- 投稿日:2019-02-18T23:44:32+09:00
PythonでGoogle Places API使ってデータ取得してみた
概要
Pythonを使用してGoogle Places APIのデータを取得した忘備録です。
APIでデータ取り出すだけならJSとかで問題ないんですが、その後データをこねこねしたかったのでPythonで取得しました。(結局使わなかったけど)公式ドキュメント等
Google Developers Places API (Googleドキュメント)
google-maps-services-python (PythonクライアントのGit)
Python Client for Google Maps Services (Pythonライブラリドキュメント)1. Google Place APIを使えるようにする
GCPのプロジェクト作成~API有効までの手順は以下のブログを参考にさせていただきました。
Google Places APIで会社付近の「お食事処」を取得してみるGCPはAPIの無料枠があるのでそれを使用します。(クレジットカードの登録が必要です)
また、APIキーのアクセス制限では、「リクエストを受け入れるサーバーIPアドレス」に自身のIPアドレスを設定するなどしておくと安全です。
キー盗まれてXX万円請求くるとか話聞くので・・・。2.APIリクエストを送ってデータ取得
ファイルの内容は以下です。
「東京渋谷駅」で位置情報を検索して、その位置から半径200m以内のレストランの情報を取得します。import googlemap import pprint # list型やdict型を見やすくprintするライブラリ key = 'Your API' # 上記で作成したAPIキーを入れる client = googlemaps.Client(key) #インスタンス作成 geocode_result = client.geocode('東京都渋谷駅') # 位置情報を検索 loc = geocode_result[0]['geometry']['location'] # 軽度・緯度の情報のみ取り出す place_result = client.places_nearby(location=loc, radius=200, type='food') #半径200m以内のレストランの情報を取得 pprint.pprint(place_result)上記ファイルを実行するとコンソールにレストランの情報一覧が表示されます。
おしまい!
最後に
レビューデータを大量に欲しかったんですが、ドキュメントみると
reviews[] a JSON array of up to five reviews.
とあり、取得制限があったので諦めました。笑
Twitter APIでも取得制限で苦しめられた覚えがあります。。。
何かいい方法があったら教えてください。
また、記事に間違いや不明な点があれば遠慮なくご指摘ください。
- 投稿日:2019-02-18T23:22:36+09:00
Scikit-learn でロジスティック回帰(確率予測編)
はじめに
ロジスティック回帰は、
- データを複数のクラスに分類する
- 事象が発生する確率を予測する
ために利用されるモデルです。
この記事では、Scikit-learnライブラリを使い、ロジスティック回帰により確率を予測する方法を備忘録として書いておきます。Scikit-learn について
Scikit-learnは、Pythonの機械学習ライブラリの一つです。
ロジスティック回帰について
ロジスティック回帰は、確率(例:機器の故障率)を予測するためのアルゴリズムです。機械学習系の文献では、分類のためのアルゴリズムとして紹介されていることが多いロジスティック回帰ですが、予測した確率(スコア)をもとにクラス分類を行う(例:機器を故障するクラス or 故障しないクラス に分類する)ものであるため、当然確率そのものを予測するためにも利用できます。
ロジスティック回帰では、対数オッズ比を説明変数 $x_i$ の線形和で表現します。予測したいこと(正事象)の確率を $p$ としたとき、オッズ比は $p/(1−p)$ と書くことができ、正事象の起こりやすさを表します。オッズ比の対数をとったものが、対数オッズです。
\log(\frac{p}{1−p}) = w_0x_0 + w_1x_1 + \cdots + w_mx_m = \sum_{i=0}^m w_ix_iここで、重み $w_0 $は $x_0=1$ として切片を表します。ロジスティック回帰は、対数オッズ比と複数の説明変数の関係を表すモデルの重み $w_i$ を学習することが目的です。
ただ、ロジスティック回帰を利用するときに関心があるのは、説明変数の値を与えたときの正事象の確率 $p$ です。そこで、上式を左辺が $p$ になるように変形すると、
p=\frac{1}{1+\exp(−\sum_{i=0}^m w_ix_i)}となります。モデルの重み $w_i$ を学習後、この式を利用して説明変数の値が与えられたときの正事象の確率を求めることができます。
ロジスティック回帰モデル
scikit-learnでロジスティック回帰をするには、linear_modelのLogisticRegressionモデル(公式ドキュメント:https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html )を使います。主に利用するメソッドは以下の通りです。
- fitメソッド:ロジスティック回帰モデルの重みを学習
- predict_probaメソッド:説明変数の値から各クラスに属する確率を予測
ここでは、sklearn.datasets ライブラリの make_classification メソッドで生成したデータに対して確率を予測します。以下のコードでは、200,000サンプルのデータを生成しており、説明変数(特徴量)の数は20、目的変数は0か1のクラスで、クラス0とクラス1のデータ数の比率はおよそ1:1です。
from sklearn.datasets import make_classification X, Y = make_classification(n_samples=200000, n_features=20, n_informative=2, n_redundant=2)以降では、説明変数Xを利用してロジスティック回帰モデルを構築し、目的変数が1となる確率を予測します。
ロジスティック回帰モデルの構築
ロジスティック回帰モデルのインスタンスを作成し、fitメソッドで説明変数の重みを学習することで、ロジスティック回帰モデルを構築します。ここでは、scikit-learnライブラリのmodel_selection.train_test_splitメソッドで、データをモデル構築用データ(学習データ)と予測精度検証用データ(検証データ)に分割し、学習データをfitメソッドの引数として与え、ロジスティック回帰モデルを構築しています。
from sklearn.model_selection import train_test_split from sklearn.linear_model import LogisticRegression X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.5, random_state=0) # 50%のデータを学習データに、50%を検証データにする lr = LogisticRegression() # ロジスティック回帰モデルのインスタンスを作成 lr.fit(X_train, Y_train) # ロジスティック回帰モデルの重みを学習ロジスティック回帰モデルのインスタンスを生成する際、モデルの重みを調整する正則化などの設定をするハイパーパラメータの設定ができます。詳細は公式ドキュメント、もしくは Scikit-learn でロジスティック回帰(クラス分類編) をご覧ください。
学習により得られた、ロジスティック回帰モデルの切片 $w_0$ はintercept_属性に、説明変数の係数 $w_1, \cdots, w_{20}$ はcoef_属性に格納されます。
print("coefficient = ", lr.coef_) print("intercept = ", lr.intercept_) coefficient = [[ 1.07367390e-03 5.17036366e-01 5.21447708e-03 -9.98281654e-03 3.44933503e-01 2.66695180e+00 -8.91173651e-03 2.27093901e-02 5.33371028e-03 -1.55647553e-02 -1.26011741e-02 -1.06324472e-03 3.09072395e+00 -4.44766398e-03 7.88774312e-03 2.99896065e-02 -1.35581106e-02 -1.96393314e-02 2.37722077e-03 2.48242512e-02]] intercept = [-0.89110432]このモデルに対し、検証データの説明変数の値を引数としてpredict_probaメソッドを実行すると、それぞれの検証データの目的変数(クラス)が0である確率と、1である確率が予測できます。出力結果の1列目が目的変数が0である確率、2列目が目的変数が1である確率です。
probs = lr.predict_proba(X_test) print(probs) [[7.17584367e-02 9.28241563e-01] [9.99301416e-01 6.98583960e-04] [1.80200179e-03 9.98197998e-01] ... [3.34485484e-02 9.66551452e-01] [6.32885474e-02 9.36711453e-01] [4.45884313e-04 9.99554116e-01]]ロジスティック回帰モデルの性能評価
確率予測の性能評価には、主に以下のような指標が用いられます。
- キャリブレーションプロット
- ロジスティック損失(logistic loss)
- brier score(ブライヤースコア)
キャリブレーションプロットは、予測した確率が実際の確率(割合)に一致するかを確認するものであり、ロジスティック損失やbrier scoreは、モデル間の予測精度の比較に用いることが多いです。
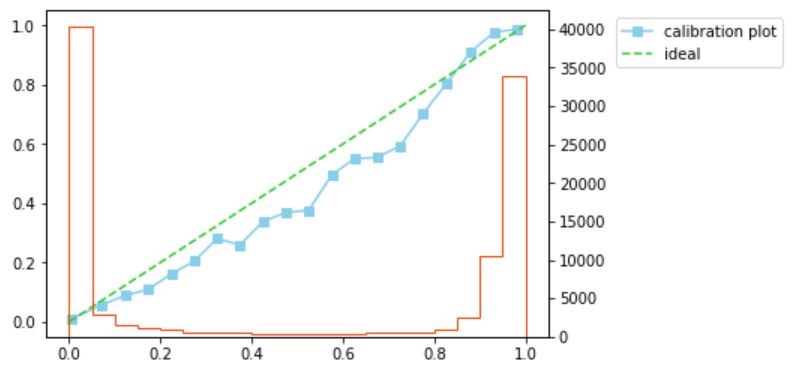
キャリブレーションプロットは、横軸をモデルで予測した目的変数が1である確率(スコア)を複数の区間(ビン)に区切ったもの、縦軸を各ビンに該当するデータのうち目的変数が実際に1であるデータの割合をとったグラフです。スコアと、実際に目的変数が1のデータの割合(分布)が一致するかを確認するために利用します。スコアと実際の割合が一致するとき、キャリブレーションプロットは45度線に乗るため、キャリブレーションプロットが45度線に近いほど、モデルの予測性能が高いといえます。
たとえば、以下のようなコードでキャリブレーションプロットを作成できます。ここでは、検証データに対して目的変数が1である確率を予測し、sklearn.calibrationライブラリのcalibration_curveメソッドを利用してキャリプレーションプロットを作成しています。今回の検証データで作成したキャリブレーションプロットは、45度線より若干下ぶれていますが、おおむね45度線に近いかな、という印象です。
import matplotlib.pyplot as plt from sklearn.calibration import calibration_curve prob = lr.predict_proba(X_test)[:, 1] # 目的変数が1である確率を予測 prob_true, prob_pred = calibration_curve(y_true=Y_test, y_prob=prob, n_bins=20) fig, ax1 = plt.subplots() ax1.plot(prob_pred, prob_true, marker='s', label='calibration plot', color='skyblue') # キャリプレーションプロットを作成 ax1.plot([0, 1], [0, 1], linestyle='--', label='ideal', color='limegreen') # 45度線をプロット ax1.legend(bbox_to_anchor=(1.12, 1), loc='upper left') ax2 = ax1.twinx() # 2軸を追加 ax2.hist(prob, bins=20, histtype='step', color='orangered') # スコアのヒストグラムも併せてプロット plt.show()
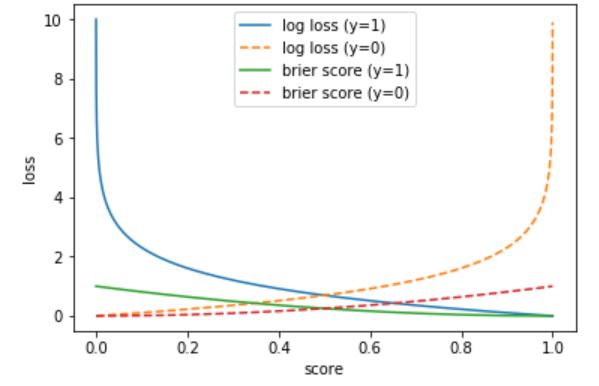
ロジスティック損失は、brier socreと同様にスコアと実際の目的変数の値の誤差を表した指標で、誤差が大きいほど損失が指数関数的に大きくなる特徴があります。式で書くと、
logistic \ \ loss = -\frac{1}{n}\sum_{i=1}^n \{y_i \log p_i + (1-y_i)\log(1-p_i)\}です。$p_i$ と $y_i$ の定義は、brier scoreの定義と同様です。
ちなみに、ロジスティック回帰は、ロジスティック損失が最小となるようにモデルの重みを学習しています。以下のコードでは、sklearn.metrics ライブラリの log_loss を利用して、検証データに対するロジスティック損失を算出しています。
from sklearn.metrics import log_loss print('logistic loss = ', log_loss(y_true=Y_test, y_pred=prob)) logistic loss = 0.13207794568463985brier socre(ブライヤースコア)は、確率予測の正確さを測るための指標のひとつで、スコアと実際の目的変数の値の平均二乗誤差で定義されます。式で書くと、
brier \ \ score = \frac{1}{n} \sum_{i=1}^n (p_i - y_i)です。ここで、$p_i$ は $i$ 番目のデータの目的変数が1であると予測した確率(スコア)、$y_i$ は $i$ 番目のデータの実際の目的変数の値です。
以下のコードでは、sklearn.metrics ライブラリの brier_score_loss を利用して、検証データに対するbrier score を算出しています。
from sklearn.metrics import brier_score_loss print('brier score = ', brier_score_loss(y_true=Y_test, y_prob=prob)) brier score = 0.031796375907874444参考までに、スコアに対してロジスティック損失とbrier scoreがどのような値をとるかを見てみます。下図では、目的変数の実績値が1のときのロジスティック損失(青実線)とbrier score(緑実線)、目的変数の実績値が0のときのロジスティック損失(黄点線)とbrier score(赤点線)をプロットしています。この図を見ると、スコアと実績値の差が大きくなったときの値は、ロジスティック損失のほうが大きくなる傾向があることがわかります。
おわりに
この記事では、scikit-learnライブラリでロジスティック回帰モデルを構築し、確率予測の性能評価をする方法について簡単に触れました。
参考
- [第2版]Python機械学習プログラミング 達人データサイエンティストによる理論と実装(https://www.amazon.co.jp/dp/B07BF5QZ41/ref=dp-kindle-redirect?_encoding=UTF8&btkr=1 )
- 投稿日:2019-02-18T23:22:00+09:00
python入門(8)
if文
if文は条件分岐を行うときに使います.条件式には比較演算子や論理演算子を使用します.
div.pya = 3 print(a, 'は', end ='') if a % 2 ==0: print('偶数') else: print('奇数')実行結果3 は奇数if文では条件を書いた後に「:」をつけます.また,pythonではインデントによって処理の塊であるブロックを指定します.インデントでは,空白半角4文字分が推奨されています.
elif
elifとは他言語でいうelse ifと同じものです.また,if文では最初にtrueだった条件を実行しそれ以降は実行しません.
div2.pya = 78 print(a, '点の人は', end = '') if a >= 90: print('秀です.') elif a >= 80: print('優です.') elif a >= 70: print('良です.') elif a >= 60: print('可です.') else: print('不可です.また来年会いましょう.')実行結果78 点の人は良です.if文のネスト
if文などの制御文の中にさらに制御文を入れることをネストと言います.
div3.pyyear = 2000 print(year, '年は', end = '') if year % 4 == 0: if (year % 100 != 0) or (year % 400 == 0): print('閏年です.') else: print('閏年ではありません.')実行結果2000 年は閏年です.最後に
if文は他言語との違いが少ないので基本は簡単にできると思います.自分のペースで学習しましょう.
- 投稿日:2019-02-18T22:16:48+09:00
Django Webアプリ作成(4) モデル作成
環境
OS : macOS Mojave
Anaconda : python3.6.7
Django==2.1.5今回の目標
アプリの中身の最重要部分"モデル"の作成
モデルとは
簡単に言うと、"データベースのデータの集合"
データベースにデータを格納しておいて状況に応じて取り出すイメージ必要なデータは...
今回のアプリは、ブログということで当然タイトルと内容(テキスト)は必要でしょう。
その他、筆者と作成日時と更新日時を要素(データ)としよう!models.py
models.py内にPostクラスを作成
blog/models.pyfrom django.db import models from django.utils import timezone class Post(models.Model): author = models.ForeignKey('auth.User', on_delete=models.CASCADE) title = models.CharField(max_length=200) text = models.TextField() created_date = models.DateTimeField( default=timezone.now) published_date = models.DateTimeField( blank=True, null=True) def publish(self): self.published_date = timezone.now() self.save() def __str__(self): return self.titleデータベースの作成と追加
データベースの作成
Terminalpython manage.py makemigrationsデータベースの追加
Terminalpython manage.py migrate管理者ページ(Django admin)の作成
blog/admin.pyに作ったモデルクラスを登録
blog/admin.pyfrom django.contrib import admin from .models import Post # Register your models here. admin.site.register(Post)スーパーユーザーの作成
管理者サイトにログインできるスパーユーザーを作成する。
Terminalpython manage.py createsuperuser管理者ページにログインして記事を投稿
開発サーバを起動
Terminalpython manage.py runserverブラウザでアクセス
ブラウザhttp://127.0.0.1:8000/admin先程登録したユーザー、パスワードでログイン
無事ログインできましたか?
3つほど記事を投稿してみましょう!次回はWebサイトのページを作っていきます!
- 投稿日:2019-02-18T22:11:12+09:00
プログラミングでわかりやすい変数名の決め方
目的
「読みやすいコードを書く」
読みやすいコードを書く上で、わかりやすい変数を命名することは非常に重要。
自分が日頃から意識している命名ルールをまとめる。*na90ya様にコメントでご指摘いただいた点を改善しております。ありがとうございます!
ルール一覧
- 1. df, tmp, data, a, 等の名前は使わない!
- 2. 何を指している変数かすぐわかる名前をつける
- 3. 一つの変数に一つの意味
- 4. 略語を使うならば、意味を残しておく
1. df, tmp, data, a, 等の言葉は使わない!
読みやすいコードを書く目的は、コードレビューやコードの改善、機能の追加等が考えられるが、その時に全ての変数がa1, a2, a3...とかだったら、なんのことやらわからない。
だから、変数名を決める時はめんどくさがらずに意味を持った名前をつける!
*例外
(例)2つの変数の中身を入れ替えるコードright = 0 left = 1 if right < left: tmp = right right = left left = tmp print(right, left)このような場合、tmpという名前で全く問題ない。
tmpはデータの一時保管場所の役割を果たしており、「この変数は他に役割がない」ことを示している。
変数の寿命(変数が3行しか登場しない)が十分短い時はこのように使用してもいい。*pythonでは下記のように簡単に記載できるが、tmpの例として上記をあげている。
right, left = left, right2. 何を指しているすぐ変数かわかる名前をつける
その変数名を見て何のデータかすぐにわかる名前をつける
例)new_dataの意味は?
1. 新たに生成したデータ
2. 何かしらフィルタをかけた後のデータnewの意味は幅広く一見何を表しているかわからない。
もしも、上記の意味のデータならば
- created_data
- selected_data, filtered_data
等の単語を使うべきだろう。
その言葉を見ただけで、なんのデータかわかるようにするといい。*オススメのサイト
codic: プログラマーのためのネーミング辞書
日本語を記入すると、それに対応する短くわかりやすい英単語を返してくれるサイト。
使い方はこちら3. 一つの変数に一つの意味
途中で変数の意味を変える or 一つの意味のデータなのに複数変数名がある はNG!
途中で変数の意味を変える
これは当たり前だが、途中で変数の内容が変わったら読みにくい。
一度変数を決めたら、その後は変数を変更しないようにする!一つの意味のデータなのに複数変数名がある
user_ID, account_ID, ID ...
別々のIDだから名前を変えていると推測するため、一つのデータには一つの変数名のみを使用する。4. 略語を使うならば、意味を残しておく
よく使う単語は略したくなる。
filter -> _f
select -> _sel
columns -> colこうして並べてみると一目瞭然だが、何も知らない人が見たらわからないかもしれない。
だから、できるだけつけるのはやめたほうがいい。
もしつけるのならば、チームで共有する。最初に略語一覧を書く。等を意識する。まとめ
自分以外の人が読む時のことを常に意識しながらプログラミングすることは非常に重要なので、ぜひ意識して実践して欲しい。
名前をつける上で非常に参考になるサイト・書籍
- 投稿日:2019-02-18T22:07:49+09:00
AtomにおけるPython開発環境構築
はじめに
AtomテキストエディタにPython開発環境を最小限の拡張パッケージで構築します。各節の名称がパッケージ名になっているので,その名前でパッケージを検索してインストールしてください。Pythonの実行環境は、Minicondaを使い、
C:\Users\daizu\Miniconda3以下にインストールされていることを想定します。適宜読み替えてください。platformio-ide-terminal
Atom内でターミナルを実行します。
Settings
- Auto Run Command: C:\Users\daizu\Miniconda3\Scripts\activate.bat base
- Shell Override: C:\Windows\System32\cmd.exe
(後から、仮想環境
baseはデフォルトで使う別の仮想環境名にしても構いません。)MagicPython
Python言語のパッケージとしてMagicPythonを使います.コアパッケージのlanguage-pythonはdisableにします.
atom-ide-ui, ide-python
AtomでPython開発をするときの必須パッケージです。まずは、Minicondaの仮想環境
atomを作成します。Atomエディタで [Ctrl]-` を入力し、platformio-ide-terminalのコマンドプロンプトを開き、以下を実行します。(base) > conda create -n atom python (base) > activate atom (atom) > pip install python-language-server[all] pyls-isort pyls-mypyAtomが
atom環境を認識できるように、パスを追加します。AtomのFile->Init Script...でinit.coffeeを開き、process.env.PATH = [ "C:\\Users\\daizu\\Miniconda3\\envs\\atom", "C:\\Users\\daizu\\Miniconda3\\envs\\atom\\Library\\bin", "C:\\Users\\daizu\\Miniconda3\\envs\\atom\\Scripts", process.env.PATH ].join(";")を追加します。(後述するように、続けて別の仮想環境をパスに追加することもできます。)これで、pycodestyle, pyflakes, isort, mypyなどがAtom上で使えるようになります。
Hydrogen
Jupyterを使って,Atom上でPythonコードの実行ができます.インタラクティブな実行が可能なので,非常に重宝します.Hydrogenを使う仮想環境下(仮に
daizuとします)で,以下を実行します。(base) > conda create -n daizu python (base) > activate daizu (daizu) > conda install jupyter (daizu) > python -m ipykernel install --user --name daizu
init.coffeeを開き、以下のように変更します。process.env.PATH = [ "C:\\Users\\daizu\\Miniconda3\\envs\\atom", "C:\\Users\\daizu\\Miniconda3\\envs\\atom\\Library\\bin", "C:\\Users\\daizu\\Miniconda3\\envs\\atom\\Scripts", "C:\\Users\\daizu\\Miniconda3\\envs\\daizu", "C:\\Users\\daizu\\Miniconda3\\envs\\daizu\\Library\\bin", "C:\\Users\\daizu\\Miniconda3\\envs\\daizu\\Scripts", process.env.PATH ].join(";")以上で、開発環境が整いました。
- 投稿日:2019-02-18T22:00:12+09:00
PythonでSharePointの特定サイトの特定リストの特定レコードのURLを取得する方法
本記事は
この記事の番外編になります。
PowerApps でセンサーデータの値を取得してみた!(ソースもあるよ!)まず最初に・・・
SharePointのレコードデータを取得するためにはどうするのか?
このようなURL構造にして
メソッドによって処理を変えます。
- Get:レコードのデータを取得
- Patch:レコードを更新
- Delete:レコードを削除
つまりは・・・
以下の手順を踏んでいけば、このURLパスが完成することになります。
- サイト名を元に検索して、サイトIDを取得する
- 取得したサイトIDからリスト名を元に検索してリストIDを取得する
- 取得したサイトID及びリストIDから検索するレコードの特定カラムの文字列を検索してレコードIDを取得する
検索に必要なデータは予め変数として格納しておきます。
では取得していきましょう。
検索用の変数
以下のようにします。
変数名 用途 SPS_SiteName 検索するサイト名称 SPS_ListName 検索するリスト名称 SPS_SearchColumn 検索対象のリスト列名 SPS_SearchRecord 検索文言 サイトIDを取得する
GetSPSSiteID# サイトIDを取得するためのURLを生成する。 SiteGet_URL = 'https://graph.microsoft.com/v1.0/sites?search=' \ + SPS_SiteName # Microsoft Graphを実行し、その結果をres1に格納する。 res1 = requests.get( SiteGet_URL, headers=headers ) # requrest処理をクローズする res1.close # res1をjsonファイルに整形 res1json = res1.json() # 結果からSiteIDを取得する。 SiteID = res1json['value'][0]['id']res1jsonの取得結果
res1json{ "@odata.context": "https://graph.microsoft.com/v1.0/$metadata#sites", "value": [ { "createdDateTime": "2018-06-08T01:54:26Z", "id": "xxxxxxxx.sharepoint.com,xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxx,xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxx", "lastModifiedDateTime": "2018-05-23T19:38:15Z", "name": "testsite", "webUrl": "https://xxxxxxxx.sharepoint.com/sites/zzzzzzzzzzzzzzzzzzzz", "displayName": "テストサイト", "root": {}, "siteCollection": { "hostname": "xxxxxxxx.sharepoint.com" } } ] }ここで詰まったところ
['value']['id']とすれば値が取得できると思っていました。
ところが、実際に投げたところ、こういうエラーが発生しました。TypeError: string indices must be integers, not str調べたところ、リストのインデックスは数値型じゃないとだめとのことです。
というわけで、値取得の方法を以下のように書き換えます。SiteID = res1json['value'][0]['id']今回、取得したjsonは1件しかない想定ですので
リストのインデックス番号「0」を付与することで
確実にパラメタを取得することができるようになります。リストIDを取得する
GetSPSListID# ListIDを取得するためのURLを生成する ListGet_URL = "https://graph.microsoft.com/v1.0/sites/" + \ SiteID + "/lists? + \ $filter=displayName eq '" + SPS_ListName + "'" # Microsoft Graphを実行し、その結果をres2に格納する。 res2 = requests.get( ListGet_URL, headers=headers ) # requrest処理をクローズする res2.close # res2をjsonファイルに整形 res2json = res2.json() # 結果からListIDを取得する ListID = res2json['value'][0]['id']res2jsonの取得結果
res2json{ "@odata.context": "https://graph.microsoft.com/v1.0/$metadata#sites('xxxxxxxx.sharepoint.com,xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxx,xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxx')/lists", "value": [ { "@odata.etag": "\"xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxx,13\"", "createdDateTime": "2019-02-13T12:51:59Z", "description": "", "eTag": "\"xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxx,13\"", "id": "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxx", "lastModifiedDateTime": "2019-02-14T13:16:31Z", "name": "IoT_Data", "webUrl": "https://https://xxxxxxxx.sharepoint.com/sites/zzzzzzzzzzzzzzzzzzzz/Lists/IoT_Data", "displayName": "IoT_Data", "createdBy": { "user": { "email": "xxx@xxx.com", "id": "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxx", "displayName": "テストユーザ" } }, "lastModifiedBy": { "user": { "email": "xxx@xxx.com", "id": "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxx", "displayName": "テストユーザ" } }, "parentReference": {}, "list": { "contentTypesEnabled": true, "hidden": false, "template": "genericList" } } ] }ここで詰まったところ
文字列をシングルクォート(')で囲っていたため
検索文字列をダブルクォート(")で囲うようにしてましたが
それだとエラーになったため
URL生成部分はダブルクォートにして以下のように宣言しました。"https://graph.microsoft.com/v1.0/sites/" + \ SiteID + "/lists? + \ $filter=displayName eq '" + SPS_ListName + "'"レコードIDを取得する
GetSPSRecordID# RecoardIDを取得するためのURLを生成する RecordGet_URL = "https://graph.microsoft.com/v1.0/sites/" + \ SiteID + "/lists/" + ListID + \ "/items?expand= + \ fields(select=Id," + SPS_SearchColumn + \ ")&filter=fields/" + SPS_SearchColumn + " eq '" + \ SPS_SearchRecord + "'" # Microsoft Graphを実行し、その結果をres3に格納する。 res3 = requests.get( RecordGet_URL, headers=headers ) # requrest処理をクローズする res3.close # res3をjsonファイルに整形 res3json = res3.json() # 結果からRecordIDを取得する RecordID = res3json['value'][0]['id']res3jsonの取得結果
res3json{ "@odata.context": "https://graph.microsoft.com/v1.0/$metadata#sites('xxxxxxxx.sharepoint.com,xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxx,xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxx')/lists('xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxx')/items", "value": [ { "@odata.etag": "\"xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxx,48752\"", "createdDateTime": "2019-02-14T13:16:31Z", "eTag": "\"xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxx\"", "id": "2", "lastModifiedDateTime": "2019-02-18T13:12:05Z", "webUrl": "https://https://xxxxxxxx.sharepoint.com/sites/zzzzzzzzzzzzzzzzzzzz/Lists/IoT_Data/2_.000", "createdBy": { "user": { "email": "xxx@xxx.com", "id": "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxx", "displayName": "テストユーザ" } }, "lastModifiedBy": { "user": { "displayName": "SharePoint アプリ" } }, "parentReference": {}, "contentType": { "id": "0x01003F9D3A2ADE72BA4BBEA8AB7FCD7ECD6D" }, "fields@odata.context": "https://graph.microsoft.com/v1.0/$metadata#sites('xxxxxxxx.sharepoint.com,xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxx,xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxx')/lists('xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxx')/items/$entity", "fields": { "@odata.etag": "\"xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxx,48752\"", "Product": "PiSensor", "id": "2" } } ] }ここで詰まったところ
検索クエリ部分ですね。
ここは試行錯誤するしかなかったです。
field で検索対象のリストからIDと検索対象のカラム名を指定し
filter関数で検索対象のカラム名のデータが何か?という指定をしています。まとめ
いかがだったでしょうか?
実運用で使用する場合は、やはりある程度変数化する必要があります。
今回、それを試していく中で、Microsoft Graph SharePoint の特性がちょっとわかった気がします。
みなさんのOffice365ライフで何かの足しになれば幸いです。

