- 投稿日:2019-04-05T23:54:11+09:00
CodilityのBinaryGapを競プロ未経験が解いてみた
BinaryGapとは
簡単に言うと、2進数の1と1に囲まれた0の数で最大の値を求める問題です。
例えば1000010100010であれば、1と1の間の0の個数は左から4, 1, 3となるので、ここでは4が答えとなります。正直、自信はありませんが100%のスコア判定をもらうことができました。Pythonのスペシャリストではない割には簡潔に書けたのではないかと思います。
Python コード
def solution(N): return len(max(str(bin(N)).replace("0b", "").split("1")[:-1]))1
str(bin(N))で与えられた10進数を2進数に変換します。その際に文字列型へ変換も行います。2
.replace("0b", "")二進数を文字列に変換すると最初にリテラルの0bがくっつきます、これをreplace(,)で削除します。3
.split("1")1で文字列を分解し、0だけの配列を作成します。4
[:-1]でスライスし、最後の要素を削除します。これは、1000や101000のように最後の0は1で囲まれてるとは言えないためです。5
str(bin(N)).replace("0b", "").split("1")[:-1]の時点で[0, 00000, 00, 00, 0]のような配列が出来上がります。これをmax( )で文字数(0の数)が一番多い要素を抜き出します。この例だと00000です。6
5で00000となったので、len()で0の個数を数えます。この値がBinaryGapの答えとなります。まとめ
今回は、アルゴリズムプログラミングに初めてトライしました。今後はCodilityの他のLessonやJavaなどでもトライしていこうと思います.
- 投稿日:2019-04-05T23:54:11+09:00
ColidityのBinaryGapを競プロ未経験が解いてみた
BinaryGapとは
簡単に言うと、2進数の1と1に囲まれた0の数で最大の値を求める問題です。
例えば1000010100010であれば、1と1の間の0の個数は左から4, 1, 3となるので、ここでは4が答えとなります。正直、自信はありませんが100%のスコア判定をもらうことができました。Pythonのスペシャリストではない割には簡潔に書けたのではないかと思います。
Python コード
def solution(N): return len(max(str(bin(N)).replace("0b", "").split("1")[:-1]))1
str(bin(N))で与えられた10進数を2進数に変換します。その際に文字列型へ変換も行います。2
.replace("0b", "")二進数を文字列に変換すると最初にリテラルの0bがくっつきます、これをreplace(,)で削除します。3
.split("1")1で文字列を分解し、0だけの配列を作成します。4
[:-1]でスライスし、最後の要素を削除します。これは、1000や101000のように最後の0は1で囲まれてるとは言えないためです。5
str(bin(N)).replace("0b", "").split("1")[:-1]の時点で[0, 00000, 00, 00, 0]のような配列が出来上がります。これをmax( )で文字数(0の数)が一番多い要素を抜き出します。この例だと00000です。6
5で00000となったので、len()で0の個数を数えます。この値がBinaryGapの答えとなります。まとめ
今回は、アルゴリズムプログラミングに初めてトライしました。今後はColidityの他のLessonやJavaなどでもトライしていこうと思います.
- 投稿日:2019-04-05T23:18:50+09:00
Dashでプレゼン資料を作った!
口上
これまで4つのDashの記事を作りました。
Dashの記事を書いたモチベーションは、データを使ったプレゼンテーションはつまらないのは、データ量が極小になっていて、発表者の示した経路しか見えず「まあそうですね」で終わることが原因で、
それを終わらすのがDashです!!
ということがいいたかったからです。
といいながら、そのプレゼンテーションを示してきませんでした。
というわけで、今回はプレゼン資料を作ってみたよってお話です。
プレゼン資料内容
今回作った資料は、Pydata Osaka可視化特会(3/24)と大阪Pythonの会(4/5)で使ったものをちょっとバージョンアップしたものです。
プレゼン資料with Dash(リンク先に飛びます)
この資料の内容は、データを使ったプレゼンのつまらない理由を話したあとに、Dashだとデータをたくさん詰め込んだ可視化ができるよ!って話をして、その後使い方を解説しています。
使い方はDATA11のページからで、14で終わるので、短く見えるけど、それまでのプレゼン風から、普通のサイト風に作っているからであって、使い方はかなり長いです。
Qiitaは技術の話以外書いたら怒られると聞いたので、とりあえず、技術の話を書いていきましょう。
注意!
Dashはウェブアプリケーションにした時に最も破壊力があるのですが、dashの最新バージョン0.40.0でherokuに上げると、エラーが出て、ちゃんと動かなかったです。reactっぽいエラーが出てきて、理由はよく分かりません。
基本形よくあるグラフ
以降ではプレゼンの概要を示していきます。
詳細はプレゼン資料を見て頂けると幸いです。最初にお断り
Dashはウェブアプリケーションなので、html要素もちょっと書かなければいけません。よく、「html,cssなしでウェブアプリが描ける最高や!」みたいに書かれていますが、ちょっと分かっていないと書けないことは最初に断っておきます。
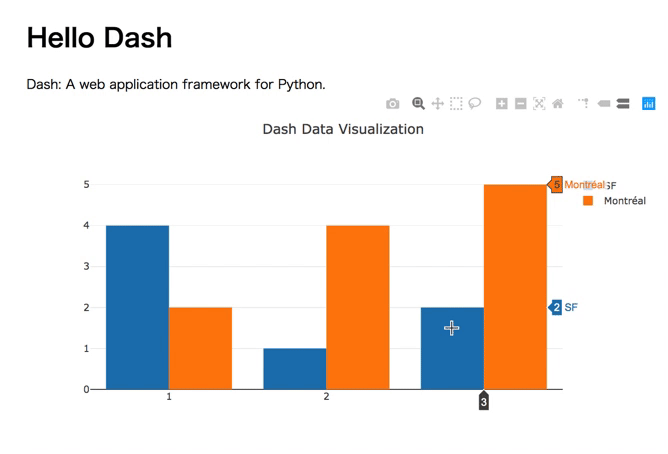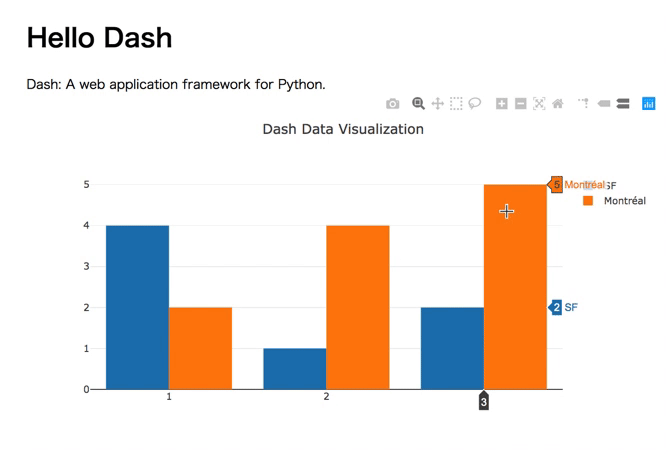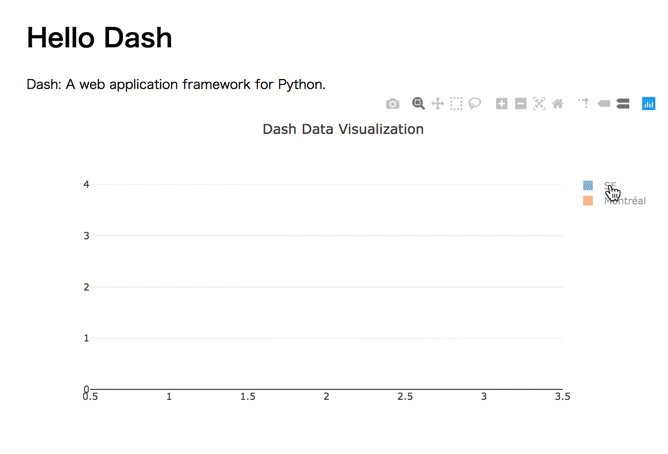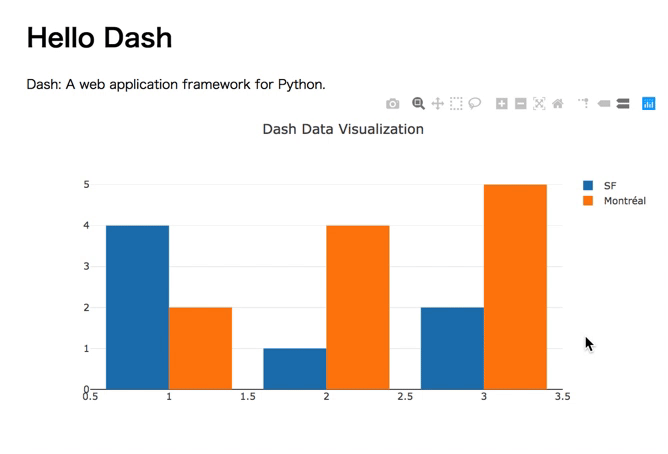
プレゼンテーションのDATA11の最初のグラフ
よく見る簡単なグラフ。しかしこれだけでも、簡単にインタラクティブなチャートになっていることがわかります。
普通、レジェンドを出すのもちょっとコードを書かなければいかなかったりするのですが、Dashの場合、必要ありません。また、そのレジェンドをクリックすると要素が消せたり出せたりします。良い。コードは以下のような感じです。
import dash import dash_core_components as dcc import dash_html_components as html external_stylesheets = ['https://codepen.io/chriddyp/pen/bWLwgP.css'] app = dash.Dash(__name__, external_stylesheets=external_stylesheets) app.layout = html.Div(children=[ html.H1(children='Hello Dash'), html.Div([ html.P('Dash: A web application framework for Python.') ]), dcc.Graph( id='example-graph', figure={ 'data': [ {'x': [1, 2, 3], 'y': [4, 1, 2], 'type': 'bar', 'name': 'SF'}, {'x': [1, 2, 3], 'y': [2, 4, 5], 'type': 'bar', 'name': u'Montréal'}, ], 'layout': { 'title': 'Dash Data Visualization' }}) ]) if __name__ == '__main__': app.run_server(debug=True)長いように思いますが、グラフのために書くのは5,6行です。これだけで、レジェンドクリックでインタラクティブに動くのはすごいですよね〜。
Dashで最も重要な機能!Callback
上のようなものだと、まぁ他でも頑張ればできるよねぇみたいになります。
しかし、Callbackを使えば、他ではありえない動きが得られます。
その例をDATA12の真ん中のグラフで見てみましょう。
ここではレディオアイテムで表示するデータを変えるということと、マウスのホバーで得られるデータをグラフの上に表示させています。
その2つをCallbackで返しています。コードは以下のようになっています。
import dash import dash_core_components as dcc import dash_html_components as html import plotly.graph_objs as go import pandas as pd import json df = pd.read_csv('./data/longform.csv', index_col=0) dfhokkaido = df[df['area']=='北海道'] app = dash.Dash(__name__) app.layout = html.Div(children=[ html.Div( html.H1('北海道のGDP、人口、一人あたりGDPの推移', style = {'textAlign': 'center'}) ), html.Div( html.H1(id='add-hover-data') ), dcc.RadioItems( id = 'dropdown-for-hokkaido', options = [{'label': i, 'value': i} for i in dfhokkaido.item.unique()], value = 'GDP' ), dcc.Graph( id="hokkaidoGraph", ) ]) @app.callback( dash.dependencies.Output('hokkaidoGraph', 'figure'), [dash.dependencies.Input('dropdown-for-hokkaido', 'value')] ) def update_graph(factor): dff = dfhokkaido[dfhokkaido['item'] == factor] return { 'data': [go.Scatter( x = dff['year'], y = dff['value'] )] } @app.callback( dash.dependencies.Output('add-hover-data', 'children'), [dash.dependencies.Input('hokkaidoGraph', 'hoverData')] ) def return_hoverdata(hoverData): return json.dumps(hoverData) if __name__ == '__main__': app.run_server(debug=True)この機能が使えるかに、Dashすげーってなるかどうかがかかっています。がんばりましょう!
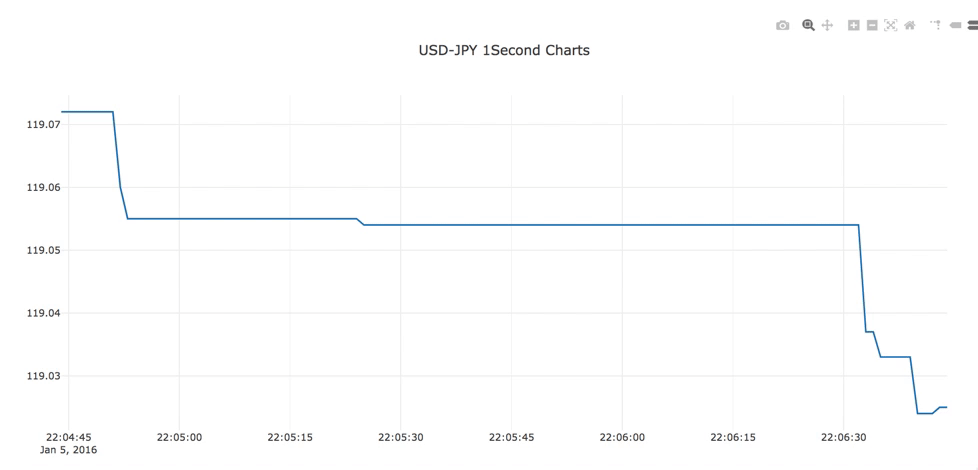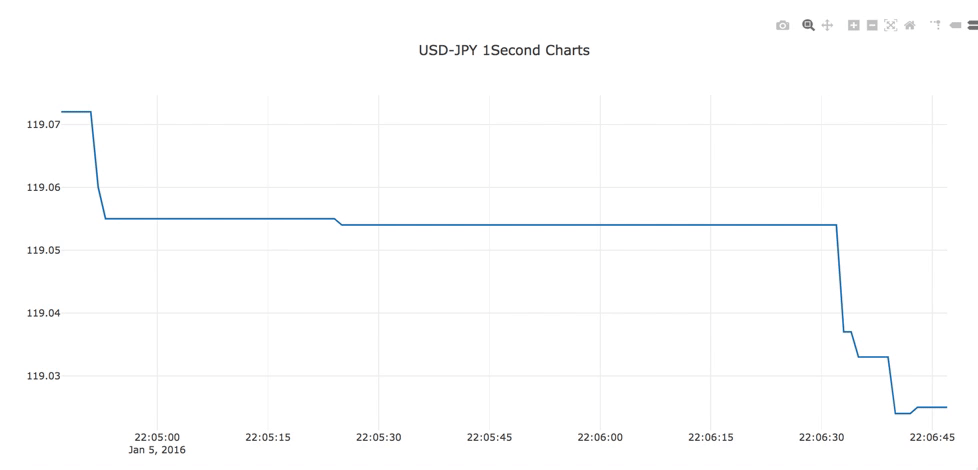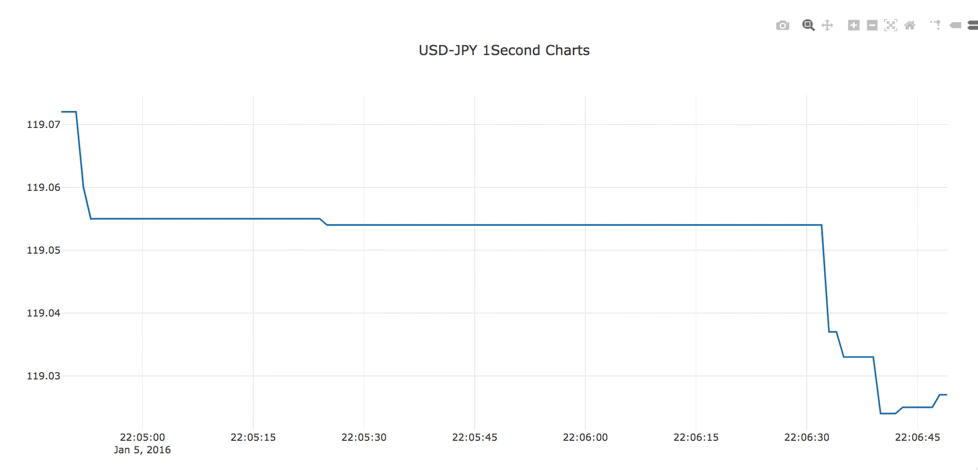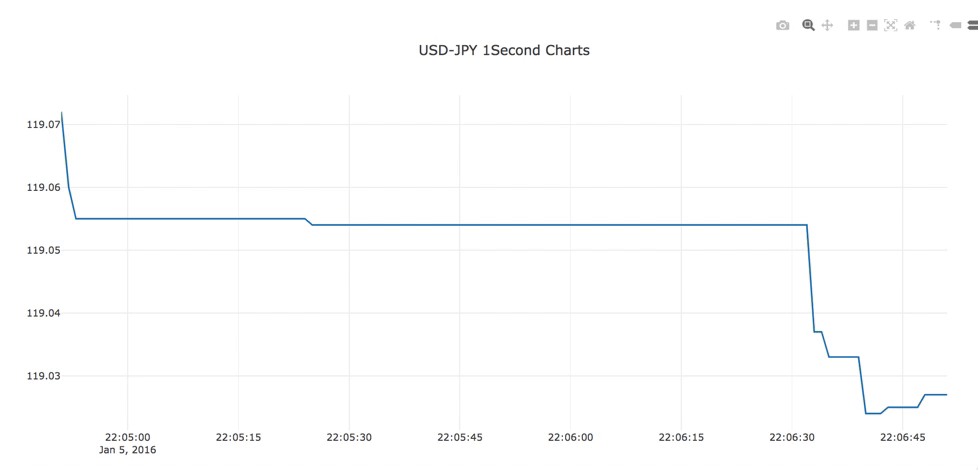
リアルタイムデータのアップデート
DATA13のはじめのチャートです。
リアルタイムなアップデートもdccのInterval機能を使えば可能です。
機能と呼ぶにはちょっと簡単すぎますが。何しろ更新時間だけ指定すればよいのです。この資料ではちょっとエセリアルタイムな動かし方をしています。過去の為替レートと今の時間をシンクロさせて、リアルタイムっぽく動かしています。そのため日付は昔の日付です。
import dash import dash_core_components as dcc import dash_html_components as html from datetime import datetime from datetime import timedelta import pandas as pd import plotly.graph_objs as go df = pd.read_csv('https://raw.githubusercontent.com/plotly/dash-web-trader/master/pairs/USDJPY.csv', index_col=1, parse_dates=['Date']) dff = df['2016/1/5'] dff = dff.resample('1S').last().bfill() app = dash.Dash(__name__) app.layout = html.Div([ html.Div([ dcc.Graph(id="usdjpy"), dcc.Interval( id = 'interval_components', interval = 1000, ) ], style={'height': '30%', 'width': '80%', 'margin': '0 auto 0', 'textAlign': 'center'}) ]) @app.callback( dash.dependencies.Output('usdjpy', 'figure'), [dash.dependencies.Input('interval_components', 'n_intervals')] ) def update_graph(n): t = datetime.now() nowHour = t.hour nowMinute = t.minute nowSecond = t.second d = datetime(2016, 1, 5, nowHour+9, nowMinute, nowSecond) period = timedelta(seconds = 120) d1 = d - period dff1 = dff.loc['{}'.format(d1): '{}'.format(d), :] return { 'data': [go.Scatter( x = dff1.index, y = dff1['Bid'] )], 'layout':{ 'height': 600, 'title': 'USD-JPY 1Second Charts' } } if __name__=='__main__': app.run_server(debug=True)dのところで時間に9を足しているのはまぁちょっとしたやり方でということで、ここではあまり触れません。ちなみにMacで動かす場合は+9を取り除かないと動きません。あしからず。
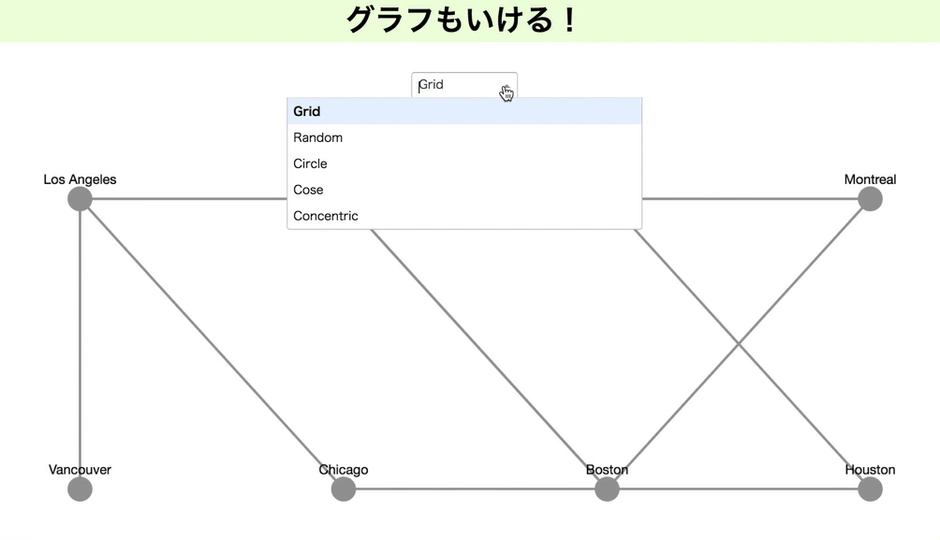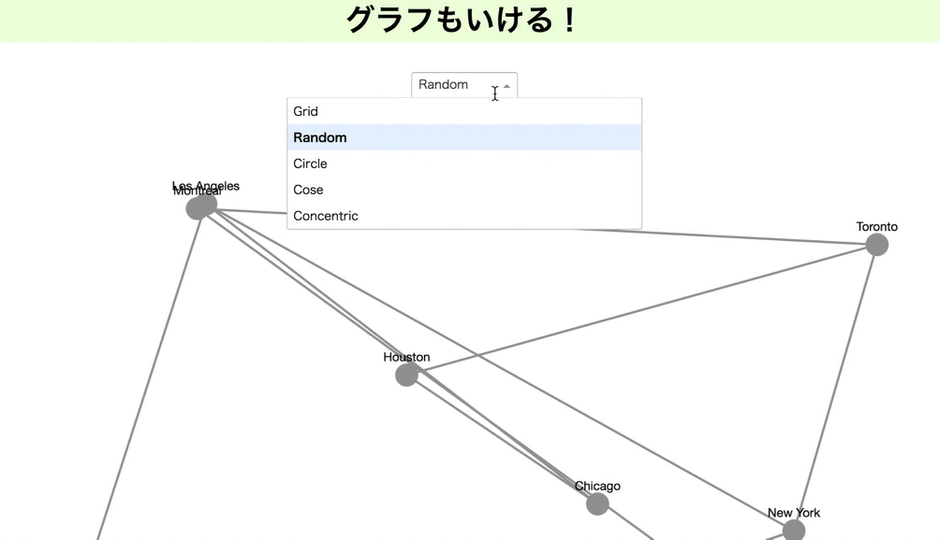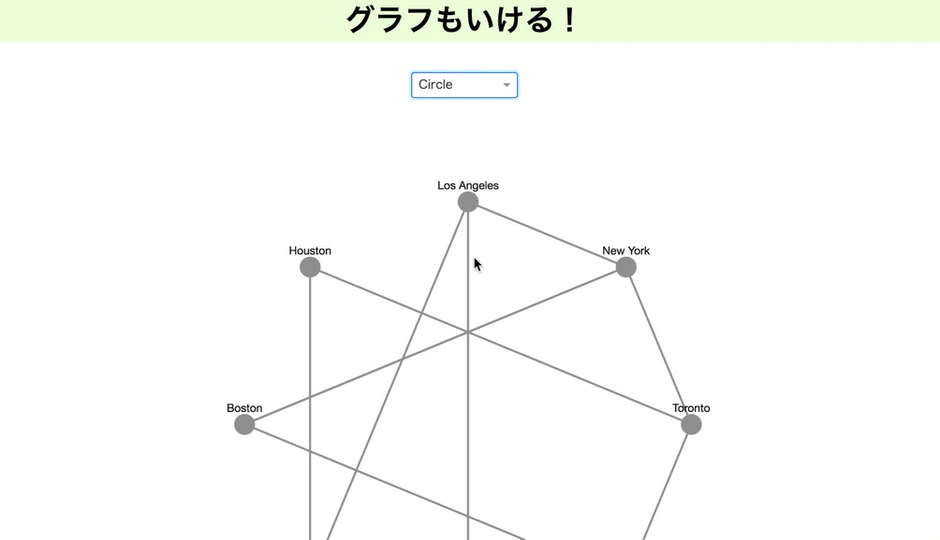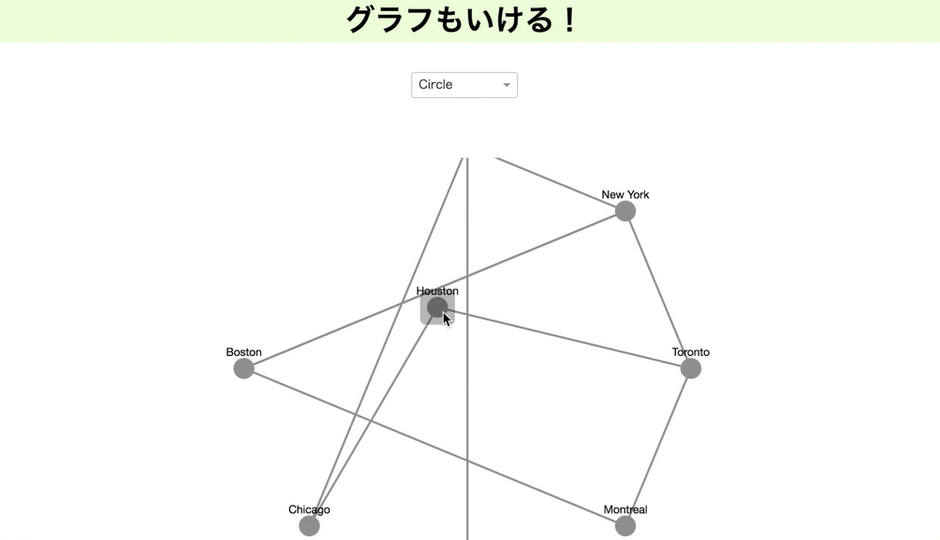
グラフも描ける
2月に新機能として発表されたグラフ。
これを使っていろいろかっこよく、関係を示したいところ。私はブロックチェーンもやっているので。しかしRDF形式をきれいに読み込ますことが出来ず、今のところはあって、こんな風に使えるということを示すだけになってしまいます。すみません。
現時点では有向にできませんと書いていますが、私が見た限りで、もしかしたらできるかもなので、もし出来た場合、お知らせ頂けると嬉しいです!
