- 投稿日:2019-08-21T22:59:43+09:00
Railsチュートリアル(第10章)
はじめに
Railsチュートリアルの第10章が終わりました。
この章では、ユーザーの更新、表示、削除を行います。
ポイントだけメモしておきます。ユーザーの編集
まずeditアクションでidを元にユーザーを取得します。
def edit @user = User.find(params[:id]) end取得したユーザーを登録時と同様に
form_forを使用して表示します。
書き方は登録時と一緒です。<%= form_for(@user) do |f| %> ... <% end %>この時に、
new_record?というメソッドを使って@userが新規のものかすでにあるものかを判断して、自動的にcreateかupdateを分けてくれます。登録時は以下のように、
update_attributesで行います。
(登録時のsave相当)def update @user = User.find(params[:id]) if @user.update_attributes(user_params) # 成功 else # 失敗 end endbeforeフィルター
コントローラーの各アクションの前に呼ばれるメソッドを定義できます。
例えば、ログインされている場合だけアクションを実行する際、先にチェックメソッドを呼ぶといった使い方ができます。以下のように、
before_actionの後に記述します。
そのままでは全てのアクションの前に呼ばれるので、限定したい場合は、後ろにonly: "メソッドシンボルの配列"を記述します。before_action :logged_in_user, only: [:edit, :update] def logged_in_user ... endフレンドリーフォワーディング
フレンドリーフォワーディングとは、簡単に言うと、
未ログイン時にAページに遷移
→ログインページにリダイレクト
→ログイン
→Aページに遷移
のように、本来のログイン後のページではなく、遷移しようとしていたページに遷移させることです。以下のように、sessionにURLを保持しておくことで実装します。
未ログイン時のリダイレクトで覚えるメソッドを呼び、ログイン後のメソッドでリダイレクトのメソッドを呼びます。
以下のようにすると、URLがなければ引数に渡したデフォルトのURLにリダイレクトできます。
また、request.original_urlで元々遷移しようとしたURLの取得、request.get?でGETリクエストかの判定ができます。# 記憶したURL (もしくはデフォルト値) にリダイレクト def redirect_back_or(default) redirect_to(session[:forwarding_url] || default) session.delete(:forwarding_url) end # アクセスしようとしたURLを覚えておく def store_location session[:forwarding_url] = request.original_url if request.get? end一覧の表示
まずindexアクションで全てのユーザーを取得します。
def index @users = User.all end取得した
@usersをeachで全て表示します。<% @users.each do |user| %> <li> <%= gravatar_for user, size: 50 %> <%= link_to user.name, user %> </li> <% end %>上記のプログラムを以下のように書くことができます。
まず、each文の内容をパーシャルにします。その際、名前を@usersの単数のuserにします。_user.html.erb<li> <%= gravatar_for user, size: 50 %> <%= link_to user.name, user %> </li>そして、以下のように
render @usersと記述することで、自動的にuserのリストだと判断し1つずつパーシャルを表示します。<%= render @users %>サンプルユーザーの作成
サンプルのユーザーを作成するために、実際にいそうな名前を作成してくれる
fakerというgemを入れます。Gemfilegem 'faker', '1.7.3'
seeds.rbというファイルに記述することで、サンプルデータを定義することができます。
以下のように、timesで一気に複数作成することができます。
fakerを使用しているのはFaker::Name.nameのところです。db/seeds.rb99.times do |n| name = Faker::Name.name email = "example-#{n+1}@railstutorial.org" password = "password" User.create!(name: name, email: email, password: password, password_confirmation: password) end
seeds.rbに定義した内容をデータベースに反映するためには、以下のようにrails db:seedを実行します。
rails db:migrate:resetはデータベースの内容をクリアしています。rails db:migrate:reset rails db:seedページネーション
ページネーションを使用するために、以下の2つのgemを入れます。
Gemfilegem 'will_paginate', '3.1.6' gem 'bootstrap-will_paginate', '1.0.0'実際に使用する箇所に以下の記述を追加します。
<%= will_paginate %>ただし、上記の記述だけでは表示できず、以下のように、
User.paginate(page: "ページ番号")を使用して、そのページの一覧を取得する必要があります。def index @users = User.paginate(page: params[:page]) end管理者権限
以下のように、管理者権限を示す
adminというboolean型のカラムを追加します。
boolean型を追加すると、admin?という真偽値を判定するメソッドが使用できます。rails generate migration add_admin_to_users admin:booleanユーザーの削除
削除する際は、destroyアクション内で、userのモデルに対して、
destroyメソッドを呼びます。def destroy User.find(params[:id]).destroy flash[:success] = "User deleted" redirect_to users_url end
- 投稿日:2019-08-21T22:45:39+09:00
【RubyonRails入門】独自のヘルパーを作成する
[Rails]独自のヘルパーをつくる
1.ヘルパー
app/helpers/forms_helper.rbmodule FormsHelper def hello(name) "こんにちは、" + name + "さん。" end def check_age(age) if age.to_i >= 15 "ようこそ、お楽しみください。" else "このサイトは15歳以上限定です。" end end end■to_i と to_s
.to_i==> int型(数字)に変換する
.to_s==> string型(文字)に変換する2.ヘルパーを元にした、ビュー
app/views/forms/formtest.html.erb<%= hello("花子") %> <!-- こんにちは、花子さん。 -->app/views/forms/input_age.html.erb<%= check_age(25) %> <!-- ようこそ、お楽しみください。 --> <%= check_age(25) %> <!-- このサイトは15歳以上限定です。 -->
- 投稿日:2019-08-21T22:06:42+09:00
DockerでRedmineのSystem Testを動かしてみた
業務でRedmineのPlugin開発をしているのですが、
せっかくDocker上で開発しているので、System TestもDocker上で実行できないかと思い試行錯誤してみました。Dockerで環境を整える
まず、ディレクトリの構成です。
ディレクトリ構成workspace/ ├── Dockerfile ├── docker-compose.yml ├── docker-compose-dev.yml ├── docker-sync.yml ├── docker-compose-test.yml ├── entrypoint.sh ├── redmine/ └── postgers/
redmineはここからclone。
postgresディレクトリは、docker-composeでコンテナを起動すれば勝手に作成されるはず。
postgres以下にはPostgreSQLのデータが保存されます。各ファイルの内容です。
Dockerfile基本の
Dockerfile。今回は
ruby:2.5のイメージを使用します。DockerfileFROM ruby:2.5 RUN gem install bundler RUN mkdir /redmine WORKDIR /redmine ENV BUNDLE_PATH /redmine/vendor/bundle ENV RAILS_ENV development COPY entrypoint.sh /usr/bin/ RUN chmod +x /usr/bin/entrypoint.sh ENTRYPOINT ["entrypoint.sh"] EXPOSE 3000 CMD ["bundle", "exec", "rails", "server", "-b", "0.0.0.0"]1
redmineは後からvolumeするのでイメージの中ではディレクトリを作成するだけです。実際はRedmineもイメージに追加して、
files、pluginsだけvolumeする方がいいかもしれません。
開発用の環境なので、環境変数はENV RAILS_ENV developmentを指定します。
entrypoint.shイメージの作成に使います。
公式のRails用のサンプルを参考にしています。(https://docs.docker.com/compose/rails/)sh#!/bin/bash set -e rm -f /redmine/tmp/pids/server.pid exec "$@"
