- 投稿日:2019-12-21T23:58:39+09:00
toio にカメラを載せてOSC制御する
これは「toio™(ロボットトイ | toio(トイオ)) Advent Calendar 2019」の21日目の記事になります。
はじめに
toioにカメラを載せたり、TouchDesignerとOSCで通信できるようにしました。
toioに物を載せたり、他のアプリと通信する時の参考になればと思います。
やったこと
- toio に DSC-RX0 をレゴパーツを組み合わせて固定した
- toio.py で倒れないように加速度を調節した
- Python TouchDesigner の間をOSCで繋いだ
- TouchDesingerで生成した色と同じ色がLEDで光るようにした(通信テスト)
環境
- MacBook Pro (2.7 GHz Intel Core i5,16 GB 1867 MHz DDR3)
- macOS Catalina
- python 2.7
toio に カメラを載せて速度制御する
一気に止めるとこれ pic.twitter.com/M9GR241T3i
— 水落 大 mizumasa (@_mizumasa) December 21, 2019モーターの速度60ぐらいだと急に止めても大丈夫ですが、速度100から0に一気に落とすと倒れます。
0.3sぐらいかけて100から0まで滑らかにスピードを落とすようにすると倒れずにすみます。
toio.pyに滑らかに速度を変化させる関数 write_data_motor_smooth 追加しました。ちなみにこうなってます。
円形プレートに穴を開けて、ポッチ2x2に収まる三脚ネジが通るようにしています。
オーディオファン ストラップアダプター 1/4インチ 三脚 ネジ穴用 2個セット オーディオファンOSCでTouchDesignerと繋ぐ
TouchDesignerからOSCでtoioのLED光らせられるようにした。分かりにくいけどこんな感じ#toio #touchdesigner #python pic.twitter.com/zHnLuPGhrv
— 水落 大 mizumasa (@_mizumasa) December 21, 2019環境構築
以前作成した Python 環境で使えるtoioライブラリ toio.py を使用します。
インストール方法はこちら -> 「toio を Mac + Python で制御できるライブラリつくった」
加えて今回は、python用OSC通信ライブラリ pyOSC をインストールしておきます。
今回の記事は経過だけでしたが、これで何をつくるのか、またどこかで共有させて頂きたいと思いますのでお楽しみに。



- 投稿日:2019-12-21T23:42:20+09:00
Houdiniからトイドローン(Tello)を動かしてみる
こちらはHoudini Apprentice Advent Calendar 2019の22日目の記事。
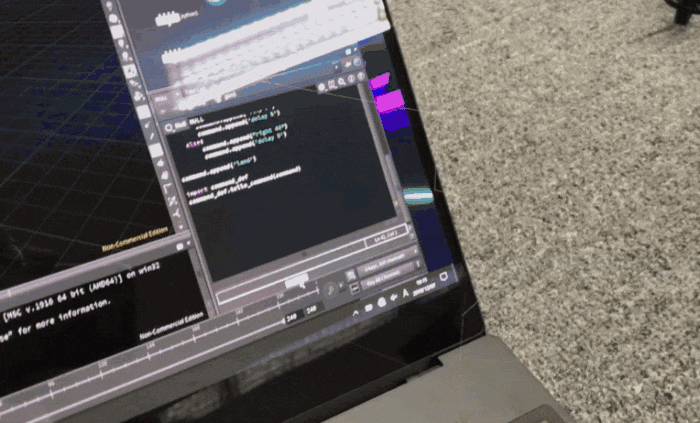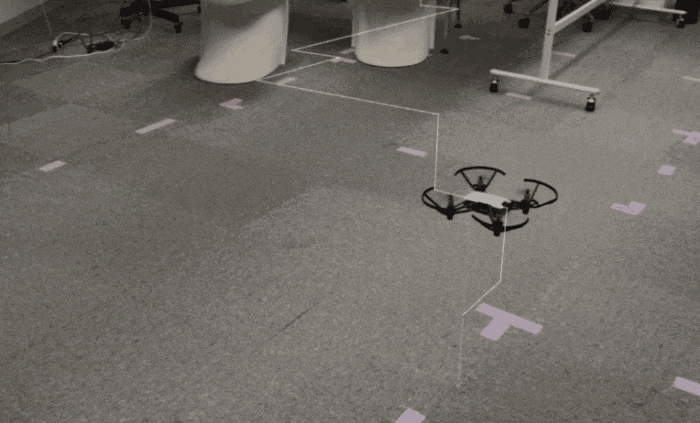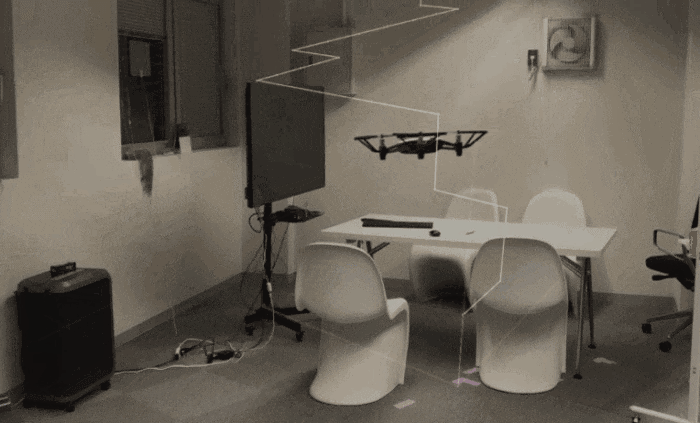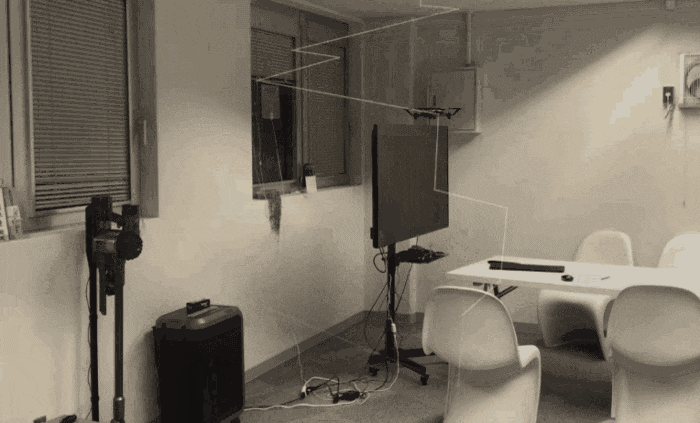
習作の予定だったがHoudiniをゴリゴリ触ったというよりか、Houdini/トイドローンの接続に悪戦苦闘したという内容になってしまった。。完成形
言葉で説明する前に、例によってとりあえずGIFを貼り付け。
(撮影動画+透過の画像キャプチャの合成)この後紹介する【 記述編 -基礎- 】で作成したもの。
要は Houdini側で作成した軌跡に沿うようにトイドローンを飛ばした、という感じ。うーん、わかりにくい。
前提編
何を作ったのか
この動いているドローンは下記の仕組みから構成されている。
(1) Houdini(VEX) : ランダムにxyz方向のいずれかに1移動、を繰り返す
(2) Houdini(Python) : (1)をドローンへの命令に書き換え、(3)に渡す
(3) Tello(Python) : DJI-SDKにて公開されているサンプルプログラムの一部を書き換え、(2)から受け取った命令を実行
(4) Houdini(Python) : (3)のPythonコードをHoudini内でimportして実行(1)については過去にHoudiniで作成したRandom Pipe Generatorで代用。
冒頭の表現を言い換えれば、今回は(2)に大半の時間を費やしたという感じ。※参考URL
・Houdiniでスケルトン天井のパイプのベースを自動生成する(*Qiita)何がしたかったのか
最近しばしば見かけるこれら↓
インテルは世界中の花火をDroneに置き換える…だそうです。花火職人はDroneがライバルになるなんて考えもしなかっただろうな。Droneが石油施設の爆破に使われるのは嫌だけど、こっちは大歓迎です。
— セキ ヤスヒサ? (@Campaign_Otaku) October 1, 2019
pic.twitter.com/nvJVsZMRSQ
LEDを取り付けた多数のドローンをコンピュータで制御し、夜空で光のショーを行う企業が米国などで活動中。半導体で有名なインテルもその一つだが、精緻な作品で定評を得つつあるのがデトロイトの Firefly 社。同社の作品の一部を紹介した動画。100台のドローンが大活躍。pic.twitter.com/hDVuSd0aaN
— Oguchi T/小口 高 (@ogugeo) November 22, 2019
のような近未来感あふれるドローン編隊飛行、Houdiniで軌跡を描いたら綺麗なのでは…?と思ったのがきっかけ。(実際どうなんですかね?幾何模様であれば定式化してドローン側に渡してあげるだけでしょうし、対応言語次第なのでしょうか)トイドローン(Toy Drone)とは
明確な定義があるわけではないが、
- 1~2万円で購入可能
- 軽量
- 操作が簡単
- モノによってはパーツ拡張にも対応
- モノによってはプログラムから操作することも可能(ScratchやPythonなど)
辺りを満たす、子供~大人まで幅広く遊べるドローンのこと、といったところか。
今回お試しで使ってみたTelloは、スマートフォンアプリ経由で接続すればアプリ画面をコントローラにして「ドローンについたカメラ」が見ている景色が見える。
今回使用したトイドローンTello 2台のスペック概要は下記の通り。
いま買うならDJI Mavic Mini(*website)辺りだと思うので、あくまで簡易的な紹介。
項目 1台目詳細 2台目詳細 商品名 Tello Boost コンボ Tello EDU 価格 ¥13,750 ¥17,050 サイズ 98×92.5×41 mm 98×92.5×41 mm 重量 81.6 g 87 g 最大飛行時間 13 min 13 min 最大飛行高度 30 m 30 m 写真 5MP (2592x1936) 5MP (2592x1936) 動画 HD 720p30 HD 720p30 SDK 1.3 2.0 後ほど触れる&詳しい方はお分かりの通り、通常のTelloとTello EDUはSDKのバージョンが異なり、編隊飛行やミッションパッド認識などに対応しているのはTello EDUのみ。お、不穏な空気だな?
※参考URL(回し者じゃないです)
・Tello(*website)
・Tello EDU(*website)
準備編
実行環境
OS : Windows 10
Houdini : Houdini Apprentice 17.5.460
Python : 2.7.15 (by pyenv) -> 2.7.15 (Houdini python)
Tello : Tello + Tello EDUTelloサイド
スマートフォンアプリ経由での飛び方は把握している前提で、TelloをPythonから操作することを考える。
アプリで接続すればもうカメラ画像はアプリに同期されるし、すぐ飛び立てるのですごい。かがくのちからってすごい。幾つか接続方法はあるが、今回はDJIが公開しているSDKであるTello-Python(*GitHub)を使用する。
ここも含めて詳細に書き始めると記事が肥大化してつらい(正直)ので、すでに詳細に解説されている記事を参考のこと。※参考URL
・DJI公式SDK「Tello-Python」を試そう
・PythonによるTello操作(基本、及びクラウドからのMQTTによる操作まで)Windowsサイド
少し前であればLinux環境での実行推奨だったようだが、現在はWindowsでも動くので挙動確認時はWindowsを選定。ただしTello-PythonはREADMEにもあるように
based on python2.7のため※、pyenvで切り替えて実行していた。※
一応3系でやれないこともないが、ImportError: No module named '_curses'エラーが生じる。こちら(*stackoverflow)を参考にpip install windows-cursesと入れてあげればモジュール的には解決するが、今度は2/3系の書き換えが必要そうなエラーが吐かれたためこれ以上確認していない。Houdini内pythonは幸か不幸か2.7系のため、バージョン切り替えは特に気にしなくとも良さげ。
【 記述編 -応用- 】ではHoudini内Pythonに別途モジュールをインストールする必要があったので後ほど触れる。
Houdiniサイド
特定のファイル(今回であれば【dji-sdk/Tello-Python】や【TelloSDK/Multi-Tello-Formation】)を実行対象として読み込みたかったので、
houdini.env内のPYTHONPATHにディレクトリパスを追記する。
記述編 -基礎-
(1)Houdini(VEX)
==================================
既に記載した通り、トイドローンに這わせたい軌跡は過去作成済みのRandom Pipe Generatorでいう
「グリッド分割された指定空間内で始点・終点を決め、最短経路までlineを伸ばすサブネット」(*Qiita)
を使いまわす。ただ(2)でHoudini Pythonに渡すため、アトリビュートに格納しておく。
(2)Houdini(Python)
==================================
Houdini側での座標1移動を、Tello側での20cm移動に対応させることを考える。
どうやらtello python commandの最低移動距離は20cmかららしい。
ただ変換するのもつまらないので、文字通り「ヒネリ」を加えてみる。「上昇して右移動」「前進して右移動」のときに限り、移動ではなくFlipで置き換えてみる。
VEX Tello-Python *** → (1, 0, 0) forward 20 *** → (0, 1, 0) up 20 (1, 0, 0) → (0, 0, 1) flip r (0, 1, 0) → (0, 0, 1) flip r (0, 0, 1) → (0, 0, 1) right 20 ※「2回以上続けて右移動」のときだけflipナシ
ただのIF文ラッシュだが、、これをpythonで書き下す。
PythonScript(Houdiniノード)node = hou.pwd() geo = node.geometry() # 使いまわしアセット # ->「xyzいずれかの方向に1移動」を0~2に対応させ、randVecというattributeに格納したもの randVec = geo.intListAttribValue("randVec") # 実行用command listを作成 # 基本は「その方向に移動」だが、ちょっとひねりでflipを混ぜてみている command = [] for i in range(1, len(randVec)): if randVec[i] == 0: command.append("forward 20") elif randVec[i] == 1: command.append("up 20") elif (randVec[i] == 2) & (randVec[i-1] != 2): command.append("flip r") else: command.append("right 20")(3)Tello(Python)
==================================
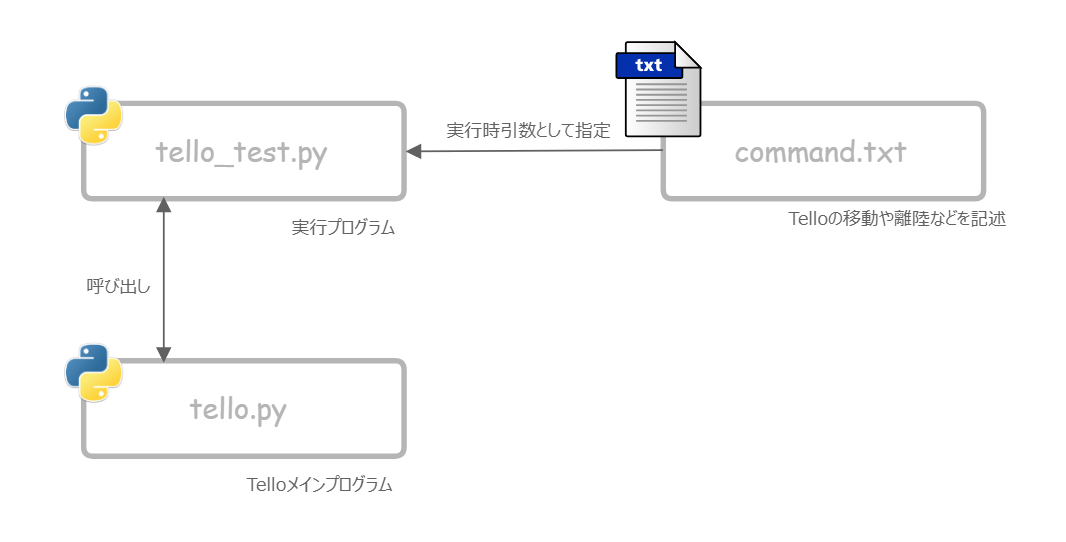
公開されているTello-Pythonは送信したい動き=コマンドをまずはcommand.txtに記述。
かつ本体であるtello_test.py実行時に引数として渡すようになっている。
今回は実行上の都合※により
tello_test.pyは関数化して引数にcommandのリストを受け取るようにする。具体的にはtello_test.pyfrom tello import Tello import sys from datetime import datetime import time # command.txt読み込み start_time = str(datetime.now()) file_name = sys.argv[1] f = open(file_name, "r") commands = f.readlines() tello = Tello() for command in commands: if command != '' and command != '\n': ...を
tello_test.py(modified)def tello_command(command): from tello import Tello import time tello = Tello() for command in commands: ...と書き換えるイメージ。
そしてtello_test.pyをHoudini内pythonに記述してHoudini内からtello.pyを呼ぶ。※
Houdini内でcommand.txtを引数としてpythonファイルを実行する方法が解らなかったというだけの話。。(4)Houdini(Python)
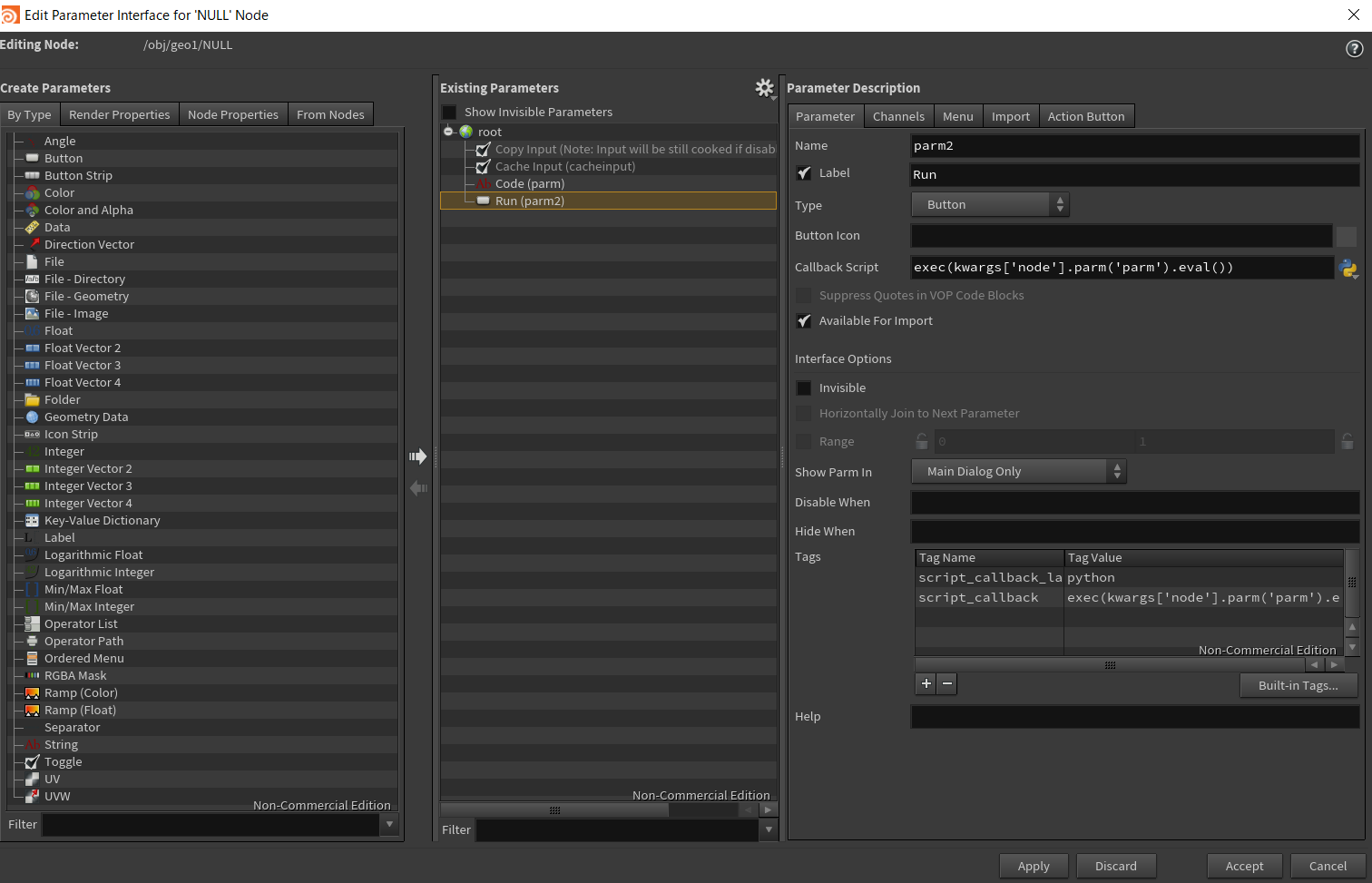
実行タイミングをこちらで制御したかったため、NULLノードにRunボタンを実装。
(2)と(3)を用いて取得したリストをtelloコマンドに変換し、「tello起動プログラムに渡す」ボタンとする。具体的にはこういうもの(何処かのサンプルファイルで見かけた)。
実行
冒頭のGIFの通り。申し訳程度に、Houdiniでの画像キャプチャを透過して動画に合成表示している。
完全一致…ではないものの、狙った挙動はできているっぽい。
記述編 -応用-
一応Houdini経由でTelloを飛ばせたは良いが、これ別にHoudiniを経由する必要がないやんけ・・・
IF文ラッシュで作成したcommandのリストをcommand.txtにコピペしてしまえばすぐに同じことが再現できてしまう。ということで編隊飛行とかスパイラル軌跡みたいなもうちょっとHoudiniらしいことをしよう。
…先に結論から言うと、あんまりうまくいかなかった。 理由は下記の通り。
- 編隊飛行にはSDK2.0対応のTello EDU版が必須
(用意していたうち1台がこれを満たさない)(とだいぶ書き進めてから気づく)- Tello SDKが斜め移動に対応していない
(これもだいぶ書き進めてから気づく)(事前準備って大事だ)とはいえ或る程度見通しは立ったので、出来たところまでは記述しようかと。
編隊飛行用のモジュールに切り替える
上記で使用したTello-Pythonは編隊飛行に対応していないため、TelloSDKのMulti-Tello-Formulation(*GitHub)を選定した。基本的にはTello-Pythonと似ており、実行時に
command.txtを渡すところも同じだったので同様に書き換える。そしてREADMEにもある通り
pipやnetifaces,netaddrのパッケージインストールが必要。HoudiniPythonpython -m pip install netifaces python -m pip install netaddrここにだいぶ時間を費やしてしまった…Houdini内Pythonにパッケージインストールをするうまい方法が浮かばず、最終的にWindowsの環境変数にHoudiniPythonを追加してcommand lineで対応。しかもnetifacesがクセモノでインストールエラー連発。
error: Microsoft Visual C++ 14.0 is required
のエラーに対して最終的にはVisual C++ 2015 Build Toolsのインストールで解決(2019版ではダメだった)。
かつpip install時に--userオプションを付与して無事環境構築完了。※参考URL
・Pip error: Microsoft Visual C++ 14.0 is required(*stackoverflow)プリミティブな軌道に沿って編隊飛行させてみる
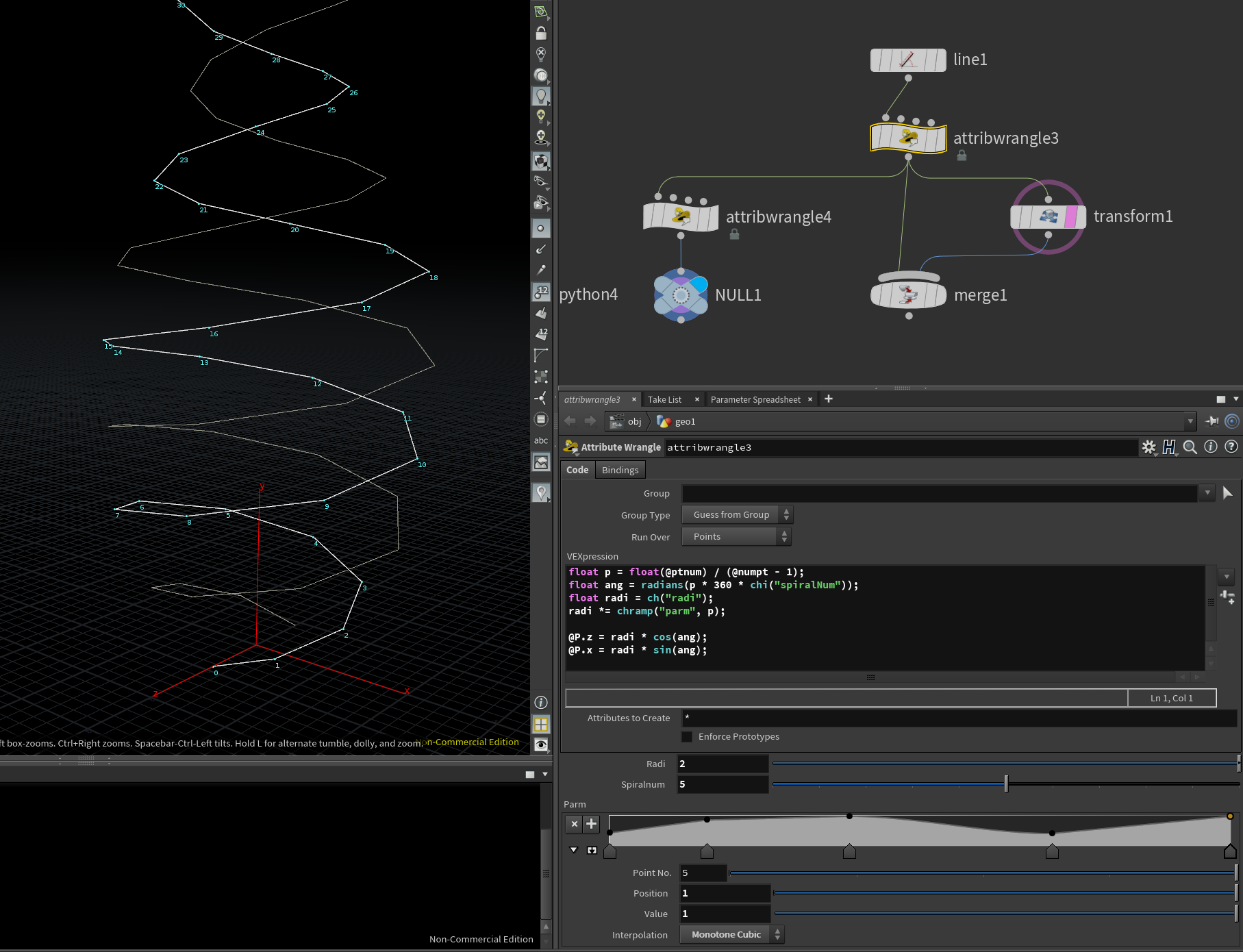
解説するほどのものではないけれど、chrampを用いて半径が途中で変わるようなspiralを書いてみる。
VEXfloat p = float(@ptnum) / (@numpt - 1); float ang = radians(p * 360 * chi("spiralNum")); float radi = ch("radi"); radi *= chramp("parm", p); @P.z = radi * cos(ang); @P.x = radi * sin(ang);これをどのようにコマンド変換するか
さて今度はxyz軸上のグリッド移動、という簡単なことにはならなそう。ということでこんな風に落とし込んでみた。
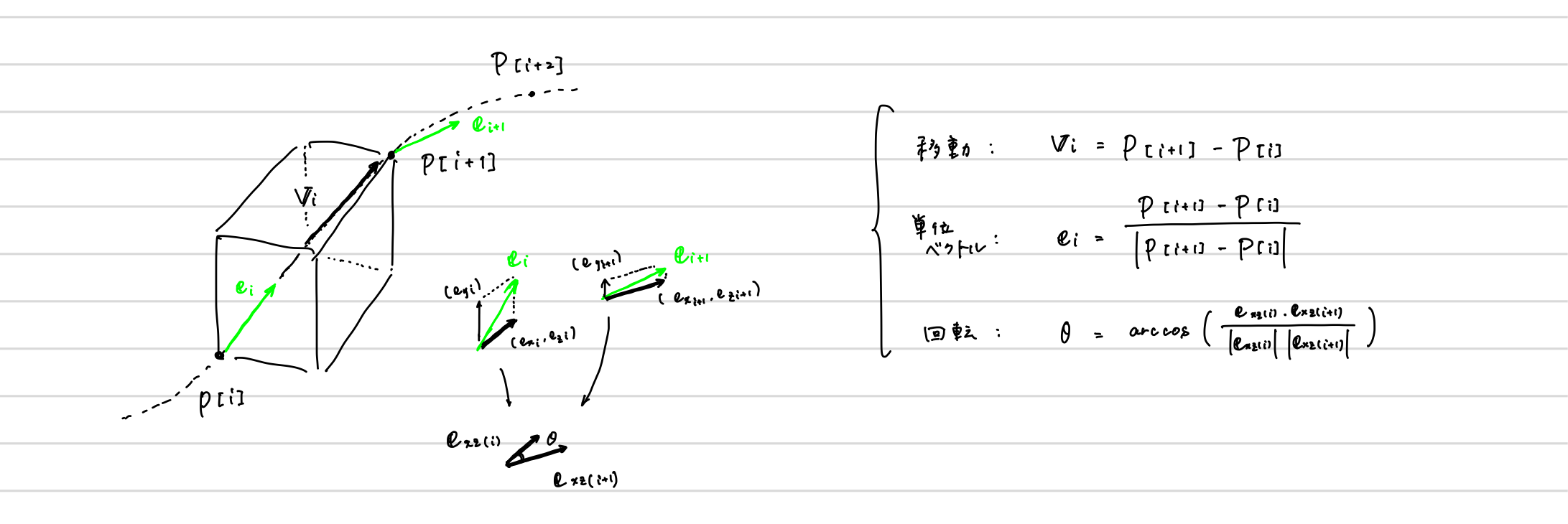
各点の座標を $P[i]$,移動ベクトルを $V_{i}$,移動ベクトルを正規化したものを単位ベクトル $e_{i}$とし、移動+ヨーイング角(Wiki)のみ回転で動かすことを考える。HoudiniはY-upなので、懐かしの余弦定理から回転角 $\theta$は下記のように書ける。
※ヨー角回転=首を横に振る方向の回転、のイメージ。平面回転というべきか。書き下す
VEX# 単位ベクトルをVEX側でアトリビュートとして作成しておく v@normalize = normalize(point(0, "P", @ptnum+1) - point(0, "P", @ptnum));↓ ↓ ↓ ↓
PythonScript(Houdiniノード)import numpy as np import math node = hou.pwd() geo = node.geometry() # すべての点を取得 points = geo.iterPoints() pos = [] norm = [] deg = [] # 移動/回転用の配列を先に計算 for point in points: # 各pointの座標を取得 pos.append(point.attribValue("P")) # 各pointにおける接線(単位)ベクトルを取得 norm.append(point.attribValue("normalize")) for i in range(len(pos) - 1): # 単位ベクトルの平面成分を取得したもの e_xz_i0 = np.array([norm[i][0], norm[i][2]]) e_xz_i1 = np.array([norm[i+1][0], norm[i+1][2]]) # 各point間移動時のyaw回転角度を取得 radi = math.acos( np.dot(e_xz_i0, e_xz_i1) / np.linalg.norm(e_xz_i0)*np.linalg.norm(e_xz_i1) ) deg.append(math.degrees(radi)) # normベクトルの何倍をcm換算で移動させるかを定義しておく dist = 50 # --------------------------- # command送信パート(定型コマンド) # --------------------------- command = [] # 複数台動かしたい場合はここでスキャン数を定義 command.append('scan N') # 飛ばしたい台数分の型番をメモ(事前にformulation.pyで動作確認が必要) command.append('1=***********') command.append('2=***********') ... command.append('テンプレートコマンド') # --------------------------- # command送信パート(軌跡依存コマンド) # --------------------------- for i in range(len(pos) - 1): # 機体を回転したら単位ベクトルの向きも変わるため回転行列を掛けていく forward = - norm[i][0] * np.cos(deg[i]) - norm[i][2] * np.sin(deg[i]) left = norm[i][0] * np.sin(deg[i]) - norm[i][2] * np.cos(deg[i]) # [dist]倍しても20cmに満たない時は20cmを採用する command.append('*>ccw ' + str(round(deg[i]))) command.append('*>forward ' + str(max(round(forward * dist), 20))) command.append('*>left ' + str(max(round(abs(left) * dist), 20))) command.append('*>up ' + str(max(round(norm[i][1] * dist), 20))) command.append('*>land') # 引数を受け取れるようにしたmulti_tello.py内multi_tello_command関数にcommandを渡す import multi_tello multi_tello.multi_tello_command(command)実行
$\huge{・・・ヨシ!}$よくない。いやー厳しい。
上記の通り、telloは斜め移動(というかマルチスレッド実行?)が出来ないので回転してから各方向に移動、という微妙な感じになる。目つむっておいて1ループ(回転+xyz移動)ごとに目を開けばまぁ…
展望編
