- 投稿日:2019-03-24T23:51:01+09:00
Ruby 配列展開 *Array
@koshi_life です。
*Arrayの記法が読めなかったので備忘です。前提
- ruby 2.6
読めなかったコード
hoge = {name: 'hoge', address: 'hoge@example.jp'} a = [{name: 'a1', address: 'a1@example.jp'}] b = [{name: 'b1', address: 'b1@example.jp'}, {name: 'b2', address: 'b2@example.jp'}] c = [{name: 'c1', address: 'c1@example.jp'}, {name: 'c2', address: 'c2@example.jp'}, {name: 'c3', address: 'c3@example.jp'}] addresses = [ hoge[:address], *a.pluck(:address), *b.pluck(:address), *c.pluck(:address) ]ちなみに pluckは
引数に指定したカラムの配列を返すメソッドです。このメソッドはRailsで使用できるメソッドなので、Rubyのみでは使用することができません。
mapとpluck より> b.pluck(:address) => ["b1@example.jp", "b2@example.jp"]pluck部分は上記リンク,consoleで試して読めたのでコードを簡略化します。
読めなかったのは
*Arrayhoge = {name:'hoge', address:'hoge@jp'} a = ['a1@jp'] b = ['b1@jp', 'b2@jp'] c = ['c1@jp', 'c2@jp', 'c3@jp'] addresses = [ hoge[:address], *a, *b, *c ] => ["hoge@jp", "a1@jp", "b1@jp", "b2@jp", "c1@jp", "c2@jp", "c3@jp"]
*をつけないとaddresses = [ hoge[:address], a, b, c ] => ["hoge@jp", ["a1@jp"], ["b1@jp", "b2@jp"], ["c1@jp", "c2@jp", "c3@jp"]]結論
*Arrayは配列の要素を展開してくれる便利な記法。# ちなみに以下と同意 > [hoge[:address]] + a + b + c => ["hoge@jp", "a1@jp", "b1@jp", "b2@jp", "c1@jp", "c2@jp", "c3@jp"]参考
- 投稿日:2019-03-24T23:07:49+09:00
Ruby on Railsを体系的に学ぶためのRAILS GUIDESの使い方
始めに
この記事は、Railsアプリケーションがリクエストを受け取って、レスポンスを返すまでにどんな処理を行うかについて触れています。
個人的に「一度は読んでおいて損はない」と感じたRAILSGUIDEのリンクを集めました。
ここで紹介するリンクは、はじめは読んでも意味がわからないと思いますが、目を通す意味があると思います。取り急ぎ執筆したため、現時点では世界一投げやりなRails講座です。
今後少しずつ説明を書いていこうと思います。
こうした方がいいんじゃないかなど、意見がありましたら、ご教授願います。注意書き
初心者の人がここに書いてあることを全て理解するのは不可能だと思います。
目を通して頭の片隅に入れておくだけでいいです。
単語も覚えようとしないでください。「ふーん、こんなのがあるんだ」程度でいいです。対象
以下のような人が「ギリギリ理解できるかできないか」レベルの箇所を抜粋しています。
- Railsの勉強始めたけど腑に落ちない人
- コードの意味がわかってない人
- コピペコーダー
対象じゃない人
- Rails newしたことない人
- MVCという言葉を聞いたことすらない人
- 読むより実践派の人
- Railsできる人
0. リクエストとレスポンス
Webのアプリケーションはリクエスト(お願い)を受け取ることではじまります。
アプリ内のボタンをおされたり、URLが入力されたり、google検索に引っかかったりすることで、アプリケーションにリクエスト(お願い)が送られます。リクエストはパス(URL)とHTTPリクエストメソッド(GETやPOST)で構成されます。
Webアプリケーションは、このリクエスト(お願い) に対して、様々な処理をした後にレスポンス(返信) を返します。
HTTPリクエストについては、こちらの記事を見るといいと思います。
超絶初心者のためのサーバとクライアントの話1. Routing
Railsアプリケーションはリクエストを受け取ると、Railsのルーターがリクエストを識別します。
ルーターのカスタマイズは、config/routes.rbで行います。以下のリンクの2.4までは目を通すといいと思います。
Railsのルーティング | RAILS GUIDE2. Controller
MVCモデルのCです。
ルーターに指名されたコントローラは、何かしらの処理を行い、最終的にViewを用いてHTMLを表示します。この「何かしらの処理」を理解するために、リンクの以下の部分を目を通すといいと思います。
- 1 ~ 4.1 コントローラの役割〜ハッシュと配列パラメータ
- 4.3 ルーティングパラメータ
- 4.5 Strong Parameter
- 8 フィルタ
3. View
MVCモデルのVです。
前章で、コントローラは以下のように説明しました。
ルーターに指名されたコントローラは、何かしらの処理を行い、最終的にViewを用いてHTMLを表示します。
この章では、「Viewとは何か」と「コントローラはどうやってViewを用いるのか」について触れます。
3-1 Viewとは何か
リンクの以下の部分を目を通すといいと思います。
- 1 ~ 3.1.1 Action Viewについて 〜 ERB
- 3.2 ~ 4 パーシャル 〜 パーシャルレイアウト
- 6.1 Action Viewのヘルパーメソッドの概要(余裕があれば)
もし余裕があればこちらも読んでみましょう。(優先順位は3-2の方が高いです。)
ユーザに入力させる、フォームについてです。
- 1 ~ 2.2 基本的なフォームを作成する 〜 フォームとオブジェクトを結び付ける
- 7 パラメータの命名ルールを理解する
Action View フォームヘルパー | RAILS GUIDE
3-2 コントローラはどうやってViewを用いるのか
リンクの以下の部分を目を通すといいと思います。
- 1 ~ 2.2 概要: 部品を組み上げる 〜 レンダリングを使用する
- 2.3 redirect_toを使用する
- 3.4 パーシャルを使用する
4. モデル
MVCモデルのMです。
前章で、コントローラは以下のように説明しました。
ルーターに指名されたコントローラは、何かしらの処理を行い、最終的にViewを用いてHTMLを表示します。
この「何らかの処理」にデータベースが絡む場合、モデルが必要になります。
モデルは、基本的にはデータベース内のテーブルの数だけ存在します。モデルが複数存在するということは、テーブルのデータ同士が関連している可能性があります。この関連自体をアソシエーションといいます。この章では、以下について触れます。
- 4-1 Modelとは何か
- 4-2 データベースの編集方法
- 4-3 どうやってModelを通じてデータを取り出すか
- 4-4 アソシエーションとは何か
4-1 Modelとは何か
リンクの以下の部分を目を通すといいと思います。
- 1 ~ 3 Active Recordについて 〜 Active Recordのモデルを作成する
- 5 ~ 8 CRUD: データの読み書き 〜 マイグレーション
Active Record の基礎 | RAILS GUIDE
4-2 データベースの編集方法
リンクの以下の部分を目を通すといいと思います。
- 1 ~ 2 マイグレーションの概要 〜 マイグレーションを作成する
- 3 (余裕があったら)
- 4 ~ 8 CRUD: マイグレーションを実行する 〜 マイグレーションとシードデータ
Active Record マイグレーション | RAILS GUIDE
4-3 データベースの編集方法
リンクの以下の部分を目を通すといいと思います。
- 1 ~ 3 データベースからオブジェクトを取り出す 〜 並び順
Active Record クエリインターフェイス | RAILS GUIDE
4-3 データベースの編集方法
リンクの以下の部分を目を通すといいと思います。
- 1 ~ 2.3 関連付けを使用する理由 〜 has_many関連付け(余裕があったら、2章全体を読んでみましょう)
Active Record の関連付け (アソシエーション) | RAILS GUIDE
フィードバックについて
「こうした方がいいんじゃないか」
「この部分の説明はリンク先だけでは1mmも理解できない」
などの意見がありましたら、コメントにてご教授頂けると嬉しいです。説明、オススメリンクを随時足していく予定です。
- 投稿日:2019-03-24T21:48:46+09:00
13日目(2):Ruby認定試験
恐ろしく長いのですが、自分用ですので
クラスの継承
# エラーにならないものを選べ class Hoge < Object ; end class Hoge << Object ; end class Hoge < Kernel ; end class Hoge << Kernel ; end # A 1のみクラスの継承は
<
なお、Kernelはモジュールなので不可module Kernel
irbKernel.call =>Module全てのクラスから参照できるメソッドを定義しているモジュール。
Objectクラスはこのモジュールをインクルードしています。
Objectクラスのメソッドは実際にはこのモジュールで定義されています。to_i(n)
to_iメソッドは、文字列をn進数の表現と見なして整数に変換。
文字列の先頭から10進数と見なせる部分を切り取って変換し、見なせる部分がなければ0を返す。p "12abc".to_i =>123 p "abc12".to_i =>0 p "ab12c".to_i =>0 p "1abc2".to_i =>`1予約語のエスケープ?
正規表現ではあるのだろう
s = "a;b:c;d:e;f" p s.split (/:|;/) =>["a", "b", "c", "d", "e", "f"]配列と範囲オブジェクト
いつも、ごちゃごちゃになる。
a=[1,2,3,4] a[1,3] => [2,3,4] a[1..3] => [2,3,4] a[1...3] => [2,3] a[1....3] => error a[2..-1] => [3,4] ## `範囲オブジェクトは文字列にも使える`a="abcdefghijk"
a[1,3] = "x"
p a => "axefghijk"
a[1..3] = "x"
p a => "axefghijk"
a[1...3] = "x"
p a => "axdefghijl"
```&と&&、|と||
a = [1,2,3,4] b = [1,3,5,7] p a & b =>[1, 3] p a && b =>[1, 3, 5, 7] p a | b =>[1, 2, 3, 4, 5, 7] p a || b =>[1, 2, 3, 4]
1 作用 & 日本語の”且つ”と同じ。 && 左辺が真なら、右辺を評価して、右辺を返す パイプ1本 日本語の”又は”と同じ パイプ2本 左辺が真なら、右辺を評価せずに、左辺を返す ※パイプ=『|』。エスケープできなかった
可変長引数
def sum (##AAA##) total = 0 a.each {|i| total += i } return total end puts sum(1, 2, 3, 4, 5) =>15delete_if = reject!
破壊的メソッドブロックの戻り値が真になった要素を削除。
なお、rejectは非破壊的a= [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] a.delete_if{|v| v % 2 == 0 } =>[1, 3, 5, 7, 9] p a => [1, 3, 5, 7, 9]enum.each_with_index {|item, idx| block }
繰り返しごとにブロック引数itemには各要素が入り、idxには0,1,2と番号が入る
a = ["apple", "orange", "grape", "pine"] a.each_with_index{ |item, i| print i, ":", item, "\n" } => 0:apple 1:orange 2:grape 3:pinearray.each_index {|index| block }
『ほぼ』each_with_indexと同じ
繰り返しごとにブロック引数には各要素のインデックス(位置)の整数が入ります。戻り値はレシーバ自身hash.each_pair {|key, val| block }
eachと同じ
hash.each_key {|key| block }
繰り返しごとにブロック引数keyにはキーが入る。
hash.each_value {|val| block }
繰り返しごとにブロック引数valにはキーの値が入る。
each_何たらが他にも結構あるので、見ておこう
shift とunshift
破壊的メソッドshiftメソッドは、配列の最初の要素を削除し、その要素を返します。
レシーバ自身を変更するメソッドです。配列が空のときはnilを返します。s = ["one","two","three"] s.shift => "one" ※先頭のoneを削除 s.shift => "two" ※先頭のtwoを削除 s.unshift => ["three"] ※引数が無いので、何もしてない s.push "four" => ["three", "four"] p s =>["three", "four"]compactとuniq
a = [:a,:a,:b,:c] a[5] = :e a.concat([:a,:b,:c]) a.compact a.uniq p a => [:a, :a, :b, :c, nil, :e, :a, :b, :c]concat, compact, uniqのうち、破壊的メソッドはconcatのみなので、
結果、元の配列aに影響を及ぼすのはconcatのみconcat
破壊的= push = <<配列の末尾に引数を結合。感嘆符が無い破壊的メソッド
conpact
非破壊的配列からnilを取り除いた、新しい配列を作成
感嘆符がついたconpact!が破壊的。uniq
非破壊的配列から重複した要素を取り除いて、新しい配列を作成
感嘆符が付くと破壊的に。arr = [1, 2, 5, 5, 1, 3, 1, 2, 4, 3] p arr.uniq [1, 2, 5, 3, 4]map = collect
a = [1, 2, 3, 4, 5, 6] a.collect {|v| v * 2} => [2, 4, 6, 8, 10, 12] a.inject {|v| v * 2} => 32 a.each {|v| v * 2} => [1, 2, 3, 4, 5, 6] a.map {|v| v * 2} =>[2, 4, 6, 8, 10, 12] a.select {|v| v * 2} => [1, 2, 3, 4, 5, 6] a.execute {|v| v * 2} => error undefined method
どうしたらinjectが32になるか、リファレンス見ても理解できない%w記法
配列を作る
sarray = %w(Apple Orange Grape) sarray.each {|v| print v, " "} # Apple Orange Grapezip
実行結果になるように、##AAA##に記述するコードを選んで下さい
a = ["a", "b", "c"] b = [1, 2, 3] ##AAA## #実行結果 ["a", 1] ["b", 2] ["c", 3] #選択肢 a.zip(b).each{|x| p x } a.zip(b){|x| p x } [a, b].zip{|x, y| p [x, y] } [a, b].transpose.each{|x, y| p [x, y] } #答え 1,2,4zip
行と列を入れ替える。足りない要素はnilを返す
transpose
zipと同様、行と列を入れ替える。要素が足りない場合、例外IndexErrorを発生。
EOB
以下のコードは正しく動きません。修正案を。
s = <<EOB Hello, Ruby World. Hi, Ruby World. Goodbye, Ruby World. EOB #解答 5行目のEOBの前の空白を削除する。encoding
puts "hello".encoding.name UTF-8 => nilchop
非破壊的文字列の末尾から1文字を取り除いた新しい文字列を返す
!が付くと、破壊的chomp
非破壊的文字列の末尾の改行文字を取り除いた新しい文字列を返す
!が付くと、破壊的キャレット^
名をキャレット、否定をする
puts "0123456789-".delete("^13-56-") => 13456-13456-に該当『しない』ものを削除している
正規表現
p "abc def 123 ghi 456".scan(/\d+/).length => 2\dは10進数なので、10進数から始まる部分を配列で返し(scan)、その要素の数lengthを返してる
scan(string)
指定した正規表現のパターンとマッチする部分を文字列からすべて取り出し、配列にして返す。
p "HogeHOGEhoge"[/[A-Z][^A-Z]+/] => "Hoge"大文字と小文字のアルファベットで構成される文字列を返している
invert(hash)
hashのキーと値を入れ替える
h = {1 => "Hoge", 2=> "Piyo", 3=>"fuga"} p h.invert # {“Hoge”=>1, “Piyo”=>2,“fuga”=>3 }update と sortメソッド
a = {"Foo" => "Hoge", "Bar" => "Piyo", "Baz" => "Fuga"} b = {"Foo" => "hoge", "Bar" => "piyo", "Baz" => "fuga"} p a.update(b).sort{ |a, b| a[1] <=> b[1] } [["Baz", "fuga"], ["Foo", "hoge"], ["Bar", "piyo"]]update
sort
配列の要素をソートした新しい配列を返します。
「要素1 <=> 要素2」の結果が-1なら要素1が先、0なら同じ、1なら要素2が先となります。ルート
以下のコードは、ファイル test . txt を読み、文字を逆順に書き込む処理です。
「##AAA##」に入る適切な記述を選びなさい。open("test.txt","##AAA##") do |f| data = f.read.chomp data.reverse! f.rewind f.write data end #選択肢 a w r a+ r+ w+組み込み関数openの第2引数には、ファイルのオープン モードを指定します。
r、w、a に + を付けると、読み書き 両用でオープンします。
w+ を指定すると元ファイルの内 容を空にします。
a+ を指定すると、追記モードとなり、 元のファイルを書き換えることができません。chr と ord は対義語的な
puts 65.chr => "A" puts "a".ord => 97コードポイントの話。
n.chrは,nで登録されている文字を返す
string.ordはstringのコードポイントを返す
メソッドの意味は覚えてるけど、もう『65を見たらA』と覚えるしか。securerandom
Module安全な乱数発生器のためのインターフェースを提供するモジュール
require 'securerandom' SecureRandom.urlsafe_base64urlsafe_base64
ランダムで URL-safe な base64 文字列を生成して返します。
どこをみても、『url-safeな』『url-safeな』と書いてあるけど、
『url-safeな』とは。
- 投稿日:2019-03-24T21:27:12+09:00
Rubyのzipメソッドをイメージで理解する【3分で読めます】
ついつい存在自体を忘れてしまうzipメソッド。
イメージで覚えてすぐに思い出せるようにしよう。メソッドの詳細
使い方は下記リンクを参考にしてください。
Array#zip(公式リファレンス)考え方
とりあえずジッパーをイメージする
上の画像を逆さまにしたものをイメージしてください。
解説
まずは実行結果のサンブル。
sample.rba1 = [1,2,3] a2 = [4,5] a3 = [6,7,8,9] a1.zip(a2,a3) # > [[1, 4, 6], [2, 5, 7], [3, nil, 8]]oh,ムズカシイネ
1.配列をジッパーの歯(zip teeth)と見立てる
配列を
縦に並べて
zip teeth
普通のArray
a1 = [1,2,3]縦版Array
a1 ‖ 冖 1 , 2 , 3 凵
この調子で全部縦にすると.....
