- 投稿日:2019-03-24T23:45:57+09:00
jarファイルの概要
プログラミング初学者です。
今回はjarファイルについて概要を知れたのでアウトプットさせていただきます。Q1: jarファイルは何で構成されているの?
それを知るためには下記の3単語を知っておく必要がある様に感じました。
① クラスライブラリ: System.out.printlnやRandomなど開発で使える便利な機能のこと
(機能は他にも沢山ある)
② クラス:クラスライブラリをまとめる箱
③ パッケージ:クラスをまとめる箱
Q:なぜクラスまでパッケージでまとめないといけないのか?
A:コード内で同じ名前で表現されるクラスを区別するため。
例えば、「java.sql.Date」と「java.util.Date」はソース内では「Date」として表現される。
どちらもクラス名が「Date」だが、パッケージ名によって区別ができる。(太字部分がパッケージ名)まとめると、、、、、、
クラスの中身 パッケージの中身 jarファイルの中身 クラスライブラリ クラス パッケージ という様な感じになっています。
jarファイルはパッケージをjar形式で圧縮したものということです。jar形式について詳細を知りたい場合は下記のURLを参考にしてください
https://wa3.i-3-i.info/word14171.html※間違ってる場所がありましたら恐れ入りますがコメントからご教授いただけると幸いです。※
- 投稿日:2019-03-24T23:17:23+09:00
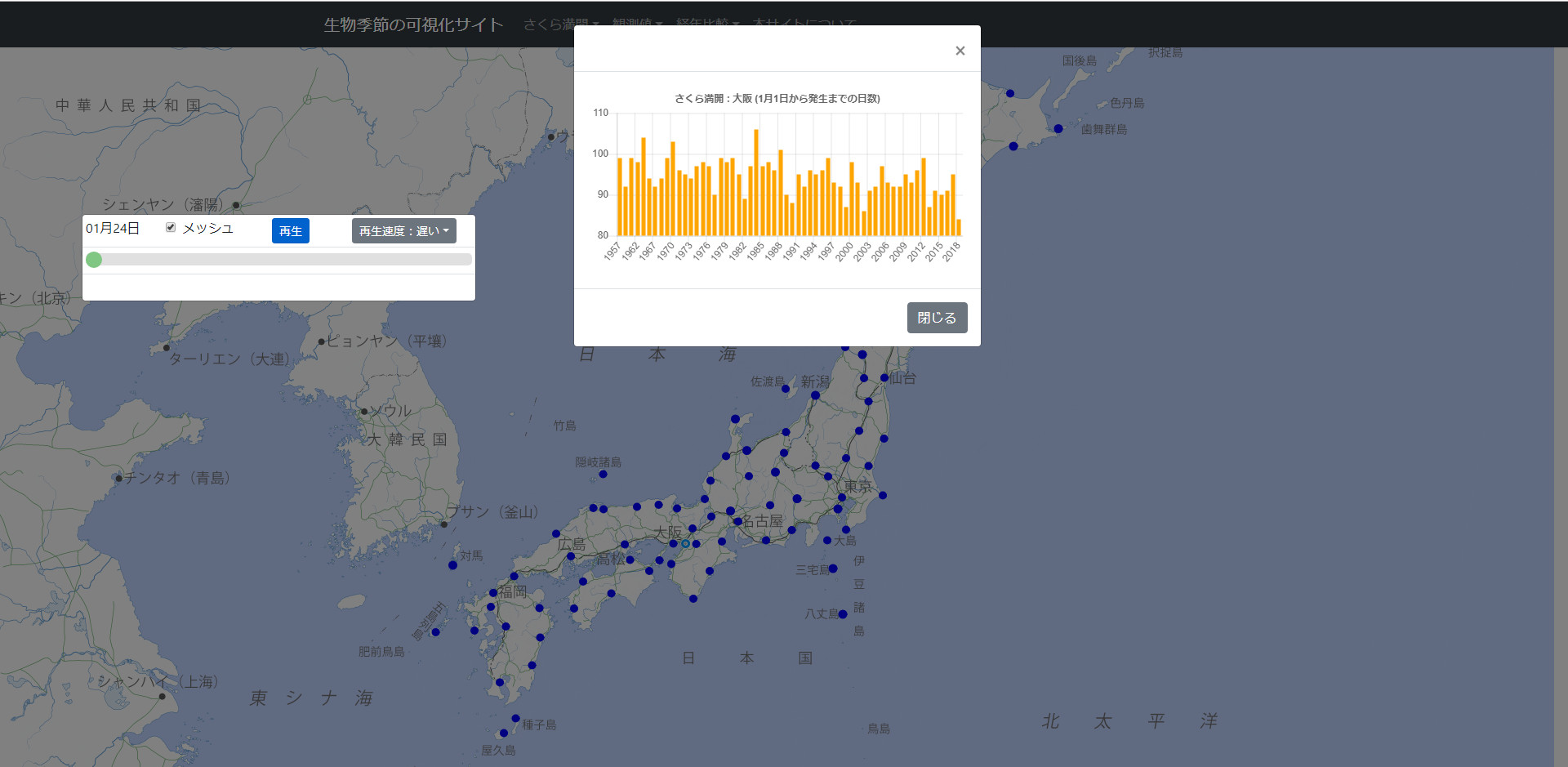
さくら前線を可視化してみる
さくら前線を可視化してみる
さくらの季節になり仕事も少し落ち着いたので、土日を利用して、気象庁生物季節観測の公開データからさくら前線の可視化をしてみました。
気象庁生物季節観測とは
気象庁では、毎年、さくらの開花日や満開日やかえでの紅葉日、つばめの初見日など、季節を代表する生物の動向が観察されています。近年は地球温暖化の影響か、さくらの開花日等が早まっているという話もありますが、生物の生活史の変化を観察することで気候変動等を観測するもの理解しています。
作った理由
別途、地球温暖化対策を計画してみようというサイトを作っているのですが、地球温暖化や生物多様性に関心があり、気候変動が生物の生活史にどんな影響を与えているか、ちょっと可視化してみたくなりました。。
作成方針
1.ライブラリ等
当初、processing.jsかp5.jsで作りたかったのですが、地理情報処理(座標変換)関係で挫けたので、結局OpenLayersで作成しました。サーバーサイドはSpark Frameworkを使用しました。
2.可視化手法
生物季節の観測値は日付データなので、毎年1月1日を起算日とする経過日数データとし、その等高線でさくらの開花・満開の前線を描画しました。等高線描画手法は、観測地点を節点とする非構造格子をデローニ分割で生成し、各三角要素を検査して描画するアルゴリズムとしました。なお、デローニ分割については数年前に一度投稿したdelaunay.jsを書き直して使用しました。成果物
作成したものは、Githubにリポジトリを登録し、Herokuにデプロイしました。
■生物季節可視化サイト:https://phenologicalmapjp.herokuapp.com/
■Githubリポジトリ:https://github.com/termat/PhenologicalMap
■動画
さくらの季節になったので、土日にさくら前線の可視化サイトを作ってみました。気候変動の影響か、さくらの満開時期が少し早まっている感じがします。#可視化 #さくら pic.twitter.com/0ES4MxLxiY
— t_mat (@t_mat) March 24, 2019経年比較データをみると、やはり最近、開花日、満開日が早まっている様子が見て取れます。
雑感
等高線データはGeoJSON形式で生成し、Openlayersに読み込ませています。その関係で可視化としてはイマイチな感じになってしまった。

- 投稿日:2019-03-24T20:13:36+09:00
Java 戻り値を試してみる
アジェンダ
- はじめに
- 投稿主が理解しているレベル
- コードでつかってみる
- 処理手順で説明する
- (結論)戻り値とはつまり、どういうものか
はじめに
この記事は、プログラミング初学者であるわたしが、説明文を読んでも全く理解が及ばなかった戻り値についてやっと理解したつもりになっていたので、同じようにさっぱりわからないよ! という方のために説明させていただく記事でございます。書籍を読んで勉強しているわけではないので、投稿主の基礎知識は低いです。(※コメントで指摘をしていただきましたので加筆修正をしています)
認識として間違っている点につきましては、コメントで教えていただけると幸いです。また、例え話がわからない! という方ははじめに謝罪させていただきます。申し訳ございません。
投稿主が理解しているレベル
わたしが現在Javaを学習する中で理解している範囲でございます。つまり、これ以外は全くわからないので、もし応用表現とかあってもわかっておりません。(という言い訳)
- 基本的な型
- メソッドの意味
- 基本変数の種類
- 基本演算子
- 基本的な条件分岐
- 繰り返し処理
