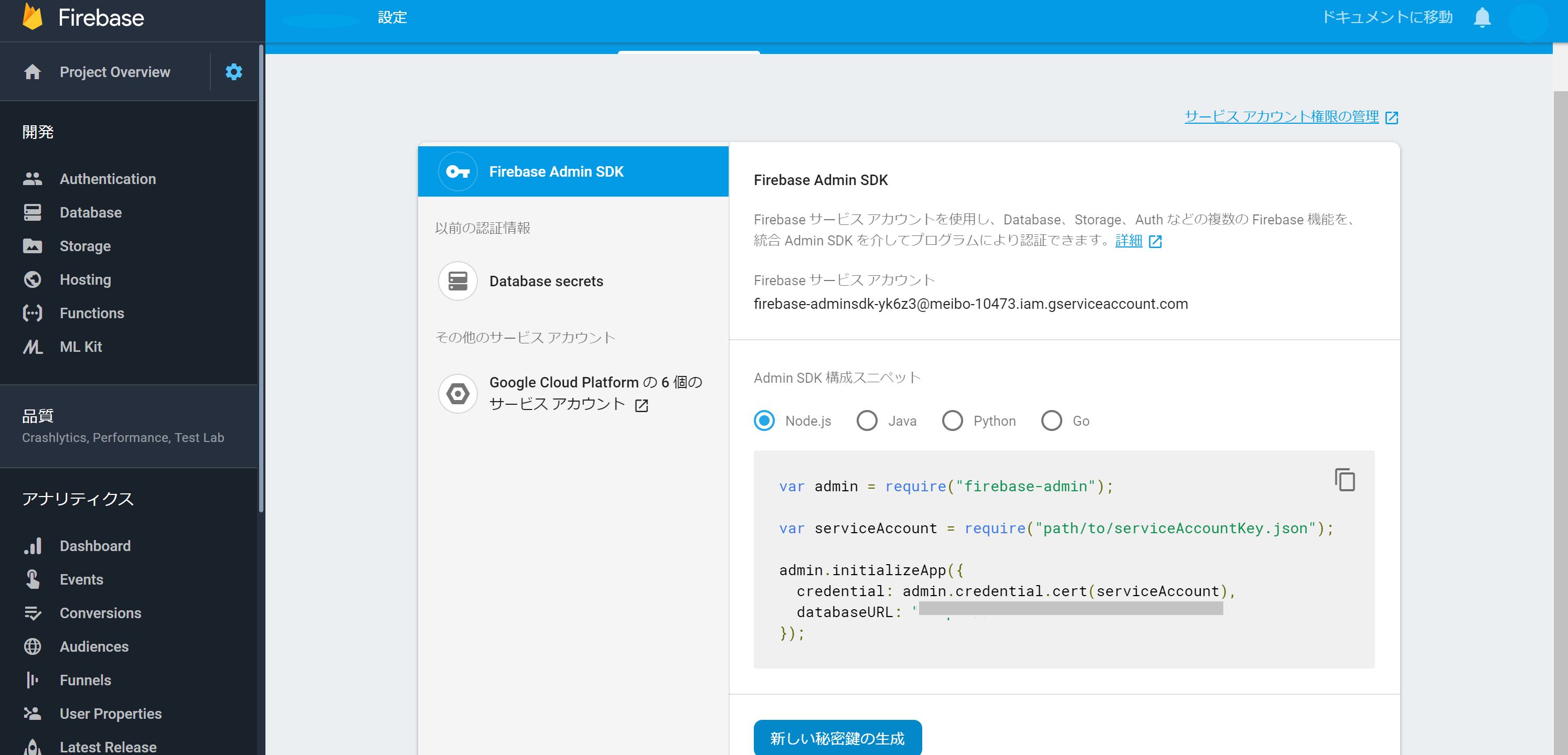
設定画面からFirebaseの秘密鍵を発行する
firebase_adminからデータをアップロード
pip install firebase_adminCloudfirestoreに関しては、公式のドキュメントが充実しているのでそこまで深くは書かないが、データを載せるだけなら以下のスクリプトでおそらく十分
credの欄に秘密鍵のディレクトリを入れる
upload.pyimport firebase_admin from firebase_admin import credentials from firebase_admin import firestore cred = credentials.Certificate("") firebase_admin.initialize_app(cred) db = firestore.client() insert_doc = {'name':'qiita', 'color':'green'} db.collection('demo').document().set(insert_doc)PyrebaseとFirebase_adminを組み合わせる
Pyrebaseで載せたデータのURLを確認する。
先ほどのコードの続き
upload_image.py#storage.child('google.jpg').put(photo_path,user['idToken']) info = storage.child('google.jpg').put(photo_path,user['idToken']) token = info['downloadTokens'] print(token)FirebaseのStorageの中に入れた画像のURLの最後につくtokenの名前がわかるので、これを組み合わせてCloudStorageに入れる。

- 投稿日:2019-06-07T22:34:38+09:00
【画像生成】AutoencoderでDenoising, Coloring, そして拡大カラー画像生成♬
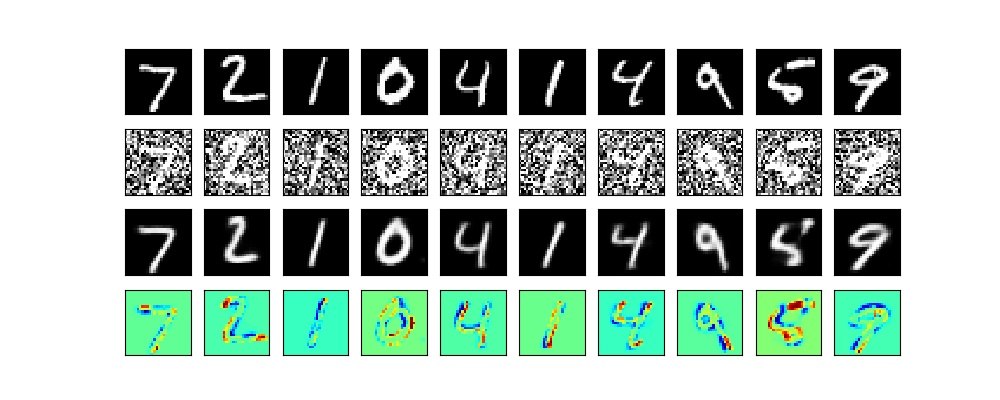
今回は、「AutoencoderでDenoising, Coloring, そして拡大画像生成」を取り上げます。
大切なことはこの3つ(元々のAutoencoder含め4つ)のことは、ほぼ同じプログラムでデータをそのように用意すればできるというところがミソです。
いつもなんとなく別々に説明されるので、難しいことかと思いがちですが、基本はAutoencoderなので簡単です。
【参考】
・畳み込みオートエンコーダによる画像の再現、ノイズ除去、セグメンテーション簡単に今回の記事を要約すると以下のようになります。
すなわち、autoencoder-decoderの学習部分のfit関数を示します。
vae.fit(x_train_gray,x_train_size, epochs=epochs, batch_size=batch_size, callbacks=callbacks, validation_data=(x_test_gray, x_test_size))これは、
入力;x_train_gray(32,32,1)のgray画像 出力;x_train_size(64,64,3)のcolor画像として学習し、
入力;x_test_gray(32,32,1)のテストgray画像 出力;x_test_size(64,64,3)のテストcolor画像で検証することになります。
すなわち、絵にすると以下のような感じです。
問題は、入力と出力を何にするかということです
そして、ドメイン間を変換する関数がencoder-decoderということになり、ドメインの性質に合わせて適切なモデルを配置すればよいことになります。
ということで、いろいろなドメイン間の変換ができることを意味しています。今回やったこと
①入力:ノイズあり画像、出力;ノイズ無し画像
②入力;Gray画像、出力;カラー画像
③入力;32x32サイズGray画像、出力;64x64サイズカラー画像基本のコードは以下に置きました
以下はMNISTのノイズ除去のコードです
・VAE/keras_conv2d_noise_reduction.py①入力:ノイズあり画像、出力;ノイズ無し画像
Denoisingのコード解説
一応、簡単に上記のコードの骨の部分を解説します。
以下のとおり、encoder-decoder-modelは前回と同様です。# encoder model inputs = Input(shape=input_shape, name='encoder_input') x = Conv2D(32, (3, 3), activation='relu', strides=2, padding='same')(inputs) x = Conv2D(64, (3, 3), activation='relu', strides=2, padding='same')(x) shape = K.int_shape(x) print("shape[1], shape[2], shape[3]",shape[1], shape[2], shape[3]) x = Flatten()(x) z_mean = Dense(latent_dim, name='z_mean')(x) encoder = Model(inputs, z_mean, name='encoder') encoder.summary() # decoder model latent_inputs = Input(shape=(latent_dim,), name='z_sampling') x = Dense(shape[1] * shape[2] * shape[3], activation='relu')(latent_inputs) x = Reshape((shape[1], shape[2], shape[3]))(x) x = Conv2DTranspose(64, (3, 3), activation='relu', strides=2, padding='same')(x) x = Conv2DTranspose(32, (3, 3), activation='relu', strides=2, padding='same')(x) outputs = Conv2DTranspose(1, (3, 3), activation='sigmoid', padding='same')(x) decoder = Model(latent_inputs, outputs, name='decoder') decoder.summary() outputs = decoder(encoder(inputs)) vae = Model(inputs, outputs, name='vae_mlp') vae.compile(loss='binary_crossentropy',optimizer='adam')変更は、以下のように入力データとしてノイズを重畳します。
【参考】
・numpy.random.normal@SciPy.org
loc;Mean (“centre”) of the distribution.
scale;Standard deviation (spread or “width”) of the distribution.
size;Output shape
np.clip;0,1を下回るまたは上回る場合に0,1に制限しますnoise_train = np.random.normal(loc=0.5, scale=0.5, size=x_train.shape) noise_test = np.random.normal(loc=0.5, scale=0.5, size=x_test.shape) # 学習に使うデータを限定する x_train_noisy = np.clip(x_train + noise_train, 0, 1) x_test_noisy = np.clip(x_test+ noise_test, 0, 1)一番大切なのは、学習のとき、入力;x_train_noisy, 出力;x_trainで学習し、検証も入力;x_test_noisy, 出力;x_testで実施しています。
実は、今回の3つのテーマではこの入力と出力を変更し、それらに合わせてネットワークなどをちょっと変更するだけで、いろいろな変換ができることがミソです。class Check_layer(keras.callbacks.Callback): def on_epoch_end(self, epoch, logs={}): if epoch%2==0: ... decoded_imgs = vae.predict(x_test_noisy[:n]) plot_irregular(x_test,x_test_noisy,decoded_imgs,epoch=epoch) ch_layer = Check_layer() callbacks = [ch_layer] # 学習 vae.fit(x_train_noisy,x_train, epochs=epochs, batch_size=batch_size, callbacks=callbacks, validation_data=(x_test_noisy, x_test))Denoisingの結果
以下のとおり、潜在空間10次元で100epochだと完全にノイズ除去してくれました。
もう少し、見ると以下のとおり、綺麗に出力できました。
②入力;Gray画像、出力;カラー画像
Coloring
同じように、カラー画像であるCifr10でgray-colorの変換を実施してみます。
コード全体は、以下のとおりです。
・VAE/keras_conv2d_coloring.py
そして、コードの大きな変更部分は、以下のとおりです。
1.描画サイズは慎重に変更しましょう
2.入力は(32,32,1)のGray画像で、出力は(32,32,3)のカラー画像
3.描画の中で、以下のとおり、カテゴリの色指定を以下のとおり1-Dに変換していますy_test1 = np.ravel(y_test) sc=plt.scatter(z_mean[:, 0], z_mean[:, 1], c=y_test1,s=50,cmap=plt.cm.jet) plt.colorbar(sc)4.学習と検証に使うGray画像変換は以下の関数を使っています
def rgb2gray(rgb): return np.dot(rgb[...,:3], [0.299, 0.587, 0.114]) x_train_gray = rgb2gray(x_train).reshape(len(x_train),32,32,1) x_test_gray = rgb2gray(x_test).reshape(len(x_test),32,32,1)5.モデルは入出力に注意して、以下のようにしました
# encoder model inputs = Input(shape=input_shape, name='encoder_input') x = Conv2D(32, (3, 3), activation='relu', strides=2, padding='same')(inputs) x = Conv2D(64, (3, 3), activation='relu', strides=2, padding='same')(x) shape = K.int_shape(x) print("shape[1], shape[2], shape[3]",shape[1], shape[2], shape[3]) x = Flatten()(x) z_mean = Dense(latent_dim, name='z_mean')(x) encoder = Model(inputs, z_mean, name='encoder') encoder.summary() # decoder model latent_inputs = Input(shape=(latent_dim,), name='z_sampling') x = Dense(shape[1] * shape[2] * shape[3], activation='relu')(latent_inputs) x = Reshape((shape[1], shape[2], shape[3]))(x) x = Conv2DTranspose(64, (3, 3), activation='relu', strides=2, padding='same')(x) x = Conv2DTranspose(32, (3, 3), activation='relu', strides=2, padding='same')(x) outputs = Conv2DTranspose(3, (3, 3), activation='sigmoid', padding='same')(x) decoder = Model(latent_inputs, outputs, name='decoder') decoder.summary() outputs = decoder(encoder(inputs)) vae = Model(inputs, outputs, name='vae_mlp') vae.compile(loss='binary_crossentropy',optimizer='adam')6.学習は以下のようにしています
入力;x_train_gray,出力;x_train、そして検証は、入力;x_test_gray, 出力;x_testで学習しています。
相変わらず、vae.compile(loss='binary_crossentropy',optimizer='adam')
として、loss='binary_crossentropy'or 'mse'で実施しました。class Check_layer(keras.callbacks.Callback): def on_epoch_end(self, epoch, logs={}): if epoch%20==0: ... n=10 decoded_imgs = vae.predict(x_test_gray[:n]) plot_irregular(x_test,x_test_gray,decoded_imgs,epoch=epoch) ch_layer = Check_layer() callbacks = [ch_layer] # autoencoderの実行 vae.fit(x_train_gray,x_train, epochs=epochs, batch_size=batch_size, callbacks=callbacks, validation_data=(x_test_gray, x_test))Coloringの結果
上段が元の絵で、中断が入力のGray画像、そして下段が色付けされた画像。
まあ、元の絵とは配色が異なりますが、一応塗れています。
100epoch
③入力;32x32サイズGray画像、出力;64x64サイズカラー画像
Grayから拡大カラー画像生成
コード全体は以下のとおりです。
・VAE/keras_conv2d_x4coloring.py
複雑な変換のようみ見えますが、上記と大きな違いは、元のCifar10画像を拡大して学習データを作成するところです。
入力のGray画像は上記のものを使います。
そして、カラー画像の拡大は以下のコードで実施します。
※本来は高精細画像を縮小して学習すればもっと高精細な変換器が作成できるはずですが、ここではさぼりました
そのためのコードは以下のとおりです。cv2.resizeを使います。
※サイズは今回は1060で計算したのでメモリーの関係で(64,64)としました
ここには示しませんが1080、8MB だと(256,256)まで拡大できました。
ただし、batch_size=8(128@1080マシン)など小さな値にしていますimg_rows, img_cols=64,64 #256,256 #128,128 X_train =[] X_test = [] for i in range(len(x_train)): dst = cv2.resize(x_train[i], (img_rows, img_cols), interpolation=cv2.INTER_CUBIC) X_train.append(dst) for i in range(len(x_test)): dst = cv2.resize(x_test[i], (img_rows, img_cols), interpolation=cv2.INTER_CUBIC) X_test.append(dst) x_train_size = np.array(X_train) x_test_size = np.array(X_test)モデルは以下のとおりとしています。
# encoder model inputs = Input(shape=input_shape, name='encoder_input') x = Conv2D(32, (3, 3), activation='relu', strides=2, padding='same')(inputs) x = Conv2D(64, (3, 3), activation='relu', strides=2, padding='same')(x) shape = K.int_shape(x) print("shape[1], shape[2], shape[3]",shape[1], shape[2], shape[3]) x = Flatten()(x) z_mean = Dense(latent_dim, name='z_mean')(x) encoder = Model(inputs, z_mean, name='encoder') encoder.summary() # decoder model latent_inputs = Input(shape=(latent_dim,), name='z_sampling') x = Dense(shape[1] * shape[2] * shape[3], activation='relu')(latent_inputs) x = Reshape((shape[1], shape[2], shape[3]))(x) x = Conv2DTranspose(64, (3, 3), activation='relu', strides=2, padding='same')(x) x = Conv2DTranspose(32, (3, 3), activation='relu', strides=2, padding='same')(x) x = Conv2DTranspose(16, (3, 3), activation='relu', strides=2, padding='same')(x) outputs = Conv2DTranspose(3, (3, 3), activation='sigmoid', padding='same')(x) decoder = Model(latent_inputs, outputs, name='decoder') decoder.summary() outputs = decoder(encoder(inputs)) vae = Model(inputs, outputs, name='vae_mlp') vae.compile(loss='mse',optimizer='adam')拡大カラー画像生成
描画時点で拡大の効果は消えちゃいますが、それぞれ拡大して上記の画像と比較すると、ギザギザが消えて少し綺麗になったように思います。以下、20epochと100epoch時点の出力です。
20epoch
100epoch
まとめ
・Autoencoder-decoderでDenoising、Coloring、そして画像拡大をやってみた
・ほぼ同じ仕組みで実施できることを示した
・精度はまだまだだが、潜在空間の次元を増やして一定精度がえられた・さらなる精度改善を実施する
・アニメ画像やコマ補間から動画生成も同様な方法で実施できるのでやってみようと思うおまけ
綺麗な画像生成するためには、潜在空間の次元をなるべく大きくするとより綺麗な画像が生成できます。ということで、今回は以下のように4096次元としています。
_________________________________________________________________ Layer (type) Output Shape Param # ================================================================= encoder_input (InputLayer) (None, 32, 32, 1) 0 _________________________________________________________________ conv2d_1 (Conv2D) (None, 16, 16, 32) 320 _________________________________________________________________ conv2d_2 (Conv2D) (None, 8, 8, 64) 18496 _________________________________________________________________ flatten_1 (Flatten) (None, 4096) 0 _________________________________________________________________ z_mean (Dense) (None, 4096) 16781312 ================================================================= Total params: 16,800,128 Trainable params: 16,800,128 Non-trainable params: 0 _________________________________________________________________ _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= z_sampling (InputLayer) (None, 4096) 0 _________________________________________________________________ dense_1 (Dense) (None, 4096) 16781312 _________________________________________________________________ reshape_1 (Reshape) (None, 8, 8, 64) 0 _________________________________________________________________ conv2d_transpose_1 (Conv2DTr (None, 16, 16, 64) 36928 _________________________________________________________________ conv2d_transpose_2 (Conv2DTr (None, 32, 32, 32) 18464 _________________________________________________________________ conv2d_transpose_3 (Conv2DTr (None, 64, 64, 16) 4624 _________________________________________________________________ conv2d_transpose_4 (Conv2DTr (None, 64, 64, 3) 435 ================================================================= Total params: 16,841,763 Trainable params: 16,841,763 Non-trainable params: 0 _________________________________________________________________





- 投稿日:2019-06-07T22:20:08+09:00
Django Girls Tutorial躓いた所 3
前回に続いて、Django Girls Tutorialを進めている。
前回以降、特に躓かずに進めているが、とりあえずgitの使い方に関するメモ
1.gitを公式サイトからインストールする
2.Githubにユーザー登録する
3.コマンドラインでgit initdeでgitリポジトリの初期化
4..gitignoreでpushしないファイルの選択
5.git statusでファイルの変更やブランチを確認
6.git addでファイルを選択
7.git commitで選択したファイルを記録
8.git remote addでリモートリポジトリを命名、選択
9.git pushでリモートリポジトリへpush
10.git pullでコードを読み込むあと、デプロイのときにエラーが出たが
settingのコードをALLOWED_HOSTS = ['.pythonanywhere.com']ではなく
ALLOWED_HOSTS = ['pythonanywhere.com']にしていたのが原因だった。書き直してgit push → pythonanywhereでgit pullで解決。
エラーが出たおかげでここは先んじて学べた。エラーが出たときのほうが理解が深まる。続きます
- 投稿日:2019-06-07T21:55:34+09:00
Python個人的メモその4:内包表記編~「1以上10以下の奇数のリスト」を一行で書けますか?~
内包表記はいいぞ
Pythonは内包表記という書き方ができます.スライスと同じくらい便利なので,これも覚えておきたいです.
そもそも内包って?
「内包」とは集合論における「内包的記法」に由来します.
高校時代の数学Aなどで習ったと思いますが,集合の表し方には2種類あり,
- 外延的記法
- 内包的記法
があります.外延的記法は単に集合に属する要素を直接書き下す記法で,
例えば{1,3,5,7,9}のように書きます.内包的記法はまず集合に属する要素xを宣言したのち,xが満たすべき条件を示します.
例えば{x | xは10以下の奇数}ですね.基本的な内包表記
これをPythonで書くとこのようになります.
set_comprehensions = {x for x in range(10) if x % 2 == 1} print(s) #{1,3,5,7,9}Pythonの内包表記における基本構文は
x for x in 何かで,後ろにif文などを持ってくることで条件を指定します.
今回はset,つまりpythonにおける集合に対して内包表記を適用しましたが,もちろん{}を[]に変えるだけでリストでも可能です.辞書内包表記
辞書型(dict, defaultdictなど)でも内包表記が可能です.
dict_comprehensionfrom collections import defaultdict key_list = ['a','bb','ccc','dddd','eeeee'] value_list = [1,2,3,4,5] #辞書作成 dd = defaultdict(int, zip(key_list, value_list)) #ddにあるもののうち,valueが偶数のものだけ抽出して新たに辞書を作成 dd2 = {key:dd[key] for key in dd if dd[key]%2==0} print(dd2) #{'dddd': 4, 'bb': 2} #ddにあるもののうち,keyの長さが3以上のものだけ抽出して新たに辞書を作成 dd3 = {key:dd[key] for key in dd if len(key) >= 3} print(dd3) #{'ccc': 3, 'dddd': 4, 'eeeee': 5}elseを入れる(三項演算子)
if付きの内包表記にelseを付けることもできます.