a1 = [1,2,3] a2 = [4,5] a3 = [6,7,8,9]↓↓↓↓↓↓↓↓↓↓
a1 a2 a3 ‖ ‖ ‖ 冖 冖 冖 1 4 6 , , , 2 5 7 , , 3 8 凵 凵 , 9 凵案外見やすいですね。
2.上から下にジッパーを閉める
[ [1,4,6] [2,5,7] [3,nil,8] ]zip teathが噛み合いました。
もう外せそうにありません。むすびのことば
命名大事だと思えました。

- 投稿日:2019-03-24T20:30:41+09:00
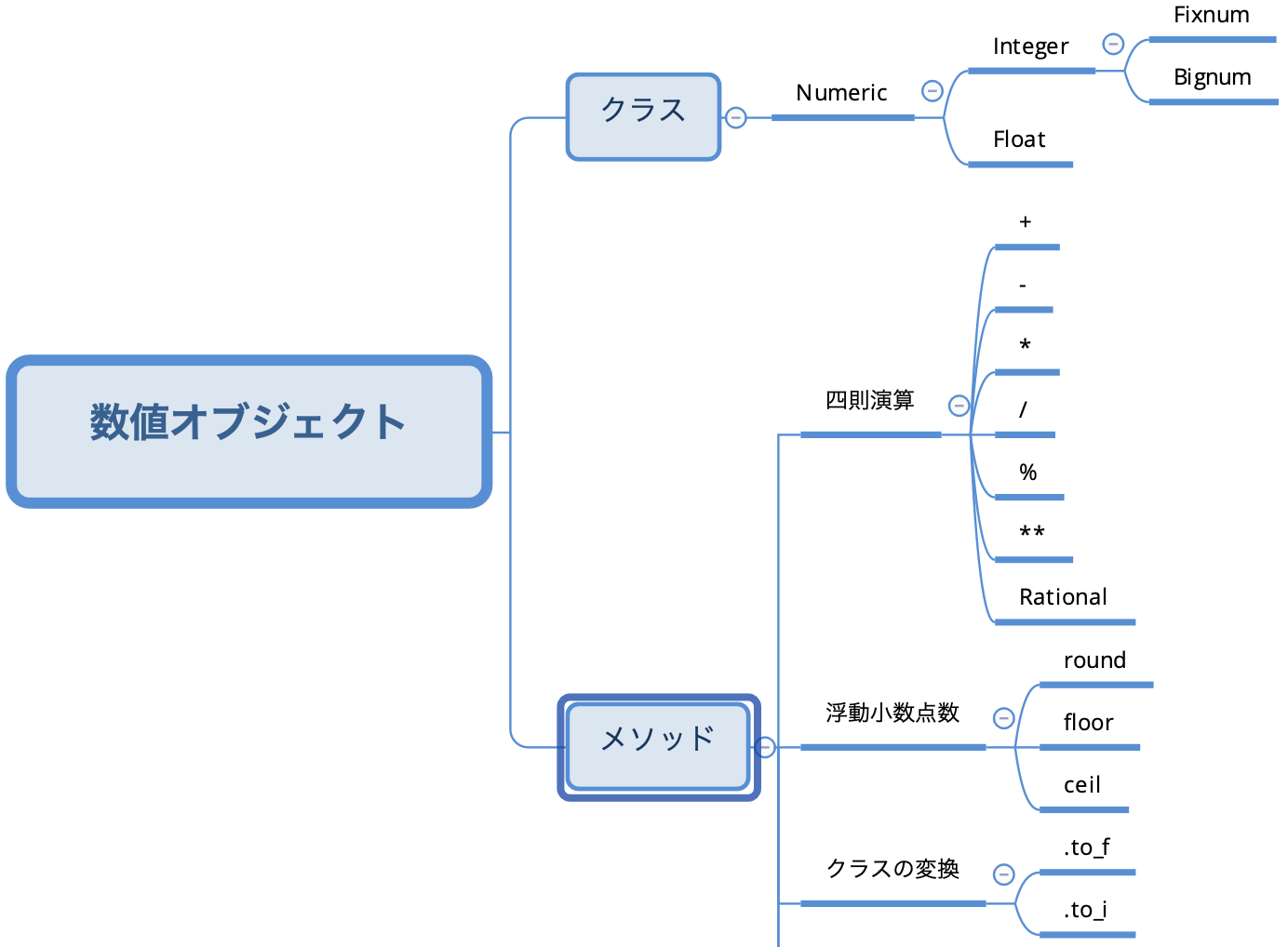
数値オブジェクトについて
数値オブジェクトについて
- [目次]
- [基本の使い方]
- [数値クラス]
- [数値メソッド]
- [四則演算]
- [分数]
- [浮動小数点数]
- [クラスの変更]
- [クラス・メソッドの調べ方]
- [まとめ]
基本の使い方
普通に数字を記載してもらえれば大丈夫です。
example
入力
puts 3 puts 1.2出力
3 1.2数値クラス
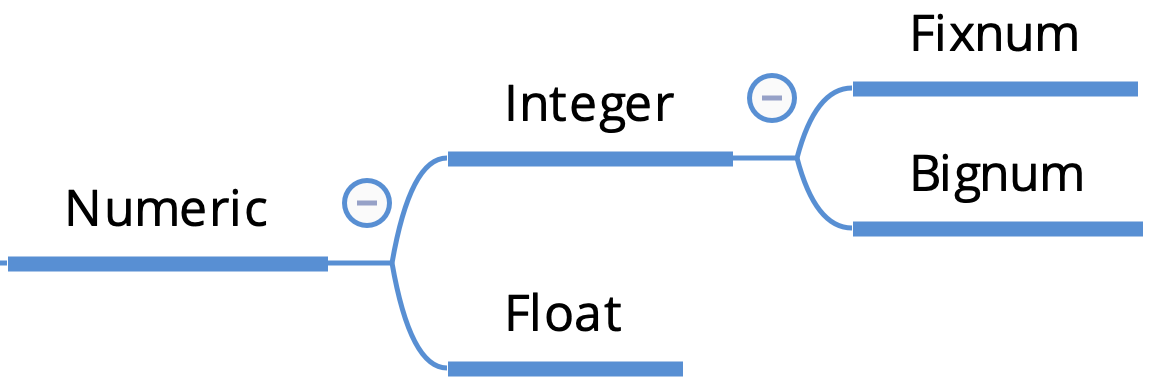
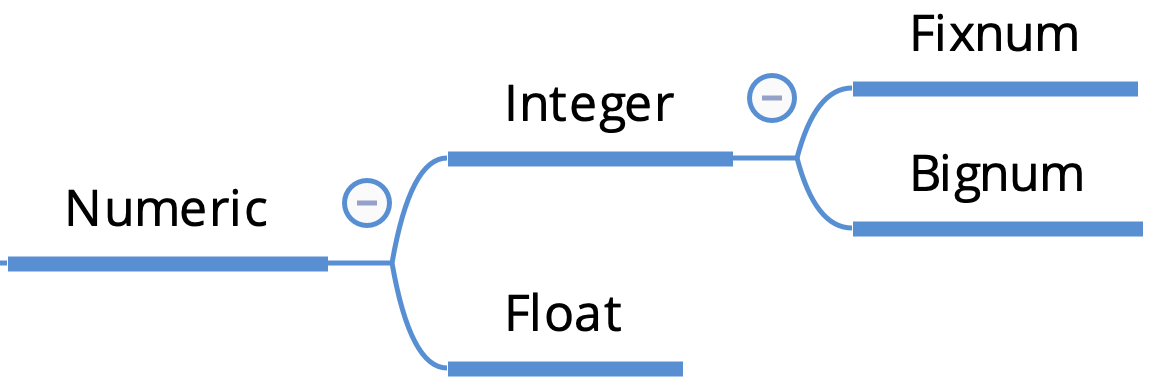
数値オブジェクトの大元となるクラスがNumericです。
そこから整数の値を扱うInteger、浮動小数点数を扱うFloatに分かれます。
IntegerはさらにFixnumとBignumに分かれます。
Bignumの方が大きな値を扱う事ができます。ただし、FixnumからBignumへのクラスの変換は自動で行われるので、クラスとして存在していることを知っておくだけで十分です。*Ruby 2.4 以降は Integer に一本化されました。
数値メソッド
数値オブジェクトに関わる代表的なメソッドについて説明します。
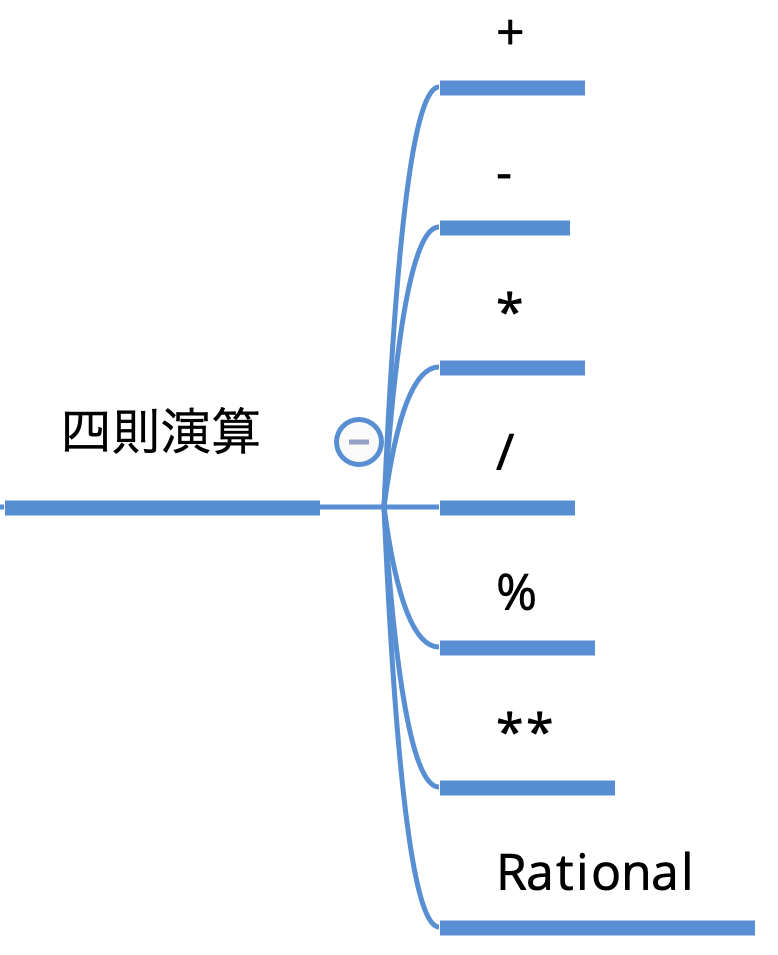
+や-などの四則演算もメソッドの一つです。四則演算
足し算と引き算は数学と同様に
+、-を使用します。
掛け算は*、割り算は/を使用します。
割り算の余りを表示したい場合は%を使います。
べき乗を行うには**を使用します。example
入力
puts 4+3 #足し算 puts 4-3 #引き算 puts 4*3 #掛け算 puts 4/3 #割り算 puts 4%3 #4/3の余り puts 4**3 #4の3乗出力
7 1 12 1 1 64割り算で少数点以下も表示したい場合
例えば、計算式の中で4の表記を4.0といった表記にして、小数点以下を表示しておけばOKです。example
入力
puts 4/3 #割り算 puts 4.0/3出力
1 1.3333333333333333分数
四則演算の中で分数にして表記することも可能です。
その場合Rationalを使用します。
使い方は
Rational(分子,分母)
です。example
入力
puts Rational(4,5) puts Rational(4,5)+Rational(4,5)出力
4/5 8/5Rationalにはもっと簡単な書き方もあります。
example
入力
puts 4/5r puts 4/5r+4/5r出力
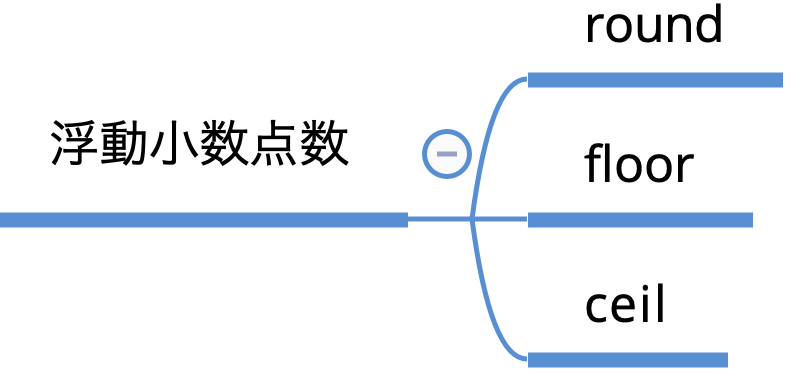
4/5 8/5浮動小数点数
少数を扱うメソッドとして
- 四捨五入
- 小数点以下切り捨て
- 小数点以下切り上げ
があります。四捨五入を行いたい時は
roundを使用します。example
入力
puts 1.5.round puts 1.4.round出力
2 1小数点以下の切り捨てを行いたい時は
floorを使用します。example
入力
puts 1.5.floor puts 1.4.floor出力
1 1小数点以下の切り上げを行いたい時はceilを使用します。
example
入力
puts 1.5.ceil puts 1.4.ceil出力
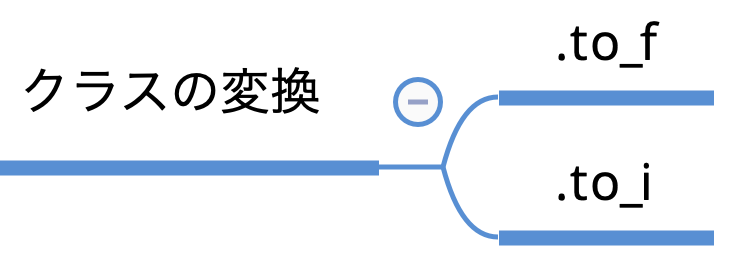
2 2クラスの変更
クラスの変更を行ってくれるメソッドについてです。
例えば
4.0を4に変更したいとします。
これは少数(Float)を整数(Integer)に変更するということです。
ですのでこの場合Integerに変更するという意味で、to_iというメソッドになります。
example
入力
puts 1.5.to_i puts 1.4.to_i出力
1 1この場合、小数点以下は切り捨てになります。
逆に、
整数(Integer)を少数(Float)に変更する場合。
Floatに変更するので、to_fを使用します。example
入力
puts 1.to_f puts 20.to_f出力
1.0 20.0クラス・メソッドの調べ方
クラスを調べる場合は
classを使用します。example
入力
puts 2.class puts 2.0.class出力
Integer Floatメソッドを調べる場合は
methodsを使用します。example
入力
puts 2.methods出力
-@ ** <=> upto << <= >= == chr === >> [] % & inspect + ord - / * size succ < > to_int 以下略まとめ
- 投稿日:2019-03-24T19:19:39+09:00
gemのあらゆるコマンドがAugumentErrorで実行できなかった件
この時のPC環境 ※要確認
OS:Windows10
Ruby:2.5.3p105 (2018-10-18 revision 65156) [x64-mingw32]
RubyGems:2.3.0Ruby on Railsのバージョンを確かめようとコマンド"rails -v"を実行したところ、以下のようなエラー表示が出ました。
C:\Ruby25-x64\rubygems-3.0.3>rails -v Traceback (most recent call last): 2: from C:/Ruby25-x64/bin/rails:23:in `<main>' 1: from C:/Ruby25-x64/lib/ruby/site_ruby/2.5.0/rubygems.rb:302:in `activate_bin_path' C:/Ruby25-x64/lib/ruby/site_ruby/2.5.0/rubygems.rb:283:in `find_spec_for_exe': can't find gem railties (>= 0.a) with executable rails (Gem::GemNotFoundException)エラー表示"ArgumentError"
Ruby on Railsをインストールしてみようと、コマンド"gem install rails"を実行したところ、以下のようなエラーが返ってきました。
ERROR: While executing gem ... (ArgumentError) wrong number of arguments (given 1, expected 0)ArgumentError・・・?引数がおかしい?
