- 投稿日:2019-04-05T23:57:37+09:00
EC2で自身のVPC_IDをmetadataから取得する
- 投稿日:2019-04-05T19:09:51+09:00
[AWS] MFAの設定(2段階認証)
AWSでのMFAの設定(2段階認証)
- AWSコンソールへのログイン時に2段階認証を実現させる機能
- 複数の方法で2段階認証を実現可能
- 仮想デバイス(スマホのアプリ)
- U2F セキュリティキー
- など、、、
- 参考
仮想デバイスでの設定方法
今回は仮想デバイスでの設定手順を記述する
アプリ
- 今回は
IIJ SmartKeyを用いるので以下どちらかを端末にインストールするAWS側の設定
今回は IAM で作成されたユーザでのログインとする
ルートユーザでは設定場所が異なる
AWS側の手順
- MFA設定するユーザでコンソールにログインする
IAMサービスを開く- サイドメニューから
ユーザーを選択- 今回MFAを設定するユーザを検索し選択する
認証情報タブを選択MFA デバイスの割り当ての管理を押下仮想 MFA デバイスを選択し続行を押下QRコードの表示を押下アプリ側の操作
- インストールした
SmartKeyを開く- 左上の
+マークを押下- AWS側で表示させたQAコードを読み込む
- 画像や各名前が問題なければ
登録を押下AWS側の操作
連続する 2 つの MFA コードを以下に入力にアプリ側で表示されている6桁の数字を入力する
- 30秒枚に新しいコードに切り替わるので暫くまつ
MFA コード 1にコードを入力MFA コード 2に更新された新しいコードを入力MFAの割り当てを押下MFA設定後のログイン
- 通常通り
ユーザー名パスワードを入力してログインMFA認証でコードの入力を求められるのでSmartKeyを開き表示されている6桁のコードを入力する補足
IIJ SmartKeyの設定
- 設定はQRコードで簡単に別端末へ共有できるので、可能であれば複数端末に共有しバックアップを作成しておく
- 複数端末ない場合はQRコードをプリントアウトするなりして保管しておく
- アプリを開く際に
パスコードTouch IDが設定できるのでアプリのセキュリティ強化の為に設定をオススメする終了する際にロックするという設定もオススメする
- アプリがバックグラウンド実行にまわった時にもアプリロックがされるのでよりセキュリティ強化できる
- 投稿日:2019-04-05T18:58:04+09:00
CloudWatch Logsを日次でエクスポートするStep Functions
はじめに
皆さん、AWS上のログってどうしてますか?
EC2/RDS/Lambda/API Gateway 等いろんなサービスがログを吐きますよね。しかし、CloudWatch Logsに保存し続けると結構なコストがかかるので、
S3に移して安く済ませたい方は多いはず!サブスクリプションフィルタでKinesisとかに送っても良いのですが、
Kinesisにもお金がかかる・・・S3へのエクスポートを使って、お安くアーカイブしたい!
と思って考え始めました。仕様調査
CloudWatch Logsのエクスポートの仕様
一つのロググループがS3にエクスポート中だと、
それが完了するまで、次のエクスポートタスクは作成出来ません。Lambda Functionの制約
CloudWatch Logsの仕様を見て、Lambda Function一つでloopしながら待つ事も考えたのですが、
Lambda FunctionのTimeoutの制限もあり、ロググループが増えたら、しんどくなる・・・解決策
リアルタイムでデータが欲しいわけじゃないから、
Step FunctionでLambda Functionを数珠つなぎにして、のんびり動かせばいい!実装
CloudFormationのテンプレート
CloudFormationの一枚のTemplateにまとめてます。(メンテナンス性悪いですが・・・)
Templateはせっかくなので、Githubに上げてみました
※初めてReadmeを英語で書いたので、拙い英語はお許しください・・・
https://github.com/Jump-Kishimoto/CloudWatchLogs-ExportUsageをもっとこう書いた方が良い!とか
どうやったらいいか分からねぇ!とかあれば、本記事へのコメント/Issue/PullRequestでいただければ喜びます!
一緒にブラッシュアップさせて下さい!Step Functionのフロー
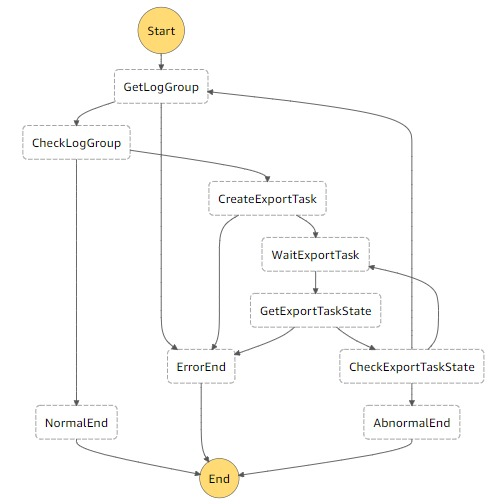
GetLogGroup
同一リージョンのCloudWatch Logsのロググループ名を取得します。
ロググループ名を取得する時、まだ次のロググループが有る場合は、NextTokenの値が返ってきますので、
それをState Machineに返却し覚えさせます。2回目以降、NextTokenがLambdaに渡されれば、そのTokenを使い次のロググループ名を取得します。
CheckLogGroup
GetLogGroupの結果、ロググループを取得出来たかを判断し、ExportTaskの作成に移ります。
CreateExportTask
GetLogGroupで取得したロググループに対して、前日分のログをS3にExportするTaskを作成する。
Exportする対象の時間はLambda Function実行タイミングの前日の0:00(JST)~当日の0:00(JST)です。例)
Lambda Functionが、2019/4/2 3:00(JST)に動いた場合
Export範囲:2019/4/1 0:00(JST) ~ 2019/4/2 0:00(JST) ←前日分をまるっと。
Lambda Functionが、2019/4/2 22:00(JST)に動いた場合
Export範囲:2019/4/1 0:00(JST) ~ 2019/4/2 0:00(JST) ←22:00に動こうが、範囲は変わらず。WaitExportTask
ロググループのExportの完了を待つため、30秒待つ
GetExportTaskState
ロググループのExportのステータスを取得する。
CheckExportTaskState
Exportが完了している場合
→ GetLogGroupの処理へ。Exportがまだ完了していない場合
→ WaitExportTaskの処理へ。簡単な流れの説明
同一リージョンにあるロググループを昇順で一つずつ取得し、一つずつExport Taskを作成します。
しばらく待ってからチェックし、終わってなければまた待つ。終わっていれば次のロググループの取得へ。というのをひたすら繰り返すだけです。
Step FunctionsのTimeOutが1年なので、State MachineがTimeoutする事はないでしょう。S3にどう吐かれるの?
s3://{Bucket名}/CWLogs/{Region名}/{YYYY}/{MM}/{DD}/{ロググループ名}/{ExportTaksID}/{ログストリーム名}/00000.gzというPathで吐かれます。
Lambda Functionのロググループなんかは"/"で区切られていますが、そのままExport先のPathとして使います。
S3マネジメントコンソール上では、サービス毎にフォルダが切られているように見えるので、見やすい気がしてます。どう使う?
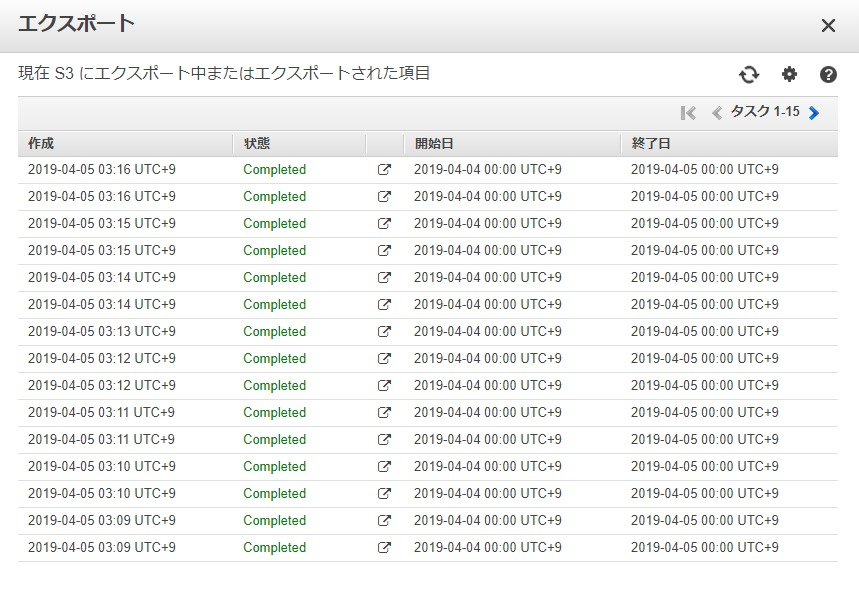
CloudWatch Eventで日次で動かしてもらうのがいいかと。
↓は3:00(JST)に日次でState Machineを動かしている時のExport状況です。
オプション
Usageにも少し書いてありますが、State Machine手動実行時に、以下の様にExportしたい日付を指定する事も出来ます。
※エラー時の手動リトライなんかで使って下さい。{ "TargetDate": "2018-08-20" }↑の例だと、2019/8/20 0:00(JST) ~ 2018/8/21 0:00(JST)の範囲で、全てのロググループをエクスポートします。
最後に
Github、初めて使ったので色々ご指摘下さい!
使いこなしたい!
IssueやPullRequestもお待ちしてます!
- 投稿日:2019-04-05T17:45:45+09:00
Upload image to S3 using Javascript AWS SDK
Getting started
Install aws-sdk using
npm$ npm install aws-sdkCreate a json file name
config.jsonin the project root directory{ "accessKeyId": "<aws-access-key>", "secretAccessKey": "<aws-secret-key>", "region": "ap-northeast-1" }Usage
Import the aws-sdk
const AWS = require('aws-sdk')Initialize S3 object for doing the operations
// load aws s3 configuration from json file AWS.config.loadFromPath(path.join(__dirname, '<relative-path-to-config.json>')) // initialize S3 object for doing operations var S3 = new AWS.S3({ apiVersion: '2006-03-01' })
- Get image from S3
// setup the params for get object operation var params = { Bucket: <path-to-where-the-target-object-is-stored> Key: <object-name-in-s3> } // Async function to get object from S3 using aws-sdk S3.getObject(params, function (err, data) { if (err) throw err console.log(data) }) .catch(err => console.log(err))
- Upload Image to S3
// setup the params for get object operation var params = { Bucket: "bucket name with path", Key: "<filename>", Body: "<image stream>" } // Async function to get object from S3 using aws-sdk S3.getObject(params, function (err, data) { if (err) throw err console.log(data) }) .catch(err => console.log(err))
- 投稿日:2019-04-05T17:09:27+09:00
Goの使い方2
ループを一定期間休む
import(“time”) time.Sleep(3 * time.Second)乱数を生成する
Goでrandを使うときは忘れずにSeedを設定しないといけない
Goにはcrypto/randというセキュアな乱数生成器seed, _ := crand.Int(crand.Reader, big.NewInt(math.MaxInt64)) rand.Seed(seed.Int64()) fmt.Println(rand.Int63())標準入力から変数の値を受け取る
Scan関数
func Scan(a ...interface{}) (n int, err os.Error) fmt.Scan(&a, &b) fmt.Println(a, b)文字列の検索
str := "The Go Programming Language" // 文字列が含まれるか判定する。 if strings.Contains(str, "Go") { fmt.Println("Contains return true!") } // 開始文字列を判定する。 if strings.HasPrefix(str, "Th") { fmt.Println("HasPrefix return true!") } // 終端文字列を判定する。 if strings.HasSuffix(str, "age") { fmt.Println("HasSuffix return true!") } // 文字列から特定の部分文字列を検索する。 // 先頭から検索して見つかった文字列位置を返す。 // 見つからない場合は -1 を返す。 if idx := strings.Index(str, "Program"); idx != -1 { fmt.Printf("Found. (index = %d)\n", idx) } // 末尾から検索して見つかった文字列位置を返す。 // 見つからない場合は -1 を返す。 if idx := strings.LastIndex(str, "a"); idx != -1 { fmt.Printf("Found. (index = %d)\n", idx) }request.goでUUID=1234567890(乱数)を標準出力
scan.goでUUID=1234567890(乱数)を検出して数値の抽出して標準出力するrequest.go
package main import( "fmt" "time" crand "crypto/rand" "math" "math/rand" "math/big" )$ vi request.go
$ go build request.go
$ vi scan.go
$ go build scan.go
$ ./request | ./scan
2550519028152033468
1331746663370969294func main() { for { seed, _ := crand.Int(crand.Reader, big.NewInt(math.MaxInt64)) rand.Seed(seed.Int64()) s :=rand.Int63() fmt.Printf("UUID=%v\n",s) time.Sleep(1 * time.Second) } }scan.go
package main import ( "fmt" "strings" ) func main() { var a string dst := "" for { fmt.Scan(&a) if strings.Contains(a,"UUID"){ dst = strings.Replace(a, "UUID=", "", 1) fmt.Println(dst) } else { fmt.Printf("none\n") } } }
- 投稿日:2019-04-05T16:36:59+09:00
AWS CloudWatchでログ検索する時によく使うコマンド
デバッグの時などに何かエラー起きてないかな?とCloudWatchのログを検索したい時ないですか?
