- 投稿日:2020-06-27T23:52:11+09:00
API Gateway + LambdaでS3にある画像を表示
概要
- API GatewayとLambdaでS3にある画像を返却する
- クライアント側からは単にURLにアクセスしたら画像が表示されるように見える
- S3をpublicにすることなく画像を表示することができる (限定公開などが可能)
- pythonでの実装
仕様がよく分からずハマったのでメモを残します.
やること
- Lambdaの作成
- API Gatewayの作成
S3は作成済みとします.
1. Lambdaの作成
Lambdaを適当な名前で作成します.ここでは
get_imageとしました.また,ランタイムはPython 3.8を選択しました.
そして関数コードに
以下のコードを登録します.import boto3 import base64 def get_img_from_s3(): s3 = boto3.client('s3') bucket_name = 'BUCKET_NAME' file_path = 'FILE_PATH' responce = s3.get_object(Bucket=bucket_name, Key=file_path) body = responce['Body'].read() body = base64.b64encode(body) return body def lambda_handler(event, context): img = get_img_from_s3() return img
bucket_nameにS3のバケットの名前,file_nameに読み込みたいS3のオブジェクト(画像)のパスを渡しS3からオブジェクトを読み込みます.そして読み込んだバイナリ形式のオブジェクトをbase64にエンコードして返却します.
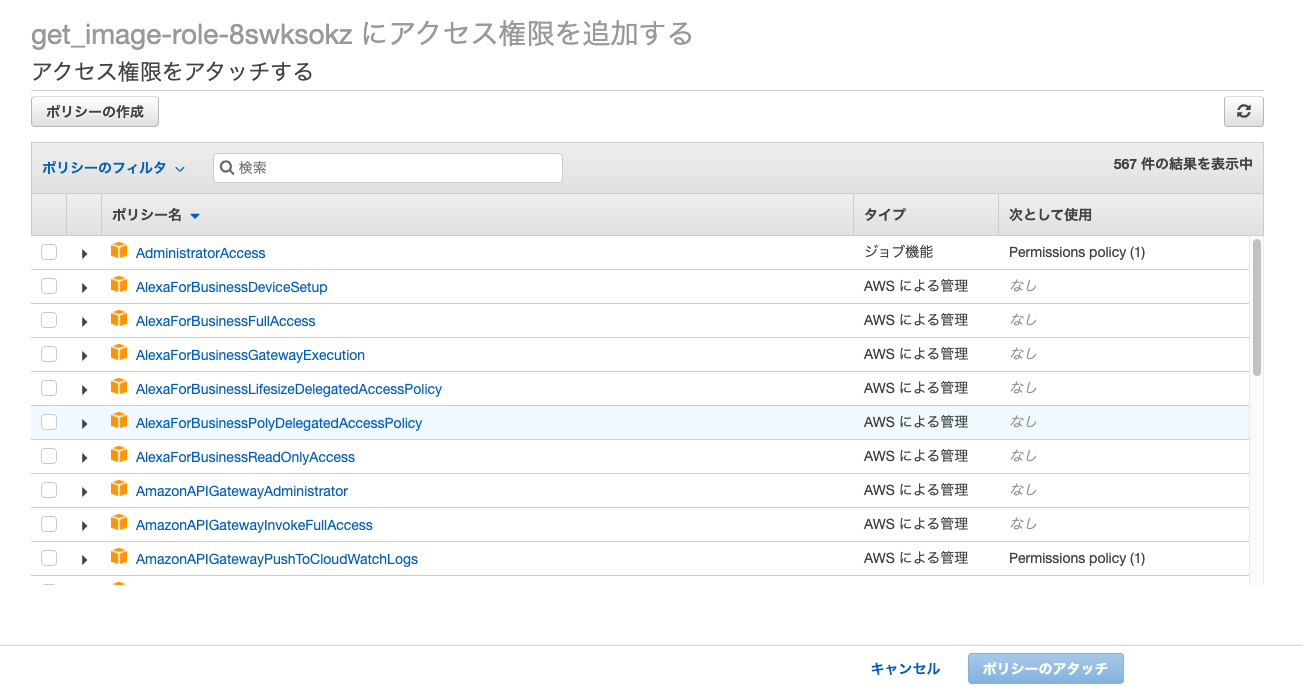
LambdaにS3へのアクセス権限を付与
作成したLambdaはS3へのアクセス権限を持っておらず,このままだとアクセスが拒否されてしまうのでS3へのアクセス権限を付与します.
まず作成したLambdaのアクセス権限のページを開きます.
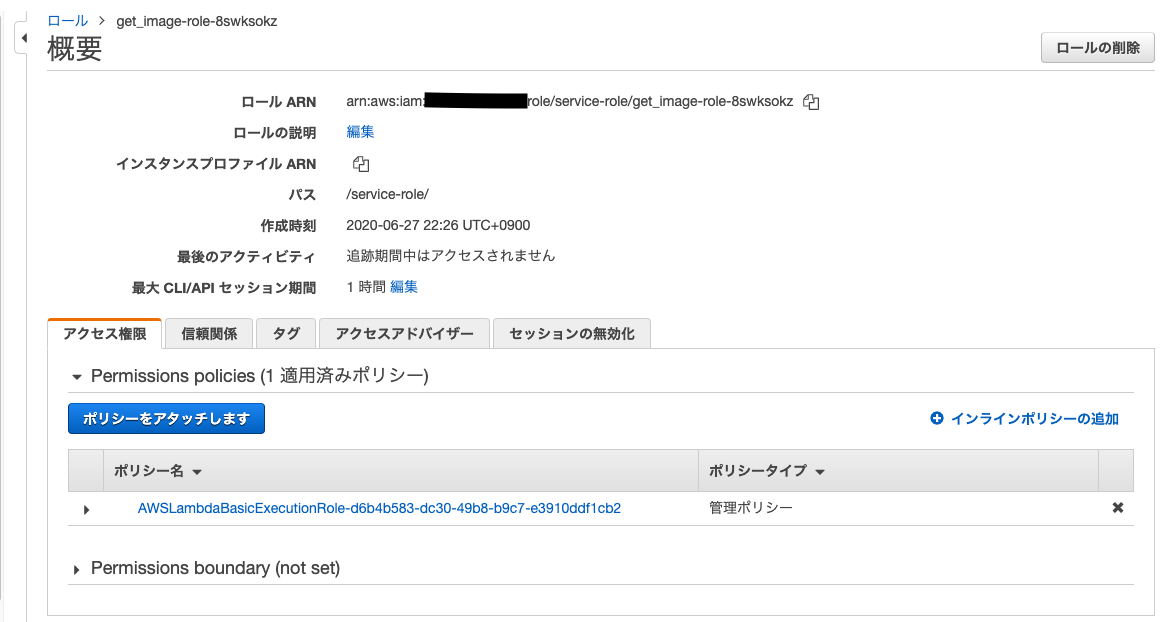
ここに自動で作成された実行ロールが割り当てられているので,この実行ロールのページを開きます.
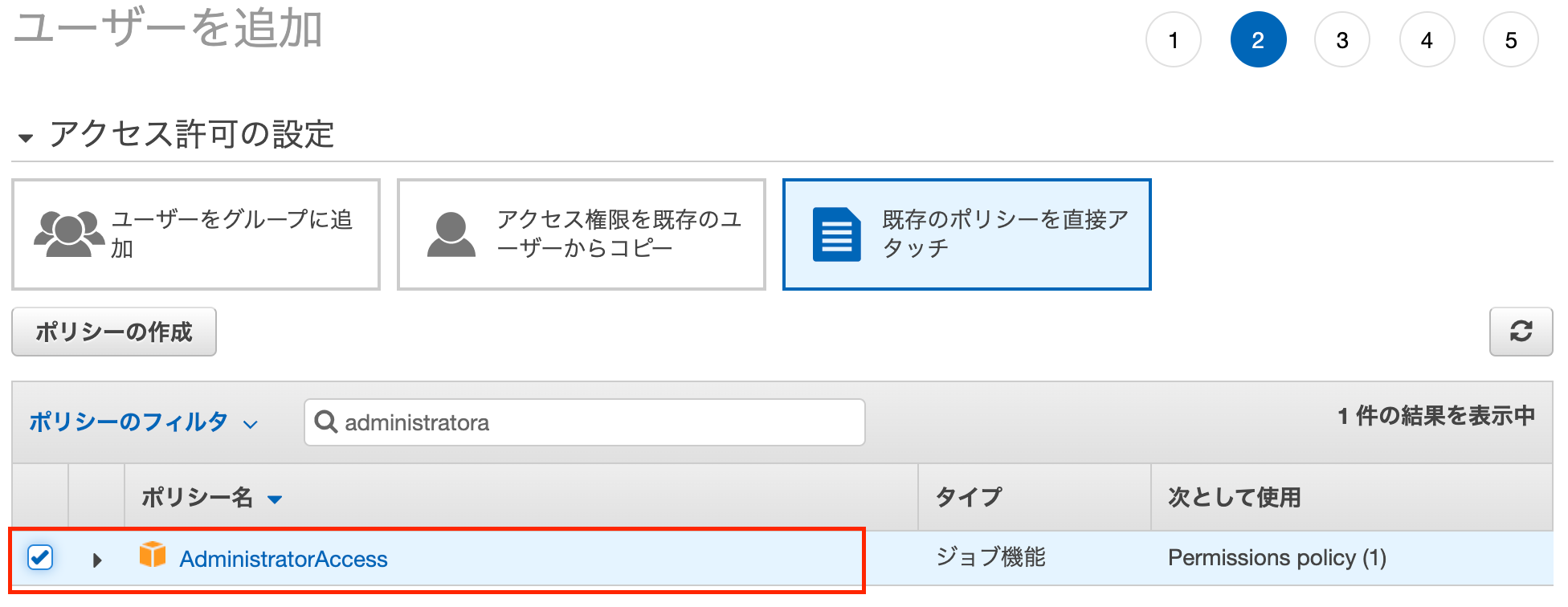
ページ中央の青いポリシーをアタッチしますというボタンを押します.
このようにいろいろなポリシーが出てきます.
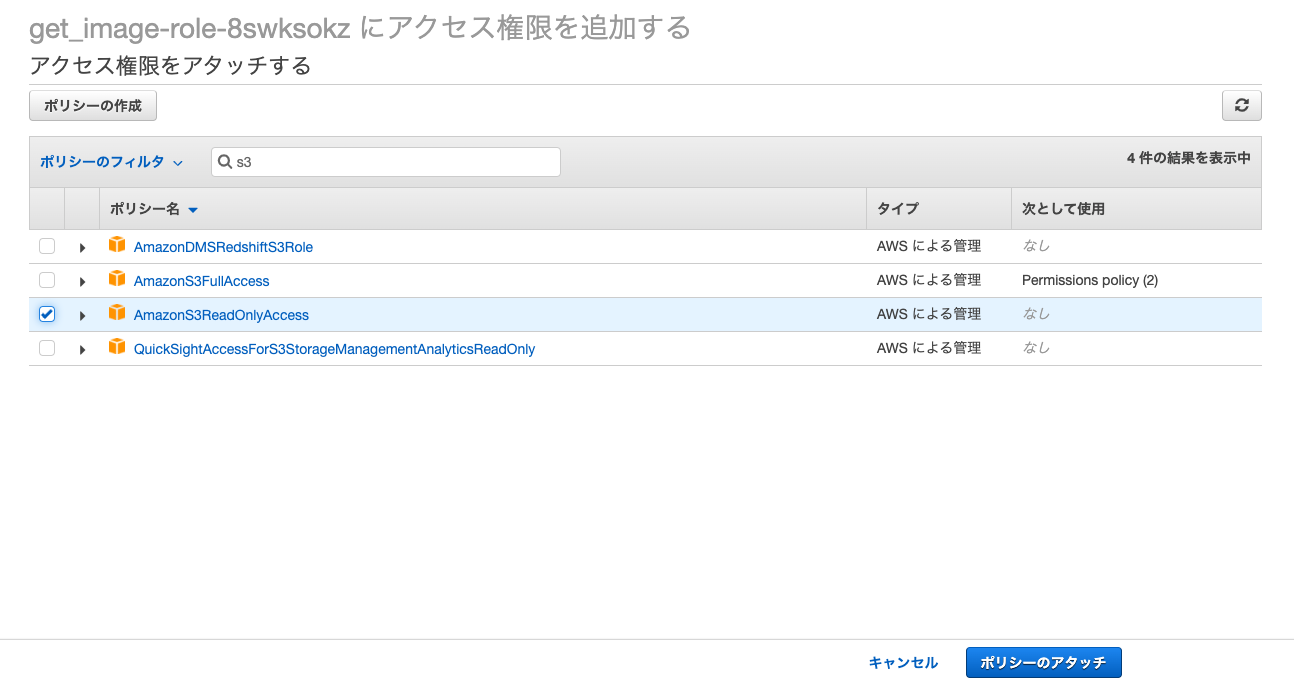
S3で検索するとS3に関するポリシーが出てきます.
今回はS3から画像を読み込むのでAmazonS3ReadOnlyAccessというポリシーをアタッチします.
これでLambdaからS3に保存されているファイルを読むことができるようになります.以上でLambdaの設定は終了です.
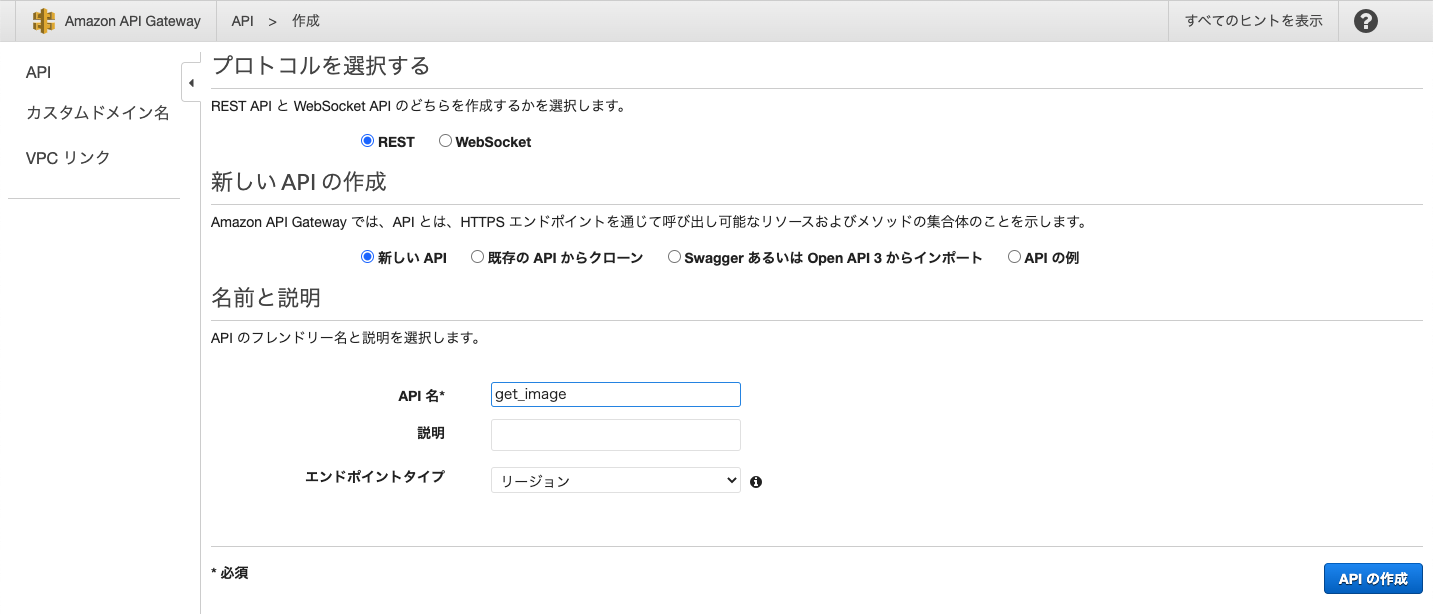
2. API Gatewayの作成
続いてAPI Gatewayの作成をします.
APIタイプはREST APIを選択し,API名は適当に
get_imageとしました.
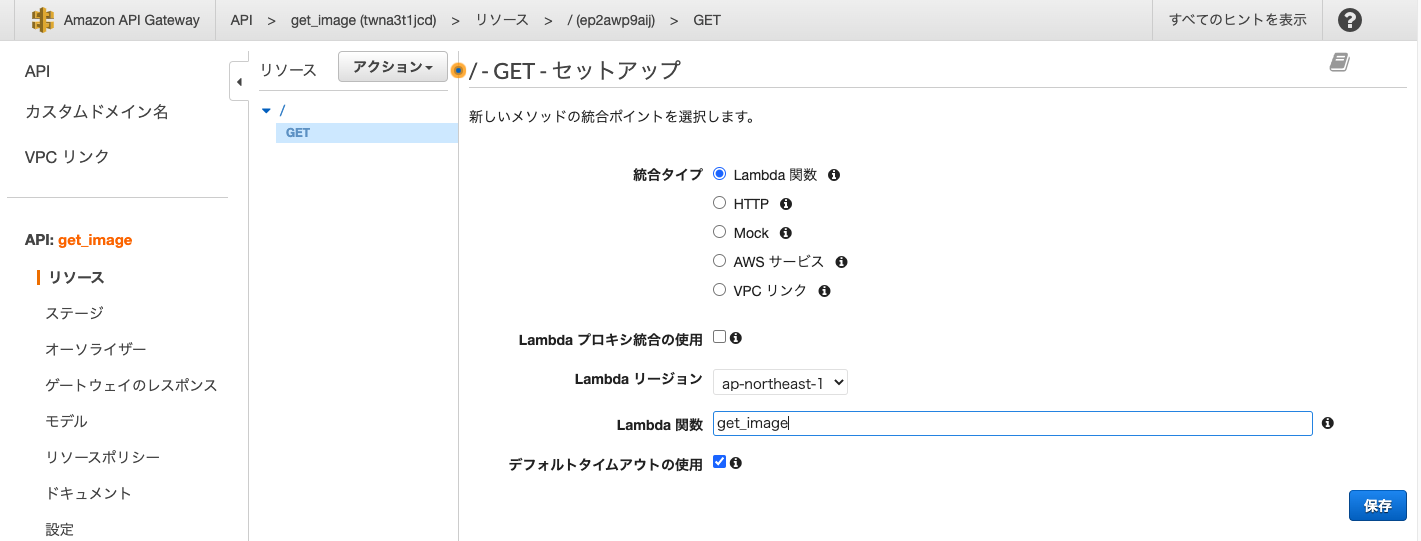
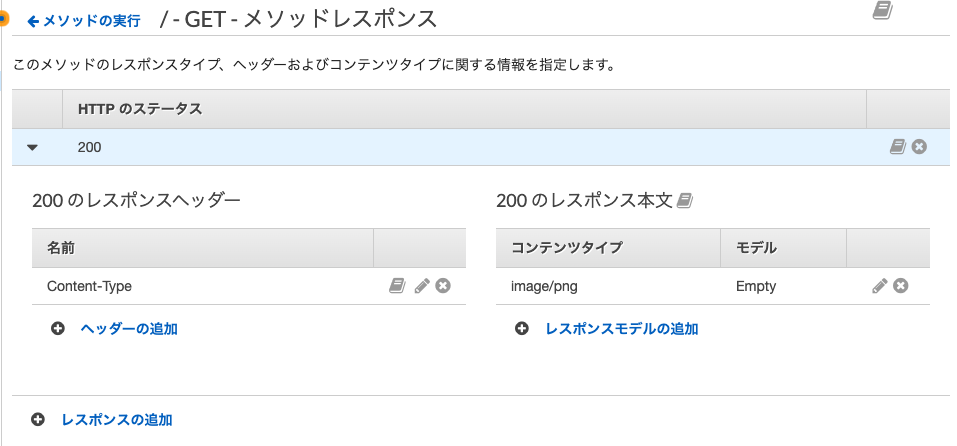
続いてGETメソッドを追加し,統合タイプにはLambdaを,Lambda関数には先ほど作成したget_imageというLambda関数を指定しました.これでAPI Gatewayが作成できたのでメソッドレスポンスの設定を行います.
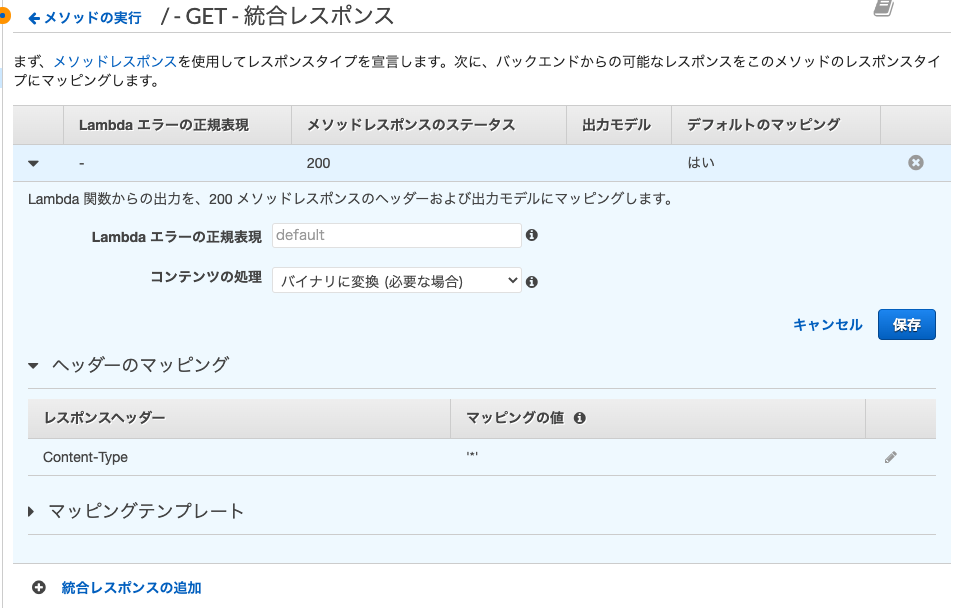
まずレスポンスヘッダーにContent-Typeを追加し,レスポンス本文のコンテンツタイプにはimage/pngを追加しました.(今回はpngを読み込んだのでimage/pngにしました.)次に統合レスポンスの設定を行います.
コンテンツの処理方法をデフォルトではパススルーになっていますが,
バイナリに変換(必要な場合)を選択します.
またヘッダーのマッピングのマッピングの値を'*'とします.以上でAPI Gatewayの設定も終了です.
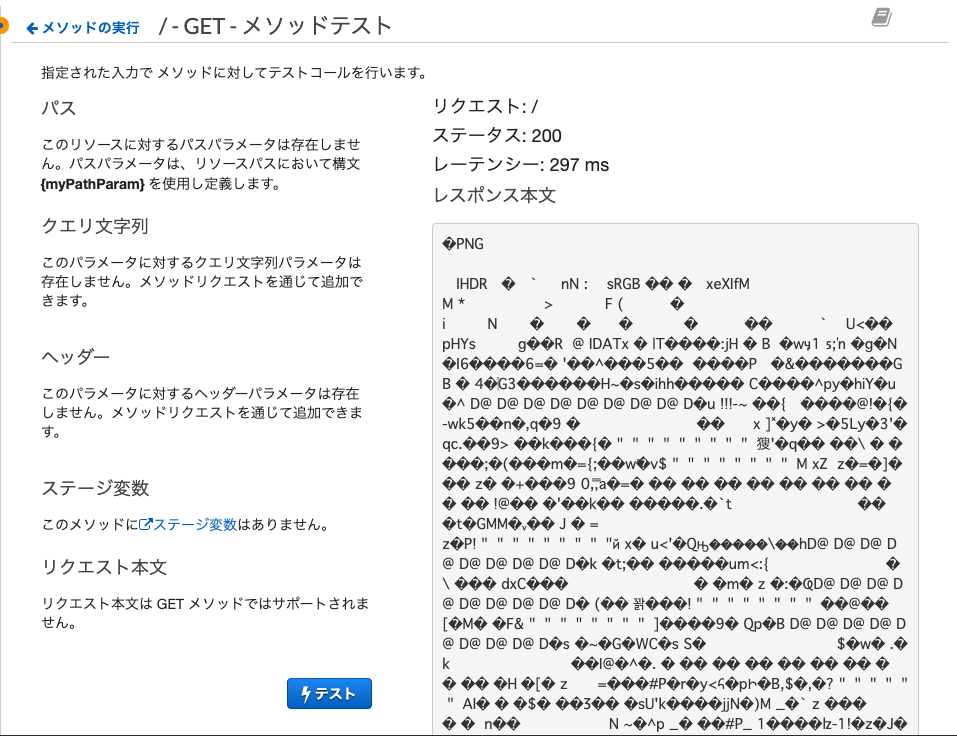
最後にAPIのテストを行うと
このようにpngのバイナリを返すことができました!実際にAPIをデプロイしてURLにアクセスすると画像が表示されます.
参考
Node.jsによる実装 Lambda + API Gateway入門。画像のDL
- 投稿日:2020-06-27T23:38:39+09:00
AWSのEC2インスタンスの監視をzabbixへ統合監視するために、zabbixのLLD(ローディスカバリー)機能を使ってみた!
LLDとは?
ローレベルディスカバリにより、コンピューター上の種々の要素に対してアイテム、トリガー、グラフを自動的に作成できます。例えば、Zabbixは使用しているマシン上のファイルシステムまたはネットワークインターフェースの監視を自動的に開始できます。そのために、各ファイルシステムまたはネットワークインターフェースに対して手動でアイテムを作成する必要はありません。さらに、定期的に実施されるディスカバリの実際の結果に基づいて不要な要素を自動的に削除するように、Zabbixを設定することができます。
zabbix公式ページ目的
今回の目的は、AWSのEC2のリソース情報の監視をzabbixに連携することとします。
その中でLLD機能を使って、アイテムとトリガーの自動作成を実施してみます。手順
以下の手順で実施していきたいと思います。
- 監視対象のEC2インスタンスのメトリクスの確認。
- zabbix上でのホストの作成
- LLDに必要なマクロ情報取得及びメトリクス値取得のためのスクリプトの配置
- LLDの作成
- 監視連携確認
環境
・監視対象のEC2
監視対象[ec2-user@xxxx ~]$ cat /etc/system-release Amazon Linux release 2 (Karoo)・zabbixサーバ用のEC2
zabbixサーバー[ec2-user@zb-server ~]$ cat /etc/system-release Amazon Linux release 2 (Karoo) [ec2-user@zb-server ~]$ zabbix_server -V zabbix_server (Zabbix) 4.2.8前提
- zabbixサーバにzabbixのインストール
- 監視対象EC2にメモリやディスクのメトリクスを作成していること
- メモリとディスクのメトリクス追加はLLDの挙動を調べる上で必須ではないと思いますが、今回監視対象としてる私のEC2インスタンス(学習用)にたまたま作成していたので、前提とさせていただきました。こちらのAWS公式ページからウィザードを使用したメモリやディスクのメトリクス作成ができますので、ご興味のある方はぜひ参考にしていただければと思います。
監視対象サーバに追加されているメトリクスの確認
監視対象サーバに関連するメトリクスをCloudwatchより確認します。私の環境では以下のメトリクスが追加されておりました。
以下の結果から17個のメトリクスが現在作成されていることがわかりました。これらのメトリクスをzabbixへ連携していきます。Macから実施しました。~ ❯❯❯ aws cloudwatch list-metrics \ --dimensions Name=InstanceId,Value=i-xxxxxxxx \ |jq '.Metrics[].MetricName' |awk '{print NR, $0}' 1 "CPUSurplusCreditBalance" 2 "MetadataNoToken" 3 "NetworkPacketsOut" 4 "DiskReadOps" 5 "CPUCreditBalance" 6 "StatusCheckFailed" 7 "NetworkOut" 8 "StatusCheckFailed_Instance" 9 "NetworkIn" 10 "CPUSurplusCreditsCharged" 11 "CPUUtilization" 12 "StatusCheckFailed_System" 13 "DiskWriteBytes" 14 "CPUCreditUsage" 15 "DiskWriteOps" 16 "NetworkPacketsIn" 17 "DiskReadBytes"コマンドの解説
・
aws cloudwatch list-metrics --dimensions Name=InstanceId,Value=i-xxxxxxxx
これはvalueで指定したEC2インスタンスのメトリクス一覧を取得するコマンドです。このコマンドを実行するためにはaws cliをインストールしなければいけません。
awc cliインストール公式ページ
・jq '.Metrics[].MetricName'
aws cloudwatch list-metricsにより出力されたJSON形式のデータの中から、メトリクス名のみを抜き出しています。
jqをインストールするためには以下を実行してください(mac)。 jqはコマンドライン上でJSONデータを整形できるなどの機能があります。brew install jq・
awk '{print NR, $0}'
これはパイプにより渡された文字の前に連番を降っています。
NR(連番) $0(パイプにより渡された文字列)
の形式で出力させています。zabbix上でのホストの作成
zabbixの管理画面を開き、監視対象のホストを作成します。
zabbix管理画面を開いたら、上タブから”設定”>"ホスト">"ホスト作成"を選択すれば以下のような新規ホスト作成画面になります。
入力項目に以下のように入力します。
ホスト名:EC2インスタンスIDを入力してください(後ほど出てくるスクリプトと関連するため)
表示名:任意の文字を入力してください。
グループ:任意のグループ名を選択してください。
そのほかはデフォルトのままで追加ボタンを押下します。
以下のように新規に監視対象のEC2インスタンスのホストが作成されたことがわかります。
スクリプトの配置
LLD機能により使用するスクリプトを配置します。
スクリプトはこちらを使わせていただきます。pythonで書かれたコードで、Pythonの公式AWS SDKであるboto3を使用しています。
このスクリプトには二つの役割があります。
- スクリプト実行により必要なメトリクス情報を取得し、そのメトリクス情報を元にアイテムを自動作成していきます。
- メトリクス値を取得し、自動的に作成されたアイテムに対して送信する。
それぞれの役割の詳しい説明は後述します。
まず、Python3とPythonの公式AWS SDKであるboto3をinstallします。
zabbix-server[ec2-user@zb-server ~]$ sudo yum install python3 -y [ec2-user@zb-server ~]$ python3 -V Python 3.7.6 [ec2-user@zb-server ~]$ pip3 -V pip 9.0.3 from /usr/lib/python3.7/site-packages (python 3.7) # ↑pip3を使ってboto3をインストールします [ec2-user@zb-server ~]$ sudo pip3 install boto3 [ec2-user@zb-server ~]$ pip3 freeze |grep boto3 boto3==1.14.12 # ↑boto3がインストールされたことを確認スクリプトの配置先は、zabbix_server.confに記載されています。
ExternalScriptsは外部チェックのタイプであるアイテムが実行するスクリプトを配置する場所のことです。
デフォルトでは、/usr/lib/zabbix/externalscriptsとなっております。zabbix-server[ec2-user@zb-server ~]$ sudo grep ExternalScripts /etc/zabbix/zabbix_server.conf ### Option: ExternalScripts # ExternalScripts=${datadir}/zabbix/externalscripts ExternalScripts=/usr/lib/zabbix/externalscripts/usr/lib/zabbix/externalscriptsにスクリプトを配置して、必要な権限を付与します。
もちろん、zabbixがスクリプトを実行するため、以下の権限に変更します。[ec2-user@zb-server ~]$ cd /usr/lib/zabbix/externalscripts/ [ec2-user@zb-server externalscripts]$ sudo vim cloudwatch_zabbix.py (スクリプトの内容をコピペ) [ec2-user@zb-server externalscripts]$ sudo chmod 755 cloudwatch_zabbix.py [ec2-user@zb-server externalscripts]$ sudo chown zabbix:zabbix cloudwatch_zabbix.py [ec2-user@zb-server externalscripts]$ ls -l cloudwatch_zabbix.py -rwxr-xr-x 1 zabbix zabbix 11147 6月 27 15:58 cloudwatch_zabbix.pyスクリプトをpython3で実行するために編集。
zabbix-server[ec2-user@zb-server externalscripts]$ sudo sed -i s/python/python3/ cloudwatch_zabbix.py [ec2-user@zb-server externalscripts]$ cat cloudwatch_zabbix.py |grep python #!/bin/env python3スクリプトが動作するかどうかの確認。-iにはインスタンスIDを入力する。
zabbix-server[ec2-user@zb-server externalscripts]$ sudo -u zabbix ./cloudwatch_zabbix.py 'ec2' -i 'i-xxxxxxxxxxx' -r 'ap-northeast-1' File "./cloudwatch_zabbix.py", line 171 print "Can't connect to zabbix server" ^ SyntaxError: Missing parentheses in call to 'print'. Did you mean print("Can't connect to zabbix server")?と思ったが、エラーが出てている。
スクリプト上で書かれているprint "Can't connect to zabbix server"が問題とのこと。。
python3では、printの書き方について変更されたとのこと。
print "hoge"
↑これはpython2でしか使えない。
ptint("hoge")
↑これはpython3・python2の両方で使える。
なので、python3に合わせるためにスクリプト上のprintをprint("文字列")になるように編集。zabbix-server[ec2-user@zb-server externalscripts]$ sudo sed -i -r "s/print ([^ \f\n\r\t]+)/print(\1)/g" cloudwatch_zabbix.py [ec2-user@zb-server externalscripts]$ cat cloudwatch_zabbix.py |grep print print("Can't connect to zabbix server") print('Data sending failure') print(response[13:]) print(json.dumps(lld_output_json))そのほかにも、python3に対応していないコードがあったので、編集。
zabbix-server[ec2-user@zb-server externalscripts]$ sudo sed -i -r "s/datapoint.has_key\((\"[a-zA-Z]+\")\)/\1 in datapoint/g" cloudwatch_zabbix.py [ec2-user@zb-server externalscripts]$ grep "datapoint in" cloudwatch_zabbix.py for datapoint in stats["Datapoints"]: for datapoint in datapoints: # ↑上のような出力が出ればOK! [ec2-user@zb-server externalscripts]$ sudo sed -i "173i\ b1, b2 = \('<4sBQ'.encode\('utf-8'\), 'ZBXD'.encode\('utf-8'\))" \ -e "s/'<4sBQ', 'ZBXD'/b1, b2/" \ -e "175a\ send_data_string = send_data_string.encode('utf-8')" \ -e "s/response += data/response += data.decode(encoding='utf-8')/" \ cloudwatch_zabbix.py && grep -e "enco" -e "struct.pack" cloudwatch_zabbix.py b1, b2 = ('<4sBQ'.encode('utf-8'), 'ZBXD'.encode('utf-8')) header = struct.pack(b1, b2, 1, len(send_data_string)) send_data_string = send_data_string.encode('utf-8') response += data.decode(encoding='utf-8') # ↑上のような出力が出ればOK!再度、取得できるか確認。JSON形式のデータが出力されればOK!
zabbix-server[ec2-user@zb-server externalscripts]$ sudo -u zabbix ./cloudwatch_zabbix.py 'ec2' -i 'i-xxxxxxx' -r 'ap-northeast-1' {"data": [{"{#METRIC.NAME}": "DiskWriteBytes", "{#METRIC.UNIT}": "Bytes", "{#METRIC.NAMESPACE}": "AWS/EC2"}, # ・・・ データが続いていく。はじめに確認した数のメトリクスを取得できているかの確認のために以下のコードを書き込む。
zabbix-server[ec2-user@zb-server externalscripts]$ sudo sed -i "232i\ print(len(lld_output_json[\"data\"]))" cloudwatch_zabbix.py # ↑ これは取得するメトリクスの数を数えるコードを挿入している [ec2-user@zb-server externalscripts]$ sudo -u zabbix ./cloudwatch_zabbix.py 'ec2' -i 'i-xxxxxx' -r 'ap-northeast-1' 17 {"data": [{"{#METRIC.NAME}": "CPUSurplusCreditBalance", # ・・・ データが続いていくcloudwatch_zabbix.pyを実行後、17と表示された。
問題なく、はじめに確認した数と一致していることを確認。
確認できたところで、挿入したコードを削除するzabbix-server[ec2-user@zb-server externalscripts]$ sudo sed -i 232d cloudwatch_zabbix.py [ec2-user@zb-server externalscripts]$ cat cloudwatch_zabbix.py |grep print print("Can't connect to zabbix server") print('Data sending failure') print(response[13:]) print(json.dumps(lld_output_json)) # ↑ここでprint(len(lld_output_json[\"data\"]))が表示されていなければ問題なく削除できている!外部チェックとは?
