- 投稿日:2020-07-09T21:59:16+09:00
Objectをnewする
はじめに
Javaの
Objectクラスはすべてのクラスのスーパークラスで非常に重要なクラスですが、それ自体をnewすることはあまりないのではないでしょうか?
この記事ではnew Object()が有意義となる二つのコード例を紹介します。メソッド内にメソッドを定義する
以下は「Javaで数学の組み合わせ(Combination)を実装する - Qiita」のコメントに記載されたコード例です。文字列の配列
dataからk個取る組み合わせを列挙して返すメソッドです。static List<String[]> combination(String[] data, int k) { List<String[]> result = new ArrayList<String[]>(); combination(data, 0, new String[k], 0, result); return result; } static void combination(String[] data, int di, String[] comb, int ci, List<String[]> result) { if (ci == comb.length) { result.add(comb.clone()); return; } for ( ; di <= data.length - (comb.length - ci); di++) { comb[ci] = data[di]; combination(data, di + 1, comb, ci + 1, result); } }2つのメソッドから構成されていて、外部から直接呼び出されるのは2引数の
combinationで、5引数のcombinationは内部的に利用されています。5引数のcombinationは自分自身を再起呼び出ししていますが、5引数の内、3引数(data,comb,result)は全く同じ値を引数として指定しています。
もしJavaがメソッドを入れ子にして定義できるのであれば、再起呼び出し時に同じ引数を記述しなくても済むはずです。残念ながらJavaではメソッドを入れ子にすることができません。
そこでnew Object()を使ってこれを書き直してみます。static List<String[]> combination(String[] data, int k) { int length = data.length; List<String[]> result = new ArrayList<String[]>(); String[] comb = new String[k]; new Object() { void combination(int di, int ci) { if (ci == k) { result.add(comb.clone()); return; } for (; di <= length - (k - ci); di++) { comb[ci] = data[di]; combination(di + 1, ci + 1); } } }.combination(0, 0); return result; }5引数の
combinationはnew Object() {}の内側に記述して固定の3引数(data,comb,result)は削除しました。
このコードのnew Object() {}は無名のインナークラスを定義して、同時にそのクラスのインスタンスを作成します。new Object() {}の後の.combination(0, 0)はインナークラス内で定義されているcombination(int di, int ci)を呼び出します。
固定の3変数(data,comb,result)はインナークラスの中から参照可能なので、呼び出しごとに引数で渡してやる必要はなくなります。
new Object()で無駄なインスタンスを作っていますが、1個作るだけなのでオーバーヘッドは小さいです。再起呼び出し時の引数が減るので、スタックの消費量は減ります。一時的なデータ保管のためのクラス
以下のようなクラスがあったとします。
public class Person { private final String name; private final String age; public Person(String name, String age) { this.name = name; this.age = age; } public String getName() { return this.name; } public String getAge() { return this.age; } }さらに以下のような
Personのリストがあったとします。List<Person> list = List.of( new Person("Yamada", "18"), new Person("Ichikawa", "72"), new Person("Sato", "39"), new Person("Tanaka", "9"));これを
ageで昇順にソートすることを考えてみます。ageは文字列なので整数としてソートするためにはこのように記述する必要があります。List<Person> result = list.stream() .sorted(Comparator.comparingInt(p -> Integer.parseInt(p.getAge()))) .collect(Collectors.toList());これはこれでうまくいきますが、値を比較する都度
Integer.parseInt(p.getAge())が2回ずつ実行されてしまうので、あまり効率がよくありません。高速なソートのアルゴリズムでもInteger.parseIntは $ 2n \log n $ 回実行されてしまいます。Map.Entry
Personのインスタンスとageを整数化したものをペアにすれば、この問題は解決します。こういう時、一時的な格納場所としてよく利用されるのがMap.Entryクラスです。List<Person> result = list.stream() .map(p -> Map.entry(Integer.parseInt(p.getAge()), p)) .sorted(Comparator.comparingInt(Entry::getKey)) .map(Entry::getValue) .collect(Collectors.toList());整数の
ageの計算は1回で済みますが、Map.Entryが使われている所が直観的にわかりにくいです。Records
Java14ではデータ保管のための不変クラスを簡単に定義できるRecordsという機能が追加されています。これを使うとこうなります。
record PersonWithAge(Person p, int age) { PersonWithAge(Person p) { this(p, Integer.parseInt(p.getAge())); } } List<Person> result = list.stream() .map(PersonWithAge::new) .sorted(Comparator.comparingInt(PersonWithAge::age)) .map(PersonWithAge::p) .collect(Collectors.toList());わかりやすくなりましたが、一時保管用のクラスを定義していて少しおおげさな感じもします。
new Object()
new Object()を使うとこうなります。List<Person> result = list.stream() .map(p -> new Object() { int intAge = Integer.parseInt(p.getAge()); Person person = p; }) .sorted(Comparator.comparingInt(obj -> obj.intAge)) .map(obj -> obj.person) .collect(Collectors.toList());
new Object() {...}はこの式の中だけで有効な一時的保管場所です。無名のクラスなのですが、この式の中ではintAgeとpersonというフィールドを持った一人前のクラスであると認識されています。まとめ
いかがだったでしょうか?
Objectクラスにもいろいろな使い方あることがわかっていただけたと思います。トリッキーな感じがするのであまりおすすめはできませんが、私はこういう書き方ができると知ってからけっこう使っています。
- 投稿日:2020-07-09T21:59:16+09:00
new Object() {}で一時的クラスを作成する
はじめに
Javaの
Objectクラスはすべてのクラスのスーパークラスで非常に重要なクラスですが、それ自体をnewすることはあまりないのではないでしょうか?
