- 投稿日:2019-03-24T23:59:01+09:00
AWS CodeStarでネストスタックテンプレートを整理する
目的
CodeStarで作成したプロジェクトについて、
- yamlファイルを分割し、
- そのファイルを整理し、
- かつ
buildspec.ymlの記述を短くする。- その上で、テンプレートが増えてもできる限りコマンドが増えないようにする。
まえがき
CodeStarを使うと、CodeBuildとCloudFormationとを使ってYamlファイルで1AWSリソースを配置することができ、しかもそれらをgitで管理できる環境を自動構築してくれるため、非常に便利だ。しかし、リソースが増えていくと、どうしてもテンプレートファイルが長くなりやすく、可読性が下がってしまう。
そんなときは、スタックのネストを使うと便利だ。しかし、(当然のことだが)yamlファイルを分割すればするほどファイル数が増えてしまい、保守しづらくなってしまうほか、
buildspec.ymlも冗長になってしまう。#このディレクトリは汚い ./--- ParentStack.yml | |- buildspec.yml | |- template-configration.json | |- templatefile1.yml | |- functionFolder1 | |- templatefile2.yml | |- functionFolder | (以下略)buildspec.yml#真面目にやろうとするとbuildspec.ymlはテンプレートが1つ増えるごとに2行ずつ増えていく。 build: commands: # Use AWS SAM to package the application by using AWS CloudFormation #First, package child package - >- aws cloudformation package --templat template1.yml --s3-bucket $S3_BUCKET --output-template export-template1.yml - >- aws cloudformation package --templat template1.yml --s3-bucket $S3_BUCKET --output-template export-template1.yml #Then, package parent stack - >- aws cloudformation package --template ParentStackFile.yml --s3-bucket $S3_BUCKET --output-template $CODEBUILD_SRC_DIR/ExportFiles/ParentStackFile.yml # Do not remove this statement. This command is required for AWS CodeStar projects. # Update the AWS Partition, AWS Region, account ID and project ID in the project ARN on template-configuration.json file so AWS CloudFormation can tag project resources. - sed -i.bak 's/\$PARTITION\$/'${PARTITION}'/g;s/\$AWS_REGION\$/'${AWS_REGION}'/g;s/\$ACCOUNT_ID\$/'${ACCOUNT_ID}'/g;s/\$PROJECT_ID\$/'${PROJECT_ID}'/g' template-configuration.json post_build: commands: - mv template-configuration.json ./ExportFiles/ - cd ExportFiles artifacts: type: zip base-directory: ./ExportFiles files: # This file is used code pipeline. - ParentStackFile.yml # They are child stackes output. - export-stack1.yml - export-stack2.yml #templates - template-configuration.jsonそこで、yamlファイルを分割しつつそのファイルを整理し、かつ
buildspec.ymlの記述を短くしたい。結論
ディレクトリ構造
以下のようなディレクトリ構造にする。
CodePipelineやCodeURIの指定等に応じて適宜変更すること。./--- ParentStack.yml | |- ExportFiles---description.txt(このファイルはファイル名、ファイル形式を問わない) | |- buildspec.yml | |- template-configration.json | |- childTemplateFiles--- template1--- templatefile1.yml | | | |- functionFolder1(lambda関数のソースを含む場合) | |- template1--- templatefile2.yml | | | |- functionFolder2(lambda関数のソースを含む場合) | (以下略)親スタックのテンプレート
親スタックは、ネストするテンプレートについて以下のように記載する。
ParentStack.ymlResources: #Nest stack Stack1: Description: This is test. Type: AWS::CloudFormation::Stack Properties: TemplateURL: './ExportFiles/export-templatefile1.yml' Stack2: Type: AWS::CloudFormation::Stack Properties: TemplateURL: './ExportFiles/export-templatefile2.yml' Parameters: ProjectId: !Ref ProjectId CodeDeployRole: !Ref CodeDeployRole Stage: !Ref Stagebuildspecの記述
buildspec.ymlを、以下のように記述する。buildspec.ymlversion: 0.2 phases: install: commands: # Upgrade AWS CLI to the latest version - pip install --upgrade awscli #First, pack child packages - cd childTemplateFiles - |、 for file in `ls -1 ./*/*.yml` do echo "$file" filename=`basename $file` echo $filename aws cloudformation package --template $file --s3-bucket $S3_BUCKET --output-template $CODEBUILD_SRC_DIR/ExportFiles/export-"$filename" done - cd .. build: commands: # Use AWS SAM to package the application by using AWS CloudFormation # This command replaces PATH to this build enviroment path - sed -i "s|PATH|$CODEBUILD_SRC_DIR|g" ParentStackFile.yml #Then, pack parent stack - >- aws cloudformation package --template ParentStackFile.yml --s3-bucket $S3_BUCKET --output-template $CODEBUILD_SRC_DIR/ExportFiles/ParentStackFile.yml # Do not remove this statement. This command is required for AWS CodeStar projects. # Update the AWS Partition, AWS Region, account ID and project ID in the project ARN on template-configuration.json file so AWS CloudFormation can tag project resources. - sed -i.bak 's/\$PARTITION\$/'${PARTITION}'/g;s/\$AWS_REGION\$/'${AWS_REGION}'/g;s/\$ACCOUNT_ID\$/'${ACCOUNT_ID}'/g;s/\$PROJECT_ID\$/'${PROJECT_ID}'/g' template-configuration.json post_build: commands: - mv template-configuration.json ./ExportFiles/ artifacts: type: zip base-directory: ./ExportFiles files: - '*'試行錯誤の内容
