- 投稿日:2019-02-18T20:52:24+09:00
Autonomous DatabaseにSQLcl接続してみてみた
Oracle SQL Developer Command Line (SQLcl) は、SQLコマンドを入力するためのコマンドライン・インタフェースです。
SQL Developerの機能がコマンドライン・インタフェースに導入されており、従来のSQL*Plusには無かった以前に実行したコマンド履歴などが使えます。
ここでは、Autonomous Databaseを作成して、SQLcl接続できるまでの手順を説明します。■Autonomous Database側設定
Autonomous Data Warehouses(ADW)とAutonomous Transaction Processing Databases(ATP)ともに同じ手順となり、ここでは、ADWを作成して接続を行います。
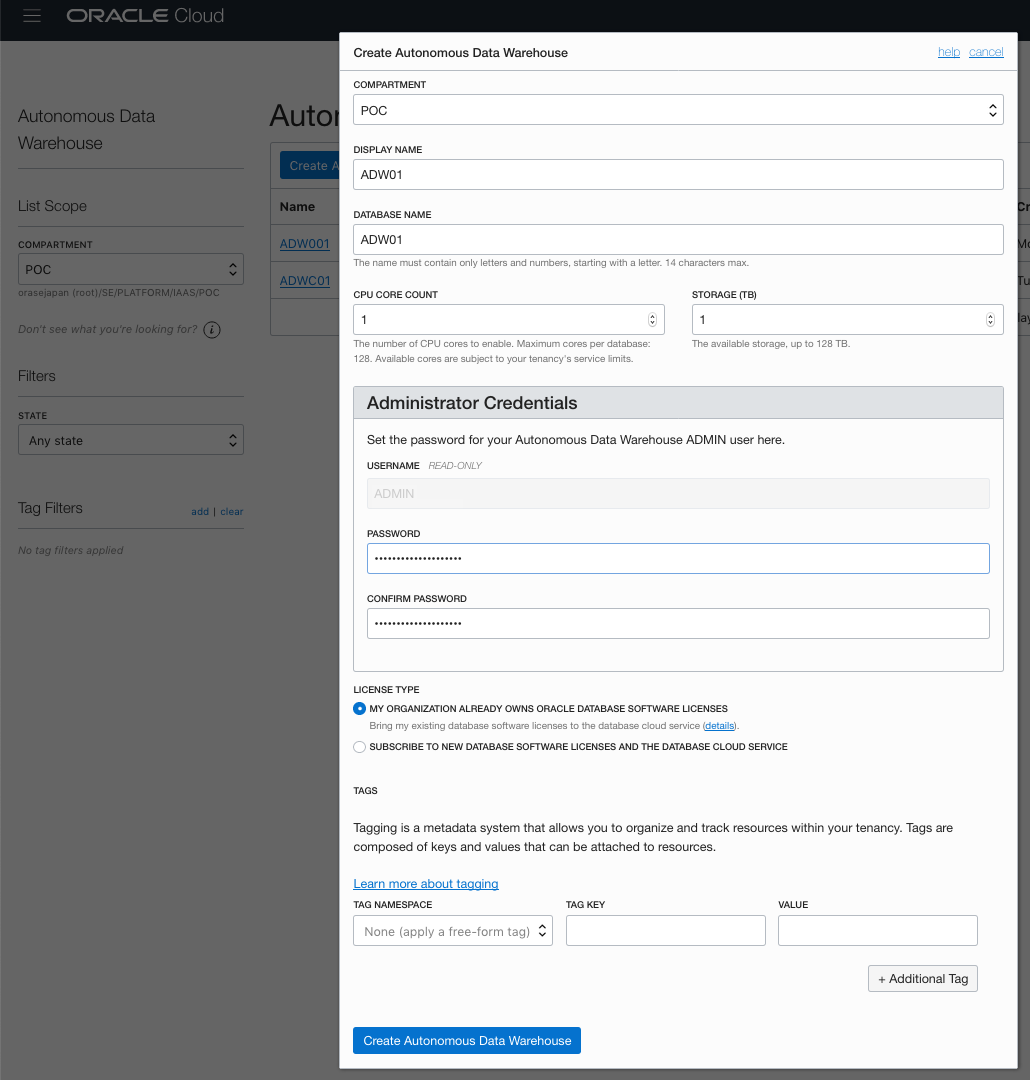
●Autonomous Data Warehouse(ADW)を作成
Autonomous Data Warehouses画面で[Create Autonomous Data Warehouses]ボタンをクリックし、以下のような情報を入力して作成します。
●クライアント資格証明(Oracle Wallet)のダウンロード
データベース接続は暗号化されており、WALLETの資格証明を使用して接続します。
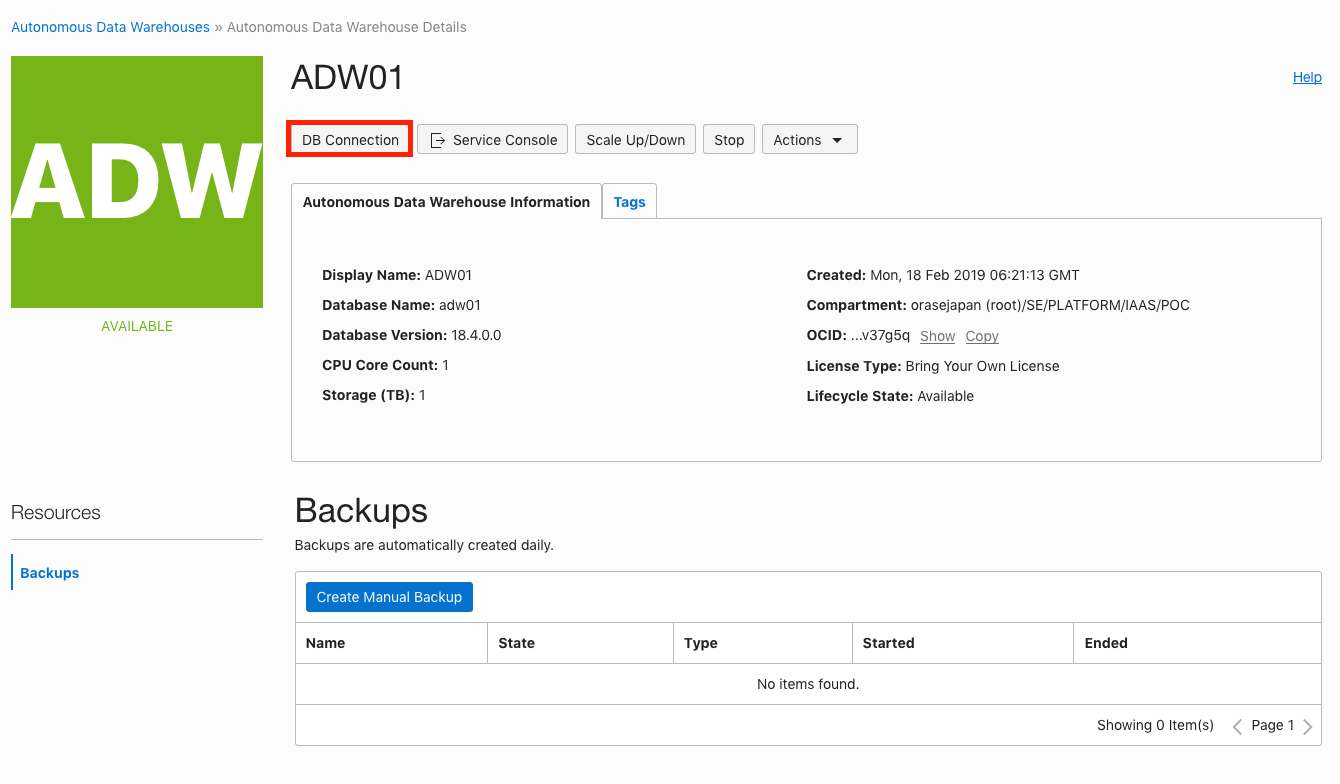
ADWでは、zip化された接続情報含めたファイルをダウンロードし、このzipを使用して接続します。①作成したADWのページに移動し、「DB Connection」をクリック
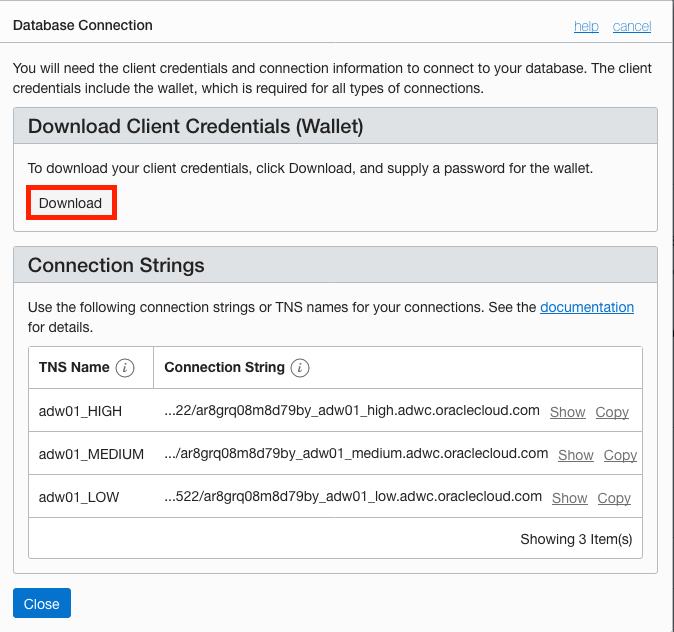
②「Database Connection」画面で、「Download」をクリック
また、この画面の「Connection Strings」項目について、
「Connection String」から、"ar8grq08m8d79by_adw01"が作成したPDB Nameであることが確認できます。
「TNS Name」には、high, mediumおよびlowの3つの定義済みのサービス名があり、用途に合わせて選択し接続しますので、メモしておきます。
定義済みDatabaseサービス名の詳しい内容は次のマニュアルを参考してください。
・マニュアル:定義済みDatabaseサービス名
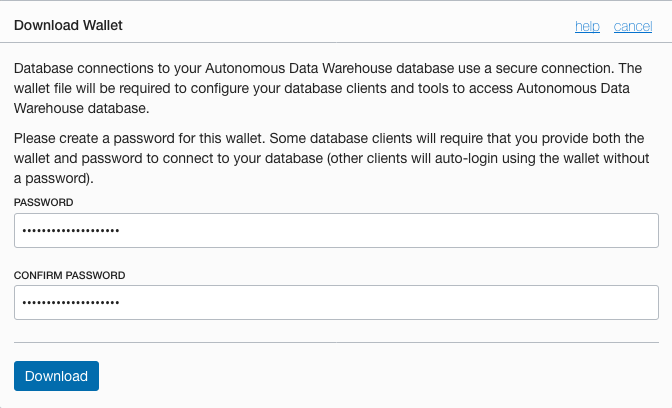
https://docs.oracle.com/cd/E83857_01/paas/autonomous-data-warehouse-cloud/user/connect-predefined.html#GUID-9747539B-FD46-44F1-8FF8-F5AC650F15BE③「Download Wallet」画面で以下を設定し、[Download]をクリック
「PASSWORD」:Oracle Walletのパスワードを設定
「Confirm Password」:確認するため再度パスワードを入力
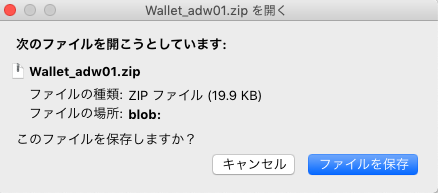
④ クライアントのセキュリティ資格証明のzipファイルを適切な場所に保存します。
ここでは、ダウンロードしたWallet_ATP01.zipを $HOME/oracle へ配置します。
[opc@client-inst ~]$ mkdir ~/oracle [opc@client-inst ~]$ mv Wallet_ATP01.zip ~/oracle/■Client側設定
●JAVA8 ダウンロードとインストール
SQLclはJavaアプリケーションであり、Java Runtime Engine(JRE)version 8以上を必要としますのでまずダウンロードしてインストールします。
①JAVA8 ダウンロード
以下Java SE Development Kit 8u201 のページから、ダウンロードします。
https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html②インストール