一応プリミティブな軌道に沿ってTelloを飛ばす見通しが立ったは良いが、これ別にHoudiniを経由する必要がないやんけ・・・(再)
序盤に紹介したTwitterリンク先のドローンアートみたいなのを表現してみたい。。grid cube的なもの
というわけでお試しで組んでみる。
おお、ドローン編隊っぽい。
Houdiniを絡めるからにはここまでやりたかったけど、諸々の制約でアイデアメモに留めることに。【Tello | Tello EDU】で編隊飛行
「だいぶ書き進めてから気づく」然りこれ然りなのだが、実はpython3に対応していてかつTelloもTello EDUも併せて編隊飛行できるリポジトリ(dwalker-uk/TelloEduSwarmSearch(*GitHub))があった…
斜め移動できない問題についてはここ(*Issue)で触れられている。
アルゴリズムは使いまわせそうだから、この辺はMavic Mini辺りのSDK公開待ち、かな。。
以上、Houdiniからトイドローンを動かすというよりか、Houdini経由で「トイドローンを動かすpythonプログラム」を叩く記事でした。
プログラミング歴浅いので、いやそもそもここってこうでしょ?みたいな箇所があれば是非ご教授頂けると嬉しいです。


- 投稿日:2019-12-21T23:35:06+09:00
Python超入門 <3> 関数
関数とは
print('Hello World!')のprint()のように何らかの作業をしたり、値を返したりするものを関数と呼びます。数学でやった関数$f(x)$に似ていますね。
また、
print('Hello World!')の'Hello World!'のような、関数が受け取る値のことを引数(ひきすう)と呼びます。
基本的に関数は引数を必要としますが、必要のないものもあります。関数は、もともとPythonの中にあるものを使うだけでなく、自分で定義することもできます。
今回は関数を定義しながら理解していきましょう。
関数を作ってみよう
Pythonの関数は
defで作ることができます。以下のプログラムを見てください。
def add(a, b): print(a + b)これで
addという関数を定義することができました。
addの括弧内のaとbが引数で、aとbの和を表示せよというプログラムですね。ここで、
add(2, 3)と入れて実行してみます。
結果は5となりましたね。
addという関数が2と3という引数を受け取りその和を表示させたわけです。このように関数を作ることで、Python超入門 <2> 変数と代入にあった、
1本50円の鉛筆と1本100円のボールペンが売っています。
Aくんは鉛筆5本とボールペン3本を買いました。
Bさんは鉛筆7本とボールペン1本を買いました。
AくんとBさんはそれぞれ何円払いましたか。という問題を
add関数を定義しておけばpencil = 50 ballpointpen = 100 add(pencil * 5, ballpointpen * 3) add(pencil * 7, ballpointpen * 1)と書くことができるようになりますね。
同じような処理を何回も行うときはこのように関数を定義しておくと楽になるでしょう。それから関数は多くの処理を一気に行うよう定義することもできます。
こんな感じに。def cal(a, b): print(a * a) print(b * b) print(a + b)値を返す関数
引数のいらない関数とはどんなものでしょうか。
例えば先ほどのプログラムをちょっと変えてみましょう。
def add(a, b): return a + b新しく
returnというものが出てきましたね。
これが何の値を返すか指定するもので、このプログラムだとa + bの値を返すということになります。続けて
x = add(2, 3) print(x)と入れて実行してみましょう。
出力は
5となりますね。
関数
addが引数2, 3を受け取り5という値を返し、それがxという変数に代入されて表示されたわけですね。引数のいらない関数
引数のいらない関数とはどんなものでしょうか。
例えば下のプログラムを見てください。
def hello(): print('Hello World!') hello()このプログラムを実行すると
Hello World!と表示されます。
こんな感じに値を受け取らない関数もあります。
- 投稿日:2019-12-21T23:14:03+09:00
Pythonと参照渡し
はじめに
いなたつアドカレの二十一日目の記事です。
今日はちょっとPythonのオブジェクトIDと参照渡しのお話を
普段Pythonをあまり使わない人間なので間違ってる部分勘違いしてる部分ありましたら優しく訂正をお願いします。。。。。。
Python's Tips
- Pythonは係引数に実引数を渡す時は参照渡し
- Pythonは全てがオブジェクト
- オブジェクトにはそれぞれオブジェクトIDがふられている
オブジェクトのIDを確認する
test.pynum1 = 1 num2 = 2 print(id(1)) # 1 print(id(num1)) # 1 print(id(1 + 1)) # 2 print(id(num1 + 1)) # 2 print(id(num2)) # 21と2のIDをいろんな方法でだしてみました。
$ python test.py 140280906740832 140280906740832 140280906740864 140280906740864 140280906740864こんな感じの出力になりました。
もう一度実行してみます。$ python test.py 140040431375456 140040431375456 140040431375488 140040431375488 140040431375488順番的には上から1,1,2,2,2のIDが出力されていますが、1回目と2回目で出力されている値はちがいますね。
そして1とnum1のオブジェクトIDが同じですね。
ここからPythonのオブジェクトIDは動的に決まっており、1と1を入れた変数のオブジェクトIDが共通であることがみて取れます。では次の実験です。
test2.pynum1 = 1 num2 = 2 print(id(1)) print(id(num1)) num1 += 1 print(id(num1)) print(id(num2))実行結果
$ python test2.py 140413757891680 140413757891680 140413757891712 1404137578917122つめと3つめの間でnum1が1から2に変わってますね、ここでオブジェクトIDも変わってます。
次の実験
test3.pynum = 1 list = [1] print(num) print(id(num)) num = 2 print(num) print(id(num)) print(list) print(id(list)) list[0] = 2 print(list) print(id(list))実行結果
$ python test3.py 1 140609807909984 2 140609807910016 [1] 140609798595120 [2] 140609798595120はい、数字は1から2に変わるとオブジェクトIDが変わってますが、リストは中の値が変わってもオブジェクトIDが変わりません。
関数に渡す
test4.pynumber_list = [1,2,3,4,5,6,7,8,9,10] def show (arg): print(arg) print(id(arg)) def update_list (arg): arg[0] = 0 print(id(number_list)) show(number_list) update_list(number_list) show(number_list)実行結果
$ python test4.py 140048610816560 [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] 140048610816560 [0, 2, 3, 4, 5, 6, 7, 8, 9, 10] 140048610816560関数に渡しても中身を書き換えてもオブジェクトIDが変わってないことがわかりますね。
まとめ
Pythonは参照渡しをしているが、数字などのイミュータブルな値にはそれぞれ固有のオブジェクトIDが存在するため、関数内部で値を書き換えると参照しているオブジェクトIDが変わるため、参照を渡してはいるものの実質値渡しのような挙動をする。
リストなどのミュータブルなオブジェクトの内部状態を変更しても、リストそのもののオブジェクトIDが変化するわけではないので、関数内部での変更はオブジェクトIDが同一の関数外部へと影響を与える。
- 投稿日:2019-12-21T23:00:46+09:00
Pythonで動く点Pを可視化する
やったこと
Pythonで動く点Pを描画し、gifとして出力しました。
例題
以下のような動く点Pの問題を可視化してみます。
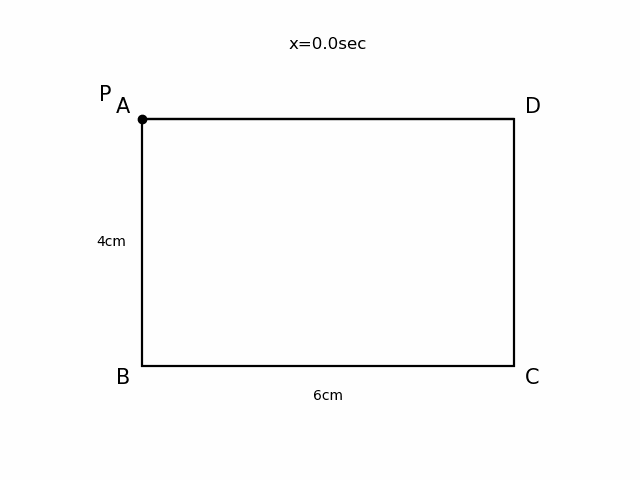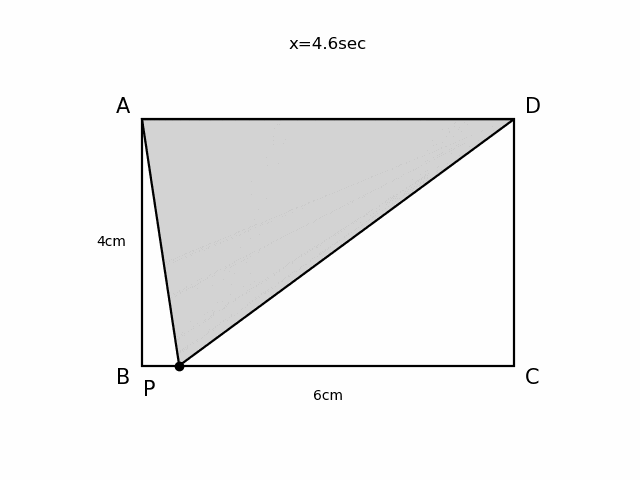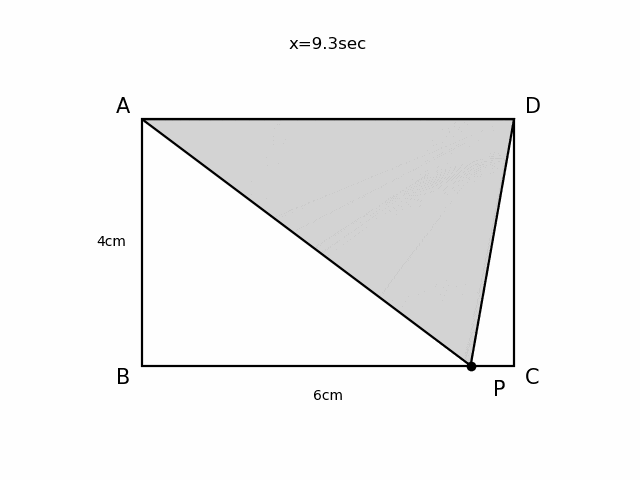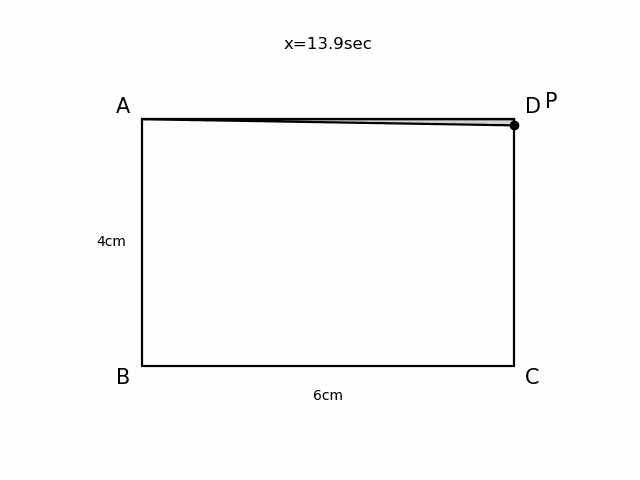
AB=4cm, BC=6cmの長方形ABCDがあり、点PはAを出発して毎秒1cmでA→B→C→Dと進む。 出発から$x$秒後の△APDの面積を$y$ cm2とする。
出典
https://math.005net.com/yoten/doten.php
(ただし、毎秒2cmを毎秒1cmとしています。)描画
環境
- Anaconda3 + jupyter notebook
- Python 3.6
- matplotlib 3.1.1
- numpy 1.16.5
1.空っぽの図をつくる
まず、図形を描画するための下準備をします。
import matplotlib.pyplot as plt fig = plt.figure() ax1 = fig.add_subplot(111) plt.show()
2.長方形を表示する
縦4cm、横6cmの長方形を作ります。ここで、座標原点$O$をどこにおくかにはいろいろな選び方があります。今回は長方形の重心(縦2cm、横3cmのところ)を原点$O$に選び、点A,B,C,Dの座標を決めます。こうしておくと、あとで長方形の一回り外側にラベルを表示させたいときにコードが簡単になります。
図形を描画するために
matplotlib.patchesを用います。また点の座標をベクトルとして扱いたいのでnumpyも入れます。長方形が枠に収まるように
set_xlim,set_ylimでx軸、y軸の範囲を長方形よりやや大きめにしておきます。点A,B,C,Dの座標を
np.array型で定義します。
pat.Polygonで長方形を作り、ax1に追加します。import numpy as np #追加 import matplotlib.pyplot as plt import matplotlib.patches as pat #追加 fig = plt.figure() ax1 = fig.add_subplot(111) ax1.set_xlim(-4,4) ax1.set_ylim(-3,3) A=np.array([-3,2]) B=np.array([-3,-2]) C=np.array([3,-2]) D=np.array([3,2]) p = pat.Polygon(xy = [A,B,C,D], edgecolor='black', facecolor='white', linewidth=1.6) ax1.add_patch(p) plt.show()
3.辺の長さ・頂点の名前を表示する
辺の長さを描画します
textは第一引数にx座標、第二引数にy座標、第三引数に名前を指定することで文字を描画できます。#辺の長さを表示する ax1.text(-3.5,0.0,"4cm",horizontalalignment='center',verticalalignment='center') ax1.text(0.0,-2.5,"6cm",horizontalalignment='center',verticalalignment='center')配置は好みに合わせて微調整してください。
つづいて、点の名前を長方形の一回り外側に表示します。辺の長さと同様に手打ちで表示位置を決めてもよいです。
import numpy as np import matplotlib.pyplot as plt import matplotlib.patches as pat fig = plt.figure() ax1 = fig.add_subplot(111) ax1.set_xlim(-4,4) ax1.set_ylim(-3,3) A=np.array([-3,2]) B=np.array([-3,-2]) C=np.array([3,-2]) D=np.array([3,2]) pol = pat.Polygon(xy = [A,B,C,D], edgecolor='black', facecolor='white', linewidth=1.6) ax1.add_patch(pol) #辺の長さを表示させる ax1.text(-3.5,0.0,"4cm",horizontalalignment='center',verticalalignment='center') ax1.text(0.0,-2.5,"6cm",horizontalalignment='center',verticalalignment='center') #頂点の名前を表示させる scale=1.1 ax1.text(A[0]*scale,A[1]*scale,"A",fontsize=15,horizontalalignment='center',verticalalignment='center') ax1.text(B[0]*scale,B[1]*scale,"B",fontsize=15,horizontalalignment='center',verticalalignment='center') ax1.text(C[0]*scale,C[1]*scale,"C",fontsize=15,horizontalalignment='center',verticalalignment='center') ax1.text(D[0]*scale,D[1]*scale,"D",fontsize=15,horizontalalignment='center',verticalalignment='center') plt.show()
4.点Pを表示する
いよいよ主役の登場です。
点Pの座標を定義し、ax1.plot()で点を表示します。点Pの名前の表示のさせ方は点A,B,C,Dと同じです。import numpy as np import matplotlib.pyplot as plt import matplotlib.patches as pat fig = plt.figure() ax1 = fig.add_subplot(111) ax1.set_xlim(-4,4) ax1.set_ylim(-3,3) A=np.array([-3,2]) B=np.array([-3,-2]) C=np.array([3,-2]) D=np.array([3,2]) pol = pat.Polygon(xy = [A,B,C,D], edgecolor='black', facecolor='white', linewidth=1.6) ax1.add_patch(pol) ax1.text(-3.5,0.0,"4cm",horizontalalignment='center',verticalalignment='center') ax1.text(0.0,-2.5,"6cm",horizontalalignment='center',verticalalignment='center') scale=1.1 ax1.text(A[0]*scale,A[1]*scale,"A",fontsize=15,horizontalalignment='center',verticalalignment='center') ax1.text(B[0]*scale,B[1]*scale,"B",fontsize=15,horizontalalignment='center',verticalalignment='center') ax1.text(C[0]*scale,C[1]*scale,"C",fontsize=15,horizontalalignment='center',verticalalignment='center') ax1.text(D[0]*scale,D[1]*scale,"D",fontsize=15,horizontalalignment='center',verticalalignment='center') P=np.array([-3.0,1.0]) #動く点Pを表示する scale_P=1.2 ax1.plot(P[0],P[1],marker='o',color='black') ax1.text(P[0]*scale_P,P[1]*scale_P,"P",fontsize=15,horizontalalignment='center',verticalalignment='center') plt.show()5.△APDを表示する
長方形ABCDをつくったときと同様に三角形APDをつくり図に追加します、ついでにx軸とy軸を消しておきます。
%matplotlib nbagg import numpy as np import matplotlib.pyplot as plt import matplotlib.patches as pat fig = plt.figure() ax1 = fig.add_subplot(111) ax1.set_xlim(-4,4) ax1.set_ylim(-3,3) A=np.array([-3,2]) B=np.array([-3,-2]) C=np.array([3,-2]) D=np.array([3,2]) pol = pat.Polygon(xy = [A,B,C,D], edgecolor='black', facecolor='white', linewidth=1.6) ax1.add_patch(pol) ax1.text(-3.5,0.0,"4cm",horizontalalignment='center',verticalalignment='center') ax1.text(0.0,-2.5,"6cm",horizontalalignment='center',verticalalignment='center') scale=1.1 ax1.text(A[0]*scale,A[1]*scale,"A",fontsize=15,horizontalalignment='center',verticalalignment='center') ax1.text(B[0]*scale,B[1]*scale,"B",fontsize=15,horizontalalignment='center',verticalalignment='center') ax1.text(C[0]*scale,C[1]*scale,"C",fontsize=15,horizontalalignment='center',verticalalignment='center') ax1.text(D[0]*scale,D[1]*scale,"D",fontsize=15,horizontalalignment='center',verticalalignment='center') P=np.array([-3.0,1.0]) scale_P=1.2 ax1.plot(P[0],P[1],marker='o',color='black') ax1.text(P[0]*scale_P,P[1]*scale_P,"P",fontsize=15,horizontalalignment='center',verticalalignment='center') #△APDを追加 S = pat.Polygon(xy = [A,P,D], edgecolor='black', facecolor='lightgray', linewidth=1.6) ax1.add_patch(S) #枠を消す plt.axis('off') plt.show()6.動かす
動く点Pを動かし、それをgif形式のアニメーションで出力します。
$x$秒後の動く点Pの座標を毎回更新し、コマ送りで描画することによってアニメーションをつくります。
- あらかじめ長方形ABCDの描画など時間が経過しても変わらない操作を
initialize()にまとめておきます。moveP(x)は経過時間から動く点Pが線分AB、BC、CDのどこにいるか場合分けを行い、動く点Pの座標を返します。- 動く点Pの速度(
velocity)は秒速1cmとし、描画間隔(timestep)は0.1秒とします。- アニメーション作成には
