- 投稿日:2019-12-21T23:55:57+09:00
新サービスに触る前に学び直す、AWSのネットワーク基礎知識まとめ
最近のAWSでは、Transit GatewayやDirect Connect Gatewayなど、ネットワークをよりシンプルに分かりやすくするための高度なネットワークサービスが増えてきました。
忙しくなってくると、ただでさえアップデートに追いつくのは大変ですが、既存のサービスの考え方を上書きするような高度なサービスが出てきたので、ワケワカラン!となる前に何とかしなければ、と不安に思っていました。ただ、これらのサービスを腹落ちして使うためには、これらのサービスが登場する以前のAWSのネットワークについて、基本的な考え方であったり、概念や知識を今一度押さえておきたいところです。
そこで一念発起して、これまでの総復習として、AWSの公式ドキュメントを読みまくり、AWSのネットワークに関する基礎知識を調べ、これらの基礎知識をさらっとおさらいできるようにまとめてみました。
最初は自分の知識整理のためだったのですが、少しずつ整理していたところ、かなりの量がまとまってきたので、公開してしまおうと思い立ちました。
気軽にスマホで1時間くらいで総復習できるようにと、できるだけ短くまとめ、簡単な表現にしています。これらの知識を総ざらいすることは、これからAWSのネットワークを学び始めたり、既存のAWSのネットワーク設計を高度化しようと考えている人だけでなく、AWS認定のネットワーク専門知識の試験対策にも良いかも知れません。
前提
- 2019年12月時点の情報です。
- AWSのネットワーク周りの基礎を振り返るためにまとめました。
- 以下の項目は入っていません。以下の項目に挑む前の知識整理と考えてまとめています。
- Transit Gateway
- Direct Connect Gateway
- Global Accelerator
1. VPC
1-1. What is VPC?
- AWS上の仮想プライベートネットワーク
- 各リージョンに配置可能
- 複数のAvailability Zone (AZ) にまたぐ (Multi-AZ) が可能
- AZは地理的に離れている
- VPC内に公開 (Public) と非公開 (Private) のネットワーク (Subnet) を配置可能
- PublicとPrivateを別のAZに配置可能
- VPCにつき1つ、インターネットへの出口 (Internet Gateway) を配置可能
- 仮想ルータ (Route Table) を複数配置可能
- SubnetごとにRoute Tableを設定可能
- Internet Gatewayへのルートがあれば、インターネットと通信可能
- VPN接続が可能
1-2. Default VPC
- リージョン毎に最初からデフォルトで存在
- リージョンに存在するAZにつき1つSubnetが存在
- Default VPCであるかどうかはマネジメントコンソールの属性を見れば分かる
- Subnetに作成したEC2には自動的にPublic IPが割り当てられる設定 (Auto-assign public IPv4がYes)
- Internet Gatewayはデフォルトで存在
- Route Tableのデフォルトゲートウェイ(0.0.0.0/0)はInternet Gateway
- Network ACLは全てのトラフィックを許可する設定
- Default VPCは削除可能
- Default VPCは1ボタンで再作成可能
- Subnet、Internet Gateway等Default VPCにデフォルトで含まれる全てのものを再作成可能
1-3. Custom VPC
- リージョンを選んで独自の設定でVPCを作成可能
- Launch VPC Wizardを使うと、4つのパターンから、Subnetも含まれている状態で、自動的にVPCを作成可能
- 通常はVPCだけ作成
- VPC作成時にTenancyを選択可能
- Defaultはアカウントを跨いだ共有領域に作成され、Dedicatedはアカウント専用領域に作成
- VPCを作成するとデフォルトでMain Network ACLとMain Route Tableが作成される
- Main Network ACLはInbound/Outbound共に全てのトラフィックが許可
- Main Route Tableでは、VPCにあるSubnet間であれば通信を許可 (local)
- VPC内にSubnetを作成可能
- SubnetのネットワークアドレスはVPCのサブセット
- AZをプルダウンで選択可能
- Subnetを作成するとデフォルトでMain Network ACLとMain Route Tableがアタッチされる
- 新しくNetwork ACLを作成してMain Network ACLと置換可能
- 新しくRoute Tableを作成してRoute Tableと置換可能
- Subnet作成直後は、Auto-assign public IPv4がNo
- Yesに変更すると、EC2構築時にPublic IPを自動アサイン可能
- Private SubnetではNoのままにしておく
1-4. VPC Limits
- リージョン毎に作成できるVPCは5個まで
- 100個まで引き上げ可能
- VPC内のSubnetは200個まで
- Elastic IPは5個まで
- Network ACLは200個、ルールは20個まで
- Route tableは200個、ルートは50個、BGPルートは100個まで
- Security Groupは2500個、ルールはInbound/Outboundで各60個、Network Interface (ENI) 毎のSecurity Groupは5個まで
1-5. Data Transfer Costs
- Data Transfer Guideが分かりやすい (価格はUS基準で記載)
- Direct Connect経由とInternet Gateway経由はInが無料、Outに課金
- Direct Connectの方がOutが安い傾向
- ロードバランサとインターネットの間の通信コストはIn/Outともに課金
- EC2とロードバランサ間の通信コストは、同じAZなら無料、異なるAZではEC2→ロードバランサに課金
- ALBとCLBでは、ALBの方が通信コストが安い
- CloudFrontからオリジンへの通信 (Out) に課金、CloudFrontへの通信 (In) は無料
- AZを跨いだEC2間の通信は、In/Outともに課金 (In/Out同時課金)
- VPC Peeringを挟んだEC2間の通信も、In/Outともに課金 (In/Out同時課金)
- リージョンを跨いだEC2間の通信は、Out側のみ課金され、Inは課金されない
- EC2同士、またEC2とRDS/RedShift/ElastiCache間の通信は同一AZでは無料
- AZを跨いだ場合、In/Outともに課金
- EC2間の通信がインターネット経由(Public IP等)となった場合、In/Outともに課金
- NAT Gatewayは、起動時間と通信データ量に応じて課金
- 起動時間ごとに課金
- NAT Gatewayを1GB通過する度に課金
- NAT Gatewayの通信データ量の課金は、EC2の通信データ量の課金と同じ
- AZを跨いだ場合に課金される点が重要
2. Subnet & Routing
2-1. Route Table
- Main Route Tableには、VPC内のいずれのSubnetとも通信できるlocalルールがデフォルトで存在
- Subnet毎にCustom Route Tableを作成してアタッチ可能
- デフォルトゲートウェイ(0.0.0.0/0)をInternet Gatewayとするルートを追加すれば、直接インターネットと通信可能 = Public Subnet
- デフォルトゲートウェイ(0.0.0.0/0)をNAT Gatewayとするルートを追加すれば、NAT Gateway経由でインターネットと通信可能 = Private Subnet
- Custom Route Tableの作成はNameタグとVPCを指定するだけ
- Route Tableを作成後にSubnetをアサイン
- Route Tableを作成後にルートを追加
- Targetが各種ゲートウェイやNetwork Interface (ENI) の場合、プルダウンでIDを選択可能
- Main Route Tableであるかどうかは属性で確認可能
2-2. Reserved IP Address
- SubnetのIPアドレスは先頭の4アドレスと最後の1アドレスが予約されている
- サブネットの1番目のアドレスがネットワークアドレス
- サブネットの2番目のアドレスがデフォルトVPCルータ
- サブネットの3番目のアドレスがデフォルトDNSサーバ
- サブネットの4番目のアドレスは将来のための予約アドレス
- サブネットの最後のアドレスはブロードキャストアドレス
2-3. Dual-Homed Instance
- 同じVPCの複数のSubnetに属するEC2のこと
- 例えばPublic SubnetとPrivate Subnetの両方に属し、両方のENIを持つ
- ENIはSubnet毎に存在し、Security GroupはENI毎に存在
- Elastic IP/Public IPは、Public SubnetのENIにアタッチ
- 通信ログを追う場合、VPC Flow LogsでENI毎にフィルタして分析できるため、ENIがPublicとPrivateで分かれていると分析が容易になる
2-4. Internet Gateway
- EC2がインターネットに通信する時、Internet Gatewayを通過する時にソースIPアドレスがPrivate IP→Public IP/Elastic IPにNATされる
- Internet GatewayはVPCのマネジメントコンソールから作成可能
- VPCを指定して作成し、VPCにアタッチして使用する
2-5. Public Subnet/Private Subnet
- Public Subnetの特徴は以下の通り
- Route TableのデフォルトゲートウェイがInternet Gateway
- (広義) Auto-assign public IPv4 addressがYes
2-6. VPC Addressing
- VPCに複数のIPv4 CIDRをアサイン可能だが、最初にアサインしたCIDRは削除できない
- VPCにアサインできるIPv6 CIDRは1個まで
- 既存のSubnetにIPv6 CIDRを追加できるが、VPCにアサインしたサイズをそのまま追加
3. EC2 in VPC
3-1. Creating EC2
- VPC、Subnet、Auto-assign Public IPを指定
- Auto-assign Public IPを指定すると、Public IPがアサインされてEC2が起動される
- ENIを設定
- Security Groupを新たに作成してアタッチ可能
- OSを操作するためにSSHを許可する
- OS内部ではPublic IPは見えない
- Public IPはEC2をStopするとリリースされ、次にStartした時に新しいPublic IPが割り当てられる
3-2. Elastic IP
- Elastic IPアドレスは、EC2をStopしても削除されず固定される
- マネジメントコンソールで作成可能
- 作成後、InstanceまたはNetwork Interfaceを指定するとアサイン可能
- 不要になればEC2からデタッチして削除する
3-3. Elastic Network Instance (ENI)
- EC2は作成直後にeth0の1個だけENIを持つ
- ENIはマネジメントコンソールから新たに作成可能
- 作成したENIをEC2にアタッチするとeth1ができる
- 以降eth2、eth3…
- ENI毎にSecurity Groupが異なるため注意
- この方法でPublic SubnetとPrivate Subnetの両方のENIを持つEC2などを作成可能
- 不要になればeth1以降のENIはデタッチして削除可能
3-4. Bastion Host
- 踏み台のこと
- まずは踏み台にSSH/RDPをして、他のサーバへのSSH/RDPは踏み台経由に限定するのがセキュア
- 踏み台のみがPublic IP/Elastic IPを持ち、他はPrivate IPのみ持つようにする
3-5. Enhanced Networking
- ネットワーク仮想化
- EC2 (仮想マシン) は物理ホスト上で稼働
- その物理ホストに仮想スイッチが存在
- ハイパーバイザーを介して無数のEC2が仮想スイッチを共有
- SR-IOV
- EC2のENIが、直接物理ホストのネットワークアダプタに接続
- SR-IOVに対応したEC2インスタンスタイプは限られる
- 対応表を見て正しいドライバをインストールすること
- ENAは最大100Gbpsをサポート
- Intel VFは最大10Gbpsをサポート
- ネットワーク性能はインスタンスタイプによるので要確認
- ドライバのロード状況はOS内部で確認可能
- 対応するためにカーネルのアップデート、バッケージのアップデートが必要なケースあり
3-6. Placement Group
- 同じAZの中には複数のデータセンタがあり、さらにデータセンタ内には複数の物理ホストがある
- 通常、EC2を構築する時、どこのデータセンタと物理ホストが選ばれるかを制御できない
- Placement Groupで、全てのEC2の配置をある程度コントロールすることが可能
- EC2初期構築時に、Placement Groupを指定して構築
- 同じインスタンスタイプを一貫して使用する方が高速化
- 後からEC2を追加できない可能性もあり
- 既存のEC2は追加できない
- Placement Groupでは、シングルフローのトラフィックが5Gbpsから10Gbps
Cluster Placement Group
- 単一AZ
- 同一リージョン内でVPC Peering経由でVPCをまたぐことが可能
- 10Gbps
- 低遅延で、ノンブロッキング、ノンオーバーサブスクライブ
- キャパシティエラーが出た場合、対応するには全てのEC2をStop→Startする必要がある
Partition Placement Group
- 単一AZ内で複数のパーティション
- 各パーティションが異なるラックに配置
- ワークロードを隔離したり複製する場合に有効
- 各AZにパーティションを持てる
Spread Placement Group
- 同一リージョンのAZにまたがって配置可能
- 全てのインスタンスを異なる電源/ネットワークを持つラックに配置
- 少数の重要なインスタンスを分散させる場合に有効
- 1グループあたり7インスタンスまで
3-7. EC2 Instance Metadata
- EC2インスタンスから http://169.254.169.254/latest/meta-data にアクセスするとメタデータを得る
- メタデータへの接続はSecurity GroupとNetwork ACLでフィルタできない
- OSの外側かつSecurity Groupの内部にあると考える
- OSのファイアウォール機能を使えば接続を遮断可能
- Proxyを経由してアクセスできないため、Proxyの設定からは除外する
- NO_PROXYを設定
3-8. AWS Config
- AWS Configのマネージドルールを活用すれば、VPCのコストを最適化できる
- eip-attached
- Elastic IPがEC2にアタッチされているか確認する
- Elastic IPはEC2にアタッチされていないと課金されてしまう
4. Network Address Translation
4-1. NAT Instance
- Public SubnetはデフォルトゲートウェイがInternet Gateway
- NAT InstanceはPrivate SubnetのEC2にインターネット接続を提供
- Public SubnetにNAT Instanceを起動
- Private SubnetのデフォルトゲートウェイをNAT Instanceに指定
- NAT Instanceは手動でスケールしたり、フェールオーバーのための仕組みが必要
- NAT InstanceのSource/Destination Checkを無効にしないと通信できない
- SourceまたはDestinationがNAT Instanceにはならないトラフィックを、NAT Instanceで送受信するため
4-2. NAT Gateway
- NAT Instanceの代わりにNAT Gatewayを採用
- Private SubnetのデフォルトゲートウェイをNAT Gatewayに指定
- 利点
- EC2が不要
- 完全マネージドサービスでスケールやパッチの管理が不要
- 複数AZに跨いで構築可能
- 複数NAT Gatewayを同一AZに構築可能
- 欠点
- 踏み台にはならない (NAT Instanceは踏み台としても使える)
- ポートフォワーディングを手動で設定できない
- セキュリティグループを割り当てることができない
- NAT GatewayはVPCのマネジメントコンソールから作成可能
- Subnetを指定し、Elastic IPを紐付けて作成
- Elastic IPを新たに作成も可能
- NAT Gatewayの制限と特徴
- 必ず1つの特定のAZに属する
- 5Gbpsの帯域をサポートし、45Gbpsまで自動的にスケールアップする
- Elastic IPを外すことはできない
- Security Groupは適用できない
- 1024-65535ポートを使用するため、Network ACLを開放する
- 送信先別に最大55000の同時接続をサポート
- 単一の送信先に1秒あたり約900の接続
- 送信先IPアドレス、送信先ポート、またはプロトコル (TCP/UDP/ICMP) が変更された場合は、追加の55000の接続を作成可能
5. VPC Peering
5-1. What is VPC Peering?
- 同じアカウントまたは異なるアカウントにある2つのVPCを接続するための機能
- VPC AからVPC Bに接続リクエストし、VPC Bが承認すれば接続
- VPC AとVPC BでIPアドレスの重複は不可
- 接続先VPCのネットワークアドレス宛のTargetをVPC Peering(pcx-…)にするルートを、Route tableに追加
- VPC 1、 VPC 2、VPC 3とあって、1-3と3-2がつながっている構成の場合
- 1と2は直接接続できない
- 1と2でPeeringすれば接続可能
- アカウントとVPCが増えるほど、トポロジーは複雑となる
5-2. VPC Peering Design
- 3つ以上のVPCがあり、共有VPCを作る場合
- 共有VPCと直接的に接続するVPC CIDRは、互いにユニークであること
- 例えば共有-A、共有-Bという構成の場合、共有とA、共有とBのCIDRは重複不可
- ただしAとBのVPCはCIDRが重複して良い
- 共有VPCのRoute Tableで宛先が特定されており、Targetが分かれていれば良い
- 共有VPCに2つSubnetがあり、各サブネットのSubnetのRoute TableでTargetが分かれていてもOK
5-3. Overlapping CIDR
- 例: VPC1-VPC2(共有VPC)-VPC3という構成
- VPC1とVPC3のCIDRが重複
- VPC1-VPC2、VPC1-VPC3のCIDRはユニーク
- VPC1とVPC3に同じIPアドレスのEC2が構築されている
- VPC2にEC2が2台あり、片方はVPC1、もう片方はVPC3と通信したい場合
- VPC1のSubnetと、VPC2のSubnetのCIDRを分けれは解決できる
- VPC1とVPC3の各EC2を、作成したSubnetに移動する
- VPC2では各SubnetのCIDRに応じてTargetを分ける
5-4. VPC Peering Connection
- リクエスタのVPCと、アクセプタのVPCを指定して作成する
- リクエストが送られてPendingとなり、リクエストがAcceptされると接続される
5-5. DNS for VPC Peering
- VPC Peeringの設定で、アクセプタVPCのホスト名をPrivate IPに解決するようにDNSの設定を追加可能
- この設定が有効になると、例えばアクセプタVPCのPublicホスト名をルックアップすると、プライベートIPアドレスが返るようになる
- 逆方向の設定も可能
5-6. Delete VPC Peering
- VPC Peeringを削除しても、Route Tableのルールは自動で消えず、Blackholeとなる
5-7. Costs of VPC Peering
- In/Outの両方に課金される
6. VPC Security and Monitoring
6-1. Security Group
- ステートフルなファイアウォール
- Inboundルールがあれば、対応するOutboundルールは不要
- ENIあたり最大5個
- Inboundはデフォルトで全拒否、Outboundはデフォルトで全許可
- Outboundのデフォルト全許可ルールは削除が可能
- 許可ルールのみ設定する
- EC2毎に異なるSecurity Groupをアタッチするのが王道
- EC2のIPアドレスではなく、Security GroupのIDを指定してアクセス許可が可能
6-2. Security Group vs Network ACL
- ENIに複数のSecurity Groupをアタッチ可能
- 後からでもSecuriuty Groupのアタッチ状況を変更可能
- Network ACLはステートレスファイアウォール
- Inboundルールに対応するOutboundルールが必要
- ルール番号が若い順に評価
- 宛先やポートを特定してDENYするルールは、ALLOWよりも先に入れるのがベストプラクティス
- Network ACLは、作成直後のデフォルトが全拒否
- ルール番号が*のルールは削除できない
- 外部からアクセスがあると、まずNetwork ACLが判定され、パスするとSecurity Groupが判定される
- EC2インスタンスのメタデータへのアクセス制限
- Security Groupでは制限できない (SGよりも内側にあると考えるべき)
- メタデータへのアクセスはOSのファイアウォールで保護する
6-3. Virtual Private Gateway
- リージョン毎に5個まで
- VPCにアタッチして使用
- デフォルトで高可用性がある
- オンプレミスのデータセンタとVPN Connectionで接続
- オンプレミス→VPC
- Next HopをVPN Routerに向ける
- ルートの伝播
- VGWからRoute TableにBGP routeが自動で追加される
- 最も具体的なプレフィックスが優先される
- 手動で設定されたルートが優先される
- ローカルのルートが優先される
6-4. VPC Endpoint
- S3とDynamo DBにプライベートアクセス
- Gateway型エンドポイントと呼ばれる
- 通常、Internet Gateway経由で接続する
- Private SubnetではNAT経由
- VPC Endpointがあると、Private SubnetからGatewayを通り直接アクセス
- Route Tableには「pl-…」宛の通信がGatewayを向くようにルートが設定される
- リージョン毎に存在
- 1つのVPCに対して1つのGatewayが紐づく
- VPC Peering経由、VPN Connection経由では接続不可
- VPC内でPublicアドレスをPrivateなEndpointアドレスに解決することが必要
- Endpointポリシーで、IAMポリシーのようにアクセス制御が可能
6-5. AWS WAF
- AWS MarketPlaceではサードパーティ製WAFアプライアンスを購入可能
- WAFサンドイッチ
- WAFをスケールするためにAutoScalingポリシー下で実行する
- 2つのロードバランサ (ELB) 間に配置
- AWS WAF
- CloudFrontまたはELBにデプロイ可能
- SQLインジェクションやクロスサイトスクリプティングなどに対応するマネージドルール
- APIでコントロール可能
- CloudFrontでコンテンツのアクセス制限をかける方法
- オリジンアクセスアイデンティティを使用
- AWS WAFのIPホワイトリストを適用してアクセス制限
6-6. VPC Flow Logs
- VPCのネットワークログ
- CloudWatch Logsに保管
- VPC、Subnet、EC2 (ENI) で作成可能
- accepted、rejected、allを選んで記録可能
- 10分毎にログが公開される
- VPC Flow Logs用のIAM Roleが必要
- VPC Flow Logsサービスとの信頼関係も必要
- ログではENI、Source、Destination、Source Port、Destination portを判断可能
- Flow Logsは作成後に変更できない
- AWS DNSサーバへのトラフィックは記録されない
- Windowsライセンス認証のためのAWSライセンスサーバへのトラフィックは記録されない
- DHCPトラフィックは記録されない
- 予約されたデフォルトVPCルータへのトラフィックは記録されない
- インスタンスメタデータへのトラフィックは記録されない
- リアルタイムには記録されない
- CloudWatch Logsに出力するためにIAM Roleが必要
- ENIごとにログストリームができる
6-7. Analyze Firewall Rules
6-8. Proxy
- EC2からのインターネット接続にホストベースのアクセス制限をかけるにはProxy EC2が必須
- 可用性を持たせるには複数AZにまたぎ、ロードバランサと併用を検討する
6-9. Deep Packet Inspection
- 通常とは異なるトラフィックを検知して分析
- AWS MarketPlaceでサードパーティ製アプライアンスを購入することで、多くの場合分析が可能
- モニタリングはCloudWatch、CloudWatch Logs、VPC Flow Logsでも可能
7. Elastic Load Balancer
7-1. What is ELB?
- EC2インスタンスのトラフィックを負荷分散
- 複数のAZに存在するインスタンスに負荷分散可能
- リージョンをまたぐには複数ELBを用意してRoute53を併用
- ELBはALB、NLB、CLBの3種類
- ヘルスチェック機能があり、応答しないEC2インスタンスにはリクエストを送らない
- Internet-Facing ELB
- Route53でPublicホスト名をエイリアスレコードで解決
- Securuty GroupをELBにアタッチしてアクセス制御可能
- マネジメントコンソールからELBの種類を選択して作成
- さらに分散するAZと、ターゲットにするEC2を選択
7-2. Listener and Encryption
- HTTP/HTTPSリスナー
- port 1-65535でHTTPまたはHTTPSをサポート
- HTTPSリスナーは暗号化と復号化をELBにオフロード
- HTTPSはX.509 SSL証明書のデプロイが必要
- AWS Certificate Managerがデプロイに使える
- サードパーティー証明のためにCSRが必要
- 複数の証明書を、複数のドメインに利用
- Fixed-Response Actions
- 特定のターゲットグループにリクエストをforward可能 (リダイレクト)
7-3. Target Group
- TargetのTypeにEC2インスタンス、IPアドレス
- ALBの背後にLambdaを配置可能
- 同じインスタンスで複数のポートをTargetに指定可能
- slow_start.duaration_seconds
- 新しく登録されたターゲットに対しトラフィックをリニアに増やすよう、時間を指定
- スティッキーセッション
- Cookieを利用して同じターゲットと通信
7-4. Host Condition/Path Condition
- Host Conditions
- example.com (APEXの例)
- dev.example.com (特定ホストの例)
- test.example.com (特定ホストの例)
- *.example.com (ワイルドカードの例)
- example.com以外のトラフィックを指す
- Path Conditions
- /img/*
- /js/*
- .example.com/img/
7-5. Connection Draining
- ELBから登録解除したり、ヘルスチェック失敗したインスタンスへのリクエストを止める
- 止めつつも、処理中のリクエストはそのまま処理を続ける
- 期間は1秒から3600秒まで
- Auto ScalingはConnection Drainingを待つ
- 簡単に有効/無効を切り替えられる
7-6. X-Forwarded
- EC2から見るとELBのプライベートアドレスから全てのリクエストが来たように見える
- 本当はELBの前にいるクライアントのIPアドレスが知りたい場合が多い
- リクエストヘッダのX-Forwardedを見ればクライアントのIPアドレスが分かる
- ALB、CLBでサポート
- 有効/無効の特別な操作は不要
8. DNS with Route 53
8-1. Route 53
- DNSレコードの種類
- A: IPv4 IPアドレス
- AAAA: IPv6 IPアドレス
- CNAME: 別ホスト名 (APEXは指定不可)
- MX: Eメール
- NS: 別のネームサーバ
- Route 53
- AWSのDNSサービス
- エンドポイントのヘルスチェックに対応
- DNSは53番ポートで稼働
- Route53 Health Check
- 間隔は調整可能
- システムが冗長構成を取る場合に使える
- Weighted Routing Policy
- ホスト名に複数IPアドレスを紐付けておき、例えばWeb1に90%、Web2に10%などの重み付けをしてリクエストを振り分け
- Latency-Based Routing Policy
- ホスト名に複数IPアドレスを紐付けておき、レイテンシに基づいて振り分け
- Failover Routing Policy
- ホスト名に複数IPアドレスを紐付けておき、通常はActive EC2インスタンスにリクエストを振り分け
- ヘルスチェックに失敗する場合には、Standby EC2にリクエストを振り分ける
- ELBは複数のリージョンを跨いでリクエストを振り分けられず、リージョン跨ぎはRoute 53の出番
- GeoLocation Routing
- リクエスタの地理的位置に基づいてリクエストを振り分け
- Alias Record
- CNAMEによく似ている
- ELBにAPEXレコードを紐付けるのに使える
8-2. Register Domains on Route 53
- マネジメントコンソールで可能
- 登録後、レコードセットが編集可能に
8-3. Simple Routing Policy
- AレコードでALIASレコードを登録するには、Aliasにチェック入れる
- ELBの場合は、TargetにELBのホスト名を入れる
- APEXにALIASを入れる場合、解決したいホスト名は空欄にする
- AレコードでALIASを使わない場合、ValueにIPアドレスを入力する
8-4. Weighted Routing Policy
- 同じホスト名に複数のターゲットを紐付け、割合を設定すれば良い
- 動作確認は、クライアントのキャッシュを削除しながら実施
8-5. Latency-Based Routing Policy
- 同じホスト名に複数のターゲットを紐付け、低レイテンシの方に振り分けられる
8-6. Failover Routing Policy
- ヘルスチェックを設定する
- エンドポイントをモニターする設定にして、モニターするIPアドレスを指定すると、グローバルIP単位で監視可能
- ドメイン名をモニターする設定にすれば、Webサイト全体の監視可能
- 同じホスト名に複数のターゲットを紐付け、片方をPrimary、もう片方をSecondaryにする
- Primaryの方に、発動条件となるヘルスチェックを紐付ける
- Primaryに紐付けたヘルスチェックが発動すると、リクエストはSecondaryに振り分けられる
- PrimaryとSecondaryの両方がダウンすれば、もちろん接続できない
8-7. GeoLocation Routing Policy
- レコードに対してロケーションを指定
- 指定したロケーションに近い位置からのリクエストの場合、当該レコードで解決
8-8. Private Hosted Zone
- インターネット経由で解決するホスト名はPublic Hosted Zoneで解決
- プライベートネットワークでしか使わないホスト名はPrivate Hosted Zoneで解決
- Hosted Zoneを作る時にPrivateを選択すれば作成可能
- 複数のVPCを1つのZoneに割り当て、複数のVPCでZoneを共有
8-9. Hybrid DNS
- オンプレミスにDNSがあるとき、VPCにRoute 53 DNS Resolverを作って、オンプレミスからフォワードすることが可能
- Inbound Endpointを作れば良い
8-10. Route53 Alias Record for CloudFront
- 地理的に一番近いEdge locationにリクエストが割り振られる
9. CloudFront
9-1. What is CloudFront?
