- 投稿日:2019-12-21T22:33:42+09:00
ガンツ7回クリアの岡八郎をJavaを使って一般化しました
はじめに
初投稿です。ITエンジニア1年目です。ご容赦ください。
この記事は超初歩的なJavaの文法しか使いません。GANTZとは
いきなりですが、みなさんGANTZ(ガンツ)って漫画知ってますか?
詳細はここでは述べませんが、強化スーツみたいのを着た主人公たちがめちゃくちゃ強い化け物と戦う、みたいな漫画です。面白いです。
ガンツの世界では敵がめちゃくちゃ強くて気をぬくとすぐに死んでしまうハラハラした世界なのですが、大阪編という話ですごい登場人物が出てきます。それが岡八郎です。岡八郎とは
GANTZの世界で戦闘に勝って特典を貯めると、GANTZをクリアすることができます。
一回クリアすると
「元の世界に帰る」「誰かを生き返らせる」「強い武器を手に入れる」
の3つから1つを選択することができます。
普通に考えたら全クリしたら元の世界に帰りたいですよね。死にたくないし。
でも岡八郎はすごいです。
なんとあのGANTZを7回もクリアしているのです。すごすぎる。
そして毎回クリアするごとに新しい武器を手に入れているので岡八郎はめちゃくちゃごつい装備を手に入れているんですよね。
それまで登場したキャラと比べても異常に強キャラ感がある、インパクトのあるキャラでした
「ガンツ7回クリアの岡八郎!」
このパワーワード感はすごいです。エンジニアとして思うこと
さて、僕はQiitaに投稿するのは初めてですが、Qiitaはガンツについて語るところではなく、プログラミングについて語るところだと聞いています。そこでITエンジニアとしてこの
「ガンツ7回クリアの岡八郎」
について考えてみたいと思います。
まずこの文を見て、少し感のいい人ならある法則性に気づくと思います。
7+1=8
7はガンツをクリアした回数、8は岡の下の名前です。
これを一般化すると
「ガンツn回クリアの岡(n+1)郎」
とすることができますね。
このように7や8をベタ打ちするよりも任意の数nを使った方がスケーラビリティに優れており、可読性も増すような気がします。Javaで書いてみる
- まずは
Oka.javaという名前のファイルを作ります- 中身に以下のコードを打ちます
public class Oka{ public static void main(String[] args){ System.out.println("ガンツ7回クリアの岡八郎"); } }これで準備ができました。ターミナルで以下のように打ち込んでみましょう。
わくわくしますね。javac Oka.java java Oka以下のように出力されれば成功です。
ガンツ7回クリアの岡八郎無事岡八郎がガンツを7回クリアすることができました。
しかし、この状態だと6回クリアしたい場合や8回クリアしたい場合に対応できません一般化する
さきほどのコードを少し改良して岡八郎を一般化しましょう。
public class Oka{ public static void main(String[] args){ //岡がガンツをクリアした回数 int n = 7; //岡を表示する System.out.println("ガンツ"+ n +"回クリアの岡"+ (n+1) +"郎"); } }以下のように出力されます。
ガンツ7回クリアの岡8郎上のコードで
n=8としてみると、出力結果は以下のように変化します。ガンツ8回クリアの岡9郎やりましたね。岡の一般化に成功しました。
for分で岡を繰り返してみる
せっかくなので岡を繰り返してみましょう。先ほどのOka.javaを次のように編集します。
public class Oka{ public static void main(String[] args){ //岡の繰り返し回数 final int oka_itr = 10; //岡を繰り返す for(int n=0; n<oka_itr; n++){ System.out.println("ガンツ"+ n +"回クリアの岡"+ (n+1) +"郎"); } } }以下のように出力されれば成功です。
ガンツ0回クリアの岡1郎 ガンツ1回クリアの岡2郎 ガンツ2回クリアの岡3郎 ガンツ3回クリアの岡4郎 ガンツ4回クリアの岡5郎 ガンツ5回クリアの岡6郎 ガンツ6回クリアの岡7郎 ガンツ7回クリアの岡8郎 ガンツ8回クリアの岡9郎 ガンツ9回クリアの岡10郎やりましたね!無事岡を繰り返すことができました。
まとめ今後の課題
今後の課題をしては
- 岡がガンツをクリアする回数を実行時に引数として指定する
- 岡をモジュール化して外部から利用する
などが考えられますが、今回はとりあえず岡の一般化に成功したのでここまでとしておきます。
ガンツを読んでて「この岡八郎、拡張性ないな〜」と思った方がいたら、是非試してみてください。余談〜岡八郎のその後〜
初登場時にものすごいインパクトを残した岡八郎ですが、そのあとすぐめちゃくちゃ強い敵にやられて死にます。完全にかませキャラとして使われてしまったのです。ガンツ7回もクリアしたのに。。
俺は忘れない。岡八郎がガンツを7回もクリアしたことを。
- 投稿日:2019-12-21T22:23:12+09:00
AWSからリリースされた、JavaでDeepLearningが扱えるライブラリDeep Java Library(DJL)に触れてみる
概要
2019/12/03AWSよりJava で機械学習モデルを開発およびデプロイするDeep Java Libraryが発表されました。
ほんの少しですが、触ってみましたので紹介します。
なお、事前知識としては、Javaは普段使っているが、ML/DLの知識は自身ほぼゼロです。
ここでは、
Java で深層学習モデルを開発するためのオープンソースライブラリである DJL を発表します。DJL には、深層学習モデルのトレーニング、テスト、デプロイを行うためのユーザーに使いやすい API が用意されています。深層学習に興味のある Java ユーザーであれば、DJL は素晴らしい出発点になります。深層学習モデルで作業する Java 開発者の場合、DJL を使えば簡単に予測をトレーニングして実行することができます。
とありましたので、期待して触ってみます。
なお、公式なページは以下ですが、Amazon/AWS色はあまり見えません。
https://djl.ai/Try
何はともあれ、チュートリアル通り動かしてみます。
https://github.com/awslabs/djl.git
からcloneし、example以下を動かすのが良さそうです。
# 適当なフォルダで実行 git clone https://github.com/awslabs/djl/cloneし終えたら、exampleフォルダに移動し、そこのREADME.mdを見てみます。
以下のように、いろいろな種類の例があるので最初に一つ目の奴をやってみます。
Single-shot Object Detection exampleをやっていきます。
まず初めにセットアップせよと言われますが、Java11+と環境変数、オプションでIntelliJでの使い方ぐらいですので、普段Javaやっている人はあまり読まずに突き進んでも良さそうです。
この例では、予め用意されたZooModelというものを使い、それに対して画像をぶつけてそこに何の動物が映っているのかを表現してくれ、その認識した箇所を四角で囲った画像も作る、という例となります。
いきなりですが、以下で動作確認することが出来ます。
(object_detection.mdより引用)cd examples
./gradlew run -Dmain=ai.djl.examples.inference.ObjectDetection実行結果として、以下が表示されます。
初回はライブラリのダウンロードなどが走るため、時間がかかりますが、2回目以降は10秒程度で終わります。$ ./gradlew run -Dmain=ai.djl.examples.inference.ObjectDetection > Task :run Loading: 100% |████████████████████████████████████████| [22:02:10] src/nnvm/legacy_json_util.cc:209: Loading symbol saved by previous version v1.5.0. Attempting to upgrade... [22:02:10] src/nnvm/legacy_json_util.cc:217: Symbol successfully upgraded! [INFO ] - Detected objects image has been saved in: build/output/detected-dog_bike_car.png [INFO ] - [ class: "car", probability: 0.99991, bounds: [x=0.611, y=0.137, width=0.293, height=0.160] class: "bicycle", probability: 0.95385, bounds: [x=0.162, y=0.207, width=0.594, height=0.588] class: "dog", probability: 0.93752, bounds: [x=0.168, y=0.350, width=0.274, height=0.593] ] BUILD SUCCESSFUL in 11s 3 actionable tasks: 1 executed, 2 up-to-date車と自転車と犬が写っているという結果が出てます。
後付けになりますが、ai.djl.examples.inference.ObjectDetectionクラスを見ると
Path imageFile = Paths.get("src/test/resources/dog_bike_car.jpg");
とあるので、この画像がInputであることがわかります。
実行後、出力された画像は
build/output/detected-dog_bike_car.pngにあります。(同クラスに実装されています)
ちゃんと出来てますね。
Inputの画像を差し替えることで、別の画像でもObject Detectionできそうです。
改めて
ai.djl.examples.inference.ObjectDetectionクラスを見ると、Javaしかわからない自分にでもなんとなくやっていることがわかります。ロガーの設定などが馴染みがあって親近感湧きますね。全部でおおまかな流れは以下のように読み取りました。
- ロガーの設定
- Inputとなる画像の読み込み
- モデルに渡す各種パラメータの設定
- MxModelZoo(MxNetベースのモデル)という予め用意されたモデルへパラメータ、画像を渡す
- 予測の実施
- 予測結果を画像へ反映
- 標準出力にも予測結果を出力
といった感じです。パラメータのところはそれぞれどんな意味があるのか詳細確認が必要ですが、用意されたモデルを使ってObject Detectionするというのはハードルが低いなと正直思いました。
依存ライブラリの確認
exampleを取り込んだプロジェクトの依存ライブラリは以下のような感じでした。
Spring系との重複とかはなさそうなので、コンフリクト起きずに併用できそうですね。
まとめ
とりあえずDJLを使って、一つの例だけやってみました。
以前、DeepLearning4Jを触ってみようかと思ったのですが、
環境構築周りで躓き、棚上げしていたのですが、今回はすんなりでした。ML/DLのシステムを全てJavaで!という感覚までは辿り着けませんでしたが、一般的なWebシステムの一機能だけML/DLを使うという際には、これをスモールスタートで使ってみるというのは良いかもしれないなと思いました。






- 投稿日:2019-12-21T21:56:45+09:00
2019年フレームワークのトレンドが見れるサイトの紹介
hotframeworks.com
URLはこちらになります。
http://hotframeworks.com/

- 投稿日:2019-12-21T20:58:21+09:00
既存JavaシステムのDBに対して簡単にWebAPIを生やすことを夢見て
背景とやりたいこと
既存のモノリシックなシステムのDBが持つデータに対して、REST APIでアクセスしたいとき、どうしますか?
そのシステム担当にREST API公開お願いしますと頼もうとすると、ちょっとよく分からないし、基盤影響とか、いろいろ考えないといけないし、それより今忙しいし、、と真面目に掛け合ってくれないということがあるかもしれません。そんなときに、既存の環境を使いつつすごく簡単にREST形式のWebAPIを生やすことができないか?と考えました。
過去の検討
自身、2017年ごろに一度調べたことがあったのですが、その際の構成は以下の感じです。
既存システム構成の例
REST API生やした後の構成
軽量なSpringBootで作ったツールの構成としては、Spring Boot+Spring Data REST+SpringFox という構成が楽なのでは無いか?と考えました。
当時のSpringコミュニティの中で、それぞれ注目を集めていたプロジェクトだったためです。Spring Data REST:SpringDataシリーズと連携し、外からのアクセス部分をRESTAPI化してくれる
SpringFox:Springプロジェクト非公式。自分のプロジェクト内のRest APIを自動で探し出し、OpenAPIドキュメントを自動で生成してくれる。また、ドキュメント上からAPIをコールするクライアント(Swagger-UI)を用意してくれる。
少し試したところ、結構これがいい感じに動いていたので、良さげと思っていました。
一方、最近改めて見るとSpringFoxのリリースの最後が2018年の6月で止まっており、
Springのバージョンも4系までの対応。
Spring5系への対応のIssueも切られているが対応がFixしていない状態ということで、
他の代替できるものが無いか調べ、サンプルを作ってみることにしました。今回の検討
最初にお題となるアプリを作ることにしました。既存のモノリスシステム内でStudentテーブルがあり、それをREST APIで突つきたいという想定です。
アプリ作成
Spring Initializr からアプリを作成するところからスタートです。
以下設定で作りました。
取得したいテーブルのEntityを作ります。キーは必要ですが、取得したいフィールドだけでよいです。
Student.java@Entity public class Student { @Id private String id; private String name; private String className; // 以降Getter,Setterなど次にDBにアクセスするRepositoryを作ります。まずは、Data REST感なく、Controllerから呼べるように普通に作ります。
StudentRepository.java@Repository public interface StudentRepository extends PagingAndSortingRepository<Student,String> { Iterable<Student> findAll(); }Controllerは以下の実装となります。
StudentRestController.java@RestController public class StudentRestController { @Autowired private StudentRepository studentRepository; @GetMapping("/students") Iterable<Student> getStudents() { return studentRepository.findAll(); } }今回はH2を使ってDBアクセスするので、諸々の設定を入れておきます。後で実験しやすいように初期SQLを流したり、アプリ終了時のデータを永続化させる設定などを入れています。
application.properties# datasource spring.datasource.driver-class-name=org.h2.Driver # DBのファイルとしての永続化先はh2dbフォルダに保存。データ初期化の際にON CONFLICTを使いたかったのでPostgreSQLモードにしておく。 spring.datasource.url=jdbc:h2:./h2db/sandbox;MODE=PostgreSQL spring.datasource.username=dev spring.datasource.password=dev # resources/sdata.sqlを使ったDBのデータ初期化をアプリ立ち上げ都度実施 spring.datasource.initialization-mode=always # データをファイルに永続化 spring.jpa.hibernate.ddl-auto=update # h2 for debug tool spring.h2.console.enabled=true spring.h2.console.path=/h2-console spring.h2.console.settings.web-allow-others=trueこの状態にしておき、resources下に以下ファイルを置いておくとテーブル作成、初期データ投入(あれば何もしない)をやってくれます。Spring Dataの機能でしょうか?便利ですね。
data.sqlCREATE TABLE IF NOT EXISTS STUDENT ( ID VARCHAR(255) NOT NULL, CLASS_NAME VARCHAR(255), NAME VARCHAR(255), PRIMARY KEY(ID) ); -- 一意制約発生を避けるため、ON CONFLICTを使用 INSERT INTO STUDENT VALUES ('1','A CLASS','TAKA') ON CONFLICT DO NOTHING; INSERT INTO STUDENT VALUES ('2','A CLASS','KASHI') ON CONFLICT DO NOTHING; INSERT INTO STUDENT VALUES ('3','B CLASS','KIKUCHI') ON CONFLICT DO NOTHING;長かったですが、これでSpringBoot+REST ControllerでのWebAPI開発完了です。
ここまではSpringDataRESTを使ってないことに留意してください。
SpringBootアプリを立ち上げ、Curlでアクセスした結果は以下の通りです。
( 参考: jqはJSONを整形、加工するコマンドラインツールです)
続いて、SpringDataRESTを組み込んで行きます。といいつつ、3ステップ(最短2ステップ)のみなので至極簡単です。
pom.xmlへの依存の追加。pom.xml<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-rest</artifactId> </dependency>先ほどのStudentRepositoryクラスへのRepositoryRestResourceアノテーションの追加
StudentRepository.java@Repository @RepositoryRestResource (collectionResourceRel = "students", path = "students") public interface StudentRepository extends PagingAndSortingRepository<Student,String> {(任意)SpringDataRESTで自動作成されるAPIの基底パスの追加
application.properties# SpringDataRESTで自動作成されるAPIの基底パス spring.data.rest.basePath=/apiこれで完了です。アプリを再立ち上げし、localhost:8080/apiにアクセスしてみましょう。SpringDataRESTによってREST APIが自動生成されたことを確認することができます。
api/studentsというURIのAPIが作成されてますので、アクセスしてみると以下の結果を得ることが出来ます。
先ほど自作したAPIより情報量が多いことに気づくでしょうか?