ロググループ名は分かってるけど、ログストリームが大量に生成されるし、複数リージョンにまたがっていて
一つ一つ見ていくのはキツイ...
という時に私は以下のようなコマンドで調べています。$ log_group_name=<your log group name> $ pattern=<keyword you want to find> $ aws ec2 describe-regions | jq '.Regions[].RegionName' | xargs -n 1 -J % aws logs filter-log-events --log-group-name $log_group_name --start-time `date -v-1d +%s` --filter-pattern $pattern --region % | jq '.events'例えば
pattern=STARTにした場合の出力はこんな感じです。
何もなかったリージョンは[]だけがでます。[] [ { "logStreamName": "2019/04/05/[$LATEST]4167bbbbbbbbbbbbbbbbbbbbbbbbbbbb", "timestamp": 1554444422379, "message": "START RequestId: 2340bbbb-bbbb-bbbb-bbbb-bbbbbbbbbbbb Version: $LATEST\n", "ingestionTime": 1554444422398, "eventId": "3466526898875119217066662794167bbbbbbbbbbbbbbbbbbbbbbbbbbbb" }, { "logStreamName": "2019/04/05/[$LATEST]4167e179faaaaaaaaaaaaaaaaaaaaaa", "timestamp": 1554444427564,--start-time
date -v-1d +%sこれは現在時刻の1日前からのログを対象にするという意味です。
私はMacを使っているので、こんな感じのdateコマンドのオプションになります。
他については以下のqiita記事で触れられていました。
https://qiita.com/hid_tgc/items/a82e00112a3683ede528以上、ちょいネタでした。
- 投稿日:2019-04-05T15:54:42+09:00
AWS CLIでecsを構築する手順
aws cliでecsを操作するコマンドは2パターンあります。(aws ecsからecs-cli)
どっちを使ってもいいんですが、一つに統一してほうがいいかも知りません。
今回はecs-cliを使おうとします。大まかな手順
AWS環境設定(configuration)
awsに繋ぐためのprofileを登録する必要があります。今回はOregonリージョン(us-west2)に環境を構築します。configuration
ecs-cli configure profile --profile-name west2-profile --access-key "XXXXXXXXXXXXXX" --secret-key "XXXXXXXXXXXXXXXXXXXXXXX" ecs-cli configure --cluster [CLUSTER_NAME] --default-launch-type EC2 --region us-west-2 --config-name west2-config結果は「.ecs/credentials」、「.ecs/config」に記録されます。
- cluster作成
SSHでecsのホスト・インスタンスにログインするためにssh keyを作成します。
AWSコンソールからEC2 Dashboardに入り、「Key Pairs」で「Create Key Pair」をクリックします。
名前を入力して(今回はwest2-keyにします)、「Create」を押します。すぐダウンロードが始まりますが、~/.sshに入れときましょう。ecs-cli up --keypair west2-key --capability-iam --size 1 --instance-type t2.small --cluster-config west2-config
- task/service実行
ecs-cli compose --project-name [PROJECT_NAME] --ecs-profile west2-profile --cluster-config west2-config service uptask実行のみ:service up -> up
project-nameはservice名、task名、task definition名になります。このまま実行するとSSMにアクセスを拒否されたと怒られます。
Fetching secret data from SSM Parameter Store in [REGION]: AccessDeniedException: User: arn:aws:sts::[ACCOUNT-ID]:assumed-role/ecsTaskExcutionRole/XXXXX is not authorized to perform: ssm:GetParameters on resource: arn:aws:ssm:[REGION]:[ACCOUNT-ID]:parameter/[パラメータ] status code: 400, request id: XXXXXXXXXX対策としては、ecsTaskExcutionRoleに次のpolicyを与える。
{ "Version": "2012-10-17", "Statement": [ { { "Effect": "Allow", "Action": "ssm:GetParameters", "Resource": "*" } ] }
- コンテナーがちゃんと立ち上がったのか確認する
ecs-cli ps --ecs-profile west2-profile --cluster-config west2-config
- コンテナーからpaprameterが読み取れたのかを確認する。(SSHでECSホストにLOGINする必要がある)
docker exec -it `CONTAINER ID` env
- サービスを削除する
ecs-cli compose --project-name [PROJECT_NAME] --ecs-profile west2-profile --cluster-config west2-config service down
- クラスター(及び関連リソース)を削除する
ecs-cli down --ecs-profile west2-profile --cluster-config west2-config Are you sure you want to delete your cluster? [y/N]確認メッセージが出るので[y]を入力して確定します。
参考
https://docs.aws.amazon.com/ja_jp/AmazonECS/latest/developerguide/ECS_CLI_reference.html
https://docs.aws.amazon.com/AmazonECS/latest/developerguide/cmd-ecs-cli-compose-ecsparams.html
https://medium.com/@felipgomesilva/using-secrets-in-aws-ecs-dc43c37ce4a1
https://dev.classmethod.jp/cloud/aws/ecs-secrets/
- 投稿日:2019-04-05T15:27:28+09:00
Railsで「CarrierWave+fog」を使ってAWSのS3へアップロード
はじめに
Railsアプリを外部サービスと連携させてみようと思い、AWSが提供するS3へ画像や動画をアップロードしてみた過程をまとめていきます。
今回はCarrierWaveで単純にアップロード機能を利用し、fogでクラウド上のs3へ簡易的にアップロードできるようにしています。AWS上での設定
S3の詳しい利用法の要点をまとめます。
①AWSアカウントの取得
AWSのアカウントを取得。原則としてクレジットカードの登録が必要になります。アカウント作成から12か月間は無料枠(最大5GB)としてS3が利用できます。②IAMユーザーの作成
続いてIAMユーザーを作成します。IAMとはAWS上のサービスを操作するユーザーと、ユーザーアクセス権限を管理するものです。
IAMがなかった場合、フルアクセスのAWSアカウントをみんなで共有することになります。
ユーザーがアクセスするための認証情報(アクセスキー、ポリシーの設定)を取得しS3へアクセスします。※ここで取得したアクセスキーIDとシークレットアクセスキーは絶対に控える&定期的に更新する
③バケットの作成
バケットとは、ファイルなどのオブジェクトを格納するための入れ物です。ここでバケット名を決めるのですが、注意が必要です。AWSバケット名の命名規則に従った名前を付けてください。https://docs.aws.amazon.com/ja_jp/AmazonS3/latest/dev/BucketRestrictions.html
自分の場合、バケット名に不適切な文字を記述してしまい、原因がわからずS3にいつまでたってもアクセスできない事態に見舞われました。続いてバケットのリージョンを設定します。リージョンとはS3のサービスが提供されている場所を意味します。「アジア・パシフィック(東京)」の場合、使用する資格情報は「ap-northeast-1」となります。
CarrierWaveの導入
gem 'carrierwave' gem 'fog'アップロードファイルの作成
$ rails g uploader file
app/uploaders/file_uploader.rbが生成されます。file_uploader.rbclass FileUploader < CarrierWave::Base require 'streamio-ffmpeg' if Rails.env.production? storage :fog else storage :file end def store_dir "uploads/#{model.class.to_s.underscore}/#{mounted_as}/#{model.id}" end def extension_white_list %w(jpg jpeg gif mp4 MOV wmv) end version :screenshot do process :screenshot def full_filename (for_file = model.logo.file) "screenshot.jpg" end end def screenshot tmpfile = File.join(File.dirname(current_path), "tmpfile") File.rename(current_path, tmpfile) movie = FFMPEG::Movie.new(tmpfile) movie.screenshot(current_path + ".jpg", { resolution: '500x600' },preserve_aspect_ratio: :width) File.rename(current_path + ".jpg", current_path) File.delete(tmpfile) end endサムネイル用にffmpegを使用しています。
今回はアップロードされたファイルが画像でも動画でも、一旦tmpフォルダーにjpgファイルとして格納し、最終保存先を開発環境時はローカルに、本番環境時はfogに設定しています。続いてcarrierwave.rbを作成します。
carrierwave.rbrequire 'carrierwave/storeage/fog' CarrierWave.configure do |config| config.fog_provider = 'fog/aws' config.fog_credentials = { provider: 'AWS', aws_access_key_id: 'アクセスキー', aws_secret_access_key: 'シークレットアクセスキー', region: 'リージョン', } config.fog_directory = 'バケット名' #日本語ファイル名の設定 CarrierWave::SanitizedFile.sanitize_regexp = /[^[:word:]\.\-\+]/ config.cache_dir = "#{Rails.root}/tmp/uploads" endモデルにuploaderを紐づけます。
gallery.rbclass Gallery < ApplicationRecord mount_uploader :file, FileUploaderviewの実装は今回は割愛します。
これで本番環境時にS3にアップロードすることができました。おわり
特に基盤となってくるuploaderとcarrierwaveの設定はまだ完全に理解していないし、不十分なところもあると思うので今後さらに深堀していきたいです。
参考
・https://qiita.com/junara/items/1899f23c091bcee3b058
・http://vdeep.net/rubyonrails-carrierwave-s3
・https://qiita.com/yukiyukimiyaiwa/items/a9e0103c8342b81f6ac1
・https://stackoverflow.com/questions/15717368/uploading-image-to-s3-using-carrierwave-and-fogs-bad-uri
- 投稿日:2019-04-05T15:25:22+09:00
Goの使い方
初めてGoを使ったまとめ
目標
標準出力を受け取ってスクリプトを実行することです。
多数のブログを参考させていただきました。ありがとうございます。
最初のチュートリアル
A Tour Gogo run と go build
凄くわかりやすいAmazonLinuxでの環境準備
簡単なHelloWorldsudo yum install go vi hoge.go go run hoge.go go build hoge.go ./hoge基本フォーマット
hoge.go
package main ←main関数がエンドポイントにされている import ( ←読み込む必要のあるパッケージを宣言する "fmt" ) func main() { fmt.Println("HolleWorld!") }go build [コンパイル後のファイル名] [コンパイルしたいファイル名] ./[コンパイル後のファイル名] go run hoge.go 自動的にコンパイル・実行をしてくれるFunction
引数と戻り値は後ろに書くので注意が必要
同じ型の場合は最後の一つに省略できるfunc swap(x, y string) (string, string) { return y, x }Named return values
戻り値となる変数に名前を付けることができる
func split(sum int) (x, y int) { x = sum * 4 / 9 y = sum - x return }覚書
Variables
varは変数を宣言します。最後に型を書くことで変数のリストを宣言できます。
var c, python, java bool var i intVariables with initializers
varでは初期化子を与えることで型の宣言を省くことができる
