- 投稿日:2019-12-21T23:28:45+09:00
OSSで動物園を開きました
はじめに
動物が好きなのでOSSのロゴで動物園を作ることにしました。世界観を失わないために、以降はOSSのロゴを動物と表現します。
前提条件
配置
ひとまず北海道にあるあの動物園を題材にさせていただきます。
受け入れる動物
受け入れる動物の条件は以下の通りです。
* その動物と分かるシルエットを含んでいる
* 〇〇フクロウとか〇〇ガエルとかの〇〇は無視する
* 名を名乗っている
* なるべくかわいくておしゃれ
* なるべく有名動物園
まだまだ空いている檻がたくさんですね。
おわりに
動物も足りないし集客力も低いしでまだまだ開園できそうにありません。これから必死で受け入れられる動物たちを探していこうと思います。
不足動物の目撃情報是非ともお待ちしております。(あと著作権問題等ありましたらご指摘ください。)

- 投稿日:2019-12-21T23:28:45+09:00
OSSで動物園
はじめに
動物が好きなのでOSSのロゴで動物園を作ることにしました。世界観を失わないために、以降はOSSのロゴを動物と表現します。
前提条件
配置
ひとまず北海道にあるあの動物園を題材にさせていただきます。
受け入れる動物
受け入れる動物の条件は以下の通りです。
* その動物と分かるシルエットを含んでいる
* 〇〇フクロウとか〇〇ガエルとかの〇〇は無視する
* 名を名乗っている
* なるべくかわいくておしゃれ
* なるべく有名動物園
まだまだ空いている檻がたくさんですね。
おわりに
動物も足りないし集客力も低いしでまだまだ開園できそうにありません。これから必死で受け入れられる動物たちを探していこうと思います。
不足動物の目撃情報是非ともお待ちしております。(あと著作権問題等ありましたらご指摘ください。)
- 投稿日:2019-12-21T22:19:46+09:00
昔ながらの方法でMacに雪を降らす
はじめに
もうすぐクリスマスですね。なのでMacで雪(もしくはペンギン)を降らそうと思います。
(書くことがあまり思いつかなかったので、これでお茶を濁すことにします。)対象読者
タイトルを見ても何のことか心当たりがない方。
何のことか予想がつく方は多分その予想で合っているので、読まなくても大丈夫だと思います。手順
以下を実施します。
(OSはmacOS Mojaveで、HomebrewとDockerがインストール済みでDockerが動いていることを前提としています。)XQuartzのインストール・設定
ターミナルを開いて以下を実行します。
$ brew update && brew cask install xquartz # 途中でパスワードを入力する必要があるかもしれません # "xquartz was successfully installed!"と表示されたら完了です $ sudo launchctl load -w /Library/LaunchAgents/org.macosforge.xquartz.startx.plist # パスワードの入力を求められたら、パスワードを入力します $ open /Applications/Utilities/XQuartz.appうまくいくとXQuartzというアプリケーションが起動しますので、設定を変更します。
以下のように設定します。
ログアウト & ログイン
設定を反映させるために一旦ログアウトし、再度ログインします。
実行
以上で準備は完了したので実行してみます。
ターミナルで以下を実行します。$ git clone https://github.com/hirota745/snow-falls.git $ cd snow-falls $ sh fall.sh # もし雪ではなくペンギンを降らせる場合は $ sh fall.sh penguin上記を実行後、数分待ちます。
全てうまくいくと、画面が切り替わり雪が降ってくるはずです。おめでとうございます。
(ちなみにしばらく待つと雪が積もったり風が吹いたりしますので、じっと見ているのも良いかもしれません。)画面が切り替わらない場合は、Command+tabを何度か押してXQuartzに切り替えます。
それでも画面が変わらない場合は、メニューから以下を選択します。
終了方法
フルスクリーンを解除するためにメニューから以下を選択します。(メニューは画面上部にマウスカーソルを持っていくと表示されます)
(たまにXQuartz自体が落ちてしまうことがありますが、終了させたいので無視して大丈夫だと思います。)
その後ターミナルでCtrl-cを入力すれば終了します。もし再度実行したいときは、ターミナルで以下を実行します。
$ sh fall.sh # もし雪ではなくペンギンを降らせる場合は $ sh fall.sh penguin仕組み
何も説明がないのもよくないので、少しどういう風に動いているか説明します。
まず動いているアプリケーション自体は、xsnow(ペンギンの場合はxpenguins)というアプリケーションです。
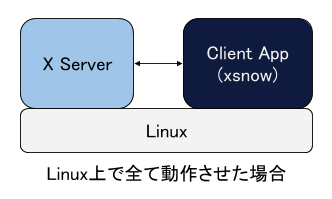
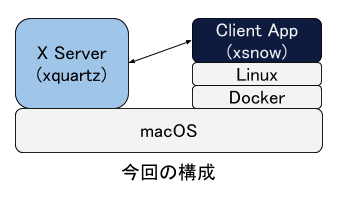
これらはLinux上で動作しています(もしかするとMac上で直接動かすこともできるかもしれませんが、試していません)。パソコンに直接LinuxをインストールしたりVirtualboxにLinuxをインストールした場合、WindowsやMacと同様にGUIアプリケーションをLinuxの画面で表示・操作することができます。Linux上でGUIアプリケーションを動作させる場合X Serverというものが必要で(GUIアプリケーション自体はX Serverと通信するClientとなります)、通常はこのX Server自体もLinux上で動作しています。(下図)
このX Server自体はClientアプリケーションが動作しているマシン上で動いている必要はなく、別マシンで動いていても問題ありません。今回の構成ではLinuxはMac上のDockerで動いていて(Debianが動いています)、Clientアプリケーション(xsnow)はそのLinux上で動いています。ただしX ServerはMac上で動かし、そこにLinuxで動いているClientアプリケーションが接続するようにしています。こうすることでMac上で直接xsnowが動いているように見えます。
(下図)
図の中の"Client App"は何でもよくて、例えばFirefoxやEmacsなども同様に動作させることができます。これらのアプリケーションの場合、今回動かしたxsnowとは違い独立したウィンドウで動作するものなので、XQuartzの「出力」タブで設定したフルスクリーンモードの設定が不要となります。そうすると、Mac上で直接動作している他のMacのアプリケーション(Finderなど)と同じ画面でLinux上で動作しているアプリケーションを表示・操作することができて、よりMac上で動いているように見えてきます。
まとめ
あまり需要はないかもしれませんが、LinuxでGUIアプリケーションを動かしてそれをMac上で表示してみました。
最近ではDocker等を使ってどこでも比較的簡単にLinuxを動かすことができますが、通常はGUIアプリケーションを動かすのではなくターミナルなどからLinuxにログインしそこでコマンドラインで作業することが多いのではないかと思います。今回やってみたようにX Serverと組み合わせれば、LinuxのGUIアプリケーションも普段使っているOSで動かしているGUIアプリケーションのように動かすことができます。これを機会にLinuxのGUIアプリケーションも使ってみるのもよいかもしれません。参考

- 投稿日:2019-12-21T21:12:41+09:00
Linuxカーネルのロックダウン機構を試してみる
投稿が遅くなってしまってすみません。Linux Advent Calendar 2019 6日目の記事です。
今日はLinuxカーネルの5.4から搭載された、カーネルロックダウン機構を試してみようと思います。カーネルロックダウン機能とは?