- 投稿日:2019-02-18T21:59:15+09:00
Pythonの組み込み関数69個を制覇する 第4回 h~i
Pythonでは、非常に多くの組み込み関数(Built-in Functions)が用意されており、ライブラリをimportせずとも様々な処理を行うことができます。
基本に立ち返って、組み込み関数の使い方を整理して行きたいと思います。
尚、実行例はWindows Subsystem for LinuxのUbuntu18.04にインストールしたPython3.7.1で作成しています。Pythonの組み込み関数69個を制覇する 第1回 a~b
Pythonの組み込み関数69個を制覇する 第2回 c~d
Pythonの組み込み関数69個を制覇する 第3回 e~g関数の使い方
各関数の使い方を記述していきます。詳細な使い方は他の記事に譲るとして、ここでは簡単な使用例を中心に掲載していきます。
hasattr()
オブジェクトに指定した属性が設定されているかを判定します。
第1引数に判定したいオブジェクトを、第2引数に判定したい属性名を渡します。>>> class Sushi(object): ... def __init__(self, neta, type): ... self.neta = neta ... self.type = type ... >>> maguro = Sushi('maguro', 'nigiri') >>> # 存在していたらTrue ... hasattr(maguro, 'neta') True >>> # 存在していなかったらFalse ... hasattr(maguro, 'taste') False >>> hasattr(maguro, 'type') Truehash()
引数には任意のオブジェクトをとり、そのハッシュ値を返します。
通常、ハッシュ値はオブジェクトのもつ__hash__()メソッドの結果を利用します。>>> hash(1) 1 >>> # 値が同じ場合はhash値は同じになる ... hash(1.0) 1 >>> hash(complex(1)) 1 >>> # 文字列 ... hash('key1') 7054912689230938466 >>> hash('key2') 4510368350215496904 >>> hash(object()) 8771476958276 >>> # __hash__()を実装するとhash()の返り値をコントロールできる ... class Hashi(object): ... def __hash__(self): ... return 2 ... >>> chopsticks = Hashi() >>> hash(chopsticks) 2ハッシュはdictで利用されるのですが、どのように使われるかはPython における hashable などがわかりやすいです。
help()
Pythonオブジェクトの説明を見ることができる非常に便利な関数です。
主にPythonの対話コンソールで使用します。引数なしで呼び出すと、対話的なヘルプが起動します。
>>> help() Welcome to Python 3.7's help utility! If this is your first time using Python, you should definitely check out the tutorial on the Internet at https://docs.python.org/3.7/tutorial/. Enter the name of any module, keyword, or topic to get help on writing Python programs and using Python modules. To quit this help utility and return to the interpreter, just type "quit". To get a list of available modules, keywords, symbols, or topics, type "modules", "keywords", "symbols", or "topics". Each module also comes with a one-line summary of what it does; to list the modules whose name or summary contain a given string such as "spam", type "modules spam". help>対話コンソールでは、オブジェクト名を入力することで、オブジェクトの説明文や持っているメソッド、属性などの情報を見ることができます。
help> str Help on class str in module builtins: class str(object) | str(object='') -> str | str(bytes_or_buffer[, encoding[, errors]]) -> str | | Create a new string object from the given object. If encoding or | errors is specified, then the object must expose a data buffer | that will be decoded using the given encoding and error handler. | Otherwise, returns the result of object.__str__() (if defined) | or repr(object). | encoding defaults to sys.getdefaultencoding(). | errors defaults to 'strict'. | | Methods defined here: (略)私の環境では、ヘルプページはlessコマンドと同じように操作することができました。
矢印キーやjkキーでの移動、/キーのあとに検索ワードを入力してドキュメント内の検索などができます。qキーでヘルプページから抜けます。
help>と表示されているときにquitまたはqと入力すると、ヘルプコンソールから抜けることができ、Pythonのプロンプトが表示されます。help> quit You are now leaving help and returning to the Python interpreter. If you want to ask for help on a particular object directly from the interpreter, you can type "help(object)". Executing "help('string')" has the same effect as typing a particular string at the help> prompt. >>>help()の引数にオブジェクトを渡すことで、ヘルプを表示することもできます。
>>> help(sum) Help on built-in function sum in module builtins: sum(iterable, start=0, \) Return the sum of a 'start' value (default: 0) plus an iterable of numbers When the iterable is empty, return the start value. This function is intended specifically for use with numeric values and may reject non-numeric types.help()関数は、オブジェクトの定義からヘルプドキュメントを生成しているので、自作の関数定義やクラス定義のヘルプを見ることもできます。
>>> class Fisherman(object): ... """釣り人""" ... def fish(self, feed:str) -> str: ... """何かを釣り上げる""" ... return 'can' ... >>> help(Fisherman)Help on class Fisherman in module __main__: class Fisherman(builtins.object) | 釣り人 | | Methods defined here: | | fish(self, feed: str) -> str | 何かを釣り上げる | | ---------------------------------------------------------------------- | Data descriptors defined here: | | __dict__ | dictionary for instance variables (if defined) | | __weakref__ | list of weak references to the object (if defined)hex()
引数に整数を渡すと、頭に
0xをつけた16進数の文字列に変換します。>>> hex(1) '0x1' >>> hex(16) '0x10' >>> hex(-99) '-0x63' >>> # floatはエラーになる ... hex(5.6) Traceback (most recent call last): File "<stdin>", line 2, in <module> TypeError: 'float' object cannot be interpreted as an integer >>> # floatを16進数にしたい場合は、float.hex()メソッドを使う ... 5.6.hex() '0x1.6666666666666p+2' >>> # intに戻すときは第2引数に底16を渡す ... int(hex(-99), 16) -99id()
引数に渡したオブジェクトの識別値を返します。
そのオブジェクトが有効である間は、常に一意の定数になることが仕様で保証されています。従って、あるオブジェクトが生存しているときに同じidになるような2つの変数は同じオブジェクトを指していることになります。
is演算子が真になるのはidの値が同一になる場合です。>>> # mutableなオブジェクトの例(int) ... x = 1 >>> id(1) 11151232 >>> id(x) 11151232 >>> x is 1 True >>> x += 1 >>> # idが変わる .... id(x) 11151264 >>> id(x) == id(2) True >>> x is 2 True >>> # mutableなオブジェクトの例(list) ... y = [] >>> id(y) 140495409735688 >>> y.append(1) >>> y [1] >>> id(y) 140495409735688 >>> # idが異なるので、別オブジェクト ... z = [1] >>> id(z) 140495410036168 >>> y is z FalseCPythonの実装では、id値はメモリ上のアドレス値になるとのことです。
input()
プロンプトを表示してユーザーからの入力を受け付け、結果を文字列として返します。
プロンプトは、引数で文字列として指定することができます。>>> result = input() Hello >>> print(result) Hello >>> name = input('名前を入力してね >>> ') 名前を入力してね >>> サブロー >>> print(name) サブロープログラム内でユーザーからの入力を受け付けることができるので非常に便利なinput()関数ですが、入力内容がプロンプトに表示されてしまうためパスワード入力には使えません。
パスワードの入力を対話的に行いたい場合はgetpassモジュールを使うのが良いでしょう。int()
整数型クラスのインスタンスオブジェクトを返却します。つまり、1や100や-9999などです。
引数には数値か、str, bytes, bytearrayといった文字列を扱うオブジェクトを渡すことができます。文字列の内容は'100'や'-200'といった 整数リテラルである必要があります。>>> # 何も渡さない場合は0 ... int() 0 >>> # 数値 ... int(100) 100 >>> int(45.0) 45 >>> int(30.5) 30 >>> int(-4.5555E3) -4555 >>> # 文字列 ... int('145') 145 >>> # bytes ... int(b'-490') -490 >>> # bytearray ... int(bytearray('50', 'ascii')) 50 >>> # 第2引数に基数を渡すことができる ... # 2進数 ... int('01001', 2) 9 >>> # 7進数 ... int('555', 7) 285 >>> # 8進数 ... int('0o555', 8) 365 >>> # 16進数 ... int('FFFF', 16) 65535引数に渡すオブジェクトに
__int__()や__trunc__()が定義されていた場合、それらの実行結果がint()の結果として返却されます。>>> # __int__()を実装する ... class MyInt(object): ... def __int__(self): ... return 42 ... >>> int(MyInt()) 42 >>> # __trunc__()を実装する ... class MyFloat(float): ... def __trunc__(self): ... import math ... return math.ceil(self) ... >>> int(MyFloat(5.5)) 5 >>> int(MyFloat(6.9)) 6isinstance()
指定したオブジェクトが、あるクラスのインスタンスかどうかを判定しTrue/Falseを返却します。親クラスや先祖クラスが比較対象の場合も同様に真を返します。
第1引数にオブジェクトを、第2引数にクラスを渡します。>>> isinstance(1, int) True >>> isinstance(1, str) False >>> # intを継承したクラス ... class NewInt(int): ... pass ... >>> isinstance(NewInt(1), int) True >>> # 抽象基底クラス(Abstract Base Class)の場合 >>> from abc import ABC >>> class MyABC(ABC):pass ... >>> class DEF(object):pass ... >>> isinstance(DEF(), MyABC) False >>> # 仮想クラスに登録すると、DEFはMyABCの子クラスとして認識される ... MyABC.register(DEF) <class '__main__.DEF'> >>> isinstance(DEF(), MyABC) True第2引数はクラスオブジェクトのタプルを渡すこともできます。その場合、要素のいずれかが対象の親(先祖)クラスであればTrueとなります。
>>> isinstance(10.5, (int, float, str)) True >>> isinstance(10.5, (int, str)) False >>> isinstance(10.5, ()) Falseissubclass()
指定したクラスオブジェクトが、あるクラスのサブクラスかどうかを判定しTrue/Falseを返却します。親クラスや先祖クラスが比較対象の場合も同様に真を返します。
第1引数にクラスオブジェクトを、第2引数にクラスを渡します。>>> issubclass(int, int) True >>> issubclass(NewInt, int) True >>> issubclass(NewInt, str) Falseiter()
iteratorオブジェクトを返します。
引数を一つまたは二つとり、それぞれのパターンで動きが変わるという少し癖のある関数です。
引数が一つの場合、__iter__()か__getitem()__をサポートしているオブジェクトである必要があります。forループの対象にできるものと考えれば問題ないでしょう。
iteratorオブジェクトをnext()関数に渡すと、要素を一つずつ返却し、最後の要素まで返却し終えるとStopIteration例外を送出します。大抵の場合は、forループで使用します。>>> i = iter([1, 2, 3]) >>> next(i) 1 >>> next(i) 2 >>> next(i) 3 >>> # 要素がなくなると例外 ... next(i) Traceback (most recent call last): File "<stdin>", line 1, in <module> StopIteration >>> for taste in iter(('Tonkotsu', 'Miso', 'Shoyu', 'Shio',)): ... print(taste, 'Ramen is Good.') ... Tonkotsu Ramen is Good. Miso Ramen is Good. Shoyu Ramen is Good. Shio Ramen is Good.iter()には第二引数としてsentinel、つまり番兵を渡すことができます。
この場合、第一引数は呼び出し可能(callable)なオブジェクトである必要があります。
このとき返却されるイテレータオブジェクトでは、__next__()が呼び出されるたびに第一引数オブジェクトを引数無しで呼び出し、返却される値が第二引数の値と同一であるとStopIterationを送出します。>>> x = 0 >>> def counter(): ... global x ... x += 1 ... return x ... >>> # ループのたびにcounter()が呼び出され、返り値が5のときに終了する >>> for i in iter(counter, 5): ... print(i) ... 1 2 3 4標準ドキュメント では、番兵を利用して、バイナリデータからブロックデータを読み込む方法を例として上げています。
第5回に続く
次回はlen()から
- 投稿日:2019-02-18T21:38:04+09:00
No.036【Python】正規表現「モジュール re」について
今回は、正規表現「モジュール re」について書いていきます。
I'll write about "re module", regular expression in python" on this page.
■ 文字列の先頭とパターン一致有無: match()関数
The judgement of agreement between a lead position of strings and a pattern: match()function
>>> import re >>> >>> w = "one two one two" >>> >>> # 文字列の先頭とパターンとの一致有無の確認:match() >>> >>> # re.match()にて調べることが可能 >>> >>> m = re.match("one",w) >>> >>> print(m) <re.Match object; span=(0, 3), match='one'> >>> # ↑ 一致の場合は、matchオブジェクトを返す>>> # matchオブジェクトは、以下のmethodを持つ >>> # group(), start(), end(), span(), etc. >>> >>> import re >>> >>> w = "one two one two" >>> >>> m = re.match("one",w) >>> print(m) <re.Match object; span=(0, 3), match='one'> >>> >>> print(m.group()) one >>> >>> print(m.start()) 0 >>> >>> print(m.end()) 3 >>> >>> print(m.span()) (0, 3)>>> # group():パターンに一致した全体を返す >>> # groups():()で囲まれた部分と一致した各文字列をタプルで取得可能 >>> >>> import re >>> w = "one two one two" >>> >>> m = re.match("(one) (two)",w) >>> >>> print(m) <re.Match object; span=(0, 7), match='one two'> >>> >>> print(m.group()) one two >>> >>> print(m.groups()) ('one', 'two') >>> >>> # 先頭に一致する文字列がない場合:Noneを返す >>> >>> m = re.match("two", w) >>> >>> print(m) None■ パターンの一致を調べる: search()
Search for pattern agreements
>>> # 先頭にない文字列を調べることが可能 >>> # re.match()と同様、一致の場合はmatchオブジェクトを返す >>> >>> import re >>> w = "one two one two" >>> >>> m = re.search("one",w) >>> >>> print(m) <re.Match object; span=(0, 3), match='one'> >>> >>> m = re.search("two",w) >>> >>> print(m) <re.Match object; span=(4, 7), match='two'> >>> #↑ 文字列中に一致箇所が複数あっても最初に一致したかのみ返す■ 一致箇所全てをリストで返す: findall()
Return all the part of agreement by lists
>>> # 一致箇所を全てリストにして返す >>> # 返すのはmatchオブジェクトではない >>> >>> import re >>> >>> w = "one two one two" >>> >>> m = re.findall("one",w) >>> >>> print(m) ['one', 'one'] >>> >>> m = re.findall("one two",w) >>> >>> print(m) ['one two', 'one two']■ 一致箇所全てをイテレータで返す: finditer()
Return all the part of agreement by iterators
>>> # re.finditer():一致箇所をmatchオブジェクトのイテレータで返す >>> # re.findallとは異なり、matchオブジェクトを得られる >>> >>> >>> import re >>> w = "one two one two" >>> >>> m = re.finditer('one', w) >>> >>> print(m) <callable_iterator object at 0x107b79fd0> >>> >>> for match in m: print(match) <re.Match object; span=(0, 3), match='one'> <re.Match object; span=(8, 11), match='one'>■ 一致箇所の置換:sub() / subn()
Replacement the part of agreement
>>> import re >>> w = "one two one two" >>> >>> m = re.sub("one", "ONE",w) >>> >>> print(m) ONE two ONE two >>> >>> m = re.sub("one two", "ONE TWO", w) >>> >>> print(m) ONE TWO ONE TWO >>> >>> #パターンの一部を囲み、置換後の文字列中の一致箇所を使用することが可能 >>> >>> m = re.sub("(one) (two)", "\\1X\\2",w) >>> >>> print(m) oneXtwo oneXtwo >>> >>> m = re.sub('(one) (two)', r'\1X\2', w) >>> >>> print(m) oneXtwo oneXtwo■ パターンによる文字列分割:split()
String division by patterns
>>> import re >>> w = "one two one two" >>> m = re.split(" ", w) >>> >>> print(m) ['one', 'two', 'one', 'two']■ 正規表現オブジェクトのコンパイル:compile()
Complie of regular expression obejcts
>>> # re.compile():同じパターンの繰り返し使用の場合 >>> # パターンをコンパイルして正規表現オブジェクトを生成したほうがいい >>> >>> import re >>> w = "one two one two" >>> >>> com = re.compile("one") >>> >>> m = com.match(w) >>> print(m) <re.Match object; span=(0, 3), match='one'> >>> >>> m = com.findall(w) >>> print(m) ['one', 'one'] >>> >>> m = com.sub("ONE", w) >>> print(m) ONE two ONE two随時に更新していきますので、
定期的な購読をよろしくお願いします。
I'll update my article at all times.
So, please subscribe my articles from now on.本記事について、
何か要望等ありましたら、気軽にメッセージをください!
If you have some requests, please leave some messages! by You-Tarinまた、「Qiita」へ投稿した内容は、随時ブログへ移動して行きたいと思いますので、よろしくお願いします。

