- 投稿日:2019-08-22T23:43:38+09:00
acts_as_listで並び替えたときに他のレコードのupdated_atを更新させない方法
課題
acts_as_listを適用しているModelに対して、新規作成(new -> save)や並び替え(insert_at)したときに他のレコードも
positionが変わるので、updated_atが更新されてしまう。https://github.com/swanandp/acts_as_list
やりたいこと
新規作成や並び替えで他のレコードの
updated_atが更新されないようにしたい。前提
- acts_as_list gem を入れている
- Modelのカラムにpositionを追加している
やってみたこと
1.record_timestamps を使ってみる(NG)
Article.record_timestamps = false Article.new.save Article.record_timestamps = trueログのクエリを見ると
updated_atが更新されてしまっている。UPDATE `article` SET `position` = (`article`.`position` - 1), `updated_at` = '2019-08-11 16:53:19' WHERE (1 = 1)2. gemを調査
acts_as_list-0.9.19/lib/acts_as_list/active_record/acts/position_column_method_definer.rb#L45あたり
define_singleton_method :update_all_with_touch do |updates| updates += touch_record_sql if touch_on_update update_all(updates) endなるほど、
touch_on_updateが怪しい。3. gemのGithubを見てみた。
README.md を読んでみたが、特に
touch_on_updateの記載はなかったが、テストコードに以下の記述があった。class SequentialUpdatesAltIdTouchDisabled < SequentialUpdatesAltId acts_as_list column: "pos", touch_on_update: false endなるほど、
touch_on_update: falseを付けてみよう。結論
touch_on_update: falseを付けたら更新できた。class Article < ActiveRecord::Base acts_as_list top_of_list: 0, add_new_at: :top, touch_on_update: false endログのクエリを見ると
updated_atが更新されていない。UPDATE `article` SET `position` = (`article`.`position` - 1) WHERE (1 = 1)
- 新規作成時: 他のレコードはpositionが +1 されるが、 updated_at は更新されない
- 並び替え時: 動かしたレコードのみ updated_at が更新される。他もpositionは変わるが、updated_at は更新されない
ついでに
- 投稿日:2019-08-22T23:41:51+09:00
登録メール自動送信機能の実装
ユーザー登録時などに自動でメールを送る機能を実装しました。
ログイン機能のあるアプリ、Webサービスで登録すると自動でメールが来る、ユーザーにとっては鬱陶しい機能を実装してみました。
これを見る誰かの参考になれば幸いです。まずAction Maileの準備
メール送信機能の実装に先立ちまして、必要な準備があります。
以下development.rbの変更 変更後はpumaの再起動が必要です。development.rbconfig.action_mailer.delivery_method = :smtp config.action_mailer.raise_delivery_errors = true config.action_mailer.smtp_settings = { address: 'smtp.gmail.com', port: 587, user_name: 'gmailアドレス', password: 'googleアカウントのパスワード', authentication: 'plain' }delivery_methodはメールを送信する方法を指定しています。
raise_delivery_errorsはメール送信失敗時にエラーを発生させるかを指定しています。
smtp_settingで:smtpの設定情報を設定します。
address: はgmailを使って送信する場合はsmtp.gmail.com
softbankならsmtp.softbank.comのように変わります。詳しくは調べてみてください。これにて事前準備は完了です。
メーラーを作成する
$ rails g mailer sample sendmail_confilmsampleメーラーにsendmail_confilmメソッドを作成
メーラーを編集
sample_mailer.rbを編集する
sample_mailer.rbdefault from: 'sample@gmail.com' def sendmail_confirm(user) @user = user mail to: user.email, subject: 'ユーザー登録ありがとうございます' #これが件名 endsendmail_confirmがコントローラーで言う所のアクションに当たります。
sendmail_confirm.html.erbを呼んできます。
またはsendmail_confirm.text.erbメールの編集
sendmail_confilm.html.erb任意のメールの内容メーラーを呼び出すためのアクションを作成する
メーラーはクライアントからのアクションを直接受け取れませんのでアクションを作成します。
mail_controller.rbdef sendmail user = User.find(id) @mail = SampleMailer.sendmail_confirm(user).deliver_now #① render plain: ’送信完了’①の文 メーラー名.メソッド()でメーラーを呼び出せます。
メールを送ってみる
以上でメールを送る準備が完了しました。
ブラウザで〜/sample/sendmail_confirm
にアクセスして送信完了です。アプリに実装する時はメールを送りたい時にメーラーを呼び出すようにコードを書くだけです。
終わり
わかりにくい部分などもあったかもしれませんが最後までお読みいただきありがとうございました。
この記事に誤りや改善点などございましたら編集リクエストにてご指摘いただけると幸いです。
- 投稿日:2019-08-22T21:55:39+09:00
『RubyOnRails』enumの使い方
初めに
プログラミングを始めて4ヶ月の初学者です。
今回enumを使う機会があったのでメモを残します。環境
・Ruby '2.3.8'
・Rails '5.2.3'emunとは
enum(イーナム)はRails4.1から導入された機能です。
enumを使用すると以下の様な事が出来ます。
DBの中では数字を保存させる。
Viewでは文字を表示させる。例:日本というテーブルに地方というカラムがあったとします。
enumを使用しない場合は、地方カラムに関東、関東、九州、四国の様に文字が登録されます。
しかし、enumを使用した場合は関東は1、関西は2、四国は3、九州は4と定義する事で、DBの中は1、1、4、3の様に保存され、Viewでは対象の文字を表示させる。emunの利点
・データ型をintegerにするとDBに数字で登録されるが、数字だけだと数字が持つ意味が共有出来ない。
一人で開発する時は自分だけが意味を理解していればいいが、チーム開発だとチーム内で意味が理解できていないといけない。
そこで、enumを使用する事で数字が何を表しているかがチーム内で共有出来る。emunの使用方法(モデル編)
対象にモデルに記述します。
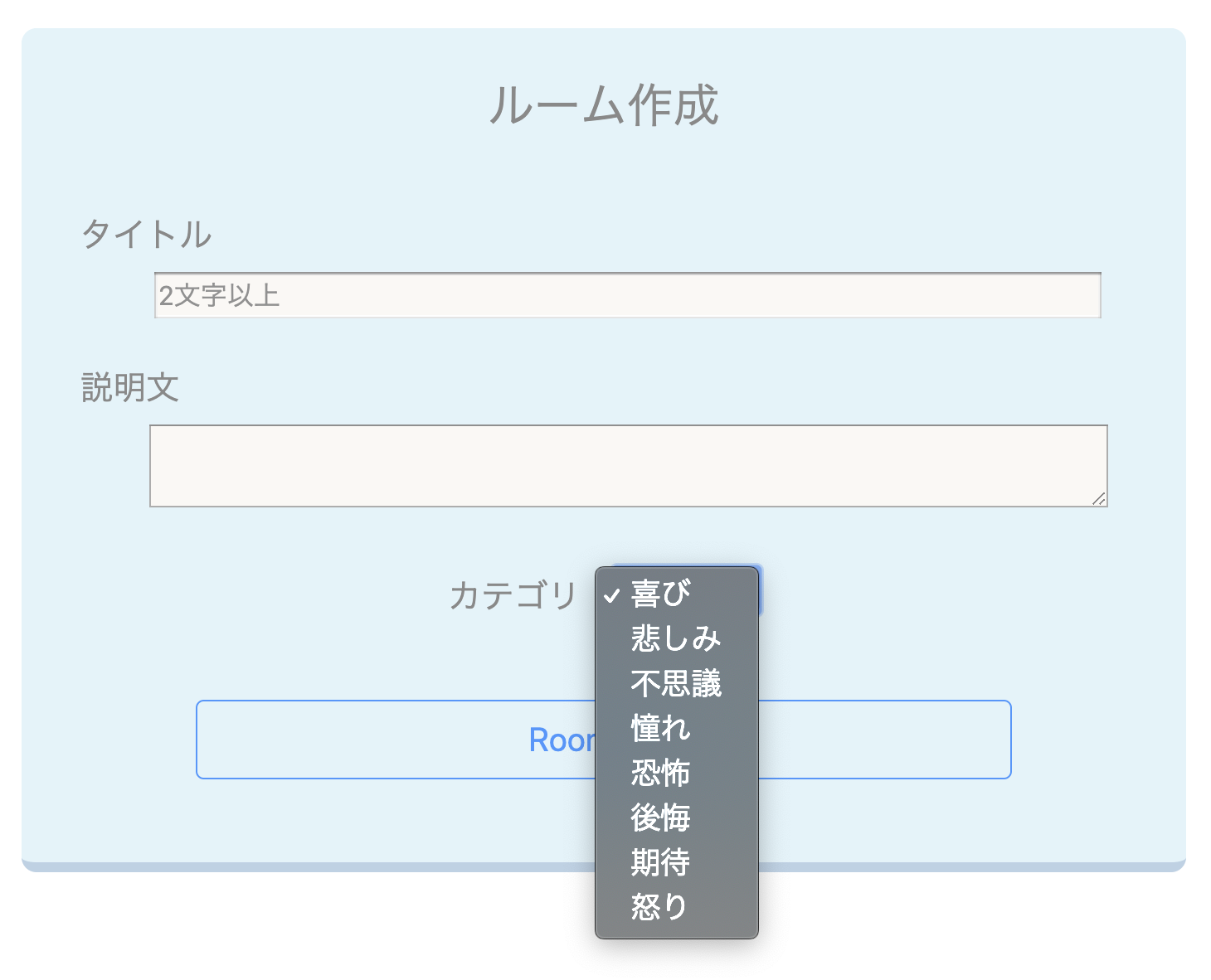
今回はroomというテーブルのcategoryカラムにenumを使用したいと思います。room.rbenum category: { 喜び: 0, 悲しみ: 1, 不思議: 2, 憧れ: 3, 恐怖: 4, 後悔: 5, 期待: 6, 怒り: 7 }これで、数字と文字を関係付ける事ができました。
emunの使用方法(view編)
今回はプルダウン形式で表示させたいと思います。
room.rb<%= form_for(@room) do |f| %> <%= f.select :category, Room.categories.keys.to_a, {} %> <% end %>これでview側で表示させる事が出来ます。
最後に
分かりにくい記事かもしれませんが、初学者の助けになれば幸いです。
- 投稿日:2019-08-22T21:25:32+09:00
mapメソッドとは?
mapメソッドとは?
mapメソッドは
配列の要素数だけ繰り返し処理を行うメソッドです。mapメソッドの書き方は?
mapメソッドは
配列が入った変数.map{|変数名|処理名}と記述します。処理後は戻り値で配列を生成します。
例を出して説明すると
@brand = Brand.all ##{グッチ、シャネル、サンローラン} @brand.map{|t| [t.name, t.id]} ##[[グッチ、1],[シャネル,2],[サンローラン,3]]といった配列が生成されます。
eachとの違いは?
eachメソッドを使用した場合、返り値はレシーバ自体になります。
一方、mapメソッドで生成された配列はそのまま保持されます。
- 投稿日:2019-08-22T20:38:13+09:00
Rails チュートリアル(8章)をRSpecでテスト
はじめに
以前書いた記事です!