var c, python, java = true, false, "no!Short variable declarations
varの代わりに:=で暗黙的な型宣言
k := 3Basic types
基本の方
bool string int int8 int16 int32 int64 uint uint8 uint16 uint32 uint64 uintptr byte // uint8 の別名 rune // int32 の別名 float32 float64 complex64 complex128 var ( fmt.Printf("Type: %T Value: %v\n", z, z) ) Type: complex128 Value: (2+3i)Zero values
変数に初期値を与えずに宣言すると、ゼロ値( zero value )が与えられます
fmt.Printf("%v\n", f)Type inference
明示的に型の宣言をしない場合に、変数の右側の値から型推測される
Constants(定数)
const Pi = 3.14 const World = "世界"Numeric Constants
数値の定数は、高精度な 値 ( values )
const (Big = 1 << 100)For繰り返し処理
初期化と後処理ステートメントの記述は任意です
for i := 0; i < 10; i++ { for ; sum < 1000; {for i := 0; i < 10; i++ {
for ; sum < 1000; {if x < 0 {If with a short statement
ifステートメントのに簡単なステートメントを書くことができる
ここで宣言された変数はifスコープ内のみ有効(elseブロックでも有効)if v := math.Pow(x, n); v < lim {Switch
上から下へcaseを評価します。 caseの条件が一致すれば、そこで停止(自動的にbreak)
Go では選択された case だけを実行してそれに続く全ての case は実行されませんswitch os := runtime.GOOS; os { case "darwin": fmt.Println("OS X.") default:Defer
defer へ渡した関数の実行を、呼び出し元の関数の終わり(returnする)まで遅延させる
defer fmt.Println("world")Stacking defers
複数ある場合LIFO(last-in-first-out)後入れ先出
Pointers
ポインタは値のメモリアドレスを指します
変数 T のポインタは、 *T 型で、ゼロ値は nil
& オペレータは、そのオペランド( operand )へのポインタを引き出しますオペレータは、ポインタの指す先の変数を示します
var p *int i := 42 p = &i // point to i fmt.Println(*p) // read i through the pointer *p = 21 // set i through the pointerStructs
struct (構造体)は、フィールド( field )の集まりです
type Vertex struct { X int Y int }Struct Fields
structのフィールドは、ドット( . )を用いてアクセスします
v := Vertex{1, 2} v.X = 4 fmt.Println(v.X)Pointers to structs
フィールド X を持つstructのポインタ p
(*p).X = p.X v := Vertex{1, 2} p := &v (*p).X = 1e9Struct Literals
structリテラルは、フィールドの値を列挙することで新しいstructの初期値の割り当てを示しています
v1 = Vertex{1, 2} // has type Vertex v2 = Vertex{X: 1} // Y:0 is implicit v3 = Vertex{} // X:0 and Y:0Arrays
[n]T 型は、型 T の n 個の変数の配列( array )を表します
var a [10]int fmt.Println(a[0], a[1])Slices
スライスは可変長
コロンで区切られた二つのインデックス low と high の境界を指定することによってスライスが形成されます
a の要素の内 1 から 3 を含むスライスを作りますa[low : high] a[1:4] primes := [6]int{2, 3, 5, 7, 11, 13} var s []int = primes[1:4] fmt.Println(s)Slices are like references to arrays
スライスはどんなデータも格納しておらず、単に元の配列の部分列を指し示しています
スライスの要素を変更すると、その元となる配列の対応する要素が変更されますa := names[0:2] a[0] = "XXX" fmt.Println(names) [XXX Paul]Slice literals
スライスのリテラルは長さのない配列リテラルのようなものです
配列リテラル : [3]bool{true, true, false}
スライス : []bool{true, true, false}Slice defaults
スライスするときは、それらの既定値を代わりに使用することで上限または下限を省略することができます
これらのスライス式は等価です:a[0:10] a[:10] a[0:] a[:] s := []int{2, 3, 5, 7, 11, 13} s = s[1:4] //[3 5 7] s = s[:2] //[3 5] s = s[1:] //[5]Slice length and capacity
スライスの長さは、それに含まれる要素の数です。
スライスの容量は、スライスの最初の要素から数えて、元となる配列の要素数です。
スライス s の長さと容量は len(s) と cap(s) という式を使用して得ることができます。fmt.Printf("len=%d cap=%d %v\n", len(s), cap(s), s) s := []int{2, 3, 5, 7, 11, 13} s = s[:0] len=0 cap=6 [] // Slice the slice to give it zero length. s = s[:4] len=4 cap=6 [2 3 5 7] // Extend its length. s = s[2:] len=2 cap=4 [5 7] // Drop its first two values.Nil slices
スライスのゼロ値は nil です
var s []int //s == nilCreating a slice with make
スライスは、組み込みの make 関数を使用して作成することができます。 これは、動的サイズの配列を作成する方法
a := make([]int, 5) //a len=5 cap=5 [0 0 0 0 0] b := make([]int, 0, 5) //b len=0 cap=5 [] c := b[:2] //c len=2 cap=5 [0 0] d := c[2:5] //d len=3 cap=3 [0 0 0]Slices of slices 二次元配列
スライスは、他のスライスを含む任意の型を含むことができます。
board := [][]string{ // Create a tic-tac-toe board. []string{"_", "_", "_"}, []string{"_", "_", "_"}, []string{"_", "_", "_"}, } board[0][0] = "X" // The players take turns.
- 投稿日:2019-04-05T14:55:03+09:00
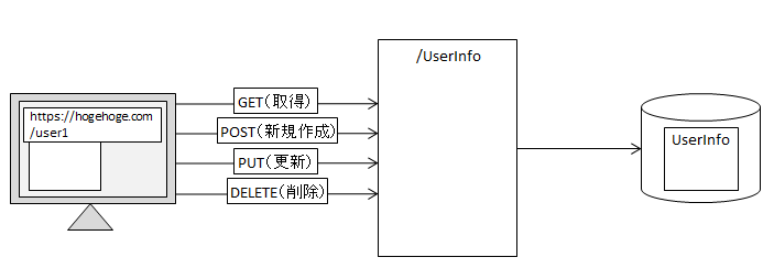
APIサービス(Lambda)REST
APIバックエンドサービスの例としてTODO管理アプリケーションのAPIバックエンドサービスをAPIGateway、Lambda、AmazonDynamoDBを使用して作成する
REST API
HTTPのメソッド action ANY すべてのメソッドをサポートする DELETE リソースの削除 GET リソースの取得 HEAD リソースのヘッダ (メタデータの取得) OPTIONS リソースがサポートしているメソッドの取得 PATCH リソースの部分的な変更 POST 子リソースの作成, リソースへのデータ追加, その他処理 冪等な操作 PUT リソースの作成、リソースの更新, リソースの削除
REST APIの設計
CloudFormationのテンプレート(json)Lambdaはnode.js4.3でデプロイできた
APIGatewayとは
ロットリン
マッピングテンプレート
モックアップ機能
バックエンドよりも先にクライアントの開発を行いたいときに、固定値を返す簡単なAPIを実装することができる
100万回のリクエストで3.5ドル
最大数十万の同時API呼び出しを受け付け処理するtodoIdリソースは{todoId}のようにしパラメータとし扱えるようにする
APIエンドポイント https://hogehoge-api.us-east-1.amazonaws.com/prod/v1/todosRESTリクエスト
#list_todos curl https://hogehoge/prod/v1/todos #get_todo curl https://hogehoge/prod/v1/todos/(todoId) #update-todo curl -X PUT -d '{"finishedAt":20}' -H Content-Type:application/json https://hogehoge/prod/v1/todos/(todoId) #delete_todo curl -X DELETE https://(todoId) #update-todo/prod/v1/(todoId) #put_list curl -X POST -d '{"title":"text"}' -H Content-Type:application/json https://(todoId)/prod/v1/todos認証
主にサーバ間での認証などを想定した認証方式であらかじめ生成したAPIキーをリクエストヘッダー(x-api-key)に含めてアクセスした場合のみ、アクセス許可する
-H x-api-key:
[注意]EC2でのリクエストは応答したがブラウザからは認証されずにリクエストを処理してもらえなかった設定方法
・メソッドごとにAPIKeyRequiredを有効化し、再デプロイ
・APIKeyを作成する
UsagePlansでキーの使用プランを作成する(どのキーをしようするか、何度一日にキーの使用を許可するか(クォータ)、1秒あたりにリクエスト数(レート)、短期的な応答(バースト))
(リソース,メソッドごとにスロットリングができるため、会員のランクごとにサービスの差別化できる)クォータリミットのエラー
{"message":"Limit Exceeded"}
認証のないメソッドを呼び出したときのエラー
{"message":"Forbidden"}curl https://(API endpoint) /( todoId) -H x-api-key:(API key)設計指針ポイント
PUT
更新成功の場合 → 204 No Content
クライアントにとって思い通りの結果になったということなので、中身は重要ではなく204で十分
DELETE
成功時 → 204 No Content
リソースがないので204が最適
失敗した時
4xxは通知することでクライアントまたはユーザが反応できる可能性があるときに利用する
トークンバケットモデル各Lambda関数のプログラム
Lambdaのhandlerのeventオブジェクトの中身は、APIGatewayの統合リクエストのマッピングテンプレートで設定したものが渡される
"todoId":"$input.params('todoId')" = event.todoIdcurlコマンド
curl -I https://(APIEndpoint)/prod/v1/todos/(todoId) -H x-api-key:hogehogePUT
curl -X PUT –d
--data (省略形-d) POSTで送信するデータを記述
application/json
{"title":"$input.params('title')"}
--header (省略-H) リクエストヘッダを指定するその他
0からREST APIについて調べてみた
RESTful API(REST API)( REpresentational State Transfer)とは、
Webシステムを外部から利用するためのプログラムの呼び出し規約(API)の種類の一つ
RESTful API(REST API)とは、Webシステムを外部から利用するためのプログラムの呼び出し規約(API)の種類の一つ
また、リソースの操作はHTTPメソッドによって指定(取得ならGETメソッド、書き込みならPOSTメソッド)され、結果はXMLやHTML、JSONなどで返される。また、処理結果はHTTPステータスコードで通知するという原則が含まれることもある
REST APIについて見出し
強調
リンク
```
- 投稿日:2019-04-05T13:54:26+09:00
存在しない属性名を使ってdynamoにupdateをかけたい時
DynaoDBのMap属性をもつアイテムに対して更新をかけたいが、その際に存在していなキー名を追加して更新したい場合の覚書。
let obj = { [departmentCode]:{ [userId]:role } } let putParams = { TableName: tenantTable, Key: { tenantId : tenantId }, UpdateExpression: 'set #u = :r', ExpressionAttributeNames: { '#u' : 'users', }, ExpressionAttributeValues: { ':r' : obj } }; let putData = await docClient.update(putParams).promise();簡単にいうと、存在しない属性名を使って更新をかけることはできない。
(ValidationException: The document path provided in the update expression is invalid for update
)
なので、確実に存在している属性名までをExpressionAttributeNamesにかき、その値としてオブジェクトを渡す。
オブジェクトはあくまで値をして渡されるだけなので、そのままの形で登録される。結果的にMap型として保存される。
- 投稿日:2019-04-05T13:19:05+09:00
AWS EC2 + nginx + PHP7.2 + Laravel で環境構築
LaravelをAWSで使うことになった
LaravelをAWSで動かせるかを確認しておけとのこと。
備忘録的なことも含めてメモしておく。今回の環境
- AWS EC2
- nginx 1.12
- PHP 7.2
- Laravel 5.5
AWSにSSH接続
EC2でインスタンスを生成します。
今回選んだサーバーの種類
Amazon Linux 2 AMI (HVM), SSD Volume TypeSSH接続する!