- 投稿日:2019-02-18T21:22:42+09:00
Django Webアプリ作成(3) アプリケーション作成
環境
OS : macOS Mojave
Anaconda : python3.6.7
Django==2.1.5ここまでの流れ
前回でDjangoアプリの大枠を作成したので、今回から中身のアプリを作成していこうと思います。
作成したいWebアプリ
3回目で書くのもおかしいかもしれないが、まず作りたいアプリを決めないといけない。
作りたいものはいろいろあるが、最初ということでブログ形式のサイトを作ってみようと思う。
Django Girls チュートリアルを参考にして作成していく。アプリケーションの作成
Terminalpython manage.py startapp blog上のコードの"blog"は作成するアプリケーションの名前であり、好きな名前をつけて良い。
実行後のファイル構成は以下のようになる。djangoblog ├── blog │ ├── __init__.py │ ├── admin.py │ ├── apps.py │ ├── migrations │ │ └── __init__.py │ ├── models.py │ ├── tests.py │ └── views.py ├── config │ ├── __init__.py │ ├── __pycache__ │ │ ├── __init__.cpython-37.pyc │ │ ├── settings.cpython-37.pyc │ │ ├── urls.cpython-37.pyc │ │ └── wsgi.cpython-37.pyc │ ├── settings.py │ ├── urls.py │ └── wsgi.py ├── db.sqlite3 ├── manage.py ├── static └── templatesアプリの登録
設定ファイル(config/setting.py)に今作成したアプリを登録する。
config/setting.pyINSTALLED_APPS = [ 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', 'blog', ]アプリディレクトリ直下にurls.pyを作成
今回は1つのアプリケーションしか作らないが、2つ以上のアプリケーションを作成する場合はアプリケーションディレクトリにurls.pyを追加したほうがわかりやすくなる。
今後のためにも、今回はその方法で進める。Terminaltouch blog/urls.pyconfig/urls.pyとblog/urls.pyをつなぐ
config/urls.pyとblog/urls.pyを編集
config/urls.pyfrom django.contrib import admin from django.urls import path, include urlpatterns = [ path('admin/', admin.site.urls), path('', include('blog.urls')) ]blog/urls.pyfrom django.urls import include, path from . import views urlpatterns = [ ]次回以降にurls.pyの役割を書くがアプリディレクトリにurls.pyを作成することで、config/urls.pyが肥大化せずアプリごとに記述することでスリムなコードになる。
これでアプリの大枠は完成!
次回、アプリの中身を作成します!
- 投稿日:2019-02-18T21:05:28+09:00
AtomのHydrogenでMatplotlib, Bokeh, HoloViewsのプロットを表示する
はじめに
AtomのHydrogenでMatplotlib, Bokeh, HoloViewsのプロットを表示する方法です。
Matplotlib
import matplotlib.pyplot as plt plt.scatter([1, 2, 3], [1, 2, 3])Jupyter Notebookで必要な
%matplotlib inlineは要りません。
Bokeh
from bokeh.plotting import figure, output_notebook, show from bokeh.resources import INLINE output_notebook(INLINE) plot = figure() plot.circle([1, 2, 3], [1, 2, 3]) show(plot)
output_notebookがないと外部ブラウザにプロットが表示されてしまいます。INLINEは必ずしも必要ないですが、こうすると、BokehJS x.x.x successfully loaded.のメッセージが確認できます。HoloViews
プロットの準備
import numpy as np import pandas as pd import holoviews as hv xs = np.arange(-10, 10.5, 0.5) ys = 100 - xs**2 df = pd.DataFrame(dict(x=xs, y=ys)) curve = hv.Curve(df,'x','y')ここまでは特定の可視化ライブラリに依存していません。
バックエンドがMatplotlibの場合
hv.extension('matplotlib') hv.render(curve)バックエンドがBokehの場合
from bokeh.io import show hv.extension('bokeh') show(hv.render(curve))HoloViewsを通してBokehのプロット表示する際には、
output_notebookは不要です。また、Jupyter Notebookの場合は、curveをセルの最後に入力するだけでプロットが表示されますが、Hydrogenの場合は、hv.renderや(Bokehの場合には)showが必要となるようです。
- 投稿日:2019-02-18T21:05:28+09:00
AtomのHydrogenでMatplotlib, Bokeh, HoloViews他のプロットを表示する
はじめに
AtomのHydrogenでMatplotlib, Bokeh, HoloViewsのプロットを表示する方法です。
Matplotlib
import matplotlib.pyplot as plt plt.scatter([1, 2, 3], [1, 2, 3])Jupyter Notebookで必要な
%matplotlib inlineは要りません。
Bokeh
from bokeh.plotting import figure, output_notebook, show from bokeh.resources import INLINE output_notebook(INLINE) plot = figure() plot.circle([1, 2, 3], [1, 2, 3]) show(plot)
output_notebookがないと外部ブラウザにプロットが表示されてしまいます。INLINEは必ずしも必要ないですが、こうすると、BokehJS x.x.x successfully loaded.のメッセージが確認できます。HoloViews
プロットの準備
import numpy as np import pandas as pd import holoviews as hv xs = np.arange(-10, 10.5, 0.5) ys = 100 - xs**2 df = pd.DataFrame(dict(x=xs, y=ys)) curve = hv.Curve(df,'x','y')ここまでは特定の可視化ライブラリに依存していません。
バックエンドがMatplotlibの場合
hv.extension('matplotlib') hv.render(curve)バックエンドがBokehの場合
from bokeh.io import show hv.extension('bokeh') show(hv.render(curve))HoloViewsを通してBokehのプロット表示する際には、
output_notebookは不要です。また、Jupyter Notebookの場合は、curveをセルの最後に入力するだけでプロットが表示されますが、Hydrogenの場合は、hv.renderや(Bokehの場合には)showが必要となるようです。hvPlot
import pandas as pd import numpy as np idx = pd.date_range('1/1/2000', periods=1000) df = pd.DataFrame(np.random.randn(1000, 4), index=idx, columns=list('ABCD')).cumsum() import hvplot.pandas show(hv.render(df.hvplot()))Altair
import altair as alt import pandas as pd source = pd.DataFrame({ 'a': ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I'], 'b': [28, 55, 43, 91, 81, 53, 19, 87, 52] }) alt.Chart(source).mark_bar().encode(x='a', y='b')
- 投稿日:2019-02-18T21:05:28+09:00
AtomのHydrogenでMatplotlib, Bokeh, HoloViewsおよび他ライブラリのプロットを表示する
はじめに
AtomのHydrogenでMatplotlib, Bokeh, HoloViewsのプロットを表示する方法です。
Matplotlib
import matplotlib.pyplot as plt plt.scatter([1, 2, 3], [1, 2, 3])Jupyter Notebookで必要な
%matplotlib inlineは要りません。
Bokeh
from bokeh.plotting import figure, output_notebook, show from bokeh.resources import INLINE output_notebook(INLINE) plot = figure() plot.circle([1, 2, 3], [1, 2, 3]) show(plot)
output_notebookがないと外部ブラウザにプロットが表示されてしまいます。INLINEは必ずしも必要ないですが、こうすると、BokehJS x.x.x successfully loaded.のメッセージが確認できます。HoloViews
プロットの準備
import numpy as np import pandas as pd import holoviews as hv xs = np.arange(-10, 10.5, 0.5) ys = 100 - xs**2 df = pd.DataFrame(dict(x=xs, y=ys)) curve = hv.Curve(df,'x','y')ここまでは特定の可視化ライブラリに依存していません。
バックエンドがMatplotlibの場合
hv.extension('matplotlib') hv.render(curve)バックエンドがBokehの場合
from bokeh.io import show hv.extension('bokeh') show(hv.render(curve))HoloViewsを通してBokehのプロット表示する際には、
output_notebookは不要です。また、Jupyter Notebookの場合は、curveをセルの最後に入力するだけでプロットが表示されますが、Hydrogenの場合は、hv.renderや(Bokehの場合には)showが必要となるようです。hvPlot
import pandas as pd import numpy as np import holoviews as hv import hvplot.pandas from bokeh.plotting import show idx = pd.date_range('1/1/2000', periods=1000) df = pd.DataFrame(np.random.randn(1000, 4), index=idx, columns=list('ABCD')).cumsum() show(hv.render(df.hvplot()))Altair
import altair as alt import pandas as pd source = pd.DataFrame({ 'a': ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I'], 'b': [28, 55, 43, 91, 81, 53, 19, 87, 52] }) alt.Chart(source).mark_bar().encode(x='a', y='b')
- 投稿日:2019-02-18T20:54:20+09:00
XGBoostを使って競艇予測をしてみる
XGBoostを使って何かいいことしてみようということで、競艇予測をしてみます!開発環境はお財布が寂しい人は大好き、Google Colaboratory!
また、Gistにも投稿してます。そっちのが分かりやすいかも。
https://gist.github.com/Daisuke0209/d9e83e7105ff18afaa0c366fa42babfa
Google Driveへのアクセス
とりあえず、Google ColaboratoryからDriveにアクセスするためマウントを取ります
XGBoost_boat_prediction.ipynb#Google Driveのマウントを取る from google.colab import drive drive.mount('/content/gdrive')データの説明
各列ごとに、あるレースの色んな情報を意味。だいたい番組表+オッズのイメージ。これらのデータはPythonでスクレイピングして取ってきました。 以下に簡単な説明
- Date:レース日
- Place:レース会場
- Race:レースNo.
- Nth-rank:Nコース走者のランク(A1とかB2とか)をラベル化したもの
- Nth-num:Nコース走者の選手番号
- Nth-ratio:Nコース走者の単勝オッズ
- Nth-exb:展示のタイム
- 1st,2nd,3rd,4th,5th,6th:何走者が何位になったか (1st:5なら一位は5コース走者)
他にもいっぱいデータがありますが、ちょっと面倒なので省略。データの全体像見たい方は、Gistの投稿を見てみてください。予想するのはとりあえず1stにしましょう!
XGBoost_boat_prediction.ipynbimport pandas as pd df=pd.read_csv("/content/gdrive/My Drive/Datasets/boat_data/boat_data.csv") df.head()説明変数と目的変数をセットします。とりあえず使ってみるなので、説明変数も少なめで。。(;´・ω・)
XGBoost_boat_prediction.ipynb#目的変数 target=['1st'] #説明変数 features = ['Place','1st-rank','2nd-rank','3rd-rank','4th-rank','5th-rank','6th-rank', '1st-ratio','2nd-ratio','3rd-ratio','4th-ratio','5th-ratio','6th-ratio']学習データとテストデータの分割
とりあえず、8割を学習に使います。
XGBoost_boat_prediction.ipynbl = len(df) train_num = int(l*0.8) df_train = df[:train_num] df_test = df[train_num:l] X_train = df_train[features] X_test = df_test[features] y_train = df_train[target] y_test = df_test[target]モデル(XGBoost)の定義
XGBoost_boat_prediction.ipynbimport xgboost as xgb model=xgb.XGBClassifier()XGBoostモデルの学習
何のパラメータも設定していませんが、お試しということで(;´・ω・)
XGBoost_boat_prediction.ipynbmodel.fit(X_train, y_train)XGBoostの予測精度の評価
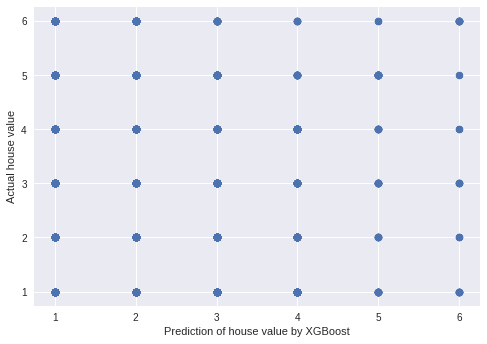
モデルの予測は1位になるのは何コースの走者かを出力します。
XGBoost_boat_prediction.ipynbimport matplotlib.pyplot as plt from sklearn.metrics import accuracy_score y_pred = model.predict(X_test) acc = accuracy_score(y_test, y_pred)*100 print('正答率は%.2f%です'%acc) plt.xlabel("Prediction of house value by XGBoost") plt.ylabel("Actual house value") plt.scatter(y_pred, df_test[target])正答率は55.51%です
(意味の無い散布図ですが。。。)
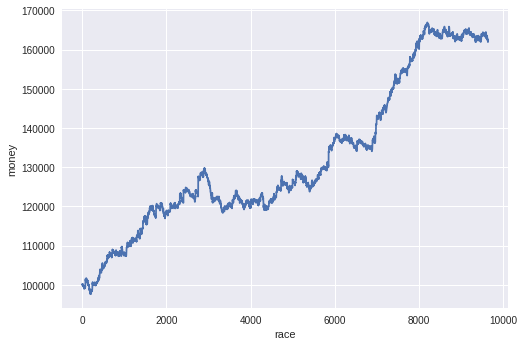
んん~。正答率55%がいいのか悪いのか。。。(;´・ω・) ということで、購入シミュレーションをしてみる競艇購入シミュレーション
XGBoost_boat_prediction.ipynb#お財布 money = 100000 #一回あたりの掛け金 kake = 100 money_rireki = [] odds = df_test['1-odds'].values.tolist() #リスト化 y_test_ls = y_test.values.tolist() for i in range(len(y_pred)): #毎レースベットする money = money - kake #XGBoostの予想が合えば払い戻しを財布に入れる if y_pred[i] == y_test_ls[i]: money = money+kake*odds[i] money_rireki.append(money) plt.xlabel('race') plt.ylabel('money') plt.plot(money_rireki)
おお(;´・ω・)めっちゃ増えとるやん!ほんまか!?
まとめ
嘘かほんとかよ―分かりませんが、なんかめちゃくちゃ儲かる結果になりました。間違えているところあれば教えてください。
- 投稿日:2019-02-18T20:54:20+09:00
XGBoostを使って競艇予測をしてみる(めっちゃ儲かる?)
XGBoostを使って何かいいことしてみようということで、競艇予測をしてみます!開発環境はお財布が寂しい人は大好き、Google Colaboratory!
また、Gistにも投稿してます。そっちのが分かりやすいかも。
https://gist.github.com/Daisuke0209/d9e83e7105ff18afaa0c366fa42babfa
Google Driveへのアクセス
とりあえず、Google ColaboratoryからDriveにアクセスするためマウントを取ります
XGBoost_boat_prediction.ipynb#Google Driveのマウントを取る from google.colab import drive drive.mount('/content/gdrive')データの説明
各列ごとに、あるレースの色んな情報を意味。だいたい番組表+オッズのイメージ。これらのデータはPythonでスクレイピングして取ってきました。 以下に簡単な説明
- Date:レース日
- Place:レース会場
- Race:レースNo.
- Nth-rank:Nコース走者のランク(A1とかB2とか)をラベル化したもの
- Nth-num:Nコース走者の選手番号
- Nth-ratio:Nコース走者の単勝オッズ
- Nth-exb:展示のタイム
- 1st,2nd,3rd,4th,5th,6th:何走者が何位になったか (1st:5なら一位は5コース走者)
他にもいっぱいデータがありますが、ちょっと面倒なので省略。データの全体像見たい方は、Gistの投稿を見てみてください。予想するのはとりあえず1stにしましょう!
XGBoost_boat_prediction.ipynbimport pandas as pd df=pd.read_csv("/content/gdrive/My Drive/Datasets/boat_data/boat_data.csv") df.head()説明変数と目的変数をセットします。とりあえず使ってみるなので、説明変数も少なめで。。(;´・ω・)
XGBoost_boat_prediction.ipynb#目的変数 target=['1st'] #説明変数 features = ['Place','1st-rank','2nd-rank','3rd-rank','4th-rank','5th-rank','6th-rank', '1st-ratio','2nd-ratio','3rd-ratio','4th-ratio','5th-ratio','6th-ratio']学習データとテストデータの分割
とりあえず、8割を学習に使います。
XGBoost_boat_prediction.ipynbl = len(df) train_num = int(l*0.8) df_train = df[:train_num] df_test = df[train_num:l] X_train = df_train[features] X_test = df_test[features] y_train = df_train[target] y_test = df_test[target]モデル(XGBoost)の定義
XGBoost_boat_prediction.ipynbimport xgboost as xgb model=xgb.XGBClassifier()XGBoostモデルの学習
何のパラメータも設定していませんが、お試しということで(;´・ω・)
XGBoost_boat_prediction.ipynbmodel.fit(X_train, y_train)XGBoostの予測精度の評価
モデルの予測は1位になるのは何コースの走者かを出力します。
XGBoost_boat_prediction.ipynbimport matplotlib.pyplot as plt from sklearn.metrics import accuracy_score y_pred = model.predict(X_test) acc = accuracy_score(y_test, y_pred)*100 print('正答率は%.2f%です'%acc) plt.xlabel("Prediction of house value by XGBoost") plt.ylabel("Actual house value") plt.scatter(y_pred, df_test[target])正答率は55.51%です
(意味の無い散布図ですが。。。)
んん~。正答率55%がいいのか悪いのか。。。(;´・ω・) ということで、購入シミュレーションをしてみる競艇購入シミュレーション
XGBoost_boat_prediction.ipynb#お財布 money = 100000 #一回あたりの掛け金 kake = 100 money_rireki = [] odds = df_test['1-odds'].values.tolist() #リスト化 y_test_ls = y_test.values.tolist() for i in range(len(y_pred)): #毎レースベットする money = money - kake #XGBoostの予想が合えば払い戻しを財布に入れる if y_pred[i] == y_test_ls[i]: money = money+kake*odds[i] money_rireki.append(money) plt.xlabel('race') plt.ylabel('money') plt.plot(money_rireki)
おお(;´・ω・)めっちゃ増えとるやん!ほんまか!?
まとめ
嘘かほんとかよ―分かりませんが、なんかめちゃくちゃ儲かる結果になりました。間違えているところあれば教えてください。
- 投稿日:2019-02-18T20:17:47+09:00
事業活動の産業(大分類)別の売上高に天候が関係しているのか調べる。
概要
観光地は天候が良い、あるいは特殊だから観光地として成立しているはずで、天候のパラメータが少なからず影響していると考えたため。特に沖縄はそうであろうと考えたため分析しようと思いました。しかし一つやるも大分類すべてやるも手間は同じなので全部やります。
天候データを取得
こちらから取得させていただきました。
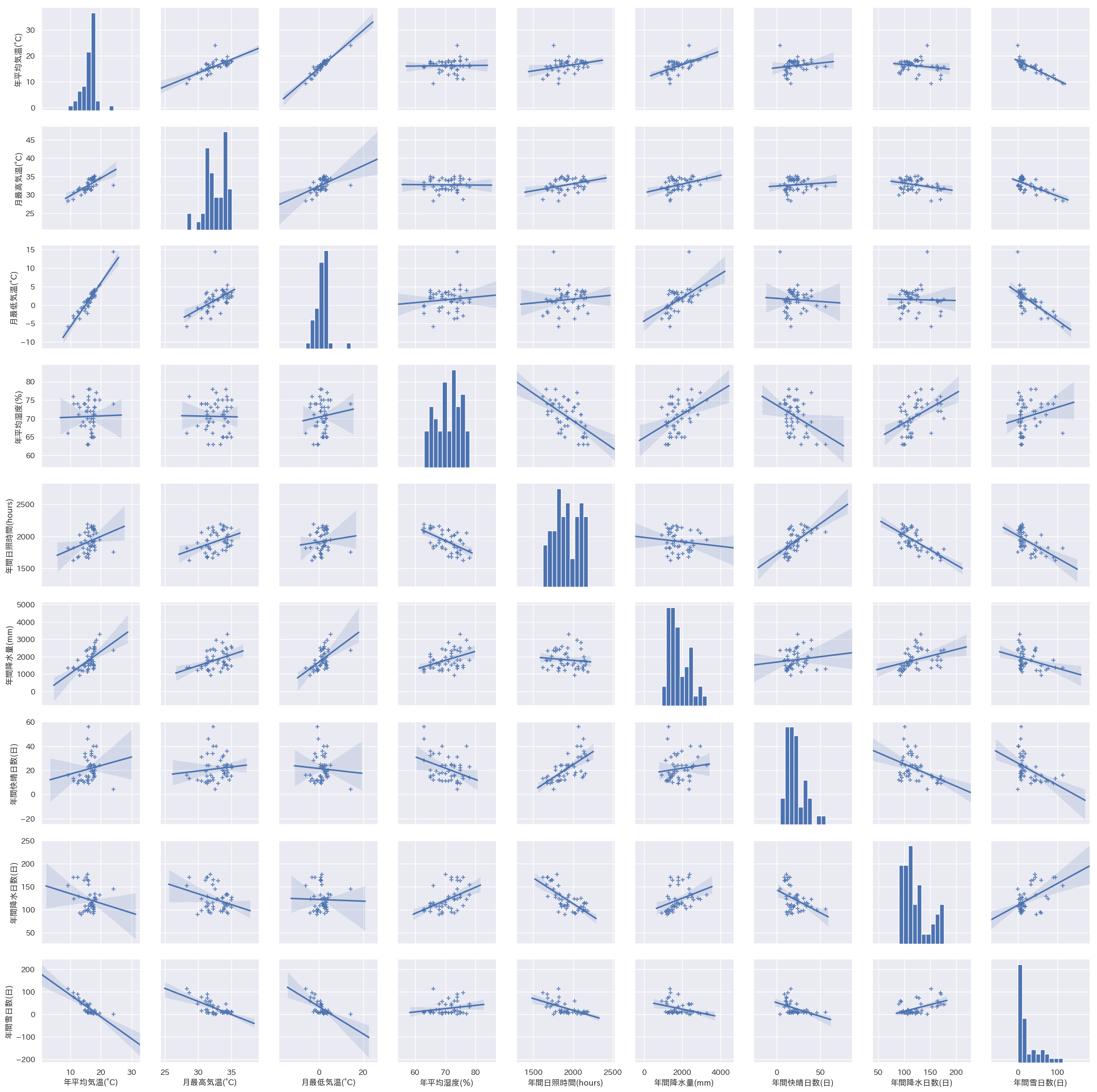
まずはざっとプロット
df = pd.read_csv('/Users/iMac/Dropbox/CSV/2016年の天候.csv') sns.pairplot(df,markers='+',kind='reg').savefig('test.png') plt.close('all') df = pd.melt(df, '都道府県') s= sns.catplot(x='都道府県', y='value', hue='variable', data=df, row=None, col='variable', col_wrap=3, estimator=np.mean, sharey=False) plt.savefig('test02.png') plt.close('all')
沖縄は平均気温はダントツ(左上)だが
快晴日数は意外にも最下位(右下)
湿度も高く、依って沖縄は冴え渡る青空というよりもどんよりとしているけど蒸しているという状態のほうが多いと推定。閑話休題
2016年の都道府県事業活動の産業別年間売上データを整形
title = '総務省_0003216893_都道府県,事業活動の産業(大分類)別年間売上高_201601-201612.csv' df_01 = pd.read_csv(dir_path + title) # 統計局は取得できなかったデータはハイフン処理するので0変換 df_01["value"] = pd.to_numeric(df_01["value"], errors='coerce').fillna(0) # いらない情報を排除 drop_list = ['合計', '全国', '海外(海外支店(現地法人は含まない)等)'] for i in drop_list: df_01 = df_01[(df_01['地域'] != i)] & # 2016年の天候データをマージ df_03 = pd.read_csv(dir_path + '2016年の天候.csv') df_01 = pd.merge(df_01, df_03, left_on='地域', right_on='都道府県')上記により、各都道府県に天候データが貼り付けられました。カラム名が重複すると
x_、y_プレフィックスがつくので気をつけて下さい。各都道府県別の統計調査項目は以下の通りとなっている。
df_01['事業活動の産業'].unique() ''' ['サービス産業計(※「情報通信業」を除く。)' 'H運輸業,郵便業' 'K不動産業,物品賃貸業' 'L学術研究,専門・技術サービス業(※「学術・開発研究機関」及び「純粋持株会社」を除く。)' 'M宿泊業,飲食サービス業' 'N生活関連サービス業,娯楽業(※「家事サービス業」を除く。)' 'O教育,学習支援業(※「学校教育」を除く。)' 'P医療,福祉(*「保健所」,「社会保険事業団体」及び「福祉事務所」を除く。)' 'Rサービス業(他に分類されないもの)(※「政治・経済・文化団体」,「宗教」及び「外国公務」を除く。)'] '''なので、これをforでまわして全てまずはプロットさせてみます。そしてせっかく作った変数なので、そのまま
statsmodelsモジュールで重回帰分析をします。for i in df_01['事業活動の産業'].unique(): df_02=df_01[(df_01['事業活動の産業'] == i)] g = sns.catplot(x='地域', y='value', hue=None, data=df_01[(df_01['事業活動の産業'] == i)], row=None, col='時間軸(年)',col_wrap=2, estimator=np.mean, ci=95, n_boot=1000,col_order=None, kind="bar",legend=True, legend_out=True, sharex=True, sharey=False ) g.fig.set_figwidth(30) g.fig.set_figheight(20) g.set_xticklabels(df_01['地域'].unique(), rotation=90) g.savefig(title + i + '02.png') plt.close('all') # 説明変数 X = df_02[['年平均気温(°C)', '年平均湿度(%)','年間降水日数(日)', '年間雪日数(日)']] # 目的変数 Y = np.array(df_02['value']) model = smf.OLS(Y, X) result = model.fit() print('全国都道府県別産業別重回帰分析'+i) print(result.summary())'サービス産業計(※「情報通信業」を除く。)'