Rails チュートリアル(3章、4章、5章)をRSpecでテスト
Rails チュートリアル(6章)をRSpecでテスト
Rails チュートリアル(7章)をRSpecでテストテストを書く(8章)
Sessionsのフラッシュメッセージのテスト(ログイン失敗)
元のテスト↓
8.1.5 フラッシュのテスト -Ruby on Rails チュートリアルspec/systems/sessions_spec.rbrequire 'rails_helper' RSpec.describe 'Sessions', type: :system do before do visit login_path end #無効な値を入力する describe 'enter an invalid values' do before do fill_in 'Email', with: '' fill_in 'Password', with: '' click_button 'Log in' end subject { page } #フラッシュメッセージが出る it 'gets an flash messages' do is_expected.to have_selector('.alert-danger', text: 'Invalid email/password combination') is_expected.to have_current_path login_path end #違うページにアクセスしたとき context 'access to other page' do before { visit root_path } #フラッシュメッセージが消える it 'is flash disappear' do is_expected.to_not have_selector('.alert-danger', text: 'Invalid email/password combination') end end end endログインのテスト(ログイン成功)
spec/systems/sessions_spec.rbRSpec.describe 'Sessions', type: :system do before do visit login_path end describe 'enter an valid values' do let!(:user) { create(:user, email: 'loginuser@example.com', password: 'password') } before do fill_in 'Email', with: 'loginuser@example.com' fill_in 'Password', with: 'password' click_button 'Log in' end subject { page } #ログインしたときのページのレイアウトの確認 it 'log in' do is_expected.to have_current_path user_path(user) #現在のページのurlについて検証 is_expected.to_not have_link nil, href: login_path click_link 'Account' #ドロップダウンリンクをクリック is_expected.to have_link 'Profile', href: user_path(user) is_expected.to have_link 'Log out', href: logout_path end end #ここから下は以前書いた分------------------------------------------------------------- describe 'enter an invalid values' do before do fill_in 'Email', with: '' fill_in 'Password', with: '' click_button 'Log in' end subject { page } it 'gets an flash messages' do is_expected.to have_selector('.alert-danger', text: 'Invalid email/password combination') is_expected.to have_current_path login_path end context 'access to other page' do before { visit root_path } it 'is flash disappear' do is_expected.to_not have_selector('.alert-danger', text: 'Invalid email/password combination') end end end end次にRequest Specで有効な値でログインしたときにセッションに値が入っているかテストします。
そのためにis_logged_in?という論理値を返すテスト用のヘルパーメソッドをつくります。Helperの作成
まず、ヘルパーを使うための設定
spec/rails_helper.rb#コメントアウトになっているので解除、なければ追加する Dir[Rails.root.join('spec', 'support', '**', '*.rb')].each { |f| require f } RSpec.configure do |config| config.include TestHelper #作成したヘルパーを追加 endspecフォルダーにsupportフォルダーをつくり、その中にヘルパーファイルを追加します。
spec/support/test_helper.rbmodule TestHelper def is_logged_in? !session[:user_id].nil? end endこれでテストで
is_logged_in?が使えます。ログインのテスト(ログイン成功)
spec/requests/access_to_sessions_spec.rbrequire 'rails_helper' RSpec.describe 'access to sessions', type: :request do let!(:user) { create(:user) } describe 'POST #create' do it 'log in and redirect to detail page' do post login_path, params: { session: { email: user.email, password: user.password } } expect(response).to redirect_to user_path(user) expect(is_logged_in?).to be_truthy #ログインしているかのテストここでis_logged_in?を使ってます。 end end endユーザー作成時にログインしているかのテスト
spec/requests/access_to_users_spec.rb# ほとんど以前書いていた分です。 describe 'POST #create' do context 'valid request' do it 'adds a user' do expect do post signup_path, params: { user: attributes_for(:user) } end.to change(User, :count).by(1) end context 'adds a user' do before { post signup_path, params: { user: attributes_for(:user) } } subject { response } it { is_expected.to redirect_to user_path(User.last) } it { is_expected.to have_http_status 302 } #ここから追加---------------------------------------------------------- it 'log in' do expect(is_logged_in?).to be_truthy end #ここまで------------------------------------------------------------- end end endログアウトのテスト
sessions_spec.rbにログアウトのテストを追記します。spec/systems/sessions_spec.rbrequire 'rails_helper' RSpec.describe 'Sessions', type: :system do before do visit login_path end describe 'enter an valid values' do let!(:user) { create(:user, email: 'loginuser@example.com', password: 'password') } before do fill_in 'Email', with: 'loginuser@example.com' fill_in 'Password', with: 'password' click_button 'Log in' end subject { page } it 'log in' do is_expected.to have_current_path user_path(user) is_expected.to_not have_link nil, href: login_path click_link 'Account' is_expected.to have_link 'Profile', href: user_path(user) is_expected.to have_link 'Log out', href: logout_path end #追記したログアウトのテストです。----------------------------------------------- it 'log out after log in' do click_link 'Account' click_link 'Log out' is_expected.to have_current_path root_path is_expected.to have_link 'Log in', href: login_path is_expected.to_not have_link 'Account' is_expected.to_not have_link nil, href: logout_path is_expected.to_not have_link nil, href: user_path(user) end #ここまで---------------------------------------------------------------- end describe 'enter an invalid values' do before do fill_in 'Email', with: '' fill_in 'Password', with: '' click_button 'Log in' end subject { page } it 'gets an flash messages' do is_expected.to have_selector('.alert-danger', text: 'Invalid email/password combination') is_expected.to have_current_path login_path end context 'access to other page' do before { visit root_path } it 'is flash disappear' do is_expected.to_not have_selector('.alert-danger', text: 'Invalid email/password combination') end end end endRequest Specでログアウトしたときにセッションがnilになっているかテストします。
spec/requests/access_to_sessions_spec.rbdescribe 'DELETE #destroy' do it 'log out and redirect to root page' do delete logout_path expect(response).to redirect_to root_path expect(is_logged_in?).to be_falsey #ここでセッションの値をテストしています。 end endこれで8章のテストがおわりです。
- 投稿日:2019-08-22T19:55:28+09:00
[rails] 孫要素のカウント数(条件)で子要素の値を返す方法
孫要素の条件で子要素の値を返す
はじめに
孫要素をincludes
Prefecture.includes(localities: :sub_locality)子モデルをキャッシュ&絞込
Prefecture.includes(:localities).references(:localities).where("localities.name = ?", '東京都')子モデル・孫モデルが存在するレコード抽出
Prefecture.joins(:localities).where("localities.name = ?", '新宿区') Prefecture.joins(localities: :sub_localities).where("sub_localities.name = ?", '西新宿')ここまでは、いろいろな記事でもっとわかりやすく書いてるものを参考にしてください。
本題
ここからが本題です!
今回ワタシが苦戦した内容が、「孫要素が必要な条件揃っていたら、子要素の値を返す」というものでした。上記の例をつくるとすると、
1つのprefectureの 紐づくlocalityに、さらに紐づくsub_localityが100以上ある場合のみ値を返すコードを作りたい試行段階
Prefecture.first.localities.joins(:sub_localities).group(:id).having('count_id >= 100').count(:id) => {2=>131, 3=>116, 11=>167, 13=>334, 15=>172, 16=>144, 17=>164, 19=>180, 24=>113, 38=>109, 186=>143}こんな感じの結果が返ってくる。
locality.idをとれたので、成功!?しかし、これで
localityを絞るには、locality_ids = Prefecture.first.localities.joins(:sub_localities).group(:id).having('count_id >= 100').count(:id).keysのようにして、
locality.idをとってきてから、Locality.where(id: locality_ids)と書かないといけない!めんどくさい
結果
一回で絞り込めないかな〜〜と検索してたらドンピシャのサイトがありました。
http://akinov.hatenablog.com/entry/2017/05/13/163911Prefecture.first.localities.joins(:sub_localities).group(:id).having("count('*') >= ?", 100) => #<ActiveRecord::AssociationRelation [#<Locality id: 11, prefecture_id: 1, name: "~~~" ]>としっかり
localityのデータが返ってきました。
having("count('*') >= ?", 100)こんな書き方でいけちゃうみたいです!
'*' ここは名前?みたいな感じなのでなんでも良き。(なはず)Prefecture.first.localities.joins(:sub_localities).group(:id).having("count('*') >= ?", 100).count => {2=>131, 3=>116, 11=>167, 13=>334, 15=>172, 16=>144, 17=>164, 19=>180, 24=>113, 38=>109, 186=>143}ちなみに、count つけるとこんな感じでデータが帰ってきます。
まとめ
- google様での検索ワードってホント大事。
- これが完全正解とは、限らないのでもっといい方法をご存じの方はご教授願います。
- 投稿日:2019-08-22T19:19:57+09:00
Railsチュートリアル 第4章 - Rails風味のRubyを学ぶ
rails consoleRailsチュートリアル本文にあるとおり、これから「
rails consoleをツールとしてRubyを学んでいこう」というパートになります。
~/.irbrcを編集し、irbにRailsチュートリアルの推奨設定を適用するirbにおけるRailsチュートリアルの推奨設定の内容は以下です。
- irbのプロンプトを簡潔な表示に置き換える
- irbの自動インデント機能をオフにする
当該設定を適用するためには、Railsが動作している環境で
~/.irbrcを編集する必要があります。私がセットアップしたDocker環境では、nanoエディタがインストールされておらず、先にインストールする必要がありました。当該Docker環境のOSはDebian 9.5なので、nanoエディタは以下の手順でインストールできました。
bash# apt-get update # apt-get install -y nanonanoエディタをインストールしたら、
~/.irbrcの内容を以下のように書き換え、変更を保存します。~/.irbrcIRB.conf[:PROMPT_MODE] = :SIMPLE IRB.conf[:AUTO_INDENT_MODE] = falsebash# pwd /var/www/sample_app # rails console Running via Spring preloader in process 948 Loading development environment (Rails 5.1.6) >>Railsチュートリアルの推奨設定が適用されたようです。
文字列の連結
ここから、
rails consoleの中でRuby言語の世界を探索してみることにします。>> first_name = "Michael" => "Michael" >> "#{first_name} Hertl" => "Michael Hertl"↑「文字列の式展開」というやり方があるのですね。実は初めて知りました。
>> first_name = "Michael" => "Michael" >> last_name = "Hertl" => "Hertl" >> first_name + " " + last_name => "Michael Hertl" >> "#{first_name} #{last_name}" => "Michael Hertl"↑「文字列変数と空白文字と文字列変数を結合する」「式展開を使って文字列変数を結合する」両方の方式で文字列変数を結合してみています。
文字列の画面出力
>> puts "foo" foo => nil >> print "foo" foo=> nil >> print "foo\n" foo => nil
putsやnilであり、標準出力への文字列の出力は副作用としてのものであるputsは文字列の最後に自動で改行コードを追加する一方、シングルクォート内の文字列
>> 'foo' => "foo" >> 'foo' + 'bar' => "foobar" >> '#{foo} bar' => "\#{foo} bar" >> '\n' => "\\n" >> 'Newlines (\n) and tabs (\t) both use the backslash character \.' => "Newlines (\\n) and tabs (\\t) both use the backslash character \\."
- シングルクォート内の文字列では、特殊文字が解釈されない
- 特殊文字の解釈の有無以外は、シングルクォート内の文字列もダブルクォート内の文字列も挙動は同じである
日本語が入力できない…?
私のDockerコンテナにおいては、次の演習に取り掛かるのに際して、シェル・Railsコンソールで日本語が入力できないことが問題になりました。
どうやら原因は、「使用していたDockerコンテナに、日本語を含むロケール関係の機能一式がインストールされていなかった」ということのようでした。
以下の通り、ロケール関係の機能一式をインストールした上で、Dockerコンテナ上で動いているDebianの環境変数
LANGを変更することにより、シェル・Railsコンソール日本語入力ができるようになりました。bash# apt-get update # apt-get install locales locales-all # export LANG=en_US.UTF-8問題解決にあたっては、以下のWebサイトを参考にさせていただきました。ありがとうございます。
演習
1.city変数に適当な市区町村を、prefecture変数に適当な都道府県を代入してください。
市区町村を
越谷市、都道府県を埼玉県にしてやってみます。>> city = "越谷市" => "越谷市" >> prefecture = "埼玉県" => "埼玉県"2. 先ほど作った変数と式展開を使って、「東京都 新宿区」のような住所の文字列を作ってみましょう。出力にはputsを使ってください。
以下に示す通り、方法は2つあります。両方やってみます。
>> puts prefecture + " " + city 埼玉県 越谷市 => nil >> puts "#{prefecture} #{city}" 埼玉県 越谷市 => nil3. 上記の文字列の間にある半角スペースをタブに置き換えてみてください。(ヒント: 改行文字と同じで、タブも特殊文字です)
タブ文字は
\tという特殊文字として表されます。>> puts "#{prefecture}\t#{city}" 埼玉県 越谷市 => nil4. タブに置き換えた文字列を、ダブルクォートからシングルクォートに置き換えてみるとどうなるでしょうか?
>> puts prefecture + '\t' + city 埼玉県\t越谷市 => nil >> puts '#{prefecture}\t#{city}' #{prefecture}\t#{city} => nilシングルクォート内においては、そもそも
#{}も展開されないのですね。その点を見落としており、puts '#{prefecture}\t#{city}'の結果に最初驚きました。オブジェクト
オブジェクトとメッセージの受け渡し
Rubyでは、全ての値はオブジェクトです。例えば、
true、nil、""(空文字列)、RUBY_VERSION(Rubyの組み込み定数の一種)といったものもオブジェクトです。あらゆるオブジェクトはメソッドを持ちます。例えば、文字列は
lengthというメソッドやempty?というメソッドに応答できます。>> "".length => 0 >> "".empty? => true >> "foobar".length => 6 >> "foobar".empty? => false分岐構文の例
以下は分岐構文の例です。irb内でブロック形式の分岐構文を書けるのですね。
>> s = "foobar" => "foobar" >> if s.empty? >> "The string is empty" >> else >> "The string is nonempty" >> end => "The string is nonempty"これまた分岐構文の例です。
elsifで条件文を複数連ねていっています。>> s = "foobar" => "foobar" >> if s.nil? >> "The variable is nil" >> elsif s.empty? >> "The string is empty" >> elsif s.include?("foo") >> "The string includes 'foo'" >> end => "The string includes 'foo'"falsyな値
Javascript界隈において、「
booleanとして評価した場合にfalseとして評価される値」のことを「falsyな値」といいます。falsyの対義語はtruthyで、こちらは「booleanとして評価した場合にtrueとして評価される値」を意味します。Rubyにおけるfalsyなオブジェクト(Rubyでは、全ての値はオブジェクトです)は、
false自身とnilの2つしか存在しません。!!false => false !!nil => falseJavascriptでfalsyとされるオブジェクトに相当する
0、-0、""(空文字列)、Float::NAN(非数)といったオブジェクトも、Rubyではtruthyです。>> !!0 => true >> !!-0 => true >> !!"" => true >> !!Float::NAN => true演習…オブジェクトとメッセージ受け渡し
1. "racecar" の文字列の長さはいくつですか?
lengthメソッドを使って調べてみてください。>> "racecar".length => 72.
reverseメソッドを使って、"racecar"の文字列を逆から読むとどうなるか調べてみてください。>> "racecar".reverse => "racecar"3. 変数
sに "racecar" を代入してください。その後、比較演算子 (==) を使って変数sとs.reverseの値が同じであるかどうか、調べてみてください。>> s = "racecar" => "racecar" >> s == s.reverse => true4. リスト 4.9を実行すると、どんな結果になるでしょうか? 変数
sに "onomatopoeia" という文字列を代入するとどうなるでしょうか?>> s = "racecar" => "racecar" >> puts "It's a palindrome!" if s == s.reverse It's a palindrome! => nil >> s = "onomatopoeia" => "onomatopoeia" >> puts "It's a palindrome!" if s == s.reverse => nilirb内でのメソッド定義
以下のように、irb内でメソッドを定義することも可能です。
>> def string_message(str = '') >> if str.empty? >> "It's an empty string!" >> else >> "The string is nonempty." >> end >> end => :string_message >> puts string_message("foobar") The string is nonempty. => nil >> puts string_message("") It's an empty string! => nil >> puts string_message It's an empty string! => nil
- メソッドの引数は省略できる
- Rubyのメソッドには「暗黙の戻り値がある」
- メソッドで引数の変数名にどんな名前を使っても、メソッドの呼び出し側には何の影響も生じない
上述の点が大切なポイントでしょうか。
演習…メソッドの定義
1. リスト 4.10のFILL_INの部分を適切なコードに置き換え、回文かどうかをチェックするメソッドを定義してみてください。
>> def palindrome_tester(s) >> if s.reverse == s >> puts "It's a palindrome!" >> else >> puts "It's not a palindrome." >> end >> end => :palindrome_tester2. 上で定義したメソッドを使って “racecar” と “onomatopoeia” が回文かどうかを確かめてみてください。
>> palindrome_tester("racecar") It's a palindrome! => nil >> palindrome_tester("onomatopoeia") It's not a palindrome. => nil3.