zabbixのitemのタイプのことで、zabbix-serverに配置されたスクリプトを実行し、その結果を取り込む機能がある。
https://www.zabbix.com/documentation/2.2/jp/manual/config/items/itemtypes/externalLLDの作成
スクリプトを配置することができたので、zabbix管理画面に戻り、LLDを作成する。
先ほど作成したホストの画面へ戻る。
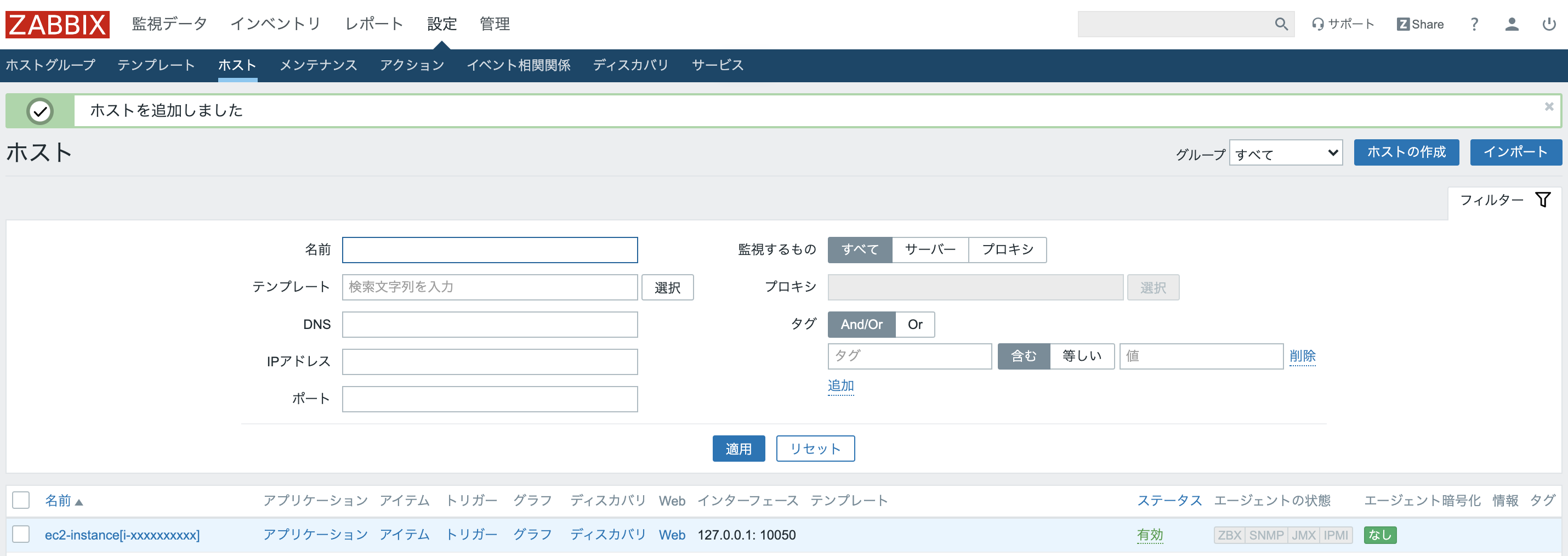
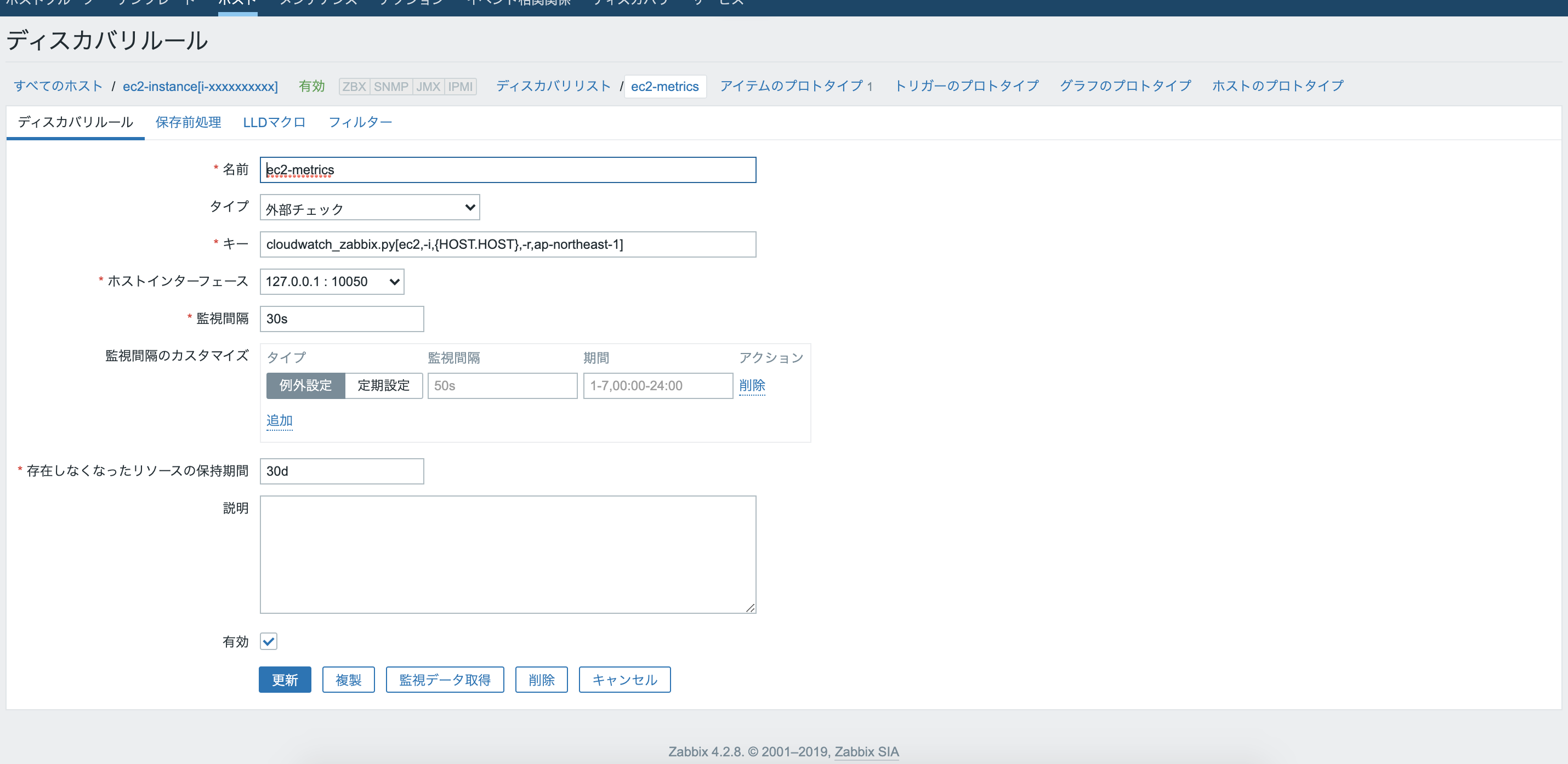
”ディスカバリールール”のタブを押下するとディスカバリールールの一覧画面へ遷移するので、右上のディスカバリールールの作成をクリックする。各項目に必要情報の入力。
名前:任意の名前を入力
タイプ:外部チェック
キー:cloudwatch_zabbix.py[ec2,-i,{HOST.HOST},-r,ap-northeast-1]
- cloudwatch_zabbix.pyは実行するスクリプトのファイル名
- []内は、スクリプト実行時の引数を入力する。{HOST.HOST}はホストの名前のこと。デフォルトで使えるzabbixのマクロとなっている。
有効:チェックを外す。
その他は今回はデフォルトのままにする。追加ボタンをクリックしてLLDを作成する。
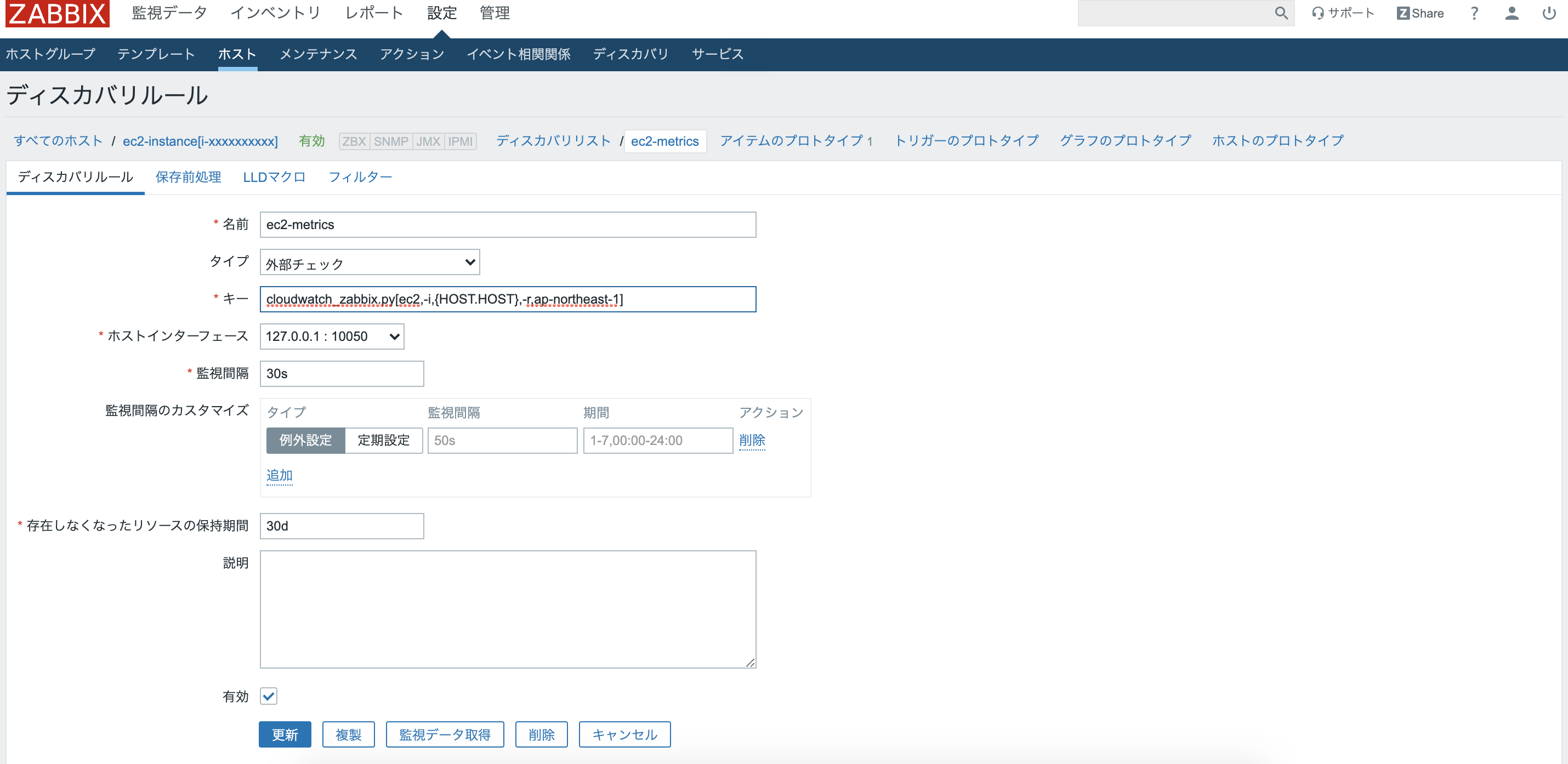
ここで設定したLLDのアイテムによりcloudwatch_zabbix.pyが実行され、以下のようなJSON形式のデータが出力される。
"{#xxx.xxx}": "xxxxxxxx"の各データが続いて設定するアイテムプロトタイプのマクロとして利用される。
ここでは、アイテムーを自動追加するためのマクロを作成するアイテムを設定している。{ "data": [ { "{#METRIC.NAME}": "CPUSurplusCreditBalance", "{#METRIC.UNIT}": "Count", "{#METRIC.NAMESPACE}": "AWS/EC2" }, { "{#METRIC.NAME}": "MetadataNoToken", "{#METRIC.UNIT}": "Count", "{#METRIC.NAMESPACE}": "AWS/EC2" }, { "{#METRIC.NAME}": "NetworkPacketsOut", "{#METRIC.UNIT}": "Count", "{#METRIC.NAMESPACE}": "AWS/EC2" },追加ボタンをクリックすると、以下のような一覧画面に遷移する。
アイテムプロトタイプの作成
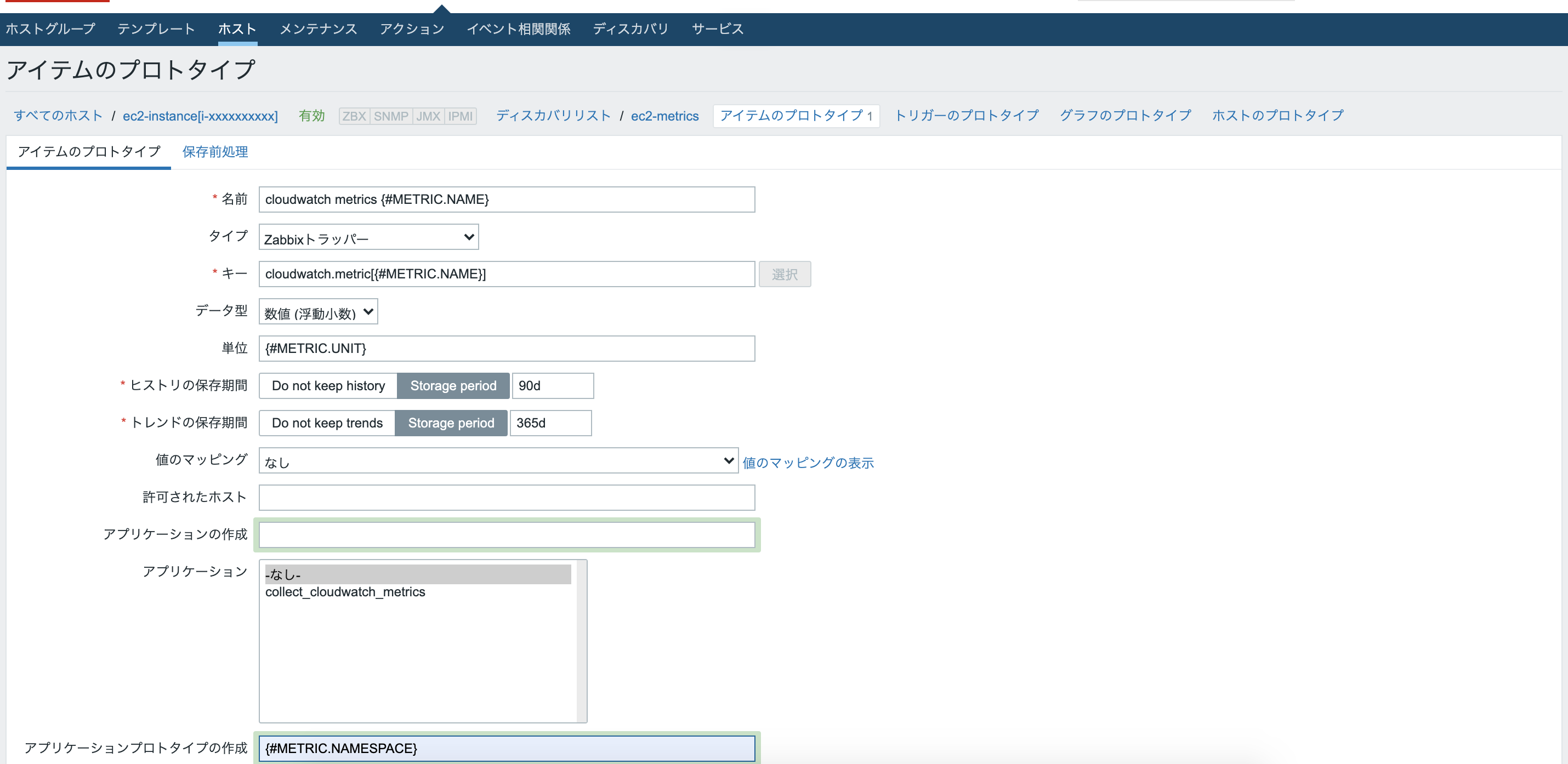
先ほど追加したec2-metricsのアイテムプロトタイプをクリックし、右上のアイテムプロトタイプの作成をクリックする。
先ほどのLLDにより出力されるマクロに対するアイテムを作成する。
以下のように入力する。
名前:cloudwatch metrics {#METRIC.NAME}
タイプ:zabbixトラッパー
キー:cloudwatch.metric[{#METRIC.NAME}]
データ型:数値(浮動小数)
単位:{#METRIC.UNIT}
アプリケーションプロトタイプの作成:{#METRIC.NAMESPACE}
その他はデフォルトのままとする。"追加"ボタンをクリックする。
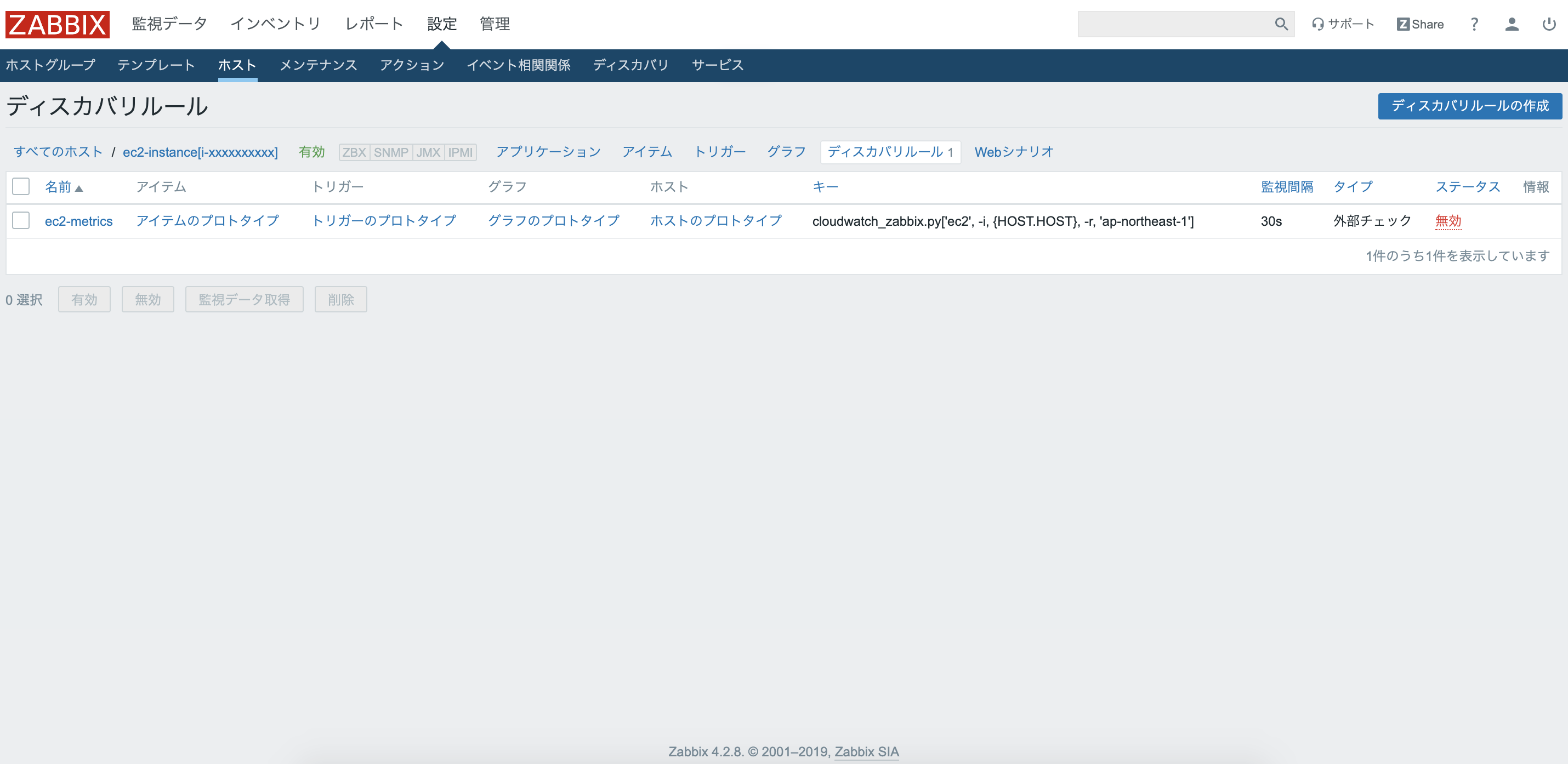
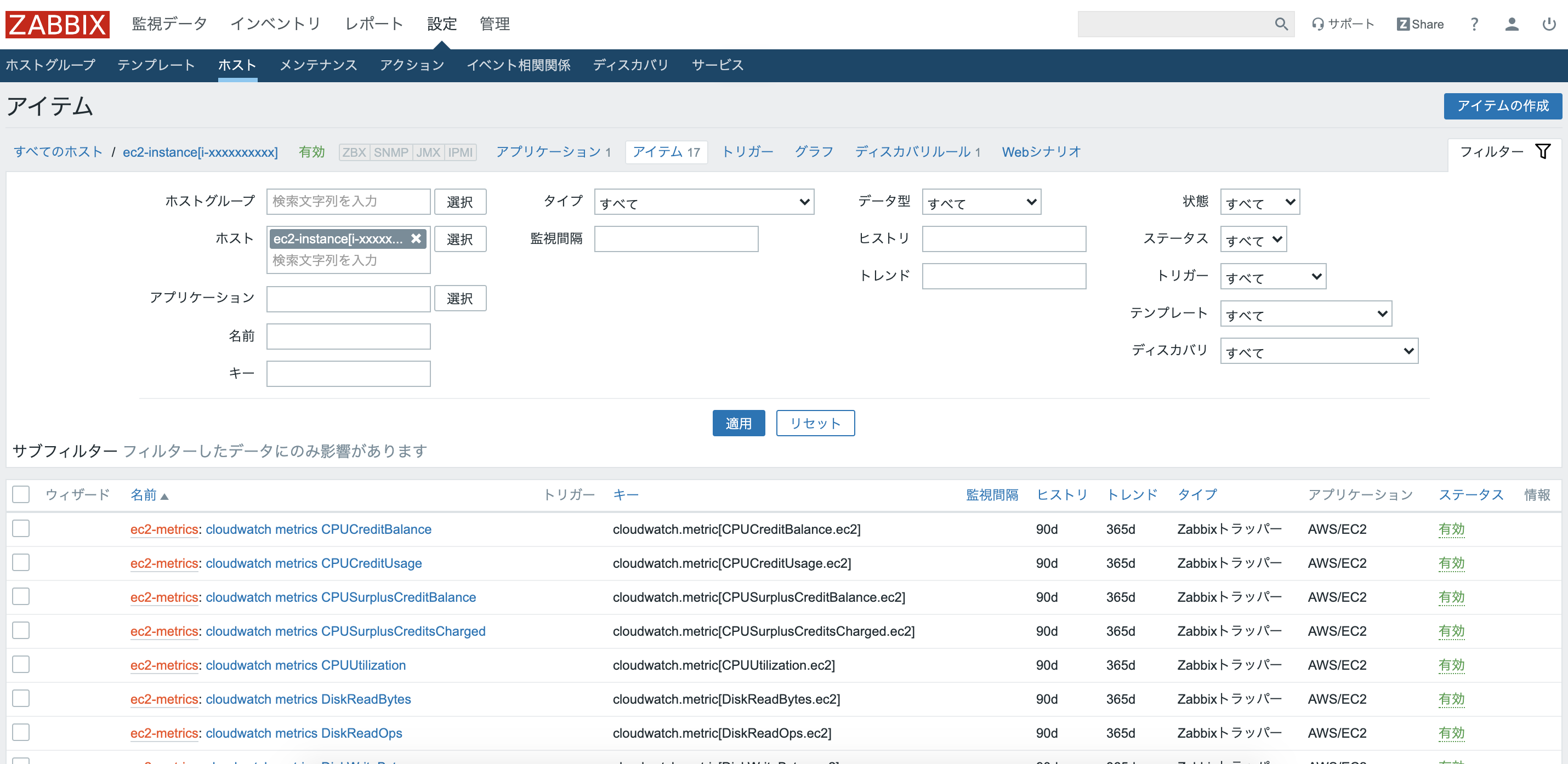
ディスカバリリストの一覧のページへいき、"ec2-metrics"をクリック。
一番下の"有効"にチェックを入れ"更新"をクリック。
すると、自動でアイテムが作成される。
ここでは、最初に作成したLLDのアイテムがスクリプトを実行し、JSONデータ(マクロ)を出力する。そのJSONデータ(マクロ)を使って、アイテムプロトタイプで作成したアイテムを雛形としてアイテムを作成している。
スクリプト内では、{#METRIC.NAME}・{#METRIC.NAMESPACE}・{#METRIC.UNIT}の値となるデータをCloudwatchから取得している。
データ送信用のアイテムを作成
今のままでは、メトリクスのアイテムが作成されただけで、肝心のメトリクスの値はまだない。
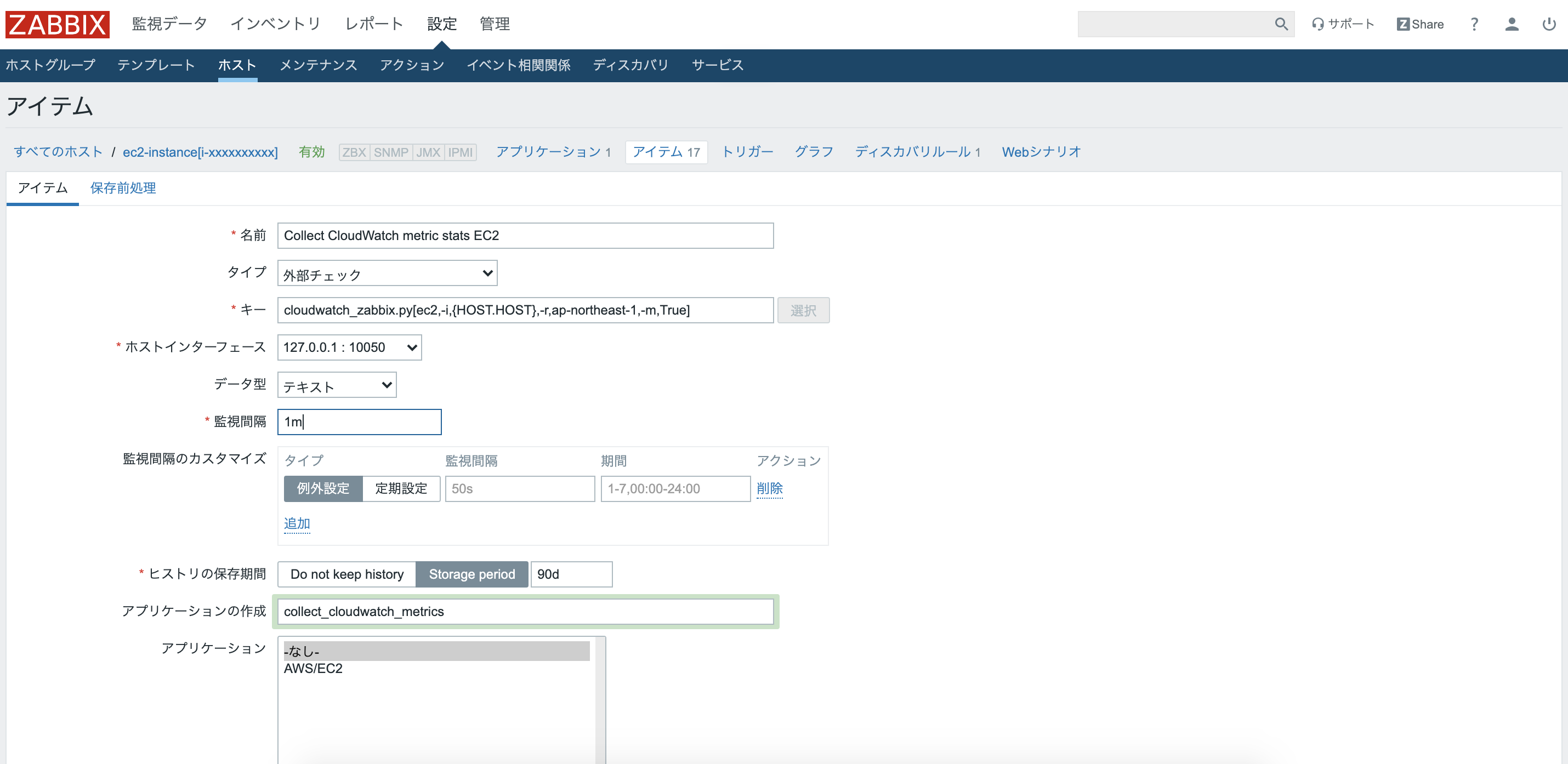
続いて、先ほど自動作成されたアイテムに対してメトリクスの値を送信するためのアイテムを追加する。上のタブから"設定">"ホスト"をクリックし、ホスト一覧の中から、"ec2-instance[i-xxxxxxxxxx]"をクリックする。
ホストのタブの中から、"アイテム"をクリックし、右上の"アイテムの作成"をクリック。
以下の写真のように各項目を入力していく。
名前:Collect CloudWatch metric stats EC2
タイプ:外部チェック
キー:cloudwatch_zabbix.py[ec2,-i,{HOST.HOST},-r,ap-northeast-1,-m,True]
データ型:テキスト
アプリケーションの作成:collect_cloudwatch_metrics
その他はデフォルトのままで"追加"をクリック。作成したCollect CloudWatch metric stats EC2のアイテムによりメトリクス値を収集し、zabbixへ値を送信する。
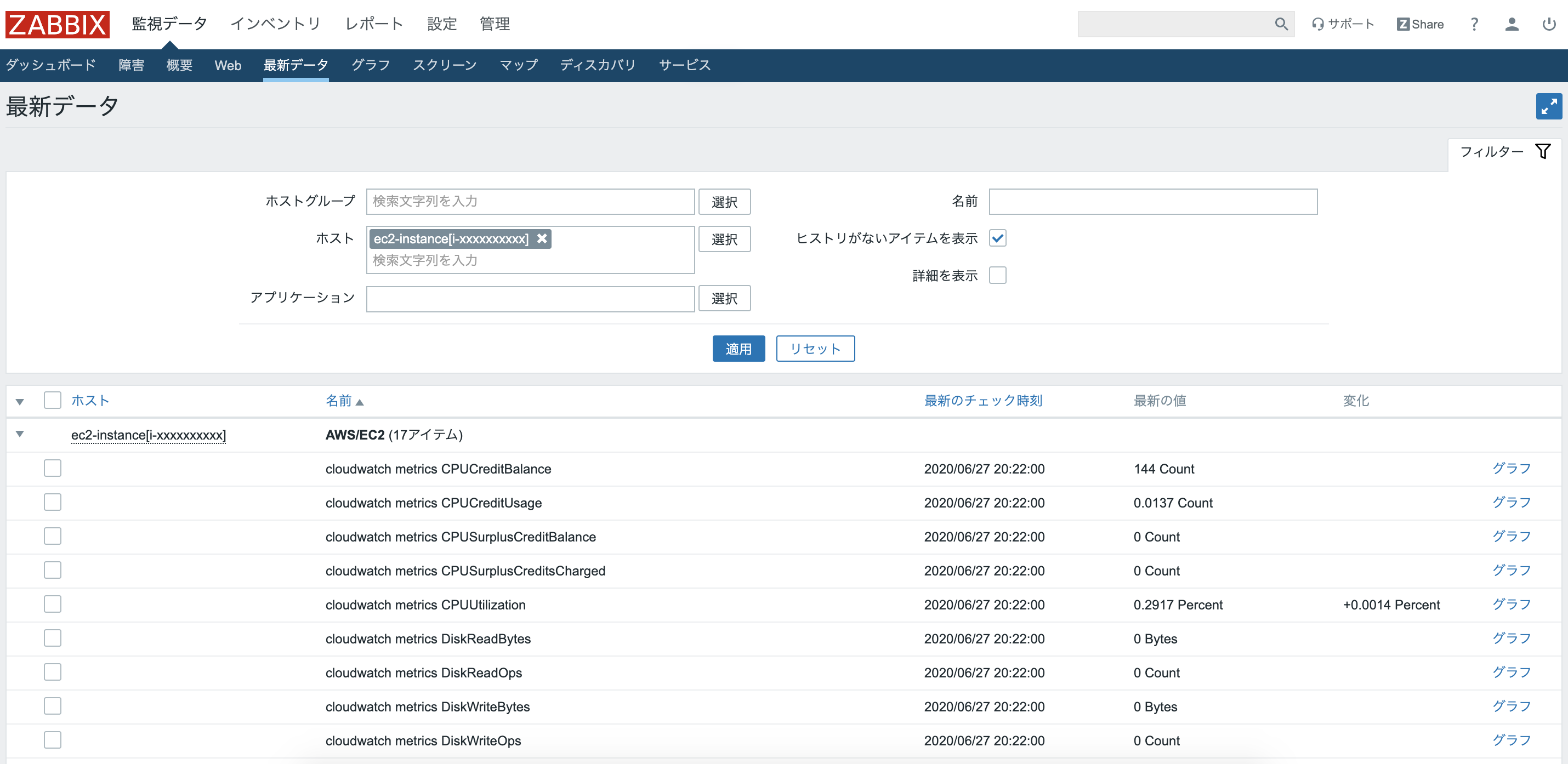
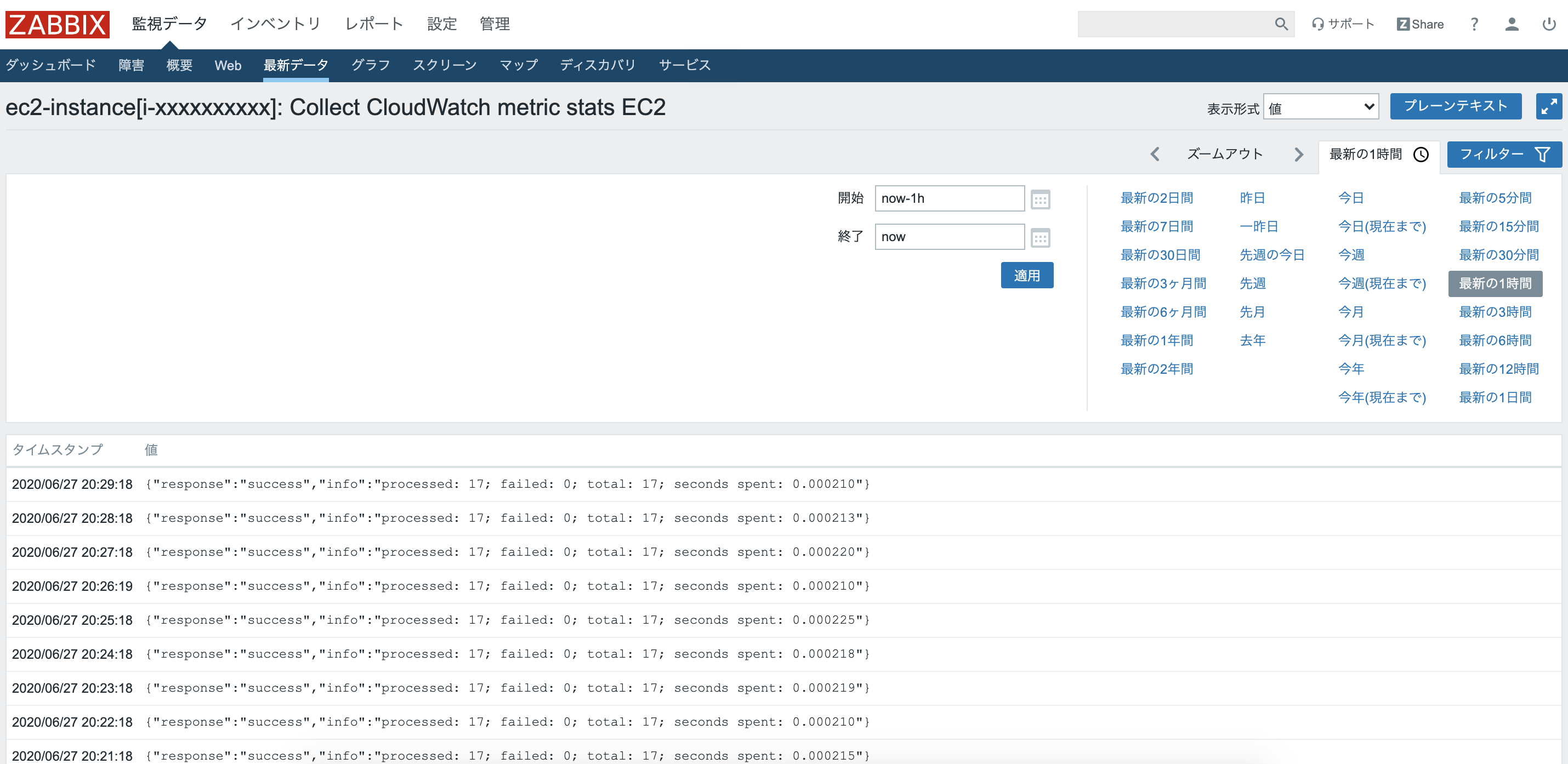
実際に送信されたのかを確認してみる。
上のタブから"監視データ">"最新データ"をクリック。
このようにそれぞれ自動作成されたアイテムに対して値が送信されていることがわかる!Collect CloudWatch metric stats EC2のアイテムは以下のようになっている。送信に成功したログが取り込まれている。
参考
- AWSリソースのzabbix統合監視について: https://aws.typepad.com/aws_partner_sa/2016/06/opsjaws-try-ops-with-zabbix-1.html

- 投稿日:2020-06-27T22:48:21+09:00
【AWS;Lambda入門】第三弾;Linebotなじゃんけんゲームで遊ぶ♬
今回は、apigatewayを利用したnode.js@Lambdaでじゃんけんゲームを作ってみた。
環境構築やプログラムなどは、全て以下の参考①~④を参考に進めた。
だいたい、最初の①と②でLinebotが動く。そして③と④でLambda版のLinebotが動いた。筆者も言っているように感動ものである。
ちなみに、ほぼ1日でLinebotが動くようになった。
したがって、コードのほとんどは参考のまんまであることをお断りしておきます。
【参考】
①LINEBotをみんなで作ろう〜環境構築編〜【GWアドベントカレンダー1日目】
②LINEBotをみんなで作ろう〜おうむ返しbotを作ろう編〜【GWアドベントカレンダー3日目】
③LINEBotをみんなで作ろう〜レイヤーとAPIgateway設定編〜【GWアドベントカレンダー7日目】
④LINEBotをみんなで作ろう〜コードを実装編〜【GWアドベントカレンダー最終日】
ということで、この先のことも考えてじゃんけんゲームを作ってみた。やったこと
・環境構築(Line)
・環境構築(Lambda@AWS)
・じゃんけんボット・環境構築(Line)
参考①の解説のとおりで環境が構築出来ました。
LINE Developerのサイトにログインできるようにする。
- ログイン→開発者名、メール入力
- プロバイダーを作成→プロバイダー名;この下にボットを構築
- 新規チャネルを作成→Messaging APIを選択
- Messaging APIのチャンル作成する→ボット名、その他
- Botの設定→
- channel secret(短い方)とChannel access token (long-lived)(長い方)をアプリ側に設定、
- アプリの公開アドレスからWebhook URLを設定、
- BotのLINE Official Account featuresのeditから
- アカウント設定で応答設定;bot オン、
- あいさつ オフ、
- 応答メッセージ オフ、
- Webhook オン
おうむ返しボット
まず、自PC、Windows10でNode.jsを利用しておうむ返しボットを作ります。
ngrokをインストールする
Download & setup ngrokから自PCのOsにあったものをダウンロードして、解凍するとngrok.exeが入っているのでこれを実行すれば(ダブルクリックで)コンソールが動きました。そこで以下を実行すると実行できます。
※ちなみに、専用コンソールで実行してください。WindowsPromptだと動きませんでした
ngrok -v
ngrok version 2.3.35node.js(v10以上推奨)をインストールする
node.js(v10以上推奨)ダウンロードからWindowsInstaller;node-v12.18.1-x64.msiをダウンロードして、インストール。
通常のコマンドラインで以下のように確認できる。
>node -v
v12.18.1エディタ
使い慣れたjupyter notebookを使いました。
おうむ返しボットのnode.jsコード
以下のようにdesktop配下にDirを作って、そこで環境構築して作業します。参考にいろいろな拡張があって凄い記事になっていました。
【参考】
⑤1時間でLINE BOTを作るハンズオン (資料+レポート) in Node学園祭2017 #nodefestcd deskTop mkdir test-linebot cd test-linebot npm init -y npm i @line/bot-sdk express次にプログラムのメインとなるindex.jsをtest-linebotフォルダ内に作成します。
エディタで以下をコピペします。
上記のとおり、短い方と長い方をBotのBasic settingsとMessaging API settingsからコピペして設定します。index.js"use strict"; const express = require("express"); const line = require("@line/bot-sdk"); const PORT = process.env.PORT || 5000; const config = { channelSecret: "短い方", channelAccessToken: "長い方" }; const app = express(); app.post("/webhook", line.middleware(config), (req, res) => { console.log(req.body.events); Promise.all(req.body.events.map(handleEvent)).then((result) => res.json(result) ); }); const client = new line.Client(config); async function handleEvent(event) { if (event.type !== "message" || event.message.type !== "text") { return Promise.resolve(null); }; let mes = { type: "text", text: event.message.text }; return client.replyMessage(event.replyToken, mes); } app.listen(PORT); console.log(`Server running at ${PORT}`);ここで、肝心な部分として、返信している文字列は
eventが以下のようなものなので、
event.message.text='動くかな?'となります。{ type: 'message', replyToken: '*******************************', source: { userId: '*****************', type: '***' }, timestamp: **************, mode: 'active', message: { type: 'text', id: '*************', text: '動くかな?' } }これで、Linebotを動かしてみます。
\Desktop\test-linebot>node index.js
Server running at 5000
この状態で、もう一個ターミナルを起動して、
ngrok http 5000
これで上記のindex.jsを公開します。
以下のような表示が出現します。以下は1時間37分ほど経過するとexpireするものになっています。
以下の表示からhttps://73e6916ab721.ngrok.ioというサイトからフォワードしていることが分かるので、ボットのWebhook URLとして、https://73e6916ab721.ngrok.io/webhookとします。
※因みにこのサーバーは一意だと思いますが、毎回起動の度に変化します。また、Session Expiresの時間も長いとき(約7時間半)も短いとき(約1時間半)もバラバラです。ngrok by @inconshreveable (Ctrl+C to quit) Session Status online Session Expires 1 hour, 37 minutes Version 2.3.35 Region United States (us) Web Interface http://127.0.0.1:4040 Forwarding http://73e6916ab721.ngrok.io -> http://localhost:5000 Forwarding https://73e6916ab721.ngrok.io -> http://localhost:5000これで動くと思います。動かなかったら、参考②や参考⑤を見てください。どちらもとても丁寧に書かれています。
出来ると、単なるおうむ返しですが、なんとなくうれしいです。・環境構築(Lambda@AWS)
今度は、上記のindex.jsをLambdaで動作させApiGatewayを利用して、Linebotと連携します。
これも、参考③のとおりです。
・AWSアカウントでログイン;コンソールへ行く
・Lambdaを開く
・Lambda関数を作成・関数名(lamdbaTst)、ランタイムNode.Node.js 12js 12.x、ロール(基本的な...)等の設定
・コンソールに戻って、(検索して)API Gatewayを選択
・RestAPI 構築・REST・新しいAPI・API名;linebotAPI・エンドポイントタイプ;リージョン・APIの作成
・アクション・メソッドの作成・Post設定
・アクション;POSTセットアップ・Lambda関数・Lambdaプロキシ統合の使用;チェック・Lambda関数;lambdaTst・保存
・Lambda関数に権限を追加するダイアログ;OK
・アクション;POSTメソッドの実行・メソッドリクエスト・HTTPリクエストヘッダー・ヘッダー追加・名前欄にX-Line-Signatureと入力、必須にチェック
・アクション・APIのデプロイ・レイヤーの作成
・デプロイされるステージ;新しいステージ・ステージ名;test1・デプロイ
・Lambdaの関数の画面へ行き、関数にAPIGatewayが連携(追加)されていれば成功
・利用するNode.js環境をzipファイルにまとめて、レイヤーとして登録する・参考③はMac環境ですが、全く同じように作成します。
・cd Desktop・mkdir nodejs・npm init -y・npm i @line/bot-sdk・nodejsディレクトリをzip圧縮
・Lambda関数ページのレイヤーを開く・レイヤーの作成でnodejs.zipをアップロード。名前はそれらしい名前;linebot-SDK。・互換性のあるランタイムオプション;node.js 12,x node.js 10.x・作成
・Lambda関数ページのレイヤーを連携・レイヤーの追加・ランタイムと互換性のあるレイヤーのリストから選択・名前;linebot-SDK
・バージョン;1・追加
・関数画面でレイヤーで読み込めていたら(下に表示されたら)成功
・関数名をクリックして下へスクロール、環境変数の項目を探す、編集をクリック・編集・ACCESSTOKEN;長い方・CHANNELSECRET;短い方・保存
・Lambda関数をクリックして、関数を以下のコードをコピペして張り付ける。・右上の保存
・WEBhookURLを設定する・API Gatewayを押下・APIエンドポイントをコピペ・LinebotのWEBhookURLに張り付ける
これで、動きました。
さて、張り付けるコードは以下のじゃんけんゲームです。じゃんけんゲームのコード
index.js"use strict"; // モジュール呼び出し const crypto = require("crypto"); const line = require("@line/bot-sdk"); // インスタンス生成 const client = new line.Client({ channelAccessToken: process.env.ACCESSTOKEN }); exports.handler = (event, context, callback) => { // 署名検証 const signature = crypto .createHmac("sha256", process.env.CHANNELSECRET) .update(event.body) .digest("base64"); const checkHeader = (event.headers || {})["X-Line-Signature"]; const body = JSON.parse(event.body); const events = body.events; console.log(events); // 署名検証が成功した場合 if (signature === checkHeader) { events.forEach(async (event) => { let message; // イベントタイプごとに関数を分ける switch (event.type) { // メッセージイベント case "message": message = await messageFunc(event); break; // フォローイベント case "follow": message = { type: "text", text: "追加ありがとうございます!" }; break; // ポストバックイベント case "postback": message = await postbackFunc(event); break; } // メッセージを返信 if (message != undefined) { client .replyMessage(body.events[0].replyToken, message) .then((response) => { const lambdaResponse = { statusCode: 200, headers: { "X-Line-Status": "OK" }, body: '{"result":"completed"}', }; context.succeed(lambdaResponse); }) .catch((err) => console.log(err)); } }); } // 署名検証に失敗した場合 else { console.log("署名認証エラー"); } }; const messageFunc = async function (event) { var mes = await mesmakeFunc(event); let message; switch (event.message.type) { case "text": message= { type: "text", text: mes }; break; case "image": message = { type: "text", text: "がぞうを受け取ったよ!" }; break; case "sticker": message= { type: "text", text: "ステッカーを送ってくれたんだね!" }; break; } if (message !== undefined) { return client.replyMessage(event.replyToken, message); } return message; }; const mesmakeFunc = async function (event) { console.log('event.text:', event.message.text); var mes = ['グー','チョキ','パー',event.message.text]; var r = Math.floor( Math.random() * 4 ); var mes0 = mes[r]; console.log('message:',mes0); return mes0; }; const postbackFunc = async function (event) { let message; message = { type: "text", text: "ポストバックイベントを受け付けました!" }; return message; };自PCでのじゃんけんゲームのコード