しかしelseを付けると三項演算子扱いになるので似て非なるものになります.if_else_comprehension#1~40の数字のうち3の倍数と3のつく数字の時だけ処理を変える fool = [str(i) + '~~!!' if i % 3 == 0 or '3' in str(i) else i for i in range(1,41)] print(fool) #[1, 2, '3~~!!', 4, 5, '6~~!!', ... 29, '30~~!!', '31~~!!', '32~~!!', '33~~!!', ... 40]当然30からの勢いが物凄いことになりますね.
それはさておき,if付き内包表記にelseが付くと最初に三項演算子(処理1 if 処理1を行う条件 else 処理2)の記述を行った後にforが来ます.if~elseをforの後ろに付けても動きません.紛らわしいですが気を付けましょう.二重内包表記
要はforの部分を二重にできるということです.
以下は二次元配列を一次元配列にする内包表記です.flatten_comprehensionlistA = [[1,2], [3,4], [5,6]] flat = [flatten for inner in listA for flatten in inner] print(flatten) #[1,2,3,4,5,6]初見だと随分見にくいですね.
まず最初のflattenで大きく切れて,そこから二重for文が続いているイメージです.flat = [ flatten for inner in listA for flatten in inner ]さいごに
内包表記は確かに簡潔に書けますが,精々これぐらいの複雑さにとどめておかないと可読性が失われます.
用法容量を守って正しく使いましょう.
- 投稿日:2019-06-07T21:51:12+09:00
GANMAの連載漫画「木曜日は君と泣きたい。」が更新されると音声で通知してくれるPythonスクリプトを書いた
GANMAの連載漫画「木曜日は君と泣きたい。」が投稿される度にお知らせをしてくれるPythonスクリプトを作った。
工藤マコト先生の描く「木曜日は君と泣きたい。」を毎回Twitter巡回で見つけるのが面倒なので、自動的にお知らせするようにしてみた。(2019年6月7日時点バージョン)
必要なもの
- Tweepy(Pipでインストール)
- mpg123(Homeberw、apt-getでインストール)
- TwitterのAPIに必要な情報
上記のインストールは他のウェブサイトの説明が優秀なので割愛。
当のコード
import os import tweepy # 認証キーの設定 https://masatoshihanai.com/php-twitter-bot-01/ を見ながら取得してください consumer_key = "自分のconsumer_key" consumer_secret = "自分のcustomer_secret" access_token = "自分のaccess_token" access_token_secret = "自分のaccess_tocken_secret" # OAuth認証 auth = tweepy.OAuthHandler(consumer_key, consumer_secret) auth.set_access_token(access_token, access_token_secret) # APIのインスタンスを生成 api = tweepy.API(auth) #screen_nameには、工藤マコト先生のアカウント名(@抜き)を指定 status_list = api.user_timeline(screen_name="m0721804") #データベースを使うほどの規模のものではないので、.txtを代わりに使用 with open("database.txt") as f: database_number = f.readline().strip() #database.txtの数値は最新の話数にしておいてください。 for i, status in enumerate(status_list): with open("database_nakitai.txt") as f: latest_number = f.readline().strip() # print(last_number) # last_number = "24" if "「木曜日は君と泣きたい。」" + database_number + "話" in status.text: print("新規掲載!") # FF IVの「勝利のファンファーレ(fanfare.mp3)」が流れるようにしているが、 # 任意で好きなmp3ファイルにしてください。 os.system("mpg123 -C fanfare.mp3") latest_number = int(database_number) + 1 with open("database_nakitai.txt", "w") as g: g.write(str(latest_number)) break if database_number == str(latest_number): print("木曜日は君と泣きたい。" + str(latest_number) + "話は既読です。") break現時点の最新話は24話なので、database.txt は24としておく。
database.txt
24
実行
ターミナル
python main.py
これで、cronか何かで自動実行するようにすれば、「不器用な先輩。」がアップロードされる度に音でお知らせしてくれる。便利!!
まさかり待ってます!
- 投稿日:2019-06-07T21:37:36+09:00
JSONからWord(docx)を作成する
Word(docx)の自動生成
はじめに
Mac環境の記事ですが、Windows環境も同じ手順になります。環境依存の部分は読み替えてお試しください。
目的
この記事を最後まで読むと、次のことができるようになります。
- デスクトップアプリを実装する
- Word(docx)の自動作成を実装する
アプリJSONデータとWord(docx)テンプレートをレンダリングして出力する。複数件のデータはページに分けて出力する。
JSONデータsample_data.json[ { "create_date": "令和元年 5月 1日", "to_company_name": "カレンダー株式会社", "to_company_department": "イヤホン本部", "relocation_date": "令和元年 7月 28日", "post_code": "123-4567", "new_address": "東京都港区サンプル1-2-3 ビルディング 60F", "new_phone_number": "1234-56-7890", "new_fax_number": "1234-56-7890" }, { "create_date": "令和元年 5月 1日", "to_company_name": "冷暖房リモコン株式会社", "to_company_department": "ティッシュケース本部", "relocation_date": "令和元年 7月 28日", "post_code": "123-4567", "new_address": "東京都港区サンプル1-2-3 ビルディング 60F", "new_phone_number": "1234-56-7890", "new_fax_number": "1234-56-7890" } ]
Word(docx)テンプレート
実行結果page 1/2
page 2/2
関連する記事
実行環境
環境 Ver. macOS Mojave 10.14.5 Python 3.7.3 tkinter 8.5 docxtpl 0.6.1 ソースコード
実際に実装内容やソースコードを追いながら読むとより理解が深まるかと思います。是非ご活用ください。
UIの実装
UIはTkinterで実装します。
Tkinterとは、Windows、MacOS、Linuxに対応するクロスプラットフォームなGUIライブラリです。
app.pyimport os import tkinter as tk from tkinter import filedialog as fdialog from tkinter import messagebox as mdialog from model import Docx class Application(tk.Frame): def __init__(self, master=None): super().__init__(master) self.create_widgets() def set_title(self): self.master.title('Create Docx') def set_menu_bar(self): self.menu_bar = tk.Menu(self.master) self.master.config(menu=self.menu_bar) file_menu = tk.Menu(self.menu_bar) file_menu.add_command(label='Exit', command=self.master.quit) self.menu_bar.add_cascade(label='File', menu=file_menu) def select_file(self, entry): entry.delete(0, tk.END) entry.insert(0, fdialog.askopenfilename(initialdir=os.getcwd())) def create_docx(self, json_url, template_url): if not os.path.exists(json_url) or not os.path.exists(template_url): mdialog.showerror('Error', 'Please select JSON and Template.') return docx = Docx(json_url=json_url, template_url=template_url) docx.render() def set_body(self): tk.Label(self.master, text='JSON:').grid(row=0, column=0) entry_json = tk.Entry(self.master) entry_json.grid(row=0, column=1, pady=5) tk.Button(self.master, text='Select...', command=lambda: self.select_file(entry_json)).grid(row=0, column=2) tk.Label(self.master, text='Template:').grid(row=1, column=0) entry_template = tk.Entry(self.master) entry_template.grid(row=1, column=1, pady=5) tk.Button(self.master, text='Select...', command=lambda: self.select_file(entry_template)).grid(row=1, column=2) tk.Button(self.master, text='Create', width=30, command=lambda: self.create_docx(entry_json.get(), entry_template.get())).grid(row=2, column=0, columnspan=3) def create_widgets(self): self.master.geometry() self.entry = tk.Entry(self.master) self.set_title() self.set_menu_bar() self.set_body() # fix tkinter bug start def fix_bug(): width_height = root.winfo_geometry().split('+')[0].split('x') width = int(width_height[0]) height = int(width_height[1]) root.geometry('{}x{}'.format(width+1, height+1)) # fix tkinter bug end if __name__ == '__main__': root = tk.Tk() app = Application(master=root) # fix tkinter bug start root.update() root.after(0, fix_bug) # fix tkinter bug end app.mainloop()
※ tkinterで白画面になる不具合がありサイズを1プラスすことで改修docx作成の実装
docxの作成はdocxtplで実装します。
docxtplとは、JSONデータとWord(docx)テンプレートをレンダリングするライブラリです。
model.pyimport cgi import json import os.path import re import sys import uuid from tkinter import messagebox as mdialog from docxtpl import DocxTemplate _illegal_unichrs = [(0x00, 0x08), (0x0B, 0x0C), (0x0E, 0x1F), (0x7F, 0x84), (0x86, 0x9F), (0xFDD0, 0xFDDF), (0xFFFE, 0xFFFF)] if sys.maxunicode >= 0x10000: # not narrow build _illegal_unichrs.extend([(0x1FFFE, 0x1FFFF), (0x2FFFE, 0x2FFFF), (0x3FFFE, 0x3FFFF), (0x4FFFE, 0x4FFFF), (0x5FFFE, 0x5FFFF), (0x6FFFE, 0x6FFFF), (0x7FFFE, 0x7FFFF), (0x8FFFE, 0x8FFFF), (0x9FFFE, 0x9FFFF), (0xAFFFE, 0xAFFFF), (0xBFFFE, 0xBFFFF), (0xCFFFE, 0xCFFFF), (0xDFFFE, 0xDFFFF), (0xEFFFE, 0xEFFFF), (0xFFFFE, 0xFFFFF), (0x10FFFE, 0x10FFFF)]) _illegal_ranges = ['%s-%s' % (chr(low), chr(high)) for (low, high) in _illegal_unichrs] _illegal_xml_chars_RE = re.compile(u'[%s]' % u''.join(_illegal_ranges)) class Docx(object): def __init__(self, json_url, template_url): self.json_url = json_url self.template_url = template_url def read_data(self): with open(self.json_url, 'r') as f: load_data = json.load(f) json_data = json.dumps(load_data) json_data = cgi.escape(json_data) json_data = json_data.replace('\n', '\\n') dict_data = json.loads(json_data) for d in dict_data: for k in d.keys(): try: d[k] = _illegal_xml_chars_RE.sub('', d[k]) except TypeError: pass return dict_data def render(self): dict_data = self.read_data() docx = DocxTemplate(self.template_url) docx.render({'applications': dict_data}) file_name = '{}.{}'.format(str(uuid.uuid4()), 'docx') save_dir = os.path.join(os.path.curdir, 'output') if not os.path.exists(save_dir): os.makedirs(save_dir) docx.save(os.path.join(save_dir, file_name)) mdialog.showinfo('Successful', 'Please check the output folder.')




- 投稿日:2019-06-07T21:37:36+09:00
Pythonを使ってJSONからWord(docx)を作成する
Word(docx)の自動作成
はじめに
Mac環境の記事ですが、Windows環境も同じ手順になります。環境依存の部分は読み替えてお試しください。
目的
この記事を最後まで読むと、次のことができるようになります。
- デスクトップアプリを実装する
- Word(docx)の自動作成を実装する
アプリJSONデータとWord(docx)テンプレートをレンダリングして出力する。複数件のデータはページに分けて出力する。
JSONデータsample_data.json[ { "create_date": "令和元年 5月 1日", "to_company_name": "カレンダー株式会社", "to_company_department": "イヤホン本部", "relocation_date": "令和元年 7月 28日", "post_code": "123-4567", "new_address": "東京都港区サンプル1-2-3 ビルディング 45F", "new_phone_number": "1234-56-7890", "new_fax_number": "1234-56-7890" }, { "create_date": "2019年 5月 1日", "to_company_name": "冷暖房リモコン株式会社", "to_company_department": "ティッシュケース本部", "relocation_date": "2019年 7月 28日", "post_code": "987-6543", "new_address": "東京都港区サンプル9-8-7 ビルディング 65F", "new_phone_number": "0987-65-4321", "new_fax_number": "0987-65-4321" } ]
Word(docx)テンプレート
実行結果page 1/2
page 2/2
関連する記事
実行環境
環境 Ver. macOS Mojave 10.14.5 Python 3.7.3 tkinter 8.5 docxtpl 0.6.1 ソースコード
実際に実装内容やソースコードを追いながら読むとより理解が深まるかと思います。是非ご活用ください。
UIの実装
UIはTkinterで実装します。
Tkinterとは、Windows、MacOS、Linuxに対応するクロスプラットフォームなGUIライブラリです。
app.pyimport os import tkinter as tk from tkinter import filedialog as fdialog from tkinter import messagebox as mdialog from model import Docx class Application(tk.Frame): def __init__(self, master=None): super().__init__(master) self.create_widgets() def set_title(self): self.master.title('Create Docx') def set_menu_bar(self): self.menu_bar = tk.Menu(self.master) self.master.config(menu=self.menu_bar) file_menu = tk.Menu(self.menu_bar) file_menu.add_command(label='Exit', command=self.master.quit) self.menu_bar.add_cascade(label='File', menu=file_menu) def select_file(self, entry): entry.delete(0, tk.END) entry.insert(0, fdialog.askopenfilename(initialdir=os.getcwd())) def create_docx(self, json_url, template_url): if not os.path.exists(json_url) or not os.path.exists(template_url): mdialog.showerror('Error', 'Please select JSON and Template.') return docx = Docx(json_url=json_url, template_url=template_url) docx.render() def set_body(self): tk.Label(self.master, text='JSON:').grid(row=0, column=0) entry_json = tk.Entry(self.master) entry_json.grid(row=0, column=1, pady=5) tk.Button(self.master, text='Select...', command=lambda: self.select_file(entry_json)).grid(row=0, column=2) tk.Label(self.master, text='Template:').grid(row=1, column=0) entry_template = tk.Entry(self.master) entry_template.grid(row=1, column=1, pady=5) tk.Button(self.master, text='Select...', command=lambda: self.select_file(entry_template)).grid(row=1, column=2) tk.Button(self.master, text='Create', width=30, command=lambda: self.create_docx(entry_json.get(), entry_template.get())).grid(row=2, column=0, columnspan=3) def create_widgets(self): self.master.geometry() self.entry = tk.Entry(self.master) self.set_title() self.set_menu_bar() self.set_body() # fix tkinter bug start def fix_bug(): width_height = root.winfo_geometry().split('+')[0].split('x') width = int(width_height[0]) height = int(width_height[1]) root.geometry('{}x{}'.format(width+1, height+1)) # fix tkinter bug end if __name__ == '__main__': root = tk.Tk() app = Application(master=root) # fix tkinter bug start root.update() root.after(0, fix_bug) # fix tkinter bug end app.mainloop()
※ tkinterで白画面になる不具合がありサイズを1プラスすることで改修docx作成の実装
docxの作成はdocxtplで実装します。
docxtplとは、JSONデータとWord(docx)テンプレートをレンダリングするライブラリです。
model.pyimport cgi import json import os.path import re import sys import uuid from tkinter import messagebox as mdialog from docxtpl import DocxTemplate _illegal_unichrs = [(0x00, 0x08), (0x0B, 0x0C), (0x0E, 0x1F), (0x7F, 0x84), (0x86, 0x9F), (0xFDD0, 0xFDDF), (0xFFFE, 0xFFFF)] if sys.maxunicode >= 0x10000: # not narrow build _illegal_unichrs.extend([(0x1FFFE, 0x1FFFF), (0x2FFFE, 0x2FFFF), (0x3FFFE, 0x3FFFF), (0x4FFFE, 0x4FFFF), (0x5FFFE, 0x5FFFF), (0x6FFFE, 0x6FFFF), (0x7FFFE, 0x7FFFF), (0x8FFFE, 0x8FFFF), (0x9FFFE, 0x9FFFF), (0xAFFFE, 0xAFFFF), (0xBFFFE, 0xBFFFF), (0xCFFFE, 0xCFFFF), (0xDFFFE, 0xDFFFF), (0xEFFFE, 0xEFFFF), (0xFFFFE, 0xFFFFF), (0x10FFFE, 0x10FFFF)]) _illegal_ranges = ['%s-%s' % (chr(low), chr(high)) for (low, high) in _illegal_unichrs] _illegal_xml_chars_RE = re.compile(u'[%s]' % u''.join(_illegal_ranges)) class Docx(object): def __init__(self, json_url, template_url): self.json_url = json_url self.template_url = template_url def read_data(self): with open(self.json_url, 'r') as f: load_data = json.load(f) json_data = json.dumps(load_data) json_data = cgi.escape(json_data) json_data = json_data.replace('\n', '\\n') dict_data = json.loads(json_data) for d in dict_data: for k in d.keys(): try: d[k] = _illegal_xml_chars_RE.sub('', d[k]) except TypeError: pass return dict_data def render(self): dict_data = self.read_data() docx = DocxTemplate(self.template_url) docx.render({'applications': dict_data}) file_name = '{}.{}'.format(str(uuid.uuid4()), 'docx') save_dir = os.path.join(os.path.curdir, 'output') if not os.path.exists(save_dir): os.makedirs(save_dir) docx.save(os.path.join(save_dir, file_name)) mdialog.showinfo('Successful', 'Please check the output folder.')
