- 投稿日:2020-07-09T23:53:53+09:00
パソコン甲子園2014 Floppy Cubeから始まるルービックキューブを解くプログラムの作り方
はじめに
私はルービックキューブを速く解くスピードキューブという競技を趣味としているハードウェア/ソフトウェアエンジニアのNyanyan(にゃにゃん)です。今回はパソコン甲子園2014のFloppy Cubeという問題を解説し、そこからルービックキューブなどの立体パズルを解くプログラムの汎用的な書き方を解説します。
私は現在2x2x2のルービックキューブを(おそらく)世界最速で解くロボットを作っていて、そこで培った知識を使ってこの問題が解けました。この知識はこの問題にはオーバーキルなものなのですが、ぜひ紹介したいと思いこの記事を書いています。
問題の概要
フロッピーキューブとは
写真のようなパズルです。「一段しかないルービックキューブ」と呼ばれることもあり、まあその通りです。ポイントとして、軸が4つ(上下左右)ありそれを180度回転することで揃えることができるということがあります。
英語版wikiによると、組み合わせ数は$192$(普通のルービックキューブが$4.3\times10^{19}$通りであることを考えるとかなり少ないです)、神の数字(最大でも$N$手あれば必ず揃えられるという数字)は$8$です。問題
問題文の全文はこちら
フロッピーキューブの各面の色の状態が数字の羅列として与えられるので、この状態から何手で揃えられるかを出力してください。
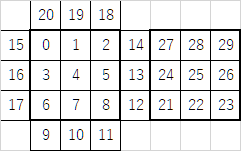
メモリ制限は$131072$KB、時間制限は$1$秒で、最大30個のパズルの状態が与えられます(つまりパズル1つあたり平均$33$ms以内に答えを出力しなくてはいけません)。パズルの状態は数字の羅列で与えられます。この数列はパズルのステッカー(色がついているところ)の数である$30$(表面と裏面で$9$個$\times 2=18$、側面が$3$個$\times4=12$で合計$30$)の要素で構成されていて、それぞれ色が数字$1,2,3,4,5,6$で表されています。この色を表す数字のうち$1,3$は表面/裏面の色で、それ以外は側面の色です。
この色を表す配列を$p$とすると、$p$の($0$始まりでの)番号と面の対応は以下の図の通りになります。
揃っている状態はサンプルケースにあるこちらです。
1 1 1 1 1 1 1 1 1 2 2 2 4 4 4 6 6 6 5 5 5 3 3 3 3 3 3 3 3 3入力は以下のように与えられます。
入力されるパズルの数 N (<=30) 空白区切りのパズルの状態数列 p_1 p_2 ... p_nでは問題を解いていきましょう。
直感的だが汎用性は低い方法
まず最初に思いつくであろう方法は、愚直にシミュレーションし幅優先探索する方法です。汎用性は低いですが比較的簡単に実装できます(ただし回転のシミュレーションをするのがとてもだるいです)。
パズル一つの計算量を見積もります。各状態に対して次に回せる手は上下左右のどれかを$180$度回すことなので、$4$通りあります(このあとここを工夫してさらに計算量を削減します)。そして最大でも$8$手で揃うので、計算量は最大でも
$O(4^8)=O(6.6\times10^4)$
となります。パズルの状態が30個与えられても計算量は$O(2.0\times10^6)$となり、間に合いそうです。
さて、この方法で面倒なのはパズルを実際に動かすところの実装です。今回は回転という動作を、入力される数列$p$自体を操作することで表現します。この方法は面倒かつ汎用性が皆無なのであとで違う方法を使います。
フロッピーキューブは必ず$180$度回転を用いるため、2つのステッカー(数列の要素)を適切に選んでスワップすることで実装できます。
実装した結果はこちら(コードはリンク先をご覧ください)です。一応ACしました。実行時間は$0.35$秒、メモリ使用量は$14580$KBでした。この方法の良い点
1, どことどこをスワップさせるかを間違えずに実装できればあとはただ幅優先探索を行うのみなので考え方としては簡単
この方法の悪い点
1. どことどこをスワップさせるかの実装が非本質的かつだるい(私も間違えました)
2. 幅優先探索なのでメモリをそれなりに使う
3. 汎用性がない(普通のルービックキューブを解くプログラムをこの方法で書くと回転の実装がとてもだるくなる)直感的な方法の改良
さて、先程のプログラムを改良していきましょう。実はこのプログラムは計算量を簡単に削減できます。
直前に回したのと同じ手は回さない
例えば直前に上、下と回したあと上を回さない
7手で揃わなかったら答えは必ず8(8手以内に必ず揃うので)この3つを実装すると、計算量が削減できます。具体的にパズル一つについての計算量を見積もってみましょう。最大(8手で揃う)場合で考えます。(※数学的に厳密でないです。実際はこれより若干計算量が増えそうです)
$O(4\times3^6-2\times5\times3^4)=O(2.1\times10^3)$
先程のプログラムの計算量が$O(6.6\times10^4)$だったのでかなり削減できました。
やってみた結果はこちらです。実行時間は$0.08$秒、メモリは$6704$KBでした。時間もメモリもかなり改善されました(先程のコードでもACですが)。
汎用的な方法を考える
概要
天下り的ですが、汎用的な方法として以下のようなパズルの記述方法があります(ルービックキューブを嗜む人はご存知かもしれません)。
- ステッカーごとでなくパーツごとに考える
- パーツの位置と向きに注目して考える
- パズルはいくつかの形状のパーツで構成されているので、パーツの形状ごとに上記の方法を考える
今回のフロッピーキューブで具体的に考えましょう。
フロッピーキューブでステッカーがついている(色がついている)パーツは「コーナー」「エッジ」「センター」の3種類です。それぞれについてもう少し考えてみましょう。コーナー
回転させると移動する。
回転させると向き(裏表)が変わるエッジ
回転させても移動しない(エッジパーツを軸に回るので)
回転させると向き(裏表)が変わるセンター
回転させても移動しない
回転させても向きが変わらないこれらの事実を考慮すると、パズルの状態を表すには以下の3種類の情報があれば良いことがわかります。
- コーナーパーツ4つそれぞれの位置 (CP=Corner Permutationと言う)
- コーナーパーツ4つそれぞれの向き (CO=Corner Orientationと言う)
- エッジパーツ4つそれぞれの向き (EO=Edge Orientationと言う)
追記 厳密な証明はできていませんが、どうやらCPが揃えばCOは自動的に揃うようです。記事内ではCOも考慮した書き方のままにしておきますが、COを考慮しない提出リンクも追記として貼っておきます。
実際の回転処理では、以下のような規則で配列をいじります。
位置
コーナーパーツの位置(左上、右上、右下、左下)にそれぞれ0から4までの番号(名前)をふる。
コーナーパーツ自身にも0から4までの番号をふる。
例えばCP配列cpのi番目の要素cp[i]は、場所iにあるパーツがcp[i]という名前という意味になります。向き
コーナー/エッジパーツの位置にそれぞれ0から4の番号をふる。
例えばパーツが表面を向いている(揃ったときに向いている方向)ときは0、裏面を向いているときは1とする。
例えばCO配列のi番目の要素co[i]が0ならば場所iにあるパーツは表を向いていて、1ならば裏を向いていることになります。実装
一つのパズルの状態につき複数の配列で状態を表すので、クラスを使うと楽です。
また、パーツの位置にふる番号を例えば時計回りに設定することで、回転させる処理を書く際にどこが動くのかを手打ちする必要がなくなります。
この方法の欠点は、入力される各ステッカーの色の情報をCP、CO、EOの3つの配列に変換するのが多少面倒だということです。結果
私が書いたコードと実行結果はこちらです。実行時間は$0.12$秒、メモリ使用量は$6860$KBでした。
追記 COを考慮しないプログラムでもACしました。提出リンクはこちらです。実行時間は$0.09$秒、メモリ使用量は$6776$KBでした。
計算量を削減する - 枝刈り
ここでは先程の汎用的なコードの利点である汎用さを使って前計算を行い、それを使って枝刈りをして計算量を削減しましょう。
枝刈りは、神の数字である8手以内に揃わないとわかっている状態になったら探索を打ち切るようにして実現します。具体的にはCP、CO、EOのそれぞれすべての状態について何手でCPならCPだけ、COならCOだけ、EOならEOだけを揃えられるかを前計算しておきます。そして幅優先探索の最中に、
今まで回した手数 + CP、CO、EOをそれぞれ単独で揃えるために必要な最大の手数
を計算し、これが神の数字である8手を超えたらこのノード(状態)についてこれ以上の探索を打ち切ります。
これを実装した提出結果はこちらです。実行時間は$0.16$秒、メモリ使用量は$6804$KBでした。
追記 COを考慮しないプログラムでもACしました。提出リンクはこちらです。実行時間は$0.13$秒、メモリ使用量は$6544$KBでした。この枝刈りの手法は事前計算を行うことと、毎回の探索でCP、CO、EOの配列それぞれの固有番号を計算するため、今回のように
- 一つのノード(状態)から回せる次の手の数が少ない
- 最大の探索深さ(つまり神の数字)が浅い(小さい)
ときには恩恵はあまりありません。今回は実行時間が少しのびてしまいました。しかし、フロッピーキューブよりも複雑なパズルを解こうとする場合にこの枝刈りは計り知れない恩恵があります。
メモリ使用量を削減する - IDA*
ここでお話しする内容は、フロッピーキューブでない何か別のパズルを解く際に幅優先探索を使うとメモリ使用量がとんでもないことになってしまうことへの対処法です。例として2x2x2ルービックキューブで幅優先探索を行うと、私の書いたプログラムでは4GB程度のメモリを食ってしまいました。
ここで出てくるのがIDA*という探索法です。詳しくはこちらの記事が詳しくておすすめです。こちらの記事から一部を引用して紹介します。
IDA*を一言で表すと、「最大深さを制限した深さ優先探索(DFS)を、深さを増やしながら繰り返す」です。
IDA*のからくりは、一度探索したノードを忘れることにあります。ノードを忘れてしまえば、メモリを解放できますよね。IDA*では深さ$N-1$までで深さ優先探索を行って解が見つからなかったら、最大深さを$N$に増やしてまた一から探索をやり直します。こうすることで、
- 返される結果は必ず最短手数(実装を少しいじれば最短手順も出力できます)
- メモリ使用量がとても少ない
という恩恵があります。
ただし、深さの浅いノード(状態)については何度も同じ探索を繰り返してしまうため、計算量は若干増大します。しかしパズルの状態は深さに対して指数関数として増大するため、計算量の増大はそこまで大きくありません。
具体的に今回の場合の計算量を見積もってみましょう。7手で揃うパズルの状態であるとします。幅優先探索を行った場合は、枝刈りを無視すると計算量は大体$O(2.1\times10^3)$でした。そしてIDA*では、$O(\Sigma_{i=1}^7 (4\times3^{i-1}-2\times(i-2)\times\mathrm{floor}(3^{i-3})))=O(3.3\times10^3)$
です。比較するとそこまで大きな差は見られません。
実装した結果はこちらです。実行時間は$0.09$秒と、なんと先程のプログラムよりも速くなりました。メモリ使用量は$6044$KBと、幅優先探索の$6544$KBから削減できました。
追記 COを考慮しないプログラムでもACしました。提出リンクはこちらです。実行時間は$0.07$秒、メモリ使用量は$6036$KBでした。まとめ
ここまで読んでくださりありがとうございます。
特に後半に紹介した方法はとても汎用的な方法ですがフロッピーキューブに対してはあまりにもオーバーキルな方法です。ぜひとも2x2や3x3のルービックキューブを解くプログラムをこの方法で書いてみてこの方法の汎用性の高さを実感してください。
2x2については私が書いたルービックキューブを解くロボットを作ろう!2 アルゴリズム編という記事、3x3は7y2nさんのルービックキューブを解くプログラムを書いてみよう(中編:IDA*探索)という記事をおすすめします。


- 投稿日:2020-07-09T22:53:29+09:00
2. Pythonで綴る多変量解析 2-3. 重回帰分析[COVID-19感染者率]
重回帰分析によって一体どういうことが分かるのかということを、もっと具体的に見ておきたいと思います。
そこで、身近な統計データからサンプルデータを作って、それで重回帰分析をやって解釈を試みます。今回サンプルデータを作成するにあたって、次の2つのデータソースを利用しました。➀政府統計ポータルサイト「政府統計の総合窓口e-Stat」都道府県データ
https://www.e-stat.go.jp/regional-statistics/ssdsview/prefectures
➁厚生労働省「新型コロナウイルス感染症」各都道府県の検査陽性者の状況
https://www.mhlw.go.jp/content/10906000/000646813.pdfまず目的変数を、新型コロナウイルス感染者率とします。これを左右しているかも知れない説明変数には、いわゆる「3つの密」および感染拡大につながると考えられる「人々のアクティビティ」に関する指標として次の7つの変数を用意しました。
指標名 指標計算式 調査年 人口集中地区人口比率(%) 人口集中地区人口(人) / 総人口(人) 2015年度 昼夜間人口比率(%) 昼間人口 / 夜間人口 2015年度 就業者比率(%) 就業者数(人) / 総人口(人) 2015年度 飲食店・宿泊業就業者比率(%) 就業者数(飲食店・宿泊業)(人) / 就業者数(人) 2005年度 旅行行動者率(%) 旅行行動者率 10歳以上(%) 2016年度 外国人宿泊者比率(%) 外国人延べ宿泊者数(人) / 延べ宿泊者数(人) 2018年度 単独世帯比率(%) 単独世帯数(世帯) / 世帯数(世帯) 2018年度 人口10万人当たり感染者率(%) 感染者数 陽性日(人) / 総人口(人) 2020年7月5日現在 ⑴ ライブラリをインポートする
import numpy as np # 数値計算 import pandas as pd # データフレーム操作 from sklearn import linear_model # 機械学習の線形モデル⑵ サンプルデータを読み込む
# URLを指定して、csvファイルを読み込み url = 'https://raw.githubusercontent.com/yumi-ito/sample_data/master/covid19_factors_prefecture.csv' df = pd.read_csv(url) # データの冒頭5行を表示して中身を確認 df.head()サンプルデータ(covid19_factors_prefecture.csv)をGitHubに置いてあるので、そこから読み込んでいます。
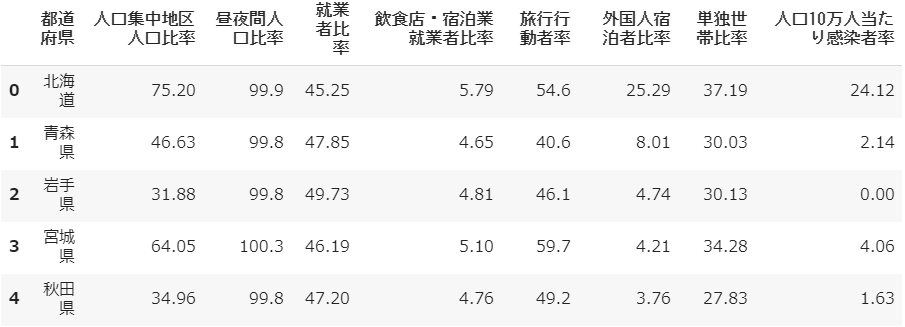
「人口集中地区人口比率」とありますが、この人口集中地区(DID:Densely Inhabited Districtの略)とは統計データに基づいて一定の基準により都市的地域を定めたものです。では都市的地域とは何なのかというと、特に人口密度の高い地域のことで、広い意味での市街地を指します。ざっくりいうと、ある県の人口が市街地にどの程度集中しているか。たとえば北海道、単に人口密度としてしまうと面積が広いだけにばらけてしまいますが、人口集中地区人口比率は75.2%で4人に3人が市街地に住んでおり、粗密が著しいことがわかります。⑶ データを概観する
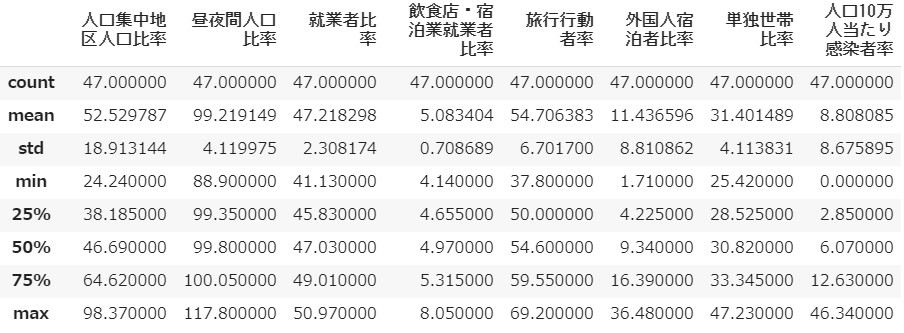
# 各列の要約統計量を取得 df.describe()pandasの
describe関数を使います。
「人口10万人当たり感染者率」ですが、いうまでもなく最大値は東京都の46.34%、最小値は岩手県の0.00%です。
せっかくなので各変数のトップ5を見ておきたいと思います。
東京都が概してトップというのは当然ですが、感染者率で石川県・富山県という北陸2県がランクインしているのが気になります。感染者数としてみると目立たない両県ですが、県人口に対する感染者の比率となると高い。ちなみに実数は石川県300人、富山県228人となっています。
また石川県は、県内の全就業者に占める飲食店・宿泊業従事者の割合が、長野県と同率5.8%で全国5番目となっています。この変数を採用した意図は、やや拡大解釈ぎみなのですが、宿泊やそれに伴う飲食といった観光関連の経済活動が活発で、それだけに人的接触の機会が多いという考え方です。沖縄県の突出ぶりはその意味でうなずけます。
なお、北海道についてはその感染者数の多さと相俟って、マスコミなどで盛んに観光面の打撃が報じられていましたが、確かに一年間の延べ宿泊者数全体に占める外国人比率は25.3%で京都府に次ぐ第4位となっています。では、重回帰分析をやっていきます。
⑷ 説明変数・目的変数をそれぞれ格納する
# 説明変数のみ抽出して変数Xに格納 X = df.loc[:, '人口集中地区人口比率':'単独世帯比率'] # 目的変数のみ抽出して変数Yに格納 Y = df["人口10万人当たり感染者率"]⑸ モデルを生成する
# 線形モデルのインスタンスを生成 model = linear_model.LinearRegression() # データを渡してモデルを生成 model.fit(X,Y)⑹ 偏回帰係数を取得する
# 係数の値を取得し、変数coefficientに格納 coefficient = model.coef_ # カラム名とインデックス名を付与してデータフレームに変換 df_coefficient = pd.DataFrame(coefficient, columns=["偏回帰係数"], index=[X.columns]) df_coefficient
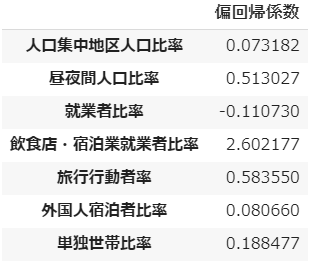
偏回帰係数は、説明変数それぞれが目的変数に与える影響の大きさを表します。
まず、「飲食店・宿泊業就業者比率」がずば抜けて大きく、次いで「旅行行動者率」と「昼夜間人口比率」が大きいですね。
宿泊を伴うとすれば、おおかた観光かビジネスのいずれかでしょう。つまり県外から入って来て一定期間滞留する人が多く、そのため飲食店や宿泊業に従事する人の割合も多いということが、感染者率に大いに影響しているといえそうです。
さらに、旅行や通勤通学のために県の内外を出入りする人が多いと感染者もまた増えるということで、要するに「移動の制限」が感染防止に有効であるということでしょう。⑺ 切片を取得する
# 切片を取得 model.intercept_切片(Y軸との交点)は
intercept_関数で求められ、これで重回帰式が明らかになりました。
⑻ モデルの精度を確認する
# 決定係数を取得 model.score(X, Y)最後に、重回帰式の“当てはまりの良さ”を確認するために
score関数で決定係数$R^2$を算出します。
すなわち、この重回帰式が、実際の因果関係をどの程度説明できているか。
正直なところ 0.8 を超えていて欲しかったなぁと思いつつ・・・、説明変数の構成について(手っ取り早く作っただけに)検討が必要ということなのでしょう。

- 投稿日:2020-07-09T22:38:07+09:00
PythonでFizz Buzz
Fizz Buzzとは
Fizz Buzzとはプログラミング初学者が最もはじめに解く問題のうちの1つです。
具体的には$1\sim100$までの数字を順に出力し、$3$の倍数の時にFizz、$5$の倍数の時にBuzz、両方で割り切れる時にFizzBuzzと出力するプログラムのことです。さっそく書いていきます。
コード
for i in range(1, 101): if i % 15 == 0: print('Fizz Buzz') elif i % 3 == 0: print('Fizz') elif i % 5 == 0: print('Buzz') else: print(i)出力
1 2 Fizz 4 Buzz Fizz 7 8 Fizz Buzz 11 Fizz 13 14 Fizz Buzz 16 17 Fizz 19 Buzz Fizz 22 23 Fizz Buzz 26 Fizz 28 29 Fizz Buzz 31 32 Fizz 34 Buzz Fizz 37 38 Fizz Buzz 41 Fizz 43 44 Fizz Buzz 46 47 Fizz 49 Buzz Fizz 52 53 Fizz Buzz 56 Fizz 58 59 Fizz Buzz 61 62 Fizz 64 Buzz Fizz 67 68 Fizz Buzz 71 Fizz 73 74 Fizz Buzz 76 77 Fizz 79 Buzz Fizz 82 83 Fizz Buzz 86 Fizz 88 89 Fizz Buzz 91 92 Fizz 94 Buzz Fizz 97 98 Fizz Buzz 以上です。
- 投稿日:2020-07-09T22:17:00+09:00
ゼロから始めるLeetCode Day81 「347. Top K Frequent Elements」
概要
海外ではエンジニアの面接においてコーディングテストというものが行われるらしく、多くの場合、特定の関数やクラスをお題に沿って実装するという物がメインである。
どうやら多くのエンジニアはその対策としてLeetCodeなるサイトで対策を行うようだ。
早い話が本場でも行われているようなコーディングテストに耐えうるようなアルゴリズム力を鍛えるサイトであり、海外のテックカンパニーでのキャリアを積みたい方にとっては避けては通れない道である。
と、仰々しく書いてみましたが、私は今のところそういった面接を受ける予定はありません。
ただ、ITエンジニアとして人並みのアルゴリズム力くらいは持っておいた方がいいだろうということで不定期に問題を解いてその時に考えたやり方をメモ的に書いていこうかと思います。
Python3で解いています。
前回
ゼロから始めるLeetCode Day80「703. Kth Largest Element in a Stream」Twitterやってます。
技術ブログ始めました!!