docker-compose.ymlRedmineの開発環境用の
docker-compose.ymlです。docker-compose.ymlversion: '3' services: redmine: build: . image: redmine:4 environment: BUNDLE_PATH: /redmine/vendor/bundle RAILS_ENV: development DB_HOST_NAME: postgres volumes: - ./redmine:/redmine ports: - 3000:3000 depends_on: - postgres postgres: image: postgres:9.6 volumes: - ./postgres:/var/lib/postgresql/data
image:属性を指定すると、docker-composeでbuildしたイメージの名前を指定できます。
BUNDLE_PATHとRAILS_ENVはDockerfileで指定しているのでここで指定する必要はありません。
docker-compose-dev.yml
docker-sync用の設定です。System Testはかなり遅いので、
docker-syncは使用した方がいいと思います。
docker-syncは別にインストールする必要があります。docker-compose-dev.ymlversion: '3' services: redmine: volumes: - redmine4_volume:/redmine postgres: volumes: - redmine4_postgres_volume:/var/lib/postgresql/data volumes: redmine4_volume: external: true redmine4_postgres_volume: external: true
servcesにはdocker-compose.ymlでの設定と変更したい属性と追加したい属性のみを記述します。
volumesにはdocker-syncで定義するvolumeの名前を宣言します。
docker-sync.ymldocker-syncの設定ファイルです。
docker-sync.ymlversion: '2' syncs: redmine4_volume: src: './redmine' sync_strategy: 'unison' redmine4_postgres_volume: src: './postgresql_data' sync_strategy: 'unison'
srcは相対パスで記述してますが、絶対パスで書いた方が安心だと思います。
docker-sync.ymlは拡張子をyamlにしたら起動できませんでした。
docker-compose-test.ymltest環境用のcomposeファイルです。
docker-compose-test.ymlversion: '3' services: redmine: environment: RAILS_ENV: test depends_on: - chrome selenium-hub: image: selenium/hub:3.141.59-selenium ports: - 4444:4444 chrome: image: selenium/node-chrome-debug:3.141.59-selenium shm_size: 2g depends_on: - selenium-hub environment: - HUB_HOST=selenium-hub - HUB_PORT=4444 ports: - 5900:5900
RAILS_ENVはテスト環境なのでtestに変更します。
chromeはchromeドライバです。
redmineのシステムテストを動かすために必要です。
selenium-hubがどうして必要なのか、まだ理解できてないんですが、多分chromeを使うために必要なんじゃないかと思ってます。Redmineを起動します。
Terminal$ cd /path/to/workspace $ docker-compose build $ docker-compose run --rm redmine bundle install $ docker-compose run --rm redmine bundle exec rake db:create db:migrateRedmineの環境が整うまでRedmineの起動ができないので
runコマンドを使用して環境を整えます。
--rmオプションはrunコマンドで作成されたコンテナを削除するためのコマンドです。ここまででRedmineの準備は完了です!
System Testを動かす
まずはコンテナ間でネットワークが繋がっているかどうかの確認です。
docker-syncを起動して起きます。
Terminal$ docker-sync startchrome側からRedmineが見えるか確認
chromeとRedmineが繋がっているのか確認したかったので、まずはchromeのコンテナからRedmineにアクセスできるかを確認します。
まずはRedmineを起動。
$ docker-compose -f docker-compose.yml -f docker-compose-dev.yml upRedmineを起動したらホストのブラウザを立ち上げて、アドレスバーに
http://localhost:5900を入力します。
画面共有をするか聞かれるのでOKを選択。
パスワードを聞かれたらsecret、黒い画面が立ち上がるはずです。起動した画面上で右クリック → Application → Network → chrome。chromeコンテナ上のchromeが起動できます。
立ち上げたchromeのアドレスバーに
http://redmine:3000を入力するとRedmineにアクセスできます。
URLのredmineはdocker-compose.ymlで指定したサービス名です。
Redmineの画面が表示されれば成功です。一度コンテナを落とします。$ docker-compose downRedmineのTestファイルを修正
Redmineのシステムテストの設定を、dockerコンテナ上で動くように変更します。
RailsのAPIとか
actionpack-5.2.3/lib/action_dispatch/system_testing/driver.rbとactionpack-5.2.3/lib/action_dispatch/system_testing/browser.rbのソースを参考にしながら
application_system_test_case.rbの設定を追加してみました。redmine/test/application_system_test_case.rbdriven_by :selenium, using: :chrome, screen_size: [1024, 900], options: { desired_capabilities: Selenium::WebDriver::Remote::Capabilities.chrome( 'chromeOptions' => { 'prefs' => { 'download.default_directory' => DOWNLOADS_PATH, 'download.prompt_for_download' => false, 'plugins.plugins_disabled' => ["Chrome PDF Viewer"] } } ), browser: :remote, url: 'http://selenium-hub:4444/wd/hub' } setup do clear_downloaded_files Setting.delete_all Setting.clear_cache Capybara.app_host = 'http://redmine:3000' end
driven_byの引数のハッシュに、ブラウザの種類browser: :remote、
ブラウザのURLurl: 'http://selenium-hub:4444/wd/hub'を追記。
setupのブロックの中にapplicationのホストCapybara.app_host = 'http://redmine:3000'を追記します。テスト実行
Terminal$ docker-compose -f docker-compose.yml -f docker-compose-dev.yml -f docker-compose.test run --rm redmine bundle exec rake test:system以下のエラーが出て動きませんでした。
TerminalNameError: uninitialized constant ApplicationSystemTestCase::Selenium /redmine/test/application_system_test_case.rb:26:in `<class:ApplicationSystemTestCase>' /redmine/test/application_system_test_case.rb:22:in `<top (required)>'エラーになった部分を
desired_capabilities: :chromeに書き換えます。redmine/test/application_system_test_case.rbdriven_by :selenium, using: :chrome, screen_size: [1024, 900], options: { desired_capabilities: :chrome, browser: :remote, url: 'http://selenium-hub:4444/wd/hub' }再度実行。
TerminalRun options: --seed 45718 # Running: ...何故か動きました。
エラーの内容は調査しきれな買ったのでまた次回。テストの実行結果はこんな感じです。
