- 投稿日:2019-08-22T23:48:31+09:00
54日目 Pythonによる機械学習できるかな?
買ってきました!
1章2章がクローリングとスクレイピング。これは何とかなりそう。
3章からチャレンジしました。テキストデータとバイナリデータ
テキストデータ
人間が読みやすい形
バイナリデータ
機械が使うのに合理的な形
バイナリで出力してみてみると・・・
test.pyfilename=“binary.bin” data=100 with open(filename, ”wb”) as f: f.write(bytearray[data])python test.py File "test.py", line 1 filename=“binary.bin” ^ SyntaxError: invalid character in identifierこのエラーを調べると、
invalid character in identifier のエラー全角?半角?Pythonにわからない文字が入っているようです。
仕方ない、一行まるまる書き換えて・・・$ python test.py File "test.py", line 3 with open(filename, ”wb”) as f: ^ SyntaxError: invalid character in identifierまた書き換えて
またエラー$ python test.py Traceback (most recent call last): File "test.py", line 4, in <module> f.write(bytearray[data]) TypeError: 'type' object is not subscriptableリストのタイプが違う???
うーん、わからん。
ともかくもう一回書き換えて実行。test.pyfilename='binary.bin' data=100 with open(filename, ) as f: f.write(bytearray[data])ようやくちゃんと実行できました。
$ ls binary.bin $ cat binary.bin d $ hexdump binary.bin 0000000 64 0000001おおー
なるほど!ただし、1bitを削る時代ではないので、今時はテキストでよい。
文字コード
Shift_JIS(改行CR+LF)、UTF-8(改行 LF)→よく見る。
HTMLでは<meta charaset=“文字セット名”>で指定する。
HTML5はUTF-8が推奨。Excelで開くとこんがらかるやつだ!XML
タグで囲んでデータをタグ付けする仕様。
<要素名 属性=“属性値”>内容</要素名>練習)横浜市の防災データを読む。
URLが変わっていた。横浜市、オープンデータ推進ページにまとまってて使いやすい。
https://www.city.yokohama.lg.jp/kurashi/bousai-kyukyu-bohan/bousai-saigai/bosai/data/data.html
ダウンロードがZipファイルだったので解凍する
with zipfile.ZipFile('data/temp/new_comp.zip') as existing_zip: existing_zip.extractall('data/temp/ext')まずはお手本を見ながらざくざく書いてみる。
xml-bonsai-z.pyfrom bs4 import Beautifulsoup import urllib.request as req import os.path #XMLをダウンロード url="https://www.city.yokohama.lg.jp/kurashi/bousai-kyukyu-bohan/bousai-saigai/bosai/data/data.files/0001_20180911.zip" #Zipがなければダウンロード、あればパス zipname="0001_20180911.zip" savename="shelter.xml" if not os.path.exists(zipname): req.urlretrieve(url, zipname) #Zipを解凍 with zipfile.ZipFile('0001_20180911.zip') as existing_zip: existing_zip.extractall() #Beautifulsoupで解析 xml = open(savename, "r", encording="utf-8").read() soup = Beautifulsoup(xml, 'html.parser') #データを各区ごとに確認 ##辞書infoを初期化 info={} #shelterタグをiに入れて1つづつ見ていく for i in soup.find_all("shelter"): name = i.find('name').string #建物名 ward = i.find('ward').string #区 addr = i.find('address').string #住所 note = i.find('notes').string #メモ #辞書infoに収録されていないward(区)だったら区を追加する。 if not (ward in info): info[ward] =[] #区ごとに項目を追加する info[ward].append(name) #区ごとに防災拠点を表示 for ward in info.keys(): print("+", ward) for name in info[ward]: print("| - ", name)さて実行!
1回目
大文字小文字が違ってた!
Beautifulsoup→BeautifulSoup$ python xml-bousai-r.py Traceback (most recent call last): File "xml-bousai-r.py", line 1, in <module> from bs4 import Beautifulsoup ImportError: cannot import name 'Beautifulsoup' from 'bs4' (/anaconda3/lib/python3.7/site-packages/bs4/__init__.py)2回目
zipfileをimportしてなかった!
$ python xml-bousai-r.py Traceback (most recent call last): File "xml-bousai-r.py", line 14, in <module> with zipfile.ZipFile('0001_20180911.zip') as existing_zip: NameError: name 'zipfile' is not defined3回目
encording???
encodingでした!$ python xml-bousai-r.py Traceback (most recent call last): File "xml-bousai-r.py", line 19, in <module> xml = open(savename, "r", encording="utf-8").read() TypeError: 'encording' is an invalid keyword argument for open()4回目
ファイルがない?
$ python xml-bousai-r.py Traceback (most recent call last): File "xml-bousai-r.py", line 19, in <module> xml = open(savename, "r", encoding="utf-8").read() FileNotFoundError: [Errno 2] No such file or directory: 'shelter.xml'どうやってもpythonでunzipできない、ギブアップ。
$ unzip 0001_20180911.zip Archive: 0001_20180911.zip inflating: shelter.xml5回目
またしてもBeautiful
soup$ python xml-bousai-r.py Traceback (most recent call last): File "xml-bousai-r.py", line 20, in <module> soup = Beautifulsoup(xml, 'html.parser') NameError: name 'Beautifulsoup' is not defined6回目
$ python xml-bousai-r.py + 鶴見区 | - 生麦小学校 | - 豊岡小学校 | - 鶴見小学校 | - 潮田小学校 | - 下野谷小学校 (以下略)できました!
解析した結果は辞書{}に入れる、これは良い収穫でした。機械学習の道のりが遠い・・・
(所要時間 3時間)
- 投稿日:2019-08-22T23:48:31+09:00
54日目 Pythonで機械学習できるかな?
買ってきました!
1章2章がクローリングとスクレイピング。これは何とかなりそう。
3章からチャレンジしました。テキストデータとバイナリデータ
テキストデータ
人間が読みやすい形
バイナリデータ
機械が使うのに合理的な形
どう違うか見てみます。バイナリで出力するプログラムを作ります。
test.pyfilename=“binary.bin” data=100 with open(filename, ”wb”) as f: f.write(bytearray[data])ありゃ、うごかない!
python test.py File "test.py", line 1 filename=“binary.bin” ^ SyntaxError: invalid character in identifierこのエラーはというと、
invalid character in identifier のエラー全角?半角?Pythonにわからない文字が入っているようです。
仕方ない、一行まるまる書き換えて・・・$ python test.py File "test.py", line 3 with open(filename, ”wb”) as f: ^ SyntaxError: invalid character in identifierまた書き換えて
またエラー$ python test.py Traceback (most recent call last): File "test.py", line 4, in <module> f.write(bytearray[data]) TypeError: 'type' object is not subscriptableリストのタイプが違う???
うーん、わからん。
ともかくもう一回書き換えて実行。test.pyfilename='binary.bin' data=100 with open(filename, ) as f: f.write(bytearray[data])ようやくちゃんと実行できました。
$ ls binary.bin $ cat binary.bin d $ hexdump binary.bin 0000000 64 0000001おおー
なるほど!ただし、1bitを削る時代ではないので、今時はテキストでよいそうです。
文字コード
Shift_JIS(改行CR+LF)、UTF-8(改行 LF)→よく見る。
HTMLでは<meta charaset=“文字セット名”>で指定する。
HTML5はUTF-8が推奨。Excelで開くとこんがらかるやつだ!XML
タグで囲んでデータをタグ付けする仕様。
<要素名 属性=“属性値”>内容</要素名>練習)横浜市の防災データを読む。
URLが変わっていた。横浜市、オープンデータ推進ページにまとまってて使いやすい。
https://www.city.yokohama.lg.jp/kurashi/bousai-kyukyu-bohan/bousai-saigai/bosai/data/data.html
ダウンロードがZipファイルだったので解凍する
with zipfile.ZipFile('data/temp/new_comp.zip') as existing_zip: existing_zip.extractall('data/temp/ext')まずはお手本を見ながらざくざく書いてみる。
xml-bonsai-z.pyfrom bs4 import Beautifulsoup import urllib.request as req import os.path #XMLをダウンロード url="https://www.city.yokohama.lg.jp/kurashi/bousai-kyukyu-bohan/bousai-saigai/bosai/data/data.files/0001_20180911.zip" #Zipがなければダウンロード、あればパス zipname="0001_20180911.zip" savename="shelter.xml" if not os.path.exists(zipname): req.urlretrieve(url, zipname) #Zipを解凍 with zipfile.ZipFile('0001_20180911.zip') as existing_zip: existing_zip.extractall() #Beautifulsoupで解析 xml = open(savename, "r", encording="utf-8").read() soup = Beautifulsoup(xml, 'html.parser') #データを各区ごとに確認 ##辞書infoを初期化 info={} #shelterタグをiに入れて1つづつ見ていく for i in soup.find_all("shelter"): name = i.find('name').string #建物名 ward = i.find('ward').string #区 addr = i.find('address').string #住所 note = i.find('notes').string #メモ #辞書infoに収録されていないward(区)だったら区を追加する。 if not (ward in info): info[ward] =[] #区ごとに項目を追加する info[ward].append(name) #区ごとに防災拠点を表示 for ward in info.keys(): print("+", ward) for name in info[ward]: print("| - ", name)さて実行!
1回目
大文字小文字が違ってた!
Beautifulsoup→BeautifulSoup$ python xml-bousai-r.py Traceback (most recent call last): File "xml-bousai-r.py", line 1, in <module> from bs4 import Beautifulsoup ImportError: cannot import name 'Beautifulsoup' from 'bs4' (/anaconda3/lib/python3.7/site-packages/bs4/__init__.py)2回目
zipfileをimportしてなかった!
$ python xml-bousai-r.py Traceback (most recent call last): File "xml-bousai-r.py", line 14, in <module> with zipfile.ZipFile('0001_20180911.zip') as existing_zip: NameError: name 'zipfile' is not defined3回目
encording???
encodingでした!$ python xml-bousai-r.py Traceback (most recent call last): File "xml-bousai-r.py", line 19, in <module> xml = open(savename, "r", encording="utf-8").read() TypeError: 'encording' is an invalid keyword argument for open()4回目
ファイルがない?
$ python xml-bousai-r.py Traceback (most recent call last): File "xml-bousai-r.py", line 19, in <module> xml = open(savename, "r", encoding="utf-8").read() FileNotFoundError: [Errno 2] No such file or directory: 'shelter.xml'どうやってもpythonでunzipできない、ギブアップ。
$ unzip 0001_20180911.zip Archive: 0001_20180911.zip inflating: shelter.xml5回目
またしてもBeautiful
soup$ python xml-bousai-r.py Traceback (most recent call last): File "xml-bousai-r.py", line 20, in <module> soup = Beautifulsoup(xml, 'html.parser') NameError: name 'Beautifulsoup' is not defined6回目
$ python xml-bousai-r.py + 鶴見区 | - 生麦小学校 | - 豊岡小学校 | - 鶴見小学校 | - 潮田小学校 | - 下野谷小学校 (以下略)できました!
解析した結果は辞書{}に入れる、これは良い収穫でした。機械学習の道のりが遠い・・・
(所要時間 3時間)
- 投稿日:2019-08-22T23:47:45+09:00
Twitter Userの投稿時間遷移と感情遷移(ML-Ask使用)
はじめに
この記事内で行っていることは、Twitter APIを用いてTwitter userのツイートを取得したツイートデータを用いて何かできないかと仮作したものです。
投稿時間遷移と感情遷移の作成プログラムは作成時期が異なるため、別物と考えてもらえると助かります。ML-Askについて詳しい説明を行っている@yukino氏の記事を見てもらえると助かります。
ML-Askでテキストの感情分析
https://qiita.com/yukinoi/items/ef6fb48b5e3694e9659cプログラムを実行する前に行う事
今回のプログラムはTwitter APIを用いて取得したデータが必要です。
以下の様なデータが入っているcsvファイルであれば可能のはず...?
created_at full_text 2018/4/10 15:22:06 笹かま食べたい 実行環境
Python 3.6.3 :: Anaconda custom (64-bit)
pandas 0.24.2
matplotlib 2.2.21.時間遷移
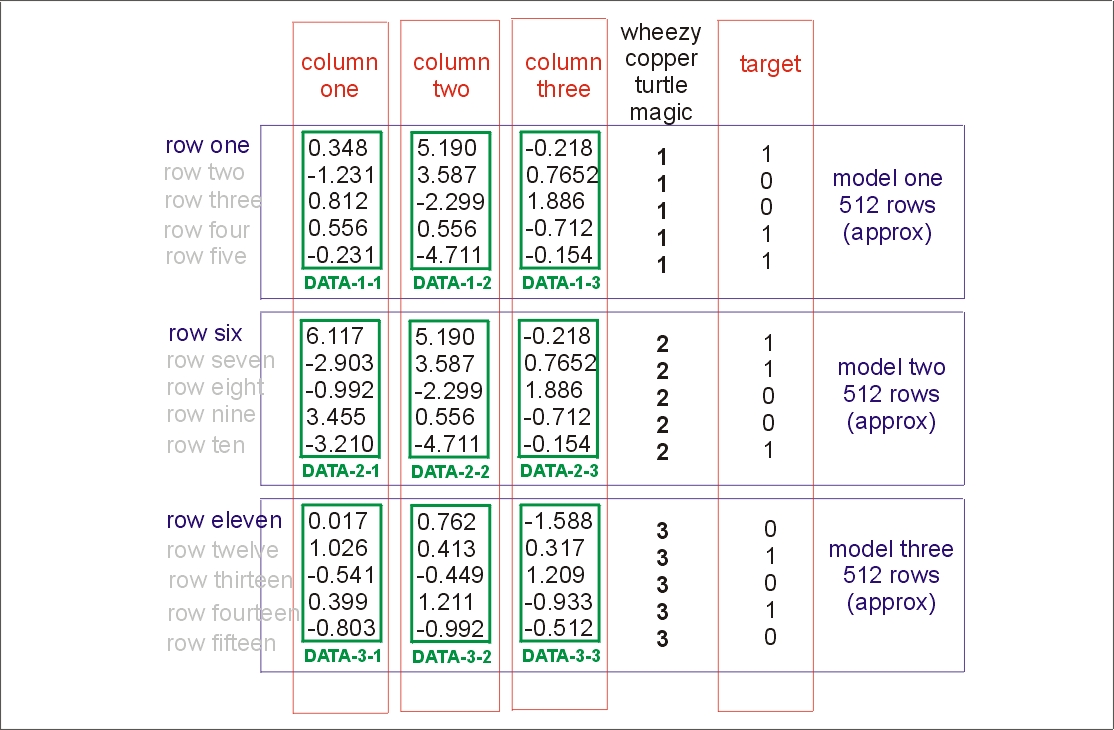
まずは時間によってツイートの投稿が変化するのか見ていきたいと思います。
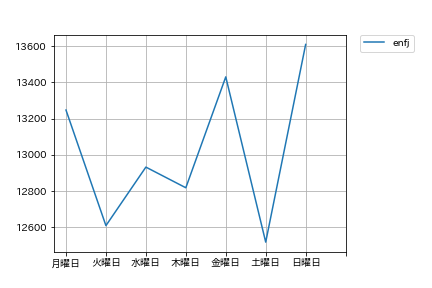
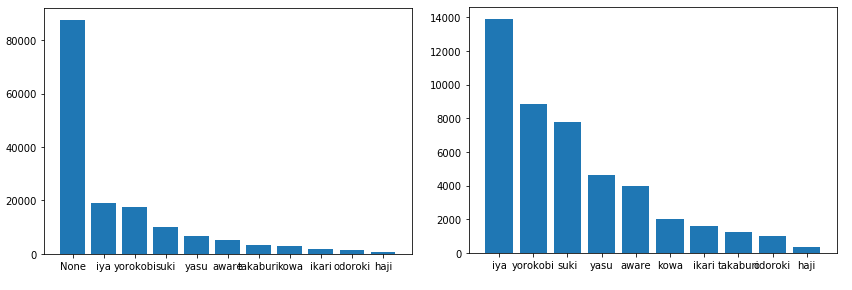
プログラムは以下の通りです。インポートするモジュールと準備import pandas as pd import matplotlib.pyplot as plt曜日によるツイート回数FILENAME_R ='任意のパス' twitter_df = pd.read_csv(FILENAME_R,index_col=None, header=0,encoding="utf_8_sig") twitter_df['created_at'] = pd.to_datetime(twitter_df['created_at']) #日付のみ抽出 df_time_date = twitter_df['created_at'].dt.date day_list = [] for date in df_time_date: day_list.append(date.weekday()) #カウント df_day = pd.DataFrame(day_list,columns=["Day"]) group_day = df_day['Day'].groupby(df_day['Day']) cd = group_day.count() cd.plot() plt.xticks((0, 1, 2, 3, 4, 5, 6, 7), ('月曜日','火曜日','水曜日','木曜日','金曜日','土曜日','日曜日'))実行してみると以下の様になります
土曜日が少ないというちょっと面白い結果になりました。
但し、金曜日、日曜日が最高潮に達するのは
※ちなみにこれは私が持っているデータのみの結果です。一概にはこの通りとなるとは言えません。
※別のデータで行った場合、日曜日土曜日が多く、火曜日が一番少ないという結果になりました。また、プログラム中の抽出部分とカウント部分を以下の様に変更し実行すると...
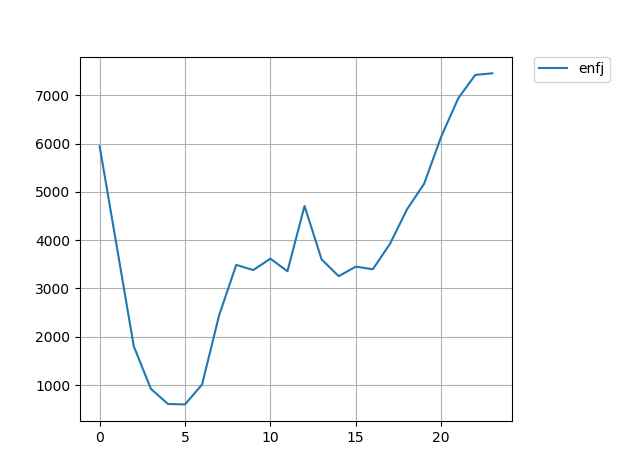
#時間のみ抽出 df_time = twitter_df['created_at'].dt.hour time_group = df_time.groupby(df_time) #カウント twitter_user_time_count = time_group.count() twitter_user_time_count.plot()
12時の昼休み頃にツイートが突起の様に増え
23,24時等の寝る前になるとツイートをする人が最高潮になるという面白い結果が出ましたね!2.感情遷移
感情分析に使用するMLAskですが、analyzeに渡すと辞書型で返ってきます。
その中で 'emotion'と'representative'がありますが、
今回のプログラムでは'representative'を使用します。以下プログラムです。
インポートするモジュールと準備import re from mlask import MLAsk emotion_analyzer = MLAsk() import pandas as pd import matplotlib.pyplot as plt関数#rep def emotion_mlask_rep(sentence): #str -> dict emotion_dict = emotion_analyzer.analyze(sentence) if emotion_dict['emotion']: emotion,text = emotion_dict['representative'] #tuple(str,list[str]) -> str,list return {emotion:len(text),'full_text':sentence} else: return {'None':1,'full_text':sentence} #前処理 pattern1 = re.compile(r'RT') #排除 pattern2= re.compile(r"@([A-Za-z0-9_]+)")#排除 pattern3 = re.compile(r'(https?|ftp)(:\/\/[-_\.!~*\'()a-zA-Z0-9;\/?:\@&=\+\$,%#]+)')#排除 pattern4 = re.compile(r'#(\w+)')#削除 def re_def(sentence_list): #list -> list subsentence_list = [] for sentence in sentence_list: sub4 = re.sub(pattern4,"",sentence) if (re.search(pattern1,sentence) or re.search(pattern2,sentence) or re.search(pattern3,sentence)) == None: subsentence_list.append(sub4) return subsentence_list前処理として以下のものを行っています。
1.リツイート、メンション、URLの含むデータの排除
2.ハッシュタグが含まれるツイートはハッシュタグ部のみ削除#csv読み込み FILENAME_R="読み込むデータのある場所への任意のパス" twitter_df = pd.read_csv(FILENAME_R,index_col=None,usecols=["created_at","full_text"], header=0,encoding="utf_8_sig") #テキストリスト化 twitter_df_text_list = twitter_df['full_text'].values.tolist() twitter_df['created_at'] = pd.to_datetime(twitter_df['created_at']) emotion_df = pd.DataFrame(index=None,columns=['full_text','yorokobi','ikari','aware','kowa', 'haji','suki','iya','takaburi', 'yasu','odoroki','None']) tmp_list = [] for sentence in twitter_df_text_list: emotion_dict = emotion_mlask_rep(sentence) #str → dict tmp_list.append(emotion_dict) emotion_df = pd.concat([emotion_df, pd.DataFrame.from_dict(tmp_list)]) twitter_df = pd.merge(twitter_df,emotion_df)tmp_listはlist型ですが、中に複数の辞書を入ってます。
emotion_df = pd.concat([emotion_df, pd.DataFrame.from_dict(tmp_list)])
この部分でemotion_dfにtmp_listに入れた辞書データを連結させています。
(最初に、emotion_dfを空のデータフレームとして宣言した理由です。)twitter_df_nan2zero = twitter_df.fillna(0) twitter_df_nan2zero = twitter_df_nan2zero.drop(['full_text'],axis=1) #Noneが1である行を除外 twitter_df_subNone = twitter_df_nan2zero[twitter_df_nan2zero['None'] != 1] twitter_df_subNone = twitter_df_subNone.drop(['None'],axis=1) twitter_df_subNone.set_index('created_at')後々、pandasのgroupeby.sum()を使用するため、Nanを0に置き換えます。
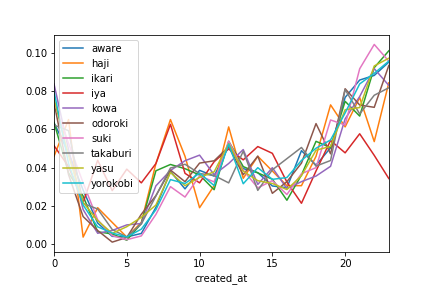
また、ML-AskとTwitterの文章の特性上判定から漏れる(Noneと判定される)ものは排除しています。##time emotion transition on twitter df_time = twitter_df_subNone['created_at'].dt.hour twitter_df_subNone['created_at'] = df_time.values time_group=twitter_df_subNone.groupby('created_at').sum() twitter_user_time_count = time_group.count() #各感情の各合計値とその時間での感情値を割る time_group_per_sum = time_group/time_group.sum() time_group_per_sum.plot() plt.savefig('任意の名前')
嫌という感情が21時ごろから減るのは少し面白いですね!
終わりに
今回使用したデータのそれぞれの判定された感情の合計値は以下の通りです。
Noneに判定されたものが多く、時点で嫌,喜びといった感情になっています。
感情分類からこぼれたデータが多くもったいないので、機械学習による感情分析に移行したほうが良いのでは?とも思いました。また左軸感情、右軸ツイートの回数、横軸 曜日etc... にすれば分かりやすかったなと少し思います。
※後々の改善点として表記
- 投稿日:2019-08-22T23:30:37+09:00
Djangoで開発するときによく使うコマンドまとめ
プロジェクトの作成
django-admin startproject プロジェクト名アプリケーションの作成
python3 manage.py startapp アプリケーション名モデルをDBに反映させる
変更差分を検知するマイグレーションファイルを作成
python3 manage.py makemigrations作成したマイグレーションファイルの変更内容をデータベースに反映
python3 manage.py migrate開発用サーバを立ち上げる
python3 manage.py runserver 0.0.0.0:8000なんかコマンドが通らなくなった時
export PATH=/usr/local/bin:/usr/bin:/bin:/usr/sbin:/sbin
- 投稿日:2019-08-22T22:14:56+09:00
MacデフォのApacheでpython CGIを呼ぶ
みなさん、こんにちは
Macにデフォルトで入っているApacheを使ってpython CGIを呼び出してみたいと思いますまずは、defaultのApacheの場所を確認します
$ which httpd /usr/sbin/httpd $ which apachectl /usr/sbin/apachectlApacheを起動します(停止はstop、再起動restartもあるよ)
$ sudo /usr/sbin/apachectl startApacheの設定ファイルhttpd.confの場所は
/etc/apache2/httpd.conf っすねhttpd.confに書いてある、コンテンツを格納するDocumentRootをみてみます
$ sudo vi /etc/apache2/httpd.confどうも/Library/WebServer/Documentsにコンテンツは格納するみたいですね
httpd.conf# DocumentRoot: The directory out of which you will serve your # documents. By default, all requests are taken from this directory, but # symbolic links and aliases may be used to point to other locations. # DocumentRoot "/Library/WebServer/Documents"引き続き、httpd.confの中で、CGIの設定をしていきます
[From]
httpd.conf165 #LoadModule cgi_module libexec/apache2/mod_cgi.so↲ 174 #LoadModule userdir_module libexec/apache2/mod_userdir.so↲ 176 #LoadModule rewrite_module libexec/apache2/mod_rewrite.so↲ 259 Options FollowSymLinks Multiviews↲ 437 #AddHandler cgi-script .cgi↲[To]
httpd.conf165 LoadModule cgi_module libexec/apache2/mod_cgi.so↲ 174 LoadModule userdir_module libexec/apache2/mod_userdir.so 176 LoadModule rewrite_module libexec/apache2/mod_rewrite.so 259 Options FollowSymLinks Multiviews ExecCGI 437 AddHandler cgi-script .cgi .py↲これで設定は完了
念の為、Apache再起動
$ sudo apachectl restartあ、pyファイル作る忘れたネ、作るネ
$ sudo vi /Library/WebServer/Documents/hello.pyhello.py#!/usr/bin/python print ("Content-type:text/html\r\n\r\n") print ('<html>') print ('<head>') print ('<title>Hello Word - First CGI Program</title>') print ('</head>') print ('<body>') print ('<h2>Good morning! This is my first python CGI</h2>') print ('</body>') print ('</html>')よーし、ブラウザでlocalhost/hello.py呼びましょう
きた!