PillowWriterとFuncAnimationを使います。animate(i)に一回の描画更新で行う操作をすべてまとめておき、FuncAnimationの引数にとることでアニメーションをつくります。anim.save()で動画の出力ができます。%matplotlib nbagg #jupyter notebook上でアニメーション表示させるために必要 import numpy as np import matplotlib.pyplot as plt import matplotlib.patches as pat from matplotlib.animation import PillowWriter,FuncAnimation #動画作成用に追加 fig = plt.figure() ax1 = fig.add_subplot(111) A=np.array([-3,2]) B=np.array([-3,-2]) C=np.array([3,-2]) D=np.array([3,2]) scale=1.1 scaleP=1.2 p = pat.Polygon(xy = [A,B,C,D], edgecolor='black', facecolor='white', linewidth=1.6) def initialize(): ax1.set_xlim(-4,4) ax1.set_ylim(-3,3) ax1.add_patch(p) ax1.text(A[0]*scale,A[1]*scale,"A",fontsize=15,horizontalalignment='center',verticalalignment='center') ax1.text(B[0]*scale,B[1]*scale,"B",fontsize=15,horizontalalignment='center',verticalalignment='center') ax1.text(C[0]*scale,C[1]*scale,"C",fontsize=15,horizontalalignment='center',verticalalignment='center') ax1.text(D[0]*scale,D[1]*scale,"D",fontsize=15,horizontalalignment='center',verticalalignment='center') ax1.text(-3.5,0.0,"4cm",horizontalalignment='center',verticalalignment='center') ax1.text(0.0,-2.5,"6cm",horizontalalignment='center',verticalalignment='center') def moveP(x): if 0<= x <4: return A+np.array([0,-1])*x*velocity elif 4<=x <10: return B+np.array([1,0])*(x-4)*velocity elif 10<= x <14: return C+np.array([0,1])*(x-10)*velocity else: return D velocity=1.0 timestep=0.1 def animate(t): plt.cla() initialize() x=timestep*t P=moveP(x) ax1.plot(P[0],P[1],marker='o',color='black') ax1.text(P[0]*scaleP,P[1]*scaleP,"P",fontsize=15,horizontalalignment='center',verticalalignment='center') S = pat.Polygon(xy = [A,P,D], edgecolor='black', facecolor='lightgray', linewidth=1.6) ax1.add_patch(S) plt.axis('off') plt.title('x=' + '{:.1f}'.format(x)+'sec') anim = FuncAnimation(fig,animate,frames=140,repeat=True,interval=timestep*1000) #anim.save("ugokutenP.gif", writer='pillow',fps=10) plt.show()




- 投稿日:2019-12-21T22:40:25+09:00
Python超入門 <2> 変数と代入
はじめに
Python含め多くのプログラミング言語において変数というものがあり、代入という作業をすることができます。
今回はこれを理解しましょう。変数と代入とは
変数とは皆さんがプログラムを書くときに自由に定義できるものです。
数学などで分からない値を$x$などの文字で置くことがあったと思いますが、雰囲気としてはそんな感じです。プログラミングの世界では、変数は基本的に何かの値を格納するものとして使われます。
その格納する作業を代入と言います。変数を使うことで、プログラムを見やすくしたり、簡単にできたりします。
変数を使ってみよう
皆さんも実際にやってみましょう。
数値の代入
Pythonの変数にはいろいろなものを代入できますが、まずは
以下のようなコードがあったとします。
print(10 + 20)これは
10+20という計算の結果を表示するプログラムで、もちろん出力は30ですね。
これを変数を使ってこのように書くこともできます。
a = 10 b = 20 print(a + b)これは、「a」という変数に10という数値を、「b」という変数に20という数値をそれぞれ代入して、最後にa+bの結果を表示させるものです。
出力を見てみましょう。
30このとき、a,bにはそれぞれ10,20という数値が代入されているので、10+20が表示されるわけですね。
むしろ理解しにくくなった、と思う人もいるかもしれません。
でもこれはとても便利なものなのです。例えばこんな問題を考えてみましょう。
1本50円の鉛筆と1本100円のボールペンが売っています。
鉛筆5本とボールペン3本を買ったら合計何円でしょう。これをプログラミングで求めるとき、もちろん、
print(50 * 5 + 100 * 3)※
*は掛け算を表します。
としてもいいですが、pencil = 50 ballpointpen = 100 sum = pencil * 5 + ballpointpen * 3 print(sum)とすると、どんな作業をしているのかわかりやすくなりませんか?
変数名は自分の好きなように決められるのでこのようにプログラムに意味をつけることができるのです。
さらに、こんな問題はどうでしょう。
1本50円の鉛筆と1本100円のボールペンが売っています。
Aくんは鉛筆5本とボールペン3本を買いました。
Bさんは鉛筆7本とボールペン1本を買いました。
AくんとBさんはそれぞれ何円払いましたか。print(50 * 5 + 100 * 3) print(50 * 7 + 100 * 1)としてもいいですが、
pencil = 50 ballpointpen = 100 A = pencil * 5 + ballpointpen * 3 B = pencil * 7 + ballpointpen * 1 print(A) print(B)とすることで、何をしているかが一目でわかりますよね。
こんな感じで変数はとても便利なものなのです。
プログラムを書く上では必要不可欠なものなので、覚えておきましょう。
- 投稿日:2019-12-21T22:35:46+09:00
Python超入門 <1> Spyderを使ってみよう
はじめに
前回はコマンドプロンプトでPythonスクリプトを走らせてみましたが、そのやり方だと基本的に一行ずつ実行することになるので長いプログラムを動かすのは面倒くさいですよね。
だから基本的には拡張子pyのファイルにPythonスクリプトを書いて、それを実行させるのが普通です。
.pyのファイルはWindows付属のメモ帳でも作ることができますが、プログラムを書くためのテキストエディタを使うと便利です。
AnacondaにはSpyderというエディタが付属しています。
今回はSpyderを使ってみましょう。Jupyter NotebookやJupyter Labというものもとても使いやすいですが私は基本的にSpyderを使っています。
Spyderの使い方
Windowsのスタートメニューのアプリの一覧からAnaconda3フォルダの中にあるSpyderをクリックして起動しましょう。
Anaconda NavigaterからSpyderを起動することもできますが、直接Spyderを起動しても大丈夫です。
画面の説明
左側
エディタです。ここに入力してプログラムを書きます。
右上
タブを切り替えることで変数の中身を表示させたり、ファイルを見ることができます。
変数エクスプローラーが非常に便利です。右下
プログラムの実行結果やエラーメッセージが表示されます。
試しに使ってみよう
左のエディタに
print('Hello World!')と入力して、上の▶ボタンかF5キーを押してください。右下の画面に
Hello World!と表示されれば成功です。
- 投稿日:2019-12-21T22:24:49+09:00
VScodeでリモートのJupyter Serverに接続したところ、リモートだけど、ローカルだった
VScodeでリモートのJupyter Serverに接続したところ、ローカルのファイルを実行でき、ファイル実行中に出力したファイルはリモートにありました。
はじめに
普段私は大学でPythonを使った数値計算の研究をしています。
研究室のPCの計算資源が乏しいので、実行環境は自宅のPCに構築していて、作業は自宅PCで起動したjupyter notebookのローカルポートをの研究室PCの同ポートにフォワーディングしています。イメージは研究室PC(ホスト名:local)
↓ [local] ssh -L 8888:localhost:8888 remote
自宅PC(ホスト名:remote)
↓ [remote] jupyter notebook
研究室PC
↓ [local] xgd-open http://localhost:8888/?token=<token>こんな感じです。この方法ではremoteのファイルしかアクセスできません。いや、少なくとも私はそう理解しています。両PCともWindowsなので、remoteで起動するjupyterの作業ディレクトリをOnedriveに設定することで、localとのファイル同期を簡単に行っていました。イメージは
C:/users/<remote_user>/onedrive == C:/users/<local_user>/onedrive
こんな感じです。
VScodeの導入
今秋、Visual Studio Codeでjupyter notebookのネイティブサポートが開始されました。
参考:VS CodeのPython拡張がJupyterをネイティブサポートしたそうなので早速使ってみた。
jupyter notebookはインタラクティブな開発環境こそ利点であれど、Atomなど高性能なテキストエディタについてくるような補助機能はなく、またWebアプリケーションであるからUIのスタイルをcssで記述しなければならなく、なにかと面倒です。
VScodeのこのアップデートはリモートjupyter serverに接続する機能もあると聞きつけ、私も乗るしかない、このビッグウェーブにと一念発起しました。しかしまだリリース数ヶ月であるからか、このリモートjupyter serverに接続するという機能に注目した記事がまるでないじゃないですか。手探りで触ってみたところ、「ローカルのファイルをリモートの実行環境で実行できる」という、私の中では真新しい技術に出会いました。しかもその挙動が直感的には理解できないものだったので、記事にして共有してみようと思いました。実行環境
お試しなので、ローカルPCは前述の研究室PCではなく、手持ちのノートPCを使いました。
ホスト名: remote ;計算資源盛り盛りのマッチョdesktop
win10, python3.6, jupyterホスト名: local ;CPUがatomのクロック1GHz程度のガリlaptop
win10, python3.6, jupyter, VScodeVScodeの環境
ネットに転がっていますので、割愛。本体と日本語とpythonアドオン入れただけです。
手探り実験
ローカルなVScodeの作業ディレクトリをlocal_dir、リモートなjupyter serverの作業ディレクトリをremote_dirとします。
まず、ローカルな環境でノートブックを起動します。VScodeのコマンドパレットに下記を打ち、空のノートブックを開きます。
Python: Create New Blank Jupyter Notebookそして、次のコードをセルに書き、実行します。
~/local_dir/whereami.ipynb#ln[1] import socket print(socket.gethostname()) #Out[1] 'local' #ローカルPCのホスト名ローカルの環境で実行できました。
次に、リモートのjupyter serverに接続します。
Python: Specify local or remote Jupyter server for connectionsするとプロンプトが出てくるので、リモートのjupyter notebookのURLを指定します。私の環境では前述の通り、別途sshした前提で
http://localhost:8888/?token=<token>ですね。
するとlocal_dirには隠しフォルダとファイルが生成されます。~/local_dir/.vscode/settings.json{ "python.dataScience.jupyterServerURI": http://localhost:8888/?token=<token> }この設定ファイルがあるディレクトリでノートブックを開くと、実行環境がリモートに移ります。
~/local_dir/whereami.ipynb#ln[1] import socket print(socket.gethostname()) #Out[1] 'remote' #リモートPCのホスト名実行ファイルの実体はどこにあるのでしょうか。
~/local_dir/whereami.ipynb#ln[2] import os print(os.path.abspath("")) #Out[2] '<remote_dir>' #jupyter serverの作業ディレクトリローカルのファイルを開いていたつもりが、リモートPCの作業ディレクトリにあるファイルを開いていることになっています。
jupyter notebookを開いたローカルのプロンプトを覗いてみると、何らかのキャッシュが行われている形跡がログに見られました。実際にはjupyter serverの作業ディレクトリにUntitled[0-9]+.ipynbという名前でローカルファイルがキャッシュされ、VScodeを終了するとキャッシュが削除されるようです。
この状態で何らかのファイル出力を試みます。~/local_dir/whereami.ipynb#ln[3] import numpy as np a = np.array([1,2,3]) np.savetxt("whereami.csv", a)whereami.csvはどこに出力されるでしょうか?
~/remote_dir/whereami.csvでした。
まとめ
リモートだけど、リモートじゃなかった!
参考
Visual Studio CodeでJupyter Notebookを動かしてみた
https://dev.classmethod.jp/server-side/python/visual-studio-code-jupyter-notebook/VS CodeのPython拡張がJupyterをネイティブサポートしたそうなので早速使ってみた。
https://qiita.com/simonritchie/items/5d865e72dba47cf8f6c0
- 投稿日:2019-12-21T22:24:49+09:00
VScodeでリモートのJupyter Serverに接続したところ、リモートだけど、ローカルだったメモ
VScodeでリモートのJupyter Serverに接続したところ、ローカルのファイルを実行でき、ファイル実行中に出力したファイルはリモートにありました。
はじめに
普段私は大学でPythonを使った数値計算の研究をしています。
研究室のPCの計算資源が乏しいので、実行環境は自宅のPCに構築していて、作業は自宅PCで起動したjupyter notebookのローカルポートをの研究室PCの同ポートにフォワーディングしています。イメージは研究室PC(ホスト名:local)
↓ [local] ssh -L 8888:localhost:8888 remote
自宅PC(ホスト名:remote)
↓ [remote] jupyter notebook
研究室PC
↓ [local] xgd-open http://localhost:8888/?token=<token>こんな感じです。この方法ではremoteのファイルしかアクセスできません。いや、少なくとも私はそう理解しています。両PCともWindowsなので、remoteで起動するjupyterの作業ディレクトリをOnedriveに設定することで、localとのファイル同期を簡単に行っていました。イメージは
C:/users/<remote_user>/onedrive == C:/users/<local_user>/onedrive
こんな感じです。
VScodeの導入
今秋、Visual Studio Codeでjupyter notebookのネイティブサポートが開始されました。
参考:VS CodeのPython拡張がJupyterをネイティブサポートしたそうなので早速使ってみた。
jupyter notebookはインタラクティブな開発環境こそ利点であれど、Atomなど高性能なテキストエディタについてくるような補助機能はなく、またWebアプリケーションであるからUIのスタイルをcssで記述しなければならなく、なにかと面倒です。
VScodeのこのアップデートはリモートjupyter serverに接続する機能もあると聞きつけ、私も乗るしかない、このビッグウェーブにと一念発起しました。しかしまだリリース数ヶ月であるからか、このリモートjupyter serverに接続するという機能に注目した記事がまるでないじゃないですか。手探りで触ってみたところ、「ローカルのファイルをリモートの実行環境で実行できる」という、私の中では真新しい技術に出会いました。しかもその挙動が直感的には理解できないものだったので、記事にして共有してみようと思いました。実行環境
お試しなので、ローカルPCは前述の研究室PCではなく、手持ちのノートPCを使いました。
ホスト名: remote ;計算資源盛り盛りのマッチョdesktop
win10, python3.6, jupyterホスト名: local ;CPUがatomのクロック1GHz程度のガリlaptop
win10, python3.6, jupyter, VScodeVScodeの環境
ネットに転がっていますので、割愛。本体と日本語とpythonアドオン入れただけです。
手探り実験
ローカルなVScodeの作業ディレクトリをlocal_dir、リモートなjupyter serverの作業ディレクトリをremote_dirとします。
まず、ローカルな環境でノートブックを起動します。VScodeのコマンドパレットに下記を打ち、空のノートブックを開きます。
Python: Create New Blank Jupyter Notebookそして、次のコードをセルに書き、実行します。
~/local_dir/whereami.ipynb#ln[1] import socket print(socket.gethostname()) #Out[1] 'local' #ローカルPCのホスト名ローカルの環境で実行できました。
次に、リモートのjupyter serverに接続します。
Python: Specify local or remote Jupyter server for connectionsするとプロンプトが出てくるので、リモートのjupyter notebookのURLを指定します。私の環境では前述の通り、別途sshした前提で
http://localhost:8888/?token=<token>ですね。
するとlocal_dirには隠しフォルダとファイルが生成されます。~/local_dir/.vscode/settings.json{ "python.dataScience.jupyterServerURI": http://localhost:8888/?token=<token> }この設定ファイルがあるディレクトリでノートブックを開くと、実行環境がリモートに移ります。
~/local_dir/whereami.ipynb#ln[1] import socket print(socket.gethostname()) #Out[1] 'remote' #リモートPCのホスト名実行ファイルの実体はどこにあるのでしょうか。
~/local_dir/whereami.ipynb#ln[2] import os print(os.path.abspath("")) #Out[2] '<remote_dir>' #jupyter serverの作業ディレクトリローカルのファイルを開いていたつもりが、リモートPCの作業ディレクトリにあるファイルを開いていることになっています。
jupyter notebookを開いたリモートのプロンプトを覗いてみると、何らかのキャッシュが行われている形跡がログに見られました。実際にはjupyter serverの作業ディレクトリにUntitled[0-9]+.ipynbという名前でローカルファイルがキャッシュされ、VScodeを終了するとキャッシュが削除されるようです。
この状態で何らかのファイル出力を試みます。~/local_dir/whereami.ipynb#ln[3] import numpy as np a = np.array([1,2,3]) np.savetxt("whereami.csv", a)whereami.csvはどこに出力されるでしょうか?
~/remote_dir/whereami.csvでした。
まとめ
リモートだけど、リモートじゃなかった!
参考
Visual Studio CodeでJupyter Notebookを動かしてみた
https://dev.classmethod.jp/server-side/python/visual-studio-code-jupyter-notebook/VS CodeのPython拡張がJupyterをネイティブサポートしたそうなので早速使ってみた。
https://qiita.com/simonritchie/items/5d865e72dba47cf8f6c0
- 投稿日:2019-12-21T22:12:33+09:00
[ffmpeg]Pythonのsubprocessを使ってffmpegしたらThe system cannot find the path specified.
環境
windows 10
python 3.7
ffmpeg 不明やろうとしたこと
command = f'ffmpeg -i "{file_path}" -vf crop={Xl}:{Yl}:{Xs}:{Ys} "{out_path}"' subprocess.call([command], shell=True)動画ファイルのクロップをするコマンドを実行しようとしています。
しかし、エラーメッセージが...The system cannot find the path specified.しかし、ファイルもちゃんと存在しているし、
print(command)してそれをコマンドプロンプトで実行すると成功する。結論
command = f'ffmpeg -i "{file_path}" -vf crop={Xl}:{Yl}:{Xs}:{Ys} "{out_path}"' subprocess.call(command, shell=True)で直りました
これに2時間ほどハマっていたので...