index.js"use strict"; const express = require("express"); const line = require("@line/bot-sdk"); const PORT = process.env.PORT || 5000; const config = { channelSecret: "短い方", channelAccessToken: "長い方" }; const app = express(); app.post("/webhook", line.middleware(config), (req, res) => { console.log(req.body.events); Promise.all(req.body.events.map(handleEvent)).then((result) => res.json(result) ); }); const client = new line.Client(config); async function handleEvent(event) { if (event.type !== "message" ) { return Promise.resolve(null); }; let mes = await messageFunc(event); console.log('mes_message:',mes); return client.replyMessage(event.replyToken, mes); }; const messageFunc = async function (event) { var mes = await mesmakeFunc(event); let message; console.log('message_message:',event.message.type); switch (event.message.type) { case "text": message= { type: "text", text: mes }; break; case "image": message = { type: "text", text: "がぞうを受け取ったよ!" }; console.log('image_message:',message); break; case "sticker": message= { type: "text", text: "ステッカーを送ってくれたんだね!" }; console.log('sticker_message:',message); break; } return message; }; const mesmakeFunc = async function (event) { console.log('event.text:', event.message.text); var mes = ['グー','チョキ','パー',event.message.text]; var r = Math.floor( Math.random() * 4 ); var mes0 = mes[r]; console.log('message:',mes0); return mes0; }; app.listen(PORT); console.log(`Server running at ${PORT}`);まとめ
・Linebotを自PCとLambdaで連携して遊んでみた
・ちょっとした拡張として、じゃんけんゲームを作成してみた・利用性の高いアプリを作ってみようと思う
- 投稿日:2020-06-27T21:50:03+09:00
Amazon CloudWatch Syntheticsで簡単監視入門
はじめに
皆さん運用監視してますか?
運用監視はいろいろと手間がかかるので敬遠されがちなんですが、運用監視の仕組みがないと、何かトラブルが起こっても気が付きません。
なので、システムを長期間安定的に稼働させるためには、運用監視の仕組みが不可欠ですよね。
今回はWebサイトの死活監視で利用できるAmazon CloudWatch Synthetics(以下Synthetics)について紹介します。Amazon CloudWatch Syntheticsとは
詳細な情報は公式のリファレンスを見て頂くとして、ざっくりと概要の説明をします。
Syntheticsを使うとWebサイトやAPIの定期的な死活監視をすることができます。
例えば、正常にWebページを取得できるか、APIを正常に呼び出すことができるか、などを定期的にチェックすることが可能です。しかも、チェックする部分はLambdaのコードになっているので、自分なりにカスタマイズすることができます。
例えば、このAPIが正常に呼び出されたらこういうレスポンスが返ってくる、というのが決まっていれば、自分でプログラムを書けばチェックすることが可能です。実際に設定してみる
では、実際に試してみましょう。
Cloudwatchの画面から、「Synthetics」>「Canaryを作成」をクリックします。
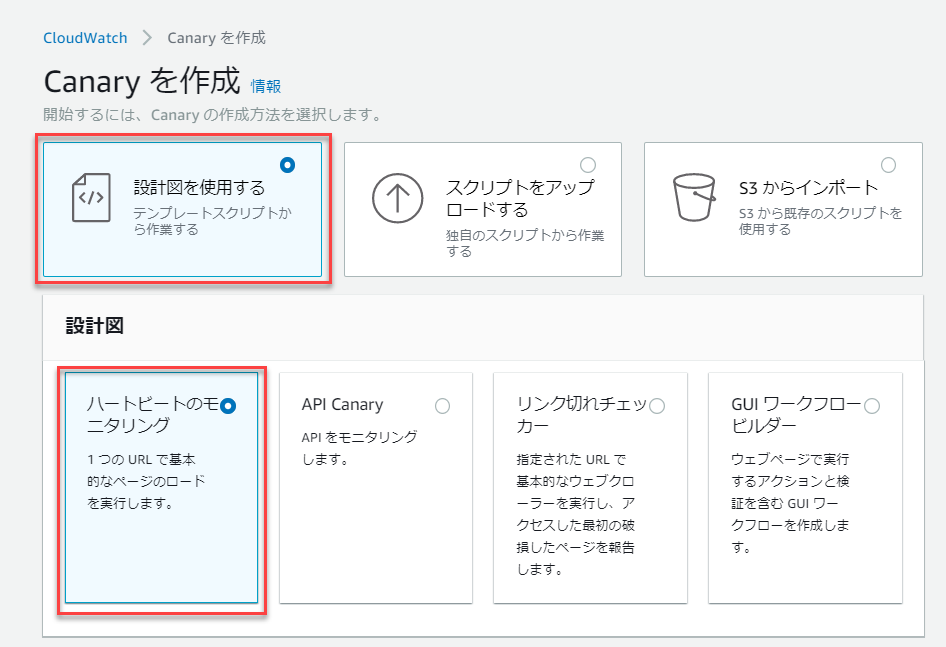
いろいろな選択肢がありますが、「設計図を使用する」を選択します。
今回はWebページの死活監視をするために、「ハートビートのモニタリング」を選択します。
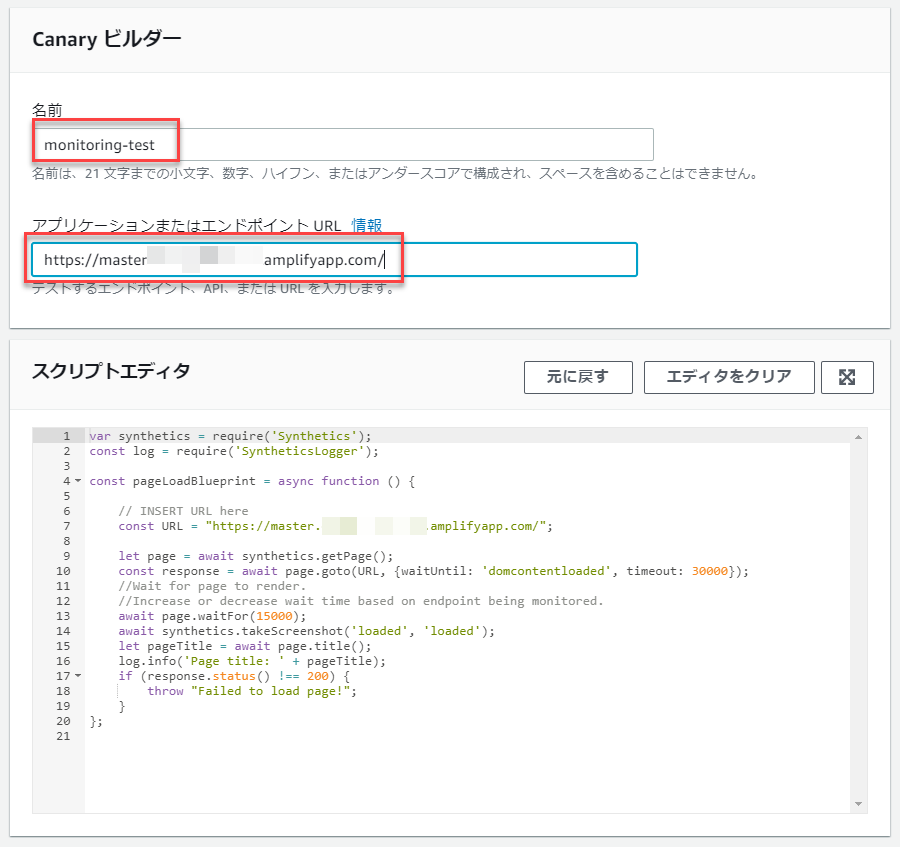
Syntheticsでは、一つの監視単位をCanaryという名前で呼びます。
Canaryの名前と、監視したいWebページのURLを記載します。
また、スクリプトエディタでは実際に実行されるスクリプトが表示されています。
もし、スクリプトのカスタマイズに興味がある方は下記を参照ください。
Canary スクリプト用のライブラリ関数
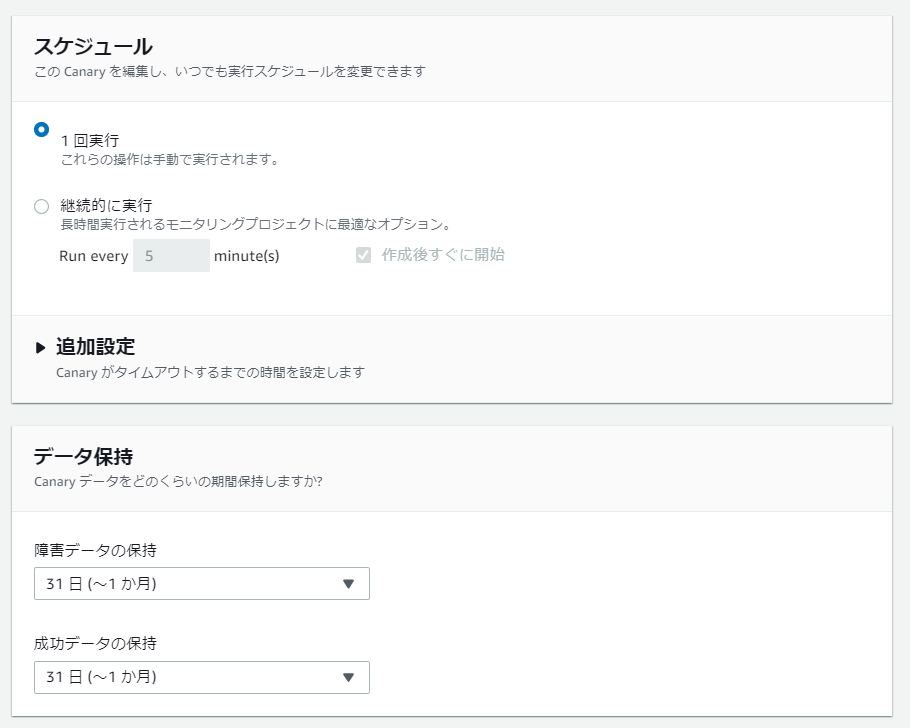
次にスクリプトをどのタイミングで実行するのか、データの保存期間の設定を行います。
今回はテストのため「1回実行」にしてみます。
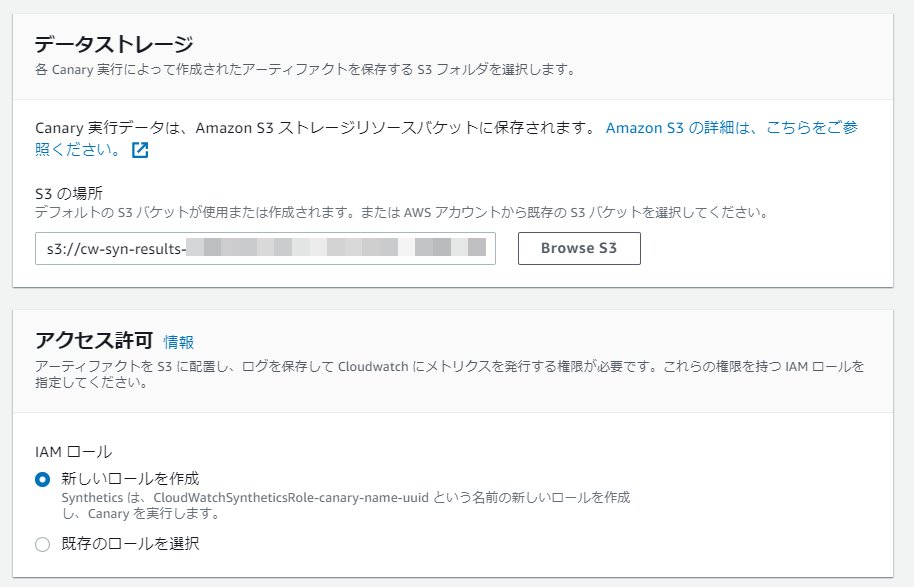
次にログ情報などを保存するS3バケットとIAM Roleの設定です。
とりあえず、デフォルトで設定します。
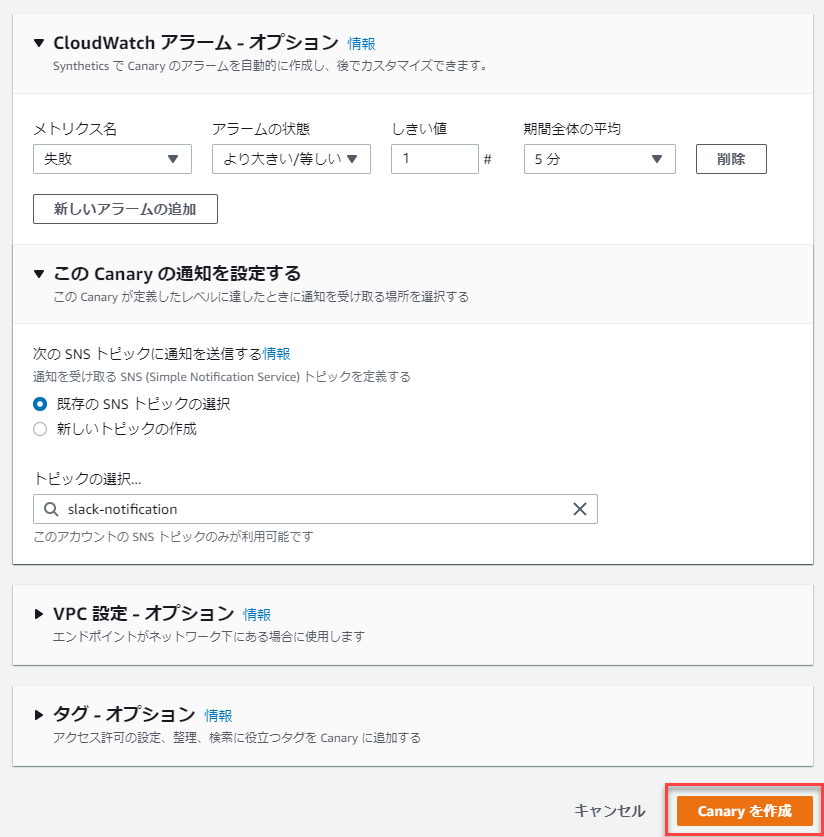
最後にCloudwatchアラームの設定を行います。
設定した閾値を超えた場合(下回った場合)に、指定したSNSトピックに通知します。
最後に「Canaryを作成」をクリックすれば、設定は完了です。
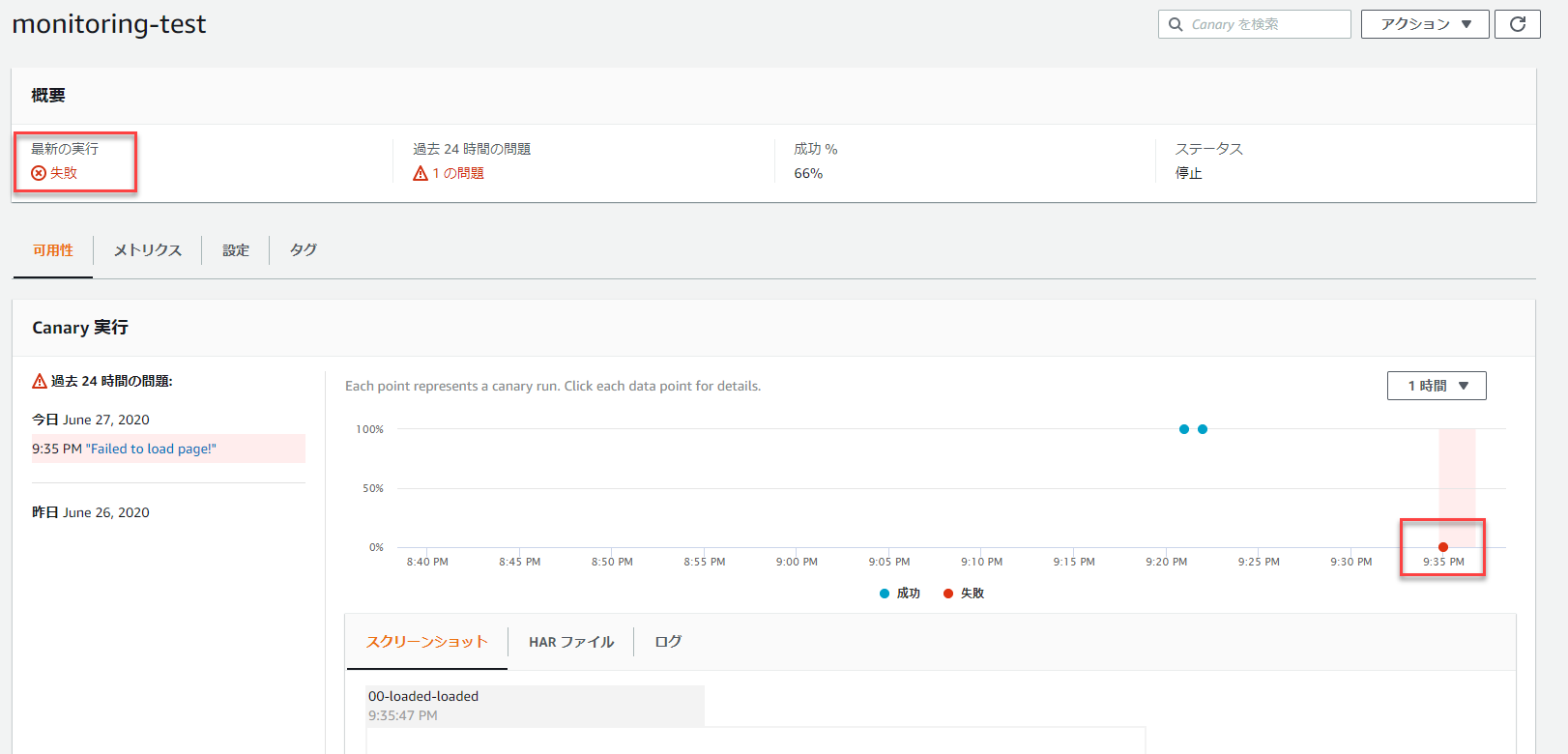
監視状況を確認してみる
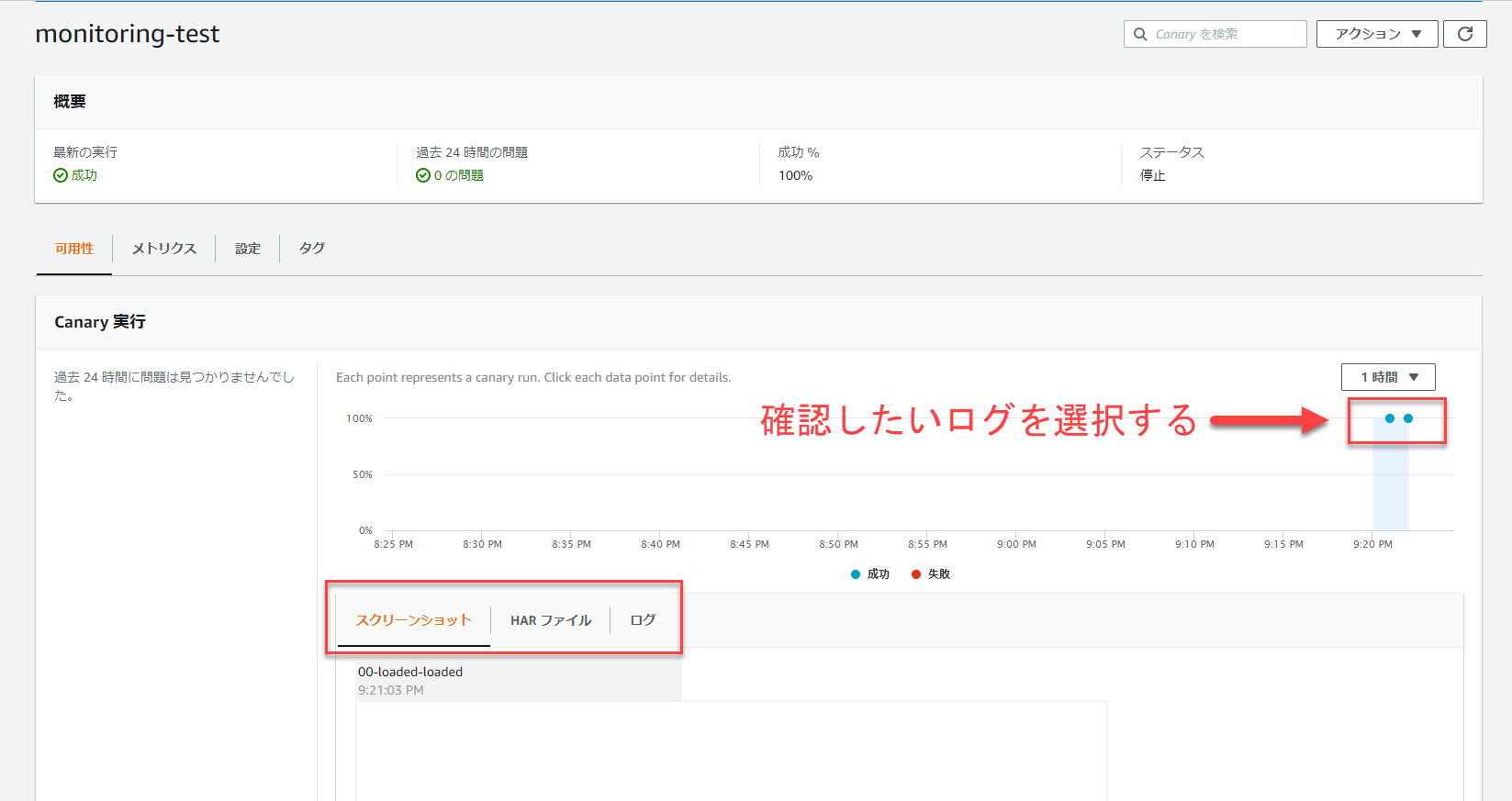
作成したCanaryは自動実行されるので、内容を確認してみます。
今回監視対象としたWebページは実際に存在するので、結果は成功として記録されます。
また、「スクリーンショット」、「HARファイル」、「ログ」も確認することが可能です。
「スクリーンショット」タブでは、画面のスクリーンショットを確認することができ、「HARファイル」タブではHARファイルの内容を確認することができ、「ログ」タブでは、実際にスクリプトが実行された際のログを確認することが可能です。
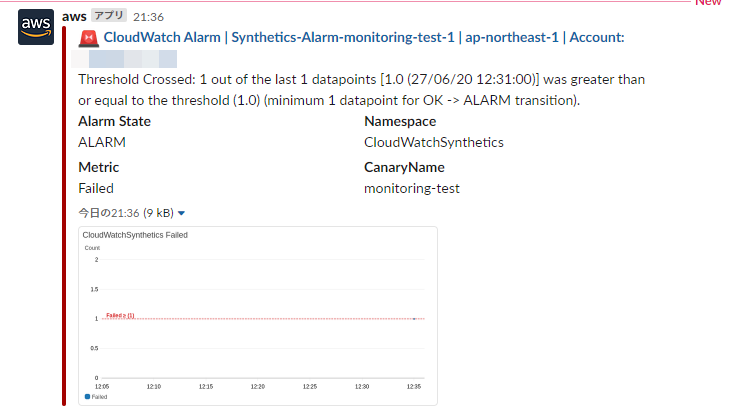
ちなみに、もしWebサイトに正常にアクセスできない場合は、エラーになります。
ChatbotとSlackを連携している場合は、下記の様なメッセージが届きます。
APIエンドポイントのテストをする場合
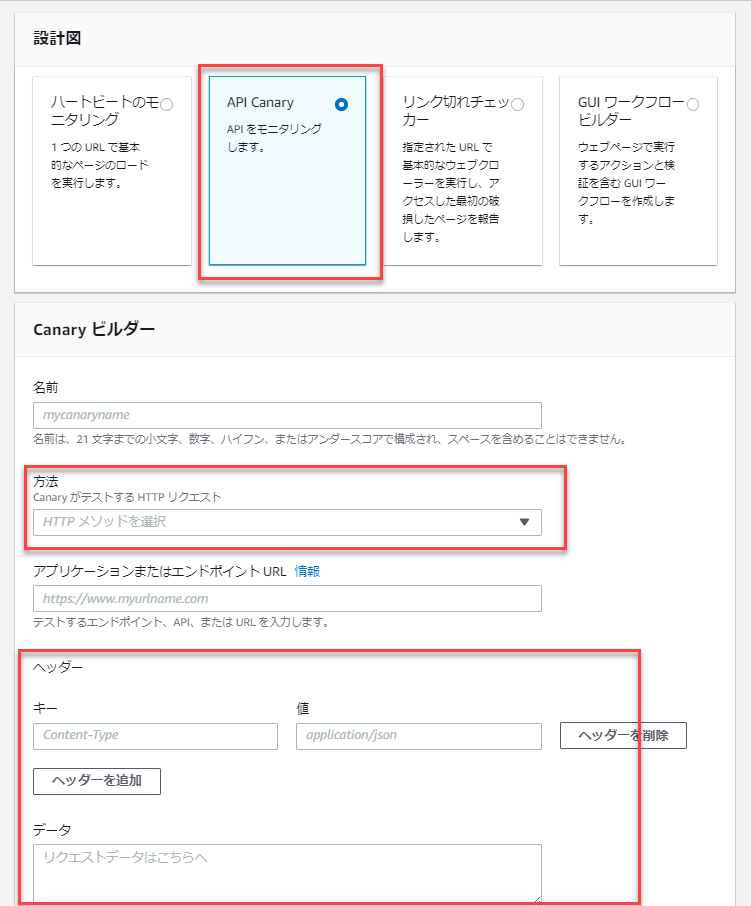
簡単にAPIエンドポイントの場合について紹介します。
設計図でAPI Canaryを選択します。
そして、HTTPメソッドの選択、ヘッダーや送信するデータの設定を行います。
スクリプトエディタの内容も「ハートビートのモニタリング」の場合とは少し違いますね。
API呼び出しが200で成功しているかどうかは簡単に確認できそうです。
最後に
Webサイトの死活監視やAPIエンドポイントの死活監視は重要だけれども、いざ仕組みを作ろうと思うと結構めんどくさいことが多いです。
ですが、Syntheticsを使うと簡単に実現できるかことがお分かりいただけたのではないでしょうか。
証明書切れでWebページにつながらなくなったり、APIのデプロイで正常に動かなくなったり、ということを検知することができるので、非常に有益なサービスだと思います。
料金もそこまで高額ではないので、皆さんぜひ使ってみてください。参考
- 投稿日:2020-06-27T21:14:52+09:00
PrometheusとGrafanaでRaspberry Piを監視
Raspberry PiにPrometheusとGrafanaをインストールして、Raspberry Pi自身を監視してみました。
環境
Raspberry Pi 3
Raspberry Pi OS(2020-05-27版)Prometheusのインストール
Raspberry Piの公式リポジトリから導入できます。
prometheusがPrometheus本体、prometheus-node-exporterはOSのメトリクス情報を取得するものです。sudo apt install prometheus prometheus-node-exporterインストールが完了すると、すでにサービスとして起動した状態となります。
2020/6/27時点でインストールされたバージョンは以下の通り。最新バージョンはPrometheusが2.19.2、Node exporterが1.0.1なので少し古そうですね。pi@raspberrypi:~ $ prometheus --version prometheus, version 2.7.1+ds (branch: debian/sid, revision: 2.7.1+ds-3) build user: pkg-go-maintainers@lists.alioth.debian.org build date: 20190210-18:10:02 go version: go1.11.5 pi@raspberrypi:~ $ prometheus-node-exporter --version node_exporter, version 0.17.0+ds (branch: debian/sid, revision: 0.17.0+ds-3) build user: pkg-go-maintainers@lists.alioth.debian.org build date: 20190131-17:33:42 go version: go1.11.5Prometheusの動作確認
Raspberry Piから
http://localhost:9090/、または他のPCからhttp://raspberrypi.local:9090/にアクセスすると、PrometheusのWeb画面にアクセスできます。
タブを
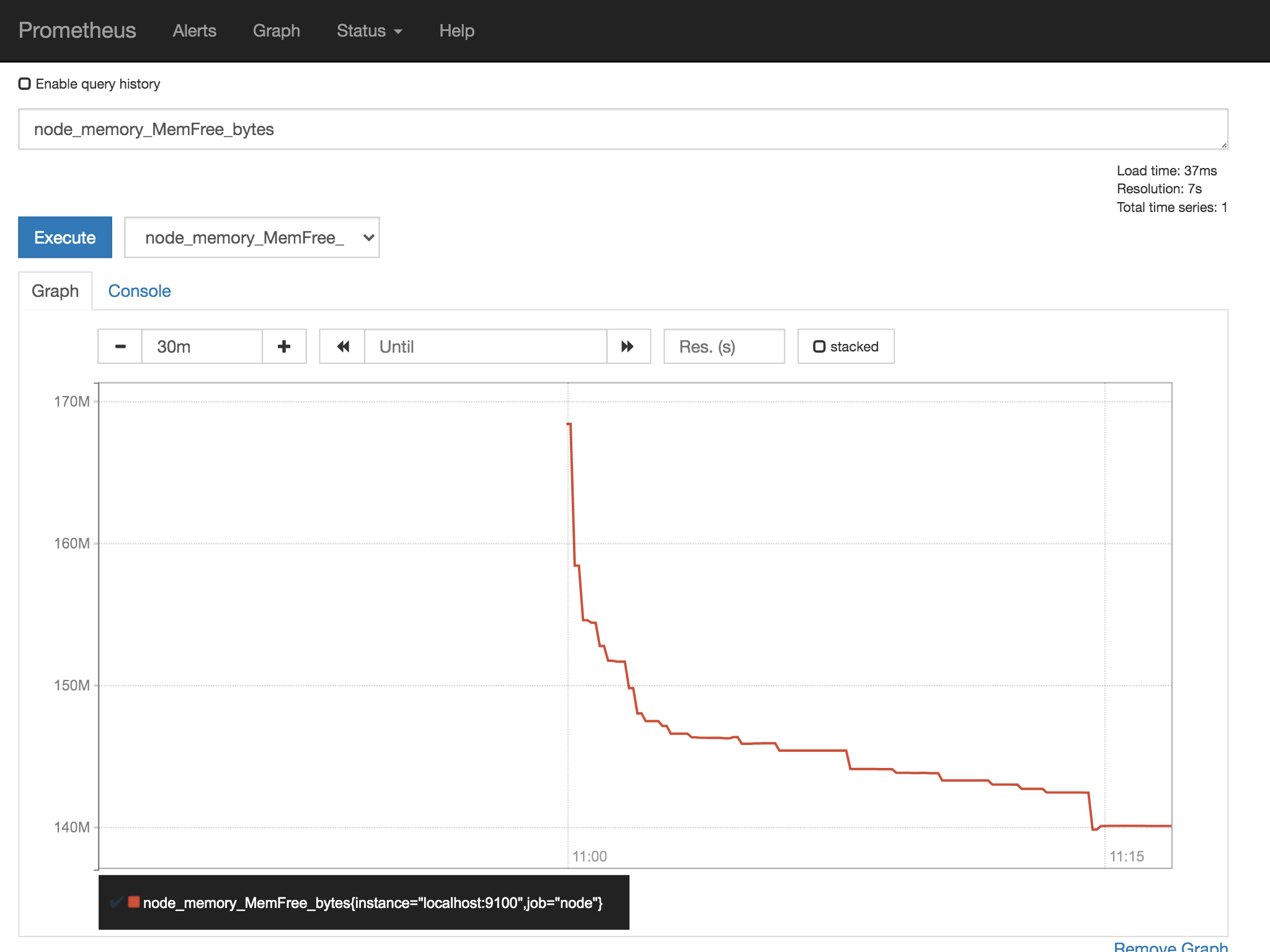
Graphに切り替えて、メトリクスを選ぶとグラフが表示されます。
すごいですね。簡単ですね。
凝ったグラフを作りたいときは、Grafanaの出番です。Grafanaのインストール
Grafanaは公式リポジトリでは提供されていないようですが、Grafanaの公式サイトでARM向けのdebパッケージが提供されています。
wget https://dl.grafana.com/oss/release/grafana_7.0.4_armhf.deb sudo apt install ./grafana_7.0.4_armhf.debGrafanaはインストールしただけでは起動しないようです。
sudo systemctl status grafana-server.serviceGrafanaの動作確認
Grafanaは
3000ポートで起動しますので、http://localhost:3000/またはhttp://raspberrypi.local:3000/でアクセスできます。
初期ユーザーは
admin、パスワードもadminです。
ログイン後はこんな感じ。
データソースの作成
GrafanaでPrometheusのデータを扱うため、データソースの設定を行います。
- 左メニューの
Configuration(ギアアイコン)からData Sourcesを選択します。
Add Data sourceを選択します。
Prometheusの右のSelectボタンを押します。
- URLに
http://localhost:9090と入力し、その他はデフォルトのままでSave & Testボタンを押します。
これでデータソースの設定が完了です。
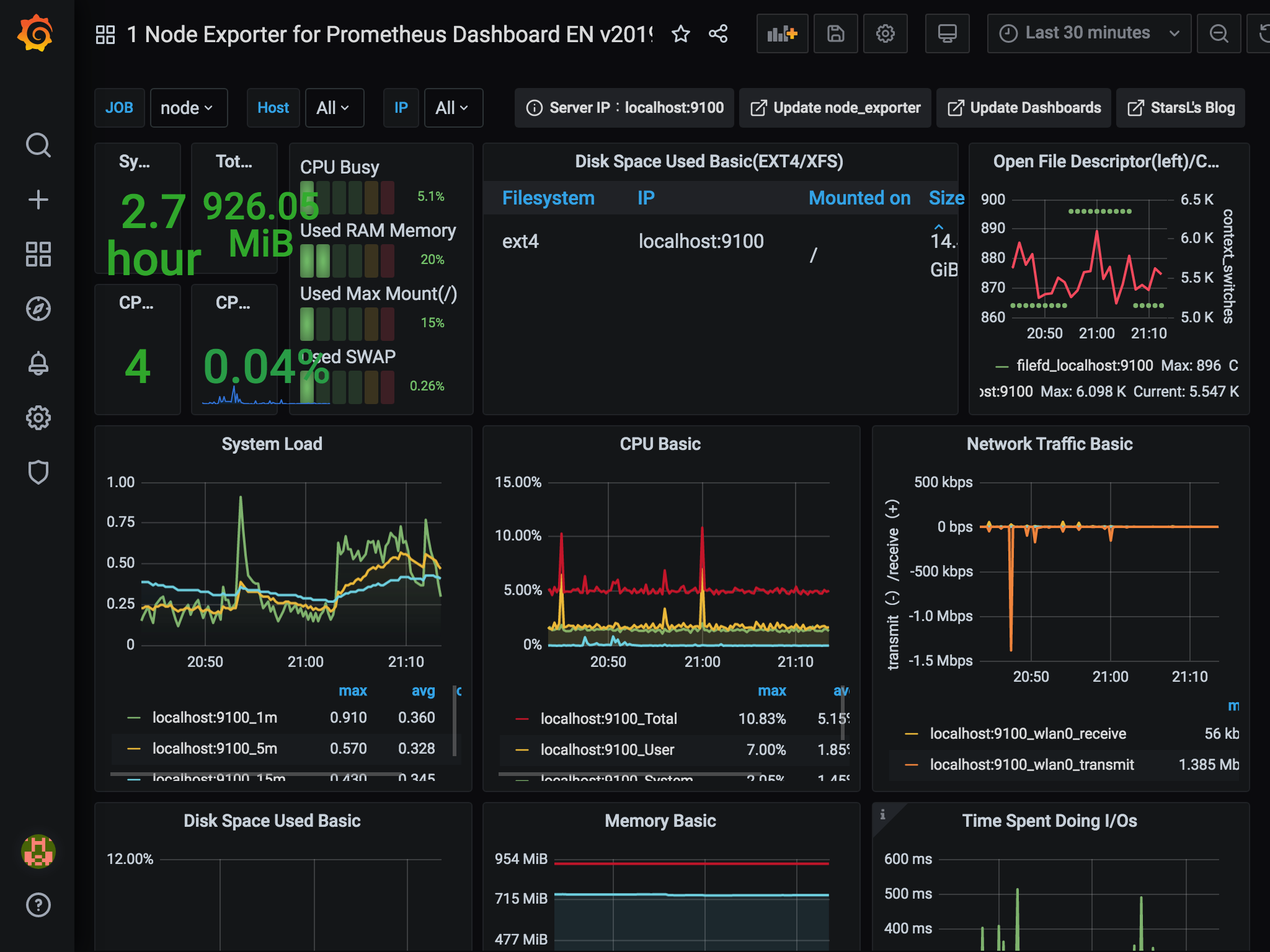
続けてダッシュボードを作成します。ダッシュボードの作成
ダッシュボード画面は一から作ることもできますが、すでに作成済みのダッシュボードが公式サイトで公開されています。オフィシャルなものからコミュニティのものまでたくさんあります。
https://grafana.com/grafana/dashboardsダッシュボードにはそれぞれIDがあり、IDを登録することで、自分のGrafanaで使用することができます。
- 左メニューの
Dashboards(四角が4つのアイコン)から、Manageを選択します。
- 画面右端の
Importを選択します。3. 画面中央の入力欄にID(今回は11074)を入力して、
Loadボタンを押します。ダッシュボードにはそれぞれIDがあり、IDを登録することで、自分のGrafanaで使用することができます。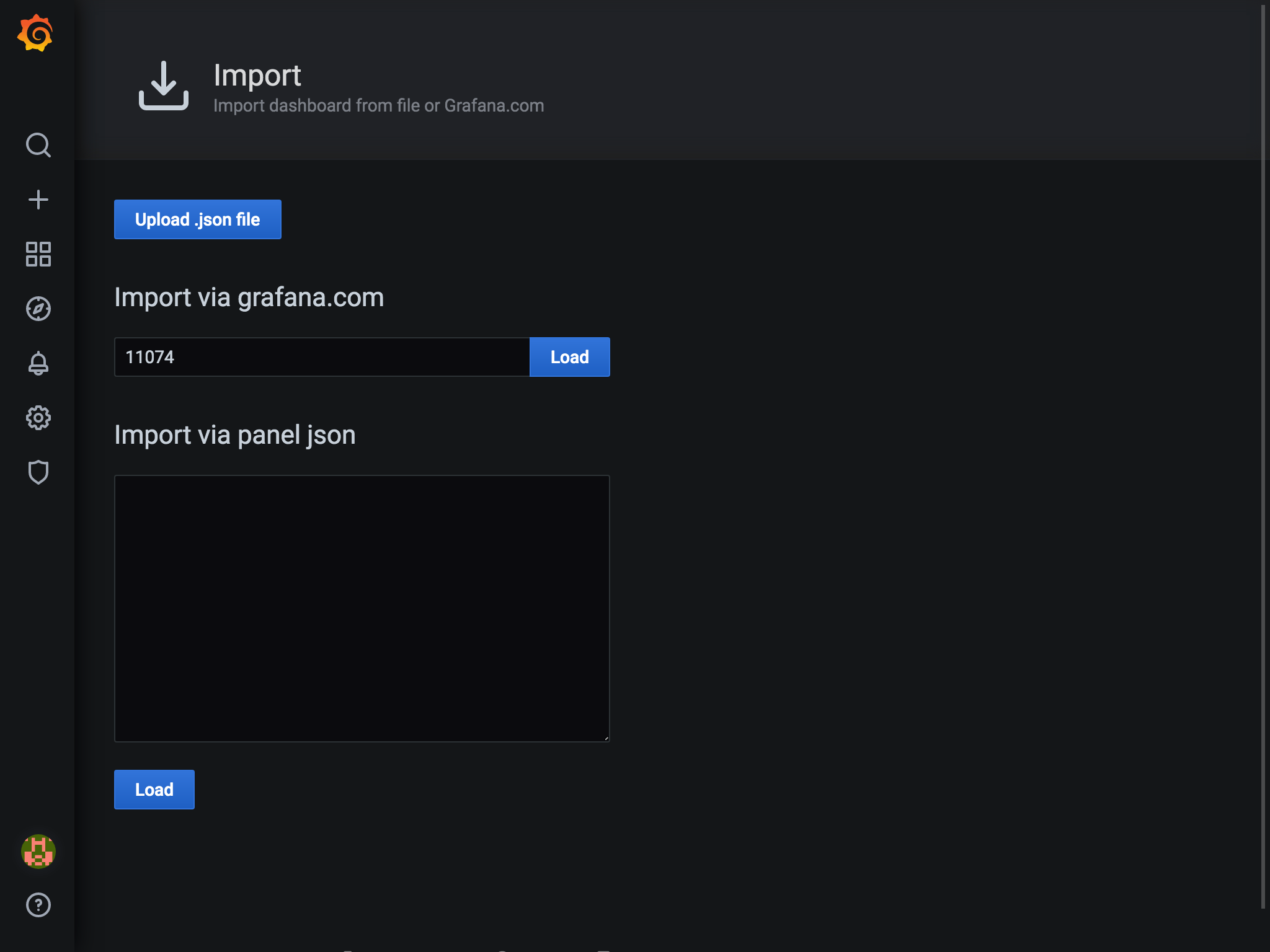
- ダッシュボードの情報が表示されます。
Prometheus Data Sourceのところで、データソースを選択し、画面下のImportボタンを押します。
これでダッシュボードができました。すっげー。
CloudWatchの監視
GrafanaはデータソースとしてCloudWatchにも対応してます。
設定画面はこんな感じ
こちらもダッシュボードを検索して追加すれば、簡単に監視ができそうです。
(いい感じの監視対象がなかったのでキャプチャはありません。。。)EC2のダッシュボードのリンクを貼っておきます。
https://grafana.com/grafana/dashboards/11265
- 投稿日:2020-06-27T19:42:30+09:00
【反省】新卒1年目がAWSの認証キーを流出させてしまいました
はじめに
私は新卒1年目で神戸のSIerに勤めています。
この度AWSキーを流出してしまうという、
エンジニアとして恥ずべき行為をしてしまったので
2度とこのような失態を踏まないように再発防止の意味を兼ねてここに記そうかと思います。
また今後AWSキーを流出してしまうことを完全に防ぐことは難しいかと思いますが、
今までAWSキーを無意識に扱っていた方の認識を改める記事になればと思います。何をしたのか
ことが起こったのは2020年6月24日。
Github Actionsを利用して、CI機能を実装しようとしていた時のこと。
やろうとしていたことはGithubのリモートリポジトリにpushされたときに、
AWS S3に公開ファイルをデプロイするというものでした。
Actionsにはワークフローとして、AWS認証キーを設定する処理が含まれていたので、
アクセスキーとシークレットキーを記述する必要がありました。
例としては下のようなイメージです。name: GithubActions_test on: push: branches: - master jobs: deploy: name: Build & Deploy runs-on: ubuntu-latest steps: - uses: actions/checkout@v2 - uses: actions/setup-node@v2-beta with: node-version: 12.x - run: yarn install - run: yarn build - name: Configure AWS Credentials uses: aws-actions/configure-aws-credentials@v1 with: aws-access-key-id: "ここにアクセスキーを書いてしまった" aws-secret-access-key: "ここにシークレットキーを書いてしまった" aws-region: ap-northeast-1 - name: Copy files to the test website with the AWS CLI run: aws s3 sync dist/ s3://"ここにバケット名のハードコーディング"今回は具体的なGithub Actionsの説明は省かせていただきます。
この処理の流れとしては、以下のようになっています。
- masterブランチにチェックアウト
- nodeのセットアップ
- モジュールをインストール
- プロジェクトをビルドし公開ファイル作成
- aws認証情報の設定
- aws s3と公開ファイルの同期(アップロード)
この過程のなかの5のところに認証情報を記述するのですが、
本来はSecretsを設定するなどして、変数として記述する必要があります。
しかしここに認証キーをハードコーディングしたために、Actionsをコミットしたと同時に
