- 投稿日:2020-07-09T20:16:28+09:00
Docker。自分がよく使うコマンドをaliasに設定「説明付き」
はじめに
私が思うよく使うDockerコマンドは、
bash_profileや、bash_rcでaliasに設定して使っています。自分の誹謗録ようなものですが、興味のある方はお試しください。
そして、もし有用なaliasを使っているならぜひ共有頂けると嬉しいです。自分も勉強目的で書いているので、間違った情報があるかもしれません。
そこはご指摘頂けるとありがたいです。alias設定内容
~/.bash_profile
以下の構文を追加
if [ -f ~/.myalias ]; then source ~/.myalias fi~/.myalias
● gist
https://gist.github.com/genie-oh/d73a224e7cb3cffab2868182eb79ccad# show full command & execute alias al='_(){ CMD=$(alias | grep "alias $1=" | cut -d = -f 2- | sed "s:^.\(.*\).$:\1:"); ARG=$(echo $@ | sed "s/^$1//"); CMD="${CMD}${ARG}"; echo "execute : ${CMD}"; echo " "; bash -c "${CMD}"; };_' # docker alias al-dock='cat ~/.myalias | grep dock | sed "s/=/ \t\= /"' alias dock='docker' alias docki='docker images' alias dockps='docker ps -a' alias dockrrm='docker run --rm' alias dockeit='docker exec -it' alias dockrm='docker rm -f' alias dockrmi='docker rmi -f' alias dockrma='docker rm -f $(docker ps -aq)' alias dockrmia='docker rmi -f $(docker images -aq)' alias dockins='docker inspect' alias dockip='docker inspect --format="{{range .NetworkSettings.Networks}}{{.IPAddress}}{{end}}"' alias docklogs='dock logs --tail 50 --follow --timestamps' alias dockc='docker-compose' alias dockcb='docker-compose build' alias dockcu='docker-compose up -d' alias dockcd='docker-compose down' alias dockccl='grep container_name docker-compose.yml'※説明
al-dock
Docker関連aliasのリストを表示
$ al al-dock execute : cat ~/.myalias | grep dock | sed "s/=/ \t\= /" # docker alias al-dock = 'cat ~/.myalias | grep dock | sed "s/=/ \t\= /"' alias dock = 'docker' alias docki = 'docker images' alias dockps = 'docker ps -a' alias dockrrm = 'docker run --rm' alias dockeit = 'docker exec -it' alias dockrm = 'docker rm -f' alias dockrmi = 'docker rmi -f' alias dockrma = 'docker rm -f $(docker ps -aq)' alias dockrmia = 'docker rmi -f $(docker images -aq)' alias dockins = 'docker inspect' alias dockip = 'docker inspect --format="{{range .NetworkSettings.Networks}}{{.IPAddress}}{{end}}"' alias docklogs = 'dock logs --tail 50 --follow --timestamps' alias dockc = 'docker-compose' alias dockcb = 'docker-compose build' alias dockcu = 'docker-compose up -d' alias dockcd = 'docker-compose down' alias dockccl = 'grep container_name docker-compose.yml'dockc, dockcb, dockcu, dockcd
docker-compose関連
docker-composeのbuild,up,downalias dockc = 'docker-compose' alias dockcb = 'docker-compose build' alias dockcd = 'docker-compose down' alias dockcu = 'docker-compose up -d'dockccl
docker-compose.yml内のコンテナーネームのリストを出力
alias dockccl = 'grep container_name docker-compose.yml'$ al dockccl execute : grep container_name docker-compose.yml container_name: lamp-web container_name: lamp-php ...省略docki
docker imageのリストを出力
alias docki = 'docker images'$ al docki execute : docker images REPOSITORY TAG IMAGE ID CREATED SIZE centos 7 b5b4d78bc90c 8 weeks ago 203MB docker-lamp-test_php latest e6d67d8f48cf 17 minutes ago 666MB ...省略dockps
dockerのコンテナーリストと実行状態を表示
alias dockps = 'docker ps -a'$ al dockps execute : docker ps -a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 6116324251dd docker-lamp-test_php "docker-php-entrypoi…" 17 minutes ago Up 17 minutes 0.0.0.0:32769->9000/tcp lamp-php ...省略dockeit
実行中のコンテナーで、interactive&ttyモードでコマンド実行
docker exec --interective --ttyalias dockeit = 'docker exec -it'$ al dockeit lamp-php bash execute : docker exec -it lamp-php bash root@37bcdbd02f92:/var/www/html# ls config gulpfile.js home_root home_sub nodeappdockrrm
コンテナーでコマンドを実行後、即時にコンテナーを終了する
コンテナー作成▶コマンド実行▶コンテナー終了alias dockrrm = 'docker run --rm'$ al dockrrm composer php -v execute : docker run --rm composer php -v PHP 7.4.7 (cli) (built: Jun 11 2020 18:58:32) ( NTS ) ...省略dockins