この記事ではnew Object()が有意義となる二つのコード例を紹介します。メソッド内にメソッドを定義する
以下は「Javaで数学の組み合わせ(Combination)を実装する - Qiita」のコメントに記載されたコード例です。文字列の配列
dataからk個取る組み合わせを列挙して返すメソッドです。static List<String[]> combination(String[] data, int k) { List<String[]> result = new ArrayList<String[]>(); combination(data, 0, new String[k], 0, result); return result; } static void combination(String[] data, int di, String[] comb, int ci, List<String[]> result) { if (ci == comb.length) { result.add(comb.clone()); return; } for ( ; di <= data.length - (comb.length - ci); di++) { comb[ci] = data[di]; combination(data, di + 1, comb, ci + 1, result); } }2つのメソッドから構成されていて、外部から直接呼び出されるのは2引数の
combinationで、5引数のcombinationは内部的に利用されています。5引数のcombinationは自分自身を再起呼び出ししていますが、5引数の内、3引数(data,comb,result)は全く同じ値を引数として指定しています。
もしJavaがメソッドを入れ子にして定義できるのであれば、再起呼び出し時に同じ引数を記述しなくても済むはずです。残念ながらJavaではメソッドを入れ子にすることができません。
そこでnew Object()を使ってこれを書き直してみます。static List<String[]> combination(String[] data, int k) { int length = data.length; List<String[]> result = new ArrayList<String[]>(); String[] comb = new String[k]; new Object() { void combination(int di, int ci) { if (ci == k) { result.add(comb.clone()); return; } for (; di <= length - (k - ci); di++) { comb[ci] = data[di]; combination(di + 1, ci + 1); } } }.combination(0, 0); return result; }5引数の
combinationはnew Object() {}の内側に記述して固定の3引数(data,comb,result)は削除しました。
このコードのnew Object() {}は無名のインナークラスを定義して、同時にそのクラスのインスタンスを作成します。new Object() {}の後の.combination(0, 0)はインナークラス内で定義されているcombination(int di, int ci)を呼び出します。
固定の3変数(data,comb,result)はインナークラスの中から参照可能なので、呼び出しごとに引数で渡してやる必要はなくなります。
new Object()で無駄なインスタンスを作っていますが、1個作るだけなのでオーバーヘッドは小さいです。再起呼び出し時の引数が減るので、スタックの消費量は減ります。一時的なデータ保管のためのクラス
以下のようなクラスがあったとします。
public class Person { private final String name; private final String age; public Person(String name, String age) { this.name = name; this.age = age; } public String getName() { return this.name; } public String getAge() { return this.age; } }さらに以下のような
Personのリストがあったとします。List<Person> list = List.of( new Person("Yamada", "18"), new Person("Ichikawa", "72"), new Person("Sato", "39"), new Person("Tanaka", "9"));これを
ageで昇順にソートすることを考えてみます。ageは文字列なので整数としてソートするためにはこのように記述する必要があります。List<Person> result = list.stream() .sorted(Comparator.comparingInt(p -> Integer.parseInt(p.getAge()))) .collect(Collectors.toList());これはこれでうまくいきますが、値を比較する都度
Integer.parseInt(p.getAge())が2回ずつ実行されてしまうので、あまり効率がよくありません。高速なソートのアルゴリズムでもInteger.parseIntは $ 2n \log n $ 回実行されてしまいます。Map.Entry
Personのインスタンスとageを整数化したものをペアにすれば、この問題は解決します。こういう時、一時的な格納場所としてよく利用されるのがMap.Entryクラスです。List<Person> result = list.stream() .map(p -> Map.entry(Integer.parseInt(p.getAge()), p)) .sorted(Comparator.comparingInt(Entry::getKey)) .map(Entry::getValue) .collect(Collectors.toList());整数の
ageの計算は1回で済みますが、Map.Entryが使われている所が直観的にわかりにくいです。Records
Java14ではデータ保管のための不変クラスを簡単に定義できるRecordsという機能が追加されています。これを使うとこうなります。
record PersonWithAge(Person p, int age) { PersonWithAge(Person p) { this(p, Integer.parseInt(p.getAge())); } } List<Person> result = list.stream() .map(PersonWithAge::new) .sorted(Comparator.comparingInt(PersonWithAge::age)) .map(PersonWithAge::p) .collect(Collectors.toList());わかりやすくなりましたが、一時保管用のクラスを定義していて少しおおげさな感じもします。
new Object()
new Object()を使うとこうなります。List<Person> result = list.stream() .map(p -> new Object() { int intAge = Integer.parseInt(p.getAge()); Person person = p; }) .sorted(Comparator.comparingInt(obj -> obj.intAge)) .map(obj -> obj.person) .collect(Collectors.toList());
new Object() {...}はこの式の中だけで有効な一時的保管場所です。無名のクラスなのですが、この式の中ではintAgeとpersonというフィールドを持った一人前のクラスであると認識されています。まとめ
いかがだったでしょうか?
Objectクラスにもいろいろな使い方あることがわかっていただけたと思います。トリッキーな感じがするのであまりおすすめはできませんが、私はこういう書き方ができると知ってからけっこう使っています。
- 投稿日:2020-07-09T21:16:23+09:00
テスト投稿
現在の開発環境を知らなかったから調べてみた
サーバ:Java
*フレームワーク→struts