- 投稿日:2019-06-07T21:15:57+09:00
再帰的にリンクを辿って画像スクレイピング
beautiful soupを使って、urlから画像のスクレイピングをしてみた。
収集元は乃木坂まとめ(http://nogizaka46matomenoma.blog.jp/)beutiful soupは結構わかりにくいところなどもあったが、一応できた。
ただ、再帰的にやると同じ画像が多くなる。これを解決する方法あったら誰か教えてください。
from urllib.request import urlopen from bs4 import BeautifulSoup import requests def get_link (url): html = urlopen(url) soup = BeautifulSoup(html, 'lxml') link_list = [] for i in soup.find_all('a'): link = i.get('href') if type(link) is str: if 'http' in link: # javascriptの何か?が混ざっている。よくわからないからtype=strとif ~ in で絞る。 link_list.append(link) return link_list def link_to_img(url): html = urlopen(url) soup = BeautifulSoup(html, 'lxml') img_list = [] for i in soup.find_all('img'): link = i.get('src') img_list.append(link) return img_list url = "http://nogizaka46matomenoma.blog.jp/" img_name_list = [] for img in img_list: try: re = requests.get(img) if len(img.split('/')[-1]) > 20: img_name = img.split('/')[-1][-20:] else : img_name = img.split('/')[-1] with open('./' + img.split('/')[-1], 'wb') as f: # img_listフォルダに格納 f.write(re.content) img_name_list.append(img_name) except: pass big_pic_list = [] for i in range(len(img_name_list)): try: pic = Image.open(img_name_list[i]) if pic.size[0] > 400 and pic.size[1] > 400: big_pic_list.append(pic) # 高さ、幅それぞれ500以上のものだけをリストにする。 except: pass
100枚くらい集まった。

- 投稿日:2019-06-07T21:02:50+09:00
FlaskとFirebaseで団体名簿のwebアプリを作った
初めてまともにWebアプリを作ったから知見をまとめる
各リンク
- Flask関連
- Flask-login関連
- Flask-Bootstrap関連
- Firebase関連
- heroku関連
やったこと
- flaskのwebページ
- Firebaseに個人データを顔写真を格納
- Flask-bootstrapを使ってレスポンシブ対応
- Flask-Loginを使ってサイトの保護
学んだこと
- firebaseとpython間でのデータの送受信
- flask-bootstrapを使ったhtml表記
- herokuでアップロード
感想
- 勉強用でherokuを使ったが、普通にAWS or GCPを使うべきだった(個人アカウントを作りたくなかったから致し方無い)
- Flask-Loginが何度もログイン要請をしてくる訳が分からない。
- バイトはデータ系なのでPython(Flask)で書いたが、JSとかGO言語とかを勉強したほうがよさそうだなと思った。
- 投稿日:2019-06-07T21:01:16+09:00
Flask基本 色々まとめておく
友人に頼まれ、先日初めてWebアプリを作ったので色々勉強したことをまとめておこうと思った。
バイトでpythonを使っている関係でFlaskで書いた。
Flaskの開発者はAprilフールの冗談でこのフレームワークを発案したらしいが、それを見た人が熱狂して結局作ったらしい。そんな細かい知識は面倒なので割愛して、いろいろまとめておく。Flask基本
app.pyfrom flask import Flask import os app = Flask(__name__) app.config = os.urandom(24) @app.route('/') def index(): return 'Hello World' @app.route('/flask') def home(): return 'Hello Flask' if __name__ == '__main__': app.run(host='127.0.0.1', port=5000, debug=True)マイクロフレームワークであるFlaskの中でも最も簡単なコードだと思われる。
ざっくり説明すると、変数appにFlaskクラスのオブジェクトを入れている。
configは一応設定用で書いたがこの場合必ずしも必要ではない。@app.route('/')は、ルーティングを意味していて、つまりページのurlを示している。
この場合だと、http://127.0.0.1:5000 を開くと Hello Worldと返ってくるし、
http://127.0.0.1:5000/flask を開くと Hello Flaskと返ってくる。app.run()でアプリがローカル上で立ち上がる仕組みになっている。
Flaskのディレクトリ構成
よくあるのが
app.py
ー application
ー /config.py
ー /view.py
ー /model.py
ー /templates
ーー/layout.html
ーー/home.html
ー /static
ーー/style.cssみたいな感じ。
app.pyだけだと膨大なコードになって、不便なのでこんな感じで分けている。
app.pyfrom application.view import app if __name__ == '__main__': app.run(host='127.0.0.1', port=5000, debug=True)applicationの中のviewからappを持ってくる。
config.pyfrom flask import Flask import os app = Flask(__name) app.config = os.urandom(24)configはこういう設定系を置いておく
view.pyfrom .config import app @app.route('/') def index(): return 'Hello World' @app.route('/flask') def home(): return 'Hello Flask'viewは主にルーティングの処理とかを書く
因みにmodel.pyはクラスを書くことが多い。
templatesとJinja2
HTMLファイルを読み込むために、view.pyを書き換える。
view.pyfrom .config import app from flask import render_template @app.route('/') def index(): return render_template('layout.html') @app.route('/flask') def home(): return render_template('home.html')これで、layout.htmlとhome.htmlをそれぞれ読み込める
HTMLファイルを入れておくのがtemplatesディレクトリになる
layout.html<h1>Hello World</h1> {% block body %}{% endblock %}home.html{% extends "layout.html" %} {% block body %} <h2>Hello Flask</h2> {% endblock %}見ていただければ分かると思うが、layout.htmlの中に
{% block body %} {% endblock %}
とあり、home.htmlにも同様なものがある。これがJinja2であり、{% extends "layout.html" %}
によって、home.htmlはlayout.htmlからHello Worldを継承することができる。model.pyについては、Flask_loginのページで書く。
- 投稿日:2019-06-07T18:56:10+09:00
【小ネタ】python pandas dataframe タグを持ったデータの横→タテ→横化
このような元データがあった際に
country tag 日本 食事,温泉 フランス 食事,ファッション,文化 オーストラリア 自然 ニュージーランド 自然 このようなデータをつくりたいときのやり方
country 食事 温泉 ファッション 文化 自然 日本 1 1 0 0 0 フランス 1 0 1 1 0 オーストラリア 0 0 0 0 1 ニュージーランド 0 0 0 0 1 まずはこの↓元となるdfを
country tag 日本 食事,温泉 フランス 食事,ファッション,文化 オーストラリア 自然 ニュージーランド 自然 temp = df.tag.str.extractall('([^,]+)')で、tag部分のみを抽出して以下のtempをつくる
0 match 0 0 食事 0 1 温泉 1 0 食事 1 1 ファッション 1 2 文化 2 0 自然 3 0 自然 不要なマルチインデクスのmatchを以下で削除して
temp = temp.reset_index(1, True)
0 0 食事 0 温泉 1 食事 1 ファッション 1 文化 2 自然 3 自然 をつくる。
さらにこのtempと最初のdfをマージして、tidyなdf3を作るdf3 = pd.merge(df,temp,left_index=True,right_index=True) df3 = df3.drop("tag",axis=1) df3 = df3.rename(columns={0:"tag_name"}) df3df3はこんな感じ
index country tag_name 0 日本 食事 0 日本 温泉 1 フランス 食事 1 フランス ファッション 1 フランス 文化 2 オーストラリア 自然 3 ニュージーランド 自然 このdf3のインデクスをcountryにする
df3 =df3.set_index("country")こんな感じになる
country tag_name 日本 食事 日本 温泉 フランス 食事 フランス ファッション フランス 文化 オーストラリア 自然 ニュージーランド 自然 このdf3をone-hotコーディングしたdf_one_hotをつくる
df_one_hot = pd.get_dummies(df3["tag_name"]) df_one_hot = df_one_hot.reset_index() df_one_hotこんな感じのものができる
country 食事 温泉 ファッション 文化 自然 0 日本 1 0 0 0 0 1 日本 0 1 0 0 0 2 フランス 1 0 0 0 0 3 フランス 0 0 1 0 0 4 フランス 0 0 0 1 0 5 オーストラリア 0 0 0 0 1 6 ニュージーランド 0 0 0 0 1 このdf_one_hotをcountryでgroupbyする
df_gby = df_one_hot.groupby("country").sum().reset_index() df_gby完成。
index country 食事 温泉 ファッション 文化 自然 0 日本 1 1 0 0 0 1 フランス 1 0 1 1 0 2 オーストラリア 0 0 0 0 1 3 ニュージーランド 0 0 0 0 1 もっとうまいやり方がありそうだが、とりあえず知ってる知識でのやり方。
- 投稿日:2019-06-07T18:41:16+09:00
協力するAI開発
協力するAI開発
記事の目的
こんにちは!今ちょうど深層学習(ディープラーニング)や強化学習の勉強をしていてAI同士を協力させると面白くないかな?と思ってこのプロジェクトを始めました。
このシリーズを通して学べる事
LSTM
強化学習
興味を用いた強化学習
アクタークリティック
簡単なゲームの作り方
Unity
Ml Agents動機
ちょうど「キングダム」という漫画
を読んで兵法や戦場における人というものの面白さに触れられてこのような思想戦を行えるゲームがしてみたかったからです。もちろん将棋やチェスみたいな簡略化したゲームはありますが戦場における以下の点を無視しているような気がしました(両方苦手ですがw)。1. 指揮系統がない
普通の戦場では命令系統があり、上からの命令と目の前の状況から次にする行動を決めると思います。しかし普通のゲームでは単純に命令を与えたらその場所に動き、駒に作戦などがありません。よって駒が自分で考えて上からの命令を参考するようにしました。
2. ランダムではない
ここで言っているのは一つの駒がもう一方の駒を攻撃したときに結果が決まっているということです。例えば飛車を歩の場所までもっていったら歩が取れるということが将棋では決まっています。しかし、正直それって正確には大してあっていないと思います。例えば四方向から誰かを囲めば確かに倒す確率は上げられるかもしれませんが逆にやられてしまう可能性が皆無というわけではないと思います。なので、そういったこと確率なども含んでみました。
3. 見える範囲
戦場において一番重要だと思うことは相手に自分の戦略が明らかにならないことです。ここで一番それができる確実な方法は相手に自分が見えないことです。よってそれを可能にするために各AIに個人個人見える範囲を設定しました。
4.動きが変
チェスや将棋にはマスがあり、双方順番に駒を進めます。しかし、実際には360度のどの方向にも動くことはできるはずでしかも両方毎秒毎秒動きます。順番などはありません。なのでそれも含めてみました。
手順
1.上の4条件を満たすゲームを考えてみる。
2. AIで学習できるようにする。
3. 結果報告
4+2n 改善したこと
5+2n 結果報告
でき次第リンクをつけておきますがここではとりあえず1を先に説明します。
とりあえず、最初の1だけここでとりあげます。1.ゲームのルール
前提に置いておきますが、このゲームは上の四つの条件を満たす最低限度のゲームを考えてみたのですが結構複雑になってしまったのでそのことはすみません。
すべてのプレイヤーは丸です。
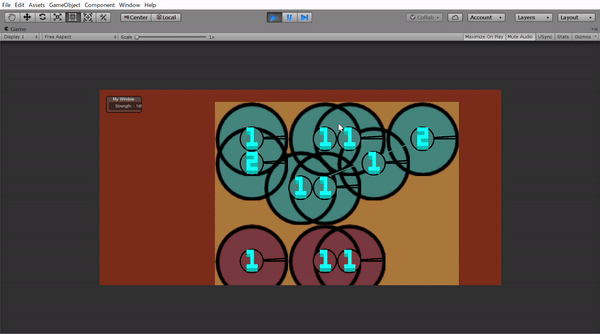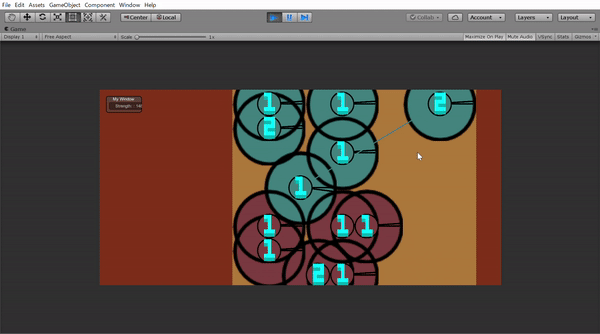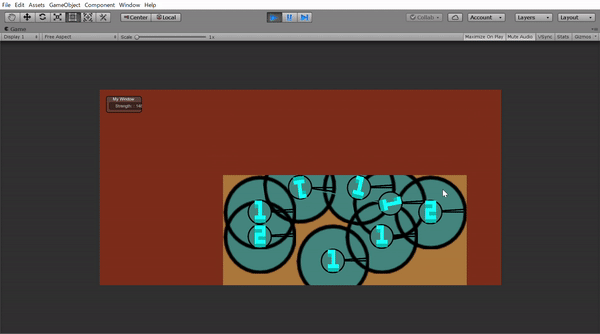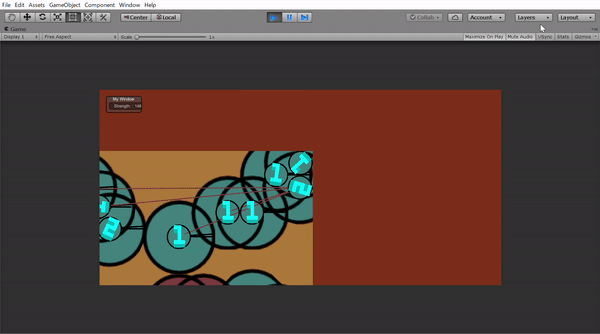
この丸は動くことができ、攻撃範囲と攻撃する角度を指定すれば敵の丸を攻撃できます。Unityで作ったら下のようになりました。(学習したモデルはのっけてないです)
このゲームにはHPとかはなく、生きていると死んでいるという二つの状態しかありません。だから攻撃範囲(二つの黒い棒の間)に入ったら死ぬか相手を殺すかの2パターンしかありません。ここで第二条件の「ランダム」をいれてみました。
具体的にはすべての兵に正規分布からてきとうに「力」というパラメターを付けます。物理にならって力を$f$となずけましょう!
ここで一対一の勝負の場合もし兵1と兵2が戦う場合、兵1が勝つ確率,$p_1$を
$$p_1 = \dfrac{f_1}{f_1+f_2}$$
と定義しました。しかし、1対4とかの場合ではどうでしょう?こういう試合を4回するだけでしたら1対1の戦いを4回繰り広げるだけとなり、兵法においてとても大切な「戦術の分断」と「多数で少数を攻撃する」ことじたいを否定してしまいます。なので、先ほど言った攻撃範囲というものも作ってみました。
攻撃範囲とは攻撃を始める角度と攻撃を終了する角度の二つによって定義しました。敵の中心が攻撃範囲に入ったら攻撃したことになります。攻撃範囲が小さければ小さいほど力$f$が大きくなり、攻撃範囲が大きいほど$f$が小さくなります。よって攻撃範囲を広くすればするほど勝ちにくくなります。
では、学習したら兵たちは全員小さい攻撃範囲になるはずというかもしれませんが攻撃範囲以外の場所からの攻撃を考えてみました。その場合は力を$\dfrac{1}{4}$くらいにするように設定しました。これがUnityの上のGifで一人で全員倒せた理由です。攻撃範囲の外から攻撃してたからです。
これによって、大勢いる際は必ず攻撃範囲を広げないといけなく、多勢の方は攻撃範囲を狭くできて勝ちやすくなるようにしました。
Gifに出ていた数も気になると思います。これは階級です。1は一番下っ端で2がその一個上3はそれのさらに上っという感じで無限に付けられます。つけ方も結構簡単で5人同じ階級の兵がいたら一番優秀な一人(一番力があるもの)は必ず一個上の階級になる。というのを繰り返すと全員に階級がつけられました。
では、階級が上の人の存在意義というのは何でしょう?これは少し将棋とか少ししたりキングダムを読んで感じたものですが「次の状態を予測する」ことでついでに言うと「より広い視野」を持つことだと個人的に思いました。なので学習の際では指令として、上からの指令と今見える盤上をもとに次に起こると予想した兵の位置や状態などを送ることにしました。結構屁理屈かもしれませんが個人的には結構な理屈です。ここでどれくらいもっと見えるかは
$$r_{base}2^{rank-1}$$
ということにしました。つまり部下の2倍の景色が見れるようにしました。Unityで見せるとしたらこんな感じです。
人間で遊ぶ場合はどうやって次の状態っというのを送るかは思いつきませんでしたので、上のように自由に階級を行き来できるようにするつもりです!



- 投稿日:2019-06-07T18:41:16+09:00
兵法ができるAI開発
兵法ができるAI開発
記事の目的
こんにちは!今ちょうど深層学習(ディープラーニング)や強化学習の勉強をしていてAI同士を協力させると面白くないかな?と思ってこのプロジェクトを始めました。
このシリーズを通して学べる事
LSTM
強化学習
興味を用いた強化学習
アクタークリティック
簡単なゲームの作り方
Unity
Ml Agents動機
ちょうど「キングダム」という漫画
を読んで兵法や戦場における人というものの面白さに触れられてこのような思想戦を行えるゲームがしてみたかったからです。もちろん将棋やチェスみたいな簡略化したゲームはありますが戦場における以下の点を無視しているような気がしました(両方苦手ですがw)。1. 指揮系統がない
普通の戦場では命令系統があり、上からの命令と目の前の状況から次にする行動を決めると思います。しかし普通のゲームでは単純に命令を与えたらその場所に動き、駒に作戦などがありません。よって駒が自分で考えて上からの命令を参考するようにしました。
2. ランダムではない
ここで言っているのは一つの駒がもう一方の駒を攻撃したときに結果が決まっているということです。例えば飛車を歩の場所までもっていったら歩が取れるということが将棋では決まっています。しかし、正直それって正確には大してあっていないと思います。例えば四方向から誰かを囲めば確かに倒す確率は上げられるかもしれませんが逆にやられてしまう可能性が皆無というわけではないと思います。なので、そういったこと確率なども含んでみました。
3. 見える範囲
戦場において一番重要だと思うことは相手に自分の戦略が明らかにならないことです。ここで一番それができる確実な方法は相手に自分が見えないことです。よってそれを可能にするために各AIに個人個人見える範囲を設定しました。
4.動きが変
チェスや将棋にはマスがあり、双方順番に駒を進めます。しかし、実際には360度のどの方向にも動くことはできるはずでしかも両方毎秒毎秒動きます。順番などはありません。なのでそれも含めてみました。
手順
1.上の4条件を満たすゲームを考えてみる。
2. AIで学習できるようにする。
3. 結果報告
4+2n 改善したこと
5+2n 結果報告
でき次第リンクをつけておきますがここではとりあえず1を先に説明します。
とりあえず、最初の1だけここでとりあげます。1.ゲームのルール
前提に置いておきますが、このゲームは上の四つの条件を満たす最低限度のゲームを考えてみたのですが結構複雑になってしまったのでそのことはすみません。
すべてのプレイヤーは丸です。
この丸は動くことができ、攻撃範囲と攻撃する角度を指定すれば敵の丸を攻撃できます。Unityで作ったら下のようになりました。(学習したモデルはのっけてないです)
このゲームにはHPとかはなく、生きていると死んでいるという二つの状態しかありません。だから攻撃範囲(二つの黒い棒の間)に入ったら死ぬか相手を殺すかの2パターンしかありません。ここで第二条件の「ランダム」をいれてみました。
具体的にはすべての兵に正規分布からてきとうに「力」というパラメターを付けます。物理にならって力を$f$となずけましょう!
ここで一対一の勝負の場合もし兵1と兵2が戦う場合、兵1が勝つ確率,$p_1$を
$$p_1 = \dfrac{f_1}{f_1+f_2}$$
と定義しました。しかし、1対4とかの場合ではどうでしょう?こういう試合を4回するだけでしたら1対1の戦いを4回繰り広げるだけとなり、兵法においてとても大切な「戦術の分断」と「多数で少数を攻撃する」ことじたいを否定してしまいます。なので、先ほど言った攻撃範囲というものも作ってみました。
攻撃範囲とは攻撃を始める角度と攻撃を終了する角度の二つによって定義しました。敵の中心が攻撃範囲に入ったら攻撃したことになります。攻撃範囲が小さければ小さいほど力$f$が大きくなり、攻撃範囲が大きいほど$f$が小さくなります。よって攻撃範囲を広くすればするほど勝ちにくくなります。
では、学習したら兵たちは全員小さい攻撃範囲になるはずというかもしれませんが攻撃範囲以外の場所からの攻撃を考えてみました。その場合は力を$\dfrac{1}{4}$くらいにするように設定しました。これがUnityの上のGifで一人で全員倒せた理由です。攻撃範囲の外から攻撃してたからです。
これによって、大勢いる際は必ず攻撃範囲を広げないといけなく、多勢の方は攻撃範囲を狭くできて勝ちやすくなるようにしました。
Gifに出ていた数も気になると思います。これは階級です。1は一番下っ端で2がその一個上3はそれのさらに上っという感じで無限に付けられます。つけ方も結構簡単で5人同じ階級の兵がいたら一番優秀な一人(一番力があるもの)は必ず一個上の階級になる。というのを繰り返すと全員に階級がつけられました。
では、階級が上の人の存在意義というのは何でしょう?これは少し将棋とか少ししたりキングダムを読んで感じたものですが「次の状態を予測する」ことでついでに言うと「より広い視野」を持つことだと個人的に思いました。なので学習の際では指令として、上からの指令と今見える盤上をもとに次に起こると予想した兵の位置や状態などを送ることにしました。結構屁理屈かもしれませんが個人的には結構な理屈です。ここでどれくらいもっと見えるかは
$$r_{base}2^{rank-1}$$
ということにしました。つまり部下の2倍の景色が見れるようにしました。Unityで見せるとしたらこんな感じです。
人間で遊ぶ場合はどうやって次の状態っというのを送るかは思いつきませんでしたので、上のように自由に階級を行き来できるようにするつもりです!
- 投稿日:2019-06-07T18:37:54+09:00
Pythonウォーミングアップ
まずはPythonで簡単な計算をしてみましょう。各自の画面中の Jupyter Notebook のセルに順次入力して(コピペ可)、「Shift + Enter」してください。
シャープ # を付けるとコメントと見なされ、それ以降の文字はPythonプログラムに無視されます。
文字列と変数
message という変数を定義して、文字列を代入しましょう。
# メッセージ message = "Pythonはいいぞ"Jupyter notebook 上では、変数名を呼び出すだけで中身を確認できます。
message'Pythonはいいぞ'丁寧に書くなら、また、コード中で出力させたいなら、真面目に print 文を使いましょう。
print(message)Pythonはいいぞもし変数名のスペルを間違えたりしたら次のようなエラーが出ます。
# マッサージ massage--------------------------------------------------------------------------- NameError Traceback (most recent call last) <ipython-input-4-d846b274cc9f> in <module> ----> 1 massage NameError: name 'massage' is not defined添字を使って、指定した位置の文字だけ出力できます。
message[0]'P'「スライス」という指定方法もあります。下記で「6:8」というのは、ややこしいですが、「0-indexで6番目からスタートし、8の一個手前で終了する」という意味です。ここで「0-index」とは、一番最初を「ゼロ」とみなす数え方のことです。(人間は 1-index でモノを数えることが多いと思いますが、コンピュータは 0-index で数えることが多いのです。
# そして輝くウルトラソウル message[6:8]'はい'添字が文字数を超えていたりするなど範囲指定を間違えていたら次のようなエラーが出ます。
message[15]--------------------------------------------------------------------------- IndexError Traceback (most recent call last) <ipython-input-7-8b79e4810453> in <module> ----> 1 message[15] IndexError: string index out of range次のようにして、「文字列の足し算」ができます。
message += " 講師はイケメン"message'Pythonはいいぞ 講師はイケメン'「文字列の掛け算」もできます。大事なことなので3回言います。
" 講師はイケメン" * 3' 講師はイケメン 講師はイケメン 講師はイケメン'「タブ補完」のススメ
コードを真面目に手打ちしていると、頻繁にスペルミスが起こります。それを避けるため「コピペ」と「タブ補完」を活用しましょう。タブ補完とは、たとえば上記のように m から始まる変数がある場合、m とだけ入力して「タブ」キーを押すと補完されます。候補が複数ある場合はその候補のリストが示されます。
予約語
以下の語は、Python の中であらかじめ定義されている「予約語」なので、変数名として使わないようにしましょう。
print(__import__('keyword').kwlist)['False', 'None', 'True', 'and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'nonlocal', 'not', 'or', 'pass', 'raise', 'return', 'try', 'while', 'with', 'yield']print(dir(__builtins__))['ArithmeticError', 'AssertionError', 'AttributeError', 'BaseException', 'BlockingIOError', 'BrokenPipeError', 'BufferError', 'BytesWarning', 'ChildProcessError', 'ConnectionAbortedError', 'ConnectionError', 'ConnectionRefusedError', 'ConnectionResetError', 'DeprecationWarning', 'EOFError', 'Ellipsis', 'EnvironmentError', 'Exception', 'False', 'FileExistsError', 'FileNotFoundError', 'FloatingPointError', 'FutureWarning', 'GeneratorExit', 'IOError', 'ImportError', 'ImportWarning', 'IndentationError', 'IndexError', 'InterruptedError', 'IsADirectoryError', 'KeyError', 'KeyboardInterrupt', 'LookupError', 'MemoryError', 'ModuleNotFoundError', 'NameError', 'None', 'NotADirectoryError', 'NotImplemented', 'NotImplementedError', 'OSError', 'OverflowError', 'PendingDeprecationWarning', 'PermissionError', 'ProcessLookupError', 'RecursionError', 'ReferenceError', 'ResourceWarning', 'RuntimeError', 'RuntimeWarning', 'StopAsyncIteration', 'StopIteration', 'SyntaxError', 'SyntaxWarning', 'SystemError', 'SystemExit', 'TabError', 'TimeoutError', 'True', 'TypeError', 'UnboundLocalError', 'UnicodeDecodeError', 'UnicodeEncodeError', 'UnicodeError', 'UnicodeTranslateError', 'UnicodeWarning', 'UserWarning', 'ValueError', 'Warning', 'ZeroDivisionError', '__IPYTHON__', '__build_class__', '__debug__', '__doc__', '__import__', '__loader__', '__name__', '__package__', '__spec__', 'abs', 'all', 'any', 'ascii', 'bin', 'bool', 'bytearray', 'bytes', 'callable', 'chr', 'classmethod', 'compile', 'complex', 'copyright', 'credits', 'delattr', 'dict', 'dir', 'display', 'divmod', 'enumerate', 'eval', 'exec', 'filter', 'float', 'format', 'frozenset', 'get_ipython', 'getattr', 'globals', 'hasattr', 'hash', 'help', 'hex', 'id', 'input', 'int', 'isinstance', 'issubclass', 'iter', 'len', 'license', 'list', 'locals', 'map', 'max', 'memoryview', 'min', 'next', 'object', 'oct', 'open', 'ord', 'pow', 'print', 'property', 'range', 'repr', 'reversed', 'round', 'set', 'setattr', 'slice', 'sorted', 'staticmethod', 'str', 'sum', 'super', 'tuple', 'type', 'vars', 'zip']簡単な数値演算
普通に数式を入れれば計算してくれます。
33 - 429数値を示す変数を定義して計算することもできます。
lotte = 33 hanshin = 4 lotte - hanshin29データの型が違うもの同士を演算しようとすると次のようなエラーが出ます。
lotte - hanshin + "なんでや阪神は関係ないやろ"--------------------------------------------------------------------------- TypeError Traceback (most recent call last) <ipython-input-15-7bdf2419ed7a> in <module> ----> 1 lotte - hanshin + "なんでや阪神は関係ないやろ" TypeError: unsupported operand type(s) for +: 'int' and 'str'リスト(list)
多くの値を「リスト」(list) という変数でまとめて取り扱うことができます。ちなみにこの数字は、ドラゴンボールの主要メンバーの戦闘力 です。
data = [5, 10, 100, 120, 180, 180, 260, 260, 190, 910, 900]data[5, 10, 100, 120, 180, 180, 260, 260, 190, 910, 900]データ型は次のようにして確認できます。
type(data)listリストの「長さ」(中に入ってるデータの個数)を確認できます。
len(data)11添字を使って、指定した場所のデータにアクセスできます。
data[2]100添字の指定が範囲を超えていれば次のようなエラーが出ます。
data[20]--------------------------------------------------------------------------- IndexError Traceback (most recent call last) <ipython-input-21-0e53c59a92d0> in <module> ----> 1 data[20] IndexError: list index out of range「スライス」という指定方法もあります。下記で「6:8」というのは、ややこしいですが、「0-indexで6番目からスタートし、8の一個手前で終了する」という意味です。ここで「0-index」とは、一番最初を「ゼロ」とみなす数え方のことです。(人間は 1-index でモノを数えることが多いと思いますが、コンピュータは 0-index で数えることが多いのです。
data[6:8][260, 260]「リストの掛け算」をすると、同じリストを指定回数繰り返したようなリストができます。
data * 2[5, 10, 100, 120, 180, 180, 260, 260, 190, 910, 900, 5, 10, 100, 120, 180, 180, 260, 260, 190, 910, 900]次のようにして、地球を襲撃しに来た人たちの戦闘力をリストに追加できます。誰のことかは こちら で確認してください。
data.append(1500) data.append(1200) data.append(4000) data.append(18000)data[5, 10, 100, 120, 180, 180, 260, 260, 190, 910, 900, 1500, 1200, 4000, 18000]指定した値を取り除くこともできます。誰が取り除かれたかは こちら で確認してください。
data.remove(190)data[5, 10, 100, 120, 180, 180, 260, 260, 910, 900, 1500, 1200, 4000, 18000]リストの末尾を取り除くためのメソッドもあります。
data.pop()18000data[5, 10, 100, 120, 180, 180, 260, 260, 910, 900, 1500, 1200, 4000]指定したデータが何個あるのかカウントするメソッドもあります。
data.count(180)2論理演算
以下の論理演算を単独で使うことはほとんどないですが、「IF文」などの条件分岐を理解する上で重要です。
180 == 180True910 == 920False910 != 920True1500 > 1333True1307 > 1500False(1500 > 1333) and (4000 > 1200)True(1500 < 1333) or (4000 > 1200)Truenot (1500 < 1333)True戦闘力 530000 の人はデータに入っているでしょうか?
