- 投稿日:2020-06-27T19:50:28+09:00
激重フルアーマーRPAは要らん。とりまシュっと操作再生だけできればいいんや【世界初編】
壱
とある作業で
「構築はコード化しているのにXX(ツール名)をインストールするのにログインして操作要るんすよね」
「RPA仕込んでおけば良くね?wwwww」は?????
RPAってUiPATH出始めの頃はUWSCや、AutoHotkeyをもっとコモディティ域に下した良い狙いだったんだけど、
いつの間にやら複雑なフローやらAPIやら、クラウド連携だのAI絡みの重厚なソリューションとして
金額的にも肥大していった。JREランタイムだの追加で色々入ってくるようになった。アンインスコめんどい。
しかも、SaaS製品と違って日本だとセキュリティ絡みで手元で動くパッケージ製品の需要の方が多そうなのに、
当然SaaSより高い。目標をセンターに入れてスイッチだけなのにとても息苦しい。弐
Linuxのexpectコマンドみたいに最低限のOSとインタフェースになってくれれば良くてOCR機能なんて要らない!
というお気持ちをツールにしました。
こんなの
んーー・・・・・別にフツーですね。
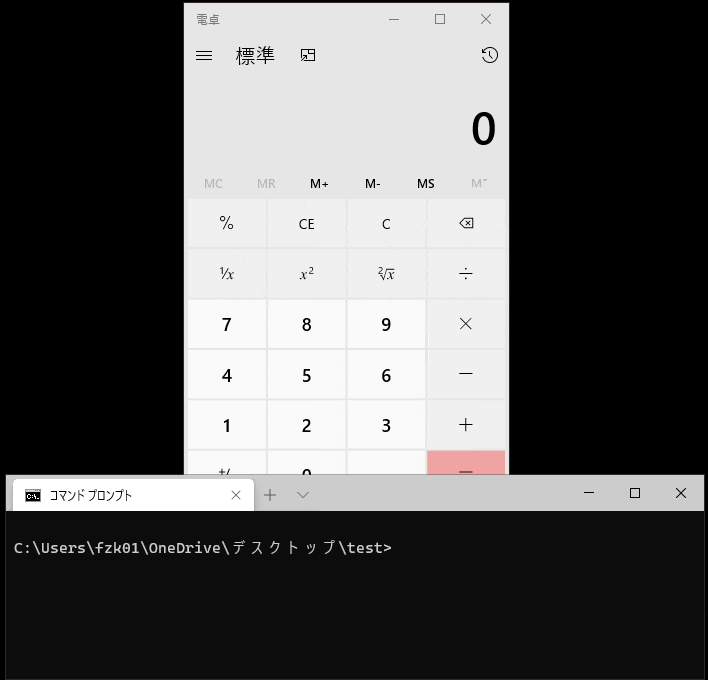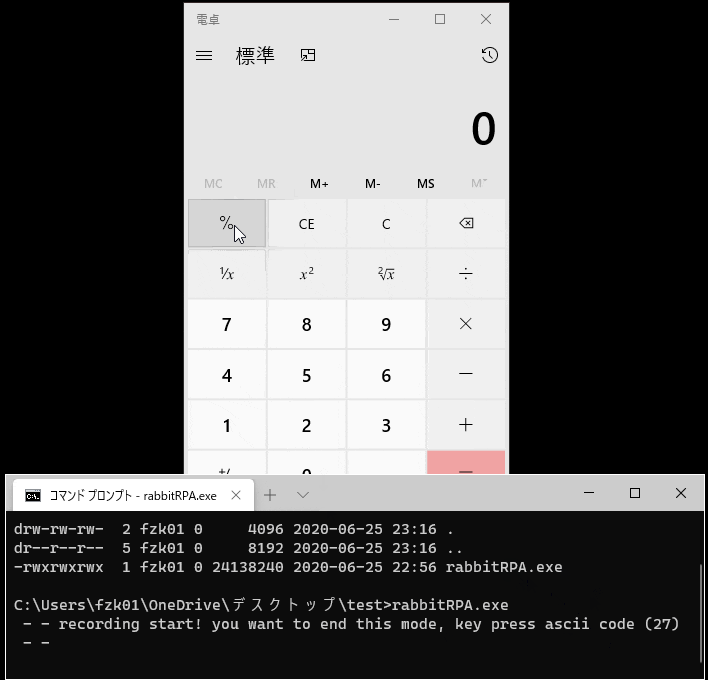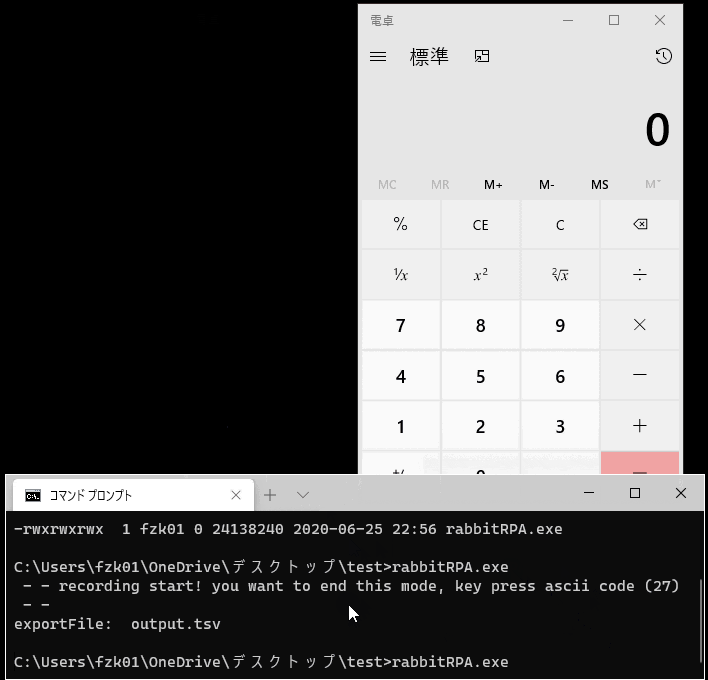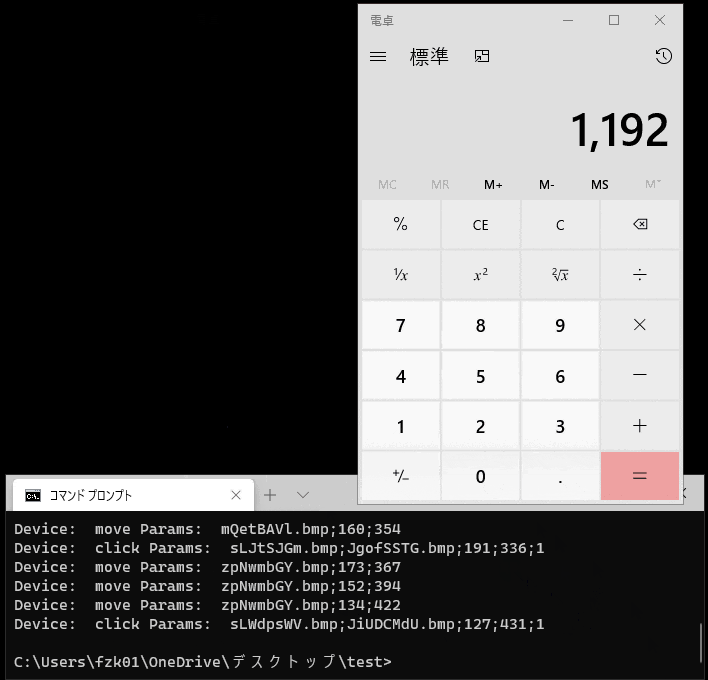
どこが凄いかと言うと、これワンバイナリに収まってるんですわ。たぶん他には無い。
つまり、ファイル一個コピーしてくればオペレーションの録画と再生が出来てしまう!