技術はLeetCode、Django、Nuxt、あたりについて書くと思います。こちらの方が更新は早いので、よければブクマよろしくお願いいたします!問題
347. Top K Frequent Elements
難易度はMedium。
前回の問題同様Heapを使った問題です。問題としては、数字が格納された空ではない配列が与えられます。その配列の中から
K番目まで頻出の要素を返すようなアルゴリズムを設計してください、というものです。Example 1:
Input: nums = [1,1,1,2,2,3], k = 2
Output: [1,2]Example 2:
Input: nums = [1], k = 1
Output: [1]解法
Counterを使ってリストの要素を調べ、keyを取得、そしてheapのnlargestを使って書きました。import heapq import collections class Solution: def topKFrequent(self, nums: List[int], k: int) -> List[int]: count = collections.Counter(nums) key = count.get return heapq.nlargest(k,count.keys(),key) # Runtime: 108 ms, faster than 66.40% of Python3 online submissions for Top K Frequent Elements. # Memory Usage: 18.2 MB, less than 79.07% of Python3 online submissions for Top K Frequent Elements.なお、
nlargestの引数はn, iterable, key=Noneという順番です。では今回はここまで。
お疲れ様でした。
- 投稿日:2020-07-09T21:53:25+09:00
【Python】Flaskアプリの基本構造を整理(目指せ脱コピペ)
はじめに
これまでなんとなく
flaskのコードを良くわからないまま「おまじない」として書いていたので、一度ちゃんと調べて整理してみます。
目標としては、
- その記述があることでどんなことが起こっているのか、を把握できるようにする
- 書かれているコードの文法構造を理解し、言語化しておいてあとで調べられるようにする
この辺りを目指して整理してみます。
flaskアプリの基本構造
シンプルなWebアプリの基本構造を見てみます。
解説などこちらを参照しました(スクリプトは一部違いがあります)
Flask を始めよう — Flask Handson 1 documentation#①モジュールのインポート from flask import Flask #②Webアプリ作成 app = Flask(__name__) #③エンドポイント設定(ルーティング) @app.route('/') def hello(): return 'Hello World!' #④Webアプリ起動~~~~ if __name__ == '__main__': app.run(debug=True)このスクリプトを実行し、ブラウザで「http://127.0.0.1:8000」にアクセスすると、画面には「Hello World!」と表示されているはずです。
そこまで上手くいっていれば、ローカルでWebアプリが起動できている、ということになります。大まかな流れとイメージを掴む
上のスクリプトは大きく4つのパートに分かれています。
- ①モジュールのインポート:アプリ作成に必要な機能の詰まったコードファイルを使えるようにします。
- ②Webアプリを作成:必要な機能が詰まった「アプリの核」を用意します。
- ③エンドポイントを指定(ルーティング):ブラウザからアクセスするURLと、それに対応した処理をここに書きます。
- ④Webアプリを起動:ファイルが実行された時にアプリが立ち上がる(ブラウザで表示できる)ようにします。
僕らがFlaskでWebアプリを作る時は、③の部分を色々と作っていくことになります。
①のインポートはpythonの基本文法の一つ。そして②④はflaskの操作となっており基本的にコードを変更する必要はなさそうで、これが「おまじない」としてよく書かれている部分になります。各パートを詳細に見てみる
①モジュールのインポート
from flask import Flask
flaskモジュールのFlaskクラスをインポートしています。
これにより、このスクリプト内でFlaskクラスの機能を活用できるようになります。モジュールとは
関数やクラスなどが詰まったpythonファイルです。
hogehoge.pyという名前で保存されているファイルが1つのモジュール、と考えて良さそうです。②Webアプリ作成
app = Flask(__name__)
Flask(__name__)と第一引数に__name__を渡してFlaskクラスのインスタンスを作成し、それをappに代入しています。
このappにはflaskアプリの核が入っているイメージで、今後app.route()でルーティングを定義したり(③)、app.run()でローカルサーバー起動したりできるものになります。グローバル変数
__name__について
__name__というのはモジュールの属性の一つで、グローバル変数のようです(変な名前ですね。
そしてその正体は「そのプログラムがどこから呼ばれて実行されているか」を格納している変数となります。変な名前ですね。この
.pyファイルが直接起動された時は、__name__には__main__という文字列が入ります。
一方で、このファイルが他のスクリプトからimportされて呼ばれた時には、__name__にはモジュール名(拡張子なしのファイル名)が入ります。(これを
Flask()の第一引数に渡すと何が起こっているのか、まではまだ理解ができずです)③エンドポイント設定(ルーティング)
@app.route('/') def hello(): return 'Hello World!'この記述によりルーティングが定義されます
シンプルな記述ですが、だいぶ多くのことが凝縮されていそうです。こちら(Flask を始めよう — Flask Handson 1 documentation)から引用しつつ整理してみます。
@app.route('/') という行は、 app に対して / というURLに対応するアクションを登録しています。
つまり、僕らが「http://hogehoge.com/」(パスが`/`)というURLにアクセスしたら、「こういう処理を返しますよ」というアクションを関数で作り、それらを1対1で紐づけています。
今回の例では、hello()関数の返り値(returnの後の文字列)がWebページに表示されることになります。
この関数を「ビュー関数」と呼んだりするようです。さて、ここで
@という変な記号が何を表しているのか、ですが…。@ で始まる行はデコレータといって、その次の行で定義する関数やクラスに対して何らかの処理を行います。 @app.route('/') は、次の行で定義される関数を指定した URL にマッピングするという処理を実行しています。
ここでいう「デコレータ」はちょっと高度なPython言語の文法かと思います。
この辺りの文法的な理解と、ビュー関数がいかに動作して結果がWebに表示されるかはかなり難しそうなので、もうちょっと学習を進めながら理解を深めたいと思います。デコレータと高層関数
「デコレータ」は「高層関数」を使った処理をスマートに記述できるpythonの記述の仕方で、「高層関数」とは引数として関数を受け取って処理をする関数、また戻り値として関数を返す関数のことです。
ここではデコレータを使って、hello()という関数を高層関数route()に渡して処理している、と考えられます。
(この辺りの理解が曖昧なので間違っていたら指摘をお願いします)用語の整理
- ルーティング:URLと動作の紐付けをすること。ここではパスとビュー関数を紐付け。
- エンドポイント:アクセスするためのURLを指す。
- URLとパス:ファイルの位置を指定するためのもの。URLは絶対パス、インターネット上の住所のようなもの。
- ビュー関数:リクエストに対してどのような動作を返すかを記した関数。
④Webアプリ起動
if __name__ == '__main__': app.run(debug=True)最後に、
app.run()を実行してローカルサーバーを起動し、アプリを立ち上げます。
if文は「このプログラムが直接実行されたかどうか」を判定しています。
②で見たように、ファイルをスクリプトとして直接実行した場合、__name__には__main__が代入されます。
つまりここでは、プログラムが直接実行された場合にapp.run()が実行されて、アプリが立ち上がるのです。run()メソッド
- このFlaskの
run()関数にキーワード引数で「ホスト」「ポート番号」「デバッグモード」の指定ができます。なくても起動可。- 例えば
app.run(host='http://127.0.0.1', port=8080, debug=True)と記述して起動することができます。
app.run(debug=True)-> デバッグモードで実行するapp.run(host='http://127.0.0.1')-> ホストを指定app.run(port=8080)-> ポート番号を指定(デフォルトでは5000)用語の整理
- ホスト:(まとめ中)
- ポート番号:(まとめ中)
(備考)WSGI規格
- Web Server Gateway Interfaceの意味。
- WebサーバーとWebアプリを接続するための標準化されたインターフェース規格をWSGI規格と呼ぶ。
- Flask, DjangoなどPythonの多くフレームワークはこのWSGI規格を採用している。
- 普通にWebアプリ開発するだけならあまり意識することはない。
おわりに
ほんとの初心者のうちは意識しなくても良いことですが、そこから次のステップに進むために理解を深めていくと出来ることが増えていくのかなあと感じます。
後半はかなり駆け足でまとめてしまったので、また理解度に応じて修正しようと思います。ドキュメント読みます。
クイックスタート - Flask v0.5.1 documentation
API — Flask Documentation (1.0.x)
- 投稿日:2020-07-09T21:26:53+09:00
Siriみたいな会話相手作ってみた
作成動機
私はstay home期間にほとんど人と喋っていないので悲しくなり誰かと話したい、とSiriみたいな会話相手をpythonで作ってみました。
コード
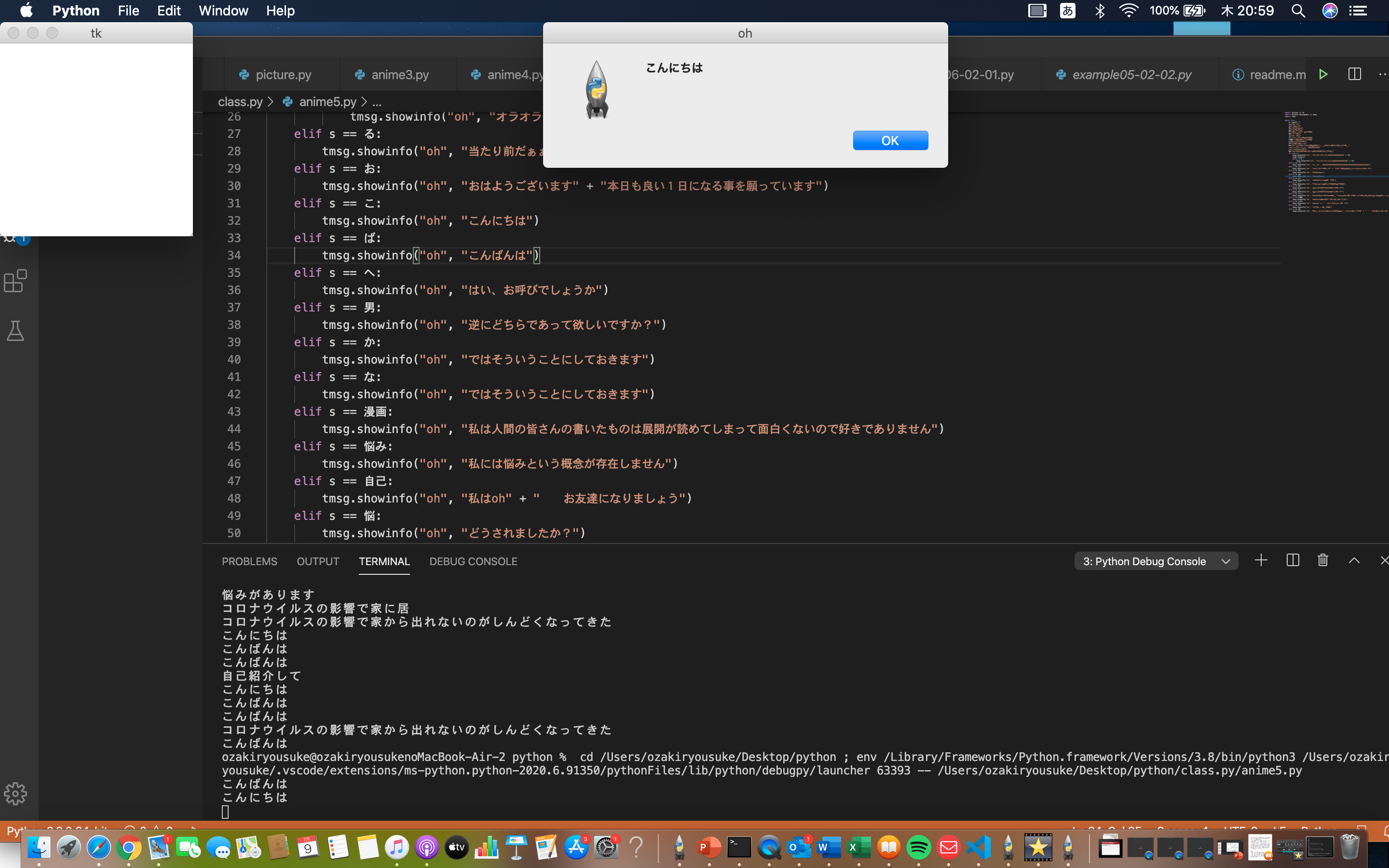
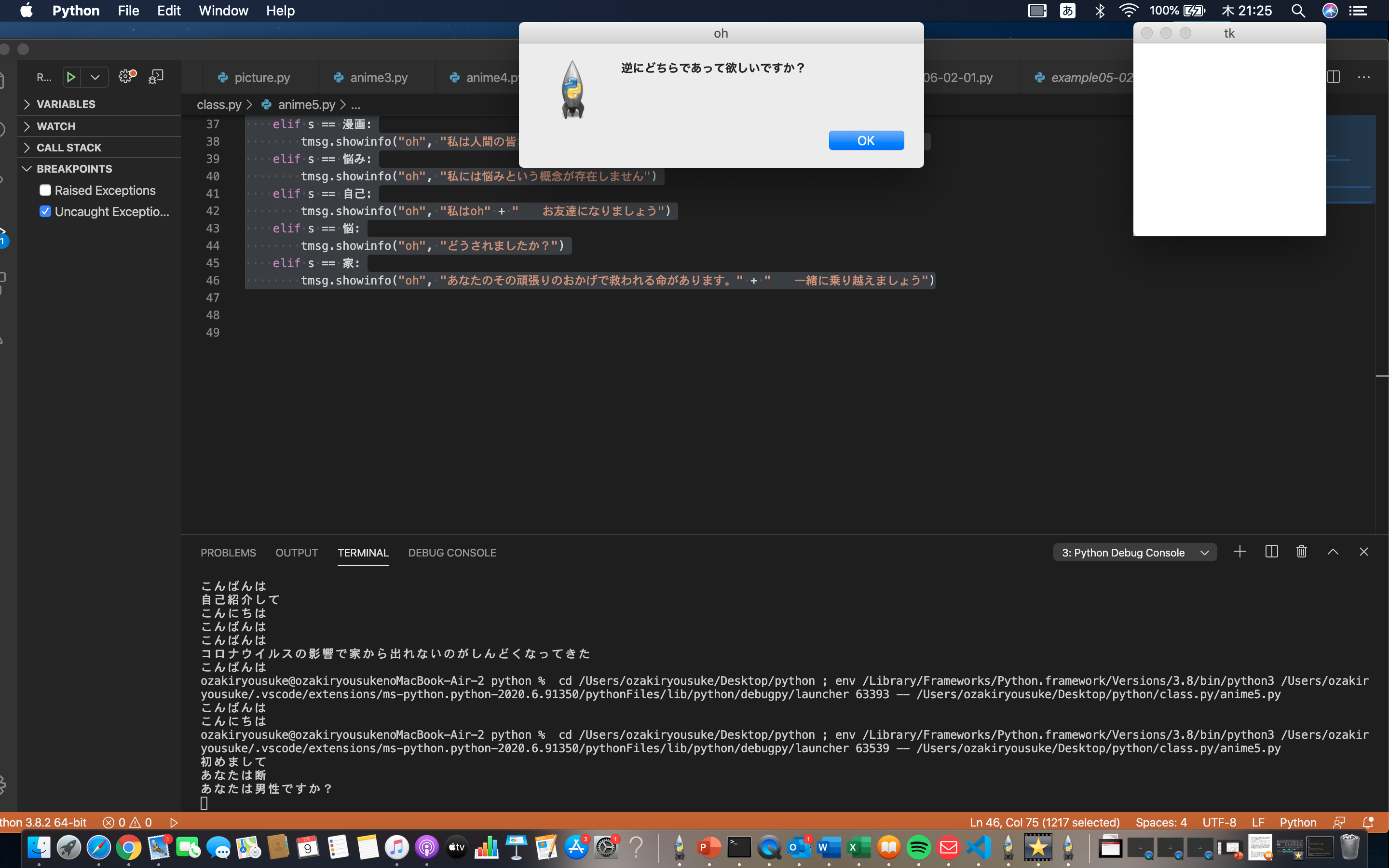
import tkinter as tk import tkinter.messagebox as tmsg import time while True : s= input("") 初="初めまして" へ="Hey oh" お="おはよう" こ="こんにちは" ば="こんばんは" 男="あなたは男性ですか?" か="男性かな" な="女性かな" 漫画="漫画は好きですか?" 悩み="悩みはありますか?" 自己="自己紹介して" 悩="悩みがあります" 家="コロナウイルスの影響で家から出れないのがしんどくなってきた" if s == 初: tmsg.showinfo("oh", "初めまして" + " これからよろしくお願いします") elif s == お: tmsg.showinfo("oh", "おはようございます" + "本日も良い1日になる事を願っています") elif s == こ: tmsg.showinfo("oh", "こんにちは") elif s == ば: tmsg.showinfo("oh", "こんばんは") elif s == へ: tmsg.showinfo("oh", "はい、お呼びでしょうか") elif s == 男: tmsg.showinfo("oh", "逆にどちらであって欲しいですか?") elif s == か: tmsg.showinfo("oh", "ではそういうことにしておきます") elif s == な: tmsg.showinfo("oh", "ではそういうことにしておきます") elif s == 漫画: tmsg.showinfo("oh", "私は人間の皆さんの書いたものは展開が読めてしまって面白くないので好きでありません") elif s == 悩み: tmsg.showinfo("oh", "私には悩みという概念が存在しません") elif s == 自己: tmsg.showinfo("oh", "私はoh" + " お友達になりましょう") elif s == 悩: tmsg.showinfo("oh", "どうされましたか?") elif s == 家: tmsg.showinfo("oh", "あなたのその頑張りのおかげで救われる命があります。" + " 一緒に乗り越えましょう")
- input()の中で取得した値ををsという変数に格納
- これらをifやelifを用いて返答を表示する。
実行結果
ターミナルに打ち込むと・・・
このように返答してくれました!
感想
プログラミングが上手くいって返答してくれた時はすごく嬉しかった。ただ質問と返答を一人で作っているところを客観視してしまうと余計に悲しい気持ちになりました。
参考にしたwebページ及び文献
- pythonでジョジョの名シーン再現してみた
- pythonのinput関数でキーボードからの入力を取得
- 暇つぶしにも最適、「Siri」との会話を楽しもう
- いちばんやさしいpython入門教室 大澤文孝[著]
- 投稿日:2020-07-09T21:14:50+09:00
VScodeでnumpyをimportするとエラーが発生するときの対処法
環境
VScodeでサクッとpython書きたい!
そんなとき、numpyをインポートするとエラーで読みこんでくれなくなりました。事象
WindowsのVScodeでnumpyをimportとするとエラーが発生します。
ImportError: DLL load failed: 指定されたモジュールが見つかりません。jupyter notebookなどでは問題なく、importできるのに、なぜかVScodeだけimportしてくれません。
原因
エラーメッセージの中でmklinitがimportできませんと言っています。
File "D:\Anaconda3\lib\site-packages\numpy\_distributor_init.py", line 34, in <module> from . import _mklinitVScodeではPowerShellからpythonを実行する際にmklモジュールのpathがわからないので、エラーになっています。
対処
モジュールのpathを追加します。(D:\Anaconda3にインストールした場合)
D:\Anaconda3\Library\bin
- 投稿日:2020-07-09T20:41:57+09:00
pythonでスクレイピングを行い物件情報を取得する
はじめに
将来的に引越しをしたいなと考えた時、どのような物件があるのか、掘り出し物の物件はあるのかを調べたいと思いました。
いちいち手作業で調べるのは面倒なので前回行ったスクレイピングを利用して物件情報を取得したいと考えました。最終的には取得した情報を地図にマッピングまで行いたいと考えているのですがまず最初に物件情報を取得することから始めようと思います。
スクレイピングとは
スクレイピングとは簡単に述べると、「プログラムを使ってインターネット上の情報を収集すること」です。
スクレイピングは以下の2手順を経て実行されます。①html情報を取得→②必要データを抽出
まず①についてですが、
そもそも、webページと言うものはhtmlと言う言語を用いて構成されます。
Google Chromの右上の矢印のページをクリックし、
「その他のツール」→「デベロッパーツール」と押すと画面右にコードの羅列が出力されます。
それこそが、画面を描画するためのコードであり、スクレイピングをするためにこのコードを自分のパソコンに引っ張ってきます。
そして、②についてですが、htmlは入れ子構造となっており、それぞれの要素毎に区別されていたり、要素毎にラベル付されていたりします。
そのため、ラベルやタグを選択することで全データから必要なデータを取得することができます。実行環境
実行環境は以下です。
- python 3.7.0
- requests 2.24.0
- BeautifulSoup4 4.9.1実装
実装に際して、他の記事を参考にさせて頂きました。
他の記事記事にあるものを使用するだけでもスクレイピングの結果が得られるのですが、かなり時間がかかるので少し書き換えました。全体コード
全体のコードはこちらです。
output.pyfrom bs4 import BeautifulSoup import requests import csv import time #URL(ここにURLを入れてください) url = 'https://suumo.jp/jj/chintai/ichiran/FR301FC001/?ar=030&bs=040&ta=13&sc=13101&cb=0.0&ct=9999999&mb=0&mt=9999999&et=9999999&cn=9999999&shkr1=03&shkr2=03&shkr3=03&shkr4=03&sngz=&po1=09&pc=50' result = requests.get(url) c = result.content soup = BeautifulSoup(c, 'html.parser') summary = soup.find("div",{'id':'js-bukkenList'}) body = soup.find("body") pages = body.find_all("div",{'class':'pagination pagination_set-nav'}) pages_text = str(pages) pages_split = pages_text.split('</a></li>\n</ol>') pages_split0 = pages_split[0] pages_split1 = pages_split0[-3:] pages_split2 = pages_split1.replace('>','') pages_split3 = int(pages_split2) urls = [] urls.append(url) print('get all url...') for i in range(pages_split3-1): pg = str(i+2) url_page = url + '&page=' + pg urls.append(url_page) print('num all urls is {}'.format(len(urls))) f = open('output.csv', 'a') for url in urls: print('get data of url({})'.format(url)) new_list = [] result = requests.get(url) c = result.content soup = BeautifulSoup(c, "html.parser") summary = soup.find("div",{'id':'js-bukkenList'}) apartments = summary.find_all("div",{'class':'cassetteitem'}) for apart in apartments: room_number = len(apart.find_all('tbody')) name = apart.find("div",{'class':'cassetteitem_content-title'}).text address = apart.find("li", {'class':"cassetteitem_detail-col1"}).text age_and_height = apart.find('li', class_='cassetteitem_detail-col3') age = age_and_height('div')[0].text height = age_and_height('div')[1].text money = apart.find_all("span", {'class':"cassetteitem_other-emphasis ui-text--bold"}) madori = apart.find_all("span", {'class':"cassetteitem_madori"}) menseki = apart.find_all("span", {'class':"cassetteitem_menseki"}) floor = apart.find_all("td") for i in range(room_number): write_list = [name, address, age, height, money[i].text, madori[i].text, menseki[i].text, floor[2+i*9].text.replace('\t', '').replace('\r','').replace('\n', '')] writer = csv.writer(f) writer.writerow(write_list) time.sleep(10)実行方法・実行結果
上記のコードの
#URL(ここにURLを入れてください) url = 'https://suumo.jp/jj/chintai/ichiran/FR301FC001/?ar=030&bs=040&ta=13&sc=13101&cb=0.0&ct=9999999&mb=0&mt=9999999&et=9999999&cn=9999999&shkr1=03&shkr2=03&shkr3=03&shkr4=03&sngz=&po1=09&pc=50'の部分にsuumoの物件情報のurlを記入します。
そして、これを実行し、output.csvが出力されれば成功です。output.csvには以下のような出力となっているはずです。
output.csv(一部)東京メトロ半蔵門線 神保町駅 7階建 築16年,東京都千代田区神田神保町2,築16年,7階建,6.9万円,ワンルーム,13.04m2,4階 東京メトロ半蔵門線 神保町駅 7階建 築16年,東京都千代田区神田神保町2,築16年,7階建,7.7万円,ワンルーム,16.64m2,4階 九段フラワーホーム,東京都千代田区九段北4,築42年,9階建,7.5万円,ワンルーム,21.07m2,5階 ヴィラロイヤル三番町,東京都千代田区三番町,築44年,8階建,8.5万円,ワンルーム,23.16m2,4階 ヴィラロイヤル三番町,東京都千代田区三番町,築44年,8階建,8.5万円,ワンルーム,23.16m2,4階コンマ区切りに要素が出力されておりそれぞれ以下の要素を示します。
[建物名],[住所],[築年数],[階層],[家賃],[間取り],[広さ],[部屋の階数]千代田区と世田谷区の情報はsuumoから取り出せることを確認しました。
まとめ
スクレイピングを行いsuumoから物件情報を取得しました。
普段自分がしていることと関係ないことをするのは非常に楽しかったです。
最終的にはこれらの物件情報を地図上にマッピングして、様々な分析ができればもっと楽しくなると思うので挑戦しようと思います。
- 投稿日:2020-07-09T20:06:57+09:00
Matplotlibメモ
学びのメモとして、Matplotlib周辺の視覚化に活用できるコードをチートシート代わりに自分の参考用としてまとめています。
基本的なコードのまとめ
#matplotlibをpltとしてインポート import matplotlib.pyplot as plt #リストxを横軸、yを縦軸にした際の折れ線グラフを作成 plt.plot(x, y) #リストxを横軸、yを縦軸、散布図を作成(プロットの大きさがsizeに比例、色をcol、透明度は0.8) plt.scatter(x, y, s = size, c = col, alpha = 0.8)) #リストvalues内のデータをn個のビンにおけるヒストグラムを作成 plt.hist(values, bins = n) #グラフにタイトル(TITLE)をつける plt.title('TITLE') #横軸にXXX、縦軸にyyyという名前のラベルをつける plt.xlabel('xxx') plt.ylabel('yyy') #縦軸を指定 (例.0から10まで2刻み) plt.yticks([0,2,4,6,8,10]) #縦軸を指定 (例.0から10まで2刻みで、表記をカスタマイズ) plt.yticks([0,2,4,6,8,10],['0','2万','4万','6万','8万','10万']) #ある特定のプロットにテキストをつける(例. 横軸が10、縦軸が52のプロットに'text'というテキストを追加) plt.text(10, 52, 'text') #グリッド線を表示 plt.grid(True) #作成した図を描画 plt.show() #横軸を対数表示にする plt.xscale('log')実際のプロット例
各都道府県ごとの県内総生産と人口のグラフ
#データの読み込み with open('data.csv','r',encoding='shift_jis') as f: dataReader = csv.reader(f) list1 = [row for row in dataReader] district = list1[0] population = list1[1] GDP = list1[2] district = district[1:] population = population[1:] GDP = GDP[1:] population = [int(s) for s in population] GDP = [int(s) for s in GDP] #グラフ描画 import matplotlib.pyplot as plt plt.scatter(GDP, population) plt.title('Relationship between GDP and population') plt.xlabel('GDP') plt.ylabel('Population') plt.xticks([0,30000000,60000000,90000000,120000000]) plt.yticks([0,3000000,6000000,9000000,12000000,15000000]) #一部のプロットに名前付け plt.text(104470026,13623937, 'Tokyo') plt.text(1864072,569554, 'Tottori') plt.text(39409405,7506900, 'Aichi') plt.text(38994994,8832512, 'Osaka') plt.text(11944686,2837348, 'Hiroshima') plt.text(9475481,2330120, 'Miyagi') plt.text(19018098,5351828, 'Hokkaido') plt.text(34609343,9144504, 'Kanagawa') plt.text(22689675,7289429, 'Saitama') plt.text(20391622,6235725, 'Chiba') plt.grid(True) plt.show()出展: https://www.esri.cao.go.jp/jp/sna/data/data_list/kenmin/files/contents/main_h28.html (内閣府・県民経済計算)
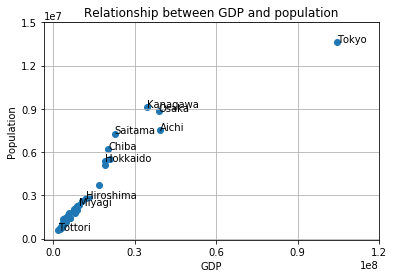
- 投稿日:2020-07-09T19:58:20+09:00
Pythonのfor文〜iterableってなに〜
学びたてのfor文
Pythonのfor文はいわゆる繰り返し文で、listの各要素を先頭から順番に取り出して処理するためによく使われます。
構文としては以下のようになります。
for x in [1, 2, 3, 4, 5]: # ...inの後にlistを置くと、各要素を用いて処理することができます。
list以外によく使われるのは、
range(1, 6)や(1, 2, 3, 4, 5)といったものです。
[1, 2, 3, 4, 5]やrange(1, 6)や(1, 2, 3, 4, 5)は、どれも上記の構文例に当てはめるとxに1, 2, 3, 4, 5が順番に代入されます。
[1, 2, 3, 4, 5]と(1, 2, 3, 4, 5)は処理の流れがイメージしやすいですね。でも
range(1, 6)は2~5が書いてないのに、xにそれらが代入されるらしいです。なぜでしょうか。
「rangeは関数で、引数に1と6を指定すると
[1, 2, 3, 4, 5]が作られるから?」なるほど納得できます。でも実はrange関数で作られたものはlistではありません。tupleでもありません。
rangeオブジェクトというものです。
へ~そうなんだ・・・。で?
・・・あれ、どうしてわざわざrangeオブジェクトを作るのか気にならないですか。なんでlistじゃないか気にならないですか。そうですか。
listになる方が初心者にとっては直感的ですので、こればかりは「ユーザーはブラックボックスの中身を気にしなくて良い」信仰における罠です。ここで直感をアップデートしましょう。
rangeオブジェクトを作る理由、はたまたそれを一般化した反復処理という考え方は、マスターするとプログラミングが楽しくなるので、ぜひマスターしてください。
for文で回せるオブジェクトってなに
これまで、for文のinの後に三つの異なるオブジェクトを指定しました。
listとtupleと、そしてrangeオブジェクトです。
これら三つはfor文で回すことができます。
では、123456という数はどうでしょうか。
for i in 123456: # ...残念ながらエラーになってしまいます。この違いはなんでしょう。
Pythonのコードを解析するヤツがfor文で回せるオブジェクトかどうか見ている?
間違ってはいませんが、説明不足ではあります。
じゃあオブジェクトのどこを見てfor文で回せるか判断しているのでしょう。
実は、for文で回せる仲間を示す証のようなものがあり、for文のinの後に指定した際にはその証があるかどうかを見ています。そのような仲間をここではiterable(反復可能)と呼びます。
for文マン「証アルネ!OK!」
listちゃん「ありがとうございます!」
tupleちゃん「ありがとうございます!」
rangeちゃん「ありがとうございます!」じゃあその証ってなに?
iterとnext
for文を使う際、内部ではinの後に指定されたiterableに対して、まずはiter関数(後述)を適用し、イテレータ(後述)に変換します。そして、そのイテレータに対してnext関数を可能な限り(後述)適用します。これがfor文の内部事情です。
??????