- CDN
- 例えばS3に置いてあるコンテンツを世界中に公開したいとき
- レイテンシが問題となる
- CloudFrontを使えばコンテンツのキャッシュを世界各地のエッジロケーションにばら撒ける
- 各地のユーザは一番近いエッジロケーションからコンテンツを受信するため低レイテンシとなる
- 設定したTTLが経過すると、エッジロケーションのコンテンツを最新化する
- 署名付きURLを使って、アクセス期限を設けることも可能
- セキュリティ
- AWS WAFとの併用
- AWS Certificate Manager
- オリジンアクセスアイデンティティ
- Distributionsはマネジメントコンソールで作成
- オリジンにS3、ELBまたはRoute53を指定可能
- Webディストリビューションで、シンプルなWebサイトのデータを配信
9-2. Distribution
- CloudFrontのマネジメントコンソールで、Distributionを作成
- Webを選択
- S3バケットのURLを指定
- オリジンアクセスアイデンティティに基づき、S3側でアクセス制限可能
9-3. HTTPS with CloudFront
- Viewer Protocol Policy
- Redirect HTTP to HTTPS
- HTTPS Only
- Origin Protocol Policy
- Match Viewer
10. Hybrid Cloud with Datacenter
10-1. Use Cases
- Disaster Recovery
- AWSをオンプレミスのDRサイトとして利用
- Cloud (Dynamic) Bursting
- ピーク時だけオンプレミスからAWSに拡張する
- Data Center Extension
- VPNでAWS VPCに接続し、オンプレミスのデータセンタを常時AWSに拡張
- 1つのデータセンタのように使う
- AWSはISOやPCIなどの多くのコンプライアンスを満たしたデータセンタである
10-2. Software VPN
- Public SubnetにVPN Softwareを導入したEC2を準備し、EIPを付与
- Route Tableでオンプレミス宛通信を上記EC2に向けるルートを作成
- Internet Gateway経由でオンプレミスとVPNを張る
- コンプライアンスに応じて準備できる
- EC2インスタンスを準備する必要があり、停止すれば接続断となってしまう
- 複数AZにまたがってVPN EC2を構築し、高可用性をもたせることは可能
10-3. Hardware (Managed) VPN
- オンプレミス側データセンタにVPNルータを置き、AWS VPC側のVirtual Private Gateway (VGW) との間でVPNを接続
- 設定が簡単
- 管理も不要
- 高い可用性
- DirectConnectと併用可能
- 通信データ量にかかる金額はDirectConnectの方が安い
10-4. Static Hardware VPN
- BGPがサポートされない環境ではStaticルーティング
- Customer Gateway (CGW) を作成
- Staticを選び、オンプレミスのルータのグローバルIPを指定
- VGWを作成
- VPN Connectionをオンプレミスのルータ (GGW) とVGW間で作成
- Site-to-Site VPN
- Staticを選択
- Static IP Prefixでオンプレミス側のネットワークアドレスを記入
- VPN Tunnel Optionsで169.254.0.0/16から/30でアドレス指定
- 予約されているアドレスは指定不可
- Route TableでVGWからのPropagateをONにする
- オンプレミスのルータに応じたコンフィグをダウンロードして、オンプレミス側で設定
10-5. BGP
- 各ネットワークをつなぐには、ルータ間でBGP PEERを結ぶ
- 互いのネットワークの経路情報を交換 (共有)
- Weight and AS Path
- Weight: 32768 (デフォルト)
- 同じ宛先でもWeightを変えることで優先付けが変わる
- Next HopとAS Pathを指定
10-6. BGP Hardware VPN
- VPNをAWS側の2つのエンドポイントとの間で張る
- エンドポイントは異なるハードウェアであり冗長性がある
- Customer Gateway (CGW) を作成
- Dynamicを選び、オンプレミスのルータのグローバルIPを指定
- VGWを作成
- Route TableでVGWからのPropagateをONにする
- VPN Connectionをオンプレミスのルータ (GGW) とVGW間で作成
- Dynamicを選択
- VPN Tunnel Optionsで169.254.0.0/16から/30でアドレス指定
- 予約されているアドレスは指定不可
- オンプレミスのルータに応じたコンフィグをダウンロードして、オンプレミス側で設定
10-7. VPN BGP Routing
- 構成例
- AWS側に2つのエンドポイントのグローバルIPアドレス
- 各TunnelにAWSのネットワークアドレス
- オンプレミス側ルータに1つのグローバルIPアドレス
- Tunnelの両端にTunnelネットワークアドレスからIPアドレスをアサイン
- オンプレミス側ルータの設定例
- 自身のプライベートネットワークに、Weight:32768、AS Path:i
- AWS側ネットワークアドレスに、Weight:0、AS Path:64512,i
- Next HopはTunnelの対向アドレス
- AWS側ルータは上記の逆となる
10-8. CloudHub
- 構成例
- AWS側 (ASN 64512)
- オンプレミスA (ASN 65000)
- オンプレミスB (ASN 65001)
- AWS側では、オンプレミスAとBに対するルートを持つ
- Next HopとAS Pathは適切に設定される
- オンプレミスBからAへのルート
- 宛先がオンプレミスAの時のNext HopをVGWに向ける
- AS Path: 64512,65000,i
- VGWを介してオンプレミスAとBが接続されるためCloudHubと呼ぶ
- AS番号は必ず分ける
10-9. Transit VPC
- 多くのVPCを接続するシチュエーション
- Transit VPCを作成し、中にSoftware VPNソリューション on EC2を作成
- その他多くのVPCでVGWを作成
- 全てのVGWとEC2の間でVPNを接続
- BGPで接続
- AS番号を適切に設定
- なぜVPC Peeringではだめなのか
- VPC PeeringのGatewayがNext Hopとなってしまう
10-10. Security Group over Region
- リージョンをまたいでSecurity Group IDを参照不可
- リージョンをまたぐ場合はIPアドレスレンジを指定してアクセス制御
10-11. Private EMR
- S3にデータを置く場合、S3 Endpointと併用する
10-12. Workspaces
- 異なるAZにある2つのPrivate Subnetと、1つのPublic Subnetの構成を推奨
- インターネット接続はNAT Gateway経由を推奨
- VPN経由で接続する場合1200 MTUを最低でも確保
11. Direct Connect
11-1. What is Direct Connect?
- VPC-VGW-Direct Conect location-オンプレミス
- Ditect Connect locationよりも左がAWS側のバックボーン
- VPNよりは複雑で、プロビジョニングには時間がかかる
- 冗長性を持たせるには、複数接続を作る必要あり
- 初期費用がVPNよりも高価
- ただしデータ通信量にかかる費用はVPNやInternet Gateway経由より安価
- 標準では暗号化されていない
- AWSのハードウェアVPNをDirect Connect上で利用可能
- 予測可能で低遅延なパフォーマンス
- DXと略される
- AWSサービスと接続するにはDX接続とVIFが必要
11-2. High Availability
- オンプレミスとAWSの間で高い冗長性を待たせる方法
- 一番高性能なのは、異なるDirect Connect locationを経由して2本のDirect Connectを接続すること
- 2本のDirect ConnectをVGWに接続
- オンプレミス側ルータも2台用意
- 副回線としてIPSec VPNを引くことでも冗長性を確保できる
- コストパフォーマンスはDXとVPNの併用の方が安価
11-3. Connection
- 構成
- Direct Connect locationにAWS側のDXルータと顧客のルータが配置される
- それぞれ別のラックに配置
- オンプレミス側データセンタとDirect Connect location間はWAN接続
- AWS側のDXルータとVGW間は、AWSのプライベートバックボーンで高速に接続
- 複数のVirual InterfaceとVLANを作成可能
- 設定の流れ
- Direct Connectを、AWS VGWとAWS側DXルータ間で作成するため、接続を要求
- AWSがリクエストを処理すると、Letter of Authorization and Connecting Facility Assignment (LOA-CFA) がダウンロード可能に
- メールが届くので確認
- AWSからの接続承認
- LOA-CFAはAWSマネジメントコンソールでダウンロードする
- LOA-CFAをコロケーションプロバイダと共有
- コロケーションプロバイダと連絡を取り合う必要あり
- AWS側DXルータと顧客ルータをクロスコネクト接続
- (だいたい) 5営業日以内には接続完了 ※プロバイダによる
- 以上で接続は完了
- ただし実際にAWS VPCと接続するには次項のVirtual Interface (VIF) が必要
11-4. Private Virtual Interface
- 前項までの通りDX接続が完了したらVIFを作成
- マネジメントコンソールで新しくVIFを作成
- VIFを作成すると、単一のVLANがVGWと顧客ルータの間に張られる
- VIFを作成するために必要なもの
- VGW (VIFを終端)
- 仮想インタフェースを保有するAWSアカウント
- VLAN ID
- BGP ASN
- AWS側ルータのピアIP
- オンプレミス側ルータのピアIP
- VIF作成後、オンプレミス側ルータ用の設定ファイルをダウンロード
- オンプレミス側ルータとVGWの間でBGPによる接続
- Route Tableでルート伝播を有効化する
11-5. Public Virtual Interface
- S3やDynamo DBのようなAWSサービスにDirect Connectで接続する場合にPublic VIFを使用
- VIFを作成するために必要なもの
- 仮想インタフェースを保有するAWSアカウント
- VLAN ID
- BGP ASN
- AWS側ルータのピアIP
- オンプレミス側ルータのピアIP
- VIF作成後、オンプレミス側ルータ用の設定ファイルをダウンロード
11-6. Hosted Connection
- Direct Connect locationに自社のルータを持たない場合、自社独自にクロスコネクト接続ができない
- そこでDirect Connectパートナー (日本では回線業者)の設備を利用して接続する
- 接続方法
- Direct Connectパートナーとコンタクトを取る
- 回線速度、ロケーションを指定
- ホスト型接続ではVLANは1つのみ
- VLANの設定はコントロールできない
- VIFも1つであり、接続ごとにPublic or Private
- 別のVIFが必要となった場合は、新たにホスト型接続を作る
- 通常の接続と比べると、柔軟性が劣るものの、特にDirect Connect location周りの設備投資が不要であり、必要な接続に対して利用料を支払うだけで良く、低コストとなる
12. Disaster Recovery
12-1. Tactics
- オンプレミスのリカバリサイトとしてAWSを利用する
- RPOとRTOを考える
- RTOは、どれだけの時間でシステムを復旧するか
- RPOは、いつの状態に戻せるようにするか
- リストアは定期的にリハーサルしておく
12-2. Backup and Restore
- プライマリサイトとリカバリサイトを用意する
- サーバ、ハイパーバイザー、ストレージを構成する各ハードウェアを物理的(地理的)にも分離させる
- プライマリサイトがダウンした時に、リカバリサイトで稼働を継続することを考える
- プライマリサイトがオンプレミスにある場合、リカバリサイトをAWSに配置することを考える
- ストレージのバックアップには、AWS MarketPlaceで販売されているサードパーティ製アプライアンスが使える
- CloudBerry等が候補
- オンプレミスからS3にバックアップ
- S3のライフサイクルポリシーで、バックアップをGlacierに移動すれば低コストで管理
- AWS上に新たなEC2を立て、S3からデータを復旧
- AWS上のリカバリサイト構築には手動の操作が多くなるため、すぐ起動できるようにCloudFormationを準備しておく
- AWS上のCold Standbyコストを節約
- EC2、ELB、RDS等を含み複雑な構成であってもすぐに起動できる
12-3. Pilot Light
- AWS上リカバリサイトでは、システムの重要なデータや機能 (例えばコンテンツ、RDS) だけを常にホストしておく
- コンテンツやデータベースは、AWS上に常に同期
- その他サーバ群はAMIを取り、セキュリティパッチ等を最新に維持しておく
- 災害時はAMIからEC2を起動し、コンテンツは同期していたもので置き換え、データベースは接続するだけ
- 都度の起動よりも手順を簡略化する方法としては、Auto Scaling Groupを設定して常時max=mix=0にしておき、有事に設定値を上げるのが良い
- 最後にDNSをプライマリサイトからリカバリサイトに切り替える
12-4. Warm Standby
- AWS側のリカバリサイトでも、常にプライマリサイトの構成を起動
- AWS上リカバリサイトが低コストになるように、各層のEC2は低スペックにする
- Auto Scaling Groupで起動しておくのが有効
- 有事はAuto ScalingでEC2の台数を増やしてリクエストをさばく
- データベースやコンテンツは常にプライマリサイトとリカバリサイトで同期
- 有事にはRoute 53のFailover Routingで切り替える
- プライマリサイトとリカバリサイトでは性能差が出るため、Weighted Routingをする場合は90:10など差をつける
12-5. Multi-Site
- AWS側のリカバリサイトでも常時プライマリサイトと同性能を確保し、有事でも稼働を継続する
- Active/Activeで起動する
- Route 53のWeighted Routingをプライマリサイトとセカンダリサイトで50:50にする
- AWS側のリカバリサイトをStandbyにする場合は、Failover Routingを使用
- 切替直後からフル性能を発揮できる
最後に
AWSの東京リージョンがリリースされてから約10年が経過していますが、昔からあるAWSのサービスは続々と機能がアドオンされ、高機能化してきました。
また、新たにリリースされるサービスの中には、既存のサービスをより使いやすくする目的のものもあります。
なぜ新たにリリースされたサービスが有益であるかを理解するには、既存のサービスの概念や仕組みを理解する必要があるでしょう。
ただ、10年という年月の中で積み上がった概念や仕組みはさすがに巨大であり、何も考えなければ、振り返るのは大変だと感じていました。
そこで一念発起し、後からでも長年の積み重ねを少しでも短時間で振り返ることができるように、まとめてみました。記事中にまとめた内容は、ほぼ公式サイトやホワイトペーパーを参考にしています。
万が一内容に誤りがあれば、お知らせいただければと思います。参考文献
AWS Whitepapers & Guides (※英語版の方が最新)
- 投稿日:2019-12-21T23:48:40+09:00
k8s deschedulerを使いこなしてスムーズなオートスケールを実現する
この記事は基本的にGKEでの利用を想定して解説していますが、AWS等他のプロバイダでも大きくは変わりません。適時読み替えてもらえると。
クラスタオートスケーラーの課題点
kubernetesでNodeのオートスケールは、ざっくり説明すると以下のような流れになる訳ですが・・・
- Podの負荷が上がり、HPAによって新しいPodがスケジューリングされる
- PodをスケジューリングさせるためのNodeが不足して、新しいNodeが立ち上がる
- 新しいNodeにPodが立ち上がる
このスケーリングには少々問題がありまして、新しいNodeがすぐに有効活用されるかと言えば、そうでも無いんですよね・・・
時間が経つに連れて新しいNodeにもPodが増えますし、負荷も分散されて行くでしょう。しかし、すでに負荷が上がりきっている既存Nodeに配置されているPodが再スケジューリングされる訳では無いので、急なスパイク等には対応できません。GKEだとNodeの立ち上がり自体は早いんですけどね・・・
deschedulerで負荷が高いNodeのPodを再スケジューリングする
そこでdeschedulerの出番です。deschedulerは条件に応じてPodを削除するためのリソースですね。
https://github.com/kubernetes-sigs/descheduler
上手く利用することで、負荷の高いNodeから負荷の低いNodeにPodを移動させることが可能になります。
導入
基本的にはGithubのREADMEに書いてある通りに進めればOKです
Docker Imageの作成
以下にImageの作成方法が説明してあります。
https://github.com/kubernetes-sigs/descheduler#running-descheduler-as-a-job-inside-of-a-pod
Imageが完成したら、GCPならGCR、AWSだったらECR等に適当にアップロードします。
権限周りの設定
各クラスタに応じて、権限周りの設定を行います。適宜必要な設定を済ませておいて下さい。
https://github.com/kubernetes-sigs/descheduler#create-a-cluster-role
ConfigMapによるDeschedulerPolicyの設定
deschedulerにはいくつかの機能が搭載されていますが、今回利用するのはLowNodeUtilizationという機能です。Nodeの消費済みリソースを閾値としてPodを再スケジューリングさせるものですね。
https://github.com/kubernetes-sigs/descheduler#lownodeutilization
LowNodeUtilizationには、二つの設定項目があります。一つ目は
thresholdsで、再スケジューリング先Nodeの条件を指定するものです。もう一つはtargetThresholdsで、これはPodを削除するNodeの条件を指定します。以下は設定の一例です。apiVersion: "descheduler/v1alpha1" kind: "DeschedulerPolicy" strategies: "LowNodeUtilization": enabled: true params: nodeResourceUtilizationThresholds: thresholds: "cpu" : 20 "memory": 30 "pods": 10 targetThresholds: "cpu" : 60 "memory": 80 "pods": 15ちょっと分かりにくいので細分化して説明します。
thresholdsの詳しい説明
まず、上の例で
thresholdsは"cpu": 20、"memory": 30、"pods": 10となっていますね。
これは日本語で説明すると、「リクエスト済みのリソースがNodeの総リソースに対してCPUが20%以内、メモリが30%以内、尚且つ配置済みのPodが10台以内のNodeを再スケジューリング対象とする」と、なります。ここで注意して欲しいのは、cpuとmemoryは割合であること、podsは台数であること、そして、全ての条件を満たすNodeだけが対象になるということです。targetThresholdsの詳しい説明
次に、
targetThresholdsは"cpu": 60、"memory": 80、"pods": 15となっていますね。これも日本語で説明すると、「リクエスト済みのリソースがNodeの総リソースに対してCPUが60%以上、メモリが80%以上、あるいは配置済みのPodが15台以上のNodeをPod削除対象とする」と、なります。注意点としては、cpu、memory、pods、3つの項目の内、いずれか一つの項目を満たせば対象になるという点です。例えばリクエスト済みのcpu率が60%を超えていれば、memoryが20%とかでも対象になります。ConfigMapとして登録する
DeschedulerPolicyをConfigMapとしてクラスタに登録します。
apiVersion: v1 kind: ConfigMap metadata: name: descheduler-policy-configmap namespace: kube-system data: policy.yaml: | apiVersion: "descheduler/v1alpha1" kind: "DeschedulerPolicy" strategies: "LowNodeUtilization": enabled: true params: nodeResourceUtilizationThresholds: thresholds: "cpu" : 20 "memory": 30 "pods": 10 targetThresholds: "cpu" : 60 "memory": 80 "pods": 15再スケジューリング処理を実行するためのCronJobを定義
公式のGithubにはJobを使った方法が紹介されていますが、実際に運用する場合はCronJobで実行させることになるでしょう。以下CronJob定義の一例です。
apiVersion: batch/v1beta1 kind: CronJob metadata: name: descheduler-job namespace: kube-system spec: schedule: "*/30 * * * *" jobTemplate: spec: template: metadata: name: descheduler-pod annotations: scheduler.alpha.kubernetes.io/critical-pod: "" spec: containers: - name: descheduler image: gcr.io/project/descheduler:v1 # アップロードしたimageを指定 volumeMounts: - mountPath: /policy-dir name: policy-volume command: - "/bin/descheduler" args: - "--policy-config-file" - "/policy-dir/policy.yaml" - "--v" - "3" restartPolicy: "Never" serviceAccountName: descheduler-sa volumes: - name: policy-volume configMap: name: descheduler-policy-configmapたくさんのPodが同時に再スケジューリングされるのを防止する
deschedulerのJobを実行すると、対象となるPodが複数ある場合に多くのPodが同時に再スケジューリングされてしまう可能性があります。そこで、
PodDisruptionBudgetを定義して同時に再スケジューリングされるPodを制限します。以下の例だと、対象のdeploymentに属するPodは同時に2台までしか再スケジューリングされなくなります。apiVersion: policy/v1beta1 kind: PodDisruptionBudget metadata: name: sample-pdb spec: maxUnavailable: 2 selector: matchLabels: app: sample # deployment等のlabelを指定まとめ
クラスタオートスケーラーでの利用を想定したdeschedulerの運用方法や、設定項目の詳細に関して紹介させてもらいました。
設定項目に関しては、ちょっと分かりづらい上に、公式のドキュメントにも詳細な挙動が説明されていないので自前で色々検証しました。個人的な不満点としては、deschedulerの対象とするリソースを選択できない点でしょうか。例えば、特定のdeploymentだけdeschedulerによる再スケジューリングの対象にしたい、kube-systemに属するPodは対象にしたくないといった用途に対応できないですね。一応、
Critical podsやDeamonSetは対象外になるなど、ある程度制限はされているみたいですが、こちら側で柔軟な選別は現状出来なさそうです。https://github.com/kubernetes-sigs/descheduler#pod-evictions
絶賛開発中みたいなので、今後にも期待したいです。
- 投稿日:2019-12-21T23:48:40+09:00
k8s Deschedulerを使いこなしてスムーズなオートスケールを実現する
この記事は基本的にGKEでの利用を想定して解説していますが、AWS等他のプロバイダでも大きくは変わりません。適時読み替えてもらえると。
クラスタオートスケーラーの課題点
kubernetesでNodeのオートスケールは、ざっくり説明すると以下のような流れになる訳ですが・・・
- Podの負荷が上がり、HPAによって新しいPodがスケジューリングされる
- PodをスケジューリングさせるためのNodeが不足して、新しいNodeが立ち上がる
- 新しいNodeにPodが立ち上がる
このスケーリングには少々問題がありまして、新しいNodeがすぐに有効活用されるかと言えば、そうでも無いんですよね・・・
時間が経つに連れて新しいNodeにもPodが増えますし、負荷も分散されて行くでしょう。しかし、すでに負荷が上がりきっている既存Nodeに配置されているPodが再スケジューリングされる訳では無いので、急なスパイク等には対応できません。GKEだとNodeの立ち上がり自体は早いんですけどね・・・
deschedulerで負荷が高いNodeのPodを再スケジューリングする
そこでdeschedulerの出番です。deschedulerは条件に応じてPodを削除するためのリソースですね。
https://github.com/kubernetes-sigs/descheduler
上手く利用することで、負荷の高いNodeから負荷の低いNodeにPodを移動させることが可能になります。
導入
基本的にはGithubのREADMEに書いてある通りに進めればOKです
Docker Imageの作成
以下にImageの作成方法が説明してあります。
https://github.com/kubernetes-sigs/descheduler#running-descheduler-as-a-job-inside-of-a-pod
Imageが完成したら、GCPならGCR、AWSだったらECR等に適当にアップロードします。
権限周りの設定
各クラスタに応じて、権限周りの設定を行います。適宜必要な設定を済ませておいて下さい。
https://github.com/kubernetes-sigs/descheduler#create-a-cluster-role
ConfigMapによるDeschedulerPolicyの設定
deschedulerにはいくつかの機能が搭載されていますが、今回利用するのはLowNodeUtilizationという機能です。Nodeの消費済みリソースを閾値としてPodを再スケジューリングさせるものですね。
https://github.com/kubernetes-sigs/descheduler#lownodeutilization
LowNodeUtilizationには、二つの設定項目があります。一つ目は
thresholdsで、再スケジューリング先Nodeの条件を指定するものです。もう一つはtargetThresholdsで、これはPodを削除するNodeの条件を指定します。以下は設定の一例です。apiVersion: "descheduler/v1alpha1" kind: "DeschedulerPolicy" strategies: "LowNodeUtilization": enabled: true params: nodeResourceUtilizationThresholds: thresholds: "cpu" : 20 "memory": 30 "pods": 10 targetThresholds: "cpu" : 60 "memory": 80 "pods": 15ちょっと分かりにくいので細分化して説明します。
thresholdsの詳しい説明
まず、上の例で
thresholdsは"cpu": 20、"memory": 30、"pods": 10となっていますね。
これは日本語で説明すると、「リクエスト済みのリソースがNodeの総リソースに対してCPUが20%以内、メモリが30%以内、尚且つ配置済みのPodが10台以内のNodeを再スケジューリング対象とする」と、なります。ここで注意して欲しいのは、cpuとmemoryは割合であること、podsは台数であること、そして、全ての条件を満たすNodeだけが対象になるということです。targetThresholdsの詳しい説明
次に、
targetThresholdsは"cpu": 60、"memory": 80、"pods": 15となっていますね。これも日本語で説明すると、「リクエスト済みのリソースがNodeの総リソースに対してCPUが60%以上、メモリが80%以上、あるいは配置済みのPodが15台以上のNodeをPod削除対象とする」と、なります。注意点としては、cpu、memory、pods、3つの項目の内、いずれか一つの項目を満たせば対象になるという点です。例えばリクエスト済みのcpu率が60%を超えていれば、memoryが20%とかでも対象になります。ConfigMapとして登録する
DeschedulerPolicyをConfigMapとしてクラスタに登録します。
apiVersion: v1 kind: ConfigMap metadata: name: descheduler-policy-configmap namespace: kube-system data: policy.yaml: | apiVersion: "descheduler/v1alpha1" kind: "DeschedulerPolicy" strategies: "LowNodeUtilization": enabled: true params: nodeResourceUtilizationThresholds: thresholds: "cpu" : 20 "memory": 30 "pods": 10 targetThresholds: "cpu" : 60 "memory": 80 "pods": 15再スケジューリング処理を実行するためのCronJobを定義
公式のGithubにはJobを使った方法が紹介されていますが、実際に運用する場合はCronJobで実行させることになるでしょう。以下CronJob定義の一例です。
apiVersion: batch/v1beta1 kind: CronJob metadata: name: descheduler-job namespace: kube-system spec: schedule: "*/30 * * * *" jobTemplate: spec: template: metadata: name: descheduler-pod annotations: scheduler.alpha.kubernetes.io/critical-pod: "" spec: containers: - name: descheduler image: gcr.io/project/descheduler:v1 # アップロードしたimageを指定 volumeMounts: - mountPath: /policy-dir name: policy-volume command: - "/bin/descheduler" args: - "--policy-config-file" - "/policy-dir/policy.yaml" - "--v" - "3" restartPolicy: "Never" serviceAccountName: descheduler-sa volumes: - name: policy-volume configMap: name: descheduler-policy-configmapたくさんのPodが同時に再スケジューリングされるのを防止する
deschedulerのJobを実行すると、対象となるPodが複数ある場合に多くのPodが同時に再スケジューリングされてしまう可能性があります。そこで、
PodDisruptionBudgetを定義して同時に再スケジューリングされるPodを制限します。以下の例だと、対象のdeploymentに属するPodは同時に2台までしか再スケジューリングされなくなります。apiVersion: policy/v1beta1 kind: PodDisruptionBudget metadata: name: sample-pdb spec: maxUnavailable: 2 selector: matchLabels: app: sample # deployment等のlabelを指定まとめ
クラスタオートスケーラーでの利用を想定したdeschedulerの運用方法や、設定項目の詳細に関して紹介させてもらいました。
設定項目に関しては、ちょっと分かりづらい上に、公式のドキュメントにも詳細な挙動が説明されていないので自前で色々検証しました。個人的な不満点としては、deschedulerの対象とするリソースを選択できない点でしょうか。例えば、特定のdeploymentだけdeschedulerによる再スケジューリングの対象にしたい、kube-systemに属するPodは対象にしたくないといった用途に対応できないですね。一応、
Critical podsやDeamonSetは対象外になるなど、ある程度制限はされているみたいですが、こちら側で柔軟な選別は現状出来なさそうです。https://github.com/kubernetes-sigs/descheduler#pod-evictions
絶賛開発中みたいなので、今後にも期待したいです。
- 投稿日:2019-12-21T23:24:22+09:00
AWS MediaPackage+SPEKEでHLS-AES 128な動画をパッケージング&配信
どうもこんにちは。
みなさん、「動画配信」やって行っていますか?
僕は最近AWSで動画をいじくりまわすシステムを作ってました。
多分これを読んでいるストリーミング畑のあなたはご存知だと思いますが、AWSにはElemental Serviceという総称で動画をいじれる機能があます。ライブ配信・パッケージング・DRM・ABR・オンプレのエンコーダとの連携などなど。
今回は、Elementalの機能の1つであるAWS SPEKEという便利機能について紹介します。AWS SPEKEとは
公式ドキュメント https://docs.aws.amazon.com/speke/latest/documentation/what-is-speke.html
SPEKE = Secure Packager and Encoder Key Exchange
簡単にまとめると、動画のパッケージャ(AWS Elemental)とDRMエンクリプタ間で、DRMキーなどの情報をセキュアにやりとりできる仕様のことです。
SPEKEが定めるI/OインターフェースにのっとってDRM情報(キーやHLS AESのURL)を返すサーバを実装すると、AWS Elementalと連携して動画をDRMすることができます。Multi DRMに対応していたりと、AWSでDRMするハードルを下げてくれる便利ツールです。もうちょっとわかりやすくまとめると、パッケージングは今まで通りAWS Elementalに任せて
DRMに必要な暗号化キーなどの情報の生成を、こっち側で作ったサーバにオフロードできるようになるということですね(オフロードの本来の意味と少しずれますがイメージ的に)。これによって動画ごとにユニークなキーを生成できたり、キーのプロバイダをクラウド・オンプレ好きな場所に構築することができるようになり、色々ハッピーなことが起こります。
SPEKEを使ってみよう
https://docs.aws.amazon.com/speke/latest/documentation/standard-payload-components.html
SPEKEはDASH IFのCPIX(Content Protection Information eXchange)という仕様をラップしています(という認識ですが、間違ってたら教えてください)。
DASH IF CPIXについての説明はこちら https://docs.unified-streaming.com/documentation/drm/cpix_intro.html
(公式のドキュメントではありませんが、分かりやすかったのでUnified Streaming社のドキュメントを貼ってます)CPIXはDRMに必要な情報をXMLベースでやりとりする仕様らしいです。正直あんまりよく分かってないんですがドキュメントに書いてある通りにデータを送ればだいたい動くので神です。
SPEKEにおいても、基本的にCPIXにのっとってXMLでデータをやりとりします。公式にVOD動画をパッケージングするときのリクエスト・レスポンス例が載っているので今回はこれを参考に
HLS AES 128で暗号化してみたいと思います。
VOD Workflow Method Call Examples - https://docs.aws.amazon.com/speke/latest/documentation/vod-workflow-methods.html1. SPEKE準拠なキーサーバを実装
いきなりですが今回実装したコードを置いちゃいます。
https://github.com/OdaDaisuke/aws-speke下記のリファレンス実装を参考にやって行きました。
awslabs/speke-reference-server - https://github.com/awslabs/speke-reference-server基本的には、リクエストで受け取ったCPIXのXMLを埋めていく処理を書くだけです。
詳しい処理については後述のステップで解説していきます。さて、キーサーバのセットアップですが今回はLambda + API Gatewayで行なっていきます。
上記コードをLambdaにアップしたら、以下のスクショにならって環境変数を設定しましょう。
KEY_STORE_BASE_URLは、HLSのマニフェストファイルのext-x-keyのベースURLになります。事前に空のバケットを作って外部からアクセスできるようにACLなど設定しましょう。
2番目のKEY_STORE_BUCKETはClearKeyを保存するバケットの名前です。そしたら、Lambda用のロールを作成して設定してあげます。この時S3とMediaPackageとAPI Gatewayの操作ポリシーを指定してあげます。
また、同時にAPI Gatewayもセットアップして適当な名前のエンドポイントでキーサーバを叩けるようにしていきますが、今回はリファレンス実装にならってcopy_protectionというエンドポイントを作りました。ちなみにこのキーサーバはAWS内部から叩けられればOKなので外部には公開しなくて大丈夫です。
※説明が駆け足ですいません..