SpringDataRESTはHATEOASされているので、情報が多く、JavaScriptなどクライアントからAPIを利用するには優位なのです。
ここまでで、DBに対してWebAPIを簡単に(?)作成することが出来ましたので、
最後にOpenAPI、SwaggerUI対応をします。SpringFoxの代替は?
SpringDataRest,OpenAPIでググって一番先に出てきたSpringdoc OpenAPIを使ってみました。
おそらくSpring公式なんですかね、URL見る限り。
公式が出たのでSpringFoxの開発が下火になったのであれば納得の流れですね。。導入方法ですが、依存先に追加するだけです。SpringFoxのときはJavaConfig作成が必須だった記憶があるのですが、こちらはStarterを用意してくれているようです。
pom.xml<dependency> <groupId>org.springdoc</groupId> <artifactId>springdoc-openapi-ui</artifactId> <version>1.1.44</version> </dependency>依存先追加後、アプリを再立ち上げし、http://localhost:8080/swagger-ui/index.html?url=/v3/api-docsにブラウザでアクセスすることで、SwaggerUIを触ることができます!
WebAPIの一覧や、実際にここからWebAPIを実行することもできるので最高です。
とぬか喜びしていましたが、よく見ると、このUIで表示されているのは最初にRESTController
を作ったものしかなく、Spring Data RESTで作ったものは作成してくれてません。SpringFoxではやってくれていたのですが、、と思い調べていたら、以下のIssueにたどり着きました。
- How does this work with Spring Data Rest ?
Documentation is available on the official page: https://springdoc.github.io/springdoc-openapi-demos/
Spring Data Rest is not a priority. It will be supported on a future release.このコメントでCloseされてました。。。
さらに下の別の方のコメントでは、SpringFoxからSpringDocに乗り換えようとしているのだけれど、この機能が無いので乗り換えられないよ、的なコメントも。なんてこった。SpringDataRestなんてものを使って楽しようとした自分が悪いのか。
確かにSpringDataRestを使ってプロジェクトを開始して、途中でやめた事例などもあり、
依存しすぎはNGという理解はあったものの、ちゃちゃっと作る分には良さそうと思ったのですが。。。結論
ということで、DB直アクセスWebAPI構築をみんな大好きSpringBootを使って簡単に実現することは現時点では難しそうです。
ここまで読み進められた方であれば、RESTControllerから組み上げる形のほうが分かりやすいと思う人もいるでしょう。
現時点では、その方法で地道に作っていくしかなさそうです。身近にJava実行環境がどこにでもがあるのでSpringBootがお手軽で良いのでは?と思いましたが、その発想に縛られず、今後調べていきます。
検証で作成したソースコード
https://github.com/omix222/springdatarestsample
今後の参考
DB固有になりますが、PostgRESTなるものがあるそうです。
https://qiita.com/kanedaq/items/0c3097604d0e86afd1e3MSクラウドのDBであるCosmosDBではRESTAPIがサポートされています。
https://docs.microsoft.com/ja-jp/rest/api/cosmos-db/製品としては多数ありますね。CDATA API Serverとか。でも有償製品ではなくOpenなものでちゃちゃっとやりたいです。なんとか。







- 投稿日:2019-12-21T19:44:09+09:00
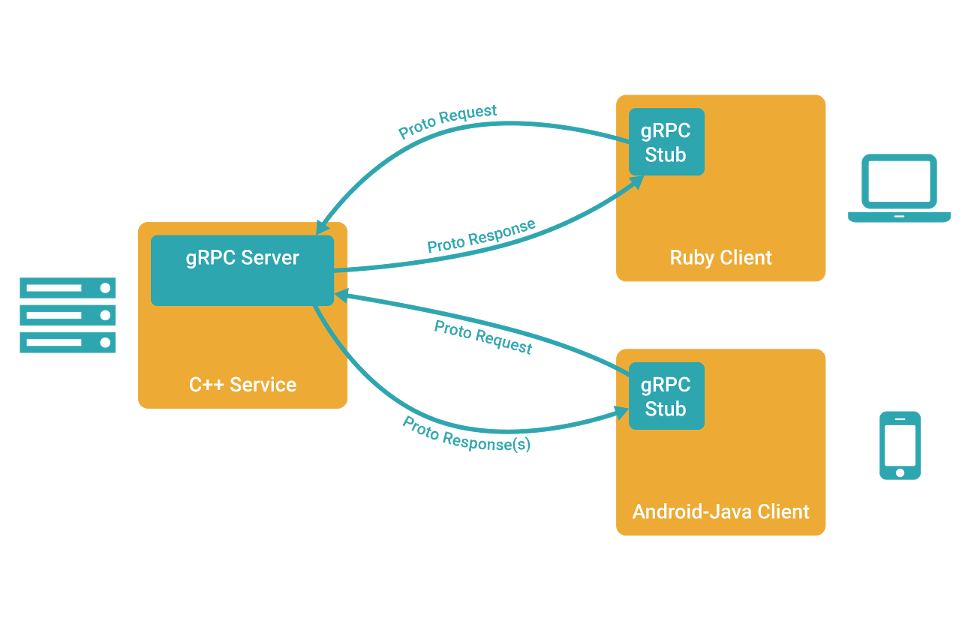
gRPCの設計・開発の勘所をまとめてみた
はじめに
フューチャーAdventCalender2 2019の22日目です。
ちなみにアドベントカレンダー1の記事はこちらから。今年で入社5年目になりますが、毎年この時期になると自分がこの1年どんな業務・技術と向き合ってきたのかを
考え直す良いきっかけでもありつつ、師走の名にふさわしいプロジェクトばかりなので貴重な休日を使わないと
記事を書くことができないのでなかなかツライです。。。と、最初に記事のクオリティには保険をかけておく。概要
2019年はKVSなどNoSQLデータベースを用いたアプリケーションの設計・開発をリードしてきました。
思い返すとCassandraの記事ばかり書いていたので今回はgRPCにフォーカスして記事を書きたいなと思います。
いままでインフラ・ミドルウェア設計・構築が中心でAPI設計・開発を真面目に行ったことがなく苦戦してきましたが、gRPCの設計・開発を通じて得た知見を少しでも皆様に還元できれば幸いです。gRPCとは
gRPCはGoogleが開発したオープンソースでProtocolBuffersを利用してデータをシリアライズし、
RESTよりも高速な通信を実現できるという点が特徴です。
またgRPCではprotoファイルと呼ばれる定義ファイルにIDL(インターフェース定義言語)でAPI仕様を
定義することでクライアント/サーバーに必要なソースの雛形をJava,C++,Python,Goなど異なる言語間であっても
それぞれに合わせたIFをprotoファイルから自動で生成することができるというのも特徴の一つです。
protoファイルはproto3の言語仕様に沿って定義を行います。
gRPCを採用するポイント
APIとしてgRPCを採用する上でよく比較されるのはRESTです。
今回私が設計・開発を担当したAPIサーバーはバックエンドのデータストア層へのCRUDを行うためのAPIであり、
KVSなどから取得したデータをprotoによって構造的に定義しRESTよりも高速に通信できるという点が
データストアAPIとして採用するメリットが一番大きかったです。また、マイクロサービスアーキテクチャを実現する上でAPI仕様を合わせるというのは非常にコストが
かかる作業でありgRPCならインターフェースを厳格なルールで保つことができるというのも
自由な設計ができるRESTと比べて採用するメリットは高いと言えます。しかし、RESTと比べて絶対的な優位性は無いので上記のメリットが享受できるかという観点で
case-by-caseで選択するのが良いと考えます。gRPC設計・開発の勘所
1. protoファイルの管理方法
1-1. ネストの深い構造的なデータはprotoファイルを分割して定義する
データストアにCassandraを採用していたため、扱うデータはフラットなデータ階層ではなく、
ネストの深い構造データでした。そのため、1つのprotoファイルにネストの深い構造データを定義することも
できますが、可読性・保守性が悪かったため、下記のようにprotoファイルを分割して定義を行いました。1つのファイルで定義する例
階層構造を1ファイルで定義することも可能ですが、1つのprotoの中に複数階層モデルを表現したり
2層、3層とネストが深くなってくると可読性・保守性共に悪くなってきます。syntax = "proto3"; option java_package = "jp.co.sample.datastore.common.model"; package common; message ParentModel { string parentId = 1; string parentNm = 2; ChildModel child = 3; // ファイル内に定義したChildModelを型に指定 } message ChildModel { string childId = 1; string childNm = 2; }複数ファイルで定義する例
ChildModelとParentModelを別ファイルで分割して定義することができるので
今回は構造単位でファイルを分けて管理しました。後続でも話しますが、Cassandraはユーザー定義型
(UDTとよばれる任意の構造体をDDLで定義することができるのでUDT単位でprotoのモデルも分割しました。syntax = "proto3"; option java_package = "jp.co.sample.datastore.common.model"; package common; message ChildModel { string childId = 1; string childNm = 2; }syntax = "proto3"; option java_multiple_files = true; option java_package = "jp.co.sample.datastore.common.model"; package common; import "common/child_model.proto"; // ChildModelを定義したprotoを指定 message ParentModel { string parentId = 1; string parentNm = 2; ChildModel child = 3; }1-2. protoファイルはDDLと合わせて管理する
gRPCではprotoファイルにAPI仕様を定義して管理するため、基本的にはこのprotoファイルをGitなどで
バージョン管理することで常にAPI仕様を最新に保つことができると言えます。しかしデータストアAPIとして利用するにあたり、アプリケーションからのリクエスト・レスポンス
パラメータの定義はprotoを管理すれば良かったのですが、Cassandraから取得したデータをprotoで
構造的に扱うためには、Cassandra側のテーブル定義と整合性を保つ必要がありました。アプリケーション開発の中でDDLの変更や更新が発生するのは日常茶飯事です。
そのため、CassandraのDDLは社内標準フォーマットのテーブル定義書ファイルで管理していたので、
その定義書をインプットとしてprotoファイルも自動生成することでテーブル定義に変更がかかっても
両者の整合性が担保できるようになりました。開発規模が大きくなるにつれてprotoとDDLの差異を吸収するのが辛くなるので
はじめのうちから仕組みを整えるのがベターです。1-3. IFモジュール管理方法
protoファイルからprotoファイルからクライアント/サーバーに必要なインターフェースの
ソースを言語ごとに自動生成することができます。しかし、毎回protoファイルから自動生成してソースをコミットするのは非常にめんどくさいし、
開発者数が増えると煩雑な作業になるため、最新のprotoファイルからインターフェースのモジュールを生成して
nexusでリポジトリに連携しパッケージ管理を行いました。今回はクライアント/サーバーともにJavaによる開発だったのでgradle経由で
nexusからパッケージ取得するよう定義しました。2. カスタムオプションを利用した共通処理の実装
API設計において、リクエストパラメータに対してバリデーション設計を行う必要があります。
gRPCではprotoファイルにデータ定義する際に必ずstringやintなど型を指定する必要があります。
mapやsetなどのコレクション型も定義して扱うことができます。そのため、クライアントからのリクエストパラメータに対して型チェックを行う必要はありませんが、
そのほかの必須チェックや桁数チェックなどのバリデーションに対しては考慮が必要になります。protoファイルではファイル、もしくはフィールドに対してCustom Optionsを利用して定義することで、
gRPCモデルからカスタムオプションを取り出して任意のハンドリングを実装することができます。2-1. カスタムオプション定義例
syntax = "proto3"; option java_multiple_files = true; option java_package = "jp.co.sample.datastore.option.model"; package option; import "google/protobuf/descriptor.proto"; extend google.protobuf.FieldOptions { bool required = 50000; // 必須チェックオプション } extend google.protobuf.FieldOptions { int32 strlen = 50001; // 桁数チェックオプション }上記で用意したカスタムオプションを任意のフィールドに定義します。
syntax = "proto3"; option java_multiple_files = true; option java_package = "jp.co.sample.datastore.common.model"; package common; import "option/custom_option.proto"; // カスタムオプションを定義したprotoをimport message User { string user_id = 1[(required)=true,(strlen)=8]; // 複数オプション定義も可能 string user_name = 2[(required)=true]; }2-2. カスタムオプションの取得方法(Java)
上記で定義したmessageモデルのUserからフィールドに設定したカスタムオプションを取得するサンプルです。
"User.getDescriptorForType().getFields()"でUserモデルのメタ情報であるFieldDescriptorが
取得でき、そのFieldDescriptorを取り回すことでオプション情報を取得することができます。for(Descriptors.FieldDescriptor fds: User.getDescriptorForType().getFields()){ System.out.println(fds.getName()) for(Map.Entry<Descriptors.FieldDescriptor,Object> entry : fds.getOptions.getAllFields().entrySet()){ System.out.println("option:" + entry.getKey().getName() + "=" entry.getValue()); } } /* 出力結果 */ // user_id // option:required=true // option:strlen=8 // user_nm // option:required=true2-3. バリデーション実装例
MessageのFieldDescriptorに対して"hasExtension()"で存在チェックをかけることもできるので
gRPCのモデルからフィールドごとに任意のオプションのバリデーション処理を実装する、ということが
可能になります。また、gRPCのモデルはMessage型という共通のインターフェースクラスを継承しており
Message型にキャストしてFieldDescriptorを取り回すことでモデルに依存せず汎用的な処理を実装できます。if(fds.getOptions().hasExtension(CustomOption.required)){ // hasExtensionでフィールドメタ情報から"required"オプションが存在するかチェック Object value = fds.getOptions().getExtension(CustomOption.required); // getExtensionでオプションの中身を取り出す // バリデーション処理実装 }3. gRPCのモデルで空文字,0を明示的に取り扱えるようにする
protoファイル内でstringやintと定義して抽出されるモデルインターフェースに値がセットされていない
フィールドの値を取り出すとデフォルト値としてstirngなら空文字、int32/int64であれば0が取得されます。例えばgRPCモデルをクライアントから受け取って、フィールドにセットされた値を基にデータストアに対して
更新をかける際にクライアントが意図して空文字や0を詰めて初期化したいのか、gRPCモデルのデフォルト値で
セットしていないだけ(更新不要)なのかをサーバー側で判定して処理することができないという問題があります。その問題を解決するために、gRPCにはwrapperクラスが用意されておりそれらを定義することで判定可能になります。
3-1. wrapperクラスを用いたprotoファイル定義例
message Test{ string value1 = 1; // 空文字をセットしたのかデフォルト値なのか判定できない int32 value2 = 2; // 0をセットしたのかデフォルト値なのか判定できない StringValue value3 = 3; // 空文字をセットしたのかデフォルト値なのか判定できる Int32Value value4 = 4; // 0をセットしたのかデフォルト値なのか判定できる }3-2. 値の存在チェック実装例