palindrome_tester("racecar")に対してnil?メソッドを呼び出し、戻り値がnilであるかどうかを確認してみてください。>> palindrome_tester("racecar").nil? It's a palindrome! => true
putsは副作用で標準出力に文字列が出力されるのであり、戻り値はnilである- Rubyのメソッドは、明示的に戻り値を指定しなければ、メソッド内で最後に評価された式の値が戻り値となる
上述の挙動を考えると、1.で定義した
palindrome_testerの戻り値は、確かに常にnilになりますね。余談…演算子もメソッドである
余談ですが、Rubyにおいては、演算子もメソッドの一種として実装されています。例えば、以下の2つの表現は同じメソッドの呼び出しになります。
>> 17 + 42 => 59 >> 17.+(42) => 59
- 投稿日:2019-08-22T19:19:57+09:00
Railsチュートリアル 第4章 - Rails風味のRubyを学ぶ …titleヘルパーが読めるようになるまで
rails consoleRailsチュートリアル本文にあるとおり、これから「
rails consoleをツールとしてRubyを学んでいこう」というパートになります。
~/.irbrcを編集し、irbにRailsチュートリアルの推奨設定を適用するirbにおけるRailsチュートリアルの推奨設定の内容は以下です。
- irbのプロンプトを簡潔な表示に置き換える
- irbの自動インデント機能をオフにする
当該設定を適用するためには、Railsが動作している環境で
~/.irbrcを編集する必要があります。私がセットアップしたDocker環境では、nanoエディタがインストールされておらず、先にインストールする必要がありました。当該Docker環境のOSはDebian 9.5なので、nanoエディタは以下の手順でインストールできました。
bash# apt-get update # apt-get install -y nanonanoエディタをインストールしたら、
~/.irbrcの内容を以下のように書き換え、変更を保存します。~/.irbrcIRB.conf[:PROMPT_MODE] = :SIMPLE IRB.conf[:AUTO_INDENT_MODE] = falsebash# pwd /var/www/sample_app # rails console Running via Spring preloader in process 948 Loading development environment (Rails 5.1.6) >>Railsチュートリアルの推奨設定が適用されたようです。
文字列の連結
ここから、
rails consoleの中でRuby言語の世界を探索してみることにします。>> first_name = "Michael" => "Michael" >> "#{first_name} Hertl" => "Michael Hertl"↑「文字列の式展開」というやり方があるのですね。実は初めて知りました。
>> first_name = "Michael" => "Michael" >> last_name = "Hertl" => "Hertl" >> first_name + " " + last_name => "Michael Hertl" >> "#{first_name} #{last_name}" => "Michael Hertl"↑「文字列変数と空白文字と文字列変数を結合する」「式展開を使って文字列変数を結合する」両方の方式で文字列変数を結合してみています。
文字列の画面出力
>> puts "foo" foo => nil >> print "foo" foo=> nil >> print "foo\n" foo => nil
putsやnilであり、標準出力への文字列の出力は副作用としてのものであるputsは文字列の最後に自動で改行コードを追加する一方、シングルクォート内の文字列
>> 'foo' => "foo" >> 'foo' + 'bar' => "foobar" >> '#{foo} bar' => "\#{foo} bar" >> '\n' => "\\n" >> 'Newlines (\n) and tabs (\t) both use the backslash character \.' => "Newlines (\\n) and tabs (\\t) both use the backslash character \\."
- シングルクォート内の文字列では、特殊文字が解釈されない
- 特殊文字の解釈の有無以外は、シングルクォート内の文字列もダブルクォート内の文字列も挙動は同じである
日本語が入力できない…?
私のDockerコンテナにおいては、次の演習に取り掛かるのに際して、シェル・Railsコンソールで日本語が入力できないことが問題になりました。
どうやら原因は、「使用していたDockerコンテナに、日本語を含むロケール関係の機能一式がインストールされていなかった」ということのようでした。
以下の通り、ロケール関係の機能一式をインストールした上で、Dockerコンテナ上で動いているDebianの環境変数
LANGを変更することにより、シェル・Railsコンソール日本語入力ができるようになりました。bash# apt-get update # apt-get install locales locales-all # export LANG=en_US.UTF-8問題解決にあたっては、以下のWebサイトを参考にさせていただきました。ありがとうございます。
演習
1.city変数に適当な市区町村を、prefecture変数に適当な都道府県を代入してください。
市区町村を
越谷市、都道府県を埼玉県にしてやってみます。>> city = "越谷市" => "越谷市" >> prefecture = "埼玉県" => "埼玉県"2. 先ほど作った変数と式展開を使って、「東京都 新宿区」のような住所の文字列を作ってみましょう。出力にはputsを使ってください。
以下に示す通り、方法は2つあります。両方やってみます。
>> puts prefecture + " " + city 埼玉県 越谷市 => nil >> puts "#{prefecture} #{city}" 埼玉県 越谷市 => nil3. 上記の文字列の間にある半角スペースをタブに置き換えてみてください。(ヒント: 改行文字と同じで、タブも特殊文字です)
タブ文字は
\tという特殊文字として表されます。>> puts "#{prefecture}\t#{city}" 埼玉県 越谷市 => nil4. タブに置き換えた文字列を、ダブルクォートからシングルクォートに置き換えてみるとどうなるでしょうか?
>> puts prefecture + '\t' + city 埼玉県\t越谷市 => nil >> puts '#{prefecture}\t#{city}' #{prefecture}\t#{city} => nilシングルクォート内においては、そもそも
#{}も展開されないのですね。その点を見落としており、puts '#{prefecture}\t#{city}'の結果に最初驚きました。オブジェクト
オブジェクトとメッセージの受け渡し
Rubyでは、全ての値はオブジェクトです。例えば、
true、nil、""(空文字列)、RUBY_VERSION(Rubyの組み込み定数の一種)といったものもオブジェクトです。あらゆるオブジェクトはメソッドを持ちます。例えば、文字列は
lengthというメソッドやempty?というメソッドに応答できます。>> "".length => 0 >> "".empty? => true >> "foobar".length => 6 >> "foobar".empty? => false分岐構文の例
以下は分岐構文の例です。irb内でブロック形式の分岐構文を書けるのですね。
>> s = "foobar" => "foobar" >> if s.empty? >> "The string is empty" >> else >> "The string is nonempty" >> end => "The string is nonempty"これまた分岐構文の例です。
elsifで条件文を複数連ねていっています。>> s = "foobar" => "foobar" >> if s.nil? >> "The variable is nil" >> elsif s.empty? >> "The string is empty" >> elsif s.include?("foo") >> "The string includes 'foo'" >> end => "The string includes 'foo'"falsyな値
Javascript界隈において、「
booleanとして評価した場合にfalseとして評価される値」のことを「falsyな値」といいます。falsyの対義語はtruthyで、こちらは「booleanとして評価した場合にtrueとして評価される値」を意味します。Rubyにおけるfalsyなオブジェクト(Rubyでは、全ての値はオブジェクトです)は、
false自身とnilの2つしか存在しません。!!false => false !!nil => falseJavascriptでfalsyとされるオブジェクトに相当する
0、-0、""(空文字列)、Float::NAN(非数)といったオブジェクトも、Rubyではtruthyです。>> !!0 => true >> !!-0 => true >> !!"" => true >> !!Float::NAN => true演習…オブジェクトとメッセージ受け渡し
1. "racecar" の文字列の長さはいくつですか?
lengthメソッドを使って調べてみてください。>> "racecar".length => 72.
reverseメソッドを使って、"racecar"の文字列を逆から読むとどうなるか調べてみてください。>> "racecar".reverse => "racecar"3. 変数
sに "racecar" を代入してください。その後、比較演算子 (==) を使って変数sとs.reverseの値が同じであるかどうか、調べてみてください。>> s = "racecar" => "racecar" >> s == s.reverse => true4. リスト 4.9を実行すると、どんな結果になるでしょうか? 変数
sに "onomatopoeia" という文字列を代入するとどうなるでしょうか?>> s = "racecar" => "racecar" >> puts "It's a palindrome!" if s == s.reverse It's a palindrome! => nil >> s = "onomatopoeia" => "onomatopoeia" >> puts "It's a palindrome!" if s == s.reverse => nilirb内でのメソッド定義
以下のように、irb内でメソッドを定義することも可能です。
