- 投稿日:2019-03-24T23:46:18+09:00
Python機械学習手遊び(デレステスコアCSV化)
この記事、何?
スマホゲームのデレステのスクリーンショット(スクショ)がいっぱい入ったフォルダから、CSVファイルを作ろうという話。
実はいろいろ手抜きだけど、なんとなく形になった。仕様
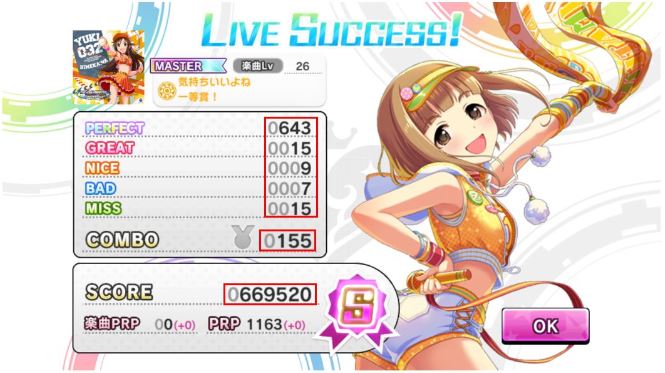
こんなファイルが入ったフォルダを指定するとCSVが出る。
画像(赤枠内が読み取りたいスコア等)
呼び出し方
>python 37-01.py (画像群)
CSV(イメージ)
PERFECT,GREAT,NICE,BAD,MISS,COMBO,SCORE
0643,0015,0009,0007,0015,0155,0669520
...冒頭から今後の課題
いくつか宿題が残っている。これらを順次解消してゆく予定。
汎用化(難易度:低 / 面白味:低)
jsonに書いてから読み込みたい値をハードコーディングしている。
画像ファイルパターン識別(難易度:中 / 面白味:中?)
未分類の無造作なファイルが入ったフォルダから「これはあのゲームの結果画面」「これはこのゲームのステータス画面」とかを判別してほしい。これはあとで分類ね。
精度向上(難易度:? / 面白味:高?)
先の記事の通り3つ読みそこなっている。
少なくともこれは正解しないと。
ただ、NGを探すのは使っていきながらNGを見つけた時に調整してゆく感じなるかなぁ・・・と。
正直、教師データを作るために目視で照合する作業を莫大にやるのがめんどいから、使っていく中で気づいたら直す感じかも。
あっ、Neural Networkを組みたいという思いはあるので、そういう意味では早々に手を入れるつもりです。中間ファイル(難易度:低? / 面白味:低)
OpenCVを使いこなせてないからtmp.pngってファイルを介在させてるけど、これ、ストレージにI/Oする必要ないよね?
重複採取の判別(難易度:低 / 面白味:中?)
スクショなので重複採取する場合がある。それを間引いたり、ゆくゆくは予測精度が高いほうを残すとか。
キャラ判別(難易度:高 / 面白味:高)
キャライラストが出るのでその子を識別(分類)したい。
参考資料
いつも通り手前味噌ですが。
このあたりを組み合わせただけです。
あっ、モデル作成を毎回学習データを作るのは避けたかったので、前回記事にjoblib.dumpを追記しました。
なのでこのスクリプトの中ではモデル作成をしていません。■Python機械学習手遊び(数字分類ことはじめ)
https://qiita.com/siinai/items/8e8f07b9539cd588dad9■Python手遊び(ファイルリスト作成)
https://qiita.com/siinai/items/d654ed0bd38d91a351f7■アイドルマスター シンデレラガールズ スターライトステージ
https://cinderella.idolmaster.jp/sl-stage/出来上がり
#37-01.py import sys import os import numpy as np import cv2 from PIL import Image from sklearn.externals import joblib args = sys.argv #フォルダ未指定だと処理を抜ける if len(args) < 2: exit() folder = args[1] #モデルの取り込み model = joblib.load('model.dmp') #対象画像の読み込み csv = [] csv.append('image,PERFECT,GREAT,NICE,BAD,MISS,COMBO,SCORE') for dirpath, dirs, files in os.walk(folder): for name in files: src = cv2.imread(dirpath + '/' + name, 1) result = dirpath + '\\' + name for j in range(7): result += ',' if j == 6: digi = 7 else: digi = 4 for i in range(digi): if j == 5: dst = src[669:721, 759+36*(i+0):759+36*(i+1)] elif j == 6: dst = src[827:876, 653+36*(i+0):653+36*(i+1)] else: dst = src[344+59*j:388+59*j, 772+33*(i+0):772+33*(i+1)] cv2.imwrite('tmp.png', dst) image = Image.open('tmp.png').convert('L') image = image.resize((8, 8), Image.ANTIALIAS) img = np.asarray(image, dtype=float) img = np.floor(16 - 16 * (img / 256)) img = img.flatten() img = img.reshape(1, 64) #予測 result += str(model.predict(img)[0]) csv.append(result) #書き込み f = open('score.csv', 'a') for line in csv: f.write(line + '\n') f.close()(出力:score.csv) image,PERFECT,GREAT,NICE,BAD,MISS,COMBO,SCORE C:\projects\qiita_data\20190303\score\Screenshot_20190227-234728.png,0608,0012,0005,0004,0007,0321,0799084 C:\projects\qiita_data\20190303\score\Screenshot_20190227-235722.png,0638,0009,0001,0003,0011,0230,0714314 C:\projects\qiita_data\20190303\score\Screenshot_20190228-002050.png,0661,0018,0004,0007,0010,0198,0698258 ...感想
しばらく前から携わっている機械学習とこの前初めて使ってみたOpenCVのおかげでこんなことがこれくらいのコードでできるということが興味深い。
質的変化と量的変化という観点で見てみると面白い。誤解を恐れずいうと、発明が質的変化。改善が量的変化。
ディープマインド社がブロック崩しを解くAIを作ったということが質的変化。
その量的変化の先にAlphaGoがある・・・と、あたしは思っている。
そういう意味であたしの中で、機械学習との出会いは質的変化。
OpenCVは原理的には初めから量的変化の延長線上にあったんだけど、現実的なコードでやれるという意味で質的変化。
一連のQiitaへの投稿と冒頭に記載した課題はすべて量的変化。
質的変化を起こすためには十分な量的変化が必要という話もあった。今まだ自分の中で量的変化を蓄えているところかも。蛇足
よく考えたら、ゲームのスクショの解析は機械学習ではなく、純粋な画像間の類似度計算で行ける気がしてきた。
「判断」の個所を関数化して、切り替えられるようにしようかな。
あと、csv見てるとあまりあたしがうまくないことがはっきりしてくる...orz
- 投稿日:2019-03-24T23:34:45+09:00
Jupyter Notebook で、ノートブックファイルのままdiffをとったり、マージしたり出来るツール nbdime
Jupyter Notebook の問題点
Jupyter Notebook は、ソースコードとアウトプットが一つの ノートブックファイル
.ipynbで管理・実行することができるので、非常に便利です。しかし、その代償として、.ipynbファイルにはソースコード以外のメタデータやアウトプットデータが含まれる為に、ソースコード部分の差分が非常に分かりにくくなってしまいます。
jupytext等で、.pyファイルにエクスポートして diffを取ることも考えられますが、.pyファイルが増えてしまい、本来の.pyファイルと混じって、これはこれで管理しづらい。
結構困る。ノートブックdiffツール nbdime
ノートブックのままdiffをとったりマージしたり出来ないかと思っていたところ、nbdime というツールでばっちりそれができるらしい!
- Github リポジトリ https://github.com/jupyter/nbdime
- 公式ドキュメント https://nbdime.readthedocs.io/en/latest/index.html
さっそく試してみました。
nbdime で出来ること
- ブラウザで、2つのノートブックのdiff を左右に並べて表示。
- コマンドラインでも、ソースコードの部分だけのdiffを表示。つまり、サーバ上でそのままdiffを確認することが出来ます。
- git と融合して使用。
Jupyter Notebook の extention で、ボタン一つで簡単に git diff を実行。
マージ機能
こんなふうに、3ペインのマージも可能。
git mergetool としても使えます。
(公式ドキュメントより)使用例
2つのノートブックのdiff
CUI
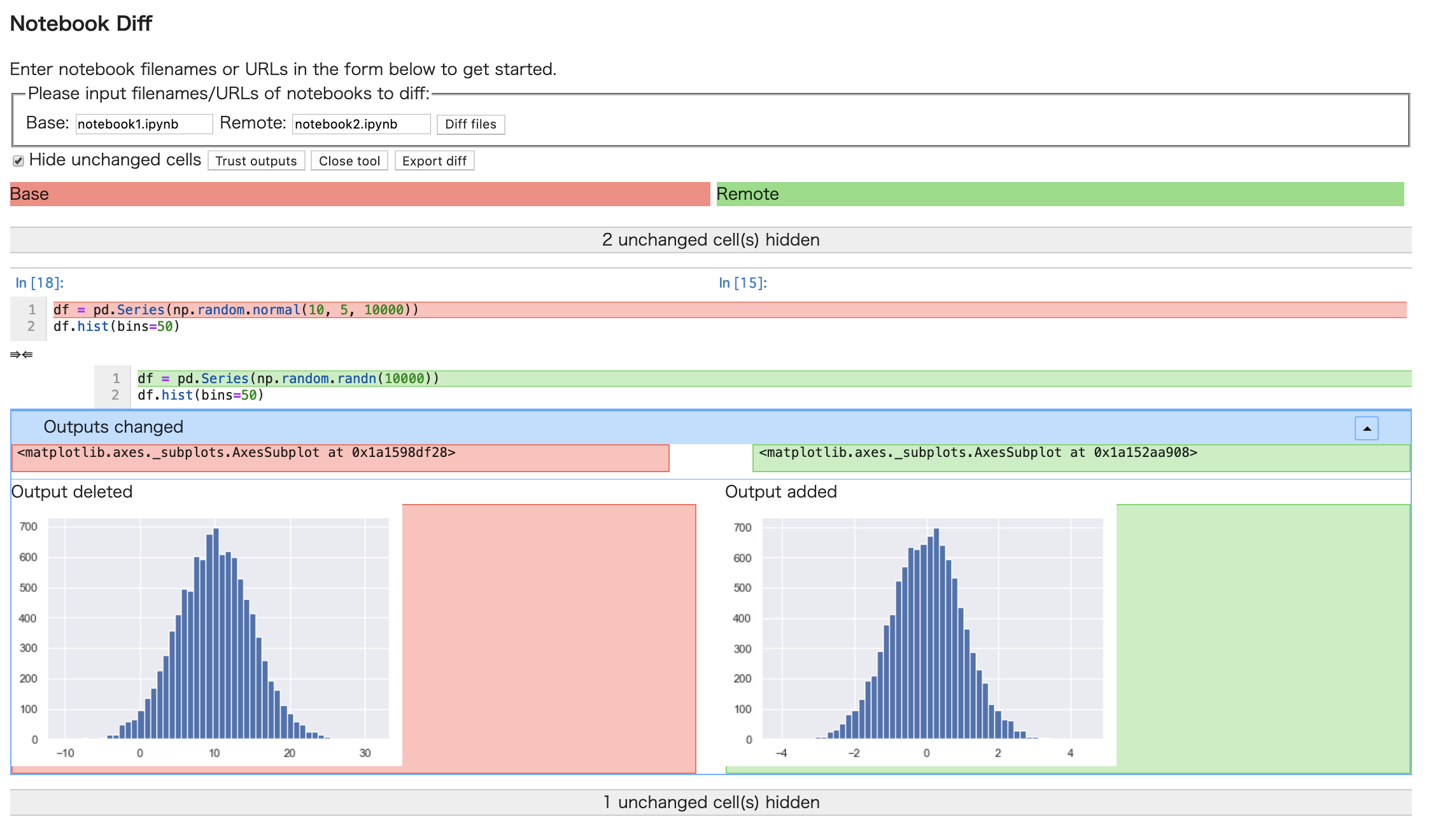
nbdiff -s notebook1.ipynb notebook2.ipynb
-sオプションで、ソースコード( インプットセル)の部分だけdiff を取ることが出来ます。結果(master *+%) $ nbdiff -s notebook1.ipynb notebook2.ipynb nbdiff notebook1.ipynb notebook2.ipynb --- notebook1.ipynb 2019-03-24 20:57:03.681159 +++ notebook2.ipynb 2019-03-24 20:55:42.867497 ## modified /cells/2/source: @@ -1,2 +1,2 @@ -df = pd.Series(np.random.normal(10, 5, 10000)) -df.hist(bins=80) +df = pd.Series(np.random.randn(10000)) +df.hist(bins=50)ソースコード以外にも、オプションで メタ情報、アウトプットを含む・含めないを指定することが出来ます。
GUI
ブラウザでノートブックを左右に並べて比較します。
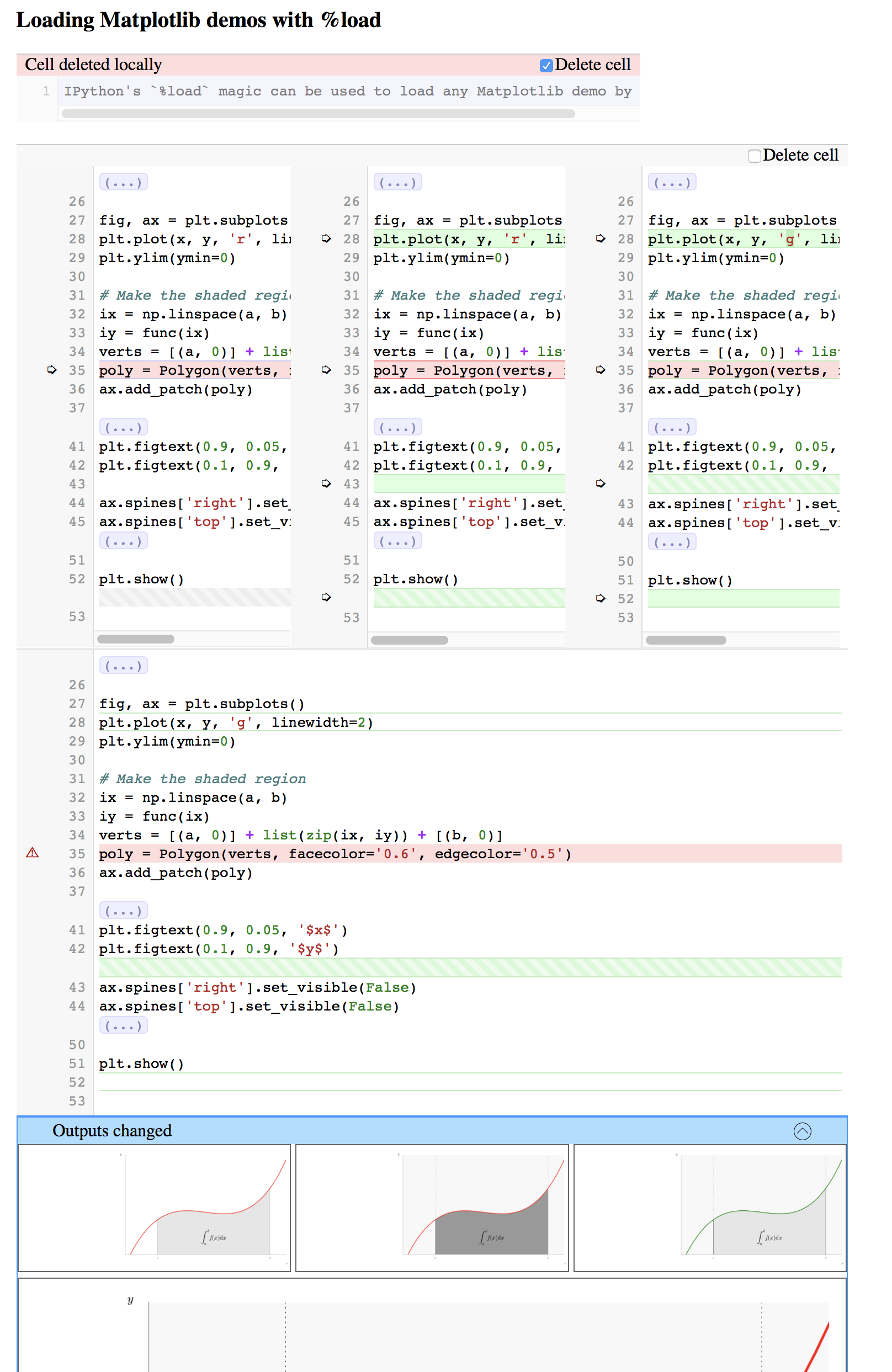
今度は-sを外して、アウトプットの差分も表示してみます。nbdiff-web notebook1.ipynb notebook2.ipynb
-sオプションをはずしたので、アウトプットの画像が異なっていることもわかります。git diff
nbdime config-git --enable --globalを実行しておくことで、ipynb ファイルに対するgit diffは、nbdiff で実行することが出来ます。設定適用前のgit_diff例@@ -20,7 +20,8 @@ "source": [ "import numpy as np\n", "import matplotlib.pyplot as plt\n", - "import hoge\n", + "import seaborn as sns\n", + "\n", "from lightgbm import LGBMRegressor\n" ] },設定適用後のgit_diff例@@ -1,4 +1,5 @@ import numpy as np import matplotlib.pyplot as plt -import hoge +import seaborn as sns + from lightgbm import LGBMRegressorいい感じです。
- 投稿日:2019-03-24T23:34:45+09:00
Jupyter Notebook ファイルのままdiffをとったり、マージしたり出来るツール nbdime
Jupyter Notebook の問題点
Jupyter Notebook は、ソースコードとアウトプットが一つの ノートブックファイル
.ipynbで管理・実行することができるので、非常に便利です。しかし、その代償として、.ipynbファイルにはソースコード以外のメタデータやアウトプットデータが含まれる為に、ソースコード部分の差分が非常に分かりにくくなってしまいます。
jupytext等で、.pyファイルにエクスポートして diffを取ることも考えられますが、.pyファイルが増えてしまい、本来の.pyファイルと混じって、これはこれで管理しづらい。
結構困った問題です。ノートブックdiffツール nbdime
ノートブックのままdiffをとったりマージしたり出来ないかと思っていたところ、nbdime というツールでばっちりそれができるらしい。
- Github リポジトリ https://github.com/jupyter/nbdime
- 公式ドキュメント https://nbdime.readthedocs.io/en/latest/index.html
さっそく試してみました。
nbdime で出来ること
- ブラウザで、2つのノートブックのdiff を左右に並べて表示。
- コマンドラインでも、ソースコードの部分だけのdiffを表示。つまり、サーバ上でそのままdiffを確認することが出来ます。
- git と融合して使用。
Jupyter Notebook の extention で、ボタン一つで簡単に git diff を実行。
Extention のインストール方法
マージ機能
3ペインのマージも可能。
git mergetool としても使えます。
(公式ドキュメントより)使用例
2つのノートブックのdiff
CUI
nbdiff -s notebook1.ipynb notebook2.ipynb
-sオプションで、ソースコード(Codeセル)の部分だけdiff を取ることが出来ます。Markdownセルなども含まれます。結果(master *+%) $ nbdiff -s notebook1.ipynb notebook2.ipynb nbdiff notebook1.ipynb notebook2.ipynb --- notebook1.ipynb 2019-03-24 20:57:03.681159 +++ notebook2.ipynb 2019-03-24 20:55:42.867497 ## modified /cells/2/source: @@ -1,2 +1,2 @@ -df = pd.Series(np.random.normal(10, 5, 10000)) -df.hist(bins=80) +df = pd.Series(np.random.randn(10000)) +df.hist(bins=50)ソースコード以外にも、オプションで メタ情報、アウトプットを含む・含めないを指定することが出来ます。
GUI
ブラウザでノートブックを左右に並べて比較します。
今度は-sを外して、アウトプットの差分も表示してみます。nbdiff-web notebook1.ipynb notebook2.ipynb
-sオプションをはずしたので、アウトプットの画像が異なっていることもわかります。git diff
nbdime config-git --enable --globalを実行しておくことで、ipynb ファイルに対するgit diffは、nbdiff で実行することが出来ます。設定適用前のgit_diff例@@ -20,7 +20,8 @@ "source": [ "import numpy as np\n", "import matplotlib.pyplot as plt\n", - "import hoge\n", + "import seaborn as sns\n", + "\n", "from lightgbm import LGBMRegressor\n" ] },設定適用後のgit_diff例@@ -1,4 +1,5 @@ import numpy as np import matplotlib.pyplot as plt -import hoge +import seaborn as sns + from lightgbm import LGBMRegressor
- 投稿日:2019-03-24T23:33:39+09:00
pi.bat
- 投稿日:2019-03-24T23:28:13+09:00
Windows10 に Python 学習環境を構築する3つの王道
Python を Windows10 で勉強する
3つの王道とその基本的な注意点を整理しました。Windows ユーザーに特有の注意点があるので Windows10 特化型。
最初に王道を行くメリットを整理しておきます。心が途中で惑わされるといけないので!王道を行けば、一番早く「Windows10 で Python を使えるようになる」
自分はこうだから、今はこういうアプリを使ってるから、こういう風に構築したいから、とか考えるより王道から選んだほうがずっと早く確実です。「Anaconda は重いらしい」とか「PyCharm でずっとやっていくのは微妙らしい」とか言ってる場合じゃないです。言ってないか。まあとにかく、早く学習開始するのがいいに決まってる!