Githubに公開された流れとなりました。流出後にしたこと
AWSキーを公開してしまったときは非常に運が良いことに上司の方がすぐに気づいてくださり
即座にAWS認証キーの無効化を行なったため、大事には至らなかったのは本当によかったです。
GithubにはAWS認証キーをpushしたときに、不正利用防止のためにすぐにメールで通知が
いくようになっているようですが、本当に救われました。恥ずかしい話なのですが、キー流出直後は、ことの重大さにあまり気づいていませんでした。
上司の方に言われるがまま、認証キーの無効化を行なって再び作業を通常通り行っていたのですが、
社内で利用しているTeamsのチャットでグループが作られ、認証キー流出の件が話し合われました。
御社のセキュリティ事業部の方と詳細に事実確認をしていく中で、少しずつやばいことをしてしまった
という実感が湧いてきました。そしてその後、上司の方から「AWSキー流出」で調べておいてと言われ、
家に帰って調べたところ、自分が行ったことの重大さを知りました。
主に以下の記事を参照させていただきました。・GitHub に AWS キーペアを上げると抜かれるってほんと???試してみよー!
・AWSで不正利用され80000ドルの請求が来た話 - Qiita
・初心者がAWSでミスって不正利用されて$6,000請求、泣きそうになったお話。 - Qiita
・AWSが不正利用され300万円の請求が届いてから免除までの一部始終 - Qiitaこれらの記事を読み、かなり自分の中で反省をしました。
自分のしたことの重大さを知り、この件でかなり自分的に落ち込み、この件が1日中ずっと頭の中に残っていて
次の日はなかなか作業が捗らなかったです。
万が一、不正利用されて企業側に数百万の請求が来ていたかと思うと、1ヶ月は落ち込んでいたことかと思います。1つ不幸中の幸いなことだったことは、流出したキーのアカウントのIAMポリシーには「S3FullAccess」のみ付与していたことです。
これが「AdministratorAcess」とかだったら、既存のキーを削除され、新しいキーを作成、EC2の作成などが
行われていた可能性もあります。今後の対策
反省と再発防止のために今後、認証キーとGithubを扱うときに自分の中でルールを定めました。
- 今までのpublicリポジトリを全て削除
- 公開する予定のないgithubのリモートリポジトリをprivateにする
- 認証キーにはGithubのSecrets機能を利用する
- AWSの認証キーは環境変数用の.envファイルに記述して.gitignoreを設定して、リモートリポジトリにpushされないようにする
- IAMユーザーのポリシーには最低限の権限を与える
- github-secretsを利用して、AWS認証キーを誤ってコミットするのを防ぐ
終わりに
私としてもこのようなはずべき行為を行ってしまったことを記事にするのは躊躇しましたが
流出を行ってしまったことを事実として受け止め、それが今の自分のセキュリティに対する認識の低さ
だということを自覚するとても良い機会となりました。
今まで無意識にアクセストークンなどの個人情報が特定できるものをGithubに無意識に公開していたため、
これを機に今後はこのような失態をしないようにAWSキーとGithubの扱いには十分に注意して取り扱っていきます。またこの度認証キー流出後、早急に対処してくださった社員の方々、本当にありがとうございました。
- 投稿日:2020-06-27T19:42:30+09:00
【反省】新卒1年目がAWSの認証キーを流出させてしまった話
はじめに
私は新卒1年目で神戸のSIerに勤めています。
この度AWSキーを流出してしまうという、
初心者であるもののエンジニアとして恥ずべき行為をしてしまったので
2度とこのような失態を踏まないように再発防止の意味を兼ねてここに記そうかと思います。また今後AWSキーを流出してしまうことを完全に防ぐことは難しいかと思いますが、
今までAWSキーを無意識に扱っていた方の認識を改めるきっかけになればと思います。何をしたのか
ことが起こったのは2020年6月24日。
Github Actionsを利用して、CI機能を実装しようとしていた時のこと。
やろうとしていたことはGithubのリモートリポジトリにpushされたときに、
AWS S3に公開ファイルをデプロイするというものでした。
Actionsにはワークフローとして、AWS認証キーを設定する処理が含まれていたので、
アクセスキーとシークレットキーを記述する必要がありました。
例としては下のようなイメージです。name: GithubActions_test on: push: branches: - master jobs: deploy: name: Build & Deploy runs-on: ubuntu-latest steps: - uses: actions/checkout@v2 - uses: actions/setup-node@v2-beta with: node-version: 12.x - run: yarn install - run: yarn build - name: Configure AWS Credentials uses: aws-actions/configure-aws-credentials@v1 with: aws-access-key-id: "ここにアクセスキーを書いてしまった" aws-secret-access-key: "ここにシークレットキーを書いてしまった" aws-region: ap-northeast-1 - name: Copy files to the test website with the AWS CLI run: aws s3 sync dist/ s3://"ここにバケット名のハードコーディング"今回は具体的なGithub Actionsの説明は省かせていただきます。
この処理の流れとしては、以下のようになっています。
- masterブランチにチェックアウト
- nodeのセットアップ
- モジュールをインストール
- プロジェクトをビルドし公開ファイル作成
- aws認証情報の設定
- aws s3と公開ファイルの同期(アップロード)
この過程のなかの5のところに認証情報を記述するのですが、
本来はSecretsを設定するなどして、変数として記述する必要があります。
しかしここに認証キーをハードコーディングしたために、Actionsをコミットしたと同時に
Githubに公開された流れとなりました。流出後にしたこと
AWSキーを公開してしまったときは非常に運が良いことに上司の方がすぐに気づいてくださり、
即座にAWS認証キーの無効化を行なったため、大事には至らなかったのは本当によかったです。
GithubにはAWS認証キーをpushしたときに、不正利用防止のためにすぐにメールで通知が
いくようになっているようですが、本当に救われました。恥ずかしい話なのですが、キー流出直後は、ことの重大さにあまり気づいていませんでした。
上司の方に言われるがまま、認証キーの無効化を行なって再び作業を通常通り行っていたのですが、
社内で利用しているTeamsのチャットでグループが作られ、認証キー流出の件が話し合われました。
弊社のセキュリティ事業部の方と詳細に事実確認をしていく中で、少しずつやばいことをしてしまった
という実感が湧いてきました。そしてその後、上司の方から「AWSキー流出」で調べておいてと言われ、
家に帰って調べたところ、自分が行ったことの重大さを知りました。
主に以下の記事を参照させていただきました。・GitHub に AWS キーペアを上げると抜かれるってほんと???試してみよー!
・AWSで不正利用され80000ドルの請求が来た話 - Qiita
・初心者がAWSでミスって不正利用されて$6,000請求、泣きそうになったお話。 - Qiita
・AWSが不正利用され300万円の請求が届いてから免除までの一部始終 - Qiitaこれらの記事を読み、かなり自分の中で反省をしました。
自分のしたことの重大さを知り、この件でかなり自分的に落ち込み、この件が1日中ずっと頭の中に残っていて
次の日はなかなか作業が捗らなかったです。
万が一、不正利用されて企業側に数百万の請求が来ていたかと思うと、1ヶ月は落ち込んでいたことかと思います。1つ不幸中の幸いなことだったことは、流出したキーのアカウントのIAMポリシーには「S3FullAccess」のみ付与していたことです。
これが「AdministratorAcess」とかだったら、既存のキーを削除され、新しいキーを作成、EC2の作成などが
行われていた可能性もあります。今後の対策
反省と再発防止のために今後、認証キーとGithubを扱うときに自分の中でルールを定めました。
- 今までのpublicリポジトリを全て削除
- 公開する予定のないgithubのリモートリポジトリをprivateにする
- 認証キーにはGithubのSecrets機能を利用する
- AWSの認証キーは環境変数用の.envファイルに記述して.gitignoreを設定して、リモートリポジトリにpushされないようにする
- IAMユーザーのポリシーには最低限の権限を与える
- github-secretsを利用して、AWS認証キーを誤ってコミットするのを防ぐ
終わりに
私としてもこのようなはずべき行為を行ってしまったことを記事にするのは躊躇しましたが
流出を行ってしまったことを事実として受け止め、それが今の自分のセキュリティに対する認識の低さ
だということを自覚するとても良い機会となりました。
今まで無意識にアクセストークンなどの個人情報が特定できるものをGithubに無意識に公開していたため、
これを機に今後はこのような失態をしないようにAWSキーとGithubの扱いには十分に注意して取り扱っていきます。またこの度認証キー流出後、早急に対処してくださった社員の方々、本当にありがとうございました。
- 投稿日:2020-06-27T19:42:30+09:00
【大反省】新卒1年目がAWSの認証キーを流出させてしまった話
はじめに
私は新卒1年目で神戸のSIerに勤めています。
この度AWSキーを流出してしまうという、
初心者であるもののエンジニアとして恥ずべき行為をしてしまったので
2度とこのような失態を踏まないように再発防止の意味を兼ねてここに記そうかと思います。また今後AWS認証キーを流出してしまうことを完全に防ぐことは難しいかと思いますが、
今までの自分と同じようにAWS認証キーを無意識に扱っていた方の認識を改めるきっかけになればと思います。何をしたのか
ことが起こったのは2020年6月24日。
Github Actionsを利用して、CI機能を実装しようとしていた時のこと。
やろうとしていたことはGithubのリモートリポジトリにpushされたときに、
AWS S3に公開ファイルをデプロイするというものでした。
Actionsにはワークフローとして、AWS認証キーを設定する処理が含まれていたので、
アクセスキーとシークレットキーを記述する必要がありました。
例としては下のようなイメージです。name: GithubActions_test on: push: branches: - master jobs: deploy: name: Build & Deploy runs-on: ubuntu-latest steps: - uses: actions/checkout@v2 - uses: actions/setup-node@v2-beta with: node-version: 12.x - run: yarn install - run: yarn build - name: Configure AWS Credentials uses: aws-actions/configure-aws-credentials@v1 with: aws-access-key-id: "ここにアクセスキーを書いてしまった" aws-secret-access-key: "ここにシークレットキーを書いてしまった" aws-region: ap-northeast-1 - name: Copy files to the test website with the AWS CLI run: aws s3 sync dist/ s3://"ここにバケット名のハードコーディング"今回は具体的なGithub Actionsの説明は省かせていただきます。
この処理の流れとしては、以下のようになっています。
- masterブランチにチェックアウト
- nodeのセットアップ
- モジュールをインストール
- プロジェクトをビルドし公開ファイル作成
- aws認証情報の設定
- aws s3と公開ファイルの同期(アップロード)
この過程のなかの5のところに認証情報を記述するのですが、
本来はSecretsを設定するなどして、変数として記述する必要があります。
しかしここに認証キーをハードコーディングしたために、Actionsをコミットしたと同時に
Githubに公開された流れとなりました。流出後にしたこと
AWSキーを公開してしまったときは非常に運が良いことに上司の方がすぐに気づいてくださり、
即座にAWS認証キーの無効化を行なったため、大事には至らなかったのは本当によかったです。
GithubにはAWS認証キーをpushしたときに、不正利用防止のためにすぐにメールで通知が
いくようになっているようですが、本当に救われました。恥ずかしい話なのですが、キー流出直後は、ことの重大さにあまり気づいていませんでした。
上司の方に言われるがまま、認証キーの無効化を行なって再び作業を通常通り行っていたのですが、
社内で利用しているTeamsのチャットでグループが作られ、認証キー流出の件が話し合われました。
弊社のセキュリティ事業部の方と詳細に事実確認をしていく中で、少しずつやばいことをしてしまった
という実感が湧いてきました。そしてその後、上司の方から「AWSキー流出」で調べておいてと言われ、
家に帰って調べたところ、自分が行ったことの重大さを知りました。
主に以下の記事を参照させていただきました。・GitHub に AWS キーペアを上げると抜かれるってほんと???試してみよー!
・AWSで不正利用され80000ドルの請求が来た話 - Qiita
・初心者がAWSでミスって不正利用されて$6,000請求、泣きそうになったお話。 - Qiita
・AWSが不正利用され300万円の請求が届いてから免除までの一部始終 - Qiitaこれらの記事を読み、かなり自分の中で反省をしました。
自分のしたことの重大さを知り、この件でかなり自分的に落ち込み、この件が1日中ずっと頭の中に残っていて
次の日はなかなか作業が捗らなかったです。
万が一、不正利用されて企業側に数百万の請求が来ていたかと思うと、1ヶ月は落ち込んでいたことかと思います。1つ不幸中の幸いなことだったことは、流出したキーのアカウントのIAMポリシーには「S3FullAccess」のみ付与していたことです。
これが「AdministratorAcess」とかだったら、既存のキーを削除され、新しいキーを作成、EC2の作成などが
行われていた可能性もあります。今後の対策
反省と再発防止のために今後、認証キーとGithubを扱うときに自分の中でルールを定めました。
- 今までのpublicリポジトリを全て削除
- 公開する予定のないgithubのリモートリポジトリをprivateにする
- 認証キーにはGithubのSecrets機能を利用する
- AWSの認証キーは環境変数用の.envファイルに記述して.gitignoreを設定して、リモートリポジトリにpushされないようにする
- IAMユーザーのポリシーには最低限の権限を与える
- github-secretsを利用して、AWS認証キーを誤ってコミットするのを防ぐ
終わりに
私としてもこのようなはずべき行為を行ってしまったことを記事にするのは躊躇しましたが
流出を行ってしまったことを事実として受け止め、それが今の自分のセキュリティに対する認識の低さ
だということを自覚するとても良い機会となりました。
今まで無意識にアクセストークンなどの個人情報が特定できるものをGithubに無意識に公開していたため、
これを機に今後はこのような失態をしないようにAWSキーとGithubの扱いには十分に注意して取り扱っていきます。またこの度認証キー流出後、早急に対処してくださった社員の方々、本当にありがとうございました。
- 投稿日:2020-06-27T19:37:39+09:00
S3に保存されたwavファイルをLambdaでGoogle Cloud Speech-to-Textを使って文字起こしする
S3に保存されたwavファイルをLambdaでGoogle Cloud Speech-to-Textを使って文字起こしする
はじめに
以下リンク記事を参考に、S3に保存されたwavファイルをLambdaでGoogle Cloud Speech-to-Textを使って文字起こしをやってみたのでまとめておきます。
S3 + ElasticTranscoder + Lambda + Google Cloud Speech-to-Text APIで、動画の音声を自動でテキストにする
?完全なる上位互換なので、私の記事は読む必要ないかと。
1. S3の作成
特別なことはしないです。
1-1. 適当なバケット名、リージョン(私は東京)で次へ
1-2. オプションの設定はノータッチ
1-3. アクセス許可の設定もノータッチ(パブリックアクセスをすべてブロック)
1-4. 確認2. ローカルでGoogle Cloud Speech-to-Text APIをインストール
Google Cloud Speech-to-Text APIを使うため、npmを使ってローカルでインストールします。
後ほどlayerとしてlambdaに追加するため、ディレクトリ名はnodejsにしてください。
mkdir nodejs
cd nodejs
npm init
npm install @google-cloud/speechnode_modulesが入ったnodejsフォルダをzip(nodejs.zip)にしておきましょう。
3. Lambda layerの作成
先ほど作成したzipファイルをlayerとしてlambdaに追加します。
3-1. Lambdaのレイヤー画面からレイヤーの作成へ
3-2. 適当な名前、説明
3-3. zipファイルをアップロード
3-4. ランタイムはご自身のNode.jsのバージョンで選択(私は10.x)
4-5. 作成4. Google Cloud Speech-to-Textのサービスアカウントを取得
lambda関数に配置するための、サービスアカウントキーをJSON形式で取得します。
4-1. GCPのAPIとサービス内のCloud Speech-to-Textへ
4-2. APIを有効化する
4-3. 認証情報で「+認証情報を作成」、サービスアカウントを選択し、サービスアカウントを作成
4-4. 作ったら鍵の追加をして、JSON形式の秘密鍵を取得5. lambda関数の作成
5-1. 関数の作成に行き、適当な名前、ランタイム(私はNode.js 10.x)を選択して作成
5-2. アクセス権限に移動し、実行ロールを選択する
5-3. S3にアクセスするポリシーをアタッチする(とりあえずAmazonS3FullAccess)
5-4. lambdaに戻ってトリガーを追加へ移動し、S3で作成したバケットを選択
5-5. 3で作成したlayerを追加(ランタイムが一致してないと出てこないので注意)
5-6. 4で作成したサービスアカウント情報を追加するため、関数コードのところで、JSONファイルを作成
5-7. ここに4でダウンロードしてきた秘密鍵JSONファイルの情報をコピペ(githubのpublic repoとかに上げないように注意!)