Linux(というかUNIX系OS)では、一般ユーザとrootユーザで権限を分離しておくことで、一般ユーザの不用意な操作でシステムの安定性が損なわれるようなケースを発生しにくくしています。しかしながら、rootユーザが不用意な操作を実行してしまった場合や、悪意のあるユーザからroot権限が奪取されてしまった場合には、この権限分離方法では対応できません。
カーネルロックダウン機構は、「rootユーザであってもシステムの変更を伴う操作に制限を付ける」機能となっており、カーネルロックダウンを設定したカーネルであれば、rootユーザであっても
/dev/mem,/dev/kmenやCPU MSR(モデル固有レジスタ)へのアクセスがブロックされ、加えてカーネルの変更(=カーネルモジュールによる機能の追加)が行えなくなります。また、この機能はシステムの操作に強い制限を課すことから、既存のシステムにそのまま適用すると動かなくなることが懸念されるため、デフォルトでは無効となっています。カーネルロックダウン機能を試してみる
機能の概要を把握したところで、さっそくカーネルロックダウン機能を試してみましょう。
まずはカーネルのビルドからです。今回はCentOS-7の環境でビルドしてみます。# cat /etc/redhat-release CentOS Linux release 7.5.1804 (Core)カーネルソースコードの取得
Linuxカーネルは5.x系の最新版(2019/12/08時点)である
5.4.2で試してみます。以下の手順でカーネルソースコードのダウンロードと展開を行います。以降のビルド手順は以前書いたLinuxカーネルのビルド手順に沿って行っています。$ curl -O https://cdn.kernel.org/pub/linux/kernel/v5.x/linux-5.4.2.tar.xz $ cd /usr/src $ sudo bash # tar Jxf /home/centos/work/linux_build/linux-5.4.2.tar.xzカーネルコンフィグでロックダウン機能を有効化する
カーネルソースコードが展開できたので、ロックダウン機能に関連するコンフィグを見てみましょう。
LOCK_DOWN_KERNEL_FORCE_から始まるコンフィグがロックダウン機能に関する設定のようです。# find . -type f | grep Kconfig | xargs grep LOCK_DOWN ./security/lockdown/Kconfig: default LOCK_DOWN_KERNEL_FORCE_NONE ./security/lockdown/Kconfig:config LOCK_DOWN_KERNEL_FORCE_NONE ./security/lockdown/Kconfig:config LOCK_DOWN_KERNEL_FORCE_INTEGRITY ./security/lockdown/Kconfig:config LOCK_DOWN_KERNEL_FORCE_CONFIDENTIALITY
LOCK_DOWN_KERNEL_FORCE_INTEGRITYを見てみると、(カーネルロックダウンを有効化した場合のデフォルトでは)"integrity"モードで稼働し、実行時におけるカーネルへの変更は無効化されるようです。config LOCK_DOWN_KERNEL_FORCE_INTEGRITY bool "Integrity" help The kernel runs in integrity mode by default. Features that allow the kernel to be modified at runtime are disabled.ということは、この設定を有効にすると、カーネルモジュールのロード時にエラーで弾かれるような動作になるような気がします。さっそくカーネルをビルドして試してみましょう。
以下の手順でLinuxカーネルのコンフィグを設定します。
$ cd linux-5.4.2 $ make defconfig $ make menuconfig
LOCK_DOWN_KERNEL_FORCE_INTEGRITYの設定箇所は以下の場所にあるようです。-> Security options -> Basic module for enforcing kernel lockdown -> Kernel default lockdown mode
make defconfig(Linuxカーネルのデフォルトコンフィグ)との差分は以下になります。
(CentOS-7以降の環境ではファイルシステムがXFSであるため、XFSをカーネルに組み込む設定にしておく必要があります)# diff -ur .config.ORIG .config | grep -v '^ ' --- .config.ORIG 2019-12-07 16:45:20.264339000 +0900 +++ .config 2019-12-07 23:17:48.150270000 +0900 @@ -725,13 +725,22 @@ +CONFIG_MODULE_SIG_FORMAT=y -# CONFIG_MODULE_SIG is not set +CONFIG_MODULE_SIG=y +# CONFIG_MODULE_SIG_FORCE is not set +CONFIG_MODULE_SIG_ALL=y +CONFIG_MODULE_SIG_SHA1=y +# CONFIG_MODULE_SIG_SHA224 is not set +# CONFIG_MODULE_SIG_SHA256 is not set +# CONFIG_MODULE_SIG_SHA384 is not set +# CONFIG_MODULE_SIG_SHA512 is not set +CONFIG_MODULE_SIG_HASH="sha1" @@ -3890,7 +3899,13 @@ -# CONFIG_XFS_FS is not set +CONFIG_XFS_FS=y +# CONFIG_XFS_QUOTA is not set +# CONFIG_XFS_POSIX_ACL is not set +# CONFIG_XFS_RT is not set +# CONFIG_XFS_ONLINE_SCRUB is not set +# CONFIG_XFS_WARN is not set +# CONFIG_XFS_DEBUG is not set @@ -4109,7 +4124,11 @@ -# CONFIG_SECURITY_LOCKDOWN_LSM is not set +CONFIG_SECURITY_LOCKDOWN_LSM=y +# CONFIG_SECURITY_LOCKDOWN_LSM_EARLY is not set +# CONFIG_LOCK_DOWN_KERNEL_FORCE_NONE is not set +CONFIG_LOCK_DOWN_KERNEL_FORCE_INTEGRITY=y +# CONFIG_LOCK_DOWN_KERNEL_FORCE_CONFIDENTIALITY is not set @@ -4332,6 +4351,7 @@ +CONFIG_MODULE_SIG_KEY="certs/signing_key.pem" @@ -4369,7 +4389,7 @@ -# CONFIG_LIBCRC32C is not set +CONFIG_LIBCRC32C=yこれで必要なカーネルコンフィグは設定できました。あとは
makeを実行し、GRUBにビルドしたカーネルのエントリを追加します。# make # make modules_install \ && cp -f arch/x86_64/boot/bzImage /boot/vmlinuz-5.4.2.x86_64 \ && mkinitrd --force /boot/initramfs-5.4.2.x86_64.img 5.4.2 \ && grub2-mkconfig -o /boot/grub2/grub.cfg再起動し、GRUBから
Linux-5.4.2を選んで起動すれば準備完了です!# uname -a Linux linuxadvcal 5.4.2 #7 SMP Sat Dec 7 22:04:12 JST 2019 x86_64 x86_64 x86_64 GNU/Linuxカーネルモジュールの読み込みはバッチリブロックされる
試しに適当なカーネルモジュールをロードしてみると、rootユーザであってもモジュールのロードが失敗(=ブロックされる)します。
# insmod /usr/lib/modules/5.4.2/build/net/netfilter/xt_nat.ko insmod: ERROR: could not insert module /usr/lib/modules/5.4.2/build/net/netfilter/xt_nat.ko: Operation not permittedこの時、コンソールには以下のメッセージが出力されます。
[ 459.212341] Lockdown: insmod: unsigned module loading is restricted; see man kernel_lockdown.7
LOCK_DOWN_KERNEL_FORCE_INTEGRITYの設定により、カーネルモジュールは一つも読み込まれていない状態になっています。# lsmod Module Size Used by #
dmesgの内容をみると、Linuxの起動直後に"Kernel is locked down from Kernel configuration;"というメッセージが出力されているので、「起動後のカーネル変更は無効化する」というLOCK_DOWN_KERNEL_FORCE_INTEGRITYの設定に沿った挙動になっています。# dmesg -T | head -n1 ; dmesg -T | egrep '(Kernel configuration|kernel_lockdown)' [日 12月 8 00:38:21 2019] Linux version 5.4.2 (root@linuxadvcal) (gcc version 4.8.5 20150623 (Red Hat 4.8.5-28) (GCC)) #7 SMP Sat Dec 7 22:04:12 JST 2019 [日 12月 8 00:38:20 2019] Kernel is locked down from Kernel configuration; see man kernel_lockdown.7 [日 12月 8 00:38:21 2019] Lockdown: swapper/0: hibernation is restricted; see man kernel_lockdown.7 [日 12月 8 00:38:55 2019] Lockdown: insmod: unsigned module loading is restricted; see man kernel_lockdown.7せっかくだからソースコードも見てみる
カーネルロックダウン機能を簡単に試してみました。挙動は何となくわかったのですが、実際にソースコードも眺めてみたくなるのが人情(?)です。さっそくソースコードも簡単に見てみましょう。
カーネルモジュールをロードした時のブロッキングはどういう流れになっている?
まずは
insmodした時にエラーにしている(モジュールのロードをブロッキングしている)箇所を探してみましょう。調査の手掛かりになるのはコンソールに出力された以下のメッセージでしょう。[日 12月 8 00:38:55 2019] Lockdown: insmod: unsigned module loading is restricted; see man kernel_lockdown.7上記のメッセージを出力しているのは以下の個所になります。
security/lockdown/lockdown.c79 /** 80 * lockdown_is_locked_down - Find out if the kernel is locked down 81 * @what: Tag to use in notice generated if lockdown is in effect 82 */ 83 static int lockdown_is_locked_down(enum lockdown_reason what) 84 { ... 89 if (kernel_locked_down >= what) { 90 if (lockdown_reasons[what]) 91 pr_notice("Lockdown: %s: %s is restricted; see man kernel_lockdown.7\n", 92 current->comm, lockdown_reasons[what]); 93 return -EPERM; 94 }メッセージ中の"unsigned module loaded"の部分は、
lockdown_readsons[what]から取得される文字列で、どうやらLOCKDOWN_MODULE_SIGNATUREという定数で参照されるようです。security/lockdown/lockdown.c19 static const char *const lockdown_reasons[LOCKDOWN_CONFIDENTIALITY_MAX+1] = { ... 21 [LOCKDOWN_MODULE_SIGNATURE] = "unsigned module loading",
LOCKDOWN_MODULE_SIGNATUREの実体はenum値となっています。include/linux/security.h104 enum lockdown_reason { 105 LOCKDOWN_NONE, 106 LOCKDOWN_MODULE_SIGNATURE, ...
