- 投稿日:2019-02-18T12:50:02+09:00
Ubuntu16.04におけるVisemeNet_tensorflowのCUDA環境及びROCm環境での動作検証したときの手順メモ
VisemeNet_tensorflow
https://github.com/yzhou359/VisemeNet_tensorflowテスト環境は以下の記事で作った環境です
https://qiita.com/_JG1WWK/items/bfb59e2589b82bf5a8b3目次
・miniconda導入
・Visemenetの準備
・CPU TensorFlowでの検証(途中エラーで動作せず)
・CUDA9.2での検証(呼び出し段階でエラーが発生して動作せず)
・ROCmでの検証(途中エラー動作せず)
・CUDA8.0+CUdnn5.1環境での検証(これのみ動作)
・まとめ
・参考サイトまずminicondaを入れます
brewならワンコマンドで済みますがこの場合は直接.shを落とします。
$ wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh $ bash ./Miniconda3-latest-Linux-x86_64.sh (すべてyesとenterで実行)インストール中
Do you wish the installer to initialize Miniconda3 in your /home/w/.bashrc ? [yes|no] [no] >>> yes Initializing Miniconda3 in /home/w/.bashrc A backup will be made to: /home/w/.bashrc-miniconda3.bakここをちゃんとyesにすると環境変数の自動設定をやってくれるのですが、ここで指定されてる/home/w/miniconda3/etc/profile.d/conda.shの実行パーミッションが許可されてないためこのままでは実行できないため
$ chmod +x /home/w/miniconda3/etc/profile.d/conda.sh $ source .bashrcとします、正直これが正しいやりかたなのかわかりませんが、これで動きます。
準備
git clone https://github.com/yzhou359/VisemeNet_tensorflow.git次にCPU用、CUDA用、ROCm用で3つcondaで環境を作ります
$ conda create -n visnet_CPU python=3.5 $ conda create -n visnet_CUDA python=3.5 $ conda create -n visnet_ROCm python=3.5次に
https://www.dropbox.com/sh/7nbqgwv0zz8pbk9/AAAghy76GVYDLqPKdANcyDuba?dl=0
から
上記の4つのファイルをダウンロードしてgit cloneしたVisenetNet_tensorflow内にある data/ckpt/pretrain_biwi/にコピーしてください。
CPUでひとまず動かす
結構突っ込まないと行けないものが多いです。
