- 投稿日:2019-02-18T19:09:00+09:00
AWSCLI で 最小環境を構築するには (VPC,Subnet,RouteTable,InternetGateway)
ステップ 1: VPC とサブネットを作成する
AWS CLI を使用して VPC およびサブネットを作成するには
- VPC を作成する。
aws ec2 create-vpc --cidr-block (ネットワークアドレス)/(CIDR)
- 返された出力内にある、VPC IDをメモる。
{ "Vpc": { "VpcId": "vpc-0c26a2d951052e32c", "InstanceTenancy": "default", "Tags": [], "CidrBlockAssociationSet": [ { "AssociationId": "vpc-cidr-assoc-060fc9f00b6ee0d45", "CidrBlock": "192.168.210.0/24", "CidrBlockState": { "State": "associated" } } ], "Ipv6CidrBlockAssociationSet": [], "State": "pending", "DhcpOptionsId": "dopt-91c238f5", "CidrBlock": "192.168.210.0/24", "IsDefault": false } }上記出力の、"VpcId": "vpc-0c26a2d951052e32c"のところ。
- サブネットを作成する。
aws ec2 create-subnet --vpc-id (VpcId) --cidr-block (作成するサブネット)※今回は1サブネットしか作成しないため、サブネット作成は割愛した。
ステップ 2: サブネットをパブリックにする。
VPCおよびサブネットを作成した後、VPCにインターネットゲートウェイをアタッチして、カスタムルートテーブルを作成し、
インターネットゲートウェイへのサブネットからのルーティングを構成する。
- インターネットゲートウェイを作成する。
aws ec2 create-internet-gateway
- 返された出力内にある、InternetGatewayIdをメモる。
{ "InternetGateway": { "Tags": [], "Attachments": [], "InternetGatewayId": "igw-0c7b18dc6e4bd7eb5" } }上記出力の、"InternetGatewayId": "igw-0c7b18dc6e4bd7eb5"のところ。
- VPC にインターネットゲートウェイをアタッチ。
aws ec2 attach-internet-gateway --vpc-id (作成したVpcIdを入力) --internet-gateway-id (作成したInternetGatewayIdを入力)
- VPC に対してカスタムルートテーブルを作成する。
aws ec2 create-route-table --vpc-id (ステップ1で作成したVpcIdを入力)
- 返された出力内にある、RouteTableIdをメモる。
{ "RouteTable": { "Associations": [], "RouteTableId": "rtb-01a5e9d1d8654077b", "VpcId": "vpc-0c26a2d951052e32c", "PropagatingVgws": [], "Tags": [], "Routes": [ { "GatewayId": "local", "DestinationCidrBlock": "192.168.210.0/24", "State": "active", "Origin": "CreateRouteTable" } ] } }上記出力の、"RouteTableId": "rtb-01a5e9d1d8654077b"のところ。
- インターネットゲートウェイへのすべてのトラフィック (0.0.0.0/0) をポイントするルートテーブルでルートを作成。
aws ec2 create-route --route-table-id (作成したRouteTableIdを入力) --destination-cidr-block 0.0.0.0/0 --gateway-id (作成したInternetGatewayIdを入力)
- 作成したルートが有効になっていることを確認
aws ec2 describe-route-tables --route-table-id (作成したRouteTableIdを入力)
このままでは作成たルートテーブルはサブネットに関連付けされていないため、サブネットからのトラフィックがインターネットゲートウェイへルーティングされるよう、VPCのサブネットへ関連づけする。
最初に、
describe-subnetsコマンドを使用してサブネット ID を取得します。
--filterオプションを使用して新しい VPC のサブネットだけを返し、
--queryオプションを使用してサブネット ID と CIDR ブロックだけを返します。aws ec2 describe-subnets --filters "Name=vpc-id,Values=(ステップ1で作成したVpcIdを入力)" --query 'Subnets[*].{ID:SubnetId,CIDR:CidrBlock}'
- 出力例
[ { "CIDR": "192.168.210.0/24", "ID": "subnet-029c6aa553f1fc6de" } ]
- カスタムルートテーブルに関連付けるサブネットを選択する。
aws ec2 associate-route-table --subnet-id (ID) --route-table-id (作成したRouteTableIdを入力)
- サブネット内で起動したインスタンスへ自動的にElastic IPを振り分けるよう設定
aws ec2 modify-subnet-attribute --subnet-id (ID) --map-public-ip-on-launch以上、EC2インスタンスの作成などは別記事で。
- 投稿日:2019-02-18T18:35:06+09:00
CloudFrontでハマった
概要
CloudFrontのdeployが完了するまで暇なので、
CloudFrontでハマったあれやこれやについて、恥を忍んで書き連ねました。
皆様におかれましては、「いやそれはねーわ」と呟きつつ、何かの参考にしていただければ幸いです。Path Patternでハマった
公開画面と管理画面があり管理画面はキャッシュしないという要件のシステム。
管理画面は「/manage/hogehoge」となる設計であるため、
CloudFrontのPath Patternを利用し、以下の通りとした。
Precedence Path Pattern Origin or Origin Group 0 manage/ ELB-hogehoge-web 1 Default (*) ELB-hogehoge-web [Default (*)]では、キャッシュする設定を行い、
[manage/]では、キャッシュしない設定とした(参考)ハマった!
数日後…。
管理画面のログイン部分が完成。完成…したはずだが、なんか動作が怪しい。
というか、そもそもログインができない時がある。
セッション周りか?バグか?と思うが、怪しい点は見つからない…
(こういうときに限って本題とは関係ないバグや設定ミスを見つけたりするのはなんでだ)原因
Path Patternは末尾に *をつける!
つまり
Precedence Path Pattern Origin or Origin Group 0 manage/* ELB-hogehoge-web 1 Default (*) ELB-hogehoge-web いや、うん、常識だよね…わかるよ…
最初に設定した時に、なんの気無しに設定しちゃったから…CloudFront経由で繋がらずハマった
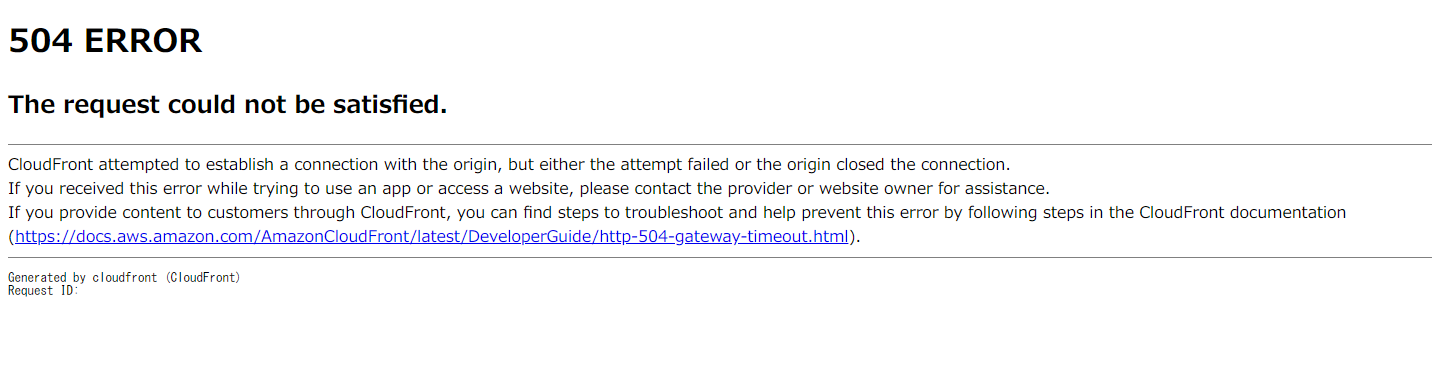
初構築でいきなりハマった。
ハマった!
CloudFront初導入!意気揚々と接続すると504エラー
原因
構築中だったため、セキュリティグループのインバウンドを自社のIPアドレスだけに絞っていた。
CloudFrontは世界中のエッジから接続されるため、HTTPS(or HTTP)のインバウンドをAny(0.0.0.0/0)で開放する必要がある。
外部公開したくない場合は、WAFによって制御する。[参考]
(または、CloudFrontのエッジサーバのIPアドレスを自動登録する仕組みを作成する [参考])次
To be continued.
(他にもいっぱいあった気がしますが、CloudFrontのdeployが完了しました)
- 投稿日:2019-02-18T18:29:29+09:00
AWS Cloud9でRailsプロジェクト作成直後にぶつかる問題の対応方法
はじめに
Ruby on Rails初心者がUdemyで入門しようとしています。環境構築で詰まるという初心者が陥りがちな罠を避けるため、AWS Cloud9を利用することにしました。すると・・・早速罠にハマったので備忘録として対応方法をまとめます。
The Complete Ruby on Rails Developer Course
https://www.udemy.com/the-complete-ruby-on-rails-developer-course/環境
- AWS Cloud9
- ruby 2.6.0p0
- Rails 5.0.7.1
Railsプロジェクト作成
Cloud9を開きます。2019/02/18現在、Cloud9は東京リージョンでは提供されていないので適当なリージョンを選択します。「Create environment」から環境を作成します。Configuration Settingsはデフォルト値で構いません。
IDEが開いたら下部のターミナルで以下のコマンドを実行します。
~/environment $ rails new sample ~/environment $ cd sample/ ~/environment/sample $ rails s -b $IP -p $PORTPreviewを実行します。
罠1 Gem::LoadError
Preview画面に何やらエラーが出ています。
Specified 'sqlite3' for database adapter, but the gem is not loaded. Add
gem 'sqlite3'to your Gemfile (and ensure its version is at the minimum required by ActiveRecord).
sqlite3がロードされていないようですが、インストールはされています。
~/environment/sample $ gem list | grep sqlite3 sqlite3 (1.4.0)対応方法
検索してもドンピシャなものが見当たりませんでしたが、どうやらsqlite3のバージョンを変えてみるとよいようです。以下のようにGemfileを修正します。
Gemfilediff --git a/Gemfile b/Gemfile index 0447f70..03752d1 100644 --- a/Gemfile +++ b/Gemfile @@ -4,7 +4,7 @@ source 'https://rubygems.org' # Bundle edge Rails instead: gem 'rails', github: 'rails/rails' gem 'rails', '~> 5.0.0' # Use sqlite3 as the database for Active Record -gem 'sqlite3' +gem 'sqlite3', '~> 1.3.6' # Use Puma as the app server gem 'puma', '~> 3.0' # Use SCSS for stylesheets変更を反映して再度試してみます。
~/environment/sample $ bundle update ~/environment/sample $ rails s -b $IP -p $PORT => Booting Puma => Rails 5.0.7.1 application starting in development on http://127.0.0.1:8080 => Run `rails server -h` for more startup options Puma starting in single mode... * Version 3.12.0 (ruby 2.6.0-p0), codename: Llamas in Pajamas * Min threads: 5, max threads: 5 * Environment: development * Listening on tcp://127.0.0.1:8080 Use Ctrl-C to stop Started GET "/" for 126.209.207.2 at 2019-02-18 09:16:09 +0000 Cannot render console from 126.209.207.2! Allowed networks: 127.0.0.1, ::1, 127.0.0.0/127.255.255.255 Processing by Rails::WelcomeController#index as HTML Parameters: {"internal"=>true} Rendering /home/ec2-user/.rvm/gems/ruby-2.6.0/gems/railties-5.0.7.1/lib/rails/templates/rails/welcome/index.html.erb Rendered /home/ec2-user/.rvm/gems/ruby-2.6.0/gems/railties-5.0.7.1/lib/rails/templates/rails/welcome/index.html.erb (3.1ms) Completed 200 OK in 17ms (Views: 7.1ms | ActiveRecord: 0.0ms)Gem::LoadErrorは消えました。
罠2 Cannot render console from 126.209.207.2!
Previewを開くと上記のようなログが出力されます(以下、抜粋)。
Cannot render console from 126.209.207.2! Allowed networks: 127.0.0.1, ::1, 127.0.0.0/127.255.255.255
このときの画面は以下のようになっています。接続が拒否されています。
対応方法
下図の赤枠で示した部分をクリックすると別タブで正常に開くことができます。
めでたしめでたし。
まとめ
環境構築の罠を避けようとして別の罠にハマる辛さがありましたが、無事Rails入門の準備ができました。




- 投稿日:2019-02-18T17:43:19+09:00
CloudWatch Agent で特定のプロセスのメトリクスを取得する方法
CloudWatch Agent で procstat プラグインが使えるようになりましたね。
いつも通り設定ファイル(config.json)の metrics => metrics_collected 内に以下のような設定を追加することで可能です。"procstat": [ { "exe": "プロセス名(正規表現可能)", "measurement": [ "cpu_usage" ] } ]これはCPU使用率を取得する例ですが、他のメトリクスも取れますよ。
取れるメトリクスは以下のページに載ってます。
※ Linux か Windows かによって取れるメトリクスが異なるみたいです。procstat で収集されるメトリクス
https://docs.aws.amazon.com/ja_jp/AmazonCloudWatch/latest/monitoring/CloudWatch-Agent-procstat-process-metrics.html#CloudWatch-Agent-procstat-process-metrics-collected
- 投稿日:2019-02-18T17:17:57+09:00
AWS認定試験 Cloud Practitoner 合格体験記
受験してきたのでまとめてみました。
背景・目的
業務でAWSを利用していたので技術アピールするため
AWS実務経験
3ヶ月
勉強期間
10時間 程度
勉強内容
公式サイトのサンプル問題
模擬試験
AWSトレーニング
AWS Cloud Practitioner Essentials (Digital) (Japanese) (デジタル) (日本語版)
https://www.aws.training/learningobject/curriculum?id=17954感想
システム構築経験があれば問題なく合格できると思います。
AWSの想定受験者として、「AWS経験半年」を想定しているが、それ未満でも十分合格可能である。
- 投稿日:2019-02-18T16:20:13+09:00
New Relic で CloudWatch Logs を監視する
New Relic でログの監視はできますか?と聞かれることがあります。
標準機能としてのログ監視機能は、2019年2月現在ありません。しかしながら、それでも
New Relic で CloudWatch Logs は監視できます
エージェントのAPIやREST APIを使って、エージェントや外部からNew Relicに任意のデータを送り込むことができるので、それを利用しますと、
こんなことができます
- CloudWatch Logsのデータを、カスタムイベントAPIで、New Relicに転送するLambda関数を作り、
- CloudWatch Logs上で、各種ログをそのLambda関数にストリームさせれば、
- 任意のログデータをNew Relic Insightsに表示・分析・監視できるようになります
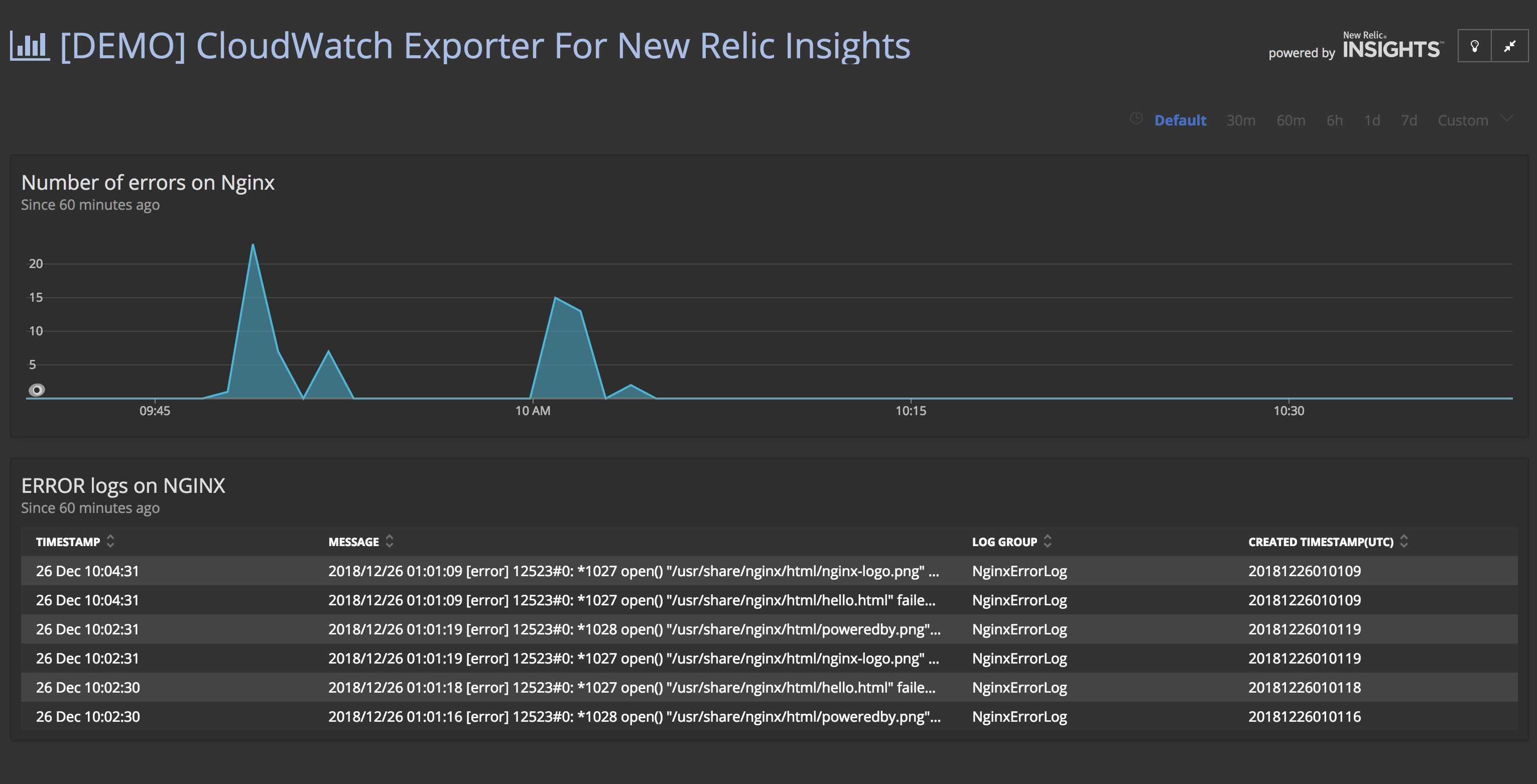
例えば、EC2上で稼働するNginxのエラーログをNew Relicに転送すると、こんな画面イメージになります
どんなメリットがあるの? 例えば
- AWS上で稼働するコンポーネントを全て含めて、エンドtoエンドの パフォーマンスやエラーの相関関係を可視化できます
- 特定の時間帯や条件に絞り込んで、ログとパフォーマンスの突き合わせができます
- アラートのベースライン比較や外れ値(Outlier)検出を使って、CloudWatch Logを監視できます
ということで、そんな Lambda関数 を作ってみました!
repoはこちらになります
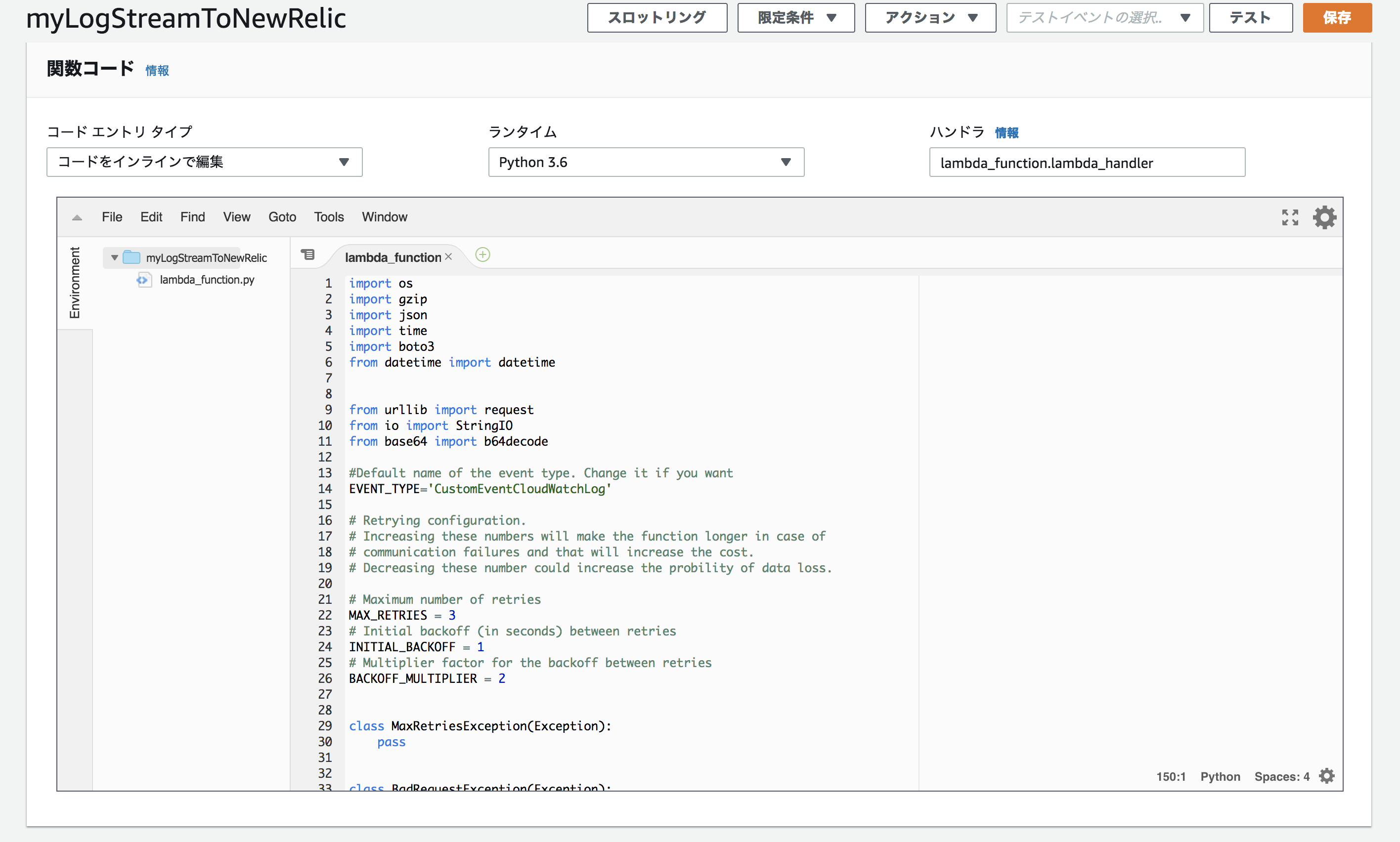
function.pyimport os import gzip import json import time import boto3 from datetime import datetime from urllib import request from io import StringIO from base64 import b64decode #Default name of the event type. Change it if you want EVENT_TYPE='CustomEventCloudWatchLog' # Retrying configuration. # Increasing these numbers will make the function longer in case of # communication failures and that will increase the cost. # Decreasing these number could increase the probility of data loss. # Maximum number of retries MAX_RETRIES = 3 # Initial backoff (in seconds) between retries INITIAL_BACKOFF = 1 # Multiplier factor for the backoff between retries BACKOFF_MULTIPLIER = 2 class MaxRetriesException(Exception): pass class BadRequestException(Exception): pass class ThrottlingException(Exception): pass def http_retryable(func): ''' Decorator that retries HTTP calls. The decorated function should perform an HTTP request and return its response. That function will be called until it returns a 200 OK response or MAX_RETRIES is reached. In that case a MaxRetriesException will be raised. If the function returns a 4XX Bad Request, it will raise a BadRequestException without any retry unless it returns a 429 Too many requests. In that case, it will raise a ThrottlingException. ''' def _format_error(e, text): return '{}. {}'.format(e, text) def wrapper_func(): backoff = INITIAL_BACKOFF retries = 0 while retries < MAX_RETRIES: if retries > 0: print('Retrying in {} seconds'.format(backoff)) time.sleep(backoff) backoff *= BACKOFF_MULTIPLIER retries += 1 try: response = func() # This exception is raised when receiving a non-200 response except request.HTTPError as e: if e.getcode() == 400: raise BadRequestException( _format_error(e, 'Unexpected payload')) elif e.getcode() == 403: raise BadRequestException( _format_error(e, 'Review your license key')) elif e.getcode() == 404: raise BadRequestException(_format_error( e, 'Review the region endpoint')) elif e.getcode() == 429: raise ThrottlingException( _format_error(e, 'Too many requests')) elif 400 <= e.getcode() < 500: raise BadRequestException(e) # This exception is raised when the service is not responding except request.URLError as e: print('There was an error. Reason: {}'.format(e.reason)) else: return response raise MaxRetriesException() return wrapper_func def _send_log_entry(log_entry, context): logs = json.loads(log_entry) for log in logs['logEvents']: data = { 'eventType':EVENT_TYPE, 'owner':logs['owner'], 'logGroup': logs['logGroup'], 'logId':log['id'], 'createdTimestamp(UTC)': (datetime.fromtimestamp(int(str(log['timestamp'])[:10]))).strftime('%Y%m%d%H%M%S'), 'message': log['message'] } print(data) @http_retryable def do_request(): req = request.Request('https://insights-collector.newrelic.com/v1/accounts/'+ os.environ['ACCOUNT_ID'] + '/events', _get_payload(data)) req.add_header('Content-Type', 'application/json') req.add_header('X-Insert-Key', _get_insert_key()) req.add_header('Content-Encoding', 'gzip') return request.urlopen(req) try: response = do_request() except MaxRetriesException as e: print('Retry limit reached. Failed to send log entry.') raise e except BadRequestException as e: print(e) else: print('Log entry sent. Response code: {}'.format(response.getcode())) def _get_payload(data): return gzip.compress(json.dumps(data).encode()) def _get_insert_key(): kms_client = boto3.client('kms') encrypted = os.environ['INSERT_KEY'] return kms_client.decrypt(CiphertextBlob=b64decode(encrypted)).get('Plaintext') def lambda_handler(event, context): if 'awslogs' in event: # CloudWatch Log entries are compressed and encoded in Base64 payload = b64decode(event['awslogs']['data']) log_entry = gzip.decompress(payload).decode('utf-8') _send_log_entry(log_entry, context) else: print('Not supported')導入手順
!!導入の前の注意点!!