アンインスコはファイル消すだけ!!インスコ自動化しようず→コピってシュ→ファイル消してクリーン
の最小手でRPAれる。
参
「あれ、ワイの端末だとラグいぞ」
「んー、その4GセロリンSATA端末は激遅で画像の書き出しが間に合ってないみたい」
「そういう環境にこそこういうツールの需要があるんじゃね?」ぐぬぬ
終
やはり環境依存の低さと動作速度とモジュールの多さからのバランスでGo言語は最強やな。
書いてて飽きる気がしないわ。
- 投稿日:2020-06-27T19:41:42+09:00
Go で競技プログラミング: 標準入力を最速で読み取る方法
Go には便利な標準ライブラリが備わっていて、簡単に標準入力を読み取ることができるようになっています。
ただ、実際競技プログラミングで使ってみると、思ったより速度が出ない、と思ったことはないでしょうか?
やるからには 1 ミリ秒でも速いコードを提出したいです。この記事では、標準ライブラリの基本的な使い方を紹介しつつ、より高速に読み取る方法を紹介していきます。
また、最後にコピペ用の Scanner ライブラリを載せています。標準ライブラリを使った読み取り方法
まずは、標準ライブラリを使った方法を軽く紹介していきます。
fmt.Scanfmt.Scan を使うと、簡単に読み取ることができます。
入力量が少ない場合は、何も考えずにこれを使うのが楽です。
以下は使い方の例です。import "fmt" func main() { var a, b int fmt.Scan(&a, &b) fmt.Println(a, b) }
int,float64,[]byte,stringなど、何でもScanを呼ぶだけで読み取ることができます。
ただし少し遅いため、大量の読み込みが発生する場合は注意が必要です。
bufio.ReaderGo には、
fmt.Scanよりも効率的に読み取ることができるライブラリとして、bufio.Reader と bufio.Scanner が用意されています。
高速に読み込むことができる一方、fmt.Scanと違い、自動で型変換をしてくれないため、自分で変換処理を実装する必要があります。
ラッパーライブラリを用意しておくと便利なため、その実装例も含め使い方を紹介します。まずは
bufio.Readerから使い方を紹介します。
やや唐突ですが以下がラッパーライブラリの実装例です。[]byte,string,intを読み込むメソッドを例として実装しました。
また、競技プログラミングにおいてエラーをハンドリングする意味はないため、省きます。import ( "bufio" "io" "strconv" "unsafe" ) type Reader struct{ *bufio.Reader } func NewReader(r io.Reader) *Reader { return &Reader{Reader: bufio.NewReader(r)} } func (r *Reader) Bytes() []byte { b, _ := r.ReadBytes('\n') return b[:len(b)-1] // '\n' が末尾についているため削る } func (r *Reader) Text() string { b := r.Bytes() // bufio.ReadBytes はバッファのコピーを返すため、unsafe.Pointer を使うことができる // string(b) で変換するより高速 return *(*string)(unsafe.Pointer(&b)) } func (r *Reader) Int() int { n, _ := strconv.Atoi(r.Text()) return n }使い方
import ( "fmt" "os" // Reader の import は省略 ) func main() { rdr := NewReader(os.Stdin) a, b := rdr.Int(), rdr.Int() fmt.Println(a, b) }
[]byteを読み取るのに、ReadBytes を呼んでいます。
特徴として、バッファの参照ではなくコピーを返します。これにより受け取った値は安全に扱うことができます。また、バッファの使い方が理想的で、かなり高速に読み取ることができます。
一方、デリミタを複数同時に指定できない、数値を取得する場合バッファコピーが余計に入る、というデメリットがあります。特に、デリミタを複数同時に指定できないのは、空白と改行が入り混じった入力が渡される場合、かなり面倒です。行単位で読み込んだあと、bytes.Split でスライス化する方法はありますが、それは遅いため使わないほうが良いでしょう。
まとめ
[]byteかstringを行単位で読み取るのに適している- デリミタが複数ある場合厳しい
- 数値の読み取りには不向き
bufio.Scannerこれもいきなりですが、実装例を紹介します。
import ( "bufio" "io" "strconv" ) type Scanner struct{ *bufio.Scanner } func NewScanner(r io.Reader) *Scanner { s := bufio.NewScanner(r) s.Split(bufio.ScanWords) // 空白文字をデリミタとする(デフォルト) return &Scanner{Scanner: s} } // bufio.Scanner.Bytes はバッファの参照を返す(コピーではない)ため少し注意 func (s *Scanner) next() []byte { s.Scan() return s.Scanner.Bytes() } func (s *Scanner) Bytes() (b []byte) { unsafe := s.next() // コピーを取らないと上書きされる可能性がある b = make([]byte, len(unsafe)) copy(b, unsafe) return } // バッファの参照に対しては、unsafe.Pointer は使えない func (s *Scanner) Text() string { return string(s.next()) } func (s *Scanner) Int() int { n, _ := strconv.Atoi(s.Text()) return n }使い方
import ( "fmt" "os" // Scanner の import は省略 ) func main() { sc := NewScanner(os.Stdin) a, b := sc.Int(), sc.Int() fmt.Println(a, b) }Split メソッドによってデリミタを自由に設定することができ、空白文字をデリミタとする bufio.ScanWords や、改行単位で読み込む bufio.ScanLines などがデフォルトで用意されています。
また、SplitFunc を自作することで、デリミタは自由自在です。しかし一方で、
bufio.Reader.ReadBytesと異なり、bufio.Scanner.Bytesはバッファの参照を返します。そのため、[]byteを読み取るときにコピーを取る必要があることに注意が必要です。さらに、読み込む量が多い場合にも注意が必要です。
bufio.Scannerの場合、読み込む量が多いと、余計なバッファコピーや、バッファの拡張が行われる可能性があります。コピーや拡張が行われると読み込み速度が低下します。まとめ
- デリミタの指定が自由にできる
bufio.Readerより数値の読み込みに適している[]byteの読み込みでは余計なコピーが走る可能性があるため、適しているとは言えない- 速度低下に注意が必要
基本的な読み取り方のまとめ
fmt.Scan→ 入力が少ない場合に使うbufio.Reader→ 行単位で[]byteまたはstringを読み込む場合に使うbufio.Scanner→ それ以外以上、Go の標準ライブラリを使った、読み込み方法を紹介しました。
しかし!バッファの使い方が理想的で速度が低下せず、複数のデリミタを指定でき、どの型でも高速に読み込める万能ライブラリは存在しないことも分かりました...。無いものは作れば良いですよね?