$ conda activate visnet_CPU $ cd VisemeNet_tensorflow/ $ pip install numpy $ pip install tensorflow==1.11.0 $ pip install python_speech_features $ pip install matplotlib $ python ./main_test.pyしかし計算中に
NotFoundError (see above for traceback): Restoring from checkpoint failed. This is most likely due to a Variable name or other graph key that is missing from the checkpoint. Please ensure that you have not altered the graph expected based on the checkpoint. Original error:が出てしまいうまくいきませんでした。
CUDA9.2
次にCUDA9.2での動作を確認します。
$ conda deactivate $ conda activate visnet_CUDA $ pip install matplotlib $ pip install numpy $ pip install python_speech_features $ pip install scipy公式には
pip install --ignore-installed --upgrade https://download.tensorflow.google.cn/linux/gpu/tensorflow_gpu-1.1.0-cp35-cp35m-linux_x86_64.whlと書かれているのでします。
ただこのまま実行しても
ImportError: libcublas.so.8.0: cannot open shared object file: No such file or directory(エラーから抜粋)
8.0のcublasライブラリがないと出ているので多分CUDA9.2ではなく8.0でないと動きません
8.0にダウングレードして再検証したいところですがここではひとまず次に移ります。ROCm編
$ conda deactivate $ conda activate visnet_ROCm $ pip install matplotlib $ pip install numpy $ pip install python_speech_features $ pip install scipy $ pip install tensorflow-rocmFailed to load the native TensorFlow runtime.案の定実行エラーになってしまいました。
もしかしてなんか足りないライブラリがあるのでは?と思いひとまず全部盛りでapt-getすることにしました。
sudo apt install -y --allow-unauthenticated rocm-dkms rocm-dev rocm-libs rocm-device-libs hsa-ext-rocr-dev hsakmt-roct-dev hsa-rocr-dev rocm-opencl rocm-opencl-dev rocm-utils rocm-profiler cxlactivitylogger miopen-hip miopengemmその結果CPUと同じように