apatch,Tomcatを使用apatch→webサーバのソフト
Tomcat→サーブレットコンテナクライアント:ASP.NetC#
*フレームワーク→ASP.NET
- 投稿日:2020-07-09T19:09:12+09:00
JavaFX 画面サイズが一定以下の場合はスクロールバーを出し、一定以上の場合は中のnodeをなるべく最大化する
今回のゴール
JavaFxをしようしてGUIアプリを作成する際にListViewを使用しましたが、以下のような要望がありました。
- ListViewはなるべく大きく表示したい
- → windowの大きさに連動して大きさが自動的に変化する
- windowサイズがある一定を下回った場合は、ListViewの大きさ変更をやめ、かつ、windowのスクロール表示にしたい。
そんな要望を満たすのに、それなりに苦労したので結果のメモ。
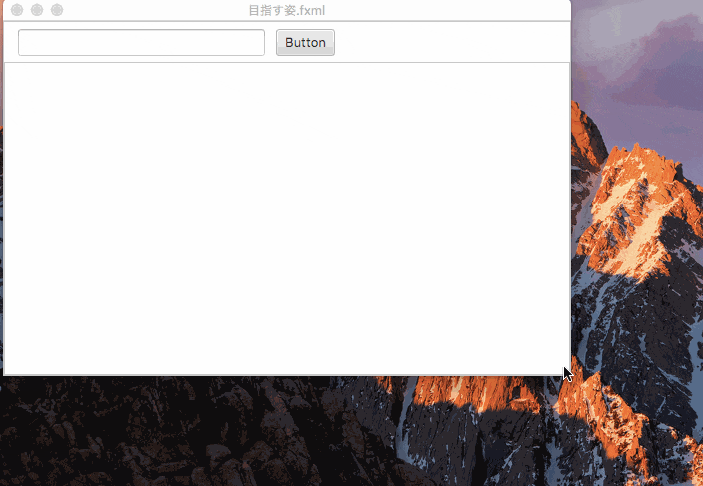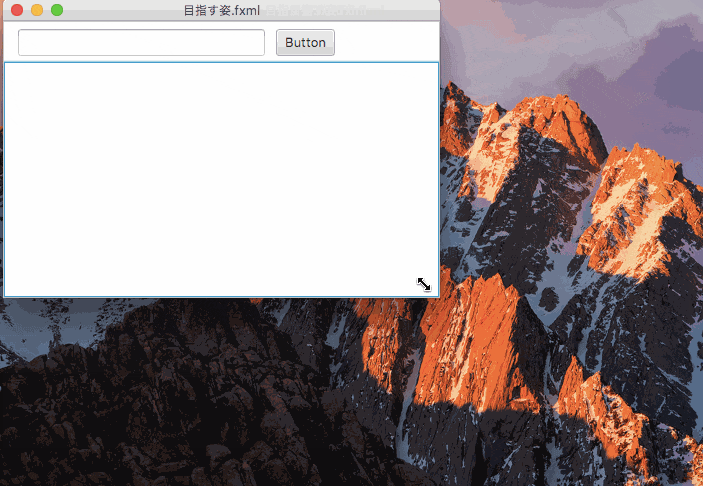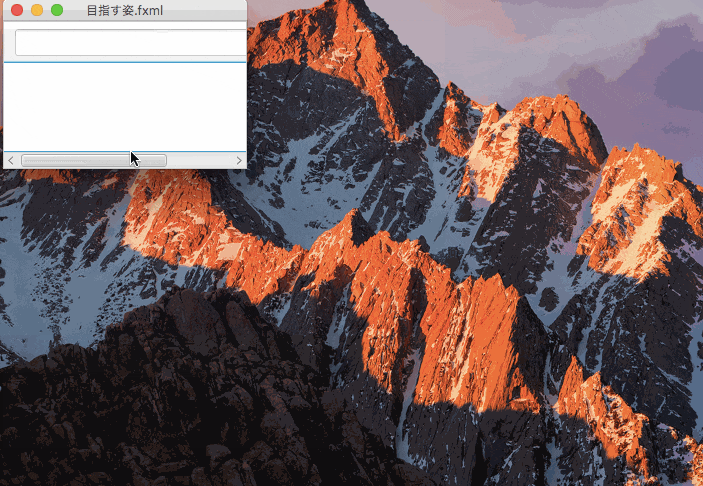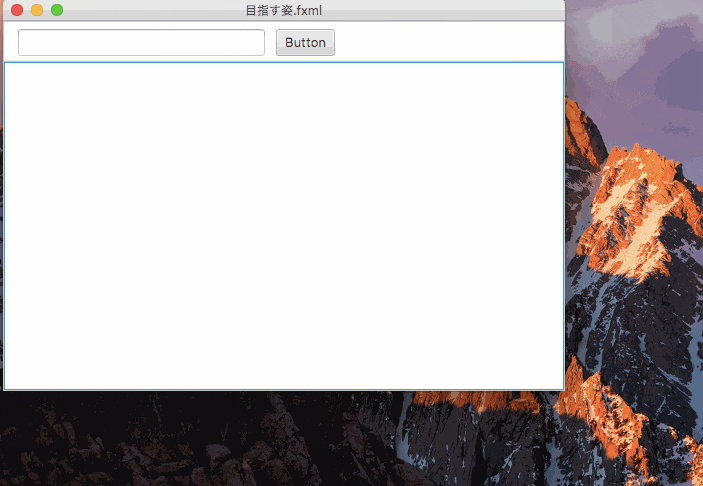
最終的に目指した動きはこんな感じ。
青枠部分がListViewで、ボタンのある位置よりも画面サイズが小さくなった場合にスクロールバーが登場し、横に部品があることを示す、といった具合。
環境
java1.8
JavaFX Scene Builder 2.0まずは結果から
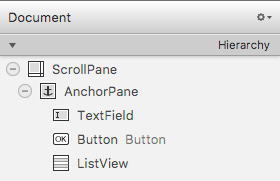
最終的な部品の構成は以下の通りで実現できた。
- ScrollPane
- AnchorPane
- TextField
- Button
- ListView
各部品の設定要点
ScrollPane
Properties-Hbar/Vbar PolicyをAS_NEEDEDとする。Layout-Fit To Width/Heightをtrue()とする。
AnchorPane
Layout-Min Width/Heightを、スクロールバーの表示を開始させたいwindowサイズに設定する。ListView
Layout-Anchor Pane Constrainsの4辺について全て固定値として設定する。実現までの道のりステップバイステップ
Windowサイズに連動するListViewの設定
以下の組み合わせにより、「Windowサイズに連動してListViewの大きさが変化する」を実現できる。
AnchorPaneとListView
使用するのは
AnchorPane。
AnchorPaneとはAnchorPane allows the edges of child nodes to be anchored to an offset from the anchor pane's edges.
中に含まれたnodeについて、親であるAnchorPaneの端からの距離を固定することができる、とのこと。
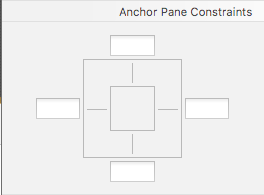
SceneBuliderでAnchorPaneの子要素にControlを追加すると、Layoutに
Anchor Pane Constraintsが表示される。
この4つのテキストボックスに入力した値(距離)で個要素の端とAnchorPaneの端とが固定される。
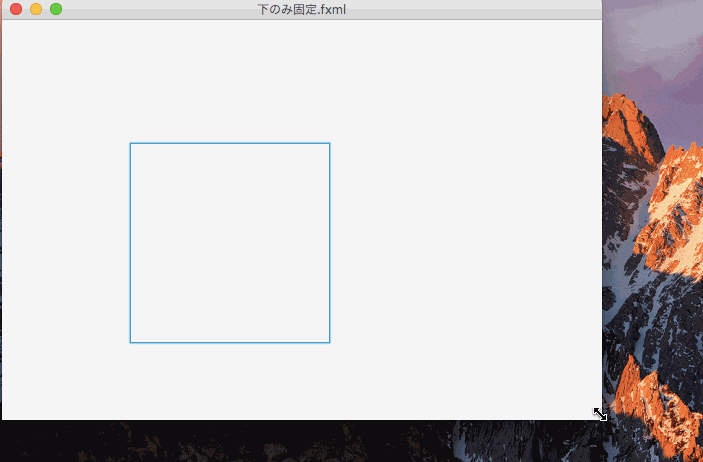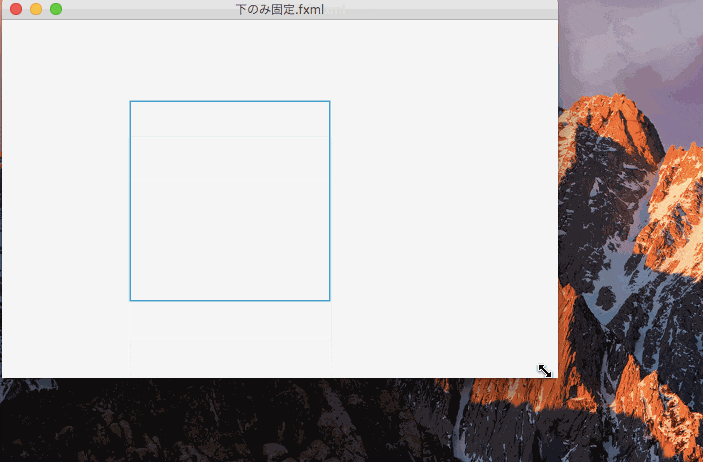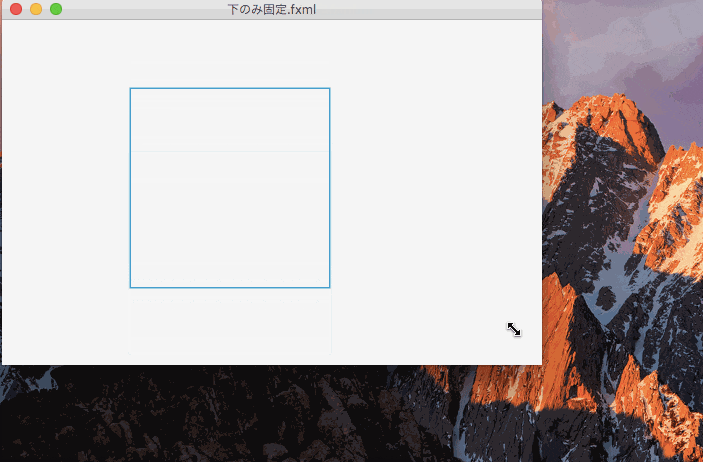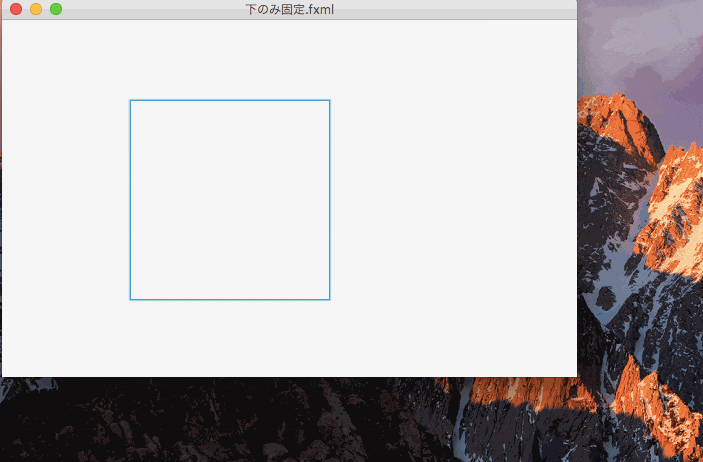
下の値のみ固定したのがこれ。
一辺のみを固定すると、コントロールの大きさは変更されず、表示位置が変更される。
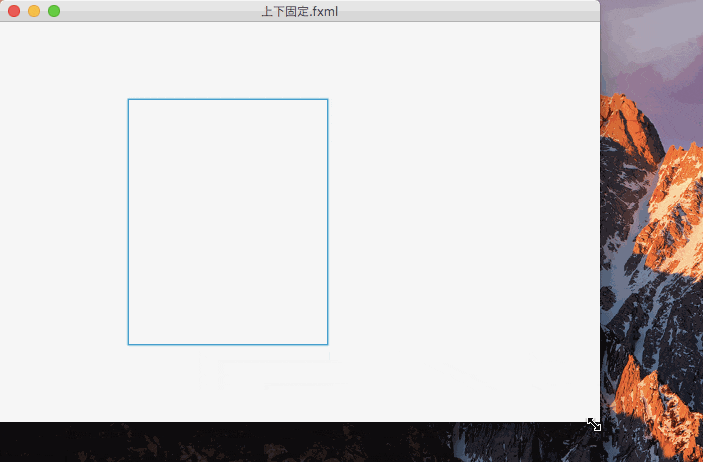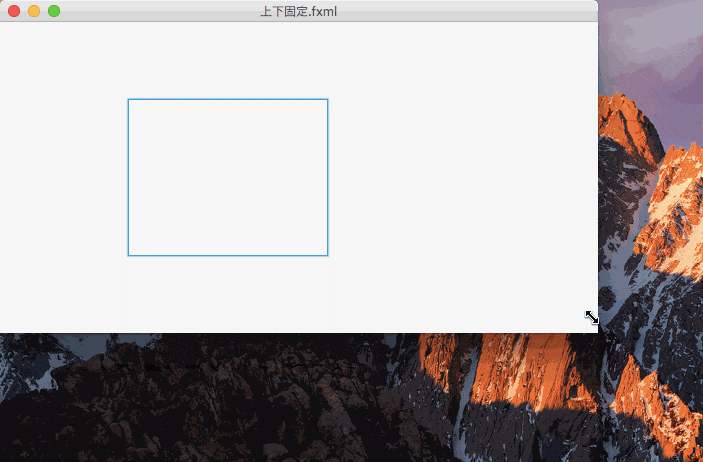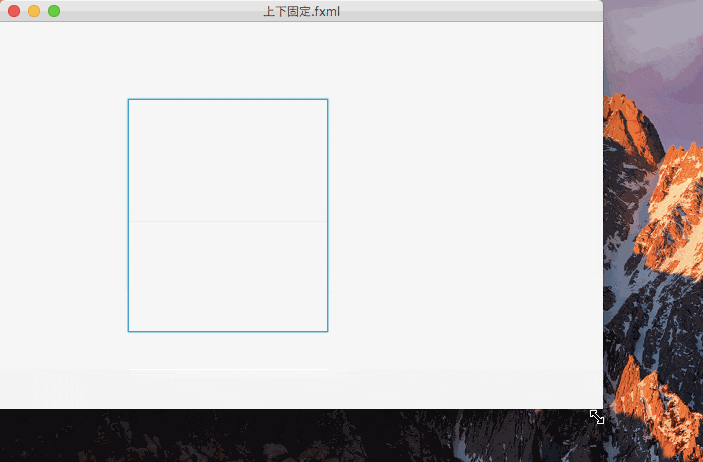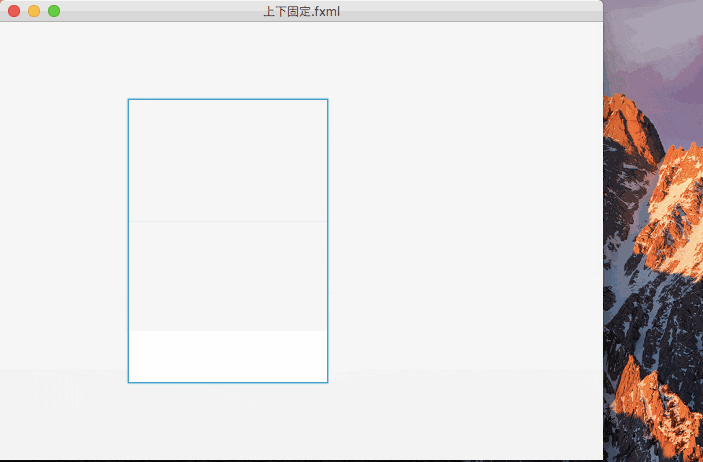
上下を固定したのがこれ。
上下を固定すると、コントロールの大きさよりも上下からの距離が優先され、コントロールの大きさが伸び縮みするのがわかる。
今回、ListViewの大きさをなるべく大きく表示させるためには、AnchorPaneに内包させるListViewについて、
Anchor Pane Constraintsの4つの辺全てについて、固定値とすれば良いことがわかった。ScrollPane内のAnchorPane
ScrollPaneには
FitTo[Width|Height]Propertyがある。
SceneBuilderではこのプロパティを
LayoutのFit To WidthとFit To Heightで設定する。この
Fit To Width/Heightの意味をドキュメントで確認するとpublic final BooleanProperty fitToWidthProperty
If true and if the contained node is a Resizable, then the node will be kept resized to match the width of the ScrollPane's viewport. If the contained node is not a Resizable, this value is ignored.
(適当な訳)
trueのとき、中に含まれるnodeがRisizableであれば、nodeはScrollPaneのviewportの幅に連動して大きさが変化する。含まれるnodeがResizableでなければこの値は無視される。
ということで、ScrollPaneの中にAnchorPaneを入れ、
Fit To Width/Heightをtrueにすることで、ScrollPane(今回の場合はWindowサイズ)の大きさを変化に連動してAnchorPaneの大きさが変化するようになった。
(AnchorPaneは、というか、JavaFXのコントロールは全てResizeable)Windowの大きさが一定以下だった場合の措置
次は「一定の幅よりもWindowの大きさが小さくなった場合は、スクロールバーを表示する」。
ScrollPaneの
FitTo[Width|Height]Propertyをtrueとした場合、内部のnodeの大きさはScrollPaneの大きさに連動して変化するが、内部のnodeのMin [Width|Height]・Max [Width|Height]を超えては大きさは変化しない様子。そこで、ScrollPaneの中のAnchorPaneの
Min Widthに、Buttonが隠れない大きさを設定すると、、、できた。結果として出来上がったfxml
目指す姿.fxml<?xml version="1.0" encoding="UTF-8"?> <?import java.lang.*?> <?import javafx.scene.control.*?> <?import javafx.scene.layout.*?> <ScrollPane fitToHeight="true" fitToWidth="true" maxHeight="-Infinity" maxWidth="-Infinity" minHeight="-Infinity" minWidth="-Infinity" prefHeight="400.0" prefWidth="600.0" xmlns:fx="http://javafx.com/fxml/1" xmlns="http://javafx.com/javafx/8"> <content> <AnchorPane minHeight="0.0" minWidth="0.0" prefHeight="343.0" prefWidth="486.0"> <children> <TextField layoutX="14.0" layoutY="7.0" prefHeight="27.0" prefWidth="247.0" /> <ListView layoutX="-4.0" layoutY="41.0" prefHeight="357.0" prefWidth="598.0" AnchorPane.bottomAnchor="0.0" AnchorPane.leftAnchor="0.0" AnchorPane.rightAnchor="0.0" AnchorPane.topAnchor="40.0" /> <Button layoutX="272.0" layoutY="7.0" mnemonicParsing="false" text="Button" /> </children></AnchorPane> </content> </ScrollPane>