という訳で Scanner ライブラリを自作してみます。Scanner ライブラリを自作する
またいきなりですが、出来上がったものがこちらになります (長い...)
import ( "io" "strconv" ) type Scanner struct { r io.Reader buf []byte split func(byte) bool size, eof, start, end int } func NewScanner(r io.Reader) *Scanner { return NewScannerSize(r, 4096) } func NewScannerSize(r io.Reader, size int) *Scanner { return &Scanner{ r: r, buf: make([]byte, size), split: func(b byte) bool { return b == ' ' || b == '\n' }, size: size, start: size, end: size, } } func (s *Scanner) Split(f func(byte) bool) { s.split = f } func (s *Scanner) Bytes() (b []byte) { unsafe, size := s.next() b = make([]byte, size) copy(b, unsafe) return } func (s *Scanner) UnsafeBytes() []byte { b, _ := s.next(); return b } func (s *Scanner) Text() string { return string(s.UnsafeBytes()) } func (s *Scanner) Int() int { n, _ := strconv.Atoi(s.Text()); return n } func (s *Scanner) next() (b []byte, size int) { for n := 0; ; { for i := s.end; i < s.size; i++ { if s.split(s.buf[i]) || i == s.eof { b, size = s.buf[s.start:i], i-s.start s.start, s.end = i+1, i+1 return } } s.end = s.size if n++; n == 2 { // 無限ループ対策 panic("lack of buffer size") } s.read() } } func (s *Scanner) read() { copy(s.buf, s.buf[s.start:s.end]) s.end -= s.start s.start = 0 n, _ := s.r.Read(s.buf[s.end:]) s.eof = s.end + n }使い方
import ( "fmt" "os" // Scanner の import は省略 ) func main() { sc := NewScanner(os.Stdin) a, b := sc.Int(), sc.Int() fmt.Println(a, b) }
bufio.Readerをベースにbufio.Scannerの使いやすさを足しています。
また、エラーハンドリングは不要なので、徹底的に削ぎ落としています。
Splitを呼ぶことでデリミタは自由自在です- 余計なバッファコピーや、バッファ拡張を行わないので、速度が低下しません
ベンチマークは最後に載せています。
型変換の高速化
ここからは型の変換について考えます。
実は型の変換を Go の標準ライブラリで行うのは基本的に遅いです!
変換処理を自作に置き換えると劇的に速くなるので、これだけでもぜひ一度使ってみてください。int
int は strconv.Atoi を使用することで取得できます。しかし Atoi には string を渡さなければなりません。
さらに、Atoi のコードを読んでみると、一度受け取った string を []byte に変換し直している ことも分かります。for _, ch := range []byte(s) {少し下を見ると、
intSizeが 64 の場合はもう少し遠回りしていることも分かります。内部的に ParseInt が呼ばれ、最終的に ParseUint まで行ってます。Go の intSize は環境によって異なりますが、私の PC(Mac) の intSize は 64 でした。ちなみに AtCoder の intSize も 64 です。一旦
intSizeが 32 だと仮定しても、標準入力からは[]byteで受け取りますので、
[]byteで受け取るstringに変換するstrconv.Atoiを呼ぶ[]byteに変換するintを得るというステップが必要になっています。intSize が 64 の場合はもう少し遠回りで、きっと安全設計がされているのだと思いますが、競技プログラミングにおいては不要です。
変換用の関数を自作して[]byteからいきなりintを得られるようにしましょう。func ParseInt(b []byte) (n int) { for _, ch := range b { ch -= '0' // 例えばchが'7'(== byte(55))なら、'0'(== byte(48))を引くと7が手に入る if ch <= 9 { n = n*10 + int(ch) } } if b[0] == '-' { return -n } return }Atoi のコードで必要な部分を、ほぼそのまま抜き出しました。
strconv.Atoiをこれに置き換えるだけで、かなり高速になります。ぜひ試してみてください。ちなみに、
if ch <= 9の判定を入れておくことで、floatの入力をintとしてパースできたりします。これも時々役に立つかもしれません。int64
int64 を得たい場合、Go の標準ライブラリでは strconv.ParseInt を使う必要がありますが、やはり少し遅いです。
int の関数がそのまま使えるので実装しましょう。func ParseInt64(b []byte) (n int64) { for _, ch := range b { ch -= '0' if ch <= 9 { n = n*10 + int64(ch) } } if b[0] == '-' { return -n } return }int を int64 に変えただけです。uint64 も同様に変換可能です。
float64
標準ライブラリの ParseFloat はやはり遅いです。
この流れでfloat64用の関数も作ってしまいましょう。// 1e0 == 0, 1e5 == 100000 var float64pow10 = []float64{ 1e0, 1e1, 1e2, 1e3, 1e4, 1e5, 1e6, 1e7, 1e8, 1e9, 1e10, 1e11, 1e12, 1e13, 1e14, 1e15, 1e16, 1e17, 1e18, 1e19, 1e20, 1e21, 1e22, } func ParseFloat(b []byte) float64 { f, dot := 0.0, 0 for i, ch := range b { if ch == '.' { dot = i + 1 continue } if ch -= '0'; ch <= 9 { f = f*10 + float64(ch) } } if dot != 0 { f /= float64pow10[len(b)-dot] } if b[0] == '-' { return -f } return f }以下のパターンが全て
floatとしてパースできるようになっています。"0", "1", "-1.1", "-100.009", "0.006", "100000", "-1103244.5", "0.00001", "10.0000", "-1.2345678901", ".001", "-.001",
float64pow10は strconv/atof.go#L413 を参考にしています。コピペ用コード例
例として、自作版の Scanner ライブラリを載せます。
bufioの方を使いたい方は自分で書き換えてください。
スライス読み込み用メソッドを足し、int64 は省略しています。import ( "io" ) type Scanner struct { r io.Reader buf []byte split func(byte) bool size, eof, start, end int } func NewScanner(r io.Reader) *Scanner { return NewScannerSize(r, 4096) } func NewScannerSize(r io.Reader, size int) *Scanner { return &Scanner{ r: r, buf: make([]byte, size), split: func(b byte) bool { return b == ' ' || b == '\n' }, size: size, start: size, end: size, } } func (s *Scanner) Split(f func(byte) bool) { s.split = f } func (s *Scanner) Bytes() (b []byte) { unsafe, size := s.next() b = make([]byte, size) copy(b, unsafe) return } func (s *Scanner) UnsafeBytes() []byte { return s.bytes() } func (s *Scanner) Text() string { return string(s.bytes()) } func (s *Scanner) Int() int { return ParseInt(s.bytes()) } func (s *Scanner) Float() float64 { return ParseFloat(s.bytes()) } func (s *Scanner) Texts(len int) []string { a := make([]string, len) for i := 0; i < len; i++ { a[i] = s.Text() } return a } func (s *Scanner) Ints(len int) []int { a := make([]int, len) for i := 0; i < len; i++ { a[i] = s.Int() } return a } func (s *Scanner) IntsMin(len int) ([]int, int) { a, min := make([]int, len), 0 for i := 0; i < len; i++ { a[i] = s.Int() if i == 0 || a[i] < min { min = a[i] } } return a, min } func (s *Scanner) IntsMax(len int) ([]int, int) { a, max := make([]int, len), 0 for i := 0; i < len; i++ { a[i] = s.Int() if i == 0 || a[i] > max { max = a[i] } } return a, max } func (s *Scanner) Floats(len int) []float64 { a := make([]float64, len) for i := 0; i < len; i++ { a[i] = s.Float() } return a } func (s *Scanner) bytes() []byte { b, _ := s.next(); return b } func (s *Scanner) next() (b []byte, size int) { for n := 0; ; { for i := s.end; i < s.size; i++ { if s.split(s.buf[i]) || i == s.eof { b, size = s.buf[s.start:i], i-s.start s.start, s.end = i+1, i+1 return } } s.end = s.size if n++; n == 2 { // 無限ループ対策 panic("lack of buffer size") } s.read() } } func (s *Scanner) read() { copy(s.buf, s.buf[s.start:s.end]) s.end -= s.start s.start = 0 n, _ := s.r.Read(s.buf[s.end:]) s.eof = s.end + n } func ParseInt(b []byte) (n int) { for _, ch := range b { ch -= '0' if ch <= 9 { n = n*10 + int(ch) } } if b[0] == '-' { return -n } return } var float64pow10 = []float64{ 1e0, 1e1, 1e2, 1e3, 1e4, 1e5, 1e6, 1e7, 1e8, 1e9, 1e10, 1e11, 1e12, 1e13, 1e14, 1e15, 1e16, 1e17, 1e18, 1e19, 1e20, 1e21, 1e22, } func ParseFloat(b []byte) float64 { f, dot := 0.0, 0 for i, ch := range b { if ch == '.' { dot = i + 1 continue } if ch -= '0'; ch <= 9 { f = f*10 + float64(ch) } } if dot != 0 { f /= float64pow10[len(b)-dot] } if b[0] == '-' { return -f } return f }ベンチマーク
ベンチマークコード
package main import ( "bytes" "fmt" "io" "testing" ) func BenchmarkScanner_Bytes(b *testing.B) { benchBytes(b, myScanner()) } func BenchmarkBufioScanner_Bytes(b *testing.B) { benchBytes(b, bufScanner()) } func BenchmarkBufioReader_Bytes(b *testing.B) { benchBytes(b, bufReader()) } func BenchmarkScanner_Text(b *testing.B) { benchText(b, myScanner()) } func BenchmarkBufioScanner_Text(b *testing.B) { benchText(b, bufScanner()) } func BenchmarkBufioReader_Text(b *testing.B) { benchText(b, bufReader()) } func BenchmarkScanner_Int64(b *testing.B) { benchInt64(b, myScanner()) } func BenchmarkBufioScanner_Int64(b *testing.B) { benchInt64(b, bufScanner()) } func BenchmarkBufioReader_Int64(b *testing.B) { benchInt64(b, bufReader()) } func BenchmarkScanner_Float(b *testing.B) { benchFloat(b, myScanner()) } func BenchmarkBufioScanner_Float(b *testing.B) { benchFloat(b, bufScanner()) } func BenchmarkBufioReader_Float(b *testing.B) { benchFloat(b, bufReader()) } func myScanner() *Scanner { return NewScannerSize(newReader(), size) } func bufScanner() *BufioScanner { return NewBufioScanner(newReader()) } func bufReader() *BufioReader { return NewBufioReader(newReader(), size) } func benchBytes(b *testing.B, r interface{ Bytes() []byte }) { b.ResetTimer() for i := 0; i < b.N; i++ { if b := r.Bytes(); !bytes.Equal(b, expectedBytes) { panic(fmt.Sprintf("%d: %v != %v", i, b, expectedBytes)) } } } func benchText(b *testing.B, r interface{ Text() string }) { b.ResetTimer() for i := 0; i < b.N; i++ { if t := r.Text(); t != expectedText { panic(fmt.Sprintf("%d: %s != %s", i, t, expectedText)) } } } func benchInt64(b *testing.B, r interface{ Int64() int64 }) { b.ResetTimer() for i := 0; i < b.N; i++ { if n := r.Int64(); n != expectedInt { panic(fmt.Sprintf("%d: %d != %d", i, n, expectedInt)) } } } func benchFloat(b *testing.B, r interface{ Float() float64 }) { b.ResetTimer() for i := 0; i < b.N; i++ { if n := r.Float(); n != expectedFloat { panic(fmt.Sprintf("%d: %g != %g", i, n, expectedFloat)) } } } var ( expectedFloat = 1e5 expectedInt = int64(expectedFloat) expectedText = fmt.Sprint(expectedInt) expectedBytes = []byte(expectedText) size = 1024 * 4 ) // 無限に Read できる io.Reader type reader struct { buf []byte pos int } func newReader() io.Reader { var r reader r.buf = append(expectedBytes, '\n') return &r } func (r *reader) Read(p []byte) (int, error) { for i := range p { p[i] = r.buf[r.pos] r.pos++ r.pos %= len(r.buf) } return len(p), nil }
BenchmarkScanner_Bytes-8 12512408 94.3 ns/op 8 B/op 1 allocs/op BenchmarkBufioScanner_Bytes-8 10503355 113 ns/op 8 B/op 1 allocs/op BenchmarkBufioReader_Bytes-8 13317040 88.2 ns/op 8 B/op 1 allocs/op BenchmarkScanner_Text-8 13103284 95.7 ns/op 8 B/op 1 allocs/op BenchmarkBufioScanner_Text-8 10414760 115 ns/op 8 B/op 1 allocs/op BenchmarkBufioReader_Text-8 11947772 93.1 ns/op 8 B/op 1 allocs/op BenchmarkScanner_Int64-8 14290854 84.3 ns/op 0 B/op 0 allocs/op BenchmarkBufioScanner_Int64-8 12132273 100 ns/op 0 B/op 0 allocs/op BenchmarkBufioReader_Int64-8 12582981 94.6 ns/op 8 B/op 1 allocs/op BenchmarkScanner_Float-8 13168230 88.1 ns/op 0 B/op 0 allocs/op BenchmarkBufioScanner_Float-8 11464554 106 ns/op 0 B/op 0 allocs/op BenchmarkBufioReader_Float-8 12112162 97.2 ns/op 8 B/op 1 allocs/op
BenchmarkScanner_**が自作 Scanner
BenchmarkBufioScanner_**がbufio.Scanner
BenchmarkBufioReader_**がbufio.Reader
を使ったベンチマークになります。実際に標準入力から読み取っているわけではないため、どれも速いです。
数値を改行ごとに無限に流す io.Reader を用意して計測しました。
数値変換関数は全て同じもの(自作)を使用しており、条件は同じです。結果は...