お疲れ様でした

- 投稿日:2019-08-22T21:17:20+09:00
【解説付き】Django チュートリアル その2 -後編-
はじめに
これは、【解説付き】Django チュートリアル その2 -前編-に続き、
はじめての Django アプリ作成、その2の後半部分に解説をつけて初学者にわかりやすく学んでいただきたいというためのものです。その2は、ボリュームがあるため前編/後編とさせていただいております。
前編はこちら
対象
- pythonはなんとなくわかってるけど、djangoを覚えたい
- 業務でdjango触ってたけど、きちんと理解したい
上記の方々を対象としています。
環境は、Macを使用して進めていきますので、Windowsユーザーの方は、Windows環境に読み替えてついてきていただければと思います。API で遊んでみる
Python 対話シェルを起動して、 Django が提供する API で遊んでみましょう。と、チュートリアルでは突発的にこんな事を言ってきます。
Python対話シェル、APIといきなり言われてもわからないですよね。API
APIとは、Application Programming Interfaceの略です。
「アプリケーションプログラムとの、コミュニケーションを行うもの」という解釈になるかと思います。プログラムとお話する痛いヤツと思われそうですが、今回のケースでいうと、
「djangoの機能を、対話的に実行するための手段」
となります。なんとなく、イメージが付きやすくなってきたと思います。
※ APIには、
WEB APIというものもあります(一般的にこちらを指すことが多い)
これについては、APIを作る解説として、改めて記事化しようと思います。Python対話シェル
Python対話シェルとは、pythonが提供するAPIです。
Python シェルを起動するには、以下のコマンドを実行します
$ python manage.py shell
pythonコマンドから、manage.pyを実行することで djangoと接続できます。djangoの対話シェルに入ったら データベースのAPIを触ってみましょう
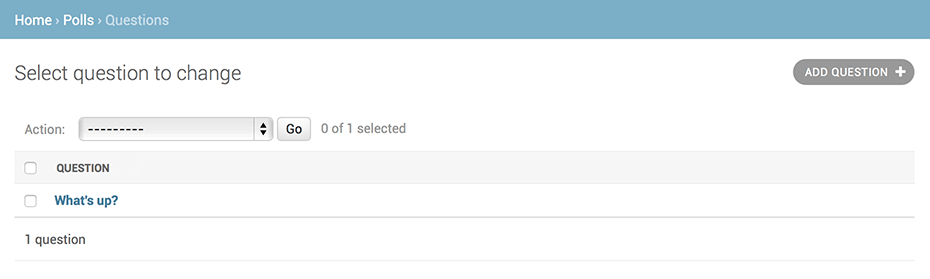
上の内容をテキスト化したもの(クリックすると表示されます)
# pollsのmodelsファイルから、Choice, Questionを読み込む >>> from polls.models import Choice, Question # Import the model classes we just wrote. # Questionの全データを取得する(現時点では0件) >>> Question.objects.all() <QuerySet []> # djangoのutileファイルから、timzeoneを読み込む >>> from django.utils import timezone # Questionクラスのインスタンスを作る。 # question_textに"What's new?"、pub_dateに、現在エリアの現在時刻を指定 >>> q = Question(question_text="What's new?", pub_date=timezone.now()) # インスタンスのsave()メソッドを実行し、DBに保存 >>> q.save() # DBに保存されることで、IDが採番される >>> q.id 1 # インスタンスのフィールドの値を確認 >>> q.question_text "What's new?" >>> q.pub_date datetime.datetime(2012, 2, 26, 13, 0, 0, 775217, tzinfo=<UTC>) # question_textを"What's up?"に変更 >>> q.question_text = "What's up?" # .save()を行うことで、変更内容がDBに反映される >>> q.save() # データが入ったので、改めて、全件取得を実行してみる >>> Question.objects.all() <QuerySet [<Question: Question object (1)>]>取得したデータが、
<Question: Question object (1)>と表示されてますよね
この状態では、どんなデータかわからないため、
polls/models.pyのQuestionモデルを編集しましょう。
__str__()メソッドをQuestionとChoiceに追加します。polls/models.pyfrom django.db import models class Question(models.Model): # ... def __str__(self): return self.question_text class Choice(models.Model): # ... def __str__(self): return self.choice_text
__str__()を書くことで、対話シェルでの見栄えだけではなく、Djangoで自動生成されるadmin(管理画面)の
一覧データ表示時にも使用されます。
モデルには、__str__()メソッドをつけるようにしましょう。デモ用にカスタムのメソッドを追加してみましょう
polls/models.pyimport datetime from django.db import models from django.utils import timezone class Question(models.Model): # ... def was_published_recently(self): return self.pub_date >= timezone.now() - datetime.timedelta(days=1)
import datetimeとfrom django.utils import timezoneを追加しました。
これは、 Python の 標準モジュールdatetimeと Django のタイムゾーン関連ユーティリティのdjango.utils.timezoneを利用するために呼び出しています。
Python でのタイムゾーンのついて詳しく知りたい方は、タイムゾーンサポートドキュメント を参照してください。もう一度
python manage.py shellを実行して確認してみましょう。
(ソースを変更した場合、対話モードを開き直さないと、変更が反映されないので気をつけてください)
上の内容をテキスト化したもの(クリックすると表示されます)
```consolefrom polls.models import Choice, Question
str()を追加したことで、オブジェクトがわかりやすくなりました。
Question.objects.all()
]>データベースから条件でフィルターして(絞り込んで)取得することができます。
.all() を filter(id=1) と変えることで、IDが1のものを取得してくれます。
Question.objects.filter(id=1)
]>filter(question_text__startswith='What') と変えることで、Whatから始まるデータを取得してくれます。
Question.objects.filter(question_text__startswith='What')
]>Questionのpub_dateを今年のデータを指定します
from django.utils import timezone
current_year = timezone.now().year
Question.objects.get(pub_date__year=current_year)
.get(id=2)を指定すると、条件とマッチする1件を取得します。
データがない場合や、複数件がhitするような指定の場合は、エラーとなります。
Question.objects.get(id=2)
Traceback (most recent call last):
...
DoesNotExist: Question matching query does not exist.Lookup by a primary key is the most common case, so Django provides a
shortcut for primary-key exact lookups.
The following is identical to Question.objects.get(id=1).
Question.objects.get(pk=1)
Make sure our custom method worked.
q = Question.objects.get(pk=1)
q.was_published_recently()
TrueGive the Question a couple of Choices. The create call constructs a new
Choice object, does the INSERT statement, adds the choice to the set
of available choices and returns the new Choice object. Django creates
a set to hold the "other side" of a ForeignKey relation
(e.g. a question's choice) which can be accessed via the API.
q = Question.objects.get(pk=1)
Display any choices from the related object set -- none so far.
q.choice_set.all()
Create three choices.
q.choice_set.create(choice_text='Not much', votes=0)
q.choice_set.create(choice_text='The sky', votes=0)
c = q.choice_set.create(choice_text='Just hacking again', votes=0)Choice objects have API access to their related Question objects.
c.question
And vice versa: Question objects get access to Choice objects.
q.choice_set.all()
, , ]>
q.choice_set.count()
3The API automatically follows relationships as far as you need.
Use double underscores to separate relationships.
This works as many levels deep as you want; there's no limit.
Find all Choices for any question whose pub_date is in this year
(reusing the 'current_year' variable we created above).
Choice.objects.filter(question_pub_date_year=current_year)
, , ]>Let's delete one of the choices. Use delete() for that.
c = q.choice_set.filter(choice_text__startswith='Just hacking')
c.delete()
```モデルのリレーションについてはリレーション先オブジェクトにアクセスする を参照してください。
API を通じた、フィールドルックアップのためのダブルアンダースコアの使い方は フィールドルックアップ を参照してください。
データーベース API の詳細は データベース API リファレンス を参照してください。Django Adminの紹介
設計思想
コンテンツの追加や変更、削除を行うための管理サイトを作ることはクリエイティブではなく、面倒に感じられることが多いと思います。
そのため、Djangoはモデル(データ)のための管理インタフェースを自動的に生成してくれます。もともとDjangoは、ニュース系のサイトを管理する目的で開発されました。
ニュース系のサイトでは、 「コンテンツの作成者 (content publisher)」と「公開 (public) 」サイトを明確に区別しています。
サイトの管理者は、新たな話題やイベント、 スポーツのスコアなどの入力にシステムを使い、コンテンツは公開用サイト上で表示されます。
Django は、サイト管理者向けのadmin(管理)機能を提供しています。admin はサイトの訪問者でなく、サイト管理者に使われることを意図しています。
管理ユーザーを作成する
最初に私達はadminサイトにログインできるユーザーを作成する必要があります。
下記のコマンドを実行します。
$ python manage.py createsuperuser好きなユーザー名を入力しEnterを押してください。
Username: adminemailアドレスを入力します。
Email address: admin@example.com最後のステップはパスワードの入力です。
確認のために、パスワードの入力を2回求められます。Password: ********** Password (again): ********* Superuser created successfully.開発サーバーの起動
Django adminサイトはデフォルトで有効化されます。
開発サーバーを起動して触れてみましょう。もしサーバーが起動していなかったら、このようにして起動しましょう
$ python manage.py runserver次はブラウザで、
http://127.0.0.1:8000/admin/にアクセスします。
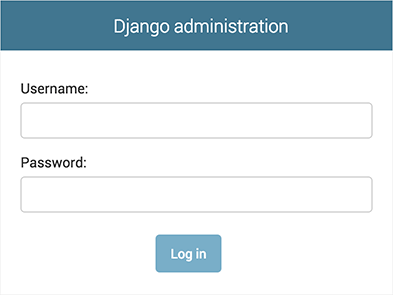
以下のような admin のログイ ン画面が表示されるはずです
translation がデフォルトで on になっているため、ログイン画面はあなたの言語で表示されるかもしれません。
これは、あなたのブラウザの設定と、 Django がその言語に翻訳されているかどうかによります。admin サイトに入る
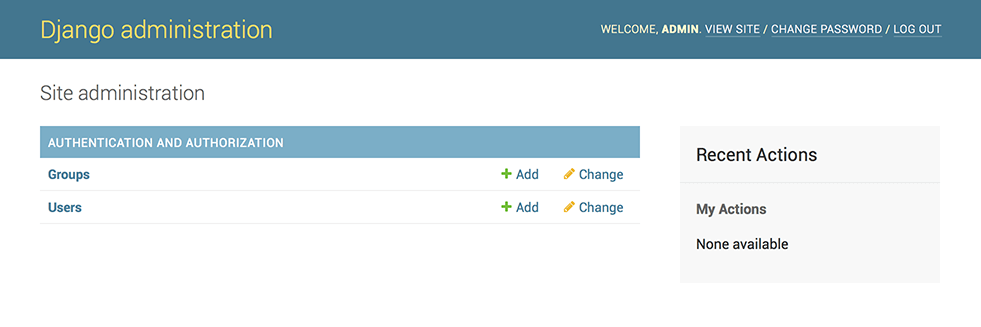
前のステップで作成したスーパーユーザーのアカウントでログインしてみましょう。
Django admin のインデックスページが表示されるはずです
groups と usersなどの編集可能なコンテンツが表示されるはずです。
これらは Django に含まれる認証フレームワーク django.contrib.auth によって提供されます。Poll アプリを admin 上で編集できるようにする
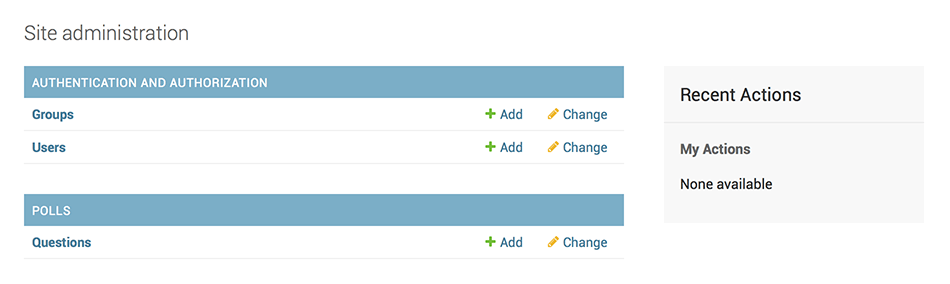
polls アプリは管理画面に表示されていましたか?
admin のインデックスページを見ても表示されていませんね。
Questionオブジェクトのadminインタフェースをadminに追加する必要があります。
追加するために、polls/admin.pyに下記のように編集しましょうpolls/admin.pyfrom django.contrib import admin from .models import Question admin.site.register(Question)admin の機能を探究してみる
私たちが
Questionを追加したので、 Django は admin インデックスページに表示してくれました。
Questionsをクリックしましょう。
questions のための "change list" ページが表示されます。
このページにはデータベース中のすべての question が表示され、あなたはその中のひとつを選んで変更することができます。
ここには、上記で作成した "What's UP?" question もあります
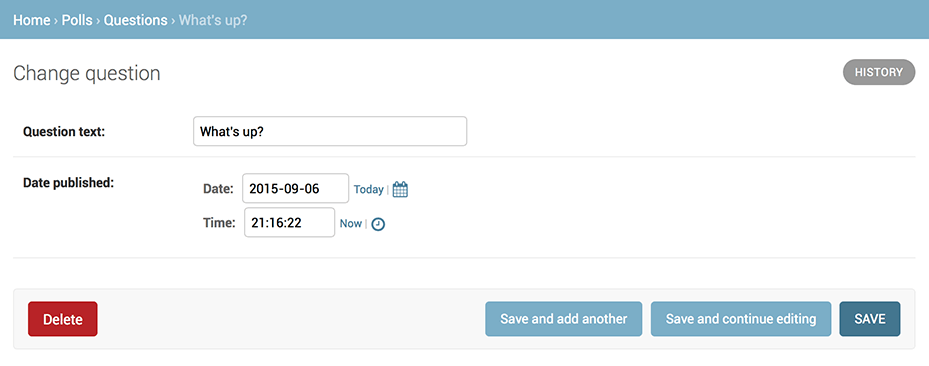
"What's up?" questionをクリックして編集してみましょう
※下記日本語版
以下の点に注意してください
- 入力フォームは
Questionモデルから自動的に生成されます。- モデルのフィールドの型 (DateTimeField 、 CharField など) に応じて、HTML 入力フォームと対応しています。
DateTimeFieldは JavaScript ショートカットがついています。
日付 (dates) のカラムには「今日 (today)」 へのショートカットとカレンダーポップアップボタンがあります。
時刻 (times) には「現在 (now)」へのショートカットと、よく入力される時刻のリストを表示するポップアップボタンがあります。ページの下部には下記のボタンが用意されています。
- 保存 (Save) – 変更を保存して、このモデルの一覧のページに戻ります。
- 保存して編集を続ける (Save and continue editing) – 変更を保存して、このオブジェクトの編集ページをリロードします。
- 保存してもう一つ追加 (Save and add another) – 変更を保存して、新たに新規追加するための空の編集ページを表示します。
- 削除 (Delete) – 削除確認ページを表示します。
もし「Date published」の値が、チュートリアルその1 で作成した questionと一致しないのであれば、
TIME_ZONEの設定が漏れていた可能性があります。
設定を変更して、ページをリロードし、正しく表示されるか確認してください。
今日や現在ショートカットをクリックして、「Date published」を変更してみましょう。
変更したら、「保存して編集を続ける」を押します。次に、右上に ある「履歴 (History)」をクリックしてみましょう。
ユーザが管理サイト上でオブジェクトに対して行った変更履歴の全てを、変更時刻と変更を行ったユーザ名付きでリストにしたページが表示されます
Modelの
APIやadminサイトに慣れてきたら、 チュートリアルその3 を読んで、pollsアプリにビューをさらに追加する方法を学習しましょう。次回予告
ここまでがdjango チュートリアルのその2 -後編- でした。
既にdjangoに触れてる人や、多言語に詳しい人ならわかるけど、初めての人にはわかりにくい部分が多いと思います。
本家のチュートリアルに補足情報を盛り込んだ形で記載しているので理解の手助けになれれば幸いです。次回は、はじめての Django アプリ作成、その3について書いていこうと思います。



- 投稿日:2019-08-22T20:26:16+09:00
pandas0.25.0で新しくなったのaggメソッド!
概要
簡単に言うと
マルチカラムをそもそもつくらないaggメソッドです!
7月の頭にpandasのaggメソッドによって生じるマルチカラムをいい感じに処理する方法について紹介しましたが, pandasの0.25.0でそこに近い機能があったので紹介します!使用するDataFrame
公式サイトと同じものを使います
import pandas as pd animals = pd.DataFrame( { "kind": ["cat", "dog", "cat", "dog"], "height": [9.1, 6.0, 9.5, 34.0], "weight": [7.9, 7.5, 9.9, 198.0], } ) # kind height weight # 0 cat 9.1 7.9 # 1 dog 6.0 7.5 # 2 cat 9.5 9.9 # 3 dog 34.0 198.0今まで通りやってみる
今まで通りaggにキーに統計の対象となるカラム名, 値に統計の種類のリストを指定した辞書を渡します.
df_old = animals.groupby('kind').agg({"height": ['min', 'max'], 'weight': ['mean']}) # height weight # min max mean # kind # cat 9.1 9.5 8.90 # dog 6.0 34.0 102.75カラムがマルチカラムになっていますね.
新しくなったaggメソッド
新しくなったaggメソッドでは引数名に統計特徴量を計算した後につけたいカラム名, 引数に第1要素が統計の対象となるカラム名, 第2要素に統計の種類を指定したタプルを指定します.(言葉で見ると難しいから下のコードを見たほうがわかりやすいかも...)
df_new = animals.groupby("kind").agg( min_height=("height", "min"), height_max=("height", "max"), hogehoge=("weight", "mean"), ) # min_height height_max hogehoge # kind # cat 9.1 9.5 8.90 # dog 6.0 34.0 102.75マルチカラムになっていないですね!
いいかんじ!感じたこと
「新しくなったaggメソッドを使うようにすれば超ハッピー!」ということではないなぁと感じました.
kaggleとかでminもmaxもmeanもmedianもvarもskewも, とにかくたくさん統計特徴量を作るんだ!という場合には今まで通りのやり方がやりやすいのかなと思いました.
ただ, 2, 3個の統計特徴量をつくるぜってときは新しいaggメソッドのやり方がお手軽にできていいなと感じました.
状況に応じて臨機応変に使っていきましょう!
- 投稿日:2019-08-22T20:26:16+09:00
pandas0.25.0で新しくなったaggメソッド!
概要
簡単に言うと
マルチカラムをそもそもつくらないaggメソッドです!
7月の頭にpandasのaggメソッドによって生じるマルチカラムをいい感じに処理する方法について紹介しましたが, pandasの0.25.0でそこに近い機能があったので紹介します!使用するDataFrame
公式サイトと同じものを使います
import pandas as pd animals = pd.DataFrame( { "kind": ["cat", "dog", "cat", "dog"], "height": [9.1, 6.0, 9.5, 34.0], "weight": [7.9, 7.5, 9.9, 198.0], } ) # kind height weight # 0 cat 9.1 7.9 # 1 dog 6.0 7.5 # 2 cat 9.5 9.9 # 3 dog 34.0 198.0今まで通りやってみる
今まで通りaggにキーに統計の対象となるカラム名, 値に統計の種類のリストを指定した辞書を渡します.
df_old = animals.groupby('kind').agg({"height": ['min', 'max'], 'weight': ['mean']}) # height weight # min max mean # kind # cat 9.1 9.5 8.90 # dog 6.0 34.0 102.75カラムがマルチカラムになっていますね.
新しくなったaggメソッド
新しくなったaggメソッドでは引数名に統計特徴量を計算した後につけたいカラム名, 引数に第1要素が統計の対象となるカラム名, 第2要素に統計の種類を指定したタプルを指定します.(言葉で見ると難しいから下のコードを見たほうがわかりやすいかも...)
df_new = animals.groupby("kind").agg( min_height=("height", "min"), height_max=("height", "max"), hogehoge=("weight", "mean"), ) # min_height height_max hogehoge # kind # cat 9.1 9.5 8.90 # dog 6.0 34.0 102.75マルチカラムになっていないですね!
いいかんじ!感じたこと
「新しくなったaggメソッドを使うようにすれば超ハッピー!」ということではないなぁと感じました.
kaggleとかでminもmaxもmeanもmedianもvarもskewも, とにかくたくさん統計特徴量を作るんだ!という場合には今まで通りのやり方がやりやすいのかなと思いました.
ただ, 2, 3個の統計特徴量をつくるぜってときは新しいaggメソッドのやり方がお手軽にできていいなと感じました.
状況に応じて臨機応変に使っていきましょう!
- 投稿日:2019-08-22T20:19:31+09:00
pythonで考えるメタクラスとは?
pythonで考えるメタクラスとは
メタクラスについて、pythonで初めて学んでみました。自分の備忘録も兼ねて、まとめてみたいと思います。
そもそもメタクラスって?