- 配列
コードでつかってみる
まずは、コードでの説明をさせていただきます。
今回はこんなコードで説明してみようと思います。qiita.jvpublic class ReturnValue{ public static void main(String[] arg){ int a = 1; int b = 5; int c = a*b; System.out.println(a + "x" + b + "=" + c); } }このコードの実行結果は
1x5=5
となります。
現時点でこのプログラムは問題なく実行できてしまいます。
このプログラムに引数と戻り値を導入して同じ結果を出したいと仮定して、プログラムをみてみましょう。まずは引数を設定するためにmainメソッドとは異なるメソッドを作成します。
ここではbackメソッドとしましょう。そして、計算式(a*b)を引数で外で処理させたいので、変数cの値にbackメソッドを指定します。qiita.jv(2)public class ReturnValue{ public static void main(String[] arg){ int a = 1; int b = 5; int c = back(); System.out.println(a + "x" + b + "=" + c); } static int back(){ } }変数intを用いているため、int型でbackメソッドを作成しました。
実行結果
1x5=5
を出すためには、backメソッド内で変数を再定義し、計算式を記述する必要があります。qiita.jv(3)public class ReturnValue{ public static void main(String[] arg){ int a = 1; int b = 5; int c = back(); System.out.println(a + "x" + b + "=" + c); } static int back(){ int a = 1; int b = 5; int c = a*b; } }backメソッドで処理させようとするとこうなります。しかし、同じ記述を別メソッドで記載している上に、int型は戻り値を設定しなければならないためそもそもerrorとなります。処理結果を返すために戻り値に返すためのreturnを記述。さらに、引数を用いて変数aとbの値をbackメソッドに引き継ぎたいと思います。そうすると、
qiita.jv(4)public class ReturnValue{ public static void main(String[] arg){ int a = 1; int b = 5; int c = back(a,b); System.out.println(a + "x" + b + "=" + c); } static int back(int x,int y){ int a =x*y; return(a); } }こうなります。
まず、引き継ぎたい値である変数aとbをbackメソッドの処理結果を返したい戻り値「int c = back();」の()内に記述します。今回の場合2つの変数であるため、「,」で区切ります。
そして引継ぎ先であるbackメソッドでは、受け継ぐ値、変数a,bを受け入れる器を用意します。今回は変数x,yを用意しました。
この時点で、mainメソッドの変数a,bの値はbackメソッドの変数x,yに引き継がれます。
つまり、int a = 1 = int x
int b = 5 = int yということになります。
int aを先ほどmainメソッドの値を引き継いだ変数x,yの値で再定義をします。
そして最後に、ここまでの処理結果である変数aの値を「int c」まで返します。
int cにreturn(a)されているため、backメソッドでの処理結果1*5の処理結果が変数cに代入され、int c = 5
となります。
System.out.println(a + "x" + b + "=" + c);
はmainメソッドでの処理となるため、backメソッドで再定義した変数aの値は反映されません。
従って、通常通り代入された値と文字列を代入させることで1x5=5
と、引数と戻り値を用いなかった式と同じ結果が得らるのです。
処理手順で説明する
ここまで、コードで説明をしましたが、外へ行ったり戻ってきたりと、よくわからないという方もいらっしゃると思います。わたしはこのような説明を聞いて、混乱していました。
ですので、ここで一連の流れを整理して説明したいと思います。
何度も申し訳ありませんが、最後に完成したコードをご覧ください。qiita.jv(4)public class ReturnValue{ public static void main(String[] arg){ int a = 1; int b = 5; //手順その1 int c = back(a,b); //手順その2 //手順その6 System.out.println(a + "x" + b + "=" + c); //手順その7 } static int back(int x,int y){ //手順その3 int a =x*y; //手順その4 return(a); //手順その5 } }今回はコードを見ていただければわかるようにコメントで処理の手順を記載しています。(わかりやすいですね!)
