- 投稿日:2019-08-22T23:43:23+09:00
AWSのサービス一覧(ちょっとだけ)
初めて触ってみた。
どういう物があるのか覚えていかないとだめなので、ちょっとづつ書いていきたい。EC2(いーしーつー)
仮想サーバを建てられる。
OpenStackやESXiと似たような感じ。
ただしOSはAmazonLinuxとかいうAmazonオリジナルっぽいやつ。IAM(あいあむ)
AWSアカウントにアクセスできるユーザとか権限なんかを設定できる。
SSHの鍵を登録したりして、コマンドラインからコードをアップロードしたりするのが楽になったりする。
ロールとかポリシーっていうのがあって、各ユーザにどのAWSのサービスの権限を与えるか設定できる。
ここがガバガバだと乗っ取られたときに大変なことになる危険性がある。
キツキツだと新しいことをやるときはいちいちココで許可してやらないとだめ。
難しい。S3(えすすりー)
FTPサーバでGETとPUTとLISTしか使えないような感じのサービス。
ストレージ。バケット(ばけつみたいなもの)を定義してあげる。
ファイルを置くことが出来る。
アップロードは基本無料とか書いてあった気がする。(ダウンロードで課金?)
安くて無制限に物が置ける。
壊れない。CloudFront(くらうどふろんと)
超でっかいWEBサーバみたいなもの。
ドキュメントルートとかにS3に置いたHTMLファイルなんかを書いてやると
ブラウザで見ることが出来る。
ただし、動くのはHTMLとCSSとJSだけみたい。
PHPは動かないから、お問い合わせサイト(フォーム入力)とかはできないみたい。Cloudfront+S3でサイトを作るのは結構当たり前になってきてる。
壊れないからね。CloudWatch(くらうどうぉっち)
AWS内で作ったものを監視してくれる。
ログとかCPUメモリ、ネットワークトラフィック、ディスクIOなどのパフォーマンスも見れるみたい。code commit(こーどこみっと)
AWSにあるgit。
ソースコード管理するリポジトリが作れる。
ここにpushしたりするには、IAMでHTTPS,SSHでCodeCommitにアクセスするユーザを生成してあげないとだめ。
ログインアカウントとは別。CodePipeline(こーどぱいぷらいん)
CodeCommit
CodeBuild
CodeDeploy
3つの親玉。リポジトリにプッシュされたのを確認して、ファイルをS3バケットやEC2にデプロイ(適用?配布?)してくれる。
わざわざサーバにアクセスしなくて住む。
と併せるとテストして自動で最新化してくれる。
3つ全部使わなくても動く。
CodeCommitとCodePipelineだけでも動いてくれる。CodeBuild(こーどびるど)
CodeCommitにあるリポジトリをテストランしてくれる。
nodeとかPHPで書かれたものとか。
動くときは裏でコンテナが立ち上がって、テストしてくれる。
テスト内容はbuildspecっていうymlファイルで書いてあげないとだめ。
AWS CLIって言われるオリジナルなコマンドラインを使うらしいので、勉強しないと…。
ブランチ単位で動作を変えたり出来るらしい。CodeDeploy(こーどでぷろい)
CodeBuildが終わったあとに配布してくれる。
まだ触ったこと無い。とりあえずこんな感じです。
アーティファクトとかロールとか聞き慣れない言葉が多くて辛い…。
- 投稿日:2019-08-22T21:44:08+09:00
RHEL7のAMIはRHEL8にインプレースアップグレードできません
経緯
RHEL8.0の新機能を試したかったので、RHEL7.6の環境を引き継ぎたく8.0にインプレースアップグレードしようとマニュアルを確認したら、できなようです。
The in-place upgrade is currently unsupported for on-demand instances on Public Clouds (Amazon EC2, Azure, Huawei Cloud, Alibaba Cloud, Google Cloud) that use Red Hat Update Infrastructure but not Red Hat Subscription Manager for a RHEL subscription.
ちなみに、試したい新機能はこちら。
Red Hat Enterprise Linux 8の新機能「セッション記録ソリューション」を試してみた参考記事
Red Hat Enterprise Linux > 8 > Upgrading to RHEL 8 > Chapter 1. Requirements and known limitations
- 投稿日:2019-08-22T21:31:08+09:00
RHEL公式AMIの探し方
この記事の目的
マーケットプレイスで表示されないRHELのAMIの探し方。
経緯
RHEL7.6のインスタンスを必要になってマーケットプレイスで検索しても見つかりませんでした。
ググったら秒速でServerworksさんの記事が見つかりました。ありがとうございます。コマンド
$ aws ec2 describe-images --owners 309956199498 --query 'sort_by(Images, &CreationDate)[*].[CreationDate,Name,ImageId]' --filters "Name=name,Values=RHEL-7*" --region ap-northeast-1 --output table ---------------------------------------------------------------------------------------------------------- | DescribeImages | +---------------------------+---------------------------------------------------+------------------------+ (省略) | 2018-08-16T19:01:34.000Z | RHEL-7.6_HVM_BETA-20180814-x86_64-0-Hourly2-GP2 | ami-05555f985af973005 | | 2018-10-17T14:14:10.000Z | RHEL-7.6_HVM_GA-20181017-x86_64-0-Hourly2-GP2 | ami-08419d23bf91152e4 | | 2019-02-06T00:23:09.000Z | RHEL-7.6_HVM_GA-20190128-x86_64-0-Hourly2-GP2 | ami-00b95502a4d51a07e | | 2019-05-15T17:07:36.000Z | RHEL-7.6_HVM-20190515-x86_64-0-Hourly2-GP2 | ami-04eb805483f5607a7 | | 2019-06-05T08:49:41.000Z | RHEL-7.7_HVM_BETA-20190530-x86_64-1-Hourly2-GP2 | ami-0f2be75e3dfc43426 | | 2019-06-18T20:13:57.000Z | RHEL-7.6_HVM-20190618-x86_64-0-Hourly2-GP2 | ami-0e3e6ca71a19ccf06 | | 2019-07-24T09:17:45.000Z | RHEL-7.7_HVM_GA-20190723-x86_64-1-Hourly2-GP2 | ami-0dc41c7805e171046 | +---------------------------+---------------------------------------------------+------------------------+参考記事
【小ネタ】Red Hat Enterprise LinuxのAMIの調べ方
How to list the latest available RHEL images on Amazon Web Services (AWS)以上です。
- 投稿日:2019-08-22T19:17:02+09:00
【初心者】AWSのlightsailでWordPressを導入するまで
リスペクトな記事(参考URL)
- Amazon Lightsailを用いてWordPressを一瞬で公開する
- ぼくのかんがえたさいきょうのWordpress@AWS環境(WordPress入りLightsail作成編)
- Lightsailで常時SSLのWordPress
本件、同様の既存記事を踏襲する内容となります。
できるだけキャプチャをいっぱい入れるように心掛けました。前提
- AWSへ登録してコンソールまで至っている
手順
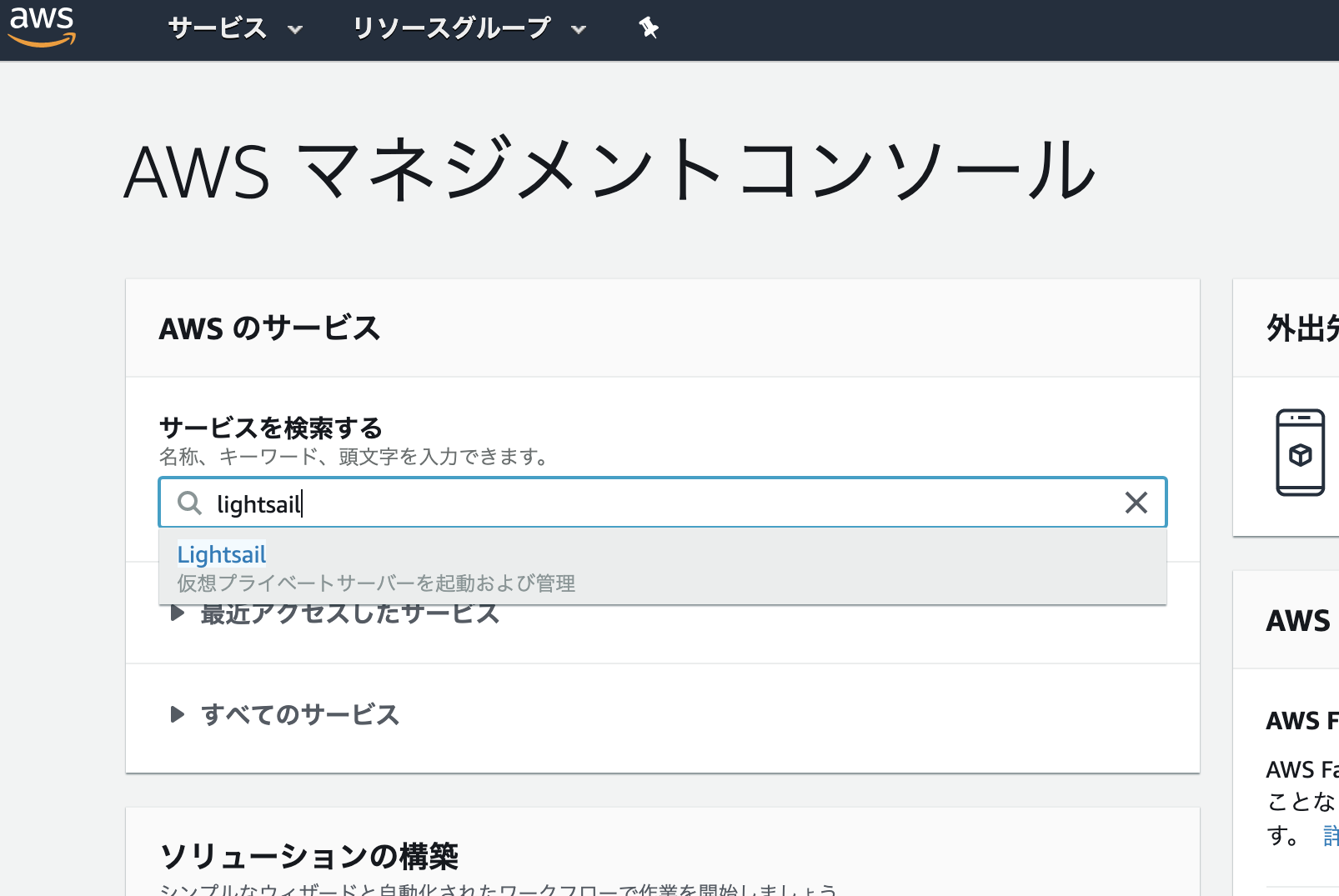
lightsail へのアクセス
サービスを検索するにlightsailと入れると、すぐに出てきます。言語設定
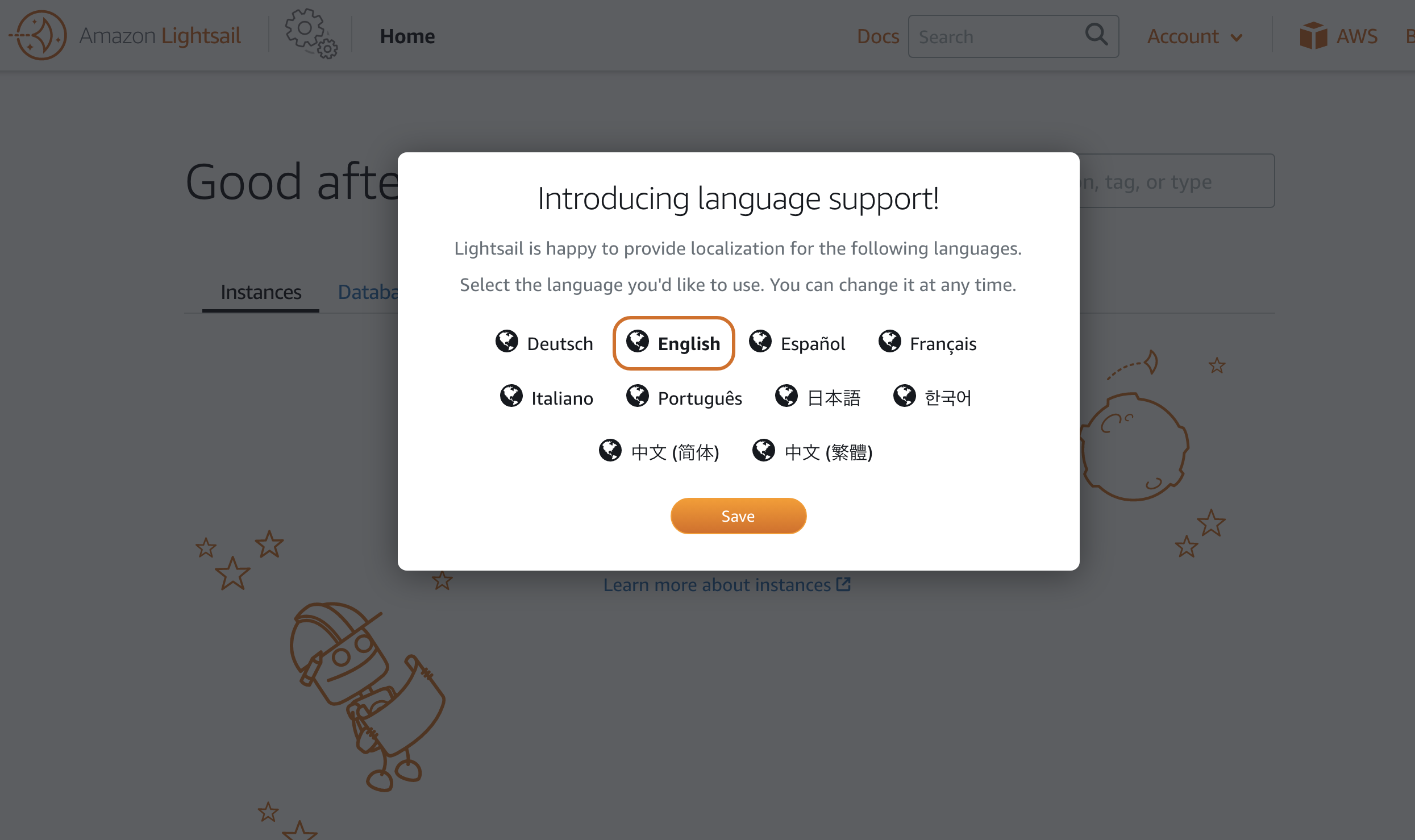
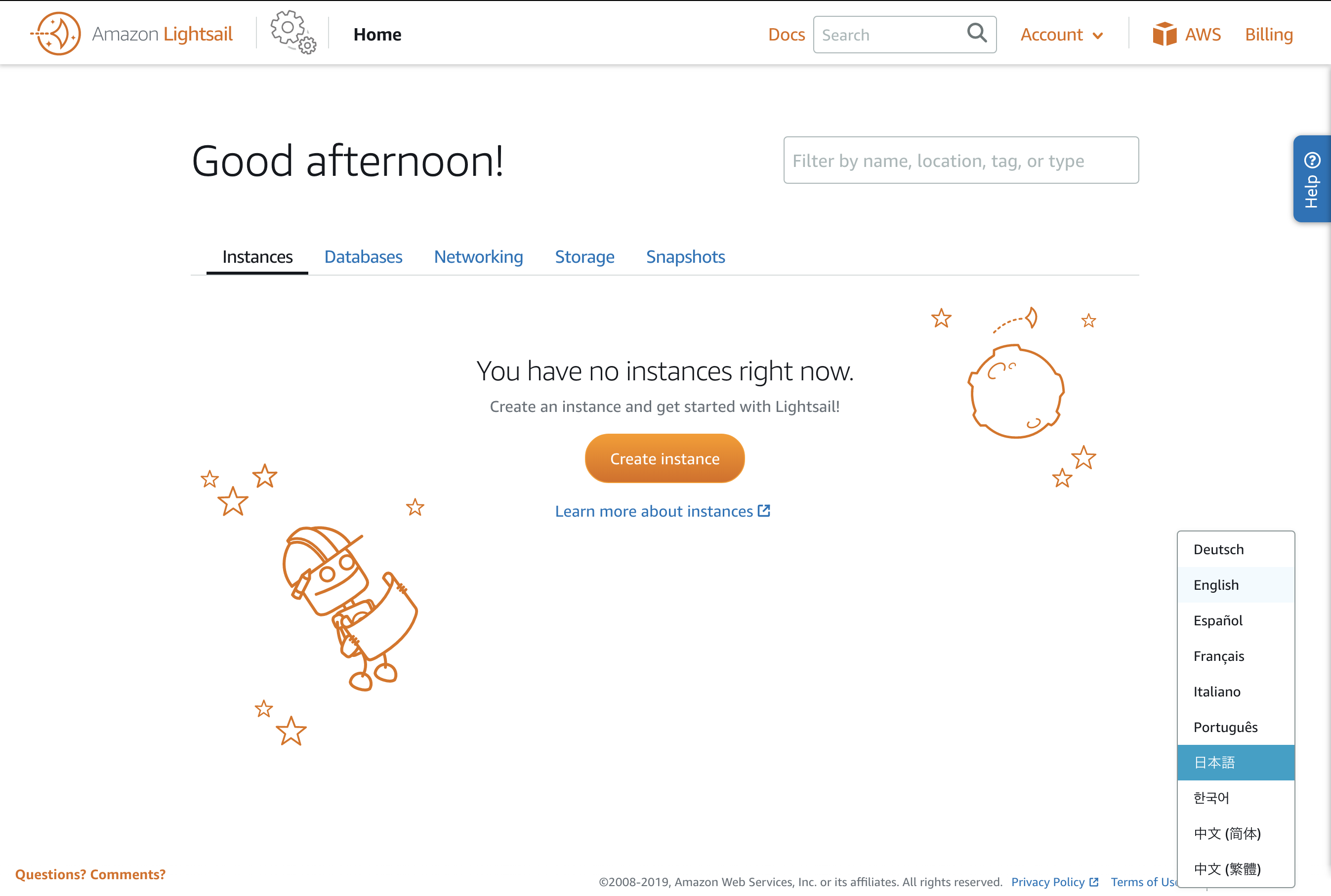
▲ 最初に言語を選択する表示が出るので日本語を選択
▲ (選択をミスっても、ページフッターの右側にあるプルダウンから選択できます)インスタンスの作成(WordPressの選択)
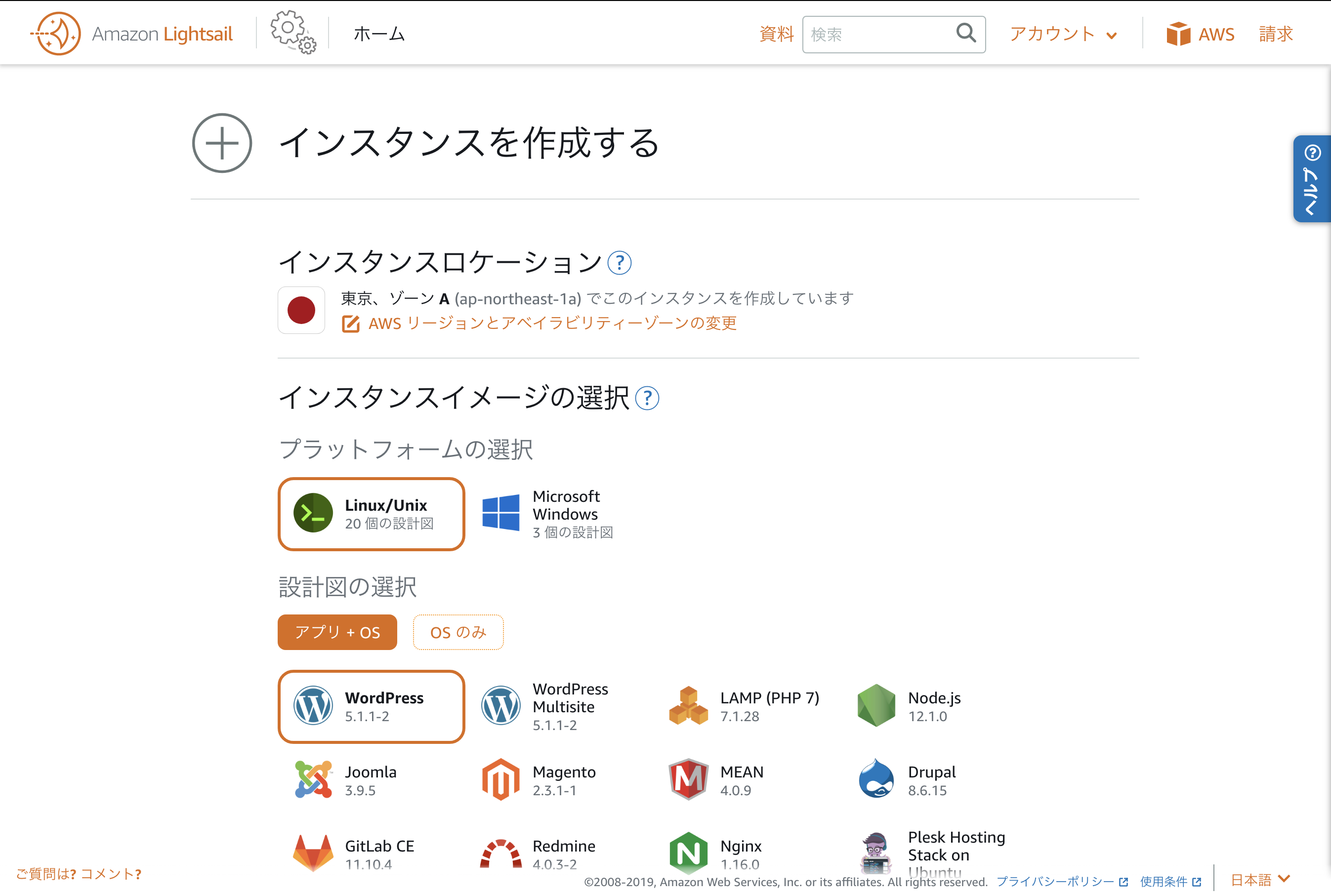
▲インスタンスの作成をクリック
▲ インスタンスロケーション→東京、ゾーンA
プラットフォームの選択→Linux/Unix
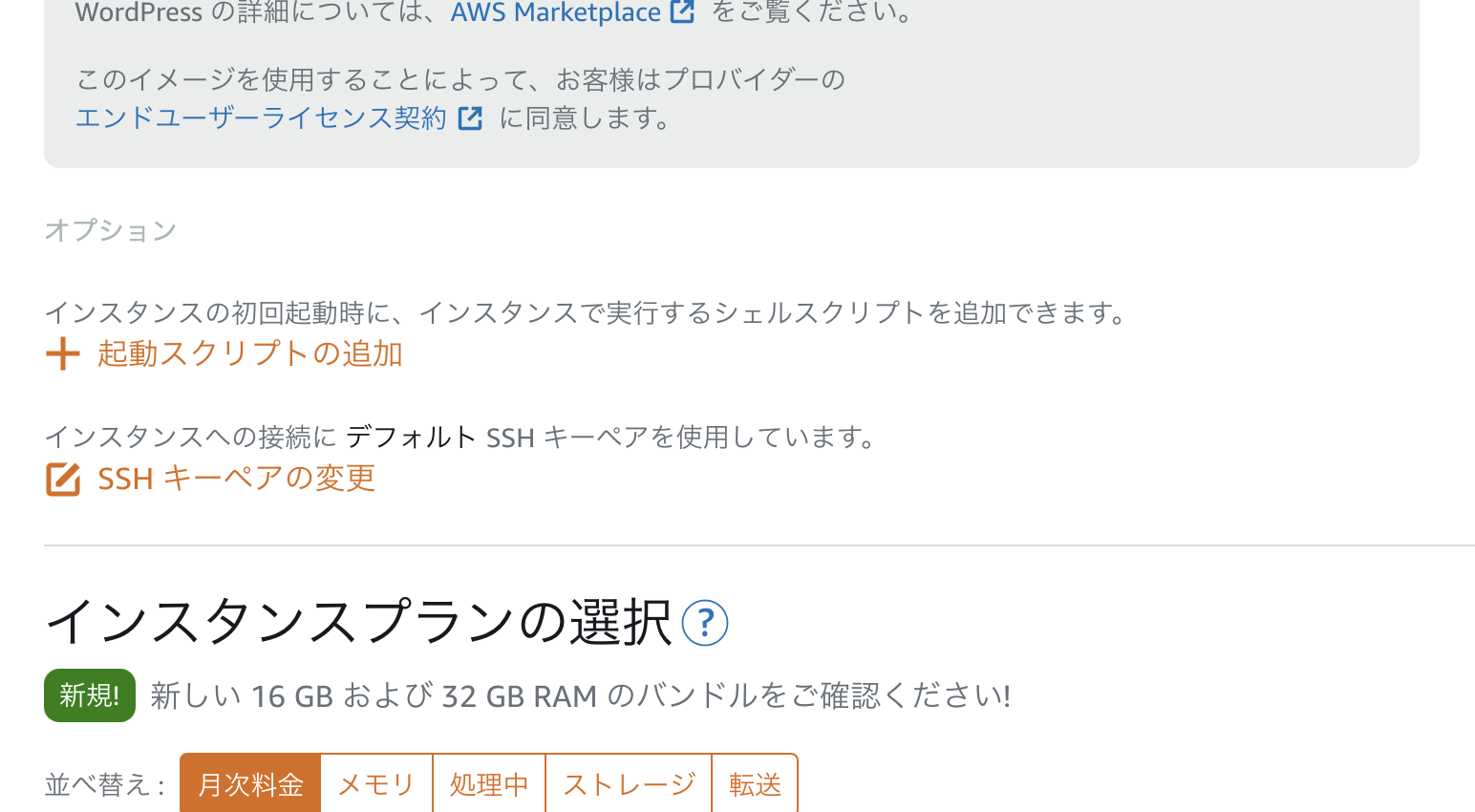
設計図の選択→WordPressSSHキーペアの変更
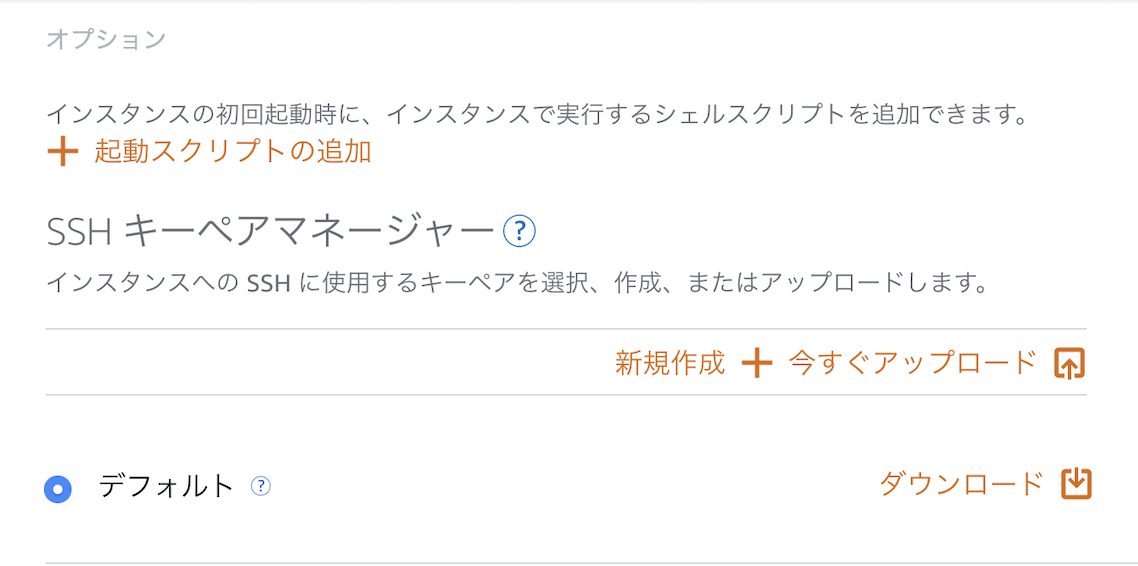
▲SSHキーペアの変更をクリック
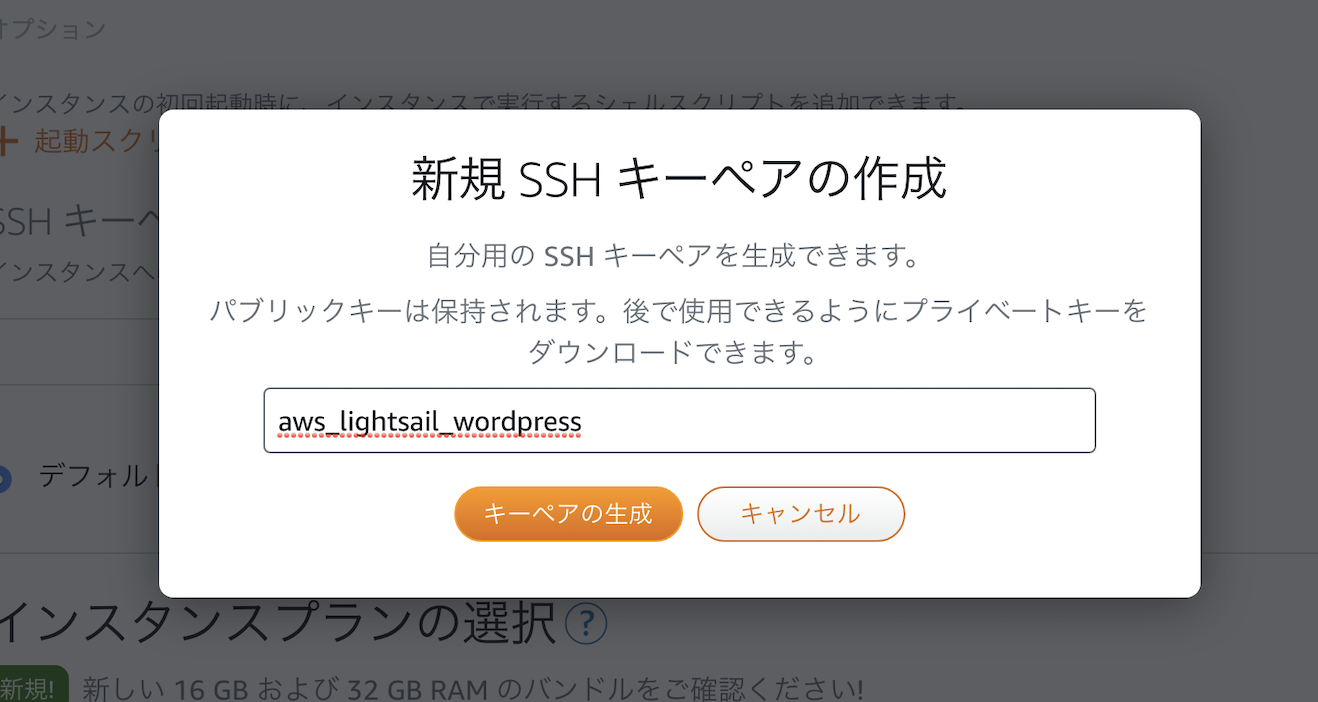
▲新規作成+をクリック
▲ 入力する名称は任意でOK(例:aws_lightsail_wordpress)
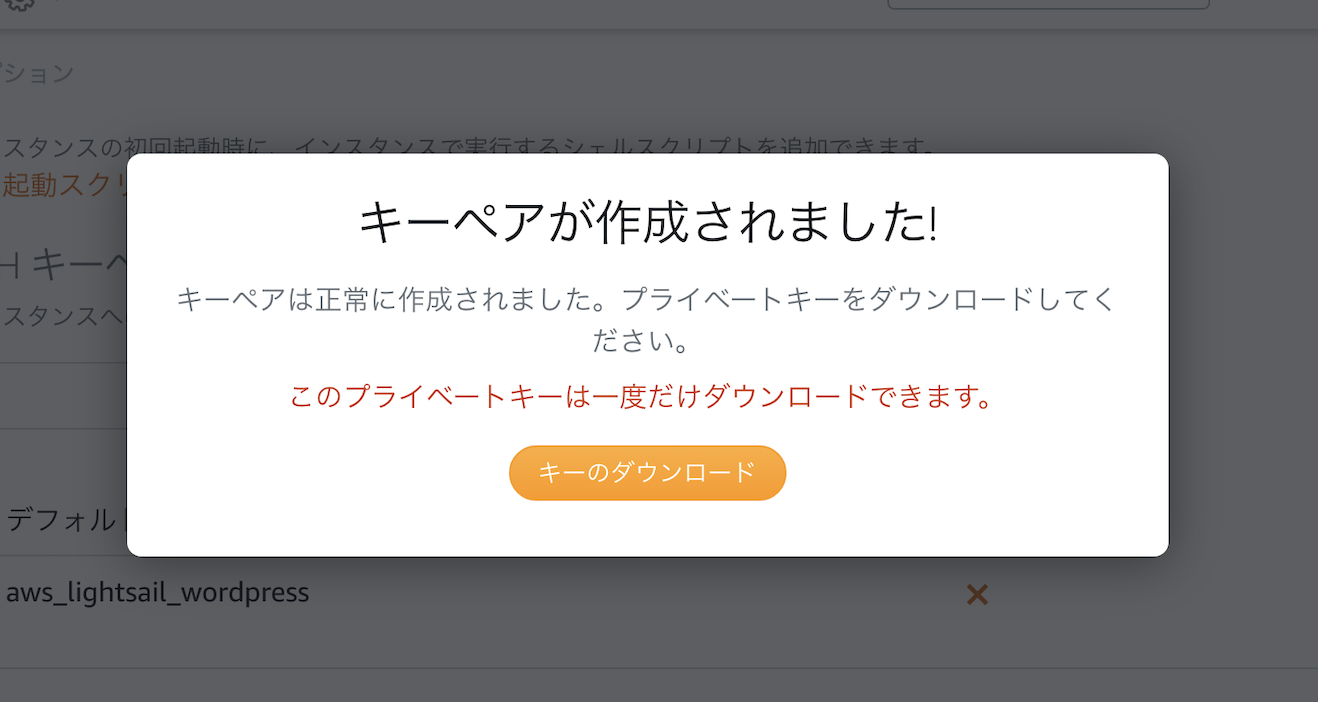
そしてキーペアの生成をクリック
▲キーのダウンロードをクリック
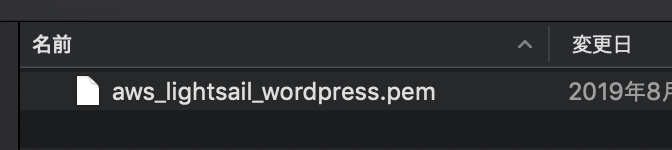
▲ 入力した名称が上記の例だと、aws_lightsail_wordpress.pemというファイルがダウンロードされます。これがSSHの秘密鍵→大切に保存しておく(後で使います)(続き)
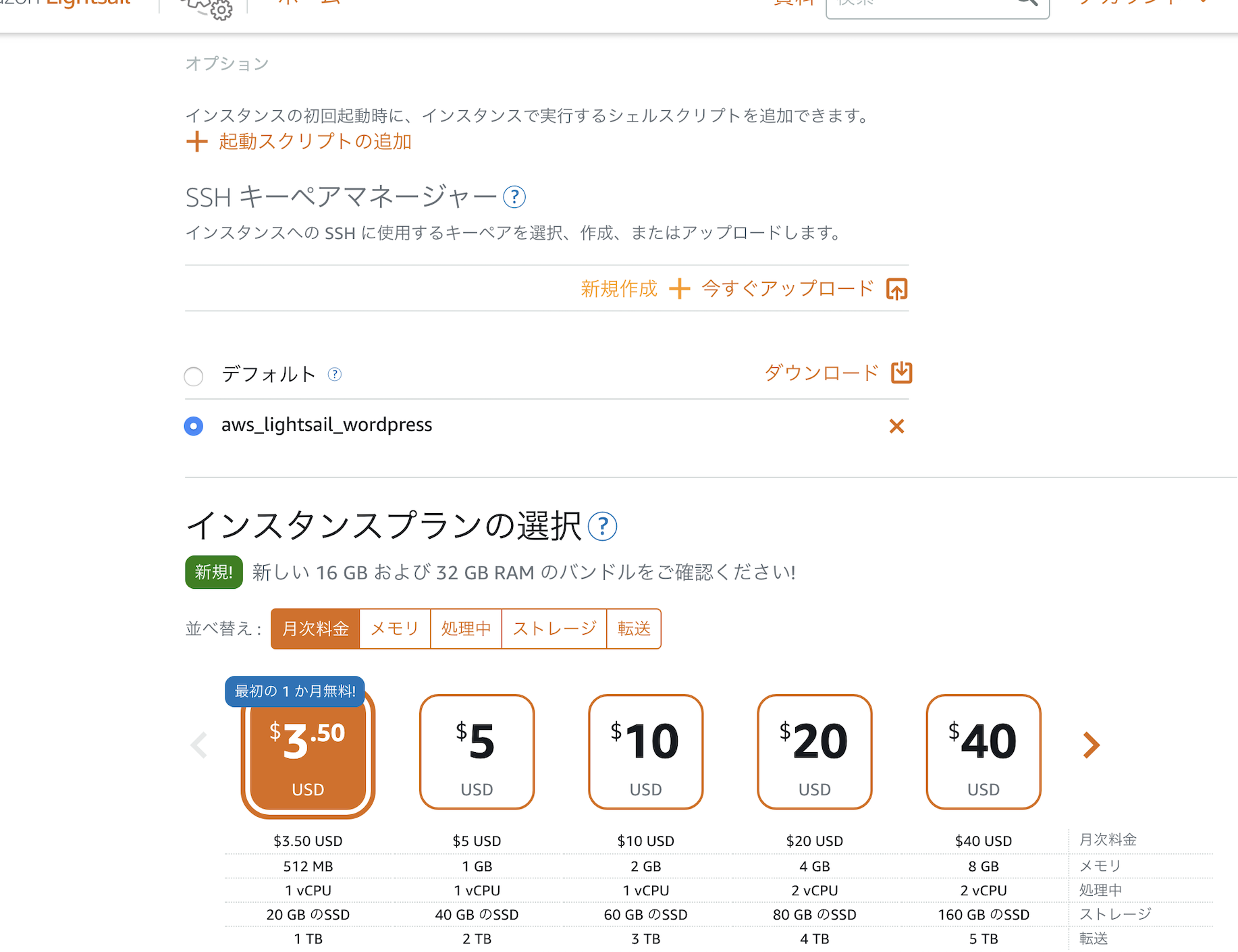
▲ インスタンプランの選択は、任意のサービスを選択してください。
(例:$3.50USD≒ 月々400円ぐらい )
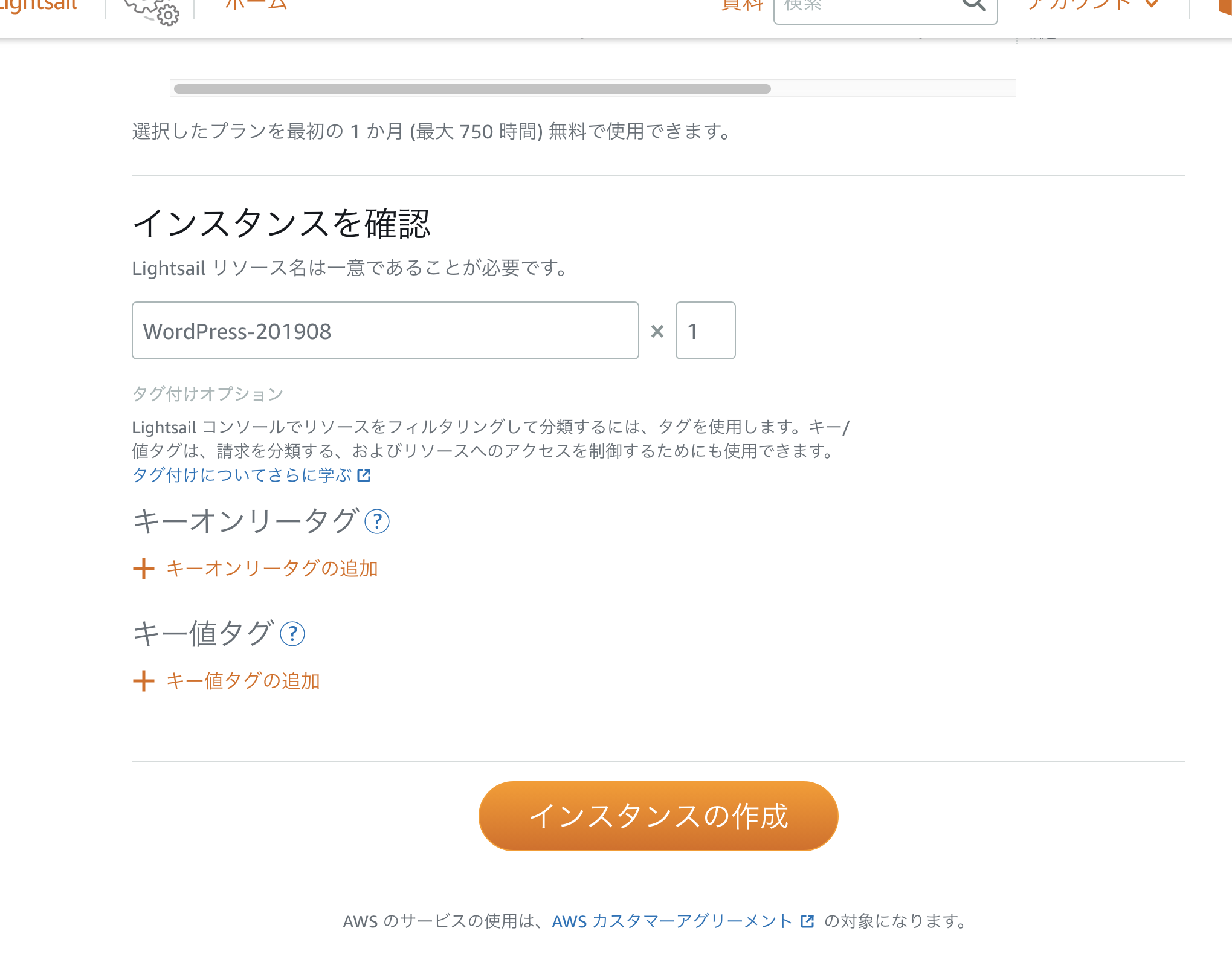
▲インスタンスの作成をクリック
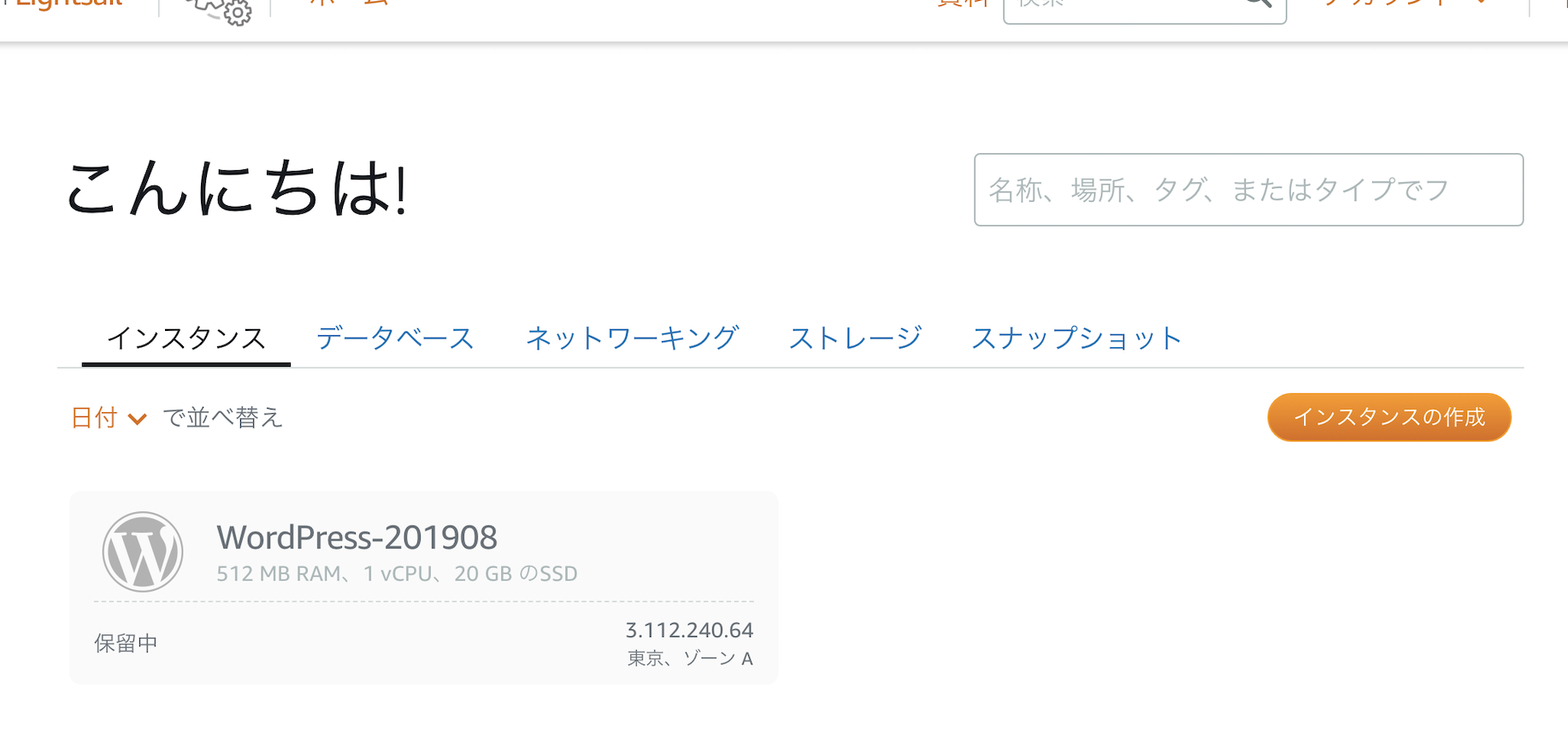
▲ (作成中)
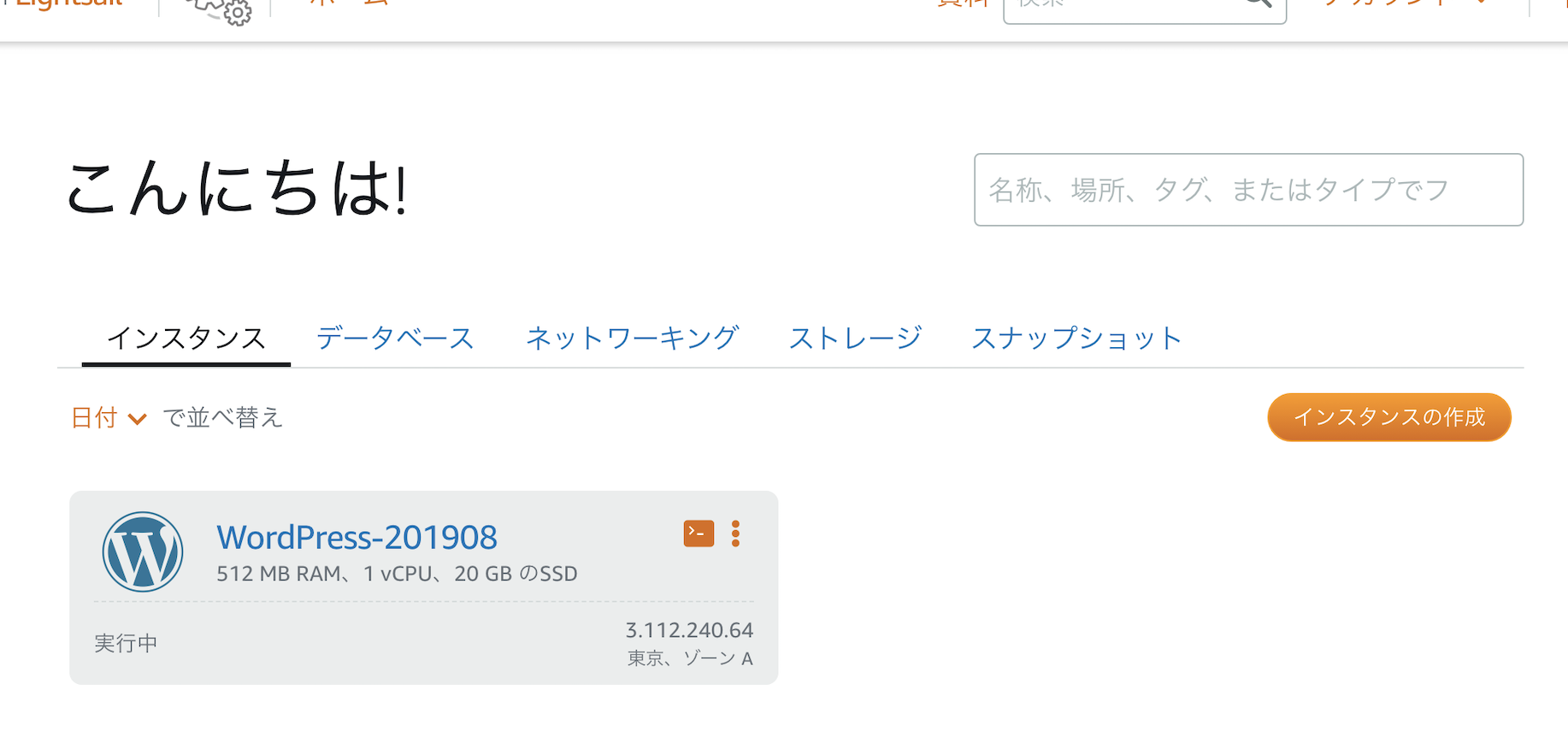
▲ 色が付いたらインスタンスの作成が完了です。
WordPress-****をクリック(上記の例ならWordPress-201908のところ)SSH接続し、WordPressへログインするパスワードを調べる
※なおログインIDは
userです
Bitnami アプリケーションおよびデータベースのデフォルトユーザー名を取得する
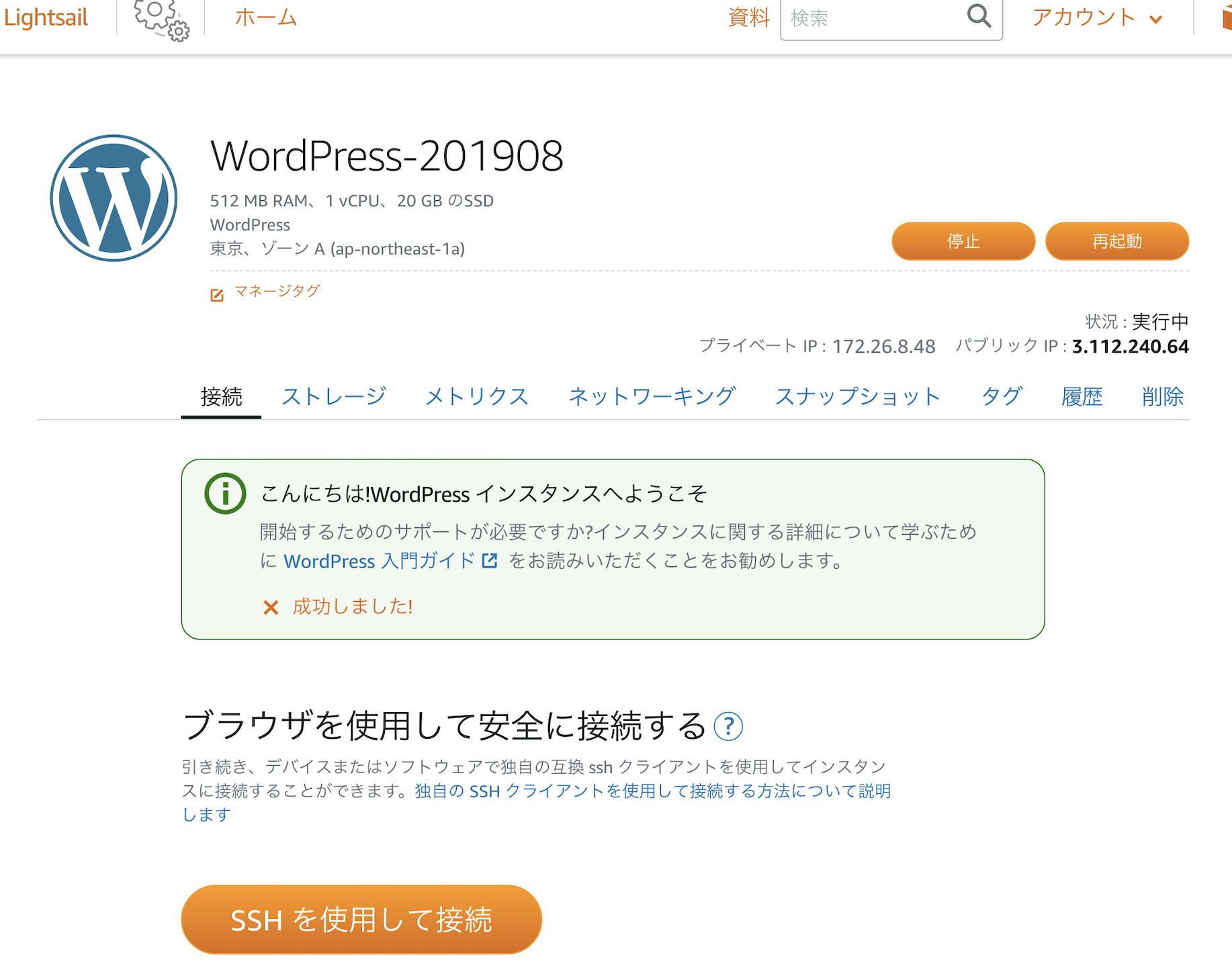
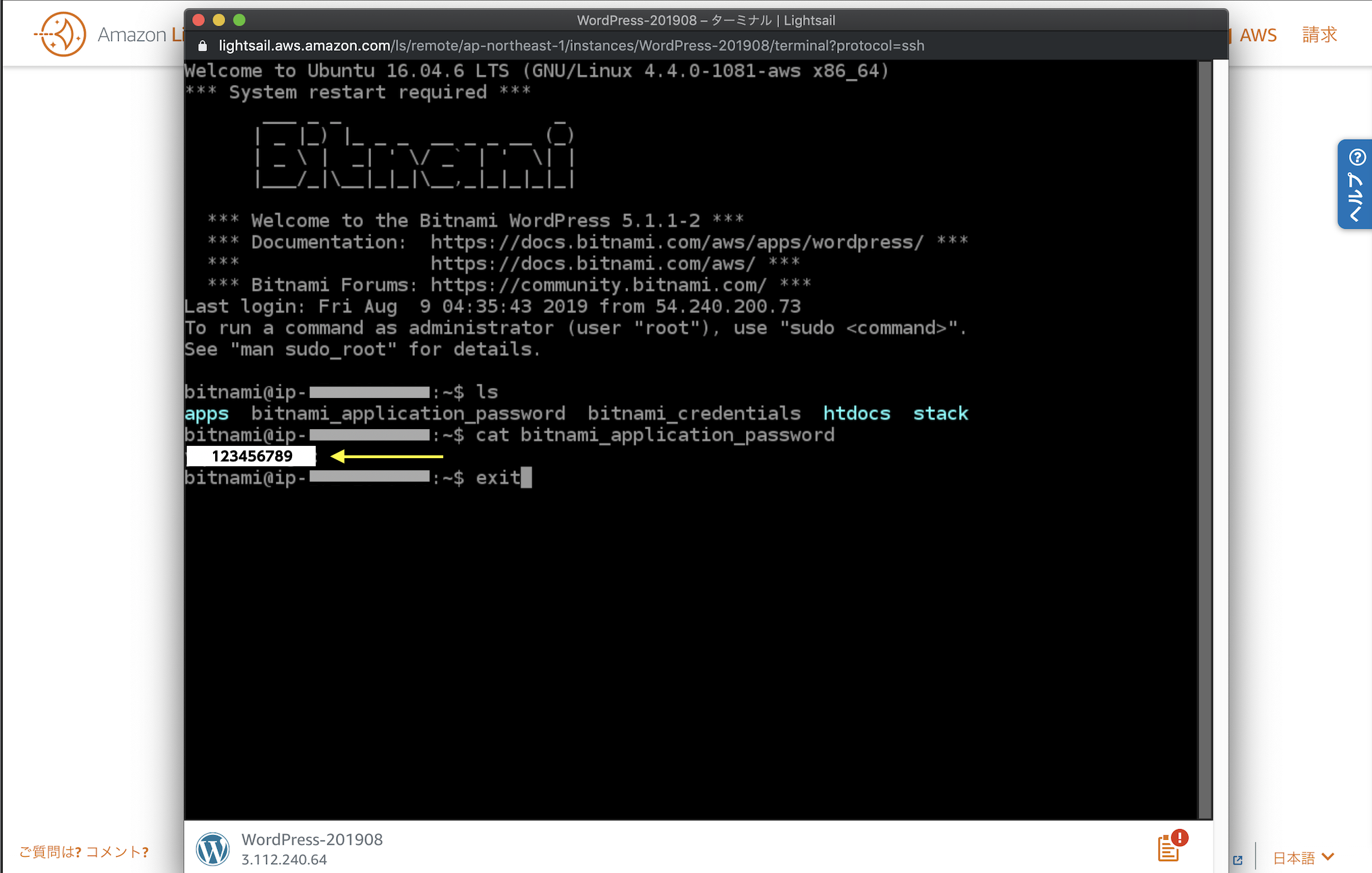
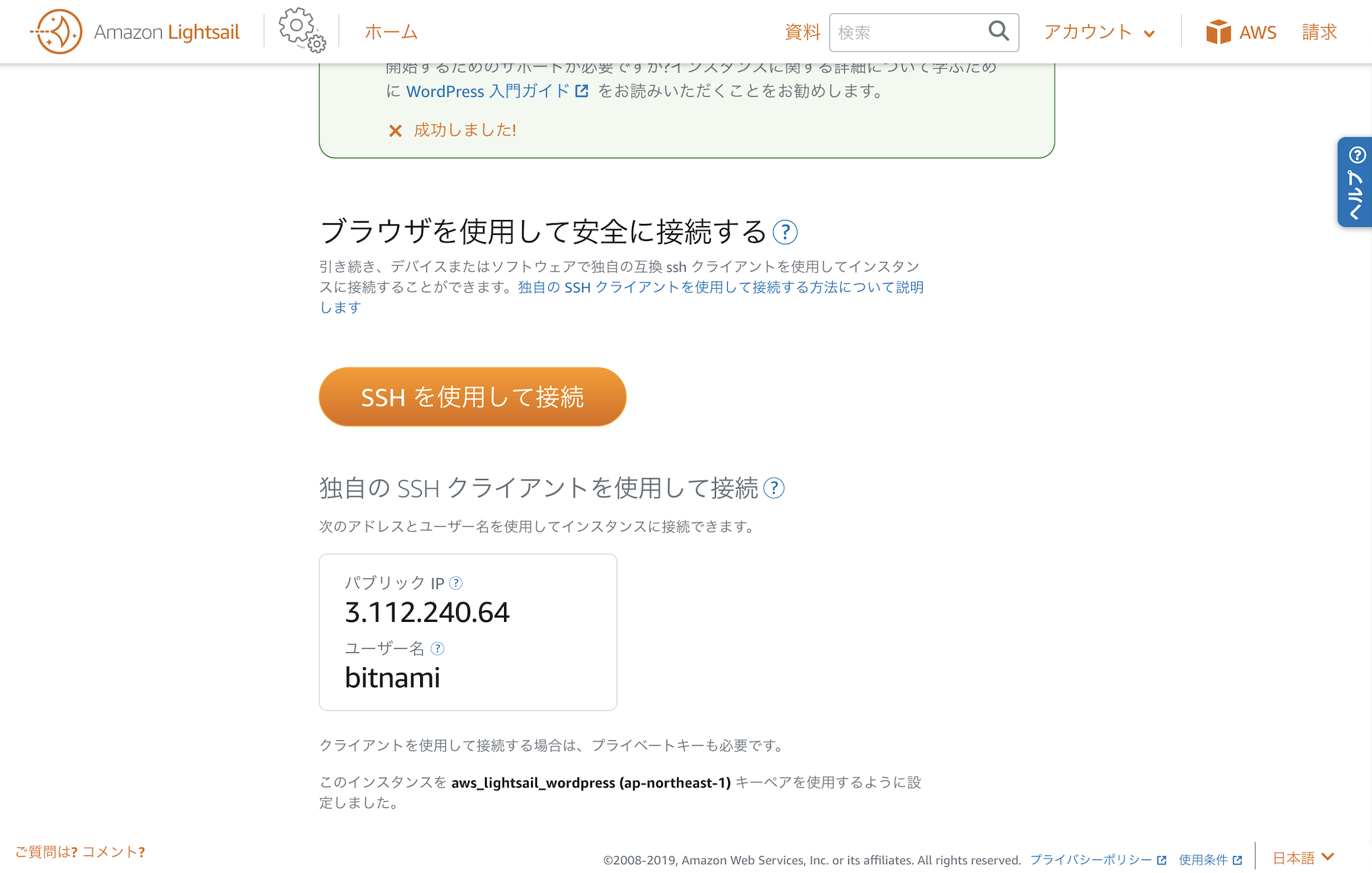
▲SSHを使用して接続をクリック
▲ 別ウィンドウでターミナルが開く
~$のあとにcat bitnami_application_passwordと入力してenterキー
→WordPressのログインパスワードが表示される(上記の例:123456789黄色矢印の所)
→どこかにコピペしておいてください(ログインするときに使います)
▲ ~$のあとに
exitと入力してenterキー
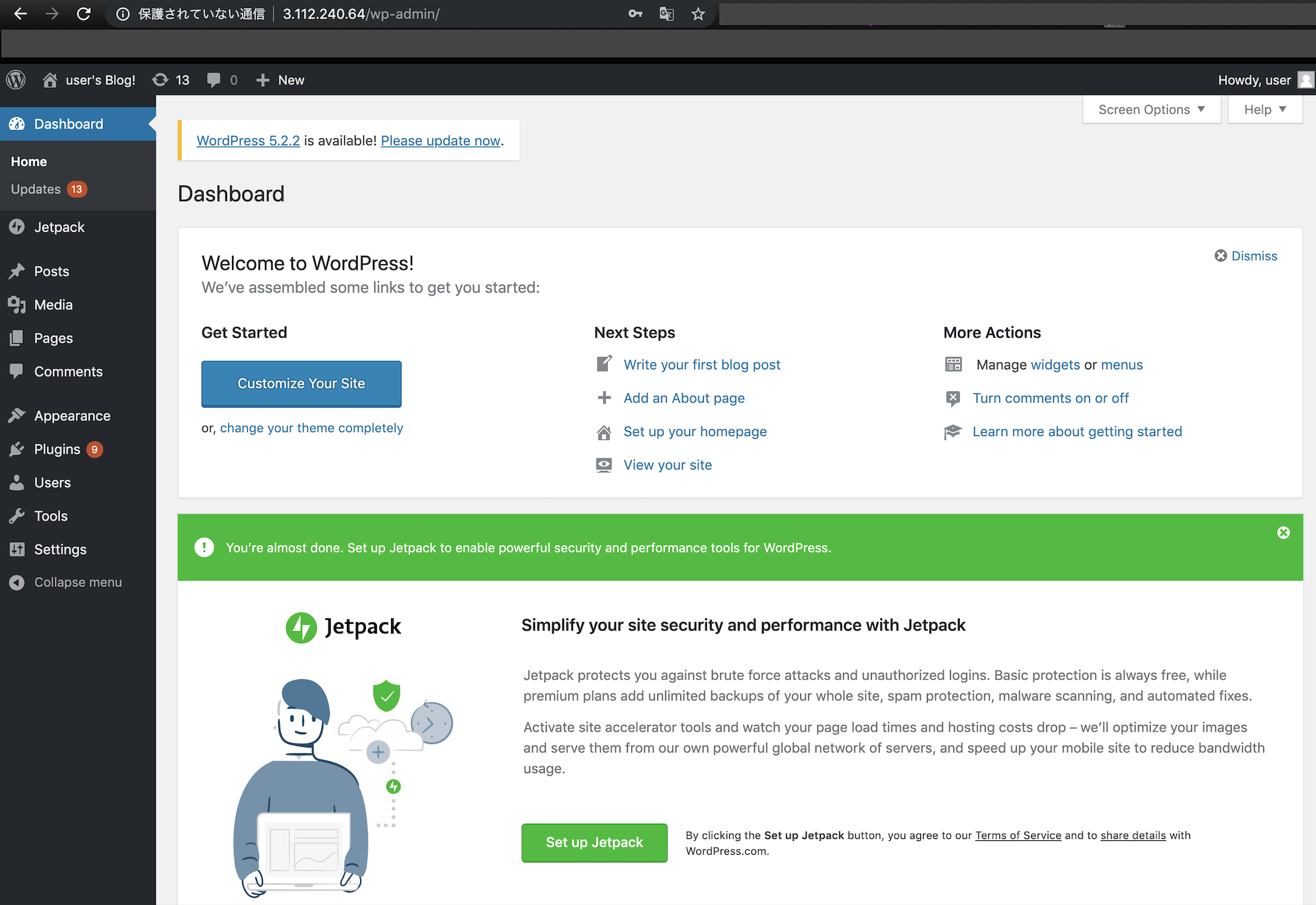
→接続が切れるので、SSH接続のウィンドウを閉じてOKです。WordPressへログインする
WordPressへのアクセス
▲ 独自のSSHクライアントを使用して接続の下部のパブリックIP(例:3.112.240.64)を
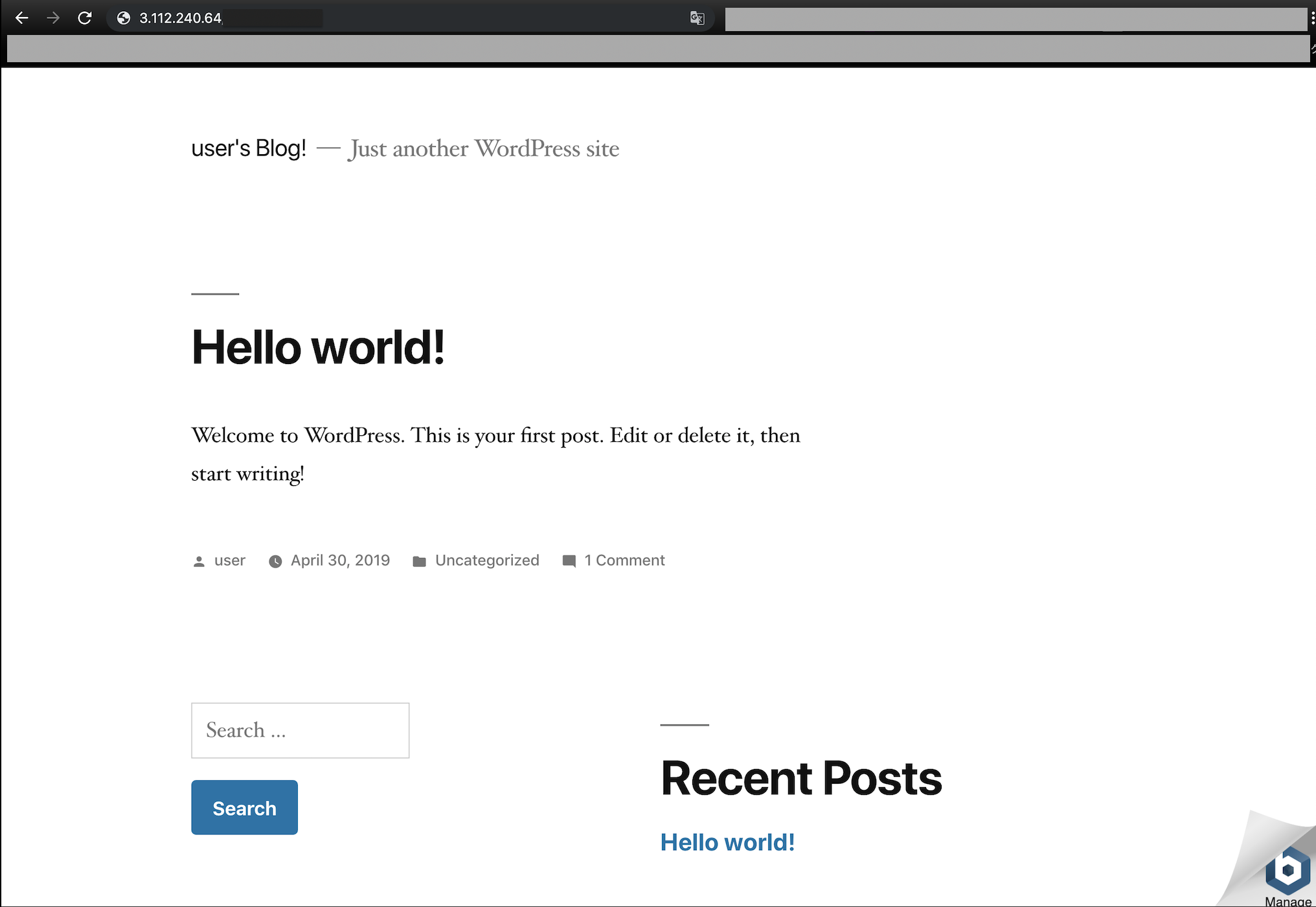
ブラウザのURL枠に入力してenterキー
▲ WordPressのTOPページが表示される。
※なお、この時点ではパブリックIPは変動します。