NotFoundError (see above for traceback): Restoring from checkpoint failed. This is most likely due to a Variable name or other graph key that is missing from the checkpoint. Please ensure that you have not altered the graph expected based on the checkpoint. Original error:が出てきてしまいました、もしかしてtensorflow-rocmのバージョンが悪いのでは?と思い
$ pip uninstall tensorflow-rocm $ pip install tensorflow-rocm==1.11.0で再実行しましたが同様の結果になってしまいました。
Githubのcudnn5.0と指定されたのでそれ以外では動かないのかもしれませんCUDA8.0編
バージョンチェンジする時はdockerを使いたいと思いましたが今回はネイティブでやりました。
手法についてはこちらを参照してください。
https://qiita.com/_JG1WWK/items/f23fe5f1fa306ecda1de
Ubuntu16.04でCUDA9.2からCUDA8.0に速攻ダウングレードしたい時のメモCUDA8.0でも動かなかったので原因をエラーログから調べてみると
ImportError: libcudnn.so.5: cannot open shared object file: No such file or directoryよく考えると計算機にcudnnが入ってないと言うことに気がついたので入れて再度テストしました。
Download cuDNN v5.1 (Jan 20, 2017), for CUDA 8.0をダウンロードするのですが、なんとNVIDIAのデペロッパープログラムに参加しないとダウンロードすらできない仕様になっているらしいのでアカウントを作って
https://developer.nvidia.com/rdp/cudnn-archive
からcuDNN v5.1 Library for Linuxをダウンロードしました。cudnn-8.0-linux-x64-v5.1.tgzを展開すると、/cudaと言うフォルダが作られる。(ここではホームディレクトリに展開した)
https://qiita.com/kazetof/items/941c3463ac452b496d59
によると
/usr/local以下に各種ファイルをコピーする流れになる~/cuda/include$ sudo cp ./cudnn.h /usr/local/cuda/include ~/cuda/include$ sudo cp ./cudnn.h /usr/local/cuda-8.0/include~/cuda/lib64にカレントディレクトリを切り替えて
~/cuda/lib64$ sudo cp ./* /usr/local/cuda/lib64 ~/cuda/lib64$ sudo cp ./* /usr/local/cuda-8.0/lib64次に.bashrcに