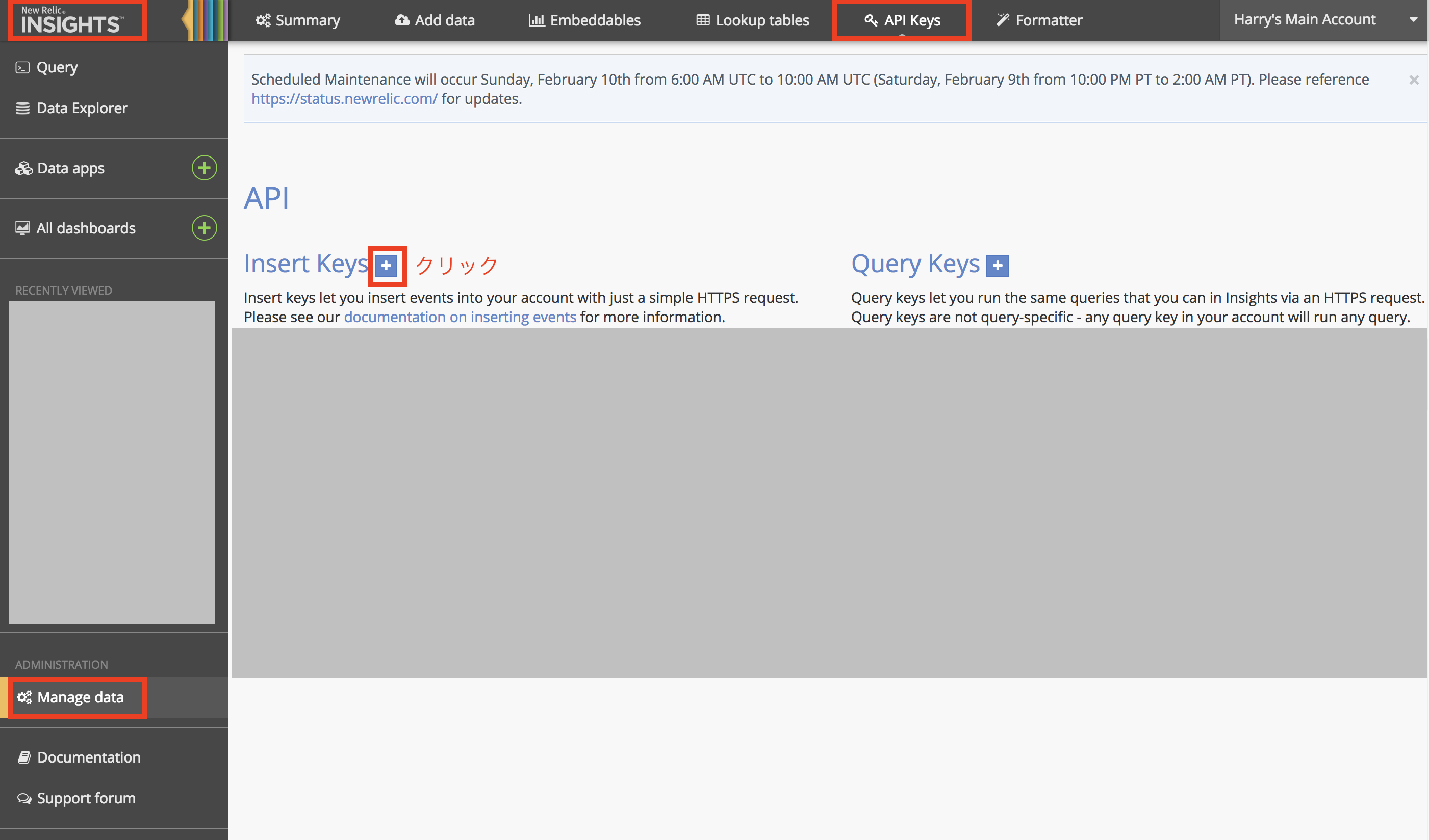
以下の手順を実施すると、最終的にLambda関数の実行によるAWS側の費用が発生します点をご確認の上、以下をお試しください1) まず最初に、上記Lambda関数で使用する以下の3つの値を準備してください
- New Relic の アカウントID
- New Relic の INSERT_KEY
"Insights" - "Manage Data" - "API Keys" の順にクリックし、”+”ボタンをクリックし、
表示される2つの値をメモしてください
- AWS の KMS キー
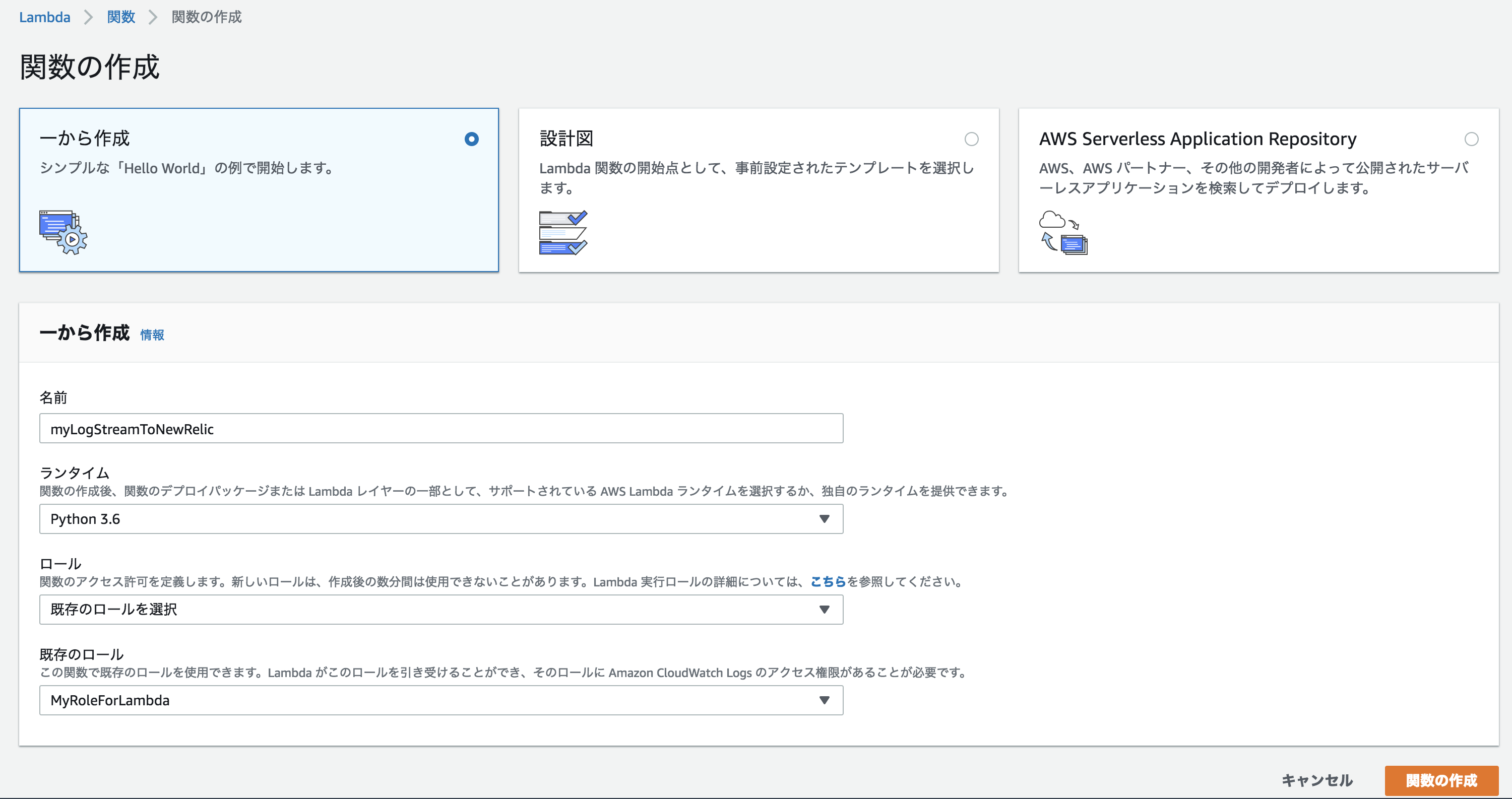
上記2つのNew RelicのIDを暗号化するために, KMSキーを利用します。AWS上でキーを作成してください。その際、キーユーザーに"Lambda basci execution"のロールを追加する必要がある点にご注意ください。作成方法はこちら2) AWS上で、上記のLambda関数を実装します
- AWS コンソールにログインします
- "関数の作成"-"一から作成"を選択し、任意の関数名、python 3.6, 'AWSLambdaBasicExecutionRole'を含む任意のロールを設定し、"関数の作成"をクリックします

function.py のデフォルトの関数を削除し、上記のLambda関数をコピーします。
環境変数に、"INSERT_KEY" と "ACCOUNT_ID" を追加し、1)でノートした値を記入します。
"伝送中に暗号化のためのヘルパーのための有効化" にチェックを入れ、"伝送中に暗号化するAWS KMSキー"に1)で作成したキーを記入し、2つの環境変数の”暗号化”をクリックします
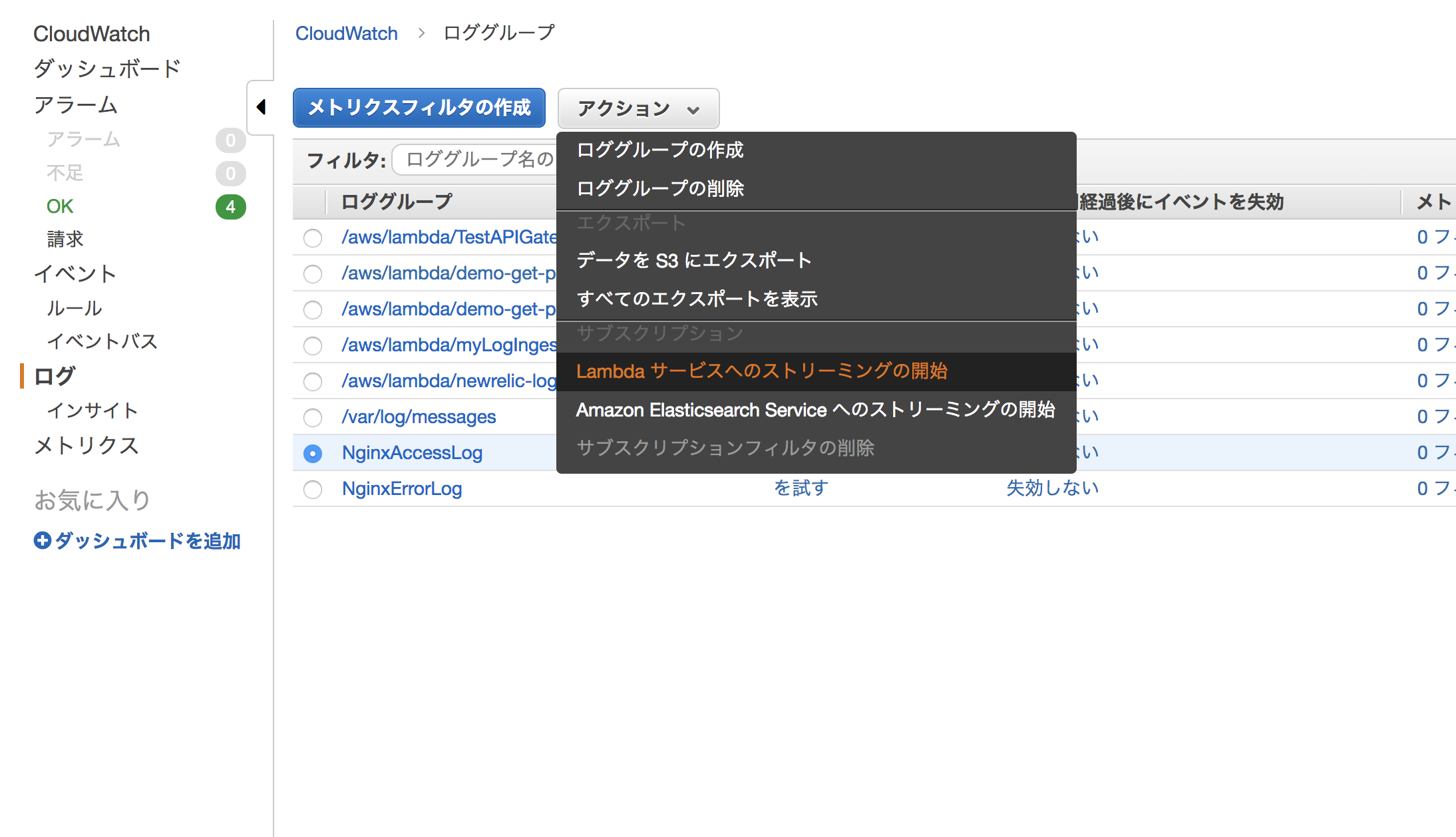
3) CloudWatch Log 上で作成したLambda関数にログをストリームします
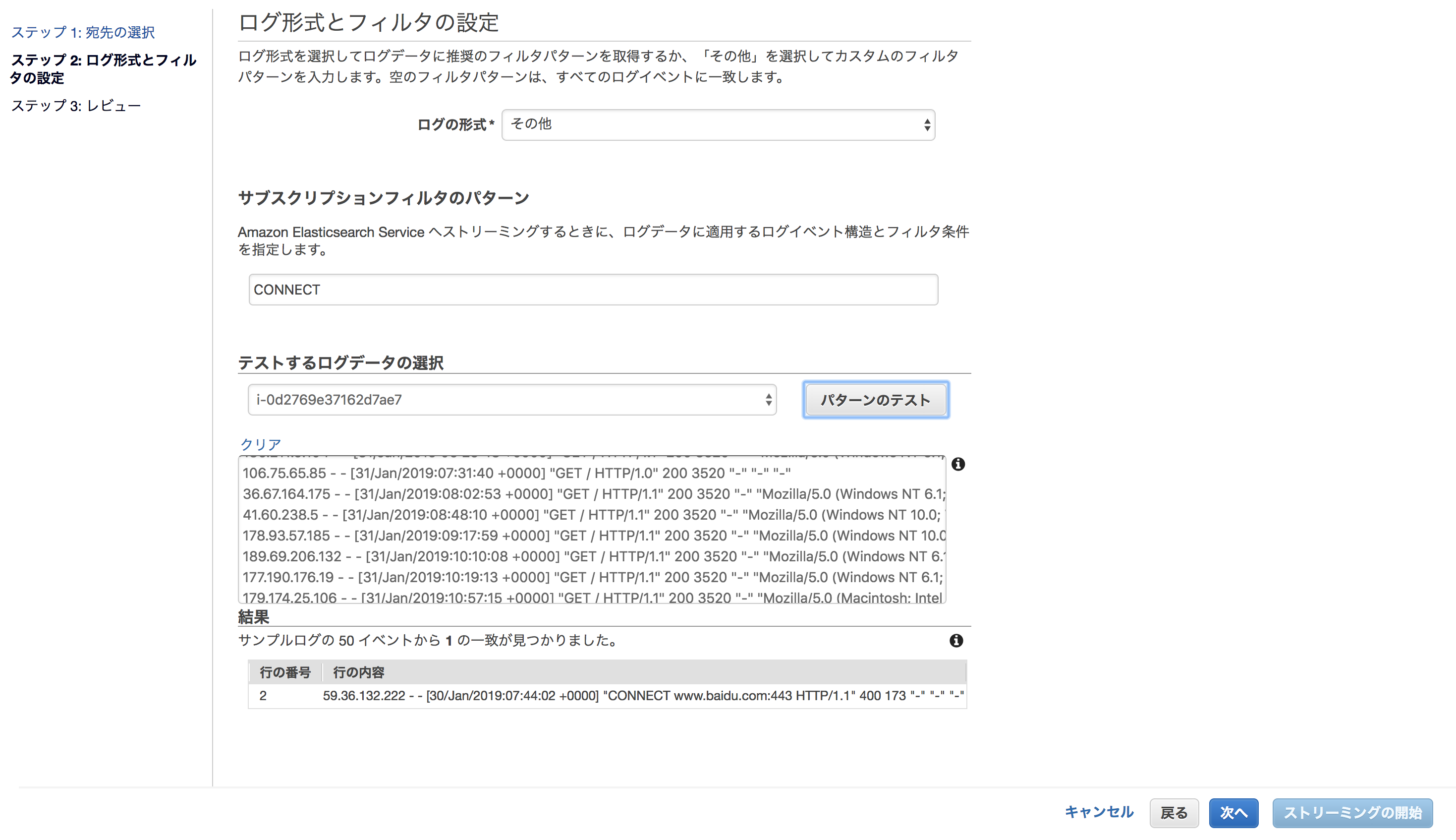
CloudWatch ”ログ”を開き、New Relicに転送したいものを選択し、”アクション”-"Lambdaサービスへのストリーミングの開始"を選択します
"Lambda関数"に、2)で作成したLambda関数名を選択し、”次へ”をクリック
"ログ形式"を選択します。ログメッセージが選択した形式でNewRelicに転送されます。
AWS側でログにフィルタリングをしてから転送したい場合は(ログ転送と、ログのNew Relicでの保存にはコストが伴いますので、必要なものに絞り込むことは重要です)、”サブスクリプションフィルタのパターン”を指定してください。設定方法はこちらをご参照ください
”次へ”-”ストリーミングの開始”をクリック
4) 確認
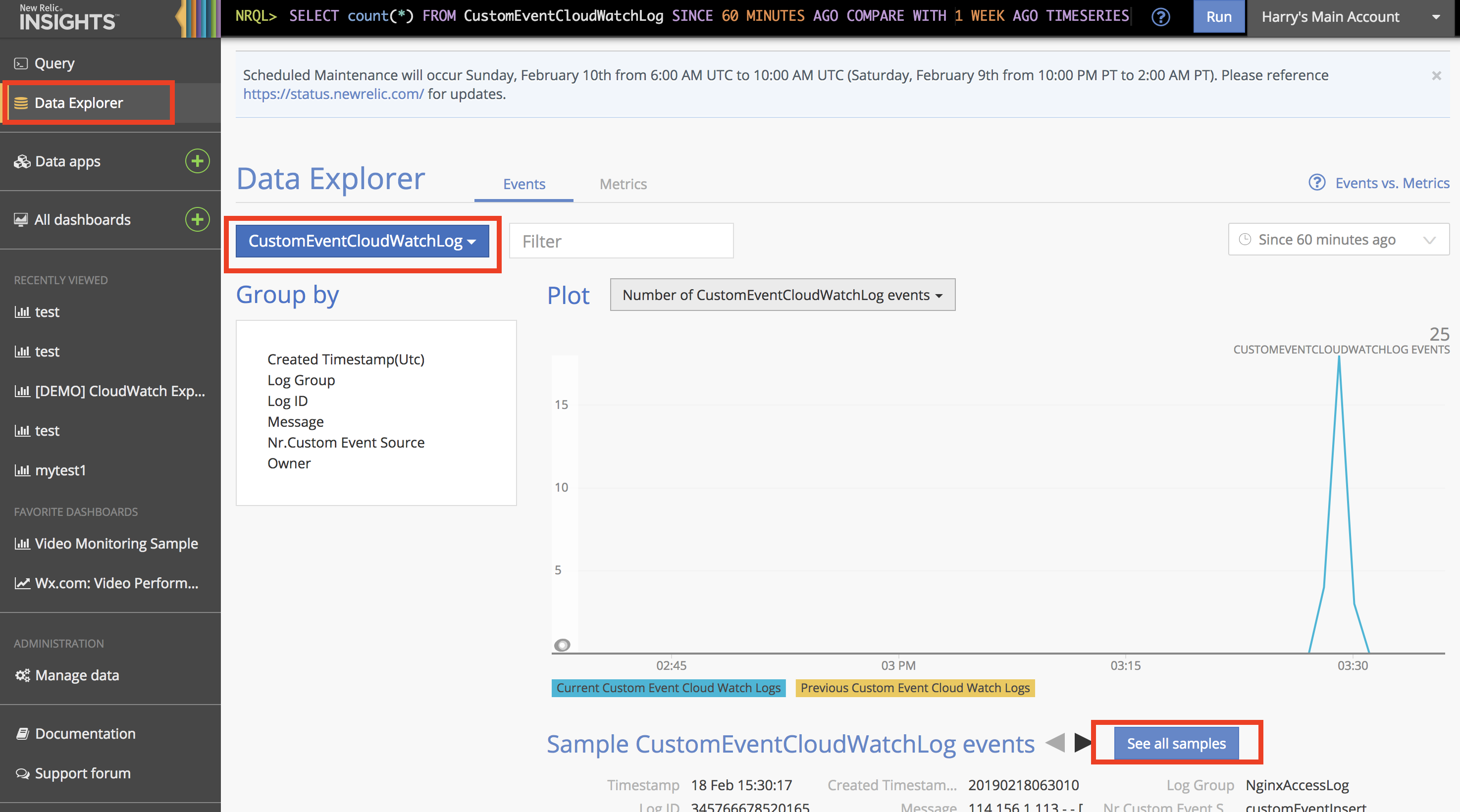
- New Relic の Insights を開き、"Data Explorer"をクリック
プルダウン(添付画像真ん中の赤枠)で、"CustomEventCloudWatchLog"を選択すると、転送されたログの件数がグラフ表示されます(ない場合は、Lambda関数でエラーが発生しているかと思われますので、関数のCloudWatchログを確認してください)
"See all samples"をクリックすると、転送されたログメッセージがリスト表示されます
NRQL(New Relic Query Language)を使って、ログから必要なメトリックを抽出します。例えば、特定の文字列を含むメッセージの件数をチャート化したい場合は、以下のクエリを実行します
SELECT count(*) FROM CustomEventCloudWatchLog where message LIKE '%<検索文字列>%' TIMESERIES以上になります
このように、New Relic の REST API を利用することで、様々な外部データをNew Relicに簡単に転送し、それによってNew Relicのパワフルな分析機能、アラート機能を利用することができるようになります
ここまでお読みいただいた方へ!
3月14日(木)六本木ミッドタウンにて、ハンズオントレーニング(無料、ランチ付き!)を開催します!本件をさらに深堀りしたようなお話もする予定ですので、本件にご興味を持たれた方は、ぜひご参加ください。(座席の数には限りがございますので、ご登録はお早めに!)