- 投稿日:2020-07-09T18:58:38+09:00
[JAVA]abstractとinterfaceの違いについて
Java言語仕様について、面接で答えられなかったことが恥ずかしかったので再度学び直します。
interface と abstractの関係について
様々な表現方法で表す。
# interface abstract 仕様面 クラス仕様としての定義をしたいときに利用する 継承関係にあり処理を再利用させたい場合に利用する 実装クラスor具体クラスとの関係 実装クラス CAN 抽象機能 具体クラス IS 抽象クラス コード的な違い
interface
// 抽象 public interface Cashier { void bill(); } //実装クラス1 public class CreditCart implements Cashier { public CreditCart(){ } @Override public void bill(){ System.out.println("billed by credit card"); } } //実装クラス2 public class Cash implements Cashier { @Override public void bill() { System.out.println("billed by cash"); } }abstract
// 抽象クラス public abstract class Animal { String name; public Animal(String name) { this.name = name; } public void sleep() { System.out.println("Sleeping"); } public abstract void speak(); } //実装クラス1 public class Human extends Animal { public Human(String name) { super(name); } @Override public void speak() { System.out.println(name + " speack human languages"); } } //実装クラス2 public class Cat extends Animal { public Cat(String name) { super(name); } @Override public void speak() { System.out.println(name + " speack cat's language"); } }修飾子のスコープ
# 同一クラス 同一パッケージ サブラクス 全て default ◯ ◯ - - private ◯ - - - protected ◯ ◯ ◯ - public ◯ ◯ ◯ ◯
- 投稿日:2020-07-09T17:42:40+09:00
PostgreSQLの時系列データのケース:時系列データの自動圧縮
本ブログは英語版からの翻訳です。オリジナルはこちらからご確認いただけます。一部機械翻訳を使用しております。翻訳の間違いがありましたら、ご指摘いただけると幸いです。
背景
時系列データベースの最も重要な特徴の一つは、時間の経過に伴う圧縮です。例えば、最終日のデータは5分程度のポイントに圧縮され、最終週のデータは30分程度のポイントに圧縮されています。
PostgreSQLの圧縮アルゴリズムはカスタマイズ可能です。例えば、単純平均圧縮、最大圧縮、最小圧縮、または回転ドア圧縮アルゴリズムに基づく圧縮などです。
PostgreSQLにおける回転ドアデータ圧縮アルゴリズムの実装 - IoT、監視、センサーのシナリオにおけるストリーミング圧縮の応用
本記事では、RRDデータベースを時間次元に応じて平均、最大、最小、合計、レコード数などの次元に圧縮したような簡単な圧縮シナリオを紹介しています。
また、ウィンドウクエリ、前年比比較、期間比較UDF(KNN計算を含む)、時間単位での一律書き込みなどの高度なSQLの使い方も紹介しています。
デザイン
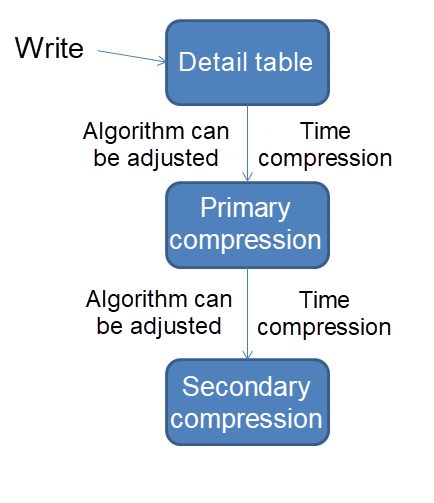
詳細テーブル
create table tbl ( id serial8 primary key, -- primary key sid int, -- sensor ID hid int, -- indicator D val float8, -- collected value ts timestamp -- acquisition time ); create index idx_tbl on tbl(ts);圧縮テーブル
1、 5分圧縮テーブル
create table tbl_5min ( id serial8 primary key, -- primary key sid int, -- sensor ID hid int, -- indicator ID val float8, -- inheritance, average, easy to do ring analysis ts timestamp, -- inheritance, start time, easy to do ring analysis val_min float8, -- minimum val_max float8, -- maximum val_sum float8, -- and val_count float8, -- number of acquisitions ts_start timestamp, -- interval start time ts_end timestamp -- interval end time ); alter table tbl_5min inherit tbl;2、 30分圧縮テーブル
create table tbl_30min ( id serial8 primary key, -- primary key sid int, -- sensor ID hid int, -- indicator ID val float8, -- inheritance, average, easy to do ring analysis ts timestamp, -- inheritance, start time, easy to do ring analysis val_min float8, -- minimum val_max float8, -- maximum val_sum float8, -- and val_count float8, -- number of acquisitions ts_start timestamp, -- interval start time ts_end timestamp -- interval end time ); alter table tbl_30min inherit tbl;3、5分間の圧縮文
with tmp1 as ( delete from only tbl where ts <= now()-interval '1 day' returning * ) insert into tbl_5min (sid, hid, val, ts, val_min, val_max, val_sum, val_count, ts_start, ts_end) select sid, hid, avg(val) as val, min(ts) as ts, min(val) as val_min, max(val) as val_max, sum(val) as val_sum, count(*) as val_count, min(ts) as ts_start, max(ts) as ts_end from tmp1 group by sid, hid, substring(to_char(ts, 'yyyymmddhh24mi'), 1, 10) || lpad(((substring(to_char(ts, 'yyyymmddhh24mi'), 11, 2)::int / 5) * 5)::text, 2, '0');4、30分圧縮文
