- 投稿日:2020-06-27T19:42:44+09:00
DBから取り出したデータを元に、星の数で評価する機能を実装する
はじめに
AmazonなどのECサイトで、商品に対して星をつけて商品の評価をしているのを、
見たことありませんか?「この商品は5つ星!これは3つ星!」のような。
アラビア数字で「これは何点」と表記されているよりも、すごくすごくわかりやすいですよね。
背景
筆者はWebフレームワークの勉強の課題として、
「読んだ技術書を評価してリストアップする」Webアプリケーションを製作中なのですが、
データベースに登録した評価カラムの数字を取り出して、その内容を星の個数として反映することを目指しました。
注意
問題解決からしばらく経ってからの投稿なので、データベースの中身などに矛盾が発生しています。
(例えば、対応する技術書の評価の数がスクリーンショットごとに異なるとか。)上の例のような、星3.5個というような小数は想定していません。
あくまで星1, 2, 3, 4, 5個としての実装です。開発環境
- Node.js 12.16.3
- Express 4.17.1
- MySQL 15.1
実装したいもの
- 星の数は常に5つ表示する
- 評価数に応じて星の色をオレンジにすることで、評価点を確認できるようにする
- 評価数に満たない部分は灰色の星として表示する
- これらによって、「評価点の最大値がいくらか」「この本の評価点がいくつか」の可読性を一気に向上させる
解決方法
まずヴァニラなHTML・CSSを用意する
まず、星を表示するソースコードを用意する必要があります。
こちらを参考にしました。
改変したところ:uncheckedというクラスも用意した(文字色をgreyに変更する)
ソースコード
<link rel="stylesheet" href="https://cdnjs.cloudflare.com/ajax/libs/font-awesome/4.7.0/css/font-awesome.min.css"> <span class="fa fa-star checked"></span> <span class="fa fa-star checked"></span> <span class="fa fa-star checked"></span> <span class="fa fa-star"></span> <span class="fa fa-star"></span>.checked { color: orange; } .unchecked { color: grey; }表示結果
実装してみる
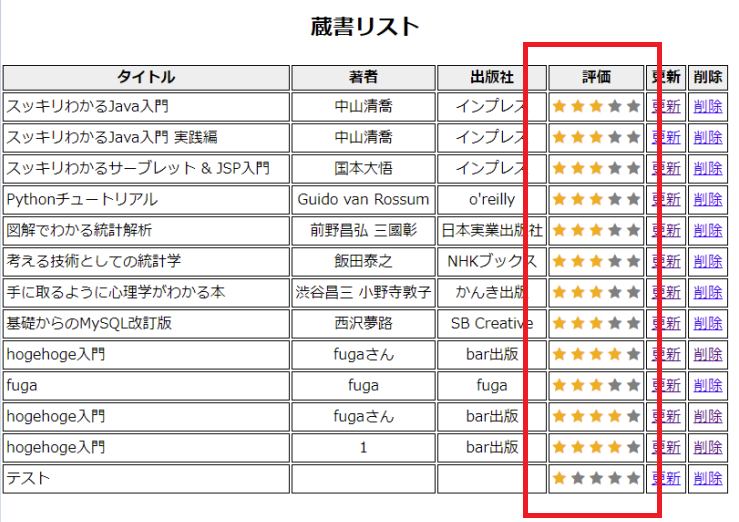
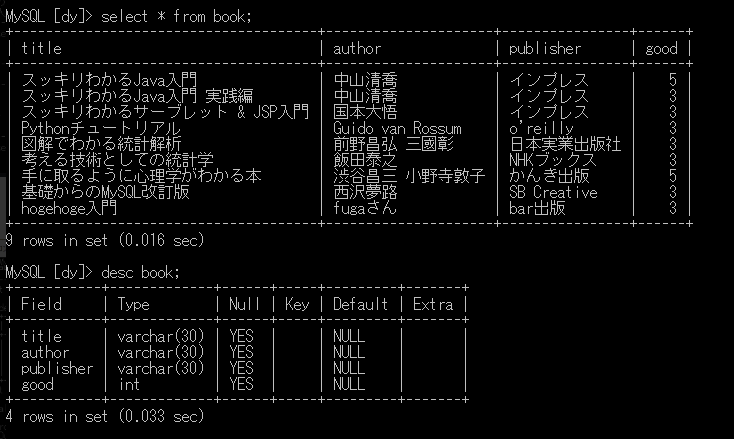
データベースの中身
このテーブルの"good"というカラムが評価(星の数)に対応します。
実装前のソースコードとスクリーンショット
app.jsapp.get("/", (req, res) => { const sql = "select * from book"; connection.query(sql, function (err, result, fields) { if (err) throw err; res.render("index", { book: result }); }); });inex.ejs<table> <tr> <th>タイトル</th> <th>著者</th> <th>出版社</th> <th>評価</th> <th>更新</th> <th>削除</th> </tr> <% book.forEach(function (value) { %> <tr> <td class="title"><%= value.title %></td> <td><%= value.author %></td> <td><%= value.publisher %></td> <td><%= value.good %></td> <td><a href="/edit/<%= value.title %>">更新</a></td> <td> <a href="/delete/<%= value.title %>" onClick="disp('<%= value.title %>'); return false;" >削除</a > </td> </tr> <% }); %> </table>
