- 投稿日:2019-03-24T18:56:17+09:00
【Finetuningの極意】動物会話のアプリをFinetuning(+中間層利用)で小規模かつ高速に作成♬
VGG16などを使ったFinetuning技法を利用して動物会話アプリを再作成してみました。
どうしても機械学習は大量データと長時間の学習がつきものと考えがちです。
しかし、実際そういう面もありますが(人間の)脳や学習経験を考えてみると、あまり学習時間をかけていないように思います。それというのも、経験というのを最大限生かすこと、そしてそれらの情報を再利用する能力が能では高いことが分かります。
>人間のこのような能力(たぶん、これを知能という)はデザインで云うアフォーダンスを成り立たせているようです
・アフォーダンス@Wikipedia
そして、機械学習として確立している技法でこの手のものは、Finetuning技術です。
ということで、Finetuningを最大限利用することを考えつつ、経験の再利用を意識して進めようと思います。
また、今回は小回りが利くように小規模マシンでも使えるように・学習できるようにを目指して簡単に作れるかにも着目して作成しました。とりあえずの目標
・アプリ【動物会話】をFinetuningで効率よく作成する
・小規模(CPU)環境で学習してみる
・多段階の識別構造を作成して効率を考える
・多段階Finetuning構造を制御するメタ学習と利用について考察する
・多品種・多目的・異種技法(画像,音,皮膚感覚,味覚,自然言語処理,計測&制御...)を取り入れた多段階Finetuningの集合体としての網の可能性Objective・Neuro網(今回導入した用語)と利用を考えるやったこと
アプリ【動物会話】をFinetuningで効率よく作成する
・Finetuningの仕組み
・Finetuningのモデルとして中間層を利用する
・小規模モデルで再学習してみる
・block毎にモデル化してみる・Finetuningの仕組み
画像分類などにおいて、学習済のモデルを利用し、それに若干の新規のネットワークモデルを付加することにより、新たな画像等についてほとんどのWeightを再利用して再学習することにより分類する手法である。
コードで見ると以下のとおり、
【参考】
・DL-FineTuning/akb_VGG16.py
オリジナルは以下を参考としています
・VGG16のFine-tuningによる17種類の花の分類# VGG16モデルと学習済み重みをロード # Fully-connected層(FC)はいらないのでinclude_top=False) input_tensor = Input(shape=x_train.shape[1:]) #(img_rows, img_cols, 3)) vgg16 = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor) # FC層を構築 top_model = Sequential() top_model.add(Flatten(input_shape=vgg16.output_shape[1:])) top_model.add(Dense(256, activation='relu')) top_model.add(Dropout(0.5)) top_model.add(Dense(num_classes, activation='softmax')) # VGG16とFCを接続 model = Model(input=vgg16.input, output=top_model(vgg16.output)) # 最後のconv層の直前までの層をfreeze #trainingするlayerを指定 VGG16では18,15,10,1など 20で全層固定 for layer in model.layers[1:18]: layer.trainable = False・Finetuningのモデルとして中間層を利用する
もう少し進んだものとして、以下があります。
【参考】
・中間レイヤーの出力を得るには?@KerasDocumentation
これを利用すると、当初のモデルの一部を利用して、小さなモデル(しかもPretrained)で学習できることが分かります。
つまり、以下のようなコードで実現できます。
ここでは、vgg16のうちblock3までを利用して、上記と同じFC層をつけて学習ができます。# VGG16モデルと学習済み重みをロード # Fully-connected層(FC)はいらないのでinclude_top=False) input_tensor = Input(shape=x_train.shape[1:]) vgg16 = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor) from keras.models import Model layer_name1 = 'block3_pool' intermediate_layer_model = Model(inputs=vgg16.input, outputs=vgg16.get_layer(layer_name1).output) # FC層を構築 top_model = Sequential() top_model.add(Flatten(input_shape=intermediate_layer_model.output_shape[1:])) #vgg16 top_model.add(Dense(15*num_classes, activation='relu')) #256 #20*num_classes top_model.add(Dropout(0.5)) top_model.add(Dense(num_classes, activation='softmax')) # VGG16とFCを接続 #model = Model(input=vgg16.input, output=top_model(vgg16.output)) model = Model(input=vgg16.input, output=top_model(intermediate_layer_model.output)) # 最後のconv層の直前までの層をfreeze #trainingするlayerを指定 VGG16では18,15,10,1など 20で全層固定 for layer in model.layers[1:1]: layer.trainable = False・小規模モデルで再学習してみる
学習データは、Train on 170 samples, validate on 59 samplesであり、
学習時間は全層Finetuningしても、全部で1分位です。model = Model(input=vgg16.input, output=top_model(intermediate_layer_model.output)) _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= input_1 (InputLayer) (None, 128, 128, 3) 0 _________________________________________________________________ block1_conv1 (Conv2D) (None, 128, 128, 64) 1792 _________________________________________________________________ block1_conv2 (Conv2D) (None, 128, 128, 64) 36928 _________________________________________________________________ block1_pool (MaxPooling2D) (None, 64, 64, 64) 0 _________________________________________________________________ block2_conv1 (Conv2D) (None, 64, 64, 128) 73856 _________________________________________________________________ block2_conv2 (Conv2D) (None, 64, 64, 128) 147584 _________________________________________________________________ block2_pool (MaxPooling2D) (None, 32, 32, 128) 0 _________________________________________________________________ block3_conv1 (Conv2D) (None, 32, 32, 256) 295168 _________________________________________________________________ block3_conv2 (Conv2D) (None, 32, 32, 256) 590080 _________________________________________________________________ block3_conv3 (Conv2D) (None, 32, 32, 256) 590080 _________________________________________________________________ block3_pool (MaxPooling2D) (None, 16, 16, 256) 0 _________________________________________________________________ sequential_1 (Sequential) (None, 3) 2949303 ================================================================= Total params: 4,684,791 Trainable params: 4,684,791 Non-trainable params: 0 _________________________________________________________________学習も50epochで以下のように使えるレベルの精度が出ています。
Train on 170 samples, validate on 59 samples Epoch 47/50 170/170 [==============================] - 1s 5ms/step - loss: 0.4210 - acc: 0.8235 - val_loss: 0.3920 - val_acc: 0.9153 Epoch 48/50 170/170 [==============================] - 1s 5ms/step - loss: 0.3996 - acc: 0.8353 - val_loss: 0.3937 - val_acc: 0.9153 Epoch 49/50 170/170 [==============================] - 1s 5ms/step - loss: 0.4695 - acc: 0.8118 - val_loss: 0.4307 - val_acc: 0.8983 Epoch 50/50 170/170 [==============================] - 1s 5ms/step - loss: 0.4508 - acc: 0.8353 - val_loss: 0.4199 - val_acc: 0.9153ということで、これだとパラメータサイズがGithubに掲載できるサイズになるので、以下にweight込みで諸々置いておきましたので、ご興味がある方はカラス会話アプリ遊んでみてください。
コードは以下に置きました
・block毎にモデル化してみる
こうなると、もっと中間層のパラメータも取得してみたくなるし、ネットワークモデルも自由に作りたくなる。
今後、個別の学習済modelをObjective・Neuroとして構造化しようと考えているので、そのためにもくっつけたりはがしたり自由度が欲しい。
ということで、vgg16は以下のコードでばらばらになりました。
コード全体は以下のとおり
・hirakegoma/FineTuning/VGG16_finetuning_block3_top3.py
こちらも、計算時間は全部で1分位です。【参考】
・Kerasでfine-tuning# VGG16モデルと学習済み重みをロード # Fully-connected層(FC)はいらないのでinclude_top=False) input_tensor = Input(shape=x_train.shape[1:]) vgg16 = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor) from keras.models import Model layer_name1 = 'block3_pool' intermediate_layer_model = Model(inputs=vgg16.input, outputs=vgg16.get_layer(layer_name1).output) inputs0 = Input(shape=intermediate_layer_model.output_shape[1:]) # Block 4 block4_conv1 = Conv2D(512, (3, 3),name='block4_conv1', activation='relu', padding='same')(inputs0) block4_conv2 = Conv2D(512, (3, 3),name='block4_conv2', activation='relu', padding='same')(block4_conv1) block4_conv3 = Conv2D(512, (3, 3),name='block4_conv3', activation='relu', padding='same')(block4_conv2) #bn4 = BatchNormalization(axis=3)(conv4_3) block4_pool = MaxPooling2D(pool_size=(2, 2),name='block4_pool')(block4_conv3) #drop4 = Dropout(0.5)(pool4) block4_model = Model(inputs=inputs0, outputs=block4_pool) inputs1 = Input(shape=block4_model.output_shape[1:]) # Block 5 block5_conv1 = Conv2D(512, (3, 3),name='block5_conv1', activation='relu', padding='same')(inputs1) block5_conv2 = Conv2D(512, (3, 3),name='block5_conv2', activation='relu', padding='same')(block5_conv1) block5_conv3 = Conv2D(512, (3, 3),name='block5_conv3', activation='relu', padding='same')(block5_conv2) #bn5 = BatchNormalization(axis=3)(conv5_3) block5_pool = MaxPooling2D(pool_size=(2, 2),name='block5_pool')(block5_conv3) #drop5 = Dropout(0.5)(pool5) block5_model = Model(inputs=inputs1, outputs=block5_pool) inputs2 = Input(shape=block5_model.output_shape[1:]) # FC層を構築 # top_model x = Flatten()(inputs2) x = Dense(15*num_classes, activation="relu")(x) x = Dropout(0.5)(x) predictions = Dense(num_classes, activation="softmax")(x) top_model = Model(inputs=inputs2, outputs=predictions) #以下はなんとなくだけどこれで動きます model = Model(inputs=intermediate_layer_model.input, outputs=top_model(block5_model(block4_model(intermediate_layer_model.output)))) # 最後のconv層の直前までの層をfreeze #trainingするlayerを指定 VGG16では18,15,10,1など 20で全層固定 for layer in model.layers[1:1]: layer.trainable = Falseまとめ
・動物会話のアプリを題材にVGG16を利用してFinetuningを実施した
・小規模モデルで学習し、小さなモデルで会話アプリができることが分かった
・構造をblock単位でばらばらにモデル化し、Weightなどを取得した今後当面は以下を実施します
・Objective・Neuroを意識して構造化したモデルを構築する
・多段モデルを作成するおまけ
model.summary() _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= input_1 (InputLayer) (None, 128, 128, 3) 0 _________________________________________________________________ block1_conv1 (Conv2D) (None, 128, 128, 64) 1792 _________________________________________________________________ block1_conv2 (Conv2D) (None, 128, 128, 64) 36928 _________________________________________________________________ block1_pool (MaxPooling2D) (None, 64, 64, 64) 0 _________________________________________________________________ block2_conv1 (Conv2D) (None, 64, 64, 128) 73856 _________________________________________________________________ block2_conv2 (Conv2D) (None, 64, 64, 128) 147584 _________________________________________________________________ block2_pool (MaxPooling2D) (None, 32, 32, 128) 0 _________________________________________________________________ block3_conv1 (Conv2D) (None, 32, 32, 256) 295168 _________________________________________________________________ block3_conv2 (Conv2D) (None, 32, 32, 256) 590080 _________________________________________________________________ block3_conv3 (Conv2D) (None, 32, 32, 256) 590080 _________________________________________________________________ block3_pool (MaxPooling2D) (None, 16, 16, 256) 0 _________________________________________________________________ model_2 (Model) (None, 8, 8, 512) 5899776 _________________________________________________________________ model_3 (Model) (None, 4, 4, 512) 7079424 _________________________________________________________________ model_4 (Model) (None, 3) 368823 ================================================================= Total params: 15,083,511 Trainable params: 15,083,511 Non-trainable params: 0 _________________________________________________________________ intermediate_layer_model.summary() _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= input_1 (InputLayer) (None, 128, 128, 3) 0 _________________________________________________________________ block1_conv1 (Conv2D) (None, 128, 128, 64) 1792 _________________________________________________________________ block1_conv2 (Conv2D) (None, 128, 128, 64) 36928 _________________________________________________________________ block1_pool (MaxPooling2D) (None, 64, 64, 64) 0 _________________________________________________________________ block2_conv1 (Conv2D) (None, 64, 64, 128) 73856 _________________________________________________________________ block2_conv2 (Conv2D) (None, 64, 64, 128) 147584 _________________________________________________________________ block2_pool (MaxPooling2D) (None, 32, 32, 128) 0 _________________________________________________________________ block3_conv1 (Conv2D) (None, 32, 32, 256) 295168 _________________________________________________________________ block3_conv2 (Conv2D) (None, 32, 32, 256) 590080 _________________________________________________________________ block3_conv3 (Conv2D) (None, 32, 32, 256) 590080 _________________________________________________________________ block3_pool (MaxPooling2D) (None, 16, 16, 256) 0 ================================================================= Total params: 1,735,488 Trainable params: 1,735,488 Non-trainable params: 0 _________________________________________________________________ block4_model.summary() _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= input_2 (InputLayer) (None, 16, 16, 256) 0 _________________________________________________________________ block4_conv1 (Conv2D) (None, 16, 16, 512) 1180160 _________________________________________________________________ block4_conv2 (Conv2D) (None, 16, 16, 512) 2359808 _________________________________________________________________ block4_conv3 (Conv2D) (None, 16, 16, 512) 2359808 _________________________________________________________________ block4_pool (MaxPooling2D) (None, 8, 8, 512) 0 ================================================================= Total params: 5,899,776 Trainable params: 5,899,776 Non-trainable params: 0 _________________________________________________________________ block5_model.summary() _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= input_3 (InputLayer) (None, 8, 8, 512) 0 _________________________________________________________________ block5_conv1 (Conv2D) (None, 8, 8, 512) 2359808 _________________________________________________________________ block5_conv2 (Conv2D) (None, 8, 8, 512) 2359808 _________________________________________________________________ block5_conv3 (Conv2D) (None, 8, 8, 512) 2359808 _________________________________________________________________ block5_pool (MaxPooling2D) (None, 4, 4, 512) 0 ================================================================= Total params: 7,079,424 Trainable params: 7,079,424 Non-trainable params: 0 _________________________________________________________________ top_model.summary() _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= input_4 (InputLayer) (None, 4, 4, 512) 0 _________________________________________________________________ flatten_1 (Flatten) (None, 8192) 0 _________________________________________________________________ dense_1 (Dense) (None, 45) 368685 _________________________________________________________________ dropout_1 (Dropout) (None, 45) 0 _________________________________________________________________ dense_2 (Dense) (None, 3) 138 ================================================================= Total params: 368,823 Trainable params: 368,823 Non-trainable params: 0 _________________________________________________________________ Train on 170 samples, validate on 59 samples Epoch 7/10 170/170 [==============================] - 1s 8ms/step - loss: 0.1337 - acc: 0.9529 - val_loss: 0.5312 - val_acc: 0.8475 Epoch 8/10 170/170 [==============================] - 1s 8ms/step - loss: 0.1697 - acc: 0.9235 - val_loss: 0.3897 - val_acc: 0.8983 Epoch 9/10 170/170 [==============================] - 1s 8ms/step - loss: 0.1005 - acc: 0.9588 - val_loss: 0.3644 - val_acc: 0.9153 Epoch 10/10 170/170 [==============================] - 1s 8ms/step - loss: 0.0764 - acc: 0.9706 - val_loss: 0.3956 - val_acc: 0.8983
- 投稿日:2019-03-24T12:10:20+09:00
CNNをディジタルフィルタ的な観点から眺める #1
CNNをディジタルフィルタ(FIRフィルタ)設計的な観点から眺めたらもしかして面白いのでは?という記事です。
CNNとディジタルフィルタの関係
そもそもCNNって?