ここではLinux版の jdk-8u201-linux-x64.rpmダウンロードしてインストールします。[root@client-inst opc]# rpm -ivh jdk-8u201-linux-x64.rpm 準備しています... ################################# [100%] 更新中 / インストール中... 1:jdk1.8-2000:1.8.0_201-fcs ################################# [100%] Unpacking JAR files... tools.jar... plugin.jar... javaws.jar... deploy.jar... rt.jar... jsse.jar... charsets.jar... localedata.jar...●SQLcl ダウンロードとインストール
① SQLcl ダウンロード
以下ページからダウンロード
https://www.oracle.com/database/technologies/appdev/sqlcl.html②SQLclインストール
ここでは、~/oracleへインストール[opc@client-inst ~]$ mv sqlcl-18.4.0.007.1818.zip ~/oracle/ [opc@client-inst ~]$ cd ~/oracle [opc@client-inst ~]$ unzip sqlcl-18.4.0.007.1818.zip Archive: sqlcl-18.4.0.007.1818.zip creating: sqlcl/ creating: sqlcl/bin/ creating: sqlcl/lib/ inflating: sqlcl/bin/sql ・・・●SQLcl接続確認
① /nologオプションを使用してSQLclを起動
[opc@client-inst ~]$ ~/oracle/sqlcl/bin/sql /nolog SQLcl: 月 2月 18 16:56:36 2019のリリース18.4 Production Copyright (c) 1982, 2019, Oracle. All rights reserved.②Oracle Walletを使用するようにSQLclセッションを構成
SQL> set cloudconfig /home/opc/oracle/Wallet_ADW01.zip 操作は正常に完了しました。 操作は正常に完了しました。 Using temp directory:/var/folders/td/ltsnlh6d01gdrm0rjh5hmn_00000gn/T/oracle_cloud_config1774995246833750575③ADWに接続
設定したパスワードを入力して接続し、SQLを実行してテストSQL> connect ADMIN@adw01_HIGH パスワード (**********?) ******************** 接続しました. SQL> select BANNER_FULL from v$version; BANNER_FULL ----------------------------------------------------------------------------------------------------------------------------- Oracle Database 18c Enterprise Edition Release 18.0.0.0.0 - Production Version 18.4.0.0.0 SQL> select NAME from v$pdbs; NAME ------------------------------------------- AR8GRQ08M8D79BY_ADW01■おまけ:SQL Developer インストール
Mac OSにSQL Developerをインストールします。
●JAVA8 ダウンロードとインストール
次のURLから、jdk-8u201-macosx-x64.dmg(Mac版) をダウンロードし、ダブルクリックしてインストール
https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html●SQL Developerダウンロード