>> def string_message(str = '') >> if str.empty? >> "It's an empty string!" >> else >> "The string is nonempty." >> end >> end => :string_message >> puts string_message("foobar") The string is nonempty. => nil >> puts string_message("") It's an empty string! => nil >> puts string_message It's an empty string! => nil
- メソッドの引数は省略できる
- Rubyのメソッドには「暗黙の戻り値がある」
- メソッドで引数の変数名にどんな名前を使っても、メソッドの呼び出し側には何の影響も生じない
上述の点が大切なポイントでしょうか。
演習…メソッドの定義
1. リスト 4.10のFILL_INの部分を適切なコードに置き換え、回文かどうかをチェックするメソッドを定義してみてください。
>> def palindrome_tester(s) >> if s.reverse == s >> puts "It's a palindrome!" >> else >> puts "It's not a palindrome." >> end >> end => :palindrome_tester2. 上で定義したメソッドを使って “racecar” と “onomatopoeia” が回文かどうかを確かめてみてください。
>> palindrome_tester("racecar") It's a palindrome! => nil >> palindrome_tester("onomatopoeia") It's not a palindrome. => nil3.
palindrome_tester("racecar")に対してnil?メソッドを呼び出し、戻り値がnilであるかどうかを確認してみてください。>> palindrome_tester("racecar").nil? It's a palindrome! => true
putsは副作用で標準出力に文字列が出力されるのであり、戻り値はnilである- Rubyのメソッドは、明示的に戻り値を指定しなければ、メソッド内で最後に評価された式の値が戻り値となる
上述の挙動を考えると、1.で定義した
palindrome_testerの戻り値は、確かに常にnilになりますね。余談…演算子もメソッドである
余談ですが、Rubyにおいては、演算子もメソッドの一種として実装されています。例えば、以下の2つの表現は同じメソッドの呼び出しになります。
>> 17 + 42 => 59 >> 17.+(42) => 59
- 投稿日:2019-08-22T18:14:28+09:00
ECS FargateでRails動かそうとして2ヶ月かかって手元に残ったもの【2.Build編】
弊社の基幹システムをVPSからAWSに移行するにあたって、まずはrailsを動かしてみる、という段階で無事に死にました☆
今後のための備忘録です。前記事: ECS FargateでRails動かそうとして2ヶ月かかって手元に残ったもの【1.docker編】
前回まででやったこと
今回やったこと
githubへのリポジトリの作成は割愛します。
今回はgithubのmasterブランチに変更をpushしたときに本番環境のコンテナイメージが自動更新されるところまでやってみます。ECR
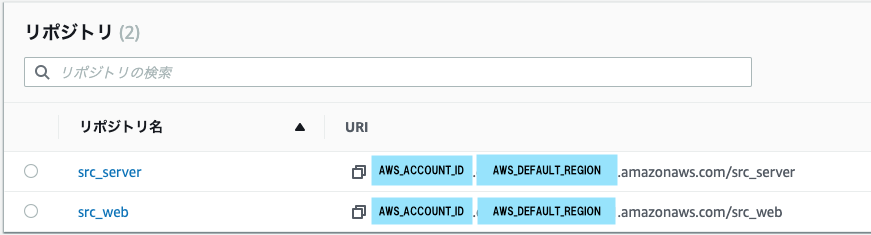
今回はリポジトリを2つ作ります。
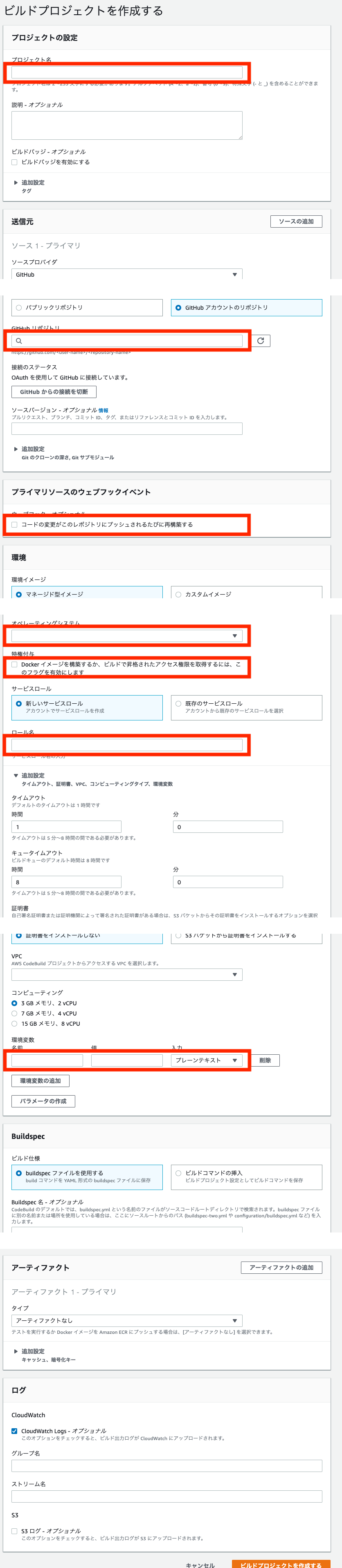
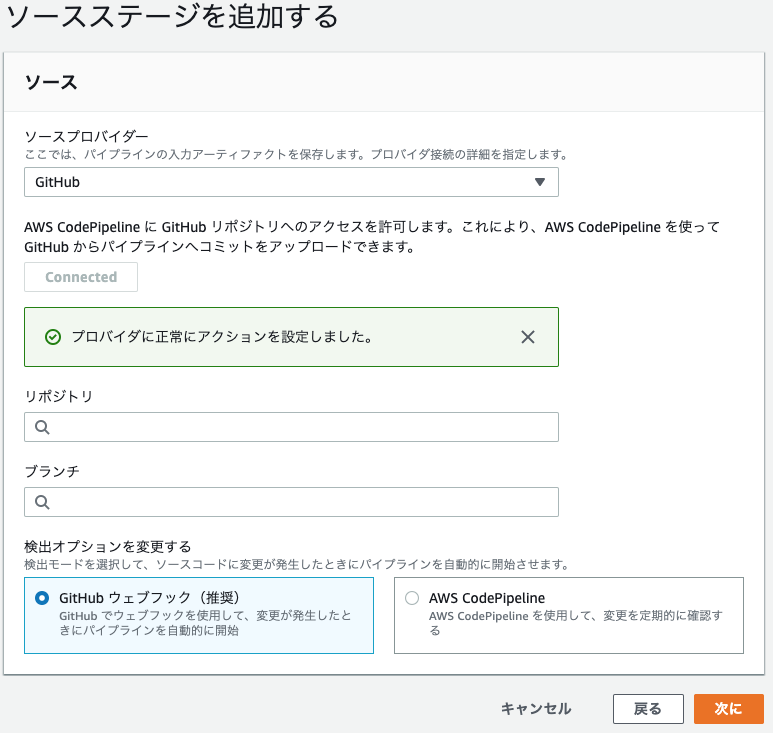
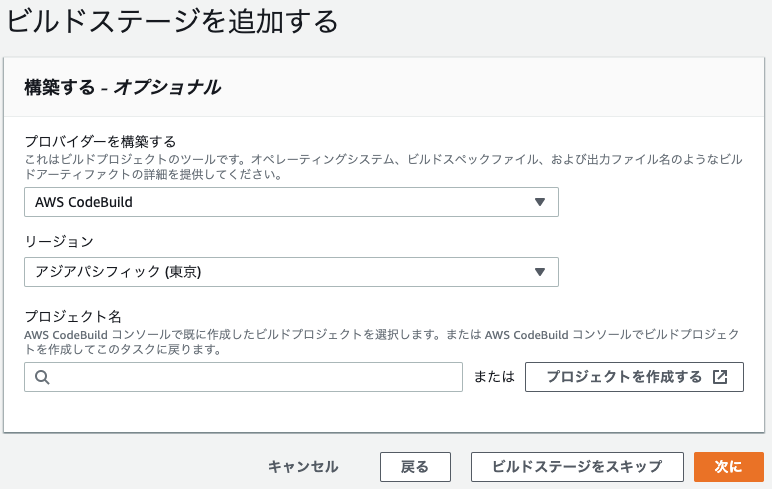
CodeBuild
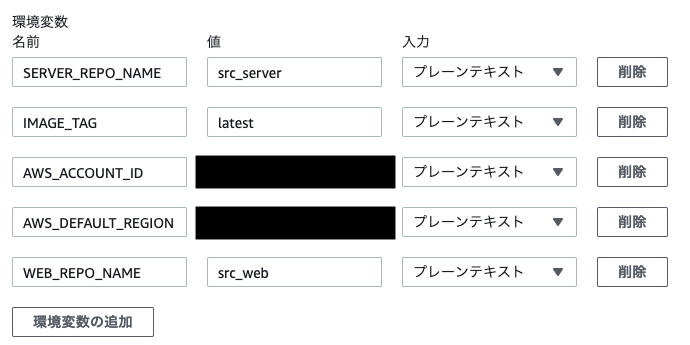
途中、環境変数を設定する部分があります。
そこには以下のように設定します。
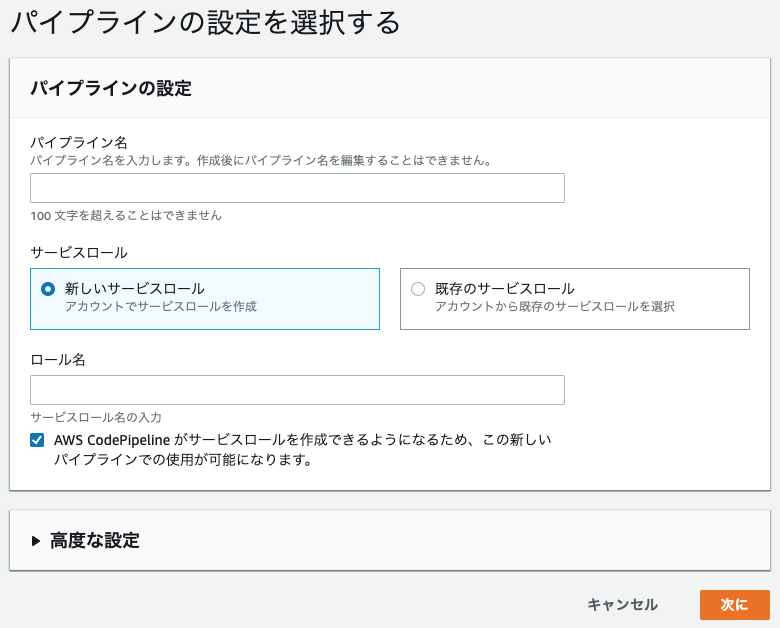
CodePipeline
ここではCodeBuildで設定したリポジトリと同じリポジトリを設定します。
そして、先程作ったCodeBuildのプロジェクト名を設定します。
CodeBuild側の設定は以上ですが、CodeBuildでコンテナをビルドするためには
buildspec.ymlというファイルが必要になります。プロジェクトルート ├ docker │ ├ mysql │ │ ├ volumes │ │ │ └ developmentのmysqlの永続化用 │ │ ├ charset.cnf │ │ ├ password.yml │ │ └ Dockerfile │ ├ nginx │ │ ├ development │ │ │ ├ default.conf │ │ │ └ Dockerfile │ │ ├ production │ │ │ ├ default.conf │ │ │ └ Dockerfile │ │ └ nginx.conf │ └ rails │ └ Dockerfile ├ src │ └ railsアプリのソース ├ .gitignore ├ buildspec.yml ←コイツ ├ docker-compose.common.yml ├ docker-compose.development.yml ├ docker-compose.production.yml └ README.mdこのファイル構成でここまで説明をしていない唯一のファイルです。
ビルドコマンドや、railsコマンド等はこのファイルに書きます。buildspec.ymlversion: 0.2 phases: install: runtime-versions: nodejs: 10 ruby: 2.6 pre_build: commands: - $(aws ecr get-login --no-include-email --region $AWS_DEFAULT_REGION) build: commands: - docker-compose -f docker-compose.production.yml build - docker-compose -f docker-compose.production.yml run --rm web rake db:migrate RAILS_ENV=production - docker-compose -f docker-compose.production.yml run --rm web rake assets:precompile RAILS_ENV=production - docker tag $WEB_REPO_NAME:$IMAGE_TAG $AWS_ACCOUNT_ID.dkr.ecr.$AWS_DEFAULT_REGION.amazonaws.com/$WEB_REPO_NAME:$IMAGE_TAG - docker tag $SERVER_REPO_NAME:$IMAGE_TAG $AWS_ACCOUNT_ID.dkr.ecr.$AWS_DEFAULT_REGION.amazonaws.com/$SERVER_REPO_NAME:$IMAGE_TAG post_build: commands: - docker push $AWS_ACCOUNT_ID.dkr.ecr.$AWS_DEFAULT_REGION.amazonaws.com/$WEB_REPO_NAME:$IMAGE_TAG - docker push $AWS_ACCOUNT_ID.dkr.ecr.$AWS_DEFAULT_REGION.amazonaws.com/$SERVER_REPO_NAME:$IMAGE_TAG先程の環境変数はここで読み込まれます。
さて、これで準備ができました。
コードを更新して、githubにpushしてみましょう。
CodePipeline上で更新が始まったことが確認できます。
更新には5分程かかります。
この時間の短縮も、今後の課題の一つです。
CodeBuild上でもリアルタイムで状況が把握できます。
COMPLETEまでフェーズが進めば、今回の目的は達成です。ここまでできたこと
次記事:Fargate編


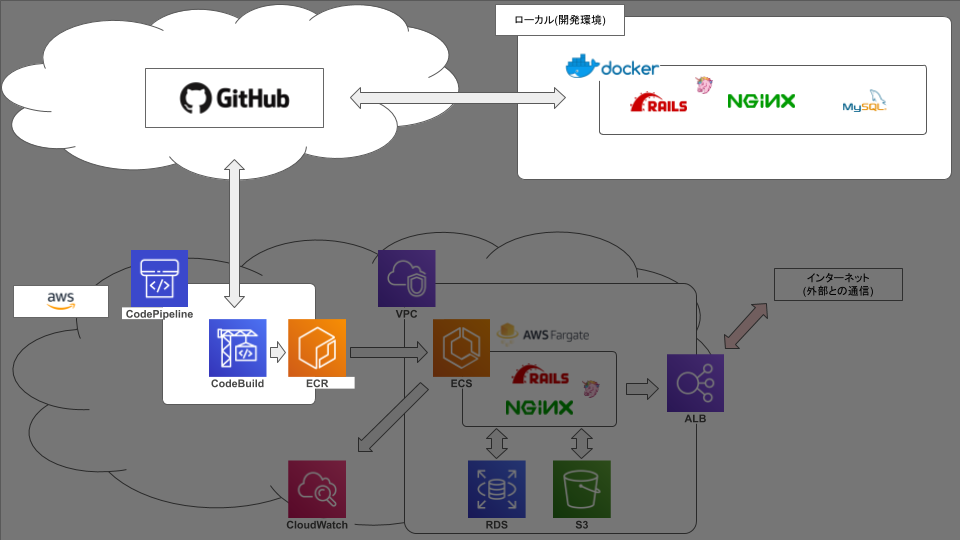
- 投稿日:2019-08-22T17:17:25+09:00
Railsのcheck_boxで親切に0を送ってくれているのは誰なのか
Railsのcheck_boxは未チェック状態だと"0"を送ってくれる
デフォルト時の挙動です
paramsを見てもわかるとおり、0が送られてきます
時と場合によってtrue/falseにしてみたりとか、いろいろあると思いますが、普通は0が送られますでも別にcheckboxのvalueが0/1で変化するわけではないんです
ある日、「checkboxのvalueが0か1で判定したいのに、チェックしてもチェック外してもvalueが1で変わらないんです
」と相談を受けました
まあその判定の善し悪しは置いておいてHTMLのcheckboxってチェックしてないとそもそも送信されないですよね
Railsのparamsはチェック時に1未チェック時に0が送られてくるので、チェックのオンオフでvalueが0/1で変わると、その子は混乱しちゃったんですね
まあ相談されてしばらくは僕も混乱してましたがじゃあいったい誰が"0"を送ってる…?
checkboxはチェックされていたら"1"を送り、チェックされていなかったらそもそもなにも送らない
では、Railsにおいて親切に"0"を送っているのは誰なんでしょうか?サンプルのフォームをscaffoldしてみて確認しました
なるほど!君か!
Railsはデフォルトでhiddenなvalueを作ってくれているんですね
チェックされた場合、checkboxの方が後なので上書きされて"1"になると…なるほどでも注意しないといけないのは、これがあくまでcheck_boxの話でcheck_box_tagはまた微妙に挙動が異なるということなんですが…それはまた別のお話(˘ω˘)
意外と詰まりやすいcheckbox
未チェック時は送信されないとか、true/falseにしたいときとか、check_box_tagを使ったときとか…なにかと詰まりやすいのがcheckboxだなあと思っています
でもこの辺の、実際に生成されているHTMLがなんなのか把握できると、詰まることも減るんじゃないかな〜と思いました
謎のvalue"0"を作る職人の存在がわかってスッキリしました

- 投稿日:2019-08-22T16:41:23+09:00
【Rails】 API開発で『Can't verify CSRF token authenticity』といわれたときの対応
現状の問題
RailsでAPI開発をしている際にエンドポイントを叩いたら以下のようなエラーが出ました。
Can't verify CSRF token authenticity. Completed 422 Unprocessable Entity in 22ms (ActiveRecord: 0.0ms)CSRFトークン認証ができなかったという内容のエラーです。
解決方法
方法1. application_controller.rbを修正
controllers/application_controller.rbを見ると以下のようなコメントがあります。Prevent CSRF attacks by raising an exception.