$ ssh -i ~/.ssh/[SHHキー.pem] ec2-user@[ドメイン名かIPアドレス(パブリック DNS (IPv4))]インスタンスの再起動でIPアドレスが変わるので気をつけよう。固定したい場合にはElastic IPで出来るらしいけどまたの機会に
enginxのインストール
結論から言うとyumでのインストールを試みたが...
amazon-linux-extras使えだと。
amazon-linux-extrasはあらかじめAWSでインストールされているソフトウェアを起動させることで簡単に利用できるシステム。以下のようなソフトが用意されている。$ amazon-linux-extras 0 ansible2 available [ =2.4.2 =2.4.6 ] 2 httpd_modules available [ =1.0 ] 3 memcached1.5 available [ =1.5.1 ] 4 nginx1.12 available [ =1.12.2 ] 5 postgresql9.6 available [ =9.6.6 =9.6.8 ] 6 postgresql10 available [ =10 ] 8 redis4.0 available [ =4.0.5 =4.0.10 ] 9 R3.4 available [ =3.4.3 ] 10 rust1 available \ [ =1.22.1 =1.26.0 =1.26.1 =1.27.2 =1.31.0 ] 11 vim available [ =8.0 ] 13 ruby2.4 available [ =2.4.2 =2.4.4 ] 15 php7.2 available \ [ =7.2.0 =7.2.4 =7.2.5 =7.2.8 =7.2.11 =7.2.13 =7.2.14 ] 16 php7.1 available [ =7.1.22 =7.1.25 ] 17 lamp-mariadb10.2-php7.2 available \ [ =10.2.10_7.2.0 =10.2.10_7.2.4 =10.2.10_7.2.5 =10.2.10_7.2.8 =10.2.10_7.2.11 =10.2.10_7.2.13 =10.2.10_7.2.14 ] 18 libreoffice available [ =5.0.6.2_15 =5.3.6.1 ] 19 gimp available [ =2.8.22 ] 20 docker=latest enabled \ [ =17.12.1 =18.03.1 =18.06.1 ] 21 mate-desktop1.x available [ =1.19.0 =1.20.0 ] 22 GraphicsMagick1.3 available [ =1.3.29 ] 23 tomcat8.5 available \ [ =8.5.31 =8.5.32 =8.5.38 ] 24 epel available [ =7.11 ] 25 testing available [ =1.0 ] 26 ecs available [ =stable ] 27 corretto8 available [ =1.8.0_192 =1.8.0_202 ] 28 firecracker available [ =0.11 ] 29 golang1.11 available [ =1.11.3 ] 30 squid4 available [ =4 ] 31 php7.3 available [ =7.3.2 ] 32 lustre2.10 available [ =2.10.5 ]amazon-linux-extrasを使っていく☆
$ sudo amazon-linux-extras install nginx1.12PHPのインストール
同様にamazon-linux-extrasでPHPをインストールしていく☆
15 php7.2 available [ =7.2.0 =7.2.4 =7.2.5 =7.2.8 =7.2.11 =7.2.13 =7.2.14 ] 16 php7.1 available [ =7.1.22 =7.1.25 ] 31 php7.3 available [ =7.3.2 ]3種類あった。今回は7.2バージョンを選択。
$ sudo amazon-linux-extras install php7.2まずはphpinfo()が動いているか確かめよう
ディレクトリを作ってコードを書く。phpならなんでもいい。
で、やること3つHTTPトラフィックの許可
AWS EC2の使っているインスタンスのセキュリティグループを探す
↓
下の方にあるタブからインバウンドを探す
↓
ブラウザから今回はアクセスできるようにするためHTTPを追加
[ 編集 → ルールの追加 → HTTPを選んで決定(他の設定はとりあえず放置で) ]nginxのドキュメントルート設定
vi /etc/nginx/nginx.confで中身を編集/etc/nginx/nginx.confserver { listen 80 default_server; listen [::]:80 default_server; server_name _; root /; ##ここを編集好きな場所にIPでアクセスした時に参照するディレクトリーを設定
今回はルートディレクトリにします。nginxとphp-fpmの開始
nginxの設定を変えたので再起動。php-fpmも再起動しとく
起動してなかったら起動する。$ service nginx restart(start) もしくは $ systemctl restart(start) nginx $ service php-fpm restart(start) もしくは $ systemctl restart(start) php-fpm 動いているかの確認には $ service nginx status もしくは $ systemctl status nginxIP[xx.xx.xxx]/phpinfoのパス
ex)123.123.1234/var/www/phpinfo/info.php にアクセス
しっかり表示されたらlaravelのインストールに移っていく☆composerのインストール
PHPのライブラリ管理のためのcomposerをインストールする。
$ curl -sS https://getcomposer.org/installer | php All settings correct for using Composer Downloading... Composer (version 1.8.4) successfully installed to: //composer.phar Use it: php composer.pharこのままだとカレントディレクトリにcomposer.pharファイルがあるのでパスが通っている場所に移動
$ echo $PATHパスの通っているところを確認
通っているところにcomposerと言うファイル名で移動
$ mv composer.phar /usr/bin/composerディレクトリーに入れてそちらにパスを通す方法でもおk。
binの中にcomposerディレクトリは必要ないのでくれぐれも作らないように起動確認
$ composer ______ / ____/___ ____ ___ ____ ____ ________ _____ / / / __ \/ __ `__ \/ __ \/ __ \/ ___/ _ \/ ___/ / /___/ /_/ / / / / / / /_/ / /_/ (__ ) __/ / \____/\____/_/ /_/ /_/ .___/\____/____/\___/_/ /_/ Composer version 1.8.4 2019-02-11 10:52:10laravelのインストール
インストールする時にmb-stringとmb-pdoが欲しい
よく分からないから先人に習ってインストール
もし余計なものが入ってるのがわかる人がいたら教えて欲しいっす!$ yum install --enablerepo=remi,remi-php70 php php-devel php-mbstring php-pdo php-gdlaravelのプロジェクトを置くディレクトリに移動
今回はsiteと言う名前のlaravelプロジェクトを作る
$ composer create-project --prefer-dist laravel/laravel site "5.5.*"多分出来てる。welcomeページ表示までのいくつかの設定を最後にする。
laravelの初期設定
laravelプロジェクト内のComposerのアップデート
php-mbstring, php-pdo, php-xmlが必要。よく分からんから先人に習う
yum install --enablerepo=remi,remi-php70 php php-devel php-mbstring php-pdo php-gd php-xmlで、アップデート
$ composer update **** **** Package manifest generated successfully. # これでてたらおkAPP_KEYの設定
.envファイルのセキュリティの為のKEYを入れてあげる。composerでインストールするとあらかじめ入っているらしいが、一応やって置くに越したことはない。
$ php artisan key:generate Application key [base64:sJQq984xxxxxxxx7PnJmiaRCBn0N5GwNtbU0lcq8Yc=] set successfully.laravelのコマンドartisanが動くかチェック
$ php artisan route Command "route" is not defined. Did you mean one of these? route:cache route:clear route:listartisanが動けばおk
nginxからの権限を許可する
storage, bootstrap/catch の権限を許可する。
$ chmod -R 777 storage/ $ chmod -R 777 bootstrap/catch/-Rはディレクトリ配下全てのオプション。
これを忘れて苦しんだので忘れないように...アクセス
ルートにlaravelのpublicを設定してあればIPアドレスにアクセスすればおk!
無事滞りなく行けばこんなページが表示されるはず!