5-8. credientials.jsonを環境変数に追加
5-9. コードはこちらのコードを拝借しています。少し変えているので以下に貼っておきます。
const AWS = require('aws-sdk'); const speech = require('@google-cloud/speech'); const client = new speech.SpeechClient(); var s3 = new AWS.S3({ apiVersion: '2012-09-25' }); exports.handler = function(event, context) { var bucket = event.Records[0].s3.bucket.name; var key = event.Records[0].s3.object.key; var name = key.split('.')[0]; var params = { Bucket: bucket, Key: key }; s3.getObject(params, function(err, data) { if (err) { console.log(err, err.stack); } else { var audioBytes = data.Body.toString('base64'); const audio = { content: audioBytes }; const config = { encoding: 'LINEAR16', sampeRateHertz: 16000, languageCode: 'ja-JP', }; const request = { audio: audio, config: config, }; client.recognize(request).then( data => { const response = data[0]; const transcription = response.results.map( result => result.alternatives[0].transcript ).join('\n'); console.log(name); console.log(transcription); }).catch(err => { console.error('ERROR:', err); } ); }; }); }最終的にはこんな感じかと↓
結果
console.log(transcription);で出力してるtranscriptionに文字起こし結果が入ってます。cloudwatch logで確認してみてください。最後に
参考記事の劣化版みたいな記事になってしまいましたが、備忘録として書かせていただきました。
劣化版なりの改良点としは以下です。
* node_modulesも一緒にzipにして、関数コードに入れようとしたがうまくいかなかったのでlayerから入れた(nodejsというファイル名にするの注意ですね)
* 環境変数としてサービスアカウントの情報を追加する手順の追加
* ソースコードの簡易化と修正間違い等ある場合はぜひコメントください。
次回はmp3の文字起こしをやってみたいと思います。参考
S3 + ElasticTranscoder + Lambda + Google Cloud Speech-to-Text APIで、動画の音声を自動でテキストにする
- 投稿日:2020-06-27T18:57:59+09:00
AWS Lambda から Amazon EFS へのアクセス
AWS Lambda から Amazon EFS へアクセスできるようになったとのことでやってみた。
これによりLambda の仕様上、512 MB という仕様制限がありましたが、これを超えるファイルの操作が可能になります。
また、S3は結果整合性ですが、EFS を利用することによりデータの一貫性が保てることができます。
新機能 – Lambda関数の共有ファイルシステム – Amazon Elastic File System for AWS Lambda
1.セキュリティグループの作成
AWS Lambda 用セキュリティグループの作成
セキュリティグループ インバウンドルール なし アウトバウンドルール すべてのトラフィック Amazon EFS 用セキュリティグループの作成
セキュリティグループ インバウンドルール NFS,TCP,2049,AWS Lambda のセキュリティグループID アウトバウンドルール すべてのトラフィック 2.Amazon EFS の作成
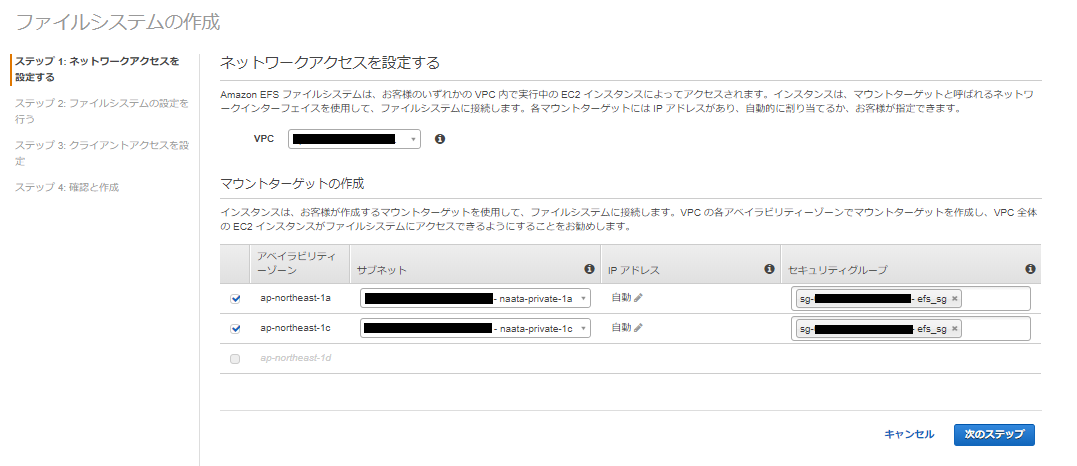
ステップ 1: ネットワークアクセスを設定する
AWS Lambda を作成する対象の VPC を選び、マウントターゲットでサブネットを選択。
セキュリティグループには、「Amazon EFS 用セキュリティグループの作成」で作成したsgを選択します。
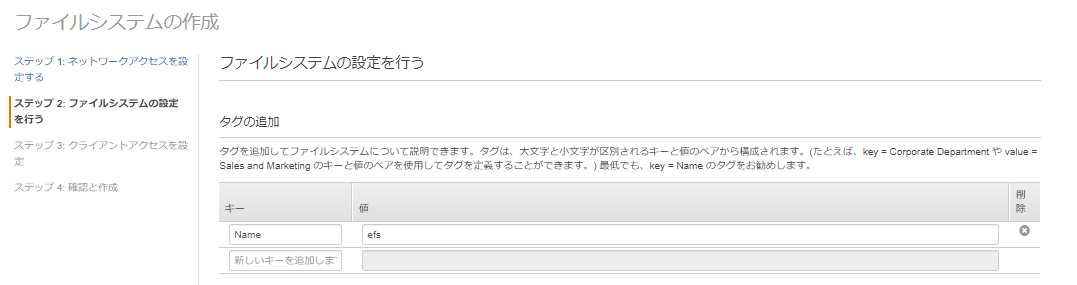
ステップ 2: ファイルシステムの設定を行う
今回は、AWS Lambda から Amazon EFS のアクセスを確認することが目的なので、タグだけを追加し、他の設定はデフォルトでいきます。
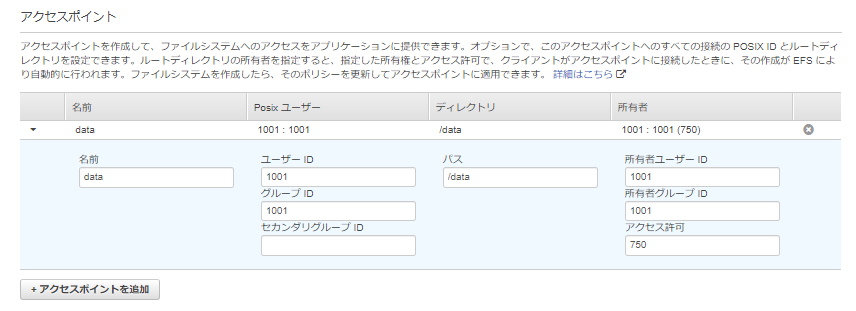
ステップ 3: クライアントアクセスを設定
AWS Lambda からアクセスするための アクセスポイントの作成 を行います。
ステップ 4: 確認と作成
「ファイルシステムの作成」をクリック。
3.AWS Lambda の作成
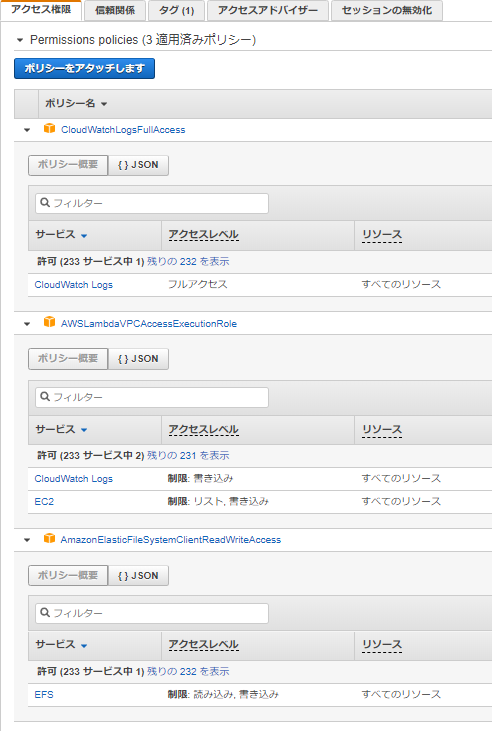
IAM ロールの作成
AWS Lambda 関数に付与する IAM ロールを作成する。
AWSLambdaVPCAccessExecutionRole
AmazonElasticFileSystemClientReadWriteAccess
CloudWatchLogsFullAccess
AWS Lambda 関数の作成
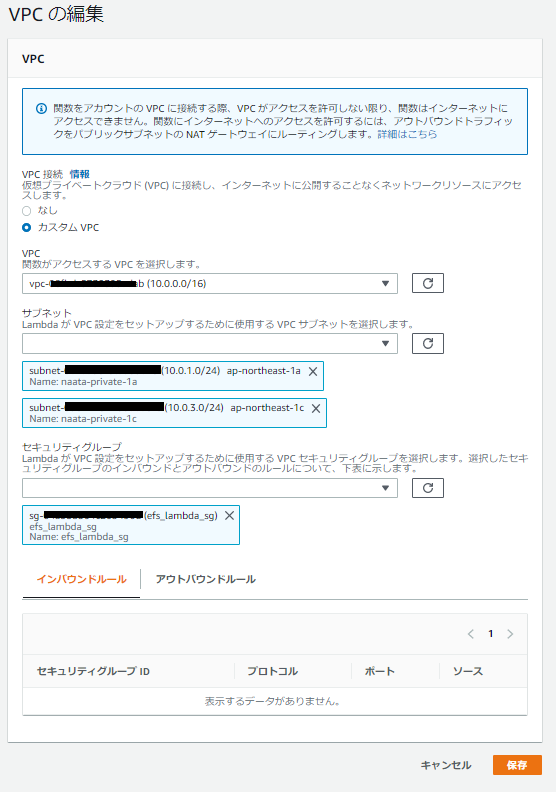
ランタイムはPython3.8、既存のロールは「IAM ロールの作成」で作成したものを指定します。
VPCとセキュリティグループは、「AWS Lambda 用セキュリティグループの作成」で作成していたものを指定します。
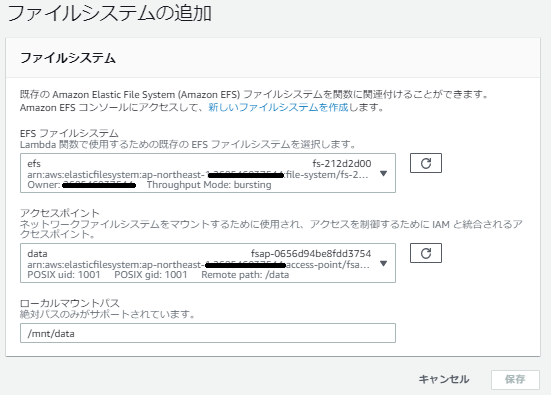
さて、今回のメインはここで、ファイルシステムの追加をします。「Amazon EFS の作成」で作成したAmazon EFS 及びアクセスポイント、ローカルマウントポイントを指定します。
次の通りLambda関数を作成します。
AWS Lambda から Amazon EFS 上にファイル efslambda.txt を作成、書き込、保存。file_path = '/mnt/data/' def lambda_handler(event, context): file_name = 'efslambda.txt' write_string = event['text'] with open(file_path + file_name, mode='w') as f: f.write(write_string) with open(file_path + file_name) as f: print(f.read())4.テスト
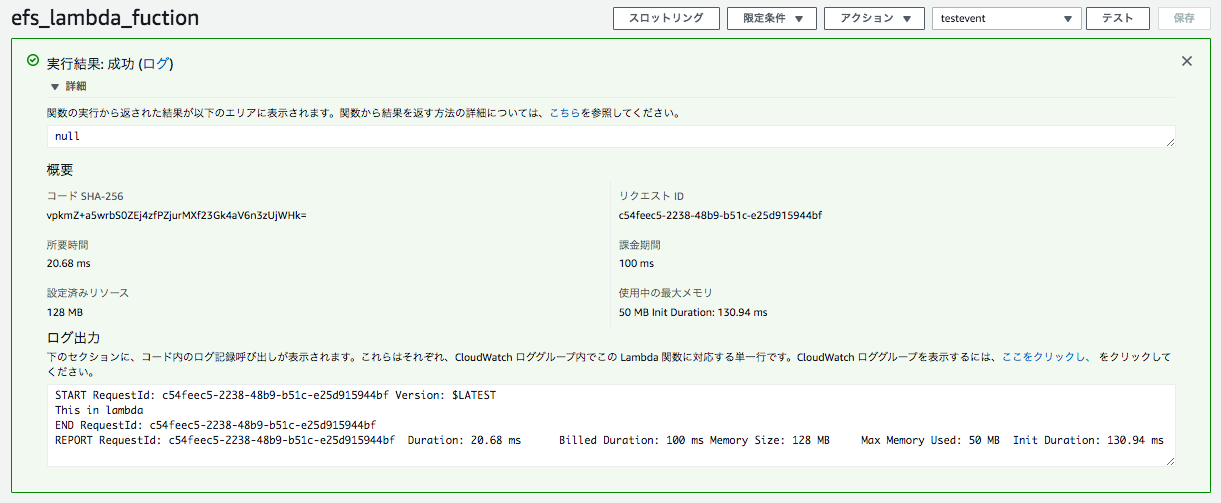
lambdaよりテストイベントを実行する。
{ "text": "This in lambda" }
- 投稿日:2020-06-27T18:36:58+09:00
AWS SAA(ソリューションアーキテクトアソシエイト)に合格するまでにやったこと
SAA(ソリューションアーキテクチャアソシエイト)資格とは
AWS認定試験は基礎コース、アソシエイト、プロフェッショナル及び専門知識を分けています。アソシエイトは役割によって「アーキテクト」、「運用」、「開発者」を分けています。ソフトウェアエンジニアですが、一番人気の「ソリューションアーキテクトアソシエイト」をチャレンジしました。
認定によって検証される能力は下記の通りです。(AWS公式ページより抜粋)
認定によって検証される能力
- AWS のテクノロジーを使用して安全で堅牢なアプリケーションを構築およびデプロイするための知識を効果的に証明すること
- 顧客の要件に基づき、アーキテクチャ設計原則に沿ってソリューションを定義できること
- プロジェクトのライフサイクルを通して、ベストプラクティスに基づく実装ガイダンスを組織に提供できること
試験の詳細
項目 説明 問題形式 単一選択及び複数選択(2つ) 実施形式 テストセンター試験 時間 130分間 受験料金 15,000円(税別) 言語 英語、日本語 言語
AWSの公式ドキュメントには基本的に専門用語そのままカタカナに訳されていますので、分かりづらいところがあります。わからない場合、いつも英語のオリジナルドキュメントを読んでいます。今回の試験も英語に選びました。
なぜ受けたのか
4年目のソフトウェアエンジンです。Azureを利用するプロジェクト経験がありますが、AWSはEC2ぐらい触ったことしかないです。
クラウド開発スキルは求められる案件はどんどん増えてきましたので、クラウド知識を勉強したほうがよいかと思いました。政府共通プラットフォームでAWS採用のニュースを見て、AWSの資格を取ろうと決意しました。
合格するまでにやったこと
AWSアカウント登録
ペーパー資格は意味がないですので、まずAWSのアカウントを作成して、主な製品を触ってみました。AWSのサービスは多すぎますので、よく使われる製品のみ注目しました。
公式ドキュメント
各製品を触りながら、それぞれの公式ドキュメントを確認しました。正直公式のドキュメントも多すぎますので、基本的にわからないところのみ読みました。後述のように受験対策の際、また公式ドキュメントを確認しないといけないです。
参考書
下記の1冊を使いました。選定理由としては、最近発売されたことです。AWSのサービスはどんどん変わりますので、最新版の内容も反映されているかと思いました。
AWS認定資格試験テキスト AWS認定 ソリューションアーキテクト-アソシエイト
問題集
やはり参考書の問題は足りない気がしますので、下記のiPhoneアプリも購入しました。
問題数が多いですので、全部解答して、間違った問題を調べ直して、結構時間がかかりました。
解答説明がないですが、やはりもう一度公式ドキュメントをちゃんと読んで理解しないといけないです。意外にちゃんと理解して、ちゃんと覚えて、実務経験も積んだ効果がありました。
アプリはテスト機能もありますので、80点以上なるまでテストを繰り返しました。
- 投稿日:2020-06-27T17:32:08+09:00
AWS Lambdaのリソースベースポリシーのサイズが上限に達して困った話
はじめに
AWS samを利用しAPI gateway + Lambdaの構成を作成していたのですが、Cloudformationの変更セットを実行中に以下のエラーを取得してしまいました。
The final policy size (20857) is bigger than the limit (20480). (Service: AWSLambda; Status Code: 400; Error Code: PolicyLengthExceededException; Request ID: xxxxxxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx)このエラーが示す内容としては、 Lambdaのリソースベースポリシーがサイズ上限に達した ということを示しています。
この状態になるとAPIのメソッドの統合リクエストのタイプにこのLambdaを指定することが出来なくなります。調べてみて
いくつか記事を漁っていると、以下の記事を発見しました。
Lambda エラー「最終ポリシーサイズが制限を超えています」を解決する方法を教えてください。この記事では、複数あるリソースベースポリシーをポリシー内のリソースの指定にワイルドカードを用いることで、ポリシーのサイズを縮小する方法を説明してくれています。
とりあえず、今あるポリシーを削除して新たにワイルドカードを含むポリシーをセットしてやればいいようです。
残念ながらAWS Lambdaのリソースベースポリシーはマネジメントコンソールからは操作することが出来ないのでCLIを使って操作していきます。削除のコマンド
以下のコマンドでLambdaのリソースベースポリシーを1件削除することが出来ます。
残念ながら一括で削除をすることは出来ないようです。
なので大量にある場合は二人で上下から削除していくか、諦めてLambdaを作り直すとかした方が良さそうですね。$ aws lambda remove-permission \ --function-name my-function \ --statement-id sid作成のコマンド
以下のコマンドでLambdaのリソースベースポリシーを1件追加することが出来ます。
aws lambda add-permission --function-name my-function \ --statement-id sid \ --action 'lambda:InvokeFunction' \ --principal 'events.amazonaws.com' \ --source-arn 'arn:aws:events:region:account-id:rule/test-*'ここで、API gatewayの指定方法がわからず詰んでいましたが、なんとか以下の指定で通すことが出来ました。
このように指定することで1個のAPIからリクエストの種類が増えても、このポリシー1つで補うことが出来ます。aws lambda add-permission --function-name my-function \ --statement-id 1 \ --action lambda:InvokeFunction \ --principal apigateway.amazonaws.com \ --source-arn arn:aws:execute-api:${region}:${AWSアカウントID}:${APIの識別子}/*samでこれをやる場合の注意点
恐らくsamに限った話ではないと思いますが、新しくワイルドカードを含むポリシーを追加後、新たにメソッドを追加したtemplateを実行すると、 追加した分の ポリシーが追加されてしまいました。放っておくと将来的に同じ事象にぶつかると思うので、逐次消すなりする必要があると思います。
最後に
APIの指定の方法がわかり、なんとか解決することが出来て良かったです。
こういったこともありえるのでAWS Lambdaは極力分割していくのが良いんでしょうね。ではまた。
参考資料
- 投稿日:2020-06-27T15:27:43+09:00
【AWS SDK for Java】S3クライアントにリトライポリシーを設定する
ジャストほしい情報が日本語でなかったのでドキュメンテーションする。
AWS SDK for Javaを利用してS3にファイルをアップロードする際に、やや詳細な設定を付加する。目次
- リトライ周りのケース概略
- とりあえず実装してみる
- 関連クラスの整理
- その他
- 参考
リトライ周りのケース概略
AWS SDK for Javaを使って、ローカルにあるS3にファイルをアップロードしたい。
そして、AWS側の都合で通信断となったり諸事情により正常稼働できないケースを見越して、AWSクライアントにリトライポリシーを仕込みたい。
今回は、AWS SDK for Javaに含まれるAmazonS3オブジェクトのシングルトンを返すユーティリティクラスを用意する。なお、本記事では自分が特に困った「クライアント生成時のオプション設定」にフォーカスを置く。そのため、ファイルアップロード前後の処理関連の説明は省略する。
とりあえず実装してみる
シンプルなクライアントオプションを詰めたクライアントを構築する。
流れとしては、リトライポリシーインスタンス、クライアント設定インスタンス、そしてクライアントの3つを準備していく。まずは、ポリシーの基本設定やAWS定義のストラテジーなどを詰めた
RetryPolicyインスタンスを返すメソッドを用意。AmazonS3Utils.java/** * ExponentialBackoffStrategyのコンストラクタにbaseDelayとmaxBackoffTimeの適切な値を入れる。 * 注意:ここではサンプルとして適当な値を入れてます。 */ private static RetryPolicy getS3BaseRetryPolicy() { return new RetryPolicy( new PredefinedRetryPolicies.SDKDefaultRetryCondition(), new PredefinedBackoffStrategies.ExponentialBackoffStrategy(0, 0), PredefinedRetryPolicies.DEFAULT_MAX_ERROR_RETRY, true ); }次に、↑で定義した
RetryPolicyインスタンスを返すメソッドを呼んで、クライアント設定を定義する。AmazonS3Utils.javaprivate static final ClientConfiguration clientConfiguration = new ClientConfiguration() .withRetryPolicy(getS3BaseRetryPolicy());そして、他のクラスやメソッドが呼び出すS3クライアントのエントリーポイントとなる
AmazonS3オブジェクトを、クライアント設定を詰めて初期化。AmazonS3Utils.javaprivate static final AmazonS3 amazonS3 = AmazonS3ClientBuilder .standard() .withClientConfiguration(clientConfiguration) .withRegion(Regions.DEFAULT_REGION) .build();ここまでの設定をまとめると、
AmazonS3Utils.javapublic final class AmazonS3Utils { /** * リトライポリシーを反映した、クライアント設定を初期化。 */ private static final ClientConfiguration clientConfiguration = new ClientConfiguration() .withRetryPolicy(getS3BaseRetryPolicy()); /** * AmazonS3インスタンスを初期化。 */ private static final AmazonS3 amazonS3 = AmazonS3ClientBuilder .standard() .withClientConfiguration(clientConfiguration) .withRegion(Regions.DEFAULT_REGION).build(); /** * ファイル操作を提供するオブジェクトを返す */ public static AmazonS3 getS3() { return amazonS3; } /** * リトライポリシーをインスタンス化。 */ private static RetryPolicy getS3BaseRetryPolicy() { return new RetryPolicy( new PredefinedRetryPolicies.SDKDefaultRetryCondition(), new PredefinedBackoffStrategies.ExponentialBackoffStrategy(0, 0), PredefinedRetryPolicies.DEFAULT_MAX_ERROR_RETRY, true ); } }これで準備完了。あとは、