ご登録はこちらから↓↓↓↓↓↓↓↓




- 投稿日:2019-02-18T16:18:59+09:00
【初心者】AWS kinesis を使ってみる
動機
- 仕事でkinesisの話題になった。知ったかぶりができるようにするため、基本的な動作を実機で確認しておく。
やったこと
- streamの作成
- streamへのデータの書き込み/読み出し(AWS CLI)
- pythonスクリプトからstreamに書き込みして、streamにレコードが書き込まれたらlambdaで処理
参考にした記事
AWS CLIを使って初めてAmazon Kinesisを使ってみた
[新機能]Kinesis Streamsが時刻ベースのイテレーターに対応しました
Lambda(Python)からKinesisにPut(API)してLambda(Python)でGet(Event)する手順(CLIでの書き込み/読み出し)
# shard 1本のstreamを作成 $ aws kinesis create-stream --stream-name mksamba-stream --shard-count 1
- 一番シンプルなshard1本でのstreamを作成。
# 1個目のデータの書き込み $ aws kinesis put-record --stream-name mksamba-stream --partition-key 123 --data anpanman { "ShardId": "shardId-000000000000", "SequenceNumber": "49593062427984882686636760320963710719404264693501526018" }
- shard1本なのでpartition-keyの内容に関わらず必ずこのshardに入る。
# 1個目のデータの読み出し $ aws kinesis get-shard-iterator --shard-id shardId-000000000000 --shard-iterator-type TRIM_HORIZON --stream-name mksamba-stream { "ShardIterator": "AAAAAAAAAAE/WfX4ZpvcDznZT70nxmW4zUu8d3o7eqAYV9niw88UuaxVrTpm/MUC1jFrBXMyhI35oPQvKDRC+u3gY5wBYQh5jKZDF9eAdtMCHB2t136KTGcpDA7i54R5CTzOf5lo1aUqzEcmX1iBRfxAnzaBfi+XpPDRXKN52fDXJXCtPF3hg5MIcCj376QTwQvm5nwKaF+1ou1yrYWrdFnKUgTy0XoP" } $ aws kinesis get-records --shard-iterator AAAAAAAAAAE/WfX4ZpvcDznZT70nxmW4zUu8d3o7eqAYV9niw88UuaxVrTpm/MUC1jFrBXMyhI35oPQvKDRC+u3gY5wBYQh5jKZDF9eAdtMCHB2t136KTGcpDA7i54R5CTzOf5lo1aUqzEcmX1iBRfxAnzaBfi+XpPDRXKN52fDXJXCtPF3hg5MIcCj376QTwQvm5nwKaF+1ou1yrYWrdFnKUgTy0XoP { "Records": [ { "Data": "YW5wYW5tYW4=", "PartitionKey": "123", "ApproximateArrivalTimestamp": 1550411747.067, "SequenceNumber": "49593062427984882686636760320963710719404264693501526018" } ], "NextShardIterator": "AAAAAAAAAAElfsIV9+Qhkuy59jiyJgfSmaA7tAhra8Pitt280V+rhWch3VaqycIduEXiSZKgIIoNcpyyx9tbpb5oaWDkttJFguomKcGVtCbsMlh3b5aO8hjySCU1BOstTkoCKo+KmB3fVY8S4e+xllLP8D0c5IfTB5wmSTg2jPhku3pgCNIbhgrdmxo5NbocHCn77DySzrBlcD4Cvm9LaaLYQuZpW4vk", "MillisBehindLatest": 0 } $ echo YW5wYW5tYW4= | base64 --decode anpanman
- まずイテレータを取得し、イテレータを指定してレコードを取得する。レコードはbase64 encodeされているためdecodeする。
#2個目のデータの書き込み $ aws kinesis put-record --stream-name mksamba-stream --partition-key 123 --data baikinman { "ShardId": "shardId-000000000000", "SequenceNumber": "49593062427984882686636760321531905854623186722540748802" }
- 同じshardに2個目のデータを書き込む。
#2個目のデータの読み出し $ aws kinesis get-shard-iterator --shard-id shardId-000000000000 --shard-iterator-type TRIM_HORIZON --stream-name mksamba-stream { "ShardIterator": "AAAAAAAAAAFWgFqMKIxJNggikvbo7dus2kgZyyYGd8F/ZY0r453xruvlXHKlRydL05PpGDs36+wD/GuwY7A6KmU94eDwgi2bGgm3KEJ7wqnz9rN0qtmftCZ2t1O/lk1ztLWQWhzShbcQWxHuM4DLj0y56ahI0tgRdELS7ltSATdMlrqBMmdzJcDE6WUKvg4ZMi6kjtvQvGYBx90HR4EuR9je4ZSkkQdg" } $ aws kinesis get-records --shard-iterator AAAAAAAAAAFWgFqMKIxJNggikvbo7dus2kgZyyYGd8F/ZY0r453xruvlXHKlRydL05PpGDs36+wD/GuwY7A6KmU94eDwgi2bGgm3KEJ7wqnz9rN0qtmftCZ2t1O/lk1ztLWQWhzShbcQWxHuM4DLj0y56ahI0tgRdELS7ltSATdMlrqBMmdzJcDE6WUKvg4ZMi6kjtvQvGYBx90HR4EuR9je4ZSkkQdg { "Records": [ { "Data": "YW5wYW5tYW4=", "PartitionKey": "123", "ApproximateArrivalTimestamp": 1550411747.067, "SequenceNumber": "49593062427984882686636760320963710719404264693501526018" }, { "Data": "YmFpa2lubWFu", "PartitionKey": "123", "ApproximateArrivalTimestamp": 1550412420.802, "SequenceNumber": "49593062427984882686636760321531905854623186722540748802" } ], "NextShardIterator": "AAAAAAAAAAGxAQrYwzNV3D84if3DuHkWj3qoZuKH7EJX0x9Chx6IHDaOe0jjrXSRGLMS614CPMuAB01Yqdat0XSqtuD3zAiD11McKb7+NrrnPJURFZMhHo9KABowzt9y6xwKId/eRqImrdlPgqDUoasCrFO9snOXYdqSeEBXp2ruEV/DYo9+FLRmF+RPSF7vS0NgV+f2KDxsmKv6MBNmzAX46E9WYQUw", "MillisBehindLatest": 0 } $ echo YmFpa2lubWFu | base64 --decode baikinman
- shard-iterator-type TRIM_HORIZON にしているため、shard内にたまっているレコードは再度表示されている。
手順(Python Scriptでstreamへ書き込み)
# kinesis-put.py import boto3 client = boto3.client('kinesis') response = client.put_record( Data="dokin-chan", PartitionKey='123', StreamName='mksamba-stream' ) print(response)
- EC2インスタンス(amazon linux 2)にて stream への put を実行。
- python3, boto3, credential, region 等は事前に設定されている前提。
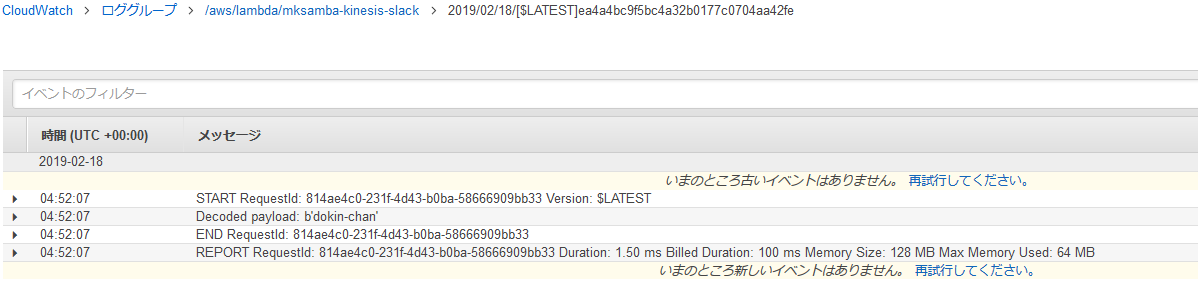
手順(lambdaでstreamから読み出し)
# kinesis-lambda.py import logging import base64 def lambda_handler(event, context): logger = logging.getLogger() logger.setLevel(logging.INFO) for record in event['Records']: #Kinesis data is base64 encoded so decode here payload=base64.b64decode(record["kinesis"]["data"]) print("Decoded payload: " + str(payload))
- AWSのサンプルコード通りにlambdaを作成する。
- data source としてkinesisを設定。
- stream に書き込みがあると、lambda が起動して読み出しが行われる。(この例では読み出してcloudwatch logsに保存するのみ)所感
- シャードとかの超基本概念は理解できたが、イテレータの指定の方法(TRIM_HORIZON)の使い方等、やっていてよくよくわからないところもあり引き続き触っていきたい。
- 投稿日:2019-02-18T15:55:34+09:00
EC2起動時にEIPのプールしているIP郡から使ってないIPを選択して割り当てるワンライナー
内容
インスタンス立てるときに特定のEIPの中からどれかをつけて立ってほしかったから作ったワンライナー
前提
- EC2からEIP触れる権限があたってること。
- 事前にIP確保しておくこと
- 確保したIPにタグをつけておくこと(タグでフィルタします)
コマンド
変数export REGION=ap-northeast-1 export TAG_NAME="hogehoge-tag"ワンライナーaws ec2 associate-address \ --region ${REGION} \ --instance-id $(curl http://169.254.169.254/latest/meta-data/instance-id) \ --allocation-id $(aws ec2 describe-addresses \ --filters "Name=tag-key,Values=Name" \ "Name=tag-value,Values=${TAG_NAME}" \ --query "Addresses[?AssociationId==\`null\`].AllocationId" \ --region ${REGION} \ --output text | cut -f 1 )
- 投稿日:2019-02-18T15:14:43+09:00
AmazonCognitoでGoogle/Facebook認証してトークンを取得する
はじめに
普段からWebアプリケーションにログイン機能を実装する際、バックエンドにAmazonCognitoを利用してきました。
Cognitoはログイン認証をサーバレスに実現してくれるマネージドなサービスです。開発者はログインユーザの情報を管理する必要が(ほとんど)ありません。
またAWSのリソースへのアクセス権限を一時的に発行することもできるので、ログイン後のトークンを利用して、アプリケーションからAWSの各リソースを利用することができます。
今回はそんなCognitoの外部IDプロバイダ認証を利用してログインし、トークンを取得するまでの流れをGoogleとFacebookでやっていこうと思います。Cognitoの準備
Cognitoのデプロイ
AmplifyCLIを利用してサクッと作っていきます。フロントはVue.jsを使っています。
この記事を参考にしていただければ、Cognitoを利用したログイン画面を用意することができると思います。その他下準備
その他細かい設定を行っていきます。
アプリクライアントの設定
上記の手順でCognitoをデプロイするとアプリクライアントが2つ作成されていると思います。
今回はWebアプリケーションからログインするので、app_clientWebとついている方のクライアントを利用します。
その設定の中の「サインインとサインアウトの URL」にhttp://localhost:8080を入力しておきます。
ドメインの設定
AmazonCognitoドメインを設定する必要があります。
左メニューから「ドメイン名」を選択して、ドメインのプレフィックスに任意の文字列を入力します。利用できるサブドメインだったら登録されます。
※このドメインは各外部IDプロバイダ認証からのリダレクトURIで利用するのでメモっておいてください。これでCognitoの下準備は完了です。
Google認証
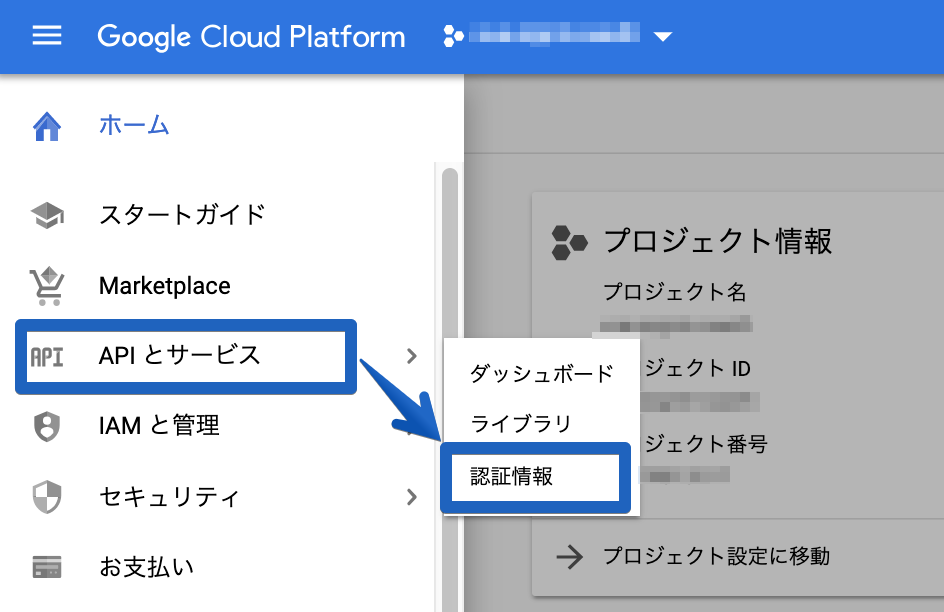
Google認証の設定はGoogleCloudPlatform(GCP)で進めていきます。
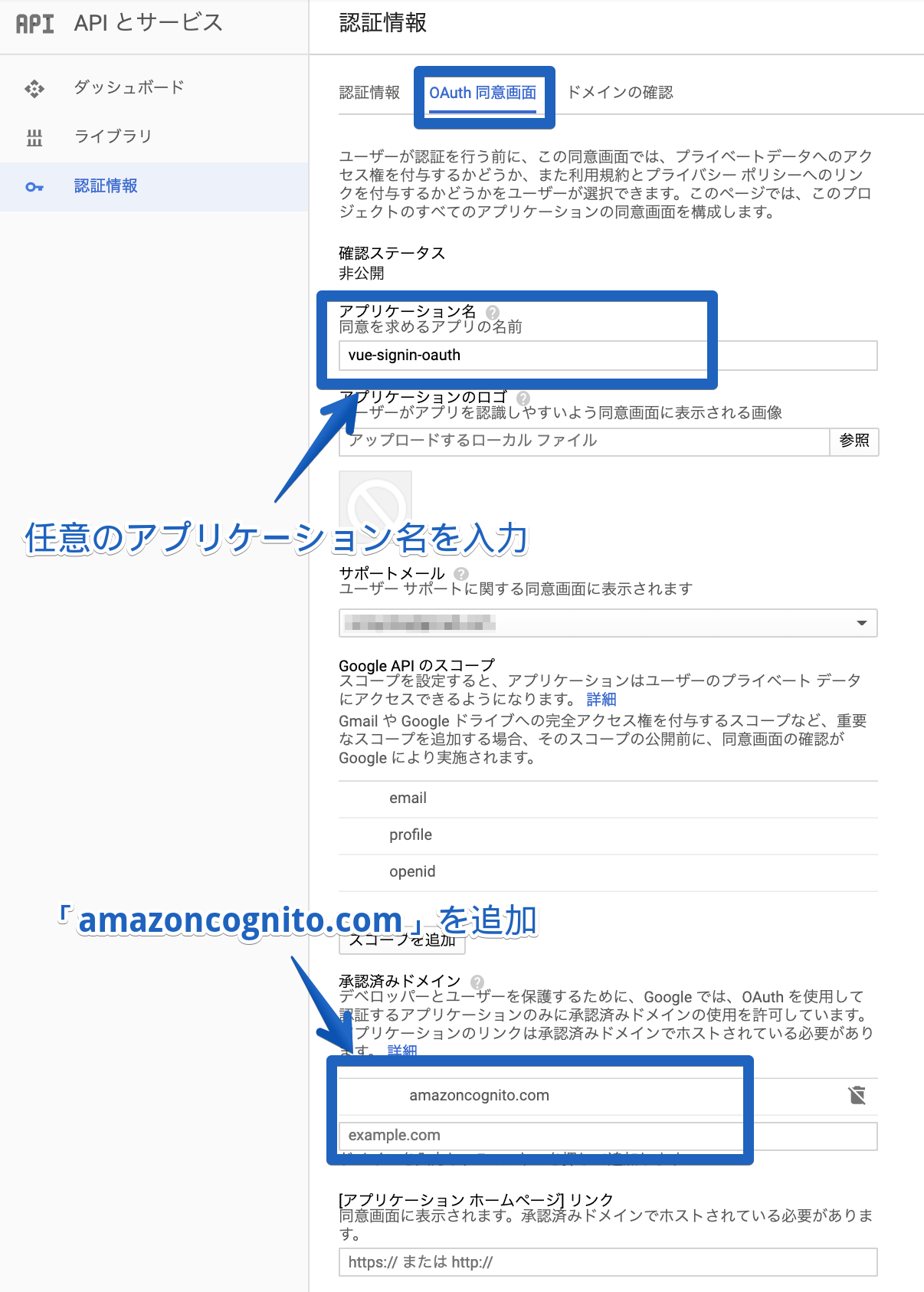
外部からGoogle認証を利用するために、認証情報の設定します。① 左メニューバーの「APIとサービス」から「認証情報」を選択する
② 「OAuth 同意画面」を選択し、必要な情報を入力する
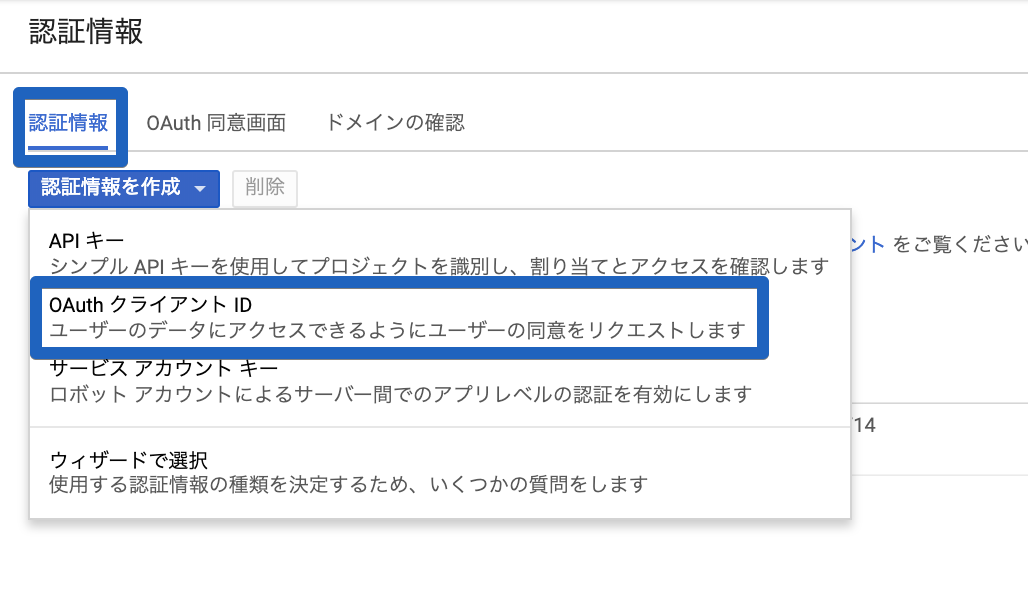
③ 「認証情報」を選択し、「OAuthクライアントID」を選択
※初めて作成する場合は画面が違いますが、同じように「OAuthクライアントID」を選択していただければ、その後は同じ内容です。
④ 必要な情報を入力していく
リダイレクトURIはhttps://<Cognitoドメイン>.auth.ap-northeast-1.amazoncognito.com/oauth2/idpresponseになります。
⑤ クライアントIDとシークレットを取得
認証情報が作成されるとIDとシークレットが表示されるので、後ほど使うのでメモっておいてください。
これでGoogleの設定は完了です。
Facebook認証
Facebook認証は「facebook for developers」で設定します。
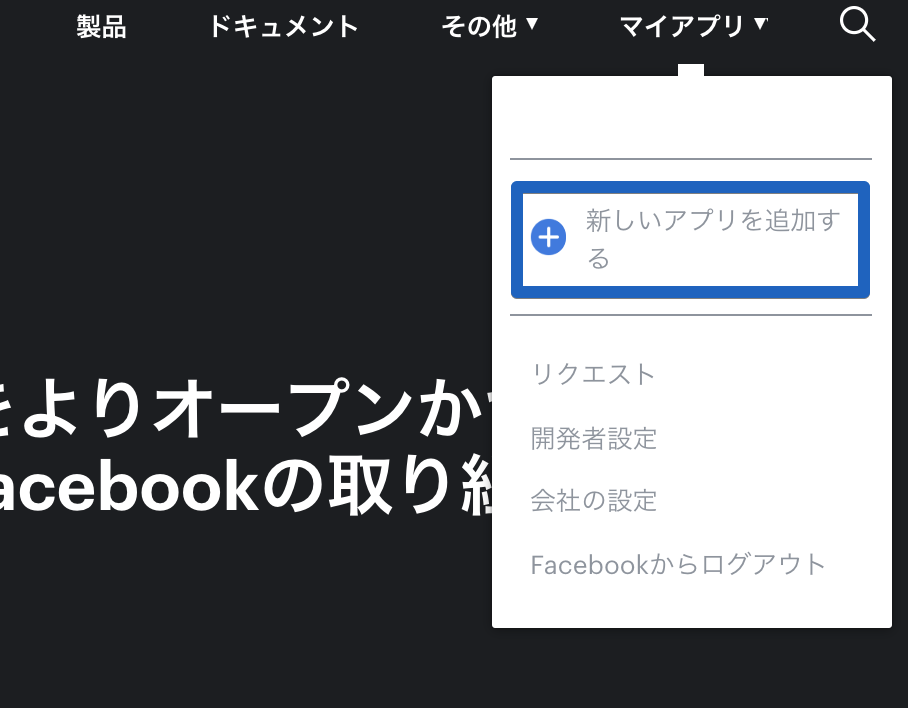
① グローバルメニュー「マイアプリ」から「新しいアプリを追加する」を選択
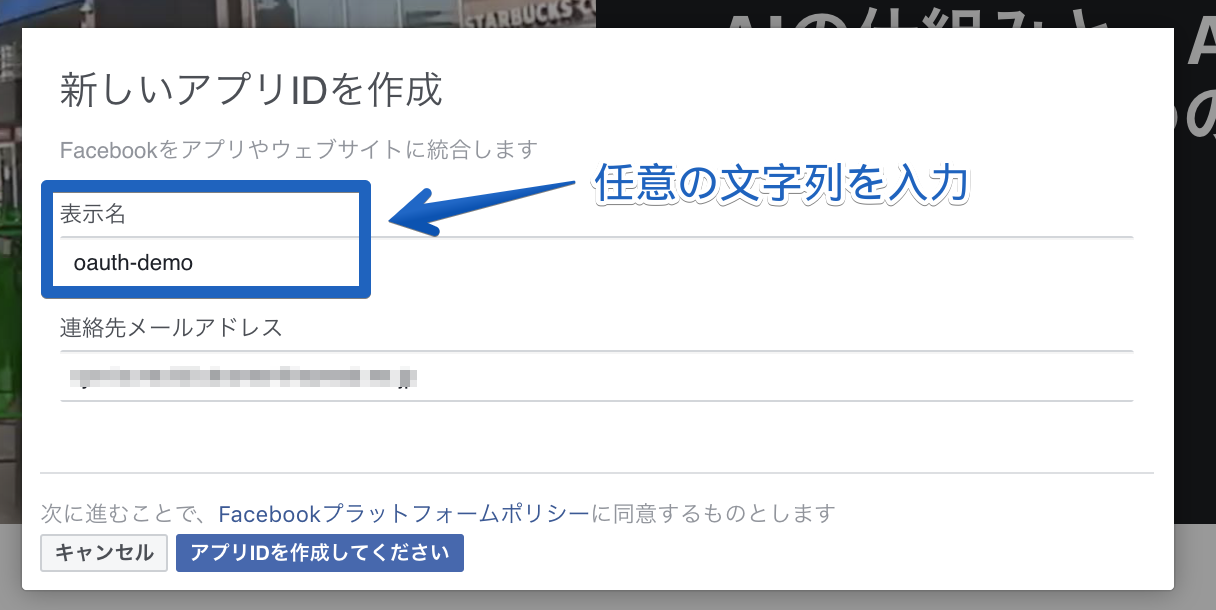
② 表示名を入力
③ ダッシュボードの「製品の追加」から「Facebookログイン」を選択
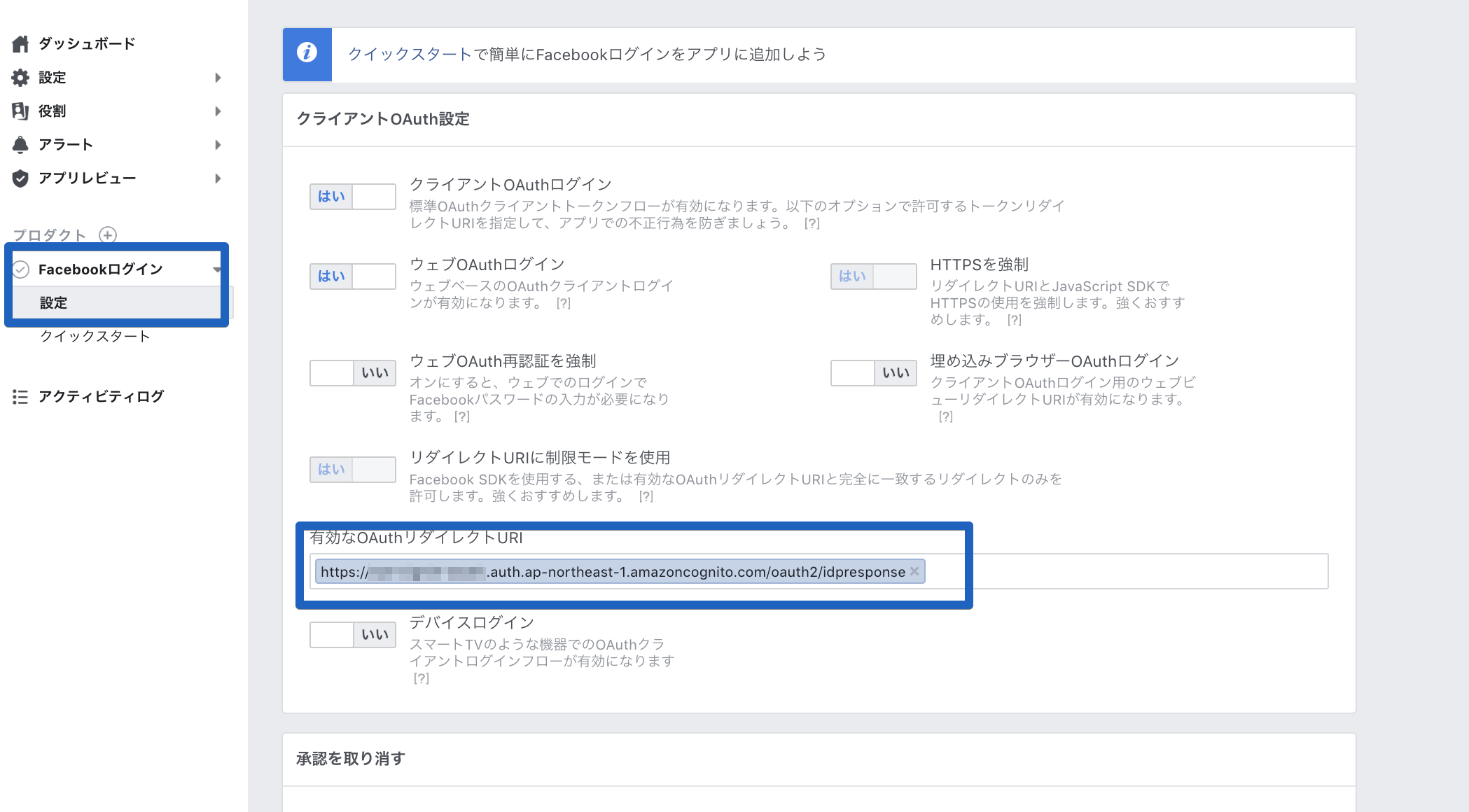
④ 左メニューの「Facebookログイン」の「設定」から、リダイレクトURIを設定
リダレクトURIはGoogleと同じです。
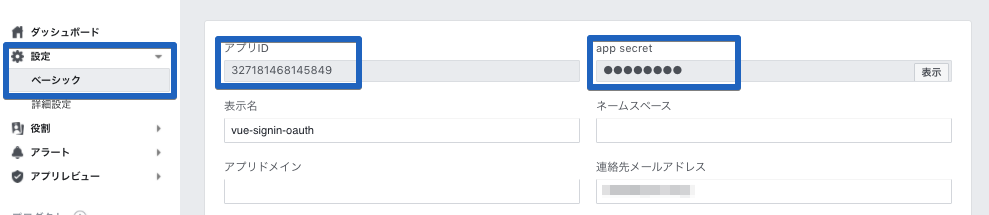
⑤ 左メニューの「設定」の「ベーシック」から「アプリID」と「app sercret」を取得
こちらも後ほど利用するのでメモっておいてください。
⑥ アプリを公開する
開発モードのままでは利用できなくなるので、公開する必要があります。
これでFacebookの設定は完了です。
アプリの設定
Webアプリケーションの処理はCognitoが用意してくれている、各外部IDプロバイダ認証用のリンクを呼ぶだけです。
ボタンのClickEventで着火させるといいかもしれませんね。script/** * CognitoDomain: AmazonCognitoドメイン * CognitoAppClientID: Cognitoに紐付いているアプリクライアントのID * RedirectURI: リダイレクト先のURI */ // Google認証 function OAuthForGoogle() { window.location.assign( "https://" + CognitoDomain + ".auth.ap-northeast-1.amazoncognito.com/oauth2/authorize?response_type=code&client_id=" + CognitoAppClientID "&redirect_uri=" + RedirectURI "&identity_provider=Google" ); } // Facebook認証 function OAuthForFacebook() { window.location.assign( "https://" + CognitoDomain + ".auth.ap-northeast-1.amazoncognito.com/oauth2/authorize?response_type=code&client_id=" + CognitoAppClientID "&redirect_uri=" + RedirectURI "&identity_provider=Facebook" ); }Google認証時の画面
Facebook認証時の画面
Cognitoトークンの取得
ログインするとURLパラメータに
codeが埋まっています。このcodeを利用してCognitoトークンを取得します。
下記のソースコードはログインしたあとのcodeを利用して、Cognitoトークンとユーザー情報を取得し、Amplifyで使えるようにlocalStorageにセットする際の一例です。scriptconst localStorageMainKey: string = "CognitoIdentityServiceProvider." + CognitoAppClientID; const code: string = this.$route.query.code as string; if (code && localStorage.getItem("loginStatus") !== "logined") { const params: URLSearchParams = new URLSearchParams(); params.append("grant_type", "authorization_code"); params.append("redirect_uri", RedirectURI); params.append("code", code); params.append("client_id", CognitoAppClientID); // Tokenの取得 axios.post(CognitoBaseURL + "/oauth2/token", params, { headers : { "Content-Type": "application/x-www-form-urlencoded" } }).then((token: any) => { const bearer: string = "Bearer " + token.data.access_token; // ユーザー情報の取得 axios.post(CognitoBaseURL + "/oauth2/userInfo", {}, { headers : { "Content-Type": "application/x-www-form-urlencoded", "Authorization": bearer } }).then((userInfo: any) => { // Amplifyを利用するためにlocalStorageにセットする const localStorageSubKey: string = localStorageMainKey + "." + userInfo.data.sub; localStorage.setItem(localStorageSubKey + ".accessToken", token.data.access_token); localStorage.setItem(localStorageSubKey + ".idToken", token.data.id_token); localStorage.setItem(localStorageSubKey + ".refreshToken", token.data.refresh_token); localStorage.setItem(localStorageSubKey + ".clockDrift", "0"); localStorage.setItem(localStorageMainKey + ".LastAuthUser", userInfo.data.sub); localStorage.setItem("loginStatus", "logined"); }); }).catch((err: any) => { console.error(err); }); }さいごに
これで、GoogleとFacebookのアカウントを使ってログインし、Cognitoからトークンを取得することができました。
ただ前述したとおり、ログインしただけではトークンを返してくれないので、取得しに行かなければいけないのが、少し手間がかかるといった印象でした。
あとはTwitter認証をしたいと思っているので、また記事を更新しようと思っています。
ではまた!!!