2. Role作成
SPEKEはMedia Live、Media Packageと連携することができますが、今回はMediaPackageと連携してみます。
最初にMediaPackageのRoleを作成します。
現在ロール作成時にデフォルトでMediaPackageを選択することができないので、最初にMediaConvertのロールとして作成した後
以下のように「信頼されたエンティティ」をmediapackage.aws.comに変更、さらにMediaPackageのFullAccessポリシーをアタッチしてください。
3. MediaPackageでパッケージング
まずは下記スクショのPackaging groupsというところから適当な名前でパッケージグループを作成してください。
次にHLS AES128のパッケージング設定を作成します。
General Settingsはこのように、
Enable Encryptionにはチェックを入れ、追加で出てくる入力フォームはこのような設定に。
Constant Initialization Vectorは、先述したIVのことで、適当な値をUUID形式で入れておけばOKです。
Key server URLには先ほど作成したキーサーバのAPI GatewayのURLを、
Role Arnには先ほど作成したMedia PackageのARNを入れ、
最後にSystem IDを設定。このSystem IDですが、HLS AESは正確にはDRMではないためSystem IDは定義されていないので、適当な値をUUID形式で入力しておきます。今回はコード側 https://github.com/OdaDaisuke/aws-speke/blob/master/src/server_response_builder.py#L13 で定義した81376844-f976-481e-a84e-cc25d39b0b33という値を設定してみました。ここまできたらパッケージングの設定は完璧です。
Save Settingを押して次に進みます。Ingest Asset
再びMediaPackageのホーム画面に戻り、
Asset->Ingest Assetに進みます。
パッケージングしたい動画があるバケットを選択し、IAM Roleには先ほど作成したMedia Packageのロールを選択します。ページ中程にある
Asset Detailsは、m3u8ファイルを選択しましょう。この時親子構造のマニフェストでなければパッケージングできないので注意です。詳しくは、https://qiita.com/daisukeoda/items/1eecfd639aeae6f1026c を参照。
最後のPackaging settingsは、先ほど作成したパッケージング設定を選択。
そして最後に「Ingest assets」を押せば、あとは勝手にDRMしつつパッケージングしてくれます。
ボタンを押したあとは下記のようにAssetsの項目が増えているはず。
最後に、項目のタイトルをクリックしてみるとこのようにPlayback details欄に再生URLが表示されているのでテスト再生してみましょう。
HLSなのでSafariで再生テストしたいわけですが、Media Packageのurlをそのまま入力するとクロスオリジンの設定で弾かれてしまうので、Whitelistに
Originを設定したCloud Frontを噛まします。そしたら、この https://videojs.github.io/videojs-contrib-hls/ HLS.jsのテストプレーヤをsafariで開き、urlを入力。
指定のurlに向かってキーがリクエストされ、復号して再生できていれば完璧です。
4. キーサーバの処理について
SPEKEキーサーバのログをみてみると、以下のようなリクエストを受け取っています。
<?xml version="1.0" encoding="UTF-8"?> <cpix:CPIX xmlns:cpix="urn:dashif:org:cpix" xmlns:pskc="urn:ietf:params:xml:ns:keyprov:pskc" xmlns:speke="urn:aws:amazon:com:speke" id="コンテンツID"> <cpix:ContentKeyList> <cpix:ContentKey kid="00112233-4455-6677-8899-aabbccddeeff"></cpix:ContentKey> </cpix:ContentKeyList> <cpix:DRMSystemList> <cpix:DRMSystem kid="00112233-4455-6677-8899-aabbccddeeff" systemId="81376844-f976-481e-a84e-cc25d39b0b33"> <cpix:PSSH /> <cpix:ContentProtectionData /> <cpix:URIExtXKey /> <speke:KeyFormat /> <speke:KeyFormatVersions /> <speke:ProtectionHeader /> </cpix:DRMSystem> </cpix:DRMSystemList> </cpix:CPIX>そしてレスポンスは以下のようなXMLです。
<cpix:CPIX xmlns:cpix="urn:dashif:org:cpix" xmlns:pskc="urn:ietf:params:xml:ns:keyprov:pskc" xmlns:speke="urn:aws:amazon:com:speke" id="コンテンツID"> <cpix:ContentKeyList> <cpix:ContentKey explicitIV="IV(UUID形式)のHEXバイナリをbase64した文字列" kid="00112233-4455-6677-8899-aabbccddeeff"> <cpix:Data> <pskc:Secret> <pskc:PlainValue>暗号化キー(UUID形式)のHEXバイナリをbase64した文字列</pskc:PlainValue> </pskc:Secret> </cpix:Data> </cpix:ContentKey> </cpix:ContentKeyList> <cpix:DRMSystemList> <cpix:DRMSystem kid="00112233-4455-6677-8899-aabbccddeeff" systemId="81376844-f976-481e-a84e-cc25d39b0b33"> <cpix:URIExtXKey>キーurlをbase64エンコードした文字列</cpix:URIExtXKey> <speke:KeyFormat>aWRlbnRpdHk=</speke:KeyFormat> <speke:KeyFormatVersions>MQ==</speke:KeyFormatVersions> </cpix:DRMSystem> </cpix:DRMSystemList> </cpix:CPIX>記事の最初の方に書いた、CPIXのXMLですね。
意味を軽く説明してみますと、
cpix:ContentKeyListのexplicitIVは、AES128またはSAMPLE AESでの暗号化の時に使うもので、CBCブロック暗号化の際に使う初期化ベクトルです。MediaPackageでIVを設定していればリクエスト時にexplicitIV属性に値が入ってくるのかと思ったんですが、どうも何も入っていなかったですね、、、(バグなのか??)。pskc:PlainValueはコンテンツの暗号化キーが入ります。
cpix:DRMSystemListの配下の要素には、DRMに使う情報を格納します。今回の場合(AES)だとURIExtXkey、KeyFormat、KeyFormatVersionsだけ必要なのでそれらの情報を埋めてあげます。
cpix:PSSHとcpix:ContentProtectionDataとspeke:ProtectionHeaderはHLS AESの際には必要ないので、要素ごと削除してレスポンスしている感じです。これらはWidevineやPlayReadyでDRMする際に共通して必要になってきますが、今回は解説しません。以上、SPEKEの最低限の説明でした。今回は説明をわかりやすくするためキーをS3にそのまま保存してましたが、本当はSSEモードで保存したり、Secrets Managerで保存させるなどセキュアに管理した方が良いと思います?♂️。
まとめ
HLS AESにおける処理を紹介してみましたが、SPEKEは他にもWidevineやPlayReady、FairplayなどのメジャーDRMに対応していたり、キーの回転やキー暗号化など、色々なことができます。
まだまだ技術が枯れておらず、そもそものDRMの仕組みを知っていないと実装にかなり苦戦しますが、結構便利な機能だと思いました。
よきDRMライフを。











- 投稿日:2019-12-21T23:24:22+09:00
AWS SPEKEでHLS-AES 128な動画をパッケージング&配信
どうもこんにちは。
みなさん、「動画配信」やって行っていますか?
僕は最近AWSで動画をいじくりまわすシステムを作ってました。
多分これを読んでいるストリーミング畑のあなたはご存知だと思いますが、AWSにはElemental Serviceという総称で動画をいじれる機能があます。ライブ配信・パッケージング・DRM・ABR・オンプレのエンコーダとの連携などなど。
今回は、Elementalの機能の1つであるAWS SPEKEという便利機能について紹介します。AWS SPEKEとは
公式ドキュメント https://docs.aws.amazon.com/speke/latest/documentation/what-is-speke.html
SPEKE = Secure Packager and Encoder Key Exchange
簡単にまとめると、動画のパッケージャ(AWS Elemental)とDRMエンクリプタ間で、DRMキーなどの情報をセキュアにやりとりできる仕様のことです。
SPEKEが定めるI/OインターフェースにのっとってDRM情報(キーやHLS AESのURL)を返すサーバを実装すると、AWS Elementalと連携して動画をDRMすることができます。Multi DRMに対応していたりと、AWSでDRMするハードルを下げてくれる便利ツールです。もうちょっとわかりやすくまとめると、パッケージングは今まで通りAWS Elementalに任せて
DRMに必要な暗号化キーなどの情報の生成を、こっち側で作ったサーバにオフロードできるようになるということですね(オフロードの本来の意味と少しずれますがイメージ的に)。これによって動画ごとにユニークなキーを生成できたり、キーのプロバイダをクラウド・オンプレ好きな場所に構築することができるようになり、色々ハッピーなことが起こります。
SPEKEを使ってみよう
https://docs.aws.amazon.com/speke/latest/documentation/standard-payload-components.html
SPEKEはDASH IFのCPIX(Content Protection Information eXchange)という仕様をラップしています(という認識ですが、間違ってたら教えてください)。
DASH IF CPIXについての説明はこちら https://docs.unified-streaming.com/documentation/drm/cpix_intro.html
(公式のドキュメントではありませんが、分かりやすかったのでUnified Streaming社のドキュメントを貼ってます)CPIXはDRMに必要な情報をXMLベースでやりとりする仕様らしいです。正直あんまりよく分かってないんですがドキュメントに書いてある通りにデータを送ればだいたい動くので神です。
SPEKEにおいても、基本的にCPIXにのっとってXMLでデータをやりとりします。公式にVOD動画をパッケージングするときのリクエスト・レスポンス例が載っているので今回はこれを参考に
HLS AES 128で暗号化してみたいと思います。
VOD Workflow Method Call Examples - https://docs.aws.amazon.com/speke/latest/documentation/vod-workflow-methods.html1. SPEKE準拠なキーサーバを実装
いきなりですが今回実装したコードを置いちゃいます。
https://github.com/OdaDaisuke/aws-speke下記のリファレンス実装を参考にやって行きました。
awslabs/speke-reference-server - https://github.com/awslabs/speke-reference-server基本的には、リクエストで受け取ったCPIXのXMLを埋めていく処理を書くだけです。
詳しい処理については後述のステップで解説していきます。さて、キーサーバのセットアップですが今回はLambda + API Gatewayで行なっていきます。
上記コードをLambdaにアップしたら、以下のスクショにならって環境変数を設定しましょう。
KEY_STORE_BASE_URLは、HLSのマニフェストファイルのext-x-keyのベースURLになります。事前に空のバケットを作って外部からアクセスできるようにACLなど設定しましょう。
2番目のKEY_STORE_BUCKETはClearKeyを保存するバケットの名前です。そしたら、Lambda用のロールを作成して設定してあげます。この時S3とMediaPackageとAPI Gatewayの操作ポリシーを指定してあげます。
また、同時にAPI Gatewayもセットアップして適当な名前のエンドポイントでキーサーバを叩けるようにしていきますが、今回はリファレンス実装にならってcopy_protectionというエンドポイントを作りました。ちなみにこのキーサーバはAWS内部から叩けられればOKなので外部には公開しなくて大丈夫です。
※説明が駆け足ですいません..
2. Role作成
SPEKEはMedia Live、Media Packageと連携することができますが、今回はMediaPackageと連携してみます。
最初にMediaPackageのRoleを作成します。
現在ロール作成時にデフォルトでMediaPackageを選択することができないので、最初にMediaConvertのロールとして作成した後
以下のように「信頼されたエンティティ」をmediapackage.aws.comに変更、さらにMediaPackageのFullAccessポリシーをアタッチしてください。
3. MediaPackageでパッケージング
まずは下記スクショのPackaging groupsというところから適当な名前でパッケージグループを作成してください。
次にHLS AES128のパッケージング設定を作成します。
General Settingsはこのように、
Enable Encryptionにはチェックを入れ、追加で出てくる入力フォームはこのような設定に。
Constant Initialization Vectorは、先述したIVのことで、適当な値をUUID形式で入れておけばOKです。
Key server URLには先ほど作成したキーサーバのAPI GatewayのURLを、
Role Arnには先ほど作成したMedia PackageのARNを入れ、
最後にSystem IDを設定。このSystem IDですが、HLS AESは正確にはDRMではないためSystem IDは定義されていないので、適当な値をUUID形式で入力しておきます。今回はコード側 https://github.com/OdaDaisuke/aws-speke/blob/master/src/server_response_builder.py#L13 で定義した81376844-f976-481e-a84e-cc25d39b0b33という値を設定してみました。ここまできたらパッケージングの設定は完璧です。
Save Settingを押して次に進みます。Ingest Asset
再びMediaPackageのホーム画面に戻り、
Asset->Ingest Assetに進みます。
パッケージングしたい動画があるバケットを選択し、IAM Roleには先ほど作成したMedia Packageのロールを選択します。ページ中程にある
Asset Detailsは、m3u8ファイルを選択しましょう。この時親子構造のマニフェストでなければパッケージングできないので注意です。詳しくは、https://qiita.com/daisukeoda/items/1eecfd639aeae6f1026c を参照。
最後のPackaging settingsは、先ほど作成したパッケージング設定を選択。
そして最後に「Ingest assets」を押せば、あとは勝手にDRMしつつパッケージングしてくれます。
ボタンを押したあとは下記のようにAssetsの項目が増えているはず。
最後に、項目のタイトルをクリックしてみるとこのようにPlayback details欄に再生URLが表示されているのでテスト再生してみましょう。
HLSなのでSafariで再生テストしたいわけですが、Media Packageのurlをそのまま入力するとクロスオリジンの設定で弾かれてしまうので、Whitelistに
Originを設定したCloud Frontを噛まします。そしたら、この https://videojs.github.io/videojs-contrib-hls/ HLS.jsのテストプレーヤをsafariで開き、urlを入力。
指定のurlに向かってキーがリクエストされ、復号して再生できていれば完璧です。
4. キーサーバの処理について
SPEKEキーサーバのログをみてみると、以下のようなリクエストを受け取っています。
<?xml version="1.0" encoding="UTF-8"?> <cpix:CPIX xmlns:cpix="urn:dashif:org:cpix" xmlns:pskc="urn:ietf:params:xml:ns:keyprov:pskc" xmlns:speke="urn:aws:amazon:com:speke" id="コンテンツID"> <cpix:ContentKeyList> <cpix:ContentKey kid="00112233-4455-6677-8899-aabbccddeeff"></cpix:ContentKey> </cpix:ContentKeyList> <cpix:DRMSystemList> <cpix:DRMSystem kid="00112233-4455-6677-8899-aabbccddeeff" systemId="81376844-f976-481e-a84e-cc25d39b0b33"> <cpix:PSSH /> <cpix:ContentProtectionData /> <cpix:URIExtXKey /> <speke:KeyFormat /> <speke:KeyFormatVersions /> <speke:ProtectionHeader /> </cpix:DRMSystem> </cpix:DRMSystemList> </cpix:CPIX>そしてレスポンスは以下のようなXMLです。
<cpix:CPIX xmlns:cpix="urn:dashif:org:cpix" xmlns:pskc="urn:ietf:params:xml:ns:keyprov:pskc" xmlns:speke="urn:aws:amazon:com:speke" id="コンテンツID"> <cpix:ContentKeyList> <cpix:ContentKey explicitIV="IV(UUID形式)のHEXバイナリをbase64した文字列" kid="00112233-4455-6677-8899-aabbccddeeff"> <cpix:Data> <pskc:Secret> <pskc:PlainValue>暗号化キー(UUID形式)のHEXバイナリをbase64した文字列</pskc:PlainValue> </pskc:Secret> </cpix:Data> </cpix:ContentKey> </cpix:ContentKeyList> <cpix:DRMSystemList> <cpix:DRMSystem kid="00112233-4455-6677-8899-aabbccddeeff" systemId="81376844-f976-481e-a84e-cc25d39b0b33"> <cpix:URIExtXKey>キーurlをbase64エンコードした文字列</cpix:URIExtXKey> <speke:KeyFormat>aWRlbnRpdHk=</speke:KeyFormat> <speke:KeyFormatVersions>MQ==</speke:KeyFormatVersions> </cpix:DRMSystem> </cpix:DRMSystemList> </cpix:CPIX>記事の最初の方に書いた、CPIXのXMLですね。
意味を軽く説明してみますと、
cpix:ContentKeyListのexplicitIVは、AES128またはSAMPLE AESでの暗号化の時に使うもので、CBCブロック暗号化の際に使う初期化ベクトルです。MediaPackageでIVを設定していればリクエスト時にexplicitIV属性に値が入ってくるのかと思ったんですが、どうも何も入っていなかったですね、、、(バグなのか??)。pskc:PlainValueはコンテンツの暗号化キーが入ります。
cpix:DRMSystemListの配下の要素には、DRMに使う情報を格納します。今回の場合(AES)だとURIExtXkey、KeyFormat、KeyFormatVersionsだけ必要なのでそれらの情報を埋めてあげます。
cpix:PSSHとcpix:ContentProtectionDataとspeke:ProtectionHeaderはHLS AESの際には必要ないので、要素ごと削除してレスポンスしている感じです。これらはWidevineやPlayReadyでDRMする際に共通して必要になってきますが、今回は解説しません。以上、SPEKEの最低限の説明でした。今回は説明をわかりやすくするためキーをS3にそのまま保存してましたが、本当はSSEモードで保存したり、Secrets Managerで保存させるなどセキュアに管理した方が良いと思います?♂️。
まとめ
HLS AESにおける処理を紹介してみましたが、SPEKEは他にもWidevineやPlayReady、FairplayなどのメジャーDRMに対応していたり、キーの回転やキー暗号化など、色々なことができます。
まだまだ技術が枯れておらず、そもそものDRMの仕組みを知っていないと実装にかなり苦戦しますが、結構便利な機能だと思いました。
よきDRMライフを。
- 投稿日:2019-12-21T22:23:12+09:00
AWSからリリースされた、JavaでDeepLearningが扱えるライブラリDeep Java Library(DJL)に触れてみる
概要
2019/12/03AWSよりJava で機械学習モデルを開発およびデプロイするDeep Java Libraryが発表されました。
ほんの少しですが、触ってみましたので紹介します。
なお、事前知識としては、Javaは普段使っているが、ML/DLの知識は自身ほぼゼロです。
ここでは、
Java で深層学習モデルを開発するためのオープンソースライブラリである DJL を発表します。DJL には、深層学習モデルのトレーニング、テスト、デプロイを行うためのユーザーに使いやすい API が用意されています。深層学習に興味のある Java ユーザーであれば、DJL は素晴らしい出発点になります。深層学習モデルで作業する Java 開発者の場合、DJL を使えば簡単に予測をトレーニングして実行することができます。
とありましたので、期待して触ってみます。
なお、公式なページは以下ですが、Amazon/AWS色はあまり見えません。
https://djl.ai/Try
何はともあれ、チュートリアル通り動かしてみます。
https://github.com/awslabs/djl.git
からcloneし、example以下を動かすのが良さそうです。
# 適当なフォルダで実行 git clone https://github.com/awslabs/djl/cloneし終えたら、exampleフォルダに移動し、そこのREADME.mdを見てみます。
以下のように、いろいろな種類の例があるので最初に一つ目の奴をやってみます。
Single-shot Object Detection exampleをやっていきます。
まず初めにセットアップせよと言われますが、Java11+と環境変数、オプションでIntelliJでの使い方ぐらいですので、普段Javaやっている人はあまり読まずに突き進んでも良さそうです。
この例では、予め用意されたZooModelというものを使い、それに対して画像をぶつけてそこに何の動物が映っているのかを表現してくれ、その認識した箇所を四角で囲った画像も作る、という例となります。
いきなりですが、以下で動作確認することが出来ます。
(object_detection.mdより引用)cd examples
./gradlew run -Dmain=ai.djl.examples.inference.ObjectDetection実行結果として、以下が表示されます。
初回はライブラリのダウンロードなどが走るため、時間がかかりますが、2回目以降は10秒程度で終わります。$ ./gradlew run -Dmain=ai.djl.examples.inference.ObjectDetection > Task :run Loading: 100% |████████████████████████████████████████| [22:02:10] src/nnvm/legacy_json_util.cc:209: Loading symbol saved by previous version v1.5.0. Attempting to upgrade... [22:02:10] src/nnvm/legacy_json_util.cc:217: Symbol successfully upgraded! [INFO ] - Detected objects image has been saved in: build/output/detected-dog_bike_car.png [INFO ] - [ class: "car", probability: 0.99991, bounds: [x=0.611, y=0.137, width=0.293, height=0.160] class: "bicycle", probability: 0.95385, bounds: [x=0.162, y=0.207, width=0.594, height=0.588] class: "dog", probability: 0.93752, bounds: [x=0.168, y=0.350, width=0.274, height=0.593] ] BUILD SUCCESSFUL in 11s 3 actionable tasks: 1 executed, 2 up-to-date車と自転車と犬が写っているという結果が出てます。
後付けになりますが、ai.djl.examples.inference.ObjectDetectionクラスを見ると
Path imageFile = Paths.get("src/test/resources/dog_bike_car.jpg");
とあるので、この画像がInputであることがわかります。
実行後、出力された画像は
build/output/detected-dog_bike_car.pngにあります。(同クラスに実装されています)
ちゃんと出来てますね。
Inputの画像を差し替えることで、別の画像でもObject Detectionできそうです。
改めて
ai.djl.examples.inference.ObjectDetectionクラスを見ると、Javaしかわからない自分にでもなんとなくやっていることがわかります。ロガーの設定などが馴染みがあって親近感湧きますね。全部でおおまかな流れは以下のように読み取りました。
- ロガーの設定
- Inputとなる画像の読み込み
- モデルに渡す各種パラメータの設定
- MxModelZoo(MxNetベースのモデル)という予め用意されたモデルへパラメータ、画像を渡す
- 予測の実施
- 予測結果を画像へ反映
- 標準出力にも予測結果を出力
といった感じです。パラメータのところはそれぞれどんな意味があるのか詳細確認が必要ですが、用意されたモデルを使ってObject Detectionするというのはハードルが低いなと正直思いました。
依存ライブラリの確認
exampleを取り込んだプロジェクトの依存ライブラリは以下のような感じでした。
Spring系との重複とかはなさそうなので、コンフリクト起きずに併用できそうですね。
まとめ
とりあえずDJLを使って、一つの例だけやってみました。
以前、DeepLearning4Jを触ってみようかと思ったのですが、
環境構築周りで躓き、棚上げしていたのですが、今回はすんなりでした。ML/DLのシステムを全てJavaで!という感覚までは辿り着けませんでしたが、一般的なWebシステムの一機能だけML/DLを使うという際には、これをスモールスタートで使ってみるというのは良いかもしれないなと思いました。






- 投稿日:2019-12-21T22:14:37+09:00
AWS RekognitionとRaspberry Piでプリン警備システムを作ってみた
この記事はIoTLT Advent Calendar 2019(Neo)の21日目の記事です。
作ったもの
今回はAmazon Rekognitionを使った職場のプリンを守る警備システムを作りました。
これで大切な職場のプリンを守ります。
aNo研様のSIerIoTLT vol.16発表で職場のプリンを守る技術を知り、警備といえばプリンだなと思い製作しました。
今回はRaspberry Piのプログラムをメインに記事を書きました。
他の部分に興味のある方がいらっしゃいましたらコメント頂けると嬉しいです。使い方
オーナー、過去に人のプリンを食べた人(=犯人)、怪しい人の3種類の人間を識別します。
オーナーが現れた場合は動作していることをTwitterで報告します。
犯人が現れた場合はゴム鉄砲を発射し警告音を鳴らします。同時にゴム鉄砲発射直後のカメラ画像を送りオーナーはTwitterで確認できます。
オーナー、犯人以外の人が現れた場合は怪しい人と認識。警告音で威嚇し犯人同様カメラ画像をTwitterでカメラ画像を確認できます。
※予めオーナーと犯人の顔写真はAmazon Rekognitionに登録します。構成
Raspberry Pi(ハードウェア)
おおよその構成はこんな感じです。
色々雑ですが、レゴを使ってカメラモジュールとゴム鉄砲を固定しています。
Raspberry Pi(ソフトウェア)
おおよその流れは以下の通りです。
- Amazon Rekognitionに予め所有者と犯人の2種類の顔を登録します。
- CameraModuleで画像を取得しまずOpenCVでカメラ内に人の顔があるか検知します。
- 顔があればboto3経由でAmazon Rekognitionにカメラ映像を送り問い合わせを行います。
- Amazon Rekognitionはカメラ映像にある顔が登録された所有者と犯人である確率を返します。それを元に所有者/犯人/(どちらでもない)怪しい人を判断します。
- 所有者であればIFTTT経由で動作状況をTwitterで報告します。
- 犯人であれば以下の動作をします。
- Pigpio経由でServoを動かしゴム鉄砲を発射!