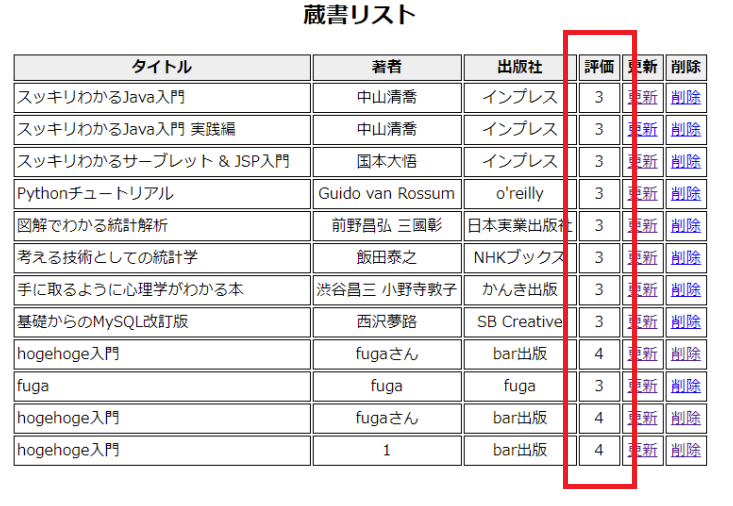
実装後のソースコードとスクリーンショット(そして補足コメント)
app.jsconst maxStar = 5; app.get("/", (req, res) => { const sql = "select * from book"; connection.query(sql, function (err, result, fields) { if (err) throw err; books = []; for (book of result) { book.colored = book.good; // 評価の数(オレンジ色の星の数) book.uncolored = maxStar - book.good; // 灰色の星の数 books.push(book); } res.render("index", { book: books }); }); });index.ejs<table> <tr> <th>タイトル</th> <th>著者</th> <th>出版社</th> <th>評価</th> <th>更新</th> <th>削除</th> </tr> <% book.forEach(function (value) { %> <tr> <td class="title"><%= value.title %></td> <td><%= value.author %></td> <td><%= value.publisher %></td> <td> <% for (let i = 0; i < value.colored; i++){ %> <span class="fa fa-star checked"></span> <% } %> <% for (let i = 0; i < value.uncolored; i++){ %> <span class="fa fa-star unchecked"></span> <% } %> </td> <td><a href="/edit/<%= value.title %>">更新</a></td> <td> <a href="/delete/<%= value.title %>" onClick="disp('<%= value.title %>'); return false;" >削除</a > </td> </tr> <% }); %> </table>
app.jsについて
実装前では「評価の数」だけあればよかったのですが、
今回は「オレンジ色に染まった星の数」「色がついていない(ように見える灰色の)星の数」という2つの変数が必要になります。
データベースからレコードを取り出したあと、
評価数の最大値(5)から、goodカラムの数を引くことで、灰色の星の数を取得し、
それらをまとめて初期化した配列 books に挿入、index.ejsへレンダリングすることで解決を図っています。index.ejsについて
ejsファイルは通常HTMLで用いるJavaScriptだけでなく、
app.jsから渡されたデータを利用したJavaScriptを埋め込むことができます。星の数について使った部分は以下です。
colored変数に格納された数だけforループしオレンジ色の星を表示、