メタクラスって何でしょう、Wikipediaで調べてみると下記のように説明されています。
オブジェクト指向プログラミングにおいてメタクラスとは、インスタンスがクラスとなるクラスのことである。通常のクラスがそのインスタンスの振る舞いを定義するように、メタクラスはそのインスタンスであるクラスを、そして更にそのクラスのインスタンスの振る舞いを定義する。
(引用:https://ja.wikipedia.org/wiki/%E3%83%A1%E3%82%BF%E3%82%AF%E3%83%A9%E3%82%B9)
つまり、クラスの振る舞いを定義するためのクラスがメタクラスだと、なんとなくイメージできます。
ここでクラスの「振る舞い」を制御したいのなら、そのクラスの親クラスを作って、継承させるのと何が違うのでしょうか。それは制御したい「振る舞い」に違いがあると思っています。
親クラス(継承)とメタクラスの違い
親クラスの継承とメタクラスの役割について、私なりにざっくり整理すると以下のようになると思っています。
制御したい「振る舞い」 具体例 親クラス インスタンス生成後の挙動(どのように動くか) 複数の子クラスで同じ名前のメソッドを使いたい(ポリモーフィズムの実現) メタクラス インスタンス生成前(生成時)の挙動(どのように定義されているか) クラス変数がすべて適切に定義されているかチェックしたい/直接関係しないクラス同士の中身も制御したい。 コード例
実際にコード例を見てみましょう。政令指定都市を定義するためのメタクラスを書いてみました。政令指定都市は人口が500万人以上の都市ですので、政令指定都市クラス定義時に人口が500万人以上かをチェックするようにします。
meta_sample.py# 政令指定都市メタクラス # メタクラスはtypeを継承する class GovermentDesignatedMetaClass(type): def __new__(meta,name,bases,attributes): # __new__関数はクラス生成時に実行される関数 # クラスの情報を受け取ることができる # name:クラス名, bases:親クラス, attributes:クラス属性 if bases != (object,): #抽象クラスは検証しない if attributes["population"] < 50000000: # 500万人未満なら例外 raise ValueError("This is not Goverment designated city") return type.__new__(meta,name,bases,attributes) # 政令指定都市親クラス # メタクラスの指定は「metaclass=...」で行う(Python3) class GovermentDesignatedCity(object, metaclass=GovermentDesignatedMetaClass): population=None #子クラスで定義する # 東京都 (政令指定都市) class Tokyo(GovermentDesignatedCity): population = 100000000 #1千万人 # 松山市 (政令指定都市ではない) class Matsuyama(GovermentDesignatedCity): population = 5000000 #50万人以上のようにメタクラスを定義し実行すると、Matsuyamaは人口が約50万人なので政令指定都市ではないため、下記のようにエラーメッセージが出力されます。
実行結果Traceback (most recent call last): File "sample.py", line 15, in <module> class Matsuyama(GovermentDesignatedCity): File "sample.py", line 5, in __new__ raise ValueError("This is not Goverment designated city") ValueError: This is not Goverment designated cityメタクラスのメリット
お気づきかと思いますが、上記コードはMatsuyamaクラスを定義しただけで、どこにもインスタンスを生成していませんし、静的クラスとしても利用していません。これこそがメタクラスのメリットの一つになります。すなわち、
メタクラスを利用することで、クラスを実装した時点でそのクラスの定義チェックを行えます
メタクラスの使いどころ
最後にメタクラスの使いどころになると考えれているシチュエーションを挙げます。
(他にも積極的に使える場面があれば、ぜひご教示ください。)
- クラス変数のチェックをしたい(今回のコード例)
- インスタンス生成時に必ず特定の関数を実行したい。(デシリアライズ時にジェネリックに行えるよう、シリアライズ時にクラスの存在を登録したいときなど)
まとめ
メタクラスはクラスがどのように定義されるかを制御でき、クラス定義時のクラス変数チェックなどに有効。
参考記事
Python の メタプログラミング (__metaclass__, メタクラス) を理解する
Python超入門その24〜メタクラスでクラスの動作をカスタマイズしてみよう〜
Brett Slatkin, "Effective Python", 2016, O'REILLY
- 投稿日:2019-08-22T18:57:29+09:00
Python:プログラミングコンテストでよく使う処理
動作確認はPython3.4で実施。(AtCoderに合わせている)
随時追加していきます。入力を受け取る
# 文字列 S = input() # 数値 N = int(input()) # 決まった数の数値(2パターンのうち好きな方) A, B, C = map(int, input().split()) A, B, C = [int(i) for i in input().split()] # 配列として数値を受け取る D = list(map(int, input().split())) D = [int(i) for i in input().split()]整数A、Bに対して、A/Bの切り捨て
>>> 5 // 2 2 >>> 5 // 3 1整数A、Bに対して、A/Bの切り上げ
(A+B-1)//B の商で求められる。>>> A = 3; B = 2 >>> (A + B - 1) // B 2 >>> A = 4; B = 2 >>> (A + B - 1) // B 2 >>> A = 5; B = 2 >>> (A + B - 1) // B 3最大公約数、最小公倍数
https://qiita.com/aki-takano/items/a43fac70b702d4f22d7e
最大再帰数を上げる
https://qiita.com/aki-takano/items/9bbb88db07db3c8f9fb5
[Python3]配列の配列をソートする
https://qiita.com/aki-takano/items/73b3f3ef90e05a441da8
メモ:n桁の2進数の数をまとめて作成
https://qiita.com/aki-takano/items/d74b023a82cbfd780bb1
組み合わせ
>>> from itertools import combinations >>> list(combinations([1,2,3], 2)) [(1, 2), (1, 3), (2, 3)]>>> a = [1,2,3] >>> for i in range(len(a)+1): ... list(combinations(a,i)) ... [()] [(1,), (2,), (3,)] [(1, 2), (1, 3), (2, 3)] [(1, 2, 3)]差集合
setを使う。(listではできない)
>>> {1,2,3,4} - {1,4} {2, 3} >>> {1,2,3,4}.difference({1,4}) # 上記と同じ {2, 3}
- 投稿日:2019-08-22T18:44:41+09:00
torrcのExcludeNodesを変更してTorの接続、ブラウジングを超高速にする方法
Tor は複数のノードを経由することで、とても匿名性を高くしている。だが、匿名性がある程度妥協できる日常のブラウジングに使うにはあまりにも遅い。そのため、匿名性を犠牲にしつつも、高速にする設定を行う。
torrc の設定
Windowsの場合
Tor Browser\Browser\TorBrowser\Data\Tor\torrcファイルを、
macOSの場合なぜかだめなので、~/Library/Application Support/TorBrowser-Data/Tor/torrcを編集Tor Browser.app/Contents/Resources/TorBrowser/Tor/torrc-defaultsを編集(ファイルパスにスペースが入っているので注意)し、以下のように設定する
StrictNodes 1 ExcludeNodes SlowServer,{bd},{be},{bf},{bg},{ba},{bb},{wf},{bl},{bm},{bn},{bo},{bh},{bi},{bj},{bt},{jm},{bv},{bw},{ws},{bq},{br},{bs},{je},{by},{bz},{ru},{rw},{rs},{lt},{re},{lu},{lr},{ro},{ls},{gw},{gu},{gt},{gs},{gr},{gq},{gp},{gy},{gg},{gf},{ge},{gd},{gb},{ga},{gn},{gm},{gl},{kw},{gi},{gh},{om},{jo},{hr},{ht},{hu},{hk},{hn},{hm},{kr},{ad},{pr},{ps},{pw},{pt},{kn},{py},{ai},{pa},{pf},{pg},{pe},{pk},{ph},{pn},{pl},{pm},{zm},{eh},{ee},{eg},{za},{ec},{al},{ao},{kz},{et},{zw},{ky},{es},{er},{me},{md},{mg},{mf},{ma},{mc},{uz},{mm},{ml},{mo},{mn},{mh},{mk},{mu},{mt},{mw},{mv},{mq},{mp},{ms},{mr},{au},{ug},{my},{mx},{vu},{fr},{aw},{af},{ax},{fi},{fj},{fk},{fm},{fo},{ni},{nl},{no},{na},{nc},{ne},{nf},{ng},{nz},{np},{nr},{nu},{ck},{ci},{ch},{co},{cn},{cm},{cl},{cc},{ca},{cg},{cf},{cd},{cz},{cy},{cx},{cr},{kp},{cw},{cv},{cu},{sz},{sy},{sx},{kg},{ke},{ss},{sr},{ki},{kh},{sv},{km},{st},{sk},{sj},{si},{sh},{so},{sn},{sm},{sl},{sc},{sb},{sa},{sg},{se},{sd},{do},{dm},{dj},{dk},{de},{ye},{at},{dz},{us},{lv},{uy},{yt},{um},{tz},{lc},{la},{tv},{tw},{tt},{tr},{lk},{li},{tn},{to},{tl},{tm},{tj},{tk},{th},{tf},{tg},{td},{tc},{ly},{va},{vc},{ae},{ve},{ag},{vg},{iq},{vi},{is},{ir},{am},{it},{vn},{aq},{as},{ar},{im},{il},{io},{in},{lb},{az},{ie},{id},{ua},{qa},{mz} EntryNodes {jp} ExitNodes {jp} # ↑日本にExitノードがなくて繋がらない場合、 {jp},{kr},{tw},{hk},{sg} など近い国を入力すると入力する。
上記設定の生成方法
pycountryとSet(集合)を使って、(すべての国 - ExcludeNodesから取り除く国)を生成する。前準備
pip install pycountryソースコード
entry_countries,include_countries,exit_countries,forbid_countriesの設定はお好みで。JPにExitがなくて繋がらない場合、近い国のコードを入れると良いだろう。
それぞれEntryNodes,ExcludeNodesのインバース(逆),ExitNodesに関係してくる。forbid_countriesは ExcludeCountries に必ず追加する国。なお、国コードは2文字の ISO 3166-1 alpha-2 である。
import pycountry import pprint pp = pprint.PrettyPrinter(indent=4) def concat_sets(countries): return ','.join(['{' + r.lower()+'}' for r in countries]) entry_countries = set({ 'JP', }) include_countries = set({ 'JP', #'KR', #'HK', #'TW', #'SG', #'PH', #'US', #'AU', }) exit_countries = set({ 'JP', }) forbid_countries = set({ ## 5-eyes #'US', #'GB', #'CA', #'AU', #'NZ', ## 9-eyes #'DK', #'FR', #'NL', #'NO', ## 14-eyes #'DE', #'BE', #'IT', #'ES', #'SE', ## 41-eyes #'AT', #'CZ', #'GR', #'HU', #'IS', #'JP', #'LU', #'PL', #'PT', #'KR', #'CH', #'TR', ## Dangerous (harmful exit) countries #'RU', #'UA', #'CN', }) all_countries = set([c.alpha_2 for c in list(pycountry.countries)]) if len(forbid_countries) > 0: exclude_countries = forbid_countries else: exclude_countries = all_countries - include_countries exclude_nodes = concat_sets(exclude_countries) entry_nodes = concat_sets(entry_countries) exit_nodes = concat_sets(exit_countries) print("StrictNodes 1") print("ExcludeNodes SlowServer," + exclude_nodes) if len(entry_nodes) > 0: print("EntryNodes " + entry_nodes) if len(exit_nodes) > 0: print("ExitNodes " + exit_nodes)実行
python countrycode.py # Macの場合、こうするとクリップボードにコピーされる # python countrycode.py | pbcopy実行すると、標準出力に設定が吐き出されるので、コピーする
理屈
Entry(Guard)ノードに日本のノードだけを使用するようにし、中間ノードとして日本以外のノードを弾くようにし、Exitノードを日本だけにすることで、日本国内だけでTor Circuitが完成され、RTT(Round Trip Time)が減り、高速になる。
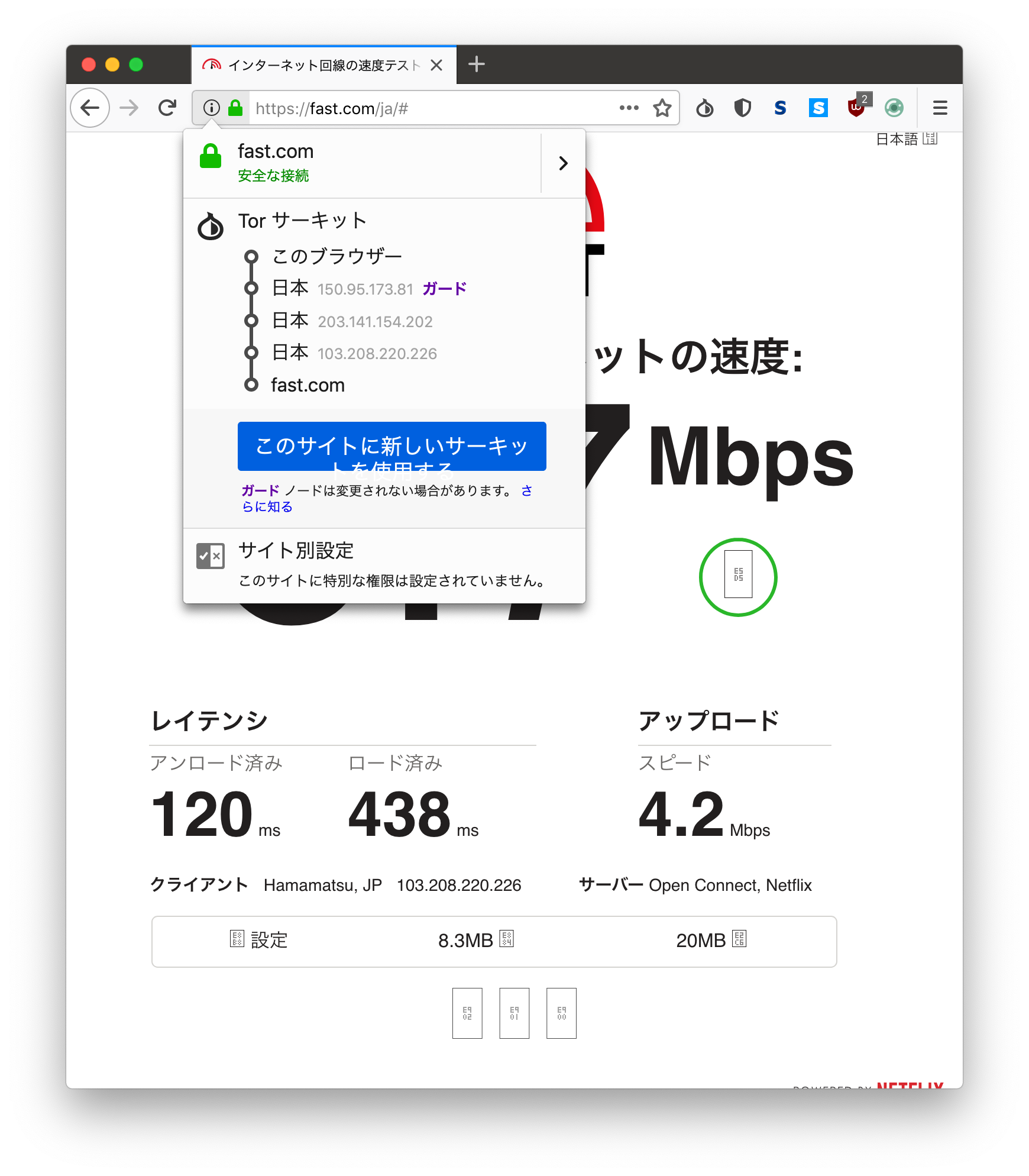
レイテンシ比較
速度の比較は意味がないので、レイテンシのみに注目する。
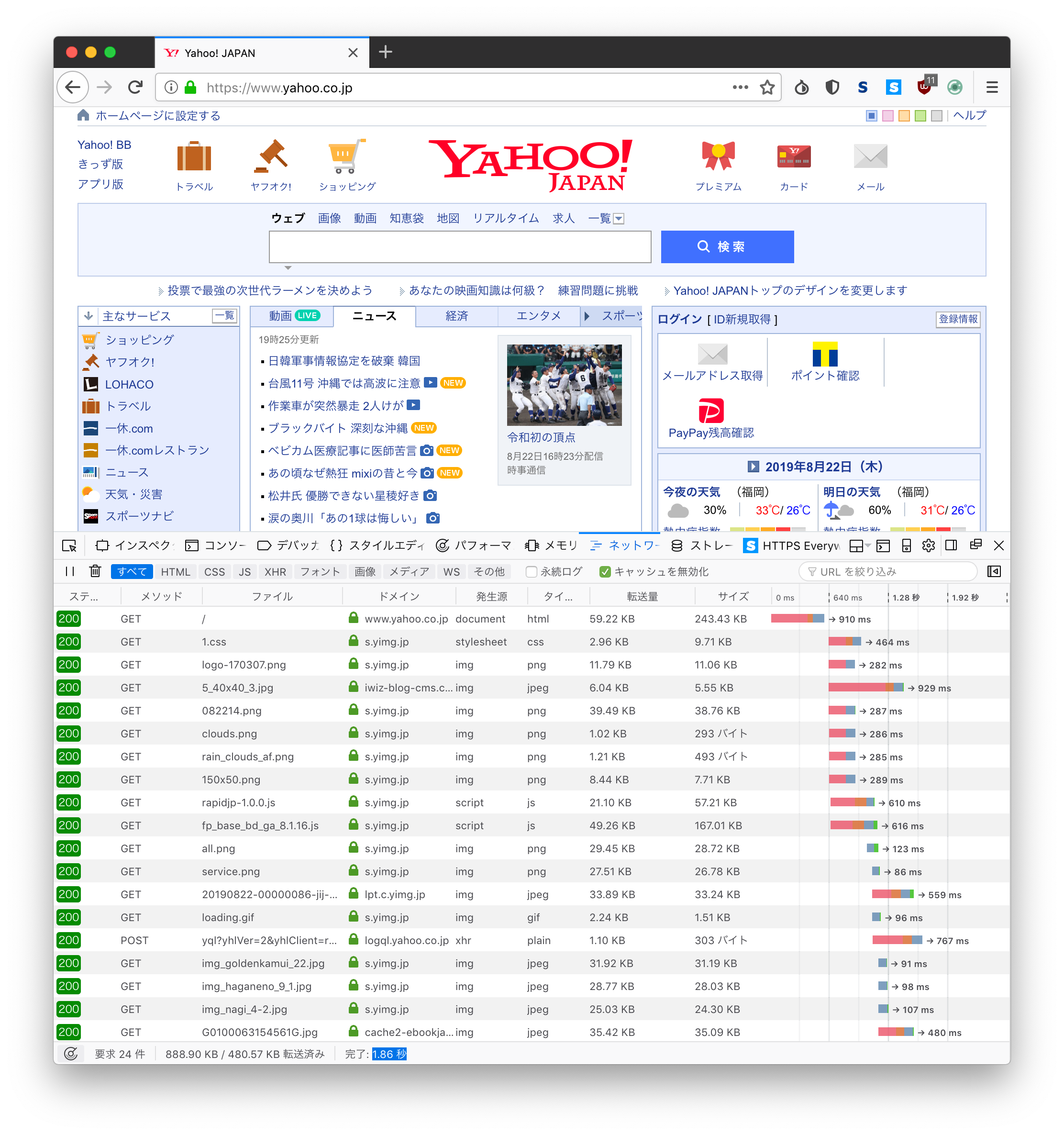
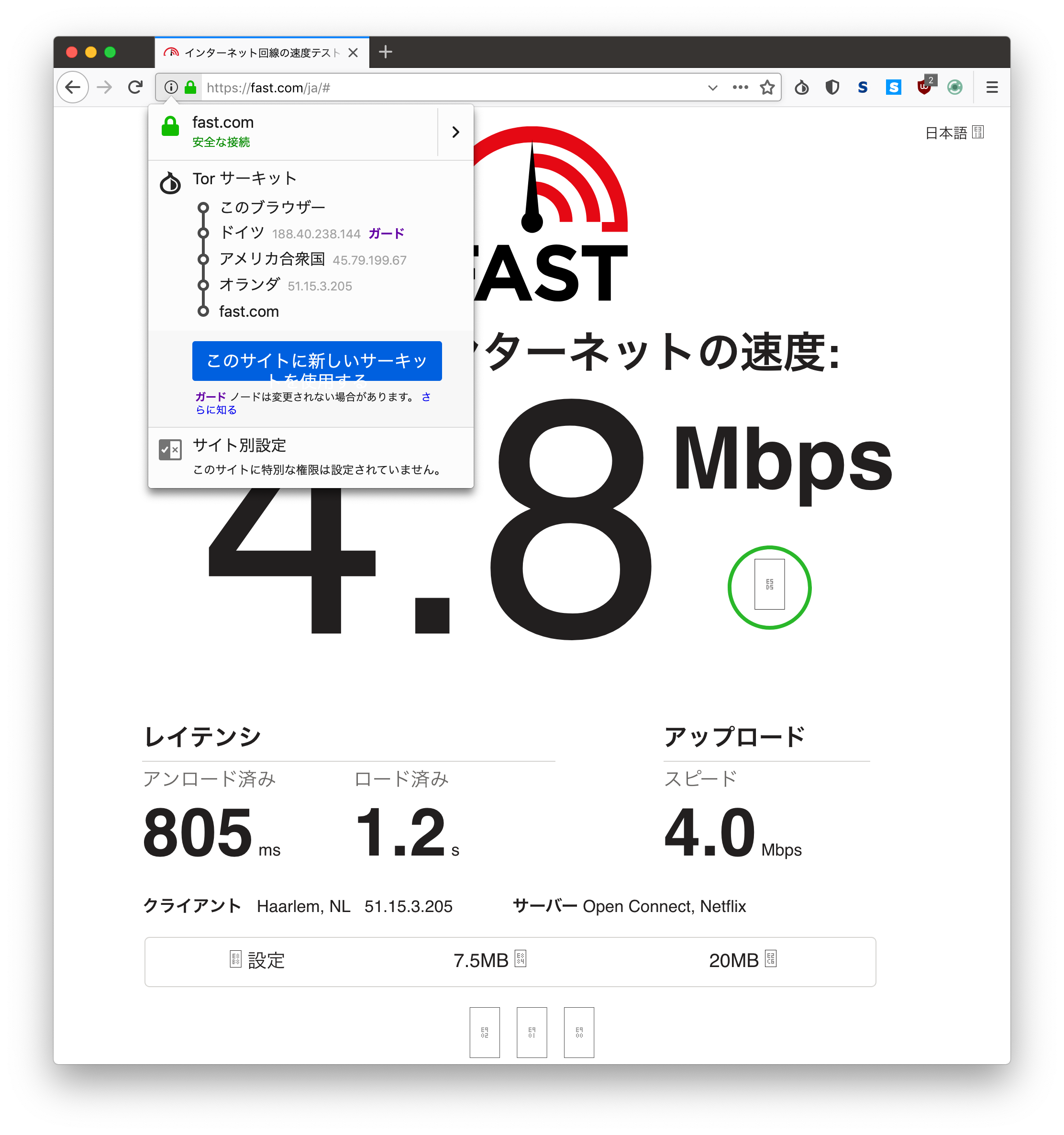
上記設定
Fast.com 120ms〜
Yahoo! Japan 1.86s
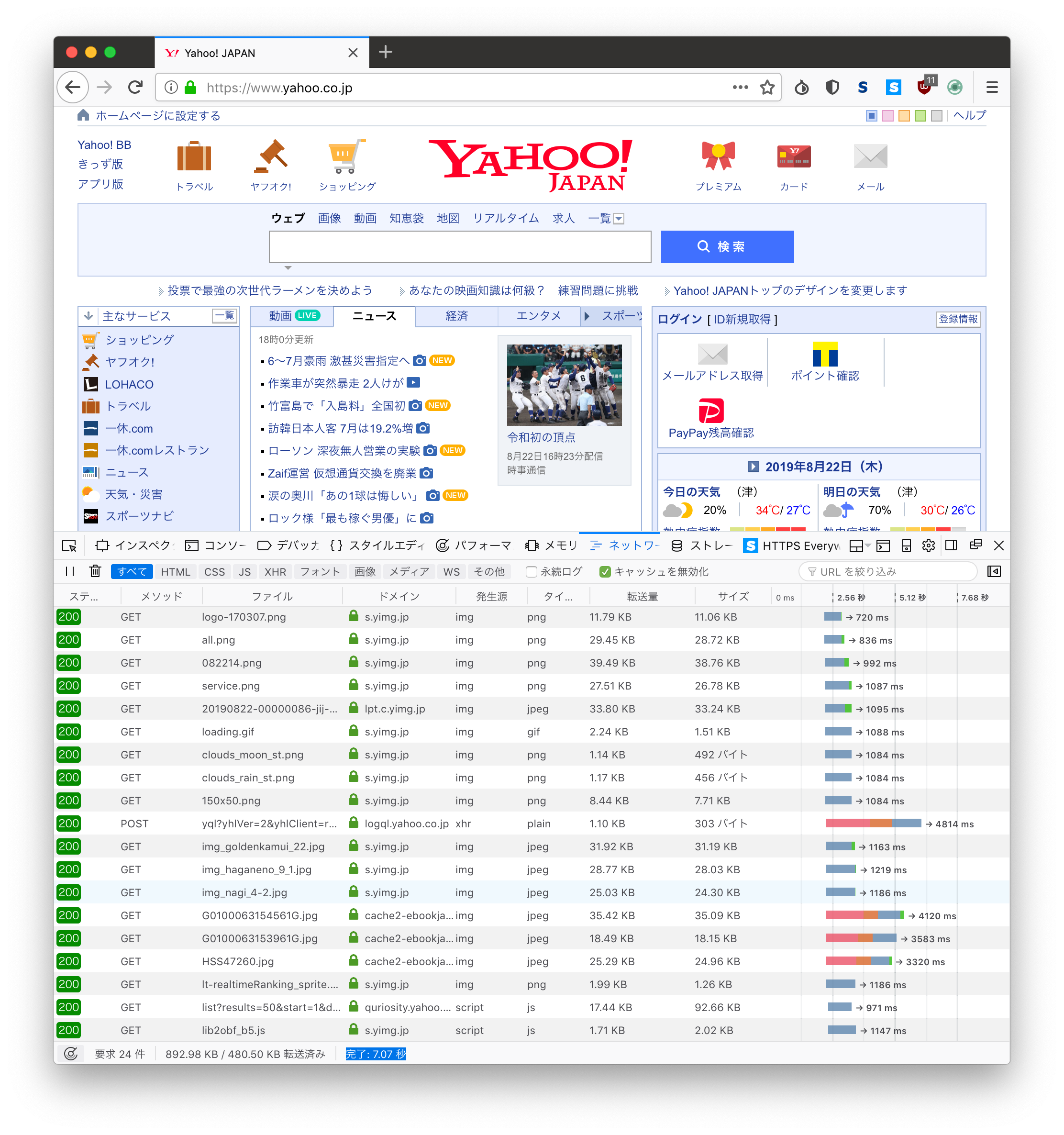
デフォルト
Fast.com 805ms〜
Yahoo! Japan 7.07s
警告
言うまでもないが、高速なブラウジングとは引き換えに、匿名性はとても低いものとなる。
例えばあなたがジャーナリストで重大事案を告発する場合やある組織のメンバーで、その組織の重要な機密を内部告発する場合などにはこの設定は使わず、日常のブラウジング程度の利用にとどめるべきだろう。
おまけ
匿名性+
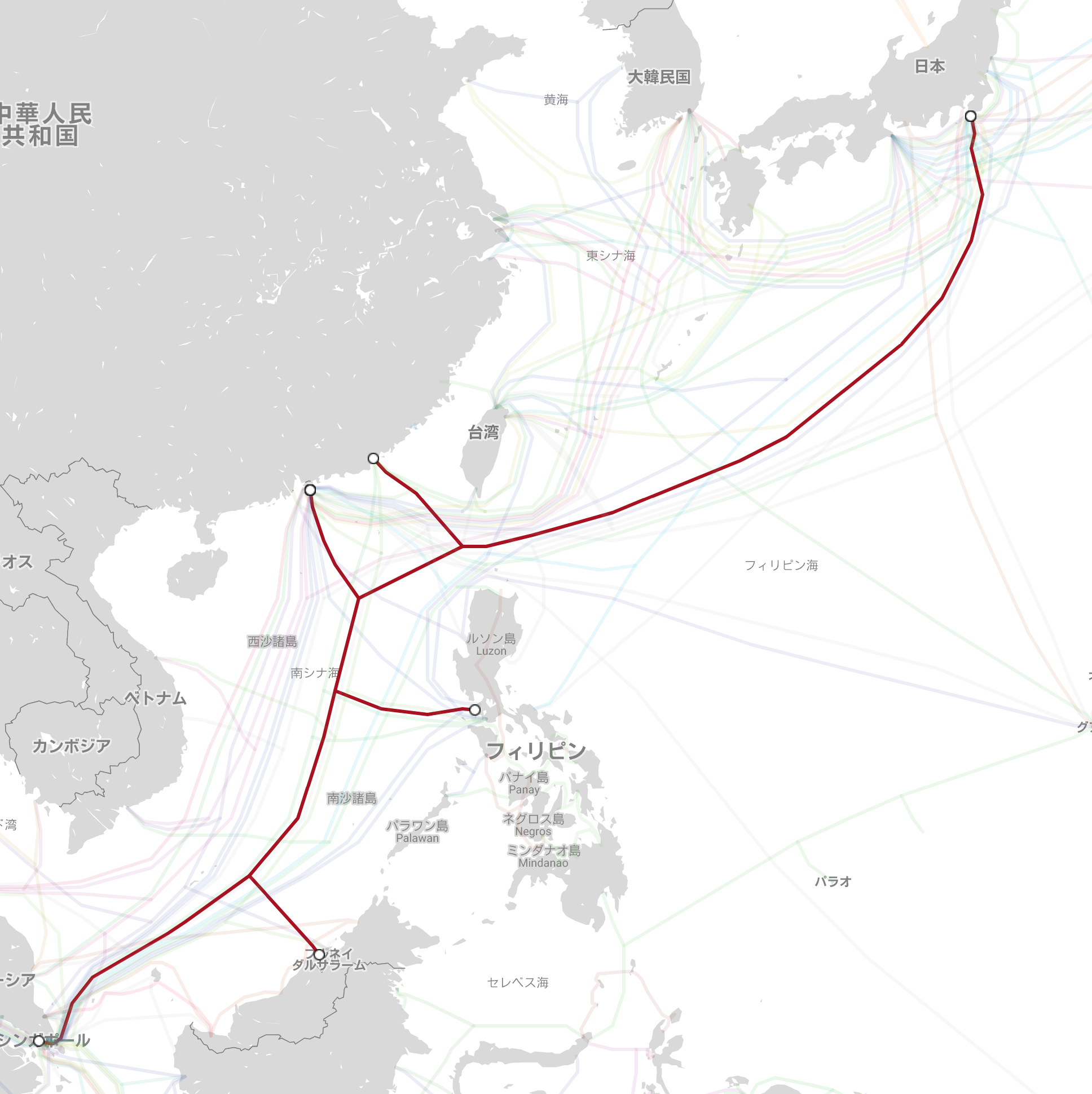
速度を少し犠牲にし、匿名性を少しあげる。経由する国は日本から出ている海底ケーブルで、1hop以内に到達できる場所。
画像はKDDIやGoogleなどによる、日本に接続されている海底ケーブルの一つ "Southeast Asia Japan Cable"
画像:Southeast Asia Japan Cable (SJC)entry_countries = set({ 'JP', }) include_countries = set({ 'JP', 'KR', 'HK', 'TW', 'SG', 'PH', }) exit_countries = set({ 'JP', })匿名性++
Entry(Guard)ノードだけをJPにし、速度をある犠牲にし匿名性を上げる。
entry_countries = set({ 'JP', }) include_countries = set({ 'JP', 'KR', 'HK', 'TW', 'SG', 'PH', }) exit_countries = set({ 'JP', 'KR', 'HK', 'TW', 'SG', 'PH', })匿名性+++
速度を犠牲にし匿名性をさらに上げる。
entry_countries = set({ 'JP', 'KR', 'HK', 'TW', 'SG', 'PH', }) include_countries = set({ 'JP', 'KR', 'HK', 'TW', 'SG', 'PH', }) exit_countries = set({ 'JP', 'KR', 'HK', 'TW', 'SG', 'PH', })匿名性++++
速度をかなり犠牲にし匿名性をさらに上げる(Torの標準レベル)。Torのデフォルト設定。特に
EntryNodes,ExitNodes,ExcludeNodesを指定しない。匿名性++++ & 安全性+ : スパイ協定を結んでいる国をExcludeNodesに追加する場合
あなたが重要な通信をする場合、設定によって速度は低速になるが、この設定を行う。
forbid_countriesに1つでも国を追加すると、上記プログラムは "除外" モードになり、forbid_countriesへの通信を一切行わない設定を出力する。
entry_countries,exit_countriesを空にする。forbid_countriesに以下を追加する。5eyes "UKUSA Agreement" を除く場合
UKUSA協定の構成国アメリカ、イギリス、カナダ、オーストラリア、ニュージーランドをTor Circuitから除外するよう設定する。
# 5-eyes 'US', 'GB', 'CA', 'AU', 'NZ',
- in 2009, the United States proposed to France to join the Five Eyes
'FR'- Five Eyes Plus "Like-Minded" Against China and Russia:
'JP','DE'- Israel, Singapore and Japan are collaborating with Five Eyes:
'IL','SG', `'JP'- In 2013 it was reported that Germany was interested in joining the Five Eyes alliance:
'DE'9-eyes を除く場合
5-eyesに加え、デンマーク、フランス、オランダ、ノルウェーの4カ国を加える。
Five Eyes # Other international cooperatives
- consists of the same members of Five Eyes working with Denmark, France, the Netherlands and Norway.
# 5-eyes 'US', 'GB', 'CA', 'AU', 'NZ', # 9-eyes 'DK', 'FR', 'NL', 'NO',14-Eyes "SSEUR" を除く場合
9-eyesに加え、ドイツ、ベルギー、イタリア、スペイン、スウェーデンを加える。SSEURとも。
Five Eyes # Other international cooperatives
- 14 nations officially known as SIGINT Seniors Europe, or "SSEUR".
- consist of the same members of Nine Eyes plus Belgium, Germany, Italy, Spain and Sweden.