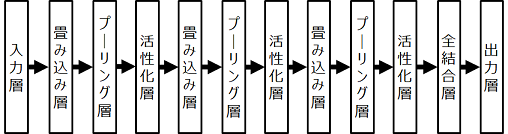
みなさんご存知のCNN(畳み込みニューラルネットワーク)とは、構成要素として畳み込み層(とプーリング層)を持ったニューラルネットワークのことです。
典型的な構成はこんな感じです。(こういった図で活性化層をわざわざ書くのはあまり見たことがないのですが、後の信号処理の記号と対応させるために書いています。)
CNNとディジタルフィルタって関係あるんですか?
CNNの畳み込み処理はディジタル信号処理のFIRフィルタの処理と同じです。
上記のCNN構成を信号処理の記号で書き直すとほぼこんな感じです。
つまりCNNの学習は「特定の波形の特徴を抽出するようにフィルタ特性とクリッピング特性を最適化する処理」と捉えることが出来ます。
ディジタルフィルタの特性
周波数特性
フィルタ特性を$f(t)$、入力信号を$x(t)$とすると畳み込み演算は
$$ \int_{- \infty } ^ {\infty} f(u) x(t-u) du $$
となります。この演算を$*$という記号を用いて
$$ f(t) * x(t) $$
と書くことがよくあります。さらに$f(t)$のフーリエ変換を$F(\omega)$、$x(t)$のフーリエ変換を$X(\omega)$とします。$f(t)$と$x(t)$の畳み込み演算をフーリエ変換すると、その結果は$F(\omega)$と$X(\omega)$の積となります。
$$ f(t) * x(t) \to F(\omega) X(\omega) $$フィルタの重みをただ眺めるだけではその特性をとらえるのは難しいのですが、フーリエ変換して周波数領域に変換することで、どの周波数成分を抽出しているのかが分かりやすくなります。
位相特性
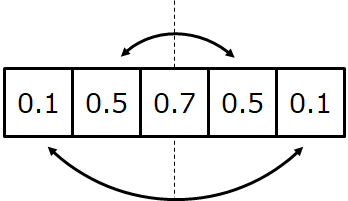
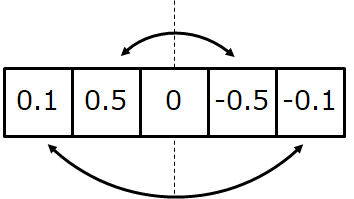
信号がフィルタを通過する際に、通過後の波形が歪まないようにするには、フィルタの重みが偶対称もしくは奇対称である必要があります。
1次元の5次フィルタを例にとると、フィルタの重みが偶対称とはこのようにフィルタの重みが左右対称になっていること。
奇対称とはこのようにフィルタの重みが左右で原点に対して対称になっていることです。
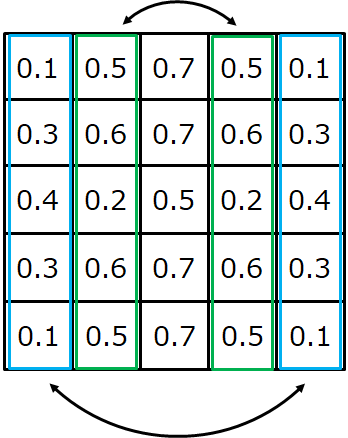
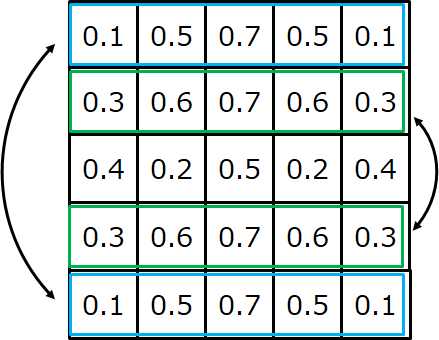
この話は画像向けのような2次元フィルタに対してはこのように拡張できます。下の画像では左から数えて1列目と5列目、2列目と4列目が偶対称になっており、横方向に対して対称性があります。
フィルタが2次元になると話は横方向だけでなくその他の方向に対しても広がります。下の画像は縦方向に偶対称であることを示しています。
実際のCNNの重み
実際にCIFAR-10のデータセットで学習させたCNNのカーネルを可視化したものが下記です。
ネットワークの構造はカーネル数10個、カーネルサイズ6x6の1層のCNNです。 @sasayabaku さんの KerasでCNNを簡単に構築 のコードを参考にさせて頂きました。10個のカーネルを縦に並べています。それぞれのカーネルについて左からRGBのそれぞれのチャネル別の重みを出力しています。
1層のCNNなので性能は全然出ていない(Accuracy=0.60程度)のですが、偶対称な重みが学習されたカーネルが結構あるように見受けられます。次は対称性を定量的に評価できるようにしたいですね。(わざわざフィルタの周波数特性の話をしたのに対称性にしか触れていないのはFFTするのがめんどくさかったからです。その話も次にやりたいです。)
追記
このあたりの内容を既に議論している論文等あれば教えて頂けると嬉しいです。


- 投稿日:2019-03-24T11:39:23+09:00
ディープラーニングを始めたいひとのLinux環境構築【Python×Keras】
LinuxでKerasを動かす際の環境構築手順をまとめました。
ディストリビューションはUbuntu 16.04 LTS、GPUで学習を行うことを想定しています。
なお、本投稿によって生じた全ての事象について私は責任を負いかねますので、必ず自己責任で行うようお願いします。
今回はこのような流れで進めていきます。
- はじめに
- Google Chromeをインストール
- Visual Studio Codeをインストール
- fishをインストール
- Pythonをインストール
- CUDAをインストール
- Tensorflow/Kerasをインストール
- Kerasでmnistの学習を実行
- 終わりに
はじめに
まずはじめにターミナルを開き、下記を実行しておきます。
$ sudo apt update $ sudo apt upgradeGoogle Chromeをインストール