次のURLからsqldeveloper-18.4.0-376.1900-macosx.app.zip(Mac版)をダウンロード
https://www.oracle.com/technetwork/jp/developer-tools/sql-developer/downloads/index.html●SQL Developerインストール
sqldeveloper-18.4.0-376.1900-macosx.app.zipを解凍
インストールは解凍するだけです。●SQL Developer設定
①解凍されたSQLDeveloperアイコンをクリックして起動
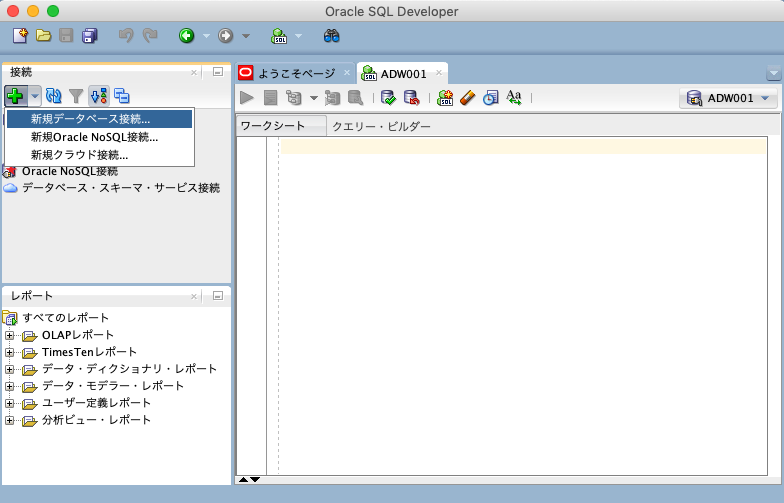
②Oracle SQL Developerを起動し、接続パネルで「接続」を右クリックし、「新規接続」を選択
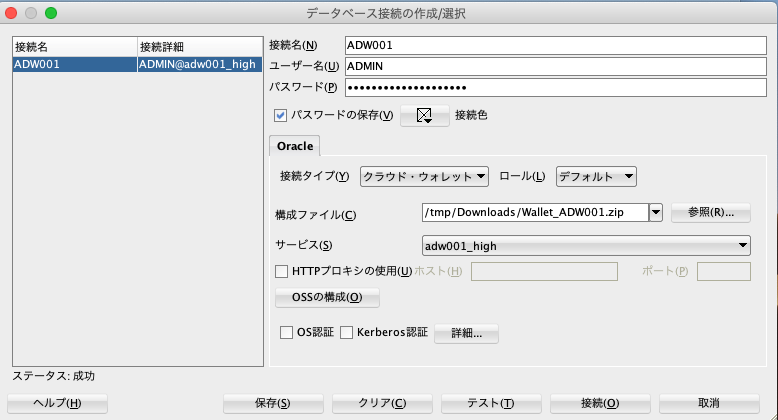
③次の情報を入力して[保存]をクリックして設定
・接続名: この接続の名前を入力します。 ・ユーザー名: データベース・ユーザー名を入力 ・パスワード: データベース・ユーザーのパスワードを入力 ・接続タイプ: クラウド・ウォレットを選択 ・構成ファイル: ブラウズをクリックし、クライアントの資格証明のzipファイルを選択 ・サービス: サービス名を選択
④接続
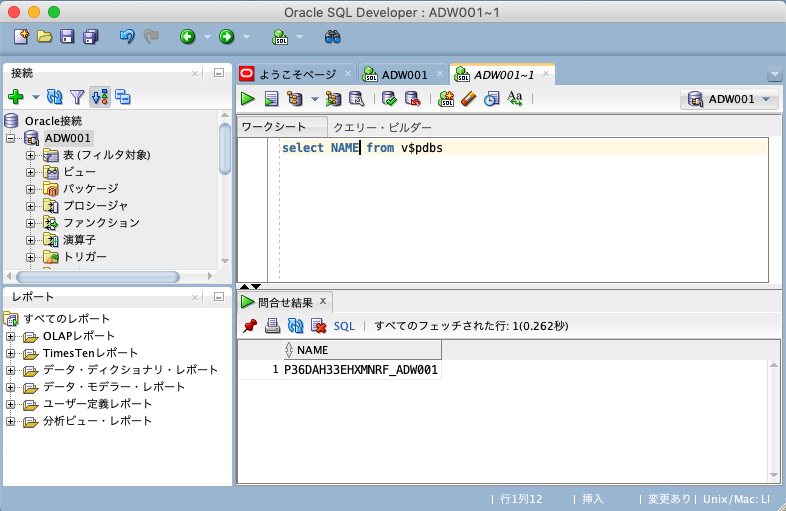
作成した接続名を右クリックして[接続]を行い
SQLを実行して接続を確認します。
■参考
・マニュアル:Oracle Autonomous Data Warehouseの使用
https://docs.oracle.com/cd/E83857_01/paas/autonomous-data-warehouse-cloud/user/connect-data-warehouse.html#GUID-94719269-9218-4FAF-870E-6F0783E209FD・Oracle SQLcl
https://www.oracle.com/database/technologies/appdev/sqlcl.html・SQL Developer
https://www.oracle.com/technetwork/jp/developer-tools/sql-developer/overview/index.html・Java SE Development Kit 8 Downloads
https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
- 投稿日:2019-02-18T12:15:11+09:00
便利なSQLコマンド
個人的に便利だと思ったSQLコマンドを書きなぐっていきます。備忘録です。
\g
表示結果を縦に表示してくれるとても素晴らしい機能
mysql> select * from test; +-------+--------+--------+--------+ | id | hostid | status | type | +-------+--------+--------+--------+ | 1 | 1 | true | a | | 2 | 1 | true | b | +-------+--------+--------+--------+ mysql> select * from test \G *************************** 1. row *************************** id: 1 hostid: 1 status: true type: a *************************** 2. row *************************** devid: 2 hostid: 1 status: true type: b 2 rows in set (0.00 sec)気になるコマンド見つけたら随時更新予定
他にも皆さんの「こんなのも便利!」などのコメント待ってます。
- 投稿日:2019-02-18T10:22:05+09:00
SQL集計条件の位置とその影響
以下のような業務データがあるとします。