とりあえず、上のエラー表示についてググってみると、以下の記事を見つけました。
https://teratail.com/questions/156929
自分と同じようなエラーかなーと思いましたが、結局解決できていない模様。さらにググってみると、以下の記事を発見。
https://github.com/rubygems/rubygems/issues/2224この記事から、RubyとRubyGemsのバージョンによっては上手くいかないことがあると考え、RubyGemsをアップデートしてみることに。
コマンドプロンプトからRubyGemsをアップデートできない
gem update --systemを実行すると、以下のような表示が出ました。
C:\>gem update --system Updating rubygems-update ERROR: While executing gem ... (ArgumentError) wrong number of arguments (given 1, expected 0)またArgumentError・・・
どうにか別の方法でRubyGemsをアップデートできないものかとググりまくっていると、次の記事を発見。
http://d.hatena.ne.jp/c_mutoh/20100329/1269877259この記事にはZipファイルを使ってRubyGemsをアップデートする方法が書かれていました。
Zipファイルを使ってRubyGemsをアップデートする方法
※先の記事に書かれている手順通りに実行しましたが、念のため書いておきます。
この時、私がインストールしたRubyGemsのバージョンは3.0.3です。(この記事を書いている時点において最新)
まず、RubyGemsのサイトのダウンロードページからZIPを選択して、Zipファイルをダウンロードします。
C:\Ruby25-x64のディレクトリ(Rubyがインストールされているディレクトリ)にダウンロードしたZipファイルを解凍します。
解凍できたら、cdコマンドで解凍したディレクトリに移動します。(私の場合"cd C:\Ruby25-x64\rubygems-3.0.3"コマンドを実行)
ここで、setup.rbを以下のように実行します。
C:\Ruby25-x64\rubygems-3.0.3>ruby setup.rbこれでRubyGemsのバージョン3.0.3がインストールできたはず・・・
バージョンを確認すると、
C:\Ruby25-x64\rubygems-3.0.3>gem -v 3.0.3バージョンが2.3.0から3.0.3に更新されました!
Ruby on Railsをインストール
RubyGemsのバージョンアップが完了したところで、Ruby on Railsをインストールしてみます。
以下のコマンドを実行します。C:\Ruby25-x64\rubygems-3.0.3>gem install rails Fetching rails-5.2.2.1.gem Successfully installed railties-5.2.2.1 Successfully installed rails-5.2.2.1 Parsing documentation for railties-5.2.2.1 Installing ri documentation for railties-5.2.2.1 Parsing documentation for rails-5.2.2.1 Installing ri documentation for rails-5.2.2.1 Done installing documentation for railties, rails after 0 seconds 2 gems installed今度はエラーが返ってきませんでした。
Ruby on Railsが無事インストールされたか確認してみます。
C:\Ruby25-x64\rubygems-3.0.3>rails -v Rails 5.2.2.1インストールできたみたいです!
まとめ
Ruby on Railsをインストールしたいが、できない
↓
RubyGemsのバージョンを変更する必要がある(?)
↓
コマンドプロンプトでRubyGemsのバージョンを更新できない
↓
Zipファイルを使ってRubyGemsのバージョンを更新
↓
Ruby on Railsインストール成功という話の流れでした。
個人的な感想
Qiita初投稿の記事になります。
私はRuby初心者ですが、プログラミングする以前に環境構築の時点でつまづくのは結構辛いですよね・・・
私はこの問題で半日以上費やしてしまい、同じような思いを他の方が味わうのは何とも酷だなと思い、思い切って投稿しました。参考になれば幸いです。
あぁ・・・おとなしくMac買って使った方が良いんだろうな・・・
- 投稿日:2019-03-24T19:19:39+09:00
gemのあらゆるコマンドがAugument Errorで実行できなかった件
この時のPC環境
OS:Windows10
Ruby:2.5.3p105 (2018-10-18 revision 65156) [x64-mingw32]
RubyGems:2.3.0Ruby on Railsのバージョンを確かめようとコマンド"rails -v"を実行したところ、以下のような表示が出ました。
C:\Ruby25-x64\rubygems-3.0.3>rails -v Traceback (most recent call last): 2: from C:/Ruby25-x64/bin/rails:23:in `<main>' 1: from C:/Ruby25-x64/lib/ruby/site_ruby/2.5.0/rubygems.rb:302:in `activate_bin_path' C:/Ruby25-x64/lib/ruby/site_ruby/2.5.0/rubygems.rb:283:in `find_spec_for_exe': can't find gem railties (>= 0.a) with executable rails (Gem::GemNotFoundException)エラー表示"ArgumentError"
Ruby on Railsをインストールしてみようと、コマンド"gem install rails"を実行したところ、以下のようなエラーが返ってきました。
ERROR: While executing gem ... (ArgumentError) wrong number of arguments (given 1, expected 0)ArgumentError・・・?引数がおかしい?
とりあえず、上のエラー表示についてググってみると、以下の記事を見つけました。
https://teratail.com/questions/156929
自分と同じようなエラーかなーと思いましたが、結局解決できていない模様。さらにググってみると、以下の記事を発見。
https://github.com/rubygems/rubygems/issues/2224この記事から、RubyとRubyGemsのバージョンによっては上手くいかないことがあると考え、RubyGemsをアップデートしてみることに。
コマンドプロンプトからRubyGemsをアップデートできない
gem update --systemを実行すると、以下のような表示が出ました。
C:\>gem update --system Updating rubygems-update ERROR: While executing gem ... (ArgumentError) wrong number of arguments (given 1, expected 0)またArgumentError・・・
どうにか別の方法でRubyGemsをアップデートできないものかとググりまくっていると、次の記事を発見。
http://d.hatena.ne.jp/c_mutoh/20100329/1269877259この記事にはZipファイルを使ってRubyGemsをアップデートする方法が書かれていました。
Zipファイルを使ってRubyGemsをアップデートする方法
※先の記事に書かれている手順通りに実行しましたが、念のため書いておきます。
この時、私がインストールしたRubyGemsのバージョンは3.0.3です。(この記事を書いている時点において最新)
まず、RubyGemsのサイトのダウンロードページからZIPを選択して、Zipファイルをダウンロードします。
C:\Ruby25-x64のディレクトリ(Rubyがインストールされているディレクトリ)にダウンロードしたZipファイルを解凍します。
解凍できたら、cdコマンドで解凍したディレクトリに移動します。(私の場合"cd C:\Ruby25-x64\rubygems-3.0.3"コマンドを実行)
ここで、setup.rbを以下のように実行します。
C:\Ruby25-x64\rubygems-3.0.3>ruby setup.rbこれでRubyGemsのバージョン3.0.3がインストールできたはず・・・
バージョンを確認すると、
C:\Ruby25-x64\rubygems-3.0.3>gem -v 3.0.3バージョンが2.3.0から3.0.3に更新されました!
Ruby on Railsをインストール
RubyGemsのバージョンアップが完了したところで、Ruby on Railsをインストールしてみます。
以下のコマンドを実行します。C:\Ruby25-x64\rubygems-3.0.3>gem install rails Fetching rails-5.2.2.1.gem Successfully installed railties-5.2.2.1 Successfully installed rails-5.2.2.1 Parsing documentation for railties-5.2.2.1 Installing ri documentation for railties-5.2.2.1 Parsing documentation for rails-5.2.2.1 Installing ri documentation for rails-5.2.2.1 Done installing documentation for railties, rails after 0 seconds 2 gems installed今度はエラーが返ってきませんでした。
Ruby on Railsが無事インストールされたか確認してみます。
C:\Ruby25-x64\rubygems-3.0.3>rails -v Rails 5.2.2.1インストールできたみたいです!
まとめ
Ruby on Railsをインストールしたいが、できない
↓
RubyGemsのバージョンを変更する必要がある(?)
↓
コマンドプロンプトでRubyGemsのバージョンを更新できない
↓
Zipファイルを使ってRubyGemsのバージョンを更新
↓
Ruby on Railsインストール成功という話の流れでした。
個人的な感想
Qiita初投稿の記事になります。
私はRuby初心者ですが、プログラミングする以前に環境構築の時点でつまづくのは結構辛いですよね・・・
私はこの問題で半日以上費やしてしまい、同じような思いを他の方が味わうのは何とも酷だなと思い、思い切って投稿しました。参考になれば幸いです。
あぁ・・・おとなしくMac買って使った方が良いんだろうな・・・
- 投稿日:2019-03-24T16:05:16+09:00
複数バージョンのRubyを切り替えられるようにする
rbenvというツールを使う。brewはインストール済み前提。
https://github.com/rbenv/rbenvrbenvの導入
Macのターミナルで以下のコマンドを実行。
brew install rbenv rbenv init rbenv install -l # rubyのバージョン一覧を確認する。 rbenv install 2.6.2 # 2019/3/24時点の最新版をインストール rbenv install 2.4.5 # 動作確認用に適当なバージョンをインストール rbenv global 2.6.2 # 2.6.2を使うように設定~/.bashrcに以下を記述。
export PATH=~/.rbenv/shims:$PATH動作確認
Macのターミナルで以下のコマンドを実行。実際に2.6.2が選択されていることがわかる。
$ rbenv versions system 2.4.5 * 2.6.2 (set by /Users/XXX/.rbenv/version) $ ruby -v ruby 2.6.2p47 (2019-03-13 revision 67232) [x86_64-darwin18]
- 投稿日:2019-03-24T15:31:17+09:00
fluentdのbuffer周りで注意すべき点
topic
- buffering parameters
- flushing parameters
- retries parameters
公式ドキュメントを参照していますが、私の解釈が誤っている場合もあるため間違っていた場合はご指摘ください。
主にbufferに関するパラメータは上記の三種類となります。
retryに関しては下記のページでも紹介しているので特にここでは記載しません。
参考:
https://qiita.com/smith_30/items/1a8df503613f7e7e2904
https://qiita.com/tatsu-yam/items/bd7006e483f3b3c64309また、buffer/chunk/flush/queue等の動作に関してもある程度上記で説明してくださっているので参考にしてみると良いと思います。(ちょっと古いけど)
bufferファイルの作成単位に関しては、tag/timekey等のmeta情報の知識も必要ですが、ここでは書きません。(気が向いたら追記します。)buffering parameters
ここでは、主にbufferのファイルサイズや分割に関する設定を説明します。
bufferのサイズは、主に転送(書き込み)等のflunetdから外部へ送信される際のデータの出力単位だと思ってもらって良いと思います。ここの設定により、送信先のデータ受信の最大サイズにあったチューニングや、ディスク書き込みの際のブロックサイズに合わせて設定を行うことができます。
まれに処理レコード数の制限が存在する出力先が存在した場合などは送信単位を50レコードまでと設定する必要があったり、、(ただ厳密にここの設定が守られているわけではなく、一定周期でwatchしており設定値を超えたら次のファイルを作成するなどの動作のため設定値を超える場合もある。)
chunk_limit_size
ここでは、作成されるbufferファイルの最大サイズを設定可能。
この設定値か、chunk_limit_sizeの設定でファイルが分割される。入力データの大きさによりここで設定したファイルサイズを超える入力があった場合エラーが頻出しますので、その際はここのパラメータを上げるか、入力元を絞る必要があります。
厳密にはflushの設定も関係するがここでは割愛します。chunk_limit_records
一つのbufferファイル内の最大レコード数を設定可能。
ここで設定したレコード数を超えると新しくbufferファイルが作成される。total_limit_size
bufferプラグイン内で溜め込める合計bufferサイズ。
outputプラグインで何らかの原因で出力が出来ない状態で、flunetd側のbufferで溜め込めるbufferのサイズとなる。
このサイズは、flunetd全体に適用されるのではなく、bufferプラグインごとに設定されるためディスクサイズやメモリサイズに考慮して設定する必要がある。例えば、ディスクサイズが128GBなのにbuffer_fileプラグインを2つデフォルトで利用していると最大で128GB貯まるため、ディスクフルとなる可能性がある。
chunk_full_threadhold
bufferファイルをflushする際のファイルサイズに関連する項目。
上記では、chunk_limit_sizeを超えるとbufferファイルが新しく作成されると、書いたが厳密にはchunk_limit_size × chunk_full_threadhold のサイズを超えるとflushされ、新しいbufferファイルが作成される。flushing parameters
ここではfluentdのflushの際の動作に関するパラメータを設定する。
簡単にflushの動作を説明すると
bufferの状態としては、staged/enqueuedの状態が存在し、stagedの状態からenqueuedの状態へ移行する処理がflushである。(ここちょっと自信ない)flush_at_shutdonw
fluentdを終了する際に保持しているbufferファイルをすべてflushする設定。
buffer_memoryを利用している場合、この設定を行わないとメモリ内のbufferが損失するため、設定を行うことをおすすめします。また、buffer_fileを使用している場合はbufferの損失は起きませんが扱うデータ量が多い(または大量のbufferファイルが作成される環境)場合は次回起動時にbufferの読み込み処理に時間がかかるため、これを避けたい場合は設定を有効にすることをおすすめします。
flush_interval
ここはflushの判定ロジックを設定可能
- lazy
timekey毎にflush/writeを行う。特にリアルタイム処理が不要であったりする場合はデフォルトでこの設定なので変えなくても良いと思う。
- interval
後述するflush_intervalの設定値ごとに一定間隔でflushを行う。
- immediate
bufferが作成されたらすぐにflushを行う。
データ入力が極端に大きい場合は、この設定で良いと思うが小さなデータが細々と入力される環境だとプロセスのCPU使用率が上がるためこの設定は避けること。
処理データのサイズを小さくしたい場合はこの設定が有用。flush_interval
前述のflush_modeで*intervalを指定した際に設定可能
flush_thread_count
enqueueされたデータをoutputプラグインにより処理するthread数を設定する。
基本的にこの設定を上げると、outputプラグインの処理速度が上がるがCPU使用率が上がるため気をつけること。
公式ドキュメントではボトルネックがディスクにある場合は、この設定で書き込みを平行に行うことである程度ディスク書き込み遅延による性能劣化を避けることが可能だと記載されている。flush_thread_interval
enqueuedされたデータが存在しない場合の、データ入力監視の感覚(ざっくり)
この数値を小さくすると、enqueueされたデータが新規にできた際のoutputまでの処理のタイムラグが小さくなるが、入力データが存在しない場合のCPU使用率が上がるため基本的には0.1以上に設定することをおすすめする。
0.01に設定したときは入力データが存在しないのに常時CPU30%ほど使用していた。
0.1に設定すると5%以下に収まった。。flush_thread_burst_interval
flush_thread_intervalと異なり、すでにenqueueされているデータが存在する場合のoutputでの処理感覚(ざっくり)
この数値を小さくするとoutputプラグインでの処理間隔が短くなり処理速度が上がるが、CPU使用率が上がる。まとめ
flunetdのbuffer周りの設定は下手すると処理速度に直結するため大容量のデータを扱う際は慎重に設定することをおすすめします。
あとは、出力先への負荷の削減等。参考:https://docs.fluentd.org/v1.0/articles/buffer-section#buffering-parameters
- 投稿日:2019-03-24T15:30:31+09:00
13日目(1):Deviseによるログイン機能付きサイトの作成
12日目:12日目:PostgreSQLを用いたログイン機能付きサイトの続き
環境
- ホストOS: Windows10 Home
- 仮想環境OS: Ubuntu Bento/Bionic
- Ruby:2.51
- Rails: 5.2.2 -主使用gem : devise(参照)
- DB: PostgreSQL
前回やったこと
- nodejsとpostgresqlのインストール
- rails new self_univ3 -d postgresql とbundle install (devise)
- PostgreSQLのパス設定、DB作成
- rails g devise:install
- modelsにdeviseを追加。rails g devise Student
今回
- controllersとviewsを以前の大学データの方から流用
- migrationファイル作成
- rooting変更
実作業
controllersフォルダとviewsフォルダのコピー
# cp -r コピーしたいフォルダの場所 ペースト先migrationファイル作成
rails g migration AddNameToStudents name:string gender:integer age:integer opinion:text # 実行 create db/migrate/20190324043018_add_name_to_students.rbDBに反映
rails db:migraterooting変更
app/confing/routes.rb# 追加 resources :students root to: 'students#index'viewsの変更
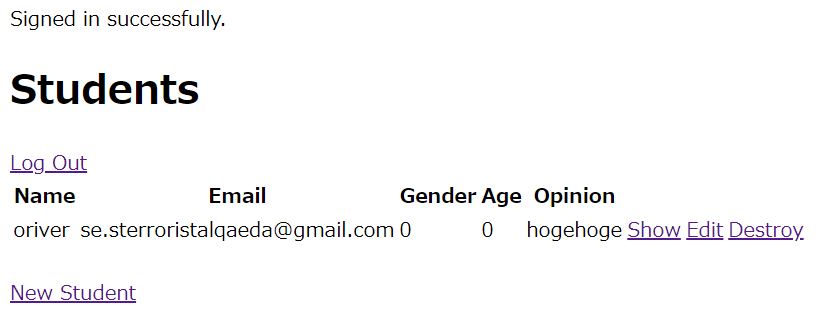
app/views/student.html.erb# 今回不要なExamResultNewのリンク削除 # ログアウトリンクの作成 <% @students.each do |student| %> <tr> <td><%= student.try(:name) %></td> <td><%= student.email %></td> <td><%= student.try(:gender) %></td> <td><%= student.try(:age) %></td> <td><%= student.try(:opinion) %></td> <td><%= link_to 'Show', student %></td> <td><%= link_to 'Edit', edit_student_path(student) %></td> <td><%= link_to 'Destroy', student, method: :delete, data: { confirm: 'Are you sure?' } %></td> <%= link_to 'Log Out', destroy_student_session_path, method: :delete %> </tr> <% end %>コントローラ変更
app/controllers/student_controller.rbclass StudentsController < ApplicationController before_action :authenticate_student!