'H運輸業,郵便業'
'K不動産業,物品賃貸業'
'L学術研究,専門・技術サービス業(※「学術・開発研究機関」及び「純粋持株会社」を除く。)'
'M宿泊業,飲食サービス業'
'N生活関連サービス業,娯楽業(※「家事サービス業」を除く。)'
'O教育,学習支援業(※「学校教育」を除く。)'
'P医療,福祉(*「保健所」,「社会保険事業団体」及び「福祉事務所」を除く。)'
'Rサービス業(他に分類されないもの)(※「政治・経済・文化団体」,「宗教」及び「外国公務」を除く。)東京が圧倒的です。。。
医療のみ偏差が少なそうなのが、高齢化社会を表していますね。
旅行産業は娯楽業に分類されます。
一番知りたかったのが天候と娯楽業の関係性なので見てみます。
全国都道府県別産業別重回帰分析N生活関連サービス業,娯楽業(※「家事サービス業」を除く。) OLS Regression Results ============================================================================== Dep. Variable: y R-squared: 0.307 Model: OLS Adj. R-squared: 0.242 Method: Least Squares F-statistic: 4.762 Date: Mon, 18 Feb 2019 Prob (F-statistic): 0.00286 Time: 20:07:56 Log-Likelihood: -731.94 No. Observations: 47 AIC: 1472. Df Residuals: 43 BIC: 1479. Df Model: 4 Covariance Type: nonrobust ============================================================================== coef std err t P>|t| [0.025 0.975] ------------------------------------------------------------------------------ 年平均気温(°C) 5.681e+04 1.76e+05 0.322 0.749 -2.99e+05 4.12e+05 年平均湿度(%) 7041.9821 4.34e+04 0.162 0.872 -8.06e+04 9.47e+04 年間降水日数(日) -3825.5116 1.2e+04 -0.319 0.751 -2.8e+04 2.04e+04 年間雪日数(日) -1603.0283 1.85e+04 -0.086 0.931 -3.9e+04 3.58e+04 ============================================================================== Omnibus: 75.362 Durbin-Watson: 1.320 Prob(Omnibus): 0.000 Jarque-Bera (JB): 953.684 Skew: 4.165 Prob(JB): 8.13e-208 Kurtosis: 23.436 Cond. No. 124. ============================================================================== Warnings: [1] Standard Errors assume that the covariance matrix of the errors is correctly specified.決定係数が低く、p値も5%を超えているので、信頼のおける結果ではなかったです。
区分が大雑把すぎたのと、
何年もデータを同じ地位域で取得しないと意味がなかったかもしれません。
次回やるときは同一県で、できるだけ長期のデータを用意するべきだと思いました。ついでなので、他のすべての分析も載せておきます。
全国都道府県別産業別重回帰分析サービス産業計(※「情報通信業」を除く。) OLS Regression Results ============================================================================== Dep. Variable: y R-squared: 0.239 Model: OLS Adj. R-squared: 0.168 Method: Least Squares F-statistic: 3.380 Date: Mon, 18 Feb 2019 Prob (F-statistic): 0.0172 Time: 20:07:50 Log-Likelihood: -830.60 No. Observations: 47 AIC: 1669. Df Residuals: 43 BIC: 1677. Df Model: 4 Covariance Type: nonrobust ============================================================================== coef std err t P>|t| [0.025 0.975] ------------------------------------------------------------------------------ 年平均気温(°C) 2.971e+05 1.44e+06 0.207 0.837 -2.6e+06 3.2e+06 年平均湿度(%) 6.222e+04 3.54e+05 0.176 0.861 -6.53e+05 7.77e+05 年間降水日数(日) -1.787e+04 9.79e+04 -0.183 0.856 -2.15e+05 1.79e+05 年間雪日数(日) -3.192e+04 1.51e+05 -0.211 0.834 -3.37e+05 2.73e+05 ============================================================================== Omnibus: 82.630 Durbin-Watson: 1.449 Prob(Omnibus): 0.000 Jarque-Bera (JB): 1354.051 Skew: 4.666 Prob(JB): 9.36e-295 Kurtosis: 27.583 Cond. No. 124. ============================================================================== Warnings: [1] Standard Errors assume that the covariance matrix of the errors is correctly specified. 全国都道府県別産業別重回帰分析H運輸業,郵便業 OLS Regression Results ============================================================================== Dep. Variable: y R-squared: 0.240 Model: OLS Adj. R-squared: 0.169 Method: Least Squares F-statistic: 3.398 Date: Mon, 18 Feb 2019 Prob (F-statistic): 0.0168 Time: 20:07:51 Log-Likelihood: -757.02 No. Observations: 47 AIC: 1522. Df Residuals: 43 BIC: 1529. Df Model: 4 Covariance Type: nonrobust ============================================================================== coef std err t P>|t| [0.025 0.975] ------------------------------------------------------------------------------ 年平均気温(°C) 7.201e+04 3.01e+05 0.240 0.812 -5.34e+05 6.78e+05 年平均湿度(%) 1.318e+04 7.41e+04 0.178 0.860 -1.36e+05 1.63e+05 年間降水日数(日) -5275.6075 2.04e+04 -0.258 0.798 -4.65e+04 3.6e+04 年間雪日数(日) -6376.5626 3.16e+04 -0.202 0.841 -7.01e+04 5.74e+04 ============================================================================== Omnibus: 78.551 Durbin-Watson: 1.321 Prob(Omnibus): 0.000 Jarque-Bera (JB): 1120.502 Skew: 4.375 Prob(JB): 4.85e-244 Kurtosis: 25.262 Cond. No. 124. ============================================================================== Warnings: [1] Standard Errors assume that the covariance matrix of the errors is correctly specified. 全国都道府県別産業別重回帰分析K不動産業,物品賃貸業 OLS Regression Results ============================================================================== Dep. Variable: y R-squared: 0.137 Model: OLS Adj. R-squared: 0.057 Method: Least Squares F-statistic: 1.708 Date: Mon, 18 Feb 2019 Prob (F-statistic): 0.166 Time: 20:07:52 Log-Likelihood: -761.14 No. Observations: 47 AIC: 1530. Df Residuals: 43 BIC: 1538. Df Model: 4 Covariance Type: nonrobust ============================================================================== coef std err t P>|t| [0.025 0.975] ------------------------------------------------------------------------------ 年平均気温(°C) -1.987e+04 3.28e+05 -0.061 0.952 -6.81e+05 6.42e+05 年平均湿度(%) 2.365e+04 8.09e+04 0.293 0.771 -1.39e+05 1.87e+05 年間降水日数(日) 299.3261 2.23e+04 0.013 0.989 -4.47e+04 4.53e+04 年間雪日数(日) -1.586e+04 3.45e+04 -0.460 0.648 -8.54e+04 5.37e+04 ============================================================================== Omnibus: 90.677 Durbin-Watson: 1.673 Prob(Omnibus): 0.000 Jarque-Bera (JB): 1948.813 Skew: 5.280 Prob(JB): 0.00 Kurtosis: 32.726 Cond. No. 124. ============================================================================== Warnings: [1] Standard Errors assume that the covariance matrix of the errors is correctly specified. 全国都道府県別産業別重回帰分析L学術研究,専門・技術サービス業(※「学術・開発研究機関」及び「純粋持株会社」を除く。) OLS Regression Results ============================================================================== Dep. Variable: y R-squared: 0.113 Model: OLS Adj. R-squared: 0.031 Method: Least Squares F-statistic: 1.371 Date: Mon, 18 Feb 2019 Prob (F-statistic): 0.260 Time: 20:07:53 Log-Likelihood: -742.28 No. Observations: 47 AIC: 1493. Df Residuals: 43 BIC: 1500. Df Model: 4 Covariance Type: nonrobust ============================================================================== coef std err t P>|t| [0.025 0.975] ------------------------------------------------------------------------------ 年平均気温(°C) -7.896e+04 2.2e+05 -0.360 0.721 -5.22e+05 3.64e+05 年平均湿度(%) 2.88e+04 5.41e+04 0.532 0.597 -8.03e+04 1.38e+05 年間降水日数(日) 1884.1298 1.49e+04 0.126 0.900 -2.82e+04 3.2e+04 年間雪日数(日) -1.586e+04 2.31e+04 -0.687 0.496 -6.24e+04 3.07e+04 ============================================================================== Omnibus: 97.599 Durbin-Watson: 1.804 Prob(Omnibus): 0.000 Jarque-Bera (JB): 2665.081 Skew: 5.845 Prob(JB): 0.00 Kurtosis: 37.989 Cond. No. 124. ============================================================================== Warnings: [1] Standard Errors assume that the covariance matrix of the errors is correctly specified. 全国都道府県別産業別重回帰分析M宿泊業,飲食サービス業 OLS Regression Results ============================================================================== Dep. Variable: y R-squared: 0.330 Model: OLS Adj. R-squared: 0.267 Method: Least Squares F-statistic: 5.286 Date: Mon, 18 Feb 2019 Prob (F-statistic): 0.00149 Time: 20:07:55 Log-Likelihood: -706.34 No. Observations: 47 AIC: 1421. Df Residuals: 43 BIC: 1428. Df Model: 4 Covariance Type: nonrobust ============================================================================== coef std err t P>|t| [0.025 0.975] ------------------------------------------------------------------------------ 年平均気温(°C) 6.414e+04 1.02e+05 0.627 0.534 -1.42e+05 2.7e+05 年平均湿度(%) -3245.7736 2.52e+04 -0.129 0.898 -5.41e+04 4.76e+04 年間降水日数(日) -2467.1229 6956.297 -0.355 0.725 -1.65e+04 1.16e+04 年間雪日数(日) 1739.5278 1.08e+04 0.162 0.872 -1.99e+04 2.34e+04 ============================================================================== Omnibus: 72.954 Durbin-Watson: 1.232 Prob(Omnibus): 0.000 Jarque-Bera (JB): 848.110 Skew: 4.006 Prob(JB): 6.84e-185 Kurtosis: 22.207 Cond. No. 124. ============================================================================== Warnings: [1] Standard Errors assume that the covariance matrix of the errors is correctly specified. 全国都道府県別産業別重回帰分析N生活関連サービス業,娯楽業(※「家事サービス業」を除く。) OLS Regression Results ============================================================================== Dep. Variable: y R-squared: 0.307 Model: OLS Adj. R-squared: 0.242 Method: Least Squares F-statistic: 4.762 Date: Mon, 18 Feb 2019 Prob (F-statistic): 0.00286 Time: 20:07:56 Log-Likelihood: -731.94 No. Observations: 47 AIC: 1472. Df Residuals: 43 BIC: 1479. Df Model: 4 Covariance Type: nonrobust ============================================================================== coef std err t P>|t| [0.025 0.975] ------------------------------------------------------------------------------ 年平均気温(°C) 5.681e+04 1.76e+05 0.322 0.749 -2.99e+05 4.12e+05 年平均湿度(%) 7041.9821 4.34e+04 0.162 0.872 -8.06e+04 9.47e+04 年間降水日数(日) -3825.5116 1.2e+04 -0.319 0.751 -2.8e+04 2.04e+04 年間雪日数(日) -1603.0283 1.85e+04 -0.086 0.931 -3.9e+04 3.58e+04 ============================================================================== Omnibus: 75.362 Durbin-Watson: 1.320 Prob(Omnibus): 0.000 Jarque-Bera (JB): 953.684 Skew: 4.165 Prob(JB): 8.13e-208 Kurtosis: 23.436 Cond. No. 124. ============================================================================== Warnings: [1] Standard Errors assume that the covariance matrix of the errors is correctly specified. 全国都道府県別産業別重回帰分析O教育,学習支援業(※「学校教育」を除く。) OLS Regression Results ============================================================================== Dep. Variable: y R-squared: 0.239 Model: OLS Adj. R-squared: 0.168 Method: Least Squares F-statistic: 3.369 Date: Mon, 18 Feb 2019 Prob (F-statistic): 0.0175 Time: 20:07:57 Log-Likelihood: -625.02 No. Observations: 47 AIC: 1258. Df Residuals: 43 BIC: 1265. Df Model: 4 Covariance Type: nonrobust ============================================================================== coef std err t P>|t| [0.025 0.975] ------------------------------------------------------------------------------ 年平均気温(°C) -1969.3981 1.81e+04 -0.109 0.914 -3.85e+04 3.46e+04 年平均湿度(%) 2082.7604 4465.986 0.466 0.643 -6923.758 1.11e+04 年間降水日数(日) -76.0979 1232.873 -0.062 0.951 -2562.424 2410.228 年間雪日数(日) -1142.2540 1905.750 -0.599 0.552 -4985.565 2701.057 ============================================================================== Omnibus: 78.308 Durbin-Watson: 1.205 Prob(Omnibus): 0.000 Jarque-Bera (JB): 1091.447 Skew: 4.370 Prob(JB): 9.89e-238 Kurtosis: 24.930 Cond. No. 124. ============================================================================== Warnings: [1] Standard Errors assume that the covariance matrix of the errors is correctly specified. 全国都道府県別産業別重回帰分析P医療,福祉(*「保健所」,「社会保険事業団体」及び「福祉事務所」を除く。) OLS Regression Results ============================================================================== Dep. Variable: y R-squared: 0.520 Model: OLS Adj. R-squared: 0.475 Method: Least Squares F-statistic: 11.65 Date: Mon, 18 Feb 2019 Prob (F-statistic): 1.71e-06 Time: 20:07:58 Log-Likelihood: -719.68 No. Observations: 47 AIC: 1447. Df Residuals: 43 BIC: 1455. Df Model: 4 Covariance Type: nonrobust ============================================================================== coef std err t P>|t| [0.025 0.975] ------------------------------------------------------------------------------ 年平均気温(°C) 1.824e+05 1.36e+05 1.344 0.186 -9.14e+04 4.56e+05 年平均湿度(%) -1.942e+04 3.35e+04 -0.580 0.565 -8.69e+04 4.81e+04 年間降水日数(日) -6610.4652 9238.144 -0.716 0.478 -2.52e+04 1.2e+04 年間雪日数(日) 1.228e+04 1.43e+04 0.860 0.395 -1.65e+04 4.11e+04 ============================================================================== Omnibus: 39.053 Durbin-Watson: 1.159 Prob(Omnibus): 0.000 Jarque-Bera (JB): 112.015 Skew: 2.271 Prob(JB): 4.75e-25 Kurtosis: 9.047 Cond. No. 124. ============================================================================== Warnings: [1] Standard Errors assume that the covariance matrix of the errors is correctly specified. 全国都道府県別産業別重回帰分析Rサービス業(他に分類されないもの)(※「政治・経済・文化団体」,「宗教」及び「外国公務」を除く。) OLS Regression Results ============================================================================== Dep. Variable: y R-squared: 0.214 Model: OLS Adj. R-squared: 0.140 Method: Least Squares F-statistic: 2.920 Date: Mon, 18 Feb 2019 Prob (F-statistic): 0.0319 Time: 20:07:59 Log-Likelihood: -733.38 No. Observations: 47 AIC: 1475. Df Residuals: 43 BIC: 1482. Df Model: 4 Covariance Type: nonrobust ============================================================================== coef std err t P>|t| [0.025 0.975] ------------------------------------------------------------------------------ 年平均気温(°C) 2.25e+04 1.82e+05 0.124 0.902 -3.44e+05 3.89e+05 年平均湿度(%) 1.012e+04 4.48e+04 0.226 0.822 -8.02e+04 1e+05 年間降水日数(日) -1801.3411 1.24e+04 -0.146 0.885 -2.67e+04 2.31e+04 年間雪日数(日) -5104.2400 1.91e+04 -0.267 0.791 -4.37e+04 3.34e+04 ============================================================================== Omnibus: 82.613 Durbin-Watson: 1.430 Prob(Omnibus): 0.000 Jarque-Bera (JB): 1352.360 Skew: 4.665 Prob(JB): 2.18e-294 Kurtosis: 27.566 Cond. No. 124. ============================================================================== Warnings: [1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
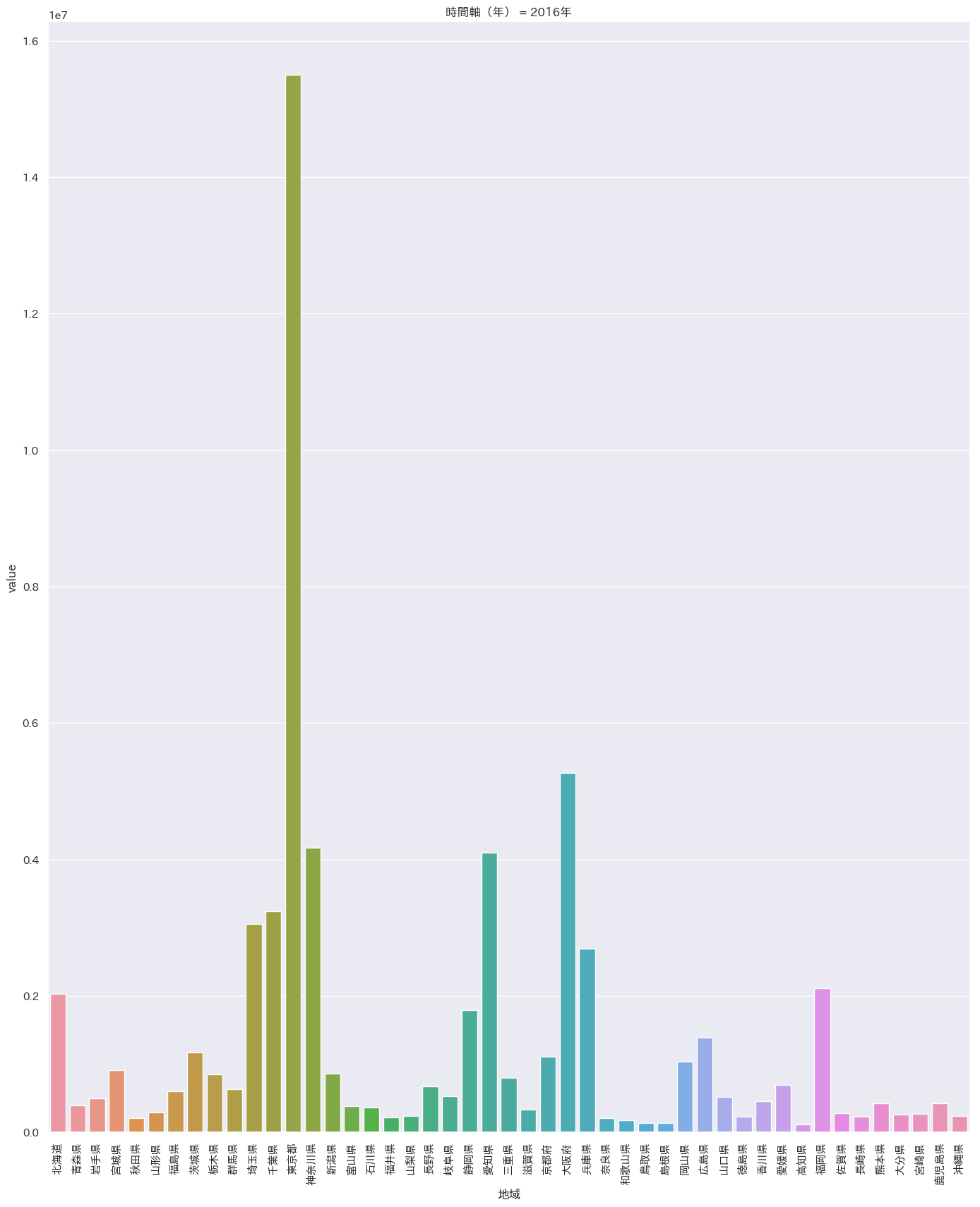
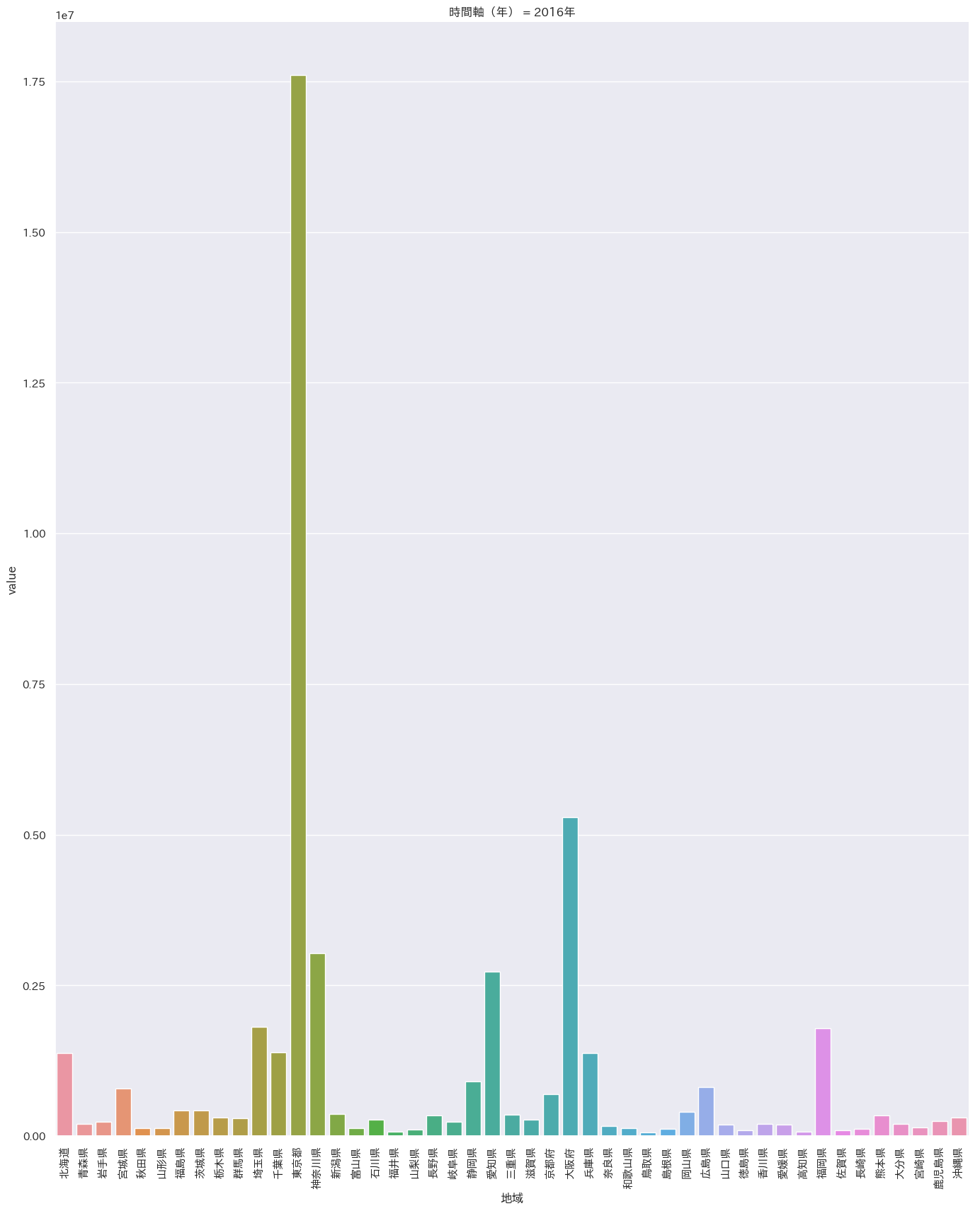
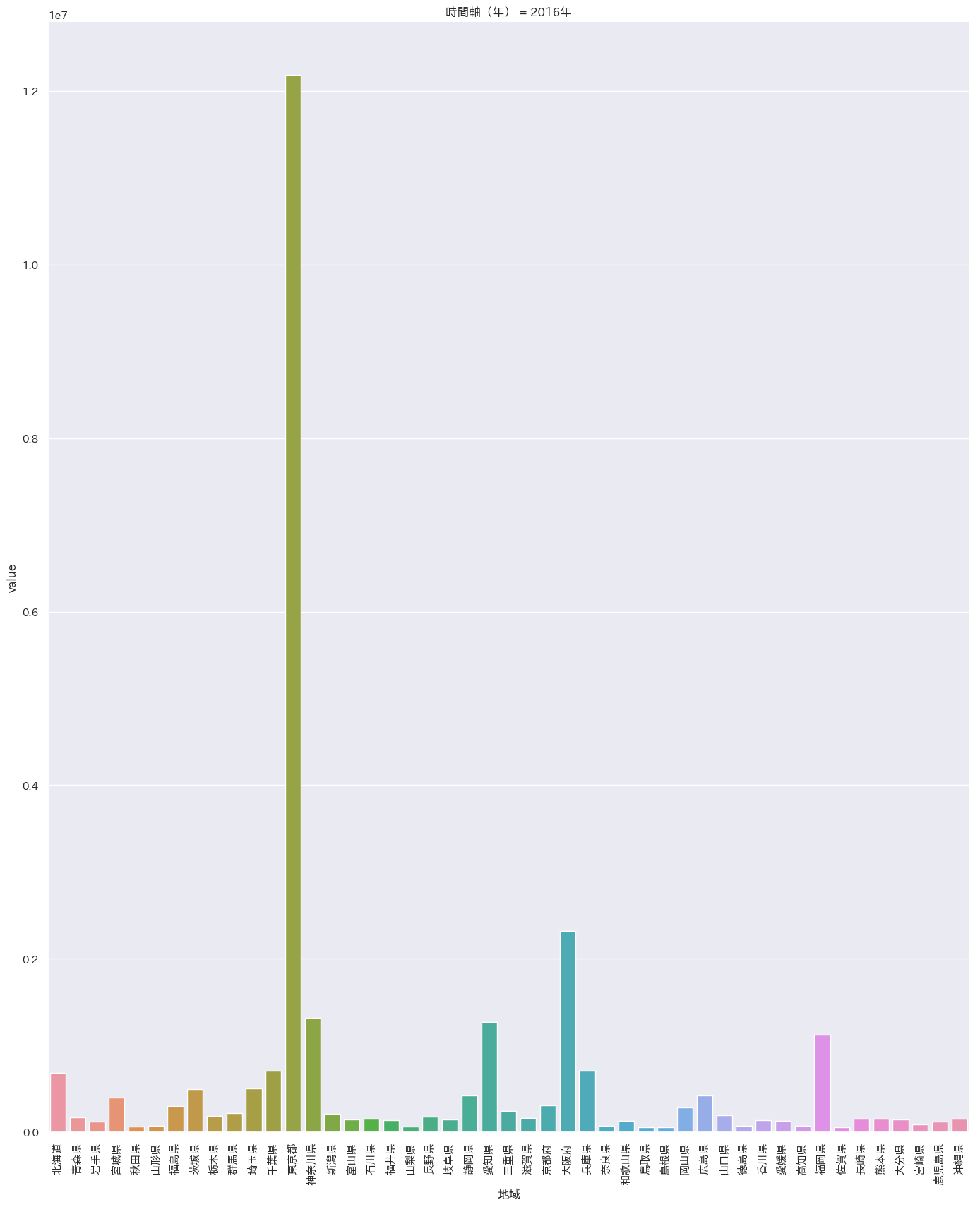
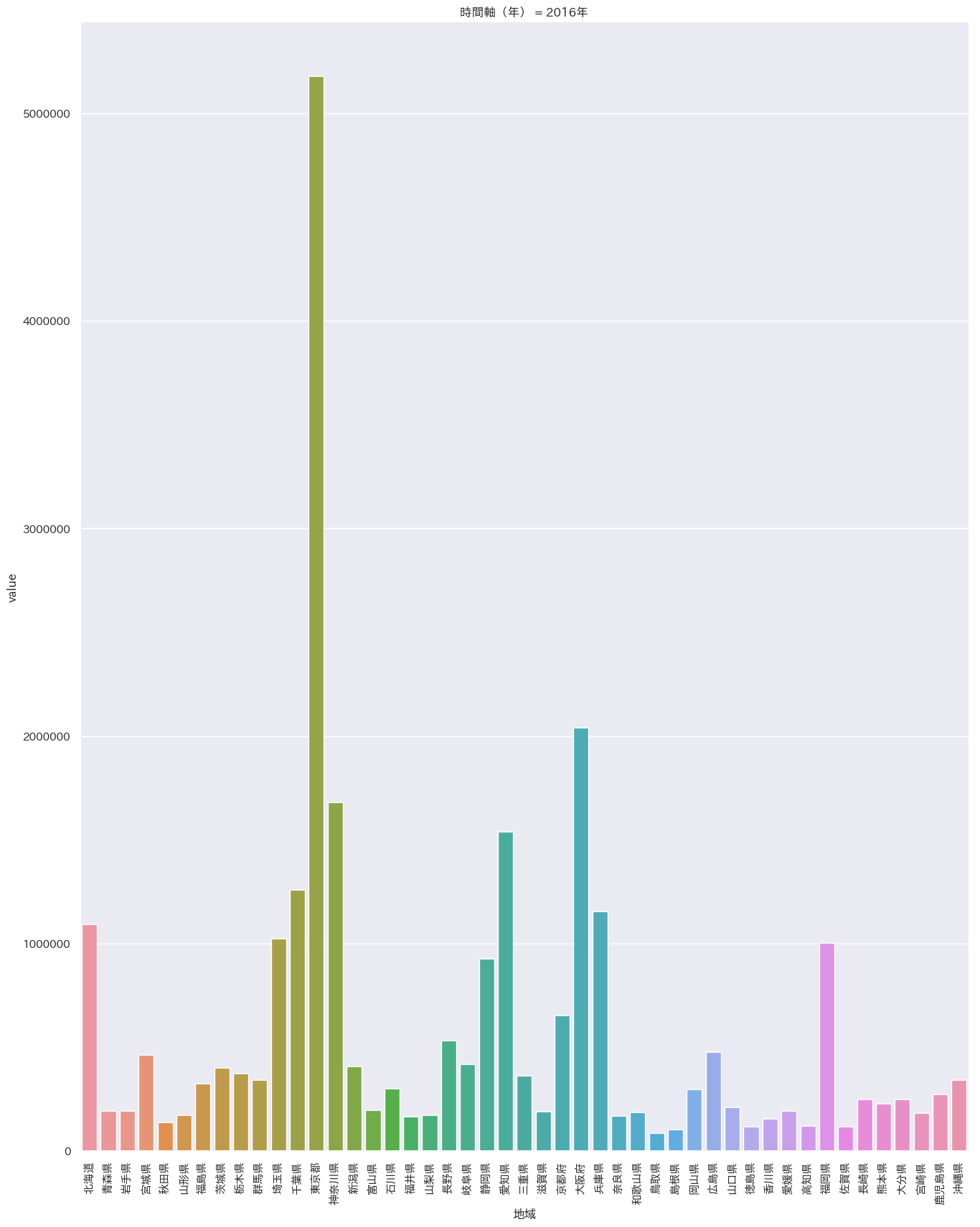
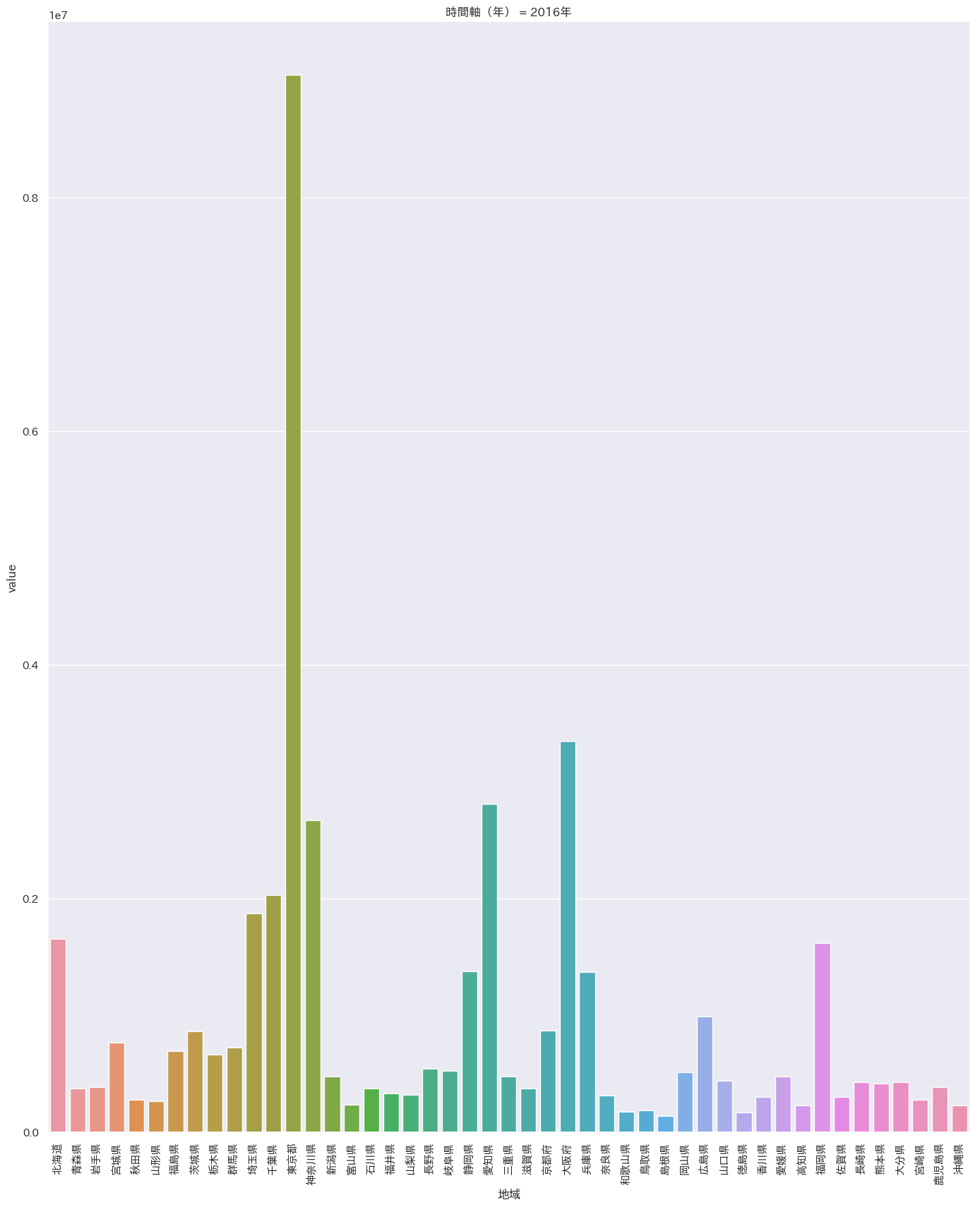