For APIs, you may want to use :null_session instead.コメントに従い、以下のように変更すれば問題は解決します。
- protect_from_forgery with: :exception + protect_from_forgery with: :null_sessionこの変更により、CSRF対策が『例外の発生』から『セッションのクリア』になります。
『セッションのクリア」の場合、処理は継続されるためAPIのエンドポイントを叩いたら結果が返ってくるようになります。方法2. APIで利用するcontrollerを修正
APIで利用するcontrollerに対して以下のメソッドを追加します。
skip_before_action :verify_authenticity_tokenこちらのほうが、
application_controller.rbを修正するのに比べて影響範囲が限定的になります。
- 投稿日:2019-08-22T15:58:42+09:00
[Rails+Vue.js]に係るCRUD入門〜Part5: Vuex設定編〜
Rails+Vue.js+Webpackerによる「Create, Read, Update, Destroy」処理のチュートリアルを記述する。
なお,前提知識として,Railsチュートリアル終了程度を想定する。<概要>
■ 記事共通
目次
実装機能
- お気に入りの本を登録,参照,編集,削除できるアプリケーションを作成する。
- 非同期通信(Ajax)による[Rails+Vue.js]のCRUD処理を実装する。
- SinglePageApplication(SPA)として実装する。
開発環境
- MacOS Mojave
- Ruby(2.5.1)
- Ruby on Rails(5.2.1)
- Vue.js(2.6.10)
- Yarn(1.17.0)
- Webpack(4.39.2)
学習情報URL
■ 本記事の内容
- Part4迄で作成した[BookHome.vue]のデータ処理について,Vuexの管理下に移行する。
- 今回のコードは,GitHubのコミット履歴で確認可能である。
- [Vuexの導入]から[ヘルパー関数による省略技法]まで
- 本記事の参考URL
<本文>
■ Vuexの導入
○1:Vuexをインストール
$ yarn add vuex○2:[store.js]を作成
app/javascript/store/store.jsimport Vue from 'vue' import Vuex from 'vuex' import router from '../router/router.js' import axios from 'axios' Vue.use(Vuex) export default new Vuex.Store({ state: {}, mutations: {} })○3:[application.js]に[store.js]を登録
app/javascript/packs/application.jsimport Vue from 'vue' import App from './App.vue' import Router from '../router/router.js' import Store from '../store/store.js' const app = new Vue({ el: '#app', router: Router, store: Store, render: h => h(App) })■ [fetchBooks]関連を移行
○1:[store.js]を修正
app/javascript/store/store.jsimport Vue from 'vue' import Vuex from 'vuex' import router from '../router/router.js' import axios from 'axios' Vue.use(Vuex) export default new Vuex.Store({ // [state]がコンポーネントにおける[data]に相当 state: { books: [] }, // [mutations]がコンポーネントにおける[methods]に相当 mutations: { fetchBooks(state) { state.books = []; axios.get('/api/books').then((res) => { for(var i = 0; i < res.data.books.length; i++) { state.books.push(res.data.books[i]); } }, (error) => { console.log(error); }); } }, })○2:[HomeBook.vue]を修正
app/javascript/pages/BookHome.vue... <script> ... data: function() { return { bookInfo: {}, bookInfoBool: false, // [store.js]に移行するため,[books]を削除 } }, computed: { // [store.js]から[books]を呼び出して,[BookHome.vue]のdata[books]に格納 books() { return this.$store.state.books } }, mounted: function() { // [fetchBooks]を[store.js]から呼び出すため,コード修正 this.$store.commit('fetchBooks') }, methods: { // [store.js]に移行するため,[fetchBooks]を削除 ... } ...■ [setBookInfo]関連を移行
○1:[store.js]を修正
app/javascript/store/store.js... state: { books: [], bookInfo: {}, bookInfoBool: false }, mutations: { ... setBookInfo(state, { id } ) { axios.get(`api/books/${id}.json`).then(res => { state.bookInfo = res.data; state.bookInfoBool = true; }); } } })○2:[HomeBook.vue]を修正
app/javascript/pages/BookHome.vue<script> ... // [data:]は,全て削除 computed: { books() { return this.$store.state.books }, // [bookInfo, bookInfoBool]を追加 bookInfo() { return this.$store.state.bookInfo }, bookInfoBool() { return this.$store.state.bookInfoBool } }, ... methods: { // [setBookInfo]を[store.js]から呼び出すため,コード修正 setBookInfo(id) { this.$store.commit('setBookInfo', { id }) }, ...■ [deleteBook]関連を移行
○1:[store.js]を修正
app/javascript/store/store.js... mutations: { ... deleteBook(state, { id } ) { axios.delete(`/api/books/${id}`).then(res => { state.bookInfo = ''; state.bookInfoBool = false; }); } ...○2:[HomeBook.vue]を修正
app/javascript/pages/BookHome.vue<script> ... methods: { setBookInfo(id) { this.$store.commit('setBookInfo', { id }) }, // [deleteBook]のコードを修正 deleteBook(id) { this.$store.commit('deleteBook', { id }) this.$store.commit('fetchBooks') }, } ...■ ヘルパー関数による省略技法
- ストアのstateを呼び出す際のコードが冗長であるため,ヘルパー関数を使用して,コードを簡略化する。
- mapStateと同様に,mapMutations, mapGetters, mapActions等も存在するが,本記事では使用しない。
- 参考URL
app/javascript/store/store.js... <script> import axios from 'axios' import { mapState } from 'vuex' export default { name: 'BookHome', computed: mapState([ 'books', 'bookInfo', 'bookInfoBool', ]), ... /* 上記のコードと同等 ~Ver.1:mapStateを使用して,異なるデータ名に格納したい場合~ computed: mapState({ books: 'books', bookInfo: 'bookInfo', bookInfoBool: 'bookInfoBool' }) ~Ver.2:デフォルト~ computed: { books() { return this.$store.state.books }, bookInfo() { return this.$store.state.bookInfo }, bookInfoBool() { return this.$store.state.bookInfoBool } } */■ 特記事項
○1:[action,getter]について
今後チュートリアルで必要性が出てきたら追記します。○2:Vuexの状態管理下に置くデータについて
Vuexの機能上,全てのデータを管理下に置くことは可能であり,複雑でもModuleを使用したら実装できるかと思います。
しかし,一つのコンポーネントでしか使用しないデータを共通の管理下に置くことは,冗長になり,管理が大変になることが予想されますので,以下の情報が判断の参考になるかと思い引用します。
- ステートに適したデータ
- サーバーからデータを取得中かどうかを表すフラグ
- ログイン中のユーザー情報など,アプリケーション全体で使用されるデータ
- ECサイトにおける商品の情報など,アプリケーションの複数の場所で使用される可能性のあるデータ
- コンポーネント側で持つべきデータ
- マウスポインタがある要素の上に存在するかどうかを表すフラグ
- ドラッグ中の要素の座標
- 入力中のフォームの値
【引用:Vue.js入門~基礎から実践アプリケーション開発まで~ 245-246.】
〜Part5: Vuex設定編終了〜
- 投稿日:2019-08-22T15:50:51+09:00
Rails6 Webpackerでエラーが出た
はじめに
Rails6で新しくアプリを作ろうと思ったがハマってしまったので、備忘録を残していきます。
アプリ作成開始
いつも通りrails newをしていきます。
$ rails new hoge_appさてサーバー軌道をさせよう。
$ rails sするとエラー発生。
$ rails s => Booting Puma => Rails 6.0.0 application starting in development => Run `rails server --help` for more startup options RAILS_ENV=development environment is not defined in config/webpacker.yml, falling back to production environment Exiting Traceback (most recent call last): 80: from bin/rails:3:in `<main>' 79: from bin/rails:3:in `load' 78: from /Users/yuichiro/app/task_app/bin/spring:15:in `<top (required)>' 77: from /Users/hoge/.rbenv/versions/2.6.3/lib/ruby/2.6.0/rubygems/core_ext/kernel_require.rb:54:in `require' 76: from /Users/hoge/.rbenv/versions/2.6.3/lib/ruby/2.6.0/rubygems/core_ext/kernel_require.rb:54:in `require' ・ ・ (省略) ・ ・ /Users/yuichiro/.rbenv/versions/2.6.3/lib/ruby/gems/2.6.0/gems/webpacker-4.0.7/lib/webpacker/configuration.rb:91:in `rescue in load': Webpacker configuration file not found /Users/yuichiro/app/task_app/config/webpacker.yml. Please run rails webpacker:install Error: No such file or directory @ rb_sysopen - /Users/yuichiro/app/task_app/config/webpacker.yml (RuntimeError)下記コマンド実行しろと言われているので実行します。
$ rails webpacker:install Yarn not installed. Please download and install Yarn from https://yarnpkg.com/lang/en/docs/install/yarnがインストールされてないと言われているので、インストールします。
$ brew install yarnyarnもインストールできたので、再度webpackerをインストール
$ rails webpacker:install identical config/webpacker.yml Copying webpack core config exist config/webpack identical config/webpack/development.js identical config/webpack/environment.js identical config/webpack/production.js identical config/webpack/test.js Copying postcss.config.js to app root directory identical postcss.config.js Copying babel.config.js to app root directory identical babel.config.js Copying .browserslistrc to app root directory identical .browserslistrc The JavaScript app source directory already exists apply /Users/yuichiro/.rbenv/versions/2.6.3/lib/ruby/gems/2.6.0/gems/webpacker-4.0.7/lib/install/binstubs.rb Copying binstubs exist bin identical bin/webpack identical bin/webpack-dev-server append .gitignore Installing all JavaScript dependencies [4.0.7] run yarn add @rails/webpacker from "." yarn add v1.17.3 [1/4] ? Resolving packages... [2/4] ? Fetching packages... [3/4] ? Linking dependencies... warning " > webpack-dev-server@3.8.0" has unmet peer dependency "webpack@^4.0.0". warning "webpack-dev-server > webpack-dev-middleware@3.7.0" has unmet peer dependency "webpack@^4.0.0". [4/4] ? Building fresh packages... success Saved 1 new dependency. info Direct dependencies └─ @rails/webpacker@4.0.7 info All dependencies └─ @rails/webpacker@4.0.7 ✨ Done in 3.92s. Installing dev server for live reloading run yarn add --dev webpack-dev-server from "." yarn add v1.17.3 [1/4] ? Resolving packages... [2/4] ? Fetching packages... [3/4] ? Linking dependencies... warning "webpack-dev-server > webpack-dev-middleware@3.7.0" has unmet peer dependency "webpack@^4.0.0". warning " > webpack-dev-server@3.8.0" has unmet peer dependency "webpack@^4.0.0". [4/4] ? Building fresh packages... success Saved 1 new dependency. info Direct dependencies └─ webpack-dev-server@3.8.0 info All dependencies └─ webpack-dev-server@3.8.0 ✨ Done in 3.25s. Webpacker successfully installed ? ?webpackerがインストール出来たので、もう一度サーバーを起動してみる。
$ rails s無事いつもの画面がでました!
まとめ
rails6からWebpackerがデフォルトでインストールされているので、webpackerやyarnをインストールしていない人は僕と同じようにハマるかもしれないので、参考にしてみてください!

- 投稿日:2019-08-22T15:11:35+09:00
NullMailかどうかをチェックする
ActionMailer::MessageDeliveryにラップされてるので、.messageを使うのがポイントです。require 'rails_helper' RSpec.describe MyMailer, type: :mailer do describe '.hoge' do subject { described_class.hoge } context 'when something is wrong' do it 'returns NullMail' do expect(subject.message).to be_a ActionMailer::Base::NullMail end end end end参考
- 投稿日:2019-08-22T14:44:02+09:00
[Rails] Could not load the 'listen' gem. Add `gem 'listen'` to the development group of your Gemfile (LoadError)
$ rails sしようとしたら、
.rbenv/versions/2.4.1/lib/ruby/gems/2.4.0/gems/ activesupport-5.1.7/lib/active_support/dependencies.rb:292:in `require': Could not load the 'listen' gem. Add `gem 'listen'` to the development group of your Gemfile (LoadError)と怒られた。
config/environments/development.rb内の
config/environments/development.rbconfig.file_watcher = ActiveSupport::EventedFileUpdateCheckerをコメントアウトしたらいけた。
参考: https://www.oipapio.com/question-890966
config.file_watcher: config.reload_classes_only_on_changeがtrueの場合にファイルシステム上のファイル更新検出に使われるクラスを指定します。デフォルトのRailsではActiveSupport::FileUpdateChecker、およびActiveSupport::EventedFileUpdateChecker(これはlistenに依存します)が指定されます。カスタムクラスはこのActiveSupport::FileUpdateChecker APIに従わなければなりません。