Test.Builder testBuilder = Test.newBuilder(); // 明示的に空文字,0をセットする testBuilder .setValue1("") .setValue2(0) .setValue3(StringValue.newBuilder().setValue("")) .setValue4(Int32Value.newBuilder().setValue(0)) ; for(Descriptors.FieldDescriptor fds : testBuilder.build().getDescriptorForType().getFields()) { if (testBuilder.hasField(fds)) { System.out.println(fds.getName() + " has field"); } else { System.out.println(fds.getName() + " has not field"); } } /*出力例*/ // value1 has not field // value2 has not field // value3 has field // value4 has field4. gRPCモデルからクエリを動的に生成する
データストアとしてCassandraを利用していたため、Cassandraのテーブルに対して
CRUD操作を行うためにはCQLと呼ばれる独自のクエリを実装する必要がありました。CassandraのCQLは基本的にSQLをベースにしているため、比較的直感的に実装はできますが、
同時更新制御を行うためのCASを意識したクエリや構造階層の深い項目(frozen UDT)に対する
Update文やMap、Set要素の追加削除などSQLでは表現できないクエリを開発者が意識して
実装する必要があったためgRPCのモデルクラスを引数に渡せばデータストアにCRUDできるように
処理を隠蔽化しました。(KVS版OR/マッパー的な)Modelクラスから動的にクエリを生成するポイントはカスタムオプションの例でも記載しましたが
Message型を利用してFieldDescriptorを取り回すことで汎用的に処理を実装できるという点です。
gRPCモデルに対して共通処理を設計する際には、Message型を利用することを意識しましょう。4.1 cqlのSELECT文実装例
public BuiltStatement select(Message message) { BuiltStatement select; try { // テーブル名セット String table = message.getDescriptorForType().getOptions().getExtension(CustomOption.entityOptions) .getTableName(); // CQL生成 Select.Selection selection = QueryBuilder.select(); Map<String, Object> partitionKeyMap = new HashMap<>(); for (Descriptors.FieldDescriptor fds : message.getDescriptorForType().getFields()) { // SELECT句作成 if (fds.getName().equals("select_enum")) { if (message.getRepeatedFieldCount(fds) > 0) { IntStream.range(0, message.getRepeatedFieldCount(fds)).forEach( i -> selection.column(message.getRepeatedField(fds, i).toString())); } else { selection.all(); } } // パーティションキー抽出 if (fds.getOptions().getExtension(CustomOption.attributeOptions).getPartitionKey() > 0 || fds.getOptions().getExtension(CustomOption.attributeOptions).getClusteringKey() > 0) { partitionKeyMap.put(fds.getName(), message.getField(fds)); } } // FROM句生成 select = selection.json().from(getTableMetadata(table)); // WHERE句作成 for (Map.Entry<String, Object> entry : partitionKeyMap.entrySet()) { Object value = entry.getValue(); if (value instanceof String) { ((Select) select).where(eq(entry.getKey(), value)); } else if ... 型判別処理省略 } else { logger.debug("パーティションの型が不正です"); throw new RuntimeException("unsupported type"); } } return select; } catch (Exception e) { e.printStackTrace(); throw new RuntimeException(e); } }Cassandraだけでなく、全文検索エンジンとしてElasticSearchも利用しており、
ElasticSearchに投げるクエリも上記のMessageクラスを利用してgRPCモデルから動的にクエリ生成を
してアプリ開発者が直接クエリを実装せずともデータストアにCRUDできるように設計しました。5. gRPCモデルを利用した便利な処理のTips
上記でも多少紹介しましたが、gRPCモデルを取扱う際に覚えておくと役立つTIPSをいくつか紹介します。
なお今回はgRPC-Javaで実装しているため、Java以外の言語で実装する際は参考程度に留めてください。
(ちょっと時間足りなかったのでTipsは後日足します。。。)5-1. gRPCモデルからJsonフォーマットで出力
gRPCモデルからJsonフォーマットを出力する。
preservingProtoFieldNamesをつけると、protoに定義したフィールド名で出力される。
preservingProtoFieldNamesをつけなければCamelケースで出力されるので用途によって使い分ける。JsonFormat.printer().preservingProtoFieldNames().print(gRPCモデル) // proto定義に沿ったフィールド名で出力 JsonFormat.printer().print(gRPCモデル) // camelケースで出力5-2. gRPCモデルの型判定
for (Descriptors.FieldDescriptor fds : gRPCモデル.getDescriptorForType().getFields()) { if (fds.isMapField()) { // フィールドがMap型か判定 } else if (fds).isRepeated()) { // フィールドがSet型か判定 } else { // コレクション以外の型 } }5-3.Messageクラスからフィールド名を指定して値を取得する
String val = (String) messageModel.getField(messageModel.getDescriptorForType().findFieldByName("フィールド名"));5-4. gRPCモデル間マージ
あるモデルから別のモデルに値をマージする例。
.ignoringUnknownFields()を利用することで、マージ先に対象のフィールドがなくても無視される。JsonFormat.parser().ignoringUnknownFields().merge( JsonFormat.printer().preservingProtoFieldNames().print(merge元のモデル),merge先のモデル);
- 投稿日:2019-12-21T18:06:55+09:00
(超初心者向け)D言語で考えるgetter/setterとproperty
Javaのgetter/setter長くてUZEEEEE!!!!と思っていたら、こういう記事を見つけたのでちょっと考えさせられました。そこで大好きな(得意ではない)D言語でちょっと考えてみようと思います。
- OpenJDK 1.8.0_222
- gdc 8.3.0
Javaのgetter/setterについて
多摩科技ACなので、一応オブジェクト指向とJavaの説明をします。本題はここからです。
オブジェクト指向はソフトウェア設計の指針の一つで、「あらゆる物はオブジェクト(関連するデータをひとまとまりにし、それに対して代入、変換、関数などを行える実体)である」という考え方のことです。
初めてその言葉を使ったアラン・ケイによれば、
- すべてはオブジェクトである。
- オブジェクトはメッセージの受け答えによってコミュニケーションする。
- オブジェクトは自身のメモリーを持つ。
- どのオブジェクトもクラスのインスタンスであり、クラスもまたオブジェクトである。
- クラスはその全インスタンスの為の共有動作を持つ。インスタンスはプログラムにおけるオブジェクトの形態である。
- プログラム実行時は、制御は最初のオブジェクトに渡され、残りはそのメッセージとして扱われる。
らしいです。
アクセス権
オブジェクトの設計図とでも言うべきものが
classで、これを最初に書かないことには何も始まりません。Test1.javaclass Student{ public String name; public int number; Student(String name, int number){ this.name = name; this.number = number; } } public class Test1{ public static void main(String[] args){ Student taro = new Student("Teraoka Taro",27); Student jiro = new Student("Yamashita Jiro",35); System.out.println("taro's name:" + taro.name); System.out.println("jiro's number:" + String.valueOf(jiro.number)); } }Java久々すぎてStringをstringって書いちゃったのは別のお話。
Studentは生徒データの設計図で、main内でnewしているtaroとjiroがその実体であるオブジェクト(インスタンス)です。
classがまとめているデータをメンバといいます。Student内のnameやnumberもメンバ(メンバ変数)です。多分それぞれ氏名と生徒番号でしょう。
Studentクラスの中にStudent(string,int)というメソッドがあります。クラスと同名のメソッドをコンストラクタと呼び、オブジェクト作成時(今回はnew Student(〜)...のところ)で呼び出されるものです。メンバ変数の前に
publicというキーワードが付加されています。これらはアクセス修飾子と呼ばれます。
いくつか種類があるのですが、とりあえず
- public:どこからでもアクセスできる
- private:自クラス内からしかアクセスできない。
だけ押さえておけばOKです。Test1.javaのname,numberをprivateにすると
Test2.javaclass Student{ private String name; private int number; Student(String name, int number){ this.name = name; this.number = number; } }コンパイルしようとした$ javac Test2.java Test2.java:15: エラー: nameはStudentでprivateアクセスされます System.out.println("taro's name:"+taro.name); ^ Test2.java:16: エラー: numberはStudentでprivateアクセスされます System.out.println("jiro's number:"+String.valueOf(jiro.number));てなことになります。
カプセル化
もし全てのメンバがpublicだと、色々と面倒なことになります。
例えばTest1.javaについて、こんなこともできちゃいます。taro.number = -23; jiro.name = null;生徒番号に負の値を使う学校なんて、性格ひん曲がりもいいところですね。ましてや名前がnullなんて馬鹿馬鹿しいにも程があります。
ともかく、プログラマのミス(もしくは悪意)によっては、このようなバグが起こるかもしれません。そこで、メンバ変数は全てprivateとし、それにアクセスするために別のメンバメソッドを用意する方法が考えられます。
Test3.javaclass Student{ private String name; private int number; Student(String name, int number){ this.name = name; this.number = number; } public String getName(){return name;} public void setName(String name){ assert name != null; this.name = name; } public int getNumber(){return number;} public void setNumber(int number){ assert number > 0; this.number = number; } } public class Test3{ public static void main(String[] args){ Student taro = new Student("Teraoka Taro",27); Student jiro = new Student("Yamashita Jiro",35); jiro.getNumber(-5) System.out.println("taro's name:" + taro.getName()); System.out.println("jiro's number:" + String.valueOf(jiro.getNumber())); } }実行しようとした$ javac Test3.java $ java -ea Test3 Exception in thread "main" java.lang.AssertionError at Student.setNumber(Test3.java:18) at Test3.main(Test3.java:27)ちゃんと再設定時に確認ができてますね(コンストラクタでもやれって話ですけど)。
このようなメンバメソッドをgetter/setterといいます。getter/setter長い
さて、試しにStudentクラスに国語、数学、英語の点数を追加してみましょう。
Test3add.javaclass Student{ private String name; private int number; private int japanese; private int math; private int english; Student(String name, int number){ this.name = name; this.number = number; } public String getName(){return name;} public void setName(String name){ assert name != null; this.name = name; } public int getNumber(){return this.number;} public void setNumber(int number){ assert number > 0; this.number = number; } public int getJapanese(){return japanese;} public void setJapanese(int japanese){ assert japanese >= 0 && japanese <= 100; this.japanese = japanese; } public int getMath(){return math;} public void setMath(int math){ assert math >= 0 && math <= 100; this.math = math; } public int getEnglish(){return english;} public void setEnglish(int english){ assert english >= 0 && english <= 100; this.english = english; } }クッソなげぇ
もしこれが10教科とかになったら...地獄ですね。
というわけで冒頭の話に戻ります。D言語で
property
とりあえずTest3.javaをproperty使って書き換えてみましょう。
test3.dclass Student{ private string _name; private int _number; @property{ void name(string _name){ assert(_name!=null); this._name=name; } string name(){return _name;} void number(int _number){ assert(_number>0); this._number=_number; } int number(){return _number;} } this(string _name, uint _number){ this._name=_name; this._number=_number; } }ん〜、コードの長さあんまり変わんなくね?