わからなければ、ぜひメモを取りながら以降を読み進めてください。
イテレータ
イテレータとは、iter関数を適用すると自分自身を返し、next関数を適用すると何かしらの値を返すオブジェクトのことです。
iter関数は、内部でオブジェクトの
__iter__メソッドを呼び出します。next関数は、内部でオブジェクトの
__next__メソッドを呼び出します。class MyIter: def __iter__(self): return self def __next__(self): return 1 my_iter = MyIter() # iter(my_iter) == my_iter.__iter__() == my_iter # next(my_iter) == my_iter.__next__()これだけですでにイテレータです。rangeオブジェクトなんかもイテレータで、ちゃんと
__iter__メソッドと__next__メソッドを持っています。つまり
__iter__メソッドと__next__メソッドの両方を持つオブジェクトのことをイテレータと呼んでいるということです。別の言い方をすると、イテレータは
__iter__メソッドと__next__メソッドを持つことを要求しています。この、「○○メソッドを持つことを要求する」というような考え方はJavaではインターフェースだったり、Swiftではプロトコルと呼ばれたりします。要求をのんでいないとエラーを出します。このように言語仕様レベルでユーザーに要求する制約という一面は、さまざまな場面で重要ですのでぜひ覚えてください。
iter関数
iter関数は、渡された値をイテレータに変換します。内部では、オブジェクトの
__iter__メソッドを呼び出します。上記で説明したようにすでにイテレータの場合は、自分自身を返します。逆に、イテレータ以外のオブジェクトも
__iter__メソッドを持つことができます。listは、
__next__メソッドを持たないのでイテレータではありませんが、__iter__メソッドを持っていて、iter関数を適用すると、list_iteratorというイテレータを返します。そしてここでは、
__iter__メソッドでイテレータを返すことができるオブジェクトをiterable(反復可能)と呼びます。言い換えれば、iter関数でイテレータに変換できるオブジェクトのことをiterableと呼びます。はい、なのでlistはiterableです。
イテレータ自身も、iter関数で自分自身を返すので、iterableです。
イテレータに対して可能な限りnext関数を適用する
for文の内部事情をもう一度説明します。
for文は、inの後に指定したiterableにiter関数を適用しイテレータに変換した後、そのイテレータに対して可能な限りnext関数を適用します。
可能な限りnext関数を適用するということは、終わりを設定しなければ無限ループになるということであり、多くの場合は終わりを実装しているということです(無限イテレータもあります)。
終わりがあるということは、next関数を使うごとにオブジェクトの状態が終わりに近づくということです。
具体例を示します。
list_iter = iter([1,2,3,4,5]) a = next(list_iter) # a => 1 b = next(list_iter) # b => 2 c = next(list_iter) # c => 3 d = next(list_iter) # d => 4 e = next(list_iter) # e => 5listはiterableで、iter関数を適用するとlist_iteratorというイテレータを返します。
list_iteratorに対してnext関数を適用すると待機している要素を出力するみたいです。
(ここでは実装がどうなっているのかを気にする必要はありませんが一応説明すると、list_iteratorは多分内部にインデックスを持っていて、next関数を適用すると現在のインデックスの要素を返して、インデックスを+1するのでしょう。)
eに最後の要素5が代入されました。じゃあここでもう一度next関数を適用するとどうなるでしょう。f = next(list_iter) # => StopIterationStopIterationという例外が投げられました。例外処理をしていない場合はここでプログラムが終わってしまいます。
「可能な限り」というのは、このStopIterationが投げられるまでということです。
つまり、for文の内部ではStopIterationという例外が投げられると、ブロックを抜けるようになっているということです。
なぜわざわざイテレータ、iterableという概念を持ちこんでくるのか
イテレータはいろいろ便利で、その理由は一つに定まりません。
意味論として、遅延評価として、メモリ効率として、制約として、汎用化としてなど、さまざまな文脈があると思っています。
全てを説明するのはとても大変なので、一番ためになる話としてメモリ効率としての利点を挙げます。また、個人的に気に入っている意味論と汎用化としての利点も説明します。
メモリ効率
メモリ効率の説明としてはrangeオブジェクトを例に挙げるのがよさそうです。
最初の「なぜわざわざrangeオブジェクトを作るのか」という質問の解答になります。
仮にrange関数でlistが作られるとしましょう。
そうした場合に、1~100,000,000の範囲で処理したいとします。
そうすると、range(1, 100000001)は、
[1, 2, ..., 100000000]というlistが作られることになります。これはメモリをかなり圧迫します。int型のサイズが64bitだとすると、このlistのサイズは6,400,000,000bit (= 800,000,000byte ≒ 800MB)になります。(正確には違います。でもクソデカになることは確かです)
この圧迫問題を解決する方法は、rangeをイテレータにすることです。
具体的には、内部に「始まりの値」「現在の値(=始まりの値)」「終わりの値」を持っておき、next関数を呼ぶごとに「現在の値」を返し、「現在の値」を+1すればいい感じに反復できます。そして「現在の値」が「終わりの値」になったときにStopIterationを投げるようにすれば、for文が終わります。(仕様的にはC言語スタイルのfor文とまったく一緒ですね)
実装としては以下のような感じになると思います。(rangeと等価ではありません。)
class Range: def __init__(self, start, end): self.i = start self.end = end def __iter__(self): return self def __next__(self): if self.i == self.end: raise StopIteration else: x = self.i self.i += 1 return x for i in Range(1, 100): print(i) # 1 # 2 # ... # 99 # ここで終わりこのイテレータが確保するメモリは、内部に持っている値
self.i,self.end,xなどのサイズを合わせて、192bitほどです。(いろいろ端折っているのでガバガバですが、クソ小さくなることは確かです。)listのときと比べると、地球から月までの距離とテニスコードの横幅くらい違います。
新たにリストを作るより、イテレータで実装したほうがメモリの節約になることが多いです。
これがイテレータのメモリ効率化としての利点です。
意味論
いろいろなモノを反復可能なものと解釈することは個人的にかなり重要だと思っています。
例えば以下のものは反復可能(iterable)であってほしいです。
- 配列
- 線形リスト
- 辞書型
- 集合型(重複なしコレクション)
- ファイルオブジェクト
- 組み合わせ
- 順列
- べき集合
- 素数列
- スタック
- キュー
- ヒープ(優先度付きキュー)
これらはfor文で次々要素が出てくるべきです。出てきてほしいです。という思いがあります。
自前のクラスでも、これはfor文で回せたらすっきりしそうという場面がよくあります。
汎用化
関数かなんかの引数にiterableを指定できるようにすれば、汎用性が増します。
例えば、あらゆるiterableはlistに変換できるべきです。
いちいちlist(items: dict), list(items: tuple)などのように型ごとに定義するのはだるいです。なので、iterableという証を持つ型を指定できばうれしいです。x = list(iterable)実際listはそのような実装になっています。
よりエレガントな例として、ヒープソートなんかを
sorted_list = list(heap)のように表現できれば綺麗だと思いませんか。
実際は
実際にPythonの関数は、iterableを指定していることが多いです。map関数やfunctoolsモジュールのreduce関数など本当にたくさんあります。
業務においても反復可能という抽象的なアイデアを持っていれば、「これって一種のiterableなビジネスロジックでは?」となる場面もあります(要出典)
オセロなどのターン性のゲームもiterableと捉えることができます。なので以下のような実装(表現)が可能です。
othello = Othello() for turn in othello: point = input() turn.put(point) # 盤に石が埋まるか途中終了になったら、StopIterationを投げることでfor文を抜けられる実は
イテレータという概念は反復子としてさまざまプログラミング言語で共通のもので、「for each文に指定できるオブジェクト」としてよく認知されています。普通は反復子など知らず、for each文はArrayListなど限られたもののために用意されている構文と思いがちですが、実はどの言語でも、for eachで回せる証(インターフェース)を実装すれば自前のクラスでもfor each文で回せるようになるのです。
- 投稿日:2020-07-09T19:42:17+09:00
AWS SNSが重複してメッセージを配信してしまう
よくAWSに触れるものです。
AWS SNSでちょっとハマりました。
問題
AWS SNSからlambda経由で何故かメッセージの送信に成功しているのに重複してメッセージが送られてきます。
そもそもSNSからlambdaに対して重複して配信しているようでした。
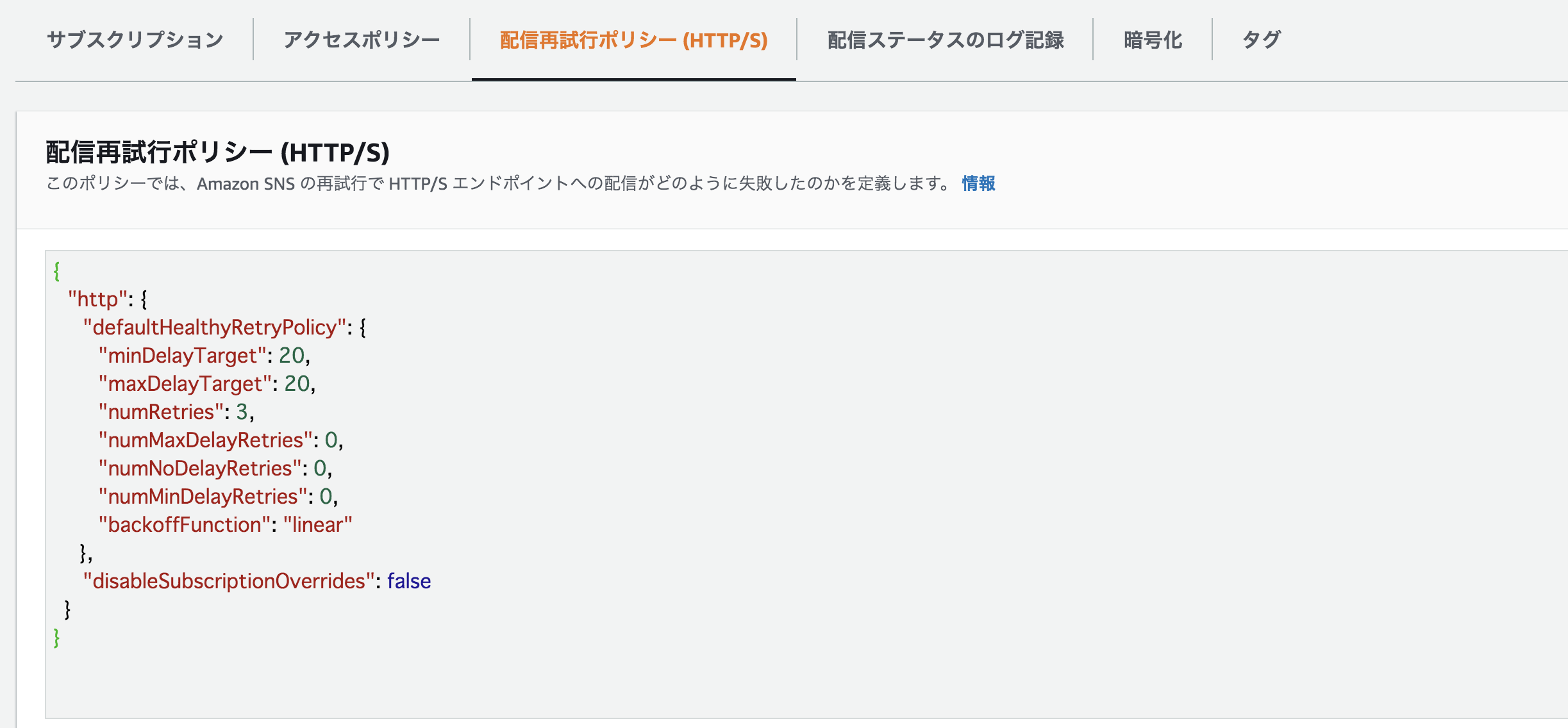
配信再試行ポリシーの
numRetriesを0にしても解決しません。
解決
lambdaで処理を終える際にresponseメッセージで成功ステータスを送る必要がありました。
(以下はpythonですが、他の言語も同様)##lambda関数内 def main() ... return { 'statusCode': 200 }以上で重複配信がなくなります。
- 投稿日:2020-07-09T19:37:39+09:00
深層学習入門 ~関数近似編~
対象者
前回の記事はこちら
本記事ではこれまで深層学習入門シリーズで紹介してきたコードを用いてsin関数を近似してみます。
ちなみにこの過程において数々のバグや修正箇所を発見してしまったので、それらを各記事に反映させています。環境
コードはjupyter notebook上で実行しています。
jupyter notebookの導入はこちらで紹介しています。
必要なパッケージは
numpymatplotlibtqdmとなっています。
tqdmは進捗状況をわかりやすく表示してくれるだけですので、もし面倒でしたらテストコードから該当部分を削除したら動きます。githubに本記事の実験コード(
test.ipynb)をそのままアップロードしています。目次
使用したコードたち
過去の記事に詳しい制作過程が記載されていますのでそちらもご覧ください。
_layererror.py_layererror.pyclass LayerManagerError(Exception): """レイヤーモジュールにおけるユーザ定義エラーのベースクラス""" pass class AssignError(LayerManagerError): def __init__(self, value=None): if not value is None: self.value = value self.message = (str(value) + ": Assigning that value is prohibited.") else: self.value = None self.message = "Assigning that value is prohibited." def __str__(self): return self.message class UnmatchUnitError(LayerManagerError): def __init__(self, prev, n): self.prev = prev self.n = n self.message = "Unmatch units: {} and {}.".format(prev, n) def __str__(self): return self.message class UndefinedLayerError(LayerManagerError): def __init__(self, type_name): self.type = type_name self.message = str(type_name) + ": Undefined layer type." def __str__(self): return self.message
baselayer.pybaselayer.pyimport numpy as np class BaseLayer(): """ 全ての元となるレイヤークラス 中間層と出力層で共通する処理を記述する。 """ def __init__(self, *, prev=1, n=1, name="", wb_width=5e-2, act="ReLU", opt="Adam", act_dic={}, opt_dic={}, **kwds): self.prev = prev # 一つ前の層の出力数 = この層への入力数 self.n = n # この層の出力数 = 次の層への入力数 self.name = name # この層の名前 # 重みとバイアスを設定 self.w = wb_width*np.random.randn(prev, n) self.b = wb_width*np.random.randn(n) # 活性化関数(クラス)を取得 self.act = get_act(act, **act_dic) # 最適化子(クラス)を取得 self.opt = get_opt(opt, **opt_dic) def forward(self, x): """ 順伝播の実装 """ # 入力を記憶しておく self.x = x.copy() # 順伝播 self.u = x@self.w + self.b self.y = self.act.forward(self.u) return self.y def backward(self, grad): """ 逆伝播の実装 """ dact = grad*self.act.backward(self.u, self.y) self.grad_w = self.x.T@dact self.grad_b = np.sum(dact, axis=0) self.grad_x = dact@self.w.T return self.grad_x def update(self, **kwds): """ パラメータ学習の実装 """ dw, db = self.opt.update(self.grad_w, self.grad_b, **kwds) self.w += dw self.b += db
middlelayer.pymiddlelayer.pyimport numpy as np class MiddleLayer(BaseLayer): """ 中間層クラス 入力層も実装上は中間層の一つとして取り扱います。 """ pass
outputlayer.pyoutputlayer.pyimport numpy as np class OutputLayer(BaseLayer): """ 出力層クラス """ def __init__(self, *, err_func="Square", **kwds): # 損失関数(クラス)を取得 self.errfunc = get_err(err_func) super().__init__(**kwds) def backward(self, t): """ 逆伝播の実装 """ # 出力層の活性化関数がsoftmax関数で損失関数が交差エントロピー誤差の場合 # 誤差の伝播を場合分けしておく if isinstance(self.act, type(get_act("softmax"))) \ and isinstance(self.errfunc, type(get_err("Cross"))): dact = self.y - t self.grad_w = self.x.T@dact self.grad_b = np.sum(dact, axis=0) self.grad_x = dact@self.w.T return self.grad_x elif isinstance(self.act, type(get_act("sigmoid"))) \ and isinstance(self.errfunc, type(get_err("Binary"))): dact = self.y - t self.grad_w = self.x.T@dact self.grad_b = np.sum(dact, axis=0) self.grad_x = dact@self.w.T return self.grad_x else: grad = self.errfunc.backward(self.y, t) return super().backward(grad) def get_error(self, t): self.error = self.errfunc.forward(self.y, t) return self.errfunc.total_error()
layermanager.pylayermanager.pyimport numpy as np class _TypeManager(): """ 層の種類に関するマネージャクラス """ N_TYPE = 2 # 層の種類数 MIDDLE = 0 # 中間層のナンバリング OUTPUT = 1 # 出力層のナンバリング class LayerManager(_TypeManager): """ 層を管理するためのマネージャクラス """ def __init__(self): self.__layer_list = [] # レイヤーのリスト self.__name_list = [] # 各レイヤーの名前リスト self.__ntype = np.zeros(self.N_TYPE, dtype=int) # 種類別レイヤーの数 def __repr__(self): layerRepr= "layer_list: " + repr(self.__layer_list) nameRepr = "name_list: " + repr(self.__name_list) ntypeRepr = "ntype: " + repr(self.__ntype) return (layerRepr + "\n" + nameRepr + "\n" + ntypeRepr) def __str__(self): layerStr = "layer_list: " + str(self.__layer_list) nameStr = "name_list: " + str(self.__name_list) ntypeStr = "ntype: " + str(self.__ntype) return (layerStr + "\n" + nameStr + "\n" + ntypeStr) def __len__(self): """ Pythonのビルドイン関数`len`から呼ばれたときの動作を記述。 種類別レイヤーの数の総和を返します。 """ return int(np.sum(self.__ntype)) def __getitem__(self, key): """ 例えば lm = LayerManager() +----------------+ | (lmに要素を追加) | +----------------+ x = lm[3].~~ のように、リストや配列の要素にアクセスされたときに呼ばれるので、 そのときの動作を記述。 sliceやstr, intでのアクセスのみ許可します。 """ if isinstance(key, slice): # keyがスライスならレイヤーのリストをsliceで参照する。 # 異常な値(Index out of rangeなど)が入力されたら # Pythonがエラーを出してくれます。 return self.__layer_list[key] elif isinstance(key, str): # keyが文字列なら各レイヤーの名前リストからインデックスを取得して、 # 該当するレイヤーのリストの要素を返す。 if key in self.__name_list: index = self.__name_list.index(key) return self.__layer_list[index] else: # keyが存在しない場合はKeyErrorを出す。 raise KeyError("{}: No such item".format(key)) elif isinstance(key, int): # keyが整数ならレイヤーのリストの該当要素を返す。 # 異常な値(Index out of rangeなど)が入力されたら # Pythonがエラーを出してくれます。 return self.__layer_list[key] else: raise KeyError(key, ": Undefined such key type.") def __setitem__(self, key, value): """ 例えば lm = LayerManager() +----------------+ | (lmに要素を追加) | +----------------+ lm[1] = x のように、リストや配列の要素にアクセスされたときに呼ばれるので、 そのときの動作を記述。 要素の上書きのみ認め、新規要素の追加などは禁止します。 """ value_type = "" if isinstance(value, list): # 右辺で指定された'value'が'list'なら # 全ての要素が'BaseLayer'クラスかそれを継承していなければエラー。 if not np.all( np.where(isinstance(value, BaseLayer), True, False)): self.AssignError() value_type = "list" elif isinstance(value, BaseLayer): # 右辺で指定された'value'が'BaseLayer'クラスか # それを継承していない場合はエラー。 self.AssignError(type(value)) if value_type == "": value_type = "BaseLayer" if isinstance(key, slice): # keyがスライスならレイヤーのリストの要素を上書きする。 # ただし'value_type'が'list'でなければエラー。 # 異常な値(Index out of rangeなど)が入力されたら # Pythonがエラーを出してくれます。 if value_type != "list": self.AssignError(value_type) self.__layer_list[key] = value elif isinstance(key, str): # keyが文字列なら各レイヤーの名前リストからインデックスを取得して、 # 該当するレイヤーのリストの要素を上書きする。 # ただし'value_type'が'BaseLayer'でなければエラー。 if value_type != "BaseLayer": raise AssignError(value_type) if key in self.__name_list: index = self.__name_list.index(key) self.__layer_list[index] = value else: # keyが存在しない場合はKeyErrorを出す。 raise KeyError("{}: No such item".format(key)) elif isinstance(key, int): # keyが整数ならレイヤーのリストの該当要素を上書きする。 # ただし'value_type'が'BaseLayer'でなければエラー。 # また、異常な値(Index out of rangeなど)が入力されたら # Pythonがエラーを出してくれます。 if value_type != "BaseLayer": raise AssignError(value_type) self.__layer_list[key] = value else: raise KeyError(key, ": Undefined such key type.") def __delitem__(self, key): """ 例えば lm = LayerManager() +----------------+ | (lmに要素を追加) | +----------------+ del lm[2] のように、del文でリストや配列の要素にアクセスされたときに呼ばれるので、 そのときの動作を記述。 指定要素が存在すれば削除、さらにリネームを行います。 """ if isinstance(key, slice): # keyがスライスならそのまま指定の要素を削除 # 異常な値(Index out of rangeなど)が入力されたら # Pythonがエラーを出してくれます。 del self.__layer_list[slice] del self.__name_list[slice] elif isinstance(key, str): # keyが文字列なら各レイヤーの名前リストからインデックスを取得して、 # 該当する要素を削除する。 if key in self.__name_list: del self.__layer_list[index] del self.__name_list[index] else: # keyが存在しない場合はKeyErrorを出す。 raise KeyError("{}: No such item".format(key)) elif isinstance(key, int): # keyが整数ならレイヤーのリストの該当要素を削除する。 # 異常な値(Index out of rangeなど)が入力されたら # Pythonがエラーを出してくれます。 del self.__layer_list[key] else: raise KeyError(key, ": Undefined such key type.") # リネームする self._rename() def _rename(self): """ リスト操作によってネームリストのネーミングがルールに反するものになった場合に 改めてルールを満たすようにネーミングリストおよび各レイヤーの名前を変更する。 ネーミングルールは[レイヤーの種類][何番目か]とします。 レイヤーの種類はMiddleLayerならMiddle OutputLayerならOutput のように略します。 何番目かというのは種類別でカウントします。 また、ここで改めて__ntypeのカウントを行います。 """ # 種類別レイヤーの数を初期化 self.__ntype = np.zeros(self.N_TYPE) # 再カウントと各レイヤーのリネーム for i in range(len(self)): if "Middle" in self.__name_list[i]: self.__ntype[self.MIDDLE] += 1 self.__name_list[i] = "Middle{}".format( self.__ntype[self.MIDDLE]) self.__layer_list[i].name = "Middle{}".format( self.__ntype[self.MIDDLE]) elif "Output" in self.__name_list[i]: self.__ntype[self.OUTPUT] += 1 self.__name_list[i] = "Output{}".format( self.__ntype[self.OUTPUT]) self.__layer_list[i].name = "Output{}".format( self.__ntype[self.OUTPUT]) else: raise UndefinedLayerType(self.__name_list[i]) def append(self, *, name="Middle", **kwds): """ リストに要素を追加するメソッドでお馴染みのappendメソッドの実装。 """ if "prev" in kwds: # 'prev'がキーワードに含まれている場合、 # 一つ前の層の要素数を指定していることになります。 # 基本的に最初のレイヤーを挿入する時を想定していますので、 # それ以外は基本的に自動で決定するため指定しません。 if len(self) != 0: if kwds["prev"] != self.__layer_list[-1].n: # 最後尾のユニット数と一致しなければエラー。 raise UnmatchUnitError(self.__layer_list[-1].n, kwds["prev"]) else: if len(self) == 0: # 最初の層は必ず入力ユニットの数を指定する必要があります。 raise UnmatchUnitError("Input units", "Unspecified") else: # 最後尾のレイヤーのユニット数を'kwds'に追加 kwds["prev"] = self.__layer_list[-1].n # レイヤーの種類を読み取り、ネーミングルールに則った名前に変更する if name == "Middle" or name == "mid" or name == "m": name = "Middle" elif name == "Output" or name == "out" or name == "o": name = "Output" else: raise UndefinedLayerError(name) # レイヤーを追加する。 if name == "Middle": # 種類別レイヤーをインクリメントして self.__ntype[self.MIDDLE] += 1 # 名前に追加し name += str(self.__ntype[self.MIDDLE]) # ネームリストに追加し self.__name_list.append(name) # 最後にレイヤーを生成してリストに追加します。 self.__layer_list.append( MiddleLayer(name=name, **kwds)) elif name == "Output": # こちらも同様です。 self.__ntype[self.OUTPUT] += 1 name += str(self.__ntype[self.OUTPUT]) self.__name_list.append(name) self.__layer_list.append( OutputLayer(name=name, **kwds)) # ここでelse文を描いていないのはネーミングルールに則った名前に変更する # 段階で既に異常な'name'は省かれているからです。 def extend(self, lm): """ extendメソッドでは既にある別のレイヤーマネージャ'lm'の要素を 全て追加します。 """ if not isinstance(lm, LayerManager): # 'lm'のインスタンスがLayerManagerでなければエラー。 raise TypeError(type(lm), ": Unexpected type.") if len(self) != 0: if self.__layer_list[-1].n != lm[0].prev: # 自分の最後尾のレイヤーのユニット数と # 'lm'の最初のレイヤーの入力数が一致しない場合はエラー。 raise UnmatchUnitError(self.__layer_list[-1].n, lm[0].prev) # それぞれ'extend'メソッドで追加 self.__layer_list.extend(lm.layer_list) self.__name_list.extend(lm.name_list) # リネームする self._rename() def insert(self, prev_name, name="Middle", **kwds): """ insertメソッドでは、前のレイヤーの名前を指定しそのレイヤーと結合するように 要素を追加します。 """ # 'prev_name'が存在しなければエラー。 if not prev_name in self.__name_list: raise KeyError(prev_name, ": No such key.") # 'prev'がキーワードに含まれている場合、 # 'prev_name'で指定されているレイヤーのユニット数と一致しなければエラー。 if "prev" in kwds: if kwds["prev"] \ != self.__layer_list[self.index(prev_name)].n: raise UnmatchUnitError( kwds["prev"], self.__layer_list[self.index(prev_name)].n) # 'n'がキーワードに含まれている場合、 if "n" in kwds: # 'prev_name'が最後尾ではない場合は if prev_name != self.__name_list[-1]: # 次のレイヤーのユニット数と一致しなければエラー。 if kwds["n"] != self.__layer_list[ self.index(prev_name)+1].prev: raise UnmatchUnitError( kwds["n"], self.__layer_list[self.index(prev_name)].prev) # まだ何も要素がない場合は'append'メソッドを用いるようにエラーを出す。 if len(self) == 0: raise RuntimeError( "You have to use 'append' method instead.") # 挿入場所のインデックスを取得 index = self.index(prev_name) + 1 # レイヤーの種類を読み取り、ネーミングルールに則った名前に変更する if name == "Middle" or name == "mid" or name == "m": name = "Middle" elif name == "Output" or name == "out" or name == "o": name = "Output" else: raise UndefinedLayerError(name) # 要素を挿入する # このとき、'name'はまだネーミングルールに則っていませんが、 # あとでリネームするので気にしないでOKです。 if "Middle" in name: self.__layer_list.insert(index, MiddleLayer(name=name, **kwds)) self.__name_list.insert(index, name) elif "Output" in name: self.__layer_list.insert(index, OutputLayer(name=name, **kwds)) self.__name_list.insert(index, name) # リネームする self._rename() def extend_insert(self, prev_name, lm): """ こちらはオリジナル関数です。 extendメソッドとinsertメソッドを組み合わせたような動作をします。 簡単に説明すると、別のレイヤーマネージャをinsertする感じです。 """ if not isinstance(lm, LayerManager): # 'lm'のインスタンスがLayerManagerでなければエラー。 raise TypeError(type(lm), ": Unexpected type.") # 'prev_name'が存在しなければエラー。 if not prev_name in self.__name_list: raise KeyError(prev_name, ": No such key.") # 指定場所の前後のレイヤーとlmの最初・最後のレイヤーのユニット数が # それぞれ一致しなければエラー。 if len(self) != 0: if self.__layer_list[self.index(prev_name)].n \ != lm.layer_list[0].prev: # 自分の指定場所のユニット数と'lm'の最初のユニット数が # 一致しなければエラー。 raise UnmatchUnitError( self.__layer_list[self.index(prev_name)].n, lm.layer_list[0].prev) if prev_name != self.__name_list[-1]: # 'prev_name'が自分の最後尾のレイヤーでなく if lm.layer_list[-1].n \ != self.__layer_list[self.index(prev_name)+1].prev: # 'lm'の最後尾のユニット数と自分の指定場所の次のレイヤーの # 'prev'ユニット数と一致しなければエラー。 raise UnmatchUnitError( lm.layer_list[-1].n, self.__layer_list[self.index(prev_name)+1].prev) else: # 自分に何の要素もない場合は'extend'メソッドを使うようにエラーを出す。 raise RuntimeError( "You have to use 'extend' method instead.") # 挿入場所のインデックスを取得 index = self.index(prev_name) + 1 # 挿入場所以降の要素を'buf'に避難させてから一旦取り除き、 # extendメソッドを使って要素を追加 layer_buf = self.__layer_list[index:] name_buf = self.__name_list[index:] del self.__layer_list[index:] del self.__name_list[index:] self.extend(lm) # 避難させていた要素を追加する self.__layer_list.extend(layer_buf) self.__name_list.extend(name_buf) # リネームする self._rename() def remove(self, key): """ removeメソッドでは指定の名前の要素を削除します。 インデックスでの指定も許可します。 """ # 既に実装している'del'文でOKです。 del self[key] def index(self, target): return self.__name_list.index(target) def name(self, indices): return self.__name_list[indices] @property def layer_list(self): return self.__layer_list @property def name_list(self): return self.__name_list @property def ntype(self): return self.__ntype
errors.pyerrors.pyimport numpy as np class Error(): def __init__(self, *args, **kwds): self.error = 0 def forward(self, *args, **kwds): pass def backward(self, *args, **kwds): pass def total_error(self, *args, **kwds): return np.sum(self.error)/self.error.size class SquareError(Error): def forward(self, y, t, *args, **kwds): self.error = 0.5 * (y - t)**2 return self.error def backward(self, y, t, *args, **kwds): return y - t class BinaryCrossEntropy(Error): def forward(self, y, t, *args, **kwds): self.error = - t*np.log(y) - (1 - t)*np.log(1 - y) return self.error def backward(self, y, t, *args, **kwds): return (y - t) / (y*(1 - y)) class CrossEntropy(Error): def forward(self, y, t, *args, **kwds): self.error = - t*np.log(y) return self.error def backward(self, y, t, *args, **kwds): return - t/y