LOCKDOWN_MODULE_SIGNATUREが参照されている箇所は、security/lockdown/lockdown.c(いまソースを追いかけている箇所)とkernel/module.cの2箇所のみのようです。
kernel/module.cではmod_verify_sig()の返り値で処理を分岐しており、そこでLOCKDOWN_MODULE_SIGNATUREを引数にしたsecurity_locked_down()を呼び出す構造になっています(2882行目)。kernel/module.c2839 #ifdef CONFIG_MODULE_SIG 2840 static int module_sig_check(struct load_info *info, int flags) 2841 { ... 2851 if (flags == 0 && 2852 info->len > markerlen && 2853 memcmp(mod + info->len - markerlen, MODULE_SIG_STRING, markerlen) == 0) { 2854 /* We truncate the module to discard the signature */ 2855 info->len -= markerlen; 2856 err = mod_verify_sig(mod, info); 2857 } 2858 2859 switch (err) { ... 2871 case -ENOPKG: 2872 reason = "Loading of module with unsupported crypto"; 2873 goto decide; ... 2876 decide: 2877 if (is_module_sig_enforced()) { 2878 pr_notice("%s is rejected\n", reason); 2879 return -EKEYREJECTED; 2880 } 2881 2882 return security_locked_down(LOCKDOWN_MODULE_SIGNATURE); 2883 2884 /* All other errors are fatal, including nomem, unparseable 2885 * signatures and signature check failures - even if signatures 2886 * aren't required. 2887 */ 2888 default: 2889 return err; 2890 }
security_locked_down()はkernel/module.cで定義されており、そこからさらにcall_int_hook()を呼んでいます。security/security.c2402 int security_locked_down(enum lockdown_reason what) 2403 { 2404 return call_int_hook(locked_down, 0, what); 2405 } 2406 EXPORT_SYMBOL(security_locked_down);
call_int_hook()は同じCファイル内で関数マクロとして定義されており、security_hook_heads.FUNC()を呼び出しています。これはマクロ展開されるため、struct security_hook_hands->locked_down()が呼び出される形になります。security/security.c38 struct security_hook_heads security_hook_heads __lsm_ro_after_init; ... 657 #define call_int_hook(FUNC, IRC, ...) ({ \ 658 int RC = IRC; \ 659 do { \ 660 struct security_hook_list *P; \ 661 \ 662 hlist_for_each_entry(P, &security_hook_heads.FUNC, list) { \ 663 RC = P->hook.FUNC(__VA_ARGS__); \ 664 if (RC != 0) \ 665 break; \ 666 } \ 667 } while (0); \ 668 RC; \ 669 })
struct security_hook_handsのメンバ変数としてlocked_downが定義されており、security/lockdown/lockdown.c内でこのメンバ変数に関数ポインタが設定されます。include/linux/lsm_hooks.h1823 struct security_hook_heads { ... 2062 struct hlist_head locked_down; 2063 } __randomize_layout;関数ポインタとして設定した
lockdown_is_locked_down()で引数whatで渡したインデックス値が配列lockdown_reasons[]として参照可能な場合に、先述した "Lockdown: insmod: unsigned module loading is restricted; see man kernel_lockdown.7" を出力しています。security/lockdown/lockdown.c83 static int lockdown_is_locked_down(enum lockdown_reason what) 84 { 85 if (WARN(what >= LOCKDOWN_CONFIDENTIALITY_MAX, 86 "Invalid lockdown reason")) 87 return -EPERM; 88 89 if (kernel_locked_down >= what) { 90 if (lockdown_reasons[what]) 91 pr_notice("Lockdown: %s: %s is restricted; see man kernel_lockdown.7\n", 92 current->comm, lockdown_reasons[what]); 93 return -EPERM; 94 } 95 96 return 0; 97 } 98 99 static struct security_hook_list lockdown_hooks[] __lsm_ro_after_init = { 100 LSM_HOOK_INIT(locked_down, lockdown_is_locked_down), 101 };このケースでは、引数
whatの値はLOCKDOWN_MODULE_SIGNATUREになっており、 "unsigned module loading" が参照されます。security/lockdown/lockdown.c19 static const char *const lockdown_reasons[LOCKDOWN_CONFIDENTIALITY_MAX+1] = { 20 [LOCKDOWN_NONE] = "none", 21 [LOCKDOWN_MODULE_SIGNATURE] = "unsigned module loading", ... 41 [LOCKDOWN_CONFIDENTIALITY_MAX] = "confidentiality", 42 };
lockdown_lsm_init()内でカーネルコンフィグとして設定したLOCK_DOWN_KERNEL_FORCE_INTEGRITYによる条件コンパイルが行われ、ロックダウンレベルがLOCKDOWN_CONFIDENTIALITY_MAXに設定されます。これは上記の配列lockdown_reasons[]において、LOCKDOWN_MODULE_SIGNATUREよりも大きな値で、これより小さい値(というか配列インデックス)の項目がカーネルロックダウンの要因として有効になるという挙動です。security/lockdown/lockdown.c51 static int lock_kernel_down(const char *where, enum lockdown_reason level) 52 { 53 if (kernel_locked_down >= level) 54 return -EPERM; 55 56 kernel_locked_down = level; 57 pr_notice("Kernel is locked down from %s; see man kernel_lockdown.7\n", 58 where); 59 return 0; 60 } ... 103 static int __init lockdown_lsm_init(void) 104 { 105 #if defined(CONFIG_LOCK_DOWN_KERNEL_FORCE_INTEGRITY) 106 lock_kernel_down("Kernel configuration", LOCKDOWN_INTEGRITY_MAX); 107 #elif defined(CONFIG_LOCK_DOWN_KERNEL_FORCE_CONFIDENTIALITY) 108 lock_kernel_down("Kernel configuration", LOCKDOWN_CONFIDENTIALITY_MAX); 109 #endif 110 security_add_hooks(lockdown_hooks, ARRAY_SIZE(lockdown_hooks), 111 "lockdown"); 112 return 0; 113 }ざっくりとした解説ですが、カーネルコンフィグで
LOCK_DOWN_KERNEL_FORCE_INTEGRITYを指定した場合の挙動の流れをソースコードから眺めることができました。まとめ
Linuxのカーネルロックダウン機構について紹介してみました。セキュリティ周りのカーネルモジュールはそれ単体で挙動が完結するものではなく、モジュールによって設定された値や関数が他のソースから利用されるため、ソースコードを読み解くのが少々難しく感じます。
pr_notice()と組み合わせ、実際に動かしながら挙動を読み解くのが良さそうです。参考URL
- 投稿日:2019-12-21T14:11:26+09:00
Emacsのperspective.elワークスペースをもっと使いやすく
この記事はEmacs Advent Calendar 2019 21日目の記事です。
20日目@tachiyamaさんの記事
最強エディタEmacsならマトリックス(っぽいこと)もできる
から引き継いで記事を書いていきます。始めに
Emacsは万を超える組み込みコマンドと、多くのパッケージを利用することができるエディタです。我々Emacsユーザは、他のプログラマに馬鹿にされても、自分のEmacsを自分好みに改良し続けて行かなければならないのです。
冗談はここまでにしておいて(冗談じゃない?)
皆さんは超有能Emacs LispパッケージEXWM(Emacs X Window Manager) を知っているでしょうか。このパッケージはEmacsをタイル型ウィンドウマネージャとして動作されるためのパッケージです。
個人の意見ですが、EXWMには大きく2つのメリットがあると思っています。
まず、X Windowアプリケーションをバッファとして扱える機能。そして、ワークスペースの概念です。EXWMのメリット
X WindowアプリケーションがEmacsのバッファとして扱えるため、
C-x bでバッファリスト表示・切り替え・キルなどが瞬時にできます。EXWMはEmacsを使うメリットの一つである、統一されたインターフェイスでの操作を体現するパッケージなのです。次にワークスペースの概念ですが、
s-n(nには0 - 9の数字)のキーバインドでワークスペースを切り替えることができます。これが非常に便利で、ワークスペース1はプログラム用、ワークスペース2はシェル、ワークスペース3はウェブブラウザというように、脳内で整理ができて、スッキリします。EXWMの問題点
もちろん、メリットばかりではなく、不便なところもあります。
そもそも、EXWMタイル型ウィンドウマネージャなので、フローティングウィンドウの扱いに関しては、普通に使いにくいです。(フローティングしたい場面はあまりない?)