import dash import dash_cytoscape as cyto import dash_html_components as html import dash_core_components as dcc from dash.dependencies import Input, Output app = dash.Dash(__name__) nodes = [ { 'data': {'id': short, 'label': label}, 'position': {'x': 20*lat, 'y': -20*long} } for short, label, long, lat in ( ('la', 'Los Angeles', 34.03, -118.25), ('nyc', 'New York', 40.71, -74), ('to', 'Toronto', 43.65, -79.38), ('mtl', 'Montreal', 45.50, -73.57), ('van', 'Vancouver', 49.28, -123.12), ('chi', 'Chicago', 41.88, -87.63), ('bos', 'Boston', 42.36, -71.06), ('hou', 'Houston', 29.76, -95.37) ) ] edges = [ {'data': {'source': source, 'target': target}} for source, target in ( ('van', 'la'), ('la', 'chi'), ('hou', 'chi'), ('to', 'mtl'), ('mtl', 'bos'), ('nyc', 'bos'), ('to', 'hou'), ('to', 'nyc'), ('la', 'nyc'), ('nyc', 'bos') ) ] elements = nodes + edges app.layout = html.Div([ dcc.Dropdown( id='dropdown-update-layout', value='grid', clearable=False, options=[ {'label': name.capitalize(), 'value': name} for name in ['grid', 'random', 'circle', 'cose', 'concentric'] ] ), cyto.Cytoscape( id='cytoscape-update-layout', layout={'name': 'grid'}, style={'width': '100%', 'height': '450px'}, elements=elements ) ]) @app.callback(Output('cytoscape-update-layout', 'layout'), [Input('dropdown-update-layout', 'value')]) def update_layout(layout): return { 'name': layout, 'animate': True } if __name__ == '__main__': app.run_server(debug=True)githubとherokuをつなぐ!(1行もコード書かない)
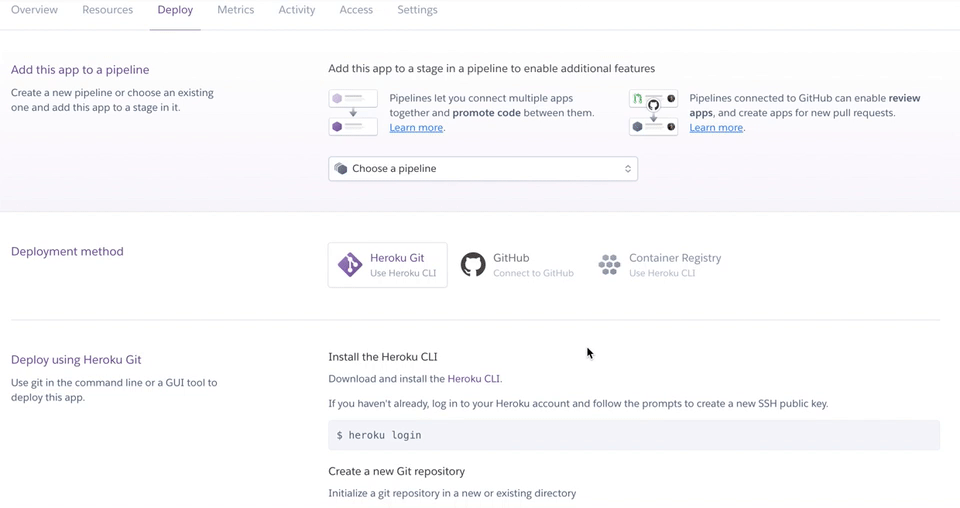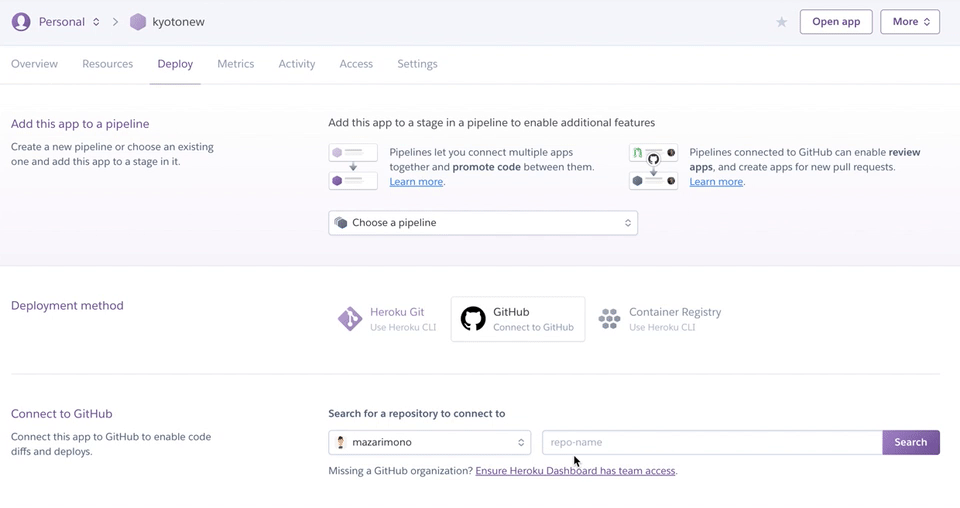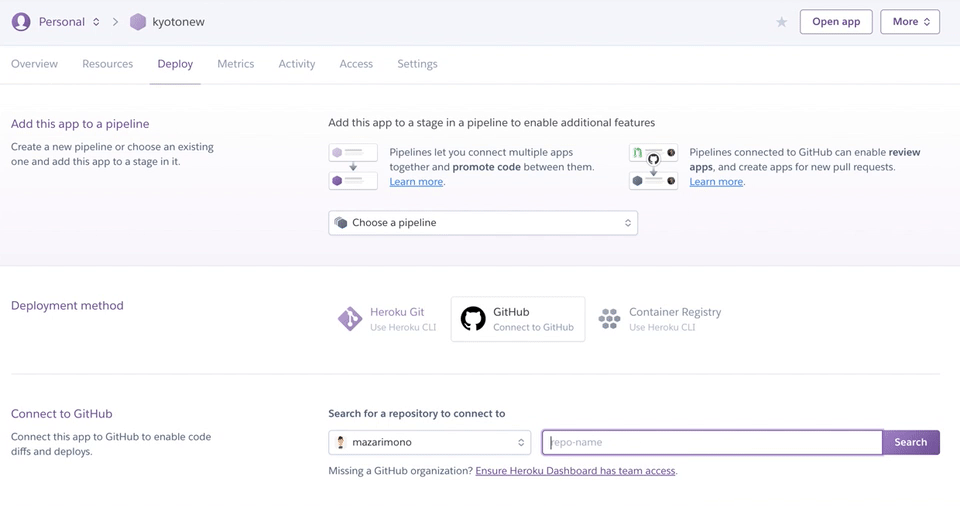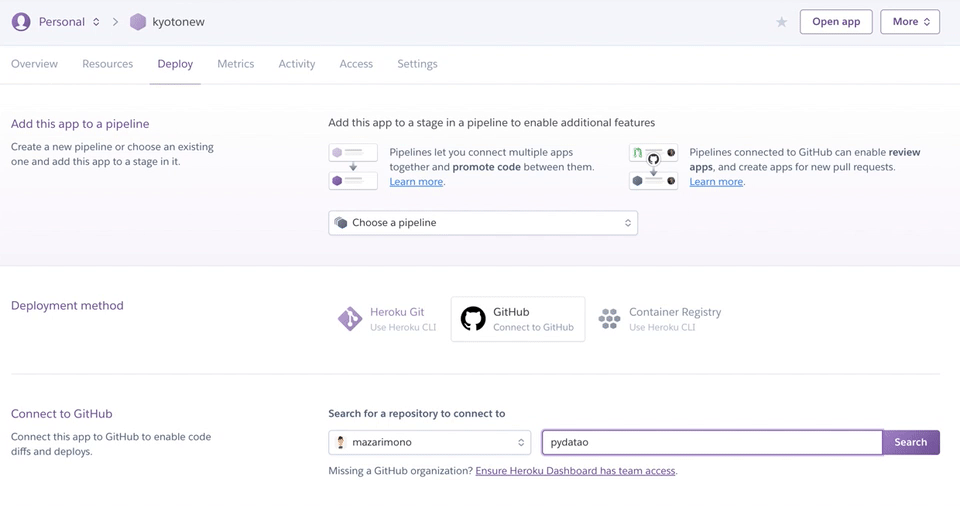
ウェブで共有するのにはherokuが便利です。
以前書いた記事では7行で上げるという短いのか長いのかわからない行数を示しましたが、今回は1行もコードを書かずに、githubにあげたコードがheroku上で動くやり方を提示します。
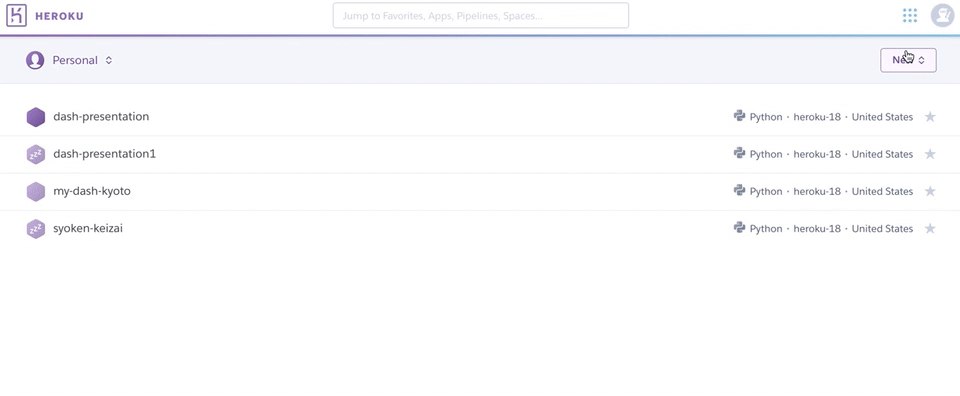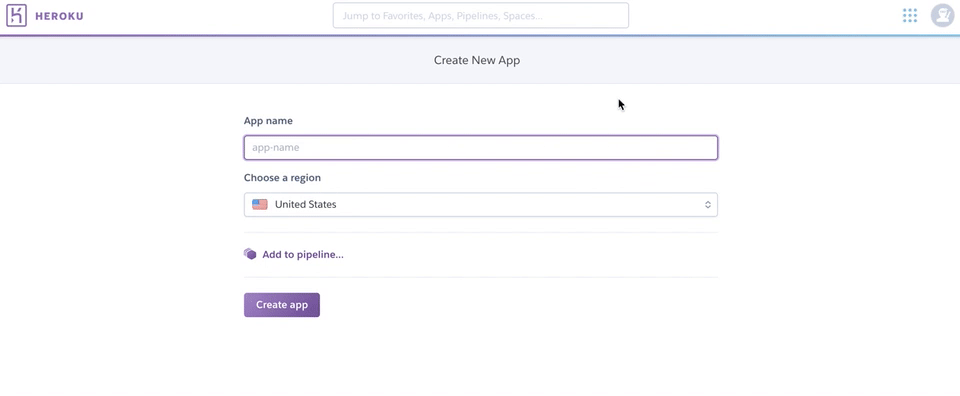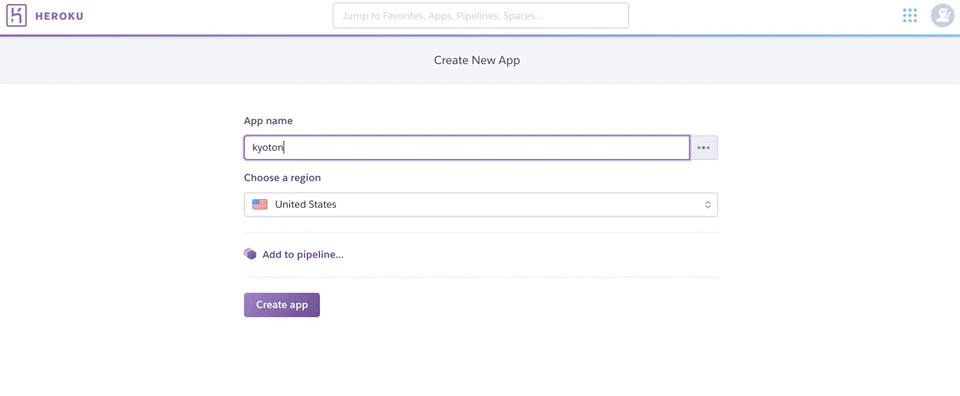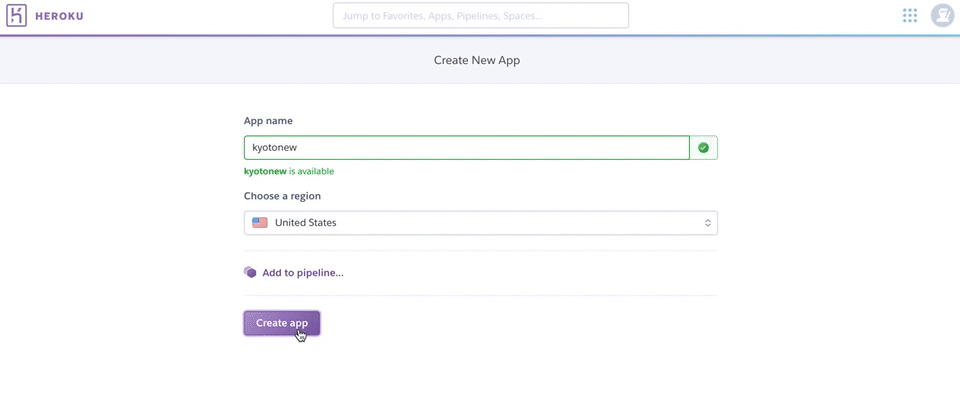
まずはherokuにアカウントを作ります。そしてダッシュボードからアプリ名を登録します。下のように使える名前だと使えるよーっていうことで、作成できます。
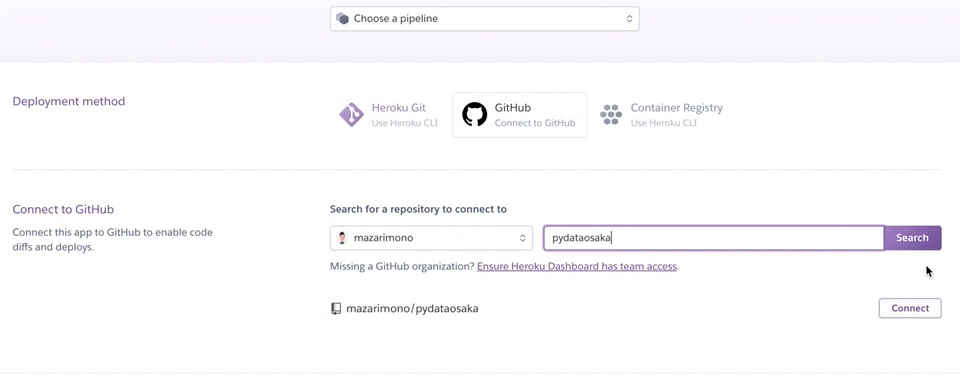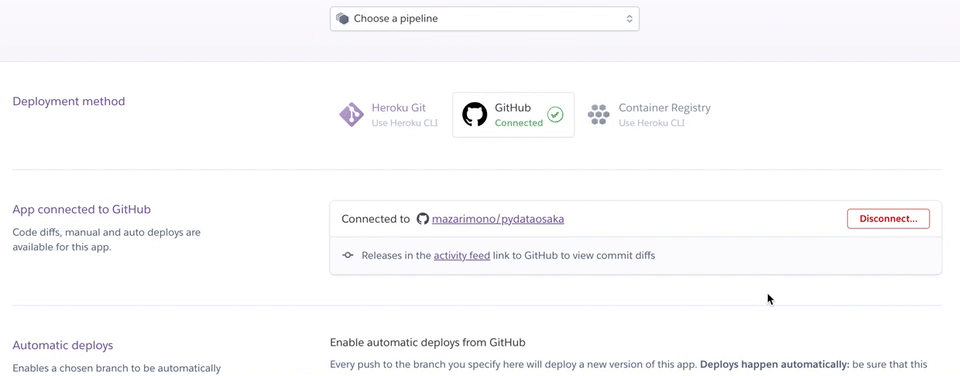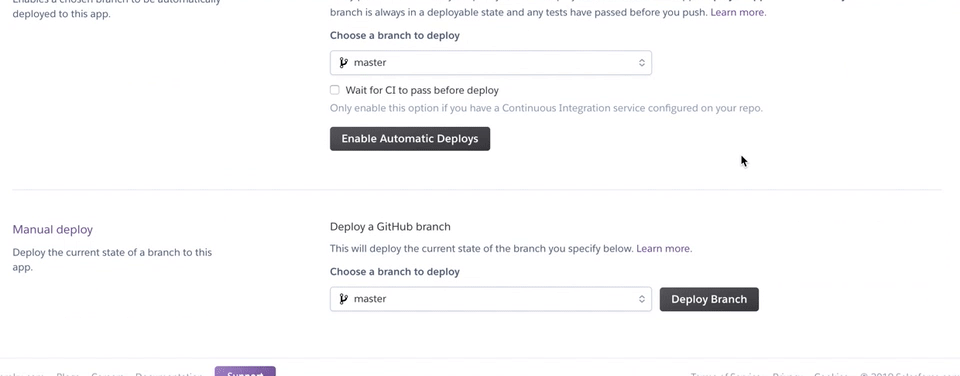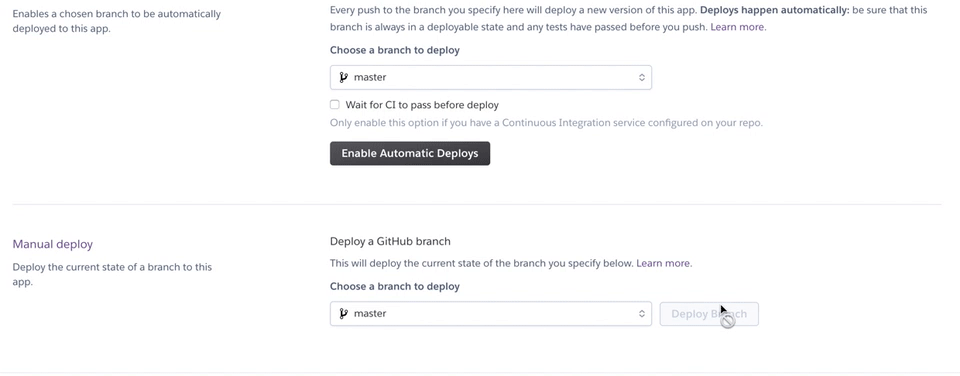
次にデプロイ画面になるので、ここでメソッドでgithubを選択すると、リポジトリを探す画面が出てくるので、そこにアップしたいリポジトリの名前を入れます。
すると、これかって聞いてくるので、あっていればconnectを押します。
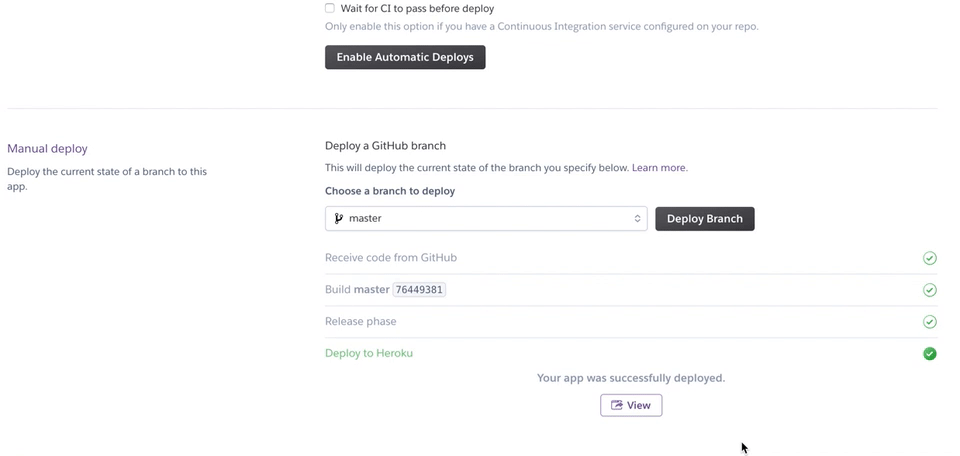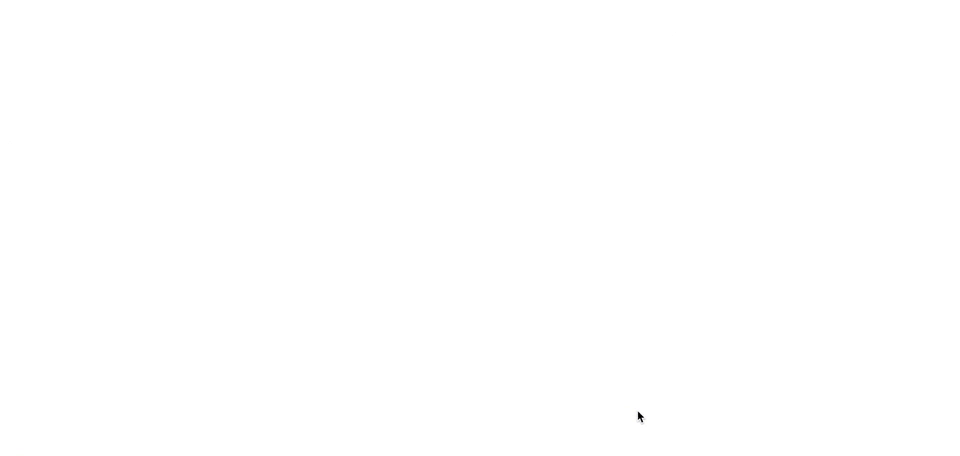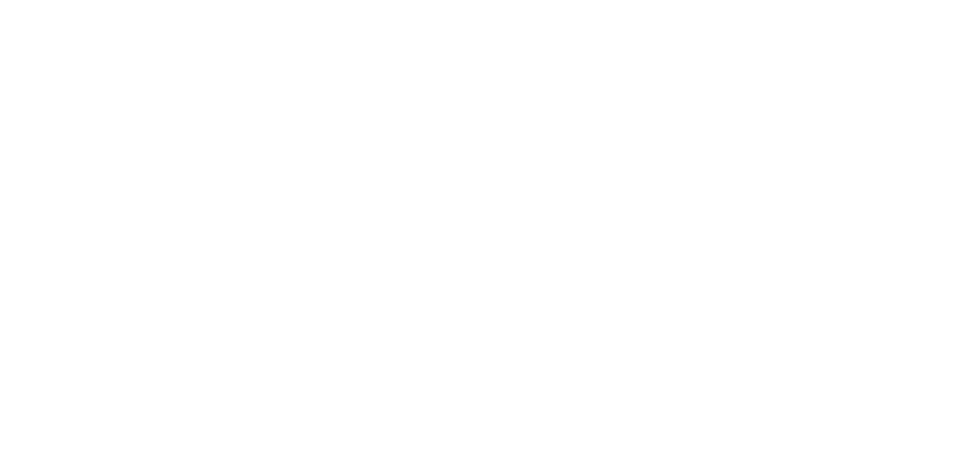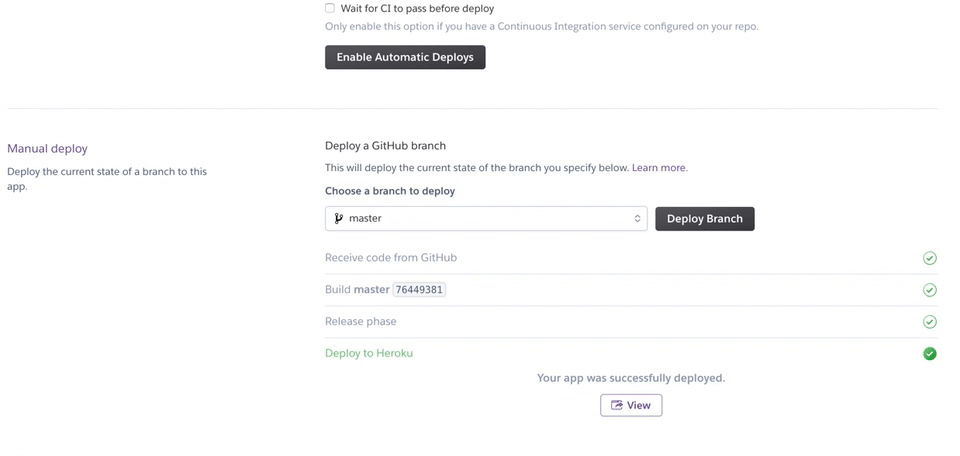
そして、下に行きmanual deployを行います。
うまくいくとDeploy to Herokuとの文字が出てくるので、その下のviewをクリックしましょう。ちゃんと出来ていれば、あなたの作ったアプリが動き始めるはずです!
まとめ
以上のような感じで、チャートが描け、ウェブ上でアップできます。
これらのような機能を使って、データをたくさん詰め込んだ資料で、良い発見を行い、日本の社会がよりよく発展していくと良いなと思っています。
そのためのデータの可視化にDashは良いぞということを書いて、この記事を終えたいと思います。
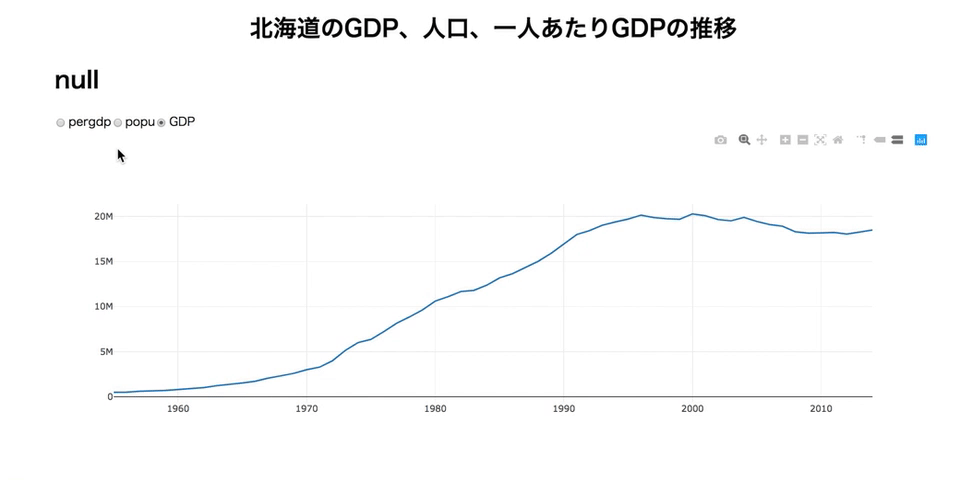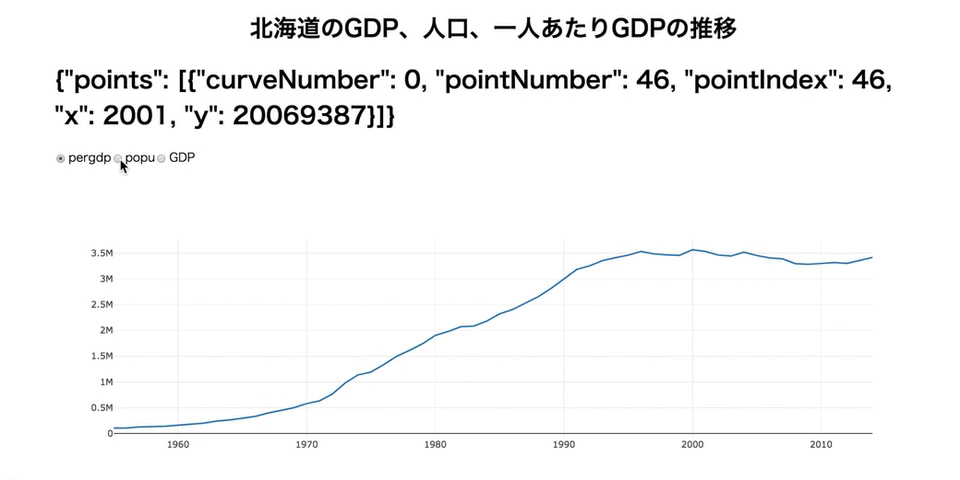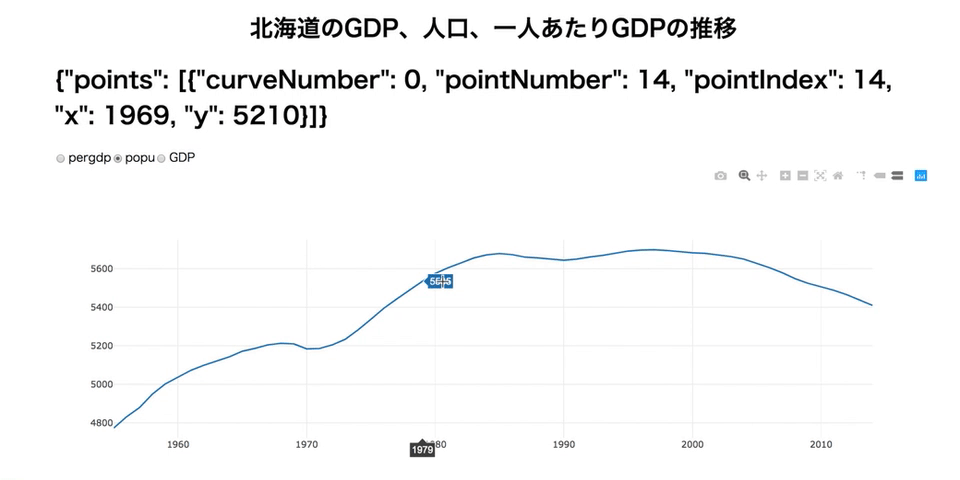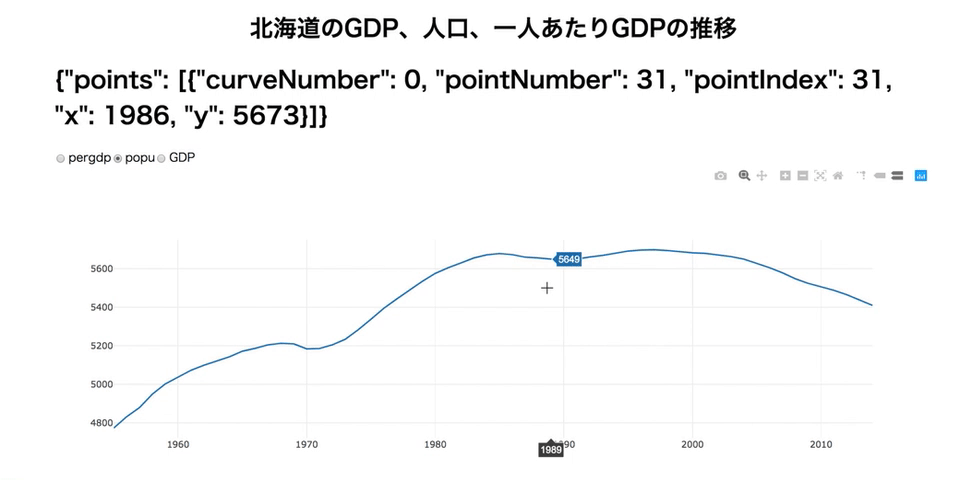
- 投稿日:2019-04-05T23:16:57+09:00
kaggle初心者がtitanicの生存者を予測してsubmit(提出)するまで
kaggleを始めたのはいいけど何をしたらいいのか分からない。
こちらの記事をかなりもとにしています。【Kaggleでタイタニックの生存者を予測をしてSubmitしてみた】
kaggle初心者はこちらの記事も参考になります
ゆるキャン△を見てキャンプしたいみたいなノリで機械学習を始めたはいいけれども何をしたらいいのか分からない。そんなレベルで初心者の私がおすすめされたのがkaggle。機械学習で一番困るであろうデータセットが豊富にあり、一連のデータの処理や学習などの先達がいるのでとても良い。とても良いが、登録したはいいけど何をしたらいいか分からない!!