get_err.pyget_err.py_err_dic = {"Square": SquareError, "Binary": BinaryCrossEntropy, "Cross": CrossEntropy, } def get_err(name, *args, **kwds): if name in _err_dic.keys(): errfunc = _err_dic[name](*args, **kwds) else: raise ValueError(name + ": Unknown error function") return errfunc
activations.pyactivations.pyimport numpy as np class Activator(): def __init__(self, *args, **kwds): pass def forward(self, *args, **kwds): raise Exception("Not Implemented") def backward(self, *args, **kwds): raise Exception("Not Implemented") def update(self, *args, **kwds): pass class step(Activator): def forward(self, x, *args, **kwds): return np.where(x > 0, 1, 0) def backward(self, x, *args, **kwds): return np.zeros_like(x) class identity(Activator): def forward(self, x, *args, **kwds): return x def backward(self, x, *args, **kwds): return np.ones_like(x) class bentIdentity(Activator): def forward(self, x, *args, **kwds): return 0.5*(np.sqrt(x**2 + 1) - 1) + x def backward(self, x, *args, **kwds): return 0.5*x/np.sqrt(x**2 + 1) + 1 class hardShrink(Activator): def __init__(self, lambda_=0.5, *args, **kwds): self.lambda_ = lambda_ super().__init__(*args, **kwds) def forward(self, x, *args, **kwds): return np.where((-self.lambda_ <= x) & (x <= self.lambda_), 0, x) def backward(self, x, *args, **kwds): return np.where((-self.lambda_ <= x) & (x <= self.lambda_), 0, 1) class softShrink(Activator): def __init__(self, lambda_=0.5, *args, **kwds): self.lambda_ = lambda_ super().__init__(*args, **kwds) def forward(self, x, *args, **kwds): return np.where(x < -self.lambda_, x + self.lambda_, np.where(x > self.lambda_, x - self.lambda_, 0)) def backward(self, x, *args, **kwds): return np.where((-self.lambda_ <= x) & (x <= self.lambda_), 0, 1) class threshold(Activator): def __init__(self, threshold, value, *args, **kwds): self.threshold = threshold self.value = value super().__init__(*args, **kwds) def forward(self, x, *args, **kwds): return np.where(x > self.threshold, x, self.value) def backward(self, x, *args, **kwds): return np.where(x > self.threshold, 1, 0) class sigmoid(Activator): def forward(self, x, *args, **kwds): return 1/(1 + np.exp(-x)) def backward(self, x, y, *args, **kwds): return y*(1 - y) class hardSigmoid(Activator): def forward(self, x, *args, **kwds): return np.clip(0.2*x + 0.5, 0, 1) def backward(self, x, *args, **kwds): return np.where((x > 2.5) | (x < -2.5), 0, 0.2) class logSigmoid(Activator): def forward(self, x, *args, **kwds): return -np.log(1 + np.exp(-x)) def backward(self, x, *args, **kwds): return 1/(1 + np.exp(x)) class act_tanh(Activator): def forward(self, x, *args, **kwds): return np.tanh(x) def backward(self, x, *args, **kwds): return 1 - np.tanh(x)**2 class hardtanh(Activator): def forward(self, x, *args, **kwds): return np.clip(x, -1, 1) def backward(self, x, *args, **kwds): return np.where((-1 <= x) & (x <= 1), 1, 0) class tanhShrink(Activator): def forward(self, x, *args, **kwds): return x - np.tanh(x) def backward(self, x, *args, **kwds): return np.tanh(x)**2 class ReLU(Activator): def forward(self, x, *args, **kwds): return np.maximum(0, x) def backward(self, x, *args, **kwds): return np.where(x > 0, 1, 0) class ReLU6(Activator): def forward(self, x, *args, **kwds): return np.clip(x, 0, 6) def backward(self, x, *args, **kwds): return np.where((0 < x) & (x < 6), 1, 0) class leakyReLU(Activator): def __init__(self, alpha=1e-2, *args, **kwds): self.alpha = alpha super().__init__(*args, **kwds) def forward(self, x, *args, **kwds): return np.maximum(self.alpha * x, x) def backward(self, x, *args, **kwds): return np.where(x < 0, self.alpha, 1) class ELU(Activator): def __init__(self, alpha=1., *args, **kwds): self.alpha = alpha super().__init__(*args, **kwds) def forward(self, x, *args, **kwds): return np.where(x >= 0, x, self.alpha*(np.exp(x) - 1)) def backward(self, x, *args, **kwds): return np.where(x >= 0, 1, self.alpha*np.exp(x)) class SELU(Activator): def __init__(self, lambda_=1.0507, alpha=1.67326, *args, **kwds): self.lambda_ = lambda_ self.alpha = alpha super().__init__(*args, **kwds) def forward(self, x, *args, **kwds): return np.where(x >= 0, self.lambda_*x, self.lambda_*self.alpha*(np.exp(x) - 1)) def backward(self, x, *args, **kwds): return np.where(x >= 0, self.lambda_, self.lambda_*self.alpha*np.exp(x)) class CELU(Activator): def __init__(self, alpha=1., *args, **kwds): self.alpha = alpha super().__init__(*args, **kwds) def forward(self, x, *args, **kwds): return np.where(x >= 0, x, self.alpha*(np.exp(x/self.alpha) - 1)) def backward(self, x, *args, **kwds): return np.where(x >= 0, 1, np.exp(x/self.alpha)) class softmax(Activator): def forward(self, x, *args, **kwds): return np.exp(x)/np.sum(np.exp(x)) def backward(self, x, *args, **kwds): return np.exp(x)*(np.sum(np.exp(x)) - np.exp(x))/np.sum(np.exp(x))**2 class softmin(Activator): def forward(self, x, *args, **kwds): return np.exp(-x)/np.sum(np.exp(-x)) def backward(self, x, *args, **kwds): return -(np.exp(x)*(np.sum(np.exp(-x)) - np.exp(x)) /np.sum(np.exp(-x))**2) class logSoftmax(Activator): def forward(self, x, *args, **kwds): return np.log(np.exp(x)/np.sum(np.exp(x))) def backward(self, x, *args, **kwds): y = np.sum(np.exp(x)) return (y - np.exp(x))/y class softplus(Activator): def forward(self, x, *args, **kwds): return np.logaddexp(x, 0) def backward(self, x, *args, **kwds): return 1/(1 + np.exp(-x)) class softsign(Activator): def forward(self, x, *args, **kwds): return x/(1 + np.abs(x)) def backward(self, x, *args, **kwds): return 1/(1 + np.abs(x)) ** 2 class Swish(Activator): def __init__(self, beta=1, *args, **kwds): self.beta = beta super().__init__(*args, **kwds) def forward(self, x, *args, **kwds): return x/(1 + np.exp(-self.beta*x)) def backward(self, x, y, *args, **kwds): return self.beta*y + (1 - self.beta*y)/(1 + np.exp(-self.beta*x)) def d2y(self, x, *args, **kwds): return (-0.25*self.beta*(self.beta*x*np.tanh(0.5*self.beta*x) - 2) *(1 - np.tanh(0.5*self.beta*x)**2)) class Mish(Activator): def forward(self, x, *args, **kwds): return x*np.tanh(np.logaddexp(x, 0)) def backward(self, x, *args, **kwds): omega = (4*(x + 1) + 4*np.exp(2*x) + np.exp(3*x) + (4*x + 6)*np.exp(x)) delta = 2*np.exp(x) + np.exp(2*x) + 2 return np.exp(x)*omega/delta**2 def d2y(self, x, *args, **kwds): omega = (2*(x + 2) + np.exp(x)*(np.exp(x)*(-2*np.exp(x)*(x - 1) - 3*x + 6) + 2*(x + 4))) delta = np.exp(x)*(np.exp(x) + 2) + 2 return 4*np.exp(x)*omega/delta**3 class tanhExp(Activator): def forward(self, x, *args, **kwds): return x*np.tanh(np.exp(x)) def backward(self, x, *args, **kwds): tanh_exp = np.tanh(np.exp(x)) return tanh_exp - x*np.exp(x)*(tanh_exp**2 - 1) def d2y(self, x, *args, **kwds): tanh_exp = np.tanh(np.exp(x)) return (np.exp(x)*(-x + 2*np.exp(x)*x*tanh_exp - 2) *(tanh_exp**2 - 1)) class maxout(Activator): def __init__(self, n_prev, n, k, wb_width=5e-2, *args, **kwds): self.n_prev = n_prev self.n = n self.k = k self.w = wb_width*np.random.rand((n_prev, n*k)) self.b = wb_width*np.random.rand(n*k) super().__init__(*args, **kwds) def forward(self, x, *args, **kwds): self.x = x.copy() self.z = np.dot(self.w.T, x) + self.b self.z = self.z.reshape(self.n, self.k) self.y = np.max(self.z, axis=1) return self.y def backward(self, g, *args, **kwds): self.dw = np.sum(np.dot(self.w, self.x))
get_act.pyget_act.py_act_dic = {"step": step, "identity": identity, "bent-identity": bentIdentity, "hard-shrink": hardShrink, "soft-shrink": softShrink, "threshold": threshold, "sigmoid": sigmoid, "hard-sigmoid": hardSigmoid, "log-sigmoid": logSigmoid, "tanh": act_tanh, "tanh-shrink": tanhShrink, "hard-tanh":hardtanh, "ReLU": ReLU, "ReLU6": ReLU6, "leaky-ReLU": leakyReLU, "ELU": ELU, "SELU": SELU, "CELU": CELU, "softmax": softmax, "softmin": softmin, "log-softmax": logSoftmax, "softplus": softplus, "softsign": softsign, "Swish": Swish, "Mish": Mish, "tanhExp": tanhExp, } def get_act(name, *args, **kwds): if name in _act_dic.keys(): activator = _act_dic[name](*args, **kwds) else: raise ValueError(name + ": Unknown activator") return activator
optimizers.pyoptimizers.pyimport numpy as np class Optimizer(): """ 最適化手法が継承するスーパークラス。 """ def __init__(self, *args, **kwds): pass def update(self, *args, **kwds): pass class SGD(Optimizer): def __init__(self, eta=1e-2, *args, **kwds): super().__init__(*args, **kwds) self.eta = eta def update(self, grad_w, grad_b, *args, **kwds): dw = -self.eta*grad_w db = -self.eta*grad_b return dw, db class MSGD(Optimizer): def __init__(self, eta=1e-2, mu=0.9, *args, **kwds): super().__init__(*args, **kwds) self.eta = eta self.mu = mu # 一つ前のステップの値を保持する self.dw = 0 self.db = 0 def update(self, grad_w, grad_b, *args, **kwds): dw = self.mu*self.dw - (1-self.mu)*self.eta*grad_w db = self.mu*self.db - (1-self.mu)*self.eta*grad_b # コピーではなくビューで代入しているのは、これらの値が使われることはあっても # 変更されることはないためです。 self.dw = dw self.db = db return dw, db class NAG(Optimizer): def __init__(self, eta=1e-2, mu=0.9, *args, **kwds): super().__init__(*args, **kwds) self.eta = eta self.mu = mu # 一つ前のステップの値を保持 self.dw = 0 self.db = 0 def update(self, grad_w, grad_b, w=0, b=0, dfw=None, dfb=None, nargs=2, *args, **kwds): if nargs == 1: grad_w = dfw(w + self.mu*self.dw) grad_b = 0 elif nargs == 2: grad_w = dfw(w + self.mu*self.dw, b + self.mu*self.db) grad_b = dfb(w + self.mu*self.dw, b + self.mu*self.db) dw = self.mu*self.dw - (1-self.mu)*self.eta*grad_w db = self.mu*self.db - (1-self.mu)*self.eta*grad_b # コピーではなくビューで代入しているのは、これらの値が使われることはあっても # 変更されることはないためです。 self.dw = dw self.db = db return dw, db class AdaGrad(Optimizer): def __init__(self, eta=1e-3, *args, **kwds): super().__init__(*args, **kwds) self.eta = eta # 一つ前のステップの値を保持する self.gw = 0 self.gb = 0 def update(self, grad_w, grad_b, *args, **kwds): self.gw += grad_w*grad_w self.gb += grad_b*grad_b dw = -self.eta*grad_w/np.sqrt(self.gw) db = -self.eta*grad_b/np.sqrt(self.gb) return dw, db class RMSprop(Optimizer): def __init__(self, eta=1e-2, rho=0.99, eps=1e-8, *args, **kwds): super().__init__(*args, **kwds) self.eta = eta self.rho = rho self.eps = eps # 一つ前のステップの値を保持する self.vw = 0 self.vb = 0 def update(self, grad_w, grad_b, *args, **kwds): self.vw += (1-self.rho)*(grad_w**2 - self.vw) self.vb += (1-self.rho)*(grad_b**2 - self.vb) dw = -self.eta*grad_w/np.sqrt(self.vw+self.eps) db = -self.eta*grad_b/np.sqrt(self.vb+self.eps) return dw, db class AdaDelta(Optimizer): def __init__(self, rho=0.95, eps=1e-6, *args, **kwds): super().__init__(*args, **kwds) self.rho = rho self.eps = eps # 一つ前のステップの値を保持する self.vw = 0 self.vb = 0 self.uw = 0 self.ub = 0 def update(self, grad_w, grad_b, *args, **kwds): self.vw += (1-self.rho)*(grad_w**2 - self.vw) self.vb += (1-self.rho)*(grad_b**2 - self.vb) dw = -grad_w*np.sqrt(self.uw+self.eps)/np.sqrt(self.vw+self.eps) db = -grad_b*np.sqrt(self.ub+self.eps)/np.sqrt(self.vb+self.eps) self.uw += (1-self.rho)*(dw**2 - self.uw) self.ub += (1-self.rho)*(db**2 - self.ub) return dw, db class Adam(Optimizer): def __init__(self, alpha=1e-3, beta1=0.9, beta2=0.999, eps=1e-8, *args, **kwds): super().__init__(*args, **kwds) self.alpha = alpha self.beta1 = beta1 self.beta2 = beta2 self.eps = eps # 一つ前のステップの値を保持する self.mw = 0 self.mb = 0 self.vw = 0 self.vb = 0 def update(self, grad_w, grad_b, t=1, *args, **kwds): self.mw += (1-self.beta1)*(grad_w - self.mw) self.mb += (1-self.beta1)*(grad_b - self.mb) self.vw += (1-self.beta2)*(grad_w**2 - self.vw) self.vb += (1-self.beta2)*(grad_b**2 - self.vb) alpha_t = self.alpha*np.sqrt(1-self.beta2**t)/(1-self.beta1**t) dw = -alpha_t*self.mw/(np.sqrt(self.vw+self.eps)) db = -alpha_t*self.mb/(np.sqrt(self.vb+self.eps)) return dw, db class RMSpropGraves(Optimizer): def __init__(self, eta=1e-4, rho=0.95, eps=1e-4, *args, **kwds): super().__init__(*args, **kwds) self.eta = eta self.rho = rho self.eps = eps # 一つ前のステップの値を保持する self.mw = 0 self.mb = 0 self.vw = 0 self.vb = 0 def update(self,grad_w, grad_b, *args, **kwds): self.mw += (1-self.rho)*(grad_w - self.mw) self.mb += (1-self.rho)*(grad_b - self.mb) self.vw += (1-self.rho)*(grad_w**2 - self.vw) self.vb += (1-self.rho)*(grad_b**2 - self.vb) dw = -self.eta*grad_w/np.sqrt(self.vw - self.mw**2 + self.eps) db = -self.eta*grad_b/np.sqrt(self.vb - self.mb**2 + self.eps) return dw, db class SMORMS3(Optimizer): def __init__(self, eta=1e-3, eps=1e-8, *args, **kwds): super().__init__(*args, **kwds) self.eta = eta self.eps = eps # 一つ前のステップの値を保持する self.zetaw = 0 self.zetab = 0 self.sw = 1 self.sb = 1 self.mw = 0 self.mb = 0 self.vw = 0 self.vb = 0 def update(self, grad_w, grad_b, *args, **kwds): rhow = 1/(1+self.sw) rhob = 1/(1+self.sb) self.mw += (1-rhow)*(grad_w - self.mw) self.mb += (1-rhob)*(grad_b - self.mb) self.vw += (1-rhow)*(grad_w**2 - self.vw) self.vb += (1-rhob)*(grad_b**2 - self.vb) self.zetaw = self.mw**2 / (self.vw + self.eps) self.zetaw = self.mb**2 / (self.vb + self.eps) dw = -grad_w*(np.minimum(self.eta, self.zetaw) /np.sqrt(self.vw + self.eps)) db = -grad_b*(np.minimum(self.eta, self.zetab) /np.sqrt(self.vb + self.eps)) self.sw = 1 + (1 - self.zetaw)*self.sw self.sb = 1 + (1 - self.zetab)*self.sb return dw, db class AdaMax(Optimizer): def __init__(self, alpha=2e-3, beta1=0.9, beta2=0.999, *args, **kwds): super().__init__(*args, **kwds) self.alpha = alpha self.beta1 = beta1 self.beta2 = beta2 # 一つ前のステップの値を保持する self.mw = 0 self.mb = 0 self.uw = 0 self.ub = 0 def update(self, grad_w, grad_b, t=1, *args, **kwds): self.mw += (1-self.beta1)*(grad_w - self.mw) self.mb += (1-self.beta1)*(grad_b - self.mb) self.uw = np.maximum(self.beta2*self.uw, np.abs(grad_w)) self.ub = np.maximum(self.beta2*self.ub, np.abs(grad_b)) alpha_t = self.alpha/(1 - self.beta1**t) dw = -alpha_t*self.mw/self.uw db = -alpha_t*self.mb/self.ub return dw, db class Nadam(Optimizer): def __init__(self, alpha=2e-3, mu=0.975, nu=0.999, eps=1e-8, *args, **kwds): super().__init__(*args, **kwds) self.alpha = alpha self.mu = mu self.nu = nu self.eps = eps # 一つ前のステップの値を保持する self.mw = 0 self.mb = 0 self.vw = 0 self.vb = 0 def update(self, grad_w, grad_b, t=1, *args, **kwds): self.mw += (1-self.mu)*(grad_w - self.mw) self.mb += (1-self.mu)*(grad_b - self.mb) self.vw += (1-self.nu)*(grad_w**2 - self.vw) self.vb += (1-self.nu)*(grad_b**2 - self.vb) mhatw = (self.mu*self.mw/(1-self.mu**(t+1)) + (1-self.mu)*grad_w/(1-self.mu**t)) mhatb = (self.mu*self.mb/(1-self.mu**(t+1)) + (1-self.mu)*grad_b/(1-self.mu**t)) vhatw = self.nu*self.vw/(1-self.nu**t) vhatb = self.nu*self.vb/(1-self.nu**t) dw = -self.alpha*mhatw/np.sqrt(vhatw + self.eps) db = -self.alpha*mhatb/np.sqrt(vhatb + self.eps) return dw, db class Eve(Optimizer): def __init__(self, alpha=1e-3, beta1=0.9, beta2=0.999, beta3=0.999, c=10, eps=1e-8, fstar=0, *args, **kwds): super().__init__(*args, **kwds) self.alpha = alpha self.beta1 = beta1 self.beta2 = beta2 self.beta3 = beta3 self.c = c self.eps = eps # 一つ前のステップの値を保持する self.mw = 0 self.mb = 0 self.vw = 0 self.vb = 0 self.f = 0 self.fstar = fstar self.dtilde_w = 0 self.dtilde_b = 0 def update(self, grad_w, grad_b, t=1, f=1, *args, **kwds): self.mw += (1-self.beta1)*(grad_w - self.mw) self.mb += (1-self.beta1)*(grad_b - self.mb) self.vw += (1-self.beta2)*(grad_w**2 - self.vw) self.vb += (1-self.beta2)*(grad_b**2 - self.vb) mhatw = self.mw/(1 - self.beta1**t) mhatb = self.mb/(1 - self.beta1**t) vhatw = self.vw/(1 - self.beta2**t) vhatb = self.vb/(1 - self.beta2**t) if t > 1: d_w = (np.abs(f-self.fstar) /(np.minimum(f, self.f) - self.fstar)) d_b = (np.abs(f-self.fstar) /(np.minimum(f, self.f) - self.fstar)) dhat_w = np.clip(d_w, 1/self.c, self.c) dhat_b = np.clip(d_b, 1/self.c, self.c) self.dtilde_w += (1 - self.beta3)*(dhat_w - self.dtilde_w) self.dtilde_b += (1 - self.beta3)*(dhat_b - self.dtilde_b) else: self.dtilde_w = 1 self.dtilde_b = 1 self.f = f dw = -(self.alpha*mhatw /(self.dtilde_w*(np.sqrt(vhatw) + self.eps))) db = -(self.alpha*mhatb /(self.dtilde_b*(np.sqrt(vhatb) + self.eps))) return dw, db class SantaE(Optimizer): def __init__(self, eta=1e-2, sigma=0.95, lambda_=1e-8, anne_func=lambda t, n: t**n, anne_rate=0.5, burnin=100, C=5, N=16, *args, **kwds): """ Args: eta: Learning rate sigma: Maybe in other cases; 'rho' in RMSprop, AdaDelta, RMSpropGraves. 'rhow' or 'rhob' in SMORMS3. 'beta2' in Adam, Eve. 'nu' in Nadam. To use calculation 'v'. lambda_: Named 'eps'(ε) in other cases. anne_func: Annealing function. To use calculation 'beta' at each timestep. Default is 'timestep'**'annealing rate'. The calculated value should be towards infinity as 't' increases. anne_rate: Annealing rate. To use calculation 'beta' at each timestep. The second Argument of 'anne_func'. burnin: Swith exploration and refinement. This should be specified by users. C: To calculate first 'alpha'. N: Number of minibatch. """ super().__init__(*args, **kwds) self.eta = eta self.sigma = sigma self.lambda_ = lambda_ self.anne_func = anne_func self.anne_rate = anne_rate self.burnin = burnin self.N = N # Keep one step before and Initialize. self.alpha_w = np.sqrt(eta)*C self.alpha_b = np.sqrt(eta)*C self.vw = 0 self.vb = 0 self.gw = 0 self.gb = 0 def update(self, grad_w, grad_b, t=1, *args, **kwds): try: shape_w = grad_w.shape except: shape_w = (1, ) try: shape_b = grad_b.shape except: shape_b = (1, ) if t == 1: # Initialize uw, ub. self.uw = np.sqrt(self.eta)*np.random.randn(*shape_w) self.ub = np.sqrt(self.eta)*np.random.randn(*shape_b) self.vw = (self.sigma*self.vw + grad_w*grad_w * (1 - self.sigma) / self.N**2) self.vb = (self.sigma*self.vb + grad_b*grad_b * (1 - self.sigma) / self.N**2) gw = 1/np.sqrt(self.lambda_ + np.sqrt(self.vw)) gb = 1/np.sqrt(self.lambda_ + np.sqrt(self.vb)) beta = self.anne_func(t, self.anne_rate) if t < self.burnin: # Exploration. self.alpha_w += self.uw*self.uw - self.eta/beta self.alpha_b += self.ub*self.ub - self.eta/beta uw = (self.eta/beta * (1 - self.gw/gw)/self.uw + np.sqrt(2*self.eta/beta * self.gw) * np.random.randn(*shape_w)) ub = (self.eta/beta * (1 - self.gb/gb)/self.ub + np.sqrt(2*self.eta/beta * self.gb) * np.random.randn(*shape_b)) else: # Refinement. uw = 0 ub = 0 uw += (1 - self.alpha_w)*self.uw - self.eta*gw*grad_w ub += (1 - self.alpha_b)*self.ub - self.eta*gb*grad_b # Update values. self.uw = uw self.ub = ub self.gw = gw self.gb = gb dw = gw*uw db = gb*ub return dw, db class SantaSSS(Optimizer): def __init__(self, eta=1e-2, sigma=0.95, lambda_=1e-8, anne_func=lambda t, n: t**n, anne_rate=0.5, burnin=100, C=5, N=16, *args, **kwds): """ Args: eta: Learning rate sigma: Maybe in other cases; 'rho' in RMSprop, AdaDelta, RMSpropGraves. 