- 投稿日:2019-02-18T15:13:02+09:00
DMSでAurora(MySQL)にデータ連携した時に文字コードをUTF8にする
しょーもない話です。すみません。
小さなことも上げておくことにしたでござる。経緯
同僚から「AWS RDS(Oracle)からAurora(MySQL)にDMSでデータ連携したい」と相談を受けたので、
ggrksと即答DMS設定方法を教えて設定したものの、Auroraで文字化けしてしまったので、その時に対処した方法を書きます。前提
前提として決まっていたこと。
- DMS
- ソース:RDS(Oracle)
- 我々の管轄内のインスタンス
- ターゲット:Aurora(MySQL)
- データ連携用のデータベースにする
- 我々の管理外のインスタンスなので、我々は設定などの内部情報を持っていない
- 対象データ(レコード)には日本語が含まれる
- そもそも私はAurora/MySQLの知識がほぼないです。
発生した問題
Auroraで文字コードがlatin1になっている為、文字化けが発生する。
「Aurora担当者からはUTF8で送ってほしい」とrequestが来たらしい。対処
- 先に、Aurora(MySQL)内に手動でデータ連携用データベースを作成し、文字コードをUTF8にしておく。
- その上で、DMSタスクを再起動する。
ね?簡単でしょ?
(想定)原因
最初、Auroraのデータ連携用データベースはDMSタスクの実行によって自動的に作られた状態になっていた。
MySQLはデフォルトの文字コード(文字セット)がlatin1になっている(らしい)。
このため、文字コードの違いから文字化けが発生していたっぽい。なので、先にデータベース作っといたらええやん。というお話でした。
- 投稿日:2019-02-18T15:05:35+09:00
LambdaからAppSyncをIAM認証で使う
LambdaからAppSyncを使いたい
事の発端は、フロントエンドからDynamoDBに投げたデータをLambdaで処理を行った後(まぁまぁ時間が掛かることを想定したもの)、反映された情報をSubscriptionによってリアクティブに更新させたいと思ったのですが、AppSyncでSubscriptionする上で、AppSyncのMutationを通さずに更新した情報はSubscriptionできなさそうなので、バックエンドのLambdaからの更新もAppSyncを使う必要がある。1
その際に、認証方法にAPI_KEYは嫌だし、Lambdaの認証のためにCognito Userを登録するのもナンセンスな気がしたので、IAM認証を。やり方
基本的に大部分こちらで説明されている方法でいけます。
ただ、こちらのサイトもAPI KEYを使って説明されているので、このままAUTH TYPEをAWS_IAMに変えても403になってしまいます。答えはとても簡単で、ここにほとんど答えが載ってますが、credentialsを渡してあげればいいです。
しかし、Credentialsに何を渡すか、どう渡すかですが、単純にLambdaの実行Roleにより取得できるCredentialsを渡してあげましょうindex.jsrequire('isomorphic-fetch'); const aws = require('aws-sdk'); //AWS-SDKの読込します const AWSAppSyncClient = require('aws-appsync').default; const gql = require('graphql-tag'); const AppSyncConfig = require('./aws-exports').default; //~~~~~Mutationやらの定義は上記サイトを参考に同じように~~~~~ exports.handler = async (event) => { const client = new AWSAppSyncClient({ url: AppSyncConfig.aws_appsync_graphqlEndpoint, region: AppSyncConfig.aws_appsync_region, auth: { type: AppSyncConfig.aws_appsync_authenticationType, credentials: ()=> aws.config.credentials //ここ!! }, disableOffline: true }); //~~~Mutationの実行などは上記サイトを参考に同じように~~~ };単純にAWS-SDKを読み込んであげることで、Credentialsの取得がなされるので、それをauth.credentialsに渡してあげるだけです。
IAM認証を使っている方の記事が少なく、何気にたどり着くのに時間が掛かったので、どなたかのお役に立てば幸いです。
この部分そもそもちゃんと検証していないので理解が間違っていたら、是非ご指摘を! ↩
- 投稿日:2019-02-18T15:00:37+09:00
AWS X-Rayでmysql-connector-pythonにバッチを当ててリクエストをトレースしてみる
はじめに
アプリケーションが処理する各種リクエストをトレースするため、AWS X-Rayを使用しています。
リクエスト処理に使うライブラリのうち、AWS SDKを含むいくつかについてはX-Ray SDK内でデフォルトでサポートされており、パッチを適用すれば簡単に処理をトレースしてくれます。
今回は、PythonでDBを操作するアプリケーションを想定し、X-Ray SDK for Pythonがサポートしている mysql-connector-python にパッチを適用してみようと思います。
AWS X-Ray - ライブラリを実装ダウンストリーム呼び出しにパッチする
環境
検証は、ローカルで行いました。
OS: macOS High Sierra
Python: 3.6.5
MySQL: 5.6実行
MySQLサーバー
適当に用意。今回はDockerでmysql:5.6イメージをプルして実行。
データベースとテーブルの用意
以下のクエリを実行。
# データベース create database xray_test; # テーブル create table user (id char(10), name char(20));X Ray デーモン
トレースした情報をAWS上のX-Rayサービスへ投げるためにX-Rayデーモンを実行させる必要があります。
今回はローカルで検証したため、macOSで実行可能なスクリプトを落として
-oオプションをつけて実行。AWS X-Ray - ローカルで X-Ray デーモンを実行する
./xray_mac -oPythonスクリプト実行
今回はSELECT・INSERT・DELETEをトレースしてみます。
import mysql.connector from aws_xray_sdk.core import xray_recorder from aws_xray_sdk.core import patch # パッチ適用 patch_allでも可 libraries = ('mysql',) patch(libraries) # X Ray の設定 xray_recorder.configure(service='mysql-connector', daemon_address="127.0.0.1:2000") # mysql セグメント開始 segment = xray_recorder.begin_segment('mysql') # 接続 conn = mysql.connector.connect(user='root', password='password', host='127.0.0.1', database='xray_test') cur = conn.cursor() # INSERT cur.execute("insert into user values ('01', 'hoge');") conn.commit() # SELECT cur.execute("select * from user;") for row in cur.fetchall(): print(row[0],row[1]) # DELETE cur.execute("delete from user where id = '01';") conn.commit() cur.close() conn.close() # mysql セグメント終了 xray_recorder.end_segment()結果
AWSコンソールで確認してみます。
トレース詳細に、こんな感じでちゃんと3リクエストがサブセグメントとして乗ってます。
試しにサプセグメントを選択すると、SQLタブが出てます。これを開くと、DBのタイプやバージョン、接続したユーザー名が表示されます。
ここの情報はSELECT・INSERT・DELETEとも同じです。
注意点
X-Rayにトレースしてもらうためには、 必ず
mysql.connector.connect関数を使ってコネクションを作る必要があります。当初はコネクションプールの操作のため
mysql.connector.pooling.MySQLConnectionPoolを使ってましたが全然トレースしてくれませんでしたバッチライブラリの中でも、サポートされている関数/されていない関数があるようなので、ご注意を・・・
まとめ
これでMySQLサーバーへのリクエストがトレースできましたが、基本的には接続先と処理時間くらいしかトレースしてくれないので、より細かい情報を取りたい場合はSQLAlchemy ORMを使うべきかなと思います。また別途検証したいと思います。
参考
MySQL Connector/Python Developer Guide


- 投稿日:2019-02-18T13:25:10+09:00
Amazon Cognitoで発生する例外(Exception)をまとめてみた
Amazon Cognito とは
ウェブアプリケーションやモバイルアプリケーションの認証、許可、ユーザー管理をしてくれる便利なサービス。
GoogleやTwitterなどのサードパーティとも連携できる優れもの。エラーレスポンスの形式
基本的に以下の形式で与えられる。
Console{ code: "NotAuthorizedException", name: "NotAuthorizedException", message: "Incorrect username or password." }
key value code 例外コード name 例外名 message 例外の詳細 例外一覧
主にSignUp, Verify, SignIn周りの例外をまとめた。
General(どのタイミングでも発生し得る)
InternalErrorException
Cognito内部での例外。余程のことが無い限り発生しないと思われる。
InvalidLambdaResponseException
Cognitoで指定できるトリガーLambda関数のレスポンスが無効である。
UnexpectedLambdaException
Cognitoで指定できるトリガーLambda関数内部で例外が発生。
ResourceNotFoundException
ResourceのID等の指定を間違っている可能性がある。そもそも作ってない説もある。
TooManyRequestsException
文字通り、requestを飛ばしすぎによる例外。
SignUp関連
CodeDeliveryFailureException
検証コードの配信に失敗した時に起こる。
InvalidEmailRoleAccessPolicyException
メールアドレス周りのRole関連による例外。
InvalidSmsRoleAccessPolicyException
これも権限周り。検証コードを発行する権限が無い。
InvalidSmsRoleTrustRelationException
これも権限周り。Roleの不一致(IDPoolやサードパーティ関連)
InvalidParameterException
必要なユーザー属性が足りなかったりした時に発生。
InvalidPasswordException
Cognito側で設定したパスワード要件を満たしていない時に発生する。
追記)パスワードの長さが足りない場合はInvalidParameterExceptionの方に引っかかるっぽい
SignIn関連
NotAuthorizedException
ユーザー認証に失敗した時。ユーザー名orパスワードが間違っています等のメッセージがいい例。
UserLambdaValidationException
Cognito側でユーザーの自己サインインを許可していない時などに起こる。
UsernameExistsException
既にユーザー名が使われている時に起こる。
UserNotConfirmedException
検証コードを入力する作業が完了していないユーザーがサインインしようとした時とか。これをキャッチして検証ページに飛ばすのが普通なのかな?
PasswordResetException
パスワードのリセットが必要な時に発生する例外。
Verify関連
CodeMismatchException
入力された検証コードが間違っている時に発生。
LimitExceededException
ログイン試行やコード検証試行の回数の上限に達した時に発生。
ExpiredCodeException
検証コードが期限切れになっている時に発生する。
UserNotFoundException
検証しようとしたメールアドレスが存在しない場合に発生する。
終わりに
Amazon Cognitoで発生する例外についてまとめました。
全てを網羅できていませんが、必要そうなものは大体ピックアップしました。
これ違うだろっていうのがあれば修正リクエストお願いします。
こちらでも気付き次第修正します。
- 投稿日:2019-02-18T13:16:00+09:00
CloudWatch+lambda+Amazon Connectでオートコールを実現しよう
作ったもの
模式図は以下の通りで、GCP上のインスタンスで上がったアラートをCloudWatchで受けて、管理者にメール・電話で通知する仕組みです。
作った背景
CloudWatchにはAgentが用意されており、オンプレサーバもAWSコンソールにて一元管理できるってのを知り、試しにGCPインスタンスをCloudWatch Agentで監視して様々な方法で通知してみようと思い作ってみました。
流れ
流れとしては以下のとおりです。
・GCPインスタンスの作成
・SSMの導入
・IAM登録
・CloudWatch Agentのインストール
・Amazon Connectの設定
・Lambdaの設定
・サブスクリプションの作成GCPインスタンス作成
outboundにInternetへの足があればOKで、特にデフォルトの設定はいじっておりません。
監視対象のサーバはGCPでなくても、オンプレサーバやIBM Cloudのサーバなどでも構わないと思います。SSMの導入
SSMの導入はCloudWatchにて監視する上で必須ではないと思いますが、便宜上導入しています。
- EC2 System Managerのアクティベーションを作成
- SSM Agentのインストール
アクティベーション作成&SSM Agentのインストール
こちらを参考にしてアクティベーションを作成しました。
https://dev.classmethod.jp/cloud/aws/ec2-systems-manager-on-premises/
[SYSTEM MANAGER共有リソース]→[アクティベーション]→[アクティベーションの作成]にて新規アクティベーションを作成します。ここで表示されるアクティベーションコードとアクティベーションIDを用いて監視対象の紐付けを行いますので控えておきましょう。続いて、GCPインスタンスにyumでSSM Agentをインストールします。
・SSM Agentのrpmをダウンロード # mkdir /tmp/ssm # curl https://amazon-ssm-ap-northeast-1.s3.amazonaws.com/latest/linux_amd64/amazon-ssm-agent.rpm -o /tmp/ssm/amazon-ssm-agent.rpm ・インストールします # yum install -y /tmp/ssm/amazon-ssm-agent.rpm ・先程控えたアクティベーションコードを使って登録します # systemctl stop amazon-ssm-agent # amazon-ssm-agent -register -code "アクティベーションコード" -id "アクティベーションID" -region "自分のリージョン" ・エージェントを起動します # systemctl start amazon-ssm-agentこれでSSMからマネージドインスタンスとして閲覧可能になります。コンピュータ名がGCPで作成したものと一致していることを確認してください。
インスタンスIDはこのアカウント固有のものが新たに付与されます。IAM登録
CloudWatch Agent用のユーザーを作成し、ポリシーは以下4つを付与してください。
AmazonEC2ReadOnlyAccess
AmazonSSMFullAccess
AmazonEC2RoleforSSM
CloudWatchAgentServerPolicyユーザー追加時に表示されるアクセスキーIDとシークレットアクセスキーを控えておきましょう。
CloudWatch Agentインストール
System Managerにてランコマンドを実行することで、CloudWatch Agentが導入出来ます。
[SYSTEM MANAGER アクション]→[ランコマンド]→[コマンドの実行]をクリックし、ドキュメントのプレフィックス名
AWS-ConfigureAWSPackageを選択してください。コマンドのパラメータは以下のよう設定し、実行してください。
- Action:Install
- Name:AmazonCloudWatchAgent
- Version:latest
以下の通り、Successfully installedと出力されればOKです。
出力Initiating arn:aws:ssm:::package/AmazonCloudWatchAgent 1.207573.0 install Plugin aws:runShellScript ResultStatus Success install output: Running sh install.sh Successfully installed arn:aws:ssm:::package/AmazonCloudWatchAgent 1.207573.0AWS CLIインストール
続いて、CloudWatch Agentのプロファイル作成のためにAWS CLIを導入します。
・pipが入っていない場合はpipのインストール # curl -O https://bootstrap.pypa.io/get-pip.py # python get-pip.py # pip --version ・pipにてAWS CLIのインストール # pip install awscli --upgrade # aws --versionCloudWatchAgentプロファイルの作成
作成したIAMユーザー情報のアクセスキーとシークレットアクセスキーで「AmazonCloudWatchAgent」プロファイルを設定します。
# aws configure --profile AmazonCloudWatchAgent AWS Access Key ID [None]: ****************** AWS Secret Access Key [None]: ********************* Default region name [None]: us-west-2 Default output format [None]:CloudWatchAgentの構成
以下コマンドを実行し、wizardを起動します。
基本はデフォルトでOKですが、自身の環境に合わせて回答を変えましょう。[root@instance-1 ~]# /opt/aws/amazon-cloudwatch-agent/bin/amazon-cloudwatch-agent-config-wizard ============================================================= = Welcome to the AWS CloudWatch Agent Configuration Manager = ============================================================= On which OS are you planning to use the agent? 1. linux 2. windows default choice: [1]: 1 Trying to fetch the default region based on ec2 metadata... Are you using EC2 or On-Premises hosts? 1. EC2 2. On-Premises default choice: [2]: 2 ←今回はEC2以外の環境に導入するため2を選択します。 Please make sure the credentials and region set correctly on your hosts. Refer to http://docs.aws.amazon.com/cli/latest/userguide/cli-chap-getting-started.html Do you want to turn on StatsD daemon? 1. yes 2. no default choice: [1]: 1 Which port do you want StatsD daemon to listen to? default choice: [8125] 8125 What is the collect interval for StatsD daemon? 1. 10s 2. 30s 3. 60s default choice: [1]: 1 What is the aggregation interval for metrics collected by StatsD daemon? 1. Do not aggregate 2. 10s 3. 30s 4. 60s default choice: [4]: 4 Do you want to monitor metrics from CollectD? 1. yes 2. no default choice: [1]: 1 Do you want to monitor any host metrics? e.g. CPU, memory, etc. 1. yes 2. no default choice: [1]: 1 Do you want to monitor cpu metrics per core? Additional CloudWatch charges may apply. 1. yes 2. no default choice: [1]: 1 Would you like to collect your metrics at high resolution (sub-minute resolution)? This enables sub-minute resolution for all metrics, but you can customize for specific metrics in the output json file. 1. 1s 2. 10s 3. 30s 4. 60s default choice: [4]: 4 Which default metrics config do you want? 1. Basic 2. Standard 3. Advanced 4. None default choice: [1]: 1 Current config as follows: { "metrics": { "metrics_collected": { "collectd": { "metrics_aggregation_interval": 60 }, "cpu": { "measurement": [ "cpu_usage_idle" ], "metrics_collection_interval": 60, "resources": [ "*" ], "totalcpu": true }, "disk": { "measurement": [ "used_percent" ], "metrics_collection_interval": 60, "resources": [ "*" ] }, "diskio": { "measurement": [ "write_bytes", "read_bytes", "writes", "reads" ], "metrics_collection_interval": 60, "resources": [ "*" ] }, "mem": { "measurement": [ "mem_used_percent" ], "metrics_collection_interval": 60 }, "net": { "measurement": [ "bytes_sent", "bytes_recv", "packets_sent", "packets_recv" ], "metrics_collection_interval": 60, "resources": [ "*" ] }, "statsd": { "metrics_aggregation_interval": 60, "metrics_collection_interval": 10, "service_address": ":8125" }, "swap": { "measurement": [ "swap_used_percent" ], "metrics_collection_interval": 60 } } } } Are you satisfied with the above config? Note: it can be manually customized after the wizard completes to add additional items. 1. yes 2. no default choice: [1]: 1 Do you have any existing CloudWatch Log Agent (http://docs.aws.amazon.com/AmazonCloudWatch/latest/logs/AgentReference.html) configuration file to import for migration? 1. yes 2. no default choice: [2]: 2 Do you want to monitor any log files? 1. yes 2. no default choice: [1]: 1 Log file path: /var/log/messages Log group name: default choice: [messages] Log stream name: default choice: [{hostname}] Do you want to specify any additional log files to monitor? 1. yes 2. no default choice: [1]: 2 ←他に監視対象がなければ2を選択します。 Saved config file to /opt/aws/amazon-cloudwatch-agent/bin/config.json successfully. Current config as follows: { "logs": { "logs_collected": { "files": { "collect_list": [ { "file_path": "/var/log/messages", "log_group_name": "messages", "log_stream_name": "{hostname}" } ] } } }, "metrics": { "metrics_collected": { "collectd": { "metrics_aggregation_interval": 60 }, "cpu": { "measurement": [ "cpu_usage_idle" ], "metrics_collection_interval": 60, "resources": [ "*" ], "totalcpu": true }, "disk": { "measurement": [ "used_percent" ], "metrics_collection_interval": 60, "resources": [ "*" ] }, "diskio": { "measurement": [ "write_bytes", "read_bytes", "writes", "reads" ], "metrics_collection_interval": 60, "resources": [ "*" ] }, "mem": { "measurement": [ "mem_used_percent" ], "metrics_collection_interval": 60 }, "net": { "measurement": [ "bytes_sent", "bytes_recv", "packets_sent", "packets_recv" ], "metrics_collection_interval": 60, "resources": [ "*" ] }, "statsd": { "metrics_aggregation_interval": 60, "metrics_collection_interval": 10, "service_address": ":8125" }, "swap": { "measurement": [ "swap_used_percent" ], "metrics_collection_interval": 60 } } } } Please check the above content of the config. The config file is also located at /opt/aws/amazon-cloudwatch-agent/bin/config.json. Edit it manually if needed. Do you want to store the config in the SSM parameter store? 1. yes 2. no default choice: [1]: 1 What parameter store name do you want to use to store your config? (Use 'AmazonCloudWatch-' prefix if you use our managed AWS policy) default choice: [AmazonCloudWatch-linux] Which region do you want to store the config in the parameter store? default choice: [us-west-2] Which AWS credential should be used to send json config to parameter store? 1. ASIA************KO(From SDK) 2. *************(From Profile: AmazonCloudWatchAgent) 3. Other default choice: [1]: 2 ←先ほど作成したプロファイルであることを確認し、選択します。 Successfully put config to parameter store AmazonCloudWatch-linux. Program exits now.CloudWatchAgent設定の配布
[SYSTEM MANAGER アクション]→[ランコマンド]→[コマンドの実行]をクリックし、
ドキュメントのプレフィックス名AmazonCloudWatch-ManageAgentを選択してください。コマンドのパラメータは以下のよう設定し、実行してください。
- Action: configure
- Mode: onPremise
- Optional Configuration Source: ssm
- Optional Configuration Location: AmazonCloudWatch-linux
- Optional Restart: yes
ターゲットは監視対象となるインスタンスを手動で選択してください。
実行後以下のようなエラーが出たら、
======== Error Log ======== 2019/02/06 09:33:29 I! AmazonCloudWatchAgent Version 1.207573.0. 2019/02/06 09:33:29 E! Error parsing /opt/aws/amazon-cloudwatch-agent/etc/amazon-cloudwatch-agent.toml, open /usr/share/collectd/types.db: no such file or directorytouchにてファイルを追加して再度ランコマンド実行してください。
mkdir /usr/share/collectd touch /usr/share/collectd/types.dbこれでAWSコンソールにてGCPインスタンスの確認が出来るようになりました。
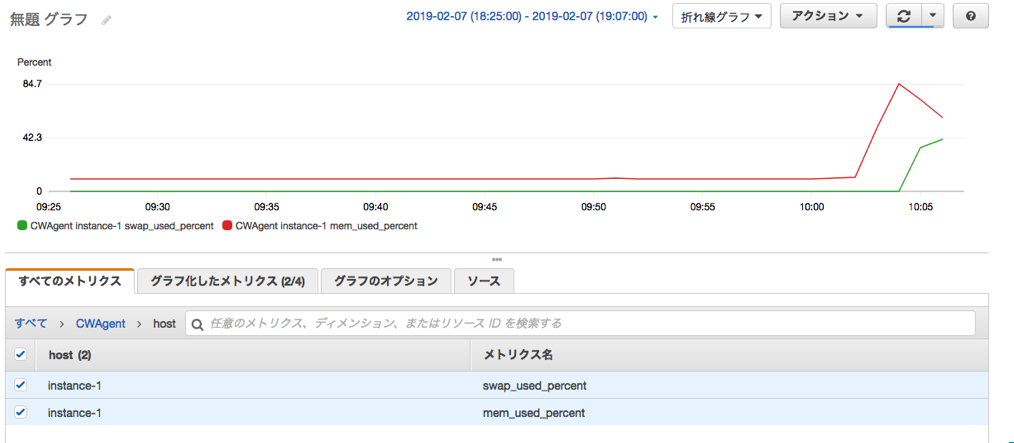