ではその手順に沿って改めてどのように処理が行われているかについて説明をしたいと思います。手順その1
変数aとbを定義しています。手順その2
backメソッドに引き継ぎたい値を変数cに定義しています。手順その3
mainメソッドから、変数a,bの値をbackメソッドの器、変数x,yが引き継ぐことができました。それによって、int x = 1、int y = 5となります。手順その4
変数aを再定義します。手順その3で受け継いだ変数x,yの計算式の結果が変数aに再定義されます。手順その5
returnによって、処理結果であるbackメソッドで再定義された変数aが呼び出し元に戻ります。手順その6
backメソッドで再定義された変数aがmainメソッドの変数cに代入されます。これによって、int c = 1*5 = 5 となります。手順その7
それぞれに代入された値と文字列を連結させて出力します。以上が、説明したコードの処理手順となります。
(結論)戻り値とはどういうものか
つまり、戻り値とは処理結果をあらわしたものなのです。(とコメントで説明していただきました。)
今回の場合は計算結果ですね。計算という処理の結果を反映させたものが戻り値となるため、戻り値=処理結果となります。わかった気になって全くわかっていなかったり、説明がわからなくなったり、余計な要素を入れたりしていたりと記事として未熟な部分ばかりで申し訳ありませんでした。
- 投稿日:2019-03-24T20:13:36+09:00
Java 戻り値とは平行世界である
アジェンダ
-はじめに
-投稿主が理解しているレベル
-戻り値とは平行世界である
-コードで説明する
-処理手順で説明する
-平行世界をつくる
-(結論)戻り値とは平行世界であるはじめに
この記事は、プログラミング初学者であるわたしが、説明文を読んでも全く理解が及ばなかった戻り値についてやっと理解したので、同じようにさっぱりわからないよ! という方のために説明させていただく記事でございます。書籍を読んで勉強しているわけではないので、投稿主の基礎知識は低いです。
認識として間違っている点につきましては、コメントで教えていただけると幸いです。また、例え話がわからない! という方ははじめに謝罪させていただきます。申し訳ございません。
投稿主が理解しているレベル
わたしが現在Javaを学習する中で理解している範囲でございます。つまり、これ以外は全くわからないので、もし応用表現とかあってもわかっておりません。(という言い訳)
-基本的な型
-メソッドの意味
-基本変数の種類
-基本演算子
-基本的な条件分岐
-繰り返し処理
-配列戻り値とは平行世界である
読んでいらっしゃる方は平行世界というものをご存知でしょうか? もしもあの時別の選択をしていれば、というもしもの世界です。有名なもので言えば、某宇宙人や未来人や超能力者がいる世界を大いに盛り上げるアニメでのエンドレスエイトでしょうか。あのアニメでは、同じ日を毎日繰り返していました。しかし、それらは全く一緒ではなく、少しずつ違いがある。あの日々は、誰かが別の選択をした平行世界だったのです。
さてここで、何故平行世界の話なぞで出来るのか。それは戻り値を利用することで、ユーザーに任意の平行世界を選ばせることができるからです。
例えばユーザーが①の選択肢をとったとする。その場合はAのような答えが返って来る。条件分岐と一緒? 確かにその通りですね。しかし条件分岐よりもより複雑なコードで、より簡単に平行世界を演出できるのが戻り値であるとわたしは(勝手に)思っています。と、ここまでイメージについて話をしてきましたが、一度ここでこの話は忘れてください。次の節では、戻り値とは具体的にどのように処理するのかをコードを用いて説明したいと思います。
コードで理解する
まずは、コードでの説明をさせていただきます。
今回はこんなコードで説明してみようと思います。qiita.jvpublic class ReturnValue{ public static void main(String[] arg){ int a = 1; int b = 5; int c = a*b; System.out.println(a + "x" + b + "=" + c); } }このコードの実行結果は
1x5=5
となります。
現時点でこのプログラムは問題なく実行できてしまいます。
このプログラムに引数と戻り値を導入して同じ結果を出したいと仮定して、プログラムをみてみましょう。まずは引数を設定するためにmainメソッドとは異なるメソッドを作成します。
ここではbackメソッドとしましょう。そして、計算式(a*b)を引数で外で処理させたいので、変数cの値にbackメソッドを指定します。qiita.jv(2)public class ReturnValue{ public static void main(String[] arg){ int a = 1; int b = 5; int c = back(); System.out.println(a + "x" + b + "=" + c); } static int back(){ } }変数intを用いているため、int型でbackメソッドを作成しました。
実行結果
1x5=5
を出すためには、backメソッド内で変数を再定義し、計算式を記述する必要があります。qiita.jv(3)public class ReturnValue{ public static void main(String[] arg){ int a = 1; int b = 5; int c = back(); System.out.println(a + "x" + b + "=" + c); } static int back(){ int a = 1; int b = 5; int c = a*b; } }backメソッドで処理させようとするとこうなります。しかし、同じ記述を別メソッドで記載している上に、int型は戻り値を設定しなければならないためそもそもerrorとなります。処理結果を返すために戻り値に返すためのreturnを記述。さらに、引数を用いて変数aとbの値をbackメソッドに引き継ぎたいと思います。そうすると、
qiita.jv(4)public class ReturnValue{ public static void main(String[] arg){ int a = 1; int b = 5; int c = back(a,b); System.out.println(a + "x" + b + "=" + c); } static int back(int x,int y){ int a =x*y; return(a); } }こうなります。
まず、引き継ぎたい値である変数aとbをbackメソッドの処理結果を返したい戻り値「int c = back();」の()内に記述します。今回の場合2つの変数であるため、「,」で区切ります。
そして引継ぎ先であるbackメソッドでは、受け継ぐ値、変数a,bを受け入れる器を用意します。今回は変数x,yを用意しました。
この時点で、mainメソッドの変数a,bの値はbackメソッドの変数x,yに引き継がれます。
つまり、int a = 1 = int x
int b = 5 = int yということになります。
int aを先ほどmainメソッドの値を引き継いだ変数x,yの値で再定義をします。
そして最後に、ここまでの処理結果である変数aの値を「int c」まで返します。
int cにreturn(a)されているため、backメソッドでの処理結果1*5の処理結果が変数cに代入され、int c = 5
となります。
System.out.println(a + "x" + b + "=" + c);
はmainメソッドでの処理となるため、backメソッドで再定義した変数aの値は反映されません。
従って、通常通り代入された値と文字列を代入させることで1x5=5
と、引数と戻り値を用いなかった式と同じ結果が得らるのです。
処理手順で説明する
ここまで、コードで説明をしましたが、外へ行ったり戻ってきたりと、よくわからないという方もいらっしゃると思います。わたしはこのような説明を聞いて、混乱していました。
ですので、ここで一連の流れを整理して説明したいと思います。
何度も申し訳ありませんが、最後に完成したコードをご覧ください。qiita.jv(4)public class ReturnValue{ public static void main(String[] arg){ int a = 1; int b = 5; //手順その1 int c = back(a,b); //手順その2 //手順その6 System.out.println(a + "x" + b + "=" + c); //手順その7 } static int back(int x,int y){ //手順その3 int a =x*y; //手順その4 return(a); //手順その5 } }今回はコードを見ていただければわかるようにコメントで処理の手順を記載しています。(わかりやすいですね!)