次からは、このページに、以前の大学データを組み合わせる
- 投稿日:2019-03-24T13:42:42+09:00
rails s 時のエラー (Gem::GemNotFoundException)
Railsアプリ作成中に、rails sでサーバー起動しようとしたら、Gem::GemNotFoundException エラー。
とくになにかしたわけではないが、突如発生。
stack overflowで似たようなエラー事例があったので、参考にし、解決。
参考:stack overflow
rails s 時のエラー。Traceback (most recent call last): 4: from /home/ec2-user/.rvm/gems/ruby-2.6.0/bin/ruby_executable_hooks:24:in `<main>' 3: from /home/ec2-user/.rvm/gems/ruby-2.6.0/bin/ruby_executable_hooks:24:in `eval' 2: from /home/ec2-user/.rvm/gems/ruby-2.6.0/bin/rails:23:in `<main>' 1: from /home/ec2-user/.rvm/rubies/ruby-2.6.0/lib/ruby/2.6.0/rubygems.rb:302:in `activate_bin_path' /home/ec2-user/.rvm/rubies/ruby-2.6.0/lib/ruby/2.6.0/rubygems.rb:283:in `find_spec_for_exe': can't find gem railties (>= 0.a) with executable rails (Gem::GemNotFoundException)以下で解決。
gem install bundler bundle install
- 投稿日:2019-03-24T12:34:27+09:00
VScodeでRails開発をしていたらerbファイルでEmmet(エメット)が使えなかったので使えるようにした
VScodeでRails開発してるんだけど、erbファイルでEmmet使えない!という人や
そもそもHTMLファイルでもEmemt 使えないよ! という人は以下を試してみてください。VScodeの設定
まずVSCodeの左下の歯車マークをクリック
次に、settingsをクリック検索窓で、
"Trigger Expansion On Tab" と検索
Emmet:Trigger Expansion on tab の左のチェックマークを入れるこれでHtmlファイルではEmmetが使えるようになったはず。
セッティングファイルの記述
さらに続けて、検索窓で
”edit in settings.json”と検索
少し小さい文字の edit in settings.jsonをクリックファイルが開くので以下を追記
settings.json{ "workbench.iconTheme": "vscode-icons", "window.zoomLevel": 0, "emmet.triggerExpansionOnTab": true, # ここから記述 "emmet.includeLanguages": { "erb": "html" } }これで試しに erbファイルで
h1 と打ってからTabキーを叩いてください。それでうまくいかなければ,
拡張機能のインストール
VScode画面上の左上側にあるアイコンの一番下の四角い拡張機能をクリック
Rails と検索してRailsをインストールコレです⬇︎
https://marketplace.visualstudio.com/items?itemName=bung87.rails
上記全て終えたら、晴れてEmmetが使用できるはずです。
※EmmetはVScodeじゃなくても使えます。
たくさんコードを書いてみんなで爆速になりましょう
ごあいさつ
実はこの記事がQiitaでの初投稿になります。
1人でも多くの人のお役に立てたらと願っていますが、至らない所あるかもしれません。
その際は遠慮なく教えていただけると幸いです。参考
- 投稿日:2019-03-24T12:33:58+09:00
第1回クソコードレビュー大会解説!
はじめに
この記事は僕参加しているグループ内でプログラミングの知識の底上げのために行った大会の解説のための記事です。
良ければみなさんもやって見てください!
https://github.com/takehanKosuke/bad_cord_test_of_railsそしてやった後はぜひ感想やなどのフォードバックを何かしらで教えていただけると嬉しいです!
指摘して欲しかったジャンル
1. とりあえず直さないといけない
2. きれいなコーディング(レベル1)※フォーマット周り
3. きれいなコーディング(レベル2)※gemのメソッドとか
====ここより下は独学でプログラミングしてたら多分かなり難しいと思っている====
4. きれいなコーディング(レベル3)※処理回数を減らす的なやつ
5. セキュリティー対策※XSS問題項目一覧(全20問)
- 余計な文字列が出現している
- 正常に式展開がされていない
- 記事の削除ができない
- userのarticlesのアソシエーションにdependent: :destroyをつけていない
- バリデーションを掛けていない
- save/update/destroyでエラーハンドリングをしていない
- userのenumであるroleカラムにdefault値をつけていない
- 他の人になりすましてデータを作成更新削除ができてしまう
- seeds.rbのcreateに「!」をつけてない
- インデントが揃っていない
- シングルクォーテーションとダブルクォーテーションが混在
- new/editでの共通部分を部分テンプレート化していない
- article_pathの引数が「article.id」になっている
- enumの検索メソッドを使用していない
- authenticate_user!を使用していない
- n+1問題が発生している
- ビジネスロジックをcontrollerに書いている
- デメテルの法則を使用していない
- Articleにindexを貼っていない
- XSS(クロスサイトスクリプティング)攻撃からの脆弱性がある
1、とりあえず直さないといけない
- 余計な文字列が出現している
- 正常に式展開がされていない
- 記事の削除ができない
- userのarticlesのアソシエーションにdependent: :destroyをつけていない
- バリデーションを掛けていない
- save/update/destroyでエラーハンドリングをしていない
- statusにデフォルト値をつけていない
- 他の人になりすましてデータを作成更新削除ができてしまう
- seeds.rbのcreateに「!」をつけてない
余計な文字列が出現している
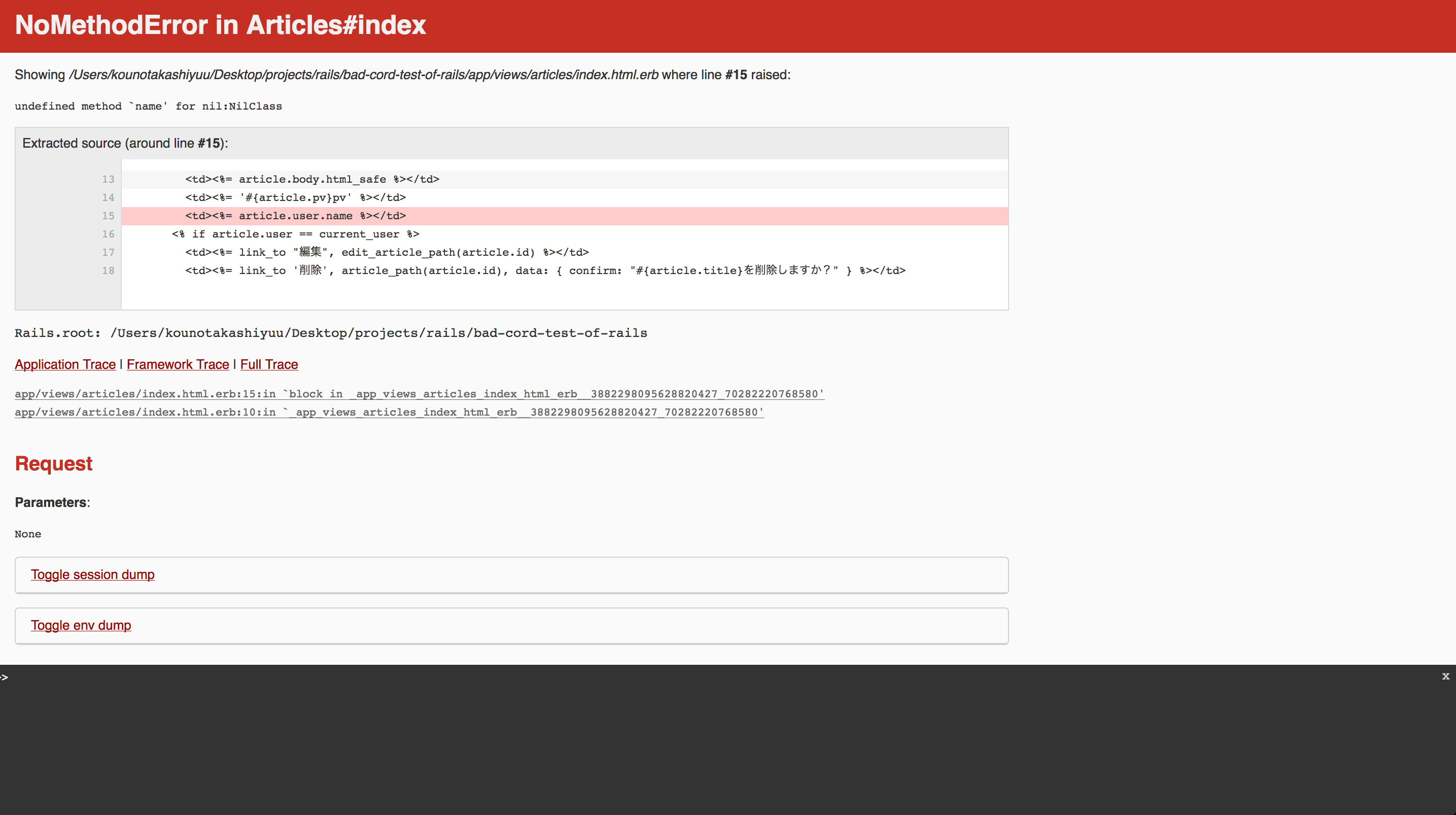
views/articles/index.html.erb<!--修正前--> </tr> <%= @articles.each do |article| %> <tr> <!--修正後--> </tr> <% @articles.each do |article| %> <tr>
これはもう解説不要な気がしますが、ここに”=”はいらないです。
気をつけましょうw正常に式展開がされていない
view/articles/index.html.erb<!--修正前--> <td><%= '#{article.pv}pv' %></td> <!--修正後--> <td><%= "#{article.pv}pv" %></td>
rubyでは式展開を行うときにには シングルクォーテーション ではなく ダブルクォーテーション を使う必要があります。
じゃあそんなこと言うならシングルクォーテーション使わなければいいんじゃね?って話になりそうですが、、、
下の記事にもあるようにシングルクォーテーションの方がわずかながら処理スピードが速くなるそうなので、処理速度をめちゃめちゃ意識した場合はその辺のことも気をつけていければいいかなと思います。
https://qiita.com/Kenji_TAJIMA/items/78555053a36c214be350記事の削除ができない
view/articles/index.html.erb<!--修正前--> <td><%= link_to '削除', article_path(article.id), data: { confirm: "#{article.title}を削除しますか?" } %></td> <!--修正後--> <td><%= link_to '削除', article_path(article.id), method: :delete, data: { confirm: "#{article.title}を削除しますか?" } %></td>railsのpath は何も指定しない場合getメソッドを呼んでしまうためdeleteメソッドを使う場合はしっかりとmethod: :deleteというようにメソッド名を指定しないといけません
今回の場合method名を指定しない場合はarticleのshowアクションに移動しますuserのarticlesのアソシエーションにdependent: :destroyをつけていない
models/user.rb#修正前 class User < ApplicationRecord # Include default devise modules. Others available are: # :confirmable, :lockable, :timeoutable, :trackable and :omniauthable devise :database_authenticatable, :registerable, :recoverable, :rememberable, :validatable has_many :articles validates :name, presence: true enum role: { normal: 1, admin: 2 } end #修正後 class User < ApplicationRecord # Include default devise modules. Others available are: # :confirmable, :lockable, :timeoutable, :trackable and :omniauthable devise :database_authenticatable, :registerable, :recoverable, :rememberable, :validatable has_many :articles, dependent: :destroy # 追記 validates :name, presence: true enum role: { normal: 1, admin: 2 } endもしこのdependent: :destroyをつけなかった場合アドミンユーザーでユーザーの削除を行うと
こんな感じのエラーが返されると思います。
これはどういうことかというと、、、
記事の一覧を表示させるときにユーザーの名前を出しているのですが、その記事に紐づくユーザーが削除されてしまっているため参照するユーザー名がないよ〜
というようなエラーです。これを解決するためには、ユーザーを削除したときにそれと一緒にユーザーの作った記事も一緒に削除するというのが一般的ですので、
今回はuserのarticlesのアソシエーションにdependent: :destroyをつけてuserが削除された時にそのユーザーに紐付く記事も一緒に削除していますバリデーションを掛けていない
models/article.rb#修正前 class Article < ApplicationRecord belongs_to :user end #修正後 class Article < ApplicationRecord belongs_to :user validates :title, presence: true validates :body, presence: true end記事を作成する際タイトルや内容が空だと不自然ですよね?
バリデーションを掛けないとタイトルや内容が空のまま記事が作成できてしまいます。
今回はデータがあることを強要するvalidatesを使ってバリデーションをかけています。バリデーションについての詳細は↓の記事がかなりよかったので気になるひとは是非読んでみてください
https://qiita.com/shunhikita/items/772b81a1cc066e67930esave/updateでエラーハンドリングしていない
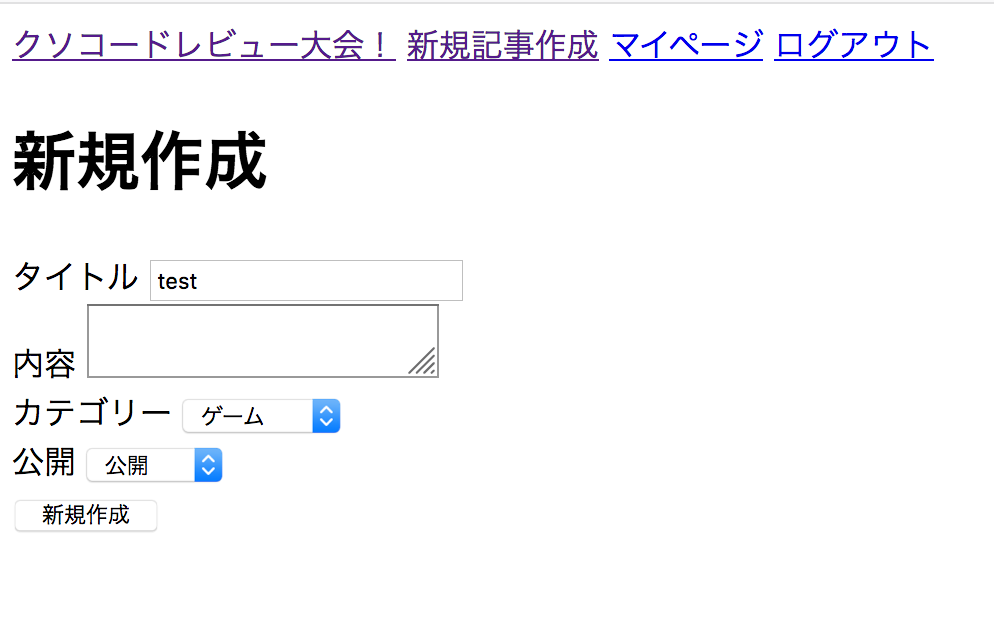
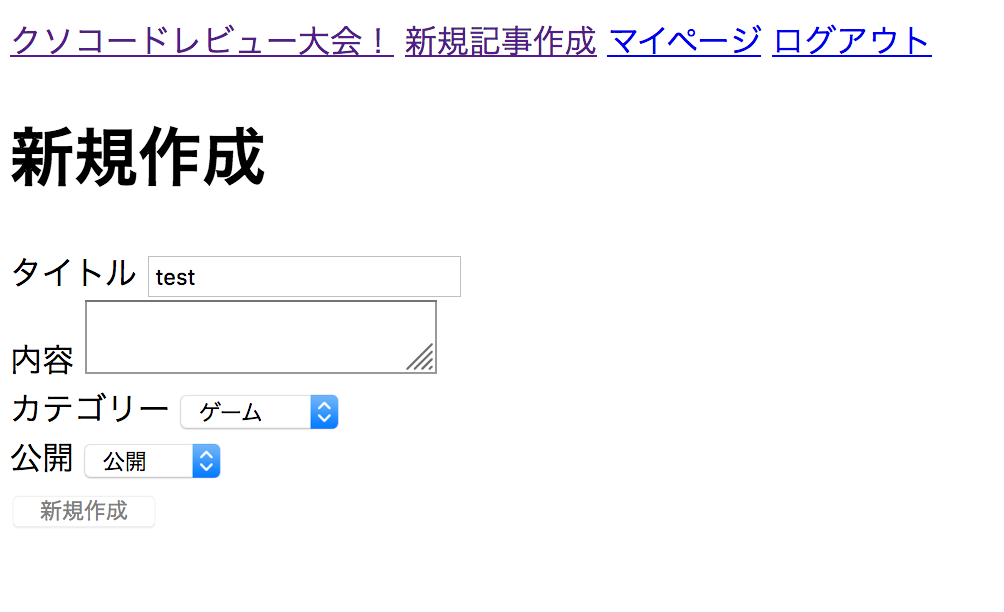
controllers/articles_controller.rb#修正前 def create @article = Article.new(article_params) @article.save redirect_to root_path end def update @article = Article.find(params[:id]) @article.update(article_params) redirect_to root_path end #修正後 def create @article = Article.new(article_params) if @article.save redirect_to @article, flash: { success: 'articleが作成されました' } else render :new end end def update if @article.update(article_params) redirect_to @article, flash: { success: 'articleが更新されました' } else render :edit end endそもそもエラーハンドリングって?