コマンドが長すぎ
まず始めたのが、特にこのコマンドが長すぎるのでどうにかして短くすること。
aws cloudformation package --template ParentStackFile.yml --s3-bucket $S3_BUCKET --output-template $CODEBUILD_SRC_DIR/ExportFiles/ParentStackFile.ymlYamlは改行の扱いが結構細かく決められている印象だったので探してみたらあった。2
どうやら、
>-とつければ良いらしい。これで長過ぎるコマンドが、次のように表記でき、見やすくなった。#文頭に>-をつけることで、改行がスペースとして扱われる。 - >- aws cloudformation package --template ParentStackFile.yml --s3-bucket $S3_BUCKET --output-template $CODEBUILD_SRC_DIR/ExportFiles/ParentStackFile.ymlただ、
sed -i.bak 's/\$PARTITION\$/'${PARTITION}'/g;s/\$AWS_REGION\$/'${AWS_REGION}'/g;s/\$ACCOUNT_ID\$/'${ACCOUNT_ID}'/g;s/\$PROJECT_ID\$/'${PROJECT_ID}'/g' template-configuration.jsonはどうにもうまく行かなかった。まあいいかと思い、次へ子スタックをまとめてパッケージしたい
子スタックをforでビルド
スタックをネストするとき、CodeStarの初期設定だと概ね以下のような流れで行う。(他にも様々なフェーズがあるが、ここでは割愛)
- install
- 最低限aws cliをアップデート。必要なら他のパッケージを入手
- build
aws cloudformation packageで子スタック→親スタックの順にパッケージ。- artifact
- パッケージされたテンプレートを送信
スタックが一つのうちは良いのだが、テンプレートファイルが増えると
aws cloudformation packageコマンドをいくつも書かなくてはならず、非常に面倒だと思った。
ところで、テンプレートファイルはymlと決めていることだし、forコマンドで.ymlファイルだけを検索し、ビルドできるのでは?と考えた。
そこで、unixコマンドのforについて調べたところ、このサイト3からちょうど良さそうなものが見つかったため、次のように書き換えてローカルで実行した。test-forfor var in `ls -1 *.yml` > do > echo $var > donerestemplate1.yml template2.yml問題は、
buildspec.yml内での記述だが、先程のページから2次のように記載すれば良いことがわかった。4buildspec.yml- cd childTemplateFiles #やらなくても良いが、気分で入れた - | for file in `ls -1 ./*/*.yml` #cdしなかったらもう一つ階層を足す do echo "$file" filename=`basename $file` echo $filename #カレントディレクトリに出力する。 aws cloudformation package --template $file --s3-bucket $S3_BUCKET --output-template $CODEBUILD_SRC_DIR/export-"$filename" done子スタックをまとめる
子スタックのテンプレートのみをまとめたフォルダを作り、そこにファイルをまとめた。
ビルドすると、lambda関数のCodeURI指定がうまく行かない。どうも、テンプレートファイルをパッケージするとき、そのテンプレートファイルがあるフォルダがカレントディレクトリとして認識されるようだ。
では、いっそのこと次のようにまとめてしまえばフォルダもスッキリする。./--- ParentStack.yml | |- buildspec.yml | |- template-configration.json | |- childTemplateFiles--- template1--- templatefile1.yml | | | |- functionFolder1(lambda関数のソースを含む場合) | |- template1--- templatefile2.yml | | | |- functionFolder2(lambda関数のソースを含む場合) | (以下略)どうせならファイルの送信もforで回したい
これでも十分短くなったが、artifactフェーズで送信するテンプレートを指定しなければならないのは面倒だ。
そこで、Exportfileという空フォルダを作り、送信するファイルはそこにまとめることにした。
そこでbuildspecを以下のように編集して実行してみる。buildspec.yml- cd childTemplateFiles - | for file in `ls -1 ./*/*.yml` do echo "$file" filename=`basename $file` echo $filename #ExportFileに出力する aws cloudformation package --template $file --s3-bucket $S3_BUCKET --output-template $CODEBUILD_SRC_DIR/ExportFiles/export-"$filename" done - ls ./ExportFilesところが、このまま実行すると「フォルダがない」と言われる。lsしても見当たらないため、ビルド環境にフォルダが作成されていないようだ。
おそらく、S3はフォルダという概念がない5ため、空フォルダを作るとS3上でNullに変換され、ビルド環境にフォルダが作成されないのではないかと考えられる。
なので、適当なファイルをExportFileにぶちこみ、もう一度実行するとSuccessfully packaged artifacts and wrote output template to fileとなった。親スタックの変更
親スタックは、テンプレートファイルを以下のように記述することで依存関係を表現できた。
ParentStack.ymlResources: #Nest stack Stack1: Description: This is test. Type: AWS::CloudFormation::Stack Properties: TemplateURL: './ExportFiles/export-templatefile1.yml' Stack2: Type: AWS::CloudFormation::Stack Properties: TemplateURL: './ExportFiles/export-templatefile2.yml' Parameters: ProjectId: !Ref ProjectId CodeDeployRole: !Ref CodeDeployRole Stage: !Ref Stageファイルの送信
最後に、送信するファイルを指定すれば完了だ。
最初は、以下のようなコマンドを試したが、全てダメだった。buildspec_reject.yml#試し artifacts: type: zip files: zip: - | for file in `ls -1 ./ExportFiles/*.yml` do echo "$file" filename=`basename $file` echo $filename #まあechoじゃだめだよね。filelistがrequiredだったのでls -1してみる type: zip files: - `ls -1` #だめです。いっそ type: zip files: . #だめでした。ここで、公式ドキュメント6を参照したところ、どうも次のようにシングルクオートで囲めば良いようだ。
buildspec_reject.yml#試し artifacts: type: zip files: zip: - ./ExportFiles/*.ymlなぜかファイルが送信できない。
post_buildなるフェーズがあるらしいので、ここでcdを使ってみる。buildspec_reject.yml#試し post_build: - cd ./ExportFiles artifacts: type: zip files: zip: - ./*.ymlところが、これを実行したところ、次のようなレスポンスが返ってきた。