getS3メソッドで設定を反映したS3クライアントを呼び出せるようになる。登場オブジェクトの整理
実装例に出てくる複数のクラスの役割を整理してみたい。
自分の調べ方が悪かったのか、やりたいことをさくっとできる感じではなかった...AmazonS3(インターフェース)
S3のオブジェクトを操作するメソッドを定義するインターフェース。
具体的な実装はクライアントビルダークラスにより提供されるようだ。
AmazonS3
このオブジェクトはインターフェースであり、具はAmazonS3ClientBuilderなどにより提供されるようだ。もともと、リトライ周りの設定を追加する前は
AmazonS3ClientBuilder.standard().build();で済ませていた。最小限の機能で済むなら、そのようなミニマルなクライアントで十分かと思う。ClientConfiguration(クラス)
ClientConfigurationは、リトライやプロキシ、ユーザエージェント文字列などAWSクライアントに追加できるオプションの設定クラス。
今回の例では自分は多少カスタマイズを加えたRetryPolicyを渡したが、PredefinedRetryPoliciesにあるstaticメソッドであるgetDefaultRetryPolicy()を呼び出すことで、デフォルト設定をクライアント設定に詰められるようだ。RetryPolicy(クラス)
RetryPolicyは、
ClientConfigurationと組み合わせて、リトライポリシーを構築するクラス。
コンストラクタに必要なオブジェクトや値を詰めて初期化する。コンストラクタには、
RetryConditionやBackoffStrategyなどのインターフェースが引数に指定されているのだが、引数のインターフェースに合うクラスに何を指定すればよいのか、最初悩んだ。いくつかコンストラクタがあるが、そのうちの一つを挙げてみるとRetryPolicy.javapublic RetryPolicy(RetryCondition retryCondition, BackoffStrategy backoffStrategy, int maxErrorRetry, boolean honorMaxErrorRetryInClientConfig) { this(retryCondition, backoffStrategy, maxErrorRetry, honorMaxErrorRetryInClientConfig, false); }いろいろ調べていくうちに、どうやらSDKは事前にある程度定義したポリシーを詰められるクラスを用意していたとわかった。
RetryConditionインターフェースには、今回の実装ではAWS SDKのデフォルトに従うことにした。PredefinedRetryPoliciesに、何種類か、使えそうな実装があるのでRetryPolicyのコンストラクタに渡せばよい。
設定にこだわりがないのであれば、デフォルト設定を返してくれるstaticプロパティDEFAULT_RETRY_CONDITIONを指定すればよさそう。BackoffStrategyインターフェースを拡張した抽象クラスV2CompatibleBackoffStrategyが用意されており、この抽象クラスを拡張したアダプターおよび各種具象クラスを使えば
BackoffStrategyインターフェース相当の引数を設定できる。詳しくいうと、PredefinedBackoffStrategiesには
V2CompatibleBackoffStrategyAdapterを拡張した、
- FullJitterBackoffStrategy
- EqualJitterBackoffStrategy
- EqualJitterBackoffStrategy
などが用意されている。RetryPolicyを初期化する際に、コンストラクタになんとかBackoffStrategyを渡すことで細かい設定を施すことが可能である。
その他
本当は公式のドキュメントで、いい感じに説明してくれているサムシングがある気がしている...
自分は探し当てられなかったため、「そんな無理せんでもこれ読んだらええんやけど」ってのがあればご指摘いただければありがたいです。参考
- 投稿日:2020-06-27T15:00:59+09:00
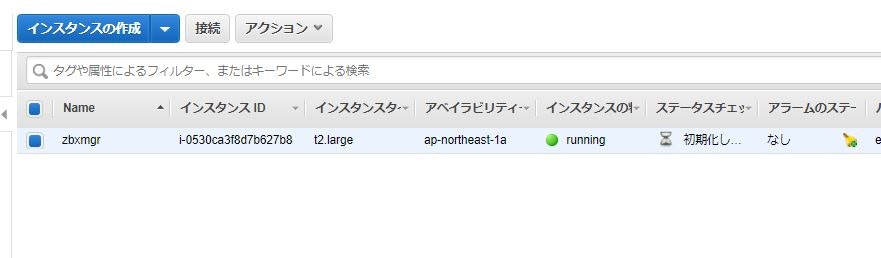
【AWS】AmazonLinuxにてZabbixマネージャー構築(AWS側設定)
はじめに
以前、下記のQiita記事を投稿しました。
【AWS】AmazonLinuxにてZabbixマネージャー構築(OS側設定)
こちらの記事ではOS側の設定を紹介しています。今回は、AWS側での設定についてアウトプットしていきたいと思います。
自宅環境
項目 説明 自宅PC Windows10 ターミナル TeraTerm 基盤環境
項目 説明 OS Amazon Linux 2 AMI (HVM), SSD Volume Type Size t2.large DB MySQL 5.7.26 ※DBはRDSを外付け
※AWSのベストプラクティスに沿って、作業用IAMユーザーにて作業
(ルートユーザーには多要素認証設定済み)構成図
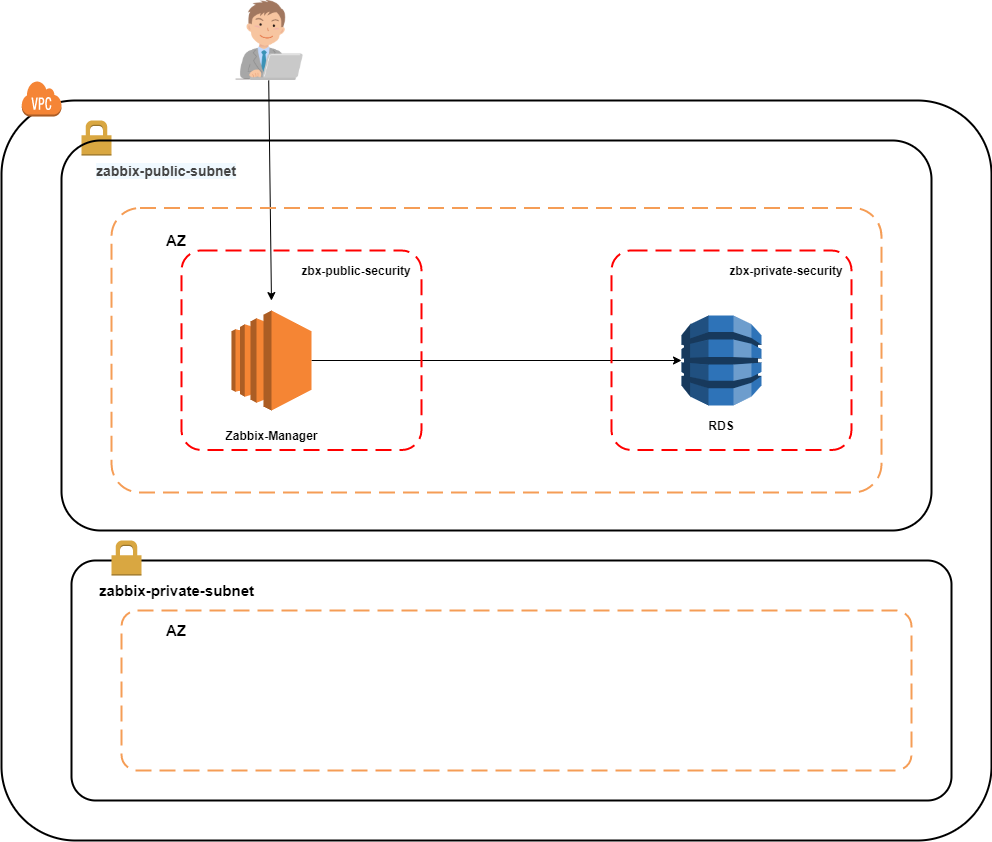
※RDSの使用上、「availability zone」が2つ以上必要であるため、サブネットを2つ作成しております。
構築手順
1.VPC作成
2.サブネット設定
3.ルートテーブル設定確認
4.セキュリティグループ設定
5.RDS(MySQL作成)
6.EC2インスタンス作成1.VPC作成
①VPCを起動
②VPCダッシュボードが起動されるので、VPCウィザードの起動をクリック
③1個のパブリックサブネットを持つVPCを選択
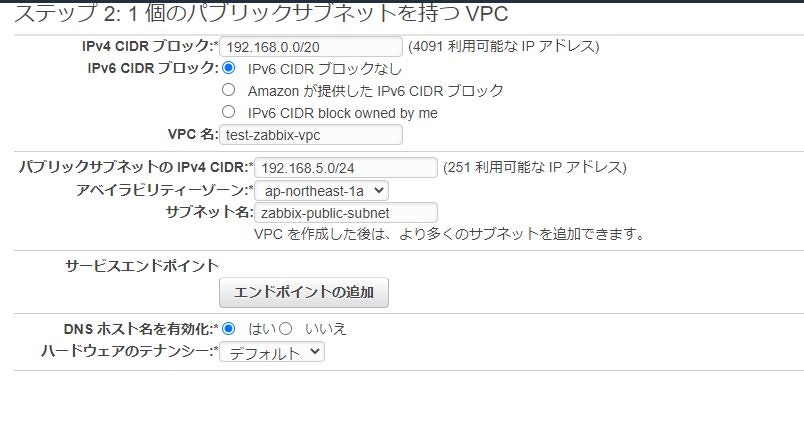
④下記のように情報を入力し、VPCの作成をクリック
- VPC
項目 設定値 IPv4 CIDR ブロック 192.168.0.0/20 IPv6 CIDR ブロック IPv6 CIDRブロックなし VPC名 test-zabbix-vpc
- パブリックサブネット
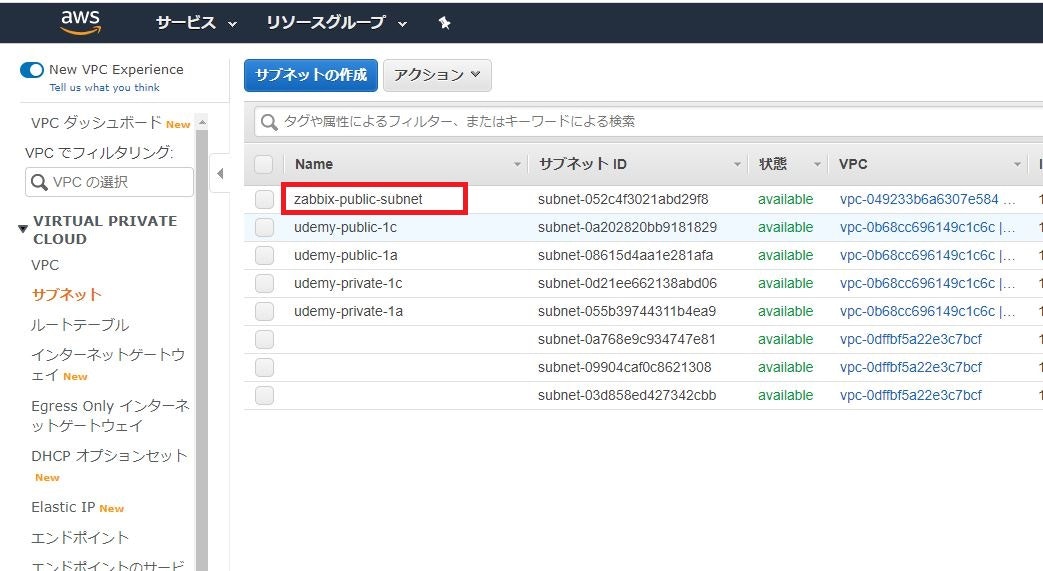
項目 設定値 パブリックサブネットの IPv4 CIDR 192.168.5.0/24 アベイラビリティーゾーン ap-norteast-1a サブネット名 zabbix-public-subnet
- DNS
項目 設定値 DNSホスト名を有効化 はい ※DNSホスト名を有効化しないと、AmazonLinuxにて
yumが出来ません。
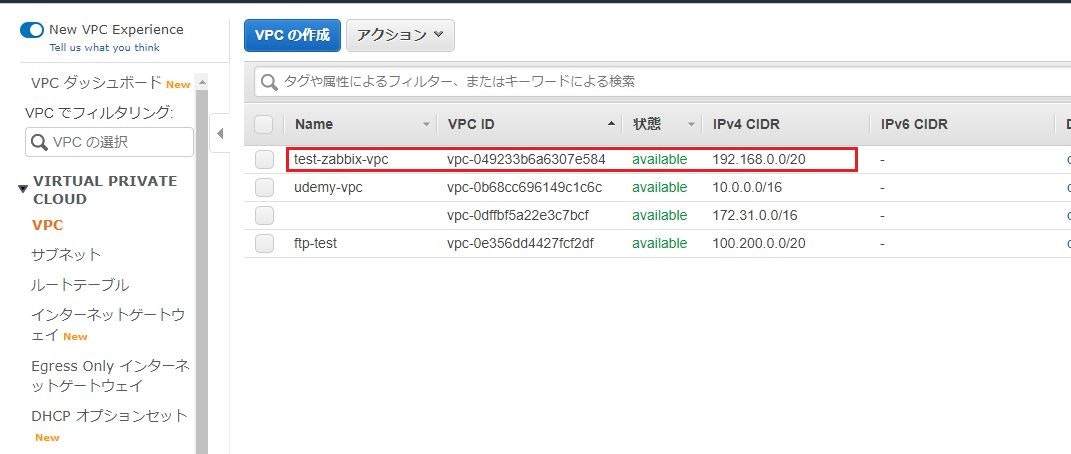
⑤VPCが正常に作成されましたと表示されることを確認。
⑥VPC一覧画面を開くと、新しくVPC(test-zabbix-vpc)が作成されていることを確認。
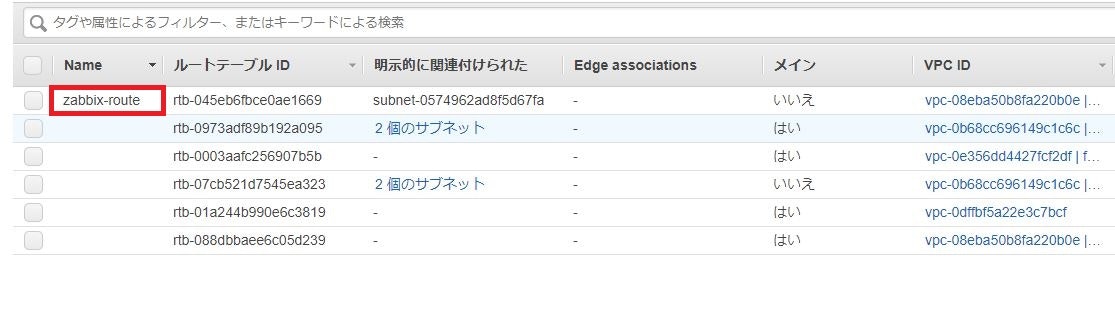
⑦「パブリックサブネット」「ルートテーブル」「インターネットゲートウェイ」も同時に作成されている。
名前は下記とする。
※名前が設定されていないものは設定
項目 名前 作成したサブネット zabbix-public-subnet 作成したルートテーブル zabbix-route 作成したインターネットゲートウェイ test-zabbix-gateway ※関連付けられているVPCを辿れば、作成したものかわかります。
サブネット
ルートテーブル
インターネットゲートウェイ
2.サブネット設定
プライベートサブネット作成
※RDSを使用するためには、サブネットを2つ以上作成する必要有り(無料枠の場合もAZが2つ必要)
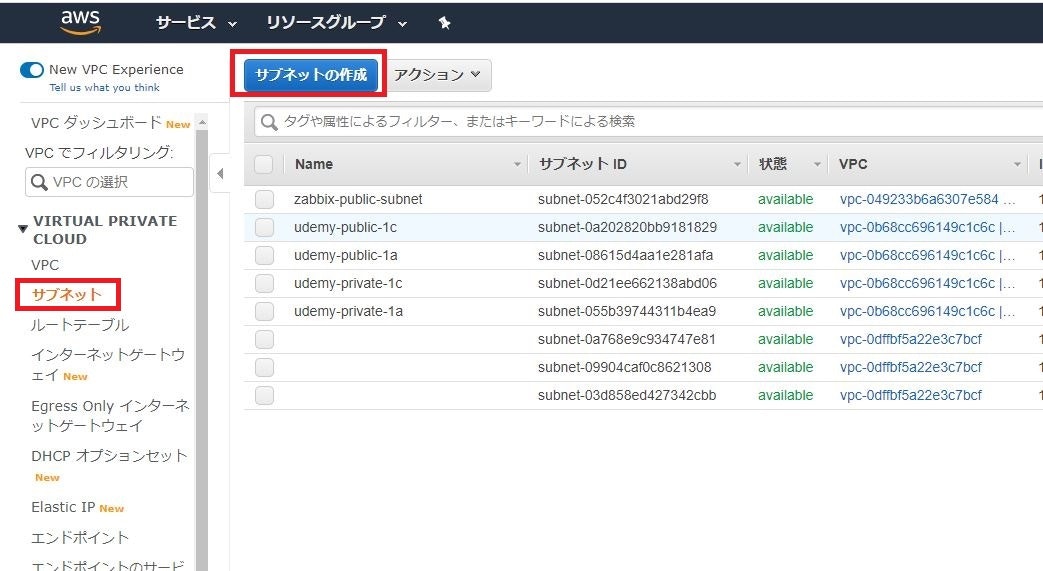
①VPCダッシュボードにてサブネット→サブネットの作成をクリック
②サブネットの作成画面にて必要情報を入力する。
項目 設定値 名前タグ zabbix-private-subnet VPC test-zabbix-vpcのVPCを選択アベイラビリティーゾーン ap-northeast-1d IPv4 CIDRブロック 192.168.10.0/24 ※アベイラビリティーゾーンは1.VPC作成で設定した場所以外を選択する。
入力完了後、作成をクリック
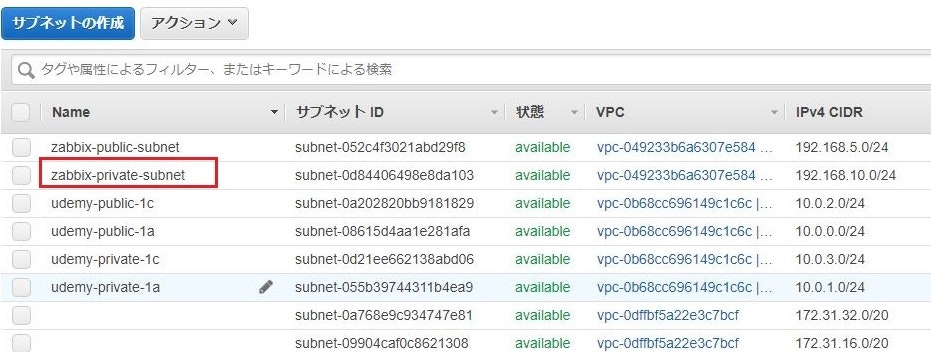
③サブネットの作成が完了すると、下記のような画面が表示される。
そのまま閉じるをクリック
④サブネット一覧にて、zabbix-private-subnetが作成されていることを確認。
パブリックIPアドレス自動割り当て設定
①サブネット一覧より「zabbix-public-subnet」を右クリック→自動割り当て IP 設定の変更をクリック
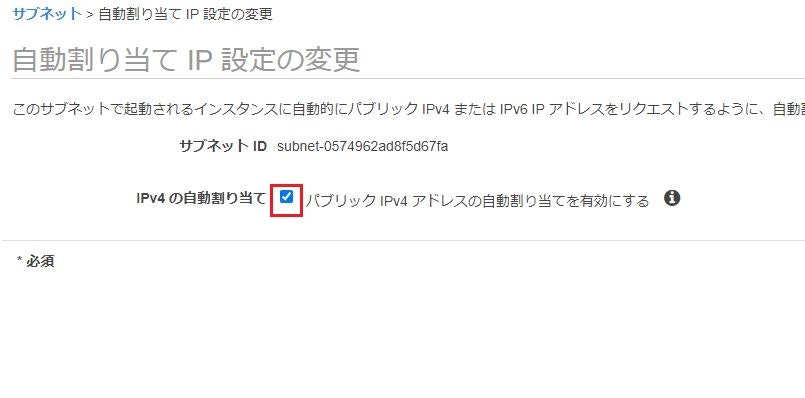
②「自動割り当てIP設定の変更」画面にて、IPv4自動割り当てにチェックを入れ、保存をクリック。
3.ルートテーブル設定確認
①ルートテーブル一覧を開き、今回作成したルートテーブル(zabbix-route)を選択。
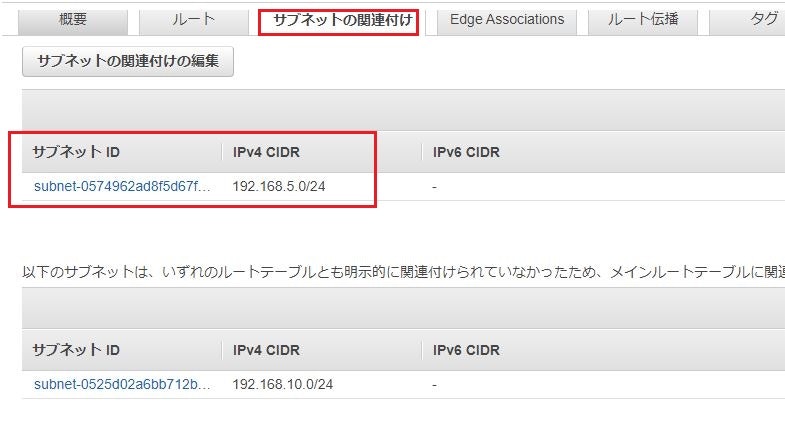
②下の画面より「サブネットの関連付け」のタブをクリックし、今回作成したサブネット(zabbix-public-subnet)との関連付けができているか確認。
※サブネットIDをクリックすると、サブネットの詳細を確認することができます。
4.セキュリティグループ設定
セキュリティグループを2つ作成
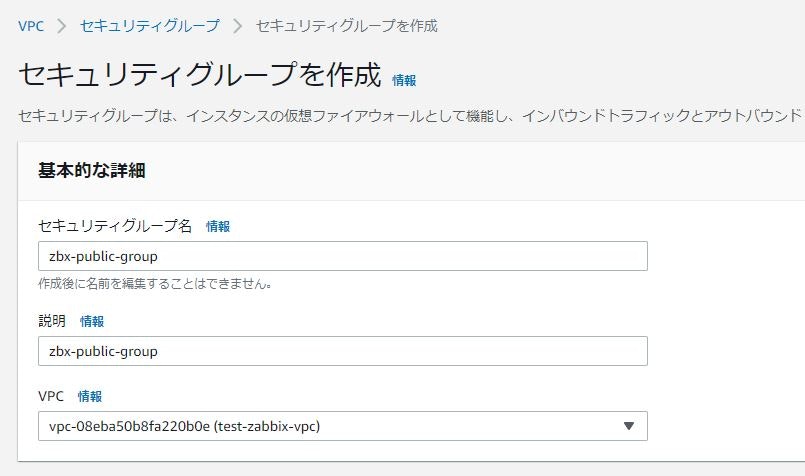
①セキュリティグループ一覧にて、セキュリティグループを作成をクリック。
②下記のように設定し、保存をクリック。
項目 設定値 セキュリティグループ名 zbx-public-group 説明 zbx-public-group VPC 「test-zabbix-vpc」を選択 ※インバウンド/アウトバウンドはまだ設定しない。
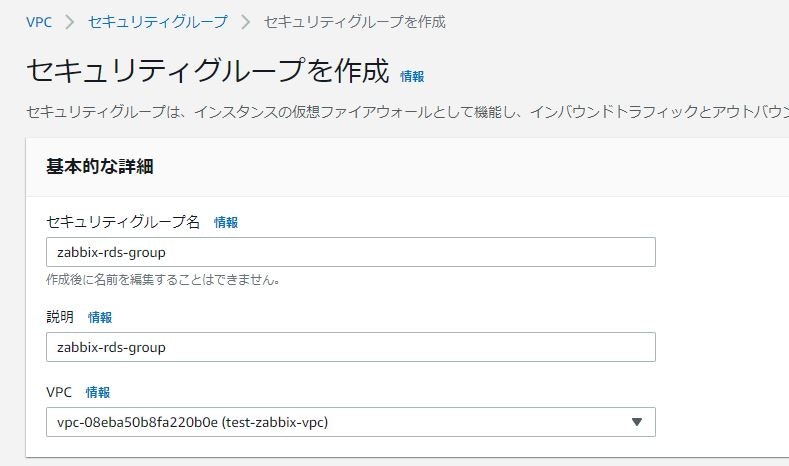
③同じ要領で、下記セキュリティグループも作成
項目 設定値 セキュリティグループ名 zbx-rds-group 説明 zbx-rds-group VPC 「test-zabbix-vpc」を選択 ※こちらも、インバウンド/アウトバウンドはまだ設定しない。
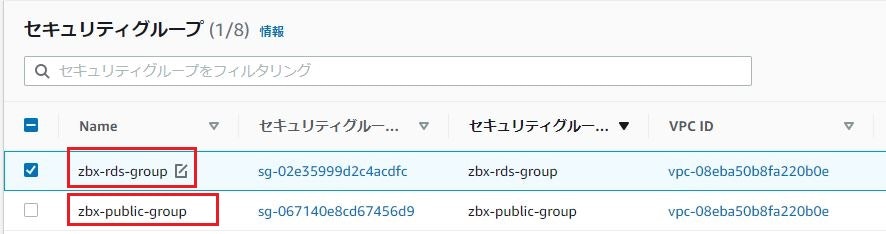
④セキュリティグループ一覧にて、2つのセキュリティグループができていることを確認。
それぞれ、分かりやすいように名前を振っておく。
セキュリティグループの設定
それぞれのセキュリティグループのインバウンドルールを下記のように設定する。
※アウトバウントルールはデフォルトで問題なし。
- zbx-public-group
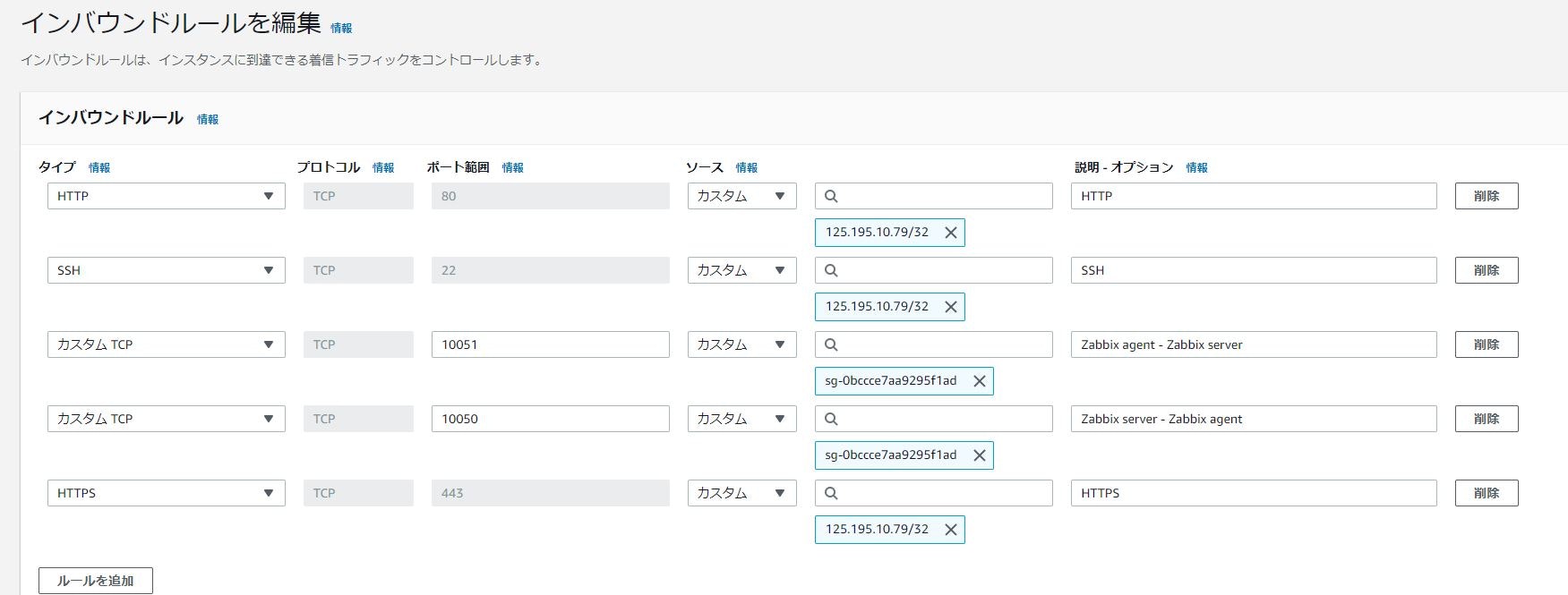
タイプ ポート範囲 ソース 説明 HTTP 80 マイIP HTTP SSH 22 マイIP SSH カスタムTCP 10051 セキュリティグループ(zbx-public-group) Zabbix agent - Zabbix server カスタムTCP 10050 セキュリティグループ(zbx-public-group) Zabbix server - Zabbix agent HTTPS 443 マイIP HTTPS
- zbx-rds-group
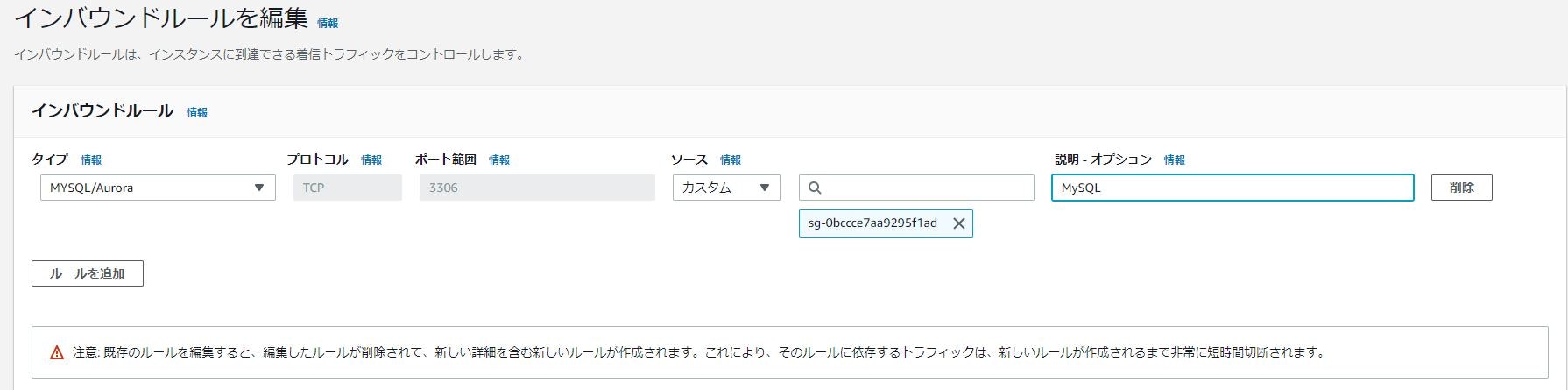
タイプ ポート範囲 ソース 説明 MySQL/Aurora 3306 セキュリティグループ(zbx-public-group) MySQL
5.RDS(MySQL作成)
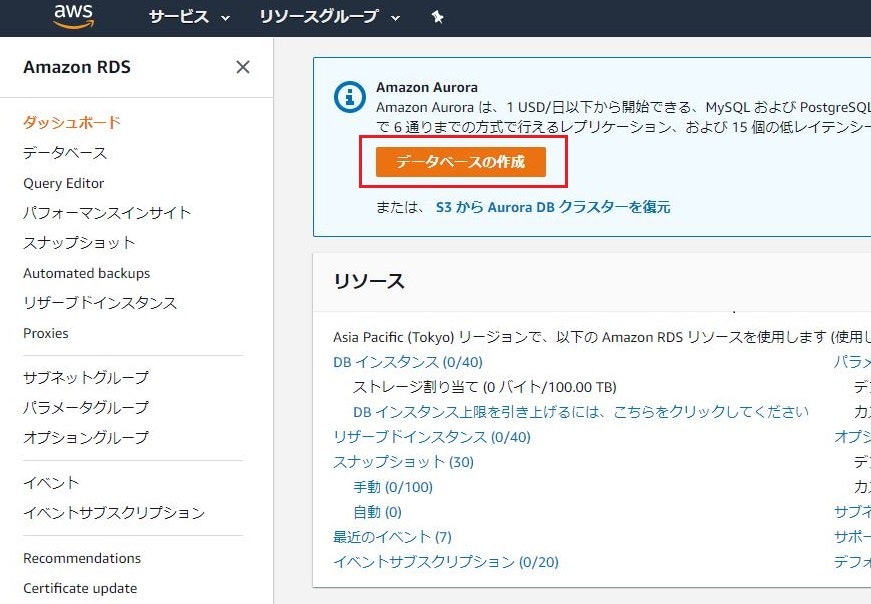
①「Amazon RDS」のダッシュボードを開き、データベースの作成をクリック
※サービスから「RDS」と検索すれば、ヒットします。
②データベース作成画面が表示されるので、下記のように設定を入れる。
※下記にて説明している設定以外はデフォルトのまま
- データベースの作成方法
項目 設定値 データベースの作成方法 標準作成
- エンジンのオプション
項目 設定値 エンジンのタイプ MySQL エディション MySQL Community バージョン MySQL 5.7.26
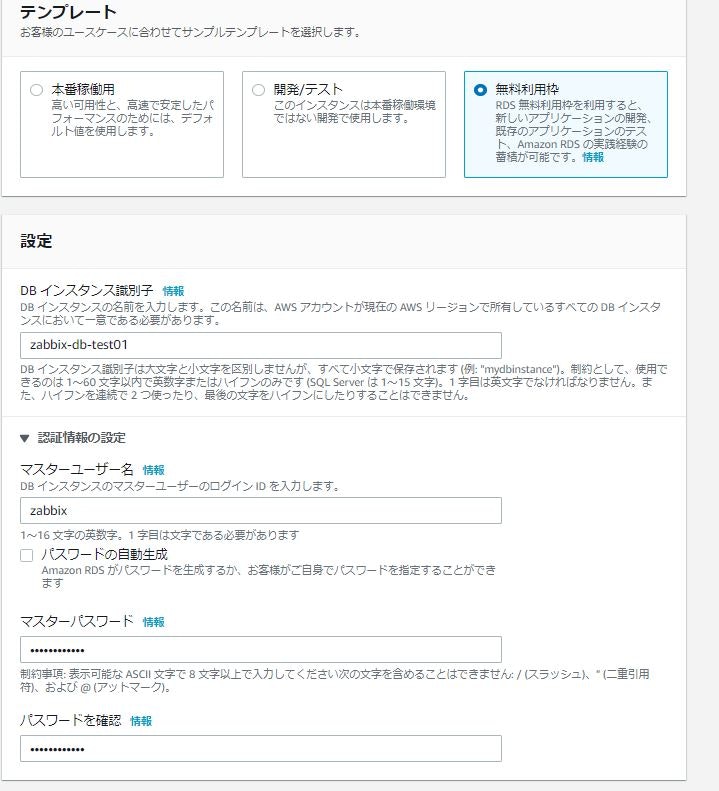
- テンプレート
項目 設定値 テンプレート 無料利用枠
- 設定
項目 設定値 DBインスタンス識別子 zabbix-db-test01 マスターユーザー名 zabbix マスターパスワード 任意のパスワード パスワードを確認 マスターパスワードと同様のパスワード ※DBインスタンス識別子は他の人が同じ名前を設定していた場合は使用不可
- Virtual Private Cloud(VPC)
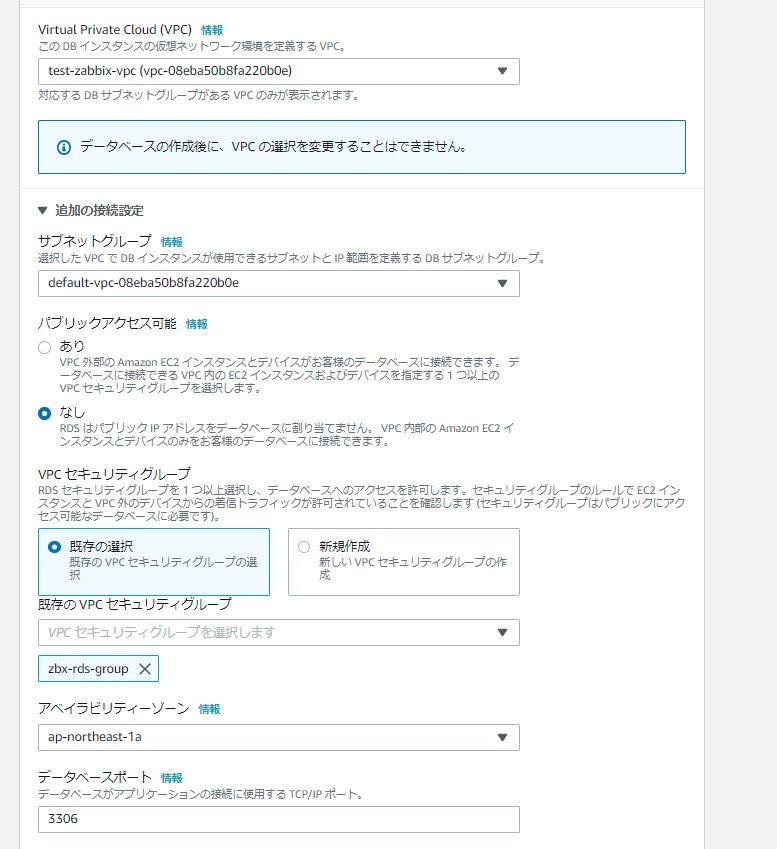
項目 設定値 VPC test-zabbix-vpc ▼追加の接続設定
項目 設定値 サブネットグループ デフォルト設定のまま パブリックアクセス可能 なし VPCセキュリティグループ 既存の設定 既存のセキュリティグループ zbx-rds-group アベイラビリティーゾーン ap-northeast-1a データベースポート 3306
- データベース認証
パスワード認証のままでOK
上記全て設定後、下部のデータベースの作成をクリック
③データベース作成が開始される。
※10分程時間がかかります。
⑦エンドポイントを控える。
DB識別子(zabbix-db-test01)をクリックすると、詳細ページが表示される。
そこに、エンドポイントが記載されているため控えておく。※Zabbix構築に使用します。
⑧データベースの作成が完了したことを確認。
6.EC2インスタンス作成
①EC2ダッシュボードにアクセスし、インスタンスの作成をクリック。
②Amazon Linux 2 AMI(HVM),SSD Volume Typeを選択する。
③t2.largeを選択し、「次のステップ」をクリック。
④「インスタンスの詳細の設定」にて下記を設定
項目 設定値 インスタンス数 1 購入オプション チェックしない ネットワーク test-zabbix-vpc サブネット zabbix-public-subnet 自動割り当てパブリックIP サブネット設定を使用(有効) ※他の設定がデフォルトで問題なし
設定完了後、「次のステップ」をクリック。
⑤「ストレージの追加」は無料枠ギリギリの30GBに変更します。
設定後、「次のステップ」をクリック
⑥タグ設定は下記のように設定し、「次のステップ」をクリック
⑦「セキュリティグループの設定」では、作成したzbx-public-groupを選択し、「確認と作成」をクリック
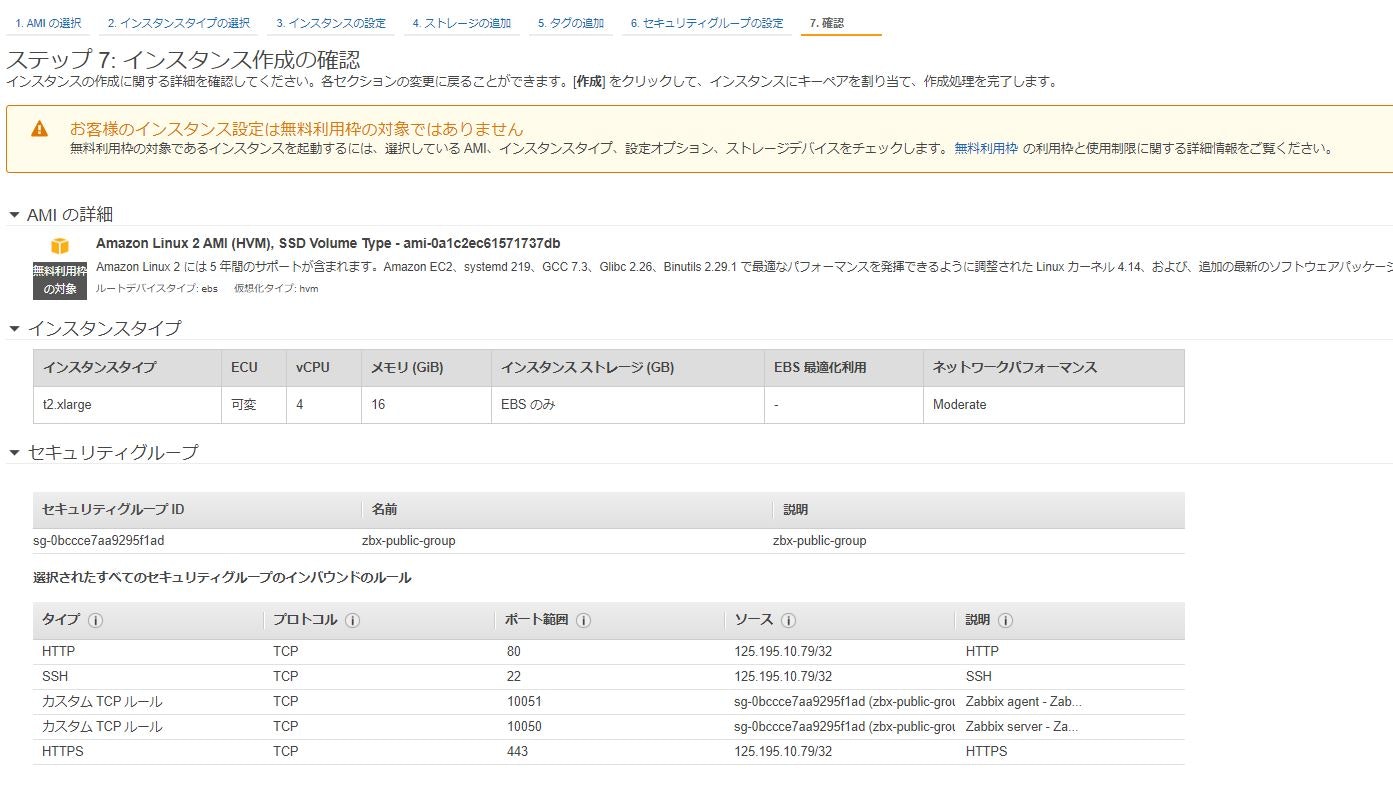
⑧内容を確認し、「起動」をクリック
⑨新しいキーペアをダウンロード。ダウンロード後、「インスタンスの作成」をクリック
インスタンスの作成処理が走る。
※EC2へログインする際に使用します。
⑩インスタンスの作成が完了したことを確認
動作確認
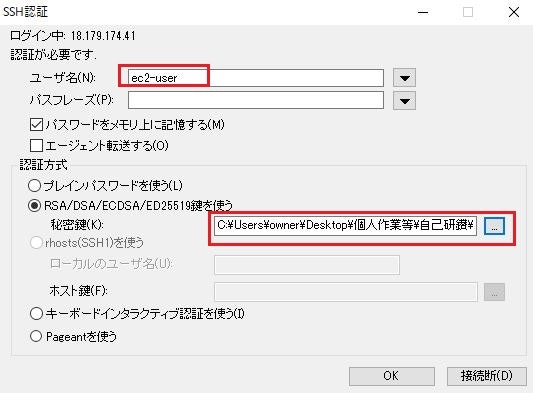
EC2ログイン確認
①ログイン情報入力
ログイン情報
項目 設定値 ユーザー名 ec2-user パスフレーズ 不要 秘密鍵 作成したキー(zabbix.pem)を指定
②下記のようにログインできることを確認。
RDS接続確認
①MySQLクライアントのインストール
sudo yum -y install mysql mysql-devel②RDSへ接続できることを確認
mysql -h RDSのエンドポイント -P 3306 -u ユーザ名 -p
項目 設定値 RDSのエンドポイント 対象RDSのエンドポイント名 ユーザー名 RDS作成時に設定したもの パスワード RDS作成時に設定したもの 実行例
※MySQLにログインできれば問題なし[root@zbxmgr ec2-user]# mysql -h test-zabbix-1.cfwpl4233294.ap-northeast-1.rds.amazonaws.com -P 3306 -u zabbix -p Enter password: ← RDS作成時に設定したパスワードを入力 Welcome to the MariaDB monitor. Commands end with ; or \g. Your MySQL connection id is 28 Server version: 5.7.26-log Source distribution Copyright (c) 2000, 2018, Oracle, MariaDB Corporation Ab and others. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. MySQL [(none)]>③MySQLから抜ける。
quitZabbix構築作業
こちらの記事にまとめてあります。
【AWS】AmazonLinuxにてZabbixマネージャー構築(OS側設定)参考











- 投稿日:2020-06-27T14:29:16+09:00
【AWS】サーバレスで Hello, World! を実行するまでのチュートリアル
通常、プログラムのコードを実行するためには Linux などのサーバを立てて、初期設定して、実行環境をインストールして・・・と手間が多いです。
しかし、AWSには Lambda という、上のようなサーバ側の準備を意識することなくコードを実行でいるサービスがあります。このチュートリアルでは、サーバレス≒サーバの構築なしでコードを実行し、 "Hello, Wolrd!" を返すまでの手順を学びます。
Lambdaコンソールを起動
AWSマネジメントコンソールにアクセスし、AWSアカウントでまずはログインします。
ログインできたら「サービス」をクリックし、検索ボックスに「Lambda」と入力します。
これでLambdaコンソールへアクセスできます。
Lambda関数を作成する
関数の作成を選択します。
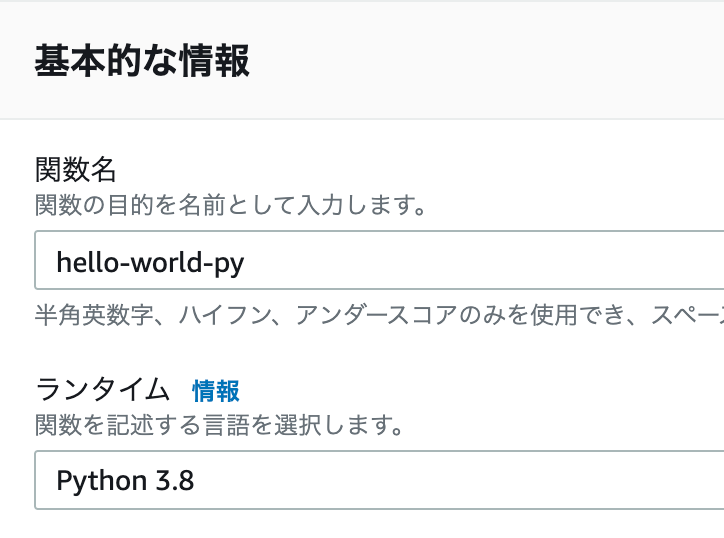
関数名はなんでもよいですが、今回はpythonでLambda関数を作るのでわかりやすくhello-world-pyと入力しましょう。
また、ランタイムは「Python 3.8」を選択します。
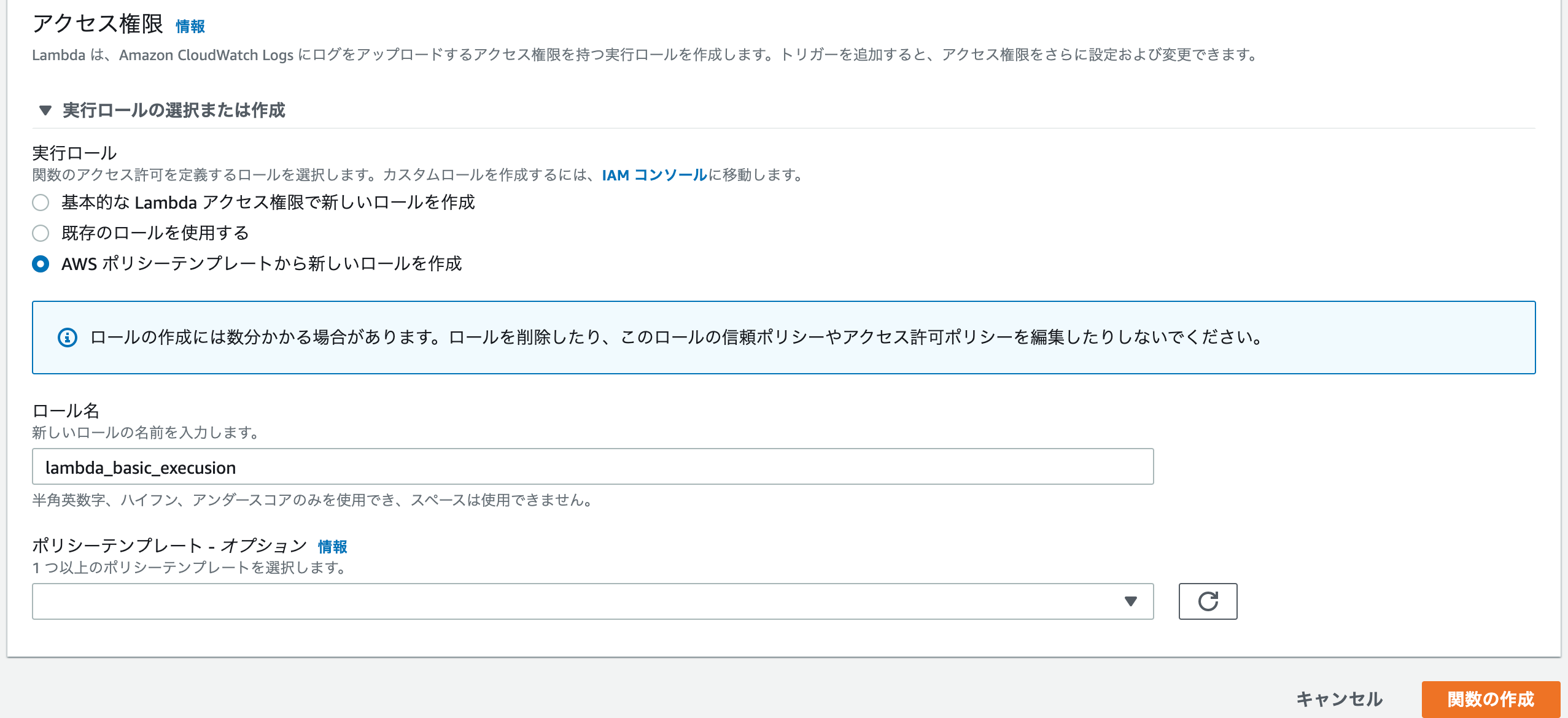
次に、この関数を実行するためのロールを作成していきます。
実行ロールの選択または作成を選択して展開したら、実行ロールではAWS ポリシーテンプレートから新しいロールを作成を選択します。
ロール名にはlambda_basic_execusionと入力します。
ポリシーテンプレートはオプションなので今回は使わず、このまま関数の作成を選択します。
少し待つと作成が完了し、このような画面に遷移するはずです。
作成したLambda関数をテストする
先ほどの画面の右上のテストイベントの選択欄をクリックし、プルダウンで表示されるテストイベントの設定を選択します。
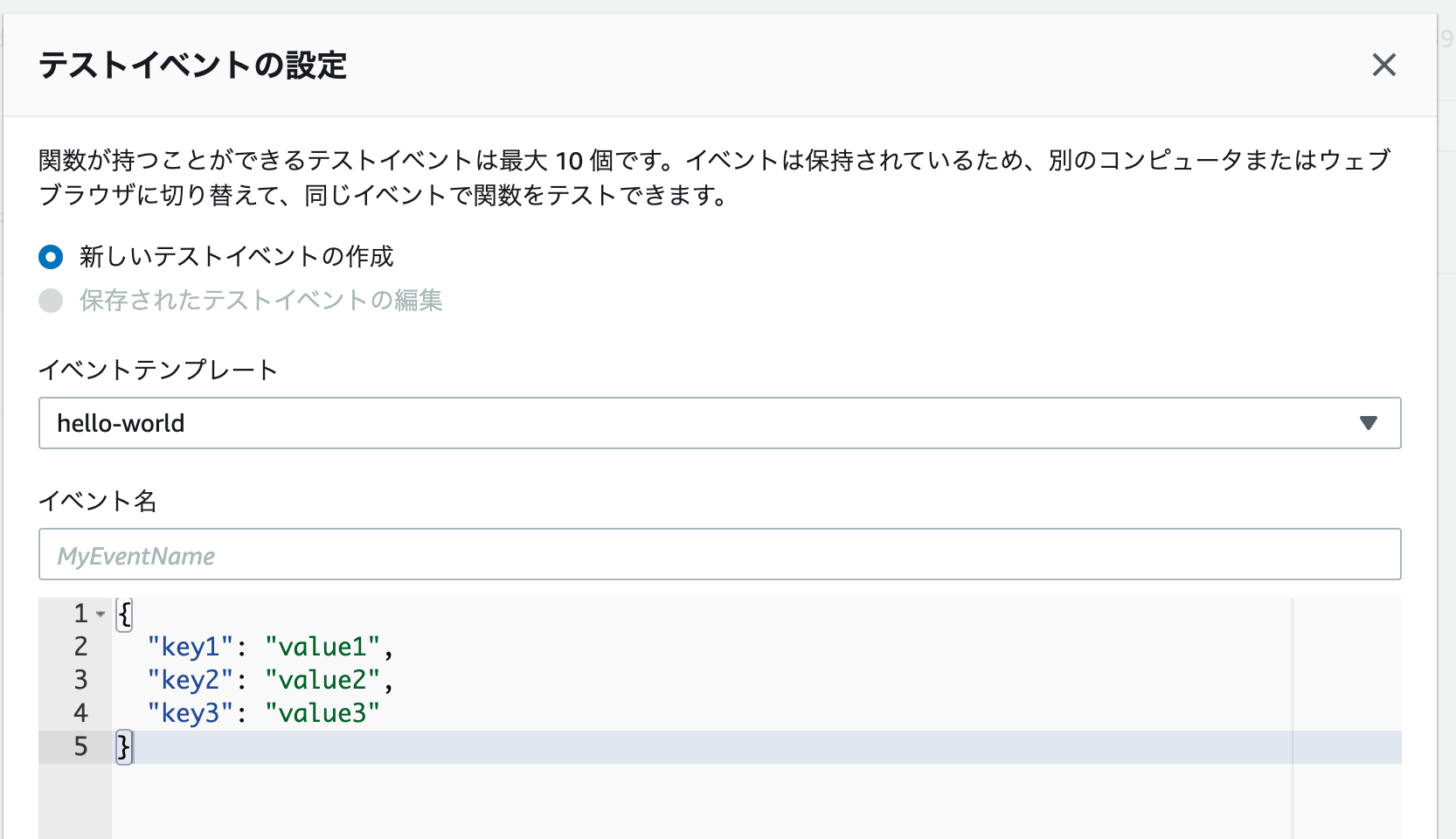
選択すると、デフォルトではこのような画面が表示されるはずです。
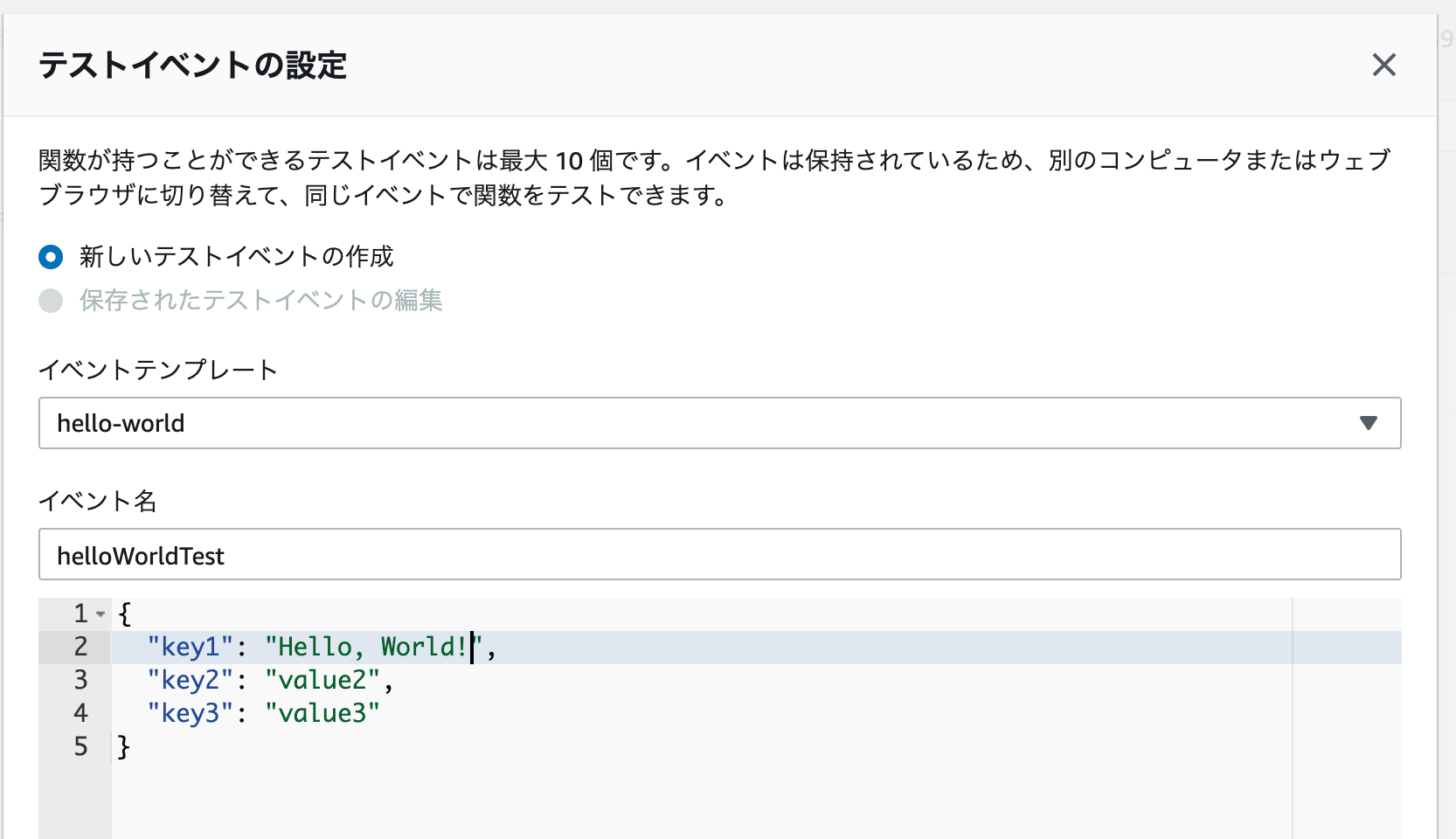
イベント名には helloWorldTest と入力し、またコード内の value1 を Hello, World!