uncolored変数に格納された数だけforループし、灰色の星を表示させます。<% for (let i = 0; i < value.colored; i++){ %> <span class="fa fa-star checked"></span> <% } %> <% for (let i = 0; i < value.uncolored; i++){ %> <span class="fa fa-star unchecked"></span> <% } %>


- 投稿日:2020-06-27T18:44:05+09:00
Mysql2::Error::ConnectionError: Can't connect to local MySQL server through socket '/var/run/mysqld/mysqld.sock'
たまに以下エラーが起きることがあります。
# RAILS_ENV=production bundle exec rake db:migrate rake aborted! Mysql2::Error::ConnectionError: Can't connect to local MySQL server through socket '/var/run/mysqld/mysqld.sock' (2)結論から言うと、DBの接続情報が誤っているためにこのエラーが起きます。
やることは
config/database.ymlに関して以下のことになります
- 次の値に対して
config/database.yml自体に設定している値config/database.ymlから指定している環境変数- 次の事態が起きていないかどうか確認する
- 値が間違っている
- DB設定の値が更新されていて、更新漏れが起きている
私は
config/database.ymlでは環境変数を指定することが多く、
いつの間にかに更新されていた環境変数を更新漏れしていたり、
dockerの他のコンテナで指定していたDB名と環境変数で指定していたDB名が間違っていたり
と度々このエラーに遭います。他のエラーのときにもこのエラー起きるかもしれませんが、私の場合100%接続情報エラーなので、このエラーが紛らわしくて仕方ないです。
接続設定間違ってるよと言ってくれれば律儀に/var/run/mysqld/mysqld.sockがどういうものを調べに行ったり、ググらなくて済むので他の場合は以下のQiitaの場合かもしれません
https://qiita.com/fujitora/items/d341c52706d1954cae28
- 投稿日:2020-06-27T16:35:52+09:00
初心者向けSQLクエリ 一覧
割と自分に向けた記事なので、可読性などは重視していない。
■Windowsコマンドプロンプトの文字コード変更方法
文字コードをUTF8に設定する場合
chcp 65001データベースを作成する
create database データベース名;データベース一覧を表示する
show databases;使うデータベースを指定する
use データベース名現在使用しているデータベースを表示する
select database();テーブルを作成する
create table テーブル名(カラム名1 データ型1, カラム名 データ型2...);すべてのテーブルを表示する
show tables;テーブルのカラム構造を表示する(desc = describe, 説明する)
desc テーブル名;データをテーブルに挿入する
insert into テーブル名(データ1, データ2...);カラム名を指定してデータをテーブルに挿入する
insert into テーブル名 (カラム名1, カラム名2...) values (データ1, データ2...)複数のデータを一度にテーブルに挿入する
insert into テーブル名(カラム名1, カラム名2...) values (データ1, データ2),
(データ1,データ2...), (データ1,データ2...)...;カラムごとのデータを表示する
select カラム名1, カラム名2... from テーブル名;すべてのカラムのデータを表示する
