- 投稿日:2019-04-05T22:17:39+09:00
MacOSにGraphQL環境を爆速で用意する方法
Prisamを使ってGraphQL環境をサクッと作って見ましょう。
今回データストアはMySQLを使います。前提
上記はすでにインストールされている前提で進めます。
1.Prismaのインストール
$ npm install -g prisma2. Prismaプロジェクトの作成
$ prisma init {プロジェクト名}今回は
test-appというプロジェクト名で進めます。実行すると対話式で進みます。
$ prisma init test-app ? Set up a new Prisma server or deploy to an existing server? (Use arrow keys) Set up a new Prisma server for local development (based on docker-compose): Use existing database Connect to existing database ❯ Create new database Set up a local database using Docker Or deploy to an existing Prisma server: Demo server Hosted demo environment incl. database (requires login) Use other server Manually provide endpoint of a running Prisma server
Create new databaseを選んで新しくデータベースを作成しましょう。? What kind of database do you want to deploy to? (Use arrow keys) ❯ MySQL MySQL compliant databases like MySQL or MariaDB PostgreSQL PostgreSQL database MongoDB Mongo Database
MySQLを選択します。? Select the programming language for the generated Prisma client (Use arrow keys) ❯ Prisma TypeScript Client Prisma Flow Client Prisma JavaScript Client Prisma Go Client Don't generate使用したいものを選んでください。
今回はPrisma TypeScript Clientを使用します。Next steps: 1. Open folder: cd test-app 2. Start your Prisma server: docker-compose up -d 3. Deploy your Prisma service: prisma deploy 4. Read more about Prisma server: http://bit.ly/prisma-server-overview Generating schema... 16ms Saving Prisma Client (TypeScript) atプロジェクトの作成はこれでOKです。
3. Dockerのセットアップ
$ cd test-appプロジェクトディレクトリに入って
$ docker-compose up -d Creating network "test-app_default" with the default driver Creating volume "test-app_mysql" with default driver Pulling prisma (prismagraphql/prisma:1.30)... 1.30: Pulling from prismagraphql/prisma . . .Dockerのセットアップが始まります。
Creating test-app_mysql_1 ... done Creating test-app_prisma_1 ... doneこれでDockerのセットアップ完了です。
Prismaデプロイ
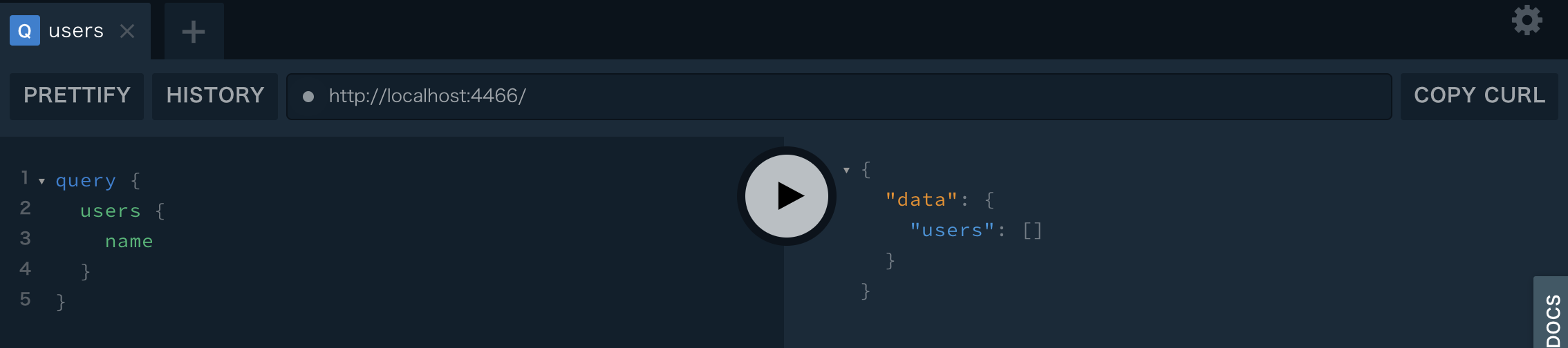
$ prisma deployCreating stage default for service default ✔ Deploying service `default` to stage `default` to server `local` 557ms Changes: User (Type) + Created type `User` + Created field `id` of type `ID!` + Created field `name` of type `String!` + Created field `updatedAt` of type `DateTime!` + Created field `createdAt` of type `DateTime!` Applying changes 1.1s Your Prisma GraphQL database endpoint is live: HTTP: http://localhost:4466 WS: ws://localhost:4466 You can view & edit your data here: Prisma Admin: http://localhost:4466/_adminスキーマなどの作成が行われて管理画面にアクセスできるようになります。
まだデータベースにデータが入っていないため、空っぽです。
MySQLにデータを追加する
Dockerを直接操作してもいいですが、今回はクライアントアプリを使って操作します。