王道を行けば、結局一番早く「Python でやりたかったことが出来るようになる」
何が必要か、何が不要か、全部わかってから最後にドンと実行するのが早いに決まってます。自分がやりたいことには具体的には何が必要か、わかってから、不要なものにも手を出すことなく無駄なく最終ゴールへ猫まっしぐら!
王道を行く
さっそく王道を進んでいきます。
Windows10(ローカル)での Python 学習に必要なもの
- Python本体
- 開発環境・学習環境(操作画面)
- ライブラリ(pandasとかmatplotlibとか)
- 何が今どこにあるのかっていう理解
最初の「Hello World!」をやるくらいなら「Python本体」と開発環境はコマンドプロンプトがあれば出来ますが、ライブラリ管理に突入すると少しリッチな画面が欲しくなります。多分。どんどん行きます。
Windows10 に Python 学習環境を構築する3つの王道
まずざっくりと紹介しておきます。
- Python本体だけ入れる
- Anaconda で入れる
- PyCharm で入れる
1. Python本体だけ入れる
- 任意の場所に「c:\pyton\python.exe」のようなデータが入る
- バージョンアップやライブラリの追加は自分でやる
- 古いバージョンのままにしておいたりも出来る
- 最初に使う画面はコマンドプロンプト
- 普通に開くとユーザー権限で開いてしまい pip install とか出来ない
- Windowsではメニュー右クリック→管理者権限で開く必要あり
2. Anaconda で入れる
- 任意の場所に「c:\Anaconda3\python.exe」のようなデータが入る
- Python本体だけ入れた時の python.exe とは別個体の python.exe が Anaconda の中に入るので、2つの別々の Python を使える(バージョン違いとか)
- ライブラリが最初から大量にインストールされる
- 開発環境 Anaconda Prompt で真っ黒ターミナル画面体験
- 普通に開くとユーザー権限で開いてしまい pip install とか出来ない
- Windowsではメニュー右クリック→管理者権限で開く必要あり
- 開発環境 Jupyter Notebook、Spyder で話題の開発画面体験
- Spyderは、Progateとかの「WEB入力学習」体験者が喜ぶ感じ
- Anaconda Navigator でライブラリを一覧管理可能
- 不要になったらアンインストールしてもOK
- Anaconda内部にあったものは消える、Python本体のみインストールしたものがあればそっちは関係ないので残る
- 今自分は Anaconda の Python を使ってるんだと認識しながら使う
3. PyCharm で入れる
- PyCharm(Python のための統合開発環境)をインストール
- 入力予測でどんどん綴りが出てくるので素早く間違いなく書ける
- 望ましくない記述は赤い波線とかで教えてもらえる
- 説明は英語だけどGoogle翻訳でだいたいわかるし英語のStackOverFlowが検索にひっかかってむしろ便利
- Python用なので設定で困ることがほぼ無くて楽、拡張とかも不要
- ライブラリ管理も当然できる
- ボリュームのあるプログラムもガツガツ作れる、デバック、GitやGitHubを使ったバージョン管理等、プログラミングの統合開発環境に普通入っているものは全部入っているので、統合開発環境としての機能を後から追加する必要がなく Python に集中できる
- 汎用的な統合開発環境で Python を使えるようにするより早く確実
他の方法、VS Code、Atom、Sublime Text 等は周辺の設定事項が多いし、「WindowsユーザーはMacOSユーザーとは微妙に違うところあるからMacの人のおすすめを鵜呑みにできない件」があるので割愛します。
楽しいけど、ステップアップする度に色々用意してたら Python学習に集中できないです、たぶん。とっとと Python を使いこなせるようになるのが一番良いに決まってます、たぶん。王道インストール3本ノック
どんどん行きます。
インストール先のディレクトリ(フォルダ場所)
- 現在ログインしているWindowsユーザー限定なら
- ユーザーディレクトリの下にインストール
- 「c:\Users(ユーザー名)\」の下にインストールされる感じ
- 自分専用PCならグローバル環境で↓
- 同じPCを使う全Windowsユーザー向けなら
- c:\ など上の階層(ユーザーディレクトリの外)にインストール
ここを押さえて次へGO
1. Python本体だけ入れる
- インストール先に Python のフォルダができる
- プログラミングソフトでそこにアクセスして使う
インストール時のチェックボックスの意味は下記
- Install launcher for all users (reccommended):チェックすると全ユーザーが使える場所にインストールされる(例)「c:\python\」、その場合は管理者権限が必要、好みの問題もあるが自分はユーザー変更する可能性があるのでチェックする
- Add Python 3.6 to PATH:チェックするとWindowsのコマンドプロンプトを起動した時にすぐ今回インストールした場所にある Python が使える(操作できる)ように環境変数(コマンドプロンプトの接続先みたいなもの)が設定される、好みもあるがネットには「コマンドプロンプトで~」という話がよく出てきて使えたほうが楽なのでチェックする、環境変数は後で必要に応じて変更可能
「インストールした Python のバージョン」、「どこにインストールしたか(全員が使える場所か、現在のWindowsログインユーザーだけが使えるユーザーディレクトリ以下か)」、「環境変数(PATH)はどうなってるか」を理解できたところでインストール完了。
コマンドプロンプトから動かせない場合(-vできない、pipできない等)
- 環境変数(PATH)問題を確認
- コマンドプロンプト(管理者用)問題を確認
- 最初が「C:\Users(username)>」ならユーザー環境
- コルタナさんアイコンから「コマンドプロンプト」検索
- いきなり開かず右クリックすると管理者用で入れる
- Power Shell でもコマンドプロンプトと同じ
- タスクバーのWhindowsマークを右クリック
- タスクバーの設定がデフォルトどおりなら Power Shell がメニューから開けるが「Windows Power Shell」も「管理者用」を選べば管理者権限で開ける
- プロクシ問題を確認
注意点1:Python本体をインストールするだけでも、PATHを通してコマンドプロンプト等で操作すれば簡単なPython学習は開始できるので、一番手軽な方法です。ただし少し勉強が進んでいってからは、pipとか、venvとか、色々な言葉が登場して、まだまだ構築のためにやることが出てきます。黒い画面での操作に今まだ詳しくなくて「すぐグラフを作りたい」というような気持ちの人は、時間を余計なことで溶かしてしまう可能性があるため、こちらの方法はおすすめしません。逆に、まずはコマンドプロンプトを使って少しずつ学び、ライブラリをインストールし、仮想環境を作り、統合開発環境もバージョン管理も使いこなしていくという成長を遂げられそうなら、このコースで遠慮なくのびのび成長してOKです。
注意点2:後からPATHを変更すると(Path を切ると)、インストールしたPython本体とコマンドプロンプトを使った勉強を再開しようとした時に、「あれっ」となると思います。そういう時は再度 Python をインストールした場所にPATHを通せばOKです。
注意点3:このコースでインストールしたPython本体は、この後紹介する方法でインストールするようなもの(Anaconda の Python とか)とは別のもので、別のところにあります。
Python本体だけ入れる場合のインストール手順おすすめ記事
まずはここから!Pythonのインストール方法【初心者向け】‐ TechAcademy2. Anaconda で入れる
- インストール先に Anaconda3 のフォルダができる
- その中に Python.exe が入る(別途Python本体のみインストールしている場合、それとは別に Anaconda の中に生まれる)
- いろいろ全部まとめてインストールされるので重い、親切が過剰
- 最初からライブラリが一気にドンと乗る
- Anaconda に入っているもの
- Python本体(Anaconda の中にできる、1.の方法でインストールされるものとは別個体)
- Anaconda Navigator(操作ソフト/各種ライブラリ管理/学習コンテンツ/コミュニティ紹介が入った案内ソフト)
- ライブラリ群(pandasとかmatplotlibとか)、これはAnaconda Navigator で見やすい一覧を見ながら、「インストール済」とか確認できるようになっているので、あとから削除したりインストールしたり管理できる
- Anaconda Prompt(コマンドプロンプト的黒画面、ユーザー環境で開くので)
- Jupyter Notebook(元はIPython、最初の勉強に良いかも)
- Spyder(科学用途のプログラミングを想定した統合開発環境)
インストール時のチェックボックスの意味は下記
- Install for : Just Me (recommended) → ユーザー環境下にインストール
- Install for : All Users (requires admin privileges) → c:\ とかユーザー横断の公共環境下にインストール、自分は個人用PCでユーザーは変更可能性があるのでこっち
- Destination Folder → インストール先、自分は c:\ の直下近くを選択
- Advanced Options
- Add Anaconda to my PATH environment variable → チェックするとWindows標準のコマンドプロンプトから「AnacondaのPython」にアクセスするようにPATHを設定してくれる
- 「Python本体だけ入れる」をやった人は選択しなくてOK(入れてある Python に PATH が通してあるはずだから、ここで「AnacondaのPython」にPATHを通す必要はない)
- 今後別途「Python本体」を入れる可能性がある人もチェックする必要なし
- ほとんどの人は「Python本体はPython本体、Anaconda内のPythonはAnaconda内のPython」で別れていて困らないはずなのでチェックする必要なし
- Register Anaconda as my default Python → Anaconda をデフォルトのPython用ソフトにしますかって感じだが、上記PATH同様、たぶん誰もが「Anaconda のみにて生きるにあらず」って感じだと思うので、余計な設定にならないようにチェック外しておけばOK
- ただし Anaconda だけインストールした状態で、「Python本体は無い」人が、後で「Pythonが使えるようになったぜ」と思ってWEB上の記事をあれこれ読み、「コマンドプロンプトでこの操作をしろ」と言われてやってみたけど思ったような結果が得られないと言うことはあり得る、自分がどこにどのPythonをインストールしているのか、くれぐれも意識的に!
- Anaconda にいろいろおまかせしすぎて、いよいよ別途本体だけインストールした Python をコマンドプロンプトから操作しようとしたら、全くうまくいかなくてよくわからなくなっちゃった場合は、そっと Anaconda を一度アンインストールすればOK、次にインストールする時は PATHも通さない、my default Python にしない
一緒におすすめされる VSCode(Visual Studio Code) はひとまず不要
- VS Code は最高だけど、Windowsユーザーで初心者だと設定がツライので、特にデータサイエンティスト志向なら不要だと思う
- VS Code のインストール先は聞かれなかった気がするけど、オールユーザーでAnaconda 使うって言ってCドライブ直下に Anaconda をインストールする人でも、ここで VS Code を一緒にインストールするとユーザーフォルダ下にインストールされる(ような気がする)
- VS Code は Anaconda Navigator からも、自分でWEBからダウンロードしても後からいくらでも自由に入れられる(後から Anaconda Navigator で入れたらユーザーフォルダ内になったのかなあ…)
- だがしかし初心者にはおススメできない
- Windows + VS Code + Python はまだまだマゾの道だと思うので、なんか出来そうと思っても、ツラくなるはずなので(多分)ツラくなったら一旦アンインストールでOK
- 初心者は VS code に惑わされず、Anaconda に入ってる Jupyter Notebook で勉強したり、PyCharm を使ったほうが少ない環境構築労力ですぐに勉強できる
Anaconda で入れる場合のインストール手順おすすめ記事
より効率よく開発できる!AnacondaでPythonの環境を構築する方法3. PyCharm で入れる
- PyCharm で Python を入れると、あれこれ詰まずに急に Python のリッチなプログラミング環境が整う
- インストールで詰まることは無いと思うし疲れちゃったので割愛
- 使い方については、慣れていなければ調べる必要があるかも
- なんだかんだで渋々 InteliJ を使っていくと最後はクセになる、はず
- Android Studio も入れてるから最後まで使うか迷ったけどWindowsユーザーは黙って入れる必要があると感じたので王道にランクイン
- ばっちり動くので結局好きになる
学習開始!
環境は整ったのでガツガツ学習! ガツガツ!
このあとは仮想環境について知っておくと良いと思うのでおすすめ記事にリンク貼っておきます。仮想環境に関するおすすめ記事
Python の実行環境を切り替えて使用する (virtualenv) - まくまくPythonノート
- 投稿日:2019-03-24T23:15:29+09:00
Python自作プログラム(Pyhttpd)徹底解説!!