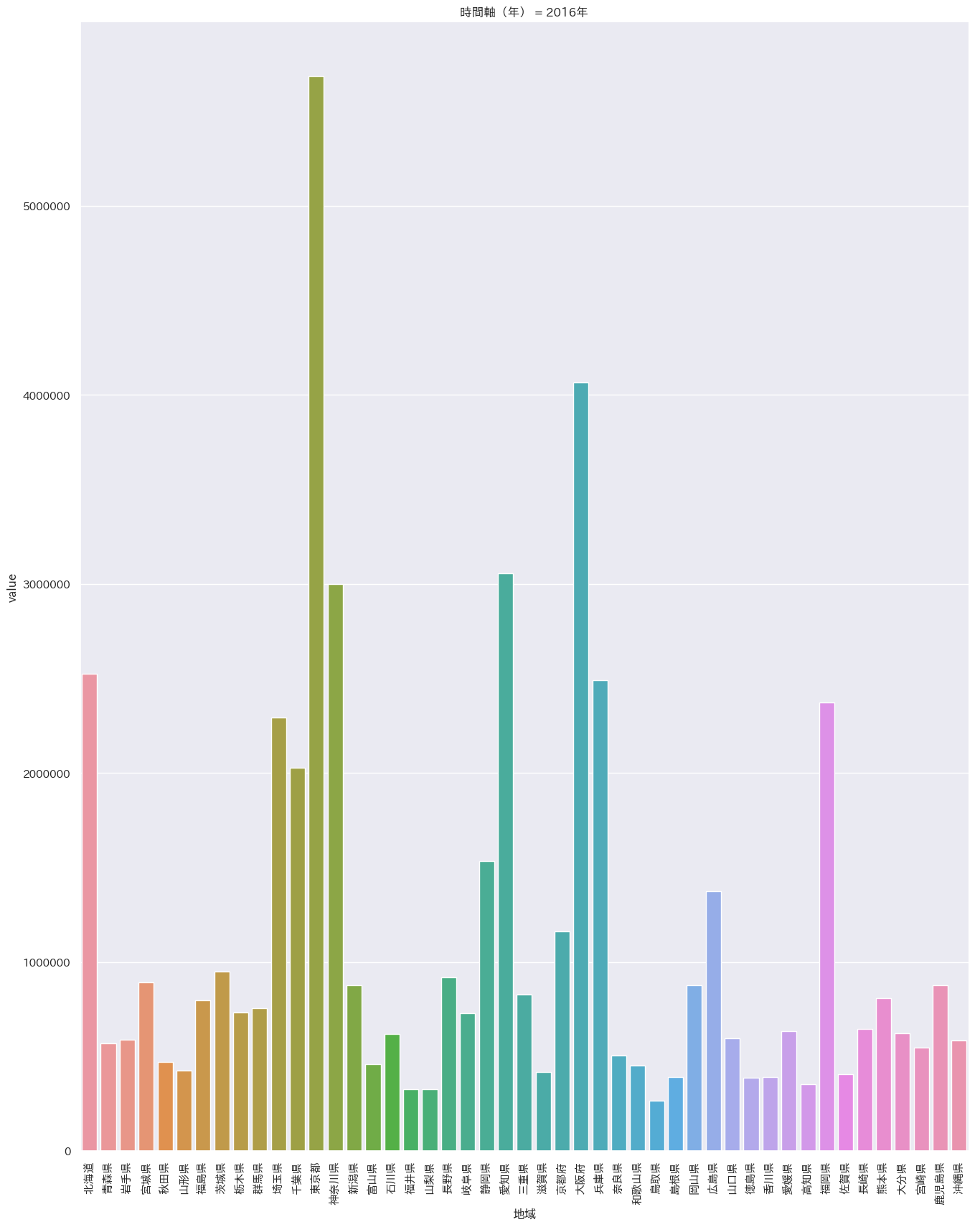

- 投稿日:2019-02-18T19:54:57+09:00
Windowsのtreeをpathに変換するコードを書いてみた。
PCを初期化したとき、初期の構造を記憶するためにディレクトリ構造を取得したくて取得したのだが、
dir C:\\* /s /b /adで取得すればいいものを
treeで取得してしまった。でも今更もっかい初期化とかできないし。どうしよう。
そうだ、唯一使えるPythonを使ってPath化しよう!ということで書いた。
コード
ちなみに私はインデントにタブを使っている。タブが好きだからだ。クソコードごめんね
import os class DirectoryTreeChangeToPath: def __init__(self, path): paths = self.shaping(self.get_file_content(path)) with open(".\\changed_directory_tree_to_path.txt","x") as f: for i in paths: f.write(i + "\n") @staticmethod def get_file_content(path, mode="r", encoding='utf-8'): if os.path.exists(path): with open(path, mode=mode, encoding=encoding) as f: for i in f: yield i else: raise FileNotFoundError @staticmethod def shaping(default_dir_tree_data): directory = [next(default_dir_tree_data)[:-2]] for i in default_dir_tree_data: i = i.replace("\n", "", -1) i = DirectoryTreeChangeToPath.pipe_count(i) DirectoryTreeChangeToPath.merge(directory,i) yield "\\".join(directory) @staticmethod def merge(subject_,object_): if len(subject_) > object_[0]: del subject_[object_[0]:] return subject_.append(object_[1]) @staticmethod def pipe_count(string): indent = 0 while True: if string[:2] in ("└─","├─"): string = string[2:] indent += 1 break elif string[:3] == "│ ": string = string[3:] indent += 1 elif string[:4] == " ": string = string[4:] indent += 1 return indent,string def main(): os.chdir(os.path.dirname(__file__)) DirectoryTreeChangeToPath(".\\infomation\\default_dir_tree_data") main()書いてる間の思考
パイプをただのインデントとしてみたら簡単に数値に置換できた。
- 投稿日:2019-02-18T19:43:10+09:00
初心者です。for文の数字を1ずつ増やしたいです。
初心者です。調べて試してみたのですが上手く出来なかったので投稿しました。
サイトからスクレイピングを行いたいのですが
http://xxx.com/00001
などのスクレイピングするサイトの数字をfor文で数字を1ずつ増やして、
その作業を7万回行いたいです。import requests
response = requests.get("http://xxx.com/00001")
data = response.json()for item in data["vsrs"]:
print(item)現在この方法でスクレイピング出来ています。
しかしfor文が上手く行きません。num = 00001
for item in date(1, 70000):
num += 1
array[0] = [item]やURLの数字をitemに置き換えて
import requests
item = [n for n in range(3)]などを試したのですが上手く出来ません。
サイトの数字7万回を増やしたあと、vsrsのデータ全てを一箇所にまとめたいです。
質問の仕方が変な点もあるかと思いますがお願いします。mac
python3.7です。
- 投稿日:2019-02-18T18:50:18+09:00
【翻訳】Minimally Sufficient Pandas(全文)
Overview
この記事は
pandasクックブック-―Pythonによるデータ処理のレシピ の著者である Ted Petrou 氏の以下の記事、を、許諾を得て翻訳したものです。
https://twitter.com/arc279/status/1095511875050033152不自然な点、間違っている点などがありましたら指摘してもらえると助かります。
以下、翻訳です。
Minimally Sufficient Pandas(必要最低限の Pandas)
この記事では、データ分析にpandasを使用する際の、私の最適と思う意見を提案します。
私の目的は、データ分析のほとんどのケースでは、ライブラリの一部の機能だけで十分であることを主張することです。
ここで紹介する必要十分な最低限の機能は、 pandas の初心者からプロフェッショナルまで役に立つでしょう。
誰もが私の提案に同意するわけではないでしょうが、それらは私の実際のライブラリの使い方、あるいは教えている手法です。
もし、あなたが同意しないか、別の提案があるなら、以下のコメントに残してください。
(訳注:元記事のコメント欄)この記事を読み終わると
- Pandas の構文などではなく、実際のデータ分析に集中するためには、一部の機能に限定しても十分であることがわかります
- Pandas を用いた一般的な、多岐にわたるデータ分析のタスクに対する、具体的な単一アプローチの指針を持つことができます
100時間以上の無料のチュートリアル動画
私は、100時間以上にも及ぶ、Pandas, Matplotlib, Seaborn, そして Scikit-Learn の非常に詳細なチュートリアル動画を公開しています。(2019年の2月より)
ぜひ Dunder Data YouTube channel を購読して更新をチェックしてください。Upcoming Classes
よりパーソナライズされた授業が必要ならば、今年の3月に予定されている Machine Learning Bootcamps in NYC の私の講義に参加してください。
Pandas は強力だが扱いが難しい
Pandas はデータ分析者の間で最もポピュラーな python のライブラリです。
かなり多くの機能を提供していますが、学習コストが高いライブラリでもあります。
これにはいくつかの理由があります:
- 一般的なタスクをこなすのに複数の方法がある
- DataFrame には240を超えるメソッドと属性がある
- (基本的に同じコードを参照している)お互いのエイリアスであるメソッドがある
- ほぼ同じ機能のメソッドがある
- 同じ目的を達するのに、異なる人によって書かれたさまざまな方法によるチュートリアルが氾濫している
- 一般的なタスクを、慣用的な方法でこなす公式のガイドラインが存在しない
- 公式のドキュメントにも、慣用的でないコードが存在する
Pandas の必要最低限の機能はなにか?
データ分析ライブラリの目的は、分析者がデータ分析に集中できるツールを提供することです。
Pandas はまさにうってつけのツールですが、分析に集中できるようにはなっていません。
代わりに、ユーザは複雑で過剰な構文を覚えることを強要されます。私は Minimally Sufficient Pandas の定義として、以下を提案します。
- たいていの要求をこなすことができるのに十分な、ライブラリの機能の一部
- コードの書き方ではなくデータの分析に集中することができること
この Pandas の必要最低限のサブセットでは:
- 単純、明白、直接的で、退屈なコードになるでしょう
- あるタスクをこなすために、ただ1つの明白な方法を選ぶようになるでしょう
- そして毎回、明白な方法を選ぶでしょう
- 脳内の短期記憶に多くのコマンドを覚えておく必要はありません
- 他人やあなたにとって、より理解しやすいコードになるでしょう
よくあるタスクの標準化
Pandas はしばしば、同じタスクをこなすのに複数のアプローチを提供します。
これは、あなたの取ったアプローチが、他人のそれとは異なるかもしれないことを意味します。
これは、1列のカラムを選択する、などの最も基本的なタスクでも発生する可能性があります。
複数の異なるアプローチを採用しても、個人による単発の分析では、多くは問題にはならないでしょう。
しかし、多人数で長期間かかる分析において、それぞれが異なるアプローチを採用した場合、大混乱を引き起こす可能性があります。一般的なタスクに対して、標準的なアプローチを採用しないことによって、各自のアプローチの僅かな違いをすべて覚えておくための、大きな認知的負荷が開発者にかかります。
各人が一般的なタスクをこなすために、それぞれの好む方法を採用することは、エラーと非効率を引き起こします。Stack Overflow の雪崩
Stack Overflow で Pandas に関する質問を検索すると、よくある一般的なタスクに対して、複数の競合するさまざまな結果が得られることは、珍しくありません。
DataFrameの列名の変更に関するこの質問には28の回答があります。
あるタスクをこなすために慣用的な方法を1つ知りたい人にとって、この大量の情報に目を通すことは非常に困難です。No Tricks
ライブラリの大部分を削ることには、いくつかの(良い)制限があります。
あいまいな Pandas のトリックをたくさん知っていることは、あなたの友達にドヤれるかもしれませんが、たいてい良いコードに繋がることはありません。
それどころか、理解しがたく、そしてデバッグがより困難な長大なコードを生み出すでしょう。Pandas の具体例
では、タスクをこなすために複数のアプローチが存在する Pandas の、具体例について説明します。
異なるアプローチを比較対照して、どちらのアプローチが望ましいかについての指針を示します。トピックは以下のとおりです:
- 単一の列を選択する
ixインデクサは非推奨atiatによるセルの選択read_csvとread_tableは重複isnaとisnull、notnaとnotnull- 算術演算子および比較演算子と、それらに対応するメソッド
- python の組み込み関数と、同名の Pandas の同名のメソッド
groupbyによる集計方法の統一- MultiIndex の扱いかた
groupbypivot_tablecrosstabの違いpivotとpivot_tablemeltとstackの類似点pivotとunstackの類似点必要最低限のガイドライン
具体例は全て以下の原則に則っています。
あるメソッドが他のメソッドよりも追加の機能を提供していない場合(つまり、その機能が他のメソッドのサブセットである場合)、それを使用するべきではありません。メソッドは、追加の独自の機能がある場合にのみ検討する必要があります。
単位の列を選択
Pandas の DataFrameから1列のデータを選択することは、最も簡単なタスクにでありながら、残念ながら、Pandas の提供する複数の手法にユーザが最初に直面するケースです。
ブラケット (
[]) またはドット表記を使用して、単一の列をシリーズとして選択できます。小さな DataFrame から、両方の方法を使用して列を選択してみましょう。>>> import pandas as pd >>> df = pd.read_csv('data/sample_data.csv', index_col=0) >>> df|以下、使用する簡単な DataFrame のサンプル|
|--|
||
ブラケット表記での選択
DataFrame の括弧の中に列名を指定すると、単一の列が Series として選択されます。
>>> df['state'] name Jane NY Niko TX Aaron FL Penelope AL Dean AK Christina TX Cornelia TX Name: state, dtype: objectドット表記での選択
あるいは、ドット表記を使用して単一の列を選択することも出来ます。出力は上記と全く同じです。
>>> df.stateドット表記の問題点
ドット表記には3つの問題点があります。以下の状況では機能しません:
- 列名にスペースが入っているとき
- 列名が DataFrame のメソッドと同じ名前であるとき
- 列名を変数で指定したいとき
列名にスペースが入っているとき
もし必要なカラム名にスペースが入っていると、ドット表記では指定することが出来ません。
Python はスペースを変数名、演算子の区切りとして扱うため、したがって、スペースを含む列名は正しい構文として扱われません。
エラーを起こしてみましょう。df.favorite food
列名にスペースを含む列の取得はブラケット表記を用いる必要があります。
df['favorite food']列名が DataFrame のメソッドと同じ名前であるとき
列の名前と DataFrame のメソッド名が競合した場合、 Pandas は常に列名ではなくメソッドを参照します。
例えば、列名countはメソッドなので、ドット表記で参照されます。
Python はメソッド自体を参照できるため、実際にはエラーになりません。
(訳注:python の関数は first-class object)
では、メソッドを参照してみましょう。df.count
初めて遭遇した場合、非常に混乱するでしょう。
1行目にbound method DataFrame.count ofと記載されています。
これは DataFrame の object の保持する何らかのメソッドである、とPythonは教えてくれます。
メソッド名の代わりに、公式な文字列表現(訳注:repr()を適用したもの)を出力します。
多くの人は、この出力を見て、何らかの分析を行った結果だと勘違いするでしょう。
しかしこれは正しくなく、ほとんど何も起こっておらず、ただオブジェクトの表現を出力するメソッドへの参照が作成さました。
それだけです。ドット表記を使用して、列が Series として選択されなかったことは明らかです。
繰り返しますが、DataFrame メソッドと同じ名前の列を選択するときは、ブラケット表記を使用する必要があります。df['count']列名を変数で指定したいとき
選択したい列名を変数に保持していたとしましょう。
この場合もブラケットを使用することが唯一の手法です。
以下は、列名の値を変数に代入してから、この変数をブラケットに渡す単純な例です。>>> col = 'height' >>> df[col]ブラケット表記はドット表記のスーパーセットである
ブラケット表記は、単一の列を指定する機能としては、ドット表記のスーパーセットです。
ドット表記では扱えない3つのケースを紹介しました。多くの Pandas はドット表記で書かれています。なぜ?
多くのチュートリアルで、単一の列を選択するのにドット表記が使われています。
ブラケット表記のほうが明らかに優れているのに、なぜでしょうか?
公式のドキュメントの多くの例に使われていたりしますし、3文字多いタイピングが面倒に感じるからかもしれません。ガイダンス:データの列を選択する際にはブラケット表記を使用する
ドット表記はブラケット表記よりも多くの機能を追加せず、使えないシチュエーションも存在します。
そのため、私は決して使いません。
唯一の利点は、3文字少ないキーストロークです。単一のデータ列を選択する際にはブラケット表記のみを使用することをお勧めします。
この非常に一般的なタスクに対して、アプローチを統一するだけで、 Pandas のコードは遥かに一貫性のあるものになります。
ixインデクサは非推奨です、使ってはいけませんPandas は行を選択する際に、ラベルでの指定と、整数での位置指定を提供しています。
この一見柔軟な2通りの方法は、初学者にとって大きな混乱の原因になります。
ixインデクサは、ラベルと整数位置の両方で行と列を選択するために、Pandas の初期に作成されましたが、
Pandas の行と列の名前は、整数と文字列どちらにもなり得ることがあるため、これはかなり曖昧で有ることが判明しました。これを明示的に選択するために、
locとilocインデクサが実装されました。
locインデクサーはラベルのみ、ilocインデクサーは整数位置のみに対して使用できます。
ixインデクサは多目的でしたが、locilocインデクサの登場により推奨されなくなりました。ガイダンス: 全ての
ixの痕跡を削除し、locおよびilocに置き換えてください
atiatによる選択DataFrame 内の単一のセルをを選択するために、さらなる2つのインデクサである
atiatが存在します。
これらは、類似のlocilocインデクサに比べて、わずかにパフォーマンスの面で優れています。
しかし、それらの機能を追加でさらに覚えておかなければならない負担ももたらします。
また、ほとんどのデータ分析において、大規模でない限りは、パフォーマンスの向上は役に立ちません。
そして、本当にパフォーマンスが問題になるケースでは、DataFrame から NumPyの配列に変換することで、パフォーマンスは大幅に向上します。パフォーマンス比較:
ilocvsiatvsNumPy単一セルを選択するケースで、
iloc、iat、 NumPy配列のパフォーマンスを比べてみましょう。
ランダムデータを含む 100k行 5列 のNumPy配列を作成します。
それを元に DataFrame に変換して、試してみましょう。>>> import numpy as np >>> a = np.random.rand(10 ** 5, 5) >>> df1 = pd.DataFrame(a) >>> row = 50000 >>> col = 3 >>> %timeit df1.iloc[row, col] 13.8 µs ± 3.36 µs per loop >>> %timeit df1.iat[row, col] 7.36 µs ± 927 ns per loop >>> %timeit a[row, col] 232 ns ± 8.72 ns per loop
ilocに比べてiatは2倍の速度も出ない一方、 NumPy配列では約60倍も速度が向上します。
パフォーマンス要件を満たすアプリケーションが本当にあるのであれば、Pandas ではなく NumPy を直接使用するべきです。ガイダンス:単一セル選択に本当にパフォーマンスが必要な場合は、
atiatではなく、 NumPy配列を使用してくださいメソッドの重複
Pandas には全く同じことをするメソッドが複数あります。
2つのメソッドが内部で全く同じ機能を使用している場合は、常に、それらは互いのエイリアスであると言います。
ライブラリ内で同じ機能の重複は完全に不要であり、名前空間を汚染し、分析者に余計な情報を覚えておくよう強制します。次のセクションでは、いくつかの重複したメソッド、あるいはよく似たメソッドについて説明します。
read_csvとread_tableの重複重複の例として、
read_csvとread_table関数を挙げましょう。
どちらもテキストファイルからデータを読み込んで、まったく同じことを行います。
唯一の違いは、read_csvがデフォルトのセパレータがカンマであるのに対して、read_tableはタブ文字であることです。
read_csvとread_tableが同じ結果になることを確認しましょう。
サンプルデータとして、public な College Scoreboard dataset を使用します。
equalsメソッドは、2つの DataFrameがまったく同じ値を持つかどうかを確認します。>>> college = pd.read_csv('data/college.csv') >>> college.head()
>>> college2 = pd.read_table('data/college.csv', delimiter=',') >>> college.equals(college2) True
read_tableは非推奨です私は、非推奨としたほうが良いと思う関数とメソッドに関して、
Pandas の Githubリポジトリ に Issue を出しています。
read_tableメソッドは非推奨のため、使用しないでください。ガイダンス:区切り文字付きテキストファイルを読み込む場合は
read_csvのみを使用してください
isnavsisnullとnotnavsnotnull
isnaisnullメソッドはどちらも、DataFrame内に欠損値があるかどうかを判別します。
結果は常に bool 値の DataFrame (あるいは Series)になります。これらのメソッドは完全に同じです。
一方が他方のエイリアスである、と前の段落で言った通り、両方は必要ありません。
naという欠損値を表す文字列が、他に欠損値を扱うdropnafillnaといったメソッド名に追加されたため、 それに合わせてisnaメソッドも追加されました。
紛らわしいことに、Pandas は欠損値の表現としてNaNNoneNaTを使用していますが、NAは使用しません。
notnaとnotnullはお互いのエイリアスであり、単にisnaの反対を返します。これも両方は必要ありません。
isnaがisnullのエイリアスであることを確認しましょう。>>> college_isna = college.isna() >>> college_isnull = college.isnull() >>> college_isna.equals(college_isnull) True私は
isnanotnaしか使いませんサフィックスに
naが付いているメソッドを使用することで、他の欠損値メソッドdropnafillnaの名前と整合が取れます。Pandasは bool 値の DataFrame を反転するための演算子
~を提供しているため、notnaの使用を避けることもできます。ガイダンス:
isnaとnotnaを使いましょう(訳注)
isnullnotnullではなく算術演算子、比較演算子とそれに対応するメソッド
全ての算術演算子には、同等の機能を提供するメソッドがあります。
(訳注:表にしました)
|op|method|
|-|-|-|
|+|add|
|-|subsubtract|
||mulmultiply|
|/|divdividetruediv|
|*|pow|
|//|floordiv|
|%|mod|全ての比較演算子にも、同等の機能のメソッドがあります。
|op|method|
|-|-|-|
|>|gt|
|<|lt|
|>=|ge|
|<=|le|
|==|eq|
|!=|ne|
ugds列(undergraduate population の略)のSeriesを選択し、100を加えることで、
+演算子とそれに対応するメソッドの両方で同じ結果が得られることを確認しましょう。>>> ugds = college['ugds'] >>> ugds_operator = ugds + 100 >>> ugds_method = ugds.add(100) >>> ugds_operator.equals(ugds_method) True各学校の zスコアを計算する
もう少し複雑な例を見てみましょう。
以下では、 institution 列をインデックスにセットして、SAT列を選択します。
これらのスコアを提供していない学校はdropnaで落とします。>>> college_idx = college.set_index('instnm') >>> sats = college_idx[['satmtmid', 'satvrmid']].dropna() >>> sats.head()
各大学の SATスコアの z-score に興味があるとしましょう。
(訳注:名前が紛らわしいですが z-score はいわゆる偏差値で、SATスコアが計算対象のスコアです)
これを計算するには、平均値を引き、標準偏差で割る必要があります。
まず各列の平均と標準偏差を計算しましょう。>>> mean = sats.mean() >>> mean satmtmid 530.958615 satvrmid 522.775338 dtype: float64 >>> std = sats.std() >>> std satmtmid 73.645153 satvrmid 68.591051 dtype: float64算術演算子を使った計算結果を見てみます。
>>> zscore_operator = (sats - mean) / std >>> zscore_operator.head()
メソッドを使った方法も算出して、結果を比べてみましょう。
>>> zscore_methods = sats.sub(mean).div(std) >>> zscore_operator.equals(zscore_methods) True実際にメソッドが必要になる場合
いまの所、演算子よりもメソッドを使ったほうが良い場面には出会ったことがありません。
メソッドを使用する場合でしか対応できないケースを見てみましょう。
college データセットには、学部生の人種の相対頻度である連続値の列が9つ含まれています。
ugds_whiteからugds_unknまでです。
これらの列を新たな DataFrame に取り出しましょう。>>> college_race = college_idx.loc[:, ‘ugds_white’:’ugds_unkn’] >>> college_race.head()
学校ごとに人種別の生徒数に関心があるとしましょう。
学部全体の人口に各列を掛ける必要があります。
Series としてugds列を選択しましょう。>>> ugds = college_idx['ugds'] >>> ugds.head() instnm Alabama A & M University 4206.0 University of Alabama at Birmingham 11383.0 Amridge University 291.0 University of Alabama in Huntsville 5451.0 Alabama State University 4811.0 Name: ugds, dtype: float64そして、先程の
college_raceにこの Series を掛けます。
直感的にはこれでうまくいきそうですが、そう上手くはいきません。
代わりに、7544列の巨大な DataFrame になります。>>> df_attempt = college_race * ugds >>> df_attempt.head()
```pydf_attempt.shape
(7535, 7544)
```インデックス あるいは 列の自動調整
Pandas のオブジェクト同士の計算は常に、互いのインデックスあるいは列の間で調整が行われます。
上記の操作では、college_race(DataFrame) とugds(Series) を掛け合わせました。
Pandasは自動的に(そして暗黙的に)college_raceの列をugdsのインデックスの値に揃えました。
college_race列の値はどれもugdsのインデックス値と一致していません。
Pandasは、一致するかどうかに関わらず、 outer join することによって調整します。
結果は、全ての値が欠損値である馬鹿げた DataFrame になります.
college_raceDataFrameの元の列名を表示するには、右端までスクロールします。メソッドを使うことで調整の方向を変更する
全ての演算子の機能は単一であり、乗算演算子
*の機能を私達が変更することは出来ません。
一方メソッドは、パラメータによって操作を制御できるようにすることが出来ます。
mulメソッドのaxisパラメータを使います上記で述べた演算子に対応する全てのメソッドには、計算の方向を変更できる
axisパラメータがあります。
DataFrame の列を Series のインデックスに合わせる代わりに、DataFrame のインデックスを Series のインデックスに合わせることができます。
今からやり方をお見せしましょう。>>> df_correct = college_race.mul(ugds, axis='index').round(0) >>> df_correct.head()
axisパラメータのデフォルト値は columns に設定されています。
適切な調整が行われるように、それを index に変更しました。ガイダンス:どうしても必要なときだけ算術/比較メソッドを使い、そうでなければ演算子を使う
算術演算子と比較演算子の方がより一般的であり、こちらを最初に試しましょう。
どうしても演算子では解決できない場合に限り、同等のメソッドを使用しましょう。Python 組み込み関数と同名のPandas のメソッド
Python のビルトイン関数と同じ名前、同じ結果を返す DataFrame / Series のメソッドがいくつかあります。これらです:
- sum
- min
- max
- abs
1列のデータでテストして、同じ結果が得られることを確認しましょう。
まず、学部生の人口の列ugdsから欠損値を除外します。>>> ugds = college['ugds'].dropna() >>> ugds.head() 0 4206.0 1 11383.0 2 291.0 3 5451.0 4 4811.0 Name: ugds, dtype: float64Verifying
sum>>> sum(ugds) 16200904.0 >>> ugds.sum() 16200904.0Verifying
max>>> max(ugds) 151558.0 >>> ugds.max() 151558.0Verifying
min>>> min(ugds) 0.0 >>> ugds.min() 0.0Verifying
abs>>> abs(ugds).head() 0 4206.0 1 11383.0 2 291.0 3 5451.0 4 4811.0 Name: ugds, dtype: float64 >>> ugds.abs().head() 0 4206.0 1 11383.0 2 291.0 3 5451.0 4 4811.0 Name: ugds, dtype: float64それぞれの処理時間を測ってみます
sumperformance>>> %timeit sum(ugds) 644 µs ± 80.3 µs per loop >>> %timeit -n 5 ugds.sum() 164 µs ± 81 µs per loop
maxperformance>>> %timeit -n 5 max(ugds) 717 µs ± 46.5 µs per loop >>> %timeit -n 5 ugds.max() 172 µs ± 81.9 µs per loop
minperformance>>> %timeit -n 5 min(ugds) 705 µs ± 33.6 µs per loop >>> %timeit -n 5 ugds.min() 151 µs ± 64 µs per loop
absperformance>>> %timeit -n 5 abs(ugds) 138 µs ± 32.6 µs per loop >>> %timeit -n 5 ugds.abs() 128 µs ± 12.2 µs per loop
summaxminのパフォーマンスの違い
summaxminは明確に差が出ています。
Pandas のメソッドが呼び出される時とは違い、Python 組み込み関数が呼び出されるときにはまったく異なるコードが実行されます。
sum(ugds)を呼び出すと、各値を1つずつ繰り返すための Python の forループが作成されるのと本質的に同等です。
一方、ugds.sum()を呼び出すと、Cで書かれた Pandas 内部の sumメソッドが実行され、forループで反復するよりもはるかに高速です。そこまで差が大きくない理由は、Pandas には多くのオーバーヘッドがあることです。
上記の代わりに NumPy array を使用して再度検証すると、10000要素の float の配列で、 Numpy array の sum はPython組み込みのsum関数を200倍ほど上回ります。
absでは結果に差が出ない理由abs関数と Pandasの absメソッドにパフォーマンスの違いがないことに注意してください。
これは内部でまったく同じコードが呼び出されているためです。
Python は abs関数の挙動を変更する手段を提供しており(訳注:__abs__マジックメソッドのこと)
、開発者はabs関数が呼び出されるたびに実行されるカスタムメソッドを実装することができます。
そのため、abs(ugds)と書いてもugds.abs()を呼び出すことと同等です。それらは文字通り同じです。ガイダンス:python 組み込みの同名の関数よりも、 Pandas のメソッドを使う
groupbyによる集約方法の統一集約を実行する際の
groupbyメソッドにはいくつかの書き方がありますが、コードの統一感の観点から、単一の書き方を採用することをお勧めします。groupby の3つの要素
通常、
groupbyメソッドを呼び出すときは集約を実行します。
最も一般的な使用法でしょう。
groupbyでの集約処理は、3つの要素に分解できます。
- 列のグループ化
- 列内のユニークな値の抽出
- 列の集約
- 値を集計される列。通常は数値型。
- 集約関数
- 値の集計方法(合計、最小、最大、平均、中央値など)
私の
groupbyの書き方Pandas は groupby で集約する際の書き方を何パターンか用意していますが、私は以下の書き方をしています。
df.groupby('grouping column').agg({'aggregating column': 'aggregating function'})州ごとの
SATの最大値を算出するgroupbyの書き方のビュッフェ以下では、州ごとの最大SATスコアを見つけるために、同じ(または類似の)結果を返す、いくつかの異なる書き方について説明します。
まず、使用するデータを見てみましょう。>>> college[['stabbr', 'satmtmid', 'satvrmid', 'ugds']].head()
Method 1:
私の推奨する集約によるグループ化のです。複雑なケースを扱います。
>>> college.groupby('stabbr').agg({'satmtmid': 'max'}).head()
Method 2a:
集約対象のカラムはブラケット記法で選択することもできます。
この場合、戻り値は DataFrame ではなく Series になることに気を付けてください。>>> college.groupby('stabbr')['satmtmid'].agg('max').head() stabbr AK 503.0 AL 590.0 AR 600.0 AS NaN AZ 580.0 Name: satmtmid, dtype: float64Method 2b:
aggのエイリアスであるaggregateメソッドを使うことも出来ます。
結果は上記と同じ Series になります。>>> college.groupby('stabbr')['satmtmid'].aggregate('max').head()Method 3:
aggメソッド経由ではなく、集約関数を直接呼ぶことも出来ます。
結果は上記と同じ Series になります。>>> college.groupby('stabbr')['satmtmid'].max().head()私の提案する方法の主な利点
この書き方だと、より複雑な集約の場合にも同じ書き方で対応できるのが、私がお勧めする理由です。
たとえば、州ごとの学部生数の平均とともに、数学と母国語の科目のSATスコアの最大値と最小値を求めたい場合は、次のようにします。>>> df.groupby('stabbr').agg({'satmtmid': ['min', 'max'], 'satvrmid': ['min', 'max'], 'ugds': 'mean'}).round(0).head(10)
この手段は、他の方法では対応できません。
ガイダンス: まずは
df.groupby('grouping column').agg({'aggregating column': 'aggregating function'})方式の書き方を検討してください(訳注)dictの順序を保持しない python3.6 未満だとカラムの追加される順序が不定になるので注意
MultiIndex の扱い方
MultiIndex、またはマルチレベルインデックスは、DataFrame に追加しづらい一方、データを見やすくする事がたまにはあるもの、
しかし多くの場合、扱いがさらに難しくなります。
groupbyの集約に複数のカラムを指定している場合、あるいは複数のカラムを集約している場合は、たいていMultiIndexに遭遇するでしょう。前の章の
groupbyの最後のサンプルと同じ結果を作成しましょう。
ただし、今回は州と宗教の両方で集約します。>>> agg_dict = {'satmtmid': ['min', 'max'], 'satvrmid': ['min', 'max'], 'ugds': 'mean'} >>> df = college.groupby(['stabbr', 'relaffil']).agg(agg_dict) >>> df.head(10).round(0)
インデックスと列が両方 MultiIndex
行と列、共に2レベルのMultiIndexになりました。
MultiIndex では、選択とさらなる処理は困難です
MultiIndex が DataFrame に追加する機能は殆どありません。
インデックスの一部を選択するための構文が異なっており、他のメソッドと共に用いるのが難しいです。
もしあなたが Pandas のエキスパートなら、インデックスの一部の選択を利用する若干のパフォーマンスが見込めるでしょうが、私は複雑さが増すことを好みません。
よりシンプルな、シングルインデックスの DataFrame を扱うことをお勧めします。シングルインデックスに変換 - 列名を変更してインデックスをリセットする
この DataFrame を変換して、単一のインデックスだけが残るようにしてみましょう。
groupbyの処理中に直接 DataFrame の列名を変更することはできません(そう、Pandas は非常に単純なことはできないのです)。
なので、手動で上書きする必要があります。
やってみましょう。>>> df.columns = ['min satmtmid', 'max satmtmid', 'min satvrmid', 'max satvrmid', 'mean ugds'] >>> df.head()
ここから、
reset_indexメソッドを使用して、各レベルごとのインデックスを列に移動させることが出来ます。>>> df.reset_index().head()
ガイダンス: MultiIndex の使用を避ける。
groupbyの呼び出し後は、列名を変更してインデックスをリセットすることによってフラット化します。
groupbypivot_tablecrosstabの類似点集約時の
groupby、pivot_table、およびpd.crosstabは本質的に同じ処理をしている、ということを知って、驚く人もいるかも知れません。ただし、それぞれに固有の使用例があるため、すべてが Minimally Sufficient Pandas に含まれるための条件を満たしています。
groupbyの集約とpivot_tableの等価性
groupbyメソッドを用いて集約をすることは、pivot_tableメソッドが行っていることと本質的には同じです。
どちらのメソッドもまったく同じデータを返しますが、shapeが異なります。
これが事実であることを証明する、簡単な例を見てみましょう。
新たに、ヒューストン市の従業員の人口統計情報を含むデータセットを使用します。>>> emp = pd.read_csv('data/employee.csv') >>> emp.head()
部門別の性別による平均給与を
groupbyで集計してみましょう。>>> emp.groupby(['dept', 'gender']).agg({'salary':'mean'}).round(-3)
pivot_tableを使ってこのデータを複製することができます。>>> emp.pivot_table(index='dept', columns='gender', values='salary', aggfunc='mean').round(-3)
値がまったく同じことに注意してください。
唯一の違いは、gender列がピボットされているため、ユニークな値が列名になっていることです。
groupbyの3要素がpivot_tableにもあります。
- 集約のキーになる列は
indexcolumnsパラメータで指定され、- 集約対象の列は
valuesパラメータに渡され、- 集計関数は
aggfuncパラメータに渡されます。両方の集約のキー列を
listとしてindexパラメーターに渡すことで、データとshapeの両方を正確に複製することが実際に可能です。>>> emp.pivot_table(index=['dept','gender'], values='salary', aggfunc='mean').round(-3)通常、
pivot_tableは2つの集約のキーを使用します。1つはインデックスとして、もう1つは列としてです。
ただし、単一の集約キー列を使用することは出来ます。
以下は、groupbyを使用して単一の集約キー列を正確に複製したものです。>>> df1 = emp.groupby('dept').agg({'salary':'mean'}).round(0) >>> df2 = emp.pivot_table(index='dept', values='salary', aggfunc='mean').round(0) >>> df1.equals(df2) Trueガイダンス: グループ間を比較する際には
pivot_tableを使う私は、グループ間で値を比較する際には
pivot_tableを好み、分析を継続したい場合はgroupbyを使用します。
上記の通り、pivot_tableの結果を見ると、男性と女性の給料が用意に比較できます。
要約することで人間に見やすくなり、記事やブログ投稿に表示されるデータの種類も少なくなります。
私はピボットテーブルを集計の結果と見なしています。
groupbyの結果はきちんとした形式になるでしょうし、
それはその後の分析を容易にするのに役立ちますが、解釈可能ではありません。
pivot_tableとpd.crosstabの等価性
pivot_tableメソッドとcrosstab関数はどちらも、同じ shape でまったく同じ結果を生成できますし、
両方ともindex、columns、values、およびaggfuncといったパラメータを共有しています。
表面上の主な違いは、crosstabは関数であり、DataFrame のメソッドではないということです。
そのため、パラメータとして列名を指定するのではなく、Series として列を使用することを強制されます。
性別と人種による平均給与の集計結果を見てみましょう。>>> emp.pivot_table(index='gender', columns='race', values='salary', aggfunc='mean').round(-3)
crosstabとまったく同じ結果を取得するには、以下のようにします。>>> pd.crosstab(index=emp['gender'], columns=emp['race'], values=emp['salary'], aggfunc='mean').round(-3)
crosstabは度数を見るために用意されていますクロス集計(分割表とも言う)は、2つの変数間の度数を示します。
これは、2つの列が指定されている場合のcrosstabのデフォルトの機能です。
すべての人種と性別の組み合わせの度数を表示してみましょう。
aggfuncを指定する必要がないことに注意してください。>>> pd.crosstab(index=emp['gender'], columns=emp['race'])
pivot_tableメソッドでも同じ結果を複製することができますが、size集約関数を使用しなければなりません。>>> emp.pivot_table(index='gender', columns='race', aggfunc='size')相対頻度 -
crosstab独自の機能この時点では
crosstabはpivot_tableメソッドの一部に過ぎません。
しかし、crosstabにしか存在しない唯一の機能があり、そのため Minimally Sufficient Subset に追加することは潜在的に価値があります。
normalizeパラメータを使用して、グループ間の相対頻度を計算することができます。たとえば、
raceごとにgenderのパーセンテージの内訳が必要な場合は、normalizeパラメータを columns に設定できます。>>> pd.crosstab(index=emp['gender'], columns=emp['race'], normalize='columns').round(2)
また以下のように、 index を指定して行を正規化したり、all を指定して DataFrame 全体を正規化することもできます。
>>> pd.crosstab(index=emp['gender'], columns=emp['race'], normalize='all').round(3)
ガイダンス: 相対頻度を見たい場合のみ
crosstabを使うそれ以外の
crosstabが必要なすべての状況は、pivot_tableで代用できます。
pivot_tableを実行した後に手動で相対頻度を計算することも可能ではあるので、crosstabはそれほど必要ではないでしょう。
しかし、読みやすく1行のコードで計算処理を書けるため、私は今後も使用していきます。
pivotとpivot_tableほとんど役に立たず、基本的に無視しても構わない
pivotメソッドがあります。
この関数はpivot_tableに似ていますが、一切集約処理をせず、indexcolumnsvaluesの3つのパラメータしかありません。
これらの3つのパラメータはすべてpivot_tableにあります。
集約せずにデータを再整形します。
新しい簡単なデータセットを使った例を見てみましょう。>>> df = pd.read_csv('data/state_fruit.csv') >>> df
pivotメソッドを使用してこのデータを変形し、fruitが列になり、weightが値になるようにしましょう。>>> df.pivot(index='state', columns='fruit', values='weight')
pivotメソッドを使うことで、集約、あるいは他の何かをせずにデータの再整形だけが出来ます。
一方、pivot_tableでは集計を行う必要があります。
この場合だと、stateとfruitごとに1つの値しかあないため、非常に多くの集約関数が同じ値を返します。
max集計関数を使用して、これとまったく同じテーブルを再作成しましょう。>>> df.pivot_table(index='state', columns='fruit', values='weight', aggfunc='max')
pivotの問題点
pivotメソッドにはいくつかの大きな問題があります。
まず、indexとcolumnsの両方が単一の列に設定されている場合にのみ処理できます。
インデックス内に複数の列を保持したい場合は、pivotを使用することはできません。
また、indexとcolumnsの同じ組み合わせが複数回現れると、集計が実行されないため、エラーが発生します。
上記と似ていますが、2行追加されているデータセットを使用して、このエラーを見てましょう。>>> df2 = pd.read_csv('data/state_fruit2.csv') >>> df2
これを
pivotしようとしても、OrangesとFloridaTexasの両方の組み合わせに重複があるため、うまくいきません。>>> df2.pivot(index='state', columns='fruit', values='weight') ValueError: Index contains duplicate entries, cannot reshapeこのデータを再整形する場合は、値をどのように集計するかを決めなければなりません。
ガイダンス:
pivot_tableのみを使用し、pivotを使用しないことを検討してください。
pivotでできることは全てpivot_tableでもできます。
この場合、集計を実行する必要がない場合でも、集約関数を指定する必要があります。
meltとstackの類似点
meltメソッドとstackメソッドはまったく同じ方法でデータを変形します。
主な違いは、meltメソッドはインデックスにあるデータに対しては使えないことです。stackメソッドは可能です。
具体例を見たほうが理解しやすいでしょう。
では、航空会社の到着遅延の小さなデータセットを読んでみましょう。>>> ad = pd.read_csv('data/airline_delay.csv') >>> ad
このデータを再構成して、
airlineairportarrival delayの3つの列を作成します。
meltメソッドに指定する2つの主なパラメータから始めましょう、
垂直方向のままにする(再形成しない)列名であるid_varsと、単一の列に再形成する列名であるvalue_varsです。>>> ad.melt(id_vars='airline', value_vars=['ATL', 'DEN', 'DFW'])
stackメソッドでもほぼ同じデータを作成できますが、それは再整形された列をインデックスに入れます。
また、現在のインデックスは保持されます。
上記と同じデータを作成するには、最初に再整形されない列にインデックスを設定する必要があります。
やってみましょう。>>> ad_idx = ad.set_index('airline') >>> ad_idx
これで、パラメータを設定せずに
stackを使用して、meltとほぼ同じ結果を得ることができます。>>> ad_idx.stack() airline AA ATL 4 DEN 9 DFW 5 AS ATL 6 DEN -3 DFW -5 B6 ATL 2 DEN 12 DFW 4 DL ATL 0 DEN -3 DFW 10 dtype: int64結果は、2レベルの MultiIndex を持つSeriesになります。
データの値は同じですが、順序が異なります。
reset_indexを呼ぶことで、単一インデックスの DataFrame に戻ります。>>> ad_idx.stack().reset_index()
meltでカラム名を変更するカラム名を直接変更することができ、MultiIndex を避けることができるため、
meltを使用することをお勧めします。
var_nameおよびvalue_nameパラメータは、再整形された列の名前を変更するためのmeltのパラメータです。
また、id_varsにないすべての列が再形成されるので、残りの全ての列を指定する必要もありません。>>> ad.melt(id_vars='airline', var_name='airport', value_name='arrival delay')
ガイダンス: 列の名前を変更することができ、MultiIndex を避けることができるため、
stackよりmeltを使用する
pivotとunstackの類似点
pivotメソッドがどのような処理を行うかは、すでに説明しました。
unstackは、インデックスを値として扱う、似たような処理です。
pivotで使用した単純なDataFrameを見てみましょう。>>> df = pd.read_csv('data/state_fruit.csv') >>> df
unstackメソッドはインデックス内の値を転置します。
pivotメソッドでindexおよびcolumnsパラメータとして使用する列に対応するように、インデックスを設定する必要があります。
やってみましょう。>>> df_idx = df.set_index(['state', 'fruit']) >>> df_idx
これで、パラメータなしで
unstackを使用できます。
これにより、インデックスレベルが実際のデータ(fruit列)に最も近くなり、その一意の値が新しい列名になります。>>> df_idx.unstack()
結果は、
pivotメソッドで返された結果とほぼ同じになりますが、列が MultiIndex になります。ガイダンス:
unstackpivotよりもpivot_tableを使う
pivotとunstackはどちらも同じように動作しますが、
上述した通り、pivot_tableはpivotが扱うことができるすべてのケースを扱うことができるため、pivot_tableを使うことをお勧めします。以上で具体例を終わります
上記の具体的な例で、Pandasで最も一般的なタスクの中で、アプローチの定型手段が無い方法を、だいたいカバーできたと思います。
いずれの例でも、私は単一のアプローチを採用することにを提案しました。
これは、私がPandasを使用してデータ分析を行うときに使用するアプローチであり、私が生徒に教えるアプローチです。The Zen of Python
Minimally Sufficient Python は Tim Peters による Python の19の格言 The Zen of Python に触発されました。
特に注目に値する格言はこれです:There should be one-- and preferably only one --obvious way to do it.
何かいいやり方があるはずだ。誰が見ても明らかな、たったひとつのやり方が。
私は Pandas が、今まで見てきたどのライブラリよりも、この手引きに従っていないことに気付きました。
Minimally Sufficient Pandas は、この原則に沿うようにユーザーを誘導する試みです。Pandas Style Guide
上記の具体例では、多くのタスクに対するガイダンスを提供しましたが、ライブラリ内の全てを網羅しているわけではありません。
同意できないガイダンスもあるでしょう。あなたがライブラリを使うのを助けるために、私は
Pandas style guideを作成することを勧めます。
これは、コードベースを統一させるために作成されるための、コーディングスタイルガイドと大差ありません。
すべての Pandas を使用している分析者のチームにとって有益なものです。
Pandasスタイルガイドを強制すると、以下のことに役立ちます:
- すべての一般的なデータ分析タスクに同じ構文を使用させることができます
- Pandas のコードを本番環境に投入するのを用意にします
- Pandasのバグに遭遇する可能性を減らします。 大量の未解決のIssueがあるため、ライブラリの一部機能に限って使用することにすると、これらを回避するのに役立ちます。
Best of the API
Pandas DataFrame APIは膨大です。
ほとんど、あるいはまったく使用されていないか、エイリアスであるメソッドが大量にあります。
以下は、ほぼすべてのタスクを完了するのに、これだけ十分だと私が考える、 DataFrame の属性とメソッドのリストです。属性
- columns
- dtypes
- index
- shape
- T
- values
集約関数
- all
- any
- count
- describe
- idxmax
- idxmin
- max
- mean
- median
- min
- mode
- nunique
- sum
- std
- var
集約関数ではない統計メソッド
- abs
- clip
- corr
- cov
- cummax
- cummin
- cumprod
- cumsum
- diff
- nlargest
- nsmallest
- pct_change
- prod
- quantile
- rank
- round
部分選択
- head
- iloc
- loc
- tail
欠損値の取り扱い
- dropna
- fillna
- interpolate
- isna
- notna
Grouping
- expanding
- groupby
- pivot_table
- resample
- rolling
データの結合
- append
- merge
その他
- asfreq
- astype
- copy
- drop
- drop_duplicates
- equals
- isin
- melt
- plot
- rename
- replace
- reset_index
- sample
- select_dtypes
- shift
- sort_index
- sort_values
- to_csv
- to_json
- to_sql
関数群
- pd.concat
- pd.crosstab
- pd.cut
- pd.qcut
- pd.read_csv
- pd.read_json
- pd.read_sql
- pd.to_datetime
- pd.to_timedelta to_sql
結論
Minimally Sufficient Pandas は、構文を見失わずに、より効果的にデータ分析で効果を上げたいという方に役立つガイドであると、強く感じます。