swapの負荷テストをするには、GCPのインスタンスにはデフォルトでSwap領域がないので以下サイトにて設定が必要です。
https://wannabe-jellyfish.hatenablog.com/entry/2018/02/04/170033free[root@instance-1 ~]# free -m total used free shared buff/cache available Mem: 3537 103 3327 1 106 3252 Swap: 511 128 383 [root@instance-1 ~]# date Thu Feb 7 10:08:07 UTC 2019 [root@instance-1 ~]#
Amazon Connectの設定
以下を参考にAmazon Connectのリソース設定及び電話番号の取得までを実施しましょう。
http://xp-cloud.jp/blog/2017/10/12/2027/次に、問い合わせフローを作成します。
今回作成したものは、電話発信がトリガーされたら用意されたメッセージを伝えるだけのとてもシンプルなものにしています。
保存して発行を選択し、このフローのARNを確認します。
フローのARNは以下のようになっておりますが、
arn:aws:connect:us-west-2:xxxxxxxxxx:instance/72ada63f-1d31-3c5r-ad48-xxxxxxxxxx/contact-flow/08d5d895-2307-4f56-8b54-xxxxxxxxxxxinstance/以下の
72ada63f-1d31-3c5r-ad48-xxxxxxxxxxインスタンスID
contact-flow/以下の08d5d895-2307-4f56-8b54-xxxxxxxxxxxがコンタクトフローID
となります。
この情報に基づいてlambdaがこのフローをキックしますので、控えておきましょう。lambda関数の作成
言語はpython3.6で作成しました。
import boto3 connect = boto3.client('connect') # ロギング import logging print('Loading function') # ロード時にメッセージを出力 def lambda_handler(event, context): logger = logging.getLogger() # loggerの初期設定 logLevel=logging.WARNING # ロギングのレベルを設定 # ロギングレベルに応じたメッセージが出力される logger.debug('1:debug') logger.info('2:info') logger.warning('3:warning') logger.error('4:error') logger.critical('5:critical') # Amazon Connect で電話をかける def call(event, context): connect.start_outbound_voice_contact( DestinationPhoneNumber='+81xxxxxxxxx', ContactFlowId='08d5d895-2307-4f56-8b54-xxxxxxxxxxx', InstanceId='72ada63f-1d31-3c5r-ad48-xxxxxxxxxx', SourcePhoneNumber='+1xxxxxxxxx', )
DestinationPhoneNumberには通知先の電話番号
ContactFlowId, InstanceIdには先程メモした問い合わせフローのコンタクトフローIDとインスタンスID
SourcePhoneNumberにはAmazon Connectにて払い出した電話番号
をそれぞれ入れます。ここで発行された関数にARNが付与されますので、このARNを用いてCloudWatchと連携します。
サブスクリプション作成
CloudWatchにて適当なアラームを作成します。
しきい値はお好みで設定し、アクション欄の[通知の送信先]にて「新しいリスト」を選択/作成してください。
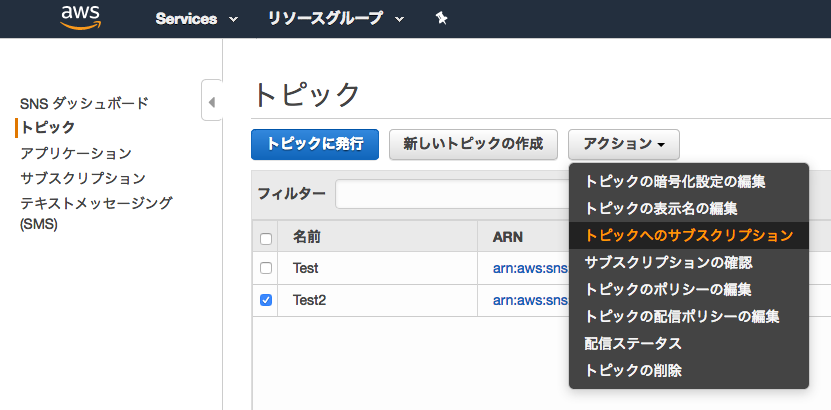
これがSNS(Simple Notification Service)における「トピック」になります。SNSコンソールに移り、作成したトピックを選択した上でアクションタブより「トピックへのサブスクリプション」を選択してください。
ポップアップにて以下の通り選択します。
- プロトコル:AWS lambda
- エンドポイント:上で作成したlambdaのARNを選択
これにてCloudWatchにて監視アラートがあがれば、
・SNSにてメール通知
・lambdaからAmazon Connect起動で電話通知
が可能になります。おわりに
複数の環境にわたったシステムをお持ちの方にとっては、AWSコンソール上で一括管理できるため非常に有用なのではと思います。
ここでは紹介していませんが、lambdaの別関数を作成してSlackにも通知を入れることも出来ます。また最初は、Twilioというサービスを用いて電話機能を実装していましたが、一度外部に出るのと音声ファイルをS3に置きパブリック・アクセスを許可する必要があるのとでセキュリティ的に断念しました。(作ることには作ったが…)
今後はアラートの内容をAmazon Connectに渡し、アラートごとに異なったメッセージを通知するようなシステムにしていきたいと思います。



- 投稿日:2019-02-18T13:12:32+09:00
Amazon ECS+Fargate入門 (terraformを使ったクラスタ構築とオートスケール、ブルーグリーンデプロイ)
はじめに
コンテナベースでインフラ実現するに伴って色々AWS上でのコンテナ周り調べたり、本番導入した際のまとめ的なメモです。
大雑把にこんなことを書いてます。
- 構成概念と基礎知識
- terraformによるコードデプロイ連携でのブルーグリーンデプロイ
- terraformによるメトリクスベースでのオートスケーリング
ECS+Fargateのインフラアーキテクチャ全体像
* AWS公式からの引用ECSとは
ECSはAWSが提供するk8sと同じようなクラスタ構成でのコンテナオケーストレーション
を実現するサービス。
ECSは実際にコンテナが稼働する複数のworkerNodeとその操作・管理を担当するmasterNodeの
クラスタ構造を採用する事で分散・冗長化・スケーラブルなインフラを構築できる。
具体的には以下のような機能を提供をしている。
- クラスタの管理(workerNodeへの自動参加・死活監視や操作など)
- クラスタ上でのコンテナのデプロイメント(ノードに対する配置戦略・生成・ローリングアップデート)
- コンテナ群のスケールイン/アウト
- 外部サービス公開用のインタフェースの定義と動作するコンテナとロードバランサとの紐付けといったような外部との接合)
- コンテナに対するヘルスチェック機能(成否に伴なった外部アクセスに対するアタッチ・デタッチやコンテナ自体に不備発生した場合の再起動)
- スケジュールジョブ
Fargateとは
ECSクラスタのワーカーノードにあたる部分は自分でecsエージェントを起動させたEC2のオートスケーリンググループを組み、
リソース管理やスケールインアウトを操作する必要があった。
ECS Fargateはワーカー部分も含めて、フルマネージドで実現しているので
Fargateを採用する事で実際にコンテナを起動させていたEC2の管理や
スケールイン/アウト/アップに伴うクラスタ自身のリソース管理や作成から解放される。AWSではEKSというkubernetesを採用したコンテナオーケストレーションサービスもあるのだけど、
こちらは現時点(2019/01)ではFargate未対応でEKS最適化されたamiイメージを元に
EC2でWorkerNodeを構成することになる。サポートするVCPUとMemoryの組み合わせはこちら
Fargateの制約やデメリット
大雑把に。
awsvpcモード必須
logDriverがawslogsに限定される
cloudwatchとの連携は用意だがそれ以外のログの収集や送信(たとえばfluentdなど)との複数コンテナ稼働時のログ収集においては一工夫しないといけなかったり。
- 共有ボリュームは~4GB
概ねサイドカーエージェントでログ転送とかする際の置き場になる気がするんだけど、上限が低いので
ローテートとかちゃんと組まないと枯渇する
kill時の設定が素のECSよかいじれなかったり
デプロイと起動が素のECSより少し遅い。
EC2と同スペック比較すると15~20%くらいは高くなる。
この辺はtask定義のパラメータにも記載があるので
また起動数などのサービス制約もあるので、緩和申請なども場合によっては必要
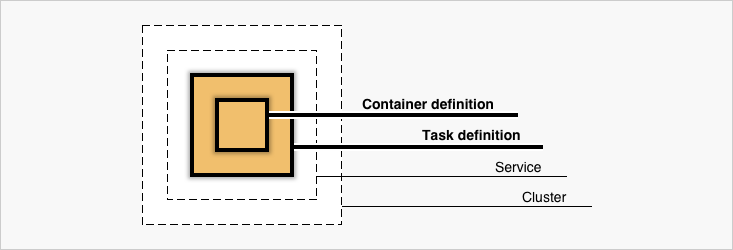
ECSを構成する要素
(AWS公式のチュートリアルからの引用
- Cluster
- Service
- Container Definition
- Task & TaskDefinition
によってECSは構成されている。
次項で項目別に記載していく。
実際にはTaskDefinition中にContainerDefinitionは内包されている。Cluster
ServiceやTaskが所属する論理的なグルーピング。
FargateでなくEC2起動タイプを選択している場合は所属するクラスタのworkerNodeであるEC2インスタンスを共有する。Task & TaskDefinition
Task
TaskDefinitionの定義を実行に移している実行されている複数のコンテナを指す。
例えばgoとnginxを組み合わせて動いているようなwebアプリケーションを二つのコンテナ構成で動作させる場合は
以下のようなコンテナの組み合わせが1Taskとして扱われる。* sample_go_application_task - nginx - goTaskDefinition
Taskの定義というと(まんま)
アプリケーションをどのようにコンテナを組み合わせるか、リソースをどれくらい許容するか、
IAMやネットワークはどのようにするか、というようなコンテナの動作に必要な情報を設定する。
具体的には以下のような情報を定義する。
すごく大雑把にいうと、docker-composeにawsインフラの情報や定義が足されたようなイメージ。
- コンテナを動かすのに必要な情報(DockerImage,Port,protocolなど)
- 動かしたいコンテナの組み合わせ
- コンテナ起動時の実行コマンドやdocker関連のパラメーター設定
- 適用するIAMロールやセキュリティグループ
- ネットワークモードや動作させるネットワーク情報
- 使用するリソース量(CPU/メモリ)
ざっくりとした例
{ "family": "sample", "networkMode": "awsvpc", "containerDefinitions": [ { "name": "nginx", "image": "nginx:latest", "essential": true, "dockerLabels": {"role:nginx"} }, { "name": "go-app", "image": "your-go-app:latest", "essential": true, "environment": [ { "name": "ENV_1", "value": "hoge" }, { "name": "ENV_2", "value": "fuga" } ] } ], "requiresCompatibilities": [ "FARGATE" ], "cpu": "256", "memory": "512" }動かすだけなら簡単に動きますが、例えばweb serverとして動作させる場合はulimitの値を設定しておかないと
ファイルディスクリプタが枯渇して爆死したりとか、memoryReservationを全く指定しないでハードリミット超えてコンテナがご臨終したりするので、パラメーターセットは公式を一度しっかり見て把握した方が良いと思います。
- 作成
aws ecs register-task-definition --cli-input-json file://$PWD/task-definitions.json更新はfamilyが存在していれば同一コマンドで行われて、バージョン値が自動でincrementされる。
Service
TaskDefinitionを束ねて外部にどのように公開するか、オートスケールを
どのような閾値で行うか、起動タイプ(EC2/Fargate)などの設定を記載できる。
例えばロードバランサへのtargetGroup追加したりなど。
- aws cliから雛形をダウンロード
aws ecs create-service --generate-cli-skeleton > service.json
- service生成
aws ecs create-service --cli-input-json file://$PWD/service.json更新は
update-serviceで行う。
全ての項目が更新可能ではなく作成時にしか変更できない項目もあり、項目数が多いので、詳細な説明は公式を確認した方が良いです。例としてはこんな感じ
{ "cluster": "test-ecs-cluster", "serviceName": "test-service", "taskDefinition": "test:30", "loadBalancers": [ { "targetGroupArn": "loadbarancerArn", "containerName": "test-nginx", "containerPort": 80 } ], "desiredCount": 2, "clientToken": "", "launchType": "FARGATE", "platformVersion": "LATEST", "deploymentConfiguration": { "maximumPercent": 200, "minimumHealthyPercent": 100 }, "networkConfiguration": { "awsvpcConfiguration": { "subnets": [ "subnet-xxxxx", "subnet-xxxxx" ], "securityGroups": [ "sg-xxxxx", ], "assignPublicIp": "DISABLED" } }, "healthCheckGracePeriodSeconds": 0, "schedulingStrategy": "REPLICA", "deploymentController": { "type": "CODE_DEPLOY" }, "propagateTags": "TASK_DEFINITION", "tags": [ { "key": "env", "value": "stage" }, { "key": "region", "value": "jp" } ], "enableECSManagedTags": false }fargate利用の場合、alb/nlbのどちらかが必須であることと、TargetGroupのtarget_typeをipで作る必要がある。
Blue/Green Deploymentしてみよう。
同じAWSのコンポーネントであるCodeDeployと連携させると結構簡単にロードバランサー振替ベースでの
Blue/Green Deploymentを実現できる。GUIでは指示に従っていけば概ね簡単に作れるので、割愛。
CUIとterraformを使っての説明。
VPC,subnet,securityGroupは説明を省くので、よしなに作ってください。クラスタ作成
resource "aws_ecs_cluster" "ecs_cluster" { name = "test-nginx-cluster" } resource "aws_cloudwatch_log_group" "ecs_log_group" { name = "/ecs/test-nginx" tags { hoge = "hoge" fuga = "fuga" } }ロードバランサ作成
手元で作ったのがNLBだったので、今回はNLBで。
ALBでもほぼ変わりません。resource "aws_lb" "lb" { name = "test-nginx-lb" internal = false subnets = [ "your_subnetid", "your_subnetid", ] load_balancer_type = "network" enable_http2 = false } ## Target Group resource "aws_lb_target_group" "lb_target_blue" { name = "blue-nlb-tg" port = 80 protocol = "TCP" vpc_id = "your_vpc_id" target_type = "ip" health_check { interval = 10 healthy_threshold = 3 unhealthy_threshold = 3 protocol = "TCP" port = "traffic-port" } } ## Target Group resource "aws_lb_target_group" "lb_target_green" { name = "green-nlb-tg" port = 80 protocol = "TCP" vpc_id = "your_vpc_id" target_type = "ip" health_check { interval = 10 healthy_threshold = 3 unhealthy_threshold = 3 protocol = "TCP" port = "traffic-port" } } ## Listeners resource "aws_lb_listener" "lb_listner" { load_balancer_arn = "${aws_lb.lb.arn}" port = 8081 protocol = "TCP" # blueとgreenのtgを動的に入れ替えるのでignoreする lifecycle { ignore_changes = ["default_action"] } default_action { target_group_arn = "${aws_lb_target_group.lb_target_blue.arn}" #初回はblueにattach type = "forward" } }IAM設定
クラスタ初回作成時に自動的でecsTaskExecutionRoleとAWSServiceRoleForECSが作成されます。
ECS運用時のどちらも必要になりますので、なければとりあえず手動でコンソールからぽちぽちと
クラスタ作っておくと吉。task定義作成
terraformでもできますが、特段terraformで扱うメリットもない気がするので
ここではaws公式に沿ってjsonで。{ "family": "test", "executionRoleArn": "arn:aws:iam::xxxxxxxx:role/ecsTaskExecutionRole", "networkMode": "awsvpc", "containerDefinitions": [ { "name": "test-nginx", "image": "nginx:latest", "ulimits": [ { "name": "nofile", "softLimit": 65536, "hardLimit": 65536 } ], "entryPoint": [ "sh", "-c" ], "portMappings": [ { "hostPort": 80, "protocol": "tcp", "containerPort": 80 } ], "command": [ "echo blue > /usr/share/nginx/html/index.html | /usr/sbin/nginx -g \"daemon off;\"" ], "memoryReservation": 256, "essential": true, "logConfiguration": { "logDriver": "awslogs", "options": { "awslogs-group": "/ecs/test-nginx", "awslogs-region": "ap-northeast-1", "awslogs-stream-prefix": "test-nginx" } } } ], "requiresCompatibilities": [ "FARGATE" ], "cpu": "512", "memory": "4096", }service作成
resource "aws_ecs_service" "ecs" { name = "test-nginx" cluster = "${aws_ecs_cluster.ecs_cluster.id}" task_definition = "test-nginx:1" desired_count = 2 launch_type = "FARGATE" deployment_minimum_healthy_percent = 100 deployment_maximum_percent = 200 network_configuration { subnets = [ "your_subnet_ids" ] security_groups = [ "yours_secuiry_groups", ] assign_public_ip = "false" } health_check_grace_period_seconds = 0 load_balancer { target_group_arn = "${aws_lb_target_group.lb_target_blue.arn}" container_name = "test-nginx" container_port = 80 } scheduling_strategy = "REPLICA" deployment_controller { type = "CODE_DEPLOY" } // deployやautoscaleで動的に変化する値を差分だしたくないので無視する lifecycle { ignore_changes = [ "desired_count", "task_definition", "load_balancer", ] } propagate_tags = "TASK_DEFINITION" }コードデプロイアプリケーションとデプロイグループの作成
- iamを付与
resource "aws_iam_role" "codedeploy" { name = "codedeploy" } ## ECS CodedeployPolicy resource "aws_iam_role_policy_attachment" "ecs_deploy" { role = "${aws_iam_role.codedeploy.id}" policy_arn = "arn:aws:iam::aws:policy/AWSCodeDeployRoleForECS" } ## Codedeploy IAM Role Policy data "aws_iam_policy_document" "codedeploy_iam_role_policy" { statement { actions = [ "autoscaling:CompleteLifecycleAction", "autoscaling:DeleteLifecycleHook", "autoscaling:DescribeAutoScalingGroups", "autoscaling:DescribeLifecycleHooks", "autoscaling:PutLifecycleHook", "autoscaling:RecordLifecycleActionHeartbeat", "ec2:DescribeInstances", "ec2:DescribeInstanceStatus", "sns:*", "tag:GetTags", "tag:GetResources", ] effect = "Allow" resources = ["*"] } }コードデプロイはこんな感じにリソースを作成する
resource "aws_codedeploy_app" "app" { compute_platform = "ECS" name = "test-ecs" } resource "aws_codedeploy_deployment_group" "group" { app_name = "test-bg-deploy" deployment_group_name = "test-bg-deploy-dg" service_role_arn = "${aws_iam_role.codedeploy.arn}" deployment_config_name = "CodeDeployDefault.ECSAllAtOnce" auto_rollback_configuration { enabled = true events = ["DEPLOYMENT_FAILURE"] } blue_green_deployment_config { deployment_ready_option { action_on_timeout = "CONTINUE_DEPLOYMENT" } terminate_blue_instances_on_deployment_success { action = "TERMINATE" termination_wait_time_in_minutes = "10" # デプロイ成功後の環境保持時間 } } deployment_style { deployment_option = "WITH_TRAFFIC_CONTROL" deployment_type = "BLUE_GREEN" } ecs_service { cluster_name = "your_ecs_cluster_name" service_name = "your_ecs_service_name" } load_balancer_info { target_group_pair_info { prod_traffic_route { listener_arns = ["${aws_lb_listener.lb_listner.arn}"] } target_group { name = "${aws_lb_target_group.lb_target_blue.name}" } target_group { name = "${aws_lb_target_group.lb_target_green.name}" } } } }ブルーグリーン関連で設定できる内容として
- 新環境にテストポートのみ振り当てて公開する
- 新環境の保持期間
- 環境振替を手動で行う or 時間指定
などが設定できるので、細かくは公式を
デプロイしてみる
このへんはECSのコンソール上から手動なりお好みで。
吐き出してるhtmlをblue,greenで切り替えつつ、while loopなどでcurlで叩き続けると
blue/greenの切り替わりが観察できます。fargateTaskをオートスケーリングしたい
オートスケールはGUI上でサービス作成をする際は画面上から一貫して作れますが
実際には別リソースなので、terraformで作成する際は、appautoscaling_targetを使います。
ここではCloudWatchAlarmと連携してCPUメトリクスでスケールイン/アウトするサンプルを。resource "aws_appautoscaling_target" "test_ecs_target" { service_namespace = "ecs" resource_id = "service/your_cluster_name/service_name" scalable_dimension = "ecs:service:DesiredCount" role_arn = "${data.aws_iam_role.ecs_service_autoscaling.arn}" min_capacity = 2 max_capacity = 12 } # Automatically scale capacity up by one resource "aws_appautoscaling_policy" "test_scale_up" { name = "scale_up" service_namespace = "ecs" resource_id = "service/your_cluster_name/service_name" scalable_dimension = "ecs:service:DesiredCount" step_scaling_policy_configuration { adjustment_type = "ChangeInCapacity" cooldown = 600 metric_aggregation_type = "Average" step_adjustment { metric_interval_lower_bound = 0 scaling_adjustment = 1 } } depends_on = ["aws_appautoscaling_target.test_ecs_target"] } # Automatically scale capacity down by one resource "aws_appautoscaling_policy" "test_scale_down" { name = "scale_down" service_namespace = "ecs" resource_id = "service/your_cluster_name/service_name" scalable_dimension = "ecs:service:DesiredCount" step_scaling_policy_configuration { adjustment_type = "ChangeInCapacity" cooldown = 600 metric_aggregation_type = "Average" step_adjustment { metric_interval_lower_bound = 0 scaling_adjustment = -1 } } depends_on = ["aws_appautoscaling_target.test_ecs_target"] } # Cloudwatch alarm that triggers the autoscaling up policy resource "aws_cloudwatch_metric_alarm" "test_cpu_high" { alarm_name = "cpu_utilization_high" comparison_operator = "GreaterThanOrEqualToThreshold" evaluation_periods = "2" metric_name = "CPUUtilization" namespace = "AWS/ECS" period = "60" statistic = "Average" threshold = "60" dimensions { ClusterName = "your_ecs_cluster_name" ServiceName = "your_ecs_service_name" } alarm_actions = ["${aws_appautoscaling_policy.test_scale_up.arn}"] } # Cloudwatch alarm that triggers the autoscaling down policy resource "aws_cloudwatch_metric_alarm" "test_cpu_low" { alarm_name = "cpu_utilization_low" comparison_operator = "LessThanOrEqualToThreshold" evaluation_periods = "2" metric_name = "CPUUtilization" namespace = "AWS/ECS" period = "60" statistic = "Average" threshold = "30" dimensions { ClusterName = "your_ecs_cluster_name" ServiceName = "your_ecs_service_name" } alarm_actions = ["${aws_appautoscaling_policy.test_scale_down.arn}"] } data "aws_iam_role" "ecs_service_autoscaling" { name = "AWSServiceRoleForApplicationAutoScaling_ECSService" }参考

- 投稿日:2019-02-18T11:52:10+09:00
お財布に優しいCatapult 4000TPSチャレンジ (その1)
Catapult 4000TPSチャレンジについて
2018/02/18 追記
このチャレンジがプライベート・ネットワークでのテストであることを明記しました。こんにちは。最近Blockchainの勉強を始めたインフラエンジニアの@hide825jpです。
皆さんは、NEMを使ってますか?私は全く使ったことがなかったのですが、先月開催された「NEMBOOT CAMP」に勉強がてら参加してきました。
NEM Bootcamp - Hello, Blockchain!