概要
前回の記事では私が作った自作プログラムのソースと、ソースを理解するためのPythonにおけるクラスなどの基本について解説しました。
今回の記事では前回載せたソースについて詳しく解説していきます。プログラム徹底解説
モジュールインポート
pyhttpd.pyimport BaseHTTPServerこれは前回の記事でも説明した通り、PythonでHTTP通信をするために作成された他のプログラムを使用するために読み込ん(インポート)でいます。
BaseHTTPServerに関するメソッドやインスタンスについてはこちらのマニュアルを参考にしてみてください。クラス定義
pyhttpd.pyclass MyRequestHandler(BaseHTTPServer.BaseHTTPRequestHandler):このプログラムでPOST、GETを使うためのクラスを定義します。
このクラスを定義し、その中でPOSTとGETのメソッドをしてインスタンス化することでPOSTとGET機能を使えるようになります。
()の中にBaseHTTPServer.BaseHTTPRequestHandlerという記述がありますが、
これはクラスの継承と呼ばれるものです。
クラスを定義する際に他のクラスをここに書くことで、書いたクラスのメソッドやインスタンスを使うことができます。メソッド定義
pyhttpd.pydef do_POST(self): def do_GET(self):実際にGET、POSTの処理を定義するメソッドを定義します。
メソッド名は基本的に自由につけることができますが、
今回の場合はBaseHTTPServerモジュールの中で「do_」というメソッド名をつけることで自動的にPOST・GETリクエストに対してメソッドを呼び出してくれます。selfはメソッドを定義する際には必ず必要となる第1引数です。
メソッドがインスタンスやクラス変数などにアクセスする際に必要になるものであると考えてください。メソッドの中の詳細
pyhttpd.py#全インスタンス定義 1 client_address = self.client_address 2 server = self.server 3 path = self.path 4 request_version = self.request_version 5 server_version = self.server_version 6 sys_version = self.sys_version 7 8 #content_len = int(self.headers.get('content-length')) 9 #requestbody = self.rfile.read(content_len).decode('utf-8') 10 #print(content_len) 11 #print('requestbody=' + requestbody) 12 print('client_address = ' + client_address[0] + ' ' + str(client_address[1])) 13 print('server = ' + server.server_name + ' ' + str(server.server_port)) 14 print('path = ' + path) 15 print('request_version = ' + request_version) 16 print('server_version = ' + server_version) 17 print('sys_version = ' + sys_version) 18 self.send_response(200) 19 self.end_headers() 20 21 # POSTリクエストに対して返却するHTMLを記述 22 f = open("/usr/local/scripts/put.html",'r') 23 self.wfile.write(f.read()) 24 f.close()1~6行目についてはこのメソッドの中で使う変数を定義しています。
self.client_addressとありますが、
継承したBaseHTTPServer.BaseHTTPRequestHandlerクラスの中にはclient_addressというインスタンスが定義してあり、
このself引数を使用してclient_addressというインスタンスにアクセスしています。12~17行目は取得したインスタンスの中身を出力しています
18行目はクライアントからPOSTリクエストが来た際に返すステータスコードを定義しています。
実際にPSOTリクエストを送ると以下のようなレスポンスが返ってきます。HTTP/1.0 200 OKこの200が18行目で定義した200にあたります。
19行目はここでヘッダーに返す部分が終了することを表します。
これ以降に書かれた部分についてはメッセージボディ部分でクライアントに返されます。22~24行目で実際にクライアントに返すメッセージボディ部分を定義します。
pyhttpd.pyf=open('/usr/local/scripts/put.html', 'r')ここでPOSTリクエストが来た際に返されるhtmlをここで開いています。
Pythonでファイルを扱う場合はファイルを読み込んで開き、処理を行う必要があります。
open関数を使って開き、close関数を使ってファイルを閉じます。
ここで実際に返しているput.htmlの中身は以下になります。put.html<!DOCTYPE html> <html lang="ja"> <head> <meta charset="utf-8"> <title>送信後ページ</title> </head> <body> <h1>データ送信後ページ</h1> <p>data was sent!</p> </body> </html>open関数で返されるものはファイルオブジェクトになります。
23行目でメッセージボディとして返す内容(htmlファイル)をメモリに書き込みます。
24行目でopen関数によって開いたファイルを閉じています。
POSTリクエストではリクエストによって送信されてきたデータをこのメソッドの中で処理しているイメージになります。pyhttpd.pyself.send_response(200) self.end_headers() f = open("/usr/local/scripts/index.html", 'r') self.wfile.write(f.read()) f.close()これはGETメソッドの処理を定義しています。
既に解説したPOSTメソッドの処理とほとんど同じですので詳細は割愛します。インスタンス生成
pyhttpd.pyserver = BaseHTTPServer.HTTPServer(('192.168.15.80',50080),MyRequestHandler) server.serve_forever()クラスは定義しただけではメソッドなどを使えないと説明しました。
最初の部分で実際にクラスをインスタンス化
定義したクラスは定義するインスタンス名 = クラス名()
のようにすることで定義します。
今回はHTTPの機能を使うためにインポートしたモジュールをインスタンス化しています。
BaseHTTPServer.HTTPServerクラスは引数として、((<サーバーとして受け付けるIPアドレス>,ポート番号),メソッドの処理を定義したクラス)
をとります。
今回は「メソッドの処理を定義したクラス」を私が自分で定義したMyRequestHandlerを使用しています。最後の
pyhttpd.pyserver.serve_forever()この部分で実際に作成したインスタンスからソケットを作成し、リクエストをリッスンしています。
このserve_forever()メソッドはSocketServerモジュールの中で定義してあるメソッドになります。
BaseHTTPServerモジュールはSocketServerモジュールを継承して作られているため、
SocketServerモジュールのメソッドも使用可能となっています。まとめ
いかがでしたでしょうか。
以上が今回私が自作したプログラムの解説になります。
今回の説明でわかりにくい部分などがあればコメントなどを頂ければ詳しく解説いたします。
- 投稿日:2019-03-24T23:08:25+09:00
flask-sqlalchemyで 行き先掲示版
はじめに
- WEBで見える/更新できる、行き先掲示板を作ってみた
- 今後
- コンボボックスで行き先を選択する
- 行き先はdbに持つ
- 行き先メンテナンスもしたい
- 時間をtimepikerで入力する
- 見栄え
- ロジックがダサい
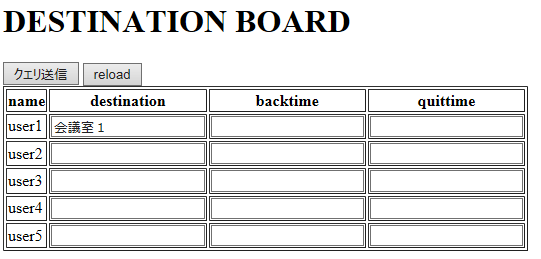
サンプル(IE11)
構成
│ app4svr.py │ app4db.py ...事前にDB作成する用のpy ├─ templates │ └─ app4.html └─ static ...空app
app4svr.py
#svr.py from flask import Flask, render_template, request from flask_sqlalchemy import SQLAlchemy app = Flask(__name__) # DB設定 app.config['SQLALCHEMY_DATABASE_URI'] = 'sqlite:///app4.db' app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = True db = SQLAlchemy(app) # db.Model を継承してクラスを定義 class Board(db.Model): __tablename__ = 'Board' #id #name 名前 #destination 行き先 #backtime 戻り予定 #quittime 退社予定 id = db.Column(db.String(3), primary_key=True) name = db.Column(db.String(20)) destination = db.Column(db.String(20)) backtime = db.Column(db.String(5)) quittime = db.Column(db.String(5)) #def __init__(self, id , name , destination , backtime , quittime ): def __init__(self, id , name ): self.id = id self.name = name self.destination = '' self.backtime = '' self.quittime = '' #self.destination = destination #self.backtime = backtime #self.quittime = quittime @app.route("/" , methods=["GET", "POST"]) def board(): if request.method == "GET": # boardsをid昇順で取得 boards = Board.query.order_by(Board.id).all() # テンプレートにwordsを渡す return render_template('app4.html', boards=boards) if request.method == "POST": def chkupd( id ): row = Board.query.get(id) #destination cellid = 'col' + id + 'b' if request.form[cellid] != row.destination : row.destination = request.form[cellid] #backtime cellid = 'col' + id + 'c' if request.form[cellid] != row.backtime : row.backtime = request.form[cellid] #quittime cellid = 'col' + id + 'd' if request.form[cellid] != row.quittime : row.quittime = request.form[cellid] db.session.commit() # rowが更新ありかチェック chkupd( 'u1' ) chkupd( 'u2' ) chkupd( 'u3' ) chkupd( 'u4' ) chkupd( 'u5' ) # 再表示 # boardsをid昇順で取得 boards = Board.query.order_by(Board.id).all() # テンプレートにwordsを渡す return render_template('app4.html', boards=boards) if __name__ == '__main__': app.run(debug=True)app4db.py
#db.py from app4svr import db, Board # テーブル作成 db.create_all() # word のリストを作成 board_list = [('u1','user1'), \ ('u2','user2'), \ ('u3','user3'), \ ('u4','user4'), \ ('u5','user5') \ ] boards = [Board(d[0],d[1]) for d in board_list] # 複数行インサート db.session.add_all(boards) db.session.commit()app4.html
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title>Hello,Alchemy World!</title> </head> <body> <div> <h1> DESTINATION BOARD </h1> <!-- ul でboardsを表示 --> <form method="post" action="/"> <input type="submit" > <input type="button" value="reload" onclick="window.location.reload();" /> <table border="1"> <!-- #name 名前 --> <!-- #destination 行き先 --> <!-- #backtime 戻り予定 --> <!-- #quittime 退社予定 --> <tr> <th>name</th> <th>destination</th> <th>backtime</th> <th>quittime</th> </tr> <!-- 配列 boards の件数分、li の表示を繰り返す --> {% for board in boards %} <tr> <td>{{ board.name }}</td> <td><input type="text" name="col{{ board.id }}b" value="{{ board.destination }}"></td> <td><input type="text" name="col{{ board.id }}c" value="{{ board.backtime }}"></td> <td><input type="text" name="col{{ board.id }}d" value="{{ board.quittime }}"></td> </tr> {% endfor %} </table> </form> </div> </body> </html>
- 投稿日:2019-03-24T22:48:34+09:00
Instagram-Crawlerを使ってみた
インスタグラムで複数タグ検索ができたら便利だなぁと思い、まずはクローラーを探すところから。
https://github.com/huaying/instagram-crawler
下準備
chromedriverをダウンロード。
https://sites.google.com/a/chromium.org/chromedriver/
バージョンはインストールされているChromeブラウザと合わせること。
inscrawler/bin/に設置。pip
pip install -r requirements.txtパスワードの設定
cp inscrawler/secret.py.dist inscrawler/secret.pysecret.pyにインスタのユーザー名とパスワードを入力します。
実行
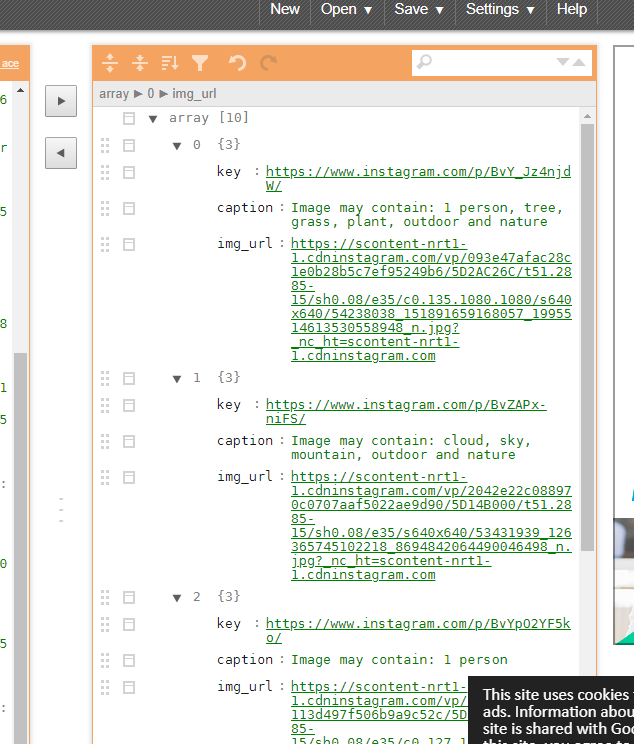
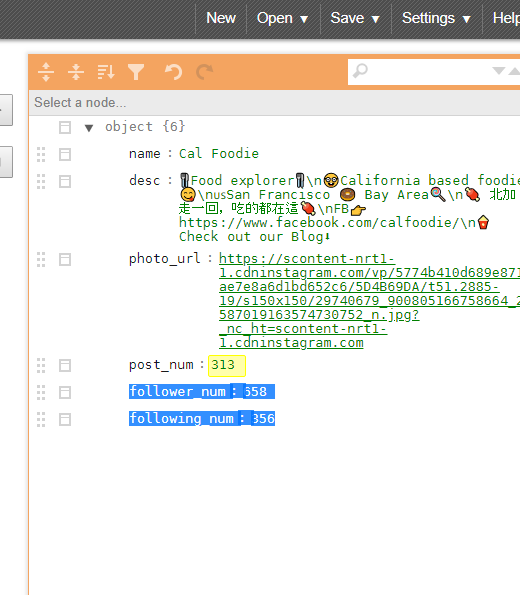
Z:\workdir\instagram-crawler>python crawler.py hashtag -t tokyo -n 10 -o ./output DevTools listening on ws://127.0.0.1:63614/devtools/browser/436e50fa-07b0-4b55-aca3-e6af1124cf66 fetching: : 33it [00:01, 21.54it/s] Done. Fetched 10 posts. Z:\workdir\instagram-crawler>hashtag モードだとkey,caption,img_url が取得できるようです
profile はプロフが取得できるようです
なんかもっと遊びたいですねー。
Ref
https://github.com/futurice/secret
https://stackoverflow.com/questions/55201226/session-not-created-this-version-of-chromedriver-only-supports-chrome-version-7
- 投稿日:2019-03-24T22:10:00+09:00
【Python】Arduino で温度センサーから室温を取得して画面に表示する(後編)
前回の記事:【Python】Arduino で温度センサーから室温を取得して画面に表示する(前編) の続きです。
Python 側ではシリアル通信モジュールを利用して、USB シリアル通信から室温データを取得します。
取得は思ったよりも簡単でしたが、インターフェースが USB なのでデバイスの抜き差しに関するコーティングがそこそこ大変でした。やりたいこと
- Arduino で温度センサーから室温を取得
- USB シリアル通信で RaspberryPi に室温データを送る
- Python で受信して画面に室温を表示する ← 今ここ!
後半で用意するもの
- Arduino Duemilanove と温度センサー一式
- Raspberry pi 3 Model B Rev 1.2 - Raspbian 9.6 (Stretch) - Python 3.5.3
こだわりポイント
- 起動時に USB が挿さっていない(シリアル通信が行われていない)場合は気温表示を無効化
- 表示中に USB が抜かれた場合は直ちに気温表示を無効化
- USB が刺さった(シリアル通信が開始・再開した)場合は直ちに表示を有効化
- USB はどのポートに挿しても問題なく認識する
- そもそも USB 抜き差し程度の例外エラーで Python プログラムが止まることはあり得ない
GitHub(Version 3.1)
https://github.com/km7902/DesktopClock
処理フロー
- プログラム開始
- デバイスがあるか検索
- シリアルポートを初期化(デバイスがあれば)
- 通信を開始し、約 1 秒ごとに気温を取得
- 通信を終了後にプログラム終了
プログラム開始
シリアル通信の状態を管理するため、変数
self.ser_initを定義します。
True のときは通信準備完了(通信中でない場合も含む)、False のときは通信準備中です。sensor.py# センサー表示クラス class Sensor(Frame): # コンストラクタ def __init__(self, master): # 通信準備中 self.ser_init=Falseデバイスがあるか検索
dev_search()で RaspberryPi に接続中のデバイスリストを取得します。
その中から Arduino Duemilanove(FT232R USB UART)があればセンサーデバイス名(/dev/ttyUSBx)を返却します。該当するものが無ければ空白を返します。参考:python の pyserial で 自動でarduino unoに接続する - Qiita
sensor_setting.py# センサーデバイスを検索 def dev_search(): dev="" # デバイスリストを取得 devices=serial.tools.list_ports.comports() for device in devices: # センサーデバイス名を取得 if device.usb_description()=="FT232R USB UART": dev=device[0] # センサーデバイス名を返却 return devシリアルポートを初期化(デバイスがあれば)
dev_search()がデバイス名を返した場合はそのポートに接続を試みます。
問題なければself.ser_init変数を True にして通信準備完了状態に変更します。
例外エラー発生時は何もせず、次のタイミングで再接続を試みます。また、通信中にデバイスが取り外された(通信準備完了かつ、認識されていない)場合は一旦接続を終了します。
sensor.py# 表示を更新 def update(self): # センサーデバイスを探す dev=sensor_setting.dev_search() try: # 通信準備中かつ、センサーデバイスが OS に認識されている場合 if not self.ser_init and dev!="": # シリアル通信の初期化 self.ser=serial.Serial(dev, sensor_setting.bps, timeout=sensor_setting.timeout) # 通信準備完了 self.ser_init=True # 例外時は何もしない except: pass # 通信準備完了かつ、認識されていない場合 if dev=="" and self.ser_init: # シリアル通信を終了 self.ser.close() # 通信準備中 self.ser_init=False通信を開始し、約 1 秒ごとに気温を取得
self.ser.open()により、通信中となります。
バッファから 1 行受信し、改行コード削除、utf-8 へ変換、整数値変換を経て画面に表示します。
例外エラー発生時は無効表示に切り替えます。sensor.pytry: # シリアル通信を開始 if self.ser.is_open==False: self.ser.open() # 1行受信(b'気温¥r¥n' の形式で受信) serval=self.ser.readline(self.ser.inWaiting()) # 改行コードを削除(b'気温') serval=serval.strip() # バイナリ形式から文字列に変換(気温) serval=serval.decode("utf-8") # 気温を更新 self.wst2.configure(text="{0}°c".format(round(float(serval)))) # 例外時 except: # 気温表示を無効化 self.wst2.configure(text="-°c") # 1秒後に再表示 self.master.after(1000, self.update)通信を終了後にプログラム終了
プログラム終了時にクラスが破棄されますが、その前にデストラクタが呼び出されます。
そのタイミングでシリアル通信を終了させます。sensor.py# デストラクタ def __del__(self): # 通信準備完了の場合 if self.ser_init: # シリアル通信を終了 self.ser.close()ソースコード全体
sensor.pyfrom tkinter import Tk, Frame, Label import os import sensor_setting import serial import sys import time # センサー表示クラス class Sensor(Frame): # コンストラクタ def __init__(self, master): # 親クラスのコンストラクタ super().__init__(master, bg="white") # スペーサ(センサー表示上部の間隔調整) self.wsp=Label(self, bg="white") self.wsp.pack(pady=20) # 温度表示 self.wst1=Label(self, text="気温", bg="white", font=("Sans", 20, "bold")) self.wst1.pack(anchor="e", padx=20, pady=5) self.wst2=Label(self, text="-°c", bg="lightblue", font=("Carlito", 40, "bold")) self.wst2.pack(anchor="e", padx=20) # 湿度表示 self.wsh1=Label(self, text="湿度", bg="white", font=("Sans", 20, "bold")) self.wsh1.pack(anchor="e", padx=20, pady=5) self.wsh2=Label(self, text="-%", bg="silver", font=("Carlito", 40, "bold")) self.wsh2.pack(anchor="e", padx=20) # 気圧表示 self.wsp1=Label(self, text="気圧", bg="white", font=("Sans", 20, "bold")) self.wsp1.pack(anchor="e", padx=20, pady=5) self.wsp2=Label(self, text="1013", bg="white", font=("Carlito", 40, "bold")) self.wsp2.pack(anchor="e", padx=20) # 通信準備中 self.ser_init=False # デストラクタ def __del__(self): # 通信準備完了の場合 if self.ser_init: # シリアル通信を終了 self.ser.close() # 表示を更新 def update(self): # センサーデバイスを探す dev=sensor_setting.dev_search() try: # 通信準備中かつ、センサーデバイスが OS に認識されている場合 if not self.ser_init and dev!="": # シリアル通信の初期化 self.ser=serial.Serial(dev, sensor_setting.bps, timeout=sensor_setting.timeout) # 通信準備完了 self.ser_init=True # 例外時は何もしない except: pass # 通信準備完了かつ、認識されていない場合 if dev=="" and self.ser_init: # シリアル通信を終了 self.ser.close() # 通信準備中 self.ser_init=False try: # シリアル通信を開始 if self.ser.is_open==False: self.ser.open() # 1行受信(b'気温¥r¥n' の形式で受信) serval=self.ser.readline(self.ser.inWaiting()) # 改行コードを削除(b'気温') serval=serval.strip() # バイナリ形式から文字列に変換(気温) serval=serval.decode("utf-8") # 気温を更新 self.wst2.configure(text="{0}°c".format(round(float(serval)))) # 例外時 except: # 気温表示を無効化 self.wst2.configure(text="-°c") # 1秒後に再表示 self.master.after(1000, self.update) # 単独処理の場合 def main(): # メインウィンドウ作成 root=Tk() # メインウィンドウタイトル root.title("Sensor") # メインウィンドウサイズ root.geometry("1024x768") # メインウィンドウの最大化 root.attributes("-zoom", "1") # 常に最前面に表示 root.attributes("-topmost", True) # メインウィンドウの背景色 root.configure(bg="white") # Sensor クラスのインスタンスを生成 sensor=Sensor(root) # 画面に配置 sensor.pack(expand=1, fill="y") # センサー表示の更新を開始(update メソッド呼び出し) sensor.update() # メインループ root.mainloop() # import sensor による呼び出しでなければ単独処理 main() を実行 if __name__ == "__main__": main()sensor_setting.pyfrom tkinter import Tk, messagebox import serial.tools.list_ports import sys bps="9600" # 通信速度は固定 timeout=None # タイムアウトなし # センサーデバイスを検索 def dev_search(): dev="" # デバイスリストを取得 devices=serial.tools.list_ports.comports() for device in devices: # センサーデバイス名を取得 if device.usb_description()=="FT232R USB UART": dev=device[0] # センサーデバイス名を返却 return dev # import sensor_setting による呼び出しでなければ単独処理を実行 if __name__ == "__main__": # デバイスを検索 dev=dev_search() # メッセージボックスだけ表示する root=Tk() root.withdraw() # 検索結果を表示 if dev!="": messagebox.showinfo("結果", "センサーデバイス名:\n" + dev) else: messagebox.showerror("結果", "センサーデバイスが見つかりませんでした") # 終了 sys.exit()成果
※湿度と気圧はダミー表示です。課題
- Python プログラムを複数プロセス同時に起動すると、古いプロセスが新しいプロセスにシリアル通信を奪われる
- 秒単位で目紛しく気温が変わるので 1 分単位に丸めた方が良い?