res[Container] 2019/03/24 10:20:34 Expanding ./* [Container] 2019/03/24 10:20:34 Found 2 file(s)どうも、カレントディレクトリを探索し、2つのymlファイル(ここではbuildspec.ymlとビルド前のParentStack.yml)を探し当てたようだ。
cdの代わりにbase-directoryを指定すると次のようになった。
buildspec_reject.yml#試し post_build: artifacts: base-directory: Export type: zip files: zip: - ./*.ymlres[Container] 2019/03/24 10:25:18 Expanding ./ExportFiles/* [Container] 2019/03/24 10:25:18 Found 10 file(s)これで成功したかと思ったが、
template-configuration.jsonも送信しなければならないため、コードを次のように変更したところ、成功した。buildspec.ymlpost_build: commands: - mv template-configuration.json ./ExportFiles/ - cd ExportFiles artifacts: type: zip base-directory: ./ExportFiles files: - '*'
jsonでも記述できるが、非常に可読性が悪く書きづらい ↩
どうでも良い情報かもしれないが、変数をバッククォートで囲むと
Permission Deniedという結果が返ってくる。どいういうことだろうか? ↩https://docs.aws.amazon.com/ja_jp/codebuild/latest/userguide/build-spec-ref.html ↩
- 投稿日:2019-03-24T22:34:30+09:00
AWS リソースのタグ規約を考える
AWS での悩みどころのひとつに EC2 インスタンスなど各種リソースの名前などタグをどう設定すべきかという点があります。調べてみても、命名規約的なものが整備されているわけではなく、個々にベスト・プラクティスがまとめられているだけ、というのが現状のようです。
皆様のご意見を参考にしたいという意味もあり、命名規約案を公開してみることにしました。こうした方がよいなど、ご意見があれば、コメント頂けると幸いです。
参考となる資料
AWS が正式に公開している資料としては次のものがあります。
ブログ記事では、次のものを参考にさせていただきました。
キーの命名規約
キー名は、次のルールに従います。
- Upper Camel Case 記法1とします。(例: BuildId)
- 標準化されていないタグキーには namespace: を付与します。namespace は Lower Camel Case 記法2とします。(例: projA:CostCenter)
なお、namespace として aws は予約されており、user も用途が決まっているため自由に使うことはできません(後述)。
残念なことに AWS が利用/生成しているキーの名前はすでに一貫性がないため、上記のルールが適用できません。AWS が利用/生成するキーには次のようなものがあります。
キー名 用途 Name リソースの表示名として使われます。 aws:createdBy AWS Billing and Cost Management にて AWS 生成コスト配分タグとして付与されます。 user:ヘッダ名 AWS Billing and Cost Management にて ユーザー定義のコスト配分タグ として利用されます。表示名となるため命名規約の適用範囲外です。 aws:cloudformation:logical-id CloudFormation で作成されたリソースに自動付与されます。 aws:cloudformation:stack-id CloudFormation で作成されたリソースに自動付与されます。 aws:cloudformation:stack-name CloudFormation で作成されたリソースに自動付与されます。 値の命名規約
タグの値は次のルールに従って設定します。
- ブール型である値は true あるいは false を設定します。
- 数値型である値は、符号、数値、小数点(および必要に応じて単位)のみからなる値として設定します。表示用にしばしば利用されるカンマ編集や指数表示は使用しません。
- 日付、時刻は ISO 8601 拡張形式で設定します。(例:2001-01-01、01:20:30、2001-01-01T01:20:30、2001-01-01T01:20:30Z)
- その他の値は特に制約を設けず、空白、記号を含む任意の文字列を設定します。
ただし、ひとつのキーに複数の値が紐づくなど構造化する必要がある場合は次のルールに従います。
- 値にサブキーを付ける場合には、イコール記号で区切ります。(例: Title=FooBar)
- 値が複合値(タプル)の場合は、パイプで区切ります。(例: 昭和|S|1926-12-25)
- 複数の値がある場合は、セミコロンで区切ります。(例: value1;value2;value3)
標準タグ・キー名
次のものを標準タグとします。これ以外のタグを付与する場合は、namespace を付与するものとします。
Name(必須)
リソースの表示名です。値の命名は次のルールに従います。
- 値は、Lower Kebab Case3とします。これは、ドメイン名やホスト名としても転用できるようするためです。
- 値は、Stack-Environment-ResourceType-Indentifier の形式とします。
- Stack には、プロジェクト名など管理単位を設定します。(詳細は Stack タグの項で説明します)
- Environment には、本番や開発など環境名を設定します。(詳細は Environment タグの項で説明します)
- ResourceType には、次のようなリソースの種類を表す略称を設定します。
- vpc: VPC
- subnet: サブネット
- igw: インターネットゲートウェイ
- nat: NAT ゲートウェイ
- dopt: DHCP オプション
- rtb: ルートテーブル
- sg: セキュリティグループ
- acl: ネットワーク ACL
- ec2: EC2 インスタンス
- Identifier には、同じようなリソースが複数ある場合に区別できる名前を設定します。複数の単語から成る場合はハイフンで区切ります。例としては次のようなものがあります。
- default: デフォルトのリソース
- public-x: AZ x にあるパブリック・サブネット
- bastion: 踏み台サーバ
- ap-1: AP サーバ 1号機
- db: DB サーバ
Stack(必須)
リソースの管理単位です。リソースグループのクエリ条件としても利用します。多くの場合、プロジェクト名やシステム名となるでしょう。値の命名は次のルールに従います。
- 英数小文字のみからなる文字列とします。複数単語から成る場合、頭文字をつなげたものや全社共通のシステム ID を使うとよいでしょう。
- VPC などプロジェクトを跨いで共有するものには global を設定します。
Stack は、リソースグループのクエリ条件として使用可能です。
Environment(必須)
環境名です。リソースグループのクエリ条件としても利用します。原則、次のいずれかを設定します。同じ用途の環境が複数ある場合には末尾に数字を付けて区別します。
- prod: 本番環境
- stage: ステージング環境
- test: テスト環境
- dev: 開発環境
- common: 共有環境
Service(任意)
デプロイされているサービス名を設定します。例えば、apache、nginx、mysql などです。必要があればハイフンで区切りバージョンを記載しても構いません。(例: apache-2.2.3)
Version(任意)
デプロイされているアプリケーションのバージョン番号を設定します。
BuildId(任意)
デプロイされているアプリケーションのビルド時に付与された ID を設定します。
ManagedBy(任意)
インフラ構築ツールの管理下にあることを示します。値には ansible、terraform などインフラ構築ツールの名前を設定します。
Owner or user:Owner(任意)
リソースの所有者(所有部署)のコードあるいは名前を設定します。コードと名前を両方記載する場合はパイプ記号で繋いで設定します。
Project or user:Project(任意)
リソースの構築元となったプロジェクトのコードあるいは名前を設定します。コードと名前を両方記載する場合はパイプ記号で繋いで設定します。
Customer or user:Customer(任意)
リソースにより機能が提供される顧客のコードあるいは名前を設定します。コードと名前を両方記載する場合はパイプ記号で繋いで設定します。