ではその手順に沿って改めてどのように処理が行われているかについて説明をしたいと思います。手順その1
変数aとbを定義しています。手順その2
backメソッドに引き継ぎたい値を変数cに定義しています。手順その3
mainメソッドから、変数a,bの値をbackメソッドの器、変数x,yが引き継ぐことができました。それによって、int x = 1、int y = 5となります。手順その4
変数aを再定義します。手順その3で受け継いだ変数x,yの計算式の結果が変数aに再定義されます。手順その5
returnによって、処理結果であるbackメソッドで再定義された変数aが呼び出し元に戻ります。手順その6
backメソッドで再定義された変数aがmainメソッドの変数cに代入されます。これによって、int c = 1*5 = 5 となります。手順その7
それぞれに代入された値と文字列を連結させて出力します。以上が、説明したコードの処理手順となります。
平行世界をつくる
ここまでの説明で戻り値については理解できましたでしょうか? 上手いこと呑み込めない人は実際に打ち込んでみましょう。その方がわかりやすいです。
ここでやっと平行世界の話に戻ります。いや、もう戻り値がわかったからいいよ! という方、どうか我慢して読んでください。ここまで説明したのはこの「戻り値とは平行世界である」というなんかそれっぽいことを言いたいからなんです! 結論ありきで説明したのでどうかお願いします。で、平行世界をつくる。ということなんですが、冒頭でお伝えしたように、戻り値は平行世界をつくることができます。何故ならば、
戻り値(return)はそこで処理を中止して結果を返すことができるから
例えば(なんか例え話ばっかりな気がする)自動販売機で飲み物を買うとします。ここで缶の飲み物を買うか、ペットボトルの飲み物を買うかという2つの選択肢があるとします。缶を買った場合、タブを開けて飲みます。ペットボトルを買った場合、キャップを開けて飲みます。
この選択での処理は手順その1
①缶を買う
②ペットボトルを買う手順その2
①タブを開ける
②キャップを開ける手順その3
①飲む
②飲むという3つの手順が必要になってくるかと思います。
しかしreturnを手順その1と手順その2の間に挟み込むことで、手順その2と手順その3は実行されず、手順その1の実行結果のみを反映することができるのです。
そんなの、手順その2と手順その3いらないよね? となると思います。しかし、手順その2もその3も選択肢によってはつかいたい! そんなこともあるでしょう。そんな時に便利なのがこの戻り値です。変数の値を変動させたり、入力による条件分岐でどこまでを実行するかを選べるという! そう! つまり平行世界をつくれるのです。
(結論)戻り値とは平行世界である
ということで結論です。戻り値をつかうことの利点
-条件分岐よりもスッキリとしたコードにできる
-細かい条件設定が可能
-平行世界をつくれる説明していくうちに、これなんか違うという気もしていましたが、そんな感じのニュアンスでとらえていただければ幸いです。肝心のコード説明に関しまして、間違いなどがございましたら、指摘していただければと思います。また、わたしの説明よりもわかりやすく簡潔な記事やサイト様も多くあると思いますので、わからない方は分かりやすいサイト様で読んでいただくのがいいかと思います。
長くなりましたが、読んでいただきまして、ありがとうございました。
- 投稿日:2019-03-24T19:17:21+09:00
モノシリックアプリケーションのリファクタリング
社内で開発しているアプリケーションが「大きな泥団子」状態になってしまっているため、開発効率が上がらない問題に直面した。そこでリファクタリングを決意。
「クリーンアーキテクチャ」、「マイクロサービスアーキテクチャ」などで勉強をしつつ、リファクタリングを行っている。
まだ完了した訳ではないけれど、リファクタリングを行うにあたり考えてきたことを整理する。モノシリックアプリケーションの現状整理
リファクタリングを行う前のアプリケーションの状態を整理してみた。
以下の問題を抱えている。
- 複数のサブシステム、自作ライブラリを一つのgitリポジトリで一括管理(ソースコード量は70万行くらい)
- これがメインの問題。この構成になっていることによって機能開発が一部のサブシステムに閉じていたとしても、CIで全てのモジュールをビルドする羽目になる。
- 一つのDBを全てのサブシステムが共有している
- DBのテーブルを少し変更するだけで全てのサブシステムに影響が及ぶ可能性がある。
- どのテーブルを変更すれば、機能開発で実現したいことができるのか調査に時間がかかる。
- 自動テストが検証したい機能以外と密結合すぎる
- 自動テスト自体が下位モジュールの詳細に依存している。結合テストのような位置付けでテストが実装されているため、下位モジュールのプロダクトコードを修正すると、色んなテストがこける。
- DBのデータをロードして行うテストもあり、メンテコストが高い。
- 一度のCIでビルドとテストを行うと2時間くらいかかる
- gitリポジトリが一つであることと、自動テストが結合テストのような位置付けで実装されていることが主な原因。自動テストによる品質担保のメリットより、開発効率の阻害のデメリットの方が大きい。
- 下位モジュールに詳細が含まれすぎている
- 下位のモジュールに詳細が含まれていることによって、機能開発では下位モジュールを頻繁に更新することになる。また、上位モジュールは詳細が下位モジュールに存在することによって、その詳細に依存することになる。結果として修正に閉じることができなくなっている。
問題へのリファクタリング
複数のサブシステム、自作ライブラリを一つのgitリポジトリで一括管理
- 現在は「機能単位」でmavenプロジェクトを分割して一つのgitリポジトリに収めているが、それを単一責任の原則に従って切り分け、別リポジトリに分割する。
一つのDBを全てのサブシステムが共有している
- DBを共有していることによって、一つのテーブルには複数の関心が詰め込まれている。よって、必然的にテーブルのカラムは膨大な量になっている。これを各サブシステム毎に必要なカラムのみを抽出したテーブルに分割し、スキーマをサブシステム単位で分割する。
自動テストが検証したい機能以外と密結合すぎる
- 既存テストコードから外部仕様を把握し、下位モジュールの抽象に依存した形でテストコードを書きながら、既存実装をリファクタリングしていく。
一度のCIでビルドとテストを行うと2時間くらいかかる
- gitリポジトリ一括管理、自動テストと実装の密結合のリファクタリングで解消される
下位モジュールに詳細が含まれすぎている
- 依存性逆転の原則を適用するようにリファクタリング。下位のモジュールは基本的には抽象クラス、インターフェースのみで構成されることを目指す。
リファクタリングの効果試算
複数のサブシステム、自作ライブラリを一つのgitリポジトリで一括管理
- ソースコード変更に対するビルド・テスト範囲が約半分になると仮定すると、ビルド・テスト時間も単純に半分になると仮定。既存のビルド・テスト時間を2時間と仮定し、一日の平均CI回数を5回と仮定すると、