TerminalRun options: --seed 45718 # Running: Capybara starting Puma... * Version 3.12.1 , codename: Llamas in Pajamas * Min threads: 0, max threads: 4 * Listening on tcp://127.0.0.1:42831 .[Screenshot]: tmp/screenshots/failures_test_project_quick_search.png E Error: QuickJumpTest#test_project_quick_search: Capybara::ElementNotFound: Unable to find link or button "Megaproject" within #<Capybara::Node::Element tag="div" path="/HTML/BODY[1]/DIV[1]/DIV[2]/DIV[1]/DIV[2]"> test/system/quick_jump_test.rb:64:in `block in test_project_quick_search' test/system/quick_jump_test.rb:60:in `test_project_quick_search' bin/rails test test/system/quick_jump_test.rb:54 .E Error: MyPageTest#test_add_block: Net::ReadTimeout: Net::ReadTimeout test/system/my_page_test.rb:64:in `test_add_block' Error: MyPageTest#test_add_block: Net::ReadTimeout: Net::ReadTimeout bin/rails test test/system/my_page_test.rb:57とりあえずテストを動かせるところまでは成功しましたが、テストは失敗しました。
エラーがいっぱい出てます。でもとりあえず動かせたから今回はここまでにします。
文章にするのは難しいですね。
参考
- 投稿日:2019-08-21T21:56:19+09:00
Railsチュートリアルの各章にかかった時間
はじめに
僕はプログラミングを勉強するにあたって、最初に選んだ言語はRubyでした。
そしてRubyのフレームワークとしてRailsを選択し、今もRailsの勉強をしています。
Railsの勉強はProgateやドットインストール、Ruby on Railsチュートリアルを利用したのですが、この記事では、その中でも最も勉強になったRailsチュートリアルの各章にかかった時間をまとめてみました。よかったら参考にしてください。
前提
全体の把握から細部の理解という流れで勉強していく方針だったので、
1週目はコードはコピペ、演習は未実施
2週目はコードはコピペと自分で打ち込み、演習は実施この流れでやった結果、どうにかコードの内容は読めばわかる程度にはなりました。
また演習の解答はこちらのサイトを参考にさせていただきました。各章の時間
第1章
1週目 180分
2週目 180分第2章
1週目 60分
2週目 180分第3章
1週目 100分
2週目 165分第4章
1週目 100分
2週目 210分第5章
1週目 90分
2週目 255分第6章
1週目 120分
2週目 170分第7章
1週目 125分
2週目 280分第8章
1週目 85分
2週目 130分第9章
1週目 85分
2週目 225分第10章
1週目 180分
2週目 180分第11章
1週目 120分
2週目 230分第12章
1週目 100分
2週目 ?分(おそらく200分程度)第13章
1週目 115分
2週目 255分第14章
1週目 195分
2週目 135分終わりに
各章の時間に関しては個人差があると思いますので、参考程度だと思っていただけるとありがたいです。
後半につれて時間もかかり難易度が上がってきているように思います。僕個人的には、第8.9章あたりのパスワード機構の作成が大変でした。多くのヘルパーメソッドが登場し、頭がこんがらがってきたからです。何かメモとかしながらやるといいのではないかと思います。
今回は時間だけでしたがいずれ各章の感想やポイントなどもまとめられたらと思います。
これからやる人は諦めず頑張ってください!
- 投稿日:2019-08-21T21:19:55+09:00
[Rails] ハッシュ入門
ハッシュ入門
二段階構造のハッシュの値をとる
d = {"test" => {"japanese" => 80, "science" => 60, "English" => 90}}"test"の中に、
さらに"japanese","science","English"のハッシュがある。===> "japanese"の中の"kobun"の値をとりたい!!
"test"の中の"japanese"の値をとる
d["test"]["japanese"]答えはシンプルでした。
逆に、
d["test"]["japanese"]は、
d => {"test" => {"japanese" => xxx}}
となることがわかります!
- 投稿日:2019-08-21T21:19:55+09:00
【RubyonRails入門】 ハッシュの値を取得する
ハッシュ入門
二段階構造のハッシュの値をとる
d = {"test" => {"japanese" => 80, "science" => 60, "English" => 90}}"test"の中に、
さらに"japanese","science","English"のハッシュがある。===> "japanese"の中の"kobun"の値をとりたい!!
"test"の中の"japanese"の値をとる
d["test"]["japanese"]答えはシンプルでした。
逆に、
d["test"]["japanese"]は、
d => {"test" => {"japanese" => xxx}}
となることがわかります!
- 投稿日:2019-08-21T20:20:58+09:00
RailsでCSVを出力する機能を実装(Shift_JIS対応)
最近の勉強で学んだ事を、ノート代わりにまとめていきます。
主に自分の学習の流れを振り返りで残す形なので色々、省いてます。
Webエンジニアの諸先輩方からアドバイスやご指摘を頂けたらありがたいです!CSVエクスポート(出力)
以下の記事を参考にさせて頂きました!
Ruby on RailsでCSV一覧出力する3つの方法まずはcsvでしっかり出力できるかを試したかったので参考にした記事の
①csv出力用のアクションを作成する方法を行いました!
これは記事にも書いている通りREST設計に背く形となるので1つのデメリットですね。
なぜならRESTfulに設計するとindexで処理すべき内容だからです。アクションはこのように定義しました。
def export @members = Member.all send_data render_to_string, filename: "members_#{Time.now.utc.strftime("%Y/%m/%d %H:%M:%S")}.csv", type: :csv endいつ出力したのかをファイル名で確認できるようにこのようなコードを追記した感じです。
filename: "members_#{Time.now.utc.strftime("%Y/%m/%d %H:%M:%S")}.csv"あとはルーティングを設定し、csv出力ファイルであるexport.csv.rubyファイルを作成して出力したい値を設定します!
require 'csv' CSV.generate do |csv| csv_column_names = [ "アカウントID", "ユーザー名", "メールアドレス", "姓", "名", "性別" ] csv << csv_column_names @members.each do |member| csv_column_values = [ member.account_id, member.user_name, member.email, member.last_name, member.first_name, member.gender ] csv << csv_column_values end endこれで最後にファイル出力する為のリンクを作成したら終了です。
<%= link_to "csv出力",csv_export_path(format: :csv) %>エクセルで読み込むためのCSVファイルにする
csvファイルを無事出力できて喜んでいたのですがここで問題がなんとエクセルと開くと文字化けが発生!
原因を調査していると理由が判明RailsアプリケーションでCSV出力をしたファイルをExcelで開くと文字化ける。
理由はExcelがUTF-8のファイルをShift_JISで開こうとしてしまうため。エクセルはShift_JISしか対応してみたいな
なんやそれ〜めちゃくちゃめんどくさい笑この記事に書いているみたいに文字コードの問題を解決する為に「BOM」を使えば上手くいくようなのですが僕の場合は上手くいかず。
参考ページを見てこのようにしたら上手くいきました!
send_data render_to_string.encode(Encoding::Windows_31J, undef: :replace, row_sep: "\r\n", force_quotes: true), filename: "members_#{Time.now.utc.strftime("%Y/%m/%d %H:%M:%S")}.csv", type: :csv参考ページ
Rubyでエンコードのエラーの対処
RailsからShift-JISとUTF-8でCSV出力する
send_dataでファイルを書き出すときの日本語ファイル名の文字化け対策
ruby on rails で utf-8 から shift_jis にしたかった
[Rails] SJISのエクスポートでの「ActionView::Template::Error (U+2212 from UTF-8 to Windows-31J):」のエラー対応
- 投稿日:2019-08-21T19:23:46+09:00
Windows で Ruby on Ruby の 環境構築 を する
目的
- WindowsでRuby on Railsの開発環境を整えられるようにする。 ※これはRails6.0.0以前の方法です。現在はこの方法では環境構築ができない可能性があります。
この記事のターゲット
- WindowsにRuby on Railsの開発環境を立ち上げたい方
- Ruby on Railsのローカル開発環境の立ち上げがうまくいかず、あきらめたくなってきた方
ローカル開発環境で必要なもの
本記事はMSYS2とRubyがすでにインストールされていること前提で進める
MSYS2とRubyのインストール方法はこちら
- MSYS2
- Ruby
- SQLite3
- Rails
SQLite3のインストール
- 下記サイトにアクセス
https://sqlite.org/index.html