[]byte→bufio.Readerが最速string→ 差はないけどbufio.Readerが最速(泣)int64→ 自作 Scanner が最速float→ 自作 Scanner が最速となりました。
string の読み込みがbufio.Readerに及ばず悲しい気持ちになりましたが、一応数値に関しては自作が最速ということで..最後に
自作 Scanner にはもっと改善の余地があるはずです。
[]byteの読み込み速度でbufio.Readerに負けていますし、Bytes()メソッドはバッファサイズを超える長いテキストを一度に読み込むことができないという欠点もあります。
興味のある方は、より速くて便利な Scanner 作りにチャレンジしてみてください。
(バッファサイズを超えるテキストの読み込みはbufio.Reader.ReadBytesを参考にすると良いです)まぁ、自作 Scanner はともかく、変換用関数だけでも使ってみてください。
また、ライブラリの必要な部分のみを抽出して、提出用コードを自動生成するツールも作りましたので、合わせて使っていただけると幸いです。
- 投稿日:2020-06-27T14:57:43+09:00
知識0からGo言語でCTF用スコアサーバを構築した結果、最高だった話
※追記
06/28:ソースコードにてのご指摘がありました。あくまでコロナ自粛から始めたので、拙いコードですので温かい目で見てもらえると嬉しいです。今後、Goについてもっと勉強していきたいと思いました。
はじめに
どうも、テスト前で何もしたくないMarnyです。
今回は、Qiita夏祭り2020_パソナテックというイベントがやっていたので記事を書いていこうかなと思います。テーマ:〇〇(言語)のみを使って、今△△(アプリ)を作るとしたら
コードの詳細を解説するより、どういったメリットがあるのか、デメリットがあるのか。そういった点に注目していきます。
開発経緯
そもそもなんでCTF用のスコアサーバを構築したかというと、同級生3人で通っている高専の
低学年用にLinuxリテラシー等を学習できる環境を作ろうぜ!という話があり、CTFを構築することになりました。
で、使用言語なんですけど、先生から「DjangoかGo使いなよ」
と言われて、僕はGoを選びました。
今じゃGo信者ですGo言語とは
シンプル、高速、メモリ効率が良い、メモリ破壊が無い、並行処理が得意などの特徴を備えている
これが一番の特徴かなと思います。
とりあえず早くて、見やすいってのがいいところですね今回はGoがすでに実行できる環境を想定しています。Goの環境を作りたい方は、Dockerなり、他の人の記事を参考にしてください。
開発環境
go version go1.13.7 mysql Ver 15.1 Distrib 10.4.11-MariaDB, for Win64 (AMD64)実際のコード
とりあえず、雑なCSSですがgithubに上げときました。
URL:https://github.com/marnysan111/SMOTY
特にログインするページは生のhtmlです例として、
main.goとuserDB.goを表示しますmain.gopackage main import ( "net/http" "sort" "strconv" "github.com/gin-contrib/sessions" "github.com/gin-contrib/sessions/cookie" "github.com/gin-gonic/gin" ) func main() { r := gin.Default() r.LoadHTMLGlob("templates/*.html") r.Static("/pictures", "./pictures") store := cookie.NewStore([]byte("secret")) r.Use(sessions.Sessions("user", store)) dbInit_users() dbInit_linux() dbInit_server() dbInit_router() //ログインページ r.GET("/", func(c *gin.Context) { c.HTML(http.StatusOK, "login.html", gin.H{}) }) //サインアップの処理 r.POST("/signup", func(c *gin.Context) { name := c.PostForm("name") password := c.PostForm("password") dbSignup(name, password) c.HTML(http.StatusOK, "signup.html", gin.H{"name": name, "password": password}) }) //ログインの処理 r.POST("/login", func(c *gin.Context) { name := c.PostForm("name") password := c.PostForm("password") session := sessions.Default(c) dblogin(name, password) session.Set("user_name", name) session.Save() c.Redirect(302, "/smoty") }) //SMOTYトップページ r.GET("/smoty", func(c *gin.Context) { session := sessions.Default(c) if session.Get("user_name") == nil { panic("ログインしてない") } c.HTML(200, "smoty.html", gin.H{"user_name": session.Get("user_name")}) }) ~~~~以下略~~~~ r.Run(":80") }userDB.gopackage main import ( "github.com/jinzhu/gorm" _ "github.com/jinzhu/gorm/dialects/mysql" ) type Users struct { gorm.Model Name string //頭文字を大文字にしないと、DBにマイグレーションできない Password string Score int } // DB接続 func dbInit_users() { db, err := gorm.Open("mysql", "root:password@/database_name?charset=utf8&parseTime=True&loc=Local") if err != nil { panic("Init失敗") } db.AutoMigrate(&Users{}) defer db.Close() } //サインアップ func dbSignup(name string, password string) { db, err := gorm.Open("mysql", "root:password@/database_name?charset=utf8&parseTime=True&loc=Local") if err != nil { panic("Signup失敗") } var users Users if err := db.Where("name = ?", name).First(&users).Error; err == nil { panic("すでに同じ名前が使われています") } else { db.Create(&Users{Name: name, Password: password}) } defer db.Close() } ~~~~以下略~~~~解説
- DBとの接続にはgormというのを使っています。日本語のドキュメントもしっかりとあったので、非常にわかりやすかったです。
- ルーティングのはginというのを使っています。すごく単純に見やすくルーティングができて、標準パッケージが理解できなかった僕からしたら最高でした。
main.goというのはルーティング、userDB.goというのはユーザのログイン関係について書かれています。Goのいいところ
ここからはGoで開発してみた結果、感じたこと,良かったと思う点について話していきます。
- エラーが見やすい
- 戻り値の使い方がおもしろい
- とりあえず早い
- いろんな書き方がある
- 自動でインデント整理してくれる(VScode)
- いろんな機能をgithubより追加できる
- 自分好みのファイル構造にできる
パッと出てきたのはこのくらいですね。
Goではエラーハンドリングをif文で
err := 処理みたいに定義したerrをerr != nilとエラーがあるかないかで判断します。
これを忘れるから嫌という人もいるらしいですが、基本的にエラーが出るので大丈夫かと思います。Goの悪いところ
- 書き方が無限過ぎて、参考にならないページが多い(と思う)
- 書いている人が少ない
振り絞ってこのくらいだと思います。
Goには色々なパッケージがあるので、ルーティングだけでも何個もやり方があります。そういったことから、同じようなコードというのはほぼほぼないのかなと思います。
あと、実装している企業さんも少ないようなのでそれも悲しい点です。感想
とにかくGoに出会えてよかったなと思います。この前Laravelを触りましたが、ファイル構造も自分の好みにできなくて少し面倒でした。
これを気にGoを使ってもらう人が増えてもらえればなと思います。気が向いたらコードの完全解説やDocker環境構築とかもしたいですね
ではではー
- 投稿日:2020-06-27T14:13:57+09:00
ネットワークプロトコルというものをプログラム的にどうやって実装するのかわずかに見えてきた話。ついでにGoでICMP エコー要求を実装する。
ネットワークの通信ってどういう仕組なの?プロトコルってどうやって実装するの?OSってどうなってんの?そんなことが気になり出す時が、IT職をやっていると訪れますよね。特にほぼ未経験でこの業界に入ってくると、いくらプログラミングやコマンドを学んでも、その先のOSやハードウェアや通信の具体的な動きが全然イメージできないんじゃないでしょうか。私もそんな1人です。
ド田舎の農学部から新卒で業務系SIerへ就職後に1度転職を経験し、IT職に着いて早5年目。OS、プロトコルの実装やハードウェアに関する仕事に関わることはありませんでした。しかし地道に学習を続けた結果、樹海を超えてようやくチラチラと平野が見えてまいりました。よく見るとその先に大きな大きな沼が見えます。たぶん深さはマントルくらいまで続いているじゃないでしょうか。知らんけど。
で、何が言いたいかというと、独学でようやく薄っすらとプロトコルの実装方法(RFCを読んでそのとおりにデータ構造を作成し正常なパケットを送信する方法)と、その時にOSやハードウェアがどんな動きをしているのかが見えてきて、ひとまずICMPエコー要求を実装できたということです。
そこで、今回は私と同様に沼が見える前の樹海で迷ってしまった方々に向け、自分なりに旗印をつけていきたいと思います(ネットワークプロトコルの実装に関して)。
稚拙な部分はあると思いますが、樹海を抜けた今だからこそ書ける内容もあると思っています。もし間違っている点や適切でない点があったら指摘いただけたら嬉しいです。質問もあればコメント欄にお願いします(遅レスです)。可能な範囲で回答します。