# 5-eyes 'US', 'GB', 'CA', 'AU', 'NZ', # 9-eyes 'DK', 'FR', 'NL', 'NO', # 14-eyes 'DE', 'BE', 'IT', 'ES', 'SE',41-eyes を除く場合
- 14-eyesに加え、オーストリア、チェコ、ギリシア、ハンガリー、アイスランド、日本、ルクセンブルク、ポーランド、ポルトガル、韓国、スイス、トルコを加える。
# 5-eyes 'US', 'GB', 'CA', 'AU', 'NZ', # 9-eyes 'DK', 'FR', 'NL', 'NO', # 14-eyes 'DE', 'BE', 'IT', 'ES', 'SE', # 41-eyes 'AT', 'CZ', 'GR', 'HU', 'IS', 'JP', 'LU', 'PL', 'PT', 'KR', 'CH', 'TR',参考文献
- 投稿日:2019-08-22T18:19:36+09:00
Jinja (Flask/SQLAlchemy) で日付をフォーマットする
Jinjaでstrftime()が使える
Flask/SQLAlchemy 使ってる方、jinja で困ってませんか?
括弧の進化ってのがあります。インデントで省略するのが Python 式「粋」な現代風の書き方であるとすると、括弧()[]{}が古風な書き方ですね。そうすると閉じ括弧で endfor など書くのは時代への逆行(反逆の精神)ですね。
本体で Python の関数を書いてもいいんですが、テンプレートでも関数が呼べます。
日付を出したい場合、フォーマットなら strftime() が使えます。
{% if blog.date_posted %} {{ blog.date_posted.strftime('%b %d, %Y') }} {% endif %}わざわざ文字列を作って渡す必要はありません。
上記のコードであれば出力結果は
Aug 20,2019(米国式)です。(マルチポストです。)
Jinja (Flask/SQLAlchemy) で日付をフォーマットする
- 投稿日:2019-08-22T17:41:42+09:00
ソートアルゴリズムの再発明をしてみる: マージソート
概要
- Pythonでソートアルゴリズムを再発明してみるだけ
- 今回はマージソートについて
- 参考サイトのサンプルコードをできるだけ見ずに実装する
- とりあえず昇順ソートのみの対応とする
マージソートの概要
- どのような条件でもわりと安定して速い
- 安定ソート
基本的な手順
- リストを半分に分割する(要素の大きさに関係なく、単純に分割する)
- 手順1について、要素数が全て1つになるまで繰り返す
- ソート済みのリスト同士をマージする。先頭要素を比較し、小さい方から順に別のリストに詰めていく(※要素数が1のリストも「ソート済み」とみなせる)
- 手順3を繰り返し、分割したリストが全てマージされたらソート完了
ソース
import random def merge_sort(lst): # 再帰の終了条件 if len(lst) == 0 or len(lst) == 1: return lst # 分割 # 今の実装だと要素数が奇数の場合は余りの要素が後ろに入るが、どちらでもよいはず length = len(lst) firstHalf = lst[0:length // 2] latterHalf = lst[length // 2:length] # 再帰呼び出し。戻り値はソートされた状態になっている firstHalf = merge_sort(firstHalf) latterHalf = merge_sort(latterHalf) # マージ処理。それぞれの先頭要素を見て小さいほうからresultに詰めていけば全体がソートされたリストになる result = [] while True: a = firstHalf[0] b = latterHalf[0] # 小さいほうをresultに追加し、元のリストからは削除 # ここが逆なら降順ソートになる if a < b: result.append(a) firstHalf.pop(0) else: result.append(b) latterHalf.pop(0) # 両方とも空なら完了 if len(firstHalf) == 0 and len(latterHalf) == 0: break # 片方だけ空なら、空じゃないほうをresultの後ろに足す if len(firstHalf) == 0: result += latterHalf break if len(latterHalf) == 0: result += firstHalf break return result lst = list(range(10)) random.shuffle(lst) print("ソート前: " + str(lst)) lst = merge_sort(lst) print("ソート後: " + str(lst))参考サイト
- 投稿日:2019-08-22T17:22:34+09:00
python 自己資料のまとめ
pythonの記事のうち、エラー関係と、docker関係と、それ以外が整理できていない。
一覧を作りながら、分類しなおしてみる。
導入
Windows(M.S.)にPython3 (Anaconda3) を導入する(7つの罠)
https://qiita.com/kaizen_nagoya/items/7bfd7ecdc4e8edcbd679Windows(M.S.) にAnaconda3(python3)を 2019年版
https://qiita.com/kaizen_nagoya/items/c05c0d690fcfd3402534Anacondaをpython利用で進める理由5つ
https://qiita.com/kaizen_nagoya/items/788f385ba9b536ce2ed8pip入門
https://qiita.com/kaizen_nagoya/items/50d8be773d6d59a58153Jython入門
https://qiita.com/kaizen_nagoya/items/e2a5751969b777d6a3afpythonの形態素解析 janomeを導入した
https://qiita.com/kaizen_nagoya/items/0ffc2e4b130ef1c2cb31Stanford Core NLP の導入
https://qiita.com/kaizen_nagoya/items/72286892aebe900966c3SuperColliderの導入(Mac編)
https://qiita.com/kaizen_nagoya/items/15574dc6aa36bb6b4bcbCertificates.command for python on macOS
https://qiita.com/kaizen_nagoya/items/29ac0a3c5554b0e9182a65歳からのプログラミング入門
https://qiita.com/kaizen_nagoya/items/1561f910c275b22d7c9fMacbook ProまたはMac miniでNVIDIAのGPUが使えるようになるまで 第一日
https://qiita.com/kaizen_nagoya/items/6b3e06645f1cd7604d56pythonのcodingを調べ試して
https://qiita.com/kaizen_nagoya/items/55e92e0636cbcd0c80beMacintosh 外付けGPU
https://qiita.com/kaizen_nagoya/items/3ff69cc58ca1a92a3120数字ではじまるファイル名
https://qiita.com/kaizen_nagoya/items/2dde95f6b1af1714ebb4pyenvを使ってMacintoshでpython2, python3を切り分けて使おう
https://qiita.com/kaizen_nagoya/items/cf93981852cc6e0b7cc2今はdockerまたはRaspberry PI を使うことを推奨しています。
docker
docker(18) なぜdockerで機械学習するか 書籍・ソース一覧作成中 (目標100)
https://qiita.com/kaizen_nagoya/items/ddd12477544bf5ba85e2docker(19) 言語処理100本ノックをdockerで。python覚えるのに最適。
https://qiita.com/kaizen_nagoya/items/7e7eb7c543e0c18438c4docker(0) 資料集
https://qiita.com/kaizen_nagoya/items/45699eefd62677f69c1ddockerでpython(1) python2(1) Qwatch(TS-WLCAM)を動かしてみた
https://qiita.com/kaizen_nagoya/items/5555e9179f102db62870error
python error collection
https://qiita.com/kaizen_nagoya/items/4b13c6c9574c44931943pip install cupyでエラーが出た 20180410
https://qiita.com/kaizen_nagoya/items/19a66d86cd7eaf733a3e今日のpython error TypeError: only length-1 arrays can be converted to Python scalars
https://qiita.com/kaizen_nagoya/items/13299f036b8795fc3048python: Error in sitecustomize; set PYTHONVERBOSE for traceback: KeyError: 'PYTHONPATH'
https://qiita.com/kaizen_nagoya/items/50e6c79810a154eb5c5a今日、pythonで出たエラー ZeroDivisionError: division by zero
https://qiita.com/kaizen_nagoya/items/1e5cb757d7ff5fe621b3今日のpython error: import visual
https://qiita.com/kaizen_nagoya/items/ae8209ba4cff4218f1e7今日のpython error: psychopy
https://qiita.com/kaizen_nagoya/items/e47f5ee6cc522485f109today's python error
https://qiita.com/kaizen_nagoya/items/cd857e2085e9974895a3今日のjupiter error: The port 8888 is already in use, trying another port.
https://qiita.com/kaizen_nagoya/items/47ade329651e8a653a4f今日のconda error: ERROR conda.core.link:execute_actions(318): An error occurred while uninstalling package
https://qiita.com/kaizennagoya/items/d77b6474aa5f5cd84457今日のconda error(2)Permission denied
https://qiita.com/kaizen_nagoya/items/8c963c699fd43b656035今日のcondo error(3)AttributeError: dlsym(0x7f9ad103cd80, archive_read_open_filename_w): symbol not found
https://qiita.com/kaizen_nagoya/items/a9fe5c23d5bc7233278fpython 動かしていて、コンピュータがうるさくなってきたら(mac, linux編)
https://qiita.com/kaizen_nagoya/items/0a774078aa50dbd22af0今日の作業記録 python error(言語処理100本ノック:18)未解決
https://qiita.com/kaizen_nagoya/items/d184d9aec28ca8428f3d今日の作業記録 python error(言語処理100本ノック:20)解決
https://qiita.com/kaizen_nagoya/items/c82ebccfef5522de53b9今日の作業記録 python error(言語処理100本ノック:30)未解決
https://qiita.com/kaizen_nagoya/items/2b8b542a93fc8d8949dc今日の作業記録 python error(言語処理100本ノック:37)未解決
https://qiita.com/kaizen_nagoya/items/d68cc9f494c8a15f9de1今日の作業記録 python error(言語処理100本ノック:42)未解決
https://qiita.com/kaizen_nagoya/items/d77b6474aa5f5cd84457今日の作業記録 python error(言語処理100本ノック:52)解決
https://qiita.com/kaizen_nagoya/items/c203a0e3b45ef7365776今日の作業記録 python error(言語処理100本ノック:56)未解決
https://qiita.com/kaizen_nagoya/items/d769c8ec1522e2d05f5e今日の作業記録 python error(言語処理100本ノック:64)未解決
https://qiita.com/kaizen_nagoya/items/70a96bb7673ec347ece7今日の作業記録 python error(言語処理100本ノック:79)未解決
https://qiita.com/kaizen_nagoya/items/bfd6037483739563ee6a今日の作業記録 python error(言語処理100本ノック:81)解決
https://qiita.com/kaizen_nagoya/items/529ed6e4427c7617f8e4今日の作業記録 python error(言語処理100本ノック:84)解決
https://qiita.com/kaizen_nagoya/items/0dc1304d54bfcc77480a今日の作業記録 python error(言語処理100本ノック:97)未解決
https://qiita.com/kaizen_nagoya/items/2a9d201f4ec0181948fecmake error: python
https://qiita.com/kaizen_nagoya/items/13c7c639e60379bc9a74docker(26) Open jij導入失敗(3)
https://qiita.com/kaizen_nagoya/items/e56556e2e9268a2007e9今日の python けいこく Unable to revert mtime: /Library/Fonts
https://qiita.com/kaizen_nagoya/items/18b011003b4c955528bbPYTHONPATHエラー@mac with brew
https://qiita.com/kaizen_nagoya/items/94bcd4846d08988ba8c3その他
ちいさな計算 python
https://qiita.com/kaizen_nagoya/items/fb88de0427f68fd82a3dqiita api python
https://qiita.com/kaizen_nagoya/items/ed9117470c59f7ede4168÷2(2+2)をpythonで
https://qiita.com/kaizen_nagoya/items/7592c0c205acff17f999プログラムちょい替え(0)一覧
https://qiita.com/kaizen_nagoya/items/296d87ef4bfd516bc394自動生成
https://qiita.com/kaizen_nagoya/items/228350db0a8fc2fd9376
- 投稿日:2019-08-22T17:08:49+09:00
Pythonで経済ニュースの情報をWebスクレイピング
前回PythonでITニュースサイトの見出しをWebスクレイピングという記事で、RequestsとBeautiful Soup、そしてCSSセレクタを使ったスクレイピングを試しました。
今回はその続編のようなもので、正規表現とPandasを使った方法で基礎的なものを記載します。
他にも似たような記事がありますがコードに誤りがあったり、うまくいかないものもあったため、自分で検証してみました。
正規表現を使う
正規表現を使えば、CSSでスクレイピング対象物を特定できない場合などに役立ちます。
今回は日経新聞のサイトにある見出しを取得します。# coding: UTF-8 # requestsと正規表現のモジュールインポート import requests import re # サイトURLを変数に格納 URL = 'https://www.nikkei.com' # get()メソッドでデータを取得 res = requests.get(URL) # ステータス確認 res.status_code == requests.codes.ok # reモジュールのfindall()関数を使い正規表現にマッチした箇所を抽出 subtitles = re.findall(r'<span class="m-miM\d{2}_titleL".*>(.+)</span></a>', res.text) # for文で出力 for i in subtitles: print(i)すると以下のように表示されたと思います。
英離脱合意、近づく崩壊 独首相「30日内に解決策を」 米国防長官、ミサイル発射実験で「中国を抑止」 「スパイダーマン」ファン不在でピンチ (ストーリー4) ランチ難民にサブスク弁当 月1万2000円で待ち時間ゼロ 至難の業「お宝株」探し 「1年で株価2倍」10年ぶり少なさ …正規表現にマッチした箇所を抽出するには、ブラウザの開発者ツールにて、
<span class=~ タイトル名 ~>のようになっているところを見つけたら、
タイトル名を抜き出すような正規表現を記載すれば、得たい情報を取得できます。Pandasを使う
データ解析用ライブラリのPandasを使ってWebスクレイピングすることも可能です。
特に表データの抽出に優れています。インストールしておきましょう。pip install pandasこちらのYahooニュース:株式ランキングをスクレイピングします。
とりあえず取得してみます。すごく短いコードですね。# coding: UTF-8 # pandasインポート import pandas as pd # サイトURLを変数に格納 URL = 'https://info.finance.yahoo.co.jp/ranking/?kd=3&mk=3&tm=d&vl=a' # pd.read_htmlでHTML内の<table>データを拾う dfs = pd.read_html(URL) # 表示 print(dfs[0])すると以下のように表示されたと思います。
来高 掲示板 0 1 8411 東証1部 (株)みずほフィナンシャルグループ ... 0.00% --- 63459300 掲示板 1 2 8306 東証1部 (株)三菱UFJフィナンシャル・グループ ... -0.26% -1.3 32270000 掲示板 2 3 3656 東証1部 KLab(株) ... +8.41% +86 23677000 掲示板 3 4 8604 東証1部 野村ホールディングス(株) ... +2.27% +9 21700100 掲示板 4 5 9434 東証1部 ソフトバンク(株) ... +0.80% +12 20954900 掲示板 …これだけではいらない情報もあると思います。項目を抽出して取り直してみます。
# coding: UTF-8 # pandasインポート import pandas as pd # サイトURLを変数に格納 URL = 'https://info.finance.yahoo.co.jp/ranking/?kd=3&mk=3&tm=d&vl=a' # pandasで表データ抽出 dfs = pd.read_html(URL) # 選択した項目のみ表示 dfs[0].columns = ['順位', 'コード', '市場', '名称', '取引値', '前日比', '出来高', '掲示板','Unnamed: 8','Unnamed: 9'] print(dfs[0][['順位','名称', '前日比', '出来高']])すると先程よりシンプルになりました。
名称 前日比 出来高 0 (株)みずほフィナンシャルグループ 154.3 0.00% 1 (株)三菱UFJフィナンシャル・グループ 500.5 -0.26% 2 KLab(株) 1109 +8.41% 3 野村ホールディングス(株) 405.3 +2.27% 4 ソフトバンク(株) 1518 +0.80% …Pandasは、CSVやExcelなどのファイルもスクレイピング可能です。また取得した情報をCSVに出力することもできます。
あとはSeleniumを使ったスクレイピング方法などあります。
Seleniumはブラウザ操作をする為のライブラリなので、ログインスタートもできます。
また機会があれば記載したいと思います。関連記事
- 投稿日:2019-08-22T17:05:47+09:00
HoloLens を TCP server とした画像の受信
動機
Python から HoloLens へ画像を送信する必要があったため,このコードを書きました.
TCP のクライアントからの送信一回で送信可能な小さな画像でなら記事がいくつか散見されるのですが, HoloLens 環境で複数回に分けて送信する方法が見つからず試行錯誤したので記録します.環境
- Unity 2017.4.24f1
- HoloLens (server) ※2じゃないよ
- HoloToolkit-Unity-2017.4.1.0
- Python3.6 (client)
大まかな処理フロー
client 側 (Python)
- Python3(client) で画像を open して byte 列で読み込み.
- base64 形式の文字列に encode.
- この base64 文字列を送信する byte 数で分割.
- 分割した base64 文字列を TCP を使って逐次的に Python から HoloLens(server) に送信.
server 側 (HoloLens)
- 分割された base64 文字列を逐次的に処理(受信->decode->ファイルへの書き込みを繰り返す).
- 受信した byte 数が指定した値より小さければ EOF とみなし最後の書き込みを行う.
- 受信した画像に応じた処理.
動作確認
- ImageReceiver.cs を Unity 内の texture を持つオブジェクトに Add します.(僕は Canvas 内に RawImage を作ってそこへ Add しました.)
- HoloLens に書き込み動作させます.
- client.py と同じディレクトリに sample.jpg (.png でも大丈夫です)用意します.
- client.py を走らせます.
- sample.jpg と同じ画像が HoloLens の view に現れたら成功です.
直接 byte 列を送受信するとなぜかファイルが壊れてしまいます.
そこで一旦 base64 という形式の文字列に変換し,これを通して送受信します.server 側のコード (HoloLens)
Unity 内で texture を持っているオブジェクトに Add して使います.
僕の環境ではなぜか画像を書き込む直前に少し delay を入れないと動作が不安定になりました.ImageReceiver.csusing UnityEngine; using System; using System.IO; using System.Security.Cryptography; using UnityEngine.UI; //<JEM>Ignore unity editor and run this code in the hololens instead</JEM> #if !UNITY_EDITOR using Windows.Networking.Sockets; using Windows.Storage.Streams; using WinRTLegacy; using System.Runtime.InteropServices.WindowsRuntime; using System.Threading.Tasks; #endif // Able to act as a reciever public class ImageReceiver : MonoBehaviour { RawImage rend; bool socketClosed = false; bool writeStringToFile = false; bool loadTexture = false; bool logSize = false; public uint BUFFER_SIZE = 8192; public uint PORT = 8080; private readonly int DELAYMILLISEC = 10; public string textAll = ""; string error_message; string error_source; #if !UNITY_EDITOR StreamSocketListener listener; #endif // Use this for initialization void Start() { #if !UNITY_EDITOR rend = this.GetComponent<RawImage>(); listener = new StreamSocketListener(); listener.ConnectionReceived += _receiver_socket_ConnectionReceived; listener.Control.KeepAlive = true; Listener_Start(); #endif } #if !UNITY_EDITOR private async void Listener_Start() { try { await listener.BindServiceNameAsync(PORT.ToString()); Debug.Log("Listener started"); Debug.Log(NetworkUtils.GetMyIPAddress() + " : " + PORT.ToString()); } catch (Exception e) { Debug.Log("Error: " + e.Message); } } private async void _receiver_socket_ConnectionReceived(StreamSocketListener sender, StreamSocketListenerConnectionReceivedEventArgs args) { try { if (loadTexture != true) { string folderPath = System.IO.Directory.GetCurrentDirectory(); string file_name = "received.png"; // Create sample file; replace if exists. // Must be set as TemporaryFolder to read files from HoloLens. Windows.Storage.StorageFolder storageFolder = Windows.Storage.ApplicationData.Current.TemporaryFolder; using (var dr = new DataReader(args.Socket.InputStream)) { using (IInputStream input = args.Socket.InputStream) { using (var imageFile = new FileStream(storageFolder.Path + @"\" + file_name, FileMode.Create)) { using (FromBase64Transform myTransform = new FromBase64Transform( FromBase64TransformMode.IgnoreWhiteSpaces)) { byte[] data = new byte[BUFFER_SIZE]; IBuffer buffer = data.AsBuffer(); uint dataRead = BUFFER_SIZE; byte[] dataTransformed = new byte[BUFFER_SIZE]; while (dataRead == BUFFER_SIZE) { await input.ReadAsync(buffer, BUFFER_SIZE, InputStreamOptions.Partial); int bytesWritten = myTransform.TransformBlock(data, 0, (int)BUFFER_SIZE, dataTransformed, 0); await Task.Delay(DELAYMILLISEC); imageFile.Write(dataTransformed, 0, bytesWritten); dataRead = buffer.Length; } dataTransformed = myTransform.TransformFinalBlock(data, 0, data.Length - (int)dataRead); imageFile.Write(dataTransformed, 0, dataTransformed.Length); myTransform.Clear(); } imageFile.Flush(); } } } loadTexture = true; } } catch (Exception e) { error_source = e.Source; error_message = e.Message; socketClosed = true; } finally { if (loadTexture == true) { using (var dw = new DataWriter(args.Socket.OutputStream)) { dw.WriteString("OK"); await dw.StoreAsync(); dw.DetachStream(); } } else { using (var dw = new DataWriter(args.Socket.OutputStream)) { dw.WriteString("NG"); await dw.StoreAsync(); dw.DetachStream(); } } } } void Update() { if (logSize) { Debug.Log("SIZE IS : " + BUFFER_SIZE.ToString()); logSize = false; } if (socketClosed) { Debug.Log(error_source); Debug.Log(error_message); Debug.Log("OOPS SOCKET CLOSED "); socketClosed = false; Debug.Log(textAll); } if (writeStringToFile) { Debug.Log("WRITTEN TO FILE"); writeStringToFile = false; } if (loadTexture) { Debug.Log("LOADING IMAGE CURRENTLY"); // Must be set as TemporaryFolder to read files from HoloLens. Windows.Storage.StorageFolder storageFolder = Windows.Storage.ApplicationData.Current.TemporaryFolder; string imgpath = storageFolder.Path + @"\" + "received.png"; Destroy(this.rend.texture); this.rend.texture = ReadPngAsTexture(imgpath); this.rend.SetNativeSize(); Debug.Log("LOADED IMAGE"); Debug.Log(textAll); loadTexture = false; } } #endif private static byte[] ReadPngFile(string path) { byte[] values; using (FileStream fileStream = new FileStream(path, FileMode.Open, FileAccess.Read)) { using (BinaryReader bin = new BinaryReader(fileStream)) { values = bin.ReadBytes((int)bin.BaseStream.Length); } } return values; } private static Texture2D ReadPngAsTexture(string path) { byte[] readBinary = ReadPngFile(path); Texture2D texture = new Texture2D(1, 1); texture.LoadImage(readBinary); return texture; } }client 側のコード (Python)
host には各自の HoloLens の IP address を入力してください.
client.pyimport socket # Import socket module import base64 N_byte = 1024*8*8 if __name__ == '__main__': host = '163.221.000.000' # here is your hololens ip address. port = 8080 # Reserve a port for your service. imgfile = './sample.jpg' with socket.socket() as s: s.connect((host, port)) s.settimeout(3) with open(imgfile, 'rb') as f: imgstring = base64.b64encode(f.read()) sub_strings = [imgstring[i: i+N_byte] for i in range(0, len(imgstring), N_byte)] print('Sending...') for sub_string in sub_strings: s.send(sub_string) print(imgstring[-20:]) print("Done Sending") s.shutdown(socket.SHUT_WR) print(s.recv(N_byte))既知のバグ
BUFFER_SIZE を下回るサイズの画像を送信すると受信できない不具合を確認しております.
最後に
右も左もわからない状況で HoloLens 用 C# コードを書いております.
問題点等ございましたら,ぜひご指摘お願いします!参考にした記事
- https://stackoverflow.com/questions/51411832/hololens-tcp-sockets-python-client-to-hololens-server
- https://codeday.me/jp/qa/20190124/164425.html
- https://symfoware.blog.fc2.com/blog-entry-786.html
- https://www.moonmile.net/blog/archives/7122
- https://qiita.com/shino_312/items/3c81ed8d8dfd0d53f25a
- https://docs.microsoft.com/ja-jp/dotnet/api/system.security.cryptography.frombase64transform?view=netframework-4.8
- https://qiita.com/tempura/items/b87eb07568d974664671
- 投稿日:2019-08-22T16:50:35+09:00
【Python】 圧縮されたファイルを一気に解凍したる!