コンテナーの状態を確認
alias dockins = 'docker inspect'$ al dockins lamp-php execute : docker inspect lamp-php [ { "Id": "6116324251ddffc8090cc605d391f89a951aeb46d32636dd62476a225a894c51", "Created": "2020-07-01T13:30:27.11145Z", ...省略dockip
コンテナーの状態で、IPだけを取得
alias dockip = 'docker inspect --format="{{range .NetworkSettings.Networks}}{{.IPAddress}}{{end}}"'$ al dockip lamp-php execute : docker inspect --format="{{range .NetworkSettings.Networks}}{{.IPAddress}}{{end}}" lamp-php 172.30.0.5docklogs
コンテナーのログを確認
alias docklogs = 'dock logs --tail 50 --follow --timestamps'$ al docklogs lamp-php execute : docker logs --tail 50 --follow --timestamps lamp-php 2020-07-01T13:30:28.338589500Z [01-Jul-2020 22:30:28] NOTICE: fpm is running, pid 1 2020-07-01T13:30:28.340324600Z [01-Jul-2020 22:30:28] NOTICE: ready to handle connectionsdockrm, dockrmi
特定のコンテナー、またはイメージを削除
alias dockrm = 'docker rm -f' alias dockrmi = 'docker rmi -f'dockrma, dockrmia
すべてのコンテナー、またはイメージを削除
alias dockrma = 'docker rm -f $(docker ps -aq)' alias dockrmia = 'docker rmi -f $(docker images -aq)'
- 投稿日:2020-07-09T12:47:36+09:00
【AWS】Wordpress「返答が正しいJSONレスポンスではありません」の対処法
現象
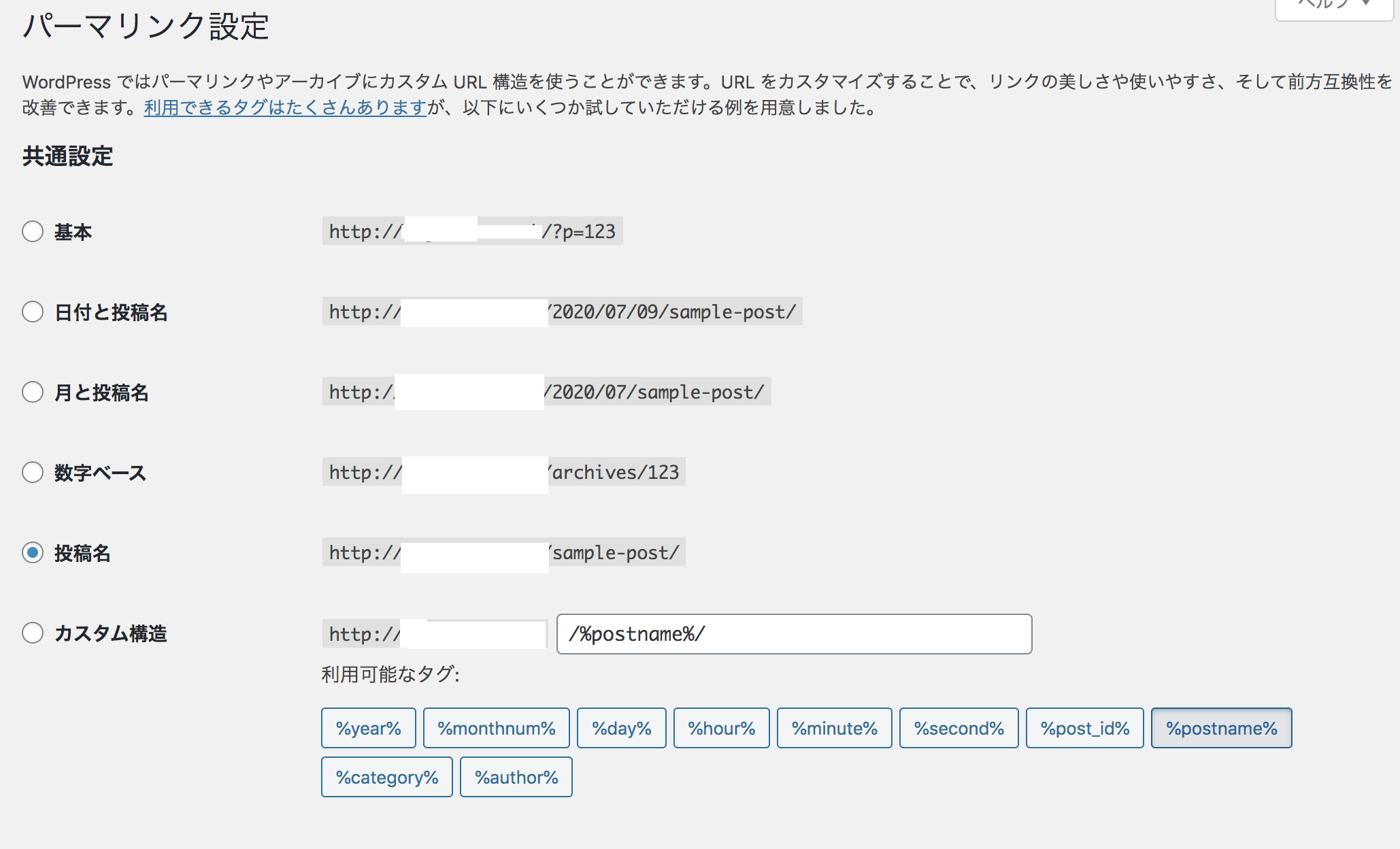
Amazon LinuxインスタンスでWordpressをたてた。その際パーマリンクを基本→投稿名に変更して記事を投稿しようとするも、「返答が正しいJSONレスポンスではありません」とエラーが出て投稿できない&トップページ以外が表示できなくなってしまった。
wordpress返答が正しいJSONレスポンスではありません
上記記事でapache設定が原因とわかった。sudo vi /etc/apache2/apache2.conf記事の通り上記コマンドで設定ファイルに入ろうとするも、Amazon Linuxではそのようなファイルがなかった。
Amazon LinuxはRedHat系ベースに対し、上のものはDabianの設定ファイルになっているためだ。参考
http://www.linux.net-japan.info/install08.html
https://www.acrovision.jp/service/aws/?p=653対処法
AWSドキュメントに方法が書いてあった。
WordPress がパーマリンクを使用できるようにするには1.該当のインスタンスに接続した上で、下記コマンドでファイルに入る。
sudo vim /etc/httpd/conf/httpd.conf2.