export CUDA_ROOT="/usr/local/cuda" export LIBRARY_PATH=$CUDA_ROOT/lib:$CUDA_ROOT/lib64:$LIBRARY_PATH export LD_LIBRARY_PATH=$CUDA_ROOT/lib64/以上のパスを通していただきます。
これでcudnnの環境構築は終わりです。この状態で
$ conda deactivate $ conda activate visnet_CUDA $ python main_test.pyしたら最後までちゃんと完走しました。
今のところ完走してくれたのはCUDA8.0+CUDNN5.1の組み合わせだけです。まとめ
素直に公式の言うとおりにCUDA8.0+cuDNN5.0+GPU tensorflowの組み合わせでやったほうが無難そうです。
ROCmの場合MIOpenとcuDNNの互換性が未知数と言う点が大きそうです。NotFoundErrorに関する情報は
http://louis-needless.hatenablog.com/entry/notfounderror-bully-me
などで参照しましたがすぐ解決に繋がりそうな糸口は見いだせませんでした。参考
https://qiita.com/kazetof/items/941c3463ac452b496d59
GPUを使えるようにする for tensorflow
- 投稿日:2019-02-18T08:27:19+09:00
TensorFlow内部構造解析 (4.6) 計算グラフ最適化処理2 GraphOptimizationPass
本記事は、連載記事 TensorFlow内部構造解析 の1つで、GraphOptimizationPassによるTensorFlowの計算グラフ最適化処理について説明した記事になります。
- TensorFlow v1.13.0-rc0
- コミットID: a8e5c41c5bbe684a88b9285e07bd9838c089e83b
TensorFlowにおける計算グラフの最適化
TensorFlowでは、以下の3つの最適化機能の仕組みを使って、ユーザが定義した計算グラフを最適化した後に実行します。
- GraphOptimizationPass ★本記事で説明
- Grappler
- GraphOptimizer
本記事では、これら3つの最適化の仕組みの中でGraphOptimizationPassによる計算グラフ最適化処理について説明します。
GraphOptimizationPassによる最適化項目
GraphOptimizationPassは、計算グラフの構造が大きく変更される前後に追加することのできる最適化処理です。
ライブラリ使用の有無などをビルドオプションで指定することによって、GraphOptimizationPassに登録されている最適化処理の有効/無効が自動的に決まります。
またGraphOptimizationPassには、TensorFlowの内部実装の制約から作られたと思われる計算グラフ変形処理も多く含まれているようです。GraphOptimizationPassとして最適化処理を追加できるフェーズは、以下に示すように4つあります。