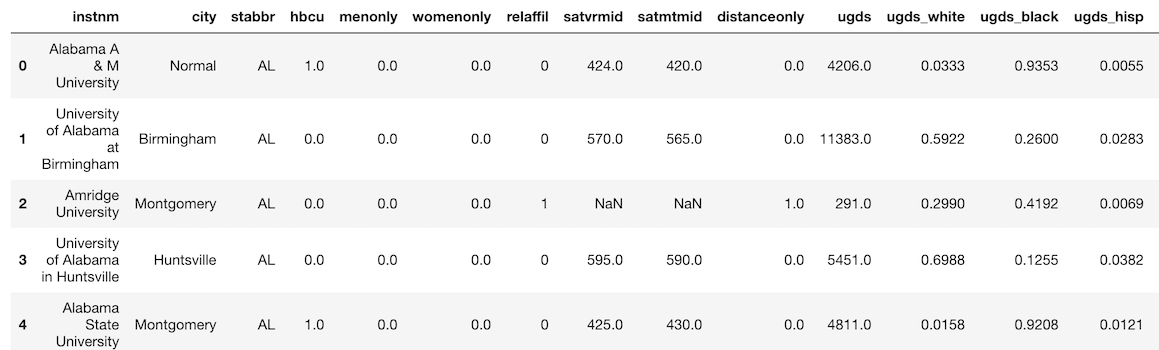
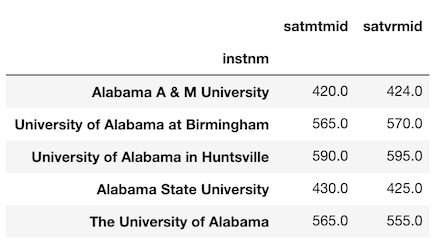
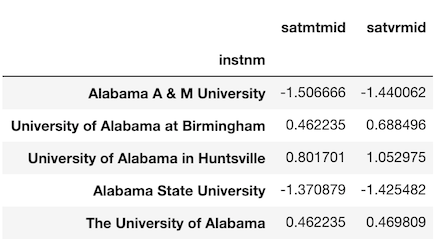
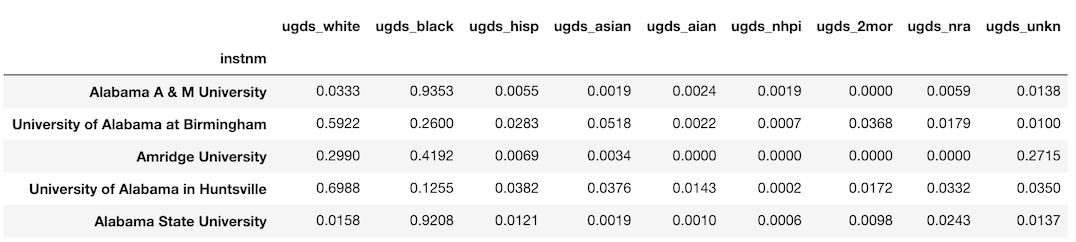

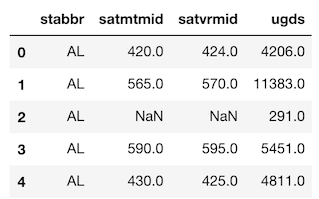
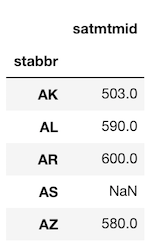
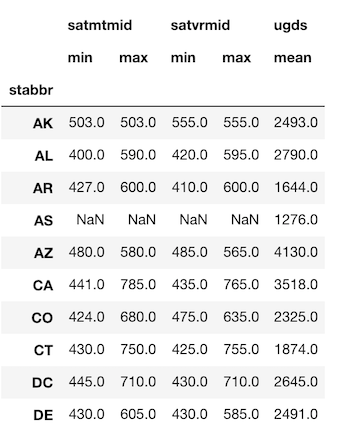
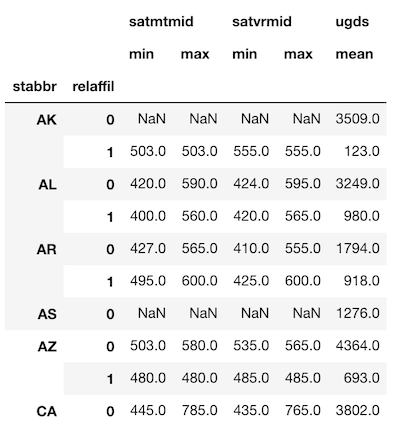
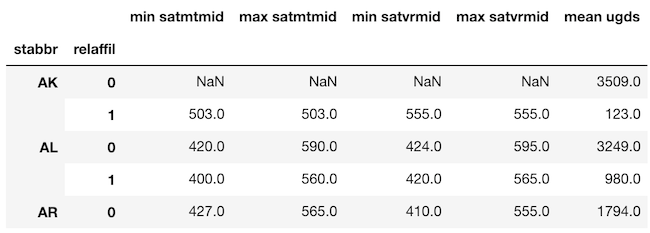
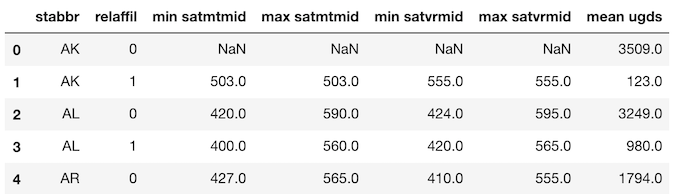
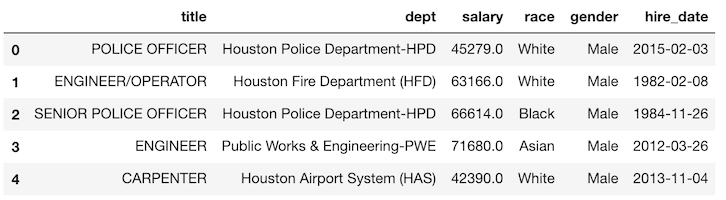
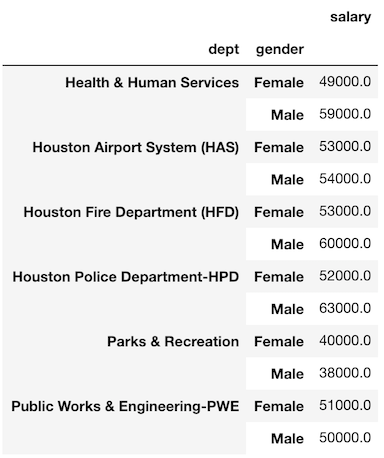
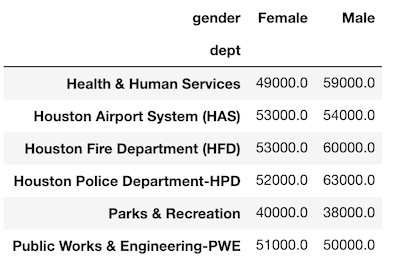
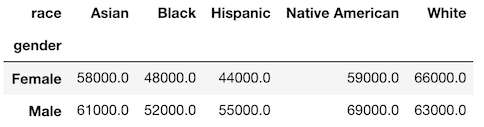
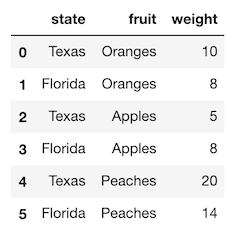

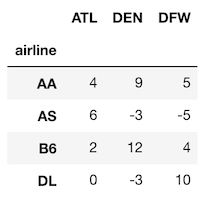
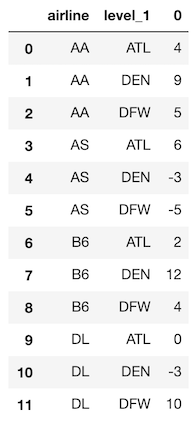
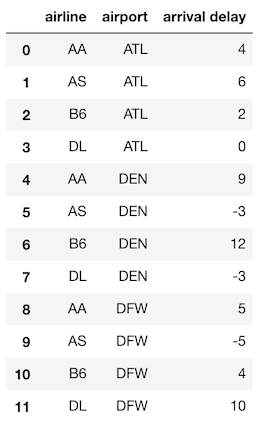

- 投稿日:2019-02-18T18:24:45+09:00
MeCab Jupyterで形態素解析をして名詞のみをリストアップした
まずは試しに解析してみる
import MeCab as mc tagger = mc.Tagger('') results = tagger.parse('列島縦断 鉄道乗りつくしの旅~JR20000km全線走破~ダイジェスト') print(results) # 列島 名詞,一般,*,*,*,*,列島,レットウ,レットー # 縦断 名詞,サ変接続,*,*,*,*,縦断,ジュウダン,ジューダン # 鉄道 名詞,一般,*,*,*,*,鉄道,テツドウ,テツドー # 乗り 名詞,接尾,一般,*,*,*,乗り,ノリ,ノリ # つくし 名詞,一般,*,*,*,*,つくし,ツクシ,ツクシ # の 助詞,連体化,*,*,*,*,の,ノ,ノ # 旅 名詞,サ変接続,*,*,*,*,旅,タビ,タビ # ~ 名詞,サ変接続,*,*,*,*,* # JR 名詞,一般,*,*,*,*,* # 20000 名詞,数,*,*,*,*,* # km 名詞,一般,*,*,*,*,* # 全線 名詞,一般,*,*,*,*,全線,ゼンセン,ゼンセン # 走破 名詞,サ変接続,*,*,*,*,走破,ソウハ,ソーハ # ~ 名詞,サ変接続,*,*,*,*,* # ダイジェスト 名詞,サ変接続,*,*,*,*,ダイジェスト,ダイジェスト,ダイジェスト # EOS文字列形式でアウトプットされ、tabやら改行やら、カンマなどいろいろ区切り文字があるのでめんどくさそう。
ちなみに名詞は名詞でも英語(ローマ字)は以下のように、カンマの区切りの数も変わるよう
tagger = mc.Tagger('') results = tagger.parse('NHK紅白歌合戦') print(results) # NHK 名詞,固有名詞,組織,*,*,*,* <= カンマ6個 # 紅白 名詞,一般,*,*,*,*,紅白,コウハク,コーハク <= カンマ8個 # 歌合戦 名詞,一般,*,*,*,*,歌合戦,ウタガッセン,ウタガッセン <= カンマ8個 # EOS名詞だけ抽出してみる
簡単な処理の順番
処理の順番的には、
①形態素解析
②改行で分割
③tabで分割
2つに別れる ["紅白","名詞,一般,*,*,*,*,紅白,コウハク,コーハク"]④後半をさらにカンマで分割
['名詞','一般','*','*','*','*','紅白','コウハク','コーハク']⑤上記リストの始まりが名詞であれば、名詞リストに追加
ソースコード
# 名詞を抽出 def extractNoun(text): tagger = mc.Tagger('') results = tagger.parse(text) keywords = [] keywords_kana = [] for r in results.split('\n'): cols = r.split("\t") if len(cols) >= 2: parts = cols[1].split(",") if parts[0].startswith("名詞"): keywords.append(cols[0]) if len(parts) > 7 keywords_kana.append(parts[7]) return keywords, keywords_kana色々試してみた
list = [ 'NHKニュース', '生活の知恵', 'ピーマン袋', '生活ほっとモーニング', '土曜元気市', 'お元気ですか日本列島', '経済羅針盤' ] for name in list: keyword, kana = extractNoun(name) print('○' + name) print('名詞 : ' + ','.join(keyword)) print('カナ : ' + ','.join(kana)) # ○NHKニュース # 名詞 : NHK,ニュース # カナ : ニュース # ○生活の知恵 # 名詞 : 生活,知恵 # カナ : セイカツ,チエ # ○ピーマン袋 # 名詞 : ピーマン,袋 # カナ : ピーマン,ブクロ # ○生活ほっとモーニング # 名詞 : 生活,モーニング # カナ : セイカツ,モーニング # ○土曜元気市 # 名詞 : 土曜,元気,市 # カナ : ドヨウ,ゲンキ,シ # ○お元気ですか日本列島 # 名詞 : 元気,日本,列島 # カナ : ゲンキ,ニッポン,レットウ # ○経済羅針盤 # 名詞 : 経済,羅針盤 # カナ : ケイザイ,ラシンバン最後に
次回は実際に名詞が羅列されたcsvやエクセルを読み込んで
いい感じにDataFrameにするところまでやりたい
- 投稿日:2019-02-18T15:49:44+09:00
python入門(7)
スライス
スライスとはシーケンスの操作ができる機能です.シーケンスとは複数の要素をまとめて扱える型のことです.pythonのシーケンスには「文字列」,「リスト」,「タプル」などがあります.
スライスは[始めの位置: 終わりの位置: 増加分]というように書くことができます.
また,添字より大きい数字になってもエラーになりません.
文字列に対するスライス
slice.pya = '123456789' print(a[2: 4]) #添字の2つ目から4つ目の手前まで print(a[:5]) #添字の最初(0)から5つ目の手前まで print(a[5:]) #添字の5つ目から最後まで print(a[-2]) #文字列の後ろから2つ目 print(a[::-1]) #添字全体を後ろから表示 print(a[2:7:2]) #添字の2つ目から7つ目の手前まで1つ飛ばしで実行結果34 12345 6789 8 987654321 357リストに対するスライス
slice2.pya = [1, 2, 3, 4, 5, 6, 7, 8, 9] print(a[2: 7]) #添字の2つ目から7つ目の手前まで print(a[:8]) #添字の最初(0)から8つ目の手前まで print(a[8:]) #添字の8つ目から最後まで print(a[:]) #全てを表示 print(a[8:2:-3]) #添字の8つ目から2つ目の手前まで2つ飛ばしで print(a[2:7:2]) #添字の2つ目から7つ目の手前まで1つ飛ばしで実行結果[3, 4, 5, 6, 7] [1, 2, 3, 4, 5, 6, 7, 8] [9] [1, 2, 3, 4, 5, 6, 7, 8, 9] [9, 6] [3, 5, 7]最後に
スライスを扱うことによってできることが増えます.スライスを利用してたくさんプログラムを組みましょう.
- 投稿日:2019-02-18T15:00:37+09:00
AWS X-Rayでmysql-connector-pythonにバッチを当ててリクエストをトレースしてみる
はじめに
アプリケーションが処理する各種リクエストをトレースするため、AWS X-Rayを使用しています。
リクエスト処理に使うライブラリのうち、AWS SDKを含むいくつかについてはX-Ray SDK内でデフォルトでサポートされており、パッチを適用すれば簡単に処理をトレースしてくれます。
今回は、PythonでDBを操作するアプリケーションを想定し、X-Ray SDK for Pythonがサポートしている mysql-connector-python にパッチを適用してみようと思います。
AWS X-Ray - ライブラリを実装ダウンストリーム呼び出しにパッチする
環境
検証は、ローカルで行いました。
OS: macOS High Sierra
Python: 3.6.5
MySQL: 5.6実行
MySQLサーバー
適当に用意。今回はDockerでmysql:5.6イメージをプルして実行。
データベースとテーブルの用意
以下のクエリを実行。
# データベース create database xray_test; # テーブル create table user (id char(10), name char(20));X Ray デーモン
トレースした情報をAWS上のX-Rayサービスへ投げるためにX-Rayデーモンを実行させる必要があります。
今回はローカルで検証したため、macOSで実行可能なスクリプトを落として
-oオプションをつけて実行。AWS X-Ray - ローカルで X-Ray デーモンを実行する
./xray_mac -oPythonスクリプト実行
今回はSELECT・INSERT・DELETEをトレースしてみます。
import mysql.connector from aws_xray_sdk.core import xray_recorder from aws_xray_sdk.core import patch # パッチ適用 patch_allでも可 libraries = ('mysql',) patch(libraries) # X Ray の設定 xray_recorder.configure(service='mysql-connector', daemon_address="127.0.0.1:2000") # mysql セグメント開始 segment = xray_recorder.begin_segment('mysql') # 接続 conn = mysql.connector.connect(user='root', password='password', host='127.0.0.1', database='xray_test') cur = conn.cursor() # INSERT cur.execute("insert into user values ('01', 'hoge');") conn.commit() # SELECT cur.execute("select * from user;") for row in cur.fetchall(): print(row[0],row[1]) # DELETE cur.execute("delete from user where id = '01';") conn.commit() cur.close() conn.close() # mysql セグメント終了 xray_recorder.end_segment()結果
AWSコンソールで確認してみます。
トレース詳細に、こんな感じでちゃんと3リクエストがサブセグメントとして乗ってます。
試しにサプセグメントを選択すると、SQLタブが出てます。これを開くと、DBのタイプやバージョン、接続したユーザー名が表示されます。
ここの情報はSELECT・INSERT・DELETEとも同じです。
注意点
X-Rayにトレースしてもらうためには、 必ず
mysql.connector.connect関数を使ってコネクションを作る必要があります。当初はコネクションプールの操作のため
mysql.connector.pooling.MySQLConnectionPoolを使ってましたが全然トレースしてくれませんでしたバッチライブラリの中でも、サポートされている関数/されていない関数があるようなので、ご注意を・・・
まとめ
これでMySQLサーバーへのリクエストがトレースできましたが、基本的には接続先と処理時間くらいしかトレースしてくれないので、より細かい情報を取りたい場合はSQLAlchemy ORMを使うべきかなと思います。また別途検証したいと思います。
参考
MySQL Connector/Python Developer Guide


- 投稿日:2019-02-18T13:14:55+09:00
NVIDIA環境でPython+Qtアプリを起動する(shader作成に失敗する場合)
PythonでQtアプリを起動すると、「QOpenGLShader: could not create shader」と表示されて失敗することがある。
原因
https://bugs.launchpad.net/ubuntu/+source/python-qt4/+bug/941826 にあるが、状況によりlibGL.so.1ではなくlibGL.soがロードされ、これがDebianパッケージのドライバだと/usr/lib/mesa-diverted/x86_64-linux-gnu/libGL.soにリンクされていることが原因である。
(NVIDIAインストーラならばこういう状況は発生しないが、カーネル更新時に自動でdkmsが働かないためドライバを入れ忘れる可能性が出てしまう、なのでパッケージを使うのが良かろう)方法
短期的には、
sudo ln -sf libGL.so.1 /usr/lib/x86_64-linux-gnu/libGL.soとすればよいが、グラフィックドライバ等の更新でmesa-divertedに戻ってしまう。恒久的に書き換えるには以下を実行すれば良い。sudo update-alternatives --install /usr/lib/mesa-diverted/libGL.so-master libGL.so-master /usr/lib/x86_64-linux-gnu/nvidia 9999 \ --slave /usr/lib/x86_64-linux-gnu/libEGL.so glx--libEGL.so-x86_64-linux-gnu /usr/lib/x86_64-linux-gnu/nvidia/current/libEGL.so.1 \ --slave /usr/lib/x86_64-linux-gnu/libGL.so glx--libGL.so-x86_64-linux-gnu /usr/lib/x86_64-linux-gnu/nvidia/current/libGL.so.1 \ --slave /usr/lib/x86_64-linux-gnu/libGLESv1_CM.so glx--libGLESv1_CM.so-x86_64-linux-gnu /usr/lib/x86_64-linux-gnu/nvidia/current/libGLESv1_CM_nvidia.so.1 \ --slave /usr/lib/x86_64-linux-gnu/libGLESv2.so glx--libGLESv2.so-x86_64-linux-gnu /usr/lib/x86_64-linux-gnu/nvidia/current/libGLESv2_nvidia.so.2このスクリプトは /var/lib/dpkg/info/glx-alternative-mesa.postinst を読んだ上で自分で構築したものである。
- 投稿日:2019-02-18T13:01:05+09:00
コンビニで直近三年何が売れてきているのか調べる。
コンビニは昔と比べて販売品目が多種多様になりました。
品目別に売上も変わってきているのか調べてみました。
統計局estatの商業動態統計のなかの
第4部 コンビニエンスストア内に目的のデータが含まれていることが判明。その中でも商品別販売額の中に前年度との増減比率データが存在していることまでつかめた。下記コードによりestatより目的のCSVを取得
df_target = df[(df['STAT_NAME_val'] == '商業動態統計調査')& (df['TITLE'].str.contains('第4部 コンビニエンスストア'))& (df['TITLE'].str.contains('商品別販売額'))] e_stat_utils.save_data_multi(p_id, df_target['id'].values, dir_path, [df_target['GOV_ORG_val'].values, df_target['id'].values, df_target['TITLE'].values, df_target['SURVEY_DATE'].values])データ確認、平成27年からは販売額と増減比率は一つのデータにまとめられている様子
2015~2017の月ごとの販売額データをプロット
title_list = ['経済産業省_0003223672_第4部 コンビニエンスストア販売 第1表 商品別販売額等及び前年(度・同期・同月)比増減率_201701-201712.csv', '経済産業省_0003199712_第4部 コンビニエンスストア販売 第1表 商品別販売額等及び前年(度・同期・同月)比増減率_201601-201612.csv', '経済産業省_0003147186_第4部 コンビニエンスストア販売 第1表 商品別販売額等及び前年(度・同期・同月)比増減率_201501-201512.csv'] for title in title_list: df_cs_01 = pd.read_csv(dir_path + title) df_cs_01["value"] = pd.to_numeric(df_cs_01["value"], errors='coerce').fillna(0) show_columns(df_cs_01) drop_list = ['平成25年', '平成26年', '平成27年', '平成25年度', '平成26年度', '平成27年 1 ~ 3 月', '平成27年 4 ~ 6 月', '平成27年 7 ~ 9 月', '平成28年 1 ~ 3 月', '平成28年 4 ~ 6 月', '平成28年 7 ~ 9 月', '平成28年10~12月', '平成27年10~12月', '平成20年', '平成21年', '平成22年', '平成20年度', '平成21年度', '平成22年 1 ~ 3 月', '平成22年 4 ~ 6 月', '平成22年 7 ~ 9 月', '平成22年10~12月''平成27年', '平成28年', '平成29年', '平成27年度', '平成28年度', '平成29年 1 ~ 3 月', '平成29年 4 ~ 6 月', '平成29年 7 ~ 9 月', '平成29年10~12月'] for i in drop_list: df_cs_01 = df_cs_01[(df_cs_01['年月(H24~H30)'] != i)] drop_list = ['合計', '合計 既存店', '商品販売額', '商品販売額 既存店', 'サービス売上高 既存店'] for i in drop_list: df_cs_01 = df_cs_01[(df_cs_01['コンビニエンス販売項目'] != i)] g = sns.catplot(x='年月(H24~H30)', y='value', hue='コンビニエンス販売項目', data=df_cs_01, row='行区分(平成27~)', col=None, col_wrap=None, estimator=np.mean, ci=None, n_boot=1000)
やはり食品販売が強い
サービス売上高の項目の詳細が統計局では明記されていなかったため大本である経済産業省を見たところ下記を発見。
商業動態統計 調査の結果
項目7の商品分類表(コンビニエンスストア) (PDF/88KB)
をご参照コンビニのATM手数料が含まれているのかどうか不明だったため経済産業省に電話し確認したが、
これは各コンビニ会社がこのサービスに含めているか否かということがわからないためそこまでは調べきれないとのことでした。所感
月ごとにサービス販売増減率が乱高下しているがそもそもの販売額全体に占めるウェイトが少ないためあまり問題にならないのかもしれない。やはりコンビニはサービスを利用してもらうついでに食品等を購入してもらうモデルなのでしょう。食品と非食品販売という主戦場は変えないが、取り込み方法がサービス利用に付随する購買なので単純に売上比で考えることはできなそうです。サービスのバリエーションの量はコンビニの優位性の一つの指標として有効かもしれません。
個人的には今後コンビニは宅配便やスーツクリーニング等々のサービス販売額の占めるウェイトが大きくなっていくと考えていたがそうでもないみたいです。
食品の売り場面積を割いてでも設置するメリットが無いです。やはりコンビニは食品と日用品を売る場所なのでしょうね。
そう考えるとセブンプレミアム戦略(自社ブランドで最も販売額の大きな品目での利益率UPと差別化)も納得いきます。朝昼夜別のデータが取れたらもっと面白いことがわかりそうなんですけどね。

- 投稿日:2019-02-18T11:31:48+09:00
Pythonによるtkinterを使った雛形(クラス化手法)
はじめに
最近はPythonを主に勉強していて、特にtkinterに触れていました。
ある程度、最初の形が定まってきたので、ここに記そうと思います。環境
- Windows 10 home
- Python 3.7.1
クラス化手法による雛形
Tkinter.pyimport tkinter as tk class Application(tk.Frame): def __init__(self,master = None): super().__init__(master) self.pack() self.master.geometry("300x300") self.master.title("雛形") def main(): win = tk.Tk() app = Application(master = win) app.mainloop() if __name__ == "__main__": main()実行
このような画面が出れば、成功です。
- 投稿日:2019-02-18T11:28:45+09:00
PythonでXMLを扱う?requests-XMLを使いましょう!
口上
これまでXMLで作られたデータを扱う際にはなぜか気分が悪かった気がします。
長い名前のものをインポートし(ここでは名前が長すぎるので触れないことにしておこう)、なんかややこしいことをやらないといけなかったからだと思います。
なんでXMLなんて作られたのだろうと思って今回色々読んでみたが、どうもコンピュータには読みやすい形のデータのようです。確かに見ていると、データに意味を持たしており、構造も分かりやすい(ような気がする)。
しかし、扱う際に面倒くさいってのが、プログラミング初心者の私にはネックで、XMLが出てきたら来た道を引き返すようにしていました。
Requests-XML
どうしても統計データを扱わないといけなくなりました。そのため、e-statという名前の国のサイトからAPIを叩くことになりました。このサイトたくさんのデータがあるので、ちょっと面白そうですね。でも使うには登録が必要です。
で使い方を見ていたら最初の例からしてXMLだったんですね・・・。でもここ以外からデータ取るととてもめんどくさそうです。そのうち書くかもしれませんが、個人的な趣味でオープンデータを扱い、一つのエクセルのデータを2日かけてcsv化するなんて沼にはまった悪夢をすぐに思い出してしまいます。
なので、pythonで何か便利なツールはないかと思って探していたら、Requests-XMLが検索に引っかかりました。
このマークrequestsと似ているので、kenneth reitzさんの作ったものかと思いきや、Erin O'connelさんが作られたようです。よく見るとpipenvもえりんさんのgithubにあります。
あと、Requests-XMLはPython3.6のみサポートのようです。たまたま私は3.6を使っているので、ラッキーだった。他のバージョンは試していません。
使い方
Requests-XMLのページではNASAの事例を使ってやっておられますが、ここではe-statのAPIを使ってみます。
e-statのAPIを叩く際にアプリケーションIDが必要です。
from requests import XMLSession session = XMLSession() r = session.get('http://api.e-stat.go.jp/rest/2.1/app/ getStatsData?appId=<your_app_ID>&statsDataId=C0020050213000&cdCat01=%23A03503') print(r.text)すると下のようにファイルの全部が出てきます(下は長いので略)。
ではデータを取ってみましょう。
データは
<VALUE tab=002‥‥></VALUE>というところに入っています。ので、
item = r.xml.xpath('//VALUE', first=True)と書くと一つ目のやつを取ってきます。取ってきたものを色々試してみたのが下の画像です。attrsで指定すると、タグ内のものを取ってくるとかもできます。
さきほどのfirst=Trueをなくすと、指定した要素の全てを取ってきます。そして使う際は、リストに入っているので、順番を指定したりして取り出します。
まとめ
てな感じで簡単に取れるようになりました。これまでXMLを見るだけで、吐き気を催していましたが、これからは元気にさばいていけそうな気がしました。
気だけかもしれませんが、雰囲気重要ですよね~w