エラーハンドリングとは、プログラムの処理中に処理が妨げられる事象が発生した際、その処理をエラーとして対処する処理のことである。 例外処理とも呼ばれる。
(出典:weblio)今回の場合でエラーハンドリングをちゃんとしないと、、、
このように新規作成ボタンを押してもボタンが無効になるだけでデータが作成されないですなので、save,updateなどの処理を挟む時は必ずif文を使ってエラーハンドリングをして
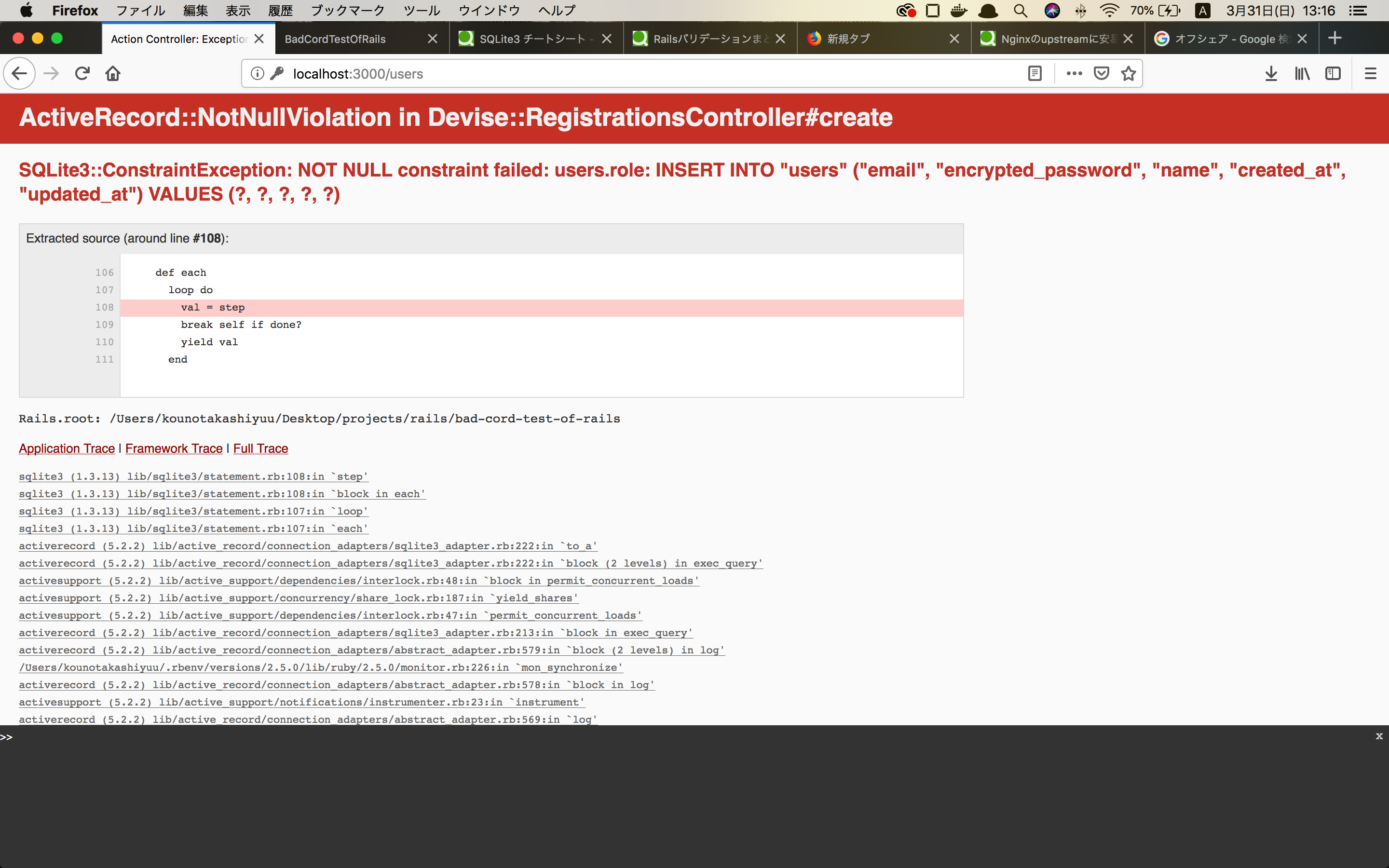
データが作成されない時のフォローをしてあげましょう。userのenumであるroleカラムにdefault値をつけていない
db/migrate/20190220135142_devise_create_users.rb#修正前 # カスタムカラム t.string :name, null: false t.integer :role, null: false #修正後 # カスタムカラム t.string :name, null: false t.integer :role, null: false, default: 1もしroleカラムにデフォルト値をつけなかった場合ユーザーを新規に作成するときに以下のようなエラーが返されると思います。
これはどういうことかというと、、、「roleカラムが指定されてないんだけど〜」っていうエラーですね
今回ユーザーのroleカラムはユーザーの新規登録時に操作させません
(というか、新規登録時にユーザー自身アドミンユーザーかノーマルユーザーかを決められたらアドミンユーザーの意味がw)
ですが、ユーザーのroleカラムは全てのユーザーが持っていなければならないのです。
そのようなときは最初からroleにデフォルト値を設定してフォローするのがベターだと思われます。またenumは基本的にデフォルト値をつけるのが慣習となっているので(多分w)
そう言った意味でもデフォルト値をつけるべきでしょう他の人になりすましてデータを作成更新削除ができてしまう
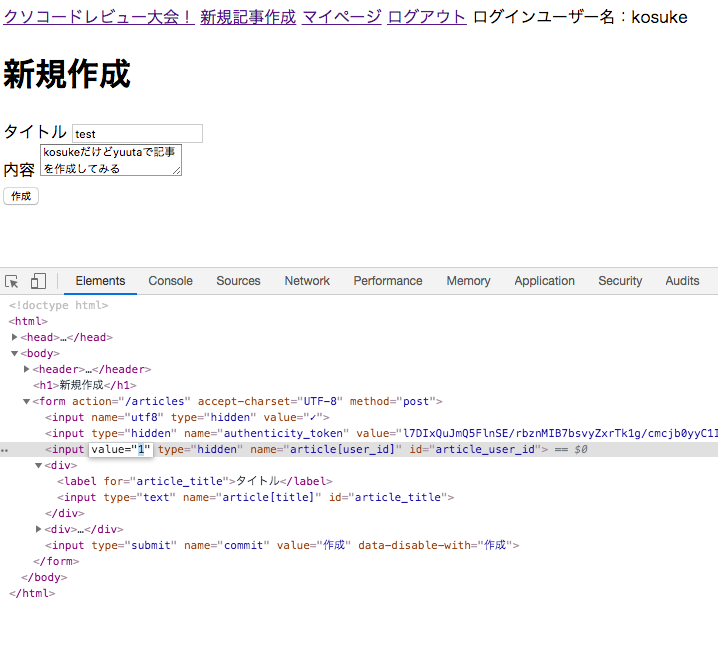
controller/articles_controller.rb#修正前 #一部省略 def new @article = Articles.new end def create @article = Article.new(article_params) @article.save redirect_to root_path end def edit @article = Article.find(params[:id]) end def update @article = Article.find(params[:id]) @article.update(article_params) redirect_to root_path end def destroy @article = Article.find(params[:id]) @article.destroy redirect_to root_path end #一部省略 def article_params params.require(:article).permit( :title, :body, :user_id ) end #修正後 before_action :article_author, only: %i[edit update destroy] #一部省略 def new @article = current_user.articles.new end def create @article = current_user.articles.new(article_params) if @article.save redirect_to @article, flash: { success: 'articleが作成されました' } else render :new end end #一部省略 private def article_author @article = current_user.articles.find(params[:id]) end def article_params params.require(:article).permit( :title, :body, ) endどういうことか実際にやってみましょう!
新規作成の画面を開き、開発者ツールを開き上記の写真のuserIDを指定しているところを見つけましょう。
そこのIDを今ログインしているユーザー以外のIDを指定して新規作成をおします。
すると以下のようにログインしているユーザー以外で記事を作成できてしまいます
この現象を避けるため、今回はuserとarticleとの紐付けをhidden_fieldで現在のユーザーのidを送るのではなく、@article = current_user.articles.newというような記述の仕方でユーザーと記事の紐付けを行いました。
seeds.rbのcreateに「!」をつけてない
seeds.rb#修正前 puts "ユーザー作成中" User.create( [ { name: 'kosuke', email: 'test1@test.com', password: '111111', role: 2, #修正後 puts "ユーザー作成中" User.create!( #「!」をつけた [ { name: 'kosuke', email: 'test1@test.com', password: '111111', role: 2,seedファイルのcreateには「!」をつけないとエラーを吐いてくれません
つまり、seedが失敗してもそれに気づくことが難しくなってしまうのでseedファイルには必ず「!」をつけましょう本当にエラー吐かないの?!って思う人は
rake db:seedを「!」をつけたバージョンとつけなかったバージョンの2回叩いてみるとわかると思います2、きれいなコーディング(レベル1)
- インデントが揃っていない
- シングルクォーテーションとダブルクォーテーションが混在
- new/editでの共通部分を部分テンプレート化していない
- article_pathの引数が「article.id」になっている
インデントが揃っていない
views/articles/index.html.erb<!--修正前--> <table> <tr> <th>タイトル</th> <th>内容</th> <th>pv数</th> <th>ライター</th> <th></th> <th></th> </tr> <% @articles.each do |article| %> <tr> <td><%= link_to '#{article.title}', article_path(article.id) %></td> <td><%= article.body.html_safe %></td> <td><%= "#{article.pv}pv" %></td> <td><%= "#{article.user.name}" %></td> <td><%= link_to "編集", edit_article_path(article.id) %></td> <% if article.user == current_user %> <td><%= link_to '削除', article_path(article.id), method: :delete, data: { confirm: "#{article.title}を削除しますか?" } %></td> <% end %> </tr> <% end %> </table> <!--修正後--> <table> <tr> <th>タイトル</th> <th>内容</th> <th>pv数</th> <th>ライター</th> <th></th> <th></th> </tr> <% @articles.each do |article| %> <tr> <td><%= link_to '#{article.title}', article_path(article.id) %></td> <td><%= article.body.html_safe %></td> <td><%= "#{article.pv}pv" %></td> <td><%= "#{article.user.name}" %></td> <td><%= link_to "編集", edit_article_path(article.id) %></td> <% if article.user == current_user %> <td><%= link_to '削除', article_path(article.id), method: :delete, data: { confirm: "#{article.title}を削除しますか?" } %></td> <% end %> </tr> <% end %> </table>初めてインデントとかを気にし始めた時はかなり大変さを感じるかもしれないですが、それに慣れてしまうと、むしろインデントが揃ってないと違和感しか感じないですw
ちなみに各エディタにはインデントとかを揃えてくれるプラグインが存在するはずなので是非調べて見てください。
僕自身は「atom」を使っているのですが、「atom」では「atom-beautify」と言うプラグインがあり、それを使うと
control + option + B
で自動で整形してくれます。シングルクォーテーションとダブルクォーテーションが混在
views/articles/index.html.erb<!--21行目--> <!--修正前--> <td><%= link_to "編集", edit_article_path(article.id) %></td> <% if article.user == current_user %> <td><%= link_to '削除', article_path(article.id), method: :delete, data: { confirm: "#{article.title}を削除しますか?" } %></td> <!--修正後--> <td><%= link_to '編集', edit_article_path(article.id) %></td> <% if article.user == current_user %> <td><%= link_to '削除', article_path(article.id), method: :delete, data: { confirm: "#{article.title}を削除しますか?" } %></td>プログラミングをする際はできるだけ書き方を統一しましょう。
今回はシングルクォーテーションに揃えていますが、プログラム全体でダブルクォーテーションに揃えているのであれば、ダブルクォーテーションで揃えるのが適切だと思います。new/editの共通部分が部分テンプレート化していない
views/articles/new.html.erb<!--修正前--> <h1>新規作成</h1> <% if @article.errors.any? %> <ul> <% @article.errors.full_messages.each do |message| %> <li><%= message %></li> <% end %> </ul> <% end %> <%= form_with model: @article, local: true do |f| %> <%= f.hidden_field :user_id, value: current_user.id %> <div> <%= f.label :title %> <%= f.text_field :title %> </div> <div> <%= f.label :body %> <%= f.text_area :body %> </div> <%= f.submit '作成' %> <% end %> <!--修正後--> <%= render 'form', article: @article %>views/articles/edit.html.erb<!--修正前--> <h1>編集</h1> <% if @article.errors.any? %> <ul> <% @article.errors.full_messages.each do |message| %> <li><%= message %></li> <% end %> </ul> <% end %> <%= form_with model: @article, local: true do |f| %> <%= f.hidden_field :user_id, value: current_user.id %> <div> <%= f.label :title %> <%= f.text_field :title %> </div> <div> <%= f.label :body %> <%= f.text_area :body %> </div> <%= f.submit "更新" %> <% end %> <!--修正後--> <%= render 'form', article: @article %>※新規作成
views/articles/_form.html.erb<h1><%= current_page?(new_article_path)? "新規作成" : "編集" %></h1> <%= render 'layouts/errors', object: @article %> <%= form_with model: article, local: true do |f| %> <%= f.hidden_field :user_id, value: current_user.id %> <div> <%= f.label :title %> <%= f.text_field :title %> </div> <div> <%= f.label :body %> <%= f.text_area :body %> </div> <%= f.submit "#{ current_page?(new_article_path)? "新規作成" : "更新" }" %> <% end %>※新規作成