select * from テーブル名;カラムのデータ型を変更する
alter table テーブル名 modify カラム名 データ型;カラムを追加する
alter table テーブル名 add カラム名 データ型;カラムを先頭に追加する
alter table テーブル名 modify カラム名 データ型 first;カラム名・データ型・位置を変更する
alter table テーブル名 change 変更前カラム名 変更後カラム名 変更後データ型カラムを削除する
alter table テーブル名 drop カラム名;主キーを設定してテーブルを作成する
create table テーブル名(カラム名 データ型 primary key)自動で連続した番号が割り振られるカラムを設定する(データ型には大抵INTが入りそう)
create table テーブル名(カラム名1 データ型1 auto_increment, カラム名2 データ型2...)連続番号を初期化する
※テーブル内のレコードを全消去してレコードを追加すると、消去前の最大値+1の番号が割り振られてしまう
※テーブル内のレコードを全消去してから使う
alter table テーブル名 auto_increment=0;カラムの初期値を設定する
alter table テーブル名(カラム名 データ型 default 初期値...);インデックスを作成する
create index インデックス名 on テーブル名(カラム名);インデックスを確認する
show index from テーブル名;インデックスを確認する(カラムごとの表示)
show index from テーブル名\G (Gは必ず大文字)インデックスの削除
drop index インデックス名 on テーブル名;テーブルのカラム構造とレコードをコピーしてテーブルを作成する
(auto_incrementなどは反映されない)
create table 新規テーブル名 select * from コピー元のテーブル名;テーブルのカラム構造だけをコピーする
create table 新規デーブル名 like コピー元のテーブル名;テーブルのすべてのレコードを、同じカラム構造の他のテーブルにコピーする
insert into コピー先のテーブル名 select * from コピー元のテーブル名;テーブルを削除する
drop table テーブル名;指定したテーブルが存在する場合は削除する
drop table if exists テーブル名;データベースの削除
drop database データベース名;テーブルを残してレコードだけ削除する
delete from テーブル名;カラム名をエイリアスにする
select カラム名 asエイリアス from テーブル名;レコードを処理して表示する(例 10000倍してhogeというエイリアスで表示)
select カラム名*10000 as hogehoge from テーブル名;文字列を結合して表示する
select concat(引数1, 引数2, 引数3...);右からn文字取り出して表示する(左から:left)
select right(カラム名, n) from テーブル名;n番目からm個取り出して表示する
select substring(カラム名, n, m) from テーブル名;"str"をi回繰り返して表示する(iがカラムを指す場合は末尾にfrom テーブル名)
select repeat("str", i);逆さから表示する
select reverse(カラム名) from tb1;表示するレコード数に制限をかける
select カラム名 from テーブル名 limit レコード数;条件に一致したレコードだけを表示する
select カラム名 from テーブル名 where 条件式;条件によって出力するリテラルを変化
select
case
when 条件式 then 出力するリテラル
when 条件式 then 出力するリテラル...