with tmp1 as ( delete from only tbl_5min where ts_start <= now()-interval '1 day' returning * ) insert into tbl_30min (sid, hid, val_min, val_max, val_sum, val_count, ts_start, ts_end) select sid, hid, min(val_min) as val_min, max(val_max) as val_max, sum(val_sum) as val_sum, sum(val_count) as val_count, min(ts_start) as ts_start, max(ts_end) as ts_end from tmp1 group by sid, hid, substring(to_char(ts_start, 'yyyymmddhh24mi'), 1, 10) || lpad(((substring(to_char(ts_start, 'yyyymmddhh24mi'), 11, 2)::int / 30) * 30)::text, 2, '0');デモ
1、1億個の詳細なテストデータを10日間で書き込んで配布。
insert into tbl (sid, hid, val, ts) select random()*1000, random()*5, random()*100, – 1000 sensors and 5 indicators per sensor. now()-interval '10 day' + (id * ((10*24*60*60/100000000.0)||' sec')::interval) – push back for 10 days as the starting point + (id * time taken for each record) from generate_series(1,100000000) t(id);2、 5分間の圧縮スケジューリング。最終日のデータについては、以下のSQLを1時間ごとにスケジューリングしています。
with tmp1 as ( delete from only tbl where ts <= now()-interval '1 day' returning * ) insert into tbl_5min (sid, hid, val, ts, val_min, val_max, val_sum, val_count, ts_start, ts_end) select sid, hid, avg(val) as val, min(ts) as ts, min(val) as val_min, max(val) as val_max, sum(val) as val_sum, count(*) as val_count, min(ts) as ts_start, max(ts) as ts_end from tmp1 group by sid, hid, substring(to_char(ts, 'yyyymmddhh24mi'), 1, 10) || lpad(((substring(to_char(ts, 'yyyymmddhh24mi'), 11, 2)::int / 5) * 5)::text, 2, '0');3、 30分の圧縮スケジューリング。直近1週間のデータについては、以下のSQLを1時間ごとにスケジューリングしています。
with tmp1 as ( delete from only tbl_5min where ts_start <= now()-interval '1 day' returning * ) insert into tbl_30min (sid, hid, val_min, val_max, val_sum, val_count, ts_start, ts_end) select sid, hid, min(val_min) as val_min, max(val_max) as val_max, sum(val_sum) as val_sum, sum(val_count) as val_count, min(ts_start) as ts_start, max(ts_end) as ts_end from tmp1 group by sid, hid, substring(to_char(ts_start, 'yyyymmddhh24mi'), 1, 10) || lpad(((substring(to_char(ts_start, 'yyyymmddhh24mi'), 11, 2)::int / 30) * 30)::text, 2, '0');概要
1、 時間を間隔でグループ化し、整数の除算+乗算を使用します。
例えば
5分の場合:substring(to_char(ts, 'yyyymmddhh24mi'), 1, 10) || lpad(((substring(to_char(ts, 'yyyymmddhh24mi'), 11, 2)::int / 5) * 5)::text, 2, '0');30分の場合:
substring(to_char(ts_start, 'yyyymmddhh24mi'), 1, 10) || lpad(((substring(to_char(ts_start, 'yyyymmddhh24mi'), 11, 2)::int / 30) * 30)::text, 2, '0')2、 均等に分散した時系列データを生成します。PGのintervalとgenerate_seriesを使うことで、対応するintervalに書き込み時間を均等に分散させることができます。
insert into tbl (sid, hid, val, ts) select random()*1000, random()*5, random()*100, – 1000 sensors and 5 indicators per sensor. now()-interval '10 day' + (id * ((10*24*60*60/100000000.0)||' sec')::interval) – push back for 10 days as the starting point + (id * time taken for each record) from generate_series(1,100000000) t(id);3、 時系列データベースの最も重要な特徴の一つは、時間の経過とともに圧縮されることです。例えば、最終日のデータは5分のポイントに圧縮され、最終週のデータは30分のポイントに圧縮されます。
PostgreSQLの圧縮アルゴリズムはカスタマイズ可能です。例えば、単純平均圧縮、最大圧縮と最小圧縮、あるいは回転ドア圧縮アルゴリズムに基づいた圧縮などです。
この記事では、RRDデータベースを時間次元に応じて平均、最大、最小、合計、レコード数、その他の次元に圧縮したような単純な圧縮シナリオを紹介します。
スケジューリングを追加します。
PostgreSQL Oracle互換性- DBMS_JOBS - 日々のメンテナンス - タイミングタスク (pgagent)
4、 圧縮後、間隔、最大値、最小値、平均値、ポイントの値が含まれています。これらの値は、グラフィックスを描画するために使用することができます。
5、PGのウィンドウ機能と組み合わせることで、前年比グラフや周期を超えたグラフを簡単に描くことができます。SQLの例は以下の通りです。
指数と加速度
create index idx_tbl_2 on tbl using btree (sid, hid, ts); create index idx_tbl_5min_2 on tbl_5min using btree (sid, hid, ts); create index idx_tbl_30min_2 on tbl_30min using btree (sid, hid, ts);複合型で、周期と周期の比較の値を返します。
create type tp as (id int8, sid int, hid int, val float8, ts timestamp);KNNアルゴリズムを含む、特定の時点の近くの指定されたSIDおよびHIDのレコードを返す、期間ごとの値関数を取得します。