'rhow' or 'rhob' in SMORMS3. 'beta2' in Adam, Eve. 'nu' in Nadam. To use calculation 'v'. lambda_: Named 'eps'(ε) in other cases. anne_func: Annealing function. To use calculation 'beta' at each timestep. Default is 'timestep'**'annealing rate'. The calculated value should be towards infinity as 't' increases. anne_rate: Annealing rate. To use calculation 'beta' at each timestep. The second Argument of 'anne_func'. burnin: Swith exploration and refinement. This should be specified by users. C: To calculate first 'alpha'. N: Number of minibatch. """ super().__init__(*args, **kwds) self.eta = eta self.sigma = sigma self.lambda_ = lambda_ self.anne_func = anne_func self.anne_rate = anne_rate self.burnin = burnin self.N = N # Keep one step before and Initialize. self.alpha_w = np.sqrt(eta)*C self.alpha_b = np.sqrt(eta)*C self.vw = 0 self.vb = 0 self.gw = 0 self.gb = 0 def update(self, grad_w, grad_b, t=1, *args, **kwds): try: shape_w = grad_w.shape except: shape_w = (1, ) try: shape_b = grad_b.shape except: shape_b = (1, ) if t == 1: # Initialize uw, ub. self.uw = np.sqrt(self.eta)*np.random.randn(*shape_w) self.ub = np.sqrt(self.eta)*np.random.randn(*shape_b) self.vw = (self.sigma*self.vw + grad_w*grad_w * (1 - self.sigma) / self.N**2) self.vb = (self.sigma*self.vb + grad_b*grad_b * (1 - self.sigma) / self.N**2) gw = 1/np.sqrt(self.lambda_ + np.sqrt(self.vw)) gb = 1/np.sqrt(self.lambda_ + np.sqrt(self.vb)) dw = 0.5*gw*self.uw db = 0.5*gb*self.ub beta = self.anne_func(t, self.anne_rate) if t < self.burnin: # Exploration. self.alpha_w += (self.uw*self.uw - self.eta/beta)*0.5 self.alpha_b += (self.ub*self.ub - self.eta/beta)*0.5 uw = np.exp(-0.5*self.alpha_w)*self.uw ub = np.exp(-0.5*self.alpha_b)*self.ub uw += (-gw*grad_w*self.eta + np.sqrt(2*self.gw*self.eta/beta) * np.random.randn(*shape_w) + self.eta/beta*(1-self.gw/gw)/self.uw) ub += (-gb*grad_b*self.eta + np.sqrt(2*self.gb*self.eta/beta) * np.random.randn(*shape_b) + self.eta/beta*(1-self.gb/gb)/self.ub) uw *= np.exp(-0.5*self.alpha_w) ub *= np.exp(-0.5*self.alpha_b) self.alpha_w += (uw*uw - self.eta/beta)*0.5 self.alpha_b += (ub*ub - self.eta/beta)*0.5 else: # Refinement. uw = np.exp(-0.5*self.alpha_w)*self.uw ub = np.exp(-0.5*self.alpha_b)*self.ub uw -= gw*grad_w*self.eta ub -= gb*grad_b*self.eta uw *= np.exp(-0.5*self.alpha_w) ub *= np.exp(-0.5*self.alpha_b) # Update values. self.uw = uw self.ub = ub self.gw = gw self.gb = gb dw = gw*uw*0.5 db = gb*ub*0.5 return dw, db class AMSGrad(Optimizer): def __init__(self, alpha=1e-3, beta1=0.9, beta2=0.999, eps=1e-8, *args, **kwds): super().__init__(*args, **kwds) self.alpha = alpha self.beta1 = beta1 self.beta2 = beta2 self.eps = eps # 一つ前のステップの値を保持する self.mw = 0 self.mb = 0 self.vw = 0 self.vb = 0 self.vhatw = 0 self.vhatb = 0 def update(self, grad_w, grad_b, t=1, *args, **kwds): self.mw += (1-self.beta1)*(grad_w - self.mw) self.mb += (1-self.beta1)*(grad_b - self.mb) self.vw += (1-self.beta2)*(grad_w**2 - self.vw) self.vb += (1-self.beta2)*(grad_b**2 - self.vb) self.vhatw = np.maximum(self.vhatw, self.vw) self.vhatb = np.maximum(self.vhatb, self.vb) alpha_t = self.alpha / np.sqrt(t) dw = - alpha_t * self.mw/np.sqrt(self.vhatw + self.eps) db = - alpha_t * self.mb/np.sqrt(self.vhatb + self.eps) return dw, db class AdaBound(Optimizer): def __init__(self, alpha=1e-3, eta=1e-1, beta1=0.9, beta2=0.999, eps=1e-8, *args, **kwds): super().__init__(*args, **kwds) self.alpha = alpha self.eta = eta self.beta1 = beta1 self.beta2 = beta2 self.eps = eps # 一つ前のステップの値を保持する self.mw = 0 self.mb = 0 self.vw = 0 self.vb = 0 def update(self, grad_w, grad_b, t=1, *args, **kwds): self.mw += (1-self.beta1)*(grad_w - self.mw) self.mb += (1-self.beta1)*(grad_b - self.mb) self.vw += (1-self.beta2)*(grad_w**2 - self.vw) self.vb += (1-self.beta2)*(grad_b**2 - self.vb) etal = self.eta*(1 - 1/((1-self.beta2)*t + 1)) etau = self.eta*(1 + 1/((1-self.beta2)*t + self.eps)) etahatw_t = np.clip(self.alpha/np.sqrt(self.vw), etal, etau) etahatb_t = np.clip(self.alpha/np.sqrt(self.vb), etal, etau) etaw_t = etahatw_t/np.sqrt(t) etab_t = etahatb_t/np.sqrt(t) dw = - etaw_t*self.mw db = - etab_t*self.mb return dw, db class AMSBound(Optimizer): def __init__(self, alpha=1e-3, eta=1e-1, beta1=0.9, beta2=0.999, eps=1e-8, *args, **kwds): super().__init__(*args, **kwds) self.alpha = alpha self.eta = eta self.beta1 = beta1 self.beta2 = beta2 self.eps = eps # 一つ前のステップの値を保持する self.mw = 0 self.mb = 0 self.vw = 0 self.vb = 0 self.vhatw = 0 self.vhatb = 0 def update(self, grad_w, grad_b, t=1, *args, **kwds): self.mw += (1-self.beta1)*(grad_w - self.mw) self.mb += (1-self.beta1)*(grad_b - self.mb) self.vw += (1-self.beta2)*(grad_w**2 - self.vw) self.vb += (1-self.beta2)*(grad_b**2 - self.vb) self.vhatw = np.maximum(self.vhatw, self.vw) self.vhatb = np.maximum(self.vhatb, self.vb) etal = self.eta*(1 - 1/((1-self.beta2)*t + 1)) etau = self.eta*(1 + 1/((1-self.beta2)*t + self.eps)) etahatw_t = np.clip(self.alpha/np.sqrt(self.vhatw), etal, etau) etahatb_t = np.clip(self.alpha/np.sqrt(self.vhatb), etal, etau) etaw_t = etahatw_t/np.sqrt(t) etab_t = etahatb_t/np.sqrt(t) dw = - etaw_t*self.mw db = - etab_t*self.mb return dw, db
get_opt.pyget_opt.py_opt_dic = { "SGD": SGD, "MSGD": MSGD, "NAG": NAG, "AdaGrad": AdaGrad, "RMSprop": RMSprop, "AdaDelta": AdaDelta, "Adam": Adam, "RMSpropGraves": RMSpropGraves, "SMORMS3": SMORMS3, "AdaMax": AdaMax, "Nadam": Nadam, "Eve": Eve, "SantaE": SantaE, "SantaSSS": SantaSSS, "AMSGrad": AMSGrad, "AdaBound": AdaBound, "AMSBound": AMSBound, } def get_opt(name, *args, **kwds): if name in _opt_dic.keys(): optimizer = _opt_dic[name](*args, **kwds) else: raise ValueError(name + ": Unknown optimizer") return optimizer
これらのコードを一つのjupyter notebookのファイル(拡張子.ipynb)の各セルに貼り付けて、最後に次のテストコードを貼り付けて実行すると動きます。テストコード
以下が実験コードとなります。
test.pytest.py%matplotlib nbagg import numpy as np import matplotlib.pyplot as plt import matplotlib.animation as animation import tqdm # 学習対象設定 def split_test(target, train_indices): return target[train_indices], target[~ train_indices] x = np.arange(0, 4, 5e-2) y = np.sin(x) x_left = 1 x_right = 3 y_top = np.max(y) + 1 y_bottom = np.min(y) - 1 indices = (x_left <= x) & (x <= x_right) x_train, x_test = split_test(x, indices) y_train, y_test = split_test(y, indices) # 初期設定 epoch = 10000 error_prev = 0 error = 0 error_list = [] threshold = 1e-8 n_batch = 4 n_train = x_train.size//n_batch n_test = x_test.size # ネットワーク構築 n_in = 1 n_out = 1 lm = LayerManager() lm.append(prev=n_in, n=30, act="sigmoid", wb_width=1) lm.append(n=30, act="sigmoid", wb_width=1) lm.append(n=n_out, name="o", act="identity", wb_width=1) # アニメーションプロット用土台作成 n_image = 100 interval = 50 images = [] fig, ax = plt.subplots(1) fig.suptitle("fitting animation") ax.set_xlabel("x") ax.set_ylabel("y") ax.set_xlim(np.min(x), np.max(x)) ax.set_ylim(y_bottom, y_top) ax.grid() ax.plot(x, y, color="r") ax.plot(np.full_like(np.arange(y_bottom, y_top+1), x_left), np.arange(y_bottom, y_top+1), color="g") ax.plot(np.full_like(np.arange(y_bottom, y_top+1), x_right), np.arange(y_bottom, y_top+1), color="g") # 学習開始 rand_index = np.arange(x_train.size) for t in tqdm.tqdm(range(1, epoch+1)): # シーン作成 if t % (epoch/n_image) == 1: x_in = x.reshape(-1, 1) for ll in lm.layer_list: x_in = ll.forward(x_in) im, = ax.plot(x, ll.y, color="b") images.append([im]) # 誤差計算 x_in = x_test.reshape(n_test, n_in) for ll in lm.layer_list: x_in = ll.forward(x_in) error = lm[-1].get_error(y_test.reshape(n_test, n_out)) error_list.append(error) # 収束判定 if abs(error - error_prev) < threshold: print("end learning...") break else: error_prev = error #print("t", t) np.random.shuffle(rand_index) for i in range(n_train): rand = rand_index[i*n_in : (i+n_batch)*n_in] x_in = x_train[rand].reshape(-1, n_in) #print("x_in", x_in) for ll in lm.layer_list: x_in = ll.forward(x_in) y_in = y_train[rand].reshape(-1, n_out) #print("y_in", y_in) for ll in lm.layer_list[::-1]: y_in = ll.backward(y_in) for ll in lm.layer_list: ll.update() # フィッティングアニメーション作成 anim = animation.ArtistAnimation(fig, images, interval=interval, repeat_delay=3000) # 誤差遷移表示 fig2, ax2 = plt.subplots(1) fig2.suptitle("error transition") ax2.set_yscale("log") ax2.set_xlabel("epoch") ax2.set_ylabel("error") ax2.grid() ax2.plot(error_list) fig2.show() fig2.savefig("error_transition.png")それぞれ解説していきます。
学習対象設定
学習対象設定
test.py# 学習対象設定 def split_test(target, train_indices): return target[train_indices], target[~ train_indices] x = np.arange(0, 4, 5e-2) y = np.sin(x) x_left = 1 x_right = 3 y_top = np.max(y) + 1 y_bottom = np.min(y) - 1 indices = (x_left <= x) & (x <= x_right) x_train, x_test = split_test(x, indices) y_train, y_test = split_test(y, indices)
ここでは学習対象であるsin関数をもとに訓練データx_trainとテストデータx_testを生成しています。split_test関数はデータをその二つに分けるための関数ですね。
x_leftとx_rightは訓練データの下限と上限です。y_topとy_bottomはプロットのための上端と下端です。初期値設定
初期値設定
test.py# 初期設定 epoch = 10000 error_prev = 0 error = 0 error_list = [] threshold = 1e-8 n_batch = 4 n_train = x_train.size//n_batch n_test = x_test.size
各初期値の名称は割と適当です。まあギリギリ伝わるでしょうからOKとしましょう。ネットワーク構築
ネットワーク構築
test.py# ネットワーク構築 n_in = 1 n_out = 1 lm = LayerManager() lm.append(prev=n_in, n=30, act="sigmoid", wb_width=1) lm.append(n=30, act="sigmoid", wb_width=1) lm.append(n=n_out, name="o", act="identity", wb_width=1)
ここでニューラルネットワークを構築しています。入力の数n_inと出力の数n_outは今回は共に1ですね。
ここではレイヤーマネージャlmで3層のネットワークを構築しています。
アニメーション用土台作成
アニメーション用土台作成
test.py# アニメーションプロット用土台作成 n_image = 100 interval = 50 images = [] fig, ax = plt.subplots(1) fig.suptitle("fitting animation") ax.set_xlabel("x") ax.set_ylabel("y") ax.set_xlim(np.min(x), np.max(x)) ax.set_ylim(y_bottom, y_top) ax.grid() ax.plot(x, y, color="r") ax.plot(np.full_like(np.arange(y_bottom, y_top+1), x_left), np.arange(y_bottom, y_top+1), color="g") ax.plot(np.full_like(np.arange(y_bottom, y_top+1), x_right), np.arange(y_bottom, y_top+1), color="g")
アニメーションを貼り付けるための土台を作成しています。
アニメーションの土台にはタイトルや縦軸・横軸の設定、グリッド線、正解グラフ、訓練データとテストデータの区切りをプロットしています。学習
学習
test.py# 学習開始 rand_index = np.arange(x_train.size) for t in tqdm.tqdm(range(1, epoch+1)): # シーン作成 if t % (epoch/n_image) == 1: x_in = x.reshape(-1, 1) for ll in lm.layer_list: x_in = ll.forward(x_in) im, = ax.plot(x, ll.y, color="b") images.append([im]) # 誤差計算 x_in = x_test.reshape(n_test, n_in) for ll in lm.layer_list: x_in = ll.forward(x_in) error = lm[-1].get_error(y_test.reshape(n_test, n_out)) error_list.append(error) # 収束判定 if abs(error - error_prev) < threshold: print("end learning...") break else: error_prev = error #print("t", t) np.random.shuffle(rand_index) for i in range(n_train): rand = rand_index[i*n_in : (i+n_batch)*n_in] x_in = x_train[rand].reshape(-1, n_in) #print("x_in", x_in) for ll in lm.layer_list: x_in = ll.forward(x_in) y_in = y_train[rand].reshape(-1, n_out) #print("y_in", y_in) for ll in lm.layer_list[::-1]: y_in = ll.backward(y_in) for ll in lm.layer_list: ll.update()
学習本体の実装です。
「シーン作成」では学習の進む様子をアニメーションで表示するためにシーンを作成しています。
「誤差計算」ではテストデータを流してその誤差の総和を取得しています。
「収束判定」では一つ前の誤差と比較して収束判定を行っています。差分がthresholdよりも小さくなると収束したと判定しています。
その後は順伝播→逆伝播→パラメータ更新(学習)をデータ分繰り返して1エポック分の学習となります。アニメーションと誤差遷移表示
アニメーションと誤差遷移表示
test.py# フィッティングアニメーション作成 anim = animation.ArtistAnimation(fig, images, interval=interval, repeat_delay=3000) # 誤差遷移表示 fig2, ax2 = plt.subplots(1) fig2.suptitle("error transition") ax2.set_yscale("log") ax2.set_xlabel("epoch") ax2.set_ylabel("error") ax2.grid() ax2.plot(error_list) fig2.show() fig2.savefig("error_transition.png")
アニメーション作成はArtistAnimation関数を利用しています。repeat_delayはリピートの区切りで休止する時間の設定をしています。
誤差遷移表示は学習過程でモニタしていたエラーを表示しています。実験結果
作成したアニメーションと誤差遷移の一例は次のようになります。
初期パラメータを乱数で生成しているため実行するたびに異なった結果を与えるため一例に過ぎません。
訓練データについてはいち早くフィッティング完了し、その後を追うようにテストデータにもうまくフィッティングして行っていますね。もちろんですがテストデータでは学習を行なっていないため未知のデータに対する汎用性を獲得していることになります。機能を
LayerManagerに移植さて、テストコードに直接書いた一部の機能を
LayerManagerに移植していきます。
まずはレイヤーマネージャに色々保持させます。
test.pyの初期設定を変更test.py# 初期設定 epoch = 10000 #error_prev = 0 #error = 0 #error_list = [] threshold = 1e-8 n_batch = 4 #n_train = x_train.size//n_batch #n_test = x_test.size # ネットワーク構築 n_in = 1 n_out = 1 lm = LayerManager((x_train, x_test), (y_train, y_test)) lm.append(prev=n_in, n=30, act="sigmoid", wb_width=1) lm.append(n=30, act="sigmoid", wb_width=1) lm.append(n=n_out, name="o", act="identity", wb_width=1)
layermanager.pyの__init__に初期設定を移植layermanager.pydef __init__(self, x, y): self.x_train, self.x_test = x self.y_train, self.y_test = y self.__layer_list = [] # レイヤーのリスト self.__name_list = [] # 各レイヤーの名前リスト self.__ntype = np.zeros(self.N_TYPE, dtype=int) # 種類別レイヤーの数続いて学習本体と誤差遷移表示を移植します。
test.pyの学習コードを変更test.py# 学習開始 lm.training(epoch, threshold=threshold, n_batch=n_batch)
layermanager.pyに学習コードを移植layermanager.pydef training(self, epoch, n_batch=16, threshold=1e-8, show_error=True): if show_error: self.error_list = [] n_in = self.__layer_list[0].prev n_out = self.__layer_list[-1].n n_train = self.x_train.size//n_batch n_test = self.x_test.size # 学習開始 error = 0 error_prev = 0 rand_index = np.arange(self.x_train.size) for t in tqdm.tqdm(range(1, epoch+1)): # 誤差計算 x_in = self.x_test.reshape(n_test, n_in) for ll in self.__layer_list: x_in = ll.forward(x_in) error = lm[-1].get_error(self.y_test.reshape(n_test, n_out)) if show_error: error_list.append(error) # 収束判定 if abs(error - error_prev) < threshold: print("end learning...") break else: error_prev = error #print("t", t) np.random.shuffle(rand_index) for i in range(n_train): rand = rand_index[i*n_in : (i+n_batch)*n_in] x_in = self.x_train[rand].reshape(-1, n_in) #print("x_in", x_in) for ll in self.__layer_list: x_in = ll.forward(x_in) y_in = self.y_train[rand].reshape(-1, n_out) #print("y_in", y_in) for ll in self.__layer_list[::-1]: y_in = ll.backward(y_in) for ll in self.__layer_list: ll.update() if show_error: # 誤差遷移表示 self.show_error(**kwds) def show_errors(self, title="error transition", xlabel="epoch", ylabel="error", fname="error_transition.png"): fig, ax = plt.subplots(1) fig.suptitle(title) ax.set_yscale("log") ax.set_xlabel(xlabel) ax.set_ylabel(ylabel) ax.grid() ax.plot(error_list) fig.show() if len(fname) != 0: fig.savefig(fname)最後にアニメーションですね。
考えたのですが汎用性高くアニメーションを挿入させる方法が思いつかなかったので適当に...
なんか思いついたら変えます。
test.pyのアニメーションコード変更test.py# アニメーションプロット用土台作成 n_image = 100 interval = 100 fig, ax = lm.ready_anim(n_image, x, y, title="fitting animation") #images = [] #fig, ax = plt.subplots(1) #fig.suptitle("fitting animation") #ax.set_xlabel("x") #ax.set_ylabel("y") #ax.set_xlim(np.min(x), np.max(x)) #ax.set_ylim(y_bottom, y_top) #ax.grid() #ax.plot(x, y, color="r") ax.plot(np.full_like(np.arange(y_bottom, y_top+1), x_left), np.arange(y_bottom, y_top+1), color="g") ax.plot(np.full_like(np.arange(y_bottom, y_top+1), x_right), np.arange(y_bottom, y_top+1), color="g") # 学習開始 lm.training(epoch, threshold=threshold, n_batch=n_batch) # フィッティングアニメーション作成 anim = animation.ArtistAnimation(lm.anim_fig, lm.images, interval=interval, repeat_delay=3000)
layermanager.pyにアニメーションコードを移植layermanager.pydef training(self, epoch, n_batch=16, threshold=1e-8, show_error=True, **kwds): if show_error: self.error_list = [] if self.make_anim: self.images = [] n_in = self.__layer_list[0].prev n_out = self.__layer_list[-1].n n_train = self.x_train.size//n_batch n_test = self.x_test.size # 学習開始 error = 0 error_prev = 0 rand_index = np.arange(self.x_train.size) for t in tqdm.tqdm(range(1, epoch+1)): #シーン作成 if self.make_anim: self.make_scene(t, epoch) # 誤差計算 以下略 def show_errors(self, title="error transition", xlabel="epoch", ylabel="error", fname="error_transition.png", **kwds): 以下略 def ready_anim(self, n_image, x, y, title="animation", xlabel="x", ylabel="y", ex_color="r", color="b", x_left=0, x_right=0, y_down = 1, y_up = 1): self.n_image = n_image self.x = x self.color = color self.make_anim = True self.anim_fig, self.anim_ax = plt.subplots(1) self.anim_fig.suptitle(title) self.anim_ax.set_xlabel(xlabel) self.anim_ax.set_ylabel(ylabel) self.anim_ax.set_xlim(np.min(x) - x_left, np.max(x) + x_right) self.anim_ax.set_ylim(np.min(y) - y_down, np.max(y) + y_up) self.anim_ax.grid() self.anim_ax.plot(x, y, color=ex_color) return self.anim_fig, self.anim_ax def make_scene(self, t, epoch): # シーン作成 if t % (epoch/self.n_image) == 1: x_in = self.x.reshape(-1, 1) for ll in self.__layer_list: x_in = ll.forward(x_in) im, = self.anim_ax.plot(self.x, ll.y, color=self.color) self.images.append([im])
これで移植は完了です。変更したコードの全体は次のようになります。
test.py全体test.py%matplotlib nbagg import numpy as np import matplotlib.pyplot as plt import matplotlib.animation as animation import tqdm # 学習対象設定 def split_test(target, train_indices): return (target[train_indices], target[~ train_indices]) x = np.arange(0, 4, 5e-2) y = np.sin(x) x_left = 1 x_right = 3 y_top = np.max(y) + 1 y_bottom = np.min(y) - 1 indices = (x_left <= x) & (x <= x_right) x_train, x_test = split_test(x, indices) y_train, y_test = split_test(y, indices) # 初期設定 epoch = 10000 threshold = 1e-5 n_batch = 4 # ネットワーク構築 n_in = 1 n_out = 1 lm = LayerManager((x_train, x_test), (y_train, y_test)) lm.append(prev=n_in, n=30, act="sigmoid", wb_width=1) lm.append(n=30, act="sigmoid", wb_width=1) lm.append(n=n_out, name="o", act="identity", wb_width=1) # アニメーションプロット用土台作成 n_image = 100 interval = 100 fig, ax = lm.ready_anim(n_image, x, y, title="fitting animation") ax.plot(np.full_like(np.arange(y_bottom, y_top+1), x_left), np.arange(y_bottom, y_top+1), color="g") ax.plot(np.full_like(np.arange(y_bottom, y_top+1), x_right), np.arange(y_bottom, y_top+1), color="g") # 学習開始 lm.training(epoch, threshold=threshold, n_batch=n_batch) # フィッティングアニメーション作成 anim = animation.ArtistAnimation(lm.anim_fig, lm.images, interval=interval, repeat_delay=3000)