else 出力するリテラル
end
from テーブル名;レコードを昇順に表示する
select * from テーブル名 order by キーとなるカラム名;レコードを降順に表示する
select * from テーブル名 order by カラム名 desc;表示するレコードの範囲を制限する
select カラム名 from テーブル名 limit 表示するレコード数 offset 表示開始レコード;グループごとに表示する
selectカラム名 from テーブル名 group by グループ化するカラム名;カラムのデータをすべて修正する(既にデータがある場合は上書きされる)
update テーブル名 set カラム名 = 設定する値;条件に一致したレコードだけ修正する
update テーブル名 set カラム名 = 設定する値 where 条件;(INT型のカラムに対して)下位n個のカラムだけ修正する
update テーブル名 set カラム名 = 設定する値 order by INT型のカラム limit n;(INT型のカラムに対して)昇順(asc)や降順(desc)に表示
select * from テーブル名 order by カラム名 asc;既存のテーブルの一部をコピーして新しいテーブルを作成する
(既存のテーブルへコピーする場合は create table ではなくinsert into)
create table 新テーブル名 select * from 旧テーブル名 where カラム名 like 値;条件に一致するレコードを削除する
delete from テーブル名 where 条件;外部ファイルからデータをインポートする(import, いmぽーと)
load data infile "db1\tb2.csv" into table tb2 fields terminated by ",";複数の抽出結果をあわせて表示する
select * from テーブル名 where 条件 union select * from テーブル名 where 条件;複数の抽出結果をあわせて表示する(重複を許容、UNION ALLを用いる)
select * from テーブル名 where 条件 union all select * from テーブル名 where 条件;複数の抽出結果をあわせて表示する1
(内部結合 on ~の条件が真のものだけ結合して、select ~のカラムを表示)
select テーブル名.カラム名, テーブル名.カラム名... from 結合するテーブル名1 join 結合するテーブル名2 on テーブル名1.カラム名 = テーブル名2.カラム名複数の抽出結果をあわせて表示する2
(where~の条件に一致するレコードだけ表示する)
(from~はカンマで区切ってもよいし、joinで区切ってもよい)select テーブル名.カラム名... from テーブル名1, テーブル名2, ... where テーブル名1.カラム名 = テーブル名2.カラム名;
複数の抽出結果をあわせて表示する3
select テーブル名.カラム名... from 結合するテーブル名1, 結合するテーブル名2, ... where テーブル名1.カラム名 = テーブル名2.カラム名共通項となるカラム名が一致しているとき、複数の抽出結果をあわせて表示する
select テーブル名.カラム名... from 結合するテーブル名1 join 結合するテーブル名2 using(カラム名);複数の抽出結果のうち、whereで指定した条件で更に抽出する(ex. 100以上で抽出)
select テーブル名.カラム名... from テーブル名1 join テーブル名2 using(カラム名) where テーブル名.カラム名 >=100;複数のテーブルを結合して抽出する
select * from テーブル名1 join テーブル名2 where 結合条件 join where 結合条件....;選択したテーブルに共通項が存在しているものだけを表示→内部結合
選択したテーブルに共通項がなくても表示→外部結合左外部結合(left)右外部結合(right)して結果を表示する