しかしpropertyによって、あたかも変数を直接いじっているような簡単操作ができます。test3.d(続き)void main(){ import std.stdio; Student saburo=new Student("Mukai Saburo",18); saburo.name.writeln; saburo.number=-1; saburo.number.writeln; }実行$ ./test3 Mukai Saburo core.exception.AssertError@test3.d(16): Assertion failure (以下略)ちゃんとAssertErrorも出ました。
invariant
しかしこのままではあんまりにあんまりです。そこで、メンバの不変条件を決定できる
invariantの存在を知ったので使ってみます。invariant内は以下の時に呼ばれます。
- コンストラクタ実行後、デストラクタ実行前
- メンバ関数の実行前と実行後
test4.dclass Student{ private string _name; private int _number; invariant{ assert(_name!=null); assert(_number>0); } @property{ void name(string _name){ this._name=name; } string name(){return _name;} void number(int _number){ this._number=_number; } int number(){return _number;} } this(string _name, uint _number){ this._name=_name; this._number=_number; } } void main(){ import std.stdio; Student saburo=new Student("Mukai Saburo",18); saburo.name.writeln; saburo.number=-1; saburo.number.writeln; }実行$ ./test3 Mukai Saburo core.exception.AssertError@test4.d(9): Assertion failure (以下略)上出来。
これなら当然コンストラクタについてもチェックできるので、そっちにassertを置く必要もありません。
ちなみにdmdのv2.081.0からこういう書き方もできるようになっているそうです。invariant(_name!=null); invariant(_number>0);参考
Qiita: 結局のところgetter/setterは要るのか?要らないのか?
dlang.org: Contract Programming
- 投稿日:2019-12-21T17:28:36+09:00
段階的に理解する O/R マッピング
はじめに
O/R マッピングとは
O/R マッピングとは、一言で言えば、オブジェクト指向プログラミング言語においてリレーショナルデータベースのレコードを通常のオブジェクトとして操作する方法である。より詳細な定義を述べるより、実際のコードを見たほうがわかりやすいだろう。以下に、低レベルの JDBC API の利用例と、高レベルの O/R マッピングフレームワークの代表格である JPA の利用例を挙げる。
public List<Issue> findByProjectId(long projectId) { String query = "select id, title, description from issue where project_id = ?"; try (PreparedStatement ps = connection.prepareStatement(query)) { ps.setLong(1, projectId); List<Issue> issues = new ArrayList<>(); try (ResultSet rs = ps.executeQuery()) { while (rs.next()) { Issue issue = new Issue(); issue.setId(rs.getLong("id")); issue.setTitle(rs.getString("title")); issue.setDescription(rs.getString("description")); issues.add(issue); } } return issues; } catch (SQLException e) { throw new RuntimeException(e); } }public List<Issue> findByProjectId(long projectId) { String query = "select i from Issue i where i.project.id = ?1"; List<Issue> issues = entityManager.createQuery(query, Issue.class) .setParameter(1, projectId).getResultList(); return issues; }両者を見比べれば O/R マッピングの優位性は明らかである。O/R マッピングを利用した後者では、定型的な記述が不要となり、より意図が明確に表現されている。
誤解される O/R マッピング
上記例ではいいことずくめに見える O/R マッピングだが、世には多くの不満の声がある。中には O/R マッピング全否定のような過激な立場もあれば、高レベルの O/R マッピングフレームワークを否定してよりシンプルな代替選択肢の利用を好む立場もある。そのような状況で高レベルの O/R マッピングフレームワーク利用を積極的に推し進める立場はむしろ少数派に見える。
なぜ O/R マッピングが嫌われるのか、そこには大きく分けて二つの理由があると考えられる。まず一つ目の理由は、高レベルの O/R マッピングフレームワークがプログラマの言うことを聞かないように見えることだろう。水面下で意図通りの SQL が実行されず、パフォーマンス問題への対応に苦労した経験のある O/R マッピングフレームワーク利用経験者は多いはずだ。この根底には O/R マッピングの基本的な機構に関する誤解があると思われる。次に二つ目の理由は、高レベルの O/R マッピングがしばしばそれに不向きなプロジェクトで利用されていることだろう。後で詳しく述べるように、スキーマへの裁量などの前提条件を満たさない状況で高レベルの O/R マッピングフレームワークを利用するのは自殺行為に近い。この根底には O/R マッピングの使い分け基準に関する誤解があると思われる。
この記事の目的
この記事では、上記のような誤解を解くために、一口に O/R マッピングと言っても複数のレベルがあることを示す。低レベルから高レベルの手段を段階的に見ていくことで、各レベルの基本的な機構がどのような課題への解決策として登場したのか、また各レベルの手段をどのような基準で使い分けるべきかが理解できるはずだ。
レベルの定義
この記事では、O/R マッピングを以下の 5 つのレベルに分けて解説する。
- レベル 1: 低レベル API
- レベル 2: 前後処理の抽象化
- レベル 3: クエリと単純なオブジェクトのマッピング
- レベル 4: クエリと関連ナビゲーション可能なオブジェクトのマッピング
- レベル 5: テーブルとオブジェクトのマッピング
これらのレベル設定はあくまで説明の便宜上のものである。Java の各種 O/R マッピングフレームワークの機能は実際には複数のレベルにオーバーラップしている。また、説明を簡潔にするため、対象の処理種別は参照系に絞り、更新系については省略する。
題材としては実際の各種 Java フレームワークを扱うため、それらの簡単な紹介記事としても読めるはずだ。ただし、機能の網羅性は重視していないため、詳しく知りたい場合はリンク先の公式ドキュメントを参照してほしい。
レベル 1: 低レベル API
まず最初に、JDK 組み込みの JDBC API をそのまま利用したデータアクセスについて見てみよう。例としてこの記事冒頭に挙げたコードを再掲する。
public List<Issue> findByProjectId(long projectId) { String query = "select id, title, description from issue where project_id = ?"; try (PreparedStatement ps = connection.prepareStatement(query)) { ps.setLong(1, projectId); List<Issue> issues = new ArrayList<>(); try (ResultSet rs = ps.executeQuery()) { while (rs.next()) { Issue issue = new Issue(); issue.setId(rs.getLong("id")); issue.setTitle(rs.getString("title")); issue.setDescription(rs.getString("description")); issues.add(issue); } } return issues; } catch (SQLException e) { throw new RuntimeException(e); } }題材はシンプルな課題管理アプリケーションである。
issueテーブルの定義は以下のようなものだ。create table issue ( id bigint primary key, project_id bigint, title varchar (100), description text );利用方法
このレベルの手法を利用するために必要なことは以下の通りである。
- クエリ文字列を指定する
- クエリパラメータを指定する
- クエリを実行する
- クエリ結果をループで走査する
- レコードをオブジェクトへ詰め替える
- リソースを管理する
- 低レベルの例外発生に対応する
課題
定型的な記述の煩雑さは問題である。コードを書く側としては、クエリを実行して結果を取ってくるだけのコードにしては記述量が多すぎる。コードを読む側としても、意図が余計なコードに埋もれてわかりにくい。
さらに、リソース管理上のリスクも見逃せない。上記例で try-with-resources を使って対応しているようなクローズ処理を忘れると、リソースリークが発生する。
選択基準
2019 年現在、プロダクションコードでこのレベルの手法を採用すべき場面はほとんどない。極度に性能を重視する場合や、何らかの事情でフレームワークの使用に制限がかかる場合に限って、このレベルの手法を使う機会があるかも知れない。ただしそれらの場合も、後述のレベル 2 に相当する手法を自前で実現することは容易だ。
レベル 2: 前後処理の抽象化
レベル 1 の定型的な記述のうち、前後処理に関するものは比較的簡単に抽象化できる。以下は Jdbi を利用した例だ。
public List<Issue> findByProjectId(long projectId) { String query = "select id, title, description from issue where project_id = ?"; List<Issue> issues = handle.createQuery(query).bind(0, projectId) .map((rs, ctx) -> { Issue issue = new Issue(); issue.setId(rs.getLong("id")); issue.setTitle(rs.getString("title")); issue.setDescription(rs.getString("description")); return issue; }).list(); return issues; }利用方法
このレベルの手法を利用するために必要なことは以下の通りである。レベル 1 に比べると明らかに削減されている。
- クエリ文字列を指定する
- クエリパラメータを指定する
- クエリを実行する
- レコードをオブジェクトへ詰め替える
課題
前後処理は抽象化されたものの、レコードのオブジェクトへの詰め替えは相変わらず煩雑だ。上記コードはあくまで例であるためカラム数も限られているが、実際のプロジェクトでは多くのカラムについて定型的な記述が必要になるだろう。
代表的な Java フレームワーク
このレベルだけに特化したフレームワークは存在しないが、Jdbi や Spring JdbcTemplate のようなレベル 3 の機能を持つフレームワークは、レベル 2 の機能をあわせて持っている。
また、レベル 1 で述べた通り、自前でこのレベルのフレームワークを構築することは容易だ。Lambda に習熟するためのいい練習台になるはずだ。
選択基準
このレベルの手法を採用すべき場面も多くはない。レベル 1 と同様に、極度に性能を重視する場合や、何らかの事情でフレームワークの使用に制限がかかる場合は選択肢に入る。また、レコードとオブジェクトの構造が大幅に異なり、手動で柔軟なマッピング処理を書く必要がある場合は、レベル 3 ではなくこのレベルにあえてとどまることもあるだろう。
レベル 3: クエリと単純なオブジェクトのマッピング
レベル 3 では、レベル 2 では手動で対応していたレコードからオブジェクトへの詰め替えを自動化する。以下はレベル 2 と同じ Jdbi の別の API を利用した例だ。
public List<Issue> findByProjectId(long projectId) { handle.registerRowMapper(BeanMapper.factory(Issue.class)); String query = "select id, title, description from issue where project_id = ?"; List<Issue> issues = handle.createQuery(query).bind(0, projectId) .mapTo(Issue.class).list(); return issues; }利用方法
このレベルの手法を利用するために必要なことは以下の通りである。
- クエリ文字列を指定する
- クエリパラメータを指定する
- クエリを実行する
課題
このレベルの手法は一見すると汎用性が高く感じられるかも知れないが、オブジェクトの関連ナビゲーションができないことは重大な欠陥だ。実際のアプリケーションは複数のテーブルで構成されている。例えばこの記事の題材であるシンプルな課題管理アプリケーションであれば、
issueテーブル以外に、多対一で関連するprojectテーブルや、一対多で関連するcommentテーブルがあるはずだ。それらのデータに対して、オブジェクト指向的な発想であれば、Issue#getProject()やIssue#getComments()のようなメソッドで関連するオブジェクトとしてアクセスできることが自然だ。だが、このレベルの手法ではそうした関連ナビゲーションは実現できない。このレベルの手法で取得できるのは、単体のオブジェクトか、オブジェクトのリスト (二次元の表構造) だけだ。関連ナビゲーションに相当するデータアクセスを実現しようとする場合は、別々のクエリで取得して自前でマージするロジックを書くか、JOIN したひとつのオブジェクトとして無理やり扱うかのどちらかしかできない。
こうした制約の下では、ドメイン駆動設計のようなリッチなドメインモデルを前提としたアーキテクチャの実現は絶望的だ。結果として、各画面の表示の都合に引きずられた個別のモデルが増殖し、ドメイン中心ではなく画面中心のアプリケーションが出来上がる。このレベルの手法で取得したオブジェクトをリッチなドメインモデルに自前で詰め替える選択肢もなくはないが、そんな面倒なことをするくらいなら素直にレベル 4-5 の手法を学習したほうが多くの場合低コストで済むはずだ。
また、OOUI のようなユーザに自由なインタラクションを提供する UI においては、関連ナビゲーションはほとんど必須の機能である。関連ナビゲーションのできないモデルは結果的に使いやすい UI の実現を阻害する要因となりうる。
代表的な Java フレームワーク
このレベルの代表的なフレームワークとしては、Jdbi と Spring JdbcTemplate が挙げられる。なお、厳密にはこの両者ともレベル 4 に相当するデータアクセスには頑張れば対応できる (が、例を見ればわかる通り、煩雑だ)。また、sql2o や、昔懐かしい Commons DbUtils など、他にも多くの選択肢がある。
また、シンプルな O/R マッピングフレームワークとして一定の支持を集めている Doma も、参照系についてはレベル 3 までにしか対応していない。こちらは頑固にも設計思想として関連ナビゲーションには対応しないことを明言している。
選択基準
UI が定型的なアプリケーションや、データアクセスが単純なバッチなど、このレベルの手法で十分な場面はそれなりにあるはずだ。当初は定型的で単純だと思っていた要件が実はそうではなかった、というありがちな展開にならないことを祈りながら使おう。
レベル 4: クエリと関連ナビゲーション可能なオブジェクトのマッピング
レベル 3 では実現できなかった関連ナビゲーションについて、MyBatis を使った実現例を見てみよう。
まず、
issueテーブルと関連するprojectcommentテーブルの定義は以下のようになる。create table project ( id bigint primary key, name varchar (100) );create table comment ( id bigint primary key, issue_id bigint, description text );次に、マッピング対象の Java クラスを以下に示す。
@Data public class Issue { private long id; private Project project; private List<Comment> comments; private String title; private String description; }@Data public class Project { private long id; private String name; }@Data public class Comment { private long id; private String description; }さらに、これらをマッピングする設定を書く。ここでは XML ベースの方式 を使用している (なお MyBatis には他に、アノテーションベースの方式もある)。
<resultMap id="issueResult" type="Issue" autoMapping="true"> <id property="id" column="id" /> <association property="project" column="project_id" select="Project.find" /> <collection property="comments" column="id" select="Comment.findByIssueId" /> </resultMap> <select id="findByProjectId" parameterType="long" resultMap="issueResult"> <![CDATA[ select id, project_id, title, description from issue where project_id = #{projectId} ]]> </select><resultMap id="projectResult" type="Project" autoMapping="true"> <id property="id" column="id" /> </resultMap> <select id="find" parameterType="long" resultMap="projectResult"> <![CDATA[ select id, name from project where id = #{id} ]]> </select><resultMap id="commentResult" type="Comment" autoMapping="true"> <id property="id" column="id" /> </resultMap> <select id="findByIssueId" parameterType="long" resultMap="commentResult"> <![CDATA[ select id, description from comment where issue_id = #{commentId} ]]> </select>最後に、上記の設定に基づいてデータアクセスを実行する。