フェーズ PRE_PLACEMENT 計算グラフの各ノードにデバイスを割り当てる前 POST_PLACEMENT 計算グラフの各ノードにデバイスを割り当てた後、かつGrapplerによって計算グラフが最適化される前 POST_REWRITE_FOR_EXEC Grapplerによって計算グラフが最適化された後、かつ計算グラフをデバイスごとに分割する前 POST_PARTITIONING 計算グラフをデバイスごとに分割した後(GraphOptimizerによって計算グラフが最適化される前) GraphOptimizationPassに登録されている最適化処理を、フェーズごとに示します。
PRE_PLACEMENT
No Optimizer名 1 FunctionalizeControlFlowPass 2 EncapsulateXlaComputationsPass 3 LowerIfWhilePass 4 ParallelConcatRemovePass 5 AccumulateNV2RemovePass 1. FunctionalizeControlFlowPass
ソースコード:
tensorflow/compiler/tf2xla/functionalize_control_flow.cc(本最適化は、TensorFlowの内部実装の事情により作られた、計算グラフ最適化処理であると推測します)
TensorFlowでは、条件分岐
tf.condやループ処理tf.while_loopを、複数のOperationを組み合わせることにより実現しています。
しかしこれはTensorFlowの内部実装からの制約によるもので、XLAのように最適化処理で計算グラフの変形を行うことが中心となるグラフコンパイラの場合、非常に扱いにくいものになっています。
このため本最適化処理では、tf.condやtf.while_loopによって生成されたノードを、XLAで最適化しやすいIfノードやWhileノードに変形します。
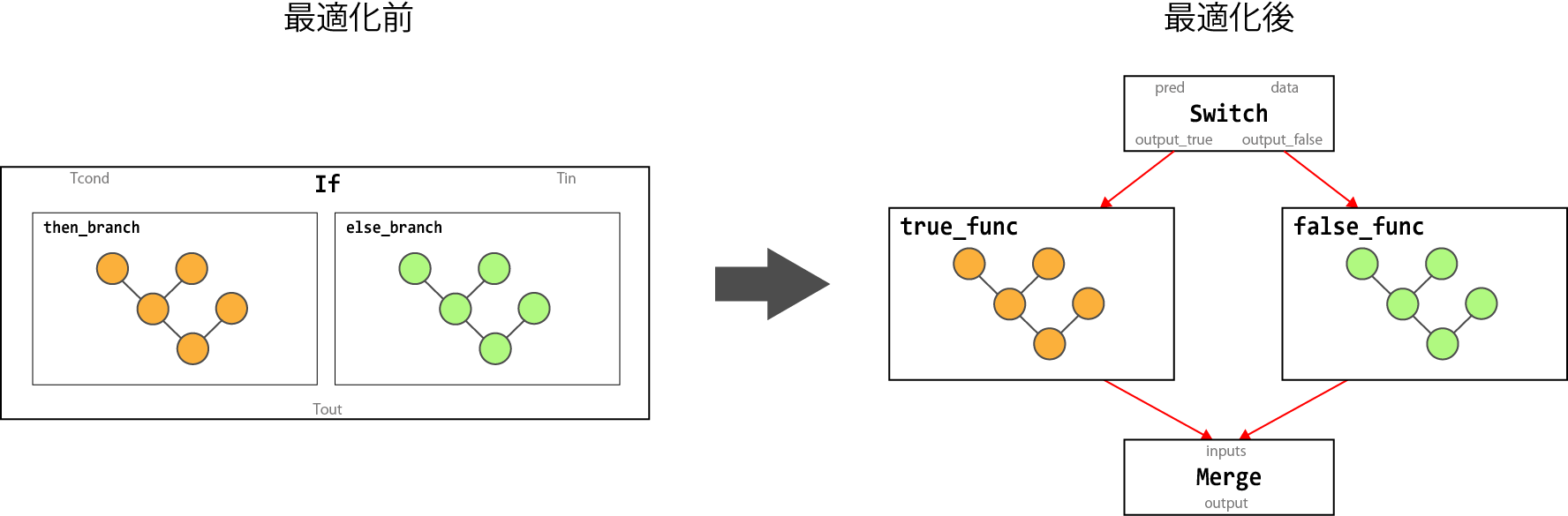
変換前 変換後 Switch, Merge If Switch, Merge, Enter, Exit, NextIteration, LoopCond While 以下の図は、
SwitchノードとMergeノードからIfノードへ変換するグラフ変形処理を示しています。
2. EncapsulateXlaComputationsPass
ソースコード:
tensorflow/compiler/jit/encapsulate_xla_computations_pass.ccTensorFlowの計算グラフを、XLAで扱う計算グラフに変換します。
XLAを使って演算することが指示されている計算グラフを、XlaLaunchノードに置き換えます。
詳細は、TensorFlow XLA 「XLAとは、から、最近の利用事例について」 に内部構造がまとめられているので、参照してみてください。3. LowerIfWhilePass
ソースコード:
tensorflow/core/common_runtime/lower_if_while.cc(本最適化は、TensorFlowの内部実装の事情により作られた、計算グラフ最適化処理であると推測します)
FunctionalizeControlFlowPass でも説明した通り、TensorFlowは条件分岐