select カラム名 from テーブル名1 left join 結合するテーブル2 on テーブル1カラム名 = テーブル2カラム名;自己結合して表示(エイリアスを用いる)
select カラム名 from テーブル名1 as エイリアス1 join テーブル名2 as エイリアス2;自己結合して表示(エイリアスを用いる)
(asを省略して表記するがカンマで区切る)
select カラム名 from テーブル名1 エイリアス1, テーブル名2 エイリアス2, ... ;サブクエリを使って最大値をもつレコードを表示する
select * from tb where カラム名 in (select max(カラム名) from テーブル名);
https://blanche-toile.com/web/mysql-like-search
//末尾一致検索の場合
SELECT * FROM テーブル名 WHERE フィールド名 LIKE '%文字列'//前方一致検索の場合
SELECT * FROM テーブル名 WHERE フィールド名 LIKE '文字列%'//部分一致検索(どこかに含まれていれば良い)の場合
SELECT * FROM テーブル名 WHERE フィールド名 LIKE '%文字列%'//jで始まりtで終わる任意の長さの文字列の場合
SELECT * FROM テーブル名 WHERE フィールド名 LIKE 'j%t'
- 投稿日:2020-06-27T16:27:52+09:00
Laravel開発用のDockerイメージできたのでシェアします。
これからLaravelを使って開発とかしていく予定だったので、すぐにスタートできるようにDockerでイメージ作りました。
同じ環境で開発してる方など、よかったら持ってってください。https://hub.docker.com/r/ryuki0529/webserver
大まかなイメージ環境
- OS:CentOS 7.8
- サーバー:Apache 2.4.6
- PHP 7.4.7
- PHPMyAdmin 5.0.2
- Composer 1.10.7
- Laravel Installer 3.1.0
- Git 2.9.5
- データベース:mysql Ver 15.1 Distrib 10.4.13-MariaDB
注意点
docker runでコンテナ作るときに、--privilegedと起動時のコマンドで/sbin/initを指定しないとsystemctlコマンド周りが使えないので注意です。これで3時間ほどハマってしまいました。詳しくは下記の記事で説明されてます。
CentOS7のコンテナでsystemctlを使うための方法ということで、最終的にコマンドは以下になります。
docker run -itd -p 80:80 --privileged webserver:1.0.2 /sbin/init docker exec -it webserver /bin/bash実際に開発とかやり始めるときはVS Codeとかでファイル編集しつつ、作業フォルダーマウントする感じだと思います。
なので基本的にはこっちかな。docker run -v '{マウント元のフォルダー}:{マウント先のディレクトリー}' -itd -p 80:80 --privileged webdevs-main:latest /sbin/init #自分の場合はこんな感じ。 #docker run -v 'K:/docker develop/mounts/webdevs-main:/var/www/html' -itd -p 80:80 --privileged webdevs-main:latest /sbin/init
- 投稿日:2020-06-27T07:55:40+09:00
【SQLのパフォーマンス検証】結合のコスト、インデックスの効果
達人に学ぶDB設計 | 正規化と非正規化、インデックスについて
前回こちらの記事で、DB設計の正規化とパフォーマンスのトレードオフについて、学習しました。その中で、結合処理のコストの高さや、インデックスによる性能改善が触れられていて、実際にどのくらいの違いがあるのか、知りたくなりました。