はじめに
【背景】
サーバ内部にあるミドルウェアのバックアップを取得しtarボールで固めて、ローカルに移動してから、そのtarボールを解凍してから次のめんどいことに気づきました。
※背景のストーリーは気にせずお願いします。。【問題】
解凍されたtarボールの内部にフォルダが大量にあって、その中身に結構な数でtarボールがそれぞれのフォルダに散らばっている・・・。一気に解凍したい。【解決】
オレヤル。内容
結論
大量のフォルダがあって、その中にtarボールが大量にあって一度に解凍できないときとかに便利です。
いちいちボタンポチポチとかだるすぎるので、作りました。** 退屈なことはPythonにやらせよう! **ですね。
import os import sys import tarfile argvs = sys.argv # コマンドライン引数で実行したいファイルを指定 # C:/Users/username/hogehoge/ とか PATH = argvs[1] # 特定のディレクトリをなめる def files(path): for pathname, dirnames, filenames in os.walk(path): for filename in filenames: yield os.path.join(pathname, filename) # tarボールの解凍 def extract_tar_file(dirname, path): with tarfile.open(path, 'r:*') as tar: tar.extractall(dirname) if __name__ == '__main__': for path in files(PATH): if path.endswith('.tar.gz'): path = path.replace('\\','/') # tarボールを保存している一つ一つのディレクトリ抽出 dirname, basename = os.path.split(path) extract_tar_file(dirname, path)※エラー処理等々はしていないので、適当に入れていただければ。
参考記事にさせていた大内容がわかりやすくとても助かりました。
ありがとうございます!追記
解凍先が上記のスクリプトで強制されているの自分で書いてキモイと思ったので、以下のように解凍先もコマンドライン引数で指定してやると解凍先も選べます。
# 解凍先をコマンドライン引数で # C:/Users/username/hogehoge/hogehoge/ とか EXT_DIR = argvs[2] # tarボールの解凍 def extract_tar_file(path): with tarfile.open(path, 'r:*') as tar: tar.extractall(EXT_DIR)結論
スクリプト組まなくていいから、LhaplusとかCubeIceダウンロードして一気に解凍しようぜ!笑
参考
- 投稿日:2019-08-22T16:23:57+09:00
PythonでITニュースサイトの見出しをWebスクレイピング
Webスクレイピングとは、Webページの情報をプログラムを使って取得できる技術です。
例えば、以下のようなことができます。
・あるサイトの特定部分のテキストを定期的に取得
・ネットオークションの価格を自動で取得
・自動でサイトにログインして、ほしい情報を取得Webページの情報を取得するため、簡単なHTML、CSSやJavascriptの知識があったほうがよいです。
今回普段よく見るITニュースサイトの見出しをWebスクレイピングで取得します。
注意
各Webサイトには、多くの場合利用規約が掲載されています。
利用規約でWebスクレイピングが禁止されている場合は実施しないでください。
APIがある場合は、APIを利用するべきです。
またWebサイトのルート直下に、robots.txtというファイルがある場合、その記述内容に従う必要があります。
※Webサイトによっては、スクレイピングを拒否するように設定しているところもあります。Webスクレイピングにも様々な方法があるので都度掲載していけたらと思います。掲載するのは基本的なことですが、コードを発展させればいろんなことができます。
Requests,Beautiful Soupを使う
2つのライブラリを使用します。
Requests:HTTPライブラリでWebページを取得するためのもの。
Beautiful Soup:HTMLパーサライブラリ。取得したWebサイトから特定のテキスト情報などを抜き出せる。そのため事前にインストールをしておきましょう。
# Requestsインストール pip install requests # Beautiful Soupインストール pip install bs4こちらのOSDN magazineの見出しを抽出します。
※Python 3.6.8でやっています。# coding: UTF-8 # モジュールインポート import requests from bs4 import BeautifulSoup # OSDN magazineのURLを変数に確認 URL = 'https://mag.osdn.jp/news/' # requests.get()でHTMLを取得 result = requests.get(URL) # BeautifulSoupの機能、html.parserでHTMLやXMLをパースできる。 data1 = BeautifulSoup(result.text, 'html.parser') # find_allでclassを指定し、見出しを取得 data2 = data1.find_all("h2", class_="entry-title") # URLを出力 print(URL) # 配列に格納された値をfor文とprint文で出力 for item in data2: print(item.getText())上記実行すると以下のように見出しの一覧が出力されると思います。
RequestsでHTMLを取得し、Beautiful Soupで特定のテキスト情報を抜き出しました。https://mag.osdn.jp/news/ 「Rust 1.37」リリース 米Microsoft、JVMのチューニング技術を持つjClarityを買収 「MongoDB 4.2」公開、Wildcard Index導入など 「Git 2.23」リリース、「git switch」や「git restore」コマンドを実験的に導入 VJにも利用できるオープンソースの動画エディタ「LiVES 3.0」リリース Fedora Rawhideに対応、エンタープライズLinux向け拡張パッケージ「EPEL 8」が公開 米Microsoft、ソースコードエディタ「Visual Studio Code 1.37」をリリース 「GCC 9.2」リリース …省略CSSセレクターを使う方法
上記の例は"entry-title"というclass属性の箇所に、見出しが記載されていると決まっていたため、そこを指定して抜き出すだけでした。
しかし見出しをaタグで囲んでいたり、タグの内容が動的に変化することもあります。
その時CSSセレクタを使うと便利です。CSSセレクタは、CSSにおいてスタイルを適用する要素を選択するための条件式です。
次はセキュリティの分野で著名な徳丸浩さんのブログ記事で一番最近アップロードされた、
記事のタイトルを抜き出します。Google Chromeでサイトを表示させF12キーで開発者ツールを表示させます。
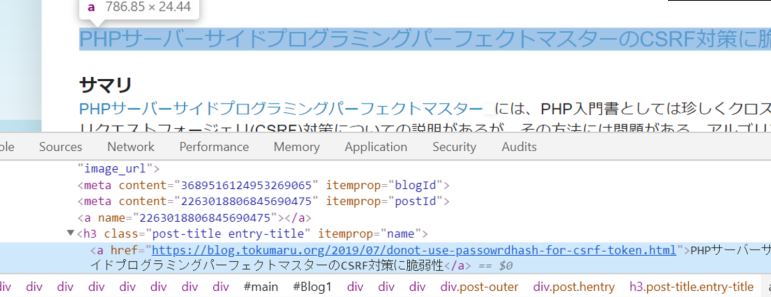
<a href=リンク先URL〜から始まる箇所で右クリックし Copy > Copy selector をクリックします。すると以下コピーされます。これがCSSセレクタです。
#Blog1 > div.blog-posts.hfeed > div:nth-child(1) > div > div.post-outer > div > h3 > a<a href=リンク先URL〜は表示されず、要素を選択する仕組みのみが表示されています。
こちらを使いコードを作成します。# coding: UTF-8 # モジュールインポート import urllib.request, urllib.error from bs4 import BeautifulSoup # サイトURLを変数に格納。 URL = "https://blog.tokumaru.org/" # URLにアクセス。戻り値はアクセスした結果やHTMLを返す。 r = urllib.request.urlopen(URL) # アクセス結果からHTMLを取り出し、BeautifulSoupの機能でhtmlパースする。 soup = BeautifulSoup(r, "html.parser") # URLを出力 print(url) # CSSセレクタを使って指定した場所を表示。.textでhtmlではなくtext形式となる。 print(soup.select_one("#Blog1 > div.blog-posts.hfeed > div:nth-child(1) > div > div.post-outer > div > h3 > a").text)すると一番最初の見出しが表示されます。
https://blog.tokumaru.org/ PHPサーバーサイドプログラミングパーフェクトマスターのCSRF対策に脆弱性ニュース見出しの簡単な取得であれば、Requests,Beautiful SoupにCSSセレクタで、
ほとんど出来ると思います。これをメールやチャットツールで通知すれば、今どんなITニュースがあるのか一目瞭然です。Webスクレイピングは他にも正規表現を使った抽出方法、Pandasを使った表データの抽出など様々な方法があります。
以下に関連記事がありますので、よろしければご覧になって下さい。
・Pythonで経済ニュースの情報をWebスクレイピング
- 投稿日:2019-08-22T16:14:26+09:00
csv形式のanotationファイルをcsvに変換する
初めに
初投稿です、お手柔らかに。datasetのanotationがcsv形式だったので、Single Shot Multibox Detector(SSD)で使えるようにpklファイルに変換するときに書いたプログラムを置いておきます。
ちなみに、SSDの参考にさせていただいたのはこちらの記事です。
数年前の記事なので、最新のverを使っている人はいくつか修正が必要だと思います。
プログラム
日本語のコメントをうざったいぐらい入れてます(笑)
csv_for_pkl.pyimport pickle as pkl import os import csv import numpy as np class CSV_preprocessor(object): def __init__(self, data_path): self.path = data_path self.num_classes = 2 #クラス数 self.data = dict() self._preprocess_CSV() def _preprocess_CSV(self): with open(self.path, 'r') as f: #fileをfとして読み込み reader = csv.reader(f) width =900 #画像の幅、anotationの中にあるならfor文内で取得してください height = 600 #画像の高さ flag = 1 #1行目をスキップするためのflag bounding_boxes = [] one_hot_classes = [] af = 'Non' for row in reader: if row[1] != af and af != 'Non': #前の行のimage_idと異なるなら保存処理 image_name = af + '.jpg' bounding_boxes = np.asarray(bounding_boxes) one_hot_classes = np.asarray(one_hot_classes) image_data = np.hstack((bounding_boxes, one_hot_classes)) self.data[image_name] = image_data bounding_boxes =[] one_hot_classes =[] if flag == 1: flag += 1 continue #anotationがboundingboxの4点を持っていたので以下のような書き方に #なりました.値の場所が不変ならその値を入力してください xmin = (min([float(row[2]), float(row[4]), float(row[6]), float(row[8])])) / width ymin = (min([float(row[3]), float(row[5]), float(row[7]), float(row[9])])) / height xmax = (max([float(row[2]), float(row[4]), float(row[6]), float(row[8])])) / width ymax = (max([float(row[3]), float(row[5]), float(row[7]), float(row[9])])) / height bounding_box = [xmin, ymin, xmax, ymax] bounding_boxes.append(bounding_box) class_name = row[10] #classの名前の場所 one_hot_class = self._to_one_hot(class_name) one_hot_classes.append(one_hot_class) af = row[1] #画像の名前の場所 image_name = af + '.jpg' #jpgで保存します bounding_boxes = np.asarray(bounding_boxes) one_hot_classes = np.asarray(one_hot_classes) image_data = np.hstack((bounding_boxes, one_hot_classes)) self.data[image_name] = image_data bounding_boxes =[] one_hot_classes =[] def _to_one_hot(self, name): one_hot_vector = [0] * self.num_classes if name == 'class name': one_hot_vector[0] = 1 elif name == 'class name': one_hot_vector[1] =1 else : print('unknown label: %s' %name) return one_hot_vector data = CSV_preprocessor('anotation pass').data pkl.dump(data, open('train.pkl','wb'))走り書きで書いたので、たぶんいろいろ直せるところはあると思います。
良かったらコメントしていってください。
- 投稿日:2019-08-22T16:02:53+09:00
list comprehension & map
list comprehension vs map + lambda
a = [1,2,3]
b = [4,5,6]list comprehension 1
c1 = [i for i in a]
output: [1, 2, 3]map 1
c2 = map(lambda i: i, a)
output:<map at 0x2d76be52240list(c2)
output:[1, 2, 3]list comprehension 2
c3 = [i+j for i,j in zip(a,b)]
output:[5, 7, 9]map 2
c4 = map(lambda i,j: i+j, a,b)
output:[5, 7, 9]list comprehension *
c5 = [i+j for i in a for j in b]
output:[5, 6, 7, 6, 7, 8, 7, 8, 9]
- 投稿日:2019-08-22T15:45:20+09:00
【Airflow on Kubernetes】JdbcOperatorの使い方
概要
AirflowでJdbcOperatorを利用してTeradataにアクセスする。
目次
Version
Requirements
- openjdk
- openjdk-11-jdk
- pip
- Teradata Driver
- terajdbc4.jar
- tdgssconfig.jar
Container
airflowのDockerコンテナに、前述のRequirementsをすべて追加する。
以下は一例なので、別の方法でもよい。Dockerfileに以下を追記する。
また、TeradataのDriverであるterajdbc4.jarとtdgssconfig.jarを用意する。# Teradata RUN apt-get install -y openjdk-11-jdk COPY jdbc/terajdbc4.jar /opt/jdbc/terajdbc4.jar COPY jdbc/tdgssconfig.jar /opt/jdbc/tdgssconfig.jarsetup.pyの以下箇所にpipモジュールを追記する。
setup.pydef do_setup(): """Perform the Airflow package setup.""" write_version() setup( name='apache-airflow', # **snip** install_requires=[ 'tzlocal>=1.4,<2.0.0', 'unicodecsv>=0.14.1', 'zope.deprecation>=4.0, <5.0', + 'JayDeBeApi>=1.1.1', + 'JPype1==0.6.3', ],Connectionを追加
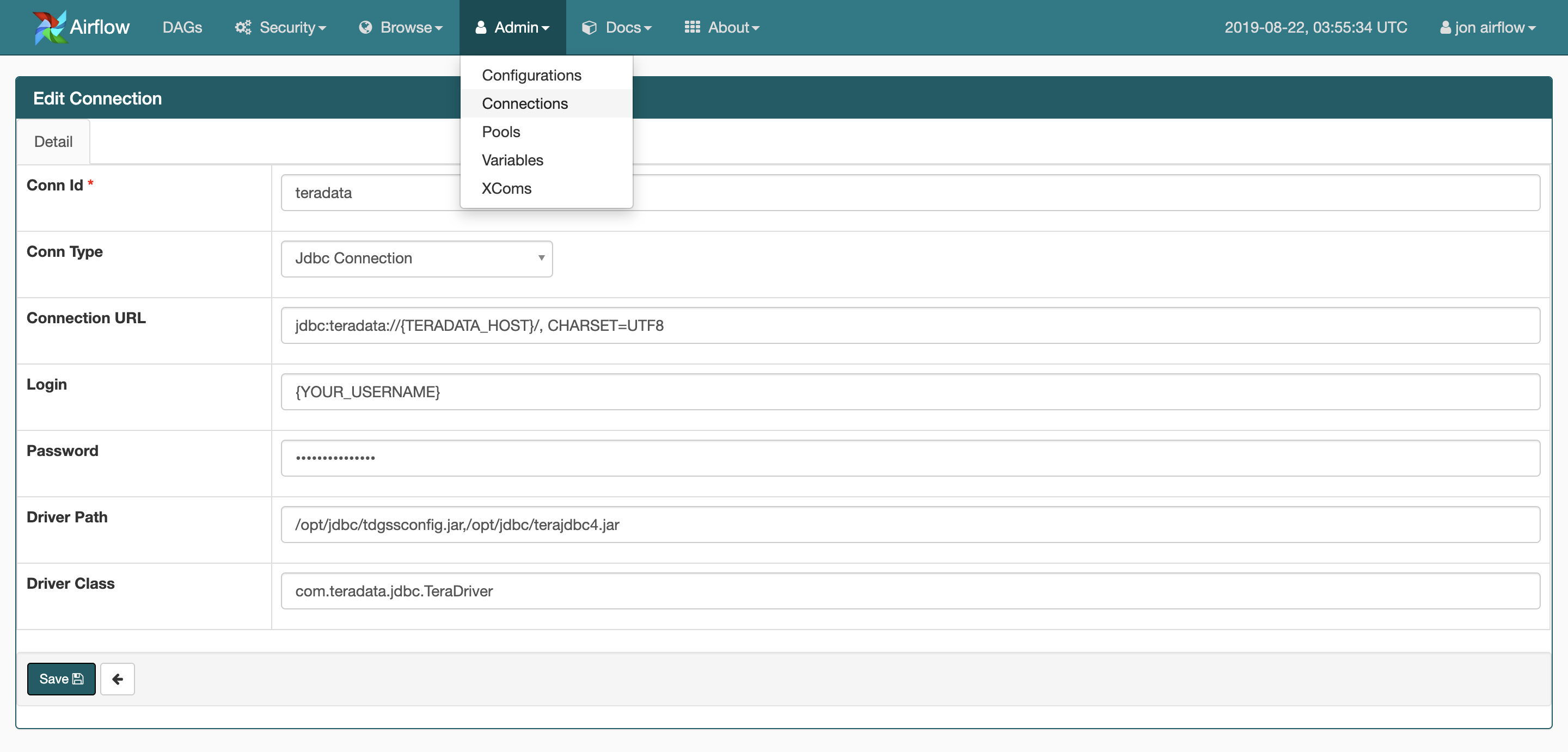
WEB UIでConnectionの設定をする。
https://{YOUR_HOST}/connection/list/
Keys Values DESC Conn Id * teradata 任意の名前 Conn Type Jdbc Connection Connection URL jdbc:teradata://{TERADATA_HOST}, CHARSET=UTF8 LDAPの場合: jdbc:teradata://{TERADATA_HOST}/LOGMECH=LDAPLogin {YOUR_USERNAME} Password {YOUR_PASSWORD} Driver Path /opt/jdbc/tdgssconfig.jar,/opt/jdbc/terajdbc4.jar 複数ある場合はカンマ区切り Driver Class com.teradata.jdbc.TeraDriver DAG
例として、以下の処理を実行するDAGを作成する。
- log_dateカラムが30日以上前のレコードをDelete
- log_dateが今日の日付のレコードをDelete/Insert
- 以下のカラムを持つテーブルを用意する
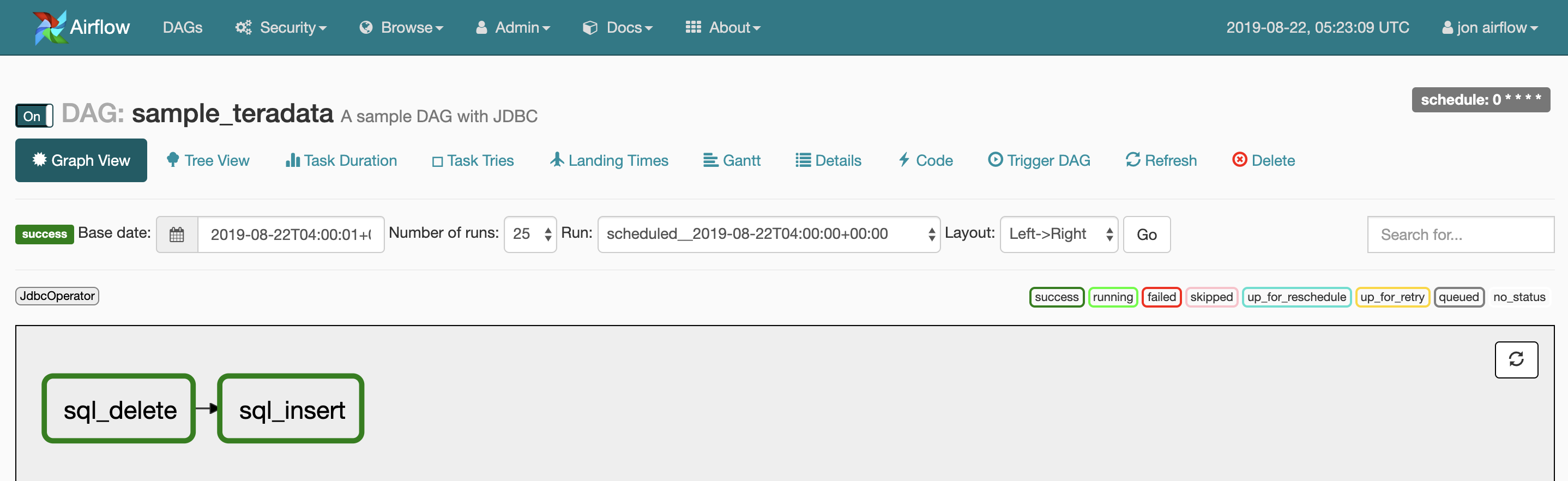
log_dateDATE FORMAT 'YYYYMMDD' NOT NULLnameVARCHAR(50) CHARACTER SET UNICODE NOT CASESPECIFICageINTEGER# -*- coding:utf-8 -*- import airflow from airflow import DAG from airflow.operators.jdbc_operator import JdbcOperator import datetime from datetime import timedelta default_args = { 'owner': 'airflow', 'depends_on_past': False, # 指定した日時から現在時刻までに実行されていないjobがすべて直ちに実行される 'start_date': airflow.utils.dates.days_ago(2), 'email': ['airflow@example.com'], 'email_on_failure': False, 'email_on_retry': False, 'retries': 1, 'retry_delay': timedelta(minutes=5), } dag = DAG( # DAG名 'sample_teradata', default_args=default_args, description='A sample DAG with JDBC', # 実行スケジュール schedule_interval='0 * * * *', ) # Lotate lotate_date = (datetime.date.today() - timedelta(days=29)).strftime("%Y%m%d") sql_task1 = JdbcOperator( task_id='sql_delete', # 設定したConn Idを入力することで接続情報がセットされる jdbc_conn_id='teradata', sql=['delete from YOUR_TABLE_NAME where log_date < \'{}\''.format(lotate_date)], params={"db":'YOUR_DB_NAME'}, dag=dag ) # DeleteInsert log_date = datetime.date.today().strftime("%Y%m%d") name = 'Smith' age = 30 sql_task2 = JdbcOperator( task_id='sql_insert', # 設定したConn Idを入力することで接続情報がセットされる jdbc_conn_id='teradata', sql=[ 'delete from YOUR_TABLE_NAME where log_date=\'{}\''.format(log_date), 'insert into YOUR_TABLE_NAME (log_date, name, age) values(\'{}\', \'{}\', {})'.format(log_date, name, age) ], params={"db":'YOUR_DB_NAME'}, dag=dag ) sql_task1 >> sql_task2Graph View
Pod
DAG実行中のPodの挙動
$ sudo kubectl get pod -w airflow-58ccbb7c66-p9ckz 2/2 Running 0 111s postgres-airflow-84dfd85977-6tpdh 1/1 Running 0 7d17h sampleteradatasqldelete-cbdc29dad6814d11a721d9fe9416a3ec 0/1 Pending 0 0s sampleteradatasqldelete-cbdc29dad6814d11a721d9fe9416a3ec 0/1 Pending 0 0s sampleteradatasqldelete-cbdc29dad6814d11a721d9fe9416a3ec 0/1 ContainerCreating 0 0s sampleteradatasqldelete-cbdc29dad6814d11a721d9fe9416a3ec 1/1 Running 0 2s sampleteradatasqldelete-cbdc29dad6814d11a721d9fe9416a3ec 0/1 Completed 0 8s sampleteradatasqldelete-cbdc29dad6814d11a721d9fe9416a3ec 0/1 Terminating 0 10s sampleteradatasqldelete-cbdc29dad6814d11a721d9fe9416a3ec 0/1 Terminating 0 10s sampleteradatasqlinsert-db4b5d25ad6f47c691d3992f62a48d38 0/1 Pending 0 0s sampleteradatasqlinsert-db4b5d25ad6f47c691d3992f62a48d38 0/1 Pending 0 0s sampleteradatasqlinsert-db4b5d25ad6f47c691d3992f62a48d38 0/1 ContainerCreating 0 0s sampleteradatasqlinsert-db4b5d25ad6f47c691d3992f62a48d38 1/1 Running 0 1s sampleteradatasqlinsert-db4b5d25ad6f47c691d3992f62a48d38 0/1 Completed 0 8s sampleteradatasqlinsert-db4b5d25ad6f47c691d3992f62a48d38 0/1 Terminating 0 10s sampleteradatasqlinsert-db4b5d25ad6f47c691d3992f62a48d38 0/1 Terminating 0 10s確認
Teradataで実際にデータがDelete、Insertされていることが確認できればOK。
関連記事
参考
- 投稿日:2019-08-22T15:28:31+09:00
python3ではじめるシステムトレード:経済データのダウンロード
経済データのダウンロード
Python3を用いて経済データをダウンロードするためには、jupyter notebookとpandas-datareaderがお勧めです。
jupyter notebook
jupyter notebookのインストールについては
Python3ではじめるシステムトレード:Jupyter notebookのインストール https://qiita.com/innovation1005/items/2f433d6d859f075033a7
を参考にしてください。ここにpandas-datareaderのインストールの説明もあります。
pandas-datareader
pandas-datareaderの基本的な情報を得るために
https://pandas-datareader.readthedocs.io/en/latest/#
をクリックしてみてください。下にスクロールすると
Install latest release version via pip
が出てきてDos promptから
$ pip install pandas-datareaderを実行します。もしもPATHの設定がうまくされていないと適切なインストールができない場合があるので、その際にはanaconda promptがおすすめです。さらに下にスクロースると
Documentation
Contents:が出てきます。さらに下にスクロールしていくと
- Data Readers
が出てきます。ここにデータをダウンロードできるお勧めのWEBが出てきます。その中で経済データに関するものは
- Federal Reserve Economic Data (FRED)
- World Bank
です。
FRED
FREDは米国のセントルイス連銀が運営するサイトで一般的には十分な世界中の公的な経済データが手に入ります。URLは
です。
世界中の97機関からデータの提供を受け、その数は570,000とあります。日本のデータに関してもここから取得したほうが便利なものも多々あります。
まず、初期化をします。
%matplotlib inline import pandas_datareader.data as web import matplotlib.pyplot as plt start="1949/5/16"つぎにいくつかのデータをダウンロードしてグラフに描いてみましょう。データはPythonでなくてもダウンロード可能です。手動でも可能です。
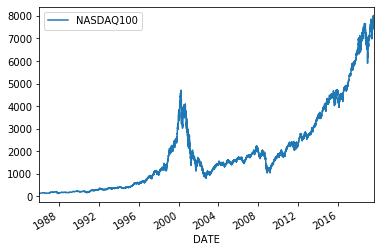
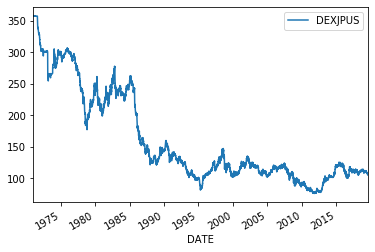
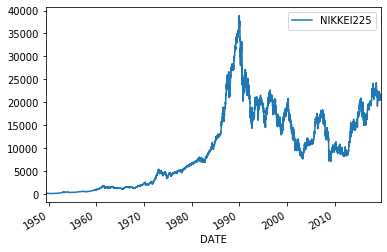
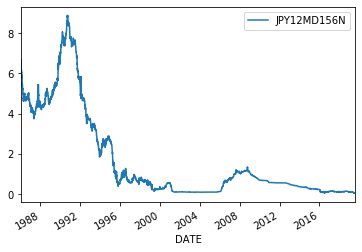
# Daily data n100 = web.DataReader("NASDAQ100", 'fred',start).dropna()# n100.plot() print(n100.head(1),n100.tail(1)) fx = web.DataReader("DEXJPUS", 'fred',start).dropna() print(fx.head(1),fx.tail(1)) fx.plot() n225 = web.DataReader("NIKKEI225","fred",start).dropna() print(n225.head(1),n225.tail(1)) n225.plot() j1 = web.DataReader("JPY12MD156N", 'fred',start).dropna() print(j1.head(1),j1.tail(1)) j1.plot()NASDAQ100
DATE
1986-01-02 131.25 NASDAQ100
DATE
2019-08-21 7733.21582
DEXJPUS
DATE
1971-01-04 357.73 DEXJPUS
DATE
2019-08-16 106.34
NIKKEI225
DATE
1949-05-16 176.21 NIKKEI225
DATE
2019-08-21 20618.57
JPY12MD156N
DATE
1986-01-02 6.4375 JPY12MD156N
DATE
2019-08-14 0.02767
月足データ
# monthly data index = web.DataReader("INTGSBJPM193N", 'fred',start).dropna() index= web.DataReader("MABMBM01JPM661S","fred",start).dropna()# Broad Money, Index for Japan index = web.DataReader("MYAGM1JPM189N","fred",start).dropna() #M1 for Japan© (MYAGM1JPM189N) index = web.DataReader("MYAGM2JPM189N","fred",start).dropna()#M2 for Japan© (MYAGM2JPM189N) index = web.DataReader("MYAGM3JPM189N","fred",start).dropna()#M3 for Japan© (MYAGM3JPM189N) index = web.DataReader("UMCSENT", 'fred',start)#University of Michigan consumer sentiment index = web.DataReader("CFNAI", 'fred',start)#10Chicago Fed National Activity Index (CFNAI) index = web.DataReader("CFNAIDIFF", 'fred',start)#Chicago Fed National Activity Index: Diffusion Index index = web.DataReader("USSLIND", 'fred',start)#leading index for the United State index = web.DataReader("INDPRO", 'fred',start)#industry production index index = web.DataReader("DGORDER", 'fred',start)#durable good order index = web.DataReader("RSXFS", 'fred',start)#Advance Retail Sales: Retail (Excluding Food Services) index = web.DataReader("GACDFSA066MSFRBPHI", 'fred',start)#Current General Activity; Diffusion Index for FRB - Philadelphia District index = web.DataReader("EXPJP", 'fred',start).dropna()#U.S. Exports of Goods by F.A.S. Basis to Japan (EXPJP) index = web.DataReader("IMPJP", 'fred',start).dropna()#U.S. Imports of Goods by Customs Basis from Ja日足データ
# Daily data index = web.DataReader("WILL5000PRFC", 'fred',start).dropna()#Wilshire 5000 Full Cap Price Index without dividend reinvestment index = web.DataReader("WILL5000INDFC", 'fred',start).dropna()#Wilshire 5000 Total Market Full Cap Index including dividend reinvestment index = web.DataReader("DGS10", 'fred',start)#10-Year Treasury Constant Maturity Rate (DGS2) index = web.DataReader("DGS5", 'fred',start).dropna() index = web.DataReader("DGS2", 'fred',start)#2-Year Treasury Constant Maturity Rate (DGS2) index = web.DataReader("DGS1", 'fred',start).dropna() index = web.DataReader("SP500", 'fred',start)#S&P 500© (SP500) index = web.DataReader("T1YFF", 'fred',start)#1-Year Treasury Constant Maturity Minus Federal Funds Rate (T1YFF) index = web.DataReader("T10YFF", 'fred',start)#10-Year Treasury Constant Maturity Minus Federal Funds Rate (T10YFF) index = web.DataReader("NIKKEI225","fred",start).dropna()#nikkei225 index = web.DataReader("DCOILWTICO","fred",start).dropna()#M3 for Japan© (MYAGM3JPM189N) index = web.DataReader("SPASTT01JPM657N","fred",start)#Total Share Prices for All Shares for Japan (SPASTT01JPM657N) index = web.DataReader("INTGSBJPM193N", 'fred',start).dropna()#Interest Rates, Government Securities, Government Bonds for Japan index = web.DataReader("JPY12MD156N", 'fred',start).dropna()#12-Month London Interbank Offered Rate (LIBOR), based on Japanese Yen index = web.DataReader("MYAGM1JPM189N","fred",start) #M1 for Japan© (MYAGM1JPM189N) index = web.DataReader("MYAGM3JPM189N","fred",start)#M3 for Japan© (MYAGM3JPM189N) index = web.DataReader("MYAGM2JPM189N","fred",start)#M2 for Japan© (MYAGM2JPM189N) index = web.DataReader("MABMBM01JPM661S","fred",start)# Broad Money, Index for Japan参考文献・サイト
「Python3ではじめるシステムトレード」(パンローリング)

- 投稿日:2019-08-22T13:18:07+09:00
小売物価統計でガソリン価格を調べる
(初出: 2018-09-22)
仕事で直近のガソリン価格を調べる必要があった。なぜか「ガソリンスタンドによって値段が違うからなあ」という反応が多いお題だが、こんなものはさくっと統計を引いてやっつけるべきものだ。そこで小売物価統計からもってくることにする。今はこうした基礎データがネットで簡単に入手できる。e-Stat を見に行こう。一回だけならリンクをたどったり検索したりで十分だが、毎月やるくらいならプログラムを書くべきだろう。e-Stat では API が用意されておりデータを引くのは簡単だ。
ユーザー登録とアプリケーション ID を取得する
手作業で登録する。メールアドレスが必要。
アプリケーション ID を取得する
手作業で登録する。40桁の16進数が得られるようだ。以下
<APPID>とする。小売物価統計からガソリン価格を取得する
統計表情報取得
提供データの一覧 を見ると小売物価統計調査の政府統計コードは 00200571 であるとわかるので、まずこいつに API からアクセスする場合の統計データ ID を調べる。
$ curl https://api.e-stat.go.jp/rest/2.1/app/getStatsList?appId=<APPID>&statsCode=00200571結果は XML で得られ、これを覗くと小売物価統計の
statsDataIdが 0003105586 であることがわかる。メタ情報取得
データ抽出条件には地域・品目・年月のコード (ID) が必要なので、その一覧を取得する。
$ curl https://api.e-stat.go.jp/rest/2.1/app/getMetaInfo?appId=<APPID>&statsDataId=0003105586こちらも結果は XML で得られる。今回必要なのは長野県松本市のガソリン価格だ。松本市の地域コードは 20202、自動車ガソリンの品目コードは 07301 であることがわかる。地域コードは地方公共団体コード (チェックディジットなし) と同一だった。
統計データ取得
統計データ本体は、XML/JSON/JSONP/CSV のいずれかの形式で取得できる。全地域全期間全品目のデータを XML で落とすのならばこうする。
$ curl https://api.e-stat.go.jp/rest/2.1/app/getStatsData?appId=<APPID>&statsDataId=0003105586松本市のデータだけ取得するには、パラメーターに
cdArea=20202を追加する。次の例では CSV での取得を行う。ただし CSV とはいっても冒頭にかなりの量のヘッダが付く。$ curl https://api.e-stat.go.jp/rest/2.1/app/getSimpleStatsData?appId=<APPID>&statsDataId=0003105586&cdArea=20202さらに品目を絞り、松本市のガソリン価格だけ取得するため、パラメーターに
cdCat01=07301を追加する。$ curl https://api.e-stat.go.jp/rest/2.1/app/getSimpleStatsData?appId=<APPID>&statsDataId=0003105586&cdArea=20202&cdCat01=07301JSON でデータを得るには、エンドポイントを若干変更する。
$ curl https://api.e-stat.go.jp/rest/2.1/app/json/getStatsDataappId=<APPID>&statsDataId=0003105586&cdArea=20202&cdCat01=07301取得したデータを解釈する
Python で処理する
使い慣れた Python で最新のガソリン価格を得よう。
$ curl -s "https://api.e-stat.go.jp/rest/2.1/app/json/getStatsData?appId=<APPID>&statsDataId=0003105586&cdArea=20202&cdCat01=07301" >result.json $ python3 -q >>> import json >>> result = json.load(open("result.json")) >>> price_history_raw = result["GET_STATS_DATA"]["STATISTICAL_DATA"]["DATA_INF"]["VALUE"] >>> price_history = sorted([(e["@time"][:4] + e["@time"][6:8], e["$"]) for e in price_history_raw]) >>> price_history[-1] ('201808', '154')簡単だ。
Javascript で処理する
JavaScript でも同じように書ける。ここではファイルからではなく直接 e-Stat から読みだしている。
const appid = "<APPID>"; const statsdataid = "0003105586"; const cdarea = "20202"; const cdcat01 = "07301"; var url = `https://api.e-stat.go.jp/rest/2.1/app/json/getStatsData?appId=${appid}&statsDataId=${statsdataid}&cdArea=${cdarea}&cdCat01=${cdcat01}`; var request = new XMLHttpRequest(); request.open("GET", url); request.responseType = "json"; request.addEventListener("load", (e) => { var prices = e.target.response["GET_STATS_DATA"]["STATISTICAL_DATA"]["DATA_INF"]["VALUE"]; var yyyymm = prices[0]["@time"]; yyyymm = yyyymm.slice(0, 4) + yyyymm.slice(6,8); var price = prices[0]["$"]; console.log(yyyymm, price); }); request.send();これまた簡単。
- 投稿日:2019-08-22T12:37:36+09:00
LeetCode / Intersection of Two Linked Lists
(ブログ記事からの転載)
[https://leetcode.com/problems/intersection-of-two-linked-lists/]
Write a program to find the node at which the intersection of two singly linked lists begins.