530000 in dataFalseもう少し複雑な処理を IF 文で書いてみます。3つの print 文のうち、どれが出力されて、どれが出力されないか確認してください。
ここから先のプログラムでは、インデント(文頭の空白文字)や、文末の「:」(コロン)などを正しく記述しないと、思った通りの動作をしなくなります。注意して使ってください。
value = 900 if value in data: print("{} is in data".format(value)) else: print("{} is not in data".format(value)) print("まだ終わりじゃないぞよ")900 is in data まだ終わりじゃないぞよちなみに、次のようにして、ちょっと複雑な文が書けます。
"{} と {} が力を合わせて {} を撃退した。".format(910, 900, 1500)'910 と 900 が力を合わせて 1500 を撃退した。'辞書(dictionary)
「添字」を任意の値(数字でも文字でも)にした「辞書」というデータ構造があります。
dict_data = {'農夫': 5, '孫悟空 (12歳)': 10, '孫悟空 (13歳;亀仙人の修行後)': 100, 'ジャッキー・チュン(亀仙人)': 120}dict_data['農夫']5存在しないキー(添字)を検索しようとするとエラーが出ます。
dict_data['孫悟空']--------------------------------------------------------------------------- KeyError Traceback (most recent call last) <ipython-input-44-5c79a6a5f839> in <module> ----> 1 dict_data['孫悟空'] KeyError: '孫悟空'キーは次のようにして後から追加できます。
dict_data['孫悟空 (16歳)'] = 180 dict_data['天津飯 (20歳)'] = 180dict_data{'農夫': 5, '孫悟空 (12歳)': 10, '孫悟空 (13歳;亀仙人の修行後)': 100, 'ジャッキー・チュン(亀仙人)': 120, '孫悟空 (16歳)': 180, '天津飯 (20歳)': 180}繰り返し処理
range と for を使って、数字を列挙できます。
for i in range(10): print(i)0 1 2 3 4 5 6 7 8 9始点と終点、および間隔を指定することもできます。
for i in range(110, 125, 3): print(i)110 113 116 119 122while 文を用いた繰り返しというものもありますが、終了条件を間違えたり、 num = num + 1 などの記述を間違えると無限ループになって計算が終わらず、その中で print 文を使っていると表示が多すぎてマシンが固まることもあるので要注意。
num = 1 while num <= 10: print(num) num = num + 11 2 3 4 5 6 7 8 9 10また、while 文が終了した後に変数の値がどうなっているか確認しておくのも大事。
num11リストに対する for 文の使い方はこう。
for x in [100, 200, 300]: print(x)100 200 300同じ長さのリストが複数あって、それを同時に回したいときは、zip を使います。
for x, y in zip([100, 200, 300], [400, 500, 600]): print(x, y)100 400 200 500 300 600複数のリストの全組み合わせを出したいなら二重ループにします。
for x in [100, 200, 300]: for y in [400, 500, 600]: print(x, y)100 400 100 500 100 600 200 400 200 500 200 600 300 400 300 500 300 600添字を参照しながら回したいなら enumerate
for i, x in enumerate([100, 200, 300]): print(i, x)0 100 1 200 2 300リストに格納された数値の合計値を求めてみましょう。
total = 0 for num in data: print("Power = ", num) total = total + numPower = 5 Power = 10 Power = 100 Power = 120 Power = 180 Power = 180 Power = 260 Power = 260 Power = 910 Power = 900 Power = 1500 Power = 1200 Power = 4000total9625辞書に格納されたキー(添字)をリストアップしてみましょう。
for dic_key in dict_data: print(dic_key)農夫 孫悟空 (12歳) 孫悟空 (13歳;亀仙人の修行後) ジャッキー・チュン(亀仙人) 孫悟空 (16歳) 天津飯 (20歳)次のようにしても同じです。
for dic_key in dict_data.keys(): print(dic_key)農夫 孫悟空 (12歳) 孫悟空 (13歳;亀仙人の修行後) ジャッキー・チュン(亀仙人) 孫悟空 (16歳) 天津飯 (20歳)値をリストアップしてみましょう。
for dic_key in dict_data: print(dict_data[dic_key])5 10 100 120 180 180次のようにしても同じです。
for dic_val in dict_data.values(): print(dic_val)5 10 100 120 180 180次のようにして、キーと値を同時に取り出すことができます。
for key, val in dict_data.items(): print(key, " の戦闘力は ", val, " です。")農夫 の戦闘力は 5 です。 孫悟空 (12歳) の戦闘力は 10 です。 孫悟空 (13歳;亀仙人の修行後) の戦闘力は 100 です。 ジャッキー・チュン(亀仙人) の戦闘力は 120 です。 孫悟空 (16歳) の戦闘力は 180 です。 天津飯 (20歳) の戦闘力は 180 です。リスト内包表記
data の数値を1個ずつ取り出して、3倍界王拳してみましょう。
data3 = [] for x in data: data3.append(x * 3)data3[15, 30, 300, 360, 540, 540, 780, 780, 2730, 2700, 4500, 3600, 12000]同じことを「リスト内包表記」という書き方で記述できます。
data3_naiho = [x * 3 for x in data]data3_naiho[15, 30, 300, 360, 540, 540, 780, 780, 2730, 2700, 4500, 3600, 12000]「戦闘力が 1000 未満の人は3倍界王拳が使えない」という制限をかけてみましょう。
[x * 3 for x in data if x >= 1000][4500, 3600, 12000]上記の計算だと、界王拳が使えない人は消されてしまいましたが、界王拳が使えない人をそのままで生き残らせたいなら次のようになります。
[x * 3 if x >= 1000 else x for x in data ][5, 10, 100, 120, 180, 180, 260, 260, 910, 900, 4500, 3600, 12000]関数を定義して使う
界王拳3倍を関数にしてみます。ただし、戦闘力が1000未満の場合は3倍にならず、そのままの戦闘力であるものとします。
def kaioh_ken_3bai(a): if a >= 1000: a = a * 3 return adata3 = [] for x in data: data3.append(kaioh_ken_3bai(x))data3[5, 10, 100, 120, 180, 180, 260, 260, 910, 900, 4500, 3600, 12000]リスト内包表記するとこんな感じです。
[kaioh_ken_3bai(x) for x in data][5, 10, 100, 120, 180, 180, 260, 260, 910, 900, 4500, 3600, 12000]map という関数を使って界王拳3倍する方法もあります。
list(map(kaioh_ken_3bai, data))[5, 10, 100, 120, 180, 180, 260, 260, 910, 900, 4500, 3600, 12000]「ラムダ式」という異名を持つ「無名関数」を使っても界王拳3倍できます。このようなラムダ式をつかって、、、
(lambda x: x * 3 if x >= 1000 else x)(1000)3000このようにします。
list(map(lambda x: x * 3 if x >= 1000 else x, data))[5, 10, 100, 120, 180, 180, 260, 260, 910, 900, 4500, 3600, 12000]関数を定義することの利点は、同じ処理を何度も繰り返したいときに使いまわせることと、次のように「再帰的」(自分が自分を呼び出す)ことができることです。次は有名なフィボナッチ数の出し方です。
def calc_fib(n): if n == 1 or n == 2: return 1 else: return calc_fib(n - 1) + calc_fib(n - 2)calc_fib(10)55クラスとインスタンス
最後に、クラスとインスタンスについて説明します。たとえば「人」をクラスとして表現すると
class Person: def self_introduction(self): print("私は {} 。私の戦闘力は {} です。".format(self.name, self.power))下記のようにして、Personというクラスに属する freeza というインスタンスが作れます。
freeza = Person()freeza.name = 'フリーザ' freeza.power = 530000freeza.self_introduction()私は フリーザ 。私の戦闘力は 530000 です。もう少し凝ったクラスを作ってみましょう。
- 初期化する関数 init を設定する
- 変身するための関数を定義する
- 変身は3回までとする
class Person: def __init__(self, x, y): self.name = x self.power = y self.stage = 1 # 第1形態からスタート self.max_transform = 3 # 3回まで変身できる def transform(self): # 変身 if self.stage <= self.max_transform: print("変身") self.power *= 2 ** self.stage self.stage += 1 else: print("マックスパワーの半分も出せばキミを宇宙のチリにすることができるんだ…") def self_introduction(self): print("私は {} (第 {} 形態)。私の戦闘力は {} です。".format(self.name, self.stage, self.power)) print("私は変身をあと {} 回残しています。".format(self.max_transform - self.stage + 1))初期化の関数を定義し、その関数は引数を必要とするので、先ほどと同じようにインスタンスを作るとエラーになります。
freeza = Person()--------------------------------------------------------------------------- TypeError Traceback (most recent call last) <ipython-input-82-140a6c210b6b> in <module> ----> 1 freeza = Person() TypeError: __init__() missing 2 required positional arguments: 'x' and 'y'引数の数を正しく指定すると動きます。
freeza = Person('フリーザ', 530000)freeza.self_introduction()私は フリーザ (第 1 形態)。私の戦闘力は 530000 です。 私は変身をあと 3 回残しています。freeza.transform()変身freeza.self_introduction()私は フリーザ (第 2 形態)。私の戦闘力は 1060000 です。 私は変身をあと 2 回残しています。freeza.transform()変身freeza.self_introduction()私は フリーザ (第 3 形態)。私の戦闘力は 4240000 です。 私は変身をあと 1 回残しています。freeza.transform()変身freeza.self_introduction()私は フリーザ (第 4 形態)。私の戦闘力は 33920000 です。 私は変身をあと 0 回残しています。freeza.transform()マックスパワーの半分も出せばキミを宇宙のチリにすることができるんだ…freeza.self_introduction()私は フリーザ (第 4 形態)。私の戦闘力は 33920000 です。 私は変身をあと 0 回残しています。変身の履歴が残っているので、これ以上変身できません。
- 投稿日:2019-06-07T18:20:50+09:00
基礎知識の補填 Python (内包表記)
内包表記(コンプリヘンション)について
今回は、内包表記について。
元々、Progate2週程度の理解しかなく現場でのソースがほとんどこの内包表記という書き方で
書かれていて、もう「for文の前についてる変数…なにこれ??」みたいな感じだった。勉強しなんとなく理解できたので、簡単にまとめていきたいと思う。
内容表記とは
for文でリストを作成していく際、短く簡潔な方法で書くこと。
他にもディクショナリやset型も扱うことができる。通常の記述方法
例:
下記のdata変数へ1~5までの数値をリストとして代入し、data = [1, 2, 3, 4, 5]配列の中身を3倍にする処理をfor文で回しながらnewData変数へ再度、入れ込んでいく
newData = [] for d in data: newData.append(d * 3) #[3, 6, 9, 12, 15]内容表記での記述
上記3行で表してた処理を1行で簡潔に記述すると以下のようになる。
newData = [d * 3 for d in data] # [3, 6, 9, 12, 15]if文を使った条件式
入れ子構造にして、if文で条件をつける場合も可能。
for d in data: if d % 2 ==0: newData.append(d) #[2, 4]上記の記述を内包表記で記述すると、以下のようになる。
newData = [d for d in data if d % 2 == 0] #[2, 4]
- 投稿日:2019-06-07T17:50:32+09:00
【Python】新卒入社して2ヶ月経ったのでKaggleのTitanicにチャレンジする②【決定木】
概要
新卒3ヶ月目になりました(自己紹介)。Python歴も2ヶ月目に突入です。
前回の記事→【Python】新卒入社して2ヶ月経ったのでKaggleのTitanicにチャレンジする【KNN】
の続きです。前回は「新卒2ヶ月目にしてTitanicスコアカンストする自分,最強では…?」という内容の記事になる予定でしたが,別にカンストしたりしなかったので,今回も機械学習とPythonのTitanic生存予測にチャレンジして,研鑽に努めていこうと思います。
それではやっていきます。
今回のやること一覧
1.データ概観,前処理,EDA
2.決定木による予測モデル構築
3.テストセットの生存予測,結果環境
- Windows10
- Anaconda
- Python 3.6.5
- JupyterNotebook
1.データ概観,前処理,EDA
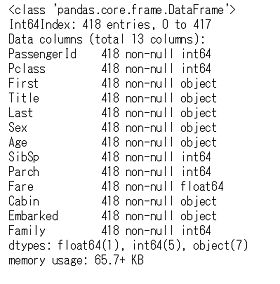
まずは使うデータの内容を確認していきます。前回に引き続き,Kaggleが提供してくれる以下12列,891行のデータを使います。
使用データ:train.csv(全12列,891行)
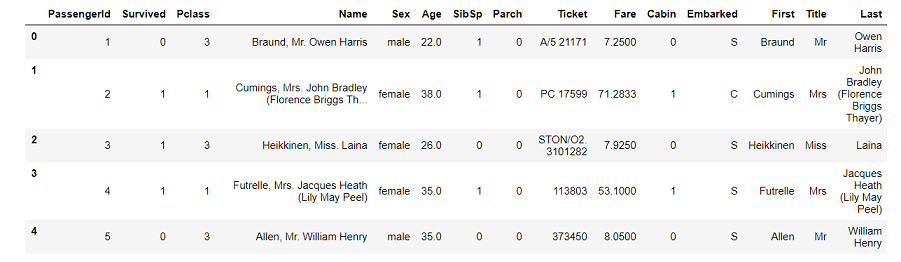
カラム 内容 説明 PassengerId 搭乗者番号 Survival 生死 0なら死亡,1なら生存 Pclass チケットの等級 1 = 1st,2 = 2nd,3 = 3rd Name 名前 「First name , 敬称 . Last name(旧姓)」のフォーマット Sex 性別 maleかfemale Age 年齢 1歳未満の場合は少数表記,推定した年齢なら「~.5」の表記 SibSp 同乗してた兄弟姉妹,配偶者の人数 Parch 同乗してた両親,子供の人数 Ticket チケット番号 Fare 運賃 Cabin 客室番号 Embarked 搭乗した港 C = Cherbourg,Q = Queenstown,S = Southampton train.csvを「df_train_raw」でDataFrame化して,行数や欠損数と,データの先頭5行を確認します。
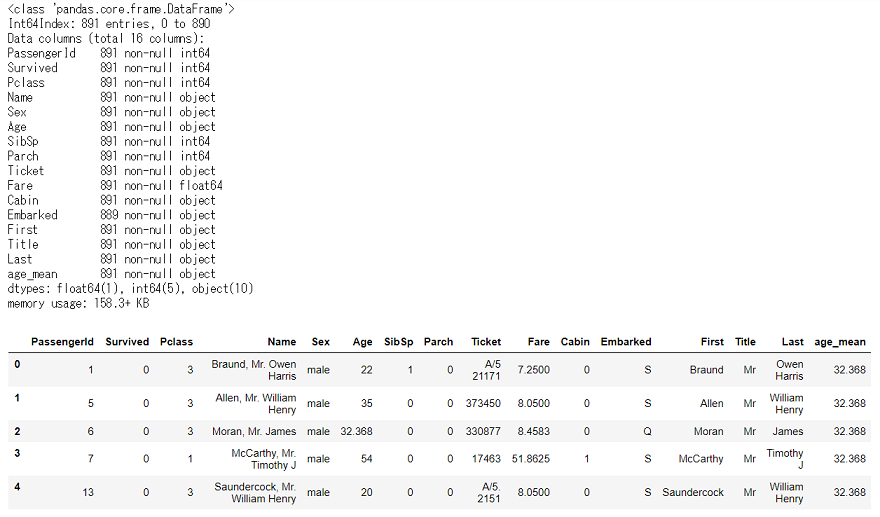
データ概観import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns %matplotlib inline df_train_raw = pd.read_csv('C:/~hoge~/train.csv') display(df_train_raw.info(), df_train_raw.head())
全体は891行,欠損値が含まれているのはAge,Cabin,Embarkedです。この辺りも前回と同じです。
欠損値の多いCabinを「あったかなかったか」の0,1にしておきましょう。CabinのNullを補完→Cabin有:1,Cabin無:0にするdf_train_raw['Cabin'].fillna(0, inplace=True) df_train_raw['Cabin'] = df_train_raw['Cabin'].where(df_train_raw['Cabin'] == 0, 1)さて,次は2番目に欠損値の多いAgeです。
前回は欠損していた場合には搭乗者全体の平均値(29.67)を入れていましたが,他のカラムを上手く使って,その人の年代をもう少し正確に予測できるといいですよね。今回は,前回使わなかったNameを使って,Ageの欠損値を補完していきましょう。
Nameは,各行「First name , 敬称 . Last name(旧姓)」という,カンマとピリオドで区切られたフォーマットになっているので,まずは名前を分割して,それぞれのFirst name,敬称,Last nameの入った新しいカラムを追加したData Frameを作りましょう。
各行のNameを分割→3カラムを追加した新しいDataFrameの作成df_train_name1 = df_train_raw['Name'].str.split(',', expand=True).rename(columns={0:'First', 1:'Other'}) df_train_name2 = df_train_name1['Other'].str.split('.', expand=True).rename(columns=({0:'Title', 1:'Last', 2:'Other'})) df_train_names = pd.concat([df_train_name1, df_train_name2], axis=1)[['First', 'Title', 'Last']] df_train_name = pd.concat([df_train_raw, df_train_names], axis=1) display(df_train_name.head())新しいData Frame「df_train_name」はこんな感じです。
今回注目するのは名前の中央にあったTitleです。
Titleが,各搭乗者の敬称です。日本人にはあまり馴染みのないものかもしれません。
今回train.csvに入っていた搭乗者の敬称全17種類はこんな感じになっていました(和訳,説明はGoogle調べ,間違ってたらすいません)搭乗者の敬称一覧
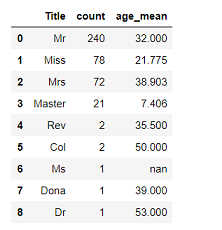
敬称 和訳 正式名,説明 Mr 男性 Mrs 既婚の女性 Miss 未婚の女性 Master 少年,青年男性 Don ドン スぺイン貴族 Rev 聖職者 Reverend Dr 医者 Doctor Mme 既婚女性 Madame Ms 女性 Major 少佐 Lady 貴族の夫人 Sir 勲爵士 Mlle 未婚の女性 Mademoiselle Col 大佐 Colonel Capt 船長 Captain the Countess 女伯爵 Jonkheer ヨンクヘール オランダ貴族 新しく作ったデータフレームをもとに,Titleごとの人数,生存率,平均年齢をまとめたData Frameを作成して,どんな感じになってるか見てみましょう。
Titleごとの人数,生存率,平均年齢のDataFrameを作成## Titleごとの人数,生存率を算出,Data Frame作成 title_list = [] survived_par_list = [] for titles in df_train_name['Title']: if titles not in title_list: title_list.append(titles) survived_par_list.append('{:.3%}'.format(df_train_name.where(df_train_name['Title'] == titles)['Survived'].sum() / df_train_name.where(df_train_name['Title'] == titles)['Survived'].count())) else: pass df_title_survived_count = pd.merge(pd.DataFrame(df_train_name['Title'].value_counts()).reset_index(), pd.DataFrame(survived_par_list, title_list).reset_index(), on='index') ## Titleごとの平均年齢を算出,Data Frame作成 title_list = [] age_mean_list = [] for titles in df_train_name['Title']: if titles not in title_list: title_list.append(titles) age_mean_list.append('{:.3f}'.format(df_train_name.where(df_train_name['Title'] == titles)['Age'].mean())) else: pass ## 作成した2つのData Frameを結合 df_title = pd.merge(df_title_survived_count, pd.DataFrame(age_mean_list, title_list).reset_index(), on='index').rename(columns=({'index':'Title', 'Title':'count', '0_x':'survive', '0_y':'age_mean'})) display(df_title)こんな感じです。