- ゴム鉄砲発車後の画像を取得。
- 警告音を出します。
- S3にboto3経由でカメラ画像をアップしてIFTTT経由で所有者にTwitterで報告します。
- 怪しい人であれば以下の動作をします。
- 警告音を出します。
- S3にboto3経由でカメラ画像をアップしてIFTTT経由で所有者にTwitterで報告します。
Raspberry Piのプログラムはこちら。
demo.py# -*- coding: utf-8 -*- from picamera.array import PiRGBArray from picamera import PiCamera import cv2, time, boto3 import requests import urllib.request, json import datetime import numpy as np from PIL import ImageFont, ImageDraw, Image import subprocess from datetime import datetime as dt import pigpio # Pi Camera FRAME_W = 640 FRAME_H = 480 # Open CV CASC_PATH = '/usr/local/share/opencv4/lbpcascades/lbpcascade_frontalface.xml' FRAME_RATE = 32 MIN_FACE_SIZE = 10 CHECK_FILE = 'check.jpg' # AWS Rekognition COLLECTION_ID = 'test' THRESHOLD = 70 MAX_FACES = 1 SERVICE_NAME = 'rekognition' LOCATE = 'ap-northeast-1' PERSON_TYPE = {0:'怪しい人', 1:'Owner', 2:'犯人', 3:''} # S3 S3_URL = 'https://s3-ap-northeast-1.amazonaws.com/' BUCKET_NAME = 'test' # IFTTT (Webhooks Settings) TRIGGER = 'rekognition' URL1 = 'https://maker.ifttt.com/trigger/' URL2 = '/with/key/xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx' EVENT = {0:'other', 1:'owner', 2:'enemy', 3:''} MESSAGE = {0:'怪しい奴がきたよ', 1:'ちゃんと監視してるよ!', 2:'犯人やっつけた!', 3:''} # Servo GPIO_NO = 18 GPIO_READY = 500 GPIO_FIRE = 1600 def rotate_servo(servo, angle): # サーボ操作 if -90 <= angle <= 90: d = ((angle + 90) * 9.5 / 180) + 2.5 servo.ChangeDutyCycle(d) else: raise ValueError("angle") def send_message(msg_no, file_name): # S3にファイルをアップロード dt_now = dt.now() s3_filename = 'img_' + dt_now.strftime('%m%d_%H%M%S') + '.jpg' s3 = boto3.resource('s3') s3.Bucket(BUCKET_NAME).upload_file(file_name, s3_filename, ExtraArgs={"ContentType": "image/jpeg"}) s3_url = S3_URL + BUCKET_NAME + "/" + s3_filename # IFTTT URL設定 url = URL1 + TRIGGER + URL2 method = "POST" headers = {"Content-Type" : "application/json"} date = datetime.datetime.now() message = MESSAGE[msg_no] + ' ' + str(date.hour) + '-' + str(date.minute) print('Send Message:', message) # PythonオブジェクトをJSONに変換する obj = {"value1" : message, "value2" : s3_url} json_data = json.dumps(obj).encode("utf-8") # httpリクエストを準備してPOST request = urllib.request.Request(url, data=json_data, method=method, headers=headers) with urllib.request.urlopen(request) as response: response_body = response.read().decode("utf-8") print('response:',response_body) def aws_rekognition(cl): #顔認証 img = open(CHECK_FILE, 'rb') img_byte = img.read() try: response = cl.search_faces_by_image(CollectionId=COLLECTION_ID, Image={'Bytes':img_byte}, FaceMatchThreshold=THRESHOLD, MaxFaces=MAX_FACES) except: return 3 print('Rekognition!') person="" #カメラに複数人写っていた場合最後の人を判定(手抜き) for faceRecord in response['FaceMatches']: person = faceRecord['Face']['ExternalImageId'] if person.endswith("owner"): rtn = 1 elif person.endswith("bad"): rtn = 2 else: rtn = 0 return rtn #GUI処理 def face_maker(frame, faces, rtn): # フォントを読み込み font = ImageFont.truetype('TanukiMagic.ttf', 48) for (x, y, w, h) in faces: # 見つかった顔を矩形で囲む cv2.rectangle(frame, (x, y), (x+w, y+h), (0, 255, 0), 2) img_pil = Image.fromarray(frame) draw = ImageDraw.Draw(img_pil) draw.text((30, 60), PERSON_TYPE[rtn], font = font, fill = (128,255,0)) frame = np.array(img_pil) return frame def main(): # 初期化 faceCascade = cv2.CascadeClassifier(CASC_PATH) camera = PiCamera() camera.resolution = (FRAME_W, FRAME_H) camera.framerate = FRAME_RATE camera.rotation = 180 rawCapture = PiRGBArray(camera, size=(FRAME_W, FRAME_H)) time.sleep(0.1) client = boto3.client(SERVICE_NAME,LOCATE) pi = pigpio.pi() old_rtn = 3 # ループ for image in camera.capture_continuous(rawCapture, format="bgr", use_video_port=True): frame = image.array #frame = cv2.flip(frame, -1) #上下反転 camera.start_preview() # OpenCVの顔検出をグレースケールで実施 gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) gray = cv2.equalizeHist( gray ) faces = faceCascade.detectMultiScale(gray, 1.1, 3, 0, (MIN_FACE_SIZE, MIN_FACE_SIZE)) # 表示調整用 #frame = cv2.resize(frame, (800,600)) # 顔あり if faces is not None: # 顔ファイル出力 cv2.imwrite(CHECK_FILE, frame) time.sleep(0.01) # AWS Rekognition rtn = aws_rekognition(client) if rtn is None: rtn = 3 frame = face_maker(frame,faces,rtn) # ビデオに表示 cv2.imshow('Video', frame) time.sleep(0.1) # 同じ結果の場合は何もしない print('rtn:', rtn, ' old_rtn:', old_rtn) if old_rtn != rtn: if(rtn == 0): # 怪しい人 subprocess.call("mpg321 warning.mp3", shell=True) send_message(rtn, CHECK_FILE) if(rtn == 1): # オーナー send_message(rtn, CHECK_FILE) if(rtn == 2): # 過去に人のプリンを食べたことがある人 pi.set_servo_pulsewidth(GPIO_NO, GPIO_READY) time.sleep(0.2) pi.set_servo_pulsewidth(GPIO_NO, GPIO_FIRE) subprocess.call("mpg321 fire.mp3", shell=True) # 攻撃後の画像をTwitterに送る camera.capture('fire.jpg') send_message(rtn, 'fire.jpg') old_rtn = rtn # qを押されたら終了 key = cv2.waitKey(1) & 0xFF rawCapture.truncate(0) if key == ord("q"): break time.sleep(0.01) cv2.destroyAllWindows() exit if __name__ == "__main__": main()IFTTT
WebhookとTwetterとの連携設定をします。
Amazon Rekognition
アマゾンウェブサービス(AWS)のAmazon Rekognition は、深層学習に基づいた画像認識および画像分析をアプリケーションに簡単に追加できるサービスです。
予めオーナー(名前の末尾がowner)と犯人(名前の末尾がbad)の画像をAmazon Rekognitionしています。
上記プログラムでboto3を利用してAWSにアクセスするとカメラ映像に近い画像名を返します。



- 投稿日:2019-12-21T22:00:19+09:00
SAM+CodeDeployでlambdaへデプロイする。
前回まではCodeDeployを用いてEC2インスタンスへのデプロイを学習しました。
今回はデプロイ対象をlambdaでやってみたいと思います。CodeDeployのアプリケーション作成画面でlambdaを選択できるので同じ要領かと思っていましたが、SAMというやつを一緒に使うみたいです。公式チュートリアルは普通に分かりやすいです。なので、今回はテンプレートyamlファイルの設定項目をここで指定していきましょう。
contents
- AWS SAM
- AWS CloudFormation
- 公式チュートリアル実施時の備忘録/トラブルシューティング
- template.ymlの解読(本題)
AWS SAM
AWS Serverless Application Model(AWS SAM)は、yaml形式で記述したテンプレートを元にして種々のAWSリソースを用いたアプリケーションを構築することができます。
ローカル上から利用するために、aws-sam-cliを利用します。AWS CloudFront
- テンプレート : アプリケーション全体の設計図(yamlベースもしくはjsonベース:コメントが書けるのでyaml推奨)
- スタック : テンプレートを元にCloudFormationが構築したリソースの集合全体(=環境自体)
CloudFormationで生成する環境は、スタック単位で管理されスタックの破棄とともに紐づいたリソースを全て削除することができる。
公式チュートリアルやってみた
SAM CLIのインストールorアップグレード
公式には以下のようにありますが多分
pipでいけると思います。
https://docs.aws.amazon.com/serverless-application-model/latest/developerguide/serverless-sam-cli-install.htmlアップグレード$ pip install --upgrade awscli $ pip install --upgrade aws-sam-cli $ sam --version
awscliを先に最新版にしたほうがいいです。botocoreのバージョンが一致しないと以下のようにエラーします。エラーメッセージERROR: awscli 1.16.304 has requirement botocore==1.13.40, but you'll have botocore 1.13.44 which is incompatible. Installing collected packages: botocore, boto3, aws-sam-translator, tomlkit, aws-sam-cli Found existing installation: botocore 1.13.40 Uninstalling botocore-1.13.40: ERROR: Could not install packages due to an EnvironmentError: [Errno 13] Permission denied: 'RECORD' Consider using the `--user` option or check the permissions.デプロイの仕組み
最終的にはディレクトリごとzipにするので、デプロイ用のディレクトリを作り、以下の構成にします。
$ tree SAM-Tutorial ├── afterAllowTraffic.js ├── beforeAllowTraffic.js ├── myFunction.js └── template.yml
ファイル 説明 myFunction.js デプロイ対象のファイル template.yml デプロイの流れを書いた仕様書(これが要) beforeAllowTraffic.js AllowTraffic前に実行するテスト afterAllowTraffic.js AllowTraffic後に実行するテスト template.ymlを元にパッケージを作成します。実行すると、
SAM-Tutorialディレクトリ内にpackage.ymlが生成し、S3バケットにはc2fe022d92156eeb459d45f02a766921`が上がっています。$ sam package --template-file template.yml --output-template-file package.yml --s3-bucket YOUR_BUCKET Uploading to c2fe022d92156eeb459d45f02a766921 4113 / 4113.0 (100.00%) Successfully packaged artifacts and wrote output template to file package.yml.続いてデプロイです。
--capabilities CAPABILITY_IAMはCloudFrontからロールを作成するのに必要な権限付与みたいな感じ必要です。sam deploy --template-file package.yml --stack-name my-date-time-app2 --capabilities CAPABILITY_IAM Deploying with following values =============================== Stack name : my-date-time-app2 Region : None Confirm changeset : False Deployment s3 bucket : None Capabilities : ["CAPABILITY_IAM"] Parameter overrides : {} #以下略当たり前なのですが、cliを実行しているIAMユーザに適切に権限を与えていないと途中でエラーします。SAMは、実質CloudFormationを利用しているので、IAMユーザには
CloudFormationFullAccessを適応してください。(FullAccessでなくてもいいのかもしれないが面倒なので未調査)
なお、今回の検証用のユーザは以下のロール適用しました。
(多分不要なものも含んでます。CodeCommiteとか今回使ってないし)
- AWSCodeCommitFullAccess
- AWSLambdaFullAccess
- IAMFullAccess
- AmazonS3FullAccess
- AWSCodeDeployFullAccess
- AWSCloudFormationFullAccess
また、実行途中で失敗した場合、自動的にロールバックされ、ステータスが
ROLLBACK_COMPLETEになります。この状態はから再度sam deployはできません。一度CloudFormationコンソールから削除します(cliでもできるはず)。
ステータスの見方についての公式ページ→https://docs.aws.amazon.com/ja_jp/AWSCloudFormation/latest/UserGuide/cfn-console-view-stack-data-resources.htmlエラーメッセージ..../a417d920-239f-11ea-9fca-0ef015a9ecfc is in ROLLBACK_COMPLETE state and can not be updated.デプロイ中はCodeDeployコンソールで進行状況が把握できる。
デプロイに成功したら、デプロイされたlambdaをコンソールから確認してみましょう。
パッケージ名+関数名+英数字となっているのでarnを取得してcliからinvokeしてみる。$ aws lambda invoke --function arn:aws:lambda:ap-northeast-1:xxxxxxxxxxxx:function:my-date-time-app2-myDateTimeFunction-1S9F2G73JFP32 --payload "{\"option\": \"date\", \"period\": \"today\"}" out.txt { "StatusCode": 200, "ExecutedVersion": "$LATEST" } $ SAM-Tutorial ls afterAllowTraffic.js myDateTimeFunction.js package.yml beforeAllowTraffic.js out.txt template.yml $ SAM-Tutorial cat out.txt {"statusCode":200,"headers":{"Content-type":"application/json"},"body":"{\"month\":12,\"day\":21,\"year\":2019}"}%この後、ローカルでmyDateTimeFunction.jsファイルを更新した場合、上記と同じ手順で
aws packageし、aws deployする。なお、CodeDeployを通してデプロイしたlambdaでもコンソール上で直接変更はできる。ただこの方法で更新したものはversionとして変更履歴に保存されないので注意。
ここからが本題
template.ymlの解読
template.ymlのオプション指定を解読していきます。
Transform(必須)
使用するSAMのバージョンを指定し、使用できるSAM構文とCloudFormationがそれをどのように処理するかを定義します。
AWS::Serverless-2016-10-31を指定する。Globals
グローバル領域。複数のリソースに対して共通の定義をできる。例えば全ての関数でランタイムは
python3.8でメモリは256を指定したいといった場合、Globalsに書くことで以降のAWS::Serverless::Functionの各Functionの項目に書かなくても継承してくれる。
Grobalsで一括定義できるのは以下のみ。
- AWS::Serverless::Function
- AWS::Serverless::Api
- AWS::Serverless::SimpleTable
Grobalsをデフォルト値のようにしてAWS::Serverless::Function側にも定義した場合その関数だけは指定した値に上書きできるとかあるのだろうか?なお、それぞれ何を指定できるかは公式参照→https://docs.aws.amazon.com/ja_jp/serverless-application-model/latest/developerguide/sam-specification-template-anatomy-globals.html
Description
その名の通り説明。
Metadata
メタデータ。追加情報です。まだ使い道がわからない。。。
Parameters
テンプレートを実行するときに、ユーザーに入力させるパラメータを定義できます。
Mappings
連想配列/辞書を定義できます。
Conditions
条件を設定します。真の場合にのみリソースを生成するなどの条件分岐が可能です。
パラメータと組み合わせた例が以下。例Parameters: EnvType: Description: Environment type. Default: test Type: String AllowedValues: - prod - test Conditions: CreateProdResources: !Equals [ !Ref EnvType, prod ] Resources: # CreateProdResourcesがfalseの場合にはインスタンスは作られない。 EC2Instance: Type: "AWS::EC2::Instance" Condition: CreateProdResources Properties: ImageId: !FindInMap [RegionMap, !Ref "AWS::Region", AMI]Output
スタック構築後に、指定した情報を出力する。
Resources(必須)
準備するリソースを指定する。いくつかピックアップして調べてみる。
AutoPublishAlias
チュートリアルのtemplate.yml# Instructs your myDateTimeFunction is published to an alias named "live". AutoPublishAlias: liveこの
AutoPublishAliasはデプロイ対象の関数が変更されたときに検出し、テンプレート上で命名したエイリアスを使用してデプロイするようにフレームワークに指示します。この指定は必須です。
やってみるとわかるのですが、sam deployするとlambdaはバージョン管理されます。$LATESTとは別にエイリアスをつけられます。
エイリアスとは、lambdaのバージョン番号に別名を付したものです。
DeploymentPreference Type
チュートリアルのtemplate.ymlDeploymentPreference: # Specifies the deployment configuration Type: Linear10PercentEvery1Minuteここでは新しいバージョンのlambdaへトラフィックを流す割合を定義しています。
Linear10PercentEvery1Minuteは1minのトラッフィクのうち10%を次バージョンへ回す設定です。クラスメソッドの実際の実験がわかりやすいです。
https://dev.classmethod.jp/server-side/serverless/understanding-lambda-deploy-with-codedeploy-using-aws-sam/また、このデプロイのタイプの設定はカナリアリリースなども選択可能であり同じく上記リンクに紹介があります。
DeploymentPreference Hooks
チュートリアルのtemplate.yml# Specifies Lambda functions for deployment lifecycle hooks Hooks: PreTraffic: !Ref beforeAllowTraffic PostTraffic: !Ref afterAllowTraffic
HooksはCodeDeployでEC2へのデプロイ時の設定にもあった通り、各イベントの前後の適切なタイミングで指定したプログラムを実行するための設定です。lmabdaへのデプロイではtrafic allowの前後2つのタイミングを選択できます。公式には以下のように説明があります。(beforeAllowTrafficとafterAllowTrafficはCloudFrontでの指定方法であり、SAMではそれぞれPreTrafficとPostTrafficに対応しております。わかりにくい!)AWS Lambda フックは、ライフサイクルイベントの名前の後の新しい行に文字列で指定された 1 つの Lambda 関数です。各フックはデプロイごとに 1 回実行されます。以下は、AppSpec ファイルに使用できるフックの説明です。
BeforeAllowTraffic – これを使用して、トラフィックがデプロイされた Lambda 関数のバージョンに移行する前にタスクを実行します。
AfterAllowTraffic – これを使用して、トラフィックがデプロイされた Lambda 関数のバージョンに移行した後でタスクを実行します。
用途としては
PreTrafficの段階で単体テストし、成功すればデプロイ、PostTrafficで結合テストし、失敗すればロールバックさせるなど一連の流れを構築できそうです。また、この
Ref!という記法はCloudFrontの組み込み関数で、以下のように読み換えられます。# パラメータ参照 !Ref {パラメーター名} # リソースの返り値を取得 !Ref {リソース名}同じく、
!Subという表現も次に出てきます。
これは文字列とパラメータを組み合わせた値を作成する際に使用します。参考) https://qiita.com/ryurock/items/766154e0afb8fdb629e2
関数ポリシー
チュートリアルのtemplate.yml# Grants this function permission to call codedeploy:PutLifecycleEventHookExecutionStatus Statement: - Effect: "Allow" Action: - "codedeploy:PutLifecycleEventHookExecutionStatus" Resource: !Sub 'arn:aws:codedeploy:${AWS::Region}:${AWS::AccountId}:deploymentgroup:${ServerlessDeploymentApplication}/*' - Version: "2012-10-17"デプロイ前後のテスト用関数から対象の関数をinvokeするにはアクセス許可をする必要があります。(正直lambdaFullアクセスを与えてしまってもいいと思ってます。)
lambda環境変数の指定
チュートリアルのtemplate.ymlEnvironment: Variables: NewVersion: !Ref myDateTimeFunction.Version


- 投稿日:2019-12-21T19:37:30+09:00
code-server オンライン環境篇 (3) Boto3 で EC2 インスタンスを立ち上げる
これは、2019年 code-server に Advent Calender の 第14日目の記事です。
前回に続き、EC2 Instance を 立ち上げたいと思います。
目次
ローカル環境篇 1日目
オンライン環境篇 1日目 作業環境を整備する
オンライン環境篇 2日目 仮想ネットワークを作成する
オンライン環境篇 3日目 Boto3 で EC2 インスタンスを立ち上げる
オンライン環境篇 4日目 Code-Serverをクラウドで動かしてみる
オンライン篇 5日目 Docker環境を構築してアレコレ
オンライン篇 6日目 簡単な起動アプリを作成してみよう
...
オンライン篇 .. Coomposeファイルで構築
オンライン篇 .. K8Sを試してみる
...
魔改造篇はじめに
RouteTable の設定をしていませんでした。 時環境では動いているのですが、
もしかすると動かないかも...で、Route Table の設定から始めます
Route Table とは
前回 Gateway を設定しましたね!! で、VPCからアクセスするIPごとに、どのGatewayを使用するかを設定することができます。
今回の場合だと、全部、Internet Gateway につなげれば良いのですが、
VPC間やSubnet間など、こまめに設定することができます。ネットワークの作成 その2です
Route Table を作成する
作成def create_route_table(vpc_id:str): res = ec2client.create_route_table(VpcId=vpc_id) print("{}".format(res)) route_table_id = res['RouteTable']['RouteTableId'] attach_tag(route_table_id) return route_table_idRoute Table には VPC をしてします。当然ですね..
とかで行けます
Routeを作成する
RouteTable に、全てのIPをInternetに接続可能なように指定しましょう
Routeを作成するdef create_route(route_table_id:str, gateway_id:str): resp = ec2client.create_route(RouteTableId=route_table_id,DestinationCidrBlock="0.0.0.0/0",GatewayId=gateway_id) print("{}".format(resp))
0.0.0.0/0が全てのIPを意味しています。
0.0.0.0から255.255.255.255Subnet に関連付けする
def associate_route_table(route_table_id:str, subnet_id:str): res = ec2client.associate_route_table(RouteTableId=route_table_id,SubnetId=subnet_id) print("{}".format(res)) associate_id = res['AssociationId'] return associate_idRoute Table を削除
def delete_route_table(): print(">>> Delete Route Table") res = ec2client.describe_route_tables(Filters=[{"Name":"tag:Name","Values":[instance_name]}]) print("{}".format(res)) for route_table in res["RouteTables"]: for association in route_table.get('Associations',[]): ec2client.disassociate_route_table(AssociationId = association['RouteTableAssociationId']) res = ec2client.delete_route_table(RouteTableId=route_table['RouteTableId']) print("{}".format(res))削除はこんな感じです。
削除する前に、associate_route_table()を呼び出して、関連付けを外す必要があります。※ 今回、Tagを利用しているのは、説明しやすいからで、
vpc_id などからも、引っ張ってこれるので、vpc_idを使うのが良いかもFilters=[{"Name":"vpc-id","Values":[vpc_id]}]SecurityGroupの修正
前回のコードは、VPCを設定し忘れていました..
作成def create_security_group(vpc_id): print(">>> CREATE SECURITY GROUP") res = ec2client.create_security_group(Description="AdventCodeServer",GroupName=instance_name,VpcId=vpc_id) print("{}".format(res)) group_id = res['GroupId'] attach_tag(group_id) return group_idここまで書いたコードは以下の通り
https://github.com/kyorohiro/advent-2019-code-server/blob/master/remote_cs01/for_aws/main.py
Instance を作成する
PEMファイルを作成する
Instance には、SSH キー を利用して接続をする想定でいます。
秘密鍵と公開鍵を作成しておきましょうPEM作成def create_pem(): pem_file = open("{}.pem".format(instance_name),"w") pem_file.write("") try: print(">>> CREATE KEY_PAIR") res = ec2client.create_key_pair(KeyName=instance_name) print("{}".format(res)) pem_file.write(res['KeyMaterial']) finally: pem_file.close() return instance_namePEM削除def delete_pem(): print(">>>> DELETE KeyPair") ec2client.delete_key_pair(KeyName=instance_name)Instanceを立ち上げる
作成def create_instance(subnet_id:str, group_id:str): print(">>>> CREATE INSTANCE") res = ec2client.run_instances(ImageId="ami-0cd744adeca97abb1",#KeyName="xx", InstanceType='t2.micro', MinCount=1,MaxCount=1,KeyName=instance_name, TagSpecifications=[ { 'ResourceType': 'instance', 'Tags': [{ 'Key': 'Name', 'Value': instance_name }] } ],NetworkInterfaces=[{"SubnetId":subnet_id,'AssociatePublicIpAddress': True,'DeviceIndex':0,'Groups': [group_id]}] ) print("{}".format(res))作成した subnetと group_id を指定します。
今回はUbuntuを指定しました。
https://aws.amazon.com/jp/amazon-linux-ami/削除def delete_instance(): print(">>>> ec2client.describe_instances") res = ec2client.describe_instances( Filters=[{"Name":"tag:Name","Values":[instance_name]}] ) print("{}".format(res)) print(">>>> DELETE Instance") for reservation in res['Reservations']: for instance in reservation['Instances']: instance_id = instance['InstanceId'] res = ec2client.terminate_instances(InstanceIds=[instance_id]) print("{}".format(res))削除も、今前通りですね。
では、今までに作成したものをつなげてみましょう。
スクリプトを走らせる、その前に
Instance の削除が完了するまで待機するスクリプトも書いておきましょう。
def wait_instance_is_terminated(): while(True): res = ec2client.describe_instances( Filters=[{"Name":"tag:Name","Values":[instance_name]}] ) terminated = False for reservation in res['Reservations']: for instance in reservation['Instances']: instance_state = instance['State']['Name'] print("------{}".format(instance_state)) if instance_state != 'terminated': terminated = True if terminated == False: break time.sleep(6)まとめ
main.pyimport boto3 from boto3_type_annotations import ec2 from botocore.exceptions import ClientError from typing import Dict, List import time import network instance_name= "advent-code-server" ec2client:ec2.Client = boto3.client("ec2") def create_pem(): pem_file = open("{}.pem".format(instance_name),"w") pem_file.write("") try: print(">>> CREATE KEY_PAIR") res = ec2client.create_key_pair(KeyName=instance_name) print("{}".format(res)) pem_file.write(res['KeyMaterial']) finally: pem_file.close() return instance_name def delete_pem(): print(">>>> DELETE KeyPair") ec2client.delete_key_pair(KeyName=instance_name) def create_instance(subnet_id:str, group_id:str): print(">>>> CREATE INSTANCE") # Ubuntu Server 18.04 LTS (HVM), SSD Volume Type - ami-0cd744adeca97abb1 (64-bit x86) / ami-0f0dcd3794e1da1e1 (64-bit Arm) # https://aws.amazon.com/jp/amazon-linux-ami/ res = ec2client.run_instances(ImageId="ami-0cd744adeca97abb1",#KeyName="xx", InstanceType='t2.micro', MinCount=1,MaxCount=1,KeyName=instance_name, TagSpecifications=[ { 'ResourceType': 'instance', 'Tags': [ { 'Key': 'Name', 'Value': instance_name } ] } ],NetworkInterfaces=[{"SubnetId":subnet_id,'AssociatePublicIpAddress': True,'DeviceIndex':0,'Groups': [group_id]}] ) print("{}".format(res)) return instance_name def delete_instance(): print(">>>> ec2client.describe_instances") res = ec2client.describe_instances( Filters=[{"Name":"tag:Name","Values":[instance_name]}] ) print("{}".format(res)) print(">>>> DELETE Instance") for reservation in res['Reservations']: for instance in reservation['Instances']: print("------{}".format(instance)) instance_id = instance['InstanceId'] print(">>>> {}".format(instance_id)) res = ec2client.terminate_instances(InstanceIds=[instance_id]) print("{}".format(res)) def wait_instance_is_terminated(): while(True): res = ec2client.describe_instances( Filters=[{"Name":"tag:Name","Values":[instance_name]}] ) terminated = False for reservation in res['Reservations']: for instance in reservation['Instances']: instance_state = instance['State']['Name'] print("------{}".format(instance_state)) if instance_state != 'terminated': terminated = True if terminated == False: break time.sleep(6) if __name__ == "__main__": res = network.create() create_pem() create_instance(res["subnet_id"], res["group_id"]) delete_instance() wait_instance_is_terminated() delete_pem() network.delete()コード全体は、以下
https://github.com/kyorohiro/advent-2019-code-server/tree/master/remote_cs02/for_aws
次回
作成した仮想 Instance を操作してみましょう!!
コード
https://github.com/kyorohiro/advent-2019-code-server/tree/master/remote_cs02
- 投稿日:2019-12-21T19:34:28+09:00
CloudFormationのYAMLを分割管理する
CloudFormation は JSON or YAML で作成したテンプレートを元に構成を管理しています。
コメントが書ける YAML を選択している方も多いかとは思いますが、CloudFormation のテンプレートは1ファイルになっている必要があり、設定項目が多くなると管理がかなり面倒です。JSON も YAML もそれ自体には import や require する機能はないのですが、json-refs(仕様は JSON Reference, JSON Pointer 参照)を使うと別ファイルを参照できるので、簡単にツール化してみました。
使い方
インストール
通常は、CloudFormation を使うプロジェクト内にインストールすれば OK です。
npm install -D @u-minor/cftemplateglobal に入れても OK です。
CloudFormation 分割テンプレートの作成
json-refs は
$ref: another_file.ymlのように、$refを使って別ファイルを指定します。
src/index.ymlを作成し、以下のように CloudFormation のトップレベルの要素を定義、Parameters等の要素を別ファイルに分離します。index.ymlAWSTemplateFormatVersion: '2010-09-09' Description: Test template Parameters: $ref: parameters.yml Resources: $ref: .resources.yml
src/parameters.ymlを作成し、テスト用のパラメータ定義をしてみます。parameters.ymlTestParam: Description: Test parameter Type: String
.resources.ymlのように「.」から始まるファイル名を指定した場合は、直接ファイルを作成せず、「.」を除いたフォルダを作成し、その中に複数の YAML ファイルを入れておくことで、自動的にマージしてくれます。
src/resources/Logs.ymlを作成し、以下のように CloudWatch の LogGroup を指定してみます。Logs.ymlLogGroup: Type: AWS::Logs::LogGroup Properties: LogGroupName: !Sub ${AWS::StackName}/${TestParam}/json-refs はノードに対して1ファイルを import する仕様なので、CloudFormation の Resources(1ノード)の中を複数ファイル分割しようとすると、json-refs のみでは対応できません。