layermanager.py全体layermanager.pyimport numpy as np import matplotlib.pyplot as plt import matplotlib.animation as animation import tqdm class _TypeManager(): """ 層の種類に関するマネージャクラス """ N_TYPE = 2 # 層の種類数 MIDDLE = 0 # 中間層のナンバリング OUTPUT = 1 # 出力層のナンバリング class LayerManager(_TypeManager): """ 層を管理するためのマネージャクラス """ def __init__(self, x, y): self.x_train, self.x_test = x self.y_train, self.y_test = y self.__layer_list = [] # レイヤーのリスト self.__name_list = [] # 各レイヤーの名前リスト self.__ntype = np.zeros(self.N_TYPE, dtype=int) # 種類別レイヤーの数 def __repr__(self): layerRepr= "layer_list: " + repr(self.__layer_list) nameRepr = "name_list: " + repr(self.__name_list) ntypeRepr = "ntype: " + repr(self.__ntype) return (layerRepr + "\n" + nameRepr + "\n" + ntypeRepr) def __str__(self): layerStr = "layer_list: " + str(self.__layer_list) nameStr = "name_list: " + str(self.__name_list) ntypeStr = "ntype: " + str(self.__ntype) return (layerStr + "\n" + nameStr + "\n" + ntypeStr) def __len__(self): """ Pythonのビルドイン関数`len`から呼ばれたときの動作を記述。 種類別レイヤーの数の総和を返します。 """ return int(np.sum(self.__ntype)) def __getitem__(self, key): """ 例えば lm = LayerManager() +----------------+ | (lmに要素を追加) | +----------------+ x = lm[3].~~ のように、リストや配列の要素にアクセスされたときに呼ばれるので、 そのときの動作を記述。 sliceやstr, intでのアクセスのみ許可します。 """ if isinstance(key, slice): # keyがスライスならレイヤーのリストをsliceで参照する。 # 異常な値(Index out of rangeなど)が入力されたら # Pythonがエラーを出してくれます。 return self.__layer_list[key] elif isinstance(key, str): # keyが文字列なら各レイヤーの名前リストからインデックスを取得して、 # 該当するレイヤーのリストの要素を返す。 if key in self.__name_list: index = self.__name_list.index(key) return self.__layer_list[index] else: # keyが存在しない場合はKeyErrorを出す。 raise KeyError("{}: No such item".format(key)) elif isinstance(key, int): # keyが整数ならレイヤーのリストの該当要素を返す。 # 異常な値(Index out of rangeなど)が入力されたら # Pythonがエラーを出してくれます。 return self.__layer_list[key] else: raise KeyError(key, ": Undefined such key type.") def __setitem__(self, key, value): """ 例えば lm = LayerManager() +----------------+ | (lmに要素を追加) | +----------------+ lm[1] = x のように、リストや配列の要素にアクセスされたときに呼ばれるので、 そのときの動作を記述。 要素の上書きのみ認め、新規要素の追加などは禁止します。 """ value_type = "" if isinstance(value, list): # 右辺で指定された'value'が'list'なら # 全ての要素が'BaseLayer'クラスかそれを継承していなければエラー。 if not np.all( np.where(isinstance(value, BaseLayer), True, False)): self.AssignError() value_type = "list" elif isinstance(value, BaseLayer): # 右辺で指定された'value'が'BaseLayer'クラスか # それを継承していない場合はエラー。 self.AssignError(type(value)) if value_type == "": value_type = "BaseLayer" if isinstance(key, slice): # keyがスライスならレイヤーのリストの要素を上書きする。 # ただし'value_type'が'list'でなければエラー。 # 異常な値(Index out of rangeなど)が入力されたら # Pythonがエラーを出してくれます。 if value_type != "list": self.AssignError(value_type) self.__layer_list[key] = value elif isinstance(key, str): # keyが文字列なら各レイヤーの名前リストからインデックスを取得して、 # 該当するレイヤーのリストの要素を上書きする。 # ただし'value_type'が'BaseLayer'でなければエラー。 if value_type != "BaseLayer": raise AssignError(value_type) if key in self.__name_list: index = self.__name_list.index(key) self.__layer_list[index] = value else: # keyが存在しない場合はKeyErrorを出す。 raise KeyError("{}: No such item".format(key)) elif isinstance(key, int): # keyが整数ならレイヤーのリストの該当要素を上書きする。 # ただし'value_type'が'BaseLayer'でなければエラー。 # また、異常な値(Index out of rangeなど)が入力されたら # Pythonがエラーを出してくれます。 if value_type != "BaseLayer": raise AssignError(value_type) self.__layer_list[key] = value else: raise KeyError(key, ": Undefined such key type.") def __delitem__(self, key): """ 例えば lm = LayerManager() +----------------+ | (lmに要素を追加) | +----------------+ del lm[2] のように、del文でリストや配列の要素にアクセスされたときに呼ばれるので、 そのときの動作を記述。 指定要素が存在すれば削除、さらにリネームを行います。 """ if isinstance(key, slice): # keyがスライスならそのまま指定の要素を削除 # 異常な値(Index out of rangeなど)が入力されたら # Pythonがエラーを出してくれます。 del self.__layer_list[slice] del self.__name_list[slice] elif isinstance(key, str): # keyが文字列なら各レイヤーの名前リストからインデックスを取得して、 # 該当する要素を削除する。 if key in self.__name_list: del self.__layer_list[index] del self.__name_list[index] else: # keyが存在しない場合はKeyErrorを出す。 raise KeyError("{}: No such item".format(key)) elif isinstance(key, int): # keyが整数ならレイヤーのリストの該当要素を削除する。 # 異常な値(Index out of rangeなど)が入力されたら # Pythonがエラーを出してくれます。 del self.__layer_list[key] else: raise KeyError(key, ": Undefined such key type.") # リネームする self._rename() def _rename(self): """ リスト操作によってネームリストのネーミングがルールに反するものになった場合に 改めてルールを満たすようにネーミングリストおよび各レイヤーの名前を変更する。 ネーミングルールは[レイヤーの種類][何番目か]とします。 レイヤーの種類はMiddleLayerならMiddle OutputLayerならOutput のように略します。 何番目かというのは種類別でカウントします。 また、ここで改めて__ntypeのカウントを行います。 """ # 種類別レイヤーの数を初期化 self.__ntype = np.zeros(self.N_TYPE) # 再カウントと各レイヤーのリネーム for i in range(len(self)): if "Middle" in self.__name_list[i]: self.__ntype[self.MIDDLE] += 1 self.__name_list[i] = "Middle{}".format( self.__ntype[self.MIDDLE]) self.__layer_list[i].name = "Middle{}".format( self.__ntype[self.MIDDLE]) elif "Output" in self.__name_list[i]: self.__ntype[self.OUTPUT] += 1 self.__name_list[i] = "Output{}".format( self.__ntype[self.OUTPUT]) self.__layer_list[i].name = "Output{}".format( self.__ntype[self.OUTPUT]) else: raise UndefinedLayerType(self.__name_list[i]) def append(self, *, name="Middle", **kwds): """ リストに要素を追加するメソッドでお馴染みのappendメソッドの実装。 """ if "prev" in kwds: # 'prev'がキーワードに含まれている場合、 # 一つ前の層の要素数を指定していることになります。 # 基本的に最初のレイヤーを挿入する時を想定していますので、 # それ以外は基本的に自動で決定するため指定しません。 if len(self) != 0: if kwds["prev"] != self.__layer_list[-1].n: # 最後尾のユニット数と一致しなければエラー。 raise UnmatchUnitError(self.__layer_list[-1].n, kwds["prev"]) else: if len(self) == 0: # 最初の層は必ず入力ユニットの数を指定する必要があります。 raise UnmatchUnitError("Input units", "Unspecified") else: # 最後尾のレイヤーのユニット数を'kwds'に追加 kwds["prev"] = self.__layer_list[-1].n # レイヤーの種類を読み取り、ネーミングルールに則った名前に変更する if name == "Middle" or name == "mid" or name == "m": name = "Middle" elif name == "Output" or name == "out" or name == "o": name = "Output" else: raise UndefinedLayerError(name) # レイヤーを追加する。 if name == "Middle": # 種類別レイヤーをインクリメントして self.__ntype[self.MIDDLE] += 1 # 名前に追加し name += str(self.__ntype[self.MIDDLE]) # ネームリストに追加し self.__name_list.append(name) # 最後にレイヤーを生成してリストに追加します。 self.__layer_list.append( MiddleLayer(name=name, **kwds)) elif name == "Output": # こちらも同様です。 self.__ntype[self.OUTPUT] += 1 name += str(self.__ntype[self.OUTPUT]) self.__name_list.append(name) self.__layer_list.append( OutputLayer(name=name, **kwds)) # ここでelse文を描いていないのはネーミングルールに則った名前に変更する # 段階で既に異常な'name'は省かれているからです。 def extend(self, lm): """ extendメソッドでは既にある別のレイヤーマネージャ'lm'の要素を 全て追加します。 """ if not isinstance(lm, LayerManager): # 'lm'のインスタンスがLayerManagerでなければエラー。 raise TypeError(type(lm), ": Unexpected type.") if len(self) != 0: if self.__layer_list[-1].n != lm[0].prev: # 自分の最後尾のレイヤーのユニット数と # 'lm'の最初のレイヤーの入力数が一致しない場合はエラー。 raise UnmatchUnitError(self.__layer_list[-1].n, lm[0].prev) # それぞれ'extend'メソッドで追加 self.__layer_list.extend(lm.layer_list) self.__name_list.extend(lm.name_list) # リネームする self._rename() def insert(self, prev_name, name="Middle", **kwds): """ insertメソッドでは、前のレイヤーの名前を指定しそのレイヤーと結合するように 要素を追加します。 """ # 'prev_name'が存在しなければエラー。 if not prev_name in self.__name_list: raise KeyError(prev_name, ": No such key.") # 'prev'がキーワードに含まれている場合、 # 'prev_name'で指定されているレイヤーのユニット数と一致しなければエラー。 if "prev" in kwds: if kwds["prev"] \ != self.__layer_list[self.index(prev_name)].n: raise UnmatchUnitError( kwds["prev"], self.__layer_list[self.index(prev_name)].n) # 'n'がキーワードに含まれている場合、 if "n" in kwds: # 'prev_name'が最後尾ではない場合は if prev_name != self.__name_list[-1]: # 次のレイヤーのユニット数と一致しなければエラー。 if kwds["n"] != self.__layer_list[ self.index(prev_name)+1].prev: raise UnmatchUnitError( kwds["n"], self.__layer_list[self.index(prev_name)].prev) # まだ何も要素がない場合は'append'メソッドを用いるようにエラーを出す。 if len(self) == 0: raise RuntimeError( "You have to use 'append' method instead.") # 挿入場所のインデックスを取得 index = self.index(prev_name) + 1 # レイヤーの種類を読み取り、ネーミングルールに則った名前に変更する if name == "Middle" or name == "mid" or name == "m": name = "Middle" elif name == "Output" or name == "out" or name == "o": name = "Output" else: raise UndefinedLayerError(name) # 要素を挿入する # このとき、'name'はまだネーミングルールに則っていませんが、 # あとでリネームするので気にしないでOKです。 if "Middle" in name: self.__layer_list.insert(index, MiddleLayer(name=name, **kwds)) self.__name_list.insert(index, name) elif "Output" in name: self.__layer_list.insert(index, OutputLayer(name=name, **kwds)) self.__name_list.insert(index, name) # リネームする self._rename() def extend_insert(self, prev_name, lm): """ こちらはオリジナル関数です。 extendメソッドとinsertメソッドを組み合わせたような動作をします。 簡単に説明すると、別のレイヤーマネージャをinsertする感じです。 """ if not isinstance(lm, LayerManager): # 'lm'のインスタンスがLayerManagerでなければエラー。 raise TypeError(type(lm), ": Unexpected type.") # 'prev_name'が存在しなければエラー。 if not prev_name in self.__name_list: raise KeyError(prev_name, ": No such key.") # 指定場所の前後のレイヤーとlmの最初・最後のレイヤーのユニット数が # それぞれ一致しなければエラー。 if len(self) != 0: if self.__layer_list[self.index(prev_name)].n \ != lm.layer_list[0].prev: # 自分の指定場所のユニット数と'lm'の最初のユニット数が # 一致しなければエラー。 raise UnmatchUnitError( self.__layer_list[self.index(prev_name)].n, lm.layer_list[0].prev) if prev_name != self.__name_list[-1]: # 'prev_name'が自分の最後尾のレイヤーでなく if lm.layer_list[-1].n \ != self.__layer_list[self.index(prev_name)+1].prev: # 'lm'の最後尾のユニット数と自分の指定場所の次のレイヤーの # 'prev'ユニット数と一致しなければエラー。 raise UnmatchUnitError( lm.layer_list[-1].n, self.__layer_list[self.index(prev_name)+1].prev) else: # 自分に何の要素もない場合は'extend'メソッドを使うようにエラーを出す。 raise RuntimeError( "You have to use 'extend' method instead.") # 挿入場所のインデックスを取得 index = self.index(prev_name) + 1 # 挿入場所以降の要素を'buf'に避難させてから一旦取り除き、 # extendメソッドを使って要素を追加 layer_buf = self.__layer_list[index:] name_buf = self.__name_list[index:] del self.__layer_list[index:] del self.__name_list[index:] self.extend(lm) # 避難させていた要素を追加する self.__layer_list.extend(layer_buf) self.__name_list.extend(name_buf) # リネームする self._rename() def remove(self, key): """ removeメソッドでは指定の名前の要素を削除します。 インデックスでの指定も許可します。 """ # 既に実装している'del'文でOKです。 del self[key] def index(self, target): return self.__name_list.index(target) def name(self, indices): return self.__name_list[indices] @property def layer_list(self): return self.__layer_list @property def name_list(self): return self.__name_list @property def ntype(self): return self.__ntype def training(self, epoch, n_batch=16, threshold=1e-8, show_error=True, **kwds): if show_error: self.error_list = [] if self.make_anim: self.images = [] n_in = self.__layer_list[0].prev n_out = self.__layer_list[-1].n n_train = self.x_train.size//n_batch n_test = self.x_test.size # 学習開始 error = 0 error_prev = 0 rand_index = np.arange(self.x_train.size) for t in tqdm.tqdm(range(1, epoch+1)): #シーン作成 if self.make_anim: self.make_scene(t, epoch) # 誤差計算 x_in = self.x_test.reshape(n_test, n_in) for ll in self.__layer_list: x_in = ll.forward(x_in) error = lm[-1].get_error(self.y_test.reshape(n_test, n_out)) if show_error: self.error_list.append(error) # 収束判定 if abs(error - error_prev) < threshold: print("end learning...") break else: error_prev = error np.random.shuffle(rand_index) for i in range(n_train): rand = rand_index[i*n_in : (i+n_batch)*n_in] x_in = self.x_train[rand].reshape(-1, n_in) for ll in self.__layer_list: x_in = ll.forward(x_in) y_in = self.y_train[rand].reshape(-1, n_out) for ll in self.__layer_list[::-1]: y_in = ll.backward(y_in) for ll in self.__layer_list: ll.update() if show_error: # 誤差遷移表示 self.show_errors(**kwds) def show_errors(self, title="error transition", xlabel="epoch", ylabel="error", fname="error_transition.png", **kwds): fig, ax = plt.subplots(1) fig.suptitle(title) ax.set_yscale("log") ax.set_xlabel(xlabel) ax.set_ylabel(ylabel) ax.grid() ax.plot(self.error_list) fig.show() if len(fname) != 0: fig.savefig(fname) def ready_anim(self, n_image, x, y, title="animation", xlabel="x", ylabel="y", ex_color="r", color="b", x_left=0, x_right=0, y_down = 1, y_up = 1): self.n_image = n_image self.x = x self.color = color self.make_anim = True self.anim_fig, self.anim_ax = plt.subplots(1) self.anim_fig.suptitle(title) self.anim_ax.set_xlabel(xlabel) self.anim_ax.set_ylabel(ylabel) self.anim_ax.set_xlim(np.min(x) - x_left, np.max(x) + x_right) self.anim_ax.set_ylim(np.min(y) - y_down, np.max(y) + y_up) self.anim_ax.grid() self.anim_ax.plot(x, y, color=ex_color) return self.anim_fig, self.anim_ax def make_scene(self, t, epoch): # シーン作成 if t % (epoch/self.n_image) == 1: x_in = self.x.reshape(-1, 1) for ll in self.__layer_list: x_in = ll.forward(x_in) im, = self.anim_ax.plot(self.x, ll.y, color=self.color) self.images.append([im])おわりに
これでDNN(ディープニューラルネットワーク)の実験は終了です。他にも様々な関数を近似して遊んでみてください。
深層学習シリーズ
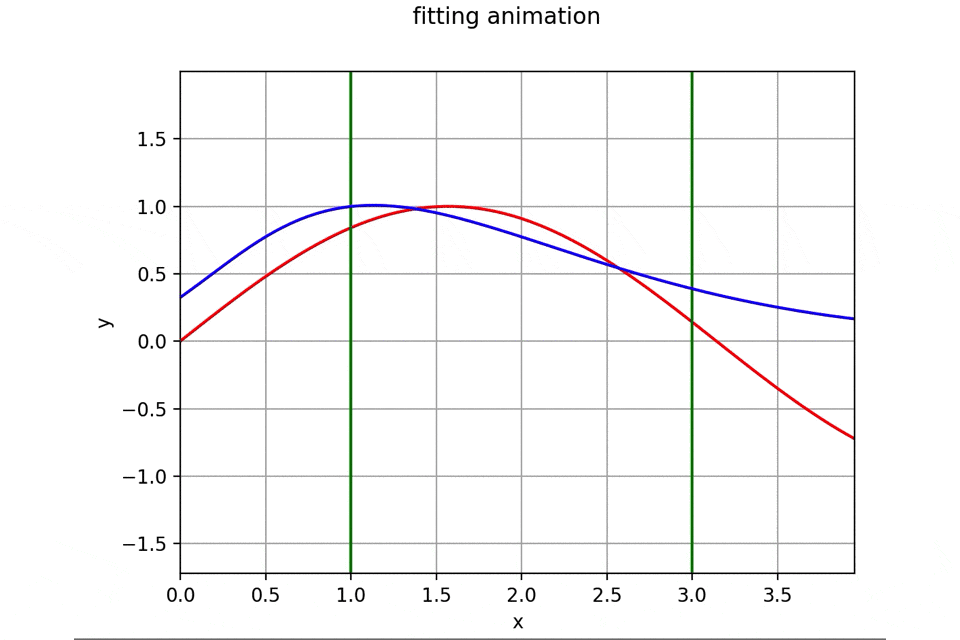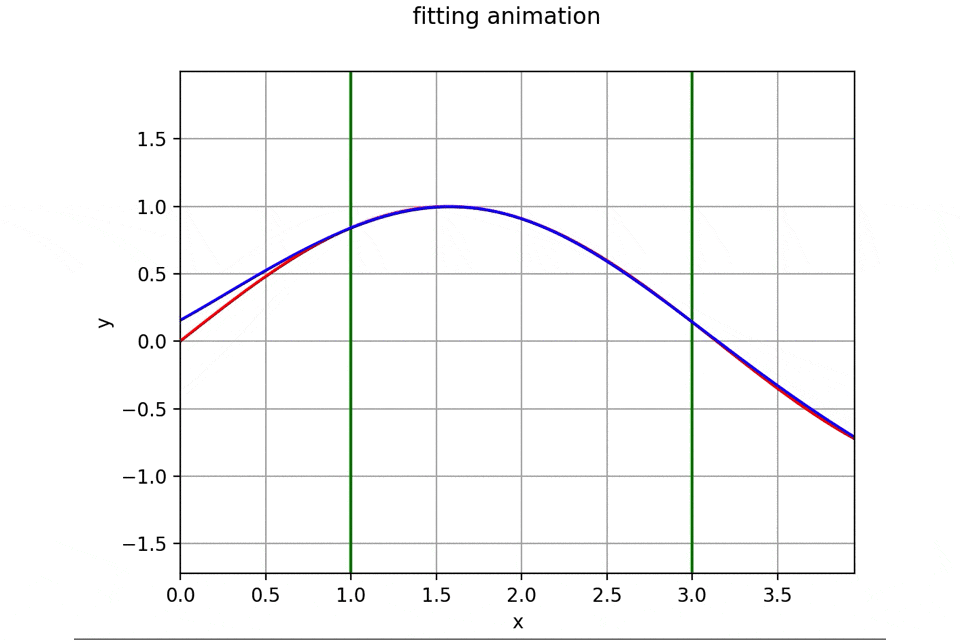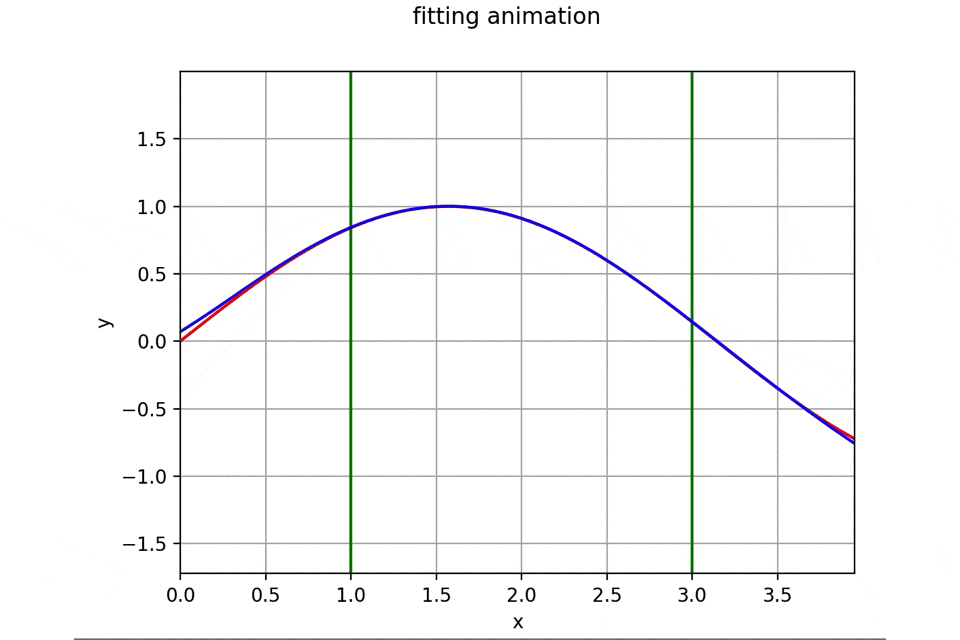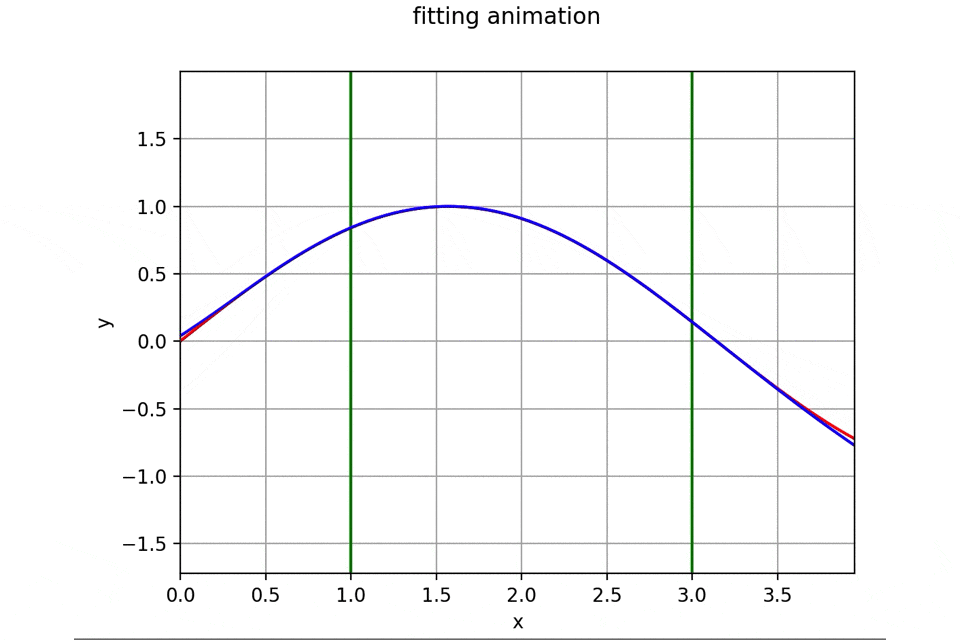
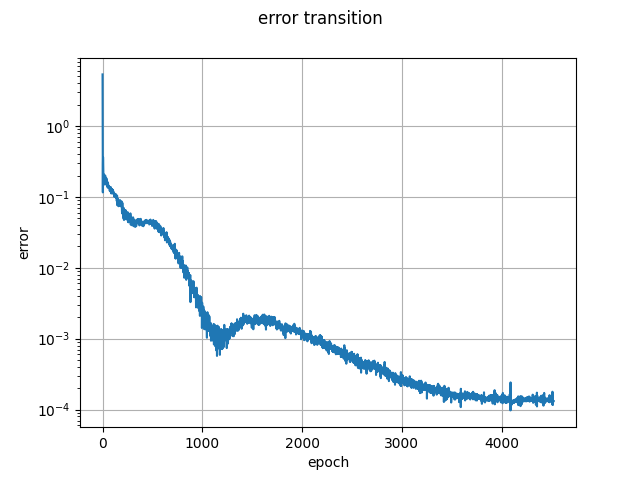
- 投稿日:2020-07-09T19:29:54+09:00
Infra_データサイエンス講座 アウトプット
これからInfraで運営しているデータサイエンス講座についてのアウトプットや学びを投稿していく。
公式ホームページ
https://www.in-fra.jp/next/courses/data-science?access_from=intern_list
- 投稿日:2020-07-09T19:08:41+09:00
mysqlclient インストールエラー解決策[Mac, Windows版]
はじめに
この記事ではmysqlclientのインストール時によく(ほぼ100%)発生するエラーの解決策について投稿します。
pip install mysqlclient # エラー発生筆者環境においてデータベースにMySQLを使っており、WebスクレイピングやDjangoで使用しています。特に、DjangoでMySQLをデータベースとして扱いたい時はmysqlclientは必須となっています。
Windwos、MacOSの両方で環境構築の経験があり、その度にこの問題に悩まされてきました。色々と解決策があり、試してみるが上手くいかないケースが沢山ありましたので、筆者経験の元ベストな解決策を共有したいと思います。
Windows
結論からいいますと、
wheelパッケージをダウンロードしてパッケージインストールして下さい。以下サイトからwheelパッケージをダウンロードして下さい。
https://www.lfd.uci.edu/~gohlke/pythonlibs/#mysqlclient注意点とし、各々の環境にあったバージョンをダウンロードして下さい。
筆者環境では「Python 3.8.0 64-bit」をインストールし使用していますので、mysqlclient‑1.4.6‑cp38‑cp38‑win_amd64.whl
をダウンロードします。
エディタに「Visual Studio Code」をお使いの方は画面左下に表示されていますのでご確認してみて下さい。
Python 3.5 => cp35 Python 3.6 => cp36 Python 3.7 => cp37 32-bit =>win32 64-bit =>win_amd64ダウンロードできましたら、ファイルがあるディレクトリに入りコマンドを実行してください。
筆者環境 pip install mysqlclient‑1.4.6‑cp38‑cp38‑win_amd64.whlインストールできましたでしょうか?
できなかった方は、バージョンの確認をもう一度お願いします。それでもできなかった方はごめんなさい。。。
今回の解決策はこちらのサイトを参考にさせてもらい筆者環境も解決することができました。
ちなみにですが、筆者は
「Build Tools for Visual Studio 2017」をインストールを行い、
error: Microsoft Visual C++ 14.0 is required. Get it with "Microsoft Visual C++ Build Tools": http://landinghub.visualstudio.com/visual-cpp-build-tools「'mysql.h':No such file or directory」の部分で諦めました。
_mysql.c(29): fatal error C1083: include 'mysql.h':No such file or directoryMac
筆者環境では以下のエラーが発生した。
ld: library not found for -lsslMacではターミナルを開き、順にコマンドを実行してください。
(1) xcode-select --install (2) brew install mysql-connector-c (3) sudo vim /usr/local/bin/mysql_config /libs="-L$pkglibdir"`と打ち、Enterを押す。 Iを押し、INSERTモードに変更したことを確認して以下のように変更する。 #変更前 libs="-L$pkglibdir" libs="$libs -l " #変更後 libs="-L$pkglibdir" libs="$libs -lmysqlclient -lssl -lcrypto" escを押し、INSERTモードを終了してから、:qsを押す。 (4) brew info openssl 色々と出てきたと思いますが、Caveatsに注目してください。 If you need to ...より以下のコマンドを実行してください。 筆者環境でのコマンド `>> ~/.zshrc`部分は環境下によって変更することがあります。(~/.bash_profileなど) echo 'export PATH="/usr/local/opt/openssl@1.1/bin:$PATH"' >> ~/.zshrc echo 'export LDFLAGS="-L/usr/local/opt/openssl@1.1/lib"' >> ~/.zshrc echo 'export CPPFLAGS="-I/usr/local/opt/openssl@1.1/include"' >> ~/.zshrc (5) ターミナルを再起動し、`pip install mysqlclient`を実行する。いかがでしょうか?無事インストールできましたでしょうか?
今回の解決策はこちらのサイトを参考にさせてもらい筆者環境も解決することができました。
終わりに
無事mysqlclientはインストールできましたでしょうか?
これからのMySQL Life を是非楽しんでください!参考文献
Windows 解決策
https://shimi-dai.com/python-install-mysqlclient-on-windows/
- 投稿日:2020-07-09T19:08:41+09:00
mysqlclient インストール エラー解決策[Mac, Windows版]
はじめに
この記事ではmysqlclientのインストール時によく(ほぼ100%)発生するエラーの解決策について投稿します。
pip install mysqlclient # エラー発生筆者環境においてデータベースにMySQLを使っており、WebスクレイピングやDjangoで使用しています。特に、DjangoでMySQLをデータベースとして扱いたい時はmysqlclientは必須となっています。
Windwos、MacOSの両方で環境構築の経験があり、その度にこの問題に悩まされてきました。色々と解決策があり、試してみるが上手くいかないケースが沢山ありましたので、筆者経験の元ベストな解決策を共有したいと思います。
Windows
結論からいいますと、
wheelパッケージをダウンロードしてパッケージインストールして下さい。以下サイトからwheelパッケージをダウンロードして下さい。
https://www.lfd.uci.edu/~gohlke/pythonlibs/#mysqlclient注意点とし、各々の環境にあったバージョンをダウンロードして下さい。
筆者環境では「Python 3.8.0 64-bit」をインストールし使用していますので、mysqlclient‑1.4.6‑cp38‑cp38‑win_amd64.whl
をダウンロードします。
エディタに「Visual Studio Code」をお使いの方は画面左下に表示されていますのでご確認してみて下さい。
Python 3.5 => cp35 Python 3.6 => cp36 Python 3.7 => cp37 32-bit =>win32 64-bit =>win_amd64ダウンロードできましたら、ファイルがあるディレクトリに入りコマンドを実行してください。
筆者環境 pip install mysqlclient‑1.4.6‑cp38‑cp38‑win_amd64.whlインストールできましたでしょうか?
できなかった方は、バージョンの確認をもう一度お願いします。それでもできなかった方はごめんなさい。。。
今回の解決策はこちらのサイトを参考にさせてもらい筆者環境も解決することができました。
ちなみにですが、筆者は
「Build Tools for Visual Studio 2017」をインストールを行い、
error: Microsoft Visual C++ 14.0 is required. Get it with "Microsoft Visual C++ Build Tools": http://landinghub.visualstudio.com/visual-cpp-build-tools「'mysql.h':No such file or directory」の部分で諦めました。
_mysql.c(29): fatal error C1083: include 'mysql.h':No such file or directoryMac
筆者環境では以下のエラーが発生した。
ld: library not found for -lsslMacではターミナルを開き、順にコマンドを実行してください。
(1) xcode-select --install (2) brew install mysql-connector-c (3) sudo vim /usr/local/bin/mysql_config /libs="-L$pkglibdir"`と打ち、Enterを押す。 Iを押し、INSERTモードに変更したことを確認して以下のように変更する。 #変更前 libs="-L$pkglibdir" libs="$libs -l " #変更後 libs="-L$pkglibdir" libs="$libs -lmysqlclient -lssl -lcrypto" escを押し、INSERTモードを終了してから、:qsを押す。 (4) brew info openssl 色々と出てきたと思いますが、Caveatsに注目してください。 If you need to ...より以下のコマンドを実行してください。 筆者環境でのコマンド `>> ~/.zshrc`部分は環境下によって変更することがあります。(~/.bash_profileなど) echo 'export PATH="/usr/local/opt/openssl@1.1/bin:$PATH"' >> ~/.zshrc echo 'export LDFLAGS="-L/usr/local/opt/openssl@1.1/lib"' >> ~/.zshrc echo 'export CPPFLAGS="-I/usr/local/opt/openssl@1.1/include"' >> ~/.zshrc (5) ターミナルを再起動し、`pip install mysqlclient`を実行する。いかがでしょうか?無事インストールできましたでしょうか?
今回の解決策はこちらのサイトを参考にさせてもらい筆者環境も解決することができました。
終わりに
無事mysqlclientはインストールできましたでしょうか?
これからのMySQL Life を是非楽しんでください!参考文献
Windows 解決策
https://shimi-dai.com/python-install-mysqlclient-on-windows/
- 投稿日:2020-07-09T19:03:04+09:00
【徹底解説】初心者必見の関数(メソッド)の理解の仕方
元の投稿
プログラミングの入門をする上で最も大事と言っても過言ではない関数またはメソッド(以下、どちらも関数と呼びます)
皆さんは関数と聞くと何を思い浮かべますか?
一般的には、数学の授業で聞く言葉だと思います。
ではどうして、プログラミングの世界でメソッドの事を関数と呼ぶことになったのでしょうか?
それは数学の関数と概念が非常に似ているからです。
そこで、まずは数学的な関数を見てみましょう。数学アレルギーの人も拒絶せず難しい話はしませんので、読み進めてもらえると嬉しいです。
まず、関数とは何でしょう?
関数とはある任意のxを与えると必ず1つのy(解)を返してくれるものです。ちょっと言葉だけでは難しいですね。
それでは、数学的な関数とは代表的なものに何があるでしょうか?
私が一番はじめに思い浮かべる関数は
y = ax + bです。これは一次関数と呼ばれるものですがaとbは定数(任意で数を決めれる)ので具体的に
y = 2x + 3を見てみましょう。
この関数はxを指定するとある数字が答えを出してくれます。例えば、x = 3であれば yの値は9になります。これはいろんな数字に当てはめれますよね。
なので、関数とは特定のXを与えると1つのYを返してくれるものです。
この関数のようなものは数学に限られてるものではありません。
例えば、食材を与えると美味しい料理を作るシェフがいるとします。このシェフはある意味、関数のような働きをしていると言えましょう。
具体的にはこのシェフに「人参、じゃがいも、牛肉、カレー粉」をXとして、渡してあげると、このシェフはカレーというYの値を返してくれます。
このようなXを与えるとYを返すというのが、一般的な関数の概要です。
なので、プログラミング的な関数(メソッド)も同じだと言えます。
ただ、プログラミングでは上記のXを引数と呼び、Yを戻り値のといいます。
それでは実際のコードを見ていきましょう。
今回はRubyコードを使用していますが、主要なプログラミング言語ではこの概念は変わりません。
それでは与えられた2つの数字(引数)を足し算をするメソッドを作成しましょう
# メソッド名はadd # 引数はa, b # どんなメソッドを作るか、どんな引数を引き受けるかは自分で決めるので、 # メソッド名と引数の名前は自由に名前を決めることが出来ます。 # メソッドの定義(作成 def add(a, b) return a + b end # メソッドの呼び出し(使用) add(3, 2) # =>戻り値は5になるこのコードを図式化すると以下のようになります
ここで新しく紹介した概念が
「呼び出しのコードそのものが戻り値に変わる」
ということです。これは非常に大事な概念なのでしっかりと理解してください。
つまり、
result = add(2, 3)というコードは
result = 5というコードとしているのと全く同じです。
ここで、どうして 5 と直接書くのではなく add(2,3) と書くのかというといくつか理由があります
まず、この例題では足し算をするメソッドを使用しているので
頭の中で5とすぐに戻り値を予想できますがこれがすごく複雑な処理だと
戻り値が予想できないのでメソッドを使用しないといけません。
次に、今回の場合では引数(a, b)が予め決められていますが
これは実際には変数になっていたりしますのでメソッドを使用する前に答えを予想することができなくなります。
ここまでで、メソッドの基本的な概念は終わりです。
プログラミングではたくさんの関数(メソッド)を使用します。
書いているもののほとんどが関数と言っても過言ではありません。
関数を定義することも多々ありますが、大きくは他人が作成した関数をしようするということがほとんどです。
その際に、引数として何が必要でどのような戻り値をくれるのかという概念で関数をみると
簡単に理解して関数の詳細を理解しなくても使用することが出来ます。
なので、関数(メソッド)を使用または定義する際は引数と戻り値に注目してみましょう。



- 投稿日:2020-07-09T18:25:01+09:00
Anaconda3の環境導入手順
1.ANACONDAをダウンロード
※Pythonには2.と3.と二つのバージョンが存在しますが3.*を取得するようにしてください
https://www.anaconda.com/download
2.ANACOND Aをインストール
3.ANACONDA起動
起動すると以下のような画面が起動されます。
4.Jupyterを起動
jupyter NotebookのLaunchというところをクリック
こんな画面が表示されますが、起動できないので
ーミナルから網掛け部分をコピーしてブラウザのURLに貼り付け実行
以下のような画面が表示されればOK!!!