普通にChromeをインストールしようとすると「インストール中」でフリーズするので、まず下記のパッケージをインストールする必要があります。
$ sudo apt install libappindicator1 # ここでエラーが発生する場合は現状インストールされているChromeを削除します。 $ sudo apt remove google-chrome-stableその後下記URLから
.devのインストーラをダウンロード、インストールを行います。
https://www.google.co.jp/chrome/browser/desktop/下記コマンドでChromeが起動します。
$ google-chromeVisual Studio Codeをインストール
ソースコードを編集する際に必要なエディタをインストールします。
ソースコードエディタは種類が豊富で、PythonにはPyCharmという統合開発環境もありますが、個人的な好みと拡張機能の多さから今回はVisual Studio Code(以下VSCode)をインストールします。
Ubuntuを使っているので下記URLから.debのインストーラをダウンロード、インストールを行います。
https://code.visualstudio.com/downloadその後下記コマンドでVSCodeが起動します。
$ codeまた下記の基本的な拡張機能をインストールしておくと便利です。
- Japanese Language Pack for VS Code
- Python extension for Visual Studio Code
次にUbuntuはデフォルトのフォントが少々見づらいので、フォントを
Fira Codeに変更します。
下記Githubの指示に沿ってインストールしていけばいいのですが、今回は下部のManual Installation通りにインストールしました。
https://github.com/tonsky/FiraCode/wiki/Linux-instructions#installing-with-a-package-managerまずシェルスクリプトを作ります。
$ touch download_and_install.sh上記のファイルを開き、リンク先に書いてあるソースコードをコピペします。
download_and_install.sh#!/usr/bin/env bash fonts_dir="${HOME}/.local/share/fonts" if [ ! -d "${fonts_dir}" ]; then echo "mkdir -p $fonts_dir" mkdir -p "${fonts_dir}" else echo "Found fonts dir $fonts_dir" fi for type in Bold Light Medium Regular Retina; do file_path="${HOME}/.local/share/fonts/FiraCode-${type}.ttf" file_url="https://github.com/tonsky/FiraCode/blob/master/distr/ttf/FiraCode-${type}.ttf?raw=true" if [ ! -e "${file_path}" ]; then echo "wget -O $file_path $file_url" wget -O "${file_path}" "${file_url}" else echo "Found existing file $file_path" fi; done echo "fc-cache -f" fc-cache -fdownload_and_install.shを実行します。
$ sh download_and_install.shこれでFira Codeをインストールできたので、VSCodeに適用します。
メニューの「Code」→「基本設定」→「設定」を開き、
Editor:Font Familyを"Fira Code Retina"、
Editor: Font Ligaturesを有効にすればフォントが変更されます。
変更されないときはRetina部分をRegularや、Boldにしたりしてみてください。
あとはメニューの「Code」→「基本設定」→「配色テーマ」から、カラーテーマを好きなものに変更します。最後に個人的に不便なプレビューモードを解除しておきます。
Workbench › Editor: Enable Previewと、
Workbench › Editor: Enable Preview From Quick Openを無効にすればOKです。fishをインストール
引き続きターミナルを操作していきますが、今回はshellにfishを使用します。