CostCenter or user:CostCenter(任意)
リソースのコスト負担者(負担部署)コードあるいは名前を設定します。コードと名前を両方記載する場合はパイプ記号で繋いで設定します。
Role or user:Role(任意)
リソースの役割を設定します。(例:Web Server、DB Server)
Contact(任意)
このインフラに関する問い合わせ先メールアドレスを設定します。
- 投稿日:2019-03-24T17:53:07+09:00
AWSの歩き方(EC2→IE接続まで)
やったこと
1.VPC周り作成
2.1.で作成したVPCを使用してEC2を作成
3.セキュリティ周りの設定
4.EC2インスタンスのソフトウェア更新
5.IE接続設定マニュアル人間を目指しているので、AWS公式のドキュメントを見ながら環境を構築していく
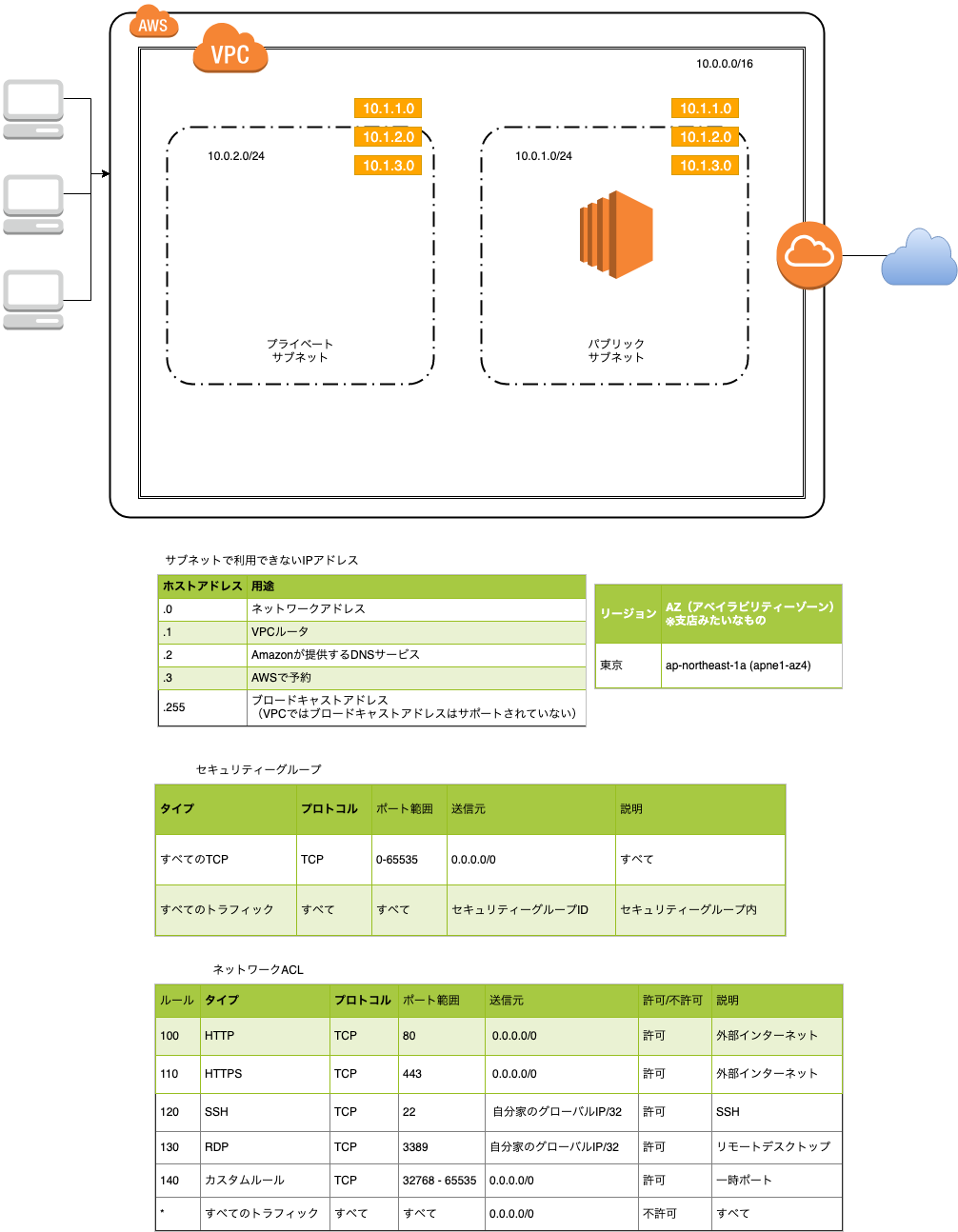
構成図
draw.ioで作成
1.VPC周り作成
・AWS サービス別資料
https://aws.amazon.com/jp/aws-jp-introduction/aws-jp-webinar-service-cut/以下の動画を参考に構築
・Amazon Virtual Private Cloud (VPC) Basic
https://youtu.be/aHEVvsk6pkI2.1.で作成したVPCを使用してEC2を作成
・Windows 仮想マシンの起動
https://aws.amazon.com/jp/getting-started/tutorials/launch-windows-vm/3.セキュリティ周りの設定
下記を参考にポートの設定
・VPC に推奨されるネットワーク ACL ルール
https://docs.aws.amazon.com/ja_jp/vpc/latest/userguide/vpc-recommended-nacl-rules.html4.EC2インスタンスのソフトウェア更新
EC2インスタンス内のソフトウェアを最新バージョンに更新
以下のチュートリアルを参考
・チュートリアル: Windows Server を実行する Amazon EC2 インスタンスに WAMP Server をインストールする
WAMP サーバーをインストールするには 3.を参照
https://docs.aws.amazon.com/ja_jp/AWSEC2/latest/WindowsGuide/install-WAMP.html5.IE接続設定
Internet Explorer セキュリティ強化の構成を無効化
・チュートリアル: Windows Server を実行する Amazon EC2 インスタンスに WAMP Server をインストールする
WAMP サーバーをインストールするには 2.を参照
https://docs.aws.amazon.com/ja_jp/AWSEC2/latest/WindowsGuide/install-WAMP.html
- 投稿日:2019-03-24T16:41:05+09:00
CodeBuildのログをLambdaでログを整形
経緯
CodeBuildのログを整形してメール通知する必要がありました。
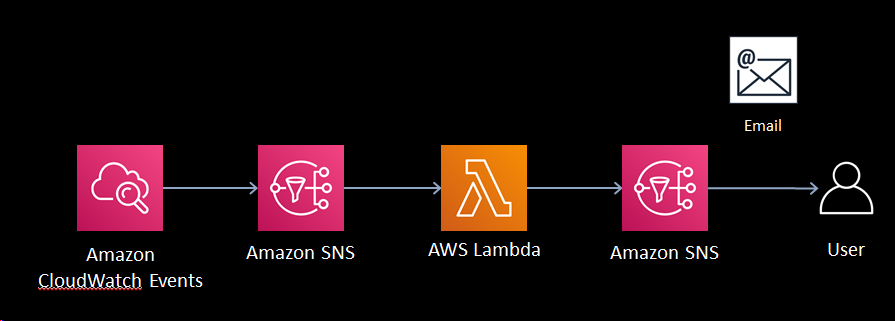
構築
今回はCodeBuildの失敗ログがトリガーになるので、CloudWatch Eventsで
CodeBuildの失敗するイベントを作成します。
そこからSNS経由でロググループとログストリーム名をLambdaで受け取り、ログをなんやかんやします。
※AWSのアイコンがアップデートされてさらにおしゃれになってました
こういう細かなアップデートがあるのもAWSの魅力ですね。
ただ、最新版にEmailのアイコンが無くなったような・・・?CloudWatch Events
項目 値 イベントパターン チェック サービス名 CodeBuild イベントタイプ CodeBuild Build State Change 特定の状態 FAILED ターゲット SNS① SNS①
- トピック名:任意
- サブスクリプション: Lambdaのエンドポイント(プロトコル:Lambda)
Lambda
設定項目 値 関数の作成 一から作成 名前 任意 ランタイム Python3.6 ロール 1つ以上のテンプレートから ロール名 任意 ポリシーテンプレート① Amazon SNS 発行ポリシー ポリシーテンプレート② CloudWatchLogsReadOnlyAccess トリガーの追加 SNS① タイムアウト 1分 環境変数 SNSarn/SNS②のArn コード
import json import boto3 import os import time TOPIC_ARN = os.environ['SNSarn'] def lambda_handler(event, context): message_unicode = event['Records'][0]['Sns']['Message'] message_dist = json.loads(message_unicode) group_name = message_dist['detail']['additional-information']['logs']['group-name'] stream_name = message_dist['detail']['additional-information']['logs']['stream-name'] time.sleep(90) client = boto3.client('logs') logs = client.get_log_events( logGroupName=group_name, logStreamName=stream_name, startFromHead=True ) body = logs['events'] message = "" for line in body: log = '{}'.format(line['message']) message = message + log + '\n' Msg = message sub = '[Codebuild FAILED]' client = boto3.client('sns') response = client.publish( TopicArn=TOPIC_ARN, Message=Msg, MessageStructure='context', Subject=sub )SNS②
- トピック名:任意
- サブスクリプション: 通知したいメールアドレス
最後に
実際に検討を行ったCodeBuildのログは7000行あり、
メールが複数来たり、内容が不足していました。
原因は(環境差があると思いますが、)CodeBuildからCloudWatch Logsにログが出力されるまで約1分差がある事です。
Lambda起動時にはログがすべて出力され切らないまま動作し、またLambdaが3秒でtimeoutしてしまいます。
そこでPythonのコード上でスリープを入れ、Lambdaのtimeoutを3秒から増やしました。するとSNSの本文に記載できる量をオーバーしてのエラーになった為、
一旦、S3へ保存し、通知したい内容を選別しSNS本文に記載する内容を絞りました。苦戦しましたが、やりたい事は実現できました。
もっとスマートな方法がありましたら、ご教示頂けますと幸いです。
- 投稿日:2019-03-24T15:42:21+09:00
Railsチュートリアル(AWSのS3のアクセス権設定)
はじめに
Ruby on Railsチュートリアルの13.4.4の本番環境での画像アップロードについて。
https://railstutorial.jp/chapters/user_microposts?version=5.1#sec-image_upload_in_productionAWSのS3を画像アップロードの場所として使うが、チュートリアルではS3の権限設定の手順が省略されている。ここでは、S3の権限設定の手順を記述する。
チュートリアルの手順に沿って、AWSにサインアップ、IAMユーザ作成、S3バケット作成までは実施している前提。
細かいことは置いておいて、とりあえずチュートリアルがこなせれば良い人向け。AWSのS3の権限の設定手順
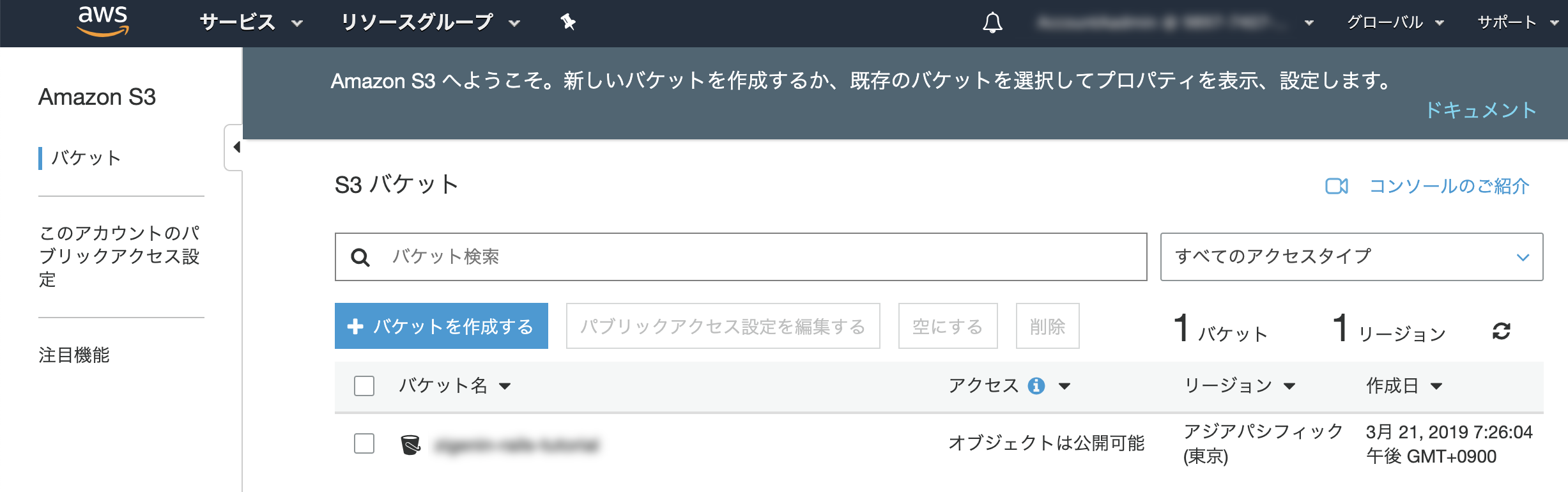
S3バケットへのパブリックアクセスを許可する
S3バケットの一覧ページを開く -> チュートリアルに沿って作成したバケットを選択。
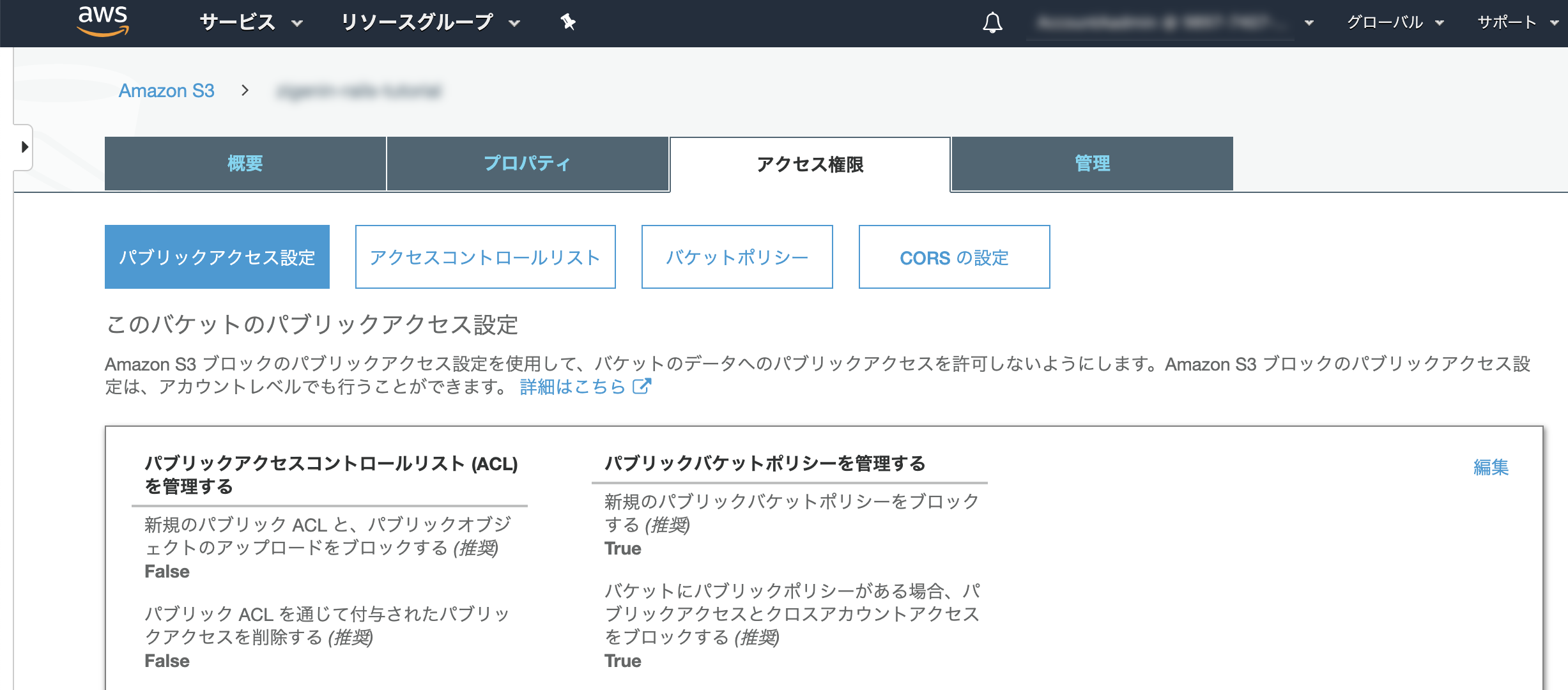
アクセス権限設定タブを選択 -> 編集を押す。
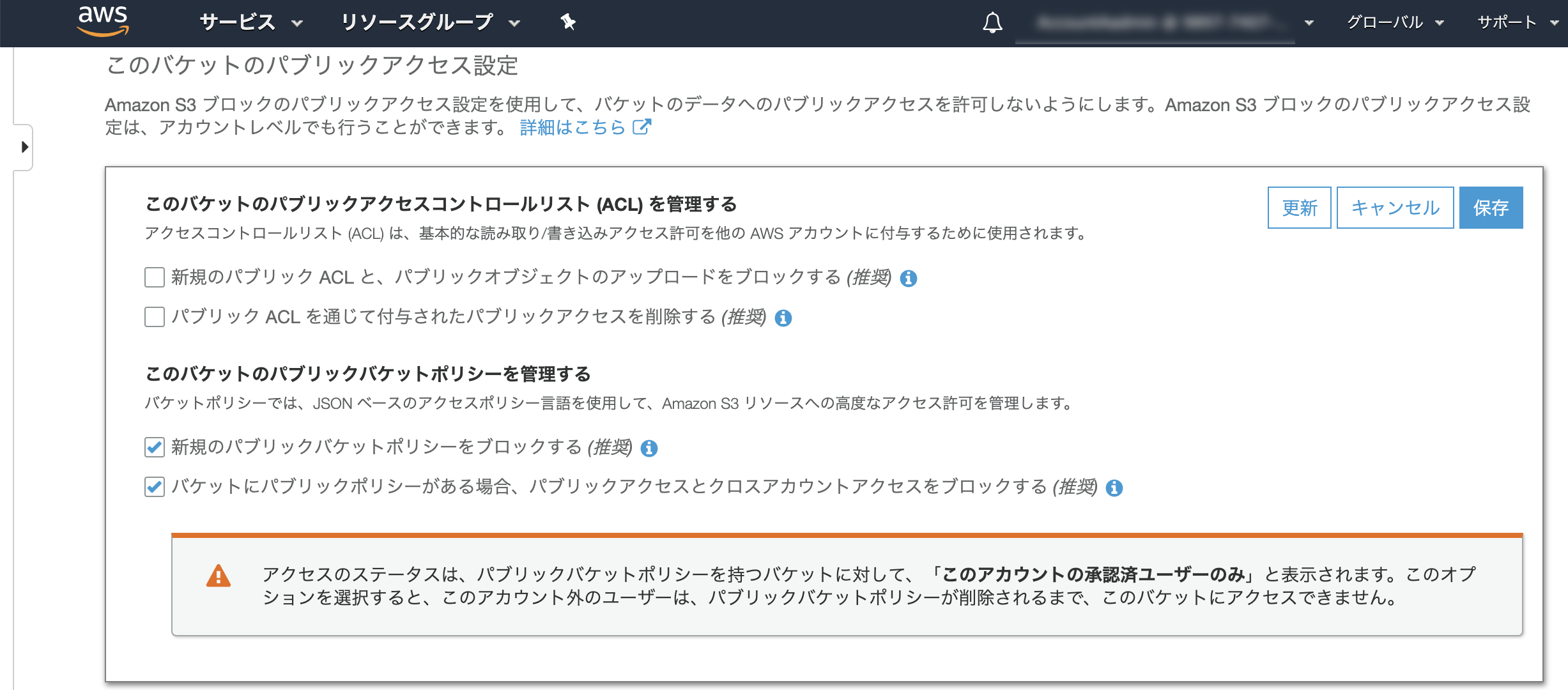
「パブリックアクセスコントロールリスト (ACL) を管理する」の項目を両方共Offにする。
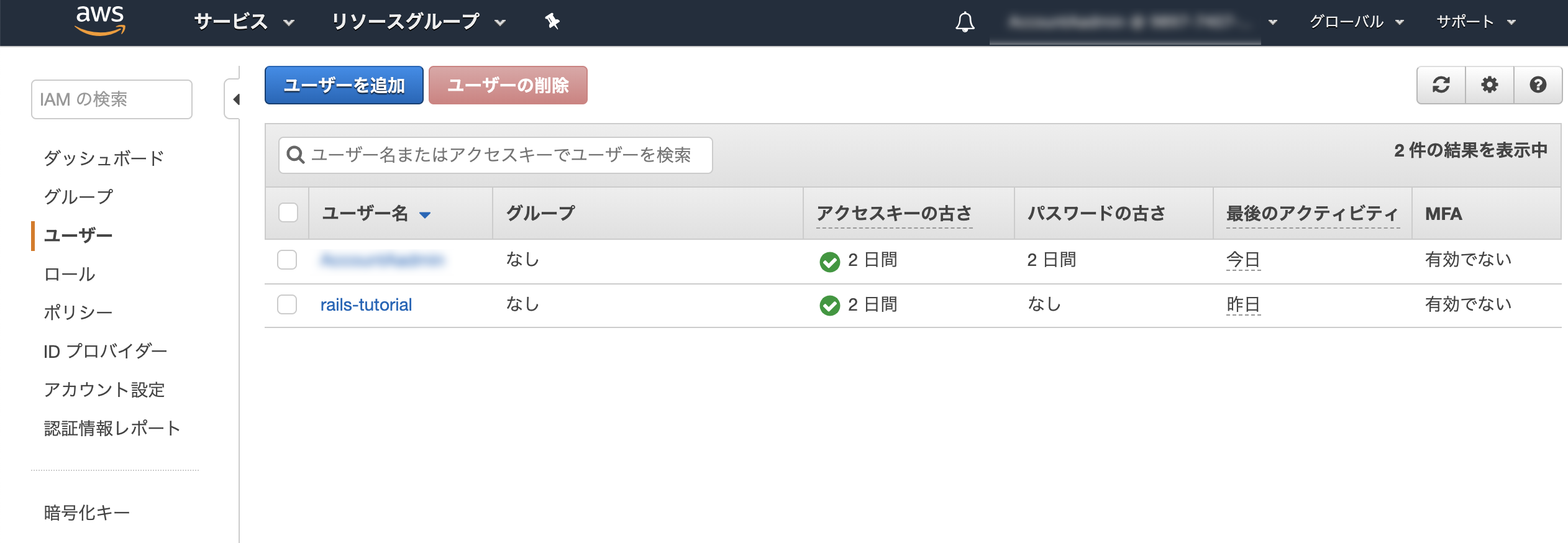
IAMユーザにS3へのアクセス権を付与する
IAMユーザの一覧を開く -> IAMユーザを開く。