※後でIPを固定にし、独自ドメインに紐付けます。ログイン画面の表示
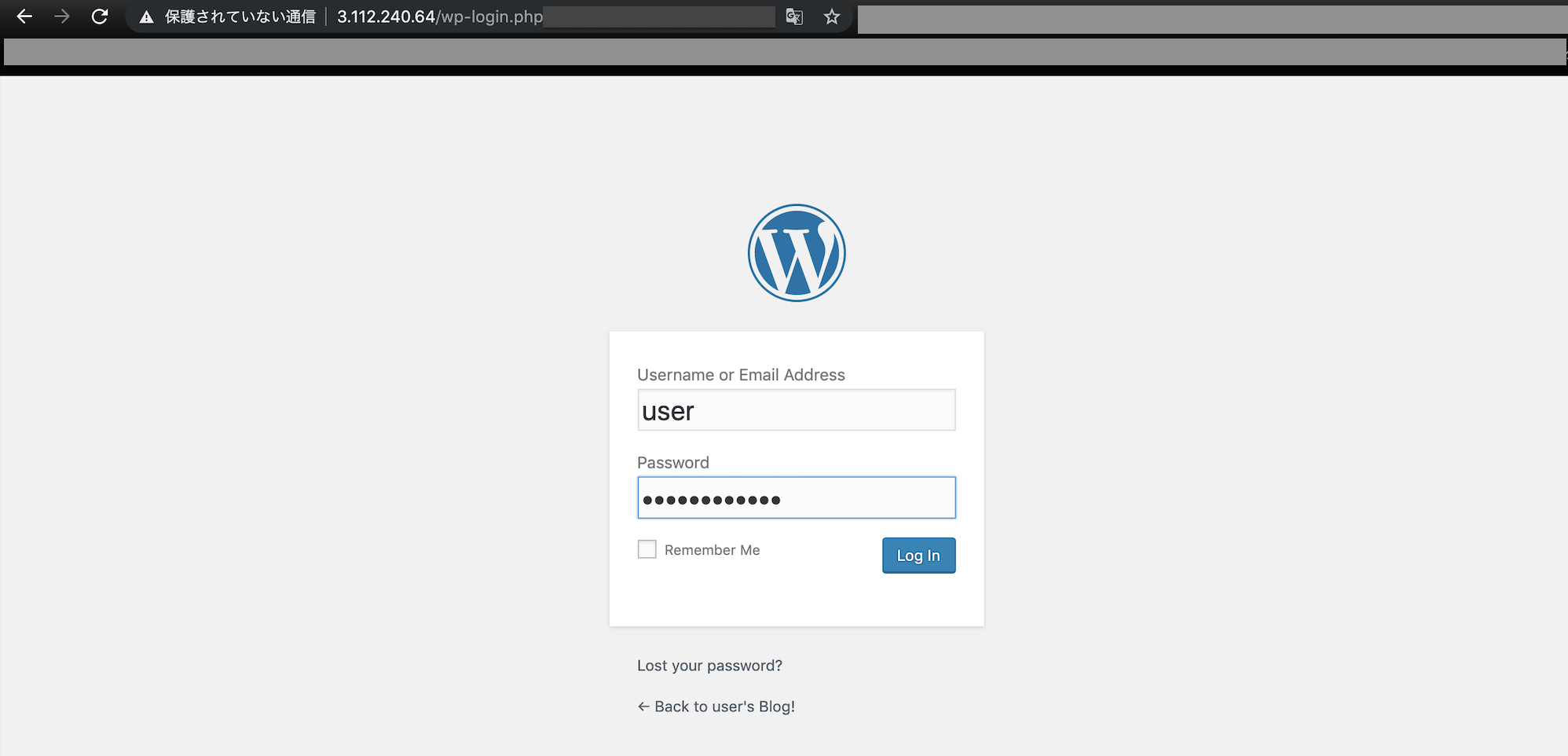
▲ ブラウザURLのパブリックIPの後ろに/wp-loginを加えてenterキー
(例:http://3.113.127.25/wp-loginへアクセス)
→ログイン画面が表示される※ログインIDは
userです
Bitnami アプリケーションおよびデータベースのデフォルトユーザー名を取得する※パスワードは、上記で調べたものです(例:
123456789)
▲ WordPressへログインできました。この後にすること
- WordPressの設定(言語設定やユーザー設定などなど)
- IPの固定化と独自ドメインの紐付け
- SSL化
- FileZillaやCyberduckのようなアプリからSSH接続し、WordPressのディレクトリを覗く
また追って記事化します。
- 投稿日:2019-08-22T18:57:26+09:00
初心者がCodeCommitから新しいリポジトリを作成した後、クローンして作業ブランチを作る
はじめに
今まで誰かが既に中に何かを作ったリポジトリからしかクローン・作業してきませんでした。
今回、自分でCodeCommitでリポジトリを作成するところからやってみて色々詰まったので、自分用のメモです。
そんな背景があるので、根本的に非効率・おかしい点があるかもしれません、その場合はすみません。記事の前提
- Mac PC
- git, AWS CLIがインストール済み
- IAMアカウントとSSHキーが紐付けてある
- SSHキーを紐付けたIAMのクレデンシャルが登録してある
動作確認環境
- バージョン
- bash:
GNU bash, version 3.2.57(1)-release (x86_64-apple-darwin18)- git:
2.17.0- AWS CLI:
aws-cli/1.16.221 Python/3.7.4 Darwin/18.7.0 botocore/1.12.2111. 新規リポジトリを作成する
AWSコンソールを開き、サービス一覧からAWS CodeCommitを選択し、「リポジトリを作成」
作成したリポジトリのページを開き、「URLのクローン」 > 「SSHのクローン」
(今回はSSHを前提に話します)2. 新規作成したリポジトリをクローンする
- コマンドライン上のリポジトリを落としてきたい場所で下記コマンドを実行
$ git clone ssh://git-codecommit.{region}.amazonaws.com/v1/repos/sample-repository Cloning into sample-repository... warning: You appear to have cloned an empty repository.最後の
warningでは「空のリポジトリ落としてきてるっぽいよ」て言われています。
- リポジトリの中に移動
$ cd sample-repositoryこの状態のブランチを確認すると、何もいません。
$ git branch # 何も表示されない# gitステータス確認 $ git status On branch master No commits yet nothing to commit (create/copy files and use "git add" to track) # gitコミットlog確認 $ git log fatal: your current branch 'master' does not have any commits yet
- (任意)Sourcetreeで開く
Sourcetreeを見ても、何もできないし何もない。
3. masterに最初のコミットをする
何も変更を行わずにコミットします。
--allow-emptyで空でもコミットできるようになります。$ git commit --allow-empty -m "first commit" [master (root-commit) xxxxxxx] first commit
- コミット内容を確認
# gitステータス確認 $ git status On branch master Your branch is based on 'origin/master', but the upstream is gone. (use "git branch --unset-upstream" to fixup) nothing to commit, working tree clean # gitコミットlog確認 $ git log commit xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx (HEAD -> master) Author: Your Name <Your Email Address> Date: Thu Aug 22 12:43:48 2019 +0900 first commit注意:
--allow-emptyオプションをつけない場合、何か新規ファイルがないと、下記からわかるように、コミットさせてくれないです。$ git commit -m "Initial commit" On branch master first commit nothing to commit4. 最初のコミットをoriginに向けてpushする
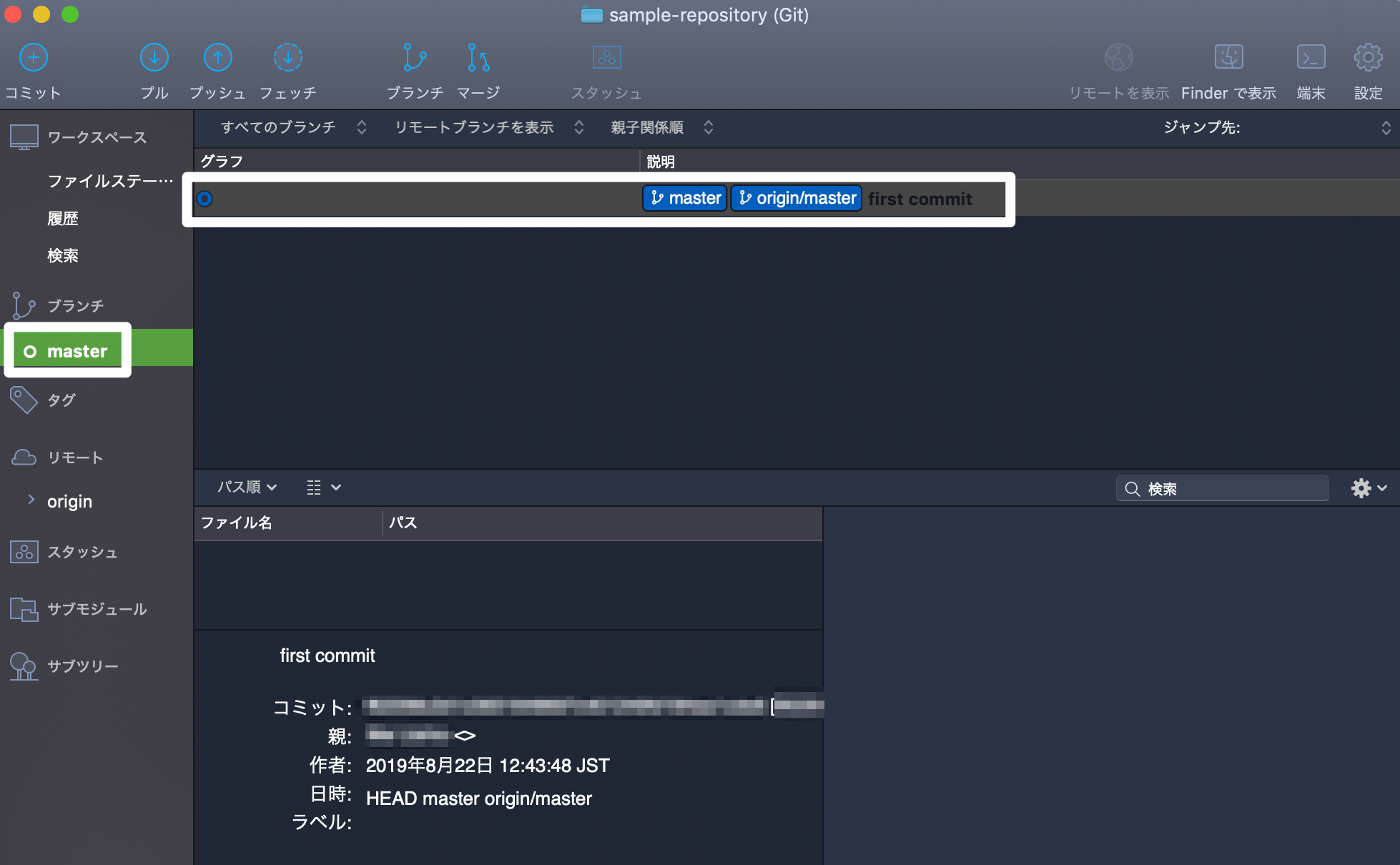
- 下記コマンドを実行
$ git push origin master Counting objects: 2, done. Writing objects: 100% (2/2), 147 bytes | 147.00 KiB/s, done. Total 2 (delta 0), reused 0 (delta 0) To ssh://git-codecommit.{region}.amazonaws.com/v1/repos/sample-repository * [new branch] master -> masterこれが終わるとようやくブランチが現れます。
- ブランチを確認
$ git branch * master
- (任意)Sourcetreeにブランチが現れたことを確認
あとはSourceTreeなりコマンドラインなりCodeCommitなりで新規ブランチを生やしましょう!