- 投稿日:2019-08-22T14:29:32+09:00
ECS FargateでRails動かそうとして2ヶ月かかって死んだ話【1.docker編】
弊社の基幹システムをVPSからAWSに移行するにあたって、まずはrailsを動かしてみる、という段階で無事に死にました☆
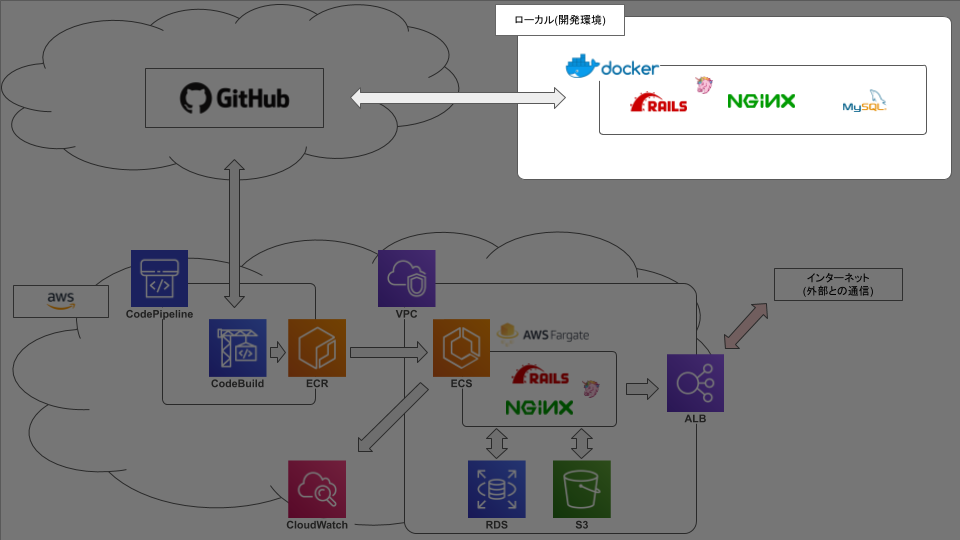
今後のための備忘録です。やりたいこと
こんな感じ。やったこと
docker
まず、ファイル構成は以下。
プロジェクトルート ├ docker │ ├ mysql │ │ ├ volumes │ │ │ └ ※mysqlの永続化に使う。後述 │ │ ├ charset.cnf │ │ ├ password.yml │ │ └ Dockerfile │ ├ nginx │ │ ├ development │ │ │ ├ default.conf │ │ │ └ Dockerfile │ │ ├ production │ │ │ ├ default.conf │ │ │ └ Dockerfile │ │ └ nginx.conf │ └ rails │ └ Dockerfile ├ src │ └ ※railsアプリのソースをここに置きます。後述 ├ .gitignore ├ buildspec.yml ├ docker-compose.common.yml ├ docker-compose.development.yml ├ docker-compose.production.yml └ README.md開発環境と本番環境で
docker-composeの内容にかなり差があるので、ファイルを分けています。
共通する内容はdocker-compose.common.ymlに記述して、なるべく助長化を防ぎます。
ただし、nginxのDockerfileに関しては環境ごとにほぼ同じ内容でファイルを分けて作っています。これも後述しますが、最後までハマり続けたポイントを解決するための苦肉の策です。
docker-compose
docker-compose.common.ymlversion: '2' services: server: environment: TZ: Asia/Tokyo ports: - '80:80' web: build: context: . dockerfile: ./docker/rails/Dockerfile ports: - '3000:3000' volumes: - ./src:/app extends: file: ./docker/mysql/password.yml service: password db: build: context: . dockerfile: ./docker/mysql/Dockerfile ports: - '3306:3306' extends: file: ./docker/mysql/password.yml service: passworddocker-compose.development.ymlversion: '2' services: datastore: image: busybox volumes: - /share - ./docker/mysql/volumes:/var/lib/mysql server: build: context: . dockerfile: ./docker/nginx/development/Dockerfile extends: file: docker-compose.common.yml service: server volumes_from: - datastore depends_on: - datastore web: extends: file: docker-compose.common.yml service: web command: bundle exec unicorn -p 3000 -c /app/config/unicorn.rb volumes_from: - datastore depends_on: - db db: extends: file: docker-compose.common.yml service: db volumes_from: - datastore depends_on: - datastoredocker-compose.production.ymlversion: '2' services: server: build: context: . dockerfile: ./docker/nginx/production/Dockerfile extends: file: docker-compose.common.yml service: server web: extends: file: docker-compose.common.yml service: web depends_on: - server environment: RAILS_ENV: production DB_HOST: ◯◯.△△.ap-northeast-1.rds.amazonaws.com DB_USERNAME: ユーザー名 DB_PASSWORD: パスワード DB_DATABASE: データベース名serviceで言えば、
development
- datastore → busybox
- server → nginx
- web → ruby(rails)
- db → mysql
production
- server → nginx
- web → ruby(rails)
といった構成になっています。
本番環境ではECS fargate上でストレージの共有ができるのでdatastoreは不要です。
また、データベースはRDSを用いるのでdbも不要です。Dockerfile
nginx
docker/nginx/development/DockerfileFROM nginx:1.11 RUN apt-get update && \ apt-get install -y apt-utils \ locales && \ sed -i -e 's/# ja_JP.UTF-8/ja_JP.UTF-8/g' /etc/locale.gen && \ locale-gen ja_JP.UTF-8 ENV LANG ja_JP.UTF-8 ENV LC_TIME C ADD ./docker/nginx/nginx.conf /etc/nginx/nginx.conf # productionでは次の行のファイルパスが変わる ADD ./docker/nginx/development/default.conf /etc/nginx/conf.d/default.confrails
docker/rails/DockerfileFROM ruby:2.2.3 RUN apt-get update -qq && \ apt-get install -y apt-utils \ build-essential \ libpq-dev \ nodejs \ mysql-client RUN mkdir /app WORKDIR /app ADD ./src/Gemfile /app/Gemfile ADD ./src/Gemfile.lock /app/Gemfile.lock RUN bundle install -j4 ADD ./src /app EXPOSE 3000 # 次の行は本番環境でしか実行されない CMD ["unicorn", "-p", "3000", "-c", "/app/config/unicorn.rb", "-E", "production"]mysql
docker/mysql/DockerfileFROM mysql:5.7 RUN apt-get update && \ apt-get install -y apt-utils \ locales && \ rm -rf /var/lib/apt/lists/* && \ echo "ja_JP.UTF-8 UTF-8" > /etc/locale.gen && \ locale-gen ja_JP.UTF-8 ENV LC_ALL ja_JP.UTF-8 ADD ./docker/mysql/charset.cnf /etc/mysql/conf.d/charset.cnfそれぞれのコンテナのコマンドやファイルのコピー、ライブラリの更新などは
Dockerfileに記述するようなイメージがあります。
また、ローカルのdockerではコマンドが動いても本番では動かない、もしくはその逆が度々あったので、railsのDockerfileにはCMDの記述がされています。その他のファイル
nginx
docker/nginx/development/default.confupstream unicorn { # productionではserver以降が 127.0.0.1:3000 になる server unix:/share/unicorn.sock; } server { listen 80 default_server; server_name localhost; root /app/public; try_files $uri/index.html $uri @unicorn; proxy_connect_timeout 600; proxy_read_timeout 600; proxy_send_timeout 600; location @unicorn { proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header Host $http_host; proxy_pass http://unicorn; } }docker/nginx/nginx.confuser nginx; worker_processes 1; error_log /var/log/nginx/error.log warn; pid /var/run/nginx.pid; events { worker_connections 1024; } http { include /etc/nginx/mime.types; default_type application/octet-stream; log_format main '$remote_addr - $remote_user [$time_local] "$request" ' '$status $body_bytes_sent "$http_referer" ' '"$http_user_agent" "$http_x_forwarded_for"'; access_log /var/log/nginx/access.log main; sendfile on; keepalive_timeout 600; include /etc/nginx/conf.d/*.conf; }ここでのポイントは
default.confの2行目の記述と、それぞれのファイルのtimeoutの時間設定です。
この2点が今回ハマって、かなりの時間を奪われたポイントでした。1. ソケットファイル
default.conf(抜粋)upstream unicorn { # productionではserver以降が 127.0.0.1:3000 になる server unix:/share/unicorn.sock; }developmentではbusyboxを使ったストレージ共有で、ソケットファイルを準備していました。
nginxとrails(unicorn)の両方から、同じソケットファイルを見ることで繋げるようなイメージですが、本番環境ではストレージの共有ができず、直接ローカルIPとポート127.0.0.1:3000を指定したら動きました。2. タイムアウト
default.conf(抜粋)proxy_connect_timeout 600; proxy_read_timeout 600; proxy_send_timeout 600;nginx.conf(抜粋)keepalive_timeout 600;railsサーバーやRDSへの接続には少なからず時間がかかります。
キャッシュが効き始めれば読み込み速度は大きく向上するのですが、初回アクセス時などは504 Gateway Time-Outのエラーになることも多くありました。
そのため、タイムアウトまでの時間を伸ばしました。
デフォルトは60秒などで設定されていると思います。mysql
docker/mysql/charset.cnf[mysqld] character-set-server=utf8mb4 collation-server=utf8mb4_general_ci [client] default-character-set=utf8mb4docker/mysql/password.ymlversion: '2' services: password: environment: MYSQL_ROOT_PASSWORD: ルートパスワード TZ: "Asia/Tokyo"セキュアな情報はできるだけコード上には書きたくなかったのですが、最低限環境変数として管理できるようにしました。
運用段階までにはもう少し改善したいです。railsソース側の変更
unicornというgemの設定と、mysqlとRDSを使い分けるための設定をします。unicorn
unicornはrailsのアプリケーションサーバとnginxのwebサーバを繋げるためのpassengerのようなモジュールの位置付けです。
単体でもサーバとして使えるらしいです。src/Gemfile# 追記 gem "unicorn"bundle installインストールが完了したら、早速設定ファイルを編集します。
src/configディレクトリにunicorn.rbファイルがない場合は作ります。src/config/unicorn.rbworker_processes 2 pid "/var/run/unicorn.pid" # developmentとproductionで場合分け if ENV['RAILS_ENV'] == 'production' listen 3000 else listen "/share/unicorn.sock" end # タイムアウトまでの時間を伸ばす timeout 600ここでも先程のnginxと同じように、開発環境と本番環境の場合分け、タイムアウトの設定をしています。
特にlistenの値はdefault.confと設定がズレていると起動後に上手く繋がらないので、ご注意ください。mysql
src/config/database.ymldefault: &default adapter: mysql2 encoding: utf8 pool: 5 timeout: 5000 development: <<: *default username: 開発環境のユーザー名 password: <%= ENV['MYSQL_ROOT_PASSWORD'] %> database: 開発環境のデータベース名 host: db production: <<: *default host: <%= ENV['DB_HOST'] %> username: <%= ENV['DB_USERNAME'] %> password: <%= ENV['DB_PASSWORD'] %> database: <%= ENV['DB_DATABASE'] %>
Dockerfileやpassword.ymlで設定してきた環境変数がここで読み込まれていきます。
developmentのhostで指定しているdbというのはdocker-compose.ymlでデータベースに設定しているサービス名です。
別の名前に設定している場合はそちらの名前にしてください。ビルドと起動
やっと動かす段階です。
dockerを起動しておいてください。
また、3000番ポート、3306番ポートを使うので、他で使っていれば、そちらを停止しておきます。
プロジェクトのルートディレクトリでコマンドを打ちます。ビルドdocker-compose -f docker-compose.development.yml -p development buildデータベース作成(初回のみ)docker-compose -f docker-compose.development.yml -p development run --rm web rake db:createマイグレート(変更があった場合のみ)docker-compose -f docker-compose.development.yml -p development run --rm web rake db:migrate起動docker-compose -f docker-compose.development.yml -p development up -dこれでブラウザで
localhostにアクセスすると、railsのホーム画面が見られると思います。
ちなみに、停止コマンドは以下です。停止docker-compose -f docker-compose.development.yml -p development stop
docker-compose -f docker-compose.development.yml -p developmentは共通なので、お使いのshellでエイリアスに登録してもいいかと思います。
当方の設定を参考に載せておきます。.zshrcalias dcdev='docker-compose -f docker-compose.development.yml -p development' # コンテナ全削除 alias drm='docker rm $(docker ps -q -a) -f' # イメージ全削除 alias dirm='docker rmi $(docker images -q) -f'次回、AWS編へ続きます。

- 投稿日:2019-08-22T14:29:32+09:00
ECS FargateでRails動かそうとして2ヶ月かかって手元に残ったもの【1.docker編】
弊社の基幹システムをVPSからAWSに移行するにあたって、まずはrailsを動かしてみる、という段階で無事に死にました☆
今後のための備忘録です。やりたいこと
こんな感じ。今回やったこと
ファイル構成
プロジェクトルート ├ docker │ ├ mysql │ │ ├ volumes │ │ │ └ ※mysqlの永続化に使う。後述 │ │ ├ charset.cnf │ │ ├ password.yml │ │ └ Dockerfile │ ├ nginx │ │ ├ development │ │ │ ├ default.conf │ │ │ └ Dockerfile │ │ ├ production │ │ │ ├ default.conf │ │ │ └ Dockerfile │ │ └ nginx.conf │ └ rails │ └ Dockerfile ├ src │ └ ※railsアプリのソースをここに置きます。後述 ├ .gitignore ├ buildspec.yml ├ docker-compose.common.yml ├ docker-compose.development.yml ├ docker-compose.production.yml └ README.md開発環境と本番環境で
docker-composeの内容にかなり差があるので、ファイルを分けています。
共通する内容はdocker-compose.common.ymlに記述して、なるべく助長化を防ぎます。
ただし、nginxのDockerfileに関しては環境ごとにほぼ同じ内容でファイルを分けて作っています。これも後述しますが、最後までハマり続けたポイントを解決するための苦肉の策です。
docker-compose
docker-compose.common.ymlversion: '2' services: server: environment: TZ: Asia/Tokyo ports: - '80:80' web: build: context: . dockerfile: ./docker/rails/Dockerfile ports: - '3000:3000' volumes: - ./src:/app extends: file: ./docker/mysql/password.yml service: password db: build: context: . dockerfile: ./docker/mysql/Dockerfile ports: - '3306:3306' extends: file: ./docker/mysql/password.yml service: passworddocker-compose.development.ymlversion: '2' services: datastore: image: busybox volumes: - /share - ./docker/mysql/volumes:/var/lib/mysql server: build: context: . dockerfile: ./docker/nginx/development/Dockerfile extends: file: docker-compose.common.yml service: server volumes_from: - datastore depends_on: - datastore web: extends: file: docker-compose.common.yml service: web command: bundle exec unicorn -p 3000 -c /app/config/unicorn.rb volumes_from: - datastore depends_on: - db db: extends: file: docker-compose.common.yml service: db volumes_from: - datastore depends_on: - datastoredocker-compose.production.ymlversion: '2' services: server: build: context: . dockerfile: ./docker/nginx/production/Dockerfile extends: file: docker-compose.common.yml service: server web: extends: file: docker-compose.common.yml service: web depends_on: - server environment: RAILS_ENV: production DB_HOST: ◯◯.△△.ap-northeast-1.rds.amazonaws.com DB_USERNAME: ユーザー名 DB_PASSWORD: パスワード DB_DATABASE: データベース名serviceで言えば、