初心者はkernelを読もうと言われるが、そもそもデータの性質が分からないカーネルを読んでも仕方ない。Forkしてコードを走らせるだけなの? ……と思っていた私が初めてsubmit(提出)したので書いてみる。
前述の記事のほとんど焼き増しになるが、kaggleを始める人の一助となればうれしい。そんなことよりSubmitだぁ!!
kaggleにはcompetitionsというのがある。テンプレ説明にはcompetitionsに参加すると期限までに学習結果を提出して順位に応じて実績や、場合によっては賞金がもらえると書かれている。
とはいえ、kaggleには別に期限も賞金もない所謂"練習"のようなcompetitionsもある。この場合、データセットと提出形式と、submit(結果を提出)した際の順位や実績が見られるのでとても有意義である。練習用なので初心者や復習、ゆっくりやりたいけど順位も気になるようないろいろなスタイルで挑めるのでとても良い。
今回はtatinicのコンペに参加してみたので手順を書いていく。練習コンペである。
OverviewとRulesとData
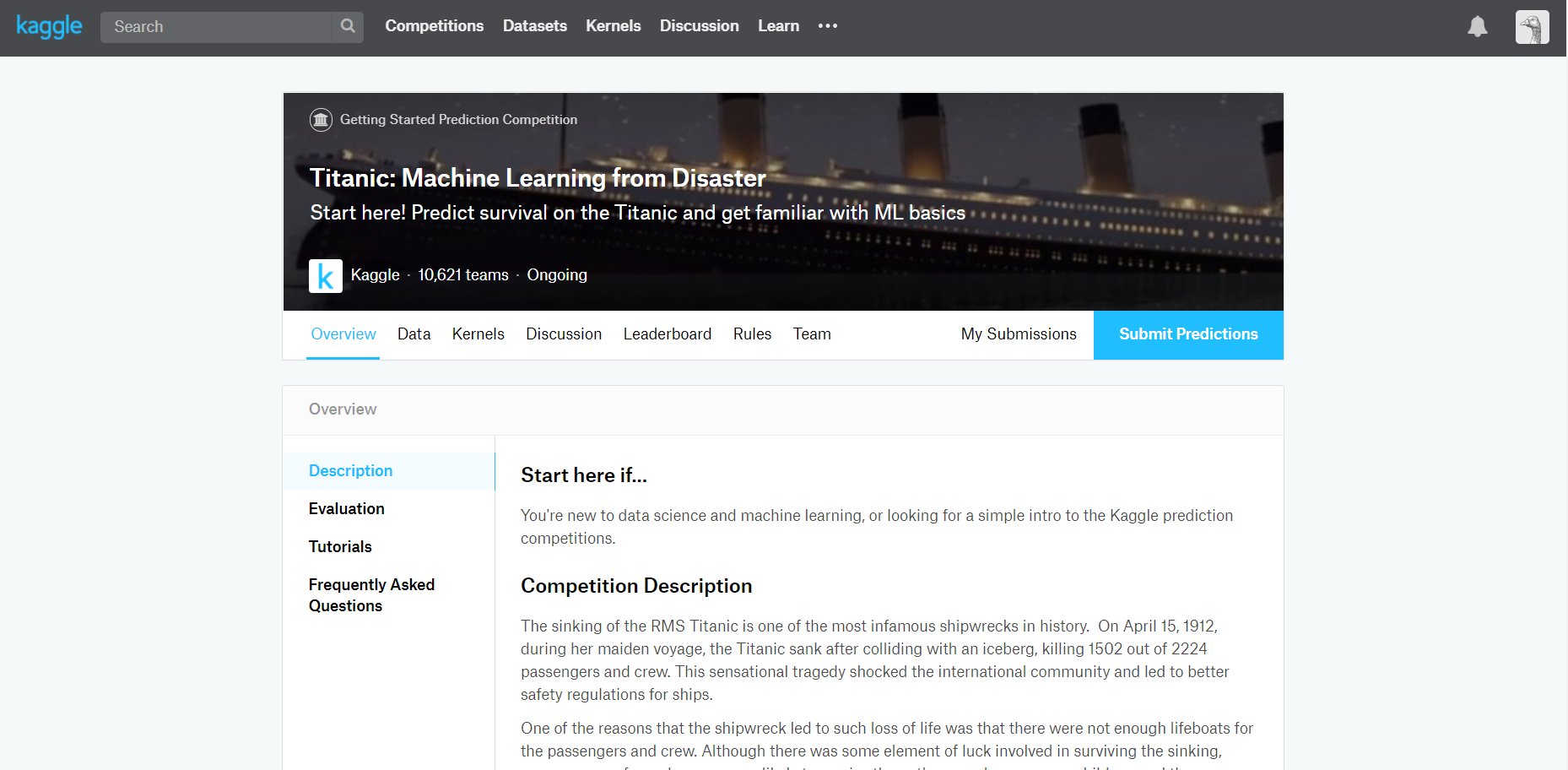
そのままずばり概要、ルール、データセットである。スクショで説明する。
kaggleのcompetitionsに参加する場合、上のタブのCompetitionsからコンペ一覧が見られる。その中から自分の気になるコンペのページに行く。コンペのページをクリックすると上のようにコンペの詳細ページが見られる。
その中で、Overview(概要)を読んで面白そうだと思ったら参加するとよい。その際、読まなくてはいけないのがRulesである。ここにはデータの扱いの規定や各種締め切り、その他のコンペのルールが書いてある。よく読もう。
Dataタブに飛ぶとそのコンペで提供されるデータの形式が見られる。画像認識とか分からないのにデータに画像があっても困るのでここも確認するとよい。以上の手順を終えてコンペに参加すると決めたら、タブ欄の一番右の青枠に「Join Competition」があるのでクリックする。その時、Rulesに同意するか求められるので了承すれば同意する。そうすれば「Join Competition」が上の画像のように「Submit Predictions」に変わる。
Dataのダウンロードもできるようになるのでlocalでコードを書くか、kernelを用いて書いてもよい。データの性質もルールも分かったので、そのコンペで公開されている他の人のkernelも参考になるだろう。あとは個々人のスタイルでコードを書いて学習・予測データを提出(Submit)するだけである。
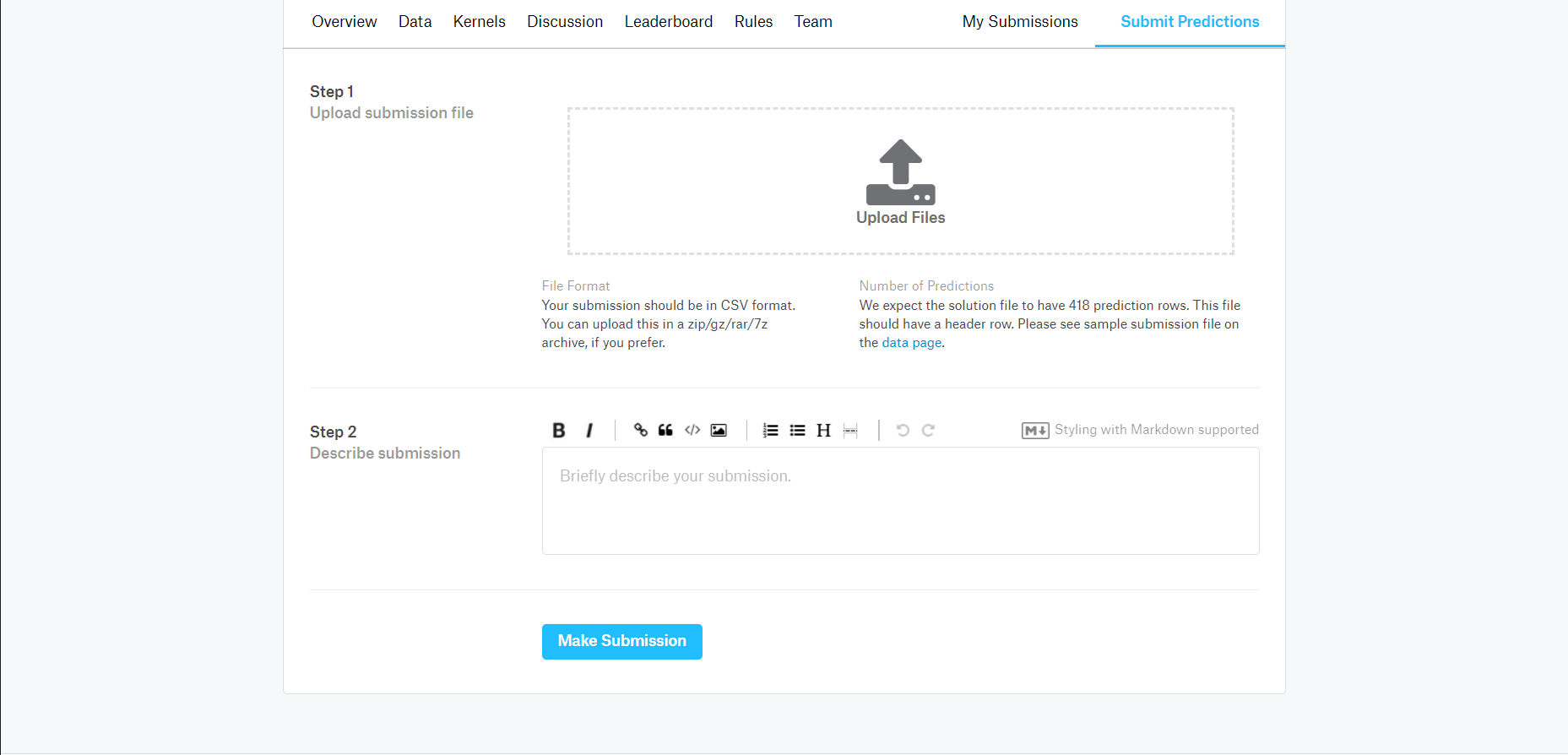
Submit手順(titanic)
Submitの方法はいくつかあるが、今回はcsvを出力してアップロードしたのでその方法を説明する。「Submit Predictions」で次のページに行く。
前述のDataタブに提出の形式が書かれているのでその形式に沿った学習結果のファイルを出力して上のページでSubmitする。ファイルをD&D、Describe submissionはGitHubのコミットコメントみたいなものなので適当に何かを書く。「Make Submission」して終わり。
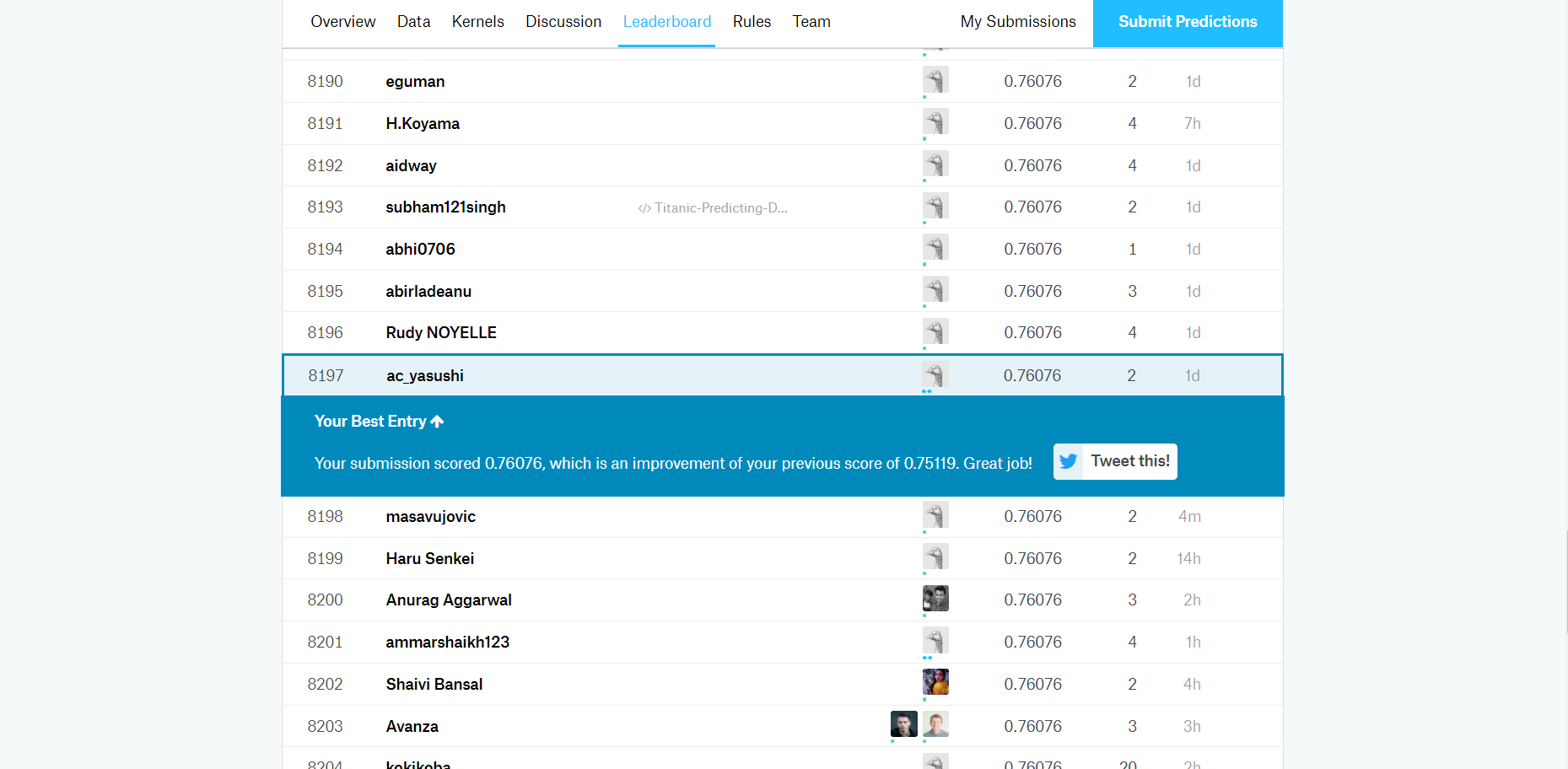
順位の確認
SubmitするとLeaderboardタブで自分の順位が表示される。
スコアは0.76076で8197番目。これを見て工夫するもよし、別のコンペに参加するもよし。
コード
コードは以下の記事にあるコード(GitHub)を全面的に参考にしている。(以下、引用元)
【Kaggleでタイタニックの生存者を予測をしてSubmitしてみた】
といっても写経してSubmitしてもしょうがないので学習部分は当然自分で書く。ただし、前処理のcsvファイルを扱うためのpandasや相関関数をヒートマップで表すseabornの使い方はとても参考になった。
一方で、引用元では使っていないデータも使ってみたり、引用元ではscikit-leranのSVMを用いているが、私は現在kerasしか使えないのでsoftmaxで分類している。前処理
引用元と2つほど異なる処理をしている。
1つは年齢の欠損値を0で埋めるのではなくrandom関数で乱数で埋めた。しかし、コードではいつの乱数で全部の欠損値を埋めているのであまり効果はない。欠損値ごとに別の乱数で埋めた行列を用意してpandasでコラムを付け足すコードや、欠損値のあるデータセットだけを抜き出して別の学習にかける方法もあったが書いてる途中では思いつかなった。
2つ目は"Cabin"の情報を捨てずに情報がある・ないの2値の形で保持した。というのも、乗客が乗っていた客室が分かる・分からないも情報になるかと思ったからだ。該当部分のコードがこちら。
titanic_by_kerasimport random # まずはNaNをfillna()関数で埋める df["Age"]=df["Age"].fillna(random.random()*100) df["Cabin"]=df["Cabin"].fillna(0) # pd.to_numericでエラーを指定することで数字に変換できないものをNaNにした後、1で埋める。 df["Cabin"]=pd.to_numeric(df["Cabin"], errors="coeres") df["Cabin"]=df["Cabin"].fillna(1)Cabinの文字列情報を1に変換するうまい方法を探したが、to_numeric関数でエラーを指定すると数値以外の型が全てNaNになるので、あとはfillna(1)で埋める。
学習
学習はkerasの3層NN、出力層はsoftmax。活性関数はrelu、層の数はテキトー。
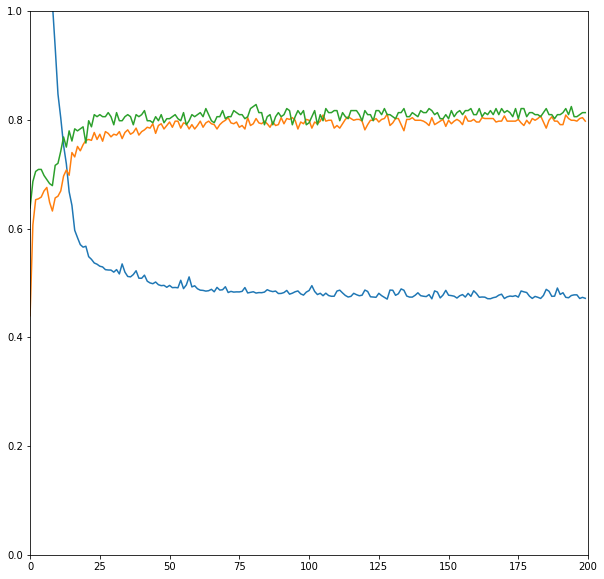
titanic_by_kerasimport keras import tensorflow as tf model=keras.Sequential([ keras.layers.Dense(10, activation=tf.nn.relu, input_dim=8), keras.layers.Dense(2, activation=tf.nn.softmax), ]) model.compile(optimizer=tf.train.AdamOptimizer(),\ loss="sparse_categorical_crossentropy",\ metrics=["accuracy"]) print(model.summary()) epochs=200 fit=model.fit(train_features, train_labels, epochs=epochs, validation_split=0.3) plt.figure(figsize=(10,10)) plt.xlim(0,epochs) plt.ylim(0, 1) plt.plot(fit.history['loss'], label="loss of training") plt.plot(fit.history['acc'], label="acc of training") plt.plot(fit.history['val_acc'], label="acc of evaluate")epochsの数を大きめにして、データの30%をvalidationに回して評価してみる。
意外と過学習が起きていない。テストデータでaccuracyは0.8程度。このモデルを使ってテストデータの乗客の生存/死亡を予測して提出する。出力は0と1のint型で提出。
結果
再掲になるが、提出するとこのような画面で自分の順位とスコアが確認できる。この学習結果では0.76076。実はこの前にepochs=50で適当に提出したのがあるので、0.75119から上がったよ!みたいなコメントが出ている。
これから様々観点からこのモデルを改良してもいいが、私的にはひと段落と言ったところである。様々なデータの処理が学べるが、これ以上頑張ってもtitanicの予想のための学習に先鋭化しすぎて、汎化の乏しさがあるからだ。
それより少し画像認識関連のCNNに興味があるのでMNISTのデータセットでもやろうかと思っている。もしくはコンペではないデータセットの学習も面白そうだ。
所感
というわけでkaggleにSubmitした話であるが、私自身kaggleでどうすればいいのか分からなかったので引用元の記事やコード、そしてなによりとにかくSubmitしてみてkaggleの仕組みを理解できたのが大きい。とりあえずSubmitしてみれば、そのテーマのモデルの改良、他の人のカーネル、周辺分野の他のデータセットなどがとても価値のある興味の対象になるので、よい。
kaggle初心者はとりあえずSubmitしてから考えてみよう!!別に誰の迷惑にもならないし!!