どのセッションも興味深いものでしたが、インフラエンジニアの私にとっては、@planethoukiさんの「Catapult 実験室『4,000トランザクション・チャレンジの報告と募集』」セッション、それにセッションの中で発表された4,000トランザクション・チャレンジ募集、これが、とても興味を引きました。
ということで、チャレンジに応募してみました。
Catapult 4000 TPSチャレンジ 応募フォーム参考にさせて頂いたこと
4000トランザクション/秒というのは、ビットコインやイーサリアムとは桁が数桁違います。個人でそんな挑戦ができるんでしょうか。
ただ、すでに@planethoukiさんが挑戦された詳細な記事があり、その後@44uk_i3さんのチャレンジ記事もあり、正直軽い気持ちで応募したのですが、、、。
@planethoukiさんの記事を読んでいただくとお分かりのように、
Azure VMのF32s_v2インスタンス -> 月額 17万なり。。
これは検証で数日使っても、それなりの金額になりますね。私のお財布にはとても痛いです。やはり法人レベルでないと厳しいのでしょうか。
でも、がんばってみました。私のチャレンジの切り口は、
お財布に優しいにCatapult 4000TPSチャレンジ
で、やってみました。
検証は、@planethoukiさんの以下のスクリプトのお世話になっております。
https://github.com/planethouki/yonsen.git今回の検証で異なる点は、@planethoukiさんのスクリプトでは、Catapultと負荷テストスクリプトが同じサーバで動くことになりますが、これは分離することにしました。コードの変更点は、ターゲットURLを「localhost」からCatapultサーバのIPに変更しただけです。
また、Catapultの構築は「catapult-service-bootstrap」を、そのまま使用しています。
https://github.com/tech-bureau/catapult-service-bootstrapAWSでのチャレンジ
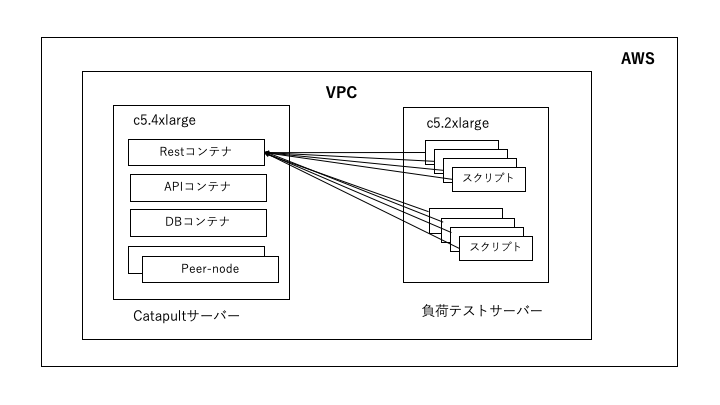
まずは、AWSで検証してみました。
構成図はこんな感じです。後で出てくるGCPもほぼ同じ構成です。負荷テスト用のサーバは、テストスクリプトが8スレッドで動くので、8コアの「c5.2xlarge」としてします。
これは、あくまでもVPC内でのテストです。
つまり、プライベート・ネットワークでのテストなります。GCPでのテストも同様です。
Catapultサーバのインスタンス・サイズは「c5.4xlarge」としました。
「c5.4xlarge」は「コンピューティング最適化 」の「現行世代」です。スペックはこんな感じです。vCPUコア: 16
メモリ: 32GB
ストレージ: EBS
OS: Ubuntu 18.04LTS
そして、お値段は、東京リージョンで「0.856USD/時間」です。なので、24時間x30日動かすと、
0.856 X 24 X 30 = 616.32 USD ≒ 6万8千円くらい
これに転送量やディスクへの課金、負荷テスト用のインスタンスの料金もかかります。
AzureのF32s_v2インスタンスより、だいぶ安くなりました。でも、まだまだ高いですね。AWSでの結果
それで、前置きはいいとして、結果です。
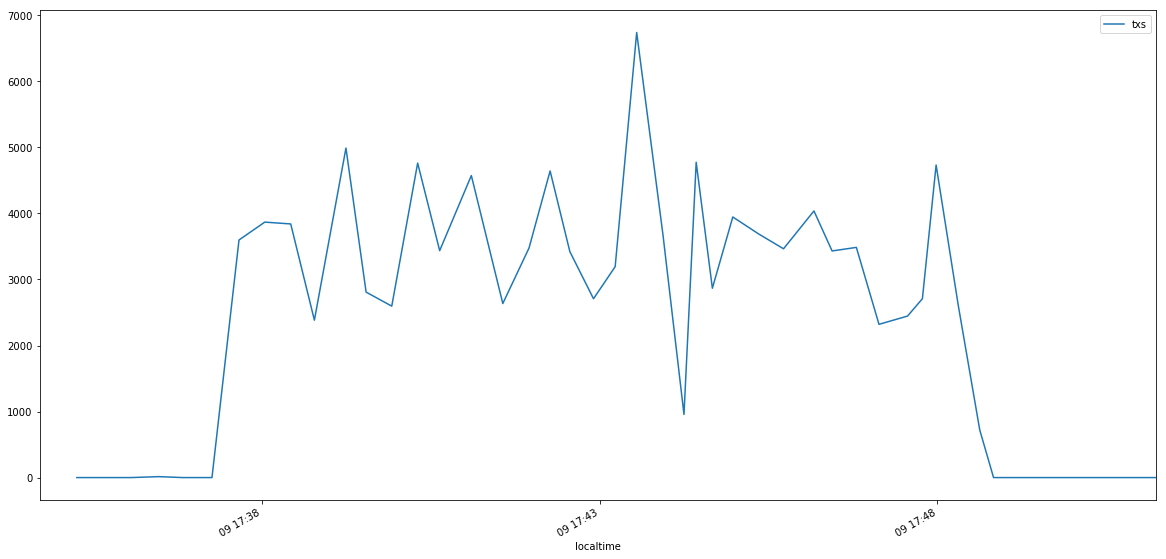
トランザクション/秒 = 1 Blockのトランザクション数 ÷ そのBlockの生成時間
で、計算してます。
トランザクションの結果をPythonのpandasで整形して、matplotlibで表示するとこんな感です。
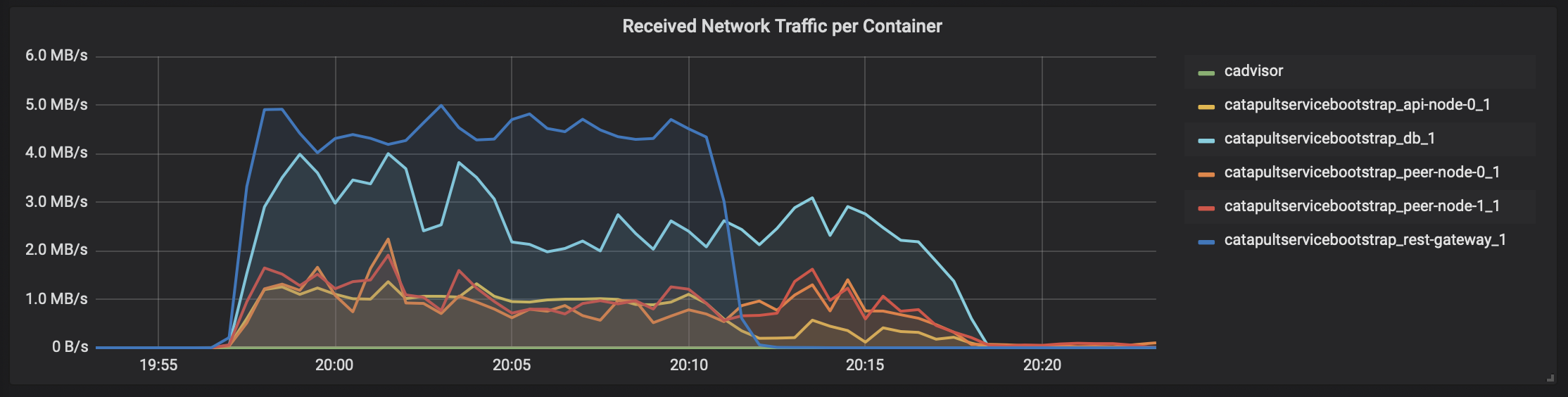
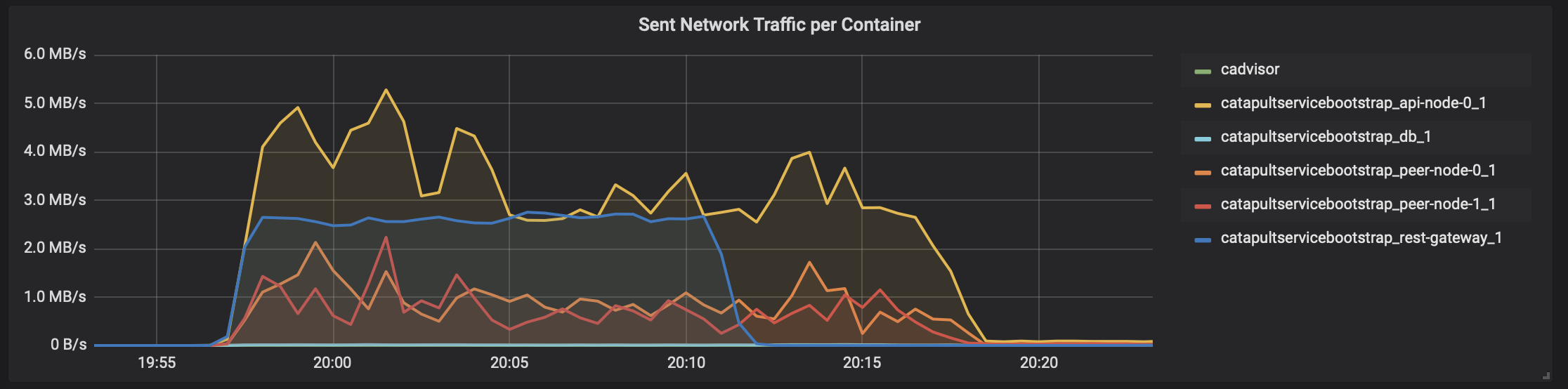
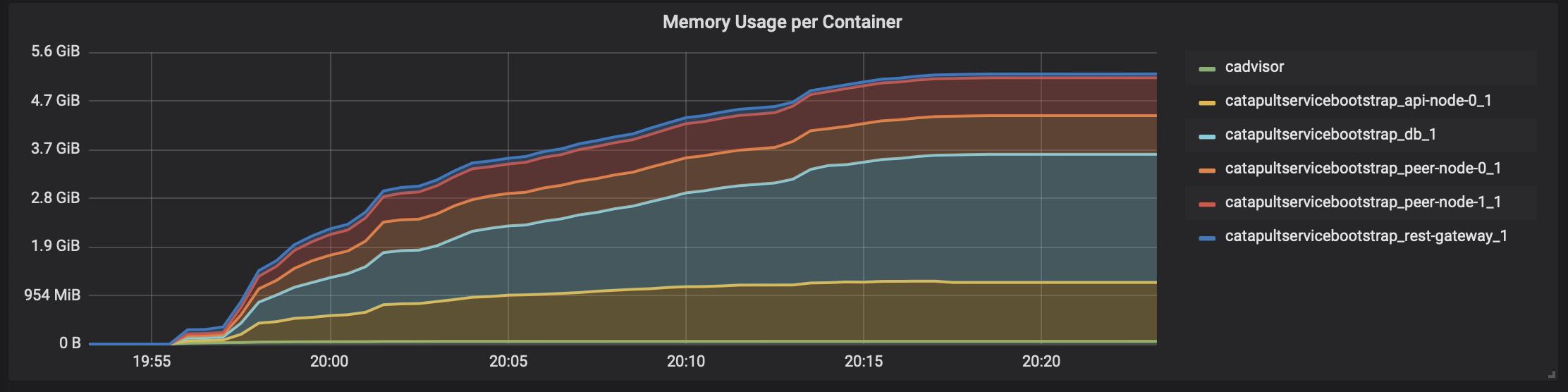
- トランザクション数の結果
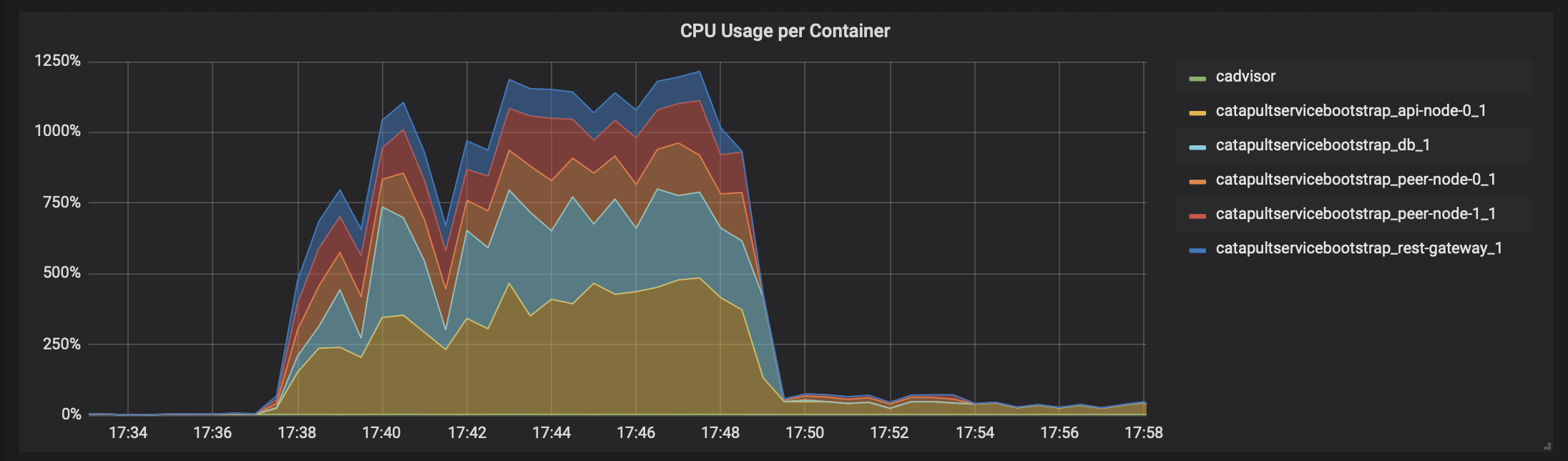
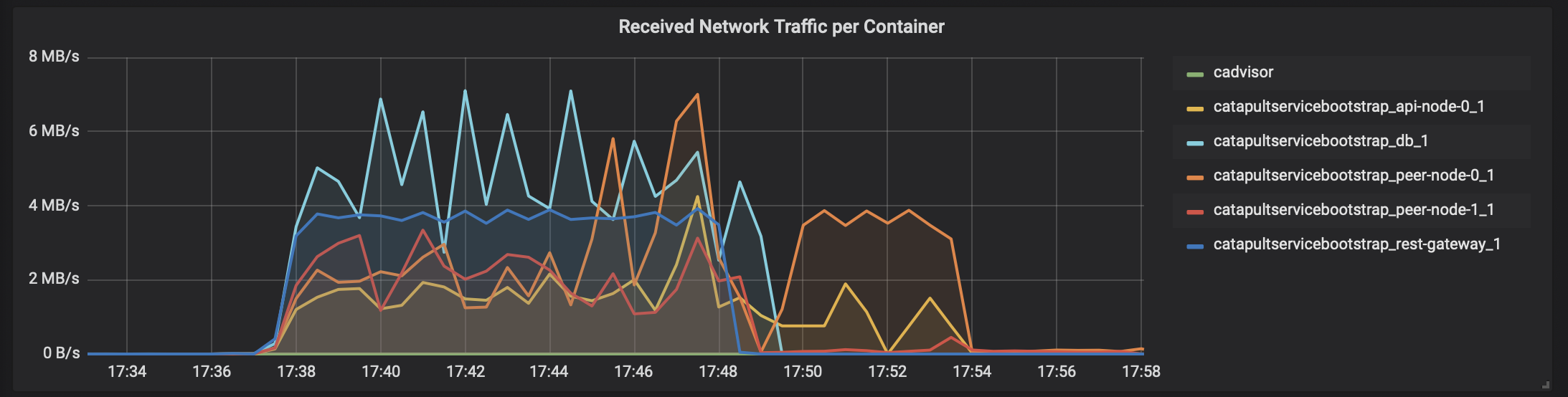
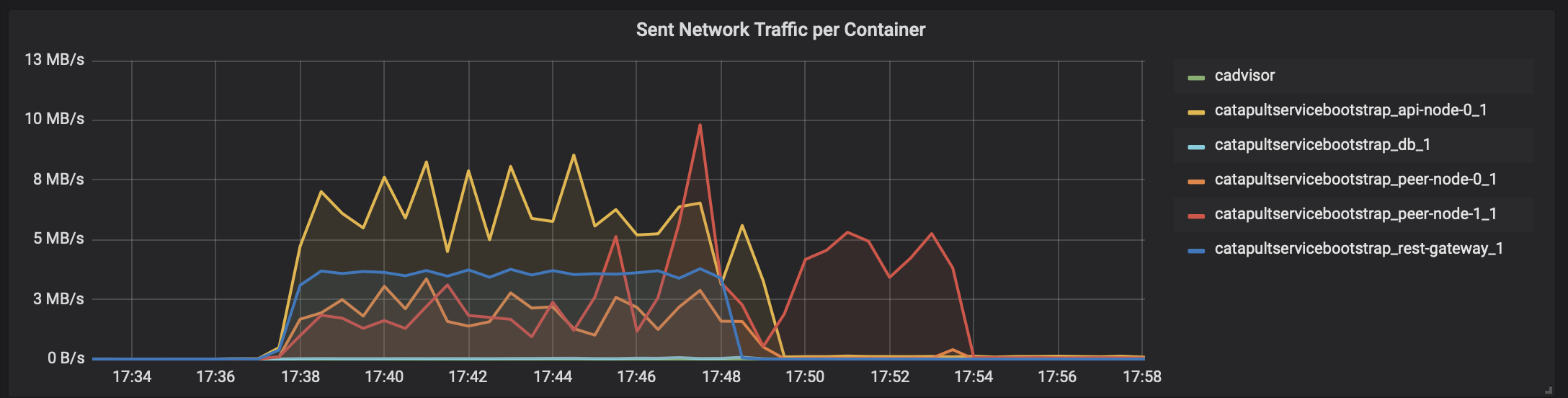
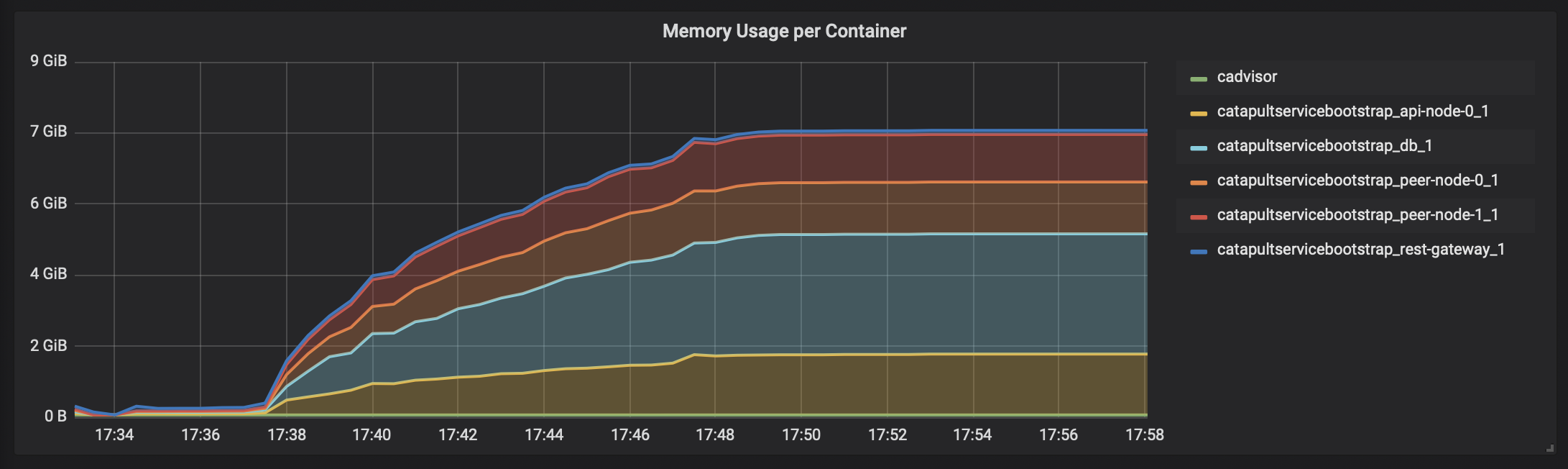
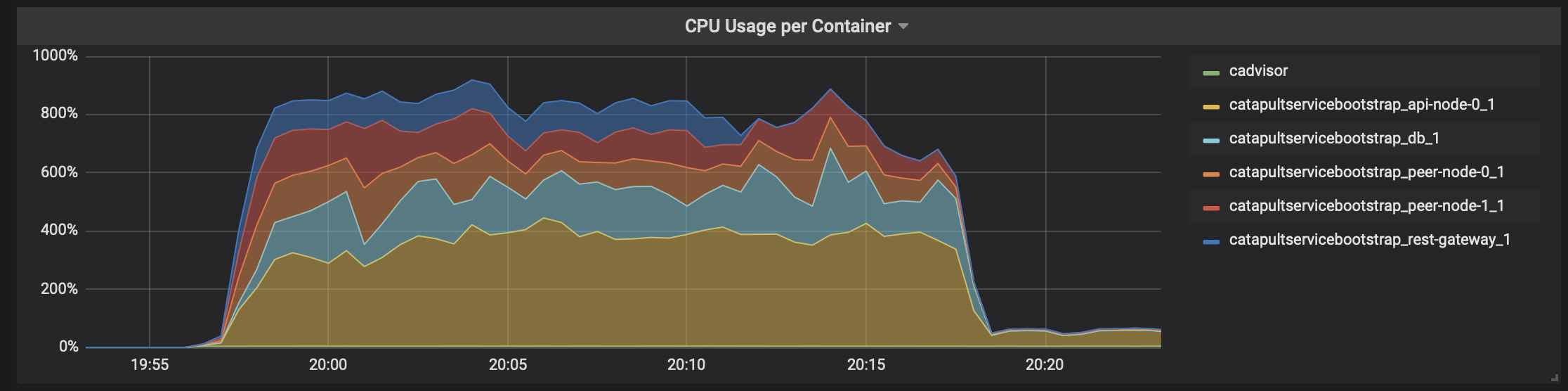
「cadvisor」 -> 「Prometheus」 -> 「Grafana」で、テスト時のCatapultサーバのDocker状況を表示すると、こんな感じになります。
各DockerコンテナのCPU使用率
ネットワーク(受信)
ネットワーク(送信)
メモリ消費状況
瞬間的に4000トランザクション/秒を何度か越えてます。ただ、リソース使い切ってないですね。。。CPUコアはホスト側のCPUリソースと合わせても16コアは必要なさそうです。メモリは無駄に大きいだけですね。
ということで、「c5.4xlarge」のひとつ下「c5.2xlarge」(8コア)でも試したのですが、瞬間的に4000TPSがで出ても、Catapultの動作が不安定でデータが取り出せなかったりで、今回のチャレンジでは断念しました。NEM素人でもすんなり4000トランザクション/秒を実現できるのは、やっぱりCatapultはすごいのかもしれません。でも、インフラ的にはまだ工夫の余地はありそうですね。
GCPでの仕切り直し
ということで、コア数の選択で融通の利く、GCPで再テストすることにしました。
結論から言うと、4000トランザクション/秒が出た一番スペックの低い単一インスタンスはこんな感です。
vCPUコア: 10
CPUプラットホーム Skylake以降
メモリ: 10GB (これは必須ではありません。9GB以上しか選択できなかったので)
OS: Ubuntu 18.04LTSそして、東京リージョンでのお値段は、設定時のGCPコンソールの月間予測で「$235.76」でした。日本円にすると2万円後半といったところでしょうか。
でも、検証なので「プリエンプティブ」でもいいですね。「プリエンプティブ」をオンにした場合は、月額予測が「$73.58」と出ました。
https://cloud.google.com/preemptible-vms/?hl=ja日本円で月額8千円台前半ですね !!!