create or replace function get_val(v_sid int, v_hid int, v_ts timestamp) returns tp as $$ select t.tp from ( select (select (id, sid, hid, val, ts)::tp tp from only tbl where sid=1 and hid=1 and ts>= now() limit 1) union all select (select (id, sid, hid, val, ts)::tp tp from only tbl where sid=1 and hid=1 and ts< now() limit 1) ) t order by (t.tp).ts limit 1; $$ language sql strict;前年比、週比、月比(これらの値は、各クエリでの計算を避けるために自動的に生成することもできます)。
select sid, hid, val, lag(val) over w1, -- 同比 get_val(sid, hid, ts-interval '1 week'), -- 周环比 get_val(sid, hid, ts-interval '1 month') -- 月环比 from tbl -- where ... ,时间区间打点。 window w1 as (partition by sid, hid order by ts)6、 PGの線形回帰と組み合わせることで、予測指標を描くことが出来ます。以下の例では、これについて詳しく説明します。
PostgreSQLの線形回帰分析を使用して予測を行う-例2は次の数日の株価終値を予測
PostgreSQLで線形回帰分析を使用する - データ予測の実装
7、 開発を容易にするために、圧縮テーブルを詳細テーブルに継承しています。これにより、UNION SQLを書く必要がなくなり、DETAILテーブルを調べるだけで、すべてのデータ(圧縮データを含む)を取得することができます。
関連事例
タイムアウト・ストリーミング - 受信メッセージのデータ例外監視を行わない
HTAPデータベースPostgreSQLのシナリオと性能テスト - 第27回 (OLTP) IoT - FEEDログ、ストリームコンピューティング、アトミック性を持つ非同期バッチ消費 (CTE)
- 投稿日:2020-07-09T17:07:06+09:00
あなたのためのJavaスレッドセーフ
問
我々は如何にして Java におけるスレッドセーフを保証すべきか。
結論
- synchronized ブロックを使いましょう。
- ロックオブジェクトはprivateインスタンスフィールドで定義しましょう。
- ロックオブジェクトはスレッドセーフの保証対象ごとに定義しましょう。
薀蓄
スレッドセーフとは
- スレッド間で可変データを共有する場合において、同期化が保証される状態。
同期化の保証とは
- 「原子性の保証」「可視性の保証」の二点を満たすものと定義する。
原子性(atomicity)の保証とは
- ある処理の開始から終了までの間、外部からの干渉を排他できること。
可視性(visibility)の保証とは
- 時系列に対して最新の値が参照できること。
Java言語仕様
Javaにおいては特に以下の制御構文が、これまでに出てきた要素に関連する。
- synchronizedブロック
- 引数に同じオブジェクトを指定したブロック間において、操作を同期化する。
- メソッドに対する synchronized 修飾は自インスタンスに対する synchronized ブロックと等価。
// 以下のsynchronizedブロック間の操作を同期化 public void foo() { synchronized (_SOME_OBJECT) { // do something } } public void bar() { synchronized (_SOME_OBJECT) { // do something } }// 以下は等価 public void foo() { synchronized (this) { // do something } } public void synchronized foo() { // do something }
- volatile修飾子
- 指定した変数の可視性を保証する。
- スレッドセーフ用途で利用できる場面自体は存在するが、今回は扱わない。
- 例えばint型やboolean型の変数は言語仕様により原子性が保証されている。
実践
以下の実装に対して、foo() と bar() を別々のスレッドから不定期に複数回呼び出すケースを考える
public void foo() { _object.update(); // _object の内部状態を変化させる処理 } public void bar() { if (_object.enabled()) { _object.getData(); // enabled() が false の場合に呼び出すと例外発生 } }synchronizedブロック無し
bar() の処理に原子性の保証が無いため、以下の順でメソッドが呼び出される可能性がある。
_object.enabled() -> _object.update() -> _object.getData()public void foo() { _object.update(); } public void bar() { if (_object.enabled()) { _object.getData(); // _object の内部状態は保証されない } }synchronizedブロックあり
ブロック内の処理の間に同期化の保証が加わり、即ち原子性についても保証される。
【 _object.update() 】 -> 【 _object.enabled() -> _object.getData() 】 -> 【 _object.update() 】ブロック単位で処理の待ち行列に格納されるイメージを持つとわかりやすい。
public void foo() { synchronized (this) { _object.update(); } } public void bar() { synchronized (this) { if (_object.enabled()) { _object.getData(); // _object の内部状態が保証される } } }synchronizedブロック一部だけあり
引数に同じオブジェクトを指定したブロック間において、操作を同期化する
synchronized ブロックはあくまで、先に上記のように述べた通りの同期化の保証である。
以下の実装は bar() 内の処理に対する同期化を保証しない。public void foo() { _object.update(); } public void bar() { synchronized (this) { if (_object.enabled()) { _object.getData(); // _object の内部状態は保証されない } } }別オブジェクトに対するsynchronizedブロック
念のための補足。
引数に異なるオブジェクトを指定したブロック間における操作も同期化は保証されない。public void foo() { synchronized (_SOME_OBJECT) { _object.update(); } } public void bar() { synchronized (this) { if (_object.enabled()) { _object.getData(); // _object の内部状態は保証されない } } }余談
- getterのような readonly な単一処理においても synchronized ブロックを使用すべきである。
- 可視性の保証のため。
- また、オブジェクトによっては読み込み処理に対して原子性が保証されないものがある。
ロックオブジェクトについて
※synchronized ブロックの引数に渡すオブジェクトのこと
デッドロック耐性
デッドロックの発生を最大限抑止するため、実装には以下の原則を適用することが望ましい。
- synchronized ブロックの範囲を最小化する
- ロックオブジェクトの共有範囲を最小化する
ロックオブジェクト選定
this
- 利用者に対して public なオブジェクトであるため、原則に対して望ましくない
- 等価である synchronized メソッドも使用すべきではない
privateクラスフィールド
- 利用者からはアクセスできないことが保証される
- インスタンス間で共有されるオブジェクトであるため、原則に対して望ましくない