development
- datastore → busybox
- server → nginx
- web → ruby(rails)
- db → mysql
production
- server → nginx
- web → ruby(rails)
といった構成になっています。
developmentのdatastoreでvolumesとしてローカルディレクトリのdocker/mysql/volumesを/var/lib/mysqlにマウントしています。
dockerはイメージを停止するとデータが消えてしまいますが、このようにすることで、開発環境のデータベースを永続化できます。
docker/mysql/volumesの中身は.gitignoreに設定して、git管理はしないようにしましょう。本番環境ではECS fargate上でストレージの共有ができるので
datastoreは不要です。
また、データベースはRDSを用いるのでdbも不要です。Dockerfile
nginx
docker/nginx/development/DockerfileFROM nginx:1.11 RUN apt-get update && \ apt-get install -y apt-utils \ locales && \ sed -i -e 's/# ja_JP.UTF-8/ja_JP.UTF-8/g' /etc/locale.gen && \ locale-gen ja_JP.UTF-8 ENV LANG ja_JP.UTF-8 ENV LC_TIME C ADD ./docker/nginx/nginx.conf /etc/nginx/nginx.conf # productionでは次の行のファイルパスが変わる ADD ./docker/nginx/development/default.conf /etc/nginx/conf.d/default.confrails
docker/rails/DockerfileFROM ruby:2.2.3 RUN apt-get update -qq && \ apt-get install -y apt-utils \ build-essential \ libpq-dev \ nodejs \ mysql-client RUN mkdir /app WORKDIR /app ADD ./src/Gemfile /app/Gemfile ADD ./src/Gemfile.lock /app/Gemfile.lock RUN bundle install -j4 ADD ./src /app EXPOSE 3000 # 次の行は本番環境でしか実行されない CMD ["unicorn", "-p", "3000", "-c", "/app/config/unicorn.rb", "-E", "production"]mysql
docker/mysql/DockerfileFROM mysql:5.7 RUN apt-get update && \ apt-get install -y apt-utils \ locales && \ rm -rf /var/lib/apt/lists/* && \ echo "ja_JP.UTF-8 UTF-8" > /etc/locale.gen && \ locale-gen ja_JP.UTF-8 ENV LC_ALL ja_JP.UTF-8 ADD ./docker/mysql/charset.cnf /etc/mysql/conf.d/charset.cnfそれぞれのコンテナのコマンドやファイルのコピー、ライブラリの更新などは
Dockerfileに記述するようにしています。
ただ、ローカルのdockerではコマンドが動いても本番では動かない、もしくはその逆が度々あったので、railsのDockerfileにはCMDの記述がされていたりしますが、productionでしか使わないコマンドがDockerfileに書いてあるのは気持ち悪い気がするので、ここは後々修正したいです。その他のファイル
nginx
docker/nginx/development/default.confupstream unicorn { # productionではserver以降が 127.0.0.1:3000 になる server unix:/share/unicorn.sock; } server { listen 80 default_server; server_name localhost; root /app/public; try_files $uri/index.html $uri @unicorn; proxy_connect_timeout 600; proxy_read_timeout 600; proxy_send_timeout 600; location @unicorn { proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header Host $http_host; proxy_pass http://unicorn; } }docker/nginx/nginx.confuser nginx; worker_processes 1; error_log /var/log/nginx/error.log warn; pid /var/run/nginx.pid; events { worker_connections 1024; } http { include /etc/nginx/mime.types; default_type application/octet-stream; log_format main '$remote_addr - $remote_user [$time_local] "$request" ' '$status $body_bytes_sent "$http_referer" ' '"$http_user_agent" "$http_x_forwarded_for"'; access_log /var/log/nginx/access.log main; sendfile on; keepalive_timeout 600; include /etc/nginx/conf.d/*.conf; }ここでのポイントは
default.confの2行目の記述と、それぞれのファイルのtimeoutの時間設定です。
この2点が今回ハマって、かなりの時間を奪われたポイントでした。1. ソケットファイル
default.conf(抜粋)upstream unicorn { # productionではserver以降が 127.0.0.1:3000 になる server unix:/share/unicorn.sock; }developmentではbusyboxを使ったストレージ共有で、ソケットファイルを準備していました。
nginxとrails(unicorn)の両方から、同じソケットファイルを見ることで繋げるようなイメージですが、本番環境ではストレージの共有ができず、直接ローカルIPとポート127.0.0.1:3000を指定したら動きました。なるべく助長なファイル構成は避けたかったのですが、nginxの設定ファイルに環境変数などを読み込ませることが手間だったので、このファイルは開発環境と本番環境でほとんど同じ内容なのですが、環境ごとにファイルを分けて対応しています。
2. タイムアウト
default.conf(抜粋)proxy_connect_timeout 600; proxy_read_timeout 600; proxy_send_timeout 600;nginx.conf(抜粋)keepalive_timeout 600;railsサーバーやRDSへの接続には少なからず時間がかかります。
キャッシュが効き始めれば読み込み速度は大きく向上するのですが、初回アクセス時などは504 Gateway Time-Outのエラーになることも多くありました。
そのため、タイムアウトまでの時間を伸ばしました。
デフォルトは60秒などで設定されていると思います。mysql
docker/mysql/charset.cnf[mysqld] character-set-server=utf8mb4 collation-server=utf8mb4_general_ci [client] default-character-set=utf8mb4docker/mysql/password.ymlversion: '2' services: password: environment: MYSQL_ROOT_PASSWORD: ルートパスワード TZ: "Asia/Tokyo"セキュアな情報はできるだけコード上には書きたくなかったのですが、最低限環境変数として管理できるようにしました。
運用段階までにはもう少し改善したいです。railsソース側の変更
当方は複数のrailsアプリケーションを管理する必要があったので、docker関連のファイルを容易に使い回せるように、あえてrailsアプリケーションのソースはsrcディレクトリに分けて配置しています。
ここではunicornというgemの設定と、mysqlとRDSを使い分けるための設定をします。unicorn
unicornはrailsのアプリケーションサーバとnginxのwebサーバを繋げるためのpassengerのようなモジュールの位置付けです。
単体でもサーバとして使えるらしいです。src/Gemfile# 追記 gem "unicorn"bundle installインストールが完了したら、早速設定ファイルを編集します。
src/configディレクトリにunicorn.rbファイルがない場合は作ります。src/config/unicorn.rbworker_processes 2 pid "/var/run/unicorn.pid" # developmentとproductionで場合分け if ENV['RAILS_ENV'] == 'production' listen 3000 else listen "/share/unicorn.sock" end # タイムアウトまでの時間を伸ばす timeout 600ここでも先程のnginxと同じように、開発環境と本番環境の場合分け、タイムアウトの設定をしています。
特にlistenの値はdefault.confと設定がズレていると起動後に上手く繋がらないので、ご注意ください。mysql
src/config/database.ymldefault: &default adapter: mysql2 encoding: utf8 pool: 5 timeout: 5000 development: <<: *default username: 開発環境のユーザー名 password: <%= ENV['MYSQL_ROOT_PASSWORD'] %> database: 開発環境のデータベース名 host: db production: <<: *default host: <%= ENV['DB_HOST'] %> username: <%= ENV['DB_USERNAME'] %> password: <%= ENV['DB_PASSWORD'] %> database: <%= ENV['DB_DATABASE'] %>
Dockerfileやpassword.ymlで設定してきた環境変数がここで読み込まれていきます。
developmentのhostで指定しているdbというのはdocker-compose.ymlでデータベースに設定しているサービス名です。
別の名前に設定している場合はそちらの名前にしてください。ビルドと起動
やっと動かす段階です。
dockerを起動しておいてください。
また、3000番ポート、3306番ポートを使うので、他で使っていれば、そちらを停止しておきます。
プロジェクトのルートディレクトリでコマンドを打ちます。ビルドdocker-compose -f docker-compose.development.yml -p development buildデータベース作成(初回のみ)docker-compose -f docker-compose.development.yml -p development run --rm web rake db:createマイグレート(変更があった場合のみ)docker-compose -f docker-compose.development.yml -p development run --rm web rake db:migrate起動docker-compose -f docker-compose.development.yml -p development up -dこれでブラウザで
localhostにアクセスすると、railsのホーム画面が見られると思います。
ちなみに、停止コマンドは以下です。停止docker-compose -f docker-compose.development.yml -p development stop
docker-compose -f docker-compose.development.yml -p developmentは共通なので、お使いのshellでエイリアスに登録してもいいかと思います。
当方の設定を参考に載せておきます。.zshrcalias dcdev='docker-compose -f docker-compose.development.yml -p development' # コンテナ全削除 alias drm='docker rm $(docker ps -q -a) -f' # イメージ全削除 alias dirm='docker rmi $(docker images -q) -f'ここまででできたこと
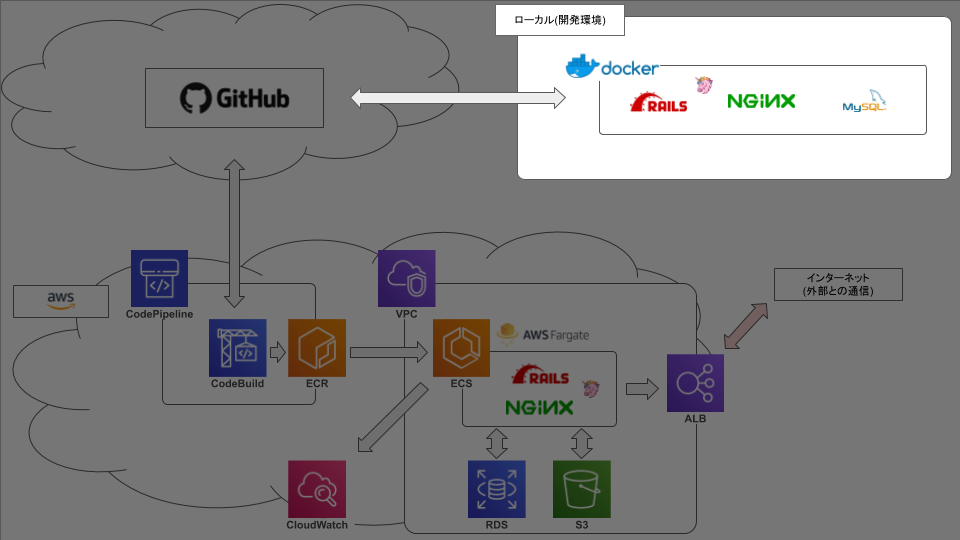
- 投稿日:2019-08-22T13:56:41+09:00
Rails チュートリアル(7章)をRSpecでテスト
はじめに
以前書いた記事です!
Rails チュートリアル(3章、4章、5章)をRSpecでテスト
Rails チュートリアル(6章)をRSpecでテスト追加しました。
Rails チュートリアル(8章)をRSpecでテスト7章のテストでは
System SpecとRequest Specどっちで書けばいいかわからず、結局、viewが絡みそうなところはSystem Specでユーザーが登録出来たなどの見えない部分はRequest Specで書きました。最初、Request Specにまとめて書いていたのですが、assignsと assert_templateが非推奨と書いてあって、新しいアプリに
rails-controller-testinggemを入れるをオススメしないと...
render_templateが使えなくなり、他の書き方が思いつかなかったのでテストを2つに分けました。参考リンク↓
http://rspec.info/blog/2016/07/rspec-3-5-has-been-released/#rails-support-for-rails-5render_template↓
Project: RSpec Rails 3.8 -Render_template matcherテストを書く(7章)
User Specテスト(有効なリクエストと無効なリクエスト)
spec/requests/access_to_users_spec.rbdescribe 'POST #create' do #有効なユーザーの検証 context 'valid request' do #ユーザーが追加される it 'adds a user' do expect do post signup_path, params: { user: attributes_for(:user) } end.to change(User, :count).by(1) end #ユーザーが追加されたときの検証 context 'adds a user' do before { post signup_path, params: { user: attributes_for(:user) } } subject { response } it { is_expected.to redirect_to user_path(User.last) } #showページにリダイレクトされる it { is_expected.to have_http_status 302 } #リダイレクト成功 end end #無効なリクエスト context 'invalid request' do #無効なデータを作成 let(:user_params) do attributes_for(:user, name: '', email: 'user@invalid', password: '', password_confirmation: '') end #ユーザーが追加されない it 'does not add a user' do expect do post signup_path, params: { user: user_params } end.to change(User, :count).by(0) end end endユーザーが追加されない検証のテストでrender_templateを使ってエラー時にnewテンプレートが渡されることを検証したかったのですが、上記の理由により出来なかったので、エラーの検証、エラー時に返すviewの検証、flash messageの検証はSystem Specに書きました。
System Spec(エラー、フラッシュメッセージなど)
spec/systems/users_spec.rbrequire 'rails_helper' RSpec.describe 'users', type: :system do describe 'user create a new account' do #有効な値が入力されたとき context 'enter an valid values' do before do visit signup_path fill_in 'Name', with: 'testuser' fill_in 'Email', with: 'testuser@example.com' fill_in 'Password', with: 'password' fill_in 'Confirmation', with: 'password' click_button 'Create my account' end #フラッシュメッセージが出る it 'gets an flash message' do expect(page).to have_selector('.alert-success', text: 'Welcome to the Sample App!') end end #無効な値が入力されたとき context 'enter an invalid values' do before do visit signup_path fill_in 'Name', with: '' fill_in 'Email', with: '' fill_in 'Password', with: '' fill_in 'Confirmation', with: '' click_button 'Create my account' end subject { page } #エラーの検証 it 'gets an errors' do is_expected.to have_selector('#error_explanation') is_expected.to have_selector('.alert-danger', text: 'The form contains 6 errors.') is_expected.to have_content("Password can't be blank", count: 2) end #今いるページのURLの検証 it 'render to /signup url' do is_expected.to have_current_path '/signup' end end end end7章おわりです。
- 投稿日:2019-08-22T13:32:08+09:00
ridgepoleで既存テーブルのデータをコピーしたりTRIGGERを設定したりする
前置き
古くからあるテーブル(