加えて、EXWMはまだ不安定な部分があります。環境によっては起動することができなかったり、キー入力が行えない場合があります。
筆者は1年程、Debian testing上で利用していましたが、ある日突然キー入力を受け付けなくなってしまいました。暗いGNOME生活
後で直そうと思いながらGNOMEに避難していたんですが、いつの間にか半年以上もGNOMEを使っていました。ですが常に、GNOME上のEmacs使いづらいなあと思っていました。特に、バッファリストが1つのみなので、大量にバッファを開く私にとっては、その切り替えが面倒で仕方がありませんでした。また、ウィンドウが一つなので、大量のバッファを一度に開くこともできず、本当に使いづらいなあと。(Vから始まるエディタよりかは、はるかに便利ですが)
perspective.elを使い始めた
そこで、バッファをグループ化し、その切り替えができるperspective.elを使い始めました。これは、ワークスペースを作り出すことができ、自由に名前をつけることができます。そして、その行き来も
C-c p s <名前>で切り替えることができます。しかし、このパッケージはあまり定着しませんでした。まず、キーバインドが長いですし、名前を打つのも面倒で、結局一つのワークスペースでことを済ましてしまいがちでした。そこで、次のように考えました。切り替えのキーバインドが単純で、名前を打つ必要がなく、perspective.elのワークスペースを移動できないものか。
そこで、ひらめいたわけです。EXWMのように
s-nで簡単にperspective.elのワークスペースを切り替えることができるようにすれば良いやと。ようやく本題
まず、やりたいことを決めます。
s-n(nには0 - 9の数字)でperspective.elのワークスペースを切り替えられるようにしたい。方法
これを実現するための方法を適当に考えます。
- 起動時にperspective.elのワークスペースを0 - 9の名前で作る。
s-nのキーバインドを(persp-switch (int-to-string n))に割り当てる。こんな感じでできそうです。簡単です。ちなみに、筆者のEmacs Lispスキルは、読めば分かる程度で、ほとんど書けません。なので、今回書いてみたコードはEmacs Lisp流の書き方には程遠いかと思われます・・・。アドバイスがあれば是非コメント欄にお願いします。
書いてみる
完成状態
一応、考えた通りの動作をするEmacs Lispのコードを最初に書いておきます。いいから早く見せろっていう人は、このコードをinit.elに書いてみてください。ちなみに、キーバインドは
s-nではなく、M-nで登録しているので、注意してください。(require 'perspective) (persp-mode 1) ;; ワークスペース生成 (mapc (lambda (i) (persp-switch (int-to-string i))) (number-sequence 0 9)) ;; キーに登録する関数を返す関数 (defun local-switch-workspace (i) (lexical-let ((index i)) (lambda () (interactive) (persp-switch (int-to-string index))))) ;; キーバインドの登録を行う (mapc (lambda (i) (global-set-key (kbd (format "M-%d" i)) (local-switch-workspace i))) (number-sequence 0 9)) ; 最初のワークスペースは"1"に設定 (persp-switch "1")ワークスペースの作成
起動時にワークスペースを生成したいので、ワークスペースを作成する処理をinit.elに直接書きます。
;; ワークスペース生成 (mapc (lambda (i) (persp-switch (int-to-string i))) (number-sequence 0 9))mapcにワークスペースを生成する関数をラムダ式と、number-sequenceで生成した0 ~ 9のリストを渡して、ワークスペースの生成を行っています。mapcは、第2引数のリストから値を一つづつ取り出し、第1引数に渡された関数に渡して実行するという関数です。この関数は非常に便利で結構多用しています。
;; キーに登録する関数を返す関数 (defun local-switch-workspace (i) (lexical-let ((index i)) (lambda () (interactive) (persp-switch (int-to-string index)))))この関数はワークスペースを切り替える関数を返します。この関数の返り値は
global-set-keyに渡されることを前提にしています。例えば、この関数に1を渡して実行すると、(persp-switch "1")を実行する関数が帰ってくることになります。その関数をglobal-set-keyに渡すわけです。
最初は、global-set-keyにlambda式を直接渡そうとしていたんですが、どうもうまく行かなくて、このような形に落ち着きました。Google先生もとい、歴戦のEmacs Lispプログラマたちの知恵の結晶を拝見した結果、lexical-letを使う関数になりました。このlexical-letはクロージャを作るために必要になっていますが、この機能はEmacs 24.1以降で利用可能なため、それ以前のEmacsを利用している方は注意が必要です。まあ、2019年の今、Emacs 24.1より前のバージョンを使っている人は珍しいでしょうが。(筆者はEmacs 26.3を使っています);; キーバインドの登録を行う (mapc (lambda (i) (global-set-key (kbd (format "M-%d" i)) (local-switch-workspace i))) (number-sequence 0 9))ここで、実際に
M-n(nは0 ~ 9の数字)にキーバインドを登録しています。内容は簡単で、mapcを使って0 ~ 9のキーにlocal-switch-workspaceの返り値の関数を登録しています。あれ、おかしいですね
s-nに登録するはずがM-nに登録しています。すみません。Super-NumberのキーバインドはGNOMEに登録されていて、Emacsに渡すことができませんでした。なので、Altキー(Metaキー)で妥協しました。; 最初のワークスペースは"1"に設定 (persp-switch "1")最後にデフォルトのワークスペースを1にして終わりです。
使ってみて
大体1週間ほど使っていますが、めちゃくちゃ捗ってます。EXWMのワークスペース切り替えに関してはほぼ完全に再現できていると思います。また、裏ではperspective.elが動いているので、perspective.elが提供する機能をそのまま利用できるという利点もあります。
あと、ちょうどアドベントカレンダーのネタにできてよかったなと。構成の紹介
最後に筆者に定着した使い方を紹介したいと思います。
WS1 ~ 4 WS5 ~ 7 WS8 ~ 9 プログラム + シェル 文章や簡単なスクリプト 空き おわりに
ワークスペース切り替えをもっとスムーズに行いたい人は是非、init.elに書いてみてください。もしかしたらハマるかもしれませんよ(`ェ´)ピャー
- 投稿日:2019-12-21T12:15:17+09:00
Linuxカーネルがx86 microcodeを扱う処理について
はじめに
お久しぶりです。@akachichonです。
さて、当初はルートファイルシステム周辺に関する記事を書こうとしましたが色々あり、今回はマイクロコードアップデートについて書きました。
なお、引用したソースコードもしくは確認に使った環境は、「Ubuntu Server 19.10」です。
Ubuntu Server19.10のソースコード取得方法については、補足「Ubuntu Linuxのカーネルソースコード取得方法」を参照してください。ルートファイルシステムイメージについて
Ubuntu Server19.10のルートファイルシステムイメージは、/boot/initrd.img-5.3.0-24-genericです。ルートファイルシステムイメージはUbuntuに限らず、多くのLinuxディストリビューションで共通だと思います。
さて、中身を確認しましょう。ルートファイルシステムイメージ内のファイル一覧を見るだけなら、lsinitramfsを使うのが楽です。lsinitramfsの実行結果fyoshida@fyoshida:~/lab/initramfs$ cp /boot/initrd.img-5.3.0-24-generic . fyoshida@fyoshida:~/lab/initramfs$ lsinitramfs initrd.img-5.3.0-24-generic . kernel kernel/x86 kernel/x86/microcode kernel/x86/microcode/AuthenticAMD.bin kernel (略) var var/lib var/lib/dhcpもう少し中身を確認したいので、cpioコマンドを使いinitramfsイメージを展開します。ところが、lsinitramfsで見たとおりのファイル群を展開できません。展開できたのは、kernelディレクトリのみです。
cpio実行結果fyoshida@fyoshida:~/lab/initramfs$ cat initrd.img-5.3.0-24-generic | cpio -id 62 blocks fyoshida@fyoshida:~/lab/initramfs$ ls initrd.img-5.3.0-24-generic kernelこの理由を調べると、kernel.orgのドキュメントに行き当たりました。
kernel.orgからの抜粋The microcode is stored in an initrd file. During boot, it is read from it and loaded into the CPU cores. The format of the combined initrd image is microcode in (uncompressed) cpio format followed by the (possibly compressed) initrd image. The loader parses the combined initrd image during boot.なるほど。initrdのイメージは「combined initrd image(結合されたinitrd image)」なので、cpioコマンドでは最初のマイクロコードが含まれたcpioフォーマット部分のみが展開できたと推測できます。そういえば、マイクロコードについては相当あやふやな知識しかない事に気づきました。
そういうことで、今回のAdvent Calendarでは「Linuxがルートファイルシステム内のマイクロコードをどう扱うか」をネタにして記事を書きます。なお、全国のAMDファンの皆様、ごめんなさい。今回はIntelのみを記事の範囲とします。
Intel SDMをもとにした説明
マイクロコードアップデートを知るためには、Intel SDM Vol.3 「9.11 MICROCODE UPDATE FACILITIES」の最初の数文が重要となります。まとめると以下のようになります。
- Intelが提供するデータブロックをプロセッサにロードすることによりエラッタを修正する機能があります。この機能のことをマイクロコードアップデートと呼びます。
- BIOSは、マイクロコードアップデートをシステム初期化時に行うための仕組みを提供する必要があります。
- この仕組み(update loader)を持つBIOSは、システム初期化時にアップデートをプロセッサにロードする責務があります。プロセッサにロードするステップは2段階です。最初のステップは必要なアップデートデータブロック(※1)をBIOSに渡すこと、2つめのステップはBIOSがアップデートデータブロックをプロセッサにロードすることです。
※1.「マイクロコードアップデートデータブロック」を示す単語として、以後「データブロック」を使います。
この文書では、最初のステップ「データブロックをBIOSに渡す」ためのLinux実装を記事にします。
Linuxカーネルのコードを読む
ソース群は、arch/x86/kernel/cpu/microcodeにあります。ファイル名称がそのまま過ぎて、とてもわかりやすいです。
arch/x86/kernel/cpu/microcodeのファイル構成fyoshida@fyoshida:~/source/ubuntu-kernel/linux-source-5.3.0$ ag microcode arch/x86/kernel/cpu/microcode/ amd.c core.c intel.c Makefile始まりはload_ucode_bsp()です。