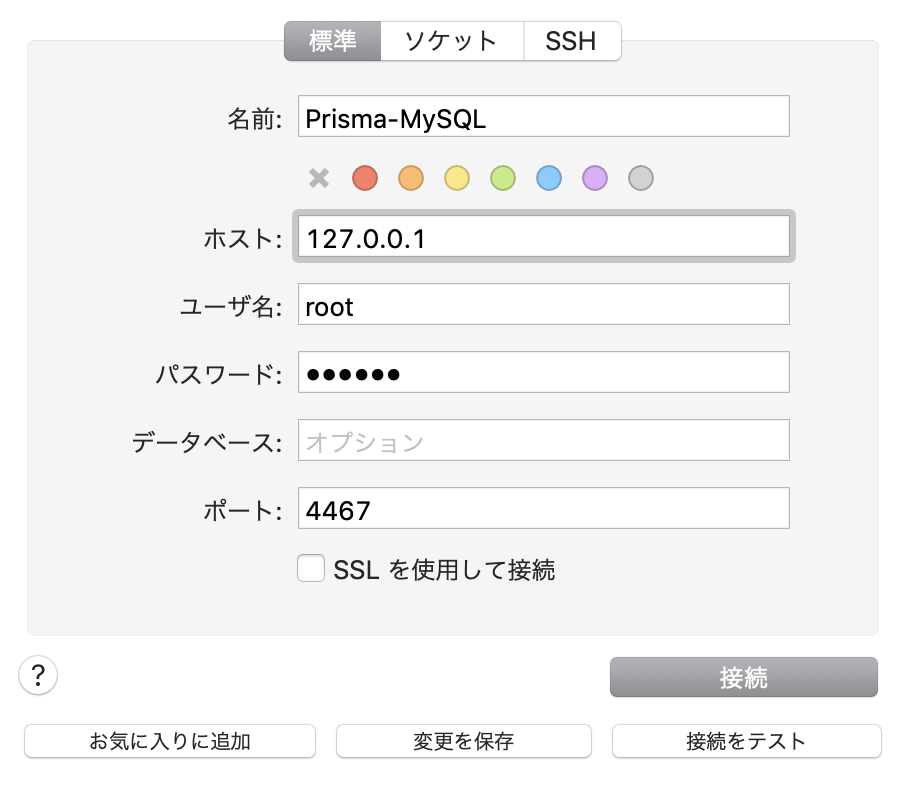
クライアントアプリからDockeへ接続するために設定ファイルを書き換えます。
docker-compose.ymlmysql: image: mysql:5.7 restart: always environment: MYSQL_ROOT_PASSWORD: prisma volumes: - mysql:/var/lib/mysql + ports: + - "4467:3306"設定を反映するため、Dockerの再起動を行います。
$ docker-compose stop※ restart もあるが、何故か反映されないためstopする
$ docker-compose up -d完了した後、Dockerステートを確認
$ docker psDockerのステートを確認する
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 532cfa5d7aff mysql:5.7 "docker-entrypoint.s…" About a minute ago Up About a minute 33060/tcp, 0.0.0.0:4467->3306/tcp hello-world_mysql_1 57133a0b6409 prismagraphql/prisma:1.30 "/bin/sh -c /app/sta…" 16 hours ago Up About a minute 0.0.0.0:4466->4466/tcp hello-world_prisma_1
mysql:5.7の項目のPORTS0.0.0.0:4467->3306になっていればOKクライアントアプリからログインする
今回は Sequel Proを使います
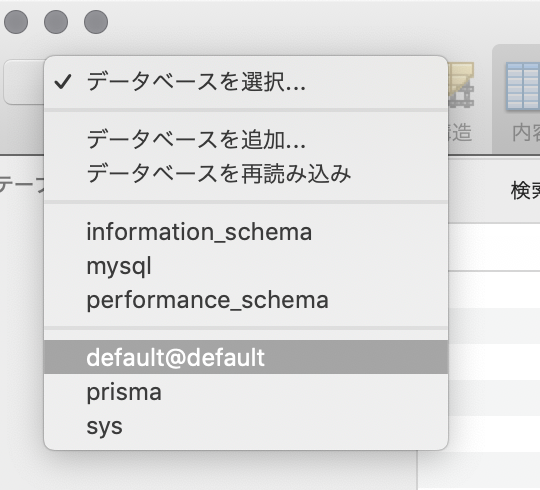
default@defaultに入ると、Userテーブルが存在するので
試しにデータを入れてみましょう。
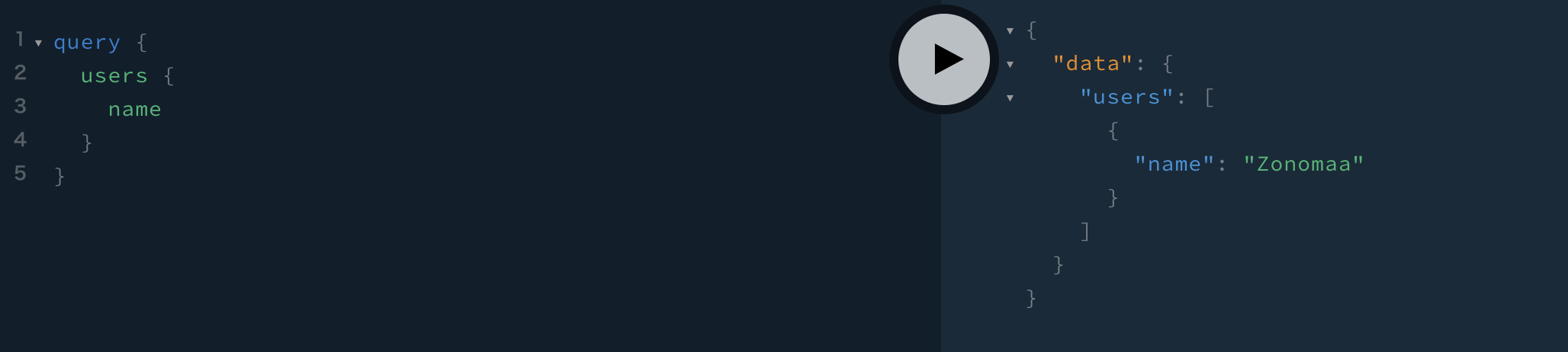
では、反映されているか確認するため、管理画面でクエリを叩いてみましょう。
反映されました!
[おまけ]カラムを追加する
Userにageを追加してみます。datamodel.prismatype User { id: ID! @unique name: String! + age: Int! }
prisma deploy変更をデプロイします
Deploying service `default` to stage `default` to server `local` 272ms Changes: User (Type) + Created field `age` of type `Int` Applying changes 1.1s Your Prisma GraphQL database endpoint is live: HTTP: http://localhost:4466 WS: ws://localhost:4466 You can view & edit your data here: Prisma Admin: http://localhost:4466/_admin変更が検知されました!
管理画面をリロードして確認しましょう。
これで、カラムの追加分が反映されました!



- 投稿日:2019-04-05T18:25:58+09:00
Google Cloud Platform上でNode.jsとMySQLを繋げてみた
はじめに
Google Cloud Platform (GCP) には魅力的な無料枠があり、操作も比較的簡単そうだったのでGCP上に構築したNode.js+MySQLのスタックを接続してみました。
今回はGCPのApp EngineにNode.jsのアプリを構築し、Cloud SQL第二世代にMySQLを構築させました。
https://cloud.google.com/sql/docs/mysql/connect-app-engine?hl=ja
接続についてはこのリファレンスを読みましたがNode.jsが載っていなかったので書き残します。料金について
App Engineは規模が小さい場合基本的に無料ですが、Cloud SQLの運用は課金されました。
無料枠について:https://cloud.google.com/free/?hl=ja
Cloud SQL料金について:https://cloud.google.com/sql/pricing?hl=jaInstanceの接続名の確認
Instanceの接続名はCloud SQLの接続に必要な項目です。
project_id:region:instance_idの形式の文字列です。
GCPの「インスタンスの詳細」画面の中の「このインスタンスに接続」というボックスの中に表示されています。
これをコピーして、環境変数として保存しておきます。.env# プロジェクト名:hoge、インスタンス名:hoge-db、地域:東京 の場合 INSTANCE_CONNECTION_NAME="hoge:asia-northeast1:hoge-db"MySQL関係の項目の確認
Node.jsからMySQLにアクセスするにはもちろんデータベース情報が必要なので、これも一緒に環境変数として保存しておきます。
.env# ... DB_USER="hogehoge" DB_PASSWORD="fugafuga" DB_DATABASE="piyopiyo"Node.js側の設定
Node.jsからMySQLに接続するモジュールは色々ありますが、
mysqlというクライエントを使いました。App Engineのスタンダード環境からCloud SQLのDatabaseに接続するときには、普通にTCPでは接続できないため、Unix Domain Socketという方法で接続します。
環境変数は