付記
今回、コードが引用元をforkして前処理と学習を書き直しただけのおんぶにだっこなので最後にGitHubのページをこっそり置いておく。"titanic_by_keras"が私のコードである。
- 投稿日:2019-04-05T21:21:31+09:00
scikit-learn ちょっと高度なFunctionTransformerの使い方
はじめに
以前に書いた記事sckit-learnのPiplineを使って、カスタム前処理をモデルの中に組み込むの続編。
前の記事では前処理関数は完全に固定したものでしたが、この関数にパラメータを含めて、Pipeline作成後にパラメータを変更できる作りにすることを目標にします。実装サンプル
以下に実装コードを記載しながら解説をします。
データ準備
アイリスデータセットを題材にします。
from sklearn.datasets import load_iris iris = load_iris() X = iris.data y = iris.target前処理関数
前処理関数 func_customの定義をします。
説明を簡単にするため、入力値Xを一定値で割り算するという関数とします。
割る値はarg1という後で変更可能なパラメータにします。def func_custom(X, arg1): return(X/arg1)カスタムフィルターの定義
FunctionTransformerクラスと先ほど定義したfunc_customを使ってカスタムフィルターを定義します。
from sklearn.preprocessing import FunctionTransformer ft = FunctionTransformer(func_custom, validate=True, kw_args={'arg1': 2})インスタンス生成時のパラメータ指定
kw_args={'arg1': 2}がポイントです。
パラメータのキー値'arg1'は、関数宣言での引数と名前をそろえます。
こうすることで関数宣言のパラメータ値を後で変更することが可能になります。パイプラインの定義
パイプラインの定義に関しては、普通の方法で行います。
from sklearn.pipeline import Pipeline from sklearn.svm import SVC pipe = Pipeline([('ft', ft),('svm', SVC(gamma='auto'))])学習・予測
いったん作ったPipelineで学習と予測を行ってみます。
ここも普通の方法ですので、解説は省略します。pipe.fit(X, y) pipe.predict(X)Pinelineから前処理を抜き出す
named_steps属性を使って、今作ったPipelineから前処理関数を抜き出してみます。
pipe.named_steps['ft']次のような結果がかえってくるはずです。
FunctionTransformer(accept_sparse=False, check_inverse=True, func=<function func_custom at 0x10d904488>, inv_kw_args=None, inverse_func=None, kw_args={'arg1': 2}, pass_y='deprecated', validate=True)前処理の挙動の確認
FunctionTransformerは、transform関数でフィルターの挙動を確認できます。現時点では以下のように入力データを2で割った答えが返ってきます。
X1 = X[:5,:] print(X1)[[5.1 3.5 1.4 0.2] [4.9 3. 1.4 0.2] [4.7 3.2 1.3 0.2] [4.6 3.1 1.5 0.2] [5. 3.6 1.4 0.2]]print(pipe.named_steps['ft'].transform(X1))[[2.55 1.75 0.7 0.1 ] [2.45 1.5 0.7 0.1 ] [2.35 1.6 0.65 0.1 ] [2.3 1.55 0.75 0.1 ] [2.5 1.8 0.7 0.1 ]]フィルター関数内のパラメータ値変更
フィルター関数内のパラメータ値は
set_params(kw_args={'arg1': 4})のようにset_params関数呼び出して値を変更できます。
変更のための実行コードと、変更後のフィルター出力結果は以下の通りです。
想定通り、入力値を4で割った結果がかえってきていることがわかると思います。パラメータ値変更
pipe.named_steps['ft'].set_params(kw_args={'arg1': 4})FunctionTransformer(accept_sparse=False, check_inverse=True, func=<function func_custom at 0x10d904488>, inv_kw_args=None, inverse_func=None, kw_args={'arg1': 4}, pass_y='deprecated', validate=True)変更後のフィルターの挙動
print(pipe.named_steps['ft'].transform(X1))[[1.275 0.875 0.35 0.05 ] [1.225 0.75 0.35 0.05 ] [1.175 0.8 0.325 0.05 ] [1.15 0.775 0.375 0.05 ] [1.25 0.9 0.35 0.05 ]]
- 投稿日:2019-04-05T19:36:31+09:00
CSVからTSVに変換するワンライナー
python -c 'import sys, csv; csv.writer(sys.stdout, delimiter="\t").writerows(csv.reader(sys.stdin))' < 入力.csv > 出力.tsv表題のテーマでググるとsedなりtrなりで単純にデリミタを置換する方法が多く紹介されています。
しかしそれではクォーテーションされた文字列の一部としてのカンマも置換されてしまいます。クォーテーションを考慮しようとすると、もはやどんなに正規表現を駆使しようとも置換では不可能なので、既成のCSVツールに頼りたくなります。
ではシェル上でパイプフィルタとして手軽に呼び出せる既成のCSVツールはどんなものがあるだろうか。ない
少なくとも私は知らない。あったら教えてください。
したがって、何らかのスクリプト言語のCSVライブラリを用いることになります。ひとまず思い浮かぶのは「電池ついてます」がウリのpythonなので、冒頭のようなワンライナーを考えました。
もちろん、デリミタ指定を変えてやればTSV → CSVもできるし、独自デリミタもできます。python -c 'import sys, csv; csv.writer(sys.stdout, delimiter=",").writerows(csv.reader(sys.stdin, delimiter="\t"))' < 入力.tsv > 出力.csvワンライナーは短さこそ至上命題なので、もっと短く書けるよというコメントを歓迎します。
もちろんpythonに限りません。
- 投稿日:2019-04-05T19:22:31+09:00
【Beginner】【AI】【機械学習】Light GBM: Titanic: Machine Learning from Disaster
本ブログは、超初心者でも機械学習を利用した予測モデルが構築できるようになる内容となってます
教材としては、Kaggle_GettingStartedのTitanic: Machine Learning from Disasterを利用し、その予測過程を解説します。本ブログは下記の順番で展開します
- データクレンジング(データ前処理)
- Light GBM(予測モデリング手法)の適用
「誰でも」 (精度は置いておいて)Light GBMという先端的な予測モデリング手法を利用して、二値分類予測モデルが解けることを目的としているので、中級者が読むとしょうもないことも、途中で記載しております
また本ブログは 下記2点を前提として進めております
- kaggleを知っている
- jupyter(データ分析プラットフォーム)を利用している
kaggleを初めてやるという方はこちらのQiitaブログからkaggleの開始方法をご確認下さい
jupyterをダウンロードしていないという方は、こちらをご参照下さい
*windowsの人はanaconda入れれば面倒な開発環境設定がいりませんので、anacondaインストールを推奨しております分析かじっていて色々用語は知ってるんだけど、一回も実装したことが無い。。という方には特におすすめです
それ以外の方でも「読んでやるよ」という方は下記にてお進みください1.データクレンジング(データ前処理)
今回、Light GBMというモデリング手法を使用します。kaggleの上位ランカーがかなり利用しており、実装は簡単ですが非常に精度の高い機械学習ライブラリとして注目されている手法です
そのLight GBMに必要なデータを与えると、予測結果を返してくれるという単純な仕組みなのですが、
与えるデータにざっくり下記の3つの条件が有ります
- 教師データと予測データのカテゴリ(列数と種類)が揃っていること(説明変数の設定)
- 欠損値(データ上の空白)が無いこと(欠損値の補完)
- 取り込まれるデータは全て「数値データ」であること(ダミー化)
数値データってintですか!?floatですか!?とかいろいろツッコミ来そうですが、最初はこれで十分です
なのでこれらの条件を満たすためにデータを綺麗にする、「データクレンジング」という処理を行います
ちょっと地味な作業になりますがお付き合いください
まず、教師データ(train)と予測データ(test)を読み込みます
厳密には予測データ(test)では無いと言われそうですが、最初はこちらの方が理解しやすいのでこのように記載しますimport pandas as pd test = pd.read_csv("test.csv" , encoding="CP932") train = pd.read_csv("train.csv", encoding = "CP932")*Tipsですが、windowsの人はencoding="CP932"をつけると日本語読み込む際に文字化けが消えます(今回は意味ないです)
*test.csvとtrain.csvはkaggleのCompetition内のTitanic:Machine Learning from Disaster(こちら)からダウンロードできます次に教師データ(train)を教師データ説明変数(train_x)と教師データ目的変数(train_y)に分け読み込み、予測データ(test)はそのまま予測データ説明変数(test_x)として読み込みます
説明変数と目的変数って?という方もググったらすぐ分かりますが、
こちらが分かりやすいです。train_x = train.drop("Survived",axis=1) train_y = train["Survived"] test_x = test躓きポイント
この後、「欠損値の補完」→「ダミー化」と進んでいくのですが、
「ダミー化」の際に、train_xとtest_xのcolumns数(列数)が揃っておく必要が有ります今の状態でダミー化してしまうと、列数が500列程数がズレてしまいLight GBMに与えるデータとして使えないので、ここからさらに説明変数に使用するカテゴリを絞ります
ここは最初実装するときに、割と躓きやすいポイントだと思いますよくモデルを作成する際にその精度を向上させるために行う「チューニング」という作業が有りますが、
この説明変数の設定もチューニングの一つです*ダミー化が分からない方はこちらをご参照下さい
「ダミー化」とは簡単に言うと、文字列データを数値化するよといったニュアンスです。詳細はリンクで
上記の躓きポイントを解消するために説明変数を絞り込みます
今回は"Name"(乗客の名前) "Ticket"(チケット番号) "Cabin"(部屋番号)は"Survived"(生存結果1:生存,0:死亡)に寄与しないという仮説を立て、この3カテゴリを省いたものを説明変数としますtrain_x = train_x.drop("Name",axis =1) train_x = train_x.drop("Ticket",axis =1) train_x = train_x.drop("Cabin",axis =1) test_x = test_x.drop("Name",axis =1) test_x = test_x.drop("Ticket",axis =1) test_x = test_x.drop("Cabin",axis =1)以上のコードで 1.説明変数の設定 が完了致しました
次に、2.欠損値の補完 を行います最初に、すぐに欠損値の補完を行うのでは無く、どのカテゴリにどの程度欠損値があるかを把握します
確認するコードは下記です。(最初に教師データ説明変数(train_x)で確認しております)train_x.isnull().sum()結果は下記です
PassengerId 0
Pclass 0
Sex 0
Age 177
SibSp 0
Parch 0
Fare 0
Embarked 2Ageの欠損が目立ちますね
Embarked(出港した港)も欠損値が2つ見られます
同様に、予測データ説明変数(test_x)でも確認しますtest_x.isnull().sum()PassengerId 0
Pclass 0
Sex 0
Age 86
SibSp 0
Parch 0
Fare 1
Embarked 0こちらも同様にAgeの欠損が目立ち、Fare(乗船料金)にも一つ欠損が見られます
以上より"Age""Fare""Embarked"に対して欠損値補完の方針を検討し、実行します今回の欠損値補完方針は下記で行います
- Age = 全体の乗船者年齢の中央値(median)
- Fare = 全体の乗船料金の中央値(median)
- Embarked = "S"(Sの港を利用した人が最も多いので)
中央値じゃなくて、平均値じゃダメなんですか!とも言われそうですが 結論OKです
ここも チューニングポイントの一つなので、この値をどう設定するかも後の予測結果に影響してきます
ただ、この中では深く議論しません。欠損値を埋めるという目的をただ遂行しますちなみにEmbarkedで"S"が一番多いのを判定したプログラムは下記です
train_x["Embarked"].value_counts()これにより下記の通り出力が有ります
S 270
C 102
Q 46
上記結果をtest_xにも適用して、Sが最も多いと判定し、欠損値の補完要素の1つとして採用致しました
value_counts()は、選択した列に含まれる文字のユニーク数をカウントしてくれるコードなので割と頻出で良く使えます話を戻して、決定した方針を元に、実際に欠損値を補完します
コードは下記ですtrain_x["Age"] = train_x["Age"].fillna(train_x["Age"].median()) train_x["Fare"] = train_x["Fare"].fillna(train_x["Fare"].median()) train_x["Embarked"] = train_x["Embarked"].fillna("S") test_x["Age"] = test_x["Age"].fillna(test_x["Age"].median()) test_x["Fare"] = test_x["Fare"].fillna(test_x["Fare"].median()) test_x["Embarked"] = test_x["Embarked"].fillna("S")fillna("補完値")でデータが空白(Nan)の値を指定した"補完値"で補完出来ます
ちなみにmedian()というのが中央値を算出するコードです以上で 2.欠損値の補完 が完了致しました
最後に、3.データをすべて数値化(ダミー化) を行いますダミー化については再掲ですがこちらをご覧ください。
そしてダミー化を行うコードは下記です
train_x_dummy = pd.get_dummies(train_x) test_x_dummy = pd.get_dummies(test_x)教師データ(train_x)、予測データ(test_x)それぞれにpd.get_dummies()を適用すれば、一行でダミー化完了です
少し長かったですが、ここまでで1.データクレンジング(データの前処理)が終了致しました
実際のAnalyticsプロジェクトでもデータクレンジング(データの前処理)はきついポイントの1つとなってますので、以前最もセクシーな職業と言われたデータサイエンティストも、業務の大半がこういった地味な作業であることがほとんどです
それでは、ここから 2.Light GBM(予測モデリング手法)の適用に移ります
2. Light GBM(予測モデリング手法)の適用
まずLight GBMを利用するために必要なライブラリ(モジュールともいったりします)を分析環境上に読み込みます
import lightgbm as lgb from sklearn import datasets from sklearn.model_selection import train_test_split from sklearn import metrics import numpy as npこれらは「おまじない」なので実践するときもコピペして使ってもらって結構です
次に、「モデル」を作成していきます
よく分析屋がモデルの構築とか、モデルの精緻化とかモデルモデル言ってますが、要は関数です
皆さんが中学、高校でやった y = ax + bとかそういったものが「モデル」ですなので、分析屋が「モデルの構築」とか言ってたら、
ああ、要はちょっと複雑な関数を作るのね、y=ax + bみたいな
とかって思っておけばいいですy = ax+bで説明すると、"y"が目的変数。今回で言うとtrain_y。カテゴリでいうと、"Survived"(生存結果1:生存,0:死亡)で、
"x"が説明変数。今回で言うとtrain_xとかになりますLight GBM(予測モデリング手法)を適用することで、上記の"a"や"b"の、係数や切片を特定することが出来ます。この係数や切片を求める行為が「モデルの構築」となります
ここら辺がまとめてある物がなくて、あえて混乱させているようにしか見えないほど難しく記載するものばかりでしたので書いてみました
「モデル」は「関数」
中学、高校でみんな「モデルの構築」やってます前置きが長くなってしまいましたがここから「モデルの構築=関数の作成」を行います
コードは下記ですmodel = lgb.LGBMClassifier() model.fit(train_x_dummy,train_y)以上です
たった二行でモデルが出来ました一行目はおまじないです
今回使用した、"lgb.LGBMClassifier()"の他に、"lgb.LGBMRegressor()"というのもあります
前者の方は分類問題で使用する関数です、今回でいうと「生き残った人と死んでしまった人を分類する」ので適用しています
後者の方は値予測(回帰問題)で使用する関数です、例でいうと、価格の予測、販売予測とかそういった具体的な数値を予測する場合に使用します。別で解説します二行目は
model.fit("教師データ説明変数"、"教師データ目的変数")
という構成です
これにより教師データから、y=ax+bのaとbを求めモデル=関数を作成しています
*注意:実際はy=ax+bでは無くもっと高次です、こんな単純じゃありませんがあくまで理解のために単純化しておりますそして最後に、「予測」を行います。
今回で言うと、予測データ説明変数(test_x)から予測データ目的変数"Survived"を予測判定しますy_pred = model.predict(test_x_dummy)以上、一行です
予測データ目的変数は"y_pred"で表現しております
y_predに予測判定結果が格納されてます。これでLight GBM(予測モデリング手法)の適用が完了し、機械学習の実装を達成致しました3.最後に
本ブログの通りに実行し、kaggleにsubmitした結果下記でした
良くもないけど悪くもないといった感じですね
何も捻り加えてないのにさすがLight GBM。。。
モデル作成部分(model = lgb.LGBMClassifier()の)()内で)まだまだチューニングの余地が多分にあるのでそこを調整するとより精度の高い予測モデルが構築できそうです!今後も更新を予定しており、次回はPricing(価格予測)の機械学習モデルの構築を予定してます
- 投稿日:2019-04-05T19:12:14+09:00
Jupyter NotebookでのpySparkコードサンプル
TL;DR
Jupyter Notebookで、pySparkで、データ前処理して、機械学習ライブラリを通して、評価値を出すところのコード例です。適当なところをコピペしたりクックブックのように使ってください。細かいところはAPIリファレンスを参照願います。
https://spark.apache.org/docs/latest/api/python/index.html筆者がなにか誤解しているとか、見つけられてないとか、もっと良いやり方があるかもしれません。有識者の突っ込み歓迎します。間違い探し遊びにどうでしょうか?
前提
Jupyter 環境で、pySparkなカーネルに接続していて、
pyspark.sql.session.SparkSessionであるようなsparkがあることが前提です。notebook環境であれば自然にそうなると思います。バージョン情報など
- JupyterLab 0.35.4
- python 3.6.6
- pySpark 2.4.0
タブ区切りファイルを読み込んで、DataFrameを生成する。
/tmp/dokosoko/test.tsvにおいてある、5カラムあるTSVファイルを読む場合。必要なカラムが先頭部分にある場合は、不要カラム以降についてはStructType.add()しなくてもよさそうです。tsvを読む例.pyfrom pyspark.sql.types import * fields = StructType()\ .add("nantoka_id", LongType(), False)\ .add("kantoka_name", StringType(), False)\ .add("dousita_value", FloatType(), False)\ .add("hogehoge_date", TimestampType(), True)\ .add("fugafuga_date", TimestampType(), True) df = spark.read.format('csv')\ .option("delimiter", "\t")\ .schema(fields).load('/tmp/dokosoko/test.tsv')行の選択・列の射影
# 選択 # 指定した期間内のレコードを取り出す例。 import datetime from dateutil.relativedelta import relativedelta string_today = '2019-04-05 10:00:00' today = datetime.datetime.strptime(string_today, '%Y-%m-%d %H:%M:%S') sevenDayBefore = today + relativedelta(days=-7) df = df .filter((sevenDayBefore < df.entry_dt ) & (df.entry_dt < today )) # 射影 df = df .select('nantoka_id', 'fugafuga_date')選択の際の条件を
&|などで繋ぐ場合カッコが必要なので注意。列順序を変えるときも射影で取り直せば良い。参考: https://stackoverflow.com/questions/42912156/python-pyspark-data-frame-rearrange-columns
列の削除
df = df.drop('nantoka_id')必要な列を選択するのと、不要な列を削除するのとどちらが速いかは未確認。(あまり変わらないかも?)
列のリネーム
df = df.withColumnRenamed('research_id', 'r_research_id')列を何らかの処理で更新する(あるいは新しい列を作り処理結果を入れる。)
withColumnが使える。更新したい列名を指定できる。新しい名前の場合はそのような列が作られる。pySparkのライブラリの関数を使う場合
日付の差を新カラムに入れる例.pyfrom pyspark.sql.functions import datediff df = df.withColumn("dateDiff", datediff(df.update_dt , df.entry_dt ))自前で処理を書く場合。
簡単な分岐の例
when() が使える。
from pyspark.sql.functions import when df = df.withColumn("count",when( 360 < col("count") , float(1)).otherwise( col("count") / 360))複雑なロジックがあるときの例
一旦udf (User Defined Function) を作って利用する。
def calcNantoka(param1, param2 ): # ここになにか複雑な処理があると思ってください。 return param1 from pyspark.sql.functions import udf # IntegerType() というように戻り値の型を指定する。 calcNantoka_udf = udf(calcNantoka, IntegerType()) df = df.withColumn("new_nantoka",calcNantoka_udf (df["hogehoge"], df["fugafuga"] ))Pythonのデコレータを使うともっと端的に書けるようですけど未確認です。
group byしてなにかする例
aggで、なにか集約して新しい列にする。件数と最大値を取る例.pygb = df.groupby(['nantoka_id']) import pyspark.sql.functions as F # 行数をカウント、最終の日付を取得。 summaryDf = gb.agg(F.count('*').alias('hogehoge_count') ,F.max('update_dt').alias('last_event_date') )条件付きで件数を取る例.pygb = df.groupby(['nantoka_id']) # 条件付きの行数カウントは一工夫必要(らしい。) cnt_cond = lambda cond: F.sum(F.when(cond, 1).otherwise(0)) response_when = gb.agg( cnt_cond(F.col('days_diff') < 1 ).alias('quick_num'), cnt_cond(F.col('days_diff') < 2 ).alias('normal_num'), cnt_cond(F.col('days_diff') < 3 ).alias('late_num') )参考:https://stackoverflow.com/questions/49021972/pyspark-count-rows-on-condition
複数のDataFrameを特定の列の値でjoinする場合
df = df.join(target, df.nantoka_id == target.nantoka_id_t ,"left")joinする列の名前を違うようにしておかないと怒られる。予めリネームしておくと良い。
注:aliasでなんとかできるかもしれない。(未確認)
列のデータの相関係数を測ってみる。
一旦一つのカラムに、配列として置き直してから
Correlation.corr()を呼ぶ。
呼んだ後、結果のDFの1行目1列目の値を取得して表示する。from pyspark.ml.feature import VectorAssembler from pyspark.ml.stat import Correlation # features カラムに置き直す。 assembler = VectorAssembler( inputCols=["hoge_value","fuga_value","some_count","dousita_num"], outputCol="features") output = assembler.transform(df) output.printSchema() pearsonCorr = Correlation.corr(output, column='features').collect()[0][0] print(str(pearsonCorr).replace('nan', 'NaN'))GeneralizedLinearRegression.fit() 向けのデータを作って呼ぶ。
相関係数の計算のように、一つのカラムに配列として置き直してからfitを呼ぶ。その際正規化とか色々あるから、
Pipelineを通すのがセオリーのようになる。XやYに分けるのとは違うので面食らう向きもあるかもしれない。1from pyspark.ml import Pipeline from pyspark.ml.feature import VectorAssembler from pyspark.ml.feature import MinMaxScaler from pyspark.ml.regression import GeneralizedLinearRegression # 入力DataFrameの、inputColのカラムの値を、1個のVectorに詰め直し、新たに features_not_scaled というカラムを作って features_not_scaled というカラム名にして入れる assembler = VectorAssembler( inputCols=["hoge_value","fuga_value","some_count","dousita_num"], outputCol="features_not_scaled") # features_not_scaled のvectorの内容を正規化して、 features カラムを作ってそこに入れる。 mmScaler = MinMaxScaler(inputCol="features_not_scaled", outputCol="features") glr = GeneralizedLinearRegression() pipeline = Pipeline(stages=[assembler, mmScaler, glr]) pipelineModel = pipeline.fit(train)RegressionEvaluator を使う。
DataFrameの2個のカラムについて、差を元にした以下のような計算を行える。
予想値と正解値との差の総合的な評価に使える。
- 決定係数
- R2
- 平均絶対誤差
- Mean Absolute Error (mae)
- 平均二乗誤差
- Mean Squared Error (mse)
- 平均平方二乗誤差
- Root Mean Square Error (rmse)
from pyspark.ml.evaluation import RegressionEvaluator #デフォルトでは、予測値が prediction カラム、 正解値が label カラムである。 evaluator = RegressionEvaluator() evaluator.evaluate(resultDataFrame) print(evaluator.evaluate(resultDataFrame, {evaluator.metricName: "r2"})) print(evaluator.evaluate(resultDataFrame, {evaluator.metricName: "mae"}))参考URL
本家APIドキュメント
https://spark.apache.org/docs/latest/api/python/index.html
僕もです。
↩
- 投稿日:2019-04-05T19:01:14+09:00
PythonでNumer0n作ってみた!(ユーザー対戦型)
始めに
Python勉強の一環で、Numer0nという、簡単にいうと数当てゲームを作成しました!
Qiitaにある似たような投稿を参考にしつつ、 自分なりにアレンジしてユーザー同士の対決に変更しました。(相手がその場にいなければひとりですが、、、)開発環境
- Python 3.7.2
- pyenv 1.2.9
numeron.pyimport random import getpass def duplication_check(num): if len(num) == len(set(num)) and len(num) == 3: return True def eat_bite_check(player_number,opponent_number): global eat global bite eat = 0 bite = 0 if player_number[0] == opponent_number[0]: eat += 1 elif player_number[0] in opponent_number: bite += 1 else: pass if player_number[1] == opponent_number[1]: eat += 1 elif player_number[1] in opponent_number: bite += 1 else: pass if player_number[2] == opponent_number[2]: eat += 1 elif player_number[2] in opponent_number: bite += 1 else: pass return (str(eat)+ 'EAT-'+ str(bite)+ 'BITE') print('Numer0nというゲームを始めます。\nルール説明は必要ですか?yes or no') answer = input() if answer == 'yes': print('\nルール説明!') print('各プレイヤーは、0~9までの数字の中から3つ使って、3桁の番号を作成します。\n0から始めても良いですが、「550」「377」といった同じ数字を2つ以上使用出来ません。') print('プレイヤーは、自身のターン時に相手が選んだと思われる3桁の番号を選択します。') print('数字と桁が合っていた場合は「EAT」、数字は合っているが桁は合っていない場合は「BITE」となります。') print('[例]\n相手の番号が「765」で、自分が予測して入力した番号が「746」であった場合、「7」は数字と桁の位置が合致しているためEAT。\n「6」は数字自体は合っているが桁の位置が違うためBITE。\nEATが1つ・BITEが1つなので、結果は「1EAT-1BITE」となります。') print('先に3EATになったプレイヤーの勝利です!\n') else: pass print('先ずはplayer1の番号を決めてください') while True: try: player1_number = getpass.getpass('3桁の数字を入力:') print('') if duplication_check(player1_number) and str.isdecimal(player1_number): player1_number = list(player1_number) break except: pass print('3桁の数値を重複無しで再入力してください') print('次にplayer2の番号を決めます') while True: try: player2_number = getpass.getpass('3桁の数字を入力:') print('') if duplication_check(player2_number) and str.isdecimal(player2_number): player2_number = list(player2_number) break except: pass print('3桁の数値を重複無しで再入力してください') eat = 0 bite = 0 print('---------------------------------------------------') print('ゲームを開始します\n') while True: while True: player1_answer = input('player2の3桁の数字を予想してください:') if duplication_check(player1_answer) and str.isdecimal(player1_answer): player1_expectation = list(player1_answer) break else: print('3桁の数値を重複無しで再入力してください\n') print('\nplayer1の結果は['+ eat_bite_check(player1_expectation,player2_number)+ ']でした\n') if eat == 3: print('player1の勝ちです\n') print('player1の番号は' + str(player1_number) + 'でした\n') break print('player2があなたの番号を予想します') print('-----------------------------------------------------') while True: player2_answer = input('player1の3桁の数字を予想してください:') if duplication_check(player2_answer) and str.isdecimal(player2_answer): player2_expectation = list(player2_answer) break else: print('3桁の数値を重複無しで再入力してください\n') print('\nplayer2の結果は['+ eat_bite_check(player2_expectation,player1_number)+ ']でした\n') if eat == 3: print('player2の勝ちです\n') print('player2の番号は' + str(player2_number) + 'でした\n') break; print('player1があなたの番号を予想します') print('-----------------------------------------------------') print('ゲームを終了します')無駄な箇所が多いかもしれませんが初学者なのでよろしくお願いします!
- 投稿日:2019-04-05T17:37:17+09:00
Amazon SageMakerで物体検出(うまい棒検出の記事を補足)
物体検出モデルを自前に作るには、Amazon SageMakerというサービスを使うのがとても便利。
ハイパーパラメータの説明も以下の通り分かりやすい。
https://docs.aws.amazon.com/ja_jp/sagemaker/latest/dg/object-detection-api-config.htmlさて、動かし方ですが、基本的には以下記事の通りに実装すればOK。多謝。
https://dev.classmethod.jp/cloud/aws/sagemaker-umaibo-object-detection/ただし、VoTTのoutputとSageMaker投入用inputのフォーマットを合わせるところのスクリプトが若干異なっていたので、以下のように修正。
file_name = '{your_file_path}' class_list = {'your_class':0} with open(file_name) as f: js = json.load(f) for k, v in js['assets'].items(): fileno = v["asset"]["name"].split(".")[0] line = {} line['file'] = fileno + '.jpg' line['image_size'] = [{ 'width':v["asset"]["size"]["width"], 'height':v["asset"]["size"]["height"], 'depth':3 }] line['annotations'] = [] for annotation in v["regions"]: line['annotations'].append( { 'class_id':class_list[annotation['tags'][0]], 'top':annotation['boundingBox']["top"], 'left':annotation['boundingBox']["left"], 'width':annotation['boundingBox']["width"], 'height':annotation['boundingBox']["height"] } ) line['categories'] = [] for name, class_id in class_list.items(): line['categories'].append( { 'class_id':class_id, 'name':name } ) f = open('./json/' + fileno + '.json', 'w') json.dump(line, f) f.close()さらにさらに、当然ながらトレーニングにはGPUインスタンスが必要なので、アカウント作りたての方はリソースの上限緩和が必要。私の場合は以下の通り申請し変更。
トレーニング:ml.p3.2xlarge
ホスティング:ml.m4.xlarge
常識かもしれませんが、念の為。ちなみに認識結果は公開できないのですが、400枚弱のアノテーション、ハイパーパラメータのチューニングはほぼなしでモデル構築したところ、F値は9割超え。素晴らしい。
- 投稿日:2019-04-05T15:52:40+09:00
sqlalchemyメモ
設定ファイルを環境変数に設定する
export FLASK_CONFIG_FILE=./local.cfgmodel変更をもとにrevisionファイル生成する
python manage.py db migraterevisionファイルを持ってデータベースを更新する
python manage.py db upgrade手動で編集するrevisionファイル作成する場合
python manage.py db revisionupgrade, downgradeのないrevisionファイルを作られる
現在のrevison情報を表示する; revison履歴を表示する
python manage.py db show python manage.py db history全revisionのsql scriptsを生成する
python manage.py db upgrade --sql > ../sql/`date "+%y%m%d%H%M"`.sql
- 投稿日:2019-04-05T15:09:11+09:00
円周率は3.05以上であることを示す。
有名な東大入試の問題の解き方を紹介します。
紙と鉛筆でも解けますが、プログラムを組んだ方がよりスムーズに解くことができます。
なぜなら正十二角形を使うからです。
正十二角形は手書きで書くと大変なのでプログラムで書いた方が楽です。
図1:JavaScriptで描いた正十二角形それでは早速、今回解いていく問題を確認しましょう。
図2:今回扱う問題1.円周率って何?
そもそも円周率って何でしょうか?