IAMユーザにアクセス権限の追加を押す
既存のポリシーを直接アタッチを選択 -> ポリシーのフィルタに'S3'を入力 -> AmazonS3FullAccessを選択して、権限付与


- 投稿日:2019-03-24T15:29:41+09:00
サーバ型(EC2)とサーバレス型(S3+APIGateway+Lambda+DynamoDB)で全件検索
こんにちはjimbot3です。
今回サーバレスをより実感できるようするために、
サーバ型(EC2)とサーバレス型(S3+APIGateway+Lambda+DynamoDB)で、
それぞれ全件検索を行うにはどのような作業が必要なのかを試してみました。作ったもの① EC2での全件検索
まず、サーバ型としてEC2オンリーで全件検索をつくりました。
これは単に、グローバルIPを持ったサーバがEC2だと容易に手に入るという理由であって、
EC2では無く "グローバルIPを持った物理サーバ" と考えても同じです。1-1 EC2を用意しMySQLのインストールとテーブルの作成
$ whoami ec2-user $ cat /etc/system-release Amazon Linux AMI release 2018.03 ######MySQLのインストールとテーブルの作成###### $ sudo yum install -y mysql mysql-server $ sudo chkconfig mysqld on $ sudo service mysqld start mysql> create database jimbot3 character set utf8; mysql> connect jimbot3 mysql> create table jimbot3 (ID varchar(32) UNIQUE, BirthDay date,Name varchar(128)); mysql> insert into jimbot3 (ID, BirthDay, Name) values('001' ,19940525, 'Nanase Nishino'); mysql> insert into jimbot3 (ID, BirthDay, Name) values('002' ,19920122, 'Mai Shinuchi'); mysql> select * from jimbot3; +------+------------+----------------+ | ID | BirthDay | Name | +------+------------+----------------+ | 001 | 1994-05-25 | Nanase Nishino | | 002 | 1992-01-22 | Mai Shinuchi | +------+------------+----------------+ 2 rows in set (0.00 sec)1-2 htmlファイルの作成
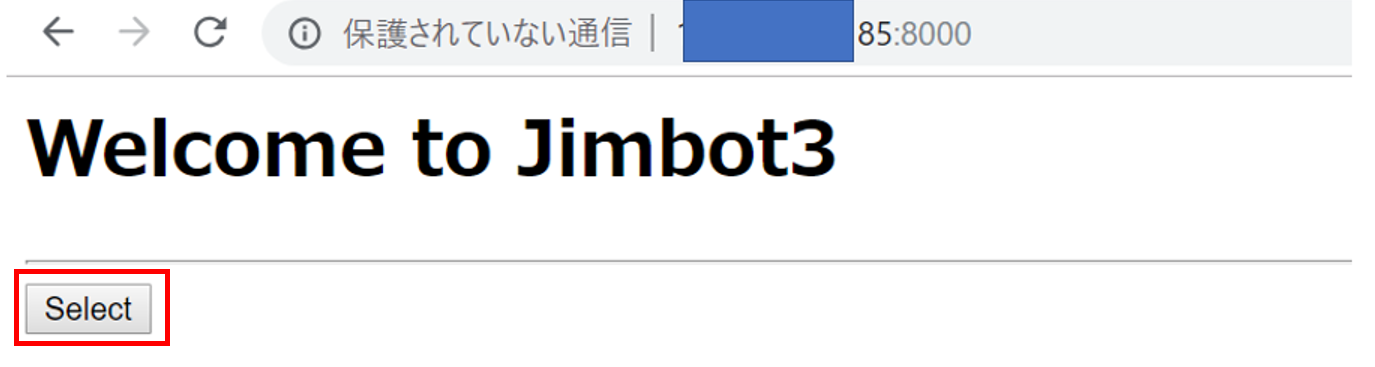
このhtmlがウェブインターフェイスになります
$ vi index.html◆index.htmlの中身は以下になります
<html lang="ja"> <head> <title>GetMember</title> <h1>Welcome to Jimbot3</h1><hr> </head> <body> <form action="/cgi-bin/getall.py" method="get"> <input type="submit" value="Select"> </form> </body> </html>1-3 htmlから呼び出されるPython実行ファイルの作成
$ sudo pip install PyMySQL $ sudo pip install --upgrade pip $ mkdir cgi-bin $ cd cgi-bin/ $ vi getall.py◆getall.pyの中身は以下に記載
#!/usr/bin/env python # -*- coding:utf-8 -*- print('Content-type: text/html; charset=UTF-8\r\n') import pymysql.cursors connection = pymysql.connect(host='localhost', user='root', password='', db='jimbot3', charset='utf8', cursorclass=pymysql.cursors.DictCursor) with connection.cursor() as cursor: sql = "SELECT * FROM jimbot3" cursor.execute(sql) results = cursor.fetchall() for r in results: print(r)実行ファイルのパーミッションの変更とhttpリクエストを受けられるようコマンド実行
$ chmod 755 getall.py $ cd $ python -m CGIHTTPServer Serving HTTP on 0.0.0.0 port 8000 ...1-4 webアクセス
http://グローバルIP:8000でアクセスしSelectボタンを押下
MySQLに登録した全件検索結果が表示される
作ったもの② S3+APIGateway+Lambda+DynamoDBでの全件検索
AWSの記事 "サーバーレス:サーバーに煩わされることなく、アプリケーションを構築、実行"
にある構成でサーバレス環境を構築。もちろんこの構成であればサーバーの管理が不要https://aws.amazon.com/jp/serverless/
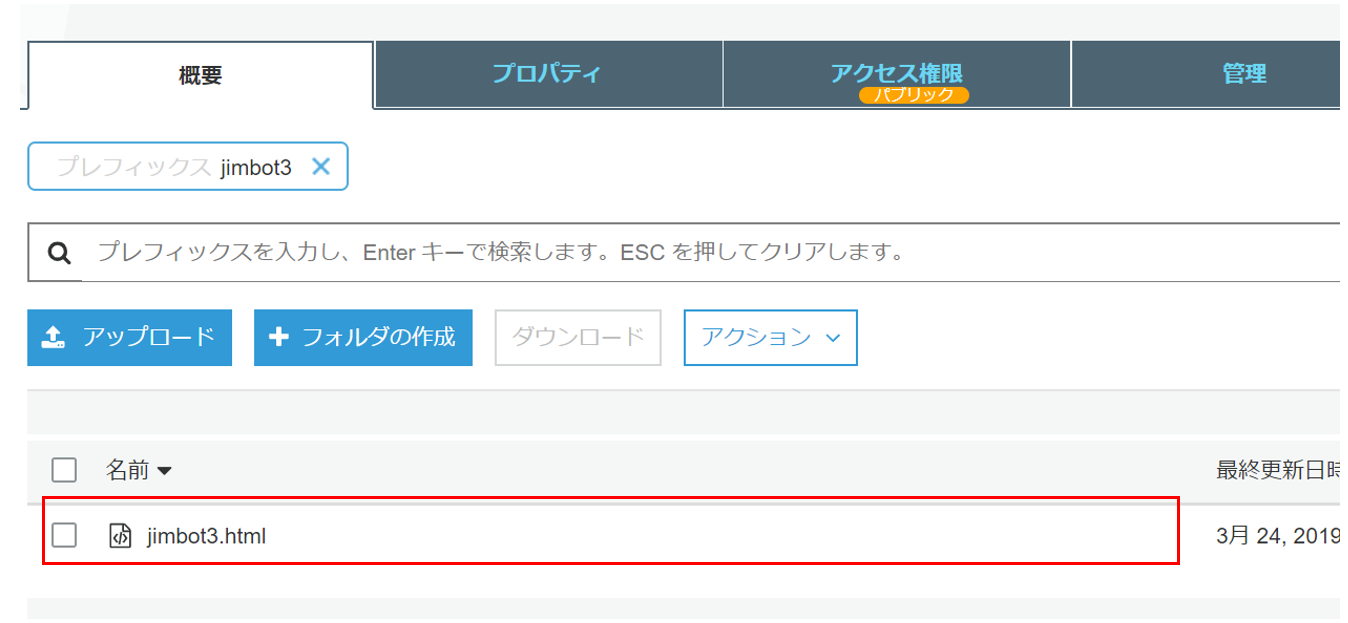
2-1 S3に以下のhtmlファイルを配置
ここに配置したhtmlがウェブインターフェイスになります
◆htmlの中身は以下になります
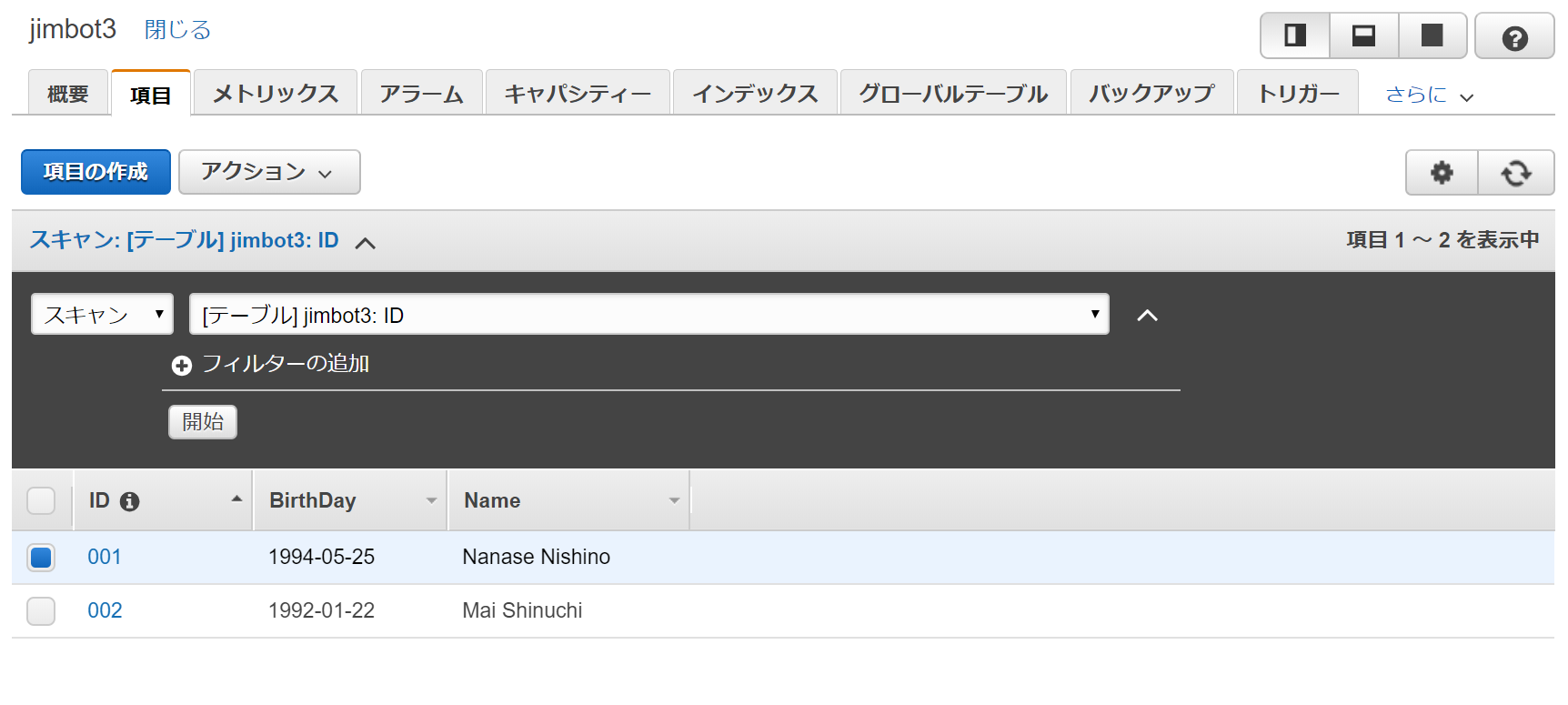
<html lang="ja"> <head> <title>GetMember</title> <h1>Welcome to Jimbot3</h1><hr> </head> <body> <form action="ここにはAPI Gatewayで作られた呼び出し用URLを記載" method="get"> <input type="submit" value="Select"> </form> </body> </html>2-2 DynamoDBに以下のテーブルを登録
DynamoDBにサーバ型でMySQL内に作ったテーブルと"ほぼ"同じテーブルを作成します。
この"ほぼ"というのはDynamoのテーブル内の値にはDate型が無いためString型で生年月日の入力をしたためです。テーブルの中身
↓
※データの詳細ですがDate型が無いです
2-3 Lambdaの作成
以下のLambdaを作成します。
このLambdaは実行されるとDynamoDBから全件検索結果を返すものです。
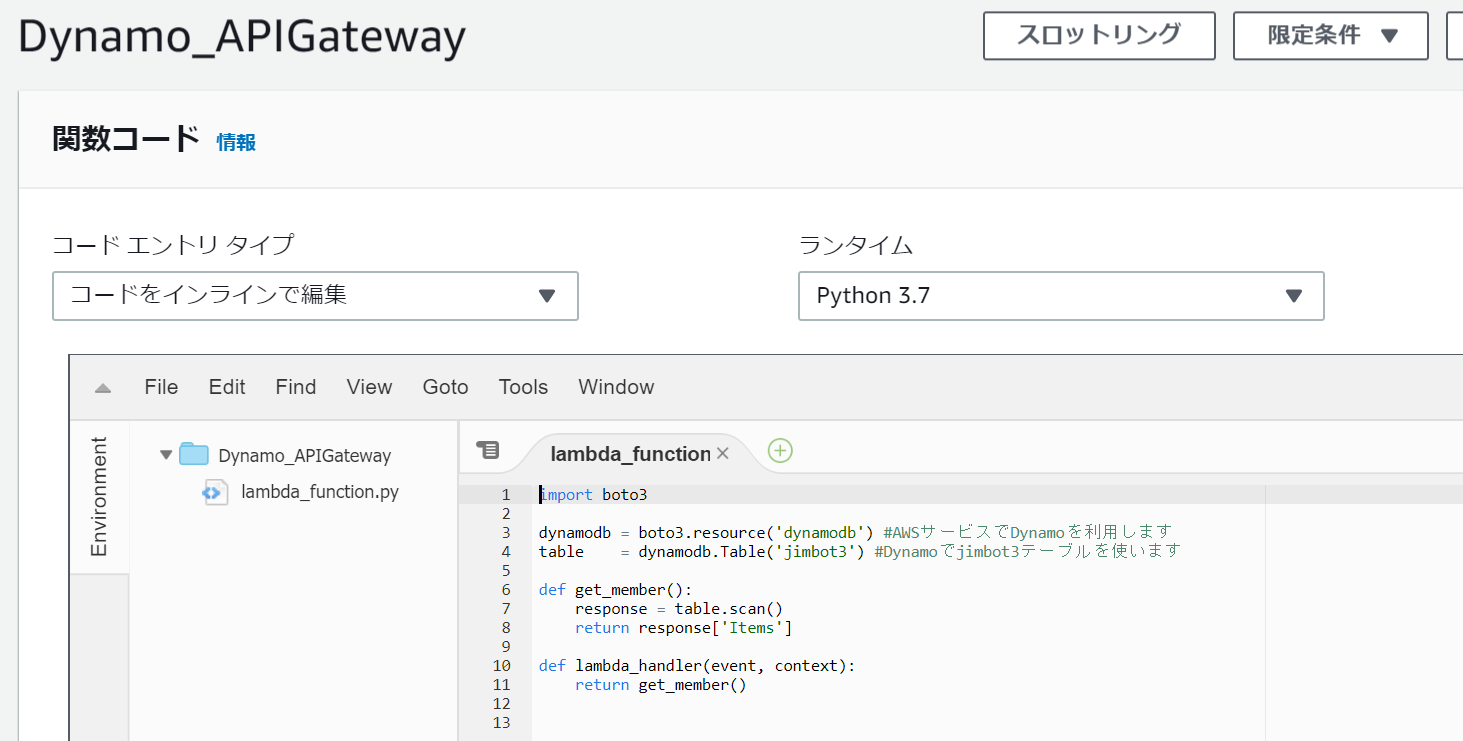
◆Lambda Dynamo_APIGatewayの中身は以下になります
import boto3 dynamodb = boto3.resource('dynamodb') #AWSサービスでDynamoを利用します table = dynamodb.Table('jimbot3') #Dynamoでjimbot3テーブルを使います def get_member(): response = table.scan() return response['Items'] def lambda_handler(event, context): return get_member()2-4 API Gatewayの設定
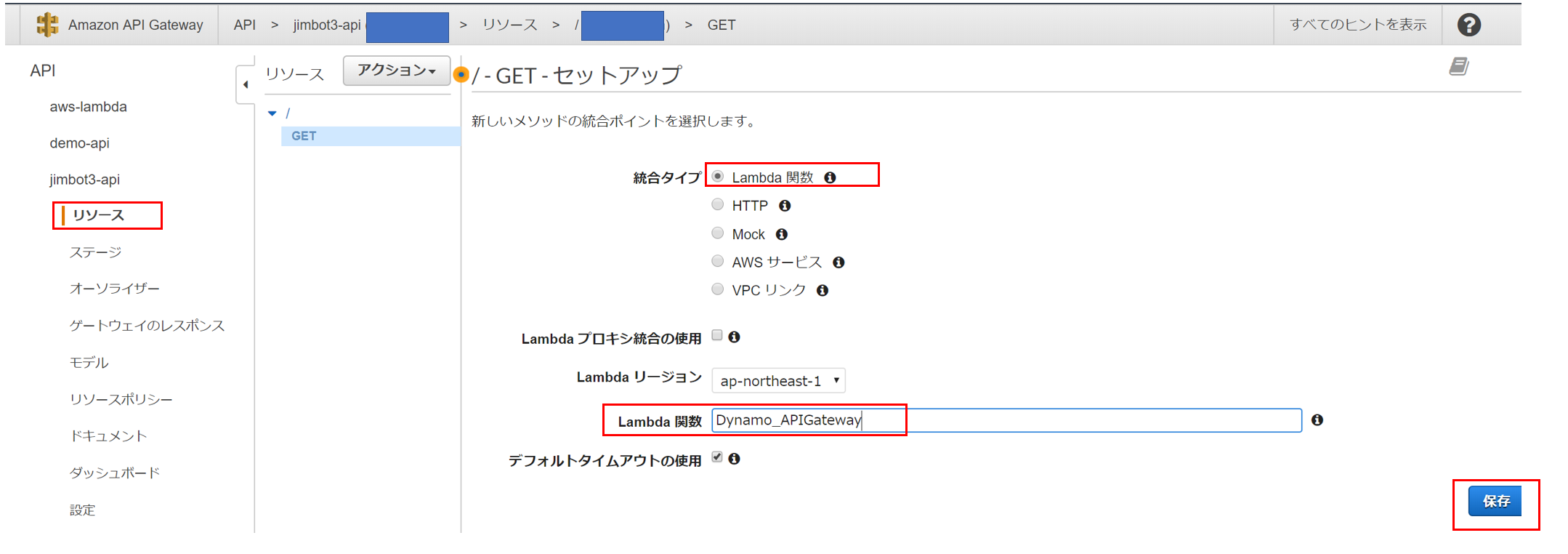
API GatewayでGETメソッドを作成し↑で作った "Dynamo_APIGateway" のLambdaを指定
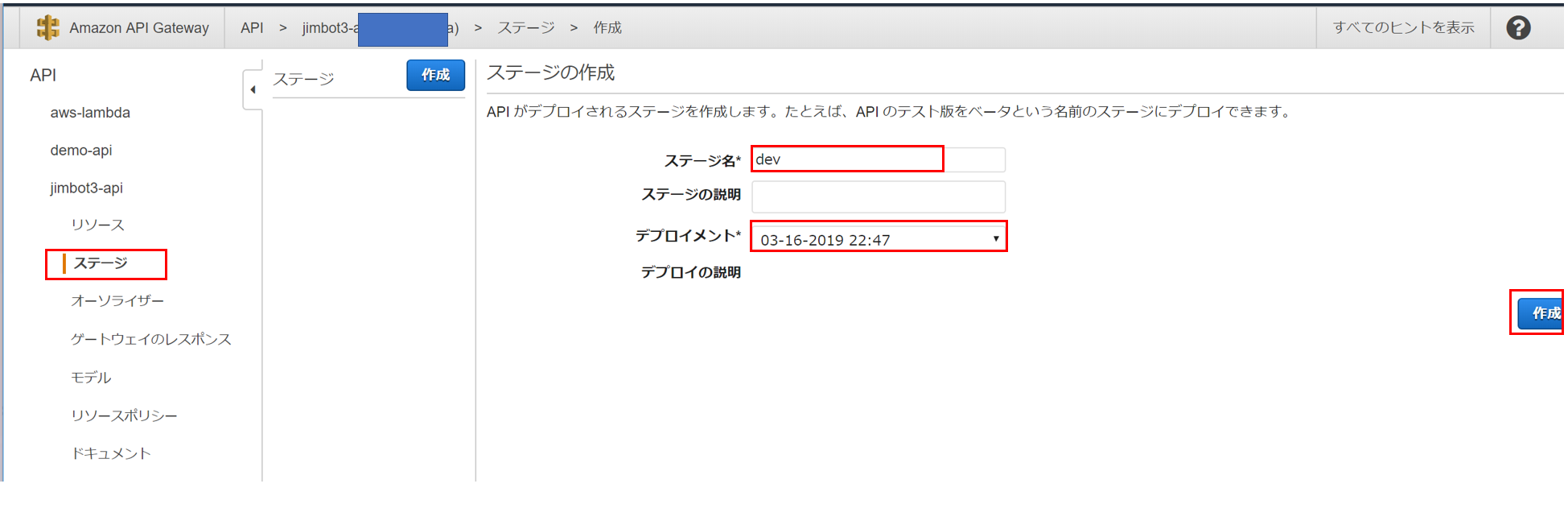
ステージ=実行する環境を作成します。
例えばdev(開発環境) と prod(本番環境) の2つのステージを用意して、dev に最新バージョンのデプロイを行い、
prod はdevでの検証完了後にデプロイを行うことができます、
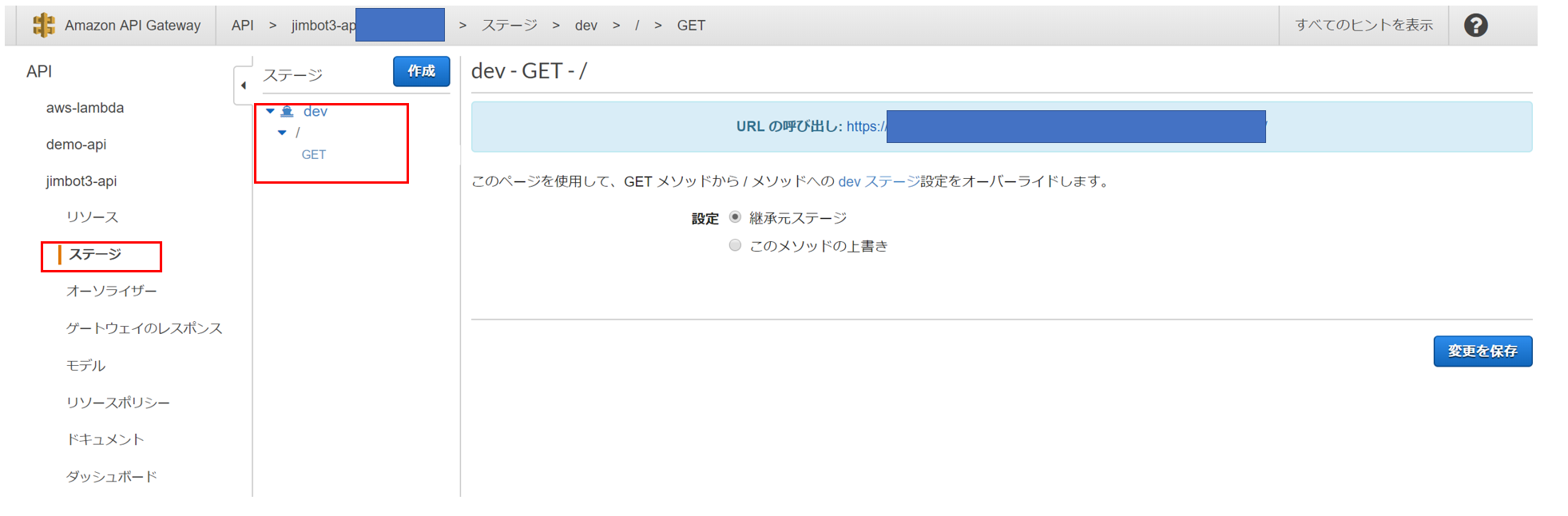
devのステージ向けにデプロイされたURLをS3のhtmlファイルに記載
2-5 webアクセス
S3のhtmlファイルにアクセスしSelectボタンを押下
全件検索結果が表示される
終わりに
サーバ型(EC2)とサーバレス型(S3+APIGateway+Lambda+DynamoDB)を比較した場合、
データをどこに置くがは違うけど原始的な考えはあまり変わらないといった印象例えば、S3内だろうがEC2内だろうがindex.htmlはあるし、
LambdaだろうがEC2内だろうが実行プログラムはあるし、