そこで、記事で扱った処理について、3つの場合に分けて、処理時間を比較してみました。
- そのまま結合を使った場合
- テーブルに集計データを持たせて、結合せずに済むようにした場合
- インデックスを利用しつつ、結合を使った場合
素人の実験ですので、おかしな部分がありましたら、コメントでご教授ください。
結果
結果を先に述べてしまうと、そのまま結合した時に比べて、結合を使わない場合は、 約19倍 、インデックスを利用した場合は、 約10倍 早くなりました。
検証方法
環境
MySQL 5.7
MySQL Workbench 8.0
MySQL Workbenchは、SQLクエリを実行して処理時間を計測したり、インデックスが使われているかをGUIで確認できる開発ツールです。
検証データ
1対多の関連を持つ「受注(orders)」テーブルと「受注明細(line_items)」テーブルを用意しました。
受注(orders)テーブル
id
受注IDorder_date
受注日customer_name
注文者名義1 2020-06-26 岡野 徹 2 2020-06-26 浜田 健一 3 2020-06-26 石井 恵子 4 2020-06-26 若山 みどり 100000 2023-03-22 庄野 弘一 受注明細(line_items)テーブル
id
受注明細IDorder_id
受注IDserial_number
受注明細連番item_name
商品名1 1 1 マカロン 2 1 2 紅茶 3 1 3 オリーブオイル 4 2 1 チョコ詰め合わせ 5 2 2 紅茶 6 2 3 日本茶 299998 100000 1 牛肉 299999 100000 2 鍋セット 300000 100000 3 米 ※赤字が主キー
簡単にするため、次のようにして大規模データを持たせました。
ordersテーブル:毎日100人の顧客が注文(1000日分、計10万レコード)
line_itemsテーブル:1回の注文で3つの商品が注文される(計30万レコード)
これらのテーブルを使って、「受注日ごとに何個の商品が注文されているかを調べる」という処理を考えます。
1. そのまま結合した場合
最初に、インデックスを作成せずに、結合を使って処理する場合のSQLクエリが以下のようになります。
SELECT orders.order_date, COUNT(*) AS item_count FROM orders INNER JOIN line_items ON orders.id = line_items.order_id GROUP BY orders.order_date LIMIT 100;2つのテーブルを内部結合して、受注日(order_date)ごとに集計した結果を100件取得します。
結果
order_date
受注日item_count
商品数2020-06-26 300 2020-06-27 300 2020-06-28 300 2020-06-29 300 2020-10-03 300 上のように、「毎日300個の商品が注文されている」という結果が得られます。
処理時間
この時、10回同じ処理をして、かかった時間の平均を求めると、 404ms でした。
この処理が頻繁に行われることを想定した場合、やや遅いのかなと思いました。
2. 集計データを持たせた場合
結合を使わずに処理するために、予め集計した「商品数(item_count)」カラムを、ordersテーブルに追加します。
受注(orders)テーブル
id
受注IDorder_date
受注日customer_name
注文者名義item_count
商品数1 2020-06-26 岡野 徹 300 2 2020-06-26 浜田 健一 300 3 2020-06-26 石井 恵子 300 4 2020-06-26 若山 みどり 300 100000 2023-03-22 庄野 弘一 300 上のテーブル構成は、前回の書籍からの引用ですが、非正規化の例としてそのまま集計データを追加しています。
改めて見ると、一人一人が300個注文しているように見えるので、本来は商品数テーブルとして分けた方が良さそうです。