- 投稿日:2019-12-21T22:10:41+09:00
Web APIつくってみた
はじめに
本記事はVolare Advent Calendar 2019の21日目の担当分です。
今回初めてiOSアプリのAPIを作ってみました。
自分が勉強中なのもあって、DjangoRESTFrameworkを使ってAPIをつくってみたので、それを記事にしていきたいと思います
作ったアプリのiOS側の記事はこちらアプリについて
アプリ作成においてメインのターゲットは私達のような一人暮らしの大学生です
アプリの決定した経緯については、
自炊をする際に献立を考えるのが面倒であるが、既存のアプリは冷蔵庫にあるものを参照して検索をかけている
→既存のもののターゲットは家族をもつ人向けである好き。嫌いを入力して自動的に献立を提示してくれるアプリがあると便利じゃんと感じた!
→基本的に作り置きはあまりしない、好きなものを好きな時に作りたい(冷蔵庫に食材があまり入っていない)
このような要点から作ることを決めました!(コンセプトが同じものがないなら作ってしまおう
)
一緒にチーム開発を行なったりゅーちゃんがアプリについて説明してくれています。
今回はこちらのバックエンドを担当しました。実装したこと
バックエンドでは、以下の5つの機能を実装しました!
- ユーザー認証
- ユーザごとの食材一覧表示
- 食材の選択状態の一括変更
- 食材のランダム表示
このうち、3つを担当したので、その部分について書いていきます!
ユーザー認証
class RegisterAuthView(GenericAPIView): permission_classes = () serializer_class = AuthSerializer def post(self, request): serializer = self.get_serializer(data=request.data) serializer.is_valid(raise_exception=True) # uuidが登録されていたらtokenを返す if User.objects.filter(uuid=serializer.data['uuid']): user = User.objects.get(uuid=serializer.data['uuid']) payload = jwt_payload_handler(user) return Response({ 'token': jwt_encode_handler(payload), }) user = User.objects.create_user(uuid=serializer.data['uuid']) user.save() if not user: raise AuthenticationFailed() payload = jwt_payload_handler(user) # ユーザー登録をする時に、デフォルトの食材を追加する user = User.objects.filter(uuid=serializer.data['uuid']).last() food = FoodConfigParam() food.create_defaultfood(user=user) return Response({ 'token': jwt_encode_handler(payload), })送られてきたUUIDと一致するユーザーがDBにあるかどうかをみて、なければユーザーを作成しています。
ユーザごとの食材一覧表示と一括変更
class UserFoodConfig(GenericAPIView): queryset = FoodConfigParam.objects.all() serializer_class = FoodConfigParamSerializer def get(self, request): foodConfigParams = FoodConfigParam.objects.filter(user=request.user) serializer = FoodConfigParamSerializer(foodConfigParams, many=True) return Response({'data': serializer.data}) def put(self, request): res = [] for config in request.data['data']: name = config['name'] rate = config['rate'] # 登録ユーザーと食材名が一致するものを抽出 foodConfigParam = FoodConfigParam.objects.get(user=request.user, name=name) # 確率を変更 serializer = FoodConfigParamSerializer(foodConfigParam, data={'rate': rate}, partial=True) serializer.is_valid(raise_exception=True) serializer.save() res.append(serializer.data) return Response({'data': res})ユーザーと食材名が一致するものを抽出し、出現率を変更するようにしました。
難しかったこと
つくってみたAPIがうまく動かなかったり、動いたけどiOSと繋げた時に予想してない動きになったり、
iOS側では極力ロジックを書かないようにしたり、通信回数を減らしたりと色々あるみたいで、、
もっとフロント側の知識もちゃんと持っておかないと意思疎通ができなくて大変なことになるなと感じました・・・
iOS側と相談して、こうすればやりやすいとかを話し合いながら進めていって、なるほど〜と勉強になりました。おわりに
今回はとりあえず動くもの、って作っていたので、RESTfulがいまだにわからずにいます
なので、django-rest-frameworkの良さをちゃんと知って、良さを活かせるように勉強しようと思いました。
最後まで読んでくださり、ありがとうございました。
- 投稿日:2019-12-21T21:56:45+09:00
2019年フレームワークのトレンドが見れるサイトの紹介
hotframeworks.com
URLはこちらになります。
http://hotframeworks.com/

- 投稿日:2019-12-21T21:34:45+09:00
scipy.sparseで疎行列入門
この記事は古川研究室 Advent Calendar 22日目の記事です.
自分は古川研究室のOBなのですが,学生さんよりお誘いいただいて参加することになりました.よろしくお願いいたします.はじめに
今回は
scipy.sparseによる実装を併記しつつ,疎行列とその表現形式について説明したいと思います.
「numpyにはある程度慣れてきたけど疎行列関連はまだ手を出してなくて…どういうものなのか少しだけ知りたい!」という人向けの記事になります.
本記事では各表現形式がどのような値を用いて疎行列を表現しているのかについて着目して説明し,最後に簡単な実験としてメモリサイズと計算速度の比較を行います.
scipy.sparseについて本記事よりも詳しく知りたい場合はこちらをご参照ください.
https://docs.scipy.org/doc/scipy/reference/sparse.htmlなお本記事はPythonのNumPyやSciPyを説明に用いますが,疎行列の概念や表現形式自体はこれらの言語やライブラリに限定されたものではなく,広く一般に使われているものです.
疎行列について
要素の多くがゼロとなっている行列は疎行列と呼ばれます.
疎行列は実データでよく現れます.例えばECサイトにある「どの人がどの商品をいくつ買ったか」というデータを愚直に行列表現しようとした場合,ユーザ総数×商品総数のドデカい行列に購入数を格納することになります.
この行列はもちろん大半の要素が0になってしまいます.以下がそのイメージです(本来はもっとユーザ数・商品数が大きく,ゼロ要素の割合がずっと大きいです).
このデータをサンプルデータとして以降の説明をしていきます.上記のデータはNumpy配列で以下のように作成できます.
import numpy as np data_np = np.array([[0, 0, 0, 2, 5], [9, 0, 1, 8, 0], [0, 0, 6, 0, 0], [0, 4, 7, 0, 3]])しかしこのようにゼロ要素も含めて扱ってしまうとメモリ的にも演算的にも無駄が多くなってしまいます.
疎行列はゼロでない要素(非ゼロな要素・nonzeroな要素)のみに焦点をあてて情報表現すると効率的です.
疎行列には様々な表現形式があり,用途に応じて使い分ける必要があります.
本記事ではCOO形式, CSR形式, CSC形式のみに絞って,その情報表現方法と利点について紹介します.
(ちなみに一番活用されるのはCSR形式になるかと思います.)本記事で説明していない初期化方法や利点・欠点などについて知りたい場合は以下をご参照ください.
https://docs.scipy.org/doc/scipy/reference/generated/scipy.sparse.coo_matrix.html
https://docs.scipy.org/doc/scipy/reference/generated/scipy.sparse.csr_matrix.html
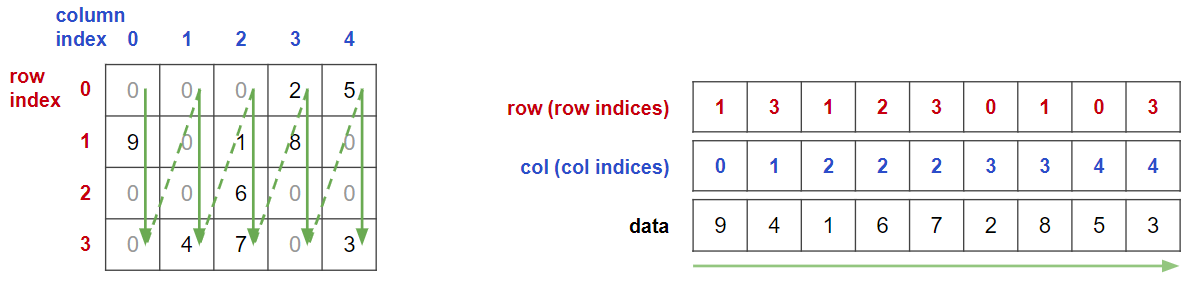
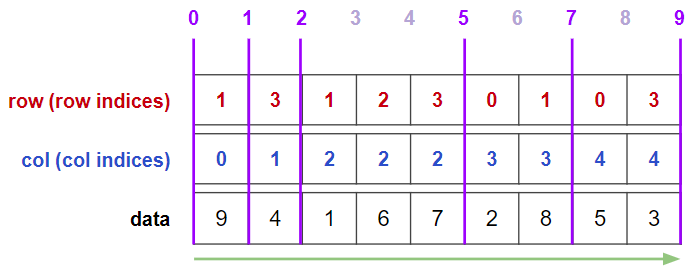
https://docs.scipy.org/doc/scipy/reference/generated/scipy.sparse.csc_matrix.htmlCOO形式
最も直観的な形式は座標形式(COOrdinate形式: COO形式)です.
疎行列を3つの1次元配列により表現します.1つは非ゼロ要素の値を単に並べたものです.(COO形式自体は並べ順は自由ですが,
scipy.sparseの挙動やのちの説明のため,本記事では図の緑線の順で並べます.)
残り2つは各非ゼロ要素の値がどのindexにあるのか示したものです.
この2つの配列により,非ゼロ要素の「座標」を表しています.
つまり,
0番ユーザが3番商品を2つ買っている
0番ユーザが4番商品を5つ買っている
1番ユーザが0番商品を9つ買っている
…
といった感じの情報表現になっています.
scipy.sparse.coo_matrix()を用いることで簡単にCOO形式に変換できます.from scipy import sparse data_coo = sparse.coo_matrix(data_np) print(data_coo)output(0, 3) 2 (0, 4) 5 (1, 0) 9 (1, 2) 1 (1, 3) 8 (2, 2) 6 (3, 1) 4 (3, 2) 7 (3, 4) 3図にある情報も表示してみます.
print(f"row: {data_coo.row}") print(f"col: {data_coo.col}") print(f"data: {data_coo.data}")outputrow: [0 0 1 1 1 2 3 3 3] col: [3 4 0 2 3 2 1 2 4] data: [2 5 9 1 8 6 4 7 3]図に示した通りのデータが格納されていますね.
なお
scipy.sparse.coo_matrix.todense()で通常の行列表現に戻せます.print(data_coo.todense())output[[0 0 0 2 5] [9 0 1 8 0] [0 0 6 0 0] [0 4 7 0 3]]COO形式の利点
関係データベース的にも自然な表現であり,データセットとして提供されているデータもこのフォーマットが多いです.
例えば映画評価データであるMovieLens 100K Datasetも以下のように簡単にCOO形式で読み込めます.import pandas as pd df = pd.read_table('ml-100k/u.data', names=['user_id', 'movie_id', 'rating', 'timestamp']) ml100k_coo = sparse.coo_matrix((df.rating, (df.user_id-1, df.movie_id-1))) print(f'number of nonzero: {ml100k_coo.nnz}') print(f'shape: {ml100k_coo.shape}')outputnumber of nonzero: 100000 shape: (943, 1682)MovieLens 100K Datasetは943人のユーザが1682個の映画に対し評価したデータで,非ゼロ要素が100000個なので,きちんと読み込めてそうですね.
(ただし,あくまで「非ゼロ要素以外には評価値0が入っている行列」となることには注意してください.「MovieLensのデータではこの行列の0の箇所は欠損値とみなして適切に取り扱う」といったようなデータ解析上の都合は,解析者側で適切に扱ってあげる必要があります.)
(あと実は先ほどのコードはcoo_matrixの引数周りで少し横着をしています.脱線になりますが丁寧バージョンが気になる場合はこちらの折りたたみを展開ください.)
MovieLens 100Kはuser_id, movie_idがたまたま連番になっているデータで,簡単にindexに変換できます
(具体的にはidが1から始まる連番になっているので,1引いて0から始まるようにすればindexのように扱えてしまう).
そういうラッキーなケースに頼らずにきちんとindexを作る場合は以下のようなコードになります.import pandas as pd df = pd.read_table('ml-100k/u.data', names=['user_id', 'movie_id', 'rating', 'timestamp']) user_id_categorical = pd.api.types.CategoricalDtype(categories=sorted(df.user_id.unique()), ordered=True) user_index = df.user_id.astype(user_id_categorical).cat.codes movie_id_categorical = pd.api.types.CategoricalDtype(categories=sorted(df.movie_id.unique()), ordered=True) movie_index = df.movie_id.astype(movie_id_categorical).cat.codes ml100k_coo = sparse.coo_matrix((df.rating, (user_index, movie_index)))また,COO形式はCSR形式やCSC形式への変換も高速です.
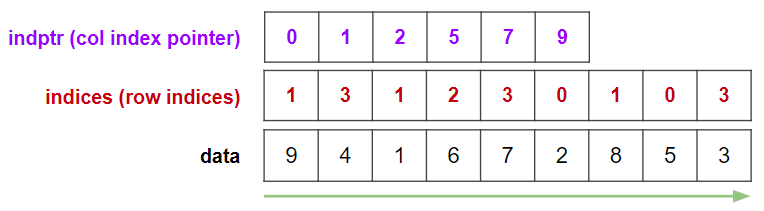
CSR形式
COO形式から話を進めると理解しやすいため,再掲します.
rowを見てみると,同じ数字が連続して並んでいることがわかります.
この情報をさらに圧縮した形式がCompressed Sparse Row形式: CSR形式と呼ばれる形式です.
(Compressed Row Storage形式: CRS形式とも呼ぶようです.直訳すると圧縮行格納形式ですね.)どのように圧縮するかのイメージを説明します.
rowの変わり目に区切り線を引いてみます.
この区切り線の情報はrowの圧縮表現になっています.
ちょうど区切りに囲まれた部分がそれぞれ0行目,1行目,2行目,3行目の情報を表現していますね.
これをrowの代わりに用います.以上をまとめると,CSR形式は以下の3つの1次元配列による表現になります.
区切り線の情報はrow indicesの変化する箇所のポインタを集めたものになっているので,row index pointerと呼ばれます.
scipy.sparse.csr_matrixでは略してindptrという変数名になっています.
scipy.sparse.coo_matrix()と同じようにscipy.sparse.csr_matrix()で簡単に作成できます.data_csr = sparse.csr_matrix(data_np) print(f"index pointer: {data_csr.indptr}") print(f"indices: {data_csr.indices}") print(f"data: {data_csr.data}")outputindex pointer: [0 2 5 6 9] indices: [3 4 0 2 3 2 1 2 4] data: [2 5 9 1 8 6 4 7 3]あるいは
data_csr = data_coo.tocsr()でも作成できます.
このように,scipy.sparse同士は.toxxx()というメソッドで相互に変換できます.CSR形式の利点
行のスライスなど,行ごとに行われる処理が得意です.
最も利点が生きるのは行列積(明確に書くと,CSR形式疎行列とベクトルとの積)になります.
実装がどうなっているのか,中身を確認してみましょう.
https://github.com/scipy/scipy/blob/41800a2fc6f86446c7fe0248748bfb371e37cd04/scipy/sparse/sparsetools/csr.h#L1100-L1137csr.htemplate <class I, class T> void csr_matvec(const I n_row, const I n_col, const I Ap[], const I Aj[], const T Ax[], const T Xx[], T Yx[]) { for(I i = 0; i < n_row; i++){ T sum = Yx[i]; for(I jj = Ap[i]; jj < Ap[i+1]; jj++){ sum += Ax[jj] * Xx[Aj[jj]]; } Yx[i] = sum; } }
Apがrow index pointer,Ajがcolumn indices,Axが非ゼロデータ,
Xxが疎行列にかけるベクトルで,Yxが計算結果のベクトルです.
ゆっくり紙に書いてみるとわかるかと思いますが,CSR形式のそれぞれのデータが効率的に扱われています.
row index pointerによって各行の情報の範囲をうまく表現しており,column indicesによってかけられるベクトルの要素をピンポイントに持ってくることができています.CSC形式
CSR形式における行と列の役割を入れ替えた表現になっています.
Compressed Sparse Column形式: CSC形式ということですね.ほとんど繰り返しになりますが,一応どういう値が入っているのかを確認しておきましょう.
行列を緑線の順に読んでいき,COO形式にします.
colの変わり目の区切り線を考えます.
これをcol index pointerとし,colの代わりに用います.
よってCSC形式は以下のような表現になります.
scipy.sparse.csc_matrix()で確認してみます.data_csc = sparse.csc_matrix(data_np) print(f"index pointer: {data_csc.indptr}") print(f"indices: {data_csc.indices}") print(f"data: {data_csc.data}")outputindex pointer: [0 1 2 5 7 9] indices: [1 3 1 2 3 0 1 0 3] data: [9 4 1 6 7 2 8 5 3]確かに図示した通りの情報が格納されています.
CSC形式の利点
列スライスなどが得意です.
あと,CSR形式ほどではないですが,行列ベクトル積が早いようです.メモリと計算時間の比較
ここまでに紹介した疎行列用の表現形式と,元の単純な行列表現について比較を行ってみましょう.
まずは先ほどCOO形式の利点の説明で用いたMovieLens 100K Datasetを使って,
各形式のメモリサイズ,特に配列の合計バイト数がどうなっているか確認してみます.ml100k_csr = ml100k_coo.tocsr() ml100k_csc = ml100k_coo.tocsc() ml100k_np = ml100k_coo.todense() print(f'np: {ml100k_np.nbytes}') print(f'coo: {ml100k_coo.data.nbytes + ml100k_coo.col.nbytes + ml100k_coo.row.nbytes}') print(f'csr: {ml100k_csr.data.nbytes + ml100k_csr.indices.nbytes + ml100k_csr.indptr.nbytes}') print(f'csc: {ml100k_csc.data.nbytes + ml100k_csc.indices.nbytes + ml100k_csc.indptr.nbytes}')outputnp: 12689008 coo: 1600000 csr: 1203776 csc: 1206732疎行列にあった表現形式になるとグッとメモリサイズが小さくなりますね.
このデータでは最も小さいメモリで済んでいるのは(僅差ですが)CSR形式ですね.次に,ランダムな数値の入ったベクトルを右からかけてみて,行列ベクトル積の計算時間を測ってみます.
x = np.random.randint(1, 10, 1682) %timeit ml100k_np @ x %timeit ml100k_coo @ x %timeit ml100k_csr @ x %timeit ml100k_csc @ xoutput3.2 ms ± 20.1 µs per loop (mean ± std. dev. of 7 runs, 100 loops each) 159 µs ± 995 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each) 92.6 µs ± 1.48 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each) 140 µs ± 1.41 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each)確かにCSR形式が最も早いようですね!
おわりに
疎行列の表現形式について説明し,簡易的に比較を行いました.参考になれば幸いです.
それでは良いスパースライフをお過ごしくださいませ!なお,本記事の用いた環境は以下の通りです.
python = '3.7.0' scipy = '1.3.3' numpy = '1.17.3' pandas = '0.25.3'






- 投稿日:2019-12-21T21:13:28+09:00
企業研究者のためのNumPyまとめ
はじめに
NumPyは、ベクトルや行列計算を高速で行うためのライブラリです。
ここでは、NumPyでよく使うメソッドなどについて解説します。
Python3系の使用を想定しています。インポート
NumPyを使うには、まずライブラリを読み込む必要があります。
慣習的に、npとすることが多いです。NumPy_1.pyimport numpy import numpy as np1次元配列
NumPyでは、リストのような配列を作ることができます。
NumPy_2.pyimport numpy as np np_arr_1 = np.array([1, 2, 5]) print(np_arr_1) print(type(np_arr_1)) print(np_arr_1**2) np_arr_2 = np.array([3, 5, 7]) print(np_arr_1 + np_arr_2) np_arr_3 = np.arange(10) print(np_arr_3) np_arr_3[0:2] = 100 print(np_arr_3)NumPyは要素同士の計算が簡単にできるのが特徴です。
NumPyを使わずに上記の処理を行おうとすると以下のようになります。NumPy_3.pyarr_1 = [1, 2, 5] for i, num in enumerate(arr_1): arr_1[i] = num ** 2 print(arr_1)NumPyの配列では、代入先の要素の値を更新すると、元の配列の値も更新されるので、注意が必要です。
元の配列が更新されないようにするには、copy()メソッドを使用します。NumPy_4.pyimport numpy as np np_arr_1 = np.array([1, 2, 5]) np_arr_2 = np_arr_1 np_arr_2[1] = 100 print(np_arr_1) print(np_arr_2) np_arr_1 = np.array([1, 2, 5]) np_arr_2 = np_arr_1.copy() np_arr_2[1] = 100 print(np_arr_1) print(np_arr_2)ある条件を満たす要素のみを取り出すことも可能です。
NumPy_5.pyimport numpy as np np_arr_1 = np.array([1, 2, 5]) print(np_arr_1[np_arr_1 % 2 == 1])NumPyでは「ユニバーサル関数」と呼ばれる、配列の各要素に対する演算結果を返す関数が用意されています。
NumPy_6.pyimport numpy as np np_arr_4 = np.array([-1, 2, -3]) print(np.abs(np_arr_4)) np_arr_5 = np.array([1, 9, 25]) print(np.sqrt(np_arr_5))NumPyでは、乱数を発生させることもできます。
NumPy_7.pyimport numpy as np np_arr_6 = np.random.randint(0, 10, 5) print(np_arr_6) np_arr_7 = np.random.randint(5) print(np_arr_7)
importの部分を書き換えることで、より短く簡単に記述することができます。Numpy_8.pyfrom numpy.random import randint np_arr_6 = randint(0, 10, 5) print(np_arr_6) np_arr_7 = randint(5) print(np_arr_7)2次元配列
2次元配列に関するメソッドは以下のようになります。
NumPy_9.pyimport numpy as np np_arr_8 = np.array([[1, 2, 3], [4, 5, 6]]) print(np_arr_8) print(np_arr_8[1]) print(np_arr_8[1, 1]) print(np_arr_8.sum()) print(np_arr_8.sum(axis=0)) # 列ごとに計算 print(np_arr_8.sum(axis=1)) # 行ごとに計算 print(np_arr_8.shape) print(np_arr_8.reshape(3, 2)) print(np_arr_8.T) print(np.transpose(np_arr_8)) print(np_arr_8.mean()) # 平均 print(np.average(np_arr_8)) # 平均 print(np.max(np_arr_8)) # 最大値 print(np.min(np_arr_8)) # 最小値 print(np.std(np_arr_8)) # 標準偏差 print(np.var(np_arr_8)) # 分散 print(np.argmax(np_arr_8)) # 最大値の要素のインデックス番号 print(np.argmin(np_arr_8)) # 最小値の要素のインデックス番号まとめ
ここでは、NumPyでよく用いられるメソッドなどを紹介してきました。
マスターするには、実際に使ってみるのが一番の近道です。参考資料・リンク
- 投稿日:2019-12-21T20:53:20+09:00
mong - Dockerのコンテナ名をランダム生成するコードをPythonに移植してみた -
goofy_grothendieck,ecstatic_lederberg,quizzical_wu, ...