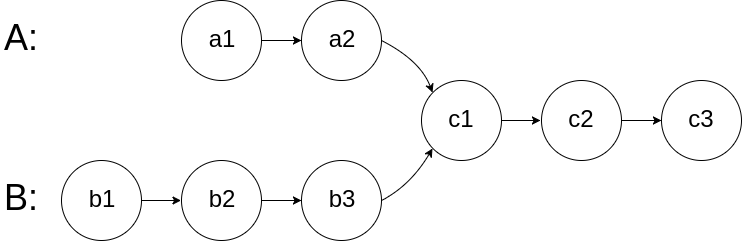
For example, the following two linked lists:
begin to intersect at node c1.Notes:
If the two linked lists have no intersection at all, return null.
The linked lists must retain their original structure after the function returns.
You may assume there are no cycles anywhere in the entire linked structure.
Your code should preferably run in O(n) time and use only O(1) memory.これもとんち的問題。2つのLinked Listが交わるnodeを返します。
ポイントはNotesのYour code should preferably run in O(n) time and use only O(1) memory.に尽きます。余計な空間計算量は使わずに解を出す必要があります。解答・解説
解法1
私のsubmitしたコード。計算量オーダーについて条件は満たしていますが、かなり冗長になっています。
2つのポインタを2つのLinked Listの始点から動かし、終点まで移動させます。
このとき先に到着するポインタと後に到着するポインタの移動距離の差をとっておきます。
再度、2つのポインタをLinked Listの始点から動かしますが、このときは後に到着したポインタをさきほどとっておいた差の分だけ先に進めておいてから、2つのポインタをスタートさせます。
そうすると、交わる点があればポインタは必ず出会いますし、逆にポインタが出会わなければ交わる点はない、ということになります。# Definition for singly-linked list. # class ListNode(object): # def __init__(self, x): # self.val = x # self.next = None class Solution(object): def getIntersectionNode(self, headA, headB): """ :type head1, head1: ListNode :rtype: ListNode """ pa = headA pb = headB diff = 0 if headA is headB: return headA while pa and pb: pa = pa.next pb = pb.next if not pa: while pb: pb = pb.next diff += 1 while diff > 0: headB = headB.next diff -= 1 else: while pa: pa = pa.next diff += 1 while diff > 0: headA = headA.next diff -= 1 while headA and headB: if headA is headB: return headA headA = headA.next headB = headB.next return None解法2
よりスッキリしたコードがこちら。
2つのポインタを2つのLinked Listの始点から動かし、終点まで移動させるのは同じですが、終点に到達したら、もう一方のLinked Listの始点に移動してさらに動いていくのがミソです。
このようにすると、headA is headBとなった地点を返してやれば、交差するnodeがあればそのnodeが返りますし、交差するnodeがなければnullが返ります。
なるほどですね。。。class Solution(object): def getIntersectionNode(self, headA, headB): """ :type head1, head1: ListNode :rtype: ListNode """ if headA is None or headB is None: return None pa = headA pb = headB while pa is not pb: pa = headB if pa is None else pa.next pb = headA if pb is None else pb.next return pa
- 投稿日:2019-08-22T12:13:43+09:00
Pythonの変数の名前を文字列として取得
Pythonの変数の名前を文字列として取得
コードは冗長ですけど、僕みたいな素人にはこれがわかりやすいのでアップ。
参考にしたのはこちらです。こちらの方が本格的です。get_var_names.py''' こちらのコードは正確に変数名を取得できない場合があるので注意。 具体的には、異なる複数の変数が以下等である場合、変数名を区別できない。 1) -5から256までの同じ値 2) '参照渡し'された同じ値やオブジェクト 3) 同じ文字列を代入した またこの時、複数の変数を区別する方法はない。 詳しくは、本文下のshiracamusさんからのコメントを参照。 以下、例。 a = 12345 b = a # 参照渡し get_var_name(a) # 'b' get_var_name(b) # 'b' ''' #!/usr/bin/env python3 a='aaa' b=[1,2,3] # only one variable def get_var_name(var): for k,v in globals().items(): if id(v) == id(var): name=k return name get_var_name(a) # 'a' # from list, multiple variables def get_var_names(vars): names=[] for var in vars: for k,v in globals().items(): if id(v) == id(var): names.append(k) return names get_var_names([a, b]) # ['a', 'b']環境
Ubuntu 18.04
Python 3.7.3
- 投稿日:2019-08-22T11:44:37+09:00
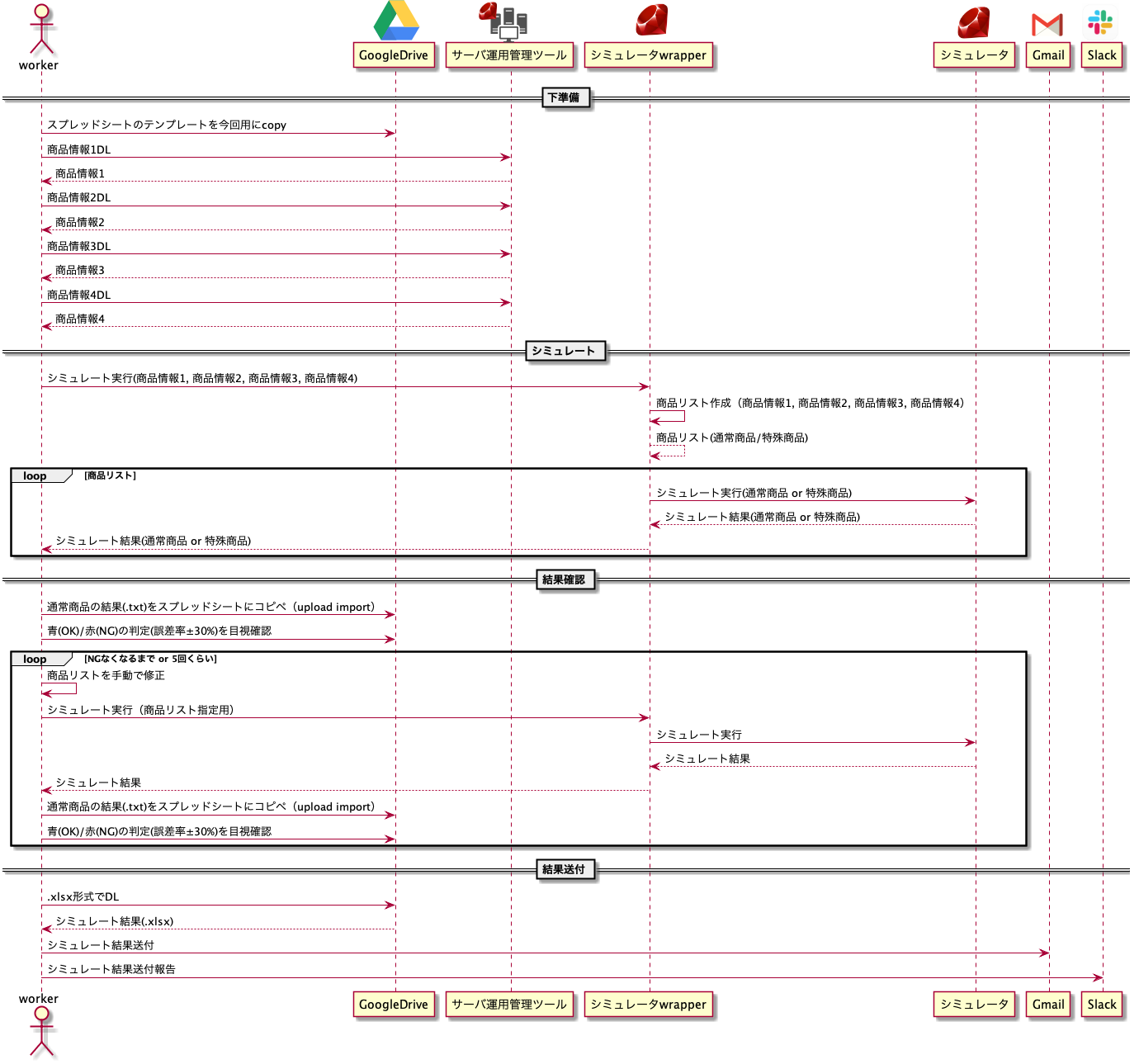
めちゃくちゃ手間のかかっていた手作業を激効率化した話
前置き
- すごく手間のいる作業が存在していた。ざっくり
- スプレッドシートを複製
- 運用管理ツールからjsonを複数DL
- シミュレータ実行
- シミュレータ実行結果をスプレッドシートに貼り付け
- 目視で結果確認(NGならリトライ)
- スプレッドシートからExcelファイルexport
- メール&Slackで報告
- 実質的な作業時間としては10~20min(リトライあるともっと)かかるが、色んなツールが必要だからとにかく面倒。
- 図にするとこんな感じ
環境
- masOS Mojave ver10.14.6
- Python 3.7.3
- pip 19.2.2
激効率化(自動化)した結果
パラメータ指定なしのコマンド一つで、欲しかったExcelファイルが作成されるようにした
自動化のポイント
1. 運用観点
無駄は無くしていこうな方針で2点対応。
1-1. スプレッドシートの廃止
シミュレート結果の確認+Excelファイル(.xlsx)を出力するだけの存在。
シミュレートの結果は機械的にチェックして、Excelファイルはテンプレートを作っておいて、それに直接結果を入れ込めばよくないか?と気づき 滅 した。
1-2. Gmailの廃止
シミュレート結果を何故かメールで添付して送る運用。
前のメールとかテンプレートを参考にメール1通作るのがめんどい。
宛先もチーム全体のMLをccにする運用であったため、宛先を絞りたいわけでもなさそうだった。
セキュリティ的にもslackはEnterpriseだし、ワークスペースをチーム単位で区切ってるし、プライベートチャンネルだし、そこに投下しても問題なさそう。
であれば、slackのチャンネルで直接やり取りすればよいじゃんという結論で、 滅 した。
2. 技術観点
2-1. Pythonでスクレイピング
下準備のここを、
この前書いた記事に沿って、ローカルに商品情報をDLできるようにした:運用管理ツール(Webアプリ)のjsonDL機能を気軽にローカルに保存したかった話
必要な情報をDLできればどうとでもなる2-2. Pythonでrubyスクリプトの実行
subprocessモジュールを利用。
以下のように実行して、rubyスクリプト側でシミュレータ結果をtxt形式で出力してくれるので、そのtxtファイルさえloadすればどうとでもできた。import subprocess res = subprocess.run(["ruby", "exec.rb", "exec.rbの引数1", "exec.rbの引数2", "exec.rbの引数3"])2-3. PythonでのExcel操作
- openpyxlを利用した。(いちいちExcel開かないで処理できるので、早くてとても素晴らしい)
- インストール
pip install openpyxl
- 全部は載せられないが、こんな感じで操作できるので、Excelに結果を出力するには十分だった
import openpyxl # Excel(.xlsx)load book = openpyxl.load_workbook(filename = "Excelファイル名") # sheet指定 sheet = book["シート名"] # 値代入 sheet.cell(row=行 , column=列, value=値) # Excel(.xlsx)save book.save("Excelファイル名")
- ちょいつまりポイント
- 値を数値として出力したい場合は、ちゃんと型変換してあげないとダメだった。
- 今回でいうと、文字列/整数/小数の3種類があったので、以下のように出し分けした
# "."/"-"を最初の1つ目削除した値を変換してみて小数判定 if data.replace(".","",1).replace("-","",1).isdigit() : # 一旦floatにしてみる d_data = float(data) if d_data.is_integer() : sheet.cell(row = row, column = column, value = int(d_data)) else : sheet.cell(row = row, column = column, value = d_data) else : sheet.cell(row = row, column = column, value = data)感想
- シミュレート時間があるのでそこまで時間短縮にはなっていないが、作業ミスもなくなり、とにかく作業が楽になった。
- スクレイピングして必要な情報かき集められればあとはどうとでもできそう
- Excel業務がいまだにあるのがアレだけど、他社絡みなのでしかたないと思いつつ、Excelに絡む効率化はPythonでいいやってなった
- 他言語/他サービスとのつなぎ合わせ的な観点でできることが増えれば、自動化の幅広がりそう
- 既存の運用手順は急ぎで組み立てられたりしてることも多い気がするので、そもそもの手順で無駄がないか(楽な手順にシフトできないか)を見てみると意外にある(気がする)
参考
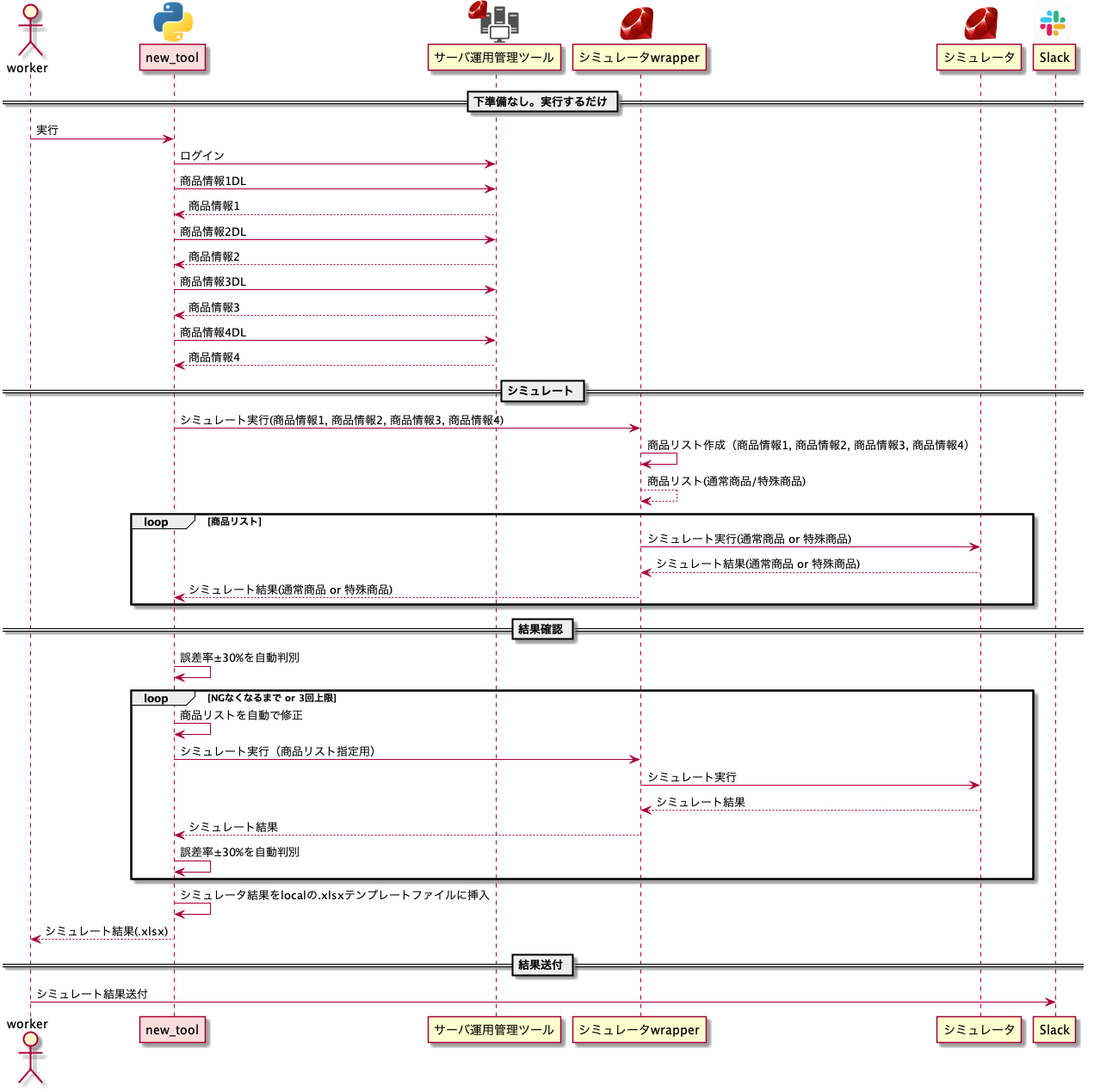

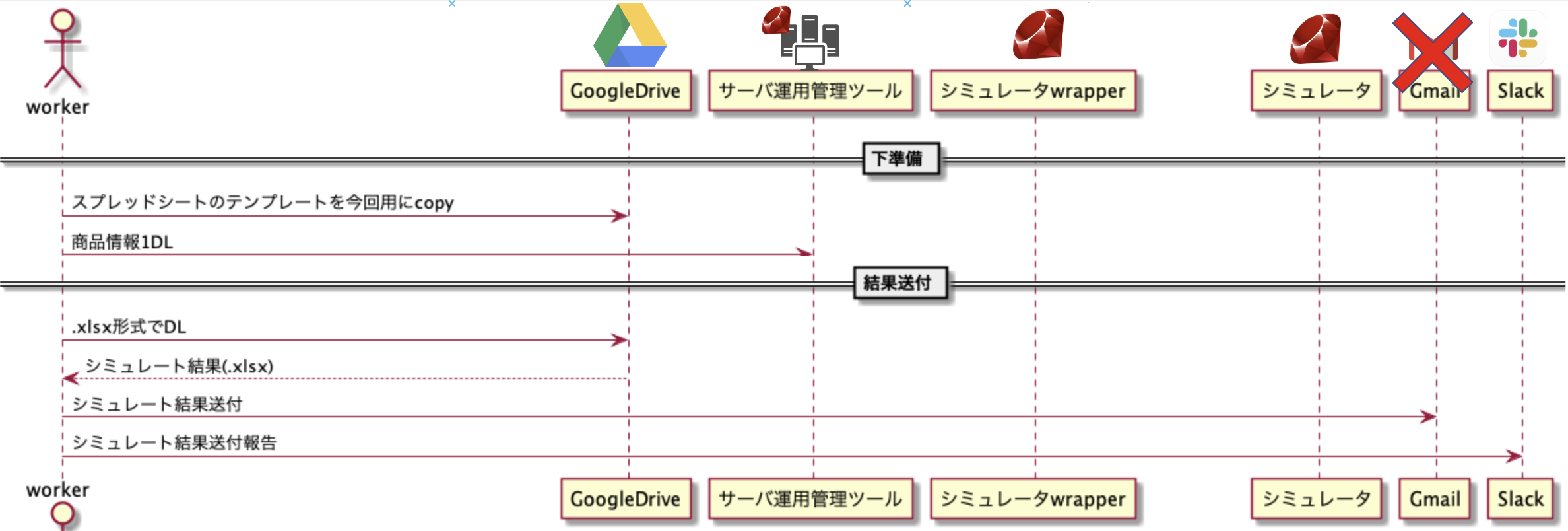
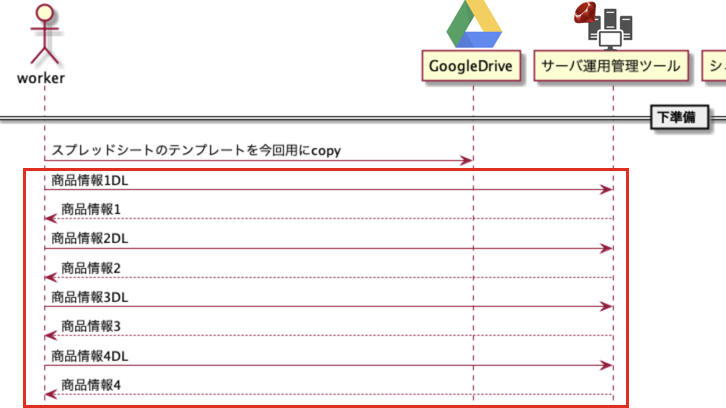
- 投稿日:2019-08-22T11:44:37+09:00
めちゃくちゃ手間のかかっていた手作業をPython使って激効率化した話
前置き
- すごく手間のいる作業が存在していた。ざっくり
- スプレッドシートを複製
- 運用管理ツールからjsonを複数DL
- シミュレータ実行
- シミュレータ実行結果をスプレッドシートに貼り付け
- 目視で結果確認(NGならリトライ)
- スプレッドシートからExcelファイルexport
- メール&Slackで報告
- 実質的な作業時間としては10~20min(リトライあるともっと)かかるが、色んなツールが必要だからとにかく面倒。
- 図にするとこんな感じ
環境
- masOS Mojave ver10.14.6
- Python 3.7.3
- pip 19.2.2
激効率化(自動化)した結果
パラメータ指定なしのコマンド一つで、欲しかったExcelファイルが作成されるようにした
自動化のポイント
1. 運用観点
無駄は無くしていこうな方針で2点対応。
1-1. スプレッドシートの廃止
シミュレート結果の確認+Excelファイル(.xlsx)を出力するだけの存在。
シミュレートの結果は機械的にチェックして、Excelファイルはテンプレートを作っておいて、それに直接結果を入れ込めばよくないか?と気づき 滅 した。
1-2. Gmailの廃止
シミュレート結果を何故かメールで添付して送る運用。
前のメールとかテンプレートを参考にメール1通作るのがめんどい。
宛先もチーム全体のMLをccにする運用であったため、宛先を絞りたいわけでもなさそうだった。
セキュリティ的にもslackはEnterpriseだし、ワークスペースをチーム単位で区切ってるし、プライベートチャンネルだし、そこに投下しても問題なさそう。
であれば、slackのチャンネルで直接やり取りすればよいじゃんという結論で、 滅 した。
2. 技術観点
2-1. Pythonでスクレイピング
下準備のここを、
この前書いた記事に沿って、ローカルに商品情報をDLできるようにした:運用管理ツール(Webアプリ)のjsonDL機能を気軽にローカルに保存したかった話
必要な情報をDLできればどうとでもなる2-2. Pythonでrubyスクリプトの実行
subprocessモジュールを利用。
以下のように実行して、rubyスクリプト側でシミュレータ結果をtxt形式で出力してくれるので、そのtxtファイルさえloadすればどうとでもできた。import subprocess res = subprocess.run(["ruby", "exec.rb", "exec.rbの引数1", "exec.rbの引数2", "exec.rbの引数3"])2-3. PythonでのExcel操作
- openpyxlを利用した。(いちいちExcel開かないで処理できるので、早くてとても素晴らしい)
- インストール
pip install openpyxl
- 全部は載せられないが、こんな感じで操作できるので、Excelに結果を出力するには十分だった
import openpyxl # Excel(.xlsx)load book = openpyxl.load_workbook(filename = "Excelファイル名") # sheet指定 sheet = book["シート名"] # 値代入 sheet.cell(row=行 , column=列, value=値) # Excel(.xlsx)save book.save("Excelファイル名")
- ちょいつまりポイント
- 値を数値として出力したい場合は、ちゃんと型変換してあげないとダメだった。
- 今回でいうと、文字列/整数/小数の3種類があったので、以下のように出し分けした
# "."/"-"を最初の1つ目削除した値を変換してみて小数判定 if data.replace(".","",1).replace("-","",1).isdigit() : # 一旦floatにしてみる d_data = float(data) if d_data.is_integer() : sheet.cell(row = row, column = column, value = int(d_data)) else : sheet.cell(row = row, column = column, value = d_data) else : sheet.cell(row = row, column = column, value = data)感想
- シミュレート時間があるのでそこまで時間短縮にはなっていないが、作業ミスもなくなり、とにかく作業が楽になった。
- スクレイピングして必要な情報かき集められればあとはどうとでもできそう
- Excel業務がいまだにあるのがアレだけど、他社絡みなのでしかたないと思いつつ、Excelに絡む効率化はPythonでいいやってなった
- 他言語/他サービスとのつなぎ合わせ的な観点でできることが増えれば、自動化の幅広がりそう
- 既存の運用手順は急ぎで組み立てられたりしてることも多い気がするので、そもそもの手順で無駄がないか(楽な手順にシフトできないか)を見てみると意外にある(気がする)
参考
- 投稿日:2019-08-22T11:09:15+09:00
AWSのIAMユーザー管理簿を毎週自動でメール配信する
はじめに
どこの企業でもセキュリティ対策のためのガイドラインやチェックリストなどがあると思うが、例えばこんな要件があるとする。
アカウントやユーザーの発行/変更/削除の記録を管理簿にて管理すること。
AWSではロールやグループを割り当てたIAMユーザーが発行される。
監査やコンプライアンスの観点からIAMユーザー管理の証跡を残すことは重要だ。1今回はこのIAMユーザーの管理簿作成を自動化してみる。
ざっくり言うと
- IAM認証情報レポートを毎週一回メールで自動配信するようにした2
- CloudWatch/Lambda/SES/S3を組み合わせた
- 社内監査やコンプライアンスチェックのためにファイルを残すことが可能
- 具体的には下記のようなメールが送られてくる
対象とする人
- 堅めの企業でAWSのセキュリティを見ている人
- 特に社内のコンプライアンスチェックや監査目的でAWSのIAMユーザーのリストを作成する必要がある人
やること
- SESでメールアドレスを認証
- Lambda関数実行用のIAMロールの作成
- Lambda関数作成
やらないこと
- 各種アラートやチェックの自動化
- アクセスキーやパスワードが全然ローテーションされていないぞ!などの警告は他のサービスで実現可能なので、ここではやらない。
- Slackなどのチャットサービスへの通知
- 会社でSlack使えない場合があるため
※ここで並べたものは「やらなくていい」ではなくて「ほんとはやった方がいい」ものである。
IAM認証情報レポート
AWS アカウントの認証情報レポートの取得 - AWS Identity and Access Management
IAM認証情報レポートとはアカウントのすべてのユーザーと、ユーザーの各種認証情報 (パスワード、アクセスキー、MFA デバイスなど) のステータスがまとめられたものである。
ファイル自体はcsvファイルとして生成される。csvファイルには下記の情報が含まれる。3
列名 説明 ユーザー ユーザ名 arn ユーザーの Amazon リソースネーム(ARN) user_creation_time ユーザーが作成された日時 (ISO 8601 日付/時刻形式) password_enabled ユーザーがパスワードを持っているかどうか password_last_used AWS アカウントのルートユーザー または IAM ユーザーのパスワードを使用して最後に AWS ウェブサイトにサインインした日時 password_last_changed ユーザーのパスワードが最後に設定された日時 password_next_rotation 新しいパスワードを設定するようユーザーに求める日時 mfa_active ユーザーに対して多要素認証 (MFA) デバイスが有効かどうか access_key_1_active ユーザーがアクセスキーがACTIVEかどうか access_key_1_last_rotated ユーザーのアクセスキーが作成または最後に変更された日時 access_key_1_last_used_date AWS API リクエストの署名にユーザーのアクセスキーが直近に使用されたときの日付と時刻 access_key_1_last_used_region アクセスキーが直近に使用された AWS リージョン access_key_1_last_used_service アクセスキーを使用して最も最近アクセスされた AWS サービス cert_1_active ユーザーのX.509 署名証明書がACTIVEかどうか cert_1_last_rotated ユーザーの署名証明書が作成または最後に変更された日時 IAM認証情報レポートはマネジメントコンソールの下記の画面からダウンロード可能である。
ただし、これを定期的に行うのは人間のやる作業ではないため自動化する。
SESでメールアドレスを認証する
単純なメール通知ならSNSで十分だが、今回はcsvファイルを添付したいのでSESを利用して送信用&受信用のメールアドレスを登録する必要がある。
詳細な手順は省略するが
- 左上の
Verify a New Email Addressボタンからメールアドレスを登録- 受信したメールに記載されたリンクへアクセスする
これでメールアドレスの認証は完了する。Statusが[verified]になればOK。