- 投稿日:2019-02-18T10:59:44+09:00
House Price してみた
自己紹介
はじめまして。某T大経済学部の佐々木です。KaggleのHousePriceをしてみたいと思います。
必要なライブラリをインポート
まずは分析に必要なライブラリをインストール。
import numpy as np import pandas as pd from pandas import Series, DataFrame import matplotlib.pyplot as plt import seaborn as sns %matplotlib inlineデータ確認
trainデータとtestデータのサイズを確認
print(train.shape) print(test.shape) #出力結果 (1460, 81) (1459, 80)特徴量を確認
train.columns #出力結果 Index(['Id', 'MSSubClass', 'MSZoning', 'LotFrontage', 'LotArea', 'Street', 'Alley', 'LotShape', 'LandContour', 'Utilities', 'LotConfig', 'LandSlope', 'Neighborhood', 'Condition1', 'Condition2', 'BldgType', 'HouseStyle', 'OverallQual', 'OverallCond', 'YearBuilt', 'YearRemodAdd', 'RoofStyle', 'RoofMatl', 'Exterior1st', 'Exterior2nd', 'MasVnrType', 'MasVnrArea', 'ExterQual', 'ExterCond', 'Foundation', 'BsmtQual', 'BsmtCond', 'BsmtExposure', 'BsmtFinType1', 'BsmtFinSF1', 'BsmtFinType2', 'BsmtFinSF2', 'BsmtUnfSF', 'TotalBsmtSF', 'Heating', 'HeatingQC', 'CentralAir', 'Electrical', '1stFlrSF', '2ndFlrSF', 'LowQualFinSF', 'GrLivArea', 'BsmtFullBath', 'BsmtHalfBath', 'FullBath', 'HalfBath', 'BedroomAbvGr', 'KitchenAbvGr', 'KitchenQual', 'TotRmsAbvGrd', 'Functional', 'Fireplaces', 'FireplaceQu', 'GarageType', 'GarageYrBlt', 'GarageFinish', 'GarageCars', 'GarageArea', 'GarageQual', 'GarageCond', 'PavedDrive', 'WoodDeckSF', 'OpenPorchSF', 'EnclosedPorch', '3SsnPorch', 'ScreenPorch', 'PoolArea', 'PoolQC', 'Fence', 'MiscFeature', 'MiscVal', 'MoSold', 'YrSold', 'SaleType', 'SaleCondition', 'SalePrice'], dtype='object')必要のない特徴量Idをひとまず削除
train=train.drop(['Id'],axis=1) test=test.drop(['Id'],axis=1)目的変数の確認
sns.distplot(train.SalePrice, bins = 25)
低所得者が多く、グラフ全体が左に寄っており、経済的不平等が起こっている。欠損値処理
まずは欠損値の数を確認
#trainデータ train.isnull().sum()[train.isnull().sum()>0] #出力結果 LotFrontage 259 Alley 1369 MasVnrType 8 MasVnrArea 8 BsmtQual 37 BsmtCond 37 BsmtExposure 38 BsmtFinType1 37 BsmtFinType2 38 Electrical 1 FireplaceQu 690 GarageType 81 GarageYrBlt 81 GarageFinish 81 GarageQual 81 GarageCond 81 PoolQC 1453 Fence 1179 MiscFeature 1406 dtype: int64 #testデータ train.isnull().sum()[train.isnull().sum()>0] #出力結果 MSZoning 4 LotFrontage 227 Alley 1352 Utilities 2 Exterior1st 1 Exterior2nd 1 MasVnrType 16 MasVnrArea 15 BsmtQual 44 BsmtCond 45 BsmtExposure 44 BsmtFinType1 42 BsmtFinSF1 1 BsmtFinType2 42 BsmtFinSF2 1 BsmtUnfSF 1 TotalBsmtSF 1 BsmtFullBath 2 BsmtHalfBath 2 KitchenQual 1 Functional 2 FireplaceQu 730 GarageType 76 GarageYrBlt 78 GarageFinish 78 GarageCars 1 GarageArea 1 GarageQual 78 GarageCond 78 PoolQC 1456 Fence 1169 MiscFeature 1408 SaleType 1 dtype: int64データの数に対して欠損値の数が極端に多い変数がいくつかあるので、内容を確認してみる。
train['FireplaceQu'].value_counts() #出力結果 Gd 380 TA 313 Fa 33 Ex 24 Po 20 Name: FireplaceQu, dtype: int64Kaggleのページでダウンロードできるdata_descriptionには
FireplaceQu: Fireplace quality
Ex : Excellent - Exceptional Masonry Fireplace
Gd : Good - Masonry Fireplace in main level
TA : Average - Prefabricated Fireplace in main living area or Masonry Fireplace in basement
Fa : Fair - Prefabricated Fireplace in basement
Po : Poor - Ben Franklin Stove
NA : No Fireplace
とあるので、Na:No Fireplaceも欠損値扱いされてしまっている。
そのような特徴量の欠損値を'None'で補完fillnaNone_list = ['Alley','BsmtCond','BsmtQual','BsmtExposure','BsmtFinType1', 'BsmtFinType2','FireplaceQu','GarageType', 'GarageFinish','GarageQual', 'GarageCond','PoolQC','Fence','MiscFeature'] for i in fillnaNone_list: train[i].fillna('None',inplace=True) test[i].fillna('None',inplace=True)同様に、値が数値の特徴量の欠損値を0で補完(ただし、'GarageYrBlt'だけは0としてしまっては後々築年数に変換した時に面倒なので0で補完しない)
zero_list=['LotFrontage','MasVnrArea','BsmtFinSF1','BsmtFinSF2','BsmtUnfSF','TotalBsmtSF','BsmtFullBath','BsmtHalfBath','GarageCars','GarageArea'] for i in zero_list: train[i].fillna(0,inplace=True) test[i].fillna(0,inplace=True)YearBuiltでGarageYrBltを補完するのが一番思いつきやすいため、補完して良いか確認するため関係を可視化
plt.plot(test.YearBuilt, test.GarageYrBlt,'.', alpha=0.5)
補完して良さそうなのでYearBuiltで補完train['GarageYrBlt'].fillna(train.YearBuilt,inplace=True) test['GarageYrBlt'].fillna(test.YearBuilt,inplace=True)ここで一旦残っている欠損値を確認
#trainデータ train.isnull().sum()[train.isnull().sum()>0] #出力結果 MasVnrType 8 Electrical 1 dtype: int64 #testデータ test.isnull().sum()[test.isnull().sum()>0] #出力結果 MSZoning 4 Utilities 2 Exterior1st 1 Exterior2nd 1 MasVnrType 16 KitchenQual 1 Functional 2 SaleType 1 dtype: int64平均値で処理すると外れ値に影響を受けやすく、カテゴリー変数に対応できないので最頻値で補完
n_list=['Electrical', 'MasVnrType', 'MSZoning', 'Functional', 'Utilities','Exterior1st', 'Exterior2nd', 'KitchenQual', 'SaleType'] for i in n_list: train[i].fillna(train[i].mode()[0],inplace=True) test[i].fillna(test[i].mode()[0],inplace=True)これで欠損値が無くなった。
特徴量
普段家を購入するとき、築年数を気にするので、西暦で書かれている特徴量を経過した年数に変換する。
#築年数、改修からの年数、売り出されてからの年数に変更する。 train['elapsed']=2018-train['YearBuilt'] train['remod_elapsed']=2018-train['YearRemodAdd'] train['sold_elapsed']=2018-train['YrSold'] train['garage_elapsed']=2018-train['GarageYrBlt'] test['elapsed']=2018-test['YearBuilt'] test['remod_elapsed']=2018-test['YearRemodAdd'] test['sold_elapsed']=2018-test['YrSold'] test['garage_elapsed']=2018-test['GarageYrBlt'] #必要なくなった列をカラムを指定して削除 drop_columns=['YearBuilt','YearRemodAdd','YrSold','GarageYrBlt'] train=train.drop(drop_columns,axis=1) test=test.drop(drop_columns,axis=1)家を購入するとき最も気にするのは何と言っても広さなので、広さを表す特徴量を作る
#部屋サイズ train['TotalSF']= train['TotalBsmtSF']+ train['1stFlrSF']+train['2ndFlrSF'] test['TotalSF']= test['TotalBsmtSF']+ test['1stFlrSF']+ test['2ndFlrSF'] #ベランダサイズ train['Porch']= train['EnclosedPorch']+ train['3SsnPorch']+ train['ScreenPorch'] + train['WoodDeckSF']+ train['OpenPorchSF'] test['Porch']= test['EnclosedPorch']+ test['3SsnPorch']+ test['ScreenPorch'] + test['WoodDeckSF']+ test['OpenPorchSF'] drop_columnsSF=['TotalBsmtSF','1stFlrSF','2ndFlrSF','EnclosedPorch','3SsnPorch','ScreenPorch','WoodDeckSF','OpenPorchSF'] train = train(drop_columnsSF,axis=1) test= test(drop_columnsSF,axis=1)特徴量が正規分布に従っていた方が精度が良くなるので歪度の高いものは偏りをなくす
#数値の偏りをなくす為に、数値データを取り出す numerical_features = train.select_dtypes(exclude = ["object"]).columns train_num = train[numerical_features] #歪度を計算 from scipy.stats import skew skewness = train_num.apply(lambda x: skew(x)) skew_features = skewness[abs(skewness)>0.5] #基本的に左に寄っていることを確認 for i in skew_features.index: sns.distplot(train[i],bins = 25) plt.xlabel(i) plt.show()e.g.)elapsed
可視化して確かめると、全ての特徴量が上のelapsedのように左に寄っていることがわかった。従って、対数変換をしたいが、値が0未満だとlogを取れないので0未満の値がないかを確認。print('train') for i in skew_features.index: print(train[train[i]<0].index) print('test') for i in skew_features.index.drop('SalePrice'): print(test[test[i]<0].index) #出力結果 train Int64Index([], dtype='int64') Int64Index([], dtype='int64') Int64Index([], dtype='int64') Int64Index([], dtype='int64') Int64Index([], dtype='int64') Int64Index([], dtype='int64') Int64Index([], dtype='int64') Int64Index([], dtype='int64') Int64Index([], dtype='int64') Int64Index([], dtype='int64') Int64Index([], dtype='int64') Int64Index([], dtype='int64') Int64Index([], dtype='int64') Int64Index([], dtype='int64') Int64Index([], dtype='int64') Int64Index([], dtype='int64') Int64Index([], dtype='int64') Int64Index([], dtype='int64') Int64Index([], dtype='int64') Int64Index([], dtype='int64') Int64Index([], dtype='int64') Int64Index([], dtype='int64') Int64Index([], dtype='int64') test Int64Index([], dtype='int64') Int64Index([], dtype='int64') Int64Index([], dtype='int64') Int64Index([], dtype='int64') Int64Index([], dtype='int64') Int64Index([], dtype='int64') Int64Index([], dtype='int64') Int64Index([], dtype='int64') Int64Index([], dtype='int64') Int64Index([], dtype='int64') Int64Index([], dtype='int64') Int64Index([], dtype='int64') Int64Index([], dtype='int64') Int64Index([], dtype='int64') Int64Index([], dtype='int64') Int64Index([], dtype='int64') Int64Index([], dtype='int64') Int64Index([], dtype='int64') Int64Index([], dtype='int64') Int64Index([1132], dtype='int64') Int64Index([], dtype='int64') Int64Index([], dtype='int64')garage_elapsedのIndex:1132が0未満だということが判明
test.loc[1132,'garage_elapsed'] #出力結果 -189.0経過年数が負の値は明らかにおかしいので、築年数で補完する
test.loc[1132,'garage_elapsed']=test.loc[1132,'elapsed']これで0未満の値は消えたので、対数log(y+1)をとる。
for x in skew_features.index: train[x]=np.log1p(train[x]) for y in skew_features.index.drop('SalePrice'): test[y]=np.log1p(test[y])次に、カテゴリー変数を数量データに変換する。
One-Hot-encodingでダミー変数化すると、特徴量が多くなりすぎてしまう。そこで、どんな特徴量にも少なからず順序関係があるのでは、と考えた。例えばNeighborhood
この地域にことを全く知らない私たちには順序が分からないが、グラフで表示してみるとNeighborhood_meanSP = train.groupby('Neighborhood')['SalePrice'].mean() Neighborhood_meanSP = Neighborhood_meanSP.sort_values() sns.pointplot(x = train.Neighborhood.values, y = train.SalePrice.values, order =Neighborhood_meanSP.index) plt.xticks(rotation=45)
と、上図のように明らかに順序関係があることがわかる。従って、 各変数の順序関係に従って、エンコーディングすれば良いと考えた
for i in train.loc[:, train.dtypes == 'object'].columns: num=-1 mapping={} for j in train.groupby(i)['SalePrice'].mean().sort_values().index: num+=1 mapping[j]=num train[i]= train[i].map(mapping) test[i]=test[i].map(mapping)object型の変数が消えたことを確認
#trainデータ train.dtypes.value_counts() #出力結果 int64 50 float64 24 dtype: int64 ##testデータ test.dtypes.value_counts() #出力結果 int64 48 float64 25 dtype: int64これで全て数字になった
外れ値を消す
外れ値を消すために、全て可視化して、目視で外れ値を消していく
for i in train.columns: plt.scatter(train[i],train['SalePrice']) plt.xlabel(i) plt.show()外れ値を消す
train = train.drop(train[(data_train['TotalSF']>8.7) & (train['SalePrice']<12.3)].index) train = train.drop(data_train[(train['GrLivArea']>8.3) & (train['SalePrice']<13)].index) train = train.drop(train[(train train['GarageArea']>1200) & (train['SalePrice']<12.5)].index)特徴量を工夫
ひとまず説明変数と目的変数に分ける
Y_train=train['SalePrice'] X_train=train.drop('SalePrice',axis=1) X_test=test特徴量を減らすため、特徴量の重要度を求める
from sklearn.metrics import accuracy_score from sklearn.ensemble import RandomForestRegressor rf = RandomForestRegressor(n_estimators=80) rf = rf.fit(X_train, Y_train) ranking = np.argsort(-rf.feature_importances_) f, ax = plt.subplots(figsize=(11, 9)) sns.barplot(x=rf.feature_importances_[ranking], y=X_train.columns.values[ranking], orient='h') ax.set_xlabel("feature importance") plt.tight_layout() plt.show()
このうち上位30この特徴量を使用X_train = X_train.iloc[:,ranking[:30]] X_test = X_test.iloc[:,ranking[:30]]また、OverallQualとTotalSFが飛び抜けているので、2つの変数を掛け合わせた新しい特徴量を作る。
X_train['QualSF']=X_train['OverallQual']*X_train['TotalSF'] X_test['QualSF']=X_test['OverallQual']*X_test['TotalSF']正規化
mean = X_train.mean(axis=0) std = X_train.std(axis=0) X_train = (X_train - mean) / std X_test = (X_test - mean) / std多重共線性をなくすために、相関の強い特徴量を削除する
correlation = X_train.corr() f , ax = plt.subplots(figsize = (20,20)) sns.heatmap(correlation,square = True, vmax=0.8,annot=True)
X_train=X_train.drop(['GrLivArea','garage_elapsed','GarageCars','remod_elapsed'],axis=1) X_test=X_test.drop(['GrLivArea','garage_elapsed','GarageCars','remod_elapsed'],axis=1)モデリング
データ数が少ないので、交差検証法、グリッドサーチを用い、複数のモデルで検証し、最も結果の良かったものを採用する。
# KFold from sklearn.model_selection import KFold kf_3 = KFold(n_splits=6, shuffle=True, random_state=0) #モデルの呼び出し from sklearn.linear_model import Lasso from sklearn.ensemble import RandomForestRegressor from sklearn.svm import SVR from sklearn.model_selection import GridSearchCV from sklearn.linear_model import ElasticNet from sklearn.linear_model import Ridge from xgboost import XGBRegressor # 各モデルのインスタンスを生成 ridge=Ridge() elastic= ElasticNet() lasso = Lasso() rf = RandomForestRegressor() svr = SVR() XGB= XGBRegressor() #グリッドサーチ用パラメータの設定 elasticnet_parameters= {'alpha':[0.1, 0.5, 1],'l1_ratio':[0.3,0.6,0.9]} lasso_parameters = {'alpha':[0.1, 0.5, 1]} rf_parameters= {'n_estimators':[100, 500, 2000], 'max_depth':[3, 5, 10]} svr_parameters = {'C':[1e-1, 1e+1, 1e+3], 'epsilon':[0.05, 0.1, 0.3]} ridge_parameters = {'alpha':[0.1, 0.5, 1]} xgb_parameters = {"learning_rate":[0.1,0.3,0.5],"max_depth": [2,3,5,10],"subsample":[0.5,0.8,0.9,1],"colsample_bytree": [0.5,1.0],} #グリッドサーチ elastic_gs=GridSearchCV(elastic, elasticnet_parameters,cv=kf_3) elastic_gs.fit(x_train,y_train) lasso_gs = GridSearchCV(lasso, lasso_parameters,cv=kf_3) lasso_gs.fit(x_train,y_train) rf_gs = GridSearchCV(rf, rf_parameters,cv=kf_3) rf_gs.fit(x_train,y_train) svr_gs = GridSearchCV(svr, svr_parameters,cv=kf_3) svr_gs.fit(x_train,y_train) ridge_gs=GridSearchCV(ridge, ridge_parameters,cv=kf_3) ridge_gs.fit(x_train,y_train) xgb_gs = GridSearchCV(XGB, xgb_parameters, cv = kf_3) xgb_gs.fit(x_train,y_train) #平均二乗誤差を計算 from sklearn.metrics import mean_squared_error def RMSE(instance, modelname): Y_pred = instance.predict(x_test) print("{}でのRMSE:{:.4f}".format(modelname ,np.sqrt(mean_squared_error(y_test, Y_pred)))) RMSE(elastic_gs,'ElasticNet') RMSE(lasso_gs,'ラッソ回帰') RMSE(rf_gs,'ランダムフォレスト') RMSE(svr_gs,'SVR') RMSE(ridge_gs,'Ridge') RMSE(xgb_gs,'XGBoost') #出力結果 ElasticNetでのRMSE:0.1630 ラッソ回帰でのRMSE:0.1689 ランダムフォレストでのRMSE:0.1349 SVRでのRMSE:0.4008 RidgeでのRMSE:0.1178 XGBoostでのRMSE:0.1272この結果より、ridgeを採用しました。
順位もぼちぼちでは無いでしょうか(12/30/2018)
Keras
せっかくKerasも習ったのでKerasで多層ニューラルネットモデル(MLP)を作成して回帰分析をしてみました。
numpy.ndarrayに変換
全結合層に入力するためにpandas.DataFrameをnumpy.ndarrayに変換します。
x_train=np.array(x_train) y_train=np.array(y_train) x_test=np.array(x_test) y_test=np.array(y_test) X_test=np.array(X_test)ネットワークの定義
from keras.models import Sequential model = Sequential() model.add(Dense(10, input_shape=(x_train.shape[1],), activation='relu')) model.add(Dense(15)) model.add(Activation('relu')) model.add(Dense(1)) from keras import optimizers optimizer = optimizers.Adam(lr=0.001, beta_1=0.9, beta_2=0.999, epsilon=1e-08) model.compile(loss='mse', optimizer=optimizer, metrics=['mae']) model.summary()今回は以下の様なネットワークの定義を定義してみました。
EarlyStoppingのインスタンスを生成
過学習を抑えるため、Kerasのearly stoppingを利用しました。
from keras.callbacks import EarlyStopping early_stop = keras.callbacks.EarlyStopping(monitor='val_loss', patience=20,verbose=0, mode='min')学習の実行
history = model.fit(x_train, y_train, epochs=500, validation_data=(x_test,y_test), verbose=1, callbacks=[early_stop])損失値(Loss)の遷移のプロット
プロットして損失値の推移を視覚化します。
def plot_history_loss(history): plt.plot(history.history['mean_absolute_error'],label="loss for training") plt.plot(history.history['val_mean_absolute_error'],label="loss for validation") plt.title('model loss') plt.xlabel('epoch') plt.ylabel('loss') plt.legend(loc='best') plt.show() plt.ylim([0,2]) plot_history_loss(history)
testデータで予測
先ほど定義した関数で、平均二乗誤差(RMSE)を出力します。
Y_pred = model.predict(x_test) print("{}でのRMSE:{:.4f}".format('MLP' ,np.sqrt(mean_squared_error(y_test, Y_pred)))) #出力結果 MLPでのRMSE:0.1780あまり結果は良くありませんでした。今度はもう少し層を深くしてみます
ネットワークの定義②
活性化関数やOptimizers等は変えずに、層を深くし、過学習を抑えるためにDropoutレイヤーを追加しました。
model = Sequential() model.add(Dense(10, input_shape=(x_train.shape[1],), activation='relu')) model.add(Dense(15)) model.add(Activation('relu')) model.add(Dropout(0.50)) model.add(Dense(100)) model.add(Activation('relu')) model.add(Dropout(0.50)) model.add(Dense(100)) model.add(Activation('relu')) model.add(Dropout(0.50)) model.add(Dense(100)) model.add(Activation('relu')) model.add(Dropout(0.50)) model.add(Dense(64)) model.add(Activation('relu')) model.add(Dense(1))
あとは先ほどと同じ様に損失値(Loss)の遷移をプロット
平均二乗誤差を出力すると、MLPでのRMSE:0.2434...むしろ悪くなってしまいました。過学習をしてしまったのかもしれません。
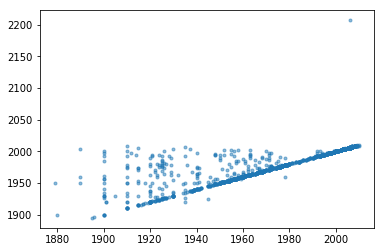
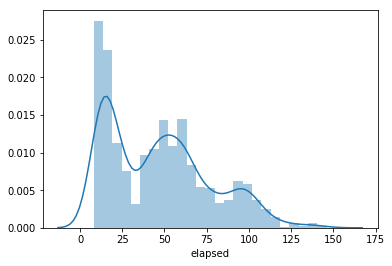
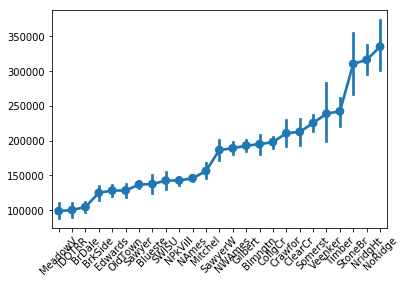