5(ビルド回数)×2×0.5(リファクタリングにより削減された時間)×20(営業日) = 100時間/1ヶ月のコスト削減が開発者一人あたりに対して見込める。一つのDBを全てのサブシステムが共有している
- DBの変更を伴う機能開発での無影響確認・DB変更箇所の調査にかかる時間を16時間(2人日)と仮定、これがDB分割を行った後では2時間になると仮定する。DB変更を伴う機能開発が月に3回発生すると仮定すると、
3(機能開発発生回数)×14(リファクタリングにより削減された時間) = 42時間/1ヶ月のコスト削減が開発者一人あたりに対して見込める。自動テストが検証したい機能以外と密結合すぎる
- 自動テストを修正するのにかかる時間を5時間と仮定、これがリファクタリングを行った後では1時間になると仮定する。自動テストを修正する機会が月に5回発生すると仮定すると、
5(機能開発発生回数)×4(リファクタリングにより削減された時間) = 20時間/1ヶ月のコスト削減が開発者一人あたりに対して見込める。下位モジュールに詳細が含まれすぎている
- これは下位モジュールの更新頻度に影響してくる。下位モジュールが抽象でのみ構成されていれば、上位のモジュールを全てビルドするという事態を避けられる。下位モジュールの更新頻度が月に10回だと仮定し、リファクタリングを行った後では月に1回になると仮定する。ソースコードのビルド・テスト時間を2時間と仮定すると、
2(ビルド・テスト時間)×9(リファクタリングにより削減された更新頻度) = 18時間/1ヶ月のコスト削減が開発者一人あたりに対して見込める。試算から考えられること
上で行った試算は何一つ正確な数値ではない。こんな試算はそもそも正確にできるはずがない。
ただ、このリファクタリングを行うことによるメリットを相手に伝えて、リファクタリングを行う許可を上位者から受けるために考えておくと良いことではある。
そして一番重要なのは、上記で試算したリファクタリングにより削減できるコストを、リファクタリングを行わない限り永久に支払い続けることになるということ。
リファクタリングにより削減できるコストは試算したが、リファクタリングにかかるコストを試算していないのはこれが理由。
リファクタリングにより削減できるコストはリファクタリングを行うことによってしか削減できない。ということはリファクタリングを行うコストが現実的でない値(100人月とか)でなければ是が非でも行うべきだと思う。
コストはこれからも増え続けていくのに、リファクタリングにかかるコストが2人月だったら行う、3人月だったら行わないといった議論はそもそもナンセンスに思う。リファクタリングを行って感じたこと
アーキテクトとして必要な知識・経験を高密度に得られる。
- 「優れたアーキテクトは実装の決定方針を最大限に遅延させることができる」とクリーンアーキテクチャでは言及されている。それを実現するにあたって、必要な「依存関係の制御」、「モジュール管理」、「結合度」を自分で考えて適用していくがリファクタリングである。そして、その効果を自分で身を以て体感できる。
現場に求められるエンジニアへ成長できる
- ソフトウェアは変化し続ける。なぜならビジネス要求は変化し続けるから。結果的に0からアプリケーションを作る力を発揮する場面よりも、既存のアプリケーションを拡張していく場面の方が圧倒的に多い。そのため、すでに動いているアプリケーションを破壊せずに開発効率を向上させ、メンテコストを下げることができるエンジニアはどんな市場においても必ず必要とされる。そういうエンジニアに求められる「メンテコストの抑えられた自動テスト」、「アジリティの高いCI/CD構築」を実現できる力をリファクタリングを通して得られる。
リファクタリングを行うにあたって参考にした資料
- 投稿日:2019-03-24T16:35:52+09:00
例外処理について
プログラミング初学者です。
今回は前回の例外の記事に続きということで例外処理についてアウトプットさせていただきます。Q1: 例外処理とは?
実行時に例外が投げられた後の処理のこと。
(例外処理をしていなければシステムは中断されますが例外処理をしておけば中断されるまでに必要な処理を実行することができます。)
(例)・「予期せぬエラーが発生しました」と表示する。
・ファイルを閉じる処理をする etc...Q2: 例外処理はどうやって書くの?
[try→catch→finally]構文で書きます。
qiita.javatry { // 実行したい処理(例外が投げられる可能性がある) } catch() { // 例外が投げられた際にキャッチしてくれる } finally { // 例外が発生しcatchされてもされなくても必ず行われる処理を書くことができる。 }finallyは別に書かなくても良い?
はい。
別に書かなくても[try→catch]だけで大丈夫です。
ですが、僕は初学者なのでまだわからないのですが、finallyがすごくありがたく感じる瞬間がいつか来るという記事をどこかで見たので書かなくてもいいけど重要なのは間違いない様です。[参考文献]
https://eng-entrance.com/java-finally※間違い等ありましたら、恐れ入りますがコメントで教えていただけると幸いです。
- 投稿日:2019-03-24T16:15:25+09:00
学習メモ01(forward/redirect)
【Java】forwardとredirect
どちらも、servletからJSPにページ遷移をするために使う命令文。
細かいところで挙動が違うらしい。(実務経験0なので実感が沸かんw)forward
RequestDispatcher rd = request.getRequestDispatcher("test01.jsp");
rd.forward(request, response);------------------------
・javax.servlet.RequestDispatcherをインポートする必要あり
・リクエストスコープを使って値をservlet→JSPに受け渡しできる
------------------------redirect
//リダイレクト
response.sendRedirect("test02.jsp");------------------------
・URLが書き換わる
------------------------
- 投稿日:2019-03-24T15:57:42+09:00
DialogのYes/Noをそれぞれbooleanで返す方法を探しています・・・
現在AndroidStudioにてJavaを使いアプリ開発の勉強を行っており、
Dialogの部分で躓いております。機能としては例を挙げると下記の様に動かしたいと考えております。
A画面にて登録ボタン押下
↓
Dialog:
登録してよろしいでしょうか
はい/いいえ
↓ ↓
はい押下 いいえを押下
↓ ↓
A画面へTrueを返す 画面へFalseを押下
↓
A画面にてTrue又はFalseを受け取り以降の処理を継続調べてみたのですが調べ方が悪いのか、
booleanをreturnするようなDialogのサンプルを見つけることが出来ませんでした。皆様のお力をお借りできませんでしょうか?