後半のTitleは人数が少ないので,生存率等あまり参考にはなりませんが,上から4種類の平均年齢が分かったのはとてもありがたいですね。これが分かれば,例えばAgeの欠損した「Master」の人に,全体平均の29歳は入れるべきでなさそうだ,など,欠損値の補完をよりその人の属性に近づいたものに出来ます。
今回は,Ageの欠損している各行には,それぞれのTitleの平均値を入れていくことにしましょう。
Ageの欠損値を補完したDataFrameの作成df_null_in = pd.merge(df_train_name, df_title[['Title', 'age_mean']], on='Title') for indexes, values in enumerate(df_null_in['Age']): if values != values: df_null_in.iloc[indexes, 5] = df_null_in.iloc[indexes, 15] else: pass df_null_in.head()こうなります。
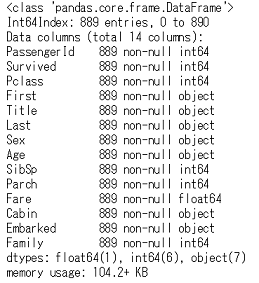
Ageの欠損がなくなりました。5行だけ出したData Frameの,上から3行目が欠損していた行ですね。ちゃんと「Mr」の平均値が入っているのが分かります。最後に,Embarkedの欠損は2件だけなのでひとまず除外して,モデル構築に必要なカラムだけのData Frameにしましょう。前回同様,家族人数のカラムも作成していきます。
予測のためのDataFrameの作成df_train = df_null_in[['PassengerId', 'Survived', 'Pclass', 'First', 'Title', 'Last', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare', 'Cabin', 'Embarked']].dropna() ## 家族人数の列FamilyはSibSp,Parchに1(自分)を足して算出 df_train['Family'] = df_train['SibSp'] + df_train['Parch'] + 1 df_train.info()
全部で14列,889行です。それでは,このData Frameを使って,生存予測のためのモデルを作っていきましょう。
2.決定木による予測モデル構築
モデル構築をする前に,前回調べた各変数とSurvivedの関係をおさらいします。
Pclass:Pclassが高いほど生存率が高い
Cabin:Cabinがあるグループはないグループよりも生存率が高い
Sex:女性は,男性よりも生存率が高い
Family:家族(複数人)で搭乗したグループは,一人で搭乗したグループより生存率が高い
Fare:運賃を7.5より少なく払っているグループは死亡者の数が生存者を上回っている
Embarked:EmbarkedがCのグループでは,生存者の数が死亡者を上回っている
Age:0歳代~10歳代のグループでは,生存者の数が死亡者を上回っているこんな感じでした。
前回同様,モデル構築に使う変数は上記の7つです。そして今回は,機械学習アルゴリズムの1つである決定木(Decision Tree)を使います。
決定木によるモデル構築に関しては,今回もPythonではじめる機械学習とPython機械学習プログラミングを参考にしました。決定木はその名の通り,いくつもの枝を持つ木のようなモデルを構築することで,データを分類していくモデルです。
それではやっていきましょう。
決定木を用いて予測モデルの構築from sklearn.model_selection import train_test_split from sklearn.tree import DecisionTreeClassifier df_train['Sex'] = df_train['Sex'].where(df_train['Sex'] == 'male', 1) df_train['Sex'] = df_train['Sex'].where(df_train['Sex'] == 1, 0) df_train.loc[:, 'Sex'] = df_train.loc[:, 'Sex'].astype(np.int64) df_train.loc[:, 'Cabin'] = df_train.loc[:, 'Cabin'].astype(np.int64) df_train.loc[:, 'Age'] = df_train.loc[:, 'Age'].astype(np.float64) df_train_x = df_train[['Pclass', 'Age', 'Sex', 'Cabin', 'Fare', 'Embarked', 'Family']] df_train_y = df_train['Survived'] df_train_category_x = pd.get_dummies(df_train_x) X_train, X_test, y_train, y_test = train_test_split(df_train_category_x, df_train_y, random_state=1) tree = DecisionTreeClassifier(random_state=1) tree.fit(X_train, y_train) tree_trainscore = round(tree.score(X_train, y_train), 5) tree_testscore = round(tree.score(X_test, y_test), 5) display(tree_trainscore, tree_testscore)結果は…
上がtrainデータ,下がtestデータに対してのスコアです。trainに対しての精度は高いですが,testの精度が低くなっています。
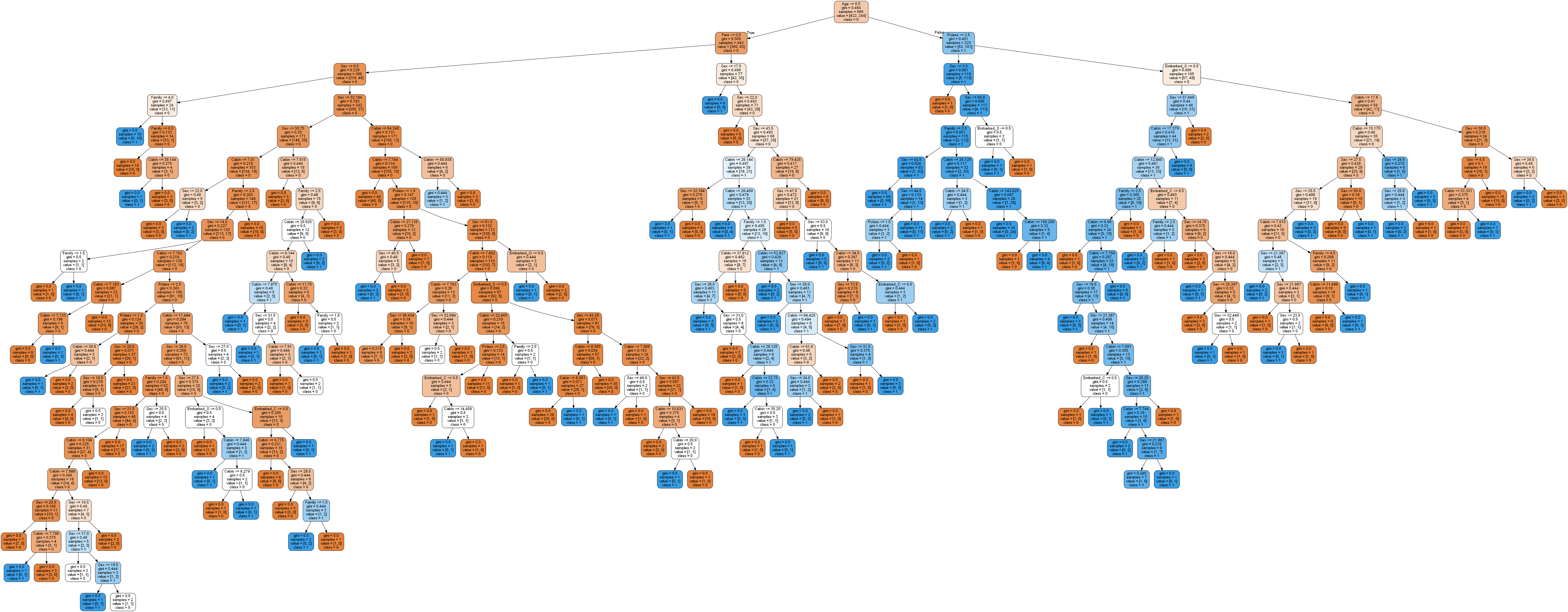
実際に,分類の為にどのようなモデルを構築したのかを確認してみましょう。
決定木の可視化## 必要に応じてpip install from pydotplus import graph_from_dot_data from sklearn.tree import export_graphviz features = ['Pclass', 'Sex', 'Age', 'Fare', 'Cabin', 'Family', 'Embarked_C', 'Embarked_Q', 'Embarked_S'] dot_data = export_graphviz(tree, filled=True, rounded=True, class_names=['0', '1'], feature_names=features, out_file=None) graph = graph_from_dot_data(dot_data) graph.write_png('tree.png')
とんでもないことになっていますね。
trainデータを出来るだけ正確に分類できるようにと,多くの枝に別れた,かなり複雑なモデルになっているのが分かります。
しかし,この内の多くは,testデータの分類には必要ない枝かもしれません。
trainデータとtestデータのスコアの乖離は,どうやらこれが原因で生じるようです。trainデータにだけ過剰に適合するのではなく,それ以外のデータにも上手く適合させられるような,汎化性能の高いモデルを構築しなくては,testデータに対する正確な予測はできないので,このままではいけませんね。
今回は,木の深さを変えてモデルを作っていきましょう。
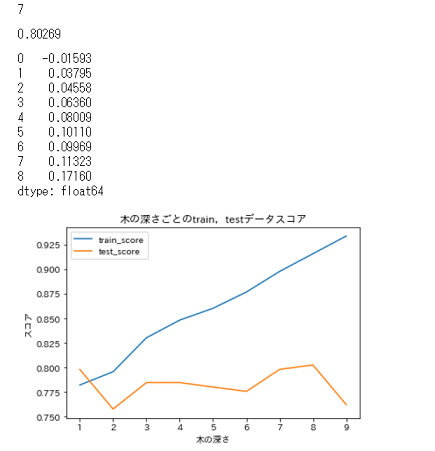
深さを1から10までの間で試して,trainとtest両データに対するスコアがどう変動するか確認していきます。
ついでに,両スコアがどのくらい離れているのかもわかるようにしましょう。depthを1から10までで試してモデルの構築,スコアの変動の可視化X_train, X_test, y_train, y_test = train_test_split(df_train_category_x, df_train_y, random_state=1) train_score_list = [] test_score_list = [] kairi_list = [] for depth in range(1, 10): tree = DecisionTreeClassifier(max_depth=depth, random_state=1) tree.fit(X_train, y_train) train_score_list.append(round(tree.score(X_train, y_train), 5)) test_score_list.append(round(tree.score(X_test, y_test), 5)) kairi_list.append(round(tree.score(X_train, y_train), 5) - round(tree.score(X_test, y_test), 5)) ax = plt.axes(ylabel='スコア', xlabel='木の深さ') ax.set_title('木の深さごとのtrain,testデータスコア') plt.plot(range(1, 10), train_score_list, label='train_score') plt.plot(range(1, 10), test_score_list, label='test_score') ax.legend() display(test_score_list.index(max(test_score_list)), max(test_score_list), pd.Series(kairi_list))結果は…
こんな感じでした。深さが8の時,testスコアが最大で0.80になっています。しかし,深さ8の時も,先ほどと同様にtrainとtestの乖離が大きく,これではやはり過剰適合に対する不安が残ります。かといって次にスコアが高いのは深さが1の場合,これは,木を見ると分かるのですが,性別だけで生死を分類している2択ですのでちょっと…
というわけで,今回はtestスコアも高く,trainスコアとの乖離も比較的小さい深さ3でやってみることにします。
モデルも決まったので,早速test.csvの予測をしていきましょう。
3.テストセットの生存予測,結果
まずはtrain.csv同様,データの確認から始めます。
データ概観df_test_raw = pd.read_csv('C:/~hoge~/test.csv') display(df_test_raw.info(), df_test_raw.head())全体は418行,欠損値が含まれているのはAge,Cabin,Fareでした。
Ageの欠損はtrainデータ同様にTitleごとの平均値を,Fareの欠損には全体の平均値を入れるようにしましょう。まずはtrain同様,Cabinの変換とTitleの確認を行います。
データ前処理:Cabin変換,Title確認df_test_raw['Cabin'].fillna(0, inplace=True) df_test_raw['Cabin'] = df_test_raw['Cabin'].where(df_test_raw['Cabin'] == 0, 1) df_test_name1 = df_test_raw['Name'].str.split(',', expand=True).rename(columns={0:'First', 1:'Other'}) df_test_name2 = df_test_name1['Other'].str.split('.', expand=True).rename(columns=({0:'Title', 1:'Last', 2:'Other'})) df_test_names = pd.concat([df_test_name1, df_test_name2], axis=1)[['First', 'Title', 'Last']] display(df_test_names.head(), df_test_names['Title'].unique())
うまく分割できました。testの方は,敬称の種類が少ないですね。
ちなみに新しい敬称「Dona」は,Donの女性形だそうです。Titleごとの人数と平均年齢もみてみましょう。
Titleごとの人数,平均年齢の算出df_test_name = pd.concat([df_test_raw, df_test_names], axis=1) title_list = [] age_mean_list = [] for titles in df_test_name['Title']: if titles not in title_list: title_list.append(titles) age_mean_list.append('{:.3f}'.format(df_test_name.where(df_test_name['Title'] == titles)['Age'].mean())) else: pass df_title = pd.merge(pd.DataFrame(df_test_name['Title'].value_counts()).reset_index(), pd.DataFrame(age_mean_list, title_list).reset_index(), on='index').rename(columns=({'index':'Title', 'Title':'count', 0:'age_mean'})) display(df_title)
TitleがMsの人は,1件だけで欠損してますね。仕方ないのでここにはtrainの方の平均年齢を入れることにしましょう。
AgeとFareの欠損値を処理して,Familyも追加したData Frame「df_test」を作成します。予測のためのDataFrameの作成dftest_null_in = pd.merge(df_test_name, df_title[['Title', 'age_mean']], on='Title') for indexes, values in enumerate(dftest_null_in['Age']): if values != values: dftest_null_in.iloc[indexes, 4] = dftest_null_in.iloc[indexes, 14] else: pass dftest_null_in['Age'].replace('nan', df_null_in.query('Title == " Ms"').loc[:, 'age_mean'].item(), inplace=True) df_test = dftest_null_in[['PassengerId', 'Pclass', 'First', 'Title', 'Last', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare', 'Cabin', 'Embarked']] df_test['Family'] = df_test['SibSp'] + df_test['Parch'] + 1 df_test['Fare'] = df_test['Fare'].fillna(df_test['Fare'].mean()) df_test = df_test.sort_values('PassengerId') df_test.info()
これで準備完了です。
それでは,Survivedの予測をして,Kaggleに提出するCSVファイルを作成していきます。
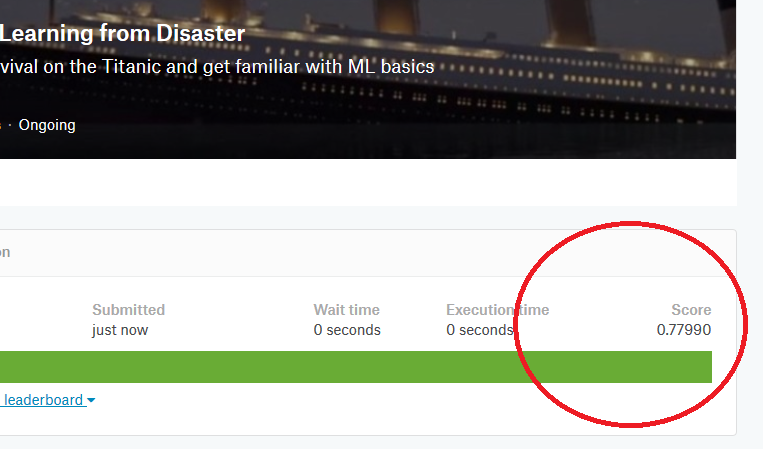
決定木を用いたテストデータの生存予測,submitファイル作成from sklearn.model_selection import train_test_split from sklearn.tree import DecisionTreeClassifier df_test['Sex'] = df_test['Sex'].where(df_test['Sex'] == 'male', 1) df_test['Sex'] = df_test['Sex'].where(df_test['Sex'] == 1, 0) df_test.loc[:, 'Sex'] = df_test.loc[:, 'Sex'].astype(np.int64) df_test.loc[:, 'Cabin'] = df_test.loc[:, 'Cabin'].astype(np.int64) df_test.loc[:, 'Age'] = df_test.loc[:, 'Age'].astype(np.float64) df_test_x = df_test[['Pclass', 'Age', 'Sex', 'Cabin', 'Family', 'Fare', 'Embarked']] df_test_category_x = pd.get_dummies(df_test_x) tree = DecisionTreeClassifier(max_depth=3, random_state=1) tree.fit(X_train, y_train) decision_tree_predict = tree.predict(df_test_category_x) decision_tree_predict = pd.Series(decision_tree_predict) submit = pd.concat([df_test_raw['PassengerId'], decision_tree_predict], axis=1).rename(columns={0:'Survived'}) submit.to_csv('gender_submission.csv')出来ました。
気になるスコアは...
0.779でした。ちょっと上がってます(前回のKNNでは0.76でした)。
小数点以下の変動に一喜一憂するのは少し悔しいですが,やっぱりスコアが上がってると嬉しいですね。しかし,そこまでガッツリ上がらなかったのは,やはり過剰適合と適合不足のバランスがうまく取れなかったせいでしょうか。
決定木ではこれが限界のようです…まとめ
今回は,前回に引き続き機械学習,Pythonの練習として,決定木を用いてTitanic生存予測にチャレンジしました。
決定木はデータに対して構築したモデルを可視化しやすい一方で,学習したデータに過剰に適合しやすく,汎化性能が低くなりがちなので,そのバランスを取って上手くテストデータにも使えるようなモデルを構築するのが難しいです。次回は,今回用いた決定木のデメリットを補う,ランダムフォレストを使ってやっていこうと思います。
参考サイト,文献
https://www.kaggle.com/c/titanic
Pythonではじめる機械学習
Python機械学習プログラミング



- 投稿日:2019-06-07T17:30:09+09:00
DjangoのキャッシュバックエンドをRedisにする
はじめに
筆者自身が、NoSQL、cacheの知識が乏しいため、この記事の対象者は以下のような方を想定しています。
- windowsユーザー
- NoSQL初学者
- キャッシュ初学者
- Djnagoプロジェクトを作成済みで、キャッシュを使いたい方
この記事のメインは、Djangoのキャッシュバックエンドで、Redisを使うことなので、
Redisのインストールは完了している前提です。
Redisのインストールについては、ほぼすっ飛ばします!Redisのインストール
1.windows向けのRedisのmsiファイルをダウンロードする。
https://github.com/microsoftarchive/redis/releases/tag/win-3.0.504 から
「Redis-x64-3.0.504.msi」をダウンロードして、起動する。2.インストーラが起動したら、どんどんNext。
インストーラの内容は普通のインストーラと同じです。笑
- 規約同意
- インストール先ディレクトリ
→環境変数にpathを追加のチェックボックスがあるので、チェックを付けておくことのが無難。- 何番ポートを使用するか
→デフォルトは「6379」。ファイアーウォールの規則に追加するかのチェックボックスがあるので、 個別で設定したくない場合は、チェックを入れることを推奨する。3.一応インストール完了確認。
コマンドプロンプトを立ち上げて、以下のように入力し、Enterを押下する。
> redis-cli.exeその後、プロンプトが以下のようになれば、インストール完了。
127.0.0.1:6379>django-redisをインストールする
1.pipでdjango-redisをインストールする。
> pip install django-redis2.djangoプロジェクトのsettings.pyにcacheの設定を追加する。
settings.pyに以下の記述を追加する。
settings.pyCACHES = { 'default': { 'BACKEND': 'django_redis.cache.RedisCache', 'LOCATION': 'redis://localhost:6379/', 'OPTIONS': { 'CLIENT_CLASS': 'django_redis.client.DefaultClient' } } }*参考までに、デフォルトのCASHESの設定はこちら
django.conf.global_settings.pyCACHES = { 'default': { 'BACKEND': 'django.core.cache.backends.locmem.LocMemCache', } }3.今回は、テンプレートの一部をキャッシュする。
現在時刻をキャッシュするのがわかりやすかったので、現在時刻をキャッシュして確認する。
参考:キャッシュを使うtest.html{% load cache %} <h2>こっちはキャッシュせず</h2> <span>{{ now }}</span> {% cache 240 now_cache%} <h2>ここはキャッシュする</h2> <span>{{ now }}</span> {% endcache %}↓表示画面
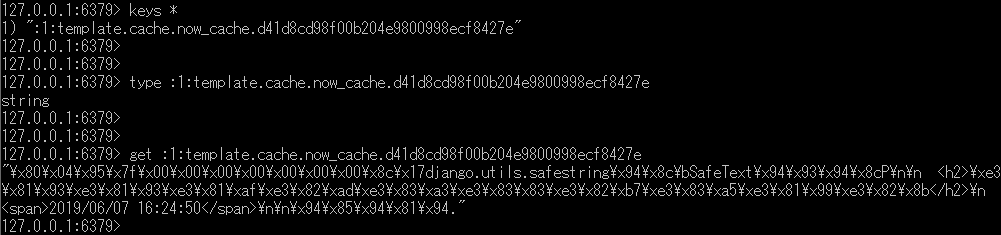
ちなみに、redis-cliで参照すると、
htmlがエスケープされて文字列として格納されていることが確認できる。
キャッシュできる範囲はview単位や、サイト単位などさまざまなので、
参考サイトの「キャッシュを使う」を参考にしてほしい。さいごに
RDBばかり使っていたせいで、Redisの値の格納の仕方に違和感を感じてしまう。
データベース名は?テーブル名は?となるが、そこがKVS(Key Value Store)の特徴といえよう。
柔軟な使用が見込めそう。
○謎の宣言
ページのキャッシュなどを活用して、レスポンスの早いwebページの作成を心掛けたい。参考サイト

- 投稿日:2019-06-07T16:52:28+09:00
家族共有のノートPCでPythonはじめてみた
お小遣いが寂しいので、副業プログラマーとしてPythonをはじめようと思う。
【わいスペック】
43歳 男性 会社員 メタボ ピエール瀧似(ノンドーピング)
20年ほど前に、仕事でHTML、PostgreSQL、PHP、Linuxを触った経験あり
その後、PCに詳しい営業として日々を過ごす。
既婚 恐妻家【よめスペック】
年上 女性 事務のパート たまに可愛い
Word Excelは使えるらしい
御朱印集めと酒が趣味
PCの調子が悪くなると不機嫌【環境】
ノートPC 1台 (Lavie:Win10Home 64bit)
wi‐fiでつながっている【要件】
Pythonの開発がある程度できる
妻が怖いのでPCが重くなるのは勘弁。【試行錯誤(環境編)】
1 無知なため、何もせずPython(Win10版)をダウンロード
→ pip install で躓く。2 dockerで仮想環境を作成。Ubuntu・pythonをダウンロード
→ PCが重くなる予兆が発生。よめにバレたらアウトなので、断念する。3 Win10にAnacondaをインストール
→ 今のところは無事に作動。【結論】
Win10ならAnacondaを導入するのが一番手早い!