率という数字が示すように「何か」と「何か」の割合のことです。
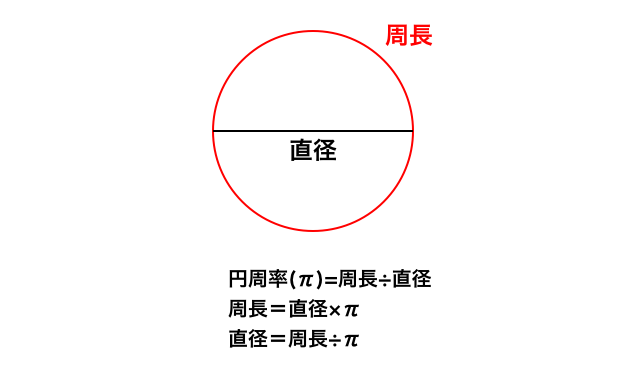
例えば「勝率」という言葉は「勝ち数」÷「試合数」で求められます。
10試合して3勝している場合勝率は3÷10で0.3になります。円周率の場合は、「円周の長さ」÷「直径」で求められます。
図3:円周率を求める式ということで「円周の長さ」÷「直径」の式を活用すると良さそうです。
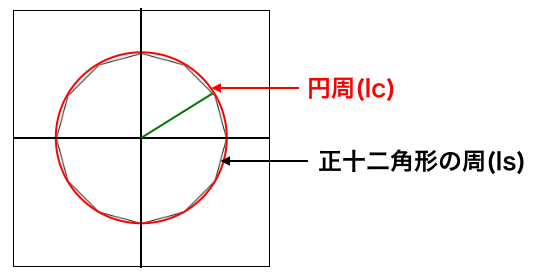
2.正十二角形を活用した解き方
図4:円と正十二角形余弦定理を活用して解きます。
余弦定理が分からない場合はGoogleで「余弦定理 とは」と検索しましょう。
(分からない単語が出てきたら検索する癖をつけましょう)
参考:Pythonによるプログラム
出展:https://qiita.com/redmeteor777/items/4b4aebd9da8db825b10dimport math # [π > 3.05 を証明せよ] while True: target_input = input("円周率がいくつより大きいことを証明しますか?") try: #入力値チェック target = float(target_input) except ValueError: print("数値を入力してください。") else: # 入力値が円周率より大きいと無限ループするため入力値をチェック if target <= math.pi: break else: print("円周率より小さい値を入力してください。") print("円周率が{}より大きいことを証明する".format(target)) print("") #正n角形の頂点の初期値を3にセット n = 3 # breakするまでループさせる while True: # 等辺の長さ1、頂角360/nの二等辺三角形の底辺の長さを求める kakudo = 360 / n # math関数の三角関数計算ではラジアンを用いるので度→ラジアンの変換が必要 radian_kakudo = math.radians( kakudo ) # 余弦定理から、底辺 x の長さは[x ^ 2 = 1 ^ 2 + 1 ^ 2 + 2 * 1 * 1 * cos(360 / n)] x = ( 1*1 + 1*1 - 2*1*1*math.cos( radian_kakudo ) ) ** 0.5 # 底辺の長さ * nを円周の近似値 y とする y = x * n print("正{0}角形のとき、辺の長さの合計は{1}".format(n , y)) if y / 2 > target: #目標値より大きくなったらブレイクして終了処理へ break # 頂点を1つ増やす n = n + 1 print("") print("円周率 = 円周 / 直径") print("") print("{0} / 2 = {1} > {2}".format(y , y / 2 , target)) print("") print("よって円周率は{}より大きい".format(target))


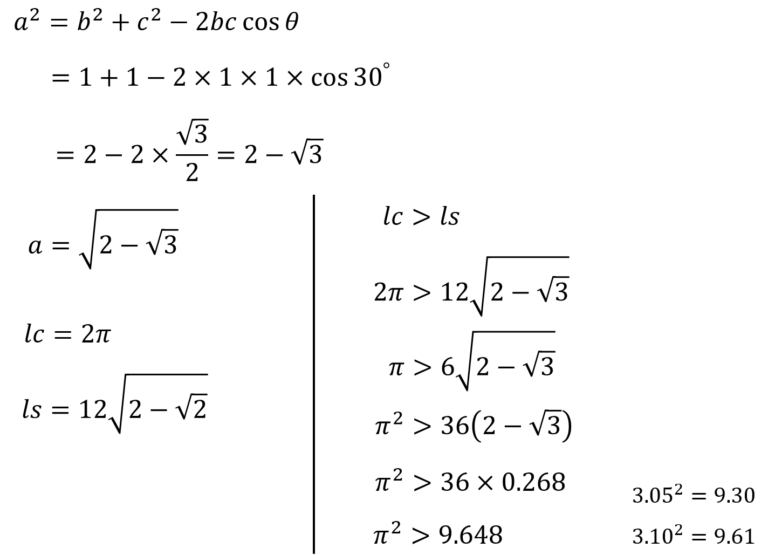
- 投稿日:2019-04-05T14:44:48+09:00
BoostnoteにAdd(再リンク)できない時にどうすればいいか
はじまり
Dropbox上でBoostnoteを管理していたら、データが消えました…
正確にはアプリから参照できなくなったですね。
boostnoteでdropboxデータの復元を試みるに記載されている内容と類似した以下のような現象が起きました。
- データはDropbox上に存在
- Boostnote mobileからは確認可能
- 再リンクが不可
環境
- MacOS Sierra 10.12.6
- Boostnote 10.11.15
- Boostnote mobileとDropbox連携(ios 12.1.4)
- python3.6
原因
Boostnoteアップデート後CSONファイルが存在するにも関わらずストレージ設定が消えてフォルダとドキュメントが表示されない障害原因と解消法がわかりやすくて助かりました。
結論的には、既存のcsonファイルにおいてcontentが空だと、読み込みがエラーになるようです。
同様の問題かどうかは、View > Toggle Developer Toolsを参照するとわかります。解消方法
やるべきことはcontentが空のファイルを見つけて、削除することです。
順番にノートの中身を確認するにはいかんせんノートの数が多かったので、以下のpythonスクリプトを
Boostnote/notesディレクトリにて行うことで探索しました。import cson from pathlib import Path p = Path.cwd() for path in p.iterdir(): with open(path) as f: c = cson.load(f) if len(c['content']) < 1: print(path.name)内容はカレントディレクトリにおけるcsonファイルのcontentが1文字より小さいものを探して、ファイル名を標準出力です。
一応、中身を確認してから表示されたファイルを削除することをお勧めします。これで再リンクできない問題は解決されるはずです。
同時に起きていた、別の問題について
Boostnoteを再起動するたびにリンクが解除され、再リンクが必要となる問題も発生していたのですが、そちらは
$HOME/Library/Application Support/Boostnoteを削除して、Boostnoteをインストールし直して強引に解決しました。
もっといい解決法がありそうですが、サボってしまいましたね…参照元
- 投稿日:2019-04-05T14:27:18+09:00
半歩ずつ進める機械学習 ~scikit-learnボストン住宅価格編~⑤
前回まで
前々回にscikit-learnの
LinearRegressionを使って
ボストン住宅価格を予測するモデルを作り、交差検証を行いました
しかし学習・テストデータの分割方法が原因(仮定)で交差検証結果のバラつきが大きい事を受けて
前回の投稿で、複数のデータ分割方法について学びました
今回は、前回学んだ事を踏まえて、モデルの検証と精度アップを試みます。まず試してみよう
前回学んだデータ分割方法は以下の三種でした
- KFold
- Stratified KFold
- Group KFold
下の二つは分類問題に使う物らしいので
現在取り組んでいるボストン住宅価格の予想にはKFold(Shuffle = True)が適切かと思いますまずはバラつきが大きかった交差検証のコード
boston.pyfrom sklearn.model_selection import cross_val_score from sklearn.linear_model import LinearRegression lr = LinearRegression() print(cross_val_score(lr,env_data,price_data,cv = 5) #[ 0.63861069 0.71334432 0.58645134 0.07842495 -0.26312455]
cross_val_scoreは引数cvに整数を指定すれば、指定された数にcross_val_scoreの中で分割してくれます。
cvにはインデックスを返すジェネレータを渡す事も可能で、その場合は渡されたジェネレータを使ってデータ分割を行うようです。
cross_val_scoreのリファレンスではランダムにインデックスを抽出してくれるジェネレータを作り、
cross_val_scoreに渡してみますboston.pyfrom sklearn.model_selection import cross_val_score from sklearn.model_selection import KFold from sklearn.linear_model import LinearRegression lr = LinearRegression() kf = KFold(n_splits = 5,shuffle = True,random_state = 1) splitter = kf.split(env_data,price_data)#ジェネレータ生成 print(cross_val_score(lr,env_data,price_data,cv = splitter)) #[0.76348092 0.64664899 0.79214918 0.65064254 0.73524062]
KFold(random_state = 1)は乱数のシードです、毎回抜き出すデータが変わってもいい場合は指定はいりません。何も考えずにデータを分割した場合と比べて結果は一目瞭然ですね
KFold(shuffle = False)
[ 0.63861069 0.71334432 0.58645134 0.07842495 -0.26312455]
KFold(shuffle = True)
[0.76348092 0.64664899 0.79214918 0.65064254 0.73524062]パッと見るとモデルが良くなったように見えますが、評価方法が変わっただけでモデルの性能が変わったワケではありません。
cross_validate
ここまで交差検証には
cross_val_scoreを使用してきましたが
交差検証を行うのにcross_validateというメソッドもあります。
このメソッドを使えば目的変数と説明変数からモデルを作る為にかかった時間が出せたり
複数の評価指標を一度に計算出来たりと、cross_val_scoreと比較して便利な部分があります。
使い方はcross_val_scoreと殆ど同じです。valid.pyfrom sklearn.model_selection import cross_val_score, cross_validate from sklearn.model_selection import KFold from sklearn.linear_model import LinearRegression lr = LinearRegression() kf = KFold(n_splits = 5,shuffle = True,random_state = 1) score = cross_val_score(lr,env_data,price_data,cv = kf,scoring = "neg_mean_squared_error") scores = cross_validate(lr,env_data,price_data,cv = kf,scoring = {"neg_mean_squared_error","neg_mean_absolute_error"}) print(score) print(scores) """ [-23.37456303 -28.62770207 -15.16049987 -27.21667391 -23.37278076] {'fit_time': array([0.05200005, 0.00099993, 0. , 0.00099993, 0.00300026]), 'score_time': array([0. , 0. , 0.00099993, 0.00099993, 0. ]), 'test_neg_mean_absolute_error': array([-3.74913847, -3.30699838, -3.02845012, -3.56953509, -3.29932279]), 'train_neg_mean_absolute_error': array([-3.19838165, -3.23054675, -3.42791942, -3.22939478, -3.26295039]), 'test_neg_mean_squared_error': array([-23.37456303, -28.62770207, -15.16049987, -27.21667391,-23.37278076]), 'train_neg_mean_squared_error': array([-21.86800809, -20.50443823, -23.79796506,-20.81849064,-21.61049124])} """
cross_validateで複数の評価指標による評価を一度に行う場合、scoring引数にdict(辞書型)を渡します。
一度に多角的な評価が可能なので、とても便利です引数 "scoring" について
ここまで
cross_valid_scoreを使う時には引数として
- 説明変数
- 目的変数
- 分割数 or ジェネレータ
上記のみを渡してきましたが、
cross_val_scoreとcross_validateには共に
scoringという引数が存在します。
これは、交差検証により、どんな指標を求めるかを指定するもので
指定無しの場合はデフォルトで推定器(Estimator)の持つ評価指標を採用します
今回のケースでは推定器はLinearRegressionなので、決定係数が採用されます。その他の指標について
scikit-learnに標準で入っている評価指標は、以下の通りです。
Scoring Function Comment Classification ‘accuracy’ metrics.accuracy_score ‘balanced_accuracy’ metrics.balanced_accuracy_score for binary targets ‘average_precision’ metrics.average_precision_score ‘brier_score_loss’ metrics.brier_score_loss ‘f1’ metrics.f1_score for binary targets ‘f1_micro’ metrics.f1_score micro-averaged ‘f1_macro’ metrics.f1_score macro-averaged ‘f1_weighted’ metrics.f1_score weighted average ‘f1_samples’ metrics.f1_score by multilabel sample ‘neg_log_loss’ metrics.log_loss requires predict_proba support ‘precision’ etc. metrics.precision_score suffixes apply as with ‘f1’ ‘recall’ etc. metrics.recall_score suffixes apply as with ‘f1’ ‘roc_auc’ metrics.roc_auc_score Clustering ‘adjusted_mutual_info_score’ metrics.adjusted_mutual_info_score ‘adjusted_rand_score’ metrics.adjusted_rand_score ‘completeness_score’ metrics.completeness_score ‘fowlkes_mallows_score’ metrics.fowlkes_mallows_score ‘homogeneity_score’ metrics.homogeneity_score ‘mutual_info_score’ metrics.mutual_info_score ‘normalized_mutual_info_score’ metrics.normalized_mutual_info_score ‘v_measure_score’ metrics.v_measure_score Regression ‘explained_variance’ metrics.explained_variance_score ‘neg_mean_absolute_error’ metrics.mean_absolute_error ‘neg_mean_squared_error’ metrics.mean_squared_error ‘neg_mean_squared_log_error’ metrics.mean_squared_log_error ‘neg_median_absolute_error’ metrics.median_absolute_error ‘r2’ metrics.r2_score リファレンスはこちら
次回へ
次回は上記スコアリング指標の内容を勉強するか、住宅価格予測モデルの精度向上のどちらかをやりたいと思います。
お願い
機械学習の初心者が、学んだ知識の確認と備忘用に投稿しています。
間違っている部分や、何かお気づきの事がありましたらご指摘頂けますと幸いです
あと、独学者なので「私も今勉強中なんです!」みたいな人がいればコメント貰えると喜びます。
- 投稿日:2019-04-05T14:17:09+09:00
[Django]管理画面の一覧表示部分に別テーブルのフィールドを表示する
はじめに
「[Django]管理画面の一覧表示部分に、(表示対象のテーブルで外部キーなどでの関連もさせていない)別テーブルのフィールドを表示する」
最終的に結構単純でしたが、同じようなことをしている人が少なくて割と悩んだのでメモ。
多分ドキュメントに丁寧に目を通した人にとっては当たり前のことかも。やりたいこと
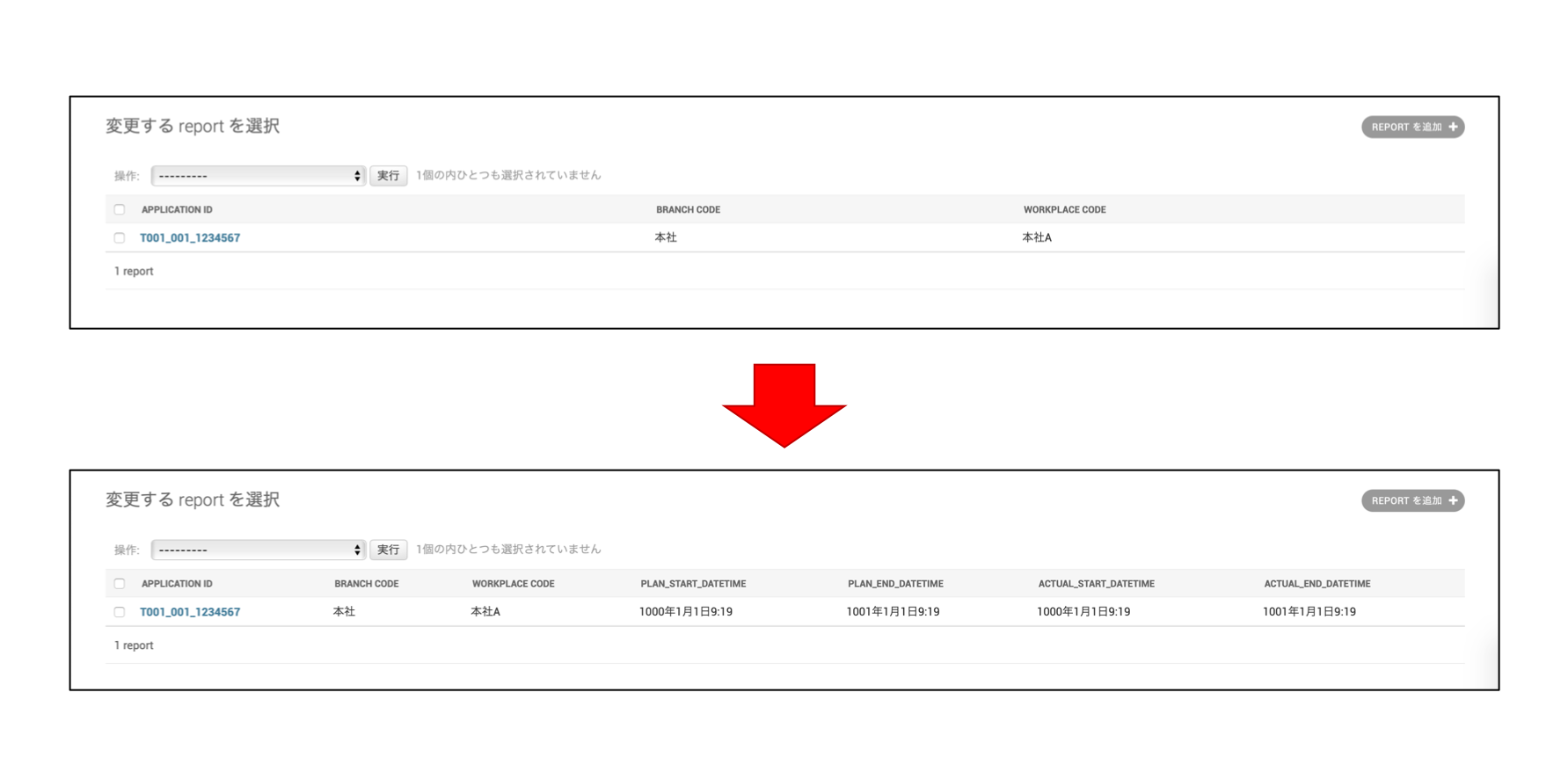
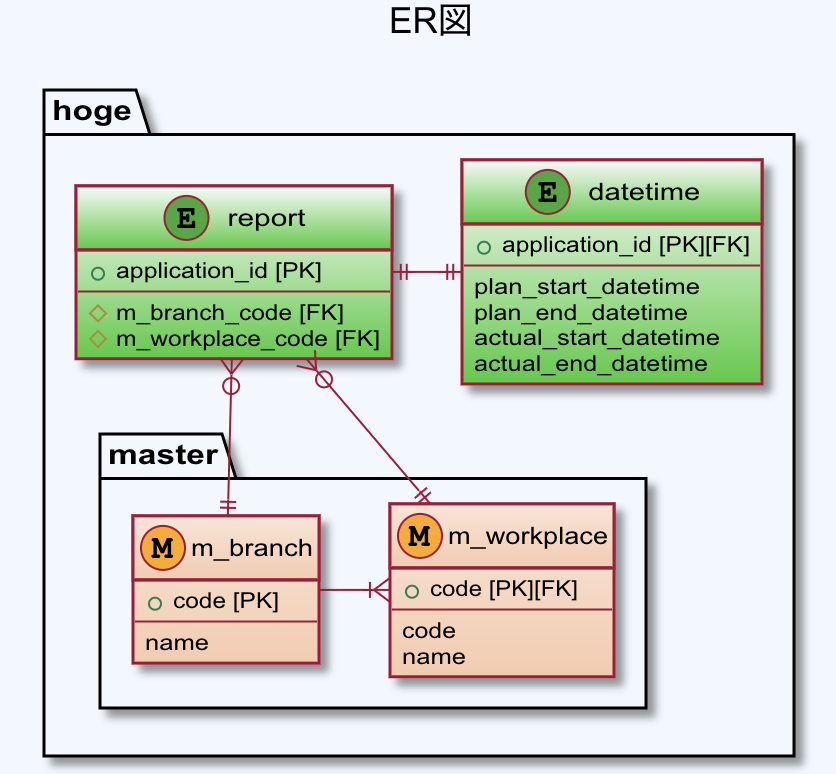
上の画面を下のような表示にしたかったのですが、この時、DBの構成は下記のER図のようになっており、日時系の値とそれ以外の値は別DBのフィールドのため、単純に
list_displayで追加することができなかった。[やりたい画面レイアウト]
[ER図]
(記事用に適当に書き換えたので、ER図と下の方のコードの整合性保ってない部分もあるかも)
要点
特に重要なのは下記の部分ですが、一応全貌を載せておきます。
重要部分1def plan_start_datetime(self, obj): list_got_objects = list(Datetime.objects.all().values_list('plan_start_datetime', flat=True)) return list_got_objects※1:取得したい情報の条件(例:「id=1」など)
重要部分2list_display = ( 'plan_start_datetime', )要点1.
<テーブル名>.objects.all()の戻り値はQuerySetなので、values_list()で値を取得する必要がある。要点2.
values_list()で取得した値をスライスして取得した「文字列」をlist_displayに渡す。以下、全貌
models.py# coding: utf-8 from django.db import models from django.utils import timezone from django.core.validators import MaxValueValidator # コードがforeign keyとして使用されるため、このクラスを先に定義している class M_branch(models.Model): def __str__(self): return self.name code = models.CharField(max_length=4, primary_key=True) name = models.CharField(max_length=128) # コードがforeign keyとして使用されるため、このクラスを先に定義している class M_workplace(models.Model): def __str__(self): return self.name branch_code = models.ForeignKey(M_branch, on_delete=models.CASCADE) code = models.CharField(max_length=4) name = models.CharField(max_length=128) class Report(models.Model): def __str__(self): return self.application_id application_id = models.CharField(max_length=32, primary_key=True) branch_code = models.ForeignKey(M_branch, on_delete=models.DO_NOTHING) workplace_code = models.ForeignKey(M_workplace, on_delete=models.DO_NOTHING) class Datetime(models.Model): def __str__(self): return self.plan_start_datetime application_id = models.OneToOneField(Report, on_delete=models.CASCADE) plan_start_datetime = models.DateTimeField() plan_end_datetime = models.DateTimeField() actual_start_datetime = models.DateTimeField() actual_end_datetime = models.DateTimeField()admin.pyfrom django.contrib import admin from .models import Report, Datetime, Participant, M_branch, M_workplace # TODO DatetimeやParticipantテーブルから必要な情報を取得して同じ表に表示する class ReportAdmin(admin.ModelAdmin): fieldsets = [ ('申請ID', {'fields': ['application_id']}), ('支部コード', {'fields': ['branch_code']}), ('職場コード', {'fields': ['workplace_code']}), ] list_display = ('application_id', 'branch_code', 'workplace_code', 'plan_start_datetime', 'plan_end_datetime', 'actual_start_datetime', 'actual_end_datetime', ) def plan_start_datetime(self, obj): list_got_objects = list(Datetime.objects.all().values_list('plan_start_datetime', flat=True)) return plan_start_datetime plan_start_datetime.short_description = 'plan_start_datetime' def plan_end_datetime(self, obj): list_got_objects = list(Datetime.objects.all().values_list('plan_end_datetime', flat=True)) return plan_end_datetime plan_end_datetime.short_description = 'plan_end_datetime' def actual_start_datetime(self, obj): list_got_objects = list(Datetime.objects.all().values_list('actual_start_datetime', flat=True)) return actual_start_datetime actual_start_datetime.short_description = 'actual_start_datetime' def actual_end_datetime(self, obj): list_got_objects = list(Datetime.objects.all().values_list('actual_end_datetime', flat=True)) return actual_end_datetime actual_end_datetime.short_description = 'actual_end_datetime' class M_branchAdmin(admin.ModelAdmin): fieldsets = [ ('支部コード', {'fields': ['code']}), ('支部名', {'fields': ['name']}), ] list_display = ('name', 'code') class M_workplaceAdmin(admin.ModelAdmin): fieldsets = [ ('支部コード', {'fields': ['branch_code']}), ('職場コード', {'fields': ['code']}), ('職場名', {'fields': ['name']}), ] list_display = ('name', 'code', 'branch_code') admin.site.register(Report, ReportAdmin) admin.site.register(M_branch, M_branchAdmin) admin.site.register(M_workplace, M_workplaceAdmin)以上。
- 投稿日:2019-04-05T13:37:01+09:00
pipenv(pyenv)で新しいpythonがinstallされないとき
1.環境
- ubuntu 18.04 (docker)
- pyenv 1.2.10-2-g3176c8b7 (2019/4/5時点最新)
2.エラー
root@b19a1760d4e6:~# pipenv install --python 3.6.8 Warning: Python 3.6.8 was not found on your system… Would you like us to install CPython 3.6.8 with pyenv? [Y/n]: Y Installing CPython 3.6.8 with pyenv (this may take a few minutes)… ✘ Failed... Something went wrong… Downloading Python-3.6.8.tar.xz... -> https://www.python.org/ftp/python/3.6.8/Python-3.6.8.tar.xz Warning: The Python you just installed is not available on your PATH, apparently.pipenvの下で動いてるpyenvでも同じ感じになった。
root@b19a1760d4e6:~# pyenv install 3.6.8 Downloading Python-3.6.8.tar.xz... -> https://www.python.org/ftp/python/3.6.8/Python-3.6.8.tar.xz root@b19a1760d4e6:~#Downloading以降が何もなく、エラーも出ない。
3.原因
findしてもPython-3.6.8.tar.xzが見つからないのでおかしいと思ったら,
wget(とcurlも)が入っていなかった.
pyenvはwgetがないと静かに死ぬのか...wget入れたらインストールできた.
root@b19a1760d4e6:~# apt install wgetdocker環境だと結構ハマりそう。
しかもpipenvから実行したときだとエラーメッセージがインストールは完了したけどパスの問題みたいにみえるのでややこしい。
4.備考
issueあげてみるか,と思ったら既にあった.
pyenv install fails silently when downloader not found
一年前&まだオープン
- 投稿日:2019-04-05T13:29:29+09:00
CPU, GPU, Parallel GPUの速度評価with mnist(MLP), cifar-10(LeNet5), sine wave(LSTM)
この記事の目的
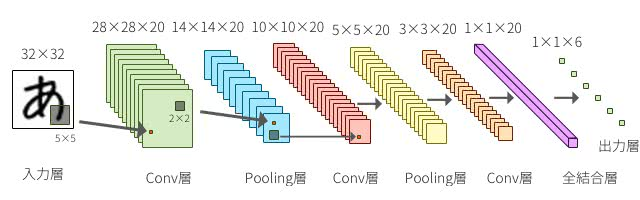
Chainerを使って、自分のパソコンのCPU、GPUの性能を評価してみる。
+プログラミング練習何をするのか
目的通りだが、
- cpu
- gpu
- gpu 2つで
の3種類を使って、次のデータ(モデル)を使って、速度評価をします。
- mnist(MLP) → 全結合NN
- cifar10(LeNet5) → CNN
- sine wave(LSTM) → RNN
みたいな感じでやっていきます。
自分の開発環境
Software
OSはUbuntu使ってます。
Ubuntu, chainer, python, cudaのバージョンは以下のとおりです。
Hardware
CPU -
Intel(R) Core(TM) i7-6850K CPU @ 3.60GHz
6 core, 12 threadsGPU -
gp102 titan x 2つ
https://www.techpowerup.com/gpu-specs/titan-x-pascal.c2863下準備
使うライブラリは以下のとおり:
import chainer import chainer.functions as F import chainer.links as L from chainer import training from chainer.training import extensions from chainer import Chainmnist(MLP)
mnistについて
MNIST(Mixed National Institute of Standards and Technology database)とは、手書き数字画像60,000枚と、テスト画像10,000枚を集めた、画像データセットです。さらに、手書きの数字「0〜9」に正解ラベルが与えられるデータセットでもあり、画像分類問題で人気の高いデータセットです。
https://udemy.benesse.co.jp/ai/mnist.html より
MLPについて
多層パーセプトロン(たそうパーセプトロン、英: Multilayer perceptron、略称: MLP)は、順伝播型(英語版)ニューラルネットワークの一分類である。MLPは少なくとも3つのノードの層からなる。入力ノードを除けば、個々のノードは非線形活性化関数を使用するニューロンである。MLPは学習のために誤差逆伝播法(バックプロパゲーション)と呼ばれる教師あり学習手法を利用する[1][2]。その多層構造と非線形活性化関数が、MLPと線形パーセプトロンを区別している。MLPは線形分離可能ではないデータを識別できる[3]。
https://ja.wikipedia.org/wiki/多層パーセプトロン より
ということで、Chainer docsにあるMLPを参考にして、次のようにモデルを定義しました。
class MLP(chainer.Chain): def __init__(self, n_units, n_out): super(MLP, self).__init__() with self.init_scope(): # Chainerがそれぞれの層を大きさを推測する self.l1 = L.Linear(None, n_units) # n_in -> n_units self.l2 = L.Linear(None, n_units) # n_units -> n_units self.l3 = L.Linear(None, n_out) # n_units -> n_out def forward(self, x): h1 = F.relu(self.l1(x)) h2 = F.relu(self.l2(h1)) return self.l3(h2)結果
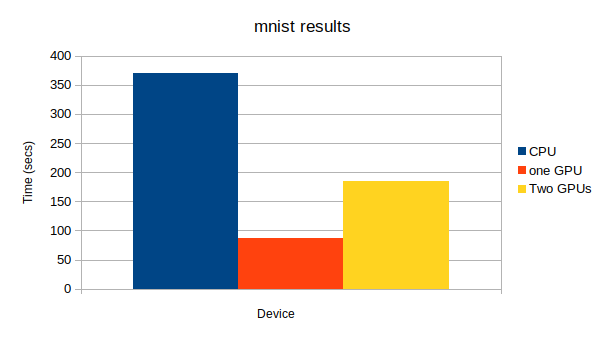
学習方法に関するコードはちょっと長く、いちいち出すとゴチャゴチャするので、最後に全部まとめて載せます。間違いがあったらぜひ、指摘してください。
上から、CPU、GPU1つ、GPU2つになっています。GPU: -1, None epoch main/loss validation/main/loss main/accuracy validation/main/accuracy elapsed_time 20 0.000392997 0.112276 1 0.9802 131.866 GPU: 0, None epoch main/loss validation/main/loss main/accuracy validation/main/accuracy elapsed_time 20 0.000861154 0.0953411 1 0.9835 34.7934 GPU: 0, 1 epoch main/loss validation/main/loss main/accuracy validation/main/accuracy elapsed_time 20 0.00679889 0.0958061 1 0.9843 75.3378
cifar-10(LeNet5)
cifar-10について
CIFAR-101)はAlexNetで有名なAlexさんらが構築したもので80 million tiny imagesから
・飛行機、犬など10クラス
・学習用データ5万枚
・評価用データ1万枚
を抽出したデータセットです。
http://starpentagon.net/analytics/cifar-10_dataset/ より
LeNet5について
LeNet(5)とは1990年代に作成された一番初めにConvolutional Neural Netowrkの基礎にあたるものを提案し使用したネットワーク.MNISTにおいて当時から高い精度を出していた.