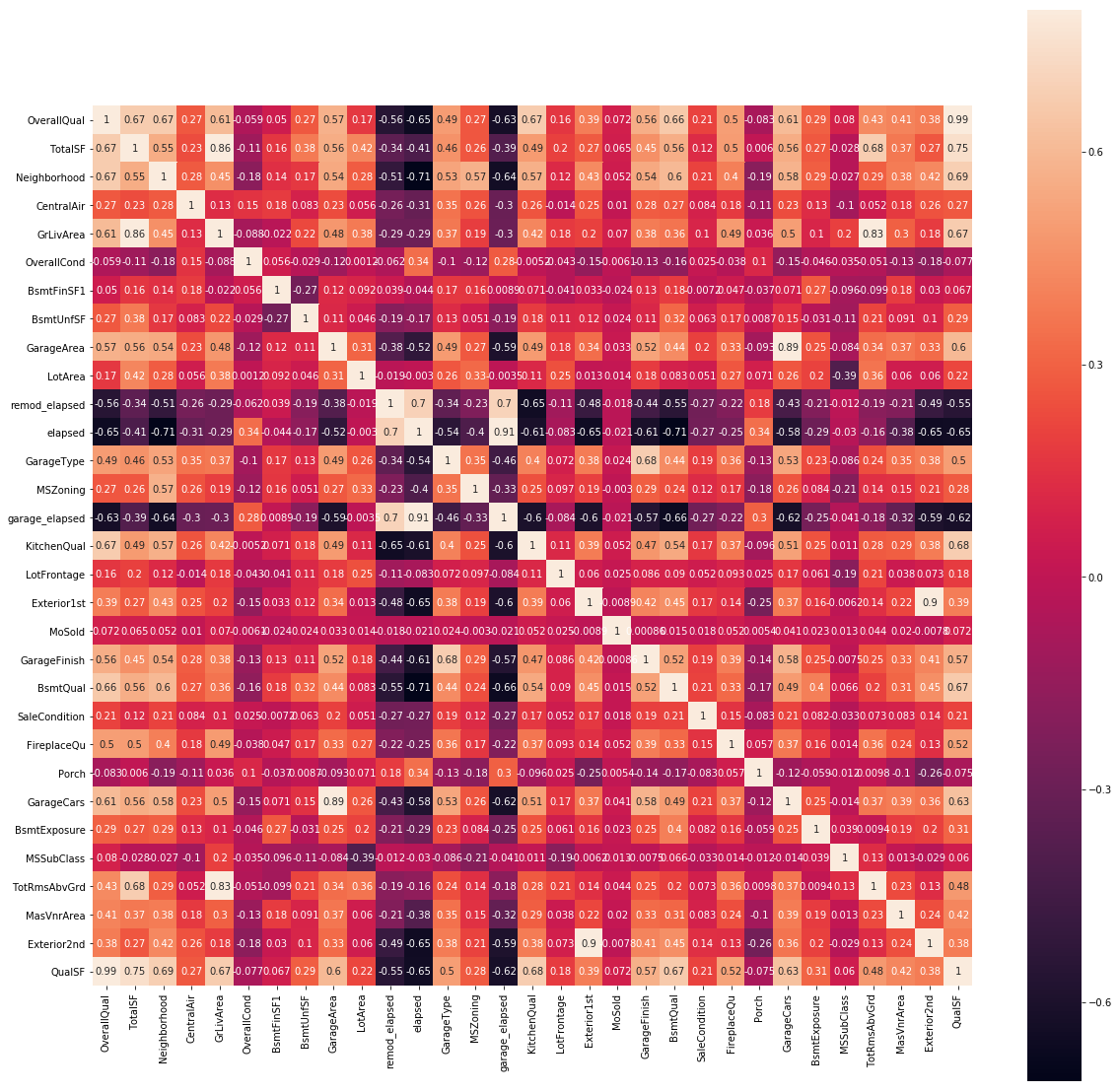


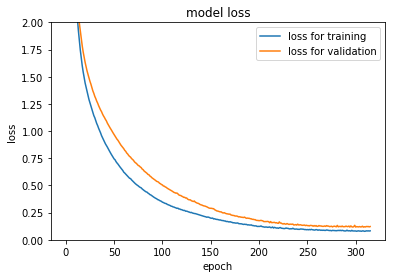

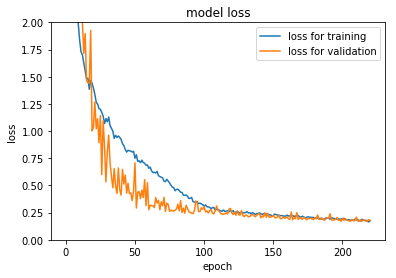
- 投稿日:2019-02-18T09:43:13+09:00
pythonのfitbitでsleepのstageを取得する
pip3 install fitbit
でいれたモジュールはAPIのバージョンが1だから、取れないっぽい。
https://github.com/orcasgit/python-fitbit/issues/128
とかをみると、1.2にすればいけるっぽい。pipでいれたモジュールの調整がよくわからなかったので、直接書き換え。
homebrewでpython3を入れたosx(macos) Mojaveでの話
/usr/local/lib/python3.7/site-packages/fitbit/api.py
API_VERSION = 1
を
API_VERSION = 1.2
に書き換える。
2箇所あるよ。これでfitbit.sleep(date=dtToday)すれば、minutesDataではなく、levelsが取れる。
- 投稿日:2019-02-18T08:52:19+09:00
【SKY-HI】歌詞の特徴をWordCloudで可視化
はじめに
私は画像処理をメインに研究をしていますが、卒論を書き終え、息抜きがてら新しい世界を見てみたいと、最近自然言語処理をやっています。そんな中、これらの記事に出会いました。
米津玄師の歌詞をWordCloudで可視化してみた。
WordCloudで凛として時雨の歌詞の傾向を可視化するなるほど。じゃあ、僕が推しているSKY-HIでもやってみようじゃないか、そう思ったのが今回の記事の動機です。SKY-HIの世界へようこそ。
(【FLYERSへ】結果に飛ぶと、JAPRISONが味わえます。)
SKY-HI
6人組スーパーパフォーマンスグループAAAのメンバーである日高光啓さんは、実はソロのラッパーSKY-HIとしても活躍しています。その活躍は日本にとどまらず、韓国のラッパーと曲を作ったり、世界ツアーを行なったりと、名実ともに日本を代表するラッパーの1人です。(もうちょっと日本のみなさんに知ってもらいたい!!!)
2019年2月現在、「SKY-HI TOUR 2019 "The JAPRISON"」開催中です!やりたいこと
WordCloudは、テキスト中で出現頻度が高い単語を複数選んできて、その頻度を大きさに反映させた画像を作ることができるツールです。例えば、以下の画像はWordCloudによって作成されたものです。
【引用:WordClouds.com】これをSKY-HIの最新アルバム「JAPRISON」の歌詞に対して適用し、歌詞を可視化、そしてJAPRISONの曲たちの歌詞の世界観を新しい視点から味わおう、というのが今回の目的です。
なお、今回の実行環境は以下の通りです。
python 3.6.8 macOSX 10.13.6 (High Sierra)準備
今回使うツールの準備をしていきます。まず、形態素解析エンジンとして公開されているMeCabと、MeCabの辞書に当たるMeCab-IPADICをインストールします。また、MeCabをPythonで使えるようにするツールとしてMeCab-Python3も入れておきます。
(余談ですが、Wikipedia先生によると、MeCabという名前はMeCab開発者が和布蕪好きだったことにより命名されたようです。超余談ですね。)brew install mecab mecab-ipadic pip install mecab-python3この時点でMeCabは使えるようになりました。
ただ、今インストールした辞書だけでは、うまく行かないことがあります。そこで新語に対応した辞書MeCab-IPADIC-NEologdが提供されています。これは、Homebrewでは入れられないので、直接githubからクローンすることになります。cd /usr/local/lib/mecab/dic git clone --depth 1 https://github.com/neologd/mecab-ipadic-neologd.git ./bin/install-mecab-ipadic-neologd -nさて、MeCabの準備が整いました。実際にTerminalで
mecabと叩くとMeCabが起動して、形態素解析ができます。terminal$ mecab AAAの日高はラッパーです AAA 名詞,固有名詞,組織,*,*,*,* の 助詞,連体化,*,*,*,*,の,ノ,ノ ラッパー 名詞,一般,*,*,*,*,* です 助動詞,*,*,*,特殊・デス,基本形,です,デス,デス EOS「AAA」が名詞(固有名詞)、組織名であり、「の」は助詞、「ラッパー」は一般名詞、「です」は助動詞であると判定されました。このように、文中の言語を、意味をもつ最小単位(形態素)の列に分割して、それぞれの形態素の品詞等を分類することを形態素解析と言います。
あとは、今回の主役WordCloudを入れます。
pip install wordcloud以上で、ツールの準備は完了です。次は実際にWordCloudで遊びます。
Let's WordCloud!
今回使うものたちをimportしておきます。
import os from os import getcwd import re import bs4 import time import requests import matplotlib import pprint from wordcloud import WordCloud, ImageColorGenerator import MeCab from PIL import Image import numpy as np import matplotlib.pyplot as plt import random歌詞の取得
このセクションについては、こちらを参考にしました。ここでは、歌ネットに掲載されているSKY-HIの曲の歌詞を抽出します。
def load(url): res = requests.get(url) res.raise_for_status() return res.text def pickup_tag(html, find_tag): soup = bs4.BeautifulSoup(str(html), 'html.parser') paragraphs = soup.find_all(find_tag) return paragraphs def scraping_web_page(url): html = requests.get(url) soup = bs4.BeautifulSoup(html.content, 'html.parser') return soup def parse(html): soup = bs4.BeautifulSoup(str(html), 'html.parser') # htmlタグの排除 kashi_row = soup.getText() kashi_row = kashi_row.replace('\n', '') kashi_row = kashi_row.replace(' ', '') # 記号の排除 kashi_row = re.sub(r'[ <>♪`‘’“”・…_!?!-/:-@[-`{-~]', '', kashi_row) # 注意書きの排除 kashi = re.sub(r'注意:.+', '', kashi_row) return kashi with open('SKY-HI.txt', 'a') as f: # アーティストページ(SKY-HI)のアドレス url = f'https://www.uta-net.com/artist/15174/' # 曲ページの先頭アドレス base_url = f'https://www.uta-net.com' # ページの取得 html = load(url) # 曲ごとのurlを格納 musics_url = [] # 歌詞を格納 kashis = '' """ 曲のurlを取得 """ # td要素の取り出し for td in pickup_tag(html, 'td'): # a要素の取り出し for a in pickup_tag(td, 'a'): # href属性にsongを含むか if 'song' in a.get('href'): # urlを配列に追加 musics_url.append(base_url + a.get('href')) """ 曲名の取得 """ titletemp = [] titles = [] soup = scraping_web_page('https://www.uta-net.com/artist/15174/')titletemp.append(soup.find_all(href=re.compile('/song/\d+/$'))) for i in range(len(titletemp[0])): temp = titletemp[0] titles.append(re.split('[><]', str(temp[i]))[2]) """ 歌詞の取得 """ for i, page in enumerate(musics_url): print('{}曲目:【{}】 \n from {}'.format(i + 1,titles[i], page)) html = load(page) for div in pickup_tag(html, 'div'): # id検索がうまく行えなかった為、一度strにキャスト div = str(div) # 歌詞が格納されているdiv要素か if r'itemprop="text"' in div: # 不要なデータを取り除く kashi = parse(div) print(kashi, end = '\n\n') # 歌詞を1つにまとめる kashis += kashi + '\n' # 1秒待機 time.sleep(1) break # 歌詞の書き込み f.write(kashis)これを実行すると、曲とそれに対応する歌詞が表示されます。
ここでは、最初の2曲分だけお見せします。出力1曲目:【New Verse -Remix- feat. eill】 from https://www.uta-net.com/song/262891/ ゴールの旗はどこ俺の居場所はこここっちを向いてよこっちよ君の為の目を閉じてリラックス、オープンスピーカー越しの君、調子はどう素っ裸の心のはるか上空まで飛ぶのに必要ないアルコール夢から覚めた時半笑えないニュースに落ちた時や心無い言葉がまた刃を研いだどきな、どきな、鬼さんこちら望んでいた未来望まれた期待そこにある人生全て愛していたい転んだら手痛いミス待ちの奴でいっぱい怖さも請け負うさ全部持ってきな笑っちまいな腫らした瞼の向こうの世界もありがたいなまだ痛みに会えた笑っちまいなその感傷も逃げ腰な自分もありがたいなまた君に会えた愛しても泣いても何度でも大したことあっても笑ってやろうシミ、次のテイクでボーカル上げてくれドラムを響かせてくれ照明の落ちたブースがやけに落ち着くのは自分と会話するツールだからさアイドル崩れの野郎口だけ達者な世渡り上手だろうラップも見かけも凄い奴なんて山ほどいる誰かの目で見るそこに生きる俺はいつもヒールいや俺自身が本当はそう思ってるのか人以上の報酬、プレッシャーの分の成功でも足に鎖、両手には手錠なぁドクター教えてくれこんな俺は正常どうしても答えが無いその時マイクの向こうの君を呼び自分自身を灯しまた帰ってこれるこの通りさぁ一緒に作ってみようぜ昨日よりもマシなストーリー笑っちまいな嫌なほど長い死ぬまでの時間もありがたいなまだ夢を見れた笑っちまいなその愛情も逃げちゃった自分もありがたいなまた僕に会えたいつかどこか枯れた涙雨が止めば腫れた瞼夢見た自分とは程遠いでも足掻く姿こそ愛おしい弱さを憎まなくてもいいどれも全部自分だからほらまた僕に会えた弱音が出る口を塞いで気がつけば口の中で腐って何が辛いのかもわからなくなるその前にねぇいつでも僕を呼んで笑っちまいな嫌なほど長い死ぬまでの時間もありがたいなまだ夢を見れた笑っちまいなその愛情も逃げちゃった自分もありがたいなまた僕に会えた愛しても泣いても何度でも大したことあっても笑ってやろう 2曲目:【愛ブルーム】 from https://www.uta-net.com/song/150035/ アスファルトされた街中で君だけが柔らかくてバグだらけの回路抜け出して連れ去る僕の役目風を泳ぐスカートにヒラリ乗っかって火遊び段取りは無視してハンドリングお望みならもう少しハードに君を誘うエージェントを上げてクレッシェンド心配ならいらない最高の一つ上をプレゼント花が色を差す茂みに足を伸ばすリアルの向こうへ先立ち宝探しのファンタジーの始まり風向きはイキナリ波打つようにみだり要するに今すぐにイキたいのさワンチャンス誘わせて近づいてストップ夢を見させて華やいで輝いて瞬いてく咲き走れ愛ブルームノイズだらけのより雲の上を見に行こう鮮やかに揺さぶる蜃気楼君の危うげな揺れをリピート自由、不自由、縛られ過ぎる下界を笑うように君がスウィング振り落とされないようにしがみつく僕にウインク太陽がジェラシー見惚れたお月様のフェイバリットタブーを破る女神神様も打つ手無し花が色を増す枯らさない様に水をやるどこまでだって僕が相手しなやかなカラダで明日を描いて鮮やかな手品に抵抗すら出来ないともするとこの先も君に落ちるワンチャンス誘わせて近づいてストップ夢を見させて華やいで輝いて瞬いてく咲き走れ愛ブルーム要するに今君とイキたいのさワンチャンス誘わせて近づいてストップ夢を見させて華やいで輝いて瞬いてく咲き走れ愛ブルームこれが全72曲分続きます。なおそれぞれの曲の歌詞を格納したものを、テキストファイル
SKY-HI.txtとして保存しています。さて、ここからいきなり形態素解析に移っても良いのですが、実は今回使用するMeCabは英語に対応していません。SKY-HIの歌詞には、よく英単語が登場するので、これに対応するためにユーザー辞書を作ることにします。
ユーザー辞書の作成
まず、適当なところにこれからユーザー辞書となるcsvファイルを作ります。
そこには、次のような形で単語を登録していきます。
表層形,左文脈ID,右文脈ID,コスト,品詞,品詞細分類1,品詞細分類2,品詞細分類3,活用型,活用形,原形,読み,発音,オプション
詳しくは公式ドキュメントをご覧いただきたいです。例えば、SKY-HIという単語を辞書に登録するには、次のように入力します。UserDic.csvSKY-HI,,,10,名詞,固有名詞,人名,名,*,*,スカイハイ,すかいはい,すかいはい,ユーザー登録このように活用形のない、例えば名詞などはこれで登録できますが、活用形のある単語は自分で活用語展開をしなければなりません。他のソフトウェアの場合、原形を入力すれば自動的にその活用形も登録してくれる、動的活用展開をしてくれることもありますが、MeCabの場合はリソースや計算コストの観点から対応していません。ただ、今回のようにWordCloudで可視化したいだけの場合、品詞が何であるかはそこまで重要ではありません。したがって、全ての英単語を名詞として登録してしまえば、作業量的には大幅に削減できます。(本当ならば、活用形も含めて辞書に登録したいです。。。)
さて、全ての単語の登録が済んだら、辞書ファイル(UserDic.csvとします)をコンパイルします。
$ /usr/local/libexec/mecab/mecab-dict-index \ -d /usr/local/lib/mecab/dic/ipadic \ -u user.dic \ -f utf-8 \ -t utf-8 UserDic.csv(ディレクトリ位置については、各々違いますが、私の例では上の通りでした。)
mecab-dict-indexで辞書のコンパイルができます。オプションについては、以下の通りです。
● -d DIR : システム辞書があるディレクトリ指定
● -u hogehoge : hogehogeというユーザー辞書ファイルを作成
● -f code : CSVファイルの文字コード
● -t code : バイナリ辞書の文字コードコンパイルが終わったら、パスを通しましょう。
$ vi /usr/local/etc/mecabrcと叩けば
出力; ; Configuration file of MeCab ; ; $Id: mecabrc.in,v 1.3 2006/05/29 15:36:08 taku-ku Exp $; ; dicdir = /usr/local/lib/mecab/dic/ipadic ; userdic = /home/foo/bar/user.dic ; output-format-type = wakati ; input-buffer-size = 8192 ; node-format = %m\n ; bos-format = %S\n ; eos-format = EOS\n ~ ~などと出てきます。この
dicdirの次の行あたりにuserdic = /usr/local/lib/mecab/dic/ipadic/user.dicを入れれば、パスが通ります。
これで、ユーザー辞書の登録は完了です。実際に単語が登録されたか、確認してみましょう。mecab$mecab SKY-HIはラッパーです SKY-HI 名詞,固有名詞,人名,名,*,*,スカイハイ,すかいはい,すかいはい,ユーザー登録 は 助詞,係助詞,*,*,*,*,は,ハ,ワ ラッパー 名詞,一般,*,*,*,*,* です 助動詞,*,*,*,特殊・デス,基本形,です,デス,デス EOSはい、ちゃんとできています。
お待たせしました。ここから、Pythonで形態素解析をおこないます。MeCabで形態素解析
形態素解析のお時間です。
まず歌詞を保存したテキストファイルを読み込み、それをutf-8でdecodeします。テキストファイルは1行に1曲分の歌詞が保存されているので、1行ごとに分割して、配列listとします。bindata = open("SKY-HI.txt", "rb").read() kashi = bindata.decode("utf-8") lines = kashi.split("\n")ここでどの曲を解析するか、選びます。その準備として、
listに保存した曲たちについて何番目に何の曲が入っているかを明示しておきます。title_table = [] for i , title in enumerate(titles): title_table.append([i, title])ここで
title_tableを叩くと出力[[0, 'New Verse -Remix- feat. eill'], [1, '愛ブルーム'], [2, 'アイリスライト'], ...(中略)... [70, 'Role Playing Soldier'], [71, 'One Night Boogie feat. THE SUPER FLYERS']]と番号と歌詞が出てきます。この番号を見て
list[59]等と指定すれば、その番号にしたがって曲を選択できます。今回はアルバムJAPRISONのリード曲「What a Wonderful World!!!」を解析に使用します。
Mecab.Taggerというクラスのインスタンスを生成し、m.parseを使用することで、歌詞を形態素に分割してくれます。なお、Taggerでは使う辞書を指定できます。MeCab-IPADIC-NEologdに加えて、先ほど作成したユーザー辞書userdicも使用しましょう。m = MeCab.Tagger("-Ochasen -d /usr/local/lib/mecab/dic/mecab-ipadic-neologd /usr/local/lib/mecab/dic/userdic") listwww= m.parse(lines[59]).split("\n")出力['なんとも\tナントモ\tなんとも\t副詞-一般\t\t', '世知辛く\tセチガラク\t世知辛い\t形容詞-自立\t形容詞・アウオ段\t連用テ接続', '見\tミ\t見る\t動詞-自立\t一段\t未然形', 'ざる\tザル\tぬ\t助動詞\t特殊・ヌ\t体言接続', '言わ\tイワ\t言う\t動詞-自立\t五段・ワ行促音便\t未然形', 'ざる\tザル\tぬ\t助動詞\t特殊・ヌ\t体言接続', '聞か\tキカ\t聞く\t動詞-自立\t五段・カ行イ音便\t未然形', 'ざる\tザル\tぬ\t助動詞\t特殊・ヌ\t体言接続', '今日\tキョウ\t今日\t名詞-副詞可能\t\t', 'も\tモ\tも\t助詞-係助詞\t\t', 'プラスチック\tプラスチック\tプラスチック\t名詞-一般\t\t', '製\tセイ\t製\t名詞-接尾-一般\t\t', 'の\tノ\tの\t助詞-連体化\t\t', '日\tヒ\t日\t名詞-非自立-副詞可能\t\t', 'が\tガ\tが\t助詞-格助詞-一般\t\t', '差す\tサス\t差す\t動詞-自立\t五段・サ行\t基本形', ...(以下略)注意:他の記事を見ると
m.parseではなくm.parseToNodeを使用している例が多いですが最新版のMeCabでは、これを用いて形態素解析を行なった後に使用できる.surface属性にバグがあるようです。今回はそれを避けるためにm.parseを使用して、そこから形態素と品詞を抜き出す方式をとりました。歌詞の中で印象的になりやすい品詞といえば、「名詞、動詞、形容詞、副詞」でしょうか。この4品詞の形態素を抽出します。また、これはWordCloudで可視化してからわかることですが、この4品詞の中でも、「その形態素抜き出されても...」となるものが登場することがあります。それが画像にデカデカと描かれても困るので、それらが除外されるように
ignoreとして格納し、除外します。words = [] yestype = ["名詞","動詞","形容詞","副詞"] ignore = ["てる","あっ","さん","よう","それ","しよう","かお","くれ","中こ","モン","かかっ","こい"] listleng = len(listwww) for i, word in enumerate(listwww): if i < listleng-2: typet = word.split('\t')[3] typet = typet.split("-")[0] if typet in yestype: temp = word.split("\t")[0] if not temp in ignore: words.append(temp)ここまでで完成した形態素列
wordsは次のようになっています。出力['なんとも', '世知辛く', '見', '言わ', '聞か', '今日', 'プラスチック', '製', '日', '差す', ...(以下略)先ほどの
listwwwと比べて「ざる」(助動詞)などが消えていることがわかります。
ここまでで、形態素解析が終わりました。あとはWordCloudで可視化するだけです!WordCloudで可視化
WordCloudで可視化する際に使用するフォントを指定する必要があります。SKY-HIは日本語詞なので、日本語対応するフォント「mplus-1m-regular」を使ってみました。日本語なら何でもいいです。
text = ' '.join(words) fpath = "/Library/Fonts/mplus-1m-regular.ttf"いよいよ可視化します。
SKY-HI「JAPRISON」は、黒背景に赤文字というCDジャケットが印象的なので、今回描くWordCloudもそんな感じにします。文字色を作成する関数を作っておきます。色はHSLで指定します。HSLについてはこちら(配色を考えるのが面倒ならhsl()を使おう)がわかりやすかったです。簡単に言うと
- H:hue(色相)、0°~360°の角度で色を指定。0°=360°が赤色
- S:saturation(彩度)、0%~100%で指定。値が高いほど純色、低いほど灰色に近づく
- L:lightness(輝度)、0%~100%で指定。50%が純色。高いほど白くなり、低いほど黒くなる。
def red_color_func(word, font_size, position, orientation, random_state=None,**kwargs): return "hsl(%d, %d%%, %d%%)" % (random.randint(0, 1), random.randint(90, 100) ,random.randint(45, 55))では
WordCloudで可視化、pyplotで描画までいきます。
背景は黒色、フォントと色調はこれまでに指定した通り、画面サイズは900×500です。wordcloud = WordCloud(background_color = "black", font_path = fpath, color_func = red_color_func, width = 900, height = 500, ).generate(text) plt.figure(figsize = [20,20]) plt.imshow(wordcloud, interpolation = 'bilinear') plt.axis("off") plt.show()出力は...
できた!What a Wonderful World!!!のフックは「ハローグッバイ」から始まるのですが、やはりそれが最も目立ちますね。JAPRISONというアルバムは「精神的や文化的な意味での監獄からそこを抜け出すための鍵を探す」ということがテーマの1つになっている(と思ってます)が、それがよくわかる、まさにリード曲という感じの結果になりました。
結果
JAPRISONの収録曲14曲をWordCloudで可視化したものを一気にご覧ください。
1. What a Wonderful World!!!
2. Shed Luster
3. Role Playing Soldier
4. 23:59
5. White Lily
6. Blue Monday
7. Doppelgänger
8. Persona
9. Shed Luster pt.2
10. New Verse
11. Marble (Rerec for JAPRISON)
12. Name Tag
※JAPRISON収録のNameTagは「Name Tag-Remix-feat.Ja Mezz&HUNGER」ですが、歌ネットにはRemix ver.の歌詞が収録されていなかったため、「Name Tag feat. SALU & Moment Joon」で代用しています。
13. Diver's High
14. Snatchaway
おわりに
この記事では、SKY-HIの曲を題材に、MeCabを用いた形態素解析の基礎、WordCloudの使い方を学びました。たまには、自分の研究分野以外の内容に触れるのも楽しいものですね。自分の分野に囚われることなく、広い世界に飛び出す一歩になりました。監獄よ!ハローグッバイ!
参考
- python3で裁判の判例データからWord Cloudを生成する
- 新し目の辞書を使ってMeCabをPythonから利用する
- 配色を考えるのが面倒ならhsl()を使おう
- PythonでWordCloudを作成してみました
- 米津玄師の歌詞をWordCloudで可視化してみた。
- WordCloudで凛として時雨の歌詞の傾向を可視化する
- mecabユーザ辞書を追加
- 形態素解析
おまけ
AAAの代表曲「恋音と雨空」でもやってみました。
やっぱ、SKY-HIとAAAじゃ雰囲気全然違いますね。以上です。お疲れ様でした。
















- 投稿日:2019-02-18T08:00:06+09:00
PGGAN「段階的な学習により実現した高解像度・安定性・多様性」
論文紹介・画像引用
PROGRESSIVE GROWING OF GANS FOR IMPROVED QUALITY, STABILITY, AND VARIATION
https://arxiv.org/pdf/1710.10196v3.pdf本研究での生成画像
Progressive Growing of GANs
低解像度の画像から始めてネットワークにレイヤーを追加して徐々に解像度を上げていくGAN
従来のGANのように、すべてのスケールについて同時に学習するのではなく
まず初めに大まかな画像構造を捉えてから段階的に細かいところに注意を向けていく
上図のN×Nは解像度がN×Nでのconvolution層を意味する
すべての層は常に訓練可能な状態である
本研究の学習ではGeneratorとDiscriminatorそれぞれが低解像度(4×4)の層だけを組み入れて始める
学習が進むにつれて徐々にGeneratorとDiscriminatorに層を追加していくことで生成画像の解像度を上げるこうすることで高解像度での画像の生成が安定化し、学習時間の短縮ができる
上図右の画像6枚は上述の段階的な学習法(解像度:1024×1024)によって生成された画像である
GeneratorとDiscriminatorの解像度を2倍にするとき新しい層を入れる16×16の解像度から32×32の解像度への移り変わりを表している(上図(a)から上図(c))
その移り変わりの間を表したのが上図(b)高解像度の層では残差ブロックのようにしている
$α$は$0$~$1$$2×$と$0.5×$はそれぞれ解像度を2倍、0.5倍にすることを意味する
$to RGB$は特徴ベクトルをRGBに変換する層、$from RGB$はその逆
どちらも$1×1$のconvolution層を使うdiscriminatorを訓練するときは、現在のネットワークの解像度に合わせて縮小された本物の画像を入れる
残差ブロックを使用しているため、Generatorの出力は2つの画像(to RGBされたもの)を足し合わせる
同じようにDiscriminatorでは2つのベクトル(from RGBされたもの)を足し合わせるネットワーク構成
上図左がGeneratorのアーキテクチャ、上図右がDiscriminatorのアーキテクチャ
どちらも3層を1ブロックにしたものを学習の途中で1つずつ追加して積み重ねているGeneratorの最後の1×1のconvolution層は$to RGB$を意味する
DIscriminatorの最初の1×1のconvolution層は$from RGB$を意味するアップサンプリングは2×2で複製、ダウンサンプリングはアベレージプーリング
潜在ベクトルは512次元で本物画像と生成画像は[-1,1]の範囲で表す
leaky ReLU($α=0.2$)を線形変換する最終層を除いて、両ネットワークのすべての層に使う
学習の流れ
4×4の解像度から始めて、Discriminatorに合計800枚の本物画像を見せるまでネットワークの学習をする
その後は次の2つの処理を交互に実行する
新しい3層ブロックを入れる(解像度を上げる)→800枚の本物画像でネットワークを安定化させる→新しい3層ブロックを入れる(解像度を上げる)→・・・工夫点(後述)
batch normalization・layer normalization・weight normalizationはどちらのネットワークにも使わないが
Generatorの3×3のconvolution層の後にpixelwise normalization(後述:Generatorにおけるピクセル特徴ベクトルの正規化)を使うバイアスは0で初期化し、重みは分散1の正規分布に従う
しかし、学習時に各層固有の定数で重みをスケーリングする(後述:学習率の均質化)Descriminatorの最終層には4×4の解像度でミニバッチ全体の標準偏差の特徴マップを追加する(後述:ミニバッチ標準偏差を使った画像多様性の向上)
最適化関数
Adam($α = 0.001, β1 = 0, β2 = 0.99, ε = 10^{−8}$)
ミニバッチサイズ
解像度($4×4~128×128$) :ミニバッチサイズ=$16$
解像度($256×256$) : ミニバッチサイズ=$14$
解像度($512×512$) : ミニバッチサイズ=$6$
解像度($1024×1024$) : ミニバッチサイズ=$3$
ミニバッチサイズを徐々に小さくするのは、メモリに乗るようにするためPGGANの良いところ
学習の安定化
最初は小さい画像のため大幅に安定して生成できる
理由:クラス情報・モード情報が少ない解像度を少しずつ上げていくことによって単純な質問に答えていくだけのような状況で学習できる
従来であれば、潜在表現から1024×1024の画像へのマッピングという難しい最終目標を達成できるように試行錯誤しなくてはならない
複雑である潜在表現から高解像度の画像へのマッピングは段階的に学んだほうが簡単(PGGANの場合)
一層入れて十分に学習する→新しい層(解像度が前回よりも高い層)を入れる→十分に学習する→・・・
一層をちゃんと学習して安定化してから次の層を入れる丁寧なやり方
(従来のGAN)
最初からすべての層を入れて一気にすべての層を学習する
PGGANと比べれば雑なやり方例)数学
(PGGANの場合)
足し算を学習する→引き算を学習する→掛け算を学習する→・・・→・・・・・・・・→センター試験の数学
(従来のGAN)
センター試験の数学(初日)実際には、WGAN-GP損失やLSGAN損失を使用して
メガピクセルスケールの画像を確実に生成するための学習を十分に安定化させる学習時間の短縮
PGGANでは大半のイテレーションが低解像度で行われるため
もちろん最終的な出力解像度にもよるが従来のGANよりも2〜6倍速く学習できるミニバッチ標準偏差を使った画像多様性の向上
GANは訓練データにある一部の画像の特徴やパターンだけを捉える傾向がある
解決策として「ミニバッチ識別」を提案するこれは個々の画像のみならずミニバッチ全体からも特徴統計量を計算することである
最終的には生成画像のミニバッチと訓練画像のミニバッチが同じ統計量を示すことが理想ミニバッチ層はDiscriminatorの最後に追加することで実装できる
ミニバッチ層では入力アクティベーションを統計量に変換するテンソルを学習する
ミニバッチの各サンプルから生成された様々な統計量が層の出力と足し合わせるためDiscriminatorは統計量を使うことができる本研究ではこの処理を大幅に単純化し、画像の多様性も向上させた
シンプルバージョン
本研究で単純化された方法は学習可能なパラメータや新しいハイパーパラメータを使うわけではない
①ミニバッチ上の各空間位置にある各特徴の標準偏差を計算する
②すべての特徴、すべての空間で平均を計算して単一の値を出す
③その値を複製して1枚の特徴マップをつくるこの層はどこにでも入れることはできるが最終層に入れるのが一番良いことがわかった
GeneratorとDiscriminatorの正規化
GANではGeneratorとDiscriminatorの学習によって値の発散が起きやすい
この問題への対策として2つの方法を提案する学習率の均質化
初期値は$N(0,1)$にし、学習時に重みを動的にスケーリングする
重みを動的にスケーリングするとは$\hat{w_i } = w_i / c$をすることである
$w_i$は重み、$c$は各層の正規化定数(Heの初期化を使う)
→スケール不変性が得られる最適化するときにスケールの影響を受けずに
パラメーターの更新ができるようになるため学習速度が上がるスケールを整えているためすべての重みに対して均質の学習速度にすることができる
Generatorにおけるピクセル特徴ベクトルの正規化
Generatorの各convolution層での計算後に各ピクセルの特徴ベクトルを正規化する
正規化は以下のようにする
$ε=10^{-8}$ $N$:特徴マップの数 $a_{x,y}$:ピクセル$(x,y)$の正規化前の特徴ベクトル
$b_{x,y}$:ピクセル$(x,y)$の正規化したの特徴ベクトルGAN評価のためのマルチスケールにおける統計的類似性
上手く学習ができたGeneratorは
局所的な画像構造がすべてのスケールにわたって本物画像と似ている画像を生成する16×16ピクセルのローパス解像度から始めて、
生成画像のラプラシアンピラミッド表現による局所画像の分布と
本物画像のラプラシアンピラミッド表現による局所画像の分布のマルチスケール統計的類似性について考える
短くいうと、マルチスケールで生成画像と本物画像の分布を比較して、分布の距離が近ければ良いGANと考える※ラプラシアンピラミッドについては"laplacian pyramid"で画像検索するとイメージがしやすくなるかもしれない
局所特徴量を得る
これまでの慣例に従って、ピラミッドはフル解像度に達するまで段階的に2倍にする
各レベルは前回のレベルをアップサンプリングしたものとの差をエンコードするラプラシアンピラミッドの各レベルは特定の空間周波数帯に対応する
ランダムに16384枚の画像を選び、各画像のラプラシアンピラミッドの各レベルから128個局所特徴量を抽出する
そうすると各レベルから$2^{21}(2.1M)$個の局所特徴量が得られる($16384×128=2^{21}$)それぞれの局所特徴量は$7×7$のピクセルで$3$チャンネル
$x∈R^{7×7×3}=R^{147}$と表せる訓練データのレベル$l$からの局所特徴量は
と表し、
生成データのレベル$l$からの局所特徴量はと表す
分布距離を測る
①各チャンネルの平均と標準偏差を求めて
訓練データの局所特徴量と生成データの局所特徴量
の正規化を行う
②xとyの統計的な類似度をsliced Wasserstein distance(SWD)で計算する
ワッサースタイン距離は輸送問題に基づいて考えられた分布の距離を測る指標ワッサースタイン距離が小さいということは分布が類似していること、すなわち
この解像度での訓練画像と生成画像は見た目も多様性も同じように見えるということを意味する最低解像度の16×16での分布距離は大まかな画像構造の類似性を表し、
高解像度での分布距離はエッジやノイズの鮮明さといったピクセルレベルでの情報の類似性を表す検証
学習構成を変えたら結果はどう変わるのか?
上表は様々な学習構成でのSWD(Sliced Wasserstein distance)とMS-SSIM(multi-scale structural similarity)の数値評価を示している
上表を見る上での注意点
一般的には評価指標の数値が良いことは、色・テクスチャなどの多様性があることを意味するが、
MS-SSIMを見るときは注意が必要だ
上図を見れば(a)よりも(h)の方が明らかにきれいな画像ができているがMS-SSIMの数値はほとんど同じであるこれはMS-SSIMという指標は生成画像の多様性のみを評価するものであり、本物画像との類似性を評価するものではないからである
一方、SVDの数値は大きく改善している結果
最初の学習構成$(a)$はGulrajani et al.(2017)である
これはGeneratorにbatch normalizationを、Discriminatorにlayer normalizationを入れて
ミニバッチサイズを64にしたものである$(b)$は段階的な学習(層を徐々に追加していく学習)のネットワーク
鮮明な画像が生成されている
生成画像の分布と本物画像の分布がより似ていることをSWDの数値が示している高解像度の画像を生成することが目的であるが、そのためにはミニバッチを小さいサイズ(メモリに乗るサイズ)にすることが必要である
このことをしたのが$(c)$である
ミニバッチサイズを64から16に変更している
両指標からもわかるが、生成画像は不鮮明であるbatch normalizationとlayer normalizationを取り除き、ハイパーパラメーターの調整をして学習課程を安定化させたのが$(d)$である
$(e*)$はミニバッチ識別を可能にしたもの(Salimans et al., 2016)だが、生成画像の多様性を評価するMS-SSIMの指標すらも向上しないという結果に終わってしまった
対照的に、本研究でのミニバッチ識別$(e)$ではSWDの平均スコアを改善し鮮明な画像の生成にも成功している
更に本研究で提案した$(f)$と$(g)$を加えるとSWDのスコアと生成画像の質はより良くなっている
最後に$(h)$ではベストネットワークを用いて十分な学習をした結果である
これまでのGANモデルよりも鮮明な画像を生成できている収束と学習時間
上図$(a)$と$(b)$は訓練時間(横軸)とSWDの数値(縦軸)
上図$(c)$は訓練時間(横軸)とDiscriminatorに見せた本物画像の枚数(縦軸)$(a)$と$(b)$はGulrajani et al. (2017)の学習構成での結果である
ただし$(a)$は段階的な学習(層を徐々に追加していく学習)のネットワークではない(最初からすべての層をネットワークに入れておく)
$(b)$は段階的な学習(層を徐々に追加していく学習)のネットワーク段階的な学習は2つのメリットがあることがわかる
・かなり優れた最適値に収束する
・学習時間を半分にすることができる収束
収束性の向上は徐々にネットワークを大きくしていくという「カリキュラム学習」によるものである
段階的な学習をしない場合はGeneratorとDiscriminatorのすべての層は
大まかな画像構成の多様性と画像の詳細、両方の中間表現を同時に見つけなくてはならないしかし段階的な学習をする場合は、
最初の頃からあった低解像度の層はすでに早い時期に収束しているため
新しい層が加わってきたらネットワークは詳細な表現を学習することのみに専念することができる上図$(b)$の低解像度である$16×16$(赤線)が非常に早く最適値に達し、残りの学習では横ばいになっていることを見るとPGGANの学習法のメリットを実感できる
低解像度の層から順番$(16,32,64,128)$に収束していくこともわかる
学習時間の短縮
縦軸はDiscriminatorに見せた本物画像の枚数である
たくさんDiscriminatorに本物画像を見せたということは、それだけ学習が進んでいることを意味する段階的学習では初期の学習が非常に速いことがわかる
これは初期段階のネットワークは層が少ないため評価が素早くできるからであるフル解像度に達すると、Discriminatorに見せる本物画像の枚数(学習速度)はどちらの方法でも同じになる
上図はPGGANでは96時間で約640万枚の本物画像を見たことを示している
PGGANでなければ同じ枚数を見るためには520時間必要になると推定できるこの場合PGGANは約5.4倍、従来よりも速いことになる