Dockerのコンテナのように,ランダムなんだけど読みやすい名前を付けたいことってありますよね?moby/mobyにGo言語のコードを見つけたのでPythonに移植してmongというライブラリにしてみました.使い方
Python 3.6と3.8で動作確認しています.Python3.5以降なら動くと思いますが,Python2はType Hintingなどが原因で動きません.
標準ライブラリだけしか使っていないので,インストールはすぐ終わるはずです.
$ pip install git+https://github.com/toshihikoyanase/mong.gitさっそく,ランダムに名前を生成してみましょう.
>>> import mong >>> ng = mong.NameGenerator() >>> ng.get_random_name() 'goofy_robinson' >>> ng.get_random_name() 'stoic_feynman'Google ColabにJupyter Notebookを用意しました.以下からすぐに試せます:
実装方針
オリジナルのコードを見ると名前の元となる単語の辞書がその大半をしめていました.移植先のコードに辞書をべた書きすると,メンテナンスが大変そうなので,オリジナルのコードから抽出する方法を選びました.
具体的には下記のとおりです.
-mong/create_dict.pyでオリジナルのコードから名前のもととなる単語の辞書を抽出しています.
-mong/moby_dict.jsonに抽出した辞書を保存しています.
-mong/name_generator.pyのNameGeneratorに名前生成ロジックを移植しています.オリジナルの実装
Dockerの名前生成コードは moby/moby にあって,Go言語で書かれています.なお,mobyはコンテナシステムのためのツール集のようです.こちらのスライドに簡潔にまとめられています.
名前は2つの語からなっていて,形容詞と有名な科学者とハッカーの人名です.それらが
_でつながれています.例
# 怒った(形容詞)_チューリング(人名) angry_turing形容詞は
left,人名はrightというリストで管理されています.left = [...]string{ "admiring", "adoring", "affectionate", "agitated",right = [...]string{ // Muhammad ibn Jābir al-Ḥarrānī al-Battānī was a founding father of astronomy. https://en.wikipedia.org/wiki/Mu%E1%B8%A5ammad_ibn_J%C4%81bir_al-%E1%B8%A4arr%C4%81n%C4%AB_al-Batt%C4%81n%C4%AB "albattani", // Frances E. Allen, became the first female IBM Fellow in 1989. In 2006, she became the first female recipient of the ACM's Turing Award. https://en.wikipedia.org/wiki/Frances_E._Allen "allen",名前の生成処理は,基本的にランダムに選択して,つなぐだけです.
// GetRandomName generates a random name from the list of adjectives and surnames in this package // formatted as "adjective_surname". For example 'focused_turing'. If retry is non-zero, a random // integer between 0 and 10 will be added to the end of the name, e.g `focused_turing3` func GetRandomName(retry int) string { begin: name := fmt.Sprintf("%s_%s", left[rand.Intn(len(left))], right[rand.Intn(len(right))]) if name == "boring_wozniak" /* Steve Wozniak is not boring */ { goto begin } if retry > 0 { name = fmt.Sprintf("%s%d", name, rand.Intn(10)) } return name }このQiita記事にもあるように,
boring_wozniakは生成されないようになっています.(出たらもう一度作り直しています.)2019年12月21日時点で,
leftは108語,rightは235語あったので合わせて25,379種類の名前が生成できます.意外と少ないような気がしますね.なお,
retry引数についてはよくわかっていなくて,処理を見てもretryしているように見えません.retry>0だと0以上9以下の整数をランダムに選んで名前の末尾につけています.これは使う側のコードを読まないとわからないかもしれません.単純に1桁種類数を増やすためかな?まとめと今後の課題
PythonでDockerコンテナ風のランダム名を生成できる mong というライブラリを作ってみました.
一応,動くところまでは書いたのですが,テストカバレッジが低かったり,エラー処理を省いていたり,CIをしていないなどいろいろ改善の余地はあります.また,pypiに登録していないので,インストールがやや面倒です.
(自分も含めて)ニーズがあればもう少し整えようかなと思っています.
参考文献
- 投稿日:2019-12-21T19:58:03+09:00
PoetryをFishで使う(Pipenvからの移行)
はじめに
2020 年の Python パッケージ管理ベストプラクティスがバズっていたので調べてみたところ、以前から気になっていたPoetryがかなり良くなっているということなので、Pipenvから移行してみた。
環境
OS: macOS 10.15 Catalina
Shell: FishPoetryのインストール
pip install poetry環境変数設定
Pipenvでは、仮想環境がプロジェクトフォルダに作成されるように、以下のように設定していた。
export PIPENV_VENV_IN_PROJECT=truePoetryでは以下のように設定すれば良いらしい。
poetry config --list poetry config virtualenvs.in-project truePipfile→pyproject.toml
Poetryではpyproject.tomlでライブラリを管理するため、変換が必要になる。
幸いにも、変換ツールpoetrifyが公開されているので、それを用いることにする(詳しくは作者のブログを参照)。pip install poetrify cd example/ poetrify generate試しにPipfileを変換してみるとうまくいった。
Pipfile[[source]] name = "pypi" url = "https://pypi.org/simple" verify_ssl = true [dev-packages] black = "==18.3a1" mypy = "*" pytest = "*" [packages] numpy = "*" scipy = "*" plotly = "*" sklearn = "*" [requires] python_version = "3.7"pyproject.toml[tool.poetry] name = "exampy" version = "0.1.0" description = "" authors = ["ryoppippi <1560508+ryoppippi@users.noreply.github.com>"] [tool.poetry.dependencies] python = "3.6.9" numpy = "^1.17.4" scipy = "^1.4.1" plotly = "^4.4.1" sklearn = "^0.0" [tool.poetry.dev-dependencies] black = "^19.10b0" mypy = "^0.761" pytest = "^5.3.2" [build-system] requires = ["poetry>=0.12"] build-backend = "poetry.masonry.api"仮想環境の構築
以下を実行すると仮想環境の構築、
poetry.lockファイルの作成が行われ、仮想環境が起動する。poetry shell
Fish向けプラグイン
筆者はFishをシェルとして使用しているが、Pipenv時代にはfish-pipenvというプラグインを愛用していた。
このプラグインは、pipenvで構築したプロジェクトのディレクトリに移動した時に自動で仮想環境をactivateしてくれる優れものであった。
残念ながらPoetry用にはまだ同等のものがなかったので、今回自作した。是非とも活用して欲しい。
fish-poetry
まとめ
Pyenvとの連携が若干微妙だったりと不満点もなくはないが、圧倒的にlockが早く終わるなど利点も多い。順次Poetryに移行していこうと思う。


- 投稿日:2019-12-21T19:53:19+09:00
【foliumで可視化】近年ファミマ増えすぎな気がする
これはMYJLab Advent Calendar 2019の21日目の記事です。サッチーが担当いたします。(遅れてすみませんでした)
今回は
すること
最近道路を挟んで向かい側同士にファミリマートがある、みたいな現象が私の地元では起きています。この現象を可視化すべく、今回はファミリーマートの店舗数の増加を都道府県ごとに時系列ヒートマップに落としてみようと思います。
使うもの
LeafletというJavaScriptでいい感じのマップを描画できるライブラリがあります。今回はPythonでLeafletを使うことができるようにしてくれるfoliumというライブラリを使って時系列ヒートマップを作成します。
早速描く
実行環境
- Jupyter Notebook
- Python 3.7.3
- folium 0.10.1
foliumはバージョンによって機能や使い方がかわってくるので、今回は必ずバージョンを0.10.1にするようにしてください。
# ライブラリ読み込み import pandas as pd import folium from folium import pluginsデータ準備
こちらのサイトにあった1999年から2019年のファミリーマートの都道府県ごとの店舗数をcsvファイルにし直してデータを用意しました。PythonのRequestsで落とせるようにしてあります。また、地図に描画するにあたって各県の緯度経度が必要です。今回は都道府県庁が存在する場所を各県の緯度経度とします。データはこちらからダウンロードできます。
# 店舗数のデータ import requests import io URL = "https://drive.google.com/uc?id=1-8tppvHwwVJWufYVskTfGz7cCrBIE0SM" r = requests.get(URL) famima_data = pd.read_csv(io.BytesIO(r.content)) famima_data.head()
近年増えているというだけあって、1999~2006年はかなり欠損値が多くなっています。
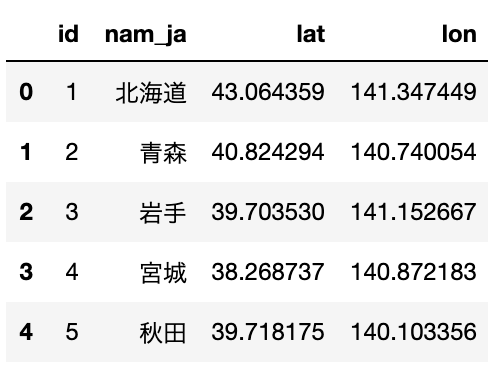
# 都道府県庁の緯度経度 geo_data = pd.read_csv("./data/prefecturalCapital.csv") geo_data.head()
次に、この2つのデータフレームを結合します。idをキーにして結合したいので、geo_dataのidを0始まりに直して結合します。欠損値は一旦0とします。
import numpy as np geo_data.id = geo_data.id - 1 merged_data = pd.merge(famima_data, geo_data[["id", "lat", "lon"]], on=["id"]) merged_data = merged_data.replace(np.nan, 0) merged_data.head()
基本のデータの準備ができました。
増加のデータに変換していく
今回は店舗数の増減の推移を可視化したいので列で差分をとります。
# 時系列のカラム名の配列を取得する time_columns = merged_data.columns[2:23].values # 店舗数のデータの部分のみ差分をとり、diff_dataとする merged_data.loc[:, time_columns] = merged_data.loc[:, time_columns].astype(float) diff_data = merged_data.copy() diff_data.loc[:, time_columns] = merged_data.loc[:, time_columns].diff(axis=1) # 1999年のデータがなくなるので削除する diff_data = diff_data.dropna(axis=1) time_columns = time_columns[1:] diff_data.head()
差分が取れたらmin-max-scalingをします。foliumは0をなぜかすごく大きな値だとみなしてしまうので、全体に1e-4を足します。
# diff_dataをスケーリングし、scaled_dataとする scaled_data = diff_data.copy() scaled_data.loc[:, time_columns] = (diff_data.loc[:, time_columns] - diff_data.loc[:, time_columns] .min().min()) / (diff_data.loc[:, time_columns] .max().max() - diff_data.loc[:, time_columns] .min().min()) scaled_data.loc[:, time_columns] = scaled_data.loc[:, time_columns] + 1e-4 scaled_data.head()
最後に、時系列ヒートマップを描画するために
[[[緯度, 経度, データ] * 47都道府県] * 1999~2019]となる3次元データを作成します。heat_map_data = [[[row['lat'],row['lon'], row[idx]] for index, row in scaled_data.iterrows()] for idx in time_columns] # データの形がわかりにくいので一つ目だけ出力 heat_map_data[0]#出力 [[43.064359, 141.347449, 0.051760516605166056], [40.824294, 140.74005400000001, 0.051760516605166056], [39.70353, 141.15266699999998, 0.05545055350553506], [38.268737, 140.872183, 0.060985608856088565], [39.718175, 140.10335600000002, 0.051760516605166056], [38.240127, 140.362533, 0.07390073800738008], [37.750146, 140.466754, 0.0923509225092251], [36.341817, 140.446796, 0.04807047970479705], [36.56575, 139.883526, 0.05545055350553506], [36.391205, 139.060917, 0.060985608856088565], [35.857771, 139.647804, 0.060985608856088565], [35.604563, 140.123179, 0.04807047970479705], [35.689184999999995, 139.691648, 0.0997309963099631], [35.447505, 139.642347, 0.06467564575645757], [37.901699, 139.022728, 0.051760516605166056], [36.695274, 137.211302, 0.06467564575645757], [36.594729, 136.62555, 0.06467564575645757], [36.065220000000004, 136.221641, 0.06283062730627306], [35.665102000000005, 138.568985, 0.05545055350553506], [36.651282, 138.180972, 0.051760516605166056], [35.39116, 136.722204, 0.05729557195571956], [34.976987, 138.383057, 0.05729557195571956], [35.180246999999994, 136.906698, 0.07574575645756458], [34.730546999999994, 136.50861, 0.06836568265682658], [35.004532, 135.868588, 0.05360553505535055], [35.020996200000006, 135.7531135, 0.05360553505535055], [34.686492, 135.518992, 0.0978859778597786], [34.69128, 135.183087, 0.08128081180811808], [34.685296, 135.832745, 0.04622546125461255], [34.224806, 135.16795, 0.08866088560885609], [35.503463, 134.238258, 0.051760516605166056], [35.472248, 133.05083, 0.051760516605166056], [34.66132, 133.934414, 0.060985608856088565], [34.396033, 132.459595, 0.06836568265682658], [34.185648, 131.470755, 0.051760516605166056], [34.065732000000004, 134.559293, 0.051760516605166056], [34.340140000000005, 134.04297, 0.051760516605166056], [33.841649, 132.76585, 0.051760516605166056], [33.55969, 133.530887, 0.051760516605166056], [33.606767, 130.418228, 0.060985608856088565], [33.249367, 130.298822, 0.05360553505535055], [32.744541999999996, 129.873037, 0.10526605166051661], [32.790385, 130.742345, 0.06652066420664207], [33.2382, 131.612674, 0.05914059040590406], [31.91109, 131.423855, 0.05729557195571956], [31.560219, 130.557906, 0.0868158671586716], [26.211538, 127.68111499999999, 0.07759077490774909]]いざ描画
japan_map = folium.Map(location=[35, 135], zoom_start=6) hm = plugins.HeatMapWithTime(heat_map_data, index=list(time_columns),auto_play=False,radius=30,max_opacity=1,gradient={0.1: 'blue', 0.25: 'lime', 0.5:'yellow',0.75: 'orange', 0.9:'red'}) hm.add_to(japan_map) japan_map
約0.52以下がマイナスを取っているはずなので、増加した場合だけを可視化しています。
動く地図うれしい・・・!!!
ざつ目に考察
- 2010年くらいまではそんなに増加していない(やはり近年の増加傾向にある)
- 2010年以降は増加が見られるが大きい都市がある都道府県ばかり
- 地方はそんなに増えていない
終わり
そんなにコードを書かずに時系列ごとのデータの推移を可視化できるのはとても便利だと思いました。なんかもっと有意義なことに使いたいものです。最後までお読みいただきありがとうございました。訂正箇所とうあればコメントをしていただけると幸いです。
参考,出所





- 投稿日:2019-12-21T19:45:18+09:00
【jinja2】for文内で加算した変数が引き継がれない問題の解決策
はじめに
バージョン
Python: 3.7.4
jinja2: 2.7.2以下のようなコードがあり、for文内でcntという変数を加算していったとします。
count_test.j2{%- set cnt = 1 -%} {%- for i in range(3) -%} {%- set cnt = cnt + 1 -%} {{ cnt }} {% endfor -%} result : {{ cnt }}実行結果(失敗例)
結果を見てみると、for文の外には変数に加算した結果が引き継がれていないことがわかります。
出力2 3 4 result : 1解決策1:リストに格納する
加算した結果をリストに格納すると上手くいきます。
加算した値をappendでリストに足して、加算前の値はpopで削除します。count_test2.j2{%- set cnt = [1] -%} {%- for i in range(3) -%} {%- set _ = cnt.append(cnt[0] + 1) -%} {%- set _ = cnt.pop(0) -%} {{ cnt[0] }} {% endfor -%} result : {{ cnt[0] }}解決策2:namespaceを使う
count_test3.j2{%- set ns = namespace(cnt=1) -%} {%- for i in range(3) -%} {%- set ns.cnt = ns.cnt + 1 -%} {{ ns.cnt }} {% endfor -%} result : {{ ns.cnt }}実行結果(成功例)
結果を見てみると、for文の外でも変数が加算されたままになっています。
出力2 3 4 result : 4
- 投稿日:2019-12-21T19:37:30+09:00
code-server オンライン環境篇 (3) Boto3 で EC2 インスタンスを立ち上げる
これは、2019年 code-server に Advent Calender の 第14日目の記事です。
前回に続き、EC2 Instance を 立ち上げたいと思います。
目次
ローカル環境篇 1日目
オンライン環境篇 1日目 作業環境を整備する
オンライン環境篇 2日目 仮想ネットワークを作成する
オンライン環境篇 3日目 Boto3 で EC2 インスタンスを立ち上げる
オンライン篇 4日目 Code-Serverをクラウドで動かしてみる
オンライン篇 5日目 Docker環境を構築してアレコレ
オンライン篇 6日目 簡単な起動アプリを作成してみよう
...
オンライン篇 .. Coomposeファイルで構築
オンライン篇 .. K8Sを試してみる
...
魔改造篇はじめに
RouteTable の設定をしていませんでした。 時環境では動いているのですが、
もしかすると動かないかも...で、Route Table の設定から始めます
Route Table とは
前回 Gateway を設定しましたね!! で、VPCからアクセスするIPごとに、どのGatewayを使用するかを設定することができます。
今回の場合だと、全部、Internet Gateway につなげれば良いのですが、
VPC間やSubnet間など、こまめに設定することができます。ネットワークの作成 その2です
Route Table を作成する
作成def create_route_table(vpc_id:str): res = ec2client.create_route_table(VpcId=vpc_id) print("{}".format(res)) route_table_id = res['RouteTable']['RouteTableId'] attach_tag(route_table_id) return route_table_idRoute Table には VPC をしてします。当然ですね..
とかで行けます
Routeを作成する
RouteTable に、全てのIPをInternetに接続可能なように指定しましょう
Routeを作成するdef create_route(route_table_id:str, gateway_id:str): resp = ec2client.create_route(RouteTableId=route_table_id,DestinationCidrBlock="0.0.0.0/0",GatewayId=gateway_id) print("{}".format(resp))
0.0.0.0/0が全てのIPを意味しています。
0.0.0.0から255.255.255.255Subnet に関連付けする
def associate_route_table(route_table_id:str, subnet_id:str): res = ec2client.associate_route_table(RouteTableId=route_table_id,SubnetId=subnet_id) print("{}".format(res)) associate_id = res['AssociationId'] return associate_idRoute Table を削除
def delete_route_table(): print(">>> Delete Route Table") res = ec2client.describe_route_tables(Filters=[{"Name":"tag:Name","Values":[instance_name]}]) print("{}".format(res)) for route_table in res["RouteTables"]: for association in route_table.get('Associations',[]): ec2client.disassociate_route_table(AssociationId = association['RouteTableAssociationId']) res = ec2client.delete_route_table(RouteTableId=route_table['RouteTableId']) print("{}".format(res))削除はこんな感じです。
削除する前に、associate_route_table()を呼び出して、関連付けを外す必要があります。※ 今回、Tagを利用しているのは、説明しやすいからで、
vpc_id などからも、引っ張ってこれるので、vpc_idを使うのが良いかもFilters=[{"Name":"vpc-id","Values":[vpc_id]}]SecurityGroupの修正
前回のコードは、VPCを設定し忘れていました..
作成def create_security_group(vpc_id): print(">>> CREATE SECURITY GROUP") res = ec2client.create_security_group(Description="AdventCodeServer",GroupName=instance_name,VpcId=vpc_id) print("{}".format(res)) group_id = res['GroupId'] attach_tag(group_id) return group_idここまで書いたコードは以下の通り
https://github.com/kyorohiro/advent-2019-code-server/blob/master/remote_cs01/for_aws/main.py
Instance を作成する
PEMファイルを作成する
Instance には、SSH キー を利用して接続をする想定でいます。
秘密鍵と公開鍵を作成しておきましょうPEM作成def create_pem(): pem_file = open("{}.pem".format(instance_name),"w") pem_file.write("") try: print(">>> CREATE KEY_PAIR") res = ec2client.create_key_pair(KeyName=instance_name) print("{}".format(res)) pem_file.write(res['KeyMaterial']) finally: pem_file.close() return instance_namePEM削除def delete_pem(): print(">>>> DELETE KeyPair") ec2client.delete_key_pair(KeyName=instance_name)Instanceを立ち上げる
作成def create_instance(subnet_id:str, group_id:str): print(">>>> CREATE INSTANCE") res = ec2client.run_instances(ImageId="ami-0cd744adeca97abb1",#KeyName="xx", InstanceType='t2.micro', MinCount=1,MaxCount=1,KeyName=instance_name, TagSpecifications=[ { 'ResourceType': 'instance', 'Tags': [{ 'Key': 'Name', 'Value': instance_name }] } ],NetworkInterfaces=[{"SubnetId":subnet_id,'AssociatePublicIpAddress': True,'DeviceIndex':0,'Groups': [group_id]}] ) print("{}".format(res))作成した subnetと group_id を指定します。
今回はUbuntuを指定しました。
https://aws.amazon.com/jp/amazon-linux-ami/削除def delete_instance(): print(">>>> ec2client.describe_instances") res = ec2client.describe_instances( Filters=[{"Name":"tag:Name","Values":[instance_name]}] ) print("{}".format(res)) print(">>>> DELETE Instance") for reservation in res['Reservations']: for instance in reservation['Instances']: instance_id = instance['InstanceId'] res = ec2client.terminate_instances(InstanceIds=[instance_id]) print("{}".format(res))削除も、今前通りですね。
では、今までに作成したものをつなげてみましょう。
スクリプトを走らせる、その前に
Instance の削除が完了するまで待機するスクリプトも書いておきましょう。
def wait_instance_is_terminated(): while(True): res = ec2client.describe_instances( Filters=[{"Name":"tag:Name","Values":[instance_name]}] ) terminated = False for reservation in res['Reservations']: for instance in reservation['Instances']: instance_state = instance['State']['Name'] print("------{}".format(instance_state)) if instance_state != 'terminated': terminated = True if terminated == False: break time.sleep(6)まとめ
main.pyimport boto3 from boto3_type_annotations import ec2 from botocore.exceptions import ClientError from typing import Dict, List import time import network instance_name= "advent-code-server" ec2client:ec2.Client = boto3.client("ec2") def create_pem(): pem_file = open("{}.pem".format(instance_name),"w") pem_file.write("") try: print(">>> CREATE KEY_PAIR") res = ec2client.create_key_pair(KeyName=instance_name) print("{}".format(res)) pem_file.write(res['KeyMaterial']) finally: pem_file.close() return instance_name def delete_pem(): print(">>>> DELETE KeyPair") ec2client.delete_key_pair(KeyName=instance_name) def create_instance(subnet_id:str, group_id:str): print(">>>> CREATE INSTANCE") # Ubuntu Server 18.04 LTS (HVM), SSD Volume Type - ami-0cd744adeca97abb1 (64-bit x86) / ami-0f0dcd3794e1da1e1 (64-bit Arm) # https://aws.amazon.com/jp/amazon-linux-ami/ res = ec2client.run_instances(ImageId="ami-0cd744adeca97abb1",#KeyName="xx", InstanceType='t2.micro', MinCount=1,MaxCount=1,KeyName=instance_name, TagSpecifications=[ { 'ResourceType': 'instance', 'Tags': [ { 'Key': 'Name', 'Value': instance_name } ] } ],NetworkInterfaces=[{"SubnetId":subnet_id,'AssociatePublicIpAddress': True,'DeviceIndex':0,'Groups': [group_id]}] ) print("{}".format(res)) return instance_name def delete_instance(): print(">>>> ec2client.describe_instances") res = ec2client.describe_instances( Filters=[{"Name":"tag:Name","Values":[instance_name]}] ) print("{}".format(res)) print(">>>> DELETE Instance") for reservation in res['Reservations']: for instance in reservation['Instances']: print("------{}".format(instance)) instance_id = instance['InstanceId'] print(">>>> {}".format(instance_id)) res = ec2client.terminate_instances(InstanceIds=[instance_id]) print("{}".format(res)) def wait_instance_is_terminated(): while(True): res = ec2client.describe_instances( Filters=[{"Name":"tag:Name","Values":[instance_name]}] ) terminated = False for reservation in res['Reservations']: for instance in reservation['Instances']: instance_state = instance['State']['Name'] print("------{}".format(instance_state)) if instance_state != 'terminated': terminated = True if terminated == False: break time.sleep(6) if __name__ == "__main__": res = network.create() create_pem() create_instance(res["subnet_id"], res["group_id"]) delete_instance() wait_instance_is_terminated() delete_pem() network.delete()コード全体は、以下
https://github.com/kyorohiro/advent-2019-code-server/tree/master/remote_cs02/for_aws
次回
作成した仮想 Instance を操作してみましょう!!