- エラー発生時の原因がわかりにくい

- 投稿日:2019-03-24T21:40:03+09:00
Googlemap API で全てのピンを地図内に収めたい時
Webアプリケーションを作っていてGooglemap API関連の機能を作っていると
登録した地点全てを地図内に収めたい時がある。写真で言うとこんな感じ。
それを行うにはJavascriptで実現していく。ネットにはいろいろ上記を実現させる方法が
書いてあったがあまり上手くいかなかった。。今回、採用したのは以下のアルゴリズム
・初めに出来る限り、ズームアップしておく。
・次に一つ一つ対象のデータを見てそのピンが地図内に収まるようにズームアウトしていく
である。
以下にソースを載せておく。
map.jsfunction initMap() { map = new google.maps.Map(document.getElementById('map'), { center: {lat: ave_latitude, lng: ave_longitude} , zoom: 16, }); var bounds = new google.maps.LatLngBounds(); for (var i = 0; i < data.length; i++) { markerLatLng = {lat: data[i]['lat'], lng: data[i]['lng']}; marker[i] = new google.maps.Marker({ position: markerLatLng, map: map }); bounds.extend(new google.maps.LatLng(data[i]['lat'], data[i]['lng'])); } map.fitBounds (bounds); }
- 投稿日:2019-03-24T21:21:45+09:00
Pythonの状態遷移パッケージ(transitions)を理解する【状態編3】
Pythonで状態遷移を実装したり動作確認をしたい方に、Pythonの状態遷移パッケージ「transitions」の使い方を説明していきたいと思います。
transitionsはPythonで状態遷移を実現するためのパッケージで、状態遷移そのものは組込みとか制御などでよく使われるものですが、それをPythonで実現したい場合にこのパッケージが有用かと思います。
その他、transitionsの概要やインストール方法、当記事で作成している状態遷移図といったグラフ表示機能の導入(GraphMachine)や設定については準備編の記事を参照頂けたらと思います。今回の話
「状態編2」ではtransitionsの「状態」に関するカスタムステートであるタグ機能と終端状態例外について紹介しました。
今回は残りのカスタムステートについて説明します。主に以下の内容になりますが、基本的に全て状態に設定される内容になります。
- 各状態でのクラスオブジェクト生成 (Volatile機能)
- 状態のタイムアウト (Timeout機能)
- add_state_featuresとカスタムステートについて
状態編2ではタグや状態遷移例外など、特定状態の識別や終端状態での例外的な話でしたが、今回は各状態でのオブジェクト生成や特殊なコールバックの話になります。
また独自のカスタムステートを作る方法についても若干触れています。まずは上から順に説明していきます。各状態でのクラスオブジェクト生成 (Volatile機能)
Cをやってきた方にとってコンパイル時に最適化を抑制するためにvolatile宣言することがままありますが、ちょっとその印象とは違います。
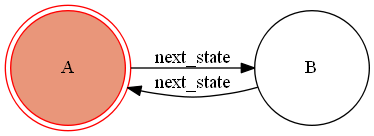
Volatileを辞書で引くと「揮発性」という訳がヒットしますが、transitionsにおけるVolatileクラスはその意味合いが強い印象です。transitionsパッケージにおけるVolatile機能は「状態に入る度にクラス型オブジェクトがmodelに割り当てられる」というもので、そのクラス型オブジェクトはその状態にいる間のみで有効になります。
ともあれ例をみてみましょう。Volatile機能の簡単な定義例from transitions import Machine from transitions.extensions.states import add_state_features, Volatile # Volatile機能を使う宣言 @add_state_features(Volatile) class CustomMachine(Machine): pass # 状態毎に作成されるクラスの定義 class VolatileClass(object): def __init__(self): self.data = 1 def increase(self): self.data += 1 # ステートマシンが割り当てられるクラス定義 class Model(object): pass # Volatile機能付き状態の定義 states = [{'name':'A', 'volatile':VolatileClass}, {'name':'B', 'volatile':VolatileClass}] model = Model() machine = CustomMachine(model=model, states=states, initial=states[0]["name"], auto_transitions=False, ordered_transitions=True)こちらをGraphMahineで再定義して図示すると以下の通りになります。
ordered_transiitons=Trueにより順序遷移が付与されていることに注意ください。
なんの変哲も無い2状態のステートマシンですが、状態に入る度にVolatileClassが状態に対し生成されます。
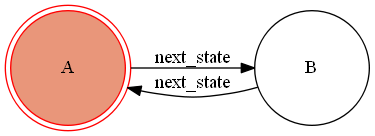
以下、動作例になります。初期状態(状態A)ではまだVolatileClassオブジェクトが割り当てられていないので、まず次の状態に遷移します。>>> model.next_state() True状態Bに遷移したので状態BにおいてVolatileClassオブジェクトが生成されました。それでは内容を確認していきましょう。
まずVolitileClassですが以下のようにself.dataというメンバ変数を持ち、それを1インクリメントするincreaseメソッドを持ちます。VolatileClassの定義class VolatileClass(object): def __init__(self): self.data = 1 def increase(self): self.data += 1現在このクラス型オブジェクトが状態Bに作られており、以下のように操作することができます。
状態BでのVolatileClassオブジェクト操作(1回目)>>> model.state # 現在の状態を確認 'B' >>> model.scope.data # VolatileClassのメンバ変数dataにアクセス 1 >>> model.scope.increase() # VolatileClassのメソッドを実行 >>> model.scope.data 2さらにメンバ変数を追加するといった事も可能です。
以下、元々持っていなかったtextメンバ変数を追加してみましょう。状態BでのVolatileClassオブジェクトへのメンバ変数text追加>>> model.scope.text # メンバ変数textは元々持っていないので例外が発生 Traceback (most recent call last): File "<input>", line 1, in <module> AttributeError: 'VolatileClass' object has no attribute 'text' >>> model.scope.text = 'text-B!' # メンバ変数textを追加 >>> model.scope.text 'text-B!'このように状態Bに割り当てられたVolatileClassオブジェクトをscopeという属性名を用いてアクセスすることができます。
さて、次は状態Aに戻って同様にVolatileClassを確認してみましょう。>>> model.next_state() True
これで状態AにもVolatileClassが生成されました。状態AでのVolatileClassオブジェクト操作model.state # 現在の状態を確認 'A' model.scope.data # VolatileClassのメンバ変数dataにアクセス 1 model.scope.text # 状態Bで追加したメンバ変数textを確認 Traceback (most recent call last): File "<input>", line 1, in <module> AttributeError: 'VolatileClass' object has no attribute 'text'この例から分かる通り、「ある状態で生成されたVolatileClassオブジェクトは引き継がれない」という事になります。
それでは状態Bに再度戻った際、先ほど状態BでのVolatileClassオブジェクトはどうなっているでしょうか。状態Bに戻って確認してみます。>>> model.next_state() True
先ほどは状態BのVolatileObjectにdata=2、text='text-B!'という値/文字列が割り当てられていました。状態BでのVolatileClassオブジェクト操作(2回目)model.state # 現在の状態を確認 'B' model.scope.data # VolatileClassのメンバ変数dataにアクセス 1 model.scope.text # 前回状態Bにいた時に追加したメンバ変数textを確認 Traceback (most recent call last): File "<input>", line 1, in <module> AttributeError: 'VolatileClass' object has no attribute 'text'これで大体わかったと思いますが、以前の状態Bで追加した内容も綺麗さっぱり初期化されおり、以前の操作にかかわらず状態に入った際に新しくVolatileClassオブジェクトが作られ初期化されるということになります。ですので、状態に入る毎にVolatileClassのコンストラクタ (def __init__(self))が実施されます。
こういう特性を持っているためVolatile (揮発性)という名が付いているのだと思います。Volatile機能のまとめと注意点
Volatileで追加指定可能な状態定義をまとめると以下の通りになります。
- volatile:状態に入った際に生成されるクラス指定
- hook:クラスオブジェクトへのアクセス属性名(default : 'scope')
なお、VolatileクラスはStateクラスの派生クラスなので、Stateクラスと同様のメソッドやメンバ変数を扱えるだけでなく、他のState派生クラスと同様に以下のように宣言することも可能です。
Volatileクラスを用いた状態の定義states = [Volatile(name='A', volatile=VolatileClass, hook='volatile'), Volatile(name='B', volatile=VolatileClass, hook='temp')]Volatile機能のまとめと注意点は以下となります。
- 状態毎に作成されるクラスVolatileClass(クラス名は変更可)を定義
- 状態定義時にvolatileキーにVolatileClassを指定することで、状態に入る度にVolatileClassオブジェクトが生成される(初期状態には生成されていない)
- 生成されるタイミングはon_enterコールバックが実施される前
- VolatileClassオブジェクトには属性名scopeでアクセスでき、属性名は状態定義時にhookキーで変更可能。
- 一度作られたVolatileClassオブジェクトは状態が変わると破棄され、新たな状態や再度同じ状態に入っても新規に作られる。
- 自己遷移ではVolatileClassオブジェクトは新たに生成されるが、内部遷移ではVolatileClassオブジェクトは保持される。
Volatile機能の捕捉
以下、上記の注意点についていくつか補足します。
Volatile機能の属性名scopeについて
VolatileClassオブジェクトへのアクセスについてはscopeという属性名を用いてアクセスしましたが、こちらは状態定義時にhookキーを用いて変更できます。
指定しない場合は冒頭の例のようにデフォルトで'scope'という名が割り当てられます。VolatileClassアクセス属性名の変更例states = [{'name':'A', 'volatile':VolatileClass, 'hook':'volatile'}, # volatileという名でVolatileClassにアクセス {'name':'B', 'volatile':VolatileClass, 'hook':'temp'}] # tempという名でVolatileClassにアクセスしたがって、このように属性名を変更した場合、状態Aと状態BではVolatileClassオブジェクトへのアクセスには別々の名前を用いてアクセスする必要があるので注意が必要です。
状態AでのVolatileClassへのアクセス>>> model.state 'A' >>> model.volatile.data 1状態BでのVolatileClassへのアクセス>>> model.state 'B' >>> model.temp.data 1自己遷移と内部遷移でのVolatile機能の挙動
状態編では特に遷移について言及していませんが、遷移には自己遷移と内部遷移があります。(詳細は遷移編1へ)
両者とも自己の状態に返るというものですが、コールバックの発生を含め微妙に動作が異なります。
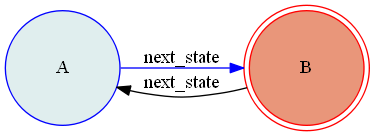
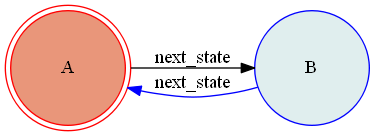
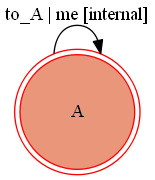
公式ドキュメントに記載はなかったのですが、実験してみたところやはりこのVolatile機能についても自己遷移と内部遷移の違いがあるので記しておきます。まず以下のような自己遷移(to_Aトリガーイベント)と内部遷移(meトリガーイベント)を持つ状態Aがあり、これにVolatile機能を付与しておきます。
コードとしては以下のようになります。自己遷移と内部遷移を持つVolatile機能付きステートマシンの定義from transitions import Machine from transitions.extensions.states import add_state_features, Volatile @add_state_features(Volatile) class CustomMachine(Machine): pass # 状態毎に作成されるクラスの定義 class VolatileClass(object): def __init__(self): self.data = 1 def increase(self): self.data += 1 # ステートマシンが割り当てられるクラス定義 class Model(object): pass # Volatile機能付き状態の定義 states = [{'name':'A', 'volatile':VolatileClass}] # 遷移の定義 transitions = [{'trigger':'to_A', 'source':'A', 'dest':'='}, # 自己遷移 {'trigger':'me', 'source':'A', 'dest':None}] # 内部遷移 model = Model() machine = CustomMachine(model=model, transitions=transitions, states=states, initial=states[0]["name"], auto_transitions=False, ordered_transitions=False)初期状態はVolatileClassオブジェクトは割り当てられていないのでまずは自身に遷移して生成しておきます。
model.to_A() Trueこれで状態AにVolatileClassオブジェクトが割り当てられました。
ここでVolatileClassオブジェクトのメンバ変数dataに操作をして値を変更しておきます。自己遷移と内部遷移を持つVolatile機能付きステートマシンの動作(準備)>>> model.scope.increase() >>> model.scope.increase() >>> model.scope.data 3現在メンバ変数data=3です。ここで自己遷移と内部遷移の違いを確認してみます。
自己遷移と内部遷移を持つVolatile機能付きステートマシンの動作>>> model.me() # 内部遷移を実行 True >>> model.scope.data 3 >>> model.to_A() # 自己遷移を実行 True >>> model.scope.data 1このように自己遷移ではVolatileClassオブジェクトが新たに生成されていますが、内部遷移ではVolatileClassオブジェクトは新たに生成されず保持されています。
言い換えれば内部遷移ではVolatileClassオブジェクトを引き継いだままトリガーイベントを起こし、遷移に付随するコールバックを起こすことが可能になります。(状態に付随するコールバックは内部遷移では起こらない点に注意)状態のタイムアウト (Timeout機能)
こちらはタイトルのままで、ある状態に入った時、一定時間経過したらコールバックを実施するというものになります。
以下実際のサンプルを見てみましょう。タイムアウト機能を持つステートマシン定義例from time import sleep from transitions import Machine from transitions.extensions.states import add_state_features, Timeout @add_state_features(Timeout) class CustomMachine(Machine): pass # Timeout機能付き状態の定義 states = [{'name': 'A', 'timeout': 3, 'on_timeout': 'action_timeout'}, {'name': 'B', 'timeout': 3, 'on_timeout': 'action_timeout'}] class Model: def action_timeout(self): print('timeout! on state ({})'.format(self.state)) model= Model() machine = CustomMachine(model=model, states=states, initial=states[0]['name'], auto_transitions=False, ordered_transitions=True)こちらは毎度おなじみ2状態で順序遷移を持つステートマシンです。今回はこちらの各状態にtimeout機能がついています。
それではこのステートマシンを動作させてみます。ひとまず今回は3秒でタイムアウトする設定としています。タイムアウト機能を持つステートマシン動作例>>> model.state 'A' >>> model.next_state() True >>> model.state 'B' >>> sleep(5) timeout! on state (B)このように状態Aから状態Bに遷移してからtimeout時間経過するとコールバックaction_timeoutが動作していることを確認できたと思います。
なおこちらもVolatileと同様に遷移が発生していない初期状態ではタイムアウトは発生しないという事になります。Timeout機能のまとめと注意点
Timeoutで追加指定可能な状態定義をまとめると以下の通りになります。
- timeout:タイムアウトするまでの時間(秒)
- on_timeout:タイムアウト時のコールバックの指定
なお、TimeoutクラスはStateクラスの派生クラスなので、Stateクラスと同様のメソッドやメンバ変数を扱えるだけでなく、他のState派生クラスと同様に以下のように宣言することも可能です。
Timeoutクラスを用いた状態の定義states = [Timeout(name='A', timeout=2, on_timeout='action_timeout'), Timeout(name='B', timeout=2, on_timeout='action_timeout')]Timeout機能のまとめと注意点は以下となります。
- タイムアウトする時間をtimeoutで指定。
- 状態に入りtimeout時間経過するとon_timeoutコールバックが実施される。
- タイムアウトがカウントダウンを開始するのは状態に入ってon_enterコールバックが実施される直前。
- タイムアウトは状態から抜けると停止し、遷移後の状態にtimeoutが設定されて入れば新たに入った状態のTimeoutのカウントダウンが開始される。
- on_timeoutコールバックで発生した例外はon_timeoutコールバック外で捕捉できない。
- 自己遷移ではTimeoutのカウントダウンはリセットされ再カウントされるが、内部遷移ではTimeoutのカウントダウンはリセットされない。
- timeout時間が設定されているのにもかかわらずon_timeoutコールバックを指定していない場合、AttributeError例外が発生する。
Timeout機能の捕捉
以下、上記の注意点についていくつか補足します。
on_timeoutコールバック内での例外について
タイムアウト自体は別スレッドで実行するので、タイムアウトで発生した例外の捕捉が行われないなど注意が必要です。
これは例えばtry~except内でトリガーイベントを起こしても、on_timeoutコールバック内で何らかの例外が発生した場合、その例外をtry~exceptでキャッチできず例外発生としてコードが停止することを意味しています。確認コードは長いので以下にしまっておきます。
確認に使用したコードと実行例はここをクリックして下さい。
on_timeoutコールバック例外を捕捉できない例from time import sleep from transitions import Machine from transitions.extensions.states import add_state_features, Timeout @add_state_features(Timeout) class CustomMachine(Machine): pass states = [{'name': 'A', 'timeout': 3, 'on_timeout': 'action_timeout'}, {'name': 'B', 'timeout': 3, 'on_timeout': 'action_timeout'}] class Model: def action_timeout(self): raise ValueError('timeout内での例外') #ここで例外を発生させる print('timeout! on state ({})'.format(self.state)) model= Model() machine = CustomMachine(model=model, states=states, initial=states[0]['name'], auto_transitions=False, ordered_transitions=True)以下のようにtry~except内でトリガーイベントを起こしてみます
>>> try: ... model.next_state() ... except: ... print('これは実施されない') Exception in thread Thread-26: Traceback (most recent call last): ~略~ ValueError: timeout内での例外上記のようにexceptで例外をキャッチできず例外として発生し、コードが停止する
自己遷移と内部遷移でのTimeout機能の挙動
こちらもVolatile機能と同様に自己遷移と内部遷移とで挙動が若干異なります。
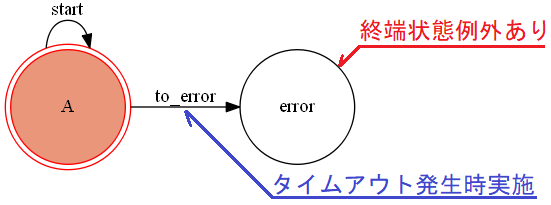
まず以下のような自己遷移(to_Aトリガーイベント)と内部遷移(meトリガーイベント)を持つ状態Aがあり、これにTimeout機能を付与しておきます。
コードとしては以下のようになります。自己遷移と内部遷移を持つTimeout機能付きステートマシンの定義from time import sleep from transitions import Machine from transitions.extensions.states import add_state_features, Timeout @add_state_features(Timeout) class CustomMachine(Machine): pass # ステートマシンが割り当てられるクラス定義 class Model(object): def action_timeout(self): print('timeout! on state ({})'.format(self.state)) # Timeout機能付き状態の定義 states = [{'name':'A', 'timeout': 1, 'on_timeout': 'action_timeout'}] # 遷移の定義 transitions = [{'trigger':'to_A', 'source':'A', 'dest':'='}, # 自己遷移 {'trigger':'me', 'source':'A', 'dest':None}] # 内部遷移 model = Model() machine = CustomMachine(model=model, transitions=transitions, states=states, initial=states[0]["name"], auto_transitions=False, ordered_transitions=False)さてこれを自己遷移と内部遷移それぞれで動かしてみたいと思います。
自己遷移と内部遷移を持つTimeout機能付きステートマシンの動作>>> model.to_A() # 自己遷移を実行(タイムアウト発生あり) ... sleep(3) timeout! on state (A) >>> model.me() # 内部遷移を実行(タイムアウト発生なし) ... sleep(3)このように内部遷移ではon_timeoutコールバックが発生していませんが、これはto_Aトリガーイベントにより既にon_timeoutコールバックが発生してしまっているためであり、内部遷移ではカウントがクリアされず再度on_timeoutが発生しないという状況になっています。もちろんこの状態でto_Aトリガーイベントにより自己遷移すれば再度カウントはクリアされ時間経過すればon_timeoutコールバックが発生します。
言い換えれば自己遷移ではカウントはクリアされタイムアウト動作が初期化されるが、内部遷移してもカウントとタイムアウト動作は初期化されず継続するということになります。タイムアウトの繰り返し実行
基本的にこのTimeout機能によるタイムアウトは状態を変えない限りワンショット(1回きり)の実行になります。
一方で自己遷移を利用することで繰り返しタイムアウトを発生させ、on_timeoutコールバックを定周期で実施させることが可能です。
以下の例をみてみましょう。自己遷移によるタイムアウトの繰り返し実行定義例from time import sleep from transitions import Machine from transitions.extensions.states import add_state_features, Timeout @add_state_features(Timeout) class CustomMachine(Machine): pass # ステートマシンが割り当てられるクラス定義 class Model(object): def action_timeout(self): print('timeout! on state ({})'.format(self.state)) self.to_A() # タイムアウトしたら再度自己遷移する # Timeout機能付き状態の定義 states = [{'name':'A', 'timeout': 1, 'on_timeout': 'action_timeout'}] # 遷移の定義 transitions = [{'trigger':'to_A', 'source':'A', 'dest':'='}] # 自己遷移 model = Model() machine = CustomMachine(model=model, transitions=transitions, states=states, initial=states[0]["name"], auto_transitions=False, ordered_transitions=False)これはタイムアウトした際に再度自己遷移してタイムアウトのカウントをリセットさせ、on_timeoutコールバックを繰り返し実行できるようにした例です。
上記を定義した後、以下のコードで実行してみましょう。自己遷移によるタイムアウトの繰り返し実行>>> model.to_A() ... sleep(10)
このように繰り返しtimeoutが実施されている事が確認できました。
※なおtimeoutは前述のとおり別スレッドで動作するので、本サンプルの停止にはCtrl+Cなどでプログラミング動作そのものを停止してください。add_state_featuresとカスタムステートについて
状態の拡張機能であるカスタムステートを定義する際にはadd_state_featuresでそれらカスタムステートを実現するためのクラスを呼び出す必要があります。
このadd_state_featuresについても補足があるので今回紹介しておきます。複数のカスタムステートの利用
今回カスタムステートを紹介する際、1機能毎にadd_state_featuresに対しState派生クラスを導入しました、実際は複数のカスタムステートを同時に割り当てることができます。
