- 投稿日:2019-04-05T22:18:01+09:00
10以上の文字列のORDER BYは気をつけないとダメ
数値でソートするカラムが数値型なら問題ないですが、
文字列型の場合のソートは挙動が変わります。数値型の場合 1,2,3,4,5,6,7,8,9,10,11 文字列型の場合 1,10,11,2,3,4,5,6,7,8,9原因としては文字列で見てしまうので最初の文字が「1」なので「1」「10」「11」が「2」より優先されてしまいます。
- 投稿日:2019-04-05T14:17:09+09:00
[Django]管理画面の一覧表示部分に別テーブルのフィールドを表示する
はじめに
「[Django]管理画面の一覧表示部分に、(表示対象のテーブルで外部キーなどでの関連もさせていない)別テーブルのフィールドを表示する」
最終的に結構単純でしたが、同じようなことをしている人が少なくて割と悩んだのでメモ。
多分ドキュメントに丁寧に目を通した人にとっては当たり前のことかも。やりたいこと
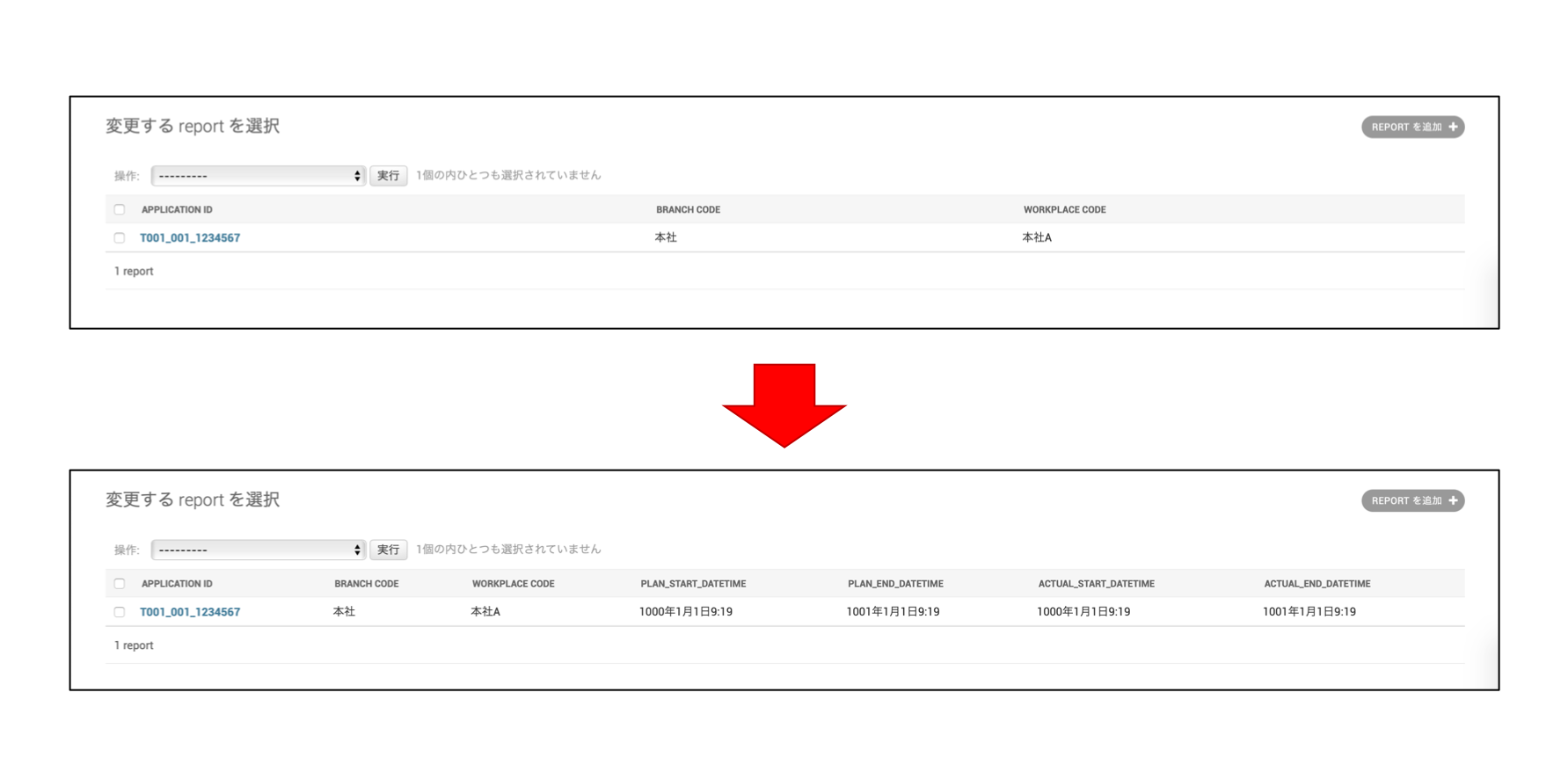