コード
https://github.com/kyorohiro/advent-2019-code-server/tree/master/remote_cs02
- 投稿日:2019-12-21T19:34:55+09:00
PyQtでFileIO
概要
前回の記事は、Qt World Summit 2019の参加報告でした。その時に、PyQtに関心が高まってきているのを感じました。機械学習とかOpenCVをサクッと利用するのにPythonは適している。そこで、PyQtでちょろっと作業してみます。
対象読者
- Pythonに興味がある
- PythonのGUI作成に触れてみたい
- Qtを使っているがPythonでは作業したこと無い
筆者の開発環境
- Windows 10 Home
- Anaconda 3 Python 3.7.4
- Python 3.6.9(conda create)
- PyQt 5.13.2
- PySide2 5.13.2
Python環境は下記のコマンドで作成している。
ー Python3.6環境 (環境名:Pytyon36)
conda create -n python36 python=3.6 spyder pandas jupyter matplotlib numpy
ー Python3.7環境 (環境名:Pytyon37)
conda create -n python37 python=3.7 spyder pandas jupyter matplotlib numpy今回はPython36の方を使用する。
その他にも下記のパッケージをインストールしておく。
pip install PyQt5
pip install PySide2
pip install opencv-pythonPySide2でQApplicationの実行時エラー
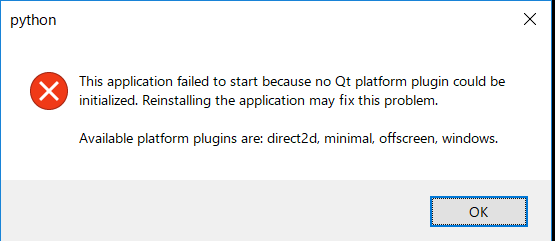
下記のようなコードを書いて実行!!としてみたら上図のようなエラーが発生する。
import sys from PySide2.QtWidgets import QApplication if __name__ == "__main__": app = QApplication([]) sys.exit(app.exec_())調べてみると、Anaconda3/envs/python37/Library/pluginsの中のパスが正常に反映されないみたいだ。PyQt5を利用するとこのエラーは出なかった。
下記のようにおまじないを入れると、きちんとplatformsのパスが認識されて実行時のエラーがでなくなった。第1のつまづきポイントだった。
import sys,os import PySide2 dirname = os.path.dirname(PySide2.__file__) plugin_path = os.path.join(dirname, 'plugins', 'platforms') os.environ['QT_QPA_PLATFORM_PLUGIN_PATH'] = plugin_pathおまじない以外の解決方法
① Anaconda3\envs\python37\Lib\site-packages\PySide2\plugins\platforms
② Anaconda3\envs\python37\Library\plugins\platforms①のqwindows.qllを②のものに置き換えるとエラーなく動作した。
完成イメージ(Gif)
詳細
インポートするパッケージ
import sys import os.path import numpy as np import cv2 from PyQt5.QtWidgets import QMainWindow, QAction, QApplication, QTextEdit, QFileDialog今回はPySide2を使用せず、PyQt5を使います。使っている感触的に、PySide2だと動作するけど、PyQt5では動作しないみたいなことが多かったし、これからはどっちを使っていくべきなのか悩ましい。
QApplication
def main(): app = QApplication(sys.argv) main_window = MainWindow() main_window.show() sys.exit(app.exec_())アプリケーションオブジェクトの生成。QApplicationを使用する。QMainWindowクラスを継承したMainWindowクラスのオブジェクトを呼び出す。
QMainWindowを継承したMainWindowクラス
class MainWindow(QMainWindow): def __init__(self): super().__init__() self.textEdit = QTextEdit() self.setCentralWidget(self.textEdit) self.statusBar() self.statusBar() openFile = QAction('&File', self) openFile.triggered.connect(self.show_file_dialog) menubar = self.menuBar() fileMenu = menubar.addMenu('&Menu') fileMenu.addAction(openFile) self.setGeometry(300, 300, 300, 200) self.setWindowTitle('Menubar') self.show()init関数の中で、ボタンやメニューバーなどの配置、Windowサイズの定義などを行う。
FileDialog
def show_file_dialog(self): file_name = QFileDialog.getOpenFileName(self, 'Open file', '/home') if file_name[0]: print(file_name[0]) self.identify_extension(file_name[0]) def identify_extension(self, path): root, ext = os.path.splitext(path) print(path) if ext == '.txt': f = open(path, 'r') with f: data = f.read() self.textEdit.setText(data) elif ext == '.jpg' or ext == '.png': read_img = ReadImg(path) b, c = read_img.open_img() d = read_img.canny(b) cv2.imshow("", d) cv2.waitKey(0) cv2.destroyAllWindows()Fileの読み込みをするのに、FileDialogを使用する。画像とテキストファイルの両方を読み込む。画像の読み込みにはOpenCVを使用する。
画像読み込みクラス
class ReadImg: def __init__(self, file): self.file = file print(self.file) def open_img(self): pic = cv2.imread(self.file) pic_color = cv2.cvtColor(pic, cv2.COLOR_BGR2RGB) return pic, pic_color def canny(self, pic): img = cv2.cvtColor(pic, cv2.COLOR_BGR2GRAY) edges = cv2.Canny(img, 100, 200) edges2 = np.zeros_like(pic) for i in (0, 1, 2): edges2[:, :, i] = edges add = cv2.addWeighted(pic, 1, edges2, 0, 4, 0) return addまとめ
C++とQMLでのアプリケーション作成はある程度慣れてきたので、Pythonの勉強もかねてPyQtの勉強を始めた。C++で作成するよりもエラーでつまづくことが多い。しかもパッケージのバージョンなどの整合性が取れないなどの面倒なタイプが多くて四苦八苦する。C++ではそんなことはほとんど経験がない。
物体検出、APIを利用して株価などのデータをWebから取得、機械学習の利用などがPythonを使用することで簡単に行っていくことができる。YOLOとかQtで動かせたらいいなって考えながら。。。
PtQtで顔検出するアプリやっと完成した。
— OMORI (@RIO18020) December 15, 2019
Pythonやっぱり実行時間長いなって思ったのと、顔検出にはおでこが見えるのが大事みたいだ(笑) pic.twitter.com/vLN0RUnqSoYOLOが動いた。これをQtに?? pic.twitter.com/0bF7InIFeQ
— OMORI (@RIO18020) December 18, 2019

- 投稿日:2019-12-21T19:26:15+09:00
TouchDesignerというものを触ってみた
先日DotFes2019に参加した際にTouchDesignerの開発者の一人Ben Voigtさんのお話を聞き、
すごく気になったので少し触ってみました!の記事です。
TouchDesignerとは?
TouchDesignerとは非常に高度な映像を製作することができる、
ノードベースのヴィジュアルプログラミング環境です。
簡単に言うと箱に線を繋ないで、プログラムを作るプログラミングツールです。簡単な特徴としては
- ノンコーディング コード描かなくてもOK
- コンパイルやビルドも必要なしです。
- そのため、プログラムの作成も高速でできる
- リアルタイム、インタラクティブに強い
- 3DCGが容易に扱える
- 様々なデバイス、ツールとの連携も容易といった感じになりますが、補足でノンコーディングについては
あくまでも使わずにできるよ!ってことであり実際使ったほうがより複雑な動きをさせたりすることができます。
ちなみにメインスクリプトはPythonになります。TouchDesignerでできることは?
できること範囲がめっちゃくちゃ広いです。
プロジェクションマッピングやVRの映像も作れたりします!参考までに以下の動画は美術館の壁中にプロジェクションをしている作品です。
この作品では50台以上のプロジェクターを使用していますが、1台のPCのみで制御しているそうです。
TouchDesignerは安定して動くため、こういった大規模の常設プロジェクトでも数多く使われています。
https://youtu.be/GpRksCaf2SI導入コストは?
4つのプランから選ぶことができます。
- PRO:2200ドル/年の最上級版です。あらゆるプロのデザイナーのニーズに応えます。
- COMMERCIAL:600ドル/年の汎用版です。商用利用が可能です。
- EDUCATIONAL:300ドル/年の教育用です。学校や学生向けで、商用利用はできません。
- NON-COMMERCIAL:無料の個人向けです。商用利用はできません。
実際に使ってみて
公式ページ(https://derivative.ca/ )からアカウントの作成とインストールします。
インストール完了後、開いてみるとこんな感じです。
ここから新規作成して映像を作っていきます!
1時間足らずでこんな映像ができました!
(※その前にチュートリアルとかは目を通してます)
使ってみて感じたことは無料でこのクオリティーのツールが使用できるのはめちゃくちゃ良いのと、直感的に操作できるのも一つの魅力ではかなと思います。
あとは個人的にAeよりTouchDesignerの方が3D映像作りやすいなと感じました。
機能とかの説明もしたいんですがめちゃくちゃ長くなるので今回はここまで!オススメの参考サイト
TouchDesignerの開発元、Derivative社のサイト
https://docs.derivative.ca/Main_Pageohkawara ayatoさんのWorkshopWorkshop
https://www.youtube.com/watch?v=R5_LWZqzAi8TouchDesignerを勉強する時に参考になるサイトまとめ
https://qiita.com/ToyoshiMorioka/items/763f425bc3381209a29f



- 投稿日:2019-12-21T18:58:23+09:00
とりあえずやってみる分子動力学シミュレーション
この記事では、分子動力学について簡単に説明して、簡単にシミュレーションを行ってみます。シミュレーションには、Atomic Simulation EnvironmentというPythonモジュールを使用することにします。
分子動力学とは
分子動力学(Molecular Dynamics: MD)は、原子や分子間の相互作用(ポテンシャル)をもとに運動方程式を解いて行くことで、原子や分子の動的過程を得ます。
私たちの身の回りにあるものは、細かく見ていけば原子や分子の集合体です。分子動力学は、この原子や分子の動きを計算することで集合体としての振る舞いを理解しようとするものです。
とりあえずやってみる
難しい理論は置いておいて、とりあえずやってみましょう。ここでは、Atomic Simulation Environment(ASE)という便利なパッケージを使うことにします。
パッケージを入れる
Pythonが必要なので適宜環境を構築してください。Python環境が整ったら、
pip install --upgrade --user aseで入ります。もし、numpy, scipy, matplotlibがない場合はこの2つもインストールします。
pip install --upgrade --user numpy scipy matplotlibこれだけで準備は完了です。
銅(Cu)のシミュレーションをやってみる
銅原子(Cu)のシミュレーションをやってみましょう。
(ここで上げる内容はチュートリアルとほとんど同じです。)初期配置を作る
シミュレーションを行うには、まず銅原子の初期配置が必要です。ここでは、銅原子をFCC上に配置します。
import matplotlib.pyplot as plt from ase.visualize.plot import plot_atoms from ase.lattice.cubic import FaceCenteredCubic size = 3 atoms = FaceCenteredCubic(directions=[[1, 0, 0], [0, 1, 0], [0, 0, 1]], symbol="Cu", size=(size, size, size), pbc=True) plot_atoms(atoms, rotation=('0x,0y,0z')) plt.show()これを実行すると、
が得られます。$3\times3\times3$のFCCが作れてますね!ポテンシャルを決める
MDを行うには、銅原子間のポテンシャルが分かっている必要があります。今回はEMT(effective medium theory)ポテンシャルを使います。
from ase.calculators.emt import EMT atoms.set_calculator(EMT())初速度を決める
シミュレーションを行うには、初期配置だけでなく、初速度も決める必要があります。ここでは、温度$300k_B$のマクスウェル=ボルツマン分布に従い速度を決定します。
from ase import units from ase.md.velocitydistribution import MaxwellBoltzmannDistribution MaxwellBoltzmannDistribution(atoms, 300 * units.kB)運動方程式を解く
最後に運動方程式(微分方程式)の解き方を決めます。
ここでは、最も簡単なミクロカノニカルアンサンブル(粒子数$N$, 体積$V$, エネルギー$E$が一定)に従う運動方程式を、速度ベルレ法で解きます。from ase import units from ase.md.verlet import VelocityVerlet dyn = VelocityVerlet(atoms, 5 * units.fs)この時、時間刻みは$5$fs(フェムト秒)。ちなみに、$1$fsとは$10^{-15}$sのこと。
MDを実行する。
これまでの準備をもとにMDを実行してみましょう。
from ase.lattice.cubic import FaceCenteredCubic from ase.md.velocitydistribution import MaxwellBoltzmannDistribution from ase.md.verlet import VelocityVerlet from ase import units from ase.calculators.emt import EMT # 初期配置をつくる(FCC) size = 3 atoms = FaceCenteredCubic(directions=[[1, 0, 0], [0, 1, 0], [0, 0, 1]], symbol="Cu", size=(size, size, size), pbc=True) # ポテンシャルにEMT(effective medium theory)を使う atoms.set_calculator(EMT()) # 300kbのマクスウェル=ボルツマン分布に従う運動量を設定する MaxwellBoltzmannDistribution(atoms, 300 * units.kB) # 速度ベルレ法でNVE一定のMD計算をする dyn = VelocityVerlet(atoms, 5 * units.fs) def printenergy(a=atoms): # ポテンシャルエネルギー、運動エネルギーの出力 epot = a.get_potential_energy() / len(a) ekin = a.get_kinetic_energy() / len(a) print('Energy per atom: Epot = %.3feV Ekin = %.3feV (T=%3.0fK) ' 'Etot = %.3feV' % (epot, ekin, ekin / (1.5 * units.kB), epot + ekin)) # MD計算 dyn.attach(printenergy, interval=10) dyn.run(1000)上記を実行すると、次のような出力が得られます。
Energy per atom: Epot = -0.006eV Ekin = 0.044eV (T=340K) Etot = 0.038eV Energy per atom: Epot = -0.006eV Ekin = 0.044eV (T=340K) Etot = 0.038eV Energy per atom: Epot = 0.029eV Ekin = 0.010eV (T= 76K) Etot = 0.038eV .....
Epotがポテンシャルエネルギー、Ekinが運動エネルギー、Etotが全エネルギーです。
グラフにしてみると、
全エネルギーがよく保存していて、NVE一定のシミュレーションが正しくできていることが分かります。
おわりに
今回のシミュレーションは、非常に小さく簡単な系に対して非常に短い時間行いました。
より実践的なシミュレーションを行うには、様々な工夫が必要です。例えば、今回はNVE一定のシミュレーションを行いましたが、実際のところNVT一定(カノニカルアンサンブル)のシミュレーションを行いたい場合の方が多いです。NVT一定のシミュレーションを行うには、Nosé–Hoover thermostatやLangevin dynamicsなどの方法を用いる必要があります。
あるいは、ポテンシャルに第一原理計算を利用する第一原理分子動力学なんてのもあります。ASEは、大変ありがたいことに、これらも簡単に試すことができます。ぜひ皆さんも一度遊んでみては。
(気づいたらASEの宣伝になってた...)


- 投稿日:2019-12-21T18:52:11+09:00
サンタ画像からサンタ識別器を作る
はじめに
人類の皆さん、こんにちは。
バーチャルYouTuber輪廻ヒロのソフトウェア担当、矢口です。今回は動画で取り上げた内容である「サンタ識別器」の解説をします。
なお、ソースコードはgithubに公開しています。
ごく短いコードなのでまずはそちらをご覧ください。https://github.com/hyaguchi947d/santa_recognition
問題設定
問題として、「サンタのイラストとサンタでないイラストの識別を行う」という設定にしました。
週一で動画を仕上げる都合上、実際にデータセット作成、コーディング、検証にかけられる時間は一日しかありません。ので、最低限のセットで設計します。画像データセット
ここが一番大変です。なぜなら、弊社は営利企業であり動画投稿は営業活動です。
すなわち商用利用可と明示してあるデータ以外は使ってはいけません。なので、まずは「いらすとや」様の規約に基づく20枚で作成していましたが、
あまりにもデータに偏りがあるため、「Pixabay」様「素材Good」様より追加を行い、
最終的には29+29の計58枚となりました。更に、正負双方のデータをtrain:test = 22:7に分割しました。
この際にも、配布元のデータが偏らないように分けています。なお、データセットの再配布やリンクは規約に抵触するため行いません。
採用する手法について
動画の内容として三段落ちにすることは決めていたので、
最初は最もかんたんな色ヒストグラム、
最後はディープラーニングとして使ってことのあるYOLO v3としました。
中間の一つですが、HOGと迷いましたがBag of Visual Wordsとしました。
どれも自分でコードを書く内容を最低限に抑えるため、
OpenCVで1時間くらいで実装できるもの、
あるいは実装せずとも動かせるもの、という条件もありました。実装
色ヒストグラム
与えられた問題は単純な2クラス分類です。
ともかく色ヒストグラムが取れさえすれば、
あとはSVMにかけて判定してもらえばよい。ということで、OpenCV Pythonとscikit-learnでさくっと作ります。
色ヒストグラムのとり方はOpenCVにチュートリアルがあり、
https://docs.opencv.org/master/dd/d0d/tutorial_py_2d_histogram.htmlSVMもscikit-learnのわかりやすいチュートリアルがあります。
https://scikit-learn.org/stable/modules/generated/sklearn.svm.SVC.htmlやっていることはごく単純で、
def color_hist_from_file(imgfile): img = cv.imread(imgfile) hist = cv.calcHist([img], [0, 1, 2], None, [8, 8, 8], [0, 256, 0, 256, 0, 256]) hist_1d = hist.flatten()[1:-1] # remove bins with (0,0,0) and (255,255,255) n_hist_1d = hist_1d / np.linalg.norm(hist_1d) return n_hist_1dこの関数の中ではbgr各チャンネルを8つに区切ったヒストグラム(8*8*8=512次元)を生成し、
そこから最初と最後のビン(真っ黒と真っ白、背景色であるため)を除いた510次元ベクトルを正規化したものを分類のためのベクトルとして用います。SVMの学習は、正例負例を連結したリストと、
それぞれに対応する(今回は1と0)ラベルのリストを生成して行います。trains = hist_train_p + hist_train_n labels = [1] * len(hist_train_p) + [0] * len(hist_train_n) clf = svm.SVC() clf.fit(trains, labels)これだけです。
Bag of Visual Words
OpenCVのまともなチュートリアルがなかった。
ただし自力実装したことがあるアルゴリズムなので最悪はなんとか、
と思っていましたが、少し悩んでOpenCVのものを使えました。こちらの記事が参考になりました。
https://hazm.at/mox/machine-learning/computer-vision/recipes/similar-image-retrieval.htmlなお、特徴点にはAKAZEを利用しています。
SIFT,SURFは特許で保護されているためです。
(この話は3ヶ月後にもう一度することになると思いますが、またその時に。)手順としては、
- 教師画像のAKAZE特徴点のkeypointsとdescriptorsを計算
-BOWKMeansTrainerにdescriptorsを追加し、辞書を作成する。
- このとき、descriptorだけを用いているのは、desciptorのクラスタリング結果から辞書サイズ数と同じVisual Wordsを生成している。
- Bag of Visual Wordsなのは、画像中にこれらVisual Wordsがいくつ含まれるかにより、画像からヒストグラムを生成するため。次元数は辞書サイズ数。
-BOWImgDescriptorExtractorに辞書を設定
- これにより、各画像のBag of Visual Wordsが求められる。
- あとはSVMを用いて画像を分類YOLO v3
darknetを使いました。以上。
しいていうなら、データセットの生成にVoTTを以前使っていたのですが、
v2になってからYOLOのデータが生成できなくなっていて、
V1はそれはそれでバグがあり(なぜかアノテーション済み画像を漏らす)、苦労しました。実験結果について
色ヒストグラム
実は単純にヒストグラム取るだけ+SVMやるだけだと、
境界部分で少し輝度が違うだけで隣接ビンに入ってしまい、
類似度が極端に低くなるケースもありました。
本来なら少し重なるようにビンを設定するとか、
隣接ビン同士は距離近くするとか、対策が必要ですが時間がなかった。なので、識別対象であるサンタヒロのイラストを寄せています。
当初サンタ服をFF0000で書いていたところ、見事にサンタじゃなくなったので
少し色調整してDD0000になおしています。Bag of Visual Words
当初グレースケールだけでやっていましたが、
RGBの各チャンネルで分離してBoVWを3つ作り、連結したものでもやりました。
結果はほとんど変わりませんでした。HOGと迷った理由の一つが、
ベクタグラフィクスが多かった(輪廻ヒロもベクタグラフィクス)ため、
エッジが優位に効くのでは、と思ったからでした。動画内でも指摘されてますが、
うまく識別できなかったのは単純に画風の問題かと思います。YOLO v3
動画の中で声担当の人がもらしていたように、
本当はここできっちり別れていればよかったんですけどね。ちなみに、当初はサンタの1クラスのみを識別するようにしていましたが、
これだとnotサンタも全部検出してしまう、人型イラスト検出器になってしまいました。
ここまで20時間30000epochくらい学習していましたが一度破棄し、
2クラスにして15時間20000epochくらいで再度やり直しています。
(経験的に20000epochで十分識別性能は出る)
とはいえひたすら待つだけなので実際にはそこまで手間はかかっていませんが。こちらも、そこまで色は優位に出ないんだな、という気づきがありました。
おわりに
週一の番組で紹介する以上、
時間もなく個人的には納得の行く結果ではなかったのですが、
どんな結果でもともかくエンタテインメントとしてオチをつけなければならなかったので、
台本自体はどんな結果に転んでもいいように書いていました。
とはいえ不正確なこと、いい加減なことを発信するわけにはいかないため、
10分の枠内で講義ができるくらいの内容をぎっちり詰め込んでみました。さすがにこの密度を毎週提供するのは難しいので
ガチ技術の話は月一くらいになるかもしれませんが、
これからも輪廻ヒロをよろしくお願いします。

- 投稿日:2019-12-21T18:17:00+09:00
Python実践データ分析100本ノックで10本くらい打ってきた学びのまとめ
pandasをどれだけ使い倒すかが今の時代大事
最近よく売れているPython実践データ分析100本ノックに毎日挑戦しています。
今回はその中から単純なものから必要なものまで得た学びを共有させていただきます
(随時更新中です)この本は実践的な例題が100本も載っています。(本のリンク(Amazon))
今後のトレンドとして
「PythonってVBAよりめっちゃシンプルにコード書けてめっちゃ資料作成が捗るわ!」
といったExcelとPythonの合わせ技ができるビジネスパーソンが社内でモテると思っています。備考ですが、オライリー本より秀和システムの機械学習の本の方が軽くて実践的で安くておすすめです(オライリー本もお金があるときは買ってます。)
早速Jupyterでコピペでいけるようなサンプル付きの例題をいくつか紹介させていただきます。(本の内容とはちょっと違います。すべては紹介できません。コスパは抜群なのでぜひお買い求めください)
(2019/12/21)@konandoiruasaさんよりコードのCSVがURLから読み込めないという指摘をいただきました。もしそういったことが起こったら以下を実行ください。@konandoiruasaさんありがとうございます。
import ssl ssl._create_default_https_context = ssl._create_unverified_contextデータを読む
シンプルにデータを読みます。
import pandas as pd customer_data= pd.read_csv('https://microlearning.site/pydata/ch1/customer_master.csv') customer_data.head()いろんなデータを読みまくる
import pandas as pd transaction_1 = pd.read_csv('https://microlearning.site/pydata/ch1/transaction_1.csv') transaction_1.head()import pandas as pd transaction_2 = pd.read_csv('https://microlearning.site/pydata/ch1/transaction_1.csv') transaction_2.head()データを結合(ジョイン)する
transaction = pd.concat([transaction_1,transaction_2],ignore_index=True) transaction.head()長さを比べるとtransactionはtransaction_1とtransaction_2を合計した列数になっていると思います
print(len(transaction_1)) print(len(transaction_2) print(len(transaction))更新履歴
- 2019/12/21 新規作成
- 投稿日:2019-12-21T18:13:36+09:00
Nginx+gunicorn構成でFlaskを使う[ローカル環境編]
本記事の概要
PythonによるWebアプリケーション学習ロードマップのStep1として、
ローカル環境において以下の構成でFlaskアプリケーションを立ち上げる手順や関連する設定について記載します。(構成は下図参照)
Pythonインストール済Mac OSを前提としています。(が、他プラットホームでも大差ないと思います。)
記事早見表
- 似たような記事を読んだとき、よくなんで?どういう意味?と感じる -> ○○ってどういうもの/こと?