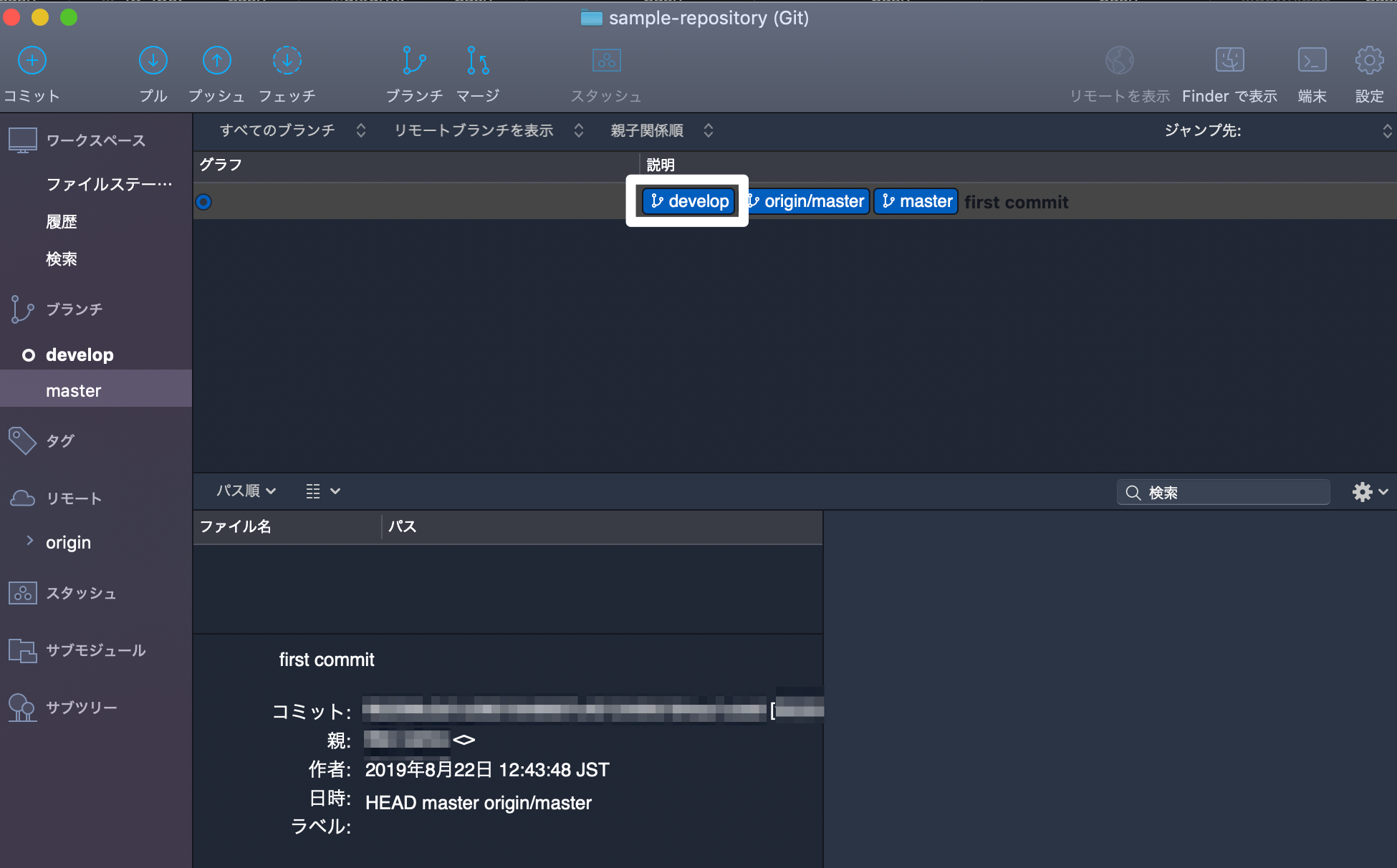
- 例:gitコマンドでmasterブランチから開発用ブランチ(例:
develop)を作成・ブランチ切り替える場合$ git checkout -b develop Switched to a new branch 'develop' # ブランチ確認 $ git branch * develop master
- (任意)gitで作成した開発用ブランチをSourcetreeで確認する
余談: masterからはコミットしない場合
masterブランチからコミットしない方がいいとよく聞くので、私は最初、masterをいじらずそこから新しいブランチを作成・チェックアウトし、上記のようにpushしました。
すると、masterのリモートの存在が消えてしまい、作ったブランチからmasterを作成しないといけなくなって面倒でした。
また、この方法では、最後にmasterブランチを作り直した後、作業用ブランチに切り替えるのを忘れそうです。
masterでコミットする中身は空ですので、はじめに説明した方法で良さそうです。
- 例: 開発用ブランチ(例:
develop)から"first commit"した場合# リポジトリ内に移動してからのコマンド $ git checkout -b "develop" Switched to a new branch 'develop' $ git commit --allow-empty -m "first commit" [develop (root-commit) 321da3b] first commit $ git push origin develop Counting objects: 2, done. Writing objects: 100% (2/2), 148 bytes | 148.00 KiB/s, done. Total 2 (delta 0), reused 0 (delta 0) To ssh://git-codecommit.{region}.amazonaws.com/v1/repos/another-sample-repository * [new branch] develop -> develop $ git checkout -b "master" Switched to a new branch 'master' Your branch is based on 'origin/master', but the upstream is gone. (use "git branch --unset-upstream" to fixup) $ git branch --unset-upstream # ブランチの切り替えを忘れずに $ git checkout develop
- 投稿日:2019-08-22T18:14:28+09:00
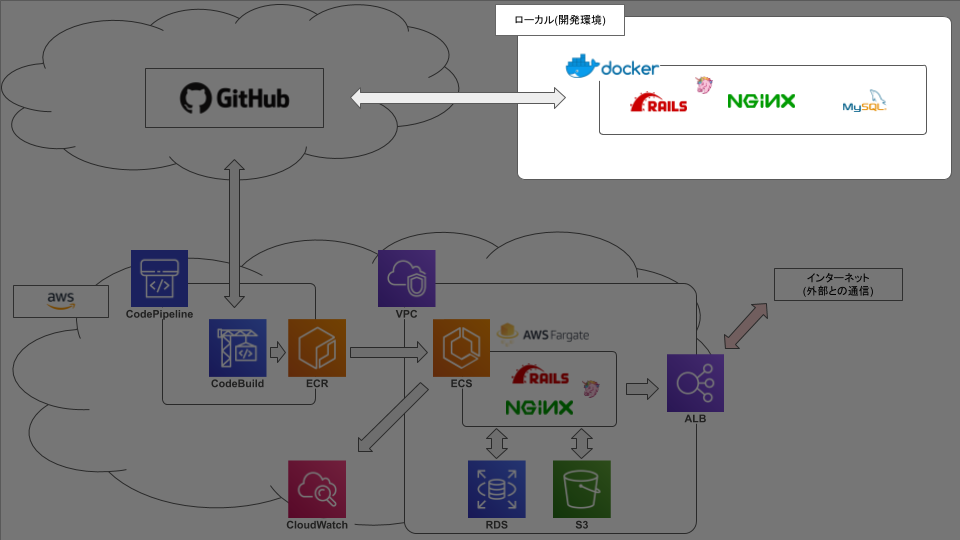
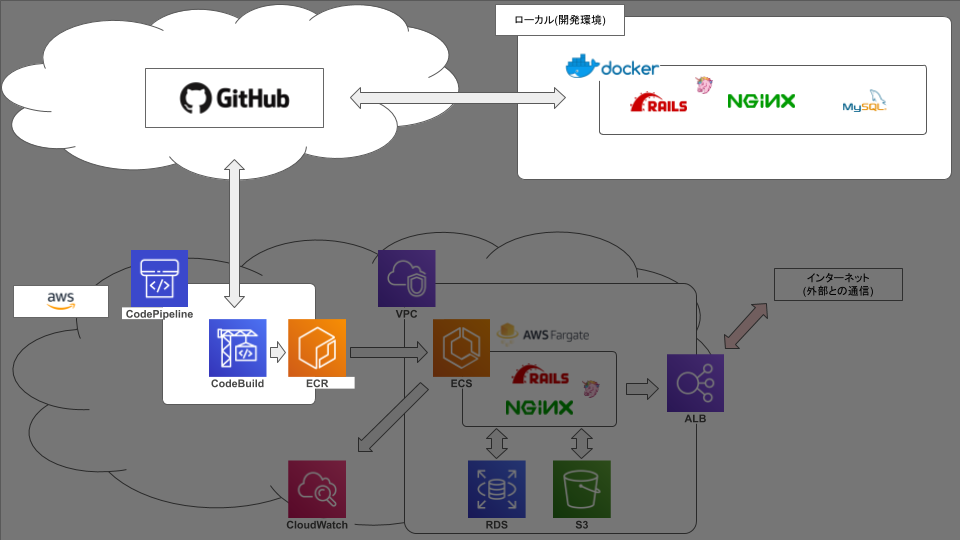
ECS FargateでRails動かそうとして2ヶ月かかって手元に残ったもの【2.Build編】
弊社の基幹システムをVPSからAWSに移行するにあたって、まずはrailsを動かしてみる、という段階で無事に死にました☆
今後のための備忘録です。前記事: ECS FargateでRails動かそうとして2ヶ月かかって手元に残ったもの【1.docker編】
前回まででやったこと
今回やったこと
githubへのリポジトリの作成は割愛します。
今回はgithubのmasterブランチに変更をpushしたときに本番環境のコンテナイメージが自動更新されるところまでやってみます。ECR
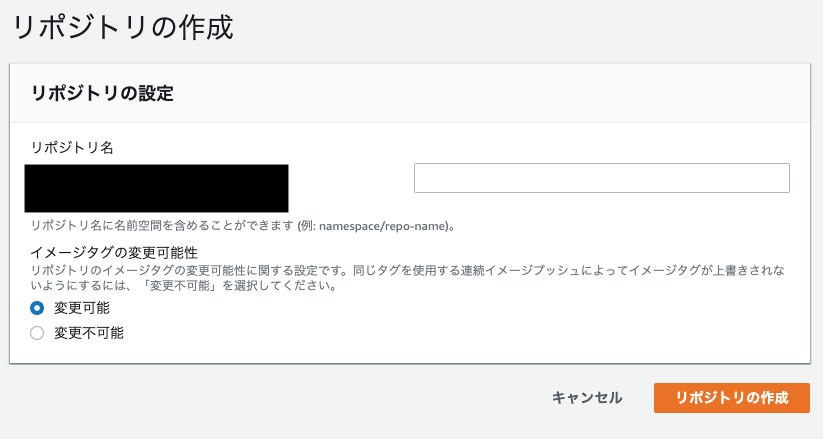
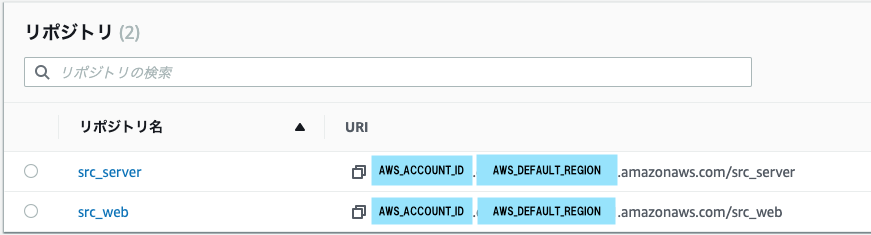
今回はリポジトリを2つ作ります。
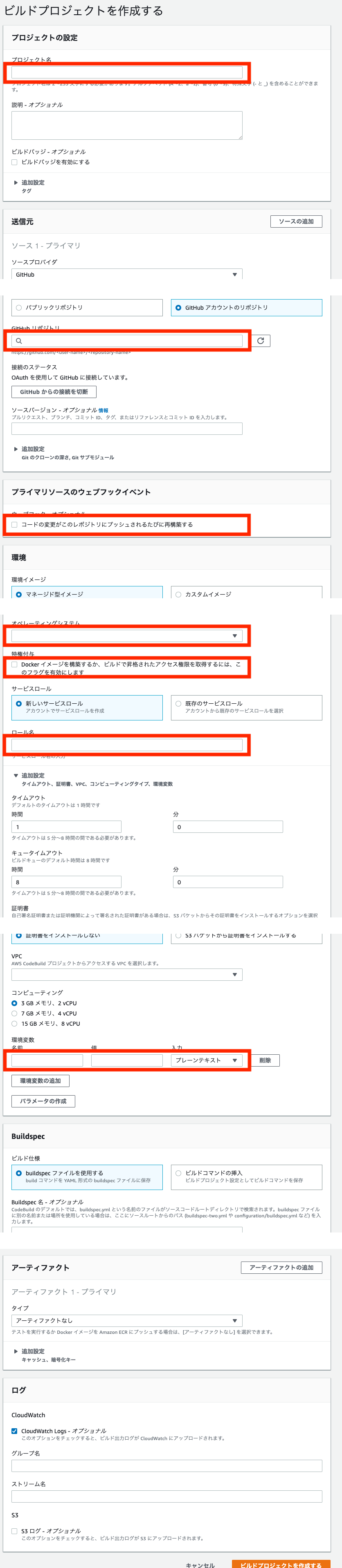
CodeBuild
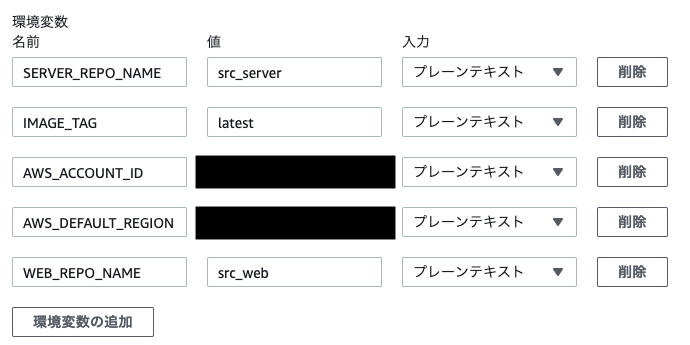
途中、環境変数を設定する部分があります。
そこには以下のように設定します。
CodePipeline
ここではCodeBuildで設定したリポジトリと同じリポジトリを設定します。
そして、先程作ったCodeBuildのプロジェクト名を設定します。
CodeBuild側の設定は以上ですが、CodeBuildでコンテナをビルドするためには
buildspec.ymlというファイルが必要になります。プロジェクトルート ├ docker │ ├ mysql │ │ ├ volumes │ │ │ └ developmentのmysqlの永続化用 │ │ ├ charset.cnf │ │ ├ password.yml │ │ └ Dockerfile │ ├ nginx │ │ ├ development │ │ │ ├ default.conf │ │ │ └ Dockerfile │ │ ├ production │ │ │ ├ default.conf │ │ │ └ Dockerfile │ │ └ nginx.conf │ └ rails │ └ Dockerfile ├ src │ └ railsアプリのソース ├ .gitignore ├ buildspec.yml ←コイツ ├ docker-compose.common.yml ├ docker-compose.development.yml ├ docker-compose.production.yml └ README.mdこのファイル構成でここまで説明をしていない唯一のファイルです。
ビルドコマンドや、railsコマンド等はこのファイルに書きます。buildspec.ymlversion: 0.2 phases: install: runtime-versions: nodejs: 10 ruby: 2.6 pre_build: commands: - $(aws ecr get-login --no-include-email --region $AWS_DEFAULT_REGION) build: commands: - docker-compose -f docker-compose.production.yml build - docker-compose -f docker-compose.production.yml run --rm web rake db:migrate RAILS_ENV=production - docker-compose -f docker-compose.production.yml run --rm web rake assets:precompile RAILS_ENV=production - docker tag $WEB_REPO_NAME:$IMAGE_TAG $AWS_ACCOUNT_ID.dkr.ecr.$AWS_DEFAULT_REGION.amazonaws.com/$WEB_REPO_NAME:$IMAGE_TAG - docker tag $SERVER_REPO_NAME:$IMAGE_TAG $AWS_ACCOUNT_ID.dkr.ecr.$AWS_DEFAULT_REGION.amazonaws.com/$SERVER_REPO_NAME:$IMAGE_TAG post_build: commands: - docker push $AWS_ACCOUNT_ID.dkr.ecr.$AWS_DEFAULT_REGION.amazonaws.com/$WEB_REPO_NAME:$IMAGE_TAG - docker push $AWS_ACCOUNT_ID.dkr.ecr.$AWS_DEFAULT_REGION.amazonaws.com/$SERVER_REPO_NAME:$IMAGE_TAG先程の環境変数はここで読み込まれます。
さて、これで準備ができました。
コードを更新して、githubにpushしてみましょう。
CodePipeline上で更新が始まったことが確認できます。
更新には5分程かかります。
この時間の短縮も、今後の課題の一つです。
CodeBuild上でもリアルタイムで状況が把握できます。
COMPLETEまでフェーズが進めば、今回の目的は達成です。ここまでできたこと
次記事:Fargate編


- 投稿日:2019-08-22T17:23:30+09:00
AWS CLIでスイッチロール(AssumeRole)する際のステップ削減
経緯
標準の?方法はコピペ工数が多く面倒に感じました。
標準の方法
AWS CLIでスイッチロールするには標準で以下になります。
※スイッチロールできる設定は済んでいる前提です。
スイッチロールしたいAWSアカウントの認証情報を取得するコマンドを実施
$ aws sts assume-role --role-arn arn:aws:iam::123456789012:role/role-name --role-session-name "RoleSession1"出力される結果 ※公式サンプル
{ "AssumedRoleUser": { "AssumedRoleId": "AROA3XFRBF535PLBIFPI4:s3-access-example", "Arn": "arn:aws:sts::123456789012:assumed-role/xaccounts3access/s3-access-example" }, "Credentials": { "SecretAccessKey": "9drTJvcXLB89EXAMPLELB8923FB892xMFI", "SessionToken": "AQoXdzELDDY//////////wEaoAK1wvxJY12r2IrDFT2IvAzTCn3zHoZ7YNtpiQLF0MqZye/qwjzP2iEXAMPLEbw/m3hsj8VBTkPORGvr9jM5sgP+w9IZWZnU+LWhmg+a5fDi2oTGUYcdg9uexQ4mtCHIHfi4citgqZTgco40Yqr4lIlo4V2b2Dyauk0eYFNebHtYlFVgAUj+7Indz3LU0aTWk1WKIjHmmMCIoTkyYp/k7kUG7moeEYKSitwQIi6Gjn+nyzM+PtoA3685ixzv0R7i5rjQi0YE0lf1oeie3bDiNHncmzosRM6SFiPzSvp6h/32xQuZsjcypmwsPSDtTPYcs0+YN/8BRi2/IcrxSpnWEXAMPLEXSDFTAQAM6Dl9zR0tXoybnlrZIwMLlMi1Kcgo5OytwU=", "Expiration": "2016-03-15T00:05:07Z", "AccessKeyId": "ASIAJEXAMPLEXEG2JICEA" } }1の結果からアクセスキー、シークレットアクセスキー、トークンをコピーし環境変数に設定
※コマンドのコピーと値のコピーで2回。アクセスキーとシークレットアクセスキー、トークンがあるのでトータル6回のコピペが必要。$ export AWS_ACCESS_KEY_ID=ASIAJEXAMPLEXEG2JICEA $ export AWS_SECRET_ACCESS_KEY=9drTJvcXLB89EXAMPLELB8923FB892xMFI $ export AWS_SESSION_TOKEN=AQoDYXdzEJr...<remainder of security token>意図した権限になっているかを以下のコマンドで確認
$ aws sts get-caller-identityステップ削減できる方法
以下のコマンドを実施
aws sts assume-role --role-arn arn:aws:iam::123456789012:role/role-name --role-session-name "RoleSession1" --query 'join(``,[`export AWS_ACCESS_KEY_ID=`,Credentials.AccessKeyId, `,export AWS_SECRET_ACCESS_KEY=`,Credentials.SecretAccessKey, `,export AWS_SESSION_TOKEN=`,Credentials.SessionToken])' --output text | tr ',' '\n'出力される結果
export AWS_ACCESS_KEY_ID=ASIAJEXAMPLEXEG2JICEA export AWS_SECRET_ACCESS_KEY=9drTJvcXLB89EXAMPLELB8923FB892xMFI export AWS_SESSION_TOKEN=AQoDYXdzEJr...<remainder of security token>1で標準出力された内容をコピペする
意図した権限になっているかを以下のコマンドで確認
$ aws sts get-caller-identity項目分けした結果どちらも3ステップになってしまいましたが、実際に作業された方であれば体感して頂けると思います。
説明
aws sts assume-roleのコマンドを実施した際に出力される結果を選ぶ
- --queryオプション
- Credentials.AccessKeyId
- Credentials.SecretAccessKey
- Credentials.SessionToken
- 上記のみ活用した場合のコマンド
aws sts assume-role --role-arn arn:aws:iam::123456789012:role/role-name --role-session-name "RoleSession1" --query '[Credentials.AccessKeyId, Credentials.SecretAccessKey, Credentials.SessionToken]'出力される結果
ASIAJEXAMPLEXEG2JICEA 9drTJvcXLB89EXAMPLELB8923FB892xMFI AQoDYXdzEJr...<remainder of security token>queryで出力した結果と環境変数にセットするコマンドを合わせて表示したい
join
- コマンド
aws sts assume-role --role-arn arn:aws:iam::123456789012:role/role-name --role-session-name "RoleSession1" --query 'join(``,[`export AWS_ACCESS_KEY_ID=`,Credentials.AccessKeyId, `export AWS_SECRET_ACCESS_KEY=`,Credentials.SecretAccessKey, `export AWS_SESSION_TOKEN=`,Credentials.SessionToken])'理想は↓
export AWS_ACCESS_KEY_ID=ASIAJEXAMPLEXEG2JICEA export AWS_SECRET_ACCESS_KEY=9drTJvcXLB89EXAMPLELB8923FB892xMFI export AWS_SESSION_TOKEN=AQoDYXdzEJr...<remainder of security token>実際は↓
export AWS_ACCESS_KEY_ID=ASIAJEXAMPLEXEG2JICEAexport AWS_SECRET_ACCESS_KEY=9drTJvcXLB89EXAMPLELB8923FB892xMFIexport AWS_SESSION_TOKEN=AQoDYXdzEJr...<remainder of security token>
- 全てが一塊になってしまっている・・・
三行に分けたい
|tr ',' '\n'
- 二個目と三個目のexportの前に,を入れる
- trコマンドで,を改行文字に置換する。
結果
export AWS_ACCESS_KEY_ID=ASIAJEXAMPLEXEG2JICEA export AWS_SECRET_ACCESS_KEY=9drTJvcXLB89EXAMPLELB8923FB892xMFI export AWS_SESSION_TOKEN=AQoDYXdzEJr...<remainder of security token>まとめ
紹介したコマンドはAmazon linux2であれば追加パッケージが必要ない事も大きな利点になっています。
ロールする対象が多い為、上記を応用したシェルを作成し活用しています。
もっと効率の良い方法があるかもしれませんが、忘備録的に残しておきます。参考にさせて頂いたページ
- 投稿日:2019-08-22T17:20:55+09:00
クロスリージョンレプリケーションをしているRDSに更新を適用するときの注意点
結論
RDSの保留中の更新を適用するとき、CRRのクラスターがある場合は先にそちらに更新を適用する必要がある。
(更新のタイプにはos-upgrade/system-update/db-upgradeの3種類がある。今回はsystem-updateなのでそれ以外も必須かは未検証。)環境
ap-northeast-1にAuroraクラスターがあり、そのCRRクラスターがus-west-2にある。
describe-db-clusters"Engine": "aurora", "EngineVersion": "5.6.10a",どちらもAurora 1.16で保留中の更新に
Aurora 1.17.8 releaseがある。やろうとしたこと
保留中のメンテナンスに
Aurora 1.17.8 releaseが来ていたので、
下記のコマンドでap-northeast-1側のクラスターに更新を適用しようとした。$ aws rds apply-pending-maintenance-action \ --resource-identifier "arn:aws:rds:ap-northeast-1:xxxxxxxxxxxx:cluster:hogehogecluster" \ --apply-action system-update \ --opt-in-type immediate発生したエラー
errorUnable to upgrade DB cluster hogehogecluster because related Aurora cross region Replica hogehogecluster-crr is not yet patched. Upgrade the Aurora cross region Replica and try again.Google翻訳関連するAuroraクロスリージョンレプリカhogehogecluster-crrにはまだパッチが適用されていないため、DBクラスターhogehogeclusterをアップグレードできません。 Auroraクロスリージョンレプリカをアップグレードして、再試行してください。おわりに
たしかにupdateによる互換性とかのことを考えれば当たり前なんですが、すっかりCRRがあることを忘れていましたね。
これのせいでメンテ時間中に作業が終わらず…。
- 投稿日:2019-08-22T14:29:32+09:00
ECS FargateでRails動かそうとして2ヶ月かかって死んだ話【1.docker編】
弊社の基幹システムをVPSからAWSに移行するにあたって、まずはrailsを動かしてみる、という段階で無事に死にました☆
今後のための備忘録です。やりたいこと
こんな感じ。やったこと
docker
まず、ファイル構成は以下。
プロジェクトルート ├ docker │ ├ mysql │ │ ├ volumes │ │ │ └ ※mysqlの永続化に使う。後述 │ │ ├ charset.cnf │ │ ├ password.yml │ │ └ Dockerfile │ ├ nginx │ │ ├ development │ │ │ ├ default.conf │ │ │ └ Dockerfile │ │ ├ production │ │ │ ├ default.conf │ │ │ └ Dockerfile │ │ └ nginx.conf │ └ rails │ └ Dockerfile ├ src │ └ ※railsアプリのソースをここに置きます。後述 ├ .gitignore ├ buildspec.yml ├ docker-compose.common.yml ├ docker-compose.development.yml ├ docker-compose.production.yml └ README.md開発環境と本番環境で
docker-composeの内容にかなり差があるので、ファイルを分けています。
共通する内容はdocker-compose.common.ymlに記述して、なるべく助長化を防ぎます。
ただし、nginxのDockerfileに関しては環境ごとにほぼ同じ内容でファイルを分けて作っています。これも後述しますが、最後までハマり続けたポイントを解決するための苦肉の策です。
docker-compose
docker-compose.common.ymlversion: '2' services: server: environment: TZ: Asia/Tokyo ports: - '80:80' web: build: context: . dockerfile: ./docker/rails/Dockerfile ports: - '3000:3000' volumes: - ./src:/app extends: file: ./docker/mysql/password.yml service: password db: build: context: . dockerfile: ./docker/mysql/Dockerfile ports: - '3306:3306' extends: file: ./docker/mysql/password.yml service: passworddocker-compose.development.ymlversion: '2' services: datastore: image: busybox volumes: - /share - ./docker/mysql/volumes:/var/lib/mysql server: build: context: . dockerfile: ./docker/nginx/development/Dockerfile extends: file: docker-compose.common.yml service: server volumes_from: - datastore depends_on: - datastore web: extends: file: docker-compose.common.yml service: web command: bundle exec unicorn -p 3000 -c /app/config/unicorn.rb volumes_from: - datastore depends_on: - db db: extends: file: docker-compose.common.yml service: db volumes_from: - datastore depends_on: - datastoredocker-compose.production.ymlversion: '2' services: server: build: context: . dockerfile: ./docker/nginx/production/Dockerfile extends: file: docker-compose.common.yml service: server web: extends: file: docker-compose.common.yml service: web depends_on: - server environment: RAILS_ENV: production DB_HOST: ◯◯.△△.ap-northeast-1.rds.amazonaws.com DB_USERNAME: ユーザー名 DB_PASSWORD: パスワード DB_DATABASE: データベース名serviceで言えば、
development
- datastore → busybox
- server → nginx
- web → ruby(rails)
- db → mysql
production
- server → nginx
- web → ruby(rails)
といった構成になっています。
本番環境ではECS fargate上でストレージの共有ができるのでdatastoreは不要です。
また、データベースはRDSを用いるのでdbも不要です。Dockerfile
nginx
docker/nginx/development/DockerfileFROM nginx:1.11 RUN apt-get update && \ apt-get install -y apt-utils \ locales && \ sed -i -e 's/# ja_JP.UTF-8/ja_JP.UTF-8/g' /etc/locale.gen && \ locale-gen ja_JP.UTF-8 ENV LANG ja_JP.UTF-8 ENV LC_TIME C ADD ./docker/nginx/nginx.conf /etc/nginx/nginx.conf # productionでは次の行のファイルパスが変わる ADD ./docker/nginx/development/default.conf /etc/nginx/conf.d/default.confrails
docker/rails/DockerfileFROM ruby:2.2.3 RUN apt-get update -qq && \ apt-get install -y apt-utils \ build-essential \ libpq-dev \ nodejs \ mysql-client RUN mkdir /app WORKDIR /app ADD ./src/Gemfile /app/Gemfile ADD ./src/Gemfile.lock /app/Gemfile.lock RUN bundle install -j4 ADD ./src /app EXPOSE 3000 # 次の行は本番環境でしか実行されない CMD ["unicorn", "-p", "3000", "-c", "/app/config/unicorn.rb", "-E", "production"]mysql
docker/mysql/DockerfileFROM mysql:5.7 RUN apt-get update && \ apt-get install -y apt-utils \ locales && \ rm -rf /var/lib/apt/lists/* && \ echo "ja_JP.UTF-8 UTF-8" > /etc/locale.gen && \ locale-gen ja_JP.UTF-8 ENV LC_ALL ja_JP.UTF-8 ADD ./docker/mysql/charset.cnf /etc/mysql/conf.d/charset.cnfそれぞれのコンテナのコマンドやファイルのコピー、ライブラリの更新などは
Dockerfileに記述するようなイメージがあります。
また、ローカルのdockerではコマンドが動いても本番では動かない、もしくはその逆が度々あったので、railsのDockerfileにはCMDの記述がされています。その他のファイル
nginx
docker/nginx/development/default.confupstream unicorn { # productionではserver以降が 127.0.0.1:3000 になる server unix:/share/unicorn.sock; } server { listen 80 default_server; server_name localhost; root /app/public; try_files $uri/index.html $uri @unicorn; proxy_connect_timeout 600; proxy_read_timeout 600; proxy_send_timeout 600; location @unicorn { proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header Host $http_host; proxy_pass http://unicorn; } }docker/nginx/nginx.confuser nginx; worker_processes 1; error_log /var/log/nginx/error.log warn; pid /var/run/nginx.pid; events { worker_connections 1024; } http { include /etc/nginx/mime.types; default_type application/octet-stream; log_format main '$remote_addr - $remote_user [$time_local] "$request" ' '$status $body_bytes_sent "$http_referer" ' '"$http_user_agent" "$http_x_forwarded_for"'; access_log /var/log/nginx/access.log main; sendfile on; keepalive_timeout 600; include /etc/nginx/conf.d/*.conf; }ここでのポイントは