dotenvというパッケージを使って取り込みました。require('dotenv').config(); const mysql = require('mysql'); const connection = mysql.createConnection({ socketPath: `/cloudsql/${process.env.INSTANCE_CONNECTION_NAME}`, user: process.env.DB_USER, password: process.env.DB_PASSWORD, database: process.env.DB_DATABASE });App Engineスタンダード環境の場合、
/cloudsql/<インスタンス接続名>のソケットが自動的に提供されるようなのでこのほかに何も設定する必要はありません。接続プール
パフォーマンスを上げるためにプールを使う場合も、同じように接続できます。
const pool = mysql.createPool({ user: process.env.DB_USER, password: process.env.DB_PASS, database: process.env.DB_NAME, socketPath: `/cloudsql/${process.env.INSTANCE_CONNECTION_NAME}` });接続数上限
プールを使用する場合、接続数の上限も設定できます。
const pool = mysql.createPool({ // ... connectionLimit: 5 });TCPとの併用
開発環境ではローカルのMySQLにTCPで接続してほしかったので、
NODE_ENVの環境変数に合わせて接続方法を変えるようにしました。const pool = process.env.NODE_ENV === 'production' ? mysql.createPool({ user: process.env.DB_USER, password: process.env.DB_PASS, database: process.env.DB_NAME, socketPath: `/cloudsql/${process.env.INSTANCE_CONNECTION_NAME}` }) : mysql.createPool({ user: process.env.DB_USER, password: process.env.DB_PASS, database: process.env.DB_NAME, host: 'localhost' });完成
gcloud app deployを実行してアクセスすると、データベースに接続できているはずです。App EngineとCloud SQLのインスタンスが別々のプロジェクトの下に作られている場合、IAMを変更する必要があります。
App EngineのサービスアカウントにCloud SQL AdminCloud SQL EditorCloud SQL Clientの役割のいずれかを与えると動くそうです。感想
GCPは比較的安価でNode.js、MySQLの環境構築をすることができるので魅力的です。リファレンスにNode.jsがなかったので少し手こずりましたが、無事接続できました。
最初の記事なので、少し間違えていたらすみませんv_v。
- 投稿日:2019-04-05T14:33:30+09:00
WordPressのサイトURLをMySQLからDB操作で直接書き換える方法
直接SQL文でWordPressのDBを操作してサイトURLを書き換える方法です。
ローカルに開発環境を構築する際などで使う用です。よく忘れるので自分用メモ。search.sqlselect * from wp_options where option_name in ('home', 'siteurl');update.sqlupdate wp_options set option_value = 'https://sample.com' where option_id in (1,2);search.sqlで検索して出てきた値が現在のサイトURLです。
update.sqlでサイトURLを任意の値(例.sample.com)に更新します。
- 投稿日:2019-04-05T14:17:09+09:00
[Django]管理画面の一覧表示部分に別テーブルのフィールドを表示する
はじめに
「[Django]管理画面の一覧表示部分に、(表示対象のテーブルで外部キーなどでの関連もさせていない)別テーブルのフィールドを表示する」
最終的に結構単純でしたが、同じようなことをしている人が少なくて割と悩んだのでメモ。
多分ドキュメントに丁寧に目を通した人にとっては当たり前のことかも。やりたいこと
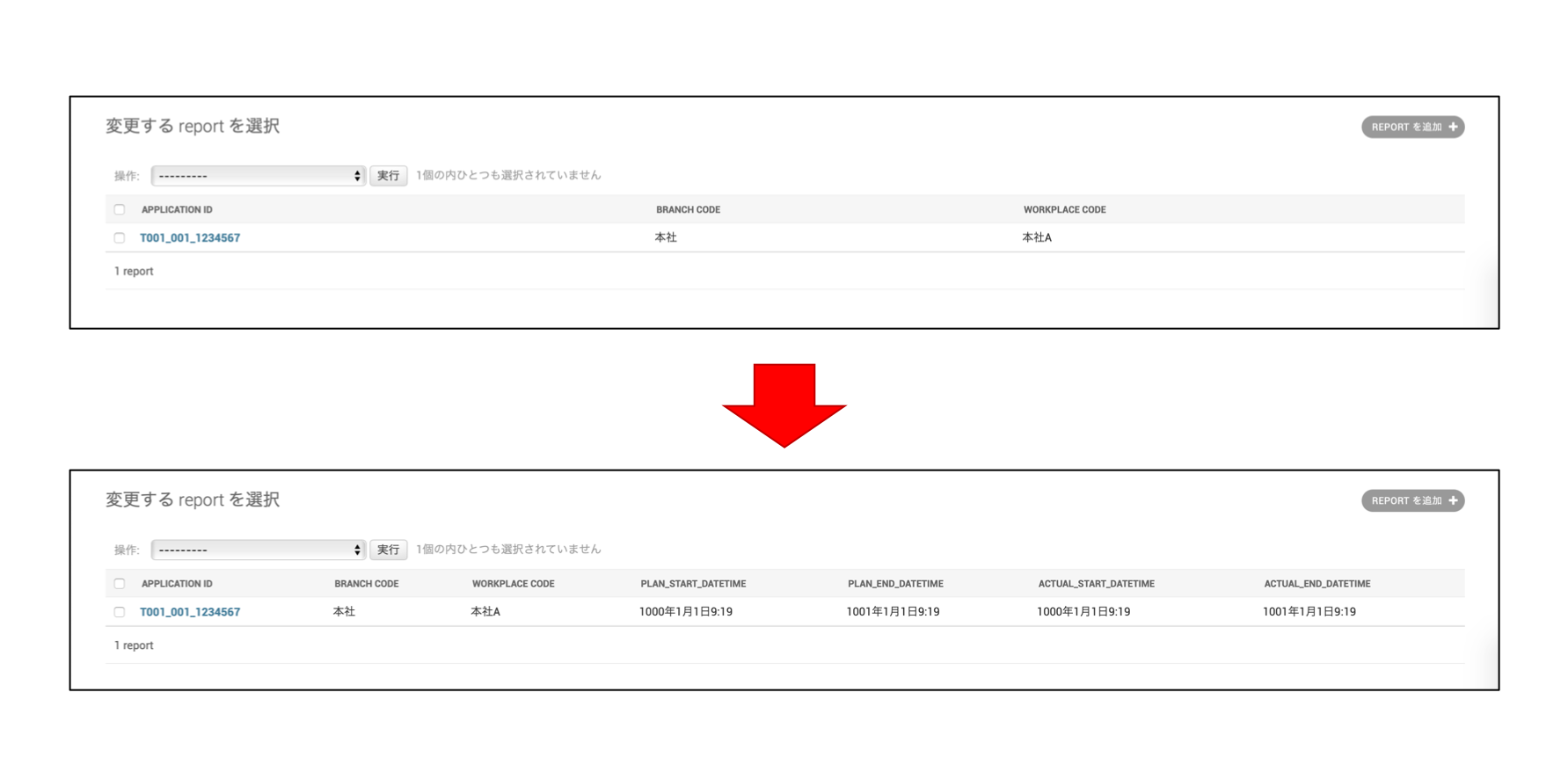
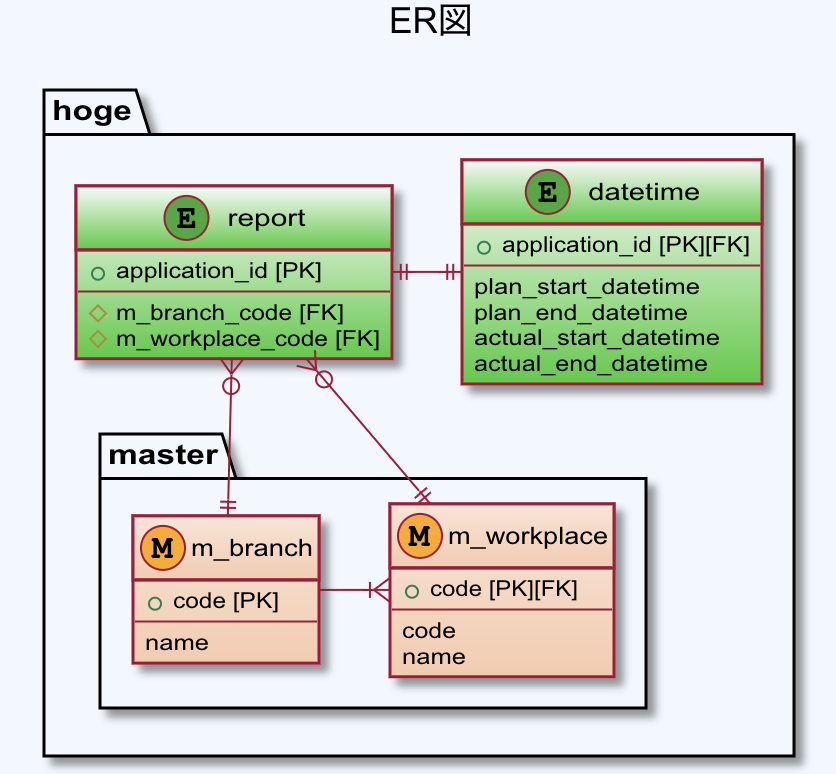
上の画面を下のような表示にしたかったのですが、この時、DBの構成は下記のER図のようになっており、日時系の値とそれ以外の値は別DBのフィールドのため、単純に
list_displayで追加することができなかった。[やりたい画面レイアウト]
[ER図]
(記事用に適当に書き換えたので、ER図と下の方のコードの整合性保ってない部分もあるかも)
要点
特に重要なのは下記の部分ですが、一応全貌を載せておきます。
重要部分1def plan_start_datetime(self, obj): list_got_objects = list(Datetime.objects.all().values_list('plan_start_datetime', flat=True)) return list_got_objects※1:取得したい情報の条件(例:「id=1」など)
重要部分2list_display = ( 'plan_start_datetime', )要点1.