SESは対応しているリージョンが少ないので注意が必要である。2019年時点では下記の3リージョンのみ利用可能。
- us-east-1(バージニア北部)
- us-west-2(オレゴン)
- eu-west-1(アイルランド)
IAMロールを作成する
Lambda関数に与えるIAMロールを事前に用意しておく。
IAMのコンソール画面の「このロールを使用するサービス」からLambda関数を選択。
今回追加で必要な権限はこの3つ。
- AmazonSESFullAccess
- AmazonS3FullAccess
- IAMReadOnlyAccess
信頼されたエンティティとしてLambdaが選択されているのを確認したら
ロールの作成を行う。Lambda関数を設定
とりあえず関数名とランタイムを指定して
関数の作成をクリック。ロールはあとで指定する。
ここでは下記の手順でLambda関数を作成する。
- ①Lambda関数コードを入力
- ②環境変数の入力
- ③実行ロールの設定
- ④CloudWatchEventの設定
① Lambda関数コードを入力
下記のコードをインラインエディタに貼り付ける。
send_iam_reportimport boto3 import re import time import datetime import os from botocore.exceptions import ClientError from email.mime.multipart import MIMEMultipart from email.mime.text import MIMEText from email.mime.application import MIMEApplication AWS_S3_BUCKET_NAME = os.environ["AWS_S3_BUCKET_NAME"] ACCOUNT_ID = os.environ["ACCOUNT_ID"] SENDER = os.environ["SENDER"] RECIPIENT = os.environ["RECIPIENT"] AWS_REGION = "us-east-1" SUBJECT = "IAMユーザーWeeklyReport" # The character encoding for the email. CHARSET = "utf-8" # The email body for recipients with non-HTML email clients. BODY_TEXT = "IAMユーザー管理リスト\n作成日時:{}".format(datetime.datetime.today()) # The HTML body of the email. BODY_HTML = """\ <html> <head></head> <body> <p>今週のIAMユーザー管理リスト</p> <p>アカウントID:{}</p> <p>作成日時:{}</p> <p>ファイル格納先:{}</p> </body> </html> """.format(ACCOUNT_ID, datetime.datetime.today(), AWS_S3_BUCKET_NAME) def lambda_handler(event, context): # 認証情報レポートを生成 iam = boto3.client('iam') response = iam.generate_credential_report() print(response) # レポート作成が完了するまで待機 while(response['State'] != 'COMPLETE'): time.sleep(1) continue result = iam.get_credential_report() print(result) # 取得日時からファイル名を生成 pattern = r"[0-9]{4}-[0-9]{2}-[0-9]{2}" date = re.search(pattern, str(result['GeneratedTime'])).group(0) fname = "{}_{}_iam_credential_report.csv".format(date.replace("-", ""), ACCOUNT_ID) ATTACHMENT = "/tmp/"+fname # S3へ保存 s3 = boto3.resource('s3') bucket = s3.Bucket(AWS_S3_BUCKET_NAME) bucket.put_object(Key='iam/'+fname, Body=result["Content"]) # tmpへ一時保存 with open('/tmp/'+fname, "wb") as f: f.write(result["Content"]) # メール配信 # Create a new SES resource and specify a region. ses = boto3.client('ses', region_name=AWS_REGION) # Create a multipart/mixed parent container. msg = MIMEMultipart('mixed') # Add subject, from and to lines. msg['Subject'] = SUBJECT msg['From'] = SENDER msg['To'] = RECIPIENT # Create a multipart/alternative child container. msg_body = MIMEMultipart('alternative') # Encode the text and HTML content and set the character encoding. This step is # necessary if you're sending a message with characters outside the ASCII range. textpart = MIMEText(BODY_TEXT.encode(CHARSET), 'plain', CHARSET) htmlpart = MIMEText(BODY_HTML.encode(CHARSET), 'html', CHARSET) # Add the text and HTML parts to the child container. msg_body.attach(textpart) msg_body.attach(htmlpart) # Define the attachment part and encode it using MIMEApplication. att = MIMEApplication(result["Content"]) # Add a header to tell the email client to treat this part as an attachment, # and to give the attachment a name. att.add_header('Content-Disposition', 'attachment', filename=os.path.basename(ATTACHMENT)) # Attach the multipart/alternative child container to the multipart/mixed # parent container. msg.attach(msg_body) # Add the attachment to the parent container. msg.attach(att) try: # Provide the contents of the email. response = ses.send_raw_email( Source=SENDER, Destinations=[ RECIPIENT ], RawMessage={ 'Data': msg.as_string(), }, # ConfigurationSetName=CONFIGURATION_SET ) # Display an error if something goes wrong. except ClientError as e: print(e.response) print(e.response['Error']['Message']) else: print("Email sent! Message ID:"), return (response['ResponseMetadata']['RequestId'])やっていることは大雑把に言うと下記の通り。
- iam_credential_reportの生成、取得
- 取得したファイルをS3へ保存
- SESによりファイルを添付したメールを送信
② 環境変数を入力
この関数ではメールアドレスやアカウントIDなどは環境変数で管理している。Lambda関数内に直接書き込んでも動作するが、コードを直接変更するのはトラブルの元なので環境変数として外部に切り出す。
こうしておけば別のアカウントに移植する際にいちいちコードを書き換える必要がない。CloudFormationでLambdaをデプロイする場合などはコードをzipファイルにまとめる際などは非常に便利。環境変数の設定は下記のようにコンソール上から行うことができる。4
③ 実行ロールの設定
既存のロールを使用するを選択し、先ほど作成したロールを割り当てる。④CloudWatchEventの設定
毎週一回レポートを作成する場合はLambda関数の
トリガーを追加をクリックして下記の通り設定すればOK。cronによるスケジュール設定はUTCで行う必要があるので注意。
参考にそのほかセキュリティ周りの作業を自動化する場合に使いそうな設定パターンをまとめておく。
時間帯 Cron式 利用例 ルール名 毎日0:00(JST) 0 15 * * ? *S3のデータ整形、ログ収集など daily_task 毎週月曜日の0:00(JST) 0 15 ? * SUN *1週間のセキュリティレポート作成など weekly_task 毎月1日の0:00(JST) 0 15 1 * ? *月間のコスト請求レポート作成など monthly_task 平日の夜22:00(JST) 0 13 ? * MON-FRI *インスタンスの設定ミス、落とし忘れなどのチェック closing_task その他ポイントとしては
- 必要に応じてメールの件名や文面を編集する
AWS_REGIONはSESを設定した時のリージョンを指定するtmpディレクトリに一時的に添付ファイルを保存→メール送信- IAMユーザーが多いと処理に時間がかかるので時間は適当に設定する
など。
おわりに
とりあえずこれ動かしておけば毎週必ずレポートが送られてくる。
「アカウントの管理しっかりやってるよね?」と言われたときにすぐに出せるようにしておくと安心。参考
Lambda・SESを使って、添付ファイル付きメールを送信する – サーバーワークスエンジニアブログ
E メールの高度なパーソナライズ - Amazon Simple Email Service
AWS SDKs を使用して raw E メールを送信する - Amazon Simple Email Service
「AWS Configで一発だろ」というツッコミはごもっともだが、非エンジニアが各種チェック作業を行う場合を考えると、ローカルファイルとして置いておくのが一番楽だと思われる。誰でも扱いやすい形式で情報を扱うことが、社内全体幸福最大化につながる。 ↩
応用すればコストレポートやS3バケット内のファイルの自動配信なども可能。 ↩
アクセスキーと証明書が複数ある場合はその分だけ列が増える。 ↩
CLIなどで登録することも可能。 ↩
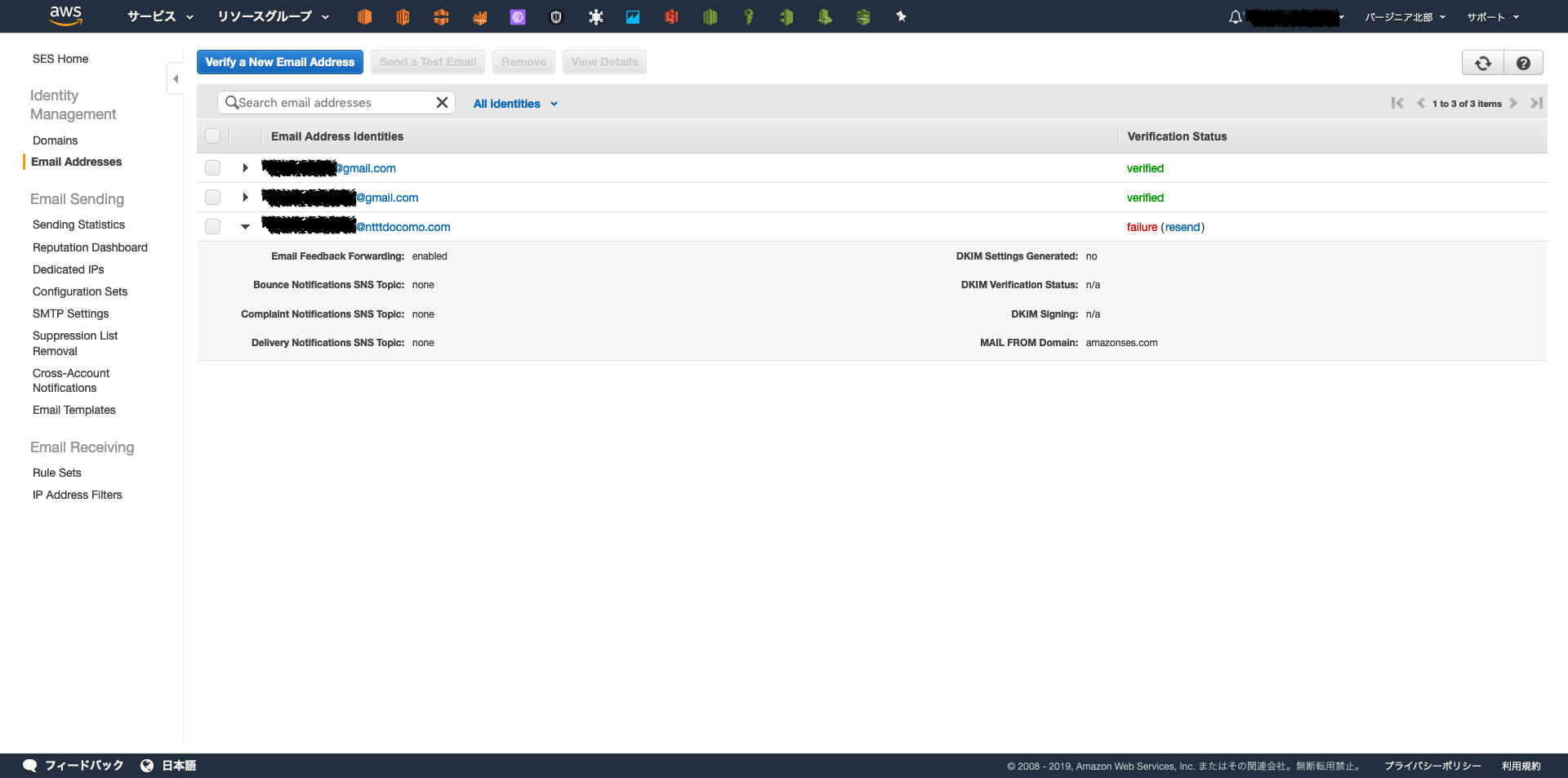
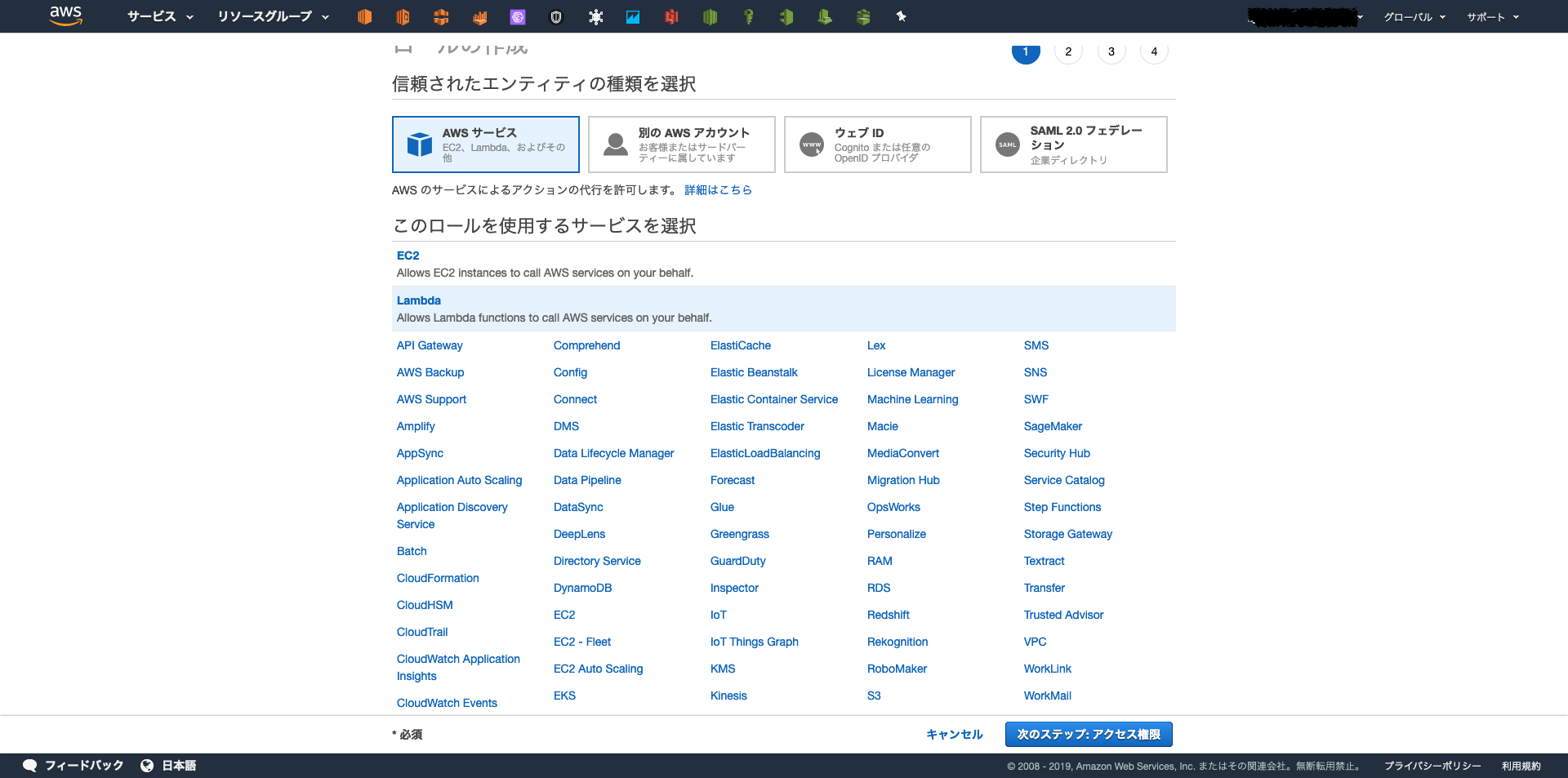
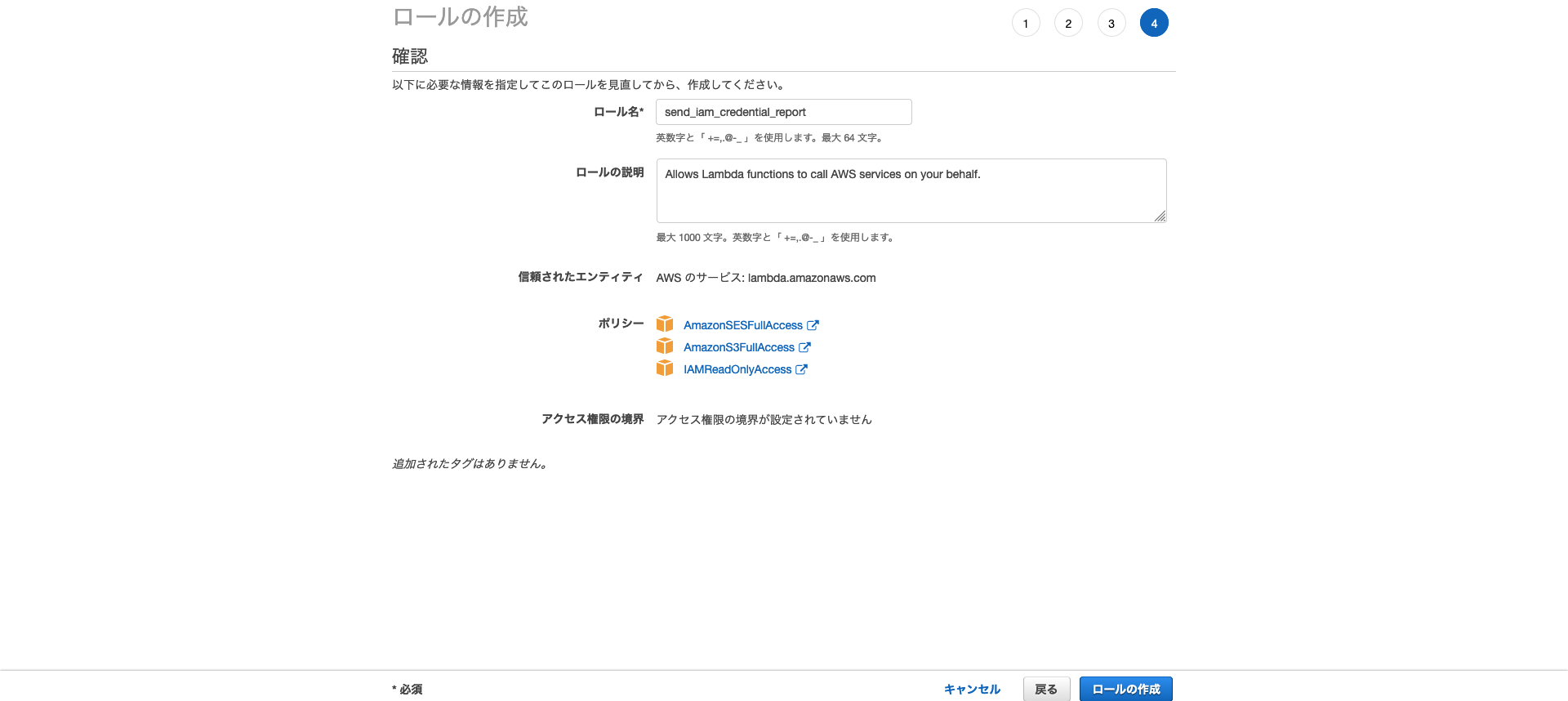
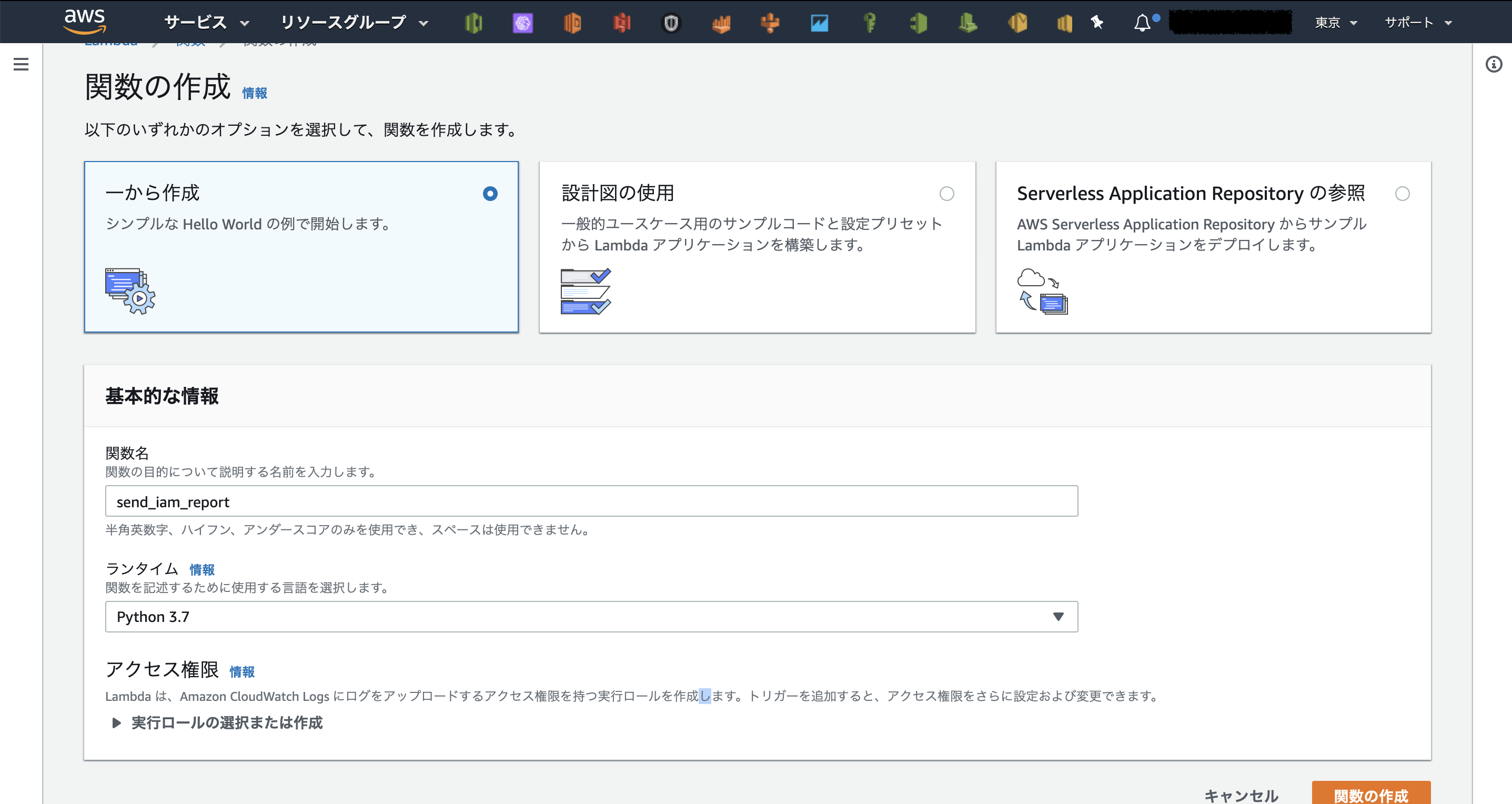
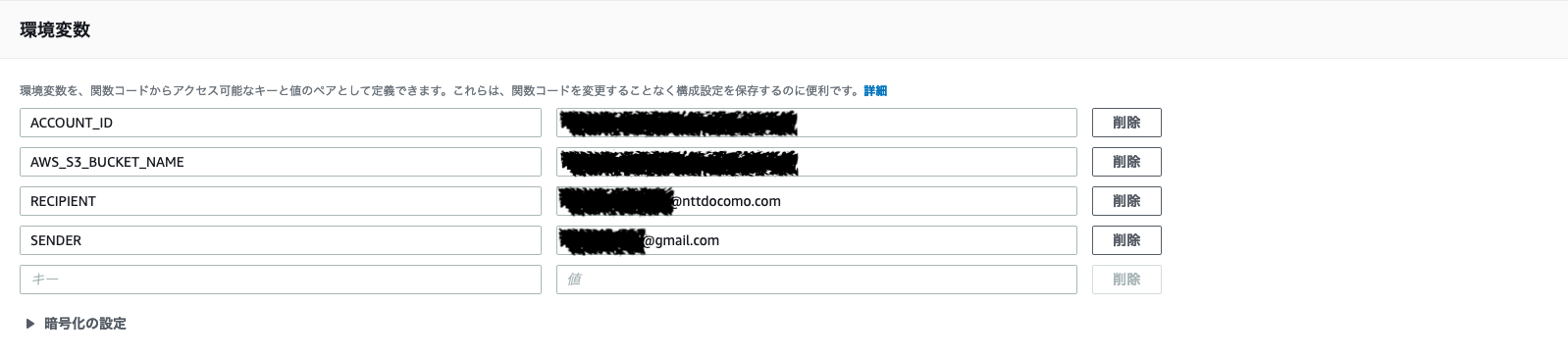
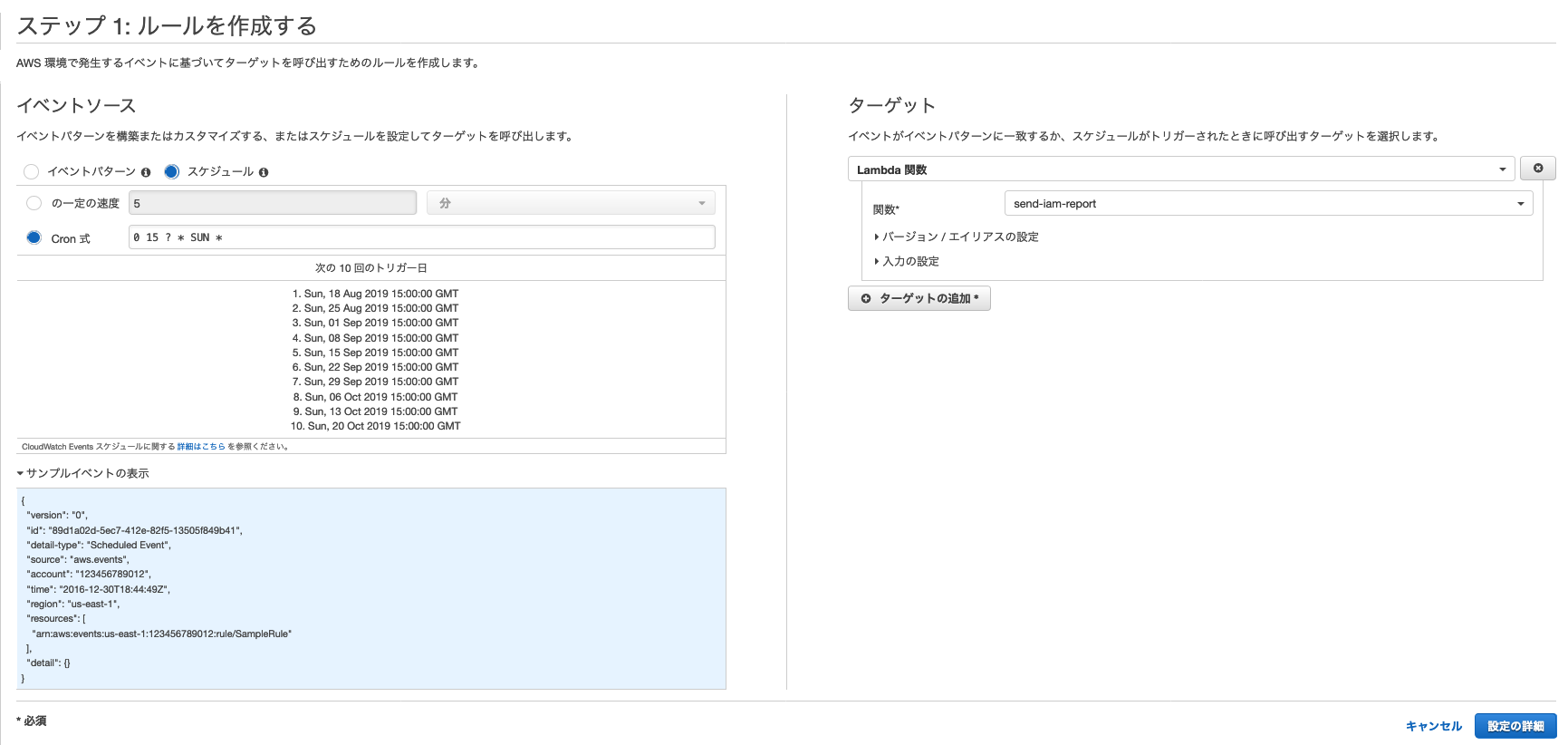
- 投稿日:2019-08-22T09:41:39+09:00
学習させたモデル(CNN)に画像をまとめて入れて出力をcsvに書き出す
前の記事にもしれっと書いていますがテストデータに対するAI君の答えをまとめて知りたくて色々と調べたのですが、見つけきれなかったので自分で作ったものを別途まとめようと思います。
CNN以外触ったことがないので他に応用できるかはわかりません。やりたいこと
タイトルの通りですが具体的にはフォルダを指定し、その中の画像に対する出力をcsvファイルに一覧としてまとめたい。
結論から言うとこんな感じになります。
実装
pandas
を使います。
以下コピペ用from keras.preprocessing import image import glob import pandas as pd filename=glob.glob("./test_images/**/*") classes = ["名前","","","",""] """ ~いろいろ設定してコンパイルまで~ """ DataFrame={"":classes} for i in filename: img = image.load_img(i, target_size=(img_cols, img_rows)) x = image.img_to_array(img) x = np.expand_dims(x, axis=0) x = x/ 255.0 DataFrame[i.lstrip("./test_images/")]=model.predict(x)[0] pd.DataFrame(DataFrame).T.to_csv('out.csv',header=None)入力枚数<分類するクラスの場合はpd.DataFrame(DataFrame).to_csv('out.csv',header=None)としたらいいかも
これを学習終了後にそのままテストデータをぶちこむようにしたのが前の記事です。
- 投稿日:2019-08-22T06:51:05+09:00
【kaggleで機械学習勉強・第三回】private-lb-probing【kaggle,python】
三回目です。
今回のコンペはtestデータ自体が欠損したものであって、kaggleだけがprivateな欠損なしのデータを持っている。
このkaggleだけが持っているデータを推測しつつモデル作成をしなければならない。この推測行為でコンペにアプローチすることをLeadearBoardProbingという。
kaggleのスコアが返ってくるleaderboardに表示されるスコア「publicScore」から本当のデータを推定すること。早速
プライベートデータセットはtrainと構造が同じなのでしょうか?
答えはyesです。
通常のカグルコンペはtestとprivateが同じデータです。このコンペはprivate部分が含まれていません。
くわしくはこちら
リンクの中で書かれているのは、以下リンクの内容
・データはwheezy-copper-turtle-magicのユニーク数512に対応した塊に分かれていて、正規分布していそうな形をしていること。
・細くとがったベル型の分布で一見正規分布ですが正確には正規分布ではありません。
・いくつかの変数は正規分布に従っています。
・512の変数に対して255個の変数があり、行の合計はだいたいtrainの全体(262144行)を512で割った数くらいです。
・前回SVMでやってみたところスコアは0.9くらいになりました。
・255個の変数を使ってしまうとオーバーフィッティングするので変数を減らすことが重要です。・モデル構築の特徴量の選択はlassoやRFEで決めるといいのではないでしょうか。
・今回のデータは平均0,標準偏差1~3.75くらいのデータでした。
・標準偏差の大きいデータを選択してモデルを作成してみるとスコア0.9くらいでした。すべて標準偏差が1だったら特徴量選択は難しかったでしょう。
本文に戻る
プライベートデータセットについて
512のモデルを作る方法だけでなく単一のモデルを作成する方法も見てみます。
abhishekさんのカーネルとvladislavさんのneural netを使います。
import numpy as np, pandas as pd, os, gc train = pd.read_csv('train.csv') test = pd.read_csv('test.csv') train.head()使える特徴量を探して、使えないものを取り除きます。
# FIND STANDARD DEVIATION OF ALL 512*256 BLOCKS useful = np.zeros((256,512)) for i in range(512): partial = train[ train['wheezy-copper-turtle-magic']==i ] useful[:,i] = np.std(partial.iloc[:,1:-1], axis=0) # CONVERT TO BOOLEANS IDENTIFYING USEFULNESS useful = useful > 1.5 import matplotlib.pyplot as plt # PLOT BOOLEANS OF USEFUL BLOCKS plt.figure(figsize=(10,20)) plt.matshow(useful.transpose(),fignum=1) plt.title('The useful datablocks of dataset', fontsize=24) plt.xlabel('256 Variable columns', fontsize=16) plt.ylabel('512 Partial datasets', fontsize=16) plt.show()標準偏差の判断基準値を1.5として、Trueになるものが黄色、Faulsが紫になる。
使えるもの(標準偏差1.5以上)が黄色であらわされている。
使えないデータ部分には0を入れましょう。
(pythonにはもっとうまいやり方があるとはおもいますが)# SET MAGIC COLUMN AS ALL USEFUL useful[146,:] = [True]*512 # REMOVE ALL USELESS BLOCKS for i in range(512): idx = train.columns[1:-1][ ~useful[:,i] ] train.loc[ train.iloc[:,147]==i,idx ] = 0.0 test.loc[ test.iloc[:,147]==i,idx ] = 0.0 #if i%25==0: print(i)使えないと認識された変数には0が入っている。
train.head()やtest.head()を確認するとわかる。NNの構築
512のモデルに分けるのでなく、特徴量選択をした後、一つのモデルだけで結果を出してみる。
# SET MAGIC COLUMN AS ALL USEFUL useful[146,:] = [True]*512 # REMOVE ALL USELESS BLOCKS for i in range(512): idx = train.columns[1:-1][ ~useful[:,i] ] train.loc[ train.iloc[:,147]==i,idx ] = 0.0 test.loc[ test.iloc[:,147]==i,idx ] = 0.0 #if i%25==0: print(i)# CUSTOM METRICS def fallback_auc(y_true, y_pred): try: return metrics.roc_auc_score(y_true, y_pred) except: return 0.5 def auc(y_true, y_pred): return tf.py_function(fallback_auc, (y_true, y_pred), tf.double)この関数はあとでニューラルネットを実行するときに使われる。
ちなみにaucというのは
http://cookie-box.hatenablog.com/entry/2019/02/10/182619このあたりを参考にして。
https://www.randpy.tokyo/entry/roc_auc これがわかりやすかった True Positive(TP): 正解データ正であるものを、正しく正と予測できた数 False Positive(FP):正解データ負であるものを、間違って正と予測した数 Flase Negative(FN):正解データ正であるものを、間違って負と予測した数 True Negative(TN):正解データ負であるものを、正しく負と予測できた数 となります。 ※以降ですが、True PositiveはTP、False PositiveはFPといったように、表記を省略させて頂きますのでご了承ください。 さて、この表から正解率を求めるとすると、 正解率:(TP+TN)/(TP+FP+FN+TN) という式で計算することができます。(分母が全体の数、分子が正解した数) 正解率を評価指標として用いるのが直感的には良さそうではあるのですが、クラスに偏りがある場合、機能しなくなるという問題があります。以上引用