- 投稿日:2019-06-07T16:15:46+09:00
Ginzaでエラーが出たらランタイムを再起動(Colaboratory)
リクルートと国立国語研究所が共同で日本語の自然言語処理(NLP)ライブラリ「GiNZA」を出しましたが、GoogleColaboratoryで使おうとするとエラーが出たので、同じ状況に陥った人のために解決法を。
インストールからのエラー
GiNZAを以下でインストールします。
GiNZAインストール!pip install "https://github.com/megagonlabs/ginza/releases/download/v1.0.2/ja_ginza_nopn-1.0.2.tgz"以下のようにコンソールから使う場合は問題なく処理できます
python -m spacy.lang.ja_ginza.cliが、次のようにPythonで使おうとするとエラーが出ます。
エラー!import spacy nlp = spacy.load('ja_ginza_nopn') doc = nlp('これじゃエラーが出ちゃう。') for sent in doc.sents: for token in sent: print(token.i, token.orth_, token.lemma_, token.pos_, token.dep_, token.head.i)ランタイムを再起動する
GiNZAをインストールしたあと、ランタイムを再起動。これで私の場合は解決しました。
理由はわかりません。知っている方がいらっしゃれば、ご教授いただければ幸いです。
- 投稿日:2019-06-07T15:46:02+09:00
【Python】rangeからリストへの変換
rangeで生成したものはイテラブルなオブジェクトだけどリストじゃない。
>>> range(3) range(0, 3)リストに変換するためによく見るのは以下。
>>> list(range(3)) [0, 1, 2]以前、以下が等価なことを教えていただいた。
>>> A = [1,2,3] >>> list(A) [1, 2, 3] >>> [*A] [1, 2, 3]つまりrange(イテレーター)をリストに変換するときも、
>>> [*range(3)] [0, 1, 2]と書ける。
可読性的にどうなんだろうと思うので、使いどきを選ぶかもしれない。
- 投稿日:2019-06-07T15:27:48+09:00
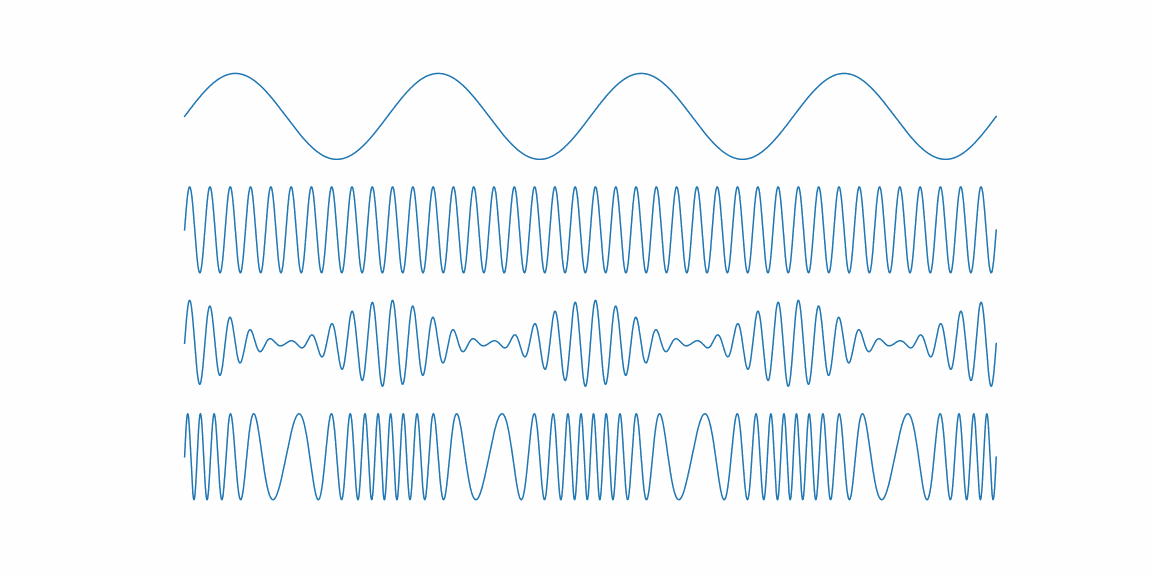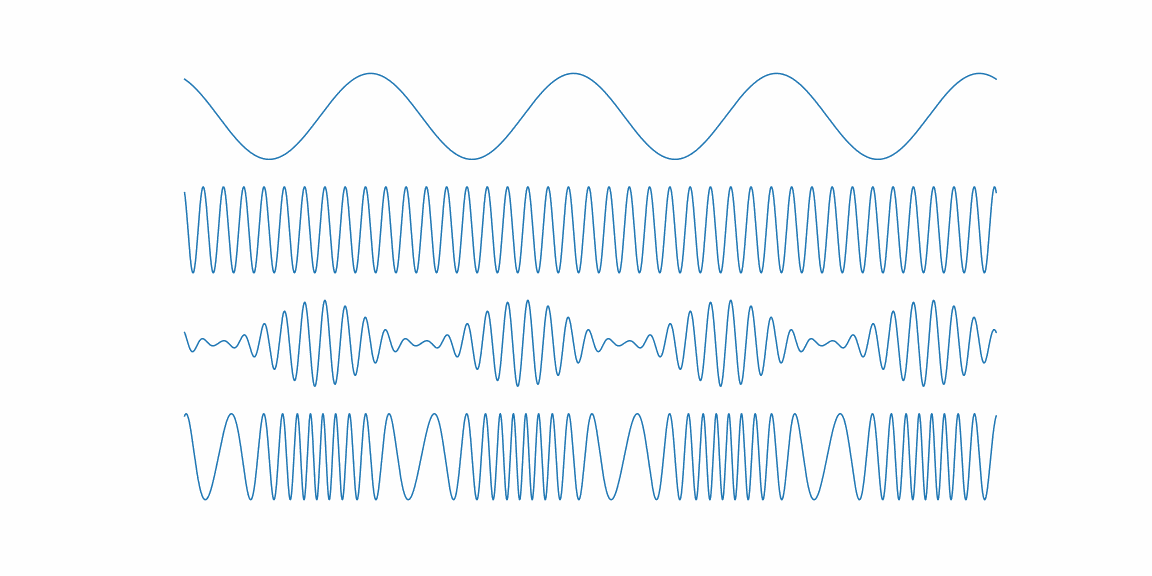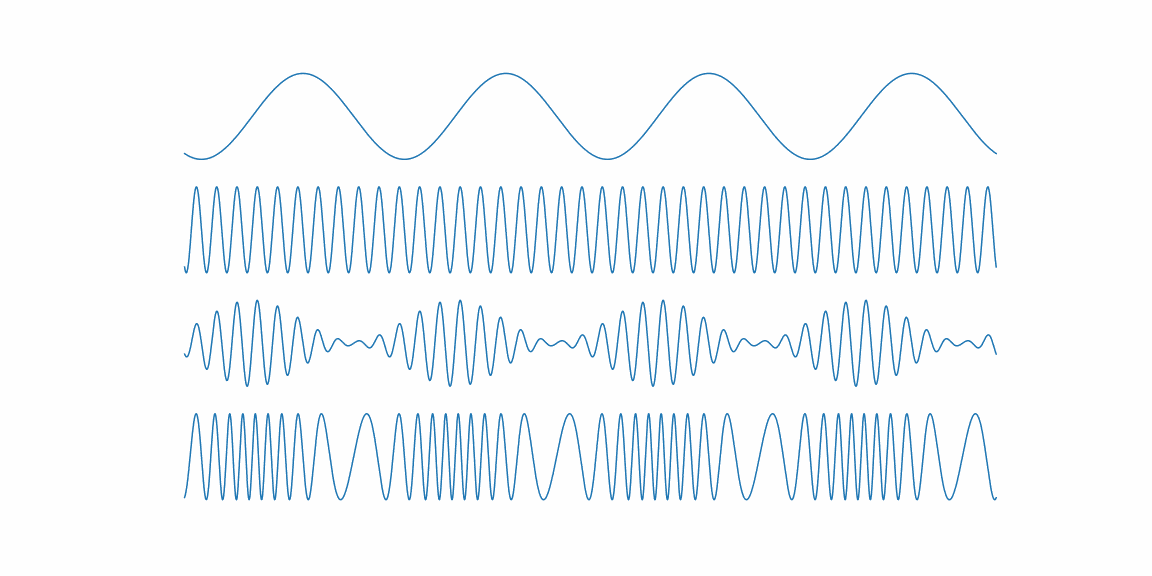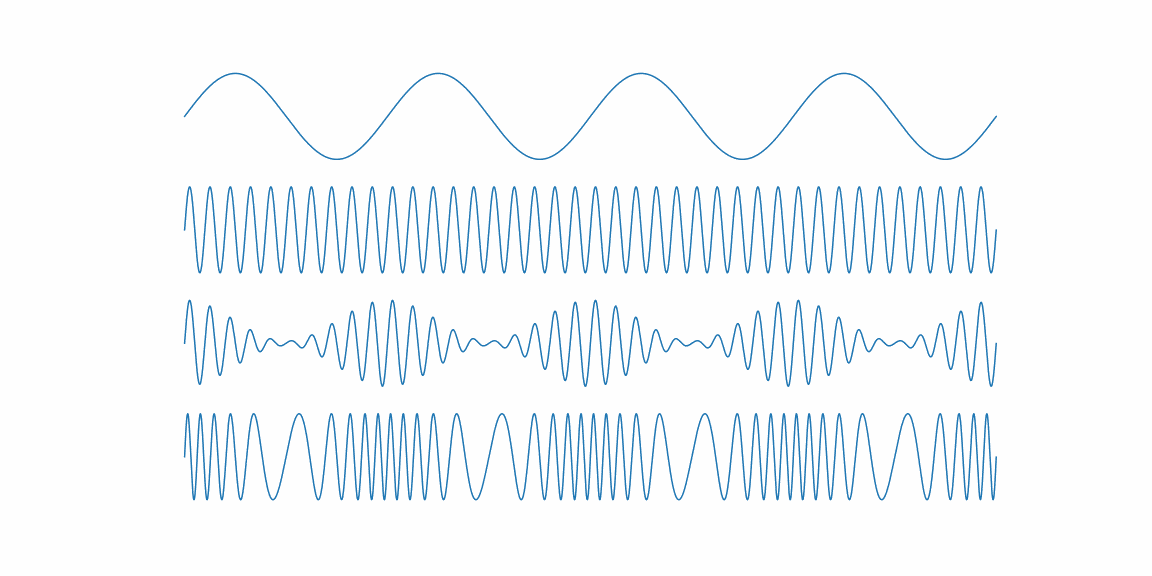
Python のグラフを GIF にしてみた
こういうGIFを作った話
単純なグラフなどは matplotlib の機能でもできるが、上記の画像など複雑になるにつれ厳しくなってくる
なのでライブラリを探した結果 animatplot がよさそうだったのでこれを使う。
簡単なグラフに関しては公式のチュートリアルが用意されている。今回のような複数のグラフを使うコードは以下の通り。
import numpy as np import matplotlib.pyplot as plt import animatplot as amp from pylab import rcParams rcParams['figure.figsize'] = 16, 8 %matplotlib ipympl # lab %matplotlib qt fs = 40000.0 fc = 40.0 fm = 4.0 fig, (ax1, ax2, ax3, ax4) = plt.subplots(4, 1) for ax in [ax1, ax2, ax3, ax4]: ax.axis('off') time = np.arange(fs) / fs ts = np.linspace(0, 1, 100) Xs, Ts = np.meshgrid(time, ts) Y_modulator = np.sin(2.0 * np.pi * fm * (Ts + Xs)) Y_carrier = np.sin(2.0 * np.pi * fc * (Ts + Xs)) Y_am = np.sin(2. * np.pi * fc * (Ts + Xs)) * (1 + 0.9 * np.cos(2.0 * np.pi * fm * (Ts + Xs))) Y_fm = np.sin(2. * np.pi * (fc * (Ts + Xs) + Y_modulator)) B_modulator = amp.blocks.Line(Xs, Y_modulator, ax=ax1) B_carrier = amp.blocks.Line(Xs, Y_carrier, ax=ax2) B_am = amp.blocks.Line(Xs, Y_am, ax=ax3) B_fm = amp.blocks.Line(Xs, Y_fm, ax=ax4) anim = amp.Animation([B_modulator, B_carrier, B_am, B_fm]) anim.save_gif("am_fm")基本的には
matplotlibの使い方と同じで、アニメーションを行う軸をaxで指定する。
最後にamp.Animationで複数のブロックを指定する。アニメーションを付けるとわかりやすいので、今後も活用していきたい。
- 投稿日:2019-06-07T15:18:35+09:00
画像のノイズ除去
はじめに
こんにちは!
今回は画像に入ったノイズの除去など画像処理について書いてみようと思います。
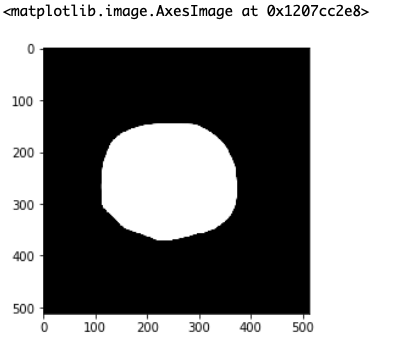
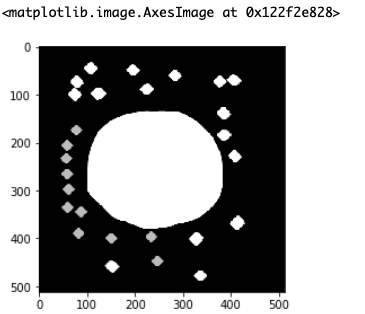
セグメンテーションのために前処理をしたら無駄なノイズが入って困った!なんて時に使えるので参考にしてみてください。今回使用する画像
今回使用するのはこの画像です。
ノイズだらけの2値画像を作ってみたので、今からこれらのノイズをちょっとずつ消していこうと思います。
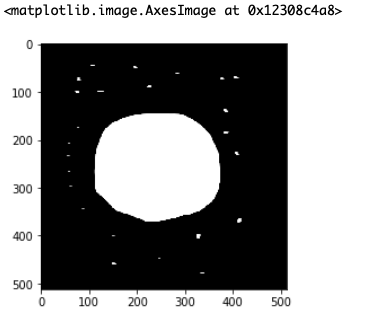
OpenCVを使うので、まだインストールしていない方はインストールの方宜しくお願いします。中央値フィルタ
一つ目は「中央値フィルタ」です。
これは今回のような細かいノイズ(通称 ごま塩ノイズ)と呼ばれるノイズを消したい時に最適です。import cv2 import matplotlib.pyplot as plt img = cv2.imread("./test.png") # アパーチャーサイズ 3, 5, or 7 など 1 より大きい奇数。数値が大きいほどぼかしが出る。 ksize=3 #中央値フィルタ img_mask = cv2.medianBlur(img,ksize) plt.imshow(img_mask)するとこのような画像になります。
まだノイズが残っていますね。
なので、カーネルサイズをどんどん大きくしてみましょう。ここで注意なのですが、カーネルサイズは1より大きい奇数でないといけません。
ksize = 15にしてみます。
これで完全にごま塩ノイズが消えました。
みなさんが自前の画像を使うときもちょっとずつksizeを変えて、その都度確認するようにしてみてください。膨張・収縮
2つ目は「膨張・収縮」です。
これらもOpenCVの機能であり、膨張処理は白色(255)の領域を膨張させ、収縮処理は白色(255)の部分を収縮させる処理です。
わかりにくいと思いうので実際にやってみましょう。ここで、収縮処理をした後に同じ回数だけ膨張処理をすることを「オープニング処理」、膨張処理をした後に同じ回数だけ収縮処理をする頃を「クロージング処理」と言います。
前者は白色のノイズ除去、後者は黒色のノイズ除去に役立ちます。
オープニング処理
まずはオープニング処理をしていきます。
import numpy as np import cv2 import matplotlib.pyplot as plt # 膨張・収縮処理 img = cv2.imread("./test.png") # 近傍の定義 neiborhood = np.array([[0, 1, 0],[1, 1, 1],[0, 1, 0]], np.uint8) # 収縮 img_erode = cv2.erode(img,neiborhood,iterations=10) # 膨張 img_dilate = cv2.dilate(img_erode,neiborhood,iterations=10) plt.imshow(img_erode)収縮処理をした後の画像がこれです。
確かに白いごま塩は消えていますが、白い部分が収縮したため、黒い部分が相対的に大きくなっています。
なので、次は膨張処理を加えます。
その後の画像がこちら
さっきよりは黒い部分が小さくなりましたね!
でもまだ足りないので、iterationsの箇所を10より大きくすると、もっと綺麗に黒いノイズが消えるのでやってみてください。クロージング処理
さっきの逆ですね。
import numpy as np import cv2 import matplotlib.pyplot as plt # 膨張・収縮処理 img = cv2.imread("./test.png") # 近傍の定義 neiborhood = np.array([[0, 1, 0],[1, 1, 1],[0, 1, 0]], np.uint8) #膨張 img_dilate = cv2.dilate(img,neiborhood,iterations=10) #収縮 img_erode = cv2.erode(img_dilate,neiborhood,iterations=10) plt.imshow(img_dilate)するとこのような画像が表示されます。
白い部分が膨張して、黒い部分がかき消されていますが、白いノイズが大きくなってしまっています。
なので収縮処理を加えるとこのようになります。
このように白いノイズが小さくなりました!
先ほどと同様にiterationを大きくするともっと綺麗に消えますが、この方が効果がわかりやすいので今はご了承ください。終わりに
いかがでしたか?
今回のノイズ処理はセグメンテーションのために頑張って色ぬりをした人のためにあるようなものです。
色塗りしたのに、なんか変なノイズが入った。。。なんて時にご活用ください。最後に、医学生である僕が所属しているツカザキ病院眼科AIチームのページも見ていただけたら幸いです!ぜひご覧ください!
ツカザキ病院眼科AIチーム DeepOculus
では、また次の記事で!