ですので、この部分は独自にマージする仕様となっています。CloudFormation テンプレートのビルド
cftemplateコマンドで src フォルダを指定すると、ビルドされたテンプレートが標準出力にアウトプットされるので、以下のようにリダイレクトでファイルに向けます。npx cftemplate src > stack.yml以下のようなテンプレートが出力されれば成功です。
stack.ymlAWSTemplateFormatVersion: '2010-09-09' Description: Test template Parameters: TestParam: Description: Test parameter Type: String Resources: LogGroup: Type: 'AWS::Logs::LogGroup' Properties: LogGroupName: !Sub '${AWS::StackName}/${TestParam}/'AWS CDK が使える今、CloudFormation テンプレートを直接管理する必要性は以前ほど少なくなってきてはいると思いますが、YAML でシンプルに定義できるメリットはまだまだあると感じています。
ぜひお試しください。
- 投稿日:2019-12-21T18:14:27+09:00
[Tips]AWS Lambdaにzipファイルアップロードをコマンド一発で行う
前提
- Node.js
- aws-cliインストール済みであること
説明
lambda関数をzipアップロードする場合、zipに固めて管理画面ポチポチするよりも、npm(Node.jsの場合)でスクリプト化しておくと良い。
コード
package.json... "scripts": { "predeploy": "zip -r Lambda.zip * -x *.zip *.json", "deploy": "aws lambda update-function-code --function-name {{ Lambda関数のARN }} fileb://Lambda.zip" }, ...実行
npm run deploy補足
npm-scriptsの「pre」プレフィックスを付けると、特定のコマンドの前に自動で実行される。
なので、上の例でpredeployを直接実行する必要はない。
「post」プレフィックスも同様で、事後処理を入れたい場合に使う。まとめ
デプロイは何度も行うことになるので、トータルで見ると時間短縮につながると思います。
- 投稿日:2019-12-21T17:07:53+09:00
【AWS SAM】Python版入門
内容
samがアップデートされて使いやすくなったらしいので、Pipenvでの環境構築からデプロイまでの流れを備忘録として残しておこうと思います。
環境
- macOS Mojave -10.14
- python3.7.4
- sam 0.38.0
目次
- Pipenvで環境構築
- アプリケーションの初期化
- デプロイ
1. Pipenvで環境構築
Pipenvインストール
$ pip install pipenvPipenv初期化
$ pipenv --python 3.7仮想環境に入る
$ pipenv shellaws-sam-cliインストール
開発時に必要なライブラリは
--devオプションをつけることで別枠に出来ます$ pipenv install aws-sam-cli --dev2. アプリケーションの初期化
この後の作業のため、
Project name [sam-app]:はpipfile等があるディレクトリと同じ名前にしましょう。テンプレートアプリケーションの生成
$ sam init Which template source would you like to use? 1 - AWS Quick Start Templates 2 - Custom Template Location Choice: 1 Which runtime would you like to use? 1 - nodejs12.x 2 - python3.8 3 - ruby2.5 4 - go1.x 5 - java11 6 - dotnetcore2.1 7 - nodejs10.x 8 - nodejs8.10 9 - python3.7 10 - python3.6 11 - python2.7 12 - java8 13 - dotnetcore2.0 14 - dotnetcore1.0 Runtime: 9 Project name [sam-app]: aws-sam-1 Allow SAM CLI to download AWS-provided quick start templates from Github [Y/n]: y AWS quick start application templates: 1 - Hello World Example 2 - EventBridge Hello World 3 - EventBridge App from scratch (100+ Event Schemas) Template selection: 1 ----------------------- Generating application: ----------------------- Name: sam-app Runtime: python3.7 Dependency Manager: pip Application Template: hello-world Output Directory: . Next steps can be found in the README file at ./aws-sam-1/README.mdここまでの作業で、ディレクトリ構成はこのようになっているハズです。
. ├── Pipfile ├── Pipfile.lock ├── README.md └── aws-sam-1 ├── README.md ├── events │ └── event.json ├── hello_world │ ├── __init__.py │ ├── app.py │ └── requirements.txt ├── template.yaml └── tests └── unit ├── __init__.py └── test_handler.pyただ、フラットな方がいいのいで
aws-sam-1/以下を一つ上の階層に持ってきます。$ mv ./aws-sam-1/* ./ $ rm -r ./aws-sam-1実行後のディレクトリ階層はこんな感じです。
1リポジトリで複数テンプレートを管理することってあまり無いので、こちらの方がスッキリしていて好きです。. ├── Pipfile ├── Pipfile.lock ├── README.md ├── events │ └── event.json ├── hello_world │ ├── __init__.py │ ├── app.py │ └── requirements.txt ├── template.yaml └── tests └── unit ├── __init__.py └── test_handler.pyアプリケーションのビルド
$ sam buildBuilding resource 'HelloWorldFunction' Running PythonPipBuilder:ResolveDependencies Running PythonPipBuilder:CopySource Build Succeeded Built Artifacts : .aws-sam/build Built Template : .aws-sam/build/template.yaml Commands you can use next ========================= [*] Invoke Function: sam local invoke [*] Deploy: sam deploy --guided実行すると、
.aws-sam/以下に色々できます。
詳しくは解説しませんが、実際にデプロイされる実行スクリプトやtemplate.yaml、ライブラリなどです。3. デプロイ
さて、ようやくデプロイですが、アップデートによってここが一番簡単になったと思います。
以前は、毎回
sam packageでソースコードや依存ファイルのアップデート等を行い、デプロイ時にはスタック名も指定しなければならないと、割と面倒でした。
アップデート後は、--guidedオプションをつけることで、それらをsamconfig.tomlというファイルにまとめてくれるようになりました。
これにより、2回目以降のデプロイは、sam deployコマンドのみでOKになります。では、アップデート後のデプロイをやっていきましょう。
~/.aws/credentialsで設定を分けている方は、--profileオプションを付けてください。デプロイ
$ sam deploy --guidedConfiguring SAM deploy ====================== Looking for samconfig.toml : Not found Setting default arguments for 'sam deploy' ========================================= Stack Name [sam-app]: aws-sam-1-stack AWS Region [us-east-1]: ap-northeast-1 #Shows you resources changes to be deployed and require a 'Y' to initiate deploy Confirm changes before deploy [y/N]: y #SAM needs permission to be able to create roles to connect to the resources in your template Allow SAM CLI IAM role creation [Y/n]: Save arguments to samconfig.toml [Y/n]: Looking for resources needed for deployment: Not found. Creating the required resources... Successfully created! Managed S3 bucket: aws-sam-cli-managed-default-samclisourcebucket-1np75dr62k62n A different default S3 bucket can be set in samconfig.toml Saved arguments to config file Running 'sam deploy' for future deployments will use the parameters saved above. The above parameters can be changed by modifying samconfig.toml Learn more about samconfig.toml syntax at https://docs.aws.amazon.com/serverless-application-model/latest/developerguide/serverless-sam-cli-config.html Deploying with following values =============================== Stack name : aws-sam-1-stack Region : ap-northeast-1 Confirm changeset : True Deployment s3 bucket : aws-sam-cli-managed-default-samclisourcebucket-1np75dr62k62n Capabilities : ["CAPABILITY_IAM"] Parameter overrides : {} Initiating deployment ===================== Uploading to aws-sam-1-stack/7f10f61137bc6dbef4059bf50229b958 532293 / 532293.0 (100.00%) Uploading to aws-sam-1-stack/0797e53a6d5052f23f1972e20e6fd8dd.template 1102 / 1102.0 (100.00%) Waiting for changeset to be created.. CloudFormation stack changeset --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Operation LogicalResourceId ResourceType --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- + Add HelloWorldFunctionHelloWorldPermissionProd AWS::Lambda::Permission + Add HelloWorldFunctionRole AWS::IAM::Role + Add HelloWorldFunction AWS::Lambda::Function + Add ServerlessRestApiDeployment47fc2d5f9d AWS::ApiGateway::Deployment + Add ServerlessRestApiProdStage AWS::ApiGateway::Stage + Add ServerlessRestApi AWS::ApiGateway::RestApi --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Changeset created successfully. arn:aws:cloudformation:ap-northeast-1:xxxxxxxxxxxx:changeSet/samcli-deploy1576913429/1265b6b9-05ac-4a26-9f75-d81099274672 Previewing CloudFormation changeset before deployment ====================================================== Deploy this changeset? [y/N]: y 2019-12-21 16:30:55 - Waiting for stack create/update to complete CloudFormation events from changeset --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- ResourceStatus ResourceType LogicalResourceId ResourceStatusReason --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- CREATE_IN_PROGRESS AWS::IAM::Role HelloWorldFunctionRole Resource creation Initiated CREATE_IN_PROGRESS AWS::IAM::Role HelloWorldFunctionRole - CREATE_COMPLETE AWS::IAM::Role HelloWorldFunctionRole - CREATE_IN_PROGRESS AWS::Lambda::Function HelloWorldFunction - CREATE_IN_PROGRESS AWS::Lambda::Function HelloWorldFunction Resource creation Initiated CREATE_COMPLETE AWS::Lambda::Function HelloWorldFunction - CREATE_IN_PROGRESS AWS::ApiGateway::RestApi ServerlessRestApi - CREATE_IN_PROGRESS AWS::ApiGateway::RestApi ServerlessRestApi Resource creation Initiated CREATE_COMPLETE AWS::ApiGateway::RestApi ServerlessRestApi - CREATE_IN_PROGRESS AWS::Lambda::Permission HelloWorldFunctionHelloWorldPermissionProd - CREATE_IN_PROGRESS AWS::Lambda::Permission HelloWorldFunctionHelloWorldPermissionProd Resource creation Initiated CREATE_IN_PROGRESS AWS::ApiGateway::Deployment ServerlessRestApiDeployment47fc2d5f9d - CREATE_COMPLETE AWS::ApiGateway::Deployment ServerlessRestApiDeployment47fc2d5f9d - CREATE_IN_PROGRESS AWS::ApiGateway::Deployment ServerlessRestApiDeployment47fc2d5f9d Resource creation Initiated CREATE_IN_PROGRESS AWS::ApiGateway::Stage ServerlessRestApiProdStage - CREATE_IN_PROGRESS AWS::ApiGateway::Stage ServerlessRestApiProdStage Resource creation Initiated CREATE_COMPLETE AWS::ApiGateway::Stage ServerlessRestApiProdStage - CREATE_COMPLETE AWS::Lambda::Permission HelloWorldFunctionHelloWorldPermissionProd - CREATE_COMPLETE AWS::CloudFormation::Stack aws-sam-1-stack - --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Stack aws-sam-1-stack outputs: ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- OutputKey-Description OutputValue ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- HelloWorldFunctionIamRole - Implicit IAM Role created for Hello World function arn:aws:iam::xxxxxxxxxxxx:role/aws-sam-1-stack-HelloWorldFunctionRole-PB5A5G9O9MBP HelloWorldApi - API Gateway endpoint URL for Prod stage for Hello World function https://xxxxxxxxxx.execute-api.ap-northeast-1.amazonaws.com/Prod/hello/ HelloWorldFunction - Hello World Lambda Function ARN arn:aws:lambda:ap-northeast-1:xxxxxxxxxxxx:function:aws-sam-1-stack- HelloWorldFunction-1QOQ29MG7346Z ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Successfully created/updated stack - aws-sam-1-stack in ap-northeast-1これでデプロイが完了しました。
HelloWorldApi - API Gateway endpoint URL for Prod stage for Hello World function https://xxxxxxxxxx.execute-api.ap-northeast-1.amazonaws.com/Prod/hello/ログに、APIGatewayへのアクセスポイントが表示されているので、アクセスしてみましょう。
curl https://xxxxxxxxxx.execute-api.ap-northeast-1.amazonaws.com/Prod/hello/{"message": "hello world"}と返ってくれば成功です。
終わりに
今回はチュートリアル用のアプリをそのまま使いましたが、
次回はDynamoDBを組み合わせてAPIを作っていきたいと思います。
- 投稿日:2019-12-21T15:09:36+09:00
SORACOM LTE-Mボタンを押して、Slackのワークフローを発動させる
これは、SORACOM Advent Calendar 2019の21日目の記事です。
SORACOM FunkとSORACOM Napterは神。
だと思っている人です。
前説
ボタンネタで書こうと思ったものの、何を書くかなーと悩んでました。
そういえば、ボタンを使って承認するって話しあったなー。
承認するといえば、ワークフロー。
そういえば、最近Slackにワークフローできたなー。よし。ボタン押したら、SORACOM Funk経由で、Lambdaを呼び出して、SlackにPOSTして、ワークフローを起動させよう。
っていうのをやってみた話です。
Funkが使える #しろボタンと#ひげボタン はもちろんですが、
AWS IoT-1ClickからLambdaを呼び出すことができるので、#あのボタン でも使えます。構成図
ソース
githubにおいてあります。
https://github.com/Kenichiro-Wada/advent-calendar/tree/master/soracom-2019AWS LambdaのNode v12.xランタイムにおいて動作確認しています。
デプロイはServerless Frameworkで実施してます。Slackのチャネル名、チャネルID、下で取得するSlackのトークンはAWS Key Management Service (KMS)で暗号化しています。
serverless-kms-secrets を導入する手順
を参考にしました。SORACOM側設定
SORACOM Funkに作成したLambdaを
SORACOM Funkを使ってみた。 に書いてあるので、こちらをみてください(宣伝)Slack API設定
以前使ったことがあるIncoming Webhookだと、できなそうだったので、APIを叩いています。
利用するために、トークンが必要なので、ワークスペースにAPIの設定を行って、取得しています。https://api.slack.com/apps
にアクセスして、Create New Appをクリックして、追加するワークスペースと、名前を設定
完成したら、左ペインの OAuth & Permissions
を選んで、権限を付与していきます。
こんな感じ
権限設定が終わったら、
OAuth Tokens & Redirect URLs にあるInstall App to Workspaceを押して、トークンを生成します。上記の通り、生成したトークンは、Lambdaの環境変数にAWS KMSを使って暗号化した上でセットしています。
Slackワークフロー
Slackのワークフローの作り方は、こんな感じ。
公式ワークフロービルダーを起動して、作成開始
名前をつけます
発動条件を決めるます
ワークフローの発動条件としては、以下がありますが、今回は絵文字リアクションを設定させています・
- チャンネルへの追加
- アクションメニュー
- 絵文字リアクション
発動させるチャンネルと、絵文字を設定します。
そのあとのアクションを決めます。
今回はフォーム作成する にしています。
表示内容などを設定します。
で、完成。あとは公開すればOK
動作
今回ボタンの動作で、以下のようなアクションにしています。
- シングルクリック : 承認 -> 承認メッセージ追加
- ダブルクリック : 否認 -> 依頼メッセージに、NGアイコンを表示して、それを条件に否認理由入力するためのワークフロー発動させています
- ロングクリック : 保留 -> 依頼メッセージに、ハンドアイコンを表示して、それを条件に否認理由入力するためのワークフロー発動させていますシングルクリック(承認)の場合
ダブルクリック(否認)の場合
ロングクリック(保留)の場合
自分個人のSlackワークスペースで作ってみたので、他にユーザーいないので。自己承認・自己否認になってますw
実際のところは・・・。
使うのか・・・と言われると。。。
こういうこともできるよってネタになります。作ってて、思ったのですが、
最後のポストしか承認できないから、
むむむ。上申の印鑑もらう行列と同じような承認もらう行列になってしまうー。注意事項
Slackのワークフローは、無料プランでは利用できません。
有料プランにする必要があります。はい。
最後に
あまりボタンのことを書いてなかったのでw、Twitterには呟いたんですが、ボタンについての所見等々を
SORACOM LTE-M Button powered by AWSが発売されてから約1年たち、Enterprise button、Button Plusが発売されて、色々な使い方ができるようになった気がします(自分では大した事例出せないのが申し訳ない)。
また、IoT1-Click経由でしかLambdaを呼べなかったけど、Funnel->AWS IoT Coreで呼ベるようになり、そして、Funkを使うことで、簡単にLambdaを呼べるようになりました。
いや、ほんとすごい。通信環境も、今年も押しまくってた時期があったんですが、1年でだいぶ改善された感じがしてます。あれ、以前より通信の成功率上がったな感(えらい上目線w)。
来年、2020/02/18にはSORACOM Technology Camp 2020があり、今回もナイトイベントあるらしいので、そこでLT募集でもあったら、募集申し込んでみようかと思う2019年の師走の午後でした。














- 投稿日:2019-12-21T14:32:02+09:00
MySQLのデフォルトパスワードを確認する
はじめに
MySQL5.7以降では、デフォルトでrootユーザーのパスワードが自動で初期設定されている。
このパスワードの調べ方のメモ。環境
OSはAmazonLinux2
MySQLのバージョンは5.7OS# cat /etc/system-release Amazon Linux release 2 (Karoo) # mysql -V mysql Ver 14.14 Distrib 5.7.28, for Linux (x86_64) using EditLine wrapperMySQLにrootログインしてみる
rootでMySQLに入ろうとすると、
Access Diniedとなり弾かれます。# mysql -u root ERROR 1045 (28000): Access denied for user 'root'@'localhost' (using password: NO)MySQLのパスワード確認
rootの初期パスワードを確認する。
初期パスワードは/var/log/mysqld.logに記述されているため、以下のコマンドで確認できる。パスワード確認# cat /var/log/mysqld.log | grep password 2019-12-13T06:12:17.402781Z 1 [Note] A temporary password is generated for root@localhost: <初期パスワード>
A temporary password is generated for root@localhost:以降の文字列が初期パスワード。
この文字列をコピペしてログインすると、MySQLにログインできるようになる。MySQLにログイン# mysql -u root -p Enter password: Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 8 Server version: 5.7.28 Copyright (c) 2000, 2019, Oracle and/or its affiliates. All rights reserved. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql>初期パスワードの変更
ログインできれば、初期パスワードは変更しておく。
初期パスワード変更mysql> set password for root@localhost='新パスワード'; Query OK, 0 rows affected (0.00 sec)
- 投稿日:2019-12-21T14:30:11+09:00
[#awscertified] AWS Certified DevOps Engineer - Professional ポイントのおさらい
失効していたので3年ぶりくらいに受けてきました。前日受けた模試が60%だったので正直無理ゲーかなと思っていましたが、なんとか受かってよかった。
消去法のような「いかにも」な解き方をしておりちゃんと理解できてない内容も多いので、復習を兼ねて留意すべきトピックなど残しておこうと思います。
出題傾向
CI/CDの話題は多いです。Code系サービスとCloudWatch(Events/Logs)は全体的に登場回数が多かったです。
「DevOpsエンジニアは〜〜〜のためにどうすべきでしょうか?」みたいな書きっぷりのパターンが多い。
分類すると以下のようなところの印象が強いです。
- ガバナンス(trailをで分析する仕組みがほしいとか、ユーザー部門に対して自社ポリシーを満たしたAMIの使用を強制するとか)
- 継続的デプロイ
- パイプラインの組み方に関する出題(AMIとかAutoScalingが絡む内容が多い、サーバーレスがほんの少しだけ)
- デプロイ戦略に関する問題(ダウンタイムを極小化したい・エラーを多数観測したらすぐに切り戻したい、とかの要件)
- ロギング(全編に渡りロギングが関連する出題は多い。アプリケーションログをどうやって分類してアラートするのか?とか、永続化して一元的に分析できるようにするにはどうしたら?とか)
- DR(RTO/RPOの要件に指定がある前提で、どの手法がベターか?とか)
AWSサービスで言うと以下で挙げるものが特に頻出した印象があります。上にあるほどよく単語が出現し、かつ重要です(私の体感値として)。
- CloudWatch Events
- CloudWatch Logs (メトリックフィルタとか)
- Code系 (特にCodeDeploy、AutoScalingとセットで出てくることがかなり多かった)
- CodePipeline
- EC2 AutoScaling (ライフサイクルフックを絡めて何かする問題もいくつか)
- Systems Manager (特にParameter Store)
- CloudFormation
- Config
他にも色々ありますが、強いて挙げるならElastic Beanstalkの少しだけDeepなネタが多少登場します。
他にはSNSやALB。SNS自体がシンプルなのでさほどがっつり調べる必要なさそうな気もしますが、登場回数だけなら割と頻出だったと思います。ALBはまぁ、SA Proでも普通に頻出トピックだと思うのでSAの対策勉強しているくらいのインプットで必要十分かなと。
出題文にはさほど出てこないもののIAMやS3周りのポリシー関係の知識は割と前提みたいなところがありそうです。
「オンプレにもデプロイしたいんだけど」とか「CI/CDパイプラインでこれこれを自動化したい(ガバナンス的なチェックやコードの自動テストなど)」のようなシチュエーションが多かった印象です。
あと、デプロイ戦略のところですが技術要素としてはRoute53、ALB(ターゲットグループ)、AutoScaling、CodeDeploy、Lambda(エイリアス)、あたりが出てきたと思います。これとセットで、「新バージョンでアプリケーションログを監視し、エラーを一定割合検出したらトリガーしてロールバックしたい」みたいな要件もちょいちょい出ました
感想
- 模試の方が難易度高い問題が多い
- 日本語が難解すぎて、後半戦は読解するのが辛かった
- 模試で慣らしてなかったら、おそらく合格は難しかった
- 問題文の最後から読む方が有効な問題も多い
- 頭が疲れるので、2分未満くらいの時間、目を閉じてリフレッシュする時間を何回かとった
- 英語の原文が見られるようになってたのが地味にありがたく、いざというときに頼りになる
- 明らかに不自然な選択肢や、ニュアンスの読解に苦慮する内容は英語も見る
- 原文だとCloudFrontだったものが日本語ではCloudFormationになってる誤植が1問(最後の見直しで原文を見て発覚)
- 日本語の記述を100%信用してはいけない。絶対にいけない
- ペース配分大事
- 途中で休憩する時間は必要。振り返りの時間も、できれば必要
- 日本語を読解するために脳のリソースが余計に消耗して集中が維持できない(加齢)
- 10分以上残す、くらいの心持ちで5/10問おきぐらいに残り時間を見ておくとよい
まとめ
疲れた・・・。次はMLでも受けようかなと思います。
- 投稿日:2019-12-21T12:56:47+09:00
[AWS]APIGateway上でExpressのpublicルーティングを通したかった
はじめに
新卒ゆるゆるアドベントカレンダー21日担当です!
最近AWSを触らせてもらう機会があり、それについて少々。背景
「あんまアクセスないサイトだし、ServerlessでWebサービス作れたら低コストな運用が出来るのでは!?」っていう流れで、AWS,Lambdaで動くWebサーバの構築をNode.js&Expressを使って行いました。
Expressのスケルトンコードを用意し、普段のようにpublic配下にクライアントJSやCSSのリソースを入れ込んで、下記のexample.htmlように自身のURLを指定してリソースを読み込んでいました。
ですが、Serverless.ymlで特定のルーティングをLambdaFunctionに紐づけて定義してしまっているため、example.htmlのようなリソースURLをリクエストされても対応するLambdaFunctionが無いと怒られるだけでした。(この問題の解明に3日ほど費やしました)sample.html<head> <link rel="stylesheet" type="text/css" href="/public/css/example.css"> </head>(以前書いた記事でExpressスケルトンコードでのサーバ構築手法も書いてるのでぜひご覧ください)
対応方法の検討
クライアントからのリソースのリクエストは「/public/」で始まる事から、以下の三つを検討しました。
- /public/でアクセスできるLambdaFunctionを定義し、そこで実際の/public/フォルダから検索して返す
- /public/でアクセスできるLambdaFunctionを定義し、そこでS3バケットから指定されたリソースを引っ張ってきて返す
- CloudFrontを使い、/public/で来たリクエストをAPIGatewayではなく直接S3バケットに向ける
純粋なAPIGatewayとLambdaの動作、Expressの動作を保証しつつ、可用性を求めた結果3を選択しました。CloundFrontはcdnとして元々導入予定且つS3の運用コストの低さからこの選択は最善であると判断しました。対応
AWSConsole上からCloudFrontの設定をしていきます。
新しいDistributionを作り、OriginにはAPIGatewayのARNを、CustumOriginにはS3のARNを設定します。Originの設定例を図1に、Behhavioursの設定例を図2に示します。図1(Originの設定例)
図2(Behaviorsの設定例)
おわりに
アドベントカレンダーのタイトルにそぐわない内容だったかもしれませんが、もしServerlessでWebサーバを作る人の参考になれば幸いです。
実際にはAWSConsoleから直接Distributionをいじるのではなく、Terraformを使ってドキュメント化を行っております。いずれそれを記事にすると思います。
更にs3へのリソースデプロイもshellで自動化したので、それもいつか記事にするかもしれません。
ご興味がある方は是非ご覧になってください。
最後まで読んでいただきありがとうございました。

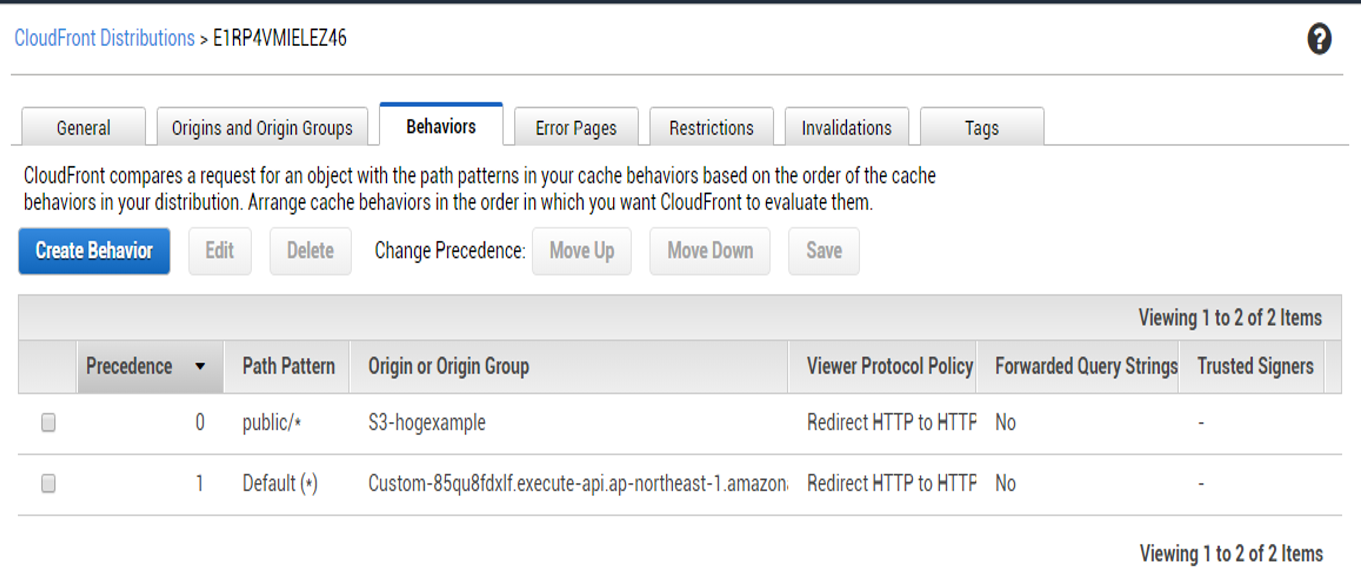
- 投稿日:2019-12-21T12:18:25+09:00
BlenderでRTX 2080 Tiの4倍速いレンダリングを体験してみる
はじめに
今回は割とちゃんとした記事を書こうと思い、普段から使っているクラウドでレンダリングする方法を説明していきます。Blenderを使っている人の多くは、モデリング用かもしれませんが、この記事がきっかけで、モデリング以外の動画作成などにも興味を持ってもらえたら嬉しいです。
ちなみに、昨日全てBlenderでモデリングして作った180°のVRの動画をuploadしたのでぜひ見ていただけたらと思っています。
今日は、コンシューマー向けのGPUで今あるものの中で一番良いのではないかと思っている、NvidiaのRTX2080 Tiよりもさらに高速でレンダリングする方法を書きます。日本語も英語の記事もほとんどないので、参考になると思います。
クラウドレンダリングとレンダーファームの違い
クラウドレンダリング とレンダーファームの違いは、インスタンスやOSの管理が異なることがあげられます。
レンダーファームの場合は、OSなどがインストール済のPCをいくつか連結したPC群に対してファイルをuploadして、そのファイルをレンダリングしてもらいます。一方で、クラウドレンダリングの場合は、OSのインストールから、レンダリングを行うソフトまで全てを自分でインストールしてから出ないと利用できません。しかし、その分カスタマイズが色々とできるのが特徴です。例えば、レンダリングの方法を変更したり、自分好みにOSをかけたり、GPUのスペックや立ち上げるインスタンスの数も自由に変更ができます。
この自由度によって、レンダーファームでは出せなかったスピードのレンダリング時の様々なカスタマイズが可能になってきます。
環境
今回は、以下の環境を構築してレンダリングを行っていきます。
- クラウドはAWS(もちろん、他のクラウドでも同じことができます。)
- Ubuntu 18.04.3 LTS
- Blender2.81実装
ここでは、実際にインスタンスを起動して、Blenderでレンダリングする方法を説明していきます。
インスタンスの実行
僕が普段使っているGPUは、Nvidia Tesla T4です。このGPUには、AWSが提供しているGPUのうち唯一RTコアが乗っています。RTコアは、リアルタイムトレーシング向けのコアで、BlenderでOptiXによる高速レンダリングを行う時に、必要になります。他にもTesla M60などは、グラフィックスに向いているとAWSのサイトの方に書いてありました。
https://aws.amazon.com/jp/ec2/instance-types/g3/Tesla T4は、AWS上では、g4dnという名前のインスタンスなので注意してください。
今回は、GPUインスタンスのOSに、Ubuntu 18.04.3 LTSを利用しています。インスタンスの環境構築
必要なインスタンスをAWSのコンソールから起動まで終われば、あとは、ターミナルなどでの操作になります。以下のコマンドをコピーして必要な環境をインストールしていきます。
初期設定
まずは、起動したインスタンスにssh接続します。
ssh -i "{your_key_name}.pem" ubuntu@{your_instance_ip}.compute-1.amazonaws.com{your_key_name}には、インスタンス起動時に設定した鍵の名前、{your_instance_ip}には、起動したインスタンスのipが入ります。権限関連で、接続を拒否される場合は、sudoでもう一度試してみてください。インスタンスに接続できたら、GPUを利用する初期設定をしていきます。
#rootユーザー切り替え sudo su - # TIMEZONEをJSTに ln -sf /usr/share/zoneinfo/Asia/Tokyo /etc/localtime #CUDAをインストール curl -O http://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64/cuda-repo-ubuntu1804_10.0.130-1_amd64.deb dpkg -i ./cuda-repo-ubuntu1804_10.0.130-1_amd64.deb apt-key adv --fetch-keys http://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64/7fa2af80.pub apt update && apt install -y cuda # GPUを有効化 nvidia-smi -pm 1 nvidia-smi --auto-boost-default=DISABLED #GPUの動作確認 nvidia-smiここまでで、起動しているインスタンスのGPUが利用可能な状態になっていれば、次のような表示が出ます。
| NVIDIA-SMI 430.26 Driver Version: 430.26 CUDA Version: 10.2 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | |===============================+======================+======================| | 0 Tesla T4 Off | 00000000:00:04.0 Off | 0 | | N/A 34C P8 28W / 149W | 11MiB / 11441MiB | 0% Default | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: GPU Memory | | GPU PID Type Process name Usage | |=============================================================================| | No running processes found | +-----------------------------------------------------------------------------+Blenderのインストール
今回利用しているOSは、Ubuntuなので、Snap StoreからBlenderをインストールしてきます。
sudo snap install blender --classic #インストールはデフォルトでは、以下のpathに行われます cd /snap/binここまでで、blenderでレンダリングができる環境が整いました。思っていた以上に簡単でした!!
Blenderでクラウドレンダリング
最後に、環境構築ができたGPUインスタンス上でレンダリングを行っていきます。
レンダリングを行うファイルのupload
初めにレンダリングを行いたいシーンを含むBlendファイルをAWSにuploadしていきます。
そのままインスタンスにuploadしてもいいですが、コストと毎回uploadするめんどくささを考えると、一旦S3にuploadしておくことをお勧めします。直接インスタンスにuploadする場合は、以下のコマンドをターミナルから叩けばできます。sudo scp -i /{path1}/.ssh/{your_key_name}.pem /{path2}/{your_blend_file_name}.blend ubuntu@{your_instance_ip}.compute.amazonaws.com:~{path1}には、AWSのインスタンスにアクセスする鍵を保存しているパスが入ります。{path2}には、uploadしたいファイルのパスが入ります。{your_blend_file_name}には、レンダリングを行いたいblendファイルの名前が入ります。
これでレンダリングをしたいファイルをuploadできたら、最後にレンダリングを行います。
レンダリングを行うときのoptionの設定方法は、以下のページから確認できます。
https://docs.blender.org/manual/en/latest/advanced/command_line/arguments.html通常のレンダリングの場合は、以下のコマンドを叩くことで開始します。
blender -b {your_blend_file_name}.blend -o ./output/f__ -s {start_frame} -e {end_frame} -a{start_frame}には、レンダリングを始めるフレーム数、{end_frame}にはレンダリングを止めるフレーム数を入力します。これで、outputディレクトリーにレンダリングが終わったファイルが生成され始めます。
ベンチマーク
最後にクラウドレンダリングをした時に、RTX2080 Tiと比較してどの程度速度が向上するかについて述べていきます。答えは、RTX2080 Tiを一台積んだPCに比べて無限に速度アップは理論上可能です。
というのも、クラウド上には、たくさんのGPUインスタンスが世界に用意されていて、それらを全て同時に利用すればレンダリング自体は、瞬時に終わります。しかも、クラウドレンダリングの場合、利用直に対しての課金であるので、複数台でレンダリングを一瞬で終わらせたとしても、一台でノロノロ終わらせたとしても、レンダリング自体にかかる総時間が変わらない場合、かかる費用は同じなのです。
(ex, 100台で1時間レンダリングをするのと、1台で100時間レンダリングするのにかかる費用は同じです。)しかし、現実的には、AWSの用意しているGPU自体の数は有限ですし、他の人がGPUを使っているので同時にたくさんのGPUを利用することは難しいかもしれません。
ここでは、わかりやすいようにAWSの提供しているg4dn.12xlargeと呼ばれるインスタンス一台をRTX2080Ti一台と比較して話します。この場合は、RTX2080Tiで12分かかったレンダリングは、g4dn.12xlargeでは、3分程度で終わりました。サンプル数は少ないですが、概ね1/4程度でレンダリングが終わる印象です。
最後に
以上がクラウドレンダリングの外観でした。まだまだ色々なカスタマイズ方法や、コスト削減方法、レンダリングのオプション等ありますが、また今後紹介していきます。twitter(@r_etx)の方でも質問を受け付けているので、何かあれば来てください!!

- 投稿日:2019-12-21T11:37:35+09:00
Route53 ヘルスチェックのエンドポイント設定のわな
こんにちは!