public List<Issue> findByProjectId(long projectId) { return sqlSession.selectList("Issue.findByProjectId", projectId); }利用方法
このレベルの手法を利用するために必要なことは以下の通りである。
- クエリ文字列を指定する
- 上記例では XML 設定で指定している
- クエリ結果とオブジェクトのマッピングを設定する
- 上記例では XML 設定で指定している
- クエリパラメータを指定する
- クエリを実行する
課題
これで関連ナビゲーションは実現できるようになったが、例を見れば明らかな通り、その設定は簡単ではない。さらに参照系クエリの種別が増えたり、更新系の insert/update/delete 処理が必要になったりした場合は、都度手動で SQL を記述する必要がある。後述の通り自動生成による対策は存在するが、効果は限定的だ。
また、定型処理の抽象化についても弱点がある。監査系カラム (登録日時、更新日時、登録ユーザ、更新ユーザ、…) の自動入力や、バージョン番号による楽観的ロックといった、レベル 5 の手法であれば容易に抽象化可能な定型処理について、このレベルの手法では都度手動で SQL を記述しなければならない。
さらに、ここまでのレベル共通の問題として、手動で SQL を記述している以上、特定の DBMS への依存性が発生する。ポータビリティを考慮した標準準拠の SQL だけで全ての要件を満たすことは困難だ。日常的な開発においてこの問題を意識する機会は少ないが、システムリプレースのような大規模改修の話が持ち上がると事態の深刻さが一気に顕在化する。
なお、レベル 5 で大暴れする N + 1 問題は、このレベルでも発生する可能性がある。ただし、このレベルの手法は自分がクエリを書いた通りにしか動かないため、その責任はフレームワークではなく自分自身にあり、また対策の仕方も明確だ。例えば、上述の例では実は N + 1 問題が発生するが、以下のようにクエリを JOIN を用いたものに置き換えれば問題は解決する。
<resultMap id="issueResultWithProjectAndComments" type="Issue" autoMapping="true"> <id property="id" column="id" /> <association property="project" columnPrefix="p_" resultMap="Project.projectResult" /> <collection property="comments" columnPrefix="c_" resultMap="Comment.commentResult" /> </resultMap> <select id="findByProjectIdWithProjectAndComments" parameterType="long" resultMap="issueResultWithProjectAndComments"> <![CDATA[ select i.id as id, i.project_id as project_id, i.title as title, i.description as description, p.id as p_id, p.name as p_name, c.id as c_id, c.description as c_description from issue i inner join project p on i.project_id = p.id left outer join comment c on i.id = c.issue_id where project_id = #{projectId} ]]> </select>付随する機構
このレベルの手法には、以下のような機構が付随する。
- Lazy Loading
- 関連ナビゲーションにおいて、
Issue#getProject()のようなメソッドが実際に呼ばれるまで SQL の実行を抑止する- 反面、N + 1 問題のリスクがある
- カスタム型変換
- データベース側のシンプルな型を Java 側のより表現力のある型に変換する
- 例として MyBatis の TypeHandler を参照
- 高度な SQL テンプレートエンジン
- SQL について、条件分岐・ループのような制御構造や、共通部分の括り出しのような抽象化を実現する
- 例として MyBatis の動的 SQL を参照
- ソースコードと設定のスキーマからの自動生成
- データベーススキーマから CRUD 処理に必要なソースコードと設定を自動生成する
- 生成された成果物を変更するとその後のデータベーススキーマの変更にうまく追従できない (Generation Gap パターンのようなワークアラウンドの効果は限定的)
- 例として MyBatis Generator を参照
- 簡単なキャッシュ
- あくまで簡単なものであり、レベル 5 で実現できるキャッシュに比べると機能は限定的
- 例として MyBatis のキャッシュ を参照
代表的な Java フレームワーク
このレベルの代表的なフレームワークは例にも挙げた MyBatis である。歴史が長いこともあって、「付随する機構」で挙げた機能をフルセットで持っている。
また、レベル 5 で登場する JPA について、その一部である Native Query はレベル 4 の手法と見なせる。ただし、MyBatis と比べると基本機能の使いやすさや「付随する機構」で挙げた機能への対応に差がある。
選択基準
データベースに関するしがらみは、レベル 4 の手法を選ぶ理由になりうる。「しがらみ」とは例えば、変更できないレガシースキーマ、UI 要件に対して齟齬があるデータ構造、既存 SQL の流用要件などである。
また、ドメイン駆動設計的なリッチなドメインモデルを前提とすると、マッピング設定の柔軟性においてレベル 5 より優れるレベル 4 の手法が有力な選択肢になる。
さらに、性能要件とチームメンバのスキルを考慮した上で、レベル 5 のパフォーマンスリスクに対するローリスク・ローリターンな代替選択肢としてレベル 4 の手法を選ぶこともある。
レベル 5: テーブルとオブジェクトのマッピング
レベル 4 ではクエリを都度手動で記述していたが、そもそも一般的なアプリケーションにおいてはテーブルとオブジェクトの構造は多くの点で似通っているため、両者をうまくマッピングできればクエリ自体は自動生成できるはずだ。以下、標準規格の JPA に準拠した Hibernate ORM を利用した例を見てみよう。
データベーススキーマはレベル 4 までと同一である。マッピング対象の Java クラスはレベル 4 と同様だが、マッピング設定用のアノテーションが追記されている。
@Data @Entity public class Issue { @Id private long id; @ManyToOne @JoinColumn(name = "project_id") private Project project; @OneToMany @JoinColumn(name = "issue_id") private List<Comment> comments; private String title; private String description; }@Data @Entity public class Project { @Id private long id; private String name; }@Entity @Data public class Comment { @Id private long id; private String description; }上記に基づいて、データアクセスを実行する。
public List<Issue> findByProjectId(long projectId) { String query = "select i from Issue i where i.project.id = ?1"; List<Issue> issues = entityManager.createQuery(query, Issue.class) .setParameter(1, projectId).getResultList(); return issues; }利用方法
このレベルの手法の利用方法は以下の通りである。
- テーブルとオブジェクトのマッピングを設定する
- 上記例ではアノテーションで指定している
- 他に、XML 設定で指定する方法もある (が、現在ではあまり使われない)
- クエリ文字列を指定する
- 上記例では DBMS 依存の SQL ではなく、抽象化された JPQL である
- 上記例ではクエリ実行時に Java コード内の文字列で指定している
- 他に、アノテーションで指定する Named Query もある
- クエリパラメータを指定する
- クエリを実行する
課題
このレベルの手法の大きな課題は意図しない SQL 発行によるパフォーマンス劣化であり、中でも代表的なものは N + 1 問題である。N + 1 問題とは、主要なテーブルへの 1 回のクエリ結果で返ってきたレコード N 件について、関連するテーブルへのクエリが N 回実行されてしまうことである。この記事の題材である課題管理アプリケーションに基づいて説明するなら、課題一覧画面のデータアクセスにおいて、
issueテーブルへの 1 回のクエリが実行された後で、ループ中にIssue#getComments()が都度呼び出されることで、commentテーブルに対して先のクエリで取得したissueレコードの件数に相当する N 回のクエリが実行されるような事態である。JPA における N + 1 問題への主要な対策手段のひとつは FETCH JOIN である。例えば、例えば、上述の例では実は N + 1 問題が発生するが、以下のようにクエリを FETCH JOIN を用いたものに置き換えれば問題の発生は抑止できる。
public List<Issue> findByProjectIdWithProjectAndComments(long projectId) { String query = "select distinct i from Issue i join fetch i.project" + " left join fetch i.comments where i.project.id = ?1"; List<Issue> issues = entityManager.createQuery(query, Issue.class) .setParameter(1, projectId).getResultList(); return issues; }実際に生成される SQL クエリは以下のようになる。
select distinct issue0_.id as id1_1_0_, project1_.id as id1_2_1_, comments2_.id as id1_0_2_, issue0_.description as descript2_1_0_, issue0_.project_id as project_4_1_0_, issue0_.title as title3_1_0_, project1_.name as name2_2_1_, comments2_.description as descript2_0_2_, comments2_.issue_id as issue_id3_0_0__, comments2_.id as id1_0_0__ from issue issue0_ inner join project project1_ on issue0_.project_id=project1_.id left outer join comment comments2_ on issue0_.id=comments2_.issue_id where issue0_.project_id=?FETCH JOIN 以外にも、@Fetch(FetchMode.SUBSELECT) を利用する方法や、Entity Graph を利用する方法などがある。また、@Where や @Filter といった細粒度の関連制御が必要になる場面もある。
パフォーマンスについては上記のような各種対策が存在するが、そもそもこれらの習得に小さくない初期学習コストがかかることはレベル 5 導入にあたっての大きな課題の一つである。おそらく多くの現場では、そうしたコストは前もって意識的に支払われることはなく、その結果として発生するパフォーマンス問題の責任が漠然とフレームワークに押し付けられているのではないだろうか。なお、Hypersistence Optimizer のような解析ツールが活用できれば、初期学習コストのある程度の低減は期待できると思われる。
また、標準規格である JPA の不備の問題もある。例えば、上述の Entity Graph の挙動には実装依存の部分があり、さらに @Where や @Filter に至っては標準化されていない Hibernate 実装依存機能である。
さらに、そもそもの制約として、レベル 5 の前提であるテーブルとオブジェクトの構造類似性が要件的に低いプロジェクトでは効果が期待できない点が挙げられる。こうした場合は自由にクエリが書けるレベル 3-4 の手法のほうが適切である。
付随する機構
このレベルの手法には、以下のような機構が付随する。
- ライフサイクル管理
- オブジェクトの変更をフレームワークが検知し、状態に応じた適切な永続化処理を行う
- プログラマの意図と異なる動作をすることが多く、O/R マッピングに対する悪評の源泉の一つ
- EBean のようにあえて変更検知を機能から外すフレームワークもある
- 高度なキャッシュ
- ライフサイクル管理の一次キャッシュに加えて、汎用的なキャッシュライブラリと連携可能な二次キャッシュが利用できる
- 例として Hibernate のキャッシュを参照
- タイプセーフクエリ
- クエリを文字列で書くとコンパイル時に誤りがチェックできないため、Java コードでクエリを書く
- JPA 標準で Criteria API が提供されているが、信じられないくらいに使いにくい
- 非標準だがより使いやすい拡張手段として QueryDSL がある
- タイプセーフクエリに特化した特殊なフレームワークとして jOOQ がある
- Lazy Loading
- レベル 4 と同様
- カスタム型変換
- レベル 4 と同様
- 例として JPA の Custom BasicType と Embeddable Type を参照
- ソースコードのスキーマからの自動生成
- レベル 4 と同様
- 例として Hibernate Tools を参照
- ソースコードからスキーマの自動生成
- 上とは逆に、Java ソースコードとマッピング設定から、データベーススキーマを自動生成する
- 例として Hibernate の Schema Generation を参照
代表的な Java フレームワーク
このレベルの代表的なフレームワークは標準規格の JPA である。JPA の実装系としては、この記事で扱った Hibernate ORM の他に、EclipseLink もある。どちらの実装系を選ぶかについては、使用するアプリケーションサーバや上位フレームワークでどちらがデフォルトになっているかに従って決めることになるだろう。
また、「付随する機構」で挙げた EBean や jOOQ、さらに Reladomo のような代替選択肢はある。どれも非標準であること、また特に jOOQ と Reladomo についてはかなり癖が強いことを考慮して、慎重に選ぶべきだ。
選択基準
課題でも触れた通り、このレベルの手法を利用するにあたっては初期学習コストやスキーマに関する厳しい前提条件がある。前提条件が満たされれば生産性に関する高いリターンが見込めるが、そうでない場合は工数の浪費要因になりかねない。
また、何らかの制約で標準準拠が強制される場合は、レベル 3-4 を飛ばしてレベル 5 の JPA しか選択肢はない (上述の通りレベル 4 相当の Native Query 機能は使える)。
プロジェクトにとって最適なレベルの手法を選ぶには
さて、どんな場面でどのレベルの手法を選ぶべきか、各レベルの「選択基準」記述とある程度重複してしまうが、改めてざっくり振り返ってみよう。
まず、レベル 1-2 から始めることは少ない。レベル 3 で十分か、もしくはレベル 4-5 が必要か、が多くの場合に最初の判断の分かれ目になる。
プロジェクトの複雑性が小さい場合はレベル 3 の手法で十分だろう。ただし、複雑性に関してわかりやすい単一の指標はなく、UI の特性・データアクセスの特性・案件の規模・チームの人員構成などから総合的に判断することになる。
プロジェクトの複雑性が大きい場合はレベル 4-5 から選ぶことになる。スキーマがレガシーもしくはマッピングの工夫が必要で不確実性の低さを重視したい場合はレベル 4 の手法を、それ以外の場合はレベル 5 の手法を選ぶことになる。
なお、現状のレベル 5 の手法が完成されているかといえばそうではない点が問題をより複雑にしている。初期学習コストの高いライフサイクル管理をオプションにする、関連ナビゲーション制御の仕様をよりシンプルにして標準に組み込む、必要に応じてリッチなレベル 4 の手法と組み合わせられるようにする、などの改善があれば、よりレベル 5 の手法を選ぶべき場面は広がるはずだ。
おわりに
以上、O/R マッピングについて、レベルを 5 段階に分けて、それぞれ固有の必然性と使い分け基準があることを示した。この記事によって、O/R マッピングに対する誤解や、開発現場での要素技術選定における不幸なミスマッチが、少しでも減ることを願う。
- 投稿日:2019-12-21T17:22:16+09:00
【初心者向け】Java8以降のStreamAPIの運用方法について
Java8以降のStreamAPIとの付き合い方
はじめに
概要
Javaで関数インターフェースを利用できるようになってから随分経ちます。結構最近だと思っていたのですが、5年も前なんですね。そんな関数インターフェースとStreamAPIですが、「分かりやすい」という人と「分かりづらい」という人で結構差があるんじゃないかなと思っています。そんな中でどのようにStreamAPIと付き合っていくかの参考になればと思って書きます。
前提
- チーム全体が若い(全員Javaでの開発経験3年以下)
- Java7ベースでの研修を受けており、Java8で追加された標準APIについては学んでいない
- 開発で使用するのはJava8以降なのでJava8のAPIをガシガシ使うお
要するに関数インターフェースもStreamもOptionalも初めましてな人たちが、Java8で開発してるよという感じです。
結論
- 中間操作(
Stream#mapやStream#filter)の引数はメソッド参照で書くsortで複数のキーを使って並び替えるなら、java.util.Comparatorを実装して書くStream#collectのボイラープレート的な処理は他に切り出すとにかく言いたいことは、メソッドチェーンに何でも詰め込むのはやめようねということです。
StreamAPIで書いたコードがわかりづらくなる要因
ラムダ式とかメソッド参照とか書き方が色々ある
関数型オブジェクトを生成する方法はいくつかありますね。
文字列を受け取り、上で定義したStringUtils#isEmptyを呼び出して結果を戻す関数オブジェクトを定義します。Function<String, Boolean> emptyChecker1 = new Function<>{ @Override public Boolean apply(String s) { return StringUtils.isEmpty(s); } } Function<String, Boolean> emptyChecker2 = s -> StringUtils.isEmpty(s); Function<String, Boolean> emptyChecker3 = StringUtils::isEmpty;特にメソッド参照が難しくて、
::の左側にクラスの名前を書くか変数名を書くかによって、どのメソッドを呼び出すか変わるし、場合によってごにょごにょされる。引数の関数が複雑すぎてよく分からない
Java開発経験1年目の子がいるところでこんなコード見せられない(懺悔)。