privateインスタンスフィールド
- 利用者からはアクセスできないことが保証される
- かつインスタンス単位で生成されるため、原則に対して最適
また、いずれの場合においてもロックオブジェクトがnullになる可能性があってはならない。
これはfinal修飾子を付与することで保証する。// 推奨実装 class Shared { private final Object _LOCK_OBJECT = new Object(); // staticにしない public void foo() { synchronized (_LOCK_OBJECT) { // do something } } public void bar() { synchronized (_LOCK_OBJECT) { // do something } } } class User { public void sample() { final Shared object = new Shared(); new Thread(() -> object.foo()).start(); new Thread(() -> object.bar()).start(); } }// ロックオブジェクトに this を使用する実装 class Shared { public void foo() { synchronized (this) { // do something } } public void bar() { synchronized (this) { // do something } } } class User { public void sample() { final Shared object = new Shared(); // この object インスタンスが Shared 内部実装のロックオブジェクトへの参照となる // そのため「ロックオブジェクトの共有範囲を最小化する」という原則に反する } }ロックオブジェクト定義
同じく共有範囲最小化の原則により、スレッドセーフを保証したい対象ごとにロックオブジェクトを定義すべきである。
class Shared { // ロック対象 private final Data _dataA = new Data(); private final Data _dataB = new Data(); private final Data _dateC = new Data(); private final Validator = _validator = new Validator(); // ロックオブジェクト private final Object _DATA_A_LOCK = new Object(); private final Object _DATA_B_LOCK = new Object(); private final Object _DATA_C_LOCK = new Object(); public void foo() { synchronized (_DATA_A_LOCK) { _dataA.update(); } synchronized (_DATA_B_LOCK) { _dataB.update(); } synchronized (_DATA_C_LOCK) { _validator.execute(); _dataC.update(); } } public void bar() { synchronized (_DATA_A_LOCK) { _dataA.get(); } synchronized (_DATA_B_LOCK) { _dataB.get(); } synchronized (_DATA_C_LOCK) { _validator.execute(); _dataC.get(); } } }ひとこと
- synchronizedメソッドを使用しない理由を聞かれたら、是非この記事を突き付けてください。
- 投稿日:2020-07-09T15:31:05+09:00
Java SE11 Silver 取得にかかった時間、使った教材
試験概要
Oracle Certified Java Programmer, Silver SE 11 認定資格は、Javaアプリケーション開発に必要とされる基本的なプログラミング知識を有し、上級者の指導のもとで開発作業を行うことができる開発初心者向け資格です。日常的なプログラミング・スキルだけでなく、さまざまなプロジェクトで発生する状況への対応能力も評価することを目的としています。Oracle Certified Java Programmer, Silver SE 11 認定資格を取得するためには、Java SE 11 Programmer I (1Z0-815-JPN) 試験の合格が必要です (認定パス)。
引用:リンク受験までのあらすじ
大学院卒業後、某大手メーカーに就職し、安定した人生を送れそうではあったが仕事に楽しみを見出すことができず退職。前から興味のあったプログラミングの学習を始めてみたところ時間を忘れて没頭してしまう。そしてエンジニアに転職することを決意し、本格的にJavaの勉強を開始。転職活動である程度評価されるオラクルOracle Certified Java Programmer, Silver SE 11を受験することを決意した。
使用した教材
- すっきりわかるJava入門: 言わずと知れた入門書。まずはこれを3周読みました。実際にコードを書いたほうがいいといいますが私はほとんど書いていません。読むだけ勉強法でした。
- 紫本: silver受験対策1冊目に購入。正直わかりずらいが頑張って2週通読。今振り返るといらなかった気がするが使える表などがあり部分によっては重宝した。黒本でどうしてもわからないところは紫本でしっかりやりこんだ。
- 黒本: こちらも言わずと知れた名著。2周行い2周目に間違えたところのみ3周行った。試験には本書と同じ内容の問題が半分ほどあったイメージ。これをやりこんでおけば合格点はさほど難しくないと思う。なお、最後の総仕上げ問題は絶対にやるべきである。私は模試はいいやと思って直前までやらなかったが、そもそもこの総仕上げ問題、それまでの各章に書いてないことも山ほど載っているので、仕上げという概念でとらえるべきではなかった。各章と同じくこちらも3周行うべきである。
勉強時間
正確に測ってないがだらだらとJavaの学習を3か月ほど行っていた。資格のことは頭になく暇つぶし程度に行っていたがこの期間でスッキリわかるを2週行っていた。そのあと資格取得に向けて本格的に勉強開始。1日2時間ほどの学習を2カ月ほど続けたため60時間ぐらい学習したことになる。
試験結果
合格。合格点は64%であったが78%で合格。これがいい結果かと言われればそうでもない気がする。
最後に
基本の勉強をして、Javaを体系的にある程度理解したらひたすら黒本をやりこめばより短い時間での合格が可能と思われる。ただ、試験合格を目的とするのかJavaを使えるようになるのを目的にするのかでも変わってくると思う。なお、私個人の意見としては一旦資格取得を目的にしていいと思う。なぜなら私はどちらかと言うと途中から資格取得を目的に学習していたが、資格取得後個人的にちょっとしたコードを書いているが割とすらすら学んだことをアウトプットできている。まずは資格取っちゃおうぐらいの気持ちで問題ないと思われる。
- 投稿日:2020-07-09T13:22:44+09:00
Java SE 7/8 Bronze 合格体験記 ーオンライン受験verー
※2020年6月7日受験時の情報です。
2020年6月、外出自粛中にオンライン受験でJava SE 7/8 Bronzeに合格しました!
と、いうことで、オンライン受験の方法や勉強方法などについてまとめてみようと思います。ちなみに勉強方法・受験方法の順で書くので、
受験方法だけ知りたい方は次のリンクをぽちっとどうぞ!
受験方法へGo※まとめるために調べていたら、Java SE 7/8 Bronzeが配信されているのは2020年7月31日までなんですね!それ以降はJava SE Bronze (1Z0-818-JPN)が後継の資格になるようです。
Java SE 7/8 Bronzeとは
Oracle社が運営する認定資格試験のうちの一つで、言語未経験者向けの入門資格。
Javaプログラムの基本的な文法やオブジェクト指向の知識を持っているかが試される。
項目 内容 出題形式 選択問題 試験時間 65分 出題数 60問 合格ライン 60% 受験料(税抜) ¥13,600(税込み¥14,960) 【個人的感想】
入門資格とはいえ、Java書けるし...と勉強しないで挑むのは危険です!