arch/x86/kernel/cpu/microcode/core.cvoid __init load_ucode_bsp(void) { // 略 cpuid_1_eax = native_cpuid_eax(1);cpuidとは、Intel SDMの言葉を借りると「To obtain processor identification information」な命令です。取得したい情報を示す番号をeaxレジスタにセットした上でcpuid命令を実行します。native_cpuid_eaxの引数は、取得したい情報を示す番号です。そして、戻り値は「cpuidを実行した結果のうち、eaxレジスタに格納された情報」です。実装は以下の通りです。
arch/x86/include/asm/processor.hstatic inline void native_cpuid(unsigned int *eax, unsigned int *ebx, unsigned int *ecx, unsigned int *edx) { /* ecx is often an input as well as an output. */ asm volatile("cpuid" : "=a" (*eax), "=b" (*ebx), "=c" (*ecx), "=d" (*edx) : "0" (*eax), "2" (*ecx) : "memory"); } #define native_cpuid_reg(reg) \ static inline unsigned int native_cpuid_##reg(unsigned int op) \ { \ unsigned int eax = op, ebx, ecx = 0, edx; \ \ native_cpuid(&eax, &ebx, &ecx, &edx); \ \ return reg; \ }以下、Intel SDMからの抜粋情報により、ここで取得する情報は「Type, Family, Model, Stepping ID」だとわかります。
また、eaxに格納される情報は以下のフォーマットに従うことも分かります。
arch/x86/kernel/cpu/microcode/core.cswitch (x86_cpuid_vendor()) { case X86_VENDOR_INTEL: if (x86_family(cpuid_1_eax) < 6) return; break;ここでは、自身が動くCPUでマイクロコードアップデートをサポートするか判定しています。マイクロコードアップデートをサポートするCPUは、「P6以降」であることを思い出してください。ついで、load_ucode_intel_bsp()が呼ばれます。
void __init load_ucode_intel_bsp(void) { struct microcode_intel *patch; struct ucode_cpu_info uci; patch = __load_ucode_intel(&uci); if (!patch) return; uci.mc = patch; apply_microcode_early(&uci, true); }load_ucode_intel_bsp()は、おおよそ以下の関数呼び出し構成となっています。
それぞれの関数概要は以下の通りです。
関数名 概要 __load_ucode_intel 適用すべきデータブロックを探します load_builtin_intel_microcode Firmware Loaderを用いて適用しようとするデータブロックの有無を判定します(※2) find_microcode_in_initrd メモリ上に展開されたinitrdからデータブロックを含むファイルを検索します collect_cpu_info_early cpuid命令などを用いて、自身が動作するCPUの情報を取得します scan_microcode ファイルに含まれるデータブロック群から最も適切なデータブロックを見つけます apply_microcode_early ここまでの処理で見つけたデータブロックをBIOSに渡します ※2. Firmware Loaderについては、こちらの良記事が詳しいです。
なお、この私の記事では、「Firmware Loaderを用いて適用しようとするデータブロックはない」ケースを前提とします。initrdからデータブロックを探す
ブートローダによって展開されたinitrdイメージの位置とサイズを取得します。
このRAM Diskイメージが、冒頭に書いた/boot/initrd.img-5.3.0-24-generic です。また、このイメージの先頭はcpioフォーマットで始まっています。よって、cpioフォーマットに従い、データブロックを含むファイルをパス名で検索します。
cpioフォーマットについては、手前味噌ですが私の書いた記事の「cpioの簡単な解説と図」を参考にしてください。arch/x86/kernel/cpu/microcode/intel.cstruct cpio_data find_microcode_in_initrd(const char *path, bool use_pa) { /* 略 */ size = (unsigned long)boot_params.ext_ramdisk_size << 32; size |= boot_params.hdr.ramdisk_size; if (size) { start = (unsigned long)boot_params.ext_ramdisk_image << 32; start |= boot_params.hdr.ramdisk_image; start += PAGE_OFFSET; } /* 略 */ return find_cpio_data(path, (void *)start, size, NULL);パス名は、以下の通りです。
arch/x86/kernel/cpu/microcode/intel.cstatic const char ucode_path[] = "kernel/x86/microcode/GenuineIntel.bin";cpioイメージを検索する
find_cpio_data()は、先のパスに相当するファイルをRAM上のcpioイメージから探し、それが置かれている領域の先頭アドレスとサイズを返します。
これらの情報は、以下の構造体で表現されます。dataはデータブロックを含むファイルの先頭位置で、sizeはファイルサイズです。include/linux/earlycpio.hstruct cpio_data { void *data; size_t size; char name[MAX_CPIO_FILE_NAME]; };initrd内のファイルを調べ、適用すべきデータブロックを見つける
ファイル内の構成は以下の通りです。
Intel SDM Vol.3によると、個々のデータブロックのフォーマットは以下の通りです。
データブロックのヘッダのうち、最も大切なパラメータはProcessor Signatureです。これは、該当マイクロコードアップデートの適用対象となるプロセッサ種別を表現した値で、「Extended family, extended model, type, family, model, stepping」から構成される値です。それぞれのデータブロックは特定のプロセッサ種別ごとにデザインされたものになります。
「特定のプロセッサ向けにデザインされている」ため、1つのデータブロックは1種類のプロセッサ種別に適用可能です。しかし、複数種類のプロセッサ種別に適用可能なデータブロックもあります。そんなときはどうするのでしょうか。
それを解決するのが、「Optional Extended Signature Table」です。平たく言いますと、このTableに2つ目以降の「適用可能なプロセッサ種別」が列挙されます。詳細は、Intel SDM Vol.3の「9.11.2 Optional Extended Signature Table」を読んでください。また、ヘッダに関して押さえるべきポイントは以下の通りです。
- Data Sizeは純粋なマイクロコードのサイズです。サイズはDWORDの倍数となります。また、0が格納されている場合、ヘッダを除去した純粋なマイクロコードのサイズは2000byteになります。
- Total Sizeはヘッダのサイズ + 純粋なマイクロコードのサイズ + Optional Extended Signature Tableのサイズです。この値は1024の倍数となります。
- Update Revisionはデータブロックのバージョンです。
scan_microcode()の処理を一言で言えば、「メモリ上のGenuineIntel.binを先頭からパースし、動いているプロセッサ種別に適用可能なデータブロックのうち、最新のものを見つけ、そのアドレスとサイズを返す」です。Intel SDM Vol.3の「9.11.3 Processor Identification」も参考にしてコードを読まれると良いです。
データブロックをBIOSに渡す
いよいよデータブロックをBIOSに渡します。
arch/x86/kernel/cpu/microcode/intel.cstatic int apply_microcode_early(struct ucode_cpu_info *uci, bool early) { /* 略 */ /* write microcode via MSR 0x79 */ native_wrmsrl(MSR_IA32_UCODE_WRITE, (unsigned long)mc->bits);native_wrmsrl()は何をしているのでしょうか。実は、Intel SDM Vol.3 「9.11.6 Microcode Update Loader」に対応した処理になります。これでデータブロックをBIOSに渡すことができます。なお、詳しい条件については、Intel SDM Vol.3 「9.11.6 Microcode Update Loader」を参照してください。
おわりに
駆け足でしたが、ルートファイルシステムイメージからデータブロックを探し、それを適用する仕組みについて見ていきました。
当初書きたいネタから脇道にそれることは多々あります。お仕事で脇道にそれるのは良くないのですが、プライベートで技術調査をするときにはそれが楽しいのです。やはりコードや文献を読んでいろいろな事柄を知ることは楽しいものですね。Advent Calendarはそんな機会を与えてくれる良い機会だと思います。それでは、今年もいろいろありましたが、残り少ない今年も、そして来年以降もHappy Hacking!
補足
Ubuntu Linuxのカーネルソースコード取得方法
少なくともUbuntu Server19.10の場合、aptコマンドでlinux-sourceを取得するのが一番楽です。ソースコードはtarで固められていますので、展開は必要です。
実行結果fyoshida@fyoshida:~$ sudo apt install linux-source fyoshida@fyoshida:~$ cd /usr/src/linux-source-5.3.0/ fyoshida@fyoshida:/usr/src/linux-source-5.3.0$ ls debian debian.master linux-source-5.3.0.tar.bz2 fyoshida@fyoshida:/usr/src/linux-source-5.3.0$ sudo tar xf linux-source-5.3.0.tar.bz2 fyoshida@fyoshida:/usr/src/linux-source-5.3.0$ ls debian debian.master linux-source-5.3.0 linux-source-5.3.0.tar.bz2 fyoshida@fyoshida:/usr/src/linux-source-5.3.0/linux-source-5.3.0$ ls arch COPYING Documentation fs ipc kernel MAINTAINERS net scripts sound update-version-dkms block CREDITS drivers include Kbuild lib Makefile README security tools usr certs crypto dropped.txt init Kconfig LICENSES mm samples snapcraft.yaml ubuntu virt参考文献、ページ
全般的にIntel SDMにはお世話になりました。やはり必携です。また、まめだぬき氏の記事は日本語で読める大変貴重な記事だと思います。私も楽しく読ませて頂きました。
また、文中で引用したその他記事についても、著者の方々に改めてお礼申し上げます。






- 投稿日:2019-12-21T11:45:08+09:00
[With image] Problem that returns to the initial screen even after restarting after installing CentOS
This article is aimed at English learning and memorandums.