list.getValues().forEach(value -> { if (CollectionUtils.isEmpty(value.getPropertyList())) { return; } if (!CollectionUtils.isEmpty(value.getPropertyList())) { Property property = value.getPropertyList().stream() .findFirst() .orElseThrow(RuntimeException::new); service.insert(value, property); return; } switch (value.getType()) { case TYPE_1: value.getProperty1().setAmount(1000); break; case TYPE_2: value.getProperty2().setAmount(1000); break; case TYPE_3: value.getProperty3().setAmount(1000); break; } service.insert(value); });わたしは処理の塊ごとに段落があることを意識してソースコードを読むようにしているのですが、
forEachの引数がこれほど長いと一息で読みきれなくて結構しんどい思いをします。3年目のわたしがこれだからきっと1年目の子たちは・・・終端処理を書くのが結構大変
Listに変換するだけであれば
Collectors.toList()を使えば一瞬で片付くのですが、ListをMapに変換する単純な処理を書くのが結構しんどいなと思ったりする。重複があったらどうするのか?など初心者からするとハードルが高いし、書くのも面倒です。Map<Key, List<Value>> map = values.stream() .collect(Collectors.groupingBy(Value::getKey));(今後運用したいと思った)StreamAPI周りのルール
経験が浅いメンバーが多く在籍していることを前提にいくつかのルールを策定しました。
中間操作の引数はメソッド参照で書く
目的は、中間操作
Stream#mapやStream#filterの引数をシンプルに保ち、可読性を向上させることです。このルールには以下のメリットがあると考えています。
クラス名(変数名)::メソッド名で呼び出すので、何をしているのかが分かりやすい- 自由に関数オブジェクトを定義できるラムダ式と違って、シンプルさを保つことができる
- コレクション要素に対する操作を要素の型に閉じ込められる
3つ目について少し分かりづらいので、中間試験のクラス内平均点を求めるプログラムの例を使って説明します。
ちなみに中間試験は国語と数学と英語の3科目を想定し、
ExaminationScoreSummary#averageの実装について考えます。public class ExaminationScore { private final Integer japaneseScore; private final Integer mathScore; private final Integer englishScore; // constractor, getter } public class ExaminationScoreSummary() { private final List<ExaminationScore> values; // constractor, getter public Integer average() { // TODO } }ラムダ式を使う場合
いかようにも実装できます。わたしがいつも書いちゃう感じで書きます。
public class ExaminationScoreSummary() { private final List<ExaminationScore> values; // constractor, getter public Integer average() { return values.stream() .mapToInt(score -> score.getJapaneseScore() + score.getMathScore() + score.getEnglishScore()) .average(); } }いや、まあこれでもいいんだけど、合計点求める時とかも毎回呼び出し元で点数を足し合わせるのはね…と。
メソッド参照を使う場合
メソッド参照の場合は、そもそも呼び出し側で足し算をするのが不可能なので、ひとまず足し算をする処理を
ExaminationScoreクラスに書きます。public class ExaminationScore { private final Integer japaneseScore; private final Integer mathScore; private final Integer englishScore; // constractor, getter public Integer getTotalScore() { return japaneseScore + mathScore + englishScore; } }経験豊富な人からすると「同じクラスのフィールド同士の計算はフィールドが定義されたメソッドに書いて凝集性を高める」ことが当たり前にできるのかもしれません。でもわたしレベルだとそういうの中々難しいんですよ。メソッド参照を使うことをルール付ければオブジェクト指向プログラミングの基本的な考え方も身につきますよというお話です。
呼び出し元はの実装はこんな感じです。
public class ExaminationScoreSummary() { private final List<ExaminationScore> values; // constractor, getter public Integer average() { return values.stream() .mapToInt(ExaminationScore::getTotalScore) .average(); } }複数のキーでのsortは、
java.util.Comparatorを使う中間試験の点数高い順に掲示しようと思ったとします。いやいや点数晒すとか問題あるんじゃ…とかは置いておいて笑
3科目あるので、国語の点数が高い順、国語の点数が同じであれば数学の点数が高い順に並び替えます。
Comparator#comparingやComparator#thenComparingを使えば、以下のように実装することが可能です。List<ExaminationScore> values = new ArrayList<>(); values .stream() .sorted(Comparator.comparing(ExaminationScore::getJapaneseScore).thenComparing(ExaminationScore::getMathScore()) .collect(Collectors.toList());並び替えもこんなに簡単にできるなんて便利です。ところで、並び替え順が複雑になったら全部ここに書くんだろうか?いやいやいや、それ結構しんどいですよ。中学校になったら5教科だったり実技科目も試験があったりしたらめちゃくちゃ長いコードになりますよ。
「どんな順番でソートするか」という定義を別の場所に書く2つの方法を紹介します。
1. コレクションの要素にComparableインターフェースを実装させる。
並べ替えの仕方をコレクション要素の型に定義するやり方です。まずは並び替えの仕方を定義します。
手順は以下の2つだけ。
- 要素のクラス宣言に
implements Comparable<要素のクラス>を追記- 要素のクラスで
public int compareTo(要素のクラス o)を実装今回は国語の点数、数学の点数、英語の点数の順に並び替えますから、以下のように実装しました。
- 国語の点数が等しくなければ、国語の点数の比較結果を
ExaminationScoreの比較結果として扱う- 国語の点数が等しく、数学の点数が等しくなければ、数学の点数の比較結果を
ExaminationScoreの比較結果として扱う- 国語、数学の点数が等しく、英語の点数が等しければ、英語の点数の比較結果を
ExaminationScoreの比較結果として扱う// 1. 要素のクラス宣言に`implements Comparable<要素のクラス>`を追記 public class ExaminationScore implements Comparable<ExaminationScore> { private final Integer japaneseScore; private final Integer mathScore; private final Integer englishScore; // constractor, getter // 2. 要素のクラスで`public int compareTo(要素のクラス o)`を実装 public int compareTo(ExaminationScore o) { if (japaneseScore.compareTo(o.japaneseScore) != 0) { return japaneseScore.compareTo(o.japaneseScore); } if (mathScore.compareTo(o.mathScore) != 0) { return mathScore.compareTo(o.mathScore); } return englishScore.compareTo(o.englishScore); } }わたしは
Comparable#compareToの戻り値で何を返せばよいのか忘れてしまうので、できるだけ並び替えのキーにする変数の比較結果を返すだけの簡単な実装を心がけています。並び替えは以下のように行います。点数の高い順に並び替えるので
Comparator#reverseOrder()を呼び出しています。List<ExaminationScore> values = new ArrayList<>(); values .stream() .sorted(Comparator.reverseOrder()) .collect(Collectors.toList());
Comparable#compareToメソッドで「点数が高ければ-1」というふうに実装すればStream#sortedの引数を省略できるのですが、分かりづらいので避けました。2. Comparatorインターフェースを実装したクラスを別に作る
1と違って並び替えの順番を別のクラスに定義します。手順は以下のとおりです。
Comparator<要素のクラス>を実装したクラスを作成public int compare(要素のクラス o1, 要素のクラス o2)を実装class ExaminationScoreComparator implements Comparator<ExaminationScore> { @Override public int compare(ExaminationScore o1, ExaminationScore o2) { if (Integer.compare(o1.getJapaneseScore(), o2.getJapaneseScore()) != 0) { return Integer.compare(o1.getJapaneseScore(), o2.getJapaneseScore()); } if (Integer.compare(o1.getMathScore(), o2.getMathScore()) != 0) { return Integer.compare(o1.getMathScore(), o2.getMathScore()); } return Integer.compare(o1.getEnglishScore(), o2.getEnglishScore()); } }並び替えは以下のように行います。
Stream#sortedの引数に上で定義したComparatorのインスタンスを渡します。List<ExaminationScore> values = new ArrayList<>(); values .stream() .sorted(new ExaminationScoreComparator().reverseOrder()) .collect(Collectors.toList());Comparable vs Comparator
結局どっちを使うのかという話ですが、基本的に
Comparatorを使って実装しましょう。自然順序付けでは、equalsと一貫性があることは、必須ではありませんが強く推奨されます。これは、明示的なコンパレータを指定しないソート・セットやソート・マップを、自然順序付けがequalsと一貫性のない要素またはキーと一緒に使用すると、セットとマップの動作が保証されなくなるからです。特に、このようなソート・セットまたはソート・マップは、セットまたはマップの一般的な規約に違反します。この規約は、equalsメソッドの用語を用いて定義されています。
公式ドキュメントにも書いてありますが、
equalsとcompareToに矛盾があると、Mapなどでの動作が保証されなくなります。Comparableを実装したクラスがキーのMapでは、Map#getでキーのequalsではなく、compareToの結果を用いるので、変なバグを踏むことになります。Java ComparableとComparator どちらを使うかにも同様のことが書いてありました。
Stream#collectのボイラープレート的な処理は他に切り出すコレクション要素内の特定のフィールドを取り出して新しいコレクションを作ったり、コレクション内の特定のフィールドをキーにしてMapにしたりすることはよくあることだと思います。こういうのはいちいちStreamAPIに触れさせずとも使えるようにしといたほうが良いと考えています。
/** * リスト要素から別のインスタンスを生成し、生成したインスタンスのリストを返却する。<br> * インスタンスの生成ロジックは第二引数で与えられた関数オブジェクトに従う。<br> * @param list リスト * @param generator リストの要素から別の型のインスタンスを生成する関数オブジェクト * @param <S> 元のリスト要素の型。 * @param <R> 新しいリスト要素の型。 * @return 生成したインスタンスのリスト */ public static <S, R> List<Property> collect(List<S> list, Function<S, R> extractor){ return list.stream() .map(extractor) .collect(Collectors.toList()); }/** * リストを特定のキーでグルーピングし、キーとリストが対になったMapを返却する。<br> * キーの生成ロジックは第二引数で与えられた関数オブジェクトに従う。<br> * @param list グルーピング対象のリスト * @param keyExtractor リストの要素からリストのキーを取得する関数オブジェクト * @param <K> キーの型。Comparableインターフェースを実装したクラスである必要がある * @param <V> リストの要素の型 * @return グルーピング結果 */ public static <K, V> Map<K, List<V>> groupingBy(List<V> list, Function<V, K> keyExtractor) { return list.stream().collect(Collectors.groupingBy(keyExtractor)); }最後に
関数インターフェースやStreamAPIはとても便利なのですが、経験の浅いメンバーが多いチームでは逆にソースコードの可読性が下がり、生産性が下がるかもしれません。この記事では3年目のわたしが考えた戯言についてつらつらと書きましたが、同じようにチームの中で書き方を工夫して、新しいJavaの機能を使ってチームの生産性が上がったみたいなことがあったら嬉しいなって思ったりしています。
- 投稿日:2019-12-21T15:05:56+09:00
JUnit 5 + Gradle による Java の自動テスト導入
概要
- JUnit 5 + Gradle による Java の自動テストについて基本的なサンプルを書く
Junit 5 とは
- JUnit は Java の自動テスト用フレームワーク
- JUnit 5 = JUnit Platform + JUnit Jupiter + JUnit Vintage
- JUnit Platform: テスト実行プラットフォーム
- JUnit Jupiter: テストコード実装用APIとテストエンジンを提供
- JUnit Vintage: JUnit 3 と JUnit 4用のテストコード実装用APIとテストエンジンを提供
今回の環境
- Java 11 (OpenJDK 11.0.2)
- JUnit Platform 1.5.2
- JUnit Jupiter 5.5.2
- Gradle 6.0.1
JUnit 5 + Gradle の基本的なサンプル
ソースコード一覧
├── build.gradle ├── settings.gradle └── src ├── main │ └── java │ └── myapp │ └── Calc.java └── test └── java └── myapp └── CalcTest.javabuild.gradle
build.gradleplugins { id 'java' } repositories { jcenter() } dependencies { // Junit Jupiter 5.5.2 を導入 // 依存関係で以下等が導入される // junit-jupiter-api:5.5.2 // junit-jupiter-engine:5.5.2 // junit-jupiter-platform-engine:1.5.2 testImplementation 'org.junit.jupiter:junit-jupiter:5.5.2' } test { // JUnit platform を使う設定 useJUnitPlatform() // 標準出力と標準エラー出力を表示 testLogging { // テスト時の標準出力と標準エラー出力を表示する showStandardStreams true // イベントを出力する (TestLogEvent) events 'started', 'skipped', 'passed', 'failed' // 例外発生時の出力設定 (TestExceptionFormat) exceptionFormat 'full' } }参考:
- JUnit 5 User Guide
- Maven Repository: org.junit.jupiter » junit-jupiter
- TestLogging - Gradle DSL Version 6.0.1
- TestLogEvent (Gradle API 6.0.1)
- TestExceptionFormat (Gradle API 6.0.1)
settings.gradle
settings.gradlerootProject.name = 'myapp'Calc.java
package myapp; public class Calc { private int base; // 基準となる値を設定 public Calc(int base) { this.base = base; } // 足す public int plus(int num) { return base + num; } // 引く public int minus(int num) { return base - num; } }CalcTest.java