fishはfriendly interactive shellの略称とのことですが、特徴はやはりわかりやすさだと感じます。コマンドを途中まで入力するとその先をわかりやすく補完してくれたり、シンタックスハイライトによってそのコマンドが正しいのか間違っているのかということも示唆してくれます。
Ubuntuのデフォルトシェルはbashですが、一応現在のシェルを確認しておきます。現在のシェルはSHELLという環境変数に設定されているので$SHELLの中身を出力することで確認できます。$ echo $SHELL /bin/bashそれではデフォルトシェルをbashからfishに変更していきます。
まずはfishをインストールします。$ sudo apt install fishインストールができたら、fishのパスを確認します。
$ which fish /usr/local/bin/fish自分のマシン環境で使用可能なシェル一覧を確認します。
$ cat /etc/shells # List of acceptable shells for chpass(1). # Ftpd will not allow users to connect who are not using # one of these shells. /bin/bash /bin/csh /bin/ksh /bin/sh /bin/tcsh /bin/zsh /usr/local/bin/fish末尾に上記fishのパスが追加されていたらOKですが、なければvimを使って手動で追記します。
下記コマンドでvimエディタを開いたらiでインサートモードに切り替え、テキストを入力します。
入力が終わったらescでノーマルモードに戻り、:wで上書き保存、:qでエディタを閉じます。$ sudo vim /etc/shells # vimがインストールされていなかったら下記を実行します。 $ sudo apt install vim下記コマンドでデフォルトシェルをfishに変更します。
chsh -s /usr/local/bin/fishこれでデフォルトシェルを変更できました。パソコンを一度ログアウトするとこの変更が適用されます。
再ログインして変更が適用されたかを確認します。ターミナルを起動し、最初のメッセージがbashのときから変わってWelcome to fish, the friendly interactive shellと表示されていたらOKです。一応現在の環境変数も確認しておきます。$ echo $SHELL /usr/local/bin/fishなお、現在使用しているシェルは下記方法でも確認できます。
cat /etc/passwd | grep usernameデフォルトシェルはbashのままfishを起動したい場合は
.bashrcの末尾にexec fishと記述しておけば同様にfishを使用できます。Pythonをインストール
pyenvをインストール
pyenvはPythonのバージョン管理ができるコマンドラインツールです。
pyenvを使うことで例えばディレクトリAではPython2系を使う、ディレクトリBではPython3系を使うといったことが可能になります。
公式Github:https://github.com/pyenv/pyenv/wiki
まず上記Githubからpyenvをホームディレクトリにダウンロードします。$ git clone git://github.com/yyuu/pyenv.git ~/.pyenv # Gitがインストールされておらず、上記でエラーが起こる場合はまずこちらを実行します。 $ apt install git次にダウンロードしたpyenvのパスを通します。
「パスを通す」とは「コマンド検索パスを追加する」ことだと考えるとわかりやすいです。コマンドライン上に入力したコマンド(例えばlsやcd)が正しく動作するのと同じように、コマンドライン上でpyenvと入力したらどのファイルを実行してねということを設定します。
現時点ではパスを通していないので下記を実行しても何も表示されません。$ which pyenvそれではpyenvのパスを通します。今回はシェルスクリプトにfishを使っているので書き込み先は
.config/fish/config.fishです。$ echo 'set -x PATH $HOME/.pyenv/bin $PATH' >> .config/fish/config.fish $ echo '. (pyenv init - | psub)' >> .config/fish/config.fish書き込みを適用します。(下記コマンドではなくターミナルを再起動しても適用されます。)
$ source .config/fish/config.fishこれでpyenvのパスが通ったので、再度下記を実行するとパスが表示されます。
$ which pyenv /home/username/.pyenv/binAnacondaをインストール