<Directory "/var/www/html">で始まるセクションを見つける。(※複数の AllowOverride行があるため、間違えないように。必ず<Directory "/var/www/html">セクションの行を探す。vimで/htmlと検索すると、すぐ見つかる。)<Directory "/var/www/html"> # # Possible values for the Options directive are "None", "All", # or any combination of: # Indexes Includes FollowSymLinks SymLinksifOwnerMatch ExecCGI MultiViews # # Note that "MultiViews" must be named *explicitly* --- "Options All" # doesn't give it to you. # # The Options directive is both complicated and important. Please see # http://httpd.apache.org/docs/2.4/mod/core.html#options # for more information. # Options Indexes FollowSymLinks # # AllowOverride controls what directives may be placed in .htaccess files. # It can be "All", "None", or any combination of the keywords: # Options FileInfo AuthConfig Limit # AllowOverride None # # Controls who can get stuff from this server. # Require all granted </Directory>3.上のセクションを
AllowOverride None行をAllowOverride Allに変更。(None→All)4.ファイルを:wqで保存する。
5.上記設定を反映させるため、
sudo systemctl restart httpd.serviceで再起動させる。sudo systemctl status httpd.serviceで念のためアクティブになっているか確認。上記設定をするとパーマリンクを基本以外にしても、記事の投稿ができたりトップページ以外も参照できるようになる。
- 投稿日:2020-07-09T10:57:25+09:00
cshで複数行のコメントアウト
複数行を一度にコメントアウトしたいとき、
<< コメントアウト文 コメントアウト文で囲む。
shやbashでは問題なかったのですが、
cshではエラーが出てしまいました。
うまくいったものがこちら。Hello_1.csh#!/bin/csh echo "Takato : Hello, Nadeshiko!" echo "Nadeshiko : Hello Takato." :<< 'COMMENT_OUT' echo "Takato : Hello Riichiro, too." echo "Riichiro : ... Hello" 'COMMENT_OUT'実行結果
Takato : Hello, Nadeshiko!
Nadeshiko : Hello Takato.
よく記事でみかけるものの、うまくいかなかったコメントアウト例Hello_2.csh#!/bin/csh echo "Takato : Hello, Nadeshiko!" echo "Nadeshiko : Hello Takato." << COMMENT_OUT echo "Takato : Hello Riichiro, too." echo "Riichiro : ... Hello" COMMENT_OUT実行結果
Takato : Hello, Nadeshiko!
Nadeshiko : Hello Takato.
Invalid null command.
結論
:<< 'コメントアウト文' 'コメントアウト文'以下がポイントのようです。
1. 文頭に「:(コロン)」を入れる
2. コメントアウトの文字列はシングルクォートで囲む
shとbashでもうまくいきました。
会話は大好きなCLOCK ZEROというゲームからです。
幼馴染の撫子に声をかけてくる転校生の鷹斗に対して不愛想な態度をとる理一郎がかわいい。
- 投稿日:2020-07-09T10:56:11+09:00
TOPコマンド結果をUSERで抽出してCSV出力する
はじめに
様々な理由から、LinuxのTOPコマンドでのパフォーマンス測定を余儀なくされている同志の方々に送ります。
目的
LinuxのTOPコマンドをバッチモードで出力したファイルを、
python3を使ってcsvファイルに整形します。top.csv(出力例)timestamp,PID,USER,PR,NI,VIRT,RES,SHR,S,%CPU,%MEM,TIME+,COMMAND 10:00:00,1000,root,20,0,160000,2000,1640,R,10.0,0.2,0:00.02,top 10:00:00,3400,httpd,20,0,150000,2000,1700,S,0.0,0.3,0:07.98,nginx:用意するもの
TOPのバッチモードで出力したファイルを用意します