from time import sleep from transitions import Machine from transitions.extensions.states import add_state_features, Timeout, Error # 終端状態例外とタイムアウトの同時付与 @add_state_features(Error, Timeout) class CustomMachine(Machine): pass class Model(object): def action_timeout(self): print('timeout!') try: self.to_error() # タイムアウトしたら次の状態へ except Exception as err: # 終端状態例外はここで発生する print("終端状態例外:", err) states = [{'name':'A', 'timeout': 2, 'on_timeout': 'action_timeout'}, {'name':'error'}] # 終端状態例外付き transitions = [{'trigger':'start', 'source':'A', 'dest':'='}, # 自己遷移 {'trigger':'to_error', 'source':'A', 'dest':'error'}] model = Model() machine = CustomMachine(model=model, transitions=transitions, states=states, initial=states[0]["name"], auto_transitions=False, ordered_transitions=False)これは以下のようなステートマシンになります。
タイムアウトが発生した際、終端状態例外付きの終端状態に遷移します。
今回はタイムアウト時間が2sec設定で5sec待つコードで確認して挙動を確認してみます。終端状態例外付きタイムアウトの動作確認>>> model.start() ... sleep(5) timeout! 終端状態例外: "Error state 'error' reached!"このように複数の状態を付けることができます。
独自のカスタムステート
実は今回紹介した元々実装されているカスタムステート以外に自身でカスタムステートを作成することができます。
詳細は言及しませんが、基本的にはカスタムステート実現するクラスを実装し、そのクラスをadd_state_featuresを使って取り込むだけです。独自のカスタムステート定義例from transitions import State, Machine # Stateクラスから継承する class OriginalState(State): def __init__(self, *args, **kwargs): # ここに状態定義時の初期化を書く # 独自キーワードはword = kwargs.pop('word', False)のように書いて辞書形式引数から受け取る super(OriginalState, self).__init__(*args, **kwargs) def enter(self, event_data): # ここに状態に入った際に行われる処理を書く super(OriginalState, self).enter(event_data) def exit(self, event_data): # ここに状態から出た際に行われる処理を書く super(OriginalState, self).exit(event_data)Stateクラスから継承されるのでenterやexit書かなくても動作しますが、必要に応じてオーバーライドしてください。
加えて上記カスタムステートをMachineに取り込む時は以下のように書きます。独自のカスタムステートの取り込み@add_state_features(OriginalState) class CustomMachine(Machine): passこれで独自のカスタムステートを反映したMachineを作成することができるはずです。
実装例としては、本家のコードが参考になるのでそちらも見てみるとよいかもしれません。まとめ
今回は各状態でのクラスオブジェクト生成 (Volatile機能)とタイムアウト(Timeout機能)について示しました。
Volatile機能の使いどころは難しいですが、状態が変わる毎に初期化されるクラスオブジェクトを利用する場合には活躍すると思います。
Timeout機能については特定状態でタイムアウトさせる場合に便利ですが、タイムアウト時にon_timeoutコールバック内で発生する例外には注意が必要です。
最後に独自のadd_state_featuresとカスタムステートを実現する方法を紹介しました。ここまでできればtransitionsをかなり使いこなしていると思います。ひとまず今回で状態編は完了になります。大体transitionsパッケージの状態に関する機能は紹介できたと思います。少しでも参考になればと思います。

- 投稿日:2019-03-24T20:25:51+09:00
pandasで欠損値を含んだ日付ごとのデータの累計値を算出する
こんな感じでできました。
import pandas as pd # 実験用データ df = pd.DataFrame({'date': ['2019-01-05', '2019-01-18', '2019-01-25', '2019-02-06', '2019-02-16', '2019-03-02'], 'value': [10, 20, 30, 40, 50, 60], 'name': ['あ', 'い', 'う', 'え', 'お', 'か']}) # 日付列を日付型に変える df['date'] = pd.to_datetime(df['date']) # 日付リストのDataFrameを作ってマージする。 df = pd.merge(pd.DataFrame({"date": pd.date_range('2019-1-1', '2019-3-31')}), df, how='left') # 累計値を新たな列として追加 df['cumsum'] = df['value'].fillna(0).cumsum() print(df)
- 投稿日:2019-03-24T20:25:51+09:00
pandasで欠損値のある日付ごとのデータの累計値を算出する
こんな感じでできました。
import pandas as pd # 実験用データ df = pd.DataFrame({'date': ['2019-01-05', '2019-01-18', '2019-01-25', '2019-02-06', '2019-02-16', '2019-03-02'], 'value': [10, 20, 30, 40, 50, 60], 'name': ['あ', 'い', 'う', 'え', 'お', 'か']}) # 日付列を日付型に変える df['date'] = pd.to_datetime(df['date']) # 日付リストのDataFrameを作ってマージする。 df = pd.merge(pd.DataFrame({"date": pd.date_range('2019-1-1', '2019-3-31')}), df, how='left') # 累計値を新たな列として追加 df['cumsum'] = df['value'].fillna(0).cumsum() print(df)
- 投稿日:2019-03-24T19:27:58+09:00
python,djangoによるいいねボタンの作り方
いいねボタンを作ります。
ボタンを押すと数字が1つずつ増えていくやつです。
僕が実際にwebアプリケーションで使用しているのがこちら。def good(request, pk): """いいねボタンをクリック.""" post = get_object_or_404(Post, pk=pk) if request.method == 'POST': # データの新規追加 post.good += 1 post.save() return redirect('board:board')では解説を。
Postモデルとプライマリーキーをpostという変数に代入します。post = get_object_or_404(Post, pk=pk)
もしurlへのアクセスがPOSTならばということなのでフォームで送信された場合ということができますね。
直接URLにアクセスした場合やGETとは違うということです。if request.method == 'POST':
post.good += 1 post.save()変数postの中身にモデルPOSTが含まれています。
.goodという形で記載するとmodels.pyのPOSTモデルにあるgoodフィールドにアクセスできます。
+= 1は1増やすという書き方です。
pythonの基礎の方でfor文を使ってループをさせるときにループするたびに数値を増やしていくというようなときは= 1という代入の仕方ではなく
+= 1という代入を使います。
厳密に書くと以下のような意味なのですが、post.good = post.good + 1pythonでは += 1と書くと同様の効果が得られるのです。
post.save()で数値を保存します。
リダイレクト先の指定。return redirect('board:board')
html部分を解説。<form action="{% url 'board:good' post.pk %}" method="post"> {% csrf_token %} <input type="submit" name="good" value="いいね" id="test">({{ post.good }} いいね)<p style="color:red"><font size="1"><strong>押すと1ページ目まで戻ってしまいます!(いつか直す!)</strong></font></p> </form>いいねボタンを押すと'board:good' post.pk に処理をします。
action="{% url 'board:good' post.pk %}board:goodのurls.pyはこのようになっています。
path('good/<int:pk>', views.good, name='good'),good関数が使用できるurlにアクセスすると数字を1増やすことができます。ただしboard:goodにはその他の機能を何も持たせていないのでredirectで元のurlに戻しているんですね。
そうするとボタンを押すと一瞬画面が切り替わり次の瞬間には数字が1だけ増えている。
という現象が完成するのです。
余談ですがJavaScriptを使用しないといいねボタンを押す度にページの一番上に戻ってしまうんですよね。
JavaScriptを勉強してページが遷移しないように改修しようと思っています。
- 投稿日:2019-03-24T18:56:17+09:00
【Finetuningの極意】動物会話のアプリをFinetuning(+中間層利用)で小規模かつ高速に作成♬
VGG16などを使ったFinetuning技法を利用して動物会話アプリを再作成してみました。
どうしても機械学習は大量データと長時間の学習がつきものと考えがちです。
しかし、実際そういう面もありますが(人間の)脳や学習経験を考えてみると、あまり学習時間をかけていないように思います。それというのも、経験というのを最大限生かすこと、そしてそれらの情報を再利用する能力が能では高いことが分かります。
>人間のこのような能力(たぶん、これを知能という)はデザインで云うアフォーダンスを成り立たせているようです
・アフォーダンス@Wikipedia
そして、機械学習として確立している技法でこの手のものは、Finetuning技術です。
ということで、Finetuningを最大限利用することを考えつつ、経験の再利用を意識して進めようと思います。
また、今回は小回りが利くように小規模マシンでも使えるように・学習できるようにを目指して簡単に作れるかにも着目して作成しました。とりあえずの目標
・アプリ【動物会話】をFinetuningで効率よく作成する
・小規模(CPU)環境で学習してみる
・多段階の識別構造を作成して効率を考える
・多段階Finetuning構造を制御するメタ学習と利用について考察する
・多品種・多目的・異種技法(画像,音,皮膚感覚,味覚,自然言語処理,計測&制御...)を取り入れた多段階Finetuningの集合体としての網の可能性Objective・Neuro網(今回導入した用語)と利用を考えるやったこと
アプリ【動物会話】をFinetuningで効率よく作成する
・Finetuningの仕組み
・Finetuningのモデルとして中間層を利用する
・小規模モデルで再学習してみる
・block毎にモデル化してみる・Finetuningの仕組み
画像分類などにおいて、学習済のモデルを利用し、それに若干の新規のネットワークモデルを付加することにより、新たな画像等についてほとんどのWeightを再利用して再学習することにより分類する手法である。
コードで見ると以下のとおり、
【参考】
・DL-FineTuning/akb_VGG16.py
オリジナルは以下を参考としています
・VGG16のFine-tuningによる17種類の花の分類# VGG16モデルと学習済み重みをロード # Fully-connected層(FC)はいらないのでinclude_top=False) input_tensor = Input(shape=x_train.shape[1:]) #(img_rows, img_cols, 3)) vgg16 = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor) # FC層を構築 top_model = Sequential() top_model.add(Flatten(input_shape=vgg16.output_shape[1:])) top_model.add(Dense(256, activation='relu')) top_model.add(Dropout(0.5)) top_model.add(Dense(num_classes, activation='softmax')) # VGG16とFCを接続 model = Model(input=vgg16.input, output=top_model(vgg16.output)) # 最後のconv層の直前までの層をfreeze #trainingするlayerを指定 VGG16では18,15,10,1など 20で全層固定 for layer in model.layers[1:18]: layer.trainable = False・Finetuningのモデルとして中間層を利用する
もう少し進んだものとして、以下があります。
【参考】
・中間レイヤーの出力を得るには?@KerasDocumentation
これを利用すると、当初のモデルの一部を利用して、小さなモデル(しかもPretrained)で学習できることが分かります。
つまり、以下のようなコードで実現できます。
ここでは、vgg16のうちblock3までを利用して、上記と同じFC層をつけて学習ができます。# VGG16モデルと学習済み重みをロード # Fully-connected層(FC)はいらないのでinclude_top=False) input_tensor = Input(shape=x_train.shape[1:]) vgg16 = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor) from keras.models import Model layer_name1 = 'block3_pool' intermediate_layer_model = Model(inputs=vgg16.input, outputs=vgg16.get_layer(layer_name1).output) # FC層を構築 top_model = Sequential() top_model.add(Flatten(input_shape=intermediate_layer_model.output_shape[1:])) #vgg16 top_model.add(Dense(15*num_classes, activation='relu')) #256 #20*num_classes top_model.add(Dropout(0.5)) top_model.add(Dense(num_classes, activation='softmax')) # VGG16とFCを接続 #model = Model(input=vgg16.input, output=top_model(vgg16.output)) model = Model(input=vgg16.input, output=top_model(intermediate_layer_model.output)) # 最後のconv層の直前までの層をfreeze #trainingするlayerを指定 VGG16では18,15,10,1など 20で全層固定 for layer in model.layers[1:1]: layer.trainable = False・小規模モデルで再学習してみる
学習データは、Train on 170 samples, validate on 59 samplesであり、
学習時間は全層Finetuningしても、全部で1分位です。model = Model(input=vgg16.input, output=top_model(intermediate_layer_model.output)) _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= input_1 (InputLayer) (None, 128, 128, 3) 0 _________________________________________________________________ block1_conv1 (Conv2D) (None, 128, 128, 64) 1792 _________________________________________________________________ block1_conv2 (Conv2D) (None, 128, 128, 64) 36928 _________________________________________________________________ block1_pool (MaxPooling2D) (None, 64, 64, 64) 0 _________________________________________________________________ block2_conv1 (Conv2D) (None, 64, 64, 128) 73856 _________________________________________________________________ block2_conv2 (Conv2D) (None, 64, 64, 128) 147584 _________________________________________________________________ block2_pool (MaxPooling2D) (None, 32, 32, 128) 0 _________________________________________________________________ block3_conv1 (Conv2D) (None, 32, 32, 256) 295168 _________________________________________________________________ block3_conv2 (Conv2D) (None, 32, 32, 256) 590080 _________________________________________________________________ block3_conv3 (Conv2D) (None, 32, 32, 256) 590080 _________________________________________________________________ block3_pool (MaxPooling2D) (None, 16, 16, 256) 0 _________________________________________________________________ sequential_1 (Sequential) (None, 3) 2949303 ================================================================= Total params: 4,684,791 Trainable params: 4,684,791 Non-trainable params: 0 _________________________________________________________________学習も50epochで以下のように使えるレベルの精度が出ています。
Train on 170 samples, validate on 59 samples Epoch 47/50 170/170 [==============================] - 1s 5ms/step - loss: 0.4210 - acc: 0.8235 - val_loss: 0.3920 - val_acc: 0.9153 Epoch 48/50 170/170 [==============================] - 1s 5ms/step - loss: 0.3996 - acc: 0.8353 - val_loss: 0.3937 - val_acc: 0.9153 Epoch 49/50 170/170 [==============================] - 1s 5ms/step - loss: 0.4695 - acc: 0.8118 - val_loss: 0.4307 - val_acc: 0.8983 Epoch 50/50 170/170 [==============================] - 1s 5ms/step - loss: 0.4508 - acc: 0.8353 - val_loss: 0.4199 - val_acc: 0.9153ということで、これだとパラメータサイズがGithubに掲載できるサイズになるので、以下にweight込みで諸々置いておきましたので、ご興味がある方はカラス会話アプリ遊んでみてください。
コードは以下に置きました
・block毎にモデル化してみる
こうなると、もっと中間層のパラメータも取得してみたくなるし、ネットワークモデルも自由に作りたくなる。
今後、個別の学習済modelをObjective・Neuroとして構造化しようと考えているので、そのためにもくっつけたりはがしたり自由度が欲しい。
ということで、vgg16は以下のコードでばらばらになりました。
コード全体は以下のとおり
・hirakegoma/FineTuning/VGG16_finetuning_block3_top3.py
こちらも、計算時間は全部で1分位です。【参考】
・Kerasでfine-tuning# VGG16モデルと学習済み重みをロード # Fully-connected層(FC)はいらないのでinclude_top=False) input_tensor = Input(shape=x_train.shape[1:]) vgg16 = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor) from keras.models import Model layer_name1 = 'block3_pool' intermediate_layer_model = Model(inputs=vgg16.input, outputs=vgg16.get_layer(layer_name1).output) inputs0 = Input(shape=intermediate_layer_model.output_shape[1:]) # Block 4 block4_conv1 = Conv2D(512, (3, 3),name='block4_conv1', activation='relu', padding='same')(inputs0) block4_conv2 = Conv2D(512, (3, 3),name='block4_conv2', activation='relu', padding='same')(block4_conv1) block4_conv3 = Conv2D(512, (3, 3),name='block4_conv3', activation='relu', padding='same')(block4_conv2) #bn4 = BatchNormalization(axis=3)(conv4_3) block4_pool = MaxPooling2D(pool_size=(2, 2),name='block4_pool')(block4_conv3) #drop4 = Dropout(0.5)(pool4) block4_model = Model(inputs=inputs0, outputs=block4_pool) inputs1 = Input(shape=block4_model.output_shape[1:]) # Block 5 block5_conv1 = Conv2D(512, (3, 3),name='block5_conv1', activation='relu', padding='same')(inputs1) block5_conv2 = Conv2D(512, (3, 3),name='block5_conv2', activation='relu', padding='same')(block5_conv1) block5_conv3 = Conv2D(512, (3, 3),name='block5_conv3', activation='relu', padding='same')(block5_conv2) #bn5 = BatchNormalization(axis=3)(conv5_3) block5_pool = MaxPooling2D(pool_size=(2, 2),name='block5_pool')(block5_conv3) #drop5 = Dropout(0.5)(pool5) block5_model = Model(inputs=inputs1, outputs=block5_pool) inputs2 = Input(shape=block5_model.output_shape[1:]) # FC層を構築 # top_model x = Flatten()(inputs2) x = Dense(15*num_classes, activation="relu")(x) x = Dropout(0.5)(x) predictions = Dense(num_classes, activation="softmax")(x) top_model = Model(inputs=inputs2, outputs=predictions) #以下はなんとなくだけどこれで動きます model = Model(inputs=intermediate_layer_model.input, outputs=top_model(block5_model(block4_model(intermediate_layer_model.output)))) # 最後のconv層の直前までの層をfreeze #trainingするlayerを指定 VGG16では18,15,10,1など 20で全層固定 for layer in model.layers[1:1]: layer.trainable = Falseまとめ
・動物会話のアプリを題材にVGG16を利用してFinetuningを実施した
・小規模モデルで学習し、小さなモデルで会話アプリができることが分かった
・構造をblock単位でばらばらにモデル化し、Weightなどを取得した今後当面は以下を実施します
・Objective・Neuroを意識して構造化したモデルを構築する
・多段モデルを作成するおまけ