<テーブル名>.objects.all()の戻り値はQuerySetなので、values_list()で値を取得する必要がある。要点2.
values_list()で取得した値をスライスして取得した「文字列」をlist_displayに渡す。以下、全貌
models.py# coding: utf-8 from django.db import models from django.utils import timezone from django.core.validators import MaxValueValidator # コードがforeign keyとして使用されるため、このクラスを先に定義している class M_branch(models.Model): def __str__(self): return self.name code = models.CharField(max_length=4, primary_key=True) name = models.CharField(max_length=128) # コードがforeign keyとして使用されるため、このクラスを先に定義している class M_workplace(models.Model): def __str__(self): return self.name branch_code = models.ForeignKey(M_branch, on_delete=models.CASCADE) code = models.CharField(max_length=4) name = models.CharField(max_length=128) class Report(models.Model): def __str__(self): return self.application_id application_id = models.CharField(max_length=32, primary_key=True) branch_code = models.ForeignKey(M_branch, on_delete=models.DO_NOTHING) workplace_code = models.ForeignKey(M_workplace, on_delete=models.DO_NOTHING) class Datetime(models.Model): def __str__(self): return self.plan_start_datetime application_id = models.OneToOneField(Report, on_delete=models.CASCADE) plan_start_datetime = models.DateTimeField() plan_end_datetime = models.DateTimeField() actual_start_datetime = models.DateTimeField() actual_end_datetime = models.DateTimeField()admin.pyfrom django.contrib import admin from .models import Report, Datetime, Participant, M_branch, M_workplace # TODO DatetimeやParticipantテーブルから必要な情報を取得して同じ表に表示する class ReportAdmin(admin.ModelAdmin): fieldsets = [ ('申請ID', {'fields': ['application_id']}), ('支部コード', {'fields': ['branch_code']}), ('職場コード', {'fields': ['workplace_code']}), ] list_display = ('application_id', 'branch_code', 'workplace_code', 'plan_start_datetime', 'plan_end_datetime', 'actual_start_datetime', 'actual_end_datetime', ) def plan_start_datetime(self, obj): list_got_objects = list(Datetime.objects.all().values_list('plan_start_datetime', flat=True)) return plan_start_datetime plan_start_datetime.short_description = 'plan_start_datetime' def plan_end_datetime(self, obj): list_got_objects = list(Datetime.objects.all().values_list('plan_end_datetime', flat=True)) return plan_end_datetime plan_end_datetime.short_description = 'plan_end_datetime' def actual_start_datetime(self, obj): list_got_objects = list(Datetime.objects.all().values_list('actual_start_datetime', flat=True)) return actual_start_datetime actual_start_datetime.short_description = 'actual_start_datetime' def actual_end_datetime(self, obj): list_got_objects = list(Datetime.objects.all().values_list('actual_end_datetime', flat=True)) return actual_end_datetime actual_end_datetime.short_description = 'actual_end_datetime' class M_branchAdmin(admin.ModelAdmin): fieldsets = [ ('支部コード', {'fields': ['code']}), ('支部名', {'fields': ['name']}), ] list_display = ('name', 'code') class M_workplaceAdmin(admin.ModelAdmin): fieldsets = [ ('支部コード', {'fields': ['branch_code']}), ('職場コード', {'fields': ['code']}), ('職場名', {'fields': ['name']}), ] list_display = ('name', 'code', 'branch_code') admin.site.register(Report, ReportAdmin) admin.site.register(M_branch, M_branchAdmin) admin.site.register(M_workplace, M_workplaceAdmin)以上。