DynamoDBだろうがMySQLだろうがテーブルデータはある。ただ、htmlファイルと比較した場合に実行プログラムは大きく異なるため、
プログラミングスキルは磨かないといけないと感じた。あと、DynamoDBは使いやすい。ただ、良くも悪くもボタンポチポチでテーブルが作れてしまうので、
「これからはDynamoDB!」などと言ってDynamoDBから入らずにRDSでも何でも良いけどちゃんとDBの基礎は付けたほうが良いと思う。


- 投稿日:2019-03-24T12:01:43+09:00
Confirmed状態のCognitoユーザーをBoto 3で即作成する
概要
指定されたユーザー情報を使って、すぐにログインできるConfirmed状態のCognitoユーザーをバックエンド側でサクッと作成したい。
admin_create_userだとForce Change Password状態となるので、この後に処理が必要。今のところの結論
import boto3 username = '{ユーザー名}' password = '{パスワード}' email = '{メールアドレス}' user_pool_id = '{ユーザープールID}' client_id = '{アプリクライアントID}' cognito_idp = boto3.client('cognito-idp') # ユーザーを作成する。 cognito_idp.admin_create_user( UserPoolId=user_pool_id, Username=username, TemporaryPassword=password, UserAttributes=[{'Name': 'email', 'Value': email}], MessageAction='SUPPRESS' ) # ログインを試みる。(パスワードの変更を要求される。) response = cognito_idp.admin_initiate_auth( UserPoolId=user_pool_id, ClientId=client_id, AuthFlow='ADMIN_NO_SRP_AUTH', AuthParameters={'USERNAME': username, 'PASSWORD': password}, ) session = response['Session'] # パスワードを変更する。 response = cognito_idp.admin_respond_to_auth_challenge( UserPoolId=user_pool_id, ClientId=client_id, ChallengeName='NEW_PASSWORD_REQUIRED', ChallengeResponses={'USERNAME': username, 'NEW_PASSWORD': password}, Session=session )解説
以下の3ステップでConfirmed状態のユーザーを作成しています。
- ユーザーの作成(
admin_create_user)- 最初の認証(
admin_initiate_auth)- パスワードの変更(
admin_respond_to_auth_challenge)1. ユーザーの作成(
admin_create_user)管理者によるユーザーの作成を行う。
通常は作成した時に仮パスワードが通知されますが、MessageAction='SUPPRESS'で無効にできます。2. 最初の認証(
admin_initiate_auth)管理者による最初の認証を試みる。
すると、以下のようなレスポンスが返却され、新しいパスワードが必要だということが分かります。この中のSessionが次の処理で必要となります。{'ChallengeName': 'NEW_PASSWORD_REQUIRED', 'ChallengeParameters': (省略), 'ResponseMetadata': (省略), 'Session': '{セッションを表す長い文字列}'}また、
AuthFlow='ADMIN_NO_SRP_AUTH'とする場合は、アプリクライアントの設定で「サーバーベースの認証でサインイン API を有効にする (ADMIN_NO_SRP_AUTH)」を有効にしておく必要があります。SRPというのは認証のプロトコルで、使用するとセキュアでない通信経路でもユーザー名とパスワードによる認証を安全に行なえるようになるようですが、実装が難しくなり、また今回は全てバックエンドでの処理となるので、使用しなくても良いこととしています。3. パスワードの変更(
admin_respond_to_auth_challenge)管理者による
NEW_PASSWORD_REQUIREDに対する返答。
成功すると各種トークンが返却され、ユーザーの状態もConfirmedへ移行します。これでめでたくユーザーが普通にログインできるようになりました!なお、コードにある通り、新しいパスワードは仮のパスワードと同じでも問題ありませんでした。
他の方法
一応、次の方法でもConfirmed状態のユーザーを作成することができます。
# ユーザーがサインアップする。 cognito_idp.sign_up( ClientId=client_id, Username=username, Password=password, UserAttributes=[{'Name': 'email',' Value': email}] ) # それを管理者が承認する。 cognito_idp.admin_confirm_sign_up( UserPoolId=user_pool_id, Username=username )簡単だったので、最初はこちらの方法を使っていたのですが、アプリクライアントの設定で「アプリベースの認証でユーザー名とパスワードの (SRP を使用しない) フローを有効にする (USER_PASSWORD_AUTH)」を無効にしたり、属性の書き込み権限を変更したりすると
sign_upができなくなるので、全て管理者の操作で行える上記の方法に変更しました。
- 投稿日:2019-03-24T09:35:24+09:00
初学者がRailsで作ったポートフォリオをAWSへデプロイするまでの記録
エンジニアへ転職するためにこちらの記事を参考にして
ポートフォリオをAWSへデプロイすることが出来たので、それまでにやったことを出会ったエラーを紹介しつつ、振り返っていきたいと思います。ポートフォリオをAWSにデプロイしてみたい、
AWSへデプロイするまで何を準備すれば良いのかわからない
という方のお役に立てれば幸いです。ちなみにこの記事はEC2へログインするところから始まります。
EC2へログインする
EC2インスタンスを作成した時に、キーペアをダウンロードしてるはずなので
それを使ってログインしていきます。あ、ちなみに今回デプロイしたアプリ名はlovekitchenなるものなので
各々アプリ名の部分は変更してくださいね。$ mv Downloads/lovekitchen.pem .ssh/ $ cd .ssh/ $ chmod 400 lovekitchen.pem $ ssh -i lovekitchen.pem ec2-user@パブリックIP
yesと入力すれば変なアスキーアートが表示されてログイン完了です。管理ユーザー作成
sudo adduser tatsuya sudo passwd tatsuya (# パスワードの登録) sudo vi visudo (# 設定を編集)ここからはVIMを使っての編集になります。
まずiを押してINSERTモードにして下さい。## Allow root to run any commands anywhere root ALL=(ALL) ALL (この下に) chiroru ALL=(ALL) ALLそしてこんな感じで編集したら、
escキーを押して、:wqで上書き保存します。
完了したら[ec2-user] sudo su - tatsuyaこれでユーザー名が変わってると思います。
以降このユーザーで作業を行なっていきます。そして一旦ログアウトして、次はローカル環境で作業します。
[tatsuya] exit [ec2-user] exit [.ssh] ssh-keygen -t rsa (公開鍵の名前を入力してエンター) (空のままエンターを2回) [.ssh] vi config (INSERT) ______________________________________ Host lovekitchen_key_rsa Hostname パブリックIP Port 22 User tatsuya IdentityFile ~/.ssh/lovekitchen_key_rsa ______________________________________ [.ssh] cat アプリ名_key_rsa.pub (ssh-rsaからlocalまでをコピー)ここから再びサーバー側の作業となります。