プログラムからパケットを流すまで
まず、何らかの通信するをプログラムを作成して、そのプログラムがNICからデータを流すまでの流れを大雑把に説明すると以下となります。
1. プログラムがCPUによってメモリに展開される 2. プログラムはパケットの元となるデータをメモリ上に作成する(演算はCPU) => 0010001111101011001111みたいな2進数のデータの羅列をイメージしてください。 3. プログラムはOSのシステムコールに上記2のデータを渡す => システムコールはハードに近い話をすると、ソフトウェア割り込みというもので実施します。 4. システムコールに基づいてOSがデバイスドライバーを呼び出す 5. デバイスドライバーはNICの送信用データを格納するレジスタに上記2のデータを書き込む(書き込むのはCPU) => 送信されるデータが一定量貯まるまでレジスタに書き込まれていきます。 6. 送信用データのレジスタが溜まったら、デバイスドライバーはNICの送信を制御するレジスタに「送信」のフラグを立てる 7. NICは送信用データが格納されたレジスタの2進数データをデジタル信号に変換し、ケーブルの先へデジタル信号を送信するこれで大雑把な流れがつかめるでしょうか。
パケットとなるデータの作り方 (前項2の説明)
ではパケットの元となるデータってどうやって作るの?っていう話です。まず本題に入る前に、軽くメモリ等の前提知識について説明します。
▼ 前提知識: メモリ上でのデータ
メモリはアドレスごとに区画があるのはご存知でしょう。そして多くの場合にメモリは1区画あたり1byte(8bit)です。つまりデータとしては以下のような感じです。なお、16進数は頭に0xとつけるのが通例です。8bitは2進数で8桁、16進数で2桁になります。2進数: 01010101 16進数: 0x55さていきなりですが、TCP/IPではIPアドレスの情報をパケット内に保持しますよね。IPv4アドレスは0.0.0.0 - 255.255.255.255の範囲です。よく見てみるとIPv4アドレスの各オクテッド(ドット毎の数字)って1byteです。つまり、メモリ上では1区画に1つのオクテッドを格納することになります。例えば、送信先として8.8.8.8 (Google Public DNS)を指定するとします。するとパケットとなるメモリ上のデータは以下のようになればいいわけで、要はこのように作っていったデータをNICのレジスタに書き込めばいいわけです。(番地は適当です)。
12番地: 0x08 13番地: 0x08 14番地: 0x08 15番地: 0x08ちなみに. (ドット)は?と思うかもしれませんが不要です。プロトコルではデータの並び順が定められているので、ドットがなくとも前から何番目に入っているからIPアドレスの何オクテッド、といったことがわかるようになっているからです。こういった決まりについてはRFCで規定されています。例えば ICMP であれば https://tools.ietf.org/html/rfc792 に記載されています。
▼ 本題: プログラムのデータ構造とメモリ
本題に入って少しソースコードを用いて説明していきます。私がよく使うGo言語用いて説明しますが、おそらく初見でも大丈夫です。以下の例は ICMP のメッセージに当たります。// 構造体の定義 type icmpMessage struct { Type uint8 // uint8 は符号なし8bit整数で1byteです。 Code uint8 Checksum uint16 // uint16 は符号なし16bit整数で2byteです。 Identifier uint16 SequenceNumber uint16 } // 構造体のインスタンス i := icmpMessage{ 0x08, 0x00, 0x0000, 0x0100, 0x0001, }上記インスタンスはメモリ上で以下のようにマップされるはずです(言語によってここは異なるかもしれません)。
12番地: 0x08 13番地: 0x00 14番地: 0x00 15番地: 0x00 16番地: 0x00 17番地: 0x01 18番地: 0x01 19番地: 0x00 ※補足 16番地と17番地が逆に見えるのは、メモリ上に格納されるデータがリトルエンディアンだからです。つまり、下の桁から若い番地に記録されるということです。18番地と19番地が逆に見えるのも同様の理由です。大雑把に言うと、例えばRFCではICMPのエコー要求をする場合に以下のように決まりがあります。
・ICMPのデータの最初の8bitで8を示せ ・ICMPのデータの9bit目から16bit目までで0を示せ詳細については https://tools.ietf.org/html/rfc792 で「Echo or Echo Reply Message」で文字列検索してみてください。
つまり、RFCの決まり通りにデータ構造を作っていけば、パケットの元となるデータがメモリ上に展開できるのです。ただし、プログラミング言語的にはstructはByte列ではなくあくまでも構造体なので、Byte列に当たる型(Goであれば[]byte)に変換したりする必要があります(メモリ上では変わらないのではと思います)。例えば以下のような感じです。
// iは先程の構造体のインスタンスです // bytes.Bufferは[]byteを扱う構造体(慣れない方はClassと思っていただければ)のインスタンスです。 // Byte列を格納数バッファを作成します。 buf := new(bytes.Buffer) // バッファに構造体をビッグエンディアンで書き込みます。 err := binary.Write(buf, binary.BigEndian, i) // ※ TCP/IPはビッグエンディアンでデータを扱います。RFCに基づいたByte列が作成できたら、それをシステムコールに渡せば我々のプログラム上でやることはおしまいです。あとはOSやデバイスドライバーがNICのレジスタを操作してデータを送信してくれます。
ICMPメッセージを実装してみる
最後に、ICMPエコー要求のメッセージ部を実装してみました。説明についてはソースコード中に記載しています。なお、今回はIPヘッダーは自作せず、IPペイロード(データ部)すなわちICMPメッセージ部のみの自作です。IPヘッダーから作るにはデータリンク層すなわちrawソケットを取得する必要があるようです。余談ですが、これはGoではsyscallパッケージを使用するようです。IPヘッダーの作成も要領は変わらず、そんなに難しくなさそうなので、また今度やってみようと思います。
package main import ( "bytes" "encoding/binary" "fmt" "net" ) type icmpMessage struct { Type uint8 Code uint8 Checksum uint16 Identifier uint16 SequenceNumber uint16 } func main() { i := icmpMessage{ 0x08, // エコー要求では Type を 8 とします。 0x00, // エコー要求では Code を 0 とします。 0x0000, // チェックサムは計算前は 0 とします。後で説明します。 0x0100, // エコー要求を特定するための ID と思ってください。任意の値。 0x0001, // エコー要求と応答の対応関係を把握するためのシーケンスです。任意の値。 } // icmpMessage 構造体を []byte すなわちバイト列に変換します。 buf := new(bytes.Buffer) err := binary.Write(buf, binary.BigEndian, i) // チェックサムを実施します。 // 後で説明しますが、チェックサムで求めた値を、再びChecksumにセットし直します。 i.Checksum = checkSum(buf) err = binary.Write(buf, binary.BigEndian, i) // IPアドレス8.8.8.8へのコネクションを作成します。 con, err := getIpV4Connect("8.8.8.8") if err != nil { fmt.Println(err) return } // ここでIPv4のペイロードにICMPメッセージのByte列を書き込み、 // ICMPが送信されます。 con.Write(buf.Bytes()) } // チェックサムです func checkSum(buf *bytes.Buffer) uint16 { // ICMPメッセージ部を16bit毎に分割します bufInt := make([]uint16, buf.Len()/2) binary.Read(buf, binary.BigEndian, bufInt) // 桁上りの可能性があるので、32bitバッファーに一旦すべて加算します。 var sum uint32 = 0 for i := 0; i < len(bufInt); i++ { sum += uint32(bufInt[i]) } // 32bitバッファーを上位16bitと下位16bitに分割します。 var front16bit uint16 = uint16((sum & 0xffff0000) >> 16) var back16bit uint16 = uint16(sum & 0x0000ffff) // 上位16bitと下位16bitを加算したあとにビット反転します。これがチェックサムの値です。 checkSum := ^(front16bit + back16bit) return checkSum } // IPv4のコネクションを取得するための処理です。 // net.Dialをラッパーしたもので、あまり難しいことはやっていません。 func getIpV4Connect(ip string) (net.Conn, error) { // ipv4へのコネクションをここで取得します。 // 内部的にIPヘッダー等はこのコネクションが作成してくれます。 con, err := net.Dial("ip4:1", ip) if err != nil { return nil, err } return con, nil }▼ 補足: チェックサムについて
ぶっちゃけICMPのRFCを読み解いて実装するまでの大まかな流れは、前項までの内容をきちんと理解した状態になればさほど難しくありませんでした。しかしチェックサムだけは数時間ハマりましたので補足を。チェックサムとはデータが破損していないかチェックするための仕組みです。クライアント側で破損していない場合のチェックサムの確認値を計算し、送信するICMPメッセージ部内に格納します。ICMPのチェックサムの流れは以下です。
1. ICMPメッセージ部全体を16bit毎に分割して全てを足し合わせる 2. 16bitより上に桁上りがあったら、17bit目以降を切り取って16bit下げシフトして、16bit部に加算する => つまり17bit,18bit...と増やすのではない。チェックサムは16bitと決まっている。 3. 上記2で求めた16bitの値について、さらに1の補数を取る(つまりbit反転)おそらくこれでいいはず。間違っていたらすいません。