- 画像のところクリック

- 画像のところクリック自分のPCにビット数合わせたものをクリックする

- 取得したsqlite-dll-win64-x64-3290000.zipを展開

- 「sqlite3.dll」というファイルを「C:¥Ruby25-x64¥bin」へコピー

- 下記サイトにアクセス

- 画像のところクリック
https://sqlite.org/index.html
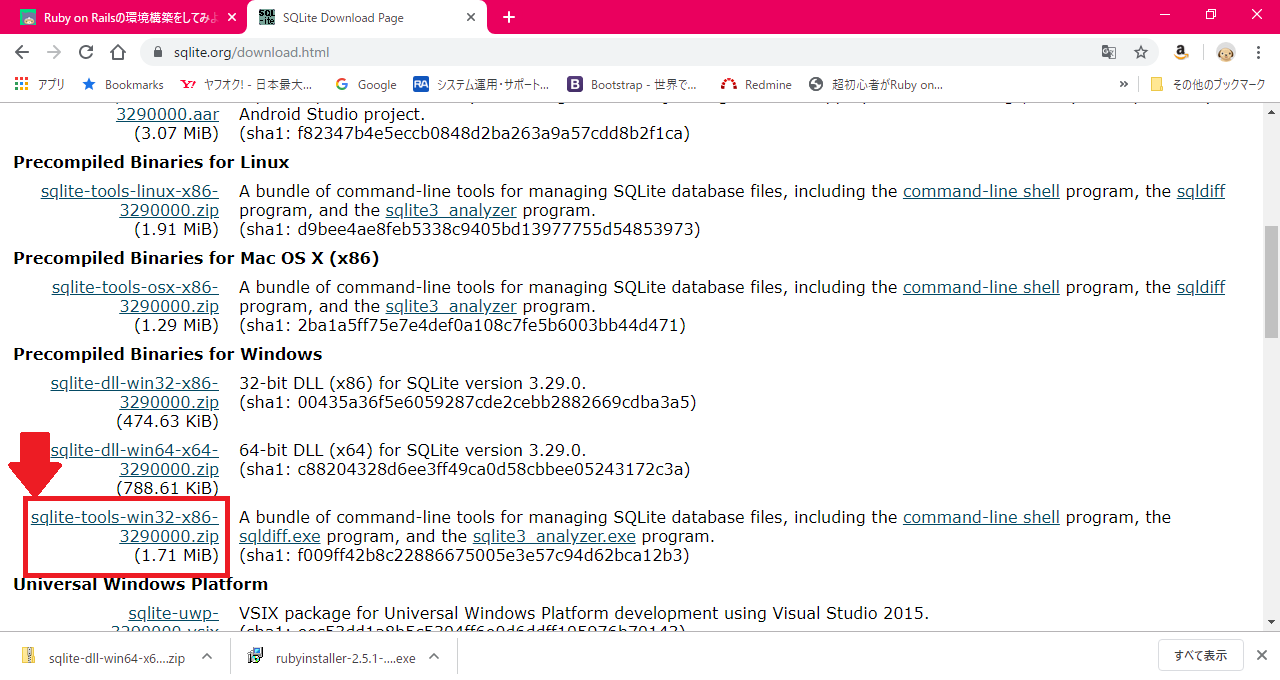
- 取得したsqlite-tools-win32-x86-3290000.zip展開

- 「sqlite3.exe」というファイルを「C:¥Ruby25-x64¥bin」へコピー

Ruby on Railsのインストール
- プロンプトを開いて下記コマンドを実行
gem install rails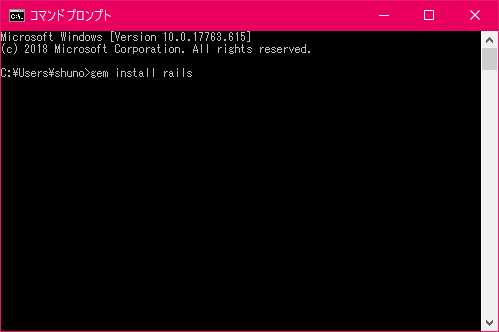
- 下記の様になればOK

- プロンプトを開いて下記コマンドを実行
rails -v- 下記の様になればOK

ためしにアプリ作ってみる
- 任意のフォルダに移動して下記コマンドを実行
rails new sample_app
1. エラーが出たので同じプロンプト内で下記コマンドを実行cd sample_app ridk exec pacman -S mingw-w64-x86_64-sqlite3
- Yを入力してエンター

- 何もなく終われば下記コマンドを実行
bundle install
- 下記画像見たいになってればOK

- PCを再起動する
サーバを立てる
- フォルダsample_appの中で下記コマンドを実行してサーバを立てる
cd sample_app rails s
1. 下記の画像のようになってればサーバ立ってる
1. ブラウザ開いて新しいタブのURL打つところに下記のURLを打つhttp://localhost:3000/
1. 下記の画像に用なかわいい画面が見れたら無事サーバ起動完了!!お疲れさん
1. ローカルサーバを止めたいときはフォルダsample_appの中で下記コマンドを実行control + c


















- 投稿日:2019-08-21T19:03:54+09:00
CSVファイルを使用してRailsアプリに反映させる
csvファイルを使用してrailsアプリに初期データを投入
チーム開発をしていて、seeds.rbからデータベースに初期データを投入する際にコードをひたすら書くのではなくcsvファイルに大量のデータを落とし込んでそれをseed.rbに読み込む記述をするという方法を使用したので、そのやり方を記録として残しておく
!!CSVファイルの作成手順
1.今回は某サイトよりデータをお借りしました
まずはデータを抽出
commnd + aで全選択コピー
2.適当な整形ツールでデータを整える
3.整えたデータをgoogle スプレッドシートで貼り付け
改行を取り除くためにツールから空白セル以外を表示
ツールからフィルターを作成
空白セル以外を表示させる
コピーして貼り付け
改行がないデータの出来上がり!!
4.numbersアプリでcsv書き起こし
データをnumbersアプリでcsvファイルとして書き起こしました
Railsに保存
今回の目的として、rake db:seedをした時にデータをデータベースに投入したいのが目的のため下記の図のファイル構成とする
dbの中に上記csvを入れてやれば良いと思います。
ブランドはデータ量が多かったのでbrandフォルダを作成してますSeeds.rbにデータベースに反映するコードを記述
#左辺nameがデータベースのカラム、右辺nameがcsvのカラム CSV.foreach('db/brand/men_brand.csv', headers: true) do |row| Brand.create( name: row['Name'], ) end
最後に
これで
rake db:seedをすればデータが反映されるはずです
親があって、子があって、孫があるなどの階層が深い場合のseeds.rbの記載方法はそれぞれ紐付けるのが難しいですよね汗
余力があればそのコードもアウトプットとして書こうと思います!!追加
vs codeの拡張機能でExcel Viewer機能を追加するとcsvファイルがみやすくなります






- 投稿日:2019-08-21T17:30:05+09:00
rspec-railsでrequest bodyを設定する方法
やることはこれだけ。
request_body = '{"key": "value"}' post '/users', params: request_body
- 投稿日:2019-08-21T17:28:42+09:00
環境変数へのAPI KEY の記載
概要
自分でアプリを作成した時にapi keyを取得していて、local環境で使用していたものの,
いざgithubにpush使用と思った際に、不正利用されないようにどうやって設定するのかと思い、調べてみました。
忘れないように書いておきます。作業
1.gemのインストール
gem 'dotenv-rails'
bundle installを実行2.env fileを作成
3.envにkeyを記載
API_KEY =xxxxxxxxxxx
ここは右辺には個人的には""などは使用しないほうがいいと思います。4.viewのapi keyを埋め込む場所に環境変数を呼び込む
<script type="text/javascript" src="https://maps.googleapis.com/maps/api/js?key=<%= ENV['API_KEY']%>"></script>
今回はgoogle map apiを使用しているので上記のような記述になりました。5.gitignoreに追加
隠しておきたいデータを定義した.envファイルをGitHubに公開ししたくないから、追加します。
最後に
bash_fileに書くほうが一般的みたいです。
調べてまとめたら記載していきたいです。
間違いがあるかもしれません。指摘して頂けると助かります。