終わりに
結構環境構築で引っかかったところが多かったので同じような人がいれば参考にして欲しい。
次回はlaravel5.5の記事が少ないと感じたので、laravelについて何か書きたいおわり

- 投稿日:2019-04-05T13:03:24+09:00
`node-lambda` で素朴にLambdaを使ってみる
node-lambdaで素朴にLambdaを使ってみる概要
AWS Lambdaを利用して何かをやりたい場合は以下のいずれかを使うのがイマドキでしょうか
そんな時代ではありますが node-lambda の紹介をします
名前の通りAWS LmabdaをNode.jsで使うときに利用します。(Node.js以外の言語には対応していません)
素朴なツールで出来ることは少ないですが、お手軽にLambdaを使ってみる分にはよいツールではないかと思いますinstall
% npm i -g node-lambdaglobalにinstallしたことにして話を進めます
初期化
適当な作業ディレクトリを作成し、そこに移動したのち
setupを実行します% node-lambda setup Running setup. /path/.env file successfully created /path/event.json file successfully created /path/deploy.env file successfully created /path/context.json file successfully created /path/event_sources.json file successfully created Setup done. Edit the .env, deploy.env, context.json, event_sources.json and event.json files as needed.%
node-lambdaが利用するファイルがもりもり作成されました。
取り急ぎ使うのはevent.jsonと.envです
.env
- Lambdaにdeployするときに利用。RoleやLambdaのメモリ設定など
deploy.env
- 名前が紛らわしいのですが、Lambdaに設定する環境変数を設定するためのファイルです
event_sources.json
- S3のイベントをトリガーにLambdaを実行したいときなどに設定します
event.json
- ローカルで実行するときに利用する
context.json
- ローカルで実行するときに利用する
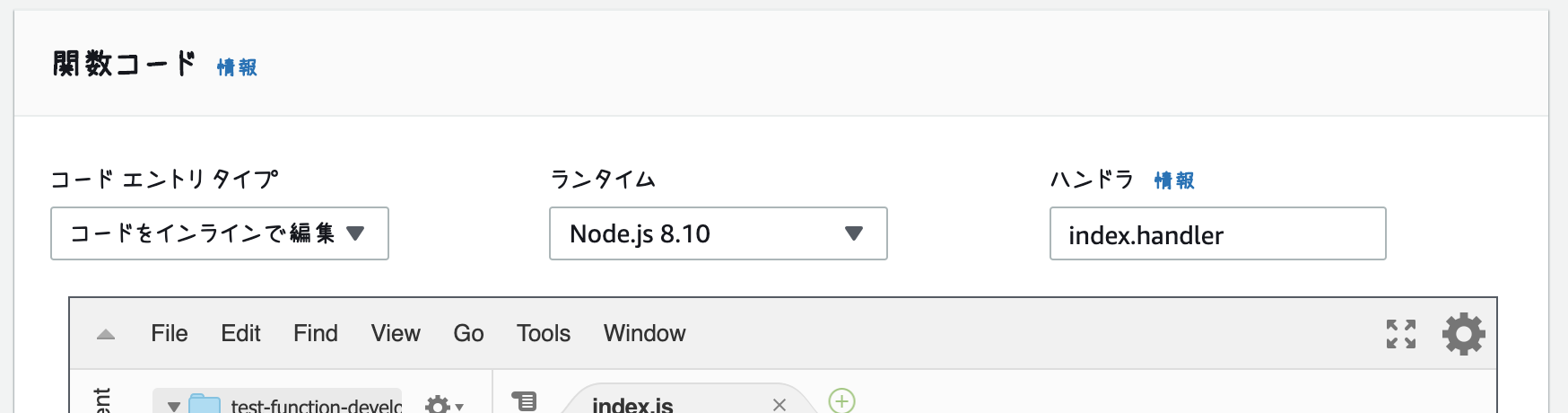
Lambdaのハンドラ例
以下のファイルを例に進めます
index.jsexports.handler = async (event, context) => { console.log('Running index.handler') console.log('==================================') console.log('event', event) console.log('==================================') console.log('Stopping index.handler') return true }ローカルで実行してみる
runを実行します。
デフォルトではindex.jsにあるhandlerという関数を実行します% node-lambda run Running index.handler ================================== event { key: 'value', key2: 'value2', other_key: 'other_value' } ================================== Stopping index.handler Result: true上述のindex.jsの内容が実行されました
引数の
eventに値が渡っていることに気付くかと思います
デフォルトではsetupで作成されたevent.jsonを引数のeventに渡します
setupで作成されるevent.jsonは以下の通りです% cat ./event.json { "key": "value", "key2": "value2", "other_key": "other_value" }設定
ローカルで動作確認できたらLambdaにdeployします
そのための設定を.envにします
~/.aws/credentialsにアクセスキーなどの設定がしてあれば以下の設定くらいで十分です
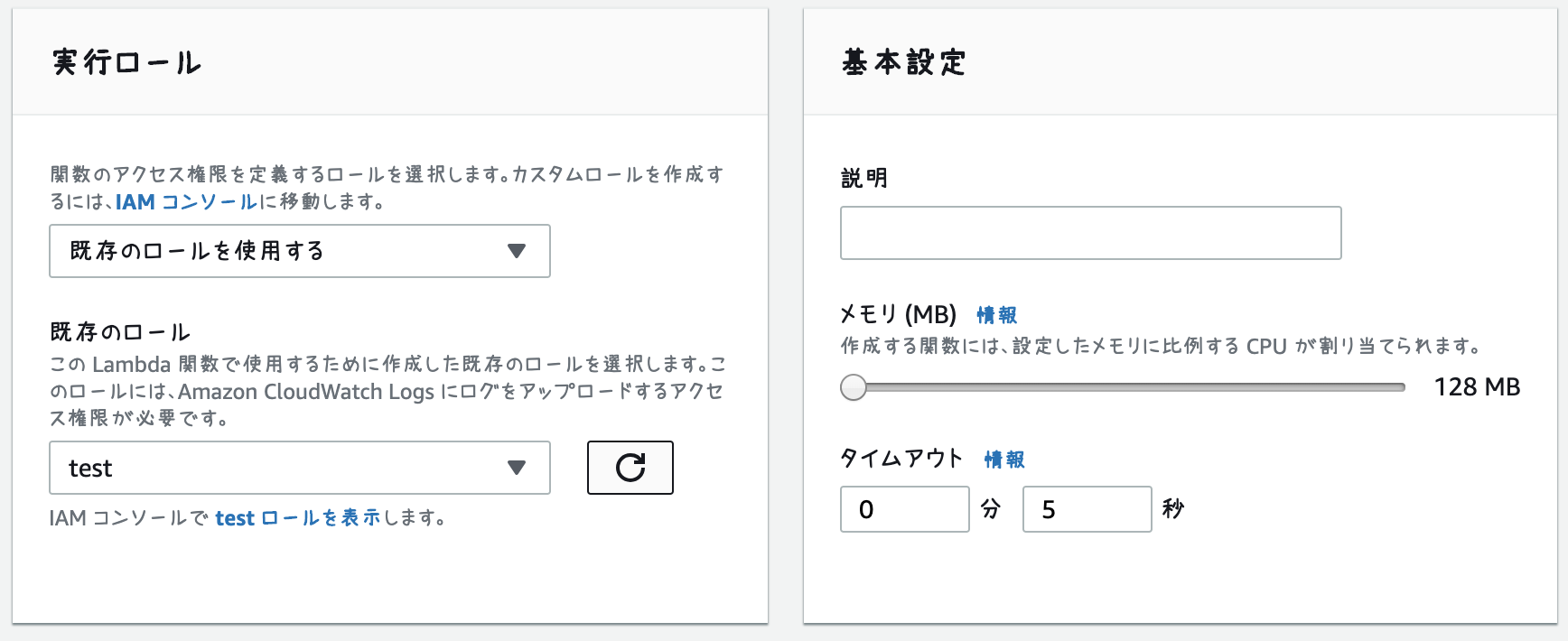
変数名から何の設定かは想像できると思いますので詳細は割愛します.envAWS_ENVIRONMENT=development AWS_ROLE_ARN=arn:aws:iam::xxx:role/test AWS_REGION=us-east-1 AWS_FUNCTION_NAME=test-function AWS_HANDLER=index.handler AWS_MEMORY_SIZE=128 AWS_TIMEOUT=5 AWS_RUNTIME=nodejs8.10deploy
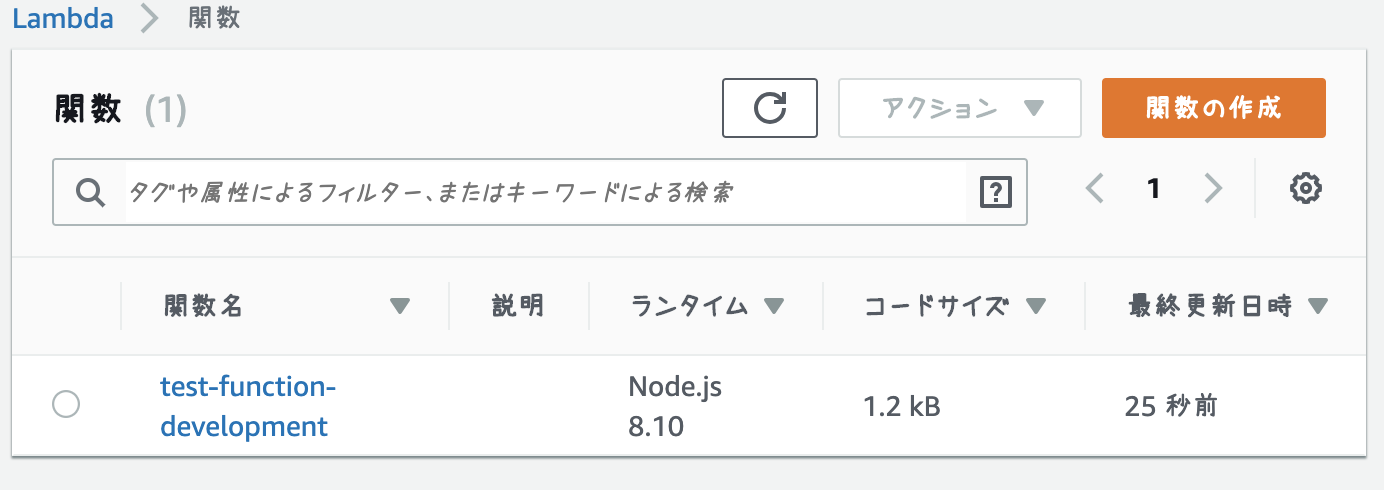
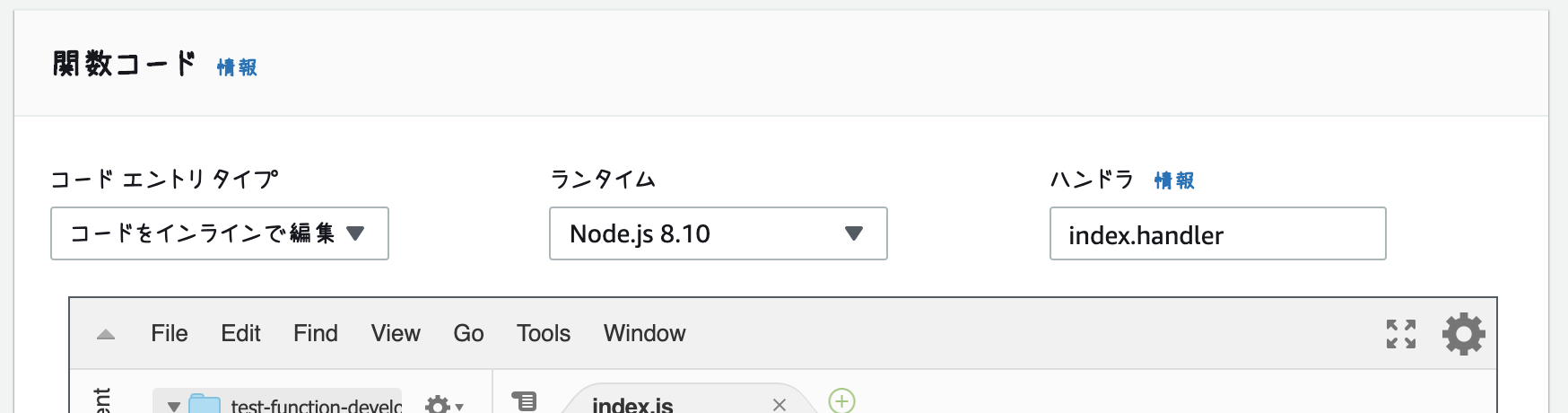
deployでLambdaにdeployします% node-lambda deploy => Moving files to temporary directory => Running npm install --production => Zipping deployment package => Zipping repo. This might take up to 30 seconds => Reading zip file to memory => Reading event source file to memory => Uploading zip file to AWS Lambda us-east-1 with parameters: { FunctionName: 'test-function-development', Code: { ZipFile: <Buffer xxx more bytes> }, Handler: 'index.handler', Role: 'arn:aws:iam::xxx:role/test', Runtime: 'nodejs8.10', Description: '', MemorySize: '128', Timeout: '5', Publish: false, VpcConfig: { SubnetIds: [], SecurityGroupIds: [] }, Environment: { Variables: null }, KMSKeyArn: '', DeadLetterConfig: { TargetArn: null }, TracingConfig: { Mode: null } } => Done uploading. Results follow: { FunctionName: 'test-function-development', FunctionArn: 'arn:aws:lambda:us-east-1:xxx:function:test-function-development', Runtime: 'nodejs8.10', Role: 'arn:aws:iam::xxx:role/test', Handler: 'index.handler', CodeSize: n, Description: '', Timeout: 5, MemorySize: 128, LastModified: '2019-04-04T09:30:17.015+0000', CodeSha256: 'zzz', Version: '$LATEST', VpcConfig: { SubnetIds: [], SecurityGroupIds: [], VpcId: '' }, KMSKeyArn: null, TracingConfig: { Mode: 'PassThrough' }, MasterArn: null, RevisionId: 'yyy' } => All tasks done. Results follow: {}以上でdeployは完了です。(
index.jsを変更した後ももう一度deployすればLambdaの更新が行えます)Webコンソールで確認すると以下の通りです
- 一覧画面の様子
- 関数詳細の設定内容の一部
Lambdaをinvoke