package myapp; import org.junit.jupiter.api.AfterAll; import org.junit.jupiter.api.AfterEach; import org.junit.jupiter.api.BeforeAll; import org.junit.jupiter.api.BeforeEach; import org.junit.jupiter.api.Test; import static org.junit.jupiter.api.Assertions.assertEquals; class CalcTest { // テスト開始前に1回だけ実行される @BeforeAll static void beforeAll() { System.out.println("CalcTest 開始"); } // テスト開始後に1回だけ実行される @AfterAll static void afterAll() { System.out.println("CalcTest 終了"); } // 各テストメソッド開始前に1回だけ実行される @BeforeEach void beforeEach() { System.out.println("CalcTest のテストメソッドをひとつ開始"); } // 各テストメソッド開始後に1回だけ実行される @AfterEach void afterEach() { System.out.println("CalcTest のテストメソッドをひとつ終了"); } // テストメソッドは private や static メソッドにしてはいけない // 値を返してもいけないので戻り値は void にする @Test void testPlus() { System.out.println("testPlus を実行: 2 + 3 = 5"); Calc calc = new Calc(2); // 第1引数: expected 想定される結果 // 第2引数: actual 実行結果 // 第3引数: message 失敗時に出力するメッセージ assertEquals(5, calc.plus(3), "2 + 3 = 5 の検証"); } @Test void testMinus() { System.out.println("testMinus を実行: 5 - 2 = 3"); Calc calc = new Calc(5); assertEquals(3, calc.minus(2), "5 - 2 = 3 の検証"); } }参考:
テスト成功時の例
$ gradle test > Task :test myapp.CalcTest STANDARD_OUT CalcTest 開始 myapp.CalcTest > testMinus() STARTED myapp.CalcTest > testMinus() STANDARD_OUT CalcTest のテストメソッドをひとつ開始 testMinus を実行: 5 - 2 = 3 CalcTest のテストメソッドをひとつ終了 myapp.CalcTest > testMinus() PASSED myapp.CalcTest > testPlus() STARTED myapp.CalcTest > testPlus() STANDARD_OUT CalcTest のテストメソッドをひとつ開始 testPlus を実行: 2 + 3 = 5 CalcTest のテストメソッドをひとつ終了 myapp.CalcTest > testPlus() PASSED myapp.CalcTest STANDARD_OUT CalcTest 終了 BUILD SUCCESSFUL in 1s 3 actionable tasks: 3 executedテスト失敗時の例
$ gradle test > Task :test FAILED myapp.CalcTest STANDARD_OUT CalcTest 開始 myapp.CalcTest > testMinus() STARTED myapp.CalcTest > testMinus() STANDARD_OUT CalcTest のテストメソッドをひとつ開始 testMinus を実行: 5 - 2 = 3 CalcTest のテストメソッドをひとつ終了 myapp.CalcTest > testMinus() FAILED org.opentest4j.AssertionFailedError: 5 - 2 = 3 の検証 ==> expected: <3> but was: <7> at org.junit.jupiter.api.AssertionUtils.fail(AssertionUtils.java:55) at org.junit.jupiter.api.AssertionUtils.failNotEqual(AssertionUtils.java:62) at org.junit.jupiter.api.AssertEquals.assertEquals(AssertEquals.java:150) at org.junit.jupiter.api.Assertions.assertEquals(Assertions.java:542) at myapp.CalcTest.testMinus(CalcTest.java:48)assertAll でまとめてテストするサンプル
サンプルコード
package myapp; import org.junit.jupiter.api.Test; import static org.junit.jupiter.api.Assertions.assertAll; import static org.junit.jupiter.api.Assertions.assertEquals; class CalcTest { @Test void testPlus() { Calc calc = new Calc(10); // まとめて検証 // 途中で失敗しても停止せずにすべて検証する assertAll( () -> assertEquals(30, calc.plus(20)), () -> assertEquals(99, calc.plus(90)), () -> assertEquals(11, calc.plus(50)), () -> assertEquals(40, calc.plus(30)) ); } }参考:
テスト失敗時の例
$ gradle test > Task :test FAILED myapp.CalcTest > testPlus() STARTED myapp.CalcTest > testPlus() FAILED org.opentest4j.MultipleFailuresError: Multiple Failures (2 failures) org.opentest4j.AssertionFailedError: expected: <99> but was: <100> org.opentest4j.AssertionFailedError: expected: <11> but was: <60> at org.junit.jupiter.api.AssertAll.assertAll(AssertAll.java:80) at org.junit.jupiter.api.AssertAll.assertAll(AssertAll.java:44) at org.junit.jupiter.api.AssertAll.assertAll(AssertAll.java:38) at org.junit.jupiter.api.Assertions.assertAll(Assertions.java:2839) at myapp.CalcTest.testPlus(CalcTest.java:15) 1 test completed, 1 failed FAILURE: Build failed with an exception.例外発生テストのサンプル
package myapp; import org.junit.jupiter.api.Test; import static org.junit.jupiter.api.Assertions.assertThrows; import static org.junit.jupiter.api.Assertions.assertTrue; import static org.junit.jupiter.api.Assertions.fail; class CalcTest { @Test void testPlus() { Calc calc = new Calc(100); // 0 で割ったら ArithmeticException が発生することを想定 ArithmeticException e = assertThrows(ArithmeticException.class, () -> calc.divide(0)); assertTrue(e instanceof ArithmeticException); } }参考資料
- 投稿日:2019-12-21T14:00:17+09:00
MyBatis Dynamic SQLで柔軟なORマッピング実装をしてみた
MyBatis Dynamic SQLを使ってみよう!
今回はMyBatis Dynamic SQLを使ってSQLを発行し、データを取得する実装を試してみました!
業務でバリバリ使うことになるかもなので、備忘録として残しておきます。
実装形式としてはSeasar2のS2JDBCに似ていて、複数のメソッドチェインを行うことで発行するSQLを作成しています。実行準備
用意したテーブルはこんな感じでシンプルなものを用意しました。
データはテキトーに数件登録しておきます。CREATE TABLE "MEMBER" ( "ID" NUMBER(8,0) , "BLOOD" VARCHAR2(20 BYTE) , "NAME" VARCHAR2(20 BYTE) , "CORP" VARCHAR2(20 BYTE) );Entityもテーブル構成に合わせて作成します。
public class Member { private Integer id; private String name; private String corp; private String blood; //getter・setterは省略 }マッパーインターフェースは下記のように作成します。
今回は複数のデータをListに返却する想定で実装しています。public interface MemberMapper { @SelectProvider(type=SqlProviderAdapter.class, method="select") @Results(id="memberResult", value={ @Result(column="ID", property="id"), @Result(column="NAME", property="name"), @Result(column="CORP", property="corp"), @Result(column="BLOOD", property="blood"), }) List<Member> selectMany(SelectStatementProvider selectStatement); }MyBatis Dynamic SQLと連携するためのサポートクラスを作成します。
取得するカラムやWHERE句の指定をするときなどに利用します。public final class MemberDynamicSqlSupport { public static final Member Member = new Member(); public static final SqlColumn <Integer> id = Member.id; public static final SqlColumn <String> name = Member.name; public static final SqlColumn <String> corp = Member.corp; public static final SqlColumn <String> blood = Member.blood; public static final class Member extends SqlTable { public final SqlColumn <Integer> id = column("ID", JDBCType.INTEGER); public final SqlColumn <String> name = column("NAME", JDBCType.VARCHAR); public final SqlColumn <String> corp = column("CORP", JDBCType.VARCHAR); public final SqlColumn <String> blood = column("BLOOD", JDBCType.VARCHAR); public Member() { super("Member"); } } }SQL実行
上記で作成したクラスを使って実際にSQLを発行するクラスを実装してみましょう。
今回はjunitを使ってテストコードを実装します。import static jp.co.stylez.support.MemberDynamicSqlSupport.*; import static org.mybatis.dynamic.sql.SqlBuilder.isEqualTo; import static org.mybatis.dynamic.sql.SqlBuilder.isLessThan; import static org.mybatis.dynamic.sql.SqlBuilder.select; @RunWith(SpringJUnit4ClassRunner.class) @ContextConfiguration(classes = MybatisConfig.class) public class Main { @Autowired ApplicationContext context; @Test public void test() { MemberMapper mapper = context.getBean(MemberMapper.class); SelectStatementProvider selectStatement = select(Member.allColumns()).from(Member).where(id, isLessThan(10)) .and(corp, isEqualTo("stylez")).build().render(RenderingStrategies.MYBATIS3); List<Member> members = mapper.selectMany(selectStatement); for (Member member : members) { System.out.println("********************"); System.out.println("id:" + member.getId()); System.out.println("name:" + member.getName()); System.out.println("corp:" + member.getCorp()); System.out.println("blood:" + member.getBlood()); System.out.println("********************"); } } }Configクラスは別途実装してデータソースやマッパースキャン対象の設定をしておきます。
XML形式でも設定可能ですが、今回はJavaで設定しました。
(設定関連の解説は割愛します)マッパースキャンでBean登録したMapperを取り出し、実際にSQLを実行しています。
実行結果は下記のようになります。
******************** id:1 name:hogehoge corp:stylez blood:B ******************** ******************** id:2 name:test.taro corp:stylez blood:O ******************** ******************** id:3 name:hiroya.endo corp:stylez blood:A ********************指定した条件のデータが複数取得出来ていることが確認できました!
実際に使ってみて…
主にWHERE句の条件指定に関して非常に柔軟な実装が可能だと感じました。
コードの可読性としても非常に高く、コーティングもしやすいので使いやすい印象でした。テーブル結合にも対応できるので、それもまた魅力の一つかと思いました。
Mapper.xmlを使用したSQLと使い分けることも可能なので、必要に応じて構成管理ができると思います。これから使う方のよい参考になれば幸いです!
参考
https://github.com/mybatis/mybatis-dynamic-sql
https://mybatis.org/mybatis-dynamic-sql/docs/conditions.html
- 投稿日:2019-12-21T12:19:23+09:00
絶対に二重サブミットを許さない友の会
MDC Advent Calendar 2019 の20日目です。投稿が21日になってすみません。割腹します。
「MDC」がどういう意味なのかよくわからなかったので、Majide Double-submit-ni Curushinderuの略だと信じてこの記事を書いています。間違ってたら教えてください。
おふざけ枠として「API Gatewayで高輪ゲートウェイ作ってみた」とかやろうとしたんですが、
高輪のことをよく知らなかったのでやめました。二重サブミットの話をします。二重サブミットとわたし
早速ですが。
人生、誰でも一度は二重サブミットと真剣に向き合う時期があると思います。二重サブミットはその名の通り二重で
submitをすることですが
「二重登録」とか「二重更新」とか「二重リクエスト」とかの言葉も概念としては同じです。
<input type="submit">を二連打するとか、POSTのリクエストを二連送信するとかの手段はどうでもよく
本質的には「二重で実行されるとシステムとして困る操作を二重ですること」と考えてよいと思います。「困る操作」は、DB更新・セッション更新・ファイル出力・他システム連携のような別レイヤへはみ出す処理や、
その処理に伴って内部で不整合が発生し、適切な画面表示やデータ返却ができないパターンが多いでしょうか。
うっかり操作で簡単に発生し得るので無対策だと痛い目を見るかもしれません。二重徴収とかね。怖いな〜〜〜以下ではシンプルなWebアプリで二重サブミットを防止する小手先実装に触れますが
OpenAPIのようないつ何者からどれだけ叩かれるかわからないエンドポイントであれば、
べき等にするとかアーキテクチャで対応するとか、「そもそも困らないように作る」ことが肝要かと思います。
リリース前モンキーテストで発覚して、一日で急遽対応しないといけない時だけ参考にしてください。許さないために
今回はゴリゴリの新技術の話ではなく、きわめて普通のWebアプリで対策する前提で考えますので
テキストボックスがあって、送信ボタンがあって、サーバで受けてDBに突っ込んで、完了画面を返すような
古式ゆかしい登録フォームなんかを想像して。肩肘張らないで。足なんかも崩して。お願いします。なお、方針としては「させない」対策と「されても耐える」対策に大別され、
前者はフロント側実装、後者はサーバ側実装が多めになります。させない
させない方です。
ボタンを押せなくする
formがボタンのクリックイベント発火を受けてsubmitされるので、
押した瞬間にボタンを非活性にして、二回目のクリックをさせないようにしようという発想です。
わかりやすい。index.js$(function() { $('button').on('click', function() { $(this).prop('disabled', true); $('form').submit(); }); });見た目にもピンと来やすいですし採用しているサイトも多いです。
スピナー(ローディング中のぐるぐる)をボタンに載せるパターンも見かけますね。
ただ回線状況等々によっては画面遷移に失敗してボタン非活性だけ発動みたいなケースもあり
非活性化という強めの処理を行っているだけあって、考慮ポイントもままあることは注意したいところ。確認ダイアログを出す
古式ゆかしすぎる。モダンなサイトでは全く見かけないですね。
window.confirm()というなんかすっごいネイティブな機能を使ったものです。
https://developer.mozilla.org/ja/docs/Web/API/Window/confirmindex.js$(function() { $('button').on('click', function() { var confirmMessage = '登録しますか?'; if (window.confirm(confirmMessage)) { // OK押下時の挙動 } else { // キャンセル押下時の挙動 } }); });ボタンを押しても
form.submit()は呼ばれず、確認ダイアログが表示されるだけなので
html上のボタン連打をしてもほとんど副作用がないのが嬉しいと思います。
なおかつ確認ダイアログはブラウザ機能で表示しているものなので、
開発者ツールなどで挙動を変えられることがなく、防御としては堅めな気がしています。
ただいかんせん古臭いですし、ワンクリック増えるのでUXとしては一段落ちるかもしれません。PRGパターンを使う
(※フォームの文字列が消えてるのは消してるんじゃなくリダイレクトで再描画されてるからです!!!)