それにGoogleさんがサーバを勝手に停止するので、この金額を下回ってくるはずです。
ところで、トランザクションの結果はこんな感じです。GCPでの負荷テストサーバも、AWSと同様にCPUを8コアとしました。
また、リソース消費の状況はこんな感じです。
各DockerコンテナのCPU使用率
ネットワーク(受信)
ネットワーク(送信)
メモリ消費状況
なんとか、4000トランザクションが出てますね。。。
最後に
最終的に自分のお財布で、なんとかなりそうな金額でチャレンジができました。
しかし、NEM素人の私ではつたない部分も多々あり、テスト手法については再検討が必要かと思います。特にテスト時の取引の中で、XEM残高をうまく調節するのが難しいようです。その他、改善すべき点は多数あり、より厳密な検証を後日やってみたいと思います。
いずれにしても、
チャレンジにかかる費用は工夫次第でだいぶ安くなりそう、
です。みなさんも挑戦してみてはいかかでしょうか。


- 投稿日:2019-02-18T09:44:54+09:00
AWSソリューションアーキテクト-アソシエイト試験に20日で合格する方法
はじめに
2019年2月16日にAWSソリューションアーキテクトアソシエイト試験に783点で合格した。
(試験結果は100から1000の間の値で示され、合格に必要な最低スコアは 720)
AWS利用経験ゼロから20日間の勉強で受かったので、勉強法や試験攻略のポイントを記す。
前提として持っていた知識
既に取得済の資格は以下。
・基本情報技術者
・LPICレベル1
AWSの業務経験
なし勉強法
1. 対策本を2周読む(目安:4日)
対策本はこれ。
徹底攻略 AWS認定 ソリューションアーキテクト – アソシエイト教科書
AWS用語を頭に馴染ませることが目的。1周だと意味不明すぎるので2周はすること。2. AWSに触れる(目安:3日)
紫本と呼ばれるこの本に沿って実機で動かしてみる。
Amazon Web Services 基礎からのネットワーク&サーバー構築 改訂版
AWSの雰囲気を体感することが目的。これは時間と手間がかかるので1周でOK。3. 対策本を再度2周読む(目安:3日)
実機に触れているので1の時よりはるかに読みやすくなっているはず。ここでも2周することで理解を深める。
4. 対策問題を解く(目安:7日)
オススメは以下2つのWebサイト。
Amazon AWS 資格取得のための演習問題集(←無料)
AWS WEB問題集で学習しよう(←有料)
(※まずは無料版をこなし余力があれば有料版の順番)
問題を解きながら本で得た知識を脳に定着させることが目的。
理解が曖昧だと思った箇所は本で調べる。本の解説ではスッキリしなければネットで調べる。5. 対策本と問題を交互に読みつつ、理解度が不安なサービスに関するBlackBeltを読む(目安:6日)
対策の総仕上げ。BlackBeltをこの段階で読むのはごちゃごちゃしていた脳が正しく最新の情報で整理される為。
試験攻略のポイント
・対策本には登場しないような用語がちょこちょこ試験問題に出てくる
⇒試験中はかなり焦るが、対策本に書かれていた内容の問題に正解できれば合格する(した)ので気にする必要はない
・模擬試験は必ず受けること
⇒試験問題のレベルと、試験環境(UI)に慣れるため
・基礎的な知識は固めておく
⇒「可用性」「耐久性」のような「○○性」の言葉の違いを理解しておくことが大前提
・似ているように思えるサービスの「役割」や「長所」の差異を理解しておく
例)Route53でできることと、CloudFrontでできることの区別
- 投稿日:2019-02-18T09:44:54+09:00
AWSソリューションアーキテクト-アソシエイト試験に20日で合格する方法(2019/2版)
はじめに
2019年2月16日にAWSソリューションアーキテクトアソシエイト試験に783点で合格した。
(試験結果は100から1000の間の値で示され、合格に必要な最低スコアは 720)
AWS利用経験ゼロから20日間の勉強で受かったので、勉強法や試験攻略のポイントを記す。
前提として持っていた知識
既に取得済の資格は以下。
・基本情報技術者
・LPICレベル1
AWSの業務経験
なし勉強法
1. 対策本を2周読む(目安:4日)
対策本はこれ。
徹底攻略 AWS認定 ソリューションアーキテクト – アソシエイト教科書
AWS用語を頭に馴染ませることが目的。1周だと意味不明すぎるので2周はすること。2. AWSに触れる(目安:3日)
紫本と呼ばれるこの本に沿って実機で動かしてみる。
Amazon Web Services 基礎からのネットワーク&サーバー構築 改訂版
AWSの雰囲気を体感することが目的。これは時間と手間がかかるので1周でOK。3. 対策本を再度2周読む(目安:3日)
実機に触れているので1の時よりはるかに読みやすくなっているはず。ここでも2周することで理解を深める。
4. 対策問題を解く(目安:7日)
オススメは以下2つのWebサイト。
Amazon AWS 資格取得のための演習問題集(←無料)
AWS WEB問題集で学習しよう(←有料)
(※まずは無料版をこなし余力があれば有料版の順番)
問題を解きながら本で得た知識を脳に定着させることが目的。
理解が曖昧だと思った箇所は本で調べる。本の解説ではスッキリしなければネットで調べる。5. 対策本と問題を交互に見つつ、理解しているか不安なサービスに関するBlackBeltを読む(目安:6日)
対策の総仕上げ。BlackBeltをこの段階で読むと、ごちゃごちゃしていた脳みそが最新の情報で整理整頓される。
試験攻略のポイント
・対策本には登場しないような用語がちょこちょこ試験問題に出てくる
⇒試験中はかなり焦るが、対策本に書かれていた内容の問題に正解できれば合格する(した)ので気にする必要はない
・模擬試験は必ず受けること
⇒試験問題のレベルと、試験環境(UI)に慣れるため
・基礎的な知識は固めておく
⇒「可用性」「耐久性」のような「○○性」の言葉の違いを理解しておくことが大前提
・似ているように思えるサービスの「役割」や「長所」の差異を理解しておく
例)Route53でできることと、CloudFrontでできることの区別
- 投稿日:2019-02-18T09:44:54+09:00
[2019/2版]AWSソリューションアーキテクト-アソシエイト試験に20日で合格する方法
はじめに
2019年2月16日にAWSソリューションアーキテクトアソシエイト試験に783点で合格した。
(試験結果は100から1000の間の値で示され、合格に必要な最低スコアは 720)
AWS利用経験ゼロから20日間の勉強で受かったので、勉強法や試験攻略のポイントを記す。
前提として持っていた知識
既に取得済の資格は以下。
・基本情報技術者
・LPICレベル1
AWSの業務経験
なし勉強法
1. 対策本を2周読む(目安:4日)
対策本はこれ。
徹底攻略 AWS認定 ソリューションアーキテクト – アソシエイト教科書
AWS用語を頭に馴染ませることが目的。1周だと意味不明すぎるので2周はすること。2. AWSに触れる(目安:3日)
紫本と呼ばれるこの本に沿って実機で動かしてみる。
Amazon Web Services 基礎からのネットワーク&サーバー構築 改訂版
AWSの雰囲気を体感することが目的。これは時間と手間がかかるので1周でOK。3. 対策本を再度2周読む(目安:3日)
実機に触れているので1の時よりはるかに読みやすくなっているはず。ここでも2周することで理解を深める。
4. 対策問題を解く(目安:7日)
オススメは以下2つのWebサイト。
Amazon AWS 資格取得のための演習問題集(←無料)
AWS WEB問題集で学習しよう(←有料)
(※まずは無料版をこなし余力があれば有料版の順番)
問題を解きながら本で得た知識を脳に定着させることが目的。
理解が曖昧だと思った箇所は本で調べる。本の解説ではスッキリしなければネットで調べる。5. 対策本と問題を交互に見つつ、理解しているか不安なサービスに関するBlackBeltを読む(目安:6日)
対策の総仕上げ。BlackBeltをこの段階で読むと、ごちゃごちゃしていた脳みそが最新の情報で整理整頓される。
試験攻略のポイント
・対策本には登場しないような用語がちょこちょこ試験問題に出てくる
⇒試験中はかなり焦るが、対策本に書かれていた内容の問題に正解できれば合格する(した)ので気にする必要はない
・模擬試験は必ず受けること
⇒試験問題のレベルと、試験環境(UI)に慣れるため
・基礎的な知識は固めておく
⇒「可用性」「耐久性」のような「○○性」の言葉の違いを理解しておくことが大前提
・似ているように思えるサービスの「役割」や「長所」の差異を理解しておく
例)Route53でできることと、CloudFrontでできることの区別
- 投稿日:2019-02-18T05:19:36+09:00
Reactの静的サイトを自動デプロイ
はじめに
今回はCI/CDの手法を学ぶために、静的サイトの自動ビルドと自動デプロイをCircleCIとAWSを用いて構築したので、ぜひ参考にしてみてください。
参考資料
https://circleci.com/docs/2.0/ecs-ecr/#section=deploymen
https://qiita.com/Sekky0905/items/7f9aa94261e17e4fd040
https://circleci.com/docs/2.0/hello-world/
https://devblog.thebase.in/entry/2018/10/31/110000概要
環境のイメージとしては以下のようになります。
前提条件
前提条件としてAWSのアカウントを保持していること、GitHubの基本が分かっていること、CircleCIのアカウントがGitHubのアカウントに紐づけられていることを前提に記事を書きます。
静的サイトのホスト
今回は静的サイトをAWSのS3にホストする形で勧めますので、S3にバケットを作って、静的サイトのホストを完了させた状態にしてください。
一応自分が書いた記事のリンクを貼っておきますので、分からなければ確認してみてください。
AWS S3で静的サイトを構築CircleCIの簡単な使い方
CircleCIに詳しい人や、CircleCIのHello Worldドキュメントを読んだことがあり、CircleCIの簡単な使い方について理解している人は飛ばしてください。また公式ドキュメントの方が自分の記事より遥かに詳しく正確に書いてますので、自分のは参考程度に見てください。
CircleCIは内部にdockerを持っていてgithubのリポジトリのルートに.circleci/config.ymlに設定を書くことで、githubにpushしたのをトリガーにしてCircleCI内でdockerイメージのビルドと各種コマンドが実行されるものになります。
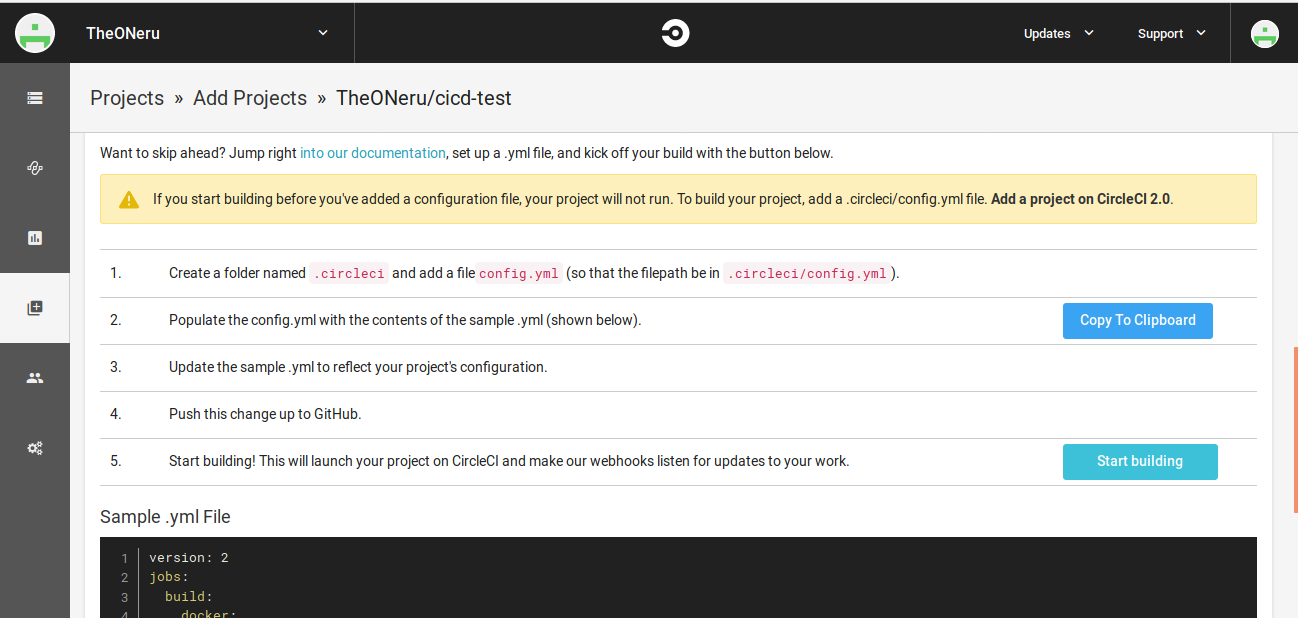
まずはgithubのリポジトリを作成してもらって、リポジトリのルートに.circleci/config.ymlを作成してください。
$ mkdir .circleci $ ls -a . .. .circleci .git $ vim .circleci/config.ymlしたら以下のコードを入力してください。
.circleci/config.ymlversion: 2 jobs: build: docker: - image: circleci/node:4.8.2 steps: - checkout - run: echo "hello world"コードを書き込んだらgit pushでpushしてください。このときリポジトリにconfig.ymlが無いとCicleCIでトリガが掛けられません。
コードの説明を簡単にすると、docker imageをCircleCIで用意されていてダウンロードの時間を少なくできるNodejsのイメージを選択し、build後にechoコマンドでhello worldを出力するものです。
次にリポジトリにトリガーをかけるためにCircleCIのアカウントページから
- Add Project
- Set Up Project

を選択後、特に何もいじらず
- Start building をクリック


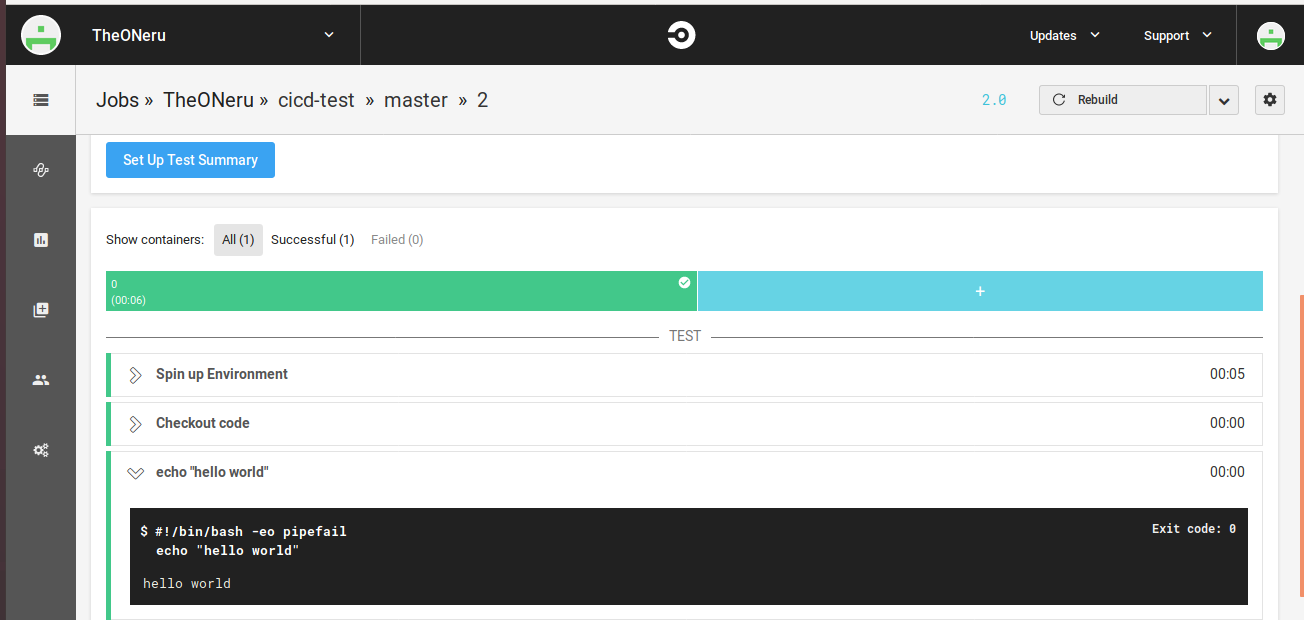
成功すると、以下のような画面になりecho "hello world"が実行され、hello worldが出力されているのが確認できます。
以上が簡単なCircleCIの説明になります。
Reactアプリのビルド
CircleCIを用いて、Reactで作成したアプリをビルドします。Reactについての詳しい説明は公式チュートリアルなどをご覧ください。
Reactチュートリアル: Intro To React【日本語翻訳】
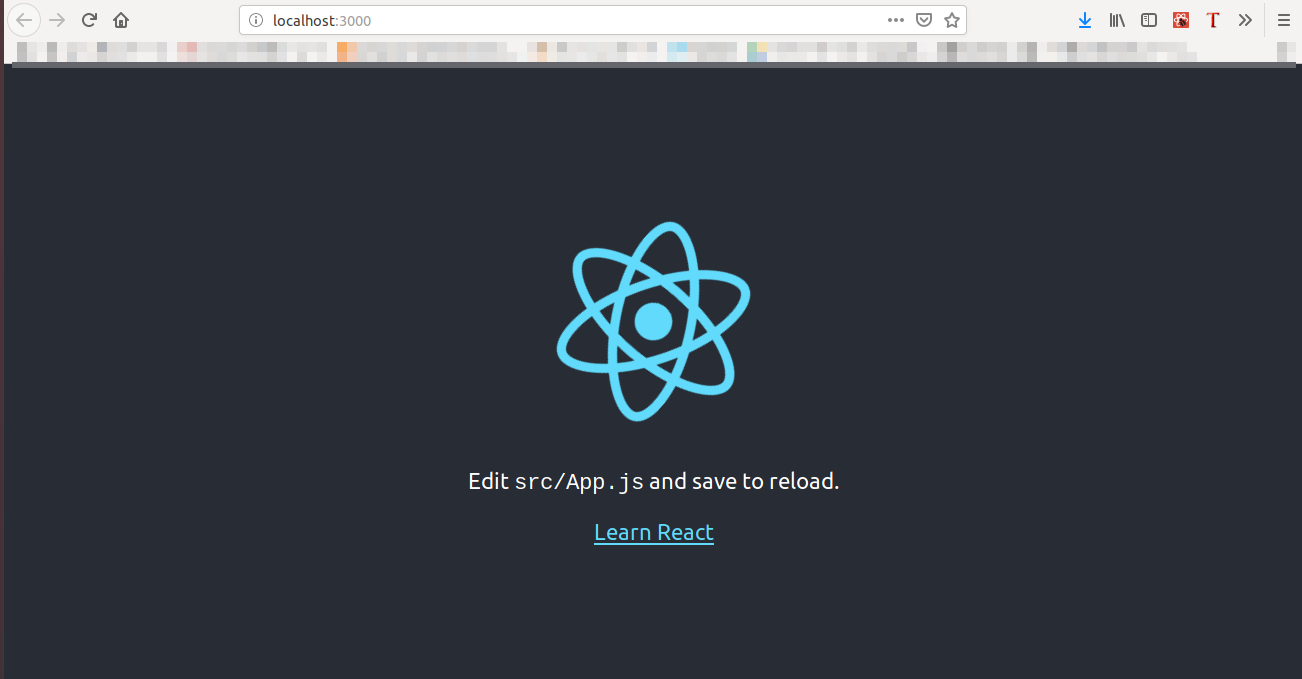
まずReactのテンプレートを作ります。nodeをインストールしてもらってnpxを使える状態で以下のコマンドを入力してください。
npx create-react-app test mv test/* ./ rm -r test/ npm run build npm start上記のコマンドで、reactアプリのテンプレートを作成し、localhost:3000でサービスが立ち上がるのを確認できるはずです。
(reactのテンプレートフォルダから中身を取り出している理由は、CircleCIでのビルド時にpackage.jsonの有るディレクトリにcheckoutしているのに、package.jsonが見つからないエラーが出たので、中身を取り出しています。原因が分からないので、もし分かる人は教えてください)
Reactアプリがたち上がったのを確認したら、以下のコードを.circleci/config.ymlに書いてください。
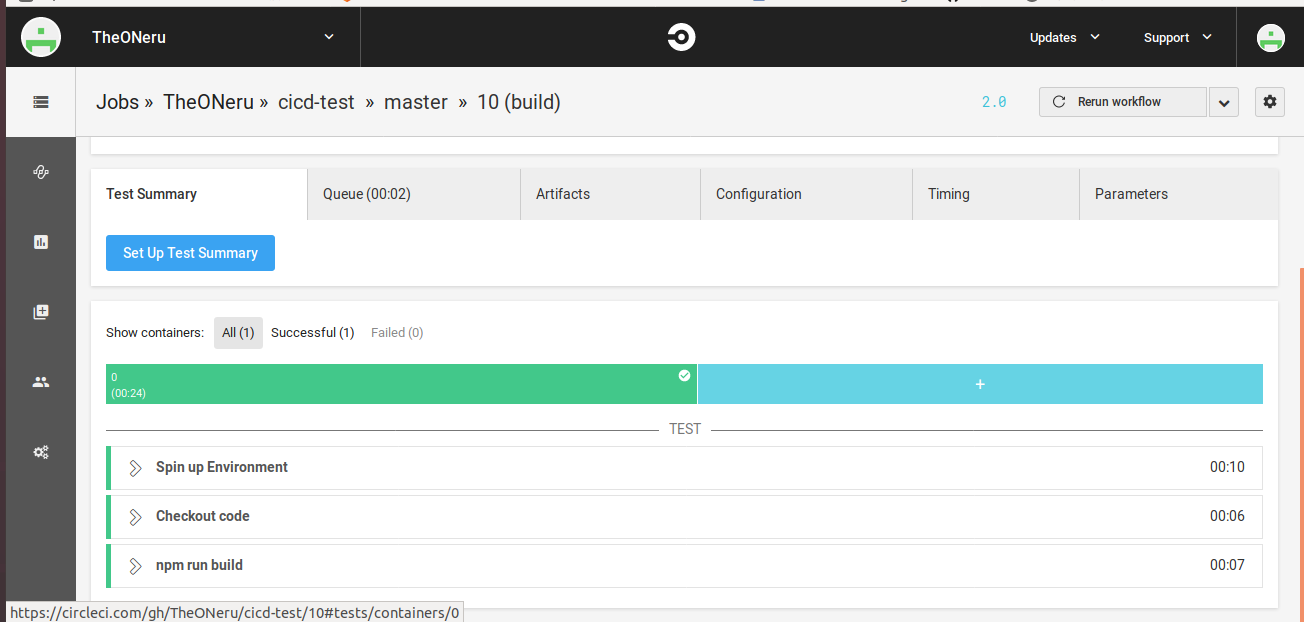
.circleci/config.ymlversion: 2 jobs: build: docker: - image: circleci/node:11.8.0 steps: - checkout - run: npm run buildリポジトリをpushして、CircleCIの画面のBuild画面から、成功すれば緑色になっているのが確認できます。(大量に赤くなっているのは、working_directoryとcheckout絡みで検証して挫折した結果です。)
成功すれば、build画面の詳細からnpm run buildが成功したことが確認できます。AWS S3に自動デプロイ
AWS S3にデプロイするために、同じようにCircleCIでpythonイメージから、更にawscliというコマンドラインからawsのリソースにアクセスできるソフトをダウンロードしてBuildした結果をデプロイします。
まず以下のコードに.circleci/config.ymlを書き直しでください。(バケット名は各自で作成したバケット名を入力してください。)
.circleci/config.ymlversion: 2 jobs: build: docker: - image: circleci/node:11.8.0 steps: - checkout - run: pwd - run: npm run build deploy: docker: - image: circleci/python:2.7-jessie steps: - run: name: Install awscli command: sudo pip install awscli - checkout - run: name: Deploy to S3 command: aws s3 sync build/ s3://バケット名 workflows: version: 2 build-deploy: jobs: - build - deploy: requires: - build filters: branches: only: master重要な点はworkflowsという所で、ここでReactのアプリをBuildした後にS3にデプロイするように実行の順番を制御しています。
実際にAWSにデプロイしているのは以下のコマンドになります。
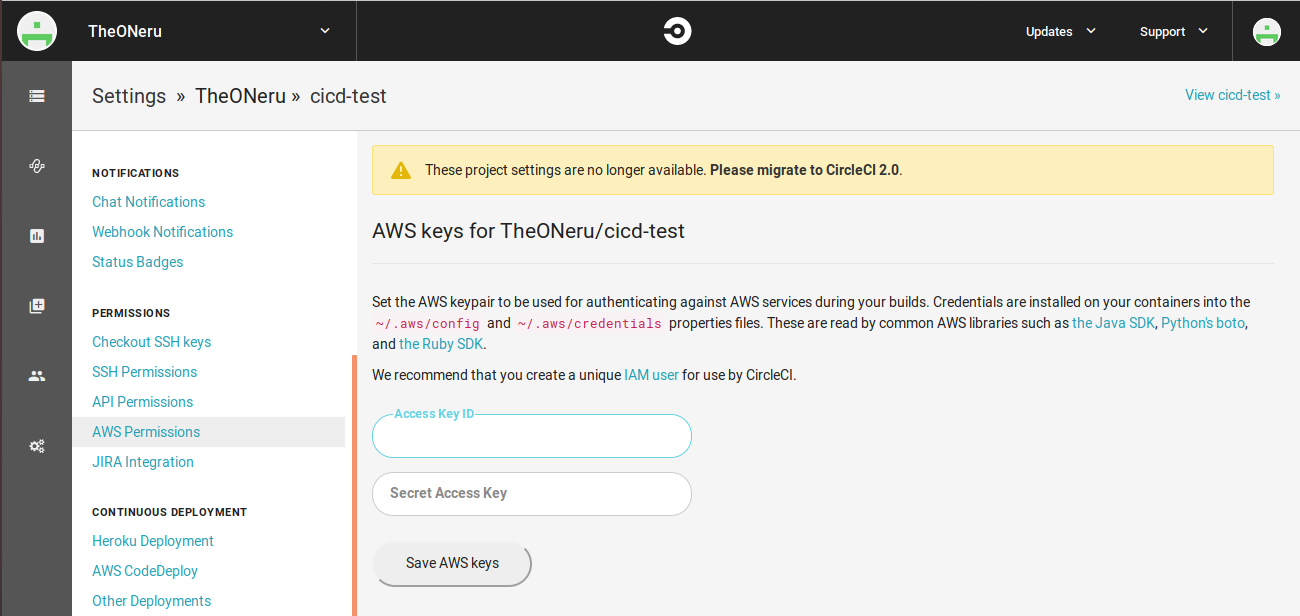
aws s3 sync build/ s3://バケット名またこのままでは、S3への権限が無いのでCircleCIに権限を付与しなければアップロードできません。そのためにIAMロールユーザーを作成してください。
実行権限はS3へのFullAccessとかで良いと思います。
詳しいことは以下の記事とか読んでください。IAMロールの公式ドキュメント
S3のアクセスコントロールまとめIAMロールユーザーが作成できたら、CircleCIのアカウントページから、
- 左のBuildsボタンをクリック
Projectの歯車をクリック
PERMISSIONSのAWS Permissionsをクリック
先程作ったIAMロールユーザーのAccess Key IDとSeacret Access Keyを入力
Save AWS keysをクリック
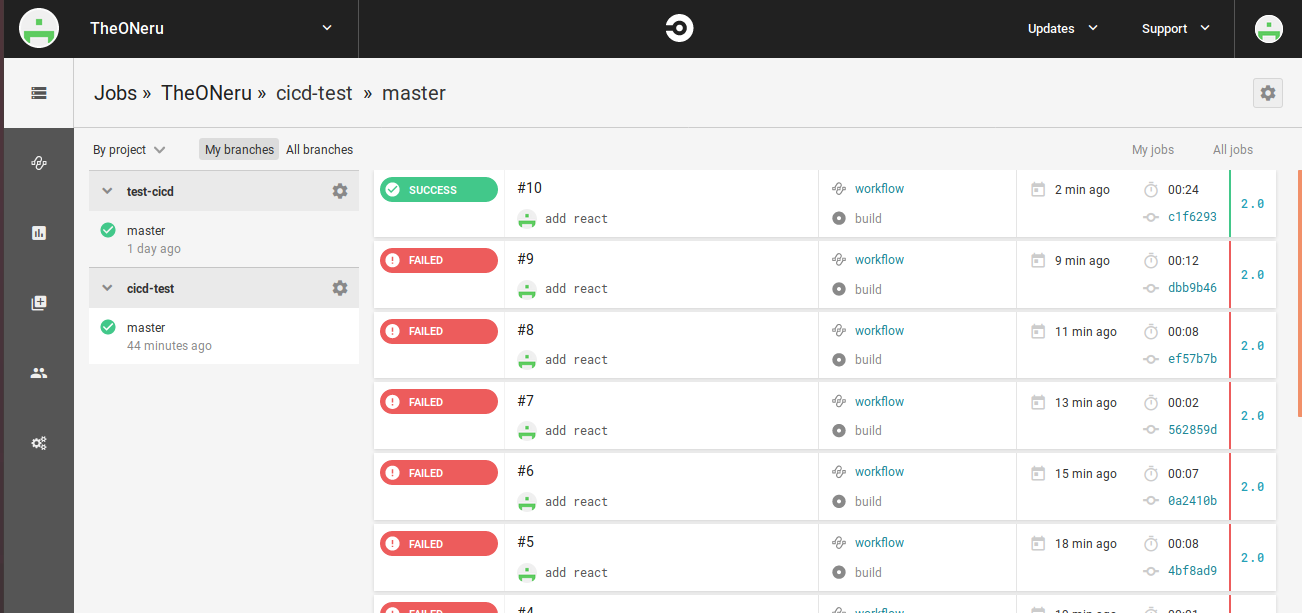
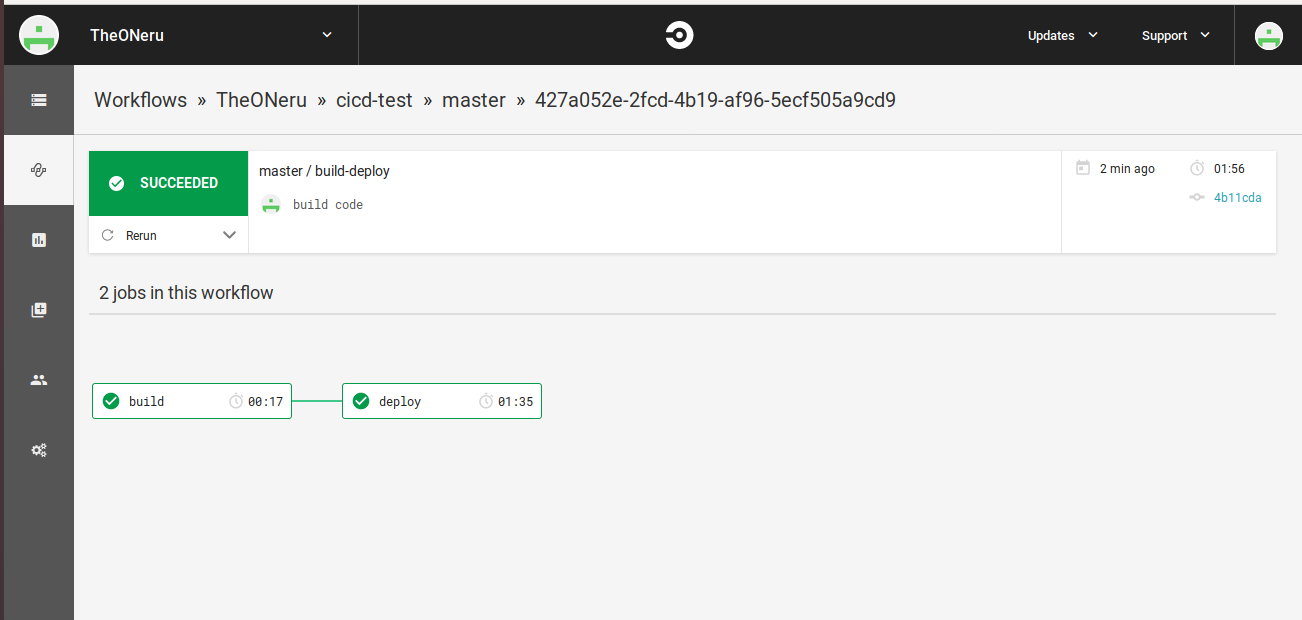
IAMロールユーザーの登録がすんだら、pushして結果を確認してみてください。
- CircleCIのWorkflowsを開く
- 詳細を見る
- buildとdeployが成功していることを確認!