TOPコマンドファイルtop -b -d 20 -c > top_org.logtop_org.logtop - 10:00:00 up 1 days, 44 min, 2 users, load average: 0.00, 0.01, 0.01 Tasks: 100 total, 1 running, 99 sleeping, 0 stopped, 1 zombie %Cpu(s): 2.0 us, 4.0 sy, 0.0 ni, 80.0 id, 5.0 wa, 0.0 hi, 2.0 si, 0.0 st KiB Mem : 1000000 total, 60000 free, 700000 used, 200000 buff/cache KiB Swap: 2000000 total, 90000 free, 2000000 used. 70000 avail Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 1000 root 20 0 160000 2000 1640 R 10.0 0.2 0:00.02 top -b -d 20 -c 4500 apache 20 0 440000 1000 8 S 0.0 0.1 0:00.01 /usr/sbin/httpd 17000 mysql 20 0 1130000 7000 0 S 0.0 0.7 20:00.00 /usr/sbin/mysqld 2 root 20 0 0 0 0 S 0.0 0.0 0:00.00 [kthreadd] 4 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 [kworker/0:0H] 6 root 20 0 0 0 0 S 0.0 0.0 0:00.00 [ksoftirqd/0] ・・・(以下略)お急ぎの方へ
本記事末尾に、分割されていないソースコードがあります。そちらを参照下さい。
その際、以下の部分だけは変更して下さい。毎回変更する部分
・抽出対象のUSER
・「TOPコマンドファイル」の場所
・「TOPコマンドファイルを整形したCSVファイル」の場所
を以下の部分で設定しています。
希望条件や、環境に合わせて変更してください。.py''' 設定情報 ''' # 抽出するUSER(未設定だと全USERで抽出。,区切りで設定) user_array =['root'] # カレントDir取得 current_dir = os.getcwd() # inputファイル名(Full PATH) input_file_name=f"{current_dir}\\before\\top_org.log" # outputファイル名(Full PATH) output_file_name=f"{current_dir}\\after\\top_csv.csv"ソースコード
解説
- 必要情報の設定
- TOPコマンドファイルの読み込み
- 先頭カラムに使うtimestampを抽出
- 対象USERのプロセスを抽出
- CSVファイル出力
という順番で進んでいきます。
1. 必要情報の設定
抽出対象となるUSERや、TOPコマンドファイルが配置している場所の指定を行います。
.py# -*- coding: utf-8 import re import os import csv ''' 設定情報 ''' # 抽出するUSER(未設定だと全USERで抽出。,区切りで設定) user_array =['root'] # カレントDir取得 current_dir = os.getcwd() # inputファイル名(Full PATH) input_file_name=f"{current_dir}\\before\\top.log" # outputファイル名(Full PATH) output_file_name=f"{current_dir}\\after\\top.log" # 1回のTOPコマンド結果の中でプロセス行の始まりは何行目か process_row_start = 8 # TOPコマンド結果でUSERカラムの位置は何カラム目か user_column = 2 # TOPコマンド結果でCOMMANDカラムの位置は何カラム目か command_column = 12
2. TOPコマンドファイルの読み込み
.py# inputファイル読み込み f = open(f"{input_file_name}", "r") toplog_lines = f.readlines() f.close()inputファイル(TOPコマンドファイル)を、1行ずつ読み込んで変数
toplog_linesに格納します。3. 先頭カラムに使うtimestampを抽出
.py# timestamp正規表現 r_top_timestamp = re.compile("top - ([0-9:]+)+") timestamp_list = [] roop_cnt = 0 for toplog_line in toplog_lines : # 正規表現でtimestamp一致したらTOPコマンドファイルの行番号を行番号を配列に入れる if r_top_timestamp.search(toplog_line) != None: timestamp_list.append(roop_cnt) roop_cnt += 1ここでは、timestamp(
top - 10:00:00 up 1 days, 44 min, 2 users, load average: 0.00, 0.01, 0.01)が、
TOPコマンドファイルの何行目に入っているのか確認し、timestamp_listに行番号を格納しています。4. 対象USERのプロセスを抽出
まずは、プロセス抽出ループの中で必要な変数を定義します。
.py# TOPコマンドでプロセス行の始まりの位置 process_row_start = 8 # TOPコマンドでプロセス行のUSERカラムの位置 user_column = 2 # TOPコマンドでプロセス行のCOMMANDカラムの位置 command_column = 12 # 1回のTOPコマンド行数カウント用変数 rows_count = 0 # timestamp格納用変数 tmp_timestamp = '' # csvに出力する文字列を格納するための配列(tmp) tmp_output_csv_list = [] # csvに出力する文字列を格納するための配列(実際の書き出しに利用) output_csv_list = []
次はTOPコマンドファイルを1行ずつループします。
以下を実施しています。
・TOPコマンド実施時間(タイムスタンプ)を抽出