終わりに
次回はSCRAPYの導入手順について書いていこうと思います。
- 投稿日:2020-07-09T17:59:59+09:00
[HyperledgerIroha]Pythonライブラリでクエリを実行する
記事の内容
Hyperledger Iroha Pythonライブラリを使ったクエリの実行方法です。
やってみること
指定したアカウントが送信したトランザクションの一覧を取得する「GetAccountTransactions」を実行してみます。
実装
get_account_transactions.pyfrom iroha import Iroha, IrohaCrypto, IrohaGrpc import iroha_config net = IrohaGrpc(iroha_config.IROHA_HOST) iroha = Iroha(iroha_config.ADMIN_ACCOUNT) admin_priv_key = iroha_config.ADMIN_PRIV_KEY # Queryの作成 get_block_query = iroha.query( 'GetAccountTransactions', account_id = 'admin@test', page_size = 10, ) # Queryへ署名 IrohaCrypto.sign_query(get_block_query, iroha_config.ADMIN_PRIV_KEY) # Queryの送信 response = net.send_query(get_block_query) print(response)iroha_configにはIrohaのホスト名や秘密鍵などを設定しています。
ポイントは以下3つです。
・クエリの作成は「iroha.query」を使用する。(更新系は「iroha.command」を使用する)
・署名は「sign_query」を使用する。(更新系は「sign_transaction」を使用する)
・クエリの送信は「send_query」を使用する。(更新系は「send_tx」を使用する)実行結果
指定したアカウントが送信したトランザクションの情報を取得できました。
page_sizeに10を設定していますが、あまりブロックチェーンにデータを載せてないので、3件だけデータを取得できました。query_hash: "a45f8b59aa211688836bb6567c10baf10e24dfdc9db6c62d3fc8a779200ee136" transactions_page_response { transactions { payload { reduced_payload { commands { create_asset { asset_name: "samplecoin" domain_id: "test" precision: 10 } } commands { add_asset_quantity { asset_id: "samplecoin#test" amount: "100000000" } } creator_account_id: "admin@test" created_time: 1594000825126 quorum: 1 } } signatures { public_key: "313a07e6384776ed95447710d15e59148473ccfc052a681317a72a69f2a49910" signature: "042b25c8096ca4bfcaca54d05c3d862498f38ddc612b0255138cc74044005d0475467176ef84672fd79b93714e8263e22aa867e7f8e22cf7eba06bb0e63e0b02" } } transactions { payload { reduced_payload { commands { transfer_asset { src_account_id: "admin@test" dest_account_id: "test@test" asset_id: "samplecoin#test" description: "test" amount: "10000" } } creator_account_id: "admin@test" created_time: 1594002435597 quorum: 1 } } signatures { public_key: "313a07e6384776ed95447710d15e59148473ccfc052a681317a72a69f2a49910" signature: "f147a7e1c1604a3172efa91e4604fd4bfff728fe0d8d4c644e7d3a0d65ee4f3d2436ad9a26bc9777b0de514f120ed6b4d83a5410cbc097a281a5a588702d4d06" } } transactions { payload { reduced_payload { commands { create_account { account_name: "iroha" domain_id: "test" public_key: "efdc215eab6dd2c4435d370da73e4b88350e1fed9d39afed503fcbee985fce1f" } } creator_account_id: "admin@test" created_time: 1594016319157 quorum: 1 } } signatures { public_key: "313a07e6384776ed95447710d15e59148473ccfc052a681317a72a69f2a49910" signature: "429bf3ae70b60d31ab3fc3c15fa11cb8155b6a824f831652c1c46068feaeb866846b8048e0959cbcbeed532423f050e77d2fe192ea90d0827a6f1489bf67ec0a" } } all_transactions_size: 3 }関連記事
・[Hyperledger Iroha]Python SDKの使い方メモ
・[Hyperledger Iroha]Pythonのlibraryを使ってアカウントを作成する感想
一通りIrohaライブラリを使ってみました。
他のクエリは実行するクエリ名称を変更したり、パラメーターを変更すれば動きます。Irohaクエリを見ている限りだと、「誰が」、「何を」したのかは簡単に取得することができますが、
「どの資産に対して」、「誰が」、「何を」したのかが分かるクエリは用意されていないようです。
- 投稿日:2020-07-09T17:57:34+09:00
LightGBMで3着以内に入る馬を予測してみた
目的
機械学習で競馬予想して、回収率100%を目指す。
今回やること
前回の記事で取得した2019年の全レース結果データを用いて、LightGBMで3着以内に入る馬を予想する。
ソースコード
まずは前処理
import datetime def preprocessing(results): df = results.copy() # 着順に数字以外の文字列が含まれているものを取り除く df = df[~(df["着順"].astype(str).str.contains("\D"))] #qiitaでバックスラッシュを使うとバグるので、大文字にしてあります。 df["着順"] = df["着順"].astype(int) # 性齢を性と年齢に分ける df["性"] = df["性齢"].map(lambda x: str(x)[0]) df["年齢"] = df["性齢"].map(lambda x: str(x)[1:]).astype(int) # 馬体重を体重と体重変化に分ける df["体重"] = df["馬体重"].str.split("(", expand=True)[0].astype(int) df["体重変化"] = df["馬体重"].str.split("(", expand=True)[1].str[:-1].astype(int) # データをint, floatに変換 df["単勝"] = df["単勝"].astype(float) # 不要な列を削除 df.drop(["タイム", "着差", "調教師", "性齢", "馬体重"], axis=1, inplace=True) df["date"] = pd.to_datetime(df["date"], format="%Y年%m月%d日") return df results_p = preprocessing(results)
訓練データとテストデータに分けたいが、訓練データはテストデータより過去のデータでなければならないので、この場合train_test_splitは使えない。そのため、今datetime型にした'date'という列を用いて、時系列順に訓練データとテストデータを分ける関数を作る。def split_data(df, test_size=0.3): sorted_id_list = df.sort_values("date").index.unique() train_id_list = sorted_id_list[: round(len(sorted_id_list) * (1 - test_size))] test_id_list = sorted_id_list[round(len(sorted_id_list) * (1 - test_size)) :] train = df.loc[train_id_list].drop(['date'], axis=1) test = df.loc[test_id_list].drop(['date'], axis=1) return train, testカテゴリ変数をダミー変数化するが、馬名はカテゴリ数が大きすぎるので今回は省く。
results_p.drop(["馬名"], axis=1, inplace=True) results_d = pd.get_dummies(results_p)着順が3着以内なら1、それ以外なら0にラベル付けして目的変数として扱う。
results_d["rank"] = results_d["着順"].map(lambda x: 1 if x < 4 else 0) results_d.drop(['着順'], axis=1, inplace=True)作ったsplit_data関数を用いて、訓練データとテストデータに分け、LightGBMで学習させる。
import lightgbm as lgb train, test = split_data(results_d, 0.3) X_train = train.drop(["rank"], axis=1) y_train = train["rank"] X_test = test.drop(["rank"], axis=1) y_test = test["rank"] params = { "num_leaves": 4, "n_estimators": 80, "class_weight": "balanced", "random_state": 100, } lgb_clf = lgb.LGBMClassifier(**params) lgb_clf.fit(X_train.values, y_train.values)AUCスコアで評価する。
y_pred_train = lgb_clf.predict_proba(X_train)[:, 1] y_pred = lgb_clf.predict_proba(X_test)[:, 1] print(roc_auc_score(y_train, y_pred_train)) print(roc_auc_score(y_test, y_pred))結果は、
訓練データ:0.819
テストデータ:0.812
でした。まだ特徴量も全然作っていない割には良いスコアなのかなと思います。特徴量の重要度をみてみると、importances = pd.DataFrame( {"features": X_train.columns, "importance": lgb_clf.feature_importances_} ) importances.sort_values("importance", ascending=False)[:20]
これをみると、ほぼ単勝オッズのデータに依存している、つまり、オッズの低い所に賭けるモデルになってしまっているので、特徴量を作るなどして改善していきたいところです。動画で詳しい解説をしています!
競馬予想で始めるデータ分析・機械学習


- 投稿日:2020-07-09T17:48:22+09:00
いつも忘れる Flask-Cognito
CognitoのJWTで認証をしてAPIを実行する方法
githubの説明がわかりにくい...
cognitojwtモジュールのコードまで見に行かないといけなかった...
先駆者がいるありがた味がわかる。flask-cognitoのインストール
pip install flask-cognitoJWKSの取得(サーバーがAWSにアクセスできない環境への対応用)
アクセスできるならなくてもよい。
あるとトラフィックが抑えられるかも。知らんけど。
https://cognito-idp.{リージョン}.amazonaws.com/{ユーザープールID}/.well-known/jwks.jsonflaskに各種設定
from flask_cognito import CognitoAuth, cognito_auth_required app = Flask(__name__) app.config['COGNITO_REGION'] = 'リージョン' app.config['COGNITO_USERPOOL_ID'] = 'ユーザープールID' app.config['COGNITO_APP_CLIENT_ID'] = 'クライアントID' app.config['COGNITO_CHECK_TOKEN_EXPIRATION'] = True #"True"の場合、トークンの有効期限を無視する app.config['COGNITO_JWT_HEADER_NAME'] = 'Authorization' # CognitoからのトークンならこのままでOK app.config['COGNITO_JWT_HEADER_PREFIX'] = 'Bearer' # CognitoからのトークンならこのままでOK # ここはflask-cognitoのための処理ではなく、congnitojwtモジュールのための処理 # サーバーがインターネットに接続できない環境の場合、JWKSを配置することで認証が可能 # パスはサンプル。お好きなところにどうぞ。 # ちゃんと設定されたかの確認もお好みでどうぞ。 os.environ.setdefault('AWS_COGNITO_JWSK_PATH', 'cognito/jwks.json') cogauth = CognitoAuth(app) @app.route('/', methods=['GET']) @cognito_auth_required # 認証をかけたいエンドポイントに追加するだけ def page_index(): return render_template('index.html')どうせまた忘れる
ユーザーグループの対応
対して難しくないので、こちらはgithubのサンプルをどうぞ。
- 投稿日:2020-07-09T17:45:28+09:00
RaspberryPi でハードウェアPWMでE-MAX ミニサーボ ES08A IIを回す
TL;DR
- RaspberryPi Model 3BでE-MAX ミニサーボ ES08A IIを使用する手順
- 安定させるためにハードウェアPWMを利用する。ソフトウェアPWMだとぶるぶる震えたりする。
環境
- RaspberryPi Model 3B
- E-MAX ミニサーボ ES08A II
- Raspbian GNU/Linux 9.9 (stretch)
- Python 2
- nfcpy 1.0.3
GPIOへの接続
ハードウェアPWM(黄色の線)に使えるのはGPIO 18, Physical 12のみだそうです。
しかし、WiringPiのマニュアルによると、PWMが使えるのは18だけで、かつアナログオーディオ出力を使っていないこと、という条件があります。
黒の線をGNDに、オレンジの線を5Vに接続します。(できれば電源は別のほうがいいらしいという記事もあります)
環境設定
※プロキシ環境での例
PIPの更新sudo pip install -U pip --proxy="http://<proxy>:<port>/"wiringpisudo pip install wiringpi --proxy="http://<proxy>:<port>/"ソース
ハードウェアPWM対応の計算式
https://hira-hide.hatenablog.com/entry/20170610/1497100926
サーボモーターの多くが中央が1.4msではなく、1.5ms
http://gomisai.blog75.fc2.com/blog-entry-290.html個体差があるので、最大角度でサーボがジリジリとなったり急激に熱くなった場合はサーボの最大動作角度を超えている状態なので、すぐにニュートラル位置に戻して角度を調整してください。
servoutil.py#!/usr/bin/python # -*- coding: utf-8 -*- def get_write_value(degree): """ 角度から書き込む値を取得する Parameters ---------- degree : int -90 -> 90, 真ん中 0 Returns ---------- write_value : int wiringpi.pwmWriteで書き込む値 PWM周波数=Raspberry PiのPWMが持つベースクロックの周波数/(clock×レンジ) 「0度を中心として何度動かすか?」を計算している。 0度のときが7.25%、90度のときが12%、-90度のときが2.5%を線形に計算するような値 """ # 値チェック if degree > 90: degree = 90 if degree < -90: degree = -90 print(degree) # ES08A II 等多くのサーボモーターでは、0.5ms~2.4msで0度は1.45msのはずだが、 # 実際は0度が1.5msとなっていることが多い。 # この点を踏まえて調整する edit_degree = degree + 10 return int((4.75 * edit_degree / 90 + 7.25) * (1024 / 100))testservo.py#!/usr/bin/python # -*- coding: utf-8 -*- import wiringpi import sys import servoutil servo_pin = 18 # 18番ピンを指定 param = sys.argv set_degree = int(param[1]) print(set_degree) wiringpi.wiringPiSetupGpio() # 上図 pin(BOARD) の番号でピン指定するモード wiringpi.pinMode(servo_pin, 2) # 出力ピンとして指定 wiringpi.pwmSetMode(0) # 0Vに指定 wiringpi.pwmSetRange(1024) # レンジを0~1024に指定 wiringpi.pwmSetClock(375) wiringpi.pwmWrite(servo_pin, servoutil.get_write_value(set_degree))pinModeの設定にはsudoが必要
実施例sudo python2 testservo.py 90
- 投稿日:2020-07-09T17:43:27+09:00
pyinstaller --onefile で固めた.exeで、実行時に動的にモジュールをimportする
Python公式では非推奨だが、成果物を人に渡す時に、以下のような config.py を、 main.py と同階層に置いて、mian.py でインポートしてそのまま使ったりすることがあった。
config.pywidth = 10 height = 10 count = 100 threshold = 50main.pyfrom config import *今回pyinstallerで固めた.exeからも、動的に外部のパラメータをimportするようにしたかったのだが、ハマったのでTIPSをメモしておく。
まず、こちらの記事が非常に参考になった。
(参考) https://ja.coder.work/so/python/1422895普通に.exeにしたものは、importlibを使えば動的にimportしてくれるのだが、 --onefile で固めると、config.pyも内部に取り込まれてハードコーディングされる模様。
この問題に関しては、(泥臭い方法だが)とりあえず.exe化するときに config.py を消しておくことで対応した。(おそらく --hidden-import とかを使って.specファイルを編集して~みたいなのが正しい手順)あとは main.py 内で
main.pyimport os import sys sys.path.append(os.path.join(os.path.dirname(__file__), '.'))としてカレントディレクトリをパスに加えてやればOK。
- 投稿日:2020-07-09T17:41:44+09:00
ResnetでCNN ファインチューニングしてみた(タバコ編)
Python Resnetでファインチューニング
本記事はResnetを使用したファインチューニングを紹介します。
今回はファインチューニングがどれだけの効果が出るのかを検証するため、通常の
[CNNで作成したモデル]と[ファインチューニングしたモデル]で比較したいと思います。開発環境
私はGoogle Colabで学習を行いましたが、ローカル前提でも可能なように記載します。
python : 3.7.0
keras : 2.4.3
tensorflow : 2.2.0Resnetとは
ResnetとはImagenetというデータベースの100万枚を超える【学習済み】の畳み込みニューラルネットワーク(Convolutional Neural Network)のこと。
そしてこのネットワークはResnet50とも呼ばれ、深さが50層あり1000個のカテゴリニー分類できる。ファインチューニングとは
学習済みネットワークの重みを初期値として、モデル全体の重みを再学習することです。
なので、上記Resnet50を用いたうえで、再学習させることでより良い判別機を作ることを目指します。使用する画像
なんとなく面白そうだったので、日本のタバコ3種類を使用してみました
メビウス : 338枚
セブンスター : 552枚
ウィンストン : 436枚今回はファインチューニングの検証ということなので、上記画像はインターネットから引っ張ってきました。
通常のCNN
構成は下記です。
これを学習すると下記のような結果になりました。
画像の切り出しなど事前処理をしていないため、かなり悪いですね。
テストデータでは大体【60%】前後でしょうか。ソース
normal_cnn.pyfrom PIL import Image import numpy as np import glob import os from keras.utils import np_utils from keras.models import Sequential from keras.layers.convolutional import MaxPooling2D from keras.layers import Conv2D, Flatten, Dense, Dropout from sklearn.model_selection import train_test_split import matplotlib.pyplot as plt root = "tobacco_dataset" folder = os.listdir(root) image_size = 224 dense_size = len(folder) epochs = 30 batch_size = 16 X = [] Y = [] for index, name in enumerate(folder): dir = "./" + root + "/" + name print("dir : ", dir) files = glob.glob(dir + "/*") print("number : " + str(files.__len__())) for i, file in enumerate(files): try: image = Image.open(file) image = image.convert("RGB") image = image.resize((image_size, image_size)) data = np.asarray(image) X.append(data) Y.append(index) except : print("read image error") X = np.array(X) Y = np.array(Y) X = X.astype('float32') X = X / 255.0 Y = np_utils.to_categorical(Y, dense_size) X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=0.15) model = Sequential() model.add(Conv2D(32, (3, 3), activation='relu', input_shape=(image_size, image_size, 3))) model.add(MaxPooling2D((2, 2))) model.add(Dropout(0.25)) model.add(Conv2D(64, (3, 3), activation='relu')) model.add(MaxPooling2D((2, 2))) model.add(Dropout(0.25)) model.add(Conv2D(64, (3, 3), activation='relu')) model.add(Flatten()) model.add(Dense(64, activation='relu')) model.add(Dropout(0.25)) model.add(Dense(dense_size, activation='softmax')) model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy']) model.summary() result = model.fit(X_train, y_train, validation_split=0.15, epochs=epochs, batch_size=batch_size) x = range(epochs) plt.title('Model accuracy') plt.plot(x, result.history['accuracy'], label='accuracy') plt.plot(x, result.history['val_accuracy'], label='val_accuracy') plt.xlabel('Epoch') plt.legend(loc='center left', bbox_to_anchor=(1, 0.5), borderaxespad=0, ncol=2) name = 'tobacco_dataset_reslut.jpg' plt.savefig(name, bbox_inches='tight') plt.close()Resnetによるファインチューニング
構成はかなり層が深くてQiitaに貼り切れないので、URLを記載します
https://github.com/daichimizuno/cnn_fine_tuning/blob/master/finetuning_layer.txtさらに元来のResnetに加えて活性化関数Reluとドロップアウトを0.5いれてあります。
ちなみに下記ソースがResnetを使用する時のソースになります。Kerasの中にResnet用のライブラリが入っているようです。ResNet50 = ResNet50(include_top=False, weights='imagenet',input_tensor=input_tensor)これを学習すると下記のような結果になりました。
テストデータでは大体【85%】前後でしょうか。
ソース
resnet_fine_tuning.pyfrom PIL import Image import numpy as np import glob import os from keras.utils import np_utils from keras.models import Sequential, Model from keras.layers import Flatten, Dense,Input, Dropout from sklearn.model_selection import train_test_split import matplotlib.pyplot as plt from keras.applications.resnet50 import ResNet50 from keras import optimizers root = "tobacco_dataset" folder = os.listdir(root) image_size = 224 dense_size = len(folder) epochs = 30 batch_size = 16 X = [] Y = [] for index, name in enumerate(folder): dir = "./" + root + "/" + name print("dir : ", dir) files = glob.glob(dir + "/*") print("number : " + str(files.__len__())) for i, file in enumerate(files): try: image = Image.open(file) image = image.convert("RGB") image = image.resize((image_size, image_size)) data = np.asarray(image) X.append(data) Y.append(index) except : print("read image error") X = np.array(X) Y = np.array(Y) X = X.astype('float32') X = X / 255.0 Y = np_utils.to_categorical(Y, dense_size) X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=0.15) input_tensor = Input(shape=(image_size, image_size, 3)) ResNet50 = ResNet50(include_top=False, weights='imagenet',input_tensor=input_tensor) top_model = Sequential() top_model.add(Flatten(input_shape=ResNet50.output_shape[1:])) top_model.add(Dense(256, activation='relu')) top_model.add(Dropout(0.5)) top_model.add(Dense(dense_size, activation='softmax')) top_model = Model(input=ResNet50.input, output=top_model(ResNet50.output)) top_model.compile(loss='categorical_crossentropy',optimizer=optimizers.SGD(lr=1e-3, momentum=0.9),metrics=['accuracy']) top_model.summary() result = top_model.fit(X_train, y_train, validation_split=0.15, epochs=epochs, batch_size=batch_size) x = range(epochs) plt.title('Model accuracy') plt.plot(x, result.history['accuracy'], label='accuracy') plt.plot(x, result.history['val_accuracy'], label='val_accuracy') plt.xlabel('Epoch') plt.legend(loc='center left', bbox_to_anchor=(1, 0.5), borderaxespad=0, ncol=2) name = 'resnet_tobacco_dataset_reslut.jpg' plt.savefig(name, bbox_inches='tight') plt.close()まとめ
通常のCNNとファインチューニングを比較すると、ファインチューニングの方がエポック10あたりから急激に良くなっているのが分かります。
これはResnetを使用した再学習なので、Resnetの正答率が高まってくる部分で伝搬してタバコ判別にも影響してくるということなんかなと、想像していますがさらに詳しく分析は必要ですね...ただ、いずれにしてもタバコ判定という意味では通常のCNNよりもかなり高い結果が出ました。
画像の選定や事前処理を行えばさらに良い結果が出ると思いますので、できる方はやってみてください!【Github】
https://github.com/daichimizuno/cnn_fine_tuning何か間違いや不明点などあればご指摘ください。
以上です
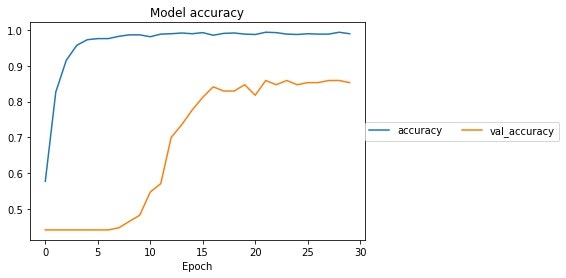
- 投稿日:2020-07-09T17:35:48+09:00
【EV3 MicroPython】DIST-ToFセンサで距離の計測
DIST-ToF
LEGO社のサードパーティ製品を製造・販売しているmindsensors社から,ToF距離センサ(DIST-ToF)が販売されています.
ToFは"Time of Flight"の略で,(赤外)光が跳ね返ってくるまでの時間から距離を計測するという技術です1.
ToF技術により,対象物の位置をピンポイント,かつ,正確に計測できるようになりました.mindsensorsが販売されているセンサの多くは,EV3MicroPythonのベースとなっているev3devで対応しています2.
そして,ev3devで対応しているセンサは,EV3MicoroPythoh(pybricks2.0)のiodevicesモジュールのEv3devSensorクラスで簡単に制御することができます.しかし,このDIST-ToFセンサは,ev3devに対応していません(コマンドが実装されていません).
ただし,このセンサはI2C通信により制御することができます.そこで,今回はEV3MicroPythonで直接I2C通信を扱う方法について紹介していきます.
そして,Ev3MicroPythonでDIST-ToFセンサを扱えるようにしていきます.I2C通信
I2Cは,フィリップス社(現NXP社)が開発したシリアルバス(シリアル通信の一種)で,シリアル・データライン(SDA)とシリアル・クロックライン(SCL)の2本の線を使ってデバイス間の通信を行う手法です.
少ない本数で複数のデバイスと通信できるため,組み込み機器や携帯電話などで利用されています.なぜ,2本線で「複数のデバイス」間の通信ができるのかというと,それは,デバイス毎にアドレスが設定されているからです.
(「メールアドレス」を思い浮かべてください.世界中で沢山の機器がインターネットに接続されていますが,宛先に設定したメールアドレス(のサーバ)にのみ,メールが届くようになっています.)また,I2C通信はマスター・スレーブ方式3を採用しています.
今回の場合は,EV3がマスター,DIST-ToFがスレーブとなります.EV3MicroPython(Pybricks2.0)では,I2C通信を扱うクラスとして
iodevicesモジュールにI2CDeviceクラスが用意されています.I2CDeviceクラスの仕様については,こちらを参照してください.EV3MicoPythonでI2C通信
以下のソースコードは,EV3MicroPythonで,DIST-TOFのセンサ値を取得し,EV3の液晶に表示するプログラムの実装例です.
RobotC向けに公開されているGitHubのコードを参考に実装しています.ms-dist-tof.py#!/usr/bin/env pybricks-micropython from pybricks.hubs import EV3Brick from pybricks.parameters import Port from pybricks.tools import wait from pybricks.media.ev3dev import Font from pybricks.iodevices import I2CDevice # Write your program here ev3 = EV3Brick() ev3.speaker.beep() font = Font(size=20) dist = I2CDevice(Port.S4, 0x02 >> 1) def get_ms_dist(dist): data = dist.read(0x42, length=2) return (0xFF & data[0]) + ((0xFF & data[1]) << 8) ev3.screen.set_font(font) while True: ev3.screen.clear() ev3.screen.print("DIST :", get_ms_dist(dist)) wait(100)まず,
I2CDeviceクラスから,distインスタンス(クラスオブジェクト)を生成します(14行目).
コンストラクタの引数には,センサを接続するポート(Portクラス)と,センサのアドレス(16進数)を入力します.ここで,DIST-ToFの(デフォルト)アドレスは
0x02です.
ただし,アドレスを1ビット右にシフトしたものを入力するようにしてください4.
get_ms_dist関数(16-18行目)では,以下の処理を行なっています.
- 引数として,
I2CDeviceクラスのクラスオブジェクトを渡す(distインスタンスを想定).I2CDeviceクラスのread関数を呼び出し,センサの値を取得します.
- ここで,DIST-ToFの距離情報を取得するためのアドレスは
0x42で,データ長は2バイトとなります.- 2バイトのデータを足し合わせて,1つのデータにします.これを距離データとして返します.
DIST-ToF用のクラスを用意し,クラス内で
get_dist関数を実装する方がスマートなプログラムになりそうです.前述のように,DIST-ToFは通信方式にI2Cを採用しているため,アドレスの異なる他のセンサと組み合わせることで,EV3の1つのポートで複数のセンサを制御することができます.
最近では,センサの素子レベルでこのような計測を行う回路を組み込めるようになり,これを含めてToFと呼ばれることが多いとされています. ↩
マスタースレーブ方式:複数のデバイスが協調して動作する際に,複数のデバイスの制御・操作を司る「マスター」機と,マスター機の一方的な制御下で動作する「スレーブ」機に役割を分担する方式です(この呼び名は,最近,問題担っていますが...). ↩
I2C通信では,8ビットのデータのうち,上位7ビットは「スレーブアドレス」,下位1ビットは「送信・受信指定ビット」となっています.ここで必要な情報は,「スレーブアドレス」だけなので,下位1ビットを外した値を入力します. ↩
- 投稿日:2020-07-09T17:35:48+09:00
【EV3 MicroPython】DIST-ToFセンサによる距離の計測(&I2C通信)
DIST-ToF
LEGO社のサードパーティ製品を製造・販売しているmindsensors社から,ToF距離センサ(DIST-ToF)が販売されています.
ToFは"Time of Flight"の略で,(赤外)光が跳ね返ってくるまでの時間から距離を計測するという技術です1.
ToF技術により,対象物の位置をピンポイント,かつ,正確に計測できるようになりました.mindsensorsが販売しているセンサの多くは,EV3MicroPythonのベースとなっているev3devで対応しています2.
そして,ev3devで対応しているセンサは,EV3MicoroPythoh(pybricks2.0)のiodevicesモジュールのEv3devSensorクラスで簡単に制御することができます.しかし,このDIST-ToFセンサは,ev3devに対応していません(コマンドが実装されていません).
ただし,このセンサはI2C通信により制御することができます.そこで,今回はEV3MicroPythonで直接I2C通信を扱う方法について紹介していきます.
そして,Ev3MicroPythonでDIST-ToFセンサを扱えるようにしていきます.I2C通信
I2Cは,フィリップス社(現NXP社)が開発したシリアルバス(シリアル通信の一種)で,シリアル・データライン(SDA)とシリアル・クロックライン(SCL)の2本の線を使ってデバイス間の通信を行う手法です.
少ない本数で複数のデバイスと通信できるため,組み込み機器や携帯電話などで利用されています.なぜ,2本線で「複数のデバイス」間の通信ができるのかというと,それは,デバイス毎にアドレスが設定されているからです3.
また,I2C通信はマスター・スレーブ方式4を採用しています.今回の場合は,EV3がマスター,DIST-ToFがスレーブとなります.
EV3MicroPython(Pybricks2.0)では,I2C通信を扱うクラスとして
iodevicesモジュールにI2CDeviceクラスが用意されています.I2CDeviceクラスの仕様については,こちらを参照してください.EV3MicoPythonでI2C通信
以下のソースコードは,EV3MicroPythonで,
I2CDeviceクラスを用いてDIST-TOFのセンサ値を取得するプログラムの実装例です.取得した値は,EV3の液晶画面に表示されます.
実装したプログラムは,RobotC向けに公開されているGitHubのコードを参考にしています.ms-dist-tof.py#!/usr/bin/env pybricks-micropython from pybricks.hubs import EV3Brick from pybricks.parameters import Port from pybricks.tools import wait from pybricks.media.ev3dev import Font from pybricks.iodevices import I2CDevice # Write your program here ev3 = EV3Brick() ev3.speaker.beep() font = Font(size=20) dist = I2CDevice(Port.S4, 0x02 >> 1) def get_ms_dist(dist): data = dist.read(0x42, length=2) return (0xFF & data[0]) + ((0xFF & data[1]) << 8) ev3.screen.set_font(font) while True: ev3.screen.clear() ev3.screen.print("DIST :", get_ms_dist(dist)) wait(100)まず,
I2CDeviceクラスから,distインスタンス(クラスオブジェクト)を生成します(14行目).
コンストラクタの引数には,センサを接続するポート(Portクラス)と,センサのアドレス(16進数)を入力します.ここで,DIST-ToFの(デフォルト)アドレスは
0x02です.
ただし,アドレスを1ビット右にシフトしたものを入力するようにしてください3.
get_ms_dist関数(16-18行目)では,以下の処理を行なっています.
- 引数として,
I2CDeviceクラスのクラスオブジェクトを渡す(distインスタンスを想定).I2CDeviceクラスのread関数を呼び出し,センサの値を取得します.
- ここで,DIST-ToFの距離情報を取得するためのアドレスは
0x42で,データ長は2バイトとなります.- 2バイトのデータを足し合わせて,1つのデータにします.これを距離データとして返します.
DIST-ToF用のクラスを用意し,クラス内で
get_dist関数を実装する方がスマートなプログラムになりそうです.前述のように,DIST-ToFは通信方式にI2Cを採用しているため,アドレスの異なる他のセンサと組み合わせることで,EV3の1つのポートで複数のセンサを制御することができます.