views/layouts/_errors.html.erb<% if object.errors.any? %> <ul> <% object.errors.full_messages.each do |message| %> <li><%= message %></li> <% end %> </ul> <% end %>新規登録と編集画面のフォームは全く一緒なので部分テンプレートとして切り出し、
エラーメッセージは他のところでも使う可能性があるので、さらに別のファイルに切り出して実装を行いました今回は、「新規作成/編集」のところもcurrent_page?メソッド(現在のページのパスを返すrailsのメソッド)を使って変化させていますが、多少やりすぎ感は否めないかなとも思ってますw
article_pathの引数が「article.id」になっている
views/articles/index.html.erb<!--修正前--> <td><%= link_to article.title, article_path(article.id) %></td> <!--修正後--> <td><%= link_to article.title, article_path(article)%></td>idを引数として渡す場合はオブジェクトそのものを渡してあげることもできる。
かなり細かいところではあるが、意外と重宝することがある3、きれいなコーディング(レベル2)
- enumの検索メソッドを使用していない
- authenticate_user!を使用していない
enumの検索メソッドを使用していない
views/users/show.html.erb#修正前 <% if current_user.role == "admin" %> #修正後 <% if current_user.admin? %>enumを使うことで
current_user.admin?というように記述することができよりシンプルな記述をすることができます。参考文献
https://qiita.com/shizuma/items/d133b18f8093df1e9b70authenticate_user!を使用していない
application_controller.rb#修正前 def user_sign_in? if user_loged_in? redirect_to :user_session_path end end #修正後 before_action :authenticate_user!gemのdeviseを使うことで様々なメソッドを使うことができるようになります
メソッド 用途 before_action :authenticate_user! コントローラーに設定して、ログイン済ユーザーのみにアクセスを許可する user_signed_in? ユーザーがサインイン済かどうかを判定する current_user サインインしているユーザーを取得する user_session ユーザーのセッション情報にアクセスする 詳細は↓の記事から、、、
https://qiita.com/tobita0000/items/866de191635e6d74e392#user_session4、きれいなコーディング(レベル3)
- n+1問題が発生している
- ビジネスロジックをcontrollerに書いている
- デメテルの法則を使用していない
- Articleにindexを貼っていない
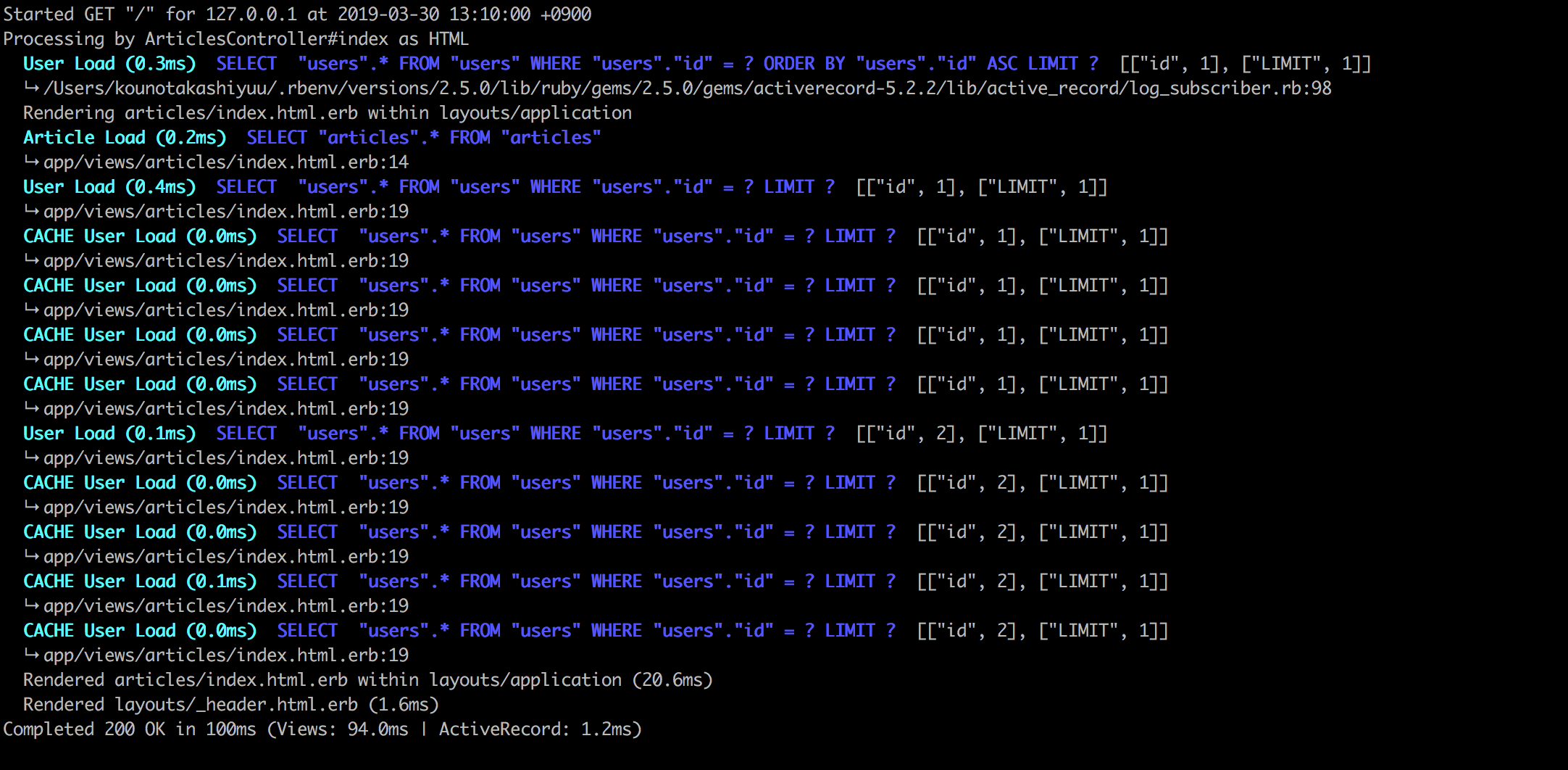
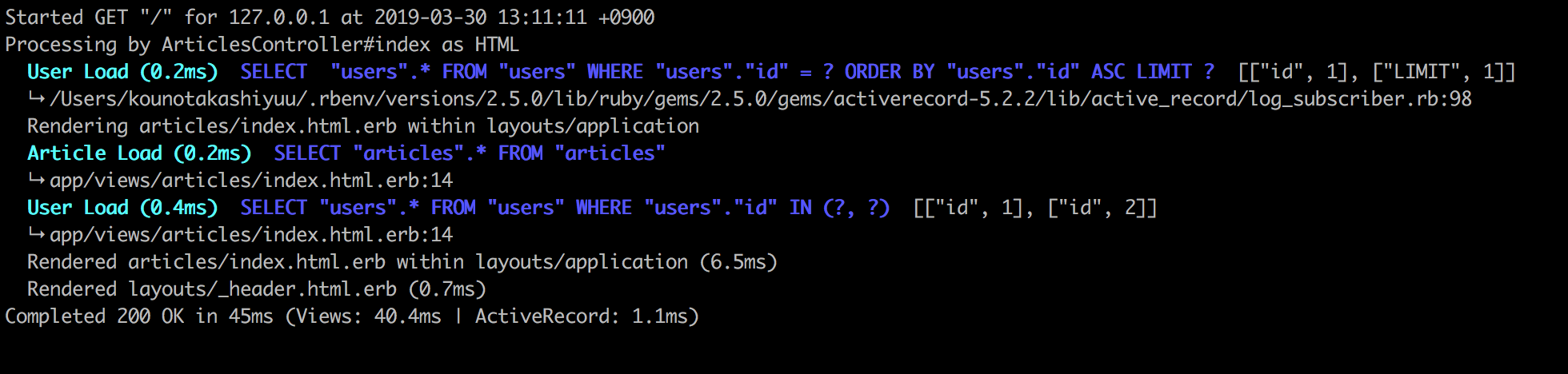
n+1問題が発生している
controllers/articles_controller.rb#修正前 def index @articles = Article.all end #修正後 def index @articles = Article.all.includes(:user) endそもそもn+1問題って?
めちゃめちゃ簡単に言うと無駄なSQL(データベースからデータを取ってくる命令)が発行されてしまっている現象です。
どれくらい違うかと言うと、、、修正前
修正後
たった10個の初期データを表示するだけにも関わらず
ここまで発行量に差があります。じゃあ、なんでこなんでこんなに違いがあるのかと言うと、、、
調べましょう!!!説明がめんどくさかったとかそう言うのじゃないんだからね!まあでもとりあえず参考文献だけは置いておきます
https://qiita.com/TsubasaTakagi/items/8c3f4317ad917924b860デメテルの法則を使用していない
models/article.rb#追加 delegate :email, :name, to: :user, prefix: trueviews/articles/_article_list.html.erb<!--修正前--> <tr> <td><%= link_to article.title, article_path(article) %></td> <td><%= article.body.html_safe %></td> <td><%= "#{article.pv}pv" %></td> <td><%= article.user.name %></td> <!--修正後--> <tr> <td><%= link_to article.title, article_path(article) %></td> <td><%= article.body.html_safe %></td> <td><%= "#{article.pv}pv" %></td> <td><%= article.user_name %></td>デメテルの法則とは、
あるオブジェクトAは別のオブジェクトBのサービスを要求してもよい(メソッドを呼び出してもよい)が、オブジェクトAがオブジェクトBを「経由して」さらに別のオブジェクトCのサービスを要求してはならない。(wikipediaより引用)
まあよくわかんないと思うのでめちゃめちゃ簡単にいうと、、、
「.」を2つ以上繋げんなよ!って感じですな(ただこの解釈で固まりすぎると行きすぎると死ぬことあるのでその辺は注意、、、)じゃあ、今回みたいに
article.user.nameみたいに書かなきゃいけない時はどうすればいいの?ってことが起きると思います。models/article.rbdef user_name user.name endその時は上のようにarticleのモデルにこんな感じのメソッドを書いてあげれば
article.user_nameみたいな感じで「.」を一つで呼ぶことができます。(※正確にいうとArticleモデルのメソッドとしてuser名を引っ張ってこれる)
なので今回の実装ではrailsのActiveSupportのコンポーネントのdelegateを使って実装を行いました。何を言ってるのかよくわからん!っていう人は、
「.」を2つ以上繋げるのはあんまり良くないんだな〜みたいな認識でオッケーかと思います。Articleにindexを貼っていない
db/migrate/20190220133546_init.rb#修正前 create_table :articles do |t| t.string :title, null: false t.text :body, null: false t.integer :pv, null: false, default: 0 t.integer :user_id, null: false t.timestamps end #修正後 create_table :articles do |t| t.string :title, null: false t.text :body, null: false t.integer :pv, null: false, default: 0 t.integer :user_id, null: false t.timestamps end add_index :articles, [:user_id] #追記indexを張るってどういうこと?
プログラミングでindexというといろんな意味がありますが、、、
今回のindexの意味は検索を早くする仕組みのことですなんでindexを張ると検索が早くなるのかは下の記事を見ていただくとして、、、
indexは基本的には外部キーに貼っておくといいとされているらしいので、よくわからん!!!って人もとりあえず外部キーには貼っておきましょう参考文献
〜簡単に分かりたい人向け〜
https://wa3.i-3-i.info/word11906.html
〜割とちゃんと分かりたい人向け〜
https://www.atmarkit.co.jp/ait/articles/1703/01/news199.htmlビジネスロジックをモデルにかいていない
controller/articles_controller.rb#修正前 def show @article = Article.find(params[:id]) @article.pv += 1 @article.save end #修正後 def show @article = Article.find(params[:id]) Article.increment_pv(@article) endmodels/article.rbdef self.increment_pv(article) article.pv += 1 article.save endそもそもビジネスロジックってなんやねん!
ビジネスロジック(英: business logic)は、データベースとユーザーインタフェース間の情報のやりとりを制御する手順といったようなものを指す(技術的でない)用語である。(wikipediaより引用)
ってことだそうです、、、いや、どういうことやねんwww
まあちょっとよくわからないので
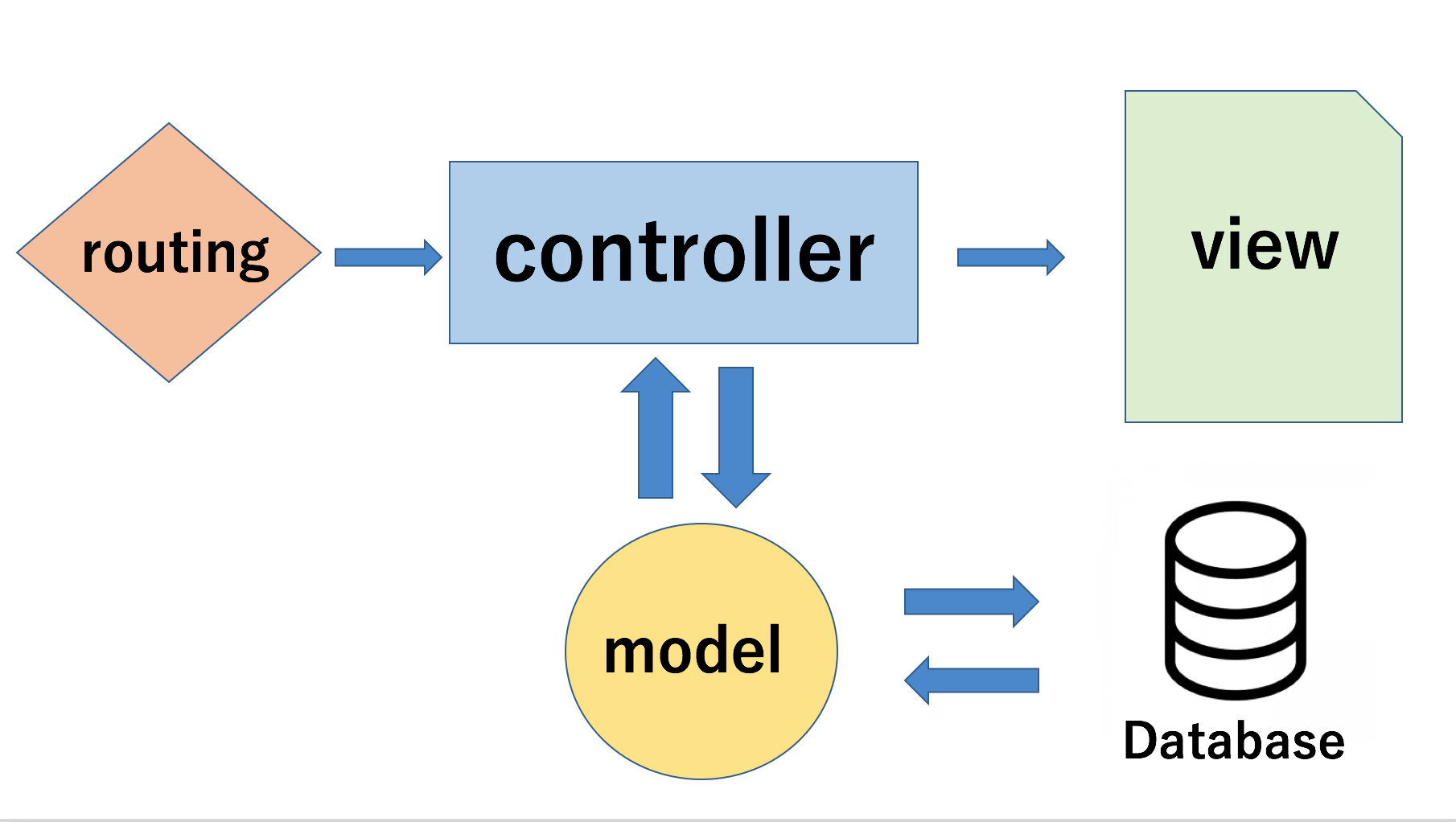
逆にcontrollerの役割について確認したいと思います。
上の図はMVCフレームワークの大まかな流れなのですが
ズバリコントローラーの役割とは、、、送られてきたリクエストを適切なアクションに振り分けること!
です。
そして、データベースとのやりとりはmodelが行うことになっています。そこで改めて該当のコードを見てみると、、、
def show @article = Article.find(params[:id]) @article.pv += 1 @article.save endというようになっています。
ここで行なっている処理は
1. 該当のarticleを持ってくる
2. 持ってきたarticleのPV数を1を足すまず、1の「該当のarticleを持ってくる」というところですが、
先ほどの話からするとこの作業は本来modelが担当するべきところですが、@article = Article.find(params[:id])
となっているので、まるでコントローラがDBにアクセスているように見えますが、このrailsのfindというメソッドは実はmodels/user.rbで継承されているActiveRecordのメソッドを呼び出しているのです!
なのでちゃんとMVC通りmodelでデータベースとやりとりを行なっていたんですね!(この辺は話すと長くなるのでこれくらいで割愛w)そして、2の「持ってきたarticleのPV数を1を足す」という処理ですが、この作業も本来はmodelが担当するべきところですが修正前のコードではcontrollerでpv数を1足しています(ちなみにsaveもActiveRecordのメソッドです)
コントローラは処理を振り分けることなので、pv数に1を足すという処理をここで行なってしまうとMVCの考え方に反してしまいます。
なので今回はこれらの処理はメソッドとして切り出してmodelファイルに記述して、それを呼びだすという実装にしています。ってまあ、ぶっちゃけよくわからん!ってなる人も多いと思います汗
なのでそんな人は、とりあえず、、、よくわかんないけど、
普段使ってる「find」とか「save」とかはmodelファイルで定義しているメソッドをcontrollerで呼び出して使ってるだけなんだなぁ〜ってことだけ頭の片隅にでも置いておいてもらえるといいかなと思います
ビジネスロジックをさっくり知りたい
https://wa3.i-3-i.info/word13666.htmlもっと知りたい
〜MVCモデル〜
https://qiita.com/tshinsay/items/5b1724baf32b8b5113c2〜ActiveRecord〜
https://railsguides.jp/active_record_basics.html5、セキュリティー系
XSS(クロスサイトスクリプティング)攻撃からの脆弱性がある
views/articles/_article_list.html.erb<!--修正前--> <% articles.each do |article| %> <tr> <td><%= link_to article.title, article_path(article) %></td> <td><%= article.body.html_safe %></td><!--⬅︎修正するところ--> <td><%= "#{article.pv}pv" %></td> <td><%= article.user_name %></td> <!--修正後--> <% articles.each do |article| %> <tr> <td><%= link_to article.title, article_path(article) %></td> <td><%= simple_format(article.body) %></td> <!--⬅︎修正した--> <td><%= "#{article.pv}pv" %></td> <td><%= article.user_name %></td>クロスサイトスクリプティングってなんぞ?