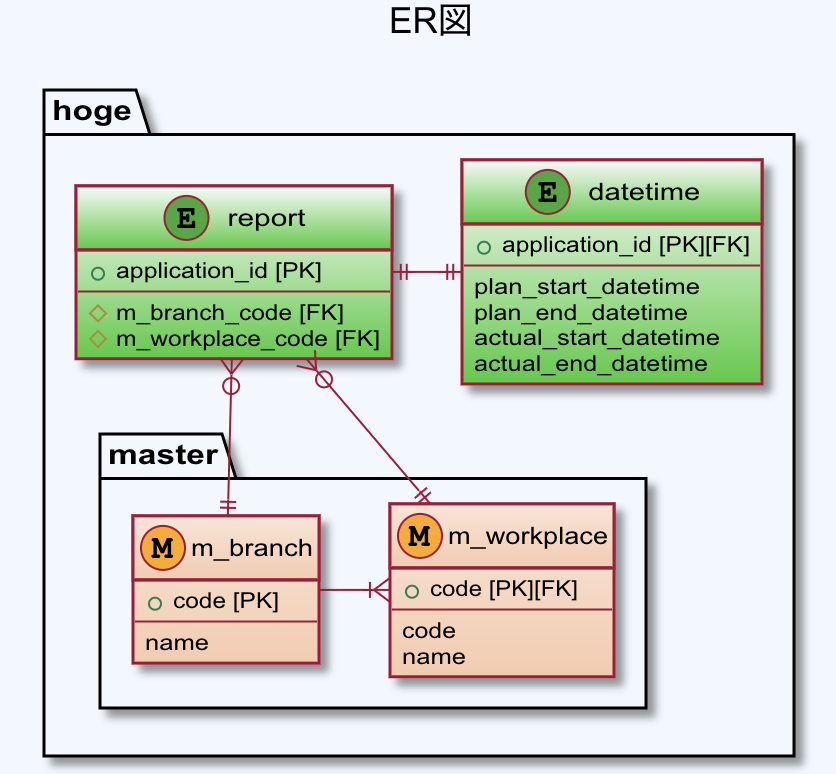
上の画面を下のような表示にしたかったのですが、この時、DBの構成は下記のER図のようになっており、日時系の値とそれ以外の値は別DBのフィールドのため、単純に
list_displayで追加することができなかった。[やりたい画面レイアウト]
[ER図]
(記事用に適当に書き換えたので、ER図と下の方のコードの整合性保ってない部分もあるかも)
要点
特に重要なのは下記の部分ですが、一応全貌を載せておきます。
重要部分1def plan_start_datetime(self, obj): list_got_objects = list(Datetime.objects.all().values_list('plan_start_datetime', flat=True)) return list_got_objects※1:取得したい情報の条件(例:「id=1」など)
重要部分2list_display = ( 'plan_start_datetime', )要点1.