以上、よろしくお願いいたします。
- 投稿日:2019-03-24T15:55:17+09:00
SpringDataJpa/集計関数等使用時に参考にした記事一覧
SpringDataJpaで集計関数等を使用したクエリーを発行する際に参考した記事の一覧を備忘録としてアップします。
[1]TERASOLUNA(6.3. データベースアクセス(JPA編))6.3.3.2. Entity以外のオブジェクトにQueryの取得結果を格納する方法(以下は抜粋です)
想定される適用ケース
Query内で集計関数を使用して集計済みの情報を取得したい場合は、集計結果をEntityにマッピングすることはできないため、別のオブジェクトにマッピングする必要がある。
実装要件
(1) Query結果を格納するJavaBeanを作成する(*1)。
(2) Queryを実行した結果でオブジェクト生成するためのコンストラクタを用意する。
*1 [Java]新人向けにJavaBeansの直列化やフィールド・プロパティの謎をPOJOとの違いを交えて解説 (@ukitiyanさんの投稿を引用させていただきました)[2]@kagamihogeさんの「spring-data-jpaの@Queryでカスタムオブジェクトを返す」
抜粋
Spring Data JPAでgroup byの集計結果などをエンティティではない自前のオブジェクトとして返す。JPQL等ネットでの調査時の留意点
下記の記事に記載の通り、Spring Data JPAは、生のJPA実装(Hibernate JPA参照実装)をラッピングしています。ネットで調査する場合、生のJPA実装に基づく記事なのか、Spring Data JPA実装に基づく記事なのかを意識して行う必要があります。
TERASOLUNA : 6.3.1.2. Spring Data JPAについて尚、こちらも良ければ参照下さい。
「SpringDataJpa/集計関数等使用時に、新しいJavaBeansを作成するのではなく既存Entityを流用して実装してみた。」
「SpringDataJpa/集計関数等使用時に、new xxxClass()を使用しない方法を試してみた。」
- 投稿日:2019-03-24T15:39:58+09:00
Tomcat 8.5.37でfurther occurrences of http header parsing errors will be logged at debug level.とエラーが出たときの対処
Tomcat 8.5.37を用いて、サーブレットの開発をしていた時のこと。
突如としてnote: further occurrences of http header parsing errors will be logged at debug level.
java.lang.IllegalArgumentException: Invalid character found in method name. HTTP method names must be tokens
at org.apache.coyote.http11.Http11InputBuffer.parseRequestLine(Http11InputBuffer.java:428)
at org.apache.coyote.http11.Http11Processor.service(Http11Processor.java:684)
at org.apache.coyote.AbstractProcessorLight.process(AbstractProcessorLight.java:66)
at org.apache.coyote.AbstractProtocol$ConnectionHandler.process(AbstractProtocol.java:806)
at org.apache.tomcat.util.net.NioEndpoint$SocketProcessor.doRun(NioEndpoint.java:1498)
at org.apache.tomcat.util.net.SocketProcessorBase.run(SocketProcessorBase.java:49)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at org.apache.tomcat.util.threads.TaskThread$WrappingRunnable.run(TaskThread.java:61)
at java.lang.Thread.run(Thread.java:748)というエラーが発生しました。その時は
https://localhost:8080/プロジェクト名
でアクセスしていたのですが、これをhttp://にすることで解決。
- 投稿日:2019-03-24T15:32:09+09:00
Java メソッド
本日学習したこと
- メソッドとは
- 戻り値
- 引数
- オーバーロード
メソッドとは
・複数のプログラムをまとめ、それを一つの処理(機能)として名前をつけたもの。
メソッドを使用するメリット
・機能単位に記述するため、修正範囲を限定できる。
・開発現場では数千〜数万行に及ぶソースコードが必要になるため、メソッドを使用してなるべくシンプルに記述することができる。(プログラムの見通しが良くなり把握しやすくなる)メソッドの定義
javapublic static 戻り値の型 メソッド名(引数){ メソッドが呼び出された後に実行される具体的な処理 }#戻り値の型はメソッド内の処理の結果の値のデータ型を記述。処理結果が数値であればint、文字列であればStringになる。 # 例えば public static int score(引数){ 処理... } #scoreというメソッドがあり点数という結果を呼び出し元に返す時、処理結果(点数)は数値なのでintになる。 #メソッドの呼び出し メソッド名(引数); #戻り値を利用できない。 #戻り値の受け取り 変数の型 変数名 = メソッド名(引数); #戻り値を変数に入れて利用できる。 #メソッドは定義しただけでは実行されない。呼び出して初めてメソッドの処理が実行される。
- 戻り値とは
呼び出されたメソッドから、呼び出し元のメソッドへ返す値(データ)のことを戻り値または返り値という。
javareturn 戻り値; #こうすることで呼び出し元のメソッドに値を返すことができる。 #この戻り値がそのメソッドの実行結果となる。引数
メソッドを呼び出す際に呼び出し元から値を渡すことができる。
javapublic static void main(String[] arg) { hello("岡村"); #helloメソッドを呼び出している。岡村という文字列のデータ(実引数)をhelloメソッドに渡している。 hello("山本"); #上記に同じ hello("佐々木"); #上記に同じ } public static void hello(String name) { #メソッド呼び出しの際、仮引数として岡村がString型の変数nameに代入される。 System.out.println(name + "さん、こんにちは"); #変数nameに代入されているデータをここで出力する。 } # 実行結果は >岡村さん、こんにちは 山本さん、こんにちは 佐々木さん、こんにちは #となる。 #引数は複数渡すことができる。その場合は、カンマ(,)で引数を区切る。 .....mainメソッド(...){ #めちゃくちゃ簡略化してます。めんどくさがってごめんなさい。 add(10, 20); #addメソッドに10,20という数値を引数として渡す。 } .....addメソッド(int a, int b){ #addメソッドは引数を受け取り、aに10,bに20が代入される。 引数を利用した処理... } #ここで注意なのが引数として記述された1番目の数値10はaに代入されるというところだ。 #()内の配置によってどの変数に代入されるかが決まる。オーバーロードとは
・同じ名前のメソッドを定義すること。多重定義ともいう。
・メソッド名が同じでもデータの型や引数の数が違えばオーバーロードできる。
- 投稿日:2019-03-24T13:42:28+09:00
SpringDataJpa/集計関数等使用時に、new xxxClass()を使用しない方法を試してみた。
この記事は、@kagamihogeさんの「spring-data-jpaの@Queryでカスタムオブジェクトを返す」の記事を参考にして実施してみたものです。@kagamihogeさん有難うございました。
CustomerRepository.javapackage hello; import java.util.List; import org.springframework.data.jpa.repository.JpaRepository; import org.springframework.data.jpa.repository.Query; public interface CustomerRepository extends JpaRepository<Customer, Long> { @Query("SELECT cu.lastName AS lastName, Count(cu.id) AS cnt FROM Customer cu GROUP BY cu.lastName") List<CustomerGroupByLastName> GroupByLastName(); public static interface CustomerGroupByLastName { public String getLastName(); public long getCnt(); } }Customer.javapackage hello; import javax.persistence.Entity; import javax.persistence.GeneratedValue; import javax.persistence.GenerationType; import javax.persistence.Id; @Entity public class Customer { @Id @GeneratedValue(strategy=GenerationType.AUTO) private Long id; private String firstName; private String lastName; protected Customer() {} public Customer(String firstName, String lastName) { this.firstName = firstName; this.lastName = lastName; } @Override public String toString() { return String.format( "Customer[id=%d, firstName='%s', lastName='%s']", id, firstName, lastName); } }Application.javapackage hello; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import org.springframework.boot.CommandLineRunner; import org.springframework.boot.SpringApplication; import org.springframework.boot.autoconfigure.SpringBootApplication; import org.springframework.context.annotation.Bean; @SpringBootApplication public class Application { private static final Logger log = LoggerFactory.getLogger(Application.class); public static void main(String[] args) { SpringApplication.run(Application.class); } @Bean public CommandLineRunner demo(CustomerRepository