http://www.thothchildren.com/chapter/59bf6f7ee319b7394d662311 よりということで、Chainer docsにあるLeNet5を参考にして、次のようにモデルを定義しました。
Mnistに使うって書いてあるのになんで、cifar-10かというと、ただただ気分です。あとでResNetも使って実装しますから、怒らないでください笑class LeNet5(Chain): def __init__(self): super(LeNet5, self).__init__() with self.init_scope(): self.conv1 = L.Convolution2D( in_channels=None, out_channels=6, ksize=5, stride=1) self.conv2 = L.Convolution2D( in_channels=6, out_channels=16, ksize=5, stride=1) self.conv3 = L.Convolution2D( in_channels=16, out_channels=120, ksize=4, stride=1) self.fc4 = L.Linear(None, 84) self.fc5 = L.Linear(84, 10) def forward(self, x): h = F.sigmoid(self.conv1(x)) h = F.max_pooling_2d(h, 2, 2) h = F.sigmoid(self.conv2(h)) h = F.max_pooling_2d(h, 2, 2) h = F.sigmoid(self.conv3(h)) h = F.sigmoid(self.fc4(h)) if chainer.config.train: return self.fc5(h) return F.softmax(self.fc5(h))結果
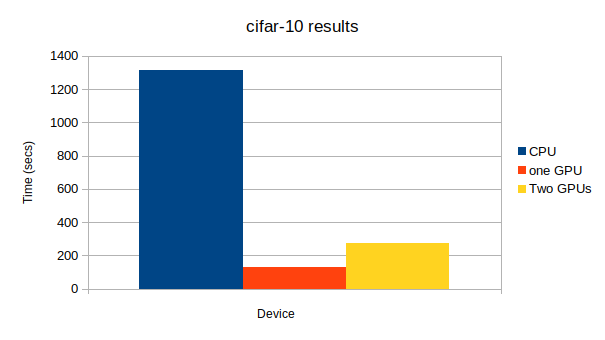
学習方法に関するコードはちょっと長く、いちいち出すとゴチャゴチャするので、最後に全部まとめて載せます。間違いがあったらぜひ、指摘してください。
上から、CPU、GPU1つ、GPU2つになっています。GPU: -1, None # Minibatch-size: 100 # epoch: 50 epoch main/loss validation/main/loss main/accuracy validation/main/accuracy elapsed_time 50 1.00791 1.92314 0.64 0.6087 1313.48 GPU: 0, None # Minibatch-size: 100 # epoch: 50 epoch main/loss validation/main/loss main/accuracy validation/main/accuracy elapsed_time 50 1.26838 1.9345 0.62 0.6039 127.483 GPU: 0, 1 # Minibatch-size: 100 # epoch: 50 epoch main/loss validation/main/loss main/accuracy validation/main/accuracy elapsed_time 50 1.02486 1.94677 0.6 0.5919 273.38
Sine Wave(LSTM)
ここのパートは以前書いた記事https://qiita.com/AtomJamesScott/items/41c4a3bd85a851f02770 の実装結果を使っていきたいと思います。
Sine Waveについて
サイン波です。
LSTMについて
LSTMとは時系列のデータを扱うRNN(再起的ニューラルネットワーク)の一種で、普通のRNNだと起こる勾配が爆発・消失する問題がないので、よく使われている。
class LSTM(Chain): n_input = 1 n_output = 1 n_units = 5 def __init__(self): super(MLP, self).__init__( l1 = L.Linear(self.n_input, self.n_units), l2 = L.LSTM(self.n_units, self.n_units), l3 = L.Linear(self.n_units, self.n_output), ) def reset_state(self): self.l2.reset_state() def __call__(self, x): h1 = self.l1(x) h2 = self.l2(h1) return self.l3(h2)結果
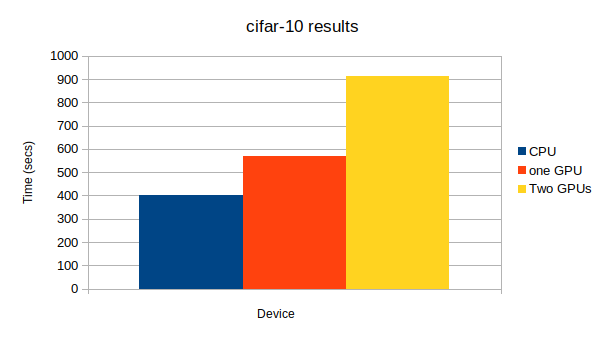
学習方法に関するコードはちょっと長く、いちいち出すとゴチャゴチャするので、最後に全部まとめて載せます。間違いがあったらぜひ、指摘してください。特にLSTMの学習はBPTTがある関係でややこしく、ミスってる可能性あります。上から、CPU、GPU1つ、GPU2つになっています。
補足 cifar-10(Resnet152)
Resnet152について
ResNetは、Microsoft Research(現Facebook AI Research)のKaiming He氏が2015年に考案したニューラルネットワークのモデルである。
CNNにおいて層を深くすることは重要な役割を果たす。層を重ねるごとに、より高度で複雑な特徴を抽出していると考えられているからだ。
Convolution層はフィルタを持ち、Pooling層と組み合わせて何らかの特徴を検出する役割を持っている。低・中・高レベルの特徴を多層形式で自然に統合し、認識レベルを強化することができる。
https://deepage.net/deep_learning/2016/11/30/resnet.html よりモデルに関してこちらを参考にしてください。
https://docs.chainer.org/en/stable/examples/cnn.html
結果GPU: 0, None # Minibatch-size: 2048 # epoch: 50 epoch main/loss validation/main/loss main/accuracy validation/main/accuracy elapsed_time 50 0.0734697 6.44621 0.975586 0.474124 1211.89 GPU: 0, 1 # Minibatch-size: 2048 # epoch: 50 epoch main/loss validation/main/loss main/accuracy validation/main/accuracy elapsed_time 50 0.0985431 6.45934 0.962891 0.459237 789.439
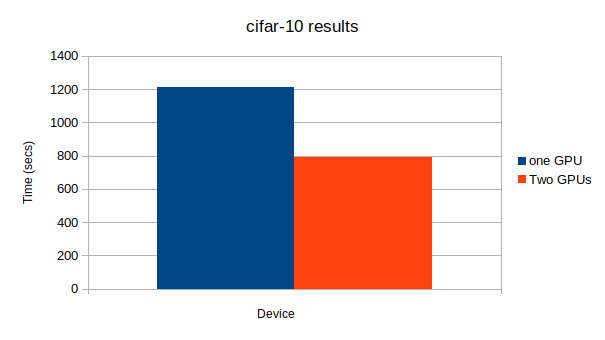
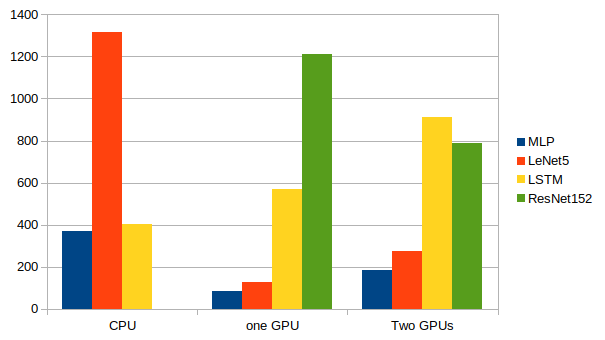
結論
複数のGPUを有効活用するのは難しいことが分かりました。
調べたところ
- Use a very small network. 小さいネットワークを使う
- Use very small batch size. 小さいバッチサイズを使う
- Create overhead for updating parameters across multiple GPUs. パラメータ更新のオーバーヘッドを大きくする
という3つのことをやってしまうと、複数のGPUを有効活用できないそうだ。
この記事でも最後に使ったResNet152が一番大きなネットワークになっており、唯一複数GPUを使ったほうが計算が早く終了した。
(CPUで実験をしなかったのはLeNet5の例から分かるとおり、conv netでCPUを使うとすごく時間かかるからです。)




- 投稿日:2019-04-05T13:04:02+09:00
経済学のためのラグランジュの未定乗数法
はじめに
この記事は、経済学を勉強していくとどこかしらで出会うことになる「ラグランジュの未定乗数法」をプログラミングで解いてみます。
あくまでも経済学に用いる「ラグランジュの未定乗数法」であり、物理学や機械学習に用いることができるかどうかはわかりません。(私は物理学も機械学習も勉強してません。)
機械学習の方のラグランジュの未定乗数法は、たなしょう氏の「ラグランジュの未定乗数法(言語処理のための機械学習入門)(https://qiita.com/Tanasho0928/items/711602df7710d3db3707 )」が丁寧に書かれているのでそちらにお願いします。ラグランジュの未定乗数法とは
経済学で用いるラグランジュの未定乗数法は、簡潔に言えば「ある制約条件の下で、ある関数を最大化(最小化)する」です。少し数学っぽく書くなら、「$g(x,y)$の下で$f(x,y)$を最大化(最小化)する」です。
また定式化を行うならば、$$ max \ \ \ f(x, y),\quad
subject \ to \ \ \ g(x, y)$$$$L(x, y, \lambda) = f(x, y) + \lambda g(x, y)$$
$\lambda$(ラムダ) はラグランジュ乗数です。Wikipediaやその他ラグランジュの未定乗数法について解説しているサイトなどでは$\lambda$の前の記号がマイナスですが、経済学においてはプラスにするようです。(なぜだったかは後日、書き足します。思い出せません。)
ざっくりと言うと、効用最大化や利潤最大化に使える便利なやつ、それがラグランジュの未定乗数法です。
計算過程が多いので、大人しく「限界代替率=価格比」とか「目的関数に制約関数を代入して一階の条件」とかを使った方が早いことは多々あります。※ここまで読んでお分かりだと思いますが、学部レベルの経済学の話しかしません(できません)。
※ラグランジュの未定乗数法に頼りすぎるあまり、経済学的意味を忘れ、ただ数学的に問題を解くようなことにならないよう気をつけましょう。私はそれに陥りました。コードの実装
簡単な効用最大化問題を普通に解いたのち、コードの実装に移ります。私はJupyter NoteBook上でPythonを用いて行います。
問. ある個人の効用関数が$u(x,y) = x^{\frac{1}{2}} y^{\frac{1}{2}} $であるとする。このとき、$x$財と$y$財の価格はともに$1$である。また個人の予算は$24$であるとする。効用を最大にする各財の需要量を求めよ。
回答.
max \ \ \ u(x, y) = x^{\frac{1}{2}} y^{\frac{1}{2}} \\ s.t. \ \ \ x + y = 24の最適解を求める。
$$ L(x, y, \lambda) = x^{\frac{1}{2}} y^{\frac{1}{2}} + \lambda(24 - x - y)$$
各変数について偏微分を行い、一階の条件\frac{\partial L}{\partial x} = \frac{1}{2}x^{-\frac{1}{2}}y^{\frac{1}{2}}-\lambda = 0 \\ \frac{\partial L}{\partial y} = \frac{1}{2}x^{\frac{1}{2}}y^{-\frac{1}{2}}-\lambda = 0 \\ \frac{\partial L}{\partial \lambda} = 24 - x - y = 0 \\を求める。これらを解くと、
x = 12 \\ y = 12 \\が求まり、各財の需要量はそれぞれ$12$であることがわかった。
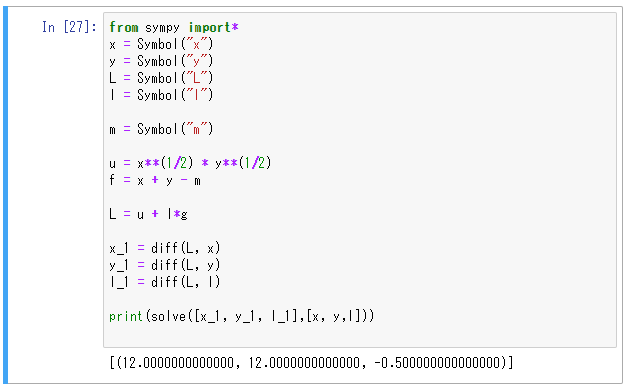
それでは、これらを実装していきます。
from sympy import* x = Symbol("x") y = Symbol("y") L = Symbol("L") l = Symbol("l")まずsympyというパッケージをインポートし、各変数を定義します。
u = x**(1/2) * y**(1/2) #object function f = 24 - x - y #constraint L = u + l*f #lagrange function効用関数と制約式を定義し、ラグランジュ関数を定義します。
x_1 = diff(L, x) y_1 = diff(L, y) l_1 = diff(L, l)sympyではdiff(関数, 微分したい変数)を用いることで偏微分を行うことができます。これを利用して各変数について一階の条件を求めます。
print(solve([x_1, y_1, l_1],[x, y,l]))sympyではsolve([方程式],[変数])を用いることで連立方程式を解くことができます。
以上が実装となります。
これを一つにまとめますと、
from sympy import* x = Symbol("x") y = Symbol("y") L = Symbol("L") l = Symbol("l") u = x**(1/2) * y**(1/2) f = 24 - x - y L = u + l*f x_1 = diff(L, x) y_1 = diff(L, y) l_1 = diff(L, l) print(solve([x_1, y_1, l_1],[x, y, l]))のようになります。このコードは私が自分なりに考えたものなので不備等多々あると思いますし厳格ではないかもしれません。
まとめ
上記のコードを実行するとこのような結果が得られます。
各需要量も正しく、ばっちりだと思います。もっとも、予算を$m$とおいたり、効用関数の指数を$a,b$などとおいたり、少し抽象度を上げると上手く計算できないという不具合もあります。ここは改善点かなと思います。
皆様の経済学の勉強の助けになれば幸いです。
間違っているところなどありましたらコメントお願いします。
- 投稿日:2019-04-05T13:02:22+09:00
Capistrano3-pipenv を書いた
一言で
ruby アプリケーションに対する、
capistrano/bundler相当の python 版、capistrano3/pipenvを書いた。詳細
Gemfilegroup :development do gem 'capistrano3-pipenv', require: false endして、
Capfilerequire 'capistrano3/pipenv' # pyenv を利用する場合 require 'capistrano3/pyenv'すると、
pyenv exec pipenv install --deployがデプロイの中で呼ばれるようになる。設定項目と、そのデフォルト値は以下
config/deploy.rb# capistrano3/pipenv set :pipenv_roles, :all set :pipenv_servers, -> { release_roles(fetch(:pipenv_roles)) } set :pipenv_flags, '--deploy' set :pipenv_env_variables, {} set :pipenv_clean_options, '--all' # capistrano3/pyenv set :pyenv_path, -> { pyenv_path = fetch(:pyenv_custom_path) pyenv_path || if fetch(:pyenv_type, :user) == :system '/usr/local/pyenv' else '$HOME/.pyenv' end } set :pyenv_roles, fetch(:pyenv_roles, :all) set :pyenv_python_dir, -> { "#{fetch(:pyenv_path)}/versions/#{fetch(:pyenv_python)}" } set :pyenv_map_bins, %w{pipenv}
- 投稿日:2019-04-05T12:36:37+09:00
LSTMに、サイン波を複数のGPUを使って学習させる。
目的
LSTMに、サイン波を複数のGPUを使って学習させる。
※コードはgithubにありますが、間違えもあるはずです。なにかあれば教えてくれるとすごくありがたいです。
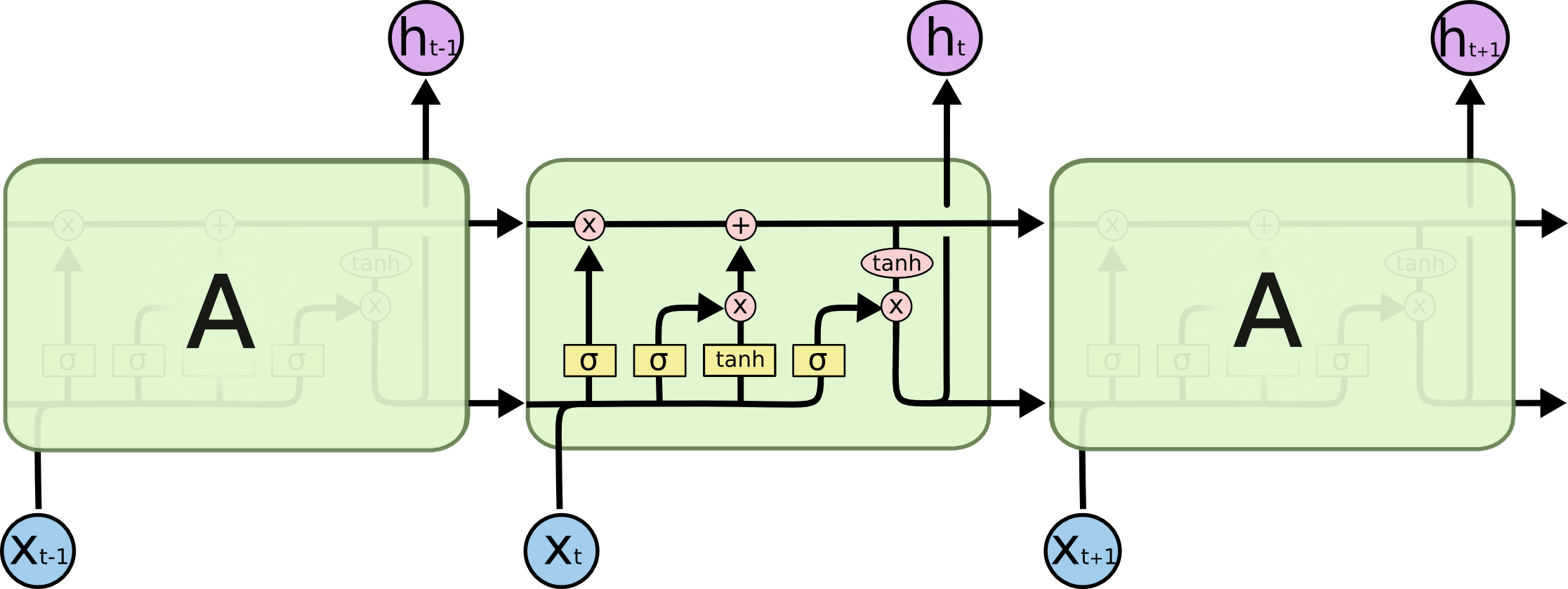
LSTMについて
LSTMとは時系列のデータを扱うRNN(再起的ニューラルネットワーク)の一種で、普通のRNNだと起こる勾配が爆発・消失する問題がないので、よく使われています。
Many2Many LSTM
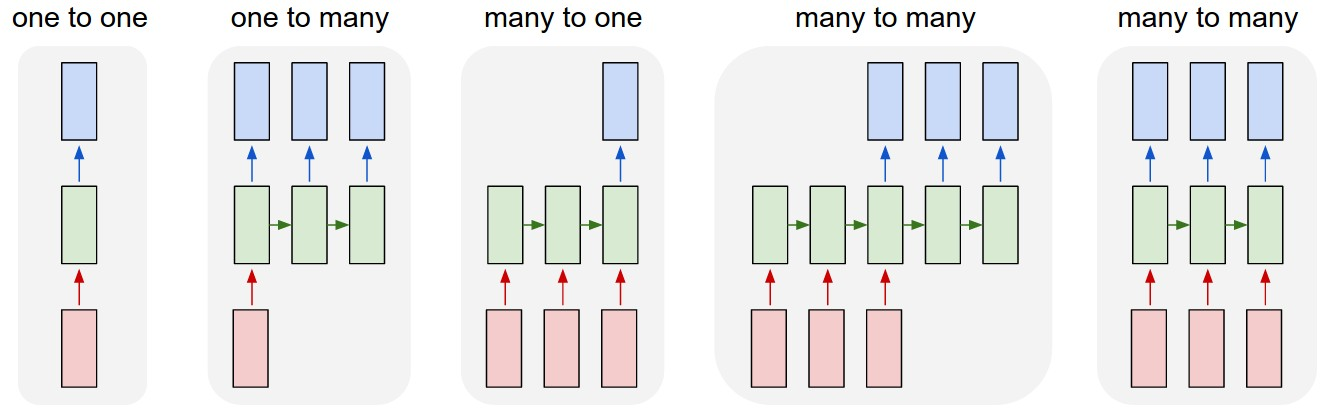
ここで作るのは以下の図の5番目のLSTMです。
Model
n_unitsは下記の図のxたちの次元を示します。
大きければ、大きいほど学習するパラメータの数が増えます。
each line carries an entire vector, from the output of one node to the inputs of others.