- 動けばいいや -> 動かしてみる
- gunicornやNginxの設定ファイルについて知りたい -> 設定ファイル、起動/終了コマンドを紐解く
動かしてみる
まずは実際に上記構成で動かしてみましょう。
必要となるパッケージをインストールしておきます。brew install nginx pip install gunicornプロジェクトの構成と各ファイルの内容
PROJECT ├── config │ ├── gunicorn_settings.py # アプリケーションサーバの設定ファイル │ └── nginx.conf # Webサーバの設定ファイル └── flask_app.py # メインとなるアプリケーション
- アプリケーションファイル
今回、アプリケーションの挙動については重要視しないので、文字列を返却するルートを2つだけ用意することとします。flask_app.pyfrom flask import Flask app = Flask(__name__) @app.route('/') def index(): return 'Index Page!' @app.route('/health') def health(): return 'Health Check OK!!'
- Webサーバ設定ファイル
gunicorn_settings.pyimport os bind = '127.0.0.1:' + str(os.getenv('PORT', 9876)) proc_name = 'Infrastructure-Practice-Flask' workers = 1
- Nginx設定ファイル
nginx.conf# 詳細は設定ファイルの項を参照 worker_processes 1; events { worker_connections 512; } http { server { listen 9123; server_name INFRA-PRACTICE-NGINX; charset UTF-8; proxy_set_header Host $host; location / { proxy_pass http://127.0.0.1:9876; } location /health/ { proxy_pass http://127.0.0.1:9876/health; } } }プロセスを起動する
Terminal# Webサーバの起動 nginx -c ${PROJECT_PATH}/config/nginx.conf # アプリケーションサーバの起動 gunicorn flask_app:app -c config/gunicorn_settings.py疎通確認する
Terminalcurl http://localhost:9123/ # -> Index Page!と返ってくればOK curl http://localhost:9123/health/ # -> Health Check OK!!と返ってくればOK設定ファイル、起動/終了コマンドを紐解く
gunicorn
設定ファイル
公式ドキュメントでは、オプション形式で記載されています。
設定ファイルを利用する場合、設定項目名をkeyとしたkey=value形式で表記します(e.g.loglevel = 'debug')。設定ファイルの拡張子は任意です。
設定の一部を以下に示します。
key 意味 型 デフォルト値 reload コードを変更したとき自動的に読み直して再起動する bool False accesslog サーバへのアクセスログ出力先
ファイルを指定、「-」だと標準出力を意味する
e.g.accesslog = logs/gunicorn_access.logstring None errorlog エラーログ出力先
ファイルを指定、「-」だと標準出力を意味する
e.g.errorlog = logs/gunicorn_err.logstring '-' proc_name psコマンドで表示されるプロセス名称
特に指定しないとdefault_proc_nameである「gunicorn」となるstring None limit_request_line リクエストの最大サイズ、DDos対策で指定
同様の項目にlimit_request_fieldsint 4094 bind 接続ホストおよびポート
HOST:PORT形式で指定
e.g.bind = os.getenv('HOST') + ':' + os.getenv('PORT')string 127.0.0.1:8000 daemon gunicornプロセスをデーモン起動する bool False workers リクエストをさばくWorkerプロセスの数
親プロセスが1つ起動し、workersの数だけ子プロセスを立てこちらでハンドルする
並列を考慮できていない場合に2以上を指定すると、不具合のもととなるint 1 worker_connections 最大接続数 int 1000 起動/終了コマンド
【起動】
Terminalgunicorn {Flaskアプリケーションファイル名}:{ファイル内のFlaskインスタンス変数名} -c {設定ファイルのパス}※設定ファイルの項で述べたとおり、Settingは起動時オプションでも指定可能。
【終了】
プロセス起動しているTerminalにおいて、Ctrl+CNginx
設定ファイル
公式ドキュメントを見てみると、gunicornの
key=value形式とは異なり、
Module内部にDirective(命令)をコンテキスト形式(curly bracket:{}で囲まれるブロック)で記述することがわかります。
Module
Module名 記載する内容 core ログ、プロセス制御
最も外側のコンテキストがこれにあたるevents イベント系処理 http Webサーバにかかわる処理
おそらく最も多く記述するのがこのモジュール※そのほか、mailやstreamが存在。
Directive Syntax in http contexthttpコンテキスト内にはserverコンテキスト、serverコンテキスト内にはさらにlocationコンテキスト
といったように、コンテキストinコンテキスト形式で記述していきます。
ここではhttpブロックの設定例を示します。例を見ることで、冒頭の設定ファイルが何を意味しているか理解が進むのではないでしょうか。
- 基本の設定
confighttp { server { listen 80; # 80番ポートで接続を待つ server_name MY_SERVER; # サーバ名はMY_SERVER charset UTF-8; # レスポンスヘッダのContent-typeをUTF-8に指定 error_page 404 /404_not_found.html; # ステータスコードが404のときに404_not_found.htmlへ内部的にリダイレクト } }
- リバースプロキシ
confighttp { server { # /indexへのアクセスを location /index { proxy_pass http://127.0.0.1:8080; # 127.0.0.1の8080ポートへリバースプロキシする proxy_set_header Host $host; # プロキシされたサーバへ渡すリクエストヘッダのうち、Hostに$hostを設定し直す proxy_read_timeout 60s; # プロキシされたサーバからの応答が60秒なかったらタイムアウトとする } } }
- アクセス制御/IPフィルタリング
configconfig http { server { location / { allow 192.168.0.1; # 192.168.0.1からのアクセスを許可して deny all; # それ以外のネットワークアクセスを拒否する } } }
- BASIC認証
confighttp { server { location / { auth_basic "Basic Auth closed site"; # BASIC認証が必須の旨を明示し、 auth_basic_user_file conf/htpasswd; # .htpasswdファイルパスを指定する } } }
- Referrerチェック
confighttp { server { # リクエストヘッダにRefererがない(none)、ヘッダにあるがhttp://またはhttps://で始まらない(blocked)、 # mintak.comで終わらない(server_names) ルートからのアクセスの場合はinvalidと判定 ->$invalid_refererに1をセット valid_referers none blocked server_names *mintak.com if ($invalid_referer) { return 403; # invalidと判定した場合は403 Forbiddenで返却 } } }
Embbed VariableNginxサーバにおける環境変数のようなもの。詳しくはこちら。
一部を以下に示します。
variable 内容 $host リクエストヘッダのHost、ない場合はサーバ名 $remote_addr 接続クライアントのアドレス $remote_port 接続クライアントのポート $status レスポンスのステータス $server_name サーバの名称 $http_name HTTPリクエストヘッダのフィールド、nameの部分にヘッダフィールド名を小文字、underscoreで設定
e.g. http_host、http_referer起動・終了コマンド
【起動】
Terminalnginx -c {設定ファイルのパス}【終了】
Terminalnginx -s stop # 上記に失敗する場合はプロセスを特定してkill ps ax | grep nginx kill -9 ${PID}【起動確認】
Terminalps aux | grep nginx # ここでnginx: master processと出てきた場合はnginxが動いている。 # PORTの確認ができるコマンド lsof -i -P | grep nginx #=> nginx 41845 mintak 6u IPv4 0x595e7f947462ada5 0t0 TCP *:9123 (LISTEN)○○ってどういうもの/こと?
ここまでのファイルを用意してコマンドをたたけば目的は達成できます。しかし、自分のような初学者には難しい言葉や概念が多く出ています。ここからは、そうしたキーワードに関して自分なりの解釈を記載していきます。
どうしてこのような構成になるのか
有識者曰く、かつてはWebサーバとアプリケーションサーバの分割はされていなかったとのこと。この構成が問題となったのは、インターネットの普及に伴い、一般公開しているサービスに対するアクセス数が増えたことでサーバへの負荷が高まり、全体的にパフォーマンスが落ちるという自体に直面したときでした。
そこで、負荷を分散させることで安定稼働することを目指し、後述のように役割に応じてサーバを分割する流れになりました。この思想が現代においては当たり前で、一般的にWebサービスはWebサーバ<-->アプリケーションサーバ<-->DBサーバという三層構造で作られているそうです。
役割ごとにプロセス(サーバ)を分けるという根本の考え方は、コーディングの際の設計思想(1クラス/1関数ごとに明確な役割は1つずつ)と通じるところがあると思います。でも
python flask_app.runで動くじゃんこれはFlaskというフレームワークがWebサーバ/アプリケーションサーバを兼任した状態で立ち上げることのできるフレームワークであるためです。
開発時の簡単な検証や動作確認をする際など、わざわざWebサーバとアプリケーションサーバを別で立ち上げるのがメンドウな場合に有用です。
このコマンドでの起動時に、WARNING: This is a development server. Do not uses it in a production development.とログが出てきます1が、あくまで開発向けであり、この構成だと大量アクセス処理でパンクするなどのリスクが大きいから本番ではやめてね、という意味です。※flask_app.pyに
app.run(host='0.0.0.0, port=9876)を追記すると上記コマンドでも立ち上がるWebサーバとアプリケーションサーバの主な役目
それぞれ一言でまとめます。詳しくはReferenceのリンクページを参照ください。
- Webサーバ :要求に対して、だれがアクセスしても変わらないもの(静的処理)を対応。TOPページなどがこれにあたりやすい。
- アプリケーションサーバ:アクセスに応じて返答が変わるもの(動的処理)を対応。会員Myページなど(会員によって表示内容が異なる)。
リバースプロキシってなんでリバース?
リバースがあるってことはフォワードがあるか、というとあります。
通常我々がプロキシと呼称しているものが、フォワードプロキシにあたります。フォワードプロキシとリバースプロキシの違いはなにか
互いにプロキシであることには変わりありません。クライアント->インターネット間での処理がフォワードプロキシ(サーバ)、インターネット->ターゲットWebサーバ間での処理がリバースプロキシ(サーバ)です。2
直接目的のサーバにつなげばいいじゃん!と思われるかもしれませんが、プロキシサーバをかませることによるメリット(下記参照)を受けることができます。
フォワードプロキシの用途
用途 詳細 省力化 1度アクセスしたサイトのデータを一時的にキャッシュしておくことで2回目以降のアクセスでは、Webにアクセスせずにキャッシュからデータを取得するフローとしてデータ取得までの時間を短縮することが可能。 コンテンツフィルタリング 特定のサイトに対するアクセスをここで遮断する。 会社PCでえっちなサイトが見られないのは大体こいつのせいリバースプロキシの用途
用途 詳細 セキュリティ強化 特定のアクセス方法(http://、https://など)ではない場合や特定のIPアドレス以外からのアクセスを遮断するなどの機構を持たせることが出来る。 負荷分散(ロードバランサ) 一度クッションとなることで、複数台あるアプリケーションサーバに対してうまいことアクセスを分配する。 高速化 静的搾取。画像、htmlファイルなどの参照用のコンテンツをキャッシュで保持することでサーバの負荷を軽減したりより速いレスポンスを返したりすることが可能。 WSGI(ウィズギー)とは
Web Server Gateway Interfaceの略。
通称上杉くん。
DjangoやFlaskはWSGI対応しているフレームワークで、gunicornやuWEGIはWSGI対応のサーバなんだよね、くらいの認識で問題ないかと思います。
登場の経緯は次のような感じ。3・フレームワークAちゃん > 私イケてるからイケてるWebサーバのαくん以外ムリ
・フレームワークBちゃん > 僕は手堅いβくんがいいな♡みたいな感じ(??)で、過去、PythonWebフレームワークごとに使用できるWebサーバが制限(逆も然り)されるということがままありました。実はαくんは、Bちゃんに使ってもらいたいのでしたが、ここでAちゃんとの許嫁的関係が足を引っ張ることになります。
この問題を解決しようと登場したのが上杉くんことWEGIです。WEGIは「サーバとフレームワークは自由にお互いを選んで恋愛接続できるようにしようよ」ということで、アプリケーションフレームワーク<-->Webサーバの関係において、どのようにやりとりをするかというルールを定めました。
WSGIとWSGI対応しているサーバ、フレームワークのおかげで、今日のワタシたちは自由にサーバとフレームワークの組み合わせを選ぶことができるようになったのであります。めでたしめでたし。References


- 投稿日:2019-12-21T17:58:38+09:00
証券会社のサイトをクローリングする
はじめに
最近、所属しているコミュニティでクローリングが流行っているので自分もやってみたくなりました。
まず、対象となる画面です。
勝手にクローリングして怒られないか?という点に関しては、どこぞのサイトで商用利用しなければ問題ないというのを見た気がするので大丈夫だと信じたいです。
では早速この画面の投資指標をクローリングしていきたいと思います。実行環境、ツール
実行環境は以下
$ sw_vers ProductName: Mac OS X ProductVersion: 10.15.1 BuildVersion: 19B88 $ python --version Python 3.7.4ツールは
BeautifulSoupを使用していきます。
パッケージのインストールは pip コマンドから。$ pip install beautifulsoup4その他のパッケージはサイトアクセス用に
requestsを使用します。ログイン、ページアクセス
クローリング対象の画面はログインが必要なのでログイン処理を実装します。
合わせて対象画面へのアクセス処理も実装しちゃいます。
こんな感じです。app.pyclass Scraper(): def __init__(self, user_id, password): self.base_url = "https://site1.sbisec.co.jp/ETGate/" self.user_id = user_id self.password = password self.login() def login(self): post = { 'JS_FLG': "0", 'BW_FLG': "0", "_ControlID": "WPLETlgR001Control", "_DataStoreID": "DSWPLETlgR001Control", "_PageID": "WPLETlgR001Rlgn20", "_ActionID": "login", "getFlg": "on", "allPrmFlg": "on", "_ReturnPageInfo": "WPLEThmR001Control/DefaultPID/DefaultAID/DSWPLEThmR001Control", "user_id": self.user_id, "user_password": self.password } self.session = requests.Session() res = self.session.post(self.base_url, data=post) res.encoding = res.apparent_encoding def financePage_html(self, ticker): post = { "_ControlID": "WPLETsiR001Control", "_DataStoreID": "DSWPLETsiR001Control", "_PageID": "WPLETsiR001Idtl10", "getFlg": "on", "_ActionID": "stockDetail", "s_rkbn": "", "s_btype": "", "i_stock_sec": "", "i_dom_flg": "1", "i_exchange_code": "JPN", "i_output_type": "0", "exchange_code": "TKY", "stock_sec_code_mul": str(ticker), "ref_from": "1", "ref_to": "20", "wstm4130_sort_id": "", "wstm4130_sort_kbn": "", "qr_keyword": "", "qr_suggest": "", "qr_sort": "" } html = self.session.post(self.base_url, data=post) html.encoding = html.apparent_encoding return html def get_fi_param(self, ticker): html = self.financePage_html(ticker) soup = BeautifulSoup(html.text, 'html.parser') print(soup)
userIDとpassword,証券番号を引数に実行します。
ログインとページアクセスの処理はについては簡単に。
URLから取得したポスト情報とrequestsパッケージを使用してあーだこーだしてます。
ちゃんとアクセスできたかを確認するため、アクセス結果をBeautifulSoup(html.text, 'html.parser')関数を使用してテキスト出力してみました。<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN"> <html lang="ja"> <head> <meta content="text/html; charset=utf-8" http-equiv="Content-Type"/> <meta content="text/css" http-equiv="Content-Style-Type"/> <meta content="text/javascript" http-equiv="Content-Script-Type"/> <meta content="IE=EmulateIE8" http-equiv="X-UA-Compatible"/><!--gethtmlコンテンツ開始--> <!-- header_domestic_001.html/// --> ・ ・ ・ <h4 class="fm01"><em>投資指標</em> 20/09期(連)</h4> </div> </div> <div class="mgt5" id="posElem_19-1"> <table border="0" cellpadding="0" cellspacing="0" class="tbl690" style="width: 295px;" summary="投資指標"> <col style="width:75px;"/> <col style="width:70px;"/> <col style="width:80px;"/> <col style="width:65px;"/> <tbody> <tr> <th><p class="fm01">予想PER</p></th> <td><p class="fm01">23.86倍</p></td> <th><p class="fm01">予想EPS</p></th> <td><p class="fm01">83.9</p></td> </tr> <tr> <th><p class="fm01">実績PBR</p></th> <td><p class="fm01">5.92倍</p></td> <th><p class="fm01">実績BPS</p></th> <td><p class="fm01">338.33</p></td> </tr> <tr> <th><p class="fm01">予想配当利</p></th> <td><p class="fm01">0.45%</p></td> <th><p class="fm01">予想1株配当</p></th> <td><p class="fm01">9〜10</p></td> ・ ・ ・ </script> <script language="JavaScript" type="text/javascript">_satellite.pageBottom();</script></body> </html>うまく対象画面にアクセスし、そのHTMLをテキストとして取得する事ができました。
HTMLからブロックごとに取得
HTMLをテキストとして取得する事はできましたが、今のままではタグやらCSSやらがたくさん入っています。
そこで、必要な部分を順番に抽出していこうと思います。
まずは投資指標が含まれるブロックを取得してみます。
BeautifulSoupのfind_all()関数を使用して特定のブロックを取得します。
投資指標は画面上だと以下のブロックに含まれます。
このブロックはHTML上だと<div id="clmSubArea">内になります。
では、find_all()関数に<div id="clmSubArea">を指定してみます。app.pydef get_fi_param(self, ticker): dict_ = {} html = self.financePage_html(ticker) soup = BeautifulSoup(html.text, 'html.parser') div_clmsubarea = soup.find_all('div', {'id': 'clmSubArea'})[0] print(div_clmsubarea)これを実行すると
<div id="clmSubArea"> <div class="mgt10"> <table border="0" cellpadding="0" cellspacing="0" class="tbl02" summary="layout"> <tbody> ・ ・ ・ <h4 class="fm01"><em>投資指標</em> 20/09期(連)</h4> </div> </div> <div class="mgt5" id="posElem_19-1"> ・ ・ ・ </tr> </tbody> </table> </div>という具合に目的のブロックを取得する事ができました。
文字列の取得
ここまでくれば、あとは目的の文字列を取得するまで同じ作業の繰り返しです。
一気にやってしまいましょう。app.pydef get_fi_param(self, ticker): dict_ = {} html = self.financePage_html(ticker) soup = BeautifulSoup(html.text, 'html.parser') div_clmsubarea = soup.find_all('div', {'id': 'clmSubArea'})[0] table = div_clmsubarea.find_all('table')[1] p_list = table.tbody.find_all('p', {'class': 'fm01'}) per = p_list[1].string.replace('\n', '') print('予想PER:' + per)
投資指標の<table>ブロックを取得し、その中の<p class="fm01">を全て取得してきます。
最後に<p class="fm01">内の文字列を取得してくれば処理終了です。$ python -m unittest tests.test -v test_lambda_handler (tests.test.TestHandlerCase) ... 予想PER:23.86倍できました。
あとは取得できた文字列をJSONなどに加工してあげればより使い勝手がよくなるでしょう。終わりに
クローリングを使うと結構簡単に欲しい情報をサイト上から取得してこられました。
用法容量をきちんと守れば、色々と役に立つ技術だと思います。
今回のコードは複数証券コードに対応できるようにして、HTML上に一覧表示するところまで作り込もうと思います。
その過程でアウトプットできる事があればまた別の機会に記載したいと思います。


- 投稿日:2019-12-21T17:58:19+09:00
【venv不要】Remote Containersで作る最強のPython開発環境【VSCode/Docker】
はじめに
人気言語Top1に輝いたり1、IPA 基本情報技術者試験の試験科目になる2などして注目を集めているPython。
でもちょっと待って!あなたはPythonのエコシステムの恩恵を正しく受けて開発できていますか?