tf.condやループ処理tf.while_loopを、複数の演算を組み合わせることにより実現しています。
しかしTensorFlow内部ではIfノード やWhileノードをそのまま扱うことができないため、TensorFlowの内部実装の制約に合うように、これらのノードを複数のノードに分解します。
変換前 変換後 If Switch, Merge While Switch, Merge, Enter, Exit, NextIteration, LoopCond 以下の図は、
IfノードをSwitchノード とMergeノードに変換するグラフ変形処理を示しています。
4. ParallelConcatRemovePass
ソースコード:
tensorflow/core/common_runtime/parallel_concat_optimizer.cc(本最適化は、TensorFlowの内部実装の事情により作られた、計算グラフ最適化処理であると推測します)
TensorFlowには、並列でConcat処理を実現するための
ParallelConcatと呼ばれるOperation1があります。
並列Concat処理の計算グラフの構築をPython側で実装すると煩雑化するために、本最適化処理が存在していると推測しています。
Pythonによる計算グラフ構築時にはParallelConcatという一時的なノードを使い、本最適化処理で並列Concat処理を実現する計算グラフに変形することで、Pythonで計算グラフを構築するよりも容易に並列Concatを実装できるのかもしれません。
5. AccumulateNV2RemovePass
ソースコード:
tensorflow/core/common_runtime/accumulate_n_optimizer.cc(本最適化は、TensorFlowの内部実装の事情により作られた、計算グラフ最適化処理であると推測します)
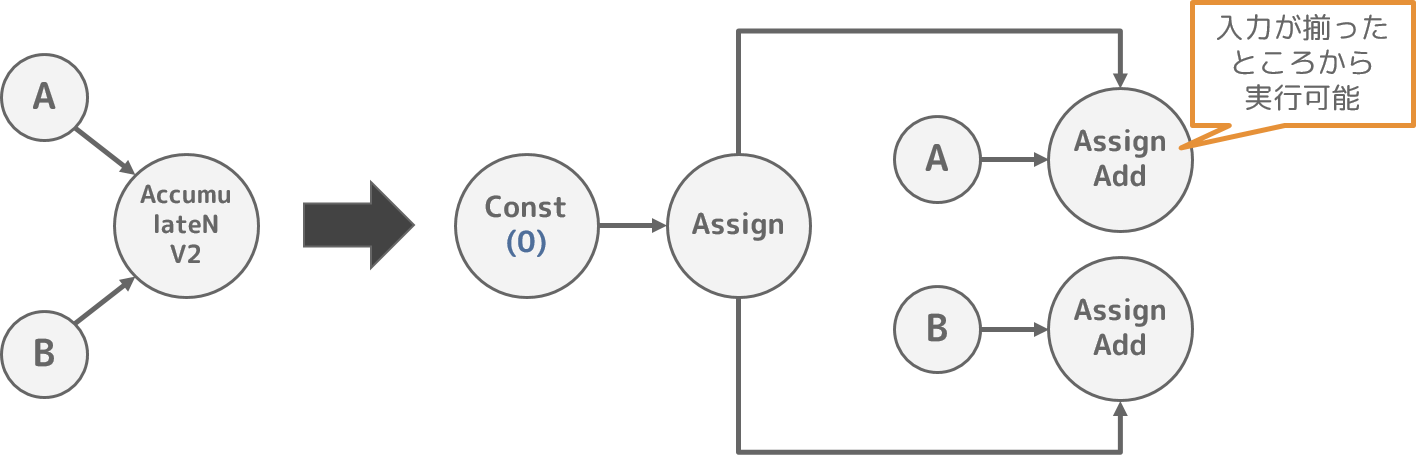
TensorFlowの
AddNOperationは入力テンソルが全て揃ってから実行するため、AddNの入力数が多くなるとピークメモリ使用量が大きくなる問題があります。
このためTensorFlowでは、準備できた入力テンソルから足し算を行っていくAccumulateNV2Operation2を提供しています。
なお、AccumulateNV2をPython側で実装すると煩雑化するために、本最適化処理が存在していると推測しています。
Pythonによる計算グラフ構築時にはAccumulateNV2という一時的なノードを使い、本最適化処理で計算グラフを変形することで、AccumulateNV2のOperationを実現しています。
POST_PLACEMENT
No Optimizer名 1 NcclReplacePass 1. NcclReplacePass
ソースコード:
tensorflow/core/nccl/nccl_rewrite.cc(本最適化は、TensorFlowの内部実装の事情により作られた、計算グラフ最適化処理であると推測します)
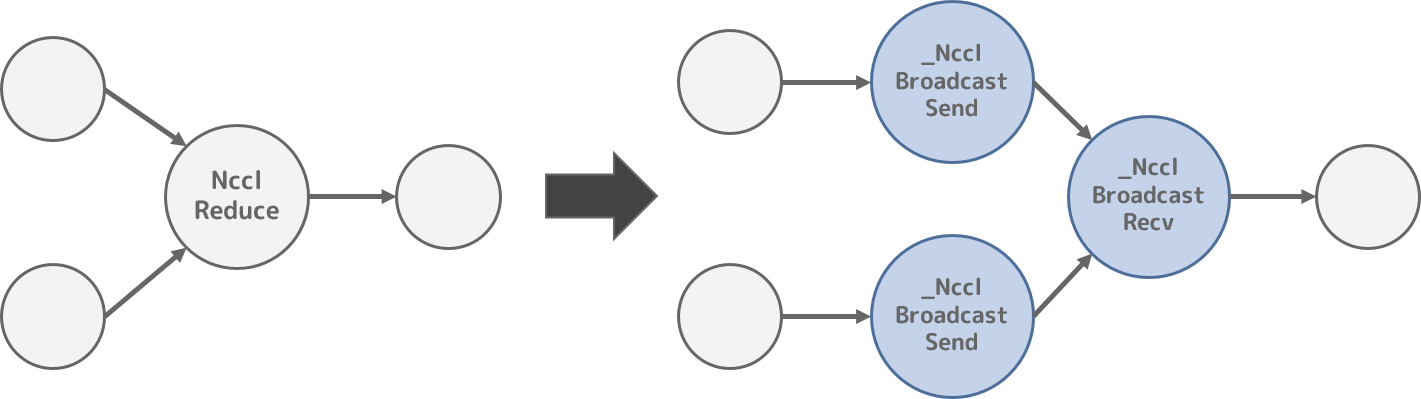
NVIDIAは、ncclというマルチGPU間で集合通信するためのライブラリを提供しています。