こちらは、ラクス Advent Calendar 2019の20日目になります。
昨日は@danonb10さんの『PostgreSQL 宣言的パーティショニングの制約事項』でした。はじめに
2019年10月に現場に変わりました。
ちょうど配属前にAWSソリューションアーキテクト アソシエイトを取得、勉強したことがしっかり頭に残っている状態でのAWS現場だったので、なんだかテンションがあがります。とはいえ、実際に業務でサービスを触るのは初めてなのですが、毎日新鮮な気持ちで勤しんでおります。はじめてしっかり携わったプロジェクトとして、マルチCDNをフェイルオーバー構成にするという、ちょっとめずらしいことをやりました。今の現場が映像配信サービスをしている会社さんだというのもあるのかな。今回、CDNフェイルオーバー構成をつくる際に直面する問題点・解決策を共有させていただきます。
やりたいこと
ざっくりですが、概要。
- AWSのRoute53のヘルスチェック・フェイルオーバールーティングを活用する
- ヘルスチェック:2つのCDN→オリジンサーバの接続を見るように
- ルーティング:加重ルーティングを採用、アクティブサーバに100、スタンバイサーバに0を設定
問題
ここで、CDNならではの問題が発生します。
CDNってフロントは複数のサーバーから構成され、複数のIPアドレスを持っていて、CDN自体も分散・冗長構成をとっています。ですので、Route53のヘルスチェックの設定をする際に、エンドポイントをIPアドレスで指定することができません。ドメインで指定します。なおかつ、CDN1/2とは同じドメインを設定したい。
普通にRoute53のヘルスチェックを設定しただけでは、下記のように、全く意味のない構成になります。
CDN1が故障し、ヘルスチェックが「異常」と判定される
CDN2にフェイルオーバーする
ヘルスチェックのエンドポイントをドメインで指定しており、CDN1/2のドメインは同じため、ヘルスチェックはCDN2を見て「正常」と判定する(本来はCDN1を見て欲しい)
CDN1にフェイルバックする(ああ…)
CDN1は故障しているので、ヘルスチェックが「異常」と判定する(ふりだし戻ります笑)
というふうに、アクティブ・スタンバイを同じドメインにしたい、かつヘルスチェックのエンドポイントをドメインで指定せざるを得ない状況が重なると、ヘルスチェックがエンドポイントを正確にとらえてくれずに、フェイルオーバーとフェイルバックをバタバタと繰り返してしまいます。IPアドレスで設定できれば問題ないんですけどね。
解決策
色々調べたのですが、直接の解決方法はありませんでした。
そもそも、「アクティブ・スタンバイを同じドメインにしたい」かつ「ヘルスチェックのエンドポイントをIPアドレスではなくドメインで指定せざるを得ない」という、そんなことあるんかいなという状況下でのヘルスチェックのやり方なんて、ググれどググれど、どこにもなく。なので、これが間違いなくベストなやり方かは正直なんとも言えないのですが、唯一の苦肉の策ということで、下記参考になれば幸いです。Route53のヘルスチェックには、「高度な設定」にて「String Matching (文字列マッチング)」という機能があります。とりあえず詳細はホワイトペーパーをご一読ください。
Route 53 で、HTTP または HTTPS リクエストをエンドポイントに送信、または指定文字列のレスポンス本文を検索することにより、エンドポイントの状態を判断するかどうか。[Search String] で指定した値がレスポンス本文に含まれる場合、Route 53 は、そのエンドポイントが正常であると見なします。レスポンス本文に含まれない場合、またはエンドポイントが応答しない場合、Route 53 は、そのエンドポイントを異常と見なします。
こいつを使って運用しようということになりました。
ヘルスチェックの内容が、指定のドメイン名、そしてレスポンス文に"I_AM_CDN1"が含まれるか、を加えていきます。まず、CDN1のヘルスチェックの設定に、レスポンス文に"I_AM_CDN1"が含まれる、文字列マッチングの設定を行います。加えて、CDN側には、CDN1のみ、レスポンスに"I_AM_CDN1"の文字列を追加するよう設定変更を行います。
こうすることで、フェイルオーバー時、下記の通り問題なく動作するようになります。
フェイルオーバー前ヘルスチェックをすると、指定のドメイン名、かつCDN1からのレスポンスには"I_AM_CDN1"が含まれるため、正常とみなします。
CDN2へのフェイルオーバー後、指定のドメイン名ではありますが、CDN2からのレスポンスには"I_AM_CDN1"が含まれていないため、「異常」とみなされるようになります。
これで、フェイルオーバー・フェイルバックでバタバタすることはなくなりました。
文字列マッチングの設定箇所
ヘルスチェックの設定をします。[エンドポイントの指定]をドメイン名とします。ここで設定を終わらせず[高度な設定]をクリックします。
文字列マッチングは下記の箇所です。5120バイト以内の文字列にする必要があるとのことです。
CloudWatchの設定はひとまずなしとし、[ヘルスチェックの作成]をクリックします。
上記の設定をすれば、フェイルオーバー後もヘルスチェックが間違いなく動作します。設定も一瞬ですね。
また、Route53のフェイルオーバールーティングはフェイルバックは自動で行う仕様なのですが、エンドポイントをドメイン名で指定・文字列マッチングにて設定を行う、と自動フェイルバックを無効にすることができます。
フェイルオーバー後に、元アクティブサーバを復旧させた後、確実に手動フェイルバックさせたい、という要望も実現できる設計となりそうです。おわりに
よく触るAWSサービスも、実は使ったことがない、調べる機会がない機能ってたくさんあるんだなぁと、勉強になりました。常に好奇心を持ってお仕事をしていきたいと思ったし、あまりブログにてまとめられていないような機能など、積極的に発信していこうと思います。
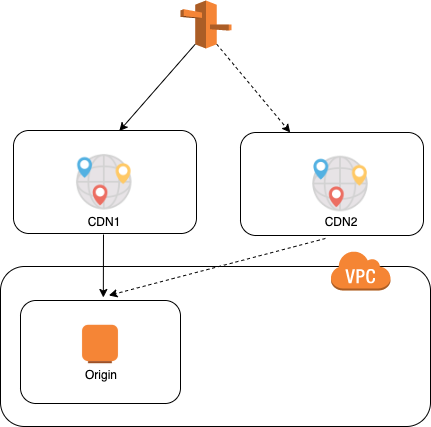
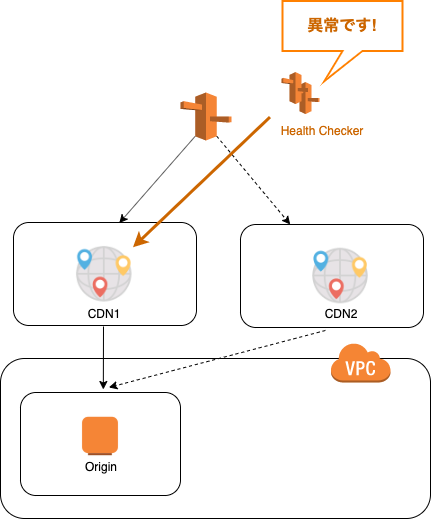
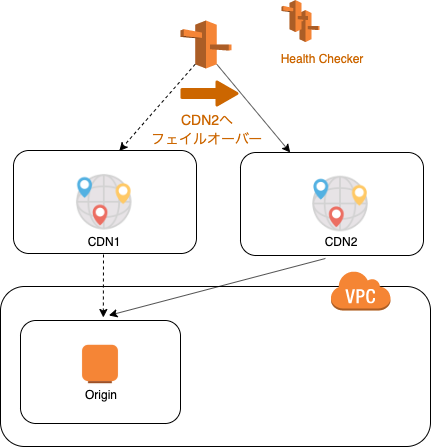
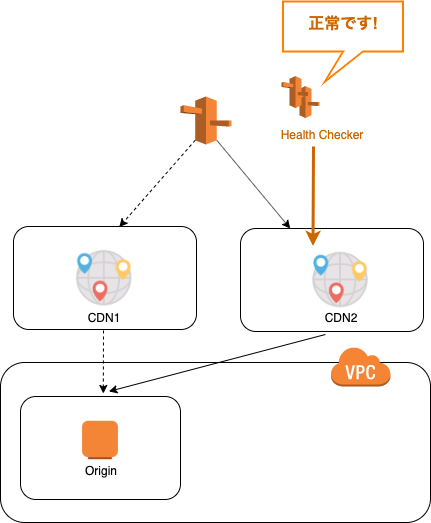
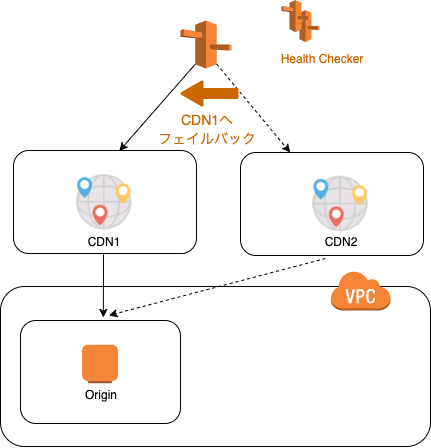
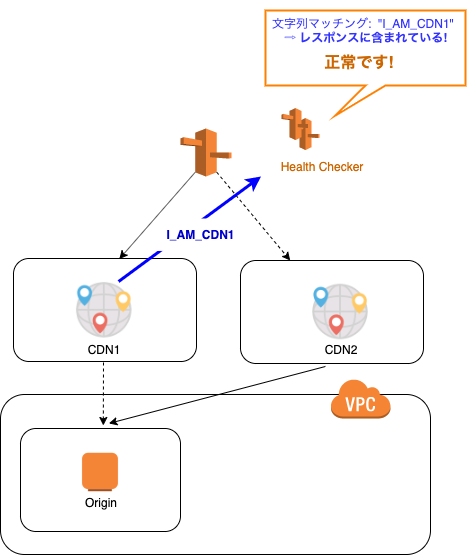

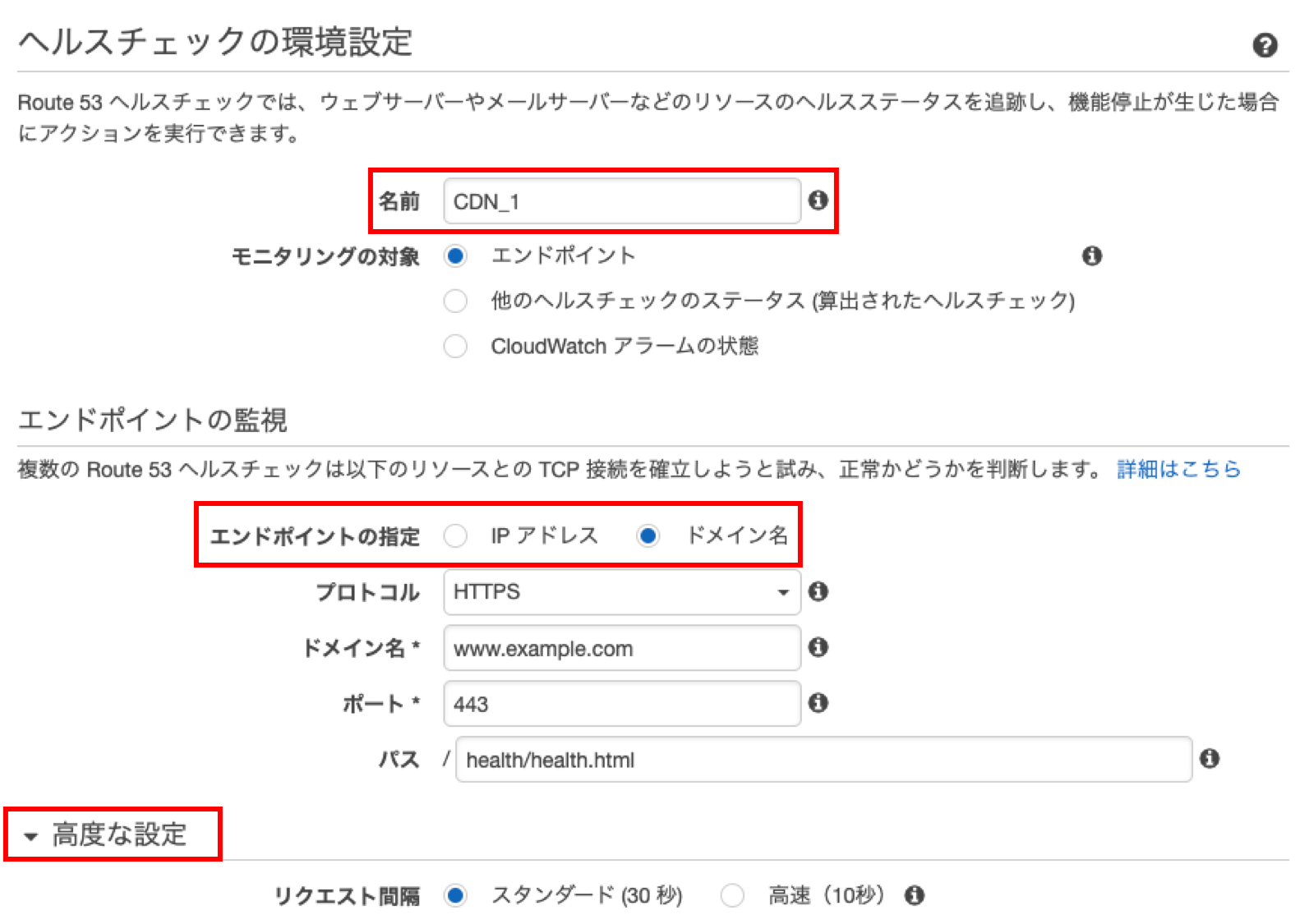

- 投稿日:2019-12-21T10:43:41+09:00
AWS Systems Manager と EC2 Instance Connect を利用して鍵管理、 Public IP なしで SSH 接続出来る EC2 インスタンス構築
この記事は Opt Technologies Advent Calendar 2019 6 日目の乗っ取り記事です
5 日目の記事は @kadokusei さんの UTM に VyOS と WireGuard を入れてみる です
7 日目の記事は @peko-858 さんの 【ScalikeJDBC 入門】SQLInterpolation を QueryDSL に書き換えてみた です
AWS Systems Manager と EC2 Instance Connect を利用して鍵管理、 Public IP なしで SSH 接続出来る EC2 インスタンス構築
tl;dr
- EC2 Instance Connect コマンドを利用して都度生成した SSH 鍵を EC2 インスタンスへアップロード
- 生成した SSH 鍵を用いて Systems Manager の Session Manager を使って SSH 接続
→SSH 鍵管理なし Public IP なしで EC2 インスタンスへ SSH 接続ができる!最高!
SSH で繋げる EC2 インスタンスが欲しい!でも・・・
- 素直に作ると Internet Gateway から SSH ポートを開けて PublicIP 割り当てて・・・と地味に大変
- 最近なら AWS Systems Manager Session Manager で SSH 接続が可能だけど、鍵は管理が必要
- Session Manager から SSH じゃない接続も出来るけど、SSH が使いたい
- 例えば踏み台サーバーとしてインスタンスを立てておいて、ポートフォワーディングして VPC 内の RDS を直接見たいとか
- 先日出た EC2 Instance Connect を使えば鍵管理はいらないが、PublicIP が必要
あちらを立てればこちらが立たず・・・と思っていましたが、組み合わせれば PublicIP なし鍵管理なしで運用できるのでは!?と思って試してみたら出来たので記録しておきます
やり方
といってもそんなに手の込んだ事はしてないです
手順としては以下のようなステップになります
- AWS Systems Manager Session Manager 経由で SSH 接続出来るよう設定をしておく
- インスタンスに繋ぎたいときは毎回 SSH 鍵を発行して
aws ec2-instance-connect send-ssh-public-keyコマンドでインスタンスに公開鍵を送る- SSH 接続する
これだけで簡単に実現できます
既に運用中のインスタンスにも導入簡単なのでサラッと入れちゃって良さそうな気持ちを得ました各種手順解説
AWS Systems Manager Session Manager 経由で SSH 接続出来るよう設定をしておく
ここに全てが書いてあるのでこの記事のとおりにやるだけ
AWS Systems Manager セッションマネージャーで SSH・SCP できるようになりました手順だけ書くと、以下のようになります。実質 SSH コンフィグの設定だけみたいなもんですね、お手軽です
- ホストの SSM エージェントを対応バージョンにアップデート
- クライアントの aws-cli と Session Manager プラグインのアップデート
- SSH コンフィグの設定
- 以下のように、ホスト名にインスタンス ID を指定したら ssm コマンドに受け流すように記述
~/.ssh/confighost i-_ mi-_ ProxyCommand sh -c "aws ssm start-session --target %h --document-name AWS-StartSSHSession --parameters 'portNumber=%p'"これでインスタンスが Public なネットワークに公開されていなくても SSH 接続が出来るようになります
ssh コマンド実行の際はホスト名をインスタンス ID で指定して実行すれば OKインスタンスに繋ぎたいときは毎回 SSH 鍵を発行して
aws ec2-instance-connect send-ssh-public-keyコマンドでインスタンスに公開鍵を送るここに全てが書いてあるので(略)
EC2 Instance Connect を使用して接続する#独自のキーと SSH クライアントを使用して接続する
- 普通に ssh-keygen で SSH 鍵を発行
- 発行した SSH 鍵を
aws ec2-instance-connect send-ssh-public-keyコマンドで指定したインスタンスに送る
- 送った SSH 鍵の有効期限が 60 秒なので注意
毎回手でやるのはいくらなんでもめんどくさいので、スクリプトを書いてコマンド一発で出来るようにしておきたい手順ですね
SSH 接続する
以下を実行するだけ
ssh -i [作った鍵] ec2-user@[対象のインスタンスのインスタンスID]チームでこの方法を使うなら最初の手順の SSH コンフィグを変更をせずに、ここの ssh コマンドに
-o ProxyCommand # 以下略を渡してあげて、それをスクリプトとして書いておくほうが導入手順が減るので良さそうですねおわりに
ということで AWS で Public IP なしの EC2 インスタンスへ SSH 接続する方法を紹介しました
一昔前は公開鍵を S3 においておいてプロビジョニングやスケールアウト時に配布、みたいな泥臭い方法で実現していたユーザーごとの SSH 接続がごく簡単な手順で実現できました
それに、既に運用中のインスタンスであっても導入は簡単そうなのでメリットは大きいんじゃないかなという感触。使わない手はないですね
いい時代になったものですAWS はいいぞ!
- 投稿日:2019-12-21T10:10:09+09:00
Elasticsearch によるログ収集と可視化(第三回)
今回はログ収集からログ可視化まで、具体的な設定内容について記載します。
検証時のデータ処理の流れ(おさらい)
「Windowsイベントログからログイン成功/失敗のログを収集・(可視化するために)集計」し、不正アクセスの疑いを検知出来るようにするために、以下の流れでデータを処理します。
各ツールの設定
各ツールの設定ファイルについて記載します。
Winlogbeat の設定
- 設定ファイル
C:\<Winlogbeatをインストールしたフォルダ>\winlogbeat-7.4.2-windows-x86_64\winlogbeat.yml
Winlogbeat から Logstash にログを転送する設定を行います。
Windows イベントログはログ量が多いため、今回はログオン・ログオフの操作が記録される Security ログのみ転送するようにしました。
Winlogbeat 自体で不要なログの削除、ログの整形を行う事も可能ですが、今回は Logstash における filter の検証を行うため、それらは使用していません。winlogbeat.yml#======================= Winlogbeat specific options =========================== winlogbeat.event_logs: # - name: Application # ignore_older: 72h # - name: System - name: Security processors: - script: lang: javascript id: security file: ${path.home}/module/security/config/winlogbeat-security.js # - name: Microsoft-Windows-Sysmon/Operational # processors: # - script: # lang: javascript # id: sysmon # file: ${path.home}/module/sysmon/config/winlogbeat-sysmon.js #==================== Elasticsearch template settings ========================== setup.template.settings: index.number_of_shards: 1 #============================== Kibana ===================================== # Kibana API の設定を行う場合に利用します。 setup.kibana: host: "172.31.43.233:5601" #================================ Outputs ===================================== output.logstash: hosts: ["172.31.43.233:5044"] #================================ Processors ===================================== # Winlogbeat で生成されるログの削除や整形の設定を行う場合に利用します。 processors: - add_host_metadata: ~ - add_cloud_metadata: ~
- サービス起動確認
Windowsサービスの管理画面で Status が Running になっていれば起動しています。
Logstash の設定
- 設定ファイル①
/etc/logstash/pipelines.yml
ログ取得(Input) > 整形(Filter) > 投入(Output) の設定を行うファイルを指定します。
デフォルトでは/etc/logstash/conf.d/配下の全ての.confファイルを読み込みます。
今回は新規で作成した/etc/logstash/conf.d/logstash.confを指定しました。pipelines.yml- pipeline.id: main # path.config: "/etc/logstash/conf.d/*.conf" path.config: "/etc/logstash/conf.d/logstash.conf"
- 設定ファイル②
/etc/logstash/conf.d/logstash.conf
ログ取得(Input) > 整形(Filter) > 投入(Output) の設定を行います。
ファイル名は任意ですが、/etc/logstash/pipelines.ymlで指定したパスと合わせる必要があります。
- input { }:Winlogbeatからログを取得する設定
- filter { }:取得したログを整形する設定
- output { }:整形したログをElasticsearchに投入する設定
logstash.confinput { beats { port => 5044 } } filter { # event id で filter する if [winlog][event_id] != 4624 and [winlog][event_id] != 4625 { drop {} } # 日時を JST に整形する ruby { code => "event.set( 'date', Time.parse( event.get('[event][created]').to_s ).localtime('+09:00').strftime('%Y-%m-%dT%H:%M:%S+0900') )" } # index 名につける年月日を整形する ruby { code => "event.set( '[@metadata][index_date]', Time.parse( event.get('[event][created]').to_s ).localtime('+09:00').strftime('%Y%m%d') )" } # 項目名を変換する mutate { rename => { "[winlog][event_id]" => "event_id" "[winlog][event_data][LogonType]" => "log_on_type" "[user][name]" => "account" "[user][domain]" => "account_domain" "[source][ip]" => "network_address" } convert => { "log_on_type" => "integer" } } # Elasticsearch に登録する項目だけ残す prune { whitelist_names => [ "date", "event_id", "log_on_type", "account", "account_domain", "network_address" ] } } output { elasticsearch { hosts => ["localhost:9200"] index => "logon_event_%{[@metadata][index_date]}" template => "/etc/logstash/templates/logon_event_template.json" template_name => "logon_event" template_overwrite => true resurrect_delay => 600 } }値の取り出し方について
以下の長い引用部分は生ログ(1行分のみ)です。
上記 logstash.conf で設定した "[winlog][event_id]" や "[user][name]" などの値は、生ログから項目を見つけ出して取り出します。
例えば "[winlog][event_id]" の値であれば、生ログの中の "winlog" の項目に含まれる "event_id" の値(以下の例では 4624 )を取り出しています。生ログから取り出している項目と値を強調表示しておきます。
{
"winlog":{"computer_name":"EC2AMAZ-DP92PI7","provider_name":"Microsoft-Windows-Security-Auditing","process":{"pid":736,"thread":{"id":776}},"api":"wineventlog"
,"activity_id":"{6072c47c-b4bd-0000-5ec5-7260bdb4d501}","task":"Logon","keywords":["Audit Success"],"logon":{"id":["0x0","0x3105b"],"type":"Network"},"version":2,"channel":"Security","record_id":26592,"provider_guid":"{54849625-5478-4994-a5ba-3e3b0328c30d}","event_id":4624,"event_data":{"TargetLogonId":"0x3105b","LogonProcessName":"NtLmSsp ","ElevatedToken":"%%1842","TransmittedServices":"-","TargetOutboundUserName":"-","TargetOutboundDomainName":"-","LogonGuid":"{00000000-0000-0000-0000-000000000000}","SubjectLogonId":"0x0","TargetLinkedLogonId":"0x0","KeyLength":"128","ImpersonationLevel":"%%1833","SubjectUserSid":"S-1-0-0","SubjectUserName":"-","TargetUserSid":"S-1-5-21-4209486975-1383129935-3790452860-500","TargetUserName":"Administrator","TargetDomainName":"EC2AMAZ-DP92PI7","LmPackageName":"NTLM V2","VirtualAccount":"%%1843","RestrictedAdminMode":"-","LogonType":"3","SubjectDomainName":"-","AuthenticationPackageName":"NTLM"},"opcode":"Info"},"user":{"domain":"EC2AMAZ-DP92PI7","name":"Administrator","id":"S-1-5-21-4209486975-1383129935-3790452860-500"},"host":{"hostname":"EC2AMAZ-DP92PI7","architecture":"x86_64","name":"EC2AMAZ-DP92PI7","os":{"name":"Windows Server 2019 Datacenter","platform":"windows","kernel":"10.0.17763.864 (WinBuild.160101.0800)","build":"17763.864","family":"windows","version":"10.0"},"id":"d76ff6ea-e75b-457c-8358-5a3e0cfde06e"},"process":{"name":"-","pid":0,"executable":"-"},"cloud":{"instance":{"id":"i-0fb0a7bb135519b80"},"machine":{"type":"t2.micro"},"availability_zone":"ap-northeast-1a","account":{"id":"086997486593"},"region":"ap-northeast-1","provider":"aws","image":{"id":"ami-0c63fb8188f151fb7"}},"log":{"level":"information"},"agent":{"hostname":"EC2AMAZ-DP92PI7","id":"0cc34436-5733-4b20-b381-e8a96901cf21","type":"winlogbeat","ephemeral_id":"74b878f1-21ed-4804-9b37-76b1ec530c1b","version":"7.4.2"},"@version":"1","ecs":{"version":"1.1.0"},"event":{"kind":"event","module":"security","category":"authentication","code":4624,"outcome":"success","type":"authentication_success","created":"2019-12-17T09:40:13.079Z","action":"Logon"},"tags":["beats_input_codec_plain_applied","_grokparsefailure"],"source":{"domain":"xxx-xxxxxxx","ip":"xxx.xxx.xxx.xxx","port":0},"@timestamp":"2019-12-17T09:40:11.402Z","message":"An account was successfully logged on.\n\nSubject:\n\tSecurity ID:\t\tS-1-0-0\n\tAccount Name:\t\t-\n\tAccount Domain:\t\t-\n\tLogon ID:\t\t0x0\n\nLogon Information:\n\tLogon Type:\t\t3\n\tRestricted Admin Mode:\t-\n\tVirtual Account:\t\tNo\n\tElevated Token:\t\tYes\n\nImpersonation Level:\t\tImpersonation\n\nNew Logon:\n\tSecurity ID:\t\tS-1-5-21-4209486975-1383129935-3790452860-500\n\tAccount Name:\t\tAdministrator\n\tAccount Domain:\t\tEC2AMAZ-DP92PI7\n\tLogon ID:\t\t0x3105B\n\tLinked Logon ID:\t\t0x0\n\tNetwork Account Name:\t-\n\tNetwork Account Domain:\t-\n\tLogon GUID:\t\t{00000000-0000-0000-0000-000000000000}\n\nProcess Information:\n\tProcess ID:\t\t0x0\n\tProcess Name:\t\t-\n\nNetwork Information:\n\tWorkstation Name:\txxx-xxxxxxx\n\tSource Network Address:\txxx.xxx.xxx.xxx\n\tSource Port:\t\t0\n\nDetailed Authentication Information:\n\tLogon Process:\t\tNtLmSsp \n\tAuthentication Package:\tNTLM\n\tTransited Services:\t-\n\tPackage Name (NTLM only):\tNTLM V2\n\tKey Length:\t\t128\n\nThis event is generated when a logon session is created. It is generated on the computer that was accessed.\n\nThe subject fields indicate the account on the local system which requested the logon. This is most commonly a service such as the Server service, or a local process such as Winlogon.exe or Services.exe.\n\nThe logon type field indicates the kind of logon that occurred. The most common types are 2 (interactive) and 3 (network).\n\nThe New Logon fields indicate the account for whom the new logon was created, i.e. the account that was logged on.\n\nThe network fields indicate where a remote logon request originated. Workstation name is not always available and may be left blank in some cases.\n\nThe impersonation level field indicates the extent to which a process in the logon session can impersonate.\n\nThe authentication information fields provide detailed information about this specific logon request.\n\t- Logon GUID is a unique identifier that can be used to correlate this event with a KDC event.\n\t- Transited services indicate which intermediate services have participated in this logon request.\n\t- Package name indicates which sub-protocol was used among the NTLM protocols.\n\t- Key length indicates the length of the generated session key. This will be 0 if no session key was requested."}なお、生ログを確認したい場合は logstash.conf 内の output { } の中に以下を追記すると、
/var/log/logstash/raw.logに生ログが出力されます。file { path => "/var/log/logstash/raw.log" }
- 設定ファイル③
/etc/logstash/templates/logon_event_template.json
Elasticsearchで扱うログのデータ型を定義するためのテンプレートファイルです。
データ型の詳細は、Elasticsearch によるログ収集と可視化(第一回)を参照してください。logon_event_template.json{ "index_patterns": "logon_event_*", "version": 1, "mappings" : { "properties": { "date": { "type": "date", "format": "yyyy-MM-dd'T'HH:mm:ssZZ" }, "event_id": { "type": "short" }, "log_on_type": { "type": "short" }, "account": { "type": "keyword" }, "account_domain": { "type": "keyword" }, "network_address": { "type": "ip" } } }, "settings": { } }
- 設定ファイル④
/etc/logstash/logstash.yml
Logstashの実行を制御するための設定ファイルです。
パイプラインの設定、設定ファイルの場所、ログオプション、その他のオプションの設定が行えます。
Winlogbeat からログを受け取るには、http.host:の設定をコメントアウトしておく必要があります。
メモ:
http.host:の設定は、デフォルトでコメントアウトされている。
設定が必要だと考えてコメントアウトを外していたが、http.host:の設定があると Winlogbeat と Logstash が繋がらない。
特定までに時間が掛かったのでメモとして残しておく。追記:
本件はローカル環境(Vagrant)では再現しなかった。
beats のアドレスは logstash.yml の http.host に依存せず、pipeline を読み込んだ際に自動的に解放されているため、原因は別にあると考えられる。logstash.yml# http.host: "0.0.0.0"
- サービス起動確認
systemctlコマンドで Logstash の status を確認します。
"Active: active (running)" の出力が確認できれば Logstash は起動しています。$ sudo systemctl status logstash ● logstash.service - logstash Loaded: loaded (/etc/systemd/system/logstash.service; enabled; vendor preset: disabled) Active: active (running) since Thu 2019-12-19 20:57:13 JST; 3min 35s ago Main PID: 4876 (java) CGroup: /system.slice/logstash.service mq4876 /bin/java -Xms1g -Xmx1g -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=75 -XX:+UseCMSInitiatingOccupancyO... Dec 19 20:57:36 ip-172-31-43-233.ap-northeast-1.compute.internal logstash[4876]: [2019-12-19T20:57:36,191][INFO ][logstash.outputs.e...n"} Dec 19 20:57:36 ip-172-31-43-233.ap-northeast-1.compute.internal logstash[4876]: [2019-12-19T20:57:36,248][INFO ][logstash.outputs.elas... Dec 19 20:57:36 ip-172-31-43-233.ap-northeast-1.compute.internal logstash[4876]: [2019-12-19T20:57:36,298][WARN ][org.logstash.instrume... Dec 19 20:57:36 ip-172-31-43-233.ap-northeast-1.compute.internal logstash[4876]: [2019-12-19T20:57:36,302][INFO ][logstash.javapipel...>"} Dec 19 20:57:36 ip-172-31-43-233.ap-northeast-1.compute.internal logstash[4876]: [2019-12-19T20:57:36,308][INFO ][logstash.outputs.e...ent Dec 19 20:57:36 ip-172-31-43-233.ap-northeast-1.compute.internal logstash[4876]: [2019-12-19T20:57:36,962][INFO ][logstash.inputs.be...4"} Dec 19 20:57:37 ip-172-31-43-233.ap-northeast-1.compute.internal logstash[4876]: [2019-12-19T20:57:37,031][INFO ][logstash.javapipel...n"} Dec 19 20:57:37 ip-172-31-43-233.ap-northeast-1.compute.internal logstash[4876]: [2019-12-19T20:57:37,234][INFO ][org.logstash.beats...044 Dec 19 20:57:37 ip-172-31-43-233.ap-northeast-1.compute.internal logstash[4876]: [2019-12-19T20:57:37,287][INFO ][logstash.agent ...[]} Dec 19 20:57:37 ip-172-31-43-233.ap-northeast-1.compute.internal logstash[4876]: [2019-12-19T20:57:37,844][INFO ][logstash.agent ...00} Hint: Some lines were ellipsized, use -l to show in full.Logstash が起動していない場合、以下コマンドを実行してサービスを起動します。
その後、再度サービス起動確認を行います。$ sudo systemctl start logstash $ $ sudo systemctl status logstash ● logstash.service - logstash Loaded: loaded (/etc/systemd/system/logstash.service; enabled; vendor preset: disabled) Active: active (running) since ...(省略)サービスが起動しない、または、サービスは起動したが想定通りに動作していないように見える場合、
/var/log/logstash/logstash-plain.logを確認します。
起動時に [ERROR ] が出た場合は致命的なエラー、[WARN ] が出た場合は設定ファイルに誤りがある場合が多いです。Logstash の自動起動の設定を行う場合、以下コマンドを実行します。
$ sudo systemctl enable logstash.service Created symlink from /etc/systemd/system/multi-user.target.wants/logstash.service to /etc/systemd/system/logstash.service.自動起動の設定状況は以下のように確認することができます。(後述の Elasticsearch と Kibana も同様です。)
$ sudo systemctl status logstash ● logstash.service - logstash Loaded: loaded (/etc/systemd/system/logstash.service; enabled; vendor preset: disabled) Active: active (running) since ...(省略) ↑ 自動起動が設定済みの場合は enabled になる。Elasticsearch の設定
今回は設定変更は行わず、デフォルトのまま使用します。
- サービス起動確認
systemctlコマンドで Elasticsearch の status を確認します。