予測値と正解クラスをひとつのデータとする。その予測値を閾値として全データを正負に振り分けたとき、TPFPTNFNがそれぞれ求まる。 これを全予測値に対して計算していく。 こうすることで、予測値と正解クラスの関係性がどれだけ正しいものなのかを確かめられる。 これをカーブにしたものがauc
2クラスを判断したいときに使える。 いろんなデータの特徴量をモデルにかけて一つの0~1の間の数字にする。 その数字と二つのクラスの分け目の閾値がうまく設定されていれば、良いモデルを使ったoutputであるといえる。
本文に戻って
# ONE-HOT-ENCODE THE MAGIC FEATURE len_train = train.shape[0] test['target'] = -1 data = pd.concat([train, test]) data = pd.concat([data, pd.get_dummies(data['wheezy-copper-turtle-magic'])], axis=1, sort=False) train = data[:len_train] test = data[len_train:]trainとtestについてmagic変数に対してonehotencorderを行う。
ここではdummiesを使っているがやっていることはonehotと同じ。# PREPARE DATA AND STANDARDIZE y = train.target #trainの正解一覧をyに入れる ids = train.id.values #idも別で保存train = train.drop(['id', 'target'], axis=1) #trainからidとtargetを取り除いておく test_ids = test.id.values #testのidは別保存 #testはtargetがない。 test = test[train.columns] test_ids = test.id.values #testのidは別保存 #testはtargetがない。 test = test[train.columns] test_preds_NN = np.zeros((len(test))) test_preds_NN #テストの予測値をいれたい scl = preprocessing.StandardScaler() #標準化(スケール)をsciに入れる scl.fit(pd.concat([train, test])) #trainとtestをくっつけたものを標準化している?r言語でいうrbind=concat train = scl.transform(train) test = scl.transform(test)ニューラルネットの構築
NFOLDS = 15 RANDOM_STATE = 42 gc.collect() # STRATIFIED K FOLD folds = StratifiedKFold(n_splits=NFOLDS, shuffle=True, random_state=RANDOM_STATE) for fold_, (trn_, val_) in enumerate(folds.split(y, y)): #print("Current Fold: {}".format(fold_)) trn_x, trn_y = train[trn_, :], y.iloc[trn_] val_x, val_y = train[val_, :], y.iloc[val_] # BUILD MODEL inp = Input(shape=(trn_x.shape[1],)) x = Dense(2000, activation="relu")(inp) x = BatchNormalization()(x) x = Dropout(0.3)(x) x = Dense(1000, activation="relu")(x) x = BatchNormalization()(x) x = Dropout(0.3)(x) x = Dense(500, activation="relu")(x) x = BatchNormalization()(x) x = Dropout(0.2)(x) x = Dense(100, activation="relu")(x) x = BatchNormalization()(x) x = Dropout(0.2)(x) out = Dense(1, activation="sigmoid")(x) clf = Model(inputs=inp, outputs=out) clf.compile(loss='binary_crossentropy', optimizer="adam", metrics=[auc]) # CALLBACKS es = callbacks.EarlyStopping(monitor='val_auc', min_delta=0.001, patience=10, verbose=0, mode='max', baseline=None, restore_best_weights=True) rlr = callbacks.ReduceLROnPlateau(monitor='val_auc', factor=0.5, patience=3, min_lr=1e-6, mode='max', verbose=0) # TRAIN clf.fit(trn_x, trn_y, validation_data=(val_x, val_y), callbacks=[es, rlr], epochs=100, batch_size=1024, verbose=0) # PREDICT TEST test_fold_preds = clf.predict(test) test_preds_NN += test_fold_preds.ravel() / NFOLDS # PREDICT OOF val_preds = clf.predict(val_x) oof_preds_NN[val_] = val_preds.ravel() # RECORD AUC val_auc = round( metrics.roc_auc_score(val_y, val_preds),5 ) all_auc_NN.append(val_auc) print('Fold',fold_,'has AUC =',val_auc) K.clear_session() gc.collect()出力結果は
Fold 0 has AUC = 0.90394 Fold 1 has AUC = 0.90558 Fold 2 has AUC = 0.90671 Fold 3 has AUC = 0.9032 Fold 4 has AUC = 0.90656 Fold 5 has AUC = 0.90635 Fold 6 has AUC = 0.90499 Fold 7 has AUC = 0.90905 Fold 8 has AUC = 0.90222 Fold 9 has AUC = 0.90496 Fold 10 has AUC = 0.90572 Fold 11 has AUC = 0.90483 Fold 12 has AUC = 0.90806 Fold 13 has AUC = 0.90164 Fold 14 has AUC = 0.90284この結果はカーネルからそのまま持ってきました。
(PCが重すぎてfold1までしか動かなかった・・・)# DISPLAY NN VALIDATION AUC val_auc = metrics.roc_auc_score(y, oof_preds_NN) print('NN_CV = OOF_AUC =', round( val_auc,5) ) print('Mean_AUC =', round( np.mean(all_auc_NN),5) ) # PLOT NN TEST PREDICTIONS plt.hist(test_preds_NN,bins=100) plt.title('NN test.csv predictions') plt.show()SVMで512のモデルを作る
SVMだと0.928をだしてくれる。
train = pd.read_csv('train.csv') test = pd.read_csv('test.csv') cols = [c for c in train.columns if c not in ['id', 'target', 'wheezy-copper-turtle-magic']] from sklearn.svm import SVC from sklearn.feature_selection import VarianceThreshold from sklearn.model_selection import StratifiedKFold from sklearn.metrics import roc_auc_score # INITIALIZE VARIABLES oof_preds_SVM = np.zeros(len(train)) test_preds_SVM = np.zeros(len(test)) # BUILD 512 SEPARATE MODELS for i in range(512): # ONLY TRAIN/PREDICT WHERE WHEEZY-MAGIC EQUALS I train2 = train[train['wheezy-copper-turtle-magic']==i] test2 = test[test['wheezy-copper-turtle-magic']==i] idx1 = train2.index; idx2 = test2.index train2.reset_index(drop=True,inplace=True) # FEATURE SELECTION (USE SUBSET OF 255 FEATURES) sel = VarianceThreshold(threshold=1.5).fit(train2[cols]) train3 = sel.transform(train2[cols]) test3 = sel.transform(test2[cols]) # STRATIFIED K FOLD skf = StratifiedKFold(n_splits=11, random_state=42) for train_index, test_index in skf.split(train3, train2['target']): # MODEL WITH SUPPORT VECTOR MACHINE clf = SVC(probability=True,kernel='poly',degree=4,gamma='auto') clf.fit(train3[train_index,:],train2.loc[train_index]['target']) oof_preds_SVM[idx1[test_index]] = clf.predict_proba(train3[test_index,:])[:,1] test_preds_SVM[idx2] += clf.predict_proba(test3)[:,1] / skf.n_splits #if i%10==0: print(i)# DISPLAY SVM VALIDATION AUC val_auc = roc_auc_score(train['target'],oof_preds_SVM) print('SVM_CV = OOF_AUC =',round(val_auc,5))SVM_CV = OOF_AUC = 0.92624# PLOT SVM TEST PREDICTIONS plt.hist(test_preds_SVM,bins=100) plt.title('SVM test.csv predictions') plt.show()
SVMとNNで計算した確率を足しあわせると
# DISPLAY ENSEMBLE VALIDATION AUC val_auc = roc_auc_score(train['target'],oof_preds_SVM+oof_preds_NN) print('Ensemble_NN+SVM_CV = OOF_AUC =',round(val_auc,5))Ensemble_NN+SVM_CV = OOF_AUC = 0.91937# PLOT ENSEMBLE TEST PREDICTIONS plt.hist(test_preds_SVM+test_preds_NN,bins=100) plt.title('Ensemble NN+SVM test.csv predictions') plt.show()
より分離できていそう??
確率が1,0以外の部分が小さくなっている。プライベートデータセットの推定
ダウンロードしたtest.csvはみんなに配られているものと同じ。
このコードをローカルで走らせたり、kaggleのカーネルで走らせたらtest.csvが読み込まれる。
256変数512種類のカテゴリカル変数、ラベル1行の合計(256*512+1)行です。
kaggleにカーネルを提出したら、このコードは二回読み込まれるでしょう。
その時、データセットが512512行のフルデータセットとなります。我々のコードが二回目読み込まれたときには、新しいsubmission.csvの結果がリーダーボードに表示されることになります。
(前提として、最初のsubmission.csvはスコアになりません。二回目のsubmissionだけです。)
このコードは、フルデータセットを与えられたときにsubmission.csvを作ります??
我々はデータセットの構造を推定することができるでしょう。リーダーボードを通して、submission.csvが変化していることが分かるから。さらに、testデータをプライベートのものとパブリックの配布されているものに分けることもできる。
idの列は偽物であることがここで話されている。
idはMD5でつくられた暗号である
リンク先のディスカッションを簡単に翻訳すると、
trainデータのidの一つ目は0train、二つ目は1train、三つめは2train
という文字をMD5で変換したものであるということ。
testも0testとかを変換しただけ。
IDがこれだけ適当に決められていることが分かれば、IDにあまり深い意味はないのかもしれないとわかりそう。
linerさんとyirunさんはよくこれを見つけられたなぁ
したがって、idのカラムをインデックスに入れて、プライベートとパブリックのデータがどう違うのかを推定することができます。import hashlib # CREATE LIST PUBLIC DATASET IDS public_ids = [] for i in range(256*512+1): st = str(i)+"test" public_ids.append( hashlib.md5(st.encode()).hexdigest() ) # DISPLAY FIRST 5 GENERATED public_ids[:5]['1c13f2701648e0b0d46d8a2a5a131a53', 'ba88c155ba898fc8b5099893036ef205', '7cbab5cea99169139e7e6d8ff74ebb77', 'ca820ad57809f62eb7b4d13f5d4371a0', '7baaf361537fbd8a1aaa2c97a6d4ccc7']testの中のidはMD5でハッシュ化されたものであることを確認
# DISPLAY FIRST 5 ACTUAL test['id'].head()0 1c13f2701648e0b0d46d8a2a5a131a53 1 ba88c155ba898fc8b5099893036ef205 2 7cbab5cea99169139e7e6d8ff74ebb77 3 ca820ad57809f62eb7b4d13f5d4371a0 4 7baaf361537fbd8a1aaa2c97a6d4ccc7 Name: id, dtype: objecttestの本当のidと比較しても相違はないので、
やはりMD5で変換されていることが分かった。# SEPARATE PUBLIC AND PRIVATE DATASETS public = test[ test['id'].isin(public_ids) ].copy() private = test[ ~test.index.isin(public.index) ].copy()プライベートデータセットの構造を特定する
プライベートデータセットの構造を決める
このリンクで説明した通り、trainとtestには、512個のカテゴリカルデータの塊があるデータセットのように見えます。
各データには256個の変数があります。つまり、データのブロックは512*216です(ヒートマップで見たやつ。ひとつのセルが131072個ある。これがtestもtrainもある。)
データには1~3.75の標準偏差があって、標準偏差1の群は役に立たないので捨てて、3.75が使えるものになります。
プライベートデータセットも同じ構造なのでしょうか?
# DETERMINE TRAIN DATASET STRUCTURE useful_train = np.zeros((256,512)) for i in range(512): partial = train[ train['wheezy-copper-turtle-magic']==i ] useful_train[:,i] = np.std(partial.iloc[:,1:-1], axis=0) useful_train = useful_train > 1.5 # DETERMINE PUBLIC TEST DATASET STRUCTURE useful_public = np.zeros((256,512)) for i in range(512): partial = public[ public['wheezy-copper-turtle-magic']==i ] useful_public[:,i] = np.std(partial.iloc[:,1:], axis=0) useful_public = useful_public > 1.5 # DETERMINE PRIVATE TEST DATASET STRUCTURE useful_private = np.zeros((256,512)) for i in range(512): partial = private[ private['wheezy-copper-turtle-magic']==i ] useful_private[:,i] = np.std(partial.iloc[:,1:], axis=0) useful_private = useful_private > 1.5if np.allclose(useful_train,useful_public): print('Public dataset has the SAME structure as train') else: print('Public dataset DOES NOT HAVE the same structure as train')結果
Public dataset has the SAME structure as train
使える変数と使えない変数を1.5で分けてみたけど、
testも1.5で判定したら、配列が等価であった。
だからプライベートデータセットも構造としては同じものである。リーダーボードを見てプライベートデータセットを考える
プライベートデータセットの構造が、trainやtestと異なる場合、すべての予測はゼロを入れることにします。
結果は0.5になるでしょう。もしプライベートデータセットがtrainやtestと同じ構造であれば、0.95を提出できます
カーネルを実行すると、プライベートデータセットがないので、すべてゼロでsubmissionします。
でもこれをkaggleに送信すると、kaggleにはプライベートデータセットがあるので合格します。sub = pd.read_csv('sample_submission.csv') if np.allclose(useful_train,useful_public) & np.allclose(useful_train,useful_private): print('We are submitting TRUE predictions for LB 0.950') sub['target'] = (test_preds_NN + test_preds_SVM) / 2.0 else: print('We are submitting ALL ZERO predictions for LB 0.500') sub['target'] = np.zeros( len(sub) ) sub.to_csv('submission.csv',index=False)結果
We are submitting ALL ZERO predictions for LB 0.500
これがリーダーボードでは0.5ではないのでプライベートデータセットが使われていることがわかる。
まとめ
これを提出するとカーネルが0.95を獲得したことがわかります。
kaggleの評価手順で二回目実行時にプライベートデータセットにアクセスして、
プライベートデータセットがトレーニングデータセットと同じデータ構造を持っていることを確認できます。さらに、この構造を変更し、512のモデルでなく、単一の高スコアを出すNNをつくることもしました。
以上
次回へ続く