default.confの2行目の記述と、それぞれのファイルのtimeoutの時間設定です。
この2点が今回ハマって、かなりの時間を奪われたポイントでした。1. ソケットファイル
default.conf(抜粋)upstream unicorn { # productionではserver以降が 127.0.0.1:3000 になる server unix:/share/unicorn.sock; }developmentではbusyboxを使ったストレージ共有で、ソケットファイルを準備していました。
nginxとrails(unicorn)の両方から、同じソケットファイルを見ることで繋げるようなイメージですが、本番環境ではストレージの共有ができず、直接ローカルIPとポート127.0.0.1:3000を指定したら動きました。2. タイムアウト
default.conf(抜粋)proxy_connect_timeout 600; proxy_read_timeout 600; proxy_send_timeout 600;nginx.conf(抜粋)keepalive_timeout 600;railsサーバーやRDSへの接続には少なからず時間がかかります。
キャッシュが効き始めれば読み込み速度は大きく向上するのですが、初回アクセス時などは504 Gateway Time-Outのエラーになることも多くありました。
そのため、タイムアウトまでの時間を伸ばしました。
デフォルトは60秒などで設定されていると思います。mysql
docker/mysql/charset.cnf[mysqld] character-set-server=utf8mb4 collation-server=utf8mb4_general_ci [client] default-character-set=utf8mb4docker/mysql/password.ymlversion: '2' services: password: environment: MYSQL_ROOT_PASSWORD: ルートパスワード TZ: "Asia/Tokyo"セキュアな情報はできるだけコード上には書きたくなかったのですが、最低限環境変数として管理できるようにしました。
運用段階までにはもう少し改善したいです。railsソース側の変更
unicornというgemの設定と、mysqlとRDSを使い分けるための設定をします。unicorn
unicornはrailsのアプリケーションサーバとnginxのwebサーバを繋げるためのpassengerのようなモジュールの位置付けです。
単体でもサーバとして使えるらしいです。src/Gemfile# 追記 gem "unicorn"bundle installインストールが完了したら、早速設定ファイルを編集します。
src/configディレクトリにunicorn.rbファイルがない場合は作ります。src/config/unicorn.rbworker_processes 2 pid "/var/run/unicorn.pid" # developmentとproductionで場合分け if ENV['RAILS_ENV'] == 'production' listen 3000 else listen "/share/unicorn.sock" end # タイムアウトまでの時間を伸ばす timeout 600ここでも先程のnginxと同じように、開発環境と本番環境の場合分け、タイムアウトの設定をしています。
特にlistenの値はdefault.confと設定がズレていると起動後に上手く繋がらないので、ご注意ください。mysql
src/config/database.ymldefault: &default adapter: mysql2 encoding: utf8 pool: 5 timeout: 5000 development: <<: *default username: 開発環境のユーザー名 password: <%= ENV['MYSQL_ROOT_PASSWORD'] %> database: 開発環境のデータベース名 host: db production: <<: *default host: <%= ENV['DB_HOST'] %> username: <%= ENV['DB_USERNAME'] %> password: <%= ENV['DB_PASSWORD'] %> database: <%= ENV['DB_DATABASE'] %>
Dockerfileやpassword.ymlで設定してきた環境変数がここで読み込まれていきます。
developmentのhostで指定しているdbというのはdocker-compose.ymlでデータベースに設定しているサービス名です。
別の名前に設定している場合はそちらの名前にしてください。ビルドと起動
やっと動かす段階です。
dockerを起動しておいてください。
また、3000番ポート、3306番ポートを使うので、他で使っていれば、そちらを停止しておきます。
プロジェクトのルートディレクトリでコマンドを打ちます。ビルドdocker-compose -f docker-compose.development.yml -p development buildデータベース作成(初回のみ)docker-compose -f docker-compose.development.yml -p development run --rm web rake db:createマイグレート(変更があった場合のみ)docker-compose -f docker-compose.development.yml -p development run --rm web rake db:migrate起動docker-compose -f docker-compose.development.yml -p development up -dこれでブラウザで
localhostにアクセスすると、railsのホーム画面が見られると思います。
ちなみに、停止コマンドは以下です。停止docker-compose -f docker-compose.development.yml -p development stop
docker-compose -f docker-compose.development.yml -p developmentは共通なので、お使いのshellでエイリアスに登録してもいいかと思います。
当方の設定を参考に載せておきます。.zshrcalias dcdev='docker-compose -f docker-compose.development.yml -p development' # コンテナ全削除 alias drm='docker rm $(docker ps -q -a) -f' # イメージ全削除 alias dirm='docker rmi $(docker images -q) -f'次回、AWS編へ続きます。

- 投稿日:2019-08-22T14:29:32+09:00
ECS FargateでRails動かそうとして2ヶ月かかって手元に残ったもの【1.docker編】
弊社の基幹システムをVPSからAWSに移行するにあたって、まずはrailsを動かしてみる、という段階で無事に死にました☆
今後のための備忘録です。やりたいこと
こんな感じ。今回やったこと
ファイル構成
プロジェクトルート ├ docker │ ├ mysql │ │ ├ volumes │ │ │ └ ※mysqlの永続化に使う。後述 │ │ ├ charset.cnf │ │ ├ password.yml │ │ └ Dockerfile │ ├ nginx │ │ ├ development │ │ │ ├ default.conf │ │ │ └ Dockerfile │ │ ├ production │ │ │ ├ default.conf │ │ │ └ Dockerfile │ │ └ nginx.conf │ └ rails │ └ Dockerfile ├ src │ └ ※railsアプリのソースをここに置きます。後述 ├ .gitignore ├ buildspec.yml ├ docker-compose.common.yml ├ docker-compose.development.yml ├ docker-compose.production.yml └ README.md開発環境と本番環境で
docker-composeの内容にかなり差があるので、ファイルを分けています。
共通する内容はdocker-compose.common.ymlに記述して、なるべく助長化を防ぎます。
ただし、nginxのDockerfileに関しては環境ごとにほぼ同じ内容でファイルを分けて作っています。これも後述しますが、最後までハマり続けたポイントを解決するための苦肉の策です。
docker-compose
docker-compose.common.ymlversion: '2' services: server: environment: TZ: Asia/Tokyo ports: - '80:80' web: build: context: . dockerfile: ./docker/rails/Dockerfile ports: - '3000:3000' volumes: - ./src:/app extends: file: ./docker/mysql/password.yml service: password db: build: context: . dockerfile: ./docker/mysql/Dockerfile ports: - '3306:3306' extends: file: ./docker/mysql/password.yml service: passworddocker-compose.development.ymlversion: '2' services: datastore: image: busybox volumes: - /share - ./docker/mysql/volumes:/var/lib/mysql server: build: context: . dockerfile: ./docker/nginx/development/Dockerfile extends: file: docker-compose.common.yml service: server volumes_from: - datastore depends_on: - datastore web: extends: file: docker-compose.common.yml service: web command: bundle exec unicorn -p 3000 -c /app/config/unicorn.rb volumes_from: - datastore depends_on: - db db: extends: file: docker-compose.common.yml service: db volumes_from: - datastore depends_on: - datastoredocker-compose.production.ymlversion: '2' services: server: build: context: . dockerfile: ./docker/nginx/production/Dockerfile extends: file: docker-compose.common.yml service: server web: extends: file: docker-compose.common.yml service: web depends_on: - server environment: RAILS_ENV: production DB_HOST: ◯◯.△△.ap-northeast-1.rds.amazonaws.com DB_USERNAME: ユーザー名 DB_PASSWORD: パスワード DB_DATABASE: データベース名serviceで言えば、
development
- datastore → busybox
- server → nginx
- web → ruby(rails)
- db → mysql
production
- server → nginx
- web → ruby(rails)
といった構成になっています。
developmentのdatastoreでvolumesとしてローカルディレクトリのdocker/mysql/volumesを/var/lib/mysqlにマウントしています。
dockerはイメージを停止するとデータが消えてしまいますが、このようにすることで、開発環境のデータベースを永続化できます。
docker/mysql/volumesの中身は.gitignoreに設定して、git管理はしないようにしましょう。本番環境ではECS fargate上でストレージの共有ができるので
datastoreは不要です。
また、データベースはRDSを用いるのでdbも不要です。Dockerfile
nginx
docker/nginx/development/DockerfileFROM nginx:1.11 RUN apt-get update && \ apt-get install -y apt-utils \ locales && \ sed -i -e 's/# ja_JP.UTF-8/ja_JP.UTF-8/g' /etc/locale.gen && \ locale-gen ja_JP.UTF-8 ENV LANG ja_JP.UTF-8 ENV LC_TIME C ADD ./docker/nginx/nginx.conf /etc/nginx/nginx.conf # productionでは次の行のファイルパスが変わる ADD ./docker/nginx/development/default.conf /etc/nginx/conf.d/default.confrails
docker/rails/DockerfileFROM ruby:2.2.3 RUN apt-get update -qq && \ apt-get install -y apt-utils \ build-essential \ libpq-dev \ nodejs \ mysql-client RUN mkdir /app WORKDIR /app ADD ./src/Gemfile /app/Gemfile ADD ./src/Gemfile.lock /app/Gemfile.lock RUN bundle install -j4 ADD ./src /app EXPOSE 3000 # 次の行は本番環境でしか実行されない CMD ["unicorn", "-p", "3000", "-c", "/app/config/unicorn.rb", "-E", "production"]mysql
docker/mysql/DockerfileFROM mysql:5.7 RUN apt-get update && \ apt-get install -y apt-utils \ locales && \ rm -rf /var/lib/apt/lists/* && \ echo "ja_JP.UTF-8 UTF-8" > /etc/locale.gen && \ locale-gen ja_JP.UTF-8 ENV LC_ALL ja_JP.UTF-8 ADD ./docker/mysql/charset.cnf /etc/mysql/conf.d/charset.cnfそれぞれのコンテナのコマンドやファイルのコピー、ライブラリの更新などは
Dockerfileに記述するようにしています。
ただ、ローカルのdockerではコマンドが動いても本番では動かない、もしくはその逆が度々あったので、railsのDockerfileにはCMDの記述がされていたりしますが、productionでしか使わないコマンドがDockerfileに書いてあるのは気持ち悪い気がするので、ここは後々修正したいです。その他のファイル
nginx
docker/nginx/development/default.confupstream unicorn { # productionではserver以降が 127.0.0.1:3000 になる server unix:/share/unicorn.sock; } server { listen 80 default_server; server_name localhost; root /app/public; try_files $uri/index.html $uri @unicorn; proxy_connect_timeout 600; proxy_read_timeout 600; proxy_send_timeout 600; location @unicorn { proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header Host $http_host; proxy_pass http://unicorn; } }docker/nginx/nginx.confuser nginx; worker_processes 1; error_log /var/log/nginx/error.log warn; pid /var/run/nginx.pid; events { worker_connections 1024; } http { include /etc/nginx/mime.types; default_type application/octet-stream; log_format main '$remote_addr - $remote_user [$time_local] "$request" ' '$status $body_bytes_sent "$http_referer" ' '"$http_user_agent" "$http_x_forwarded_for"'; access_log /var/log/nginx/access.log main; sendfile on; keepalive_timeout 600; include /etc/nginx/conf.d/*.conf; }ここでのポイントは
default.confの2行目の記述と、それぞれのファイルのtimeoutの時間設定です。
この2点が今回ハマって、かなりの時間を奪われたポイントでした。1. ソケットファイル
default.conf(抜粋)upstream unicorn { # productionではserver以降が 127.0.0.1:3000 になる server unix:/share/unicorn.sock; }developmentではbusyboxを使ったストレージ共有で、ソケットファイルを準備していました。
nginxとrails(unicorn)の両方から、同じソケットファイルを見ることで繋げるようなイメージですが、本番環境ではストレージの共有ができず、直接ローカルIPとポート127.0.0.1:3000を指定したら動きました。なるべく助長なファイル構成は避けたかったのですが、nginxの設定ファイルに環境変数などを読み込ませることが手間だったので、このファイルは開発環境と本番環境でほとんど同じ内容なのですが、環境ごとにファイルを分けて対応しています。
2. タイムアウト
default.conf(抜粋)proxy_connect_timeout 600; proxy_read_timeout 600; proxy_send_timeout 600;nginx.conf(抜粋)keepalive_timeout 600;railsサーバーやRDSへの接続には少なからず時間がかかります。
キャッシュが効き始めれば読み込み速度は大きく向上するのですが、初回アクセス時などは504 Gateway Time-Outのエラーになることも多くありました。
そのため、タイムアウトまでの時間を伸ばしました。
デフォルトは60秒などで設定されていると思います。mysql
docker/mysql/charset.cnf[mysqld] character-set-server=utf8mb4 collation-server=utf8mb4_general_ci [client] default-character-set=utf8mb4docker/mysql/password.ymlversion: '2' services: password: environment: MYSQL_ROOT_PASSWORD: ルートパスワード TZ: "Asia/Tokyo"セキュアな情報はできるだけコード上には書きたくなかったのですが、最低限環境変数として管理できるようにしました。
運用段階までにはもう少し改善したいです。railsソース側の変更
当方は複数のrailsアプリケーションを管理する必要があったので、docker関連のファイルを容易に使い回せるように、あえてrailsアプリケーションのソースはsrcディレクトリに分けて配置しています。
ここではunicornというgemの設定と、mysqlとRDSを使い分けるための設定をします。unicorn
unicornはrailsのアプリケーションサーバとnginxのwebサーバを繋げるためのpassengerのようなモジュールの位置付けです。
単体でもサーバとして使えるらしいです。src/Gemfile# 追記 gem "unicorn"bundle installインストールが完了したら、早速設定ファイルを編集します。
src/configディレクトリにunicorn.rbファイルがない場合は作ります。src/config/unicorn.rbworker_processes 2 pid "/var/run/unicorn.pid" # developmentとproductionで場合分け if ENV['RAILS_ENV'] == 'production' listen 3000 else listen "/share/unicorn.sock" end # タイムアウトまでの時間を伸ばす timeout 600ここでも先程のnginxと同じように、開発環境と本番環境の場合分け、タイムアウトの設定をしています。
特にlistenの値はdefault.confと設定がズレていると起動後に上手く繋がらないので、ご注意ください。mysql
src/config/database.ymldefault: &default adapter: mysql2 encoding: utf8 pool: 5 timeout: 5000 development: <<: *default username: 開発環境のユーザー名 password: <%= ENV['MYSQL_ROOT_PASSWORD'] %> database: 開発環境のデータベース名 host: db production: <<: *default host: <%= ENV['DB_HOST'] %> username: <%= ENV['DB_USERNAME'] %> password: <%= ENV['DB_PASSWORD'] %> database: <%= ENV['DB_DATABASE'] %>
Dockerfileやpassword.ymlで設定してきた環境変数がここで読み込まれていきます。
developmentのhostで指定しているdbというのはdocker-compose.ymlでデータベースに設定しているサービス名です。
別の名前に設定している場合はそちらの名前にしてください。ビルドと起動
やっと動かす段階です。
dockerを起動しておいてください。
また、3000番ポート、3306番ポートを使うので、他で使っていれば、そちらを停止しておきます。
プロジェクトのルートディレクトリでコマンドを打ちます。ビルドdocker-compose -f docker-compose.development.yml -p development buildデータベース作成(初回のみ)docker-compose -f docker-compose.development.yml -p development run --rm web rake db:createマイグレート(変更があった場合のみ)docker-compose -f docker-compose.development.yml -p development run --rm web rake db:migrate起動docker-compose -f docker-compose.development.yml -p development up -dこれでブラウザで
localhostにアクセスすると、railsのホーム画面が見られると思います。
ちなみに、停止コマンドは以下です。停止docker-compose -f docker-compose.development.yml -p development stop
docker-compose -f docker-compose.development.yml -p developmentは共通なので、お使いのshellでエイリアスに登録してもいいかと思います。
当方の設定を参考に載せておきます。.zshrcalias dcdev='docker-compose -f docker-compose.development.yml -p development' # コンテナ全削除 alias drm='docker rm $(docker ps -q -a) -f' # イメージ全削除 alias dirm='docker rmi $(docker images -q) -f'ここまででできたこと
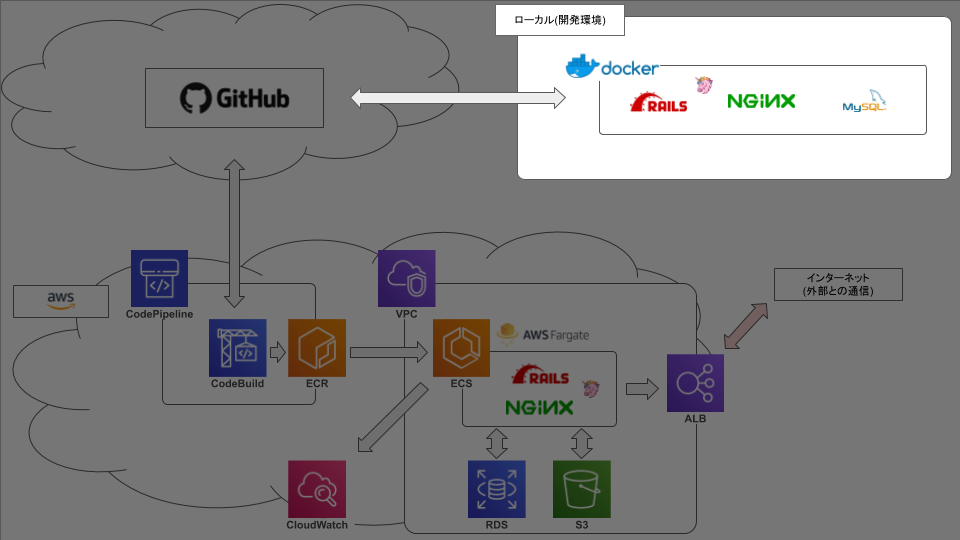
- 投稿日:2019-08-22T14:28:59+09:00
AWS Loft Tokyoに行ってみたよ
はじめに
前から興味はあったけど、敷居が高そうでなかなか行けてなかったけど特攻してみました。
プログラミングに触れて3ヶ月、AWSは無料枠しか使っていない私でも入れるものなのか…基本情報
まず軽くAWSLoftTokyoの情報から
細かい情報は公式さんでAWS Loft は、AWS を利用中のスタートアップおよびデベロッパーのための施設です。
リラックスした雰囲気のコ・ワーキングスペースや毎週開催される様々なセミナー、AWS のテクノロジーに熟達した AWS のソリューションアーキテクトやサポートエンジニアへいつでも技術的な相談が可能な「Ask An Expert カウンター」もご用意しております。
ぜひ AWS Loft Tokyo へお越しください。ざっくりAmazonがAWSの利用者に対して、提供している場所です。
会社でディベロッパーやってる人とかしか入れないと思っていたのですが、アカウントさえ持っていれば入れるそうなのできてみました。ちなみに無料枠しか使っていないようなアカウントです。いざ潜入
ビルに入ると受付があり、警備員にAWSLoftを利用しにきた旨を伝えます。その後すんなりエレベーターで17階へ。
受付で初回に確認されることは
・AWSアカウントのマイアカウントのページ→登録にIDが必要なのと、アクティブなユーザーかを確認してるようです
・本人確認書類→免許証など。名刺2枚でもいいらしいです
・個人情報→住所やら。職業を記入するところがありますが、無職ならfreeとか書いておけばいいそうです。
以上を入力したら、一通りの説明と入場者用のシールを渡されます。
ここに名前とか会社名、職種が記入されるので適当には書かない方がいいです!あとwifiの情報も書いてあります。
シールを見えるところに貼ったらあとは自由に使えます。
ちなみに2回目以降はメールアドレスの入力と、本人確認書類だけでいいそうです。中の印象
非常に良いです。その一言につきます。
中にドリンクを売っているところがありますが、安いですしウォーターサーバーも無料でありますし。
予想はもう少しカジュアルな場所かと思っていましたが、どちらかと言えば、みんな集中して黙々と作業をしている感じです。
内装は如何にもWeb系キラキラ環境みたいな感じでむしろ場違い感すらあります。
昼過ぎに行ったのですが、8割くらい席が埋まっていました。
中の情報は公式さんや他の投稿の方が参考になると思うので割愛します。まとめ
特攻した甲斐がありました。どうやら本当にアカウントさえ持っていれば職業としてエンジニアじゃなくても問題なく利用出来る場所の様なのでぜひ近くの方は一度利用してみると良いと思います。
個人的には普段勉強している渋谷よりも近いですし、雰囲気も非常に好みなので、しばらく機会があればこちらで勉強しようかなと思いました!