- 投稿日:2019-04-05T09:28:50+09:00
Heroku(PHP+MySQL)でWebサービス公開手順
はじめに
localhostでPHP+MySQLで開発したものを、Herokuで公開するためのもの
OS: mac
PHP: フレームワーク無し
DB: MySQL1.Herokuに登録
https://www.heroku.com/
クレジットカードを登録しておきます。2.Heroku CLIをインストール
https://devcenter.heroku.com/articles/heroku-cli
$ heroku login3.アプリ作成
ここではデスクトップにheroku-appというディレクトリを作ります。
$ cd Desktop $ mkdir heroku-app $ cd heroku-appアプリを作成します。アプリ名を指定しない場合は自動で割り振られます。
$ heroku create アプリ名4.composer
composer.jsonというファイルを作成します。
touch composer.jsonphpのバージョン7を指定します。これが正しいのか分かりませんがこれで動きました。
"ext-mbstring": "*"とすることでmb_xxxの関数(mb_strlenとか)が使えるようになります。指定しないでmb_xxxの関数を使うとCall to undefined functionエラーになります。composer.json{ "require": { "php": "~7.0", "ext-mbstring": "*" } }デフォルトのPHPが入っていることが前提です。
$ curl -sS https://getcomposer.org/installer | php $ mv composer.phar /usr/local/bin/composerターミナルを再起動して確認します。大丈夫ならインストールします。
$ cd Desktop/heroku-app $ composer -v $ composer install5.Gitリポジトリ作成
$ git init $ git remote add heroku https://git.heroku.com/アプリ名.git $ git remote -v6.ClearDBアドオンをインストール
herokuでmysqlを使うための設定です。
$ heroku addons:add cleardb:ignite7.Workbenchをインストール、設定
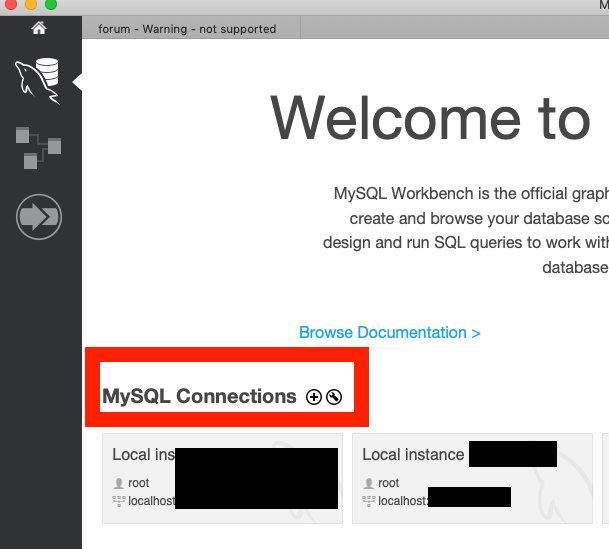
Workbenchを使うことで、phpMyAdminのようにGUIでデータベースを管理できます。
インストールが完了したら赤枠で囲ったMySQL Connectionsの横の+をクリックして設定画面を開きます。
heroku configコマンドでCLEARDB_DATABASE_URLを確認します。$ heroku configこれを元に入力していきます。
CLEARDB_DATABASE_URL: mysql://ユーザ名:パスワード@サーバ名/データベース?reconnect=true
Connection Name: 適当な名前
Hostname: サーバ名
Username: ユーザ名
Password: パスワード
Default Schema: データベース入力を終えたら、
Test Connectionをクリック→上で入力したパスワードを入力→Connection Warning画面が出る→Continue Anyway→Successfully made the MySQL connection→OK→OK8.phpMyAdminからDBエクスポート→WorkbenchにDBインポート
phpMyAdminからエクスポート
phpMyAdminからエクスポートしたいDBを選択→
詳細にチェック→出力をファイルに保存する→実行Workbenchにインポート
7.で設定したものに接続して
AdministraionタブからData Import/Restore→Import from Self-Contained Fileにチェックを入れてphpMyAdminからエクスポートしたsqlファイルを選択します。
Default Target Schemaを指定します。newの方ではなくてセレクトメニューでデフォルトのものを指定します。
なぜかフリーズしたように?選択できないときがありますが、謎です。
最後にStart Importをクリックします。9.PHPのDB接続設定を変更する
local用から本番用に書き換える必要があります。
function.phpfunction dbConnect(){ $db = parse_url($_SERVER['CLEARDB_DATABASE_URL']); $db['dbname'] = ltrim($db['path'], '/'); $dsn = "mysql:host={$db['host']};dbname={$db['dbname']};charset=utf8"; $user = $db['user']; $password = $db['pass']; $options = array( PDO::ATTR_ERRMODE => PDO::ERRMODE_EXCEPTION, PDO::ATTR_DEFAULT_FETCH_MODE => PDO::FETCH_ASSOC, PDO::MYSQL_ATTR_USE_BUFFERED_QUERY =>true, ); $dbh = new PDO($dsn,$user,$password,$options); return $dbh; }10.herokuへデプロイ
$ git add -A $ git commit -m "commit" $ git push heroku masterheroku openでブラウザを開いて表示してくれます。localと同じようにDBのデータ等ちゃんと表示できていれば完了です。
$ heroku open11.WorkbenchでDBの中身を確認する
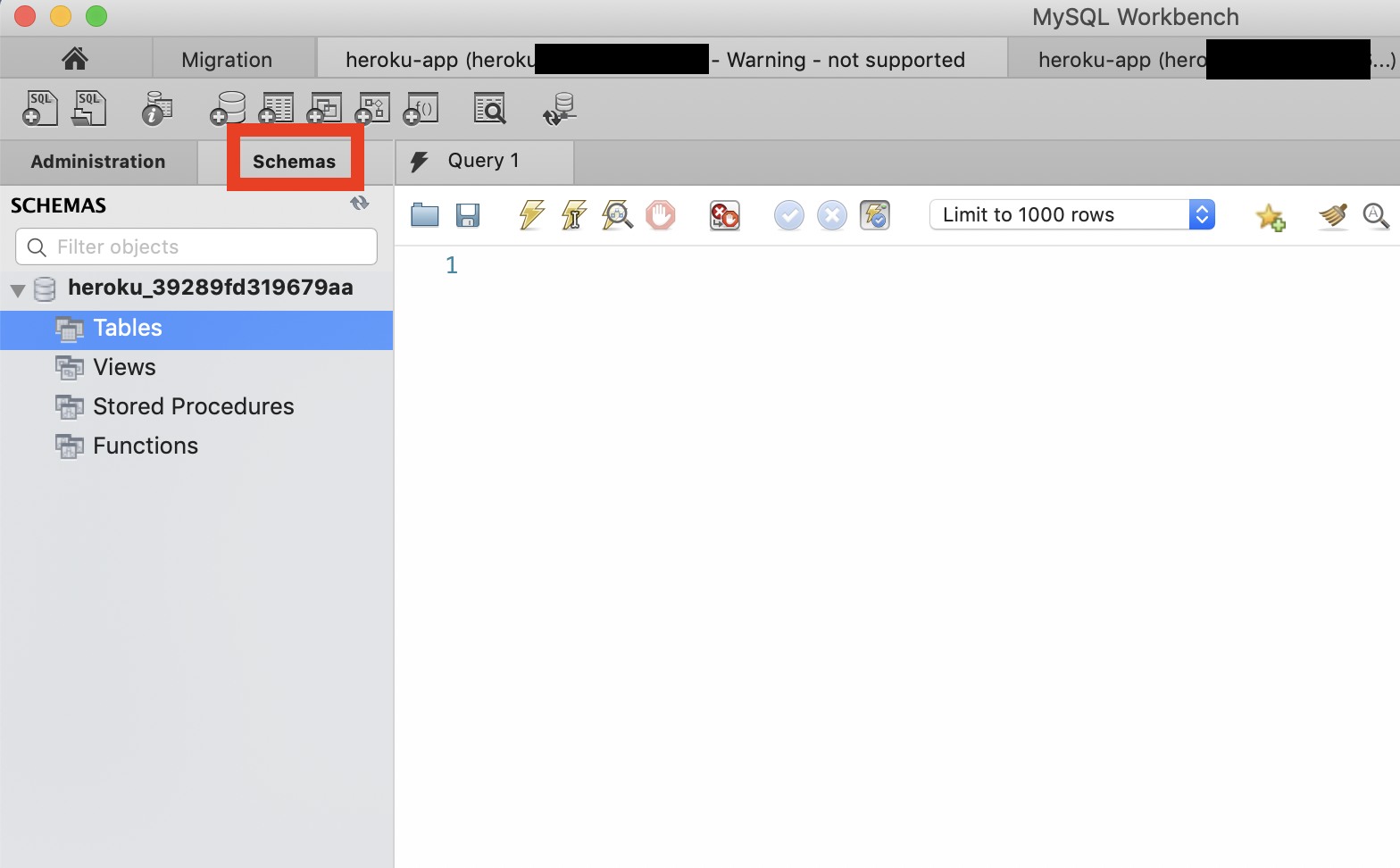
赤枠で囲った
Schemas→Tables
各テーブルにマウスホバーすると、右にアイコンが出る(赤枠で囲った所)ので一番右のカレンダーみたいなアイコンをクリックするとデータが確認できます。または、SQL文を打ち込んで雷アイコンを押してもデータ確認ができます。
その他エラーなど
・herokuはphpログファイルとかエラーが見れないようなので、見るには
ini_set('display_errors',1)を一時的に使います。・
Error Code: 2013. Lost connection to MySQL server〜というエラーが出る場合
→https://stackoverflow.com/questions/10563619/error-code-2013-lost-connection-to-mysql-server-during-query・composer.jsonを編集したら作業ディレクトリで
composer updateを行う$ composer update参考:
herokuでPHPからMySQL(ClearDB)を使うhttp://blog.a-way-out.net/blog/2014/12/11/heroku-php-mysql/
herokuがcomposer.lock必須になったのでcomposerの入れ方をメモしておくhttp://kayakuguri.github.io/blog/2015/08/25/composer-lock-require/
Heroku データベースの管理(ClearDB アドオンによる MySQL の利用)http://www.ownway.info/Ruby/heroku/how/management/database/cleardb
MySQL WorkbenchをMacにインストールする方法https://programmingnavi.com/77/
heroku環境でmb_xxx関数を使うと、Fatal error: Call to undefined function …のエラーが表示されるhttps://qiita.com/taro-hida/items/f677abe2bc3b689002b3

- 投稿日:2019-04-05T09:28:50+09:00
HerokuでWebサービス公開(PHP+MySQL)
はじめに
localhostでPHP+MySQLで開発したものを、Herokuで公開するためのもの
OS: mac
PHP: フレームワーク無し
DB: MySQL1.Herokuに登録
https://www.heroku.com/
クレジットカードを登録しておきます。2.Heroku CLIをインストール
https://devcenter.heroku.com/articles/heroku-cli
$ heroku login3.アプリ作成
ここではデスクトップにheroku-appというディレクトリを作ります。
$ cd Desktop $ mkdir heroku-app $ cd heroku-appアプリを作成します。アプリ名を指定しない場合は自動で割り振られます。
$ heroku create アプリ名4.composer
composer.jsonというファイルを作成します。
touch composer.jsonphpのバージョン7を指定します。これが正しいのか分かりませんがこれで動きました。
"ext-mbstring": "*"とすることでmb_xxxの関数(mb_strlenとか)が使えるようになります。指定しないでmb_xxxの関数を使うとCall to undefined functionエラーになります。composer.json{ "require": { "php": "~7.0", "ext-mbstring": "*" } }デフォルトのPHPが入っていることが前提です。
$ curl -sS https://getcomposer.org/installer | php $ mv composer.phar /usr/local/bin/composerターミナルを再起動して確認します。大丈夫ならインストールします。
$ cd Desktop/heroku-app $ composer -v $ composer install5.Gitリポジトリ作成
$ git init $ git remote add heroku https://git.heroku.com/アプリ名.git $ git remote -v6.ClearDBアドオンをインストール
herokuでmysqlを使うための設定です。
$ heroku addons:add cleardb:ignite7.Workbenchをインストール、設定
Workbenchを使うことで、phpMyAdminのようにGUIでデータベースを管理できます。
インストールが完了したら赤枠で囲ったMySQL Connectionsの横の+をクリックして設定画面を開きます。
heroku configコマンドでCLEARDB_DATABASE_URLを確認します。$ heroku configこれを元に入力していきます。
CLEARDB_DATABASE_URL: mysql://ユーザ名:パスワード@サーバ名/データベース?reconnect=true
Connection Name: 適当な名前
Hostname: サーバ名
Username: ユーザ名
Password: パスワード
Default Schema: データベース入力を終えたら、
Test Connectionをクリック→上で入力したパスワードを入力→Connection Warning画面が出る→Continue Anyway→Successfully made the MySQL connection→OK→OK8.phpMyAdminからDBエクスポート→WorkbenchにDBインポート
phpMyAdminからエクスポート
phpMyAdminからエクスポートしたいDBを選択→
詳細にチェック→出力をファイルに保存する→実行Workbenchにインポート
7.で設定したものに接続して
AdministraionタブからData Import/Restore→Import from Self-Contained Fileにチェックを入れてphpMyAdminからエクスポートしたsqlファイルを選択します。
Default Target Schemaを指定します。newの方ではなくてセレクトメニューでデフォルトのものを指定します。
なぜかフリーズしたように?選択できないときがありますが、謎です。
最後にStart Importをクリックします。9.PHPのDB接続設定を変更する
local用から本番用に書き換える必要があります。
function.phpfunction dbConnect(){ $db = parse_url($_SERVER['CLEARDB_DATABASE_URL']); $db['dbname'] = ltrim($db['path'], '/'); $dsn = "mysql:host={$db['host']};dbname={$db['dbname']};charset=utf8"; $user = $db['user']; $password = $db['pass']; $options = array( PDO::ATTR_ERRMODE => PDO::ERRMODE_EXCEPTION, PDO::ATTR_DEFAULT_FETCH_MODE => PDO::FETCH_ASSOC, PDO::MYSQL_ATTR_USE_BUFFERED_QUERY =>true, ); $dbh = new PDO($dsn,$user,$password,$options); return $dbh; }10.herokuへデプロイ
$ git add -A $ git commit -m "commit" $ git push heroku masterheroku openでブラウザを開いて表示してくれます。localと同じようにDBのデータ等ちゃんと表示できていれば完了です。
$ heroku open11.WorkbenchでDBの中身を確認する
赤枠で囲った
Schemas→Tables
各テーブルにマウスホバーすると、右にアイコンが出る(赤枠で囲った所)ので一番右のカレンダーみたいなアイコンをクリックするとデータが確認できます。または、SQL文を打ち込んで雷アイコンを押してもデータ確認ができます。