"Active: active (running)" の出力が確認できれば Elasticsearch は起動しています。$ sudo systemctl status elasticsearch ● elasticsearch.service - Elasticsearch Loaded: loaded (/usr/lib/systemd/system/elasticsearch.service; enabled; vendor preset: disabled) Active: active (running) since Thu 2019-12-19 21:30:15 JST; 27s ago Docs: http://www.elastic.co Main PID: 5256 (java) CGroup: /system.slice/elasticsearch.service tq5256 /usr/share/elasticsearch/jdk/bin/java -Xms1g -Xmx1g -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=75 -XX... mq5348 /usr/share/elasticsearch/modules/x-pack-ml/platform/linux-x86_64/bin/controller Dec 19 21:30:02 ip-172-31-43-233.ap-northeast-1.compute.internal systemd[1]: Starting Elasticsearch... Dec 19 21:30:03 ip-172-31-43-233.ap-northeast-1.compute.internal elasticsearch[5256]: OpenJDK 64-Bit Server VM warning: Option UseCo...se. Dec 19 21:30:15 ip-172-31-43-233.ap-northeast-1.compute.internal systemd[1]: Started Elasticsearch. Hint: Some lines were ellipsized, use -l to show in full.上記の例ではOpenJDKのエラーが出ていますが、UseConcMarkSweepGC オプションが廃止された旨が書かれていました。
無視しても構わないと思いますが、/etc/elasticsearch/jvm.options の "-XX:+UseConcMarkSweepGC" をコメントアウトすればエラーは出なくなりました。Elasticsearch が起動していない場合、以下コマンドを実行してサービスを起動します。
その後、再度サービス起動確認を行います。$ sudo systemctl start elasticsearch $ $ sudo systemctl status elasticsearch ● elasticsearch.service - Elasticsearch Loaded: loaded (/usr/lib/systemd/system/elasticsearch.service; enabled; vendor preset: disabled) Active: active (running) since ...(省略)Elasticsearch の自動起動の設定を行う場合、以下コマンドを実行します。
$ sudo systemctl enable elasticsearch.service Created symlink from /etc/systemd/system/multi-user.target.wants/elasticsearch.service to /usr/lib/systemd/system/elasticsearch.service.サービス起動後の確認
サービス起動後、
curlコマンドで以下①~④の確認が最低限必要です。① 起動確認:
_cat/health?v
1台構成の場合、status は yellow になります。$ curl http://localhost:9200/_cat/health?v epoch timestamp cluster status node.total node.data shards pri relo init unassign pending_tasks max_task_wait_time active_shards_percent 1577076238 04:43:58 elasticsearch yellow 1 1 17 17 0 0 14 0 - 54.8%② template 登録確認:
_templates/template名
template名は logstash.conf 内の output -> elasticsearch -> template_name で指定した名前になります。
/etc/logstash/templates/logon_event_template.jsonではないので注意が必要です。$ curl http://localhost:9200/_template/logon_event {"logon_event":{"order":0,"version":1,"index_patterns":["logon_event_*"],"settings":{},"mappings":{"properties":{"date":{"format":"yyyy-MM-dd'T'HH:mm:ssZZ","type":"date"},"event_id":{"type":"short"},"account_domain":{"type":"keyword"},"network_address":{"type":"ip"},"log_on_type":{"type":"short"},"account":{"type":"keyword"}}},"aliases":{}}} # 結果を見やすくしたい場合は以下のように実行する $ curl http://localhost:9200/_template/logon_event?pretty { "logon_event" : { "order" : 0, "version" : 1, "index_patterns" : [ "logon_event_*" ], "settings" : { }, "mappings" : { "properties" : { "date" : { "format" : "yyyy-MM-dd'T'HH:mm:ssZZ", "type" : "date" }, "event_id" : { "type" : "short" }, "account_domain" : { "type" : "keyword" }, "network_address" : { "type" : "ip" }, "log_on_type" : { "type" : "short" }, "account" : { "type" : "keyword" } } }, "aliases" : { } } }③ index 登録確認:
_cat/indices
対象の index が登録されていることを確認します。$ curl http://localhost:9200/_cat/indices yellow open logon_event_20191221 cmTnDqRTTcK-HC9zmcsNBA 1 1 50 0 43.6kb 43.6kb yellow open logon_event_20191217 u76prV2OS0i9ssxqtPFseA 1 1 0 0 283b 283b yellow open logon_event_20191222 lpPYxEtjQWO5kkBVinr8Nw 1 1 36 0 18.6kb 18.6kb yellow open logon_event_20191223 BsQEZFLoQRqpbLS2dV26xw 1 1 272 0 61.3kb 61.3kb yellow open logon_event_20191219 LNzgU-h3Q1ujSq0MxIfx5Q 1 1 50 0 41.9kb 41.9kb④データ登録確認:
index名/_search
対象の index にデータが登録されていることを確認します。$ curl http://localhost:9200/logon_event_20191222/_search {"took":1,"timed_out":false,"_shards":{"total":1,"successful":1,"skipped":0,"failed":0},"hits":{"total":{"value":36,"relation":"eq"},"max_score":1.0,"hits":[{"_index":"logon_event_20191222","_type":"_doc","_id":"aLysLW8BK6oXitToHspB","_score":1.0,"_source":{"account_domain":"NT AUTHORITY", ...(省略) # 結果を見やすくしたい場合は以下のように実行する $ curl http://localhost:9200/logon_event_20191222/_search?pretty { "took" : 1, "timed_out" : false, "_shards" : { "total" : 1, "successful" : 1, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : { "value" : 36, "relation" : "eq" }, "max_score" : 1.0, "hits" : [ { "_index" : "logon_event_20191222", "_type" : "_doc", "_id" : "aLysLW8BK6oXitToHspB", "_score" : 1.0, "_source" : { "account_domain" : "NT AUTHORITY", "date" : "2019-12-22T21:54:10+0900", "event_id" : 4624, "log_on_type" : 0, "account" : "SYSTEM" } }, (省略)Kibana の設定
今回は設定変更は行わず、デフォルトのまま使用します。
- サービス起動確認
systemctlコマンドで Kibana の status を確認します。
"Active: active (running)" の出力が確認できれば Kibana は起動しています。$ sudo systemctl status kibana ● kibana.service - Kibana Loaded: loaded (/etc/systemd/system/kibana.service; enabled; vendor preset: disabled) Active: active (running) since Thu 2019-12-19 21:39:59 JST; 24s ago Main PID: 5438 (node) CGroup: /system.slice/kibana.service mq5438 /usr/share/kibana/bin/../node/bin/node /usr/share/kibana/bin/../src/cli -c /etc/kibana/kibana.yml Dec 19 21:39:59 ip-172-31-43-233.ap-northeast-1.compute.internal systemd[1]: Started Kibana. Dec 19 21:39:59 ip-172-31-43-233.ap-northeast-1.compute.internal systemd[1]: Starting Kibana...Kibana が起動していない場合、以下コマンドを実行してサービスを起動します。
その後、再度サービス起動確認を行います。$ sudo systemctl start logstash $ $ sudo systemctl status logstash ● kibana.service - Kibana Loaded: loaded (/etc/systemd/system/kibana.service; enabled; vendor preset: disabled) Active: active (running) since ...(省略)Kibana の自動起動の設定を行う場合、以下コマンドを実行します。
$ sudo systemctl enable kibana.service Created symlink from /etc/systemd/system/multi-user.target.wants/kibana.service to /etc/systemd/system/kibana.service.Kibana によるログの可視化
ここからは Kibana の Web UI について記載します。
Kibana Web UI へのアクセス
ブラウザから以下にアクセスし、Kibana の Web UI が表示されることを確認します。
http://<kibanaサーバのIPアドレス>:5601index パターン作成
可視化したいログの index のパターンを作成します。
左側メニューの Management のアイコンから設定画面を表示します。
以下の通りに設定を進めます。
1. Index Patterns のリンクをクリック
2. [Create index pattern] ボタンをクリック
3. Index pattern のテキストフォームにindex名を入力して、[Next step] のボタンをクリック
※今回はlogon_event_*と入力
4. Time Filter field name のプルダウンからdateを選択
5. [Create index pattern] ボタンをクリック続いて、ログを読み込んでいるか確認します。
1. 左側メニューから Discover のアイコンをクリック
2. 下図の赤枠①のプルダウンから先ほど設定した index を選択
※今回はlogon_event_*を選択
3. 下図の赤枠②で対象ログの検索期間を指定
ログの表示が確認できれば index のパターン作成は完了です。
Visualize の設定
ログからグラフや表を作成して、ログを可視化します。
左側メニューの Visualize のアイコンから設定画面を表示します。
以下の通りに設定を進めます。( Visualize には様々な機能があります。以下は一例です。)
1. [Create new visualization] ボタンをクリック
2. 作成したいグラフや表の種類を選択
※今回は Pie を選択
3. 可視化するログの index名 を選択
※今回はlogon_event_*を選択
4. Buckets のパネルにある Add をクリックし、Split slices を選択
5. Aggregation のプルダウンから Terms を選択
6. Field のプルダウンから可視化したい Field を選択
※今回はevent_idを選択
7. ▷ボタンをクリック画面右側にグラフが表示できれば Visualize は成功です。
※対象ログの検索期間にログが1件も存在しない場合はグラフが表示されません。
Visualize の設定を保存します。
1. 画面左上の Save をクリック
2. Title のテキストフォームに任意の値を入力
3. [Confirm Save] ボタンをクリック再度、左側メニューの Visualize のアイコンをクリックして、作成した Visualize があれば設定は完了です。
Dashboard の設定
Visualize で作成したグラフや表を Dashboard に設置します。
Dashboard を使うと、1つの画面で複数の情報をまとめて確認できるようになります。
左側メニューの Dashboards のアイコンから設定画面を表示します。
以下の通りに設定を進めます。
1. [Create new dashboard] ボタンをクリック
2. 画面左上の Add をクリック
3. Add panels のパネルから、設置したい Visualize を選択
※選択した時点で Dashboard に Visualize を
4. Dashboard に Visualize が設置されているので、Add panels のパネルの [×] ボタンをクリック画面にグラフが表示できれば Dashboard の作成は成功です。
※対象ログの検索期間にログが1件も存在しない場合はグラフが表示されません。
Dashboard の設定を保存します。
1. 画面左上の Save をクリック
2. Title のテキストフォームに任意の値を入力
3. [Confirm Save] ボタンをクリック再度、左側メニューの Dashboard のアイコンをクリックして、作成した Dashboard があれば設定は完了です。
不正アクセスの疑いを検知するための Dashboard
Visualize や Dashboard の機能でログを可視化することで、不正アクセスの疑いを視覚的に検知できるようになります。
Sample Dashboard
上図の Dashboard では、例えばログオン失敗のログ(event_id:4625)が多数検出された場合、不正アクセスの疑いがあるので詳細な調査を行うきっかけになります。
[参考] 苦労した点
今回は基本的な内容を中心に検証を行いましたが、どこにどの設定を書けば良いのか迷ってしまったり、設定ファイルに誤りがあって想定通りの動作をさせるまでに時間が掛かったりと、苦労する場面もありました。
参考までに特に苦労した点を以下に記載します。logstash の Port を外部に公開する方法
今回でいうなら、WinLogBeat から Logstash に繋げる方法。
- Elasticsearch 同様、http.host を "0.0.0.0" で公開していたが、この状態では Winlogbeat(別ホスト) から参照できなかった
- logstash.yml の http.host の指定を消さないと外部ホストからアクセスできないようだ
追記:
本件はローカル環境(Vagrant)では再現しなかった。
beats のアドレスは logstash.yml の http.host に依存せず、pipeline を読み込んだ際に自動的に解放されているため、原因は別にあると考えられる。logstash で prune filter を使って 必要な項目だけを抽出する
logstash で不要な項目を消すには remove_field という共通オプションを使用すればよいが、Winlogbeat のように不要な項目が多すぎる場合は手間がかかる。
このとき、prune filter と whitelist_names のオプションを指定することで、必要なファイルだけを残して不要な項目を消すことができる。https://www.elastic.co/guide/en/logstash/current/plugins-filters-prune.html
正規表現対応になっているので完全一致する際は文字列を ^$ で括る必要あり※日本語では記事が無かったので英語で検索。
公式フォーラムの回答で prune filter を使えばできる、という回答を見つけた。logstash における timezone の parse
logstash -> output -> elasticsearch において illegal_argument_exception が発生した。
date 型の parse で発生しており、timezone の +09:00 が指摘されていた。
- data 型データ例:
2019-12-24T11:22:33+09:00- elasticsearch の
date format:yyyy-MM-dd'T'HH:mm:ssZZ(ZZ は timezone)- logstash 6.2.1 出は発生しなかった。7.4.2 だと発生する
公式ドキュメントをたどっていくと、"date 型の parse は JAVA の日時指定に準拠する" と記載があった。
https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping-date-format.html#custom-date-formatsJava の公式ドキュメント(class DateTimeFormatter のページ)を見ると、Offset Z の項目に以下の様な記述がある。
https://docs.oracle.com/javase/8/docs/api/java/time/format/DateTimeFormatter.html"without a colon, such as '+0130'" => コロン無しで指定する "Six or more letters throws IllegalArgumentException" => 6文字以上はエラーになる上記の記述から、今回 timezone に指定した "+09:00" の表記は上記のいずれにも反しているのでアウト(コロンがあり6文字)。
1つ目の指示通り "+0900"(コロン無し5文字)が正しいフォーマットだった。さいごに
Elasticsearch によるログ収集と可視化について、全三回に渡って記事を掲載してきました。
来年以降の活動がどうなるかは未定ですが、私たちの記事を最後まで読んで頂きありがとうございました。








- 投稿日:2019-12-21T08:18:33+09:00
lambda_handler外のグローバル変数に気をつけよう(datatime)
はじめに
ジョブが作成されてからLambdaが実行されるまでの間の時間(滞留時間)を取得する
Lambdaを作成していた時に
現在日時を取得するためにdatatimeを使用していたのですが、
そこで「AWS Lambdaは関数インスタンスを再利用」というのに見事にハマったので、
記事にしてみたいと思います。最初に作成していたコード
まずLambdaが実行された現在日時を取得するための
コードを簡略化したものが以下になります。from datatime import datatime now = datetime.now() def lambda_handler(event, context): method_a() def method_a(): method_b() def method_b(): method_c() def method_c(): # xはジョブの作成日時を表しています。 data = now - x print(data)
- ジョブの作成時刻を
x- 現在時刻を
now- 滞留時間を
timeとして表しています。
時刻を表すnowをグローバル変数として宣言して
どのメソッドでも使えるようにしてました。ローカルでは成功したけど…
ローカルでは滞留時間を取得できたので、
そのままビルドデプロイしてLambdaを作成しました。
最初のLambdaのテストも成功して問題はありませんでした。よし大丈夫だ!もう一回テストして確認しよう…
あれ!?滞留時間がおかしい!!!!!!
1回目で上手く取得できていた滞留時間が
2回目以降上手く取得できませんでした。何回やっても
timeがおかしい。そこでまたビルドデプロイして
Lambdaを更新させてみたところ上手くいきました。しかし、また2回目以降はダメでした。
原因は
そこで原因調査のために色々調べていると
こちらの記事に出会いました!ずばり原因は、lambda_handler外で宣言したグローバル変数の
nowでした。どうやらLambdaはパフォーマンス向上のために
関数のインスタンスを再利用するみたいです。https://aws.amazon.com/jp/lambda/faqs/
つまり一回目に取得した
nowの日時がキャッシュされ
2回目以降も同じ値が再利用されていたみたいです。常にLambdaの関数インスタンスは新規で作成されているものだと
思っていたので、全く気づきませんでした!!lambda_handler内にグローバルに変数を置きたい
原因を理解したところで
とりあえずnowをlambda_handler内に置きました。
これでLambdaが実行されるたびに新しくnowの日時を取得してきてくれます。from datatime import datatime def lambda_handler(event, context): now = datetime.now() method_a(now) def method_a(now): method_b(now) def method_b(now): method_c(now) def method_c(now): # xはジョブの作成日時を表しています。 data = now - x print(data)この形でも実行できるのですが、
こんなにメソッドを経由して渡すのはかっこ悪いので
以下のように修正しました。from datatime import datatime def lambda_handler(event, context): global now now = datetime.now() method_a() def method_a(): method_b() def method_b(): method_c() def method_c(): # xはジョブの作成日時を表しています。 data = now - x print(data)これで無事、2回目以降も
ちゃんとnowが実行した日時を取得してくれるようになり
dataも上手く取得できました。まとめ
Lambdaの関数インスタンスの再利用については
初耳だったので、とても勉強になりました。あとは、グローバル変数はとても便利ですが
思わぬバグを引き起こす原因になりやすいということを
身を持って実感しました。使い方には気を付けていこうと思います。

- 投稿日:2019-12-21T08:18:33+09:00
lambda_handler外のグローバル変数に気をつけよう(datetime)
はじめに
ジョブが作成されてからLambdaが実行されるまでの間の時間(滞留時間)を取得する
Lambdaを作成していた時に
現在日時を取得するためにdatetimeを使用していたのですが、
そこで「AWS Lambdaは関数インスタンスを再利用」というのに見事にハマったので、
記事にしてみたいと思います。最初に作成していたコード
まずLambdaが実行された現在日時を取得するための
コードを簡略化したものが以下になります。from datetime import datetime now = datetime.now() def lambda_handler(event, context): method_a() def method_a(): method_b() def method_b(): method_c() def method_c(): # xはジョブの作成日時を表しています。 time = now - x print(data)
- ジョブの作成時刻を
x- 現在時刻を
now- 滞留時間を
timeとして表しています。
時刻を表すnowをグローバル変数として宣言して
どのメソッドでも使えるようにしてました。ローカルでは成功したけど…
ローカルでは滞留時間を取得できたので、
そのままビルドデプロイしてLambdaを作成しました。
最初のLambdaのテストも成功して問題はありませんでした。よし大丈夫だ!もう一回テストして確認しよう…
あれ!?滞留時間がおかしい!!!!!!
1回目で上手く取得できていた滞留時間が
2回目以降上手く取得できませんでした。何回やっても
timeがおかしい。そこでまたビルドデプロイして
Lambdaを更新させてみたところ上手くいきました。しかし、また2回目以降はダメでした。
原因は
そこで原因調査のために色々調べていると
こちらの記事に出会いました!ずばり原因は、lambda_handler外で宣言したグローバル変数の
nowでした。どうやらLambdaはパフォーマンス向上のために
関数のインスタンスを再利用するみたいです。https://aws.amazon.com/jp/lambda/faqs/
つまり一回目に取得した
nowの日時がキャッシュされ
2回目以降も同じ値が再利用されていたみたいです。常にLambdaの関数インスタンスは新規で作成されているものだと
思っていたので、全く気づきませんでした!!lambda_handler内にグローバルに変数を置きたい
原因を理解したところで
とりあえずnowをlambda_handler内に置きました。
これでLambdaが実行されるたびに新しくnowの日時を取得してきてくれます。from datetime import datetime def lambda_handler(event, context): now = datetime.now() method_a(now) def method_a(now): method_b(now) def method_b(now): method_c(now) def method_c(now): # xはジョブの作成日時を表しています。 time = now - x print(data)この形でも実行できるのですが、
こんなにメソッドを経由して渡すのはかっこ悪いので
以下のように修正しました。from datetime import datetime def lambda_handler(event, context): global now now = datetime.now() method_a() def method_a(): method_b() def method_b(): method_c() def method_c(): # xはジョブの作成日時を表しています。 time = now - x print(data)これで無事、2回目以降も
ちゃんとnowが実行した日時を取得してくれるようになり
timeも上手く取得できました。まとめ
Lambdaの関数インスタンスの再利用については
初耳だったので、とても勉強になりました。あとは、グローバル変数はとても便利ですが
思わぬバグを引き起こす原因になりやすいということを
身を持って実感しました。使い方には気を付けていこうと思います。
- 投稿日:2019-12-21T03:13:03+09:00
AWS SageMaker Studioを使ってみる
はじめに
一週間ほど前にJupyterじゃなくてJupyterLabを勧めるN個の理由という記事を書きました。全然話は変わりますが、AWSの新製品発表会のre:InventというイベントでSageMaker Studioという製品が発表されました。AWSで今まで存在していたSageMakerのサービスを1つの画面で管理できることができるようです。今まで自分のローカル環境かGoogle Colaboratoryでしか機械学習をしたことのない僕ですが、このSageMaker Studioを試して見たいと思います。
使ってみる
使ってみます。SegeMaker Studioは現在preview releaseとなっており、近所の東京リージョンでは使用できません。使用できるのはオハイオ(us-east-2)のみになっています。
普通のJupyterLabって感じです。ショートカット等は僕の使う範囲(セルの移動、モード切り替え程度)では普通に使えます。
せっかくなのでSageMakerのサービスの1つであるSageMaker Autopilotを使ってみます。SageMaker Autopilotについて
公式によるとSageMaker Autopilotは以下のように説明されています。
Amazon SageMaker Autopilot は、完全な制御と可視性を維持しながら、データに基づいて分類または回帰用の最適な機械学習モデルを自動的にトレーニングおよび調整します。
AutoML的なモノっぽいです。AutoMLにプラスして自動でデプロイしてくれたりするいいやつです。
僕はすぐに分析したいデータが手元にないので以下の動画を参考に試してみます。https://www.youtube.com/watch?v=qMEtqJPhqpA
使用するデータはUCIの配布しているデータで、銀行の顧客データと定期預金を申し込んだかどうかのデータセットです。
データのインポート
%%sh wget -N https://archive.ics.uci.edu/ml/machine-learning-databases/00222/bank-additional.zip unzip -o bank-additional.zipデータのインポート、表示
import pandas as pd data = pd.read_csv('./bank-additional/bank-additional-full.csv', sep=';') pd.set_option('display.max_columns', 500) # Make sure we can see all of the columns pd.set_option('display.max_rows', 50) # Keep the output on one page data.head(10)今回のデータは正解ラベルがyes, noの二値になっています。それぞれの数を数えてみます
data["y"].value_counts()resultno 36548 yes 4640不均衡ですね(小並感)。分析は今回の趣旨ではないので飛ばします。
この調整するところから面倒なデータもAutopilotがなんとかしてくれるみたいです。
とりあえず、trainとtestに分割して保存しておきます。import numpy as np train_data, test_data, _ = np.split(data.sample(frac=1, random_state=123), [int(0.95 * len(data)), int(len(data))]) # Save to CSV files train_data.to_csv('automl-train.csv', index=False, header=True, sep=',') # Need to keep column names test_data.to_csv('automl-test.csv', index=False, header=True, sep=',') import sagemaker prefix = 'sagemaker/DEMO-automl-dm/input' sess = sagemaker.Session() uri = sess.upload_data(path="automl-train.csv", key_prefix=prefix) print(uri)Autopilot Experimentの作成
SageMaker StudioからAutopilot Expreimentを作成します
項目を埋めます。最後の項目は、Noを選択するとSageMakerが自動で生成してくれたモデルを試せるnotebookを作成してくれるようです。
Create Experimentを押すと自動でモデルの構築が始まります。プロセスは大きく分けて3つの処理をしてくれます
- データの分析
- 特徴量エンジニアリング
- モデルのチューニング
結果をみた感じ、もう僕がやらずに機械に任せた方がいいのではって感じでした。技術の進歩すごい。
処理がまだ終わってないのですが、すごく眠いので今回はここまでにします。s
不安な点
AWSに限らずにクラウドサービス全般に言えることですが、料金体系がとてもわかりづらいです。今回のSageMaker Studioもいくらモデルの作成にかかるのかがよくわかりませんでした…
僕がボケてたとはいえ、GCPでDataProc使った時にクラスタ消し忘れて7000円吹き飛んだ恨みは消えてないぞ…まとめ
日本語のやってみた記事が少なかったのでやってみました。
AutoMLなめてたっていうのが正直な感想です。ただ、SageMakerの機能を統合できるという側面が強いので、SageMakerの機能をフルで使い人にはおすすめだけど単にJupyterみたいな環境が欲しい人にはどうかな?って感じでした。


- 投稿日:2019-12-21T02:39:52+09:00
TerraformでALBの高度なリスナールールがより簡潔に書けるようになる前の話
この記事はニフティグループ Advent Calendar 2019の21日目の記事です。
昨日は@shin27さんの「MySQLの外部レプリケーションを使って最小限のダウンタイムでAWS RDSに移行する」でした。実は現在、@shin27さんと同じ部署でして、日々悩みながらも楽しく頑張っている姿を見ていました。
はじめに
この記事では、2019年12月14日に私が書いた「TerraformでALBの高度なリスナールールがより簡潔に書けるようになった話」に関連して、AWSプロバイダーのv2.41.0以前の世界では、管理の仕方をどうしていたのかを書きます。
自己紹介
はじめまして、ななです。
普段は既存のシステムを運用したり、GoプログラムやTerraformコードを書いたり、またエンジニアをより元気にするためにそのシステムを題材にモダン化を図ったりしています。
あと、2019年を振り返ると、一番の思い出は「AWS Summit Tokyo 2019」の2日目で登壇したことですね。詳細はこちらの記事に書いてありますので、興味がある方は覗いてみてください。
ここで本題に入る前に2019年12月14日に投稿した記事がどういうものだったのかを復習してみる
「TerraformでALBの高度なリスナールールがより簡潔に書けるようになった話」では、2019年12月14日 (日本時間) にリリースされたAWSプロバイダーのv2.42.0の中にあるALBの高度なリスナールールに関するアップデートについて書いています。
ALBの高度なリスナールールには色々なパターンがありますが、その記事ではHTTPヘッダーを題材にしました。Terraformでの詳細な書き方や他のパターンについては公式のドキュメントにも書いてありますので、そちらもあわせてご確認ください。
Terraformで実際にALBの高度なリスナールールを書いてみる
前提となる環境
- Terraform v0.12
- AWSプロバイダー v2.41.0以前(なおv2.42.0以降でも動きます)
設定内容
今回もChromeやSafariブラウザを判定するリスナールールを実現してみます。
elb.tfから一部抜粋した設定を以下に示しています。elb.tfresource "aws_cloudformation_stack" "http_header_based_routing" { name = "http-header-based-routing-stack" template_body = <<STACK { "Resources": { "ListenerRuleBasedOnHTTPHeader": { "Type": "AWS::ElasticLoadBalancingV2::ListenerRule", "Properties": { "Actions": [{ "Type": "forward", "TargetGroupArn": "${aws_lb_target_group.tg.arn}" }], "Conditions": [{ "Field": "http-header", "HttpHeaderConfig": { "HttpHeaderName": "User-Agent", "Values": [ "*Chrome*", "*Safari*" ] } }], "ListenerArn": "${aws_lb_listener.front_end.arn}", "Priority": 10 } } } } STACK }以下のコマンドを用いてデプロイした後で、AWSマネジメントコンソールで確認します。
$ terraform init $ terraform plan $ terraform apply以下の図を見るとちゃんと設定されていますね。
ここでTerraformから作成したCloudFormationのスタックの様子を見てみましょう。まずはスタックの情報を見てみると、「CREATE_COMPLETE」になっていますね。
次にイベントを見てみると、これも「CREATE_COMPLETE」になっていますね。
最後にテンプレートの情報を見てみると、上記で記述された内容が入っていますね。しかも変数が展開されています。
ちなみに、ALBの高度なリスナールールは、Terraformでより簡潔に書けるようになった後と比べると、コードの記述量が2倍近くになっています。一見するとメンテナンスが大変に見えますね。
しかしながら、CloudFormationの既存コードを活かせるため、CloudFormationの記述方法で詰まった際にはAWS公式サポートを享受できたり、公式ドキュメントを活用できたりするので良いですね。またTerraformでしか基本的に書きたくないという方にもマッチする方法ですね。まとめ
今回は、2019年12月14日に書いた記事の比較対象として、TerraformでALBの高度なリスナールールがより簡潔に書けるようになる前の話を書きました。皆さんも既存のコードを活かしつつインフラ運用に関してどんどん最適化を図っていきましょう。
ありがとうございました。明日は@hamakou108さんです!よろしくお願いします。
余談 その1
この記事を書いている時に、TerraformとAWS Cloud Development Kit (AWS CDK) を連携しようと試みているこちらの記事を偶然見つけました。CDKの界隈でも同じように考える人が居るんだなと感じました。
余談 その2
AWSプロバイダーのv2.43.0がリリースされましたね。高度なリスナールール周りでも修正があったようです。
参考サイト






- 投稿日:2019-12-21T02:21:18+09:00
GitLab Runner Kubernetes Executor
はじめに
GitLabはGitLab Runnerを組み合わせることでCI/CDを実現できます。