顧客表:
・メイン口座とサブ口座を開設可能。(Mはメイン、Sはサブ)
・メイン口座のみを持つ顧客も存在。
・サブ持っていない場合、空きの文字列で保存
顧客番号 メイン口座番号 サブ口座番号 0001 0001M 0001S 0002 0002M 0002S 0003 0003M '' 残高表:
・口座番号で管理
・三種類の区分
口座番号 金額 区分 0001M 1000 株 0001M 1000 現金 0001M 1000 不動産 0001S 100 株 0001S 100 現金 0001S 100 不動産 0002M 2000 株 0002M 2000 現金 0002M 2000 不動産 0002S 200 株 0002S 200 現金 0002S 200 不動産 0003M 3000 株 0003M 3000 現金 0003M 3000 不動産 目的:顧客ごとでメイン口座とサブ口座の残高合計を抽出
*:区分は現金のみ
メイン口座 サブ口座 合計 0001M 0001S 1100 0002M 0002S 2200 0003M 3000 業務視点からの設計
残高表にメイン口座とサブ口座レコードは混在しているため、
1、まずは顧客表から顧客IDを抽出
2、残高表からメイン口座のレコードを抽出して上記1の結果と結合
3、もう一回残高表からサブ口座のレコードを抽出して上記2までの結果と結合また、サブ口座が存在しない状況もあるので、顧客表にLEFT JOINすると考えていました。
試行1
上記内容を踏まえて、以下のSQLで結果を抽出してみましたが、結果は予想と違います。
select z2.kouza as main_kouza, z3.kouza as sub_kouza, case when z3.amount is not null then z2.amount + z3.amount else z2.amount end as sum from ( select id from kokyaku )as z1 left join zandaka as z2 on left(z2.kouza, 4) = z1.id and substring(z2.kouza from '.$') = 'M' left join zandaka as z3 on left(z3.kouza, 4) = z1.id and substring(z3.kouza from '.$') = 'S' where z2.kbn = '現金' and z3.kbn = '現金'結果
メイン口座 サブ口座 合計 0001M 0001S 1100 0002M 0002S 2200 サブ口座を持っていない顧客情報は抽出されませんでした。
試行2
区分条件をwhereではなく、各テーブルのJOINのON句に移動したところ、
予想と同じような結果を抽出できました。select z2.kouza as main_kouza, z3.kouza as sub_kouza, case when z3.amount is not null then z2.amount + z3.amount else z2.amount end as sum from ( select id from kokyaku )as z1 left join zandaka as z2 on left(z2.kouza, 4) = z1.id and substring(z2.kouza from '.$') = 'M' and z2.kbn = '現金' left join zandaka as z3 on left(z3.kouza, 4) = z1.id and substring(z3.kouza from '.$') = 'S' and z3.kbn = '現金'結果
メイン口座 サブ口座 合計 0001M 0001S 1100 0002M 0002S 2200 0003M 3000 試行1と試行2結果が異なる原因
結合の処理順番は原因になると見られます。
試行1では、区分条件は最後のwhereにあるので、
各テーブルを結合してから、区分によってレコードが結果表削除されます。
しかし、結合の処理で、z3、即ちサブ口座表に、0003に該当するデータがないため
結合した結果表に、0003の行で、z3.kbnと相当するレコードはNULLになります。