その他エラー
・herokuはphpログファイルとかエラーが見れないようなので、見るには
ini_set('display_errors',1)を一時的に使います。・
Error Code: 2013. Lost connection to MySQL server〜というエラーが出る場合
→https://stackoverflow.com/questions/10563619/error-code-2013-lost-connection-to-mysql-server-during-query参考:
herokuでPHPからMySQL(ClearDB)を使うhttp://blog.a-way-out.net/blog/2014/12/11/heroku-php-mysql/
herokuがcomposer.lock必須になったのでcomposerの入れ方をメモしておくhttp://kayakuguri.github.io/blog/2015/08/25/composer-lock-require/
Heroku データベースの管理(ClearDB アドオンによる MySQL の利用)http://www.ownway.info/Ruby/heroku/how/management/database/cleardb
MySQL WorkbenchをMacにインストールする方法https://programmingnavi.com/77/
heroku環境でmb_xxx関数を使うと、Fatal error: Call to undefined function …のエラーが表示されるhttps://qiita.com/taro-hida/items/f677abe2bc3b689002b3
- 投稿日:2019-04-05T00:57:13+09:00
MySQLのInnoDBのトランザクション周りについて調べたことをまとめた
元々NoSQLしか使用していなく、今年に入って転職して初めて業務でMySQLを使用しだした。
雰囲気で使ってる感じがしてよくないなと思ったので、色々調べた。今回まとめたのは、MySQLのInnoDBのトランザクションについての一部。
この記事でまとめる対象の事柄は、既に詳しく素晴らしい記事が存在するが、それなりに難しい内容なのでそれらを読みながら理解の補助的に、またメモ的にまとめたものが本記事。また、「この概念を理解するには、事前に〇〇の概念の理解が必要で、それを理解するにはこの記事がわかりやすい」といった形で自分が後から振り返られるようにもまとめた。
この記事はあくまでも理解の補助と、どの概要を学んだ方が良いかということをまとめた記事なので、詳細な理解は紹介している記事を読んだ方が良い。
トランザクションの分離レベル
トランザクションにはACID属性というものがあって、その中のI(Isolation)が分離性と呼ばれるもの。
トランザクションの分離にはレベルが存在する。
詳細は以下の記事等を参照。大事なのは、どの分離レベルにおいて、どんな不都合な読み込みが行われるかを認識することだと思う。
[RDBMS][SQL]トランザクション分離レベルについて極力分かりやすく解説 - Qiita
MySQLのInnoDBの Repeatable Read
MySQLのデフォルトのエンジンであるInnoDBのデフォルトのトランザクションの分離レベルはRepeatable Readである。
一般的に、Repeatable Readは、ダーティリードとファジーリードは防ぐことができるけれども、ファントムリードは防ぐことができない。
ファントムリードは、以下のようだとある。
別のトランザクションで挿入されたデータが見えることにより、一貫性がなくなる現象。
引用元: [RDBMS][SQL]トランザクション分離レベルについて極力分かりやすく解説 - Qiita
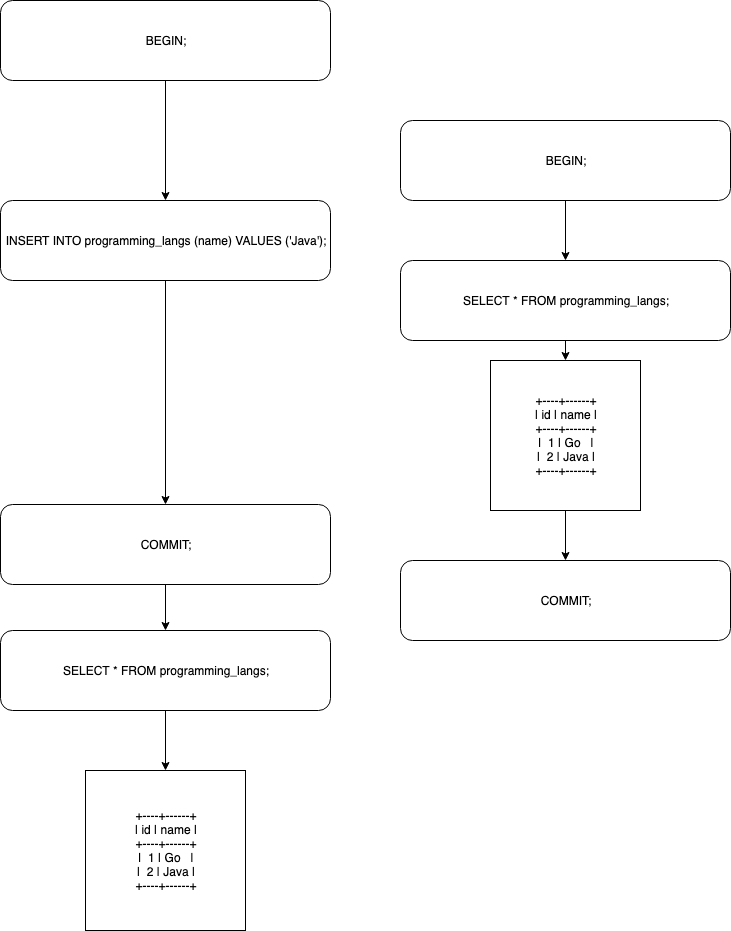
一般的なRepeatable Readの場合のシミュレーションすると以下のような感じ(実際にやったわけではない)
事前に以下のような操作を行なっているとする。
CREATE TABLE programming_langs ( id INT AUTO_INCREMENT NOT NULL PRIMARY KEY, name VARCHAR(20) ); show tables; +-------------------+ | Tables_in_sample | +-------------------+ | programming_langs | +-------------------+ INSERT INTO programming_langs (name) VALUES ('Go');Repeatable Readの場合のトランザクションのシミュレーション
上記のように、左側のトランザクションがInsertしたデータを右側のトランザクションが読み込めてしまう。(ファントムリード)
しかし、MySQLの InnoDB は、 Repeatable Read であっても、別のトランザクションで挿入されたデータをうまいことやりくりしており、一貫性があるように見える。
実際にやってみた。
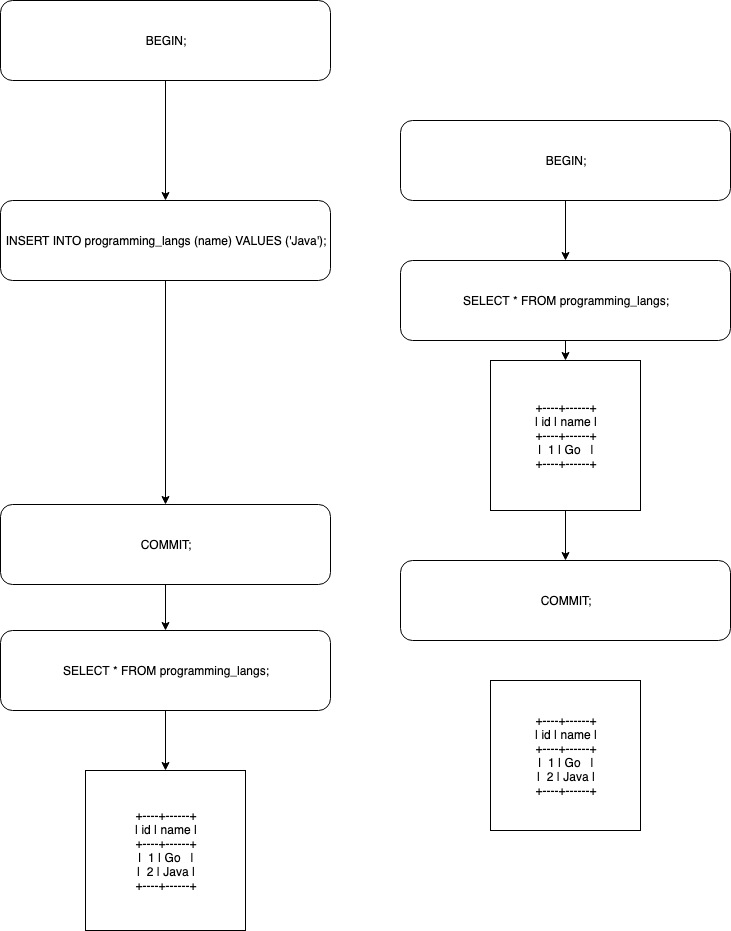
事前に以下のような操作を行なっているとする。
CREATE TABLE programming_langs ( id INT AUTO_INCREMENT NOT NULL PRIMARY KEY, name VARCHAR(20) ); show tables; +-------------------+ | Tables_in_sample | +-------------------+ | programming_langs | +-------------------+ INSERT INTO programming_langs (name) VALUES ('Go');Repeatable ReadのMySQL InnoDBでの操作を図にしたもの
(実際にMySQLでやってみたが、見易さを考慮して図にしている)
ファントムリードが生じていないように見える。
これはなぜだろうか。実は、MVCC(MultiVersion Concurrency Control)という仕組みを用いているからである。
MVCC
MySQLのドキュメントによれば
Acronym for “multiversion concurrency control”. This technique lets InnoDB transactions with certain isolation levels perform consistent read operations; that is, to query rows that are being updated by other transactions, and see the values from before those updates occurred. This is a powerful technique to increase concurrency, by allowing queries to proceed without waiting due to locks held by the other transactions.