- 投稿日:2019-06-07T14:56:38+09:00
[Kaggle]Santander Customer Transaction Prediction(その3)
Santander Customer Transaction Prediction に挑戦してみた。(その3)
この記事は「Santander Customer Transaction Prediction に挑戦してみた。(その2)」の続きです。
- [Santander Customer Transaction Prediction に挑戦してみた。(その1)
- [Santander Customer Transaction Prediction に挑戦してみた。(その2)
(8)コールバック
コールバックを組み込む
今回使用したコールバックは「ReduceLROnPlateau」で、訓練中に学習率を調整してくれる魔法のようなものです。
使い方はとても簡単で、下記のリストを作成してからモデルに入れるだけです。(8-2)
コールバックは検証データを監視するため、モデルには"validation_data = (x_val, y_val)"を入れる8-1callbacks_list = [keras.callbacks.ReduceLROnPlateau( monitor = "val_loss", #損失値を監視 factor = 0.1, #コールバックが起動したら、学習率に0.1をかける(位を一つ下げる) patience = 5, #検証データでの"val_loss"が5エポック改善されなければ起動 )]コールバックを組み込んだモデル
一般的なモデルに、1行加えるだけで魔法が使えます。Kerasに感謝
8-2now_list = high_feature_list + medium_feature_list print(len(now_list)) x_train_in_model = x_train_ss[:, now_list]#モデルに入れる訓練データ y_train_in_model = y_train_ss[:, now_list]#モデルに入れるテストデータ percent_train = 80#訓練データに使う割合(残りは検証データ)[%] train_num = round(200000*(percent_train/100))#訓練データに使うデータ数(残りは検証データ) par_train = x_train_in_model[:train_num, :] par_targets = train_targets[:train_num] val_train = x_train_in_model[train_num:, :] val_targets = train_targets[train_num:] b_size = 1024 epoch = 12 model = Sequential() model.add(Dense(64, input_shape = (len(now_list), ), activation = "relu")) model.add(Dense(32, activation = "relu")) model.add(Dropout(0.5)) model.add(Dense(32, activation = "relu")) model.add(Dropout(0.5)) model.add(Dense(1, activation = "sigmoid")) model.compile(optimizer = optimizers.Adam(), loss = "binary_crossentropy", metrics = ["acc"]) history = model.fit(par_train, par_targets, epochs = epoch, batch_size = b_size, callbacks = callbacks_list, #このように記載するだけで、コールバックを組み込める validation_data = (val_train, val_targets))#コールバック使用時、ここは必須
(9)提出
提出用データを作成
提出データは0〜1の確率で提出するそうです。0と1の値に直して提出しないように注意してください。
(インデックスをつけていいかなどがわかりにくく、いつも1回は弾かれます・・・)9-1ans = model.predict(y_train_in_model) #ans = np.round(ans).astype(int)とすると0・1になる ans = ans.flatten() ans = ans.tolist() print(len(ans)) data = {"target": ans} ans_df = pd.DataFrame(data) ans_df.index = test["ID_code"] ans_df.to_csv("sub_1_Santander_Customer_Transaction_Prediction.csv")結果
提出期限が過ぎているからか、順位は確認できませんでした・・・
(左)Private Score (右)Public Score


- 投稿日:2019-06-07T14:48:58+09:00
【超基礎】python 一部のカラム名の変更
- 投稿日:2019-06-07T14:48:58+09:00
【超基礎】python pandas dataframe 一部のカラム名の変更
- 投稿日:2019-06-07T14:31:02+09:00
[Kaggle]Santander Customer Transaction Prediction(その2)
Santander Customer Transaction Prediction に挑戦してみた。(その2)
この記事は「Santander Customer Transaction Prediction に挑戦してみた。(その1)」の続きです。
- Santander Customer Transaction Prediction に挑戦してみた。(その1)
- Santander Customer Transaction Prediction に挑戦してみた。(その3)
(5)正規化
平均0・標準偏差1に正規化
今回は「平均0・標準偏差1」となるように正規化しました。
(テストデータは訓練データを使って正規化されています。テストデータを使って計算された値は使用するべきではありません。)5-1#正規化 stdsc = StandardScaler() x_train_ss = stdsc.fit_transform(x_train)#訓練データを正規化 #テストデータは、訓練データを使って正規化 train_mean = np.mean(x_train, axis=0)#訓練データの平均 train_std = np.std(x_train, axis=0)#訓練データの標準偏差 y_train_ss = (y_train - train_mean) / train_std#テストデータを正規化(6)検証開始
モデル作成
様々なモデルを作り検証しここにたどり着きました。(後ほど、学習率の修正やコールバックを組み込む)
何割訓練データとして使うのかや、使うデータを簡単に変えられるように組んであります。6-1now_list = high_feature_list + medium_feature_list#使うデータ print(len(now_list)) x_train_in_model = x_train_ss[:, now_list]#モデルに入れる訓練データ y_train_in_model = y_train_ss[:, now_list]#モデルに入れるテストデータ percent_train = 80#訓練データに使う割合(残りは検証データ)[%] train_num = round(200000*(percent_train/100))#訓練データに使うデータ数(残りは検証データ) par_train = x_train_in_model[:train_num, :] par_targets = train_targets[:train_num] val_train = x_train_in_model[train_num:, :] val_targets = train_targets[train_num:] b_size = 1024#色々変更してみる epoch = 12#色々変更してみる model = Sequential() #層の数や変数の数は調整 model.add(Dense(64, input_shape = (len(now_list), ), activation = "relu")) model.add(Dense(32, activation = "relu")) #model.add(Dropout(0.5))#過学習を抑えることができる model.add(Dense(32, activation = "relu")) #model.add(Dropout(0.5)) model.add(Dense(1, activation = "sigmoid")) #学習率は後ほど・・・ model.compile(optimizer = optimizers.Adam(), loss = "binary_crossentropy", metrics = ["acc"]) history = model.fit(par_train, par_targets, epochs = epoch, batch_size = b_size, validation_data = (val_train, val_targets))検証結果をグラフにする
下記のコードを実行するとグラフが現れます。この後、学習率の調整を行いますが、上のモデルのハイパラメータを調整することで、そこそこの結果は得られました。
6-2plt.plot(range(len(history.history["acc"])), history.history["acc"], color = "red", label="acc") plt.plot(range(len(history.history["val_acc"])), history.history["val_acc"], color = "blue", label="val_acc") plt.legend() plt.grid(True) plt.show() plt.plot(range(len(history.history["loss"])), history.history["loss"], color = "red", label="loss") plt.plot(range(len(history.history["val_loss"])), history.history["val_loss"], color = "blue", label="val_loss") plt.legend() plt.grid(True) plt.show()(7)学習率
最適な学習率を探す
7-1now_list = high_feature_list + medium_feature_list print(len(now_list)) x_train_in_model = x_train_ss[:, now_list]#モデルに入れる訓練データ y_train_in_model = y_train_ss[:, now_list]#モデルに入れるテストデータ percent_train = 80#訓練データに使う割合(残りは検証データ)[%] train_num = round(200000*(percent_train/100))#訓練データに使うデータ数(残りは検証データ) par_train = x_train_in_model[:train_num, :] par_targets = train_targets[:train_num] val_train = x_train_in_model[train_num:, :] val_targets = train_targets[train_num:] b_size = 512 epoch = 80 lr_loss_list = []#それぞれの学習率に対して、"loss"を記録する lr_list = [10**x for x in range(-7, 0)]#学習率のリスト for i in lr_list: print("学習率「"+str(i)+"」の検証開始") model = Sequential() model.add(Dense(16, input_shape = (len(now_list), ), activation = "relu")) model.add(Dense(8, activation = "relu")) model.add(Dense(4, activation = "relu")) model.add(Dense(1, activation = "sigmoid")) model.compile(optimizer = optimizers.Adam(lr = i), loss = "binary_crossentropy", metrics = ["acc"]) history = model.fit(par_train, par_targets, epochs = epoch, batch_size = b_size, validation_data = (val_train, val_targets), verbose = 0) lr_loss_list.append(history.history["loss"]) print("学習率「"+str(i)+"」の検証終了")グラフに示す
7-2#学習率を調査 mean_loss_lr = [np.mean(x) for x in lr_loss_list] print(len(mean_loss_lr)) plt.plot(lr_list, mean_loss_lr) plt.xscale('log')#対数軸にする plt.xlabel("lr") plt.ylabel("loss") plt.grid(True) plt.show()
参考にした記事によると、"loss"が最小になっている時の学習率を採用するのではないとのことです。今回、初めて学習率の設定を試みてみましたが、いくつに設定していいかわからなかったのでとても参考になりました。
本で勉強していたときは、学習率を0.001にとっている場合が多かった印象ですが、今回はそれよりも小さな値がいいようです。続きはこちらから
Santander Customer Transaction Prediction に挑戦してみた。(その3)

- 投稿日:2019-06-07T13:46:47+09:00
[Kaggle]Santander Customer Transaction Prediction(その1)
Santander Customer Transaction Prediction に挑戦してみた。(その1)
Santander Customer Transaction Prediction に挑戦をしてみました。(提出期限は過ぎており、3つのチュートリアルを経て、4回目の挑戦)
このコンペは、20万人のデータ(1人につき200個のデータがあるが、何のデータかは不明)を分析し、その顧客は「サービスを購入するか?」、「ローンを払えるか?」を決めるものです。(多分・・・)
何のデータかも明かされておらず、目的も定かではいようでしたが、要するに、20万人を「0」「1」に振り分ける二値分類の問題です。ですが、提出するデータは0〜1の確率で示したものなのでご注意ください。(1回目の提出は0、1に変換して出してしまいました・・・)
- Santander Customer Transaction Prediction に挑戦してみた。(その2)
- Santander Customer Transaction Prediction に挑戦してみた。(その3)
参考文献
https://book.mynavi.jp/ec/products/detail/id=90124
https://www.manning.com/books/deep-learning-with-python
この記事について
- Kerasを用いて分析
- プログラミングを初めて1ヶ月の初心者が書いています。(もちろん、機械学習も初めて)
- コピペで提出まで完了しますが、モデルや前処理が良いものとは限りません。
開発環境
- python 3.7.3
- jupyter 1.0.0
- Keras 2.2.4
- matplotlib 3.1.0
- numpy 1.16.4
- pandas 0.24.2
- tensorflow 1.13.1
- scikit-learn 0.21.2
- scipy 1.3.0
- seaborn 0.9.0
0-1import pandas as pd import numpy as np import matplotlib.pyplot as plt %matplotlib inline from sklearn.preprocessing import StandardScaler import keras from keras.models import Sequential from keras.layers import Dense, Activation, Dropout from keras import optimizers(1)訓練データとテストデータ
使用するデータをダウンロード
データはこちらからダウンロードできます。(https://www.kaggle.com/c/santander-customer-transaction-prediction/data)
データの読み込み
1-1#ファイルの場所を指定します train = pd.read_csv("/Users/*****/Desktop/Kggale/santander-customer-transaction-prediction/train.csv") test = pd.read_csv("/Users/*****/Desktop/Kggale/santander-customer-transaction-prediction/test.csv")データの中身を確認する
訓練データ
訓練データは「200000行202列」で構成されており、20万人1人1人に「ID_code」と「target(ラベル)」と「200個のデータ」が与えられています。
1-2print(train.shape) train.head()テストデータ
こちらも訓練データと同じ構成をしていますが、「target」が記されていない、「200000行201列」です。このコンペは、テストデータの「target」 を予測する問題です。
1-3print(test.shape) test.head()統計量の確認(訓練データ)
今回は、特に使用しませんでしたが、どの程度データにばらつきがあるのかなどを確認しました。
検証に行く前に正規化を行なっていますが、しなくてもいいのでは?とも思いました。1-4train.describe()
(2)データをニューラルネットワーク用に変換
NumPy配列にする
DataFrameから値を取り出して、浮動小数点数のベクトルに変換しました。
2-1x_train = train.iloc[:, 2:].values.astype("float32")#訓練データ train_targets = train["target"].values.astype("float32")#訓練データラベル y_train = test.iloc[:, 1:].values.astype("float32")#テストデータ(3)データを詳しく見る