- 投稿日:2019-08-21T16:22:36+09:00
Rails チュートリアル(6章)をRSpecでテスト
はじめに
以前書いた他の章の記事です。
Rails チュートリアル(3章、4章、5章)をRSpecでテスト追加しました。
Rails チュートリアル(7章)をRSpecでテストテストの準備
factory_bot_railsはテスト用のデータを作成するため、shoulda-matchersはバリデーションのテストをするために入れます。(他にも色々なテストで使えるみたいです)gemfilegroup :development, :test do gem 'factory_bot_rails' gem 'shoulda-matchers' end$ bundle installShoulda-Matchersの設定
spec/rails_helper.rbRSpec.configure do |config| # 省略 end #--------------追加部分--------------------------- Shoulda::Matchers.configure do |config| config.integrate do |with| with.test_framework :rspec with.library :rails end end #--------------追加部分---------------------------テストを書く(6章)
FactoryBotでユーザーの作成
spec/factories/users.rbFactoryBot.define do factory :user do name { 'Example User' } sequence(:email) { |n| "user_#{n}@example.com" } end endUserモデルバリデーションテスト(name, email)
spec/models/user_spec.rbrequire 'rails_helper' RSpec.describe User, type: :model do #facrory botが存在するかのテストです it 'has a valid factory bot' do expect(build(:user)).to be_valid end #ここからバリデーションのテストです describe 'validations' do it { is_expected.to validate_presence_of(:name) } it { is_expected.to validate_presence_of(:email) } it { is_expected.to validate_length_of(:name).is_at_most(50) } it { is_expected.to validate_length_of(:email).is_at_most(255) } it do is_expected.to allow_values('first.last@foo.jp', 'user@example.com', 'USER@foo.COM', 'A_US-ER@foo.bar.org', 'alice+bob@baz.cn').for(:email) end it do is_expected.to_not allow_values('user@example,com', 'user_at_foo.org', 'user.name@example.', 'foo@bar_baz.com', 'foo@bar+baz.com').for(:email) end describe 'validate unqueness of email' do let!(:user) { create(:user, email: 'original@example.com') } it 'is invalid with a duplicate email' do user = build(:user, email: 'original@example.com') expect(user).to_not be_valid end it 'is case insensitive in email' do user = build(:user, email: 'ORIGINAL@EXAMPLE.COM') expect(user).to_not be_valid end end end endほとんど、
shoulda-matchersを使って書いてます。
詳しくはここ↓
thoughtbot/shoulda-matchers -Githubemailのユニークのバリデーションだけ
shoulda-matchersを使ってないです。使うと以下のように書けます。it { is_expected.to validate_uniqueness_of(:email).case_insensitive }ただ、使うとundefined method `downcase!' for nil:NilClassとエラーが出てします。
before_saveが読み込めないみたいだけどなんでかな???Userモデルbefore_saveのテスト(#email_downcase)
spec/models/user_spec.rbRSpec.describe User, type: :model do # 上記省略 describe 'before_save' do describe '#email_downcase' do let!(:user) { create(:user, email: 'ORIGINAL@EXAMPLE.COM') } it 'makes email to low case' do expect(user.reload.email).to eq 'original@example.com' end end end endここで
let!をを使ってます。だとlet遅延評価され、テスト前にuserがデータベースに登録されず、user.reload.emailの値がnilになってしまいます。
let!を使うことでbefore doみたいに先に実行されるみたいです。Userモデルのバリデーションテスト(password)
FactoryBotにパスワードの追加
spec/factories/users.rbFactoryBot.define do factory :user do name { 'Example User' } sequence(:email) { |n| "user_#{n}@example.com" } password { 'password' } password_confirmation { 'password' } end endUserモデルのテスト(password)
models/user_spec.rbrequire 'rails_helper' RSpec.describe User, type: :model do it 'has a valid factory bot' do expect(build(:user)).to be_valid end # 追加した部分のみ書いてます。 describe 'validations' do describe 'validate presence of password' do it 'is invalid with a blank password' do user = build(:user, password: ' ' * 6) expect(user).to_not be_valid end end it { is_expected.to validate_length_of(:password).is_at_least(6) } end endパスワードの長さと空文字について検証しています。
本当は空文字の検証も
shoulda-matchersで書こうと思ったのですが、空文字が無視されてしまったので、やめました。ここまでで、6章おわりです。
- 投稿日:2019-08-21T16:09:06+09:00
GitHubでセキュリティ脆弱性のアラートが来てビビりながら対応した話
はじめに
いつも通りポートフォリオを作っていた時のこと、自分のデポジトリーを見た時に
いきな怖いマークの付いた通知が来ていました。
なんのアラートなのか確認をしてみるとnokogiriに脆弱性が見つかったらしく早くバージョンをアップしろとのこと。
すぐさまバージョンを上げようと思ったのですが、なんか「Gemfile.lock」を書き換えろと言われているみたいなのですが、変更するのは「Gemfile」じゃないの?と疑問に思い調べながらバージョンをあげることにしました。
1.「Gemfile」と「Gemfile.lock」の違いって何?
1-1.Gemfileについて
Gemfileとは、使用するgem(パッケージ)を記入することでbundle installコマンドを実行すればGemfileに記述されているgemの中でインストールされていないものを見つけてインストールを実行してくれる。
1-2.Gemfile.lockについて
Gemfile.lockとは、Gemfileを元に実際にインストールされたgemを記録しており、インストールされているバージョンまで記載している。
1-3.両ファイルの違い
Gemfileは、インストールするgemを指定するファイル
Gemfile.lockは、実際にインストールされたものを記載したファイルインストールの内容をいじるのはGemfileで間違っていないみたいなのでGemfileに加筆をしていきます。
2.バージョンアップまでの手順
2-1.現状のGemfileの中身
Gemfilesource 'https://rubygems.org' git_source(:github) { |repo| "https://github.com/#{repo}.git" } ruby '2.5.5' # Bundle edge Rails instead: gem 'rails', github: 'rails/rails' gem 'rails', '~> 5.2.3' # Use sqlite3 as the database for Active Record gem 'sqlite3' # Use Puma as the app server gem 'puma', '~> 3.11' # Use SCSS for stylesheets gem 'sass-rails', '~> 5.0' # Use Uglifier as compressor for JavaScript assets gem 'uglifier', '>= 1.3.0' # See https://github.com/rails/execjs#readme for more supported runtimes # gem 'mini_racer', platforms: :ruby gem 'active_hash' gem 'nokogiri' ...(省略)見ての通り特にバージョンを指定していないなかったみたいです。
2-2.バージョンの指定
Gemfile...(省略) gem 'nokogiri', ">= 1.10.4" ...(省略)GitHubで通知された通りに、1.10.4以上をインストールするように記述します。
2-2.バージョンのアップデート
$ gem update nokogiri数分待ったらアップデートの完了
2-3.GitHubにマージ後
アップデートが完了しましたので、そのままGitHubにマージをしてGitHubを覗いてみると
まだアラートが出ていました;;;
ファイルを見直してみると、どうもGemfile.lockの記述が変わっていないみたいなので
反映される条件を探してみました。2-4.Gemfile.lockに反映するには
bundle installをしないと、Gemfileに反映されないとのことなので改めて更新のために実行
$ bundle install The dependency tzinfo-data (>= 0) will be unused by any of the platforms Bundler is installing for. Bundler is installing for ruby but the dependency is only for x86-mingw32, x86-mswin32, x64-mingw32, java. To add those platforms to the bundle, run `bundle lock --add-platform x86-mingw32 x86-mswin32 x64-mingw32 java`. Fetching gem metadata from https://rubygems.org/............ Fetching gem metadata from https://rubygems.org/. You have requested: nokogiri >= 1.10.4 The bundle currently has nokogiri locked at 1.10.3. Try running `bundle update nokogiri` If you are updating multiple gems in your Gemfile at once, try passing them all to `bundle update`めっちゃエラー吐いた。
2-5.再・Gemfile.lockに反映するには
$ bundle update nokogiri言われた通りにbundle update nokogiriを実行したらGemfile.lockも自動で反映されました!
とわ言え、アラートが消えるかわからないのでひとまずGitHubにマージしてTOPを確かめてみると...
無事消えてました。
3.その他
gem updateとbundle updateの違いが謎なので次回以降詳しく調べてみます。(余力があれば記事にします。)
検索クエリには「gem update vs bundle update」なんてものもあるぐらいなので調べてみるのが面白そうな気がしています。