model.summary() _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= input_1 (InputLayer) (None, 128, 128, 3) 0 _________________________________________________________________ block1_conv1 (Conv2D) (None, 128, 128, 64) 1792 _________________________________________________________________ block1_conv2 (Conv2D) (None, 128, 128, 64) 36928 _________________________________________________________________ block1_pool (MaxPooling2D) (None, 64, 64, 64) 0 _________________________________________________________________ block2_conv1 (Conv2D) (None, 64, 64, 128) 73856 _________________________________________________________________ block2_conv2 (Conv2D) (None, 64, 64, 128) 147584 _________________________________________________________________ block2_pool (MaxPooling2D) (None, 32, 32, 128) 0 _________________________________________________________________ block3_conv1 (Conv2D) (None, 32, 32, 256) 295168 _________________________________________________________________ block3_conv2 (Conv2D) (None, 32, 32, 256) 590080 _________________________________________________________________ block3_conv3 (Conv2D) (None, 32, 32, 256) 590080 _________________________________________________________________ block3_pool (MaxPooling2D) (None, 16, 16, 256) 0 _________________________________________________________________ model_2 (Model) (None, 8, 8, 512) 5899776 _________________________________________________________________ model_3 (Model) (None, 4, 4, 512) 7079424 _________________________________________________________________ model_4 (Model) (None, 3) 368823 ================================================================= Total params: 15,083,511 Trainable params: 15,083,511 Non-trainable params: 0 _________________________________________________________________ intermediate_layer_model.summary() _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= input_1 (InputLayer) (None, 128, 128, 3) 0 _________________________________________________________________ block1_conv1 (Conv2D) (None, 128, 128, 64) 1792 _________________________________________________________________ block1_conv2 (Conv2D) (None, 128, 128, 64) 36928 _________________________________________________________________ block1_pool (MaxPooling2D) (None, 64, 64, 64) 0 _________________________________________________________________ block2_conv1 (Conv2D) (None, 64, 64, 128) 73856 _________________________________________________________________ block2_conv2 (Conv2D) (None, 64, 64, 128) 147584 _________________________________________________________________ block2_pool (MaxPooling2D) (None, 32, 32, 128) 0 _________________________________________________________________ block3_conv1 (Conv2D) (None, 32, 32, 256) 295168 _________________________________________________________________ block3_conv2 (Conv2D) (None, 32, 32, 256) 590080 _________________________________________________________________ block3_conv3 (Conv2D) (None, 32, 32, 256) 590080 _________________________________________________________________ block3_pool (MaxPooling2D) (None, 16, 16, 256) 0 ================================================================= Total params: 1,735,488 Trainable params: 1,735,488 Non-trainable params: 0 _________________________________________________________________ block4_model.summary() _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= input_2 (InputLayer) (None, 16, 16, 256) 0 _________________________________________________________________ block4_conv1 (Conv2D) (None, 16, 16, 512) 1180160 _________________________________________________________________ block4_conv2 (Conv2D) (None, 16, 16, 512) 2359808 _________________________________________________________________ block4_conv3 (Conv2D) (None, 16, 16, 512) 2359808 _________________________________________________________________ block4_pool (MaxPooling2D) (None, 8, 8, 512) 0 ================================================================= Total params: 5,899,776 Trainable params: 5,899,776 Non-trainable params: 0 _________________________________________________________________ block5_model.summary() _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= input_3 (InputLayer) (None, 8, 8, 512) 0 _________________________________________________________________ block5_conv1 (Conv2D) (None, 8, 8, 512) 2359808 _________________________________________________________________ block5_conv2 (Conv2D) (None, 8, 8, 512) 2359808 _________________________________________________________________ block5_conv3 (Conv2D) (None, 8, 8, 512) 2359808 _________________________________________________________________ block5_pool (MaxPooling2D) (None, 4, 4, 512) 0 ================================================================= Total params: 7,079,424 Trainable params: 7,079,424 Non-trainable params: 0 _________________________________________________________________ top_model.summary() _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= input_4 (InputLayer) (None, 4, 4, 512) 0 _________________________________________________________________ flatten_1 (Flatten) (None, 8192) 0 _________________________________________________________________ dense_1 (Dense) (None, 45) 368685 _________________________________________________________________ dropout_1 (Dropout) (None, 45) 0 _________________________________________________________________ dense_2 (Dense) (None, 3) 138 ================================================================= Total params: 368,823 Trainable params: 368,823 Non-trainable params: 0 _________________________________________________________________ Train on 170 samples, validate on 59 samples Epoch 7/10 170/170 [==============================] - 1s 8ms/step - loss: 0.1337 - acc: 0.9529 - val_loss: 0.5312 - val_acc: 0.8475 Epoch 8/10 170/170 [==============================] - 1s 8ms/step - loss: 0.1697 - acc: 0.9235 - val_loss: 0.3897 - val_acc: 0.8983 Epoch 9/10 170/170 [==============================] - 1s 8ms/step - loss: 0.1005 - acc: 0.9588 - val_loss: 0.3644 - val_acc: 0.9153 Epoch 10/10 170/170 [==============================] - 1s 8ms/step - loss: 0.0764 - acc: 0.9706 - val_loss: 0.3956 - val_acc: 0.8983
- 投稿日:2019-03-24T18:31:17+09:00
【Python】Arduino で温度センサーから室温を取得して画面に表示する(前編)
前回の記事:【Python】置き時計の画面表示と機能を整理してみた の続きです。
今回から電子工作も交えたプログラミングになります。
電子工作といえば、知る人ぞ知る定番マイコンボードの「Arduino」を使います。
とりあえず、数年前に買った旧式の「Duemilanove」で作ってみますがパターンが完成したら、小型のマイコンボードに移植する予定です。
なので、まだハンダ付けはしません。しばらくは食パンの板で我慢しましょう。やりたいこと
- Arduino で温度センサーから室温を取得
- USB シリアル通信で RaspberryPi に室温データを送る
- Python で受信して画面に室温を表示する
前半で用意するもの
- Arduino Duemilanove
- Arduino IDE 1.8.9 (Linux ARM 版)
- ブレッドボード
- 温度センサー LM61BIZ(秋月電子通商)
- Raspberry pi 3 Model B Rev 1.2 - Raspbian 9.6 (Stretch)
Arduino IDE のセットアップ
Arduino IDE をダウンロードします。
https://www.arduino.cc/en/Main/Software
Linux ARM 32 bits を選択ダウンロードしたファイルを RaspberryPi に転送します。
$ scp ~/Downloads/arduino-1.8.9-linuxarm.tar.xz pi@192.168.X.X:~転送したファイルを RaspberryPi 側で解凍してインストールします。
$ ssh pi@192.168.X.X pi@192.168.X.X's password: $ xzcat arduino-1.8.9-linuxarm.tar.xz | tar xfv - $ cd ~/arduino-1.8.9 $ sudo ./install.shデスクトップに Arduino IDE というアイコンが現れます。
ダブルクリックして起動します。
下のような感じの画面が表示されたらインストールは完了です。
(今回のスケッチを開いている状態ですがそこは気にしない)
回路図
こんなのをイメージしました。
温度センサーの回路図はシンプルです。
fritzing というソフトを使って書いてみました。
Arduino UNO が描かれていますが、大人の事情なので気にしない。現物がこちら
スケッチ
Arduino IDE でソフトウェア部分のコードを記述(スケッチ)します。
TempSensor.inoint sensorPin = A0; int sensorValue = 0; void setup() { // put your setup code here, to run once: Serial.begin(9600); } void loop() { // put your main code here, to run repeatedly: sensorValue = analogRead(sensorPin); float temp = modTemp(sensorValue); Serial.println(temp); delay(1000); } float modTemp(int analog_val) { float v = 5000; float tempC = (((v * analog_val) / 1024) - 600) / 10; return tempC; }ソースコード参考:Arduinoで作る簡易百葉箱 | Device Plus - デバプラ
Serial.beginで 9,600 bps のシリアル通信を開始。
loop()に突入すると、analogRead(sensorPin = A0)で温度センサーの情報を読み取ります。modTemp(analog_val)にてアナログな入力値をデジタルな温度に変換し、Serial.printlnで温度をシリアル出力します。これを 1 秒ごとに繰り返す処理ですね。今回の回路の特性として、
- Arduino アナログポートは 0-5V の入力をデジタルな数値 0-1023 で表現する
- 0 ℃ のときに温度センサーの出力電圧は 600 mV となる
- 温度センサーは 5V を入力すると -30 〜 100 ℃ の間で、300 mV から 1600mV を出力する(らしい)
- 1 ℃ 変化すると、出力電圧は 10mV 変化する
ということなので、
modTemp(analog_val)関数は以下のような処理をしてデジアナ変換を行なっています。入力電圧 v = 5,000 mV、analog_val = 168 の状態であるとき (((5,000 * 168) / 1024) - 600) / 10 を評価する。評価の過程は以下の通り。 以下の計算式で、Arduino の A/D 変換値から温度センサーの出力電圧に変換する。 5,000 * 168 = 840,000 840,000 / 1024 = 822.722820763956905 (mV) 0 °C のときの出力電圧 600 mV を計算から除外する。 822.722820763956905 - 600 = 222.722820763956905 (mV) 1 °C あたり 10mV 変化するため 10 で割る。 222.722820763956905 / 10 = 22.27 (°C)スケッチを実行する
Arduino IDE にて
1.スケッチ → 検証・コンパイルを実行して、赤文字エラーが画面に表示されないことを確認
2.ツール → ボード → Arduino Duemilanove or Diecimilaを選択
3.ツール → シリアルポート → /dev/ttyUSB0を選択
4.スケッチ → マイコンボードに書き込むを実行して、問題なく書き込みが完了することを確認
5.ツール → シリアルモニタを表示する
という感じで室温っぽいデータが表示されれば成功です。
後編では、このデータを Python で処理して画面に表示させます。
![Screenshot_20190324[1].png](https://qiita-image-store.s3.amazonaws.com/0/362854/d0541682-ca00-87c0-e43c-424a969e6ce5.png)
![Screenshot_20190324[2].png](https://qiita-image-store.s3.amazonaws.com/0/362854/81b70910-a692-efa5-0e48-aba47afaebba.png)
![Screenshot_20190324[3].png](https://qiita-image-store.s3.amazonaws.com/0/362854/2d51c04f-6b51-7875-f7ad-3e639bee0907.png)

![Screenshot_20190324[4].png](https://qiita-image-store.s3.amazonaws.com/0/362854/0f2b3838-afb1-cd5b-5e91-bf46015fd8df.png)
- 投稿日:2019-03-24T18:29:33+09:00
【Selenium】xpathでidタグを指定した後にvalueを指定する【Python】
Python、Seleniumでxpathを用いて、
idタグを指定した後にvalueを指定する。例:
id = "hogeId"内のINPUT要素であるvalue = "login"をクリックするhoge.py# importなど from selenium import webdriver driver = webdriver.Chrome(executable_path=".\driver\chromedriver.exe") # idタグを指定した後にvalueを指定する。 driver.find_element_by_xpath("//*[@id='hogeId']/descendant::input[@value='login']").click()descendant:子孫の集合
- 投稿日:2019-03-24T18:29:33+09:00
【Selenium】xpathでidタグを指定した後にvalueをクリックする【Python】
Python、Seleniumでxpathを用いて、
idタグを指定した後にvalue要素をクリックする。例:
id = "hogeId"内のINPUT要素であるvalue = "login"をクリックするhoge.py# importなど from selenium import webdriver driver = webdriver.Chrome(executable_path=".\driver\chromedriver.exe") # idタグを指定した後にvalueを指定する。 driver.find_element_by_xpath("//*[@id='hogeId']/descendant::input[@value='login']").click()descendant:子孫の集合
- 投稿日:2019-03-24T18:25:39+09:00
pandas 列へ値の代入についてのメモ書き
はじめに
DataFrameのスライスには、直接値を代入できない。
例
下記のようにdf3というDataFrameがあり、
単価列のNanバリューを埋めたいという要件があったとして。# サンプルとしてこんなDataFrameがあります。 >> df3 0 1 2 単価 price 0 0 1 2 10.0 20.0 1 3 4 5 NaN NaN 2 6 7 8 NaN NaN# 単価列のNaNに0を代入したいので、、、、 >> df3[df3["単価"].isnull()][["単価"]] = 0 # と、しました。が、、、、 # Warningが表示され失敗しました。 >> /usr/local/lib/python3.6/dist-packages/ipykernel_launcher.py:1: SettingWithCopyWarning: A value is trying to be set on a copy of a slice from a DataFrame. Try using .loc[row_indexer,col_indexer] = value instead See the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/indexing.html#indexing-view-versus-copy """Entry point for launching an IPython kernel.Google翻訳:
DataFrameのスライスのコピーに値を設定しようとしています。
代わりに.loc [row_indexer、col_indexer] = valueを試してください。正解
# 正解はこちらのようです。 df3.loc[df3["単価"].isnull(),["単価"]] = 0この例の場合は、Nanバリューなのでfillna関数とか使えばいいのかもしれないのだけども。一応。
- 投稿日:2019-03-24T17:21:16+09:00
Seleniumを使ってiframeを出たり入ったりしよう
なぜか取れないiframeの中身
以前スクレイピングをしていた際、検証モードからセレクタを指定しているのにも関わらず
selenium.common.exceptions.NoSuchElementException
とエラーを吐きました。
中を見ると操作したい部分がiframe構造の中に入っており、どうやらiframeの外からでは中のDOMを操作できないようになっていました。面倒だったので対処法を残しておきます。
iframeに入ろう!
iframe = driver.find_element_by_css_selector('欲しいiframeのcssセレクタ') driver.switch_to_frame(iframe)これでiframe内のDOMにアクセスできるようになりました。
iframeから抜けてみよう!
driver.switch_to.default_content()一行でiframeから抜け出せます。
最後に
この記事を見ると、iframe内のリンクを直接開く方法もありますね。
seleniumで操作しなければいけない工数が少ない場合は、こちらの記事にある方がお勧めだと思います。
- 投稿日:2019-03-24T17:21:16+09:00
Seleniumを使ってiframeを出たり入ったり
なぜか取れないiframeの中身
以前スクレイピングをしていた際、検証モードからセレクタを指定しているのにも関わらず
selenium.common.exceptions.NoSuchElementException
とエラーを吐きました。
中を見ると操作したい部分がiframe構造の中に入っており、どうやらiframeの外からでは中のDOMを操作できないようになっていました。面倒だったので対処法を残しておきます。
iframeに入ろう!
iframe = driver.find_element_by_css_selector('欲しいiframeのcssセレクタ') driver.switch_to_frame(iframe)これでiframe内のDOMにアクセスできるようになりました。
iframeから抜けてみよう!
driver.switch_to.default_content()一行でiframeから抜け出せます。
最後に
この記事を見ると、iframe内のリンクを直接開く方法もありますね。
seleniumで操作しなければいけない工数が少ない場合は、こちらの記事にある方がお勧めだと思います。
- 投稿日:2019-03-24T16:26:46+09:00
Seleniumでリンクテキストを部分一致で探し、クリック(find, click)
hoge.pyfrom selenium import webdriver driver = webdriver.Chrome(executable_path=".\driver\chromedriver.exe") driver.find_element_by_partial_link_text("hoge").click()
- 投稿日:2019-03-24T16:15:56+09:00
単語のベクトル化 辞書はwiki やってみた。
https://www.udemy.com/tensorflow_rnn/
こちらの講座で学んだことを超自分用にアウトプット。
Wikiからデータをダウンロード
https://dumps.wikimedia.org/jawiki/latest
の
jawiki-latest-pages-articles.xml.bz2 をダウンロード2GB越えなので、時間がかかる。。。
wp2txt
上記ファイルはXMLなので、textファイルに変換する必要がある。
ので、Ruby製のwp2txtを使用。
gem install wp2txtMecabのインストール
...後日記述(おそらく)
ダウンロードしたwikiの整形
- bz2 -> xml に解凍
wp2txt --input-file [ファイル名]- 1つのファイルにまとめる
cat [ファイル名]*.txt > [出力ファイル名]- 分かち書きファイルへ変換
mecab -b 100000 -Owakati [ファイル名] -o [出力ファイル名]Word2Vexのモデルを生成
from gensim.models import word2vec data = word2vec.Text8Corpus('[出力ファイル名]') model = word2vec.Word2Vec(data, size=100)モデルを保存し、ベクトル演算
model.save('[hoge.model]') # 結果を試す。 model.most_similar(positive='Linux') model.most_similar(positive=['王様', '女性'], negative=['男性'])感想
mecabもWord2vecもSUGEEEEEEEEEEEEEEEEE!!!!!!
- 投稿日:2019-03-24T13:53:17+09:00
回帰予測で多ラベル・複数項目を出力させたい!
プロジェクトで「多ラベルの回帰予測」をしなければならないことになりました。
※機械の自動運転なのですが、調整する値が20個ほどあるですが、多ラベル出力に対応していないregressorが結構あるので
その時に使ったscikit-learnのMultiOuputRegressorについて書いていきます!回帰予測で他ラベル出力するには
回帰予測で他ラベル出力するにはいくつか方法があります。
1. 元々他ラベル出力に対応しているRegressorを採用する
→scikit-learnのRandomForestが代表的ですが、もともと他ラベル出力に対応しているものがあります。
これを使えば、複数のラベルが入ったデータを学習データとして与えても大丈夫!2. ニューラルネットワークを使う
→ニューラルネットワークは隠れ層や出力層の数を変えられるため、当然出力層の数を変えれば多ラベル出力も可能です。
(私はニューラルネットワークを使ったことがないクソ雑魚のため、この案はスルーしました)3. scikit-learnのMultiOutputRegressorを使う
→これを使えば多ラベル出力に対応していないRegressorも出力させることができます。RandomForest おっそ...
いや、これなんですよね...
上の方法を見たとき「いや、じゃあRandomForest使えよ」って思いませんでした?
私も最初RandomForestで頑張ってたわけなんですが学習遅くね...?ということなんですよ。
精度は別に悪くないと思うんですけどね。そこで、kaggleで使ったことのあるLightGBMを使ってみたところ、クッソ爆速。
「じゃあ、LightGBMに変えよー!」と思ったらLightGBMは多ラベル出力に対応してないんですね...
そのままデータを渡して学習させようとするとValueErrorになってしまいます。ValueError: DataFrame for label cannot have multiple columnsそういう時にMultiOutputRegressorなんすわぁ
そういう「使いたいRegressorがあるけど多ラベル出力に対応してない」時に使えるのが
MultiOutputRegressor!!
使い方は正直めちゃくちゃ簡単です。
例えばLightBGMで以下のように書いて、yがラベルだとしますよね?import lightgbm as lgb params={'learning_rate': 0.05, 'objective':'mae', 'metric':'mae', 'num_leaves': 7, 'verbose': 0, 'bagging_fraction': 0.7, 'feature_fraction': 0.7 } reg = lgb.LGBMRegressor(**params, n_estimators=500) reg.fit(x, y)これが、こう!
from sklearn.multioutput import MultiOutputRegressor import lightgbm as lgb params={'learning_rate': 0.5, 'objective':'mae', 'metric':'mae', 'num_leaves': 9, 'verbose': 0, 'bagging_fraction': 0.7, 'feature_fraction': 0.7 } reg = MultiOutputRegressor(lgb.LGBMRegressor(**params, n_estimators=500)) reg.fit(x, y)そう!LightGBMのオブジェクト作成するところを
MultiOutputRegressor()で包むだけです。
これだけで、多ラベルデータを学習・予測できるようになります。やったぜ。課題?
MultiOutputRegressor使っていて問題とまでは言いませんが感じたことを書いていきます。
各ラベルの予測モデルよりは精度が落ちている気がする
これ、当たり前といえば当たり前な気がしますがそんな気がします。
MultiOuputRegressorを使わずに、ラベルの数だけモデルを作って予測させた場合と比べると
やはり少しですが精度が落ちてます。これは、モデルをひとつにすることで、本来必要ないデータも学習することになるからだと思います。
あるラベルでは必要ないデータでも、他のラベルの学習に必要なデータであれば全て学習データに含める必要があります。
結果的に、各ラベル単位で見ると無駄に多い学習データを使っていることになります。MultiOuputRegressorの内部的な仕組みとしては、ラベルの数だけ独立して予測させているようなので
やはり不要なデータが増えているのが要因なんでしょうなあ。feature_importanceが使えない
これも仕方ないのかもしれませんが、特徴量選択によく使うので使えないのは困ります。
私はfeature_importanceを見るためだけに各ラベルごとのモデルを作って見てました。二度手間。
(上でも書いたように、内部的にはラベルごとに独立で動いているので結果はほとんど同じはず)for文ぶん回して放っておくだけなので言う程手間でもないんですが、
やはりMultiOuputRegressorで包んだやつから直接見れたらラクなのになーとは思っちゃいますね。終わり
とはいえとはいえ、導入も物凄く簡単で便利なので、ぜひ使ってみてくださいー!