repository) { return (args) -> { // save a couple of customers repository.save(new Customer("Jack", "Bauer")); repository.save(new Customer("Chloe", "O'Brian")); repository.save(new Customer("Kim", "Bauer")); repository.save(new Customer("David", "Palmer")); repository.save(new Customer("Michelle", "Dessler")); // fetch all customers log.info("Customers found with findAll():"); log.info("-------------------------------"); for (Customer customer : repository.findAll()) { log.info(customer.toString()); } log.info(""); // Customers'Count GroupByLastName log.info("Customers'Count GroupByLastName with GroupByLastName():"); log.info("--------------------------------------------"); repository.GroupByLastName().forEach(result -> { log.info("LastName = " + result.getLastName() + " Count = " + result.getCnt()); }); log.info(""); }; } }実行結果.loghello.Application : Started Application in 3.026 seconds (JVM running for 4.501) hello.Application : Customers found with findAll(): hello.Application : ------------------------------- hello.Application : Customer[id=1, firstName='Jack', lastName='Bauer'] hello.Application : Customer[id=2, firstName='Chloe', lastName='O'Brian'] hello.Application : Customer[id=3, firstName='Kim', lastName='Bauer'] hello.Application : Customer[id=4, firstName='David', lastName='Palmer'] hello.Application : Customer[id=5, firstName='Michelle', lastName='Dessler'] hello.Application : hello.Application : Customers'Count GroupByLastName with GroupByLastName(): hello.Application : -------------------------------------------- hello.Application : LastName = Bauer Count = 2 hello.Application : LastName = O'Brian Count = 1 hello.Application : LastName = Palmer Count = 1 hello.Application : LastName = Dessler Count = 1 hello.Application :併せて、こちらの記事も参考ください。
「SpringDataJpa/集計関数等使用時に、新しいJavaBeansを作成するのではなく既存Entityを流用して実装してみた」
- 投稿日:2019-03-24T13:28:49+09:00
Testcontainers で Spring Boot + MyBatis のテスト実行中だけ MySQL のコンテナを起動
はじめに
Testcontainers を使用すると、JUnit のテスト中だけ MySQL のコンテナを起動することができます。
SimpleMySQLTest.java というサンプルコードを見ると結構簡単に使えそうですが、Spring Boot + MyBatis で試してみたら結構苦労したので、どうすれば動くかまとめておきます。
まずは普通に Spring Boot + MyBatis を動かす
Testcontainers でテストを試す前に、動くコードを書いておきます。
MyBatis のコードを作成
UserRepositoryImpl.java、UserMapper.java、UserMapper.xml の 3 ファイルを作成します。
UserRepositoryImpl.javapackage springdockerexample.infrastructure.user; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.stereotype.Repository; import springdockerexample.domain.user.Name; import springdockerexample.domain.user.User; import springdockerexample.domain.user.UserRepository; import springdockerexample.domain.user.Users; import java.util.List; @Repository public class UserRepositoryImpl implements UserRepository { @Autowired private UserMapper mapper; @Override public Users findAll() { List<User> users = mapper.selectAll(); return new Users(users); } }UserMapper.javapackage springdockerexample.infrastructure.user; import org.apache.ibatis.annotations.Mapper; import org.apache.ibatis.annotations.Param; import springdockerexample.domain.user.Name; import springdockerexample.domain.user.User; import java.util.List; @Mapper public interface UserMapper { List<User> selectAll(); }UserMapper.xml<?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd" > <mapper namespace="springdockerexample.infrastructure.user.UserMapper"> <resultMap id="user" type="springdockerexample.domain.user.User"> <result property="name.value" column="name"/> <result property="age.value" column="age"/> </resultMap> <select id="selectAll" resultMap="user"> SELECT name, age FROM users </select> </mapper>プロパティファイルを用意
DB の接続情報を application.yaml に書きます。
application.yamlspring: datasource: url: jdbc:mysql://localhost/mydb username: user password: password driverClassName: com.mysql.cj.jdbc.Driverテストデータを用意
開発・テスト用のデータをファイルに用意します。
src/test/resources/docker-entrypoint-initdb.d/init.sqlUSE `mydb`; CREATE TABLE `users` ( `name` VARCHAR(255) NOT NULL, `age` int NOT NULL ); INSERT INTO `users` (`name`, `age`) VALUES ('Alice', 20), ('Bob', 30);ローカルでコンテナを起動
Spring Boot + MyBatis の動作確認のため、Docker Compose で MySQL を起動します。
このとき、先ほど用意した SQL ファイルを docker-entrypoint-initdb.d にマウントすることで、データが自動的に挿入されます。
docker-compose.yamlversion: '3' services: my-db: image: mysql:5.7.25 ports: - 3306:3306 volumes: - ./src/test/resources/docker-entrypoint-initdb.d:/docker-entrypoint-initdb.d environment: MYSQL_ROOT_PASSWORD: root MYSQL_DATABASE: mydb MYSQL_USER: user MYSQL_PASSWORD: password動作確認
spring-dev-tools を入れておけば、
./mvnw spring-boot:runで起動します。$ ./mvnw spring-boot:run $ curl localhost:8080/users {"users":[{"name":"Alice","age":20},{"name":"Bob","age":30}]}無事動作しています。
※ RestController なども書いていますが、記事への掲載は省略しました。
このように、Docker Compose で起動したコンテナでテストすることも可能ですが、それではテストケースごとにコンテナを起動し直したりすることはできません。
JUnit のテストの中で自由自在にコンテナを起動するため、Testcontainers を使います。
Testcontainers で JUnit 実行中だけコンテナを起動
テスト用の MySQL 起動 + 接続情報設定
「testcontainersで使い捨てのデータベースコンテナを用意してSpring Bootアプリケーションのテストをおこなう」を参考に、テスト用の MySQL コンテナの起動と Context への接続情報設定のため、以下のファイルを作成します。