<テーブル名>.objects.all()の戻り値はQuerySetなので、values_list()で値を取得する必要がある。要点2.
values_list()で取得した値をスライスして取得した「文字列」をlist_displayに渡す。以下、全貌
models.py# coding: utf-8 from django.db import models from django.utils import timezone from django.core.validators import MaxValueValidator # コードがforeign keyとして使用されるため、このクラスを先に定義している class M_branch(models.Model): def __str__(self): return self.name code = models.CharField(max_length=4, primary_key=True) name = models.CharField(max_length=128) # コードがforeign keyとして使用されるため、このクラスを先に定義している class M_workplace(models.Model): def __str__(self): return self.name branch_code = models.ForeignKey(M_branch, on_delete=models.CASCADE) code = models.CharField(max_length=4) name = models.CharField(max_length=128) class Report(models.Model): def __str__(self): return self.application_id application_id = models.CharField(max_length=32, primary_key=True) branch_code = models.ForeignKey(M_branch, on_delete=models.DO_NOTHING) workplace_code = models.ForeignKey(M_workplace, on_delete=models.DO_NOTHING) class Datetime(models.Model): def __str__(self): return self.plan_start_datetime application_id = models.OneToOneField(Report, on_delete=models.CASCADE) plan_start_datetime = models.DateTimeField() plan_end_datetime = models.DateTimeField() actual_start_datetime = models.DateTimeField() actual_end_datetime = models.DateTimeField()admin.pyfrom django.contrib import admin from .models import Report, Datetime, Participant, M_branch, M_workplace # TODO DatetimeやParticipantテーブルから必要な情報を取得して同じ表に表示する class ReportAdmin(admin.ModelAdmin): fieldsets = [ ('申請ID', {'fields': ['application_id']}), ('支部コード', {'fields': ['branch_code']}), ('職場コード', {'fields': ['workplace_code']}), ] list_display = ('application_id', 'branch_code', 'workplace_code', 'plan_start_datetime', 'plan_end_datetime', 'actual_start_datetime', 'actual_end_datetime', ) def plan_start_datetime(self, obj): list_got_objects = list(Datetime.objects.all().values_list('plan_start_datetime', flat=True)) return plan_start_datetime plan_start_datetime.short_description = 'plan_start_datetime' def plan_end_datetime(self, obj): list_got_objects = list(Datetime.objects.all().values_list('plan_end_datetime', flat=True)) return plan_end_datetime plan_end_datetime.short_description = 'plan_end_datetime' def actual_start_datetime(self, obj): list_got_objects = list(Datetime.objects.all().values_list('actual_start_datetime', flat=True)) return actual_start_datetime actual_start_datetime.short_description = 'actual_start_datetime' def actual_end_datetime(self, obj): list_got_objects = list(Datetime.objects.all().values_list('actual_end_datetime', flat=True)) return actual_end_datetime actual_end_datetime.short_description = 'actual_end_datetime' class M_branchAdmin(admin.ModelAdmin): fieldsets = [ ('支部コード', {'fields': ['code']}), ('支部名', {'fields': ['name']}), ] list_display = ('name', 'code') class M_workplaceAdmin(admin.ModelAdmin): fieldsets = [ ('支部コード', {'fields': ['branch_code']}), ('職場コード', {'fields': ['code']}), ('職場名', {'fields': ['name']}), ] list_display = ('name', 'code', 'branch_code') admin.site.register(Report, ReportAdmin) admin.site.register(M_branch, M_branchAdmin) admin.site.register(M_workplace, M_workplaceAdmin)以上。
- 投稿日:2019-04-05T00:57:13+09:00
MySQLのInnoDBのトランザクション周りについて調べたことをまとめた
元々NoSQLしか使用していなく、今年に入って転職して初めて業務でMySQLを使用しだした。
雰囲気で使ってる感じがしてよくないなと思ったので、色々調べた。今回まとめたのは、MySQLのInnoDBのトランザクションについての一部。
この記事でまとめる対象の事柄は、既に詳しく素晴らしい記事が存在するが、それなりに難しい内容なのでそれらを読みながら理解の補助的に、またメモ的にまとめたものが本記事。また、「この概念を理解するには、事前に〇〇の概念の理解が必要で、それを理解するにはこの記事がわかりやすい」といった形で自分が後から振り返られるようにもまとめた。
この記事はあくまでも理解の補助と、どの概要を学んだ方が良いかということをまとめた記事なので、詳細な理解は紹介している記事を読んだ方が良い。
トランザクションの分離レベル
トランザクションにはACID属性というものがあって、その中のI(Isolation)が分離性と呼ばれるもの。
トランザクションの分離にはレベルが存在する。
詳細は以下の記事等を参照。大事なのは、どの分離レベルにおいて、どんな不都合な読み込みが行われるかを認識することだと思う。
[RDBMS][SQL]トランザクション分離レベルについて極力分かりやすく解説 - Qiita
MySQLのInnoDBの Repeatable Read