Anacondaは機械学習やデータサイエンスをするうえで必要になる色々なPythonパッケージをまとめて提供してくれます。
現時点ではどのバージョンもインストールしていないので下記を実行するとsystemというデフォルト項目だけが表示されます。$ pyenv versions * systemインストールできるバージョンを確認します。
下記を実行するとpyenvでインストールできるバージョンがリスト表示されます。$ pyenv install -l今回は
anaconda3-5.2.0をインストールします。anacondaのバージョンが新しすぎるとtensorflowをインストールできないことがあるので注意してください。$ pyenv install anaconda3-5.2.0ここで再度下記を実行するとインストールできていることがわかります。
*が現在適用されているバージョンを示します。$ pyenv versions * system anaconda3-5.2.0 (set by /home/username/.pyenv/version)pyenvではインストールしたバージョンを現在のアカウント全体で使うか、特定のディレクトリだけで使うかを指定することができます。今回はanaconda3-5.2.0をアカウント全体に適用します。
$ pyenv global anaconda3-5.2.0下記を実行すると
*が移動していることがわかります。$ pyenv versions system * anaconda3-5.2.0 (set by /home/username/.pyenv/version)CUDAをインストール
CUDAはGPUを使って学習を行う際に必要になります。
まず公開鍵を取得します。$ sudo apt-key adv --fetch-keys http://developer.download.nvidia.com/compute/cuda/repos/ubuntu1604/x86_64/7fa2af80.pub続いてパッケージをダウンロードします。
$ wget http://developer.download.nvidia.com/compute/cuda/repos/ubuntu1604/x86_64/cuda-repo-ubuntu1604_9.2.88-1_amd64.debダウンロードしたパッケージをインストールします。
$ sudo dpkg -i cuda-repo-ubuntu1604_9.2.88-1_amd64.debAPTをアップデートし、下記をインストールします。
$ sudo apt update $ sudo apt install cuda cuda-driversここでPCを再起動します。
$ sudo rebootこのあと
.config/fish/config.fishに追記します。$ echo 'set -x PATH /usr/local/cuda/bin $PATH' >> .config/fish/config.fish $ echo 'set -x LD_LIBRARY_PATH /usr/local/cuda/lib64 $LD_LIBRARY_PATH' >> .config/fish/config.fish最後にログオフをして再度ログイン後、下記コマンドを実行、接続しているGPUが表示されたらOKです。
$ nvidia-smiTensorflow/Kerasをインストール
続いてTensorflow、そのあとにKerasの順でインストールします。
今回はGPUを使用するのでtensor-gpuとしていますが、tensorflowだけでも問題はありません。$ conda install tensorflow-gpu $ conda install kerasKerasを実行
最後にKerasでmnistの学習を実行して動作確認をします。
コードはこちらを使用します。
https://github.com/keras-team/keras/blob/master/examples/mnist_cnn.py適当なPythonファイルを作成します。
$ touch train.py作成した
train.pyに上記URLのコードをコピペして保存、下記を実行します。
エラーなく処理が進めばクリアです!$ python train.py終わりに
私なりの手順を書かせていただきましたが、上記の手順のなかで不備や漏れ、お気づきのことがございましたらコメントをいただけますと幸いです。
また本稿作成にあたり下記を参考にさせていただきました。
https://qiita.com/shuntksh/items/1995e87fe5c1ac88296f
https://qiita.com/tkmpypy/items/9bd9692ad44dcd5710da
https://qiita.com/yukoba/items/3692f1cb677b2383c983