- 投稿日:2019-08-21T15:27:58+09:00
『レストラン口コミサイト』の制作過程
はじめに
ポートフォリオ用で制作したサイトのまとめです。
現在の進行状況を随時更新していきます。現状
現在やっている作業
画像が編集画面で出ないので、修正中
ブックマーク機能の実装
dockerの導入実装済み機能
レストラン投稿機能
レストラン名での検索機能
ジャンルやシーンでの検索機能
コメント機能
ユーザー登録、削除機能
投稿の削除機能未実装機能(実装予定)
単体テスト
統合テスト
管理ユーザー機能アプリ概要
使用した技術
今回はRails+mysql+AWS+bootstrapでアプリを作っていきます。
AWSではEC2+S3を使用し、デプロイをしました。
credentials.yml.encのまとめ記事
AWSデプロイでのエラーまとめ解決したい事とアプリへの想い
アプリを作ろうとしたキッカケはレストランの口コミサイトは数多くあるが、数が多すぎて大事な日にいく様なレストラン
(グランメゾン)の情報を探すのに困っていました。
みんなも同じ様な経験をしているのと、私が元調理師と言うのも合わさってかよく友達からオススメのレストランを聞かれる事があったので、私の知っているレストランをベースにまとめようとしたのがキッカケです。出来ること、価値
オススメのレストランの投稿と、その投稿に対してコメントする事も出来ます。
簡単にコメント出来る様にしたかったのでログイン無しで出来るようにしました。
また、グランメゾンの様なレストランの場合、値段や場所よりもお店の雰囲気であったり、利用目的が優先されるので、利用シーンの登録とそこからの検索機能を実装しました。課題と反省
①如何に投稿の質を保つか(機能面)
元々は1ユーザー1投稿しか出来ない仕様で進めていましたが、投稿しようとしたレストランが既にあった場合、どうするかと言う問題が発生してしまいました。
既にあった場合、投稿出来なくするか投稿出来て、なんらかの情報で紐づけるの二択ですがどちらも根本的解決にはなりませんでした。
投稿出来なくする場合、他の投稿をする→質を保つと言う意味でこの方式を取ろうと思ったのに、それが出来なくなってしまう
情報で紐づける→必ず共通する情報が少ない。店名は特に鮨屋や料亭に多いですが、同じ様な名前が多いです。また、鮨〇〇を〇〇と表記すると紐付けられなくなってしまいます。
なので紐づけするとしたら住所や電話番号で紐づける必要があると思いました。書いている段階で気が付いたので、その様な形で実装していきます。②テストを後回しにしてしまった(実装面)
実際にアプリを公開する想定で進めていましたが、テストを後回しにしてしました。都度書いていくのが理想ですが、後回しにしてしまったので、次に作るときには反省を生かして書いていきたいです。詰まった所
主にQiitaにてまとめています。
都度追加します。まとめ
まとまり次第追加します。
- 投稿日:2019-08-21T13:32:31+09:00
railsのroutes.rbのmemberとcollectionの違いは?
はじめに
Railsでroutes.rbを設定するとき、memberやcollectionを記述することがあります。
routes.rbresources :users do member do get :logout end end resource :user_sign_ups do collection do get :tell end endこのmemberやcollectionはどんな役割をしているのでしょうか?
memberとcollectionの違いは?
簡単に言うと、
routingにidが付くか付かないかの違いです。もう少しわかりやすく説明するために例をだして解説します。
resources :users do member do get :logout end end
users#logoutをmemberでルーティングを設定すると、URLは以下のようになります。/users/:id/logoutこのようにuserを識別するための:idが追加されます。
では、collectionでルーティングを設定した場合はどうなるでしょう?
resource :user_sign_ups do collection do get :tell end end
user_sign_ups#tellをcollectionでルーティングを設定しました。すると
/user_sign_ups/tellurlに:idが追加されていません。
:idでurlを識別する必要がない場合はcollectionで設定します。
おわりに
まとめると
・memberは特定のデータにアクションを利用する
・collectionは全体のデータにアクションを利用するときに設定します・
- 投稿日:2019-08-21T09:40:55+09:00
Rails6の開発環境をDockerで構築しようとしたらドハマりした件
概要
Dockerでの開発環境構築に慣れていない私は、練習がてら公式の手順を元にRailsの開発環境を構築してみることに。
https://docs.docker.com/compose/rails/その時ハマった事象と解決方法のメモ。
落とし穴
最近 Rails6がリリース されたということで、せっかくだから使ってみるかな!
→それが悲劇の始まりとは知る由もなく...Your Ruby version is 2.6.3, but your Gemfile specified 2.6.0 問題
事象
Build the Project の手順で
docker-compose buildした時に出たエラーメッセージ。$ docker-compose build db uses an image, skipping Building web Step 1/15 : FROM ruby:2.6 ---> 8fe6e1f7b421 Step 2/15 : RUN apt-get update -qq && apt-get install -y nodejs postgresql-client ---> Using cache ---> b487730f3d14 : (中略) : Step 9/15 : RUN bundle install ---> Running in 3e945eba544e Your Ruby version is 2.6.3, but your Gemfile specified 2.6.0 ERROR: Service 'web' failed to build: The command '/bin/sh -c bundle install' returned a non-zero code: 18要するに、Gemfileで指定してるバージョンとアンタの環境のRubyバージョンが違ってまっせ、ということなんですが、これを解決するのにハマった。
解決プロセス
バージョン調査
バージョン違いまっせと言われているので、まずRubyのバージョンを確認するわけですが、この時にローカル環境のバージョンを確認したのが良くなかった。
コンテナ初級者あるある。$ which ruby /Users/username/.rbenv/shims/ruby(デフォルトのパスではなく)rbenvで指定されたパスを指している。
$ ruby -v ruby 2.6.0p0 (2018-12-25 revision 66547) [x86_64-darwin18]RubyのバージョンはGemfileの記述と同じく 2.6.0 である。
$ rbenv versions system 2.3.0 2.4.1 2.5.1 2.5.3 * 2.6.0 (set by /Users/username/Work/training/docker-begin/.ruby-version)そもそもruby 2.6.3 はインストールすらされていない!
なんでだ!キーッ!!となったわけですが、、そういや、コンテナに環境作るんだからローカルのインストール状況関係ないよね?
と思い直したのでした。
解決方法
DockerfileのFROM句では、マイナーバージョンを明示しない限り最新版が指定されるらしい。
例えばFROM ruby:2.6とすると、その時最新バージョンである2.6.3と認識される模様。
ソースは自身の試行錯誤
Dockerfileを確認するとまさに
2.6としていたため、下記のように明示してやることで無事docker-compose build出来たのでした。FROM ruby:2.6.0rails server 立ち上がってない問題
事象
無事手順を終えウェルカムページが見れる状態になったハズなのですが、どういう訳か
localhost:3000にアクセス出来ない。
コンテナは問題なく立ち上がっているはずなのに...
$ docker-compose ps Name Command State Ports ------------------------------------------------------------------------------------ docker-begin_db_1 docker-entrypoint.sh postgres Up 5432/tcp docker-begin_web_1 entrypoint.sh bash -c rm - ... Up 0.0.0.0:3000->3000/tcpなぜだ。
解決プロセス
docker logsしてみる
こんな時には
docker logsするといいよ、とどこかの誰が言っていたのでやってみる。$ docker logs docker-begin_web_1 => Booting Puma => Rails 6.0.0 application starting in development => Run `rails server --help` for more startup options RAILS_ENV=development environment is not defined in config/webpacker.yml, falling back to production environment Exiting /usr/local/bundle/gems/webpacker-4.0.7/lib/webpacker/configuration.rb:91:in `rescue in load': Webpacker configuration file not found /myapp/config/webpacker.yml. Please run rails webpacker:install Error: No such file or directory @ rb_sysopen - /myapp/config/webpacker.yml (RuntimeError) from /usr/local/bundle/gems/webpacker-4.0.7/lib/webpacker/configuration.rb:87:in `load' from /usr/local/bundle/gems/webpacker-4.0.7/lib/webpacker/configuration.rb:84:in `data' from /usr/local/bundle/gems/webpacker-4.0.7/lib/webpacker/configuration.rb:80:in `fetch' from /usr/local/bundle/gems/webpacker-4.0.7/lib/webpacker/configuration.rb:39:in `public_path' from /usr/local/bundle/gems/webpacker-4.0.7/lib/webpacker/configuration.rb:43:in `public_output_path' from /usr/local/bundle/gems/webpacker-4.0.7/lib/webpacker/configuration.rb:47:in `public_manifest_path' from /usr/local/bundle/gems/webpacker-4.0.7/lib/webpacker/manifest.rb:83:in `load' : (中略) :あれ、rails serverが立ち上がってない...
開発環境にconfig/webpacker.ymlが定義されていない??Webpackerをインストール
どうやら、Rails6 ではWebpacker がデフォルトで導入されるようになったらしい。
てことは、Webpackerをインストールしてやらないとrails serverも立ち上がらないということなのかな?
ということで、Webpackerをインストールするために必要なyarnであったりNode.jsであったりをインストールするぞ!という命令をDockerfileに書いてやる。
FROM ruby:2.6.0 RUN apt-get update -qq && apt-get install -y nodejs postgresql-client ######################################################################## # yarnパッケージ管理ツールをインストール RUN apt-get update && apt-get install -y curl apt-transport-https wget && \ curl -sS https://dl.yarnpkg.com/debian/pubkey.gpg | apt-key add - && \ echo "deb https://dl.yarnpkg.com/debian/ stable main" | tee /etc/apt/sources.list.d/yarn.list && \ apt-get update && apt-get install -y yarn # Node.jsをインストール RUN curl -sL https://deb.nodesource.com/setup_7.x | bash - && \ apt-get install nodejs ####################################################################### : (中略) :そしてWebpackerをインストール。
$ docker-compose run web bundle exec rails webpacker:install Starting docker-begin_db_1 ... done RAILS_ENV=development environment is not defined in config/webpacker.yml, falling back to production environment create config/webpacker.yml Copying webpack core config create config/webpack create config/webpack/development.js create config/webpack/environment.js create config/webpack/production.js create config/webpack/test.js : (中略) : info Visit https://yarnpkg.com/en/docs/cli/add for documentation about this command. Webpacker successfully installed ? ?問題なくインストール出来たのでもう一度コンテナを起動!
無事スタートラインに立つことが出来たのでした
※その後、ついでにRubyのバージョンを
2.6.3に上げてもう一度同様の手順を試しました。参考