TensorFlowには、ncclを使ってGPU間で集合通信するためのAPIとして、tf.contrib.nccl.all_sumなどの Python API を提供しており、これらのAPIを利用することによりマルチGPU間で集合通信することができます。
このようなncclを使ったマルチGPU間の集合通信を行うPython APIを実現するために、NcclAllReduceやNcclReduce、NcclBroadcastOperationを使ってTensorFlowの計算グラフを構築します。
しかしこれらのOperationは、TensorFlow内部では_Sendや_Recvのように、データの送信と受信で異なるノードとして実現した方が都合がよいと考えられ(推測です)、_NcclReduceSendなどのノードに置き換えられます。
POST_REWRITE_FOR_EXEC
No Optimizer名 1 MarkForCompilationPass 2 IncreaseDynamismForAutoJitPass 3 PartiallyDeclusterPass 4 EncapsulateSubgraphsPass 5 BuildXlaOpsPass 1. MarkForCompilationPass
ソースコード:
tensorflow/compiler/jit/mark_for_compilation_pass.ccTensorFlowの計算グラフをXLAで扱う計算グラフに変換するために実行する、計算グラフ変形処理です。
XLAを使って演算することが可能な計算グラフのノードに、XLAで実行することを示すフラグを設定します。
詳細は、TensorFlow XLA 「XLAとは、から、最近の利用事例について」 に内部構造がまとめられているので、参照してみてください。2. IncreaseDynamismForAutoJitPass
ソースコード:
tensorflow/compiler/jit/increase_dynamism_for_auto_jit_pass.ccTensorFlowの計算グラフをXLAで扱う計算グラフに変換するために実行する、計算グラフ変形処理です。
テンソルのサイズが変化するなどでSlice等に指定するサイズが変更された場合、XLAから見ると計算グラフが変化したように見えてしまうため、XLAは再コンパイルしてしまいます。
再コンパイルによる性能悪化の影響は大きいため、XLAからみるとあたかも計算グラフが変更されていないような計算グラフに変形し、XLAが再コンパイルしないようにします。
具体的な計算グラフの変形処理としては、以下のようなケースが考えられます。Slice(x, begin, size) \quad \Longrightarrow \quad Slice(x, begin, Size(x, begin))3. PartiallyDeclusterPass
ソースコード:
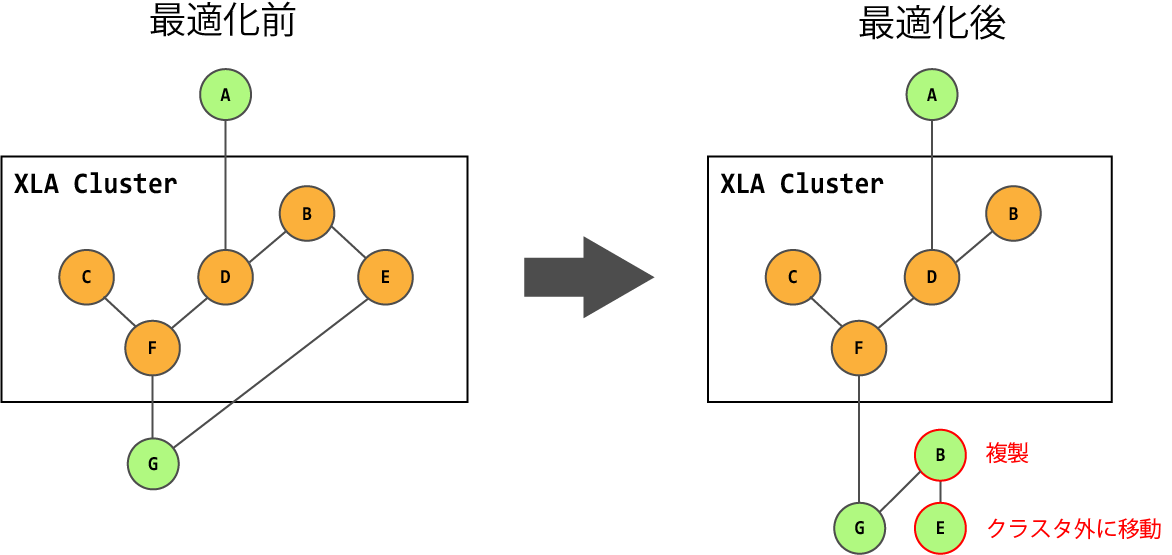
tensorflow/compiler/jit/partially_decluster_pass.ccTensorFlowの計算グラフをXLAで扱う計算グラフに変換するために実行する、計算グラフ変形処理です。