Since the author is Japanese and supports Japanese, error handling may differ between different overseas versions.
Please note. m (_ _) mBackground
I tried to install VirtualBox → CentOS8 to touch Linux on Mac, but there was a problem that it returned to the initial screen as if nothing happened even if I installed it many times.
I was stuck for about a day and a half, saying, "Compatibility of Catalina just released? Or setting of security software? Or something damaged during download, or ...".Development Environment
・ VirtualBox: 6.0.14 r133895
・ Host OS: MacOS Catalina 10.15
・ Guest OS: CentOS 8.0.1905Cause & Solution
The cause was that the HDD priority of the boot media at the time of startup was lower than the optical. (* The image has been modified.)
It seems that the initial screen was displayed (but the capacity was buried by installation) if the HDD was later to select CentOS installed by the boot loader by restarting.
Other
Please point out any mistakes in expression, etc., because they are poor English engineers and they are learning.?♂️
Thank you for reading!ありがとうございました!

- 投稿日:2019-12-21T11:45:08+09:00
[With image] Problem that returns to the initial screen even after restarting after installing CentOS8
This article is aimed at English learning and memorandums.
Since the author is Japanese and supports Japanese, error handling may differ between different overseas versions.
Please note. m (_ _) mBackground
I tried to install VirtualBox → CentOS8 to touch Linux on Mac, but there was a problem that it returned to the initial screen as if nothing happened even if I installed it many times.
I was stuck for about a day and a half, saying, "Compatibility of Catalina just released? Or setting of security software? Or something damaged during download, or ...".Development Environment
・ VirtualBox: 6.0.14 r133895
・ Host OS: MacOS Catalina 10.15
・ Guest OS: CentOS 8.0.1905Cause & Solution
The cause was that the HDD priority of the boot media at the time of startup was lower than the optical. (* The image has been modified.)
It seems that the initial screen was displayed (but the capacity was buried by installation) if the HDD was later to select CentOS installed by the boot loader by restarting.
Other
Please point out any mistakes in expression, etc., because they are poor English engineers and they are learning.?♂️
Thank you for reading!ありがとうございました!

- 投稿日:2019-12-21T11:45:08+09:00
【With image】 Problem that returns to the initial screen even after restarting after installing CentOS8 (VirtualBox)
This article is aimed at English learning and memorandums.
Since the author is Japanese and supports Japanese, error handling may differ between different overseas versions.
Please note. m (_ _) mBackground
I tried to install VirtualBox → CentOS8 to touch Linux on Mac, but there was a problem that it returned to the initial screen as if nothing happened even if I installed it many times.
I was stuck for about a day and a half, saying, "Compatibility of Catalina just released? Or setting of security software? Or something damaged during download, or ...".Development Environment
・ VirtualBox: 6.0.14 r133895
・ Host OS: MacOS Catalina 10.15
・ Guest OS: CentOS 8.0.1905Cause & Solution
The cause was that the HDD priority of the boot media at the time of startup was lower than the optical. (* The image has been modified.)
It seems that the initial screen was displayed (but the capacity was buried by installation) if the HDD was later to select CentOS installed by the boot loader by restarting.
Other
Please point out any mistakes in expression, etc., because they are poor English engineers and they are learning.?♂️
Thank you for reading!ありがとうございました!
- 投稿日:2019-12-21T11:04:39+09:00
Friendly ArmのZeroPiでsambaを使ってファイルサーバを立てる【OSインストール編】
初めに
以下の記事の続きになります。
Friendly ArmのZeroPiでsambaを使ってファイルサーバを立てる【個人輸入編】手に入ったZeroPiのセットアップを行っていきます。
とは言ってもfriendly armの公式から落としてきたイメージをmicro SDに焼くだけですので楽ちんです。
環境
Windows 10 64bit
OSイメージの取得
設定等々については、公式のwikiが非常に充実しています。
若干カーネルは古いですが、ZeroPi用に仕立てたOSが準備されているので、
これを使いましょう。まずはwikiにあるダウンロードリンクを辿ってイメージをダウンロード
http://wiki.friendlyarm.com/wiki/index.php/ZeroPi#Install_OS
google driveから落としましょう。
下のほうにあるZeroPi-xxxxxx.7zをダウンロード。
この中に、インストールするイメージと、
イメージをmicroSDに焼きこむツールが入っています。
2つのイメージが入っていますが、今回はubuntucoreがベースのfriendlycoreを使います。
イメージ書き込み
入ってる書き込みツールをそのまま使ってもいいですが、バージョンが古いです。
イメージ書き込みツールはほかにもたくさんあります。
私はbalenaEtcherを使いました。
https://www.balena.io/etcher/イメージを選択して、焼きこむメディアを選択して、スタート。
シンプルですね。
起動
出来上がったmicroSDを差し込みます。
向きは以下の通りですので、逆向きに無理やり突っ込んで壊さないようにしてください。
差し込むとこんな感じ
電源スイッチはありませんので、USBケーブルを指したら電源が付きます。
ZeroPiへのアクセス
さて、起動画面でも見てやるか、と思ったときに気づく訳です。
「あれ、ディスプレイ出力・・・?」引っかかったな!そんなものはないぞ!
まあこれを買う人はわかって買ってるはずだから大丈夫ですよね!・・・・ですよね?
でも大丈夫、Ethernetケーブルからアクセスが可能です。
ZeroPiはデフォルトでDHCPサーバ(≒ご自宅のルータ)からIPをもらいますので、そこあてにSSHで飛ばせばいいのです。LANへの物理的接続
まずはZeroPiをお手持ちのPCと同一のLAN内に接続してください。
なお初回設定では、インターネットに直刺しなど、不特定多数の人間がアクセスする場所にはつながないでください。
後述の通りデフォルトのID・パスの組み合わせで誰でもアクセスできますので。この時点でZeroPiにIPが割り当てられているはずです。
IPの特定
どのIPが割り当てられたかわからない?