old_posts)を新しいテーブル(new_posts)に切り替える対応をしていて、その過程でレコードを同期するためにridgepoleでいろいろ操作したのでそのメモです。コード
# old_postsにある既存のレコードをすべてnew_postsにコピーする execute(<<-COPY) do |c| INSERT INTO new_posts(title, content, created_at, updated_at) SELECT title, content, created_at, updated_at FROM old_posts; COPY # まだnew_postsにレコードがない場合のみ実行 c.raw_connection.query(<<-SQL).count.zero? SELECT 1 FROM new_posts SQL end # TRIGGERを設定して、old_postsへのレコード追加時にnew_postsにもレコード追加する execute(<<-TRIGGER) do |c| CREATE TRIGGER copy_post AFTER INSERT ON old_posts FOR EACH ROW BEGIN INSERT INTO new_posts(title, content, created_at, updated_at) VALUES (NEW.title, NEW.content, NEW.created_at, NEW.updated_at); END; TRIGGER # まだcopy_post TRIGGERがない場合のみ実行 c.raw_connection.query(<<-SQL).count.zero? SHOW TRIGGERS WHERE `Trigger` = 'copy_post' SQL end今回は扱うテーブルの性質上、レコード更新/削除時は考慮していません。
(必要な場合は別途TRIGGERを追加していけばOK)このあと、モデルのテーブル名を変更するなどの対応を進めていく予定。
いやー、DB系操作するの結構疲れるなぁ。

以上です。

参考
- 投稿日:2019-08-22T12:42:50+09:00
Rails / Active Record / Migration よく使うものまとめ
概要
環境
まとめ一覧
テーブルにNOT NULL制約とデフォルト値制約をつけたカラムを追加
(例) Sampleモデルに「デフォルト値 0」「NOT NULL」 制約をつけた Integer型の sample_columnカラムを追加する場合
YYYYMMDDhhmmss_samples.rbclass Samples < ActiveRecord::Migration[5.1] def change add_column :samples, :sample_column, :integer change_column_default :samples, :sample_column, from: nil, to: 0 change_column_null :samples, :sample_column, false, 0 end end
- 投稿日:2019-08-22T12:28:49+09:00
Rails6 のちょい足しな新機能を試す68(CurrentAttributes.before_reset 編)
はじめに
Rails 6 に追加されそうな新機能を試す第68段。 今回は、
CurrentAttributes.before_reset編です。
Rails 6 では、CurrentAttributesにbefore_resetコールバックが追加されました。
reset される前に呼ばれます。
また、resetコールバックの別名としてafter_resetが追加されています。Ruby 2.6.3, Rails 6.0.0.rc1 で確認しました。Rails 6.0.0.rc1 は
gem install rails --prereleaseでインストールできます。
(Rails 6.0.0 がリリースされましたが、動作確認した時点での最新は、 Rails 6.0.0.rc1でした。悪しからず)
$ rails --version Rails 6.0.0.rc1ちょっと適切な例を思いつかなかったので、 User Agent の情報をログに出力するために、
before_resetを無理矢理、使ってみます。プロジェクトを作る
rails new rails6_0_0rc1 cd rails6_0_0rc1User の CRUD を作る
User の CRUD を作ります。
bin/rails g scaffold User nameCurrentAttributes の派生クラスを作る
user_agent属性を追加してbefore_resetでログに、 User Agent の情報を出力するようにします。app/models/current.rbclass Current < ActiveSupport::CurrentAttributes attribute :user_agent before_reset { log_user_agent } private def log_user_agent Rails.logger.info("#{Thread.current}: user_agent = #{Current.user_agent}") end endCurrentRequest を作る
ApplicationControllerでインクルードするためのモジュールを作ります。app/controllers/concerns/current_request.rbmodule CurrentRequest extend ActiveSupport::Concern included do before_action do Current.user_agent = request.user_agent end end endApplicationController を修正する
ApplicationControllerでCurrentRequestをインクルードします。app/controllers/application_controller.rbclass ApplicationController < ActionController::Base include CurrentRequest end動作確認する
rails serverを起動してから、ブラウザで http://localhost:3000/users にアクセスしてみます。ログに User Agent の情報が表示されることがわかります。
... #<Thread:0x0000556a86f33bd0@puma 004@/usr/local/bundle/gems/puma-3.12.1/lib/puma/thread_pool.rb:89 run>: user_agent = Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36試したソース
試したソースは以下にあります。
https://github.com/suketa/rails6_0_0rc1/tree/try068_current_attribute_before_reset参考情報
- 投稿日:2019-08-22T11:19:18+09:00
paramsとform_withについて【初学者の備忘録】
paramsとは
・HTTPリクエストで送信されたデータを、一時的に保存するためのメソッド
なのですが、内部の動きはその通りでも、初学者にとっては、コードをパッと見るだけではよくわからないのです。。。
この記事ではあるあるなコードで解説します。viewでの動き
まず、下記のようにform_withで入力データを飛ばすことを考えます。
posts_controller.rbdef new @posts = Post.new endnew.html.erb(posts_controller)<div class="container"> <%= form_with(model: @posts, local: true) do |f| %> <div class="form-group"> <%= f.label :title, "タイトル" %> <%= f.text_field :title, class: "form-control" %> </div> <div class="form-group"> <%= f.label :summary, "要約" %> <%= f.text_area :summary, size: "20x5", class: "form-control" %> </div> <div class="form-group"> <%= f.label :description, "本文" %> <%= f.text_area :description, size: "20x10", class: "form-control" %> </div> <div class="form-group"> <%= f.label :url, "参考URL" %> <%= f.text_area :url, size: "20x1", class: "form-control" %> </div> <%= f.submit "投稿する", class: "btn btn-primary" %> <% end %> </div>理解したいポイント
1. <% form_with(model: @posts... の、model: @postsの部分。
2. <%= f.text_field :title...や、<%= f.text_area :summary...などの入力フォームの属性詳細
1.<% form_with(model: @posts... の、model: @postsの部分。
→form_withでmodelオプションをつけると、
引数のインスタンス(@posts)が何も情報を持っていない場合、createアクションへ、
情報を持っている場合、updateアクションへ自動的に振り分けてくれます。→今回はnewしているので、createアクションへ飛びます。
2.<%= f.text_field :titleの部分
→:titleは、あくまでparamsに保存する際のキーです。
最終的に、DBのtitleカラムに保存するため、:titleとする必要があります。
paramsに保存するだけなら、ここは:user_nameでも:timeでも良いです。:titleとしない場合、ストロングパラメーターの検証を通るが、DBに保存することができません。
(permit(:hoge)は合わせる必要ありですが)
ここら辺が、こんがらがるポイントかと思っています。DBへの保存処理は、次のcreateアクションで実施します。
下記のような。posts_controller.rbdef create @post = current_user.posts.new(post_params) if @post.save! redirect_to @post, notice: "「#{@post.title}」を投稿しました。" else render :new end end private def post_params params.require(:post).permit(:title, :summary, :description, :url) endポイントは、
post_paramsメソッド内の、
params.require(:post).permit(:title, :summary, :description, :url)です。
この:postとか、:titleは、あくまでparamsで受け取った値のキーを指定しているだけです。createメソッドの
@post = current_user.posts.new(post_params)の部分で初めて
paramsからキーと値が渡されます。
paramsのキーとDBカラムが一致しない場合は、ここでエラーが表示されてしまいます。
- 投稿日:2019-08-22T10:56:19+09:00
iQueryの$でis not defined;をはかれた時の対処法
「$」マークでエラーが出た時の対処法。
app/assets/javascripts/ファイル名.js
にjQueryで記述する際の最初に使う「$」マークでエラーが出た時は実は簡単に消せます。
前提として、app/assets/javascripts/application.jsには
//= require jquery //= require jquery.turbolinks //= require jquery_ujs //= require rails-ujs //= require bootstrap //= require activestorage //= require turbolinks //= require_tree .これらが書かれてるものとします。
注意: require_tree.は一番最後の記述にしてください。解決方法
エラー画面にもあるadd /* global $*/を上にそのまま追加することによってエラーは消えます。
他にも解決策があると思いますが自分でこれで解決したので投稿させていただきます。
誰かの助けになれば幸いです。


- 投稿日:2019-08-22T09:28:23+09:00
『苦手克服』Railsモデルの関連付け、class_name、foreign_key
記事の対象者
Rialsの初学者、モデルの関連付けに苦手意識のある人、わたくし
記事を書こうと思った経緯
個人開発をしている時に理解できずなかなか進めなかったのでこれを機に復習しようと思いました
今回やりたいこと
chat.participants でチャットの参加者を取り出し
participant.chats で参加しているチャットを取り出すモデル構成
chat.rb has_many :participants, through: :chat_relations has_many :chat_relations user.rb has_many :chats, through: :chat_relations has_many :chat_relations chat_relation.rb belongs_to :chats belongs_to :participant, class_name: "User"テーブル構成
create_table :chat_relations do |t| t.references :chat t.references :participant t.timestamps endchat.relations
SQL
chat.participants =>User Load (0.3ms) SELECT `users`.* FROM `users` INNER JOIN `chat_relations` ON `users`.`id` = `chat_relations`.`participant_id` WHERE `chat_relations`.`chat_id` = 8解説
SELECT `users`.*
=>class_name: "User"としているのでusersテーブルを探しに行く
FROM `users` INNER JOIN `chat_relations` ON `users`.`id` = `chat_relations`.`participant_id`
"users.id" = "chat_relations.participant_id" を条件に usersテーブルとchat_relationsを結合する
INNER JOINは結合相手がいないレコードは消滅する特徴をもっているので
userテーブルからusers.id = participant_idの存在するレコード以外を消すことで擬似的にparticipantsテーブルを作る
WHERE `chat_relations`.`chat_id` = 8
=>結合してできたテーブルからchat_idで絞り込むclass_name
最初に定義しておく
紐づく = 参照先の主キーと参照元の外部キーが同じである ということ今回は例としてこのオブジェクトを使います chat_relation = #<ChatRelation:0x00007f96f8aef100 id: 1, chat_id: 8, participant_id: 2,....>chat_relationに紐づくchatを取得する
つまり"chats.id" = "chat_relations.chat_id" のレコードを探すchat_relation.chat =>SELECT `chats`.* FROM `chats` WHERE `chats`.`id` = 8 LIMIT 1chat_relationに紐づくparticipantを取得する
"participants.id = chat_relations.participant_id" のレコードを探す
participantsテーブルは存在しないのでusersテーブルからレコードを探す
"users.id" = "chat_relations.participant_id"のレコードを探すchat_relation.participant User Load (0.3ms) SELECT `users`.* FROM `users` WHERE `users`.`id` = 2 LIMIT 1このようにclass_nameを指定すると指定したテーブルからレコードを探す
foreign_key
belongs_to :participant, class_name: "User"と
belongs_to :participant, class_name: "User", foreign_key: participant_idは同じ意味である
外部キーは指定しなければ "参照先モデル名_id"(今回ならparticipant_id) になる
foreign_keyオプションを指定した場合、指定したカラムが外部キーとなる例:) belongs_to :participant, class_name: "User", foreign_key: id の場合 chat_relation.participant =>User Load (0.2ms) SELECT `users`.* FROM `users` WHERE `users`.`id` = 1 LIMIT 1 belongs_to :participant, class_name: "User" もしくは belongs_to :participant, class_name: "User", foreign_key: participant_id の場合 chat_relation.participant User Load (0.3ms) SELECT `users`.* FROM `users` WHERE `users`.`id` = 2 LIMIT 1
- 投稿日:2019-08-22T06:54:42+09:00
初学者のメモ デプロイ後のエラー文を確認する方法
はじめに
プログラミングを初めて4ヶ月目に突入した初学者です。
デプロイ時にエラーが発生しましたが、エラー内容を確認方法が分からず躓いたのでメモを残します。
Qiita初投稿の為、暖かい目で見て頂ければと思います。環境
開発
・Ruby '2.3.8'
・Rails '5.2.3'
・vagrantデプロイ
・AWS
・nginx
・unicornエラー
ローカル環境ではエラーが発生しなくても、デプロイ後エラーが出ることがあります。
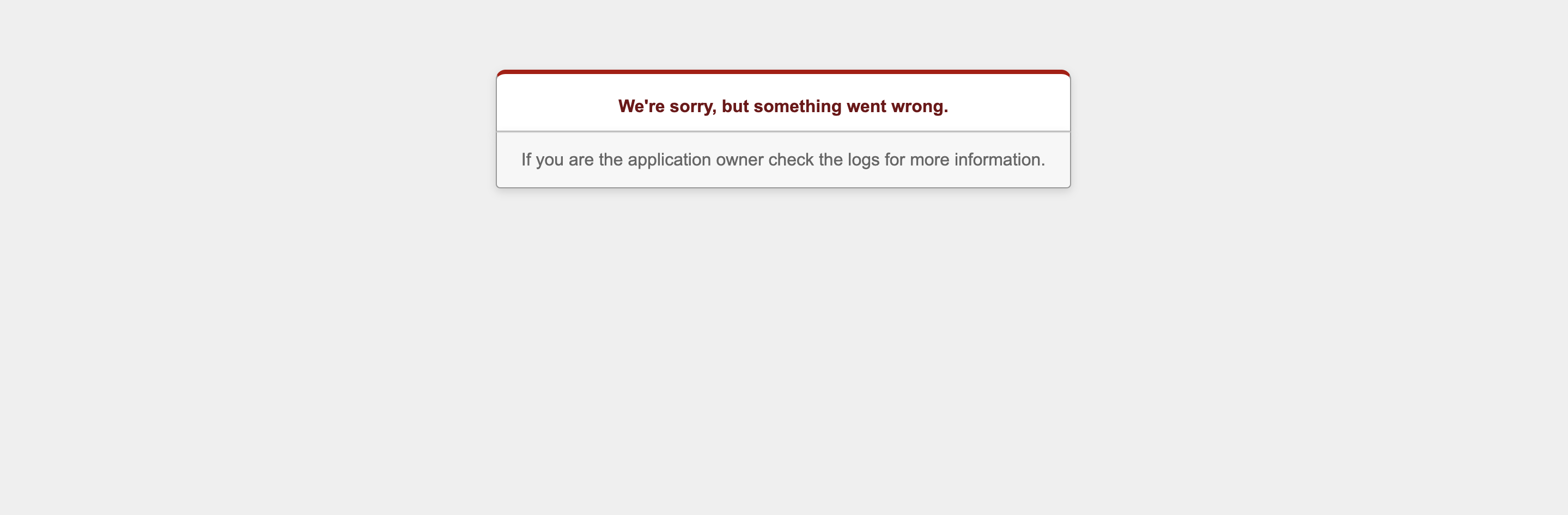
デプロイ後にエラーがあると以下の画面が表示されます
これだけでは、エラーの原因は分かりません。
We're sorry, but something went wrong.をGoogleで検索しても様々な記事(原因)が出てくるのでエラー箇所を絞ることが出来ませんでした。
また、Google chromeの検証機能をしようして同様にエラー箇所を絞ることが出来ませんでした。エラーログを確認するには・・・
エラー箇所の絞るにはログをみる必要があります。
ログは以下の場所で確認することが出来ます。
・デプロイ後のログ確認
”アプリケーション名/log/production.log”
・開発中でのログ確認
”アプリケーション名/log/development.log”エラーログの確認方法
1. EC2にssh接続する
2.cd /var/www/html/アプリケーション名でに移動する。
3.cat log/production.logを実行する。
4. 実行すると今までのログが表示されます。
今回のエラー箇所は下から8、9行目になります。
ActionView::Template::Error (Mysql2::Error: FUNCTION portfolio.RANDAM does not exist: SELECT users .* FROM users ORDER BY RANDAM()):エラー箇所の修正
ランダム表示を今回実装したのですが、記述が正しくなかったのでエラーが発生したようです。
・修正前
@users = User.order("RANDAM()").all
・修正前
@users = User.order("RAND()").all
mysqlではRANDしか使用出来ないみたいです。※今回はEC2環境で変更しています。
sudo vi app/controllers/エラー箇所のコントローラ名デプロイ環境に変更を適応させる
今回はunicornを使用しているので
sudo service unicorn restartを実行します。
これでエラーは解消され、正しく表示されました。