に変更します。
入力できたら、右下の作成を選択します。
いよいよ、作成した helloWorldTest を実行します。
右上のテストをクリックしてみましょう。
成功すると、実行結果は成功となるはずです。
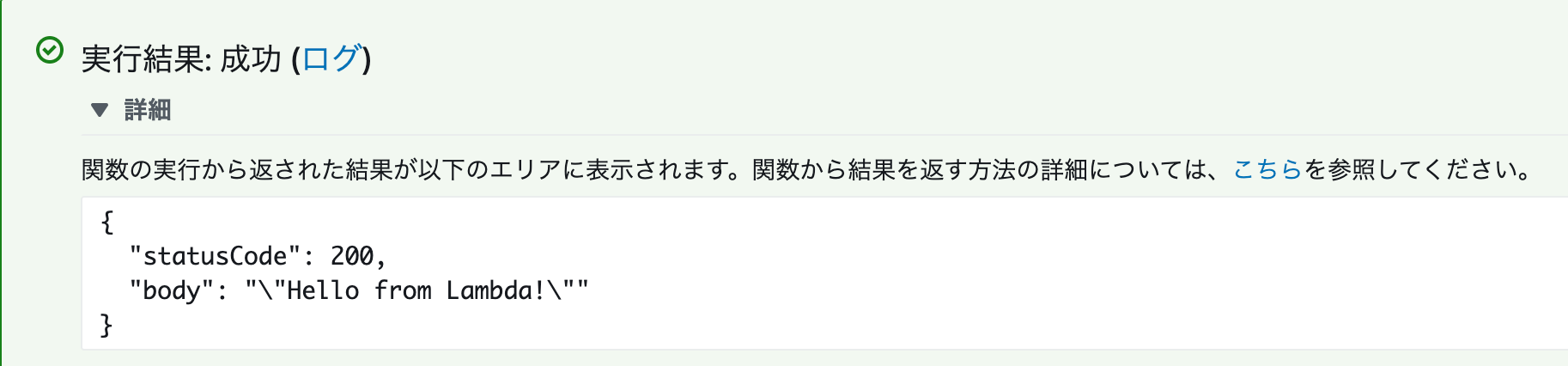
テスト結果の確認
前の画面で 詳細 をクリックすると、テスト結果の詳細を確認できます。
ここでは、JSON形式でvalueの一つとしてHello,World!と送信した結果に対する応答がステータスコード200と共に返ってきているのがわかります。
今回実行されたコード自体はLambdaコンソール内の下の方にあり、今回はhelloWorld用のテンプレートを使用しています。



- 投稿日:2020-06-27T14:24:21+09:00
DjangoをLambdaを使ってサーバレスにデプロイする
DjangoをAWS Lambdaにデプロイできました。Serverless Frameworkを使うと簡単です。
URLとレポジトリはこちらです。
https://django-sls-helloworld.umihi.co/
https://github.com/umihico/django-sls-helloworldslsのデフォルトプロジェクトを作成し、f1a13ba
動作確認したらカスタムドメインをプラグインをインストールします。0970afe
API GatewayはURL末端につくstage名を外せず、djangoのルーティングと相性が悪いようで、カスタムドメインを先に整えました。$ serverless create --template aws-python3 --path django-sls-helloworld # プロジェクト作成 $ cd django-sls-helloworld $ serverless deploy # 一度デプロイ $ serverless invoke -f hello # 正常に動くかテスト { "statusCode": 200, "body": "{\"message\": \"Go Serverless v1.0! Your function executed successfully!\", \"input\": {}}" } $ sls plugin install -n serverless-domain-manager # ドメイン設定のためのプラグインインストールserverless.ymlを編集します。603753b
serverless.yml+ custom: + customDomain: + domainName: django-sls-helloworld.umihi.co + certificateName: umihi.co + basePath: '' + stage: ${opt:stage, self:provider.stage} + createRoute53Record: true + endpointType: 'edge' + securityPolicy: tls_1_2 provider: name: aws runtime: python3.8$ sls create_domain # 最大40分かかると言われるが、次のデプロイコマンドはすぐにできる。ただドメイン適用に時間がかかるだけ。 $ sls deployこれで、カスタムドメイン設定されたWEBページが完成しました。次にDjangoに必要なライブラリをインストールします。80e8f1b
$ sls plugin install -n serverless-python-requirements以下のファイルを追加し、不要ですがインポートされてるかテストのため、handler.pyも編集しました。ec47570
requirements.pyimport os import sys requirements = os.path.join( os.path.split(__file__)[0], '.requirements', ) if requirements not in sys.path: sys.path.append(requirements)requirements.txtDjango Werkzeug PyMySQLhandler.pyimport json + import requirements def hello(event, context): + # testing import libraries + import django + import werkzeug + import pymysql body = { "message": "Go Serverless v1.0! Your function executed successfully!",デプロイし、
serverless invoke -f helloが正常であれば、importは成功です。
次に、Djangoのプロジェクトを作成します。930a0c2
そして、サーバレスライブラリ用のWSGIプラグインをインストールします。52386e4$ django-admin startproject django_sls_helloworld . $ sls plugin install -n serverless-wsgi最後に、
MySQLdbの代わりにPyMySQLをインストールする修正と、その際に指摘されるバージョン違いを修正し、30361dd
ALLOWED_HOSTに設定したドメインを名を加え、1966857
LambdaがWSGIを参照するように振り分けます。1dce3d3django_sls_helloworld/settings.pyimport os + import pymysql + + pymysql.version_info = (1, 4, 2, "final", 0) + pymysql.install_as_MySQLdb() # Build paths inside the project like this: os.path.join(BASE_DIR, ...) 省略 DATABASES = { 'default': { - 'ENGINE': 'django.db.backends.sqlite3', - 'NAME': os.path.join(BASE_DIR, 'db.sqlite3'), + 'ENGINE': 'django.db.backends.mysql', + 'NAME': 'djangodemo', } } 省略 - ALLOWED_HOSTS = [] + ALLOWED_HOSTS = ["django-sls-helloworld.umihi.co"]serveless.ymlendpointType: 'edge' securityPolicy: tls_1_2 + wsgi: + app: django_sls_helloworld.wsgi.application + packRequirements: false 省略 functions: hello: - handler: handler.hello + handler: wsgi_handler.handler # The following are a few example events you can configureデプロイしてお馴染みの画面がカスタムドメイン先でも現れました。以上です。
ちなみに使い捨てプロジェクトなので、DEBUG=Trueでデプロイし、かつSECRET_KEYもGithubにあげてますが、実運用ではタブーなのでご注意ください。
- 投稿日:2020-06-27T14:24:02+09:00
[Terraform]AWS事始め
概要
TerraformでAWSリソースを扱い始めるためのチュートリアルのような内容を記載します。
ハンズオンライクに、terraformコマンドでEC2インスタンスを生成できることを本記事でのゴールとします。前提
- MacOSである
- Homebrewを導入している
- AWSアカウントを保持している
手順
1. セットアップ
1.1. AWS IAMユーザー払い出し
terraformコマンドで、AWSとのやりとりを行うためのユーザーを作成します。※以下の画面キャプチャは執筆時点のものです。今後変更される可能性がある点について承知おきください。
AWSマネジメントコンソールにログインし、IAMへ移動->「ユーザーを追加」をクリックします。
ユーザー名には任意の名称、アクセスの種類は「プログラムによるアクセス」にチェックを入れます。
権限には
Administrator Accessを設定します。
※本来この権限を設定すべきではありません。しかし今回は検証用IAMユーザーであることと、適切な権限を割り振ることにコストを割く必要がないように最も強い権限を付与することとします。
必要があれば次ページでタグを設定し、「ユーザーの作成」をクリックします。
作成後の以下の画面での「アクセスキーID」「シークレットアクセスキー」を控えます。(認証情報)
1.2. ローカル実行環境の設定
ローカルPCで
terraformコマンドを実行できる環境のセットアップを行います。terraformのインストール
terraformのバージョンマネージャーであるtfenvを用いることにします。tfenv
homebrewでインストールを行います。
$ brew install tfenvterraform
続いて、
terraformをインストールします。おおまかには以下の手順となります。
list-remoteコマンドでインストール可能なバージョンを取得installコマンドで上記のうち、任意のバージョンを指定してインストールuseコマンドで使用バージョンを設定下記に、本記事執筆時点での最新バージョン
0.12.26を利用する例を示します。Terminal# インストール可能バージョンの取得 $ tfenv list-remote 0.13.0-beta2 0.13.0-beta1 0.12.26 0.12.25 # 以下略 # 0.12.26バージョンでインストール実行 $ tfenv install 0.12.26 Installing Terraform v0.12.26 Downloading release tarball from https://releases.hashicorp.com/terraform/0.12.26/terraform_0.12.26_darwin_amd64.zip ########################################################################################################################################################################### 100.0% Downloading SHA hash file from https://releases.hashicorp.com/terraform/0.12.26/terraform_0.12.26_SHA256SUMS No keybase install found, skipping OpenPGP signature verification Archive: tfenv_download.aEAgae/terraform_0.12.26_darwin_amd64.zip inflating: /usr/local/Cellar/tfenv/2.0.0/versions/0.12.26/terraform Installation of terraform v0.12.26 successful. To make this your default version, run 'tfenv use 0.12.26' # 0.12.26バージョンの使用を明示 $ tfenv use 0.12.26 # terraformバージョン確認 $ terraform version Terraform v0.12.26 # c.f. インストール済バージョンを確認 $ tfenv list * 0.12.26 (set by /Users/mintak/infra-workspace/terraform/.terraform-version) 0.12.25これでインストールは完了ですが、コマンド入力コストを低減するために自動補完を有効にしておきましょう。
(実際には.bashrc.zshrcにcompleteコマンドが追記されます。)Terminal$ terraform -install-autocompleteaws認証情報設定
terraformでAWSへアクセスするための認証情報を設定します。
認証情報の設定方法はいくつかありますが、ここでは名前付きプロファイルにて設定を行うこととします。aws-cliインストール
これがなくてもプロファイルは作成できるのですが、コンソールからAWSアクセスを行うこともあると思うので、このタイミングでインストールを実施しておくのがよいでしょう。
Terminal$ brew install awscli1.1 で作成したIAMユーザーの認証情報を名前付きプロファイルとして設定します。
Terminal$ aws configure --profile YOUR_PROFILE_NAME AWS Access Key ID[None]: 1.1のアクセスキーID AWS Secret Access Key[None]: 1.1のシークレットアクセスキー Default region name[None]: ap-northeast-1 Default output format[None]: json # アクセス確認 $ aws sts get-caller-identity --profile YOUR_PROFILE_NAME # 結果が返ってくればOKコマンドの都度
--profile YOUR_PROFILE_NAMEを打つのは面倒なので、今回作成したプロファイルを自動的に使用するように環境変数AWS_PROFILEを設定しておくと良いでしょう。.bashrcexport AWS_PROFILE=YOUR_PROFILE_NAMEgit-secrets
認証情報がGitコミット時に不用意に公開されないようにするため、念の為いれておくとカタイです。
キーやパスワードといったものをGitコミットしようとしたときに警告を発してくれます。Terminal$ brew install git-secrets $ git secrets --register-aws --global $ git secrets --install ~/.git-templates/git-secrets $ git config --global init.templatedir '~/.git-templates/git-secrets'2. 実行ファイルの作成
AWS上にEC2インスタンス(
t2.micro)を1つ作成するためのコードを記述していきます。
- フォルダ構成
directory |- main.tf 実行対象 |- providers.tf プロバイダ設定 |- variables.tf 変数設定
- 各ファイル
providers.tfterraform { required_version = ">=0.12" } provider aws { region = "ap-northeast-1" profile = "YOUR_PROFILE_NAME" # 1.2で作成したプロファイルの名称を設定、名前付きプロファイルから認証情報を読み込む }main.tfresource aws_instance tutorial { ami = "ami-063f4c001c8a7c154" # 直接指定しているがもっといい設定方法はある instance_type = var.aws_instance_type # tfvarsで指定した値 or variables.tfで設定したdefaultが設定される tags = { Name = var.aws_instance_tag_name } }variables.tfvariable aws_instance_type { type = string description = "AWSインスタンス種別" default = "t2.micro" } variable aws_instance_tag_name { type = string description = "AWSインスタンスタグ:Name" default = "terraform-tutorial" }3. リソース作成 / 削除
3.1. plan
いきなり作成コマンドを実行するのはやはり気が引けるので、実行したときの結果のだいたいの予測ができるコマンドがあります。それが
planコマンドです。まずはこれで変更内容を把握しましょう。
エラーとなる場合は、エラー内容が表示されます。
下記の例のように、「applyして、どうぞ」となっていれば実行できる状態です。
※ただし、planが成功したといってapplyが成功するとは限りません。Terminal$ terraform plan ------------------------------------------------------------------------ An execution plan has been generated and is shown below. Resource actions are indicated with the following symbols: + create Terraform will perform the following actions: # aws_instance.tutorial will be created + resource "aws_instance" "tutorial" { + ami = "ami-0a1c2ec61571737db" + arn = (known after apply) + associate_public_ip_address = (known after apply) + availability_zone = (known after apply) + cpu_core_count = (known after apply) + cpu_threads_per_core = (known after apply) + get_password_data = false + host_id = (known after apply) + id = (known after apply) + instance_state = (known after apply) + instance_type = "t2.micro" + ipv6_address_count = (known after apply) + ipv6_addresses = (known after apply) + key_name = (known after apply) + network_interface_id = (known after apply) + outpost_arn = (known after apply) + password_data = (known after apply) + placement_group = (known after apply) + primary_network_interface_id = (known after apply) + private_dns = (known after apply) + private_ip = (known after apply) + public_dns = (known after apply) + public_ip = (known after apply) + security_groups = (known after apply) + source_dest_check = true + subnet_id = (known after apply) + tags = { + "Name" = "terraform-tutorial" } + tenancy = (known after apply) + volume_tags = (known after apply) + vpc_security_group_ids = (known after apply) # 中略 } Plan: 1 to add, 0 to change, 0 to destroy. ------------------------------------------------------------------------ Note: You didn't specify an "-out" parameter to save this plan, so Terraform can't guarantee that exactly these actions will be performed if "terraform apply" is subsequently run.3.2. apply
3.1. planが成功したら、いよいよ
applyコマンドでリソースを作成してみましょう。
planと同様の変更内容がコンソールに表示された後、Do you want to perform these actions?と尋ねられるため、問題なければ「yes」と入力することでリソース作成が開始されます。Terminal$ terraform apply # 中略 Plan: 1 to add, 0 to change, 0 to destroy. Do you want to perform these actions? Terraform will perform the actions described above. Only 'yes' will be accepted to approve. Enter a value: yes aws_instance.tutorial: Creating... aws_instance.tutorial: Still creating...[10s elapsed] aws_instance.tutorial: Still creating...[20s elapsed] aws_instance.tutorial: Still creating...[30s elapsed] aws_instance.tutorial: Creation complete after 34s[id=i-0f6cd3a49eb01d903] Apply complete! Resources: 1 added, 0 changed, 0 destroyed.実際にマネジメントコンソールを見てみると、新しくインスタンスが生成されていることがわかります。
3.3. destroy
本来はこのままでよいのですが、個人アカウントでクラウドリソースを作ったままにしておくと、知らないうちに課金が発生してしまうため、実際の作成が確認できたらリソース削除を行いましょう。
destroyコマンドを使用します。
※今回使用したt2.microはアカウント作成から1年間無料枠の対象なので、この対象となっている方はそこまで目くじら立てる必要はないかもしれません。Terminal$ terraform destroy # 中略 Plan: 0 to add, 0 to change, 1 to destroy. aws_instance.tutorial: Destroying... [id=i-0f6cd3a49eb01d903] aws_instance.tutorial: Still destroying... [id=i-0f6cd3a49eb01d903, 10s elapsed] aws_instance.tutorial: Still destroying... [id=i-0f6cd3a49eb01d903, 20s elapsed] aws_instance.tutorial: Still destroying... [id=i-0f6cd3a49eb01d903, 30s elapsed] aws_instance.tutorial: Destruction complete after 30s Destroy complete! Resources: 1 destroyed.EC2では
terminatedステータスになったのち、一定時間たつとコンソールからも見えない状態となります。
これでひとまず、EC2インスタンスの作成および削除を行うことができました。
その他のリソースを作成するには2の実行ファイルの内容を都度変更していく必要がありますが、3の実行に関しては流れは同じです。References



- 投稿日:2020-06-27T11:36:19+09:00
Kops環境(EC2)でbastionのSSHポート番号を後から変更した
はじめに
勉強用の検証環境で、Kopsでクラスターをセットアップした後に、(kopsコマンド実行時に作成された)bastionのSSHポート番号を変更しようとしたところ、少しはまってしまいました。対応した内容をメモで残します。(検証したのは今年の3月ごろ。)
あくまで個人の作業メモです。ご自分てプロジェクト等の環境で対応される場合には、公式のドキュメント等も確認の上、事前に検証して手順を確立してから対応されることをおすすめします。状況
何も考えずに対応してSSHがつながらなくなり、困惑した経緯。(恥をさらすところではありますが、、)
- kopsでクラスターを作成後、bastionのポート番号を変更したいから変えなくちゃ!、とPC(Win)のTeratermを起動
- 2つTerminalを起動し、/etc/ssh/sshd_config を書き換え、sudo sshd -tとsudo service sshd restart を実行
- Teminalが2つとも落ちる!(当然だ!)
状況把握のログ
- 端末から、ELBのポート接続を確認すると、変更前のポートでは接続でき、変更後のポートでは接続できないことを確認(
telnet://<ELB-URL>:<port-number>)- ELBのポート構成に新しいポート番号を追加するが、新しいポートでは接続できない状態
- AWS管理コンソールからロードバランサーの状況をみると、ELBからbastionが見えない状態になっていた
- bastionのEC2は起動している
- ロードバランサーのヘルスチェックのポート変更が必要(pingプロトコル、pingポート)
- ELBからbastionを見るとin serviceになった -ロードバランサーへのインバウンドのセキュリティーグループのポート番号を追加
- しかし、端末から、ELBのポート接続を確認すると、まだNG(以前のポートでは接続可能)
- bastion側のインバウンドのセキュリティーグループのポート番号も追加
- つながった!!(旧ポート番号をセキュリティーグループのインバウンド指定から削除)
変更が必要な個所のまとめ
後から変更する場合には以下の編集が必要
- ロードバランサーのリスナーの編集
- ロードバランサーのヘルスチェックのポートの編集
- ロードバランサーへのインバウンドのセキュリティーグループの編集
- bastion側のインバウンドのセキュリティーグループの編集以上。
- 投稿日:2020-06-27T10:39:12+09:00
(自分用)AWS_2(リモートアクセス/Apacheをインストール/ファイルを互いに送受信)
項目
- 仮想マシンにリモートアクセスをする
- HTTPサーバーのApacheをインストールし、ページを公開
- ローカルと仮想マシン双方で、ファイルを転送し合う
1.仮想マシンへリモートアクセスする
ターミナル# ".ssh"と言うフォルダがあるかを確認する $ ls -a -l # 無ければ`mkdir .ssh`で作成 # 前回のダウンロードしたキーを".ssh"の中に移動 $ mv ~/Desktop/FirstKey.pem ~/.ssh # 仮想マシンとの関連付けみたいな事をしてる、多分 $ chmod 400 ~/.ssh/FirstKey.pem # 仮想マシンへリモートアクセスしている、()は要らないの忘れずに # 最初だけ何か聞かれるので、yesと答える $ ssh -i ~/.ssh/FirstKey.pem ec2-user@(前回設定したパブリックIPアドレス) # 仮想マシン内は"$$ ~~"で表現、これで仮想マシンのアクセスからログアウト $$ exit
- 取り敢えず上からやっていけば大丈夫なはず
2.HTTPサーバーのApacheをインストールし、ページを公開
ターミナル# 取り敢えずログイン $ ssh -i ~/.ssh/FirstKey.pem ec2-user@(パブリックIP) # まず仮想マシンを最新版に $$ sudo yum -y update # sudoコマンドでApacheをインストール $$ sudo yum -y install httpd # Apacheを作動 $$ sudo service httpd start # 動くようにする $$ sudo chkconfig httpd on # /var/www/htmlの中身を確認、Apacheはここにhtmlコンテンツがあると動く $$ ls /var/www/html # sudoコマンドでviを起動し、前述の中に作られた"index.html"に何か書くよと言う事 $$ sudo vi /var/www/html/index.htmlindex.html<!-- まずは"i"か"A"を選択して記述モードを起動 --> <h1> Hello World </h1> <!-- "esc"を押した後、":wq"を入力してEnter、これは保存して終了ってこと --!>
- この後に
http://(パブリックIP)にアクセスし、Hello World出来てれば完了3.ローカル環境と仮想環境の双方でファイルを転送し合う
ターミナル# scpコマンドでファイルを転送する、先に転送側と何を転送するか、後ろに何処へを記載 $ scp -i ~/.ssh/FirstKey.pem ec2-user@(パブリックIP):/var/www/html/index.html ~/Desktop # これでデスクトップに"index.html"が来ているはず # 前述の様に先に転送側や何を、後ろに何処へ $ scp -i ~/.ssh/FirstKey.pem ~/Desktop/index.html ec2-user@(パブリックIP): #仮想マシンに接続 $ ssh -i ~/.ssh/FirstKey.pem ec2-user@(パブリックIP) # lsで受信確認後、"/var/www/html"に移しておく $$ ls $$ sudo mv ~/index.html /var/www/html #この後一応パブリックIPにアクセスしてブラウザで動くか確認してみる # 一々mvするのも面倒くさいので、勝手に行くようにする(ここからはほぼ呪文) $$ sudo groupadd www $$ sudo usermod -a -G www ec2-user # 実行後"ec2 user wheel www"と表示されればOK $$ groups $$ sudo chown -R root:www /var/www $$ sudo chmod 2775 /var/www $$ find /var/www -type d -exec sudo chmod 2775 {} \; $$ find /var/www -type f -exec sudo chmod 0664 {} \; $$ exit # ここまでで終了 # scpコマンドを使うタイミングで、どのディレクトリへ移動するか迄指定している。差異は前述のリモートへ転送と比較すべし $ scp -i ~/.ssh/FirstKey.pem ~/Desktop/index.html ec2-user@(パブリックIP):/var/www/html4.終わりに
- 何となく筋道というか光が見えて来たのでは?
- ApacheをFlaskで使うのはどうやるんだろう
追記
- 急を要す場合は取り敢えず
/var/www/html内にディレクトリ作ってPythonやらFlaskやらを入れれば良いってところだけ- phpMyAdminも調べれば出てくるから同じ所で良い感じにぽい
- 投稿日:2020-06-27T09:45:49+09:00
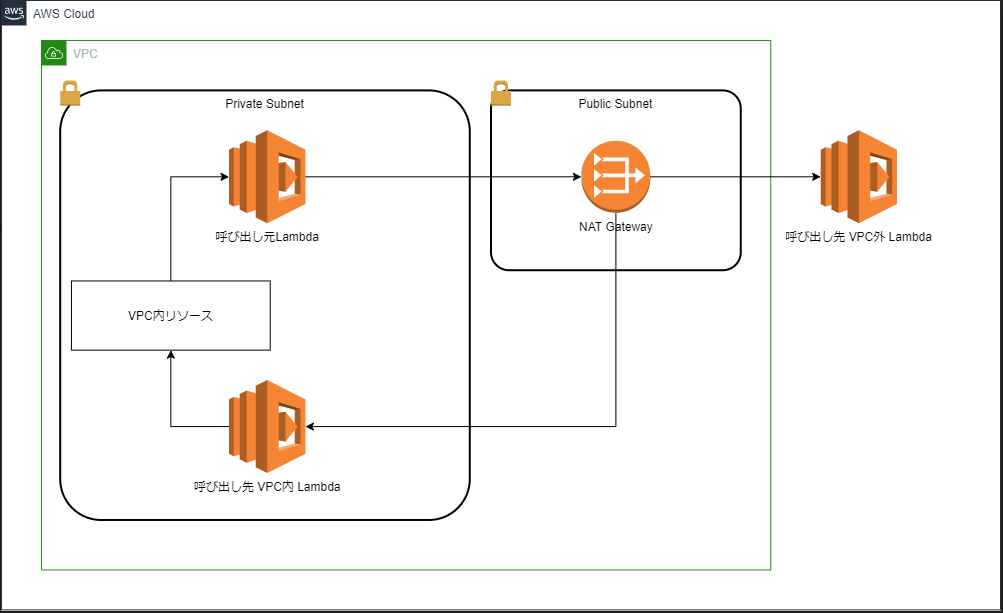
【AWS】VPC内のLambdaから別のLambdaを呼び出す
ちょっと前にやったことなので記憶があいまいですが、
今後もやる可能性のある事なので備忘録として残しておこうと思います。VPC内で実行するLambda
AWSのEC2やRDSなどのVPC内のリソースにLambdaでアクセスする場合、
LambdaにVPC設定をすることで可能になります↓【AWS】LambdaをVPC内で実行し、EC2のMySQLにアクセスする
https://www.geekfeed.co.jp/geekblog/lambda_vpcしかし一方で、VPCにpublicなサブネットを設定していない場合、VPC内Lambdaからは外部のネットワークに接続することができなくなります。
つまり以下のアクセスが不可能となります。
- VPC内Lambda→VPC内Lambda
- VPC内Lambda→VPC外Lambda
- VPC内Lambda→VPC外リソース(PrivateLinkがサポートされているもの以外)
例えば、VPC内リソースからデータ取得後、そのデータを別リソースに保存したりする場合などに
データ取得Lambda→データ保存Lambdaというように連携することがあると思いますが、
LambdaからLambdaを呼び出す場合もネットワーク経由で行うため、これができなくなってしまいます。
※Lambdaを呼び出そうとしたときにTimeoutになります。今回はこれを解決し、VPC内Lambdaから外部リソースへのアクセスができるように設定したいと思います。
方針
PrivateLinkによる外部サービスアクセス
まず、冒頭に書いた「3. VPC内Lambda→VPC外リソース」ですが、
AWSのサービスでPrivateLinkがサポートされている場合、Publicサブネットの設定などの面倒な設定はせずに
VPC内Lambdaから外部サービスへのアクセスが可能です。例えば、EC2, CloudWatch, SNSなどの多くのサービスがPrivateLinkにサポートされています。
PrivateLinkがサポートしているサービスはこちらを参照が、Lambdaは無いです。
そこで、Lambdaやその他の外部リソースにアクセスできるようにするため、
VPCそのものに設定を加えていきたいと思います。構成
VPCにNAT Gatewayを持つPublicサブネットを作成し、PrivateサブネットからそのNAT Gateway経由でアクセスします。
Publicサブネット+NAT Gatewayの設定
VPCを作成した時点でPrivateサブネットは作成されているはずですので、
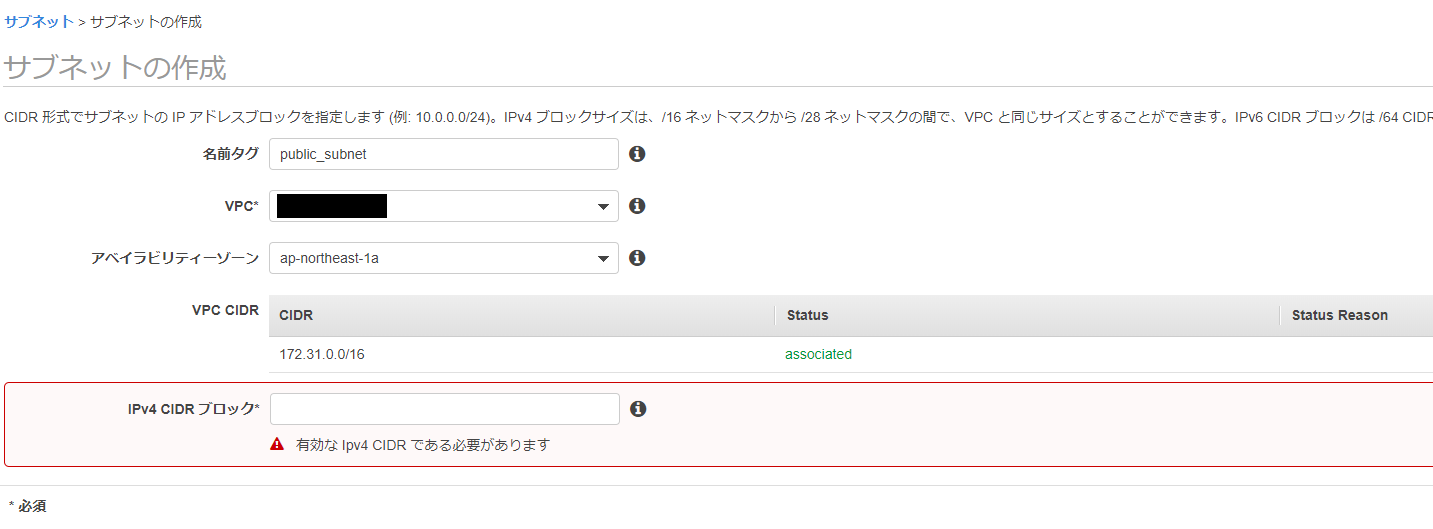
Publicサブネットの作成からしていきたいと思います。①Publicサブネットの作成
普通にサブネットを作成します。わかりやすいようにNameタグを設定しておきます。
AZの指定ですが、すでにVPC Lambdaで設定しているPrivateサブネットが存在するAZを指定しておきます。
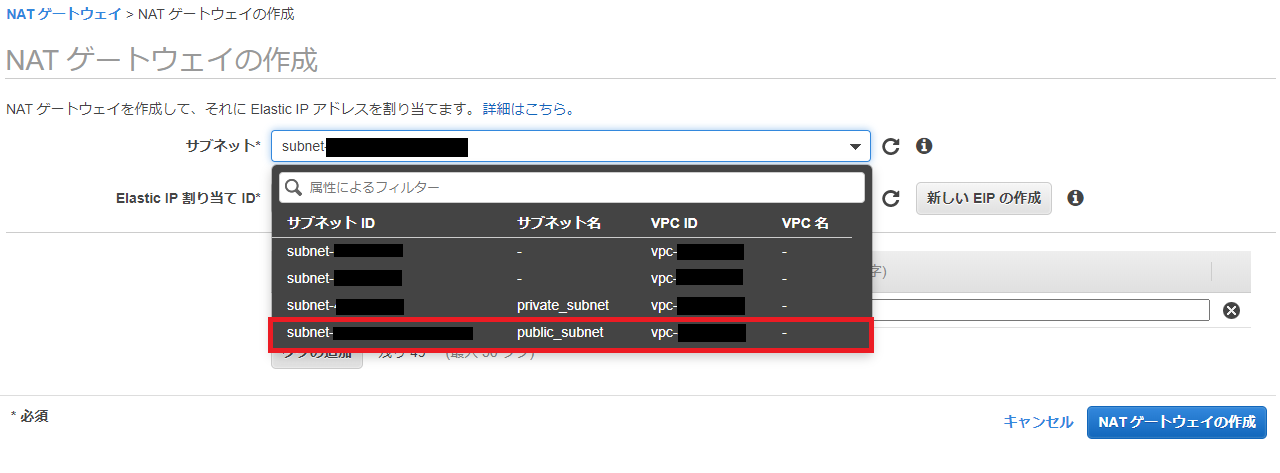
②NAT Gatewayの作成
NAT Gatewayを作成します。
①で作成したPublicサブネットを指定します。
③ルートテーブルの設定
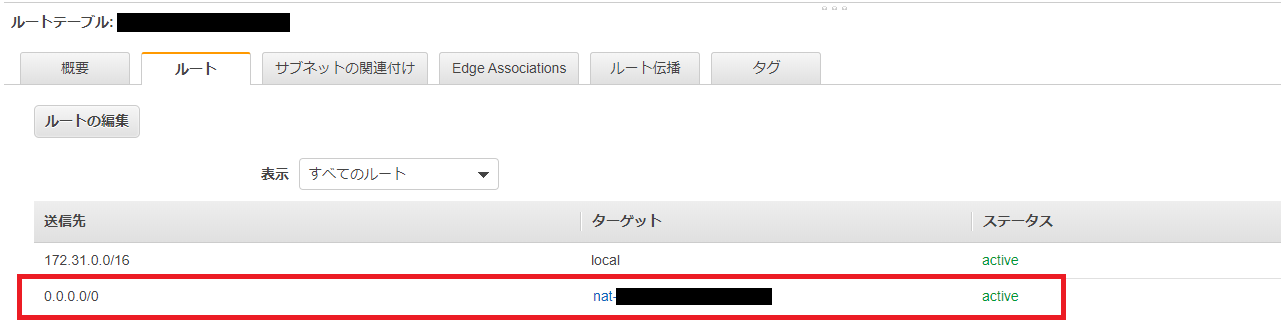
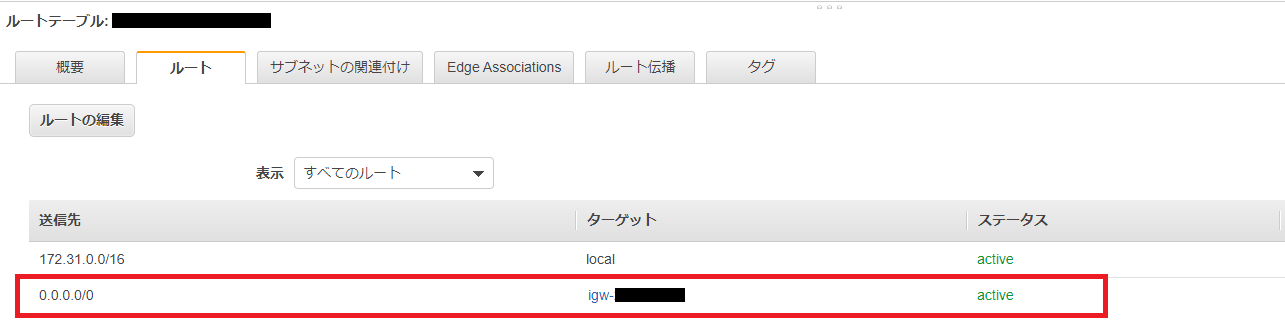
さてここまでprivate, publicと言ってきましたが、
AWSの参考記事にも書かれている通り、注: サブネットがプライベートであるかパブリックであるかは、そのルートテーブルにより決まります。パブリックサブネットにはインターネットゲートウェイを指すルートがあり、プライベートサブネットにはありません。
です。
つまり以下の手順によって
NAT Gatewayを設定したサブネットがPrivateサブネットになり、
Internet Gatewayを設定したサブネットがPublicサブネットになります。Privateサブネットを関連付けたルートテーブルの作成
デフォルトで作成されているルートテーブルがあると思いますが、新規に作成しています。
NAT Gatewayを設定します。
Publicサブネットを関連付けたルートテーブルの作成
VPC作成時のInternet Gatewayを設定します。
以上で設定終了です。
アクセスの流れ的には
VPC内Lambda (private subnet) → NAT Gateway (public subnet) → Internet Gateway → 外部
って感じですかね?AWS歴3か月の雑魚なので認識間違ってたらすみません。
lambdaの呼び出し方
通常のlambda呼び出しと変わりません。
ランタイムはNode.jsです。lambda.jsconst AWS = require('aws-sdk'); const lambda = new AWS.Lambda(); exports.handler = function(event, context, callback) { // ペイロード。呼び出すLambda関数に受け渡す引数的な。 let payload = { "hoge":"huga" }; // ペイロードをStringにする。 payload = JSON.stringify(payload); // invoke引数設定 let params = { FunctionName:"実行するlambda名", InvocationType:"RequestResponse", Payload:payload }; // Lambda関数呼び出し lambda.invoke(params, function(err, data){ if(err){ context.fail(err); } context.succeed(data); }); }備考
参考のAWSリンクにもありますが、
private、publicのサブネットを持ったVPC作成を一発でやる方法があります。
用途がはっきりしているVPCを作成する場合はこれも使えるかも。参考
How do I give internet access to my Lambda function in a VPC?