ごり押しで探しましょう。
(もっとスマートなやり方を募集しています)ただ、全部のIPを探しに行くのはしんどいので、まずはpingにお返事してくれる端末を探します。
とりあえず20個ぐらいでいいでしょう。
XXの部分は自身のLANの範囲で選びましょう。ipconfigあたりをたたいたら出てきます。cmd>for /L %f in (1,1,20) do ping -n 1 -w 50 192.168.XX.%f | find "受信 = 1"これで応答があるのがZeroPiのIP候補です。
(特定できてない?あーあー聞こえない)SSHによる接続
まずSSHクライアントを手に入れましょう。
なんでもいいですが、windows標準にしましょうか。
この辺りを参考にしました。
https://www.onebizlife.com/windows10-ssh-client-1980ほかにもteratermやputtyなどがあります。
ログインid/パスは公式の通りです。
http://wiki.friendlyarm.com/wiki/index.php/ZeroPi#System_Loginid:pi pass:piあとは先ほど調べた候補に
アタックします接続を試みます。powershell>ssh pi@192.168.X.Y
つながりましたね。
パスワードの変更
パスワードを変えておきましょう。
pi@ZeroPi:~$ passwd Changing password for pi. (current) UNIX password: Enter new UNIX password: Retype new UNIX password: passwd: password updated successfullyrootユーザの無効化
まず、ubuntuのくせにrootユーザが有効な上にsshからもアクセスできてしまうので、
無効化しておきましょう。bashpi@ZeroPi:~$ sudo passwd -l root passwd: password expiry information changed.終わりに
今回はOSインストール編でした。
次はsambaの設定編です。








- 投稿日:2019-12-21T03:10:25+09:00
機械学習入門以前。~機械学習以外なのに機械学習で必要な技術~
はじめに
タイトルは、「Cプログラミング入門以前 著:村山 公保」からお借りしました。
つまり、機械学習を学ぶ訳じゃないけど、機械学習には必要な技術っていっぱいあるよね。
って話をします。まず自己紹介したいと思います。
経歴
大学学部・院共に人工知能研究室におりました。
最初はボルツマンマシンなどを元に色々研究していましたが、
訳あって院生時代はとある会社に研究アルバイトとして採用していただきまして、
修論もそこでの研究成果を書かせていただいて、卒業しました。機械学習に入る前の時代
自分は割とプログラムは書けた方だったのですが、
知らない単語はそもそも検索のしようがないので、
ずっと技術学びたい・・・!って思いながらも検索できず、
苦悩の日々を過ごしました。研究室に入ってから、Qiitaの存在を知り、Pythonを知ることができ
機械学習を学ぶことができました。全てはQiitaのおかげで、言葉が分からなくて検索もできなかった頃から
徐々にワードを知ることができ、結果的に機械学習を学ぶことができました。基本的に「機械学習、どう学んだか」についてはこれで終わりです。
あとはおまけみたいなものですが、お読みいただけると幸いです。
(おもちゃ付きのガムみたいな)機械学習入門以前。
今回は、Qiitaへの感謝も込めて
機械学習の文中では出てこないけど、機械学習する上では必須のツール
などについて用語を羅列して、簡単な説明をしていきます。
お付き合いください。Linux編
機械学習とLinuxは切っても切り離せない関係にあります。
Macじゃ力不足だし、WindowsだとPython入れるのが面倒だしゆえに機械学習では、半ば強制的にLinuxを使うことになります。
その方法や便利コマンド、必要な知識などについて解説していきます。windowsでLinuxを扱う
Windows10には最近Windows Subsystem for Linuxと呼ばれる機能があります。
コレを使うことでwindows上に擬似的にLinux環境を使うことができます。インストール方法などはググればいくらでも出てきます。
Microsoft公式のツールです。SSH
SecuredShellの略でSSHです。
基本的には遠隔サーバにログインするための機能だと思ってください。
つまり、これを使うとリモートサーバにアクセスができます。SSHを使うと何が嬉しいかというと、Macのインターフェースを使いながら
計算自体そのものはLinuxに任せることができるということです。
また、自分の使うインターフェースはMacかWindowsかどうかは問われません。
どちらでも使うことができます。セキュリティ上の注意
自宅サーバや研究室サーバなどで、外部公開しながらSSHをしたい場合もあります。
その場合はsshd.conf上の設定で以下の点を守れば基本的には持ちます。
- PermitRootLoginをnoにする。
- PasswordAuthenticationをnoにする。
- (noにしても本体目の前にして直にアクセスする上ではpasswordでログインできます)
- 公開鍵認証に設定する。
公開鍵認証上でSSHをするとパスワード不要でセキュアにリモートに入れますので
公開鍵認証にしましょう。てかネットに晒すならそれ以外の選択肢はないです。仕組み等はここでは詳しくは説明しません。
簡単に言えば、
-ssh-keygenをすれば公開鍵と秘密鍵ペアができるから
- 公開鍵をauthorized_keysに設定してsshd_config色々設定して
- アクセスする側の~/.ssh/configにIdentityFile ~/.ssh/id_rsaみたいに設定すれば安全にログインできます。
詳しくはggってください。tmux
SSHでリモートに接続しながら計算を行っていると、
長い計算時間の間にネットワークが切れたりすると計算結果が無に帰ります。SSHが切れてもずっと状態を保持し続けたいですよね?
tmuxには、実はそれが可能なのです。tmuxにはセッションという概念があります。
それはSSHが切れても擬似ターミナルを永遠にプロセス内に残しておくことができるのです。tmuxはubuntu18.04LTSにはおそらく入ってるかと思われますので、インストールはしなくて大丈夫です。
新しいセッションを立ち上げる
tmuxのセッションの起動のさせ方は
tmux new -s session_nameです。session_nameは自由に名前をつけてあげてください。
tmuxは基本prefixキーというのを最初に押してなんでも操作します。
prefixキーはデフォルトでctrl+bなのですが、ctrl+aにしておくと
めちゃめちゃ捗るのでおすすめです。セッションをlogout
セッションそのものを無くしたいときは
logoutしましょう。セッションを保持したまま元のshに戻る
デタッチと呼ばれる操作です。
prefix,dの順番に押しましょうSSHから切断されたあと、セッションに戻る
tmux aとターミナルに入力しましょう画面を分割する。
tmuxは画面を分割することもできます。
prefix, %と入力すると縦に画面が割れます。
prefix, "と入力すると横に画面が割れます。時計を表示
実は時計も表示できます。
tmux clock-modeとするとできます。全体のチートシート
prefix, ?でも出ますが、
https://qiita.com/nmrmsys/items/03f97f5eabec18a3a18b
こちらの記事参考にしていただけると良いかと思います。
~/.tmux.conftmuxも色々設定ができます。
色々といっても設定は様々で、私は以下の二つの記事を参考にしました。達人に学ぶ.tmux.confの基本設定
tmux で Prefix key が押されているかどうかを表示する自分が常に使っている設定は以下の通りです。
# prefixキーをC-aに変更する<img width="727" alt="スクリーンショット 2019-12-21 1.33.27.png" src="https://qiita-image-store.s3.ap-northeast-1.amazonaws.com/0/182970/b5e6f309-53c3-0174-2b76-682a65156b75.png"> set -g prefix C-a # C-bのキーバインドを解除する unbind C-b # 設定ファイルをリロードする bind r source-file ~/.tmux.conf \; display "Reloaded!" # C-a*2でtmux内のプログラムにC-aを送る bind C-a send-prefix # | でペインを縦に分割する bind | split-window -h # - でペインを横に分割する bind - split-window -v # 256色端末を使用する set -g default-terminal "screen-256color" #prefixキーが押されているか確認できるようにする set-option -g status-left '#[fg=cyan,bg=#303030]#{?client_prefix,#[reverse],} #H[#S] #[default]'基本的にコレで事足ります。
htop
htopはリソースを見ることができるツールです。
コレで実際どのくらいのCPUリソースに負荷が掛かっているのかを見ることができます。
nvtop
nvtopはhtopのGPU版です。
htopもあればnvtopもあるといった感じでしょうか。
GPUを使っているのかどうかもコレで見ることができます。ubuntuだと19.04の場合は
aptとかで入れられるけど、
基本はソースをビルドする必要あり。vi/vim
SSH上など、Linux上で何かとファイルをいじる可能性は高いです。
そんな時に使うのはviとVimです。viとvimの違いは、
vi+色々な機能=vimです。viだけだと色々と面倒臭いです。
vi、vimコマンドで開けます。基本的に以下のことを覚えておけば大丈夫でしょう。
normalモード
カーソルを動かしたり、undoしたり検索したりするのも基本ここでやります
知っておくと便利な機能を列挙します。:q 終了 :q! 強制終了 :w 上書き :100 100行目に移動 /word wordを検索(+nで次の一致単語に移動) u Undo(windowsで言うctrl+z的な動作) dd 現在の行削除(windowsで言うctrl+x的な動作) yy 現在の行をコピー(ctrl+c的な動作) p ペースト(ctrl+v的な動作) hjkl ←↓↑→に対応(macだと日本語入力でzhとすると←と出たりします)insertモード
iキーやOとか押すとinsertモードになります。
インサートモードであれば、文字を入力できます。
normalモードに戻る時はESCを押しましょう。
(macでESCキーが元に戻ったのはVimmerが原因...?)詳しくはググればいくらでも操作方法がありますので、
是非調べてみてくださいその他コマンド
find
文字通りファイルを探してくれます。
find [start_dir]使い方的には
find ~/ | grep 特定したいファイルとかでファイルの在りかを探せたりします。
tree
ファイルをTree形式で見せてくれます。
全体構成を把握したい時はこれをいつも使ってます。
ログが大量に流れちゃうのが問題ですが(wc
ファイル行数を確認します
tsvファイルでどれくらいの行数か知りたい時とかに有効
あるいはfindさせてdf/du
ファイルサイズを測ってくれます。
dfは全体のファイルサイズの容量を、
duは個別のファイルサイズの容量をそれぞれ見せてくれます。df -hFilesystem Size Used Avail Use% Mounted on udev 16G 0 16G 0% /dev tmpfs 3.2G 1.5M 3.2G 1% /run /dev/sdb3 916G 33G 837G 4% / tmpfs 16G 88K 16G 1% /dev/shm tmpfs 5.0M 4.0K 5.0M 1% /run/lock tmpfs 16G 0 16G 0% /sys/fs/cgroup
-hオプションは容量に対して単位表示をしてくれます。
FileSystemの項にあるのがdev(device)とその具体的な名前です。
/dev/sdb3がSSDとかの具体的なハードウェアになります。
基本的にsd[x][n]と名前をつけられます。詳しくはggってください。一方、個別のファイル容量をみたい場合は
duコマンドが有効です。
例えばカレントのフォルダで容量一覧をみたい場合はdu -hs ~/*とするとカレントに個別に乗っかってるファイル容量を全てみてくれます。
どれが重いか見せてくれるわけです。grep
大量のログから該当する表記だけ抽出して見たい場合に使います。
find ~/ | grep filenameと言ったパイプ処理でログを流してあげて、
filenameに該当する部分だけを抽出できます
後述のregexにも対応しています。cat
ファイルを直で出力できます。パイプを組み合わせて
cat /var/log/auth.log | grep sudo
とかでファイル内検索とかしてあげられます。less/head/tail
120GBとかいうクソ馬鹿デカtsvが送られた時に
vim logfile.tsvとかやると死ぬほど時間かかります。
(そもそもそう言うレベルのtsvはparquetで送ろうね!)そんな時に、lessコマンドは一部だけ読み込んで、
画面表示してくれます。
headは先頭数行分を表示してくれます。
tailは最後から数行分を表示してくれます。jq
jsonファイルをいい感じにしてくれます。
詳細はこちら:jq コマンドを使う日常のご紹介をご参照ください。sed
文字列を置き換えてくれます。
s/a/b/g→aをbに変換
よくエンジニア界隈でも、パッとs/の/が/gとかslackで飛ばされたりするくらい、
共通言語化しています。python編
Pythonは知ってるけどインストールとかどーすんの?って人だったり
色々知ってるけどLinuxでバージョン管理するのどーしたらいいか迷う...