- 投稿日:2019-08-21T06:36:27+09:00
ActiveRecordを使ってFROM句のサブクエリを書く方法
ActiveRecordで複数テーブルを
JOINしてGROUP BYする処理を書く時、GROUP BYする前に重複排除を目的としたDISTINCTをする必要があり「FROM句のサブクエリを書く」というシチュエーションに遭遇しました。SQLだと簡単に書けるのですがActiveRecordだとどう書くべきかわからなかったので、まとめます。
結論
先にサブクエリに相当する処理をActiveRecordで記述し変数に代入しておき、
ModelClass.from("(#{subquery.to_sql}) AS sub").select('sub.columnA, sub.columnB')のように
fromメソッドを呼び出すことでFROM句のサブクエリとして処理できます。遭遇したシチュエーション
各テーブルは以下のようになっています。
要約するとこういった状況です。
- 和食とイタリアンを扱うレストラン(大衆系レストラン)とイタリアンのみ扱うレストラン(高級レストラン)がある
- それぞれ3件ずつの予約が入っている
- イタリアンを扱うレストランの予約件数(3+3=6)と和食を扱うレストランの予約件数(3)を取得したい
SELECT id, restaurant_id, guest_name, reserved_at FROM reservations; 1|1|岩瀬 好近|2019-08-01 13:00:00 2|1|戸田 良市|2019-08-01 14:00:00 3|2|森 信好|2019-08-01 15:00:00 4|2|平山 利次|2019-08-01 11:00:00 5|1|金城 義勝|2019-08-01 18:00:00 6|2|関 知実|2019-08-01 19:00:00 SELECT id, name FROM restaurants; 1|大衆系レストラン 2|高級レストラン SELECT id, restaurant_id, name FROM courses; 1|1|焼き魚コース 2|1|串カツ三昧 3|1|寿司セット 4|1|コラボピザ 5|2|高級ピッツア 6|2|色とりどりのパスタ 7|2|イタリアンフルコース SELECT id, restaurant_id, name, category_id FROM courses; 1|1|焼き魚コース|1 2|1|串カツ三昧|1 3|1|寿司セット|1 4|1|コラボピザ|2 5|2|高級ピッツア|2 6|2|色とりどりのパスタ|2 7|2|イタリアンフルコース|2 SELECT id, name FROM categories; 1|和食 2|イタリアン解決方法
各テーブルをJOINして、
categories.nameとreservations.idをSELECT DISTINCTするサブクエリを定義します。(subquery変数に代入)
fromメソッドにsubqueryをサブクエリに展開して渡し、group→selectを呼ぶことでカテゴリ別の予約件数を取得できました。subquery = Reservation.all .joins(restaurant: { courses: :category }) .select(%( distinct categories.name AS category_name, reservations.id AS reservation_id )) reservations = Reservation.from("(#{subquery.to_sql}) AS reservations") .group('reservations.category_name') .select(%( reservations.category_name AS category_name, COUNT(reservations.reservation_id) AS reservation_count )) reservations.map do|reservation| [reservation.category_name, reservation.reservation_count] end => [["イタリアン", 6], ["和食", 3]](2019/8/21 13:38追記)
@jnchito さんがCOUNT(DISTINCT some_column)を使った方法をコメントくださいました。
確かに、こちらの方がスッキリ書けます。ありがとうございます。Reservation .joins(restaurant: { courses: :category }) .group('categories.name') .distinct .count(:id)(参考)サブクエリを使わず誤った値を取得してしまった事例
参考までに最初に書いたコードを晒します。 このコードは正しい予約件数を取得できません。
reservations = Reservation.all .joins(restaurant: { courses: :category }) .group('categories.name') .select(%( categories.name AS category_name, COUNT(reservations.id) AS reservation_count )) reservations.map do|reservation| [reservation.category_name, reservation.reservation_count] end => [["イタリアン", 12], ["和食", 9]]原因はGROUP BYする直前のテーブルを参照すると一目瞭然です。
1つのレストランに複数のコースが存在することで、JOINした時に各レストランのコースの数だけレコードが重複してしまうことが原因です。SELECT reservations.id, restaurants.NAME, courses.NAME, categories.NAME FROM "reservations" INNER JOIN "restaurants" ON "restaurants"."id" = "reservations"."restaurant_id" INNER JOIN "courses" ON "courses"."restaurant_id" = "restaurants"."id" INNER JOIN "categories" ON "categories"."id" = "courses"."category_id"; 1|大衆系レストラン|焼き魚コース|和食 2|大衆系レストラン|焼き魚コース|和食 5|大衆系レストラン|焼き魚コース|和食 1|大衆系レストラン|串カツ三昧|和食 2|大衆系レストラン|串カツ三昧|和食 5|大衆系レストラン|串カツ三昧|和食 1|大衆系レストラン|寿司セット|和食 2|大衆系レストラン|寿司セット|和食 5|大衆系レストラン|寿司セット|和食 1|大衆系レストラン|コラボピザ|イタリアン 2|大衆系レストラン|コラボピザ|イタリアン 5|大衆系レストラン|コラボピザ|イタリアン 3|高級レストラン|高級ピッツア|イタリアン 4|高級レストラン|高級ピッツア|イタリアン 6|高級レストラン|高級ピッツア|イタリアン 3|高級レストラン|色とりどりのパスタ|イタリアン 4|高級レストラン|色とりどりのパスタ|イタリアン 6|高級レストラン|色とりどりのパスタ|イタリアン 3|高級レストラン|イタリアンフルコース|イタリアン 4|高級レストラン|イタリアンフルコース|イタリアン 6|高級レストラン|イタリアンフルコース|イタリアン前項のようにサブクエリで
DISTINCTした上でGROUP BYすることで、重複を排除した件数を取得できます。参考