素朴なツールだけあってLambdaをinvokeする機能は提供されていません。
READMEにもある通りawsコマンドでinvokeするか、Webコンソールで実行して動作確認しましょうまとめ
素朴なツール
node-lambdaでAWS Lambdaを使ってみました
イマドキなツールと比べると見劣りする部分も多いですが、内部でCloudFormationを使っているということもなくお手軽にLambdaをはじめるには十分だと思います
また素朴なツールなのでコードを読むとシンプルにAPIを使ってLambdaにdeployしたり、トリガーとなるイベントの紐付け方などが理解しやすいかもしれません
- 投稿日:2019-04-05T12:48:30+09:00
AmazonLinux コマンド
自分の覚書のために多数の方を参考にさせていただいています。
AmazoLinuxはRedHat系のディストリービュージョンになる
CentOSやRHELに近い
Amazon Linuxの特徴とCentOSとの違い まとめコマンド
ディストリービュージョンの確認cat /etc/system-releaseyumでインストール済みのパッケージを表示する
yum list installed | more //テキストを1画面ずつ止めながら表示する sudo find / -name hoge //ファイル検索yumコマンドで既にインストールしたソフトを調べる
コマンド――実行コマンドのフルパスを表示する$ which echo --> /bin/echoシェルのコマンドの解釈を調べることができる
$ sh -x -c "find . -name "cloudwatch"" + find . -name cloudwatch ./cloudwatchプロセスを強制終了する
$ ps ax | grep scan 7858 pts/3 Tl 0:00 ./scan 7986 pts/2 S+ 0:00 grep --color=auto scan $ kill 7858プロセス管理
ps aux //システムに走っている全てのプロセスを表示する ps auxf //プロセススリーを表示してくれる-a コマンドラインの引数を表示する
-p ユーザIDを表示する
-u ユーザIDを表示する
-c 同じ内容のツリーをまとめないで表示するpstree -apuc //pstreeコマンド プロセスの親子関係が把握しやすいパイプライン処理・標準入出力によるデータ処理
「|」(縦棒)はパイプと呼び、あるコマンドの出力を別のプログラムの入力に引き渡す操作./request | ./scanteeコマンドの使い方
teeコマンドについて詳しくまとめました 【Linuxコマンド集ルートディレクトリからファイル名で検索する
find / -type f -name "*201904*"find *.dat | tee find.txt //findコマンドの実行内容が画面出力され、ファイルに上書きされるオプション -a(オプション--append
catコマンドでファイルに書き込み
catコマンドでファイルに書き込みをする
ファイルをまるごと書き換えるcat <<EOF > ファイル 書き込む内容 EOFファイルの末尾に追加して書き込む
cat <<EOF >> ファイル 付け足す内容 EOFListen portの確認
lsofコマンドで覚えておきたい使い方9個sudo lsof -i -P //プロセスが使用しているポートを確認するsudo ss -ltunp //接続待ちをしているソケットを確認する初期解析方法
サービスを確認するコマンドはたくさんあるtopコマンド リアルタイムにプロセスの状態を表示
top //システム全体の負荷、プロセス、CPU、メモリ、スワップの統計情報メモリ上に常駐して要求に応じてサービスを提供する(各種システムサービスやサーバープログラム)等のデーモンが起動するためのファイルが格納されている
(起動スクリプトと呼ばれている)ls /etc/init.dchkconfigネットワーク型ファイアウォール
iptables --list環境変数の設定
一覧取得
sudo printenv変数の値変更
export HOSTNAME="ip-3.91.104.214"特定の環境編巣の値を取得する
echo $HOSTNAME~/.bash_profileに環境変数を設定しておくとログインするときに関設定してくれる
sudo vi ~/.bash_profile export HOSTNAME="ip-3.91.104.214"コピペコマンド
cat <<EOF >> ~/.bash_profile export HOSTNAME="ip-3.91.104.214" EOFtailコマンドについて詳しくまとめました 【Linuxコマンド集】
tail -n 2 -fv /var/log/messages //ファイルの最終2行から表示を行い、最終行を追跡するyumの使い方
yum clean all yum list installed sudo yum remove perl-CGI.noarch //xxx packages excluded due to repository priority protections とエラーが出たときに使うと有効的 yum provides perl-URI sudo yum install -y perl-URI-1.60-9.8.amzn1.noarch例
yum provides *Compress sudo yum install -y perl-Compress-Raw-Zlib-2.061-4.1.amzn1.x86_64 sudo mv /usr/lib64/perl5/vendor_perl/Compress/Raw/Zlib.pm /usr/lib64/perl5/vendor_perl/Compress/Zlib.pm見出し
強調
リンク
```
- 投稿日:2019-04-05T11:34:42+09:00
AWS MediaLiveの「Input Loss Action」に要注意!
はじめに
MediaLiveとMediaPackageの構成で、ライブ配信環境を構築していたところ、
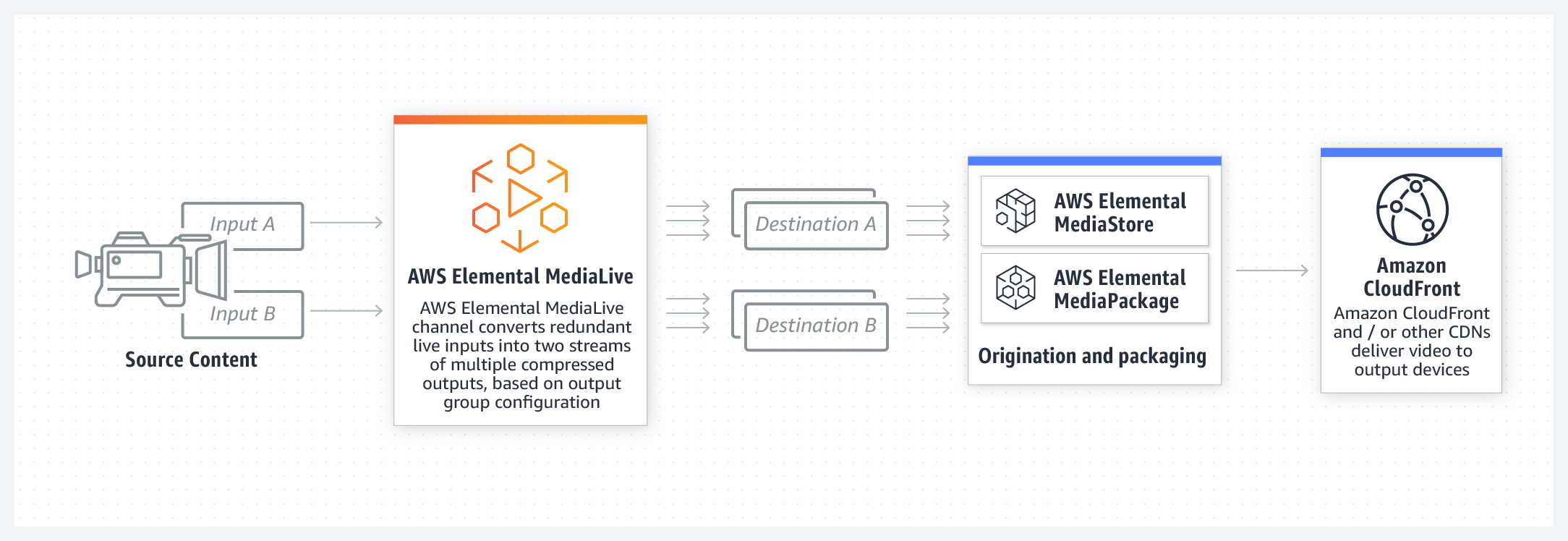
MediaPackageの入力冗長が上手く切り替わらないという問題にハマったので、解決策をここで共有します。構成
Source×2(RTMP) - MediaLive(HLS) - MediaPackage - CloudFront
(出典:https://aws.amazon.com/jp/medialive/)Input Loss Action
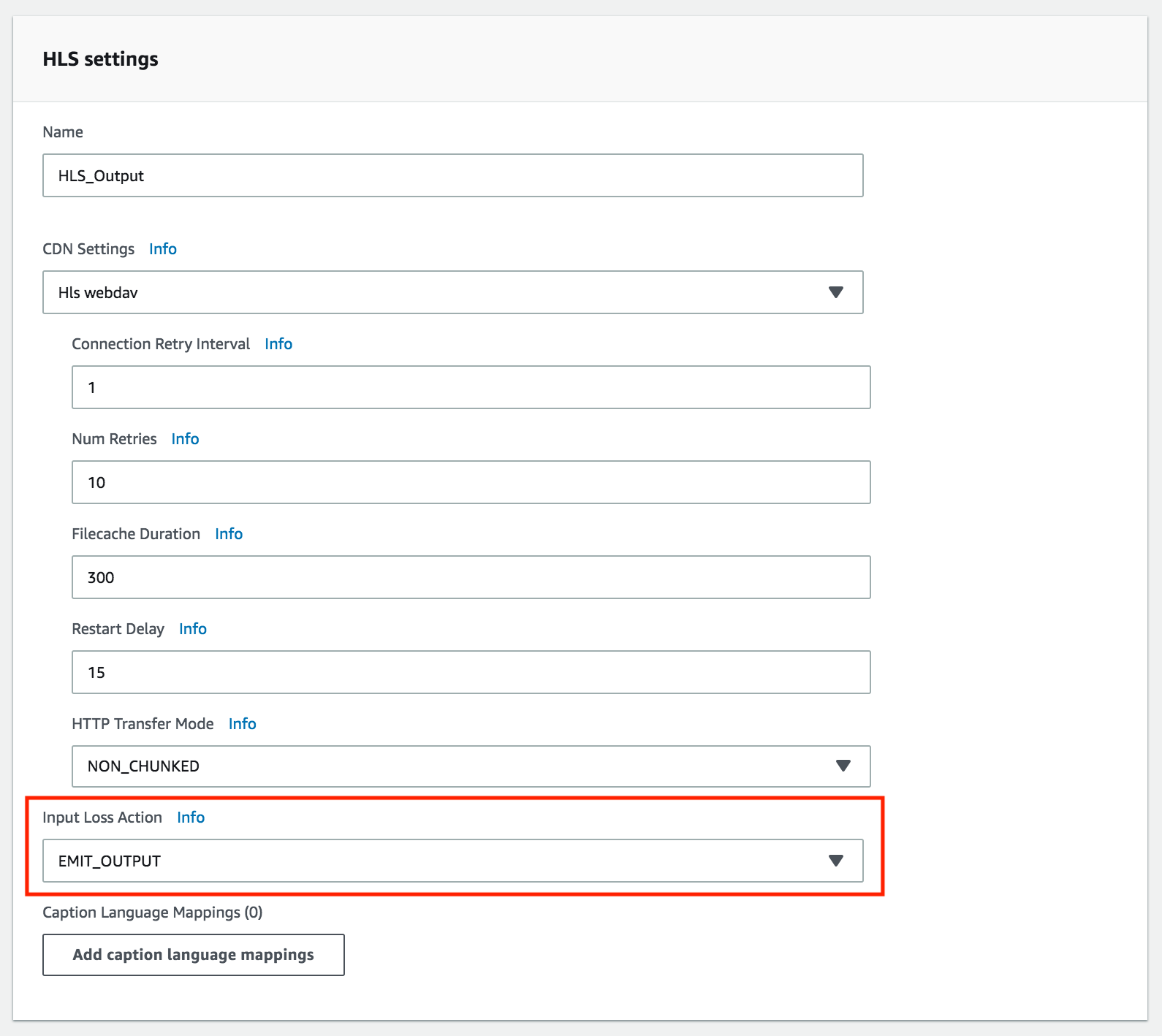
MedialiveのHLSアウトプット設定の中に「Input Loss Action」という項目があります。
今回の主役(というか黒幕?)は、このパラメータです。Input Loss Actionは、文字通り映像入力が喪失したときの挙動を設定するパラメータです。
現在は下記の2つの設定値のうち、どちらかを選ぶ仕様になっています。
- EMIT_OUTPUT:映像入力が止まっても、黒い画面をアウトプットに流し続ける。
- PAUSE_OUTPUT:映像入力が止まると、アウトプットへの送信を停止する。
※ちなみに、DEFAULTでは「EMIT_OUTPUT」となっています。
このパラメータについて、AWSドキュメントには下記の記載があります。
Fields for the HLS Group - HLS Group Destinations - HLS SettingsIf you're sending output to AWS Elemental MediaPackage, set this field to PAUSE_OUTPUT. In this way, if MediaLive stops producing output on one pipeline, MediaPackage will detect the lack of content on its current input and will switch to the other input. Content loss will be minimized. (If you set this field to EMIT_OUTPUT, MediaLive sends filler frames to MediaPackage. MediaPackage doesn't consider filler frames to be lost content and therefore won't switch to its other input.)