みたいな人におすすめです。version管理編
pyenv
ユーザごとにPythonバージョンをインストールしてくれます。
詳細はこちら:【永久保存版】pyenv+venvをubuntuに入れる【もう迷わない】pyenvをインストールしたら、
pyenv install python-versionで希望のpythonバージョンを入れましょう。
基本的にはanacondaとかより一番シンプルなやつを持ってきた方がいいです。
pyenv install 3.6.9とか
そうすると、個人フォルダにpythonを入れてくれるので、他のユーザの環境を汚染したりしません。venv
venvはpythonのパッケージ管理ツールです。
基本となるpythonをpyenvで選んであげて、
venvで環境を作成してpipとかしてあげるとGoodです。
詳細はこちら:【永久保存版】pyenv+venvをubuntuに入れる【もう迷わない】IDE編
vscode
vscodeにはssh機能が付いていて、公開鍵設定を自動で読んで
いい感じに秘密鍵を使ってSSHしながらリモートサーバのファイルをいじれたりします。
一方でvenvあたりのパッケージとかを謎に読もうとして、
コーディングにはあまり向いていない印象です。
(venv+vscodeでいい感じにコーディング中にコード候補とか出してくれるのあったら情報求む!)jupyter_notebook
Jupyter_notebookとは、Webブラウザ上で起動するIDEです。
基本的にリモートサーバ上で起動させて、
notebookを書き込んでは計算だけはリモート鯖にやらせたい時に便利です。Google Colaboratory
環境は全部Google側が用意してくれる系のIDEです。
環境構築等一切やらなくて済むのが特徴です。
Googleのリソースを使ってPythonをコーディングできます。
ありがたいことにGPUやTPUリソースも使わせてくれます。
基本はJupyter notebookと同じですが、リソースはGoogleが管理っていうだけですね。便利ライブラリ編
tqdm
進捗管理バーを出してくれます。
DeepLearningやその他クッソ重い処理が今どれくらい進んでいるのか、
すぐに把握できるのがいい点です。
データサイエンスは基本クソデカファイルを処理するので、
進捗バーがあるとだいたい何分(時には30時間とか)かかるからその間switchでゲームしよ
なんてこともできるわけです。機械学習には必須です。使い方は公式を参照してください。
multiprocessとか、数値モニタリングとかの機能も備わってます。pandas
tsvとかparquetファイルをテーブル的にいい〜感じに処理してくれるツールです。
データサイエンスやる上ではほぼ必須でしょう。
使い方などはkaggleやってると嫌でも覚えます。matplotlib
グラフを表示できます。
基本的にKaggleやってると嫌でも遭遇します。
他の手段としてはseaborn,plotlyなどがあります。Pickle
pythonのオブジェクトなんでも保存します。
途中の状態を保存しておきたいですよね。
Kerasで作ったmodelを保存したいとか、長時間かけて作ったXGBoostのモデルを保存したいとか
そういった時に、丸ごと保存するのがpickleです。
丸ごと保存したpickleは、その機能も全部保存されるので、
解凍してすぐ予測用に使いたいとかでも、機能します。その他覚えておくと良い概念
regex
正規表現っていうやつです。
大量にある文章中の電話番号を検索して取りたいって時にこれを使うとヨシ
電話番号の例だと
\d{3,4}[-]?\d{3,4}[-]?\d{4}
とかで取れます。(なんもわからんと怪文書なんですけどね)Docker
いわゆる仮想マシンではないんですが、MySQLとかのミドルウェアを切り離して
独立化させて、環境を汚さないようにできるのがDockerです。
Dockerの知識がないと、MySQLとかを本体にインストールして・・・
ああっ失敗したみたいな面倒なことが発生します。DockerはMySQLやnginxといったサービスを分割してコンテナという単位に押し込んでしまいます。
このコンテナという物はいくらでも捨てて、いくらでも生産できるので、
環境の構築が非常に楽です。詳しくは、Dockerで検索すれば非常に大量の情報が出てくるので、
そちらを参考にされると良いかと思われます。LocalForwarding/ポートフォワーディング
計算だけは強いGPUのクソでっかいデスクトップPCに計算させて、
コーディングとか指示だけは手元のMacから。みたいな都合のいい使い方をしたい場合は、
ポートフォワーディング+jupyterNotebookをおすすめします。ポートフォワーディングについては以前記事を書きましたので、そちらで紹介します。
データサイエンティストなら誰もが通る、リモートサーバのJupyter Notebook (Lab)へのアクセス方法まとめケース別、逆引き辞書
case1. MacBook使いたいけどGPUも欲しい。どうしたらいい?
答え
基本操作はMacBookで、強いPCとして1台別に用意しましょう。
強いPCはなんでも大丈夫です。ゲーミング用のGPUマシンを購入しても大丈夫ですし、
GCP,AWSを使った方が大抵の場合お得だったり簡単だったりします。なんでも大丈夫ですが、基本必要なやることは、
GPUサーバでsshd設定ちゃんとして、なんとかして
ポートフォワーディングしてjupyterをlocalhostで表示させるようにすればおkcase2. 自宅に強いubuntuPCを置いて、家の中だけでいいからSSHでアクセスしたりしたい。
答え
強いPCにubuntuをインスコして、ルータ内設定のDHCPで強いPCだけ固定しましょう
大抵macアドレスとかで認識してるので、
このmacアドレスにDHCPで172.168.1.22を必ず指定してあげてね
と設定すればおk
あとはSSH設定して、公開鍵を送って、172.168.1.22にSSHしたらいい。case3. インターネットを経由して外から自宅サーバにSSHアクセスするには?
答え
結構やばいからある程度知識得てからやった方がいい。 やる方法はいくらでもあります
まずセキュリティの知識をsshd_configあたりググって得てから、
ルータ側で、どの内側ポートをどの外側ポートに出せばいいか設定したげればおk
環境とプロバイダによりきりなんですが、基本外側ipは変わりまくるので、
DDNSという技術を使うと固定のドメインにアクセスすれば外からアクセスできるという感じです。case4. 強いPC用意するお金ありませんけど機械学習できますか?
Colabratory使ってくれ!...GPUもあるぞ!
基本Colab使うのがGoodでしょう。無料ですし
でも使いすぎると結構切られたり、めっちゃ遅くなったりします。
その時はGCP使いましょ。お金そんなかからないから大丈夫だって〜〜〜〜〜case5. みんなで共用のGPU鯖建てたい、環境構築どうしたらいい?
pyenv+venv使おう!それで全てがうまくいくよ。
pyenvはsudo権も不要でインストール可能なので、権限管理も簡単です。
aptのバージョン依存とかもないと思って基本は大丈夫なので
(インストール時ビルドは走るから、無の状態でやってね〜は流石に無理ですが。)
sudo権なども管理しやすく、便利です。case6. githubとかにnotebookを管理したいけどどうしたらいい?
colabの機能を使うとcommit+pushとかできて、差分も見やすいよ
こちらの記事Colabratoryって画面上だけでGitHubにPushして差分まで見れちゃうって知ってた?
でできます。case7. 研究上で、モデルのバージョン管理とか面倒で何かいい方法ある?
GCPやAWSにあります。
GCPならAIプラットフォーム、AWSならSageMakerとか!
case8. 学習データってどうやって集めたらええの・・・
スクレイピング、KaggleDatasets、論文、GCP/AWSアノテータ活用などなど
これは場合によるんですが、
研究の場合、一つのデータセットで成績を競うみたいなやつだと元の論文があるからそれ参考にでいい。
独自研究の場合、クローリング/スクレイピングとかで検索すればやり方は出てきます。
本当に新しくデータセット作りたい場合、Cloudにもアノテーション機能があります。それを利用してみては?おわりに
何かこれどうしたらいいの?みたいな質問はなるべくここのCaseに挙げて回答していく所存ですので、
何かあればぜひ質問してください。
長いおまけに付き合っていただき、ありがとうございました。