- 投稿日:2019-08-22T12:28:41+09:00
AWS Media Serviceの学習方法について
はじめに
こんにちは。ktsuchiです。
今の会社に転職してから、ちょうど1年が経ちました。
約3ヶ月前には後輩が入ってきて、賑やかな日々を送っています。今回は、AWSが新たなトレーニングメニューとして
Media Serviceのページを公開したので、そのことについて記事にします。概要
2019年8月6日、AWS Media Blogにて
AWS Media Serviceの学習方法についての情報が公開されました。
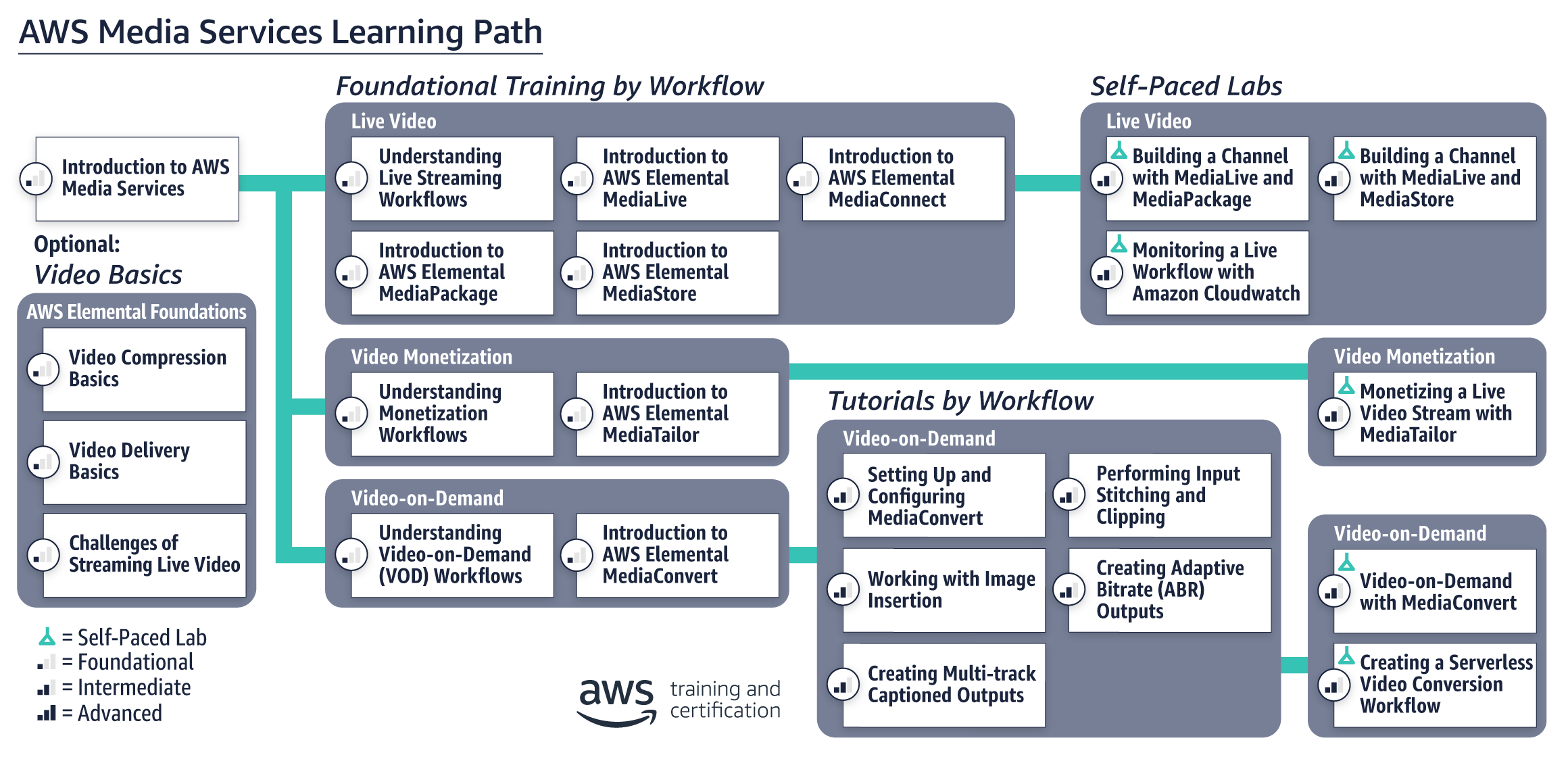
- AWS Media Services Learning Path
出典:https://aws.amazon.com/jp/blogs/media/aws-media-services-learning-path/
===
トレーニングページの導入文には、このように書かれています。
この学習過程は、専用のビデオ機器を実行する際に必要とされる時間、労力、費用をかけずに、AWS メディアサービスでプロフェッショナル品質のメディアエクスペリエンスを実現する方法を学びたいという方を対象としています。
基本的な動画の概念から技術的な詳細へと進み、AWS クラウドの動画処理、ストレージ、および収益化のワークフローを使用して、組織がライブおよびオンデマンドのビデオを配信できるようにします。
AWSが用意したトレーニングメニューに沿って学習を進めることによって
受講者がスムーズにMedia Serviceを理解し、利用できるようになるのが狙いのようですね。コース内容
ページに記載があった、コースの詳細を抜粋します。
基本的な内容から、実践的な操作まで網羅されているようです。
コース概要 詳細 ビデオの基礎 動画圧縮の基礎、動画配信の基礎、ストリーミング動画の課題 ライブ動画 MediaLive / MediaConnect / MediaPackage / MediaStoreの概要、etc. 動画の収益化 収益化ワークフロー、MediaTailor の概要、etc. ビデオオンデマンド MediaConvert の概要、画像挿入の操作、ABR出力の作成、etc. 出典:https://aws.amazon.com/jp/training/path-mediaservices/
触ってみた
せっかくなので、試しに「動画圧縮の基礎」のコースを開始してみました。
トレーニングページには、日本語の記載がありましたが、
実際の内容は、音声も資料も全て英語となっていました。おわりに
僕も1年前まで、動画に関しては門外漢だったので、
このようなトレーニングが用意されているのは、勉強する上でとてもありがたいですね。MediaServiceの情報を効率よく得たい方や
MediaServiceに興味はあるけどまだ触ったことない方には、ピッタリかと思います。英語の勉強にもなるので、一石二鳥ですね。
参考
AWS Media Services Learning Path
https://aws.amazon.com/jp/blogs/media/aws-media-services-learning-path/AWS メディアサービス トレーニングページ
https://aws.amazon.com/jp/training/path-mediaservices/

- 投稿日:2019-08-22T12:25:02+09:00
CloudWatch Alarmのアクションの無効をスケジューリングしてみた
CloudWatch Alarmのアクションは設定するとデフォルトで有効となります。マネジメントコンソールではアクションを無効にすることができないみたいなのでaws-cliで無効化をしてみました。
TL;DR
CloudWatchAlarmのアクションはaws-cliでなら無効化できます。
Lambda(Python)でもやってみました。
LambdaとCloudWatchEventでスケジューリングします。対象読者 or 前提条件 or 環境
- ある一定の期間だけ監視による処理を無効化したい人
- AWS-CLI
- AWS SDK (Python - boto3)
- 2019/08/22時点の情報
- CloudWatchAlarmは設定済
AWSマネジメントコンソールでの表記
CloudWatchのコンソール画面で、アクションの有効/無効を確認します。
最近、CloudWatchのコンソール画面のUIは新しいデザインに変更となりました。
- 旧コンソール
[アクションが有効になっています]にチェックを入れ、確認します。
- 新コンソール
新デザインの画面ではこのような感じです。
有効/無効の確認はコンソールではこのように確認できます。
AWS-CLIで無効化
CloudWatchアラームの表示
- アラーム一覧を表示してみます
aws cloudwatch describe-alarmsコマンドのオプションは次のとおり
describe-alarms
[--alarm-names ]
[--alarm-name-prefix ]
[--state-value ]
[--action-prefix ]
[--cli-input-json ]
[--starting-token ]
[--page-size ]
[--max-items ]
[--generate-cli-skeleton ]この記事では
demo-alermというNameのアラームを以降対象とします。
※alarmのスペルが間違っているのはスルーしてください。('ω')aws cloudwatch describe-alarms --alarm-names demo-alerm{ "MetricAlarms": [ { "AlarmName": "demo-alerm", "AlarmArn": "arn:aws:cloudwatch:ap-northeast-1:************:alarm:demo-alerm", "AlarmDescription": "demo", "AlarmConfigurationUpdatedTimestamp": "2019-08-22T01:24:19.696Z", "ActionsEnabled": true, "OKActions": [], "AlarmActions": [ "arn:aws:sns:ap-northeast-1:************:test" ], "InsufficientDataActions": [], "StateValue": "INSUFFICIENT_DATA", "StateReason": "Insufficient Data: 1 datapoint was unknown.", "StateReasonData": "{\"version\":\"1.0\",\"queryDate\":\"2019-08-05T13:11:02.108+0000\",\"statistic\":\"Average\",\"period\":300,\"recentDatapoints\":[],\"threshold\":90.0}", "StateUpdatedTimestamp": "2019-08-05T13:11:02.112Z", "MetricName": "CPUUtilization", "Namespace": "AWS/EC2", "Statistic": "Average", "Dimensions": [ { "Name": "InstanceId", "Value": "i-*****************" } ], "Period": 300, "EvaluationPeriods": 1, "DatapointsToAlarm": 1, "Threshold": 90.0, "ComparisonOperator": "GreaterThanThreshold", "TreatMissingData": "missing" } ] }
"ActionsEnabled": trueになっているのが確認できました。これをfalseに変更します。
アクションの無効化
disable-alarm-actionsを使用します。
オプションは次のとおり。disable-alarm-actions
--alarm-names
[--cli-input-json ]
[--generate-cli-skeleton ]aws cloudwatch disable-alarm-actions --alarm-names demo-alerm確認してみます。
{ "MetricAlarms": [ { "AlarmName": "demo-alerm", "AlarmArn": "arn:aws:cloudwatch:ap-northeast-1:************:alarm:demo-alerm", "AlarmDescription": "demo", "AlarmConfigurationUpdatedTimestamp": "2019-08-22T02:15:26.395Z", "ActionsEnabled": false, "OKActions": [], "AlarmActions": [ "arn:aws:sns:ap-northeast-1:************:test" ], "InsufficientDataActions": [], "StateValue": "INSUFFICIENT_DATA", "StateReason": "Insufficient Data: 1 datapoint was unknown.", "StateReasonData": "{\"version\":\"1.0\",\"queryDate\":\"2019-08-05T13:11:02.108+0000\",\"statistic\":\"Average\",\"period\":300,\"recentDatapoints\":[],\"threshold\":90.0}", "StateUpdatedTimestamp": "2019-08-05T13:11:02.112Z", "MetricName": "CPUUtilization", "Namespace": "AWS/EC2", "Statistic": "Average", "Dimensions": [ { "Name": "InstanceId", "Value": "i-*****************" } ], "Period": 300, "EvaluationPeriods": 1, "DatapointsToAlarm": 1, "Threshold": 90.0, "ComparisonOperator": "GreaterThanThreshold", "TreatMissingData": "missing" } ] }
"ActionsEnabled": falsefalseに変更されました。コンソールを確認してみましょう。
無効になっていることが確認できました。
アクションの有効化
有効にするには、
enable-alarm-actionsを使用します。aws cloudwatch enable-alarm-actions --alarm-names demo-alerm同様にオプションは次のとおり。
enable-alarm-actions
--alarm-names
[--cli-input-json ]
[--generate-cli-skeleton ]確認をして
"ActionsEnabled": true,画面では有効になっていればOKです。AWS SDK (Python boto3)でアラームを無効化(Lambda)
AWS-CLIでやったことをAWS-SDK(Python-boto3)でやってみます。
CloudWatchアラームの表示
boto3 でアラームを表示してみます。
※json形式をコマンドラインに見やすく表示するためにpprintを使用しています。ソースコードは次のとおり。
import boto3 from pprint import pprint client = boto3.client('cloudwatch') response = client.describe_alarms(AlarmNames=['demo-alerm']) pprint(response)アクションの無効化
CloudWatchAlarmのアクションを無効化します。
ソースコードは次のとおり。import boto3 from pprint import pprint def show_cloudwatch_alarm(): client = boto3.client('cloudwatch') response = client.describe_alarms(AlarmNames=['demo-alerm']) pprint(response) cloudwatch = boto3.resource('cloudwatch') alarm = cloudwatch.Alarm('demo-alerm') #alarm.enable_actions() alarm.disable_actions() show_cloudwatch_alarm()
'ActionsEnabled': FalseとなっていればOKです。アクションの有効化
CloudWatchAlarmのアクションを有効化します。
ソースコードは次のとおり。import boto3 from pprint import pprint def show_cloudwatch_alarm(): client = boto3.client('cloudwatch') response = client.describe_alarms(AlarmNames=['demo-alerm']) pprint(response) cloudwatch = boto3.resource('cloudwatch') alarm = cloudwatch.Alarm('demo-alerm') alarm.enable_actions() #alarm.disable_actions() show_cloudwatch_alarm()
'ActionsEnabled': TrueとなっていればOKです。LambdaとCloudWatchEventで無効化をスケジューリングする
細かい設定はこの記事では割愛します。
Lambdaを準備する
IAMロールには
CloudWatchFullAccessを使用しました。テストイベントは次の2つを用意し対応させています。
テストイベント①
{ "param": "enable" }テストイベント②
{ "param": "disable" }ソースコード
import boto3 from pprint import pprint def show_cloudwatch_alarm(): client = boto3.client('cloudwatch') response = client.describe_alarms(AlarmNames=['demo-alerm']) pprint(response) def lambda_handler(event, context): cloudwatch = boto3.resource('cloudwatch') alarm = cloudwatch.Alarm('demo-alerm') param = event['param'] if(param == 'enable'): alarm.enable_actions() elif(param == 'disable'): alarm.disable_actions() else: print('パラメータが正しく設定されていません。') show_cloudwatch_alarm()CloudWatchEventでLambdaをスケジューリングする
Lambda関数の名前は
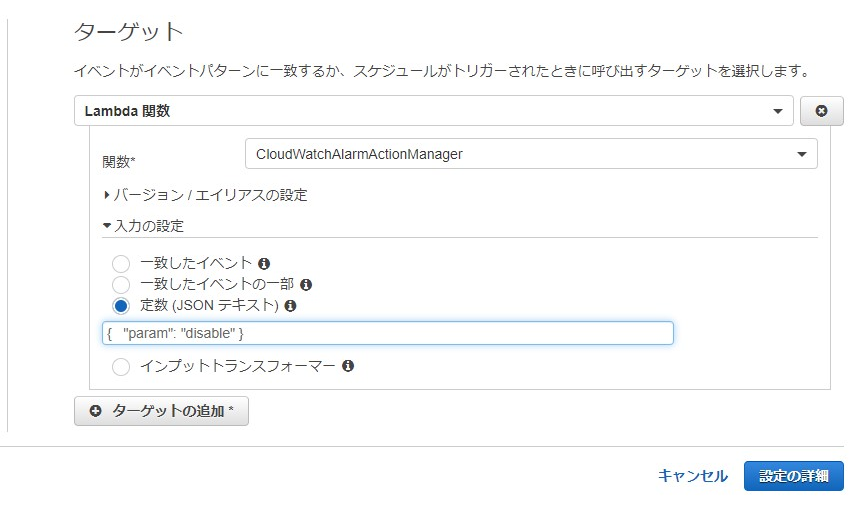
CloudWatchAlarmActionManagerとしました。無効化する場合には、次の図のように
{ "param": "disable" }と入力します。
有効化する場合には、
{ "param": "enable" }とします。result
5分後に設定し、無事無効化できました。
参考
あとがき
これで、任意のタイミングで通知やその他の監視によるトリガーのアクションを無効にしておくことができるようになりました。
記事を作成した後に検索してみたら、既に情報は出回ってました。('ω')
下記に一部取り上げておきます。ご参考までにどうぞ。

- 投稿日:2019-08-22T12:25:02+09:00
CloudWatch Alarmアクションの無効をスケジューリングしてみた
CloudWatch Alarmのアクションは設定するとデフォルトで有効となります。マネジメントコンソールではアクションを無効にすることができないみたいなのでaws-cliで無効化をしてみました。
また、CloudWatchEventでスケジューリングも検証します。TL;DR
CloudWatchAlarmのアクションはaws-cliでなら無効化できます。
Lambda(Python)でもやってみました。
LambdaとCloudWatchEventでスケジューリングします。対象読者 or 前提条件 or 環境
- ある一定の期間だけ監視による処理を無効化したい人
- AWS-CLI
- AWS SDK (Python - boto3)
- 2019/08/22時点の情報
- CloudWatchAlarmは設定済
AWSマネジメントコンソールでの表記
CloudWatchのコンソール画面で、アクションの有効/無効を確認します。
最近、CloudWatchのコンソール画面のUIは新しいデザインに変更となりました。
- 旧コンソール
[アクションが有効になっています]にチェックを入れ、確認します。
- 新コンソール
新デザインの画面ではこのような感じです。
有効/無効の確認はコンソールではこのように確認できます。
AWS-CLIで無効化
CloudWatchアラームの表示
- アラーム一覧を表示してみます
aws cloudwatch describe-alarmsコマンドのオプションは次のとおり
describe-alarms
[--alarm-names ]
[--alarm-name-prefix ]
[--state-value ]
[--action-prefix ]
[--cli-input-json ]
[--starting-token ]
[--page-size ]
[--max-items ]
[--generate-cli-skeleton ]この記事では
demo-alermというNameのアラームを以降対象とします。
※alarmのスペルが間違っているのはスルーしてください。('ω')aws cloudwatch describe-alarms --alarm-names demo-alerm{ "MetricAlarms": [ { "AlarmName": "demo-alerm", "AlarmArn": "arn:aws:cloudwatch:ap-northeast-1:************:alarm:demo-alerm", "AlarmDescription": "demo", "AlarmConfigurationUpdatedTimestamp": "2019-08-22T01:24:19.696Z", "ActionsEnabled": true, "OKActions": [], "AlarmActions": [ "arn:aws:sns:ap-northeast-1:************:test" ], "InsufficientDataActions": [], "StateValue": "INSUFFICIENT_DATA", "StateReason": "Insufficient Data: 1 datapoint was unknown.", "StateReasonData": "{\"version\":\"1.0\",\"queryDate\":\"2019-08-05T13:11:02.108+0000\",\"statistic\":\"Average\",\"period\":300,\"recentDatapoints\":[],\"threshold\":90.0}", "StateUpdatedTimestamp": "2019-08-05T13:11:02.112Z", "MetricName": "CPUUtilization", "Namespace": "AWS/EC2", "Statistic": "Average", "Dimensions": [ { "Name": "InstanceId", "Value": "i-*****************" } ], "Period": 300, "EvaluationPeriods": 1, "DatapointsToAlarm": 1, "Threshold": 90.0, "ComparisonOperator": "GreaterThanThreshold", "TreatMissingData": "missing" } ] }
"ActionsEnabled": trueになっているのが確認できました。これをfalseに変更します。
アクションの無効化
disable-alarm-actionsを使用します。
オプションは次のとおり。disable-alarm-actions
--alarm-names
[--cli-input-json ]
[--generate-cli-skeleton ]aws cloudwatch disable-alarm-actions --alarm-names demo-alerm確認してみます。
{ "MetricAlarms": [ { "AlarmName": "demo-alerm", "AlarmArn": "arn:aws:cloudwatch:ap-northeast-1:************:alarm:demo-alerm", "AlarmDescription": "demo", "AlarmConfigurationUpdatedTimestamp": "2019-08-22T02:15:26.395Z", "ActionsEnabled": false, "OKActions": [], "AlarmActions": [ "arn:aws:sns:ap-northeast-1:************:test" ], "InsufficientDataActions": [], "StateValue": "INSUFFICIENT_DATA", "StateReason": "Insufficient Data: 1 datapoint was unknown.", "StateReasonData": "{\"version\":\"1.0\",\"queryDate\":\"2019-08-05T13:11:02.108+0000\",\"statistic\":\"Average\",\"period\":300,\"recentDatapoints\":[],\"threshold\":90.0}", "StateUpdatedTimestamp": "2019-08-05T13:11:02.112Z", "MetricName": "CPUUtilization", "Namespace": "AWS/EC2", "Statistic": "Average", "Dimensions": [ { "Name": "InstanceId", "Value": "i-*****************" } ], "Period": 300, "EvaluationPeriods": 1, "DatapointsToAlarm": 1, "Threshold": 90.0, "ComparisonOperator": "GreaterThanThreshold", "TreatMissingData": "missing" } ] }
"ActionsEnabled": falsefalseに変更されました。コンソールを確認してみましょう。
無効になっていることが確認できました。
アクションの有効化
有効にするには、
enable-alarm-actionsを使用します。aws cloudwatch enable-alarm-actions --alarm-names demo-alerm同様にオプションは次のとおり。
enable-alarm-actions
--alarm-names
[--cli-input-json ]
[--generate-cli-skeleton ]確認をして
"ActionsEnabled": true,画面では有効になっていればOKです。AWS SDK (Python boto3)でアラームを無効化(Lambda)
AWS-CLIでやったことをAWS-SDK(Python-boto3)でやってみます。
CloudWatchアラームの表示
boto3 でアラームを表示してみます。
※json形式をコマンドラインに見やすく表示するためにpprintを使用しています。ソースコードは次のとおり。
import boto3 from pprint import pprint client = boto3.client('cloudwatch') response = client.describe_alarms(AlarmNames=['demo-alerm']) pprint(response)アクションの無効化
CloudWatchAlarmのアクションを無効化します。
ソースコードは次のとおり。import boto3 from pprint import pprint def show_cloudwatch_alarm(): client = boto3.client('cloudwatch') response = client.describe_alarms(AlarmNames=['demo-alerm']) pprint(response) cloudwatch = boto3.resource('cloudwatch') alarm = cloudwatch.Alarm('demo-alerm') #alarm.enable_actions() alarm.disable_actions() show_cloudwatch_alarm()
'ActionsEnabled': FalseとなっていればOKです。アクションの有効化
CloudWatchAlarmのアクションを有効化します。
ソースコードは次のとおり。import boto3 from pprint import pprint def show_cloudwatch_alarm(): client = boto3.client('cloudwatch') response = client.describe_alarms(AlarmNames=['demo-alerm']) pprint(response) cloudwatch = boto3.resource('cloudwatch') alarm = cloudwatch.Alarm('demo-alerm') alarm.enable_actions() #alarm.disable_actions() show_cloudwatch_alarm()
'ActionsEnabled': TrueとなっていればOKです。LambdaとCloudWatchEventで無効化をスケジューリングする
細かい設定はこの記事では割愛します。
Lambdaを準備する
IAMロールには
CloudWatchFullAccessを使用しました。テストイベントは次の2つを用意し対応させています。
テストイベント①
{ "param": "enable" }テストイベント②
{ "param": "disable" }ソースコード
import boto3 from pprint import pprint def show_cloudwatch_alarm(): client = boto3.client('cloudwatch') response = client.describe_alarms(AlarmNames=['demo-alerm']) pprint(response) def lambda_handler(event, context): cloudwatch = boto3.resource('cloudwatch') alarm = cloudwatch.Alarm('demo-alerm') param = event['param'] if(param == 'enable'): alarm.enable_actions() elif(param == 'disable'): alarm.disable_actions() else: print('パラメータが正しく設定されていません。') show_cloudwatch_alarm()CloudWatchEventでLambdaをスケジューリングする
Lambda関数の名前は
CloudWatchAlarmActionManagerとしました。無効化する場合には、次の図のように
{ "param": "disable" }と入力します。
有効化する場合には、
{ "param": "enable" }とします。result
5分後に設定し、無事無効化できました。
参考
あとがき
これで、任意のタイミングで通知やその他の監視によるトリガーのアクションを無効にしておくことができるようになりました。
記事を作成した後に検索してみたら、既に情報は出回ってました。('ω')
下記に一部取り上げておきます。ご参考までにどうぞ。
- 投稿日:2019-08-22T12:20:00+09:00
CloudFormationでarnを直接指定せずに、取得する方法
経緯
他のスタックで作成したlayerを参照するlambdaをCloudFormationで作成するときに、layerが更新されるたびにarnが変わってしまい、いちいちテンプレートを修正する必要があったので、何か方法がないかと調べました。
layerのarnarn:aws:lambda:【リージョン】:【アカウントID】:layer:【名前】:【バージョン】バージョンが1,2,3・・・と更新されるため、必ず最新を指定したいときにテンプレートの修正が必要になってしまう。
解決策
スタック名とキーでlayerを指定する。
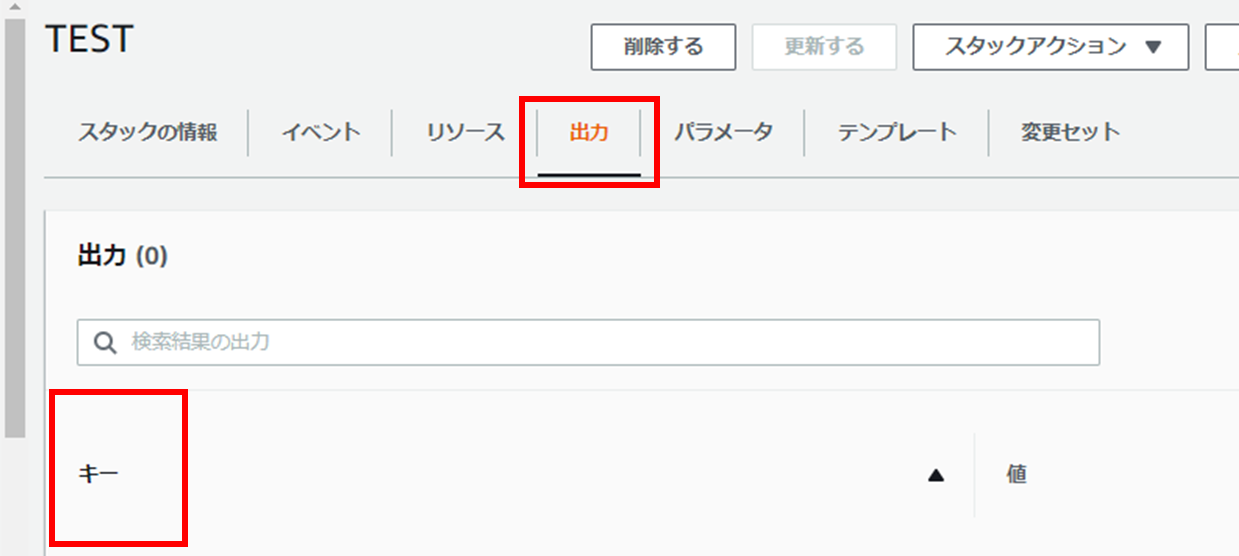
${cf:【スタック名】.【キー】}キーはCloudFormationの管理コンソールから確認可能。
対象のスタックの出力タブで確認する。
キーを指定することで値のarnが取得できる。
これで、テンプレートを修正することなく毎回最新のlayerが指定される。最後に
こういう小技集ほしいですね。
- 投稿日:2019-08-22T12:19:31+09:00
CircleCI Orbs使ってnext.jsアプリをECSにデプロイ
CircleCI Orbsってやつが出てたので、調べてたら下記のようなサンプルが見つかった。
これ見ただけで置き換える価値がありそうだなって思うよね!orbs: aws-cli: circleci/aws-cli@0.1.13 aws-ecr: circleci/aws-ecr@6.2.0 aws-ecs: circleci/aws-ecs@0.0.11- aws-ecr/build-and-push-image: repo: "${AWS_RESOURCE_NAME_PREFIX}" tag: << parameters.env >> - aws-ecs/update-service: family: "${AWS_RESOURCE_NAME_PREFIX}" service-name: "${AWS_RESOURCE_NAME_PREFIX}-service" cluster-name: << parameters.cluster >>Orbsって?