Post - Redirect - Getの略でPRGです。こちらはサーバ側実装です。
こんなんたまに出ますよね。
REST周りの話はそれだけで記事一本分になりそうなので割愛しますが、
POSTリクエストに対して返却された画面でリロードを行うと、
直前のPOSTリクエストが再度サーバに対して送信されてしまいます(フォーム再送信)。そのため、POSTリクエストを受け付けた後にリダイレクトを行って
GETリクエストに対して画面を返却するようにします。
そうすることでリロードはGETリクエストに対してのみ行われ、POSTリクエストは再送信されなくなります。
(GIF画像でも、POSTの/createに飛んだ後にGETの/indexに転送されているのがわかるかと思います)サーバでPOSTリクエストを受け取って、リダイレクトして、画面を返却して・・・という順序なので
最初のPOSTリクエストを二連打された日にゃ何もできませんが、後のリロードは防げます。そういうものです。されても耐える
されても耐えます。男の子だから・・・
セッションと画面にトークンを格納する
ここら辺から急にじゃばじゃばしてきます。Spring使います。
登録画面をクライアントに返却する際に、セッションと画面に同じ値を格納しておき、
画面に載せた値はsubmitで送信させ、
POSTリクエストを受け取った直後、二つの値を比較してリクエストの真正性を確認する方法です。
確認して正しいと判断した場合はトークンを削除or上書きし、2回目以降のリクエストが来ても弾くようにします。Controller.java@GetMapping("/index") public String index(Model model, SessionDto session, UserForm userForm) { String randomStr = RandomString.make(10); session.setToken(randomStr); userForm.setToken(randomStr); // 後略 } @PostMapping("/create") public String create(Model model, SessionDto session, @ModelAttribute UserForm userForm) { if (!session.getToken().equals(userForm.getToken())) { return "/error"; } session.setToken(""); // 後略 }CSRF対策と発想は似ていますが、同一人物でも2回目以降は弾くという点では異なります。
ちなみにみんな大好きSpring SecurityのCSRFトークンは同セッション中は不変です(たぶん)。
なので戻る遷移から再送信されても弾けず、二重サブミット対策にはなりません。ちなみにこちらの方法ですが・・・
検証中にjsのform.submit()複数回実行で動作確認していたところ
Controllerのメソッド内で画面を返却するまでは、セッションに対するsetが反映されないような雰囲気がありました。
(あくまで雰囲気なので詳しい方補足ください)要するに、
リクエスト1 : セッションと画面からトークンを取得し比較 -> "token1"が返ってくる
リクエスト1 : セッションのトークンを"token2"で上書き -> この時点でセッション内トークンは"token2"のはず
リクエスト2 : セッションと画面からトークンを取得し比較 -> なぜかここも"token1"が返ってくる
という挙動です。
この時はRedisにセッションを格納していたので、Springboot+Redis特有のやつ?
SpringbootからRedisに書き込まれるタイミングの問題? とか思ってたんですが・・・トークンをRedisに直接格納する
Springの挙動がよくわからないのでRedisに直接詰めることにしました。
この方法ならredisTemplateを呼び出したタイミングで確実にredisへのアクセスが行われ
データの読み取り・書き込みが即時実行されます。
プロシュート兄貴も「『直』は素早いんだぜ」って言ってたし・・・@Autowired private StringRedisTemplate redisTemplate; @GetMapping("/index") public String index(Model model, SessionDto session, UserForm userForm) { String userUniqueKey = session.getUserId() + session.getUserName(); String randomStr = RandomString.make(10); redisTemplate.opsForValue().set(userUniqueKey, randomStr); // 後略 } @PostMapping("/create") public String create(Model model, SessionDto session, @ModelAttribute UserForm userForm) { String userUniqueKey = session.getUserId() + session.getUserName(); String value = redisTemplate.opsForValue().get(userUniqueKey); if (value == null) { return "/error"; } redisTemplate.delete(userUniqueKey); // 後略 }Spring sessionを無視して自分でRedisアクセスを行うことになります。
Springboot+Redisの構成の場合、Controllerのメソッド引数に値を適当に詰めたりして持ち回していれば
特に意識せずとも、Springbootが発行したSessionIdをキーにRedisへのデータ登録が行われます。ですが直アクセスなので、そのユーザのセッションを一意に特定するようなキーを自分で設定せねばなりません。
DB的にprimaryな値がよいかと思いますが、ここは防ぎたいパターンに応じてチューンしてください。DBのレコードの存在チェックをする
前項の方法は、「セッションを使って防ぐ」というよりは「インメモリデータベースを使って防ぐ」といった感じでした。
インメモリデータベースで防げるならオンディスクデータベースでも防げそうです。
(そもそもインメモリデータベースを採用していないケースも多いと思いますし)こちらの場合は「排他テーブル」を作成しておき、以下のような流れで処理することになります。
(1) POSTリクエストを受ける
(2) ユーザを特定する一意な情報で排他テーブルを検索する
(3) 既にレコードが存在した場合はエラーに流す
(4) レコードが存在しない場合はレコードを新規に作成する
(5) 申込内容のDB登録やら他システム連携やらをする
(6) 全ての業務処理が完了した後、排他テーブルのレコードを削除するトランザクション境界の設定や、(5)でエラーとなった場合の排他レコードの扱いなど
綿密な設計をしないと必要以上にロックが掛かりかねないので、難易度や影響範囲は上がります。ちなみに、わざわざ排他テーブルを新設せずとも
POSTリクエストを受けてDBへの登録が走るシステムなのであれば、
POSTリクエストを受けた直後に、DBに既に登録があるかをチェックしにいき
問題ない場合だけDBへ申込内容のinsertを行う、という処理順序にすることで
同様の対策を行うことができます。ただし、POSTリクエストを契機に他システムへの連携等を行って、実行結果を最終的にDBに詰めたい等で
(1) POSTリクエストを受ける
(2) 他システム連携を行う
(3) 申込内容と連携結果のDB登録を行うという流れになっている場合は、
(1) POSTリクエストを受ける
(2) 申込内容のDB登録を行う
(3) 他システム連携を行う
(4) 申込内容レコードを、他システム連携結果で更新する「先に空のハコを作っておいて二重登録を防ぎ、後から必要な情報を更新する」という流れにせざるを得なくなります。
こちらは排他テーブルの場合と同様、(3)でエラーとなったときの扱いを密に設計する必要があります。DBの力を借りる
前項で「排他」という言葉を使いましたが、排他に関してのプロフェッショナルは言わずもがなDBです。
悲観ロックとか楽観ロックとか監獄ロックとかいろいろありますが、
基本思想レベルで真剣に二重登録と向き合っている世界なので、せっかくならそこに相乗りしましょう。楽ちん
今回はmysqlの
select for updateを使いました。
詳細な挙動は他で語り尽くされているので割愛しますが、
端的に言うと「commitするまで他のプロセスからのクエリ発行を待機させる」ものです。
(for updateが付随しない単なるselectであれば一応通りますが、古いデータが返ります)この機能を利用して、POSTリクエストを受けた直後に排他を掛け始めて
全ての処理が完了したときにcommit(もしくはDB更新で自然体でcommit)する、という流れになります。こちらのやり方はとにかく確実です。
長年積み重ねられてきた排他制御の叡智にあやかるのでとにかく守られます。前項でも触れたロックかかりすぎちゃう問題はこちらにもありますが、
mysqlの行ロックはデフォルト50秒、設定によってセッションごとのロック時間変更もできるようなので
一度しくじったら一生排他、データ修正するまで触れませんゲームクリアさようなら〜ということにはならなさそうです。
https://dev.mysql.com/doc/refman/8.0/en/innodb-parameters.html#sysvar_innodb_lock_wait_timeoutmysqlmysql> set innodb_lock_wait_timeout = 30;ちなみにOracleはクエリごとに設定できるって。
oracleSQL> SELECT col FROM table WHERE col = 1 FOR UPDATE OF col WAIT 10 ;なお他の方法とは異なり、二重サブミットされていることをアプリケーションレイヤで検知するのではなく
アプリケーションがおバカで二重サブミットを許容したとしても、DB側で弾くという方法なので
「二重サブミットされたらこういうハンドリングをしたい!」というニーズがある場合はもう一工夫必要になります。2回目のリクエストはサーバまでは正常に疎通できるものの、GIF画像の通りDB接続で待たされるような挙動となるので
Java的に言うとSQLTimeoutExceptionあたりがthrowされます。
排他による想定通りのタイムアウトなのか、スロークエリやDB側不調によるタイムアウトなのか判別できないため
二重サブミットの防止はできても、二重サブミットの検知は他と比べると難しくなります。まとめ
「処理を禁止する」という強い制御をかける話なので、どれも多少なりとも副作用があります。
またユーザビリティや処理難易度、アーキテクチャ等を考えると、どれか一案だけ採用して終わりということもないかなと思います。
この世から二重サブミットがなくなる日まで戦い続けるので、他にいい方法があったらぜひ教えてください。
あと記事投稿遅れまして誠に申し訳ございませんでした。。。。。。。。参考
SpringにはないけどTERASOLUNAでは二重サブミット防止モジュールがあるらしいです
4.5. 二重送信防止 — TERASOLUNA Server Framework for Java (5.x) Development Guideline 5.3.1.RELEASE documentation先行研究
さいきょうの二重サブミット対策





- 投稿日:2019-12-21T11:07:27+09:00
アルゴリズム体操6
Move zeros to left
説明
一つの整数型の配列が渡されます。
配列内の他の要素の順序を維持しながら、0に等しいすべての要素を左に移動させるアルゴリズムを実装しましょう。
次の整数配列を見てみましょう。
すべての0に等しい要素を左に移動すると、配列は次のようになります。(0以外の要素の順序を維持する必要があります)
Solution
Runtime Complexity O(n)
0の要素を配列から探す必要があります。
Memory Complexity O(1)
二つのポインター(反復子)を使うことで渡された配列のみで実装できます。
アルゴリズムの主な流れは
2つのマーカーread_index と write_indexを配列の最後の要素に配置させます。
read_index が 0 以上の間に
read_indexが「0」を指している場合は read_indexのみを減少させる。
read_indexがゼロ以外を指す場合、write_indexにread_indexの要素を書き込み、write_indexとread_index の両方を減少。read_indexが-1になり、ループを抜けて、現在のwrite_indexから0まで配列の要素を0にアサインしていく。
完成
実装
moveZeroToLeft.javapublic class moveZerosToLeft { public void move_zeros_to_left_in_array(int[] A) { int readIndex = A.length - 1; int writeIndex = A.length -1; while (readIndex >= 0) { if (A[readIndex] != 0) { A[writeIndex] = A[readIndex]; writeIndex--; } readIndex--; } while (writeIndex >= 0) { A[writeIndex] = 0; writeIndex--; } } }Mina.javaimport java.util.Arrays; public class Main { public static void main(String[] args) { // write your code here moveZerosToLeft algorithm = new moveZerosToLeft(); int[] v = new int[]{1, 10, -1, 11, 5, 0, -7, 0, 25, -35}; System.out.println("Original Array: " + Arrays.toString(v)); algorithm.move_zeros_to_left_in_array(v); for (int item : v) { System.out.print(item + ", "); } } }Output










- 投稿日:2019-12-21T11:07:27+09:00
アルゴリズム体操7
Move zeros to left
説明
一つの整数型の配列が渡されます。
配列内の他の要素の順序を維持しながら、0に等しいすべての要素を左に移動させるアルゴリズムを実装しましょう。
次の整数配列を見てみましょう。
すべての0に等しい要素を左に移動すると、配列は次のようになります。(0以外の要素の順序を維持する必要があります)
Solution
Runtime Complexity O(n)
0の要素を配列から探す必要があります。
Memory Complexity O(1)
二つのポインター(反復子)を使うことで渡された配列のみで実装できます。
アルゴリズムの主な流れは
2つのマーカーread_index と write_indexを配列の最後の要素に配置させます。
read_index が 0 以上の間に
read_indexが「0」を指している場合は read_indexのみを減少させる。
read_indexがゼロ以外を指す場合、write_indexにread_indexの要素を書き込み、write_indexとread_index の両方を減少。read_indexが-1になり、ループを抜けて、現在のwrite_indexから0まで配列の要素を0にアサインしていく。
完成
実装
moveZeroToLeft.javapublic class moveZerosToLeft { public void move_zeros_to_left_in_array(int[] A) { int readIndex = A.length - 1; int writeIndex = A.length -1; while (readIndex >= 0) { if (A[readIndex] != 0) { A[writeIndex] = A[readIndex]; writeIndex--; } readIndex--; } while (writeIndex >= 0) { A[writeIndex] = 0; writeIndex--; } } }Mina.javaimport java.util.Arrays; public class Main { public static void main(String[] args) { // write your code here moveZerosToLeft algorithm = new moveZerosToLeft(); int[] v = new int[]{1, 10, -1, 11, 5, 0, -7, 0, 25, -35}; System.out.println("Original Array: " + Arrays.toString(v)); algorithm.move_zeros_to_left_in_array(v); for (int item : v) { System.out.print(item + ", "); } } }Output
- 投稿日:2019-12-21T00:54:42+09:00
java 変数宣言
変数宣言についても書きます。
Javaの変数宣言(識別子)
Javaのプログラムの中で変数を使うためには
まずはじめに「変数の宣言」というものを行わなければならない。プログラムの中で、変数を使うためには名前が付けられていなければならない。
この変数の名前のことを識別子と読んでいる。また、変数には扱うデータの種類によって型が決まっている。この型を指定しなければならない。
基本
基本の書き方はこちら
型名 識別子;例:年齢の場合
intで数字の型を指定
ageで変数名(識別子)を指定int age;変数に値を代入する
Javaの場合は以下のように記号「=」(イコール)を使用して
左側に宣言した識別子で表される変数名を、右側に式を記述する。尚、変数と「=」の間のスペースはあっても無くてもどちらでも問題ない。
変数名(識別子) = 式;例:30と指定
ageという変数に、30という値を代入することを意味している。age = 30;変数に変数値を代入する
これは、sameAgeという変数に、ageという変数に入っている値と同じものを代入することを意味している。
sameAge = age;宣言と代入をまとめて
宣言と代入をまとめて書くこともできる。
型名 識別子 = 式;int age = 24;