以上、ドッカーンと説明してきました。誰かの役に立てたら嬉しいです。今度は IP ヘッダーから自作し、ARPとTCPを実装しようと思っていますので、そのときにまた記事を書きたいと思います。
- 投稿日:2020-06-27T11:40:50+09:00
DocBase APIのGo Clientを作った
いろんなドキュメンテーションサービスあるけれど、DocBaseがミニマルでいい感じ。
だけどマイナー故か、APIクライアントはほとんどない。APIドキュメントは充実しているので、参考にAPI Clientライブラリを作っておきました。
https://github.com/kyoh86/go-docbase
DocBase×Goユーザーの皆様よしなに。
- 投稿日:2020-06-27T10:45:33+09:00
Google Codelabsに任意のURLのiframeを埋め込む
はじめに
Codelabsのナビゲーションをつかって、独自のチュートリアルページを作りたい。その際、iframeでいろいろ埋め込みたいが、claatのセキュリティ制限で、プリコンパイルのバイナリでは限られたドメインしかiframe埋め込み許可されていない。
(claatとはGoogle Docsまたはmdの原稿をソースに、Codelabsのhtmlを生成するプログラムです。)ならば、claatのソースに手を加えて、makeしよう!ホワイトリストにドメインを追記するだけだぜ!
環境
以下の内容は、WSL2のUbuntu上で確かめました。
手順
基本的には、claatのreadme.mdを基本として行います。もっとよいやり方あれば教えて下さい。
claatのインスト
$ go get github.com/googlecodelabs/tools/claatする。cf.) README.md#install
ソースの書き換え(whitelistへの追加)
前段の操作で
~/go/binにバイナリが、~/go/srcにソースが入ったものとして書き進めます。
~/go/src/github.com/googlecodelabs/tools/claat/types/node.goの以下の部分に任意のドメインを追加します。node.go// iframe whitelist - set of domains allow to embed iframes in a codelab. var IframeWhitelist = []string{ "google.com", "google.dev", "dartlang.org", "web.dev", "observablehq.com", "repl.it", "codepen.io", "glitch.com", "carto.com", }make
次のようにすると、
./binにclaatというバイナリができてる。嬉しい。$ pwd $HOME/go/src/github.com/googlecodelabs/tools/claat $ makeおわりに
- むし歯と歯周病は予防できる病気です。朝、昼、晩、1日3回、歯をみがきましょう。
- 健口は健康の要(かなめ)です。歯科医院に定期的に通って、歯のチェックアップを受けましょう。
- 投稿日:2020-06-27T00:08:27+09:00
yukicoder contest 254 参戦記
yukicoder contest 254 参戦記
A 1095 Smallest Kadomatsu Subsequence
ナイーブに書くと O(N2) になってしまう. 最初はセグ木かなあと思ったけど、指定値以上の最小値の検索が出来る気がしなかったので、平衡二分探索木となりました. 中心の門松より左側と右側の平衡二分探索木をメンテしつつ、凸の場合は最小値、凹の場合は真ん中の大きさ以上の最小値を求めて、門松列の大きさの最小値を求めればいいだけ. O(NlogN).
package main import ( "bufio" "fmt" "math" "os" "strconv" "strings" ) var ( y uint = 88172645463325252 ) func xorshift() uint { y ^= y << 7 y ^= y >> 9 return y } type treapNode struct { value int priority uint count int left *treapNode right *treapNode } func newTreapNode(v int) *treapNode { return &treapNode{v, xorshift(), 1, nil, nil} } func treapRotateRight(n *treapNode) *treapNode { l := n.left n.left = l.right l.right = n return l } func treapRotateLeft(n *treapNode) *treapNode { r := n.right n.right = r.left r.left = n return r } func treapInsert(n *treapNode, v int) *treapNode { if n == nil { return newTreapNode(v) } if n.value == v { n.count++ return n } if n.value > v { n.left = treapInsert(n.left, v) if n.priority > n.left.priority { n = treapRotateRight(n) } } else { n.right = treapInsert(n.right, v) if n.priority > n.right.priority { n = treapRotateLeft(n) } } return n } func treapDelete(n *treapNode, v int) *treapNode { if n == nil { panic("node is not found!") } if n.value > v { n.left = treapDelete(n.left, v) return n } if n.value < v { n.right = treapDelete(n.right, v) return n } // n.value == v if n.count > 1 { n.count-- return n } if n.left == nil && n.right == nil { return nil } if n.left == nil { n = treapRotateLeft(n) } else if n.right == nil { n = treapRotateRight(n) } else { // n.left != nil && n.right != nil if n.left.priority < n.right.priority { n = treapRotateRight(n) } else { n = treapRotateLeft(n) } } return treapDelete(n, v) } func treapCount(n *treapNode) int { if n == nil { return 0 } return n.count + treapCount(n.left) + treapCount(n.right) } func treapString(n *treapNode) string { if n == nil { return "" } result := make([]string, 0) if n.left != nil { result = append(result, treapString(n.left)) } result = append(result, fmt.Sprintf("%d:%d", n.value, n.count)) if n.right != nil { result = append(result, treapString(n.right)) } return strings.Join(result, " ") } func treapMin(n *treapNode) int { if n.left != nil { return treapMin(n.left) } return n.value } func treapGEMin(n *treapNode, v int) int { if n.value == v { return v } if n.value > v { if n.left != nil { return treapGEMin(n.left, v) } return n.value } // n.value < v if n.right != nil { return treapGEMin(n.right, v) } return math.MaxInt64 } func treapMax(n *treapNode) int { if n.right != nil { return treapMax(n.right) } return n.value } type treap struct { root *treapNode size int } func (t *treap) Insert(v int) { t.root = treapInsert(t.root, v) t.size++ } func (t *treap) Delete(v int) { t.root = treapDelete(t.root, v) t.size-- } func (t *treap) String() string { return treapString(t.root) } func (t *treap) Count() int { return t.size } func (t *treap) Min() int { return treapMin(t.root) } func (t *treap) Max() int { return treapMax(t.root) } func (t *treap) GEMin(v int) int { return treapGEMin(t.root, v) } func min(x, y int) int { if x < y { return x } return y } func main() { defer flush() N := readInt() A := make([]int, N) for i := 0; i < N; i++ { A[i] = readInt() } lt := &treap{} rt := &treap{} lt.Insert(A[0]) for i := 2; i < N; i++ { rt.Insert(A[i]) } result := math.MaxInt64 for i := 1; i < N-1; i++ { a := lt.Min() b := rt.Min() if a <= A[i] && b <= A[i] { // printf("凸 %d %d %d\n", a, A[i], b) result = min(result, a+A[i]+b) } c := lt.GEMin(A[i]) d := rt.GEMin(A[i]) if c != math.MaxInt64 && d != math.MaxInt64 && c >= A[i] && d >= A[i] { // printf("凹 %d %d %d\n", c, A[i], d) result = min(result, c+A[i]+d) } lt.Insert(A[i]) rt.Delete(A[i+1]) } if result == math.MaxInt64 { println(-1) } else { println(result) } } const ( ioBufferSize = 1 * 1024 * 1024 // 1 MB ) var stdinScanner = func() *bufio.Scanner { result := bufio.NewScanner(os.Stdin) result.Buffer(make([]byte, ioBufferSize), ioBufferSize) result.Split(bufio.ScanWords) return result }() func readString() string { stdinScanner.Scan() return stdinScanner.Text() } func readInt() int { result, err := strconv.Atoi(readString()) if err != nil { panic(err) } return result } func readInts(n int) []int { result := make([]int, n) for i := 0; i < n; i++ { result[i] = readInt() } return result } var stdoutWriter = bufio.NewWriter(os.Stdout) func flush() { stdoutWriter.Flush() } func printf(f string, args ...interface{}) (int, error) { return fmt.Fprintf(stdoutWriter, f, args...) } func println(args ...interface{}) (int, error) { return fmt.Fprintln(stdoutWriter, args...) }追記: 以下でも通る. 左右からの累積 Min を使っている. 指定値以上の最小値の検索が出来ていないので Ai を B としたときの 凹 タイプの門松列が作成できる場合でも、作成できないとしてしまうことがある. 嘘解法じゃないかと思いつつ、反例を考えているが思いつかない. O(N).
from itertools import accumulate INF = float('inf') N, *A = map(int, open(0).read().split()) l = list(accumulate(A, min)) r = list(accumulate(A[::-1], min))[::-1] result = INF # 凸 タイプの門松列の場合 for i in range(1, N - 1): a = l[i - 1] b = A[i] c = r[i + 1] if a <= b and c <= b: result = min(result, a + b + c) # 凹 タイプの門松列の場合 for i in range(1, N - 1): a = l[i - 1] b = A[i] c = r[i + 1] if b <= a and b <= c: result = min(result, a + b + c) if result == INF: print(-1) else: print(result)B 1096 Range Sums
ナイーブに書くと O(N3) になってしまう. 累積和しても O(N2). 更にセグ木を投入することにより、O(NlogN) になって解けた.
from operator import add from itertools import accumulate class SegmentTree: _f = None _size = None _offset = None _data = None def __init__(self, size, f): self._f = f self._size = size t = 1 while t < size: t *= 2 self._offset = t - 1 self._data = [0] * (t * 2 - 1) def build(self, iterable): f = self._f data = self._data data[self._offset:self._offset + self._size] = iterable for i in range(self._offset - 1, -1, -1): data[i] = f(data[i * 2 + 1], data[i * 2 + 2]) def query(self, start, stop): def iter_segments(data, l, r): while l < r: if l & 1 == 0: yield data[l] if r & 1 == 0: yield data[r - 1] l = l // 2 r = (r - 1) // 2 f = self._f it = iter_segments(self._data, start + self._offset, stop + self._offset) result = next(it) for e in it: result = f(result, e) return result N, *A = map(int, open(0).read().split()) a = list(accumulate(A)) st = SegmentTree(N, add) st.build(a) result = 0 result += st.query(0, N) for i in range(1, N): result += st.query(i, N) - a[i - 1] * (N - i) print(result)追記: Ai が答えに足し込まれるのは l = 1, .., i かつ r = i, ..., N のときなので、答えに足し込まれる回数は (i + 1) × (N - i) 回となると考えれば簡単だった. O(N).
N, *A = map(int, open(0).read().split()) result = 0 for i in range(N): # l = 0 .. i, r = i .. N - 1 result += A[i] * (i + 1) * (N - i) print(result)追々記: セグ木ではなく Sparse table で解いたと言う人がいたのだが、Disjoint sparse table の間違え? Sparse table は演算に冪等性が必要だが、Min とは違い Sum にはそれはないので. Disjoint sparse table の実装を持ってないので試せなかった.
追々々記: Disjoint sparse table を実装した.
from itertools import accumulate from operator import add class DisjointSparseTable: _f = None _data = None _lookup = None def __init__(self, a, f): self._f = f b = 0 while (1 << b) <= len(a): b += 1 _data = [[0] * len(a) for _ in range(b)] _data[0] = a[:] for i in range(1, b): shift = 1 << i for j in range(0, len(a), shift << 1): t = min(j + shift, len(a)) _data[i][t - 1] = a[t - 1] for k in range(t - 2, j - 1, -1): _data[i][k] = f(a[k], _data[i][k + 1]) if t >= len(a): break _data[i][t] = a[t] r = min(t + shift, len(a)) for k in range(t + 1, r): _data[i][k] = f(_data[i][k - 1], a[k]) self._data = _data _lookup = [0] * (1 << b) for i in range(2, len(_lookup)): _lookup[i] = _lookup[i >> 1] + 1 self._lookup = _lookup def query(self, start, stop): stop -= 1 if start >= stop: return self._data[0][start] p = self._lookup[start ^ stop] return self._f(self._data[p][start], self._data[p][stop]) N, *A = map(int, open(0).read().split()) a = list(accumulate(A)) st = DisjointSparseTable(a, add) result = 0 result += st.query(0, N) for i in range(1, N): result += st.query(i, N) - a[i - 1] * (N - i) print(result)C 1097 Remainder Operation
終了2分前に解けて嬉しかった. 余りは N 回以内に同じ余りが出てきてループする. ループ検出して、1周期の長さと1ループ中の増分を求めればクエリに O(1) で回答できるようになるので O(N + Q) で解けた. ABC167D - Teleporter を思い出した.
from sys import stdin readline = stdin.readline N = int(readline()) A = list(map(int, readline().split())) X = 0 b = [-1] c = [X] used = set() while True: r = X % N X += A[r] if r in used: break used.add(r) b.append(r) c.append(X) b.append(r) c.append(X) loop_start = b.index(b[-1]) loop_len = len(b) - loop_start - 1 Q = int(readline()) for _ in range(Q): K = int(readline()) if K < len(b): print(c[K]) else: K -= loop_start a = K // loop_len K %= loop_len K += loop_start print(c[K] + a * (c[-1] - c[loop_start]))