・プロセスを1カラムずつ確認し抽出対象USERであれば、csv出力対象とする.pyfor toplog_line in toplog_lines : # 1回のTOP行数カウント +1 rows_count +=1 # 行末尾の改行を削除 toplog_line = toplog_line.rstrip() # 改行のみの場合、次の行へ if not toplog_line : continue # タイムスタンプ行の場合、リストに追加し、次の行へ if r_top_timestamp.search(toplog_line) != None: print(toplog_line) tmp_timestamp = r_top_timestamp.search(toplog_line).group(1) # 1回のTOPコマンド結果、行数カウント初期化 rows_count = 1 continue # プロセス行の場合、Userが一致すれば抽出する if rows_count >= process_row_start: column_number = 0 row_data = toplog_line.split(" ") # タイムスタンプを設定 tmp_output_csv_list = [tmp_timestamp] # 行末まで繰り返す for column_data in row_data: if column_data =="": # 空白の場合次のカラムへ continue column_number += 1 # COMMANDカラムまでのデータをtmpリストに入れる if column_number <= command_column : tmp_output_csv_list.append(column_data) else : continue # 抽出対象レコードかをチェックする # 抽出対象USER、または、user_array指定なしのとき抽出対象レコード選定 if column_number == user_column : user_key_flg = True for key_user in user_array: # 抽出対象USER、または、user_array指定なしのとき抽出対象レコード if ( str(column_data) == key_user ): user_key_flg = True break else: user_key_flg = False if user_key_flg == True : pass else: break # for-else :条件を満たしたときのみ、CSV抽出リストに追加する else: output_csv_list.append(tmp_output_csv_list)5. CSVファイル出力
csv抽出リスト
output_csv_listの中身をcsvに出力します。.py# CSV書き出し csv_header = ['timestamp','USER','PR','NI','VIRT','RES','SHR','%CPU','%MEM','TIME+','COMMAND'] with open(f'{output_file_name}','w') as f: csv_writer = csv.writer( f, delimiter = ',', lineterminator = '\n') csv_writer.writerow(csv_header) csv_writer.writerows(output_csv_list)
csv_writer = csv.writer( f, delimiter = ',', lineterminator = '\n')の、
delimiter = ','を、
delimiter = '\t'にすれば、tsvファイル(タブ区切りファイル)にもなります。
お好みでどうぞ。ソースコードまとめ
.py''' Topコマンドのプロセス行をUSERで抽出しcsvファイルに出力する timestamp,USER,PR,NI,VIRT,RES,SHR,%CPU,%MEM,TIME+,COMMAND ''' import re import os import csv ''' 設定情報 ''' # 抽出するUSER(未設定だと全USERで抽出。,区切りで設定) user_array =['apache','httpd'] # カレントDir取得 current_dir = os.getcwd() # inputファイル名(Full PATH) input_file_name=f"{current_dir}\\before\\top.log" # outputファイル名(Full PATH) output_file_name=f"{current_dir}\\after\\top.log" # TOPコマンドでプロセス行の始まりの位置 process_row_start = 8 # TOPコマンドでプロセス行のUSERカラムの位置 user_column = 2 # TOPコマンドでプロセス行のCOMMANDカラムの位置 command_column = 12 # timestamp正規表現 r_top_timestamp = re.compile("top - ([0-9:]+)+") ######## main 処理 ############# if __name__ == '__main__' : '''---------------------- toplogファイル読み込み ----------------------''' # inputファイル読み込み f = open(f"{input_file_name}", "r") toplog_lines = f.readlines() f.close() '''---------------------- timestamp行の抽出 ----------------------''' timestamp_list = [] roop_cnt = 0 for toplog_line in toplog_lines : # 正規表現でtimestamp一致したら行番号を配列に入れる if r_top_timestamp.search(toplog_line) != None: timestamp_list.append(roop_cnt) roop_cnt += 1 '''-------------------------- 対象Userのプロセスを抽出 --------------------------''' rows_count = 0 tmp_timestamp = '' tmp_output_csv_list = [] output_csv_list = [] for toplog_line in toplog_lines : # 1回のTOP行数カウント +1 rows_count +=1 # 行末尾の改行を削除 toplog_line = toplog_line.rstrip() # 改行のみの場合次の行へ if not toplog_line : continue # タイムスタンプ行の場合、リストに追加する if r_top_timestamp.search(toplog_line) != None: print(toplog_line) tmp_timestamp = r_top_timestamp.search(toplog_line).group(1) # 1回のTOPコマンド結果、行数カウント初期化 rows_count = 1 continue # プロセス行の場合、Userが一致すれば抽出する if rows_count >= process_row_start: column_number = 0 row_data = toplog_line.split(" ") # タイムスタンプを設定 tmp_output_csv_list = [tmp_timestamp] # 行末まで繰り返す for column_data in row_data: if column_data =="": # 空白の場合次のカラムへ continue column_number += 1 # COMMANDカラムまでのデータをtmpリストに入れる if column_number <= command_column : tmp_output_csv_list.append(column_data) else : continue # 抽出対象レコードかをチェックする # 抽出対象USER、または、user_array指定なしのとき抽出対象レコード if column_number == user_column : user_key_flg = True for key_user in user_array: # 抽出対象USER、または、user_array指定なしのとき抽出対象レコード if ( str(column_data) == key_user ): user_key_flg = True break else: user_key_flg = False if user_key_flg == True : pass else: break # for文をbreak以外で抜けたらCSV抽出リストに追加する else: output_csv_list.append(tmp_output_csv_list) '''-------------------------- ファイル書き込み --------------------------''' # CSV書き出し csv_header = ['timestamp','USER','PR','NI','VIRT','RES','SHR','%CPU','%MEM','TIME+','COMMAND'] with open(f'{output_file_name}','w') as f: csv_writer = csv.writer( f, delimiter = ',', lineterminator = '\n') csv_writer.writerow(csv_header) csv_writer.writerows(output_csv_list)2020/07/09
# -*- coding: utf-8はpython3では非推奨でしたので削除しました。
参考記事:https://qiita.com/KEINOS/items/6efc1147b917d7811b5b以上です。
感想
ツールもなく、TOPコマンド結果だけ渡されて、「まとめといて」と言われる方々の負担が減りますように。
- 投稿日:2020-07-09T10:40:19+09:00
apt-get のプロキシ設定は小文字!!!!!
プロキシ環境下で Docker イメージをビルドしたいことがあったので、ARG でプロキシの情報を設定できるようにしてビルドした。
FROM debian # プロキシ環境下でビルドする場合に指定する ARG HTTP_PROXY ARG HTTPS_PROXY RUN apt-get update \ && apt-get install -y ... \ && rm -rf /var/lib/apt/lists/*$ docker build --build-arg HTTP_PROXY=... --build-arg HTTPS_PROXY=... . (略) Err:1 http://deb.debian.org/debian buster InRelease Cannot initiate the connection to prod.debian.map.fastly.net:80 (2a04:4e42:1a::204). - connect (101: Network is unreachable) Could not connect to prod.debian.map.fastly.net:80 (151.101.108.204), connection timed out Cannot initiate the connection to deb.debian.org:80 (2a04:4e42:1a::645). - connect (101: Network is unreachable) Could not connect to deb.debian.org:80 (151.101.110.133), connection timed outは?
プロキシ通せてないやんけ。なぜこれでうまくいかないのか半日頭を悩ませて判明した正解がこちら。
FROM debian # プロキシ環境下でビルドする場合に指定する ARG http_proxy ARG https_proxy RUN apt-get update \ && apt-get install -y ... \ && rm -rf /var/lib/apt/lists/*$ docker build --build-arg http_proxy=... --build-arg https_proxy=... .「環境変数は大文字で指定するもの」「環境変数が Case Sensitive なわけがない」という思い込みが敗因です・・・。
各位プロキシ環境下で apt-get を使う際は気をつけましょう。