オブジェクト指向の概念と試験問題でひっかけてくる文法ルールを押さえるために試験対策の勉強は必要でしょう...。私のスペック
- 新卒2年目
- 理系出身エンジニア
- Javaの実務経験なし
研修等で触った経験はあるが1年のブランクで記憶があやsii...という状況でした。
なぜ受験しようと思ったか
- オブジェクト指向に興味があった
- 普段フロント周りの業務を行っているので、あえて別の資格に挑戦しようと思った
- Javaの勉強をしたらサーバーサイドの知識も少しつくかなという期待
勉強方法
勉強時間
勉強時間:25~30時間
平日・休日何時間ときっちり決めず、約1か月間少しずつ勉強を進めていました。参考書
上記2冊の参考書で勉強しました。使い分けとしては、
「スッキリ...」:基本的なオブジェクト指向とJavaの知識を勉強。(実践含む)
「徹底攻略...」:スッキリを解いた後に知識確認として問題を解く。+模擬問題集で試験問題の把握。というように「勉強用」と「確認用」で参考書を分け、スッキリを解いて、問題集を解いて...と並行して使っていました。試験直前は模擬問題だけ何度か解いています。
【個人的感想】
時間がなく試験対策に特化したいなら「徹底攻略」のような参考書1冊でも十分対策ができると思います。
初めからまともに問題を解くと知識がなくてつまりますが、分からない部分はガンガン飛ばして答えを確認し、繰り返して解きなおすことで、問題傾向を知る+解説で学ぶ。ができます!文字ばかりだと内容が頭に入らない。手を動かして学びたい人は「スッキリ」も読むことがお勧め!
イラストも多くオブジェクト指向の解説など、かなり分かりやすかったです!?
(ただし試験対策本なしに「スッキリ」だけだと受験は難しそう...。)受験方法
受験までには
1. アカウント作成
2. 受験申込
3. 実際の受験の流れがあります。
申し込みの手順にフォーカスして書かれる記事もあるなど、受験前の手順は少々ややこしいです。
受験日が決まってなくとも、まず初めに1. アカウント作成だけでも終わらせてしまいましょう!1. アカウント作成
受験のために2つのアカウントが必要となります。
1. Oracle.com アカウント
2. ピアソンVUEアカウント受験前に必要な手続きはもちろん公式ページにも書いてあるのですが、
下記の記事がスクショ付きで分かりやすかったので、スッと説明を譲ります...。Java Bronze資格試験の申し込み手順がややこしすぎるぅぅぅぅ泣
アカウントがないと申し込みをしたいタイミングで申し込めないので、先に作っておくとよいと思います。
認証作業というものに少し時間がかかるのです。2. 受験申込
受験の申込みはピアソンVUEから行うのですが、受験料の支払い方法には2通りの方法があります。
1. 受験チケット(6ヶ月間有効)だけ先に買う。その後受験日直前にチケットを使って受験申込。
2.受験申込時にクレジットカードで受験料を支払う。(オンラインの申込みの場合、申込み後48h以内の受験が必要)支払いタイミングの違いですね。
また受験チケットだと場合によっては安く買えることもあるようです。(再販パートナーの割引?)ただ、受験申込自体はどちらでも必要になるので、個人的には2がおススメです。
【受験チケット購入での失敗小話】
泣く泣く見送る「オラクル認定資格試験 再受験無料キャンペーン」...
2019年12月頃~2020年5月31日まで、1度受験失敗しても無料で再受験できるというオラクルのキャンペーンがありました。
(割と定期的に開催されているようです!)
-- 5月末日の3日前
「無料で再受験できるし、折角だから5月中に受験しよー」
Java SE 7/8 Bronze公式ページ
「ふんふん。支払い方法が2つあって、申込んだら2日以内に受験しないといけないのかー」
「じゃあ、チケット先買ってそれから申し込もう。早めの準備が大事だからね!(ドヤ)」
画面右の赤丸部分をぽちっと押してチケットを購入しました。
-- メール届く
「よし受付が完了...。いや、受付処理は終了してません...?あれ、チケットっていつ使えるようになるんだ?」
-- 受験チケットの購入前に必ずご確認くださいページを見る。
「み、3営業日前後かかる...だと...!?」
-- 4日後
受付完了メールが届きました。
...うーん6月?
と、いうことで5月までのオラクルキャンペーンに間に合わなかったのでした。
オンラインのチケットだからすぐに届くわけではないのです...。
皆さんは注意書きをしっかり読みましょう。
やはり私のオススメはこちら。
2.受験申込時にクレジットカードで受験料を支払う。(オンラインの申込みの場合、申込み後48h以内の受験が必要)
3. 実際の受験
スクショなどがなく詳細説明ができないのですが、アカウントページ(おそらくOracleの)からサクサク受験は始められます。
カメラで身分証明書を写して...なども特になく、模擬試験を受けるくらいの手軽さで受験できました。
逆に心の準備が間に合わず、しばらくドキドキしながら問題解いていました。
落ち着いて深呼吸してください。
結果
当日中に、試験結果が見れるようになった旨のメールが届きました。
-- 結果確認
合格!やったね!
最後に
受験しての感想をば...。
1問1分な問題数なのであまり回答時間の余裕はありません。
やはり、何かしらで模擬問題を解いて時間配分はつかんだ方が良いと思います。冒頭の受験目的は果たせたのでしょうか?
- オブジェクト指向に興味があった
→オブジェクト指向の考えは受験前より深まったと思います。
- 普段フロント周りの業務を行っているので、あえて別の資格に挑戦しようと思った
→受験・合格したので、挑戦は無事果たせましたね!
- Javaの勉強をしたらサーバーサイドの知識も少しつくかなという期待
→流石にサーバーサイドの知識はこれだけではつきませんでした...!
ただ少しは...という点では、今回勉強した知識を経て以前よりサーバーよりの事柄にも少しはとっつきやすくなった気がしています。さて、ここまで読んでいただいた皆さん。ありがとうございます!
書き始めてから月末に試験配信が終了することを知るという出遅れ感のある記事でした...。なんだか申し訳ない...。
ただ、新しい試験も似たような形式のようなので(オンライン受験もあるし)そちらを受ける際にも多少参考にはなるかなと思っています...!
この記事が、何かのお役に立つと嬉しいです。
それでは!


- 投稿日:2020-07-09T12:38:51+09:00
Eclipse Debug_Shell使い方
1.ブレークポイント
2.デバック実行
3.ブレークポイントにて処理が停止したことを確認
4.Debug Shellにて
throw new java.sql.SQLException("何かしらのメッセージ");
右クリック→実行
- 投稿日:2020-07-09T10:54:27+09:00
文字の重複カウント(substring)
import java.util.*; //文章strのなかで指定文字targetの重複する回数をカウントする public class Main { public static void main(String[] args) { Scanner sc = new Scanner(System.in); ArrayList<String> list = new ArrayList<String>(); //重複数の合計 int count = 0; String target = sc.nextLine(); String str = sc.nextLine(); //文を一文字ずつlistに詰める。 for(int i = 1; i < str.length() + 1; i++){ list.add(str.substring(i - 1, i)); } //listを0番から順番に抜出しtarget変数と等しければcountにプラス1 for(int i = 0; i < list.size(); i++) { if (target.equals(list.get(i))){ count++; } } System.out.println(count); } } /* //substringより短い書き方。 public class Main { public static void main(String[] args) { Scanner sc = new Scanner(System.in); String s = sc.nextLine(); //splitはString[]を返す //引数に正規表現が入る //例:(,)カンマごとに区切ることになる。 String[] str = sc.nextLine().split(""); int count = 0; for (String p : str) { if (s.equals(p)) { count++; } } System.out.println(count); } } */