[.ssh] ssh -i lovekitchen.pem ec2-user@パブリックIP [ec2-user] sudo su - tatsuya [tatsuya] mkdir .ssh [tatsuya] chmod 700 .ssh [tatsuya] cd .ssh [tatsuya] vi authorized_keys __________________________ さっきコピーした鍵をペースト __________________________ [tatsuya] exit [ec2-user] exit [.ssh] ssh lovekitchen_key_rsaこれでログインできればユーザーの設定は完了!
最後にec2-userではログイン出来ないようにします。[tatsuya] sudo vi /etc/ssh/sshd_config _______________________________ DenyUsers ec2-user (ec2-userではログイン出来ない) _______________________________ [tatsuya] sudo service sshd reload (設定を反映) [tatsuya] exit [.ssh] ssh -i アプリ名.pem ec2-user@パブリックIP ec2-user@パブリックIP: Permission denied (publickey). と表示されればOK!これで諸々の準備は完了したので
これからはいよいよプラグインをインストールしたり
アプリをGithubからcloneしたりしていきます。環境構築編
unicornのインストール
ここはローカル環境での作業となります。
Gemfilegroup :production do gem 'unicorn' end$ bundle install次は
unicornの設定ファイルを作成し、編集して行きます。config/unicorn.conf.rb$worker = 2 $timeout = 30 $app_dir = "/var/www/projects/アプリ名" $listen = File.expand_path 'tmp/sockets/.unicorn.sock', $app_dir $pid = File.expand_path 'tmp/pids/unicorn.pid', $app_dir $std_log = File.expand_path 'log/unicorn.log', $app_dir # set config worker_processes $worker working_directory $app_dir stderr_path $std_log stdout_path $std_log timeout $timeout listen $listen pid $pid # loading booster preload_app true # before starting processes before_fork do |server, worker| defined?(ActiveRecord::Base) and ActiveRecord::Base.connection.disconnect! old_pid = "#{server.config[:pid]}.oldbin" if old_pid != server.pid begin Process.kill "QUIT", File.read(old_pid).to_i rescue Errno::ENOENT, Errno::ESRCH end end end # after finishing processes after_fork do |server, worker| defined?(ActiveRecord::Base) and ActiveRecord::Base.establish_connection enddatabase.ymlを編集
config/database.ymlproduction: <<: *default database: lovekitchen_production username: root password:リポジトリへ反映させて行きます。
$ git add . $ git commit $ git push origin masterNginxのインストール
[tatsuya] sudo yum update (サーバーをアップデート) [tatsuya] sudo yum install -y nginx (Nginxをインストール) [tatsuya] sudo /etc/init.d/nginx start (起動確認) [tatsuya] sudo chkconfig nginx on (自動起動を設定)作業用ディレクトリの作成
[tatsuya] cd / [tatsuya| /] sudo chown tatsuya var [tatsuya| /] cd var [tatsuya| var] sudo mkdir www [tatsuya| var] sudo chown tatsuya www [tatsuya| var] cd www [tatsuya| www] sudo mkdir projects [tatsuya| www] sudo chown tatsuya projectsプラグインをインストール
*この中に後々問題となるプラグインが含まれてます(泣)
[tatsuya] sudo yum install git make gcc-c++ patch openssl-devel libyaml-devel libffi-devel libicu-devel libxml2 libxslt libxml2-devel libxslt-devel zlib-devel readline-devel mysql mysql-server mysql-devel ImageMagick ImageMagick-devel epel-releaseNode.js 6xをインストール
[tatsuya] curl -sL https://rpm.nodesource.com/setup_6.x | sudo bash -yarnをインストール
[tatsuya] sudo npm install yarn -grbenvをインストール
[tatsuya] git clone https://github.com/sstephenson/rbenv.git ~/.rbenv [tatsuya] echo 'export PATH="$HOME/.rbenv/bin:$PATH"' >> ~/.bash_profile [tatsuya] echo 'eval "$(rbenv init -)"' >> ~/.bash_profile [tatsuya] source ~/.bash_profileruby-buildをインストール
[tatsuya] git clone https://github.com/sstephenson/ruby-build.git ~/.rbenv/plugins/ruby-build [tatsuya] rbenv rehashrubyをインストール
[tatsuya] rbenv install -v 2.5.3 [tatsuya] rbenv global 2.5.3 [tatsuya] rbenv rehash [tatsuya] ruby -vここも特に問題なかったです。
rubyがちゃんとインストールされた時はホッとしました。
とにかくコマンド一つ実行するだけでドキドキでしたよもう。Githubと連携
ここからGithubと連携して、そして自分のアプリをさっき作ったディレクトリにクローンしていきます。
[tatsuya| ~] vi .gitconfig ----------------------------------- [user] name (gitに登録した名前) email (gitに登録したメールアドレス) [color] ui = true [url "github:"] InsteadOf = https://github.com/ InsteadOf = git@github.com: ----------------------------------- [tatsuya| ~] chmod 700 .ssh [tatsuya| ~] cd .ssh [tatsuya| .ssh] ssh-keygen -t rsa [tatsuya| .ssh] vi config ----------------------------------- Host github Hostname github.com User git IdentityFile ~/.ssh/aws_git_rsa ----------------------------------- [tatsuya| .ssh] chmod 600 config [tatsuya| .ssh] cat aws_git_rsa.pubこのコピーした公開鍵をGithubへアップして行きます。
まずGithubの右上にあるアカウントメニューからSettingsへ進んで下さい。
次はこちらのSSH and GPG Keysへ進みます。
[Title] aws_git_rsa [Key] さっきコピーしたaws_git_rsa.pubこれで
Add SSH Keyで完了!