開発環境をうまく作ることで、 入力補間やフォーマッターによって開発が効率化されるだけでなく静的解析によって予期せぬ不具合を未然に防ぐことができ、①簡単 ②爆速 ③安全 にプログラムを書くことができます。
もちろんそのような快適な環境を作るためのHow to記事はたくさんありますが、問題はせっかくオレオレPython開発環境を作れたとしても、それを異なるPC間で共有するのが困難であるということです。
なぜなら、
- Pythonやpipで入れるモジュールのバージョンを揃えてインストールしないといけない
- fommter / linter / IDEの拡張機能を揃えてインストール&設定しないといけない
という、開発環境に依存する問題が発生するからです。
個人 / 複数人を問わず、異なるPC間であっても同一の動作をすることが保証されて欲しい。
かつ、 テキストエディタでプロジェクトを開くだけで、その開発環境が勝手に構築されて欲しいという要求があります。ということで、この記事では、VSCodeのRemote Containerを使うことでこの問題を解決します。
本記事で述べる方法を用いると、以下のようなことが実現されます。
- Win / Mac / Linuxを問わず、全ての環境で同一の動作をすることが保証される3、ポータブルなPython開発環境が作れる
- 新しい環境でも、プロジェクトを開いただけで静的解析や自動フォーマットなどの全ての設定が完了する
では、やっていきましょう
インストール
本記事では、以下のツールを用います。
他の記事を参考にしながらインストールしてください。
- VSCode
- Docker
ターミナルから以下のコマンドが打てれば準備完了です。
$ docker --version Docker version 19.03.5, build 633a0eaRemote Containersの設定
まずは、開発用のディレクトリを適当に作りVSCodeで開きましょう。
$ mkdir python-test
以下のようなディレクトリ構成を作ります
. └── python-test ├── .devcontainer │ ├── Dockerfile │ └── devcontainer.json ├── .vscode │ └── extensions.json └── src └── main.pyそれぞれのファイルには以下の内容をコピペしてください。
.devcontainer/DockerfileFROM python:3.7.3-slim RUN apt-get update \ && apt-get install -y --no-install-recommends \ apt-utils \ gcc \ build-essential \ && pip install --no-cache-dir \ autopep8 \ flake8 \ && apt-get autoremove -y \ && apt-get clean -y \ && rm -rf /var/lib/apt/lists/*ここで、
FROM python:3.7.3-slimの部分の数字を変えると、好きなPythonのバージョンを指定することができます。.devcontainer/devcontainer.json{ "name": "Python Project", "dockerFile": "Dockerfile", "settings": { "terminal.integrated.shell.linux": "/bin/bash", "python.pythonPath": "/usr/local/bin/python" }, "extensions": [ "ms-python.python" ] }ここで、
"name": "Python Project"の部分は好きな文字列にしてしまって構いません。
settingsには、.vscode/settins.jsonで書くものと同一のものを記述することができます。本来bashのパスやpythonのパスは環境依存であるため個人ごとに設定する必要があるのですが、今回はコンテナ内で実行されるのでパスの情報が既知であり、固定することができるというのがポイントです。また、
extensionsには、VSCodeの拡張機能を加えることができ、ここに記述した拡張機能は自動でインストールされます。VSCodeの拡張機能を強制的にインストールさせることができるのはRemote Containersならではなので、全員にインストールして欲しい拡張機能はここに書きましょう。今回はVSCode用のPython拡張機能を追加しています。src/main.pyimport sys print(sys.version_info)Pythonスクリプトはバージョンを出力するものとでもしておきましょう。
.vscode/extensions.json{ "recommendations": [ "ms-vscode-remote.remote-containers" ] }VSCodeの拡張機能のRecommendationsにRemote Containersを指定します。
注意しなければならないのはdevcontainer.json内のextensionsと違って、記述しても実際にインストールされるわけではありません。ですので、ファイルをコピペし終わったら実際にインストールするためにVSCodeを開き直してください。
すると、右下に以下のようなポップアップが出てくると思います。Install Allを選び、Remote Containerをインストールしましょう。
無事、インストールできたらVSCodeの左下に緑色のボタンが表示されます。
開くと、このようなメニューがでるので、
「Remote-Containers: Open Folder in Container...」を選びます。
フォルダ選択画面がでたら、プロジェクトのディレクトリ(今回の場合はpython-test)を選びましょう。すると
.devcontainer/Dockerfileに記述したコンテナのビルドが自動で走ります。detailsを開くことで 経過を見ることができます。もしbuildにこけてしまった場合もdetailsを見ましょう。
ビルドが正常に終わったらそのままコンテナを起動し接続してくれます。コンテナに接続されたらVSCodeの内部ターミナルを開いてください。
おや?なにやらシェルのユーザーがrootになっていて、ディレクトリも
/workspacesになっていますね。これは、ホストOS(Win / Macとか) のターミナルではなく、ホストOSから独立したコンテナのターミナルに入れていることを示しています。Docker分かんないよ!という方もいるかもしれませんが、とりあえずPythonを実行してみましょう。
/workspaces/python-test# python src/main.py sys.version_info(major=3, minor=7, micro=3, releaselevel='final', serial=0)
FROM python:3.7.3-slimで指定したバージョンのpythonが入っていますね!
これで基本的な設定は完了です。今後は他のPCで
git cloneしても、「Remote-Containers: Open Folder in Container...」でコンテナの中に入ることで、同一の環境を再現することができます。requirements.txtの設定
ここはコンテナの中なので、この中で好きに
pip installしても構いません。ここでインストールしたモジュールはホストOSにはまったく影響を与えることがないので、破壊的に開発を進めることができます。/workspaces/python-test# pip install numpy /workspaces/python-test# python >>> import numpy as np >>> np.__version__ '1.17.4'また、再度コンテナをビルドして作り直すとインストールしたモジュールは消えます。そこで、開発を進める中でこのpipモジュールはfixしよう!となった場合、Pythonで慣例として使われている
requirements.txtを作って、そこにpip installするモジュールを書くこととしましょう。ディレクトリ構成と
requirements.txtの書き方は以下の通りです。. └── python-test ├── .devcontainer │ ├── Dockerfile │ └── devcontainer.json ├── .vscode │ └── extensions.json └── requirements.txtrequirements.txtnumpy==1.17.4requirements.txtには、
pip installする際のバージョンを固定して書くことができます。再現性を担保するために、バージョンは固定することが望ましいです。そして、
devcontainer.jsonを以下のようにしましょう。.devcontainer/devcontainer.json{ "name": "Python Project", "dockerFile": "Dockerfile", "settings": { "terminal.integrated.shell.linux": "/bin/bash", "python.pythonPath": "/usr/local/bin/python" }, "extensions": [ "ms-python.python" ], "postCreateCommand": "pip install -r requirements.txt" }
postCreateCommandというのが追加されましたね。これは、コンテナが生成された後に実行するコマンドです。今後はrequirements.txtに記述したモジュールが必ずインストールされます。ファイルを更新したら、更新をコンテナに反映させるために、左下の緑色のボタンを押して、「Remote-Containers: Rebuild Container」を選びましょう。
formatter / linterを設定する
続いて、formatter / linterを設定していきます。
pythonのformatter / linterを追加したときのdevcontainer.jsonは以下のとおりです。.devcontainer/devcontainer.json{ "name": "Python Project", "dockerFile": "Dockerfile", "settings": { "terminal.integrated.shell.linux": "/bin/bash", "python.pythonPath": "/usr/local/bin/python", "python.linting.pylintEnabled": false, "python.linting.flake8Enabled": true, "python.linting.flake8Args": [ "--ignore=E402,E501" ], "python.formatting.provider": "autopep8", "python.formatting.autopep8Args": [ "--ignore", "E402,E501", "--max-line-length", "150" ], "[python]": { "editor.formatOnSave": true } }, "extensions": [ "ms-python.python" ], "postCreateCommand": "pip install -r requirements.txt", }linterとしてflake8、 formatterとしてautopep8を指定し、それぞれE402(Module level import not at top of file)とE501(Line too long)を無視しています。ファイルのセーブ時にformatがかかるようにしています。
これでこんなふうなめちゃくちゃなコードを書いても、
before.pya =0 def method1(args) : print( args) def method2() : if a ==0: method1( "hoge" + "fuga" )このように、保存する際に整形してくれます。
after.pya = 0 def method1(args): print(args) def method2(): if a == 0: method1("hoge" + "fuga")通常、このようなformatter / linterの設定は
.vscode/settings.jsonに記述します。しかし、.vscode/settings.jsonは個人の設定ファイルであるから、.gitignoreに設定しているプロジェクトも多いです。加えて、pip install flake8 autopep8を手動で実行する必要があるので、設定ファイルを書いたからといって、formatter / linterが適用されるわけではありません。一方で、今回はRemote Containersの設定ファイルに書くことができるので、共有もしやすいですし、確実にflake8やautopep8が入っている状態を再現できるので "フォーマットがかかっていないソースコードがコミットされる"ということも防ぐことができます。
ところで、
pip install flake8 autopep8はどこで実行していたのでしょうか?
答えは.devcontainer/Dockerfileの中にあります。.devcontainer/DockerfileFROM python:3.7.3-slim RUN apt-get update \ && apt-get install -y --no-install-recommends \ apt-utils \ gcc \ build-essential \ && pip install --no-cache-dir \ autopep8 \ flake8 \ && apt-get autoremove -y \ && apt-get clean -y \ && rm -rf /var/lib/apt/lists/*もしあなたが、コンテナ内で
pytestを記述したいと思った場合は追加することができます。.devcontainer/DockerfileRUN pip install --no-cache-dir \ autopep8 \ flake8 \ pytestまた、autopep8やflake8は開発時に必要なのであって、実行時には不要です。そうしたモジュールはDockerfileに書いて、実行時に必要なファイルは
requirements.txtに書く、という使い分けができます。静的型解析
最後にPython3.6以降4で使えるType Hintsを導入しましょう。Type Hintsを導入することで、QoLが爆上がりします。
devcontainer.jsonを以下のようにしましょう
ここでは、Type Hintsの静的解析ツールとして、pyrightを用います。.devcontainer/devcontainer.json"extensions": [ "ms-python.python", "ms-pyright.pyright" ],変更したら、左下の緑色のボタンを押して、「Remote-Containers: Rebuild Container」を選びましょう。
続いて、pyrightの設定ファイルを書きます。
ディレクトリ構成は以下の通りです。. └── python-test ├── pyrightconfig.json └── src └── main.pypyrightconfig.json{ "include": [ "src" ], "reportTypeshedErrors": false, "reportMissingImports": true, "reportMissingTypeStubs": false, "pythonVersion": "3.7", "pythonPlatform": "Linux", "executionEnvironments": [ { "root": "src" } ] }pyrightconfig.jsonの詳しい書き方は他の記事を参照してください。(もしかしたら自分が他に書くかも)
ここで、
src/main.pyを編集してみましょう。src/main.pydef hello(name: str, age: int) -> str: result1: str = "My name is " + name + ".\n" result2: int = "I am " + str(age) + " years old." return result1 + result2 result: int = 10 result = hello(name="Otao", age=23) print(result)pythonのType Hintsでは、このように関数や変数に型アノテーションを付けることができます。
pyrightを導入した状態でsrc/main.pyを開くと、、、
result2はint型なので、str型は代入できないよ!
str型とint型の+演算子は定義されてないよ!!
resultはint型で定義されてるのに、そこにstr型を代入しようとしているよ!!!
hello関数の定義も貼っておくね!!!
といった風に、型にまつわるエラーを表示してくれます。Type Hintsを使うことは以下の理由からおすすめです。
- 型を定義することによって可読性がめちゃくちゃ上がる
- 予期せぬ型が変数に入ってきて不具合を起こす可能性が下がる
- VSCode上の入力補完機能が効く
ぜひ導入しましょう。
まぁ不思議なことに(?)このスクリプト、実行はできるんですよねw
(Type Hintsはあくまでアノテーションなので、実行時には無視されます。)/workspaces/python-test# python3 src/main.py My name is Otao. I am 23 years old.終わりに
快適なPythonライフを!
(記事は適宜更新します。)
- 著者情報
- Twitter: @0meo
習得したいプログラミング言語、したくない言語, https://tech.nikkeibp.co.jp/atcl/nxt/column/18/00501/111200004/ ↩
プレス発表 基本情報技術者試験における出題を見直し, https://www.ipa.go.jp/about/press/20190124.html ↩
実際にはホストOSによって挙動が違うことがあり、Dockerfileの修正が必要になることもあります。 ↩
関数へのType Hintsは3.5からあったので正確ではありませんが、変数にも型アノテーションを付けれるようになったのは3.6以降なので、3.6以降を使って欲しいです ↩









- 投稿日:2019-12-21T17:52:06+09:00
Hello World!してから1年でKaggle contributorになった話
はじめに
この記事は初心者でも,やってみたらと意外となんとか頑張れるというポエムです.
機械学習を始めたきっかけ
普段は診療放射線技師として医療機関に勤務している非情報系学部出身者です.
プログラム経験はまったくありません.2017年ごろに大学院へ進学しようと決心しまして
院試対策としてTOEFLの勉強をしていました.
リスニング対策の一つとして北米放射線学会のpodcastをよく聞いていました.
Radiology Podcasts | RSNA仕事でも必要なネタを英語で解説してくれるので有難かったです.
めでたく2018年の試験で大学院に合格し,一息つけました.2018年8月ごろのradiology podcastでは
医療画像にもAIが使われるようになること
AI関係の論文も増えているので2019年にradiology AIも刊行するという内容でした.その中で
・機械学習には無料で使用できるフレームワーク(tensorflow,caffe..)がいろいろある.
・画像を学習させておくと結果が出る.
・そのままだとダメなので,きちんと検証してね.
・NIHが大規模な胸部XPデータセットを公開する予定で,それは誰でも使える.という話があり,早速調べてPythonとやらが良さそうに見え
2018年11月ごろ'Hello world!'しました.肺炎コンペ
胸部XPのデータセットをあれこれ調べているうちに
RSNAが公開しているデータセットを見つけました.
これをコンペ形式で何やらやっているらしい,ということでたどり着いたのが
kaggle rsna-pneumonia-detection-challengeです.pythonですら操れないのに,機械学習などわかるわけもなく
ただひたすらNotebooksやDiscussionを読みました.自分もやってみたい!と手を動かしたり
udacityで
機械学習のコースを受講して勉強しました.
カレーさんのチュートリアルを買い
見よう見まねでtitanicにsubmitして,kaggleデビューしました.カレーさんのチュートリアルは本当に勉強になりました.
指示が具体的で,コードも書いてあるため
一つ一つが何をしているのかがわかりやすいです.
それにしても日本語で説明してもらえるって良いですね!環境
計算環境ですがGPUなどもなく10年ほど前に購入した古いノートがあるだけです.
ローカルで機械学習は無理だなと思っていましたが
Kaggle kernel上なら,かなりのことができました.
Google colabratoryの存在を知り,現在ほとんどこの2つで作業しています.肺炎コンペのコードを使って
自院の患者さんの胸部XPからGGO検出とかもやってみました.
(もちろん倫理とかいろいろ許可を取ってやってます.)
初期の肺がんや間質性肺炎,非定型抗酸菌症などの症例を試しましたが
今一つな結果しか得られませんでした.
これは私のモデルの精度が出せてないせいかと思います.
これは2019年6月のFHSという国際会議で発表しました.気が付いたら,contributorになれたっぽい
contributorの資格要件は主に次の4つと,プロファイルの入力です.
-Run 1 script
-Make 1 competition submission
-Make 1 comment
-Cast 1 upvoteどうでしょうか,contributorはわりと簡単になれそうです.
なんだか気が付かないうちに,全部クリアしていたので
プロファイルを埋めてcontributorになりました.最後に
contributorになったからと言って
初心者であることに変わりはなく,あまり価値のあるものではありません.
それでもKaggleを知っていて,
多少手を動かす人なんだ,くらいの印象にはなるかもしれないなと思っています.
肺炎コンペでは上位に日本人のチームが入っていて,本当にすごいなと感動しました.
いつか自分もメダルを取れるように頑張りたいです.
- 投稿日:2019-12-21T17:50:41+09:00
Airflowのwebserverと、読み込みに時間がかかるDAGの話
クリスマスも近いので、Airflowのwebserverの話をしましょう。
言いたいこと
- 読み込みに時間がかかるDAGがあると
- そのDAGが読み込めないかもよ
- Airflowの管理画面にアクセス出来ないかもよ
- タスク数だけなら割と多くても大丈夫だよ
- Componserのデフォルト設定でも、千程度はいける?
- 未来は明るいよ
Airflowを構成するモジュール
今回の主役のwebserverは、Airflowのモジュールの一つです。
他のモジュールには、
- scheduler
- DAG/Taskのスケジューリング・状態の管理
- worker
- タスクインスタンスを実際に実行
- database
- TaskInstance・DagRun・xcom・Variableなどの保持
- executor
- スケジュールされたタスクをworkerに配分
などがあります。
詳しは、Astronomerさんの記事がわかりやすいです。webserverとは
webserverは、管理画面(下図)・CLIコマンド(の一部)・APIなどを担当するモジュールで、
- DAG/task instanceなどの状況把握
- DAG/task instanceの再実行や、ステータスの変更
などの処理を受け付けます。
内部的には、Flask+Gunicornの構成となっており、画面からのエンドポイントはここらへんに定義されています。
(図はAirflow公式ページより)読み込みに時間がかかるDAG問題
webserverは、リクエストを受け付けるだけではなく、DAGファイルを定期的に読み込みます。
その結果、DAGファイルの読み込みに時間がかかると、
- 該当のDAGが読み込めない
- webserverへのアクセスが重くなる
- アクセスすら出来ない(エラーページ表示)
ことがあり、
などでも注意喚起?されています。
読み込みに時間がかかる?
DAGの読み込みに時間がかかるのと、DAGRunの実行に時間がかかるのは、混同しそうですが別の話で、今回問題にしているのは前者です。
例を出すと、これは読み込みに時間がかかるDAGで、
sleep(10000000) start = DummyOperator(task_id='start')これはDAGRunの実行に時間がかかるDAGです。
def hoge(): sleep(1000000) slow_task = PythonOperator( task_id='query_' + str(i), python_callable=hoge, )タスク数が多かったり、タスクの外で外部にアクセスしていると、読み込みが遅くなる可能性があります。
webserverがDAGをパースする流れ
細かい流れが気になる人向けに:
- webserver起動時に、定期的に(※)子プロセス(gunicorn worker)を再起動するように設定
- エンドポイントのファイルのロード時にDagBagオブジェクトが作られる
- DagBagオブジェクトが作られる中で、DAGファイルがパースされる
※ 具体的にはworker_refresh_interval秒
タスク数との関係
Cloud Composer(Airflow 1.10.2)・BigQueryOperatorのみのDAGで試したところ:
- DAGあたりに1000タスクくらいでは、デフォルト設定でも表示が出来る
- DAGあたりに3000タスクくらいになると、デフォルト設定では表示ができなくなる
- webserverが重くてもSchedulerやWorkerは動きます(Stackdriverで確認)
- タイムアウト(worker_refresh_interval)を伸ばしたり、読み込みを非同期(async_dagbag_loader)にするといける
なお、 Graph ViewやTree Viewだけが重い時は、default_dag_run_display_numberを変えるといいらしいです。
明るい未来の話
この「読み込みに時間がかかるDAG」に関しては、改善がいくつか提案されています。
Cloud Composerでは、webserver上のDAGの読み込みを非同期にするオプションが実装されており、Airflow1.10.4にも移植されています。
まだドラフトですが、AIP-24 DAG Persistence in DB using JSON for Airflow Webserver and (optional) Schedulerという提案は、より大幅な変更で、
- webserverでのDAGのパースはやめる
- schedulerがDAGをパースし、シリアライズ結果をDBに入れる
- webserverは、その結果を使う
オプションを提案しています。
(webserverが状態を持っているのが、そもそも良くないよねという話もあるらしい)Cloud Compserのwebserver
Cloud Composerのwebserverに関してのメモです:
- テナントプロジェクト(顧客管理外のプロジェクト)・CPU2コアのGAE Flexibleで動く
- スペックは変えられない…
- GKEクラスタの方にwebserverを移すことが出来る
- Airflow設定変えてもダメなら、試す価値はあるかも
ちなみに、Astronomer.ioの方はvCPU・メモリのサイズを変えられます。
- 投稿日:2019-12-21T17:20:51+09:00
NetworkXのファイル形式からC++でノード構造を格納する
グラフとは点の辺で構築される一般的なデータ構造の一つです。
身近な例では友人ネットワークやWebページなどもグラフとして表現することができます。現在、グラフを扱う場合PythonのNetworkxが非常に便利なツールとなっています。
書きやすく簡単なとても便利なライブラリです。
グラフを扱ってみようと思ったらまず試してみると良さそうです。-【Python】NetworkX 2.0の基礎的な使い方まとめ
- Python の NetworkX 入門
しかし、NetworkXには大規模なグラフに対して非常に処理が重くなってしまうという問題点があります。
そこで本記事では処理が高速であるC++を用い、NetworkXでグラフを構築するときのファイル形式のままC++でのグラフ構築の情報に用いる方法を紹介します。
前提知識としてC++の一通りの書き方は知っているものとします。
なおNetworkxについての記述がありますがNetworkXについて知らなくても問題はありません。
NetworkX形式のノード
NetworkXでは行ごとの各頂点のスペース区切りで頂点の出次点が書かれています。
※今回NetworkXのファイル形式にこだわりましたが、後述のsplit関数の区切り文字を変更すればcsv形式にも対応できます。
この記事を参考にエッジのリストは こちら の Facebook のグラフを使用します。
(リンク先のページ下部にある "facebook_combined.txt.gz" が該当ファイル)ファイルはこのような形式になっています。
facebook_combined.txt0 1 0 2 0 3 0 4 0 5 0 6 ︙(始点ノードid) (終点ノードid) という形式です。
このようなノード情報に対してNetworkXでは一瞬でできますがC++ではひと手間必要です。
実際の手順として
1. ファイルの読み込み
2. ストリングの分割
3. vectorへの代入順に説明していきます。
ファイルの読み込み
string path = argv[1]; string num_nodes = stoi(argv[2]); ifstream ifs(path); vector<vector<int>> nodes; nodes = vector<vector<int>>(num_nodes);String の分割関数
vector<string> split(string& input, char delimiter){ istringstream stream(input); string field; vector<string> result; while (getline(stream, field, delimiter)) { result.push_back(field); } return result; }C++ でよくあるstringの分割関数です。
対象のstringと分割文字を引数にしてその分割文字でstringを分割しvectorを返します。ファイルを一行ずつ読み込みsplitしたあとvectorに代入
string str; int from, to; while(getline(ifs, str)){ // スペース区切りで分割 vector<string> strvec = split(str, ' '); from = stoi(strvec.at(0)); to = stoi(strvec.at(1)); nodes[from].push_back(to); }getline関数でファイルを一行ずつ読み込みsplit 関数を用いることでスペース区切りで分割された行を解釈します。
結果として返ってきた始点ノードid と終点ノードid の情報をvector に代入します。
こうしてノードの構造情報をvector に格納することができました。確認
for(int i = 0; i < num_nodes; i++){ cout << i << "->"; for(int j = 0; j < nodes[i].size(); j++){ cout << nodes[i][j]; if(j != nodes[i].size()-1)cout << ","; } cout << endl; }結果
1->48,53,54,73,88,92,119,126,133,194,236,280,299,315,322,346 2->20,115,116,149,226,312,326,333,343 3->9,25,26,67,72,85,122,142,170,188,200,228,274,280,283,323 4->78,152,181,195,218,273,275,306,328 ︙このようにノードのエッジ情報を確認することができます。
ここまでするのでも大変ですね。