XLAを使って実行する計算グラフのノードのクラスタに含まれるノードの中で、XLAで実行しない方が性能面でよいと判断された場合は、当該ノードをクラスタから外すか、クラスタ外に当該ノードをコピーします。
クラスタから外す判断材料としては、以下が考えられています。
- ホスト-デバイス間のメモリコピー処理を削減可能か
- XLAの再コンパイル回数を削減可能か
4. EncapsulateSubgraphsPass
ソースコード:
tensorflow/compiler/jit/encapsulate_subgraphs_pass.ccTensorFlowの計算グラフをXLAで扱う計算グラフに変換するために実行する、計算グラフ変形処理です。
XLAを使って実行する計算グラフのノードのクラスタをサブグラフ化(Function化)して、後続のBuildXlaOpsBassに渡します。
詳細は、TensorFlow XLA 「XLAとは、から、最近の利用事例について」 に内部構造がまとめられているので、参照してみてください。5. BuildXlaOpsPass
ソースコード:
tensorflow/compiler/jit/build_xla_ops_pass.ccTensorFlowの計算グラフをXLAで扱う計算グラフに変換するために実行する、計算グラフ変形処理です。
EncapsulateSubgraphsPassによってFunction化した計算グラフのノードのクラスタを、_XlaCompileノードと_XlaRunノードに置き換えます。
詳細は、TensorFlow XLA 「XLAとは、から、最近の利用事例について」 に内部構造がまとめられているので、参照してみてください。POST_PARTITIONING
No Optimizer名 1 MklToTfConversionPass 2 MklLayoutRewritePass 1. MklLayoutRewritePass
ソースコード:
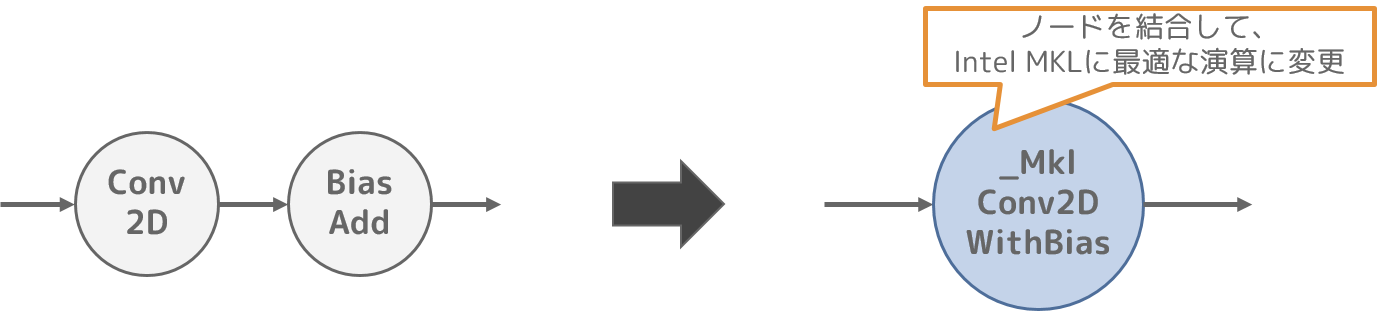
tensorflow/core/graph/mkl_layout_pass.ccIntel MKL3を有効化してTensorFlowを利用する場合、Intel MKLにとって最適に演算できる計算グラフとなるように計算グラフを変形します。
本最適化では、複数ノードの結合や演算途中で出力される中間データの再利用により、Intel MKLで最適に演算可能な処理を増やします。
ここではConv2DノードとBiasAddノードを、_MklConv2DWithBiasノードに結合する例を示します。
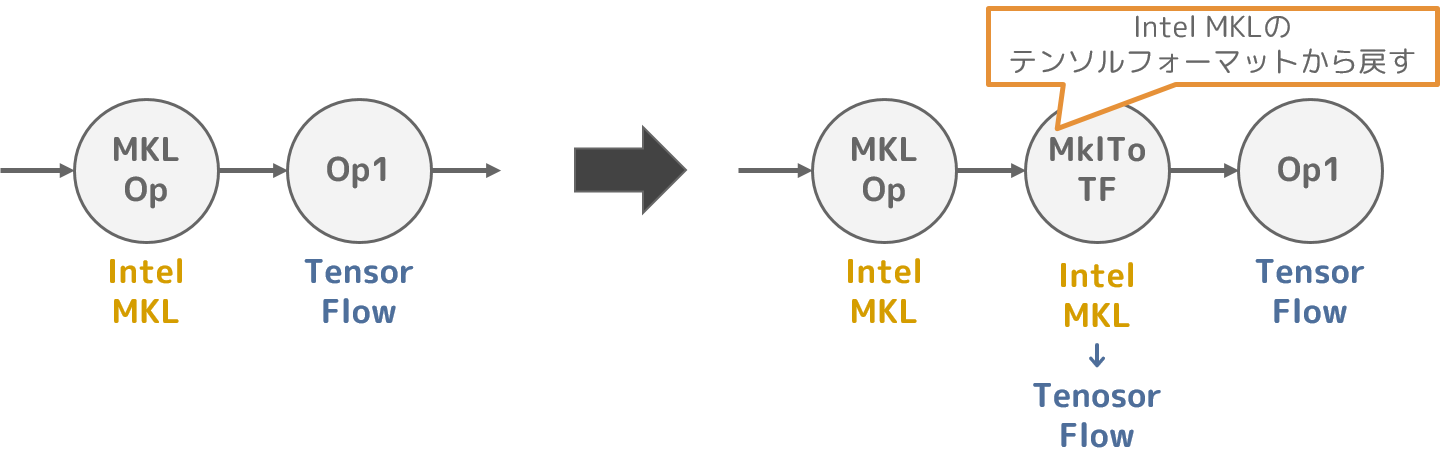
2. MklToTfConversionPass
ソースコード:
tensorflow/core/graph/mkl_tfconversion_pass.ccIntel MKLには最適なテンソルフォーマットがあり、Intel MKLを使って演算する場合はこのテンソルフォーマットを利用することで、性能の向上が見込めます。
ただし、Intel MKLに適したテンソルフォーマットは、TensorFlowのテンソルフォーマットとは異なります。
このため、本最適化処理ではIntel MKLに適したテンソルフォーマットと、TensorFlowのテンソルフォーマットの間の差異による矛盾が発生しないように、テンソルフォーマットを変換するノードを追加します。