顧客番号 口座(メイン) ... 区分 口座(サブ) ... 区分 ... 0001 0001M ... 現金 0001S ... 現金 ... 0001 0001M ... 現金 0001S ... 株 ... 0001 0001M ... 現金 0001S ... 不動産 ... 0002 0002M ... 現金 0002S ... 現金 ... 0002 0002M ... 現金 0002S ... 株 ... 0002 0002M ... 現金 0002S ... 不動産 ... 0003 0003M ... 現金 NULL ... NULL ... where句にある条件は、結果テーブルの全体に影響するため、
ここに「z3.kbn = '現金'」入れると、最後の一行レコードが削除され、
0003のデータがなくなります。JOINのON句にある条件は、結合する前のテーブル(サブクエリのようで)を
影響するため、ここに区分条件を入れると、レコード2行のテーブル(サブ)が
レコード3行のテーブル(メイン)にLEFT JOINされるため、0003のデータは残ります。試行3(最終版)
口座番号に顧客番号が含まれているため、処理としては顧客表は不要になります。
select z1.kouza, z2.kouza, --nullのカラムがあれば合計はでないので、caseで処理 case when z2.amount is not null then z1.amount + z2.amount else z1.amount end from zandaka as z1 --同じ顧客のサブ口座のみを抽出、さらに区分を現金に限定 left join zandaka as z2 --サブ口座該当判定 on substring(z2.kouza from '.$') = 'S' and --同じ顧客であるかを判定 left(z1.kouza, 4) = left(z2.kouza, 4) and --現金限定 z2.kbn = '現金' where z1.kbn = '現金' and substring(z1.kouza from '.$') = 'M'まとめ
・WHERE句にある条件はテーブルが結合されてから結果テーブルに適用される
*:結合した結果にNULLのレコードがある場合、結合されたテーブルのカラムを
条件としてWHERE句に入れると、結果は不完全になるかもしれない
・JOINのON句にある条件が適用されてからテーブルは結合されるまた、JOINする前にテーブルのレコードを減らさないと、パフォーマンスにも
影響がでるでしょう。
- 投稿日:2019-02-18T06:48:10+09:00
csvqについてのいろいろ
csvq - SQL-like query language for csv は元々5人程のユーザに使ってもらうために公開していたもので,過去にドイツのほうでLinux MagazinやLinuxUserに小さく紹介してもらったことはあったのですが,先週より日本からのアクセスが増えたので,使うにあたってのちょっとしたことなどをこちらに書いておきます
想定用途
csvその他対応フォーマットの簡易的な計算や確認,微修正等.
クエリ実行の他,関数定義や外部コマンドの呼び出し,IFやWHILE等の制御構文により,複数のステートメントを組み合わせた簡単なスクリプトを書き,定型の処理として用意すること等も可能ですが,これらの機能は決してcsvをデータストアとして利用することを推奨するものではありません
読み込まれたcsvのデータはすべてメモリ上に保持されるため,データ量やマシンの搭載メモリ容量次第で快適に操作できる件数は変わってきます.目安として,搭載メモリ16GBのマシン上で,join等を利用しない1テーブルのみの読み込みでは最大1000万件程度のデータを想定しています
他の代替となるツールとの違いについて
csvqは,実行バイナリひとつでなるべく簡易に複数プラットフォーム上で同等の操作をおこなうことができるようにすることを目的としています.実行バイナリとcsvq用のクエリまたはスクリプトを記述したファイルを受け渡すことで,他のツールや実行者の使用するシステムに依存することなく同等の結果を得ることができます
その他,対話シェル,データ更新用クエリ等の機能があります
インストール