VPC内のLambdaからインターネットにアクセスする
- 投稿日:2020-06-27T09:30:00+09:00
AWS認定ソリューションアーキテクト–アソシエイト合格から一年振り返り
Q.資格をとって何が変わったか。
AWSに関する仕事を多く任されるようになった事が大きな変化でした。
今まで、仕事で使用したサービス
・lambda
・API Gateway
・Dynamodb
・ECS
・ECR
・CodeCommit
・CodeBuild
・ElastiCache
・VPC周り
・Cludwatch
・S3
・RDS
資格をとったら、結果がついてくるなぁと改めて思いました。。
会社で資格持っている人が少なかったらなおさらですね。一年間でこんなに新しいことを勉強できたなんて、ありがたいや。
ECS,Dynamodbあたりは、休日も調べものをしていましたよ、よくやった(笑)Q.新しいサービスを使うときはどうしているのか。
まずブラックベルトをみる。それにつきますね。
youtubeがあったりするので、家でざっとみたり。
https://aws.amazon.com/jp/aws-jp-introduction/aws-jp-webinar-service-cut/Q.新しい情報はどこから仕入れているか。
なんだかんだで、週刊AWSしか見ていないですね。
https://aws.amazon.com/jp/blogs/news/tag/%E9%80%B1%E5%88%8Aaws/
会社のサイボウズに月曜日にスケジュールを登録しています。
週刊AWSをみるっと。(もちろん、スケジュールは非公開で)一般的には、リリースノートを見られているのかもしれないですね。
http://aws.amazon.com/releasenotesQ.更新に向けて
資格は3年更新なのですが、たぶん直前に勉強します!
ですので、週刊AWSが頼りの綱です。あとは、会社で補助金がでるようにしれっとマネージャあたりに言い続けたいですね。
会社では、資格手当(月XX万)、資格試験手当、があるのですが。
まぁアップデートされていないので、AWSの資格試験を受けた時は実費でした。
模擬試験含め2万ぐらいかかりましたかね。。
私のために、ぜひ補助金を!
- 投稿日:2020-06-27T02:51:13+09:00
Herokuで一定期間経つとアップロードした画像が消えてしまう理由とその対処法
今回起きた問題
初めて制作したアプリをデプロイしたはいいものの、画像を投稿して一定期間経つと「あれ....画像が消えてる!?」と画像が全て消えてデータが投稿文章だけになっていました。
原因
一定時間経つとHeroku上のリポジトリ (Dyno) が最後のコミットの状態にリセットされるため、画像が保存できないとのこと。
解決法
自分はクラウドストレージを使用して解決しました。今回はfogとawsのS3と画像アップロードにCarrierWaveを使用しています。
1.fog
fogとはRubyでクラウドサービスを使いやすくするためのGemです。
まずはfogをインストールします。gemfileの以下の記述をしたら bundle installをしますgem 'fog'開発環境ではローカルファイルに画像保存で問題ありませんが、本番環境ではクラウドストレージサービス(fog)に保存するように条件分岐させます。
app/uploaders/〇〇〇〇_uploader.rbif Rails.env.production? storage :fog else storage :file end2.S3
S3はAWSのサービスの一つです。
ここでの流れは
①AWSのアカウントを作成する
②AWS Identity and Access Management (IAM)でユーザーとグループ(AmazonS3FullAccess)作成(アクセスキーとシークレットアクセスキーは後から使うのでcsvはダウンロードしておくと良い)
③作成したユーザーでログインし、サービス「S3」にてバケットを作成する
といったものです
参考記事
【AWS】【S3】作成手順 & アップロード手順 & アクセス権限設定手順3.CarrierWaveの設定
config/initializers/carrierwave.rbif Rails.env.production? CarrierWave.configure do |config| config.fog_credentials = { provider: 'AWS', aws_access_key_id: ENV['ACCESS_KEY_ID'], aws_secret_access_key: ENV['SECRET_ACCESS_KEY'], region: 'ap-northeast-1' # S3バケット作成時に指定したリージョン。 } config.fog_directory = 'food-pictures-bucket' # 作成したS3バケット名 end end上記についてファイルに直接鍵の名前を書いてしまうと悪用されることがあるので、環境変数で設定しおきましょう。
4.Herokuの環境変数設定
$ heroku config:set ACCESS_KEY_ID=アクセスキー $ heroku config:set SECRET_ACCESS_KEY=シークレットアクセスキーここまできたらターミナルで git push heroku master でデプロイしまししょう
終わりに
herokuでアップロードするだけでも他のクラウドサービスのことや秘密鍵のことについての知識が必要で大変でしたがこの方法でうまくいいきました。
この記事が少しでも参考になれば幸いです。
- 投稿日:2020-06-27T01:56:14+09:00
理想を追い求めたCI/CDパイプラインをTerraformで実装するためのポイント
はじめに
CI/CDパイプラインは素晴らしい。
AWSのCode兄弟を使ったパイプラインは、機能をAWSに閉じ込めながらなんでもできる万能感を感じる。
しかし、チュートリアルに載っているようなシンプルなパイプラインだけでは、現実にある課題を解決することはできない。金融サービス向けに理想のCI/CDを追い求めたお話は、そんな現実にある課題もひっくるめてある程度解決してくれるベストプラクティスだと考えている。
が、実際にこれを運用しようとすると、クロスアカウントで色々なことをしなければならず、シンプルなパイプラインと比べると難易度が高くなる。
この記事では、このパイプラインを実現するためのクロスアカウント設定を中心にポイントを整理しながらTerraformで実装してみる。
前提知識として、以下が必要である(この時点でちょっとハードルが高い)。
- (実際に試してみるなら)クロスアカウントな環境
- IAM関連の知識(Assune Roleをちゃんと理解している必要あり)
- Terraformをある程度書いたことがある(記事中の構成は全然美しくないので、必要に応じてリファクタしてもらいたい……)
- EventBridgeの概念を理解している
動かしてみる前に
確認のためにアカウントを行き来するので、アカウント跨ぎのスイッチロールを入れておいた方が良い。
また、Terraformも複数アカウントの処理が必要になるので、CLIの設定をしておく。
AWS CLIで複数アカウントのアクセスキーを管理して扱う設定
構成図
上記を構成するためのTerrafromは以下の通り。
. ├── 00_main.tf ├── 01_variables.tf ├── 02_data_sources.tf ├── 11_iam_role_build_account.tf ├── 12_iam_role_service_account.tf ├── 13_iam_role_cross_account.tf ├── 21_s3_cross_account.tf ├── 22_kms_cross_account.tf ├── 23_ecr_cross_account.tf ├── 31_s3_build_account.tf ├── 32_codebuild_build_account.tf ├── 33_codepipeline_build_account.tf ├── 34_codebuild_service_account.tf ├── 35_codepipeline_service_account.tf ├── 41_cloudwatch_event_build_account.tf ├── 42_event_pattern_build_account.json ├── 43_cloudwatch_event_service_account.tf └── 44_event_pattern_service_account.jsonうーん、複雑!これはなかなか大変なので、細かく刻んで確認をしていこう。
もうちょっとイケてる分類がある気がするけど、ひとまず今回はこれで。プロバイダの設定
main.tfにクロスアカウントのプロバイダ設定を入れておく。なお、この記事中では、以下のように環境名を定義している。
- build_account: Mavenでjavaのビルドする環境
- service_account: 実際にこの後にECSなりにデプロイする環境
00_main.tfprovider "aws" { alias = "build_account" shared_credentials_file = "~/.aws/credentials" profile = "build_account" region = "ap-northeast-1" } provider "aws" { alias = "service_account" shared_credentials_file = "~/.aws/credentials" profile = "service_account" region = "ap-northeast-1" }また、それぞれのアカウントIDを参照したりするために、以下の設定を入れておこう。
02_data_sources.tf################################################################################ # Account Identity # ################################################################################ data "aws_caller_identity" "build_account" { provider = aws.build_account } data "aws_caller_identity" "service_account" { provider = aws.service_account }これは、
${data.aws_caller_identity.service_account.account_id}とすることで、アカウントIDを拾える。CodeCommitのクロスアカウント設定
概要
まずはCodeCommitのクロスアカウント設定だ。
基本的にDevelopers.IOの以下の記事が分かりやすいのでこれを参考にする。【Developers.IO】CodePipelineでアカウントをまたいだパイプラインを作成してみる
ぶっちゃけ言えばこの記事でほぼ完成なのだが、趣旨はCodeCommitから先まで考えてIaC化することなので、一旦は気にしないことにしよう。
記事内に書いてあるように、以下の条件を満たす必要がある。
CodePipeline/CodeBuildはS3に暗号化されたファイルを置くことでアーティファクトをやり取りしています。 そのため、こういったアカウントをまたいだパイプラインを構築するには以下のような設定がされている必要があります。
- CodePipeline/CodeBuildで暗号化キーが指定されていること
- CodePipelineで開発環境のCodeCommitにアクセスするアクションについて、開発アカウント側のCodeCommitアクセス用IAMロールが指定されていること。
- 開発アカウント側のCodeCommitアクセス用IAMロールでCodeCommitのリポジトリにアクセスできること
- 本番環境アカウントのCodePipelineのサービスロールからリソース側のアカウントのCodeCommitアクセス用ロールにAssumeRoleできること
- アーティファクト用S3バケットおよびそのオブジェクトの暗号化に使うKMSの暗号化キーに対して適切なロールにアクセス権が与えられていること
- CodePipelineのサービスロールからアクセスできること
- CodeBuildのサービスロールからアクセスできること
- CodeCommitアクセス用ロールからアクセスできること
つまり、CodePipeline/CodeBuildで暗号化キーを指定した上で、以下の図のようなアクセス権限を持つようにIAMロールおよびS3バケット、KMS暗号化キーを設定していく必要があります
service_accountにCodeCommitがアーティファクトを格納するためのIAMロール
クロスアカウントで必要になるIAMロールを作成しておく。
リソース定義ではproviderで、どちらのアカウントに作成するかを明示しておこう。
デフォルトもあるが、書いておかないとたぶん後で読んだときにワケがわからなくなると思う。設定の詳細な意味は、↑のDevelopers.IOの記事と重複するので割愛する。
13_iam_role_cross_account.tf################################################################################ # IAM Role for CodeCommit(Cross Account) # ################################################################################ resource "aws_iam_role" "codecommit_cross_account" { provider = "aws.build_account" name = "${local.codecommit_ca_iam_role_name}" assume_role_policy = "${data.aws_iam_policy_document.codecommit_cross_account_trust.json}" } data "aws_iam_policy_document" "codecommit_cross_account_trust" { statement { effect = "Allow" actions = [ "sts:AssumeRole", ] principals { type = "AWS" identifiers = [ "arn:aws:iam::${data.aws_caller_identity.service_account.account_id}:root", ] } } } resource "aws_iam_policy" "codecommit_cross_account" { provider = "aws.build_account" name = "codecommit-cross-account-policy" description = "CodeCommit Cross Account Policy" policy = "${data.aws_iam_policy_document.codecommit_cross_account.json}" } data "aws_iam_policy_document" "codecommit_cross_account" { version = "2012-10-17" statement { sid = "UploadArtifactPolicy" effect = "Allow" actions = [ "s3:PutObject", "s3:PutObjectAcl", ] resources = [ "${aws_s3_bucket.service_artifact.arn}/*", ] } statement { sid = "KMSAccessPolicy" effect = "Allow" actions = [ "kms:DescribeKey", "kms:GenerateDataKey*", "kms:Encrypt", "kms:ReEncrypt*", "kms:Decrypt", ] resources = [ "${aws_kms_key.cross_account.arn}", ] } statement { sid = "CodeCommitAccessPolicy" effect = "Allow" actions = [ "codecommit:GetBranch", "codecommit:GetCommit", "codecommit:UploadArchive", "codecommit:GetUploadArchiveStatus", "codecommit:CancelUploadArchive", ] resources = [ "${data.aws_codecommit_repository.application.arn}", ] } } resource "aws_iam_role_policy_attachment" "codebuild1" { provider = "aws.build_account" role = "${aws_iam_role.codecommit_cross_account.name}" policy_arn = "${aws_iam_policy.codecommit_cross_account.arn}" }ソースアーティファクトバケットの暗号化
クロスアカウントでCodeCommitのソースアーティファクトバケットを暗号化するためのKMSを定義する。
data.aws_iam_user.kms_key_manager.arnは、暗号化の管理IAMユーザをあらかじめ決めておき、
データソースで参照しておく。また、
aws_iam_role.codebuild_service_account.arnとaws_iam_role.codepipeline_service_account.arnは後でパイプラインを作るところでリソースを定義している。22_kms_cross_account.tf################################################################################ # KMS # ################################################################################ resource "aws_kms_key" "cross_account" { description = "KMS Key for CodePipeline" policy = "${data.aws_iam_policy_document.kms_cross_account.json}" } resource "aws_kms_alias" "cross_account" { name = "alias/${local.key_alias_name}" target_key_id = "${aws_kms_key.cross_account.key_id}" } data "aws_iam_policy_document" "kms_cross_account" { version = "2012-10-17" statement { sid = "Enable IAM User Permissions" effect = "Allow" principals { type = "AWS" identifiers = [ "arn:aws:iam::${data.aws_caller_identity.service_account.account_id}:root", ] } actions = [ "kms:*", ] resources = [ "*", ] } statement { sid = "Allow access for Key Administrators" effect = "Allow" principals { type = "AWS" identifiers = [ "${data.aws_iam_user.kms_key_manager.arn}", ] } actions = [ "kms:Create*", "kms:Describe*", "kms:Enable*", "kms:List*", "kms:Put*", "kms:Update*", "kms:Revoke*", "kms:Disable*", "kms:Get*", "kms:Delete*", "kms:TagResource", "kms:UntagResource", "kms:ScheduleKeyDeletion", "kms:CancelKeyDeletion", ] resources = [ "*", ] } statement { sid = "Allow use of the key" effect = "Allow" principals { type = "AWS" identifiers = [ "${aws_iam_role.codebuild_service_account.arn}", "${aws_iam_role.codepipeline_service_account.arn}", "arn:aws:iam::${data.aws_caller_identity.build_account.account_id}:root" ] } actions = [ "kms:Encrypt", "kms:Decrypt", "kms:ReEncrypt*", "kms:GenerateDataKey*", "kms:DescribeKey" ] resources = [ "*", ] } statement { sid = "Allow attachment of persistent resources" effect = "Allow" principals { type = "AWS" identifiers = [ "${aws_iam_role.codebuild_service_account.arn}", "${aws_iam_role.codepipeline_service_account.arn}", "arn:aws:iam::${data.aws_caller_identity.build_account.account_id}:root" ] } actions = [ "kms:CreateGrant", "kms:ListGrants", "kms:RevokeGrant" ] resources = [ "*", ] condition { test = "Bool" variable = "kms:GrantIsForAWSResource" values = [ "true", ] } } }ソースアーティファクトバケットの定義
アーティファクトバケットもbuild_account側からアクセスできるように設定をする。
21_s3_cross_account.tf################################################################################ # S3 # ################################################################################ resource "aws_s3_bucket" "service_artifact" { provider = "aws.service_account" bucket = "${local.service_artifact_s3bucket_name}" } resource "aws_s3_bucket_policy" "cross_account" { provider = "aws.service_account" bucket = "${aws_s3_bucket.service_artifact.id}" policy = "${data.aws_iam_policy_document.s3_cross_account.json}" } data "aws_iam_policy_document" "s3_cross_account" { version = "2012-10-17" statement { sid = "DenyUnEncryptedObjectUploads" effect = "Deny" principals { type = "AWS" identifiers = [ "*", ] } actions = [ "s3:PutObject", ] resources = [ "arn:aws:s3:::${aws_s3_bucket.service_artifact.id}/*" ] condition { test = "StringNotEquals" variable = "s3:x-amz-server-side-encryption" values = [ "aws:kms", ] } } statement { sid = "DenyInsecureConnections" effect = "Deny" principals { type = "AWS" identifiers = [ "*", ] } actions = [ "s3:*", ] resources = [ "arn:aws:s3:::${aws_s3_bucket.service_artifact.id}/*" ] condition { test = "Bool" variable = "aws:SecureTransport" values = [ "false", ] } } statement { sid = "CrossAccountS3GetPutPolicy" effect = "Allow" principals { type = "AWS" identifiers = [ "arn:aws:iam::${data.aws_caller_identity.build_account.account_id}:root", ] } actions = [ "s3:Get*", "s3:Put*", ] resources = [ "arn:aws:s3:::${aws_s3_bucket.service_artifact.id}/*" ] } statement { sid = "CrossAccountS3ListPolicy" effect = "Allow" principals { type = "AWS" identifiers = [ "arn:aws:iam::${data.aws_caller_identity.build_account.account_id}:root", ] } actions = [ "s3:ListBucket", ] resources = [ "arn:aws:s3:::${aws_s3_bucket.service_artifact.id}" ] } }ECRのクロスアカウント設定
他と比べると随分とシンプルだが、service_accountからbuild_accountのECRにアクセスしてpullしていくので、そのための設定を行う必要がある。
23_ecr_cross_account.tf################################################################################ # ECR # ################################################################################ resource "aws_ecr_repository_policy" "cross_account" { provider = aws.build_account repository = "${data.aws_ecr_repository.build_account.name}" policy = "${data.aws_iam_policy_document.ecr_cross_account.json}" } data "aws_iam_policy_document" "ecr_cross_account" { statement { effect = "Allow" actions = [ "ecr:GetAuthorizationToken", "ecr:GetDownloadUrlForLayer", "ecr:BatchGetImage", "ecr:BatchCheckLayerAvailability", ] principals { type = "AWS" identifiers = [ "arn:aws:iam::${data.aws_caller_identity.service_account.account_id}:root", ] } } }パイプラインの作成
build_account側パイプライン
ここはそんなに凝ったことはやっていない。
S3バケット
build_account側のアーティファクト用のS3バケットを作っておく。
これは普通のパイプラインに必要なリソースなので、特別なことは特にない。31_s3_build_account.tf################################################################################ # S3 # ################################################################################ resource "aws_s3_bucket" "build_artifact" { provider = "aws.build_account" bucket = "${local.build_artifact_s3bucket_name}" }IAMロール
IAMロールも普通にパイプラインに必要なポリシをアタッチしたサービスロールを作れば良い。
ちょっと面倒になってFullAccessとかの管理ポリシを使ってるのはご容赦いただきたい……。11_iam_role_build_account.tf################################################################################ # IAM Role for CodeBuild # ################################################################################ resource "aws_iam_role" "codebuild_build_account" { provider = "aws.build_account" name = "${local.codebuild_iam_role_name}" assume_role_policy = "${data.aws_iam_policy_document.codebuild_build_account_trust.json}" } data "aws_iam_policy_document" "codebuild_build_account_trust" { statement { effect = "Allow" actions = [ "sts:AssumeRole", ] principals { type = "Service" identifiers = [ "codebuild.amazonaws.com", ] } } } resource "aws_iam_role_policy_attachment" "codebuild_build_account1" { provider = "aws.build_account" role = "${aws_iam_role.codebuild_build_account.name}" policy_arn = "arn:aws:iam::aws:policy/AWSCodeBuildDeveloperAccess" } resource "aws_iam_role_policy_attachment" "codebuild_build_account2" { provider = "aws.build_account" role = "${aws_iam_role.codebuild_build_account.name}" policy_arn = "arn:aws:iam::aws:policy/AmazonEC2ContainerRegistryPowerUser" } resource "aws_iam_role_policy_attachment" "codebuild_build_account3" { provider = "aws.build_account" role = "${aws_iam_role.codebuild_build_account.name}" policy_arn = "arn:aws:iam::aws:policy/AmazonS3FullAccess" } resource "aws_iam_role_policy_attachment" "codebuild_build_account4" { provider = "aws.build_account" role = "${aws_iam_role.codebuild_build_account.name}" policy_arn = "arn:aws:iam::aws:policy/CloudWatchLogsFullAccess" } ################################################################################ # IAM Role for CodePipeline # ################################################################################ resource "aws_iam_role" "codepipeline_build_account" { provider = "aws.build_account" name = "${local.codepipeline_iam_role_name}" assume_role_policy = "${data.aws_iam_policy_document.codepipeline_build_account_trust.json}" } data "aws_iam_policy_document" "codepipeline_build_account_trust" { statement { effect = "Allow" actions = [ "sts:AssumeRole", ] principals { type = "Service" identifiers = [ "codepipeline.amazonaws.com", ] } } } resource "aws_iam_role_policy_attachment" "codepipeline_build_account1" { provider = "aws.build_account" role = "${aws_iam_role.codepipeline_build_account.name}" policy_arn = "arn:aws:iam::aws:policy/AWSCodePipelineFullAccess" } resource "aws_iam_role_policy_attachment" "codepipeline_build_account2" { provider = "aws.build_account" role = "${aws_iam_role.codepipeline_build_account.name}" policy_arn = "arn:aws:iam::aws:policy/AWSCodeCommitFullAccess" } resource "aws_iam_role_policy_attachment" "codepipeline_build_account3" { provider = "aws.build_account" role = "${aws_iam_role.codepipeline_build_account.name}" policy_arn = "arn:aws:iam::aws:policy/AmazonS3FullAccess" } resource "aws_iam_role_policy_attachment" "codepipeline_build_account4" { provider = "aws.build_account" role = "${aws_iam_role.codepipeline_build_account.name}" policy_arn = "arn:aws:iam::aws:policy/AWSCodeBuildDeveloperAccess" }CodeBuild
32_codebuild_build_account.tf################################################################################ # CodeBuild for Build Account # ################################################################################ resource "aws_codebuild_project" "build_account" { provider = "aws.build_account" name = "${local.build_project_name}" service_role = "${aws_iam_role.codebuild_build_account.arn}" source { type = "CODEPIPELINE" buildspec = "buildspec_build_account.yml" } artifacts { type = "CODEPIPELINE" } environment { type = "LINUX_CONTAINER" compute_type = "BUILD_GENERAL1_SMALL" image = "aws/codebuild/standard:3.0-19.11.26" privileged_mode = "true" } cache { type = "LOCAL" modes = [ "LOCAL_CUSTOM_CACHE", ] } }CodePipeline
33_codepipeline_build_account.tf################################################################################ # CodePipeline for Build Account # ################################################################################ resource "aws_codepipeline" "build_account" { provider = "aws.build_account" name = "${local.codepipeline_name}" role_arn = "${aws_iam_role.codepipeline_build_account.arn}" artifact_store { type = "S3" location = "${aws_s3_bucket.build_artifact.bucket}" } stage { name = "Source" action { run_order = 1 name = "Source" category = "Source" owner = "AWS" provider = "CodeCommit" version = "1" output_artifacts = ["SourceArtifact"] configuration = { RepositoryName = "${local.repository_name}" BranchName = "master" } } } stage { name = "Build" action { run_order = 2 name = "Build" category = "Build" owner = "AWS" provider = "CodeBuild" version = "1" input_artifacts = ["SourceArtifact"] output_artifacts = ["BuildArtifact"] configuration = { ProjectName = "${aws_codebuild_project.build_account.name}" } } } }service_account側パイプライン
ここも、build_account同様、特別なことはしていない。
IAMロール
12_iam_role_service_account.tf################################################################################ # IAM Role for CodeBuild # ################################################################################ resource "aws_iam_role" "codebuild_service_account" { provider = "aws.service_account" name = "${local.codebuild_iam_role_name}" assume_role_policy = "${data.aws_iam_policy_document.codebuild_service_account_trust.json}" } data "aws_iam_policy_document" "codebuild_service_account_trust" { statement { effect = "Allow" actions = [ "sts:AssumeRole", ] principals { type = "Service" identifiers = [ "codebuild.amazonaws.com", ] } } } resource "aws_iam_role_policy_attachment" "codebuild_service_account1" { provider = "aws.service_account" role = "${aws_iam_role.codebuild_service_account.name}" policy_arn = "${aws_iam_policy.codebuild_service_account_custom.arn}" } resource "aws_iam_policy" "codebuild_service_account_custom" { provider = "aws.service_account" name = "code-build-policy" description = "CodeBuild Policy" policy = "${data.aws_iam_policy_document.codebuild_service_account_custom.json}" } data "aws_iam_policy_document" "codebuild_service_account_custom" { version = "2012-10-17" statement { sid = "CloudWatchLogsPolicy" effect = "Allow" actions = [ "logs:CreateLogGroup", "logs:CreateLogStream", "logs:PutLogEvents", ] resources = [ "*", ] } statement { sid = "S3ObjectPolicy" effect = "Allow" actions = [ "s3:PutObject", "s3:GetObject", "s3:GetObjectVersion", ] resources = [ "*", ] } } resource "aws_iam_role_policy_attachment" "codebuild_service_account2" { provider = "aws.service_account" role = "${aws_iam_role.codebuild_service_account.name}" policy_arn = "arn:aws:iam::aws:policy/AmazonEC2ContainerRegistryPowerUser" } ################################################################################ # IAM Role for CodePipeline # ################################################################################ resource "aws_iam_role" "codepipeline_service_account" { provider = "aws.service_account" name = "${local.codepipeline_iam_role_name}" assume_role_policy = "${data.aws_iam_policy_document.codepipeline_service_account_trust.json}" } data "aws_iam_policy_document" "codepipeline_service_account_trust" { statement { effect = "Allow" actions = [ "sts:AssumeRole", ] principals { type = "Service" identifiers = [ "codepipeline.amazonaws.com", ] } } } resource "aws_iam_role_policy_attachment" "codepipeline_service_account" { provider = "aws.service_account" role = "${aws_iam_role.codepipeline_service_account.name}" policy_arn = "${aws_iam_policy.codepipeline_service_account_custom.arn}" } resource "aws_iam_policy" "codepipeline_service_account_custom" { provider = "aws.service_account" name = "code-pipeline-policy" description = "CodePipeline Policy" policy = "${data.aws_iam_policy_document.codepipeline_service_account_custom.json}" } data "aws_iam_policy_document" "codepipeline_service_account_custom" { version = "2012-10-17" statement { sid = "AssumeRolePolicy" effect = "Allow" actions = [ "sts:AssumeRole", ] resources = [ "arn:aws:iam::${data.aws_caller_identity.build_account.account_id}:role/*", ] } statement { sid = "S3Policy" effect = "Allow" actions = [ "s3:PutObject", "s3:GetObject", "s3:GetObjectVersion", "s3:GetBucketVersioning", ] resources = [ "*", ] } statement { sid = "CodeBuildPolicy" effect = "Allow" actions = [ "codebuild:BatchGetBuilds", "codebuild:StartBuild", ] resources = [ "*", ] } }CodeBuild
34_codebuild_service_account.tf################################################################################ # CodeBuild for Service Account # ################################################################################ resource "aws_codebuild_project" "service_account" { provider = "aws.service_account" name = "${local.build_project_name}" service_role = "${aws_iam_role.codebuild_service_account.arn}" source { type = "CODEPIPELINE" buildspec = "buildspec_service_account.yml" } artifacts { type = "CODEPIPELINE" } environment { type = "LINUX_CONTAINER" compute_type = "BUILD_GENERAL1_SMALL" image = "aws/codebuild/standard:3.0-19.11.26" privileged_mode = "true" environment_variable { name = "BUILD_ACCOUNT_ID" value = "${data.aws_caller_identity.build_account.account_id}" } } cache { type = "LOCAL" modes = [ "LOCAL_CUSTOM_CACHE", ] }CodePipeline
35_codepipeline_service_account.tf################################################################################ # CodePipeline for Service Account # ################################################################################ resource "aws_codepipeline" "service_account" { provider = "aws.service_account" name = "${local.codepipeline_name}" role_arn = "${aws_iam_role.codepipeline_service_account.arn}" artifact_store { type = "S3" location = "${aws_s3_bucket.service_artifact.bucket}" encryption_key { id = "${aws_kms_key.cross_account.arn}" type = "KMS" } } stage { name = "Source" action { run_order = 1 name = "Source" category = "Source" owner = "AWS" provider = "CodeCommit" version = "1" output_artifacts = ["SourceArtifact"] configuration = { RepositoryName = "${local.repository_name}" BranchName = "master" PollForSourceChanges = "false" } role_arn = "${aws_iam_role.codecommit_cross_account.arn}" } } stage { name = "Build" action { run_order = 2 name = "Build" category = "Build" owner = "AWS" provider = "CodeBuild" version = "1" input_artifacts = ["SourceArtifact"] output_artifacts = ["BuildArtifact"] configuration = { ProjectName = "${aws_codebuild_project.service_account.name}" } } } }EventBridgeでアカウント間を繋ぐ
さて、ここまでできたら、あとはパイプラインを繋ぐだけだ。
EventBridgeでイベント送信するには、
- 送信(build_account)側で、受信(service_account)側へのデフォルトイベントバスにイベントを書き込むための権限
- 受信(service_account)側のデフォルトイベントバスに送信(build_account)側のアクセス許可を追加
が必要である。どちらも、1つだけ準備しておけば充分なので、IaC化はしない。
送信(build_account)側のIAMロール設定
以下のポリシを持ったIAMロールを作っておく
インラインポリシー{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "events:PutEvents" ], "Resource": [ "arn:aws:events:ap-northeast-1:受信(service_account)側のアカウントID:event-bus/default" ] } ] }信頼性ポリシー{ "Version": "2012-10-17", "Statement": [ { "Sid": "", "Effect": "Allow", "Principal": { "Service": "events.amazonaws.com" }, "Action": "sts:AssumeRole" } ] }受信(service_account)側のデフォルトイベントバスのアクセス許可
サービスの「EventBridge」のトップ画面で以下のボタンを押下する。
以下の画面が開くので、送信(build_account)側のアカウントIDを登録する。
送信(build_account)側のイベント送信トリガの設定
送信(build_account)側でパイプラインの完了を検知してイベント送信するCloudWatch Eventのルールを作る。
"detail-type": [ "CodePipeline Pipeline Execution State Change" ],がパイプラインの更新をひっかけるイベント定義で、
"detail": { "state": [ "SUCCEEDED" ] },が、パイプラインの成功をフィルタするための定義だ。
これで、パイプライン成功時に
local.service_event_bus_arnにイベント送信するという定義が出来上がる。41_cloudwatch_event_build_account.tf################################################################################ # CloudWatch Event for Build Account # ################################################################################ resource "aws_cloudwatch_event_rule" "codepipeline_success_build_account" { provider = "aws.build_account" name = "${local.event_rule_name}" description = "${var.prefix} CodePipeline Success Event Rule" event_pattern = "${data.template_file.event_pattern_build_account.rendered}" } resource "aws_cloudwatch_event_target" "event_bus_build_account" { provider = "aws.build_account" rule = "${aws_cloudwatch_event_rule.codepipeline_success_build_account.name}" target_id = "${local.event_target_id}" arn = "${local.service_event_bus_arn}" role_arn = "${data.aws_iam_role.send_event_to_service_account.arn}" } data "template_file" "event_pattern_build_account" { template = file("${path.module}/42_event_pattern_build_account.json") vars = { codepipeline_arn = "${aws_codepipeline.build_account.arn}" } }42_event_pattern_build_account.json{ "source": [ "aws.codepipeline" ], "detail-type": [ "CodePipeline Pipeline Execution State Change" ], "detail": { "state": [ "SUCCEEDED" ] }, "resources": [ "${codepipeline_arn}" ] }受信(service_account)側のイベント処理
送信側の設定に似ているが、送信側から送られてきたイベントをさらに処理して、
aws_codepipeline.service_account.arnをキックするようにしている。
自分のパイプライン成功をフックしてしまわないように、イベントのルールで"account": [ "${build_account_id}" ],として、以下のようにしてbuild_accountのアカウントIDを渡してフィルタしている。
vars = { build_account_id = "${data.aws_caller_identity.build_account.account_id}" }CloudWatch Eventとイベントフィルタ定義の全体像は以下のような感じになる。
43_cloudwatch_event_service_account.tf################################################################################ # CloudWatch Event for Service Account # ################################################################################ resource "aws_cloudwatch_event_rule" "codepipeline_success_service_account" { provider = "aws.service_account" name = "${local.event_rule_name}" description = "${var.prefix} CodePipeline Success Event Rule" event_pattern = "${data.template_file.event_pattern_service_account.rendered}" } resource "aws_cloudwatch_event_target" "event_bus_service_account" { provider = "aws.service_account" rule = "${aws_cloudwatch_event_rule.codepipeline_success_service_account.name}" target_id = "${local.event_target_id}" arn = "${aws_codepipeline.service_account.arn}" role_arn = "${data.aws_iam_role.start_pipeline_service_account.arn}" } data "template_file" "event_pattern_service_account" { template = file("${path.module}/44_event_pattern_service_account.json") vars = { build_account_id = "${data.aws_caller_identity.build_account.account_id}" codepipeline_arn = "${aws_codepipeline.build_account.arn}" } }44_event_pattern_service_account.json{ "source": [ "aws.codepipeline" ], "account": [ "${build_account_id}" ], "detail-type": [ "CodePipeline Pipeline Execution State Change" ], "detail": { "state": [ "SUCCEEDED" ] }, "resources": [ "${codepipeline_arn}" ] }これで、2つのパイプラインをEventBridgeで接続して連動できるようになった!
その他
CloudWatch Eventのイベントトリガが正しく発行されたか確認するには
[CloudWatch Events から実行された SSM RunCommand や Lambda のログについて]
以下の記事が分かりやすくて良かった。
(https://qiita.com/kusokamayarou/items/6e1ee054ecae437dadaa)
ただし、実際にはCloudTrailを追いかけるのはかったるくてしょうがないので、結局は、以下の手順で確認するのが一番楽だった。
- 一番シンプルなイベントトリガを作り、Lambda関数をターゲットにする。 Lambda関数では、
import pprint ~中略~ pprint.pprint(event)して、イベントトリガのJSONの内容をダンプする。万が一、トリガが正しく引かれていないなら、この時点でCloudWatch Logsに何も出ないので、そこでトリガが引かれない原因の切り分けができる。
2. ↑で表示した内容に合わせ、イベントパターンを編集する。だいたいイベントパターンのマッチングが間違ってるからトリガが発動しないのだよ……。

- 投稿日:2020-06-27T00:59:13+09:00
理解していますか?各クラウドの「アカウント」
いきなりですが
皆さんはAWS,GCP,Azureの「アカウント」の違いわかりますか?
私は分かりません
各クラウドで名称が違いますが
その中でも特に難しいのが「アカウント」だと思います
調べてまとめましたアカウントの意味
AWS (一応)完全に独立したリソースやユーザの集合
開発や本番などで分けると良いGCP 正確にはアカウントというものはない
個人ユーザで用いるGoogleアカウントと
マシンユーザで用いるサービスアカウントがあるAzure Azure アカウントは、請求関係を表します。 Azure アカウントは、ユーザー ID、1 つ以上の Azure サブスクリプション、および関連する Azure リソースのセットです。[1] 一般的なイメージだとGCPのように、個人を表すものかなと思います。
Qiitaもアカウントは個人ユーザを表していますね。
AWSの使い方は初めは違和感がありましたが、だんだん慣れて来きました。
一番理解しづらいのがAzureです。これはAzureADとサブスクリプションを理解していないと分かりづらいです。この辺りは別の機会にまとめようと思います。最後に
最後まで読んでいただきありがとうございます!
参考資料