- 投稿日:2019-08-21T01:11:18+09:00
factory_botでhas_many throughアソシエーションを作成
はじめに
rspecでモデルスペックを作成してるときにhas_many_throughのアソシエーションを持ったfactoryを作成しようとして作成の仕方がわからずかなりハマったので備忘録としてまとめます
テーブル構造
models/article.rbclass Article < ApplicationRecord has_many :article_categories has_many :categories, through: :article_categories validates :title, presence: true validates :body, presence: true validate :select_categories def select_categories errors.add(:article_categories, 'を1つ以上選択してください') if article_categories.size.zero? end endmodels/category.rbclass Category < ApplicationRecord has_many :article_categories has_many :articles, through: :article_categories endarticle_category.rbclass ArticleCategory < ApplicationRecord belongs_to :article belongs_to :category end今回はarticleとcategoryが多対多の関連を持っており、さらにarticleは作成する際1つ以上のcategoryをもつ必要のあるバリデーションが存在するような状況です
factoryの作成
spec/factories/articles.rbFactoryBot.define do factory :article do title { 'タイトル' } body { 'テキストテキストテキストテキストテキスト' } after(:build) do |article| category = create(:category) article.article_categories << build(:article_category, article: article, category: category) end end endspec/factories/categories.rbFactoryBot.define do factory :category do name { 'カテゴリー名' } end endspec/factories/article_categories.rbFactoryBot.define do factory :article_category do article category end end上記のように記述することでarticle作成と同時に関連テーブルまで作成し、バリデーションを通過させることができます
テスト結果
spec/models/article_spec.rbrequire 'rails_helper' RSpec.describe Article, type: :model do it "有効なarticleを生成できる" do expect(create(:article)).to be_valid end end$ rspec --example '有効なarticleを生成できる' . Finished in 0.03327 seconds (files took 2.8 seconds to load) 1 example, 0 failures無事テストが通ることが確認できました!
factory_girlからfactory_botに名前変更してからfactory_botの記事がほとんど見つからなくて泣いてますw
これ以外にもっと良いやり方を知ってる方いたらコメントなどで教えていただけると嬉しいです!参考文献
factory_bot公式ドキュメント
GETTING_STARTED.mdhttps://github.com/thoughtbot/factory_bot/blob/master/GETTING_STARTED.md
stackoverflow

- 投稿日:2019-08-21T01:11:18+09:00
factory_botでhas_many_throughアソシエーションを作成
はじめに
rspecでモデルスペックを作成してるときにhas_many_throughのアソシエーションを持ったfactoryを作成しようとして作成の仕方がわからずかなりハマったので備忘録としてまとめます
テーブル構造
models/article.rbclass Article < ApplicationRecord has_many :article_categories has_many :categories, through: :article_categories validates :title, presence: true validates :body, presence: true validate :select_categories def select_categories errors.add(:article_categories, 'を1つ以上選択してください') if article_categories.size.zero? end endmodels/category.rbclass Category < ApplicationRecord has_many :article_categories has_many :articles, through: :article_categories endarticle_category.rbclass ArticleCategory < ApplicationRecord belongs_to :article belongs_to :category end今回はarticleとcategoryが多対多の関連を持っており、さらにarticleは作成する際1つ以上のcategoryをもつ必要のあるバリデーションが存在するような状況です
factoryの作成
spec/factories/articles.rbFactoryBot.define do factory :article do title { 'タイトル' } body { 'テキストテキストテキストテキストテキスト' } after(:build) do |article| category = create(:category) article.article_categories << build(:article_category, article: article, category: category) end end endspec/factories/categories.rbFactoryBot.define do factory :category do name { 'カテゴリー名' } end endspec/factories/article_categories.rbFactoryBot.define do factory :article_category do article category end end上記のように記述することでarticle作成と同時に関連テーブルまで作成し、バリデーションを通過させることができます
テスト結果
spec/models/article_spec.rbrequire 'rails_helper' RSpec.describe Article, type: :model do it "有効なarticleを生成できる" do expect(create(:article)).to be_valid end end$ rspec --example '有効なarticleを生成できる' . Finished in 0.03327 seconds (files took 2.8 seconds to load) 1 example, 0 failures無事テストが通ることが確認できました!
factory_girlからfactory_botに名前変更してからfactory_botの記事がほとんど見つからなくて泣いてますw
これ以外にもっと良いやり方を知ってる方いたらコメントなどで教えていただけると嬉しいです!参考文献
factory_bot公式ドキュメント
GETTING_STARTED.mdhttps://github.com/thoughtbot/factory_bot/blob/master/GETTING_STARTED.md
stackoverflow