This technique is not universal in the database world. Some other database products, and some other MySQL storage engines, do not support it.
引用元: MySQLのドキュメント
上記を意訳しつつ、まとめると以下のような感じ。
- MVCCを使用すると、特定のトランザクションの分離レベルのInnoDBで、一貫性のある読み取り操作が可能に
- 他のトランザクションが更新した行を照会する際に、更新前の状態を見ることができる
- 他のトランザクションのロックを待たずに、クエリを進めることができるのでMVCCだと、同時実行性を高めることができる
他のトランザクションが更新した行を照会する際に、更新前の状態を見ることができる
これがまさにMySQLのInnoDBではRepeatable Readであっても別のトランザクションで挿入されたデータをうまいことやりくりして、一貫性があるように見える(ファントムリードが起きない)ことに寄与している。
これはファントムリードでは、トランザクション内で挿入したデータを別のトランザクション内で見えてしまうが、それを回避することができるということだ。
MVCCの仕組みの説明は、以下がわかりやすいのでこちらを参照。
MySQLのMVCC - Qiita公式でも詳しく仕組みが記されている。
MVCCが故の注意
行ロックをすることなく一貫性を出せるのと、複数のトランザクションが同一のテーブルを操作するとき、お互いのロックを待つことなく操作できるので、同時実行性が上がる。
しかし、行ロックをしないが故に生じ得るLost Updateという問題も存在する。
以下に詳しく記述されているので参照。
漢(オトコ)のコンピュータ道: InnoDBのREPEATABLE READにおけるLocking Readについての注意点詳しくは上記の記事を参照した方が良いが、記事を読んだ際に頭を整理するためにこれまで書いてきた内容と合わせて、以下のようなメモをしながら読んだので載せておく。
- Lost Update
- MVCCは、行ロックをとるわけではないので2つのトランザクションが重なったときには、後で更新した方の値が最終的に反映される
- Locking Read
- Lost Updateを防ぐためには、Locking Readを使用する
- Lost Update は行にロックをかけていないから生じるわけで、それならば行をロックすればええやんという感じ
- 排他ロックと共有ロックを行える構文が存在する
- 排他ロックと共有ロックはこの記事がわかりやすい
- 逆説的な話だが、MVCCでRepeatable Readでもファントムリードを防げているのは、MVCCによって、DB_ROLL_PTRの値を見ているからで、Locking Readの場合はそうでなくファントムリードが生じる
- > Locking ReadはREAD COMMITTED
- > UPDATEとDELETEやデフォルトでLocking Readの挙動
DB_ROLL_PTR ... そのレコードの過去の値を持つundo log recordへのポインタ
引用元: MySQLのMVCC - Qiita
ロックの仕組み
MySQLのロックにはレコードロック、ギャップロック、ネクストキーロックの3つがある。
以下の記事が非常にわかりやすいので、参照。MySQL(InnoDB)のネクストキーロックの仕組みと範囲を図解する - 備忘録の裏のチラシ
ただ、「レコードロックっていうのは実際は、インデックスレコードのロックだよ」みたいな感じでインデックスの知識が必要。
ここで必要なインデックスの知識も、ただクエリの性能向上のための便利なものという理解ではなく内部の仕組みの理解が必要みたいだ。(特にクラスタインデックスとセカンダリインデックス)なので、上記のロックの記事を読む前に以下の記事等でインデックスの仕組みについて学んでからの方が良さそう。
インデックスの記事
漢(オトコ)のコンピュータ道: 知って得するInnoDBセカンダリインデックス活用術!MySQL :: MySQL 5.6 リファレンスマニュアル :: 14.2.13.2 クラスタインデックスとセカンダリインデックス
MySQL with InnoDB のインデックスの基礎知識とありがちな間違い - クックパッド開発者ブログ
MySQL(InnoDB)のインデックスについての備忘録 - What is it, naokirin?
参考にさせていただいたサイト
ACID属性
トランザクション分離レベル
[RDBMS][SQL]トランザクション分離レベルについて極力分かりやすく解説 - Qiita
MVCC
ロック
MySQLでSELECT FOR UPDATEと行ロックの挙動を検証してみた - JUST FOR FUNMySQL - InnoDBのロック関連まとめ - Qiita
世界の何処かで MySQL(InnoDB)の REPEATABLE READ に嵌る人を1人でも減らすために - KAYAC engineers' blog
doc/innodb.md at master · ichirin2501/doc
漢(オトコ)のコンピュータ道: InnoDBのREPEATABLE READにおけるLocking Readについての注意点
アプリケーションエンジニアが知っておくべきMySQLのロック - Qiita
MySQL(InnoDB)のネクストキーロックの仕組みと範囲を図解する - 備忘録の裏のチラシ
インデックス
漢(オトコ)のコンピュータ道: 知って得するInnoDBセカンダリインデックス活用術!MySQL :: MySQL 5.6 リファレンスマニュアル :: 14.2.13.2 クラスタインデックスとセカンダリインデックス
- 投稿日:2019-04-05T00:41:57+09:00
RailsでMySQLに絵文字を保存したい
特に設定しなければ絵文字を書いて保存しようとすると、
Incorrect string valueのエラーが発生します。絵文字を保存する場合は、
config/database.ymlのencodingをutfmb4にします。default: &default adapter: mysql2 encoding: utf8mb4 pool: <%= ENV.fetch("RAILS_MAX_THREADS") { 5 } %> username: root password: socket: /tmp/mysql.sockまた、テーブルを作る際も
CHARSET=utfmb4を設定します。create_table "test_table", options: "CHARSET=utf8mb4" do |t| t.string "name", null: false endすでに、DBを作っている場合は一度DBをdropして、DBから作り直す必要があります。
補足(2019/04/07)
MySQLで絵文字(4バイト文字)が対応しているバージョンは5.5以降ですので、それ以前のバージョンには対応していません。
- 投稿日:2019-04-05T00:41:57+09:00
RailsでDBに絵文字を保存したい
特に設定しなければ絵文字を書いて保存しようとすると、
Incorrect string valueのエラーが発生します。絵文字を保存する場合は、
config/database.ymlのencodingをutfmb4にします。default: &default adapter: mysql2 encoding: utf8mb4 pool: <%= ENV.fetch("RAILS_MAX_THREADS") { 5 } %> username: root password: socket: /tmp/mysql.sockまた、テーブルを作る際も
CHARSET=utfmb4を設定します。create_table "test_table", options: "CHARSET=utf8mb4" do |t| t.string "name", null: false endすでに、DBを作っている場合は一度DBをdropして、DBから作り直す必要があります。