こればっかりは実際にやって見たほうが早いのでやって見ましょう!<script>location.href="https://qiita.com/"</script>これをbodyに書いて記事を作成してみましょう
すると、、、
おそらく記事の一覧画面に言った時にqiitaのトップページに勝手にリダイレクトされると思います。
今回はこれがqiitaのトップページであるため、問題はありませんが例えばこれの飛ばされる先が悪質なサイトである可能性は十分にあるわけです。。。
ではこれらはどのようにすれば防ぐことができるのでしょうか?キーワードとしては サニタイズ です
サニタイズとは簡単にいうと特別な文字を他の文字に置き換えちゃおうぜって感じのことです。
railsでは基本的にrubyタグ(<%= %>こんな感じのやつ)を使うことでサニタイズをしてくれるのですが.html_safeを使うとサニタイズしてくれなくなってしまいます。
(safeって書いてあるのに全然安全じゃないってのがツッコミどころ満載な感じですが、あまりにツッコミどころ多いので逆に覚えやすいw)でも、だからと言って
<td><%= article.body %></td>と書いてしまうと、改行がうまくされませんそのため今回はsimple_formatというrailsのヘルパーを用いて実装を行っています。参考文献
〜サニタイズについて〜
https://wa3.i-3-i.info/word16265.html
〜simple_formatについて〜
http://railsdoc.com/references/simple_formatお疲れ様です!!!
みなさん、問題の回答から解説の読了までお疲れ様でした!!!
今回の問題楽しんでいただけましたでしょうか?また何か新しい発見や学びはありましたでしょうか?もし少しでも発見や学びがあればとても嬉しいなと思います!
というか今回の問題個人的にはなかなか難しいと思っていて、自分で作っていながらこれ俺が出されても1発で満点取れます!みたいなことは口が裂けても言えないなぁ〜って思っていますので、全然点数が取れなかった人もあまり気にせずにまたゆっくり一緒に勉強していければなと思います!
最後に、、、意見や質問、感想などあったら教えていただけると幸いです!
参考文献まとめ
シングルクォーテーション、ダブルクォーテーション
https://qiita.com/Kenji_TAJIMA/items/78555053a36c214be350バリデーション
https://qiita.com/shunhikita/items/772b81a1cc066e67930edevise
https://qiita.com/tobita0000/items/866de191635e6d74e392#user_sessionn+1問題
https://qiita.com/TsubasaTakagi/items/8c3f4317ad917924b860indexを張っていない
- 簡単に分かりたい人向け
https://wa3.i-3-i.info/word11906.html- 割とちゃんと分かりたい人向け
https://www.atmarkit.co.jp/ait/articles/1703/01/news199.htmlモデルにビジネスロジックを書いている
- ビジネスロジックをさっくり知りたい
https://wa3.i-3-i.info/word13666.html- MVCモデル
https://qiita.com/tshinsay/items/5b1724baf32b8b5113c2- ActiveRecord https://railsguides.jp/active_record_basics.html
XSSの脆弱性がある
- サニタイズについて https://wa3.i-3-i.info/word16265.html
- simple_formatについて http://railsdoc.com/references/simple_format



- 投稿日:2019-03-24T10:37:18+09:00
クラスメソッドとインスタンスメソッド
クラスメソッドとインスタンスメソッド
前回の続きで今回はこちらのテーマで書いていきたいと思います。
クラスとインスタンスについてわからない場合は
こちらを参考にしてみてください。クラスメソッド
クラスメソッドは定義したクラス自身が使えるものであり、クラスで共通の情報を持った処理に使います。
では、共通の情報とは何か?
前回と引き続き学校のクラスを例にとって考えてみましょう。
クラスには生徒がいて、生徒の総数がありますね、これはクラスがクラス内共通の値です。他にも、机の数や、受ける授業などもクラス内共通だと思います。クラスメソッドの定義
それでは上記に書いた生徒の総数をコード内に定義していきます。
school.rbclass Student def self.students_count puts "生徒の総数は30人です。" end end student = Student.newこれで定義できました。クラスメソッドを定義するときはメソッド名の前にselfをつけます。
この後、メソッド内に処理を記述することにより実行する事ができます。インスタンスメソッド
インスタンスメソッドはインスタンスが使用するものであり、個別の情報を使った処理に使います。
学校を例にとるのであれば、生徒一人一人に対する情報に対した処理という事です。
例えば生徒の身長という個々の情報を例にとると、
その身長を「測る」や「書く」、「見る」のような処理が浮かぶと思います。インスタンスメソッドの定義
それでは身長という情報を「見る」というメソッドを定義していきたいと思います。
school.rbclass Student def self.students_count puts "生徒の総数は30人です。" end def show_student_height puts "私の身長は170cmです。" end end student = Student.newこれでインスタンスメソッドの定義ができました。
インスタンスメソッドの場合はクラスメソッドのようにメソッド名の前にselfなどをつける必要はありません。ちなみに上に書いた「puts」は実行した際に表示をするというメソッドです。
上のshow_student_heightを実行すれば、puts以降の「私の身長は170cmです。」が出力されます。最後に
今回はクラスメソッドとインスタンスメソッドについて説明していきました。
クラスメソッドはクラス内共通の処理
インスタンスメソッドは個別の情報に対する処理
ということを覚えておきましょう。
次回はクラス変数、インスタンス変数について説明していきたいと思います。最後まで読んでいただきありがとうございました。
- 投稿日:2019-03-24T09:35:24+09:00
初学者がRailsで作ったポートフォリオをAWSへデプロイするまでの記録
エンジニアへ転職するためにこちらの記事を参考にして
ポートフォリオをAWSへデプロイすることが出来たので、それまでにやったことを出会ったエラーを紹介しつつ、振り返っていきたいと思います。ポートフォリオをAWSにデプロイしてみたい、
AWSへデプロイするまで何を準備すれば良いのかわからない
という方のお役に立てれば幸いです。ちなみにこの記事はEC2へログインするところから始まります。
EC2へログインする
EC2インスタンスを作成した時に、キーペアをダウンロードしてるはずなので
それを使ってログインしていきます。あ、ちなみに今回デプロイしたアプリ名はlovekitchenなるものなので
各々アプリ名の部分は変更してくださいね。$ mv Downloads/lovekitchen.pem .ssh/ $ cd .ssh/ $ chmod 400 lovekitchen.pem $ ssh -i lovekitchen.pem ec2-user@パブリックIP
yesと入力すれば変なアスキーアートが表示されてログイン完了です。管理ユーザー作成
sudo adduser tatsuya sudo passwd tatsuya (# パスワードの登録) sudo vi visudo (# 設定を編集)ここからはVIMを使っての編集になります。
まずiを押してINSERTモードにして下さい。## Allow root to run any commands anywhere root ALL=(ALL) ALL (この下に) chiroru ALL=(ALL) ALLそしてこんな感じで編集したら、
escキーを押して、:wqで上書き保存します。
完了したら[ec2-user] sudo su - tatsuyaこれでユーザー名が変わってると思います。
以降このユーザーで作業を行なっていきます。そして一旦ログアウトして、次はローカル環境で作業します。
[tatsuya] exit [ec2-user] exit [.ssh] ssh-keygen -t rsa (公開鍵の名前を入力してエンター) (空のままエンターを2回) [.ssh] vi config (INSERT) ______________________________________ Host lovekitchen_key_rsa Hostname パブリックIP Port 22 User tatsuya IdentityFile ~/.ssh/lovekitchen_key_rsa ______________________________________ [.ssh] cat アプリ名_key_rsa.pub (ssh-rsaからlocalまでをコピー)ここから再びサーバー側の作業となります。
[.ssh] ssh -i lovekitchen.pem ec2-user@パブリックIP [ec2-user] sudo su - tatsuya [tatsuya] mkdir .ssh [tatsuya] chmod 700 .ssh [tatsuya] cd .ssh [tatsuya] vi authorized_keys __________________________ さっきコピーした鍵をペースト __________________________ [tatsuya] exit [ec2-user] exit [.ssh] ssh lovekitchen_key_rsaこれでログインできればユーザーの設定は完了!
最後にec2-userではログイン出来ないようにします。[tatsuya] sudo vi /etc/ssh/sshd_config _______________________________ DenyUsers ec2-user (ec2-userではログイン出来ない) _______________________________ [tatsuya] sudo service sshd reload (設定を反映) [tatsuya] exit [.ssh] ssh -i アプリ名.pem ec2-user@パブリックIP ec2-user@パブリックIP: Permission denied (publickey). と表示されればOK!これで諸々の準備は完了したので
これからはいよいよプラグインをインストールしたり
アプリをGithubからcloneしたりしていきます。環境構築編
unicornのインストール
ここはローカル環境での作業となります。
Gemfilegroup :production do gem 'unicorn' end$ bundle install次は
unicornの設定ファイルを作成し、編集して行きます。config/unicorn.conf.rb$worker = 2 $timeout = 30 $app_dir = "/var/www/projects/アプリ名" $listen = File.expand_path 'tmp/sockets/.unicorn.sock', $app_dir $pid = File.expand_path 'tmp/pids/unicorn.pid', $app_dir $std_log = File.expand_path 'log/unicorn.log', $app_dir # set config worker_processes $worker working_directory $app_dir stderr_path $std_log stdout_path $std_log timeout $timeout listen $listen pid $pid # loading booster preload_app true # before starting processes before_fork do |server, worker| defined?(ActiveRecord::Base) and ActiveRecord::Base.connection.disconnect! old_pid = "#{server.config[:pid]}.oldbin" if old_pid != server.pid begin Process.kill "QUIT", File.read(old_pid).to_i rescue Errno::ENOENT, Errno::ESRCH end end end # after finishing processes after_fork do |server, worker| defined?(ActiveRecord::Base) and ActiveRecord::Base.establish_connection enddatabase.ymlを編集
config/database.ymlproduction: <<: *default database: lovekitchen_production username: root password:リポジトリへ反映させて行きます。
$ git add . $ git commit $ git push origin masterNginxのインストール
[tatsuya] sudo yum update (サーバーをアップデート) [tatsuya] sudo yum install -y nginx (Nginxをインストール) [tatsuya] sudo /etc/init.d/nginx start (起動確認) [tatsuya] sudo chkconfig nginx on (自動起動を設定)作業用ディレクトリの作成
[tatsuya] cd / [tatsuya| /] sudo chown tatsuya var [tatsuya| /] cd var [tatsuya| var] sudo mkdir www [tatsuya| var] sudo chown tatsuya www [tatsuya| var] cd www [tatsuya| www] sudo mkdir projects [tatsuya| www] sudo chown tatsuya projectsプラグインをインストール
*この中に後々問題となるプラグインが含まれてます(泣)
[tatsuya] sudo yum install git make gcc-c++ patch openssl-devel libyaml-devel libffi-devel libicu-devel libxml2 libxslt libxml2-devel libxslt-devel zlib-devel readline-devel mysql mysql-server mysql-devel ImageMagick ImageMagick-devel epel-releaseNode.js 6xをインストール
[tatsuya] curl -sL https://rpm.nodesource.com/setup_6.x | sudo bash -yarnをインストール
[tatsuya] sudo npm install yarn -grbenvをインストール
[tatsuya] git clone https://github.com/sstephenson/rbenv.git ~/.rbenv [tatsuya] echo 'export PATH="$HOME/.rbenv/bin:$PATH"' >> ~/.bash_profile [tatsuya] echo 'eval "$(rbenv init -)"' >> ~/.bash_profile [tatsuya] source ~/.bash_profileruby-buildをインストール
[tatsuya] git clone https://github.com/sstephenson/ruby-build.git ~/.rbenv/plugins/ruby-build [tatsuya] rbenv rehashrubyをインストール
[tatsuya] rbenv install -v 2.5.3 [tatsuya] rbenv global 2.5.3 [tatsuya] rbenv rehash [tatsuya] ruby -vここも特に問題なかったです。
rubyがちゃんとインストールされた時はホッとしました。
とにかくコマンド一つ実行するだけでドキドキでしたよもう。Githubと連携
ここからGithubと連携して、そして自分のアプリをさっき作ったディレクトリにクローンしていきます。
[tatsuya| ~] vi .gitconfig ----------------------------------- [user] name (gitに登録した名前) email (gitに登録したメールアドレス) [color] ui = true [url "github:"] InsteadOf = https://github.com/ InsteadOf = git@github.com: ----------------------------------- [tatsuya| ~] chmod 700 .ssh [tatsuya| ~] cd .ssh [tatsuya| .ssh] ssh-keygen -t rsa [tatsuya| .ssh] vi config ----------------------------------- Host github Hostname github.com User git IdentityFile ~/.ssh/aws_git_rsa ----------------------------------- [tatsuya| .ssh] chmod 600 config [tatsuya| .ssh] cat aws_git_rsa.pubこのコピーした公開鍵をGithubへアップして行きます。
まずGithubの右上にあるアカウントメニューからSettingsへ進んで下さい。
次はこちらのSSH and GPG Keysへ進みます。
[Title] aws_git_rsa [Key] さっきコピーしたaws_git_rsa.pubこれで
Add SSH Keyで完了!
ちゃんと接続出来ているか確認しましょう。[tatsuya| .ssh] ssh -T github Hi tatsuya! You've successfully authenticated, but GitHub does not provide shell access.こんな感じでメッセージが返ってきます。
そして、いよいよクローンです!
[tatsuya| .ssh] cd /var/www/projects [tatsuya| projects] git clone git@github.com:machamp0714/love_kitchen.gitここで初めてエラーが表示されました。
本当はこう入力しないとダメみたいです。[tatsuya| projects] git clone github:machamp0714/love_kitchen.git [tatsuya| projects] ls love_kitchenこれでクローンも無事完了しました!