本記事で使ったコードはここのものを参考にしました
→https://qiita.com/chachay/items/052406176c55dd5b9a6a
ただいろいろ修正・改変しているところがあるので注意してください。class LSTM(Chain): n_input = 1 n_output = 1 n_units = 5 #大きければ、大きいほど学習するパラメータの数が増える。 def __init__(self): super(LSTM, self).__init__( l1 = L.Linear(self.n_input, self.n_units), l2 = L.LSTM(self.n_units, self.n_units), l3 = L.Linear(self.n_units, self.n_output), ) def reset_state(self): self.l2.reset_state() def __call__(self, x): h1 = self.l1(x) h2 = self.l2(h1) return self.l3(h2)データ
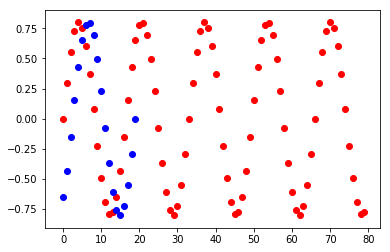
import numpy as np import matplotlib.pyplot as plt import chainer import chainer.functions as F import chainer.links as L from chainer import report, training, Chain, cuda, datasets, iterators, optimizers, Variable, function from chainer.training import extensions from chainer.datasets import tuple_dataset import cupy import six # データ作成 N_data = 1000 N_Loop = 3 t = np.linspace(0., 2*np.pi*N_Loop, num=N_data) X = 0.8*np.sin(2.0*t) # データセット N_train = int(N_data*0.8) N_test = int(N_data*0.2) tmp_DataSet_X= np.array(X).astype(np.float32) x_train, x_test = np.array(tmp_DataSet_X[:N_train]),np.array(tmp_DataSet_X[N_train:]) train = tuple_dataset.TupleDataset(x_train) test = tuple_dataset.TupleDataset(x_test) plt.scatter(range(0,len(x_train)), x_train,c="red") plt.scatter(range(0,len(x_test)), x_test, c="blue") plt.show()
学習の流れ
Chainer trainer for LSTM
https://docs.chainer.org/en/stable/guides/trainer.html より
ニューラルネットワークを学習させたいときは、パラメータを何度も更新するトレーニングループを実行する必要があります。
典型的なトレーニングループは以下の手順で構成されています。
- 訓練データセットの反復
- 抽出ミニバッチの前処理
- ニューラルネットワークのforward/backward計算
- パラメータの更新
- 検証データセットで現パラメータの評価
- ログ記録と表示
GPUを複数有効活用したいときは、2〜4の工程を並列に行うことになるのでここを自分で書く必要があります。
参考にした記事はCPUで学習させていたので、GPUでも走るようにちょっとコードを変えました。複数のGPUで走るらせるには、LSTM_std_updaterとLSTM_prl_updaterにupdaterを分ける必要がありました。
これはChainerでそもそもStandardUpdaterとParallelUpdaterを分けているためしょうがないかと思います。残りのコードはgithubから取ってください。
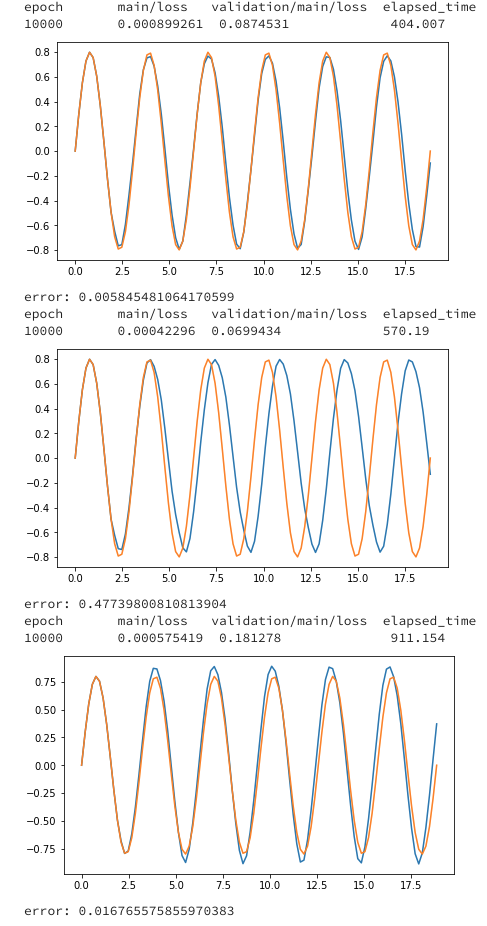
class LSTM_std_updater(training.StandardUpdater): def __init__(self, train_iter, optimizer, device): super().__init__(train_iter, optimizer, device=device) self.seq_length = train_iter.seq_length def update_core(self): loss = 0 train_iter = self.get_iterator('main') optimizer = self.get_optimizer('main') for i in range(self.seq_length): batch = train_iter.__next__() x, t = self.converter(batch, self.device) loss += optimizer.target(chainer.Variable(x.reshape((-1, 1))), chainer.Variable(t.reshape((-1, 1)))) optimizer.target.zerograds() loss.backward() loss.unchain_backward() optimizer.update() class LSTM_prl_updater(training.ParallelUpdater): def __init__(self, train_iter, optimizer, devices): super().__init__(train_iter, optimizer, devices=devices) self.seq_length = train_iter.seq_length def update_core(self): losses = [0 for i in self._models] train_iter = self.get_iterator('main') optimizer = self.get_optimizer('main') for i in range(self.seq_length): batch = train_iter.__next__() #ここから並列計算用の処理 n = len(self._models) xt_list = {} for i, key in enumerate(six.iterkeys(self._models)): xt_list[key] = self.converter( batch[i::n], self._devices[key]) for model in six.itervalues(self._models): model.cleargrads() _losses = [] for model_key, model in six.iteritems(self._models): x, t = xt_list[model_key] loss_func = self.loss_func or model with function.force_backprop_mode(): dev_id = self._devices[model_key] dev_id = dev_id if 0 <= dev_id else None with cuda.get_device_from_id(dev_id): _loss = loss_func(x, t) _losses.append(_loss) losses = [sum(x) for x in zip(losses, _losses)] optimizer.target.zerograds() for loss in losses: loss.backward() loss.unchain_backward() optimizer.update()結果
上記のデータで学習させた結果です。
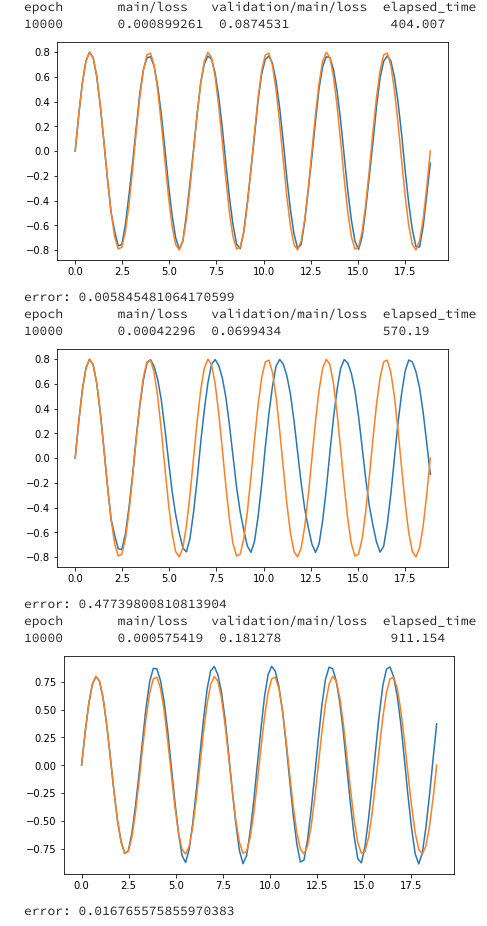
初期データ(N_data*0.1個)を用いてt+1を予測
予測したt+1を用いてt+2を予測
予測を用いて予測するの繰り返しmodel_cpu = run_LSTM(gpu0=-1, batchsize=10, seqlen=10, epoch=10000) plot_test(model_cpu) model_1gpu = run_LSTM(gpu0=0,batchsize=10,seqlen=10, epoch=10000) plot_test(model_1gpu) model_2gpu = run_LSTM(gpu0=0,gpu1=1,batchsize=10,seqlen=10, epoch=10000) plot_test(model_2gpu)
GPUのほうが遅いのは、ハイパーパラメータの設定で、batchsizeやLSTMのn_unitsが小さくなっているため、GPUを活かせてないことが原因にあるかと思います。

- 投稿日:2019-04-05T11:56:38+09:00
折れ曲がった測線への点群の投影
はじめに
地球科学データを扱っていると、測線沿いに点群を投影するような作業が生じることがある。例えば地震活動の深さを示す断面図作成であったり、反射法地震波探査データを重合するためのデータ処理などである。測線が東西南北方向の完全な直線であれば実装は極めて簡単だが、現実の測線はそうはいかないことが多い。
しかしPythonで図形処理を行うShapelyモジュール(公式ドキュメント)を利用すると、折れ曲がった測線であっても極めてシンプルに実装できる(下図)。
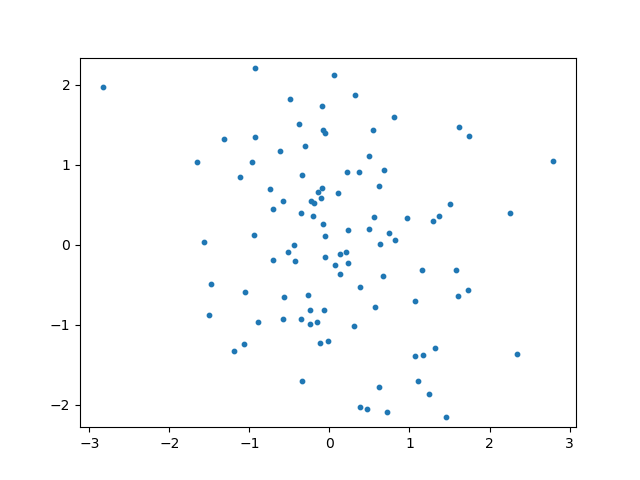
サンプルデータの生成
簡単のため、ここではランダムに生成した二次元正規分布に従った点群を考える。
XYZ_PolygonalInterpolation.pyimport numpy as np import matplotlib.pyplot as plt ## 0を中心とした正規分布に従う100点の点群を生成 X,Y = np.random.randn(100), np.random.randn(100) ## 描画 fig, ax = plt.subplots() ax.scatter(X,Y, s=10) ax.axis('equal') #X軸とY軸を等しくする plt.show()
測線の設定
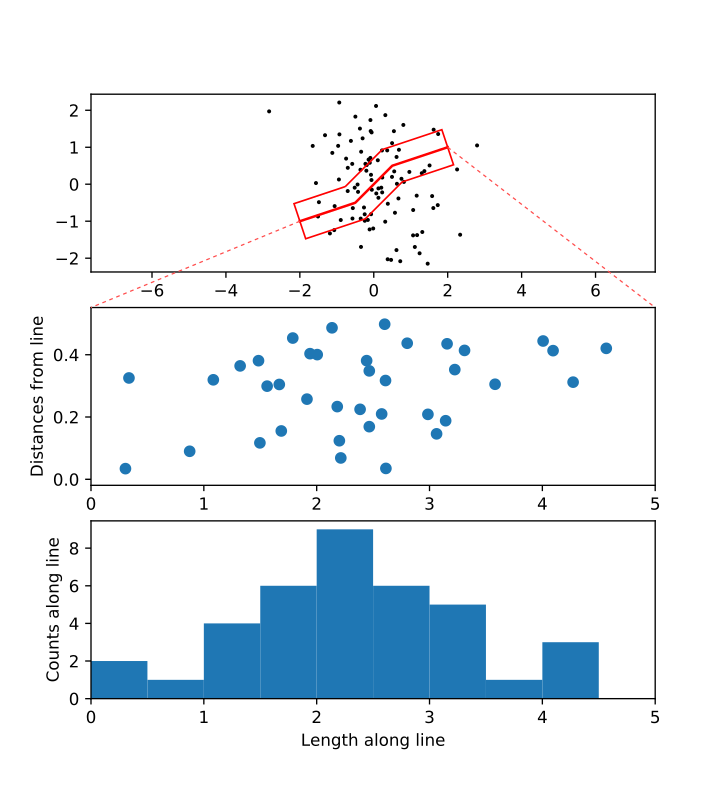
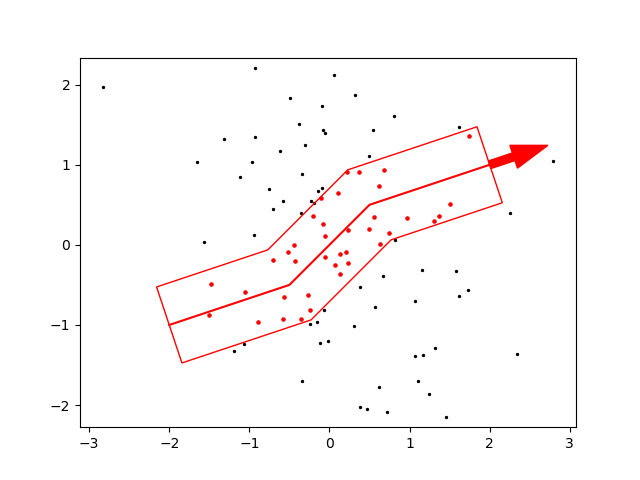
ここに以下のような折れ曲がった測線を仮定し、Shapelyのbuffer()によって測線に一定の幅をもたせたポリゴンを生成する。(この辺の仕組みはSVGと同じである)
ポリゴンの内側にある点はcontains()により検出できる。
Shapelyオブジェクトはdescartesモジュール(デカルト? 同名のプロジェクトが沢山あるので注意)を用いることで簡単にmatplotlibのpatchへ変換し描画できる。XYZ_PolygonalInterpolation.py## ShapelyおよびShapelyオブジェクトをMatplotlibへ変換するdescartesモジュールを使う from shapely.geometry import Point, Polygon, LineString from descartes import PolygonPatch ## 折れ線の座標, 折れ線のShapelyオブジェクト path = np.array([[-2,-1],[-0.5,-0.5],[0.5,0.5],[2,1]]) line = LineString(path) ## 折れ線に幅(0.5)をもたせて生成したポリゴンのShapelyオブジェクト。capとjoinで終端や変曲点の取り扱いを指定する poly = line.buffer(0.5, cap_style=2, join_style=2) ## 点群の中でポリゴンに含まれるもののインデックス idx = [i for i in range(len(X)) \ if poly.contains(Point((X[i],Y[i])))] ## Matplotlibによる描画 fig, ax = plt.subplots() ax.scatter(X,Y, c='black', s=2) #全ての点を黒で ax.scatter(np.take(X,idx), np.take(Y,idx), c='red', s=5) #ポリゴン内の点を赤で ax.add_patch(PolygonPatch(poly, facecolor=(0,0,0,0), edgecolor=(1,0,0,1))) #ポリゴンをdescartesモジュールを使って描画。色はRGBAで指定している。 ax.plot(path[:,0], path[:,1], color=(1,0,0,1)) #測線 ax.arrow(x=path[-1,0], y=path[-1,1], \ dx=(path[-1,0]-path[-2,0])*0.2, \ dy=(path[-1,1]-path[-2,1])*0.2, \ width=0.1, color=(1,0,0,1)) #おまけの矢印。 ax.axis('equal'); plt.show()
図形への投影
Shapelyのproject()を用いることで、ポリゴン内の点を直線に投影し、始点からの距離を求めることができる。これを横軸に用いると折れ線沿いのX軸とすることができる。
XYZ_PolygonalInterpolation.py## ポリゴン内の点を直線へ投影し、直線上の始点からの距離を得る lengths = np.array([line.project(Point((X[i],X[i]))) for i in idx]) lmin, lmax = np.floor(lengths.min()), np.ceil(lengths.max()) #グラフ1および2描画用の最大最小値 ## Matplotlibによる描画 fig, ax = plt.subplots(3) #3つのグラフを同時に描く ## グラフ0は前図の省略版 ax[0].scatter(X,Y, c='black', s=2) ax[0].add_patch(PolygonPatch(poly, facecolor=(0,0,0,0), edgecolor=(1,0,0,1))) ax[0].plot(path[:,0], path[:,1], color=(1,0,0,1)) ax[0].axis('equal') ## グラフ1は各点の直線からの距離 ax[1].scatter(x=lengths, y=distances) #代わりにyに震源深さ(Z)などを与えれば断面図になる ax[1].set_ylabel('Distances from line') ax[1].set_xlim(lmin, lmax) #グラフ2と合わせる ## グラフ2は投影された点群数のヒストグラム ax[2].hist(lengths, bins=np.arange(lmin,lmax,0.5)) ax[2].set_xlim(lmin, lmax) #グラフ1と合わせる ax[2].set_ylabel('Counts along line') ax[2].set_xlabel('Length along line') plt.show()
※画像の点線はわかりやすくするためにInkscapeで付加したおわりに
色々な応用方法が考えられる。例えば自分の場合、shapefileを読めるようにしてQGISで描いたshapefileで描かれた測線に対してすぐ断面図を作ることができるようなコードにした。
- 投稿日:2019-04-05T11:27:28+09:00
PythonとOpenCVを使った笑顔認識
まずはOpenCV使ってカメラからの画像取得
CamCap.pyimport cv2 capture = cv2.VideoCapture(0) capture.set(3,320)# 320 320 640 720 横の長さ capture.set(4,240)#180 240 360 405 縦の長さ while True: ret, img = capture.read() img = cv2.flip(img,1)#鏡表示にするため. cv2.imshow('img',img) # key Operation key = cv2.waitKey(10) if key ==27 or key ==ord('q'): #escまたはqキーで終了 break capture.release() cv2.destroyAllWindows() print("Exit")
ord()は引数のアスキーコードを返す.ちなみにchr()はアスキーコードに対する文字を返す.OpenCV使って顔認識
OpenCVでの笑顔認識は,前処理として顔認識が必要(顔認識した領域に対して,さらに笑顔認識を掛ける,という仕組み).
なので,顔認識をする.FaceDetect.pyimport cv2 capture = cv2.VideoCapture(0) capture.set(3,320)# 320 320 640 720 capture.set(4,240)#180 240 360 405 face_cascade = cv2.CascadeClassifier('./haarcascade_frontalface_default.xml') while True: ret, img = capture.read() img = cv2.flip(img,1)#鏡表示にするため. gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) faces = face_cascade.detectMultiScale(gray, 1.1, 5) for (x,y,w,h) in faces: cv2.circle(img,(int(x+w/2),int(y+h/2)),int(w/2),(0, 0, 255),2) # red cv2.imshow('img',img) # key Operation key = cv2.waitKey(10) if key ==27 or key ==ord('q'): #escまたはqキーで終了 break capture.release() cv2.destroyAllWindows() print("Exit")
haarcascade_frontalface_default.xmlは,OpenCVをWin10のPCにインストール(というかDLして解凍してWorkに置いただけ)したときに,./opencv/sources/data/haarcascades/からコピーした.他の入手法としてGithubで検索掛ければすぐにGetできる.
これをカレントディレクトリに置いた.
face_cascade.detectMultiScaleの引数について,1.1というのはscaleFactorといって,公式マニュアルでは,"Parameter specifying how much the image size is reduced at each image scale."とある.正直よくわからない.なので,いろいろ調べてたら,参考資料2と3に挙げてるページで丁寧に説明してくれてた.要はパターンマッチングするときに,モデルのサイズを徐々に上げながら何度も画像内を探索してるんだけど,モデルのサイズを上げる(逆に言えば画像のサイズを下げる)時の比率のことらしい.だとすると,この値は1以上でないとダメなのは当然なのだけど,比率を上げれば上げるほど,探索は早く終わるが,見逃しが多くなり,誤検出は減る.逆に比率が1に近いほど,探索は時間がかかるが,見逃しは減り,誤検出は増える.うーむ・・・5はminNeighborsで,公式マニュアルでは"Parameter specifying how many neighbors each candidate rectangle should have to retain it."とある.モデルのサイズを変えて何度も探索するときに,その矩形領域がモデルのサイズを変えても安定的にマッチしてるかどうかってこと?よー分からん.とりあえず値を下げると見逃し率は下がるが,誤検出が増える感じ.
detectMultiScaleのアウトプットは,顔と認識した矩形領域の左上のx,y座標と幅w・高さhのリスト.なので,それを一個ずつ開いて,顔領域に円形を描く.あと,
int()については,場合によっては座標値や半径が小数になることがあり,「整数でないとだめ」といわれることがあるので型キャスト.参考:
1)公式マニュアル
https://docs.opencv.org/4.0.1/d1/de5/classcv_1_1CascadeClassifier.html#aaf8181cb63968136476ec4204ffca498
2)認識処理の中身の概説記事.わかりやすいし,リンクも素晴らしい.
https://qiita.com/FukuharaYohei/items/ec6dce7cc5ea21a51a82
3)ScaleFactorの説明
http://workpiles.com/2015/04/opencv-detectmultiscale-scalefactor/OpenCV使って笑顔認識
顔認識ができたので,今度は笑顔認識.処理の流れとしては,顔認識した領域に対して笑顔認識処理を掛けるという流れ.
SmileDetect.pyimport cv2 capture = cv2.VideoCapture(0) capture.set(3,640)# 320 320 640 720 capture.set(4,360)#180 240 360 405 face_cascade = cv2.CascadeClassifier('./haarcascade_frontalface_default.xml') smile_cascade = cv2.CascadeClassifier('./haarcascade_smile.xml') while True: ret, img = capture.read() img = cv2.flip(img,1)#鏡表示にするため. gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) faces = face_cascade.detectMultiScale(gray, 1.1, 5) for (x,y,w,h) in faces: cv2.circle(img,(int(x+w/2),int(y+h/2)),int(w/2),(255, 0, 0),2) # blue roi_gray = gray[y:y+h, x:x+w] #Gray画像から,顔領域を切り出す. smiles= smile_cascade.detectMultiScale(roi_gray,scaleFactor= 1.2, minNeighbors=10, minSize=(20, 20))#笑顔識別 if len(smiles) >0 : for(sx,sy,sw,sh) in smiles: cv2.circle(img,(int(x+sx+sw/2),int(y+sy+sh/2)),int(sw/2),(0, 0, 255),2)#red cv2.imshow('img',img) # key Operation key = cv2.waitKey(5) if key ==27 or key ==ord('q'): #escまたはeキーで終了 break capture.release() cv2.destroyAllWindows() print("Exit")
haarcascade_smile.xmlはhaarcascade_frontalface_default.xmlと同様にGet.
やってるのは,先に示した顔認識器にかけた後,顔領域を切り出して笑顔認識器にかけて,笑顔と認識された領域に赤い丸を付けるというもの.
detectMultiScaleの中身で,今回は引数にはっきりと変数名もつけてみた.minSize=(20,20)は認識するうえでの閾値(これ以下の領域は認識処理をしない).やってみると,顔を認識すると青い円が表示され,笑顔を作ると赤い円が表示される.
やってみるとどうも口元の形でマッチングしてるのがわかる.参考:
https://github.com/mwyau/python-opencv-smile-detector/blob/master/smiledetector.py笑顔の強度指標
笑顔の強度に応じて反応するようにしたい.ということで,笑顔の強度指標を考えてみる.
参考に挙げている強度指標のソースに書き込まれてるコメントから,The number of detected neighbors(detectMultiScaleが吐き出すリストの長さ)が笑顔の強度を測る材料になるらしい.ただ,これは探索してる画像のサイズや輝度にも依存してるので,その部分を正規化する必要がある.参考にあるCPPの笑顔認識強度指標では,この点について,「同じ画像から取った近傍矩形数」を基準にすることでサイズの影響を回避しようとしてるっぽい.
つまり,最初に認識した笑顔の近傍矩形数を最小,また過去の認識した中で最も近傍矩形数が多いときを最大として,現在の近傍矩形数-最小と最大―最小の比を出してる(分母が0になるのを回避するために⁺1してる).確かにこうすると,画像のサイズや輝度の影響は受けにくくなるけど,これだと近傍矩形数が高くなるごとに,最大が更新されていってしまい,だんだん認識のハードルが上がっていってしまう.それに,人それぞれでの判定ということもできない.
なので,これをそのまま使うわけにはいかない.
ということで考えた方針
(1)サイズに対しては,顔の領域を切り出した後,その画像のリサイズして,統一する.
(2)輝度に対しては,切り出した顔領域のグレースケール値について,最大値と最小値を取得して,それらで正規化.この方針に基づいて,以下のように強度指標を実装してみた.
加工した顔領域画像を笑顔認識処理にかけて,得られた近傍矩形数をもとに強度を計算.
変域を0から1の間にしたいので,その範囲に来るようにLVという係数を設定.ただ,単純に係数をかけるだけなので,近傍数をたくさん認識してる場合には1を超えることがある.なので場合には,強制的に1にする.こうすると,LVは単なる係数というだけでなく,笑顔認識の難易度パラメータにもなる.なお,顔の領域の統一のために,顔領域の認識の際に,100x100を最小領域値に設定.
さらに,得られた強度指標をもとに円の表示色も変えてみた.
SmileIntensity.pyimport cv2 import numpy as np capture = cv2.VideoCapture(0) capture.set(3,640)# 320 320 640 720 capture.set(4,480)#180 240 360 405 face_cascade = cv2.CascadeClassifier('./haarcascade_frontalface_default.xml') smile_cascade = cv2.CascadeClassifier('./haarcascade_smile.xml') while True: ret, img = capture.read() img = cv2.flip(img,1)#鏡表示にするため. gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) faces = face_cascade.detectMultiScale(gray, 1.1, 5, minSize=(100,100)) for (x,y,w,h) in faces: cv2.rectangle(img,(x,y),(x+w,y+h),(255, 0, 0),2) # blue #Gray画像から,顔領域を切り出す. roi_gray = gray[y:y+h, x:x+w] #サイズを縮小 roi_gray = cv2.resize(roi_gray,(100,100)) #cv2.imshow("roi_gray",roi_gray) #確認のためサイズ統一させた画像を表示 # 輝度で規格化 lmin = roi_gray.min() #輝度の最小値 lmax = roi_gray.max() #輝度の最大値 for index1, item1 in enumerate(roi_gray): for index2, item2 in enumerate(item1) : roi_gray[index1][index2] = int((item2 - lmin)/(lmax-lmin) * item2) #cv2.imshow("roi_gray2",roi_gray) #確認のため輝度を正規化した画像を表示 smiles= smile_cascade.detectMultiScale(roi_gray,scaleFactor= 1.1, minNeighbors=0, minSize=(20, 20))#笑顔識別 if len(smiles) >0 : # 笑顔領域がなければ以下の処理を飛ばす.#if len(smiles) <=0 : continue でもよい.その場合以下はインデント不要 # サイズを考慮した笑顔認識 smile_neighbors = len(smiles) #print("smile_neighbors=",smile_neighbors) #確認のため認識した近傍矩形数を出力 LV = 2/100 intensityZeroOne = smile_neighbors * LV if intensityZeroOne > 1.0: intensityZeroOne = 1.0 #print(intensityZeroOne) #確認のため強度を出力 for(sx,sy,sw,sh) in smiles: cv2.circle(img,(int(x+(sx+sw/2)*w/100),int(y+(sy+sh/2)*h/100)),int(sw/2*w/100), (255*(1.0-intensityZeroOne), 0, 255*intensityZeroOne),2)#red cv2.imshow('img',img) # key Operation key = cv2.waitKey(5) if key ==27 or key ==ord('q'): #escまたはeキーで終了 break capture.release() cv2.destroyAllWindows() print("Exit")ちなみに,輝度の正規化をするときに,浮動小数点の値のままだとdetectMultiScaleが受け付けてくれないので,配列に格納されている値を整数型にする必要があるのだが,単純の行列演算をint()でくくるだけではキャストしてくれない(これも多分下に記述してるPythonの配列の仕様によるものと考えられる).なので,一個一個取り出して整数型にしてやる必要があった.(本当はもっとスマートな別の方法があるのかもしれないが,私の力では見つけられなかった)
そこで,ちょっと嵌まったのが,pythonとC系列の言語での配列の違い.
Cとかだと,2次元配列といっても,1次元ベクトルと互換性があるので(正しくはメモリ上でそのまま値がざーっと並んでるだけなので,h行w列の配列の場合,A[m][n]=A[m*w+n]),そのままベクトルとして演算できたり,あるいは各要素にアクセスするのにfor文を1回回すだけですんだのだが,Pythonの場合は2次元配列は「1次元配列のリスト」という形で表現されていて,メモリ上ですべてのデータが並んでいるわけではないらしい.ところで,やっていて面白いことに気がづいた.顔を認識するときに,矩形領域を示すベクトルとして,x, y, w, hが出力されているが,どうも切り出しているのは長方形ではなく正方形らしい.つまりw==h.
あと,輝度のコントロールは実はあんまり意味がないかもしれない.
参考
1) OpenCV公式のCascade_Classifyerのマニュアル(英語)
https://docs.opencv.org/2.4/modules/objdetect/doc/cascade_classification.html
2) Haar Cascadesを使った顔検出(日本語)
http://labs.eecs.tottori-u.ac.jp/sd/Member/oyamada/OpenCV/html/py_tutorials/py_objdetect/py_face_detection/py_face_detection.html#face-detection
3) 強度指標も書いてあるソース(CPP)
https://github.com/opencv/opencv/blob/master/samples/cpp/smiledetect.cpp
4) 配列(Array)の最大,最小
https://www.lisz-works.com/entry/numpy-argmax
https://deepage.net/features/numpy-max.html
5) Pythonでの2次元配列について
http://delta114514.hatenablog.jp/entry/2018/01/02/233002ちょっとした遊びを入れる
n人以上が同時に一定強度以上の笑顔を一定時間維持できるとクリアとなるゲームにしてみる.