- 投稿日:2019-03-24T13:01:11+09:00
Djangoで会員登録やログイン|Userモデル拡張のアプリを作りました
概要
Djangoには会員管理機能が内包されており、これを利用することである程度サクッとWebサービスを開発することができます。しかし、テンプレートの自作や会員登録部分の実装は必要なので、毎回同じ作業をしなくて済むように雛形を作成してGithubにアップしました。
機能
- 会員登録
- ログイン
- パスワード変更
- パスワードを忘れた時のメール送信からの再発行
- 退会
- マイページ
デモ
こんな人向け
- 簡単な開発をする時に会員管理の実装が面倒
- 見た目はBootstrap4ベースでOK
- 会員認証はE-mailとパスワードで行いたい
動かし方
Githubから取得
- Githubからダウンロードするか、下記コマンドでクローンしてください。
git clone https://github.com/motoitanigaki/django-account-ja.git動かす
cd django-account-ja pip install -r requirements.txt python manage.py migrate python manage.py runserver python manage.py createsuperuser
runserverコマンドが成功すると、http://127.0.0.1:8000/から動作を確認できるようになります。中身の解説
全体像
Djangoには
django/contrib/authという会員管理のためのパッケージが内包されているため、基本的にはこれを最大限利用しつつ、少しのコードで求めている形を実現できるようにしていきます。
全体像としては下記の感じです。
青い部分が今回作成したアプリ、緑の部分はDjangoが標準で提供している機能です。オレンジの矢印は処理の流れを、オレンジの数字はこの記事での説明の順番と対応しています。
ざっくりの流れは下記です。
- Userモデルを
AbstractBaseUserクラスを継承して新たに作成- url振り分け設定を追記。元々提供されている機能はそのまま使いつつ、それ以外は新しく作成するViewを利用するようにする。
- 元々提供されている機能を少し見てみる
- 会員登録やプロフィール部分は自分で機能を作成
- Templateは全く用意されていないので、全て作成。元々提供されている機能(View)もここで作成したTemplateを利用することになる
1. Userモデルを
AbstractBaseUserクラスを継承して新たに作成Djangoのデフォルトの
UserクラスはAbstractUserというクラスを継承していて、このAbstractUserというクラスはusernameと
そして、UserManagerというクラスの_create_userというユーザーを作成するための関数内でこの両方を求める作りになっているため、python manage.py createsuperuserコマンドでスーパーユーザーを作成すると、usernameと今回は
usernameは使わずUserクラスとUserManagerクラスを自作します。なお、会員管理機能のカスタマイズは
AbstractUserとAbstractBaseUserのどちらが良いのか、という議論があります。この説明はこちらの記事に譲ります。自作する
models.pyファイルは下記のようになります。account/models.pyfrom django.contrib.auth.models import AbstractBaseUser, UserManager, PermissionsMixin from django.db import models from django.utils.translation import gettext_lazy as _ from django.core.mail import send_mail from django.utils import timezone class UserManager(UserManager): def _create_user(self, email, password, **extra_fields): email = self.normalize_email(email) user = self.model(email=email, **extra_fields) user.set_password(password) user.save(using=self._db) return user def create_user(self, email, password=None, **extra_fields): extra_fields.setdefault('is_staff', False) extra_fields.setdefault('is_superuser', False) return self._create_user(email, password, **extra_fields) def create_superuser(self, email, password, **extra_fields): extra_fields.setdefault('is_staff', True) extra_fields.setdefault('is_superuser', True) if extra_fields.get('is_staff') is not True: raise ValueError('Superuser must have is_staff=True.') if extra_fields.get('is_superuser') is not True: raise ValueError('Superuser must have is_superuser=True.') return self._create_user(email, password, **extra_fields) class User(AbstractBaseUser, PermissionsMixin): email = models.EmailField(_('email address'), unique=True) is_staff = models.BooleanField( _('staff status'), default=False, help_text=_('Designates whether the user can log into this admin site.'), ) is_active = models.BooleanField( _('active'), default=True, help_text=_( 'Designates whether this user should be treated as active. ' 'Unselect this instead of deleting accounts.' ), ) date_joined = models.DateTimeField(_('date joined'), default=timezone.now) objects = UserManager() EMAIL_FIELD = 'email' USERNAME_FIELD = 'email' REQUIRED_FIELDS = [] class Meta: verbose_name = _('user') verbose_name_plural = _('users') def clean(self): super().clean() self.email = self.__class__.objects.normalize_email(self.email) def email_user(self, subject, message, from_email=None, **kwargs): """Send an email to this user.""" send_mail(subject, message, from_email, [self.email], **kwargs)
AbstractBaseUserと比較すると、今回は使わないusername、first_name、last_nameが削除されています。ここで注意なのが
USERNAME_FIELD = 'email'という部分です。
Djangoではログインの認証やメール送信など様々なところでUSERNAME_FIELDで定義しているフィールドを利用します。通常usernameフィールドを利用するところを代わりに
本来は恐らくUSERNAME_FIELD経由で参照するのではなくEMAIL_FIELDを参照する形で色々な処理を行うべきだと思いますが、USERNAME_FIELDは
django/auth/contrib/auth/backends.pydjango/auth/contrib/forms.pydjango/auth/contrib/checks.py- などなど
で利用されているため、その深淵へ入り込むことは断念しました。
2. url振り分け設定を追記
ちなみに今回作成したプロジェクトはTwo Scoops of Djangoに乗っ取り、
settings.pyやmanage.pyが含まれるアプリをconfigという名前で作成し、ユーザー管理用のアプリをaccountという名前で作成し、設定系の情報とそれ以外の機能を分けています。
なので、このプロジェクトを基本としてWebサービスを作成する場合はpython manage.py startapp [アプリ名]コマンドで新しくアプリを作成して利用することを推奨します。Djangoではurl振り分けは各アプリ内に記述する形になりますが、一番最初に参照される
urls.pyはこの基底アプリ(今回だとconfig)です。config/urls.pyfrom django.contrib import admin from django.urls import path, include from account.views import Top urlpatterns = [ path('', Top.as_view(), name='top'), path('admin/', admin.site.urls), path('accounts/', include('account.urls')), # 2. 自作の機能へ振り分け path('accounts/', include('django.contrib.auth.urls')), # 1. 元々提供されている機能へ振り分け ]ポイントは2つあります
- 元々提供されている機能へ振り分け
Djangoではログイン、パスワード変更、パスワード再発行といった機能がdjango.contrib.auth内で提供されてるため、こちらへの振り分けをincludeで記載します。- 自作の機能へ振り分け
会員登録やプロフィール部分は元々提供されていないので、accountアプリ内で実装する必要があります。そこへの振り分けを記載します。3. 元々提供されている機能を少し見てみる
会員管理に関してどのあたりの機能が用意されているか、少し見てみます。
django/contrib/auth/urlsurlpatterns = [ path('login/', views.LoginView.as_view(), name='login'), path('logout/', views.LogoutView.as_view(), name='logout'), path('password_change/', views.PasswordChangeView.as_view(), name='password_change'), path('password_change/done/', views.PasswordChangeDoneView.as_view(), name='password_change_done'), path('password_reset/', views.PasswordResetView.as_view(), name='password_reset'), path('password_reset/done/', views.PasswordResetDoneView.as_view(), name='password_reset_done'), path('reset/<uidb64>/<token>/', views.PasswordResetConfirmView.as_view(), name='password_reset_confirm'), path('reset/done/', views.PasswordResetCompleteView.as_view(), name='password_reset_complete'), ]ログイン、ログアウト、パスワードの変更、パスワード再発行といった機能がそれぞれ用意されていることがわかります。ここで宣言されているurlに則れば、対象の機能が利用できそうです。
例えば
~/accounts/loginというurlが踏まれると、ログインのためのLoginViewが呼ばれます。ちょっと見てみましょう。django/contrib/auth/views.pyclass LoginView(SuccessURLAllowedHostsMixin, FormView): """ Display the login form and handle the login action. """ form_class = AuthenticationForm authentication_form = None redirect_field_name = REDIRECT_FIELD_NAME template_name = 'registration/login.html' redirect_authenticated_user = False extra_context = None ...フロントにレスポンスする時に用いるTemplateが
template_name = 'registration/login.html'とすでに宣言されています。このhtmlファイルの実態はまだ存在しないので、後ほどこのディレクトリ構造に従ってファイルを作成していきます。4. 会員登録やプロフィール部分は自分で機能を作成
Djangoが元々提供していない会員登録やプロフィール画面などは自分で実装していきます。
まずurls.pyから作成します。account/urls.pyfrom django.urls import path from django.views.generic import TemplateView from . import views app_name = 'accounts' urlpatterns = [ path('profile/', views.ProfileView.as_view(), name='profile'), path('signup/', views.SignUpView.as_view(), name='signup'), path('delete_confirm', TemplateView.as_view(template_name='registration/delete_confirm.html'), name='delete-confirmation'), path('delete_complete', views.DeleteView.as_view(), name='delete-complete'), ]続いて対応するViewファイルを作成します。
account/views.pyfrom django.urls import reverse_lazy from django.views import generic from django.shortcuts import render from django.contrib.auth.mixins import LoginRequiredMixin from django.contrib.auth import ( get_user_model, logout as auth_logout, ) from .forms import UserCreateForm User = get_user_model() class Top(generic.TemplateView): template_name = 'top.html' class SignUpView(generic.CreateView): form_class = UserCreateForm success_url = reverse_lazy('login') template_name = 'registration/signup.html' class ProfileView(LoginRequiredMixin, generic.View): def get(self, *args, **kwargs): return render(self.request,'registration/profile.html') class DeleteView(LoginRequiredMixin, generic.View): def get(self, *args, **kwargs): user = User.objects.get(email=self.request.user.email) user.is_active = False user.save() auth_logout(self.request) return render(self.request,'registration/delete_complete.html')
User = get_user_model()の記述が無いと、自作したUserモデルを利用しないので注意が必要です。また、新しいユーザを作成するための
UserCreationFormというクラスが提供されていますが、usernameを利用しないため一部変更するためにUserCreateFormというクラスを作成し、それをSignUpViewで利用しています。
UserCreateFormは下記です。account/forms.pyfrom django.contrib.auth.forms import UserCreationForm from django.contrib.auth import get_user_model User = get_user_model() class UserCreateForm(UserCreationForm): class Meta: model = User if User.USERNAME_FIELD == 'email': fields = ('email',) else: fields = ('username', 'email') def __init__(self, *args, **kwargs): super().__init__(*args, **kwargs) for field in self.fields.values(): field.widget.attrs['class'] = 'form-control'5. Templateは全く用意されていないので、全て作成
あとは元々提供されている機能、新しく作成した機能ともに利用するためのTemplateファイルをガシガシ作っていきます。
見た目は(めちゃくちゃこだわるというわけではないので)Bootstrap4を利用しています。
また、Formに対して自動的にBootstrap4のクラスをあてがってくれるdjango-bootstrap4というライブラリがあるので、今回はこれを利用します。
pipでインストールした後の利用上の注意としては
settings.pyのINSTALLED_APPSにbootstrap4を追加- 利用するテンプレート内に
{% load bootstrap4 %}を追加を忘れないことです。
これを使うとTemplateの
<form>タグがとてもすっきりします。例えばログインのTemplateを見てみるとaccount/templates/registration/login.html{% extends "base_centered.html" %} {% load bootstrap4 %} {% block content %} <h5 class="card-title text-center">ログイン</h5> <form action="{% url 'login' %}" method="POST"> {% bootstrap_form form %} <button type="submit" class="btn btn-primary btn-block">ログイン</button> <input type="hidden" name="next" value="{{ next }}"/> {% csrf_token %} </form> <a href="{% url 'password_reset' %}">パスワードをお忘れですか?</a> {% endblock %}という感じになります。
ちなみにTemplateが結構多いので、いくつか分割・部品化をしています。
ディレクトリ構造としては下記の感じで、
├── templates │ ├── base.html │ ├── base_centered.html │ ├── registration │ │ ├── base.html │ │ ├── delete_complete.html │ │ ├── delete_confirm.html │ │ ├── logged_out.html │ │ ├── login.html │ │ ├── password_change_done.html │ │ ├── password_change_form.html │ │ ├── password_reset_complete.html │ │ ├── password_reset_confirm.html │ │ ├── password_reset_done.html │ │ ├── password_reset_email.html │ │ ├── password_reset_form.html │ │ ├── password_reset_subject.txt │ │ ├── profile.html │ │ ├── signup.html │ │ └── subnav.html │ └── top.html図にするとこんな感じです。
会員登録やログインの画面は中央寄せのよくあるデザインで統一しているため、
base_centered.htmlというファイルにそのフレームだけ記載し共通化して、前述のlogin.html等中身を埋め込むイメージです。大体の構造は以上です。
これで個人開発の時にいつもひいひい言っていた会員管理周りが爆速になると思うとテンション爆上がり。最後に、今回下記ブログやサイトには大変お世話になりました。ありがとうございました。
Django2 でユーザー認証(ログイン認証)を実装するチュートリアル -2- サインアップとログイン・ログアウト
Django における認証処理実装パターン
Djangoで、会員登録機能を自作する

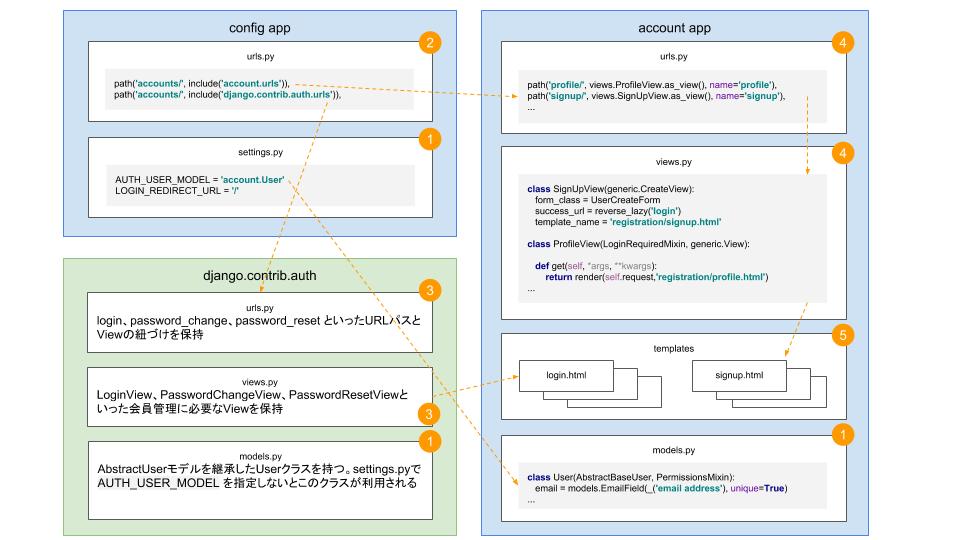
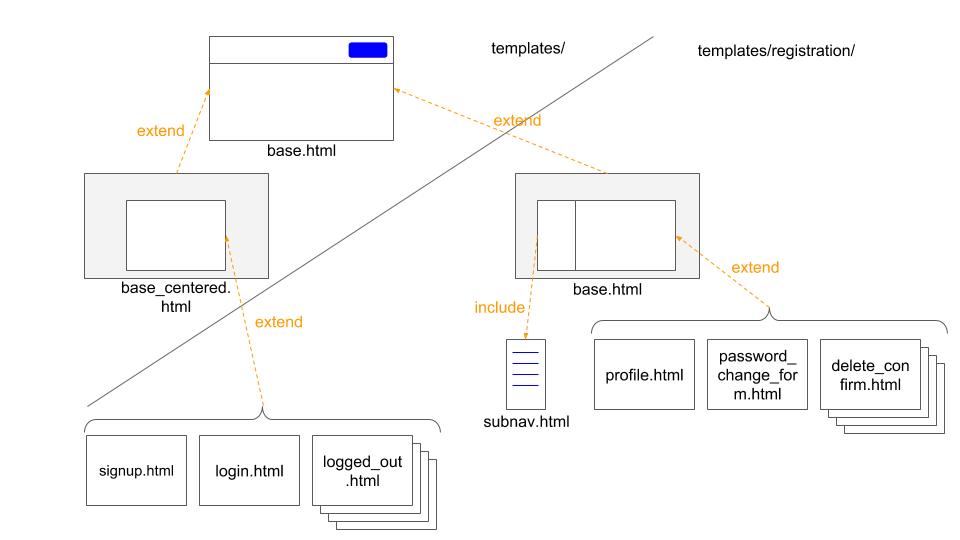
- 投稿日:2019-03-24T12:01:43+09:00
Confirmed状態のCognitoユーザーをBoto 3で即作成する
概要
指定されたユーザー情報を使って、すぐにログインできるConfirmed状態のCognitoユーザーをバックエンド側でサクッと作成したい。
admin_create_userだとForce Change Password状態となるので、この後に処理が必要。今のところの結論
import boto3 username = '{ユーザー名}' password = '{パスワード}' email = '{メールアドレス}' user_pool_id = '{ユーザープールID}' client_id = '{アプリクライアントID}' cognito_idp = boto3.client('cognito-idp') # ユーザーを作成する。 cognito_idp.admin_create_user( UserPoolId=user_pool_id, Username=username, TemporaryPassword=password, UserAttributes=[{'Name': 'email', 'Value': email}], MessageAction='SUPPRESS' ) # ログインを試みる。(パスワードの変更を要求される。) response = cognito_idp.admin_initiate_auth( UserPoolId=user_pool_id, ClientId=client_id, AuthFlow='ADMIN_NO_SRP_AUTH', AuthParameters={'USERNAME': username, 'PASSWORD': password}, ) session = response['Session'] # パスワードを変更する。 response = cognito_idp.admin_respond_to_auth_challenge( UserPoolId=user_pool_id, ClientId=client_id, ChallengeName='NEW_PASSWORD_REQUIRED', ChallengeResponses={'USERNAME': username, 'NEW_PASSWORD': password}, Session=session )解説
以下の3ステップでConfirmed状態のユーザーを作成しています。
- ユーザーの作成(
admin_create_user)- 最初の認証(
admin_initiate_auth)- パスワードの変更(
admin_respond_to_auth_challenge)1. ユーザーの作成(
admin_create_user)管理者によるユーザーの作成を行う。
通常は作成した時に仮パスワードが通知されますが、MessageAction='SUPPRESS'で無効にできます。2. 最初の認証(
admin_initiate_auth)管理者による最初の認証を試みる。
すると、以下のようなレスポンスが返却され、新しいパスワードが必要だということが分かります。この中のSessionが次の処理で必要となります。{'ChallengeName': 'NEW_PASSWORD_REQUIRED', 'ChallengeParameters': (省略), 'ResponseMetadata': (省略), 'Session': '{セッションを表す長い文字列}'}また、
AuthFlow='ADMIN_NO_SRP_AUTH'とする場合は、アプリクライアントの設定で「サーバーベースの認証でサインイン API を有効にする (ADMIN_NO_SRP_AUTH)」を有効にしておく必要があります。SRPというのは認証のプロトコルで、使用するとセキュアでない通信経路でもユーザー名とパスワードによる認証を安全に行なえるようになるようですが、実装が難しくなり、また今回は全てバックエンドでの処理となるので、使用しなくても良いこととしています。3. パスワードの変更(
admin_respond_to_auth_challenge)管理者による
NEW_PASSWORD_REQUIREDに対する返答。
成功すると各種トークンが返却され、ユーザーの状態もConfirmedへ移行します。これでめでたくユーザーが普通にログインできるようになりました!なお、コードにある通り、新しいパスワードは仮のパスワードと同じでも問題ありませんでした。
他の方法
一応、次の方法でもConfirmed状態のユーザーを作成することができます。