go getで最新のコミットを取得,ビルドし作成されるバイナリとReleaseページで配布する最新のバイナリは常に同一のものとなりますので,どちらの方法でインストールしても大丈夫です
他のパッケージに対して依存関係等のないツールですので,パッケージ管理システムでの配布は予定していません
計算結果の出力について
データはすべてstringまたはnull値として読み込まれ,なにも操作をしなければそのままの形で出力されます
演算子や関数でデータを操作した時点で自動で型の変換が行われます.where句等の中での型変換はselect句での出力には影響しません.select句の中で操作した出力結果を別の場所で利用する際にはそれぞれの値が適切な形になっているのか確認してください.データの型を明示的に指定する関数,データの形式を整えるための関数等も用意してあります
構文の確認
オンラインリファレンスを開かなくても,syntaxサブコマンドもしくはインタラクティブシェル上でのSYNTAXコマンドにより,使用可能な構文を確認できます.これはあくまでもcsvqの構文であり,SQLの構文を確認するためのものではありません
内部処理
読み込んだデータを1行1行地道に計算しているだけです.むずかしいことはなにもやっていません
大量データ検索の高速化
身も蓋もない話になりますが,出来るだけ多くのメモリと出来るだけ読み込み速度の速いSSDと出来るだけ多くのコアを持ったCPUを利用してください
-pオプションで並列処理の数を指定できます.デフォルトではOSの認識するコア数の半分の値となっています.Intel HTテクノロジー等の同時マルチスレッディングはこのツールの利用においてはあまり高速化には役立ちません.CPUのコア数とスレッド数が同数のシステムを使用している場合には,この値を変更することで,より高速化が可能です
その他,検索条件の最適化等もありませんので,テーブルの結合条件はwhere句ではなくjoin句に書く,より多くのレコードを絞り込める条件を条件式の左辺に書く等の,計算順序を意識した書き方が有用です.ただし,これらのことを考慮しなければならないような状況においては多くの場合,既存のDBMS等の利用を検討することがより良い選択肢となるかと思います
使用例
以下は現在の最新バージョン(1.8.3 Released on 2019/02/17)で動作を確認してあります
スクリプトの拡張子はなんでも良いのですが,.sqlまたは.cqlのファイルはインタラクティブシェル上で,SOURCEコマンドの引数の補完の候補として表示されるようにしてあります
例えばどこかの国の地方行政区分を簡易ツリー表示してみる
以下の機能の使用
- 組み込み関数
- ユーザ定義関数
- 変数
- 条件文
- 算術,文字列結合演算子
データ
government.csvid,name,parent_id 1,ラダトーム, 2,りゅうおうのしろ, 3,ガライ,1 4,マイラ,1 5,リムルダール,1 6,ドムドーラ,1 7,メルキド,1 8,あめのほこら,4 9,せいなるほこら,5実行スクリプト
list_gov.sql/* * ソート用文字列作成関数 * (現在WITH句のRECURSIVEでは幅優先探索のみ可能なため,結果のソートが必要) */ DECLARE gen_route FUNCTION (@id, @parent_route) AS BEGIN VAR @r := LPAD(@id, 2, '0'); IF @parent_route IS NULL THEN --ソート時の自動型変換で数値として解釈されることを防ぐため先頭に文字を付加 RETURN 'R' || @r; END IF; RETURN @parent_route || '-' || @r; END; /* * クエリ */ WITH RECURSIVE govs (id, name, parent_id, level, route) AS ( SELECT id, name, parent_id, 0, gen_route(id, null) FROM government WHERE parent_id IS NULL UNION ALL SELECT g.id, g.name, g.parent_id, t.level + 1, gen_route(g.id, t.route) FROM government g INNER JOIN govs t ON t.id = g.parent_id ) SELECT id, LPAD(name, LEN(name)+level, ' ') AS name, level, route FROM govs ORDER BY route;実行結果