ちゃんと接続出来ているか確認しましょう。[tatsuya| .ssh] ssh -T github Hi tatsuya! You've successfully authenticated, but GitHub does not provide shell access.こんな感じでメッセージが返ってきます。
そして、いよいよクローンです!
[tatsuya| .ssh] cd /var/www/projects [tatsuya| projects] git clone git@github.com:machamp0714/love_kitchen.gitここで初めてエラーが表示されました。
本当はこう入力しないとダメみたいです。[tatsuya| projects] git clone github:machamp0714/love_kitchen.git [tatsuya| projects] ls love_kitchenこれでクローンも無事完了しました!
Gemをインストール
お次は、
bundlerをインストールします。
この時、Gemfile.lockに記載されているbundlerのバージョンと合わせました。bundlerをインストール [tatsuya| projects] gem install bundler -v 1.7.1 Gemfileを作成 [tatsuya| projects] bundle init Gemfileを編集 [tatsuya| projects] vi Gemfile ------------------------------- *コメントアウトを外して、versionを記載 gem "rails", '5.2.2' ------------------------------- [tatsuya| projects] bundle install --path vendor/bundle --jobs=4 [tatsuya| projects] bundle exec rails -v # Rails 5.2.2次はクローンしたディレクトリへ移動してgemをインストールして行きます。
[tatsuya| projects] cd love_kitchen [tatsuya| love_kitchen] bundle install --path vendor/bundleするとここで次のエラーが出現。。。
/home/tatsuya/.rbenv/versions/2.5.3/bin/ruby -r ./siteconf20190321-31332-65ucq1.rb extconf.rb checking for gcc... yes checking for Magick-config... yes checking for outdated ImageMagick version (<= 6.8.9)... *** extconf.rb failed *** Could not create Makefile due to some reason, probably lack of necessary libraries and/or headers. Check the mkmf.log file for more details. You may need configuration options. Provided configuration options: --with-opt-dir --without-opt-dir --with-opt-include --without-opt-include=${opt-dir}/include --with-opt-lib --without-opt-lib=${opt-dir}/lib --with-make-prog --without-make-prog --srcdir=. --curdir --ruby=/home/tatsuya/.rbenv/versions/2.5.3/bin/$(RUBY_BASE_NAME) To see why this extension failed to compile, please check the mkmf.log which can be found here: /var/www/projects/love_kitchen/vendor/bundle/ruby/2.5.0/extensions/x86_64-linux/2.5.0-static/rmagick-3.0.0/mkmf.log extconf failed, exit code 1 Gem files will remain installed in /var/www/projects/love_kitchen/vendor/bundle/ruby/2.5.0/gems/rmagick-3.0.0 for inspection. Results logged to /var/www/projects/love_kitchen/vendor/bundle/ruby/2.5.0/extensions/x86_64-linux/2.5.0-static/rmagick-3.0.0/gem_make.out An error occurred while installing rmagick (3.0.0), and Bundler cannot continue. Make sure that gem install rmagick -v '3.0.0' --source 'https://rubygems.org/' succeeds before bundling. In Gemfile: rmagickエラー文を見る限りどうも
rmagickをインストールすることが出来ないようです。
ローカル環境でインストールした際も同じようなエラーが出たので、これもversion関連が
原因だろうなと思い、この時はすぐに解決できると思っていました。ですが、ここで問題発生。
そもそも、AmazonLinuxのyum標準リポジトリにあるImageMagickのversionは一番新しいやつが6.7.8と古く、
ここで欲しいのはversionが6.8.9以上の物なので、ImageMagickのversionを新しいものにするというシンプルな
解決策を実行することが出来ません。色々調べた結果、yum先生とremi先生のお力を借りればImageMagick6系の最新版をインストール出来るみたいなので
こちらを試してみました。ちなみに、rmagickはImageMagickのversionを7系にしてしまうと使えないので注意してください。remiリポジトリを追加
[tatsuya] rpm -Uvh http://rpms.famillecollet.com/enterprise/remi-release-6.rpmCentOS-Baseリポジトリを追加
[tatsuya] vi /etc/yum.repos.d/CentOS-Base.repo -------------------------------------------------------------------------- [base] name=CentOS-6 - Base mirrorlist=http://mirrorlist.centos.org/?release=6&arch=x86_64&repo=os gpgcheck=1 enabled=0 gpgkey=http://mirror.centos.org/centos/RPM-GPG-KEY-CentOS-6 --------------------------------------------------------------------------古いパッケージを削除
[tatsuya] yum remove -y libtiff [tatsuya] yum remove -y ImageMagick ImageMagick-develImageMagick6系の最新版をインストール
[tatsuya] yum install -y libtiff --enablerepo=remi,epel,base --disablerepo=amzn-main [tatsuya] yum install -y ImageMagick6 ImageMagick6-devel ImageMagick6-libs --enablerepo=remi,epel,base [tatsuya] yum install -y libwebp libwebp-devel --enablerepo=epel --disablerepo=amzn-main [tatsuya] yum install -y ImageMagick6 ImageMagick6-devel ImageMagick6-libs --enablerepo=remi,epel,baseこれで欲しいversionのImageMagickがインストール出来たので,もう一度
bundle installを実行します。[tatsuya| love_kitchen] bundle install --path vendor/bundleこれでインストール完了です。
僕の環境の場合、このエラーだけしか生じませんでした。nginxの設定
次は、nginxの設定ファイルを作成し、編集して行きます。
[tatsuya| love_kitchen] sudo vi /etc/nginx/conf.d/アプリ名.conf ---------------------------------------------------------------------- upstream unicorn_server { server unix:/var/www/projects/love_kitchen/tmp/sockets/.unicorn.sock fail_timeout=0; } server { listen 80; client_max_body_size 4G; server_name IPアドレス; keepalive_timeout 5; # Location of our static files root /var/www/projects/love_kitchen/public; location ~ ^/assets/ { root /var/www/projects/love_kitchen/public; } location / { proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header Host $http_host; proxy_redirect off; if (!-f $request_filename) { proxy_pass http://unicorn_server; break; } } error_page 500 502 503 504 /500.html; location = /500.html { root /var/www/projects/love_kitchen/public; } } アプリ名や、IPアドレスはご自身の環境に合わせてください。 ---------------------------------------------------------------------- nginxを再起動 [tatsuya| love_kitchen] sudo service nginx restart 権限を設定 [tatsuya| love_kitchen] sudo chmod -R 775 /var/lib/nginx mysqlを起動 [tatsuya| love_kitchen] sudo service mysqld start マイグレーションを実行 [tatsuya| love_kitchen] bundle exec rails db:migration RAILS_ENV=production Missing encryption key to decrypt file with. Ask your team for your master key and write it to /xxx/my-app/config/master.key or put it in the ENV['RAILS_MASTER_KEY']. Exitingマイグレーションを実行しようとしたら、こんなエラーが出ました。
どうもconfig/master.keyがないので怒られてるみたいです。そういえば
master.keyは、.gitignoreに記載されていてリポジトリには反映されないのを思い出しました。
というわけで、ローカル環境でmaster.keyの中身をコピーして、本番環境の方にもmaster.keyファイルを作成してあげます。[tatsuya| love_kitchen] vi config/master.key ---------------------------------- 自分のアプリのconfig/master.keyをコピペ ---------------------------------- [tatsuya| love_kitchen] bundle exec rails db:migration RAILS_ENV=productionこれで全ての準備が完了しました。
あとはrailsアプリを起動するだけです。railsアプリを起動する
railsアプリをプリコンパイル [tatsuya| love_kitchen] bundle exec assets:precompile RAILS_ENV=production nginxを再起動 [tatsuya| love_kitchen] sudo service nginx restart unicornを起動 [tatsuya| love_kitchen] bundle exec unicorn_rails -c /var/www/projects/love_kitchen/config/unicorn.conf.rb -D -E production Mysql2::Error::ConnectionError: Can't connect to local MySQL server through socket '/tmp/mysql.sock' (2)unicornを起動するコマンドを入力するとこんなエラーが出ました。
mysql.sockの場所がおかしいのでしょうか。mysql.sockの場所を調べる [tatsuya| love_kitchen] mysql_config --socket /var/lib/mysql/mysql.sock
/var/lib/mysql.sockにあることが判明したので、
database.ymlを編集します。[tatsuya| love_kitchen] vi config/database.yml ------------------------------------------------ production: <<: *default database: love_kitchen_production username: root password: socket: /var/lib/mysql/mysql.sock ------------------------------------------------ 再びunicornを起動 [tatsuya| love_kitchen] bundle exec unicorn_rails -c /var/www/projects/love_kitchen/config/unicorn.conf.rb -D -E production bundler: failed to load command: unicorn_railsお次はこんなエラーが。。。。。。。。。
unicorn_railsの他に、unicornコマンドもあるみたいなので、そちらを試してみることに。[tatsuya| love_kitchen] bundle exec unicorn -c /var/www/projects/love_kitchen/config/unicorn.conf.rb -D -E production [tatsuya| love_kitchen] ps -ef | grep unicorn | grep -v grep プロセスが3行表示されるこれでようやっと行けたかな?と思い、ブラウザに直接IPアドレスを入力!
http://IPアドレス遂にRailsアプリが起動しました!!!!!
ここまで来るのに丸一日かかってしまいましたが、挑戦してホント良かったです。
今は取り敢えずデプロイしました、みたいな感じなのでこれからちゃんと勉強して行きたいですね。参考にした記事
世界一丁寧なAWS解説。EC2を利用して、RailsアプリをAWSにあげるまで
ホントに素晴らしい記事ありがとうございます。