# ユーザーがサインアップする。 cognito_idp.sign_up( ClientId=client_id, Username=username, Password=password, UserAttributes=[{'Name': 'email',' Value': email}] ) # それを管理者が承認する。 cognito_idp.admin_confirm_sign_up( UserPoolId=user_pool_id, Username=username )簡単だったので、最初はこちらの方法を使っていたのですが、アプリクライアントの設定で「アプリベースの認証でユーザー名とパスワードの (SRP を使用しない) フローを有効にする (USER_PASSWORD_AUTH)」を無効にしたり、属性の書き込み権限を変更したりすると
sign_upができなくなるので、全て管理者の操作で行える上記の方法に変更しました。
- 投稿日:2019-03-24T11:39:23+09:00
ディープラーニングを始めたいひとのLinux環境構築【Python×Keras】
LinuxでKerasを動かす際の環境構築手順をまとめました。
ディストリビューションはUbuntu 16.04 LTS、GPUで学習を行うことを想定しています。
なお、本投稿によって生じた全ての事象について私は責任を負いかねますので、必ず自己責任で行うようお願いします。
今回はこのような流れで進めていきます。
- はじめに
- Google Chromeをインストール
- Visual Studio Codeをインストール
- fishをインストール
- Pythonをインストール
- CUDAをインストール
- Tensorflow/Kerasをインストール
- Kerasでmnistの学習を実行
- 終わりに
はじめに
まずはじめにターミナルを開き、下記を実行しておきます。
$ sudo apt update $ sudo apt upgradeGoogle Chromeをインストール
普通にChromeをインストールしようとすると「インストール中」でフリーズするので、まず下記のパッケージをインストールする必要があります。
$ sudo apt install libappindicator1 # ここでエラーが発生する場合は現状インストールされているChromeを削除します。 $ sudo apt remove google-chrome-stableその後下記URLから
.devのインストーラをダウンロード、インストールを行います。
https://www.google.co.jp/chrome/browser/desktop/下記コマンドでChromeが起動します。
$ google-chromeVisual Studio Codeをインストール
ソースコードを編集する際に必要なエディタをインストールします。
ソースコードエディタは種類が豊富で、PythonにはPyCharmという統合開発環境もありますが、個人的な好みと拡張機能の多さから今回はVisual Studio Code(以下VSCode)をインストールします。
Ubuntuを使っているので下記URLから.debのインストーラをダウンロード、インストールを行います。
https://code.visualstudio.com/downloadその後下記コマンドでVSCodeが起動します。
$ codeまた下記の基本的な拡張機能をインストールしておくと便利です。
- Japanese Language Pack for VS Code
- Python extension for Visual Studio Code
次にUbuntuはデフォルトのフォントが少々見づらいので、フォントを
Fira Codeに変更します。
下記Githubの指示に沿ってインストールしていけばいいのですが、今回は下部のManual Installation通りにインストールしました。
https://github.com/tonsky/FiraCode/wiki/Linux-instructions#installing-with-a-package-managerまずシェルスクリプトを作ります。
$ touch download_and_install.sh上記のファイルを開き、リンク先に書いてあるソースコードをコピペします。
download_and_install.sh#!/usr/bin/env bash fonts_dir="${HOME}/.local/share/fonts" if [ ! -d "${fonts_dir}" ]; then echo "mkdir -p $fonts_dir" mkdir -p "${fonts_dir}" else echo "Found fonts dir $fonts_dir" fi for type in Bold Light Medium Regular Retina; do file_path="${HOME}/.local/share/fonts/FiraCode-${type}.ttf" file_url="https://github.com/tonsky/FiraCode/blob/master/distr/ttf/FiraCode-${type}.ttf?raw=true" if [ ! -e "${file_path}" ]; then echo "wget -O $file_path $file_url" wget -O "${file_path}" "${file_url}" else echo "Found existing file $file_path" fi; done echo "fc-cache -f" fc-cache -fdownload_and_install.shを実行します。
$ sh download_and_install.shこれでFira Codeをインストールできたので、VSCodeに適用します。
メニューの「Code」→「基本設定」→「設定」を開き、
Editor:Font Familyを"Fira Code Retina"、
Editor: Font Ligaturesを有効にすればフォントが変更されます。
変更されないときはRetina部分をRegularや、Boldにしたりしてみてください。
あとはメニューの「Code」→「基本設定」→「配色テーマ」から、カラーテーマを好きなものに変更します。最後に個人的に不便なプレビューモードを解除しておきます。
Workbench › Editor: Enable Previewと、
Workbench › Editor: Enable Preview From Quick Openを無効にすればOKです。fishをインストール
引き続きターミナルを操作していきますが、今回はshellにfishを使用します。
fishはfriendly interactive shellの略称とのことですが、特徴はやはりわかりやすさだと感じます。コマンドを途中まで入力するとその先をわかりやすく補完してくれたり、シンタックスハイライトによってそのコマンドが正しいのか間違っているのかということも示唆してくれます。
Ubuntuのデフォルトシェルはbashですが、一応現在のシェルを確認しておきます。現在のシェルはSHELLという環境変数に設定されているので$SHELLの中身を出力することで確認できます。$ echo $SHELL /bin/bashそれではデフォルトシェルをbashからfishに変更していきます。
まずはfishをインストールします。$ sudo apt install fishインストールができたら、fishのパスを確認します。
$ which fish /usr/local/bin/fish自分のマシン環境で使用可能なシェル一覧を確認します。
$ cat /etc/shells # List of acceptable shells for chpass(1). # Ftpd will not allow users to connect who are not using # one of these shells. /bin/bash /bin/csh /bin/ksh /bin/sh /bin/tcsh /bin/zsh /usr/local/bin/fish末尾に上記fishのパスが追加されていたらOKですが、なければvimを使って手動で追記します。
下記コマンドでvimエディタを開いたらiでインサートモードに切り替え、テキストを入力します。
入力が終わったらescでノーマルモードに戻り、:wで上書き保存、:qでエディタを閉じます。$ sudo vim /etc/shells # vimがインストールされていなかったら下記を実行します。 $ sudo apt install vim下記コマンドでデフォルトシェルをfishに変更します。
chsh -s /usr/local/bin/fishこれでデフォルトシェルを変更できました。パソコンを一度ログアウトするとこの変更が適用されます。
再ログインして変更が適用されたかを確認します。ターミナルを起動し、最初のメッセージがbashのときから変わってWelcome to fish, the friendly interactive shellと表示されていたらOKです。一応現在の環境変数も確認しておきます。$ echo $SHELL /usr/local/bin/fishなお、現在使用しているシェルは下記方法でも確認できます。
cat /etc/passwd | grep usernameデフォルトシェルはbashのままfishを起動したい場合は
.bashrcの末尾にexec fishと記述しておけば同様にfishを使用できます。Pythonをインストール
pyenvをインストール
pyenvはPythonのバージョン管理ができるコマンドラインツールです。
pyenvを使うことで例えばディレクトリAではPython2系を使う、ディレクトリBではPython3系を使うといったことが可能になります。
公式Github:https://github.com/pyenv/pyenv/wiki
まず上記Githubからpyenvをホームディレクトリにダウンロードします。$ git clone git://github.com/yyuu/pyenv.git ~/.pyenv # Gitがインストールされておらず、上記でエラーが起こる場合はまずこちらを実行します。 $ apt install git次にダウンロードしたpyenvのパスを通します。
「パスを通す」とは「コマンド検索パスを追加する」ことだと考えるとわかりやすいです。コマンドライン上に入力したコマンド(例えばlsやcd)が正しく動作するのと同じように、コマンドライン上でpyenvと入力したらどのファイルを実行してねということを設定します。
現時点ではパスを通していないので下記を実行しても何も表示されません。$ which pyenvそれではpyenvのパスを通します。今回はシェルスクリプトにfishを使っているので書き込み先は
.config/fish/config.fishです。$ echo 'set -x PATH $HOME/.pyenv/bin $PATH' >> .config/fish/config.fish $ echo '. (pyenv init - | psub)' >> .config/fish/config.fish書き込みを適用します。(下記コマンドではなくターミナルを再起動しても適用されます。)
$ source .config/fish/config.fishこれでpyenvのパスが通ったので、再度下記を実行するとパスが表示されます。
$ which pyenv /home/username/.pyenv/binAnacondaをインストール
Anacondaは機械学習やデータサイエンスをするうえで必要になる色々なPythonパッケージをまとめて提供してくれます。
現時点ではどのバージョンもインストールしていないので下記を実行するとsystemというデフォルト項目だけが表示されます。$ pyenv versions * systemインストールできるバージョンを確認します。
下記を実行するとpyenvでインストールできるバージョンがリスト表示されます。$ pyenv install -l今回は
anaconda3-5.2.0をインストールします。anacondaのバージョンが新しすぎるとtensorflowをインストールできないことがあるので注意してください。$ pyenv install anaconda3-5.2.0ここで再度下記を実行するとインストールできていることがわかります。
*が現在適用されているバージョンを示します。$ pyenv versions * system anaconda3-5.2.0 (set by /home/username/.pyenv/version)pyenvではインストールしたバージョンを現在のアカウント全体で使うか、特定のディレクトリだけで使うかを指定することができます。今回はanaconda3-5.2.0をアカウント全体に適用します。
$ pyenv global anaconda3-5.2.0下記を実行すると
*が移動していることがわかります。$ pyenv versions system * anaconda3-5.2.0 (set by /home/username/.pyenv/version)CUDAをインストール
CUDAはGPUを使って学習を行う際に必要になります。
まず公開鍵を取得します。$ sudo apt-key adv --fetch-keys http://developer.download.nvidia.com/compute/cuda/repos/ubuntu1604/x86_64/7fa2af80.pub続いてパッケージをダウンロードします。
$ wget http://developer.download.nvidia.com/compute/cuda/repos/ubuntu1604/x86_64/cuda-repo-ubuntu1604_9.2.88-1_amd64.debダウンロードしたパッケージをインストールします。
$ sudo dpkg -i cuda-repo-ubuntu1604_9.2.88-1_amd64.debAPTをアップデートし、下記をインストールします。
$ sudo apt update $ sudo apt install cuda cuda-driversここでPCを再起動します。
$ sudo rebootこのあと
.config/fish/config.fishに追記します。$ echo 'set -x PATH /usr/local/cuda/bin $PATH' >> .config/fish/config.fish $ echo 'set -x LD_LIBRARY_PATH /usr/local/cuda/lib64 $LD_LIBRARY_PATH' >> .config/fish/config.fish最後にログオフをして再度ログイン後、下記コマンドを実行、接続しているGPUが表示されたらOKです。
$ nvidia-smiTensorflow/Kerasをインストール
続いてTensorflow、そのあとにKerasの順でインストールします。
今回はGPUを使用するのでtensor-gpuとしていますが、tensorflowだけでも問題はありません。$ conda install tensorflow-gpu $ conda install kerasKerasを実行
最後にKerasでmnistの学習を実行して動作確認をします。
コードはこちらを使用します。
https://github.com/keras-team/keras/blob/master/examples/mnist_cnn.py適当なPythonファイルを作成します。
$ touch train.py作成した
train.pyに上記URLのコードをコピペして保存、下記を実行します。
エラーなく処理が進めばクリアです!$ python train.py終わりに
私なりの手順を書かせていただきましたが、上記の手順のなかで不備や漏れ、お気づきのことがございましたらコメントをいただけますと幸いです。
また本稿作成にあたり下記を参考にさせていただきました。
https://qiita.com/shuntksh/items/1995e87fe5c1ac88296f
https://qiita.com/tkmpypy/items/9bd9692ad44dcd5710da
https://qiita.com/yukoba/items/3692f1cb677b2383c983
- 投稿日:2019-03-24T10:17:57+09:00
emacs の org-beamer-export-to-pdf 設定手順
目的
emacs のテキスト編集モードの一つである org-mode で M-x org-beamer-export-to-pdf (C-c C-e l P) コマンド一発により、以下のようなスライドを簡単に生成できるように構築する。
設定手順
環境
- Windows: 10 Pro
- Emacs: 26.1
- Org mode: 9.1.9
- Python: 3.7.2
- platex: e-pTeX 3.14159265-p3.8.1-180226-2.6(utf8.sjis)(TeX Live 2018/W32TeX)
ソースコードへの色付け(シンタックスハイライト)は minted を使用するため、Python の Pygments もインストールする1。
インストール手順を簡易化するため、可能な限り、空っぽの OS に各プログラムをデフォルトのままインストールする(Anaconda などを用いないように書いておく)。また、将来を考えて emacs26、 Python3 の構築としたが、日々の運用は emacs 25, Python2 で行っている(init.el はそのままで動く)。TeX Live 2018 のインストール
- ここから install-tl-windows.exe をダウンロードして実行
- [Unpack only] にチェック
- [Next] を選択
- [Destination Folder] で適当な場所を選択(たとえば [C:\texliveinstaller])
- [Next] を選択
- [Install] を選択
- しばらくして完了したら、[Close] を選択
- [C:\texliveinstaller\install-tl-20190227\tlpkg\installer\wget] フォルダを開く
- [.wgetrc] を作成する (Powershell であれば ni .wgetrc で作成可能)
[.wgetrc] の中身は以下のとおり
http_proxy=http://proxy.example.net:port ftp_proxy=http://proxy.example.net:port use_proxy=on[C:\texliveinstaller\install-tl-20190227\install-tl-windows.bat] を実行2
Python のインストール
- ここから、[Windows x86-64 executable installer] をダウンロード
- [python-3.7.2-amd64-webinstall.exe] を実行
- 画面に従いインストール(デフォルトでは、たとえば [C:/Users/Administrator/AppData/Local/Programs/Python/Python37/] 以下にインストールされる)
以下を実行3
PS > .\pip.exe install pygments --proxy=user@proxy.hoge.jp:portemacs のインストール
- ここ以下から [emacs-26.1-x86_64-win-ime-20180619.zip] をダウンロード
- [C:\emacs-26.1] に展開
- [C:\emacs-26.1\bin\runemacs.exe] を実行4
init.el の設定
; -*- Mode: Emacs-Lisp ; Coding: utf-8 -*- PATHを追加する (setenv "PATH" (concat "C:/texlive/2018/bin/win32;" "C:/Users/Administrator/AppData/Local/Programs/Python/Python37/Scripts;" (getenv "PATH"))) (setq exec-path (parse-colon-path (getenv "PATH"))) (require 'ox-latex) (require 'ox-beamer) (setq org-latex-pdf-process '("platex -shell-escape %f" "platex -shell-escape %f" "pbibtex %b" "platex -shell-escape %f" "platex -shell-escape %f" "dvipdfmx %b.dvi")) (setq org-export-latex-listings t) (setq org-latex-listings 'minted) (setq org-beamer-outline-frame-title "目次") (setq org-latex-minted-options '(("frame" "lines") ("framesep=2mm") ("linenos=true") ("baselinestretch=1.2") ("fontsize=\\footnotesize") ("breaklines") ))サンプル
たとえば、以下のようなテキストファイルを作成して、C-c C-e l P とすると冒頭の PDF が一発で作成できる(emacs.png はどこから拾っておくこと)。
# -*- Mode: org ; Coding: utf-8-unix -*- #+TITLE: Sample for Beamer with Org-mode #+AUTHOR: @clothoid #+OPTIONS: H:2 toc:t num:t #+LATEX_CLASS: beamer #+LATEX_CLASS_OPTIONS: [dvipdfmx,12pt] #+BEAMER_THEME: metropolis #+LATEX_HEADER: \usepackage{bxdpx-beamer} #+LATEX_HEADER: \usepackage{pxjahyper} #+LATEX_HEADER: \usepackage{minijs} #+LATEX_HEADER: \usepackage{minted} #+LATEX_HEADER: \renewcommand{\kanjifamilydefault}{\gtdefault} * その1: 基本的な使い方 ** 最初のスライド M-x org-beamer-export-to-pdf 一発で PDF が作成できます。 ** 次のスライド *** Eric Fraga さんへ :PROPERTIES: :BEAMER_COL: 0.48 :BEAMER_ENV: block :END: 作ってくれてありがとう *** みなさんへ :PROPERTIES: :BEAMER_COL: 0.48 :BEAMER_ACT: <2-> :BEAMER_ENV: block :END: 使ってくれてありがとう * その2: 装飾など ** 箇条書き #+ATTR_BEAMER: :overlay +- - りんご - バナナ - オレンジ ** 文字の装飾 文字を装飾する記法もいくつか用意されています。 - *太字 abc* - /斜体 abc/ - _下線付き abc_ - +取消線付き acb+ - =コード abc= - ~等幅 abc~ ** リスト 1. January - 元旦 - 成人の日 2. Feburuary - 建国記念の日 ** 引用 以下は引用です。 #+BEGIN_QUOTE すべてをできる限りシンプルにせよ. ただしそれ以上はシンプルにするな. -- アインシュタイン #+END_QUOTE ** テーブル #+ATTR_LaTeX: align=|l|r|r|r|r|r| |----------+----+----+----+----+-------| | | Q1 | Q2 | Q3 | Q4 | Total | |----------+----+----+----+----+-------| | PC | 30 | 0 | 50 | 0 | 80 | | Software | 5 | 15 | 20 | 3 | 43 | | Network | 2 | 2 | 2 | 2 | 8 | |----------+----+----+----+----+-------| | Sum | 37 | 17 | 72 | 5 | 131 | |----------+----+----+----+----+-------| * その3: 応用編 ** 数式 *** 文中で数式を使用する例: $\sum_{i=1}^n a_i x_i \ge b$ の時、どうすればいいのか、誰か教えてください。 私には分かりません。 *** ブロックとして数式を使用する例: \begin{eqnarray*} x & = & \sqrt{\frac{a}{b}} \end{eqnarray*} ** プログラムソース #+BEGIN_SRC c++ #include <iostream> int main(int argc, char** argv) { std::cout << "Hello, world." << std::endl; return 0; } #+END_SRC ** 画像 #+ATTR_LATEX: :float wrap :width 0.16\textwidth :placement :options angle=45 file:emacs.png Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum. ** 脚注 ここに脚注です[fn:fntest] * Footnotes [fn:fntest] これは脚注です参考
脚注
2 コマンドラインオプションで –no-persistent-downloads をつけると早くなるらしい(未確認)
3 pip.exe は C:/Users/Administrator/AppData/Local/Programs/Python/Python37/Scripts にある

- 投稿日:2019-03-24T10:08:47+09:00
AnsibleでUbuntu 16.04にPython2を導入するplaybook例。冪等性やchanged ハンドリング対応
概要
以下のplayにPython導入ずみ環境対応やchangedハンドリングを追加してみました
- Ubuntu 16.04 で ansible を使う
- Ansible rawモジュールを使用してUbuntu 16.04にPython2を導入
- とりあえずapt決め打ち
- rawモジュールを使用する為、gather_facts: false
- Pythonが既に使用可能ならば、which pythonの結果より
- failed_when:, changed_when: の除外対象とする
- Pythonの導入を行なった場合、rcを特定の値(ここでは100)とし
- failed_when: の除外対象とする
play例
- hosts: all gather_facts: false tasks: - name: install python2 for Ubuntu 16.04 raw: which python || ( apt update && apt --yes install python && exit 100 ) register: result failed_when: result.rc not in [0,100] changed_when: result.rc != 0参考