200個のデータをヒストグラムで表示(保存)
200個のデータをそれぞれ、「"target"が0の人」「"target"が1の人」に分けて、ヒストグラムで表示
"target"が0の人と1の人の人数が大きく異なり、グラフを重ね合わせると比較しにくいため、y軸を両方設定し、比較しやすいようにした。3-1train_columns_name = train.columns[2:]#データのカラムの名前のリスト for i in range(len(train_columns_name)): hist_data = train.iloc[:, [1, (i+2)]] hist_data_0 = hist_data[hist_data["target"]==0] hist_data_1 = hist_data[hist_data["target"]==1] fig, ax1 = plt.subplots(figsize = (20, 10)) # ax1とax2を関連させる ax2 = ax1.twinx() ax1.hist(hist_data_0[train_columns_name[i]], bins = 300, label="0", alpha = 0.5, color = "red") ax2.hist(hist_data_1[train_columns_name[i]], bins = 300, label="1", alpha = 0.5, color = "cornflowerblue") handler1, label1 = ax1.get_legend_handles_labels() handler2, label2 = ax2.get_legend_handles_labels() # 凡例をまとめて出力する ax1.legend(handler1 + handler2, label1 + label2) plt.title("var_"+str(i), fontsize=20) #通常、下の2行のどちらかはコメントアウト plt.savefig("var_"+str(i)+".png")#表示だけなら、ここをコメントアウト plt.show()#保存だけなら、ここをコメントアウト保存された画像(グラフ)を見て、"target"を決まる際に影響が大きそうなものを選ぶ
次のように分類した(明確に分けるプログラムを組んだわけではなく、目視での確認のため、僕の価値観が大きく影響している気がします・・・)
- 大きく影響しそうなもの
- 少しは影響してそうなもの
- 影響してなさそうなもの
200枚の画像を載せるわけには行かないので、いくつか紹介します。
赤色のヒストグラムが「0の人」、青色のヒストグラムが「1の人」です。■大きく影響しそうなもの
赤と青にズレが大きいものは、影響が大きいと判断しました。
■少しは影響してそうなもの
■影響してなさそうなもの
振り分け結果
下のように振り分けてみました。(狙ったわけではありませんが、約3等分されています。)
目視で振り分けましたが、きっちりとしたルールを設けて振り分けるのがいいかなと思いました。3-2#■大きく影響しそうなもの high_feature_list = [1,6,9,12,13,18,21,22,26,32,33,34,40,44,53,56,67, 68,75,76,78,80,81,82,86,87,89,92,108,109,110,121,122, 123,133,134,139,146,148,164,165,166,169,170,173,174, 177,179,184,188,190,191,192,197,198,199] #■少しは影響してそうなもの medium_feature_list = [0,2,5,20,23,24,28,31,35,36,43,48,49,51,52,58, 63,66,70,71,77,83,85,88,90,91,93,94,95,99,101,104,105, 106,107,111,112,114,115,116,118,119,120,125,127,128, 130,131,132,135,137,141,142,143,145,147,149,150,153, 154,155,156,157,162,163,167,172,178,180,186,187,193, 194,195,196] #■影響してなさそうなもの low_feature_list = [3,4,7,8,10,11,14,15,16,17,19,25,27,29,30,37,38,39, 41,42,45,46,47,50,54,55,57,59,60,61,62,64,65,69,72,73,74, 79,84,96,97,98,100,102,103,113,117,124,126,129,136,138, 140,144,151,152,158,159,160,161,168,171,175,176,181,182, 183,185,189](4)[番外編]面白い形をしたヒストグラムができました!
一体、どんなデータをとったらこのようになるのか知りたいです。何のデータかわからないことがとても残念です・・・
(他にも面白いデータがありました)
続きはこちらから
Santander Customer Transaction Prediction に挑戦してみた。(その2)

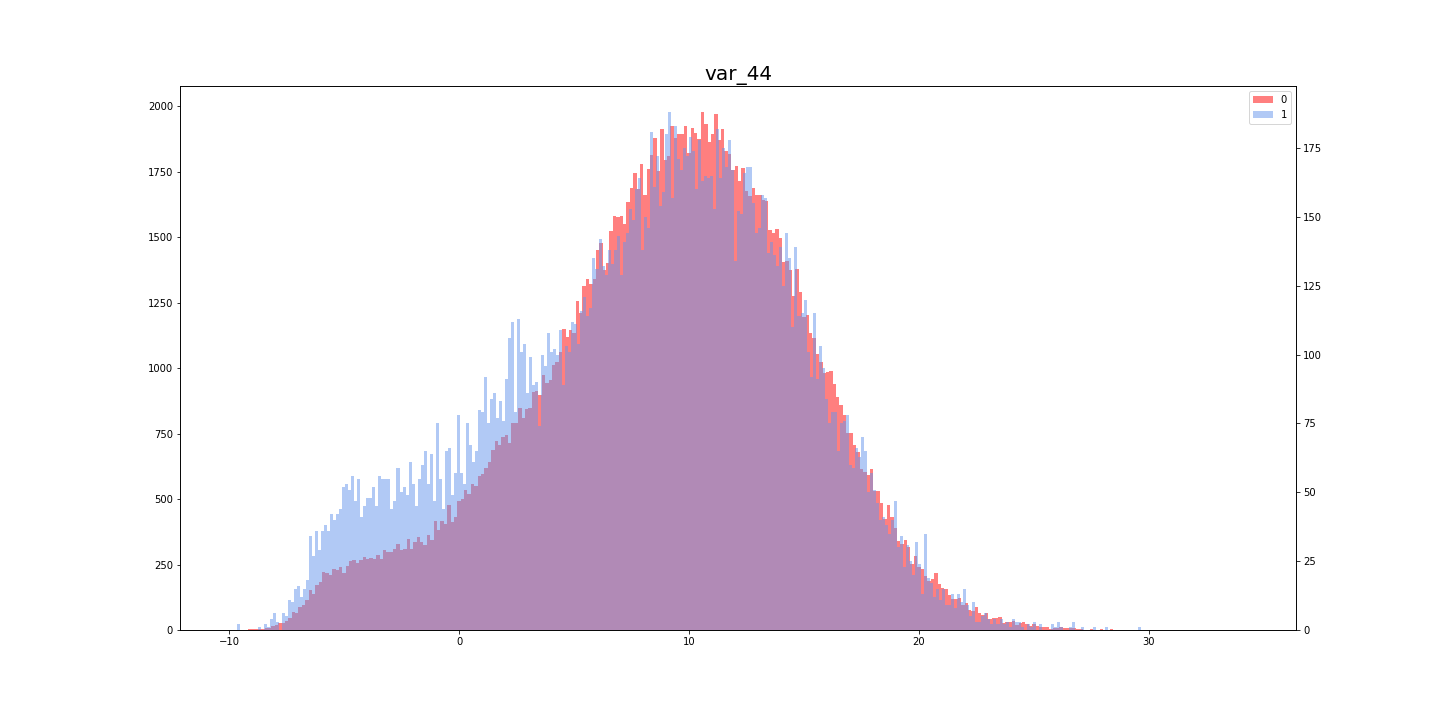
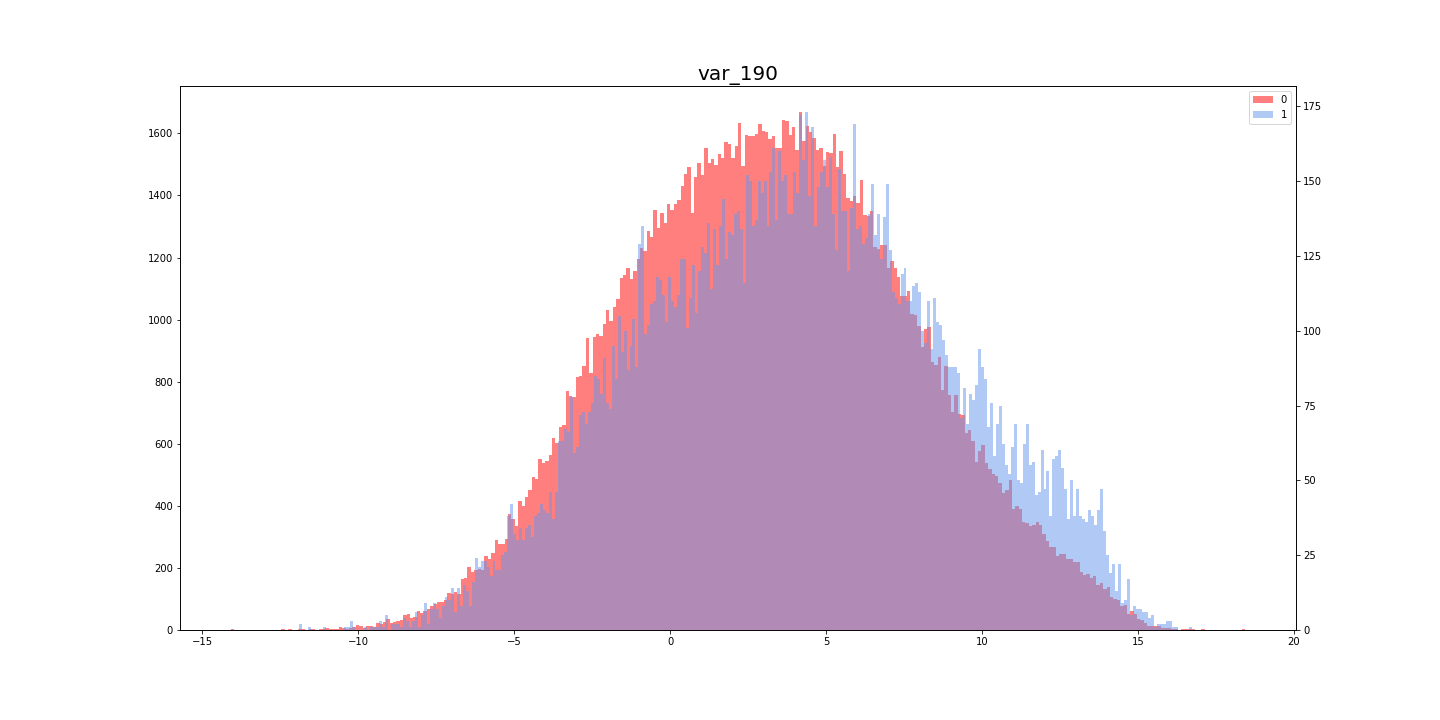
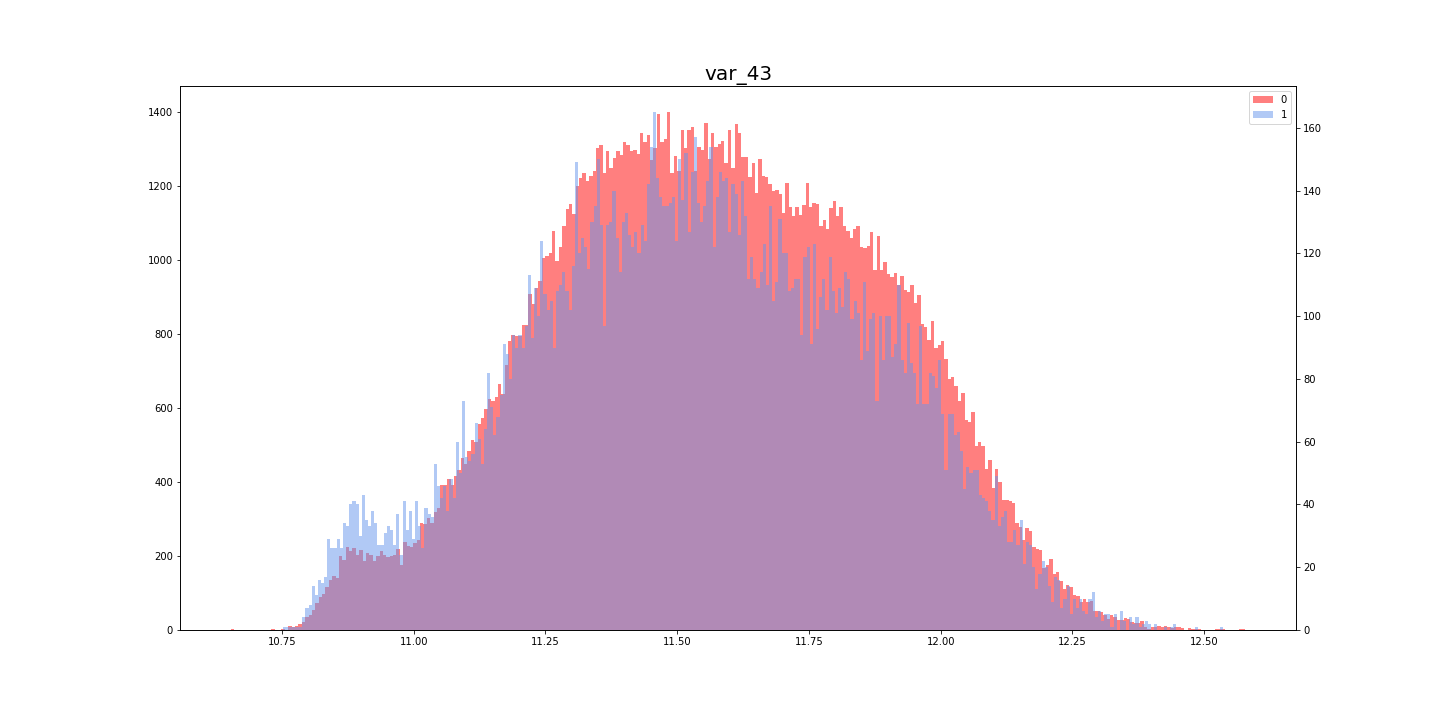
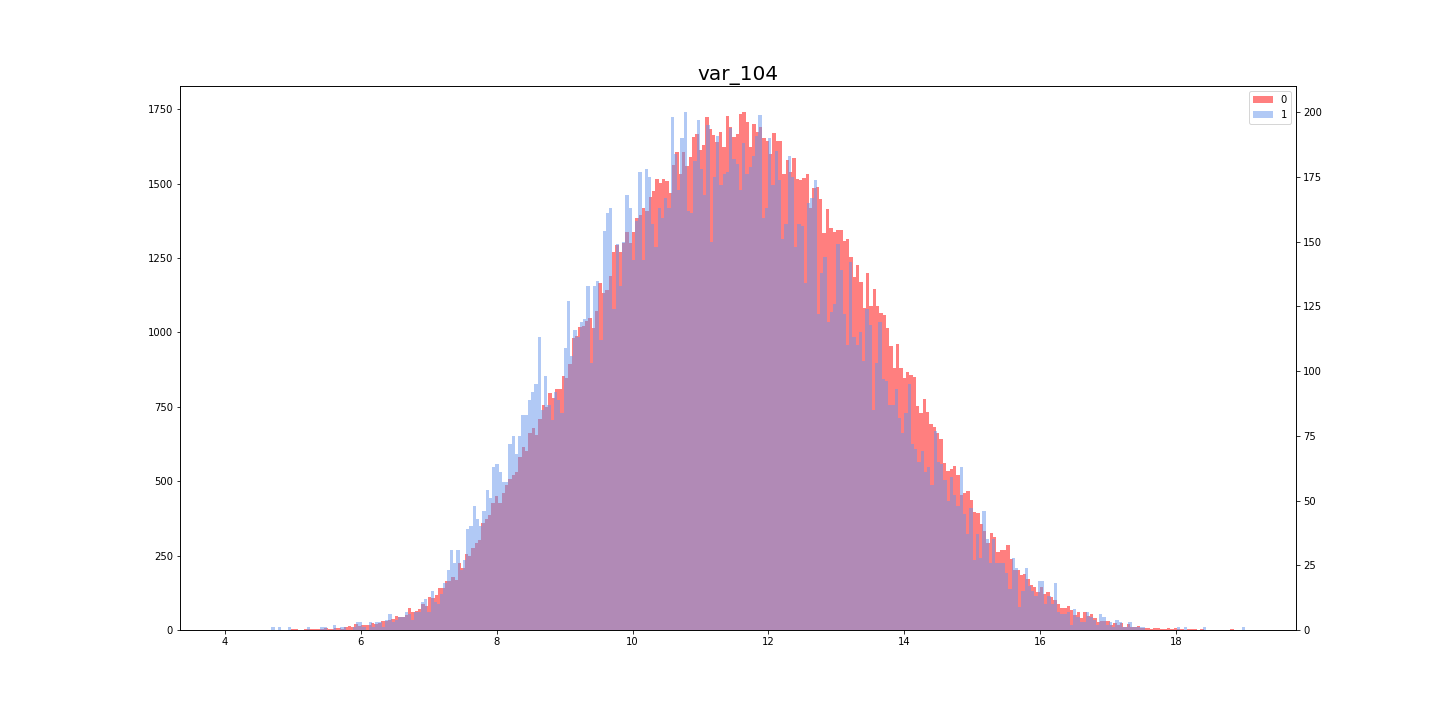
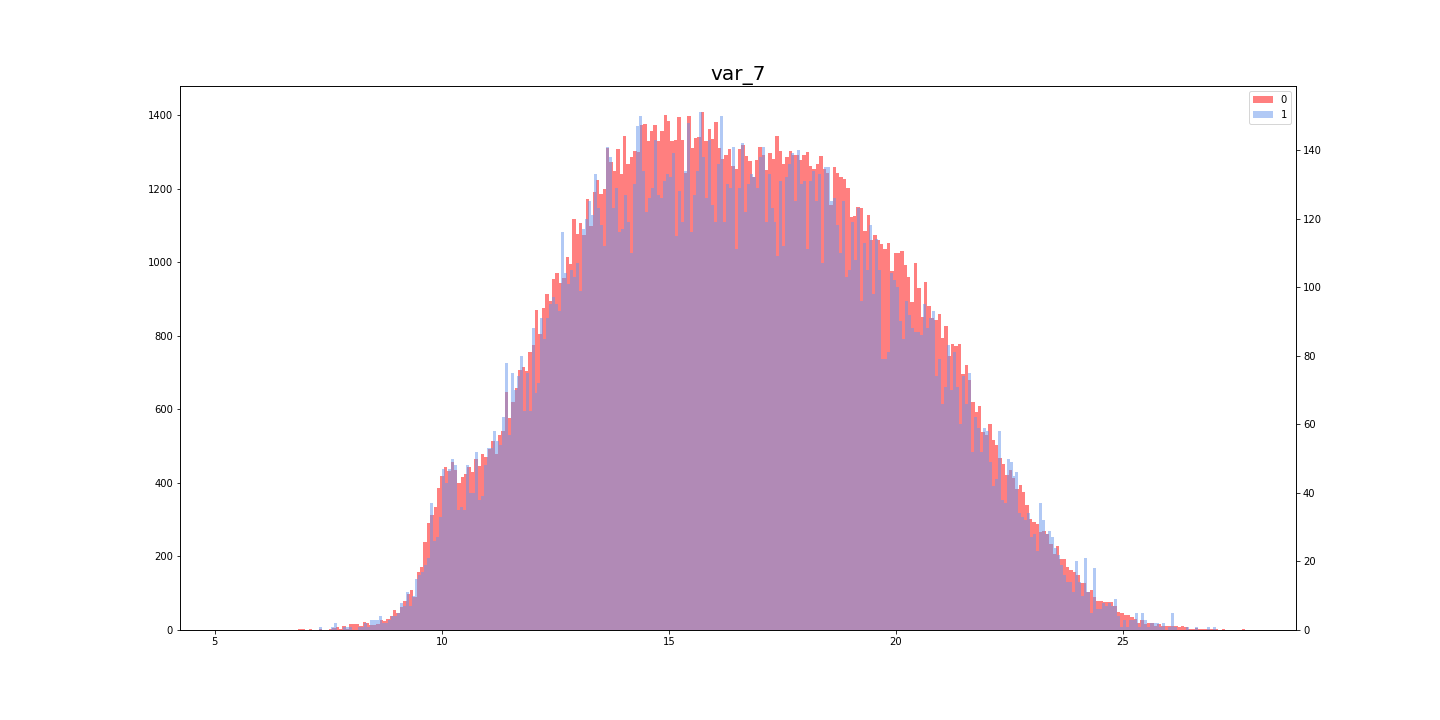
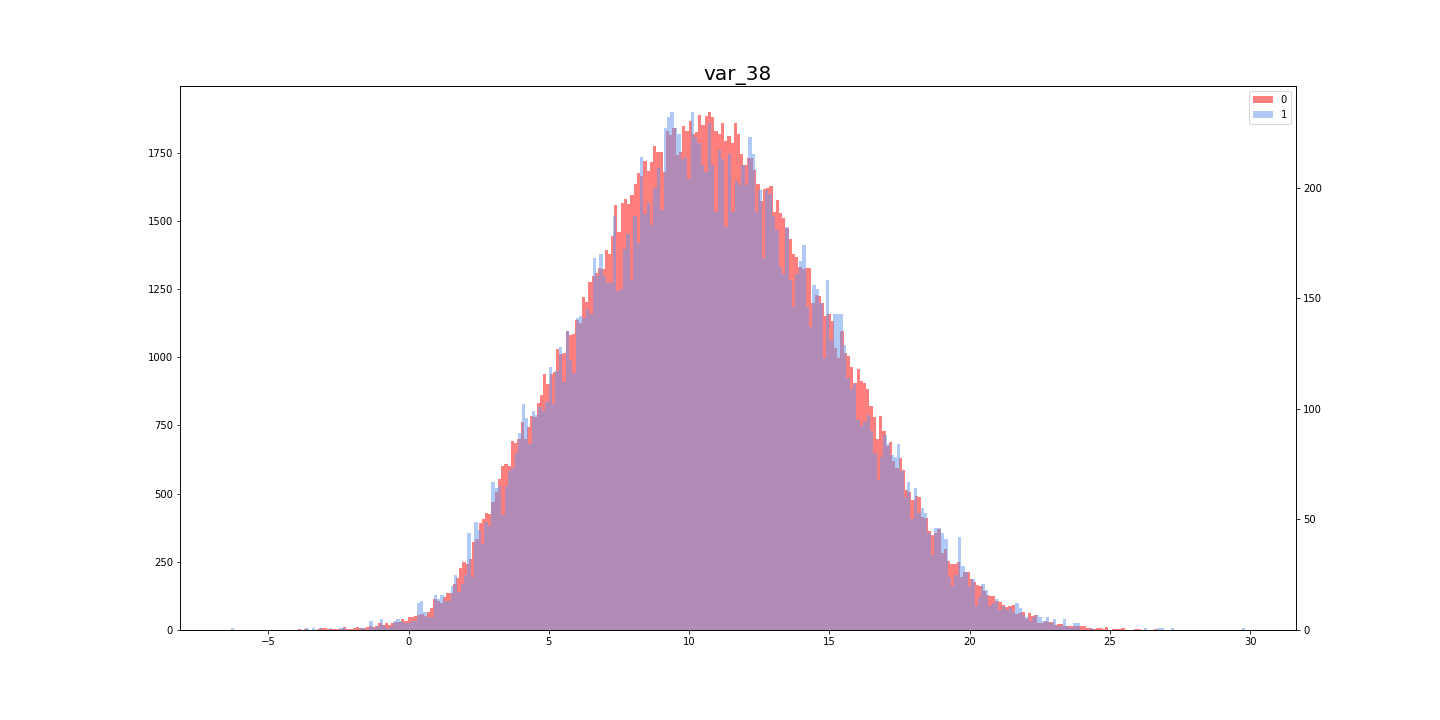
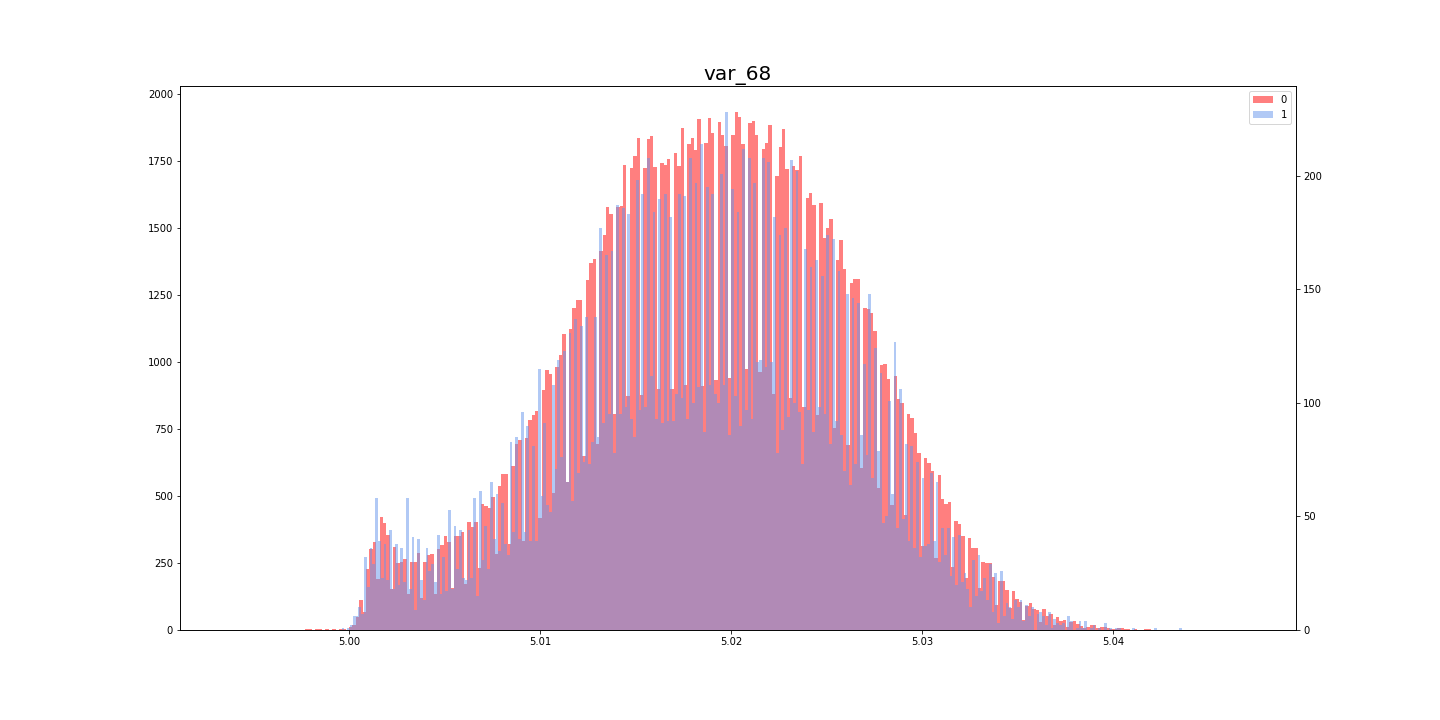
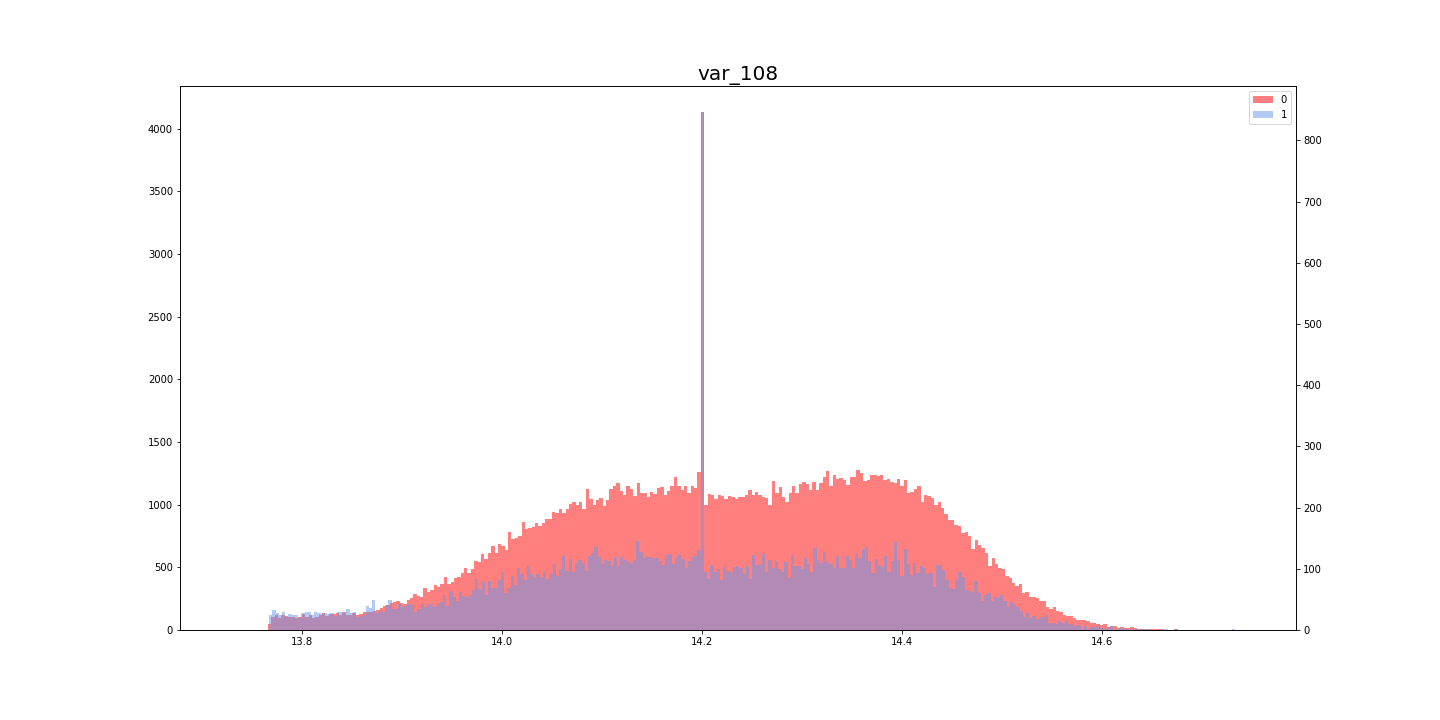
- 投稿日:2019-06-07T12:59:57+09:00
Python学びたければこれ読んどけばな本
みんなのPython 第4版
https://www.amazon.co.jp/dp/479738946X/入門 Python 3
https://www.amazon.co.jp/dp/4873117380/エキスパートPythonプログラミング改訂2版
https://www.amazon.co.jp/dp/4048930613/Pythonプロフェッショナルプログラミング 第3版
https://www.amazon.co.jp/dp/4798053821/Effective Python ―Pythonプログラムを改良する59項目
https://www.amazon.co.jp/dp/4873117569/
- 投稿日:2019-06-07T12:29:15+09:00
PythonでRedisにアクセスする
TL;DR
- PythonからRedisにアクセスするためのライブラリを知りたい
redis-pyというものを使うらしいので、ちょっと試してみたRedis
Key Value Storeの有名どころですね。
値として取れるものも、単純なものだけではなくList、Set、Soted set、Hash、HyperLogLogs、Streamなどを扱うことができます。
An introduction to Redis data types and abstractions
今回は、Redisの
5.0.5を使用します。Dockerイメージで。$ docker container run -it --rm --name redis redis:5.0.5 $ docker inspect redis | grep IPAddress "SecondaryIPAddresses": null, "IPAddress": "172.17.0.2", "IPAddress": "172.17.0.2",PythonからRedisへアクセスするためには、
redis-pyというものがメジャーなようなので、こちらを使用して試してみることにします。環境および
redis-pyのインストール利用するPythonのバージョン。
$ python3 -V Python 3.6.7
redis-pyのインストールとバージョン。$ pip3 install redis $ pip3 freeze ... redis==3.2.1
redis-pyを使って、PythonからRedisにアクセスするとりあえず、Getting Startedを見ながら書いてみましょう。
あんまり使い方が書かれていないのですが、コードを見つつ、なんとなく書いてみます…。
https://github.com/andymccurdy/redis-py/blob/3.2.1/redis/client.py
hello-redis.py
import redis redis_client = redis.Redis(host = '172.17.0.2', port = 6379) ## Simple redis_client.set('key1', 'value1') assert redis_client.get('key1') == b'value1' assert redis_client.get('key1').decode('utf-8') == 'value1' ## Hash redis_client.hmset('hash_key1', { 'member1': 'hash_value1', 'member2': 'hash_value2' }) assert redis_client.hget('hash_key1', 'member1') == b'hash_value1' assert redis_client.hgetall('hash_key1') == { b'member1': b'hash_value1', b'member2': b'hash_value2' }実行。
$ python3 hello-redis.py動きました。
ところで、レスポンスが
byteで返ってきているので、ひたすらdecodeすることになります。ここで、ドキュメントをちゃんと見ると、
decode_responsesをTrueにすればよいとあるのでこちらを使ってみましょう。If all string responses from a client should be decoded, the user can specify decode_responses=True to Redis.init. In this case, any Redis command that returns a string type will be decoded with the encoding specified.
hello-redis-decoded.py
import redis redis_client = redis.Redis(host = '172.17.0.2', port = 6379, decode_responses = True) ## Simple redis_client.set('key1', 'value1') assert redis_client.get('key1') == 'value1' ## Hash redis_client.hmset('hash_key1', { 'member1': 'hash_value1', 'member2': 'hash_value2' }) assert redis_client.hget('hash_key1', 'member1') == 'hash_value1' assert redis_client.hgetall('hash_key1') == { 'member1': 'hash_value1', 'member2': 'hash_value2' }スッキリしましたね。
とりあえず、基本的な使い方はこんな感じでしょうか。
接続時のオプションなどは、ちゃんと見た方が良さそうです。
https://github.com/andymccurdy/redis-py/blob/3.2.1/redis/client.py#L605-L615
その他の機能
ドキュメントを見ると、コネクションプールなどの機能もあるようです。
Hiredisとか、面白いですね
RedisチームがCで実装したパーサーで、Hiredisをインストールすると
redis-pyのパース処理が早くなるようです。$ pip3 install hiredis
redis-py自身が、Hiredisを意識したソースコードになっています。https://github.com/andymccurdy/redis-py/blob/3.2.1/redis/connection.py#L434-L437
あと、ドキュメントには記載がなさそうですが、Redis Clusterも使えそうなので、そのうち試してみたいところ。
https://github.com/andymccurdy/redis-py/blob/3.2.1/redis/client.py#L492-L514
Redis Sentinelのサポートは書かれているんですけどね。
今回はこれくらいで。
- 投稿日:2019-06-07T12:29:15+09:00
redis-pyを使って、PythonからRedisにアクセスする
TL;DR
- PythonからRedisにアクセスするためのライブラリを知りたい
redis-pyというものを使うらしいので、ちょっと試してみたRedis
Key Value Storeの有名どころですね。
値として取れるものも、単純なものだけではなくList、Set、Soted set、Hash、HyperLogLogs、Streamなどを扱うことができます。
An introduction to Redis data types and abstractions
今回は、Redisの
5.0.5を使用します。Dockerイメージで。$ docker container run -it --rm --name redis redis:5.0.5 $ docker inspect redis | grep IPAddress "SecondaryIPAddresses": null, "IPAddress": "172.17.0.2", "IPAddress": "172.17.0.2",PythonからRedisへアクセスするためには、
redis-pyというものがメジャーなようなので、こちらを使用して試してみることにします。環境および
redis-pyのインストール利用するPythonのバージョン。
$ python3 -V Python 3.6.7
redis-pyのインストールとバージョン。$ pip3 install redis $ pip3 freeze ... redis==3.2.1
redis-pyを使って、PythonからRedisにアクセスするとりあえず、Getting Startedを見ながら書いてみましょう。
あんまり使い方が書かれていないのですが、コードを見つつ、なんとなく書いてみます…。
https://github.com/andymccurdy/redis-py/blob/3.2.1/redis/client.py
hello-redis.py
import redis redis_client = redis.Redis(host = '172.17.0.2', port = 6379) ## Simple redis_client.set('key1', 'value1') assert redis_client.get('key1') == b'value1' assert redis_client.get('key1').decode('utf-8') == 'value1' ## Hash redis_client.hmset('hash_key1', { 'member1': 'hash_value1', 'member2': 'hash_value2' }) assert redis_client.hget('hash_key1', 'member1') == b'hash_value1' assert redis_client.hgetall('hash_key1') == { b'member1': b'hash_value1', b'member2': b'hash_value2' }実行。
$ python3 hello-redis.py動きました。
ところで、レスポンスが
byteで返ってきているので、ひたすらdecodeすることになります。ここで、ドキュメントをちゃんと見ると、
decode_responsesをTrueにすればよいとあるのでこちらを使ってみましょう。If all string responses from a client should be decoded, the user can specify decode_responses=True to Redis.init. In this case, any Redis command that returns a string type will be decoded with the encoding specified.
hello-redis-decoded.py
import redis redis_client = redis.Redis(host = '172.17.0.2', port = 6379, decode_responses = True) ## Simple redis_client.set('key1', 'value1') assert redis_client.get('key1') == 'value1' ## Hash redis_client.hmset('hash_key1', { 'member1': 'hash_value1', 'member2': 'hash_value2' }) assert redis_client.hget('hash_key1', 'member1') == 'hash_value1' assert redis_client.hgetall('hash_key1') == { 'member1': 'hash_value1', 'member2': 'hash_value2' }スッキリしましたね。
とりあえず、基本的な使い方はこんな感じでしょうか。
接続時のオプションなどは、ちゃんと見た方が良さそうです。
https://github.com/andymccurdy/redis-py/blob/3.2.1/redis/client.py#L605-L615
その他の機能
ドキュメントを見ると、コネクションプールなどの機能もあるようです。
Hiredisとか、面白いですね
RedisチームがCで実装したパーサーで、Hiredisをインストールすると
redis-pyのパース処理が早くなるようです。$ pip3 install hiredis
redis-py自身が、Hiredisを意識したソースコードになっています。https://github.com/andymccurdy/redis-py/blob/3.2.1/redis/connection.py#L434-L437
あと、ドキュメントには記載がなさそうですが、Redis Clusterも使えそうなので、そのうち試してみたいところ。
https://github.com/andymccurdy/redis-py/blob/3.2.1/redis/client.py#L492-L514
Redis Sentinelのサポートは書かれているんですけどね。
今回はこれくらいで。