このGitLab CIでは.gitlab_ci.ymlでジョブを定義しますが、GitLab Runner自体がジョブを実行するのではなくGitLab Runnerで設定されたExecutorが実行します。Executorは例えば次のものがあります。
- Shell Executor
- Docker Executor
- Kubernetes Executor
今回は、Kubernetes上にデプロイしたPodがジョブを実行するKubernetes Executorに焦点を絞って説明します。
Kubernetes Executorの構成
Kubernetes ExecutorはGitLab CIでジョブ実行時にKubernetes上にPodとして立ち上がります。
上図にある通り、GitLab CI Job Podには次の3種類のコンテナが存在します。
- Helperコンテナ(1個)
- Buildコンテナ(1個)
- Serviceコンテナ(0個以上)
それぞれ説明していきます。
Helperコンテナ
主にGit操作を行うコンテナです。
プロジェクトのCI/CD設定でgit cloneとgit fetchを選択できますが、実際にこれを行うのがHelperコンテナです。コンテナイメージはGitLab Runnerに設定します。
Gitの設定を変更したい場合は公式のイメージをベースイメージとして独自の物を作成します。Buildコンテナ
Helperコンテナが取得したソースコードをもとに
.gitlab_ci.ymlの内容のジョブを実行するのがBuildコンテナです。
.gitlab_ci.ymlで指定したイメージがBuildコンテナとなりますが、指定していない場合はGitLab Runnerに設定したイメージが使用されます。Serviceコンテナ
ジョブ実行時にBuildコンテナがアクセスできるコンテナがServiceコンテナです。
これは0個以上デプロイされます。すなわち.gitlab_ci.ymlに定義しなければデプロイされることはありません。Serviceコンテナには例えばMysql、Redis、dindなどが挙げられます。
ジョブ実行までの流れ
順序は次のようになります。
- GitLab RunnerがGitLabでジョブが発動したかを検知する。
- GitLab RunnerがジョブPodを作成する。
- ジョブPod内のHelperコンテナがGitLabから
git cloneもしくはgit fetchする。- ジョブPod内のBuildコンテナが
.gitlab_ci.ymlに記述されたジョブを実行する。図ではGitLab Runnerが同一クラスタにデプロイされているものとしています。
ポーリングの時間間隔はGitLab Runnerで設定できます。
Kubernetes Executorの検証
実際にJob Podをデプロイして検証します。
GitLab Runnerのデプロイ
Helmfileを使用します。
releases[].values[].runners.imageに設定するのはデフォルトのBuildコンテナのイメージです。
releases[].values[].runners.privilegedとreleases[].values[].runners.envに設定している値はdindを使用するためのものです。GitLabをKubernetes上にデプロイしている場合、
releases[].values[].gitlabUrlにService名を指定しても疎通はできますがArtifactsアップロードに失敗するので注意しないといけません。helmfile.yamlrepositories: - name: gitlab url: https://charts.gitlab.io/ releases: - name: gitlab-runner namespace: dev chart: gitlab/gitlab-runner version: 0.11.0 values: - image: gitlab/gitlab-runner:alpine-v12.5.0 gitlabUrl: http://gitlab.example.com runnerRegistrationToken: "XXXXXXXXXX" rbac: create: true resources: ["pods", "pods/exec", "secrets"] verbs: ["get", "list", "watch", "create", "patch", "delete"] clusterWideAccess: false metrics: enabled: false runners: image: busybox:1.31.1 privileged: true env: DOCKER_HOST: tcp://localhost:2375下記コマンドでデプロイします。
$ helmfile applyジョブの実行
GitLab RunnerをGitLabに紐付けた後にプロジェクトに
.gitlab_ci.ymlを作成します。
Podの解析のためにsleepさせてます。.gitlab_ci.ymlimage: docker:18.09.7 services: - docker:18.09.7-dind build: stage: test script: - sleep 3600ジョブを実行させます。
Running with gitlab-runner 12.5.0 (577f813d) on gitlab-runner-gitlab-runner-5cdf6fd4f6-vqrzq 3xycVVoJ Using Kubernetes namespace: dev Using Kubernetes executor with image docker:18.09.7 ... Waiting for pod dev/runner-3xycvvoj-project-1-concurrent-0ngfr2 to be running, status is Pending Running on runner-3xycvvoj-project-1-concurrent-0ngfr2 via gitlab-runner-gitlab-runner-5cdf6fd4f6-vqrzq... Fetching changes with git depth set to 50... Initialized empty Git repository in /builds/root/test/.git/ Created fresh repository. From http://gitlab.moguta.ml/root/test * [new ref] refs/pipelines/8 -> refs/pipelines/8 * [new branch] master -> origin/master Checking out f493d24c as master... Skipping Git submodules setup $ sleep 3600Job Podの確認
Podを確認すると3つのコンテナが存在することが分かります。
$ kubectl get pod -n dev runner-3xycvvoj-project-1-concurrent-0ngfr2 runner-3xycvvoj-project-1-concurrent-0ngfr2 3/3 Running 0 5m25sさらに中身を見ていきます。なお、GitLabのドメインは
gitlab.example.comに変換していて載せています。$ kubectl describe pod -n dev runner-3xycvvoj-project-1-concurrent-0ngfr2 ... Containers: build: Container ID: docker://f46846ec84f6517bb63dc1f2fd466126130b3014c344690debee465f2016aadc Image: docker:18.09.7 Image ID: docker-pullable://docker@sha256:310156c95007d6cca1417d0692786fe4da816b886a08bc7de97edf02cab4db31 Port: <none> Host Port: <none> Command: sh -c if [ -x /usr/local/bin/bash ]; then exec /usr/local/bin/bash elif [ -x /usr/bin/bash ]; then exec /usr/bin/bash elif [ -x /bin/bash ]; then exec /bin/bash elif [ -x /usr/local/bin/sh ]; then exec /usr/local/bin/sh elif [ -x /usr/bin/sh ]; then exec /usr/bin/sh elif [ -x /bin/sh ]; then exec /bin/sh elif [ -x /busybox/sh ]; then exec /busybox/sh else echo shell not found exit 1 fi State: Running Started: Sat, 21 Dec 2019 01:20:45 +0900 Ready: True Restart Count: 0 Environment: FF_CMD_DISABLE_DELAYED_ERROR_LEVEL_EXPANSION: false FF_USE_LEGACY_BUILDS_DIR_FOR_DOCKER: false FF_USE_LEGACY_VOLUMES_MOUNTING_ORDER: false CI_RUNNER_SHORT_TOKEN: 3xycVVoJ CI_BUILDS_DIR: /builds CI_PROJECT_DIR: /builds/root/test CI_CONCURRENT_ID: 0 CI_CONCURRENT_PROJECT_ID: 0 CI_SERVER: yes CI_PIPELINE_ID: 8 CI_PIPELINE_URL: http://gitlab.example.com/root/test/pipelines/8 CI_JOB_ID: 9 CI_JOB_URL: http://gitlab.example.com/root/test/-/jobs/9 CI_BUILD_ID: 9 CI_REGISTRY_USER: gitlab-ci-token CI: true GITLAB_CI: true GITLAB_FEATURES: CI_SERVER_HOST: gitlab.example.com CI_SERVER_NAME: GitLab CI_SERVER_VERSION: 12.5.3 CI_SERVER_VERSION_MAJOR: 12 CI_SERVER_VERSION_MINOR: 5 CI_SERVER_VERSION_PATCH: 3 CI_SERVER_REVISION: CI_JOB_NAME: build CI_JOB_STAGE: test CI_COMMIT_SHA: f493d24c574d3deee3e0284f6f413cd20b9a7e83 CI_COMMIT_SHORT_SHA: f493d24c CI_COMMIT_BEFORE_SHA: 4bddec9c21af3e1fcedde2a81f62eb03d9afaa2b CI_COMMIT_REF_NAME: master CI_COMMIT_REF_SLUG: master CI_NODE_TOTAL: 1 CI_DEFAULT_BRANCH: master CI_BUILD_REF: f493d24c574d3deee3e0284f6f413cd20b9a7e83 CI_BUILD_BEFORE_SHA: 4bddec9c21af3e1fcedde2a81f62eb03d9afaa2b CI_BUILD_REF_NAME: master CI_BUILD_REF_SLUG: master CI_BUILD_NAME: build CI_BUILD_STAGE: test CI_PROJECT_ID: 1 CI_PROJECT_NAME: test CI_PROJECT_TITLE: test CI_PROJECT_PATH: root/test CI_PROJECT_PATH_SLUG: root-test CI_PROJECT_NAMESPACE: root CI_PROJECT_URL: http://gitlab.example.com/root/test CI_PROJECT_VISIBILITY: private CI_PROJECT_REPOSITORY_LANGUAGES: CI_PAGES_DOMAIN: example.com CI_PAGES_URL: http://root.example.com/test CI_REGISTRY: registry.example.com CI_REGISTRY_IMAGE: registry.example.com/root/test CI_API_V4_URL: http://gitlab.example.com/api/v4 CI_PIPELINE_IID: 8 CI_CONFIG_PATH: .gitlab-ci.yml CI_PIPELINE_SOURCE: push CI_COMMIT_MESSAGE: Update .gitlab-ci.yml CI_COMMIT_TITLE: Update .gitlab-ci.yml CI_COMMIT_DESCRIPTION: CI_COMMIT_REF_PROTECTED: true CI_RUNNER_ID: 1 CI_RUNNER_DESCRIPTION: gitlab-runner-gitlab-runner-5cdf6fd4f6-vqrzq CI_RUNNER_TAGS: GITLAB_USER_ID: 1 GITLAB_USER_EMAIL: admin@example.com GITLAB_USER_LOGIN: root GITLAB_USER_NAME: Administrator CI_DISPOSABLE_ENVIRONMENT: true CI_RUNNER_VERSION: 12.5.0 CI_RUNNER_REVISION: 577f813d CI_RUNNER_EXECUTABLE_ARCH: linux/amd64 Mounts: /builds from repo (rw) /var/run/secrets/kubernetes.io/serviceaccount from default-token-8gjvw (ro) helper: Container ID: docker://de720b5d7dc94b57b47f8581b36ccf9ad263449ffdd69707e3a9c08c8c845dbd Image: gitlab/gitlab-runner-helper:x86_64-577f813d Image ID: docker-pullable://gitlab/gitlab-runner-helper@sha256:bd932463587dbd419c6f37667f7c3d63d5595ca2c5e446d81267838698828036 Port: <none> Host Port: <none> Command: sh -c if [ -x /usr/local/bin/bash ]; then exec /usr/local/bin/bash elif [ -x /usr/bin/bash ]; then exec /usr/bin/bash elif [ -x /bin/bash ]; then exec /bin/bash elif [ -x /usr/local/bin/sh ]; then exec /usr/local/bin/sh elif [ -x /usr/bin/sh ]; then exec /usr/bin/sh elif [ -x /bin/sh ]; then exec /bin/sh elif [ -x /busybox/sh ]; then exec /busybox/sh else echo shell not found exit 1 fi State: Running Started: Sat, 21 Dec 2019 01:20:45 +0900 Ready: True Restart Count: 0 Environment: FF_CMD_DISABLE_DELAYED_ERROR_LEVEL_EXPANSION: false FF_USE_LEGACY_BUILDS_DIR_FOR_DOCKER: false FF_USE_LEGACY_VOLUMES_MOUNTING_ORDER: false CI_RUNNER_SHORT_TOKEN: 3xycVVoJ CI_BUILDS_DIR: /builds CI_PROJECT_DIR: /builds/root/test CI_CONCURRENT_ID: 0 CI_CONCURRENT_PROJECT_ID: 0 CI_SERVER: yes CI_PIPELINE_ID: 8 CI_PIPELINE_URL: http://gitlab.example.com/root/test/pipelines/8 CI_JOB_ID: 9 CI_JOB_URL: http://gitlab.example.com/root/test/-/jobs/9 CI_BUILD_ID: 9 CI_REGISTRY_USER: gitlab-ci-token CI: true GITLAB_CI: true GITLAB_FEATURES: CI_SERVER_HOST: gitlab.example.com CI_SERVER_NAME: GitLab CI_SERVER_VERSION: 12.5.3 CI_SERVER_VERSION_MAJOR: 12 CI_SERVER_VERSION_MINOR: 5 CI_SERVER_VERSION_PATCH: 3 CI_SERVER_REVISION: CI_JOB_NAME: build CI_JOB_STAGE: test CI_COMMIT_SHA: f493d24c574d3deee3e0284f6f413cd20b9a7e83 CI_COMMIT_SHORT_SHA: f493d24c CI_COMMIT_BEFORE_SHA: 4bddec9c21af3e1fcedde2a81f62eb03d9afaa2b CI_COMMIT_REF_NAME: master CI_COMMIT_REF_SLUG: master CI_NODE_TOTAL: 1 CI_DEFAULT_BRANCH: master CI_BUILD_REF: f493d24c574d3deee3e0284f6f413cd20b9a7e83 CI_BUILD_BEFORE_SHA: 4bddec9c21af3e1fcedde2a81f62eb03d9afaa2b CI_BUILD_REF_NAME: master CI_BUILD_REF_SLUG: master CI_BUILD_NAME: build CI_BUILD_STAGE: test CI_PROJECT_ID: 1 CI_PROJECT_NAME: test CI_PROJECT_TITLE: test CI_PROJECT_PATH: root/test CI_PROJECT_PATH_SLUG: root-test CI_PROJECT_NAMESPACE: root CI_PROJECT_URL: http://gitlab.example.com/root/test CI_PROJECT_VISIBILITY: private CI_PROJECT_REPOSITORY_LANGUAGES: CI_PAGES_DOMAIN: example.com CI_PAGES_URL: http://root.example.com/test CI_REGISTRY: registry.example.com CI_REGISTRY_IMAGE: registry.example.com/root/test CI_API_V4_URL: http://gitlab.example.com/api/v4 CI_PIPELINE_IID: 8 CI_CONFIG_PATH: .gitlab-ci.yml CI_PIPELINE_SOURCE: push CI_COMMIT_MESSAGE: Update .gitlab-ci.yml CI_COMMIT_TITLE: Update .gitlab-ci.yml CI_COMMIT_DESCRIPTION: CI_COMMIT_REF_PROTECTED: true CI_RUNNER_ID: 1 CI_RUNNER_DESCRIPTION: gitlab-runner-gitlab-runner-5cdf6fd4f6-vqrzq CI_RUNNER_TAGS: GITLAB_USER_ID: 1 GITLAB_USER_EMAIL: admin@example.com GITLAB_USER_LOGIN: root GITLAB_USER_NAME: Administrator CI_DISPOSABLE_ENVIRONMENT: true CI_RUNNER_VERSION: 12.5.0 CI_RUNNER_REVISION: 577f813d CI_RUNNER_EXECUTABLE_ARCH: linux/amd64 Mounts: /builds from repo (rw) /var/run/secrets/kubernetes.io/serviceaccount from default-token-8gjvw (ro) svc-0: Container ID: docker://cad84f7dad65eb0447190ea53df5dcbe608cb6937c1bc1bf74f9edc21a42f6a6 Image: docker:18.09.7-dind Image ID: docker-pullable://docker@sha256:a490c83561c1cef49b6fe12aba2c31f908391ec3efe4eb173225809c981e50c3 Port: <none> Host Port: <none> State: Running Started: Sat, 21 Dec 2019 01:20:45 +0900 Ready: True Restart Count: 0 Environment: FF_CMD_DISABLE_DELAYED_ERROR_LEVEL_EXPANSION: false FF_USE_LEGACY_BUILDS_DIR_FOR_DOCKER: false FF_USE_LEGACY_VOLUMES_MOUNTING_ORDER: false CI_RUNNER_SHORT_TOKEN: 3xycVVoJ CI_BUILDS_DIR: /builds CI_PROJECT_DIR: /builds/root/test CI_CONCURRENT_ID: 0 CI_CONCURRENT_PROJECT_ID: 0 CI_SERVER: yes CI_PIPELINE_ID: 8 CI_PIPELINE_URL: http://gitlab.example.com/root/test/pipelines/8 CI_JOB_ID: 9 CI_JOB_URL: http://gitlab.example.com/root/test/-/jobs/9 CI_BUILD_ID: 9 CI_REGISTRY_USER: gitlab-ci-token CI: true GITLAB_CI: true GITLAB_FEATURES: CI_SERVER_HOST: gitlab.example.com CI_SERVER_NAME: GitLab CI_SERVER_VERSION: 12.5.3 CI_SERVER_VERSION_MAJOR: 12 CI_SERVER_VERSION_MINOR: 5 CI_SERVER_VERSION_PATCH: 3 CI_SERVER_REVISION: CI_JOB_NAME: build CI_JOB_STAGE: test CI_COMMIT_SHA: f493d24c574d3deee3e0284f6f413cd20b9a7e83 CI_COMMIT_SHORT_SHA: f493d24c CI_COMMIT_BEFORE_SHA: 4bddec9c21af3e1fcedde2a81f62eb03d9afaa2b CI_COMMIT_REF_NAME: master CI_COMMIT_REF_SLUG: master CI_NODE_TOTAL: 1 CI_DEFAULT_BRANCH: master CI_BUILD_REF: f493d24c574d3deee3e0284f6f413cd20b9a7e83 CI_BUILD_BEFORE_SHA: 4bddec9c21af3e1fcedde2a81f62eb03d9afaa2b CI_BUILD_REF_NAME: master CI_BUILD_REF_SLUG: master CI_BUILD_NAME: build CI_BUILD_STAGE: test CI_PROJECT_ID: 1 CI_PROJECT_NAME: test CI_PROJECT_TITLE: test CI_PROJECT_PATH: root/test CI_PROJECT_PATH_SLUG: root-test CI_PROJECT_NAMESPACE: root CI_PROJECT_URL: http://gitlab.example.com/root/test CI_PROJECT_VISIBILITY: private CI_PROJECT_REPOSITORY_LANGUAGES: CI_PAGES_DOMAIN: example.com CI_PAGES_URL: http://root.example.com/test CI_REGISTRY: registry.example.com CI_REGISTRY_IMAGE: registry.example.com/root/test CI_API_V4_URL: http://gitlab.example.com/api/v4 CI_PIPELINE_IID: 8 CI_CONFIG_PATH: .gitlab-ci.yml CI_PIPELINE_SOURCE: push CI_COMMIT_MESSAGE: Update .gitlab-ci.yml CI_COMMIT_TITLE: Update .gitlab-ci.yml CI_COMMIT_DESCRIPTION: CI_COMMIT_REF_PROTECTED: true CI_RUNNER_ID: 1 CI_RUNNER_DESCRIPTION: gitlab-runner-gitlab-runner-5cdf6fd4f6-vqrzq CI_RUNNER_TAGS: GITLAB_USER_ID: 1 GITLAB_USER_EMAIL: admin@example.com GITLAB_USER_LOGIN: root GITLAB_USER_NAME: Administrator CI_DISPOSABLE_ENVIRONMENT: true CI_RUNNER_VERSION: 12.5.0 CI_RUNNER_REVISION: 577f813d CI_RUNNER_EXECUTABLE_ARCH: linux/amd64 Mounts: /builds from repo (rw) /var/run/secrets/kubernetes.io/serviceaccount from default-token-8gjvw (ro) ... Volumes: repo: Type: EmptyDir (a temporary directory that shares a pod's lifetime) Medium: default-token-8gjvw: Type: Secret (a volume populated by a Secret) SecretName: default-token-8gjvw Optional: false ...コンテナは
build、helper、svc-0の3つです。
PodはEmptyDirをVolumeとして利用していて、/builds以下にソースコードが配置されることが分かります。Serviceコンテナが増えると
svc-1、svc-2と増えていきます。
resourceのrequestsを大きめに取るとNodeのリソースが足らずにPending状態になってしまうので注意しましょう。おわりに
GitLab RunnerのExecutorの1つであるKubernetes Executorを説明しました。
helmを使えば簡単にデプロイできるので導入コストは非常に低いと思います。
公式ドキュメントが豊富なので今後使用する人は増えていきそうです。
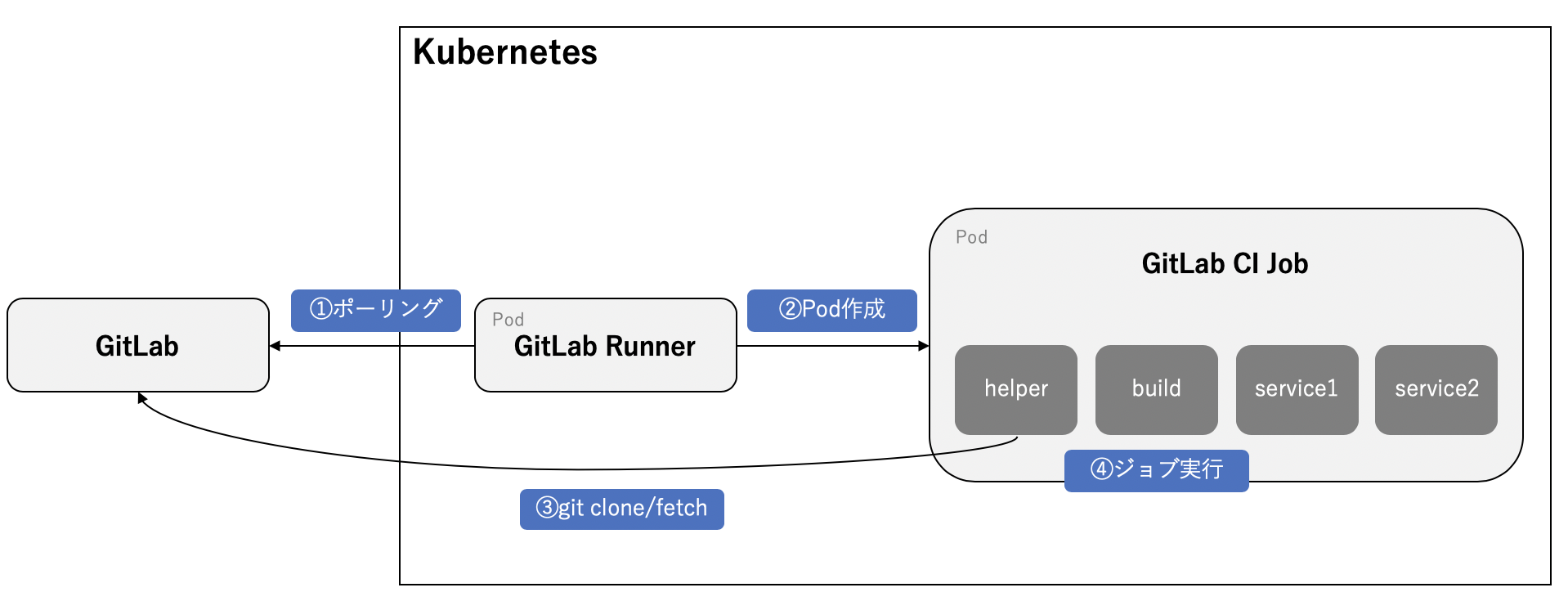
- 投稿日:2019-12-21T00:45:03+09:00
Alexa Skill Builder - Specialtyを取得するまでにやったこと
この記事はFusic Advent Calendar 2019の21日目の記事です。
昨日は@Y_uuuの「RailsアプリをECS FargateへデプロイするCI/CD pipelineを構築する」でした。
re:Invent内のワークショップはこんな実践的なものがあるんですね。。すごく勉強になりそうです。
Laravelでの同じ機構も作ってみたいなと思いました!
昨日AWS認定試験の一つ、Alexa Skill Builderを受験してきました。
初のSpecialty試験だったので、どうなることやらと思っていましたが、
なんとか合格することができました。今回はAlexa Skill Builder取得までに自分が取り組んだことをご紹介します。
少しでも次に受験する方への手助けになればよいかなと思います。
勉強前の知識
勉強前にやってたこと
- 普段の業務はLaravelやVueを書くことが多いです。
- 業務でAlexaスキルの作成に携わったことはありません。
- 学生のハンズオンでAlexaスキル作成の手伝いをしたり、会社の開発合宿で趣味レベルのAlexaスキルを作ったりしていました。
- AWSの資格は他にSolutions Architect - Associateだけ取得していたため、AWSのサービス全般に関する、基礎的な知識は持っていました。
勉強前に作ったスキル
セッションアトリビュートを使ってDynamoDBに値を保持して、VUI上でポ○モン風のゲームが遊べるスキルを作成しました。
Dialogやセッションアトリビュートを実際に手で使って覚えることができたのでよかったです。
公開まではしていません。
試験勉強としてやった内容
公式の試験ガイドを読み、出題範囲を確認
まずは、AWSの公式が出している試験ガイドを読んで、出題範囲を確認します。
AWS 認定 Alexa スキルビルダー – スペシャリティサンプル問題を解く
次に上記と同じリンク先にある、サンプル問題を解きます。
10題ほどの問題があります。
難易度は本番の問題とほぼ同じくらいのイメージです。AWS公式のデジタルトレーニングを受ける
公式が出しているデジタルトレーニングを受けました。
動画がたくさんある上に、中身は英語ですので、苦労します。
自分の場合
- とにかく問題数を解きたかった
- 試験自体日本語で受けるので、日本語でinputしたかった
という理由で、動画は見ずに、Chrome拡張のGoogle翻訳を使って、文章と設問だけ答える形で進めました。
模擬試験を解く
4000円くらいで模擬試験を受けることができます。
自分の場合、前回ソリューションアーキテクトを取得した際のクーポンがあったので、無料で受けることができました。
20問くらいで受験自体はすぐ終わります。
模擬試験の結果は60%でした。
答えは表示されないので、どの問題が正解かはわかりませんが、どのような問題が出題されるかのイメージが湧いていいかと思います。
AWSスキルトレーニングを受ける
AWSスキルトレーニングを受けることもできます。
試験の役に立ちそうなものを一部だけ選んで、やってみました。
A CLOUD GURUのAlexa Skill Builderコースを受ける
有料ですが、かなりのボリュームのコースがあります。
またチャプターごとにテスト形式で確認もできるため、問題をとにかく解いておきたい場合は便利です。
1週間の無料体験ができるため、試験のために1週間だけ登録するのもありかと。
ただ、全て英語なのと、確認テストが若干バグっている感じもしたので、お気をつけを!
動画を2倍速再生などができるのは、とても便利でした。試験を受けてみて
試験結果
正直試験中は、自信のない問題が多すぎて、合格できる気がしてませんでした。。
そのため試験後、合格の文字が出現した時はとても嬉しかったです。
当日の夜には、試験結果を見ることができました。
思ってたよりは余裕があったみたいでよかったです。
勉強した甲斐があったなあと。ここをもっと勉強しておいた方がよかったと思う点
個人的にもっと勉強しておいたらよかったなーと思った点としては
カスタムスキル以外のスキル
スマートホームスキルやビデオスキルなどは、触ったことがなかったので、もう少し触る時間とれたらなーとは思いました。
あと、カスタムスキルの中でも画面付きのスキルについても、もう少し勉強しておけばよかったなーと思います。
ASK CLIを使ったスキルの開発
実はこれまで、コンソール上でしかAlexaスキルを作ったことがありませんでした。
そのためCLIでのスキルの作成の問題に手こずった印象があります。
コンソール画面だけではなく、CLIでのスキル開発もやっておくと、自信持てると思います。まとめ
以上、 Alexa Skill Builderを取得するまでにやったこと、でした。
最後まで読んでいただき、ありがとうございました。
明日はFusicエバンジェリストの @seike460 さんの記事ですね!
Goについての何かしらが書かれる模様です。お楽しみに!!
- 投稿日:2019-12-21T00:38:29+09:00
F# でAWS Lambdaのはじめかた
Problem
AWS Lambda が、.NET Core 2.1 をサポートされて、1年以上経過しました。
しかし、サポートされているのはC#だけではありません。F#もまた同様です。
F#は.NETで実行される機能言語であり、C#で記述されたAWS SDK for .NETなど、他の.NET言語で記述されたパッケージを使用できます。これまでに、F#を使用したAWS Lambdaのプロジェクトを作ったことがない方にも分かるように作り方をまとめます。
Solution
開発環境
Windowsの場合
開発環境は以下の通りです。
項目 値 IDE Visual Studio 2019 Macの場合
項目 値 IDE Visual Studio Code 準備
Windowsの場合
AWS Toolkit for Visual Studio のインストール
AWS Toolkit for Visual Studioをインストールしておくことで、簡単にプロジェクトを作成することができます。
こちらからダウンロードし、インストールしましょう。Macの場合
Amazon.Lambda.Templates のインストール
Amazon.Lambda.Templatesをインストールしておくことにより、
dotnetコマンドで簡単にプロジェクトを作成することができます。
こちらからダウンロードし、インストールしましょう。
また、こちらはWindowsでも使用することができます。プロジェクトを作る
プロジェクトを作りましょう。
Windowsの場合
Create a new projectよりAWS Lambda Project with Tests(.Net Core - F#)を選択します。
プロジェクト名を入力後、使用するテンプレートを選択します。今回の例ではEmpty Functionを選択しました。
Macの場合
dotnet new lambda.EmptyFunction -o HelloLambda -lang f# code ./HelloLambda -rこれで、プロジェクトWindow/Macのいずれかで、プロジェクトを作成することができました。
それでは、プロジェクトで作成されたファイルのいくつかを見てみましょう。生成されたファイル
Functions.fs: - Lambdaのハンドラーを定義します。namespace HelloLambda open Amazon.Lambda.Core open System // Assembly attribute to enable the Lambda function's JSON input to be converted into a .NET class. [<assembly: LambdaSerializer(typeof<Amazon.Lambda.Serialization.Json.JsonSerializer>)>] () type Function() = /// <summary> /// A simple function that takes a string and does a ToUpper /// </summary> /// <param name="input"></param> /// <param name="context"></param> /// <returns></returns> member __.FunctionHandler (input: string) (_: ILambdaContext) = match input with | null -> String.Empty | _ -> input.ToUpper()aws-lambda-tools-defaults.json –デプロイに必要な設定情報が含まれています。
{ "Information" : [ "This file provides default values for the deployment wizard inside Visual Studio and the AWS Lambda commands added to the .NET Core CLI.", "To learn more about the Lambda commands with the .NET Core CLI execute the following command at the command line in the project root directory.", "dotnet lambda help", "All the command line options for the Lambda command can be specified in this file." ], "profile" : "default", "region" : "ap-northeast-1", "configuration" : "Release", "framework" : "netcoreapp2.1", "function-runtime" : "dotnetcore2.1", "function-memory-size" : 256, "function-timeout" : 30, "function-handler" : "HelloLambda::HelloLambda.Function::FunctionHandler" }実行してみる
Windowsの場合
AWS .NET Mock Lambda Test Tool (Preview)を使用することでLambda関数の処理を確かめることができます。
Macの場合
WindowsのようなToolkitはないので、単体テストコードを使用することでLambda関数の処理を確かめることができます。
テストコードはプロジェクトフォルダ/test/プロジェクト名.Tests/にあります。namespace HelloLambda.Tests open Xunit open Amazon.Lambda.TestUtilities open HelloLambda module FunctionTest = [<Fact>] let ``Invoke ToUpper Lambda Function``() = // Invoke the lambda function and confirm the string was upper cased. let lambdaFunction = Function() let context = TestLambdaContext() let upperCase = lambdaFunction.FunctionHandler "hello world" context Assert.Equal("HELLO WORLD", upperCase) [<EntryPoint>] let main _ = 0cd HelloLambda/test/HelloLambda.Tests dotnet testConclusion
AWS Lambdaプロジェクトを作成し、実行して検証するところまではこれでできるようになりました。
S3のPutイベントを元にサムレイル画像を生成したり、リアルタイムにストリーミングデータを処理したり...色々と試してみてください。