仕様としては,
1)それぞれの顔領域を囲む矩形の色は,笑顔の強度に応じて変化する.(赤がMax,青がMin)
2)規定の人数の笑顔を認識すると,画面上でカウントダウンを表示する
3)クリアすると音が鳴る
4)規定の人数,規定の時間は定数として冒頭で設定smilegame.pyimport cv2 import numpy as np import time import pygame.mixer capture = cv2.VideoCapture(0) #capture.set(cv2.CAP_PROP_FOURCC,cv2.VideoWriter_fourcc(*'MJPG')) #capture.set(cv2.CAP_PROP_FPS, 30) #capture.set(cv2.CAP_PROP_FRAME_HEIGHT,600)#180 240 360 405 capture.set(cv2.CAP_PROP_FRAME_WIDTH,1920)# 320 320 640 720 #cv2.namedWindow('img', cv2.WND_PROP_FULLSCREEN) print( capture.get(cv2.CAP_PROP_FPS) ) print( capture.get(cv2.CAP_PROP_FRAME_WIDTH) ) print( capture.get(cv2.CAP_PROP_FRAME_HEIGHT) ) LV_GAIN = 5/100 #Smile_neighborからIntensityに変換するときのGain TH_SMILE_NUM= 8 #所定の笑顔認識数 TH_SMILE_TIME= 5#維持しないといけない秒数 #笑顔強度に応じたRGBの色を返す def Intensity2RGB( intensityZeroOne ): if intensityZeroOne < 0.1: return (255, 0, 0) elif intensityZeroOne < 0.2: return (255, 127, 0) elif intensityZeroOne < 0.3: return (255, 255, 0) elif intensityZeroOne < 0.4: return (127, 255, 0) elif intensityZeroOne < 0.5: return (0, 255, 0) elif intensityZeroOne < 0.6: return (0, 255, 127) elif intensityZeroOne < 0.7: return (0, 255, 255) elif intensityZeroOne < 0.8: return (0, 127, 255) else : return (0, 0, 255) face_cascade = cv2.CascadeClassifier('./haarcascade_frontalface_default.xml') smile_cascade = cv2.CascadeClassifier('./haarcascade_smile.xml') #時間計測のための変数 f_timecount = False t_starttime = 0 #ゲームクリアしたかどうか f_clear = False #効果音を鳴らすための処理 pygame.mixer.init() pygame.mixer.music.load("chaim.mp3") while True: if f_clear ==False: ret, img = capture.read() img = cv2.flip(img,1)#鏡表示にするため. gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) faces = face_cascade.detectMultiScale(gray, 1.1, 5, minSize=(50,50)) #笑顔カウンタをリセット smilecount = 0 for (x,y,w,h) in faces: #顔領域切り出し roi_gray = gray[y:y+h, x:x+w] #サイズを規格化 roi_gray = cv2.resize(roi_gray,(100,100)) # # 輝度で規格化 # lmin = roi_gray.min() #輝度の最小値 # lmax = roi_gray.max() #輝度の最大値 # for index1, item1 in enumerate(roi_gray): # for index2, item2 in enumerate(item1) : # roi_gray[index1][index2] = int((item2 - lmin)/(lmax-lmin) * item2) #笑顔認識 smiles= smile_cascade.detectMultiScale(roi_gray,scaleFactor= 1.1, minNeighbors=0, minSize=(20, 20)) #笑顔強度の算出 smile_neighbors = len(smiles) intensityZeroOne = smile_neighbors * LV_GAIN #if intensityZeroOne > 1.0: intensityZeroOne = 1.0 #顔領域に矩形描画(色は強度に応じて) cv2.rectangle(img,(x,y),(x+w,y+h), Intensity2RGB( intensityZeroOne ) ,2) # blue #笑顔強度が0.8以上の場合,笑顔としてカウント if intensityZeroOne >= 0.8 : smilecount+=1 print("笑顔数=",smilecount) #認識した笑顔数を表示 #時間計測 if smilecount >= TH_SMILE_NUM: # もし笑顔数が閾値超えてたら if f_timecount == False: #もしまだカウントダウンが始まってなかったら f_timecount=True t_start = time.time() else :#カウントダウンが始まってたら if time.time() - t_start < TH_SMILE_TIME: #もしカウントダウンが閾値超えてないなら tremain = TH_SMILE_TIME - (time.time() - t_start) #残り時間の算出 cv2.putText(img, str(np.ceil(tremain)), (50,50),cv2.FONT_HERSHEY_SIMPLEX, 2, (0,255,0)) else:#もしカウントダウンが閾値超えたら cv2.putText(img, "OK!!", (50,50), cv2.FONT_HERSHEY_SIMPLEX, 2, (0,255,0)) #成功の記載 #ゲームクリアのフラグ f_clear= True else : #笑顔数が閾値を下回ったら f_timecount = False # 時間計測をストップ t_start = 0.0 cv2.imshow('img',img) if f_clear == True : #ゲームクリアのフラグが立ってたら #音を鳴らすコード pygame.mixer.music.play(3) time.sleep(1) pygame.mixer.music.stop() # key Operation key = cv2.waitKey(5) if key ==27 or key ==ord('q'): #escまたはeキーで終了 break elif key == ord('r'): #ゲームをリスタート f_clear=False capture.release() cv2.destroyAllWindows() print("Exit")
- 投稿日:2019-04-05T11:19:16+09:00
語の種類の静的確率(タイプ確率)を求める
DBPediaには、各エンティティのタイプ情報を持つデータがあります。今回は、Wikipediaから各メンションがどのエンティティと紐付いているかを統計的に算出し、その上でDBPediaと結びつけることで、語のタイプ確率を求めます。
実行
git clone https://github.com/sugiyamath/entity_types_scripts cd entity_types_scripts wget http://downloads.dbpedia.org/2016-10/core/instance_types_en.ttl.bz2 wget https://dumps.wikimedia.org/enwiki/latest/enwiki-latest-pages-articles.xml.bz2 bunzip2 *.bz2 mv enwiki-latest-pages-articles.xml dump python build_types.py python extract_mention.py python json2marisa.py python mprob.py "Obama"出力例
python mprob.py "Obama" {'Animal': 0.007423904974016332, 'City': 0.05493689680772086, 'MusicalArtist': 0.0007423904974016332, 'President': 0.8916109873793615, 'RailwayLine': 0.0007423904974016332, 'School': 0.0007423904974016332, 'SoccerPlayer': 0.011878247958426132, 'owl#Thing': 0.03192279138827023} python mprob.py "Einstein" {'Album': 0.003913894324853229, 'ArtificialSatellite': 0.0136986301369863, 'Congressman': 0.0019569471624266144, 'Film': 0.0019569471624266144, 'InformationAppliance': 0.0019569471624266144, 'Person': 0.009784735812133072, 'RaceHorse': 0.05675146771037182, 'School': 0.005870841487279843, 'Scientist': 0.8473581213307241, 'Software': 0.009784735812133072, 'Song': 0.007827788649706457, 'Station': 0.0136986301369863, 'TelevisionShow': 0.01761252446183953, 'University': 0.005870841487279843, 'owl#Thing': 0.0019569471624266144} python mprob.py "Kyoto" {'AdministrativeRegion': 0.08986175115207373, 'Award': 0.00030721966205837174, 'City': 0.8935483870967742, 'Company': 0.00030721966205837174, 'Country': 0.00015360983102918587, 'Diocese': 0.00015360983102918587, 'GolfTournament': 0.00030721966205837174, 'HistoricBuilding': 0.00030721966205837174, 'Museum': 0.0006144393241167435, 'PublicTransitSystem': 0.0004608294930875576, 'Racecourse': 0.0015360983102918587, 'RailwayLine': 0.0009216589861751152, 'Single': 0.001075268817204301, 'SoccerClub': 0.00030721966205837174, 'Song': 0.001228878648233487, 'Station': 0.0006144393241167435, 'University': 0.004301075268817204, 'WorldHeritageSite': 0.0004608294930875576, 'owl#Thing': 0.003533026113671275} python mprob.py "Google" {'Company': 0.9876835622927522, 'InformationAppliance': 0.00023685457129322596, 'Organisation': 7.895152376440866e-05, 'Software': 0.0007105637138796779, 'Website': 0.010342649613137533, 'owl#Thing': 0.0009474182851729038} python mprob.py "Python" {'ComedyGroup': 0.005298318359824925, 'Film': 0.0055286800276434, 'ProgrammingLanguage': 0.9518544114259387, 'Reptile': 0.008062658373646624, 'RollerCoaster': 0.0034554250172771253, 'Software': 0.000691085003455425, 'TelevisionShow': 0.000230361667818475, 'Weapon': 0.00598940336328035, 'owl#Thing': 0.01888965676111495} python mprob.py "Andy Hunt" {'SoccerPlayer': 0.8780487804878049, 'Writer': 0.12195121951219512}コードの中身
build_types.py
dbpediaのtypesをjsonへ。
import re from tqdm import tqdm import json def load(filename): out = {} out2 = {} with open(filename) as f: for line in tqdm(f): if line.startswith("<") and '__' not in line: line = line.split() entity = line[0].split("/")[-1][:-1] if entity not in out: out[entity] = [] out[entity].append(line[2].split("/")[-1][:-1]) for k,vs in tqdm(out.items()): out2[k] = list(set(vs)) return out2 def save(out, filename): with open(filename, "w") as f: json.dump(out, f, indent=4, sort_keys=True) if __name__ == "__main__": save(load("./instance_types_en.ttl"), "out.json")extract_mention.py
wikipediaのダンプからアンカーを取り出して、「表現(mention)」と「エンティティ(Wikipediaページ名)」に分けて、「ある表現があるエンティティである回数」の統計をとる。
# coding: utf-8 import re from tqdm import tqdm def extract_mention_and_entity(exp): tmp = exp[2:-2] tmp2 = tmp[0].upper() + tmp[1:] if "|" in tmp2: entity, mention = tmp2.split("|") mention = mention.strip() else: entity = tmp2[:] mention = tmp[:] entity = entity.strip() entity = entity.replace(" ", "_") return entity, mention if __name__ == "__main__": import json reg = re.compile(r"\[\[.+?\]\]") out = {} with open("dump", errors='ignore') as f: for line in tqdm(f): exps = re.findall(reg, line) for exp in exps: try: entity, mention = extract_mention_and_entity(exp) except: continue if mention in out: if entity in out[mention]: out[mention][entity] += 1 else: out[mention][entity] = 1 else: out[mention] = {} with open("mention_stat.json", "w") as f: json.dump(out, f)json2marisa.py
生成したjsonデータをmarisa_trieへ変換。
import json import sys from marisa_trie import BytesTrie if __name__ == "__main__": print("load types") with open("./types.json") as f: data = json.load(f) print("types to trie") trie = BytesTrie([(k,bytes(json.dumps(v), "utf-8")) for k,v in data.items()]) print("saving...") trie.save("types.marisa") print("load mention_stat") with open("./mention_stat.json") as f: data = json.load(f) print("mention_stat to trie") trie = BytesTrie([(k,bytes(json.dumps(v), "utf-8")) for k,v in data.items()]) print("saving...") trie.save("mention_stat.marisa") print("Done!")mprob.py
モジュール本体。
# coding: utf-8 from typing import Tuple, Dict from marisa_trie import BytesTrie import json Probs = Dict[str, float] def typeprob(mention:str, mstat:BytesTrie, types:BytesTrie) -> Probs: """ Calculate type probabilities of the mention. Returns probabilities as dictionary (keys are type, values are prob). pre: len(mention) > 0 pre: len(mstat[mention]) > 0 pre: type(json.loads(mstat[mention][0].decode()))) == dict """ total = 0 prob = {} stat = json.loads(mstat[mention][0].decode()) for k,v in stat.items(): try: enttypes = json.loads(types[k][0].decode()) except: continue for enttype in enttypes: if enttype not in prob: prob[enttype] = 0 prob[enttype] += int(v) total += int(v) return dict([(k,float(v)/float(total)) for k,v in prob.items()]) if __name__ == "__main__": import sys import pprint mstat = BytesTrie() types = BytesTrie() mstat.load("./mention_stat.marisa") types.load("./types.marisa") pprint.pprint(typeprob(sys.argv[1], mstat, types))注意
このプログラムの実行には8G程度のメモリが必要です。
- 投稿日:2019-04-05T10:52:27+09:00
Pyinstallerでコンソール画面出さず、1ファイルのexeにする方法
- 投稿日:2019-04-05T08:37:10+09:00
pythonでAtCoder -ABC007-
対象
- AtCoder初心者(緑よりもランクが下の人)
- pythonがそれなりにかける人
- 数学やプログラミングに対する深い理解を持っていない人
- Ex) DP, 深さ優先探索, メモ化再帰の実装ができない
動機
AtCoderは全ての問題に対して解説スライドが存在するが
解説をみて何となく理論を理解しても独力で実装ができない場合が多かった。他の提出を見ても親切に解説コメントがついている回答はあまり存在せず、理解を実装に落とすことに苦労したため、簡単にでも解説がある回答はないものかと思い立ったことが動機である。
同様の苦労をしている人のためにも、稚拙なコードではあるが何らかの参考になればと思い
私の回答とそれに対する簡単なコメントを付与したコードをアップロードする。実行環境
- python3
A
A.pyprint(int(input())-1)B
B.pyfrom string import ascii_lowercase alphabet = ascii_lowercase A = input() if len(A) == 1: i = alphabet.index(A) print(-1 if i == 0 else alphabet[i-1]) else: print(A[:-1])アルファベットを出す標準ライブラリがあるので使ってみました。
C
C.pyfrom queue import Queue R, C = map(int, input().split(' ')) Sy, Sx = map(int, input().split(' ')) Gy, Gx = map(int, input().split(' ')) L = [[s for s in input()] for _ in range(R)] move = [(0, -1), (0, 1), (1, 0), (-1, 0)] q = Queue() ans = 0 q.put([(Sy, Sx)]) L[Sy-1][Sx-1] = '#' while not q.empty(): pos = q.get() valid_pos = [] for p in pos: for m in move: y, x = p[0]+m[0], p[1]+m[1] if y == Gy and x == Gx: ans += 1 print(ans) exit() if L[y-1][x-1] == '.': L[y-1][x-1] = '#' valid_pos.append((y, x)) if len(valid_pos) != 0: q.put(valid_pos) ans += 1 print(ans-1)解説の通り、Queueを使って幅優先探索を実装しました。
もう少し効率よく書けそうな気はします。D
D.pydef except_4_9(length): # 桁DPのテーブルを作る t = [[0] * 2 for _ in range(len(length)+1)] t[0][1] = 1 for i in range(len(length)): for j in range(len(t[0])): n = int(length[i]) # 制限を受けない桁 if j == 0: t[i+1][j] += t[i][j] * 8 # 制限を受ける桁 else: for k in range(n+1): if k in [4, 9]: continue # n==kの場合次の桁も制限を受ける if n == k: t[i+1][1] += t[i][j] # n!=kの場合次の桁は制限を受けない else: t[i+1][0] += t[i][j] return sum(t[len(length)]) N, M = map(int, input().split(' ')) print(1 + M-except_4_9(str(M)) - (N-except_4_9(str(N-1))))桁DPと呼ばれる解法を使っています。
終わりに
ABC→特に何も見ずに回答
D→解説、他の回答から実装以上です。
- 投稿日:2019-04-05T07:58:59+09:00
seabornで軸が省略される場合の対処法
seabornで大きいヒートマップを出力すると自動で軸を省略してくれる。
数値ならいいけど軸が文字列だったりすると困る。
seaborn 0.9.0 documentationに設定が載ってたので、
今後また躓いた時のために軸を省略しない方法を簡単に書き残す。何も考えずに出力した場合
seabornを用いて以下のようなコードで30×30のランダム行列をヒートマップ化してみる。
import matplotlib.pyplot as plt import seaborn as sns import pandas as pd import numpy as np N = 30 #正方行列サイズ X = np.random.rand(N,N) #ランダムな行列の生成 hoge = [str(i+1) for i in range(N)] #適当なラベル df = pd.DataFrame(X,index = hoge,columns = hoge) #データフレーム化 sns.heatmap(df) #ヒートマップ作成 plt.show() #表示このような
マイクラのブロックヒートマップが作成される。
1,3,5...と軸が省略される。
普段は困らないけど軸が文字列だったりすると困る時がある。軸を省略しないで出力する
以下のようにキーワード引数を設定する。
sns.heatmap(df, xticklabels = 1, #x軸 yticklabels = 1 #y軸 ) #ヒートマップ作成するとこうなる。
無事軸ラベルが省略されずに幸せになれる。
以上。
- 投稿日:2019-04-05T07:58:59+09:00
seabornのヒートマップで軸が省略される
seabornで大きいヒートマップを出力すると自動で軸を省略してくれる。
数値ならいいけど軸が文字列だったりすると困る。
seaborn 0.9.0 documentationに設定が載ってたので、
今後また躓いた時のために軸を省略しない方法を簡単に書き残す。何も考えずに出力した場合
seabornを用いて以下のようなコードで30×30のランダム行列をヒートマップ化してみる。
import matplotlib.pyplot as plt import seaborn as sns import pandas as pd import numpy as np N = 30 #正方行列サイズ X = np.random.rand(N,N) #ランダムな行列の生成 hoge = [str(i+1) for i in range(N)] #適当なラベル df = pd.DataFrame(X,index = hoge,columns = hoge) #データフレーム化 sns.heatmap(df) #ヒートマップ作成 plt.show() #表示このような
マイクラのブロックヒートマップが作成される。
1,3,5...と軸が省略される。
普段は困らないけど軸が文字列だったりすると困る時がある。軸を省略しないで出力する
以下のようにキーワード引数を設定する。
sns.heatmap(df, xticklabels = 1, #x軸 yticklabels = 1 #y軸 ) #ヒートマップ作成するとこうなる。
無事軸ラベルが省略されずに幸せになれる。
以上。
- 投稿日:2019-04-05T07:37:31+09:00
Pythonの配列のZip化
names = ['Jenny', 'Alexus', 'Sam', 'Grace']
dogs_names = ['Elphonse', 'Dr. Doggy DDS', 'Carter', 'Ralph']
names_and_dogs_names = zip(names, dogs_names)
print(list(names_and_dogs_names))
↑inputはzipだが、printするときはlistで行う
- 投稿日:2019-04-05T06:18:11+09:00
Python+Flask+Blueprintにおけるユニットテスト実施方法
Python+Flask+Blueprintの環境でどのようにユニットテストを実施するかを書いていく。
基本的には、unittestモジュールを使いながらテストを行い、coverageモジュールで、テストカバレッジを測定していく方法となる。
今回は実際のコードを共有しながら、どのようにテストを実施するかを共有していく。
なお、以下の記事のプログラムをベースとしている。一緒に参考にされたい。Python+Flask+Blueprintを使ったAPIサーバの構成とサンプルプログラム
Python+Flask+Blueprintにおけるエラーハンドリング
環境
今回の記事を始める前の環境。
- Mac OSX Mojave(10.14.3)
- Python 3.7.2
- Click==7.0
- Flask==1.0.2
- Flask-Cors==3.0.7
- itsdangerous==1.1.0
- Jinja2==2.10
- MarkupSafe==1.1.1
- six==1.12.0
- Werkzeug==0.15.1
この記事の中で以下のモジュールを追加した。
- coverage==4.5.3
さて、早速作っていく。
applicaiton.pyの修正
冒頭でも述べたとおり、unittestとcoverageモジュールを使って実装していく。
application.pyimport os import sys import click from app import create_app COV = None if os.getenv('FLASK_COVERAGE'): import coverage COV = coverage.coverage(branch=True, include='app/*') COV.start() # print(os.getenv('FLASK_CONFIG')) app = create_app(os.getenv('FLASK_CONFIG') or 'default') @app.cli.command() @click.option('--coverage/--no-coverage', default=False, help='Run tests under code coverage.') def test(coverage): """Run the unit tests.""" if coverage and not os.getenv('FLASK_COVERAGE'): import subprocess os.environ['FLASK_COVERAGE'] = '1' sys.exit(subprocess.call(sys.argv)) import unittest tests = unittest.TestLoader().discover('tests') unittest.TextTestRunner(verbosity=2).run(tests) if COV: COV.stop() COV.save() print('Coverage Summary:') COV.report() basedir = os.path.abspath(os.path.dirname(__file__)) covdir = os.path.join(basedir, 'tmp/coverage') COV.html_report(directory=covdir) print('HTML version: file://%s/index.html' % covdir) COV.erase() @app.cli.command() @click.option('--length', default=25, help='Number of functions to include in the profiler report.') @click.option('--profile-dir', default=None, help='Directory where profiler data files are saved.') def profile(length, profile_dir): """Start the application under the code profiler.""" from werkzeug.contrib.profiler import ProfilerMiddleware app.wsgi_app = ProfilerMiddleware(app.wsgi_app, restrictions=[length], profile_dir=profile_dir) app.run()ここで使っているclickというのは既存のCLI(Command Line Interface、ここでは以下に出てくる
flask test --coverageなど)にオプションを追加するモジュール。
flask test --no-coverageと実行した場合はレポートなし、flask test --coverageと実行した場合はレポート付きで結果を出力するようにした。
unittest.TestLoader().discover('tests')ではテストケースが格納されるフォルダを指定している。
ここではtestsを使うので作っておく。mkdir testsまずは、coverageレポートなしで試してみる。
$ flask test --no-coverage ---------------------------------------------------------------------- Ran 0 tests in 0.000s OKテストケースをつくってないからシンプル。
次に、coverageレポート付きで実行する。
$ flask test --coverage ---------------------------------------------------------------------- Ran 0 tests in 0.000s OK Coverage Summary: Name Stmts Miss Branch BrPart Cover ---------------------------------------------------------- app/__init__.py 10 4 0 0 60% app/apiv1/__init__.py 3 0 0 0 100% app/apiv1/errors.py 16 10 0 0 38% app/apiv1/testapp.py 11 7 0 0 36% app/create_response.py 7 5 0 0 29% app/exceptions.py 2 0 0 0 100% ---------------------------------------------------------- TOTAL 49 26 0 0 47% HTML version: file:///Users/okayHyatt/flask/tmp/coverage/index.htmlこういうレポートを自動で作ってくれる。
さらにコードの中に入って、どのラインが実行されたかも見られる。
後は実際にテストケースを書いていく。テストケースを書くのは慣れがいると思う。
テストケースを書く
testsフォルダの中にtestから始まるファイルがテストケースのファイルとみなされるので、ファイル名には注意が必要。ますは、
app/test_function.pyをテストケースのやり方を示すために作成し、app/apiv1/test_app.pyを以下のように変更する。app/test_function.pydef test(): return Trueapp/apiv1/testapp.pyfrom . import api from flask import render_template, request, current_app, abort # from app.exceptions import ValidationError import base64 @api.route('/test', methods=['GET']) def test(): from app.test_function import test if not test(): abort(400) from app.create_response import create_response content = render_template('ok.json') # content = render_template('okay.json') status_code = 200 mimetype = 'application/json' response = create_response(content, status_code, mimetype) return response見ての通り、
test_function.pyのtestは必ずTrueを返す関数である。
app/apiv1/testapp.pyではその関数がFalseになったらabortをあげるように変更した。このように、想定の挙動はTrueを返す関数だが、Flaseが返ってきたときを例外処理として対処することはよくある。
そのときにどのようにテストするかを説明する。まずはサンプルのコードを共有する。
tests/test_testapp.pymport unittest from app import create_app from unittest.mock import patch class TestCase(unittest.TestCase): def setUp(self): self.app = create_app('testing') self.app_context = self.app.app_context() self.app_context.push() self.client = self.app.test_client() def tearDown(self): self.app_context.pop() def test_function(self): with patch('app.test_function.test') as mock_test: mock_test.return_value = False response = self.client.get('v1/test') # response = self.client.post('v1/test') self.assertEqual(response.status_code, 400)SetUpはテストのためのクライアントを作成する処理で、tearDownは終了する処理である。
大事なのはtest_functionで、ここでpatchモジュールを使って、app/apiv1/testapp.py内の関数の返り値を変更している。その上でself.client.get('v1/test')でGETリクエストを送り、self.assertEqual(response.status_code, 200)で期待するステータスコードとなっているかをチェックする仕組みになっている。
この関数の返り値を変更できるということを知っておくことは、テストする際に重要である。基本的にはこのやり方で、coverageレポートの結果が100%になるように、テストケースをひたすら書いていく。
おわり
私はこのテストケースの作成の仕方に慣れるのに時間がかかったが、この記事を読んでくれている方がテストのやり方をすぐ理解してくれたら嬉しい。
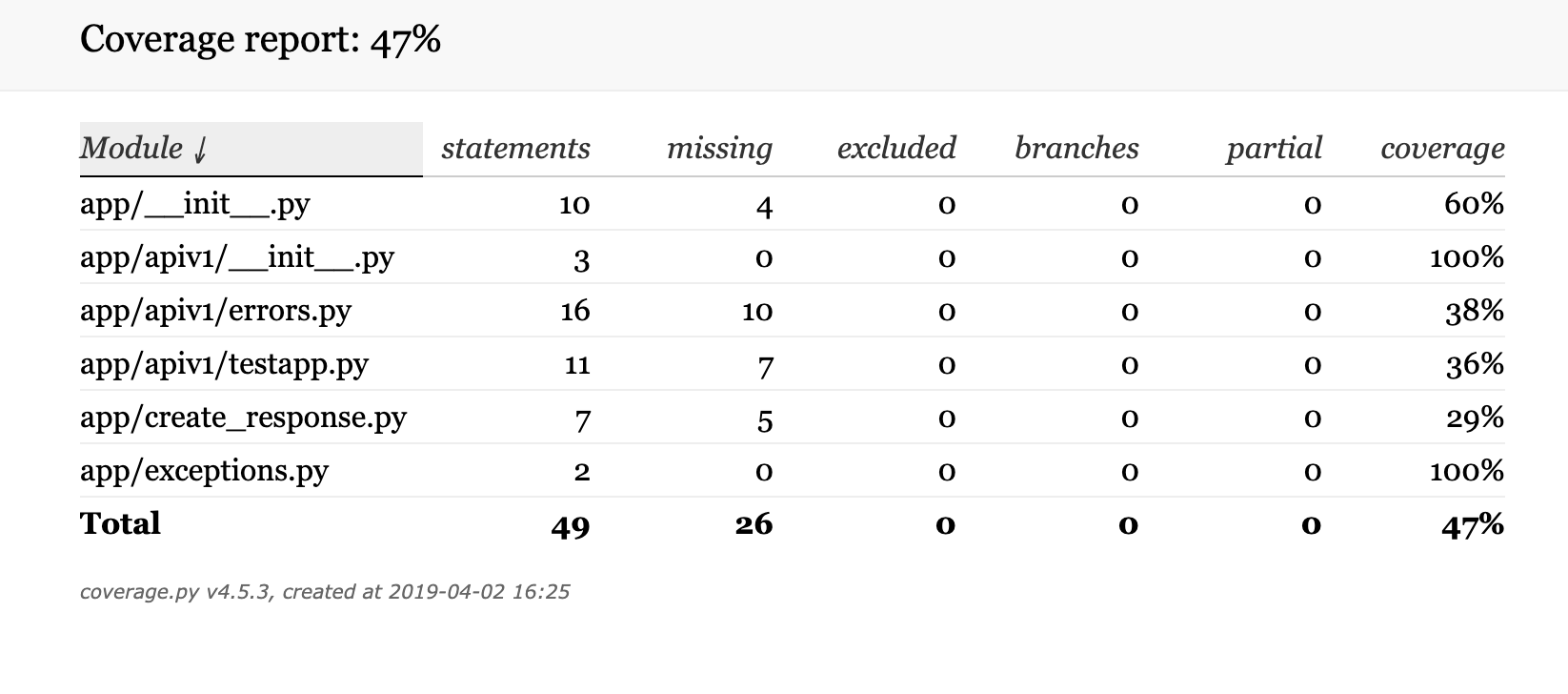
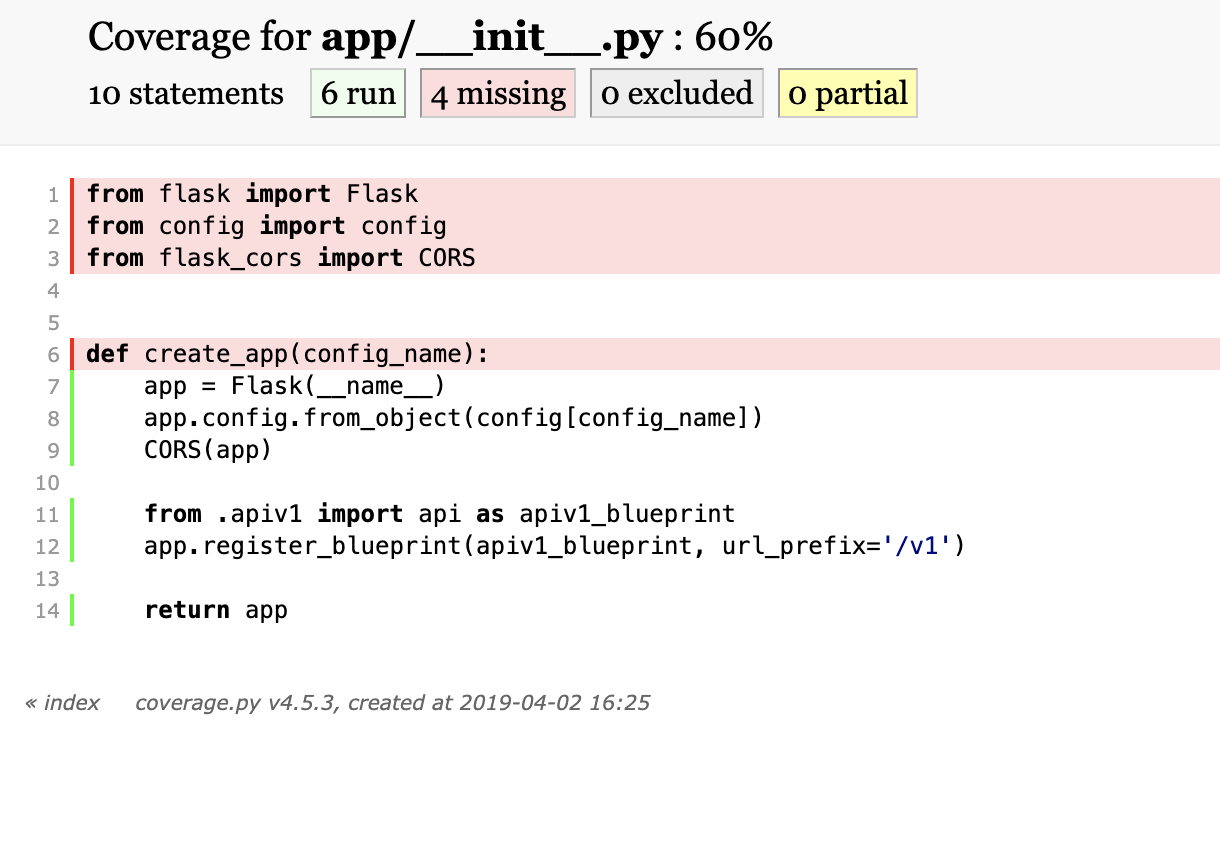
- 投稿日:2019-04-05T02:03:28+09:00
FastAPIでCORSを回避
はじめに
FastAPIを使っていてCORSの問題にぶち当たり
2時間ほど詰まってしまったので、他に困っている人に向けて解決方法を残します。問題のソースコード
問題のソースコードはこのようになっています。
今回は公式でも取り上げられているようなサンプルプログラムを参考に作っています。
https://fastapi.tiangolo.com/tutorial/first-steps/main.pyfrom fastapi import FastAPI app = FastAPI() @app.get("/users/") def read_users(): return {"id": 1, "name": "taro"} @app.get("/users/{user_id}") def read_user(user_id: int): return {"user_id": user_id}FastAPIの起動
$ uvicorn main:app --reload --host 0.0.0.0 --port 8000http://localhost:8000 で待機します
症状
FastAPIが待機している
http://localhost:8000に対して
アプリケーションのhttp://localhost:8080からアクセスすると
下記のようなエラーがchromeのコンソール上で確認されました。Access to fetch at 'http://localhost:8000/users/' from origin 'http://localhost:8080' has been blocked by CORS policy: No 'Access-Control-Allow-Origin' header is present on the requested resource. If an opaque response serves your needs, set the request's mode to 'no-cors' to fetch the resource with CORS disabled.エラーを見てみるとCORSのポリシーによって
http://localhost:8080はブロックされているようなので、
どうやらサーバ側でアプリケーションURLを許可するかCORSを回避してあげれば良さそうです。解決方法
通常であれば、サーバからのレスポンスヘッダーに
Access-Control-Allow-Origin: *を追加してあげればよいのですが、FastAPIの場合は直接ヘッダー情報を追加するのではなく、下記のような対応をとります。
main.pyfrom fastapi import FastAPI from starlette.middleware.cors import CORSMiddleware # 追加 app = FastAPI() # CORSを回避するために追加(今回の肝) app.add_middleware( CORSMiddleware, allow_origins=["*"] ) @app.get("/users") def read_users(): return {"id": 1, "name": "taro"} @app.get("/users/{user_id}") def read_user(user_id: int): return {"user_id": user_id}今回、解決にあたって、こちらの方が実装しているコードを参考にしました。
おわりに
CORSについてエラーが起きたとき、当初はCORSについてまったく知識がなかったので、どう対処してよいかわかりませんでしたが、フィックスしていくに当たって、理解を深めることができよかったです。ただ、2時間消費してしまったのはつらい...
少しでも他の方のお役に立てればと思います。