configの標準化、パッケージングのために設定まとめたものみたい。
いろいろあるから興味があれば、レジストリ見てみよう。https://circleci.com/orbs/registry/
ブランチ別実行
ブランチ別で作業したい場合、以前はif文かいてたと思うけど、
変数渡したり、ブランチにfilterかけて実行制御できるみたい。楽ちんだ。Using Environment Variables - CircleCI - https://circleci.com/docs/2.0/env-vars/
deploy: parameters: env: type: enum enum: ["staging", "latest"] cluster: type: enum enum: ["awesomeApp-ECSCluster-stg"] executor: name: default steps: - checkout workflows: setup_and_deploy: jobs: - setup - deploy: name: deploy_staging env: staging cluster: "awesomeApp-ECSCluster-stg" requires: - test filters: branches: only: stagingサンプル
めんどいからサンプル全文貼る。
CircleCIのENVに色々挿してあるのでそこだけ注意。circleci/config.ymlversion: 2.1 orbs: aws-cli: circleci/aws-cli@0.1.13 aws-ecr: circleci/aws-ecr@6.2.0 aws-ecs: circleci/aws-ecs@0.0.11 executors: default: working_directory: ~/workspace docker: - image: circleci/node:10 commands: restore_pkg: steps: - restore_cache: name: Restore node pkg dependencies key: yarn-{{ checksum "yarn.lock" }}-{{ .Environment.CACHE_VERSION_NPM }} save_pkg: steps: - save_cache: name: Cache npm pkg dependencies key: yarn-{{ checksum "yarn.lock" }}-{{ .Environment.CACHE_VERSION_NPM }} paths: - ~/workspace/node_modules jobs: setup: executor: name: default environment: AWS_DEFAULT_OUTPUT: json steps: - checkout - attach_workspace: at: workspace - aws-cli/install - aws-cli/configure: aws-access-key-id: AWS_ACCESS_KEY_ID aws-region: AWS_REGION - restore_pkg - run: name: Install dependencies command: yarn - save_pkg test: executor: name: default steps: - checkout - restore_pkg - run: name: Run test command: yarn test test_build: parameters: env: type: enum enum: ["development"] executor: name: default steps: - checkout - restore_pkg - setup_remote_docker: docker_layer_caching: true - run: name: next build command: yarn build - run: name: docker build command: docker build -t "${AWS_RESOURCE_NAME_PREFIX}:${CIRCLE_SHA1}" . deploy: parameters: env: type: enum enum: ["staging", "latest"] cluster: type: enum enum: ["awesomeApp-ECSCluster", "awesomeApp-ECSCluster-stg"] executor: name: default steps: - checkout - restore_pkg - setup_remote_docker: docker_layer_caching: true - run: name: next build command: yarn build - aws-ecr/build-and-push-image: repo: "${AWS_RESOURCE_NAME_PREFIX}" tag: << parameters.env >> - aws-ecs/update-service: family: "${AWS_RESOURCE_NAME_PREFIX}" service-name: "${AWS_RESOURCE_NAME_PREFIX}-service" cluster-name: << parameters.cluster >> workflows: setup_and_deploy: jobs: - setup - test: requires: - setup - test_build: name: build_development env: development requires: - test filters: branches: ignore: - master - staging - deploy: name: deploy_staging env: staging cluster: "awesomeApp-ECSCluster-stg" requires: - test filters: branches: only: staging - deploy: name: deploy_production env: latest cluster: "awesomeApp-ECSCluster" requires: - test filters: branches: only: master
- 投稿日:2019-08-22T11:09:15+09:00
AWSのIAMユーザー管理簿を毎週自動でメール配信する
はじめに
どこの企業でもセキュリティ対策のためのガイドラインやチェックリストなどがあると思うが、例えばこんな要件があるとする。
アカウントやユーザーの発行/変更/削除の記録を管理簿にて管理すること。
AWSではロールやグループを割り当てたIAMユーザーが発行される。
監査やコンプライアンスの観点からIAMユーザー管理の証跡を残すことは重要だ。1今回はこのIAMユーザーの管理簿作成を自動化してみる。
ざっくり言うと
- IAM認証情報レポートを毎週一回メールで自動配信するようにした2
- CloudWatch/Lambda/SES/S3を組み合わせた
- 社内監査やコンプライアンスチェックのためにファイルを残すことが可能
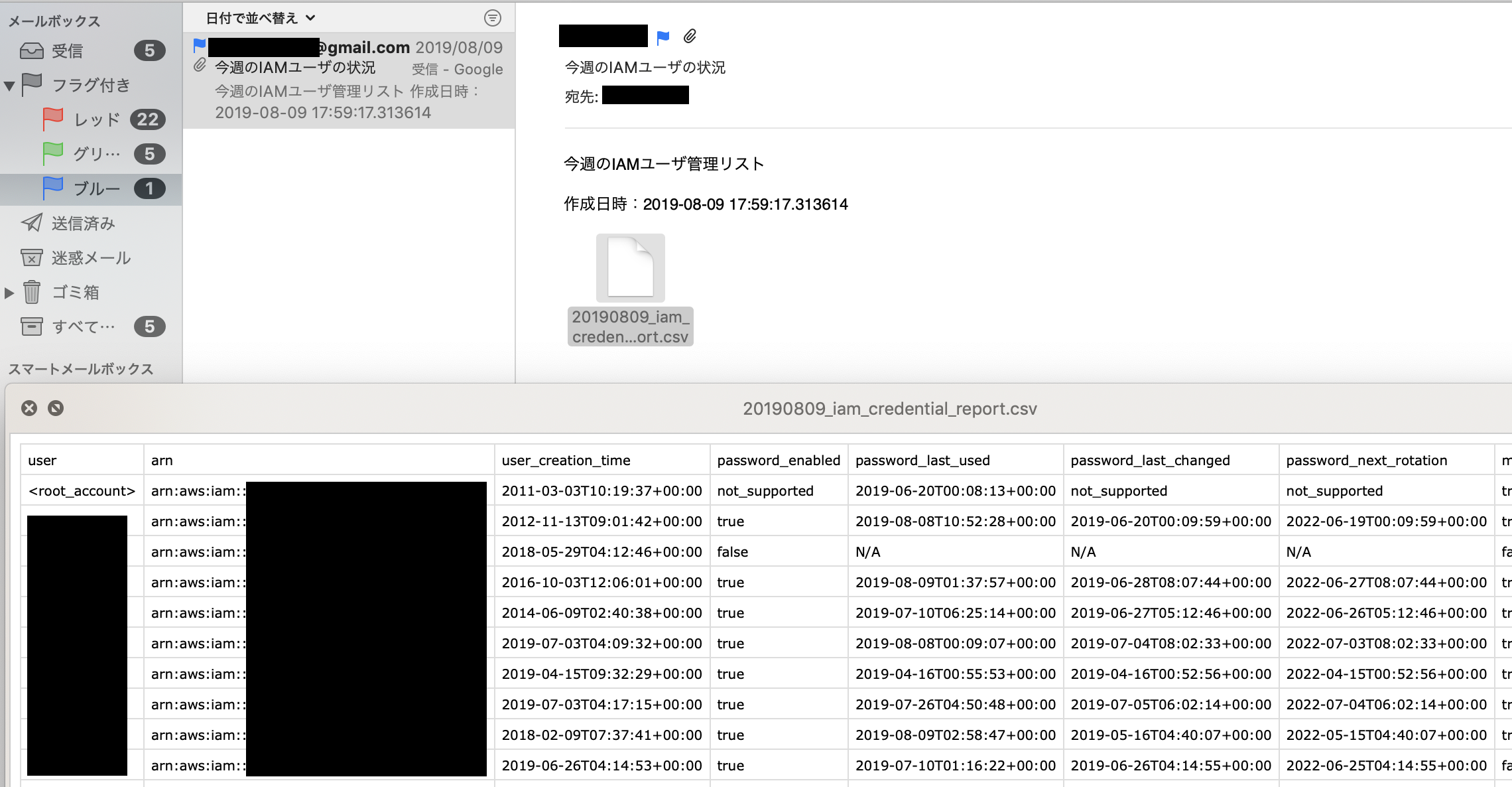
- 具体的には下記のようなメールが送られてくる
対象とする人
- 堅めの企業でAWSのセキュリティを見ている人
- 特に社内のコンプライアンスチェックや監査目的でAWSのIAMユーザーのリストを作成する必要がある人
やること
- SESでメールアドレスを認証
- Lambda関数実行用のIAMロールの作成
- Lambda関数作成
やらないこと
- 各種アラートやチェックの自動化
- アクセスキーやパスワードが全然ローテーションされていないぞ!などの警告は他のサービスで実現可能なので、ここではやらない。
- Slackなどのチャットサービスへの通知
- 会社でSlack使えない場合があるため
※ここで並べたものは「やらなくていい」ではなくて「ほんとはやった方がいい」ものである。
IAM認証情報レポート
AWS アカウントの認証情報レポートの取得 - AWS Identity and Access Management
IAM認証情報レポートとはアカウントのすべてのユーザーと、ユーザーの各種認証情報 (パスワード、アクセスキー、MFA デバイスなど) のステータスがまとめられたものである。
ファイル自体はcsvファイルとして生成される。csvファイルには下記の情報が含まれる。3
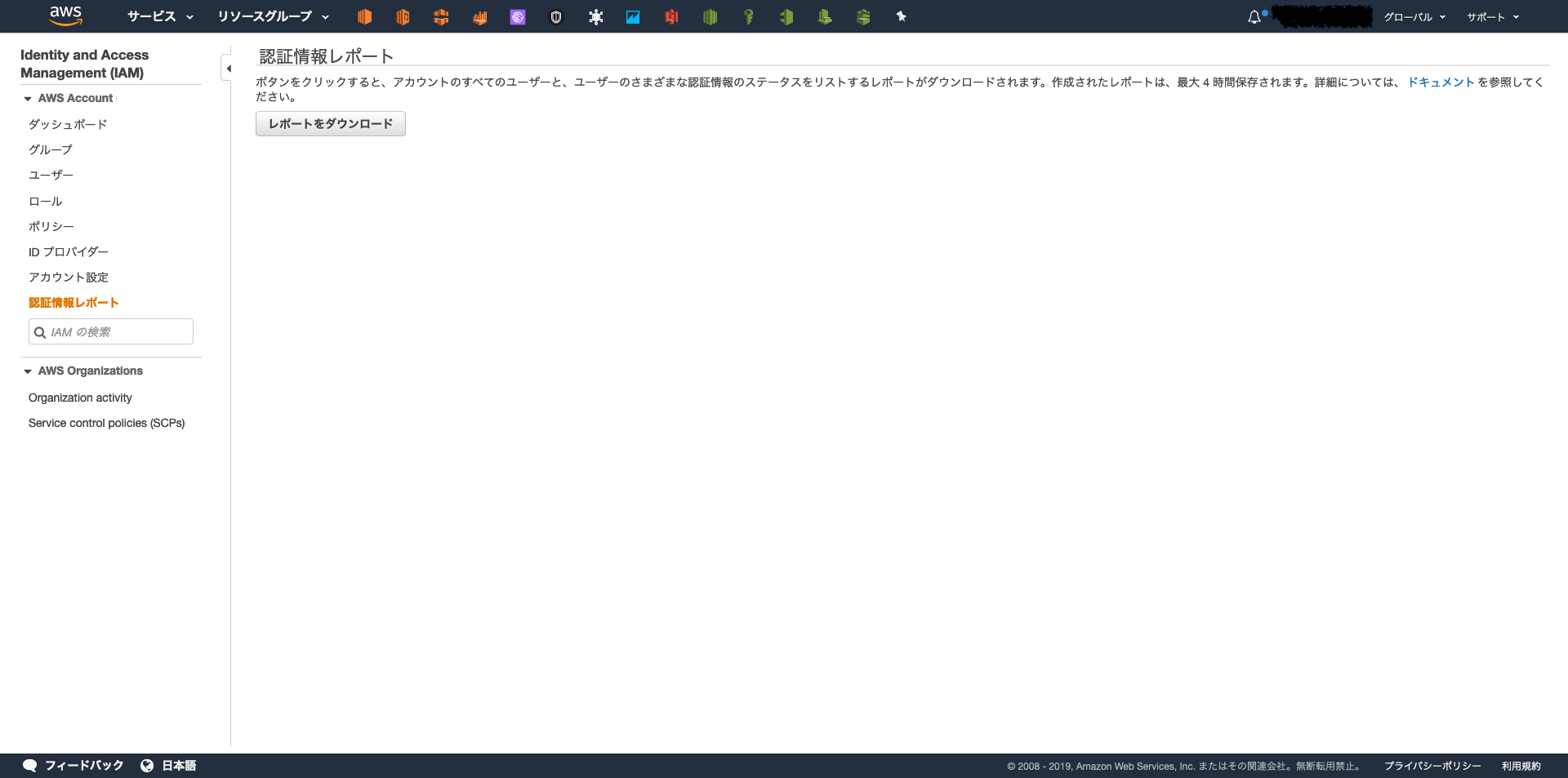
列名 説明 ユーザー ユーザ名 arn ユーザーの Amazon リソースネーム(ARN) user_creation_time ユーザーが作成された日時 (ISO 8601 日付/時刻形式) password_enabled ユーザーがパスワードを持っているかどうか password_last_used AWS アカウントのルートユーザー または IAM ユーザーのパスワードを使用して最後に AWS ウェブサイトにサインインした日時 password_last_changed ユーザーのパスワードが最後に設定された日時 password_next_rotation 新しいパスワードを設定するようユーザーに求める日時 mfa_active ユーザーに対して多要素認証 (MFA) デバイスが有効かどうか access_key_1_active ユーザーがアクセスキーがACTIVEかどうか access_key_1_last_rotated ユーザーのアクセスキーが作成または最後に変更された日時 access_key_1_last_used_date AWS API リクエストの署名にユーザーのアクセスキーが直近に使用されたときの日付と時刻 access_key_1_last_used_region アクセスキーが直近に使用された AWS リージョン access_key_1_last_used_service アクセスキーを使用して最も最近アクセスされた AWS サービス cert_1_active ユーザーのX.509 署名証明書がACTIVEかどうか cert_1_last_rotated ユーザーの署名証明書が作成または最後に変更された日時 IAM認証情報レポートはマネジメントコンソールの下記の画面からダウンロード可能である。
ただし、これを定期的に行うのは人間のやる作業ではないため自動化する。
SESでメールアドレスを認証する
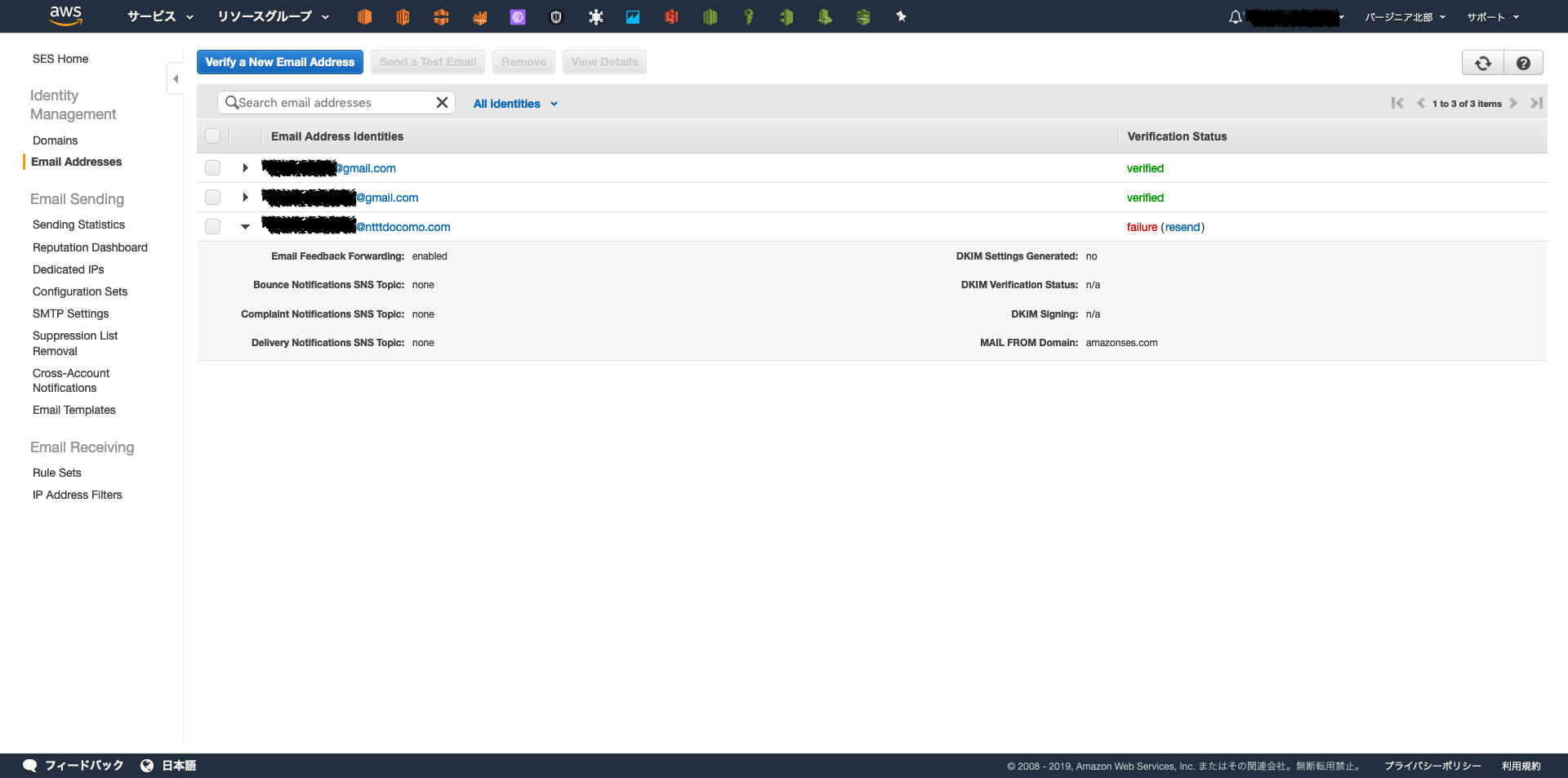
単純なメール通知ならSNSで十分だが、今回はcsvファイルを添付したいのでSESを利用して送信用&受信用のメールアドレスを登録する必要がある。
詳細な手順は省略するが
- 左上の
Verify a New Email Addressボタンからメールアドレスを登録- 受信したメールに記載されたリンクへアクセスする
これでメールアドレスの認証は完了する。Statusが[verified]になればOK。
SESは対応しているリージョンが少ないので注意が必要である。2019年時点では下記の3リージョンのみ利用可能。
- us-east-1(バージニア北部)
- us-west-2(オレゴン)
- eu-west-1(アイルランド)
IAMロールを作成する
Lambda関数に与えるIAMロールを事前に用意しておく。
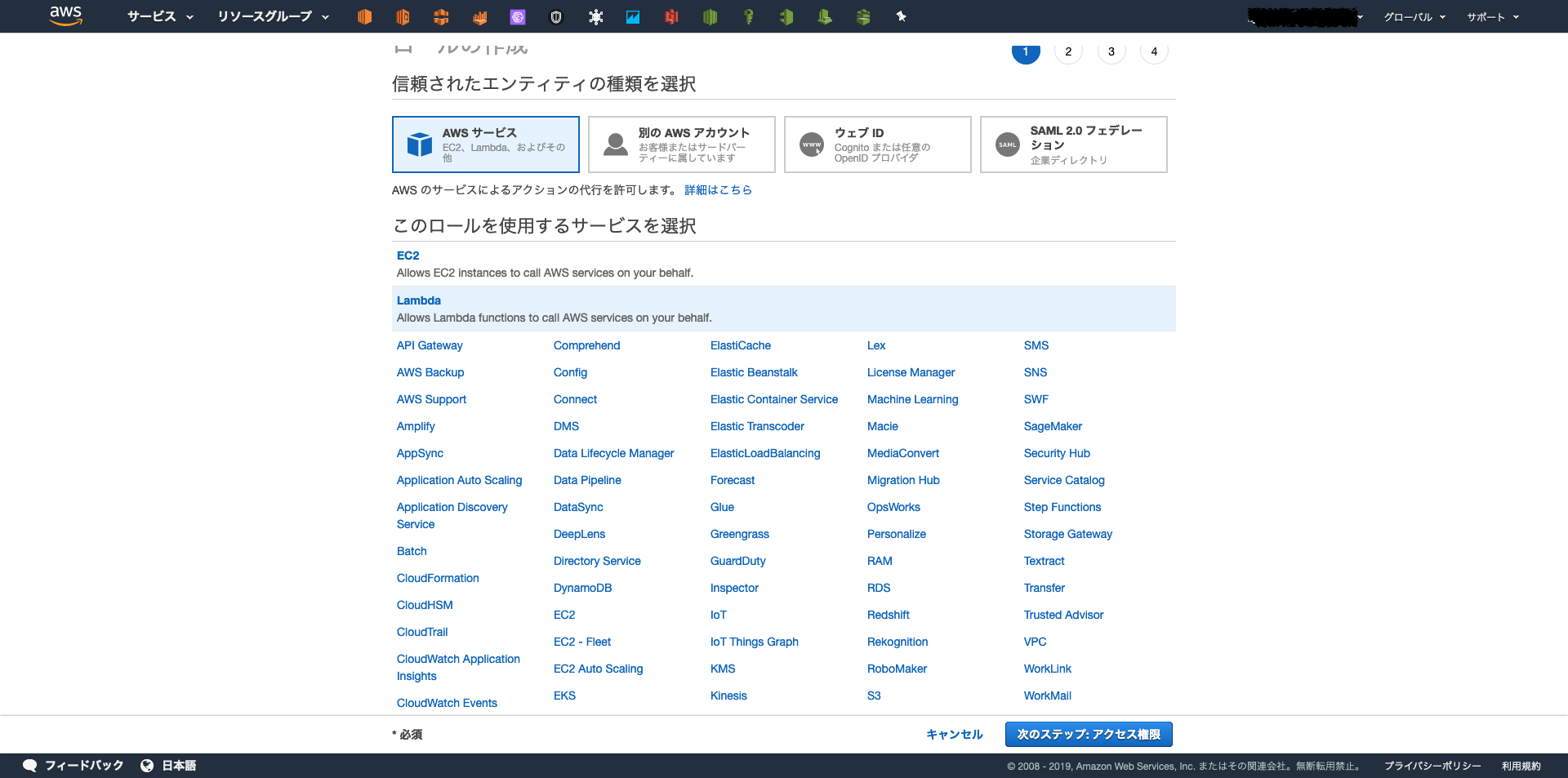
IAMのコンソール画面の「このロールを使用するサービス」からLambda関数を選択。
今回追加で必要な権限はこの3つ。
- AmazonSESFullAccess
- AmazonS3FullAccess
- IAMReadOnlyAccess
信頼されたエンティティとしてLambdaが選択されているのを確認したら
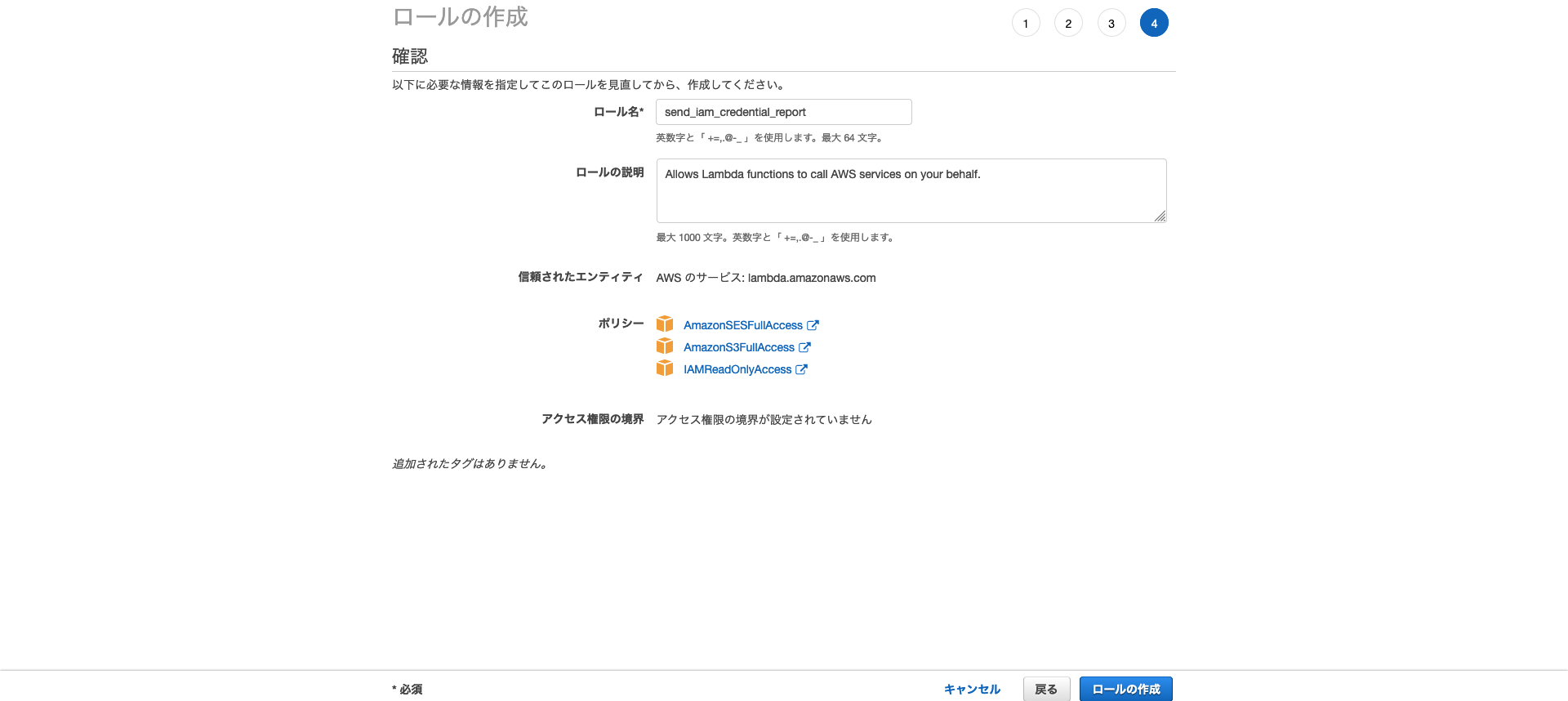
ロールの作成を行う。Lambda関数を設定
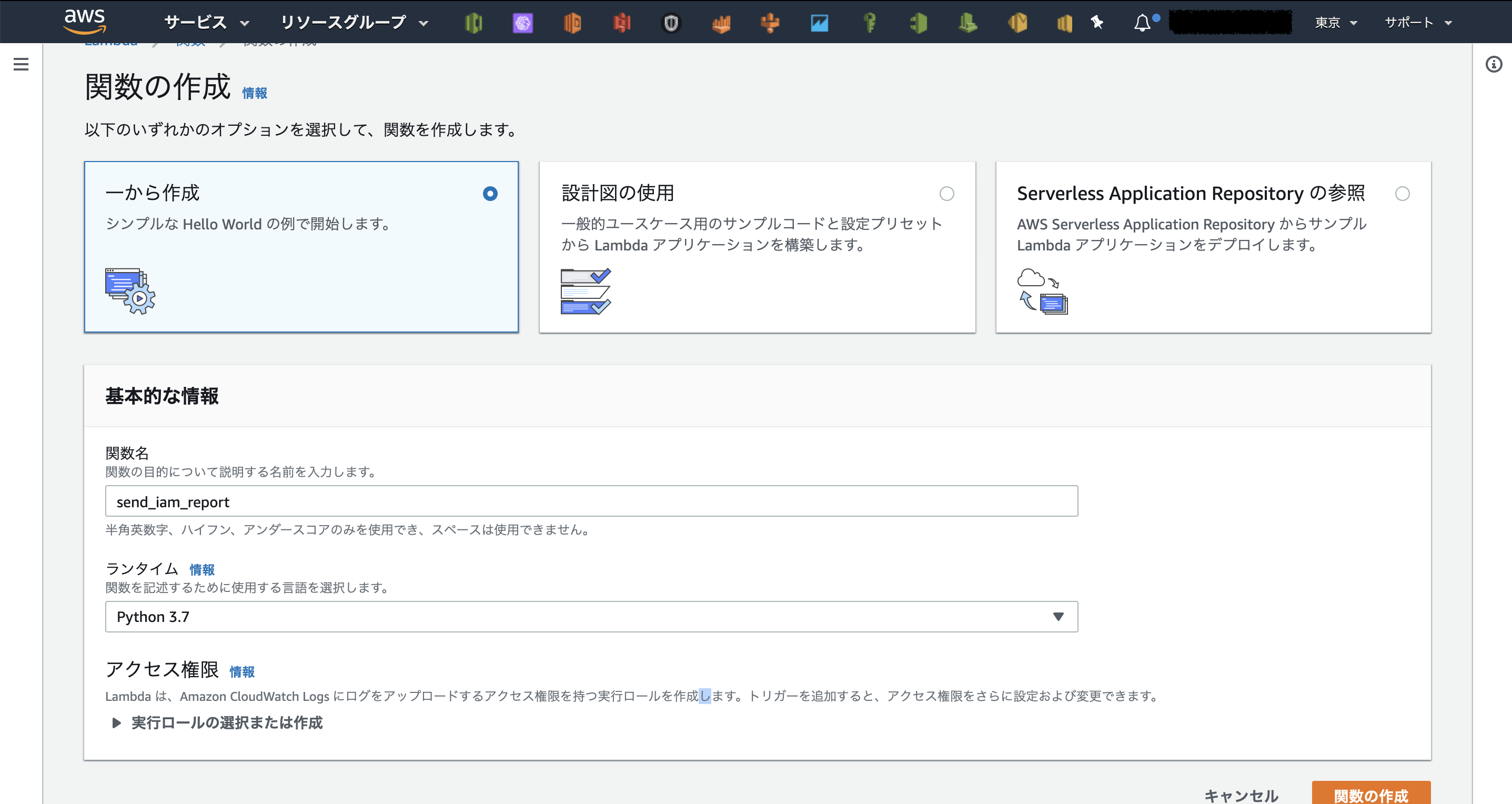
とりあえず関数名とランタイムを指定して
関数の作成をクリック。ロールはあとで指定する。
ここでは下記の手順でLambda関数を作成する。
- ①Lambda関数コードを入力
- ②環境変数の入力
- ③実行ロールの設定
- ④CloudWatchEventの設定
① Lambda関数コードを入力
下記のコードをインラインエディタに貼り付ける。
send_iam_reportimport boto3 import re import time import datetime import os from botocore.exceptions import ClientError from email.mime.multipart import MIMEMultipart from email.mime.text import MIMEText from email.mime.application import MIMEApplication AWS_S3_BUCKET_NAME = os.environ["AWS_S3_BUCKET_NAME"] ACCOUNT_ID = os.environ["ACCOUNT_ID"] SENDER = os.environ["SENDER"] RECIPIENT = os.environ["RECIPIENT"] AWS_REGION = "us-east-1" SUBJECT = "IAMユーザーWeeklyReport" # The character encoding for the email. CHARSET = "utf-8" # The email body for recipients with non-HTML email clients. BODY_TEXT = "IAMユーザー管理リスト\n作成日時:{}".format(datetime.datetime.today()) # The HTML body of the email. BODY_HTML = """\ <html> <head></head> <body> <p>今週のIAMユーザー管理リスト</p> <p>アカウントID:{}</p> <p>作成日時:{}</p> <p>ファイル格納先:{}</p> </body> </html> """.format(ACCOUNT_ID, datetime.datetime.today(), AWS_S3_BUCKET_NAME) def lambda_handler(event, context): # 認証情報レポートを生成 iam = boto3.client('iam') response = iam.generate_credential_report() print(response) # レポート作成が完了するまで待機 while(response['State'] != 'COMPLETE'): time.sleep(1) continue result = iam.get_credential_report() print(result) # 取得日時からファイル名を生成 pattern = r"[0-9]{4}-[0-9]{2}-[0-9]{2}" date = re.search(pattern, str(result['GeneratedTime'])).group(0) fname = "{}_{}_iam_credential_report.csv".format(date.replace("-", ""), ACCOUNT_ID) ATTACHMENT = "/tmp/"+fname # S3へ保存 s3 = boto3.resource('s3') bucket = s3.Bucket(AWS_S3_BUCKET_NAME) bucket.put_object(Key='iam/'+fname, Body=result["Content"]) # tmpへ一時保存 with open('/tmp/'+fname, "wb") as f: f.write(result["Content"]) # メール配信 # Create a new SES resource and specify a region. ses = boto3.client('ses', region_name=AWS_REGION) # Create a multipart/mixed parent container. msg = MIMEMultipart('mixed') # Add subject, from and to lines. msg['Subject'] = SUBJECT msg['From'] = SENDER msg['To'] = RECIPIENT # Create a multipart/alternative child container. msg_body = MIMEMultipart('alternative') # Encode the text and HTML content and set the character encoding. This step is # necessary if you're sending a message with characters outside the ASCII range. textpart = MIMEText(BODY_TEXT.encode(CHARSET), 'plain', CHARSET) htmlpart = MIMEText(BODY_HTML.encode(CHARSET), 'html', CHARSET) # Add the text and HTML parts to the child container. msg_body.attach(textpart) msg_body.attach(htmlpart) # Define the attachment part and encode it using MIMEApplication. att = MIMEApplication(result["Content"]) # Add a header to tell the email client to treat this part as an attachment, # and to give the attachment a name. att.add_header('Content-Disposition', 'attachment', filename=os.path.basename(ATTACHMENT)) # Attach the multipart/alternative child container to the multipart/mixed # parent container. msg.attach(msg_body) # Add the attachment to the parent container. msg.attach(att) try: # Provide the contents of the email. response = ses.send_raw_email( Source=SENDER, Destinations=[ RECIPIENT ], RawMessage={ 'Data': msg.as_string(), }, # ConfigurationSetName=CONFIGURATION_SET ) # Display an error if something goes wrong. except ClientError as e: print(e.response) print(e.response['Error']['Message']) else: print("Email sent! Message ID:"), return (response['ResponseMetadata']['RequestId'])やっていることは大雑把に言うと下記の通り。
- iam_credential_reportの生成、取得
- 取得したファイルをS3へ保存
- SESによりファイルを添付したメールを送信
② 環境変数を入力
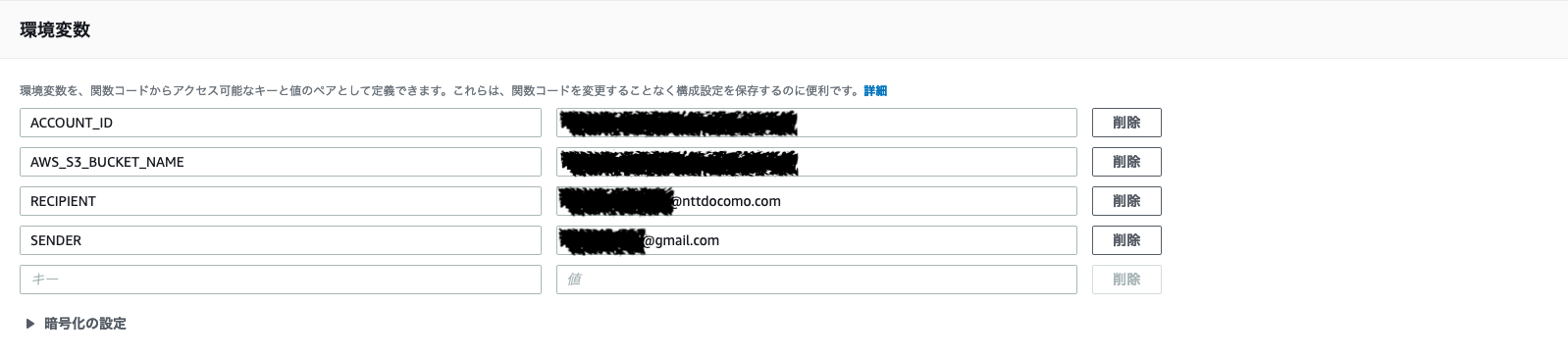
この関数ではメールアドレスやアカウントIDなどは環境変数で管理している。Lambda関数内に直接書き込んでも動作するが、コードを直接変更するのはトラブルの元なので環境変数として外部に切り出す。
こうしておけば別のアカウントに移植する際にいちいちコードを書き換える必要がない。CloudFormationでLambdaをデプロイする場合などはコードをzipファイルにまとめる際などは非常に便利。環境変数の設定は下記のようにコンソール上から行うことができる。4
③ 実行ロールの設定
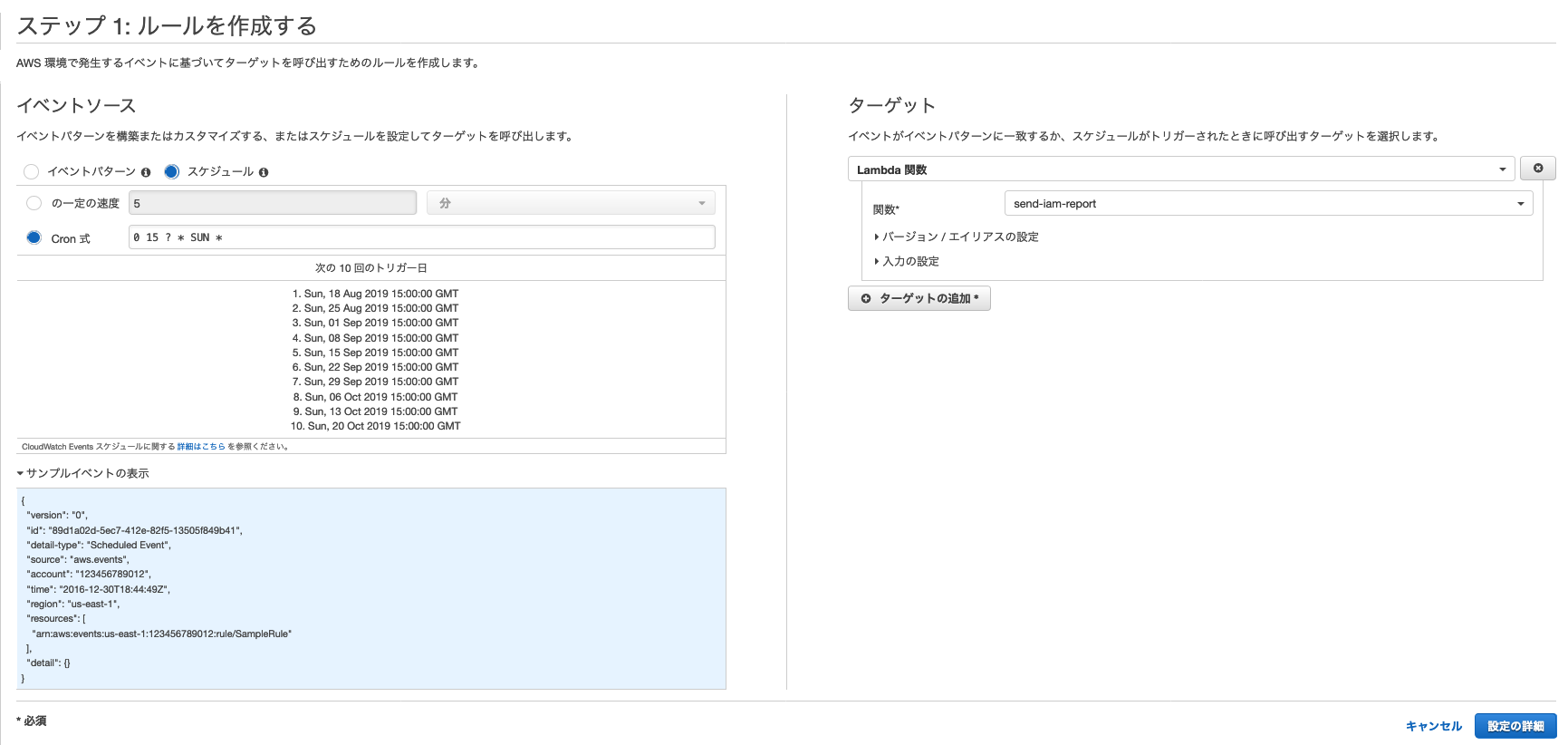
既存のロールを使用するを選択し、先ほど作成したロールを割り当てる。④CloudWatchEventの設定
毎週一回レポートを作成する場合はLambda関数の
トリガーを追加をクリックして下記の通り設定すればOK。cronによるスケジュール設定はUTCで行う必要があるので注意。
参考にそのほかセキュリティ周りの作業を自動化する場合に使いそうな設定パターンをまとめておく。
時間帯 Cron式 利用例 ルール名 毎日0:00(JST) 0 15 * * ? *S3のデータ整形、ログ収集など daily_task 毎週月曜日の0:00(JST) 0 15 ? * SUN *1週間のセキュリティレポート作成など weekly_task 毎月1日の0:00(JST) 0 15 1 * ? *月間のコスト請求レポート作成など monthly_task 平日の夜22:00(JST) 0 13 ? * MON-FRI *インスタンスの設定ミス、落とし忘れなどのチェック closing_task その他ポイントとしては
- 必要に応じてメールの件名や文面を編集する
AWS_REGIONはSESを設定した時のリージョンを指定するtmpディレクトリに一時的に添付ファイルを保存→メール送信- IAMユーザーが多いと処理に時間がかかるので時間は適当に設定する
など。
おわりに
とりあえずこれ動かしておけば毎週必ずレポートが送られてくる。
「アカウントの管理しっかりやってるよね?」と言われたときにすぐに出せるようにしておくと安心。参考
Lambda・SESを使って、添付ファイル付きメールを送信する – サーバーワークスエンジニアブログ
E メールの高度なパーソナライズ - Amazon Simple Email Service
AWS SDKs を使用して raw E メールを送信する - Amazon Simple Email Service
「AWS Configで一発だろ」というツッコミはごもっともだが、非エンジニアが各種チェック作業を行う場合を考えると、ローカルファイルとして置いておくのが一番楽だと思われる。誰でも扱いやすい形式で情報を扱うことが、社内全体幸福最大化につながる。 ↩
応用すればコストレポートやS3バケット内のファイルの自動配信なども可能。 ↩
アクセスキーと証明書が複数ある場合はその分だけ列が増える。 ↩
CLIなどで登録することも可能。 ↩
- 投稿日:2019-08-22T11:00:57+09:00
AWSCDK for TypeScript で cdk deploy 前に tsc を実行しなくてもデプロイできる方法
はじめに
AWSCDKをTypeScriptで書いていて、tscでJSにビルドしてからデプロイをしていたんですが、「毎回ビルドめんどくさいし忘れるしなんとかしたい」って思って、毎回ビルド→デプロイっていう手順を踏まなくてもいいようにしたので、その備忘録。
何をするか
ts-nodeで対象ファイルはtsファイルのまま、デプロイ実行時にビルドするようにしますnpx で
ts-nodeを実行する場合CDKのAppファイル (
cdk-app.ts) のファイル名は適宜書き換えてください。edit cdk.json
cdkコマンド実行時にAppファイルに対して実行されるコマンドを修正します
cdk.json{ "app": "npx ts-node bin/cdk-app.ts" }予め
ts-nodeをインストールしておくパターン (例)install
ts-node$ yarn add ts-nodeadd to package.json
package.jsonのscriptsにコマンドを追記しますpackage.json{ ... "scripts": { "build": "tsc", "watch": "tsc -w", "cdk": "cdk", "cdk-app": "ts-node bin/cdk-app.ts" }, ... }edit cdk.json
cdk.json{ "app": "yarn cdk-app" }さいごに
これでtsファイルをビルドせずにデプロイ実行してから気づいて、虚無の時間を過ごさずに済みますね!
ではまた!!!
- 投稿日:2019-08-22T06:54:42+09:00
初学者のメモ デプロイ後のエラー文を確認する方法
はじめに
プログラミングを初めて4ヶ月目に突入した初学者です。
デプロイ時にエラーが発生しましたが、エラー内容を確認方法が分からず躓いたのでメモを残します。
Qiita初投稿の為、暖かい目で見て頂ければと思います。環境
開発
・Ruby '2.3.8'
・Rails '5.2.3'
・vagrantデプロイ
・AWS
・nginx
・unicornエラー
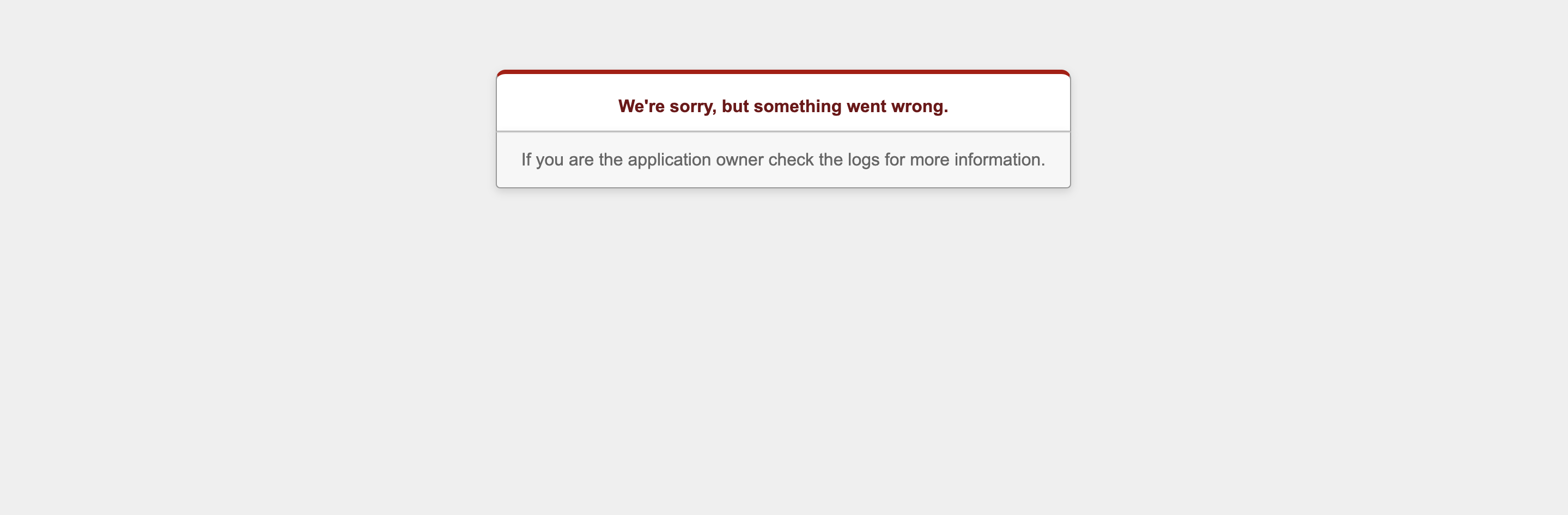
ローカル環境ではエラーが発生しなくても、デプロイ後エラーが出ることがあります。
デプロイ後にエラーがあると以下の画面が表示されます
これだけでは、エラーの原因は分かりません。
We're sorry, but something went wrong.をGoogleで検索しても様々な記事(原因)が出てくるのでエラー箇所を絞ることが出来ませんでした。
また、Google chromeの検証機能をしようして同様にエラー箇所を絞ることが出来ませんでした。エラーログを確認するには・・・
エラー箇所の絞るにはログをみる必要があります。
ログは以下の場所で確認することが出来ます。
・デプロイ後のログ確認
”アプリケーション名/log/production.log”
・開発中でのログ確認
”アプリケーション名/log/development.log”エラーログの確認方法
「ターミナル」
1. EC2にssh接続する
2. $cd /var/www/html/アプリケーション名でに移動する。
3. $cat log/production.logを実行する。
4. 実行すると今までのログが表示されます。
今回のエラー箇所は下から8、9行目になります。
ActionView::Template::Error (Mysql2::Error: FUNCTION portfolio.RANDAM does not exist: SELECT users .* FROM users ORDER BY RANDAM()):エラー箇所の修正
ランダム表示を今回実装したのですが、記述が正しくなかったのでエラーが発生したようです。
・修正前
@users = User.order("RANDAM()").all
・修正前
@users = User.order("RAND()").all
mysqlではRANDしか使用出来ないみたいです。※今回はEC2環境で変更しています。
sudo vi app/controllers/エラー箇所のコントローラ名デプロイ環境に変更を適応させる
今回はunicornを使用しているので
sudo service unicorn restartを実行します。
これでエラーは解消され、正しく表示されました。

- 投稿日:2019-08-22T02:17:14+09:00
VSCode + Xdebug + AWS(EC2, Ubuntu18.04)の設定
PortForwardの設定がポイントかな。AWSのインバウンド・アウトバウンドには追記の必要なし。
TeratermのTERATERM.INIに追記
DefaultForwarding=R9001:localhost:9001TeratermでAWSに接続
ポートフォワーディングセットしてから接続。
xdebugインストール
apt install php-xdebug
php.iniに追記
/etc/php/7.2/cli/php.ini #cliでも使いたいなら
/etc/php/7.2/apache2/php.ini
に追記。xdebug.remote_port=9001 xdebug.remote_enable=1 xdebug.remote_autostart=1 xdebug.remote_host=localhost xdebug.remote_log=/tmp/xdebug.log※ xdebug.soの追記は不要。
VSCodeの設定
launch.json
{ "version": "0.2.0", "configurations": [ { "name": "xdebug", "type": "php", "request": "launch", "port": 9001, "pathMappings": { "/var/www/html": "${workspaceFolder}" } } ] }
- 投稿日:2019-08-22T00:33:47+09:00
AWS Well-Architected(AWSによる優れた設計のフレームワーク)
知識習得の為の書き留&整理
ドキュメント
AWS Well-Architected フレームワーク ホワイトペーパー(PDF)
一般的な設計原則(AWS環境)
- 必要なキャパシティーを当て推量しない
- 本番規模でテストする
- 実験を行いやすくなる
- アーキテクチャを進化させることができる
- データに基づくアーキテクチャを構築する
- ゲームデーを通して向上を図る
優れた設計の柱
- セキュリティ
- 信頼性
- パフォーマンス効率
- コストの最適化
- 運用の優秀性
セキュリティの柱
リスクの評価と軽減戦略によって、ビジネスの価値を生み出しながら、情報、システム、およびアセットを保護する能力
- アイデンティティとアクセスの管理
- 検出制御
- インフラストラクチャの保護
- データ保護
- インシデントへの対応
信頼性の柱
インフラストラクチャまたはサービスの障害から復旧し、需要に応じたコンピューティングリソースを動的に取得し、設定ミスや一時的なネットワークの問題などによる中断を軽減するシステムの能力
- 基盤
- 変更管理
- 障害管理
パフォーマンス効率の柱
システムの要件を満たすためにコンピューティングリソースを効率的に使用し、要求の変化とテクノロジーの進化に対してもその効率性を維持する能力
- 選択
- 確認
- モニタリング
- トレードオフ
コスト最適化の柱
不必要なコストや最適でないリソースを回避または排除する能力
- コスト効率の良いリソース
- 需要と供給の一致
- 支出の認識
- 時間の経過に伴う最適化
運用の優秀性
ビジネス価値を提供し、サポートのプロセスと手順を継続的に向上させるためにシステムを実行、モニタリングできる能力
- 準備
- 運用
- 応答