MySQLContainerContextInitializer.javapackage springdockerexample.testhelper; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import org.springframework.boot.test.util.TestPropertyValues; import org.springframework.context.ApplicationContextInitializer; import org.springframework.context.ConfigurableApplicationContext; import org.testcontainers.containers.BindMode; import org.testcontainers.containers.MySQLContainer; import org.testcontainers.containers.output.Slf4jLogConsumer; public class MySQLContainerContextInitializer implements ApplicationContextInitializer<ConfigurableApplicationContext> { private static final String MYSQL_IMAGE = "mysql:5.7.25"; private static final String DATABASE_NAME = "mydb"; private static final String USERNAME = "user"; private static final String PASSWORD = "password"; private static final int PORT = 3306; private static final String INIT_SQL = "docker-entrypoint-initdb.d/init.sql"; private static final String INIT_SQL_IN_CONTAINER = "/docker-entrypoint-initdb.d/init.sql"; private static final Logger LOGGER = LoggerFactory.getLogger(MySQLContainerContextInitializer.class); private static final MySQLContainer MYSQL = (MySQLContainer) new MySQLContainer(MYSQL_IMAGE) .withDatabaseName(DATABASE_NAME) .withUsername(USERNAME) .withPassword(PASSWORD) .withExposedPorts(PORT) .withLogConsumer(new Slf4jLogConsumer(LOGGER)) .withClasspathResourceMapping(INIT_SQL, INIT_SQL_IN_CONTAINER, BindMode.READ_ONLY); static { MYSQL.start(); } @Override public void initialize(ConfigurableApplicationContext context) { String mysqlJdbcUrl = MYSQL.getJdbcUrl(); TestPropertyValues.of("spring.datasource.url=" + mysqlJdbcUrl) .applyTo(context.getEnvironment()); } }この内容を順に説明していきます。
MySQL のコンテナの設定
private static final MySQLContainer MYSQL = (MySQLContainer) new MySQLContainer(MYSQL_IMAGE) .withDatabaseName(DATABASE_NAME) .withUsername(USERNAME) .withPassword(PASSWORD) .withExposedPorts(PORT) .withLogConsumer(new Slf4jLogConsumer(LOGGER)) .withClasspathResourceMapping(INIT_SQL, INIT_SQL_IN_CONTAINER, BindMode.READ_ONLY);ここでは、先ほど docker-compose.yaml で書いていた内容とほとんど同じ設定を Java で記述しています。
new MySQLContainer(MYSQL_IMAGE) でイメージ名を指定し、データベース名やユーザ名、パスワードといった設定もここで行なっています。
また、withClasspathResourceMapping で DB の初期化用の SQL をマウントしています。
同様にして、 MySQL の設定ファイルもマウントできるようです。MySQL のコンテナ起動
static { MYSQL.start(); }MySQL のコンテナを起動しています。
MySQL.start() は後述する initialize 内の MySQL.getJdbUrl() より先に実行される必要があります。この例ではサボっていますが、終了時に MySQL.stop() を呼び出したほうがお行儀がいいと思われます。
接続情報の設定
Testcontainers で起動した MySQL に接続するためのポートは動的に割り当てられるため、それを踏まえて動的に接続情報を設定する必要があります。
MySQLContainerContextInitializer というクラスを作成したのは、Spring Bootの設定を動的に変更するためです。
具体的な設定方法は以下の通りです。
@Override public void initialize(ConfigurableApplicationContext context) { String mysqlJdbcUrl = MYSQL.getJdbcUrl(); TestPropertyValues.of("spring.datasource.url=" + mysqlJdbcUrl) .applyTo(context.getEnvironment()); }ちなみに、MySQL への接続情報を MySQLContainer インスタンスから取得する必要があることは、SimpleMySQLTest.java の以下の部分からも分かります。
SimpleMySQLTest.java@NonNull protected ResultSet performQuery(MySQLContainer containerRule, String sql) throws SQLException { HikariConfig hikariConfig = new HikariConfig(); hikariConfig.setDriverClassName(containerRule.getDriverClassName()); hikariConfig.setJdbcUrl(containerRule.getJdbcUrl()); hikariConfig.setUsername(containerRule.getUsername()); hikariConfig.setPassword(containerRule.getPassword()); HikariDataSource ds = new HikariDataSource(hikariConfig); Statement statement = ds.getConnection().createStatement(); statement.execute(sql); ResultSet resultSet = statement.getResultSet(); resultSet.next(); return resultSet; }テストの記述
Spirng Boot のテストを通常通り記載します。
UserRepositoryImplTest.javapackage springdockerexample.infrastructure.user; import org.junit.Test; import org.junit.runner.RunWith; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.boot.test.context.SpringBootTest; import org.springframework.test.context.ContextConfiguration; import org.springframework.test.context.junit4.SpringRunner; import springdockerexample.domain.user.UserRepository; import springdockerexample.domain.user.Users; import springdockerexample.testhelper.MySQLContainerContextInitializer; import static org.hamcrest.core.Is.is; import static org.junit.Assert.assertThat; @RunWith(SpringRunner.class) @SpringBootTest @ContextConfiguration(initializers = { MySQLContainerContextInitializer.class }) public class UserRepositoryImplTest { @Autowired UserRepository userRepository; @Test public void test() { Users users = userRepository.findAll(); assertThat(users.count(), is(2)); } }ポイントは、
@ContextConfiguration(initializers = { MySQLContainerContextInitializer.class })で先ほど作成したクラスを指定し、MySQL の起動と接続情報の設定を行なっているところです。あとは普通の JUnit のテストを記述すれば、問題なく DB にアクセスできます。
まとめ
まとめると全然難しくないのですが、実際には結構苦労しました。
セットアップし終えてしまえば便利に使えるかもしれません。Testcontainers は DB 以外にも任意のコンテナに対応しているので、自由自在な自動テストが可能になります。
なお、この記事の内容の最終的なファイル構成はおおよそ以下のようになっています。
$ tree . ├── pom.xml ├── ... └── src ├── main │ ├── java │ │ └── springdockerexample │ │ ├── SpringDockerExampleApplication.java │ │ ├── ... │ │ └── infrastructure │ │ └── user │ │ ├── UserMapper.java │ │ └── UserRepositoryImpl.java │ └── resources │ ├── application.yaml │ └── springdockerexample │ └── infrastructure │ └── user │ └── UserMapper.xml └── test ├── java │ └── springdockerexample │ ├── SpringDockerExampleApplicationTests.java │ ├── infrastructure │ │ └── user │ │ └── UserRepositoryImplTest.java │ └── testhelper │ └── MySQLContainerContextInitializer.java └── resources └── docker-entrypoint-initdb.d └── init.sqlソースコードは こちら です。
- 投稿日:2019-03-24T02:10:06+09:00
例外について
プログラミング初学者です。
今回は例外処理を学んだのでアウトプットさせていただきます。
間違っている点等ありましたら、恐れ入りますがコメントからよろしくお願いします。Q1: 例外とは?
プログラム実行時に検知されるエラーのこと
Q2: プログラム実行時とは?
javaの実行までの仕組みは以下のようになっています。
上記の図の(実行)で出るエラーが例外
Q3: 例外が出たらどうなるの?
コンソールにエラー文が出て処理が中断されます。
Q4例外が出た時、処理が中断されない方法はあるの?
あります。
その方法が例外処理です。
※例外処理についてはQiitaの別の記事で書きます。
今回は例外についてだけです。参考にしたサイトはこちらをクリック