ポイントを要約してみます。
- MediaPackageをOutputに指定している場合は「PAUSE_OUTPUT」を設定するように。
- MediaLiveの片方のPipelineが止まった場合、MediaPackageはそれを検知してもう一方のInputに切り替える。
- 「EMIT_OUTPUT」を設定すると、(Pipeline停止時に)MediaLiveからMediaPackageにfiller frameを送る。
- MediaPackageはfiller frameを"コンテンツの喪失"とはみなさないため、他のInputに切り替えない。
つまり、
「MediaLiveのInputが止まった場合にもう片方のInputに切り替えたかったら、PAUSE_OUTPUTに設定してね!」
ということだと僕は解釈しました。
検証
2つの設定値でどのような挙動の違いがあるか検証してみます。
MediaLiveのInputにSourceを2本流し込みます。1. EMIT_OUTPUTの場合
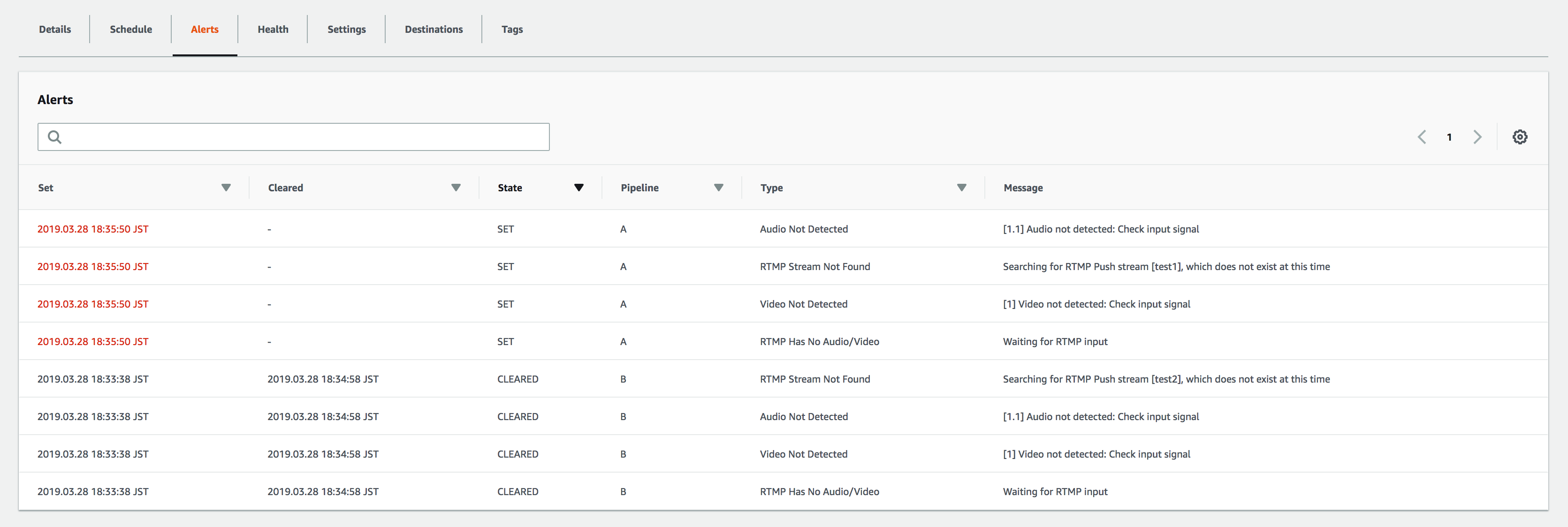
Input1の入力を止めると、アラートが上がりました。
※Input1(=PipelineA)でストリーム入力が検知できていないことを示しています。
視聴画面では、動画ファイルの映像から黒い画面に変わり、動画が再生され続けています。
しばらくそのままにしていても、Input2には切り替わりません。
2. PAUSE_OUTPUTの場合
input1を停止させると、ストリーム入力が検知しないのは先程と同様。
ただ、視聴画面は先程と違って黒い画面にはならずに、Input2に送った動画に切り替わりました。
おわりに
MediaLiveとMediaPackageの構成を組む際に、注意が必要なパラメータを紹介しました。
設定値1つだけで、再生時の挙動が大きく変わってしまうのは怖いですね…ポチポチと設定できてしまうAWSマネージドサービスだからこそ、
公式ドキュメントには目を通しておく必要があるという教訓を得ました。ということで、MediaLiveとMediaPackageを使用して冗長化させたい場合は、
「Input Loss Action」をPAUSE_OUTPUTにするのをお忘れなく!!参考
AWSドキュメント : 入力冗長の仕組み
AWSドキュメント : Fields for the HLS Group - HLS Group Destinations - HLS Settings
- 投稿日:2019-04-05T10:19:51+09:00
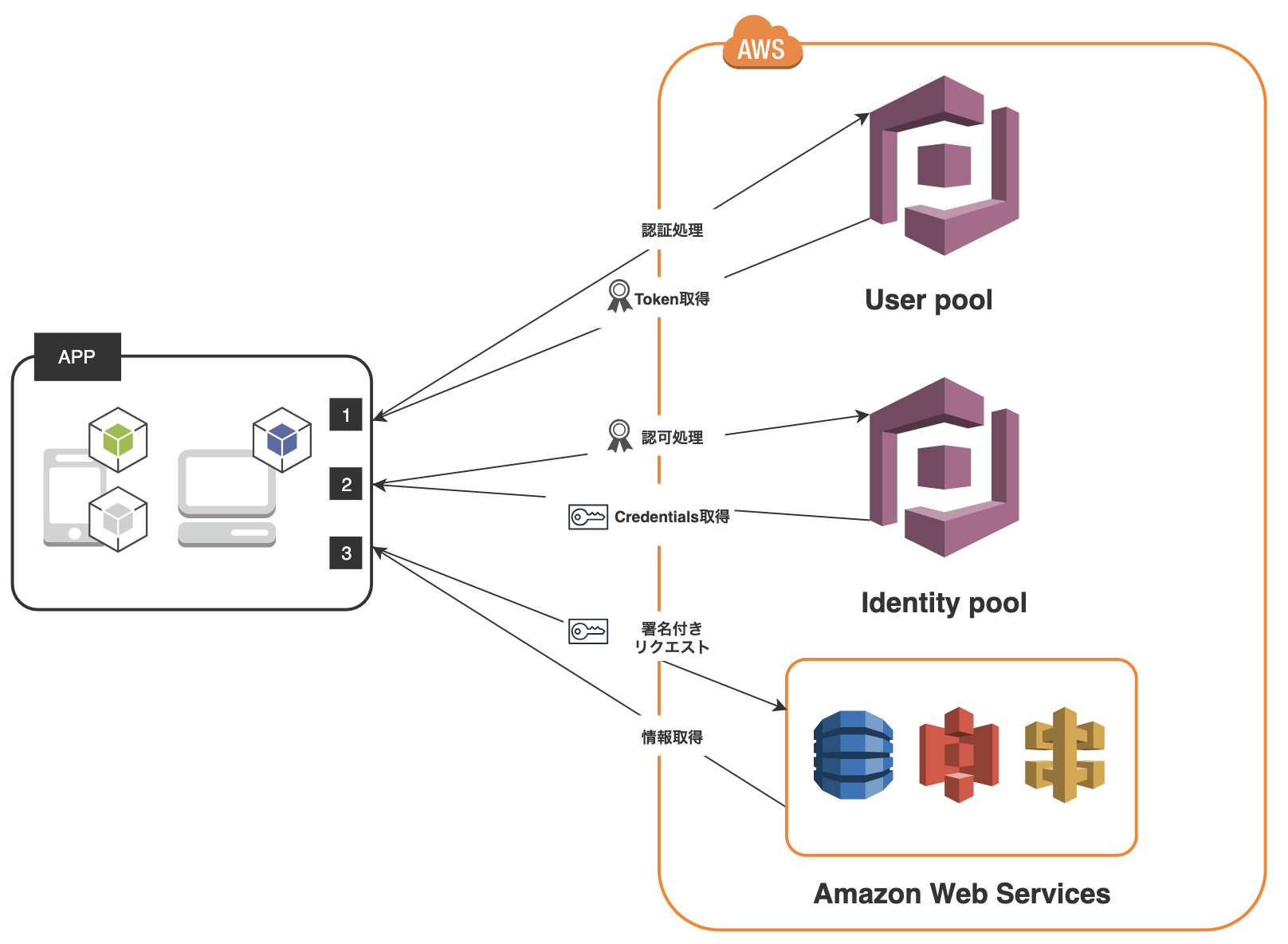
Amazon Cognito を利用した認証と認可の流れ - 概要の理解 編
概要
当記事は、Amazon Cognito を利用した認証と認可の流れを実装するうえで、自分が概要の理解に努めた記録を纏めたものになります。また、上記の図は 公式の説明図 を 自分が理解しやすいように加筆、修正をさせていただいた ものになります。
Amazon Cognito の機能
Amazon Cognito は大きく分けると User pool, Identity pool, Sync の3つの機能から構成されています。 Sync については、当記事の認証と認可の流れでは利用しないため調査を行っていません。
User pool について
User pool は、ユーザーに関連する情報を格納し保持しつづける機能や、ユーザーのサインアップ、サインイン ( Google、Facebook、Amazon 経由などにも対応しています) 機能等を提供してくれています。「認証と認可の流れ」 では 認証 を担ってくれる機能だと理解しています。
参考資料
Identity pool について
Identity pool は、Credentials を生成してくれます。この Credentials の実体は、 Identity pool に設定された IAM Role を、AWS STS(Security Token Service) がユーザーのリクエスト毎に発行した IAM Role と同等の権限を持った一時的な認証情報 を指します。
Identity pool の AWS 公式ドキュメント中には 認可 という言葉は一度もでてこないのですが、これは IAM Role の役割を思い出すと合点がいきました。 IAM Role は、AWS のサービスなど認可されたエンティティに割り当てるために用意されたものです。つまり、それを払い出す Identity pool (厳密には AWS STS)は「認証と認可の流れ」では 認可 を担ってくれる機能になると理解しています。
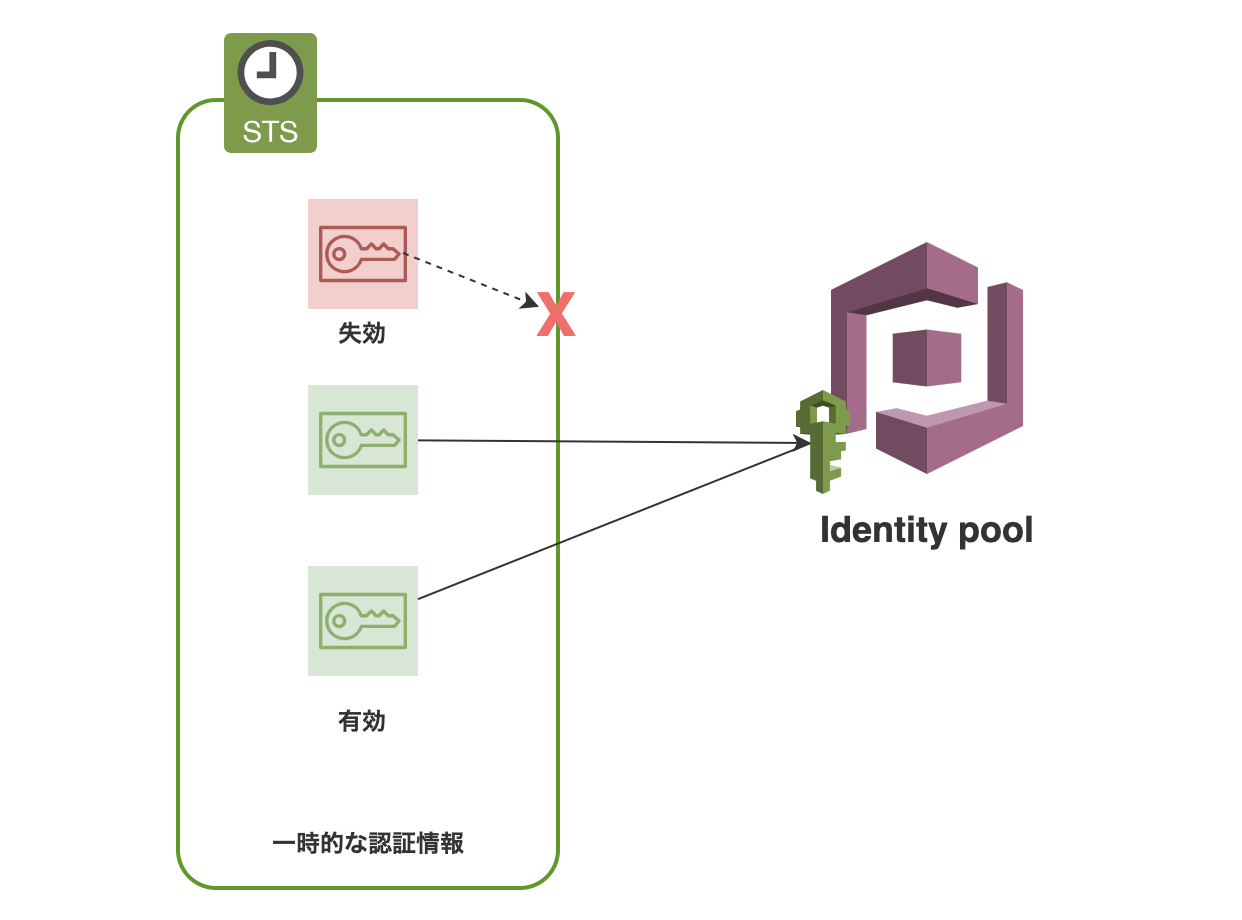
文章で纏めているだけでは理解するのが難しかったので、Identity pool で行われることに焦点をあて、下記の図を作成して理解に努めました。AWS 公式の図ではないので正確なものではありませんが結果として理解に繋がりました。
参考資料
- 公式ドキュメント - AWS Security Token Service
- 公式ドキュメント - Amazon Cognito ID プール
- クラスメソッド株式会社 - 都元様 - IAMロール徹底理解 〜 AssumeRoleの正体
処理の説明
1. 認証処理
User pool に対し認証処理を実行します。これは新規ユーザー情報のサインアップであったり、既存ユーザーの情報を用いたサインインにあたる処理になります。認証処理が成功すると、 User pool から下記のレスポンスが返却されます。
{ "AuthenticationResult": { "AccessToken": "string", "ExpiresIn": number, "IdToken": "string", "NewDeviceMetadata": { "DeviceGroupKey": "string", "DeviceKey": "string" }, "RefreshToken": "string", "TokenType": "string" }, "ChallengeName": "string", "ChallengeParameters": { "string" : "string" }, "Session": "string" }User pool から返却されたレスポンスには、以下の Token が含まれています。
IdToken
認証されたユーザーに関するクレーム(OIDC 標準クレーム)が含まれています。 主に Identity pool に対し AWS リソースに対する Credentials を要求する場合に用いられます。有効期限は、ユーザーが認証に成功してから 1 時間後に有効期限切れになります。失効した IdToken を利用することはできません。
AccessToken
IdToken 同様に、認証されたユーザーに関するクレーム(id情報をのぞく)が含まれています。主に User pool 内のユーザー属性を追加、変更、または削除する場合に利用します。有効期限は、ユーザーが認証に成功してから 1 時間後に有効期限切れになります。失効した AccessToken を利用することはできません。RefreshToken を用いて再発行するか認証を再試行する必要があります。
RefreshToken
新規 AccessToken, IdToken の取得時に利用します。この時、RefreshToken は再生成されません。RefreshToken が失効した場合は、再度、認証を試行する必要があります。 有効期限は、デフォルトではユーザーが認証に成功してから 30 日後に有効期限が切れます。RefreshToken の有効期限は 1 ~ 3650(日) の範囲で任意の値に設定可能です。