S3の静的ホスト先のURLを開いてデプロイ出来ているかの確認
成功!
まとめ
筆者はあまり、CI/CDについて詳しくは無いのでセキュリティなどや、もっと良いやり方が有るのかもしれませんが、取り敢えずgithubにpushするだけで自動ビルド&自動デプロイが出来たので知識の整理のために書きました。
間違っている点や、もっとこうするべきだという点が有りましたらコメント下さい!

- 投稿日:2019-02-18T00:33:01+09:00
CloudFomation:"errorMessage": "Unable to import module 'GreengrassLambda'"への対処
これまでの経緯・前提等
- Greengrassを使って、RaspberryPiにLambdaをデプロイしたい
- バージョン管理等も含めてやりたかったため、CloudFormationをつかって以下のようなYamlを書き、デプロイした
- lambdaの関数は、greengrass-hello-worldをコピペした。(Python2.7)
- GreengrassへのLambdaのデプロイ・サブスクリプションの設定はドキュメント通りに行ったが、Topicが飛んでこない。
- おかしいと思い、適当なイベントを作成し、テストしてみたところ、以下のようなエラーが発生しており、これが原因でトピックが飛んでこないものと考えられる
error_massage"errorMessage": "Unable to import module 'GreengrassLambda'"logSTART RequestId: d8e9bd79-7324-45b7-a9fc-9947bae2a222 Version: $LATEST Unable to import module 'GreengrassLambda': No module named greengrass_common.function_arn_fields END RequestId: d8e9bd79-7324-45b7-a9fc-9947bae2a222 REPORT RequestId: d8e9bd79-7324-45b7-a9fc-9947bae2a222 Duration: 0.47 ms Billed Duration: 100 ms Memory Size: 128 MB Max Memory Used: 44 MB
- 実際、コンソールでgreengrass-hello-worldを作成し、テストを行うと上記エラーは発生せず、RaspberryPiにデプロイするときちんとTpicが飛んでくる
(以下、長いので読み飛ばしてください。)
要するに、pipでgreengrasssdkをダウンロードしてるし大丈夫でしょ、と思ってたtemplate.ymlAWSTemplateFormatVersion: 2010-09-09 Transform: - AWS::Serverless-2016-10-31 - AWS::CodeStar Parameters: ProjectId: Type: String Description: CodeStar projectId used to associate new resources to team members CodeDeployRole: Type: String Description: IAM role to allow AWS CodeDeploy to manage deployment of AWS Lambda functions Stage: Type: String Description: The name for a project pipeline stage, such as Staging or Prod, for which resources are provisioned and deployed. Default: '' Globals: Function: AutoPublishAlias: live DeploymentPreference: Enabled: true Type: Canary10Percent5Minutes Role: !Ref CodeDeployRole Resources: GreengrassLambda: Type: AWS::Serverless::Function Properties: Handler: GreengrassLambda.lambda_handler CodeUri: GreengrassLambda Runtime: python2.7 Role: !GetAtt GreengrassLambdaRole.Arn Timeout: 25 GreengrassLambdaRole: Description: Creating service role in IAM for AWS Lambda Type: AWS::IAM::Role Properties: RoleName: !Sub 'CodeStar-${ProjectId}-GreengrassRole' AssumeRolePolicyDocument: Statement: - Effect: Allow Principal: Service: [lambda.amazonaws.com] Action: sts:AssumeRole Path: / ManagedPolicyArns: - arn:aws:iam::aws:policy/service-role/AWSGreengrassResourceAccessRolePolicy - arn:aws:iam::aws:policy/service-role/AWSLambdaBasicExecutionRole PermissionsBoundary: !Sub 'arn:${AWS::Partition}:iam::${AWS::AccountId}:policy/CodeStar_${ProjectId}_PermissionsBoundary'buildspec.ymlversion: 0.2 phases: install: commands: # Upgrade AWS CLI to the latest version - pip install --upgrade awscli - pip install greengrasssdk build: commands: # Use AWS SAM to package the application by using AWS CloudFormation - aws cloudformation package --template template.yml --s3-bucket $S3_BUCKET --output-template template-export.yml # Do not remove this statement. This command is required for AWS CodeStar projects. # Update the AWS Partition, AWS Region, account ID and project ID in the project ARN on template-configuration.json file so AWS CloudFormation can tag project resources. - sed -i.bak 's/\$PARTITION\$/'${PARTITION}'/g;s/\$AWS_REGION\$/'${AWS_REGION}'/g;s/\$ACCOUNT_ID\$/'${ACCOUNT_ID}'/g;s/\$PROJECT_ID\$/'${PROJECT_ID}'/g' template-configuration.json artifacts: type: zip files: - template-export.yml - template-configuration.json原因
pipではgreengrasssdkはインストールされるが、付属する
greengrass_commonとgreengrass_ipc_python_sdkはインストールされていなかった。このため、インポートエラーが発生した対処法
AWS IoTコンソールからSDKをダウンロードし、
greengrass_commonとgreengrass_ipc_python_sdkをpythonファイルと同一ディレクトリに保存する。感想
端的に言ってエラーログを最後まで読んでいなかった。これが原因で2日は潰れた。
"errorMessage": "Unable to import moduleで検索すると、ファイルでなくディレクトリを圧縮したときに起こる例ばかりが検索に引っかかり、これがさらに混乱のもととなってしまった。っていうかお願いだからpipで
greengrass_commonとgreengrass_ipc_python_sdkもインストールできるようにしてほしい
- 投稿日:2019-02-18T00:12:47+09:00
GROWI の特定のページを定期的にメール送信する (AWS Serverless Framework)
オープンソースの Wiki システム GROWI の API を利用して、特定のページを定期的にメール送信してみます。
環境
- Windows 10 Pro 1809 / Windows Subsystem for Linux (Bash on windows) Ubuntu 16.04.4 LTS
- たぶんMacでも一緒
- TypeScript: 2.9.2
- Serverless Framework: 1.33.2
- GROWI: 3.3.8
- 予め growi-docker-compose を使って ConoHa VPS 上で起動しておいた GROWI を使います
また、AWSの下記サービスを利用します
- AWS Lambda: API取得とメール送信プログラムを実行します
- Amazon SES: メールを送信します
- Amazon CloudWatch: 今回は、Lambdaを定期的に実行するために利用します
GROWI の準備
- 「ユーザー設定」→「API設定」→「現在のAPI Token」の値をメモしておく
- 「管理」→「セキュリティ設定」→「ゲストユーザーのアクセス」を「閲覧のみ許可」にしておく
GROWI には現在APIのドキュメントは無いようですが、どのような物があるかはルーティングファイルから推測できます。今回用いる記事単体のAPIは
/_api/pages.get?access_token=(アクセストークン)&path=(パス)というURLになります。実際にアクセスしてみると、ページの情報がJSONで取得できることを確認しておきます。GETなのでブラウザで直接叩くだけで良いです。AWS SES の利用準備
E メールアドレスの検証 - Amazon Simple Email Service に沿って、メールアドレスを認証しておきます。
Serverless Framework の利用準備
Serverless Framework をインストールしておきます。
$ npm install --global serverlessデプロイするために、 Serverless Framework - AWS Lambda Guide - Credentials に沿って認証情報を設定しておきます。必要に応じて awslabs/git-secrets もインストールしておきましょう。
Serverlessプロジェクトの作成
準備ができたら、 Serverless のコードを書いていきます。
$ serverless create --template aws-nodejs-typescript --path growi-to-mail $ cd growi-to-mail $ npm install --save-dev $ npm install --save aws-sdkGit 管理する場合は、お好みで下記も実行しておきます。
$ git init $ curl https://raw.githubusercontent.com/github/gitignore/master/Node.gitignore > .gitignore # お好みで $ echo 'package-lock.json binary' >> .gitattributes # お好みで $ git remote add origin https://github.com/USERNAME/REPOSITORY.git # GitHubに上げるならメール送信プログラム
下記のようなプログラムで、GROWIの特定ページをメール送信できます。
handler.tsimport * as AWS from 'aws-sdk'; import * as https from 'https'; const aws_region = 'us-west-2'; const mail_to = ['受信用E-mailアドレス']; const mail_from = '送信用E-mailアドレス'; const growi_url = 'GROWIのURL 例: https://demo.growi.org/'; const growi_access_token = 'メモしたアクセストークン'; const growi_pages_path = '送信したいパス'; export const hello = async (event, context) => { console.log('スタート!'); const ses = new AWS.SES({region: aws_region}); const url = `${growi_url}_api/pages.get?access_token=${growi_access_token}&path=${growi_pages_path}`; return new Promise(function(resolve, reject) { https.get(url, (resp) => { let data = ''; resp.on('data', (chunk) => { data += chunk; }); resp.on('end', () => { const page = JSON.parse(data); ses.sendEmail({ Source: mail_from, Destination: { ToAddresses: mail_to }, Message: { Subject: { Data: page['page']['path'] }, Body: { Text: { Data: page['page']['revision']['body'] } } } }, function(err, data) { console.log('成功!'); }); }); }); }); }(本当は特定パス以下のすべての記事を取得したいのですが、URL一本で取得できるAPIは無いようなので、お預け)
デプロイの設定
serverless.ymlにデプロイ用の設定を記述していきます。serverless.ymlservice: name: growi-to-mail plugins: - serverless-webpack provider: name: aws runtime: nodejs8.10 region: us-west-2 iamRoleStatements: - Effect: 'Allow' Action: - ses:SendEmail Resource: '*' functions: hello: handler: handler.hello events: - schedule: cron(0/3 * * * ? *)
scheduleの設定にはcron記法が利用できます。詳細は Serverless Framework のドキュメントや Amazon CloudWatch のドキュメントを参照してください。デプロイ
$ serverless deployこれで、上記設定なら3分に1度メールが飛んでくると思います。
片付け
下記コマンドで、デプロイしたlambda等を削除できます。
$ serverless remove参考
- 投稿日:2019-02-18T00:02:21+09:00
AWS + Laravel + Vue.js でQiitaのストックを整理するサービスを作りました!【個人開発】
概要
Qiitaのストックを整理するためのサービス「Mindexer(ミンデクサー)」をリリースしました?
この記事では、Mindexerで利用している技術について、解説したいと思います。GitHubでソースコードも公開しています。
https://github.com/nekochans/qiita-stocker-frontend
https://github.com/nekochans/qiita-stocker-backend
https://github.com/nekochans/qiita-stocker-terraformサービスについて
個人サービスを開発しようとしたきっかけは、技術力の向上のためでした。でも、どうせなら自分だけでなく、多くの人に使ってもらえるようなサービスが良いと思いQiitaのストックを整理するためのサービスを作りました。
こんな問題抱えてませんか?
- Qiitaのストック一覧を見ても何のためにストックした記事か思い出せない
- 後で読もうと思ってとりあえずストックしたけれど、読まれない記事が溜まっていく
- ストックから欲しい記事を探せない
開発者はこれらの問題を抱えていました?
ストックを整理する機能を追加する
これらの問題はすべて、ストックの整理ができていないことに要因があるではないかと考え、ストックを整理するためのサービスを作りました。整理するための手段として、自分専用のカテゴリを作成する機能を追加しています。記事をフォルダに分けるようなイメージです。
カテゴリの追加・編集・削除
ストックをカテゴリに分類
カテゴライズを解除
Qiitaのアカウントを持っていれば、すぐに使い始めることができます!
Mindexer | Qiitaのストックを整理するためのサービスです
アプリケーションアーキテクチャ概要
バックエンドはREST APIを提供し、フロントエンドはVue.js/Vuexを利用したSPAとなっています。
また、バックエンドにはDDD(ドメイン駆動設計)を採用しています。
インフラはAWSを採用し、すべてTerraformで管理しています。
Qiitaのストック記事の取得には、Qiita API v2 を利用しています。インフラ構成
AWS構成図
フロントエンド
ビルドしたSPAのソースコードをS3にデプロイし、CloudFrontで配信しています。
バックエンド
EC2にWEBサーバーを構築し、RDSはAurora MySQLを使用しています。
RDSにはAurora Serverlessも検討しましたが、Aurora Serverlessはオンデマンドで起動するため、初回起動時に25秒ほど時間がかかります。一般ユーザ向けのサービスには不適切であると判断し、Aurora MySQLを採用しました。バックエンド
技術要素
- Laravel5.7
- nginx
- Amazon Aurora(MySQL)
概要
Laravelを使用してREAT APIを作成しています。
DDD(ドメイン駆動設計)を取り入れ、ビジネスロジックであるドメインモデルを技術の関心事を分離し、変化に強いコードとなることを意識しました。ソースコード
https://github.com/nekochans/qiita-stocker-backendREST API
バックエンドが返すAPIは、RESTの原則に沿った形でAPIを設計しています。URLが操作する対象のリソースを指定し、それに対するCRUD操作をHTTPメソッドで指定する、というものです。
APIの設計については、翻訳: WebAPI 設計のベストプラクティスを参考にさせて頂きましたので、詳細はこちらをご確認頂ければと思います。
エラーの設計については、WebAPIでエラーをどう表現すべき?15のサービスを調査してみたを参考に下記の通り定義しています。
{ "code":エラーコード, "message":"エラーメッセージ", "errors":{ "フィールド名":[ "エラーエラーメッセージ" ], } }
errorsはバリデーション エラーの場合のみ使用。ドメイン駆動設計
ドメイン駆動設計で実装するにあたって、レイヤードアーキテクチャを採用しています。
実際のディレクトリ構成とレイヤードアーキテクチャの関係は以下の通りです。
レイヤードアーキテクチャの説明に不要な部分は、下記の図には載せていません。app ├── Http ------------- プレゼンテーション層 │ ├── Controllers │ └── Middleware ├── Infrastructure --- インフラストラクチャ層 │ └── Repositories │ ├── Api │ └── Eloquent ├── Models ------------ ドメイン層 │ └── Domain └── Services ---------- アプリケーション層レイヤードアーキテクチャの層ごとに、実装のポイントを解説していきたいと思います。
プレゼンテーション層
コントローラーにおいて、HTTPリクエストを受け取る・レスポンスを返すことのみを責務としています。
コントローラーには、ビジネスルールや知識を記述しないことを意識しています。アプリケーション層
シナリオクラスを作成しています。
シナリオクラスの責務は、ドメイン層が提供するビジネスロジックを調整することです。
ここにおいても、ビジネスルールや知識は含めないことを意識しています。ドメイン層
ビジネスルールや知識を表す層です。
エンティティ・値オブジェクト
ドメイン知識を
エンティティ、値オブジェクトとして表現しています。
エンティティと値オブジェクトの違いは、「識別」を持つかどうかで区別しています。また、エンティティ・値オブジェクトの生成にBuilderパターンを採用しています。
バリデーション
バリデーションもドメイン知識であると考え、仕様パターンを定義しています。
下記の例では、カテゴリ名のバリデーションチェックを行なっています。
バリデーション自体を、エンティティ・値オブジェクトに追加する方法もあると思いますが、その場合
エンティティ・値オブジェクトが複雑になると思い、仕様パターンを採用しました。app/Models/Domain/Category/CategorySpecification.phpclass CategorySpecification { /** * CategoryNameValue が作成可能か確認する * * @param array $requestArray * @return array */ public static function canCreateCategoryNameValue(array $requestArray): array { $validator = \Validator::make($requestArray, [ 'name' => 'required|max:50', ]); if ($validator->fails()) { return $validator->errors()->toArray(); } return []; } }独自例外
ステータスコード、メッセージ、レスポンスの形式は全てドメイン知識であるため、ドメイン層に定義しています。
リポジトリインターフェース
データの永続化は、インフラストラクチャ層の責務ですが、そのインターフェースをドメイン層で定義しています。
インターフェースを定義することによって、データを永続する際はドメイン層からインターフェースのメソッドのみを呼び出せばよく、永続化に関する技術的な関心事を知る必要が無くなります。
また、フレームワークへの依存を避けるため、Eloquentに依存しない形でインターフェースを定義しています。インフラストラクチャ層
Repositoryを定義しています。ストレージへのアクセス手段として利用し、ドメイン知識は持ちません。
ここでは、DBの操作はLaravelのEloquentoモデルを利用しています。テストについて
APIの単位でテストクラスを作成しています。
API単位でテストを作成するメリットとして、APIのIFさえ変わらなければ動作を保証できるというメリットがあります。開発中に何度か仕様を変更する必要性が出てきたのですが、テストで動作の保証ができる分、仕様を変更することへのハードルがすごく低くなりました。また何度かリファクタリングを行いましたが、その際もリファクタリングの工数を減らすことができ、開発を続けながらコードを改善することができたと思います。
テストについて下記の記事を参考にさせていただきました。
Laravel 5.3でREST APIのテストコードを書く以下は、細かい部分になりますが、テストで使用した技術について参考になりそうなポイントです。
Guzzleを使ったMockの作成
HTTPクライアントにGuzzleを使用しています。主にQiitaAPIへのリクエストに使用しています。
Guzzleは非同期リクエストが可能であったり使い勝手がいいHTTPクライアントライブラリでしたが、テストにおいても簡単にMockを作成をすることができ便利でした。
Testing Guzzle Clientsテストコードの抜粋となりますが、Mockクライアントを生成するメソッドを下記の通り定義しています。
tests/Feature/AbstractTestCase.phpprotected function setMockGuzzle($responses) { app()->bind(Client::class, function () use ($responses) { $mock = []; foreach ($responses as $response) { $mock[] = new Response($response[0], $response[1] ?? [], $response[2] ?? null); } $mock = new MockHandler($mock); $handler = HandlerStack::create($mock); return new Client(['handler' => $handler]); }); }例えば、「ステータスコード200、ヘッダーは"total-count: 20"、BodyはJSON」のレスポンスを作成する場合、下記のように配列を引数で渡すことで作成できます。複数のレスポンスを作成する場合は、配列を追加するだです。
$this->setMockGuzzle([[200, ['total-count' => 20], '{ hoge: hoge}']]);カバレッジを出力
テストケースが十分に網羅されているか確認するために、カバレッジの出力を行なって確認しています。カバレッジを100%を目指すことが目的ではなく、テストが十分に網羅されていないコードを検出することを目的としています。
カバレッジの出力結果のイメージです。
フロントエンド
技術要素
- Vue.js + Vuex
- Vue Router
- TypeScript
- Jest
- vue-test-utils
- Bulma
概要
Vue.js/Vuexを利用したSPAを作成しています。
Vueのプロジェクトは、Vue CLIのテンプレートを利用。スタイルについては、CSSフレームワークのBulmaを採用しています。ソースコード
https://github.com/nekochans/qiita-stocker-frontend設計
コンポーネント
ディレクトリを2つに大きく分けています。
- pages
- components
pagesは、Vue Routerのルーティングに対応するコンポーネントです。将来的に、Nuxt.jsに乗り換えたいという思いもありこのような形にしています。
componentsのコンポーネントを組み合わせることによって、全体のレイアウトを構築しています。またpagesの特徴として、Storeを直接参照できるようにしています。
componentsのコンポーネントは、比較的大きいコンポーネントとしています。
このような形にしている背景としては、以下のような理由が挙げられます。
- CSSフレームワークのBulmaを利用しているため、コンポーネントにスタイルを閉じ込める重要性があまりない
- サービスの規模が大きくないため、大きめのコンポーネントで実装を進めたほうが開発効率が良い
componentsは、Storeに依存しない設計にしています。
なぜ、このような形にしているかというと、コンポーネントの依存を少なくすることで、コンポーネントの再利用性を高め、テストをしやすくするためです。今後も開発を進めていく予定なので、コンポーネントの設計は見直す必要が出てくるかもしれません。
Store
状態管理のため、Vuexを利用しています。
基本的には、Vuexのコアコンセプトを基に作成しており、特筆すべき点は無いのですが、下記の点だけ考慮しています。VuexではコンポーネントからMutationを直接コミットすることが可能となっていますが、このプロジェクトでは、コンポーネントから操作する際は、必ずActionを経由するようにしています。理由は、データの流れを見やすくするためです。多少コードが冗長になるデメリットもあるかと思いますが、複数人での開発になった場合、データの流れが明確になっているほうが不具合の発生が少なくなるのではないかと考えています。
テストについて
テストフレームワークはJest、コンポーネントのテストにはvue-test-utilsを使用しています。
Jestは、テストランナーとアサーションの機能を兼ね備えており、Jestのみでテストを実行できるという点で採用してしています。
テスト対象は、全てのコンポーネントとVuexのモジュールです。E2Eのテストは導入していません。コンポーネント
各コンポーネントのテストケースを作成しています。
テスト観点は、Jestの
describe()の単位で下記の通りです。コンポーネント単体の振る舞いだけでなく、コンポーネント同士の連携についてもテストしています。props
propsが正しく受け取れているか。method
methodが正しく動作しているか。
主に、子コンポーネントのメソッドの実行により、親コンポーネントのメソッドがemitされているかを確認しています。template
正しくレンダリングされているか。
DOMイベントが発火した際に、メソッドが実行されるか。
子コンポーネントとの結合テストとして、子コンポーネントのイベントが発火した際に期待する親コンポーネントのイベントが発火しているか。Vuexのモジュール
VuexのGetter、Mutation、Actionのテストケースを使用しています。
ここはビジネスロジックが詰まった部分であるので、テストケースとしては必須になると思います。現在、全てのテストケースを1つのファイルに書いておりテストファイルが肥大化しているため、Getter、Mutation、Action単位で分割する予定です。
(もうちょっと何か書くかも。これくらいで問題ない・・?)
改善点
実際に上記の観点でテストケースを作成しましたが、コンポーネントのテストにおいて、全てのコンポーネントのテストを書くのは大変でした・・・
細かい単位でコンポーネントが作成されており、かつ、再利用されているというケースにおいては、コンポーネントのテストを書くメリットがあると思いますが、今回ようなコンポーネントの再利用があまりされていないケースでは、全てのコンポーネントのテストを書くことはメリットがあまりないのではないかと思いました。
Storeに依存するコンポーネントに限定したテストでもよかったのではないかと思っています。
この点については、改善していきます!デザインについて
CSSフレームワークであるBulmaを使用しています。UIコンポーネントのElementUIやVuetifyについても検討しましたが、カスタマイズのしやすさという観点からBulmaを採用しています。
実際にBulmaを使って見たメリットは下記の通りです。レスポンシブ対応
CSSを読み込むだけで、レスポンシブ対応が完了する点が非常に便利でした。
例えばヘッダーのメニューについても、Bulmaだけでハンバガーメニューへの切り替えが可能です。
学習コストの低さ
Bulma公式のドキュメントに情報が揃っているので、ここを確認すればだいたいのことは実現できました。また、公式のExpoにBulmaを利用したwebサイトの一覧があるので、これらを参考にしながらデザインをしています。今後改善していきたい事
技術面
現時点では、以下を対応する予定です。
- CI/CDを導入しテスト&デプロイを自動化する
- フロントエンドを Nuxt.js ベースにしてPWAに対応させる
- APIサーバーをDockerで動作するように改修する(AWS Fargateとか使うかも)
機能の追加によって新しい技術の導入が必要になると思うので、これからも継続的に改善を続けていこうと思っています!
機能
最小限の機能しかないので、これからはもっとリッチにしていきたいと思っています。
現時点では、以下の機能があったらより便利かなと考えています?
- カテゴリの並び替え
- 検索機能の追加 → ストックした記事を検索出来る機能
- メモ機能の追加 → カテゴライズした記事に自分用のメモを追加出来る機能
実際に使ってみて、フィードバックを頂けますと励みになります?♀️
開発の進め方
このサービスは、2人で作成しています。
主な開発は自分(kobayashi-m42)が担当し、レビューや技術的なアドバイスを@keitakn にしてもらうという形で進めています。開発ルールの設定
プロジェクトの開始時点で、開発のルールを設定しました。
最初に認識を合わせておくことで、スムーズな開発が可能になりますので、チームで開発する場合は設定しておくといいと思います。
- Gitのコミットルール
- PRの作成ルール
- 全ての課題に共通するDoneの定義
スクラム開発
スクラム開発で開発を進めました。2人という少人数のチームのため、正確なスクラム開発ではありませんが、スクラムの開発方式をとっています。概要は以下の通りです。
- スプリントは2週間
- 2週間に1度、スプリント計画を対面で行う
- 普段のコミュニケーション手段はSlack
また、スクラムを導入するにあたりZenHubを使いました。Chromeの拡張機能をインストールすることで使い始めることができます。今まで、プロジェクト管理ツールであるBacklogを使用したスクラム開発をしたこともありましたが、個人的にはZenHubの方が使い勝手がよかったという印象です。
ZenHubを使ったスクラム開発の始め方は、下記の記事に詳しく書かれていますので、こちらをご覧ください。
ZenHubで始めるスクラム開発あとがき
ゼロからサービスを作成するために、企画、技術の選定、設計、実装、デザイン・・・など全て担当し、技術的に多くのことを学ぶことができました。やはり、手を動かして何かを作ることが、技術を身に着ける上で一番大切だと実感しました。
ひとまず、リリースすることができ安堵していますが、これからも「Mindexer」というサービスを成長させながら、技術力を上げていきたいと思っています!
無料で公開していますので、多くの人に使っていただけると嬉しいです?
ソースコードもこちらで公開しています!
ここにはMindexerのソースコードだけでなく、プロジェクトの雛形となるようなboilerplateも追加しています!