MySQLのデフォルトのエンジンであるInnoDBのデフォルトのトランザクションの分離レベルはRepeatable Readである。
一般的に、Repeatable Readは、ダーティリードとファジーリードは防ぐことができるけれども、ファントムリードは防ぐことができない。
ファントムリードは、以下のようだとある。
別のトランザクションで挿入されたデータが見えることにより、一貫性がなくなる現象。
引用元: [RDBMS][SQL]トランザクション分離レベルについて極力分かりやすく解説 - Qiita
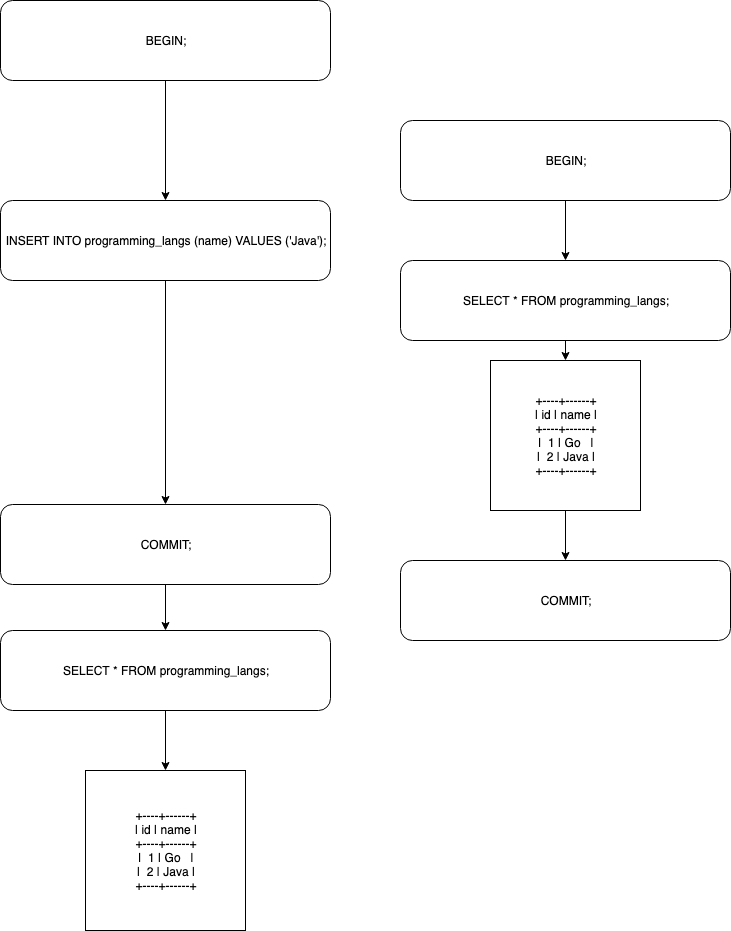
一般的なRepeatable Readの場合のシミュレーションすると以下のような感じ(実際にやったわけではない)
事前に以下のような操作を行なっているとする。
CREATE TABLE programming_langs ( id INT AUTO_INCREMENT NOT NULL PRIMARY KEY, name VARCHAR(20) ); show tables; +-------------------+ | Tables_in_sample | +-------------------+ | programming_langs | +-------------------+ INSERT INTO programming_langs (name) VALUES ('Go');Repeatable Readの場合のトランザクションのシミュレーション
上記のように、左側のトランザクションがInsertしたデータを右側のトランザクションが読み込めてしまう。(ファントムリード)
しかし、MySQLの InnoDB は、 Repeatable Read であっても、別のトランザクションで挿入されたデータをうまいことやりくりしており、一貫性があるように見える。
実際にやってみた。
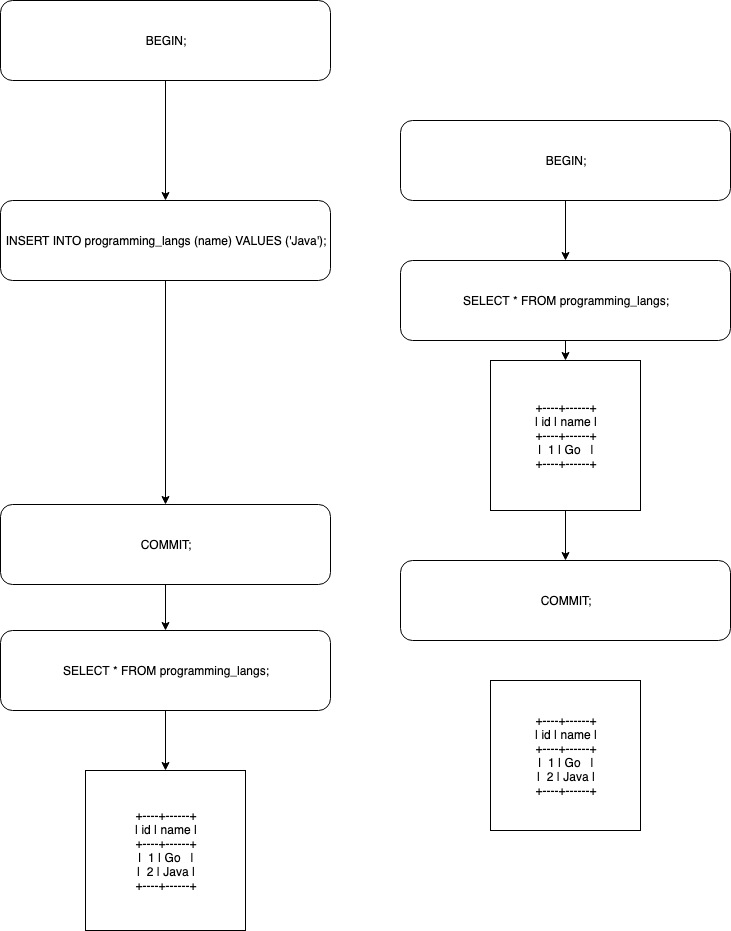
事前に以下のような操作を行なっているとする。
CREATE TABLE programming_langs ( id INT AUTO_INCREMENT NOT NULL PRIMARY KEY, name VARCHAR(20) ); show tables; +-------------------+ | Tables_in_sample | +-------------------+ | programming_langs | +-------------------+ INSERT INTO programming_langs (name) VALUES ('Go');Repeatable ReadのMySQL InnoDBでの操作を図にしたもの
(実際にMySQLでやってみたが、見易さを考慮して図にしている)
ファントムリードが生じていないように見える。
これはなぜだろうか。実は、MVCC(MultiVersion Concurrency Control)という仕組みを用いているからである。
MVCC
MySQLのドキュメントによれば
Acronym for “multiversion concurrency control”. This technique lets InnoDB transactions with certain isolation levels perform consistent read operations; that is, to query rows that are being updated by other transactions, and see the values from before those updates occurred. This is a powerful technique to increase concurrency, by allowing queries to proceed without waiting due to locks held by the other transactions.
This technique is not universal in the database world. Some other database products, and some other MySQL storage engines, do not support it.