$ csvq -s list_gov.sql +----+--------------------+-------+-----------+ | id | name | level | route | +----+--------------------+-------+-----------+ | 1 | ラダトーム | 0 | R01 | | 3 | ガライ | 1 | R01-03 | | 4 | マイラ | 1 | R01-04 | | 8 | あめのほこら | 2 | R01-04-08 | | 5 | リムルダール | 1 | R01-05 | | 9 | せいなるほこら | 2 | R01-05-09 | | 6 | ドムドーラ | 1 | R01-06 | | 7 | メルキド | 1 | R01-07 | | 2 | りゅうおうのしろ | 0 | R02 | +----+--------------------+-------+-----------+例えばどこかのお店の日次売上を確認してみる
以下の機能の使用
- フラグ設定(出力をそのままマークダウンとして利用できる形式に)
- 一時テーブル
- 環境変数による外部からの値受け渡し
- 文字列の置換による動的生成クエリの実行
- 副問い合わせ
データ
items.csvid,category_id,name 1,1,やくそう 2,1,キメラのつばさ 3,1,たいまつ 4,2,こんぼう 5,2,どうのつるぎ 6,2,はがねのつるぎ 7,3,ぬののふく 8,3,くさりかたびら 9,3,はがねのよろいitem_category.csvid,name 1,アイテム 2,ぶき 3,ぼうぐsales_20180217.csvid,item_id,price,quantity,created 1,1,24,1,2018-02-17T07:01:05 2,3,8,2,2018-02-17T08:05:59 3,1,24,4,2018-02-17T08:06:37 4,5,180,2,2018-02-17T08:06:48 5,1,24,1,2018-02-17T08:30:05 6,6,1500,1,2018-02-17T08:45:20 7,2,70,1,2018-02-17T08:46:03 8,7,20,1,2018-02-17T09:03:04 9,8,300,1,2018-02-17T09:12:21 10,6,1500,1,2018-02-17T09:31:03 11,9,3000,1,2018-02-17T09:31:15 12,1,24,2,2018-02-17T09:31:25 13,2,70,1,2018-02-17T09:31:32 14,1,24,1,2018-02-17T10:05:20 15,1,24,6,2018-02-17T11:41:15 16,1,24,2,2018-02-17T12:40:06 17,3,8,2,2018-02-17T12:40:19実行スクリプト
sales_report.sql/* * フラグ設定 */ ADD '%Y%m%d' TO @@DATETIME_FORMAT; --YYYYMMDD形式のStringをDatetimeへ自動変換可能とする SET @@FORMAT TO GFM; --SELECTクエリの出力形式をGithub Flavored Markdownテーブルに /* * 日付が環境変数にセットされているか確認 */ IF @%SALES_DATE == '' THEN TRIGGER ERROR '@%SALES_DATE is empty.'; END IF; /* * 一時テーブル作成 */ VAR @create_tmp_view := ' DECLARE sales VIEW (id, item_id, price, quantity, amount) AS SELECT id, item_id, price, quantity, price*quantity FROM `sales_%s`; '; EXECUTE @create_tmp_view USING @%SALES_DATE; /* * データ抽出,表示 */ PRINTF '## 売上 %s' USING DATETIME_FORMAT(@%SALES_DATE, '%Y-%m-%d'); ECHO '\n### 売上数\n\n'; SELECT i.id, MAX(i.3) AS name, --テーブル内の列番号でカラム指定可能 SUM(s.quantity) AS sales_quantity FROM items i LEFT JOIN sales s ON s.item_id = i.id GROUP BY i.id ORDER BY sales_quantity DESC NULLS LAST; ECHO '\n### 売上額\n\n'; SELECT i.id, MAX(i.name) AS name, SUM(s.amount) AS sales_amount FROM items i LEFT JOIN sales s ON s.item_id = i.id GROUP BY i.id ORDER BY sales_amount DESC NULLS LAST; ECHO '\n### カテゴリ別売上額順位\n\n'; SELECT c.name AS category, RANK() OVER (PARTITION BY c.id ORDER BY t.sales_amount DESC NULLS LAST) AS `rank`, t.name AS name, t.sales_amount AS sales_amount FROM (SELECT i.id, MAX(i.category_id) AS category_id, MAX(i.name) AS name, SUM(s.amount) AS sales_amount FROM items i LEFT JOIN sales s ON s.item_id = i.id GROUP BY i.id) t INNER JOIN item_category c ON c.id = t.category_id ORDER BY c.id ASC, `rank` ASC; EXIT;実行結果
$ env SALES_DATE=20180217 csvq -s sales_report.sql ## 売上 2018-02-17 ### 売上数 | id | name | sales_quantity | | ---- | -------------- | -------------: | | 1 | やくそう | 17 | | 3 | たいまつ | 4 | | 2 | キメラのつばさ | 2 | | 5 | どうのつるぎ | 2 | | 6 | はがねのつるぎ | 2 | | 7 | ぬののふく | 1 | | 8 | くさりかたびら | 1 | | 9 | はがねのよろい | 1 | | 4 | こんぼう | | ### 売上額 | id | name | sales_amount | | ---- | -------------- | -----------: | | 9 | はがねのよろい | 3000 | | 6 | はがねのつるぎ | 3000 | | 1 | やくそう | 408 | | 5 | どうのつるぎ | 360 | | 8 | くさりかたびら | 300 | | 2 | キメラのつばさ | 140 | | 3 | たいまつ | 32 | | 7 | ぬののふく | 20 | | 4 | こんぼう | | ### カテゴリ別売上額順位 | category | rank | name | sales_amount | | -------- | ---: | -------------- | -----------: | | アイテム | 1 | やくそう | 408 | | アイテム | 2 | キメラのつばさ | 140 | | アイテム | 3 | たいまつ | 32 | | ぶき | 1 | はがねのつるぎ | 3000 | | ぶき | 2 | どうのつるぎ | 360 | | ぶき | 3 | こんぼう | | | ぼうぐ | 1 | はがねのよろい | 3000 | | ぼうぐ | 2 | くさりかたびら | 300 | | ぼうぐ | 3 | ぬののふく | 20 |