このテーブルから、受注日ごとの商品数を得るSQLクエリは以下のようになります。
SELECT DISTINCT order_date, item_count FROM orders LIMIT 100;DISTINCTで、重複する受注日を1つにまとめています。これで、1の時と同じように毎日300個の注文があるという結果が得られます。
処理時間
この処理の10回の平均時間は、 20.8ms でした。そのまま結合した場合(404ms)に比べて、 約19倍 も速くなっています。
実際に比較してみることで、結合処理のコストの高さが実感できました。ただ、集計データを持たせると、更新の処理が複雑になるということも、意識しておく必要があります。
3. インデックスを利用した場合
1の結合を使った処理において、必要なカラムにインデックスを作成することで、処理を高速化させます。
再掲SELECT orders.order_date, COUNT(*) AS item_count FROM orders INNER JOIN line_items ON orders.id = line_items.order_id GROUP BY orders.order_date LIMIT 100;インデックスを作成するにあたって、次のことを考慮しました。
- インデックスは、基本的に1つのテーブルに対して1つが使われる
- WHERE句やORDER_BY句、GROUP_BY句、または結合条件に使用されているカラムに作成する
そこで、2つのテーブルの次のカラムにインデックスを追加しました。
- ordersテーブル:GROUP_BYで使用されている、「order_date」カラム
- line_itemsテーブル:結合条件で使用されている「order_id」カラム
処理時間
最初に結合条件の「order_id」カラムにだけインデックスを追加しましたが、処理平均時間は、418msで、効果がありませんでした。
次に「order_date」カラムにもインデックスを追加すると、10回の処理平均時間は 40.7ms になりました。
1と全く同じSQLですが、インデックスを作成するだけで 約10倍 も高速になるということが分かりました。条件次第だとは思いますが、適切に改善できれば、結合処理も十分実用に耐えるのではないかと思います。
MySQL Workbench の使用感
脇道に逸れますが、MySQL Workbenchを利用すると、SQLクエリ実行時にインデックスが使われているか、重い処理はどこかが視覚的に分かり、便利でした。
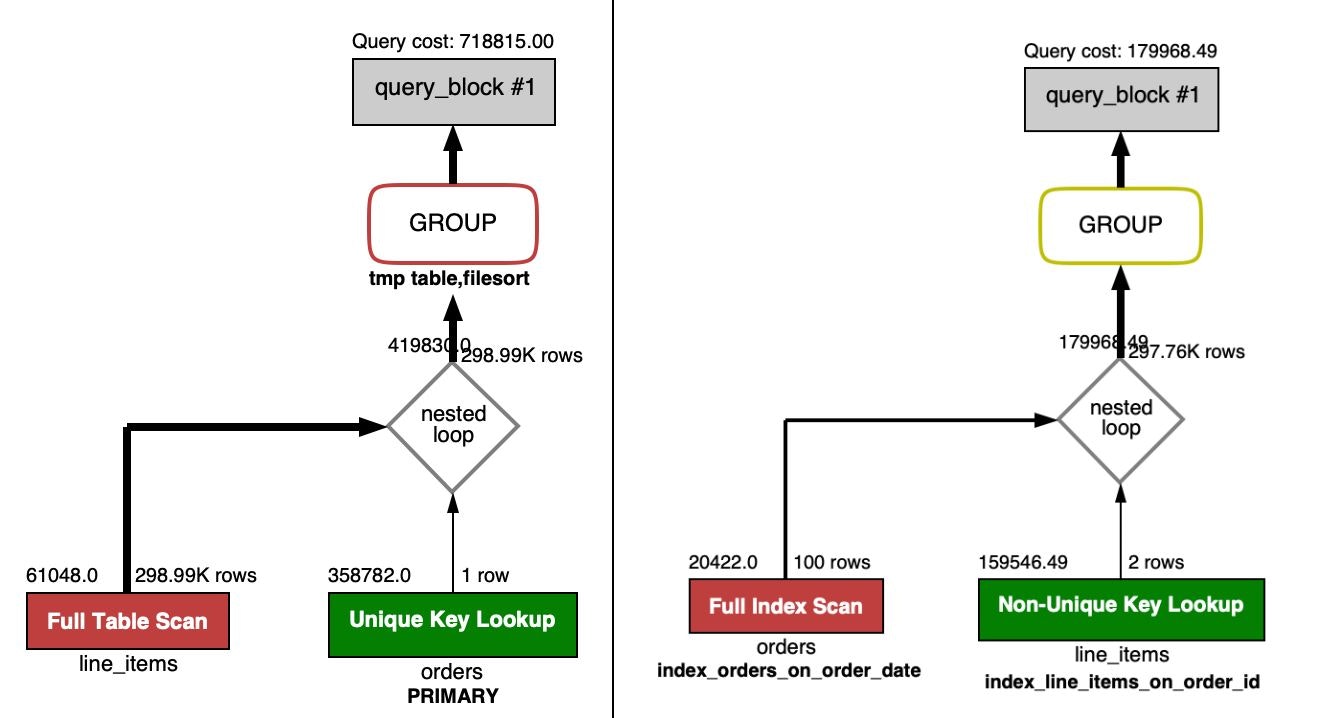
下の画像は、左がインデックス作成前、右がインデックス作成後の、結合を含むSQLクエリを表した図です。
色がついている部分は、赤いほど高コストで、青い(緑)ほど低コストということを表しています。
右を見ると、2つのインデックスが使われていて、わずかですが、GROPU_BYの処理の色が変わっていることが確認できます。
結合条件を絞り込むことで、もっと改善することができるのではないかと思います。
参考:[MySQL Workbench] VISUAL EXPLAIN でインデックスの挙動を確認する
DBMSによる結合処理の違い
こちらの記事から、結合処理には次の3種類があることを知りました。
- Nested Loop Join
- Hash Join
- Merge Join
このうち、OracleとPostgreSQLには3つとも実装されていて、MySQLでは「Nested Loop Join」だけが実装されているということです。
RDBMSの、そのような細かな違いも把握しておきたいと思いました。
おわりに
実際に大規模データを作って実験してみることで、処理の仕方やインデックスの有無によるパフォーマンスの違いを実感することができました。
実験は1→3→2の順番で行ったのですが、3で2つ目のインデックスを追加した時に、あまりの処理時間の速さに、目を疑ってしまいました 笑。
適切なカラムに貼れば、たったそれだけでこんなにも違いが出るのだと分かり、インデックスはDB設計で必須のものだと改めて感じました。