IdToken と AccessToken についての補足
IdToken, AccessToken は JWT(Json Web Tokens) 形式で格納されています。JWT は2者間でやりとりされる軽量なある主体に関するひと纏まりの情報で、情報のセットを JSON Object として文字列で表現して、情報に対するデジタル署名や MAC と暗号化の両方が可能になるというものです。
アプリケーションの外部で AccessToken と IdToken を利用する場合、JWT が悪意あるものによって変更されている可能性があることを前提にして 必ず Token を承認する前に Token の署名を確認し、改ざんが行われていないかを検証しましょう。
参考資料
- 公式ドキュメント - User pool Tokens の使用
- 公式ドキュメント - JSON Web Tokens の検証
- JSON Web Token (JWT) draft-ietf-oauth-json-web-token-11
2. 認可処理
認証処理で取得した Token 中に含まれる IdToken を利用して、AWS リソースに対する Credentials を要求します。このときに取得される Credentials の実体は、上記の 「Identity pool について」 の項でも纏めたとおり、Identity pool に設定された IAM Role と同等の権限を持った一時的な認証情報 を指します。
デフォルトでは、 Credentials が払い出されてから 1 時間後に有効期限が切れます。 Credentials の有効期限は 3,600 (1 時間) ~ 43,200(12 時間) 秒の範囲であれば、任意の値に IAM Role の設定から可能です。
認可処理に成功すると、Identity pool から下記のレスポンスが返却されます。この中に含まれる Credentials を利用して、署名付きのリクエストを作成します。
{ "Credentials": { "AccessKeyId": "string", "Expiration": number, "SecretKey": "string", "SessionToken": "string" }, "IdentityId": "string" }参考資料
3. 署名付きリクエスト
最後に、取得した Credentials を利用して署名付きリクエストを作成します。署名付きリクエストの作成手順は AWS 公式に記載されていますが、各種言語毎の署名付きリクエストを簡単に作成できるように AWS が SDK を用意してくれています。SDK が利用できない場合をのぞいて SDK を積極的に利用しましょう。
参考資料
次回
下記のいずれかになると思います。
- もう少し Amazon Cognito について理解を深める
- 大好きな PHP で Amazon Cognito を利用した認証と認可の流れを実装
- 投稿日:2019-04-05T06:41:20+09:00
Herokuに画像を投稿する方法
【前提】
・localでの画像投稿の設定はできてる
・画像投稿は gem carrierwave を使用しての投稿AWS S3を使う
Railsでの開発をしていてHerokuにアップしたところ、git上に入っている画像は表示されていた(背景画像とかロゴ画像とか)がサービス利用の中で画像を投稿したときの表示ができていなかったので調べたところAWS S3というサービスを使うらしい。
AWSは今まで使ったことがなかったが意外と簡単に設定ができた。アカウント登録
こちらから登録できます。
以下の記事をよんでAWSってこわ、、、っていうイメージがあったので私を含む初学者の方の取り扱いには気をつけてください、、、(私もこうなりかけた)
登録から1年間は利用無料らしいです。
初心者がAWSでミスって不正利用されて$6,000請求、泣きそうになったお話。 - Qiitaやることリスト
アカウント登録後に作るものとしては
AWS関連
- IAMグループ、ユーザー登録(ここでCSVファイルダウンロード←Macで普通に開けなくてもエディタで開けます)
- S3バケットの作成
Rails関連
- gemインストール("fog-aws")
- config/initializers/carrierwave.rb作成&設定記述
- uploadersフォルダのファイルに画像の格納場所記述AWS関連の設定はこちらの記事を読み進めて行けば確実にできます!
【Rails】S3へ『CarrierWave+fog』を使って画像アップロードする方法
【Rails5】AWS S3+CarrierWave+Fog::AWSを利用して画像アップロード機能を作成するRailsでの設定
gemインストール
Gemfile.gem 'fog-aws'$ bundle install作成&設定記述(keyはべた書き禁止!!!!!)
config/initializers/carrierwave.rbrequire 'carrierwave/storage/abstract' require 'carrierwave/storage/file' require 'carrierwave/storage/fog' if Rails.env.production? CarrierWave.configure do |config| config.fog_provider = 'fog/aws' config.fog_credentials = { provider: 'AWS', aws_access_key_id: 'IAM登録で取得したアクセスキー', aws_secret_access_key: 'IAM登録で取得したシークレットアクセスキー', region: 'ap-northeast-1' # S3バケット作成時に指定したリージョン。左記は東京を指す } config.fog_directory = 's3-rails-image-uploader' # 作成したS3バケット名 end # 日本語ファイル名の設定 CarrierWave::SanitizedFile.sanitize_regexp = /[^[:word:]\.\-\+]/ enduploaders/image_uploader.rb#fogに画像格納 if Rails.env.production? storage :fog else storage :file end簡単!!!?
- 投稿日:2019-04-05T02:11:48+09:00
HomebrewでAWS CLIを入れようとしてエラーした。
対象
macOS Mojave バージョン10.14.4
brewアップデート
brew updateAWS CLIインストール
brew install awscliここでこけました。
...(略) Error: An unexpected error occurred during the `brew link` step The formula built, but is not symlinked into /usr/local Permission denied @ dir_s_mkdir - /usr/local/Frameworks Error: Permission denied @ dir_s_mkdir - /usr/local/Frameworks
sudo mkdir /usr/local/Frameworks
sudo chown $(whoami):admin /usr/local/FrameworksErrorの処理はしたのでもう一度!
brew install awscli確認
% aws --version [2:10:48] aws-cli/1.16.130 Python/3.7.3 Darwin/18.5.0 botocore/1.12.120