Gemをインストール
お次は、
bundlerをインストールします。
この時、Gemfile.lockに記載されているbundlerのバージョンと合わせました。bundlerをインストール [tatsuya| projects] gem install bundler -v 1.7.1 Gemfileを作成 [tatsuya| projects] bundle init Gemfileを編集 [tatsuya| projects] vi Gemfile ------------------------------- *コメントアウトを外して、versionを記載 gem "rails", '5.2.2' ------------------------------- [tatsuya| projects] bundle install --path vendor/bundle --jobs=4 [tatsuya| projects] bundle exec rails -v # Rails 5.2.2次はクローンしたディレクトリへ移動してgemをインストールして行きます。
[tatsuya| projects] cd love_kitchen [tatsuya| love_kitchen] bundle install --path vendor/bundleするとここで次のエラーが出現。。。
/home/tatsuya/.rbenv/versions/2.5.3/bin/ruby -r ./siteconf20190321-31332-65ucq1.rb extconf.rb checking for gcc... yes checking for Magick-config... yes checking for outdated ImageMagick version (<= 6.8.9)... *** extconf.rb failed *** Could not create Makefile due to some reason, probably lack of necessary libraries and/or headers. Check the mkmf.log file for more details. You may need configuration options. Provided configuration options: --with-opt-dir --without-opt-dir --with-opt-include --without-opt-include=${opt-dir}/include --with-opt-lib --without-opt-lib=${opt-dir}/lib --with-make-prog --without-make-prog --srcdir=. --curdir --ruby=/home/tatsuya/.rbenv/versions/2.5.3/bin/$(RUBY_BASE_NAME) To see why this extension failed to compile, please check the mkmf.log which can be found here: /var/www/projects/love_kitchen/vendor/bundle/ruby/2.5.0/extensions/x86_64-linux/2.5.0-static/rmagick-3.0.0/mkmf.log extconf failed, exit code 1 Gem files will remain installed in /var/www/projects/love_kitchen/vendor/bundle/ruby/2.5.0/gems/rmagick-3.0.0 for inspection. Results logged to /var/www/projects/love_kitchen/vendor/bundle/ruby/2.5.0/extensions/x86_64-linux/2.5.0-static/rmagick-3.0.0/gem_make.out An error occurred while installing rmagick (3.0.0), and Bundler cannot continue. Make sure that gem install rmagick -v '3.0.0' --source 'https://rubygems.org/' succeeds before bundling. In Gemfile: rmagickエラー文を見る限りどうも
rmagickをインストールすることが出来ないようです。
ローカル環境でインストールした際も同じようなエラーが出たので、これもversion関連が
原因だろうなと思い、この時はすぐに解決できると思っていました。ですが、ここで問題発生。
そもそも、AmazonLinuxのyum標準リポジトリにあるImageMagickのversionは一番新しいやつが6.7.8と古く、
ここで欲しいのはversionが6.8.9以上の物なので、ImageMagickのversionを新しいものにするというシンプルな
解決策を実行することが出来ません。色々調べた結果、yum先生とremi先生のお力を借りればImageMagick6系の最新版をインストール出来るみたいなので
こちらを試してみました。ちなみに、rmagickはImageMagickのversionを7系にしてしまうと使えないので注意してください。remiリポジトリを追加
[tatsuya] rpm -Uvh http://rpms.famillecollet.com/enterprise/remi-release-6.rpmCentOS-Baseリポジトリを追加
[tatsuya] vi /etc/yum.repos.d/CentOS-Base.repo -------------------------------------------------------------------------- [base] name=CentOS-6 - Base mirrorlist=http://mirrorlist.centos.org/?release=6&arch=x86_64&repo=os gpgcheck=1 enabled=0 gpgkey=http://mirror.centos.org/centos/RPM-GPG-KEY-CentOS-6 --------------------------------------------------------------------------古いパッケージを削除
[tatsuya] yum remove -y libtiff [tatsuya] yum remove -y ImageMagick ImageMagick-develImageMagick6系の最新版をインストール
[tatsuya] yum install -y libtiff --enablerepo=remi,epel,base --disablerepo=amzn-main [tatsuya] yum install -y ImageMagick6 ImageMagick6-devel ImageMagick6-libs --enablerepo=remi,epel,base [tatsuya] yum install -y libwebp libwebp-devel --enablerepo=epel --disablerepo=amzn-main [tatsuya] yum install -y ImageMagick6 ImageMagick6-devel ImageMagick6-libs --enablerepo=remi,epel,baseこれで欲しいversionのImageMagickがインストール出来たので,もう一度
bundle installを実行します。[tatsuya| love_kitchen] bundle install --path vendor/bundleこれでインストール完了です。
僕の環境の場合、このエラーだけしか生じませんでした。nginxの設定
次は、nginxの設定ファイルを作成し、編集して行きます。
[tatsuya| love_kitchen] sudo vi /etc/nginx/conf.d/アプリ名.conf ---------------------------------------------------------------------- upstream unicorn_server { server unix:/var/www/projects/love_kitchen/tmp/sockets/.unicorn.sock fail_timeout=0; } server { listen 80; client_max_body_size 4G; server_name IPアドレス; keepalive_timeout 5; # Location of our static files root /var/www/projects/love_kitchen/public; location ~ ^/assets/ { root /var/www/projects/love_kitchen/public; } location / { proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header Host $http_host; proxy_redirect off; if (!-f $request_filename) { proxy_pass http://unicorn_server; break; } } error_page 500 502 503 504 /500.html; location = /500.html { root /var/www/projects/love_kitchen/public; } } アプリ名や、IPアドレスはご自身の環境に合わせてください。 ---------------------------------------------------------------------- nginxを再起動 [tatsuya| love_kitchen] sudo service nginx restart 権限を設定 [tatsuya| love_kitchen] sudo chmod -R 775 /var/lib/nginx mysqlを起動 [tatsuya| love_kitchen] sudo service mysqld start マイグレーションを実行 [tatsuya| love_kitchen] bundle exec rails db:migration RAILS_ENV=production Missing encryption key to decrypt file with. Ask your team for your master key and write it to /xxx/my-app/config/master.key or put it in the ENV['RAILS_MASTER_KEY']. Exitingマイグレーションを実行しようとしたら、こんなエラーが出ました。
どうもconfig/master.keyがないので怒られてるみたいです。そういえば
master.keyは、.gitignoreに記載されていてリポジトリには反映されないのを思い出しました。
というわけで、ローカル環境でmaster.keyの中身をコピーして、本番環境の方にもmaster.keyファイルを作成してあげます。[tatsuya| love_kitchen] vi config/master.key ---------------------------------- 自分のアプリのconfig/master.keyをコピペ ---------------------------------- [tatsuya| love_kitchen] bundle exec rails db:migration RAILS_ENV=productionこれで全ての準備が完了しました。
あとはrailsアプリを起動するだけです。railsアプリを起動する
railsアプリをプリコンパイル [tatsuya| love_kitchen] bundle exec assets:precompile RAILS_ENV=production nginxを再起動 [tatsuya| love_kitchen] sudo service nginx restart unicornを起動 [tatsuya| love_kitchen] bundle exec unicorn_rails -c /var/www/projects/love_kitchen/config/unicorn.conf.rb -D -E production Mysql2::Error::ConnectionError: Can't connect to local MySQL server through socket '/tmp/mysql.sock' (2)unicornを起動するコマンドを入力するとこんなエラーが出ました。
mysql.sockの場所がおかしいのでしょうか。mysql.sockの場所を調べる [tatsuya| love_kitchen] mysql_config --socket /var/lib/mysql/mysql.sock
/var/lib/mysql.sockにあることが判明したので、
database.ymlを編集します。[tatsuya| love_kitchen] vi config/database.yml ------------------------------------------------ production: <<: *default database: love_kitchen_production username: root password: socket: /var/lib/mysql/mysql.sock ------------------------------------------------ 再びunicornを起動 [tatsuya| love_kitchen] bundle exec unicorn_rails -c /var/www/projects/love_kitchen/config/unicorn.conf.rb -D -E production bundler: failed to load command: unicorn_railsお次はこんなエラーが。。。。。。。。。
unicorn_railsの他に、unicornコマンドもあるみたいなので、そちらを試してみることに。[tatsuya| love_kitchen] bundle exec unicorn -c /var/www/projects/love_kitchen/config/unicorn.conf.rb -D -E production [tatsuya| love_kitchen] ps -ef | grep unicorn | grep -v grep プロセスが3行表示されるこれでようやっと行けたかな?と思い、ブラウザに直接IPアドレスを入力!
http://IPアドレス遂にRailsアプリが起動しました!!!!!
ここまで来るのに丸一日かかってしまいましたが、挑戦してホント良かったです。
今は取り敢えずデプロイしました、みたいな感じなのでこれからちゃんと勉強して行きたいですね。参考にした記事
世界一丁寧なAWS解説。EC2を利用して、RailsアプリをAWSにあげるまで
ホントに素晴らしい記事ありがとうございます。
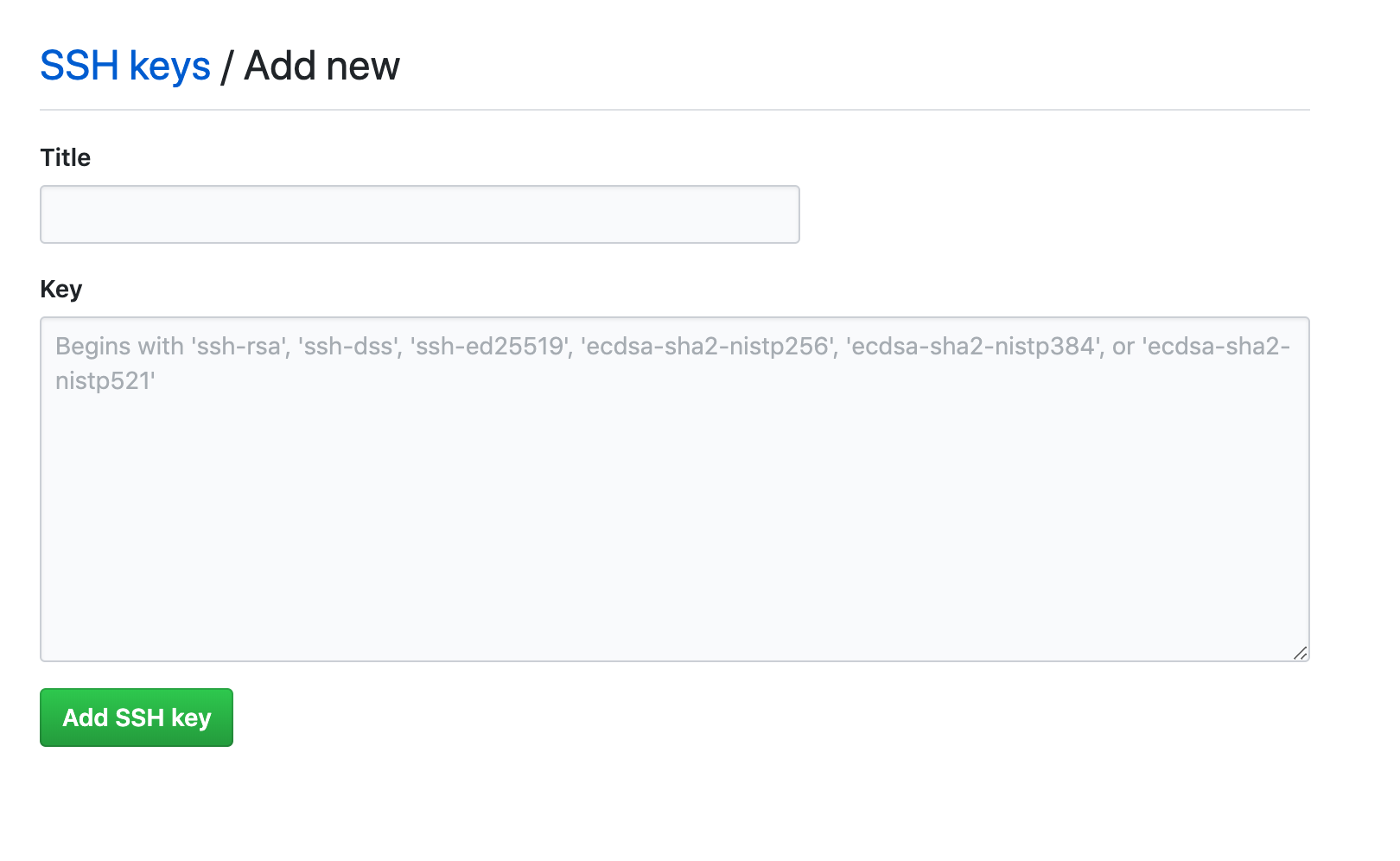
- 投稿日:2019-03-24T04:57:53+09:00
Rails開発をVScodeしていたらerbファイルでEmmet(エメット)が使えなかったので使えるようにした
VScodeでRails開発してるんだけど、erbファイルでEmmet使えない!という人や
そもそもHTMLファイルでもEmemt 使えないよ! という人は以下を試してみてください。VScodeの設定
まずVSCodeの左下の歯車マークをクリック
次に、settingsをクリック検索窓で、
"Trigger Expansion On Tab" と検索
Emmet:Trigger Expansion on tab の左のチェックマークを入れるこれでHtmlファイルではEmmetが使えるようになったはず。
セッティングファイルの記述
さらに続けて、検索窓で
”edit in settings.json”と検索
少し小さい文字の edit in settings.jsonをクリックファイルが開くので以下を追記
settings.json{ "workbench.iconTheme": "vscode-icons", "window.zoomLevel": 0, "emmet.triggerExpansionOnTab": true, # ここから記述 "emmet.includeLanguages": { "erb": "html" } }これで試しに erbファイルで
h1 と打ってからTabキーを叩いてください。それでうまくいかなければ,
拡張機能のインストール
VScode画面上の左上側にあるアイコンの一番下の四角い拡張機能をクリック
Rails と検索してRailsをインストールコレです⬇︎
https://marketplace.visualstudio.com/items?itemName=bung87.rails
上記全て終えたら、晴れてEmmetが使用できるはずです。
※EmmetはVScodeじゃなくても使えます。
たくさんコードを書いてみんなで爆速になりましょう
ごあいさつ
実はこの記事がQiitaでの初投稿になります。
1人でも多くの人のお役に立てたらと願っていますが、至らない所あるかもしれません。
その際は遠慮なく教えていただけると幸いです。参考
- 投稿日:2019-03-24T00:35:02+09:00
Ruby 2.5.xでdeep-coverを使うときは、エッジケースのバグがあるので注意
Ruby 2.5.x + deep-coverでエッジケースのバグを見つけました。
原因はおそらくRubyのバグです。
Ruby 2.6.0では再現しません。詳細はこちら
https://github.com/deep-cover/deep-cover/issues/47deep-coverを有効にすると、以下のコードの挙動が変化します。
class NgClass def self.my_class_method( a0: 0, a1: 0, a2: 0, a3: 0, a4: 0, a5: 0, a6: 0, a7: 0, a8: 0, a9: 0, b0: 0, b1: 0, b2: 0, b3: 0, b4: 0, b5: 0, b6: 0, b7: 0, b8: 0, b9: 0, c0: 0, c1: 0, c2: 0, c3: 0, c4: 0, c5: 0, c6: 0, c7: 0, c8: 0, c9: 0, d0: 0, d1: 0, x: 0 ) x end enddeep-coverなしでも以下のコードはRuby 2.5.xで仕様どおりに動きません
deep-coverが書き換えたコード
($_cov ||= {})[0]||=Array.new(38,0);$_cov[0][37]+=1;_temp=nil;((_temp=(class NgClassRewritten $_cov[0][36]+=1;((_temp=(def (self).my_class_method( a0: ($_cov[0][0]+=1;0), a1: ($_cov[0][1]+=1;0), a2: ($_cov[0][2]+=1;0), a3: ($_cov[0][3]+=1;0), a4: ($_cov[0][4]+=1;0), a5: ($_cov[0][5]+=1;0), a6: ($_cov[0][6]+=1;0), a7: ($_cov[0][7]+=1;0), a8: ($_cov[0][8]+=1;0), a9: ($_cov[0][9]+=1;0), b0: ($_cov[0][10]+=1;0), b1: ($_cov[0][11]+=1;0), b2: ($_cov[0][12]+=1;0), b3: ($_cov[0][13]+=1;0), b4: ($_cov[0][14]+=1;0), b5: ($_cov[0][15]+=1;0), b6: ($_cov[0][16]+=1;0), b7: ($_cov[0][17]+=1;0), b8: ($_cov[0][18]+=1;0), b9: ($_cov[0][19]+=1;0), c0: ($_cov[0][20]+=1;0), c1: ($_cov[0][21]+=1;0), c2: ($_cov[0][22]+=1;0), c3: ($_cov[0][23]+=1;0), c4: ($_cov[0][24]+=1;0), c5: ($_cov[0][25]+=1;0), c6: ($_cov[0][26]+=1;0), c7: ($_cov[0][27]+=1;0), c8: ($_cov[0][28]+=1;0), c9: ($_cov[0][29]+=1;0), d0: ($_cov[0][30]+=1;0), d1: ($_cov[0][31]+=1;0), x: ($_cov[0][32]+=1;0) ) $_cov[0][34]+=1;_temp=nil;x end);$_cov[0][33]+=1;_temp=_temp)) end);$_cov[0][35]+=1;_temp=_temp))Rubyの修正差分
誰か、元となるrubyの修正差分やバグ報告を知っていたら教えてください。
- 投稿日:2019-03-24T00:13:14+09:00
railsで複合主キーをやめるmigration
概要
railsのシステムでは複合主キーは認められてません。全てテーブルがidという自動採番の主キーを持つのが決まりです。
それはわかっていたのですが、多対多の中間テーブル、例えば、モデルで言えば下記ようなものです。
class User < ApplicationRecord has_many :user_skills has_many :skills, inverse_of: :users, through: :user_skills end class Skill < ApplicationRecord has_many :user_skills has_many :users, inverse_of: :skills, through: :user_skills end # これが私のいうところの中間テーブルです。 class UserSkill < ApplicationRecord belongs_to :skill belongs_to :user endこれだけは自分の経験上納得がいかないというか、先入観も大きかったと思いますが、下記の理由で複合主キーを使っていました。
- 必要のないIDの分の無駄な容量が増える
- 頻繁にすげ替えが行われるとIDが枯渇するんじゃないか?
ただ、それで運用してみていくつかの問題がわかっています。
- UserSkillをレシーバーにして削除ができない。
- UserSkillをレシーバーにして更新ができない。
- UserSkillをeager_loadできない。
他にもあるかもしれませんが、今の所私が把握してるのは上記です。
問題点に関して言えば容量はだいぶ低価格になってきてるし、アクセス速度の早いステレージもだいぶ低価格になってきてます。IDの枯渇に関してはbigintであれば一般的なシステムでは多分問題にならないので気にしなくてもいいかも。
こういうGemもあるのですが、いつまでメンテナンスされるかわからないし、メンテナンスが止まったからといって自分でどうにかならないくらい深いところに手を入れてるGEMだと思いました。
そこでRailsの恩恵を受けた方がいいと思うテーブルに関しては複合主キーをやめてみようと思い、そのmigarationを書いてみました。
class UserSkillToSinglePKey < ActiveRecord::Migration[5.2] def change remove_foreign_key :user_skill, :skill remove_foreign_key :user_skill, :user reversible do |change| change.up do execute 'ALTER TABLE user_skill DROP PRIMARY KEY' end change.down do execute 'ALTER TABLE user_skill ADD PRIMARY KEY (skill_id, user_id)' end end add_column :user_skill, :id, :primary_key, unsigned: true, first: true add_foreign_key :user_skill, :skill add_foreign_key :user_skill, :user end endポイントとしては生SQLのところで
reversibleを使ってる点、foreign_keyを外さないと主キーをDROPできないことと、add_column :user_skill, :id, :primary_keyとすると、勝手にAUTOINCREMENTになるところくらいですかね。もし、運用しているサービスにやるのであれば、テーブルロックがかかるのでレコード数によっては問題になるかもしれません。また、一度外部制約を外すので不整合が起きる可能性があるとは思いますのでその点のも考慮に入れてください。