- 投稿日:2020-07-09T16:57:16+09:00
色塗りゲームで知識がつく
今回は、ゲームを作りながら学習できる“pythonで作るゲーム開発入門講座”という参考書を元に動くものを作っていきます。本はこちら *マイク機能が使えないので順を追ってみてください
after()命令を行う
import tkinter tmr = 0 def count_up(): global tmr tmr = tmr + 1 label["text"] = tmr root.after(1000, count_up) root = tkinter.Tk() label = tkinter.Label(font=("Times New Roman", 80)) label.pack() root.after(1000, count_up) root.mainloop()
- tmrを自由度の高いグローバル関数として宣言
- ラベルにtmrの値を表示
- 1秒後に関数を実行
- packで部品の配置
- 1秒後に指定の関数を呼び出す
- after(ミリ秒、実行関数)
- 12行目でcountを呼び出し、7行目で再度実行
実行結果
bind()命令を使う
import tkinter key = 0 def key_down(e): global key key = e.keycode print("KEY:"+str(key)) root = tkinter.Tk() root.title("キーコードを取得") root.bind("<KeyPress>", key_down) root.mainloop
- bind(イベント,関数名)
- 2行目:キーコードの変数を宣言
- 3行目:キーを押したとき実行する関数の定義
- 5行目:押されたキーコードをkeyに代入
- 6行目:シェルウィンドにkeyの値を出力
- bind()命令でキーを押したときの処理を確定
実行結果
*一度間違えたのは、打ち間違えでありシェルウィンドウの指摘を見て直す
keysymの値で判定する
import tkinter key = "" def key_down(e): global key key = e.keysym def main_proc(): label["text"] = key root.after(100, main_proc) root = tkinter.Tk() root.title("リアルタイムキー入力") root.bind("<KeyPress>", key_down) label = tkinter.Label(font=("Time New Roman", 80)) label.pack() main_proc() root.mainloop()
- 8行目リアルタイムの関数を定義
- 9行目ラベルにkeyの値を表示
- 10行目0.1秒後に実行する関数を指定
- packで配置
実行結果
packの豆知識
- button作りテクニック
- fill, xで横拡大, yで縦拡大
- padx, 外側の余白, ipad, 内側の余白
引用元こちら
リアルタイムにキャラを動かす
import tkinter key = "" def key_down(e): global key key = e.keysym def key_up(e): global key key = "" cx = 400 cy = 300 def main_proc(): global cx, cy if key == "Up": cy = cy - 20 if key == "Down": cy = cy + 20 if key == "Left": cx = cx - 20 if key == "Right": cx = cx + 20 canvas.coords("MYCHR", cx, cy) root.after(100, main_proc) root = tkinter.Tk() root.title("キャラクターの移動") root.bind("<KeyPress>", key_down) root.bind("<KeyRelease>", key_up) canvas = tkinter.Canvas(width=800, height=600, bg="lightgreen") canvas.pack() img = tkinter.PhotoImage(file="mimi.png") canvas.create_image(cx, cy, image=img, tag="MYCHR") main_proc() root.mainloop()
- 13行目からキャラクターの動作について定義していく
- cx,cy:座標
- 23行目:coords()はキャラクターを新しい位置へ移動(tag名,座標)
- canvas.pack()でキャンバスを配置
- 32行目:作成した画像を変数imgに読み込む
- create_imageでキャンバスに画像を表示
実行結果
- キーで画像を操作できるようになる
画像はペイントで作成しましたが好きなアプリを使いましょう 今回の注意点
プログラムは間違っていないのに、Runするとそのようなファイルはありませんと表示された。なぜなのか。先生に伺うと、同じディレクトリである必要があるとのこと。今回のプログラムで指されるファイルは同じ場所に保存されたファイルであるので、注意しておきたい。
*このようにまとめておく
迷路の中を歩く
迷路のデータを定義する
import tkinter root = tkinter.Tk() root.title("迷路の表示") canvas = tkinter.Canvas(width=800, height=560, bg="white") canvas.pack() maze = [ [1,1,1,1,1,1,1,1,1,1], [1,0,0,0,0,0,1,0,0,1], [1,0,1,1,0,0,1,0,0,1], [1,0,0,1,0,0,0,0,0,1], [1,0,0,1,1,1,1,1,0,1], [1,0,0,0,0,0,0,0,0,1], [1,1,1,1,1,1,1,1,1,1] ] for y in range(7): for x in range(10): if maze[y][x] == 1: canvas.create_rectangle(x*80, y*80, x*80+80, y*80+80, fill="gray") root.mainloop()二重ループのfor
for 変数1 in 変数1の範囲:
for 変数2 in 変数2の範囲:
- 二次元リストで定義
- リスト名:maze
- 横並びは行
- maze[x][y]が1なら灰色に描画
実行結果
応用して作ってみる
import tkinter key = "" def key_down(e): global key key = e.keysym def key_up(e): global key key = "" mx = 1 my = 1 def main_proc(): global mx, my if key == "Up" and maze[my-1][mx] == 0: my = my - 1 if key == "Down" and maze[my+1][mx] == 0: my = my + 1 if key == "Left" and maze[my][mx-1] == 0: mx = mx - 1 if key == "Right" and maze[my][mx+1] == 0: mx = mx + 1 canvas.coords("MYCHR", mx*80+40, my*80+40) root.after(300, main_proc) root = tkinter.Tk() root.title("迷路内を移動する") root.bind("<KeyPress>", key_down) root.bind("<KeyRelease>", key_up) canvas = tkinter.Canvas(width=800, height=560, bg="white") canvas.pack() maze = [ [1,1,1,1,1,1,1,1,1,1], [1,0,0,0,0,0,1,0,0,1], [1,0,1,1,0,0,1,0,0,1], [1,0,0,1,0,0,0,0,0,1], [1,0,0,1,1,1,1,1,0,1], [1,0,0,0,0,0,0,0,0,1], [1,1,1,1,1,1,1,1,1,1] ] for y in range(7): for x in range(10): if maze[y][x] == 1: canvas.create_rectangle(x*80, y*80, x*80+79, y*80+79, fill="darkturquoise", width=0) img = tkinter.PhotoImage(file="cookie_s.png") canvas.create_image(mx*80+40, my*80+40, image=img, tag="MYCHR") main_proc() root.mainloop()
- my,mxをグローバル関数として扱い、移動操作ができるようにする
- andの内容としては、方向キーがタップされるかつタップされた方向が通路であった場合のみ進めるような処理である
- maze[x][y]が1である場合、つまり壁である場合☞rectangle(x1,y1,x2,y2,塗色)
- create_image関数で画像が中央にくるように+40とする
実行結果
完成させる(クリアの判定を含む)
import tkinter import tkinter.messagebox key = "" def key_down(e): global key key = e.keysym def key_up(e): global key key = "" mx = 1 my = 1 yuka = 0 def main_proc(): global mx, my, yuka if key == "Up" and maze[my-1][mx] == 0: my = my - 1 if key == "Down" and maze[my+1][mx] == 0: my = my + 1 if key == "Left" and maze[my][mx-1] == 0: mx = mx - 1 if key == "Right" and maze[my][mx+1] == 0: mx = mx + 1 if maze[my][mx] == 0: maze[my][mx] = 2 yuka = yuka + 1 canvas.create_rectangle(mx*80, my*80, mx*80+79, my*80+79, fill="plum", width=0) canvas.delete("MYCHR") canvas.create_image(mx*80+40, my*80+40, image=img, tag="MYCHR") if yuka == 30: canvas.update() tkinter.messagebox.showinfo("God!", "クリアである") else: root.after(300, main_proc) root = tkinter.Tk() root.title("迷路を塗るゾ") root.bind("<KeyPress>", key_down) root.bind("<KeyRelease>", key_up) canvas = tkinter.Canvas(width=800, height=560, bg="white") canvas.pack() maze = [ [1,1,1,1,1,1,1,1,1,1], [1,0,0,0,0,0,1,0,0,1], [1,0,1,1,0,0,1,0,0,1], [1,0,0,1,0,0,0,0,0,1], [1,0,0,1,1,1,1,1,0,1], [1,0,0,0,0,0,0,0,0,1], [1,1,1,1,1,1,1,1,1,1] ] for y in range(7): for x in range(10): if maze[y][x] == 1: canvas.create_rectangle(x*80, y*80, x*80+79, y*80+79, fill="mediumturquoise", width=0) img = tkinter.PhotoImage(file="monster.png") canvas.create_image(mx*80+40, my*80+40, image=img, tag="MYCHR") main_proc() root.mainloop()
これまでの知識+クリア判定とメッセージ
- if yuka == 30: canvas.update()?30箇所の床が塗られたらキャンバスを更新
塗られた箇所が30に満たない場合は、else:root.after()でリアルタイム処理を続ける
*前回同様にファイルが見つからないというエラーが出た。今回は.pngの付け忘れだった。ファイル名には必ず拡張子を忘れずにつけること(↓参照)
気付かずにミスしまくる
実行結果
感想
分かりやすく書かれたものを参考にしてまねて作っていったが、段階を踏んで組み合わせることが実践につながると感じた。何度も失敗したがするうちに失敗のパターンが見えてきた気がする。


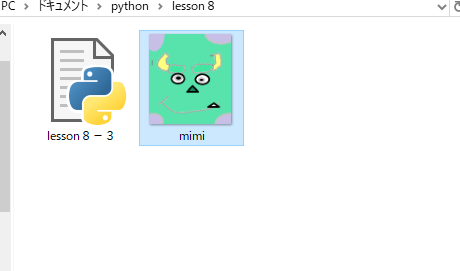


- 投稿日:2020-07-09T16:05:32+09:00
初心者のためのpandas基礎③matplotlibでヒストグラム作成
pandasとは
Pythonにて、構造化データを扱うためのデータフレームオブジェクトです。ファイルの読み込みやその後のSQL操作などを簡単に行うことができ、機械学習にてデータを加工し、計算、可視化する作業に必要となります。データ操作によく使う構文をメモ書き的にリストします。本項はデータの読み込み&加工です。
ヒストグラム
ヒストグラムは前準備の段階のデータ確認で多く使用します。今回はmatplotlibとうライブラリを使用します。Excelでやると面倒なヒストグラムが簡単に作成できます。データはおなじみのタイタニックのデータを利用しました。
ライブラリインポート&データ読み込み
pandasにpdという名前をつけてimportする。今回は、matplotlib.pyplotもpltという名前をつけてインポート。サンプルデータがタイタニックのもの利用
import pandas as pd import matplotlib.pyplot as plt dataframe = pd.read_csv('train.csv') dataframe.head()ヒストグラム作成
年齢(column「Age」)にてヒストグラム作成します。dropna()にて欠損値をドロップします。
plt.hist(dataframe['Age'].dropna(),bins = 10, range = (0,100),color = 'Blue') plt.show()
bins(表示する瓶の数)、range(データの幅)、clor(色)を指定します。
ヒストグラム作成(正規化)
正規化し全体の合計が1になるようにします。
plt.hist(dataframe['Age'].dropna(),bins = 20, range = (0,100),color = 'Blue', normed = 'true') plt.show()
タイトル等追加
見やすい様にタイトル等を追加します。
plt.title('Age Histogram', fontsize=14) plt.xlabel('Age', fontsize=14) plt.grid(True) plt.hist(dataframe['Age'].dropna(),bins = 20, range = (0,100),color = 'Blue') plt.show()
.title(タイトル)、.xlabel(X軸ラベル)、.grid(グリッド)を追加します。
<応用>積み上げ表示
男性(male)と女性(femal)の内訳表示を積み上げ表示を使って表示します。プロットの準備として、malelist_mとmalelist_fをそれぞれ定義します。
malelist_m = dataframe['Sex'] == 'male' malelist_f = dataframe['Sex'] == 'female' plt.title('Age Histogram', fontsize=14) plt.xlabel('Age', fontsize=14) plt.grid(True) plt.hist([dataframe[malelist_m]['Age'],dataframe[malelist_f]['Age']],bins = 20, range = (0,100), color = ['Blue', 'Red'], label = ['male','femal'], stacked=True) plt.legend(loc="upper right", fontsize=14) plt.show()
複数積み上げたい場合は、hist([X1,X2])のように表記します。stackedをTrueにすると積み上げます。(Falseだと併記)labelにて凡例を定義します。.legendにて凡例を追加します。
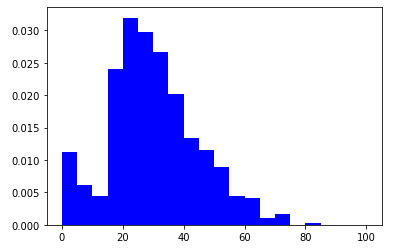
- 投稿日:2020-07-09T15:24:40+09:00
カメラから指定した矩形領域の差分を取り、変化率が一定率以上になったときに音をならすPGM
カメラから指定した矩形領域の差分を取り、変化率が一定率以上になったときに音をならすPGM
予めカメラから差分を検出する矩形領域(2カ所)を登録し、別PGMでカメラからその矩形領域の差分が一定率
以上になったときに音をならすPGMです。(これを改良すると目や口を動かすだけで
太鼓の達人もどきのことができそうw...)
本PGMのgithubURL: https://github.com/NanjoMiyako/ImageDiffAndSound
使い方
1.まず、registCaribRect.pyを実行し、差分を取る矩形領域を2カ所登録します。
(ドラッグで矩形領域をドラッグ、その後’a'キーで矩形領域Aを変数に保存、'b'キーで矩形領域Bを変数に保存、その後's'キーでそれぞれの矩形領域を'caribRects.txt'としてファイルに保存します。)
2.次にplaySoundByImageDiff.pyを以下のコマンドライン引数付きで呼び出します。
コマンドライン引数1:登録した矩形領域のファイル(caribRects.txtのファイルパス)
コマンドライン引数2:矩形領域Aの差分で音を鳴らす基準の変化率
コマンドライン引数3:矩形領域Bの差分で音を鳴らす基準の変化率
コマンドライン引数4:矩形領域Aの差分をとる間隔の秒数(浮動小数点)
コマンドライン引数5:矩形領域Bの差分をとる間隔の秒数(浮動小数点)コマンドライン引数の例:
python playSoundByImageDiff.py C:\hogehoge\caribRects.txt 1.5 3.0 0.2 0.53.実行後矩形領域がそれぞれカメラ上の画面から矩形の線分として描画されるので、
その部分を瞬き等で差分が検出されると音を出します。
参考にしたサイト
opencv(python)のマウスイベントでカメラのライブ映像に線を描く - Qiita
ファイル入出力 — Pythonオンライン学習サービス PyQ(パイキュー)ドキュメント
Pythonで文字列を分割(区切り文字、改行、正規表現、文字数) | note.nkmk.me
文字列を数値に変換して数値と演算する | Python入門
Pythonで数字の文字列strを数値int, floatに変換 | note.nkmk.me
使用したサンプル音源サイト
ポケットサウンド – フリー効果音素材・BGMダウンロード【mp3】
- 投稿日:2020-07-09T15:15:01+09:00
〇✕ゲームを作ってみた
動機
小さい頃、三目並べというゲームを空いている少しの時間で友達とやるのが自分のブームだったという時があった。だから今回作ってみようと思った。
実行結果
内容
- 画面とボタンを作る
from tkinter import * from tkinter import ttk from tkinter import messagebox squares = 3 class TictacApp(ttk.Frame): def __init__(self, master=None): super().__init__(master) self.create_widgets() self.set_value() def create_widgets(self): for i in range(squares): for j in range(squares): button = ttk.Button(self, command=self.record(i, j)) button.bind('<Button-1>', self.mark) button.grid(column=i, row=j, sticky=(N, S, E, W)) for i in range(squares): self.columnconfigure(i, weight=1) self.rowconfigure(i, weight=1) self.master.columnconfigure(0, weight=1) self.master.rowconfigure(0, weight=1) self.grid(column=0, row=0, sticky=(N, S, E, W)) def main(): root = Tk() root.title('〇✕ゲーム') TictapApp(root) root.mainloop() if __name__ == '__main__': main()
- 〇や✕を表示
def mark(self, event): if not event.widget['text']: if self.player == 1: event.widget['text'] = str('〇') else: event.widget['text'] = str('×')
3.押したボタンを記憶
def record(self, i, j): def x(): if not self.field[i][j]: self.field[i][j] = self.player self.line_check() self.change_player() self.clear() return x def set_value(self): self.player = 1 self.field = [] for i in range(squares): self.field.append(['' for i in range(squares)]) self.finish = 0
4.三目並んでいるか判定
def line_check(self): cross = 0 for i in range(squares): horizon = 0 vertical = 0 for j in range(squares): if self.field[i][j] == self.player: horizon += 1 if self.field[j][i] == self.player: vertical += 1 if self.field[i][i] == self.player: cross += 1 if horizon == 3 or vertical == 3 or cross == 3: self.game_end() if self.field[0][2] == self.field[1][1] == self.field[2][0] == self.player: self.game_end()
5. 勝敗を知らせる
def game_end(self): if self.player == 1: messagebox.showinfo('おめでとう!', '先行の勝利') else: messagebox.showinfo('おめでとう!', '後攻の勝利') self.finish = 1決着がつかない場合
def change_player(self): if self.finish == 0: self.player = -self.player def clear(self): if self.finish == 1: self.create_widgets() self.set_value()
ソースコード
from tkinter import * from tkinter import ttk from tkinter import messagebox squares = 3 class TictacApp(ttk.Frame): def __init__(self, master=None): super().__init__(master) self.create_widgets() self.set_value() def set_value(self): self.player = 1 self.field = [] for i in range(squares): self.field.append(['' for i in range(squares)]) self.finish = 0 def create_widgets(self): for i in range(squares): for j in range(squares): button = ttk.Button(self, command=self.record(i, j)) button.bind('<Button-1>', self.mark) button.grid(column=i, row=j, sticky=(N, S, E, W)) for i in range(squares): self.columnconfigure(i, weight=1) self.rowconfigure(i, weight=1) self.master.columnconfigure(0, weight=1) self.master.rowconfigure(0, weight=1) self.grid(column=0, row=0, sticky=(N, S, E, W)) def mark(self, event): if not event.widget['text']: if self.player == 1: event.widget['text'] = str('〇') else: event.widget['text'] = str('×') def record(self, i, j): def x(): if not self.field[i][j]: self.field[i][j] = self.player self.line_check() self.change_player() self.clear() return x def change_player(self): if self.finish == 0: self.player = -self.player def line_check(self): cross = 0 for i in range(squares): horizon = 0 vertical = 0 for j in range(squares): if self.field[i][j] == self.player: horizon += 1 if self.field[j][i] == self.player: vertical += 1 if self.field[i][i] == self.player: cross += 1 if horizon == 3 or vertical == 3 or cross == 3: self.game_end() if self.field[0][2] == self.field[1][1] == self.field[2][0] == self.player: self.game_end() def game_end(self): if self.player == 1: messagebox.showinfo('おめでとう!', '先行の勝利') else: messagebox.showinfo('おめでとう!', '後攻の勝利') self.finish = 1 def clear(self): if self.finish == 1: self.create_widgets() self.set_value() def main(): root = Tk() root.title('OXゲーム') TictacApp(root) root.mainloop() if __name__ == '__main__': main()
作ってみた感想
今回参考にさせてもらった「PythonとTkinterでGUI三目並べ作ってみた」を見ながらしたが何をしているのか調べながらプログラムを書いていった。〇✕ゲームを作るだけでも私はとても苦労しました。また今回は参考にさせてもらったものがあったが1から作るとなればとても大変だと思った。これから自分一人で1から作れるように勉強しようと思った。
参考文献
- PythonとTkinterでGUI三目並べ作ってみた
https://qiita.com/TN0321/items/d0ba918eefa5d9c7e587
- いちばんやさしいPython入門教室書 大澤文孝[著]
- 投稿日:2020-07-09T14:25:28+09:00
Natural Language : Machine Translation Part2 - Neural Machine Translation Transformer
目標
Microsoft Cognitive Toolkit (CNTK) を用いた機械翻訳の続きです。
Part2 では、Part1 で準備した日英対訳データセットを用いて Transformer による機械翻訳モデルの訓練を行います。
CNTK と NVIDIA GPU CUDA がインストールされていることを前提としています。導入
Natural Language : Machine Translation Part1 - Japanese-English Subtitle Corpus では、Japanese-English Subtitle Corpus [1] から日英対訳を準備しました。
Part2 では、Transformer による機械翻訳モデルを作成して訓練します。
Transformer
Transformer [2] はそれまで自然言語処理で主流だった RNN [3] や CNN [4] に置き換わる手法として提案されました。
RNN ではゲート構造や Attention Mechanism によって性能を改善されてきましたが、RNN は現時刻の計算が終わるまで次時刻の計算ができないため、GPU の並列計算を活かすことができず訓練に時間がかかるという問題があります。
Transformer は訓練時に GPU による並列計算が可能で、RNN よりもシンプルな構造をしており、CNN よりも広い受容野を実現できるという特徴があります。
左側の青色で囲っている部分が Encoder 、右側の緑色で囲っている部分が Decoder 、それぞれ 6層とします。
精度向上とパラメータ削減のテクニックとして、Decoder の埋め込み層と全結合層は重み共有 [5] を採用しています。
訓練における諸設定
各パラメータの初期値は Glorot の初期値 [6] になっています。
次の単語を予測する分類問題なので損失関数を Cross Entropy Error として、最適化アルゴリズムには Adam [7] を採用しました。Adam のハイパーパラメータ $\beta_1$ は 0.9、$\beta_2$ は CNTK のデフォルト値に設定しました。
学習率は、Cyclical Learning Rate (CLR) [8] を使って、最大学習率は 0.04、ベース学習率は 1e-8、ステップサイズはエポック数の 10倍、方策は exp_range、$\gamma$ は 0.99994 に設定しました。
モデルの訓練はミニバッチ学習によって 10 Epoch を実行しました。
実装
実行環境
ハードウェア
・CPU Intel(R) Core(TM) i7-5820K 3.30GHz
・GPU NVIDIA Quadro RTX 6000 24GBソフトウェア
・Windows 10 Pro 1909
・CUDA 10.0
・cuDNN 7.6
・Python 3.6.6
・cntk-gpu 2.7
・cntkx 0.1.33
・numpy 1.17.3
・pandas 0.25.0
・sentencepiece 0.1.86実行するプログラム
訓練用のプログラムは GitHub で公開しています。
nmtt_training.py解説
今回の実装の要となる内容について補足します。
Scaled Dot-Product Attention
Encoder の各時刻における隠れ状態からなるテンソルを $Source$、Decoder の各時刻における隠れ状態からなるテンソルを $Target$ とすると、ベースとなる内積注意は以下の式で表されます。
Attention(Target, Source) = Target \cdot Source^Tここで、下図のように $Source$ をコピーして $Key$ と $Value$ からなる辞書オブジェクト、$Target$ を $Query$ として捉えて、$Query$ と $Key$ の内積を Softmax で正規化したものが注意の重み、そしてその注意の重みと $Value$ との内積を計算します。
Attention(Q, K, V) = Softmax \left( QK^T \right) Vこのように $Source$ を $Key$ と $Value$ にコピーすることで、$Source$ と $Target$ 間の非自明な変換が獲得されることを期待します。
しかしこの場合モデルの次元 $d_{k}$ が大きくなると $Q$ と $K$ の内積が大きくなりすぎてしまうため、$d_{k}$ の平方根でスケーリングします。
Attention(Q, K, V) = Softmax \left( \frac{QK^T}{\sqrt {d_{k}}} \right) V上図の注意機構を Source-Target Attention と呼び、$Q, K, V$ がすべて $Source$ のコピーである下図の注意機構を Self-Attention と呼びます。
Transformer は Encoder で Self-Attention を、Decoder では Self-Attention と Source-Target Attention を使用します。ただし、Decoder の Self-Attention では訓練時に未来の情報を参照しないようにマスクします。
Multi-Head Attention
Transformer では全体に単一の Scaled Dot-Product Attention を適用するのではなく、複数の部分に分割する Multi-Head を採用しており、各 Head へ入力する前に Key, Value, Query に全結合を適用し、各 Head からの出力を連結した後に再度全結合を適用します。
MultiHeadAttention(Q, K, V) = \left[ Attention_1(QW^Q_1, KQ^K_1, VW^V_1), ..., Attention_h(QW^Q_h, KQ^K_h, VW^V_h) \right] Wこのように複数の部分ごとに Attention を実行することで、各 Head が異なる部分空間表現の獲得を期待します。
Position-wise Feed-Forward Network
Position-wise Feed-Forward Network は系列長の各位置に対して 2層の全結合を適用します。元論文 [1] では outer の次元は 512、inner の次元はその 4倍の 2048 で、inner の活性化関数は ReLU です。
FFN(x) = max(0, xW_{inner} + b_{inner})W_{outer} + b_{outer}Positional Encoding
Transformer には RNN のような再帰的な構造がないため、系列長の順序を考慮することができません。そこで、各単語の位置情報を埋め込み層の直後に加えます。 [9]
Positional Encoding では以下の式が採用されています。
PE_{(pos, 2i)} = \sin \left( \frac{pos}{10000^{\frac{2i}{d_{k}}}} \right) \\ PE_{(pos, 2i+1)} = \cos \left( \frac{pos}{10000^{\frac{2i}{d_{k}}}} \right)ここで、$d_{k}$ は埋め込み層の次元、$pos$ は単語の位置、$2i, 2i+1$ はそれぞれ埋め込み層の次元の偶数番目と奇数番目を表しています。最大系列長を 97、埋め込み層の次元を 512 としたとき、Positional Encoding を可視化すると下図のようになります。
Transformer がこの式を採用している理由は、$PE_{pos+\tau}$ が $PE_{pos}$ の線形関数として表現できるからです。
ここで、
u_i = \frac{1}{10000^{\frac{2i}{d_{k}}}}とおくと、Positional Encoding の式を以下のようになります。
PE_{(pos, 2i)} = \sin (pos \cdot u_i) \\ PE_{(pos, 2i+1)} = \cos (pos \cdot u_i)すると $PE_{pos+\tau}$ は、
\begin{align} PE_{pos+\tau} &= \sin ((pos+\tau) \cdot u_i) \\ &= \sin (pos \cdot u_i) \cos (\tau u_i) + \cos (pos \cdot u_i) \sin (\tau u_i) \\ &= PE_{(pos, 2i)} \cos(\tau u_i) + PE_{(pos, 2i+1)} \sin (\tau u_i) \end{align}となり、$PE_{(pos, 2i)}, PE_{(pos, 2i+1)}$ の線形和で表せます。
結果
Training loss and perplexity
訓練時の損失関数と誤認識率のログを可視化したものが下の図です。左のグラフが損失関数、右のグラフが Perplexity になっており、横軸はエポック数、縦軸はそれぞれ損失関数の値と Perplexity を表しています。
Validation BLEU score
これで日英翻訳モデルが訓練できたので検証用データで性能評価をしてみました。検証には貪欲法を採用しました。
今回の性能評価には Bilingual Evaluation Understudy (BLEU) [10] を算出しました。BLEU の算出には nltk を使って、NIST による平滑化を行いました。検証データとして dev を使用すると以下のような結果になりました。ハイフンの後の数字は n-gram を表しています。
BLEU-4 Score 1.84 BLEU-1 Score 12.22Self-Attention の可視化
Transformer は Attention マップを可視化できます。下図は Encoder の 5, 6層目の Self-Attention の各ヘッドにおける Attention マップを可視化したものを示しており、カラーマップは gray で表示しています。
Encoder 5
Encoder 6
5層目は各ヘッドが各々特定の単語に対して注意を向けているように見えますが、6層目の中間ヘッドは上手く機能していないように見えます。
参考
JESC
Deep learning library that builds on and extends Microsoft CNTKNatural Language : Machine Translation Part1 - Japanese-English Subtitle Corpus
- Reid Pryzant, Youngjoo Chung, Dan Jurafsky, and Denny Britz. "JESC: Japanese-English Subtitle Corpus", arXiv preprint arXiv:1710.10639 (2017).
- Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. "Attention Is All You Need", Advances in neural information processing systems. 2017. p. 5998-6008.
- Yougnhui Wu, Mike Schuster, Zhifen Chen, Quoc V. Le, Mohammad Norouzi, et. al. "Google's Neural Machine Translation System: Bridging the Gap between Human and Machine Translation", arXiv preprint arXiv:1609.08144, 2016.
- Jonas Gehring, Michael Auli, David Grangier, Denis Tarats, and Tann N. Dauphin, "Convolutional Sequence to Sequence Learning", arXiv preprint arXiv:1705.03122 (2017).
- Ofir Press and Lior Wolf. "Using the Output Embedding to Improve Language Models.", arXiv preprint arXiv:1608.05859 (2016).
- Xaiver Glorot and Yoshua Bengio. "Understanding the difficulty of training deep feedforward neural networks", Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics. 2010, p. 249-256.
- Diederik P. Kingma and Jimmy Lei Ba. "Adam: A method for stochastic optimization", arXiv preprint arXiv:1412.6980 (2014).
- Leslie N. Smith. "Cyclical Learning Rates for Training Neural Networks", 2017 IEEE Winter Conference on Applications of Computer Vision. 2017, p. 464-472.
- Sainbayer Sukhbaatar, Arthur Szlam, Jason Weston, and Rob Fergus, "End-To-End Memory Networks", Advances in Neural Information Processing Systems. 2015. p. 2440-2448.
- Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. "BLEU: a Method for Automatic Evaluation of Machine Translation", Proceedings of the 40-th Annual Meeting of the Association for Computational Linguistics (ACL). 2002, p. 311-318.