引用元: MySQLのドキュメント
上記を意訳しつつ、まとめると以下のような感じ。
- MVCCを使用すると、特定のトランザクションの分離レベルのInnoDBで、一貫性のある読み取り操作が可能に
- 他のトランザクションが更新した行を照会する際に、更新前の状態を見ることができる
- 他のトランザクションのロックを待たずに、クエリを進めることができるのでMVCCだと、同時実行性を高めることができる
他のトランザクションが更新した行を照会する際に、更新前の状態を見ることができる
これがまさにMySQLのInnoDBではRepeatable Readであっても別のトランザクションで挿入されたデータをうまいことやりくりして、一貫性があるように見える(ファントムリードが起きない)ことに寄与している。
これはファントムリードでは、トランザクション内で挿入したデータを別のトランザクション内で見えてしまうが、それを回避することができるということだ。
MVCCの仕組みの説明は、以下がわかりやすいのでこちらを参照。
MySQLのMVCC - Qiita公式でも詳しく仕組みが記されている。
MVCCが故の注意
行ロックをすることなく一貫性を出せるのと、複数のトランザクションが同一のテーブルを操作するとき、お互いのロックを待つことなく操作できるので、同時実行性が上がる。
しかし、行ロックをしないが故に生じ得るLost Updateという問題も存在する。
以下に詳しく記述されているので参照。
漢(オトコ)のコンピュータ道: InnoDBのREPEATABLE READにおけるLocking Readについての注意点詳しくは上記の記事を参照した方が良いが、記事を読んだ際に頭を整理するためにこれまで書いてきた内容と合わせて、以下のようなメモをしながら読んだので載せておく。
- Lost Update
- MVCCは、行ロックをとるわけではないので2つのトランザクションが重なったときには、後で更新した方の値が最終的に反映される
- Locking Read
- Lost Updateを防ぐためには、Locking Readを使用する
- Lost Update は行にロックをかけていないから生じるわけで、それならば行をロックすればええやんという感じ
- 排他ロックと共有ロックを行える構文が存在する
- 排他ロックと共有ロックはこの記事がわかりやすい
- 逆説的な話だが、MVCCでRepeatable Readでもファントムリードを防げているのは、MVCCによって、DB_ROLL_PTRの値を見ているからで、Locking Readの場合はそうでなくファントムリードが生じる
- > Locking ReadはREAD COMMITTED
- > UPDATEとDELETEやデフォルトでLocking Readの挙動
DB_ROLL_PTR ... そのレコードの過去の値を持つundo log recordへのポインタ
引用元: MySQLのMVCC - Qiita
ロックの仕組み
MySQLのロックにはレコードロック、ギャップロック、ネクストキーロックの3つがある。
以下の記事が非常にわかりやすいので、参照。MySQL(InnoDB)のネクストキーロックの仕組みと範囲を図解する - 備忘録の裏のチラシ
ただ、「レコードロックっていうのは実際は、インデックスレコードのロックだよ」みたいな感じでインデックスの知識が必要。
ここで必要なインデックスの知識も、ただクエリの性能向上のための便利なものという理解ではなく内部の仕組みの理解が必要みたいだ。(特にクラスタインデックスとセカンダリインデックス)なので、上記のロックの記事を読む前に以下の記事等でインデックスの仕組みについて学んでからの方が良さそう。
インデックスの記事
漢(オトコ)のコンピュータ道: 知って得するInnoDBセカンダリインデックス活用術!MySQL :: MySQL 5.6 リファレンスマニュアル :: 14.2.13.2 クラスタインデックスとセカンダリインデックス
MySQL with InnoDB のインデックスの基礎知識とありがちな間違い - クックパッド開発者ブログ
MySQL(InnoDB)のインデックスについての備忘録 - What is it, naokirin?
参考にさせていただいたサイト
ACID属性
トランザクション分離レベル
[RDBMS][SQL]トランザクション分離レベルについて極力分かりやすく解説 - Qiita
MVCC
ロック
MySQLでSELECT FOR UPDATEと行ロックの挙動を検証してみた - JUST FOR FUNMySQL - InnoDBのロック関連まとめ - Qiita
世界の何処かで MySQL(InnoDB)の REPEATABLE READ に嵌る人を1人でも減らすために - KAYAC engineers' blog
doc/innodb.md at master · ichirin2501/doc
漢(オトコ)のコンピュータ道: InnoDBのREPEATABLE READにおけるLocking Readについての注意点
アプリケーションエンジニアが知っておくべきMySQLのロック - Qiita
MySQL(InnoDB)のネクストキーロックの仕組みと範囲を図解する - 備忘録の裏のチラシ
インデックス
漢(オトコ)のコンピュータ道: 知って得するInnoDBセカンダリインデックス活用術!MySQL :: MySQL 5.6 リファレンスマニュアル :: 14.2.13.2 クラスタインデックスとセカンダリインデックス